
code
stringlengths 501
5.19M
| package
stringlengths 2
81
| path
stringlengths 9
304
| filename
stringlengths 4
145
|
|---|---|---|---|
Use these directories to rapidly deploy your system to the cloud. This means you can provide a preview of [working software](https://apilogicserver.github.io/Docs/Working-Software-Now/) for your team:
* **Developers** can use the API to begin custom User Interface development
* **Business Users** can use the Admin App to see *working screens*, enabling **collaboration** with the development team.
> For example procedures, [click here](https://apilogicserver.github.io/Docs/DevOps-Containers-Deploy-Multi/).
These directories simplify the sometimes-tricky deployment to the cloud.
1. Use `auth-db` to prepare a docker image that includes test database data, including security
2. Start with `docker-image` to create an image for deployment
3. Use `docker-compose-dev-local` to verify multi-container (application, database) execution
4. Use `docker-compose-dev-azure` to deploy this multi-container system to azure
5. Optionally, use `docker-compose-dev-local-nginx` to explore an additional web server container - nginx
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/devops/readme-devops.md
|
readme-devops.md
|
# +++++++++++ GENERAL DEBUGGING TIPS +++++++++++
# getting imports and sys.path right can be fiddly!
# We've tried to collect some general tips here:
# https://help.pythonanywhere.com/pages/DebuggingImportError
# +++++++++++ HELLO WORLD +++++++++++
# A little pure-wsgi hello world we've cooked up, just
# to prove everything works. You should delete this
# code to get your own working.
HELLO_WORLD = """<html>
<head>
<title>PythonAnywhere hosted web application</title>
</head>
<body>
<h1>Hello, World!</h1>
<p>
This is the default welcome page for a
<a href="https://www.pythonanywhere.com/">PythonAnywhere</a>
hosted web application.
</p>
<p>
Find out more about how to configure your own web application
by visiting the <a href="https://www.pythonanywhere.com/web_app_setup/">web app setup</a> page
</p>
</body>
</html>"""
"""
def application(environ, start_response):
if environ.get('PATH_INFO') == '/':
status = '200 OK'
content = HELLO_WORLD
else:
status = '404 NOT FOUND'
content = 'Page not found.'
response_headers = [('Content-Type', 'text/html'), ('Content-Length', str(len(content)))]
start_response(status, response_headers)
yield content.encode('utf8')
"""
# Below are templates for Django and Flask. You should update the file
# appropriately for the web framework you're using, and then
# click the 'Reload /yourdomain.com/' button on the 'Web' tab to make your site
# live.
# +++++++++++ VIRTUALENV +++++++++++
# If you want to use a virtualenv, set its path on the web app setup tab.
# Then come back here and import your application object as per the
# instructions below
# +++++++++++ CUSTOM WSGI +++++++++++
# If you have a WSGI file that you want to serve using PythonAnywhere, perhaps
# in your home directory under version control, then use something like this:
#
#import sys
#
#path = '/home/ApiLogicServer/path/to/my/app
#if path not in sys.path:
# sys.path.append(path)
#
#from my_wsgi_file import application # noqa
# +++++++++++ DJANGO +++++++++++
# To use your own django app use code like this:
#import os
#import sys
#
## assuming your django settings file is at '/home/ApiLogicServer/mysite/mysite/settings.py'
## and your manage.py is is at '/home/ApiLogicServer/mysite/manage.py'
#path = '/home/ApiLogicServer/mysite'
#if path not in sys.path:
# sys.path.append(path)
#
#os.environ['DJANGO_SETTINGS_MODULE'] = 'mysite.settings'
#
## then:
#from django.core.wsgi import get_wsgi_application
#application = get_wsgi_application()
# +++++++++++ FLASK +++++++++++
# Flask works like any other WSGI-compatible framework, we just need
# to import the application. Often Flask apps are called "app" so we
# may need to rename it during the import:
#
#
import sys
#
## The "/home/ApiLogicServer" below specifies your home
## directory -- the rest should be the directory you uploaded your Flask
## code to underneath the home directory. So if you just ran
## "git clone [email protected]/myusername/myproject.git"
## ...or uploaded files to the directory "myproject", then you should
## specify "/home/ApiLogicServer/myproject"
path = 'python_anywhere_path' # updated in creation process
if path not in sys.path:
sys.path.append(path)
#
from api_logic_server_run import flask_app as application # noqa
#
# NB -- many Flask guides suggest you use a file called run.py; that's
# not necessary on PythonAnywhere. And you should make sure your code
# does *not* invoke the flask development server with app.run(), as it
# will prevent your wsgi file from working.
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/devops/python-anywhere/python_anywhere_wsgi.py
|
python_anywhere_wsgi.py
|
import subprocess, os, time, requests, sys, re, io
from typing import List
from shutil import copyfile
import shutil
from sys import platform
from subprocess import DEVNULL, STDOUT, check_call
from pathlib import Path
from dotmap import DotMap
import json
def print_run_output(msg, input):
print(f'\n{msg}')
print_lines = input.split("\\n")
for each_line in print_lines:
print(each_line)
def print_byte_string(msg, byte_string):
print(msg)
for line in byte_string.decode('utf-8').split('\n'):
print (line)
def check_command(command_result, special_message: str=""):
result_stdout = ""
result_stderr = ''
if command_result is not None:
if command_result.stdout is not None:
result_stdout = str(command_result.stdout)
if command_result.stderr is not None:
result_stderr = str(command_result.stderr)
if "Trace" in result_stderr or \
"Error" in result_stderr or \
"allocation failed" in result_stdout or \
"error" in result_stderr or \
"Cannot connect" in result_stderr or \
"Traceback" in result_stderr:
if 'alembic.runtime.migration' in result_stderr:
pass
else:
print_byte_string("\n\n==> Command Failed - Console Log:", command_result.stdout)
print_byte_string("\n\n==> Error Log:", command_result.stderr)
if special_message != "":
print(f'{special_message}')
raise ValueError("Traceback detected")
def run_command(cmd: str, msg: str = "", new_line: bool=False,
cwd: Path=None, show_output: bool=False) -> object:
""" run shell command (waits)
:param cmd: string of command to execute
:param msg: optional message (no-msg to suppress)
:param cwd: path to current working directory
:param show_output print command result
:return: dict print(ret.stdout.decode())
"""
print(f'{msg}, with command: \n{cmd}')
try:
# result_b = subprocess.run(cmd, cwd=cwd, shell=True, stderr=subprocess.STDOUT)
result = subprocess.run(cmd, cwd=cwd, shell=True, capture_output=True)
if show_output:
print_byte_string(f'{msg} Output:', result.stdout)
special_message = msg
if special_message.startswith('\nCreate MySQL classicmodels'):
msg += "\n\nOften caused by docker DBs not running: see https://apilogicserver.github.io/Docs/Architecture-Internals/#do_docker_database"
check_command(result, msg)
"""
if "Traceback" in result_stderr:
print_run_output("Traceback detected - stdout", result_stdout)
print_run_output("stderr", result_stderr)
raise ValueError("Traceback detected")
"""
except Exception as err:
print(f'\n\n*** Failed {err} on {cmd}')
print_byte_string("\n\n==> run_command Console Log:", result.stdout)
print_byte_string("\n\n==> Error Log:", result.stderr)
raise
return result
# ***************************
# MAIN CODE
# ***************************
'''
this approach works, but
* does not show nginx output
* docker-compose errors are visible, but hidden (eg, improper command: bash /app/startX.sh)
'''
current_path = Path(os.path.abspath(os.path.dirname(__file__)))
project_path = current_path.parent.parent
print(f'\n\ndocker_compose running at \n'
f'..current_path: {current_path} \n'
f'..project_path: {project_path:}\n')
docker_compose_command = 'docker-compose -f ./devops/docker-compose/docker-compose.yml up'
result_build = run_command(docker_compose_command,
cwd=project_path,
msg=f'\nStarting docker-compose',
show_output=True)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/devops/docker-compose-dev-local-nginx/unused/unused-docker-compose.py
|
unused-docker-compose.py
|
# intended for use in portal cli - not to be run on your local machine.
projectname="apilogicserver_project_name_lower" # lower case, only
resourcegroup="apilogicserver_project_name_lower_rg"
dockerrepositoryname="apilogicserver" # change this to your DockerHub Repository
githubaccount="apilogicserver" # change this to your GitHub account
version="1.0.0"
# see docs: https://apilogicserver.github.io/Docs/DevOps-Containers-Deploy-Multi/
# modeled after: https://learn.microsoft.com/en-us/azure/app-service/tutorial-multi-container-app
# which uses: https://github.com/Azure-Samples/multicontainerwordpress
# login to Azure Portal CLI (substitute your github account for apilogicserver)
# git clone https://github.com/apilogicserver/apilogicserver_project_name_lower.git
# cd apilogicserver_project_name_lower
# sh devops/docker-compose-dev-azure/azure-deploy.sh
echo " "
if [ "$#" -eq 0 ]; then
echo "..using defaults - press ctl+C to stop run"
else
if [ "$1" = "." ]; then
echo "..using defaults"
else
echo "using arg overrides"
projectname="$1"
githubaccount="$2"
dockerrepositoryname="$3"
resourcegroup="$4"
fi
fi
echo " "
echo "Azure Deploy here - Azure Portal CLI commands to deploy project, 1.0"
echo " "
echo "Prereqs"
echo " 1. You have published your project to GitHub: https://github.com/${githubaccount}/${projectname}.git"
echo " 2. You have built your project image, and pushed it to DockerHub: ${dockerrepositoryname}/${projectname}"
echo " "
echo "Steps performed on Azure Portal CLI to enable running these commands:"
echo " # we really only need the docker compose file"
echo " git clone https://github.com/$githubaccount/$projectname.git"
echo " cd classicmodels"
echo " "
echo "Then, in Azure CLI:"
echo " sh devops/docker-compose-dev-azure/azure-deploy.sh [ . | args ]"
echo " . means use defaults:"
echo " ${dockerrepositoryname}/${projectname}:${version}"
echo " <args> = projectname githubaccount dockerrepositoryname resourcegroupname"
echo " "
# security assumed; disable this if you are not using security
if [ ! -f "./database/authentication_models.py" ]
then
echo "\nYou need to activate security first. With mysql-container running...\n"
echo "ApiLogicServer add-auth --project_name=. --db_url=mysql+pymysql://root:p@localhost:3306/authdb"
echo "\nRebuild your image"
echo "\nThen, stop mysql-container\n"
exit 1
else
echo "\n... security check complete\n"
fi
read -p "Verify settings above, then press ENTER to proceed> "
set -x # echo commands
# create container group
az group create --name $resourcegroup --location "westus"
# create service plan
az appservice plan create --name myAppServicePlan --resource-group $resourcegroup --sku S1 --is-linux
# create docker compose app
az webapp create --resource-group $resourcegroup --plan myAppServicePlan --name apilogicserver_project_name_lower --multicontainer-config-type compose --multicontainer-config-file devops/docker-compose-dev-azure/docker-compose-dev-azure.yml
set +x # reset echo
echo "enable logging: https://learn.microsoft.com/en-us/azure/app-service/troubleshoot-diagnostic-logs#enable-application-logging-linuxcontainer"
echo " To enable web server logging for Windows apps in the Azure portal, navigate to your app and select App Service logs"
echo " For Web server logging, select Storage to store logs on blob storage, or File System to store logs on the App Service file system"
echo " "
echo "Completed. Browse to the app:"
echo "https://$projectname.azurewebsites.net"
echo " "
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/devops/docker-compose-dev-azure/azure-deploy.sh
|
azure-deploy.sh
|
# To build container for your ApiLogicProject:
# create / customize your project as you normally would
# edit this file: change your_account/your_repository as appropriate
# be sure to add security (already done for demo)
# in terminal (not in VSCode docker - docker is not installed there)
# $ cd <your project>
# $ sh devops/docker-image/build_image.sh .
projectname="apilogicserver_project_name_lower" # lower case, only
repositoryname="apilogicserver"
version="1.0.0"
debug() {
debug="disabled"
# echo "$1"
}
debug "\n"
debug "build_image here 1.0"
if [ $# -eq 0 ]; then
echo "\nBuilds docker image for API Logic Project\n"
echo " cd <project home directory>"
echo " sh devops/docker/build_image.sh [ . | <docker-id> ]"
echo " . means use defaults:"
echo " ${repositoryname}/${projectname}:${version}"
echo " <docker-id> means use explicit args: <repository-name> <project-name> <version> eg,"
echo " sh build_image.sh myrepository myproject 1.0.1"
echo " "
exit 0
fi
echo " "
if [ "$1" = "." ]; then
debug "..using defaults"
else
debug "using arg overrides"
repositoryname="$1"
projectname="$2"
version="$3"
fi
echo "Building ${repositoryname}/${projectname}\n"
docker build -f devops/docker-image/build_image.dockerfile -t ${repositoryname}/${projectname} --rm .
status=$?
if [ $status -eq 0 ]; then
echo "\nImage built successfully.. test:\n"
echo " sh devops/docker-image/run_image.sh"
echo " "
echo "\nNext steps:"
echo " docker tag ${repositoryname}/${projectname} ${repositoryname}/${projectname}:${version}"
echo " docker push ${repositoryname}/${projectname}:${version} # requires docker login"\"
echo " "
echo " docker tag ${repositoryname}/${projectname} ${repositoryname}/${projectname}:latest"
echo " docker push ${repositoryname}/${projectname}:latest"
echo " "
echo "Image ready to deploy; e.g. on Azure: https://apilogicserver.github.io/Docs/DevOps-Containers-Deploy"
else
echo "docker build unsuccessful\n"
exit 1
fi
echo " "
exit 0
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/devops/docker-image/build_image.sh
|
build_image.sh
|
from typing import Dict, Tuple
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.orm import session
from sqlalchemy import event, MetaData, and_, or_
import safrs
from sqlalchemy import event, MetaData
from sqlalchemy.orm import with_loader_criteria, DeclarativeMeta
import logging, sys
from flask_jwt_extended import current_user
from config import Args
authentication_provider = Args.security_provider
security_logger = logging.getLogger(__name__)
security_logger.debug(f'\nAuthorization loaded via api_logic_server_run.py -- import \n')
db = safrs.DB # Use the safrs.DB, not db!
session = db.session # sqlalchemy.orm.scoping.scoped_session
class Security:
@classmethod
def set_user_sa(cls):
from flask import g
g.isSA = True
@classmethod
def current_user(cls):
"""
User code calls this as required to get user/roles (eg, multi-tenant client_id)
see https://flask-login.readthedocs.io/en/latest/
"""
return current_user
@staticmethod
@classmethod
def current_user_has_role(role_name: str) -> bool:
'''
Helper, e.g. rules can determine if update allowed
If user has role xyz, then for update authorization s/he can...
'''
result = False
for each_role in Security.current_user().UserRoleList:
if role_name == each_role.name:
result = True
break
return result
class Grant:
"""
Invoke these to declare Role Permissions.
Use code completion to discover models.
"""
grants_by_table : Dict[str, list[object]] = {}
'''
Dict keyed by Table name (obtained from class name), value is a (role, filter)
'''
def __init__(self, on_entity: DeclarativeMeta,
to_role: str = "",
filter: object = None):
'''
Create grant for <on_entity> / <to_role>
Example
=======
Grant( on_entity = models.Category, # use code completion
to_role = Roles.tenant,
filter = models.Category.Id == Security.current_user().client_id) # User table attributes
Args
----
on_entity: a class from models.py
to_role: valid role name from Authentication Provider
filter: where clause to be added
per calls from declare_security.py
'''
self.class_name : str = on_entity._s_class_name # type: ignore
self.role_name : str = to_role
self.filter = filter
self.entity :DeclarativeMeta = on_entity
self.table_name : str = on_entity.__tablename__ # type: ignore
if (self.table_name not in self.grants_by_table):
Grant.grants_by_table[self.table_name] = []
Grant.grants_by_table[self.table_name].append( self )
@staticmethod
def exec_grants(orm_execute_state):
'''
SQLAlchemy select event for current user's roles, append that role's grant filter to the SQL before execute
if you have a select() construct, you can add new AND things just calling .where() again.
e.g. existing_statement.where(or_(f1, f2)) .
u2 is a manager and a tenant
'''
user = Security.current_user()
mapper = orm_execute_state.bind_arguments['mapper']
table_name = mapper.persist_selectable.fullname # mapper.mapped_table.fullname disparaged
try:
from flask import g
if g.isSA or user.id == 'sa':
security_logger.debug("sa (eg, set_user_sa()) - no grants apply")
return
except:
security_logger.debug("no user - ok (eg, system initialization)")
if table_name in Grant.grants_by_table:
grant_list = list()
grant_entity = None
for each_grant in Grant.grants_by_table[table_name]:
grant_entity = each_grant.entity
for each_user_role in user.UserRoleList:
if each_grant.role_name == each_user_role.role_name:
security_logger.debug(f'Amend Grant for class / role: {table_name} / {each_grant.role_name} - {each_grant.filter}')
grant_list.append(each_grant.filter())
grant_filter = or_(*grant_list)
orm_execute_state.statement = orm_execute_state.statement.options(
with_loader_criteria(grant_entity, grant_filter ))
security_logger.debug(f"Grants applied for {table_name}")
else:
security_logger.debug(f"No Grants for {table_name}")
@event.listens_for(session, 'do_orm_execute')
def receive_do_orm_execute(orm_execute_state):
"listen for the 'do_orm_execute' event from SQLAlchemy"
if (
Args.security_enabled
and orm_execute_state.is_select
and not orm_execute_state.is_column_load
and not orm_execute_state.is_relationship_load
):
security_logger.debug(f'receive_do_orm_execute alive')
mapper = orm_execute_state.bind_arguments['mapper']
table_name = mapper.persist_selectable.fullname # mapper.mapped_table.fullname disparaged
if table_name == "User":
pass
security_logger.debug(f'No grants - avoid recursion on User table')
elif session._proxied._flushing: # type: ignore
security_logger.debug(f'No grants during logic processing')
else:
Grant.exec_grants(orm_execute_state) # SQL read check grants
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/security/system/authorization.py
|
authorization.py
|
import logging, sys
from flask import Flask
from flask import jsonify, request
from flask_jwt_extended import JWTManager
from flask_jwt_extended import jwt_required as jwt_required_ori
from flask_jwt_extended import create_access_token
from datetime import timedelta
from functools import wraps
import config
from config import Args
from security.authentication_provider.abstract_authentication_provider import Abstract_Authentication_Provider
from flask_cors import CORS, cross_origin
authentication_provider : Abstract_Authentication_Provider = config.Config.SECURITY_PROVIDER # type: ignore
# note: direct config access is disparaged, but used since args not set up when this imported
security_logger = logging.getLogger(__name__)
JWT_EXCLUDE = 'jwt_exclude'
def jwt_required(*args, **kwargs):
from flask import request
_jwt_required_ori = jwt_required_ori(*args, **kwargs)
def _wrapper(fn):
if request.endpoint == 'api.authentication-User.login':
return fn
return _jwt_required_ori(fn)
return _wrapper
def configure_auth(flask_app: Flask, database: object, method_decorators: list[object]):
"""
Called on server start by api_logic_server_run to
- initialize jwt
- establish Flask end points for login.
Args:
flask_app (Flask): _description_
database (object): _description_
method_decorators (object): _description_
Returns:
_type_: (no return)
"""
flask_app.config["PROPAGATE_EXCEPTIONS"] = True
flask_app.config["JWT_SECRET_KEY"] = "ApiLogicServerSecret" # Change this!
flask_app.config["JWT_ACCESS_TOKEN_EXPIRES"] = timedelta(minutes=222) # change as you see fit
flask_app.config["JWT_REFRESH_TOKEN_EXPIRES"] = timedelta(days=30)
jwt = JWTManager(flask_app)
@flask_app.route("/api/auth/login", methods=["POST"])
@cross_origin(supports_credentials=False)
def login():
"""
Post id/password, returns token to be placed in header of subsequent requests.
Returns:
string: access token
"""
if request.method == 'OPTIONS':
return jsonify(success=True)
username = request.json.get("username", None)
password = request.json.get("password", None)
user = authentication_provider.get_user(username, password)
if not user or not user.check_password(password):
return jsonify("Wrong username or password"), 401
access_token = create_access_token(identity=user) # serialize and encode
return jsonify(access_token=access_token)
@jwt.user_identity_loader
def user_identity_lookup(user):
return user.id
@jwt.user_lookup_loader
def user_lookup_callback(_jwt_header, jwt_data):
identity = jwt_data["sub"]
return authentication_provider.get_user(identity, "")
method_decorators.append(jwt_required())
security_logger.info("\nAuthentication loaded -- api calls now require authorization header")
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/security/system/authentication.py
|
authentication.py
|
from security.authentication_provider.abstract_authentication_provider import Abstract_Authentication_Provider
from typing import List, Optional
import safrs
from safrs import jsonapi_rpc
from safrs import SAFRSBase
from flask_jwt_extended import get_jwt_identity
from flask_jwt_extended import create_refresh_token
from flask_jwt_extended import create_access_token
from flask import abort
# **********************
# in mem auth provider
# **********************
users = {}
from dataclasses import dataclass
@dataclass
class DataClassUserRole:
role_name: str
class DataClassUser(safrs.JABase):
"""
Required machinery for swagger visibility
"""
def __init__(self, name: str, id: str, client_id: int, password: str):
self.id = id
self.password= password
self.client_id = client_id
self.name = name
self.UserRoleList = []
# called by authentication
def check_password(self, password=None):
# print(password)
return password == self.password
@classmethod
@jsonapi_rpc(http_methods=["POST"])
def login(self, *args, **kwargs): # yaml comment => swagger description
""" # yaml creates Swagger description
args :
id: u1
password: p
"""
# test using swagger -> try it out (includes sample data, above)
id = kwargs.get("id", None)
password = kwargs.get("password", None)
user = users[id]
if not user or not user.check_password(password):
abort(401, "Wrong username or password")
access_token = create_access_token(identity=user)
return { "access_token" : access_token}
@dataclass
class DataClassUserZ(SAFRSBase):
name: str
client_id: int
id: str
password: str
UserRoleList: Optional [List[DataClassUserRole]] = None
# called by authentication
def check_password(self, password=None):
# print(password)
return password == self.password
@classmethod
@jsonapi_rpc(valid_jsonapi=False)
def login(cls, *args, **kwargs):
"""
description: Login - Generate a JWT access token
args:
username: user
password: password
"""
username = kwargs.get("username", None)
password = kwargs.get("password", None)
user = users[id]
if not user or not user.check_password(password):
abort(401, "Wrong username or password")
access_token = create_access_token(identity=user)
return { "access_token" : access_token}
class Authentication_Provider(Abstract_Authentication_Provider):
@staticmethod
def get_user(id: str, password: str) -> object:
"""
Must return a row object with attributes name and UserRoleList (others as required)
role_list is a list of row objects with attribute name
row object is a DotMap (as here) or a SQLAlchemy row
"""
return users[id]
@staticmethod
def initialize(api):
api.expose_object(DataClassUser)
def add_user(name: str, id: int, password: str):
user = DataClassUser( name=name, id=name, client_id=id, password=password)
users[name] = user
return user
sam = add_user("sam", 1, "p")
sam_role_list = [DataClassUserRole(role_name="manager")]
sam.UserRoleList = sam_role_list
aneu = add_user("aneu", 1, "p")
aneu_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
aneu.UserRoleList = aneu_role_list
c1 = add_user("u1", 1, "p")
c1_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
c1.UserRoleList = c1_role_list
c2 = add_user("u2", 2, "p")
c2_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="renter")]
c2.UserRoleList = c1_role_list
m = add_user("mary", 5, "p")
m_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
m.UserRoleList = c1_role_list
sam_row = Authentication_Provider.get_user("sam", "")
print(f'Sam: {sam_row}')
"""
this is a super-simplistic auth_provider, to demonstrate the "provide your own" approach
will typically user provider for sql
to test
1. Create project: nw-
2. Use memory.auth_provider in config.py
3. Disable api/authentication_expose_api.py
"""
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/security/authentication_provider/memory/auth_provider.py
|
auth_provider.py
|
from security.authentication_provider.abstract_authentication_provider import Abstract_Authentication_Provider
from typing import List, Optional
from safrs import jsonapi_rpc
# **********************
# in mem auth provider
# **********************
users = {}
from dataclasses import dataclass
@dataclass
class DataClassUserRole:
role_name: str
@dataclass
class DataClassUser:
name: str
client_id: int
id: str
password: str
UserRoleList: Optional [List[DataClassUserRole]] = None
# called by authentication
def check_password(self, password=None):
# print(password)
return password == self.password
@classmethod
@jsonapi_rpc(valid_jsonapi=False)
def login(cls, *args, **kwargs):
"""
description: Login - Generate a JWT access token
args:
username: user
password: password
"""
username = kwargs.get("username", None)
password = kwargs.get("password", None)
user = users[id]
if not user or not user.check_password(password):
abort(401, "Wrong username or password")
access_token = create_access_token(identity=user)
return { "access_token" : access_token}
class Authentication_Provider(Abstract_Authentication_Provider):
@staticmethod
def get_user(id: str, password: str) -> object:
"""
Must return a row object with attributes name and UserRoleList (others as required)
role_list is a list of row objects with attribute name
row object is a DotMap (as here) or a SQLAlchemy row
"""
return users[id]
def add_user(name: str, id: int, password: str):
user = DataClassUser( name=name, id=name, client_id=id, password=password)
users[name] = user
return user
sam = add_user("sam", 1, "p")
sam_role_list = [DataClassUserRole(role_name="manager")]
sam.UserRoleList = sam_role_list
aneu = add_user("aneu", 1, "p")
aneu_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
aneu.UserRoleList = aneu_role_list
c1 = add_user("u1", 1, "p")
c1_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
c1.UserRoleList = c1_role_list
c2 = add_user("u2", 2, "p")
c2_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="renter")]
c2.UserRoleList = c1_role_list
m = add_user("mary", 5, "p")
m_role_list = [DataClassUserRole(role_name="manager"), DataClassUserRole(role_name="tenant")]
m.UserRoleList = c1_role_list
sam_row = Authentication_Provider.get_user("sam", "")
print(f'Sam: {sam_row}')
"""
this is a super-simplistic auth_provider, to demonstrate the "provide your own" approach
will typically user provider for sql
to test
1. Create project: nw-
2. Use memory.auth_provider in config.py
3. Disable api/authentication_expose_api.py
"""
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/security/authentication_provider/memory/auth_provider_no_swagger.py
|
auth_provider_no_swagger.py
|
from security.authentication_provider.abstract_authentication_provider import Abstract_Authentication_Provider
import sqlalchemy as sqlalchemy
import database.authentication_models as authentication_models
from flask import Flask
import safrs
from safrs.errors import JsonapiError
from dotmap import DotMap # a dict, but you can say aDict.name instead of aDict['name']... like a row
from sqlalchemy import inspect
from http import HTTPStatus
import logging
# **********************
# sql auth provider
# **********************
db = None
session = None
logger = logging.getLogger(__name__)
class ALSError(JsonapiError):
def __init__(self, message, status_code=HTTPStatus.BAD_REQUEST):
super().__init__()
self.message = message
self.status_code = status_code
class Authentication_Provider(Abstract_Authentication_Provider):
@staticmethod
def get_user(id: str, password: str = "") -> object:
"""
Must return a row object with attributes:
* name
* role_list: a list of row objects with attribute name
Args:
id (str): _description_
password (str, optional): _description_. Defaults to "".
Returns:
object: row object is a SQLAlchemy row
* Row Caution: https://docs.sqlalchemy.org/en/14/errors.html#error-bhk3
"""
def row_to_dotmap(row, row_class):
rtn_dotmap = DotMap()
mapper = inspect(row_class)
for each_column in mapper.columns:
rtn_dotmap[each_column.name] = getattr(row, each_column.name)
return rtn_dotmap
global db, session
if db is None:
db = safrs.DB # Use the safrs.DB for database access
session = db.session # sqlalchemy.orm.scoping.scoped_session
try:
user = session.query(authentication_models.User).filter(authentication_models.User.id == id).one()
except Exception as e:
logger.info(f'*****\nauth_provider FAILED looking for: {id}\n*****\n')
logger.info(f'excp: {str(e)}\n')
# raise e
raise ALSError(f"User {id} is not authorized for this system")
use_db_row = True
if use_db_row:
return user
else:
pass
rtn_user = row_to_dotmap(user, authentication_models.User)
rtn_user.UserRoleList = []
user_roles = getattr(user, "UserRoleList")
for each_row in user_roles:
each_user_role = row_to_dotmap(each_row, authentication_models.UserRole)
rtn_user.UserRoleList.append(each_user_role)
return rtn_user # returning user fails per caution above
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/security/authentication_provider/sql/auth_provider.py
|
auth_provider.py
|
import requests
from pathlib import Path
import os
import ast
import sys
import click
"""
Creates wiki file from test/behave/behave.log, with rule use.
Tips
* use 2 spaces (at end) for newline
* for tab: & emsp;
"""
tab = " "
behave_debug_info = " # "
wiki_data = []
debug_scenario = "XXGood Order Custom Service"
scenario_doc_strings = {}
""" dict of scenario_name, array of strings """
def remove_trailer(line: str) -> str:
""" remove everything after the ## """
end_here = line.find("\t\t##")
result = line[0:end_here]
return result
def line_spacer():
wiki_data.append("\n")
wiki_data.append(" ")
wiki_data.append(" ")
wiki_data.append("\n")
def get_current_readme(prepend_wiki: str):
""" initialize wiki_data with readme up to {report_name} """
report_name = "Behave Logic Report"
with open(prepend_wiki) as readme:
readme_lines = readme.readlines()
need_spacer = True
for each_readme_line in readme_lines:
if '# ' + report_name in each_readme_line:
need_spacer = False
break
wiki_data.append(each_readme_line[0:-1])
if need_spacer:
line_spacer()
wiki_data.append(f'# {report_name}')
def get_truncated_scenario_name(scenario_name: str) -> str:
""" address max file length (chop at 26), illegal characters """
scenario_trunc = scenario_name
if scenario_trunc is not None and len(scenario_trunc) >= 26:
scenario_trunc = scenario_name[0:25]
scenario_trunc = f'{str(scenario_trunc).replace(" ", "_")}'
return scenario_trunc
def show_logic(scenario: str, logic_logs_dir: str):
""" insert s{logic_logs_dir}/scenario.log into wiki_data as disclosure area """
scenario_trunc = get_truncated_scenario_name(scenario)
logic_file_name = f'{logic_logs_dir}/{scenario_trunc}.log'
logic_file_name_path = Path(logic_file_name)
if not logic_file_name_path.is_file(): # debug code
# wiki_data.append(f'unable to find Logic Log file: {logic_file_name}')
if scenario == debug_scenario:
print(f'RELATIVE: {logic_file_name} in {os.getcwd()}')
full_name = f'{os.getcwd()}/{logic_file_name}'
print(f'..FULL: {os.getcwd()}/{logic_file_name}')
logic_file_name = '{logic_logs_dir}/test.log'
with open(logic_file_name) as logic:
logic_lines = logic.readlines()
else:
logic_log = []
rules_used = []
wiki_data.append("<details markdown>")
wiki_data.append("<summary>Tests - and their logic - are transparent.. click to see Logic</summary>")
line_spacer()
scenario_trunc = get_truncated_scenario_name(scenario)
if scenario_trunc in scenario_doc_strings:
wiki_data.append(f'**Logic Doc** for scenario: {scenario}')
wiki_data.append(" ")
for each_doc_string_line in scenario_doc_strings[scenario_trunc]:
wiki_data.append(each_doc_string_line[0: -1])
line_spacer()
wiki_data.append(f'**Rules Used** in Scenario: {scenario}')
wiki_data.append("```")
with open(logic_file_name) as logic:
logic_lines = logic.readlines()
is_logic_log = True
for each_logic_line in logic_lines:
each_logic_line = remove_trailer(each_logic_line)
if is_logic_log:
if "Rules Fired" in each_logic_line:
is_logic_log = False
continue
else:
logic_log.append(each_logic_line)
else:
if 'logic_logger - INFO' in each_logic_line:
pass
break
wiki_data.append(each_logic_line + " ")
wiki_data.append("```")
wiki_data.append(f'**Logic Log** in Scenario: {scenario}')
wiki_data.append("```")
for each_logic_log in logic_log:
each_line = remove_trailer(each_logic_log)
wiki_data.append(each_line)
wiki_data.append("```")
wiki_data.append("</details>")
def get_docStrings(steps_dir: str):
steps_dir_files = os.listdir(steps_dir)
indent = 4 # skip leading blanks
for each_steps_dir_file in steps_dir_files:
each_steps_dir_file_path = Path(steps_dir).joinpath(each_steps_dir_file)
if each_steps_dir_file_path.is_file():
with open(each_steps_dir_file_path) as f:
step_code = f.readlines()
# print(f'Found File: {str(each_steps_dir_file_path)}')
for index, each_step_code_line in enumerate(step_code):
if each_step_code_line.startswith('@when'):
comment_start = index + 2
if '"""' in step_code[comment_start]:
# print(".. found doc string")
doc_string_line = comment_start+1
doc_string = []
while (True):
if '"""' in step_code[doc_string_line]:
break
doc_string.append(step_code[doc_string_line][indent:])
doc_string_line += 1
scenario_line = doc_string_line+1
if 'scenario_name' not in step_code[scenario_line]:
print(f'\n** Warning - scenario_name not found '\
f'in file {str(each_steps_dir_file_path)}, '\
f'after line {scenario_line} -- skipped')
else:
scenario_code_line = step_code[scenario_line]
scenario_name_start = scenario_code_line.find("'") + 1
scenario_name_end = scenario_code_line[scenario_name_start+1:].find("'")
scenario_name = scenario_code_line[scenario_name_start:
scenario_name_end + scenario_name_start+1]
if scenario_name == debug_scenario:
print(f'got {debug_scenario}')
scenario_trunc = get_truncated_scenario_name(scenario_name)
# print(f'.... truncated scenario_name: {scenario_trunc} in {scenario_code_line}')
scenario_doc_strings[scenario_trunc] = doc_string
# print("that's all, folks")
def main(behave_log: str, scenario_logs: str, wiki: str, prepend_wiki: str):
""" main driver """
get_docStrings(steps_dir="features/steps")
get_current_readme(prepend_wiki=prepend_wiki)
contents = None
with open(behave_log) as f:
contents = f.readlines()
just_saw_then = False
current_scenario = ""
for each_line in contents:
if just_saw_then and each_line == "\n":
show_logic(scenario=current_scenario, logic_logs_dir=scenario_logs)
just_saw_then = False
if each_line.startswith("Feature"):
wiki_data.append(" ")
wiki_data.append(" ")
each_line = "## " + each_line
if each_line.startswith(" Scenario"):
each_line = tab + each_line
if each_line.startswith(" Given") or \
each_line.startswith(" When") or \
each_line.startswith(" Then"):
if each_line.startswith(" Then"):
just_saw_then = True
each_line = tab + tab + each_line
each_line = each_line[:-1]
debug_loc = each_line.find(behave_debug_info)
if debug_loc > 0:
each_line = each_line[0 : debug_loc]
each_line = each_line.rstrip()
if "Scenario" in each_line:
current_scenario = each_line[18:]
wiki_data.append(" ")
wiki_data.append(" ")
wiki_data.append("### " + each_line[8:])
each_line = each_line + " " # wiki for "new line"
wiki_data.append(each_line)
with open(wiki, 'w') as rpt:
rpt.write('\n'.join(wiki_data))
wiki_full_path = Path(wiki).absolute()
print(f'Wiki Output: {wiki_full_path}\n\n')
def print_args(args, msg):
print(msg)
for each_arg in args:
print(f' {each_arg}')
print(" ")
@click.group()
@click.pass_context
def cli(ctx):
"""
Combine behave.log and scenario_logic_logs to create Behave Logic Report
"""
pass
@cli.command("run")
@click.pass_context
@click.option('--behave_log',
default=f'logs/behave.log', # cwd set to test/api_logic_server_behave
# prompt="Log from behave test suite run [behave.log]",
help="Help")
@click.option('--scenario_logs',
default=f'logs/scenario_logic_logs',
# prompt="Logic Log directory from ",
help="Help")
@click.option('--wiki',
default=f'reports/Behave Logic Report.md',
# prompt="Log from behave test suite run [api_logic_server_behave]",
help="Help")
@click.option('--prepend_wiki',
default=f'reports/Behave Logic Report Intro micro.md',
# prompt="Log from behave test suite run [Behave Logic Report Intro]",
help="Help")
def run(ctx, behave_log: str, scenario_logs: str, wiki: str, prepend_wiki: str):
main(behave_log = behave_log, scenario_logs = scenario_logs, wiki = wiki, prepend_wiki = prepend_wiki)
if __name__ == '__main__': # debugger & python command line start here
# eg: python api_logic_server_cli/cli.py create --project_name=~/Desktop/test_project
# unix: python api_logic_server_cli/cli.py create --project_name=/home/ApiLogicProject
print(f'\nBehave Logic Report 1.1, started at {os.getcwd()}')
commands = sys.argv
if len(sys.argv) > 1:
print_args(commands, f'\n\nCommand Line Arguments:')
cli()
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/test/api_logic_server_behave/behave_logic_report.py
|
behave_logic_report.py
|
# Behave Creates Executable Test Suite, Documentation
You can optionally use the Behave test framework to (here is an [Agile Approach for using Behave](https://github.com/valhuber/ApiLogicServer/wiki/Logic:-Tutorial)):
1. **Create and Run an Executable Test Suite:** in your IDE, create test definitions (similar to what is shown in the report below), and Python code to execute tests. You can then execute your test suite with 1 command.
2. **Requirements and Test Documentation:** as shown below, you can then create a wiki report that documents your requirements, and the tests (**Scenarios**) that confirm their proper operation.
* **Integrated Logic Documentation:** the report integrates your logic, including a logic report showing your logic (rules and Python), and a Logic Log that shows exactly how the rules executed. Logic Doc is transparent to business users, so can further contribute to Agile Collaboration.
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/behave-summary.png?raw=true" height="600"></figure>
[Behave](https://behave.readthedocs.io/en/stable/tutorial.html) is a framework for defining and executing tests. It is based on [TDD (Test Driven Development)](http://dannorth.net/introducing-bdd/), an Agile approach for defining system requirements as executable tests.
# Using Behave
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/TDD-ide.png?raw=true"></figure>
Behave is pre-installed with API Logic Server. Use it as shown above:
1. Create `.feature` files to define ***Scenarios*** (aka tests) for ***Features*** (aka Stories)
2. Code `.py` files to implement Scenario tests
3. Run Test Suite: Launch Configuration `Behave Run`. This runs all your Scenarios, and produces a summary report of your Features and the test results.
4. Report: Launch Configuration `Behave Report` to create the wiki file shown at the top of this page.
These steps are further defined, below. Explore the samples in the sample project.
## 1. Create `.feature` file to define Scenario
Feature (aka Story) files are designed to promote IT / business user collaboration.
## 2. Code `.py` file to implement test
Implement your tests in Python. Here, the tests are largely _read existing data_, _run transaction_, and _test results_, using the API. You can obtain the URLs from the swagger.
Key points:
* Link your scenario / implementations with annotations, as shown for _Order Placed with excessive quantity_.
* Include the `test_utils.prt()` call; be sure to use specify the scenario name as the 2nd argument. This is what drives the name of the Logic Log file, discussed below.
* Optionally, include a Python docstring on your `when` implementation as shown above, delimited by `"""` strings (see _"Familiar logic pattern"_ in the screen shot, above). If provided, this will be written into the wiki report.
* Important: the system assumes the following line identifies the scenario_name; be sure to include it.
## 3. Run Test Suite: Launch Configuration `Behave Run`
You can now execute your Test Suite. Run the `Behave Run` Launch Configuration, and Behave will run all of the tests, producing the outputs (`behave.log` and `<scenario.logs>` shown above.
* Windows users will need to run `Windows Behave Run`
* You can run just 1 scenario using `Behave Scenario`
* You can set breakpoints in your tests
The server must be running for these tests. Use the Launch Configuration `ApiLogicServer`, or `python api_logic_server_run.py`. The latter does not run the debugger, which you may find more convenient since changes to your test code won't restart the server.
## 4. Report: Launch Configuration `Behave Report'
Run this to create the wiki reports from the logs in step 3.
# Behave Logic Report
## Feature: About Sample
### Scenario: Transaction Processing
  Scenario: Transaction Processing
   Given Sample Database
   When Transactions are submitted
   Then Enforce business policies with Logic (rules + code)
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Rules Used** in Scenario: Transaction Processing
```
```
**Logic Log** in Scenario: Transaction Processing
```
Rule Bank[0x112748b20] (loaded 2022-04-24 11:30:09.684176
Mapped Class[Customer] rules
Constraint Function: None
Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>
Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>
Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None
Mapped Class[Order] rules
Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None
RowEvent Order.congratulate_sales_rep()
Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None
RowEvent Order.clone_order()
Mapped Class[OrderDetail] rules
Derive OrderDetail.Amount as Formula (1): as_expression=lambda row: row.UnitPrice * row.Qua [...
Derive OrderDetail.UnitPrice as Copy(Product.UnitPrice
Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDat
Mapped Class[Product] rules
Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>
Derive Product.UnitsInStock as Formula (1): <function
Mapped Class[Employee] rules
Constraint Function: <function declare_logic.<locals>.raise_over_20_percent at 0x1129501f0>
RowEvent Employee.audit_by_event()
Copy to: EmployeeAudi
Logic Bank - 22 rules loaded - 2022-04-24 11:30:21,866 - logic_logger - INF
```
</details>
## Feature: Application Integration
### Scenario: GET Customer
  Scenario: GET Customer
   Given Customer Account: VINET
   When GET Orders API
   Then VINET retrieved
### Scenario: GET Department
  Scenario: GET Department
   Given Department 2
   When GET Department with SubDepartments API
   Then SubDepartments returned
## Feature: Place Order
### Scenario: Good Order Custom Service
  Scenario: Good Order Custom Service
   Given Customer Account: ALFKI
   When Good Order Placed
   Then Logic adjusts Balance (demo: chain up)
   Then Logic adjusts Products Reordered
   Then Logic sends email to salesrep
   Then Logic adjusts aggregates down on delete order
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Good Order Custom Service
We place an Order with an Order Detail. It's one transaction.
Note how the `Order.OrderTotal` and `Customer.Balance` are *adjusted* as Order Details are processed.
Similarly, the `Product.UnitsShipped` is adjusted, and used to recompute `UnitsInStock`
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/declare-logic.png?raw=true"></figure>
> **Key Takeaway:** sum/count aggregates (e.g., `Customer.Balance`) automate ***chain up*** multi-table transactions.
**Events - Extensible Logic**
Inspect the log for __Hi, Andrew - Congratulate Nancy on their new order__.
The `congratulate_sales_rep` event illustrates logic
[Extensibility](https://github.com/valhuber/LogicBank/wiki/Rule-Extensibility)
- using Python to provide logic not covered by rules,
like non-database operations such as sending email or messages.
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/send-email.png?raw=true"></figure>
There are actually multiple kinds of events:
* *Before* row logic
* *After* row logic
* On *commit,* after all row logic has completed (as here), so that your code "sees" the full logic results
Events are passed the `row` and `old_row`, as well as `logic_row` which enables you to test the actual operation, chaining nest level, etc.
You can set breakpoints in events, and inspect these.
**Rules Used** in Scenario: Good Order Custom Service
```
Customer
1. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
2. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
3. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
4. RowEvent Order.congratulate_sales_rep()
5. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
6. RowEvent Order.clone_order()
7. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
8. Derive OrderDetail.UnitPrice as Copy(Product.UnitPrice)
9. Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDate
10. Derive OrderDetail.Amount as Formula (1): as_expression=lambda row: row.UnitPrice * row.Qua [...]
Product
11. Derive Product.UnitsInStock as Formula (1): <function>
12. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Good Order Custom Service
```
Logic Phase: ROW LOGIC(session=0x112f92e50) (sqlalchemy before_flush) - 2022-04-24 11:30:22,093 - logic_logger - INF
..OrderDetail[None] {Insert - client} Id: None, OrderId: None, ProductId: 1, UnitPrice: None, Quantity: 1, Discount: 0, Amount: None, ShippedDate: None row: 0x112fafd00 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,094 - logic_logger - INF
..OrderDetail[None] {copy_rules for role: Product - UnitPrice} Id: None, OrderId: None, ProductId: 1, UnitPrice: 18.0000000000, Quantity: 1, Discount: 0, Amount: None, ShippedDate: None row: 0x112fafd00 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,099 - logic_logger - INF
..OrderDetail[None] {Formula Amount} Id: None, OrderId: None, ProductId: 1, UnitPrice: 18.0000000000, Quantity: 1, Discount: 0, Amount: 18.0000000000, ShippedDate: None row: 0x112fafd00 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,101 - logic_logger - INF
....Product[1] {Update - Adjusting Product: UnitsShipped} Id: 1, ProductName: Chai, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 10 boxes x 20 bags, UnitPrice: 18.0000000000, UnitsInStock: 39, UnitsOnOrder: 0, ReorderLevel: 10, Discontinued: 0, UnitsShipped: [0-->] 1 row: 0x112fafee0 session: 0x112f92e50 ins_upd_dlt: upd - 2022-04-24 11:30:22,102 - logic_logger - INF
....Product[1] {Formula UnitsInStock} Id: 1, ProductName: Chai, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 10 boxes x 20 bags, UnitPrice: 18.0000000000, UnitsInStock: [39-->] 38, UnitsOnOrder: 0, ReorderLevel: 10, Discontinued: 0, UnitsShipped: [0-->] 1 row: 0x112fafee0 session: 0x112f92e50 ins_upd_dlt: upd - 2022-04-24 11:30:22,103 - logic_logger - INF
....Order[None] {Adjustment logic chaining deferred for this parent parent do_defer_adjustment: True, is_parent_submitted: True, is_parent_row_processed: False, Order} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: [None-->] 18.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: [None-->] 1, CloneFromOrder: None row: 0x112f92d60 session: 0x112f92e50 ins_upd_dlt: * - 2022-04-24 11:30:22,107 - logic_logger - INF
..OrderDetail[None] {Insert - client} Id: None, OrderId: None, ProductId: 2, UnitPrice: None, Quantity: 2, Discount: 0, Amount: None, ShippedDate: None row: 0x112fafe80 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,108 - logic_logger - INF
..OrderDetail[None] {copy_rules for role: Product - UnitPrice} Id: None, OrderId: None, ProductId: 2, UnitPrice: 19.0000000000, Quantity: 2, Discount: 0, Amount: None, ShippedDate: None row: 0x112fafe80 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,111 - logic_logger - INF
..OrderDetail[None] {Formula Amount} Id: None, OrderId: None, ProductId: 2, UnitPrice: 19.0000000000, Quantity: 2, Discount: 0, Amount: 38.0000000000, ShippedDate: None row: 0x112fafe80 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,111 - logic_logger - INF
....Product[2] {Update - Adjusting Product: UnitsShipped} Id: 2, ProductName: Chang, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 24 - 12 oz bottles, UnitPrice: 19.0000000000, UnitsInStock: 17, UnitsOnOrder: 40, ReorderLevel: 25, Discontinued: 0, UnitsShipped: [0-->] 2 row: 0x112fcae50 session: 0x112f92e50 ins_upd_dlt: upd - 2022-04-24 11:30:22,112 - logic_logger - INF
....Product[2] {Formula UnitsInStock} Id: 2, ProductName: Chang, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 24 - 12 oz bottles, UnitPrice: 19.0000000000, UnitsInStock: [17-->] 15, UnitsOnOrder: 40, ReorderLevel: 25, Discontinued: 0, UnitsShipped: [0-->] 2 row: 0x112fcae50 session: 0x112f92e50 ins_upd_dlt: upd - 2022-04-24 11:30:22,113 - logic_logger - INF
....Order[None] {Adjustment logic chaining deferred for this parent parent do_defer_adjustment: True, is_parent_submitted: True, is_parent_row_processed: False, Order} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: [18.0000000000-->] 56.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: [1-->] 2, CloneFromOrder: None row: 0x112f92d60 session: 0x112f92e50 ins_upd_dlt: * - 2022-04-24 11:30:22,116 - logic_logger - INF
..Order[None] {Insert - client} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: 56.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: 2, CloneFromOrder: None row: 0x112f92d60 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,117 - logic_logger - INF
....Customer[ALFKI] {Update - Adjusting Customer: Balance, UnpaidOrderCount, OrderCount} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 2158.0000000000, CreditLimit: 2300.0000000000, OrderCount: [15-->] 16, UnpaidOrderCount: [10-->] 11 row: 0x112fde340 session: 0x112f92e50 ins_upd_dlt: upd - 2022-04-24 11:30:22,126 - logic_logger - INF
Logic Phase: COMMIT(session=0x112f92e50) - 2022-04-24 11:30:22,128 - logic_logger - INF
..Order[None] {Commit Event} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: 56.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: 2, CloneFromOrder: None row: 0x112f92d60 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,130 - logic_logger - INF
..Order[None] {Hi, Andrew - Congratulate Nancy on their new order} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: 56.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: 2, CloneFromOrder: None row: 0x112f92d60 session: 0x112f92e50 ins_upd_dlt: ins - 2022-04-24 11:30:22,134 - logic_logger - INF
```
</details>
### Scenario: Bad Order Custom Service
  Scenario: Bad Order Custom Service
   Given Customer Account: ALFKI
   When Order Placed with excessive quantity
   Then Rejected per Check Credit
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Bad Order Custom Service
Familiar logic patterns:
* Constrain a derived result
* Chain up, to adjust parent sum/count aggregates
Logic Design ("Cocktail Napkin Design")
* Customer.Balance <= CreditLimit
* Customer.Balance = Sum(Order.AmountTotal where unshipped)
* Order.AmountTotal = Sum(OrderDetail.Amount)
* OrderDetail.Amount = Quantity * UnitPrice
* OrderDetail.UnitPrice = copy from Product
**Rules Used** in Scenario: Bad Order Custom Service
```
Customer
1. Constraint Function: None
2. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
3. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
4. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
5. RowEvent Order.clone_order()
6. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
7. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
8. Derive OrderDetail.UnitPrice as Copy(Product.UnitPrice)
9. Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDate
10. Derive OrderDetail.Amount as Formula (1): as_expression=lambda row: row.UnitPrice * row.Qua [...]
Product
11. Derive Product.UnitsInStock as Formula (1): <function>
12. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Bad Order Custom Service
```
Logic Phase: ROW LOGIC(session=0x1130778b0) (sqlalchemy before_flush) - 2022-04-24 11:30:22,485 - logic_logger - INF
..Order[None] {Insert - client} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 10, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: None, Country: None, City: None, Ready: None, OrderDetailCount: None, CloneFromOrder: None row: 0x113077610 session: 0x1130778b0 ins_upd_dlt: ins - 2022-04-24 11:30:22,486 - logic_logger - INF
....Customer[ALFKI] {Update - Adjusting Customer: UnpaidOrderCount, OrderCount} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: 2102.0000000000, CreditLimit: 2300.0000000000, OrderCount: [15-->] 16, UnpaidOrderCount: [10-->] 11 row: 0x113068490 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,492 - logic_logger - INF
..OrderDetail[None] {Insert - client} Id: None, OrderId: None, ProductId: 1, UnitPrice: None, Quantity: 1111, Discount: 0, Amount: None, ShippedDate: None row: 0x113077eb0 session: 0x1130778b0 ins_upd_dlt: ins - 2022-04-24 11:30:22,495 - logic_logger - INF
..OrderDetail[None] {copy_rules for role: Product - UnitPrice} Id: None, OrderId: None, ProductId: 1, UnitPrice: 18.0000000000, Quantity: 1111, Discount: 0, Amount: None, ShippedDate: None row: 0x113077eb0 session: 0x1130778b0 ins_upd_dlt: ins - 2022-04-24 11:30:22,497 - logic_logger - INF
..OrderDetail[None] {Formula Amount} Id: None, OrderId: None, ProductId: 1, UnitPrice: 18.0000000000, Quantity: 1111, Discount: 0, Amount: 19998.0000000000, ShippedDate: None row: 0x113077eb0 session: 0x1130778b0 ins_upd_dlt: ins - 2022-04-24 11:30:22,498 - logic_logger - INF
....Product[1] {Update - Adjusting Product: UnitsShipped} Id: 1, ProductName: Chai, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 10 boxes x 20 bags, UnitPrice: 18.0000000000, UnitsInStock: 40, UnitsOnOrder: 0, ReorderLevel: 10, Discontinued: 0, UnitsShipped: [-1-->] 1110 row: 0x113077790 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,499 - logic_logger - INF
....Product[1] {Formula UnitsInStock} Id: 1, ProductName: Chai, SupplierId: 1, CategoryId: 1, QuantityPerUnit: 10 boxes x 20 bags, UnitPrice: 18.0000000000, UnitsInStock: [40-->] -1071, UnitsOnOrder: 0, ReorderLevel: 10, Discontinued: 0, UnitsShipped: [-1-->] 1110 row: 0x113077790 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,501 - logic_logger - INF
....Order[None] {Update - Adjusting Order: AmountTotal, OrderDetailCount} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 10, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: [None-->] 19998.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: [None-->] 1, CloneFromOrder: None row: 0x113077610 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,503 - logic_logger - INF
......Customer[ALFKI] {Update - Adjusting Customer: Balance} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 22100.0000000000, CreditLimit: 2300.0000000000, OrderCount: 16, UnpaidOrderCount: 11 row: 0x113068490 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,505 - logic_logger - INF
......Customer[ALFKI] {Constraint Failure: balance (22100.0000000000) exceeds credit (2300.0000000000)} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 22100.0000000000, CreditLimit: 2300.0000000000, OrderCount: 16, UnpaidOrderCount: 11 row: 0x113068490 session: 0x1130778b0 ins_upd_dlt: upd - 2022-04-24 11:30:22,506 - logic_logger - INF
```
</details>
### Scenario: Alter Item Qty to exceed credit
  Scenario: Alter Item Qty to exceed credit
   Given Customer Account: ALFKI
   When Order Detail Quantity altered very high
   Then Rejected per Check Credit
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Alter Item Qty to exceed credit
Same constraint as above.
> **Key Takeaway:** Automatic Reuse (_design one, solve many_)
**Rules Used** in Scenario: Alter Item Qty to exceed credit
```
Customer
1. Constraint Function: None
2. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
3. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
4. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
5. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
6. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
7. Derive OrderDetail.Amount as Formula (1): as_expression=lambda row: row.UnitPrice * row.Qua [...]
Product
8. Derive Product.UnitsInStock as Formula (1): <function>
9. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Alter Item Qty to exceed credit
```
Logic Phase: ROW LOGIC(session=0x113077df0) (sqlalchemy before_flush) - 2022-04-24 11:30:22,614 - logic_logger - INF
..OrderDetail[1040] {Update - client} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: [15-->] 1110, Discount: 0.25, Amount: 684.0000000000, ShippedDate: None row: 0x113057d90 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,615 - logic_logger - INF
..OrderDetail[1040] {Formula Amount} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: [15-->] 1110, Discount: 0.25, Amount: [684.0000000000-->] 50616.0000000000, ShippedDate: None row: 0x113057d90 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,616 - logic_logger - INF
..OrderDetail[1040] {Prune Formula: ShippedDate [['Order.ShippedDate']]} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: [15-->] 1110, Discount: 0.25, Amount: [684.0000000000-->] 50616.0000000000, ShippedDate: None row: 0x113057d90 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,617 - logic_logger - INF
....Product[28] {Update - Adjusting Product: UnitsShipped} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: 26, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] 1095 row: 0x11311c7f0 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,619 - logic_logger - INF
....Product[28] {Formula UnitsInStock} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: [26-->] -1069, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] 1095 row: 0x11311c7f0 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,620 - logic_logger - INF
....Order[10643] {Update - Adjusting Order: AmountTotal} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: 2013-09-22, ShippedDate: None, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: [1086.00-->] 51018.0000000000, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x113077820 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,625 - logic_logger - INF
......Customer[ALFKI] {Update - Adjusting Customer: Balance} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 52034.0000000000, CreditLimit: 2300.0000000000, OrderCount: 15, UnpaidOrderCount: 10 row: 0x1130777c0 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,628 - logic_logger - INF
......Customer[ALFKI] {Constraint Failure: balance (52034.0000000000) exceeds credit (2300.0000000000)} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 52034.0000000000, CreditLimit: 2300.0000000000, OrderCount: 15, UnpaidOrderCount: 10 row: 0x1130777c0 session: 0x113077df0 ins_upd_dlt: upd - 2022-04-24 11:30:22,629 - logic_logger - INF
```
</details>
### Scenario: Alter Required Date - adjust logic pruned
  Scenario: Alter Required Date - adjust logic pruned
   Given Customer Account: ALFKI
   When Order RequiredDate altered (2013-10-13)
   Then Balance not adjusted
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Alter Required Date - adjust logic pruned
We set `Order.RequiredDate`.
This is a normal update. Nothing depends on the columns altered, so this has no effect on the related Customer, Order Details or Products. Contrast this to the *Cascade Update Test* and the *Custom Service* test, where logic chaining affects related rows. Only the commit event fires.
> **Key Takeaway:** rule pruning automatically avoids unnecessary SQL overhead.
**Rules Used** in Scenario: Alter Required Date - adjust logic pruned
```
Customer
1. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
2. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
3. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
4. RowEvent Order.congratulate_sales_rep()
5. RowEvent Order.clone_order()
```
**Logic Log** in Scenario: Alter Required Date - adjust logic pruned
```
Logic Phase: ROW LOGIC(session=0x113129c70) (sqlalchemy before_flush) - 2022-04-24 11:30:22,726 - logic_logger - INF
..Order[10643] {Update - client} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: [2013-09-22-->] 2013-10-13 00:00:00, ShippedDate: None, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11314d130 session: 0x113129c70 ins_upd_dlt: upd - 2022-04-24 11:30:22,728 - logic_logger - INF
Logic Phase: COMMIT(session=0x113129c70) - 2022-04-24 11:30:22,730 - logic_logger - INF
..Order[10643] {Commit Event} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: [2013-09-22-->] 2013-10-13 00:00:00, ShippedDate: None, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11314d130 session: 0x113129c70 ins_upd_dlt: upd - 2022-04-24 11:30:22,731 - logic_logger - INF
```
</details>
### Scenario: Set Shipped - adjust logic reuse
  Scenario: Set Shipped - adjust logic reuse
   Given Customer Account: ALFKI
   When Order ShippedDate altered (2013-10-13)
   Then Balance reduced 1086
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Set Shipped - adjust logic reuse
We set `Order.ShippedDate`.
This cascades to the Order Details, per the `derive=models.OrderDetail.ShippedDate` rule.
This chains to adjust the `Product.UnitsShipped` and recomputes `UnitsInStock`, as above
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/order-shipped-date.png?raw=true"></figure>
> **Key Takeaway:** parent references (e.g., `OrderDetail.ShippedDate`) automate ***chain-down*** multi-table transactions.
> **Key Takeaway:** Automatic Reuse (_design one, solve many_)
**Rules Used** in Scenario: Set Shipped - adjust logic reuse
```
Customer
1. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
2. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
3. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
4. RowEvent Order.congratulate_sales_rep()
5. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
6. RowEvent Order.clone_order()
7. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
8. Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDate
Product
9. Derive Product.UnitsInStock as Formula (1): <function>
10. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Set Shipped - adjust logic reuse
```
Logic Phase: ROW LOGIC(session=0x113129dc0) (sqlalchemy before_flush) - 2022-04-24 11:30:22,931 - logic_logger - INF
..Order[10643] {Update - client} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: 2013-10-13, ShippedDate: [None-->] 2013-10-13, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11314da90 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,932 - logic_logger - INF
....Customer[ALFKI] {Update - Adjusting Customer: Balance, UnpaidOrderCount} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 1016.0000000000, CreditLimit: 2300.0000000000, OrderCount: 15, UnpaidOrderCount: [10-->] 9 row: 0x1131698e0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,936 - logic_logger - INF
....OrderDetail[1040] {Update - Cascading Order.ShippedDate (,...)} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: None row: 0x113169280 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,940 - logic_logger - INF
....OrderDetail[1040] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: None row: 0x113169280 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,941 - logic_logger - INF
....OrderDetail[1040] {Formula ShippedDate} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: [None-->] 2013-10-13 row: 0x113169280 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,942 - logic_logger - INF
......Product[28] {Update - Adjusting Product: UnitsShipped} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: 26, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] -15 row: 0x1131691c0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,944 - logic_logger - INF
......Product[28] {Formula UnitsInStock} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: [26-->] 41, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] -15 row: 0x1131691c0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,945 - logic_logger - INF
....OrderDetail[1041] {Update - Cascading Order.ShippedDate (,...)} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: None row: 0x1131698b0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,947 - logic_logger - INF
....OrderDetail[1041] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: None row: 0x1131698b0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,947 - logic_logger - INF
....OrderDetail[1041] {Formula ShippedDate} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: [None-->] 2013-10-13 row: 0x1131698b0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,948 - logic_logger - INF
......Product[39] {Update - Adjusting Product: UnitsShipped} Id: 39, ProductName: Chartreuse verte, SupplierId: 18, CategoryId: 1, QuantityPerUnit: 750 cc per bottle, UnitPrice: 18.0000000000, UnitsInStock: 69, UnitsOnOrder: 0, ReorderLevel: 5, Discontinued: 0, UnitsShipped: [0-->] -21 row: 0x113169b50 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,950 - logic_logger - INF
......Product[39] {Formula UnitsInStock} Id: 39, ProductName: Chartreuse verte, SupplierId: 18, CategoryId: 1, QuantityPerUnit: 750 cc per bottle, UnitPrice: 18.0000000000, UnitsInStock: [69-->] 90, UnitsOnOrder: 0, ReorderLevel: 5, Discontinued: 0, UnitsShipped: [0-->] -21 row: 0x113169b50 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,951 - logic_logger - INF
....OrderDetail[1042] {Update - Cascading Order.ShippedDate (,...)} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: None row: 0x1131696d0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,953 - logic_logger - INF
....OrderDetail[1042] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: None row: 0x1131696d0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,954 - logic_logger - INF
....OrderDetail[1042] {Formula ShippedDate} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: [None-->] 2013-10-13 row: 0x1131696d0 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,954 - logic_logger - INF
......Product[46] {Update - Adjusting Product: UnitsShipped} Id: 46, ProductName: Spegesild, SupplierId: 21, CategoryId: 8, QuantityPerUnit: 4 - 450 g glasses, UnitPrice: 12.0000000000, UnitsInStock: 95, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 0, UnitsShipped: [0-->] -2 row: 0x113172250 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,956 - logic_logger - INF
......Product[46] {Formula UnitsInStock} Id: 46, ProductName: Spegesild, SupplierId: 21, CategoryId: 8, QuantityPerUnit: 4 - 450 g glasses, UnitPrice: 12.0000000000, UnitsInStock: [95-->] 97, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 0, UnitsShipped: [0-->] -2 row: 0x113172250 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,957 - logic_logger - INF
Logic Phase: COMMIT(session=0x113129dc0) - 2022-04-24 11:30:22,959 - logic_logger - INF
..Order[10643] {Commit Event} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: 2013-10-13, ShippedDate: [None-->] 2013-10-13, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11314da90 session: 0x113129dc0 ins_upd_dlt: upd - 2022-04-24 11:30:22,961 - logic_logger - INF
```
</details>
### Scenario: Reset Shipped - adjust logic reuse
  Scenario: Reset Shipped - adjust logic reuse
   Given Shipped Order
   When Order ShippedDate set to None
   Then Logic adjusts Balance by -1086
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Reset Shipped - adjust logic reuse
Same logic as above.
> **Key Takeaway:** Automatic Reuse (_design one, solve many_)
**Rules Used** in Scenario: Reset Shipped - adjust logic reuse
```
Customer
1. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
2. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
3. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
4. RowEvent Order.congratulate_sales_rep()
5. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
6. RowEvent Order.clone_order()
7. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
8. Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDate
Product
9. Derive Product.UnitsInStock as Formula (1): <function>
10. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Reset Shipped - adjust logic reuse
```
Logic Phase: ROW LOGIC(session=0x11317f5e0) (sqlalchemy before_flush) - 2022-04-24 11:30:23,163 - logic_logger - INF
..Order[10643] {Update - client} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: 2013-10-13, ShippedDate: [2013-10-13-->] None, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11317f850 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,164 - logic_logger - INF
....Customer[ALFKI] {Update - Adjusting Customer: Balance, UnpaidOrderCount} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [1016.0000000000-->] 2102.0000000000, CreditLimit: 2300.0000000000, OrderCount: 15, UnpaidOrderCount: [9-->] 10 row: 0x11317fe80 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,167 - logic_logger - INF
....OrderDetail[1040] {Update - Cascading Order.ShippedDate (,...)} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: 2013-10-13 row: 0x1131867c0 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,171 - logic_logger - INF
....OrderDetail[1040] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: 2013-10-13 row: 0x1131867c0 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,172 - logic_logger - INF
....OrderDetail[1040] {Formula ShippedDate} Id: 1040, OrderId: 10643, ProductId: 28, UnitPrice: 45.6000000000, Quantity: 15, Discount: 0.25, Amount: 684.0000000000, ShippedDate: [2013-10-13-->] None row: 0x1131867c0 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,173 - logic_logger - INF
......Product[28] {Update - Adjusting Product: UnitsShipped} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: 41, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [-15-->] 0 row: 0x11317fbb0 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,175 - logic_logger - INF
......Product[28] {Formula UnitsInStock} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: [41-->] 26, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [-15-->] 0 row: 0x11317fbb0 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,176 - logic_logger - INF
....OrderDetail[1041] {Update - Cascading Order.ShippedDate (,...)} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: 2013-10-13 row: 0x113186820 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,177 - logic_logger - INF
....OrderDetail[1041] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: 2013-10-13 row: 0x113186820 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,178 - logic_logger - INF
....OrderDetail[1041] {Formula ShippedDate} Id: 1041, OrderId: 10643, ProductId: 39, UnitPrice: 18.0000000000, Quantity: 21, Discount: 0.25, Amount: 378.0000000000, ShippedDate: [2013-10-13-->] None row: 0x113186820 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,179 - logic_logger - INF
......Product[39] {Update - Adjusting Product: UnitsShipped} Id: 39, ProductName: Chartreuse verte, SupplierId: 18, CategoryId: 1, QuantityPerUnit: 750 cc per bottle, UnitPrice: 18.0000000000, UnitsInStock: 90, UnitsOnOrder: 0, ReorderLevel: 5, Discontinued: 0, UnitsShipped: [-21-->] 0 row: 0x11307b280 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,181 - logic_logger - INF
......Product[39] {Formula UnitsInStock} Id: 39, ProductName: Chartreuse verte, SupplierId: 18, CategoryId: 1, QuantityPerUnit: 750 cc per bottle, UnitPrice: 18.0000000000, UnitsInStock: [90-->] 69, UnitsOnOrder: 0, ReorderLevel: 5, Discontinued: 0, UnitsShipped: [-21-->] 0 row: 0x11307b280 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,182 - logic_logger - INF
....OrderDetail[1042] {Update - Cascading Order.ShippedDate (,...)} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: 2013-10-13 row: 0x113186760 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,183 - logic_logger - INF
....OrderDetail[1042] {Prune Formula: Amount [['UnitPrice', 'Quantity']]} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: 2013-10-13 row: 0x113186760 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,184 - logic_logger - INF
....OrderDetail[1042] {Formula ShippedDate} Id: 1042, OrderId: 10643, ProductId: 46, UnitPrice: 12.0000000000, Quantity: 2, Discount: 0.25, Amount: 24.0000000000, ShippedDate: [2013-10-13-->] None row: 0x113186760 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,185 - logic_logger - INF
......Product[46] {Update - Adjusting Product: UnitsShipped} Id: 46, ProductName: Spegesild, SupplierId: 21, CategoryId: 8, QuantityPerUnit: 4 - 450 g glasses, UnitPrice: 12.0000000000, UnitsInStock: 97, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 0, UnitsShipped: [-2-->] 0 row: 0x11307b310 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,186 - logic_logger - INF
......Product[46] {Formula UnitsInStock} Id: 46, ProductName: Spegesild, SupplierId: 21, CategoryId: 8, QuantityPerUnit: 4 - 450 g glasses, UnitPrice: 12.0000000000, UnitsInStock: [97-->] 95, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 0, UnitsShipped: [-2-->] 0 row: 0x11307b310 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,187 - logic_logger - INF
Logic Phase: COMMIT(session=0x11317f5e0) - 2022-04-24 11:30:23,189 - logic_logger - INF
..Order[10643] {Commit Event} Id: 10643, CustomerId: ALFKI, EmployeeId: 6, OrderDate: 2013-08-25, RequiredDate: 2013-10-13, ShippedDate: [2013-10-13-->] None, ShipVia: 1, Freight: 29.4600000000, ShipName: Alfreds Futterkiste, ShipAddress: Obere Str. 57, ShipCity: Berlin, ShipRegion: Western Europe, ShipPostalCode: 12209, ShipCountry: Germany, AmountTotal: 1086.00, Country: None, City: None, Ready: True, OrderDetailCount: 3, CloneFromOrder: None row: 0x11317f850 session: 0x11317f5e0 ins_upd_dlt: upd - 2022-04-24 11:30:23,191 - logic_logger - INF
```
</details>
### Scenario: Clone Existing Order
  Scenario: Clone Existing Order
   Given Shipped Order
   When Cloning Existing Order
   Then Logic Copies ClonedFrom OrderDetails
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Clone Existing Order
We create an order, setting CloneFromOrder.
This copies the CloneFromOrder OrderDetails to our new Order.
The copy operation is automated using `logic_row.copy_children()`:
1. `place_order.feature` defines the test
2. `place_order.py` implements the test. It uses the API to Post an Order, setting `CloneFromOrder` to trigger the copy logic
3. `declare_logic.py` implements the logic, by invoking `logic_row.copy_children()`. `which` defines which children to copy, here just `OrderDetailList`
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/clone-order.png?raw=true"></figure>
`CopyChildren` For more information, [see here](https://github.com/valhuber/LogicBank/wiki/Copy-Children)
Useful in row event handlers to copy multiple children types to self from copy_from children.
child-spec := < ‘child-list-name’ | < ‘child-list-name = parent-list-name’ >
child-list-spec := [child-spec | (child-spec, child-list-spec)]
Eg. RowEvent on Order
which = ["OrderDetailList"]
logic_row.copy_children(copy_from=row.parent, which_children=which)
Eg, test/copy_children:
child_list_spec = [
("MileStoneList",
["DeliverableList"] # for each Milestone, get the Deliverables
),
"StaffList"
]
> **Key Takeaway:** copy_children provides a deep-copy service.
**Rules Used** in Scenario: Clone Existing Order
```
Customer
1. Constraint Function: None
2. Derive Customer.UnpaidOrderCount as Count(<class 'database.models.Order'> Where <function declare_logic.<locals>.<lambda> at 0x11291e940>)
3. Derive Customer.OrderCount as Count(<class 'database.models.Order'> Where None)
4. Derive Customer.Balance as Sum(Order.AmountTotal Where <function declare_logic.<locals>.<lambda> at 0x11282c280>)
Order
5. RowEvent Order.clone_order()
6. Derive Order.OrderDetailCount as Count(<class 'database.models.OrderDetail'> Where None)
7. Derive Order.AmountTotal as Sum(OrderDetail.Amount Where None)
OrderDetail
8. Derive OrderDetail.UnitPrice as Copy(Product.UnitPrice)
9. Derive OrderDetail.ShippedDate as Formula (2): row.Order.ShippedDate
10. Derive OrderDetail.Amount as Formula (1): as_expression=lambda row: row.UnitPrice * row.Qua [...]
Product
11. Derive Product.UnitsInStock as Formula (1): <function>
12. Derive Product.UnitsShipped as Sum(OrderDetail.Quantity Where <function declare_logic.<locals>.<lambda> at 0x11291e700>)
```
**Logic Log** in Scenario: Clone Existing Order
```
Logic Phase: ROW LOGIC(session=0x11318f370) (sqlalchemy before_flush) - 2022-04-24 11:30:23,373 - logic_logger - INF
..Order[None] {Insert - client} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: None, Country: None, City: None, Ready: None, OrderDetailCount: None, CloneFromOrder: 10643 row: 0x11318f2e0 session: 0x11318f370 ins_upd_dlt: ins - 2022-04-24 11:30:23,374 - logic_logger - INF
....Customer[ALFKI] {Update - Adjusting Customer: UnpaidOrderCount, OrderCount} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: 2102.0000000000, CreditLimit: 2300.0000000000, OrderCount: [15-->] 16, UnpaidOrderCount: [10-->] 11 row: 0x11318f250 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,383 - logic_logger - INF
....OrderDetail[None] {warning: Order (OrderId not None... fixing} Id: None, OrderId: [None-->] 10643, ProductId: [None-->] 28, UnitPrice: None, Quantity: [None-->] 15, Discount: [None-->] 0.25, Amount: None, ShippedDate: None row: 0x11307b9d0 session: 0x11318f370 ins_upd_dlt: ins - 2022-04-24 11:30:23,387 - logic_logger - INF
....OrderDetail[None] {Insert - Copy Children OrderDetailList} Id: None, OrderId: None, ProductId: [None-->] 28, UnitPrice: None, Quantity: [None-->] 15, Discount: [None-->] 0.25, Amount: None, ShippedDate: None row: 0x11307b9d0 session: 0x11318f370 ins_upd_dlt: ins - 2022-04-24 11:30:23,388 - logic_logger - INF
....OrderDetail[None] {copy_rules for role: Product - UnitPrice} Id: None, OrderId: None, ProductId: [None-->] 28, UnitPrice: [None-->] 45.6000000000, Quantity: [None-->] 15, Discount: [None-->] 0.25, Amount: None, ShippedDate: None row: 0x11307b9d0 session: 0x11318f370 ins_upd_dlt: ins - 2022-04-24 11:30:23,390 - logic_logger - INF
....OrderDetail[None] {Formula Amount} Id: None, OrderId: None, ProductId: [None-->] 28, UnitPrice: [None-->] 45.6000000000, Quantity: [None-->] 15, Discount: [None-->] 0.25, Amount: [None-->] 684.0000000000, ShippedDate: None row: 0x11307b9d0 session: 0x11318f370 ins_upd_dlt: ins - 2022-04-24 11:30:23,391 - logic_logger - INF
......Product[28] {Update - Adjusting Product: UnitsShipped} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: 26, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] 15 row: 0x113172130 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,392 - logic_logger - INF
......Product[28] {Formula UnitsInStock} Id: 28, ProductName: Rössle Sauerkraut, SupplierId: 12, CategoryId: 7, QuantityPerUnit: 25 - 825 g cans, UnitPrice: 45.6000000000, UnitsInStock: [26-->] 11, UnitsOnOrder: 0, ReorderLevel: 0, Discontinued: 1, UnitsShipped: [0-->] 15 row: 0x113172130 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,393 - logic_logger - INF
......Order[None] {Update - Adjusting Order: AmountTotal, OrderDetailCount} Id: None, CustomerId: ALFKI, EmployeeId: 1, OrderDate: None, RequiredDate: None, ShippedDate: None, ShipVia: None, Freight: 11, ShipName: None, ShipAddress: None, ShipCity: None, ShipRegion: None, ShipPostalCode: None, ShipCountry: None, AmountTotal: [None-->] 684.0000000000, Country: None, City: None, Ready: None, OrderDetailCount: [None-->] 1, CloneFromOrder: 10643 row: 0x11318f2e0 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,395 - logic_logger - INF
........Customer[ALFKI] {Update - Adjusting Customer: Balance} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 2786.0000000000, CreditLimit: 2300.0000000000, OrderCount: 16, UnpaidOrderCount: 11 row: 0x11318f250 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,397 - logic_logger - INF
........Customer[ALFKI] {Constraint Failure: balance (2786.0000000000) exceeds credit (2300.0000000000)} Id: ALFKI, CompanyName: Alfreds Futterkiste, ContactName: Maria Anders, ContactTitle: Sales Representative, Address: Obere Str. 57A, City: Berlin, Region: Western Europe, PostalCode: 12209, Country: Germany, Phone: 030-0074321, Fax: 030-0076545, Balance: [2102.0000000000-->] 2786.0000000000, CreditLimit: 2300.0000000000, OrderCount: 16, UnpaidOrderCount: 11 row: 0x11318f250 session: 0x11318f370 ins_upd_dlt: upd - 2022-04-24 11:30:23,398 - logic_logger - INF
```
</details>
## Feature: Salary Change
### Scenario: Audit Salary Change
  Scenario: Audit Salary Change
   Given Employee 5 (Buchanan) - Salary 95k
   When Patch Salary to 200k
   Then Salary_audit row created
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Audit Salary Change
Observe the logic log to see that it creates audit rows:
1. **Discouraged:** you can implement auditing with events. But auditing is a common pattern, and this can lead to repetitive, tedious code
2. **Preferred:** approaches use [extensible rules](https://github.com/valhuber/LogicBank/wiki/Rule-Extensibility#generic-event-handlers).
Generic event handlers can also reduce redundant code, illustrated in the time/date stamping `handle_all` logic.
This is due to the `copy_row` rule. Contrast this to the *tedious* `audit_by_event` alternative:
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/salary_change.png?raw=true"></figure>
> **Key Takeaway:** use **extensible own rule types** to automate pattern you identify; events can result in tedious amounts of code.
**Rules Used** in Scenario: Audit Salary Change
```
Employee
1. RowEvent Employee.audit_by_event()
```
**Logic Log** in Scenario: Audit Salary Change
```
Logic Phase: ROW LOGIC(session=0x113197cd0) (sqlalchemy before_flush) - 2022-04-24 11:30:23,435 - logic_logger - INF
..Employee[5] {Update - client} Id: 5, LastName: Buchanan, FirstName: Steven, Title: Sales Manager, TitleOfCourtesy: Mr., BirthDate: 1987-03-04, HireDate: 2025-10-17, Address: 14 Garrett Hill, City: London, Region: British Isles, PostalCode: SW1 8JR, Country: UK, HomePhone: (71) 555-4848, Extension: 3453, Photo: None, Notes: Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as a sales representative in 1992, he spent 6 months in an orientation program at the Seattle office and then returned to his permanent post in London. He was promoted to sales manager in March 1993. Mr. Buchanan has completed the courses 'Successful Telemarketing' and 'International Sales Management.' He is fluent in French., ReportsTo: 2, PhotoPath: http://accweb/emmployees/buchanan.bmp, EmployeeType: Commissioned, Salary: [95000.0000000000-->] 200000, WorksForDepartmentId: 3, OnLoanDepartmentId: None, UnionId: None, Dues: None row: 0x1131a62b0 session: 0x113197cd0 ins_upd_dlt: upd - 2022-04-24 11:30:23,436 - logic_logger - INF
..Employee[5] {BEGIN Copy to: EmployeeAudit} Id: 5, LastName: Buchanan, FirstName: Steven, Title: Sales Manager, TitleOfCourtesy: Mr., BirthDate: 1987-03-04, HireDate: 2025-10-17, Address: 14 Garrett Hill, City: London, Region: British Isles, PostalCode: SW1 8JR, Country: UK, HomePhone: (71) 555-4848, Extension: 3453, Photo: None, Notes: Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as a sales representative in 1992, he spent 6 months in an orientation program at the Seattle office and then returned to his permanent post in London. He was promoted to sales manager in March 1993. Mr. Buchanan has completed the courses 'Successful Telemarketing' and 'International Sales Management.' He is fluent in French., ReportsTo: 2, PhotoPath: http://accweb/emmployees/buchanan.bmp, EmployeeType: Commissioned, Salary: [95000.0000000000-->] 200000, WorksForDepartmentId: 3, OnLoanDepartmentId: None, UnionId: None, Dues: None row: 0x1131a62b0 session: 0x113197cd0 ins_upd_dlt: upd - 2022-04-24 11:30:23,440 - logic_logger - INF
....EmployeeAudit[None] {Insert - Copy EmployeeAudit} Id: None, Title: Sales Manager, Salary: 200000, LastName: Buchanan, FirstName: Steven, EmployeeId: None, CreatedOn: None row: 0x11318fee0 session: 0x113197cd0 ins_upd_dlt: ins - 2022-04-24 11:30:23,443 - logic_logger - INF
....EmployeeAudit[None] {early_row_event_all_classes - handle_all sets 'Created_on} Id: None, Title: Sales Manager, Salary: 200000, LastName: Buchanan, FirstName: Steven, EmployeeId: None, CreatedOn: 2022-04-24 11:30:23.443805 row: 0x11318fee0 session: 0x113197cd0 ins_upd_dlt: ins - 2022-04-24 11:30:23,444 - logic_logger - INF
Logic Phase: COMMIT(session=0x113197cd0) - 2022-04-24 11:30:23,444 - logic_logger - INF
..Employee[5] {Commit Event} Id: 5, LastName: Buchanan, FirstName: Steven, Title: Sales Manager, TitleOfCourtesy: Mr., BirthDate: 1987-03-04, HireDate: 2025-10-17, Address: 14 Garrett Hill, City: London, Region: British Isles, PostalCode: SW1 8JR, Country: UK, HomePhone: (71) 555-4848, Extension: 3453, Photo: None, Notes: Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as a sales representative in 1992, he spent 6 months in an orientation program at the Seattle office and then returned to his permanent post in London. He was promoted to sales manager in March 1993. Mr. Buchanan has completed the courses 'Successful Telemarketing' and 'International Sales Management.' He is fluent in French., ReportsTo: 2, PhotoPath: http://accweb/emmployees/buchanan.bmp, EmployeeType: Commissioned, Salary: [95000.0000000000-->] 200000, WorksForDepartmentId: 3, OnLoanDepartmentId: None, UnionId: None, Dues: None row: 0x1131a62b0 session: 0x113197cd0 ins_upd_dlt: upd - 2022-04-24 11:30:23,446 - logic_logger - INF
```
</details>
### Scenario: Raise Must be Meaningful
  Scenario: Raise Must be Meaningful
   Given Employee 5 (Buchanan) - Salary 95k
   When Patch Salary to 96k
   Then Reject - Raise too small
<details>
<summary>Tests - and their logic - are transparent.. click to see Logic</summary>
**Logic Doc** for scenario: Raise Must be Meaningful
Observe the use of `old_row
`
> **Key Takeaway:** State Transition Logic enabled per `old_row`
**Rules Used** in Scenario: Raise Must be Meaningful
```
Employee
1. Constraint Function: <function declare_logic.<locals>.raise_over_20_percent at 0x1129501f0>
```
**Logic Log** in Scenario: Raise Must be Meaningful
```
Logic Phase: ROW LOGIC(session=0x11314d100) (sqlalchemy before_flush) - 2022-04-24 11:30:23,643 - logic_logger - INF
..Employee[5] {Update - client} Id: 5, LastName: Buchanan, FirstName: Steven, Title: Sales Manager, TitleOfCourtesy: Mr., BirthDate: 1987-03-04, HireDate: 2025-10-17, Address: 14 Garrett Hill, City: London, Region: British Isles, PostalCode: SW1 8JR, Country: UK, HomePhone: (71) 555-4848, Extension: 3453, Photo: None, Notes: Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as a sales representative in 1992, he spent 6 months in an orientation program at the Seattle office and then returned to his permanent post in London. He was promoted to sales manager in March 1993. Mr. Buchanan has completed the courses 'Successful Telemarketing' and 'International Sales Management.' He is fluent in French., ReportsTo: 2, PhotoPath: http://accweb/emmployees/buchanan.bmp, EmployeeType: Commissioned, Salary: [95000.0000000000-->] 96000, WorksForDepartmentId: 3, OnLoanDepartmentId: None, UnionId: None, Dues: None row: 0x11307b130 session: 0x11314d100 ins_upd_dlt: upd - 2022-04-24 11:30:23,644 - logic_logger - INF
..Employee[5] {Constraint Failure: Buchanan needs a more meaningful raise} Id: 5, LastName: Buchanan, FirstName: Steven, Title: Sales Manager, TitleOfCourtesy: Mr., BirthDate: 1987-03-04, HireDate: 2025-10-17, Address: 14 Garrett Hill, City: London, Region: British Isles, PostalCode: SW1 8JR, Country: UK, HomePhone: (71) 555-4848, Extension: 3453, Photo: None, Notes: Steven Buchanan graduated from St. Andrews University, Scotland, with a BSC degree in 1976. Upon joining the company as a sales representative in 1992, he spent 6 months in an orientation program at the Seattle office and then returned to his permanent post in London. He was promoted to sales manager in March 1993. Mr. Buchanan has completed the courses 'Successful Telemarketing' and 'International Sales Management.' He is fluent in French., ReportsTo: 2, PhotoPath: http://accweb/emmployees/buchanan.bmp, EmployeeType: Commissioned, Salary: [95000.0000000000-->] 96000, WorksForDepartmentId: 3, OnLoanDepartmentId: None, UnionId: None, Dues: None row: 0x11307b130 session: 0x11314d100 ins_upd_dlt: upd - 2022-04-24 11:30:23,646 - logic_logger - INF
```
</details>
Completed at April 24, 2022 11:30:2
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/test/api_logic_server_behave/reports/Behave Logic Report Sample.md
|
Behave Logic Report Sample.md
|
# Behave Creates Executable Test Suite, Documentation
You can optionally use the Behave test framework to:
1. **Create and Run an Executable Test Suite:** in your IDE, create test definitions (similar to what is shown in the report below), and Python code to execute tests. You can then execute your test suite with 1 command.
2. **Requirements and Test Documentation:** as shown below, you can then create a wiki report that documents your requirements, and the tests (**Scenarios**) that confirm their proper operation.
* **Logic Documentation:** the report integrates your logic, including a logic report showing your logic (rules and Python), and a Logic Log that shows exactly how the rules executed. Logic Doc can further contribute to Agile Collaboration.
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/behave-summary.png?raw=true" height="600"></figure>
[Behave](https://behave.readthedocs.io/en/stable/tutorial.html) is a framework for defining and executing tests. It is based on [TDD (Test Driven Development)](http://dannorth.net/introducing-bdd/), an Agile approach for defining system requirements as executable tests.
# Using Behave
<figure><img src="https://github.com/valhuber/ApiLogicServer/wiki/images/behave/TDD-ide.png?raw=true"></figure>
Behave is pre-installed with API Logic Server. Use it as shown above:
1. Create `.feature` files to define ***Scenarios*** (aka tests) for ***Features*** (aka Stories)
2. Code `.py` files to implement Scenario tests
3. Run Test Suite: Launch Configuration `Behave Run`. This runs all your Scenarios, and produces a summary report of your Features and the test results.
4. Report: Launch Configuration `Behave Report` to create the wiki file shown at the top of this page.
These steps are further defined, below. Explore the samples in the sample project.
## 1. Create `.feature` file to define Scenario
Feature (aka Story) files are designed to promote IT / business user collaboration.
## 2. Code `.py` file to implement test
Implement your tests in Python. Here, the tests are largely _read existing data_, _run transaction_, and _test results_, using the API. You can obtain the URLs from the swagger.
Key points:
* Link your scenario / implementations with annotations, as shown for _Order Placed with excessive quantity_.
* Include the `test_utils.prt()` call; be sure to use specify the scenario name as the 2nd argument. This is what drives the name of the Logic Log file, discussed below.
* Optionally, include a Python docstring on your `when` implementation as shown above, delimited by `"""` strings (see _"Familiar logic pattern"_ in the screen shot, above). If provided, this will be written into the wiki report.
* Important: the system assumes the following line identifies the scenario_name; be sure to include it.
## 3. Run Test Suite: Launch Configuration `Behave Run`
You can now execute your Test Suite. Run the `Behave Run` Launch Configuration, and Behave will run all of the tests, producing the outputs (`behave.log` and `<scenario.logs>` shown above.
* Windows users will need to run `Windows Behave Run`
* You can run just 1 scenario using `Behave Scenario`
* You can set breakpoints in your tests
The server must be running for these tests. Use the Launch Configuration `ApiLogicServer`, or `python api_logic_server_run.py`. The latter does not run the debugger, which you may find more convenient since changes to your test code won't restart the server.
## 4. Report: Launch Configuration `Behave Report'
Run this to create the wiki reports from the logs in step 3.
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/test/api_logic_server_behave/reports/Behave Logic Report Intro.md
|
Behave Logic Report Intro.md
|
# API Logic Project - `venv` Setup
Once you use `ApiLogicServer` to create your project, you need to create the `venv` Python environment (unless you are using the Docker version of API Logic Server).
## Create the `venv'
Proceed as described in the [API Logic Server Readme](https://github.com/valhuber/ApiLogicServer/blob/main/README.md#installation). This contains the latest information.
You may find the command line scripts in this folder helpful to save typing.
* The `.ps1` version is for Windows PowerShell
* The `-linux` version has been tested for Ubuntu, and
* The `venv.sh` has been tested on the Mac.
