Spaces:
Running
on
CPU Upgrade

Running
on
CPU Upgrade

| title: Appoint Ready - MedGemma Demo | |
| emoji: 📋 | |
| colorFrom: blue | |
| colorTo: gray | |
| sdk: docker | |
| models: | |
| - google/medgemma-27b-text-it | |
| pinned: false | |
| license: apache-2.0 | |
| short_description: 'Simulated Pre-visit Intake Demo built using MedGemma' | |
| ## Table of Contents | |
| - [Demo Description](#demo-description) | |
| - [Technical Architecture](#technical-architecture) | |
| - [Running the Demo Locally](#running-the-demo-locally) | |
| - [Models used](#models-used) | |
| - [Caching](#caching) | |
| - [Disclaimer](#disclaimer) | |
| - [Other Models and Demos](#other-models-and-demos) | |
| # AppointReady: Simulated Pre-visit Intake Demo built using MedGemma | |
| Healthcare providers often seek efficient ways to gather comprehensive patient information before appointments. This demo illustrates how MedGemma could be used in an application to streamline pre-visit information collection and utilization. | |
| The demonstration first asks questions to gather pre-visit information. | |
| After it has identified and collected relevant information, the demo application generates a pre-visit report using both collected and health record information (stored as FHIR resources for this demonstration). This type of intelligent pre-visit report can help providers be more efficient and effective while also providing an improved experience for patients compared to traditional intake forms. | |
| At the conclusion of the demo, you can view an evaluation of the pre-visit report which provides additional insights into the quality of the demonstrated capabilities. For this evaluation, MedGemma is provided the patient's reference diagnosis, allowing MedGemma to create a self-evaluation report highlighting strengths as well as areas for improvement. | |
| ## Technical Architecture | |
| This application is composed of several key components: | |
| * **Frontend**: A web interface built with React that provides the user interface for the chat and report visualization. | |
| * **Backend**: A Python server built with Gunicorn/Flask that handles the application logic. It communicates with the LLMs, manages the conversation flow, and generates the final pre-visit report. | |
| * **API called**: | |
| * **MedGemma**: Acts as the clinical assistant, asking relevant questions and summarizing information. | |
| * **Gemini**: Role-plays as the patient, providing responses based on a predefined scenario. | |
| * **Gemini TTS**: Generative text-to-speech model. | |
| * **Deployment**: The entire application is containerized using Docker for easy deployment and scalability. | |
