Spaces:
Paused

Paused
| # DPO Trainer | |
| [](https://huggingface.co/models?other=dpo,trl) [](https://github.com/huggingface/smol-course/tree/main/2_preference_alignment) | |
| ## Overview | |
| TRL supports the DPO Trainer for training language models from preference data, as described in the paper [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290) by [Rafael Rafailov](https://huggingface.co/rmrafailov), Archit Sharma, Eric Mitchell, [Stefano Ermon](https://huggingface.co/ermonste), [Christopher D. Manning](https://huggingface.co/manning), [Chelsea Finn](https://huggingface.co/cbfinn). | |
| The abstract from the paper is the following: | |
| > While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF). However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model. In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss. The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods. Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train. | |
| The first step is to train an SFT model, to ensure the data we train on is in-distribution for the DPO algorithm. | |
| Then, fine-tuning a language model via DPO consists of two steps and is easier than [PPO](ppo_trainer): | |
| 1. **Data collection**: Gather a [preference dataset](dataset_formats#preference) with positive and negative selected pairs of generation, given a prompt. | |
| 2. **Optimization**: Maximize the log-likelihood of the DPO loss directly. | |
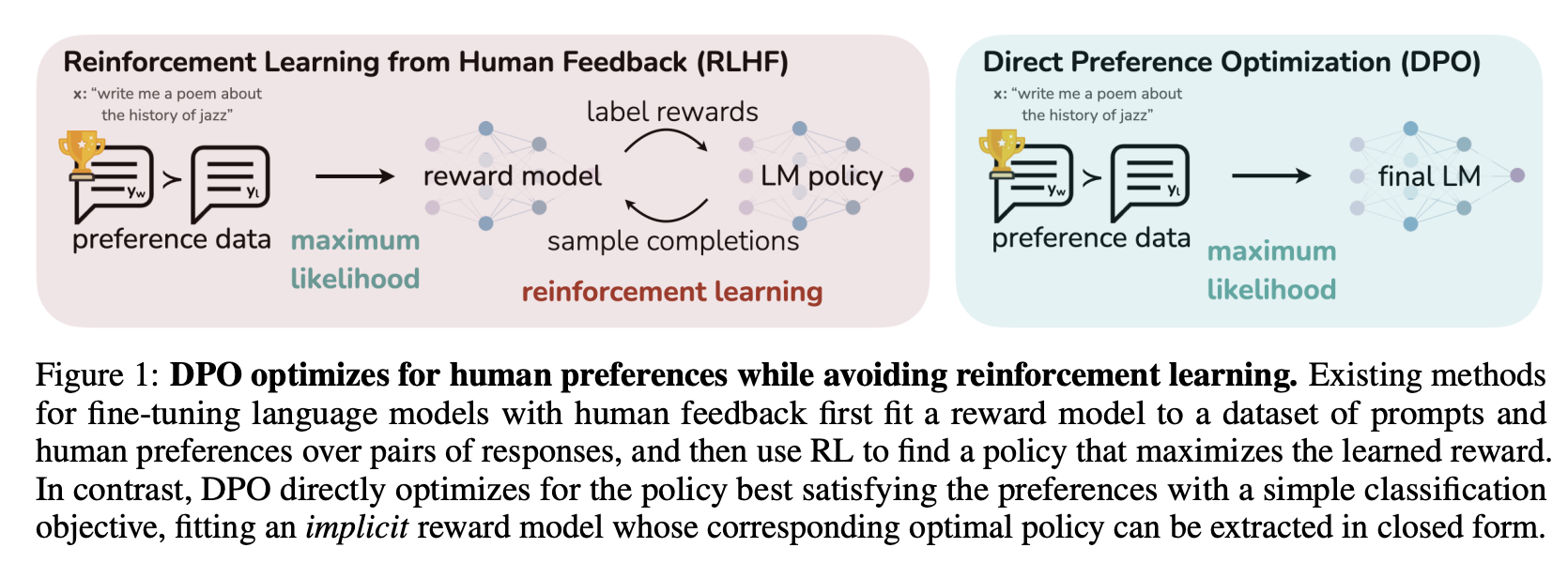
| This process is illustrated in the sketch below (from [Figure 1 of the DPO paper](https://huggingface.co/papers/2305.18290)): | |
|  | |
| Read more about DPO algorithm in the [original paper](https://huggingface.co/papers/2305.18290). | |
| ## Quick start | |
| This example demonstrates how to train a model using the DPO method. We use the [Qwen 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) as the base model. We use the preference data from the [UltraFeedback dataset](https://huggingface.co/datasets/openbmb/UltraFeedback). You can view the data in the dataset here: | |
| <iframe | |
| src="https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized/embed/viewer/default/train?row=0" | |
| frameborder="0" | |
| width="100%" | |
| height="560px" | |
| ></iframe> | |
| Below is the script to train the model: | |
| ```python | |
| # train_dpo.py | |
| from datasets import load_dataset | |
| from trl import DPOConfig, DPOTrainer | |
| from transformers import AutoModelForCausalLM, AutoTokenizer | |
| model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct") | |
| tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct") | |
| train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train") | |
| training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10) | |
| trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset) | |
| trainer.train() | |
| ``` | |
| Execute the script using the following command: | |
| ```bash | |
| accelerate launch train_dpo.py | |
| ``` | |
| Distributed across 8 GPUs, the training takes approximately 3 minutes. You can verify the training progress by checking the reward graph. An increasing trend in the reward margin indicates that the model is improving and generating better responses over time. | |
|  | |
| To see how the [trained model](https://huggingface.co/trl-lib/Qwen2-0.5B-DPO) performs, you can use the [Transformers Chat CLI](https://huggingface.co/docs/transformers/quicktour#chat-with-text-generation-models). | |
| <pre><code>$ transformers chat trl-lib/Qwen2-0.5B-DPO | |
| <strong><span style="color: red;"><shirin_yamani>:</span></strong> | |
| What is Huggingface? | |
| <strong><span style="color: blue;"><trl-lib/Qwen2-0.5B-DPO>:</span></strong> | |
| Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets for the development of machine learning models and applications. It provides a repository of over 300, 000 pre-trained models in Huggingface is a platform that allows users to access a variety of open-source machine learning resources such as pre-trained models and datasets for the development of machine learning models and applications. It provides a repository of over 300, 000 pre-trained models in a variety of languages, enabling users to explore and utilize the latest techniques and technologies in the field of machine learning. | |