## Verify the `venv'
Optionally, you can check your Python environment by running:
```
Python py.py
```
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/venv_setup/readme_venv.md
|
readme_venv.md
|
import os, sys
import subprocess
from pathlib import Path
def print_at(label: str, value: str):
tab_to = 24 - len(label)
spaces = ' ' * tab_to
print(f'{label}: {spaces}{value}')
def show(cmd: str):
try:
result_b = subprocess.check_output(cmd, shell=True)
result = str(result_b) # b'pyenv 1.2.21\n'
result = result[2: len(result)-3]
print_at(cmd, result)
except Exception as e:
# print(f'Failed: {cmd} - {str(e)}')
pass
def get_api_logic_server_dir() -> str:
"""
:return: ApiLogicServer dir, eg, /Users/val/dev/ApiLogicServer
"""
running_at = Path(__file__)
python_path = running_at.parent.absolute()
parent_path = python_path.parent.absolute()
return str(parent_path)
def python_status():
print(" ")
print("\nPython Status here, 4.3\n")
dir = get_api_logic_server_dir()
test_env = "/workspaces/../home/api_logic_server/"
if os.path.exists(test_env):
dir = test_env
sys.path.append(dir) # e.g, on Docker -- export PATH=" /home/app_user/api_logic_server_cli"
try:
import api_logic_server_cli.cli as cli
except Exception as e:
cli = None
pass
command = "?"
if sys.argv[1:]:
if sys.argv[1] == "welcome":
command = "welcome"
elif sys.argv[1] == "sys-info":
command = "sys-info"
else:
print("unknown command - using sys-info")
command = "sys-info"
if command == "sys-info":
print("\nEnvironment Variables...")
env = os.environ
for each_variable in os.environ:
print(f'.. {each_variable} = {env[each_variable]}')
print("\nPYTHONPATH..")
for p in sys.path:
print(".." + p)
print("")
print(f'sys.prefix (venv): {sys.prefix}\n\n')
import socket
try:
hostname = socket.gethostname()
local_ip = socket.gethostbyname(hostname)
except:
local_ip = f"cannot get local ip from {hostname}"
print(f"{local_ip}")
api_logic_server_version = None
try:
api_logic_server_version = cli.__version__
except:
pass
if api_logic_server_version:
print_at('ApiLogicServer version', cli.__version__)
else:
print_at('ApiLogicServer version', f'*** ApiLogicServer not installed in this environment ***')
if command == "sys-info":
print_at('ip (gethostbyname)', local_ip)
print_at('on hostname', hostname)
print_at('python sys.version', sys.version)
print("")
print("Typical API Logic Server commands:")
print(" ApiLogicServer create-and-run --project_name=/localhost/api_logic_server --db_url=")
print(" ApiLogicServer run-api --project_name=/localhost/api_logic_server")
print(" ApiLogicServer run-ui --project_name=/localhost/api_logic_server # login admin, p")
print(" ApiLogicServer sys-info")
print(" ApiLogicServer version")
print("")
if command != "sys-info":
print("For more information, use python py.py sys-info")
print("")
if __name__ == '__main__':
python_status()
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/base/venv_setup/py.py
|
py.py
|
# Allocate Payment to Outstanding Orders
This project is to illustrate the use of Allcation.
Allocation is a pattern where:
> A ```Provider``` allocates to a list of ```Recipients```,
>creating ```Allocation``` rows.
For example, imagine a ```Customer``` has a set of outstanding
```Orders```, and pays all/several off with a single ```Payment```.
## Data Model

## Requirements
When the ```Payment``` is inserted, our system must:
1. Allocate the ```Payment``` to ```Orders``` that have ```AmountOwed```, oldest first
1. Keep track of how the ```Payment``` is allocated, by creating
a ```PaymentAllocation```
1. As the ```Payment``` is allocated,
1. Update the ```Order.AmountOwed```, and
1. Adjust the ```Customer.Balance```
# Setup
Create the project:
```
ApiLogicServer create --project_name=allocation --db_url=allocation
```
After you establish the venv in the usual manner, you canopen the project in your IDE and run launch configuration `ApiLogicServer`.
# Test
Use `sh test/test.sh`
# Walkthrough

The test illustrates allocation logic for our inserted payment,
which operates as follows:
1. The triggering event is the insertion of a ```Payment```, which triggers:
1. The ```allocate``` rule. It performs the allocation:
1. Obtains the list of recipient orders by calling the function```unpaid_orders```
1. For each recipient (```Order```), the system...
1. Creates a ```PaymentAllocation```, links it to the ```Order``` and ```Payment```,
1. Invokes the default ```while_calling_allocator```, which
1. Reduces ```Payment.AmountUnAllocated```
1. Inserts the ```PaymentAllocation```, which runs the following rules:
* r1 ```PaymentAllocation.AmountAllocated``` is derived ;
this triggers the next rule...
* r2 ```Order.AmountPaid``` is adjusted; that triggers...
* r3 ```Order.AmountOwed``` is derived; that triggers
* r4 ```Customer.Balance``` is adjusted
1. Returns whether the ```Payment.AmountUnAllocated``` has remaining value ( > 0 ).
1. Tests the returned result
1. If true (allocation remains), the loop continues for the next recipient
1. Otherwise, the allocation loop is terminated
#### Log Output
Logic operation is visible in the log
```
Logic Phase: BEFORE COMMIT - 2020-12-23 05:56:45,682 - logic_logger - DEBUG
Logic Phase: ROW LOGIC (sqlalchemy before_flush) - 2020-12-23 05:56:45,682 - logic_logger - DEBUG
..Customer[ALFKI] {Update - client} Id: ALFKI, CompanyName: Alfreds Futterkiste, Balance: 1016.00, CreditLimit: 2000.00 row@: 0x10abbea00 - 2020-12-23 05:56:45,682 - logic_logger - DEBUG
..Payment[None] {Insert - client} Id: None, Amount: 1000, AmountUnAllocated: None, CustomerId: None, CreatedOn: None row@: 0x10970f610 - 2020-12-23 05:56:45,682 - logic_logger - DEBUG
..Payment[None] {BEGIN Allocate Rule, creating: PaymentAllocation} Id: None, Amount: 1000, AmountUnAllocated: None, CustomerId: None, CreatedOn: None row@: 0x10970f610 - 2020-12-23 05:56:45,683 - logic_logger - DEBUG
....PaymentAllocation[None] {Insert - Allocate Payment} Id: None, AmountAllocated: None, OrderId: None, PaymentId: None row@: 0x10abbe700 - 2020-12-23 05:56:45,684 - logic_logger - DEBUG
....PaymentAllocation[None] {Formula AmountAllocated} Id: None, AmountAllocated: 100.00, OrderId: None, PaymentId: None row@: 0x10abbe700 - 2020-12-23 05:56:45,684 - logic_logger - DEBUG
......Order[10692] {Update - Adjusting Order} Id: 10692, CustomerId: ALFKI, OrderDate: 2013-10-03, AmountTotal: 878.00, AmountPaid: [778.00-->] 878.00, AmountOwed: 100.00 row@: 0x10ac82370 - 2020-12-23 05:56:45,685 - logic_logger - DEBUG
......Order[10692] {Formula AmountOwed} Id: 10692, CustomerId: ALFKI, OrderDate: 2013-10-03, AmountTotal: 878.00, AmountPaid: [778.00-->] 878.00, AmountOwed: [100.00-->] 0.00 row@: 0x10ac82370 - 2020-12-23 05:56:45,685 - logic_logger - DEBUG
........Customer[ALFKI] {Update - Adjusting Customer} Id: ALFKI, CompanyName: Alfreds Futterkiste, Balance: [1016.00-->] 916.00, CreditLimit: 2000.00 row@: 0x10abbea00 - 2020-12-23 05:56:45,685 - logic_logger - DEBUG
....PaymentAllocation[None] {Insert - Allocate Payment} Id: None, AmountAllocated: None, OrderId: None, PaymentId: None row@: 0x10ac6a850 - 2020-12-23 05:56:45,686 - logic_logger - DEBUG
....PaymentAllocation[None] {Formula AmountAllocated} Id: None, AmountAllocated: 330.00, OrderId: None, PaymentId: None row@: 0x10ac6a850 - 2020-12-23 05:56:45,686 - logic_logger - DEBUG
......Order[10702] {Update - Adjusting Order} Id: 10702, CustomerId: ALFKI, OrderDate: 2013-10-13, AmountTotal: 330.00, AmountPaid: [0.00-->] 330.00, AmountOwed: 330.00 row@: 0x10ac824f0 - 2020-12-23 05:56:45,686 - logic_logger - DEBUG
......Order[10702] {Formula AmountOwed} Id: 10702, CustomerId: ALFKI, OrderDate: 2013-10-13, AmountTotal: 330.00, AmountPaid: [0.00-->] 330.00, AmountOwed: [330.00-->] 0.00 row@: 0x10ac824f0 - 2020-12-23 05:56:45,686 - logic_logger - DEBUG
........Customer[ALFKI] {Update - Adjusting Customer} Id: ALFKI, CompanyName: Alfreds Futterkiste, Balance: [916.00-->] 586.00, CreditLimit: 2000.00 row@: 0x10abbea00 - 2020-12-23 05:56:45,686 - logic_logger - DEBUG
....PaymentAllocation[None] {Insert - Allocate Payment} Id: None, AmountAllocated: None, OrderId: None, PaymentId: None row@: 0x10ac6a9d0 - 2020-12-23 05:56:45,687 - logic_logger - DEBUG
....PaymentAllocation[None] {Formula AmountAllocated} Id: None, AmountAllocated: 570.00, OrderId: None, PaymentId: None row@: 0x10ac6a9d0 - 2020-12-23 05:56:45,687 - logic_logger - DEBUG
......Order[10835] {Update - Adjusting Order} Id: 10835, CustomerId: ALFKI, OrderDate: 2014-01-15, AmountTotal: 851.00, AmountPaid: [0.00-->] 570.00, AmountOwed: 851.00 row@: 0x10ac82550 - 2020-12-23 05:56:45,688 - logic_logger - DEBUG
......Order[10835] {Formula AmountOwed} Id: 10835, CustomerId: ALFKI, OrderDate: 2014-01-15, AmountTotal: 851.00, AmountPaid: [0.00-->] 570.00, AmountOwed: [851.00-->] 281.00 row@: 0x10ac82550 - 2020-12-23 05:56:45,688 - logic_logger - DEBUG
........Customer[ALFKI] {Update - Adjusting Customer} Id: ALFKI, CompanyName: Alfreds Futterkiste, Balance: [586.00-->] 16.00, CreditLimit: 2000.00 row@: 0x10abbea00 - 2020-12-23 05:56:45,688 - logic_logger - DEBUG
..Payment[None] {END Allocate Rule, creating: PaymentAllocation} Id: None, Amount: 1000, AmountUnAllocated: 0.00, CustomerId: None, CreatedOn: None row@: 0x10970f610 - 2020-12-23 05:56:45,688 - logic_logger - DEBUG
Logic Phase: COMMIT - 2020-12-23 05:56:45,689 - logic_logger - DEBUG
Logic Phase: FLUSH (sqlalchemy flush processing - 2020-12-23 05:56:45,689 - logic_logger - DEBUG
add_payment, update completed
```
## Key Points
Allocation illustrates some key points regarding logic.
### Extensibility
While Allocation is part of Logic Bank, you could have recognized
the pattern yourself, and provided the implementation. This is
enabled since Event rules can invoke Python. You can make your
Python code generic, using meta data (from SQLAlchemy),
parameters, etc.
For more information, see [Extensibility](https://github.com/valhuber/LogicBank/wiki/Rule-Extensibility#3-extended-rules).
### Rule Chaining
Note how the created ```PaymentAllocation``` row triggered
the more standard rules such as sums and formulas. This
required no special machinery: rules watch and react to changes in data -
if you change the data, rules will "notice" that, and fire. Automatically.
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/allocation/Logic-Allocation.md
|
Logic-Allocation.md
|
# API Fiddle
Run under Codespaces -- [click here](https://github.com/codespaces/new?hide_repo_select=true&ref=main&repo=641207071).
<details markdown>
<br>
<summary>Welcome: Learn about APIs, using Flask and SQLAlchemy -- via a Codespaces "API Fiddle" </summary>
**Background context**
* **RESTful APIs** have become an accepted approach for **networked database access**
* **JSON:API** is an API **standard** for **self-service** APIs
* Microservice concepts stress that **APIs should enforce the *business logic*** for integrity and security
**About this site**
* *What:* **Learn how to build such APIs, using Flask and SQLAlchemy**
* *Why:* learn using a **complete executable environment**, a complement to conventional tutorials and docs:
* Akin to a **JS Fiddle** - but here for a *complete environment:* running sample projects with live, updatable databases.
* **Test the API** on the live database, with Swagger, cURL and an Admin App
* **Discover instant creation** and **logic enforcement**, using API Logic Server<br><br>
* **Explore the project code** -- use the debugger, experiment with it.
* *How:* the enabling technology is Codespaces
* It creates a cloud machine for these projects, and **starts VSCode in your Browser.** This eliminates install, configuration, and risk to your local machine.
**What's in this Project**
This contains 2 ready-to-run projects:<br>
| Project | What it is | Use it to explore... | Notes |
|:---- |:------|:-----------|:-----------|
| 1. Learn APIs using Flask SqlAlchemy | Northwind Database<br>- Single Endpoint | **Flask / SQLAlchemy** basics | With HTTP, REST background |
| 2. Learn JSON_API using API Logic Server | Northwind Database<br> - All Endpoints<br>- With Logic<br>- With Admin App | **JSON:API**, and<br>Rule-based business logic | You can start here if only interested in JSON:API |
| Next Steps | Create other sample databases | More examples - initial project creation from Database |
These projects use the [Northwind Sample Database](https://apilogicserver.github.io/Docs/Sample-Database/) (customers, orders, products).
> Suggestion: close *Welcome*, above, to proceed.
</details fiddle>
---
</details>
<details markdown>
<br>
<summary>1. Learn APIs using Flask SqlAlchemy -- Fully customizable, but slow</summary>
This first app (_1. Learn Flask / SQLAlchemy_) illustrates a typical framework-based approach for creating projects - a minimal project for seeing core Flask and SQLAlchemy services in action. Let's run/test it, then explore the code.
<details markdown>
<summary> Run / Test </summary>
To run the basic app:
1. Click **Run and Debug** (you should see **1. Learn APIs using Flask SqlAlchemy**), and the green button to start the server
* Do ***Not*** click `Open in Browser`<br><br>
2. Copy the `cURL` text,<br>Open the `bash` window, and <br>Paste the `cURL` text
* Observe the resulting response text<br><br>

</details>
<details markdown>
<summary> Explore the Code </summary>
[**Open the readme**](./1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/readme.md) to understand Flask / SQLAlchemy usage
* The readme also provides brief background on APIs, Flask, and SQLAlchemy
</details>
<details markdown>
<summary> --> Fully Customizable, but Faster Would Be Better</summary>
Frameworks like Flask are flexible, and leverage your existing dev environment (IDE, git, etc). But the manual effort is time-consuming, and complex. This minimal project **does not provide:**
<img align="right" width="150" height="150" src="https://github.com/ApiLogicServer/Docs/blob/main/docs/images/vscode/app-fiddle/horse-feathers.jpg?raw=true" alt="Horse Feathers">
* an API endpoint for each table
* We saw above it's straightforward to provide a *single endpoint.* It's quite another matter -- ***weeks to months*** -- to provide endpoints for **all** the tables, with pagination, filtering, and related data access. That's a horse of an entirely different feather.<br><br>
* a User Interface
* any security, or business logic (multi-table derivations and constraints).
Below, we'll see an approach that combines the ***flexibility of a framework with the speed of low-code.***
</details>
When you are done, **stop** the server (Step 3).
> You might want to close _1. Learn APIs using Flask SqlAlchemy..._, above.
---
</details>
<details markdown>
<summary>2. Learn JSON_API using API Logic Server -- Standard API, Logic Enabled, Declarative</summary>
<br>
<details markdown>
<summary> Project Overview</summary>
<br>
Project 2 is much more like a real server:
1. It implements a **JSON:API -- a *standard* definition** for filtering, sorting, pagination, and multi-table retrieval.
* Such **standards eliminate complex and time-consuming design**
* (*Rest*, unlike SQL, does not dictate syntax)<br><br>
* JSON:APIs are **self-service**, with *consumer-defined* response inclusion
* Similar to GraphQL, clients declare what data to include, rather than relying on pre-defined resources.<br><br>
2. It implements an **Admin App** (ReactAdmin)
3. It implements **business logic**
First, let's explore the service: 2.a) Start the Server, 2.b) Explore the JSON:API, and 2.c) Explore JSON:API Update Logic.
Then, we'll see how to create it.
> You might want to close _Project Overview_, above.
</details project overview>
<details markdown>
<summary> 2.a) Start the Server and Open the Admin App</summary>
1. Start the Server:
1. Click **Run and Debug**
2. Use the dropdown to select **2. Learn JSON_API using API Logic Server**, and
3. Click the green button to start the server
<br><br>
2. **Open in Browser** as shown below (you'll need to wait a moment for the server to restart for debug support).
* This opens the Admin App, which provides access to Swagger.

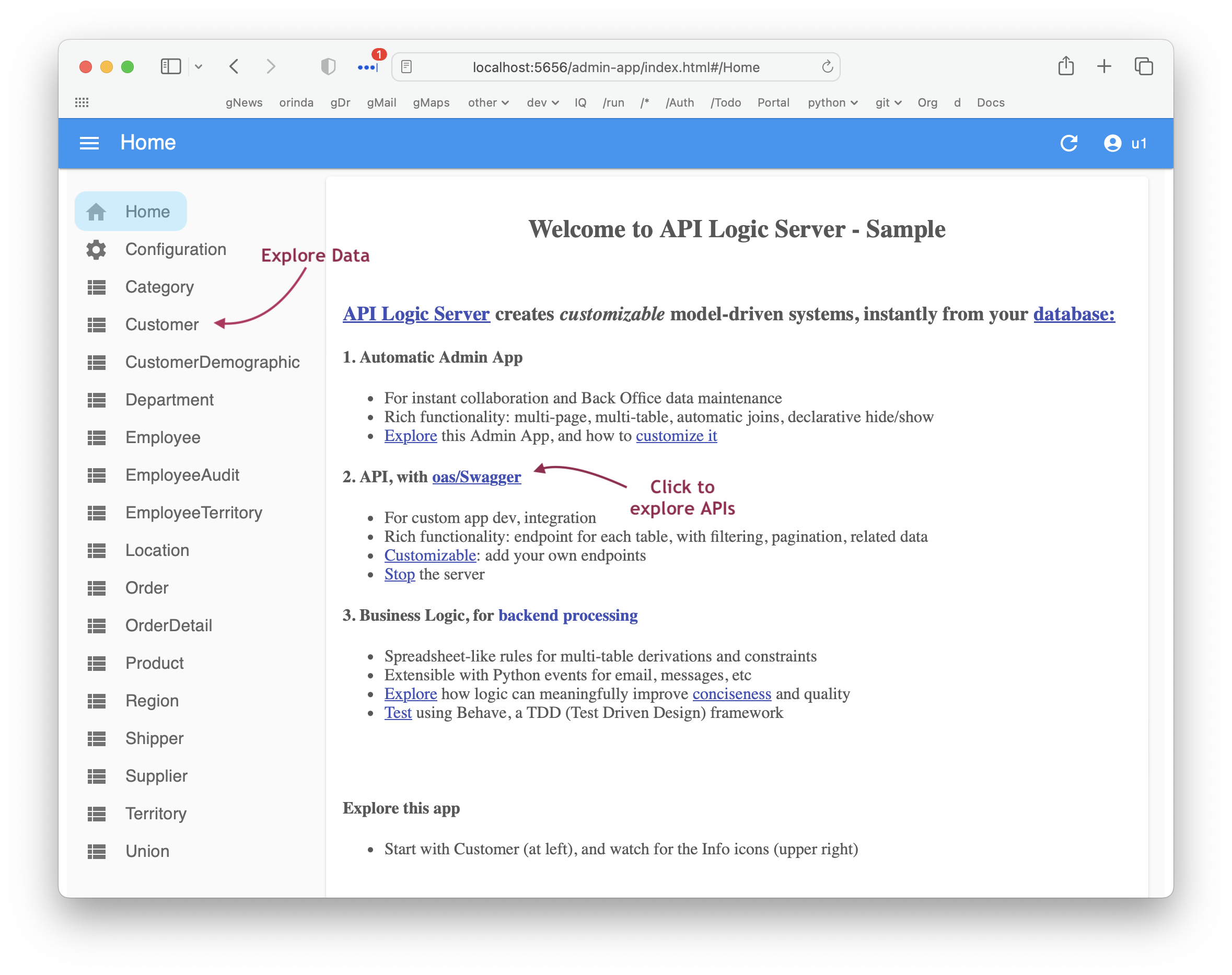
</details run project>
<details markdown>
<summary> 2.b) Explore JSON:API Get Using Swagger</summary>
<br>
Let's now use Swagger (automatically created) to explore the API.
<details markdown>
<summary> b.1) Open Swagger from the Admin App Home Page </summary>
Automatic Swagger: from the **Home** page of the Admin App, execute it like this:
1. Click the link: **2. API, with oas/Swagger**
2. Click **Customer**
3. Click **Get**
4. Click **Try it out**
5. Click **Execute**:

</details swagger>
<details markdown>
<summary> b.2) Consumer-defined response: the include argument</summary>
Note the `include` argument; you can specify:
```
OrderList,OrderList.OrderDetailList,OrderList.OrderDetailList.Product
```
You can paste the `Customer` response into tools like [jsongrid](https://jsongrid.com/json-grid), shown below. Note the response *includes* OrderDetail data:
</details consumer>
<details markdown>
<summary> b.3) Additional Services </summary>
Servers often include non-JSON:API endpoints, such as the `ServicesEndPoint - add_order` to post an Order and its OrderDetails.
> Suggestion: close *2.b) Explore JSON:API Get Using Swagger*, above, to proceed.
</details extensible>
</details what is json:api>
<details markdown>
<summary> 2.c) Explore JSON:API Patch Logic </summary>
APIs must ensure that updates adhere to business rules: **multi-table derivations and constraints**. Such business logic is not only critical, it's extensive: it often constitutes **nearly half the code**.
It's what makes an API a service.
**Patch to test logic**
This server implements such logic. Test it by `patch`ing the data below in the Terminal Window:
```bash
curl -X 'PATCH' \
'http://localhost:5656/api/OrderDetail/1040/' \
-H 'accept: application/vnd.api+json' \
-H 'Content-Type: application/json' \
-d '{
"data": {
"attributes": {
"Quantity": 160
},
"type": "OrderDetail",
"id": "1040"
}
}'
```
We see that it fails - as it *should*. Note this is a non-trivial ***muti-table*** transaction - it must:
1. Get the price from the Product
2. Compute the amount (price * quantity), which requires we...
3. Adjust the Order amount, which requires we...
4. Adjust the Customer balance, which enables us to...
5. Check the credit limit - we see it's exceeded, so we roll the transaction back and return the error response
> You might want to close _2.c) Explore JSON:API Patch Logic_, above.
</details explore api logic server>
<details markdown>
<summary> Creation is Automated: Project, SQLAlchemy Models, API, Admin, Logic </summary>
You could code all this using Flask and SQLAlchemy... but it would *take a **long** time*.
In fact, this system was not coded by hand - it was **created using API Logic Server** -- an open source project providing:
* **Automatic Creation:** a single command creates the project from your database: SQLAlchemy Models, API, and the Admin App
* **Customize with your IDE:** declare spreadsheet-like **business logic rules**, and code extra API endpoints using the same Flask / SQLAlchemy techniques described in the first project
* Rules are 40X more concise than code.<br><br>
Use the [```Detailed Tutorial```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/tutorial.md) to further explore this app.
<details markdown>
<summary> Explore Creating New Projects</summary>
As noted above, you can create projects with a single command. To help you explore, there are several pre-installed sqlite sample databases:
```bash
cd API_Fiddle
ApiLogicServer create --db_url=sqlite:///sample_db.sqlite --project_name=nw
# that's a bit of a mouthful, so abbreviations are provided for pre-included samples
ApiLogicServer create --project_name=nw --db_url=nw # same sample as 2, above
ApiLogicServer create --project_name=nw- --db_url=nw- # no customization
ApiLogicServer create --project_name=chinook --db_url=chinook # artists and albums
ApiLogicServer create --project_name=classicmodels --db_url=classicmodels # customers, orders
ApiLogicServer create --project_name=todo --db_url=todo # 1 table database
```
Then, **restart** the server as above, using the pre-created Run Configuration for `Execute <new project>`.<br><br>
> Next, try it on your own databases: if you have a database, you can have an API and an Admin app in minutes.
> > Note: The system provides shorthand notations for the pre-installed sample databases above. For your own databases, you will need to provide a SQLAlchemy URI for the `db_url` parameter. These can be tricky - try `ApiLogicServer examples`, or, when all else fails, [try the docs](https://apilogicserver.github.io/Docs/Database-Connectivity/).
</details new projects>
<details markdown>
<summary>Key Takeaways: JSON:APIs -- Instantly, With Logic and Admin App; Standard Tools </summary>
**JSON:APIs** are worth a look:
* **Eliminate design complexity and delays** with standards
* **Eliminate bottlenecks** in backend development with Self-service APIs
**API Logic Server** creates JSON:API systems instantly:
1. **Instantly executable projects** with the `ApiLogicServer create` command, providing:
* **a JSON:API:** end point for each table -- multi-table, filtering, sorting, pagination... ready for custom app dev
* **an Admin App:** multi-page, multi-table apps... ready for business user agile collaboration<br><br>
2. **Leverage Standard Tools** for development and deployment:
* Dev: customize and debug with **<span style="background-color:Azure;">standard dev tools</span>**. Use *your IDE (e.g. <span style="background-color:Azure;">VSCode, PyCharm</span>)*, <span style="background-color:Azure;">Python</span>, and Flask/SQLAlchemy to create new services. Manage projects with <span style="background-color:Azure;">GitHub</span>.
* Deploy: **containerize** your project - deploy on-premise or to the cloud <span style="background-color:Azure;">(Azure, AWS, etc)</span>.
* *Flexible as a framework, Faster then Low Code for Admin Apps*
3. ***Declare* security and multi-table constraint/validation logic**, using **declarative spreadsheet-like rules**. Addressing the backend *half* of your system, logic consists of rules, extensible with Python event code.
* *40X more concise than code - unique to API Logic Server*<br><br>
</details key takeaways>
</details automated creation>
</details 2. JSON_API>
---
<details markdown>
<summary>Appendix: What is API Logic Server</summary>
**What is Installed**
API Logic server installs with `pip`, in a docker container, or (here) in codespaces. As shown below, it consists of a:
* **CLI:** the `ApiLogicServer create` command you saw above
* **Runtime Packages:** for API, UI and Logic execution<br>
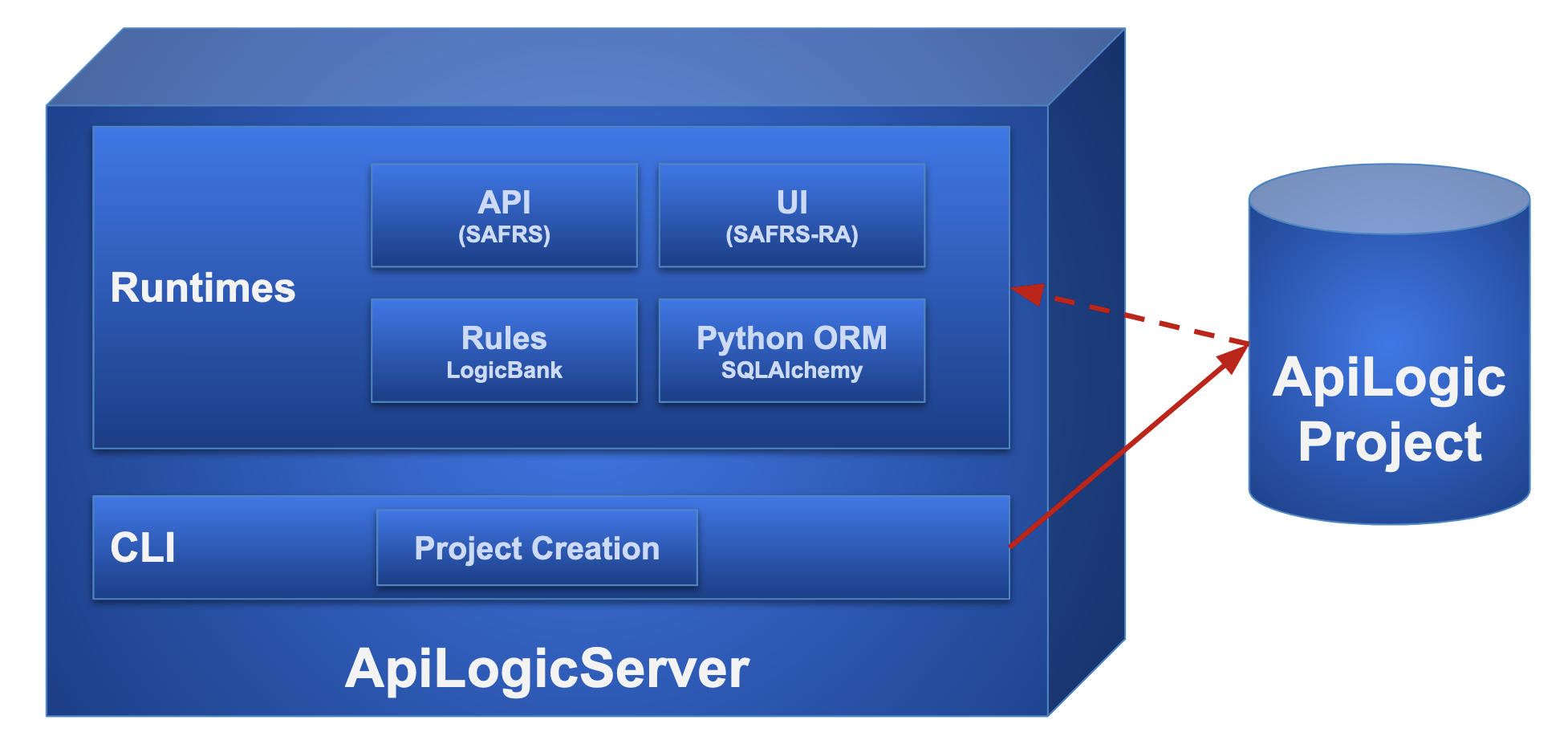
**Development Architecture**
It operates as shown below:
* A) Create your database as usual
* B) Use the CLI to generate an executable project
* E.g.: `ApiLogicServer create --project_name=nw --db_url=nw-`
* The system reads your database to create an executable API Logic Project<br>
* C) Customize and debug it in VSCode, PyCharm, etc.
* Declare logic, code new endpoints, customize the data model
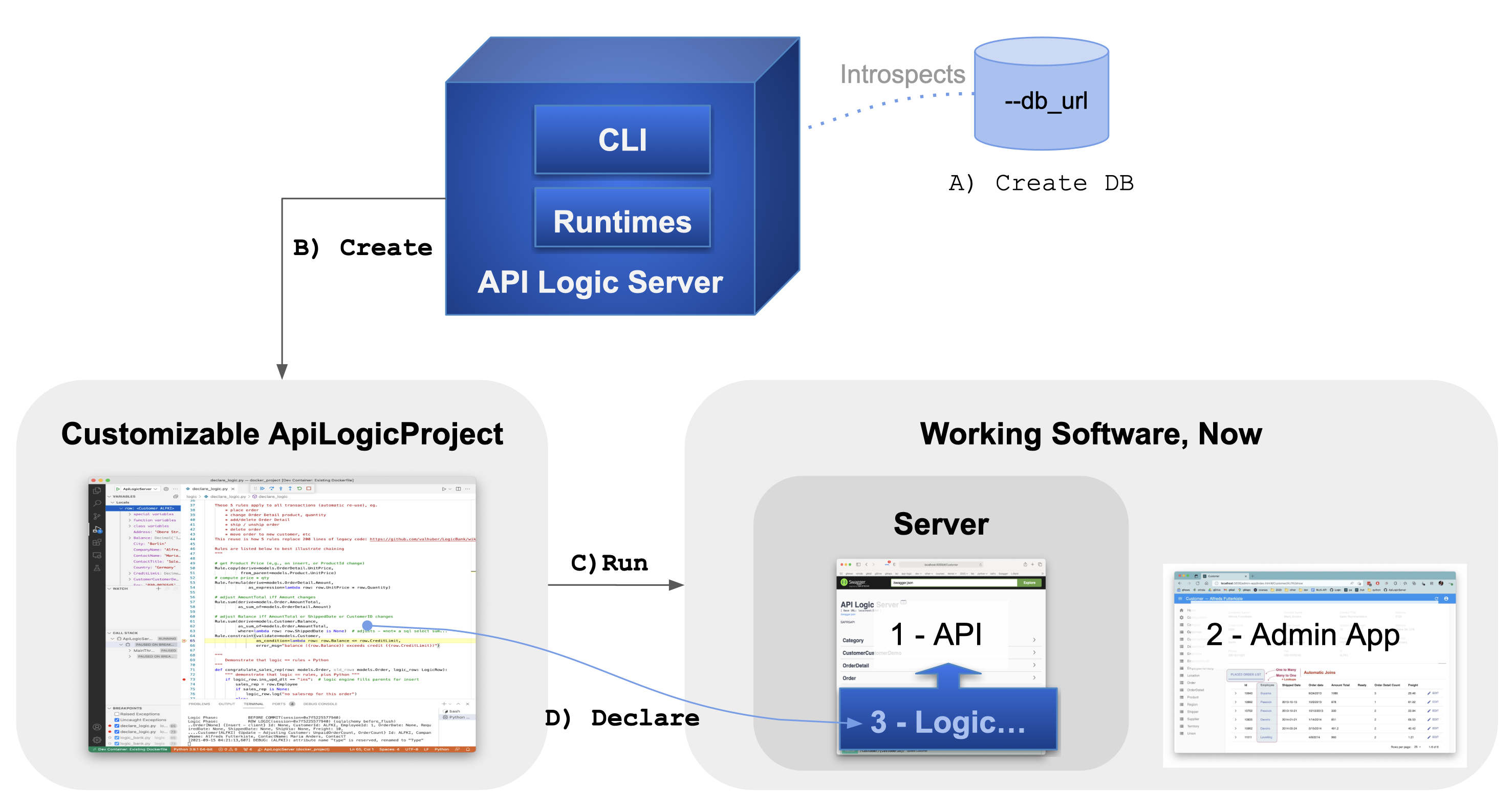
**Standard, Scalable Modern Architecture**
* A modern 3-tiered architecture, accessed by **APIs**
* Logic is **automatically invoked**, operating as a SQLAlchemy event listener
* Observe logic is *automatic re-used* by web apps and custom services
* **Containerized** for scalable cloud deployment - the project includes a dockerfile to containerize it to DockerHub.
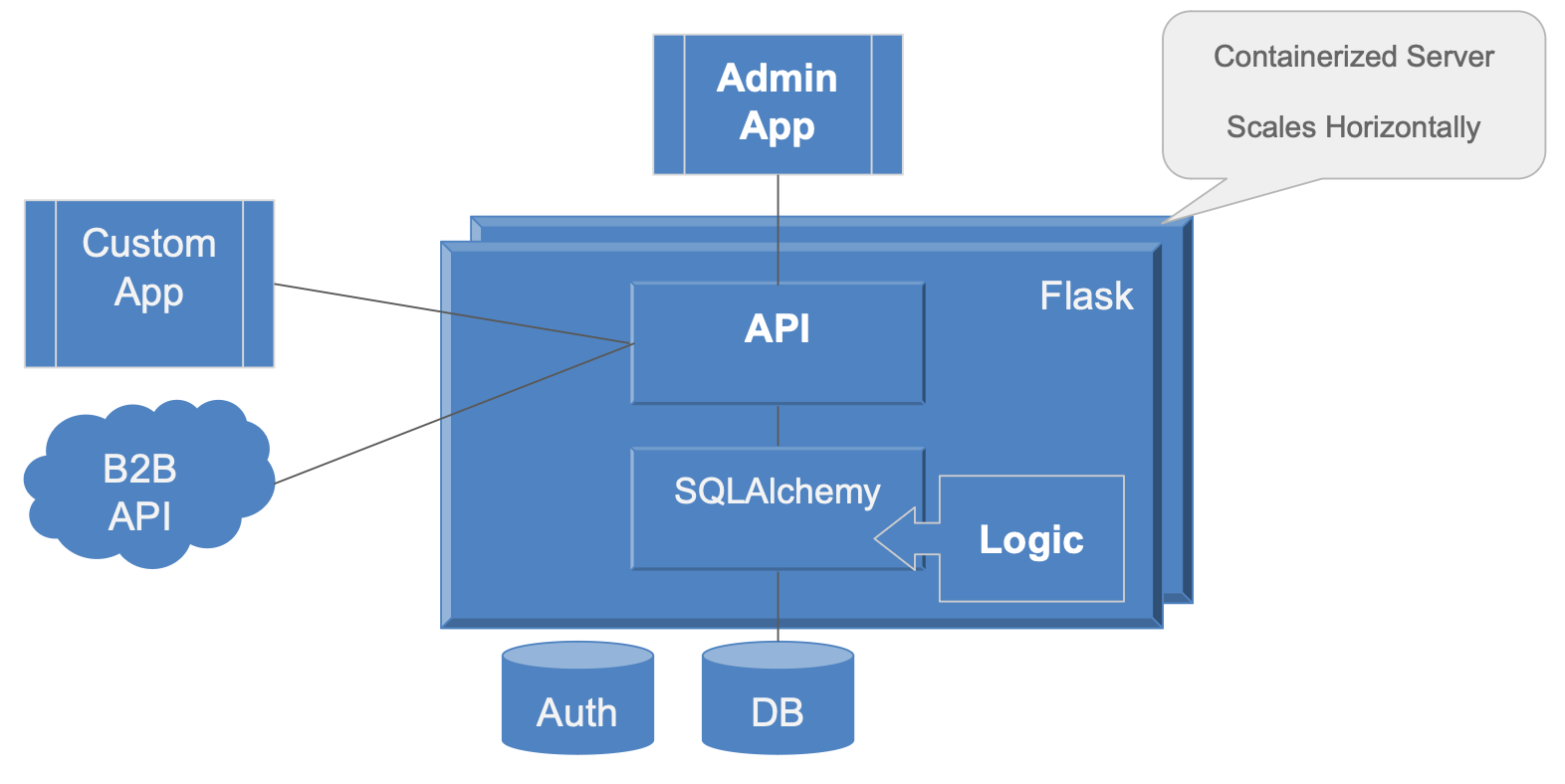
</details what is api logic server>
<details markdown Key technology>
<summary>Appendix: Key Technology Concepts Review</summary>
<p align="center">
<h2 align="center">Key Technology Concepts</h2>
</p>
<p align="center">
Select a skill of interest, and<br>Click the link to see sample code
</p>
| Tech Area | Skill | 1. Learn APIs Example | 2. Learn JSON:API Example | Notes |
|:---- |:------|:-----------|:--------|:--------|
| __Flask__ | Setup | [```flask_basic.py```](1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/flask_basic.py) | [```api_logic_server_run.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/api_logic_server_run.py) | |
| | Events | | [```ui/admin/admin_loader.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/ui/admin/admin_loader.py) | |
| __API__ | Create End Point | [```api/end_points.py```](1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/api/end_points.py) | [```api/customize_api.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/api/customize_api.py) | see `def order():` |
| | Call endpoint | | [```test/.../place_order.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/test/api_logic_server_behave/features/steps/place_order.py) | |
| __Config__ | Config | [```config.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/config.py) | | |
| | Env variables | | [```config.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/config.py) | os.getenv(...) |
| __SQLAlchemy__ | Data Model Classes | [```database/models.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/database/models.py) | | |
| | Read / Write | [```api/end_points.py```](3.%20Basic_App/api/end_points.py) | [```api/customize_api.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/api/customize_api.py) | see `def order():` |
| | Multiple Databases | | [```database/bind_databases.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/database/bind_databases.py) | |
| | Events | | [```security/system/security_manager.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/security/system/security_manager.py) | |
| __Logic__ | Business Rules | n/a | [```logic/declare_logic.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/logic/declare_logic.py) | ***Unique*** to API Logic Server |
| __Security__ | Multi-tenant | n/a | [```security/declare_security.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/security/declare_security.py) | |
| __Behave__ | Testing | | [```test/.../place_order.py```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/test/api_logic_server_behave/features/steps/place_order.py) | |
| __Alembic__ | Schema Changes | | [```database/alembic/readme.md```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/database/alembic/readme.md) | |
| __Docker__ | Dev Env | | [```.devcontainer/devcontainer.json```](.devcontainer/devcontainer.json) | See also "For_VS_Code.dockerFile" |
| | Containerize Project | | [```devops/docker/build-container.dockerfile```](./2.%20Learn%20JSON_API%20using%20API%20Logic%20Server/devops/docker/build-container.dockerfile) | |
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/readme.md
|
readme.md
|
import sqlite3
from os import path
import logging
import sys
from typing import Any, Optional, Tuple
import sqlalchemy
from sqlalchemy.ext.hybrid import hybrid_property
from sqlalchemy.orm import object_mapper
import flask_sqlalchemy
from logic_bank.rule_bank.rule_bank import RuleBank
app_logger = logging.getLogger(__name__)
def log(msg: object) -> None:
app_logger.debug(msg)
# print("TIL==> " + msg)
def connection() -> sqlite3.Connection:
ROOT: str = path.dirname(path.realpath(__file__))
log(ROOT)
_connection = sqlite3.connect(path.join(ROOT, "sqlitedata.db"))
return _connection
def dbpath(dbname: str) -> str:
ROOT: str = path.dirname(path.realpath(__file__))
log('ROOT: '+ROOT)
PATH: str = path.join(ROOT, dbname)
log('DBPATH: '+PATH)
return PATH
def json_to_entities(from_row: str or object, to_row):
"""
transform json object to SQLAlchemy rows, for save & logic
:param from_row: json service payload: dict - e.g., Order and OrderDetailsList
:param to_row: instantiated mapped object (e.g., Order)
:return: updates to_row with contents of from_row (recursively for lists)
"""
def get_attr_name(mapper, attr)-> Tuple[Optional[Any], str]:
""" returns name, type of SQLAlchemy attr metadata object """
attr_name = None
attr_type = "attr"
if hasattr(attr, "key"):
attr_name = attr.key
elif isinstance(attr, hybrid_property):
attr_name = attr.__name__
elif hasattr(attr, "__name__"):
attr_name = attr.__name__
elif hasattr(attr, "name"):
attr_name = attr.name
if attr_name == "OrderDetailListX" or attr_name == "CustomerX":
print("Debug Stop")
if isinstance(attr, sqlalchemy.orm.relationships.RelationshipProperty): # hasattr(attr, "impl"): # sqlalchemy.orm.relationships.RelationshipProperty
if attr.uselist:
attr_type = "list"
else: # if isinstance(attr.impl, sqlalchemy.orm.attributes.ScalarObjectAttributeImpl):
attr_type = "object"
return attr_name, attr_type
row_mapper = object_mapper(to_row)
for each_attr_name in from_row:
if hasattr(to_row, each_attr_name):
for each_attr in row_mapper.attrs:
mapped_attr_name, mapped_attr_type = get_attr_name(row_mapper, each_attr)
if mapped_attr_name == each_attr_name:
if mapped_attr_type == "attr":
value = from_row[each_attr_name]
setattr(to_row, each_attr_name, value)
elif mapped_attr_type == "list":
child_from = from_row[each_attr_name]
for each_child_from in child_from:
child_class = each_attr.entity.class_
# eachOrderDetail = OrderDetail(); order.OrderDetailList.append(eachOrderDetail)
child_to = child_class() # instance of child (e.g., OrderDetail)
json_to_entities(each_child_from, child_to)
child_list = getattr(to_row, each_attr_name)
child_list.append(child_to)
pass
elif mapped_attr_type == "object":
log("a parent object - skip (future - lookups here?)")
break
rule_count = 0
from flask import request, jsonify
def rules_report():
"""
logs report of all rules, using rules_bank.__str__()
"""
global rule_count
rules_bank = RuleBank()
logic_logger = logging.getLogger("logic_logger")
rule_count = 0
logic_logger.debug(f'\nThe following rules have been activated\n')
list_rules = rules_bank.__str__()
loaded_rules = list(list_rules.split("\n"))
for each_rule in loaded_rules:
logic_logger.info(each_rule + '\t\t## ')
rule_count += 1
logic_logger.info(f'Logic Bank - {rule_count} rules loaded')
def server_log(request, jsonify):
"""
Used by test/*.py - enables client app to log msg into server
"""
import os
import datetime
from pathlib import Path
import logging
global rule_count
def add_file_handler(logger, name: str, log_dir):
"""Add a file handler for this logger with the specified `name` (and
store the log file under `log_dir`)."""
# Format for file log
for each_handler in logger.handlers:
each_handler.flush()
handler_name = str(each_handler)
if "stderr" in handler_name:
pass
# print(f'do not delete stderr')
else:
logger.removeHandler(each_handler)
fmt = '%(asctime)s | %(levelname)8s | %(filename)s:%(lineno)d | %(message)s'
formatter = logging.Formatter(fmt)
formatter = logging.Formatter('%(message)s - %(asctime)s - %(name)s - %(levelname)s')
# Determine log path/file name; create log_dir if necessary
now = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
log_name = f'{str(name).replace(" ", "_")}' # {now}'
if len(log_name) >= 26:
log_name = log_name[0:25]
if not os.path.exists(log_dir):
try:
os.makedirs(log_dir)
except:
app_logger.info(f'util.add_file_handler unable to create dir {log_dir}')
log_dir = '/tmp' if sys.platform.startswith('linux') else '.'
app_logger.info(f'Defaulting to {log_dir}.')
log_file = os.path.join(log_dir, log_name) + '.log'
if os.path.exists(log_file):
os.remove(log_file)
else:
pass # file does not exist
# Create file handler for logging to a file (log all five levels)
# print(f'create file handler for logging: {log_file}')
logger.file_handler = logging.FileHandler(log_file)
logger.file_handler.setLevel(logging.DEBUG)
logger.file_handler.setFormatter(formatter)
logger.addHandler(logger.file_handler)
msg = request.args.get('msg')
test = request.args.get('test')
if test is not None and test != "None":
if test == "None":
print(f'None for msg: {msg}')
logic_logger = logging.getLogger('logic_logger') # for debugging user logic
# logic_logger.info("\n\nLOGIC LOGGER HERE\n")
dir = request.args.get('dir')
add_file_handler(logic_logger, test, Path(os.getcwd()).joinpath(dir))
if msg == "Rules Report":
rules_report()
logic_logger.info(f'Logic Bank {__version__} - {rule_count} rules loaded')
else:
app_logger.info(f'{msg}')
return jsonify({"result": f'ok'})
def format_nested_object(row
, replace_attribute_tag: str = ""
, remove_links_relationships: bool = False) -> dict:
"""
Args:
row (safrs.DB.Model): models instance (object + related objects)
replace_attribute_tag (str): replace _attribute_ tag with this name
remove_links_relationships (bool): remove these tags
Example: in sample nw project, see customize_api: order()
Returns:
_type_: row suitable for safrs response (a dict)
"""
row_as_dict = jsonify(row).json
log(f'row_to_dict: {row_as_dict}')
if replace_attribute_tag != "":
row_as_dict[replace_attribute_tag] = row_as_dict.pop('attributes')
if remove_links_relationships:
row_as_dict.pop('links')
row_as_dict.pop('relationships')
return row_as_dict
def rows_to_dict(result: flask_sqlalchemy.BaseQuery) -> list:
"""
Converts SQLAlchemy result (mapped or raw) to dict array of un-nested rows
Args:
result (object): list of serializable objects (e.g., dict)
Returns:
list of rows as dicts
"""
rows = []
for each_row in result:
row_as_dict = {}
log(f'type(each_row): {type(each_row)}')
if isinstance (each_row, sqlalchemy.engine.row.Row): # raw sql, eg, sample catsql
key_to_index = each_row._key_to_index # note: SQLAlchemy 2 specific
for name, value in key_to_index.items():
row_as_dict[name] = each_row[value]
else:
row_as_dict = each_row.to_dict()
rows.append(row_as_dict)
return rows
def sys_info():
"""
Print env and path
"""
import os, socket
print("\n\nsys_info here")
print("\nEnvironment Variables...")
env = os.environ
for each_variable in os.environ:
print(f'.. {each_variable} = {env[each_variable]}')
print("\nPYTHONPATH..")
for p in sys.path:
print(".." + p)
print("")
print(f'sys.prefix (venv): {sys.prefix}\n')
print("")
hostname = socket.gethostname()
try:
local_ip = socket.gethostbyname(hostname)
except:
local_ip = f"Warning - Failed local_ip = socket.gethostbyname(hostname) with hostname: {hostname}"
print(f"hostname={hostname} on local_ip={local_ip}\n\n")
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/1. Learn APIs using Flask SqlAlchemy/util.py
|
util.py
|
from os import environ, path
from pathlib import Path
import os
from dotenv import load_dotenv
import logging
# for complete flask_sqlachemy config parameters and session handling,
# read: file flask_sqlalchemy/__init__.py AND flask/config.py
'''
app.config.setdefault('SQLALCHEMY_DATABASE_URI', 'sqlite:///:memory:')
app.config.setdefault('SQLALCHEMY_BINDS', None)
app.config.setdefault('SQLALCHEMY_NATIVE_UNICODE', None)
app.config.setdefault('SQLALCHEMY_ECHO', False)
app.config.setdefault('SQLALCHEMY_RECORD_QUERIES', None)
app.config.setdefault('SQLALCHEMY_POOL_SIZE', None)
app.config.setdefault('SQLALCHEMY_POOL_TIMEOUT', None)
app.config.setdefault('SQLALCHEMY_POOL_RECYCLE', None)
app.config.setdefault('SQLALCHEMY_MAX_OVERFLOW', None)
app.config.setdefault('SQLALCHEMY_COMMIT_ON_TEARDOWN', False)
'''
basedir = path.abspath(path.dirname(__file__))
load_dotenv(path.join(basedir, "default.env"))
app_logger = logging.getLogger('api_logic_server_app')
class Config:
"""Set Flask configuration from .env file."""
# General Config
SECRET_KEY = environ.get("SECRET_KEY")
FLASK_APP = environ.get("FLASK_APP")
FLASK_ENV = environ.get("FLASK_ENV")
DEBUG = environ.get("DEBUG")
running_at = Path(__file__)
project_abs_dir = running_at.parent.absolute()
# Database
SQLALCHEMY_DATABASE_URI = f"sqlite:///{str(project_abs_dir.joinpath('database/db.sqlite'))}"
# override SQLALCHEMY_DATABASE_URI here as required
app_logger.debug(f'config.py - SQLALCHEMY_DATABASE_URI: {SQLALCHEMY_DATABASE_URI}')
# as desired, use env variable: export SQLALCHEMY_DATABASE_URI='sqlite:////Users/val/dev/servers/docker_api_logic_project/database/db.sqliteXX'
if os.getenv('SQLALCHEMY_DATABASE_URI'): # e.g. export SECURITY_ENABLED=true
SQLALCHEMY_DATABASE_URI = os.getenv('SQLALCHEMY_DATABASE_URI')
app_logger.debug(f'.. overridden from env variable: {SQLALCHEMY_DATABASE_URI}')
SQLALCHEMY_TRACK_MODIFICATIONS = False
PROPAGATE_EXCEPTIONS = False
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/1. Learn APIs using Flask SqlAlchemy/config.py
|
config.py
|
# 1. Learn APIs using Flask / SQLAlchemy
This is a manually coded server providing a few APIs for [this database](https://apilogicserver.github.io/Docs/Sample-Database/).
It is the smallest example of a typical project for a modern database API server.
# APIs
Here's a brief overview of APIs.
## Requirement: Networked Database Access
Most database applications require networked database access. You simply cannot call database access libraries (e.g., ODBC, JDBC) from a mobile app or a remote computer for B2B or application integration.
## RESTful APIs: Leverage HTTP, JSON
REST has emerged as a loose standard for APIs, by leveraging 2 key technology elements:
* **HTTP protocol:** Web Browsers utilize this, invoking `Get` commands to obtain `html` responses, but HTTP is far more extensive as shown in the table below.
* **JSON:** JavaScript Object Notation is supported by virtually all language, providing readable formatting for objects/properties, including lists and sub-objects.
## Example: retrieve some data
HTTP is invoked with a URL, as shown in the following cURL command, identifies a verb, a server/port, an endpoint (`order`) and arguments:
```
curl -X GET "http://localhost:8080/order?Id=10643"
```
## Key Elements
| HTTP Component | Designates | Notes | Example |
|:----|:--------|:--------|:--------|
| **Verb** | `Post`, `Get`, `Patch`, `Delete` | Maps well to ***crud*** | `Get` |
| Server:port | Identifies server | | http://localhost:8080 |
| **Endpoint** | Can be series of nodes | Analogous to **table/view** name | `Order` |
| **Arguments** | Key/values Start with `?`, separate by `&` | E.g., **filter/sort**. Caution: special characters | `?Id=10643` |
| Return Code | Success/failure | a number | 200 means success |
| **Response** | The requested data | JSON format | See below |
| **Request** | Data for insert, update | JSON format | Not used for `Get` |
| *Header* | **Authentication** | typically a token | Commonly JWT (Java Web Token) |
<details markdown>
<br>
<summary>Response Example</summary>
```json
{
"AmountTotal": "1086.00",
"City": "None",
"CloneFromOrder": "None",
"Country": "None",
"CustomerId": "ALFKI",
"Customer_Name": "Alfreds Futterkiste",
"EmployeeId": "6",
"Freight": "29.4600000000",
"Id": "10643",
"OrderDate": "2013-08-25",
"OrderDetailCount": "3",
"OrderDetailListAsDicts": [
{
"Amount": "684.0000000000",
"Discount": "0.25",
"Id": "1040",
"OrderId": "10643",
"ProductId": "28",
"ProductName": "R\u00f6ssle Sauerkraut",
"Quantity": "15",
"ShippedDate": "None",
"UnitPrice": "45.6000000000"
},
{
"Amount": "378.0000000000",
"Discount": "0.25",
"Id": "1041",
"OrderId": "10643",
"ProductId": "39",
"ProductName": "Chartreuse verte",
"Quantity": "21",
"ShippedDate": "None",
"UnitPrice": "18.0000000000"
},
{
"Amount": "24.0000000000",
"Discount": "0.25",
"Id": "1042",
"OrderId": "10643",
"ProductId": "46",
"ProductName": "Spegesild",
"Quantity": "2",
"ShippedDate": "None",
"UnitPrice": "12.0000000000"
}
],
"Ready": "True",
"RequiredDate": "2013-09-22",
"ShipAddress": "Obere Str. 57",
"ShipCity": "Berlin",
"ShipCountry": "Germany",
"ShipName": "Alfreds Futterkiste",
"ShipZip": "12209",
"ShipRegion": "Western Europe",
"ShipVia": "1",
"ShippedDate": "None"
}
```
</details>
### Considerable Design Required
There is ***considerable*** variation with RESTful servers:
* how the arguments are specified
* how exactly are request/response objects structured, etc.
Resolving these is a substantial design task, requiring considerable time and experience. Standards such as **JSON:API** can therefore save time and improve quality.
# Python Frameworks
Creating an API Server requires 2 basic tools: a Framework, and database access.
There are several libraries for creating Web Servers in Python, including Django, Fast API, and Flask. Here we will explore:
* Flask - a framework for receiving HTTP calls and returning responses
* SQLAlchemy - SQL Access
## Framework - Flask
A framework is a "your code goes here" library, providing backend functions to handle api calls, html calls, etc. The framework provides key basic functions such as:
* listening for incoming calls, and **invoking your code** (your 'handler')
* providing **access to url parameters and request data**
* enabling you to **return a response** in a designated format, such as html or json
A popular framework in Python is ***Flask***, illustrated in this application. Basically:
```python
@app.route('/order', methods=['GET']) # Tell Flask: call this on order request
def order():
order_id = request.args.get('Id') # Obtain URL argument from Flask
```
## Data Access - SQLAlchemy ORM
In your handler, you may need to read or write database data. You can use raw SQL, or an ORM (Object Relational Manager) such as SQLAlchemy. ORMs can facilitate database access:
* **use Objects** (instead of dictionaries), which provide IDE services such as code completion to simplify coding and reduce errors
* simplified **access to related data** (e.g., a simple way to get the OrderDetails for an Order)
* **custom naming** - independent of database table/columns
* See `Category.CategoryName`, `Order.ShipZip`<br><br>
* other services, such as support for type hierarchies
There are 2 basic elements for using an ORM:
* provide **data model classes** - these are used to read/write data, and can also be used to create / update the database structure (add tables and columns). See `database/models.py`:
```python
class Customer(Base):
__tablename__ = 'Customer'
_s_collection_name = 'Customer'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CompanyName = Column(String(8000))
OrderList = relationship('Order', cascade_backrefs=False, backref='Customer')
```
* use **data access** - verbs to read/write data. See `api/end_points.py`:
```python
order = db.session.query(models.Order).filter(models.Order.Id == order_id).one()
for each_order_detail in order.OrderDetailList: # SQLAlchemy related data access
```
---
# Exploring the App
## App Structure
Long before you use the Flask/SQLAlchemy tools, you need to create project structure. You can explore [```1. Learn APIs using Flask SqlAlchemy```](../1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/):
* `api` - a directory for api code
* `database` - a directory for SQLAlchemy artifacts
There are also important devops artifacts:
* `.devcontainer/` - files here enable your project to be run in docker images (including Codespaces), and to package your application as an image for production deployment
* `config.py` - use this to set up key configuration parameters, including code to override them with environment variables
## Server
See [```flask_basic.py```](/1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/flask_basic.py) to see how to establish a Flask server. It's this program you ran to start the server.
## API
Explore [```api/end_points.py```](/1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/api/end_points.py) for examples of handling api calls. See `def order():`.
## Data Access
There are 2 files to explore for SQLAlchemy:
* See [```database/models.py```](/1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/database/models.py) for examples of defining objects (models) for database rows. These correspond to the tables in your database.
* See [```api/end_points.py```](/1.%20Learn%20APIs%20using%20Flask%20SqlAlchemy/api/end_points.py) for examples of SQLAlchemy calls. See `def order():`.
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/1. Learn APIs using Flask SqlAlchemy/readme.md
|
readme.md
|
from sqlalchemy import Boolean, Column, DECIMAL, Date, Float, ForeignKey, ForeignKeyConstraint, Integer, LargeBinary, String, Table, Text, text
from sqlalchemy.orm import relationship
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM.
########################################################################################################################
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base()
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Category(Base):
__tablename__ = 'CategoryTableNameTest'
_s_collection_name = 'Category'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CategoryName = Column('CategoryName_ColumnName', String(8000)) # logical name
Description = Column(String(8000))
Client_id = Column(Integer)
class Customer(Base):
__tablename__ = 'Customer'
_s_collection_name = 'Customer'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
Balance = Column(DECIMAL)
CreditLimit = Column(DECIMAL)
OrderCount = Column(Integer, server_default=text("0"))
UnpaidOrderCount = Column(Integer, server_default=text("0"))
Client_id = Column(Integer)
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Customer')
class CustomerDemographic(Base):
__tablename__ = 'CustomerDemographic'
_s_collection_name = 'CustomerDemographic'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CustomerDesc = Column(String(8000))
allow_client_generated_ids = True
class Department(Base):
__tablename__ = 'Department'
_s_collection_name = 'Department'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
DepartmentId = Column(ForeignKey('Department.Id'))
DepartmentName = Column(String(100))
# see backref on parent: Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList')
Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList') # special handling for self-relationships
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='Department1')
class Location(Base):
__tablename__ = 'Location'
_s_collection_name = 'Location'
__bind_key__ = 'None'
country = Column(String(50), primary_key=True)
city = Column(String(50), primary_key=True)
notes = Column(String(256))
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Location')
class Product(Base):
__tablename__ = 'Product'
_s_collection_name = 'Product'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
ProductName = Column(String(8000))
SupplierId = Column(Integer, nullable=False)
CategoryId = Column(Integer, nullable=False)
QuantityPerUnit = Column(String(8000))
UnitPrice = Column(DECIMAL, nullable=False)
UnitsInStock = Column(Integer, nullable=False)
UnitsOnOrder = Column(Integer, nullable=False)
ReorderLevel = Column(Integer, nullable=False)
Discontinued = Column(Integer, nullable=False)
UnitsShipped = Column(Integer)
OrderDetailList = relationship('OrderDetail', cascade_backrefs=False, backref='Product')
class Region(Base):
__tablename__ = 'Region'
_s_collection_name = 'Region'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
RegionDescription = Column(String(8000))
class SampleDBVersion(Base):
__tablename__ = 'SampleDBVersion'
_s_collection_name = 'SampleDBVersion'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Notes = Column(String(800))
class Shipper(Base):
__tablename__ = 'Shipper'
_s_collection_name = 'Shipper'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
Phone = Column(String(8000))
class Supplier(Base):
__tablename__ = 'Supplier'
_s_collection_name = 'Supplier'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
ShipZip = Column('ShipPostalCode', String(8000)) # manual fix - alias
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
HomePage = Column(String(8000))
class Territory(Base):
__tablename__ = 'Territory'
_s_collection_name = 'Territory'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
TerritoryDescription = Column(String(8000))
RegionId = Column(Integer, nullable=False)
allow_client_generated_ids = True
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Territory')
class Union(Base):
__tablename__ = 'Union'
_s_collection_name = 'Union'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Name = Column(String(80))
EmployeeList = relationship('Employee', cascade_backrefs=False, backref='Union')
t_sqlite_sequence = Table(
'sqlite_sequence', metadata,
Column('name', NullType),
Column('seq', NullType)
)
class Employee(Base):
__tablename__ = 'Employee'
_s_collection_name = 'Employee'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
LastName = Column(String(8000))
FirstName = Column(String(8000))
Title = Column(String(8000))
TitleOfCourtesy = Column(String(8000))
BirthDate = Column(String(8000))
HireDate = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
HomePhone = Column(String(8000))
Extension = Column(String(8000))
Notes = Column(String(8000))
ReportsTo = Column(Integer, index=True)
PhotoPath = Column(String(8000))
EmployeeType = Column(String(16), server_default=text("Salaried"))
Salary = Column(DECIMAL)
WorksForDepartmentId = Column(ForeignKey('Department.Id'))
OnLoanDepartmentId = Column(ForeignKey('Department.Id'))
UnionId = Column(ForeignKey('Union.Id'))
Dues = Column(DECIMAL)
# see backref on parent: Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Union = relationship('Union', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList_Department1')
EmployeeAuditList = relationship('EmployeeAudit', cascade_backrefs=False, backref='Employee')
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Employee')
OrderList = relationship('Order', cascade_backrefs=False, backref='Employee')
class EmployeeAudit(Base):
__tablename__ = 'EmployeeAudit'
_s_collection_name = 'EmployeeAudit'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Title = Column(String)
Salary = Column(DECIMAL)
LastName = Column(String)
FirstName = Column(String)
EmployeeId = Column(ForeignKey('Employee.Id'))
CreatedOn = Column(Text)
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeAuditList')
class EmployeeTerritory(Base):
__tablename__ = 'EmployeeTerritory'
_s_collection_name = 'EmployeeTerritory'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False)
TerritoryId = Column(ForeignKey('Territory.Id'))
allow_client_generated_ids = True
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeTerritoryList')
# see backref on parent: Territory = relationship('Territory', cascade_backrefs=False, backref='EmployeeTerritoryList')
class Order(Base):
__tablename__ = 'Order'
_s_collection_name = 'Order'
__bind_key__ = 'None'
__table_args__ = (
ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city']),
)
Id = Column(Integer, primary_key=True)
CustomerId = Column(ForeignKey('Customer.Id'), nullable=False, index=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False, index=True)
OrderDate = Column(String(8000))
RequiredDate = Column(Date)
ShippedDate = Column(String(8000))
ShipVia = Column(Integer)
Freight = Column(DECIMAL, server_default=text("0"))
ShipName = Column(String(8000))
ShipAddress = Column(String(8000))
ShipCity = Column(String(8000))
ShipRegion = Column(String(8000))
ShipZip = Column('ShipPostalCode', String(8000)) # manual fix - alias
ShipCountry = Column(String(8000))
AmountTotal = Column(DECIMAL(10, 2))
Country = Column(String(50))
City = Column(String(50))
Ready = Column(Boolean, server_default=text("TRUE"))
OrderDetailCount = Column(Integer, server_default=text("0"))
CloneFromOrder = Column(ForeignKey('Order.Id'))
# see backref on parent: parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList')
# see backref on parent: Location = relationship('Location', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Customer = relationship('Customer', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='OrderList')
parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList') # special handling for self-relationships
OrderDetailList = relationship('OrderDetail', cascade='all, delete', cascade_backrefs=False, backref='Order') # manual fix
class OrderDetail(Base):
__tablename__ = 'OrderDetail'
_s_collection_name = 'OrderDetail'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
OrderId = Column(ForeignKey('Order.Id'), nullable=False, index=True)
ProductId = Column(ForeignKey('Product.Id'), nullable=False, index=True)
UnitPrice = Column(DECIMAL)
Quantity = Column(Integer, server_default=text("1"), nullable=False)
Discount = Column(Float, server_default=text("0"))
Amount = Column(DECIMAL)
ShippedDate = Column(String(8000))
# see backref on parent: Order = relationship('Order', cascade_backrefs=False, backref='OrderDetailList')
# see backref on parent: Product = relationship('Product', cascade_backrefs=False, backref='OrderDetailList')
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/1. Learn APIs using Flask SqlAlchemy/database/models.py
|
models.py
|
import logging
from flask import request, jsonify
from database import models
import util
from sqlalchemy import inspect
def row2dict(row):
"""
Get dict for row.
Note mapped rows are *logical*, not physical db table/column names.
* see Category, Order.ShipZip
https://docs.sqlalchemy.org/en/20/orm/mapping_styles.html#inspection-of-mapped-instances
Args:
row (_type_): row instance (mapped object)
Returns:
_type_: dict of attr names/values
"""
mapper = inspect(row.__class__).mapper
return {
c.key: str(getattr(row, c.key))
for c in mapper.attrs # not: for c in row.__table__.columns
}
def flask_events(app, db):
"""
Illustrate flask events
"""
app_logger = logging.getLogger(__name__)
@app.route('/hello_world')
def hello_world():
"""
Illustrates simplest possible endpoint, with url args.
The url suffix is specified in the annotation.
Test it with: http://localhost:8080/hello_world?user=Basic_App
Returns:
json : a simple string
"""
user = request.args.get('user') # obtain URL argument from Flask via built-in request object
app_logger.info(f'{user}')
return jsonify({"result": f'hello, {user}'}) # the api response (in json)
@app.route('/order', methods=['GET']) # tell Flask: call this function when /order request occurs
def order():
"""
End point to return a nested result set response, from related database rows
Illustrates:
1. Obtain URL argument from Flask
2. Read data from SQLAlchemy, and related data (via foreign keys)
3. Restructure row results to desired json (e.g., for tool such as Sencha)
4. Use Flask to return nested response json
Test:
http://localhost:8080/order?Id=10643
curl -X GET "http://localhost:8080/order?Id=10643"
"""
# 1. Obtain URL argument from Flask
order_id = request.args.get('Id')
# 2. Read data from SQLAlchemy
order = db.session.query(models.Order).\
filter(models.Order.Id == order_id).one()
app_logger.info(f'\n Breakpoint - examine order in debugger \n')
# 3. Restructure row results - format as result_std_dict
result_std_dict = util.format_nested_object(row2dict(order)
, remove_links_relationships=False)
result_std_dict['Customer_Name'] = order.Customer.CompanyName # eager fetch
result_std_dict['OrderDetailListAsDicts'] = []
for each_order_detail in order.OrderDetailList: # SQLAlchemy related data access
each_order_detail_dict = util.format_nested_object(row=row2dict(each_order_detail)
, remove_links_relationships=False)
each_order_detail_dict['ProductName'] = each_order_detail.Product.ProductName
result_std_dict['OrderDetailListAsDicts'].append(each_order_detail_dict)
# 4. Use Flask to return nested response json (Flask jsonifies dict)
return result_std_dict # rest response
@app.route('/stop')
def stop(): # test it with: http://localhost:8080/stop?msg=API stop - Stop Basic App Server
"""
Use this to stop the server from the Browser.
See: https://stackoverflow.com/questions/15562446/how-to-stop-flask-application-without-using-ctrl-c
"""
import os, signal
msg = request.args.get('msg')
app_logger.info(f'\nStopped server: {msg}\n')
os.kill(os.getpid(), signal.SIGINT)
return jsonify({ "success": True, "message": "Server is shutting down..." })
logging.info("\n\n..Basic App, exposing end points: hello_world, order, stop\n")
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/fiddle/1. Learn APIs using Flask SqlAlchemy/api/end_points.py
|
end_points.py
|
# intended for use in portal cli - not to be run on your local machine.
projectname="apilogicserver_project_name_lowerngnix" # lower case, only. not unique in resourcegroup
resourcegroup="apilogicserver_project_name_lower_rg_ngnix"
dockerrepositoryname="apilogicserver" # change this to your DockerHub Repository
githubaccount="apilogicserver" # change this to your GitHub account
version="1.0.0"
# see docs: https://apilogicserver.github.io/Docs/DevOps-Containers-Deploy-Multi/
# modeled after: https://learn.microsoft.com/en-us/azure/app-service/tutorial-multi-container-app
# which uses: https://github.com/Azure-Samples/multicontainerwordpress
# login to Azure Portal CLI (substitute your github account for apilogicserver)
# git clone https://github.com/apilogicserver/classicmodels.git
# cd classicmodels
# sh devops/docker-compose-dev-azure-nginx/azure-deploy.sh
echo " "
if [ "$#" -eq 0 ]; then
echo "..using defaults - press ctl+C to stop run"
else
if [ "$1" = "." ]; then
echo "..using defaults"
else
echo "using arg overrides"
projectname="$1"
githubaccount="$2"
dockerrepositoryname="$3"
resourcegroup="$4"
fi
fi
echo " "
echo "Azure Deploy here - Azure Portal CLI commands to deploy project, 1.0"
echo " "
echo "Prereqs"
echo " 1. You have published your project to GitHub: https://github.com/${githubaccount}/${projectname}.git"
echo " 2. You have built your project image, and pushed it to DockerHub: ${dockerrepositoryname}/${projectname}"
echo " "
echo "Steps performed on Azure Portal CLI to enable running these commands:"
echo " # we really only need the docker compose file"
echo " git clone https://github.com/$githubaccount/$projectname.git"
echo " cd classicmodels"
echo " "
echo "Then, in Azure CLI:"
echo " sh devops/docker-compose-dev-azure-ngnix/azure-deploy.sh [ . | args ]"
echo " . means use defaults:"
echo " ${dockerrepositoryname}/${projectname}:${version}"
echo " <args> = projectname githubaccount dockerrepositoryname resourcegroupname"
echo " "
read -p "Verify settings above, then press ENTER to proceed> "
echo " "
echo "check webapp and security..."
if [ ! -d "./devops/docker-compose-dev-azure-nginx/www/admin-app" ]
then
echo "\nYou need to install the etc/www directories first - use sh devops/docker-compose-dev-azure-nginx/install-webapp.sh\n"
exit 1
else
echo "... web app check complete"
fi
if [ ! -f "./database/authentication_models.py" ]
then
echo "\nYou need to activate security first. With mysql-container running...\n"
echo "ApiLogicServer add-auth --project_name=. --db_url=mysql+pymysql://root:p@localhost:3306/authdb"
echo "then stop mysql-container\n"
exit 1
else
echo "... security check complete"
fi
echo " "
set -x # echo commands
# create container group
az group create --name $resourcegroup --location "westus"
# create service plan
az appservice plan create --name myAppServicePlan --resource-group $resourcegroup --sku S1 --is-linux
# create docker compose app
az webapp create --resource-group $resourcegroup --plan myAppServicePlan --name $projectname --multicontainer-config-type compose --multicontainer-config-file ./devops/docker-compose-dev-azure-nginx/docker-compose-dev-azure-nginx.yml
set +x # reset echo
echo "enable logging: https://learn.microsoft.com/en-us/azure/app-service/troubleshoot-diagnostic-logs#enable-application-logging-linuxcontainer"
echo " To enable web server logging for Windows apps in the Azure portal, navigate to your app and select App Service logs"
echo " For Web server logging, select Storage to store logs on blob storage, or File System to store logs on the App Service file system"
echo " "
echo "Completed. Browse to the app:"
echo "https://$projectname.azurewebsites.net"
echo " "
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/nginx_exp/docker-compose-dev-azure-nginx/azure-deploy.sh
|
azure-deploy.sh
|
import subprocess, os, time, requests, sys, re, io
from typing import List
from shutil import copyfile
import shutil
from sys import platform
from subprocess import DEVNULL, STDOUT, check_call
from pathlib import Path
from dotmap import DotMap
import json
def print_run_output(msg, input):
print(f'\n{msg}')
print_lines = input.split("\\n")
for each_line in print_lines:
print(each_line)
def print_byte_string(msg, byte_string):
print(msg)
for line in byte_string.decode('utf-8').split('\n'):
print (line)
def check_command(command_result, special_message: str=""):
result_stdout = ""
result_stderr = ''
if command_result is not None:
if command_result.stdout is not None:
result_stdout = str(command_result.stdout)
if command_result.stderr is not None:
result_stderr = str(command_result.stderr)
if "Trace" in result_stderr or \
"Error" in result_stderr or \
"allocation failed" in result_stdout or \
"error" in result_stderr or \
"Cannot connect" in result_stderr or \
"Traceback" in result_stderr:
if 'alembic.runtime.migration' in result_stderr:
pass
else:
print_byte_string("\n\n==> Command Failed - Console Log:", command_result.stdout)
print_byte_string("\n\n==> Error Log:", command_result.stderr)
if special_message != "":
print(f'{special_message}')
raise ValueError("Traceback detected")
def run_command(cmd: str, msg: str = "", new_line: bool=False,
cwd: Path=None, show_output: bool=False) -> object:
""" run shell command (waits)
:param cmd: string of command to execute
:param msg: optional message (no-msg to suppress)
:param cwd: path to current working directory
:param show_output print command result
:return: dict print(ret.stdout.decode())
"""
print(f'{msg}, with command: \n{cmd}')
try:
# result_b = subprocess.run(cmd, cwd=cwd, shell=True, stderr=subprocess.STDOUT)
result = subprocess.run(cmd, cwd=cwd, shell=True, capture_output=True)
if show_output:
print_byte_string(f'{msg} Output:', result.stdout)
special_message = msg
if special_message.startswith('\nCreate MySQL classicmodels'):
msg += "\n\nOften caused by docker DBs not running: see https://apilogicserver.github.io/Docs/Architecture-Internals/#do_docker_database"
check_command(result, msg)
"""
if "Traceback" in result_stderr:
print_run_output("Traceback detected - stdout", result_stdout)
print_run_output("stderr", result_stderr)
raise ValueError("Traceback detected")
"""
except Exception as err:
print(f'\n\n*** Failed {err} on {cmd}')
print_byte_string("\n\n==> run_command Console Log:", result.stdout)
print_byte_string("\n\n==> Error Log:", result.stderr)
raise
return result
# ***************************
# MAIN CODE
# ***************************
'''
this approach works, but
* does not show nginx output
* docker-compose errors are visible, but hidden (eg, improper command: bash /app/startX.sh)
'''
current_path = Path(os.path.abspath(os.path.dirname(__file__)))
project_path = current_path.parent.parent
print(f'\n\ndocker_compose running at \n'
f'..current_path: {current_path} \n'
f'..project_path: {project_path:}\n')
docker_compose_command = 'docker-compose -f ./devops/docker-compose/docker-compose.yml up'
result_build = run_command(docker_compose_command,
cwd=project_path,
msg=f'\nStarting docker-compose',
show_output=True)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/prototypes/nginx_exp/docker-compose-dev-azure-nginx/unused/unused-docker-compose.py
|
unused-docker-compose.py
|
import sys, logging, inspect, builtins, os, argparse, tempfile, atexit, shutil, io
import traceback
import safrs
from sqlalchemy import CHAR, Column, DateTime, Float, ForeignKey, Index, Integer, String, TIMESTAMP, Table, Text, UniqueConstraint, text
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from flask_sqlalchemy import SQLAlchemy
from flask import Flask, redirect
from flask_swagger_ui import get_swaggerui_blueprint
from safrs import SAFRSBase, jsonapi_rpc
from safrs import search, SAFRSAPI
from io import StringIO
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import MetaData
from flask_cors import CORS
from sqlacodegen_wrapper.sqlacodegen.sqlacodegen.codegen import CodeGenerator
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
from pathlib import Path
from shutil import copyfile
import os, sys
from pathlib import Path
from os.path import abspath
from api_logic_server_cli.cli_args_project import Project
log = logging.getLogger(__name__)
MODEL_DIR = tempfile.mkdtemp() # directory where the generated models.py will be saved
on_import = False
sqlacodegen_dir = os.path.join(os.path.dirname(__file__), "sqlacodegen")
if not os.path.isdir(sqlacodegen_dir):
log.debug("sqlacodegen not found")
sys.path.insert(0, MODEL_DIR)
sys.path.insert(0, sqlacodegen_dir)
# despite compile error, runs due to logic_bank_utils.add_python_path(project_dir="ApiLogicServer", my_file=__file__)
# FIXME from sqlacodegen.codegen import CodeGenerator
# from sqlacodegen.sqlacodegen.codegen import CodeGenerator # No module named 'sqlacodegen.sqlacodegen'
def get_args():
""" unused by ApiLogicServer """
parser = argparse.ArgumentParser(description="Generates SQLAlchemy model code from an existing database.")
parser.add_argument("url", nargs="?", help="SQLAlchemy url to the database")
parser.add_argument("--version", action="store_true", help="print the version number and exit")
parser.add_argument("--host", default="0.0.0.0", help="host (interface ip) to run")
parser.add_argument("--port", default=5000, type=int, help="host (interface ip) to run")
parser.add_argument("--models", default=None, help="Load models from file instead of generating them dynamically")
parser.add_argument("--schema", help="load tables from an alternate schema")
parser.add_argument("--tables", help="tables to process (comma-separated, default: all)")
parser.add_argument("--noviews", action="store_true", help="ignore views")
parser.add_argument("--noindexes", action="store_true", help="ignore indexes")
parser.add_argument("--noconstraints", action="store_true", help="ignore constraints")
parser.add_argument("--nojoined", action="store_true", help="don't autodetect joined table inheritance")
parser.add_argument("--noinflect", action="store_true", help="don't try to convert tables names to singular form")
parser.add_argument("--noclasses", action="store_true", help="don't generate classes, only tables")
parser.add_argument("--outfile", help="file to write output to (default: stdout)")
parser.add_argument("--maxpagelimit", default=250, type=int, help="maximum number of returned objects per page (default: 250)")
args = parser.parse_args()
if args.version:
version = pkg_resources.get_distribution("sqlacodegen").parsed_version # noqa: F821
log.debug(version.public)
exit()
if not args.url:
log.debug("You must supply a url\n", file=sys.stderr)
parser.print_help()
exit(1)
log.debug(f'.. ..Dynamic model import successful')
return args
def fix_generated(code, args):
""" minor numeric vs. string replacements
"""
if "sqlite" in args.url: # db.session.bind.dialect.name == "sqlite": FIXME review
code = code.replace("Numeric", "String")
if "mysql" in args.url:
code = code.replace("Numeric", "String")
code = code.replace(", 'utf8_bin'","")
if "mssql" in args.url:
bad_import = "from sqlalchemy.dialects.mysql import *" # prevents safrs bool not iterable
line1 = "# coding: utf-8\n"
code = code.replace(bad_import,"# " + bad_import)
code = code.replace(line1, line1 + bad_import + "\n")
# code = code.replace("Column(Image)","Column(Text)") FAILS - incompatible type
if "postgres" in args.url:
code = code.replace("Column(LargeBinary)","Column(Text)")
# Column(IMAGE)
code = code.replace("Column(IMAGE)","Column(NTEXT)")
return code
uri_info = [
'Examples:',
' ApiLogicServer create-and-run',
' ApiLogicServer create-and-run --db_url=sqlite:////Users/val/dev/todo_example/todos.db --project_name=todo',
' ApiLogicServer create-and-run --db_url=mysql+pymysql://root:p@mysql-container:3306/classicmodels '
'--project_name=/localhost/docker_db_project',
' ApiLogicServer create-and-run --db_url=mssql+pyodbc://sa:Posey3861@localhost:1433/NORTHWND?'
'driver=ODBC+Driver+17+for+SQL+Server&trusted_connection=no',
' ApiLogicServer create-and-run --db_url=postgresql://postgres:[email protected]/postgres',
' ApiLogicServer create --project_name=my_schema --db_url=postgresql://postgres:p@localhost/my_schema',
' ApiLogicServer create --db_url=postgresql+psycopg2:'
'//postgres:password@localhost:5432/postgres?options=-csearch_path%3Dmy_db_schema',
' ApiLogicServer create --project_name=Chinook \\',
' --host=ApiLogicServer.pythonanywhere.com --port= \\',
' --db_url=mysql+pymysql://ApiLogicServer:***@ApiLogicServer.mysql.pythonanywhere-services.com/ApiLogicServer\$Chinook',
'',
'Where --db_url is one of...',
' <default> Sample DB - https://apilogicserver.github.io/Docs/Sample-Database/',
' nw- Sample DB, no customizations - add later with perform_customizations.py',
' <SQLAlchemy Database URI> Your own database - https://docs.sqlalchemy.org/en/14/core/engines.html',
' Other URI examples: - https://apilogicserver.github.io/Docs/Database-Connectivity//',
' ',
'Docs: https://apilogicserver.github.io/Docs/'
]
def print_uri_info():
"""
Creates and optionally runs a customizable ApiLogicServer project, Example
URI examples, Docs URL
"""
global uri_info
for each_line in uri_info:
sys.stdout.write(each_line + '\n')
sys.stdout.write('\n')
def write_models_py(model_file_name, models_mem):
"""
write models_mem to disk as model_file_name
Args:
model_file_name (str): name of models.py file
models_mem (str): the actual models code (long string with \n)
"""
with open(model_file_name, "w") as text_file:
text_file.write(models_mem)
def create_models_py(model_creation_services: ModelCreationServices, abs_db_url: str, project_directory: str):
"""
Create `models.py` (using sqlacodegen, via this wrapper at create_models_py() ).
Called on creation of ModelCreationServices.__init__ (ctor - singleton).
1. It calls `create_models_memstring`:
* It returns the `models_py` text to be written to the projects' `database/models.py`.
* It uses a modification of [sqlacodgen](https://github.com/agronholm/sqlacodegen), by Alex Grönholm -- many thanks!
* An important consideration is disambiguating multiple relationships between the same 2 tables
* See relationships between `Department` and `Employee`.
* [See here](https://apilogicserver.github.io/Docs/Sample-Database/) for a database diagram.
* It transforms database names to resource names - capitalized, singular
* These (not table names) are used to create api and ui model
2. It then calls `write_models_py`
ModelCreationServices.__init__ then calls `create_resource_list`:
* This is the meta data iterated by the creation modules to create api and ui model classes.
* Important: models are sometimes _supplied_ (`use_model`), not generated, because:
* Many DBs don't define FKs into the db (e.g. nw.db).
* Instead, they define "Virtual Keys" in their model files.
* To leverage these, we need to get resource Metadata from model classes, not db
:param model_creation_services: ModelCreationServices
:param abs_db_url: the actual db_url (not relative, reflects sqlite [nw] copy)
:param project: project directory
"""
class DotDict(dict):
"""dot.notation access to dictionary attributes"""
# thanks: https://stackoverflow.com/questions/2352181/how-to-use-a-dot-to-access-members-of-dictionary/28463329
__getattr__ = dict.get
__setattr__ = dict.__setitem__
__delattr__ = dict.__delitem__
def get_codegen_args():
""" DotDict of url, outfile, version """
codegen_args = DotDict({})
codegen_args.url = abs_db_url
# codegen_args.outfile = models_file
codegen_args.outfile = project_directory + '/database/models.py'
codegen_args.version = False
codegen_args.model_creation_services = model_creation_services
opt_locking_file_name = f'{model_creation_services.project.api_logic_server_dir_path.joinpath("templates/opt_locking.txt")}'
with open(opt_locking_file_name, 'r') as file:
opt_locking_data = file.read()
model_creation_services.opt_locking = opt_locking_data.replace('replace_opt_locking_attr', model_creation_services.project.opt_locking_attr)
return codegen_args
num_models = 0
model_full_file_name = "*"
project = model_creation_services.project
if project.command in ('create', 'create-and-run', 'rebuild-from-database', 'add_db'):
if project.use_model is None or model_creation_services.project.use_model == "":
code_gen_args = get_codegen_args()
model_full_file_name = code_gen_args.outfile
if model_creation_services.project.bind_key != "":
model_full_file_name = project.project_directory_path.joinpath('database').joinpath(project.model_file_name)
# model_full_file_name = "/".join(model_file_name.split("/")[:-1]) + "/" + model_creation_services.project.bind_key + "_" + model_file_name.split("/")[-1]
log.debug(f' a. Create Models - create database/{project.model_file_name}, using sqlcodegen')
log.debug(f'.. .. ..For database: {abs_db_url}')
models_mem, num_models = create_models_memstring(code_gen_args) # calls sqlcodegen
write_models_py(model_full_file_name, models_mem)
model_creation_services.resource_list_complete = True
else: # use pre-existing (or repaired) existing model file
model_full_file_name = str(Path(project_directory).joinpath('database/models.py'))
use_model_path = Path(model_creation_services.project.use_model).absolute()
log.debug(f' a. Use existing {use_model_path} - copy to {project_directory + "/database/models.py"}')
copyfile(use_model_path, model_full_file_name)
elif project.command == 'create-ui':
model_full_file_name = model_creation_services.resolve_home(name = model_creation_services.use_model)
elif project.command == "rebuild-from-model":
log.debug(f' a. Use existing database/models.py to rebuild api and ui models - verifying')
model_full_file_name = project_directory + '/database/models.py'
else:
error_message = f'System error - unexpected command: {project.command}'
raise ValueError(error_message)
msg = f'.. .. ..Create resource_list - dynamic import database/{model_creation_services.project.model_file_name}, inspect {num_models} classes'
return model_full_file_name, msg # return to ctor, create resource_list
def create_models_memstring(args) -> str:
""" Get models as string, using codegen & SQLAlchemy metadata
Args:
args (_type_): dict of codegen args (url etc)
Called by ApiLogicServer CLI > ModelCreationServices > create_models_py
Uses: https://docs.sqlalchemy.org/en/20/core/reflection.html
metadata_obj = MetaData()
metadata_obj.reflect(bind=someengine)
Returns:
str: to be written to models.py
"""
engine = create_engine(args.url) # type _engine.Engine
metadata = MetaData() # SQLAlchemy 1.4: metadata = MetaData(engine)
try:
# metadata.reflect(engine, args.schema, not args.noviews, tables) # load metadata - this opens the db
metadata.reflect(bind=engine) # loads metadata.tables
except:
track = traceback.format_exc()
log.info(track)
log.info(f'\n***** Database failed to open: {args.url} *****\n')
# log.info(f'.. See example above\n')
# print_uri_info()
log.info(f'\n...see https://apilogicserver.github.io/Docs/Troubleshooting/#database-failed-to-open \n\n')
# log.info(f'\n***** Database failed to open: {args.url} -- see examples above *****\n')
exit(1)
if "sqlite" in args.url: # db.session.bind.dialect.name == "sqlite": FIXME
connection = engine.connect()
connection.execute(text("PRAGMA journal_mode = OFF"))
'''
# dirty hack for sqlite
# engine.execute("""PRAGMA journal_mode = OFF""") # SQLAlchemy 1.4 code fails in 2.x
# 'Engine' object has no attribute 'execute' - moved to connection (where is that?)
# engine.update_execution_options("""PRAGMA journal_mode = OFF""")
# takes 1 positional argument but 2 were given
# engine.update_execution_options({"journal_mode": "OFF"})
# takes 1 positional argument but 2 were given
# connection.execute("""PRAGMA journal_mode = OFF""")
# ==> Not an executable object: 'PRAGMA journal_mode = OFF'
# ==> AttributeError: 'str' object has no attribute '_execute_on_connection'
# connection.execution_options({"journal_mode": "OFF"})
# ==> Connection.execution_options() takes 1 positional argument but 2 were given
'''
########################################
# call sqlacodegen
########################################
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(engine) # SQLAlchemy2
args.model_creation_services.session = Session()
capture = StringIO() # generate and return the model
# outfile = io.open(args.outfile, 'w', encoding='utf-8') if args.outfile else capture # sys.stdout
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses, args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
models_py = fix_generated(models_py, args)
return models_py, len(generator.models)
if on_import:
""" unused by ApiLogicServer """
args = get_args()
app = Flask("DB App")
CORS(app, origins=["*"])
app.config.update(
SQLALCHEMY_TRACK_MODIFICATIONS=0,
MAX_PAGE_LIMIT=args.maxpagelimit
)
app.config.update(SQLALCHEMY_DATABASE_URI=args.url, DEBUG=True, JSON_AS_ASCII=False)
SAFRSBase.db_commit = False
db = builtins.db = SQLAlchemy(app) # set db as a global variable to be used in employees.py
models = codegen(args)
log.debug(models)
#
# Write the models to file, we could try to exec() but this makes our code more complicated
# Also, we can modify models.py in case things go awry
#
if args.models:
model_dir = os.path.dirname(args.models)
sys.path.insert(0, model_dir)
else:
with open(os.path.join(MODEL_DIR, "models.py"), "w+") as models_f:
models_f.write(models)
# atexit.register(lambda : shutil.rmtree(MODEL_DIR))
import models
def start_api(HOST="0.0.0.0", PORT=5000):
""" unused - safrs code to create/start api """
OAS_PREFIX = "" # swagger prefix
with app.app_context():
api = SAFRSAPI(
app,
host=HOST,
port=PORT,
prefix=OAS_PREFIX,
api_spec_url=OAS_PREFIX + "/swagger",
schemes=["http", "https"],
description="exposed app",
)
for name, model in inspect.getmembers(models):
bases = getattr(model, "__bases__", [])
if SAFRSBase in bases:
# Create an API endpoint
# Add search method so we can perform lookups from the frontend
model.search = search
api.expose_object(model)
# Set the JSON encoder used for object to json marshalling
# app.json_encoder = SAFRSJSONEncoder
# Register the API at /api
# swaggerui_blueprint = get_swaggerui_bluelog.debug('/api', '/api/swagger.json')
# app.register_bluelog.debug(swaggerui_blueprint, url_prefix='/api')
@app.route("/")
def goto_api():
return redirect(OAS_PREFIX)
if __name__ == "__main__":
HOST = args.host
PORT = args.port
start_api(HOST, PORT)
log.debug("API URL: http://{}:{}/api , model dir: {}".format(HOST, PORT, MODEL_DIR))
app.run(host=HOST, port=PORT)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen_wrapper.py
|
sqlacodegen_wrapper.py
|
This is a tool that reads the structure of an existing database and generates the appropriate
SQLAlchemy model code, using the declarative style if possible.
