
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1167e23f4ae786445dca883c3bf5e163df73a531 | 1,753 | md | Markdown | structurizr-examples/src/com/structurizr/example/documentation/adr/0008-use-iso-8601-format-for-dates.md | gdubya/java | 2029a1de71d593c7e7a4c658016077f2a4212350 | [
"Apache-2.0"
] | 881 | 2015-01-13T06:07:02.000Z | 2022-03-30T20:53:47.000Z | structurizr-examples/src/com/structurizr/example/documentation/adr/0008-use-iso-8601-format-for-dates.md | gdubya/java | 2029a1de71d593c7e7a4c658016077f2a4212350 | [
"Apache-2.0"
] | 139 | 2015-02-10T12:17:38.000Z | 2022-03-05T11:06:04.000Z | structurizr-examples/src/com/structurizr/example/documentation/adr/0008-use-iso-8601-format-for-dates.md | gdubya/java | 2029a1de71d593c7e7a4c658016077f2a4212350 | [
"Apache-2.0"
] | 301 | 2015-01-01T10:37:14.000Z | 2022-03-25T14:00:53.000Z | # 8. Use ISO 8601 Format for Dates
Date: 2017-02-21
## Status
Accepted
## Context
`adr-tools` seeks to communicate the history of architectural decisions of a
project. An important component of the history is the time at which a decision
was made.
To communicate effectively, `adr-tools` should present information as
unambiguously as possible. That means that culture-neutral data formats should
be preferred over culture-specific formats.
Existing `adr-tools` deployments format dates as `dd/mm/yyyy` by default. That
formatting is common formatting in the United Kingdom (where the `adr-tools`
project was originally written), but is easily confused with the `mm/dd/yyyy`
format preferred in the United States.
The default date format may be overridden by setting `ADR_DATE` in `config.sh`.
## Decision
`adr-tools` will use the ISO 8601 format for dates: `yyyy-mm-dd`
## Consequences
Dates are displayed in a standard, culture-neutral format.
The UK-style and ISO 8601 formats can be distinguished by their separator
character. The UK-style dates used a slash (`/`), while the ISO dates use a
hyphen (`-`).
Prior to this decision, `adr-tools` was deployed using the UK format for dates.
After adopting the ISO 8601 format, existing deployments of `adr-tools` must do
one of the following:
* Accept mixed formatting of dates within their documentation library.
* Update existing documents to use ISO 8601 dates by running `adr upgrade-repository`
---
This Architecture Decision Record (ADR) was written by Nat Pryce as a part of [adr-tools](https://github.com/npryce/adr-tools), and is reproduced here under the [Creative Commons Attribution 4.0 International (CC BY 4.0) license](https://creativecommons.org/licenses/by/4.0/). | 38.108696 | 276 | 0.77182 | eng_Latn | 0.997233 |
116881b36e85f89366304f584ba769305d00d68b | 9,137 | md | Markdown | docs/lecture_07/Lecture_7.3.md | ClimateCompatibleGrowth/nismod_teaching_kit | da9b334a9736970fb11ef8f6fe9c663a4ddda672 | [
"CC-BY-4.0"
] | 1 | 2021-08-09T13:00:56.000Z | 2021-08-09T13:00:56.000Z | docs/lecture_07/Lecture_7.3.md | ClimateCompatibleGrowth/nismod_teaching_kit | da9b334a9736970fb11ef8f6fe9c663a4ddda672 | [
"CC-BY-4.0"
] | 5 | 2021-08-13T07:16:28.000Z | 2021-12-16T09:24:59.000Z | docs/lecture_07/Lecture_7.3.md | ClimateCompatibleGrowth/nismod_teaching_kit | da9b334a9736970fb11ef8f6fe9c663a4ddda672 | [
"CC-BY-4.0"
] | 1 | 2022-01-26T11:06:53.000Z | 2022-01-26T11:06:53.000Z | ---
title: Mini-Lecture 7.3 -- Methods for decision making under uncertainty
keywords:
- Decision making under deep uncertainty
- Exploratory analysis
- Adaptive planning
authors:
- Orlando Roman
---
In this mini-lecture we will describe the most classical methods for
decision-making under deep uncertainty (DMDU), looking at their
applicability and differences.
# Learning objectives
- List and describe some DMDU methods
- Explain when a particular method is preferred.
# Introduction
One typical approach to address uncertain problems is through the
evaluation of scenarios as explorations of plausible futures, where
sensitivity analyses are carried out on the inputs to see the
consequences in the outputs. However, evaluating a deeply uncertain
future through a traditional scenario technique has important
challenges:
- In complex systems, it is difficult to clearly visualise the
relationship between inputs and outputs. These are often non-linear,
with regions of extreme sensitivity to particular assumptions, and
threshold points that are difficult to identify.
- The number of possible scenarios that can be analysed are limited,
even for visualisation purposes, so instead a small number of
plausible alternatives tends to be evaluated, and only those that
are believed to contain the most important uncertainties are taken
into account. Normally, the entire spectrum of the problem cannot be
evaluated.
- It is difficult to establish monitoring criteria, decision rules or
triggering points for decision-making, as these rely on how the
future unfolds.
Hence, in the face of deep uncertainty, the decision-making community is
using innovative decision support methods. These tools combine creative
thinking of scenario techniques, the capabilities of stress testing and
the deliberative process of decision-making in a systematised fashion,
thus reducing possible biases. The most commonly used methods will be
described in this mini-lecture.
# Exploratory analysis
One of the first decision-making under deep uncertainty (DMDU) tools,
and the basis of the most recent approaches, is the so-called
"Exploratory Analysis", which is a wide exploration of many alternative
scenarios [@Bankes1993] opening up a range of plausible future
states. Figure 7.3.1 shows different approaches for analysing future
scenarios. The normative approach is based on the best forecast, while
the predictive approach intends to account for variability in the future
state. On the other hand, the exploratory approach takes a wider look
into the future alternatives asking "what if" questions and evaluating
all plausible alternatives. Therefore, the exploration of potential
futures might guide the decision-making process by finding
vulnerabilities and best strategies. In principle, when the future
proves hard to predict, plans ought to be robust and flexible
[@Lempert2019]. One approach is to evaluate this set of future states
to identify robust decisions in the present, that is, decisions that
work well whatever the future may be. A second, and complementary
approach, is to identify decision points to adapt over time, encouraging
flexibility for uncertainty management.
{width=100%}
**Figure 7.3.1:** Types of future scenario approaches [@McGowan2019]
Some open source tools have been created with this purpose, such as the
Exploratory Modelling Analysis (EMA) Workbench [@Kwakkel2017]. This
tool has the capability of connecting any model created in different
programming languages and softwares, such as Vensim or Excel, to perform
computational experiments and deal with uncertainty. The main purpose of
the analysis is to find regions of sensitivity, grouping and
classification of future states or optimisation of strategies under
uncertainty.
# Robust decision-making (RDM)
Robust decision-making (RDM) is a method that uses analytics to perform
an exploratory model allowing the evaluation of hundreds of alternative
strategies, uncertainties and possible futures [@Groves2007]. RDM
starts by proposing possible strategies which are then evaluated against
different possible futures, checking vulnerabilities and generating
feedback loops to build even better strategies.
{width=100%}
**Figure 7.3.2:** Iterative steps in RDM [@Lempert2019]
Figure 7.3.2 shows the steps of the process:
1. First, 'decision framing' is where stakeholders identify the
alternatives, uncertainties and performance indicators they wish to
evaluate (wider range).