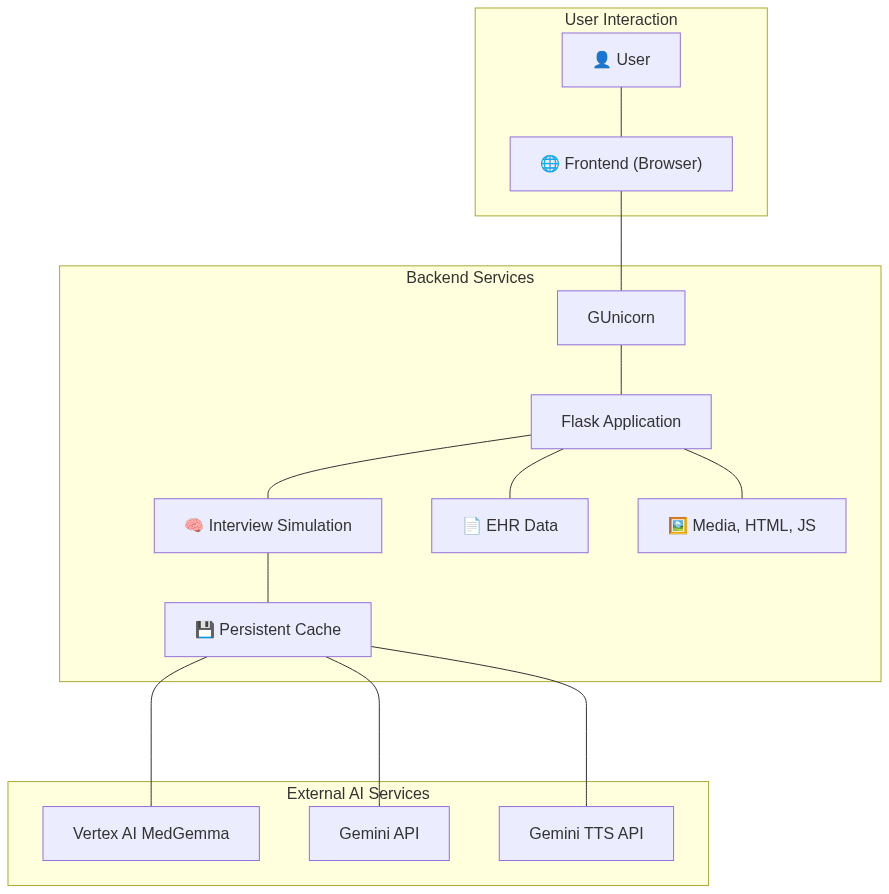
| A high-level overview of the architecture: | |
| [](https://mermaid.live/edit#pako:eNqFk81u00AQx19ltVIlkJzIdpM69i1NShpEpQqnHMAcFnvTrGqvrfW6DUS5cUTiS-IKByRegQPileARmN1N7DgE4Yt3_vObnfHMeIXjPKE4wNeCFAs0G0ccwXN0hMZ0zjhFE5FXRWnUsnphsAhflVSgKZdUkFiynEfYIOpRvmcR_v35_Vd9jvDzxvlA5BDFEw28eVfb6N6pyO-Avl_joEb8r8ynJL5RfEjFLYtpuZt5csVZnAsOl2-P7eQpKW_Aqd9oWBQpi4kpf4fSn3XL6F3IsirVfl3tty-NCzW-VuyIxAuq6Q8_0SUVJSvh66TRW-TZ-eMxkUSzH18rEym7xYQSMsTDsqSy1OCnH7--v0UXNGHEQuezi0cWehj-p2FnS6iZkxQNpweb9oQKSZfDKSQwRwVCignNsnY5oDDOhpcKNWcExgFkNgsbBIwWtlNls2ajnHOqN2mza3rBOp1OvSBGrtdFueoZ893hmyg14U2IHrYSDwx2H9lMZV_eHYTxHbhLk2bQvN4FLW5bvKd3mo7-wwO9wxb8myzBgRQVtXBGRUaUiVcqJsJyQTPYrACOCZ2TKpVquGsIKwh_mufZNhJ-5OsFDuYkLcGqioRIOmYE1iSrVQGtpWKUV1zioNf39SU4WOElDhzH7_quNzhxB57XcwZuz8IvQe47XdexvZ5r9zzH953-2sKvdF67Ozju2_aJ43gD1_aOfW_9ByuAZrY) | |
| <!--```mermaid | |
| graph TD | |
| %% Define Groups | |
| subgraph "User Interaction" | |
| User["👤 User"] | |
| Frontend["🌐 Frontend (Browser)"] | |
| end | |
| subgraph "Backend Services" | |
| GUnicorn["GUnicorn"] | |
| Flask["Flask Application"] | |
| InterviewSimulation["🧠 Interview Simulation"] | |
| Cache["💾 Persistent Cache"] | |
| EHRData["📄 EHR Data"] | |
| StaticAssets["🖼️ Media, HTML, JS"] | |
| end | |
| subgraph "External AI Services" | |
| VertexAI["Vertex AI MedGemma"] | |
| GeminiAPI["Gemini API"] | |
| GeminiTTS["Gemini TTS API"] | |
| end | |
| %% Define Connections | |
| User --- Frontend | |
| Frontend --- GUnicorn | |
| GUnicorn --- Flask | |
| Flask --- InterviewSimulation | |
| Flask --- EHRData | |
| Flask --- StaticAssets | |
| InterviewSimulation --- Cache | |
| Cache --- VertexAI | |
| Cache --- GeminiAPI | |
| Cache --- GeminiTTS | |
| ```--> | |
| ## Running the Demo Locally | |
| To run this demo on your own machine, you'll need to have Docker installed. | |
| ### Prerequisites | |
| * Docker | |
| * Git | |
| * A Google Cloud project with the Vertex AI API enabled. | |
| ### Setup & Configuration | |
| 1. **Clone the repository:** | |
| ```bash | |
| git clone https://huggingface.co/spaces/google/appoint-ready | |
| cd appoint-ready | |
| ``` | |
| 2. **Configure environment variables:** | |
| This project uses an `env.list` file for configuration, which is passed to Docker. Create this file in the root directory. | |
| ```ini | |
| # env.list | |
| GEMINI_API_KEY="your-gemini-token" | |
| GENERATE_SPEECH=false or true | |
| GCP_MEDGEMMA_ENDPOINT=medgemma vertex ai endpoint | |
| GCP_MEDGEMMA_SERVICE_ACCOUNT_KEY="service-account-key json" | |
| ``` | |
| GEMINI_API_KEY: Key can be generated via [aistudio](https://aistudio.google.com/apikey). | |