This tool was written as a replacement for `sqlautocode`_, which was suffering from several issues
(including, but not limited to, incompatibility with Python 3 and the latest SQLAlchemy version).
.. _sqlautocode: http://code.google.com/p/sqlautocode/
Features
========
* Supports SQLAlchemy 0.8.x - 1.2.x
* Produces declarative code that almost looks like it was hand written
* Produces `PEP 8`_ compliant code
* Accurately determines relationships, including many-to-many, one-to-one
* Automatically detects joined table inheritance
* Excellent test coverage
.. _PEP 8: http://www.python.org/dev/peps/pep-0008/
Usage instructions
==================
Installation
------------
To install, do::
pip install sqlacodegen
Example usage
-------------
At the minimum, you have to give sqlacodegen a database URL. The URL is passed directly to
SQLAlchemy's `create_engine()`_ method so please refer to `SQLAlchemy's documentation`_ for
instructions on how to construct a proper URL.
Examples::
sqlacodegen postgresql:///some_local_db
sqlacodegen mysql+oursql://user:password@localhost/dbname
sqlacodegen sqlite:///database.db
To see the full list of options::
sqlacodegen --help
.. _create_engine(): http://docs.sqlalchemy.org/en/latest/core/engines.html#sqlalchemy.create_engine
.. _SQLAlchemy's documentation: http://docs.sqlalchemy.org/en/latest/core/engines.html
Why does it sometimes generate classes and sometimes Tables?
------------------------------------------------------------
Unless the ``--noclasses`` option is used, sqlacodegen tries to generate declarative model classes
from each table. There are two circumstances in which a ``Table`` is generated instead:
* the table has no primary key constraint (which is required by SQLAlchemy for every model class)
* the table is an association table between two other tables (see below for the specifics)
Model class naming logic
------------------------
The table name (which is assumed to be in English) is converted to singular form using the
"inflect" library. Then, every underscore is removed while transforming the next letter to upper
case. For example, ``sales_invoices`` becomes ``SalesInvoice``.
Relationship detection logic
----------------------------
Relationships are detected based on existing foreign key constraints as follows:
* **many-to-one**: a foreign key constraint exists on the table
* **one-to-one**: same as **many-to-one**, but a unique constraint exists on the column(s) involved
* **many-to-many**: an association table is found to exist between two tables
A table is considered an association table if it satisfies all of the following conditions:
#. has exactly two foreign key constraints
#. all its columns are involved in said constraints
Relationship naming logic
-------------------------
Relationships are typically named based on the opposite class name. For example, if an ``Employee``
class has a column named ``employer`` which has a foreign key to ``Company.id``, the relationship
is named ``company``.
A special case for single column many-to-one and one-to-one relationships, however, is if the
column is named like ``employer_id``. Then the relationship is named ``employer`` due to that
``_id`` suffix.
If more than one relationship would be created with the same name, the latter ones are appended
numeric suffixes, starting from 1.
Getting help
============
If you have problems or other questions, you can either:
* Ask on the `SQLAlchemy Google group`_, or
* Ask on the ``#sqlalchemy`` channel on `Freenode IRC`_
.. _SQLAlchemy Google group: http://groups.google.com/group/sqlalchemy
.. _Freenode IRC: http://freenode.net/irc_servers.shtml
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/README.rst
|
README.rst
|
from __future__ import unicode_literals, division, print_function, absolute_import
import inspect
import re
import sys, logging
from collections import defaultdict
from importlib import import_module
from inspect import FullArgSpec # val-311
from keyword import iskeyword
import sqlalchemy
import sqlalchemy.exc
from sqlalchemy import (
Enum, ForeignKeyConstraint, PrimaryKeyConstraint, CheckConstraint, UniqueConstraint, Table,
Column, Float)
from sqlalchemy.schema import ForeignKey
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.types import Boolean, String
from sqlalchemy.util import OrderedDict
import yaml
import datetime
# The generic ARRAY type was introduced in SQLAlchemy 1.1
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
from api_logic_server_cli.create_from_model.meta_model import Resource, ResourceRelationship, ResourceAttribute
log = logging.getLogger(__name__)
sqlalchemy_2_hack = True
""" exploring migration failures (True) """
sqlalchemy_2_db = True
""" prints / debug stops """
"""
handler = logging.StreamHandler(sys.stderr)
formatter = logging.Formatter('%(message)s') # lead tag - '%(name)s: %(message)s')
handler.setFormatter(formatter)
log.addHandler(handler)
log.propagate = True
"""
try:
from sqlalchemy import ARRAY
except ImportError:
from sqlalchemy.dialects.postgresql import ARRAY
# SQLAlchemy 1.3.11+
try:
from sqlalchemy import Computed
except ImportError:
Computed = None
# Conditionally import Geoalchemy2 to enable reflection support
try:
import geoalchemy2 # noqa: F401
except ImportError:
pass
_re_boolean_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \(0, 1\)")
_re_column_name = re.compile(r'(?:(["`]?)(?:.*)\1\.)?(["`]?)(.*)\2')
_re_enum_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \((.+)\)")
_re_enum_item = re.compile(r"'(.*?)(?<!\\)'")
_re_invalid_identifier = re.compile(r'[^a-zA-Z0-9_]' if sys.version_info[0] < 3 else r'(?u)\W')
class _DummyInflectEngine(object):
@staticmethod
def singular_noun(noun):
return noun
# In SQLAlchemy 0.x, constraint.columns is sometimes a list, on 1.x onwards, always a
# ColumnCollection
def _get_column_names(constraint):
if isinstance(constraint.columns, list):
return constraint.columns
return list(constraint.columns.keys())
def _get_constraint_sort_key(constraint):
if isinstance(constraint, CheckConstraint):
return 'C{0}'.format(constraint.sqltext)
return constraint.__class__.__name__[0] + repr(_get_column_names(constraint))
class ImportCollector(OrderedDict):
""" called for each col to collect all the imports """
def add_import(self, obj):
type_ = type(obj) if not isinstance(obj, type) else obj
""" eg., column.type, or sqlalchemy.sql.schema.Column """
pkgname = type_.__module__
""" eg, sqlalchemy.sql.schema, then set to sqlalchemy """
# The column types have already been adapted towards generic types if possible, so if this
# is still a vendor specific type (e.g., MySQL INTEGER) be sure to use that rather than the
# generic sqlalchemy type as it might have different constructor parameters.
if pkgname.startswith('sqlalchemy.dialects.'):
dialect_pkgname = '.'.join(pkgname.split('.')[0:3])
dialect_pkg = import_module(dialect_pkgname)
if type_.__name__ in dialect_pkg.__all__:
pkgname = dialect_pkgname
else:
if sqlalchemy_2_hack:
pkgname = "sqlalchemy"
if type_.__name__.startswith("Null"):
pkgname = 'sqlalchemy.sql.sqltypes'
if type_.__name__.startswith("Null"): # troublemakes: Double, NullType
if sqlalchemy_2_db == True:
debug_stop = f'Debug Stop: ImportCollector - target type_name: {type_.__name__}'
else: # FIXME HORRID HACK commented out: sqlalchemy.__all__ not in SQLAlchemy2
"""
in SQLAlchemy 1.4, sqlalchemy.__all__ contained:
['ARRAY', 'BIGINT', 'BINARY', 'BLANK_SCHEMA', 'BLOB', 'BOOLEAN',
'BigInteger', 'Boolean', 'CHAR', 'CLOB', 'CheckConstraint',
'Column', 'ColumnDefault', 'Computed', 'Constraint',
'DATE', 'DATETIME', 'DDL', 'DECIMAL', 'Date', 'DateTime',
'DefaultClause', 'Enum', 'FLOAT', 'FetchedValue', 'Float',
'ForeignKey', 'ForeignKeyConstraint', 'INT', 'INTEGER',
'Identity', 'Index', 'Integer', 'Interval'...]
type_.__module__ is sqlalchemy.sql.sqltypes
"""
pkgname = 'sqlalchemy' if type_.__name__ in sqlalchemy.__all__ else type_.__module__
type_name = type_.__name__
self.add_literal_import(pkgname, type_name) # (sqlalchemy, Column | Integer | String...)
def add_literal_import(self, pkgname, name):
names = self.setdefault(pkgname, set())
names.add(name)
class Model(object):
def __init__(self, table):
super(Model, self).__init__()
self.table = table
self.schema = table.schema
global code_generator
bind = code_generator.model_creation_services.session.bind
# Adapt column types to the most reasonable generic types (ie. VARCHAR -> String)
for column in table.columns:
try:
if table.name == "OrderDetail" and column.name == "Discount":
debug_stop = f'Model.__init__ target column -- Float in GA/RC2, Double in Gen'
column.type = self._get_adapted_type(column.type, bind) # SQLAlchemy2 (was column.table.bind)
except Exception as e:
# remains unchanged, eg. NullType()
if "sqlite_sequence" not in format(column):
print(f"#Failed to get col type for {format(column)} - {column.type}")
def __str__(self):
return f'Model for table: {self.table} (in schema: {self.schema})'
def _get_adapted_type(self, coltype, bind):
"""
Uses dialect to compute SQLAlchemy type (e.g, String, not VARCHAR, for sqlite)
Args:
coltype (_type_): database type
bind (_type_): e.g, code_generator.model_creation_services.session.bind
Returns:
_type_: SQLAlchemy type
"""
compiled_type = coltype.compile(bind.dialect) # OrderDetai.Discount: FLOAT (not DOUBLE); coltype is DOUBLE
if compiled_type == "DOUBLE":
if sqlalchemy_2_db == True:
debug_stop = "Debug stop - _get_adapted_type, target compiled_type"
for supercls in coltype.__class__.__mro__:
if not supercls.__name__.startswith('_') and hasattr(supercls, '__visit_name__'):
# Hack to fix adaptation of the Enum class which is broken since SQLAlchemy 1.2
kw = {}
if supercls is Enum:
kw['name'] = coltype.name
try:
new_coltype = coltype.adapt(supercls)
except TypeError:
# If the adaptation fails, don't try again
break
for key, value in kw.items():
setattr(new_coltype, key, value)
if isinstance(coltype, ARRAY):
new_coltype.item_type = self._get_adapted_type(new_coltype.item_type, bind)
try:
# If the adapted column type does not render the same as the original, don't
# substitute it
if new_coltype.compile(bind.dialect) != compiled_type:
# Make an exception to the rule for Float and arrays of Float, since at
# least on PostgreSQL, Float can accurately represent both REAL and
# DOUBLE_PRECISION
if not isinstance(new_coltype, Float) and \
not (isinstance(new_coltype, ARRAY) and
isinstance(new_coltype.item_type, Float)):
break
except sqlalchemy.exc.CompileError:
# If the adapted column type can't be compiled, don't substitute it
break
# Stop on the first valid non-uppercase column type class
coltype = new_coltype
if supercls.__name__ != supercls.__name__.upper():
break
if coltype == "NullType": # troublemakers: Double(), NullType
if sqlalchemy_2_db == True:
debug_stop = "Debug stop - _get_adapted_type, target returned coltype"
return coltype
def add_imports(self, collector):
if self.table.columns:
collector.add_import(Column)
for column in self.table.columns:
if self.table.name == "productlines" and column.name == "image":
if sqlalchemy_2_db:
debug_stop = f'add_imports - target column stop - {column.type}'
collector.add_import(column.type)
if column.server_default:
if Computed and isinstance(column.server_default, Computed):
collector.add_literal_import('sqlalchemy', 'Computed')
else:
collector.add_literal_import('sqlalchemy', 'text')
if isinstance(column.type, ARRAY):
collector.add_import(column.type.item_type.__class__)
for constraint in sorted(self.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'ForeignKeyConstraint')
else:
collector.add_literal_import('sqlalchemy', 'ForeignKey')
elif isinstance(constraint, UniqueConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'UniqueConstraint')
elif not isinstance(constraint, PrimaryKeyConstraint):
collector.add_import(constraint)
for index in self.table.indexes:
if len(index.columns) > 1:
collector.add_import(index)
@staticmethod
def _convert_to_valid_identifier(name):
assert name, 'Identifier cannot be empty'
if name[0].isdigit() or iskeyword(name):
name = '_' + name
elif name == 'metadata':
name = 'metadata_'
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes for superclass version (why override?)
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub('_', name)
return result
class ModelTable(Model):
def __init__(self, table):
super(ModelTable, self).__init__(table)
self.name = self._convert_to_valid_identifier(table.name)
def add_imports(self, collector):
super(ModelTable, self).add_imports(collector)
try:
collector.add_import(Table)
except Exception as exc:
print("Failed to add imports {}".format(collector))
class ModelClass(Model):
parent_name = 'Base'
def __init__(self, table, association_tables, inflect_engine, detect_joined):
super(ModelClass, self).__init__(table)
self.name = self._tablename_to_classname(table.name, inflect_engine)
self.children = []
self.attributes = OrderedDict()
self.foreign_key_relationships = list()
self.rendered_model = "" # ApiLogicServer
self.rendered_child_relationships = ""
""" child relns for this model (eg, OrderList accessor for Customer) """
self.rendered_parent_relationships = ""
""" parent relns for this model (eg, Customer accessor for Order) """
self.rendered_model_relationships = "" # appended at end ( render() )
""" child relns for this model - appended during render() REMOVE ME """
# Assign attribute names for columns
for column in table.columns:
self._add_attribute(column.name, column)
# Add many-to-one relationships (to parent)
pk_column_names = set(col.name for col in table.primary_key.columns)
parent_accessors = {}
""" dict of parent_table, current count (0, 1, 2... >1 ==> multi-reln) """
if self.name == "Employee":
debug_stop = "nice breakpoint"
for constraint in sorted(table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
target_cls = self._tablename_to_classname(constraint.elements[0].column.table.name,
inflect_engine)
this_included = code_generator.is_table_included(self.table.name)
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if (detect_joined and self.parent_name == 'Base' and set(_get_column_names(constraint)) == pk_column_names):
self.parent_name = target_cls # evidently not called for ApiLogicServer
else:
multi_reln_count = 0
if target_cls in parent_accessors:
multi_reln_count = parent_accessors[target_cls] + 1
parent_accessors.update({target_cls: multi_reln_count})
else:
parent_accessors[target_cls] = multi_reln_count
relationship_ = ManyToOneRelationship(self.name, target_cls, constraint,
inflect_engine, multi_reln_count)
if this_included and target_included:
self._add_attribute(relationship_.preferred_name, relationship_)
else:
log.debug(f"Parent Relationship excluded: {relationship_.preferred_name}") # never occurs?
# Add many-to-many relationships
for association_table in association_tables:
fk_constraints = [c for c in association_table.constraints
if isinstance(c, ForeignKeyConstraint)]
fk_constraints.sort(key=_get_constraint_sort_key)
target_cls = self._tablename_to_classname(
fk_constraints[1].elements[0].column.table.name, inflect_engine)
relationship_ = ManyToManyRelationship(self.name, target_cls, association_table)
self._add_attribute(relationship_.preferred_name, relationship_)
@classmethod
def _tablename_to_classname(cls, tablename, inflect_engine):
"""
camel-case and singlularize, with provisions for reserved word (Date) and collisions (Dates & _Dates)
"""
tablename = cls._convert_to_valid_identifier(tablename)
if tablename in ["Dates"]: # ApiLogicServer
tablename = tablename + "Classs"
camel_case_name = ''.join(part[:1].upper() + part[1:] for part in tablename.split('_'))
if camel_case_name in ["Dates"]:
camel_case_name = camel_case_name + "_Classs"
result = inflect_engine.singular_noun(camel_case_name) or camel_case_name
if result == "CategoryTableNameTest": # ApiLogicServer
result = "Category"
return result
@staticmethod
def _convert_to_valid_identifier(name): # TODO review
assert name, "Identifier cannot be empty"
if name[0].isdigit() or iskeyword(name):
name = "_" + name
elif name == "metadata":
name = "metadata_"
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes, ModelClass version
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub("_", name)
return result
def _add_attribute(self, attrname, value):
""" add table column AND parent-relationship to attributes
disambiguate relationship accessor names (append tablename with 1, 2...)
"""
attrname = tempname = self._convert_to_valid_identifier(attrname)
if self.name == "Employee" and attrname == "Department":
debug_stop = "nice breakpoint"
counter = 1
while tempname in self.attributes:
tempname = attrname + str(counter)
counter += 1
self.attributes[tempname] = value
return tempname
def add_imports(self, collector):
super(ModelClass, self).add_imports(collector)
if any(isinstance(value, Relationship) for value in self.attributes.values()):
collector.add_literal_import('sqlalchemy.orm', 'relationship')
for child in self.children:
child.add_imports(collector)
class Relationship(object):
def __init__(self, source_cls, target_cls):
super(Relationship, self).__init__()
self.source_cls = source_cls
""" for API Logic Server, the child class """
self.target_cls = target_cls
""" for API Logic Server, the parent class """
self.kwargs = OrderedDict()
class ManyToOneRelationship(Relationship):
def __init__(self, source_cls, target_cls, constraint, inflect_engine, multi_reln_count):
super(ManyToOneRelationship, self).__init__(source_cls, target_cls)
column_names = _get_column_names(constraint)
colname = column_names[0]
tablename = constraint.elements[0].column.table.name
self.foreign_key_constraint = constraint
if not colname.endswith('_id'):
self.preferred_name = inflect_engine.singular_noun(tablename) or tablename
else:
self.preferred_name = colname[:-3]
# Add uselist=False to One-to-One relationships
if any(isinstance(c, (PrimaryKeyConstraint, UniqueConstraint)) and
set(col.name for col in c.columns) == set(column_names)
for c in constraint.table.constraints):
self.kwargs['uselist'] = 'False'
# Handle self referential relationships
if source_cls == target_cls:
# self.preferred_name = 'parent' if not colname.endswith('_id') else colname[:-3]
if colname.endswith("id") or colname.endswith("Id"):
self.preferred_name = colname[:-2]
else:
self.preferred_name = "parent" # hmm, why not just table name
self.preferred_name = self.target_cls # FIXME why was "parent", (for Order)
pk_col_names = [col.name for col in constraint.table.primary_key]
self.kwargs['remote_side'] = '[{0}]'.format(', '.join(pk_col_names))
self.parent_accessor_name = self.preferred_name
""" parent accessor (typically parent (target_cls)) """
# assert self.target_cls == self.preferred_name, "preferred name <> parent"
self.child_accessor_name = self.source_cls + "List"
""" child accessor (typically child (target_class) + "List") """
if multi_reln_count > 0: # disambiguate multi_reln
self.parent_accessor_name += str(multi_reln_count)
self.child_accessor_name += str(multi_reln_count)
# If the two tables share more than one foreign key constraint,
# SQLAlchemy needs an explicit primaryjoin to figure out which column(s) to join with
common_fk_constraints = self.get_common_fk_constraints(
constraint.table, constraint.elements[0].column.table)
if len(common_fk_constraints) > 1:
self.kwargs['primaryjoin'] = "'{0}.{1} == {2}.{3}'".format(
source_cls, column_names[0], target_cls, constraint.elements[0].column.name)
# eg, 'Employee.OnLoanDepartmentId == Department.Id'
# and, for SQLAlchemy 2, neds foreign_keys: foreign_keys='[Employee.OnLoanDepartmentId]'
foreign_keys = "'["
for each_column_name in column_names:
foreign_keys += source_cls + "." + each_column_name + ", "
self.kwargs['foreign_keys'] = foreign_keys[0 : len(foreign_keys)-2] + "]'"
pass
@staticmethod
def get_common_fk_constraints(table1, table2):
"""Returns a set of foreign key constraints the two tables have against each other."""
c1 = set(c for c in table1.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table2)
c2 = set(c for c in table2.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table1)
return c1.union(c2)
class ManyToManyRelationship(Relationship):
def __init__(self, source_cls, target_cls, assocation_table):
super(ManyToManyRelationship, self).__init__(source_cls, target_cls)
prefix = (assocation_table.schema + '.') if assocation_table.schema else ''
self.kwargs['secondary'] = repr(prefix + assocation_table.name)
constraints = [c for c in assocation_table.constraints
if isinstance(c, ForeignKeyConstraint)]
constraints.sort(key=_get_constraint_sort_key)
colname = _get_column_names(constraints[1])[0]
tablename = constraints[1].elements[0].column.table.name
self.preferred_name = tablename if not colname.endswith('_id') else colname[:-3] + 's'
# Handle self referential relationships
if source_cls == target_cls:
self.preferred_name = 'parents' if not colname.endswith('_id') else colname[:-3] + 's'
pri_pairs = zip(_get_column_names(constraints[0]), constraints[0].elements)
sec_pairs = zip(_get_column_names(constraints[1]), constraints[1].elements)
pri_joins = ['{0}.{1} == {2}.c.{3}'.format(source_cls, elem.column.name,
assocation_table.name, col)
for col, elem in pri_pairs]
sec_joins = ['{0}.{1} == {2}.c.{3}'.format(target_cls, elem.column.name,
assocation_table.name, col)
for col, elem in sec_pairs]
self.kwargs['primaryjoin'] = (
repr('and_({0})'.format(', '.join(pri_joins)))
if len(pri_joins) > 1 else repr(pri_joins[0]))
self.kwargs['secondaryjoin'] = (
repr('and_({0})'.format(', '.join(sec_joins)))
if len(sec_joins) > 1 else repr(sec_joins[0]))
code_generator = None # type: CodeGenerator
""" Model needs to access state via this global, eg, included/excluded tables """
class CodeGenerator(object):
template = """\
# coding: utf-8
{imports}
{metadata_declarations}
{models}"""
def is_table_included(self, table_name: str) -> bool:
"""
Determines table included per self.include_tables / exclude tables.
See Run Config: Table Filters Tests
Args:
table_name (str): _description_
Returns:
bool: True means included
"""
table_inclusion_db = False
if self.include_tables is None: # first time initialization
include_tables_dict = {"include": [], "exclude": []}
if self.model_creation_services.project.include_tables != "":
with open(self.model_creation_services.project.include_tables,'rt') as f: #
include_tables_dict = yaml.safe_load(f.read())
f.close()
log.debug(f"include_tables specified: \n{include_tables_dict}\n") # {'include': ['I*', 'J', 'X*'], 'exclude': ['X1']}
# https://stackoverflow.com/questions/3040716/python-elegant-way-to-check-if-at-least-one-regex-in-list-matches-a-string
# https://www.w3schools.com/python/trypython.asp?filename=demo_regex
# ApiLogicServer create --project_name=table_filters_tests --db_url=table_filters_tests --include_tables=../table_filters_tests.yml
self.include_tables = include_tables_dict["include"] \
if "include" in include_tables_dict else ['.*'] # ['I.*', 'J', 'X.*']
if self.include_tables is None:
self.include_tables = ['.*']
self.include_regex = "(" + ")|(".join(self.include_tables) + ")" # include_regex: (I.*)|(J)|(X.*)
self.include_regex_list = map(re.compile, self.include_tables)
self.exclude_tables = include_tables_dict["exclude"] \
if "exclude" in include_tables_dict else ['a^']
if self.exclude_tables is None:
self.exclude_tables = ['a^']
self.exclude_regex = "(" + ")|(".join(self.exclude_tables) + ")"
if self.model_creation_services.project.include_tables != "":
if table_inclusion_db:
log.debug(f"include_regex: {self.include_regex}")
log.debug(f"exclude_regex: {self.exclude_regex}\n")
log.debug(f"Test Tables: I, I1, J, X, X1, Y\n")
table_included = True
if self.model_creation_services.project.bind_key == "authentication":
if table_inclusion_db:
log.debug(f".. authentication always included")
else:
if len(self.include_tables) == 0:
if table_inclusion_db:
log.debug(f"All tables included: {table_name}")
else:
if re.match(self.include_regex, table_name):
if table_inclusion_db:
log.debug(f"table included: {table_name}")
else:
if table_inclusion_db:
log.debug(f"table excluded: {table_name}")
table_included = False
if not table_included:
if table_inclusion_db:
log.debug(f".. skipping exclusions")
else:
if len(self.exclude_tables) == 0:
if table_inclusion_db:
log.debug(f"No tables excluded: {table_name}")
else:
if re.match(self.exclude_regex, table_name):
if table_inclusion_db:
log.debug(f"table excluded: {table_name}")
table_included = False
else:
if table_inclusion_db:
log.debug(f"table not excluded: {table_name}")
return table_included
def __init__(self, metadata, noindexes=False, noconstraints=False, nojoined=False,
noinflect=False, noclasses=False, model_creation_services = None,
indentation=' ', model_separator='\n\n',
ignored_tables=('alembic_version', 'migrate_version'),
table_model=ModelTable,
class_model=ModelClass,
template=None, nocomments=False):
"""
ApiLogicServer sqlacodegen_wrapper invokes this as follows;
capture = StringIO() # generate and return the model
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses,
args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
"""
super(CodeGenerator, self).__init__()
global code_generator
""" instance of CodeGenerator - access to model_creation_services, meta etc """
code_generator = self
self.metadata = metadata
self.noindexes = noindexes
self.noconstraints = noconstraints
self.nojoined = nojoined
""" not used by API Logic Server """
self.noinflect = noinflect
self.noclasses = noclasses
self.model_creation_services = model_creation_services # type: ModelCreationServices
self.generate_relationships_on = "parent" # "child"
""" FORMELRY, relns were genned ONLY on parent (== 'parent') """
self.indentation = indentation
self.model_separator = model_separator
self.ignored_tables = ignored_tables
self.table_model = table_model
self.class_model = class_model
""" class (not instance) of ModelClass [defaulted for ApiLogicServer] """
self.nocomments = nocomments
self.children_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.parents_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.include_tables = None # regex of tables included
self.exclude_tables = None # excluded
self.inflect_engine = self.create_inflect_engine()
if template:
self.template = template
# Pick association tables from the metadata into their own set, don't process them normally
links = defaultdict(lambda: [])
association_tables = set()
skip_association_table = True
for table in metadata.tables.values():
# Link tables have exactly two foreign key constraints and all columns are involved in
# them
fk_constraints = [constr for constr in table.constraints
if isinstance(constr, ForeignKeyConstraint)]
if len(fk_constraints) == 2 and all(col.foreign_keys for col in table.columns):
if skip_association_table: # Chinook playlist tracks, SqlSvr, Postgres Emp Territories
debug_str = f'skipping associate table: {table.name}'
debug_str += "... treated as normal table, with automatic joins"
else:
association_tables.add(table.name)
tablename = sorted(
fk_constraints, key=_get_constraint_sort_key)[0].elements[0].column.table.name
links[tablename].append(table)
# Iterate through the tables and create model classes when possible
self.models = []
self.collector = ImportCollector()
self.classes = {}
for table in metadata.sorted_tables:
# Support for Alembic and sqlalchemy-migrate -- never expose the schema version tables
if table.name in self.ignored_tables:
continue
table_included = self.is_table_included(table_name= table.name)
if not table_included:
log.debug(f"====> table skipped: {table.name}")
continue
"""
if any(regex.match(table.name) for regex in self.include_regex_list):
log.debug(f"list table included: {table.name}")
else:
log.debug(f"list table excluded: {table.name}")
"""
if noindexes:
table.indexes.clear()
if noconstraints:
table.constraints = {table.primary_key}
table.foreign_keys.clear()
for col in table.columns:
col.foreign_keys.clear()
else:
# Detect check constraints for boolean and enum columns
for constraint in table.constraints.copy():
if isinstance(constraint, CheckConstraint):
sqltext = self._get_compiled_expression(constraint.sqltext)
# Turn any integer-like column with a CheckConstraint like
# "column IN (0, 1)" into a Boolean
match = _re_boolean_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
table.constraints.remove(constraint)
table.c[colname].type = Boolean()
continue
# Turn any string-type column with a CheckConstraint like
# "column IN (...)" into an Enum
match = _re_enum_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
items = match.group(2)
if isinstance(table.c[colname].type, String):
table.constraints.remove(constraint)
if not isinstance(table.c[colname].type, Enum):
options = _re_enum_item.findall(items)
table.c[colname].type = Enum(*options, native_enum=False)
continue
# Tables vs. Classes ********
# Only form model classes for tables that have a primary key and are not association
# tables
if "productvariantsoh-20190423" in (table.name + "") or "unique_no_key" in (table.name + ""):
debug_str = "target table located"
""" create classes iff unique col - CAUTION: fails to run """
has_unique_constraint = False
if not table.primary_key:
for each_constraint in table.constraints:
if isinstance(each_constraint, sqlalchemy.sql.schema.UniqueConstraint):
has_unique_constraint = True
print(f'\n*** ApiLogicServer -- Note: {table.name} has unique constraint, no primary_key')
# print(f'\nTEST *** {table.name} not table.primary_key = {not table.primary_key}, has_unique_constraint = {has_unique_constraint}')
unique_constraint_class = model_creation_services.project.infer_primary_key and has_unique_constraint
if unique_constraint_class == False and (noclasses or not table.primary_key or table.name in association_tables):
model = self.table_model(table)
else: # create ModelClass() instance
model = self.class_model(table, links[table.name], self.inflect_engine, not nojoined) # computes attrs (+ roles)
self.classes[model.name] = model
self.models.append(model)
model.add_imports(self.collector) # end mega-loop for table in metadata.sorted_tables
# Nest inherited classes in their superclasses to ensure proper ordering
for model in self.classes.values():
if model.parent_name != 'Base':
self.classes[model.parent_name].children.append(model)
self.models.remove(model)
# Add either the MetaData or declarative_base import depending on whether there are mapped
# classes or not
if not any(isinstance(model, self.class_model) for model in self.models):
self.collector.add_literal_import('sqlalchemy', 'MetaData')
else:
self.collector.add_literal_import('sqlalchemy.ext.declarative', 'declarative_base')
def create_inflect_engine(self):
if self.noinflect:
return _DummyInflectEngine()
else:
import inflect
return inflect.engine()
def render_imports(self):
"""
Returns:
str: data type imports, from ImportCollector
"""
render_imports_result = '\n'.join('from {0} import {1}'.format(package, ', '.join(sorted(names)))
for package, names in self.collector.items())
return render_imports_result
def render_metadata_declarations(self):
nw_info = ""
if self.model_creation_services.project.nw_db_status in ["nw", "nw+"]:
nw_info = """#
# Sample Database (Northwind) -- https://apilogicserver.github.io/Docs/Sample-Database/
#
# Search:
# manual - illustrates you can make manual changes to models.py
# example - more complex cases (explore in database/db_debug.py)
"""
api_logic_server_imports = f"""########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# Created:
# Database:
# Dialect:
#
# mypy: ignore-errors
{nw_info}########################################################################################################################
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy.orm import relationship
from sqlalchemy.orm import Mapped
from sqlalchemy.sql.sqltypes import NullType
from typing import List
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.mysql import *
"""
if self.model_creation_services.project.bind_key != "":
api_logic_server_imports = api_logic_server_imports.replace('Base = declarative_base()',
f'Base{self.model_creation_services.project.bind_key} = declarative_base()')
api_logic_server_imports = api_logic_server_imports.replace('metadata = Base.metadata',
f'metadata = Base{self.model_creation_services.project.bind_key}.metadata')
if "sqlalchemy.ext.declarative" in self.collector: # Manually Added for safrs (ApiLogicServer)
# SQLAlchemy2: 'MetaData' object has no attribute 'bind'
bind = self.model_creation_services.session.bind # SQLAlchemy2
dialect_name = bind.engine.dialect.name # sqlite , mysql , postgresql , oracle , or mssql
if dialect_name in ["firebird", "mssql", "oracle", "postgresql", "sqlite", "sybase", "mysql"]:
rtn_api_logic_server_imports = api_logic_server_imports.replace("mysql", dialect_name)
else:
rtn_api_logic_server_imports = api_logic_server_imports
print(".. .. ..Warning - unknown sql dialect, defaulting to msql - check database/models.py")
rtn_api_logic_server_imports = rtn_api_logic_server_imports.replace(
"Created:", "Created: " + str(datetime.datetime.now().strftime("%B %d, %Y %H:%M:%S")))
rtn_api_logic_server_imports = rtn_api_logic_server_imports.replace(
"Database:", "Database: " + self.model_creation_services.project.abs_db_url)
rtn_api_logic_server_imports = rtn_api_logic_server_imports.replace(
"Dialect:", "Dialect: " + dialect_name)
return rtn_api_logic_server_imports
return "metadata = MetaData()" # (stand-alone sql1codegen - never used in API Logic Server)
def _get_compiled_expression(self, statement: sqlalchemy.sql.expression.TextClause):
"""Return the statement in a form where any placeholders have been filled in."""
bind = self.model_creation_services.session.bind # SQLAlchemy2
# https://docs.sqlalchemy.org/en/20/errors.html#a-bind-was-located-via-legacy-bound-metadata-but-since-future-true-is-set-on-this-session-this-bind-is-ignored
return str(statement.compile( # 'MetaData' object has no attribute 'bind' (unlike SQLAlchemy 1.4)
bind = bind, compile_kwargs={"literal_binds": True}))
@staticmethod
def _getargspec_init(method):
try:
if hasattr(inspect, 'getfullargspec'):
return inspect.getfullargspec(method)
else:
return inspect.getargspec(method)
except TypeError:
if method is object.__init__:
return ArgSpec(['self'], None, None, None)
else:
return ArgSpec(['self'], 'args', 'kwargs', None)
@classmethod
def render_column_type(cls, coltype):
args = []
kwargs = OrderedDict()
argspec = cls._getargspec_init(coltype.__class__.__init__)
defaults = dict(zip(argspec.args[-len(argspec.defaults or ()):],
argspec.defaults or ()))
missing = object()
use_kwargs = False
for attr in argspec.args[1:]:
# Remove annoyances like _warn_on_bytestring
if attr.startswith('_'):
continue
value = getattr(coltype, attr, missing)
default = defaults.get(attr, missing)
if value is missing or value == default:
use_kwargs = True
elif use_kwargs:
kwargs[attr] = repr(value)
else:
args.append(repr(value))
if argspec.varargs and hasattr(coltype, argspec.varargs):
varargs_repr = [repr(arg) for arg in getattr(coltype, argspec.varargs)]
args.extend(varargs_repr)
if isinstance(coltype, Enum) and coltype.name is not None:
kwargs['name'] = repr(coltype.name)
for key, value in kwargs.items():
args.append('{}={}'.format(key, value))
rendered = coltype.__class__.__name__
if args:
rendered += '({0})'.format(', '.join(args))
if rendered.startswith("CHAR("): # temp fix for non-double byte chars
rendered = rendered.replace("CHAR(", "String(")
return rendered
def render_constraint(self, constraint):
def render_fk_options(*opts):
opts = [repr(opt) for opt in opts]
for attr in 'ondelete', 'onupdate', 'deferrable', 'initially', 'match':
value = getattr(constraint, attr, None)
if value:
opts.append('{0}={1!r}'.format(attr, value))
return ', '.join(opts)
if isinstance(constraint, ForeignKey): # TODO: need to check is_included here?
remote_column = '{0}.{1}'.format(constraint.column.table.fullname,
constraint.column.name)
return 'ForeignKey({0})'.format(render_fk_options(remote_column))
elif isinstance(constraint, ForeignKeyConstraint):
local_columns = _get_column_names(constraint)
remote_columns = ['{0}.{1}'.format(fk.column.table.fullname, fk.column.name)
for fk in constraint.elements]
return 'ForeignKeyConstraint({0})'.format(
render_fk_options(local_columns, remote_columns))
elif isinstance(constraint, CheckConstraint):
return 'CheckConstraint({0!r})'.format(
self._get_compiled_expression(constraint.sqltext))
elif isinstance(constraint, UniqueConstraint):
columns = [repr(col.name) for col in constraint.columns]
return 'UniqueConstraint({0})'.format(', '.join(columns))
@staticmethod
def render_index(index):
extra_args = [repr(col.name) for col in index.columns]
if index.unique:
extra_args.append('unique=True')
return 'Index({0!r}, {1})'.format(index.name, ', '.join(extra_args))
def render_column(self, column: Column, show_name: bool):
"""_summary_
Args:
column (Column): column attributes
show_name (bool): True means embed col name into render_result
Returns:
str: eg. Column(Integer, primary_key=True), Column(String(8000))
"""
global code_generator
fk_debug = False
kwarg = []
is_sole_pk = column.primary_key and len(column.table.primary_key) == 1
dedicated_fks_old = [c for c in column.foreign_keys if len(c.constraint.columns) == 1]
dedicated_fks = [] # c for c in column.foreign_keys if len(c.constraint.columns) == 1
for each_foreign_key in column.foreign_keys:
if fk_debug:
log.debug(f'FK: {each_foreign_key}') #
log.debug(f'render_column - is fk: {dedicated_fks}')
if code_generator.is_table_included(each_foreign_key.column.table.name) \
and len(each_foreign_key.constraint.columns) == 1:
dedicated_fks.append(each_foreign_key)
else:
log.debug(f'Excluded single field fl on {column.table.name}.{column.name}')
if len(dedicated_fks) > 1:
log.error(f'codegen render_column finds unexpected col with >1 fk:'
f'{column.table.name}.{column.name}')
is_unique = any(isinstance(c, UniqueConstraint) and set(c.columns) == {column}
for c in column.table.constraints)
is_unique = is_unique or any(i.unique and set(i.columns) == {column}
for i in column.table.indexes)
has_index = any(set(i.columns) == {column} for i in column.table.indexes)
server_default = None
# Render the column type if there are no foreign keys on it or any of them points back to
# itself
render_coltype = not dedicated_fks or any(fk.column is column for fk in dedicated_fks)
if 'DataTypes.char_type DEBUG ONLY' == str(column):
debug_stop = "Debug Stop: Column" # char_type = Column(CHAR(1, 'SQL_Latin1_General_CP1_CI_AS'))
if column.key != column.name:
kwarg.append('key')
if column.primary_key:
kwarg.append('primary_key')
if not column.nullable and not is_sole_pk:
kwarg.append('nullable')
if is_unique:
column.unique = True
kwarg.append('unique')
if self.model_creation_services.project.infer_primary_key:
# print(f'ApiLogicServer infer_primary_key for {column.table.name}.{column.name}')
column.primary_key = True
kwarg.append('primary_key')
elif has_index:
column.index = True
kwarg.append('index')
if Computed and isinstance(column.server_default, Computed):
expression = self._get_compiled_expression(column.server_default.sqltext)
persist_arg = ''
if column.server_default.persisted is not None:
persist_arg = ', persisted={}'.format(column.server_default.persisted)
server_default = 'Computed({!r}{})'.format(expression, persist_arg)
elif column.server_default:
# The quote escaping does not cover pathological cases but should mostly work FIXME SqlSvr no .arg
# not used for postgres/mysql; for sqlite, text is '0'
if not hasattr( column.server_default, 'arg' ):
server_default = 'server_default=text("{0}")'.format('0')
else:
default_expr = self._get_compiled_expression(column.server_default.arg)
if '\n' in default_expr:
server_default = 'server_default=text("""\\\n{0}""")'.format(default_expr)
else:
default_expr = default_expr.replace('"', '\\"')
server_default = 'server_default=text("{0}")'.format(default_expr)
comment = getattr(column, 'comment', None)
if (column.name + "") == "xx_id":
print(f"render_column target: {column.table.name}.{column.name}") # ApiLogicServer fix for putting this at end: index=True
if show_name and column.table.name != 'sqlite_sequence':
log.debug(f"render_column show name is true: {column.table.name}.{column.name}") # researching why
rendered_col_type = self.render_column_type(column.type) if render_coltype else ""
rendered_name = repr(column.name) if show_name else ""
render_result = 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return render_result
def render_relationship(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.target_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_relationship_on_parent(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.source_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_table(self, model):
# Manual edit:
# replace invalid chars for views etc TODO review ApiLogicServer -- using model.name vs model.table.name
table_name = model.name
bad_chars = r"$-+ "
if any(elem in table_name for elem in bad_chars):
print(f"Alert: invalid characters in {table_name}")
table_name = table_name.replace("$", "_S_")
table_name = table_name.replace(" ", "_")
table_name = table_name.replace("+", "_")
if model.table.name == "Plus+Table":
debug_stop = "Debug Stop on table"
rendered = "t_{0} = Table(\n{1}{0!r}, metadata,\n".format(table_name, self.indentation)
for column in model.table.columns:
if column.name == "char_type DEBUG ONLY":
debug_stop = "Debug Stop - column"
rendered += '{0}{1},\n'.format(self.indentation, self.render_column(column, True))
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue # TODO: need to check is_included here?
rendered += '{0}{1},\n'.format(self.indentation, self.render_constraint(constraint))
for index in model.table.indexes:
if len(index.columns) > 1:
rendered += '{0}{1},\n'.format(self.indentation, self.render_index(index))
if model.schema:
rendered += "{0}schema='{1}',\n".format(self.indentation, model.schema)
table_comment = getattr(model.table, 'comment', None)
if table_comment:
quoted_comment = table_comment.replace("'", "\\'").replace('"', '\\"')
rendered += "{0}comment='{1}',\n".format(self.indentation, quoted_comment)
return rendered.rstrip('\n,') + '\n)\n'
def render_class(self, model):
""" returns string for model class, written into model.py by sqlacodegen_wrapper """
super_classes = model.parent_name
if self.model_creation_services.project.bind_key != "":
super_classes = f'Base{self.model_creation_services.project.bind_key}, db.Model, UserMixin'
rendered = 'class {0}(SAFRSBase, {1}): # type: ignore\n'.format(model.name, super_classes) # ApiLogicServer
# f'Base{self.model_creation_services.project.bind_key} = declarative_base()'
else:
rendered = 'class {0}(SAFRSBase, {1}):\n'.format(model.name, super_classes) # ApiLogicServer
rendered += '{0}__tablename__ = {1!r}\n'.format(self.indentation, model.table.name)
end_point_name = model.name
if self.model_creation_services.project.bind_key != "":
if self.model_creation_services.project.model_gen_bind_msg == False:
self.model_creation_services.project.model_gen_bind_msg = True
log.debug(f'.. .. ..Setting bind_key = {self.model_creation_services.project.bind_key}')
end_point_name = self.model_creation_services.project.bind_key + \
self.model_creation_services.project.bind_key_url_separator + model.name
rendered += '{0}_s_collection_name = {1!r} # type: ignore\n'.format(self.indentation, end_point_name)
if self.model_creation_services.project.bind_key != "":
bind_key = self.model_creation_services.project.bind_key
else:
bind_key = "None"
rendered += '{0}__bind_key__ = {1!r}\n'.format(self.indentation, bind_key) # usually __bind_key__ = None
# Render constraints and indexes as __table_args__
autonum_col = False
table_args = []
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
if constraint._autoincrement_column is not None:
autonum_col = True
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue
# eg, Order: ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city'])
this_included = code_generator.is_table_included(model.table.name)
target_included = True
if isinstance(constraint, ForeignKeyConstraint): # CheckConstraints don't have elements
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if this_included and target_included:
table_args.append(self.render_constraint(constraint))
else:
log.debug(f'foreign key constraint excluded on {model.table.name}: '
f'{self.render_constraint(constraint)}')
for index in model.table.indexes:
if len(index.columns) > 1:
table_args.append(self.render_index(index))
table_kwargs = {}
if model.schema:
table_kwargs['schema'] = model.schema
table_comment = getattr(model.table, 'comment', None)
if table_comment:
table_kwargs['comment'] = table_comment
kwargs_items = ', '.join('{0!r}: {1!r}'.format(key, table_kwargs[key])
for key in table_kwargs)
kwargs_items = '{{{0}}}'.format(kwargs_items) if kwargs_items else None
if table_kwargs and not table_args:
rendered += '{0}__table_args__ = {1}\n'.format(self.indentation, kwargs_items)
elif table_args:
if kwargs_items:
table_args.append(kwargs_items)
if len(table_args) == 1:
table_args[0] += ','
table_args_joined = ',\n{0}{0}'.format(self.indentation).join(table_args)
rendered += '{0}__table_args__ = (\n{0}{0}{1}\n{0})\n'.format(
self.indentation, table_args_joined)
# Render columns
# special case id: https://github.com/valhuber/ApiLogicServer/issues/69#issuecomment-1579731936
rendered += '\n'
for attr, column in model.attributes.items():
if isinstance(column, Column):
show_name = attr != column.name
rendered_column = '{0}{1} = {2}\n'.format(
self.indentation, attr, self.render_column(column, show_name))
if column.name == "id": # add name to Column(Integer, primary_key=True)
""" add name to Column(Integer, primary_key=True) - but makes system fail
rendered_column = rendered_column.replace(
'id = Column(', 'Id = Column("id", ')
log.debug(f' id = Column(Integer, primary_key=True) -->'\
f' Id = Column("id", Integer, primary_key=True)')
"""
if model.name not in["User", "Api"]:
log.info(f'** Warning: id columns will not be included in API response - '
f'{model.name}.id\n')
attr_typing = True # verify this in nw database/db_debug.py
if attr_typing:
if "= Column(DECIMAL" in rendered_column:
rendered_column = rendered_column.replace(
f'= Column(DECIMAL',
f': DECIMAL = Column(DECIMAL'
)
rendered += rendered_column
if not autonum_col:
rendered += '{0}{1}'.format(self.indentation, "allow_client_generated_ids = True\n")
if any(isinstance(value, Relationship) for value in model.attributes.values()):
pass
# rendered += '\n'
self.render_relns(model = model)
# Render subclasses
for child_class in model.children:
rendered += self.model_separator + self.render_class(child_class) # ApiLogicServer - not executed
# rendered += "\n # END RENDERED CLASS\n" # useful for debug, as required
return rendered
def render_relns(self, model: ModelClass):
""" accrue
Update for SQLAlchemy 2 typing
https://docs.sqlalchemy.org/en/20/tutorial/orm_related_objects.html#tutorial-orm-related-objects
e.g. for single field relns:
children (in customer...)
* OrderList : Mapped[List['Order']] = relationship(back_populates="Customer")
parent (in order...)
* Customer : Mapped["Customer"] = relationship(back_populates="OrderList")
specials:
* self-relns: https://docs.sqlalchemy.org/en/20/orm/self_referential.html
* multi-relns: https://docs.sqlalchemy.org/en/20/orm/join_conditions.html#handling-multiple-join-paths
* suggests foreign_keys=[] on child only, *but* parent too (eg, Dept)
* https://github.com/sqlalchemy/sqlalchemy/discussions/10034
* Department : Mapped["Department"] = relationship("Department", foreign_keys='[Employee.OnLoanDepartmentId]', back_populates=("EmployeeList"))
* EmployeeList : Mapped[List["Employee"]] = relationship("Employee", foreign_keys='[Employee.OnLoanDepartmentId]', back_populates="Department")
Args:
model (ModelClass): gen reln accessors for this model
Returns:
Just updates model.rendered_parent_relationships
"""
backrefs = {}
""" <class>.<children-accessor: <children-accessor """
# TODO mult-reln https://docs.sqlalchemy.org/en/20/orm/join_conditions.html#handling-multiple-join-paths
for attr, relationship in model.attributes.items(): # this list has parents only, order random
if isinstance(relationship, Relationship):
reln: ManyToOneRelationship = relationship # for typing; each parent for model child
multi_reln_fix = ""
if "foreign_keys" in reln.kwargs:
multi_reln_fix = 'foreign_keys=' + reln.kwargs["foreign_keys"] + ', '
pass
parent_model = self.classes[reln.target_cls]
parent_accessor_name = reln.parent_accessor_name
self_reln_fix = ""
if "remote_side" in reln.kwargs:
self_reln_fix = 'remote_side=' + reln.kwargs["remote_side"] + ', '
parent_accessor = f' {attr} : Mapped["{reln.target_cls}"] = relationship({multi_reln_fix}{self_reln_fix}back_populates=("{reln.child_accessor_name}"))\n'
child_accessor_name = reln.child_accessor_name
child_accessor = f' {child_accessor_name} : Mapped[List["{reln.source_cls}"]] = '\
f'relationship({multi_reln_fix}back_populates="{reln.parent_accessor_name}")\n'
if model.name == "Employee": # Emp has Department and Department1
debug_str = "nice breakpoint"
model.rendered_parent_relationships += parent_accessor
parent_model.rendered_child_relationships += child_accessor
def render(self, outfile=sys.stdout):
""" create model from db, and write models.py file to in-memory buffer (outfile)
relns created from not-yet-seen children, so
* save *all* class info,
* then append rendered_model_relationships (since we might see parent before or after child)
"""
for model in self.models: # class, with __tablename__ & __collection_name__ cls variables, attrs
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
model.rendered_model = self.render_class(model) # also sets parent_model.rendered_model_relationships
rendered_models = [] # now append the rendered_model + rendered_model_relationships
for model in self.models:
if isinstance(model, self.class_model):
each_rendered_model = model.rendered_model
reln_accessors = "\n # parent relationships (access parent)\n"
if self.model_creation_services.project.nw_db_status in ["nw", "nw+"]:
if model.name == "Employee":
reln_accessors = "\n # parent relationships (access parent) -- example: multiple join paths\n"
reln_accessors += " # .. https://docs.sqlalchemy.org/en/20/orm/join_conditions.html#handling-multiple-join-paths\n"
elif model.name == "Department":
reln_accessors = "\n # parent relationships (access parent) -- example: self-referential\n"
reln_accessors += " # .. https://docs.sqlalchemy.org/en/20/orm/self_referential.html\n"
each_rendered_model += reln_accessors
each_rendered_model += model.rendered_parent_relationships
each_rendered_model += "\n # child relationships (access children)\n"
each_rendered_model += model.rendered_child_relationships
each_rendered_model += "\n" + self.model_creation_services.opt_locking
rendered_models.append(each_rendered_model)
elif isinstance(model, self.table_model): # eg, views, database id generators, etc
rendered_models.append(self.render_table(model))
output = self.template.format(
imports=self.render_imports(),
metadata_declarations=self.render_metadata_declarations(),
models=self.model_separator.join(rendered_models).rstrip('\n'))
print(output, file=outfile) # write the in-mem class file
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/codegen.py
|
codegen.py
|
from __future__ import unicode_literals, division, print_function, absolute_import
import argparse
import io
import sys
import pkg_resources
from sqlalchemy.engine import create_engine
from sqlalchemy.schema import MetaData
from sqlacodegen_wrapper.sqlacodegen_wrapper import CodeGenerator
def main(calling_args=None):
if calling_args:
args = calling_args
else:
parser = argparse.ArgumentParser(description="Generates SQLAlchemy model code from an existing database.")
parser.add_argument("url", nargs="?", help="SQLAlchemy url to the database")
parser.add_argument("--version", action="store_true", help="print the version number and exit")
parser.add_argument("--schema", help="load tables from an alternate schema")
parser.add_argument("--tables", help="tables to process (comma-separated, default: all)")
parser.add_argument("--noviews", action="store_true", help="ignore views")
parser.add_argument("--noindexes", action="store_true", help="ignore indexes")
parser.add_argument("--noconstraints", action="store_true", help="ignore constraints")
parser.add_argument("--nojoined", action="store_true", help="don't autodetect joined table inheritance")
parser.add_argument("--noinflect", action="store_true", help="don't try to convert tables names to singular form")
parser.add_argument("--noclasses", action="store_true", help="don't generate classes, only tables")
parser.add_argument("--outfile", help="file to write output to (default: stdout)")
args = parser.parse_args()
if args.version:
version = pkg_resources.get_distribution('sqlacodegen').parsed_version
print(version.public)
return
if not args.url:
print('You must supply a url\n', file=sys.stderr)
parser.print_help()
return
# Use reflection to fill in the metadata
engine = create_engine(args.url)
try:
# dirty hack for sqlite TODO review ApiLogicServer
engine.execute("""PRAGMA journal_mode = OFF""")
except:
pass
metadata = MetaData(engine)
tables = args.tables.split(',') if args.tables else None
metadata.reflect(engine, args.schema, not args.noviews, tables)
# Write the generated model code to the specified file or standard output
outfile = io.open(args.outfile, 'w', encoding='utf-8') if args.outfile else sys.stdout
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints, args.nojoined,
args.noinflect, args.noclasses, nocomments=args.nocomments)
generator.render(outfile)
class DotDict(dict):
""" APiLogicServer dot.notation access to dictionary attributes """
# thanks: https://stackoverflow.com/questions/2352181/how-to-use-a-dot-to-access-members-of-dictionary/28463329
__getattr__ = dict.get
__setattr__ = dict.__setitem__
__delattr__ = dict.__delitem__
def sqlacodegen(db_url: str, models_file: str):
""" ApiLogicServer entry for in-process invocation """
calling_args = DotDict({})
calling_args.url = db_url
calling_args.outfile = models_file
calling_args.version = False
main(calling_args)
# print("imported")
# main()
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/main.py
|
main.py
|
from __future__ import unicode_literals, division, print_function, absolute_import
import inspect
import re
import sys, logging
from collections import defaultdict
from importlib import import_module
from inspect import FullArgSpec # val-311
from keyword import iskeyword
import sqlalchemy
import sqlalchemy.exc
from sqlalchemy import (
Enum, ForeignKeyConstraint, PrimaryKeyConstraint, CheckConstraint, UniqueConstraint, Table,
Column, Float)
from sqlalchemy.schema import ForeignKey
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.types import Boolean, String
from sqlalchemy.util import OrderedDict
import yaml
# The generic ARRAY type was introduced in SQLAlchemy 1.1
from api_logic_server_cli.create_from_model.model_creation_services import Resource, ResourceRelationship, \
ResourceAttribute
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
log = logging.getLogger(__name__)
"""
handler = logging.StreamHandler(sys.stderr)
formatter = logging.Formatter('%(message)s') # lead tag - '%(name)s: %(message)s')
handler.setFormatter(formatter)
log.addHandler(handler)
log.propagate = True
"""
try:
from sqlalchemy import ARRAY
except ImportError:
from sqlalchemy.dialects.postgresql import ARRAY
# SQLAlchemy 1.3.11+
try:
from sqlalchemy import Computed
except ImportError:
Computed = None
# Conditionally import Geoalchemy2 to enable reflection support
try:
import geoalchemy2 # noqa: F401
except ImportError:
pass
_re_boolean_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \(0, 1\)")
_re_column_name = re.compile(r'(?:(["`]?)(?:.*)\1\.)?(["`]?)(.*)\2')
_re_enum_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \((.+)\)")
_re_enum_item = re.compile(r"'(.*?)(?<!\\)'")
_re_invalid_identifier = re.compile(r'[^a-zA-Z0-9_]' if sys.version_info[0] < 3 else r'(?u)\W')
cascade_backref_value = False
""" True for SQLAlchemy 1.4, False for 2 """
class _DummyInflectEngine(object):
@staticmethod
def singular_noun(noun):
return noun
# In SQLAlchemy 0.x, constraint.columns is sometimes a list, on 1.x onwards, always a
# ColumnCollection
def _get_column_names(constraint):
if isinstance(constraint.columns, list):
return constraint.columns
return list(constraint.columns.keys())
def _get_constraint_sort_key(constraint):
if isinstance(constraint, CheckConstraint):
return 'C{0}'.format(constraint.sqltext)
return constraint.__class__.__name__[0] + repr(_get_column_names(constraint))
class ImportCollector(OrderedDict):
def add_import(self, obj):
type_ = type(obj) if not isinstance(obj, type) else obj
pkgname = type_.__module__
# The column types have already been adapted towards generic types if possible, so if this
# is still a vendor specific type (e.g., MySQL INTEGER) be sure to use that rather than the
# generic sqlalchemy type as it might have different constructor parameters.
if pkgname.startswith('sqlalchemy.dialects.'):
dialect_pkgname = '.'.join(pkgname.split('.')[0:3])
dialect_pkg = import_module(dialect_pkgname)
if type_.__name__ in dialect_pkg.__all__:
pkgname = dialect_pkgname
else:
pkgname = 'sqlalchemy' if type_.__name__ in sqlalchemy.__all__ else type_.__module__
self.add_literal_import(pkgname, type_.__name__)
def add_literal_import(self, pkgname, name):
names = self.setdefault(pkgname, set())
names.add(name)
class Model(object):
def __init__(self, table):
super(Model, self).__init__()
self.table = table
self.schema = table.schema
# Adapt column types to the most reasonable generic types (ie. VARCHAR -> String)
for column in table.columns:
try:
column.type = self._get_adapted_type(column.type, column.table.bind)
except:
# print('Failed to get col type for {}, {}'.format(column, column.type))
if "sqlite_sequence" not in format(column):
print("#Failed to get col type for {}".format(column))
def __str__(self):
return f'Model for table: {self.table} (in schema: {self.schema})'
def _get_adapted_type(self, coltype, bind):
compiled_type = coltype.compile(bind.dialect)
for supercls in coltype.__class__.__mro__:
if not supercls.__name__.startswith('_') and hasattr(supercls, '__visit_name__'):
# Hack to fix adaptation of the Enum class which is broken since SQLAlchemy 1.2
kw = {}
if supercls is Enum:
kw['name'] = coltype.name
try:
new_coltype = coltype.adapt(supercls)
except TypeError:
# If the adaptation fails, don't try again
break
for key, value in kw.items():
setattr(new_coltype, key, value)
if isinstance(coltype, ARRAY):
new_coltype.item_type = self._get_adapted_type(new_coltype.item_type, bind)
try:
# If the adapted column type does not render the same as the original, don't
# substitute it
if new_coltype.compile(bind.dialect) != compiled_type:
# Make an exception to the rule for Float and arrays of Float, since at
# least on PostgreSQL, Float can accurately represent both REAL and
# DOUBLE_PRECISION
if not isinstance(new_coltype, Float) and \
not (isinstance(new_coltype, ARRAY) and
isinstance(new_coltype.item_type, Float)):
break
except sqlalchemy.exc.CompileError:
# If the adapted column type can't be compiled, don't substitute it
break
# Stop on the first valid non-uppercase column type class
coltype = new_coltype
if supercls.__name__ != supercls.__name__.upper():
break
return coltype
def add_imports(self, collector):
if self.table.columns:
collector.add_import(Column)
for column in self.table.columns:
collector.add_import(column.type)
if column.server_default:
if Computed and isinstance(column.server_default, Computed):
collector.add_literal_import('sqlalchemy', 'Computed')
else:
collector.add_literal_import('sqlalchemy', 'text')
if isinstance(column.type, ARRAY):
collector.add_import(column.type.item_type.__class__)
for constraint in sorted(self.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'ForeignKeyConstraint')
else:
collector.add_literal_import('sqlalchemy', 'ForeignKey')
elif isinstance(constraint, UniqueConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'UniqueConstraint')
elif not isinstance(constraint, PrimaryKeyConstraint):
collector.add_import(constraint)
for index in self.table.indexes:
if len(index.columns) > 1:
collector.add_import(index)
@staticmethod
def _convert_to_valid_identifier(name):
assert name, 'Identifier cannot be empty'
if name[0].isdigit() or iskeyword(name):
name = '_' + name
elif name == 'metadata':
name = 'metadata_'
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes for superclass version (why override?)
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub('_', name)
return result
class ModelTable(Model):
def __init__(self, table):
super(ModelTable, self).__init__(table)
self.name = self._convert_to_valid_identifier(table.name)
def add_imports(self, collector):
super(ModelTable, self).add_imports(collector)
try:
collector.add_import(Table)
except Exception as exc:
print("Failed to add imports {}".format(collector))
class ModelClass(Model):
parent_name = 'Base'
def __init__(self, table, association_tables, inflect_engine, detect_joined):
super(ModelClass, self).__init__(table)
self.name = self._tablename_to_classname(table.name, inflect_engine)
self.children = []
self.attributes = OrderedDict()
self.foreign_key_relationships = list()
self.rendered_model = "" # ApiLogicServer
self.rendered_model_relationships = "" # appended at end ( render() )
# Assign attribute names for columns
for column in table.columns:
self._add_attribute(column.name, column)
# Add many-to-one relationships (to parent)
pk_column_names = set(col.name for col in table.primary_key.columns)
for constraint in sorted(table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
target_cls = self._tablename_to_classname(constraint.elements[0].column.table.name,
inflect_engine)
this_included = code_generator.is_table_included(self.table.name)
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if (detect_joined and self.parent_name == 'Base' and
set(_get_column_names(constraint)) == pk_column_names):
self.parent_name = target_cls
else:
relationship_ = ManyToOneRelationship(self.name, target_cls, constraint,
inflect_engine)
if this_included and target_included:
self._add_attribute(relationship_.preferred_name, relationship_)
else:
log.debug(f"Parent Relationship excluded: {relationship_.preferred_name}")
# Add many-to-many relationships
for association_table in association_tables:
fk_constraints = [c for c in association_table.constraints
if isinstance(c, ForeignKeyConstraint)]
fk_constraints.sort(key=_get_constraint_sort_key)
target_cls = self._tablename_to_classname(
fk_constraints[1].elements[0].column.table.name, inflect_engine)
relationship_ = ManyToManyRelationship(self.name, target_cls, association_table)
self._add_attribute(relationship_.preferred_name, relationship_)
@classmethod
def _tablename_to_classname(cls, tablename, inflect_engine):
"""
camel-case and singlularize, with provisions for reserved word (Date) and collisions (Dates & _Dates)
"""
tablename = cls._convert_to_valid_identifier(tablename)
if tablename in ["Dates"]: # ApiLogicServer
tablename = tablename + "Classs"
camel_case_name = ''.join(part[:1].upper() + part[1:] for part in tablename.split('_'))
if camel_case_name in ["Dates"]:
camel_case_name = camel_case_name + "_Classs"
result = inflect_engine.singular_noun(camel_case_name) or camel_case_name
if result == "CategoryTableNameTest": # ApiLogicServer
result = "Category"
return result
@staticmethod
def _convert_to_valid_identifier(name): # TODO review
assert name, "Identifier cannot be empty"
if name[0].isdigit() or iskeyword(name):
name = "_" + name
elif name == "metadata":
name = "metadata_"
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes, ModelClass version
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub("_", name)
return result
def _add_attribute(self, attrname, value):
""" add table column/relationship to attributes
disambiguate relationship accessor names (append tablename with 1, 2...)
"""
attrname = tempname = self._convert_to_valid_identifier(attrname)
counter = 1
while tempname in self.attributes:
tempname = attrname + str(counter)
counter += 1
self.attributes[tempname] = value
return tempname
def add_imports(self, collector):
super(ModelClass, self).add_imports(collector)
if any(isinstance(value, Relationship) for value in self.attributes.values()):
collector.add_literal_import('sqlalchemy.orm', 'relationship')
for child in self.children:
child.add_imports(collector)
class Relationship(object):
def __init__(self, source_cls, target_cls):
super(Relationship, self).__init__()
self.source_cls = source_cls
self.target_cls = target_cls
self.kwargs = OrderedDict()
class ManyToOneRelationship(Relationship):
def __init__(self, source_cls, target_cls, constraint, inflect_engine):
super(ManyToOneRelationship, self).__init__(source_cls, target_cls)
column_names = _get_column_names(constraint)
colname = column_names[0]
tablename = constraint.elements[0].column.table.name
self.foreign_key_constraint = constraint
if not colname.endswith('_id'):
self.preferred_name = inflect_engine.singular_noun(tablename) or tablename
else:
self.preferred_name = colname[:-3]
# Add uselist=False to One-to-One relationships
if any(isinstance(c, (PrimaryKeyConstraint, UniqueConstraint)) and
set(col.name for col in c.columns) == set(column_names)
for c in constraint.table.constraints):
self.kwargs['uselist'] = 'False'
# Handle self referential relationships
if source_cls == target_cls:
# self.preferred_name = 'parent' if not colname.endswith('_id') else colname[:-3]
if colname.endswith("id") or colname.endswith("Id"):
self.preferred_name = colname[:-2]
else:
self.preferred_name = "parent" # hmm, why not just table name
pk_col_names = [col.name for col in constraint.table.primary_key]
self.kwargs['remote_side'] = '[{0}]'.format(', '.join(pk_col_names))
# If the two tables share more than one foreign key constraint,
# SQLAlchemy needs an explicit primaryjoin to figure out which column(s) to join with
common_fk_constraints = self.get_common_fk_constraints(
constraint.table, constraint.elements[0].column.table)
if len(common_fk_constraints) > 1:
self.kwargs['primaryjoin'] = "'{0}.{1} == {2}.{3}'".format(
source_cls, column_names[0], target_cls, constraint.elements[0].column.name)
@staticmethod
def get_common_fk_constraints(table1, table2):
"""Returns a set of foreign key constraints the two tables have against each other."""
c1 = set(c for c in table1.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table2)
c2 = set(c for c in table2.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table1)
return c1.union(c2)
class ManyToManyRelationship(Relationship):
def __init__(self, source_cls, target_cls, assocation_table):
super(ManyToManyRelationship, self).__init__(source_cls, target_cls)
prefix = (assocation_table.schema + '.') if assocation_table.schema else ''
self.kwargs['secondary'] = repr(prefix + assocation_table.name)
constraints = [c for c in assocation_table.constraints
if isinstance(c, ForeignKeyConstraint)]
constraints.sort(key=_get_constraint_sort_key)
colname = _get_column_names(constraints[1])[0]
tablename = constraints[1].elements[0].column.table.name
self.preferred_name = tablename if not colname.endswith('_id') else colname[:-3] + 's'
# Handle self referential relationships
if source_cls == target_cls:
self.preferred_name = 'parents' if not colname.endswith('_id') else colname[:-3] + 's'
pri_pairs = zip(_get_column_names(constraints[0]), constraints[0].elements)
sec_pairs = zip(_get_column_names(constraints[1]), constraints[1].elements)
pri_joins = ['{0}.{1} == {2}.c.{3}'.format(source_cls, elem.column.name,
assocation_table.name, col)
for col, elem in pri_pairs]
sec_joins = ['{0}.{1} == {2}.c.{3}'.format(target_cls, elem.column.name,
assocation_table.name, col)
for col, elem in sec_pairs]
self.kwargs['primaryjoin'] = (
repr('and_({0})'.format(', '.join(pri_joins)))
if len(pri_joins) > 1 else repr(pri_joins[0]))
self.kwargs['secondaryjoin'] = (
repr('and_({0})'.format(', '.join(sec_joins)))
if len(sec_joins) > 1 else repr(sec_joins[0]))
code_generator = None # type: CodeGenerator
""" Model needs to access state here, eg, included/excluded tables """
class CodeGenerator(object):
template = """\
# coding: utf-8
{imports}
{metadata_declarations}
{models}"""
def is_table_included(self, table_name: str) -> bool:
"""
Determines table included per self.include_tables / exclude tables.
See Run Config: Table Filters Tests
Args:
table_name (str): _description_
Returns:
bool: True means included
"""
if self.include_tables is None: # first time initialization
include_tables_dict = {"include": [], "exclude": []}
if self.model_creation_services.project.include_tables != "":
with open(self.model_creation_services.project.include_tables,'rt') as f: #
include_tables_dict = yaml.safe_load(f.read())
f.close()
log.debug(f"include_tables specified: \n{include_tables_dict}\n") # {'include': ['I*', 'J', 'X*'], 'exclude': ['X1']}
# https://stackoverflow.com/questions/3040716/python-elegant-way-to-check-if-at-least-one-regex-in-list-matches-a-string
# https://www.w3schools.com/python/trypython.asp?filename=demo_regex
# ApiLogicServer create --project_name=table_filters_tests --db_url=table_filters_tests --include_tables=../table_filters_tests.yml
self.include_tables = include_tables_dict["include"] \
if "include" in include_tables_dict else ['.*'] # ['I.*', 'J', 'X.*']
if self.include_tables is None:
self.include_tables = ['.*']
self.include_regex = "(" + ")|(".join(self.include_tables) + ")" # include_regex: (I.*)|(J)|(X.*)
self.include_regex_list = map(re.compile, self.include_tables)
self.exclude_tables = include_tables_dict["exclude"] \
if "exclude" in include_tables_dict else ['a^']
if self.exclude_tables is None:
self.exclude_tables = ['a^']
self.exclude_regex = "(" + ")|(".join(self.exclude_tables) + ")"
if self.model_creation_services.project.include_tables != "":
log.debug(f"include_regex: {self.include_regex}")
log.debug(f"exclude_regex: {self.exclude_regex}\n")
log.debug(f"Test Tables: I, I1, J, X, X1, Y\n")
table_included = True
if self.model_creation_services.project.bind_key == "authentication":
log.debug(f".. authentication always included")
else:
if len(self.include_tables) == 0:
log.debug(f"All tables included: {table_name}")
else:
if re.match(self.include_regex, table_name):
log.debug(f"table included: {table_name}")
else:
log.debug(f"table excluded: {table_name}")
table_included = False
if not table_included:
log.debug(f".. skipping exlusions")
else:
if len(self.exclude_tables) == 0:
log.debug(f"No tables excluded: {table_name}")
else:
if re.match(self.exclude_regex, table_name):
log.debug(f"table excluded: {table_name}")
table_included = False
else:
log.debug(f"table not excluded: {table_name}")
return table_included
def __init__(self, metadata, noindexes=False, noconstraints=False, nojoined=False,
noinflect=False, noclasses=False, model_creation_services = None,
indentation=' ', model_separator='\n\n',
ignored_tables=('alembic_version', 'migrate_version'),
table_model=ModelTable,
class_model=ModelClass,
template=None, nocomments=False):
"""
ApiLogicServer sqlacodegen_wrapper invokes this as follows;
capture = StringIO() # generate and return the model
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses,
args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
"""
super(CodeGenerator, self).__init__()
global code_generator
code_generator = self
self.metadata = metadata
self.noindexes = noindexes
self.noconstraints = noconstraints
self.nojoined = nojoined
self.noinflect = noinflect
self.noclasses = noclasses
self.model_creation_services = model_creation_services # type: ModelCreationServices
self.generate_relationships_on = "parent" # "child"
self.indentation = indentation
self.model_separator = model_separator
self.ignored_tables = ignored_tables
self.table_model = table_model
self.class_model = class_model
""" class (not instance) of ModelClass [defaulted for ApiLogicServer] """
self.nocomments = nocomments
self.children_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.parents_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.include_tables = None # regex of tables included
self.exclude_tables = None # excluded
self.inflect_engine = self.create_inflect_engine()
if template:
self.template = template
# Pick association tables from the metadata into their own set, don't process them normally
links = defaultdict(lambda: [])
association_tables = set()
skip_association_table = True
for table in metadata.tables.values():
# Link tables have exactly two foreign key constraints and all columns are involved in
# them
fk_constraints = [constr for constr in table.constraints
if isinstance(constr, ForeignKeyConstraint)]
if len(fk_constraints) == 2 and all(col.foreign_keys for col in table.columns):
if skip_association_table: # Chinook playlist tracks, SqlSvr, Postgres Emp Territories
debug_str = f'skipping associate table: {table.name}'
debug_str += "... treated as normal table, with automatic joins"
else:
association_tables.add(table.name)
tablename = sorted(
fk_constraints, key=_get_constraint_sort_key)[0].elements[0].column.table.name
links[tablename].append(table)
# Iterate through the tables and create model classes when possible
self.models = []
self.collector = ImportCollector()
self.classes = {}
for table in metadata.sorted_tables:
# Support for Alembic and sqlalchemy-migrate -- never expose the schema version tables
if table.name in self.ignored_tables:
continue
table_included = self.is_table_included(table_name= table.name)
if not table_included:
log.debug(f"====> table skipped: {table.name}")
continue
"""
if any(regex.match(table.name) for regex in self.include_regex_list):
log.debug(f"list table included: {table.name}")
else:
log.debug(f"list table excluded: {table.name}")
"""
if noindexes:
table.indexes.clear()
if noconstraints:
table.constraints = {table.primary_key}
table.foreign_keys.clear()
for col in table.columns:
col.foreign_keys.clear()
else:
# Detect check constraints for boolean and enum columns
for constraint in table.constraints.copy():
if isinstance(constraint, CheckConstraint):
sqltext = self._get_compiled_expression(constraint.sqltext)
# Turn any integer-like column with a CheckConstraint like
# "column IN (0, 1)" into a Boolean
match = _re_boolean_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
table.constraints.remove(constraint)
table.c[colname].type = Boolean()
continue
# Turn any string-type column with a CheckConstraint like
# "column IN (...)" into an Enum
match = _re_enum_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
items = match.group(2)
if isinstance(table.c[colname].type, String):
table.constraints.remove(constraint)
if not isinstance(table.c[colname].type, Enum):
options = _re_enum_item.findall(items)
table.c[colname].type = Enum(*options, native_enum=False)
continue
# Tables vs. Classes ********
# Only form model classes for tables that have a primary key and are not association
# tables
if "productvariantsoh-20190423" in (table.name + "") or "unique_no_key" in (table.name + ""):
debug_str = "target table located"
""" create classes iff unique col - CAUTION: fails to run """
has_unique_constraint = False
if not table.primary_key:
for each_constraint in table.constraints:
if isinstance(each_constraint, sqlalchemy.sql.schema.UniqueConstraint):
has_unique_constraint = True
print(f'\n*** ApiLogicServer -- {table.name} has unique constraint, no primary_key')
# print(f'\nTEST *** {table.name} not table.primary_key = {not table.primary_key}, has_unique_constraint = {has_unique_constraint}')
unique_constraint_class = model_creation_services.project.infer_primary_key and has_unique_constraint
if unique_constraint_class == False and (noclasses or not table.primary_key or table.name in association_tables):
model = self.table_model(table)
else:
model = self.class_model(table, links[table.name], self.inflect_engine, not nojoined) # computes attrs (+ roles)
self.classes[model.name] = model
self.models.append(model)
model.add_imports(self.collector) # end mega-loop for table in metadata.sorted_tables
# Nest inherited classes in their superclasses to ensure proper ordering
for model in self.classes.values():
if model.parent_name != 'Base':
self.classes[model.parent_name].children.append(model)
self.models.remove(model)
# Add either the MetaData or declarative_base import depending on whether there are mapped
# classes or not
if not any(isinstance(model, self.class_model) for model in self.models):
self.collector.add_literal_import('sqlalchemy', 'MetaData')
else:
self.collector.add_literal_import('sqlalchemy.ext.declarative', 'declarative_base')
def create_inflect_engine(self):
if self.noinflect:
return _DummyInflectEngine()
else:
import inflect
return inflect.engine()
def render_imports(self):
return '\n'.join('from {0} import {1}'.format(package, ', '.join(sorted(names)))
for package, names in self.collector.items())
def render_metadata_declarations(self):
api_logic_server_imports = """
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.mysql import *
########################################################################################################################
"""
if self.model_creation_services.project.bind_key != "":
api_logic_server_imports = api_logic_server_imports.replace('Base = declarative_base()',
f'Base{self.model_creation_services.project.bind_key} = declarative_base()')
api_logic_server_imports = api_logic_server_imports.replace('metadata = Base.metadata',
f'metadata = Base{self.model_creation_services.project.bind_key}.metadata')
if "sqlalchemy.ext.declarative" in self.collector: # Manually Added for safrs (ApiLogicServer)
dialect_name = self.metadata.bind.engine.dialect.name # sqlite , mysql , postgresql , oracle , or mssql
if dialect_name in ["firebird", "mssql", "oracle", "postgresql", "sqlite", "sybase"]:
rtn_api_logic_server_imports = api_logic_server_imports.replace("mysql", dialect_name)
else:
rtn_api_logic_server_imports = api_logic_server_imports
print(".. .. ..Warning - unknown sql dialect, defaulting to msql - check database/models.py")
return rtn_api_logic_server_imports
return "metadata = MetaData()" # (stand-alone sql1codegen - never used in API Logic Server)
def _get_compiled_expression(self, statement):
"""Return the statement in a form where any placeholders have been filled in."""
return str(statement.compile(
self.metadata.bind, compile_kwargs={"literal_binds": True}))
@staticmethod
def _getargspec_init(method):
try:
if hasattr(inspect, 'getfullargspec'):
return inspect.getfullargspec(method)
else:
return inspect.getargspec(method)
except TypeError:
if method is object.__init__:
return ArgSpec(['self'], None, None, None)
else:
return ArgSpec(['self'], 'args', 'kwargs', None)
@classmethod
def render_column_type(cls, coltype):
args = []
kwargs = OrderedDict()
argspec = cls._getargspec_init(coltype.__class__.__init__)
defaults = dict(zip(argspec.args[-len(argspec.defaults or ()):],
argspec.defaults or ()))
missing = object()
use_kwargs = False
for attr in argspec.args[1:]:
# Remove annoyances like _warn_on_bytestring
if attr.startswith('_'):
continue
value = getattr(coltype, attr, missing)
default = defaults.get(attr, missing)
if value is missing or value == default:
use_kwargs = True
elif use_kwargs:
kwargs[attr] = repr(value)
else:
args.append(repr(value))
if argspec.varargs and hasattr(coltype, argspec.varargs):
varargs_repr = [repr(arg) for arg in getattr(coltype, argspec.varargs)]
args.extend(varargs_repr)
if isinstance(coltype, Enum) and coltype.name is not None:
kwargs['name'] = repr(coltype.name)
for key, value in kwargs.items():
args.append('{}={}'.format(key, value))
rendered = coltype.__class__.__name__
if args:
rendered += '({0})'.format(', '.join(args))
if rendered.startswith("CHAR("): # temp fix for non-double byte chars
rendered = rendered.replace("CHAR(", "String(")
return rendered
def render_constraint(self, constraint):
def render_fk_options(*opts):
opts = [repr(opt) for opt in opts]
for attr in 'ondelete', 'onupdate', 'deferrable', 'initially', 'match':
value = getattr(constraint, attr, None)
if value:
opts.append('{0}={1!r}'.format(attr, value))
return ', '.join(opts)
if isinstance(constraint, ForeignKey): # TODO: need to check is_included here?
remote_column = '{0}.{1}'.format(constraint.column.table.fullname,
constraint.column.name)
return 'ForeignKey({0})'.format(render_fk_options(remote_column))
elif isinstance(constraint, ForeignKeyConstraint):
local_columns = _get_column_names(constraint)
remote_columns = ['{0}.{1}'.format(fk.column.table.fullname, fk.column.name)
for fk in constraint.elements]
return 'ForeignKeyConstraint({0})'.format(
render_fk_options(local_columns, remote_columns))
elif isinstance(constraint, CheckConstraint):
return 'CheckConstraint({0!r})'.format(
self._get_compiled_expression(constraint.sqltext))
elif isinstance(constraint, UniqueConstraint):
columns = [repr(col.name) for col in constraint.columns]
return 'UniqueConstraint({0})'.format(', '.join(columns))
@staticmethod
def render_index(index):
extra_args = [repr(col.name) for col in index.columns]
if index.unique:
extra_args.append('unique=True')
return 'Index({0!r}, {1})'.format(index.name, ', '.join(extra_args))
def render_column(self, column: Column, show_name: bool):
"""_summary_
Args:
column (Column): column attributes
show_name (bool): True means embed col name into render_result
Returns:
str: eg. Column(Integer, primary_key=True), Column(String(8000))
"""
global code_generator
kwarg = []
is_sole_pk = column.primary_key and len(column.table.primary_key) == 1
dedicated_fks_old = [c for c in column.foreign_keys if len(c.constraint.columns) == 1]
dedicated_fks = [] # c for c in column.foreign_keys if len(c.constraint.columns) == 1
for each_foreign_key in column.foreign_keys:
log.debug(f'FK: {each_foreign_key}') #
log.debug(f'render_column - is fk: {dedicated_fks}')
if code_generator.is_table_included(each_foreign_key.column.table.name) \
and len(each_foreign_key.constraint.columns) == 1:
dedicated_fks.append(each_foreign_key)
else:
log.debug(f'Excluded single field fl on {column.table.name}.{column.name}')
if len(dedicated_fks) > 1:
log.error(f'codegen render_column finds unexpected col with >1 fk:'
f'{column.table.name}.{column.name}')
is_unique = any(isinstance(c, UniqueConstraint) and set(c.columns) == {column}
for c in column.table.constraints)
is_unique = is_unique or any(i.unique and set(i.columns) == {column}
for i in column.table.indexes)
has_index = any(set(i.columns) == {column} for i in column.table.indexes)
server_default = None
# Render the column type if there are no foreign keys on it or any of them points back to
# itself
render_coltype = not dedicated_fks or any(fk.column is column for fk in dedicated_fks)
if 'DataTypes.char_type DEBUG ONLY' == str(column):
print("Debug Stop: Column") # char_type = Column(CHAR(1, 'SQL_Latin1_General_CP1_CI_AS'))
if column.key != column.name:
kwarg.append('key')
if column.primary_key:
kwarg.append('primary_key')
if not column.nullable and not is_sole_pk:
kwarg.append('nullable')
if is_unique:
column.unique = True
kwarg.append('unique')
if self.model_creation_services.project.infer_primary_key:
# print(f'ApiLogicServer infer_primary_key for {column.table.name}.{column.name}')
column.primary_key = True
kwarg.append('primary_key')
elif has_index:
column.index = True
kwarg.append('index')
if Computed and isinstance(column.server_default, Computed):
expression = self._get_compiled_expression(column.server_default.sqltext)
persist_arg = ''
if column.server_default.persisted is not None:
persist_arg = ', persisted={}'.format(column.server_default.persisted)
server_default = 'Computed({!r}{})'.format(expression, persist_arg)
elif column.server_default:
# The quote escaping does not cover pathological cases but should mostly work FIXME SqlSvr no .arg
# not used for postgres/mysql; for sqlite, text is '0'
if not hasattr( column.server_default, 'arg' ):
server_default = 'server_default=text("{0}")'.format('0')
else:
default_expr = self._get_compiled_expression(column.server_default.arg)
if '\n' in default_expr:
server_default = 'server_default=text("""\\\n{0}""")'.format(default_expr)
else:
default_expr = default_expr.replace('"', '\\"')
server_default = 'server_default=text("{0}")'.format(default_expr)
comment = getattr(column, 'comment', None)
if (column.name + "") == "xx_id":
print(f"render_column target: {column.table.name}.{column.name}") # ApiLogicServer fix for putting this at end: index=True
if show_name and column.table.name != 'sqlite_sequence':
log.isEnabledFor(f"render_column show name is true: {column.table.name}.{column.name}") # researching why
render_result = 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return render_result
def render_relationship(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.target_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_relationship_on_parent(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.source_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_table(self, model):
# Manual edit:
# replace invalid chars for views etc TODO review ApiLogicServer -- using model.name vs model.table.name
table_name = model.name
bad_chars = r"$-+ "
if any(elem in table_name for elem in bad_chars):
print("sys error")
table_name = table_name.replace("$", "_S_")
table_name = table_name.replace(" ", "_")
table_name = table_name.replace("+", "_")
if model.table.name == "Plus+Table":
print("Debug Stop on table")
rendered = "t_{0} = Table(\n{1}{0!r}, metadata,\n".format(table_name, self.indentation)
for column in model.table.columns:
if column.name == "char_type DEBUG ONLY":
print("Debug Stop - column")
rendered += '{0}{1},\n'.format(self.indentation, self.render_column(column, True))
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue # TODO: need to check is_included here?
rendered += '{0}{1},\n'.format(self.indentation, self.render_constraint(constraint))
for index in model.table.indexes:
if len(index.columns) > 1:
rendered += '{0}{1},\n'.format(self.indentation, self.render_index(index))
if model.schema:
rendered += "{0}schema='{1}',\n".format(self.indentation, model.schema)
table_comment = getattr(model.table, 'comment', None)
if table_comment:
quoted_comment = table_comment.replace("'", "\\'").replace('"', '\\"')
rendered += "{0}comment='{1}',\n".format(self.indentation, quoted_comment)
return rendered.rstrip('\n,') + '\n)\n'
def render_class(self, model):
""" returns string for model class, written into model.py by sqlacodegen_wrapper """
super_classes = model.parent_name
if self.model_creation_services.project.bind_key != "":
super_classes = f'Base{self.model_creation_services.project.bind_key}, db.Model, UserMixin'
rendered = 'class {0}(SAFRSBase, {1}): # type: ignore\n'.format(model.name, super_classes) # ApiLogicServer
# f'Base{self.model_creation_services.project.bind_key} = declarative_base()'
else:
rendered = 'class {0}(SAFRSBase, {1}):\n'.format(model.name, super_classes) # ApiLogicServer
rendered += '{0}__tablename__ = {1!r}\n'.format(self.indentation, model.table.name)
end_point_name = model.name
if self.model_creation_services.project.bind_key != "":
if self.model_creation_services.project.model_gen_bind_msg == False:
self.model_creation_services.project.model_gen_bind_msg = True
log.debug(f'.. .. ..Setting bind_key = {self.model_creation_services.project.bind_key}')
end_point_name = self.model_creation_services.project.bind_key + \
self.model_creation_services.project.bind_key_url_separator + model.name
rendered += '{0}_s_collection_name = {1!r} # type: ignore\n'.format(self.indentation, end_point_name)
if self.model_creation_services.project.bind_key != "":
bind_key = self.model_creation_services.project.bind_key
else:
bind_key = "None"
rendered += '{0}__bind_key__ = {1!r}\n'.format(self.indentation, bind_key) # usually __bind_key__ = None
# Render constraints and indexes as __table_args__
autonum_col = False
table_args = []
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
if constraint._autoincrement_column is not None:
autonum_col = True
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue
# eg, Order: ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city'])
this_included = code_generator.is_table_included(model.table.name)
target_included = True
if isinstance(constraint, ForeignKeyConstraint): # CheckConstraints don't have elements
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if this_included and target_included:
table_args.append(self.render_constraint(constraint))
else:
log.debug(f'foreign key constraint excluded on {model.table.name}: '
f'{self.render_constraint(constraint)}')
for index in model.table.indexes:
if len(index.columns) > 1:
table_args.append(self.render_index(index))
table_kwargs = {}
if model.schema:
table_kwargs['schema'] = model.schema
table_comment = getattr(model.table, 'comment', None)
if table_comment:
table_kwargs['comment'] = table_comment
kwargs_items = ', '.join('{0!r}: {1!r}'.format(key, table_kwargs[key])
for key in table_kwargs)
kwargs_items = '{{{0}}}'.format(kwargs_items) if kwargs_items else None
if table_kwargs and not table_args:
rendered += '{0}__table_args__ = {1}\n'.format(self.indentation, kwargs_items)
elif table_args:
if kwargs_items:
table_args.append(kwargs_items)
if len(table_args) == 1:
table_args[0] += ','
table_args_joined = ',\n{0}{0}'.format(self.indentation).join(table_args)
rendered += '{0}__table_args__ = (\n{0}{0}{1}\n{0})\n'.format(
self.indentation, table_args_joined)
# Render columns
# special case id: https://github.com/valhuber/ApiLogicServer/issues/69#issuecomment-1579731936
rendered += '\n'
for attr, column in model.attributes.items():
if isinstance(column, Column):
show_name = attr != column.name
rendered_column = '{0}{1} = {2}\n'.format(
self.indentation, attr, self.render_column(column, show_name))
if column.name == "id": # add name to Column(Integer, primary_key=True)
""" add name to Column(Integer, primary_key=True) - but makes system fail
rendered_column = rendered_column.replace(
'id = Column(', 'Id = Column("id", ')
log.debug(f' id = Column(Integer, primary_key=True) -->'\
f' Id = Column("id", Integer, primary_key=True)')
"""
if model.name not in["User", "Api"]:
log.info(f'** Warning: id columns will not be included in API response - '
f'{model.name}.id\n')
rendered += rendered_column
if not autonum_col:
rendered += '{0}{1}'.format(self.indentation, "allow_client_generated_ids = True\n")
# Render relationships (declared in parent class, backref to child)
if any(isinstance(value, Relationship) for value in model.attributes.values()):
rendered += '\n'
backrefs = {}
for attr, relationship in model.attributes.items():
if isinstance(relationship, Relationship): # ApiLogicServer changed to insert backref
attr_to_render = attr
if self.generate_relationships_on != "child":
attr_to_render = "# see backref on parent: " + attr # relns not created on child; comment out
rel_render = "{0}{1} = {2}\n".format(self.indentation, attr_to_render, self.render_relationship(relationship))
rel_parts = rel_render.split(")") # eg, Department = relationship(\'Department\', remote_side=[Id]
backref_name = model.name + "List"
""" disambiguate multi-relns, eg, in the Employee child class, 2 relns to Department:
Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList')
Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList_Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
unique_name = relationship.target_cls + '.' + backref_name
if unique_name in backrefs: # disambiguate
backref_name += "_" + attr
back_ref = f', cascade_backrefs=cascade_backref_value, backref=\'{backref_name}\''
rel_render_with_backref = rel_parts[0] + \
back_ref + \
")" + rel_parts[1]
# rendered += "{0}{1} = {2}\n".format(self.indentation, attr, self.render_relationship(relationship))
""" disambiguate multi-relns, eg, in the Department parent class, 2 relns to Employee:
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
if relationship.target_cls not in self.classes:
print(f'.. .. ..ERROR - {model.name} -- missing parent class: {relationship.target_cls}')
print(f'.. .. .. .. Parent Class may be missing Primary Key and Unique Column')
print(f'.. .. .. .. Attempting to continue - you may need to repair model, or address database design')
continue
parent_model = self.classes[relationship.target_cls] # eg, Department
parent_relationship_def = self.render_relationship_on_parent(relationship)
parent_relationship_def = parent_relationship_def[:-1]
# eg, for Dept: relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id')
child_role_name = model.name + "List"
parent_role_name = attr
if unique_name in backrefs: # disambiguate
child_role_name += '1' # FIXME - fails for 3 relns
if model.name != parent_model.name:
parent_relationship = f'{child_role_name} = {parent_relationship_def}, cascade_backrefs=cascade_backref_value, backref=\'{parent_role_name}\')'
else: # work-around for self relns
"""
special case self relns:
not DepartmentList = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='Department')
but Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList')
"""
parent_relationship = f'{parent_role_name} = {parent_relationship_def}, cascade_backrefs=cascade_backref_value, backref=\'{child_role_name}\')'
parent_relationship += " # special handling for self-relationships"
if self.generate_relationships_on != "parent": # relns not created on parent; comment out
parent_relationship = "# see backref on child: " + parent_relationship
parent_model.rendered_model_relationships += " " + parent_relationship + "\n"
if model.name == "OrderDetail":
debug_str = "nice breakpoint"
rendered += rel_render_with_backref
backrefs[unique_name] = backref_name
if relationship.source_cls.startswith("Ab"):
pass
elif isinstance(relationship, ManyToManyRelationship): # eg, chinook:PlayList->PlayListTrack
print(f'many to many should not occur on: {model.name}.{unique_name}')
else: # fixme dump all this, right?
use_old_code = False # so you can elide this
if use_old_code:
resource = self.model_creation_services.resource_list[relationship.source_cls]
resource_relationship = ResourceRelationship(parent_role_name = attr,
child_role_name = backref_name)
resource_relationship.child_resource = relationship.source_cls
resource_relationship.parent_resource = relationship.target_cls
# gen key pairs
for each_pair in relationship.foreign_key_constraint.elements:
pair = ( str(each_pair.column.name), str(each_pair.parent.name) )
resource_relationship.parent_child_key_pairs.append(pair)
resource.parents.append(resource_relationship)
parent_resource = self.model_creation_services.resource_list[relationship.target_cls]
parent_resource.children.append(resource_relationship)
if use_old_code:
if relationship.source_cls not in self.parents_map: # todo old code remove
self.parents_map[relationship.source_cls] = list()
self.parents_map[relationship.source_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
if relationship.target_cls not in self.children_map:
self.children_map[relationship.target_cls] = list()
self.children_map[relationship.target_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
pass
# Render subclasses
for child_class in model.children:
rendered += self.model_separator + self.render_class(child_class)
# rendered += "\n # END RENDERED CLASS\n" # useful for debug, as required
return rendered
def render(self, outfile=sys.stdout):
""" create model from db, and write models.py file to in-memory buffer (outfile)
relns created from not-yet-seen children, so
* save *all* class info,
* then append rendered_model_relationships
"""
for model in self.models: # class, with __tablename__ & __collection_name__ cls variables, attrs
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
model.rendered_model = self.render_class(model) # also sets parent_model.rendered_model_relationships
rendered_models = [] # now append the rendered_model + rendered_model_relationships
for model in self.models:
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
if model.rendered_model_relationships != "": # child relns (OrderDetailList etc)
model.rendered_model_relationships = "\n" + model.rendered_model_relationships
rendered_models.append(model.rendered_model + model.rendered_model_relationships)
rendered_models.append(self.model_creation_services.opt_locking)
elif isinstance(model, self.table_model): # eg, views, database id generators, etc
rendered_models.append(self.render_table(model))
output = self.template.format(
imports=self.render_imports(),
metadata_declarations=self.render_metadata_declarations(),
models=self.model_separator.join(rendered_models).rstrip('\n'))
print(output, file=outfile)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/codegen/codegenX-merged.py
|
codegenX-merged.py
|
from __future__ import unicode_literals, division, print_function, absolute_import
import inspect
import re
import sys, logging
from collections import defaultdict
from importlib import import_module
from inspect import FullArgSpec # val-311
from keyword import iskeyword
import sqlalchemy
import sqlalchemy.exc
from sqlalchemy import (
Enum, ForeignKeyConstraint, PrimaryKeyConstraint, CheckConstraint, UniqueConstraint, Table,
Column, Float)
from sqlalchemy.schema import ForeignKey
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.types import Boolean, String
from sqlalchemy.util import OrderedDict
import yaml
# The generic ARRAY type was introduced in SQLAlchemy 1.1
from api_logic_server_cli.create_from_model.model_creation_services import Resource, ResourceRelationship, \
ResourceAttribute
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
log = logging.getLogger(__name__)
"""
handler = logging.StreamHandler(sys.stderr)
formatter = logging.Formatter('%(message)s') # lead tag - '%(name)s: %(message)s')
handler.setFormatter(formatter)
log.addHandler(handler)
log.propagate = True
"""
try:
from sqlalchemy import ARRAY
except ImportError:
from sqlalchemy.dialects.postgresql import ARRAY
# SQLAlchemy 1.3.11+
try:
from sqlalchemy import Computed
except ImportError:
Computed = None
# Conditionally import Geoalchemy2 to enable reflection support
try:
import geoalchemy2 # noqa: F401
except ImportError:
pass
_re_boolean_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \(0, 1\)")
_re_column_name = re.compile(r'(?:(["`]?)(?:.*)\1\.)?(["`]?)(.*)\2')
_re_enum_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \((.+)\)")
_re_enum_item = re.compile(r"'(.*?)(?<!\\)'")
_re_invalid_identifier = re.compile(r'[^a-zA-Z0-9_]' if sys.version_info[0] < 3 else r'(?u)\W')
class _DummyInflectEngine(object):
@staticmethod
def singular_noun(noun):
return noun
# In SQLAlchemy 0.x, constraint.columns is sometimes a list, on 1.x onwards, always a
# ColumnCollection
def _get_column_names(constraint):
if isinstance(constraint.columns, list):
return constraint.columns
return list(constraint.columns.keys())
def _get_constraint_sort_key(constraint):
if isinstance(constraint, CheckConstraint):
return 'C{0}'.format(constraint.sqltext)
return constraint.__class__.__name__[0] + repr(_get_column_names(constraint))
class ImportCollector(OrderedDict):
def add_import(self, obj):
type_ = type(obj) if not isinstance(obj, type) else obj
pkgname = type_.__module__
# The column types have already been adapted towards generic types if possible, so if this
# is still a vendor specific type (e.g., MySQL INTEGER) be sure to use that rather than the
# generic sqlalchemy type as it might have different constructor parameters.
if pkgname.startswith('sqlalchemy.dialects.'):
dialect_pkgname = '.'.join(pkgname.split('.')[0:3])
dialect_pkg = import_module(dialect_pkgname)
if type_.__name__ in dialect_pkg.__all__:
pkgname = dialect_pkgname
else:
pkgname = 'sqlalchemy' if type_.__name__ in sqlalchemy.__all__ else type_.__module__
self.add_literal_import(pkgname, type_.__name__)
def add_literal_import(self, pkgname, name):
names = self.setdefault(pkgname, set())
names.add(name)
class Model(object):
def __init__(self, table):
super(Model, self).__init__()
self.table = table
self.schema = table.schema
# Adapt column types to the most reasonable generic types (ie. VARCHAR -> String)
for column in table.columns:
try:
column.type = self._get_adapted_type(column.type, column.table.bind)
except:
# print('Failed to get col type for {}, {}'.format(column, column.type))
if "sqlite_sequence" not in format(column):
print("#Failed to get col type for {}".format(column))
def __str__(self):
return f'Model for table: {self.table} (in schema: {self.schema})'
def _get_adapted_type(self, coltype, bind):
compiled_type = coltype.compile(bind.dialect)
for supercls in coltype.__class__.__mro__:
if not supercls.__name__.startswith('_') and hasattr(supercls, '__visit_name__'):
# Hack to fix adaptation of the Enum class which is broken since SQLAlchemy 1.2
kw = {}
if supercls is Enum:
kw['name'] = coltype.name
try:
new_coltype = coltype.adapt(supercls)
except TypeError:
# If the adaptation fails, don't try again
break
for key, value in kw.items():
setattr(new_coltype, key, value)
if isinstance(coltype, ARRAY):
new_coltype.item_type = self._get_adapted_type(new_coltype.item_type, bind)
try:
# If the adapted column type does not render the same as the original, don't
# substitute it
if new_coltype.compile(bind.dialect) != compiled_type:
# Make an exception to the rule for Float and arrays of Float, since at
# least on PostgreSQL, Float can accurately represent both REAL and
# DOUBLE_PRECISION
if not isinstance(new_coltype, Float) and \
not (isinstance(new_coltype, ARRAY) and
isinstance(new_coltype.item_type, Float)):
break
except sqlalchemy.exc.CompileError:
# If the adapted column type can't be compiled, don't substitute it
break
# Stop on the first valid non-uppercase column type class
coltype = new_coltype
if supercls.__name__ != supercls.__name__.upper():
break
return coltype
def add_imports(self, collector):
if self.table.columns:
collector.add_import(Column)
for column in self.table.columns:
collector.add_import(column.type)
if column.server_default:
if Computed and isinstance(column.server_default, Computed):
collector.add_literal_import('sqlalchemy', 'Computed')
else:
collector.add_literal_import('sqlalchemy', 'text')
if isinstance(column.type, ARRAY):
collector.add_import(column.type.item_type.__class__)
for constraint in sorted(self.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'ForeignKeyConstraint')
else:
collector.add_literal_import('sqlalchemy', 'ForeignKey')
elif isinstance(constraint, UniqueConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'UniqueConstraint')
elif not isinstance(constraint, PrimaryKeyConstraint):
collector.add_import(constraint)
for index in self.table.indexes:
if len(index.columns) > 1:
collector.add_import(index)
@staticmethod
def _convert_to_valid_identifier(name):
assert name, 'Identifier cannot be empty'
if name[0].isdigit() or iskeyword(name):
name = '_' + name
elif name == 'metadata':
name = 'metadata_'
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes for superclass version (why override?)