2. Second, 'evaluate strategy across futures' is a systematic
development of the entire spectrum of possible scenarios, generating
a range of futures, against which the performance of the originally
proposed alternatives will be evaluated.
3. Third, 'vulnerability analysis' is where data mining and machine
learning algorithms are used to identify the vulnerabilities of each
alternative, which allow modification or unifying alternatives, thus
creating new ones. This feedback loop is the most creative process
and where the method generates the most value.
4. Fourth, 'trade-off analysis' is where the different alternatives
generated are compared based on their performance, such as their
robustness (best in most futures), regrets (the difference between
the chosen and the optimal solution) or others identified. This step
allows a transparent decision-making process for the different
stakeholders.
5. Lastly, based on the results, the process allows to develop new
futures and strategies to be evaluated in a new round of analysis.
The RDM method allows iteration and learning in each round of analysis
until a satisfactory robust strategy is found.
# Real/engineering options analysis
The previous methods exploit concepts such as the exploration of futures
and robustness. In contrast, Real Options Analysis [@deNeufville2011]
maintains the exploratory approach and focuses on flexibility -- the
capability to adapt over time -- which is also used in the Dynamic
Adaptive Planning approach, described in the next section.
In the treatment of uncertainty, the Real or Engineering Options
methodology is able to explore technical alternatives (such as the size,
height or capacities) with more depth than other DMDU methods
[@deNeufville2019]. Therefore, this methodology is well suited for
evaluating individual engineering projects under uncertainty. Real
Options assumes that adding flexibility has a cost (e.g. building a
power plant with the ability to be expanded is more costly than not) and
intends to estimate the value of flexibility under future uncertainty.
This means, it estimates if the benefit of the added flexibility is
worth the cost, given future uncertainty.
Figure 7.3.3 shows the results of 1,000 simulations under different
climatological and physical variables. The results computed how many
times an expansion of desalination capacity was needed over the lifetime
of the project. Therefore, the likeliness and timing of potential
expansion can be evaluated by the decision-maker.
{width=100%}
**Figure 7.3.3:** Distribution of desalination capacity added over 1,000
simulations [@Fletcher2019]
# Dynamic Adaptive Planning
The RDM and Real Options methods can be complemented very well with the
dynamic adaptive approach [@Kwakkel2016]. While the RDM method allows
understanding of the functioning of systems, identifies vulnerabilities
and allows a transparent comparison between the options, adaptive
planning emphasises dynamic adaptation over time.
Figure 7.3.4 shows a simple example of an adaptive pathway applied to
long-term planning, where there are four possible strategies: A, B, C
and D. The Figure shows the concept of tipping points: where the
strategies are no longer satisfactory, a new course of action is
required.
{width=100%}
**Figure 7.3.4:** Adaptation pathways map [@Haasnoot2013]
For instance, Actions A and D are effective in the long term (usually
these are expensive alternatives or with negative impacts on other
fronts). However, if one chooses Action B, it will become necessary to
change strategy after 10 years (e.g. due to increased demand), this
being a tipping point where the strategy is no longer satisfactory. The
same happens with Action C, which needs to be changed in the long term
because a tipping point will also be reached (e.g. due to climate
change).
In this way, different possible pathways can be generated embedding
flexibility that allows adaptation over time to other, better
strategies. In practice, the estimation of tipping points or adaptation
triggers is not easy but can be obtained [@Hall2019].
# Summary
In this mini-lecture we explained the need of more sophisticated methods
when facing complex systems and a huge range of possible scenarios. Then
we described four of the most used methods in practice: exploratory
analysis, robust decision making (RDM), real/engineering options and
dynamic adaptive pathways.
| 46.146465 | 72 | 0.801138 | eng_Latn | 0.99938 |
1168e91176ed6d9902769085fdcf41dad07cb040 | 1,288 | md | Markdown | src/vision/applications.md | carllerche/wg-async-foundations | d93fcde413e96a4b3fc11cc9679fd027c9db71da | [
"Apache-2.0",
"MIT"
] | null | null | null | src/vision/applications.md | carllerche/wg-async-foundations | d93fcde413e96a4b3fc11cc9679fd027c9db71da | [
"Apache-2.0",
"MIT"
] | null | null | null | src/vision/applications.md | carllerche/wg-async-foundations | d93fcde413e96a4b3fc11cc9679fd027c9db71da | [
"Apache-2.0",
"MIT"
] | null | null | null | # ⚡ Applications
## What is this
This section describes the kinds of projects that people build using Async Rust. As you can see, there are quite a few, and we're surely missing some! For each application area, we also have a short description and some frequently asked questions that help to identify what makes this application area special.
## Application areas
* [Operating systems](./applications/os.md)
* [Embedded devices](./applications/embedded.md)
### Don't find your application here?
We just started creating this list, and it's obviously very incomplete. We would welcome PRs to flesh it out! Here is a list of applications we came up with when brainstorming that may be useful:
- Web site
- High performance server
- High performance disk I/O
- Web framework
- Protocol or other leaf libraries (e.g., HTTP, QUIC, Redis, etc)
- SDKs for web services
- Middleware and other sorts of "wrapper" libraries (e.g., async-compression)
- Media streaming
- Consumer of web services (e.g., running things on a compute service, storing and retrieving things with a storage service)
- Embedded
- GUI application
- Parallel data processing
- Distributed HPC (compute clusters)
- Database clients
- Database servers
- Async runtimes for others to use
- Operating systems
- More?
| 36.8 | 311 | 0.767081 | eng_Latn | 0.99802 |
11691da6eff490796fc54d1fd041d344d112f671 | 4,850 | md | Markdown | docs/framework/wcf/feature-details/security-concepts-used-in-wcf.md | yunuskorkmaz/docs.tr-tr | e73dea6e171ca23e56c399c55e586a61d5814601 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/security-concepts-used-in-wcf.md | yunuskorkmaz/docs.tr-tr | e73dea6e171ca23e56c399c55e586a61d5814601 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/security-concepts-used-in-wcf.md | yunuskorkmaz/docs.tr-tr | e73dea6e171ca23e56c399c55e586a61d5814601 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
description: "Hakkında daha fazla bilgi edinin: WCF 'de kullanılan güvenlik kavramları"
title: WCF'de Kullanılan Güvenlik Kavramları
ms.date: 03/30/2017
ms.assetid: 3b9dfcf5-4bf1-4f35-9070-723171c823a1
ms.openlocfilehash: 5ad5b80c69e5dec5675879984fbcd2585b295dd4
ms.sourcegitcommit: ddf7edb67715a5b9a45e3dd44536dabc153c1de0
ms.translationtype: MT
ms.contentlocale: tr-TR
ms.lasthandoff: 02/06/2021
ms.locfileid: "99779770"
---
# <a name="security-concepts-used-in-wcf"></a>WCF'de Kullanılan Güvenlik Kavramları
Windows Communication Foundation (WCF) güvenliği, daha önce kullanılan ve çeşitli güvenlik altyapılarında dağıtılan kavramlar üzerine kurulmuştur.