| </code></pre> | |
| ## Expected dataset type | |
| DPO requires a [preference dataset](dataset_formats#preference). The [`DPOTrainer`] supports both [conversational](dataset_formats#conversational) and [standard](dataset_formats#standard) dataset formats. When provided with a conversational dataset, the trainer will automatically apply the chat template to the dataset. | |
| Although the [`DPOTrainer`] supports both explicit and implicit prompts, we recommend using explicit prompts. If provided with an implicit prompt dataset, the trainer will automatically extract the prompt from the `"chosen"` and `"rejected"` columns. For more information, refer to the [preference style](dataset_formats#preference) section. | |
| ### Special considerations for vision-language models | |
| The [`DPOTrainer`] supports fine-tuning vision-language models (VLMs). For these models, a vision dataset is required. To learn more about the specific format for vision datasets, refer to the [Vision dataset format](dataset_formats#vision-datasets) section. | |
| Additionally, unlike standard text-based models where a `tokenizer` is used, for VLMs, you should replace the `tokenizer` with a `processor`. | |
| ```diff | |
| - model = AutoModelForCausalLM.from_pretrained(model_id) | |
| + model = AutoModelForVision2Seq.from_pretrained(model_id) | |
| - tokenizer = AutoTokenizer.from_pretrained(model_id) | |
| + processor = AutoProcessor.from_pretrained(model_id) | |
| trainer = DPOTrainer( | |
| model, | |
| args=training_args, | |
| train_dataset=train_dataset, | |
| - processing_class=tokenizer, | |
| + processing_class=processor, | |
| ) | |
| ``` | |
| For a complete example of fine-tuning a vision-language model, refer to the script in [`examples/scripts/dpo_vlm.py`](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_vlm.py). | |
| ## Example script | |
| We provide an example script to train a model using the DPO method. The script is available in [`trl/scripts/dpo.py`](https://github.com/huggingface/trl/blob/main/trl/scripts/dpo.py) | |
| To test the DPO script with the [Qwen2 0.5B model](https://huggingface.co/Qwen/Qwen2-0.5B-Instruct) on the [UltraFeedback dataset](https://huggingface.co/datasets/trl-lib/ultrafeedback_binarized), run the following command: | |
| ```bash | |
| accelerate launch trl/scripts/dpo.py \ | |
| --model_name_or_path Qwen/Qwen2-0.5B-Instruct \ | |
| --dataset_name trl-lib/ultrafeedback_binarized \ | |
| --num_train_epochs 1 \ | |
| --logging_steps 25 \ | |
| --output_dir Qwen2-0.5B-DPO | |
| ``` | |
| ## Logged metrics | |
| While training and evaluating we record the following reward metrics: | |
| - `rewards/chosen`: the mean difference between the log probabilities of the policy model and the reference model for the chosen responses scaled by beta | |
| - `rewards/rejected`: the mean difference between the log probabilities of the policy model and the reference model for the rejected responses scaled by beta | |
| - `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards | |
| - `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards | |
| ## Loss functions | |
| The DPO algorithm supports several loss functions. The loss function can be set using the `loss_type` parameter in the [`DPOConfig`]. The following loss functions are supported: | |
| | `loss_type=` | Description | | |
| | -------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | |
| | `"sigmoid"` (default) | Given the preference data, we can fit a binary classifier according to the Bradley-Terry model and in fact the [DPO](https://huggingface.co/papers/2305.18290) authors propose the sigmoid loss on the normalized likelihood via the `logsigmoid` to fit a logistic regression. | | |