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub('_', name)
return result
class ModelTable(Model):
def __init__(self, table):
super(ModelTable, self).__init__(table)
self.name = self._convert_to_valid_identifier(table.name)
def add_imports(self, collector):
super(ModelTable, self).add_imports(collector)
try:
collector.add_import(Table)
except Exception as exc:
print("Failed to add imports {}".format(collector))
class ModelClass(Model):
parent_name = 'Base'
def __init__(self, table, association_tables, inflect_engine, detect_joined):
super(ModelClass, self).__init__(table)
self.name = self._tablename_to_classname(table.name, inflect_engine)
self.children = []
self.attributes = OrderedDict()
self.foreign_key_relationships = list()
self.rendered_model = "" # ApiLogicServer
self.rendered_model_relationships = "" # appended at end ( render() )
# Assign attribute names for columns
for column in table.columns:
self._add_attribute(column.name, column)
# Add many-to-one relationships (to parent)
pk_column_names = set(col.name for col in table.primary_key.columns)
for constraint in sorted(table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
target_cls = self._tablename_to_classname(constraint.elements[0].column.table.name,
inflect_engine)
this_included = code_generator.is_table_included(self.table.name)
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if (detect_joined and self.parent_name == 'Base' and
set(_get_column_names(constraint)) == pk_column_names):
self.parent_name = target_cls
else:
relationship_ = ManyToOneRelationship(self.name, target_cls, constraint,
inflect_engine)
if this_included and target_included:
self._add_attribute(relationship_.preferred_name, relationship_)
else:
log.debug(f"Parent Relationship excluded: {relationship_.preferred_name}")
# Add many-to-many relationships
for association_table in association_tables:
fk_constraints = [c for c in association_table.constraints
if isinstance(c, ForeignKeyConstraint)]
fk_constraints.sort(key=_get_constraint_sort_key)
target_cls = self._tablename_to_classname(
fk_constraints[1].elements[0].column.table.name, inflect_engine)
relationship_ = ManyToManyRelationship(self.name, target_cls, association_table)
self._add_attribute(relationship_.preferred_name, relationship_)
@classmethod
def _tablename_to_classname(cls, tablename, inflect_engine):
"""
camel-case and singlularize, with provisions for reserved word (Date) and collisions (Dates & _Dates)
"""
tablename = cls._convert_to_valid_identifier(tablename)
if tablename in ["Dates"]: # ApiLogicServer
tablename = tablename + "Classs"
camel_case_name = ''.join(part[:1].upper() + part[1:] for part in tablename.split('_'))
if camel_case_name in ["Dates"]:
camel_case_name = camel_case_name + "_Classs"
result = inflect_engine.singular_noun(camel_case_name) or camel_case_name
if result == "CategoryTableNameTest": # ApiLogicServer
result = "Category"
return result
@staticmethod
def _convert_to_valid_identifier(name): # TODO review
assert name, "Identifier cannot be empty"
if name[0].isdigit() or iskeyword(name):
name = "_" + name
elif name == "metadata":
name = "metadata_"
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes, ModelClass version
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub("_", name)
return result
def _add_attribute(self, attrname, value):
""" add table column/relationship to attributes
disambiguate relationship accessor names (append tablename with 1, 2...)
"""
attrname = tempname = self._convert_to_valid_identifier(attrname)
counter = 1
while tempname in self.attributes:
tempname = attrname + str(counter)
counter += 1
self.attributes[tempname] = value
return tempname
def add_imports(self, collector):
super(ModelClass, self).add_imports(collector)
if any(isinstance(value, Relationship) for value in self.attributes.values()):
collector.add_literal_import('sqlalchemy.orm', 'relationship')
for child in self.children:
child.add_imports(collector)
class Relationship(object):
def __init__(self, source_cls, target_cls):
super(Relationship, self).__init__()
self.source_cls = source_cls
self.target_cls = target_cls
self.kwargs = OrderedDict()
class ManyToOneRelationship(Relationship):
def __init__(self, source_cls, target_cls, constraint, inflect_engine):
super(ManyToOneRelationship, self).__init__(source_cls, target_cls)
column_names = _get_column_names(constraint)
colname = column_names[0]
tablename = constraint.elements[0].column.table.name
self.foreign_key_constraint = constraint
if not colname.endswith('_id'):
self.preferred_name = inflect_engine.singular_noun(tablename) or tablename
else:
self.preferred_name = colname[:-3]
# Add uselist=False to One-to-One relationships
if any(isinstance(c, (PrimaryKeyConstraint, UniqueConstraint)) and
set(col.name for col in c.columns) == set(column_names)
for c in constraint.table.constraints):
self.kwargs['uselist'] = 'False'
# Handle self referential relationships
if source_cls == target_cls:
# self.preferred_name = 'parent' if not colname.endswith('_id') else colname[:-3]
if colname.endswith("id") or colname.endswith("Id"):
self.preferred_name = colname[:-2]
else:
self.preferred_name = "parent" # hmm, why not just table name
pk_col_names = [col.name for col in constraint.table.primary_key]
self.kwargs['remote_side'] = '[{0}]'.format(', '.join(pk_col_names))
# If the two tables share more than one foreign key constraint,
# SQLAlchemy needs an explicit primaryjoin to figure out which column(s) to join with
common_fk_constraints = self.get_common_fk_constraints(
constraint.table, constraint.elements[0].column.table)
if len(common_fk_constraints) > 1:
self.kwargs['primaryjoin'] = "'{0}.{1} == {2}.{3}'".format(
source_cls, column_names[0], target_cls, constraint.elements[0].column.name)
@staticmethod
def get_common_fk_constraints(table1, table2):
"""Returns a set of foreign key constraints the two tables have against each other."""
c1 = set(c for c in table1.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table2)
c2 = set(c for c in table2.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table1)
return c1.union(c2)
class ManyToManyRelationship(Relationship):
def __init__(self, source_cls, target_cls, assocation_table):
super(ManyToManyRelationship, self).__init__(source_cls, target_cls)
prefix = (assocation_table.schema + '.') if assocation_table.schema else ''
self.kwargs['secondary'] = repr(prefix + assocation_table.name)
constraints = [c for c in assocation_table.constraints
if isinstance(c, ForeignKeyConstraint)]
constraints.sort(key=_get_constraint_sort_key)
colname = _get_column_names(constraints[1])[0]
tablename = constraints[1].elements[0].column.table.name
self.preferred_name = tablename if not colname.endswith('_id') else colname[:-3] + 's'
# Handle self referential relationships
if source_cls == target_cls:
self.preferred_name = 'parents' if not colname.endswith('_id') else colname[:-3] + 's'
pri_pairs = zip(_get_column_names(constraints[0]), constraints[0].elements)
sec_pairs = zip(_get_column_names(constraints[1]), constraints[1].elements)
pri_joins = ['{0}.{1} == {2}.c.{3}'.format(source_cls, elem.column.name,
assocation_table.name, col)
for col, elem in pri_pairs]
sec_joins = ['{0}.{1} == {2}.c.{3}'.format(target_cls, elem.column.name,
assocation_table.name, col)
for col, elem in sec_pairs]
self.kwargs['primaryjoin'] = (
repr('and_({0})'.format(', '.join(pri_joins)))
if len(pri_joins) > 1 else repr(pri_joins[0]))
self.kwargs['secondaryjoin'] = (
repr('and_({0})'.format(', '.join(sec_joins)))
if len(sec_joins) > 1 else repr(sec_joins[0]))
code_generator = None # type: CodeGenerator
""" Model needs to access state here, eg, included/excluded tables """
class CodeGenerator(object):
template = """\
# coding: utf-8
{imports}
{metadata_declarations}
{models}"""
def is_table_included(self, table_name: str) -> bool:
"""
Determines table included per self.include_tables / exclude tables.
See Run Config: Table Filters Tests
Args:
table_name (str): _description_
Returns:
bool: True means included
"""
if self.include_tables is None: # first time initialization
include_tables_dict = {"include": [], "exclude": []}
if self.model_creation_services.project.include_tables != "":
with open(self.model_creation_services.project.include_tables,'rt') as f: #
include_tables_dict = yaml.safe_load(f.read())
f.close()
log.debug(f"include_tables specified: \n{include_tables_dict}\n") # {'include': ['I*', 'J', 'X*'], 'exclude': ['X1']}
# https://stackoverflow.com/questions/3040716/python-elegant-way-to-check-if-at-least-one-regex-in-list-matches-a-string
# https://www.w3schools.com/python/trypython.asp?filename=demo_regex
# ApiLogicServer create --project_name=table_filters_tests --db_url=table_filters_tests --include_tables=../table_filters_tests.yml
self.include_tables = include_tables_dict["include"] \
if "include" in include_tables_dict else ['.*'] # ['I.*', 'J', 'X.*']
if self.include_tables is None:
self.include_tables = ['.*']
self.include_regex = "(" + ")|(".join(self.include_tables) + ")" # include_regex: (I.*)|(J)|(X.*)
self.include_regex_list = map(re.compile, self.include_tables)
self.exclude_tables = include_tables_dict["exclude"] \
if "exclude" in include_tables_dict else ['a^']
if self.exclude_tables is None:
self.exclude_tables = ['a^']
self.exclude_regex = "(" + ")|(".join(self.exclude_tables) + ")"
if self.model_creation_services.project.include_tables != "":
log.debug(f"include_regex: {self.include_regex}")
log.debug(f"exclude_regex: {self.exclude_regex}\n")
log.debug(f"Test Tables: I, I1, J, X, X1, Y\n")
table_included = True
if self.model_creation_services.project.bind_key == "authentication":
log.debug(f".. authentication always included")
else:
if len(self.include_tables) == 0:
log.debug(f"All tables included: {table_name}")
else:
if re.match(self.include_regex, table_name):
log.debug(f"table included: {table_name}")
else:
log.debug(f"table excluded: {table_name}")
table_included = False
if not table_included:
log.debug(f".. skipping exlusions")
else:
if len(self.exclude_tables) == 0:
log.debug(f"No tables excluded: {table_name}")
else:
if re.match(self.exclude_regex, table_name):
log.debug(f"table excluded: {table_name}")
table_included = False
else:
log.debug(f"table not excluded: {table_name}")
return table_included
def __init__(self, metadata, noindexes=False, noconstraints=False, nojoined=False,
noinflect=False, noclasses=False, model_creation_services = None,
indentation=' ', model_separator='\n\n',
ignored_tables=('alembic_version', 'migrate_version'),
table_model=ModelTable,
class_model=ModelClass,
template=None, nocomments=False):
"""
ApiLogicServer sqlacodegen_wrapper invokes this as follows;
capture = StringIO() # generate and return the model
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses,
args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
"""
super(CodeGenerator, self).__init__()
global code_generator
code_generator = self
self.metadata = metadata
self.noindexes = noindexes
self.noconstraints = noconstraints
self.nojoined = nojoined
self.noinflect = noinflect
self.noclasses = noclasses
self.model_creation_services = model_creation_services # type: ModelCreationServices
self.generate_relationships_on = "parent" # "child"
self.indentation = indentation
self.model_separator = model_separator
self.ignored_tables = ignored_tables
self.table_model = table_model
self.class_model = class_model
""" class (not instance) of ModelClass [defaulted for ApiLogicServer] """
self.nocomments = nocomments
self.children_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.parents_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.include_tables = None # regex of tables included
self.exclude_tables = None # excluded
self.inflect_engine = self.create_inflect_engine()
if template:
self.template = template
# Pick association tables from the metadata into their own set, don't process them normally
links = defaultdict(lambda: [])
association_tables = set()
skip_association_table = True
for table in metadata.tables.values():
# Link tables have exactly two foreign key constraints and all columns are involved in
# them
fk_constraints = [constr for constr in table.constraints
if isinstance(constr, ForeignKeyConstraint)]
if len(fk_constraints) == 2 and all(col.foreign_keys for col in table.columns):
if skip_association_table: # Chinook playlist tracks, SqlSvr, Postgres Emp Territories
debug_str = f'skipping associate table: {table.name}'
debug_str += "... treated as normal table, with automatic joins"
else:
association_tables.add(table.name)
tablename = sorted(
fk_constraints, key=_get_constraint_sort_key)[0].elements[0].column.table.name
links[tablename].append(table)
# Iterate through the tables and create model classes when possible
self.models = []
self.collector = ImportCollector()
self.classes = {}
for table in metadata.sorted_tables:
# Support for Alembic and sqlalchemy-migrate -- never expose the schema version tables
if table.name in self.ignored_tables:
continue
table_included = self.is_table_included(table_name= table.name)
if not table_included:
log.debug(f"====> table skipped: {table.name}")
continue
"""
if any(regex.match(table.name) for regex in self.include_regex_list):
log.debug(f"list table included: {table.name}")
else:
log.debug(f"list table excluded: {table.name}")
"""
if noindexes:
table.indexes.clear()
if noconstraints:
table.constraints = {table.primary_key}
table.foreign_keys.clear()
for col in table.columns:
col.foreign_keys.clear()
else:
# Detect check constraints for boolean and enum columns
for constraint in table.constraints.copy():
if isinstance(constraint, CheckConstraint):
sqltext = self._get_compiled_expression(constraint.sqltext)
# Turn any integer-like column with a CheckConstraint like
# "column IN (0, 1)" into a Boolean
match = _re_boolean_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
table.constraints.remove(constraint)
table.c[colname].type = Boolean()
continue
# Turn any string-type column with a CheckConstraint like
# "column IN (...)" into an Enum
match = _re_enum_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
items = match.group(2)
if isinstance(table.c[colname].type, String):
table.constraints.remove(constraint)
if not isinstance(table.c[colname].type, Enum):
options = _re_enum_item.findall(items)
table.c[colname].type = Enum(*options, native_enum=False)
continue
# Tables vs. Classes ********
# Only form model classes for tables that have a primary key and are not association
# tables
if "productvariantsoh-20190423" in (table.name + "") or "unique_no_key" in (table.name + ""):
debug_str = "target table located"
""" create classes iff unique col - CAUTION: fails to run """
has_unique_constraint = False
if not table.primary_key:
for each_constraint in table.constraints:
if isinstance(each_constraint, sqlalchemy.sql.schema.UniqueConstraint):
has_unique_constraint = True
print(f'\n*** ApiLogicServer -- {table.name} has unique constraint, no primary_key')
# print(f'\nTEST *** {table.name} not table.primary_key = {not table.primary_key}, has_unique_constraint = {has_unique_constraint}')
unique_constraint_class = model_creation_services.project.infer_primary_key and has_unique_constraint
if unique_constraint_class == False and (noclasses or not table.primary_key or table.name in association_tables):
model = self.table_model(table)
else:
model = self.class_model(table, links[table.name], self.inflect_engine, not nojoined) # computes attrs (+ roles)
self.classes[model.name] = model
self.models.append(model)
model.add_imports(self.collector) # end mega-loop for table in metadata.sorted_tables
# Nest inherited classes in their superclasses to ensure proper ordering
for model in self.classes.values():
if model.parent_name != 'Base':
self.classes[model.parent_name].children.append(model)
self.models.remove(model)
# Add either the MetaData or declarative_base import depending on whether there are mapped
# classes or not
if not any(isinstance(model, self.class_model) for model in self.models):
self.collector.add_literal_import('sqlalchemy', 'MetaData')
else:
self.collector.add_literal_import('sqlalchemy.ext.declarative', 'declarative_base')
def create_inflect_engine(self):
if self.noinflect:
return _DummyInflectEngine()
else:
import inflect
return inflect.engine()
def render_imports(self):
return '\n'.join('from {0} import {1}'.format(package, ', '.join(sorted(names)))
for package, names in self.collector.items())
def render_metadata_declarations(self):
api_logic_server_imports = """
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.mysql import *
########################################################################################################################
"""
if self.model_creation_services.project.bind_key != "":
api_logic_server_imports = api_logic_server_imports.replace('Base = declarative_base()',
f'Base{self.model_creation_services.project.bind_key} = declarative_base()')
api_logic_server_imports = api_logic_server_imports.replace('metadata = Base.metadata',
f'metadata = Base{self.model_creation_services.project.bind_key}.metadata')
if "sqlalchemy.ext.declarative" in self.collector: # Manually Added for safrs (ApiLogicServer)
dialect_name = self.metadata.bind.engine.dialect.name # sqlite , mysql , postgresql , oracle , or mssql
if dialect_name in ["firebird", "mssql", "oracle", "postgresql", "sqlite", "sybase"]:
rtn_api_logic_server_imports = api_logic_server_imports.replace("mysql", dialect_name)
else:
rtn_api_logic_server_imports = api_logic_server_imports
print(".. .. ..Warning - unknown sql dialect, defaulting to msql - check database/models.py")
return rtn_api_logic_server_imports
return "metadata = MetaData()" # (stand-alone sql1codegen - never used in API Logic Server)
def _get_compiled_expression(self, statement):
"""Return the statement in a form where any placeholders have been filled in."""
return str(statement.compile(
self.metadata.bind, compile_kwargs={"literal_binds": True}))
@staticmethod
def _getargspec_init(method):
try:
if hasattr(inspect, 'getfullargspec'):
return inspect.getfullargspec(method)
else:
return inspect.getargspec(method)
except TypeError:
if method is object.__init__:
return ArgSpec(['self'], None, None, None)
else:
return ArgSpec(['self'], 'args', 'kwargs', None)
@classmethod
def render_column_type(cls, coltype):
args = []
kwargs = OrderedDict()
argspec = cls._getargspec_init(coltype.__class__.__init__)
defaults = dict(zip(argspec.args[-len(argspec.defaults or ()):],
argspec.defaults or ()))
missing = object()
use_kwargs = False
for attr in argspec.args[1:]:
# Remove annoyances like _warn_on_bytestring
if attr.startswith('_'):
continue
value = getattr(coltype, attr, missing)
default = defaults.get(attr, missing)
if value is missing or value == default:
use_kwargs = True
elif use_kwargs:
kwargs[attr] = repr(value)
else:
args.append(repr(value))
if argspec.varargs and hasattr(coltype, argspec.varargs):
varargs_repr = [repr(arg) for arg in getattr(coltype, argspec.varargs)]
args.extend(varargs_repr)
if isinstance(coltype, Enum) and coltype.name is not None:
kwargs['name'] = repr(coltype.name)
for key, value in kwargs.items():
args.append('{}={}'.format(key, value))
rendered = coltype.__class__.__name__
if args:
rendered += '({0})'.format(', '.join(args))
if rendered.startswith("CHAR("): # temp fix for non-double byte chars
rendered = rendered.replace("CHAR(", "String(")
return rendered
def render_constraint(self, constraint):
def render_fk_options(*opts):
opts = [repr(opt) for opt in opts]
for attr in 'ondelete', 'onupdate', 'deferrable', 'initially', 'match':
value = getattr(constraint, attr, None)
if value:
opts.append('{0}={1!r}'.format(attr, value))
return ', '.join(opts)
if isinstance(constraint, ForeignKey): # TODO: need to check is_included here?
remote_column = '{0}.{1}'.format(constraint.column.table.fullname,
constraint.column.name)
return 'ForeignKey({0})'.format(render_fk_options(remote_column))
elif isinstance(constraint, ForeignKeyConstraint):
local_columns = _get_column_names(constraint)
remote_columns = ['{0}.{1}'.format(fk.column.table.fullname, fk.column.name)
for fk in constraint.elements]
return 'ForeignKeyConstraint({0})'.format(
render_fk_options(local_columns, remote_columns))
elif isinstance(constraint, CheckConstraint):
return 'CheckConstraint({0!r})'.format(
self._get_compiled_expression(constraint.sqltext))
elif isinstance(constraint, UniqueConstraint):
columns = [repr(col.name) for col in constraint.columns]
return 'UniqueConstraint({0})'.format(', '.join(columns))
@staticmethod
def render_index(index):
extra_args = [repr(col.name) for col in index.columns]
if index.unique:
extra_args.append('unique=True')
return 'Index({0!r}, {1})'.format(index.name, ', '.join(extra_args))
def render_column(self, column: Column, show_name: bool):
"""_summary_
Args:
column (Column): column attributes
show_name (bool): True means embed col name into render_result
Returns:
str: eg. Column(Integer, primary_key=True), Column(String(8000))
"""
global code_generator
kwarg = []
is_sole_pk = column.primary_key and len(column.table.primary_key) == 1
dedicated_fks_old = [c for c in column.foreign_keys if len(c.constraint.columns) == 1]
dedicated_fks = [] # c for c in column.foreign_keys if len(c.constraint.columns) == 1
for each_foreign_key in column.foreign_keys:
log.debug(f'FK: {each_foreign_key}') #
log.debug(f'render_column - is fk: {dedicated_fks}')
if code_generator.is_table_included(each_foreign_key.column.table.name) \
and len(each_foreign_key.constraint.columns) == 1:
dedicated_fks.append(each_foreign_key)
else:
log.debug(f'Excluded single field fl on {column.table.name}.{column.name}')
if len(dedicated_fks) > 1:
log.error(f'codegen render_column finds unexpected col with >1 fk:'
f'{column.table.name}.{column.name}')
is_unique = any(isinstance(c, UniqueConstraint) and set(c.columns) == {column}
for c in column.table.constraints)
is_unique = is_unique or any(i.unique and set(i.columns) == {column}
for i in column.table.indexes)
has_index = any(set(i.columns) == {column} for i in column.table.indexes)
server_default = None
# Render the column type if there are no foreign keys on it or any of them points back to
# itself
render_coltype = not dedicated_fks or any(fk.column is column for fk in dedicated_fks)
if 'DataTypes.char_type DEBUG ONLY' == str(column):
print("Debug Stop: Column") # char_type = Column(CHAR(1, 'SQL_Latin1_General_CP1_CI_AS'))
if column.key != column.name:
kwarg.append('key')
if column.primary_key:
kwarg.append('primary_key')
if not column.nullable and not is_sole_pk:
kwarg.append('nullable')
if is_unique:
column.unique = True
kwarg.append('unique')
if self.model_creation_services.project.infer_primary_key:
# print(f'ApiLogicServer infer_primary_key for {column.table.name}.{column.name}')
column.primary_key = True
kwarg.append('primary_key')
elif has_index:
column.index = True
kwarg.append('index')
if Computed and isinstance(column.server_default, Computed):
expression = self._get_compiled_expression(column.server_default.sqltext)
persist_arg = ''
if column.server_default.persisted is not None:
persist_arg = ', persisted={}'.format(column.server_default.persisted)
server_default = 'Computed({!r}{})'.format(expression, persist_arg)
elif column.server_default:
# The quote escaping does not cover pathological cases but should mostly work FIXME SqlSvr no .arg
# not used for postgres/mysql; for sqlite, text is '0'
if not hasattr( column.server_default, 'arg' ):
server_default = 'server_default=text("{0}")'.format('0')
else:
default_expr = self._get_compiled_expression(column.server_default.arg)
if '\n' in default_expr:
server_default = 'server_default=text("""\\\n{0}""")'.format(default_expr)
else:
default_expr = default_expr.replace('"', '\\"')
server_default = 'server_default=text("{0}")'.format(default_expr)
comment = getattr(column, 'comment', None)
if (column.name + "") == "xx_id":
print(f"render_column target: {column.table.name}.{column.name}") # ApiLogicServer fix for putting this at end: index=True
if show_name and column.table.name != 'sqlite_sequence':
log.isEnabledFor(f"render_column show name is true: {column.table.name}.{column.name}") # researching why
render_result = 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
"""
return render_result
def render_relationship(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.target_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_relationship_on_parent(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.source_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_table(self, model):
# Manual edit:
# replace invalid chars for views etc TODO review ApiLogicServer -- using model.name vs model.table.name
table_name = model.name
bad_chars = r"$-+ "
if any(elem in table_name for elem in bad_chars):
print("sys error")
table_name = table_name.replace("$", "_S_")
table_name = table_name.replace(" ", "_")
table_name = table_name.replace("+", "_")
if model.table.name == "Plus+Table":
print("Debug Stop on table")
rendered = "t_{0} = Table(\n{1}{0!r}, metadata,\n".format(table_name, self.indentation)
for column in model.table.columns:
if column.name == "char_type DEBUG ONLY":
print("Debug Stop - column")
rendered += '{0}{1},\n'.format(self.indentation, self.render_column(column, True))
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue # TODO: need to check is_included here?
rendered += '{0}{1},\n'.format(self.indentation, self.render_constraint(constraint))
for index in model.table.indexes:
if len(index.columns) > 1:
rendered += '{0}{1},\n'.format(self.indentation, self.render_index(index))
if model.schema:
rendered += "{0}schema='{1}',\n".format(self.indentation, model.schema)
table_comment = getattr(model.table, 'comment', None)
if table_comment:
quoted_comment = table_comment.replace("'", "\\'").replace('"', '\\"')
rendered += "{0}comment='{1}',\n".format(self.indentation, quoted_comment)
return rendered.rstrip('\n,') + '\n)\n'
def render_class(self, model):
""" returns string for model class, written into model.py by sqlacodegen_wrapper """
super_classes = model.parent_name
if self.model_creation_services.project.bind_key != "":
super_classes = f'Base{self.model_creation_services.project.bind_key}, db.Model, UserMixin'
rendered = 'class {0}(SAFRSBase, {1}): # type: ignore\n'.format(model.name, super_classes) # ApiLogicServer
# f'Base{self.model_creation_services.project.bind_key} = declarative_base()'
else:
rendered = 'class {0}(SAFRSBase, {1}):\n'.format(model.name, super_classes) # ApiLogicServer
rendered += '{0}__tablename__ = {1!r}\n'.format(self.indentation, model.table.name)
end_point_name = model.name
if self.model_creation_services.project.bind_key != "":
if self.model_creation_services.project.model_gen_bind_msg == False:
self.model_creation_services.project.model_gen_bind_msg = True
log.debug(f'.. .. ..Setting bind_key = {self.model_creation_services.project.bind_key}')
end_point_name = self.model_creation_services.project.bind_key + \
self.model_creation_services.project.bind_key_url_separator + model.name
rendered += '{0}_s_collection_name = {1!r} # type: ignore\n'.format(self.indentation, end_point_name)
if self.model_creation_services.project.bind_key != "":
bind_key = self.model_creation_services.project.bind_key
else:
bind_key = "None"
rendered += '{0}__bind_key__ = {1!r}\n'.format(self.indentation, bind_key) # usually __bind_key__ = None
# Render constraints and indexes as __table_args__
autonum_col = False
table_args = []
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
if constraint._autoincrement_column is not None:
autonum_col = True
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue
# eg, Order: ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city'])
this_included = code_generator.is_table_included(model.table.name)
target_included = True
if isinstance(constraint, ForeignKeyConstraint): # CheckConstraints don't have elements
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if this_included and target_included:
table_args.append(self.render_constraint(constraint))
else:
log.debug(f'foreign key constraint excluded on {model.table.name}: '
f'{self.render_constraint(constraint)}')
for index in model.table.indexes:
if len(index.columns) > 1:
table_args.append(self.render_index(index))
table_kwargs = {}
if model.schema:
table_kwargs['schema'] = model.schema
table_comment = getattr(model.table, 'comment', None)
if table_comment:
table_kwargs['comment'] = table_comment
kwargs_items = ', '.join('{0!r}: {1!r}'.format(key, table_kwargs[key])
for key in table_kwargs)
kwargs_items = '{{{0}}}'.format(kwargs_items) if kwargs_items else None
if table_kwargs and not table_args:
rendered += '{0}__table_args__ = {1}\n'.format(self.indentation, kwargs_items)
elif table_args:
if kwargs_items:
table_args.append(kwargs_items)
if len(table_args) == 1:
table_args[0] += ','
table_args_joined = ',\n{0}{0}'.format(self.indentation).join(table_args)
rendered += '{0}__table_args__ = (\n{0}{0}{1}\n{0})\n'.format(
self.indentation, table_args_joined)
# Render columns
# special case id: https://github.com/valhuber/ApiLogicServer/issues/69#issuecomment-1579731936
rendered += '\n'
for attr, column in model.attributes.items():
if isinstance(column, Column):
show_name = attr != column.name
rendered_column = '{0}{1} = {2}\n'.format(
self.indentation, attr, self.render_column(column, show_name))
if column.name == "id": # add name to Column(Integer, primary_key=True)
""" add name to Column(Integer, primary_key=True) - but makes system fail
rendered_column = rendered_column.replace(
'id = Column(', 'Id = Column("id", ')
log.debug(f' id = Column(Integer, primary_key=True) -->'\
f' Id = Column("id", Integer, primary_key=True)')
"""
if model.name not in["User", "Api"]:
log.info(f'** Warning: id columns will not be included in API response - '
f'{model.name}.id\n')
rendered += rendered_column
if not autonum_col:
rendered += '{0}{1}'.format(self.indentation, "allow_client_generated_ids = True\n")
# Render relationships (declared in parent class, backref to child)
if any(isinstance(value, Relationship) for value in model.attributes.values()):
rendered += '\n'
backrefs = {}
for attr, relationship in model.attributes.items():
if isinstance(relationship, Relationship): # ApiLogicServer changed to insert backref
attr_to_render = attr
if self.generate_relationships_on != "child":
attr_to_render = "# see backref on parent: " + attr # relns not created on child; comment out
rel_render = "{0}{1} = {2}\n".format(self.indentation, attr_to_render, self.render_relationship(relationship))
rel_parts = rel_render.split(")") # eg, Department = relationship(\'Department\', remote_side=[Id]
backref_name = model.name + "List"
""" disambiguate multi-relns, eg, in the Employee child class, 2 relns to Department:
Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList')
Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList_Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
unique_name = relationship.target_cls + '.' + backref_name
if unique_name in backrefs: # disambiguate
backref_name += "_" + attr
back_ref = f', cascade_backrefs=True, backref=\'{backref_name}\''
rel_render_with_backref = rel_parts[0] + \
back_ref + \
")" + rel_parts[1]
# rendered += "{0}{1} = {2}\n".format(self.indentation, attr, self.render_relationship(relationship))
""" disambiguate multi-relns, eg, in the Department parent class, 2 relns to Employee:
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
if relationship.target_cls not in self.classes:
print(f'.. .. ..ERROR - {model.name} -- missing parent class: {relationship.target_cls}')
print(f'.. .. .. .. Parent Class may be missing Primary Key and Unique Column')
print(f'.. .. .. .. Attempting to continue - you may need to repair model, or address database design')
continue
parent_model = self.classes[relationship.target_cls] # eg, Department
parent_relationship_def = self.render_relationship_on_parent(relationship)
parent_relationship_def = parent_relationship_def[:-1]
# eg, for Dept: relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id')
child_role_name = model.name + "List"
parent_role_name = attr
if unique_name in backrefs: # disambiguate
child_role_name += '1' # FIXME - fails for 3 relns
if model.name != parent_model.name:
parent_relationship = f'{child_role_name} = {parent_relationship_def}, cascade_backrefs=True, backref=\'{parent_role_name}\')'
else: # work-around for self relns
"""
special case self relns:
not DepartmentList = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='Department')
but Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList')
"""
parent_relationship = f'{parent_role_name} = {parent_relationship_def}, cascade_backrefs=True, backref=\'{child_role_name}\')'
parent_relationship += " # special handling for self-relationships"
if self.generate_relationships_on != "parent": # relns not created on parent; comment out
parent_relationship = "# see backref on child: " + parent_relationship
parent_model.rendered_model_relationships += " " + parent_relationship + "\n"
if model.name == "OrderDetail":
debug_str = "nice breakpoint"
rendered += rel_render_with_backref
backrefs[unique_name] = backref_name
if relationship.source_cls.startswith("Ab"):
pass
elif isinstance(relationship, ManyToManyRelationship): # eg, chinook:PlayList->PlayListTrack
print(f'many to many should not occur on: {model.name}.{unique_name}')
else: # fixme dump all this, right?
use_old_code = False # so you can elide this
if use_old_code:
resource = self.model_creation_services.resource_list[relationship.source_cls]
resource_relationship = ResourceRelationship(parent_role_name = attr,
child_role_name = backref_name)
resource_relationship.child_resource = relationship.source_cls
resource_relationship.parent_resource = relationship.target_cls
# gen key pairs
for each_pair in relationship.foreign_key_constraint.elements:
pair = ( str(each_pair.column.name), str(each_pair.parent.name) )
resource_relationship.parent_child_key_pairs.append(pair)
resource.parents.append(resource_relationship)
parent_resource = self.model_creation_services.resource_list[relationship.target_cls]
parent_resource.children.append(resource_relationship)
if use_old_code:
if relationship.source_cls not in self.parents_map: # todo old code remove
self.parents_map[relationship.source_cls] = list()
self.parents_map[relationship.source_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
if relationship.target_cls not in self.children_map:
self.children_map[relationship.target_cls] = list()
self.children_map[relationship.target_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
pass
# Render subclasses
for child_class in model.children:
rendered += self.model_separator + self.render_class(child_class)
# rendered += "\n # END RENDERED CLASS\n" # useful for debug, as required
return rendered
def render(self, outfile=sys.stdout):
""" create model from db, and write models.py file to in-memory buffer (outfile)
relns created from not-yet-seen children, so
* save *all* class info,
* then append rendered_model_relationships
"""
for model in self.models: # class, with __tablename__ & __collection_name__ cls variables, attrs
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
model.rendered_model = self.render_class(model) # also sets parent_model.rendered_model_relationships
rendered_models = [] # now append the rendered_model + rendered_model_relationships
for model in self.models:
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
if model.rendered_model_relationships != "": # child relns (OrderDetailList etc)
model.rendered_model_relationships = "\n" + model.rendered_model_relationships
rendered_models.append(model.rendered_model + model.rendered_model_relationships)
rendered_models.append(self.model_creation_services.opt_locking)
elif isinstance(model, self.table_model): # eg, views, database id generators, etc
rendered_models.append(self.render_table(model))
output = self.template.format(
imports=self.render_imports(),
metadata_declarations=self.render_metadata_declarations(),
models=self.model_separator.join(rendered_models).rstrip('\n'))
print(output, file=outfile)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/codegen/codegen.py
|
codegen.py
|
from __future__ import unicode_literals, division, print_function, absolute_import
import inspect
import re
import sys, logging
from collections import defaultdict
from importlib import import_module
from inspect import FullArgSpec # val-311
from keyword import iskeyword
import sqlalchemy
import sqlalchemy.exc
from sqlalchemy import (
Enum, ForeignKeyConstraint, PrimaryKeyConstraint, CheckConstraint, UniqueConstraint, Table,
Column, Float)
from sqlalchemy.schema import ForeignKey
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.types import Boolean, String
from sqlalchemy.util import OrderedDict
import yaml
# The generic ARRAY type was introduced in SQLAlchemy 1.1
from api_logic_server_cli.create_from_model.model_creation_services import Resource, ResourceRelationship, \
ResourceAttribute
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
log = logging.getLogger(__name__)
"""
handler = logging.StreamHandler(sys.stderr)
formatter = logging.Formatter('%(message)s') # lead tag - '%(name)s: %(message)s')
handler.setFormatter(formatter)
log.addHandler(handler)
log.propagate = True
"""
try:
from sqlalchemy import ARRAY
except ImportError:
from sqlalchemy.dialects.postgresql import ARRAY
# SQLAlchemy 1.3.11+
try:
from sqlalchemy import Computed
except ImportError:
Computed = None
# Conditionally import Geoalchemy2 to enable reflection support
try:
import geoalchemy2 # noqa: F401
except ImportError:
pass
_re_boolean_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \(0, 1\)")
_re_column_name = re.compile(r'(?:(["`]?)(?:.*)\1\.)?(["`]?)(.*)\2')
_re_enum_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \((.+)\)")
_re_enum_item = re.compile(r"'(.*?)(?<!\\)'")
_re_invalid_identifier = re.compile(r'[^a-zA-Z0-9_]' if sys.version_info[0] < 3 else r'(?u)\W')
class _DummyInflectEngine(object):
@staticmethod
def singular_noun(noun):
return noun
# In SQLAlchemy 0.x, constraint.columns is sometimes a list, on 1.x onwards, always a
# ColumnCollection
def _get_column_names(constraint):
if isinstance(constraint.columns, list):
return constraint.columns
return list(constraint.columns.keys())
def _get_constraint_sort_key(constraint):
if isinstance(constraint, CheckConstraint):
return 'C{0}'.format(constraint.sqltext)
return constraint.__class__.__name__[0] + repr(_get_column_names(constraint))
class ImportCollector(OrderedDict):
def add_import(self, obj):
type_ = type(obj) if not isinstance(obj, type) else obj
pkgname = type_.__module__
# The column types have already been adapted towards generic types if possible, so if this
# is still a vendor specific type (e.g., MySQL INTEGER) be sure to use that rather than the
# generic sqlalchemy type as it might have different constructor parameters.
if pkgname.startswith('sqlalchemy.dialects.'):
dialect_pkgname = '.'.join(pkgname.split('.')[0:3])
dialect_pkg = import_module(dialect_pkgname)
if type_.__name__ in dialect_pkg.__all__:
pkgname = dialect_pkgname
else:
pkgname = 'sqlalchemy' if type_.__name__ in sqlalchemy.__all__ else type_.__module__
self.add_literal_import(pkgname, type_.__name__)
def add_literal_import(self, pkgname, name):
names = self.setdefault(pkgname, set())
names.add(name)
class Model(object):
def __init__(self, table):
super(Model, self).__init__()
self.table = table
self.schema = table.schema
# Adapt column types to the most reasonable generic types (ie. VARCHAR -> String)
for column in table.columns:
try:
column.type = self._get_adapted_type(column.type, column.table.bind)
except:
# print('Failed to get col type for {}, {}'.format(column, column.type))
if "sqlite_sequence" not in format(column):
print("#Failed to get col type for {}".format(column))
def __str__(self):
return f'Model for table: {self.table} (in schema: {self.schema})'
def _get_adapted_type(self, coltype, bind):
compiled_type = coltype.compile(bind.dialect)
for supercls in coltype.__class__.__mro__:
if not supercls.__name__.startswith('_') and hasattr(supercls, '__visit_name__'):
# Hack to fix adaptation of the Enum class which is broken since SQLAlchemy 1.2
kw = {}
if supercls is Enum:
kw['name'] = coltype.name
try:
new_coltype = coltype.adapt(supercls)
except TypeError:
# If the adaptation fails, don't try again
break
for key, value in kw.items():
setattr(new_coltype, key, value)
if isinstance(coltype, ARRAY):
new_coltype.item_type = self._get_adapted_type(new_coltype.item_type, bind)
try:
# If the adapted column type does not render the same as the original, don't
# substitute it
if new_coltype.compile(bind.dialect) != compiled_type:
# Make an exception to the rule for Float and arrays of Float, since at
# least on PostgreSQL, Float can accurately represent both REAL and
# DOUBLE_PRECISION
if not isinstance(new_coltype, Float) and \
not (isinstance(new_coltype, ARRAY) and
isinstance(new_coltype.item_type, Float)):
break
except sqlalchemy.exc.CompileError:
# If the adapted column type can't be compiled, don't substitute it
break
# Stop on the first valid non-uppercase column type class
coltype = new_coltype
if supercls.__name__ != supercls.__name__.upper():
break
return coltype
def add_imports(self, collector):
if self.table.columns:
collector.add_import(Column)
for column in self.table.columns:
collector.add_import(column.type)
if column.server_default:
if Computed and isinstance(column.server_default, Computed):
collector.add_literal_import('sqlalchemy', 'Computed')
else:
collector.add_literal_import('sqlalchemy', 'text')
if isinstance(column.type, ARRAY):
collector.add_import(column.type.item_type.__class__)
for constraint in sorted(self.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'ForeignKeyConstraint')
else:
collector.add_literal_import('sqlalchemy', 'ForeignKey')
elif isinstance(constraint, UniqueConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'UniqueConstraint')
elif not isinstance(constraint, PrimaryKeyConstraint):
collector.add_import(constraint)
for index in self.table.indexes:
if len(index.columns) > 1:
collector.add_import(index)
@staticmethod
def _convert_to_valid_identifier(name):
assert name, 'Identifier cannot be empty'
if name[0].isdigit() or iskeyword(name):
name = '_' + name
elif name == 'metadata':
name = 'metadata_'
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes for superclass version (why override?)
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub('_', name)
return result
class ModelTable(Model):
def __init__(self, table):
super(ModelTable, self).__init__(table)
self.name = self._convert_to_valid_identifier(table.name)
def add_imports(self, collector):
super(ModelTable, self).add_imports(collector)
try:
collector.add_import(Table)
except Exception as exc:
print("Failed to add imports {}".format(collector))
class ModelClass(Model):
parent_name = 'Base'
def __init__(self, table, association_tables, inflect_engine, detect_joined):
super(ModelClass, self).__init__(table)
self.name = self._tablename_to_classname(table.name, inflect_engine)
self.children = []
self.attributes = OrderedDict()
self.foreign_key_relationships = list()
self.rendered_model = "" # ApiLogicServer
self.rendered_model_relationships = "" # appended at end ( render() )
# Assign attribute names for columns
for column in table.columns:
self._add_attribute(column.name, column)
# Add many-to-one relationships (to parent)
pk_column_names = set(col.name for col in table.primary_key.columns)
for constraint in sorted(table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
target_cls = self._tablename_to_classname(constraint.elements[0].column.table.name,
inflect_engine)
this_included = code_generator.is_table_included(self.table.name)
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if (detect_joined and self.parent_name == 'Base' and
set(_get_column_names(constraint)) == pk_column_names):
self.parent_name = target_cls
else:
relationship_ = ManyToOneRelationship(self.name, target_cls, constraint,
inflect_engine)
if this_included and target_included:
self._add_attribute(relationship_.preferred_name, relationship_)
else:
log.debug(f"Parent Relationship excluded: {relationship_.preferred_name}")
# Add many-to-many relationships
for association_table in association_tables:
fk_constraints = [c for c in association_table.constraints
if isinstance(c, ForeignKeyConstraint)]
fk_constraints.sort(key=_get_constraint_sort_key)
target_cls = self._tablename_to_classname(
fk_constraints[1].elements[0].column.table.name, inflect_engine)
relationship_ = ManyToManyRelationship(self.name, target_cls, association_table)
self._add_attribute(relationship_.preferred_name, relationship_)
@classmethod
def _tablename_to_classname(cls, tablename, inflect_engine):
"""
camel-case and singlularize, with provisions for reserved word (Date) and collisions (Dates & _Dates)
"""
tablename = cls._convert_to_valid_identifier(tablename)
if tablename in ["Dates"]: # ApiLogicServer
tablename = tablename + "Classs"
camel_case_name = ''.join(part[:1].upper() + part[1:] for part in tablename.split('_'))
if camel_case_name in ["Dates"]:
camel_case_name = camel_case_name + "_Classs"
result = inflect_engine.singular_noun(camel_case_name) or camel_case_name
if result == "CategoryTableNameTest": # ApiLogicServer
result = "Category"
return result
@staticmethod
def _convert_to_valid_identifier(name): # TODO review
assert name, "Identifier cannot be empty"
if name[0].isdigit() or iskeyword(name):
name = "_" + name
elif name == "metadata":
name = "metadata_"
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes, ModelClass version
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub("_", name)
return result
def _add_attribute(self, attrname, value):
""" add table column/relationship to attributes
disambiguate relationship accessor names (append tablename with 1, 2...)
"""
attrname = tempname = self._convert_to_valid_identifier(attrname)
counter = 1
while tempname in self.attributes:
tempname = attrname + str(counter)
counter += 1
self.attributes[tempname] = value
return tempname
def add_imports(self, collector):
super(ModelClass, self).add_imports(collector)
if any(isinstance(value, Relationship) for value in self.attributes.values()):
collector.add_literal_import('sqlalchemy.orm', 'relationship')
for child in self.children:
child.add_imports(collector)
class Relationship(object):
def __init__(self, source_cls, target_cls):
super(Relationship, self).__init__()
self.source_cls = source_cls
self.target_cls = target_cls
self.kwargs = OrderedDict()
class ManyToOneRelationship(Relationship):
def __init__(self, source_cls, target_cls, constraint, inflect_engine):
super(ManyToOneRelationship, self).__init__(source_cls, target_cls)
column_names = _get_column_names(constraint)
colname = column_names[0]
tablename = constraint.elements[0].column.table.name
self.foreign_key_constraint = constraint
if not colname.endswith('_id'):
self.preferred_name = inflect_engine.singular_noun(tablename) or tablename
else:
self.preferred_name = colname[:-3]
# Add uselist=False to One-to-One relationships
if any(isinstance(c, (PrimaryKeyConstraint, UniqueConstraint)) and
set(col.name for col in c.columns) == set(column_names)
for c in constraint.table.constraints):
self.kwargs['uselist'] = 'False'
# Handle self referential relationships
if source_cls == target_cls:
# self.preferred_name = 'parent' if not colname.endswith('_id') else colname[:-3]
if colname.endswith("id") or colname.endswith("Id"):
self.preferred_name = colname[:-2]
else:
self.preferred_name = "parent" # hmm, why not just table name
pk_col_names = [col.name for col in constraint.table.primary_key]
self.kwargs['remote_side'] = '[{0}]'.format(', '.join(pk_col_names))
# If the two tables share more than one foreign key constraint,
# SQLAlchemy needs an explicit primaryjoin to figure out which column(s) to join with
common_fk_constraints = self.get_common_fk_constraints(
constraint.table, constraint.elements[0].column.table)
if len(common_fk_constraints) > 1:
self.kwargs['primaryjoin'] = "'{0}.{1} == {2}.{3}'".format(
source_cls, column_names[0], target_cls, constraint.elements[0].column.name)
@staticmethod
def get_common_fk_constraints(table1, table2):
"""Returns a set of foreign key constraints the two tables have against each other."""
c1 = set(c for c in table1.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table2)
c2 = set(c for c in table2.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table1)
return c1.union(c2)
class ManyToManyRelationship(Relationship):
def __init__(self, source_cls, target_cls, assocation_table):
super(ManyToManyRelationship, self).__init__(source_cls, target_cls)
prefix = (assocation_table.schema + '.') if assocation_table.schema else ''
self.kwargs['secondary'] = repr(prefix + assocation_table.name)
constraints = [c for c in assocation_table.constraints
if isinstance(c, ForeignKeyConstraint)]
constraints.sort(key=_get_constraint_sort_key)
colname = _get_column_names(constraints[1])[0]
tablename = constraints[1].elements[0].column.table.name
self.preferred_name = tablename if not colname.endswith('_id') else colname[:-3] + 's'
# Handle self referential relationships
if source_cls == target_cls:
self.preferred_name = 'parents' if not colname.endswith('_id') else colname[:-3] + 's'
pri_pairs = zip(_get_column_names(constraints[0]), constraints[0].elements)
sec_pairs = zip(_get_column_names(constraints[1]), constraints[1].elements)
pri_joins = ['{0}.{1} == {2}.c.{3}'.format(source_cls, elem.column.name,
assocation_table.name, col)
for col, elem in pri_pairs]
sec_joins = ['{0}.{1} == {2}.c.{3}'.format(target_cls, elem.column.name,
assocation_table.name, col)
for col, elem in sec_pairs]
self.kwargs['primaryjoin'] = (
repr('and_({0})'.format(', '.join(pri_joins)))
if len(pri_joins) > 1 else repr(pri_joins[0]))
self.kwargs['secondaryjoin'] = (
repr('and_({0})'.format(', '.join(sec_joins)))
if len(sec_joins) > 1 else repr(sec_joins[0]))
code_generator = None # type: CodeGenerator
""" Model needs to access state here, eg, included/excluded tables """
class CodeGenerator(object):
template = """\
# coding: utf-8
{imports}
{metadata_declarations}
{models}"""
def is_table_included(self, table_name: str) -> bool:
"""
Determines table included per self.include_tables / exclude tables.
See Run Config: Table Filters Tests
Args:
table_name (str): _description_
Returns:
bool: True means included
"""
if self.include_tables is None: # first time initialization
include_tables_dict = {"include": [], "exclude": []}
if self.model_creation_services.project.include_tables != "":
with open(self.model_creation_services.project.include_tables,'rt') as f: #
include_tables_dict = yaml.safe_load(f.read())
f.close()
log.debug(f"include_tables specified: \n{include_tables_dict}\n") # {'include': ['I*', 'J', 'X*'], 'exclude': ['X1']}
# https://stackoverflow.com/questions/3040716/python-elegant-way-to-check-if-at-least-one-regex-in-list-matches-a-string
# https://www.w3schools.com/python/trypython.asp?filename=demo_regex
# ApiLogicServer create --project_name=table_filters_tests --db_url=table_filters_tests --include_tables=../table_filters_tests.yml
self.include_tables = include_tables_dict["include"] \
if "include" in include_tables_dict else ['.*'] # ['I.*', 'J', 'X.*']
if self.include_tables is None:
self.include_tables = ['.*']
self.include_regex = "(" + ")|(".join(self.include_tables) + ")" # include_regex: (I.*)|(J)|(X.*)
self.include_regex_list = map(re.compile, self.include_tables)
self.exclude_tables = include_tables_dict["exclude"] \
if "exclude" in include_tables_dict else ['a^']
if self.exclude_tables is None:
self.exclude_tables = ['a^']
self.exclude_regex = "(" + ")|(".join(self.exclude_tables) + ")"
if self.model_creation_services.project.include_tables != "":
log.debug(f"include_regex: {self.include_regex}")
log.debug(f"exclude_regex: {self.exclude_regex}\n")
log.debug(f"Test Tables: I, I1, J, X, X1, Y\n")
table_included = True
if self.model_creation_services.project.bind_key == "authentication":
log.debug(f".. authentication always included")
else:
if len(self.include_tables) == 0:
log.debug(f"All tables included: {table_name}")
else:
if re.match(self.include_regex, table_name):
log.debug(f"table included: {table_name}")
else:
log.debug(f"table excluded: {table_name}")
table_included = False
if not table_included:
log.debug(f".. skipping exlusions")
else:
if len(self.exclude_tables) == 0:
log.debug(f"No tables excluded: {table_name}")
else:
if re.match(self.exclude_regex, table_name):
log.debug(f"table excluded: {table_name}")
table_included = False
else:
log.debug(f"table not excluded: {table_name}")
return table_included
def __init__(self, metadata, noindexes=False, noconstraints=False, nojoined=False,
noinflect=False, noclasses=False, model_creation_services = None,
indentation=' ', model_separator='\n\n',
ignored_tables=('alembic_version', 'migrate_version'),
table_model=ModelTable,
class_model=ModelClass,
template=None, nocomments=False):
"""
ApiLogicServer sqlacodegen_wrapper invokes this as follows;
capture = StringIO() # generate and return the model
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses,
args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
"""
super(CodeGenerator, self).__init__()
global code_generator
code_generator = self
self.metadata = metadata
self.noindexes = noindexes
self.noconstraints = noconstraints
self.nojoined = nojoined
self.noinflect = noinflect
self.noclasses = noclasses
self.model_creation_services = model_creation_services # type: ModelCreationServices
self.generate_relationships_on = "parent" # "child"
self.indentation = indentation
self.model_separator = model_separator
self.ignored_tables = ignored_tables
self.table_model = table_model
self.class_model = class_model
""" class (not instance) of ModelClass [defaulted for ApiLogicServer] """
self.nocomments = nocomments
self.children_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.parents_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.include_tables = None # regex of tables included
self.exclude_tables = None # excluded
self.inflect_engine = self.create_inflect_engine()
if template:
self.template = template
# Pick association tables from the metadata into their own set, don't process them normally
links = defaultdict(lambda: [])
association_tables = set()
skip_association_table = True
for table in metadata.tables.values():
# Link tables have exactly two foreign key constraints and all columns are involved in
# them
fk_constraints = [constr for constr in table.constraints
if isinstance(constr, ForeignKeyConstraint)]
if len(fk_constraints) == 2 and all(col.foreign_keys for col in table.columns):
if skip_association_table: # Chinook playlist tracks, SqlSvr, Postgres Emp Territories
debug_str = f'skipping associate table: {table.name}'
debug_str += "... treated as normal table, with automatic joins"
else:
association_tables.add(table.name)
tablename = sorted(
fk_constraints, key=_get_constraint_sort_key)[0].elements[0].column.table.name
links[tablename].append(table)
# Iterate through the tables and create model classes when possible
self.models = []
self.collector = ImportCollector()
self.classes = {}
for table in metadata.sorted_tables:
# Support for Alembic and sqlalchemy-migrate -- never expose the schema version tables
if table.name in self.ignored_tables:
continue
table_included = self.is_table_included(table_name= table.name)
if not table_included:
log.debug(f"====> table skipped: {table.name}")
continue
"""
if any(regex.match(table.name) for regex in self.include_regex_list):
log.debug(f"list table included: {table.name}")
else:
log.debug(f"list table excluded: {table.name}")
"""
if noindexes:
table.indexes.clear()
if noconstraints:
table.constraints = {table.primary_key}
table.foreign_keys.clear()
for col in table.columns:
col.foreign_keys.clear()
else:
# Detect check constraints for boolean and enum columns
for constraint in table.constraints.copy():
if isinstance(constraint, CheckConstraint):
sqltext = self._get_compiled_expression(constraint.sqltext)
# Turn any integer-like column with a CheckConstraint like
# "column IN (0, 1)" into a Boolean
match = _re_boolean_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
table.constraints.remove(constraint)
table.c[colname].type = Boolean()
continue
# Turn any string-type column with a CheckConstraint like
# "column IN (...)" into an Enum
match = _re_enum_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
items = match.group(2)
if isinstance(table.c[colname].type, String):
table.constraints.remove(constraint)
if not isinstance(table.c[colname].type, Enum):
options = _re_enum_item.findall(items)
table.c[colname].type = Enum(*options, native_enum=False)
continue
# Tables vs. Classes ********
# Only form model classes for tables that have a primary key and are not association
# tables
if "productvariantsoh-20190423" in (table.name + "") or "unique_no_key" in (table.name + ""):
debug_str = "target table located"
""" create classes iff unique col - CAUTION: fails to run """
has_unique_constraint = False
if not table.primary_key:
for each_constraint in table.constraints:
if isinstance(each_constraint, sqlalchemy.sql.schema.UniqueConstraint):
has_unique_constraint = True
print(f'\n*** ApiLogicServer -- {table.name} has unique constraint, no primary_key')
# print(f'\nTEST *** {table.name} not table.primary_key = {not table.primary_key}, has_unique_constraint = {has_unique_constraint}')
unique_constraint_class = model_creation_services.project.infer_primary_key and has_unique_constraint
if unique_constraint_class == False and (noclasses or not table.primary_key or table.name in association_tables):
model = self.table_model(table)
else:
model = self.class_model(table, links[table.name], self.inflect_engine, not nojoined) # computes attrs (+ roles)
self.classes[model.name] = model
self.models.append(model)
model.add_imports(self.collector) # end mega-loop for table in metadata.sorted_tables
# Nest inherited classes in their superclasses to ensure proper ordering
for model in self.classes.values():
if model.parent_name != 'Base':
self.classes[model.parent_name].children.append(model)
self.models.remove(model)
# Add either the MetaData or declarative_base import depending on whether there are mapped
# classes or not
if not any(isinstance(model, self.class_model) for model in self.models):
self.collector.add_literal_import('sqlalchemy', 'MetaData')
else:
self.collector.add_literal_import('sqlalchemy.ext.declarative', 'declarative_base')
def create_inflect_engine(self):
if self.noinflect:
return _DummyInflectEngine()
else:
import inflect
return inflect.engine()
def render_imports(self):
return '\n'.join('from {0} import {1}'.format(package, ', '.join(sorted(names)))
for package, names in self.collector.items())
def render_metadata_declarations(self):
api_logic_server_imports = """
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.mysql import *
########################################################################################################################
"""
if self.model_creation_services.project.bind_key != "":
api_logic_server_imports = api_logic_server_imports.replace('Base = declarative_base()',
f'Base{self.model_creation_services.project.bind_key} = declarative_base()')
api_logic_server_imports = api_logic_server_imports.replace('metadata = Base.metadata',
f'metadata = Base{self.model_creation_services.project.bind_key}.metadata')
if "sqlalchemy.ext.declarative" in self.collector: # Manually Added for safrs (ApiLogicServer)
dialect_name = self.metadata.bind.engine.dialect.name # sqlite , mysql , postgresql , oracle , or mssql
if dialect_name in ["firebird", "mssql", "oracle", "postgresql", "sqlite", "sybase"]:
rtn_api_logic_server_imports = api_logic_server_imports.replace("mysql", dialect_name)
else:
rtn_api_logic_server_imports = api_logic_server_imports
print(".. .. ..Warning - unknown sql dialect, defaulting to msql - check database/models.py")
return rtn_api_logic_server_imports
return "metadata = MetaData()" # (stand-alone sql1codegen - never used in API Logic Server)
def _get_compiled_expression(self, statement):
"""Return the statement in a form where any placeholders have been filled in."""
return str(statement.compile(
self.metadata.bind, compile_kwargs={"literal_binds": True}))
@staticmethod
def _getargspec_init(method):
try:
if hasattr(inspect, 'getfullargspec'):
return inspect.getfullargspec(method)
else:
return inspect.getargspec(method)
except TypeError:
if method is object.__init__:
return ArgSpec(['self'], None, None, None)
else:
return ArgSpec(['self'], 'args', 'kwargs', None)
@classmethod
def render_column_type(cls, coltype):
args = []
kwargs = OrderedDict()
argspec = cls._getargspec_init(coltype.__class__.__init__)
defaults = dict(zip(argspec.args[-len(argspec.defaults or ()):],
argspec.defaults or ()))
missing = object()
use_kwargs = False
for attr in argspec.args[1:]:
# Remove annoyances like _warn_on_bytestring
if attr.startswith('_'):
continue
value = getattr(coltype, attr, missing)
default = defaults.get(attr, missing)
if value is missing or value == default:
use_kwargs = True
elif use_kwargs:
kwargs[attr] = repr(value)
else:
args.append(repr(value))
if argspec.varargs and hasattr(coltype, argspec.varargs):
varargs_repr = [repr(arg) for arg in getattr(coltype, argspec.varargs)]
args.extend(varargs_repr)
if isinstance(coltype, Enum) and coltype.name is not None:
kwargs['name'] = repr(coltype.name)
for key, value in kwargs.items():
args.append('{}={}'.format(key, value))
rendered = coltype.__class__.__name__
if args:
rendered += '({0})'.format(', '.join(args))
if rendered.startswith("CHAR("): # temp fix for non-double byte chars
rendered = rendered.replace("CHAR(", "String(")
return rendered
def render_constraint(self, constraint):
def render_fk_options(*opts):
opts = [repr(opt) for opt in opts]
for attr in 'ondelete', 'onupdate', 'deferrable', 'initially', 'match':
value = getattr(constraint, attr, None)
if value:
opts.append('{0}={1!r}'.format(attr, value))
return ', '.join(opts)
if isinstance(constraint, ForeignKey): # TODO: need to check is_included here?
remote_column = '{0}.{1}'.format(constraint.column.table.fullname,
constraint.column.name)
return 'ForeignKey({0})'.format(render_fk_options(remote_column))
elif isinstance(constraint, ForeignKeyConstraint):
local_columns = _get_column_names(constraint)
remote_columns = ['{0}.{1}'.format(fk.column.table.fullname, fk.column.name)
for fk in constraint.elements]
return 'ForeignKeyConstraint({0})'.format(
render_fk_options(local_columns, remote_columns))
elif isinstance(constraint, CheckConstraint):
return 'CheckConstraint({0!r})'.format(
self._get_compiled_expression(constraint.sqltext))
elif isinstance(constraint, UniqueConstraint):
columns = [repr(col.name) for col in constraint.columns]
return 'UniqueConstraint({0})'.format(', '.join(columns))
@staticmethod
def render_index(index):
extra_args = [repr(col.name) for col in index.columns]
if index.unique:
extra_args.append('unique=True')
return 'Index({0!r}, {1})'.format(index.name, ', '.join(extra_args))
def render_column(self, column, show_name):
global code_generator
kwarg = []
is_sole_pk = column.primary_key and len(column.table.primary_key) == 1
dedicated_fks_old = [c for c in column.foreign_keys if len(c.constraint.columns) == 1]
dedicated_fks = [] # c for c in column.foreign_keys if len(c.constraint.columns) == 1
for each_foreign_key in column.foreign_keys:
log.debug(f'FK: {each_foreign_key}') #
log.debug(f'render_column - is fk: {dedicated_fks}')
if code_generator.is_table_included(each_foreign_key.column.table.name) \
and len(each_foreign_key.constraint.columns) == 1:
dedicated_fks.append(each_foreign_key)
else:
log.debug(f'Excluded single field fl on {column.table.name}.{column.name}')
if len(dedicated_fks) > 1:
log.error(f'codegen render_column finds unexpected col with >1 fk:'
f'{column.table.name}.{column.name}')
is_unique = any(isinstance(c, UniqueConstraint) and set(c.columns) == {column}
for c in column.table.constraints)
is_unique = is_unique or any(i.unique and set(i.columns) == {column}
for i in column.table.indexes)
has_index = any(set(i.columns) == {column} for i in column.table.indexes)
server_default = None
# Render the column type if there are no foreign keys on it or any of them points back to
# itself
render_coltype = not dedicated_fks or any(fk.column is column for fk in dedicated_fks)
if 'DataTypes.char_type DEBUG ONLY' == str(column):
print("Debug Stop: Column") # char_type = Column(CHAR(1, 'SQL_Latin1_General_CP1_CI_AS'))
if column.key != column.name:
kwarg.append('key')
if column.primary_key:
kwarg.append('primary_key')
if not column.nullable and not is_sole_pk:
kwarg.append('nullable')
if is_unique:
column.unique = True
kwarg.append('unique')
if self.model_creation_services.project.infer_primary_key:
# print(f'ApiLogicServer infer_primary_key for {column.table.name}.{column.name}')
column.primary_key = True
kwarg.append('primary_key')
elif has_index:
column.index = True
kwarg.append('index')
if Computed and isinstance(column.server_default, Computed):
expression = self._get_compiled_expression(column.server_default.sqltext)
persist_arg = ''
if column.server_default.persisted is not None:
persist_arg = ', persisted={}'.format(column.server_default.persisted)
server_default = 'Computed({!r}{})'.format(expression, persist_arg)
elif column.server_default:
# The quote escaping does not cover pathological cases but should mostly work FIXME SqlSvr no .arg
# not used for postgres/mysql; for sqlite, text is '0'
if not hasattr( column.server_default, 'arg' ):
server_default = 'server_default=text("{0}")'.format('0')
else:
default_expr = self._get_compiled_expression(column.server_default.arg)
if '\n' in default_expr:
server_default = 'server_default=text("""\\\n{0}""")'.format(default_expr)
else:
default_expr = default_expr.replace('"', '\\"')
server_default = 'server_default=text("{0}")'.format(default_expr)
comment = getattr(column, 'comment', None)
if (column.name + "") == "debug_column_name":
db = 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
print("Debug Stop") # ApiLogicServer fix for putting this at end: index=True
return 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
def render_relationship(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.target_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_relationship_on_parent(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.source_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_table(self, model):
# Manual edit:
# replace invalid chars for views etc TODO review ApiLogicServer -- using model.name vs model.table.name
table_name = model.name
bad_chars = r"$-+ "
if any(elem in table_name for elem in bad_chars):
print("sys error")
table_name = table_name.replace("$", "_S_")
table_name = table_name.replace(" ", "_")
table_name = table_name.replace("+", "_")
if model.table.name == "Plus+Table":
print("Debug Stop on table")
rendered = "t_{0} = Table(\n{1}{0!r}, metadata,\n".format(table_name, self.indentation)
for column in model.table.columns:
if column.name == "char_type DEBUG ONLY":
print("Debug Stop - column")
rendered += '{0}{1},\n'.format(self.indentation, self.render_column(column, True))
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue # TODO: need to check is_included here?
rendered += '{0}{1},\n'.format(self.indentation, self.render_constraint(constraint))
for index in model.table.indexes:
if len(index.columns) > 1:
rendered += '{0}{1},\n'.format(self.indentation, self.render_index(index))
if model.schema:
rendered += "{0}schema='{1}',\n".format(self.indentation, model.schema)
table_comment = getattr(model.table, 'comment', None)
if table_comment:
quoted_comment = table_comment.replace("'", "\\'").replace('"', '\\"')
rendered += "{0}comment='{1}',\n".format(self.indentation, quoted_comment)
return rendered.rstrip('\n,') + '\n)\n'
def render_class(self, model):
""" returns string for model class, written into model.py by sqlacodegen_wrapper """
super_classes = model.parent_name
if self.model_creation_services.project.bind_key != "":
super_classes = f'Base{self.model_creation_services.project.bind_key}, db.Model, UserMixin'
rendered = 'class {0}(SAFRSBase, {1}): # type: ignore\n'.format(model.name, super_classes) # ApiLogicServer
# f'Base{self.model_creation_services.project.bind_key} = declarative_base()'
else:
rendered = 'class {0}(SAFRSBase, {1}):\n'.format(model.name, super_classes) # ApiLogicServer
rendered += '{0}__tablename__ = {1!r}\n'.format(self.indentation, model.table.name)
end_point_name = model.name
if self.model_creation_services.project.bind_key != "":
if self.model_creation_services.project.model_gen_bind_msg == False:
self.model_creation_services.project.model_gen_bind_msg = True
log.debug(f'.. .. ..Setting bind_key = {self.model_creation_services.project.bind_key}')
end_point_name = self.model_creation_services.project.bind_key + \
self.model_creation_services.project.bind_key_url_separator + model.name
rendered += '{0}_s_collection_name = {1!r} # type: ignore\n'.format(self.indentation, end_point_name)
if self.model_creation_services.project.bind_key != "":
bind_key = self.model_creation_services.project.bind_key
else:
bind_key = "None"
rendered += '{0}__bind_key__ = {1!r}\n'.format(self.indentation, bind_key) # usually __bind_key__ = None
# Render constraints and indexes as __table_args__
autonum_col = False
table_args = []
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
if constraint._autoincrement_column is not None:
autonum_col = True
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue
# eg, Order: ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city'])
this_included = code_generator.is_table_included(model.table.name)
target_included = True
if isinstance(constraint, ForeignKeyConstraint): # CheckConstraints don't have elements
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if this_included and target_included:
table_args.append(self.render_constraint(constraint))
else:
log.debug(f'foreign key constraint excluded on {model.table.name}: '
f'{self.render_constraint(constraint)}')
for index in model.table.indexes:
if len(index.columns) > 1:
table_args.append(self.render_index(index))
table_kwargs = {}
if model.schema:
table_kwargs['schema'] = model.schema
table_comment = getattr(model.table, 'comment', None)
if table_comment:
table_kwargs['comment'] = table_comment
kwargs_items = ', '.join('{0!r}: {1!r}'.format(key, table_kwargs[key])
for key in table_kwargs)
kwargs_items = '{{{0}}}'.format(kwargs_items) if kwargs_items else None
if table_kwargs and not table_args:
rendered += '{0}__table_args__ = {1}\n'.format(self.indentation, kwargs_items)
elif table_args:
if kwargs_items:
table_args.append(kwargs_items)
if len(table_args) == 1:
table_args[0] += ','
table_args_joined = ',\n{0}{0}'.format(self.indentation).join(table_args)
rendered += '{0}__table_args__ = (\n{0}{0}{1}\n{0})\n'.format(
self.indentation, table_args_joined)
# Render columns
rendered += '\n'
for attr, column in model.attributes.items():
if isinstance(column, Column):
show_name = attr != column.name
rendered += '{0}{1} = {2}\n'.format(
self.indentation, attr, self.render_column(column, show_name))
if not autonum_col:
rendered += '{0}{1}'.format(self.indentation, "allow_client_generated_ids = True\n")
# Render relationships (declared in parent class, backref to child)
if any(isinstance(value, Relationship) for value in model.attributes.values()):
rendered += '\n'
backrefs = {}
for attr, relationship in model.attributes.items():
if isinstance(relationship, Relationship): # ApiLogicServer changed to insert backref
attr_to_render = attr
if self.generate_relationships_on != "child":
attr_to_render = "# see backref on parent: " + attr # relns not created on child; comment out
rel_render = "{0}{1} = {2}\n".format(self.indentation, attr_to_render, self.render_relationship(relationship))
rel_parts = rel_render.split(")") # eg, Department = relationship(\'Department\', remote_side=[Id]
backref_name = model.name + "List"
""" disambiguate multi-relns, eg, in the Employee child class, 2 relns to Department:
Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList')
Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList_Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
unique_name = relationship.target_cls + '.' + backref_name
if unique_name in backrefs: # disambiguate
backref_name += "_" + attr
back_ref = f', cascade_backrefs=False, backref=\'{backref_name}\''
rel_render_with_backref = rel_parts[0] + \
back_ref + \
")" + rel_parts[1]
# rendered += "{0}{1} = {2}\n".format(self.indentation, attr, self.render_relationship(relationship))
""" disambiguate multi-relns, eg, in the Department parent class, 2 relns to Employee:
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
if relationship.target_cls not in self.classes:
print(f'.. .. ..ERROR - {model.name} -- missing parent class: {relationship.target_cls}')
print(f'.. .. .. .. Parent Class may be missing Primary Key and Unique Column')
print(f'.. .. .. .. Attempting to continue - you may need to repair model, or address database design')
continue
parent_model = self.classes[relationship.target_cls] # eg, Department
parent_relationship_def = self.render_relationship_on_parent(relationship)
parent_relationship_def = parent_relationship_def[:-1]
# eg, for Dept: relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id')
child_role_name = model.name + "List"
parent_role_name = attr
if unique_name in backrefs: # disambiguate
child_role_name += '1' # FIXME - fails for 3 relns
if model.name != parent_model.name:
parent_relationship = f'{child_role_name} = {parent_relationship_def}, cascade_backrefs=False, backref=\'{parent_role_name}\')'
else: # work-around for self relns
"""
special case self relns:
not DepartmentList = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='Department')
but Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList')
"""
parent_relationship = f'{parent_role_name} = {parent_relationship_def}, cascade_backrefs=False, backref=\'{child_role_name}\')'
parent_relationship += " # special handling for self-relationships"
if self.generate_relationships_on != "parent": # relns not created on parent; comment out
parent_relationship = "# see backref on child: " + parent_relationship
parent_model.rendered_model_relationships += " " + parent_relationship + "\n"
if model.name == "OrderDetail":
debug_str = "nice breakpoint"
rendered += rel_render_with_backref
backrefs[unique_name] = backref_name
if relationship.source_cls.startswith("Ab"):
pass
elif isinstance(relationship, ManyToManyRelationship): # eg, chinook:PlayList->PlayListTrack
print(f'many to many should not occur on: {model.name}.{unique_name}')
else: # fixme dump all this, right?
use_old_code = False # so you can elide this
if use_old_code:
resource = self.model_creation_services.resource_list[relationship.source_cls]
resource_relationship = ResourceRelationship(parent_role_name = attr,
child_role_name = backref_name)
resource_relationship.child_resource = relationship.source_cls
resource_relationship.parent_resource = relationship.target_cls
# gen key pairs
for each_pair in relationship.foreign_key_constraint.elements:
pair = ( str(each_pair.column.name), str(each_pair.parent.name) )
resource_relationship.parent_child_key_pairs.append(pair)
resource.parents.append(resource_relationship)
parent_resource = self.model_creation_services.resource_list[relationship.target_cls]
parent_resource.children.append(resource_relationship)
if use_old_code:
if relationship.source_cls not in self.parents_map: # todo old code remove
self.parents_map[relationship.source_cls] = list()
self.parents_map[relationship.source_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
if relationship.target_cls not in self.children_map:
self.children_map[relationship.target_cls] = list()
self.children_map[relationship.target_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
pass
# Render subclasses
for child_class in model.children:
rendered += self.model_separator + self.render_class(child_class)
# rendered += "\n # END RENDERED CLASS\n" # useful for debug, as required
return rendered
def render(self, outfile=sys.stdout):
""" create model from db, and write models.py file to in-memory buffer (outfile)
relns created from not-yet-seen children, so save *all* class info, then append rendered_model_relationships
"""
for model in self.models: # class, with __tablename__ & __collection_name__ cls variables, attrs
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
model.rendered_model = self.render_class(model) # also sets parent_model.rendered_model_relationships
rendered_models = [] # now append the rendered_model + rendered_model_relationships
for model in self.models:
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
if model.rendered_model_relationships != "": # child relns (OrderDetailList etc)
model.rendered_model_relationships = "\n" + model.rendered_model_relationships
rendered_models.append(model.rendered_model + model.rendered_model_relationships)
rendered_models.append(self.model_creation_services.opt_locking)
elif isinstance(model, self.table_model): # eg, views, database id generators, etc
rendered_models.append(self.render_table(model))
output = self.template.format(
imports=self.render_imports(),
metadata_declarations=self.render_metadata_declarations(),
models=self.model_separator.join(rendered_models).rstrip('\n'))
print(output, file=outfile)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/codegen/codegenX.py
|
codegenX.py
|
from __future__ import unicode_literals, division, print_function, absolute_import
import inspect
import re
import sys, logging
from collections import defaultdict
from importlib import import_module
from inspect import FullArgSpec # val-311
from keyword import iskeyword
import sqlalchemy
import sqlalchemy.exc
from sqlalchemy import (
Enum, ForeignKeyConstraint, PrimaryKeyConstraint, CheckConstraint, UniqueConstraint, Table,
Column, Float)
from sqlalchemy.schema import ForeignKey
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.types import Boolean, String
from sqlalchemy.util import OrderedDict
import yaml
# The generic ARRAY type was introduced in SQLAlchemy 1.1
from api_logic_server_cli.create_from_model.model_creation_services import Resource, ResourceRelationship, \
ResourceAttribute
from api_logic_server_cli.create_from_model.model_creation_services import ModelCreationServices
log = logging.getLogger(__name__)
"""
handler = logging.StreamHandler(sys.stderr)
formatter = logging.Formatter('%(message)s') # lead tag - '%(name)s: %(message)s')
handler.setFormatter(formatter)
log.addHandler(handler)
log.propagate = True
"""
try:
from sqlalchemy import ARRAY
except ImportError:
from sqlalchemy.dialects.postgresql import ARRAY
# SQLAlchemy 1.3.11+
try:
from sqlalchemy import Computed
except ImportError:
Computed = None
# Conditionally import Geoalchemy2 to enable reflection support
try:
import geoalchemy2 # noqa: F401
except ImportError:
pass
_re_boolean_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \(0, 1\)")
_re_column_name = re.compile(r'(?:(["`]?)(?:.*)\1\.)?(["`]?)(.*)\2')
_re_enum_check_constraint = re.compile(r"(?:(?:.*?)\.)?(.*?) IN \((.+)\)")
_re_enum_item = re.compile(r"'(.*?)(?<!\\)'")
_re_invalid_identifier = re.compile(r'[^a-zA-Z0-9_]' if sys.version_info[0] < 3 else r'(?u)\W')
class _DummyInflectEngine(object):
@staticmethod
def singular_noun(noun):
return noun
# In SQLAlchemy 0.x, constraint.columns is sometimes a list, on 1.x onwards, always a
# ColumnCollection
def _get_column_names(constraint):
if isinstance(constraint.columns, list):
return constraint.columns
return list(constraint.columns.keys())
def _get_constraint_sort_key(constraint):
if isinstance(constraint, CheckConstraint):
return 'C{0}'.format(constraint.sqltext)
return constraint.__class__.__name__[0] + repr(_get_column_names(constraint))
class ImportCollector(OrderedDict):
def add_import(self, obj):
type_ = type(obj) if not isinstance(obj, type) else obj
pkgname = type_.__module__
# The column types have already been adapted towards generic types if possible, so if this
# is still a vendor specific type (e.g., MySQL INTEGER) be sure to use that rather than the
# generic sqlalchemy type as it might have different constructor parameters.
if pkgname.startswith('sqlalchemy.dialects.'):
dialect_pkgname = '.'.join(pkgname.split('.')[0:3])
dialect_pkg = import_module(dialect_pkgname)
if type_.__name__ in dialect_pkg.__all__:
pkgname = dialect_pkgname
else:
pkgname = 'sqlalchemy' if type_.__name__ in sqlalchemy.__all__ else type_.__module__
self.add_literal_import(pkgname, type_.__name__)
def add_literal_import(self, pkgname, name):
names = self.setdefault(pkgname, set())
names.add(name)
class Model(object):
def __init__(self, table):
super(Model, self).__init__()
self.table = table
self.schema = table.schema
# Adapt column types to the most reasonable generic types (ie. VARCHAR -> String)
for column in table.columns:
try:
column.type = self._get_adapted_type(column.type, column.table.bind)
except:
# print('Failed to get col type for {}, {}'.format(column, column.type))
if "sqlite_sequence" not in format(column):
print("#Failed to get col type for {}".format(column))
def __str__(self):
return f'Model for table: {self.table} (in schema: {self.schema})'
def _get_adapted_type(self, coltype, bind):
compiled_type = coltype.compile(bind.dialect)
for supercls in coltype.__class__.__mro__:
if not supercls.__name__.startswith('_') and hasattr(supercls, '__visit_name__'):
# Hack to fix adaptation of the Enum class which is broken since SQLAlchemy 1.2
kw = {}
if supercls is Enum:
kw['name'] = coltype.name
try:
new_coltype = coltype.adapt(supercls)
except TypeError:
# If the adaptation fails, don't try again
break
for key, value in kw.items():
setattr(new_coltype, key, value)
if isinstance(coltype, ARRAY):
new_coltype.item_type = self._get_adapted_type(new_coltype.item_type, bind)
try:
# If the adapted column type does not render the same as the original, don't
# substitute it
if new_coltype.compile(bind.dialect) != compiled_type:
# Make an exception to the rule for Float and arrays of Float, since at
# least on PostgreSQL, Float can accurately represent both REAL and
# DOUBLE_PRECISION
if not isinstance(new_coltype, Float) and \
not (isinstance(new_coltype, ARRAY) and
isinstance(new_coltype.item_type, Float)):
break
except sqlalchemy.exc.CompileError:
# If the adapted column type can't be compiled, don't substitute it
break
# Stop on the first valid non-uppercase column type class
coltype = new_coltype
if supercls.__name__ != supercls.__name__.upper():
break
return coltype
def add_imports(self, collector):
if self.table.columns:
collector.add_import(Column)
for column in self.table.columns:
collector.add_import(column.type)
if column.server_default:
if Computed and isinstance(column.server_default, Computed):
collector.add_literal_import('sqlalchemy', 'Computed')
else:
collector.add_literal_import('sqlalchemy', 'text')
if isinstance(column.type, ARRAY):
collector.add_import(column.type.item_type.__class__)
for constraint in sorted(self.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'ForeignKeyConstraint')
else:
collector.add_literal_import('sqlalchemy', 'ForeignKey')
elif isinstance(constraint, UniqueConstraint):
if len(constraint.columns) > 1:
collector.add_literal_import('sqlalchemy', 'UniqueConstraint')
elif not isinstance(constraint, PrimaryKeyConstraint):
collector.add_import(constraint)
for index in self.table.indexes:
if len(index.columns) > 1:
collector.add_import(index)
@staticmethod
def _convert_to_valid_identifier(name):
assert name, 'Identifier cannot be empty'
if name[0].isdigit() or iskeyword(name):
name = '_' + name
elif name == 'metadata':
name = 'metadata_'
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes for superclass version (why override?)