| GENERATE_SPEECH: Should the demo generate speech not found in cache. Default is false. | |
| GCP_MEDGEMMA_ENDPOINT: Deploy MedGemma via [Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/medgemma). | |
| ### Execution | |
| 1. **Build and run the Docker containers:** | |
| ```bash | |
| run_local.sh | |
| ``` | |
| 2. **Access the application:** | |
| Once the containers are running, you can access the demo in your web browser at `http://localhost:[PORT]`. (e.g., `http://localhost:7860`). | |
| # Models used | |
| This demo uses four models: | |
| * MedGemma 27b-text-it: https://huggingface.co/google/medgemma-27b-text-it \ | |
| For this demo MedGemma-27b was deployed via Model Garden (https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/medgemma). | |
| * Gemini: https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-5-flash \ | |
| We use Gemini to role play the patient while MedGemma plays the clinical assistant. | |
| * Gemini TTS: https://ai.google.dev/gemini-api/docs/models#gemini-2.5-flash-preview-tts \ | |
| As an alternative consider using Clould Text-to-Speech: https://cloud.google.com/text-to-speech | |
| * Veo 3: Was used to generate patient avatar animation https://gemini.google/overview/video-generation | |
| ## Caching | |
| This demo is functional, and results are persistently cached to reduce environmental impact. | |
| ## Disclaimer | |
| This demonstration is for illustrative purposes only and does not represent a finished or approved | |
| product. It is not representative of compliance to any regulations or standards for | |
| quality, safety or efficacy. Any real-world application would require additional development, | |
| training, and adaptation. The experience highlighted in this demo shows MedGemma's baseline | |
| capability for the displayed task and is intended to help developers and users explore possible | |
| applications and inspire further development. | |
| This is not an officially supported Google product. This project is not | |
| eligible for the [Google Open Source Software Vulnerability Rewards | |
| Program](https://bughunters.google.com/open-source-security). | |
| # Other Models and Demos | |
| See other demos here: https://huggingface.co/collections/google/hai-def-concept-apps-6837acfccce400abe6ec26c1 | |
| MedGemma is finetunable - see colab here: https://github.com/Google-Health/medgemma/blob/main/notebooks/fine_tune_with_hugging_face.ipynb | |
| # Contacts | |
| * This demo is part of Google's [Health AI Developer Foundations (HAI-DEF)](https://developers.google.com/health-ai-developer-foundations?referral=appoint-ready) | |
| * Technical info - contact [@lirony](https://huggingface.co/lirony) | |
| * Press only: [email protected] |