| | `"hinge"` | The [RSO](https://huggingface.co/papers/2309.06657) authors propose to use a hinge loss on the normalized likelihood from the [SLiC](https://huggingface.co/papers/2305.10425) paper. In this case, the `beta` is the reciprocal of the margin. | | |
| | `"ipo"` | The [IPO](https://huggingface.co/papers/2310.12036) authors provide a deeper theoretical understanding of the DPO algorithms and identify an issue with overfitting and propose an alternative loss. In this case, the `beta` is the reciprocal of the gap between the log-likelihood ratios of the chosen vs the rejected completion pair and thus the smaller the `beta` the larger this gaps is. As per the paper the loss is averaged over log-likelihoods of the completion (unlike DPO which is summed only). | | |
| | `"exo_pair"` | The [EXO](https://huggingface.co/papers/2402.00856) authors propose to minimize the reverse KL instead of the negative log-sigmoid loss of DPO which corresponds to forward KL. Setting non-zero `label_smoothing` (default `1e-3`) leads to a simplified version of EXO on pair-wise preferences (see Eqn. (16) of the [EXO paper](https://huggingface.co/papers/2402.00856)). The full version of EXO uses `K>2` completions generated by the SFT policy, which becomes an unbiased estimator of the PPO objective (up to a constant) when `K` is sufficiently large. | | |
| | `"nca_pair"` | The [NCA](https://huggingface.co/papers/2402.05369) authors shows that NCA optimizes the absolute likelihood for each response rather than the relative likelihood. | | |
| | `"robust"` | The [Robust DPO](https://huggingface.co/papers/2403.00409) authors propose an unbiased estimate of the DPO loss that is robust to preference noise in the data. Like in cDPO, it assumes that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0) | | |
| | `"bco_pair"` | The [BCO](https://huggingface.co/papers/2404.04656) authors train a binary classifier whose logit serves as a reward so that the classifier maps {prompt, chosen completion} pairs to 1 and {prompt, rejected completion} pairs to 0. For unpaired data, we recommend the dedicated [`BCOTrainer`]. | | |
| | `"sppo_hard"` | The [SPPO](https://huggingface.co/papers/2405.00675) authors claim that SPPO is capable of solving the Nash equilibrium iteratively by pushing the chosen rewards to be as large as 1/2 and the rejected rewards to be as small as -1/2 and can alleviate data sparsity issues. The implementation approximates this algorithm by employing hard label probabilities, assigning 1 to the winner and 0 to the loser. | | |
| | `"aot"` or `loss_type="aot_pair"` | The [AOT](https://huggingface.co/papers/2406.05882) authors propose to use Distributional Preference Alignment Via Optimal Transport. Traditionally, the alignment algorithms use paired preferences at a sample level, which does not ensure alignment on the distributional level. AOT, on the other hand, can align LLMs on paired or unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. Specifically, `loss_type="aot"` is appropriate for paired datasets, where each prompt has both chosen and rejected responses; `loss_type="aot_pair"` is for unpaired datasets. In a nutshell, `loss_type="aot"` ensures that the log-likelihood ratio of chosen to rejected of the aligned model has higher quantiles than that ratio for the reference model. `loss_type="aot_pair"` ensures that the chosen reward is higher on all quantiles than the rejected reward. Note that in both cases quantiles are obtained via sorting. To fully leverage the advantages of the AOT algorithm, it is important to maximize the per-GPU batch size. | | |
| | `"apo_zero"` or `loss_type="apo_down"` | The [APO](https://huggingface.co/papers/2408.06266) method introduces an "anchored" version of the alignment objective. There are two variants: `apo_zero` and `apo_down`. The `apo_zero` loss increases the likelihood of winning outputs while decreasing the likelihood of losing outputs, making it suitable when the model is less performant than the winning outputs. On the other hand, `apo_down` decreases the likelihood of both winning and losing outputs, but with a stronger emphasis on reducing the likelihood of losing outputs. This variant is more effective when the model is better than the winning outputs. | | |