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub('_', name)
return result
class ModelTable(Model):
def __init__(self, table):
super(ModelTable, self).__init__(table)
self.name = self._convert_to_valid_identifier(table.name)
def add_imports(self, collector):
super(ModelTable, self).add_imports(collector)
try:
collector.add_import(Table)
except Exception as exc:
print("Failed to add imports {}".format(collector))
class ModelClass(Model):
parent_name = 'Base'
def __init__(self, table, association_tables, inflect_engine, detect_joined):
super(ModelClass, self).__init__(table)
self.name = self._tablename_to_classname(table.name, inflect_engine)
self.children = []
self.attributes = OrderedDict()
self.foreign_key_relationships = list()
self.rendered_model = "" # ApiLogicServer
self.rendered_model_relationships = "" # appended at end ( render() )
# Assign attribute names for columns
for column in table.columns:
self._add_attribute(column.name, column)
# Add many-to-one relationships (to parent)
pk_column_names = set(col.name for col in table.primary_key.columns)
for constraint in sorted(table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, ForeignKeyConstraint):
target_cls = self._tablename_to_classname(constraint.elements[0].column.table.name,
inflect_engine)
this_included = code_generator.is_table_included(self.table.name)
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if (detect_joined and self.parent_name == 'Base' and
set(_get_column_names(constraint)) == pk_column_names):
self.parent_name = target_cls
else:
relationship_ = ManyToOneRelationship(self.name, target_cls, constraint,
inflect_engine)
if this_included and target_included:
self._add_attribute(relationship_.preferred_name, relationship_)
else:
log.debug(f"Parent Relationship excluded: {relationship_.preferred_name}")
# Add many-to-many relationships
for association_table in association_tables:
fk_constraints = [c for c in association_table.constraints
if isinstance(c, ForeignKeyConstraint)]
fk_constraints.sort(key=_get_constraint_sort_key)
target_cls = self._tablename_to_classname(
fk_constraints[1].elements[0].column.table.name, inflect_engine)
relationship_ = ManyToManyRelationship(self.name, target_cls, association_table)
self._add_attribute(relationship_.preferred_name, relationship_)
@classmethod
def _tablename_to_classname(cls, tablename, inflect_engine):
"""
camel-case and singlularize, with provisions for reserved word (Date) and collisions (Dates & _Dates)
"""
tablename = cls._convert_to_valid_identifier(tablename)
if tablename in ["Dates"]: # ApiLogicServer
tablename = tablename + "Classs"
camel_case_name = ''.join(part[:1].upper() + part[1:] for part in tablename.split('_'))
if camel_case_name in ["Dates"]:
camel_case_name = camel_case_name + "_Classs"
result = inflect_engine.singular_noun(camel_case_name) or camel_case_name
if result == "CategoryTableNameTest": # ApiLogicServer
result = "Category"
return result
@staticmethod
def _convert_to_valid_identifier(name): # TODO review
assert name, "Identifier cannot be empty"
if name[0].isdigit() or iskeyword(name):
name = "_" + name
elif name == "metadata":
name = "metadata_"
name = name.replace("$", "_S_") # ApiLogicServer valid name fixes, ModelClass version
name = name.replace(" ", "_")
name = name.replace("+", "_")
name = name.replace("-", "_")
result = _re_invalid_identifier.sub("_", name)
return result
def _add_attribute(self, attrname, value):
""" add table column/relationship to attributes
disambiguate relationship accessor names (append tablename with 1, 2...)
"""
attrname = tempname = self._convert_to_valid_identifier(attrname)
counter = 1
while tempname in self.attributes:
tempname = attrname + str(counter)
counter += 1
self.attributes[tempname] = value
return tempname
def add_imports(self, collector):
super(ModelClass, self).add_imports(collector)
if any(isinstance(value, Relationship) for value in self.attributes.values()):
collector.add_literal_import('sqlalchemy.orm', 'relationship')
for child in self.children:
child.add_imports(collector)
class Relationship(object):
def __init__(self, source_cls, target_cls):
super(Relationship, self).__init__()
self.source_cls = source_cls
self.target_cls = target_cls
self.kwargs = OrderedDict()
class ManyToOneRelationship(Relationship):
def __init__(self, source_cls, target_cls, constraint, inflect_engine):
super(ManyToOneRelationship, self).__init__(source_cls, target_cls)
column_names = _get_column_names(constraint)
colname = column_names[0]
tablename = constraint.elements[0].column.table.name
self.foreign_key_constraint = constraint
if not colname.endswith('_id'):
self.preferred_name = inflect_engine.singular_noun(tablename) or tablename
else:
self.preferred_name = colname[:-3]
# Add uselist=False to One-to-One relationships
if any(isinstance(c, (PrimaryKeyConstraint, UniqueConstraint)) and
set(col.name for col in c.columns) == set(column_names)
for c in constraint.table.constraints):
self.kwargs['uselist'] = 'False'
# Handle self referential relationships
if source_cls == target_cls:
# self.preferred_name = 'parent' if not colname.endswith('_id') else colname[:-3]
if colname.endswith("id") or colname.endswith("Id"):
self.preferred_name = colname[:-2]
else:
self.preferred_name = "parent" # hmm, why not just table name
pk_col_names = [col.name for col in constraint.table.primary_key]
self.kwargs['remote_side'] = '[{0}]'.format(', '.join(pk_col_names))
# If the two tables share more than one foreign key constraint,
# SQLAlchemy needs an explicit primaryjoin to figure out which column(s) to join with
common_fk_constraints = self.get_common_fk_constraints(
constraint.table, constraint.elements[0].column.table)
if len(common_fk_constraints) > 1:
self.kwargs['primaryjoin'] = "'{0}.{1} == {2}.{3}'".format(
source_cls, column_names[0], target_cls, constraint.elements[0].column.name)
@staticmethod
def get_common_fk_constraints(table1, table2):
"""Returns a set of foreign key constraints the two tables have against each other."""
c1 = set(c for c in table1.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table2)
c2 = set(c for c in table2.constraints if isinstance(c, ForeignKeyConstraint) and
c.elements[0].column.table == table1)
return c1.union(c2)
class ManyToManyRelationship(Relationship):
def __init__(self, source_cls, target_cls, assocation_table):
super(ManyToManyRelationship, self).__init__(source_cls, target_cls)
prefix = (assocation_table.schema + '.') if assocation_table.schema else ''
self.kwargs['secondary'] = repr(prefix + assocation_table.name)
constraints = [c for c in assocation_table.constraints
if isinstance(c, ForeignKeyConstraint)]
constraints.sort(key=_get_constraint_sort_key)
colname = _get_column_names(constraints[1])[0]
tablename = constraints[1].elements[0].column.table.name
self.preferred_name = tablename if not colname.endswith('_id') else colname[:-3] + 's'
# Handle self referential relationships
if source_cls == target_cls:
self.preferred_name = 'parents' if not colname.endswith('_id') else colname[:-3] + 's'
pri_pairs = zip(_get_column_names(constraints[0]), constraints[0].elements)
sec_pairs = zip(_get_column_names(constraints[1]), constraints[1].elements)
pri_joins = ['{0}.{1} == {2}.c.{3}'.format(source_cls, elem.column.name,
assocation_table.name, col)
for col, elem in pri_pairs]
sec_joins = ['{0}.{1} == {2}.c.{3}'.format(target_cls, elem.column.name,
assocation_table.name, col)
for col, elem in sec_pairs]
self.kwargs['primaryjoin'] = (
repr('and_({0})'.format(', '.join(pri_joins)))
if len(pri_joins) > 1 else repr(pri_joins[0]))
self.kwargs['secondaryjoin'] = (
repr('and_({0})'.format(', '.join(sec_joins)))
if len(sec_joins) > 1 else repr(sec_joins[0]))
code_generator = None # type: CodeGenerator
""" Model needs to access state here, eg, included/excluded tables """
class CodeGenerator(object):
template = """\
# coding: utf-8
{imports}
{metadata_declarations}
{models}"""
def is_table_included(self, table_name: str) -> bool:
"""
Determines table included per self.include_tables / exclude tables.
See Run Config: Table Filters Tests
Args:
table_name (str): _description_
Returns:
bool: True means included
"""
if self.include_tables is None: # first time initialization
include_tables_dict = {"include": [], "exclude": []}
if self.model_creation_services.project.include_tables != "":
with open(self.model_creation_services.project.include_tables,'rt') as f: #
include_tables_dict = yaml.safe_load(f.read())
f.close()
log.debug(f"include_tables specified: \n{include_tables_dict}\n") # {'include': ['I*', 'J', 'X*'], 'exclude': ['X1']}
# https://stackoverflow.com/questions/3040716/python-elegant-way-to-check-if-at-least-one-regex-in-list-matches-a-string
# https://www.w3schools.com/python/trypython.asp?filename=demo_regex
# ApiLogicServer create --project_name=table_filters_tests --db_url=table_filters_tests --include_tables=../table_filters_tests.yml
self.include_tables = include_tables_dict["include"] \
if "include" in include_tables_dict else ['.*'] # ['I.*', 'J', 'X.*']
if self.include_tables is None:
self.include_tables = ['.*']
self.include_regex = "(" + ")|(".join(self.include_tables) + ")" # include_regex: (I.*)|(J)|(X.*)
self.include_regex_list = map(re.compile, self.include_tables)
self.exclude_tables = include_tables_dict["exclude"] \
if "exclude" in include_tables_dict else ['a^']
if self.exclude_tables is None:
self.exclude_tables = ['a^']
self.exclude_regex = "(" + ")|(".join(self.exclude_tables) + ")"
if self.model_creation_services.project.include_tables != "":
log.debug(f"include_regex: {self.include_regex}")
log.debug(f"exclude_regex: {self.exclude_regex}\n")
log.debug(f"Test Tables: I, I1, J, X, X1, Y\n")
table_included = True
if self.model_creation_services.project.bind_key == "authentication":
log.debug(f".. authentication always included")
else:
if len(self.include_tables) == 0:
log.debug(f"All tables included: {table_name}")
else:
if re.match(self.include_regex, table_name):
log.debug(f"table included: {table_name}")
else:
log.debug(f"table excluded: {table_name}")
table_included = False
if not table_included:
log.debug(f".. skipping exlusions")
else:
if len(self.exclude_tables) == 0:
log.debug(f"No tables excluded: {table_name}")
else:
if re.match(self.exclude_regex, table_name):
log.debug(f"table excluded: {table_name}")
table_included = False
else:
log.debug(f"table not excluded: {table_name}")
return table_included
def __init__(self, metadata, noindexes=False, noconstraints=False, nojoined=False,
noinflect=False, noclasses=False, model_creation_services = None,
indentation=' ', model_separator='\n\n',
ignored_tables=('alembic_version', 'migrate_version'),
table_model=ModelTable,
class_model=ModelClass,
template=None, nocomments=False):
"""
ApiLogicServer sqlacodegen_wrapper invokes this as follows;
capture = StringIO() # generate and return the model
generator = CodeGenerator(metadata, args.noindexes, args.noconstraints,
args.nojoined, args.noinflect, args.noclasses,
args.model_creation_services)
args.model_creation_services.metadata = generator.metadata
generator.render(capture) # generates (preliminary) models as memstring
models_py = capture.getvalue()
"""
super(CodeGenerator, self).__init__()
global code_generator
code_generator = self
self.metadata = metadata
self.noindexes = noindexes
self.noconstraints = noconstraints
self.nojoined = nojoined
self.noinflect = noinflect
self.noclasses = noclasses
self.model_creation_services = model_creation_services # type: ModelCreationServices
self.generate_relationships_on = "parent" # "child"
self.indentation = indentation
self.model_separator = model_separator
self.ignored_tables = ignored_tables
self.table_model = table_model
self.class_model = class_model
""" class (not instance) of ModelClass [defaulted for ApiLogicServer] """
self.nocomments = nocomments
self.children_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.parents_map = dict()
""" key is table name, value is list of (parent-role-name, child-role-name, relationship) ApiLogicServer """
self.include_tables = None # regex of tables included
self.exclude_tables = None # excluded
self.inflect_engine = self.create_inflect_engine()
if template:
self.template = template
# Pick association tables from the metadata into their own set, don't process them normally
links = defaultdict(lambda: [])
association_tables = set()
skip_association_table = True
for table in metadata.tables.values():
# Link tables have exactly two foreign key constraints and all columns are involved in
# them
fk_constraints = [constr for constr in table.constraints
if isinstance(constr, ForeignKeyConstraint)]
if len(fk_constraints) == 2 and all(col.foreign_keys for col in table.columns):
if skip_association_table: # Chinook playlist tracks, SqlSvr, Postgres Emp Territories
debug_str = f'skipping associate table: {table.name}'
debug_str += "... treated as normal table, with automatic joins"
else:
association_tables.add(table.name)
tablename = sorted(
fk_constraints, key=_get_constraint_sort_key)[0].elements[0].column.table.name
links[tablename].append(table)
# Iterate through the tables and create model classes when possible
self.models = []
self.collector = ImportCollector()
self.classes = {}
for table in metadata.sorted_tables:
# Support for Alembic and sqlalchemy-migrate -- never expose the schema version tables
if table.name in self.ignored_tables:
continue
table_included = self.is_table_included(table_name= table.name)
if not table_included:
log.debug(f"====> table skipped: {table.name}")
continue
"""
if any(regex.match(table.name) for regex in self.include_regex_list):
log.debug(f"list table included: {table.name}")
else:
log.debug(f"list table excluded: {table.name}")
"""
if noindexes:
table.indexes.clear()
if noconstraints:
table.constraints = {table.primary_key}
table.foreign_keys.clear()
for col in table.columns:
col.foreign_keys.clear()
else:
# Detect check constraints for boolean and enum columns
for constraint in table.constraints.copy():
if isinstance(constraint, CheckConstraint):
sqltext = self._get_compiled_expression(constraint.sqltext)
# Turn any integer-like column with a CheckConstraint like
# "column IN (0, 1)" into a Boolean
match = _re_boolean_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
table.constraints.remove(constraint)
table.c[colname].type = Boolean()
continue
# Turn any string-type column with a CheckConstraint like
# "column IN (...)" into an Enum
match = _re_enum_check_constraint.match(sqltext)
if match:
colname = _re_column_name.match(match.group(1)).group(3)
items = match.group(2)
if isinstance(table.c[colname].type, String):
table.constraints.remove(constraint)
if not isinstance(table.c[colname].type, Enum):
options = _re_enum_item.findall(items)
table.c[colname].type = Enum(*options, native_enum=False)
continue
# Tables vs. Classes ********
# Only form model classes for tables that have a primary key and are not association
# tables
if "productvariantsoh-20190423" in (table.name + "") or "unique_no_key" in (table.name + ""):
debug_str = "target table located"
""" create classes iff unique col - CAUTION: fails to run """
has_unique_constraint = False
if not table.primary_key:
for each_constraint in table.constraints:
if isinstance(each_constraint, sqlalchemy.sql.schema.UniqueConstraint):
has_unique_constraint = True
print(f'\n*** ApiLogicServer -- {table.name} has unique constraint, no primary_key')
# print(f'\nTEST *** {table.name} not table.primary_key = {not table.primary_key}, has_unique_constraint = {has_unique_constraint}')
unique_constraint_class = model_creation_services.project.infer_primary_key and has_unique_constraint
if unique_constraint_class == False and (noclasses or not table.primary_key or table.name in association_tables):
model = self.table_model(table)
else:
model = self.class_model(table, links[table.name], self.inflect_engine, not nojoined) # computes attrs (+ roles)
self.classes[model.name] = model
self.models.append(model)
model.add_imports(self.collector) # end mega-loop for table in metadata.sorted_tables
# Nest inherited classes in their superclasses to ensure proper ordering
for model in self.classes.values():
if model.parent_name != 'Base':
self.classes[model.parent_name].children.append(model)
self.models.remove(model)
# Add either the MetaData or declarative_base import depending on whether there are mapped
# classes or not
if not any(isinstance(model, self.class_model) for model in self.models):
self.collector.add_literal_import('sqlalchemy', 'MetaData')
else:
self.collector.add_literal_import('sqlalchemy.ext.declarative', 'declarative_base')
def create_inflect_engine(self):
if self.noinflect:
return _DummyInflectEngine()
else:
import inflect
return inflect.engine()
def render_imports(self):
return '\n'.join('from {0} import {1}'.format(package, ', '.join(sorted(names)))
for package, names in self.collector.items())
def render_metadata_declarations(self):
api_logic_server_imports = """
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.mysql import *
########################################################################################################################
"""
if self.model_creation_services.project.bind_key != "":
api_logic_server_imports = api_logic_server_imports.replace('Base = declarative_base()',
f'Base{self.model_creation_services.project.bind_key} = declarative_base()')
api_logic_server_imports = api_logic_server_imports.replace('metadata = Base.metadata',
f'metadata = Base{self.model_creation_services.project.bind_key}.metadata')
if "sqlalchemy.ext.declarative" in self.collector: # Manually Added for safrs (ApiLogicServer)
dialect_name = self.metadata.bind.engine.dialect.name # sqlite , mysql , postgresql , oracle , or mssql
if dialect_name in ["firebird", "mssql", "oracle", "postgresql", "sqlite", "sybase"]:
rtn_api_logic_server_imports = api_logic_server_imports.replace("mysql", dialect_name)
else:
rtn_api_logic_server_imports = api_logic_server_imports
print(".. .. ..Warning - unknown sql dialect, defaulting to msql - check database/models.py")
return rtn_api_logic_server_imports
return "metadata = MetaData()" # (stand-alone sql1codegen - never used in API Logic Server)
def _get_compiled_expression(self, statement):
"""Return the statement in a form where any placeholders have been filled in."""
return str(statement.compile(
self.metadata.bind, compile_kwargs={"literal_binds": True}))
@staticmethod
def _getargspec_init(method):
try:
if hasattr(inspect, 'getfullargspec'):
return inspect.getfullargspec(method)
else:
return inspect.getargspec(method)
except TypeError:
if method is object.__init__:
return ArgSpec(['self'], None, None, None)
else:
return ArgSpec(['self'], 'args', 'kwargs', None)
@classmethod
def render_column_type(cls, coltype):
args = []
kwargs = OrderedDict()
argspec = cls._getargspec_init(coltype.__class__.__init__)
defaults = dict(zip(argspec.args[-len(argspec.defaults or ()):],
argspec.defaults or ()))
missing = object()
use_kwargs = False
for attr in argspec.args[1:]:
# Remove annoyances like _warn_on_bytestring
if attr.startswith('_'):
continue
value = getattr(coltype, attr, missing)
default = defaults.get(attr, missing)
if value is missing or value == default:
use_kwargs = True
elif use_kwargs:
kwargs[attr] = repr(value)
else:
args.append(repr(value))
if argspec.varargs and hasattr(coltype, argspec.varargs):
varargs_repr = [repr(arg) for arg in getattr(coltype, argspec.varargs)]
args.extend(varargs_repr)
if isinstance(coltype, Enum) and coltype.name is not None:
kwargs['name'] = repr(coltype.name)
for key, value in kwargs.items():
args.append('{}={}'.format(key, value))
rendered = coltype.__class__.__name__
if args:
rendered += '({0})'.format(', '.join(args))
if rendered.startswith("CHAR("): # temp fix for non-double byte chars
rendered = rendered.replace("CHAR(", "String(")
return rendered
def render_constraint(self, constraint):
def render_fk_options(*opts):
opts = [repr(opt) for opt in opts]
for attr in 'ondelete', 'onupdate', 'deferrable', 'initially', 'match':
value = getattr(constraint, attr, None)
if value:
opts.append('{0}={1!r}'.format(attr, value))
return ', '.join(opts)
if isinstance(constraint, ForeignKey): # TODO: need to check is_included here?
remote_column = '{0}.{1}'.format(constraint.column.table.fullname,
constraint.column.name)
return 'ForeignKey({0})'.format(render_fk_options(remote_column))
elif isinstance(constraint, ForeignKeyConstraint):
local_columns = _get_column_names(constraint)
remote_columns = ['{0}.{1}'.format(fk.column.table.fullname, fk.column.name)
for fk in constraint.elements]
return 'ForeignKeyConstraint({0})'.format(
render_fk_options(local_columns, remote_columns))
elif isinstance(constraint, CheckConstraint):
return 'CheckConstraint({0!r})'.format(
self._get_compiled_expression(constraint.sqltext))
elif isinstance(constraint, UniqueConstraint):
columns = [repr(col.name) for col in constraint.columns]
return 'UniqueConstraint({0})'.format(', '.join(columns))
@staticmethod
def render_index(index):
extra_args = [repr(col.name) for col in index.columns]
if index.unique:
extra_args.append('unique=True')
return 'Index({0!r}, {1})'.format(index.name, ', '.join(extra_args))
def render_column(self, column, show_name):
global code_generator
kwarg = []
is_sole_pk = column.primary_key and len(column.table.primary_key) == 1
dedicated_fks_old = [c for c in column.foreign_keys if len(c.constraint.columns) == 1]
dedicated_fks = [] # c for c in column.foreign_keys if len(c.constraint.columns) == 1
for each_foreign_key in column.foreign_keys:
log.debug(f'FK: {each_foreign_key}') #
log.debug(f'render_column - is fk: {dedicated_fks}')
if code_generator.is_table_included(each_foreign_key.column.table.name) \
and len(each_foreign_key.constraint.columns) == 1:
dedicated_fks.append(each_foreign_key)
else:
log.debug(f'Excluded single field fl on {column.table.name}.{column.name}')
if len(dedicated_fks) > 1:
log.error(f'codegen render_column finds unexpected col with >1 fk:'
f'{column.table.name}.{column.name}')
is_unique = any(isinstance(c, UniqueConstraint) and set(c.columns) == {column}
for c in column.table.constraints)
is_unique = is_unique or any(i.unique and set(i.columns) == {column}
for i in column.table.indexes)
has_index = any(set(i.columns) == {column} for i in column.table.indexes)
server_default = None
# Render the column type if there are no foreign keys on it or any of them points back to
# itself
render_coltype = not dedicated_fks or any(fk.column is column for fk in dedicated_fks)
if 'DataTypes.char_type DEBUG ONLY' == str(column):
print("Debug Stop: Column") # char_type = Column(CHAR(1, 'SQL_Latin1_General_CP1_CI_AS'))
if column.key != column.name:
kwarg.append('key')
if column.primary_key:
kwarg.append('primary_key')
if not column.nullable and not is_sole_pk:
kwarg.append('nullable')
if is_unique:
column.unique = True
kwarg.append('unique')
if self.model_creation_services.project.infer_primary_key:
# print(f'ApiLogicServer infer_primary_key for {column.table.name}.{column.name}')
column.primary_key = True
kwarg.append('primary_key')
elif has_index:
column.index = True
kwarg.append('index')
if Computed and isinstance(column.server_default, Computed):
expression = self._get_compiled_expression(column.server_default.sqltext)
persist_arg = ''
if column.server_default.persisted is not None:
persist_arg = ', persisted={}'.format(column.server_default.persisted)
server_default = 'Computed({!r}{})'.format(expression, persist_arg)
elif column.server_default:
# The quote escaping does not cover pathological cases but should mostly work FIXME SqlSvr no .arg
# not used for postgres/mysql; for sqlite, text is '0'
if not hasattr( column.server_default, 'arg' ):
server_default = 'server_default=text("{0}")'.format('0')
else:
default_expr = self._get_compiled_expression(column.server_default.arg)
if '\n' in default_expr:
server_default = 'server_default=text("""\\\n{0}""")'.format(default_expr)
else:
default_expr = default_expr.replace('"', '\\"')
server_default = 'server_default=text("{0}")'.format(default_expr)
comment = getattr(column, 'comment', None)
if (column.name + "") == "debug_column_name":
db = 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
print("Debug Stop") # ApiLogicServer fix for putting this at end: index=True
return 'Column({0})'.format(', '.join(
([repr(column.name)] if show_name else []) +
([self.render_column_type(column.type)] if render_coltype else []) +
[self.render_constraint(x) for x in dedicated_fks] +
[repr(x) for x in column.constraints] +
([server_default] if server_default else []) +
['{0}={1}'.format(k, repr(getattr(column, k))) for k in kwarg] +
(['comment={!r}'.format(comment)] if comment and not self.nocomments else [])
))
def render_relationship(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.target_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_relationship_on_parent(self, relationship) -> str:
''' returns string like: Department = relationship(\'Department\', remote_side=[Id])
'''
rendered = 'relationship('
args = [repr(relationship.source_cls)]
if 'secondaryjoin' in relationship.kwargs:
rendered += '\n{0}{0}'.format(self.indentation)
delimiter, end = (',\n{0}{0}'.format(self.indentation),
'\n{0})'.format(self.indentation))
else:
delimiter, end = ', ', ')'
args.extend([key + '=' + value for key, value in relationship.kwargs.items()])
return rendered + delimiter.join(args) + end
def render_table(self, model):
# Manual edit:
# replace invalid chars for views etc TODO review ApiLogicServer -- using model.name vs model.table.name
table_name = model.name
bad_chars = r"$-+ "
if any(elem in table_name for elem in bad_chars):
print("sys error")
table_name = table_name.replace("$", "_S_")
table_name = table_name.replace(" ", "_")
table_name = table_name.replace("+", "_")
if model.table.name == "Plus+Table":
print("Debug Stop on table")
rendered = "t_{0} = Table(\n{1}{0!r}, metadata,\n".format(table_name, self.indentation)
for column in model.table.columns:
if column.name == "char_type DEBUG ONLY":
print("Debug Stop - column")
rendered += '{0}{1},\n'.format(self.indentation, self.render_column(column, True))
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue # TODO: need to check is_included here?
rendered += '{0}{1},\n'.format(self.indentation, self.render_constraint(constraint))
for index in model.table.indexes:
if len(index.columns) > 1:
rendered += '{0}{1},\n'.format(self.indentation, self.render_index(index))
if model.schema:
rendered += "{0}schema='{1}',\n".format(self.indentation, model.schema)
table_comment = getattr(model.table, 'comment', None)
if table_comment:
quoted_comment = table_comment.replace("'", "\\'").replace('"', '\\"')
rendered += "{0}comment='{1}',\n".format(self.indentation, quoted_comment)
return rendered.rstrip('\n,') + '\n)\n'
def render_class(self, model):
""" returns string for model class, written into model.py by sqlacodegen_wrapper """
super_classes = model.parent_name
if self.model_creation_services.project.bind_key != "":
super_classes = f'Base{self.model_creation_services.project.bind_key}, db.Model, UserMixin'
rendered = 'class {0}(SAFRSBase, {1}): # type: ignore\n'.format(model.name, super_classes) # ApiLogicServer
# f'Base{self.model_creation_services.project.bind_key} = declarative_base()'
else:
rendered = 'class {0}(SAFRSBase, {1}):\n'.format(model.name, super_classes) # ApiLogicServer
rendered += '{0}__tablename__ = {1!r}\n'.format(self.indentation, model.table.name)
end_point_name = model.name
if self.model_creation_services.project.bind_key != "":
if self.model_creation_services.project.model_gen_bind_msg == False:
self.model_creation_services.project.model_gen_bind_msg = True
log.debug(f'.. .. ..Setting bind_key = {self.model_creation_services.project.bind_key}')
end_point_name = self.model_creation_services.project.bind_key + \
self.model_creation_services.project.bind_key_url_separator + model.name
rendered += '{0}_s_collection_name = {1!r} # type: ignore\n'.format(self.indentation, end_point_name)
if self.model_creation_services.project.bind_key != "":
bind_key = self.model_creation_services.project.bind_key
else:
bind_key = "None"
rendered += '{0}__bind_key__ = {1!r}\n'.format(self.indentation, bind_key) # usually __bind_key__ = None
# Render constraints and indexes as __table_args__
autonum_col = False
table_args = []
for constraint in sorted(model.table.constraints, key=_get_constraint_sort_key):
if isinstance(constraint, PrimaryKeyConstraint):
if constraint._autoincrement_column is not None:
autonum_col = True
continue
if (isinstance(constraint, (ForeignKeyConstraint, UniqueConstraint)) and
len(constraint.columns) == 1):
continue
# eg, Order: ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city'])
this_included = code_generator.is_table_included(model.table.name)
target_included = True
if isinstance(constraint, ForeignKeyConstraint): # CheckConstraints don't have elements
target_included = code_generator.is_table_included(constraint.elements[0].column.table.name)
if this_included and target_included:
table_args.append(self.render_constraint(constraint))
else:
log.debug(f'foreign key constraint excluded on {model.table.name}: '
f'{self.render_constraint(constraint)}')
for index in model.table.indexes:
if len(index.columns) > 1:
table_args.append(self.render_index(index))
table_kwargs = {}
if model.schema:
table_kwargs['schema'] = model.schema
table_comment = getattr(model.table, 'comment', None)
if table_comment:
table_kwargs['comment'] = table_comment
kwargs_items = ', '.join('{0!r}: {1!r}'.format(key, table_kwargs[key])
for key in table_kwargs)
kwargs_items = '{{{0}}}'.format(kwargs_items) if kwargs_items else None
if table_kwargs and not table_args:
rendered += '{0}__table_args__ = {1}\n'.format(self.indentation, kwargs_items)
elif table_args:
if kwargs_items:
table_args.append(kwargs_items)
if len(table_args) == 1:
table_args[0] += ','
table_args_joined = ',\n{0}{0}'.format(self.indentation).join(table_args)
rendered += '{0}__table_args__ = (\n{0}{0}{1}\n{0})\n'.format(
self.indentation, table_args_joined)
# Render columns
rendered += '\n'
for attr, column in model.attributes.items():
if isinstance(column, Column):
show_name = attr != column.name
rendered += '{0}{1} = {2}\n'.format(
self.indentation, attr, self.render_column(column, show_name))
if not autonum_col:
rendered += '{0}{1}'.format(self.indentation, "allow_client_generated_ids = True\n")
# Render relationships (declared in parent class, backref to child)
if any(isinstance(value, Relationship) for value in model.attributes.values()):
rendered += '\n'
backrefs = {}
for attr, relationship in model.attributes.items():
if isinstance(relationship, Relationship): # ApiLogicServer changed to insert backref
attr_to_render = attr
if self.generate_relationships_on != "child":
attr_to_render = "# see backref on parent: " + attr # relns not created on child; comment out
rel_render = "{0}{1} = {2}\n".format(self.indentation, attr_to_render, self.render_relationship(relationship))
rel_parts = rel_render.split(")") # eg, Department = relationship(\'Department\', remote_side=[Id]
backref_name = model.name + "List"
""" disambiguate multi-relns, eg, in the Employee child class, 2 relns to Department:
Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList')
Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList_Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
unique_name = relationship.target_cls + '.' + backref_name
if unique_name in backrefs: # disambiguate
backref_name += "_" + attr
back_ref = f', cascade_backrefs=True, backref=\'{backref_name}\''
rel_render_with_backref = rel_parts[0] + \
back_ref + \
")" + rel_parts[1]
# rendered += "{0}{1} = {2}\n".format(self.indentation, attr, self.render_relationship(relationship))
""" disambiguate multi-relns, eg, in the Department parent class, 2 relns to Employee:
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='Department1')
cascade_backrefs=True, backref='EmployeeList_Department1' <== need to append that "1"
"""
if relationship.target_cls not in self.classes:
print(f'.. .. ..ERROR - {model.name} -- missing parent class: {relationship.target_cls}')
print(f'.. .. .. .. Parent Class may be missing Primary Key and Unique Column')
print(f'.. .. .. .. Attempting to continue - you may need to repair model, or address database design')
continue
parent_model = self.classes[relationship.target_cls] # eg, Department
parent_relationship_def = self.render_relationship_on_parent(relationship)
parent_relationship_def = parent_relationship_def[:-1]
# eg, for Dept: relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id')
child_role_name = model.name + "List"
parent_role_name = attr
if unique_name in backrefs: # disambiguate
child_role_name += '1' # FIXME - fails for 3 relns
if model.name != parent_model.name:
parent_relationship = f'{child_role_name} = {parent_relationship_def}, cascade_backrefs=True, backref=\'{parent_role_name}\')'
else: # work-around for self relns
"""
special case self relns:
not DepartmentList = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='Department')
but Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList')
"""
parent_relationship = f'{parent_role_name} = {parent_relationship_def}, cascade_backrefs=True, backref=\'{child_role_name}\')'
parent_relationship += " # special handling for self-relationships"
if self.generate_relationships_on != "parent": # relns not created on parent; comment out
parent_relationship = "# see backref on child: " + parent_relationship
parent_model.rendered_model_relationships += " " + parent_relationship + "\n"
if model.name == "OrderDetail":
debug_str = "nice breakpoint"
rendered += rel_render_with_backref
backrefs[unique_name] = backref_name
if relationship.source_cls.startswith("Ab"):
pass
elif isinstance(relationship, ManyToManyRelationship): # eg, chinook:PlayList->PlayListTrack
print(f'many to many should not occur on: {model.name}.{unique_name}')
else: # fixme dump all this, right?
use_old_code = False # so you can elide this
if use_old_code:
resource = self.model_creation_services.resource_list[relationship.source_cls]
resource_relationship = ResourceRelationship(parent_role_name = attr,
child_role_name = backref_name)
resource_relationship.child_resource = relationship.source_cls
resource_relationship.parent_resource = relationship.target_cls
# gen key pairs
for each_pair in relationship.foreign_key_constraint.elements:
pair = ( str(each_pair.column.name), str(each_pair.parent.name) )
resource_relationship.parent_child_key_pairs.append(pair)
resource.parents.append(resource_relationship)
parent_resource = self.model_creation_services.resource_list[relationship.target_cls]
parent_resource.children.append(resource_relationship)
if use_old_code:
if relationship.source_cls not in self.parents_map: # todo old code remove
self.parents_map[relationship.source_cls] = list()
self.parents_map[relationship.source_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
if relationship.target_cls not in self.children_map:
self.children_map[relationship.target_cls] = list()
self.children_map[relationship.target_cls].append(
(
attr, # to parent, eg, Department, Department1
backref_name, # to children, eg, EmployeeList, EmployeeList_Department1
relationship.foreign_key_constraint
) )
pass
# Render subclasses
for child_class in model.children:
rendered += self.model_separator + self.render_class(child_class)
# rendered += "\n # END RENDERED CLASS\n" # useful for debug, as required
return rendered
def render(self, outfile=sys.stdout):
""" create model from db, and write models.py file to in-memory buffer (outfile)
relns created from not-yet-seen children, so save *all* class info, then append rendered_model_relationships
"""
for model in self.models: # class, with __tablename__ & __collection_name__ cls variables, attrs
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
model.rendered_model = self.render_class(model) # also sets parent_model.rendered_model_relationships
rendered_models = [] # now append the rendered_model + rendered_model_relationships
for model in self.models:
if isinstance(model, self.class_model):
# rendered_models.append(self.render_class(model))
if model.rendered_model_relationships != "": # child relns (OrderDetailList etc)
model.rendered_model_relationships = "\n" + model.rendered_model_relationships
rendered_models.append(model.rendered_model + model.rendered_model_relationships)
rendered_models.append(self.model_creation_services.opt_locking)
elif isinstance(model, self.table_model): # eg, views, database id generators, etc
rendered_models.append(self.render_table(model))
output = self.template.format(
imports=self.render_imports(),
metadata_declarations=self.render_metadata_declarations(),
models=self.model_separator.join(rendered_models).rstrip('\n'))
print(output, file=outfile)
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/codegen/codegenZ.py
|
codegenZ.py
|
from sqlalchemy import Boolean, Column, DECIMAL, Date, Double, ForeignKey, ForeignKeyConstraint, Integer, String, Text, text
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# Created: June 08, 2023 20:00:57
# Database: sqlite:////Users/val/dev/servers/ApiLogicProject/database/db.sqlite
# Dialect: sqlite
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Category(SAFRSBase, Base):
__tablename__ = 'CategoryTableNameTest'
_s_collection_name = 'Category' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CategoryName = Column(String(8000))
Description = Column(String(8000))
Client_id = Column(Integer)
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Customer(SAFRSBase, Base):
__tablename__ = 'Customer'
_s_collection_name = 'Customer' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
Balance = Column(DECIMAL)
CreditLimit = Column(DECIMAL)
OrderCount = Column(Integer, server_default=text("0"))
UnpaidOrderCount = Column(Integer, server_default=text("0"))
Client_id = Column(Integer)
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Customer')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class CustomerDemographic(SAFRSBase, Base):
__tablename__ = 'CustomerDemographic'
_s_collection_name = 'CustomerDemographic' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CustomerDesc = Column(String(8000))
allow_client_generated_ids = True
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Department(SAFRSBase, Base):
__tablename__ = 'Department'
_s_collection_name = 'Department' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
DepartmentId = Column(ForeignKey('Department.Id'))
DepartmentName = Column(String(100))
# see backref on parent: Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList')
Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList') # special handling for self-relationships
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='Department1')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Location(SAFRSBase, Base):
__tablename__ = 'Location'
_s_collection_name = 'Location' # type: ignore
__bind_key__ = 'None'
country = Column(String(50), primary_key=True)
city = Column(String(50), primary_key=True)
notes = Column(String(256))
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Location')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Product(SAFRSBase, Base):
__tablename__ = 'Product'
_s_collection_name = 'Product' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
ProductName = Column(String(8000))
SupplierId = Column(Integer, nullable=False)
CategoryId = Column(Integer, nullable=False)
QuantityPerUnit = Column(String(8000))
UnitPrice = Column(DECIMAL, nullable=False)
UnitsInStock = Column(Integer, nullable=False)
UnitsOnOrder = Column(Integer, nullable=False)
ReorderLevel = Column(Integer, nullable=False)
Discontinued = Column(Integer, nullable=False)
UnitsShipped = Column(Integer)
OrderDetailList = relationship('OrderDetail', cascade_backrefs=False, backref='Product')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Region(SAFRSBase, Base):
__tablename__ = 'Region'
_s_collection_name = 'Region' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
RegionDescription = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class SampleDBVersion(SAFRSBase, Base):
__tablename__ = 'SampleDBVersion'
_s_collection_name = 'SampleDBVersion' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Notes = Column(String(800))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Shipper(SAFRSBase, Base):
__tablename__ = 'Shipper'
_s_collection_name = 'Shipper' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
Phone = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Supplier(SAFRSBase, Base):
__tablename__ = 'Supplier'
_s_collection_name = 'Supplier' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
HomePage = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Territory(SAFRSBase, Base):
__tablename__ = 'Territory'
_s_collection_name = 'Territory' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
TerritoryDescription = Column(String(8000))
RegionId = Column(Integer, nullable=False)
allow_client_generated_ids = True
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Territory')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Union(SAFRSBase, Base):
__tablename__ = 'Union'
_s_collection_name = 'Union' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Name = Column(String(80))
EmployeeList = relationship('Employee', cascade_backrefs=False, backref='Union')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Employee(SAFRSBase, Base):
__tablename__ = 'Employee'
_s_collection_name = 'Employee' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
LastName = Column(String(8000))
FirstName = Column(String(8000))
Title = Column(String(8000))
TitleOfCourtesy = Column(String(8000))
BirthDate = Column(String(8000))
HireDate = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
HomePhone = Column(String(8000))
Extension = Column(String(8000))
Notes = Column(String(8000))
ReportsTo = Column(Integer, index=True)
PhotoPath = Column(String(8000))
EmployeeType = Column(String(16), server_default=text("Salaried"))
Salary = Column(DECIMAL)
WorksForDepartmentId = Column(ForeignKey('Department.Id'))
OnLoanDepartmentId = Column(ForeignKey('Department.Id'))
UnionId = Column(ForeignKey('Union.Id'))
Dues = Column(DECIMAL)
# see backref on parent: Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Union = relationship('Union', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList_Department1')
EmployeeAuditList = relationship('EmployeeAudit', cascade_backrefs=False, backref='Employee')
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Employee')
OrderList = relationship('Order', cascade_backrefs=False, backref='Employee')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class EmployeeAudit(SAFRSBase, Base):
__tablename__ = 'EmployeeAudit'
_s_collection_name = 'EmployeeAudit' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Title = Column(String)
Salary = Column(DECIMAL)
LastName = Column(String)
FirstName = Column(String)
EmployeeId = Column(ForeignKey('Employee.Id'))
CreatedOn = Column(Text)
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeAuditList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class EmployeeTerritory(SAFRSBase, Base):
__tablename__ = 'EmployeeTerritory'
_s_collection_name = 'EmployeeTerritory' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False)
TerritoryId = Column(ForeignKey('Territory.Id'))
allow_client_generated_ids = True
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeTerritoryList')
# see backref on parent: Territory = relationship('Territory', cascade_backrefs=False, backref='EmployeeTerritoryList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Order(SAFRSBase, Base):
__tablename__ = 'Order'
_s_collection_name = 'Order' # type: ignore
__bind_key__ = 'None'
__table_args__ = (
ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city']),
)
Id = Column(Integer, primary_key=True)
CustomerId = Column(ForeignKey('Customer.Id'), nullable=False, index=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False, index=True)
OrderDate = Column(String(8000))
RequiredDate = Column(Date)
ShippedDate = Column(String(8000))
ShipVia = Column(Integer)
Freight = Column(DECIMAL, server_default=text("0"))
ShipName = Column(String(8000))
ShipAddress = Column(String(8000))
ShipCity = Column(String(8000))
ShipRegion = Column(String(8000))
ShipZip = Column('ShipPostalCode', String(8000)) # manual fix - alias
ShipCountry = Column(String(8000))
AmountTotal = Column(DECIMAL(10, 2))
Country = Column(String(50))
City = Column(String(50))
Ready = Column(Boolean, server_default=text("TRUE"))
OrderDetailCount = Column(Integer, server_default=text("0"))
CloneFromOrder = Column(ForeignKey('Order.Id'))
# see backref on parent: parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList')
# see backref on parent: Location = relationship('Location', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Customer = relationship('Customer', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='OrderList')
parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList') # special handling for self-relationships
OrderDetailList = relationship('OrderDetail', cascade_backrefs=False, backref='Order')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class OrderDetail(SAFRSBase, Base):
__tablename__ = 'OrderDetail'
_s_collection_name = 'OrderDetail' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
OrderId = Column(ForeignKey('Order.Id'), nullable=False, index=True)
ProductId = Column(ForeignKey('Product.Id'), nullable=False, index=True)
UnitPrice = Column(DECIMAL)
Quantity = Column(Integer, server_default=text("1"), nullable=False)
Discount = Column(Double, server_default=text("0"))
Amount = Column(DECIMAL)
ShippedDate = Column(String(8000))
# see backref on parent: Order = relationship('Order', cascade_backrefs=False, backref='OrderDetailList')
# see backref on parent: Product = relationship('Product', cascade_backrefs=False, backref='OrderDetailList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/compare_gen_vs_rc2/models.py
|
models.py
|
from sqlalchemy import Boolean, Column, DECIMAL, Date, Float, ForeignKey, ForeignKeyConstraint, Integer, String, Table, Text, text
from sqlalchemy.orm import relationship
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Category(SAFRSBase, Base):
__tablename__ = 'CategoryTableNameTest'
_s_collection_name = 'Category' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CategoryName = Column(String(8000))
Description = Column(String(8000))
Client_id = Column(Integer)
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Customer(SAFRSBase, Base):
__tablename__ = 'Customer'
_s_collection_name = 'Customer' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
Balance = Column(DECIMAL)
CreditLimit = Column(DECIMAL)
OrderCount = Column(Integer, server_default=text("0"))
UnpaidOrderCount = Column(Integer, server_default=text("0"))
Client_id = Column(Integer)
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Customer')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class CustomerDemographic(SAFRSBase, Base):
__tablename__ = 'CustomerDemographic'
_s_collection_name = 'CustomerDemographic' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CustomerDesc = Column(String(8000))
allow_client_generated_ids = True
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Department(SAFRSBase, Base):
__tablename__ = 'Department'
_s_collection_name = 'Department' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
DepartmentId = Column(ForeignKey('Department.Id'))
DepartmentName = Column(String(100))
# see backref on parent: Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList')
Department = relationship('Department', remote_side=[Id], cascade_backrefs=False, backref='DepartmentList') # special handling for self-relationships
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='Department1')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Location(SAFRSBase, Base):
__tablename__ = 'Location'
_s_collection_name = 'Location' # type: ignore
__bind_key__ = 'None'
country = Column(String(50), primary_key=True)
city = Column(String(50), primary_key=True)
notes = Column(String(256))
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=False, backref='Location')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Product(SAFRSBase, Base):
__tablename__ = 'Product'
_s_collection_name = 'Product' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
ProductName = Column(String(8000))
SupplierId = Column(Integer, nullable=False)
CategoryId = Column(Integer, nullable=False)
QuantityPerUnit = Column(String(8000))
UnitPrice = Column(DECIMAL, nullable=False)
UnitsInStock = Column(Integer, nullable=False)
UnitsOnOrder = Column(Integer, nullable=False)
ReorderLevel = Column(Integer, nullable=False)
Discontinued = Column(Integer, nullable=False)
UnitsShipped = Column(Integer)
OrderDetailList = relationship('OrderDetail', cascade_backrefs=False, backref='Product')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Region(SAFRSBase, Base):
__tablename__ = 'Region'
_s_collection_name = 'Region' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
RegionDescription = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class SampleDBVersion(SAFRSBase, Base):
__tablename__ = 'SampleDBVersion'
_s_collection_name = 'SampleDBVersion' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Notes = Column(String(800))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Shipper(SAFRSBase, Base):
__tablename__ = 'Shipper'
_s_collection_name = 'Shipper' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
Phone = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Supplier(SAFRSBase, Base):
__tablename__ = 'Supplier'
_s_collection_name = 'Supplier' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
HomePage = Column(String(8000))
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Territory(SAFRSBase, Base):
__tablename__ = 'Territory'
_s_collection_name = 'Territory' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
TerritoryDescription = Column(String(8000))
RegionId = Column(Integer, nullable=False)
allow_client_generated_ids = True
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Territory')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Union(SAFRSBase, Base):
__tablename__ = 'Union'
_s_collection_name = 'Union' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Name = Column(String(80))
EmployeeList = relationship('Employee', cascade_backrefs=False, backref='Union')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
t_sqlite_sequence = Table(
'sqlite_sequence', metadata,
Column('name', NullType),
Column('seq', NullType)
)
class Employee(SAFRSBase, Base):
__tablename__ = 'Employee'
_s_collection_name = 'Employee' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
LastName = Column(String(8000))
FirstName = Column(String(8000))
Title = Column(String(8000))
TitleOfCourtesy = Column(String(8000))
BirthDate = Column(String(8000))
HireDate = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
HomePhone = Column(String(8000))
Extension = Column(String(8000))
Notes = Column(String(8000))
ReportsTo = Column(Integer, index=True)
PhotoPath = Column(String(8000))
EmployeeType = Column(String(16), server_default=text("Salaried"))
Salary = Column(DECIMAL)
WorksForDepartmentId = Column(ForeignKey('Department.Id'))
OnLoanDepartmentId = Column(ForeignKey('Department.Id'))
UnionId = Column(ForeignKey('Union.Id'))
Dues = Column(DECIMAL)
# see backref on parent: Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Union = relationship('Union', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=False, backref='EmployeeList_Department1')
EmployeeAuditList = relationship('EmployeeAudit', cascade_backrefs=False, backref='Employee')
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=False, backref='Employee')
OrderList = relationship('Order', cascade_backrefs=False, backref='Employee')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class EmployeeAudit(SAFRSBase, Base):
__tablename__ = 'EmployeeAudit'
_s_collection_name = 'EmployeeAudit' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Title = Column(String)
Salary = Column(DECIMAL)
LastName = Column(String)
FirstName = Column(String)
EmployeeId = Column(ForeignKey('Employee.Id'))
CreatedOn = Column(Text)
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeAuditList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class EmployeeTerritory(SAFRSBase, Base):
__tablename__ = 'EmployeeTerritory'
_s_collection_name = 'EmployeeTerritory' # type: ignore
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False)
TerritoryId = Column(ForeignKey('Territory.Id'))
allow_client_generated_ids = True
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='EmployeeTerritoryList')
# see backref on parent: Territory = relationship('Territory', cascade_backrefs=False, backref='EmployeeTerritoryList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Order(SAFRSBase, Base):
__tablename__ = 'Order'
_s_collection_name = 'Order' # type: ignore
__bind_key__ = 'None'
__table_args__ = (
ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city']),
)
Id = Column(Integer, primary_key=True)
CustomerId = Column(ForeignKey('Customer.Id'), nullable=False, index=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False, index=True)
OrderDate = Column(String(8000))
RequiredDate = Column(Date)
ShippedDate = Column(String(8000))
ShipVia = Column(Integer)
Freight = Column(DECIMAL, server_default=text("0"))
ShipName = Column(String(8000))
ShipAddress = Column(String(8000))
ShipCity = Column(String(8000))
ShipRegion = Column(String(8000))
ShipZip = Column('ShipPostalCode', String(8000)) # manual fix - alias
ShipCountry = Column(String(8000))
AmountTotal = Column(DECIMAL(10, 2))
Country = Column(String(50))
City = Column(String(50))
Ready = Column(Boolean, server_default=text("TRUE"))
OrderDetailCount = Column(Integer, server_default=text("0"))
CloneFromOrder = Column(ForeignKey('Order.Id'))
# see backref on parent: parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList')
# see backref on parent: Location = relationship('Location', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Customer = relationship('Customer', cascade_backrefs=False, backref='OrderList')
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=False, backref='OrderList')
parent = relationship('Order', remote_side=[Id], cascade_backrefs=False, backref='OrderList') # special handling for self-relationships
OrderDetailList = relationship('OrderDetail', cascade='all, delete', cascade_backrefs=False, backref='Order') # manual fix
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class OrderDetail(SAFRSBase, Base):
__tablename__ = 'OrderDetail'
_s_collection_name = 'OrderDetail' # type: ignore
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
OrderId = Column(ForeignKey('Order.Id'), nullable=False, index=True)
ProductId = Column(ForeignKey('Product.Id'), nullable=False, index=True)
UnitPrice = Column(DECIMAL)
Quantity = Column(Integer, server_default=text("1"), nullable=False)
Discount = Column(Float, server_default=text("0"))
Amount = Column(DECIMAL)
ShippedDate = Column(String(8000))
# see backref on parent: Order = relationship('Order', cascade_backrefs=False, backref='OrderDetailList')
# see backref on parent: Product = relationship('Product', cascade_backrefs=False, backref='OrderDetailList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/compare_gen_vs_rc2/models_rc2.py
|
models_rc2.py
|
from sqlalchemy import Column, DECIMAL, Date, ForeignKey, Integer, SmallInteger, String, Text
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# Created: June 10, 2023 14:46:39
# Database: sqlite:////Users/val/dev/servers/install/ApiLogicServer/classicmodels_sqlite/database/db.sqlite
# Dialect: sqlite
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from safrs import jsonapi_attr
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Office(SAFRSBase, Base):
__tablename__ = 'offices'
_s_collection_name = 'Office' # type: ignore
__bind_key__ = 'None'
officeCode = Column(String(10), primary_key=True)
city = Column(String(50), nullable=False)
phone = Column(String(50), nullable=False)
addressLine1 = Column(String(50), nullable=False)
addressLine2 = Column(String(50))
state = Column(String(50))
country = Column(String(50), nullable=False)
postalCode = Column(String(15), nullable=False)
territory = Column(String(10), nullable=False)
allow_client_generated_ids = True
EmployeeList = relationship('Employee', cascade_backrefs=False, backref='office')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Productline(SAFRSBase, Base):
__tablename__ = 'productlines'
_s_collection_name = 'Productline' # type: ignore
__bind_key__ = 'None'
productLine = Column(String(50), primary_key=True)
textDescription = Column(String(4000))
htmlDescription = Column(Text)
image = Column(NullType)
allow_client_generated_ids = True
ProductList = relationship('Product', cascade_backrefs=False, backref='productline')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Employee(SAFRSBase, Base):
__tablename__ = 'employees'
_s_collection_name = 'Employee' # type: ignore
__bind_key__ = 'None'
employeeNumber = Column(Integer, primary_key=True)
lastName = Column(String(50), nullable=False)
firstName = Column(String(50), nullable=False)
extension = Column(String(10), nullable=False)
email = Column(String(100), nullable=False)
officeCode = Column(ForeignKey('offices.officeCode'), nullable=False, index=True)
reportsTo = Column(ForeignKey('employees.employeeNumber'), index=True)
jobTitle = Column(String(50), nullable=False)
# see backref on parent: office = relationship('Office', cascade_backrefs=False, backref='EmployeeList')
# see backref on parent: parent = relationship('Employee', remote_side=[employeeNumber], cascade_backrefs=False, backref='EmployeeList')
parent = relationship('Employee', remote_side=[employeeNumber], cascade_backrefs=False, backref='EmployeeList') # special handling for self-relationships
CustomerList = relationship('Customer', cascade_backrefs=False, backref='employee')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Product(SAFRSBase, Base):
__tablename__ = 'products'
_s_collection_name = 'Product' # type: ignore
__bind_key__ = 'None'
productCode = Column(String(15), primary_key=True)
productName = Column(String(70), nullable=False)
productLine = Column(ForeignKey('productlines.productLine'), nullable=False, index=True)
productScale = Column(String(10), nullable=False)
productVendor = Column(String(50), nullable=False)
productDescription = Column(Text, nullable=False)
quantityInStock = Column(SmallInteger, nullable=False)
buyPrice = Column(DECIMAL(10, 2), nullable=False)
MSRP = Column(DECIMAL(10, 2), nullable=False)
allow_client_generated_ids = True
# see backref on parent: productline = relationship('Productline', cascade_backrefs=False, backref='ProductList')
OrderdetailList = relationship('Orderdetail', cascade_backrefs=False, backref='product')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Customer(SAFRSBase, Base):
__tablename__ = 'customers'
_s_collection_name = 'Customer' # type: ignore
__bind_key__ = 'None'
customerNumber = Column(Integer, primary_key=True)
customerName = Column(String(50), nullable=False)
contactLastName = Column(String(50), nullable=False)
contactFirstName = Column(String(50), nullable=False)
phone = Column(String(50), nullable=False)
addressLine1 = Column(String(50), nullable=False)
addressLine2 = Column(String(50))
city = Column(String(50), nullable=False)
state = Column(String(50))
postalCode = Column(String(15))
country = Column(String(50), nullable=False)
salesRepEmployeeNumber = Column(ForeignKey('employees.employeeNumber'), index=True)
creditLimit = Column(DECIMAL(10, 2))
# see backref on parent: employee = relationship('Employee', cascade_backrefs=False, backref='CustomerList')
OrderList = relationship('Order', cascade_backrefs=False, backref='customer')
PaymentList = relationship('Payment', cascade_backrefs=False, backref='customer')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Order(SAFRSBase, Base):
__tablename__ = 'orders'
_s_collection_name = 'Order' # type: ignore
__bind_key__ = 'None'
orderNumber = Column(Integer, primary_key=True)
orderDate = Column(Date, nullable=False)
requiredDate = Column(Date, nullable=False)
shippedDate = Column(Date)
status = Column(String(15), nullable=False)
comments = Column(Text)
customerNumber = Column(ForeignKey('customers.customerNumber'), nullable=False, index=True)
# see backref on parent: customer = relationship('Customer', cascade_backrefs=False, backref='OrderList')
OrderdetailList = relationship('Orderdetail', cascade_backrefs=False, backref='order')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Payment(SAFRSBase, Base):
__tablename__ = 'payments'
_s_collection_name = 'Payment' # type: ignore
__bind_key__ = 'None'
customerNumber = Column(ForeignKey('customers.customerNumber'), primary_key=True, nullable=False)
checkNumber = Column(String(50), primary_key=True, nullable=False)
paymentDate = Column(Date, nullable=False)
amount = Column(DECIMAL(10, 2), nullable=False)
allow_client_generated_ids = True
# see backref on parent: customer = relationship('Customer', cascade_backrefs=False, backref='PaymentList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
class Orderdetail(SAFRSBase, Base):
__tablename__ = 'orderdetails'
_s_collection_name = 'Orderdetail' # type: ignore
__bind_key__ = 'None'
orderNumber = Column(ForeignKey('orders.orderNumber'), primary_key=True, nullable=False)
productCode = Column(ForeignKey('products.productCode'), primary_key=True, nullable=False, index=True)
quantityOrdered = Column(Integer, nullable=False)
priceEach = Column(DECIMAL(10, 2), nullable=False)
orderLineNumber = Column(SmallInteger, nullable=False)
allow_client_generated_ids = True
# see backref on parent: order = relationship('Order', cascade_backrefs=False, backref='OrderdetailList')
# see backref on parent: product = relationship('Product', cascade_backrefs=False, backref='OrderdetailList')
@jsonapi_attr
def _check_sum_(self): # type: ignore [no-redef]
if isinstance(self, flask_sqlalchemy.model.DefaultMeta):
# print("class")
return None
else:
if hasattr(self,"_check_sum_property"):
return self._check_sum_property
else:
return None # property does not exist during initialization
@_check_sum_.setter
def _check_sum_(self, value): # type: ignore [no-redef]
self._check_sum_property = value
S_CheckSum = _check_sum_
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/classic_models/models_gen.py
|
models_gen.py
|
from sqlalchemy import Column, DECIMAL, Date, ForeignKey, Integer, SmallInteger, String, Text
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
#
# mypy: ignore-errors
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs, flask_sqlalchemy
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base() # type: flask_sqlalchemy.model.DefaultMeta
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Office(SAFRSBase, Base):
__tablename__ = 'offices'
_s_collection_name = 'Office' # type: ignore
__bind_key__ = 'None'
officeCode = Column(String(10), primary_key=True)
city = Column(String(50), nullable=False)
phone = Column(String(50), nullable=False)
addressLine1 = Column(String(50), nullable=False)
addressLine2 = Column(String(50))
state = Column(String(50))
country = Column(String(50), nullable=False)
postalCode = Column(String(15), nullable=False)
territory = Column(String(10), nullable=False)
allow_client_generated_ids = True
EmployeeList = relationship('Employee', cascade_backrefs=True, backref='office')
class Productline(SAFRSBase, Base):
__tablename__ = 'productlines'
_s_collection_name = 'Productline' # type: ignore
__bind_key__ = 'None'
productLine = Column(String(50), primary_key=True)
textDescription = Column(String(4000))
htmlDescription = Column(Text)
image = Column(NullType)
allow_client_generated_ids = True
ProductList = relationship('Product', cascade_backrefs=True, backref='productline')
class Employee(SAFRSBase, Base):
__tablename__ = 'employees'
_s_collection_name = 'Employee' # type: ignore
__bind_key__ = 'None'
employeeNumber = Column(Integer, primary_key=True)
lastName = Column(String(50), nullable=False)
firstName = Column(String(50), nullable=False)
extension = Column(String(10), nullable=False)
email = Column(String(100), nullable=False)
officeCode = Column(ForeignKey('offices.officeCode'), nullable=False, index=True)
reportsTo = Column(ForeignKey('employees.employeeNumber'), index=True)
jobTitle = Column(String(50), nullable=False)
# see backref on parent: office = relationship('Office', cascade_backrefs=True, backref='EmployeeList')
# see backref on parent: parent = relationship('Employee', remote_side=[employeeNumber], cascade_backrefs=True, backref='EmployeeList')
parent = relationship('Employee', remote_side=[employeeNumber], cascade_backrefs=True, backref='EmployeeList') # special handling for self-relationships
CustomerList = relationship('Customer', cascade_backrefs=True, backref='employee')
class Product(SAFRSBase, Base):
__tablename__ = 'products'
_s_collection_name = 'Product' # type: ignore
__bind_key__ = 'None'
productCode = Column(String(15), primary_key=True)
productName = Column(String(70), nullable=False)
productLine = Column(ForeignKey('productlines.productLine'), nullable=False, index=True)
productScale = Column(String(10), nullable=False)
productVendor = Column(String(50), nullable=False)
productDescription = Column(Text, nullable=False)
quantityInStock = Column(SmallInteger, nullable=False)
buyPrice = Column(DECIMAL(10, 2), nullable=False)
MSRP = Column(DECIMAL(10, 2), nullable=False)
allow_client_generated_ids = True
# see backref on parent: productline = relationship('Productline', cascade_backrefs=True, backref='ProductList')
OrderdetailList = relationship('Orderdetail', cascade_backrefs=True, backref='product')
class Customer(SAFRSBase, Base):
__tablename__ = 'customers'
_s_collection_name = 'Customer' # type: ignore
__bind_key__ = 'None'
customerNumber = Column(Integer, primary_key=True)
customerName = Column(String(50), nullable=False)
contactLastName = Column(String(50), nullable=False)
contactFirstName = Column(String(50), nullable=False)
phone = Column(String(50), nullable=False)
addressLine1 = Column(String(50), nullable=False)
addressLine2 = Column(String(50))
city = Column(String(50), nullable=False)
state = Column(String(50))
postalCode = Column(String(15))
country = Column(String(50), nullable=False)
salesRepEmployeeNumber = Column(ForeignKey('employees.employeeNumber'), index=True)
creditLimit = Column(DECIMAL(10, 2))
# see backref on parent: employee = relationship('Employee', cascade_backrefs=True, backref='CustomerList')
OrderList = relationship('Order', cascade_backrefs=True, backref='customer')
PaymentList = relationship('Payment', cascade_backrefs=True, backref='customer')
class Order(SAFRSBase, Base):
__tablename__ = 'orders'
_s_collection_name = 'Order' # type: ignore
__bind_key__ = 'None'
orderNumber = Column(Integer, primary_key=True)
orderDate = Column(Date, nullable=False)
requiredDate = Column(Date, nullable=False)
shippedDate = Column(Date)
status = Column(String(15), nullable=False)
comments = Column(Text)
customerNumber = Column(ForeignKey('customers.customerNumber'), nullable=False, index=True)
# see backref on parent: customer = relationship('Customer', cascade_backrefs=True, backref='OrderList')
OrderdetailList = relationship('Orderdetail', cascade_backrefs=True, backref='order')
class Payment(SAFRSBase, Base):
__tablename__ = 'payments'
_s_collection_name = 'Payment' # type: ignore
__bind_key__ = 'None'
customerNumber = Column(ForeignKey('customers.customerNumber'), primary_key=True, nullable=False)
checkNumber = Column(String(50), primary_key=True, nullable=False)
paymentDate = Column(Date, nullable=False)
amount = Column(DECIMAL(10, 2), nullable=False)
allow_client_generated_ids = True
# see backref on parent: customer = relationship('Customer', cascade_backrefs=True, backref='PaymentList')
class Orderdetail(SAFRSBase, Base):
__tablename__ = 'orderdetails'
_s_collection_name = 'Orderdetail' # type: ignore
__bind_key__ = 'None'
orderNumber = Column(ForeignKey('orders.orderNumber'), primary_key=True, nullable=False)
productCode = Column(ForeignKey('products.productCode'), primary_key=True, nullable=False, index=True)
quantityOrdered = Column(Integer, nullable=False)
priceEach = Column(DECIMAL(10, 2), nullable=False)
orderLineNumber = Column(SmallInteger, nullable=False)
allow_client_generated_ids = True
# see backref on parent: order = relationship('Order', cascade_backrefs=True, backref='OrderdetailList')
# see backref on parent: product = relationship('Product', cascade_backrefs=True, backref='OrderdetailList')
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/sqlacodegen_wrapper/sqlacodegen/sqlacodegen/als_safrs_310/classic_models/models_ga.py
|
models_ga.py
|
from sqlalchemy import Boolean, Column, DECIMAL, Date, Float, ForeignKey, ForeignKeyConstraint, Integer, LargeBinary, String, Table, Text, text
from sqlalchemy.orm import relationship
from sqlalchemy.sql.sqltypes import NullType
from sqlalchemy.ext.declarative import declarative_base
########################################################################################################################
# Classes describing database for SqlAlchemy ORM, initially created by schema introspection.
#
# Alter this file per your database maintenance policy
# See https://apilogicserver.github.io/Docs/Project-Rebuild/#rebuilding
from safrs import SAFRSBase
from flask_login import UserMixin
import safrs
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
Base = declarative_base()
metadata = Base.metadata
#NullType = db.String # datatype fixup
#TIMESTAMP= db.TIMESTAMP
from sqlalchemy.dialects.sqlite import *
########################################################################################################################
class Category(SAFRSBase, Base):
__tablename__ = 'CategoryTableNameTest'
_s_collection_name = 'Category'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CategoryName = Column(String(8000))
Description = Column(String(8000))
class Customer(SAFRSBase, Base):
__tablename__ = 'Customer'
_s_collection_name = 'Customer'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
Balance = Column(DECIMAL)
CreditLimit = Column(DECIMAL)
OrderCount = Column(Integer, server_default=text("0"))
UnpaidOrderCount = Column(Integer, server_default=text("0"))
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=True, backref='Customer')
class CustomerDemographic(SAFRSBase, Base):
__tablename__ = 'CustomerDemographic'
_s_collection_name = 'CustomerDemographic'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
CustomerDesc = Column(String(8000))
allow_client_generated_ids = True
class Department(SAFRSBase, Base):
__tablename__ = 'Department'
_s_collection_name = 'Department'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
DepartmentId = Column(ForeignKey('Department.Id'))
DepartmentName = Column(String(100))
# see backref on parent: Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList')
Department = relationship('Department', remote_side=[Id], cascade_backrefs=True, backref='DepartmentList') # special handling for self-relationships
EmployeeList = relationship('Employee', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='Department')
EmployeeList1 = relationship('Employee', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='Department1')
class Location(SAFRSBase, Base):
__tablename__ = 'Location'
_s_collection_name = 'Location'
__bind_key__ = 'None'
country = Column(String(50), primary_key=True)
city = Column(String(50), primary_key=True)
notes = Column(String(256))
allow_client_generated_ids = True
OrderList = relationship('Order', cascade_backrefs=True, backref='Location')
class Product(SAFRSBase, Base):
__tablename__ = 'Product'
_s_collection_name = 'Product'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
ProductName = Column(String(8000))
SupplierId = Column(Integer, nullable=False)
CategoryId = Column(Integer, nullable=False)
QuantityPerUnit = Column(String(8000))
UnitPrice = Column(DECIMAL, nullable=False)
UnitsInStock = Column(Integer, nullable=False)
UnitsOnOrder = Column(Integer, nullable=False)
ReorderLevel = Column(Integer, nullable=False)
Discontinued = Column(Integer, nullable=False)
UnitsShipped = Column(Integer)
OrderDetailList = relationship('OrderDetail', cascade_backrefs=True, backref='Product')
class Region(SAFRSBase, Base):
__tablename__ = 'Region'
_s_collection_name = 'Region'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
RegionDescription = Column(String(8000))
class SampleDBVersion(SAFRSBase, Base):
__tablename__ = 'SampleDBVersion'
_s_collection_name = 'SampleDBVersion'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Notes = Column(String(800))
class Shipper(SAFRSBase, Base):
__tablename__ = 'Shipper'
_s_collection_name = 'Shipper'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
Phone = Column(String(8000))
class Supplier(SAFRSBase, Base):
__tablename__ = 'Supplier'
_s_collection_name = 'Supplier'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
CompanyName = Column(String(8000))
ContactName = Column(String(8000))
ContactTitle = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
Phone = Column(String(8000))
Fax = Column(String(8000))
HomePage = Column(String(8000))
class Territory(SAFRSBase, Base):
__tablename__ = 'Territory'
_s_collection_name = 'Territory'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
TerritoryDescription = Column(String(8000))
RegionId = Column(Integer, nullable=False)
allow_client_generated_ids = True
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=True, backref='Territory')
class Union(SAFRSBase, Base):
__tablename__ = 'Union'
_s_collection_name = 'Union'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Name = Column(String(80))
EmployeeList = relationship('Employee', cascade_backrefs=True, backref='Union')
t_sqlite_sequence = Table(
'sqlite_sequence', metadata,
Column('name', NullType),
Column('seq', NullType)
)
class Employee(SAFRSBase, Base):
__tablename__ = 'Employee'
_s_collection_name = 'Employee'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
LastName = Column(String(8000))
FirstName = Column(String(8000))
Title = Column(String(8000))
TitleOfCourtesy = Column(String(8000))
BirthDate = Column(String(8000))
HireDate = Column(String(8000))
Address = Column(String(8000))
City = Column(String(8000))
Region = Column(String(8000))
PostalCode = Column(String(8000))
Country = Column(String(8000))
HomePhone = Column(String(8000))
Extension = Column(String(8000))
Photo = Column(LargeBinary)
Notes = Column(String(8000))
ReportsTo = Column(Integer, index=True)
PhotoPath = Column(String(8000))
EmployeeType = Column(String(16), server_default=text("Salaried"))
Salary = Column(DECIMAL)
WorksForDepartmentId = Column(ForeignKey('Department.Id'))
OnLoanDepartmentId = Column(ForeignKey('Department.Id'))
UnionId = Column(ForeignKey('Union.Id'))
Dues = Column(DECIMAL)
# see backref on parent: Department = relationship('Department', primaryjoin='Employee.OnLoanDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList')
# see backref on parent: Union = relationship('Union', cascade_backrefs=True, backref='EmployeeList')
# see backref on parent: Department1 = relationship('Department', primaryjoin='Employee.WorksForDepartmentId == Department.Id', cascade_backrefs=True, backref='EmployeeList_Department1')
EmployeeAuditList = relationship('EmployeeAudit', cascade_backrefs=True, backref='Employee')
EmployeeTerritoryList = relationship('EmployeeTerritory', cascade_backrefs=True, backref='Employee')
OrderList = relationship('Order', cascade_backrefs=True, backref='Employee')
class EmployeeAudit(SAFRSBase, Base):
__tablename__ = 'EmployeeAudit'
_s_collection_name = 'EmployeeAudit'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
Title = Column(String)
Salary = Column(DECIMAL)
LastName = Column(String)
FirstName = Column(String)
EmployeeId = Column(ForeignKey('Employee.Id'))
CreatedOn = Column(Text)
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=True, backref='EmployeeAuditList')
class EmployeeTerritory(SAFRSBase, Base):
__tablename__ = 'EmployeeTerritory'
_s_collection_name = 'EmployeeTerritory'
__bind_key__ = 'None'
Id = Column(String(8000), primary_key=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False)
TerritoryId = Column(ForeignKey('Territory.Id'))
allow_client_generated_ids = True
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=True, backref='EmployeeTerritoryList')
# see backref on parent: Territory = relationship('Territory', cascade_backrefs=True, backref='EmployeeTerritoryList')
class Order(SAFRSBase, Base):
__tablename__ = 'Order'
_s_collection_name = 'Order'
__bind_key__ = 'None'
__table_args__ = (
ForeignKeyConstraint(['Country', 'City'], ['Location.country', 'Location.city']),
)
Id = Column(Integer, primary_key=True)
CustomerId = Column(ForeignKey('Customer.Id'), nullable=False, index=True)
EmployeeId = Column(ForeignKey('Employee.Id'), nullable=False, index=True)
OrderDate = Column(String(8000))
RequiredDate = Column(Date)
ShippedDate = Column(String(8000))
ShipVia = Column(Integer)
Freight = Column(DECIMAL, server_default=text("0"))
ShipName = Column(String(8000))
ShipAddress = Column(String(8000))
ShipCity = Column(String(8000))
ShipRegion = Column(String(8000))
ShipPostalCode = Column(String(8000))
ShipCountry = Column(String(8000))
AmountTotal = Column(DECIMAL(10, 2))
Country = Column(String(50))
City = Column(String(50))
Ready = Column(Boolean, server_default=text("TRUE"))
OrderDetailCount = Column(Integer, server_default=text("0"))
CloneFromOrder = Column(ForeignKey('Order.Id'))
# see backref on parent: parent = relationship('Order', remote_side=[Id], cascade_backrefs=True, backref='OrderList')
# see backref on parent: Location = relationship('Location', cascade_backrefs=True, backref='OrderList')
# see backref on parent: Customer = relationship('Customer', cascade_backrefs=True, backref='OrderList')
# see backref on parent: Employee = relationship('Employee', cascade_backrefs=True, backref='OrderList')
parent = relationship('Order', remote_side=[Id], cascade_backrefs=True, backref='OrderList') # special handling for self-relationships
OrderDetailList = relationship('OrderDetail', cascade_backrefs=True, backref='Order')
class OrderDetail(SAFRSBase, Base):
__tablename__ = 'OrderDetail'
_s_collection_name = 'OrderDetail'
__bind_key__ = 'None'
Id = Column(Integer, primary_key=True)
OrderId = Column(ForeignKey('Order.Id'), nullable=False, index=True)
ProductId = Column(ForeignKey('Product.Id'), nullable=False, index=True)
UnitPrice = Column(DECIMAL)
Quantity = Column(Integer, server_default=text("1"), nullable=False)
Discount = Column(Float, server_default=text("0"))
Amount = Column(DECIMAL)
ShippedDate = Column(String(8000))
# see backref on parent: Order = relationship('Order', cascade_backrefs=True, backref='OrderDetailList')
# see backref on parent: Product = relationship('Product', cascade_backrefs=True, backref='OrderDetailList')
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/fragments/modelsZZ.py
|
modelsZZ.py
|
# App Fiddle
<details markdown>
<summary>Welcome to the Flask/SQLAlchemy "App Fiddle"</summary>
You've perhaps used JS Fiddle to explore JavaScript and HTML. With the power of Codespaces, we can now provide a "fiddle" for a *complete application.*
Use this ***Application Fiddle*** to learn Flask/SQLAlchemy in Codespaces. You have 4 running apps - execute them, explore the code, alter them (e.g., create endpoints, issue queries), use the debugger, etc.
These projects all use the [Northwind Sample Database](https://apilogicserver.github.io/Docs/Sample-Database/). Other databases are also provided in Next Steps.
Start with the first application (`0. App_Fiddle`)- a basic, hand-coded Flask/SQLAlchemy App.
Then, discover **API Logic Server** - an Open Source CLI to create executable projects, **instantly,** with a single command. Projects are **fully customizable** in your IDE, using both standard code, and unique spreadsheet like **rules** for logic and security - 40X more concise than manual code.
The Key Technology Concepts (at end) is an inventory of essential skills for creating Flask/SQLAlchemy systems. Each are illustrated here.
</details>
<details markdown>
|
ApiLogicServer
|
/ApiLogicServer-9.2.18-py3-none-any.whl/api_logic_server_cli/templates/app_fiddle.md
|
app_fiddle.md
|
# ApiMeter
[](https://git.umlife.net/qa/YmApiMeter/commits/master)
[](https://git.umlife.net/qa/YmApiMeter/commits/master)
ApiMeter 是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。基于 Python 开发,支持 Python 2.7和3.3以上版本,可运行于 macOS、Linux、Windows平台。
### 一、安装方式
```
pip install ApiMeter
```
### 二、版本升级
```
pip install -U ApiMeter
```
### 三、使用方式
在 ApiMeter 安裝成功后,可以使用 apimeter、ymapi、ymapimeter 命令进行调用,如:
```
$ apimeter -V
1.0.0
$ ymapi -V
1.0.0
$ ymapimeter -V
1.0.0
$ apimeter -h
usage: main.py [-h] [-V] [--no-html-report]
[--html-report-name HTML_REPORT_NAME]
[--html-report-template HTML_REPORT_TEMPLATE]
[--log-level LOG_LEVEL] [--log-file LOG_FILE]
[--dot-env-path DOT_ENV_PATH] [--failfast]
[--startproject STARTPROJECT]
[--validate [VALIDATE [VALIDATE ...]]]
[--prettify [PRETTIFY [PRETTIFY ...]]]
[testset_paths [testset_paths ...]]
One-stop solution for HTTP(S) testing.
positional arguments:
testset_paths testset file path
optional arguments:
-h, --help show this help message and exit
-V, --version show version
--no-html-report do not generate html report.
--html-report-name HTML_REPORT_NAME
specify html report name, only effective when
generating html report.
--html-report-template HTML_REPORT_TEMPLATE
specify html report template path.
--log-level LOG_LEVEL
Specify logging level, default is INFO.
--log-file LOG_FILE Write logs to specified file path.
--dot-env-path DOT_ENV_PATH
Specify .env file path, which is useful for keeping
production credentials.
--failfast Stop the test run on the first error or failure.
--startproject STARTPROJECT
Specify new project name.
--validate [VALIDATE [VALIDATE ...]]
Validate JSON testset format.
--prettify [PRETTIFY [PRETTIFY ...]]
Prettify JSON testset format.
$ ymapimeter test_file.yml or test_file.ymal or test_file.json or test_dir/
test result and report ...
```
### 四、开发者模式
1、ApiMeter使用 pipenv 对依赖包进行管理,如果你没有安装,安装命令如下:
```
pip install pipenv
```
2、拉取 ApiMeter 源代码:
```
git clone [email protected]:qa/YmApiMeter.git
```
3、进入仓库目录,安装依赖:
```
cd YmApiMeter/
pipenv install --dev
```
4、进入测试目录,运行单元测试:
```
export PYTHONPATH=`pwd`
cd tests/
# 直接命令行输出测试结果
pipenv run python -m unittest discover
或
# 当前目录输出测试报告unit_test_report.html
pipenv run python all_test.py
或
# 计算单元测试覆盖率,在当前目录下生成.coverage统计结果文件
pipenv run coverage run --source=../apimeter -m unittest discover
# 命令行中输出直观的文字报告
pipenv run coverage report -m
# 将统计结果转化为HTML报告,在当前目录下生成htmlcov报告目录,查看里面的index.html文件即可
pipenv run coverage html
```
5、进入仓库目录,进行代码规范检测:
```
# 直接命令行中输出结果
pipenv run python -m flake8
或
# 通过flake8chart插件将结果转化为csv表格和svg图片
pipenv run python -m flake8 --statistics | flake8chart --chart-type=PIE --chart-output=flake8_pie_report.svg --csv-output=flake8_data.csv
或
# 通过flake8_formatter_junit_xml插件将结果转化为junit格式报告
pipenv run python -m flake8 --format junit-xml --output-file flake8_junit_report.xml
或
# 通过falke8-junit-report插件将结果转化为junit格式报告
pipenv run python -m flake8 --output-file flake8.txt
pipenv run python -m flake8_junit flake8.txt flake8_junit_report.xml
```
6、开发调试,运行方式:
```
pipenv run python main.py apimeter -h
```
### 五、一键上传 PYPI 并打 TAG
每次在 __about__.py 更新版本号后,运行以下命令,实现自动化打包上传 PYPI ,同时根据版本号自动打 TAG 并推送到仓库:
```
pipenv run python setup.py upload
```
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/README.md
|
README.md
|
import copy
import os
import sys
from apimeter import exception, testcase, utils
from apimeter.compat import OrderedDict
class Context(object):
""" Manages context functions and variables.
context has two levels, testset and testcase.
"""
def __init__(self):
self.testset_shared_variables_mapping = OrderedDict()
self.testcase_variables_mapping = OrderedDict()
self.testcase_parser = testcase.TestcaseParser()
self.init_context()
def init_context(self, level='testset'):
"""
testset level context initializes when a file is loaded,
testcase level context initializes when each testcase starts.
"""
if level == "testset":
self.testset_functions_config = {}
self.testset_request_config = {}
self.testset_shared_variables_mapping = OrderedDict()
# testcase config shall inherit from testset configs,
# but can not change testset configs, that's why we use copy.deepcopy here.
self.testcase_functions_config = copy.deepcopy(self.testset_functions_config)
self.testcase_variables_mapping = copy.deepcopy(self.testset_shared_variables_mapping)
self.testcase_parser.bind_functions(self.testcase_functions_config)
self.testcase_parser.update_binded_variables(self.testcase_variables_mapping)
if level == "testset":
self.import_module_items(["apimeter.built_in"], "testset")
def config_context(self, config_dict, level):
if level == "testset":
self.testcase_parser.file_path = config_dict.get("path", None)
requires = config_dict.get('requires', [])
self.import_requires(requires)
function_binds = config_dict.get('function_binds', {})
self.bind_functions(function_binds, level)
# import_module_functions will be deprecated soon
module_items = config_dict.get('import_module_items', []) \
or config_dict.get('import_module_functions', [])
self.import_module_items(module_items, level)
variables = config_dict.get('variables') \
or config_dict.get('variable_binds', OrderedDict())
self.bind_variables(variables, level)
def import_requires(self, modules):
""" import required modules dynamically
"""
for module_name in modules:
globals()[module_name] = utils.get_imported_module(module_name)
def bind_functions(self, function_binds, level="testcase"):
""" Bind named functions within the context
This allows for passing in self-defined functions in testing.
e.g. function_binds:
{
"add_one": lambda x: x + 1, # lambda function
"add_two_nums": "lambda x, y: x + y" # lambda function in string
}
"""
eval_function_binds = {}
for func_name, function in function_binds.items():
if isinstance(function, str):
function = eval(function)
eval_function_binds[func_name] = function
self.__update_context_functions_config(level, eval_function_binds)
def import_module_items(self, modules, level="testcase"):
""" import modules and bind all functions within the context
"""
sys.path.insert(0, os.getcwd())
for module_name in modules:
imported_module = utils.get_imported_module(module_name)
imported_functions_dict = utils.filter_module(imported_module, "function")
self.__update_context_functions_config(level, imported_functions_dict)
imported_variables_dict = utils.filter_module(imported_module, "variable")
self.bind_variables(imported_variables_dict, level)
def bind_variables(self, variables, level="testcase"):
""" bind variables to testset context or current testcase context.
variables in testset context can be used in all testcases of current test suite.
@param (list or OrderDict) variables, variable can be value or custom function.
if value is function, it will be called and bind result to variable.
e.g.
OrderDict({
"TOKEN": "YouMi",
"random": "${gen_random_string(5)}",
"json": {'name': 'user', 'password': '123456'},
"md5": "${gen_md5($TOKEN, $json, $random)}"
})
"""
if isinstance(variables, list):
variables = utils.convert_to_order_dict(variables)
for variable_name, value in variables.items():
variable_eval_value = self.eval_content(value)
if level == "testset":
self.testset_shared_variables_mapping[variable_name] = variable_eval_value
self.bind_testcase_variable(variable_name, variable_eval_value)
def bind_testcase_variable(self, variable_name, variable_value):
""" bind and update testcase variables mapping
"""
self.testcase_variables_mapping[variable_name] = variable_value
self.testcase_parser.update_binded_variables(self.testcase_variables_mapping)
def bind_extracted_variables(self, variables):
""" bind extracted variables to testset context
@param (OrderDict) variables
extracted value do not need to evaluate.
"""
for variable_name, value in variables.items():
self.testset_shared_variables_mapping[variable_name] = value
self.bind_testcase_variable(variable_name, value)
def __update_context_functions_config(self, level, config_mapping):
"""
@param level: testset or testcase
@param config_type: functions
@param config_mapping: functions config mapping
"""
if level == "testset":
self.testset_functions_config.update(config_mapping)
self.testcase_functions_config.update(config_mapping)
self.testcase_parser.bind_functions(self.testcase_functions_config)
def eval_content(self, content):
""" evaluate content recursively, take effect on each variable and function in content.
content may be in any data structure, include dict, list, tuple, number, string, etc.
"""
return self.testcase_parser.eval_content_with_bindings(content)
def get_parsed_request(self, request_dict, level="testcase"):
""" get parsed request with bind variables and functions.
@param request_dict: request config mapping
@param level: testset or testcase
"""
if level == "testset":
request_dict = self.eval_content(
request_dict
)
self.testset_request_config.update(request_dict)
testcase_request_config = utils.deep_update_dict(
copy.deepcopy(self.testset_request_config),
request_dict
)
parsed_request = self.eval_content(
testcase_request_config
)
return parsed_request
def eval_check_item(self, validator, resp_obj):
""" evaluate check item in validator
@param (dict) validator
{"check": "status_code", "comparator": "eq", "expect": 201}
{"check": "$resp_body_success", "comparator": "eq", "expect": True}
@param (object) resp_obj
@return (dict) validator info
{
"check": "status_code",
"check_value": 200,
"expect": 201,
"comparator": "eq"
}
"""
check_item = validator["check"]
# check_item should only be the following 5 formats:
# 1, variable reference, e.g. $token
# 2, function reference, e.g. ${is_status_code_200($status_code)}
# 3, dict or list, maybe containing variable/function reference, e.g. {"var": "$abc"}
# 4, string joined by delimiter. e.g. "status_code", "headers.content-type"
# 5, regex string, e.g. "LB[\d]*(.*)RB[\d]*"
if isinstance(check_item, (dict, list)) \
or testcase.extract_variables(check_item) \
or testcase.extract_functions(check_item):
# format 1/2/3
check_value = self.eval_content(check_item)
else:
try:
# format 4/5
check_value = resp_obj.extract_field(check_item)
except exception.ParseResponseError:
msg = "failed to extract check item from response!\n"
msg += "response content: {}".format(resp_obj.content)
raise exception.ParseResponseError(msg)
validator["check_value"] = check_value
# expect_value should only be in 2 types:
# 1, variable reference, e.g. $expect_status_code
# 2, actual value, e.g. 200
expect_value = self.eval_content(validator["expect"])
validator["expect"] = expect_value
validator["check_result"] = "unchecked"
return validator
def do_validation(self, validator_dict):
""" validate with functions
"""
# TODO: move comparator uniform to init_task_suites
comparator = utils.get_uniform_comparator(validator_dict["comparator"])
validate_func = self.testcase_parser.get_bind_function(comparator)
if not validate_func:
raise exception.FunctionNotFound("comparator not found: {}".format(comparator))
check_item = validator_dict["check"]
check_value = validator_dict["check_value"]
expect_value = validator_dict["expect"]
if (check_value is None or expect_value is None) \
and comparator not in ["is", "eq", "equals", "=="]:
raise exception.ParamsError("Null value can only be compared with comparator: eq/equals/==")
try:
validator_dict["check_result"] = "passed"
validate_func(validator_dict["check_value"], validator_dict["expect"])
except (AssertionError, TypeError):
err_msg = "\n" + "\n".join([
"\tcheck item name: %s;" % check_item,
"\tcheck item value: %s (%s);" % (check_value, type(check_value).__name__),
"\tcomparator: %s;" % comparator,
"\texpected value: %s (%s)." % (expect_value, type(expect_value).__name__)
])
validator_dict["check_result"] = "failed"
raise exception.ValidationError(err_msg)
def eval_validators(self, validators, resp_obj):
"""evaluate validators with context variable mapping.
@param (list) validators
@param (object) resp_obj
"""
return [
self.eval_check_item(testcase.parse_validator(validator), resp_obj) for validator in validators
]
def validate(self, validators):
""" make validations
"""
for validator_dict in validators:
self.do_validation(validator_dict)
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/context.py
|
context.py
|
import json
import re
from apimeter import exception, logger, utils
from apimeter.compat import OrderedDict, basestring
from requests.structures import CaseInsensitiveDict
from requests.models import PreparedRequest
text_extractor_regexp_compile = re.compile(r".*\(.*\).*")
class ResponseObject(object):
def __init__(self, resp_obj):
""" initialize with a requests.Response object
@param (requests.Response instance) resp_obj
"""
self.resp_obj = resp_obj
def __getattr__(self, key):
try:
if key == "json":
value = self.resp_obj.json()
else:
value = getattr(self.resp_obj, key)
self.__dict__[key] = value
return value
except AttributeError:
err_msg = "ResponseObject does not have attribute: {}".format(key)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
def _extract_field_with_regex(self, field):
""" extract field from response content with regex.
requests.Response body could be json or html text.
@param (str) field should only be regex string that matched r".*\(.*\).*"
e.g.
self.text: "LB123abcRB789"
field: "LB[\d]*(.*)RB[\d]*"
return: abc
"""
matched = re.search(field, self.text)
if not matched:
err_msg = u"Failed to extract data with regex!\n"
err_msg += u"response content: {}\n".format(self.content)
err_msg += u"regex: {}\n".format(field)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
return matched.group(1)
def _extract_field_with_delimiter(self, field):
""" response content could be json or html text.
@param (str) field should be string joined by delimiter.
e.g.
"status_code"
"headers"
"cookies"
"content"
"headers.content-type"
"content.person.name.first_name"
"""
try:
# string.split(sep=None, maxsplit=-1) -> list of strings
# e.g. "content.person.name" => ["content", "person.name"]
try:
top_query, sub_query = field.split('.', 1)
except ValueError:
top_query = field
sub_query = None
if top_query == "cookies":
cookies = self.cookies
try:
return cookies[sub_query]
except KeyError:
err_msg = u"Failed to extract attribute from cookies!\n"
err_msg += u"cookies: {}\n".format(cookies)
err_msg += u"attribute: {}".format(sub_query)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
elif top_query == "elapsed":
if sub_query in ["days", "seconds", "microseconds"]:
return getattr(self.elapsed, sub_query)
elif sub_query == "total_seconds":
return self.elapsed.total_seconds()
else:
err_msg = "{}: {} is not valid timedelta attribute.\n".format(field, sub_query)
err_msg += "elapsed only support attributes: days, seconds, microseconds, total_seconds.\n"
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
try:
top_query_content = getattr(self, top_query)
except AttributeError:
err_msg = u"Failed to extract attribute from response object: resp_obj.{}".format(top_query)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
if sub_query:
if not isinstance(top_query_content, (dict, CaseInsensitiveDict, list)):
try:
# TODO: remove compatibility for content, text
if isinstance(top_query_content, bytes):
top_query_content = top_query_content.decode("utf-8")
if isinstance(top_query_content, PreparedRequest):
top_query_content = top_query_content.__dict__
else:
top_query_content = json.loads(top_query_content)
except json.decoder.JSONDecodeError:
err_msg = u"Failed to extract data with delimiter!\n"
err_msg += u"response content: {}\n".format(self.content)
err_msg += u"regex: {}\n".format(field)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
# e.g. key: resp_headers_content_type, sub_query = "content-type"
return utils.query_json(top_query_content, sub_query)
else:
# e.g. key: resp_status_code, resp_content
return top_query_content
except AttributeError:
err_msg = u"Failed to extract value from response!\n"
err_msg += u"response content: {}\n".format(self.content)
err_msg += u"extract field: {}\n".format(field)
logger.log_error(err_msg)
raise exception.ParamsError(err_msg)
def extract_field(self, field):
""" extract value from requests.Response.
"""
msg = "extract field: {}".format(field)
try:
if text_extractor_regexp_compile.match(field):
value = self._extract_field_with_regex(field)
else:
value = self._extract_field_with_delimiter(field)
msg += "\t=> {}".format(value)
logger.log_debug(msg)
# TODO: unify ParseResponseError type
except (exception.ParseResponseError, TypeError):
logger.log_error("failed to extract field: {}".format(field))
raise
return value
def extract_response(self, extractors):
""" extract value from requests.Response and store in OrderedDict.
