
An Illusion of Progress? Assessing the Current State of Web Agents
Paper • 2504.01382 • Published • 4
|
|
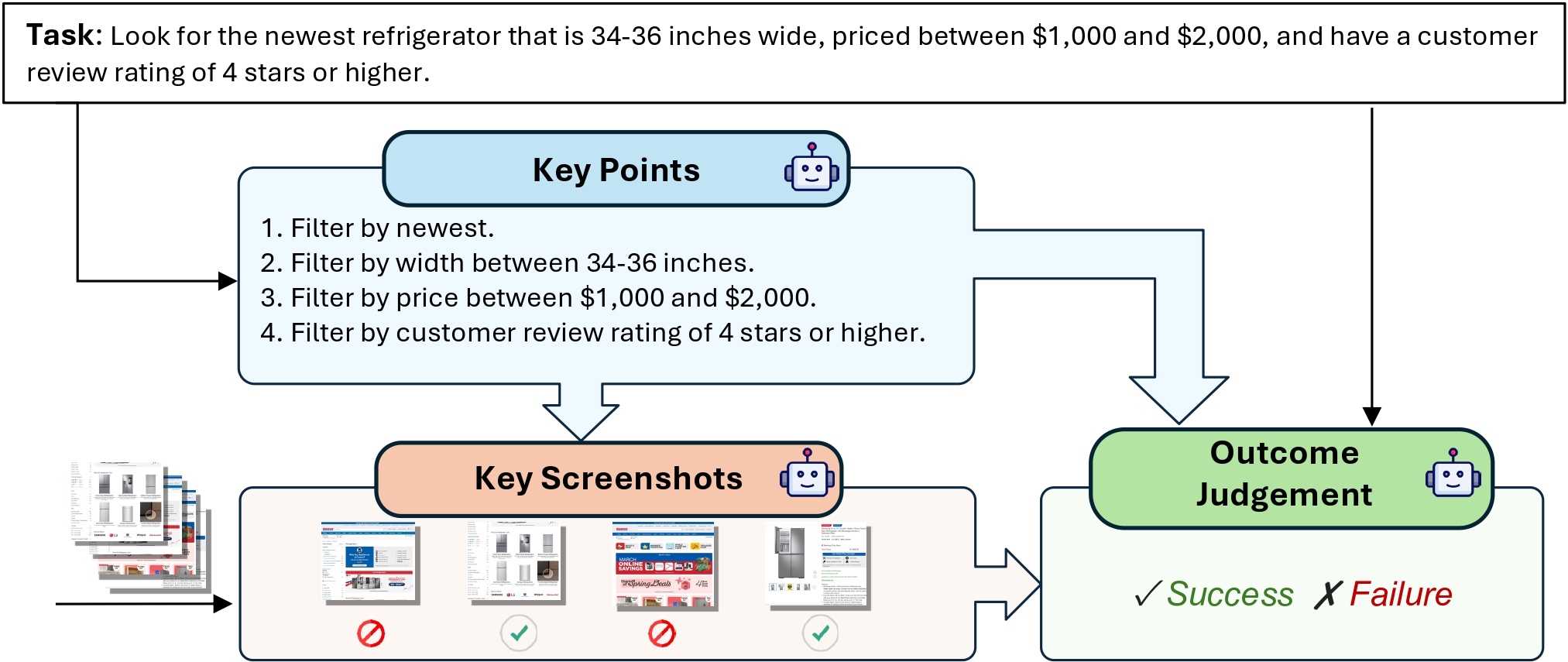
WebJudge preserves critical intermediate screenshots while mitigating the token overload issue, resulting in more accurate and reliable evaluations. Please check our paper for more details.