| | `"discopop"` | The [DiscoPOP](https://huggingface.co/papers/2406.08414) paper uses LLMs to discover more efficient offline preference optimization losses. In the paper the proposed DiscoPOP loss (which is a log-ratio modulated loss) outperformed other optimization losses on different tasks (IMDb positive text generation, Reddit TLDR summarization, and Alpaca Eval 2.0). | | |
| ### Label smoothing | |
| The [cDPO](https://ericmitchell.ai/cdpo.pdf) is a tweak on the DPO loss where we assume that the preference labels are noisy with some probability. In this approach, the `label_smoothing` parameter in the [`DPOConfig`] is used to model the probability of existing label noise. To apply this conservative loss, set `label_smoothing` to a value greater than 0.0 (between 0.0 and 0.5; the default is 0.0). | |
| ### Syncing the reference model | |
| The [TR-DPO](https://huggingface.co/papers/2404.09656) paper suggests syncing the reference model weights after every `ref_model_sync_steps` steps of SGD with weight `ref_model_mixup_alpha` during DPO training. To toggle this callback use the `sync_ref_model=True` in the [`DPOConfig`]. | |
| ### RPO loss | |
| The [RPO](https://huggingface.co/papers/2404.19733) paper implements an iterative preference tuning algorithm using a loss related to the RPO loss in this [paper](https://huggingface.co/papers/2405.16436) that essentially consists of a weighted SFT loss on the chosen preferences together with the DPO loss. To use this loss, set the `rpo_alpha` in the [`DPOConfig`] to an appropriate value. The paper suggests setting this weight to `1.0`. | |
| ### WPO loss | |
| The [WPO](https://huggingface.co/papers/2406.11827) paper adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. To use this method, set the `use_weighting` flag to `True` in the [`DPOConfig`]. | |
| ### LD-DPO loss | |
| The [LD-DPO](https://huggingface.co/papers/2409.06411) paper decomposes the portion of the response that exceeds the desired length into two components — human-like preferences and verbosity preference — based on a mixing coefficient \\( \alpha \\). To use this method, set the `ld_alpha` in the [`DPOConfig`] to an appropriate value. The paper suggests setting this value between `0.0` and `1.0`. | |
| ### For Mixture of Experts Models: Enabling the auxiliary loss | |
| MOEs are the most efficient if the load is about equally distributed between experts. | |
| To ensure that we train MOEs similarly during preference-tuning, it is beneficial to add the auxiliary loss from the load balancer to the final loss. | |
| This option is enabled by setting `output_router_logits=True` in the model config (e.g. [`~transformers.MixtralConfig`]). | |
| To scale how much the auxiliary loss contributes to the total loss, use the hyperparameter `router_aux_loss_coef=...` (default: `0.001`) in the model config. | |
| ## Accelerate DPO fine-tuning using `unsloth` | |
| You can further accelerate QLoRA / LoRA (2x faster, 60% less memory) using the [`unsloth`](https://github.com/unslothai/unsloth) library that is fully compatible with `SFTTrainer`. Currently `unsloth` supports only Llama (Yi, TinyLlama, Qwen, Deepseek etc) and Mistral architectures. Some benchmarks for DPO listed below: | |
| | GPU | Model | Dataset | 🤗 | 🤗 + Flash Attention 2 | 🦥 Unsloth | 🦥 VRAM saved | | |
| | -------- | --------- | ---------- | --- | --------------------- | --------- | ------------ | | |
| | A100 40G | Zephyr 7b | Ultra Chat | 1x | 1.24x | **1.88x** | -11.6% | | |
| | Tesla T4 | Zephyr 7b | Ultra Chat | 1x | 1.09x | **1.55x** | -18.6% | | |
| First install `unsloth` according to the [official documentation](https://github.com/unslothai/unsloth). Once installed, you can incorporate unsloth into your workflow in a very simple manner; instead of loading `AutoModelForCausalLM`, you just need to load a `FastLanguageModel` as follows: | |
| ```diff | |
| from datasets import load_dataset | |
| from trl import DPOConfig, DPOTrainer | |