@param (list) extractors
[
{"resp_status_code": "status_code"},
{"resp_headers_content_type": "headers.content-type"},
{"resp_content": "content"},
{"resp_content_person_first_name": "content.person.name.first_name"}
]
@return (OrderDict) variable binds ordered dict
"""
if not extractors:
return {}
logger.log_info("start to extract from response object.")
extracted_variables_mapping = OrderedDict()
extract_binds_order_dict = utils.convert_to_order_dict(extractors)
for key, field in extract_binds_order_dict.items():
if not isinstance(field, basestring):
raise exception.ParamsError("invalid extractors in testcase!")
extracted_variables_mapping[key] = self.extract_field(field)
return extracted_variables_mapping
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/response.py
|
response.py
|
import os
import pickle
from unittest.case import SkipTest
from requests.cookies import cookiejar_from_dict
from apimeter import exception, logger, response, utils
from apimeter.client import HttpSession
from apimeter.context import Context
class Runner(object):
def __init__(self, config_dict=None, http_client_session=None):
self.http_client_session = http_client_session
self.evaluated_validators = []
self.context = Context()
config_dict = config_dict or {}
self.init_config(config_dict, "testset")
# testset setup hooks
testset_setup_hooks = config_dict.pop("setup_hooks", [])
if testset_setup_hooks:
self.do_hook_actions(testset_setup_hooks)
# testset teardown hooks
self.testset_teardown_hooks = config_dict.pop("teardown_hooks", [])
def __del__(self):
if self.testset_teardown_hooks:
self.do_hook_actions(self.testset_teardown_hooks)
def init_config(self, config_dict, level):
""" create/update context variables binds
@param (dict) config_dict
@param (str) level, "testset" or "testcase"
testset:
{
"name": "smoke testset",
"path": "tests/data/demo_testset_variables.yml",
"requires": [], # optional
"function_binds": {}, # optional
"import_module_items": [], # optional
"variables": [], # optional
"request": {
"base_url": "http://127.0.0.1:5000",
"headers": {
"User-Agent": "iOS/2.8.3"
}
}
}
testcase:
{
"name": "testcase description",
"requires": [], # optional
"function_binds": {}, # optional
"import_module_items": [], # optional
"variables": [], # optional
"request": {
"url": "/api/get-token",
"method": "POST",
"headers": {
"Content-Type": "application/json"
}
},
"json": {
"sign": "90f418f08992a091d031696c6dd97a674842b1f2"
}
}
@param (str) context level, testcase or testset
"""
# convert keys in request headers to lowercase
config_dict = utils.lower_config_dict_key(config_dict)
self.context.init_context(level)
self.context.config_context(config_dict, level)
request_config = config_dict.get('request', {})
parsed_request = self.context.get_parsed_request(request_config, level)
base_url = parsed_request.pop("base_url", None)
self.http_client_session = self.http_client_session or HttpSession(base_url)
return parsed_request
def _handle_skip_feature(self, testcase_dict):
""" handle skip feature for testcase
- skip: skip current test unconditionally
- skipIf: skip current test if condition is true
- skipUnless: skip current test unless condition is true
"""
skip_reason = None
if "skip" in testcase_dict:
skip_reason = testcase_dict["skip"]
elif "skipIf" in testcase_dict:
skip_if_condition = testcase_dict["skipIf"]
if self.context.eval_content(skip_if_condition):
skip_reason = "{} evaluate to True".format(skip_if_condition)
elif "skipUnless" in testcase_dict:
skip_unless_condition = testcase_dict["skipUnless"]
if not self.context.eval_content(skip_unless_condition):
skip_reason = "{} evaluate to False".format(skip_unless_condition)
if skip_reason:
raise SkipTest(skip_reason)
def do_hook_actions(self, actions):
for action in actions:
logger.log_debug("call hook: {}".format(action))
self.context.eval_content(action)
def run_test(self, testcase_dict):
""" run single testcase.
@param (dict) testcase_dict
{
"name": "testcase description",
"skip": "skip this test unconditionally",
"times": 3,
"requires": [], # optional, override
"function_binds": {}, # optional, override
"variables": [], # optional, override
"request": {
"url": "http://127.0.0.1:5000/api/users/1000",
"method": "POST",
"headers": {
"Content-Type": "application/json",
"authorization": "$authorization",
"random": "$random"
},
"body": '{"name": "user", "password": "123456"}'
},
"extract": [], # optional
"validate": [], # optional
"setup_hooks": [], # optional
"teardown_hooks": [] # optional
}
@return True or raise exception during test
"""
# check skip
self._handle_skip_feature(testcase_dict)
# prepare
parsed_request = self.init_config(testcase_dict, level="testcase")
self.context.bind_testcase_variable("request", parsed_request)
# setup hooks
setup_hooks = testcase_dict.get("setup_hooks", [])
setup_hooks.insert(0, "${setup_hook_prepare_kwargs($request)}")
self.do_hook_actions(setup_hooks)
try:
url = parsed_request.pop('url')
method = parsed_request.pop('method')
group_name = parsed_request.pop("group", None)
except KeyError:
raise exception.ParamsError("URL or METHOD missed!")
logger.log_info("{method} {url}".format(method=method, url=url))
logger.log_debug("request kwargs(raw): {kwargs}".format(kwargs=parsed_request))
# 如果当前目录存在cookies文件,则加载进来【os.getcwd() -> /Users/zhangchuzhao/Project/python/dev/YmApiMeter】
cookie_file = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'cookies')
if os.path.exists(cookie_file):
with open(cookie_file, 'rb') as f:
cookies = pickle.load(f)
cookie_dict = {}
for cookie in cookies:
cookie_dict[cookie['name']] = cookie['value']
cookie_jar = cookiejar_from_dict(cookie_dict)
parsed_request['cookies'] = cookie_jar
# request
resp = self.http_client_session.request(
method,
url,
name=group_name,
**parsed_request
)
resp_obj = response.ResponseObject(resp)
# teardown hooks
teardown_hooks = testcase_dict.get("teardown_hooks", [])
if teardown_hooks:
self.context.bind_testcase_variable("response", resp_obj)
self.do_hook_actions(teardown_hooks)
# extract
extractors = testcase_dict.get("extract", []) or testcase_dict.get("extractors", [])
extracted_variables_mapping = resp_obj.extract_response(extractors)
self.context.bind_extracted_variables(extracted_variables_mapping)
# validate
validators = testcase_dict.get("validate", []) or testcase_dict.get("validators", [])
try:
self.evaluated_validators = self.context.eval_validators(validators, resp_obj)
self.context.validate(self.evaluated_validators)
except (exception.ParamsError, exception.ResponseError,
exception.ValidationError, exception.ParseResponseError):
# log request
err_req_msg = "request: \n"
err_req_msg += "headers: {}\n".format(parsed_request.pop("headers", {}))
for k, v in parsed_request.items():
err_req_msg += "{}: {}\n".format(k, v)
logger.log_error(err_req_msg)
# log response
err_resp_msg = "response: \n"
err_resp_msg += "status_code: {}\n".format(resp_obj.status_code)
err_resp_msg += "headers: {}\n".format(resp_obj.headers)
err_resp_msg += "content: {}\n".format(resp_obj.content)
logger.log_error(err_resp_msg)
raise
def extract_output(self, output_variables_list):
""" extract output variables
"""
variables_mapping = self.context.testcase_variables_mapping
output = {}
for variable in output_variables_list:
if variable not in variables_mapping:
logger.log_warning(
"variable '{}' can not be found in variables mapping, failed to output!".format(variable)
)
continue
output[variable] = variables_mapping[variable]
return output
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/runner.py
|
runner.py
|
import re
import time
import requests
import urllib3
from apimeter import logger
from apimeter.exception import ParamsError
from requests import Request, Response
from requests.exceptions import (InvalidSchema, InvalidURL, MissingSchema,
RequestException)
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
absolute_http_url_regexp = re.compile(r"^https?://", re.I)
class ApiResponse(Response):
def raise_for_status(self):
if hasattr(self, 'error') and self.error:
raise self.error
Response.raise_for_status(self)
class HttpSession(requests.Session):
"""
Class for performing HTTP requests and holding (session-) cookies between requests (in order
to be able to log in and out of websites). Each request is logged so that ApiMeter can
display statistics.
This is a slightly extended version of `python-request <http://python-requests.org>`_'s
:py:class:`requests.Session` class and mostly this class works exactly the same. However
the methods for making requests (get, post, delete, put, head, options, patch, request)
can now take a *url* argument that's only the path part of the URL, in which case the host
part of the URL will be prepended with the HttpSession.base_url which is normally inherited
from a ApiMeter class' host property.
"""
def __init__(self, base_url=None, *args, **kwargs):
super(HttpSession, self).__init__(*args, **kwargs)
self.base_url = base_url if base_url else ""
self.init_meta_data()
def _build_url(self, path):
""" prepend url with hostname unless it's already an absolute URL """
if absolute_http_url_regexp.match(path):
return path
elif self.base_url:
return "{}/{}".format(self.base_url.rstrip("/"), path.lstrip("/"))
else:
raise ParamsError("base url missed!")
def init_meta_data(self):
""" initialize meta_data, it will store detail data of request and response
"""
self.meta_data = {
"request": {
"url": "N/A",
"method": "N/A",
"headers": {},
"start_timestamp": None
},
"response": {
"status_code": "N/A",
"headers": {},
"content_size": "N/A",
"response_time_ms": "N/A",
"elapsed_ms": "N/A",
"encoding": None,
"content": None,
"content_type": ""
}
}
def request(self, method, url, name=None, **kwargs):
"""
Constructs and sends a :py:class:`requests.Request`.
Returns :py:class:`requests.Response` object.
:param method:
method for the new :class:`Request` object.
:param url:
URL for the new :class:`Request` object.
:param name: (optional)
Placeholder, make compatible with Locust's HttpSession
:param params: (optional)
Dictionary or bytes to be sent in the query string for the :class:`Request`.
:param data: (optional)
Dictionary or bytes to send in the body of the :class:`Request`.
:param headers: (optional)
Dictionary of HTTP Headers to send with the :class:`Request`.
:param cookies: (optional)
Dict or CookieJar object to send with the :class:`Request`.
:param files: (optional)
Dictionary of ``'filename': file-like-objects`` for multipart encoding upload.
:param auth: (optional)
Auth tuple or callable to enable Basic/Digest/Custom HTTP Auth.
:param timeout: (optional)
How long to wait for the server to send data before giving up, as a float, or \
a (`connect timeout, read timeout <user/advanced.html#timeouts>`_) tuple.
:type timeout: float or tuple
:param allow_redirects: (optional)
Set to True by default.
:type allow_redirects: bool
:param proxies: (optional)
Dictionary mapping protocol to the URL of the proxy.
:param stream: (optional)
whether to immediately download the response content. Defaults to ``False``.
:param verify: (optional)
if ``True``, the SSL cert will be verified. A CA_BUNDLE path can also be provided.
:param cert: (optional)
if String, path to ssl client cert file (.pem). If Tuple, ('cert', 'key') pair.
"""
def log_print(request_response):
msg = "\n================== {} details ==================\n".format(request_response)
for key, value in self.meta_data[request_response].items():
msg += "{:<16} : {}\n".format(key, value)
logger.log_debug(msg
)
# record original request info
self.meta_data["request"]["method"] = method
self.meta_data["request"]["url"] = url
self.meta_data["request"].update(kwargs)
self.meta_data["request"]["start_timestamp"] = time.time()
# prepend url with hostname unless it's already an absolute URL
url = self._build_url(url)
kwargs.setdefault("timeout", 120)
response = self._send_request_safe_mode(method, url, **kwargs)
# record the consumed time
self.meta_data["response"]["response_time_ms"] = \
round((time.time() - self.meta_data["request"]["start_timestamp"]) * 1000, 2)
self.meta_data["response"]["elapsed_ms"] = response.elapsed.microseconds / 1000.0
# record actual request info
self.meta_data["request"]["url"] = (response.history and response.history[0] or response).request.url
self.meta_data["request"]["headers"] = dict(response.request.headers)
self.meta_data["request"]["body"] = response.request.body
# log request details in debug mode
log_print("request")
# record response info
self.meta_data["response"]["ok"] = response.ok
self.meta_data["response"]["url"] = response.url
self.meta_data["response"]["status_code"] = response.status_code
self.meta_data["response"]["reason"] = response.reason
self.meta_data["response"]["headers"] = dict(response.headers)
self.meta_data["response"]["cookies"] = response.cookies or {}
self.meta_data["response"]["encoding"] = response.encoding
self.meta_data["response"]["content"] = response.content
self.meta_data["response"]["text"] = response.text
self.meta_data["response"]["content_type"] = response.headers.get("Content-Type", "")
try:
self.meta_data["response"]["json"] = response.json()
except ValueError:
self.meta_data["response"]["json"] = None
# get the length of the content, but if the argument stream is set to True, we take
# the size from the content-length header, in order to not trigger fetching of the body
if kwargs.get("stream", False):
self.meta_data["response"]["content_size"] = \
int(self.meta_data["response"]["headers"].get("content-length") or 0)
else:
self.meta_data["response"]["content_size"] = len(response.content or "")
# log response details in debug mode
log_print("response")
try:
response.raise_for_status()
except RequestException as e:
logger.log_error(u"{exception}".format(exception=str(e)))
else:
logger.log_info(
"""status_code: {}, response_time(ms): {} ms, response_length: {} bytes""".format(
self.meta_data["response"]["status_code"],
self.meta_data["response"]["response_time_ms"],
self.meta_data["response"]["content_size"]
)
)
return response
def _send_request_safe_mode(self, method, url, **kwargs):
"""
Send a HTTP request, and catch any exception that might occur due to connection problems.
Safe mode has been removed from requests 1.x.
"""
try:
msg = "processed request:\n"
msg += "> {method} {url}\n".format(method=method, url=url)
msg += "> kwargs: {kwargs}".format(kwargs=kwargs)
logger.log_debug(msg)
return requests.Session.request(self, method, url, **kwargs)
except (MissingSchema, InvalidSchema, InvalidURL):
raise
except RequestException as ex:
resp = ApiResponse()
resp.error = ex
resp.status_code = 0 # with this status_code, content returns None
resp.request = Request(method, url).prepare()
return resp
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/client.py
|
client.py
|
import datetime
import json
import os
import random
import re
import string
import time
from apimeter.compat import basestring, builtin_str, integer_types, str
from apimeter.exception import ParamsError
from requests_toolbelt import MultipartEncoder
""" built-in functions
"""
def gen_random_string(str_len):
""" generate random string with specified length
"""
return ''.join(
random.choice(string.ascii_letters + string.digits) for _ in range(str_len))
def get_timestamp(str_len=13):
""" get timestamp string, length can only between 0 and 16
"""
if isinstance(str_len, integer_types) and 0 < str_len < 17:
return builtin_str(time.time()).replace(".", "")[:str_len]
raise ParamsError("timestamp length can only between 0 and 16.")
def get_current_date(fmt="%Y-%m-%d"):
""" get current date, default format is %Y-%m-%d
"""
return datetime.datetime.now().strftime(fmt)
def multipart_encoder(field_name, file_path, file_type=None, file_headers=None):
if not os.path.isabs(file_path):
file_path = os.path.join(os.getcwd(), file_path)
filename = os.path.basename(file_path)
with open(file_path, 'rb') as f:
fields = {
field_name: (filename, f.read(), file_type)
}
return MultipartEncoder(fields)
def multipart_content_type(multipart_encoder):
return multipart_encoder.content_type
""" built-in comparators
"""
def equals(check_value, expect_value):
assert check_value == expect_value
def less_than(check_value, expect_value):
assert check_value < expect_value
def less_than_or_equals(check_value, expect_value):
assert check_value <= expect_value
def greater_than(check_value, expect_value):
assert check_value > expect_value
def greater_than_or_equals(check_value, expect_value):
assert check_value >= expect_value
def not_equals(check_value, expect_value):
assert check_value != expect_value
def string_equals(check_value, expect_value):
assert builtin_str(check_value) == builtin_str(expect_value)
def length_equals(check_value, expect_value):
assert isinstance(expect_value, integer_types)
assert len(check_value) == expect_value
def length_greater_than(check_value, expect_value):
assert isinstance(expect_value, integer_types)
assert len(check_value) > expect_value
def length_greater_than_or_equals(check_value, expect_value):
assert isinstance(expect_value, integer_types)
assert len(check_value) >= expect_value
def length_less_than(check_value, expect_value):
assert isinstance(expect_value, integer_types)
assert len(check_value) < expect_value
def length_less_than_or_equals(check_value, expect_value):
assert isinstance(expect_value, integer_types)
assert len(check_value) <= expect_value
def contains(check_value, expect_value):
assert isinstance(check_value, (list, tuple, dict, basestring))
assert expect_value in check_value
def contained_by(check_value, expect_value):
assert isinstance(expect_value, (list, tuple, dict, basestring))
assert check_value in expect_value
def type_match(check_value, expect_value):
def get_type(name):
if isinstance(name, type):
return name
elif isinstance(name, basestring):
try:
return __builtins__[name]
except KeyError:
raise ValueError(name)
else:
raise ValueError(name)
assert isinstance(check_value, get_type(expect_value))
def regex_match(check_value, expect_value):
assert isinstance(expect_value, basestring)
assert isinstance(check_value, basestring)
assert re.match(expect_value, check_value)
def startswith(check_value, expect_value):
assert builtin_str(check_value).startswith(builtin_str(expect_value))
def endswith(check_value, expect_value):
assert builtin_str(check_value).endswith(builtin_str(expect_value))
""" built-in hooks
"""
def setup_hook_prepare_kwargs(request):
if request["method"] == "POST":
content_type = request.get("headers", {}).get("content-type")
if content_type and "data" in request:
# if request content-type is application/json, request data should be dumped
if content_type.startswith("application/json") and isinstance(request["data"], (dict, list)):
request["data"] = json.dumps(request["data"])
if isinstance(request["data"], str):
request["data"] = request["data"].encode('utf-8')
def sleep_N_secs(n_secs):
""" sleep n seconds
"""
time.sleep(n_secs)
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/built_in.py
|
built_in.py
|
import io
import multiprocessing
import os
import sys
from locust.main import main
from apimeter.logger import color_print
from apimeter.testcase import TestcaseLoader
def parse_locustfile(file_path):
""" parse testcase file and return locustfile path.
if file_path is a Python file, assume it is a locustfile
if file_path is a YAML/JSON file, convert it to locustfile
"""
if not os.path.isfile(file_path):
color_print("file path invalid, exit.", "RED")
sys.exit(1)
file_suffix = os.path.splitext(file_path)[1]
if file_suffix == ".py":
locustfile_path = file_path
elif file_suffix in ['.yaml', '.yml', '.json']:
locustfile_path = gen_locustfile(file_path)
else:
# '' or other suffix
color_print("file type should be YAML/JSON/Python, exit.", "RED")
sys.exit(1)
return locustfile_path
def gen_locustfile(testcase_file_path):
""" generate locustfile from template.
"""
locustfile_path = 'locustfile.py'
template_path = os.path.join(
os.path.dirname(os.path.realpath(__file__)),
"templates",
"locustfile_template"
)
TestcaseLoader.load_test_dependencies()
testset = TestcaseLoader.load_test_file(testcase_file_path)
host = testset.get("config", {}).get("request", {}).get("base_url", "")
with io.open(template_path, encoding='utf-8') as template:
with io.open(locustfile_path, 'w', encoding='utf-8') as locustfile:
template_content = template.read()
template_content = template_content.replace("$HOST", host)
template_content = template_content.replace("$TESTCASE_FILE", testcase_file_path)
locustfile.write(template_content)
return locustfile_path
def start_master(sys_argv):
sys_argv.append("--master")
sys.argv = sys_argv
main()
def start_slave(sys_argv):
if "--slave" not in sys_argv:
sys_argv.extend(["--slave"])
sys.argv = sys_argv
main()
def run_locusts_with_processes(sys_argv, processes_count):
processes = []
manager = multiprocessing.Manager()
for _ in range(processes_count):
p_slave = multiprocessing.Process(target=start_slave, args=(sys_argv,))
p_slave.daemon = True
p_slave.start()
processes.append(p_slave)
try:
if "--slave" in sys_argv:
[process.join() for process in processes]
else:
start_master(sys_argv)
except KeyboardInterrupt:
manager.shutdown()
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/locusts.py
|
locusts.py
|
import copy
import sys
import unittest
from apimeter import exception, logger, runner, testcase, utils
from apimeter.compat import is_py3
from apimeter.report import HtmlTestResult, get_platform, get_summary, render_html_report
from apimeter.testcase import TestcaseLoader
from apimeter.utils import load_dot_env_file, print_output
class TestCase(unittest.TestCase):
""" create a testcase.
"""
def __init__(self, test_runner, testcase_dict):
super(TestCase, self).__init__()
self.test_runner = test_runner
self.testcase_dict = copy.copy(testcase_dict)
def runTest(self):
""" run testcase and check result.
"""
try:
self.test_runner.run_test(self.testcase_dict)
finally:
if hasattr(self.test_runner.http_client_session, "meta_data"):
self.meta_data = self.test_runner.http_client_session.meta_data
self.meta_data["validators"] = self.test_runner.evaluated_validators
self.test_runner.http_client_session.init_meta_data()
class TestSuite(unittest.TestSuite):
""" create test suite with a testset, it may include one or several testcases.
each suite should initialize a separate Runner() with testset config.
@param
(dict) testset
{
"name": "testset description",
"config": {
"name": "testset description",
"path": "testset_file_path",
"requires": [],
"function_binds": {},
"parameters": {},
"variables": [],
"request": {},
"output": []
},
"testcases": [
{
"name": "testcase description",
"parameters": {},
"variables": [], # optional, override
"request": {},
"extract": {}, # optional
"validate": {} # optional
},
testcase12
]
}
(dict) variables_mapping:
passed in variables mapping, it will override variables in config block
"""
def __init__(self, testset, variables_mapping=None, http_client_session=None):
super(TestSuite, self).__init__()
self.test_runner_list = []
self.config = testset.get("config", {})
self.output_variables_list = self.config.get("output", [])
self.testset_file_path = self.config.get("path")
config_dict_parameters = self.config.get("parameters", [])
config_dict_variables = self.config.get("variables", [])
variables_mapping = variables_mapping or {}
config_dict_variables = utils.override_variables_binds(config_dict_variables, variables_mapping)
config_parametered_variables_list = self._get_parametered_variables(
config_dict_variables,
config_dict_parameters
)
self.testcase_parser = testcase.TestcaseParser()
testcases = testset.get("testcases", [])
for config_variables in config_parametered_variables_list:
# config level
self.config["variables"] = config_variables
test_runner = runner.Runner(self.config, http_client_session)
for testcase_dict in testcases:
testcase_dict = copy.copy(testcase_dict)
# testcase level
testcase_parametered_variables_list = self._get_parametered_variables(
testcase_dict.get("variables", []),
testcase_dict.get("parameters", [])
)
for testcase_variables in testcase_parametered_variables_list:
testcase_dict["variables"] = testcase_variables
# eval testcase name with bind variables
variables = utils.override_variables_binds(
config_variables,
testcase_variables
)
self.testcase_parser.update_binded_variables(variables)
try:
testcase_name = self.testcase_parser.eval_content_with_bindings(testcase_dict["name"])
except (AssertionError, exception.ParamsError):
logger.log_warning("failed to eval testcase name: {}".format(testcase_dict["name"]))
testcase_name = testcase_dict["name"]
self.test_runner_list.append((test_runner, variables))
self._add_test_to_suite(testcase_name, test_runner, testcase_dict)
def _get_parametered_variables(self, variables, parameters):
""" parameterize varaibles with parameters
"""
cartesian_product_parameters = testcase.parse_parameters(
parameters,
self.testset_file_path
) or [{}]
parametered_variables_list = []
for parameter_mapping in cartesian_product_parameters:
parameter_mapping = parameter_mapping or {}
variables = utils.override_variables_binds(
variables,
parameter_mapping
)
parametered_variables_list.append(variables)
return parametered_variables_list
def _add_test_to_suite(self, testcase_name, test_runner, testcase_dict):
if is_py3:
TestCase.runTest.__doc__ = testcase_name
else:
TestCase.runTest.__func__.__doc__ = testcase_name
test = TestCase(test_runner, testcase_dict)
[self.addTest(test) for _ in range(int(testcase_dict.get("times", 1)))]
@property
def output(self):
outputs = []
for test_runner, variables in self.test_runner_list:
out = test_runner.extract_output(self.output_variables_list)
if not out:
continue
in_out = {
"in": dict(variables),
"out": out
}
if in_out not in outputs:
outputs.append(in_out)
return outputs
# class TaskSuite(unittest.TestSuite):
# """ create task suite with specified testcase path.
# each task suite may include one or several test suite.
# """
# def __init__(self, testsets, mapping=None, http_client_session=None):
# """
# @params
# testsets (dict/list): testset or list of testset
# testset_dict
# or
# [
# testset_dict_1,
# testset_dict_2,
# {
# "name": "desc1",
# "config": {},
# "api": {},
# "testcases": [testcase11, testcase12]
# }
# ]
# mapping (dict):
# passed in variables mapping, it will override variables in config block
# """
# super(TaskSuite, self).__init__()
# mapping = mapping or {}
#
# if not testsets:
# raise exception.TestcaseNotFound
#
# if isinstance(testsets, dict):
# testsets = [testsets]
#
# self.suite_list = []
# for testset in testsets:
# suite = TestSuite(testset, mapping, http_client_session)
# self.addTest(suite)
# self.suite_list.append(suite)
#
# @property
# def tasks(self):
# return self.suite_list
def init_test_suites(path_or_testsets, mapping=None, http_client_session=None):
""" initialize TestSuite list with testset path or testset dict
@param path_or_testsets: YAML/JSON testset file path or testset list
path: path could be in several type
- absolute/relative file path
- absolute/relative folder path
- list/set container with file(s) and/or folder(s)
testsets (dict/list): testset or list of testset
testset_dict
or
[
testset_dict_1,
testset_dict_2,
{
"config": {},
"api": {},
"testcases": [testcase1, testcase2]
}
]
mapping(dict)
passed in variables mapping, it will override variables in config block
"""
if not testcase.is_testsets(path_or_testsets):
TestcaseLoader.load_test_dependencies()
testsets = TestcaseLoader.load_testsets_by_path(path_or_testsets)
else:
testsets = path_or_testsets
# TODO: move comparator uniform here
mapping = mapping or {}
if not testsets:
raise exception.TestcaseNotFound
if isinstance(testsets, dict):
testsets = [testsets]
test_suite_list = []
for testset in testsets:
test_suite = TestSuite(testset, mapping, http_client_session)
test_suite_list.append(test_suite)
return test_suite_list
class ApiMeter(object):
def __init__(self, **kwargs):
""" initialize test runner
@param (dict) kwargs: key-value arguments used to initialize TextTestRunner
- resultclass: HtmlTestResult or TextTestResult
- failfast: False/True, stop the test run on the first error or failure.
- dot_env_path: .env file path
"""
dot_env_path = kwargs.pop("dot_env_path", None)
load_dot_env_file(dot_env_path)
kwargs.setdefault("resultclass", HtmlTestResult)
self.runner = unittest.TextTestRunner(**kwargs)
self.summary = {
"success": True,
"stat": {},
"time": {},
"platform": get_platform(),
"details": []
}
def run(self, path_or_testsets, mapping=None):
""" start to run test with varaibles mapping
@param path_or_testsets: YAML/JSON testset file path or testset list
path: path could be in several type
- absolute/relative file path
- absolute/relative folder path
- list/set container with file(s) and/or folder(s)
testsets: testset or list of testset
- (dict) testset_dict
- (list) list of testset_dict
[
testset_dict_1,
testset_dict_2
]
@param (dict) mapping:
if mapping specified, it will override variables in config block
"""
try:
test_suite_list = init_test_suites(path_or_testsets, mapping)
except exception.TestcaseNotFound:
logger.log_error("Testcases not found in {}".format(path_or_testsets))
sys.exit(1)
def accumulate_stat(origin_stat, new_stat):
"""accumulate new_stat to origin_stat
"""
for key in new_stat:
if key not in origin_stat:
origin_stat[key] = new_stat[key]
elif key == "start_at":
origin_stat[key] = min(origin_stat[key], new_stat[key])
else:
origin_stat[key] += new_stat[key]
for test_suite in test_suite_list:
result = self.runner.run(test_suite)
test_suite_summary = get_summary(result)
self.summary["success"] &= test_suite_summary["success"]
test_suite_summary["name"] = test_suite.config.get("name")
test_suite_summary["base_url"] = test_suite.config.get("request", {}).get("base_url", "")
test_suite_summary["output"] = test_suite.output
print_output(test_suite_summary["output"])
accumulate_stat(self.summary["stat"], test_suite_summary["stat"])
accumulate_stat(self.summary["time"], test_suite_summary["time"])
self.summary["details"].append(test_suite_summary)
return self
def gen_html_report(self, html_report_name=None, html_report_template=None):
""" generate html report and return report path
@param (str) html_report_name:
output html report file name
@param (str) html_report_template:
report template file path, template should be in Jinja2 format
"""
return render_html_report(
self.summary,
html_report_name,
html_report_template
)
class LocustTask(object):
def __init__(self, path_or_testsets, locust_client, mapping=None):
self.test_suite_list = init_test_suites(path_or_testsets, mapping, locust_client)
def run(self):
for test_suite in self.test_suite_list:
for test in test_suite:
try:
test.runTest()
except exception.MyBaseError as ex:
from locust.events import request_failure
request_failure.fire(
request_type=test.testcase_dict.get("request", {}).get("method"),
name=test.testcase_dict.get("request", {}).get("url"),
response_time=0,
exception=ex
)
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/task.py
|
task.py
|
import io
import os
import time
import platform
import unittest
from base64 import b64encode
from collections import Iterable
from datetime import datetime
from jinja2 import Template, escape
from requests.structures import CaseInsensitiveDict
from apimeter import logger
from apimeter.__about__ import __version__
from apimeter.compat import basestring, bytes, json, numeric_types
def get_platform():
return {
"apimeter_version": __version__,
"python_version": "{} {}".format(
platform.python_implementation(),
platform.python_version()
),
"platform": platform.platform()
}
def get_summary(result):
""" get summary from test result
"""
summary = {
"success": result.wasSuccessful(),
"stat": {
'testsRun': result.testsRun,
'failures': len(result.failures),
'errors': len(result.errors),
'skipped': len(result.skipped),
'expectedFailures': len(result.expectedFailures),
'unexpectedSuccesses': len(result.unexpectedSuccesses)
}
}
summary["stat"]["successes"] = \
summary["stat"]["testsRun"] - \
summary["stat"]["failures"] - \
summary["stat"]["errors"] - \
summary["stat"]["skipped"] - \
summary["stat"]["expectedFailures"] - \
summary["stat"]["unexpectedSuccesses"]
if getattr(result, "records", None):
summary["time"] = {
'start_at': result.start_at,
'duration': result.duration
}
summary["records"] = result.records
else:
summary["records"] = []
return summary
def render_html_report(summary, html_report_name=None, html_report_template=None):
""" render html report with specified report name and template
if html_report_name is not specified, use current datetime
if html_report_template is not specified, use default report template
"""
if not html_report_template:
html_report_template = os.path.join(
os.path.abspath(os.path.dirname(__file__)),
"templates",
"default_report_template.html"
)
logger.log_debug("No html report template specified, use default.")
else:
logger.log_info("render with html report template: {}".format(html_report_template))
logger.log_info("Start to render Html report ...")
logger.log_debug("render data: {}".format(summary))
report_dir_path = os.path.join(os.getcwd(), "reports")
start_at_timestamp = int(summary["time"]["start_at"])
start_at_datetime = datetime.fromtimestamp(start_at_timestamp).strftime('%Y-%m-%d-%H-%M-%S')
summary["time"]["start_datetime"] = start_at_datetime
if html_report_name:
summary["html_report_name"] = html_report_name
report_dir_path = os.path.join(report_dir_path, html_report_name)
html_report_name += "-{}.html".format(start_at_datetime)
else:
summary["html_report_name"] = ""
html_report_name = "{}.html".format(start_at_datetime)
if not os.path.isdir(report_dir_path):
os.makedirs(report_dir_path)
for suite_summary in summary["details"]:
for record in suite_summary.get("records"):
meta_data = record['meta_data']
stringify_data(meta_data, 'request')
stringify_data(meta_data, 'response')
with io.open(html_report_template, "r", encoding='utf-8') as fp_r:
template_content = fp_r.read()
report_path = os.path.join(report_dir_path, html_report_name)
with io.open(report_path, 'w', encoding='utf-8') as fp_w:
rendered_content = Template(template_content).render(summary)
fp_w.write(rendered_content)
logger.log_info("Generated Html report: {}".format(report_path))
return report_path
def stringify_data(meta_data, request_or_response):
"""
meta_data = {
"request": {},
"response": {}
}
"""
headers = meta_data[request_or_response]["headers"]
request_or_response_dict = meta_data[request_or_response]
for key, value in request_or_response_dict.items():
if isinstance(value, list):
value = json.dumps(value, indent=2, ensure_ascii=False)
elif isinstance(value, bytes):
try:
encoding = meta_data["response"].get("encoding")
if not encoding or encoding == "None":
encoding = "utf-8"
content_type = meta_data["response"]["content_type"]
if "image" in content_type:
meta_data["response"]["content_type"] = "image"
value = "data:{};base64,{}".format(content_type, b64encode(value).decode(encoding))
else:
value = escape(value.decode(encoding))
except UnicodeDecodeError:
pass
elif not isinstance(value, (basestring, numeric_types, Iterable)):
# class instance, e.g. MultipartEncoder()
value = repr(value)
meta_data[request_or_response][key] = value
class HtmlTestResult(unittest.TextTestResult):
"""A html result class that can generate formatted html results.
Used by TextTestRunner.
"""
def __init__(self, stream, descriptions, verbosity):
super(HtmlTestResult, self).__init__(stream, descriptions, verbosity)
self.records = []
def _record_test(self, test, status, attachment=''):
self.records.append({
'name': test.shortDescription(),
'status': status,
'attachment': attachment,
"meta_data": test.meta_data
})
def startTestRun(self):
self.start_at = time.time()
def startTest(self, test):
""" add start test time """
super(HtmlTestResult, self).startTest(test)
logger.color_print(test.shortDescription(), "magenta")
def addSuccess(self, test):
super(HtmlTestResult, self).addSuccess(test)
self._record_test(test, 'success')
print("")
def addError(self, test, err):
super(HtmlTestResult, self).addError(test, err)
self._record_test(test, 'error', self._exc_info_to_string(err, test))
print("")
def addFailure(self, test, err):
super(HtmlTestResult, self).addFailure(test, err)
self._record_test(test, 'failure', self._exc_info_to_string(err, test))
print("")
def addSkip(self, test, reason):
super(HtmlTestResult, self).addSkip(test, reason)
self._record_test(test, 'skipped', reason)
print("")
def addExpectedFailure(self, test, err):
super(HtmlTestResult, self).addExpectedFailure(test, err)
self._record_test(test, 'ExpectedFailure', self._exc_info_to_string(err, test))
print("")
def addUnexpectedSuccess(self, test):
super(HtmlTestResult, self).addUnexpectedSuccess(test)
self._record_test(test, 'UnexpectedSuccess')
print("")
@property
def duration(self):
return time.time() - self.start_at
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/report.py
|
report.py
|
import copy
import csv
import hashlib
import hmac
import imp
import importlib
import io
import json
import os.path
import random
import string
import types
import yaml
from datetime import datetime
from requests.structures import CaseInsensitiveDict
from apimeter import exception, logger
from apimeter.compat import OrderedDict, is_py2, is_py3
SECRET_KEY = "YouMi"
def gen_random_string(str_len):
return ''.join(
random.choice(string.ascii_letters + string.digits) for _ in range(str_len))
def gen_md5(*str_args):
return hashlib.md5("".join(str_args).encode('utf-8')).hexdigest()
def get_sign(*args):
content = ''.join(args).encode('ascii')
sign_key = SECRET_KEY.encode('ascii')
sign = hmac.new(sign_key, content, hashlib.sha1).hexdigest()
return sign
def remove_prefix(text, prefix):
""" remove prefix from text
"""
if text.startswith(prefix):
return text[len(prefix):]
return text
class FileUtils(object):
@staticmethod
def _check_format(file_path, content):
""" check testcase format if valid
"""
if not content:
# testcase file content is empty
err_msg = u"Testcase file content is empty: {}".format(file_path)
logger.log_error(err_msg)
raise exception.FileFormatError(err_msg)
elif not isinstance(content, (list, dict)):
# testcase file content does not match testcase format
err_msg = u"Testcase file content format invalid: {}".format(file_path)
logger.log_error(err_msg)
raise exception.FileFormatError(err_msg)
@staticmethod
def _load_yaml_file(yaml_file):
""" load yaml file and check file content format
"""
with io.open(yaml_file, 'r', encoding='utf-8') as stream:
yaml_content = yaml.load(stream)
FileUtils._check_format(yaml_file, yaml_content)
return yaml_content
@staticmethod
def _load_json_file(json_file):
""" load json file and check file content format
"""
with io.open(json_file, encoding='utf-8') as data_file:
try:
json_content = json.load(data_file)
except exception.JSONDecodeError:
err_msg = u"JSONDecodeError: JSON file format error: {}".format(json_file)
logger.log_error(err_msg)
raise exception.FileFormatError(err_msg)
FileUtils._check_format(json_file, json_content)
return json_content
@staticmethod
def _load_csv_file(csv_file):
""" load csv file and check file content format
@param
csv_file: csv file path
e.g. csv file content:
username,password
test1,111111
test2,222222
test3,333333
@return
list of parameter, each parameter is in dict format
e.g.
[
{'username': 'test1', 'password': '111111'},
{'username': 'test2', 'password': '222222'},
{'username': 'test3', 'password': '333333'}
]
"""
csv_content_list = []
with io.open(csv_file, encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
csv_content_list.append(row)
return csv_content_list
@staticmethod
def load_file(file_path):
if not os.path.isfile(file_path):
raise exception.FileNotFoundError("{} does not exist.".format(file_path))
file_suffix = os.path.splitext(file_path)[1].lower()
if file_suffix == '.json':
return FileUtils._load_json_file(file_path)
elif file_suffix in ['.yaml', '.yml']:
return FileUtils._load_yaml_file(file_path)
elif file_suffix == ".csv":
return FileUtils._load_csv_file(file_path)
else:
# '' or other suffix
err_msg = u"Unsupported file format: {}".format(file_path)
logger.log_warning(err_msg)
return []
@staticmethod
def load_folder_files(folder_path, recursive=True):
""" load folder path, return all files in list format.
@param
folder_path: specified folder path to load
recursive: if True, will load files recursively
"""
if isinstance(folder_path, (list, set)):
files = []
for path in set(folder_path):
files.extend(FileUtils.load_folder_files(path, recursive))
return files
if not os.path.exists(folder_path):
return []
file_list = []
for dirpath, dirnames, filenames in os.walk(folder_path):
filenames_list = []
for filename in filenames:
if not filename.endswith(('.yml', '.yaml', '.json')):
continue
filenames_list.append(filename)
for filename in filenames_list:
file_path = os.path.join(dirpath, filename)
file_list.append(file_path)
if not recursive:
break
return file_list
def query_json(json_content, query, delimiter='.'):
""" Do an xpath-like query with json_content.
@param (json_content) json_content
json_content = {
"ids": [1, 2, 3, 4],
"person": {
"name": {
"first_name": "Leo",
"last_name": "Lee",
},
"age": 29,
"cities": ["Guangzhou", "Shenzhen"]
}
}
@param (str) query
"person.name.first_name" => "Leo"
"person.cities.0" => "Guangzhou"
@return queried result
"""
if json_content == "":
raise exception.ResponseError("response content is empty!")
try:
for key in query.split(delimiter):
if isinstance(json_content, list):
json_content = json_content[int(key)]
elif isinstance(json_content, (dict, CaseInsensitiveDict)):
json_content = json_content[key]
else:
raise exception.ParseResponseError(
"response content is in text format! failed to query key {}!".format(key))
except (KeyError, ValueError, IndexError):
raise exception.ParseResponseError("failed to query json when extracting response!")
return json_content
def get_uniform_comparator(comparator):
""" convert comparator alias to uniform name
"""
if comparator in ["eq", "equals", "==", "is"]:
return "equals"
elif comparator in ["lt", "less_than"]:
return "less_than"
elif comparator in ["le", "less_than_or_equals"]:
return "less_than_or_equals"
elif comparator in ["gt", "greater_than"]:
return "greater_than"
elif comparator in ["ge", "greater_than_or_equals"]:
return "greater_than_or_equals"
elif comparator in ["ne", "not_equals"]:
return "not_equals"
elif comparator in ["str_eq", "string_equals"]:
return "string_equals"
elif comparator in ["len_eq", "length_equals", "count_eq"]:
return "length_equals"
elif comparator in ["len_gt", "count_gt", "length_greater_than", "count_greater_than"]:
return "length_greater_than"
elif comparator in ["len_ge", "count_ge", "length_greater_than_or_equals", "count_greater_than_or_equals"]:
return "length_greater_than_or_equals"
elif comparator in ["len_lt", "count_lt", "length_less_than", "count_less_than"]:
return "length_less_than"
elif comparator in ["len_le", "count_le", "length_less_than_or_equals", "count_less_than_or_equals"]:
return "length_less_than_or_equals"
else:
return comparator
def deep_update_dict(origin_dict, override_dict):
""" update origin dict with override dict recursively
e.g. origin_dict = {'a': 1, 'b': {'c': 2, 'd': 4}}
override_dict = {'b': {'c': 3}}
return: {'a': 1, 'b': {'c': 3, 'd': 4}}
"""
if not override_dict:
return origin_dict
for key, val in override_dict.items():
if isinstance(val, dict):
tmp = deep_update_dict(origin_dict.get(key, {}), val)
origin_dict[key] = tmp
elif val is None:
# fix #64: when headers in test is None, it should inherit from config
continue
else:
origin_dict[key] = override_dict[key]
return origin_dict
def is_function(tup):
""" Takes (name, object) tuple, returns True if it is a function.
"""
name, item = tup
return isinstance(item, types.FunctionType)
def is_variable(tup):
""" Takes (name, object) tuple, returns True if it is a variable.
"""
name, item = tup
if callable(item):
# function or class
return False
if isinstance(item, types.ModuleType):
# imported module
return False
if name.startswith("_"):
# private property
return False
return True
def get_imported_module(module_name):
""" import module and return imported module
"""
return importlib.import_module(module_name)
def get_imported_module_from_file(file_path):
""" import module from python file path and return imported module
"""
if is_py3:
imported_module = importlib.machinery.SourceFileLoader(
'module_name', file_path).load_module()
elif is_py2:
imported_module = imp.load_source('module_name', file_path)
else:
raise RuntimeError("Neither Python 3 nor Python 2.")
return imported_module
def filter_module(module, filter_type):
""" filter functions or variables from import module
@params
module: imported module
filter_type: "function" or "variable"
"""
filter_type = is_function if filter_type == "function" else is_variable
module_functions_dict = dict(filter(filter_type, vars(module).items()))
return module_functions_dict
def search_conf_item(start_path, item_type, item_name):
""" search expected function or variable recursive upward
@param
start_path: search start path
item_type: "function" or "variable"
item_name: function name or variable name
"""
dir_path = os.path.dirname(os.path.abspath(start_path))
target_file = os.path.join(dir_path, "youmi.py")
if os.path.isfile(target_file):
imported_module = get_imported_module_from_file(target_file)
items_dict = filter_module(imported_module, item_type)
if item_name in items_dict:
return items_dict[item_name]
else:
return search_conf_item(dir_path, item_type, item_name)
if dir_path == start_path: # system root path
err_msg = "{} not found in recursive upward path!".format(item_name)
if item_type == "function":
raise exception.FunctionNotFound(err_msg)
else:
raise exception.VariableNotFound(err_msg)
return search_conf_item(dir_path, item_type, item_name)
def lower_dict_keys(origin_dict):
""" convert keys in dict to lower case
e.g.
Name => name, Request => request
URL => url, METHOD => method, Headers => headers, Data => data
"""
if not origin_dict or not isinstance(origin_dict, dict):
return origin_dict
return {
key.lower(): value
for key, value in origin_dict.items()
}
def lower_config_dict_key(config_dict):
""" convert key in config dict to lower case, convertion will occur in three places:
1, all keys in config dict;
2, all keys in config["request"]
3, all keys in config["request"]["headers"]
"""
# convert keys in config dict
config_dict = lower_dict_keys(config_dict)
if "request" in config_dict:
# convert keys in config["request"]
config_dict["request"] = lower_dict_keys(config_dict["request"])
# convert keys in config["request"]["headers"]
if "headers" in config_dict["request"]:
config_dict["request"]["headers"] = lower_dict_keys(config_dict["request"]["headers"])
return config_dict
def convert_to_order_dict(map_list):
""" convert mapping in list to ordered dict
@param (list) map_list
[
{"a": 1},
{"b": 2}
]
@return (OrderDict)
OrderDict({
"a": 1,
"b": 2
})
"""
ordered_dict = OrderedDict()
for map_dict in map_list:
ordered_dict.update(map_dict)
return ordered_dict
def update_ordered_dict(ordered_dict, override_mapping):
""" override ordered_dict with new mapping
@param
(OrderDict) ordered_dict
OrderDict({
"a": 1,
"b": 2
})
(dict) override_mapping
{"a": 3, "c": 4}
@return (OrderDict)
OrderDict({
"a": 3,
"b": 2,
"c": 4
})
"""
new_ordered_dict = copy.copy(ordered_dict)
for var, value in override_mapping.items():
new_ordered_dict.update({var: value})
return new_ordered_dict
def override_variables_binds(variables, new_mapping):
""" convert variables in testcase to ordered mapping, with new_mapping overrided
"""
if isinstance(variables, list):
variables_ordered_dict = convert_to_order_dict(variables)
elif isinstance(variables, (OrderedDict, dict)):
variables_ordered_dict = variables
else:
raise exception.ParamsError("variables error!")
return update_ordered_dict(
variables_ordered_dict,
new_mapping
)
def print_output(outputs):
if not outputs:
return
content = "\n================== Variables & Output ==================\n"
content += '{:<6} | {:<16} : {:<}\n'.format("Type", "Variable", "Value")
content += '{:<6} | {:<16} : {:<}\n'.format("-" * 6, "-" * 16, "-" * 27)
def prepare_content(var_type, in_out):
content = ""
for variable, value in in_out.items():
if is_py2:
if isinstance(variable, unicode): # noqa
variable = variable.encode("utf-8")
if isinstance(value, unicode): # noqa
value = value.encode("utf-8")
content += '{:<6} | {:<16} : {:<}\n'.format(var_type, variable, value)
return content
for output in outputs:
_in = output["in"]
_out = output["out"]
if not _out:
continue
content += prepare_content("Var", _in)
content += "\n"
content += prepare_content("Out", _out)
content += "-" * 56 + "\n"
logger.log_debug(content)
def create_scaffold(project_path):
if os.path.isdir(project_path):
folder_name = os.path.basename(project_path)
logger.log_warning(u"Folder {} exists, please specify a new folder name.".format(folder_name))
return
logger.color_print("Start to create new project: {}\n".format(project_path), "GREEN")
def create_path(path, ptype):
if ptype == "folder":
os.makedirs(path)
elif ptype == "file":
open(path, 'w').close()
return "created {}: {}\n".format(ptype, path)
path_list = [
(project_path, "folder"),
(os.path.join(project_path, "tests"), "folder"),
(os.path.join(project_path, "tests", "api"), "folder"),
(os.path.join(project_path, "tests", "suite"), "folder"),
(os.path.join(project_path, "tests", "testcases"), "folder"),
(os.path.join(project_path, "tests", "youmi.py"), "file")
]
msg = ""
for p in path_list:
msg += create_path(p[0], p[1])
logger.color_print(msg, "BLUE")
def load_dot_env_file(path):
""" load .env file and set to os.environ
"""
if not path:
path = os.path.join(os.getcwd(), ".env")
if not os.path.isfile(path):
logger.log_debug(".env file not exist: {}".format(path))
return
else:
if not os.path.isfile(path):
raise exception.FileNotFoundError("env file not exist: {}".format(path))
logger.log_info("Loading environment variables from {}".format(path))
with io.open(path, 'r', encoding='utf-8') as fp:
for line in fp:
variable, value = line.split("=")
variable = variable.strip()
os.environ[variable] = value.strip()
logger.log_debug("Loaded environment variable: {}".format(variable))
def validate_json_file(file_list):
""" validate JSON testset format
"""
for json_file in set(file_list):
if not json_file.endswith(".json"):
logger.log_warning("Only JSON file format can be validated, skip: {}".format(json_file))
continue
logger.color_print("Start to validate JSON file: {}".format(json_file), "GREEN")
with io.open(json_file) as stream:
try:
json.load(stream)
except ValueError as e:
raise SystemExit(e)
print("OK")
def prettify_json_file(file_list):
""" prettify JSON testset format
"""
for json_file in set(file_list):
if not json_file.endswith(".json"):
logger.log_warning("Only JSON file format can be prettified, skip: {}".format(json_file))
continue
logger.color_print("Start to prettify JSON file: {}".format(json_file), "GREEN")
dir_path = os.path.dirname(json_file)
file_name, file_suffix = os.path.splitext(os.path.basename(json_file))
outfile = os.path.join(dir_path, "{}.pretty.json".format(file_name))
with io.open(json_file, 'r', encoding='utf-8') as stream:
try:
obj = json.load(stream)
except ValueError as e:
raise SystemExit(e)
with io.open(outfile, 'w', encoding='utf-8') as out:
json.dump(obj, out, indent=4, separators=(',', ': '))
out.write('\n')
print("success: {}".format(outfile))
def get_python2_retire_msg():
retire_day = datetime(2020, 1, 1)
today = datetime.now()
left_days = (retire_day - today).days
if left_days > 0:
retire_msg = "Python 2 will retire in {} days, why not move to Python 3?".format(left_days)
else:
retire_msg = "Python 2 has been retired, you should move to Python 3."
return retire_msg
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/utils.py
|
utils.py
|
import argparse
import multiprocessing
import os
import sys
from apimeter import logger
from apimeter.__about__ import __description__, __version__
from apimeter.compat import is_py2
from apimeter.task import ApiMeter
from apimeter.utils import (create_scaffold, get_python2_retire_msg, prettify_json_file, validate_json_file)
def main_apimeter():
""" API test: parse command line options and run commands.
"""
parser = argparse.ArgumentParser(description=__description__)
parser.add_argument(
'-V', '--version', dest='version', action='store_true',
help="show version")
parser.add_argument(
'testset_paths', nargs='*',
help="testset file path")
parser.add_argument(
'--no-html-report', action='store_true', default=False,
help="do not generate html report.")
parser.add_argument(
'--html-report-name',
help="specify html report name, only effective when generating html report.")
parser.add_argument(
'--html-report-template',
help="specify html report template path.")
parser.add_argument(
'--log-level', default='INFO',
help="Specify logging level, default is INFO.")
parser.add_argument(
'--log-file',
help="Write logs to specified file path.")
parser.add_argument(
'--dot-env-path',
help="Specify .env file path, which is useful for keeping production credentials.")
parser.add_argument(
'--failfast', action='store_true', default=False,
help="Stop the test run on the first error or failure.")
parser.add_argument(
'--startproject',
help="Specify new project name.")
parser.add_argument(
'--validate', nargs='*',
help="Validate JSON testset format.")
parser.add_argument(
'--prettify', nargs='*',
help="Prettify JSON testset format.")
args = parser.parse_args()
logger.setup_logger(args.log_level, args.log_file)
if is_py2:
logger.log_warning(get_python2_retire_msg())
if args.version:
logger.color_print("{}".format(__version__), "GREEN")
exit(0)
if args.validate:
validate_json_file(args.validate)
exit(0)
if args.prettify:
prettify_json_file(args.prettify)
exit(0)
project_name = args.startproject
if project_name:
project_path = os.path.join(os.getcwd(), project_name)
create_scaffold(project_path)
exit(0)
runner = ApiMeter(failfast=args.failfast, dot_env_path=args.dot_env_path).run(args.testset_paths)
if not args.no_html_report:
runner.gen_html_report(
html_report_name=args.html_report_name,
html_report_template=args.html_report_template
)
summary = runner.summary
return 0 if summary["success"] else 1
def main_locust():
""" Performance test with locust: parse command line options and run commands.
"""
logger.setup_logger("INFO")
try:
from apimeter import locusts
except ImportError:
msg = "Locust is not installed, install first and try again.\n"
msg += "install command: pip install locustio"
logger.log_warning(msg)
exit(1)
sys.argv[0] = 'locust'
if len(sys.argv) == 1:
sys.argv.extend(["-h"])
if sys.argv[1] in ["-h", "--help", "-V", "--version"]:
locusts.main()
sys.exit(0)
try:
testcase_index = sys.argv.index('-f') + 1
assert testcase_index < len(sys.argv)
except (ValueError, AssertionError):
logger.log_error("Testcase file is not specified, exit.")
sys.exit(1)
testcase_file_path = sys.argv[testcase_index]
sys.argv[testcase_index] = locusts.parse_locustfile(testcase_file_path)
if "--processes" in sys.argv:
""" locusts -f locustfile.py --processes 4
"""
if "--no-web" in sys.argv:
logger.log_error("conflict parameter args: --processes & --no-web. \nexit.")
sys.exit(1)
processes_index = sys.argv.index('--processes')
processes_count_index = processes_index + 1
if processes_count_index >= len(sys.argv):
""" do not specify processes count explicitly
locusts -f locustfile.py --processes
"""
processes_count = multiprocessing.cpu_count()
logger.log_warning("processes count not specified, use {} by default.".format(processes_count))
else:
try:
""" locusts -f locustfile.py --processes 4 """
processes_count = int(sys.argv[processes_count_index])
sys.argv.pop(processes_count_index)
except ValueError:
""" locusts -f locustfile.py --processes -P 8888 """
processes_count = multiprocessing.cpu_count()
logger.log_warning("processes count not specified, use {} by default.".format(processes_count))
sys.argv.pop(processes_index)
locusts.run_locusts_with_processes(sys.argv, processes_count)
else:
locusts.main()
|
ApiMeter
|
/ApiMeter-1.2.8.tar.gz/ApiMeter-1.2.8/apimeter/cli.py
|
cli.py
|
# ApiPyTelegram | apt
telegram bots core for python.
## Installation
Install my-project with pip
```bash
pip install PyTelegramApi
```
## Usage/Examples
```python
import ApiPyTelegram
ApiPyTelegram.apt() #you token goes here
ApiPyTelegram.message.text(12345, "test you") # first arg is chat id
```
[Get user chat id here](https://t.me/getmyid_bot)
## License
[MIT](https://choosealicense.com/licenses/mit/)
## Documentation
[Documentation](https://linktodocumentation)
## Contributing
Contributions are always welcome!
See `contributing.md` for ways to get started.
Please adhere to this project's `Powered by apt.` .
|
ApiPyTelegram
|
/ApiPyTelegram-0.1.tar.gz/ApiPyTelegram-0.1/README.md
|
README.md
|
class Config:
"""Config Object For an Api
Object that store Api configurations that will be needed
to execute requests
Args:
name(String: Required):
string to reference a Config api object
don't call 2 api with the same name or
an api config will be delete
base_url(String: Required):
url common part for all your requests with this api
ex
"https://api" will allow to create requests like
--> "https://api/firstpath"
--> "https://api/secondpath"
--> "https://api/thirdpath"
auth(Map: Optional):
if you need an authentication for the api
provide their the authentication header field
(ex: Authorization) and the token
like
auth -> {'the auth field here': 'Your token here'}
headers(Map: Optional):
if you need to provide other headers to api
do it like 'auth' argument (multiple header key/value accepted)
ex
header -> {
'first_header_field':'first_header_val',
'second_header_field':'second_header_val',
etc...
}
"""
name: str
base_url: str
auth: dict
headers: dict
def __init__(self, name: str, base_url: str, auth: dict = None, headers: dict = None):
self.name = name
self.base_url = base_url
self.auth = auth
self.headers = headers
def __eq__(self, other):
""" '==' operator implemented: same 'name' attribut -> equality """
return self.name == other.name
def __repr__(self):
return "Config(name=%r, base_url=%r, auth=%r, headers=%r)" % (self.name, self.base_url, self.auth, self.headers)
def __hash__(self):
"""
hash implemented like: same 'name' attribut -> same hash
ApiConfig delete dupplicates names for Config objects
so Config objects in ApiConfigs.configs have unique hash
"""
return hash(self.name)
|
ApiRequestManager
|
/ApiRequestManager-1.0.5-py3-none-any.whl/src/Config.py
|
Config.py
|
from typing import List
from src.Pipelines import ApiPipeline
from src.RequestFactory import RequestFactory
from collections.abc import Callable
from src.instance_method_decorator import instance_method_wrapper
from src.Config import Config
from src.ConfigPath import ConfigPath
def make_api_pipe(api_name: str, writer: Callable, sleeping_time: float = None):
""" pipe maker for Api requests
Arguments:
api_name(Required):
String.
Api identifier bound to a Config name in ConfigPath (check Pipeline doc)
ConfigPath(
Config(name="random_name".......)
)
"random_name" <-- api_name
writer(Required):
Callable which take an List(request.requests) in argument.
Function which override the ApiPipeline.write method (check ApiPipeline doc)
sleeping_time(Optional):
Float.
The time in second to sleep between 2 requests (check Pipeline doc)
Return:
pipe_instance:
An Instance of pipe (an ApiPipeline subclass with 'writer' arg that override ApiPipeline.write method)
"""
pipe_cls = type("pipe_cls", (ApiPipeline, ), {"write": instance_method_wrapper(writer)})
pipe_instance = pipe_cls(request_factory=RequestFactory(api_name), sleeping_time=sleeping_time)
del pipe_cls
return pipe_instance
def run_api_pipe(pipe_instance, request_arguments: List[tuple], retry_fails: bool = False, transaction_rate: int = None):
""" pip runner to execute a pipe instance
Arguments:
pipe_instance(Required):
An Instance of pipe (an ApiPipeline subclass with 'writer' arg that override ApiPipeline.write method)
call make_api_pipe function to get a pipe_instance (see the doc above)
request_arguments(Required):
a list of 2-tuple elements like ("end_url", {"param_name": "param_val"})
to provide request configurations check the RequestFactory doc
retry_fails(Optional):
Boolean.
if put to 'True', request which failed will be executed a second time
transaction_rate(Optional):
Int.
The number of request results to be passed to the pipe.write method each time
if not configured, write method is executed once after all pipe requests processed
check Pipeline Documentation
Return:
err_log:
a log where are stored all requests informations which failed
(2 times if 'retry_fails' argument is set to True)
"""
retry = retry_fails
pipe_instance.load_data(request_arguments)
pipe_instance.run_pipe(transaction_rate=transaction_rate)
log = pipe_instance.err_params_log()
if retry:
retry = False
pipe_instance.load_data(log)
pipe_instance.run_pipe(transaction_rate=transaction_rate)
return pipe_instance.err_log
|
ApiRequestManager
|
/ApiRequestManager-1.0.5-py3-none-any.whl/src/make_pipe.py
|
make_pipe.py
|
from datetime import datetime
import requests
import time
from abc import ABC, abstractmethod
from src.RequestFactory import RequestFactory
class GenericPipeline(ABC):
"""Abstract Pipeline class
All Pipeline class must inherit from this class
methods read, process and write needs to be override in the subclass
"""
_data = None
def load_data(self, data):
"""Check if data is an iterable and load data in self._data attribute
if data argument hasn't __iter__ method implemented,
ValueError is raised
"""
if hasattr(data, '__iter__'):
self._data = data
else:
raise ValueError("PyPipeline data must be a Generator or a Sequence(implement __iter__ method)")
@abstractmethod
def read(self, entry):
"""called in first for each element of the 'data' loaded (to parse)
Arguments:
entry:
a data element that is passed through this function in run_pipe method
"""
pass
@abstractmethod
def process(self, entry):
"""called in second for each element of the 'data' loaded (to process transformations)
Arguments:
entry:
a data element that is passed through this function in run_pipe method
"""
pass
@abstractmethod
def write(self, entry_pack):
"""called in third for groups of elements of the 'data' loaded (to write it in base for example)
Arguments:
entry_pack:
a group of data element that is passed through this function in run_pipe method
"""
pass
def run_pipe(self, transaction_rate=None):
"""method to call to execute the pipe
Arguments:
transaction_rate(Optional):
Integer.
Provides the number of data elements that need to be write together
with the write method
Put it to 1(one) to write after each element process
if transaction_rate number is higher than data length, write method
is executed once for all data elements at the end
if transaction_rate number is None(Not specified) write method is called
once a the end of the pipe
"""
# vide le cache d'erreur
if hasattr(self, '_err_log'):
self._err_log = []
if transaction_rate is not None:
count = 0
data_storage = []
for entry in self._data:
data_fragment = self.read(entry)
data_fragment = self.process(data_fragment)
if data_fragment is not None:
data_storage.append(data_fragment)
count += 1
if count == transaction_rate:
self.write(data_storage)
count = 0
data_storage = []
if data_storage:
self.write(data_storage)
else:
data_storage = []
for entry in self._data:
data_fragment = self.read(entry)
data_fragment = self.process(data_fragment)
if data_fragment is not None:
data_storage.append(data_fragment)
if data_storage:
self.write(data_storage)
class ApiPipeline(GenericPipeline, ABC):
""" Abstract ApiPipeline
All ApiPipeline class must inherit from this class
methods read, process and write needs to be override in the subclass
Arguments:
request_factory(Required):
RequestFactory instance (see the doc).
A RequestFactory instance that will create all requests of the pipe
sleeping_time(Optional):
Float.
If api calls need to be delayed, add the time in seconds you
want that pipe sleep after each request to 'sleeping_time' argument
"""
request_factory = None
_err_log = []
@property
def err_log(self):
""" List of errors occured during Pipe
Log objects are 4-tuple like
("entry", "status_code_if_there_is", "datetime", "typeError")
Errors catched are requests.exceptions.ConnectionError, Timeout, and HttpError
"""
return [(str(err[0]), err[1], err[2], err[3]) for err in self._err_log]
def err_params_log(self):
"""return error logs parameters to rerun the pipe with failed requests"""
return [err[0].get_request_params() for err in self._err_log]
def __init__(self, request_factory: RequestFactory, sleeping_time: float = None):
if not isinstance(request_factory, RequestFactory):
raise ValueError("request_factory argument needs to be an instance of RequestFactory")
self.request_factory = request_factory
self._sleeping_time = sleeping_time
def read(self, entry):
"""wrap request parameters in the requestFactory
create a request with a data element passed in argument
and the requestFactory
Data elements are not validated!
data element need to be a 2-tuple (end_url:string, params:dict)
Arguments:
entry:
a data element that is passed through this function in run_pipe method
a correct data element for api call is
("the end of the url", {"param_name":"param_val"})
or
("the end of the url", None) if there is no params
or
(None, None) if there is no params and no end_url
"""
read = self.request_factory(*entry)
return read
def process(self, entry):
"""execute the requests created by read() method and sleep if needed
if an error Occurs during request execution an log object is added to
err_log argument
Log objects are 4-tuple like
("entry", "status_code_if_there_is", "datetime", "typeError")
Errors catched are requests.exceptions.ConnectionError, Timeout, and HttpError
Arguments:
entry:
a request element that is passed through this function in run_pipe method
check read() method documentation
"""
start_time = time.time()
try:
result = entry.get_response()
except requests.exceptions.ConnectionError as e:
self._err_log.append((entry, None, datetime.now(), "ConnectionError"), )
result = None
except requests.exceptions.Timeout as e:
self._err_log.append((entry, None, datetime.now(), "TimeOut"), )
result = None
try:
result.raise_for_status()
except requests.exceptions.HTTPError as e:
self._err_log.append((entry, result.status_code, datetime.now(), "HttpError"),)
result = None
if self._sleeping_time is not None and result is not None:
run_time = time.time() - start_time
if run_time < self._sleeping_time:
time.sleep(self._sleeping_time - run_time)
return result
def __eq__(self, other):
"""Pipe with same request factorys are equals"""
return self.request_factory == other.request_factory
def __hash__(self):
"""Pipe with same request fatorys have same hash"""
return hash(self.request_factory)
def __repr__(self):
return f"{self.__class__.__name__}(%r, %r)" % (self.request_factory, self._sleeping_time)
@abstractmethod
def write(self, entry_pack):
"""called in third for groups of elements of the 'data' loaded (to write it in base for example)
You need to override this method. Provide the behavior you want for this data after the processing
Arguments:
entry_pack:
a group of requests_results that is passed through this function in run_pipe method
"""
pass
|
ApiRequestManager
|
/ApiRequestManager-1.0.5-py3-none-any.whl/src/Pipelines.py
|
Pipelines.py
|
# Library implementing API
___
<p align="center">
<a href="https://pypi.org/project/ApiSpbStuRuz/">
<img src="https://img.shields.io/badge/download-PyPi-red.svg">
</a>
<img src="https://img.shields.io/badge/made%20by-Dafter-orange.svg">
<img src="https://img.shields.io/github/license/DafterT/ApiSpbStuRuz">
<img src="https://img.shields.io/github/last-commit/DafterT/ApiSpbStuRuz">
</p>
___
## How to use:
You are required to create an `ApiSpbStuRuz` using `async with` statement. For example like this:
```Python
import asyncio
import ApiSpbStuRuz
async def main():
async with ApiSpbStuRuz.ApiSpbStuRuz() as api:
teacher = await api.get_teacher_by_id(999335)
print(teacher)
if __name__ == "__main__":
asyncio.run(main())
```
When you create a class, you have a number of parameters:
* **create_logger** - if you want to use a logger, pass True, otherwise don't change.
* **path_log** - the path to the folder where the logger will write logs.
Before using, do not forget to enable the logger.
* **try_create_dict** - If you want the logger not to try to create a folder with logs,
then turn off this parameter.
* **proxy** - If you want to use a proxy for requests, then pass them to this parameter.
Proxies are not used as standard. The proxy should be transmitted in the format required by the aiohttp library
* **timeout** - If you want to change the request timeout from 5 seconds, then use this parameter
___
## Functions:
* `get_faculties` - returns a list of faculties
* `get_faculty_by_id` - gets the id of the faculty, returns an object with the faculty
* `get_groups_on_faculties_by_id` - gets the faculty number, returns a list of groups in this faculty
* `get_teachers` - returns a list of teachers (can take a long time to run because there is a lot of data)
* `get_teacher_by_id` - returns the teacher by his id (not oid)
* `get_teacher_scheduler_by_id` - returns the teacher's schedule by its id (not oid)
* `get_teacher_scheduler_by_id_and_date` - returns the teacher's schedule by its id (not oid) on a specific
date (actually returns the schedule for the week on which this date is)
* `get_buildings` - returns a list of buildings
* `get_building_by_id` - returns a building by its id
* `get_rooms_by_building_id` - returns rooms in a building by its id
* `get_rooms_scheduler_by_id_and_building_id` - returns the schedule of the room by its id in the building by its id
* `get_rooms_scheduler_by_id_and_building_id_and_date` - returns the schedule of the room by its id in the building by
its id on a certain date (actually returns the schedule for the week on which this date is)
* `get_groups_scheduler_by_id` - returns the group schedule by its id
* `get_groups_scheduler_by_id_and_date` - returns the group schedule by its id by date
(actually returns the schedule for the week on which this date is)
* `get_groups_by_name` - returns a group object by its name (сan return multiple objects)
* `get_teachers_by_name` - returns a teacher object by her name (сan return multiple objects)
* `get_rooms_by_name` - returns a room object by its name (сan return multiple objects)
___
## Paths:
* **https://ruz.spbstu.ru/api/v1/ruz**
* **/faculties** - getting a list of faculties (institutes)
* **/id** - getting the name by the id of the department (institute)
* **/groups** - getting a list of groups by department (institute) id
* **/teachers** - list of all teachers
* **/id** - search for a teacher by id
* **/scheduler** - teacher's schedule by his id for the current week
* **?date=yyyy-mm-dd** - teacher's schedule by his id for the week with the entered date
* **/buildings** - list of "structures"/buildings (Note that it has a bunch of garbage values)
* **/id** - search for "structures" by id
* **/rooms** - list of rooms in a building by its id
* **/id/scheduler** - schedule by room's id
* **?date=yyyy-mm-dd** - similarly by date
* **/scheduler/id** - getting a schedule by group id for the current week
* **?date=yyyy-mm-dd** - getting a week by a specific date
* **/search**
* **/groups?q=name** - search for a group by its name (example name="3530901/10001" -> 35376)
* **/teachers?q=name** - search for a teacher by first name/last name/patronymic/full_name (replace spaces with
%20 when requested)
* **/rooms?q=name** - search by audience name
___
## Files:
* **apiSpbStuRuz.py** - this file implements the basic API logic
* **dataClasses.py** - this file contains all the data classes into which the received data is converted
* **logConfig.py** - this file contains the settings for the logger
* **apiSpbStuRuzExeptions.py** - this file contains all the exceptions that are thrown during the operation of the
application
* **apiPaths.py** - this file stores all the paths that the library uses for requests to the server
___
|
ApiSpbStuRuz
|
/ApiSpbStuRuz-1.1.2.tar.gz/ApiSpbStuRuz-1.1.2/README.md
|
README.md
|
MIT License
Copyright (c) 2023 Simonovsky Daniil Leonidovich
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
|
ApiSpbStuRuz
|
/ApiSpbStuRuz-1.1.2.tar.gz/ApiSpbStuRuz-1.1.2/License.md
|
License.md
|
# ApiTestEz
#### 1.0.28 更新
1. [新增用例生成器](#jump_case)`CaseBuilderSchema`.
2. 修复命令行Bug.
#### 1.0.26 更新
1. 增加自定义用例数据加载方式,例:
```python
from api_test_ez.core.case.frame.frame_case_loader import CaseLoaderMiddleware
class DBCaseLoaderMiddleware(CaseLoaderMiddleware):
def load_test_data(self) -> list:
configs = self.configs # ez project configs
# do something
data_set = [{}, {}]
return data_set
```
#### 1.0.24 更新
1. 修复`-version`命令行问题
2. `case_filepath`支持以**项目根目录**为参照的相对路径,EZ首先按全路径查找,如果未找到文件则按相对路径查找
### 介绍
让API测试变得简单。<br>
ApiTestEz(以下简称EZ)主要提供以下3方面的核心功能:<br>
1. `ez.cfg`提供多个层级的配置环境;
2. 完成对http请求的封装,测试人员只用关注*Request*参数的传递,和对*Response*的校验;
3. 引入反序列化断言。
---
### 安装教程
pip install ApiTestEz
---
### Quick Start
---
#### 最小测试项目
|-- EzTestDemo
|-- <project_name>
| |-- test_whatever.py
| |-- ez.cfg (optional: module priority)
|-- settings
|-- project.cfg
`test_whatever.py`
```python
import unittest
from api_test_ez.core.case import UnitCase
class SomeTest(UnitCase):
def beforeRequest(self):
self.request.url = "http://www.baidu.com"
def test_something(self):
assert self.response.status_code == 200
if __name__ == '__main__':
unittest.main()
```
---
#### 完整项目
|-- EzTestDemo
|-- <project_name>
| |-- <test_api_dir>
| | |-- test_whatever.py
| | |-- ez.cfg (optional: package priority)
| | |-- model.py (optional)
| |-- ez.cfg (optional: module priority)
|-- settings
|-- project.cfg
|-- ez.cfg (optional: project priority)
|-- <resource> (optional)
|-- <case_files> (optional)
*`project.cfg`*为项目标识,它告诉EZ项目根目录和项目*`settings.py`*存放位置。<br>
*`setting.py`*提供项目初始化设置项,如**`log`**、**`report`**配置。<br>
*`ez.cfg`*与*`settings`*的区别在于,*`ez.cfg`*提供业务相关的配置,如*`http`*的*`headers`*、*`case_filepath`*(用例存放目录)、*`auto_request`*(自动完成请求)开关等,你还可以在里面放置业务需要的特殊变量,这些变量将会存放在*self.request.meta*中。它包含了多个层级`['case', 'package', 'module', 'project', 'command', 'default']`,优先级一次递减。<br>
关于*`setting.py`*和*`ez.cfg`*支持的配置详情后述。<br>
<br>
*ez.cfg*是EZ框架的核心功能之一。下面,通过使用ez.cfg,我们来完成一个简单的请求。<br>
`project.cfg`
*project.cfg*中存放`settings.py`可**导入**的路径,如将`settings.py`和`project.cfg`放置在同一路径,则按如下写法:
```ini
[settings]
default = settings
```
`ez.cfg`
```ini
[HTTP]
url = http://www.baidu.com
```
`test_whatever.py`
```python
import unittest
from api_test_ez.core.case import UnitCase
class SomeTest(UnitCase):
def test_something(self):
assert self.response.status_code == 200
if __name__ == '__main__':
unittest.main()
```
---
#### <span id="jump">EZ和[ddt](https://github.com/datadriventests/ddt)一起工作</span>
EZ支持`ddt`
假设我们有多个接口需要测试。(这里我们使用一些fake api:https://dummyjson.com/products/<page> )。
我们得到10个需要测试的接口 https://dummyjson.com/products/1 ~ https://dummyjson.com/products/10 。它们将返回10种不同型号的手机信息。<br>
显然,这10个接口在测试过程中很大程度上是相似的,我们希望编写同一个类来完成对这10个接口的测试。<br>
首先,我们需要一份用例文件,它负责储存用例编号、接口信息、期望结果等内容。EZ支持多种格式的用例文件:*Excel*、*YAML*、*JSON*、*Pandas*、*HTML*、*Jira*等,它使用[tablib](https://tablib.readthedocs.io/en/stable/)读取用例文件。
这里我们使用*Excel*作为存储用例文件。<br>
<br>
`case.xlsx`<br>
| case_name | path |
|-----------|--------------|
| TC0001 | /products/1 |
| TC0002 | /products/2 |
| TC0003 | /products/3 |
| TC0004 | /products/4 |
| TC0005 | /products/5 |
| TC0006 | /products/6 |
| TC0007 | /products/7 |
| TC0008 | /products/8 |
| TC0009 | /products/9 |
| TC0010 | /products/10 |
我们将请求的域名放在`ez.cfg`中以便切换测试环境时统一管理,同时将用例路径存放在`ez.cfg`中,以便EZ发现用例。<br>
```ini
[CASE]
case_filepath = /<some path>/case.xlsx
[HTTP]
host = https://dummyjson.com
```
> *在`ez.cfg`中,HTTP method默认为GET。*
在`test_whatever.py`中,现阶段不做出改变,我们将在后面的介绍中深入认识[断言](#断言)。
```python
import unittest
from api_test_ez.core.case import UnitCase
class SomeTest(UnitCase):
def test_something(self):
assert self.response.status_code == 200
if __name__ == '__main__':
unittest.main()
```
---
### EZ中的组件
在EZ中,每个测试实例拥有两个实例变量:`self.request`和`self.response`。同时,`request`充当着上下文的作用,它存放`http`相关属性和`meta`两类属性。而`response`则提供请求响应数据断言等作用。
1. **Request**
---
- PIPELINE
EZ目前只支持了基于`unittest`的封装,在EZ中可以使用`unittest`的所有特性。EZ在`setUp`和`tearDown`的基础上,提供了3个额外的hook方法:`beforeRequest`、`doRequest`、`afterRequest`。<br>
它们的执行顺序如下:
```
|-- setUp
| |-- beforeRequest
| | |-- doRequest (if __autoRequest__ == 'on')
| | |-- afterRequest (if __autoRequest__ == 'on')
| |-- testMethod
|-- tearDown
```
`doRequest`和`afterRequest`仅在*自动请求*(即`__autoRequest__ == 'on'`)时被调用。而`doRequest`可以显式调用,同样的,`__autoRequest__`也可以在测试代码中显式指定。<br>
---
- `beforeRequest`
通常我们在`beforeRequest`中完成对请求数据的封装。<br>
1. 显式指定url
```python
def beforeRequest(self):
self.request.url = "http://www.baidu.com"
```
2. 在请求前需要通过另一个请求得到需要传递的参数
```python
def beforeRequest(self):
resp = self.request.http.get('https://somehost.com/login').json()
self.body = {'token': resp.get('token')}
```
- `afterRequest`
在`afterRequest`中,我们完成对请求响应数据的清洗或对请求环境的还原。<br>
1. 清除登录态
```python
def afterRequest(self):
self.request.http.get('https://somehost.com/logout')
```
2. 当用户登录失败,跳过测试用例
```python
def afterRequest(self):
if self.response.bean.login_status == 0:
self.skipTest("Login fail, skip test method.")
```
> *response的bean属性将json数据转化为bean对象。*
- `doRequest`
`doRequest`完成了对请求的封装,它接受一个Request参数,并返回EzResponse对象。通常我们只需要决定**显式**或**自动**调用它。<br>
但如果你需要重写它,请遵循`request`传递参数,并返回`EzResponse`对象的规则。这将在后续的断言中很有用。
- `initRequest`
`initRequest`是一个特殊的hook函数,它在测试对象初始化时被加载。<br>
它负责找到测试用例集中每个用户的测试数据、完成对`ddt`数据的加载、并将加载完成的用例数据(包含从`ez.cfg`中加载的数据)传递给`request`完成初始化。
---
- `request`参数。
1. http相关属性:<br>
`http`: 存放`Http`实例对象。<br>
`owner`: 标识该`request`对象属于哪个用例。<br>
`url`: 请求的url。<br>
`host`: 请求的host。<br>
`path`: 请求的path。<br>
`method`: 请求的method。<br>
`body`: 请求的body。<br>
2. meta:<br>
`meta`: 除去以上http相关属性,其他来自于**用例文件**、**`ez.cfg`**的字段都将储存在`meta`中。<br>
`meta`对象具有两个属性`bean`和`data`,`bean`属性将字典转化为bean对象;`data`将config属性按字典返回。
---
2. **Response**
在测试类中,除了`request`EZ还提供了`response`,它是`EzResponse`的实例。`response`在`requests.Response`的基础上提供了3个额外的属性和方法:
- `bean`属性: 将字典转化为bean对象。这样我们能像访问属性一样访问字典。例:
```python
self.response.json()
# {"name": "Bruce", "favorite": [{"category": "sports", "name": "basketball"}, {"category": "sports", "name": "football"}]}
resp_bean = self.response.bean
resp_bean.name
# "Bruce"
resp_bean.favorite[0].category
# "sports"
resp_bean.favorite[0].name
# basketball
```
- `validate`方法: `validate`接收一个`marshmallow.Schema`对象参数,并依据`Schema`模型进行校验。点击[marshmallow](https://github.com/marshmallow-code/marshmallow)了解更多信息。<br>
关于`marshmallow`的使用我们将在下面详细阐述。
- ~~`pair`方法(已废弃)~~: `pair`接收一个`ValidatorModel`参数,它是与`marshmallow.Schema`类似(事先未找到类似的轮子,所以重复造了一个)。引入`marshmallow`后不再维护。
---
### 断言
在EZ中,对于复杂场景的断言推荐大家使用序列化模型的方式。这种是一种更加pythonic的断言方式,它使得代码更加干净优雅,逻辑更加清晰简洁。EZ中提供 ~~`ValidatorModel`(已废弃)~~ 和`marshmallow.Schema`两种模型。
- EZ中断言的简单的使用:<br>
<br>
以上面的测试用例为例,`model.py`
```python
from api_test_ez.ez.serialize.fields import IntegerField, StringField, ListField
from api_test_ez.ez.serialize.models import ValidatorModel
class PhoneValidate(ValidatorModel):
id = IntegerField(required=True)
title = StringField(required=True)
category = StringField(required=True, should_in=["smartphones", "laptops"])
images = ListField(required=True, count_should_gte=1)
```
以上模型要求:
1. `id`: `required=True`表明`id`为返回结果必须字段,且它的数据类型必须是`integer`,如果不符合则会引发`ValidationError`错误;
2. `title`: 同样,`title`也是必须字段,且它的数据类型必须是`string`;
3. `category`: 除了满足以上两点,`should_be="smartphones"`表明该字段返回值必须是`"smartphones"`;
4. `images`: 这是一个列表,且它的成员个数必须大于1。
<br>
让我们接着 [上面](#jump) 的例子,继续修改`test_whatever.py`。
<br>
```python
import unittest
from api_test_ez.core.case import UnitCase
from tests.case.node.models import PhoneValidate
class SomeTest(UnitCase):
def test_something(self):
self.response.pair(PhoneValidate())
if __name__ == '__main__':
unittest.main()
```
`pair`方法会对模型进行校验,并在产生错误时抛出`ValidationError`异常。<br>
<br>
**使用`marshmallow`翻译上述逻辑**<br>
<br>
`model.py`
```python
from marshmallow import Schema, fields, INCLUDE
from marshmallow import validate
class PhoneSchema(Schema):
id = fields.Integer(required=True, strict=True)
title = fields.String(required=True)
category = fields.String(required=True, validate=validate.OneOf(["smartphones", "laptops"]))
images = fields.List(fields.String(), required=True, validate=validate.Length(min=1))
class Meta:
unknown = INCLUDE
```
>*关于`marshmallow`的更多使用方法和解释[请点击](https://github.com/marshmallow-code/marshmallow)。*
在引入`marshmallow`后,`EzResponse`提供了新的验证方法`validate`。<br>
<br>
在`test_whatever.py`中验证。
```python
class SomeTest(UnitCase):
def test_something(self):
self.response.validate(PhoneValidate())
```
- 一个稍复杂的例子
现在我们对`thumbnail`做校验,确保它返回的图片是我们发送请求的产品的图片。我们之前在`request.path`中储存了请求的产品信息如`/products/1`。<br>
另外,我们对`category`重新添加校验,假如我们已知id小于等于5时是`smartphones`,大于5时是`laptops`。
我们在模型`model.py`中添加这部分字段。
<br>
```python
# ValidatorModel
class PhoneValidate(ValidatorModel):
id = IntegerField(required=True)
title = StringField(required=True)
category = StringField(required=True)
images = ListField(required=True, count_should_gte=1)
thumbnail = StringField(required=True)
# marshmallow
class PhoneSchema(Schema):
id = fields.Integer(required=True, strict=True)
title = fields.String(required=True)
category = fields.String(required=True)
images = fields.List(fields.String(), required=True, validate=validate.Length(min=1))
thumbnail = fields.String(required=True)
class Meta:
unknown = INCLUDE
@validates("thumbnail")
def validate_thumbnail(self, value):
request = self.context.get("request")
if request:
if request.path not in value:
raise ValidationError(f"The `thumbnail` should contain `{request.path!r}`.")
else:
raise ValidationError("Get `request` object fail.")
@validates_schema
def validate_category(self, data, **kwargs):
if data['id'] <= 5:
if data['category'] != "smartphones":
raise ValidationError(f"Expect `smartphones`, but `{data['category']!r}` found.")
else:
if data['category'] != "laptops":
raise ValidationError(f"Expect `smartphones`, but `{data['category']!r}` found.")
```
由于涉及到了对外部变量的依赖,我们需要在断言前动态修改模型属性。<br>
<br>
`test_whatever.py`
```python
# ValidatorModel
class SomeTestVM(UnitCase):
def test_something(self):
pv = PhoneValidate()
# thumbnail validate
pv.thumbnail.should_cotain(self.request.path)
# # category validate
if self.response.bean.id <= 5:
pv.category.should_be("smartphones")
else:
pv.category.should_be("laptops")
self.response.pair(pv)
# marshmallow
class SomeTestMM(UnitCase):
def test_something(self):
ps = PhoneSchema()
ps.context["request"] = self.request
self.response.validate(ps)
```
---
### 测试报告
- HtmlReporter
```python
from api_test_ez.core.report import HtmlReporter, BRReporter
# HTMLTestRunner
report = HtmlReporter(case_path='<some_case_path>')
report.run()
# BeautifulReport
report = BRReporter(case_path='<some_case_path>', report_theme=)
report.run()
```
`HtmlReporter`接收3个参数:<br>
1. `case_path`: 用例脚本文件路径,如果**目录**将会遍历目录下的python文件以找到**所有**测试用例。<br>
2. `report_title`: 报告页面中的title,如果为*None*将会读取项目settings.py文件中的`REPORT_TITLE`字段。<br>
3. `report_desc`: 报告页面中的描述,如果为*None*将会读取项目settings.py文件中的`REPORT_DESC`字段。<br>
`BRReporter`除以上参数外,多出一个参数:<br>
1. `report_theme`: `BeautifulReport`报告主题,包含`theme_default`,`theme_cyan`,`theme_candy`,`theme_memories`。如果为*None*将会读取项目settings.py文件中的`BR_REPORT_THEME`字段。默认主题为`theme_default`。<br>
### Settings
| Key | Desc | Default |
|--------------------|---------------------|-----------------------------------------------------------------------------------|
| CONSOLE_LOG_LEVEL | 控制台日志等级 | INFO |
| CONSOLE_LOG_FORMAT | 控制台日志格式 | %(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] [%(thread)d] - %(message)s |
| FILE_LOG_LEVEL | 日志文件等级 | DEBUG |
| FILE_LOG_FORMAT | 日志文件格式 | %(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] [%(thread)d] - %(message)s |
| FILE_LOG_PATH | 日志文件路径 | 默认为`None`,表示不输出日志文件。 |
| REPORT_DIR | 报告文件目录 | *report*,表示输出在当前运行目录./report下。 |
| REPORT_FILE_NAME | 报告文件名称 | 默认以当前时间格式命名, "%Y_%m_%d_%H_%M_%S.html"。 |
| REPORT_TITLE | 报告名称 | ApiTestEz Report。 |
| REPORT_DESC | 报告描述 | This is an api-test report generated by ApiTestEz. |
| BR_REPORT_THEME | BeautifulReport报告主题 | theme_default |
### ez.cfg
| Key | Desc | Default | Storage Location | Tag |
|---------------|----------|---------------------------------------------------------------------------------------------------|------------------|--------|
| url | 请求链接 | None | request.http | [HTTP] |
| host | 请求host | 当url为None时,url=host+path | request.http | [HTTP] |
| path | 请求path | 当url为None时,url=host+path | request.http | [HTTP] |
| method | 请求方式 | GET | request.http | [HTTP] |
| body | 请求body | None | request.http | [HTTP] |
| body | 请求body格式 | 默认为data,支持json,files,stream详见requests库 | request.http | [HTTP] |
| case_load | 用例读取模块 | 如果存在将以指定模块加载用例数据,格式:<module>.<case_loader_class>,例:your_project.path.modul.DBCaseLoaderMiddleware | NA | [CASE] |
| case_filepath | 用例路径 | 用例文件绝对或相对路径,默认将以FileCaseLoaderMiddleware加载测试用例数据 | NA | [CASE] |
| *others* | 其他任意配置项 | 如果存在将以key, value形式存储在request.meta中 | request.meta | [META] |
`config`优先级:
- `default`: 0,
- `package`: 10,
- `module`: 20,
- `project`: 30,
- `case`: 40,
- `command`: 50,
>*`command`优先级最高。而对于`ez.cfg`配置文件,越靠近用例层优先级越高。*
### marshmallow之EzSchema
在`EzSchema`中,你可以动态修改字段的校验规则。
```python
from api_test_ez.ez.ez_marshmallow import EzSchema
from marshmallow import fields, validate
class PhoneSchema(EzSchema):
id = fields.Integer(required=True, strict=True)
title = fields.String(required=True)
category = fields.String(required=True)
images = fields.List(fields.String(), required=True, validate=validate.Length(min=1))
if __name__ == '__main__':
ps = PhoneSchema()
ps.title.validate = validate.OneOf(["smartphones", "laptops"])
```
### `ez`命令行
EZ目前仅支持`unittest`运行测试用例。它除了支持所有[`unittest`](https://docs.python.org/zh-cn/3/library/unittest.html#command-line-interface)命令行参数外,还支持以下设置内容:
**位置参数**:
- `action`: 指定`EZ`命令的行为,`run`或`dry-run`。<br>
- `run`: 运行测试用例并生成报告。(当为设置report目录时,会以`dry-run`运行)
- `dry-run`: 试运行测试用例。
- `cases_path`: 要运行的用例**脚本**路径。
**可选参数**
- `-h`, `--help`: 帮助文档
- `-version`, `--version`: 显示`ApiTestEz`版本号
- `-fk`, `--framework`: 如何运行测试。`unittest`或`pytest`(暂未支持),默认`unittest`.
- `-cfg`, `--config`: 设置配置,优先级为`command`。例:*-cfg host=127.0.0.1*。
- `-cfgf`, `--config-file`: 设置配置文件,必须是`ez.cfg`格式的文件,优先级`command`。
- `-rs`, `--report-style`: 报告样式选择。`html`(即: HtmlReporter)或`br`(即: BRReporter)。默认`br`。
- `-rt`, `--report-theme`: BRReporter主题. 默认: `theme_default`。支持: `theme_default`, `theme_default`,`theme_default`, `theme_cyan`, `theme_candy`, `theme_memories`。
- `-rf`, `--report-file`: 报告文件路径。
>*例:ez run <path_or_dir_to_case_script> -cfg host=127.0.0.1 -rs html*
### <span id="jump_case">用例生成器</span>
假如我们有一个**注册**接口需要测试,接口有4个字段需要传入(`username`/`password`/`invite_code`/`trust_value`),如下:
| keys | value1 | value2 | value3 |
|-------------|----------------|-------------|---------------|
| username | [email protected] | 13300000000 | bruce_william |
| password | testgmail | 123456 | brucewil& |
| invite_code | gmail_ivt | phone_ivt | bruce_ivt |
| trust_value | 30 | 100 | 1 |
抛开密码校验场景不考虑,我们需要进行以下场景测试:
1. `username`和`invite_code`的交叉使用是否能正常注册(假设程序要求邮箱、手机号、用户名注册的用户邀请码要一一对应);
2. `trust_value`的边界值是否校验正确(假设使用手机号注册不限制用户年龄,其他情况需要满足年龄:100<`trust_value`);
3. `trust_value`和`invite_code`的判定关系是否正常(假设`phone_ivt`邀请的用户,只需要满足信任值`trust_value`>=30)
针对如上场景,我们可能需要列出所有测试数据,并穷举所有测试情况,并生成用例,如果将`password`考虑进去,那会使得整个用例设计过程异常复杂。
好在,现在`EZ`提供了这样的功能。
- 创建用例模型
```python
from api_test_ez.ez.case_builder.schema import CaseBuilderSchema
from api_test_ez.ez.case_builder.fields import (
IterableField
)
class SignupApiCaseSchema(CaseBuilderSchema):
username = IterableField(value=["[email protected]", "13300000000", "bruce_william"], iterative_mode='EXH')
invite_code = IterableField(value=["gmail_ivt", "phone_ivt", "bruce_ivt"], iterative_mode='EXH')
trust_value = IterableField(value=[30, 100, 1], iterative_mode='EXH')
```
`EZ.CaseBuilderSchema`目前支持3种字段类型:`UniqueField`/`IterableField`/`FixedField`
`IterableField`:会参与计算的字段,`value`必须是一个可迭代的对象。`fmt`目前支持两种计算方式:`ORT`(Orthogonal,正交)和`EXH`(Exhaustive,穷举)。
`UniqueField`:唯一且自增的字段,会按用例条数及提供的`value`格式化为自增字符串,通常用作用例标题,例:case_1/case2/...。
`FixedField`:固定的字段,会自动填充到每条用例中。
- 生成用例
```python
signup_cs = SignupApiCaseSchema()
signup_cs.build()
```
>[
>
>[ {'username': '[email protected]'}, {'invite_code': 'gmail_ivt'}, {'trust_value': 30}],
>
>[ {'username': '[email protected]'}, {'invite_code': 'gmail_ivt'}, {'trust_value': 100}],
>
> ...