WCF, HTTP (HTTPS) üzerinde Güvenli Yuva Katmanı (SSL) gibi bazı altyapıların bazılarını destekler. Ancak, WCF, SOAP kodlu iletiler üzerinden daha yeni birlikte çalışabilen güvenlik standartları (WS-Security gibi) uygulayarak mevcut güvenlik altyapılarını desteklemeye daha fazla yardımcı vardır. Mevcut mekanizmalar veya yeni birlikte çalışabilen standartlar kullanıyor olmanız durumunda, her ikisinin de her ikisi de aynı olan güvenlik kavramlarıdır. Mevcut altyapıların arkasındaki kavramları ve daha yeni standartları anlamak, bir uygulama için en iyi güvenlik modelini uygulamaya yönelik bir merkezidir.
## <a name="introduction-to-security-for-wcf-web-services"></a>WCF Web Hizmetleri güvenliğine giriş
Microsoft düzenleri ve uygulamalar grubu, [WCF güvenlik kılavuzu](https://archive.codeplex.com/?p=wcfsecurityguide)adlı bir ayrıntılı teknik incelemeyi yazdı. Bu Teknik İnceleme, Web Hizmetleri, anahtar WCF güvenlik kavramları, intranet uygulama senaryoları ve Internet uygulaması senaryolarıyla bağlantılı olarak temel güvenlik kavramlarını açıklamaktadır.
## <a name="industry-wide-security-specifications"></a>Industry-Wide güvenlik belirtimleri
### <a name="public-key-infrastructure"></a>Ortak anahtar altyapısı
Ortak anahtar altyapısı (PKI), genel anahtar şifrelemesi kullanılarak elektronik bir işlemde yer alan her bir tarafı doğrulayan ve kimlik doğrulayan dijital sertifikalar, sertifika yetkilileri ve diğer kayıt yetkilileri sistemidir.
### <a name="kerberos-protocol"></a>Kerberos protokolü
*Kerberos protokolü* , bir Windows etki alanında kullanıcıların kimliğini doğrulayan bir güvenlik mekanizması oluşturmaya yönelik bir belirtimdir. Bir kullanıcının etki alanı içindeki diğer varlıklarla güvenli bir bağlam kurmasını sağlar. Windows 2000 ve üzeri platformlar Kerberos protokolünü varsayılan olarak kullanır. Sistem mekanizmalarını anlamak, intranet istemcilerle etkileşime girebilen bir hizmet oluştururken faydalıdır. Bunlara ek olarak, *Web Hizmetleri güvenliği Kerberos bağlama* yaygın olarak yayınlandığından, Internet istemcileriyle iletişim kurmak için Kerberos protokolünü kullanabilirsiniz (yani, Kerberos protokolü birlikte kullanılabilir). Windows 'da Kerberos protokolünün nasıl uygulandığı hakkında daha fazla bilgi için bkz. [Microsoft Kerberos](/windows/win32/secauthn/microsoft-kerberos).
### <a name="x509-certificates"></a>X. 509.440 sertifikaları
X. 509.440 sertifikaları, güvenlik uygulamalarında kullanılan birincil kimlik bilgileri biçimidir. X. 509.440 sertifikaları hakkında daha fazla bilgi için bkz. [x. 509.440 ortak anahtar sertifikaları](/windows/win32/seccertenroll/about-x-509-public-key-certificates). X. 509.440 sertifikaları bir sertifika deposunda depolanır. Windows çalıştıran bir bilgisayarda, her biri farklı bir amaca sahip birkaç tür sertifika deposu vardır. Farklı mağazalar hakkında daha fazla bilgi için bkz. [sertifika depoları](/previous-versions/windows/it-pro/windows-server-2003/cc757138(v=ws.10)).
## <a name="web-services-security-specifications"></a>Web Hizmetleri Güvenliği belirtimleri
Sistem tanımlı bağlamalar, yaygın olarak kullanılan birçok Web hizmeti güvenlik belirtimini destekler. Sistem tarafından sağlanmış bağlamaların ve destekledikleri Web hizmeti belirtimlerinin tam listesi için bkz. [System-Provided birlikte çalışabilirlik bağlamaları tarafından desteklenen Web Hizmetleri protokolleri](web-services-protocols-supported-by-system-provided-interoperability-bindings.md)
## <a name="access-control-mechanisms"></a>Erişim Denetimi Mekanizmaları
WCF, bir hizmet veya işleme erişimi denetlemek için çeşitli yollar sağlar. Aralarında
1. <xref:System.Security.Permissions.PrincipalPermissionAttribute>
2. ASP.NET üyelik sağlayıcısı
3. ASP.NET rol sağlayıcısı
4. Yetkilendirme Yöneticisi
5. Kimlik modeli
Bu konular hakkında daha fazla bilgi için bkz. [Access Control mekanizmaları](access-control-mechanisms.md)
## <a name="see-also"></a>Ayrıca bkz.
- [Güvenliğe genel bakış](security-overview.md)
- [Windows Server App Fabric için güvenlik modeli](/previous-versions/appfabric/ee677202(v=azure.10))
| 79.508197 | 821 | 0.813608 | tur_Latn | 0.999614 |
116958f2f57140cbbcf5ab0cdb7ce822939e4270 | 144 | md | Markdown | _posts/0000-01-02-erinB1101.md | erinB1101/github-slideshow | 3e9b2152a087f6c40d9c9e6b03dd942180417b7d | [
"MIT"
] | null | null | null | _posts/0000-01-02-erinB1101.md | erinB1101/github-slideshow | 3e9b2152a087f6c40d9c9e6b03dd942180417b7d | [
"MIT"
] | 3 | 2021-01-23T05:22:56.000Z | 2021-01-23T06:00:26.000Z | _posts/0000-01-02-erinB1101.md | erinB1101/github-slideshow | 3e9b2152a087f6c40d9c9e6b03dd942180417b7d | [
"MIT"
] | null | null | null | ---
layout: slide
title: "Welcome to our second slide!"
---
edit file button is on the right top of this section
Use the left arrow to go back!
| 20.571429 | 52 | 0.722222 | eng_Latn | 0.99976 |
1169da11bde82abd2f8a1a11e1347479d2f3e46a | 72 | md | Markdown | src/apis/NativeEventEmitter.md | withmikrav/reason-react-native | 529d1f2b92aebf1c20fd436614f99b93fd4cd6e5 | [
"MIT"
] | null | null | null | src/apis/NativeEventEmitter.md | withmikrav/reason-react-native | 529d1f2b92aebf1c20fd436614f99b93fd4cd6e5 | [
"MIT"
] | null | null | null | src/apis/NativeEventEmitter.md | withmikrav/reason-react-native | 529d1f2b92aebf1c20fd436614f99b93fd4cd6e5 | [
"MIT"
] | null | null | null | ---
id: apis/NativeEventEmitter
title: NativeEventEmitter
wip: true
---
| 12 | 27 | 0.75 | dan_Latn | 0.247743 |
116a1524e996ec35b89e82695cd2461ddcaccd86 | 1,065 | md | Markdown | api/PowerPoint.AddIn.Loaded.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/PowerPoint.AddIn.Loaded.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | api/PowerPoint.AddIn.Loaded.md | ryanmajidi/VBA-Docs | 8b07050f4ff38fcabda606284ec5f6f6634e9569 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: AddIn.Loaded Property (PowerPoint)
keywords: vbapp10.chm521008
f1_keywords:
- vbapp10.chm521008
ms.prod: powerpoint
api_name:
- PowerPoint.AddIn.Loaded
ms.assetid: 8becb17d-dbe4-b151-e66b-3463f3a862f5
ms.date: 06/08/2017
---
# AddIn.Loaded Property (PowerPoint)
Determines whether the specified add-in is loaded. Read/write.