| Model | Auto-Eval | SeeAct | Agent-E | Browser Use | Claude 3.5 | Claude 3.7 | Operator | Avg AR |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | Autonomous Eval | 84.7 | 85.0 | 76.0 | 83.7 | 75.5 | 71.7 | 79.4 |
| AgentTrek Eval | 73.0 | 64.3 | 63.3 | -- | -- | -- | 66.9 | |
| WebVoyager | -- | 75.3 | 71.3 | 74.0 | 72.0 | 76.7 | 73.9 | |
| WebJudge | 86.7 | 86.0 | 81.4 | 86.3 | 79.1 | 81.8 | 83.6 | |
| o4-mini | Autonomous Eval | 79.7 | 85.7 | 86.0 | 84.3 | 68.0 | 73.3 | 79.5 |
| WebVoyager | -- | 80.3 | 79.0 | 81.7 | 74.3 | 78.3 | 78.7 | |
| WebJudge | 85.3 | 86.3 | 89.3 | 87.0 | 82.3 | 83.7 | 85.7 | |
| WebJudge-7B | 86.0 | 87.3 | 88.3 | 89.7 | 84.3 | 86.3 | 87.0 |
| Methods | AB | VWA | WA | Work | Wk++ | Overall |
|---|---|---|---|---|---|---|
| Rule-based* | 25.0 | 85.2 | 79.0 | 100.0 | 83.3 | 83.8 |
| Autonomous Eval* | 83.3 | 61.2 | 67.6 | 96.4 | 59.3 | 67.6 |
| GPT-4o (A11y Tree)* | 77.8 | 63.0 | 70.2 | 94.6 | 63.0 | 69.8 |
| WebJudge (GPT-4o) | 66.7 | 69.8 | 72.6 | 92.3 | 75.0 | 73.7 |
| WebJudge-7B | 80.0 | 66.7 | 77.5 | 100.0 | 70.0 | 75.7 |
| WebJudge (o4-mini) | 100.0 | 74.5 | 81.2 | 100.0 | 90.0 | 82.0 |
WebJudge significantly outperforms existing methods, achieving impressive overall precision of 73.7% 75.7% and 82.0% on WebArena (WA), VisualWebArena (VWA), AssistantBench (AB), WorkArena (Work) and WorkArena++ (Wk++) across 1302 trajectories.
The high precision suggests that WebJudge holds potential as a robust and scalable reward model for downstream applications such as Rejection Sampling Fine-Tuning, Reflection, and Reinforcement Learning.
vllm serve osunlp/WebJudge-7B --port PORT --api-key API_KEY
or
API_PORT=PORT llamafactory-cli api examples/inference/qwen2_vl.yaml
Please check our Repository and Paper for more details about prompt.
text = """**Task**: {task}
**Key Points for Task Completion**: {key_points}
The snapshot of the web page is shown in the image."""
messages = [
{"role": "system", "content": system_msg},
{
"role": "user",
"content": [
{"type": "text", "text": text},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{jpg_base64_image}", "detail": "high"},
},
],
}
]
completion = client.chat.completions.create(
model=model_path,
messages=messages,
temperature=0
)
Note: Online-Mind2Web is derived from the original Mind2Web dataset. We kindly ask that you cite both the original and this work when using or referencing the data.
@article{xue2025illusionprogressassessingcurrent,
title={An Illusion of Progress? Assessing the Current State of Web Agents},
author={Tianci Xue and Weijian Qi and Tianneng Shi and Chan Hee Song and Boyu Gou and Dawn Song and Huan Sun and Yu Su},
year={2025},
eprint={2504.01382},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.01382},
}
@inproceedings{deng2023mind2web,
author = {Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Sam and Wang, Boshi and Sun, Huan and Su, Yu},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Oh and T. Naumann and A. Globerson and K. Saenko and M. Hardt and S. Levine},
pages = {28091--28114},
publisher = {Curran Associates, Inc.},
title = {Mind2Web: Towards a Generalist Agent for the Web},
url = {https://proceedings.neurips.cc/paper_files/paper/2023/file/5950bf290a1570ea401bf98882128160-Paper-Datasets_and_Benchmarks.pdf},
volume = {36},
year = {2023}
}