>
> ]
- 保存用例
```python
signup_cs.save(file_path="<case_path_to_save>", fmt="xlsx")
```
>
>*`save`方法使用`tablib`库作为导出方法,它同样可以导出其他其他类型的文件,如:fmt="csv", fmt="yml", fmt="json"等`tablib`支持的所有方式。*
- 绑定相关字段
接下来我们要说到上面被我们忽略的`password`。 除了以上导出字段,我们可能还希望将账号和密码绑定起来,`CaseBuilderSchema`中支持嵌套模型的灵活配置方式
*方式1*
```python
from api_test_ez.ez.case_builder.schema import CaseBuilderSchema
from api_test_ez.ez.case_builder.fields import (
IterableField,
FixedField
)
class SignupApiCaseSchema(CaseBuilderSchema):
userinfo = IterableField(value=[
[
{"username": "[email protected]"},
{"password": "testgmail"},
],
[
{"username": "13300000000"},
{"password": "123456"},
],
[
{"username": "bruce_william"},
{"password": "brucewil&"},
],
], iterative_mode='EXH')
invite_code = IterableField(value=["gmail_ivt", "phone_ivt", "bruce_ivt"], iterative_mode='EXH')
trust_value = IterableField(value=[30, 100, 1], iterative_mode='EXH')
```
*方式2*
```python
from api_test_ez.ez.case_builder.schema import CaseBuilderSchema
from api_test_ez.ez.case_builder.fields import (
IterableField,
FixedField
)
class MailUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="[email protected]")
password = FixedField(value="testgmail")
class PhoneUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="13300000000")
password = FixedField(value="123456")
class NormalUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="bruce_william")
password = FixedField(value="brucewil&")
class SignupApiCaseSchema(CaseBuilderSchema):
userinfo = IterableField(value=[MailUserCaseSchema, PhoneUserCaseSchema, NormalUserCaseSchema], iterative_mode='EXH')
invite_code = IterableField(value=["gmail_ivt", "phone_ivt", "bruce_ivt"], iterative_mode='EXH')
trust_value = IterableField(value=[30, 100, 1], iterative_mode='EXH')
```
- 保存用例
```python
signup_cs.save(file_path="<case_path_to_save>", fmt="xlsx")
```
>
- 加入用例标题
```python
from api_test_ez.ez.case_builder.schema import CaseBuilderSchema
from api_test_ez.ez.case_builder.fields import (
IterableField,
FixedField,
UniqueField
)
class MailUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="[email protected]")
password = FixedField(value="testgmail")
class PhoneUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="13300000000")
password = FixedField(value="123456")
class NormalUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="bruce_william")
password = FixedField(value="brucewil&")
class SignupApiCaseSchema(CaseBuilderSchema):
userinfo = IterableField(value=[MailUserCaseSchema, PhoneUserCaseSchema, NormalUserCaseSchema], iterative_mode='EXH')
invite_code = IterableField(value=["gmail_ivt", "phone_ivt", "bruce_ivt"], iterative_mode='EXH')
trust_value = IterableField(value=[30, 100, 1], iterative_mode='EXH')
case_name = UniqueField(value="signup_case")
```
- 保存
```python
signup_cs.save(file_path="<case_path_to_save>", fmt="xlsx")
```
>
- 使用正交模式
除了穷举,你还可以使用正交的方式,这样会使得你的用例变得更少
```python
from api_test_ez.ez.case_builder.schema import CaseBuilderSchema
from api_test_ez.ez.case_builder.fields import (
IterableField,
FixedField,
UniqueField
)
class MailUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="[email protected]")
password = FixedField(value="testgmail")
class PhoneUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="13300000000")
password = FixedField(value="123456")
class NormalUserCaseSchema(CaseBuilderSchema):
username = FixedField(value="bruce_william")
password = FixedField(value="brucewil&")
class SignupApiCaseSchema(CaseBuilderSchema):
userinfo = IterableField(value=[MailUserCaseSchema, PhoneUserCaseSchema, NormalUserCaseSchema], iterative_mode='ORT')
invite_code = IterableField(value=["gmail_ivt", "phone_ivt", "bruce_ivt"], iterative_mode='ORT')
trust_value = IterableField(value=[30, 100, 1], iterative_mode='ORT')
case_name = UniqueField(value="signup_case")
```
> 
> **请注意:你需要主观判断计算字段的权重,目前暂不支持权重设置,正交对你设定的字段视为同级别进行计算。**
>
> 当然,你也可以在模型中同时使用穷举和正交,`EZ`默认优先使用**穷举**,随后对计算结果与*需要参与正交的字段*(如果有,没有将省略此步骤)进行**正交**。
>
> 如:你可以将`userinfo`和`invite_code`设置`EXH`,将`trust_value`设置`ORT`,`EZ`将对`userinfo`&`invite_code`进行穷举,随后将穷举结果与`trust_value`进行正交。
>
> **你当然也可以在嵌套的模型中使用正交或穷举。**
### TODO
1. 用例支持入参,例:f"{'X-Forwarded-For': ${province_ip} }"
2. ~~url拆分host + path~~
3. ~~报告~~
4. ~~序列化断言实现~~
5. ~~cmdline~~
6. 项目构建工具:ez create xxxx
7. 基于pytest的用例实现
8. ~~pypi setup~~
9. 完善注释,文档
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/README.md
|
README.md
|
import argparse
import os
import pathlib
import sys
from unittest import TestProgram
from api_test_ez.core.report import BRReporter, HtmlReporter, DryRun
from api_test_ez.project import Project
EZ_SUPPORT_ACTION = [
'run',
'dry-run'
]
class EzCommand:
def __init__(self, argv=None):
if argv is None:
argv = sys.argv[1:]
self.project = None
self.process_args(argv)
@staticmethod
def parse_ez_parent():
parser = argparse.ArgumentParser(add_help=False, exit_on_error=False)
# action
parser.add_argument('action',
choices=['run'],
help='Command action.'
'For example: `ez run` <test_cases_path>')
# run cases
parser.add_argument('cases_path',
help='Run the next parameters as the test case.'
'For example: ez run <test_cases_path>')
return parser
@staticmethod
def parse_ez_args():
# parser = argparse.ArgumentParser(add_help=False, parents=[parent])
parser = argparse.ArgumentParser(add_help=True, exit_on_error=False)
# action
parser.add_argument('action',
choices=['run', 'dry-run'],
help='Command action.'
'For example: `ez run`')
# run cases
parser.add_argument('cases_path',
help='Run the next parameters as the test case.'
'For example: ez run <test_cases_path>')
# version
with open(os.path.join(os.path.dirname(__file__), 'VERSION'), 'rb') as f:
version = f.read().decode('ascii').strip()
parser.add_argument('-version', '--version',
action='version',
version=f'ApiTestEz version {version}',
help='Current EZ version.')
# framework
parser.add_argument('-fk', '--framework', dest='framework',
default='unittest',
choices=['unittest', 'pytest'],
help='`unittest` or `pytest`, how to EZ run cases, `unittest` as default.')
# config
parser.add_argument('-cfg', '--config', dest='config',
action="extend", nargs="+",
help='Set EZ config, priority `command`. '
'For example: `-cfg host=127.0.0.1`, '
'details: https://github.com/bruce4520196/ApiTestEz.')
# config file
parser.add_argument('-cfgf', '--config-file', dest='config_file',
help='Set EZ <config_file_path>, priority `command`. '
'details: https://github.com/bruce4520196/ApiTestEz.')
# report style
parser.add_argument('-rs', '--report-style', dest='report_style',
default='br',
choices=['html', 'br'],
help='Report style. default `html`. '
'support: `html` (ie: HtmlReporter), `br` (ie: BRReporter)')
# beautiful report theme
parser.add_argument('-rt', '--report-theme', dest='report_theme',
default='theme_default',
choices=['theme_default', 'theme_default', 'theme_cyan', 'theme_candy', 'theme_memories'],
help='Beautiful report theme. default `theme_default`. '
'support: `theme_default`, `theme_default`,`theme_default`, '
'`theme_cyan`, `theme_candy`, `theme_memories`')
# report file
parser.add_argument('-rf', '--report-file', dest='report_file',
help='Report file path.')
return parser
def process_args(self, argv):
ez_parser = self.parse_ez_args()
if len(argv) == 0:
ez_parser.print_help()
return
if argv[0] == '-version' or argv[0] == '--version':
ez_parser.parse_args()
return
if argv[0] not in EZ_SUPPORT_ACTION:
print(f'EZ COMMAND ERROR: unknown action-word `{argv[0]}`. Support word must in {EZ_SUPPORT_ACTION}. See: \n')
ez_parser.print_help()
return
if len(argv) == 1:
print(f'EZ COMMAND ERROR: expect a <case-file-path> after the action-word `{argv[0]}`. See: \n')
ez_parser.print_help()
return
if argv[1].startswith('-'):
print(f'EZ COMMAND ERROR: expect a <case-file-path> after the action-word `{argv[0]}`, '
f'but `{argv[1]}` found. See: \n')
ez_parser.print_help()
return
args, unknown_args = ez_parser.parse_known_args(argv)
cases_path = args.cases_path
if not cases_path:
print('EZ COMMAND ERROR: `cases_path` not found. See: \n')
ez_parser.print_help()
return
if not os.path.isfile(cases_path) or not os.path.isfile(cases_path):
print('EZ COMMAND ERROR: `cases_path` is not a file or dir. See: \n')
ez_parser.print_help()
return
project = Project(ez_file_path=cases_path if os.path.isdir(cases_path) else os.path.dirname(cases_path))
if args.report_style:
project.settings.set('REPORT_STYLE', args.report_style)
if args.report_theme:
project.settings.set('BR_REPORT_THEME', args.report_theme)
if args.report_file:
project.settings.set('REPORT_DIR', os.path.dirname(args.report_file))
project.settings.set('REPORT_FILE_NAME', os.path.basename(args.report_file))
if args.config_file:
if os.path.exists(args.config_file):
print(f'EZ COMMAND ERROR: can not find ez-config-file `{args.config_file}`.')
ez_parser.print_help()
else:
project.configs.set_config(args.config_file, priority='command')
if args.config:
for cfg in args.config:
if '=' not in cfg:
print('EZ COMMAND ERROR: config format error, For example: `-cfg host=127.0.0.1`. See: \n')
ez_parser.print_help()
return
project.configs.set(*cfg.split('=', 1), priority='command')
if args.action == 'run':
if project.report.report_dir:
if args.report_style == 'br':
BRReporter(args.cases_path).run()
return
elif args.report_style == 'html':
HtmlReporter(args.cases_path).run()
return
else:
print(f'EZ COMMAND WARNING: `{args.report_style}` is not supported `report_style`, '
f'run tests as dry-run. See: \n')
ez_parser.print_help()
else:
print(f'EZ COMMAND WARNING: `report_dir` does not set, run tests as dry-run.\n')
# ez_parser.print_help()
DryRun(args.cases_path).run()
return
elif args.action == 'dry-run':
DryRun(args.cases_path).run()
return
else:
print(f'EZ COMMAND ERROR: {args.action} is not supported `action`. See: \n')
ez_parser.print_help()
return
def main():
EzCommand()
if __name__ == '__main__':
main()
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/cmd.py
|
cmd.py
|
import sys
from api_test_ez.ez import get_config, Log
from api_test_ez.ez.decorator import singleton
from api_test_ez.project.configs import Configs
from api_test_ez.project.settings import Settings
import os
ENV_EZ_PROJECT_DIR = 'EZ_PROJECT_DIR'
ENV_EZ_SETTINGS_MODULE = 'EZ_SETTINGS_MODULE'
def closest_file(file_name, path='.', prev_path=None):
"""Return the path to the closest project.cfg file by traversing the current
directory and its parents
"""
if path == prev_path:
return ''
path = os.path.abspath(path)
cfg_file = os.path.join(path, file_name)
if os.path.exists(cfg_file):
return cfg_file
return closest_file(file_name, os.path.dirname(path), path)
def search_file(file_name: str, path: str = '.', prev_path: str = None, search_result=None):
"""Return the path list to the case.cfg file by traversing the current
directory and its parents
"""
if search_result is None:
search_result = []
if path == prev_path:
return search_result
path = os.path.abspath(path)
cfg_file = os.path.join(path, file_name)
if os.path.exists(cfg_file):
search_result.append(cfg_file)
return search_file(file_name, path=os.path.dirname(path), prev_path=path, search_result=search_result)
def init_project(project='default'):
# project config
ez_cfg_name = 'project.cfg'
project_cfg_path = closest_file(ez_cfg_name)
cfg = get_config(project_cfg_path)
if cfg.has_option('settings', project):
project_settings_path = cfg.get('settings', project)
os.environ[ENV_EZ_SETTINGS_MODULE] = project_settings_path
os.environ[ENV_EZ_PROJECT_DIR] = os.path.abspath(os.path.dirname(project_cfg_path))
sys.path.append(os.environ[ENV_EZ_PROJECT_DIR])
def get_ez_settings():
if ENV_EZ_SETTINGS_MODULE not in os.environ:
init_project()
_settings = Settings()
settings_module_path = os.environ.get(ENV_EZ_SETTINGS_MODULE)
if settings_module_path:
_settings.set_module(settings_module_path)
return _settings
def get_ez_config(ez_file_path):
# ez case config
ez_cfg_name = 'ez.cfg'
ez_cfg_filelist = search_file(ez_cfg_name, path=ez_file_path)
_configs = Configs()
support_file_config_priority = ['package', 'module', 'project']
for ez_cfg_file in ez_cfg_filelist:
if len(support_file_config_priority) <= 0:
break
_configs.set_config(ez_cfg_file, support_file_config_priority.pop(0))
return _configs
def get_ez_logger(project_settings: Settings, logger_name=None):
"""
:param project_settings:
:param logger_name:
:return:
"""
console_format = project_settings.get('CONSOLE_LOG_FORMAT')
console_log_level = project_settings.get('CONSOLE_LOG_LEVEL')
file_format = project_settings.get('FILE_LOG_FORMAT')
file_log_level = project_settings.get('FILE_LOG_LEVEL')
file_log_path = project_settings.get('FILE_LOG_PATH')
log = Log(logger_name=logger_name)
if console_format:
log.console_format = console_format
if console_log_level:
log.console_log_level = console_log_level
if file_format:
log.file_format = file_format
if file_log_level:
log.file_log_level = file_log_level
logger = log.init_logger(file_log_path)
return logger
class ReportConfig:
def __init__(self, project_settings: Settings):
self._report_dir = project_settings.get("REPORT_DIR")
self._report_file_name = project_settings.get("REPORT_FILE_NAME")
self._report_file_path = os.path.join(self._report_dir, self._report_file_name) if self._report_dir else None
self._report_title = project_settings.get("REPORT_TITLE")
self._report_desc = project_settings.get("REPORT_DESC")
self._report_theme = project_settings.get("BR_REPORT_THEME")
@property
def report_file_path(self):
return self._report_file_path
@property
def report_title(self):
return self._report_title
@property
def report_desc(self):
return self._report_desc
@property
def report_dir(self):
return self._report_dir
@property
def report_file_name(self):
return self._report_file_name
@property
def theme(self):
return self._report_theme
@singleton
class Project:
"""Ez initialize"""
def __init__(self, ez_file_path, env_name=None):
self.env_name = env_name if env_name else os.path.dirname(ez_file_path)
self._settings = get_ez_settings()
self._configs = get_ez_config(ez_file_path)
self._logger = get_ez_logger(self._settings, self.env_name)
self._report = ReportConfig(self._settings)
@property
def settings(self):
return self._settings
@property
def configs(self):
return self._configs
@property
def logger(self):
return self._logger
@property
def report(self):
return self._report
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/project/__init__.py
|
__init__.py
|
import ast
import os
import sys
if sys.version_info[:2] >= (3, 8):
from collections.abc import MutableMapping
else:
from collections import MutableMapping
from api_test_ez.ez import get_config
CONFIG_PRIORITIES = {
'default': 0,
'project': 10,
'module': 20,
'package': 30,
'case': 40,
'command': 50,
}
def get_config_priority(priority):
"""
Small helper function that looks up a given string priority
"""
return CONFIG_PRIORITIES[priority]
class BaseConfigs(MutableMapping):
"""
Instances of this class behave like dictionaries,
store with their ``(key, value)`` pairs.
but values will store as a list order by ``priority``.
when you want ``get`` value, it will return the value of the highest priority (maybe now is enough).
"""
def __init__(self, *args, **kwargs):
self.attributes = {}
self.update(*args, **kwargs)
def __delitem__(self, name) -> None:
del self.attributes[name]
def __getitem__(self, name):
if name not in self:
return None
return self.attributes[name].value
def __len__(self) -> int:
return len(self.attributes)
def __iter__(self):
return iter(self.attributes)
def __setitem__(self, name, value):
self.set(name, value)
def __contains__(self, name):
return name in self.attributes
def set_config(self, config_path, priority='default'):
"""
Store project from a module.
:param config_path: the config file path
:type config_path: string
:param priority: the priority of the configs.
:type priority: string
"""
cfg = get_config(config_path)
for title, selection in cfg.items():
for key, value in selection.items():
try:
value = ast.literal_eval(value)
except SyntaxError:
pass
except ValueError:
pass
self.set(key.lower(), value, priority=priority)
def set(self, name, value, priority='default'):
"""
Store a key/value attribute with a given priority.
:param name: the setting name
:type name: string
:param value: the value to associate with the setting
:type value: any
:param priority: the priority of the setting. Should be a key of
CONFIG_PRIORITIES or an integer
:type priority: string or int
"""
priority = get_config_priority(priority)
if name not in self:
if isinstance(value, ConfigAttribute):
self.attributes[name] = value
else:
self.attributes[name] = ConfigAttribute(value, priority)
else:
self.attributes[name].set(value, priority)
def get(self, name, default=None):
"""
Get a config value without affecting its original type.
:param name: the setting name
:type name: string
:param default: the value to return if no setting is found
:type default: any
"""
return self[name] if self[name] is not None else default
def pop(self, name, default=None):
"""
Pop a config value from `name` and delete key in config.
:param name:
:param default:
:return:
"""
value = self[name] if self[name] is not None else default
if self.attributes.get(name):
del self.attributes[name]
return value
def to_dict(self):
"""
Change `Config` to `dict`.
:return:
"""
return {k: v for k, v in self.items()}
class ConfigAttribute(object):
"""
Class for storing data related to configs attributes.
This class is intended for internal usage, you should try Configs class
for setting configurations, not this one.
"""
def __init__(self, value, priority):
self.value = value
self.priority = priority
def set(self, value, priority):
"""Sets value if priority is higher or equal than current priority."""
if priority >= self.priority:
self.value = value
self.priority = priority
def __str__(self):
return "<ConfigAttribute value={self.value!r} " \
"priority={self.priority}>".format(self=self)
__repr__ = __str__
class Configs(BaseConfigs):
"""
This object stores ApiTestEz project for the configuration of internal
components, and can be used for any further customization.
"""
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.set_config(os.path.join(os.path.dirname(__file__), "default_configs.cfg"))
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/project/configs/__init__.py
|
__init__.py
|
import copy
import os
from importlib import import_module
from ddt import ddt, data, feed_data
from api_test_ez.core.case.errors import HttpRequestException, CaseFileNotFoundException
from api_test_ez.core.case.frame.frame_case_loader import FileCaseLoaderMiddleware
from api_test_ez.core.case.frame.frame_unittest import UnitHttpFrame
from api_test_ez.core.case.http.request import Request
from api_test_ez.core.case.http.response import EzResponse
from api_test_ez.ez import Http
from api_test_ez.project import Project
def ez_ddt_setter(cls):
"""Set `%values` (`DATA_ATTR` from ddt) for testMethods.
`ddt` will copy methods which have `DATA_ATTR` attribute.
So we set it to all the testMethods (sometimes we need set some method exactly,
it will be supported maybe next version).
Then Unittest can run all of these cases."""
DATA_ATTR = "%values"
if hasattr(cls, "load_data"):
load_func = getattr(cls, "load_data")
values = getattr(load_func, DATA_ATTR)
for name, func in list(cls.__dict__.items()):
if name.startswith("test"):
setattr(func, DATA_ATTR, values)
return cls
DATA_HOLDER = "%data_holder"
class CaseMetaclass(type):
"""Mapping test method and ddt data.
`ddt` only copy the method which is decorated by `data`,
let's make test_method and ddt_data map."""
def __new__(mcs, name, bases, attrs):
super_new = super().__new__
# If a base class just call super new
if name == 'UnitCase':
return super_new(mcs, name, bases, attrs)
for base_class in bases:
if base_class is UnitCase:
# Find data functions
ddt_func_names = []
for base_attr_name in dir(base_class):
if base_attr_name.startswith('load_data'):
ddt_func_names.append(base_attr_name)
# If data function is None, let test run itself.
if len(ddt_func_names) == 0:
return super_new(mcs, name, bases, attrs)
new_attrs = {}
# Mapping test methods and data functions
for func_name, func in attrs.items():
if func_name.startswith('test'):
for ddt_func_name in ddt_func_names:
test_name = ddt_func_name.replace('load_data', func_name)
# Let's set a `%data_owner` attr to test function
# Then we can find the data later.
# We can not copy function directly, create it from `ddt.feed_data`.
_func = feed_data(func, test_name, func.__doc__)
setattr(_func, DATA_HOLDER, ddt_func_name)
new_attrs.update({test_name: _func})
else:
# other methods should be added without modified
new_attrs.update({func_name: func})
return super_new(mcs, name, bases, new_attrs)
return super_new(mcs, name, bases, attrs)
@ddt
class UnitCase(UnitHttpFrame, metaclass=CaseMetaclass):
# env init
case_path_dir = os.getcwd()
ez_project = Project(ez_file_path=case_path_dir, env_name=os.path.basename(case_path_dir))
configs = ez_project.configs
logger = ez_project.logger
# load test data
case_loader_str = configs.get("case_loader")
if case_loader_str:
# Case-loader define as <module>.<case_loader_class>
case_loader_str_list = case_loader_str.split('.')
case_loader_module_str = ".".join(case_loader_str_list[:-1])
case_loader_class_str = case_loader_str_list[-1]
case_loader_module = import_module(case_loader_module_str)
case_loader_class = getattr(case_loader_module, case_loader_class_str)
else:
# default
case_loader_class = FileCaseLoaderMiddleware
case_loader = case_loader_class(configs)
data_set = case_loader.load_test_data()
# set request here, bcz the data in `ez.config` can not be load in again.
__autoRequest__ = configs.get("auto_request")
def __new__(cls, methodName, *args, **kwargs):
# bcz of `__classcell__` error, copy config at here.
cls.local_config = copy.deepcopy(cls.configs)
return super(UnitHttpFrame, cls).__new__(cls, *args, **kwargs)
def __init__(self, methodName):
self.request = Request(http=Http())
self.response = EzResponse(logger=self.logger)
self.request.owner = methodName
self.response.owner = methodName
self.initRequest(methodName)
super(UnitCase, self).__init__(methodName)
@data(*data_set)
def load_data(self, case_data: dict):
for key, value in case_data.items():
self.local_config.set(key, value, priority="case")
def initRequest(self, testmethod_name):
# Find my ddt data holder via testmethod_name.
if hasattr(self, testmethod_name):
test_func = getattr(self, testmethod_name)
if hasattr(test_func, DATA_HOLDER):
data_holder = getattr(test_func, DATA_HOLDER)
if hasattr(self, data_holder):
_ddt_data_func = getattr(self, data_holder)
_ddt_data_func()
self.request.set(self.local_config)
return self.request
def doRequest(self, request=None):
if request:
self.request.set(request)
self.logger.debug(repr(self.request))
# Prepare request
http = self.request.http
url = self.request.url
method = self.request.method.lower()
body = self.request.body
body_type = self.request.body_type
# Request start
if url and hasattr(http, method):
do = getattr(http, method)
self.response.set(do(url=url, **{body_type: body}))
http.close()
self.logger.debug(repr(self.response))
else:
if not url:
raise HttpRequestException(err="`url` can not be None.")
else:
raise HttpRequestException(err=f"Not support request method `{method}`")
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/core/case/__init__.py
|
__init__.py
|
import logging
from json import JSONDecodeError
from requests import Response
from api_test_ez.ez.decorator.jsonbean import json_bean
from api_test_ez.ez.serialize.errors import ValidationError
from api_test_ez.ez.serialize.models import ValidatorModel
from marshmallow import Schema, utils
from api_test_ez.project import get_ez_logger, get_ez_settings
class EzResponse(Response):
__slots__ = ("owner", "response", "logger")
def __init__(self, logger, response: Response = None):
super().__init__()
self.response = response
self.logger = logger
self._owner = None
def __getattribute__(self, item):
if item not in ("owner", "response", "logger") and not item.startswith('__') and hasattr(self.response, item):
return self.response.__getattribute__(item)
else:
return super(EzResponse, self).__getattribute__(item)
# @property
# def content(self) -> bytes:
# return self.response.content
def set(self, response: Response):
self.response = response
@property
@json_bean
def bean(self):
if self.response:
return self.json()
else:
return None
def pair(self, model: ValidatorModel, full_repr=False):
if self.response:
validate_result = model.validate(self.response.json(), full_repr)
if 'ValidationError' in str(validate_result):
validation_error = ValidationError(f'[{self.owner}] {validate_result}')
self.logger.error(validation_error)
raise validation_error
else:
raise ValidationError(f'[{self.owner}] {self.__str__()}')
def validate(self, schema: Schema):
"""Validate from marshmallow."""
if self.response is not None:
# Reload the `validators` of the `fields` which in `schema`.
# In case the `validate` is modified.
for field_name, field_obj in schema.declared_fields.items():
if field_obj.validate is None:
field_obj.validators = []
elif callable(field_obj.validate):
field_obj.validators = [field_obj.validate]
elif utils.is_iterable_but_not_string(field_obj.validate):
field_obj.validators = list(field_obj.validate)
else:
raise ValueError(
"The 'validate' parameter must be a callable "
"or a collection of callables."
)
return schema.load(self.response.json())
else:
raise ValidationError(f'[{self.owner}] {self.__str__()}')
def __str__(self):
if self.response is not None:
return f"<{self.__class__.__name__}> {self.owner}:\n" \
f"{self.response.text!r}"
else:
return f"<{self.__class__.__name__}> {self.owner}: response is None, " \
f"maybe you didn't send the request or request failed?"
__repr__ = __str__
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/core/case/http/response.py
|
response.py
|
from api_test_ez.ez import Http
from api_test_ez.ez.decorator.jsonbean import json_bean
class Request(object):
def __init__(self, http: Http):
self._http = http
self._http_data = {}
self._meta_data = {}
self._url = None
self._host = None
self._path = None
self._method = None
self._body = None
self._owner = None
self._body_type = None
def _filter_data(self, request_data):
if request_data:
self._url = request_data.pop("url", default=None)
self._host = request_data.pop("host", default=None)
self._path = request_data.pop("path", default=None)
self._body_type = request_data.pop("body_type", default="data")
if self._url is None and self._host:
if not self._host.startswith('http'):
self._host = f'http://{self._host}'
if self._path:
self._url = f'{self._host}{self._path}' \
if self._path.startswith('/') \
else f'{self._host}/{self._path}'
else:
self._url = self._host
self._method = request_data.pop("method")
self._body = request_data.pop("body", default=None)
# http
self._http_data = {
"headers": request_data.pop("headers"),
"timeout": request_data.pop("timeout"),
"cookies": request_data.pop("cookies"),
"retry": request_data.pop("retry"),
"proxies": request_data.pop("proxies"),
"allow_redirects": request_data.pop("allow_redirects"),
"verify": request_data.pop("verify"),
}
# meta
self._meta_data = request_data
def set(self, request_data):
self._filter_data(request_data)
for key, value in self._http_data.items():
if value:
if hasattr(self._http, key):
setattr(self._http, key, value)
@property
def owner(self):
return self._owner
@owner.setter
def owner(self, value):
self._owner = value
@property
def url(self):
return self._url
@url.setter
def url(self, value):
self._url = value
@property
def host(self):
return self._host
@host.setter
def host(self, value):
self._host = value
@property
def path(self):
return self._path
@path.setter
def path(self, value):
self._path = value
@property
def method(self):
return self._method
@method.setter
def method(self, value):
self._method = value
@property
def body(self):
return self._body
@body.setter
def body(self, value):
self._body = value
@property
def body_type(self):
return self._body_type
@body_type.setter
def body_type(self, value):
self._body_type = value
@property
def http(self):
return self._http
@property
def meta(self):
return RequestMetaData(self._meta_data)
def __str__(self):
return f'<{self.__class__.__name__}> [{self.owner}]:\n' \
f'url: {self._url!r}\n' \
f'method: {self._method!r}\n' \
f'body: {self._body!r}\n' \
f'http_data: {self._http_data!r}\n' \
f'meta: {self.meta.data!r}'
__repr__ = __str__
class RequestMetaData:
def __init__(self, meta_dict):
self._meta_dict = meta_dict
@property
@json_bean
def bean(self):
return self._meta_dict.to_dict()
@property
def data(self):
return self._meta_dict.to_dict()
if __name__ == '__main__':
http = Http()
request = Request(http)
request.set(
{
"url": 0,
"method": 11,
"body": 12,
"headers": 1,
"timeout": 2,
"cookies": 3,
"retry": 4,
"proxies": 5,
"allow_redirects": 6,
"verify": 7,
}
)
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/core/case/http/request.py
|
request.py
|
import os
import unittest
from abc import ABC, abstractmethod
from BeautifulReport import BeautifulReport
from api_test_ez.libs import HTMLTestRunner
from api_test_ez.project import Project
from unittest.loader import defaultTestLoader
class Reporter(ABC):
def __init__(self, case_path, report_title=None, report_desc=None, *args, **kwargs):
self.case_file_name = None
if os.path.isdir(case_path):
self.case_file_dir = case_path
else:
self.case_file_dir = os.path.dirname(case_path)
self.case_file_name = os.path.basename(case_path)
project = Project(ez_file_path=self.case_file_dir)
self.settings = project.settings
# log
self.logger = project.logger
# report file
self.report = project.report
self.report_dir = self.report.report_dir
self.report_file_name = self.report.report_file_name
self.report_file_path = project.report.report_file_path
self.report_title = report_title if report_title else project.report.report_title
self.report_desc = report_desc if report_desc else project.report.report_desc
def load_tests(self):
"""Load tests from a dir. It is same as the `load_tests` protocol in `unittest`."""
if self.case_file_name:
return defaultTestLoader.discover(self.case_file_dir, pattern=f'{self.case_file_name}')
else:
return defaultTestLoader.discover(self.case_file_dir, pattern='*.py')
@abstractmethod
def run(self):
pass
def send(self):
pass
class HtmlReporter(Reporter):
"""HTMLTestRunner"""
def run(self):
if not os.path.exists(self.report_dir):
os.makedirs(self.report_dir)
fp = open(self.report_file_path, 'wb')
try:
suit = self.load_tests()
self.logger.info("********TEST BEGIN********")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=f'{self.report_title}',
description=f'API:\n{self.report_desc}')
runner.run(suit)
except IOError as ex:
self.logger.error(str(ex))
finally:
self.logger.info("********TEST END*********")
fp.close()
class BRReporter(Reporter):
"""BeautifulReport"""
def __init__(self, case_path, report_theme=None, *args, **kwargs):
super().__init__(case_path, *args, **kwargs)
self.report_theme = report_theme if report_theme else self.report.theme
def run(self):
if not os.path.exists(self.report_dir):
os.makedirs(self.report_dir)
suit = self.load_tests()
result = BeautifulReport(suit)
result.report(
filename=self.report_file_name,
description=self.report_title,
report_dir=self.report_dir,
theme=self.report_theme
)
class DryRun(Reporter):
"""DryRun"""
def __init__(self, case_path, *args, **kwargs):
super().__init__(case_path, *args, **kwargs)
def run(self):
suite = self.load_tests()
runner = unittest.TextTestRunner()
runner.run(suite)
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/core/report/__init__.py
|
__init__.py
|
import os
import logging
from enum import Enum
Log_Format = '%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] [%(thread)d] - %(message)s'
class LogLevel(Enum):
CRITICAL = 'CRITICAL'
FATAL = 'FATAL'
ERROR = 'ERROR'
WARNING = 'WARNING'
INFO = 'INFO'
DEBUG = 'DEBUG'
NOTSET = 'NOTSET'
_logLevelName = ['CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET']
class Log:
def __init__(self, logger_name=None):
self.default_log_level = "DEBUG"
self.logger = logging.getLogger(logger_name)
# default console format
self._console_format = Log_Format
# default file format
self._file_format = Log_Format
# set log level
self._file_log_level = LogLevel.DEBUG.value
self._console_log_level = LogLevel.INFO.value
def init_logger(self, file_log_path=None):
if file_log_path:
# make dir
dir_path = os.path.dirname(file_log_path)
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# file handler
file_handler = self.build_file_handler(file_log_path)
self.logger.addHandler(file_handler)
# console handler
console_handler = self.build_console_handler()
self.logger.addHandler(console_handler)
self.logger.setLevel(self.default_log_level)
return self.logger
@property
def console_format(self):
"""
log format
:return:
"""
return self._console_format
@console_format.setter
def console_format(self, log_format: str):
"""
:param log_format:
:return:
"""
self._console_format = log_format
@property
def file_format(self):
"""
log format
:return:
"""
return self._file_format
@file_format.setter
def file_format(self, log_format: str):
"""
:param log_format:
:return:
"""
self._file_format = log_format
@property
def file_log_level(self):
"""
:return:
"""
return self._file_log_level
@file_log_level.setter
def file_log_level(self, level: str):
"""
:param level: file log level in ['CRITICAL' | 'FATAL' | 'ERROR' | 'WARN' | 'WARNING' | 'INFO' | 'DEBUG']
:return:
"""
level = level.upper()
if level in _logLevelName:
self._file_log_level = level
else:
self.logger.error("Set log level error: unknown level name. Level name must in: "
"['CRITICAL' | 'FATAL' | 'ERROR' | 'WARN' | 'WARNING' | 'INFO' | 'DEBUG']")
@property
def console_log_level(self):
"""
:return:
"""
return self._console_log_level
@console_log_level.setter
def console_log_level(self, level: str):
"""
:param level: file log level in ['CRITICAL' | 'FATAL' | 'ERROR' | 'WARN' | 'WARNING' | 'INFO' | 'DEBUG']
:return:
"""
level = level.upper()
if level in _logLevelName:
self._console_log_level = level
else:
self.logger.error("Set log level error: unknown level name. Level name must in: "
"['CRITICAL' | 'FATAL' | 'ERROR' | 'WARN' | 'WARNING' | 'INFO' | 'DEBUG']")
def build_file_handler(self, file_log_path):
"""
build file handler
:param file_log_path:
:return:
"""
formatter = logging.Formatter(self._file_format)
file_handler = logging.FileHandler(file_log_path, encoding='utf-8')
file_handler.setLevel(self.file_log_level) # set level
file_handler.setFormatter(formatter) # set format
return file_handler
def build_console_handler(self):
"""
build console handler
:return:
"""
formatter = logging.Formatter(self._console_format)
console_handler = logging.StreamHandler()
console_handler.setLevel(self.console_log_level) # set level
console_handler.setFormatter(formatter) # set format
return console_handler
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/log/log.py
|
log.py
|
from enum import Enum
import requests
import urllib3
urllib3.disable_warnings()
class Method:
GET = 'GET'
POST = 'POST'
HEAD = 'HEAD'
OPTIONS = 'OPTIONS'
DELETE = 'DELETE'
PUT = 'PUT'
PATCH = 'PATCH'
class Http:
def __init__(self, headers=None, timeout=3, allow_redirects=False, verify=False, proxies=None, retry=1):
"""
Http初始化
:param headers: 请求头。
:param timeout: 超时时间。
:param with_session: 是否创建session,默认创建。
:param allow_redirects: 是否允许重定向,默认否。
:param verify: 是否进行https证书验证,默认否。
如果开启:verify='/<path>/<file_name>.pem'。
:param retry: 请求重试次数。
"""
self._headers = headers
self._timeout = timeout
self._session = requests.session()
self._allow_redirects = allow_redirects
self._verify = verify
self._proxies = proxies
self._retry = retry
self._cookies = None
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
@property
def timeout(self):
"""
获取超时时间
:return:
"""
return self._timeout
@timeout.setter
def timeout(self, value: int):
"""
设置超时时间
:param value:
:return:
"""
self._timeout = value
@property
def headers(self):
"""
获取请求头
:return:
"""
return self._headers
@headers.setter
def headers(self, value):
"""
设置请求头
:param value:
:return:
"""
self._headers = value
@property
def session(self):
"""
获取session
:param value:
:return:
"""
return self._session
@session.setter
def session(self, value):
"""
设置session
:param value:
:return:
"""
self._session = value
@property
def cookies(self):
"""
:return:
"""
return self._cookies
@cookies.setter
def cookies(self, value):
"""
:return:
"""
self._cookies = value
@property
def retry(self):
"""
获取重试次数
:return:
"""
return self._retry
@retry.setter
def retry(self, value: int):
"""
设置重试次数
:return:
"""
self._retry = value
@property
def proxies(self):
"""
获取代理
:return:
"""
return self._proxies
@proxies.setter
def proxies(self, value):
"""
设置代理
:param value:
:return:
"""
self._proxies = value
@property
def allow_redirects(self):
"""
获取是否允许重定向
:return:
"""
return self._allow_redirects
@allow_redirects.setter
def allow_redirects(self, value):
"""
设置是否允许重定向
:param value:
:return:
"""
self._allow_redirects = value
@property
def verify(self):
"""
获取是否开启https认证
:return:
"""
return self._verify
@verify.setter
def verify(self, value):
"""
设置是否开启https认证
:param value:
:return:
"""
self._verify = value
def close(self):
if self._session:
self._session.close()
def m_request(self, method, url, **kwargs):
for i in range(self._retry):
try:
return self.session.request(method=method, url=url, headers=self._headers, cookies=self._cookies,
timeout=self._timeout, allow_redirects=self._allow_redirects,
proxies=self._proxies, verify=self._verify, **kwargs)
except Exception as e:
print(e)
else:
return None
def get(self, url, **kwargs):
"""发送 GET 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param **kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
return self.m_request(method=Method.GET, url=url, **kwargs)
def post(self, url, data=None, json=None, **kwargs):
"""发送 POST 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param json: (optional) json to send in the body of the :class:`Request`.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
return self.m_request(method=Method.POST, url=url, data=data, json=json, **kwargs)
def options(self, url, **kwargs):
"""发送 OPTIONS 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', True)
return self.m_request(method=Method.OPTIONS, url=url, **kwargs)
def head(self, url, **kwargs):
"""发送 HEAD 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
kwargs.setdefault('allow_redirects', False)
return self.m_request(method=Method.HEAD, url=url, **kwargs)
def put(self, url, data=None, **kwargs):
"""发送 PUT 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
return self.m_request(method=Method.PUT, url=url, data=data, **kwargs)
def patch(self, url, data=None, **kwargs):
"""发送 PATCH 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary, bytes, or file-like object to send in the body of the :class:`Request`.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
return self.m_request(method=Method.PATCH, url=url, data=data, **kwargs)
def delete(self, url, **kwargs):
"""发送 DELETE 请求. Returns :class:`Response` 对象.
:param url: URL for the new :class:`Request` object.
:param kwargs: Optional arguments that ``request`` takes.
:rtype: requests.Response
"""
return self.m_request(method=Method.DELETE, url=url, **kwargs)
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/http/http.py
|
http.py
|
from collections import defaultdict
class ValidationError(AssertionError):
"""Validation exception.
May represent an error validating a field or a
Model containing fields with validation errors.
:ivar errors: A dictionary of errors for fields within this
document or list, or None if the error is for an
individual field.
"""
errors = {}
field_name = None
_message = None
def __init__(self, message="", **kwargs):
super().__init__(message)
self.errors = kwargs.get("errors", {})
self.field_name = kwargs.get("field_name")
self.message = message
def __str__(self):
return f"{self.__class__.__name__}({self.message},)"
__repr__ = __str__
def __getattribute__(self, name):
message = super().__getattribute__(name)
if name == "message":
if self.field_name:
message = "%s" % message
if self.errors:
message = f"{message}({self._format_errors()})"
return message
def _get_message(self):
return self._message
def _set_message(self, message):
self._message = message
message = property(_get_message, _set_message)
def to_dict(self):
"""Returns a dictionary of all errors within a document
Keys are field names or list indices and values are the
validation error messages, or a nested dictionary of
errors for an embedded document or list.
"""
def build_dict(source):
errors_dict = {}
if isinstance(source, dict):
for field_name, error in source.items():
errors_dict[field_name] = build_dict(error)
elif isinstance(source, ValidationError) and source.errors:
return build_dict(source.errors)
else:
return str(source)
return errors_dict
if not self.errors:
return {}
return build_dict(self.errors)
def _format_errors(self):
"""Returns a string listing all errors within a document"""
def generate_key(value, prefix=""):
if isinstance(value, list):
value = " ".join([generate_key(k) for k in value])
elif isinstance(value, dict):
value = " ".join([generate_key(v, k) for k, v in value.items()])
results = f"{prefix}.{value}" if prefix else value
return results
error_dict = defaultdict(list)
for k, v in self.to_dict().items():
error_dict[generate_key(v)].append(k)
return " ".join([f"{k}: {v}" for k, v in error_dict.items()])
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/serialize/errors.py
|
errors.py
|
import copy
from api_test_ez.ez.serialize.errors import ValidationError
from api_test_ez.ez.serialize.fields import BaseField, StringField, IntegerField
__all__ = ["ValidatorModel"]
class ModelMetaclass(type):
def __new__(mcs, name, bases, attrs):
super_new = super().__new__
# If a base class just call super new
if name == "ValidatorModel":
return super_new(mcs, name, bases, attrs)
# Discover any fields
fields_mapping = {}
for attr_name, attr_value in attrs.items():
if issubclass(attr_value.__class__, BaseField) \
or attr_value.__class__.__base__.__name__ in __all__: # is subclass of `ValidatorModel`
fields_mapping.update({attr_name: attr_value})
attrs.update({attr_name: attr_value})
# Record all fields.
attrs["__declared_fields__"] = fields_mapping
return super_new(mcs, name, bases, attrs)
class ValidatorModel(metaclass=ModelMetaclass):
def __init__(self, *args, **values):
self.__fields_mapping__ = copy.deepcopy(getattr(self, "__declared_fields__"))
if args:
raise TypeError(
"Instantiating a field with positional arguments is not "
"supported. Please use `field_name=value` keyword arguments."
)
self.source_values = values
def validate(self, data: dict, full_repr=True):
"""
:param data:
:param full_repr: Determines the completeness of the returned result data.
Must be `True` when call internally.
:return:
"""
data.update(self.source_values)
fields_mapping = copy.deepcopy(getattr(self, "__fields_mapping__"))
for k, v in fields_mapping.items():
try:
# If `v` is `ValidateModel`, we validate it by itself.
# We use `setattr` to set attributes, in order to trigger `__set__`.
if isinstance(v, ValidatorModel):
setattr(self, k, v.validate(data[k]))
else:
setattr(self, k, data[k])
v = getattr(self, k)
data.update({k: v})
except KeyError:
if getattr(v, 'required', None):
_error = ValidationError("Field is required but not provided.")
setattr(self, k, repr(_error))
data.update({k: repr(_error)})
if full_repr:
return data
else:
return getattr(self, "__fields_mapping__")
def __str__(self):
return f"<{self.__class__.__name__}> {getattr(self, '__fields_mapping__')}"
__repr__ = __str__
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/serialize/models.py
|
models.py
|
import re
from abc import abstractmethod, ABC
from api_test_ez.ez.serialize.errors import ValidationError
__all__ = ["StringField", "IntegerField", "ListField", "DynamicListField"]
validator_funcs = [
'should_be', 'should_in', 'should_contain', 'should_like',
# For list field
'count_should_be', 'count_should_gt', 'count_should_lt',
'count_should_gte', 'count_should_lte',
# For list members
'members_should_contain_model'
]
class BaseField(ABC):
field_type = None
def __init__(self, required=False, null=False, **kwargs):
self.required = required
self.null = null
self.name = None
# Discover any validator function, which start with `should_`.
# Store in `validator_funcs` dict.
self.validate_funcs = {}
for key, value in kwargs.items():
if key in validator_funcs:
self.validate_funcs.update({key: value})
def __set_name__(self, owner, name):
self.name = name
def __get__(self, instance, owner):
# return getattr(instance.__fields_mapping__, self.validated_name, None)
return instance.__fields_mapping__.get(self.name)
def __set__(self, instance, value):
# return maybe `errors` or `value`.
value = self.validate(value)
instance.__fields_mapping__[self.name] = value
def error(self, message="", errors=None, field_name=None):
"""Raise a ValidationError."""
field_name = field_name if field_name else self.name
return ValidationError(message, errors=errors, field_name=field_name)
def _func_should_be(self, value, expect_value):
if value != expect_value:
return self.error("[Lv2] %s should be %s but %s found." % (self.__class__.__name__, expect_value, value))
return value
def _func_should_in(self, value, expect_value):
if value not in expect_value:
return self.error("[Lv2] %s %s does not in %s." % (self.__class__.__name__, value, expect_value))
return value
def _func_should_contain(self, value, expect_value):
if expect_value not in value:
return self.error("[Lv2] %s %s does not contain %s." % (self.__class__.__name__, value, expect_value))
return value
@staticmethod
def _validation_is_error(value):
if "ValidationError" in str(value):
return True
return False
def validate(self, value):
"""Perform validation on a value."""
# Lv1 validate
# If validate fail, just return value.
if self._validation_is_error(value):
return value
if self.field_type is not None:
value = self._validate_types(value, self.field_type)
# If validate fail, just return value.
if self._validation_is_error(value):
return value
# Lv2 validate
value = self._validate_should_funcs(value)
return value
def _validate_should_funcs(self, value):
# call `func_should_`.
if len(self.validate_funcs) > 0:
for should, expect_value in self.validate_funcs.items():
func = getattr(self, "_func_%s" % should)
value = func(value, expect_value)
return value
def _validate_types(self, value, field_type):
if not isinstance(value, field_type):
return self.error(f"[Lv1] {self.__class__.__name__} only accepts {self.field_type} values. "
f"but {value!r} found.")
return value
class StringField(BaseField):
__slots__ = ('should_be', 'should_in', 'should_contain', 'should_like')
field_type = str
def _func_should_like(self, value, expect_regex):
res = re.search(expect_regex, value)
if res:
return value
else:
return self.error(f"[Lv2] {self.__class__.__name__} {value!r} does not match {expect_regex!r}.")
class IntegerField(BaseField):
__slots__ = ('should_be', 'should_in', 'should_contain', 'should_like')
field_type = int
class ListField(BaseField):
__slots__ = ('should_be', 'should_in', 'should_contain', 'should_not_contain',
# For list field
'count_should_be', 'count_should_gt', 'count_should_lt',
'count_should_gte', 'count_should_lte', 'should_no_duplicates'
# For list members
'members_should_contain_model'
)
field_type = list
def __init__(self, *fields, **kwargs):
self.fields = fields
super().__init__(**kwargs)
def _func_should_contain(self, value, expect_value):
if isinstance(expect_value, list):
if len(set(value).intersection(set(expect_value))) != len(expect_value):
return self.error("[Lv2] %s %s does not contain %s." % (self.__class__.__name__, value, expect_value))
else:
if expect_value not in value:
return self.error("[Lv2] %s %s does not contain %s." % (self.__class__.__name__, value, expect_value))
return value
def _func_should_no_duplicates(self, value, expect_value=True):
# bcz dict can not be `set`, loop to validate.
if isinstance(expect_value, bool):
new_list = []
for v in value:
if v not in new_list:
new_list.append(v)
if len(new_list) != len(value):
return self.error("[Lv2] %s %s has duplicate data." % (self.__class__.__name__, value))
else:
return self.error(f"[Lv2] `should_no_duplicates` only accepts bool params, but {expect_value!r} found.")
def _func_should_not_contain(self, value, expect_value):
if isinstance(expect_value, list):
if len(set(value).intersection(set(expect_value))) > 0:
return self.error("[Lv2] %s %s should not contain %s." % (self.__class__.__name__, value, expect_value))
else:
if expect_value in value:
return self.error("[Lv2] %s %s should not contain %s." % (self.__class__.__name__, value, expect_value))
return value
def _func_should_in(self, value, expect_value):
if isinstance(expect_value, list):
if len(set(value).intersection(set(expect_value))) != len(value):
return self.error("[Lv2] %s %s does not in %s." % (self.__class__.__name__, value, expect_value))
return value
else:
return self.error(f"[Lv1] {self.__class__.__name__} only accepts {self.field_type} values. "
f"but {expect_value!r} found.")
def _func_count_should_be(self, value, expect_value):
if isinstance(expect_value, int):
if len(value) == expect_value:
return value
else:
return self.error("[Lv2] %s count should be %s, but %s found."
% (self.__class__.__name__, expect_value, len(value)))
else:
return self.error(f"[Lv2] `count_should_be` only accepts integer params, but {expect_value!r} found.")
def _func_count_should_gt(self, value, expect_value):
if isinstance(expect_value, int):
if len(value) > expect_value:
return value
else:
return self.error("[Lv2] %s count should greater than %s, but %s found."
% (self.__class__.__name__, expect_value, len(value)))
else:
return self.error(f"[Lv2] `count_should_gt` only accepts integer params, but {expect_value!r} found.")
def _func_count_should_gte(self, value, expect_value):
if isinstance(expect_value, int):
if len(value) >= expect_value:
return value
else:
return self.error("[Lv2] %s count should greater than or equal to %s, but %s found."
% (self.__class__.__name__, expect_value, len(value)))
else:
return self.error(f"[Lv2] `count_should_gte` only accepts integer params, but {expect_value!r} found.")
def _func_count_should_lt(self, value, expect_value):
if isinstance(expect_value, int):
if len(value) < expect_value:
return value
else:
return self.error("[Lv2] %s count should less than %s, but %s found."
% (self.__class__.__name__, expect_value, len(value)))
else:
return self.error(f"[Lv2] `count_should_lt` only accepts integer params, but {expect_value!r} found.")
def _func_count_should_lte(self, value, expect_value):
if isinstance(expect_value, int):
if len(value) <= expect_value:
return value
else:
return self.error("[Lv2] %s count should less than or equal to %s, but %s found."
% (self.__class__.__name__, expect_value, len(value)))
else:
return self.error(f"[Lv2] `count_should_lte` only accepts integer params, but {expect_value!r} found.")
def _func_members_should_contain_model(self, value, expect_model):
"""It requires that members must contain a specific validator-model"""
# Due to complications of circular imports, judge class by `__class__.__base__.__name__`.
if expect_model.__class__.__base__.__name__ == 'ValidatorModel':
for v in value:
v = expect_model.validate(v)
if self._validation_is_error(v):
return self.error(f"[Lv2] {self.__class__.__name__}'s members should contain {expect_model!r}, "
f"but {v!r} does not match.")
return value
else:
return self.error(f"[Lv2] `members_should_contain_model` only accepts ValidatorModel params, "
f"but {type(expect_model)!r} found.")
def validate(self, value):
# Lv1 validate
# If validate fail, just return value.
if self._validation_is_error(value):
return value
if self.field_type is not None:
value = self._validate_types(value, self.field_type)
# If validate fail, just return value.
if self._validation_is_error(value):
return value
if len(self.fields) > len(value):
return self.error(f"[Lv1] {self.__class__.__name__} expects {len(self.fields)} objects, but {len(value)} found.")
for i, v in enumerate(self.fields):
if issubclass(v.__class__, BaseField):
v = v.validate(value[i])
# Due to complications of circular imports, judge class by `__class__.__base__.__name__`.
elif v.__class__.__base__.__name__ == 'ValidatorModel':
v = v.validate(value[i])
value[i] = v
# Lv2 validate
value = self._validate_should_funcs(value)
return value
class DynamicListField(ListField):
"""This filed can be a little complicated.
It validates every field and try to find a match result.
We will loop through all elements to do this.
This may take a long time."""
__slots__ = ('should_be', 'should_in', 'should_contain', 'should_not_contain',
# For list field
'count_should_be', 'count_should_gt', 'count_should_lt',
'count_should_gte', 'count_should_lte', 'should_no_duplicates',
# For list members
'members_should_contain_model'
)
field_type = list
def _func_should_be(self, value: list, expect_value):
if isinstance(expect_value, list):
value.sort()
expect_value.sort()
if value == expect_value:
return value
return self.error("[Lv2] %s should be %s but %s found." % (self.__class__.__name__, expect_value, value))
def validate(self, value):
original_value = value
# Lv1 validate
# If validate fail, just return value.
if self._validation_is_error(value):
return value
if self.field_type is not None:
value = self._validate_types(value, self.field_type)
# If validate fail, just return value.
if self._validation_is_error(value):
return value
int_field_list = []
str_field_list = []
lst_field_list = []
model_field_list = []
int_value_list = []
str_value_list = []
lst_value_list = []
dict_value_list = []
# Categorize fields, to validate if field type match.
for field in self.fields:
if isinstance(field, IntegerField):
int_field_list.append(field)
elif isinstance(field, StringField):
str_field_list.append(field)
elif isinstance(field, ListField) or isinstance(field, DynamicListField):
lst_field_list.append(field)
# Due to complications of circular imports, judge class by `__class__.__base__.__name__`.
elif field.__class__.__base__.__name__ == 'ValidatorModel':
model_field_list.append(field)
# Categorize values
for v in value:
if isinstance(v, int):
int_value_list.append(v)
elif isinstance(v, str):
str_value_list.append(v)
elif isinstance(v, list):
lst_value_list.append(v)
elif isinstance(v, dict):
dict_value_list.append(v)
# At first, the count of values list should always >= the count of fields list.
if len(int_field_list) > len(int_value_list):
return self.error(f"Expect {len(int_field_list)} integer objects, but {len(int_value_list)} found.")
if len(str_field_list) > len(str_value_list):
return self.error(f"Expect {len(str_field_list)} string objects, but {len(str_value_list)} found.")
if len(lst_field_list) > len(lst_value_list):
return self.error(f"Expect {len(lst_field_list)} list objects, but {len(lst_value_list)} found.")
if len(model_field_list) > len(dict_value_list):
return self.error(f"Expect {len(model_field_list)} dict objects, but {len(dict_value_list)} found.")
# Then we validate all the type one by one.
# A list to record validate result.
validate_result = []
for field in self.fields:
value = 'not_assigned'
if isinstance(field, IntegerField):
value, int_value_list = self._validate_field_in_value_list(field, int_value_list)
elif isinstance(field, StringField):
value, str_value_list = self._validate_field_in_value_list(field, str_value_list)
elif isinstance(field, ListField) or isinstance(field, DynamicListField):
value, lst_value_list = self._validate_field_in_value_list(field, lst_value_list)
elif field.__class__.__base__.__name__ == 'ValidatorModel':
value, dict_value_list = self._validate_field_in_value_list(field, dict_value_list)
if self._validation_is_error(value):
validate_result.append(value)
return validate_result
# Lv2 validate, we need use original value to validate.
validate_result = self._validate_should_funcs(original_value)
return validate_result
@staticmethod
def _validate_field_in_value_list(field, value_list: list):
value = None
lv2_value = None
for value in value_list:
value = field.validate(value)
# If validate pass, remove the value to avoid validation conflicts.
if 'ValidationError' not in str(value):
value_list.remove(value)
return value, value_list
else:
# Lv2 error means the validation goes to final stage. we should take this error priority to Lv1.
if '[Lv2]' in str(value):
lv2_value = value
return lv2_value if lv2_value else value, value_list
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/serialize/fields.py
|
fields.py
|
import itertools
from collections import namedtuple
from typing import Dict, List, Iterable, Callable
import tablib
from allpairspy import AllPairs
from api_test_ez.ez.case_builder.fields import UniqueField, IterableField, BaseField, FixedField
def to_pairs(name, field): # In order to be consistent with the `allpairspy.Pairs` type
return namedtuple("Pairs", name)(field)
class CaseBuilderSchemaMeta(type):
def __new__(mcs, name, bases, attrs):
klass = super().__new__(mcs, name, bases, attrs)
# If a base class just call super new
if name == "CaseBuilderSchema":
return klass
# filter fields
klass._ort_iterable_fields = []
klass._exh_iterable_fields = []
klass._unique_field = []
klass._fixed_field = []
for attr_name, attr_value in attrs.items():
if issubclass(attr_value.__class__, IterableField):
if attr_value.iterative_mode == 'ORT':
klass._ort_iterable_fields.append(
mcs._convert_field_to_list(attr_name, attr_value.value)
)
elif attr_value.iterative_mode == 'EXH':
klass._exh_iterable_fields.append(
mcs._convert_field_to_list(attr_name, attr_value.value)
)
elif issubclass(attr_value.__class__, UniqueField):
klass._unique_field.append(
{attr_name: attr_value.value}
)
elif issubclass(attr_value.__class__, FixedField):
klass._fixed_field.append(
{attr_name: attr_value.value}
)
return klass
@staticmethod
def _convert_field_to_list(
field_name,
field_value: Iterable
) -> List[dict]:
return [{field_name: value} for value in field_value]
class CaseBuilderSchema(metaclass=CaseBuilderSchemaMeta):
def __init__(
self,
ort_filter_func: Callable = lambda x: True,
exh_filter_func: Callable = lambda x: True
):
self._ort_filter_func = ort_filter_func
self._exh_filter_func = exh_filter_func
def _fields_build(self):
# self._exh_iterable_fields:
# [
# [{"a": 1}, {"a": 2}],
# [{"b": 3}, {"b": 4}],
# ]
# self._ort_iterable_fields:
# [
# [{"c": 5}, {"c": 6}],
# [{"d": 7}, {"d": 8}],
# ]
# 1. generate the "EXH" (Exhaustive) field.
computed_fields = []
if len(self._exh_iterable_fields) > 0:
# computed_exh_fields:
# [
# [{"a": 1}, {"b": 3}],
# [{"a": 1}, {"b": 4}],
# [{"a": 2}, {"b": 3}],
# [{"a": 2}, {"b": 4}],
# ]
computed_fields = self._iter_field_build(self._exh_iterable_fields, "EXH")
# 2. generate the "ORT" (Orthogonal) field.
if len(self._ort_iterable_fields) > 0:
if len(computed_fields) > 0:
# `self._ort_iterable_fields` append `computed_exh_fields`:
# [
# # self._ort_iterable_fields
# [{"c": 5}, {"c": 6}],
# [{"d": 7}, {"d": 8}],
# # computed_exh_fields
# [
# [{"a": 1}, {"b": 3}],
# [{"a": 1}, {"b": 4}],
# [{"a": 2}, {"b": 3}],
# [{"a": 2}, {"b": 4}],
# ],
# ]
self._ort_iterable_fields.append(computed_fields)
computed_fields = self._iter_field_build(self._ort_iterable_fields, "ORT")
# computed_ort_fields:
# [
# [{'c': 5}, {'d': 7}, [{'a': 1}, {'b': 3}]],
# [{'c': 6}, {'d': 8}, [{'a': 1}, {'b': 3}]],
# [{'c': 6}, {'d': 7}, [{'a': 1}, {'b': 4}]],
# [{'c': 5}, {'d': 8}, [{'a': 1}, {'b': 4}]],
# [{'c': 5}, {'d': 8}, [{'a': 2}, {'b': 3}]],
# [{'c': 6}, {'d': 7}, [{'a': 2}, {'b': 3}]],
# [{'c': 6}, {'d': 7}, [{'a': 2}, {'b': 4}]],
# [{'c': 5}, {'d': 8}, [{'a': 2}, {'b': 4}]],
# ]
# self._unique_field
# [{"e": 9}]
# self._fixed_field
# [{"f": 10}, {"g": 11}]
# 3. merge `computed_ort_fields` / `fixed_field` / `unique_field`.
merged_rows = []
if len(computed_fields) > 0:
for i, row in enumerate(computed_fields):
# merge `fixed_field`
new_row = row + self._fixed_field
# merge `unique_field`
for unique_field in self._unique_field:
new_unique_field = {
name: f"{value}_{str(i).zfill(len(str(len(computed_fields))))}"
for name, value in unique_field.items()
}
new_row.append(new_unique_field)
merged_rows.append(new_row)
else: # maby `computed_ort_fields` is []
# merge `fixed_field`
new_row = self._fixed_field
# merge `unique_field`
for unique_field in self._unique_field:
new_unique_field = {
name: f"{value}_01"
for name, value in unique_field.items()
}
new_row.append(new_unique_field)
merged_rows.append(new_row)
return merged_rows
def unpack_row(self):
# rows:
# [{'a': CaseBuilderSchema}, {'b': '2'}, [{'c': '6'}, {'d': '8'}], {'name': 'case_23'}],
rows = self._fields_build()
new_rows = []
for row in rows:
new_row = []
inner_row_schema = None
for cell in row:
if isinstance(cell, list):
# [{'c': '4'}, {'d': '7'}]
new_row += cell
elif isinstance(cell, dict):
for v in cell.values():
try:
if issubclass(v, CaseBuilderSchema):
inner_row_schema = v
except TypeError:
if isinstance(v, list):
new_row += v
else:
new_row.append(cell)
else:
raise Exception(f'Unknown type in row: {cell}')
if inner_row_schema:
# Exhaustive `new_row` and `inner_row_list`
inner_rows = inner_row_schema().unpack_row()
# `inner_rows`: [[{'name': '1'}, {'age': 2}]]
# `new_row`: [{'b': '2'}, {'c': '4'}, {'d': '7'}, {'fix': 5}, {'name': 'case_01'}]
# merge `inner_rows` and `new_row`
for inner_row in inner_rows:
new_rows.append(inner_row + new_row)
else:
new_rows.append(new_row)
return new_rows
def _iter_field_build(self, iterable_fields, rule):
if len(iterable_fields) <= 1:
print("Warning: Algorithm-Rule must provide more than one option.")
return iterable_fields
if rule == "EXH":
return self._exh_algorithm(iterable_fields, filter_func=self._exh_filter_func)
elif rule == "ORT":
return self._ort_algorithm(iterable_fields, filter_func=self._ort_filter_func)
else:
raise Exception(f"Unknown Algorithm-Rule: {rule}")
@staticmethod
def _ort_algorithm(iterable_fields: List[List[dict]], filter_func: Callable = lambda x: True):
return [pair for pair in AllPairs(iterable_fields, filter_func=filter_func)]
@staticmethod
def _exh_algorithm(iterable_fields: List[List[dict]], filter_func: Callable = lambda x: True) -> List[List[dict]]:
_exh_pairs = []
for pair in itertools.product(*iterable_fields):
if filter_func(pair):
_exh_pairs.append(list(pair))
return _exh_pairs
def build(self):
"""
:rtype: [ [dict] ]
"""
return self.unpack_row()
def save(self, file_path="", fmt="xlsx"):
data = tablib.Dataset()
cases = self.build()
headers = []
if len(cases) > 0:
d = []
for case in cases:
values = []
for cell in case:
for k, v in cell.items():
if k not in headers:
headers.append(k)
values.append(v)
d.append(values)
data.append(values)
data.headers = headers
export_data = data.export(fmt)
with open(file_path, 'wb') as fw:
fw.write(export_data)
else:
raise Exception(f"Case build failed, pls check fields in builder-schema.")
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/ez/case_builder/schema.py
|
schema.py
|
from __future__ import print_function
# -*- coding: utf-8 -*-
"""
A TestRunner for use with the Python unit testing framework. It
generates a HTML report to show the result at a glance.
The simplest way to use this is to invoke its main method. E.g.
import unittest
import HTMLTestRunner
... define your tests ...
if __name__ == '__main__':
HTMLTestRunner.main()
For more customization options, instantiates a HTMLTestRunner object.
HTMLTestRunner is a counterpart to unittest's TextTestRunner. E.g.
# output to a file
fp = file('my_report.html', 'wb')
runner = HTMLTestRunner.HTMLTestRunner(
stream=fp,
title='My unit test',
description='This demonstrates the report output by HTMLTestRunner.'
)
# Use an external stylesheet.
# See the Template_mixin class for more customizable options
runner.STYLESHEET_TMPL = '<link rel="stylesheet" href="my_stylesheet.css" type="text/css">'
# run the test
runner.run(my_test_suite)
------------------------------------------------------------------------
Copyright (c) 2004-2007, Wai Yip Tung
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are
met:
* Redistributions of source code must retain the above copyright notice,
this list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
* Neither the name Wai Yip Tung nor the names of its contributors may be
used to endorse or promote products derived from this software without
specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS
IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED
TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A
PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER
OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,
EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO,
PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR
PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF
LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING
NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""
# URL: http://tungwaiyip.info/software/HTMLTestRunner.html
__author__ = "Wai Yip Tung"
__version__ = "0.9.1"
"""
Change History
Version 0.9.1
* 用Echarts添加执行情况统计图 (灰蓝)
Version 0.9.0
* 改成Python 3.x (灰蓝)
Version 0.8.3
* 使用 Bootstrap稍加美化 (灰蓝)
* 改为中文 (灰蓝)
Version 0.8.2
* Show output inline instead of popup window (Viorel Lupu).
Version in 0.8.1
* Validated XHTML (Wolfgang Borgert).
* Added description of test classes and test base.
Version in 0.8.0
* Define Template_mixin class for customization.
* Workaround a IE 6 bug that it does not treat <script> block as CDATA.
Version in 0.7.1
* Back port to Python 2.3 (Frank Horowitz).
* Fix missing scroll bars in detail log (Podi).
"""
# TODO: color stderr
# TODO: simplify javascript using ,ore than 1 class in the class attribute?
import datetime
import sys
import io
import time
import unittest
from xml.sax import saxutils
# ------------------------------------------------------------------------
# The redirectors below are used to capture output during testing. Output
# sent to sys.stdout and sys.stderr are automatically captured. However
# in some base sys.stdout is already cached before HTMLTestRunner is
# invoked (e.g. calling logging.basicConfig). In order to capture those
# output, use the redirectors for the cached stream.
#
# e.g.
# >>> logging.basicConfig(stream=HTMLTestRunner.stdout_redirector)
# >>>
class OutputRedirector(object):
""" Wrapper to redirect stdout or stderr """
def __init__(self, fp):
self.fp = fp
def write(self, s):
self.fp.write(s)
def writelines(self, lines):
self.fp.writelines(lines)
def flush(self):
self.fp.flush()
stdout_redirector = OutputRedirector(sys.stdout)
stderr_redirector = OutputRedirector(sys.stderr)
# ----------------------------------------------------------------------
# Template
class Template_mixin(object):
"""
Define a HTML template for report customerization and generation.
Overall structure of an HTML report
HTML
+------------------------+
|<html> |
| <head> |
| |
| STYLESHEET |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </head> |
| |
| <body> |
| |
| HEADING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| REPORT |
| +----------------+ |
| | | |
| +----------------+ |
| |
| ENDING |
| +----------------+ |
| | | |
| +----------------+ |
| |
| </body> |
|</html> |
+------------------------+
"""
STATUS = {
0: u'通过',
1: u'失败',
2: u'错误',
}
DEFAULT_TITLE = 'Unit Test Report'
DEFAULT_DESCRIPTION = ''
# ------------------------------------------------------------------------
# HTML Template
HTML_TMPL = r"""<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>%(title)s</title>
<meta name="generator" content="%(generator)s"/>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<link href="http://cdn.bootcss.com/bootstrap/3.3.0/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcss.com/echarts/3.8.5/echarts.common.min.js"></script>
<!-- <script type="text/javascript" src="js/echarts.common.min.js"></script> -->
%(stylesheet)s
</head>
<body>
<script language="javascript" type="text/javascript"><!--
output_list = Array();
/* level - 0:Summary; 1:Failed; 2:All */
function showCase(level) {
trs = document.getElementsByTagName("tr");
for (var i = 0; i < trs.length; i++) {
tr = trs[i];
id = tr.id;
if (id.substr(0,2) == 'ft') {
if (level < 1) {
tr.className = 'hiddenRow';
}
else {
tr.className = '';
}
}
if (id.substr(0,2) == 'pt') {
if (level > 1) {
tr.className = '';
}
else {
tr.className = 'hiddenRow';
}
}
}
}
function showClassDetail(cid, count) {
var id_list = Array(count);
var toHide = 1;
for (var i = 0; i < count; i++) {
tid0 = 't' + cid.substr(1) + '.' + (i+1);
tid = 'f' + tid0;
tr = document.getElementById(tid);
if (!tr) {
tid = 'p' + tid0;
tr = document.getElementById(tid);
}
id_list[i] = tid;
if (tr.className) {
toHide = 0;
}
}
for (var i = 0; i < count; i++) {
tid = id_list[i];
if (toHide) {
document.getElementById('div_'+tid).style.display = 'none'
document.getElementById(tid).className = 'hiddenRow';
}
else {
document.getElementById(tid).className = '';
}
}
}
function showTestDetail(div_id){
var details_div = document.getElementById(div_id)
var displayState = details_div.style.display
// alert(displayState)
if (displayState != 'block' ) {
displayState = 'block'
details_div.style.display = 'block'
}
else {
details_div.style.display = 'none'
}
}
function html_escape(s) {
s = s.replace(/&/g,'&');
s = s.replace(/</g,'<');
s = s.replace(/>/g,'>');
return s;
}
/* obsoleted by detail in <div>
function showOutput(id, name) {
var w = window.open("", //url
name,
"resizable,scrollbars,status,width=800,height=450");
d = w.document;
d.write("<pre>");
d.write(html_escape(output_list[id]));
d.write("\n");
d.write("<a href='javascript:window.close()'>close</a>\n");
d.write("</pre>\n");
d.close();
}
*/
--></script>
<div id="div_base">
%(heading)s
%(report)s
%(ending)s
%(chart_script)s
</div>
</body>
</html>
""" # variables: (title, generator, stylesheet, heading, report, ending, chart_script)
ECHARTS_SCRIPT = """
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('chart'));
// 指定图表的配置项和数据
var option = {
title : {
text: '测试执行情况',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a} <br/>{b} : {c} ({d}%%)"
},
color: ['#95b75d', 'grey', '#b64645'],
legend: {
orient: 'vertical',
left: 'left',
data: ['通过','失败','错误']
},
series : [
{
name: '测试执行情况',
type: 'pie',
radius : '60%%',
center: ['50%%', '60%%'],
data:[
{value:%(Pass)s, name:'通过'},
{value:%(fail)s, name:'失败'},
{value:%(error)s, name:'错误'}
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.5)'
}
}
}
]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
""" # variables: (Pass, fail, error)
# ------------------------------------------------------------------------
# Stylesheet
#
# alternatively use a <link> for external style sheet, e.g.
# <link rel="stylesheet" href="$url" type="text/css">
STYLESHEET_TMPL = """
<style type="text/css" media="screen">
body { font-family: Microsoft YaHei,Consolas,arial,sans-serif; font-size: 80%; }
table { font-size: 100%; }
pre { white-space: pre-wrap;word-wrap: break-word; }
/* -- heading ---------------------------------------------------------------------- */
h1 {
font-size: 16pt;
color: gray;
}
.heading {
margin-top: 0ex;
margin-bottom: 1ex;
}
.heading .attribute {
margin-top: 1ex;
margin-bottom: 0;
}
.heading .description {
margin-top: 2ex;
margin-bottom: 3ex;
}
/* -- css div popup ------------------------------------------------------------------------ */
a.popup_link {
}
a.popup_link:hover {
color: red;
}
.popup_window {
display: none;
position: relative;
left: 0px;
top: 0px;
/*border: solid #627173 1px; */
padding: 10px;
/*background-color: #E6E6D6; */
font-family: "Lucida Console", "Courier New", Courier, monospace;
text-align: left;
font-size: 8pt;
/* width: 500px;*/
}
}
/* -- report ------------------------------------------------------------------------ */
#show_detail_line {
margin-top: 3ex;
margin-bottom: 1ex;
}
#result_table {
width: 99%;
}
#header_row {
font-weight: bold;
color: #303641;
background-color: #ebebeb;
}
#total_row { font-weight: bold; }
.passClass { background-color: #bdedbc; }
.failClass { background-color: #ffefa4; }
.errorClass { background-color: #ffc9c9; }
.passCase { color: #6c6; }
.failCase { color: #FF6600; font-weight: bold; }
.errorCase { color: #c00; font-weight: bold; }
.hiddenRow { display: none; }
.testcase { margin-left: 2em; }
/* -- ending ---------------------------------------------------------------------- */
#ending {
}
#div_base {
position:absolute;
top:0%;
left:5%;
right:5%;
width: auto;
height: auto;
margin: -15px 0 0 0;
}
</style>
"""
# ------------------------------------------------------------------------
# Heading
#
HEADING_TMPL = """
<div class='page-header'>
<h1>%(title)s</h1>
%(parameters)s
</div>
<div style="float: left;width:50%%;"><p class='description'>%(description)s</p></div>
<div id="chart" style="width:50%%;height:400px;float:left;"></div>
""" # variables: (title, parameters, description)
HEADING_ATTRIBUTE_TMPL = """<p class='attribute'><strong>%(name)s:</strong> %(value)s</p>
""" # variables: (name, value)
# ------------------------------------------------------------------------
# Report
#
REPORT_TMPL = u"""
<div class="btn-group btn-group-sm">
<button class="btn btn-default" onclick='javascript:showCase(0)'>总结</button>
<button class="btn btn-default" onclick='javascript:showCase(1)'>失败</button>
<button class="btn btn-default" onclick='javascript:showCase(2)'>全部</button>
</div>
<p></p>
<table id='result_table' class="table table-bordered">
<colgroup>
<col align='left' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
<col align='right' />
</colgroup>
<tr id='header_row'>
<td>测试套件/测试用例</td>
<td>总数</td>
<td>通过</td>
<td>失败</td>
<td>错误</td>
<td>查看</td>
</tr>
%(test_list)s
<tr id='total_row'>
<td>总计</td>
<td>%(count)s</td>
<td>%(Pass)s</td>
<td>%(fail)s</td>
<td>%(error)s</td>
<td> </td>
</tr>
</table>
""" # variables: (test_list, count, Pass, fail, error)
REPORT_CLASS_TMPL = u"""
<tr class='%(style)s'>
<td>%(desc)s</td>
<td>%(count)s</td>
<td>%(Pass)s</td>
<td>%(fail)s</td>
<td>%(error)s</td>
<td><a href="javascript:showClassDetail('%(cid)s',%(count)s)">详情</a></td>
</tr>
""" # variables: (style, desc, count, Pass, fail, error, cid)
REPORT_TEST_WITH_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'>
<!--css div popup start-->
<a class="popup_link" onfocus='this.blur();' href="javascript:showTestDetail('div_%(tid)s')" >
%(status)s</a>
<div id='div_%(tid)s' class="popup_window">
<pre>%(script)s</pre>
</div>
<!--css div popup end-->
</td>
</tr>
""" # variables: (tid, Class, style, desc, status)
REPORT_TEST_NO_OUTPUT_TMPL = r"""
<tr id='%(tid)s' class='%(Class)s'>
<td class='%(style)s'><div class='testcase'>%(desc)s</div></td>
<td colspan='5' align='center'>%(status)s</td>
</tr>
""" # variables: (tid, Class, style, desc, status)
REPORT_TEST_OUTPUT_TMPL = r"""%(id)s: %(output)s""" # variables: (id, output)
# ------------------------------------------------------------------------
# ENDING
#
ENDING_TMPL = """<div id='ending'> </div>"""
# -------------------- The end of the Template class -------------------
TestResult = unittest.TestResult
class _TestResult(TestResult):
# note: _TestResult is a pure representation of results.
# It lacks the output and reporting ability compares to unittest._TextTestResult.
def __init__(self, verbosity=1):
TestResult.__init__(self)
self.stdout0 = None
self.stderr0 = None
self.success_count = 0
self.failure_count = 0
self.error_count = 0
self.verbosity = verbosity
# result is a list of result in 4 tuple
# (
# result code (0: success; 1: fail; 2: error),
# TestCase object,
# Test output (byte string),
# stack trace,
# )
self.result = []
self.subtestlist = []
def startTest(self, test):
TestResult.startTest(self, test)
# just one buffer for both stdout and stderr
self.outputBuffer = io.StringIO()
stdout_redirector.fp = self.outputBuffer
stderr_redirector.fp = self.outputBuffer
self.stdout0 = sys.stdout
self.stderr0 = sys.stderr
sys.stdout = stdout_redirector
sys.stderr = stderr_redirector
def complete_output(self):
"""
Disconnect output redirection and return buffer.
Safe to call multiple times.
"""
if self.stdout0:
sys.stdout = self.stdout0
sys.stderr = self.stderr0
self.stdout0 = None
self.stderr0 = None
return self.outputBuffer.getvalue()
def stopTest(self, test):
# Usually one of addSuccess, addError or addFailure would have been called.
# But there are some path in unittest that would bypass this.
# We must disconnect stdout in stopTest(), which is guaranteed to be called.
self.complete_output()
def addSuccess(self, test):
if test not in self.subtestlist:
self.success_count += 1
TestResult.addSuccess(self, test)
output = self.complete_output()
self.result.append((0, test, output, ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
def addError(self, test, err):
self.error_count += 1
TestResult.addError(self, test, err)
_, _exc_str = self.errors[-1]
output = self.complete_output()
self.result.append((2, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('E ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('E')
def addFailure(self, test, err):
self.failure_count += 1
TestResult.addFailure(self, test, err)
_, _exc_str = self.failures[-1]
output = self.complete_output()
self.result.append((1, test, output, _exc_str))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
def addSubTest(self, test, subtest, err):
if err is not None:
if getattr(self, 'failfast', False):
self.stop()
if issubclass(err[0], test.failureException):
self.failure_count += 1
errors = self.failures
errors.append((subtest, self._exc_info_to_string(err, subtest)))
output = self.complete_output()
self.result.append((1, test, output + '\nSubTestCase Failed:\n' + str(subtest),
self._exc_info_to_string(err, subtest)))
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
else:
self.error_count += 1
errors = self.errors
errors.append((subtest, self._exc_info_to_string(err, subtest)))
output = self.complete_output()
self.result.append(
(2, test, output + '\nSubTestCase Error:\n' + str(subtest), self._exc_info_to_string(err, subtest)))
if self.verbosity > 1:
sys.stderr.write('E ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('E')
self._mirrorOutput = True
else:
self.subtestlist.append(subtest)
self.subtestlist.append(test)
self.success_count += 1
output = self.complete_output()
self.result.append((0, test, output + '\nSubTestCase Pass:\n' + str(subtest), ''))
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(subtest))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
class HTMLTestRunner(Template_mixin):
def __init__(self, stream=sys.stdout, verbosity=1, title=None, description=None):
self.stream = stream
self.verbosity = verbosity
if title is None:
self.title = self.DEFAULT_TITLE
else:
self.title = title
if description is None:
self.description = self.DEFAULT_DESCRIPTION
else:
self.description = description
self.startTime = datetime.datetime.now()
def run(self, test):
"Run the given test case or test suite."
result = _TestResult(self.verbosity)
test(result)
self.stopTime = datetime.datetime.now()
self.generateReport(test, result)
print('\nTime Elapsed: %s' % (self.stopTime-self.startTime), file=sys.stderr)
return result
def sortResult(self, result_list):
# unittest does not seems to run in any particular order.
# Here at least we want to group them together by class.
rmap = {}
classes = []
for n,t,o,e in result_list:
cls = t.__class__
if cls not in rmap:
rmap[cls] = []
classes.append(cls)
rmap[cls].append((n,t,o,e))
r = [(cls, rmap[cls]) for cls in classes]
return r
def getReportAttributes(self, result):
"""
Return report attributes as a list of (name, value).
Override this to add custom attributes.
"""
startTime = str(self.startTime)[:19]
duration = str(self.stopTime - self.startTime)
status = []
if result.success_count: status.append(u'通过 %s' % result.success_count)
if result.failure_count: status.append(u'失败 %s' % result.failure_count)
if result.error_count: status.append(u'错误 %s' % result.error_count )
if status:
status = ' '.join(status)
else:
status = 'none'
return [
(u'开始时间', startTime),
(u'运行时长', duration),
(u'状态', status),
]
def generateReport(self, test, result):
report_attrs = self.getReportAttributes(result)
generator = 'HTMLTestRunner %s' % __version__
stylesheet = self._generate_stylesheet()
heading = self._generate_heading(report_attrs)
report = self._generate_report(result)
ending = self._generate_ending()
chart = self._generate_chart(result)
output = self.HTML_TMPL % dict(
title = saxutils.escape(self.title),
generator = generator,
stylesheet = stylesheet,
heading = heading,
report = report,
ending = ending,
chart_script = chart
)
self.stream.write(output.encode('utf8'))
def _generate_stylesheet(self):
return self.STYLESHEET_TMPL
def _generate_heading(self, report_attrs):
a_lines = []
for name, value in report_attrs:
line = self.HEADING_ATTRIBUTE_TMPL % dict(
name = saxutils.escape(name),
value = saxutils.escape(value),
)
a_lines.append(line)
heading = self.HEADING_TMPL % dict(
title = saxutils.escape(self.title),
parameters = ''.join(a_lines),
description = saxutils.escape(self.description),
)
return heading
def _generate_report(self, result):
rows = []
sortedResult = self.sortResult(result.result)
for cid, (cls, cls_results) in enumerate(sortedResult):
# subtotal for a class
np = nf = ne = 0
for n,t,o,e in cls_results:
if n == 0: np += 1
elif n == 1: nf += 1
else: ne += 1
# format class description
if cls.__module__ == "__main__":
name = cls.__name__
else:
name = "%s.%s" % (cls.__module__, cls.__name__)
doc = cls.__doc__ and cls.__doc__.split("\n")[0] or ""
desc = doc and '%s: %s' % (name, doc) or name
row = self.REPORT_CLASS_TMPL % dict(
style = ne > 0 and 'errorClass' or nf > 0 and 'failClass' or 'passClass',
desc = desc,
count = np+nf+ne,
Pass = np,
fail = nf,
error = ne,
cid = 'c%s' % (cid+1),
)
rows.append(row)
for tid, (n,t,o,e) in enumerate(cls_results):
self._generate_report_test(rows, cid, tid, n, t, o, e)
report = self.REPORT_TMPL % dict(
test_list = ''.join(rows),
count = str(result.success_count+result.failure_count+result.error_count),
Pass = str(result.success_count),
fail = str(result.failure_count),
error = str(result.error_count),
)
return report
def _generate_chart(self, result):
chart = self.ECHARTS_SCRIPT % dict(
Pass=str(result.success_count),
fail=str(result.failure_count),
error=str(result.error_count),
)
return chart
def _generate_report_test(self, rows, cid, tid, n, t, o, e):
# e.g. 'pt1.1', 'ft1.1', etc
has_output = bool(o or e)
tid = (n == 0 and 'p' or 'f') + 't%s.%s' % (cid+1,tid+1)
name = t.id().split('.')[-1]
doc = t.shortDescription() or ""
desc = doc and ('%s: %s' % (name, doc)) or name
tmpl = has_output and self.REPORT_TEST_WITH_OUTPUT_TMPL or self.REPORT_TEST_NO_OUTPUT_TMPL
script = self.REPORT_TEST_OUTPUT_TMPL % dict(
id=tid,
output=saxutils.escape(o+e),
)
row = tmpl % dict(
tid=tid,
Class=(n == 0 and 'hiddenRow' or 'none'),
style=(n == 2 and 'errorCase' or (n == 1 and 'failCase' or 'none')),
desc=desc,
script=script,
status=self.STATUS[n],
)
rows.append(row)
if not has_output:
return
def _generate_ending(self):
return self.ENDING_TMPL
##############################################################################
# Facilities for running tests from the command line
##############################################################################
# Note: Reuse unittest.TestProgram to launch test. In the future we may
# build our own launcher to support more specific command line
# parameters like test title, CSS, etc.
class TestProgram(unittest.TestProgram):
"""
A variation of the unittest.TestProgram. Please refer to the base
class for command line parameters.
"""
def runTests(self):
# Pick HTMLTestRunner as the default test runner.
# base class's testRunner parameter is not useful because it means
# we have to instantiate HTMLTestRunner before we know self.verbosity.
if self.testRunner is None:
self.testRunner = HTMLTestRunner(verbosity=self.verbosity)
unittest.TestProgram.runTests(self)
main = TestProgram
##############################################################################
# Executing this module from the command line
##############################################################################
if __name__ == "__main__":
main(module=None)
|
ApiTestEz
|
/ApiTestEz-1.0.30.tar.gz/ApiTestEz-1.0.30/api_test_ez/libs/HTMLTestRunner.py
|
HTMLTestRunner.py
|
===================
Easy Api Validation
===================
This is a python-package that makes data-validation easier for python developers.
It provides interfaces like Field, IterableField, Validaion etc for validation.
Quick Start
-----------
In order to use this library, you first need to go through the following steps:
Installation
~~~~~~~~~~~~
Install this library in a `virtualenv`_ using pip. `virtualenv`_ is a tool to
create isolated Python environments. The basic problem it addresses is one of
dependencies and versions, and indirectly permissions.
With `virtualenv`_, it's possible to install this library without needing system
install permissions, and without clashing with the installed system
dependencies.
.. _`virtualenv`: https://virtualenv.pypa.io/en/latest/
Supported Python Versions
^^^^^^^^^^^^^^^^^^^^^^^^^
Python >= 3.5
Mac/Linux
^^^^^^^^^
.. code-block:: sh
$ pip install virtualenv
$ virtualenv venv -p python3
$ . venv/bin/activate
$ source venv/bin/activate
$ pip install git+https://github.com/soni-vikas/api-validaion.git#egg=api-validation'
Example Usage
~~~~~~~~~~~~~
Validation.validate:
It will return tuple of length 2: validated_payload, error_flag, validation_status
In case of any validation failure, the first value will be the error message & the second value will be True.
In case there are no errors, the first value will be the validated payload, the second value will be False
Field: describes how to validate a field.
IteratorField: subclass of Field, used for a list or any other iterator.
1. Example: Validate literals
.. code:: py
from api.validations import Validation
print(Validation.validate("123", int, "user")) # (123, True)
2. Example: Custom validation
.. code:: py
from api.validations import Validation
def _check_in_list(x, ls):
if x not in ls:
raise ValueError()
return x
device = ["cpu", "gpu"]
print(Validation.validate("cpu", lambda x: _check_in_list(x, device), "device"))
# ('cpu', False)
print(Validation.validate("amd", lambda x: _check_in_list(x, device), "device"))
# ("Field 'device' is in an invalid format.", True)
3. Example: Validation for iterables using Field
.. code:: py
from api.validations import Validation
from api.validations import Field, IterableField
import re
employee = {
"name": "vikas soni",
"phone": "8080808080",
"org_ids": [
123,
345
]
}
validation_dict = {
"name": Field(required=True, pattern=re.compile("[a-z]+( [a-z]+)*"), null=True),
"phone": Field(required=True, pattern=re.compile("^[1-9][0-9]{9}$"), null=True),
"org_ids": IterableField(required=True, sub_pattern=int)
}
payload, error = Validation.validate(employee, validation_dict)
print(payload)
print(error)
# {'name': 'vikas soni', 'phone': '8080808080', 'org_ids': [123, 345]}
# False
3. Example: Validation for iterables using JSON schema
.. code:: py
from api.validations import Validation
import re
employee = {
"name": "vikas soni",
"phone": "8080808080",
"org_ids": [
123,
345
]
}
validation_dict = {
"name": {
'pattern': re.compile(r'[a-z]+( [a-z]+)*'),
'required': True,
'null': True
},
"phone": {
'pattern': re.compile("^[1-9][0-9]{9}$"),
'required': True,
'null': True
},
"org_ids": {
'pattern': list,
'required': True,
'null': False,
'sub_pattern': int
}
}
payload, error = Validation.validate(employee, validation_dict)
print(payload)
print(error)
# {'name': 'vikas soni', 'phone': '8080808080', 'org_ids': [123, 345]}
# False
for more examples, see tests cases available in tests/
Development
-----------
Getting Started
~~~~~~~~~~~~~~~
Assuming that you have Python and ``virtualenv`` installed, set up your
environment and install the required dependencies defined above:
.. code-block:: sh
$ git clone https://github.com/soni-vikas/api-validaion.git
$ cd api-validation
$ virtualenv venv -p python3
...
$ . venv/bin/activate
$ pip install -e .
Running Tests
~~~~~~~~~~~~~
You can run tests in all supported Python versions using ``python setup.py test``. By default,
it will run all of the unit and functional tests.
.. code-block:: sh
$ python setup.py test
You can also run individual tests with your default Python version:
see ```--help```.