## Syntax
_expression_. `Loaded`
_expression_ A variable that represents an [AddIn](./PowerPoint.AddIn.md) object.
## Return value
MsoTriState
## Remarks
The value of the **Loaded** property can be one of these **MsoTriState** constants.
|Constant|Description|
|:-----|:-----|
|**msoFalse**|TThe specified add-in is not loaded. |
|**msoTrue**| The specified add-in is loaded.|
## Example
This example adds MyTools.ppa to the list in the **Add-Ins** tab and then loads it.
```vb
Addins.Add("c:\my documents\mytools.ppa").Loaded = msoTrue
```
This example unloads the add-in named "MyTools."
```vb
Application.Addins("mytools").Loaded = msoFalse
```
## See also
[AddIn Object](PowerPoint.AddIn.md)
| 16.136364 | 84 | 0.714554 | eng_Latn | 0.900966 |
116a228bb3410a09855085a5bdddc5accb31d35b | 5,944 | md | Markdown | docs/ide/deploying-visual-cpp-application-by-using-the-vcpp-redistributable-package.md | anmrdz/cpp-docs.es-es | f3eff4dbb06be3444820c2e57b8ba31616b5ff60 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ide/deploying-visual-cpp-application-by-using-the-vcpp-redistributable-package.md | anmrdz/cpp-docs.es-es | f3eff4dbb06be3444820c2e57b8ba31616b5ff60 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/ide/deploying-visual-cpp-application-by-using-the-vcpp-redistributable-package.md | anmrdz/cpp-docs.es-es | f3eff4dbb06be3444820c2e57b8ba31616b5ff60 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Implementar una aplicación mediante el paquete redistribuible (C++) | Microsoft Docs
ms.custom: ''
ms.date: 09/17/2018
ms.technology:
- cpp-ide
ms.topic: conceptual
dev_langs:
- C++
helpviewer_keywords:
- walkthrough, deploying a Visual C++ application by using the redistributable package
ms.assetid: e59becbf-b8c6-4c8e-bab3-b69cc1ed3e5e
author: corob-msft
ms.author: corob
ms.workload:
- cplusplus
ms.openlocfilehash: 9759811554fd0998a919c9939a0441c63c26a3f8
ms.sourcegitcommit: 338e1ddc2f3869d92ba4b73599d35374cf1d5b69
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 09/20/2018
ms.locfileid: "46494353"
---
# <a name="walkthrough-deploying-a-visual-c-application-by-using-the-visual-c-redistributable-package"></a>Tutorial: Implementar una aplicación de Visual C++ mediante el paquete redistribuible de Visual C++
En este artículo paso a paso se describe cómo usar el paquete redistribuible de Visual C++ para implementar una aplicación de Visual C++.
## <a name="prerequisites"></a>Requisitos previos
Para completar este tutorial, debe tener estos componentes:
- Un equipo con Visual Studio instalado.
- Un equipo adicional que no tenga las bibliotecas de Visual C++.
### <a name="to-use-the-visual-c-redistributable-package-to-deploy-an-application"></a>Para usar el paquete redistribuible de Visual C++ para implementar una aplicación
1. Cree y compile una aplicación MFC siguiendo los pasos de [Tutorial: Implementar una aplicación de Visual C++ mediante un proyecto de instalación](walkthrough-deploying-a-visual-cpp-application-by-using-a-setup-project.md).
1. Cree un archivo, denomínelo setup.bat y agréguele los comandos siguientes. Cambie `MyMFCApplication` por el nombre del proyecto.
```cmd
@echo off
vcredist_x86.exe
mkdir "C:\Program Files\MyMFCApplication"
copy MyMFCApplication.exe "C:\Program Files\MyMFCApplication"
```
1. Cree un archivo de instalación autoextraíble:
1. En un símbolo del sistema o en la ventana **Ejecutar**, ejecute iexpress.exe.
1. Seleccione **Crear un nuevo archivo Self Extraction Directive** y, después, haga clic en el botón **Siguiente**.
1. Seleccione **Extract files and run an installation command** (Extraer los archivos y ejecutar un comando de instalación) y, después, haga clic en el botón **Siguiente**.
1. En el cuadro de texto, escriba el nombre de la aplicación MFC y, después, haga clic en el botón **Siguiente**.
1. En la página **Pregunta de confirmación**, seleccione **No preguntar** y, después, haga clic en el botón **Siguiente**.
1. En la página **Contrato de licencia**, seleccione **Do not display a license** (No mostrar una licencia) y, después, haga clic en **Siguiente**.
1. En la página **Archivos del paquete**, agregue los archivos siguientes y, después, haga clic en **Siguiente**.
- La aplicación MFC (archivo .exe).
- vcredist_x86.exe. Este archivo se encuentra en \Archivos de programa (x86)\Microsoft Visual Studio \<versión>\SDK\Bootstrapper\Packages\. También puede descargar este archivo desde [Microsoft](https://www.microsoft.com/download/confirmation.aspx?id=5555).
- El archivo setup.bat que creó en el paso anterior.
1. En la página **Install Program to Launch** (Programa de instalación para iniciar), en el cuadro de texto **Programa de instalación**, escriba la línea de comandos siguiente y, después, haga clic en **Siguiente**.
**cmd.exe /c "setup.bat"**
1. En la página **Mostrar ventana**, Seleccione **Predeterminada** y, después, haga clic en **Siguiente**.
1. En la página **Finished message** (Mensaje finalizado), seleccione **Sin mensaje** y, después, haga clic en **Siguiente**.
1. En la página **Package Name and Options** (Nombre y opciones del paquete), escriba un nombre para el archivo de instalación autoextraíble, seleccione la opción **Store files using Long File Name inside Package** (Almacenar los archivos con el nombre de archivo largo dentro del paquete) y, después, haga clic en **Siguiente**. El final del nombre de archivo debe ser Setup.exe; por ejemplo, *MyMFCApplicationSetup.exe*.
1. En la página **Configure restart** (Configurar reinicio), seleccione **No restart** (Sin reinicio) y, después, haga clic en **Siguiente**.
1. En la página **Save Self Extraction Directive** (Guardar directiva de extracción automática), seleccione **Save Self Extraction Directive (SED) file** (Guardar archivo de directiva de extracción automática [SED]) y, después, haga clic en **Siguiente**.
1. En la página **Crear paquete**, haga clic en **Siguiente**. Elija **Finalizar**.
1. Pruebe el archivo de instalación autoextraíble en el otro equipo, que no tiene las bibliotecas de Visual C++:
1. En el otro equipo, descargue una copia del archivo de instalación y, después, ejecútelo para instalarlo y siga los pasos que proporciona. Según las opciones seleccionadas, la instalación podría requerir el comando **Ejecutar como administrador**.
1. Ejecute la aplicación MFC.
El archivo de instalación autoextraíble instala la aplicación MFC que se encuentra en la carpeta que especificó en el paso 2. La aplicación se ejecuta correctamente porque el instalador del paquete redistribuible de Visual C++ se incluye en el archivo de instalación autoextraíble.
> [!IMPORTANT]
> Para determinar qué versión del tiempo de ejecución está instalada, el programa de instalación comprueba la clave del Registro \HKLM\SOFTWARE\Microsoft\VisualStudio\\\<versión>\VC\Runtimes\\<platform>. Si la versión instalada actualmente es más reciente que la que el programa de instalación está intentando instalar, el programa de instalación devuelve un valor correcto sin instalar la versión anterior y deja una entrada adicional en la página de programas instalados del Panel de Control.
