Spaces:
Running


Running
| # Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language | |
| ### CVPR 2024 | |
| [](https://aka.ms/denseav) [](https://arxiv.org/abs/2406.05629) [](https://colab.research.google.com/github/mhamilton723/DenseAV/blob/main/demo.ipynb) | |
| [](https://huggingface.co/spaces/mhamilton723/DenseAV) | |
| [//]: # ([](https://huggingface.co/papers/2403.10516)) | |
| [](https://paperswithcode.com/sota/speech-prompted-semantic-segmentation-on?p=separating-the-chirp-from-the-chat-self) | |
| [](https://paperswithcode.com/sota/sound-prompted-semantic-segmentation-on?p=separating-the-chirp-from-the-chat-self) | |
| [Mark Hamilton](https://mhamilton.net/), | |
| [Andrew Zisserman](https://www.robots.ox.ac.uk/~az/), | |
| [John R. Hershey](https://research.google/people/john-hershey/), | |
| [William T. Freeman](https://billf.mit.edu/about/bio) | |
| 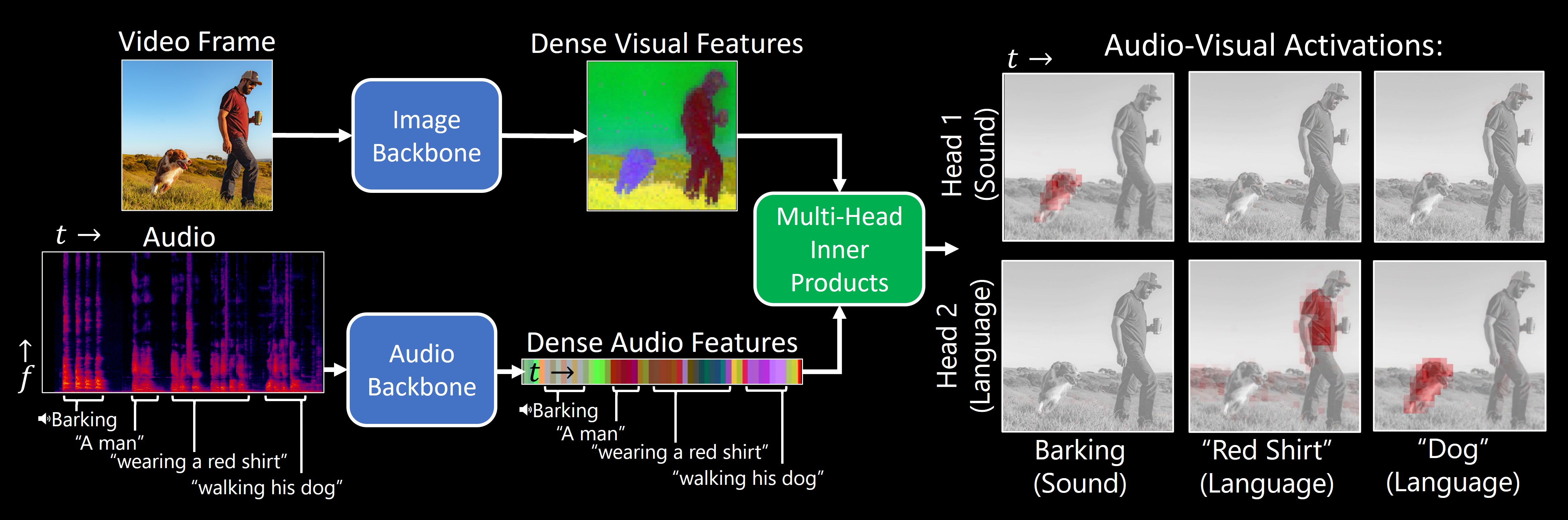 | |
| **TL;DR**:Our model, DenseAV, learns the meaning of words and the location of sounds (visual grounding) without supervision or text. | |
| https://github.com/mhamilton723/DenseAV/assets/6456637/ba908ab5-9618-42f9-8d7a-30ecb009091f | |
| ## Contents | |
| <!--ts--> | |
| * [Install](#install) | |
| * [Model Zoo](#model-zoo) | |
| * [Getting Datasets](#getting-atasets) | |
| * [Evaluate Models](#evaluate-models) | |
| * [Train a Model](#train-model) | |
| * [Local Gradio Demo](#local-gradio-demo) | |
| * [Coming Soon](coming-soon) | |
| * [Citation](#citation) | |
| * [Contact](#contact) | |
| <!--te--> | |
| ## Install | |
| To use DenseAV locally clone the repository: | |
| ```shell script | |
| git clone https://github.com/mhamilton723/DenseAV.git | |
| cd DenseAV | |
| pip install -e . | |
| ``` | |
| ## Model Zoo | |
| To see examples of pretrained model usage please see our [Collab notebook](https://colab.research.google.com/github/mhamilton723/DenseAV/blob/main/demo.ipynb). We currently supply the following pretrained models: | |
| | Model Name | Checkpoint | Torch Hub Repository | Torch Hub Name | | |
| |-------------------------------|----------------------------------------------------------------------------------------------------------------------------------|----------------------|--------------------| | |
| | Sound | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_sound.ckpt) | mhamilton723/DenseAV | sound | | |
| | Language | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_language.ckpt) | mhamilton723/DenseAV | language | | |
| | Sound + Language (Two Headed) | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_2head.ckpt) | mhamilton723/DenseAV | sound_and_language | | |
| For example, to load the model trained on both sound and language: | |
| ```python | |
| model = torch.hub.load("mhamilton723/DenseAV", 'sound_and_language') | |
| ``` | |
| ### Load from HuggingFace | |
| ```python | |
| from denseav.train import LitAVAligner | |
| model1 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound") | |