.. code-block:: sh
$ python setup.py test --help
For any query raise an issue or create a pull request.
|
ApiValidations
|
/ApiValidations-1.0.0.tar.gz/ApiValidations-1.0.0/README.rst
|
README.rst
|
from typing import Dict, Tuple, Union
from collections import Iterable
from .exceptions import ValidationError
from .fields import Field
class Validation:
_error_formats = {
"required": "Field{} '{}' {} required but not provided.",
"invalid_format": "Field{} '{}' {} in an invalid format.",
"unknowns": "Field{} '{}' {} in unknown validation rule.",
}
@classmethod
def _validate(cls, payload: Dict, validation_rule: Union[Dict, Field, callable], base=None) -> Tuple[Dict, Dict]:
"""
:returns
"""
errors_dict = {k: [] for k in cls._error_formats}
new_payload = {}
if isinstance(validation_rule, Dict) or isinstance(validation_rule, Dict):
for key in validation_rule:
str_field = key if base is None else '{}.{}'.format(base, key)
if key not in payload:
# if key is not present, check if it was required or in case any default value.
if validation_rule[key].get('required', False) and 'default' not in validation_rule[key]:
errors_dict['required'].append(str_field)
else:
# only set default value if it exists
if 'default' in validation_rule[key]:
new_payload[key] = validation_rule[key]['default']
else:
pattern = validation_rule[key].get('pattern')
if validation_rule[key].get("sub_pattern"):
if issubclass(pattern, Iterable):
new_payload[key] = []
pattern = validation_rule[key].get('sub_pattern')
if isinstance(payload.get(key), Iterable):
for i, _ in enumerate(payload.get(key)):
_payload, _error_dict = cls._validate(_, pattern, str_field+".{}".format(i))
if not cls._is_error(_error_dict):
new_payload[key].append(_payload)
else:
errors_dict['required'] += _error_dict["required"]
errors_dict['invalid_format'] += _error_dict["invalid_format"]
else:
errors_dict['required'] += str_field
errors_dict['invalid_format'] += str_field
else:
errors_dict['invalid_format'].append(str_field)
# if value is None & null is True
elif validation_rule[key].get('null', False) and payload[key] is None:
new_payload[key] = None
# no checks
elif pattern is None:
new_payload[key] = payload.get(key)
# check if pattern is again a dict, recursive check
elif isinstance(pattern, Field) or isinstance(pattern, Dict):
if isinstance(payload.get(key), dict):
_payload, _error_dict = cls._validate(payload.get(key), pattern, str_field)
if not cls._is_error(_error_dict):
new_payload[key] = _payload
else:
errors_dict['required'] += _error_dict["required"]
errors_dict['invalid_format'] += _error_dict["invalid_format"]
else:
errors_dict['invalid_format'].append(str_field)
# check if pattern is re.compile("regex")
elif hasattr(pattern, 'match') and callable(pattern.match): # pattern is a regex
if pattern.match(str(payload.get(key))):
new_payload[key] = payload.get(key)
else:
errors_dict['invalid_format'].append(str_field)
# check if pattern is any callback type
elif callable(pattern): # pattern is a callable type, or a lambda function for preprocessing
try:
new_payload[key] = pattern(payload.get(key))
except Exception as e:
errors_dict['invalid_format'].append(str_field)
# do not parse, unknown error
else:
errors_dict['unknowns'].append(str_field)
elif callable(validation_rule):
# pattern is a callable type, or a lambda function for preprocessing
try:
new_payload = validation_rule(payload)
except Exception as e:
errors_dict['invalid_format'].append(str(base))
return new_payload, errors_dict
@classmethod
def _is_error(cls, error_dict):
for k, v in error_dict.items():
if v:
return True
return False
@classmethod
def _return(cls, payload, error, raise_exception):
if raise_exception and error:
raise ValidationError(payload)
return payload, error
@classmethod
def validate(cls, payload, validate_dict: Union[Dict, Field, callable], base=None, raise_exception=False):
"""
:param payload: input payload
:param validate_dict: validation rules
:param raise_exception:
if raise_exception is True:
if error:
ValidationError will be raised
else:
if error:
returns error_message, True
else:
returns new_payload, False
:return:
"""
payload, error_dict = cls._validate(payload, validate_dict, base)
if not cls._is_error(error_dict):
return cls._return(payload, False, raise_exception)
else:
messages = []
for k, v in cls._error_formats.items():
if len(error_dict[k]):
messages.append(v.format(
's' if len(error_dict[k]) > 1 else '',
"', '".join(sorted(error_dict[k])),
'are' if len(error_dict[k]) > 1 else 'is', ))
return cls._return("\n".join(messages), True, raise_exception)
if __name__ == "__main__":
pass
|
ApiValidations
|
/ApiValidations-1.0.0.tar.gz/ApiValidations-1.0.0/api/validations/validate.py
|
validate.py
|
# ApiWrap
Simple HTTP POST API wrapper for Python classes.
# Example:
Copy the Python code below into a file (eg. `api_server.py`)
```python
#!/usr/bin/env python
from wrapit.api_wrapper import create_app
# The class to be wrapped
class Calculator:
def add(self, x, y):
return x + y
def sub(self, x, y):
return x - y
def mult(self, x, y):
return x * y
def div(self, x, y):
return x / y
# Create an instance of the class
calculator = Calculator()
# Create an app by wrapping this instance
app = create_app(calculator)
# Main program
if __name__ == "__main__":
# Start the app accepting connections from arbitraty hosts on a port
app.run(host="0.0.0.0", port=5555)
```
# Running the API server
```
./api_server.py
```
# Testing the API server
```
curl -s --request POST \
--url http://127.0.0.1:5000/ \
--header 'Content-Type: application/json' \
--data '{"endpoint": "add", "payload": {"x": 8, "y": 5}}'
```
The output should be:
```
{"endpoint": "add", "payload": 13, "success": true}
```
|
ApiWrap
|
/ApiWrap-0.1.1.tar.gz/ApiWrap-0.1.1/README.md
|
README.md
|
from apimatic_core.configurations.global_configuration import GlobalConfiguration
from apimatic_core.decorators.lazy_property import LazyProperty
from verizon5gmecvnspapi.configuration import Configuration
from verizon5gmecvnspapi.controllers.base_controller import BaseController
from verizon5gmecvnspapi.configuration import Environment
from verizon5gmecvnspapi.http.auth.o_auth_2 import OAuth2
from verizon5gmecvnspapi.controllers.service_onboarding_controller\
import ServiceOnboardingController
from verizon5gmecvnspapi.controllers.service_metadata_controller\
import ServiceMetadataController
from verizon5gmecvnspapi.controllers.repositories_controller\
import RepositoriesController
from verizon5gmecvnspapi.controllers.csp_profiles_controller\
import CSPProfilesController
from verizon5gmecvnspapi.controllers.service_claims_controller\
import ServiceClaimsController
from verizon5gmecvnspapi.controllers.o_auth_authorization_controller\
import OAuthAuthorizationController
class Verizon5gmecvnspapiClient(object):
@LazyProperty
def service_onboarding(self):
return ServiceOnboardingController(self.global_configuration)
@LazyProperty
def service_metadata(self):
return ServiceMetadataController(self.global_configuration)
@LazyProperty
def repositories(self):
return RepositoriesController(self.global_configuration)
@LazyProperty
def csp_profiles(self):
return CSPProfilesController(self.global_configuration)
@LazyProperty
def service_claims(self):
return ServiceClaimsController(self.global_configuration)
@LazyProperty
def o_auth_authorization(self):
return OAuthAuthorizationController(self.global_configuration)
def __init__(self, http_client_instance=None,
override_http_client_configuration=False, http_call_back=None,
timeout=60, max_retries=0, backoff_factor=2,
retry_statuses=[408, 413, 429, 500, 502, 503, 504, 521, 522, 524],
retry_methods=['GET', 'PUT'],
environment=Environment.PRODUCTION,
o_auth_client_id='TODO: Replace',
o_auth_client_secret='TODO: Replace', o_auth_token=None,
o_auth_scopes=None, vz_m_2_m_token='TODO: Replace',
config=None):
if config is None:
self.config = Configuration(
http_client_instance=http_client_instance,
override_http_client_configuration=override_http_client_configuration,
http_call_back=http_call_back,
timeout=timeout,
max_retries=max_retries,
backoff_factor=backoff_factor,
retry_statuses=retry_statuses,
retry_methods=retry_methods,
environment=environment,
o_auth_client_id=o_auth_client_id,
o_auth_client_secret=o_auth_client_secret,
o_auth_token=o_auth_token,
o_auth_scopes=o_auth_scopes,
vz_m_2_m_token=vz_m_2_m_token)
else:
self.config = config
self.global_configuration = GlobalConfiguration(self.config)\
.global_errors(BaseController.global_errors())\
.base_uri_executor(self.config.get_base_uri)\
.user_agent(BaseController.user_agent(), BaseController.user_agent_parameters())\
.global_header('VZ-M2M-Token', self.config.vz_m_2_m_token)
self.initialize_auth_managers(self.global_configuration)
self.global_configuration = self.global_configuration.auth_managers(self.auth_managers)
def initialize_auth_managers(self, global_config):
http_client_config = global_config.get_http_client_configuration()
self.auth_managers = { key: None for key in ['global']}
self.auth_managers['global'] = OAuth2(http_client_config.o_auth_client_id, http_client_config.o_auth_client_secret, http_client_config.o_auth_token, global_config, http_client_config.o_auth_scopes)
return self.auth_managers
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/verizon_5_gmecvnspapi_client.py
|
verizon_5_gmecvnspapi_client.py
|
from enum import Enum
from verizon5gmecvnspapi.api_helper import APIHelper
from apimatic_core.http.configurations.http_client_configuration import HttpClientConfiguration
from apimatic_requests_client_adapter.requests_client import RequestsClient
from verizon5gmecvnspapi.models.o_auth_token import OAuthToken
class Environment(Enum):
"""An enum for SDK environments"""
PRODUCTION = 0
STAGING = 1
class Server(Enum):
"""An enum for API servers"""
SERVICES = 0
OAUTH_SERVER = 1
class Configuration(HttpClientConfiguration):
"""A class used for configuring the SDK by a user.
"""
@property
def environment(self):
return self._environment
@property
def o_auth_client_id(self):
return self._o_auth_client_id
@property
def o_auth_client_secret(self):
return self._o_auth_client_secret
@property
def o_auth_scopes(self):
return self._o_auth_scopes
@property
def vz_m_2_m_token(self):
return self._vz_m_2_m_token
@property
def o_auth_token(self):
if type(self._o_auth_token) is OAuthToken:
return OAuthToken.from_dictionary(APIHelper.to_dictionary(self._o_auth_token))
else:
return self._o_auth_token
def __init__(
self, http_client_instance=None,
override_http_client_configuration=False, http_call_back=None,
timeout=60, max_retries=0, backoff_factor=2,
retry_statuses=[408, 413, 429, 500, 502, 503, 504, 521, 522, 524],
retry_methods=['GET', 'PUT'], environment=Environment.PRODUCTION,
o_auth_client_id='TODO: Replace', o_auth_client_secret='TODO: Replace',
o_auth_token=None, o_auth_scopes=None, vz_m_2_m_token='TODO: Replace'
):
super().__init__(http_client_instance, override_http_client_configuration, http_call_back, timeout, max_retries,
backoff_factor, retry_statuses, retry_methods)
# Current API environment
self._environment = environment
# OAuth 2 Client ID
self._o_auth_client_id = o_auth_client_id
# OAuth 2 Client Secret
self._o_auth_client_secret = o_auth_client_secret
# Object for storing information about the OAuth token
if type(o_auth_token) is OAuthToken:
self._o_auth_token = OAuthToken.from_dictionary(APIHelper.to_dictionary(o_auth_token))
else:
self._o_auth_token = o_auth_token
# TODO: Replace
self._o_auth_scopes = o_auth_scopes
# M2M Session Token
self._vz_m_2_m_token = vz_m_2_m_token
# The Http Client to use for making requests.
super().set_http_client(self.create_http_client())
def clone_with(self, http_client_instance=None,
override_http_client_configuration=None, http_call_back=None,
timeout=None, max_retries=None, backoff_factor=None,
retry_statuses=None, retry_methods=None, environment=None,
o_auth_client_id=None, o_auth_client_secret=None,
o_auth_token=None, o_auth_scopes=None, vz_m_2_m_token=None):
http_client_instance = http_client_instance or super().http_client_instance
override_http_client_configuration = override_http_client_configuration or super().override_http_client_configuration
http_call_back = http_call_back or super().http_callback
timeout = timeout or super().timeout
max_retries = max_retries or super().max_retries
backoff_factor = backoff_factor or super().backoff_factor
retry_statuses = retry_statuses or super().retry_statuses
retry_methods = retry_methods or super().retry_methods
environment = environment or self.environment
o_auth_client_id = o_auth_client_id or self.o_auth_client_id
o_auth_client_secret = o_auth_client_secret or self.o_auth_client_secret
o_auth_token = o_auth_token or self.o_auth_token
o_auth_scopes = o_auth_scopes or self.o_auth_scopes
vz_m_2_m_token = vz_m_2_m_token or self.vz_m_2_m_token
return Configuration(
http_client_instance=http_client_instance,
override_http_client_configuration=override_http_client_configuration,
http_call_back=http_call_back, timeout=timeout,
max_retries=max_retries, backoff_factor=backoff_factor,
retry_statuses=retry_statuses, retry_methods=retry_methods,
environment=environment, o_auth_client_id=o_auth_client_id,
o_auth_client_secret=o_auth_client_secret, o_auth_token=o_auth_token,
o_auth_scopes=o_auth_scopes, vz_m_2_m_token=vz_m_2_m_token
)
def create_http_client(self):
return RequestsClient(
timeout=super().timeout, max_retries=super().max_retries,
backoff_factor=super().backoff_factor, retry_statuses=super().retry_statuses,
retry_methods=super().retry_methods,
http_client_instance=super().http_client_instance,
override_http_client_configuration=super().override_http_client_configuration,
response_factory=super().http_response_factory
)
# All the environments the SDK can run in
environments = {
Environment.PRODUCTION: {
Server.SERVICES: 'https://5gedge.verizon.com/api/mec/services',
Server.OAUTH_SERVER: 'https://thingspace.verizon.com/api/ts/v1'
},
Environment.STAGING: {
Server.SERVICES: 'https://staging.5gedge.verizon.com/api/mec/services',
Server.OAUTH_SERVER: 'https://staging.thingspace.verizon.com/api/ts/v1'
}
}
def get_base_uri(self, server=Server.SERVICES):
"""Generates the appropriate base URI for the environment and the
server.
Args:
server (Configuration.Server): The server enum for which the base
URI is required.
Returns:
String: The base URI.
"""
return self.environments[self.environment][server]
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/configuration.py
|
configuration.py
|
from apimatic_core.authentication.header_auth import HeaderAuth
from apimatic_core.utilities.auth_helper import AuthHelper
from verizon5gmecvnspapi.controllers.o_auth_authorization_controller import\
OAuthAuthorizationController
class OAuth2(HeaderAuth):
@property
def error_message(self):
"""Display error message on occurrence of authentication failure
in ClientCredentialsAuth
"""
return "ClientCredentialsAuth: o_auth_token.access_token is undefined or expired."
def __init__(self, o_auth_client_id, o_auth_client_secret, o_auth_token, config, o_auth_scopes=None):
auth_params = {}
self._o_auth_client_id = o_auth_client_id
self._o_auth_client_secret = o_auth_client_secret
self._o_auth_token = o_auth_token
self._o_auth_scopes = o_auth_scopes
self._o_auth_api = OAuthAuthorizationController(config)
if self._o_auth_token:
auth_params["Authorization"] = "Bearer {}".format(self._o_auth_token.access_token)
super().__init__(auth_params=auth_params)
def is_valid(self):
return self._o_auth_token and not self.token_expired(self._o_auth_token)
def build_basic_auth_header(self):
""" Builds the basic auth header for endpoints in the
OAuth Authorization Controller.
Returns:
str: The value of the Authentication header.
"""
return "Basic {}".format(AuthHelper.get_base64_encoded_value(self._o_auth_client_id, self._o_auth_client_secret))
def fetch_token(self, additional_params=None):
""" Authorizes the client.
additional_params (dict): Any additional form parameters.
Returns:
OAuthToken: The OAuth token.
"""
token = self._o_auth_api.request_token(
self.build_basic_auth_header(),
' '.join(self._o_auth_scopes) if (isinstance(self._o_auth_scopes, list)) else self._o_auth_scopes,
additional_params
)
if hasattr(token, 'expires_in'):
current_utc_timestamp = AuthHelper.get_current_utc_timestamp()
token.expiry = AuthHelper.get_token_expiry(current_utc_timestamp, token.expires_in)
return token
@staticmethod
def token_expired(token):
""" Checks if OAuth token has expired.
Returns:
bool: True if token has expired, False otherwise.
"""
return hasattr(token, 'expiry') and AuthHelper.is_token_expired(token.expiry)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/http/auth/o_auth_2.py
|
o_auth_2.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class EdgeServiceOnboardingResult(object):
"""Implementation of the 'EdgeServiceOnboardingResult' model.
Error response attribute of a service.
Attributes:
code (string): Code of the error. eg: SDMS_000_000.
message (string): Brief description of the error in the form of a
message.
remedy_message (string): Suggestion on how to fix the issue.
"""
# Create a mapping from Model property names to API property names
_names = {
"code": 'code',
"message": 'message',
"remedy_message": 'remedyMessage'
}
_optionals = [
'code',
'message',
'remedy_message',
]
def __init__(self,
code=APIHelper.SKIP,
message=APIHelper.SKIP,
remedy_message=APIHelper.SKIP):
"""Constructor for the EdgeServiceOnboardingResult class"""
# Initialize members of the class
if code is not APIHelper.SKIP:
self.code = code
if message is not APIHelper.SKIP:
self.message = message
if remedy_message is not APIHelper.SKIP:
self.remedy_message = remedy_message
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
code = dictionary.get("code") if dictionary.get("code") else APIHelper.SKIP
message = dictionary.get("message") if dictionary.get("message") else APIHelper.SKIP
remedy_message = dictionary.get("remedyMessage") if dictionary.get("remedyMessage") else APIHelper.SKIP
# Return an object of this model
return cls(code,
message,
remedy_message)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/edge_service_onboarding_result.py
|
edge_service_onboarding_result.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.csp_profile import CSPProfile
class CSPProfileData(object):
"""Implementation of the 'CSPProfileData' model.
Response to CSP profile list.
Attributes:
count (int): Total number of records available.
csp_profile_list (list of CSPProfile): List of all available CSP
profile available within the user's organization.
"""
# Create a mapping from Model property names to API property names
_names = {
"count": 'count',
"csp_profile_list": 'cspProfileList'
}
_optionals = [
'count',
'csp_profile_list',
]
def __init__(self,
count=APIHelper.SKIP,
csp_profile_list=APIHelper.SKIP):
"""Constructor for the CSPProfileData class"""
# Initialize members of the class
if count is not APIHelper.SKIP:
self.count = count
if csp_profile_list is not APIHelper.SKIP:
self.csp_profile_list = csp_profile_list
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
count = dictionary.get("count") if dictionary.get("count") else APIHelper.SKIP
csp_profile_list = None
if dictionary.get('cspProfileList') is not None:
csp_profile_list = [CSPProfile.from_dictionary(x) for x in dictionary.get('cspProfileList')]
else:
csp_profile_list = APIHelper.SKIP
# Return an object of this model
return cls(count,
csp_profile_list)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/csp_profile_data.py
|
csp_profile_data.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.boundary import Boundary
from verizon5gmecvnspapi.models.compatibility import Compatibility
from verizon5gmecvnspapi.models.edge_service_onboarding_result import EdgeServiceOnboardingResult
from verizon5gmecvnspapi.models.observability_template import ObservabilityTemplate
from verizon5gmecvnspapi.models.service_dependency import ServiceDependency
from verizon5gmecvnspapi.models.service_error import ServiceError
from verizon5gmecvnspapi.models.service_handler_id import ServiceHandlerId
from verizon5gmecvnspapi.models.service_onboarding_additional_params import ServiceOnboardingAdditionalParams
from verizon5gmecvnspapi.models.service_resource import ServiceResource
from verizon5gmecvnspapi.models.service_swagger_spec_id import ServiceSwaggerSpecId
from verizon5gmecvnspapi.models.service_tag import ServiceTag
from verizon5gmecvnspapi.models.workflow import Workflow
from verizon5gmecvnspapi.models.workload import Workload
class Service(object):
"""Implementation of the 'Service' model.
A customer service on 5G MEC platform using 5G MEC portal.
Attributes:
id (string): System generated unique UUID.
name (string): Name of the service needs to be deployed.
description (string): Description of the service needs to be
deployed.
version (string): Version of the service needs to be deployed.
metadata (list of ServiceOnboardingAdditionalParams): Properties are
metadata attributes.
tags (list of ServiceTag): List of service tags.
categories (list of string): Can be any name just to define it under a
category.
is_favourite (bool): Boolean value to set/unset the service as
favorite.
is_deleted (bool): Boolean to support soft delete of a version of a
service.
compatibility (list of Compatibility): Compatibility would have the
attribute CSP which is Cloud service provider e.g.
AWS_PUBLIC_CLOUD, AWS_WL, AWS_OUTPOST, AZURE_EDGE,
AZURE_PUBLIC_CLOUD.
resource (ServiceResource): Resource of the service.
created_date (datetime): Auto-derived time of creation. Part of
response only.
last_modified_date (datetime): Last modified time. Part of response
only.
created_by (string): User who created the service. Part of response
only.
last_modified_by (string): User who last modified the service. Part of
response only.
error (ServiceError): Errors related to service.
error_response (EdgeServiceOnboardingResult): Error response attribute
of a service.
state (ServiceStateEnum): Can have any value as - DRAFT, DESIGN,
TESTING, PUBLISH, CERTIFY, READY_TO_USE, DEPRECATE, DELETED.
status (ServiceStatusEnum): Can have any value as - DRAFT_INPROGRESS,
DRAFT_COMPLETE, DESIGN_INPROGRESS, DESIGN_FAILED,
DESIGN_COMPLETED, VALIDATION_INPROGRESS, VALIDATION_FAILED,
VALIDATION_COMPLETED, TESTING_INPROGRESS, TESTING_FAILED,
TESTING_COMPLETED, READY_TO_USE_INPROGRESS, READY_TO_USE_FAILED,
READY_TO_USE_COMPLETED, READY_TO_PRIVATE_USE_INPROGRESS,
READY_TO_PRIVATE_USE_FAILED, READY_TO_PRIVATE_USE_COMPLETED,
PUBLISH_INPROGRESS, PUBLISH_FAILED, PUBLISH_COMPLETED,
CERTIFY_INPROGRESS, CERTIFY_FAILED, CERTIFY_COMPLETED,
DEPRECATE_INPROGRESS, DEPRECATE_FAILED, DEPRECATE_COMPLETED,
MARKDELETE_INPROGRESS, MARKDELETE_FAILED, MARKDELETE_COMPLETED.
mtype (ServiceTypeEnum): Service Type e.g. Installation, Operations,
Custom.
service_handler_id (ServiceHandlerId): Auto-generated Id of
serviceHandlerId created.
observability_template (ObservabilityTemplate): Attribute of service.
service_swagger_spec_id (ServiceSwaggerSpecId): Auto-generated Id of
service handler Swagger specification file uploaded.
workflows (list of Workflow): TODO: type description here.
workloads (list of Workload): TODO: type description here.
dependencies (list of ServiceDependency): Dependencies of the
service.
boundaries (list of Boundary): Boundaries would have attributes csp,
region and zoneId.
"""
# Create a mapping from Model property names to API property names
_names = {
"name": 'name',
"version": 'version',
"id": 'id',
"description": 'description',
"metadata": 'metadata',
"tags": 'tags',
"categories": 'categories',
"is_favourite": 'isFavourite',
"is_deleted": 'isDeleted',
"compatibility": 'compatibility',
"resource": 'resource',
"created_date": 'createdDate',
"last_modified_date": 'lastModifiedDate',
"created_by": 'createdBy',
"last_modified_by": 'lastModifiedBy',
"error": 'error',
"error_response": 'errorResponse',
"state": 'state',
"status": 'status',
"mtype": 'type',
"service_handler_id": 'serviceHandlerId',
"observability_template": 'observabilityTemplate',
"service_swagger_spec_id": 'serviceSwaggerSpecId',
"workflows": 'workflows',
"workloads": 'workloads',
"dependencies": 'dependencies',
"boundaries": 'boundaries'
}
_optionals = [
'id',
'description',
'metadata',
'tags',
'categories',
'is_favourite',
'is_deleted',
'compatibility',
'resource',
'created_date',
'last_modified_date',
'created_by',
'last_modified_by',
'error',
'error_response',
'state',
'status',
'mtype',
'service_handler_id',
'observability_template',
'service_swagger_spec_id',
'workflows',
'workloads',
'dependencies',
'boundaries',
]
_nullables = [
'description',
'categories',
'boundaries',
]
def __init__(self,
name=None,
version=None,
id=APIHelper.SKIP,
description=APIHelper.SKIP,
metadata=APIHelper.SKIP,
tags=APIHelper.SKIP,
categories=APIHelper.SKIP,
is_favourite=APIHelper.SKIP,
is_deleted=APIHelper.SKIP,
compatibility=APIHelper.SKIP,
resource=APIHelper.SKIP,
created_date=APIHelper.SKIP,
last_modified_date=APIHelper.SKIP,
created_by=APIHelper.SKIP,
last_modified_by=APIHelper.SKIP,
error=APIHelper.SKIP,
error_response=APIHelper.SKIP,
state=APIHelper.SKIP,
status=APIHelper.SKIP,
mtype=APIHelper.SKIP,
service_handler_id=APIHelper.SKIP,
observability_template=APIHelper.SKIP,
service_swagger_spec_id=APIHelper.SKIP,
workflows=APIHelper.SKIP,
workloads=APIHelper.SKIP,
dependencies=APIHelper.SKIP,
boundaries=APIHelper.SKIP):
"""Constructor for the Service class"""
# Initialize members of the class
if id is not APIHelper.SKIP:
self.id = id
self.name = name
if description is not APIHelper.SKIP:
self.description = description
self.version = version
if metadata is not APIHelper.SKIP:
self.metadata = metadata
if tags is not APIHelper.SKIP:
self.tags = tags
if categories is not APIHelper.SKIP:
self.categories = categories
if is_favourite is not APIHelper.SKIP:
self.is_favourite = is_favourite
if is_deleted is not APIHelper.SKIP:
self.is_deleted = is_deleted
if compatibility is not APIHelper.SKIP:
self.compatibility = compatibility
if resource is not APIHelper.SKIP:
self.resource = resource
if created_date is not APIHelper.SKIP:
self.created_date = APIHelper.RFC3339DateTime(created_date) if created_date else None
if last_modified_date is not APIHelper.SKIP:
self.last_modified_date = APIHelper.RFC3339DateTime(last_modified_date) if last_modified_date else None
if created_by is not APIHelper.SKIP:
self.created_by = created_by
if last_modified_by is not APIHelper.SKIP:
self.last_modified_by = last_modified_by
if error is not APIHelper.SKIP:
self.error = error
if error_response is not APIHelper.SKIP:
self.error_response = error_response
if state is not APIHelper.SKIP:
self.state = state
if status is not APIHelper.SKIP:
self.status = status
if mtype is not APIHelper.SKIP:
self.mtype = mtype
if service_handler_id is not APIHelper.SKIP:
self.service_handler_id = service_handler_id
if observability_template is not APIHelper.SKIP:
self.observability_template = observability_template
if service_swagger_spec_id is not APIHelper.SKIP:
self.service_swagger_spec_id = service_swagger_spec_id
if workflows is not APIHelper.SKIP:
self.workflows = workflows
if workloads is not APIHelper.SKIP:
self.workloads = workloads
if dependencies is not APIHelper.SKIP:
self.dependencies = dependencies
if boundaries is not APIHelper.SKIP:
self.boundaries = boundaries
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
name = dictionary.get("name") if dictionary.get("name") else None
version = dictionary.get("version") if dictionary.get("version") else None
id = dictionary.get("id") if dictionary.get("id") else APIHelper.SKIP
description = dictionary.get("description") if "description" in dictionary.keys() else APIHelper.SKIP
metadata = None
if dictionary.get('metadata') is not None:
metadata = [ServiceOnboardingAdditionalParams.from_dictionary(x) for x in dictionary.get('metadata')]
else:
metadata = APIHelper.SKIP
tags = None
if dictionary.get('tags') is not None:
tags = [ServiceTag.from_dictionary(x) for x in dictionary.get('tags')]
else:
tags = APIHelper.SKIP
categories = dictionary.get("categories") if "categories" in dictionary.keys() else APIHelper.SKIP
is_favourite = dictionary.get("isFavourite") if "isFavourite" in dictionary.keys() else APIHelper.SKIP
is_deleted = dictionary.get("isDeleted") if "isDeleted" in dictionary.keys() else APIHelper.SKIP
compatibility = None
if dictionary.get('compatibility') is not None:
compatibility = [Compatibility.from_dictionary(x) for x in dictionary.get('compatibility')]
else:
compatibility = APIHelper.SKIP
resource = ServiceResource.from_dictionary(dictionary.get('resource')) if 'resource' in dictionary.keys() else APIHelper.SKIP
created_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("createdDate")).datetime if dictionary.get("createdDate") else APIHelper.SKIP
last_modified_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("lastModifiedDate")).datetime if dictionary.get("lastModifiedDate") else APIHelper.SKIP
created_by = dictionary.get("createdBy") if dictionary.get("createdBy") else APIHelper.SKIP
last_modified_by = dictionary.get("lastModifiedBy") if dictionary.get("lastModifiedBy") else APIHelper.SKIP
error = ServiceError.from_dictionary(dictionary.get('error')) if 'error' in dictionary.keys() else APIHelper.SKIP
error_response = EdgeServiceOnboardingResult.from_dictionary(dictionary.get('errorResponse')) if 'errorResponse' in dictionary.keys() else APIHelper.SKIP
state = dictionary.get("state") if dictionary.get("state") else APIHelper.SKIP
status = dictionary.get("status") if dictionary.get("status") else APIHelper.SKIP
mtype = dictionary.get("type") if dictionary.get("type") else APIHelper.SKIP
service_handler_id = ServiceHandlerId.from_dictionary(dictionary.get('serviceHandlerId')) if 'serviceHandlerId' in dictionary.keys() else APIHelper.SKIP
observability_template = ObservabilityTemplate.from_dictionary(dictionary.get('observabilityTemplate')) if 'observabilityTemplate' in dictionary.keys() else APIHelper.SKIP
service_swagger_spec_id = ServiceSwaggerSpecId.from_dictionary(dictionary.get('serviceSwaggerSpecId')) if 'serviceSwaggerSpecId' in dictionary.keys() else APIHelper.SKIP
workflows = None
if dictionary.get('workflows') is not None:
workflows = [Workflow.from_dictionary(x) for x in dictionary.get('workflows')]
else:
workflows = APIHelper.SKIP
workloads = None
if dictionary.get('workloads') is not None:
workloads = [Workload.from_dictionary(x) for x in dictionary.get('workloads')]
else:
workloads = APIHelper.SKIP
dependencies = None
if dictionary.get('dependencies') is not None:
dependencies = [ServiceDependency.from_dictionary(x) for x in dictionary.get('dependencies')]
else:
dependencies = APIHelper.SKIP
if 'boundaries' in dictionary.keys():
boundaries = [Boundary.from_dictionary(x) for x in dictionary.get('boundaries')] if dictionary.get('boundaries') else None
else:
boundaries = APIHelper.SKIP
# Return an object of this model
return cls(name,
version,
id,
description,
metadata,
tags,
categories,
is_favourite,
is_deleted,
compatibility,
resource,
created_date,
last_modified_date,
created_by,
last_modified_by,
error,
error_response,
state,
status,
mtype,
service_handler_id,
observability_template,
service_swagger_spec_id,
workflows,
workloads,
dependencies,
boundaries)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service.py
|
service.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class OAuthToken(object):
"""Implementation of the 'OAuthToken' model.
OAuth 2 Authorization endpoint response
Attributes:
access_token (string): Access token
token_type (string): Type of access token
expires_in (long|int): Time in seconds before the access token
expires
scope (string): List of scopes granted This is a space-delimited list
of strings.
expiry (long|int): Time of token expiry as unix timestamp (UTC)
refresh_token (string): Refresh token Used to get a new access token
when it expires.
"""
# Create a mapping from Model property names to API property names
_names = {
"access_token": 'access_token',
"token_type": 'token_type',
"expires_in": 'expires_in',
"scope": 'scope',
"expiry": 'expiry',
"refresh_token": 'refresh_token'
}
_optionals = [
'expires_in',
'scope',
'expiry',
'refresh_token',
]
def __init__(self,
access_token=None,
token_type=None,
expires_in=APIHelper.SKIP,
scope=APIHelper.SKIP,
expiry=APIHelper.SKIP,
refresh_token=APIHelper.SKIP):
"""Constructor for the OAuthToken class"""
# Initialize members of the class
self.access_token = access_token
self.token_type = token_type
if expires_in is not APIHelper.SKIP:
self.expires_in = expires_in
if scope is not APIHelper.SKIP:
self.scope = scope
if expiry is not APIHelper.SKIP:
self.expiry = expiry
if refresh_token is not APIHelper.SKIP:
self.refresh_token = refresh_token
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
access_token = dictionary.get("access_token") if dictionary.get("access_token") else None
token_type = dictionary.get("token_type") if dictionary.get("token_type") else None
expires_in = dictionary.get("expires_in") if dictionary.get("expires_in") else APIHelper.SKIP
scope = dictionary.get("scope") if dictionary.get("scope") else APIHelper.SKIP
expiry = dictionary.get("expiry") if dictionary.get("expiry") else APIHelper.SKIP
refresh_token = dictionary.get("refresh_token") if dictionary.get("refresh_token") else APIHelper.SKIP
# Return an object of this model
return cls(access_token,
token_type,
expires_in,
scope,
expiry,
refresh_token)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/o_auth_token.py
|
o_auth_token.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.repository import Repository
class OperationsWf(object):
"""Implementation of the 'OperationsWf' model.
`operationsWf` attribute of a service.
Attributes:
event_type (EventTypeEnum): Workflow event type. Ex: BACKUP, RESTORE,
MOVE, SUSPEND, STOP, AUTOSCALE, DEPRECATE.
upload_type (UploadTypeEnum): Allowed values are: GIT files
(PULL_FROM_REPO), MANUAL_UPLOAD.
repository_id (string): Repository ID of an existing repository.
repository (Repository): Users can create a repository to maintain
service artifacts. Repository would be either a Git or HELM
repository.
source_code_type (SourceCodeTypeEnum): Source code type can be JAVA or
GO.
revision_type (WorkloadRevisionTypeEnum): Revision type can be a
BRANCH or TAG.
name (string): Branch or tag name.
path (string): The workflow path.
"""
# Create a mapping from Model property names to API property names
_names = {
"event_type": 'eventType',
"upload_type": 'uploadType',
"repository_id": 'repositoryId',
"repository": 'repository',
"source_code_type": 'sourceCodeType',
"revision_type": 'revisionType',
"name": 'name',
"path": 'path'
}
_optionals = [
'event_type',
'upload_type',
'repository_id',
'repository',
'source_code_type',
'revision_type',
'name',
'path',
]
def __init__(self,
event_type=APIHelper.SKIP,
upload_type=APIHelper.SKIP,
repository_id=APIHelper.SKIP,
repository=APIHelper.SKIP,
source_code_type=APIHelper.SKIP,
revision_type=APIHelper.SKIP,
name=APIHelper.SKIP,
path=APIHelper.SKIP):
"""Constructor for the OperationsWf class"""
# Initialize members of the class
if event_type is not APIHelper.SKIP:
self.event_type = event_type
if upload_type is not APIHelper.SKIP:
self.upload_type = upload_type
if repository_id is not APIHelper.SKIP:
self.repository_id = repository_id
if repository is not APIHelper.SKIP:
self.repository = repository
if source_code_type is not APIHelper.SKIP:
self.source_code_type = source_code_type
if revision_type is not APIHelper.SKIP:
self.revision_type = revision_type
if name is not APIHelper.SKIP:
self.name = name
if path is not APIHelper.SKIP:
self.path = path
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
event_type = dictionary.get("eventType") if dictionary.get("eventType") else APIHelper.SKIP
upload_type = dictionary.get("uploadType") if dictionary.get("uploadType") else APIHelper.SKIP
repository_id = dictionary.get("repositoryId") if dictionary.get("repositoryId") else APIHelper.SKIP
repository = Repository.from_dictionary(dictionary.get('repository')) if 'repository' in dictionary.keys() else APIHelper.SKIP
source_code_type = dictionary.get("sourceCodeType") if dictionary.get("sourceCodeType") else APIHelper.SKIP
revision_type = dictionary.get("revisionType") if dictionary.get("revisionType") else APIHelper.SKIP
name = dictionary.get("name") if dictionary.get("name") else APIHelper.SKIP
path = dictionary.get("path") if dictionary.get("path") else APIHelper.SKIP
# Return an object of this model
return cls(event_type,
upload_type,
repository_id,
repository,
source_code_type,
revision_type,
name,
path)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/operations_wf.py
|
operations_wf.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class AwsCspProfile(object):
"""Implementation of the 'AwsCspProfile' model.
Information related to manage resources in AWS infrastructure.
Attributes:
cred_type (AwsCspProfileCredTypeEnum): Credential type of AWS CSP
profile.
access_key (string): AWS Access Key.
secret_key (string): AWS Secret Key.
role_arn (string): CSP AWS Role ARN.
account_id (string): AWS account ID.
external_id (string): AWS external ID.
"""
# Create a mapping from Model property names to API property names
_names = {
"cred_type": 'credType',
"access_key": 'accessKey',
"secret_key": 'secretKey',
"role_arn": 'roleARN',
"account_id": 'accountId',
"external_id": 'externalId'
}
_optionals = [
'cred_type',
'access_key',
'secret_key',
'role_arn',
'account_id',
'external_id',
]
def __init__(self,
cred_type=APIHelper.SKIP,
access_key=APIHelper.SKIP,
secret_key=APIHelper.SKIP,
role_arn=APIHelper.SKIP,
account_id=APIHelper.SKIP,
external_id=APIHelper.SKIP):
"""Constructor for the AwsCspProfile class"""
# Initialize members of the class
if cred_type is not APIHelper.SKIP:
self.cred_type = cred_type
if access_key is not APIHelper.SKIP:
self.access_key = access_key
if secret_key is not APIHelper.SKIP:
self.secret_key = secret_key
if role_arn is not APIHelper.SKIP:
self.role_arn = role_arn
if account_id is not APIHelper.SKIP:
self.account_id = account_id
if external_id is not APIHelper.SKIP:
self.external_id = external_id
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
cred_type = dictionary.get("credType") if dictionary.get("credType") else APIHelper.SKIP
access_key = dictionary.get("accessKey") if dictionary.get("accessKey") else APIHelper.SKIP
secret_key = dictionary.get("secretKey") if dictionary.get("secretKey") else APIHelper.SKIP
role_arn = dictionary.get("roleARN") if dictionary.get("roleARN") else APIHelper.SKIP
account_id = dictionary.get("accountId") if dictionary.get("accountId") else APIHelper.SKIP
external_id = dictionary.get("externalId") if dictionary.get("externalId") else APIHelper.SKIP
# Return an object of this model
return cls(cred_type,
access_key,
secret_key,
role_arn,
account_id,
external_id)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/aws_csp_profile.py
|
aws_csp_profile.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.resource_base import ResourceBase
class ServiceResource(object):
"""Implementation of the 'ServiceResource' model.
Resource of the service.
Attributes:
compute_resources (ResourceBase): Resource Base of the service.
gpu_required (bool): GPU required or not for onboarding service.
gpu (ResourceBase): Resource Base of the service.
storage (ResourceBase): Resource Base of the service.
memory (ResourceBase): Resource Base of the service.
latency (ResourceBase): Resource Base of the service.
request_rate (ResourceBase): Resource Base of the service.
bandwidth (ResourceBase): Resource Base of the service.
"""
# Create a mapping from Model property names to API property names
_names = {
"compute_resources": 'computeResources',
"gpu_required": 'gpuRequired',
"gpu": 'gpu',
"storage": 'storage',
"memory": 'memory',
"latency": 'latency',
"request_rate": 'requestRate',
"bandwidth": 'bandwidth'
}
_optionals = [
'compute_resources',
'gpu_required',
'gpu',
'storage',
'memory',
'latency',
'request_rate',
'bandwidth',
]
def __init__(self,
compute_resources=APIHelper.SKIP,
gpu_required=False,
gpu=APIHelper.SKIP,
storage=APIHelper.SKIP,
memory=APIHelper.SKIP,
latency=APIHelper.SKIP,
request_rate=APIHelper.SKIP,
bandwidth=APIHelper.SKIP):
"""Constructor for the ServiceResource class"""
# Initialize members of the class
if compute_resources is not APIHelper.SKIP:
self.compute_resources = compute_resources
self.gpu_required = gpu_required
if gpu is not APIHelper.SKIP:
self.gpu = gpu
if storage is not APIHelper.SKIP:
self.storage = storage
if memory is not APIHelper.SKIP:
self.memory = memory
if latency is not APIHelper.SKIP:
self.latency = latency
if request_rate is not APIHelper.SKIP:
self.request_rate = request_rate
if bandwidth is not APIHelper.SKIP:
self.bandwidth = bandwidth
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
compute_resources = ResourceBase.from_dictionary(dictionary.get('computeResources')) if 'computeResources' in dictionary.keys() else APIHelper.SKIP
gpu_required = dictionary.get("gpuRequired") if dictionary.get("gpuRequired") else False
gpu = ResourceBase.from_dictionary(dictionary.get('gpu')) if 'gpu' in dictionary.keys() else APIHelper.SKIP
storage = ResourceBase.from_dictionary(dictionary.get('storage')) if 'storage' in dictionary.keys() else APIHelper.SKIP
memory = ResourceBase.from_dictionary(dictionary.get('memory')) if 'memory' in dictionary.keys() else APIHelper.SKIP
latency = ResourceBase.from_dictionary(dictionary.get('latency')) if 'latency' in dictionary.keys() else APIHelper.SKIP
request_rate = ResourceBase.from_dictionary(dictionary.get('requestRate')) if 'requestRate' in dictionary.keys() else APIHelper.SKIP
bandwidth = ResourceBase.from_dictionary(dictionary.get('bandwidth')) if 'bandwidth' in dictionary.keys() else APIHelper.SKIP
# Return an object of this model
return cls(compute_resources,
gpu_required,
gpu,
storage,
memory,
latency,
request_rate,
bandwidth)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service_resource.py
|
service_resource.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.repository import Repository
class CustomWf(object):
"""Implementation of the 'CustomWf' model.
`customWf` attribute of a service.
Attributes:
event_name (string): Custom event being created for a workflow.
upload_type (UploadTypeEnum): Allowed values are: GIT files
(PULL_FROM_REPO), MANUAL_UPLOAD.
repository_id (string): Repository ID for an existing repository.
repository (Repository): Users can create a repository to maintain
service artifacts. Repository would be either a Git or HELM
repository.
source_code_type (SourceCodeTypeEnum): Source code type can be JAVA or
GO.
revision_type (WorkloadRevisionTypeEnum): Revision type can be a
BRANCH or TAG.
name (string): Branch or tag name.
path (string): The workflow path.
"""
# Create a mapping from Model property names to API property names
_names = {
"event_name": 'eventName',
"upload_type": 'uploadType',
"repository_id": 'repositoryId',
"repository": 'repository',
"source_code_type": 'sourceCodeType',
"revision_type": 'revisionType',
"name": 'name',
"path": 'path'
}
_optionals = [
'event_name',
'upload_type',
'repository_id',
'repository',
'source_code_type',
'revision_type',
'name',
'path',
]
def __init__(self,
event_name=APIHelper.SKIP,
upload_type=APIHelper.SKIP,
repository_id=APIHelper.SKIP,
repository=APIHelper.SKIP,
source_code_type=APIHelper.SKIP,
revision_type=APIHelper.SKIP,
name=APIHelper.SKIP,
path=APIHelper.SKIP):
"""Constructor for the CustomWf class"""
# Initialize members of the class
if event_name is not APIHelper.SKIP:
self.event_name = event_name
if upload_type is not APIHelper.SKIP:
self.upload_type = upload_type
if repository_id is not APIHelper.SKIP:
self.repository_id = repository_id
if repository is not APIHelper.SKIP:
self.repository = repository
if source_code_type is not APIHelper.SKIP:
self.source_code_type = source_code_type
if revision_type is not APIHelper.SKIP:
self.revision_type = revision_type
if name is not APIHelper.SKIP:
self.name = name
if path is not APIHelper.SKIP:
self.path = path
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
event_name = dictionary.get("eventName") if dictionary.get("eventName") else APIHelper.SKIP
upload_type = dictionary.get("uploadType") if dictionary.get("uploadType") else APIHelper.SKIP
repository_id = dictionary.get("repositoryId") if dictionary.get("repositoryId") else APIHelper.SKIP
repository = Repository.from_dictionary(dictionary.get('repository')) if 'repository' in dictionary.keys() else APIHelper.SKIP
source_code_type = dictionary.get("sourceCodeType") if dictionary.get("sourceCodeType") else APIHelper.SKIP
revision_type = dictionary.get("revisionType") if dictionary.get("revisionType") else APIHelper.SKIP
name = dictionary.get("name") if dictionary.get("name") else APIHelper.SKIP
path = dictionary.get("path") if dictionary.get("path") else APIHelper.SKIP
# Return an object of this model
return cls(event_name,
upload_type,
repository_id,
repository,
source_code_type,
revision_type,
name,
path)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/custom_wf.py
|
custom_wf.py
|
class ServiceStatusEnum(object):
"""Implementation of the 'ServiceStatus' enum.
Current status of the service.
Attributes:
DRAFT_INPROGRESS: TODO: type description here.
DRAFT_COMPLETE: TODO: type description here.
DESIGN_INPROGRESS: TODO: type description here.
DESIGN_FAILED: TODO: type description here.
DESIGN_COMPLETED: TODO: type description here.
VALIDATION_INPROGRESS: TODO: type description here.
VALIDATION_FAILED: TODO: type description here.
VALIDATION_COMPLETED: TODO: type description here.
TESTING_INPROGRESS: TODO: type description here.
TESTING_FAILED: TODO: type description here.
TESTING_COMPLETED: TODO: type description here.
READY_TO_USE_INPROGRESS: TODO: type description here.
READY_TO_USE_FAILED: TODO: type description here.
READY_TO_USE_COMPLETED: TODO: type description here.
READY_TO_PRIVATE_USE_INPROGRESS: TODO: type description here.
READY_TO_PRIVATE_USE_FAILED: TODO: type description here.
READY_TO_PRIVATE_USE_COMPLETED: TODO: type description here.
PUBLISH_INPROGRESS: TODO: type description here.
PUBLISH_FAILED: TODO: type description here.
PUBLISH_COMPLETED: TODO: type description here.
CERTIFY_INPROGRESS: TODO: type description here.
CERTIFY_FAILED: TODO: type description here.
CERTIFY_COMPLETED: TODO: type description here.
DEPRECATE_INPROGRESS: TODO: type description here.
DEPRECATE_FAILED: TODO: type description here.
DEPRECATE_COMPLETED: TODO: type description here.
MARKDELETE_INPROGRESS: TODO: type description here.
MARKDELETE_FAILED: TODO: type description here.
MARKDELETE_COMPLETED: TODO: type description here.
"""
DRAFT_INPROGRESS = 'DRAFT_INPROGRESS'
DRAFT_COMPLETE = 'DRAFT_COMPLETE'
DESIGN_INPROGRESS = 'DESIGN_INPROGRESS'
DESIGN_FAILED = 'DESIGN_FAILED'
DESIGN_COMPLETED = 'DESIGN_COMPLETED'
VALIDATION_INPROGRESS = 'VALIDATION_INPROGRESS'
VALIDATION_FAILED = 'VALIDATION_FAILED'
VALIDATION_COMPLETED = 'VALIDATION_COMPLETED'
TESTING_INPROGRESS = 'TESTING_INPROGRESS'
TESTING_FAILED = 'TESTING_FAILED'
TESTING_COMPLETED = 'TESTING_COMPLETED'
READY_TO_USE_INPROGRESS = 'READY_TO_USE_INPROGRESS'
READY_TO_USE_FAILED = 'READY_TO_USE_FAILED'
READY_TO_USE_COMPLETED = 'READY_TO_USE_COMPLETED'
READY_TO_PRIVATE_USE_INPROGRESS = 'READY_TO_PRIVATE_USE_INPROGRESS'
READY_TO_PRIVATE_USE_FAILED = 'READY_TO_PRIVATE_USE_FAILED'
READY_TO_PRIVATE_USE_COMPLETED = 'READY_TO_PRIVATE_USE_COMPLETED'
PUBLISH_INPROGRESS = 'PUBLISH_INPROGRESS'
PUBLISH_FAILED = 'PUBLISH_FAILED'
PUBLISH_COMPLETED = 'PUBLISH_COMPLETED'
CERTIFY_INPROGRESS = 'CERTIFY_INPROGRESS'
CERTIFY_FAILED = 'CERTIFY_FAILED'
CERTIFY_COMPLETED = 'CERTIFY_COMPLETED'
DEPRECATE_INPROGRESS = 'DEPRECATE_INPROGRESS'
DEPRECATE_FAILED = 'DEPRECATE_FAILED'
DEPRECATE_COMPLETED = 'DEPRECATE_COMPLETED'
MARKDELETE_INPROGRESS = 'MARKDELETE_INPROGRESS'
MARKDELETE_FAILED = 'MARKDELETE_FAILED'
MARKDELETE_COMPLETED = 'MARKDELETE_COMPLETED'
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service_status_enum.py
|
service_status_enum.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.repository import Repository
class InstallationWf(object):
"""Implementation of the 'InstallationWf' model.
`installationWf` attribute of a service.
Attributes:
hook_type (HookTypeEnum): TODO: type description here.
upload_type (UploadTypeEnum): Allowed values are: GIT files
(PULL_FROM_REPO), MANUAL_UPLOAD.
repository_id (string): Repository ID of an existing repository.
repository (Repository): Users can create a repository to maintain
service artifacts. Repository would be either a Git or HELM
repository.
source_code_type (SourceCodeTypeEnum): Source code type can be JAVA or
GO.
revision_type (WorkloadRevisionTypeEnum): Revision type can be a
BRANCH or TAG.
name (string): Branch or tag name.
path (string): The workflow path.
"""
# Create a mapping from Model property names to API property names
_names = {
"hook_type": 'hookType',
"upload_type": 'uploadType',
"repository_id": 'repositoryId',
"repository": 'repository',
"source_code_type": 'sourceCodeType',
"revision_type": 'revisionType',
"name": 'name',
"path": 'path'
}
_optionals = [
'hook_type',
'upload_type',
'repository_id',
'repository',
'source_code_type',
'revision_type',
'name',
'path',
]
def __init__(self,
hook_type=APIHelper.SKIP,
upload_type=APIHelper.SKIP,
repository_id=APIHelper.SKIP,
repository=APIHelper.SKIP,
source_code_type=APIHelper.SKIP,
revision_type=APIHelper.SKIP,
name=APIHelper.SKIP,
path=APIHelper.SKIP):
"""Constructor for the InstallationWf class"""
# Initialize members of the class
if hook_type is not APIHelper.SKIP:
self.hook_type = hook_type
if upload_type is not APIHelper.SKIP:
self.upload_type = upload_type
if repository_id is not APIHelper.SKIP:
self.repository_id = repository_id
if repository is not APIHelper.SKIP:
self.repository = repository
if source_code_type is not APIHelper.SKIP:
self.source_code_type = source_code_type
if revision_type is not APIHelper.SKIP:
self.revision_type = revision_type
if name is not APIHelper.SKIP:
self.name = name
if path is not APIHelper.SKIP:
self.path = path
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
hook_type = dictionary.get("hookType") if dictionary.get("hookType") else APIHelper.SKIP
upload_type = dictionary.get("uploadType") if dictionary.get("uploadType") else APIHelper.SKIP
repository_id = dictionary.get("repositoryId") if dictionary.get("repositoryId") else APIHelper.SKIP
repository = Repository.from_dictionary(dictionary.get('repository')) if 'repository' in dictionary.keys() else APIHelper.SKIP
source_code_type = dictionary.get("sourceCodeType") if dictionary.get("sourceCodeType") else APIHelper.SKIP
revision_type = dictionary.get("revisionType") if dictionary.get("revisionType") else APIHelper.SKIP
name = dictionary.get("name") if dictionary.get("name") else APIHelper.SKIP
path = dictionary.get("path") if dictionary.get("path") else APIHelper.SKIP
# Return an object of this model
return cls(hook_type,
upload_type,
repository_id,
repository,
source_code_type,
revision_type,
name,
path)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/installation_wf.py
|
installation_wf.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class DependentService(object):
"""Implementation of the 'DependentService' model.
This service is dependent on other service.
Attributes:
name (string): Name of the service needs to be deployed.
version (string): Version of the service being used.
status (ServiceStatusEnum): Can have any value as - DRAFT_INPROGRESS,
DRAFT_COMPLETE, DESIGN_INPROGRESS, DESIGN_FAILED,
DESIGN_COMPLETED, VALIDATION_INPROGRESS, VALIDATION_FAILED,
VALIDATION_COMPLETED, TESTING_INPROGRESS, TESTING_FAILED,
TESTING_COMPLETED, READY_TO_USE_INPROGRESS, READY_TO_USE_FAILED,
READY_TO_USE_COMPLETED, READY_TO_PRIVATE_USE_INPROGRESS,
READY_TO_PRIVATE_USE_FAILED, READY_TO_PRIVATE_USE_COMPLETED,
PUBLISH_INPROGRESS, PUBLISH_FAILED, PUBLISH_COMPLETED,
CERTIFY_INPROGRESS, CERTIFY_FAILED, CERTIFY_COMPLETED,
DEPRECATE_INPROGRESS, DEPRECATE_FAILED, DEPRECATE_COMPLETED,
MARKDELETE_INPROGRESS, MARKDELETE_FAILED, MARKDELETE_COMPLETED.
mtype (DependentServicesTypeEnum): List of dependent services type.
created_by (string): User who created the service. Part of response
only.
last_modified_by (string): User who last modified the service. Part of
response only.
instances (int): Instances of a service.
"""
# Create a mapping from Model property names to API property names
_names = {
"name": 'name',
"version": 'version',
"status": 'status',
"mtype": 'type',
"created_by": 'createdBy',
"last_modified_by": 'lastModifiedBy',
"instances": 'Instances'
}
_optionals = [
'name',
'version',
'status',
'mtype',
'created_by',
'last_modified_by',
'instances',
]
_nullables = [
'mtype',
]
def __init__(self,
name=APIHelper.SKIP,
version=APIHelper.SKIP,
status=APIHelper.SKIP,
mtype=APIHelper.SKIP,
created_by=APIHelper.SKIP,
last_modified_by=APIHelper.SKIP,
instances=APIHelper.SKIP):
"""Constructor for the DependentService class"""
# Initialize members of the class
if name is not APIHelper.SKIP:
self.name = name
if version is not APIHelper.SKIP:
self.version = version
if status is not APIHelper.SKIP:
self.status = status
if mtype is not APIHelper.SKIP:
self.mtype = mtype
if created_by is not APIHelper.SKIP:
self.created_by = created_by
if last_modified_by is not APIHelper.SKIP:
self.last_modified_by = last_modified_by
if instances is not APIHelper.SKIP:
self.instances = instances
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
name = dictionary.get("name") if dictionary.get("name") else APIHelper.SKIP
version = dictionary.get("version") if dictionary.get("version") else APIHelper.SKIP
status = dictionary.get("status") if dictionary.get("status") else APIHelper.SKIP
mtype = dictionary.get("type") if "type" in dictionary.keys() else APIHelper.SKIP
created_by = dictionary.get("createdBy") if dictionary.get("createdBy") else APIHelper.SKIP
last_modified_by = dictionary.get("lastModifiedBy") if dictionary.get("lastModifiedBy") else APIHelper.SKIP
instances = dictionary.get("Instances") if dictionary.get("Instances") else APIHelper.SKIP
# Return an object of this model
return cls(name,
version,
status,
mtype,
created_by,
last_modified_by,
instances)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/dependent_service.py
|
dependent_service.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class SelectedService(object):
"""Implementation of the 'SelectedService' model.
Service which is selected.
Attributes:
name (string): Name of the service needs to be deployed.
version (string): Name of the service user is created.
state (ServiceStateEnum): Can have any value as - DRAFT, DESIGN,
TESTING, PUBLISH, CERTIFY, READY_TO_USE, DEPRECATE, DELETED.
"""
# Create a mapping from Model property names to API property names
_names = {
"name": 'name',
"version": 'version',
"state": 'state'
}
_optionals = [
'name',
'version',
'state',
]
def __init__(self,
name=APIHelper.SKIP,
version=APIHelper.SKIP,
state=APIHelper.SKIP):
"""Constructor for the SelectedService class"""
# Initialize members of the class
if name is not APIHelper.SKIP:
self.name = name
if version is not APIHelper.SKIP:
self.version = version
if state is not APIHelper.SKIP:
self.state = state
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
name = dictionary.get("name") if dictionary.get("name") else APIHelper.SKIP
version = dictionary.get("version") if dictionary.get("version") else APIHelper.SKIP
state = dictionary.get("state") if dictionary.get("state") else APIHelper.SKIP
# Return an object of this model
return cls(name,
version,
state)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/selected_service.py
|
selected_service.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.custom_wf import CustomWf
from verizon5gmecvnspapi.models.installation_wf import InstallationWf
from verizon5gmecvnspapi.models.operations_wf import OperationsWf
class Workflow(object):
"""Implementation of the 'Workflow' model.
Workflow attribute of a service.
Attributes:
name (string): The service version workflow name.
version (string): The service version workflow value.
id (string): Auto-generated UUID for each workdflow triggered.
mtype (WorkflowTypeEnum): Service type e.g. Installation, Operations,
Custom.
installation_wf (InstallationWf): `installationWf` attribute of a
service.
operations_wf (OperationsWf): `operationsWf` attribute of a service.
custom_wf (CustomWf): `customWf` attribute of a service.
files (list of string): Files which are being generated.
status (string): Status of the workflow.
created_date (datetime): The date on which the workflow is created.
last_modified_date (datetime): The date when the created workflow was
last modified.
created_by (string): Identity of the user who created the workflow.
updated_by (string): Identity of the user who updated the workflow.
"""
# Create a mapping from Model property names to API property names
_names = {
"name": 'name',
"version": 'version',
"id": 'id',
"mtype": 'type',
"installation_wf": 'installationWf',
"operations_wf": 'operationsWf',
"custom_wf": 'customWf',
"files": 'files',
"status": 'status',
"created_date": 'createdDate',
"last_modified_date": 'lastModifiedDate',
"created_by": 'createdBy',
"updated_by": 'updatedBy'
}
_optionals = [
'id',
'mtype',
'installation_wf',
'operations_wf',
'custom_wf',
'files',
'status',
'created_date',
'last_modified_date',
'created_by',
'updated_by',
]
def __init__(self,
name=None,
version=None,
id=APIHelper.SKIP,
mtype=APIHelper.SKIP,
installation_wf=APIHelper.SKIP,
operations_wf=APIHelper.SKIP,
custom_wf=APIHelper.SKIP,
files=APIHelper.SKIP,
status=APIHelper.SKIP,
created_date=APIHelper.SKIP,
last_modified_date=APIHelper.SKIP,
created_by=APIHelper.SKIP,
updated_by=APIHelper.SKIP):
"""Constructor for the Workflow class"""
# Initialize members of the class
self.name = name
self.version = version
if id is not APIHelper.SKIP:
self.id = id
if mtype is not APIHelper.SKIP:
self.mtype = mtype
if installation_wf is not APIHelper.SKIP:
self.installation_wf = installation_wf
if operations_wf is not APIHelper.SKIP:
self.operations_wf = operations_wf
if custom_wf is not APIHelper.SKIP:
self.custom_wf = custom_wf
if files is not APIHelper.SKIP:
self.files = files
if status is not APIHelper.SKIP:
self.status = status
if created_date is not APIHelper.SKIP:
self.created_date = APIHelper.RFC3339DateTime(created_date) if created_date else None
if last_modified_date is not APIHelper.SKIP:
self.last_modified_date = APIHelper.RFC3339DateTime(last_modified_date) if last_modified_date else None
if created_by is not APIHelper.SKIP:
self.created_by = created_by
if updated_by is not APIHelper.SKIP:
self.updated_by = updated_by
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
name = dictionary.get("name") if dictionary.get("name") else None
version = dictionary.get("version") if dictionary.get("version") else None
id = dictionary.get("id") if dictionary.get("id") else APIHelper.SKIP
mtype = dictionary.get("type") if dictionary.get("type") else APIHelper.SKIP
installation_wf = InstallationWf.from_dictionary(dictionary.get('installationWf')) if 'installationWf' in dictionary.keys() else APIHelper.SKIP
operations_wf = OperationsWf.from_dictionary(dictionary.get('operationsWf')) if 'operationsWf' in dictionary.keys() else APIHelper.SKIP
custom_wf = CustomWf.from_dictionary(dictionary.get('customWf')) if 'customWf' in dictionary.keys() else APIHelper.SKIP
files = dictionary.get("files") if dictionary.get("files") else APIHelper.SKIP
status = dictionary.get("status") if dictionary.get("status") else APIHelper.SKIP
created_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("createdDate")).datetime if dictionary.get("createdDate") else APIHelper.SKIP
last_modified_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("lastModifiedDate")).datetime if dictionary.get("lastModifiedDate") else APIHelper.SKIP
created_by = dictionary.get("createdBy") if dictionary.get("createdBy") else APIHelper.SKIP
updated_by = dictionary.get("updatedBy") if dictionary.get("updatedBy") else APIHelper.SKIP
# Return an object of this model
return cls(name,
version,
id,
mtype,
installation_wf,
operations_wf,
custom_wf,
files,
status,
created_date,
last_modified_date,
created_by,
updated_by)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/workflow.py
|
workflow.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class RunningInstance(object):
"""Implementation of the 'RunningInstance' model.
Running instance of a service.
Attributes:
instance_name (string): Service instance name.
instance_id (string): Service instance ID.
csp (string): Cloud Service Provider.
status (ServiceStatusEnum): Can have any value as - DRAFT_INPROGRESS,
DRAFT_COMPLETE, DESIGN_INPROGRESS, DESIGN_FAILED,
DESIGN_COMPLETED, VALIDATION_INPROGRESS, VALIDATION_FAILED,
VALIDATION_COMPLETED, TESTING_INPROGRESS, TESTING_FAILED,
TESTING_COMPLETED, READY_TO_USE_INPROGRESS, READY_TO_USE_FAILED,
READY_TO_USE_COMPLETED, READY_TO_PRIVATE_USE_INPROGRESS,
READY_TO_PRIVATE_USE_FAILED, READY_TO_PRIVATE_USE_COMPLETED,
PUBLISH_INPROGRESS, PUBLISH_FAILED, PUBLISH_COMPLETED,
CERTIFY_INPROGRESS, CERTIFY_FAILED, CERTIFY_COMPLETED,
DEPRECATE_INPROGRESS, DEPRECATE_FAILED, DEPRECATE_COMPLETED,
MARKDELETE_INPROGRESS, MARKDELETE_FAILED, MARKDELETE_COMPLETED.
"""
# Create a mapping from Model property names to API property names
_names = {
"instance_name": 'instanceName',
"instance_id": 'instanceID',
"csp": 'CSP',
"status": 'status'
}
_optionals = [
'instance_name',
'instance_id',
'csp',
'status',
]
def __init__(self,
instance_name=APIHelper.SKIP,
instance_id=APIHelper.SKIP,
csp=APIHelper.SKIP,
status=APIHelper.SKIP):
"""Constructor for the RunningInstance class"""
# Initialize members of the class
if instance_name is not APIHelper.SKIP:
self.instance_name = instance_name
if instance_id is not APIHelper.SKIP:
self.instance_id = instance_id
if csp is not APIHelper.SKIP:
self.csp = csp
if status is not APIHelper.SKIP:
self.status = status
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
instance_name = dictionary.get("instanceName") if dictionary.get("instanceName") else APIHelper.SKIP
instance_id = dictionary.get("instanceID") if dictionary.get("instanceID") else APIHelper.SKIP
csp = dictionary.get("CSP") if dictionary.get("CSP") else APIHelper.SKIP
status = dictionary.get("status") if dictionary.get("status") else APIHelper.SKIP
# Return an object of this model
return cls(instance_name,
instance_id,
csp,
status)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/running_instance.py
|
running_instance.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class ServiceOnboardingHelmGitTag(object):
"""Implementation of the 'ServiceOnboardingHelmGitTag' model.
TODO: type model description here.
Attributes:
tag_name (string): The user can provide tagName for the Helm chart.
helm_chart_path (string): The user can provide the path to the Helm
chart.
values_yaml_paths (list of string): The user can provide an array of
values.YAML files paths.
"""
# Create a mapping from Model property names to API property names
_names = {
"tag_name": 'tagName',
"helm_chart_path": 'helmChartPath',
"values_yaml_paths": 'valuesYamlPaths'
}
_optionals = [
'values_yaml_paths',
]
def __init__(self,
tag_name=None,
helm_chart_path=None,
values_yaml_paths=APIHelper.SKIP):
"""Constructor for the ServiceOnboardingHelmGitTag class"""
# Initialize members of the class
self.tag_name = tag_name
self.helm_chart_path = helm_chart_path
if values_yaml_paths is not APIHelper.SKIP:
self.values_yaml_paths = values_yaml_paths
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
tag_name = dictionary.get("tagName") if dictionary.get("tagName") else None
helm_chart_path = dictionary.get("helmChartPath") if dictionary.get("helmChartPath") else None
values_yaml_paths = dictionary.get("valuesYamlPaths") if dictionary.get("valuesYamlPaths") else APIHelper.SKIP
# Return an object of this model
return cls(tag_name,
helm_chart_path,
values_yaml_paths)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service_onboarding_helm_git_tag.py
|
service_onboarding_helm_git_tag.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.service import Service
class Services(object):
"""Implementation of the 'Services' model.
Response to get all services.
Attributes:
total_records (int): Will display the total number of records
fetched.
service_res_list (list of Service): Response to fetch all services.
"""
# Create a mapping from Model property names to API property names
_names = {
"total_records": 'totalRecords',
"service_res_list": 'serviceResList'
}
_optionals = [
'total_records',
'service_res_list',
]
def __init__(self,
total_records=APIHelper.SKIP,
service_res_list=APIHelper.SKIP):
"""Constructor for the Services class"""
# Initialize members of the class
if total_records is not APIHelper.SKIP:
self.total_records = total_records
if service_res_list is not APIHelper.SKIP:
self.service_res_list = service_res_list
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
total_records = dictionary.get("totalRecords") if dictionary.get("totalRecords") else APIHelper.SKIP
service_res_list = None
if dictionary.get('serviceResList') is not None:
service_res_list = [Service.from_dictionary(x) for x in dictionary.get('serviceResList')]
else:
service_res_list = APIHelper.SKIP
# Return an object of this model
return cls(total_records,
service_res_list)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/services.py
|
services.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class ResourceBase(object):
"""Implementation of the 'ResourceBase' model.
Resource Base of the service.
Attributes:
unit (string): Resource unit ex :MB.
value (long|int): Resource value e.g. 200MB.
max (long|int): Resource max value e.g. 400MB.
min (long|int): Resource min value e.g. 10MB.
"""
# Create a mapping from Model property names to API property names
_names = {
"unit": 'unit',
"value": 'value',
"max": 'max',
"min": 'min'
}
_optionals = [
'unit',
'value',
'max',
'min',
]
def __init__(self,
unit=APIHelper.SKIP,
value=APIHelper.SKIP,
max=APIHelper.SKIP,
min=APIHelper.SKIP):
"""Constructor for the ResourceBase class"""
# Initialize members of the class
if unit is not APIHelper.SKIP:
self.unit = unit
if value is not APIHelper.SKIP:
self.value = value
if max is not APIHelper.SKIP:
self.max = max
if min is not APIHelper.SKIP:
self.min = min
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
unit = dictionary.get("unit") if dictionary.get("unit") else APIHelper.SKIP
value = dictionary.get("value") if dictionary.get("value") else APIHelper.SKIP
max = dictionary.get("max") if dictionary.get("max") else APIHelper.SKIP
min = dictionary.get("min") if dictionary.get("min") else APIHelper.SKIP
# Return an object of this model
return cls(unit,
value,
max,
min)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/resource_base.py
|
resource_base.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class EdgeServiceOnboardingDeleteResult(object):
"""Implementation of the 'EdgeServiceOnboardingDeleteResult' model.
Response to delete a service.
Attributes:
message (string): Message confirms if the action was success or
failure.
status (string): Will provide the current status of the action.
sub_status (string): Displays the proper response with status.
"""
# Create a mapping from Model property names to API property names
_names = {
"message": 'message',
"status": 'status',
"sub_status": 'subStatus'
}
_optionals = [
'message',
'status',
'sub_status',
]
def __init__(self,
message=APIHelper.SKIP,
status=APIHelper.SKIP,
sub_status=APIHelper.SKIP):
"""Constructor for the EdgeServiceOnboardingDeleteResult class"""
# Initialize members of the class
if message is not APIHelper.SKIP:
self.message = message
if status is not APIHelper.SKIP:
self.status = status
if sub_status is not APIHelper.SKIP:
self.sub_status = sub_status
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
message = dictionary.get("message") if dictionary.get("message") else APIHelper.SKIP
status = dictionary.get("status") if dictionary.get("status") else APIHelper.SKIP
sub_status = dictionary.get("subStatus") if dictionary.get("subStatus") else APIHelper.SKIP
# Return an object of this model
return cls(message,
status,
sub_status)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/edge_service_onboarding_delete_result.py
|
edge_service_onboarding_delete_result.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class AzureCspProfile(object):
"""Implementation of the 'AzureCspProfile' model.
Information related to manage resources in Azure infrastructure.
Attributes:
tenant_id (string): Azure tenant ID.
subscription_id (string): Azure subscription ID.
client_id (string): Azure client ID.
client_secret (string): Azure client secret.
"""
# Create a mapping from Model property names to API property names
_names = {
"tenant_id": 'tenantID',
"subscription_id": 'subscriptionID',
"client_id": 'clientId',
"client_secret": 'clientSecret'
}
_optionals = [
'tenant_id',
'subscription_id',
'client_id',
'client_secret',
]
def __init__(self,
tenant_id=APIHelper.SKIP,
subscription_id=APIHelper.SKIP,
client_id=APIHelper.SKIP,
client_secret=APIHelper.SKIP):
"""Constructor for the AzureCspProfile class"""
# Initialize members of the class
if tenant_id is not APIHelper.SKIP:
self.tenant_id = tenant_id
if subscription_id is not APIHelper.SKIP:
self.subscription_id = subscription_id
if client_id is not APIHelper.SKIP:
self.client_id = client_id
if client_secret is not APIHelper.SKIP:
self.client_secret = client_secret
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
tenant_id = dictionary.get("tenantID") if dictionary.get("tenantID") else APIHelper.SKIP
subscription_id = dictionary.get("subscriptionID") if dictionary.get("subscriptionID") else APIHelper.SKIP
client_id = dictionary.get("clientId") if dictionary.get("clientId") else APIHelper.SKIP
client_secret = dictionary.get("clientSecret") if dictionary.get("clientSecret") else APIHelper.SKIP
# Return an object of this model
return cls(tenant_id,
subscription_id,
client_id,
client_secret)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/azure_csp_profile.py
|
azure_csp_profile.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.dependent_service import DependentService
from verizon5gmecvnspapi.models.edge_service_onboarding_result import EdgeServiceOnboardingResult
from verizon5gmecvnspapi.models.running_instance import RunningInstance
from verizon5gmecvnspapi.models.selected_service import SelectedService
class ServiceDeleteResult(object):
"""Implementation of the 'ServiceDeleteResult' model.
Response to delete a service.
Attributes:
selected_service (SelectedService): Service which is selected.
dependent_service (list of DependentService): List of dependent
services.
running_instances (list of RunningInstance): List of running
Instance.
error_details (EdgeServiceOnboardingResult): Error response attribute
of a service.
"""
# Create a mapping from Model property names to API property names
_names = {
"selected_service": 'selectedService',
"dependent_service": 'dependentService',
"running_instances": 'runningInstances',
"error_details": 'errorDetails'
}
_optionals = [
'selected_service',
'dependent_service',
'running_instances',
'error_details',
]
def __init__(self,
selected_service=APIHelper.SKIP,
dependent_service=APIHelper.SKIP,
running_instances=APIHelper.SKIP,
error_details=APIHelper.SKIP):
"""Constructor for the ServiceDeleteResult class"""
# Initialize members of the class
if selected_service is not APIHelper.SKIP:
self.selected_service = selected_service
if dependent_service is not APIHelper.SKIP:
self.dependent_service = dependent_service
if running_instances is not APIHelper.SKIP:
self.running_instances = running_instances
if error_details is not APIHelper.SKIP:
self.error_details = error_details
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
selected_service = SelectedService.from_dictionary(dictionary.get('selectedService')) if 'selectedService' in dictionary.keys() else APIHelper.SKIP
dependent_service = None
if dictionary.get('dependentService') is not None:
dependent_service = [DependentService.from_dictionary(x) for x in dictionary.get('dependentService')]
else:
dependent_service = APIHelper.SKIP
running_instances = None
if dictionary.get('runningInstances') is not None:
running_instances = [RunningInstance.from_dictionary(x) for x in dictionary.get('runningInstances')]
else:
running_instances = APIHelper.SKIP
error_details = EdgeServiceOnboardingResult.from_dictionary(dictionary.get('errorDetails')) if 'errorDetails' in dictionary.keys() else APIHelper.SKIP
# Return an object of this model
return cls(selected_service,
dependent_service,
running_instances,
error_details)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service_delete_result.py
|
service_delete_result.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class ServiceError(object):
"""Implementation of the 'ServiceError' model.
Errors related to service.
Attributes:
error_category (string): Category defined under which the error
falls.
error_code (string): Error Code is required.
error_desc (string): Error description is required.
error_subcategory (string): Sub-category of the error defined.
"""
# Create a mapping from Model property names to API property names
_names = {
"error_category": 'errorCategory',
"error_code": 'errorCode',
"error_desc": 'errorDesc',
"error_subcategory": 'errorSubcategory'
}
_optionals = [
'error_category',
'error_code',
'error_desc',
'error_subcategory',
]
def __init__(self,
error_category=APIHelper.SKIP,
error_code=APIHelper.SKIP,
error_desc=APIHelper.SKIP,
error_subcategory=APIHelper.SKIP):
"""Constructor for the ServiceError class"""
# Initialize members of the class
if error_category is not APIHelper.SKIP:
self.error_category = error_category
if error_code is not APIHelper.SKIP:
self.error_code = error_code
if error_desc is not APIHelper.SKIP:
self.error_desc = error_desc
if error_subcategory is not APIHelper.SKIP:
self.error_subcategory = error_subcategory
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
error_category = dictionary.get("errorCategory") if dictionary.get("errorCategory") else APIHelper.SKIP
error_code = dictionary.get("errorCode") if dictionary.get("errorCode") else APIHelper.SKIP
error_desc = dictionary.get("errorDesc") if dictionary.get("errorDesc") else APIHelper.SKIP
error_subcategory = dictionary.get("errorSubcategory") if dictionary.get("errorSubcategory") else APIHelper.SKIP
# Return an object of this model
return cls(error_category,
error_code,
error_desc,
error_subcategory)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/service_error.py
|
service_error.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class Boundary(object):
"""Implementation of the 'Boundary' model.
Deployment boundary of a service.
Attributes:
csp (CSPCompatibilityEnum): Cloud service provider e.g.
AWS_PUBLIC_CLOUD, AWS_WL, AWS_OUTPOST, AZURE_EDGE,
AZURE_PUBLIC_CLOUD.
region (string): Boundary region e.g. US East (Ohio).
zone_id (list of string): Zones listed under a specific region.
"""
# Create a mapping from Model property names to API property names
_names = {
"csp": 'csp',
"region": 'region',
"zone_id": 'zoneId'
}
_optionals = [
'csp',
'region',
'zone_id',
]
def __init__(self,
csp='AWS_WL',
region=APIHelper.SKIP,
zone_id=APIHelper.SKIP):
"""Constructor for the Boundary class"""
# Initialize members of the class
self.csp = csp
if region is not APIHelper.SKIP:
self.region = region
if zone_id is not APIHelper.SKIP:
self.zone_id = zone_id
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
csp = dictionary.get("csp") if dictionary.get("csp") else 'AWS_WL'
region = dictionary.get("region") if dictionary.get("region") else APIHelper.SKIP
zone_id = dictionary.get("zoneId") if dictionary.get("zoneId") else APIHelper.SKIP
# Return an object of this model
return cls(csp,
region,
zone_id)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/boundary.py
|
boundary.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
class Tag(object):
"""Implementation of the 'Tag' model.
Any name for the tag.
Attributes:
id (string): Id of the user creating the repository.
key (string): Key properties/metadata attribute.
description (string): Description for the repository being created.
value (string): Properties/metadata value attribute.
created_date (datetime): Date when the repository was created.
last_modified_date (datetime): Date when the repository was updated.
created_by (string): User information by whom the repository was
created.
updated_by (string): User information by whom the repository was
updated.
"""
# Create a mapping from Model property names to API property names
_names = {
"key": 'key',
"id": 'id',
"description": 'description',
"value": 'value',
"created_date": 'createdDate',
"last_modified_date": 'lastModifiedDate',
"created_by": 'createdBy',
"updated_by": 'updatedBy'
}
_optionals = [
'id',
'description',
'value',
'created_date',
'last_modified_date',
'created_by',
'updated_by',
]
def __init__(self,
key=None,
id=APIHelper.SKIP,
description=APIHelper.SKIP,
value=APIHelper.SKIP,
created_date=APIHelper.SKIP,
last_modified_date=APIHelper.SKIP,
created_by=APIHelper.SKIP,
updated_by=APIHelper.SKIP):
"""Constructor for the Tag class"""
# Initialize members of the class
if id is not APIHelper.SKIP:
self.id = id
self.key = key
if description is not APIHelper.SKIP:
self.description = description
if value is not APIHelper.SKIP:
self.value = value
if created_date is not APIHelper.SKIP:
self.created_date = APIHelper.RFC3339DateTime(created_date) if created_date else None
if last_modified_date is not APIHelper.SKIP:
self.last_modified_date = APIHelper.RFC3339DateTime(last_modified_date) if last_modified_date else None
if created_by is not APIHelper.SKIP:
self.created_by = created_by
if updated_by is not APIHelper.SKIP:
self.updated_by = updated_by
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
key = dictionary.get("key") if dictionary.get("key") else None
id = dictionary.get("id") if dictionary.get("id") else APIHelper.SKIP
description = dictionary.get("description") if dictionary.get("description") else APIHelper.SKIP
value = dictionary.get("value") if dictionary.get("value") else APIHelper.SKIP
created_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("createdDate")).datetime if dictionary.get("createdDate") else APIHelper.SKIP
last_modified_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("lastModifiedDate")).datetime if dictionary.get("lastModifiedDate") else APIHelper.SKIP
created_by = dictionary.get("createdBy") if dictionary.get("createdBy") else APIHelper.SKIP
updated_by = dictionary.get("updatedBy") if dictionary.get("updatedBy") else APIHelper.SKIP
# Return an object of this model
return cls(key,
id,
description,
value,
created_date,
last_modified_date,
created_by,
updated_by)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/tag.py
|
tag.py
|
from verizon5gmecvnspapi.api_helper import APIHelper
from verizon5gmecvnspapi.models.repository import Repository
from verizon5gmecvnspapi.models.service_onboarding_helm_git_branch import ServiceOnboardingHelmGitBranch
from verizon5gmecvnspapi.models.service_onboarding_helm_git_tag import ServiceOnboardingHelmGitTag
from verizon5gmecvnspapi.models.service_onboarding_helm_helmrepo import ServiceOnboardingHelmHelmrepo
from verizon5gmecvnspapi.models.service_onboarding_helm_yaml_git_tag import ServiceOnboardingHelmYamlGitTag
from verizon5gmecvnspapi.models.service_onboarding_terraform_git_branch import ServiceOnboardingTerraformGitBranch
from verizon5gmecvnspapi.models.service_onboarding_terraform_git_tag import ServiceOnboardingTerraformGitTag
from verizon5gmecvnspapi.models.service_onboarding_yaml_git_branch import ServiceOnboardingYamlGitBranch
class Workload(object):
"""Implementation of the 'Workload' model.
Workload attribute of a service.
Attributes:
id (string): The auto-generated Id of the workload.
name (string): Name of the workload needs to be deployed.
description (string): A brief workload description.
package_type (ServiceDependencyPackageTypeEnum): Deployment package
type.
upload_type (UploadTypeEnum): Allowed values are: GIT files
(PULL_FROM_REPO), MANUAL_UPLOAD.
repository_type (WorkloadRepositoryTypeEnum): Repository types
allowed: GIT/HELM.
repository_id (string): In case of 'Pull files from my repository',
The user can provide the existing repositoryID.
repository (Repository): Users can create a repository to maintain
service artifacts. Repository would be either a Git or HELM
repository.
files (list of string): Files which are being generated.
revision_type (WorkloadRevisionTypeEnum): Revision type can be a
BRANCH or TAG.
helm_git_branch (ServiceOnboardingHelmGitBranch): TODO: type
description here.
helm_git_tag (ServiceOnboardingHelmGitTag): TODO: type description
here.
helm_yaml_git_tag (ServiceOnboardingHelmYamlGitTag): TODO: type
description here.
helm_helmrepo (ServiceOnboardingHelmHelmrepo): TODO: type description
here.
yaml_git_branch (ServiceOnboardingYamlGitBranch): TODO: type
description here.
terraform_git_branch (ServiceOnboardingTerraformGitBranch): TODO: type
description here.
terraform_git_tag (ServiceOnboardingTerraformGitTag): TODO: type
description here.
created_date (datetime): The date on which the workload is created.
last_modified_dte (datetime): The date when the created workload was
last modified.
created_by (string): Identity of the user who created the workload.
updated_by (string): Identity of the user who updated the workload.
"""
# Create a mapping from Model property names to API property names
_names = {
"name": 'name',
"id": 'id',
"description": 'description',
"package_type": 'packageType',
"upload_type": 'uploadType',
"repository_type": 'repositoryType',
"repository_id": 'repositoryId',
"repository": 'repository',
"files": 'files',
"revision_type": 'revisionType',
"helm_git_branch": 'helmGitBranch',
"helm_git_tag": 'helmGitTag',
"helm_yaml_git_tag": 'helmYamlGitTag',
"helm_helmrepo": 'helmHelmrepo',
"yaml_git_branch": 'yamlGitBranch',
"terraform_git_branch": 'terraformGitBranch',
"terraform_git_tag": 'terraformGitTag',
"created_date": 'createdDate',
"last_modified_dte": 'lastModifiedDte',
"created_by": 'createdBy',
"updated_by": 'updatedBy'
}
_optionals = [
'id',
'description',
'package_type',
'upload_type',
'repository_type',
'repository_id',
'repository',
'files',
'revision_type',
'helm_git_branch',
'helm_git_tag',
'helm_yaml_git_tag',
'helm_helmrepo',
'yaml_git_branch',
'terraform_git_branch',
'terraform_git_tag',
'created_date',
'last_modified_dte',
'created_by',
'updated_by',
]
_nullables = [
'description',
'package_type',
'repository_type',
'repository_id',
'files',
]
def __init__(self,
name=None,
id=APIHelper.SKIP,
description=APIHelper.SKIP,
package_type=APIHelper.SKIP,
upload_type=APIHelper.SKIP,
repository_type=APIHelper.SKIP,
repository_id=APIHelper.SKIP,
repository=APIHelper.SKIP,
files=APIHelper.SKIP,
revision_type=APIHelper.SKIP,
helm_git_branch=APIHelper.SKIP,
helm_git_tag=APIHelper.SKIP,
helm_yaml_git_tag=APIHelper.SKIP,
helm_helmrepo=APIHelper.SKIP,
yaml_git_branch=APIHelper.SKIP,
terraform_git_branch=APIHelper.SKIP,
terraform_git_tag=APIHelper.SKIP,
created_date=APIHelper.SKIP,
last_modified_dte=APIHelper.SKIP,
created_by=APIHelper.SKIP,
updated_by=APIHelper.SKIP):
"""Constructor for the Workload class"""
# Initialize members of the class
if id is not APIHelper.SKIP:
self.id = id
self.name = name
if description is not APIHelper.SKIP:
self.description = description
if package_type is not APIHelper.SKIP:
self.package_type = package_type
if upload_type is not APIHelper.SKIP:
self.upload_type = upload_type
if repository_type is not APIHelper.SKIP:
self.repository_type = repository_type
if repository_id is not APIHelper.SKIP:
self.repository_id = repository_id
if repository is not APIHelper.SKIP:
self.repository = repository
if files is not APIHelper.SKIP:
self.files = files
if revision_type is not APIHelper.SKIP:
self.revision_type = revision_type
if helm_git_branch is not APIHelper.SKIP:
self.helm_git_branch = helm_git_branch
if helm_git_tag is not APIHelper.SKIP:
self.helm_git_tag = helm_git_tag
if helm_yaml_git_tag is not APIHelper.SKIP:
self.helm_yaml_git_tag = helm_yaml_git_tag
if helm_helmrepo is not APIHelper.SKIP:
self.helm_helmrepo = helm_helmrepo
if yaml_git_branch is not APIHelper.SKIP:
self.yaml_git_branch = yaml_git_branch
if terraform_git_branch is not APIHelper.SKIP:
self.terraform_git_branch = terraform_git_branch
if terraform_git_tag is not APIHelper.SKIP:
self.terraform_git_tag = terraform_git_tag
if created_date is not APIHelper.SKIP:
self.created_date = APIHelper.RFC3339DateTime(created_date) if created_date else None
if last_modified_dte is not APIHelper.SKIP:
self.last_modified_dte = APIHelper.RFC3339DateTime(last_modified_dte) if last_modified_dte else None
if created_by is not APIHelper.SKIP:
self.created_by = created_by
if updated_by is not APIHelper.SKIP:
self.updated_by = updated_by
@classmethod
def from_dictionary(cls,
dictionary):
"""Creates an instance of this model from a dictionary
Args:
dictionary (dictionary): A dictionary representation of the object
as obtained from the deserialization of the server's response. The
keys MUST match property names in the API description.
Returns:
object: An instance of this structure class.
"""
if dictionary is None:
return None
# Extract variables from the dictionary
name = dictionary.get("name") if dictionary.get("name") else None
id = dictionary.get("id") if dictionary.get("id") else APIHelper.SKIP
description = dictionary.get("description") if "description" in dictionary.keys() else APIHelper.SKIP
package_type = dictionary.get("packageType") if "packageType" in dictionary.keys() else APIHelper.SKIP
upload_type = dictionary.get("uploadType") if dictionary.get("uploadType") else APIHelper.SKIP
repository_type = dictionary.get("repositoryType") if "repositoryType" in dictionary.keys() else APIHelper.SKIP
repository_id = dictionary.get("repositoryId") if "repositoryId" in dictionary.keys() else APIHelper.SKIP
repository = Repository.from_dictionary(dictionary.get('repository')) if 'repository' in dictionary.keys() else APIHelper.SKIP
files = dictionary.get("files") if "files" in dictionary.keys() else APIHelper.SKIP
revision_type = dictionary.get("revisionType") if dictionary.get("revisionType") else APIHelper.SKIP
helm_git_branch = ServiceOnboardingHelmGitBranch.from_dictionary(dictionary.get('helmGitBranch')) if 'helmGitBranch' in dictionary.keys() else APIHelper.SKIP
helm_git_tag = ServiceOnboardingHelmGitTag.from_dictionary(dictionary.get('helmGitTag')) if 'helmGitTag' in dictionary.keys() else APIHelper.SKIP
helm_yaml_git_tag = ServiceOnboardingHelmYamlGitTag.from_dictionary(dictionary.get('helmYamlGitTag')) if 'helmYamlGitTag' in dictionary.keys() else APIHelper.SKIP
helm_helmrepo = ServiceOnboardingHelmHelmrepo.from_dictionary(dictionary.get('helmHelmrepo')) if 'helmHelmrepo' in dictionary.keys() else APIHelper.SKIP
yaml_git_branch = ServiceOnboardingYamlGitBranch.from_dictionary(dictionary.get('yamlGitBranch')) if 'yamlGitBranch' in dictionary.keys() else APIHelper.SKIP
terraform_git_branch = ServiceOnboardingTerraformGitBranch.from_dictionary(dictionary.get('terraformGitBranch')) if 'terraformGitBranch' in dictionary.keys() else APIHelper.SKIP
terraform_git_tag = ServiceOnboardingTerraformGitTag.from_dictionary(dictionary.get('terraformGitTag')) if 'terraformGitTag' in dictionary.keys() else APIHelper.SKIP
created_date = APIHelper.RFC3339DateTime.from_value(dictionary.get("createdDate")).datetime if dictionary.get("createdDate") else APIHelper.SKIP
last_modified_dte = APIHelper.RFC3339DateTime.from_value(dictionary.get("lastModifiedDte")).datetime if dictionary.get("lastModifiedDte") else APIHelper.SKIP
created_by = dictionary.get("createdBy") if dictionary.get("createdBy") else APIHelper.SKIP
updated_by = dictionary.get("updatedBy") if dictionary.get("updatedBy") else APIHelper.SKIP
# Return an object of this model
return cls(name,
id,
description,
package_type,
upload_type,
repository_type,
repository_id,
repository,
files,
revision_type,
helm_git_branch,
helm_git_tag,
helm_yaml_git_tag,
helm_helmrepo,
yaml_git_branch,
terraform_git_branch,
terraform_git_tag,
created_date,
last_modified_dte,
created_by,
updated_by)
|
Apiamtic-python
|
/Apiamtic_python-1.6.9-py3-none-any.whl/verizon5gmecvnspapi/models/workload.py
|
workload.py
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.