## <a name="see-also"></a>Vea también
[Ejemplos de implementación](deployment-examples.md)<br/>
| 58.851485 | 500 | 0.758244 | spa_Latn | 0.976409 |
116a848107495a0cff83cbc4ba69e6c43967617e | 1,893 | md | Markdown | doc/Windows-build-instructions-README.md | mammix2/spectre | d65b3d5e93e3aa00525b0bcf827b7d7850ad1c48 | [
"MIT"
] | null | null | null | doc/Windows-build-instructions-README.md | mammix2/spectre | d65b3d5e93e3aa00525b0bcf827b7d7850ad1c48 | [
"MIT"
] | null | null | null | doc/Windows-build-instructions-README.md | mammix2/spectre | d65b3d5e93e3aa00525b0bcf827b7d7850ad1c48 | [
"MIT"
] | null | null | null | SpectreCoin Building from source for Windows (XSPEC)
====================================================
Install MSVC 2017 and Qt SDK (Pick MSVC 64 bit and QtWebEngine)
------------
- Visual studio: https://www.visualstudio.com/downloads/
- Qt SDK: https://www.qt.io/download-qt-installer
Here is the components from Qt SDK that we really need to compile our application (Keep Qt creator selected as well). If MingW is ticked you may untick that (Unless you need it for other projects)

Once you install Visual studio. Go to Windows start menu and find "Visual studio installer"
Modify visual studio and make sure all those components are picked.

Easy (Prebuilt libs)
--------------------
Since quit many of our users found it hard to compile. Especially on Windows. We are adding an easy way and provided prebuilt package for all the libraries required to compile Spectre wallet. Go ahead and download all the libraries from the following link:
https://github.com/spectrecoin/spectre/releases/download/v1.4.0-alpha/Prebuild.Spectre.libraries.zip
Clone Spectre source. You can simply download a “Zip” from github.
Now unzip Prebuild Spectre libraries.zip that you just downloaded into the source root folder. Once done properly you should end up with “src”, “packages64bit” and “tor” all into one folder. Here is a screenshot of how it looks like after all the files are living together in the same folder.

Now go ahead and open a the file src/src.pro (It should open up with Qt Creator). Make sure our MSVC 64 bit compiler is selected. Click configure and build and run as usual with Qt.
| 48.538462 | 292 | 0.749604 | eng_Latn | 0.981535 |
116ac7778cc36d0c5a6a8212206b93573e8a82cf | 144 | md | Markdown | docs/get-started/setup-developer-env.md | mattias-kindborg-at-work/acap-documentation | 2826b4c493a1813827fc116beebce21dd06bfbd0 | [
"FSFAP"
] | 4 | 2021-09-30T10:03:16.000Z | 2021-11-17T13:58:08.000Z | docs/get-started/setup-developer-env.md | mattias-kindborg-at-work/acap-documentation | 2826b4c493a1813827fc116beebce21dd06bfbd0 | [
"FSFAP"
] | 16 | 2021-11-17T09:30:19.000Z | 2022-03-30T15:22:51.000Z | docs/get-started/setup-developer-env.md | mattias-kindborg-at-work/acap-documentation | 2826b4c493a1813827fc116beebce21dd06bfbd0 | [
"FSFAP"
] | 2 | 2021-11-17T09:09:06.000Z | 2022-02-28T12:56:35.000Z | ---
layout: default
parent: Get started
title: Set up developer environment
has_children: true
nav_order: 1
---
# Set up developer environment
| 14.4 | 35 | 0.763889 | eng_Latn | 0.980957 |
116b787dd817987405b4a3852818966501f4cc8c | 75 | md | Markdown | README.md | gabygarro/FESTECBot | b00ea1a8d656c9eaed2a8a4f2c8c057fca11f4cc | [
"MIT"
] | null | null | null | README.md | gabygarro/FESTECBot | b00ea1a8d656c9eaed2a8a4f2c8c057fca11f4cc | [
"MIT"
] | null | null | null | README.md | gabygarro/FESTECBot | b00ea1a8d656c9eaed2a8a4f2c8c057fca11f4cc | [
"MIT"
] | null | null | null | # FESTECBot
Código de @FESTECBot en Telegram. Construido con @bot-brother.
| 25 | 62 | 0.786667 | spa_Latn | 0.90968 |
116bc8df0fca5cf6cf2b36ce621caa7c16d81604 | 2,012 | md | Markdown | source/includes/_futures_rest_prv_tx_history.md | bithumbfutures/bithumb-futures-api-doc | b683dccb713cf677f9c5de633e05b5ae25d54cad | [
"Apache-2.0"
] | null | null | null | source/includes/_futures_rest_prv_tx_history.md | bithumbfutures/bithumb-futures-api-doc | b683dccb713cf677f9c5de633e05b5ae25d54cad | [
"Apache-2.0"
] | 4 | 2020-02-26T11:41:47.000Z | 2021-05-20T12:49:28.000Z | source/includes/_futures_rest_prv_tx_history.md | bithumbfutures/bithumb-futures-api-doc | b683dccb713cf677f9c5de633e05b5ae25d54cad | [
"Apache-2.0"
] | null | null | null | ### Transactions History
> Sample Resonse
```json
{
"code": 0,
"data": {
"data": [
{
"time": 1574640000000,
"asset": "BTC",
"amount": "-0.129",
"txType": "Takeover",
"status": "SUCCESS",
"requestId": "09naslvPvsSLxl9A"
}
],
"hasNext": false,
"page": 1,
"pageSize": 10
}
}
```
#### Permissions
You need view permission to access this API.
#### HTTP Request
`GET /api/pro/v1/futures/tx-history`
#### Signature
You should sign the message in header as specified in [**Authenticate a RESTful Request**](#sign-a-request) section.
#### Prehash String
`<timestamp>+futures/tx-history`
#### HTTP Parameters
Name | Type | Required | Value Range | Description
------------ | ------ | -------- | ------------------------------ |---------------
**page** | `Int` | No | page number, starting from 1 |
**pageSize** | `Int` | No | page size, must be positive |
#### Response
This API returns paginated data.