| model2 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-language") | |
| model3 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound-language") | |
| ``` | |
| ## Getting Datasets | |
| Our code assumes that all data lives in a common directory on your system, in these examples we use `/path/to/your/data`. Our code will often reference this directory as the `data_root` | |
| ### Speech and Sound Prompted ADE20K | |
| To download our new Speech and Sound prompted ADE20K Dataset: | |
| ```bash | |
| cd /path/to/your/data | |
| wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSoundPrompted.zip | |
| unzip ADE20KSoundPrompted.zip | |
| wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSpeechPrompted.zip | |
| unzip ADE20KSpeechPrompted.zip | |
| ``` | |
| ### Places Audio | |
| First download the places audio dataset from its [original source](https://groups.csail.mit.edu/sls/downloads/placesaudio/downloads.cgi). | |
| To run the code the data will need to be processed to be of the form: | |
| ``` | |
| [Instructions coming soon] | |
| ``` | |
| ### Audioset | |
| Because of copyright issues we cannot make [Audioset](https://research.google.com/audioset/dataset/index.html) easily availible to download. | |
| First download this dataset through appropriate means. [This other project](https://github.com/ktonal/audioset-downloader) appears to make this simple. | |
| To run the code the data will need to be processed to be of the form: | |
| ``` | |
| [Instructions coming soon] | |
| ``` | |
| ## Evaluate Models | |
| To evaluate a trained model first clone the repository for | |
| [local development](#local-development). Then run | |
| ```shell | |
| cd featup | |
| python evaluate.py | |
| ``` | |
| After evaluation, see the results in tensorboard's hparams tab. | |
| ```shell | |
| cd ../logs/evaluate | |
| tensorboard --logdir . | |
| ``` | |
| Then visit [https://localhost:6006](https://localhost:6006) and click on hparams to browse results. We report "advanced" speech metrics and "basic" sound metrics in our paper. | |
| ## Train a Model | |
| ```shell | |
| cd denseav | |
| python train.py | |
| ``` | |
| ## Local Gradio Demo | |
| To run our [HuggingFace Spaces hosted DenseAV demo](https://huggingface.co/spaces/mhamilton723/FeatUp) locally first install DenseAV for local development. Then run: | |
| ```shell | |
| python gradio_app.py | |
| ``` | |
| Wait a few seconds for the demo to spin up, then navigate to [http://localhost:7860/](http://localhost:7860/) to view the demo. | |
| ## Coming Soon: | |
| - Bigger models! | |
| ## Citation | |
| ``` | |
| @misc{hamilton2024separating, | |
| title={Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language}, | |
| author={Mark Hamilton and Andrew Zisserman and John R. Hershey and William T. Freeman}, | |
| year={2024}, | |
| eprint={2406.05629}, | |
| archivePrefix={arXiv}, | |
| primaryClass={cs.CV} | |
| } | |
| ``` | |
| ## Contact | |
| For feedback, questions, or press inquiries please contact [Mark Hamilton](mailto:[email protected]) | |