| - from transformers import AutoModelForCausalLM, AutoTokenizer | |
| + from unsloth import FastLanguageModel | |
| - model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct") | |
| - tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct") | |
| + model, tokenizer = FastLanguageModel.from_pretrained("Qwen/Qwen2-0.5B-Instruct") | |
| + model = FastLanguageModel.get_peft_model(model) | |
| train_dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train") | |
| - training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10) | |
| + training_args = DPOConfig(output_dir="Qwen2-0.5B-DPO", logging_steps=10, bf16=True) | |
| trainer = DPOTrainer(model=model, args=training_args, processing_class=tokenizer, train_dataset=train_dataset) | |
| trainer.train() | |
| ``` | |
| The saved model is fully compatible with Hugging Face's transformers library. Learn more about unsloth in their [official repository](https://github.com/unslothai/unsloth). | |
| ## Reference model considerations with PEFT | |
| You have three main options (plus several variants) for how the reference model works when using PEFT, assuming the model that you would like to further enhance with DPO was tuned using (Q)LoRA. | |
| 1. Simply create two instances of the model, each loading your adapter - works fine but is very inefficient. | |
| 2. Merge the adapter into the base model, create another adapter on top, then leave the `ref_model` param null, in which case DPOTrainer will unload the adapter for reference inference - efficient, but has potential downsides discussed below. | |
| 3. Load the adapter twice with different names, then use `set_adapter` during training to swap between the adapter being DPO'd and the reference adapter - slightly less efficient compared to 2 (~adapter size VRAM overhead), but avoids the pitfalls. | |
| ### Downsides to merging QLoRA before DPO (approach 2) | |
| As suggested by [Benjamin Marie](https://medium.com/@bnjmn_marie/dont-merge-your-lora-adapter-into-a-4-bit-llm-65b6da287997), the best option for merging QLoRA adapters is to first dequantize the base model, then merge the adapter. Something similar to [this script](https://github.com/jondurbin/qlora/blob/main/qmerge.py). | |
| However, after using this approach, you will have an unquantized base model. Therefore, to use QLoRA for DPO, you will need to re-quantize the merged model or use the unquantized merge (resulting in higher memory demand). | |
| ### Using option 3 - load the adapter twice | |
| To avoid the downsides with option 2, you can load your fine-tuned adapter into the model twice, with different names, and set the model/ref adapter names in [`DPOTrainer`]. | |
| For example: | |
| ```python | |
| # Load the base model. | |
| bnb_config = BitsAndBytesConfig( | |
| load_in_4bit=True, | |
| llm_int8_threshold=6.0, | |
| llm_int8_has_fp16_weight=False, | |
| bnb_4bit_compute_dtype=torch.bfloat16, | |
| bnb_4bit_use_double_quant=True, | |
| bnb_4bit_quant_type="nf4", | |
| ) | |
| model = AutoModelForCausalLM.from_pretrained( | |
| "mistralai/mixtral-8x7b-v0.1", | |
| load_in_4bit=True, | |
| quantization_config=bnb_config, | |
| attn_implementation="flash_attention_2", | |
| torch_dtype=torch.bfloat16, | |
| device_map="auto", | |
| ) | |
| model.config.use_cache = False | |
| # Load the adapter. | |
| model = PeftModel.from_pretrained( | |
| model, | |
| "/path/to/peft", | |
| is_trainable=True, | |
| adapter_name="train", | |
| ) | |
| # Load the adapter a second time, with a different name, which will be our reference model. | |
| model.load_adapter("/path/to/peft", adapter_name="reference") | |
| # Initialize the trainer, without a ref_model param. | |
| training_args = DPOConfig( | |
| model_adapter_name="train", | |
| ref_adapter_name="reference", | |
| ) | |
| dpo_trainer = DPOTrainer( | |
| model, | |
| args=training_args, | |
| ... | |
| ) | |
| ``` | |
| ## DPOTrainer | |
| [[autodoc]] DPOTrainer | |
| ## DPOConfig | |
| [[autodoc]] DPOConfig | |
| ## DataCollatorForPreference | |
| [[autodoc]] trainer.dpo_trainer.DataCollatorForPreference | |