Name | Type | Description
--------------- | -------- | --------------
**time** | `Long` | UTC timestamp in milliseconds
**asset** | `String` | asset code, e.g. `BTC`
**amount** | `String` | changed amount
**txType** | `String` | transaction type, such as PositionInjection, Takeover, etc
**status** | `String` | SUCCESS / FAIED
**requestId** | `String` | A unique identifier for this balance change event
Currently, there are four possible values for **status**:
* `Takeover`
* `CollateralConversion`
* `PositionInjection`
* `PositionInjectionBLP`
#### Code Sample
Please refer to python code to [get open orders](https://github.com/bithumbfutures/bithumb-futures-api-demo/blob/master/python/query-futures-tx-history.py)
| 26.826667 | 156 | 0.510934 | eng_Latn | 0.479931 |
116d30b2cd045b9a768dd48e4817d3e4a5f3c9a1 | 4,508 | md | Markdown | docs/interfaces/paymentinitializeoptions.md | pedroterriquez95/checkout-sdk-js | 36d46a807b75bfe2dca8670b4f6cf947193a6152 | [
"MIT"
] | null | null | null | docs/interfaces/paymentinitializeoptions.md | pedroterriquez95/checkout-sdk-js | 36d46a807b75bfe2dca8670b4f6cf947193a6152 | [
"MIT"
] | null | null | null | docs/interfaces/paymentinitializeoptions.md | pedroterriquez95/checkout-sdk-js | 36d46a807b75bfe2dca8670b4f6cf947193a6152 | [
"MIT"
] | null | null | null | [@bigcommerce/checkout-sdk](../README.md) > [PaymentInitializeOptions](../interfaces/paymentinitializeoptions.md)
# PaymentInitializeOptions
## Type parameters
#### TParams
## Hierarchy
↳ [PaymentRequestOptions](paymentrequestoptions.md)
**↳ PaymentInitializeOptions**
## Index
### Properties
* [adyenv2](paymentinitializeoptions.md#adyenv2)
* [amazon](paymentinitializeoptions.md#amazon)
* [bluesnapv2](paymentinitializeoptions.md#bluesnapv2)
* [braintree](paymentinitializeoptions.md#braintree)
* [braintreevisacheckout](paymentinitializeoptions.md#braintreevisacheckout)
* [chasepay](paymentinitializeoptions.md#chasepay)
* [creditCard](paymentinitializeoptions.md#creditcard)
* [gatewayId](paymentinitializeoptions.md#gatewayid)
* [googlepayadyenv2](paymentinitializeoptions.md#googlepayadyenv2)
* [googlepayauthorizenet](paymentinitializeoptions.md#googlepayauthorizenet)
* [googlepaybraintree](paymentinitializeoptions.md#googlepaybraintree)
* [googlepaystripe](paymentinitializeoptions.md#googlepaystripe)
* [klarna](paymentinitializeoptions.md#klarna)
* [klarnav2](paymentinitializeoptions.md#klarnav2)
* [masterpass](paymentinitializeoptions.md#masterpass)
* [methodId](paymentinitializeoptions.md#methodid)
* [params](paymentinitializeoptions.md#params)
* [paypalexpress](paymentinitializeoptions.md#paypalexpress)
* [square](paymentinitializeoptions.md#square)
* [stripev3](paymentinitializeoptions.md#stripev3)
* [timeout](paymentinitializeoptions.md#timeout)
---
## Properties
<a id="adyenv2"></a>
### `<Optional>` adyenv2
**● adyenv2**: *[AdyenV2PaymentInitializeOptions](adyenv2paymentinitializeoptions.md)*
___
<a id="amazon"></a>
### `<Optional>` amazon
**● amazon**: *[AmazonPayPaymentInitializeOptions](amazonpaypaymentinitializeoptions.md)*
___
<a id="bluesnapv2"></a>
### `<Optional>` bluesnapv2
**● bluesnapv2**: *[BlueSnapV2PaymentInitializeOptions](bluesnapv2paymentinitializeoptions.md)*
___
<a id="braintree"></a>
### `<Optional>` braintree
**● braintree**: *[BraintreePaymentInitializeOptions](braintreepaymentinitializeoptions.md)*
___
<a id="braintreevisacheckout"></a>
### `<Optional>` braintreevisacheckout
**● braintreevisacheckout**: *[BraintreeVisaCheckoutPaymentInitializeOptions](braintreevisacheckoutpaymentinitializeoptions.md)*
___
<a id="chasepay"></a>
### `<Optional>` chasepay
**● chasepay**: *[ChasePayInitializeOptions](chasepayinitializeoptions.md)*
___
<a id="creditcard"></a>
### `<Optional>` creditCard
**● creditCard**: *[CreditCardPaymentInitializeOptions](creditcardpaymentinitializeoptions.md)*
___
<a id="gatewayid"></a>
### `<Optional>` gatewayId
**● gatewayId**: * `undefined` | `string`
*
___
<a id="googlepayadyenv2"></a>
### `<Optional>` googlepayadyenv2
**● googlepayadyenv2**: *[GooglePayPaymentInitializeOptions](googlepaypaymentinitializeoptions.md)*
___
<a id="googlepayauthorizenet"></a>
### `<Optional>` googlepayauthorizenet
**● googlepayauthorizenet**: *[GooglePayPaymentInitializeOptions](googlepaypaymentinitializeoptions.md)*
___
<a id="googlepaybraintree"></a>
### `<Optional>` googlepaybraintree
**● googlepaybraintree**: *[GooglePayPaymentInitializeOptions](googlepaypaymentinitializeoptions.md)*
___
<a id="googlepaystripe"></a>
### `<Optional>` googlepaystripe
**● googlepaystripe**: *[GooglePayPaymentInitializeOptions](googlepaypaymentinitializeoptions.md)*
___
<a id="klarna"></a>
### `<Optional>` klarna
**● klarna**: *[KlarnaPaymentInitializeOptions](klarnapaymentinitializeoptions.md)*
___
<a id="klarnav2"></a>
### `<Optional>` klarnav2
**● klarnav2**: *[KlarnaV2PaymentInitializeOptions](klarnav2paymentinitializeoptions.md)*
___
<a id="masterpass"></a>
### `<Optional>` masterpass
**● masterpass**: *[MasterpassPaymentInitializeOptions](masterpasspaymentinitializeoptions.md)*
___
<a id="methodid"></a>
### methodId
**● methodId**: *`string`*
___
<a id="params"></a>
### `<Optional>` params
**● params**: *[TParams]()*
___
<a id="paypalexpress"></a>
### `<Optional>` paypalexpress
**● paypalexpress**: *[PaypalExpressPaymentInitializeOptions](paypalexpresspaymentinitializeoptions.md)*
___
<a id="square"></a>
### `<Optional>` square
**● square**: *[SquarePaymentInitializeOptions](squarepaymentinitializeoptions.md)*
___
<a id="stripev3"></a>
### `<Optional>` stripev3
**● stripev3**: *[StripeV3PaymentInitializeOptions](stripev3paymentinitializeoptions.md)*
___
<a id="timeout"></a>
### `<Optional>` timeout
**● timeout**: *`Timeout`*
___
| 23.357513 | 128 | 0.753327 | kor_Hang | 0.302678 |
116d9fc628c3b6f2abb68a810a80e94c4f143299 | 428 | md | Markdown | slides/integration-4.md | juniorhc/intro-to-mocha | 7c4f577f71e93a988b91508d62db829f07ff8eb9 | [
"Apache-2.0"
] | 7 | 2018-07-06T22:32:46.000Z | 2021-08-28T14:49:14.000Z | slides/integration-4.md | juniorhc/intro-to-mocha | 7c4f577f71e93a988b91508d62db829f07ff8eb9 | [
"Apache-2.0"
] | null | null | null | slides/integration-4.md | juniorhc/intro-to-mocha | 7c4f577f71e93a988b91508d62db829f07ff8eb9 | [
"Apache-2.0"
] | 1 | 2020-05-24T09:56:09.000Z | 2020-05-24T09:56:09.000Z | ## An Integration Test
### "Nodeback" style
```js
it('should respond with JSON object containing timestamp',
function (done) {
request(app).get('/unix-timestamp')
.expect(200).end((err, res) => {
if (err) {
return done(err);
}
assert.ok(res.body.timestamp < 1e10);
done();
});
});
```
note:
don't forget to highlight async nature
**next slide**: promise style
| 17.12 | 58 | 0.567757 | eng_Latn | 0.590539 |
116dba14127cf53ab50627254d460379c9f1b58f | 2,554 | md | Markdown | wdk-ddi-src/content/wdm/nf-wdm-etwunregister.md | amrutha-chandramohan/windows-driver-docs-ddi | 35e28164591cadf5ef3d6238cdddd4b88f2b8768 | [
"CC-BY-4.0",
"MIT"
] | 3 | 2021-12-23T14:02:21.000Z | 2022-02-13T00:40:38.000Z | wdk-ddi-src/content/wdm/nf-wdm-etwunregister.md | amrutha-chandramohan/windows-driver-docs-ddi | 35e28164591cadf5ef3d6238cdddd4b88f2b8768 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/wdm/nf-wdm-etwunregister.md | amrutha-chandramohan/windows-driver-docs-ddi | 35e28164591cadf5ef3d6238cdddd4b88f2b8768 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
UID: NF:wdm.EtwUnregister
title: EtwUnregister function (wdm.h)
description: The EtwUnregister function unregisters the event provider and must be called before the provider exits.
old-location: devtest\etwunregister.htm
tech.root: devtest
ms.date: 02/23/2018
keywords: ["EtwUnregister function"]
ms.keywords: EtwUnregister, EtwUnregister function [Driver Development Tools], devtest.etwunregister, etw_km_04787c1b-049f-4b92-b75c-3da660d51164.xml, wdm/EtwUnregister
req.header: wdm.h
req.include-header: Wdm.h, Ntddk.h
req.target-type: Universal
req.target-min-winverclnt: Available in Windows Vista and later versions of Windows.
req.target-min-winversvr:
req.kmdf-ver:
req.umdf-ver:
req.ddi-compliance: PowerIrpDDis
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib: NtosKrnl.lib
req.dll: NtosKrnl.exe
req.irql: PASSIVE_LEVEL
targetos: Windows
req.typenames:
f1_keywords:
- EtwUnregister
- wdm/EtwUnregister
topic_type:
- APIRef
- kbSyntax
api_type:
- DllExport
api_location:
- NtosKrnl.exe
api_name:
- EtwUnregister
---
# EtwUnregister function
## -description
The <b>EtwUnregister</b> function unregisters the event provider and must be called before the provider exits.
## -parameters
### -param RegHandle
[in]
A pointer to the provider registration handle, which is returned by the <b>EtwRegister</b> function if the event provider registration is successful.
## -returns
The <b>EtwUnregister</b> function returns a status code of STATUS_SUCCESS if the event provider was successfully unregistered with ETW.
## -remarks
After tracing is complete, a driver must call the <b>EtwUnregister</b> function to unregister the provider. For every call to <b>EtwRegister</b> there must be a corresponding call to <b>EtwUnregister</b>. Failure to unregister the event provider can cause errors when the process is unloaded because the callbacks associated with the process are no longer valid. No tracing calls should be made that fall outside of the code bounded by the <b>EtwRegister</b> and <b>EtwUnregister</b> functions. For the best performance, you can call the <b>EtwRegister</b> function in your <b>DriverEntry</b> routine and the <b>EtwUnregister</b> function in your <b>DriverUnload</b> routine.
Callers of <b>EtwRegister</b> must be running at IRQL = PASSIVE_LEVEL in the context of a system thread.
## -see-also
<a href="/windows-hardware/drivers/ddi/wdm/nf-wdm-etwregister">EtwRegister</a>
| 36.485714 | 677 | 0.758418 | eng_Latn | 0.910223 |
116ee68f341d5530e15594843280a950c6dc838f | 4,991 | md | Markdown | docs/webhooks.md | jcleblanc/box-windows-sdk-v2 | 24d4522b07a1ea31f46895e6d289d9339333bda5 | [
"Apache-2.0"
] | 134 | 2015-01-20T19:21:34.000Z | 2022-02-17T00:03:45.000Z | docs/webhooks.md | jcleblanc/box-windows-sdk-v2 | 24d4522b07a1ea31f46895e6d289d9339333bda5 | [
"Apache-2.0"
] | 666 | 2015-01-03T03:35:11.000Z | 2022-03-02T08:36:16.000Z | docs/webhooks.md | jcleblanc/box-windows-sdk-v2 | 24d4522b07a1ea31f46895e6d289d9339333bda5 | [
"Apache-2.0"
] | 154 | 2015-01-15T22:56:48.000Z | 2022-03-21T16:15:05.000Z | Webhooks
========
A webhook object enables you to attach events triggers to Box files and folders. These
event triggers monitor events on Box objects and notify your application, via HTTP
requests to a URL of your choosing, when they occur.
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
- [Create a Webhook](#create-a-webhook)
- [Get All Webhooks](#get-all-webhooks)
- [Get a Webhook"s Information](#get-a-webhooks-information)
- [Validate a Webhook Message](#validate-a-webhook-message)
- [Delete a Webhook](#delete-a-webhook)
- [Update a Webhook](#update-a-webhook)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
Create a Webhook
----------------
To attach a webhook to an item, call the
`WebhooksManager.CreateWebhookAsync(BoxWebhookRequest webhookRequest)`
method with the type and ID of the item, a URL to send notifications to, and a list
of triggers.
<!-- sample post_webhooks -->
```c#
var webhookParams = new BoxWebhookRequest()
{
Target = new BoxRequestEntity()
{
Type = BoxType.file,
Id = "22222"
},
Triggers = new List<string>()
{
"FILE.PREVIEWED"
},
Address = "https://example.com/webhook"
};
BoxWebhook webhook = await client.WebhooksManager.CreateWebhookAsync(webhookParams);
```
Similarly, webhooks can be created for folders.
<!-- sample post_webhooks for_folder -->
```c#
var webhookParams = new BoxWebhookRequest()
{
Target = new BoxRequestEntity()
{
Type = BoxType.folder,
Id = "22222"
},
Triggers = new List<string>()
{
"FILE.UPLOADED",
"FILE.DOWNLOADED"
},
Address = "https://example.com/webhook
};
BoxWebhook webhook = await client.WebhooksManager.CreateWebhookAsync(webhookParams);
```
Get All Webhooks
----------------
Get a list of all webhooks for the requesting application and user by calling the
`WebhooksManager.GetWebhooksAsync (int limit = 100, string nextMarker = null, bool autoPaginate=false)`
method. The maximum limit per page of results is 200, Box uses the default limit of 100.
<!-- sample get_webhooks -->
```c#
BoxCollectionMarkerBased<BoxWebhook> webhooks = await client.WebhooksManager.GetWebhooksAsync();
```
Get a Webhook"s Information
---------------------------
Retrieve information about a specific webhook by calling `WebhooksManager.GetWebhookAsync(string id)`
to retrieve a webhook by ID.
<!-- sample get_webhooks_id -->
```c#
BoxWebhook webhook = await client.WebhooksManager.GetWebhookAsync("12345");
```
Validate a Webhook Message
--------------------------
When you receive a webhook message from Box, you should validate it by calling
the static `WebhooksManager.VerifyWebhook(string deliveryTimestamp, string signaturePrimary, string signatureSecondary, string payload, string primaryWebhookKey, string secondaryWebhookKey)`
method with the components of the webhook message.
<!-- sample x_webhooks validate_signatures -->
```c#
using Box.V2.Managers;
var body = "{\"type\":\"webhook_event\",\"webhook\":{\"id\":\"1234567890\"},\"trigger\":\"FILE.UPLOADED\",\"source\":{\"id\":\"1234567890\",\"type\":\"file\",\"name\":\"Test.txt\"}}";
var headers = new Dictionary<string, string>()
{
{ "box-delivery-id", "f96bb54b-ee16-4fc5-aa65-8c2d9e5b546f" },
{ "box-delivery-timestamp", "2020-01-01T00:00:00-07:00" },
{ "box-signature-algorithm", "HmacSHA256" } ,
{ "box-signature-primary", "6TfeAW3A1PASkgboxxA5yqHNKOwFyMWuEXny/FPD5hI=" },
{ "box-signature-secondary", "v+1CD1Jdo3muIcbpv5lxxgPglOqMfsNHPV899xWYydo=" },
{ "box-signature-version", "1" }
};
var primaryKey = "Fd28OJrZ8oNxkgmS7TbjXNgrG8v";
var secondaryKey = "KWkROAOiof4zhYUHbAmiVn63cMj"
bool isValid = BoxWebhooksManager.VerifyWebhook(
deliveryTimestamp: headers["box-delivery-timestamp"],
signaturePrimary: headers["box-signature-primary"],
signatureSecondary: headers["box-signature-secondary"],
payload: body,
primaryWebhookKey: primaryKey,
secondaryWebhookKey: secondaryKey
);
```
Delete a Webhook
----------------
A file or folder's webhook can be removed by calling `WebhooksManager.DeleteWebhookAsync(string id)`
with the ID of the webhook object.
<!-- sample delete_webhooks_id -->
```c#
await client.WebhooksManager.DeleteWebhookAsync("11111");
```
Update a Webhook
----------------
Update a file or folder's webhook by calling `WebhooksManager.UpdateWebhookAsync(BoxWebhookRequest webhookRequest)`
with the fields of the webhook object to update.
<!-- sample put_webhooks_id -->
```c#
var updates = new BoxWebhookRequest()
{
Id = "12345",
Address = "https://example.com/webhooks/fileActions
};
BoxWebhook updatedWebhook = await client.WebhooksManager.UpdateWebhookAsync(updates);
```
| 32.835526 | 191 | 0.687638 | yue_Hant | 0.692728 |
116fbf78b60e095aca88e4c6e647f4397b3b3a32 | 428 | md | Markdown | _events/les-aventuriers-de-larche-perdue.md | arnaudlevy/histoire-numerique | ebd73b69305ba449d63acf956b622064891a0940 | [
"MIT"
] | 2 | 2022-03-22T09:03:08.000Z | 2022-03-25T11:36:06.000Z | _events/les-aventuriers-de-larche-perdue.md | noesya/culturesnumeriques | ebd73b69305ba449d63acf956b622064891a0940 | [
"MIT"
] | null | null | null | _events/les-aventuriers-de-larche-perdue.md | noesya/culturesnumeriques | ebd73b69305ba449d63acf956b622064891a0940 | [
"MIT"
] | null | null | null | ---
title: Les Aventuriers de l'arche perdue
kind: films
year: 1981
persons:
- steven-spielberg
abstract: Les Aventuriers de l'arche perdue (Raiders of the Lost Ark) est un
film d'aventures fantastique américain réalisé par Steven Spielberg et
coproduit par George Lucas, sorti en 1981.
image: /assets/images/events/les-aventuriers-de-l-arche-perdue.jpeg
url: https://www.allocine.fr/film/fichefilm_gen_cfilm=121.html
---
| 32.923077 | 76 | 0.778037 | fra_Latn | 0.723705 |
116ff5d9f27157f7848ebccc0bb0945c7942e0d9 | 6,241 | md | Markdown | content/articles/20210307.md | MarcCollado/safare | 4fa988acc20acdbda891d51c7cfbbf6c62b31020 | [
"MIT"
] | 2 | 2020-12-04T13:48:59.000Z | 2020-12-16T10:55:00.000Z | content/articles/20210307.md | MarcCollado/safare | 4fa988acc20acdbda891d51c7cfbbf6c62b31020 | [
"MIT"
] | 4 | 2022-02-04T14:45:27.000Z | 2022-02-04T14:45:28.000Z | content/articles/20210307.md | MarcCollado/safareig | 4fa988acc20acdbda891d51c7cfbbf6c62b31020 | [
"MIT"
] | null | null | null | ---
title: 'Creadors dos punt zero'
path: '/bugada/creadors-dos-punt-zero'
date: '2021-03-10'
tags: ['creadors', 'economia', 'història', 'xarxes socials']
author: 'Marc Collado'
meta: 'La tecnologia ens permet connectar i donar suport a creadors, sense intermediaris. Un canvi de paradigma amb el potencial de redefinir Internet.'
featured: false
published: true
---
Des d'un punt de vista molt pragmàtic, Substack no és més que una eina per enviar butlletins electrònics. Una carta de presentació que difícilment impressionaria a l'elit tecnològica. Els butlletins electrònics són quasi més vells que Internet mateix. Craigslist, un dels avis de la xarxa, va debutar l'any 1995 en aquest format.
No obstant això, avui en dia aquest facilitador de butlletins és en boca de tothom. S'ha convertit en l'eina de publicació de la faràndula emprenedora. I doncs, si no tenim res nou a l'horitzó, què la fa tan interessant? Com ha aconseguit aquesta volada?
## Per què ara?
Més que el retorn del butlletí, ens agrada pensar que Substack és la manifestació visible d'una tendència subjacent amb el potencial de redefinir Internet tal com el coneixem.
Malgrat això, per entendre bé aquest fenomen ens cal remuntar-nos als inicis dels 2000. El blog era encara el principal mitjà de publicació a la xarxa. En aquelles èpoques, si un volia expressar-se a l'inèdit univers digital, ho havia de fer pagant un alt cost tècnic, amb eines a l'abast d'uns pocs visionaris que van copsar abans que ningú l'avenir d'aquella tecnologia.
Els blogs eren eines que es mantenien al marge en termes de distribució i descobriment. Encara que costi de creure, Internet era llavors un oceà blau, feblement interconnectat. A diferència d'avui, la dificultat no reia en fer visible el contingut. Ans el contrari, el repte era la creació, esdevenir aquell utopista que veia en la xarxa una tecnologia amb el potencial de canviar el món.
## Internet 2.0
En aquest context, un nou tipus de producte entra en escena. Estem parlant de plataformes avui en dia omnipresents, com Facebook o Twitter, que donaven llavors els primers passos. Idees originades en dormitoris de campus universitaris, sense ni tan sols saber-ho, amagaven el potencial per redefinir el funcionament del mateix medi en el qual es van crear. Internet s'endinsava en una nova era — l'anomenat 2.0 — on el contingut ja no el generaven quatre gats, sinó que qualsevol usuari hi podia contribuir. La xarxa es convertia en un espai més assequible i connectat. Un lloc concebut pels usuaris, on tothom hi era benvingut.
Però el que inicialment es presentà com una democratització de la xarxa, va esdevenir un cavall de Troia amb conseqüències inesperades. Aquests agregadors van alterar la mateixa naturalesa d'Internet i el van convertir en un espai tancat, centralitzat i, sobretot, gratuït. Un gratuït amb asterisc i molta lletra petita, on sense preguntar gaire vàrem bescanviar comoditat per privacitat.
Se'ns va vendre un Internet pel qual no havíem de pagar. El que no se'ns va dir és que el cost de mantenir aquesta promesa seria una guerra inexhaurible per les nostres dades i la nostra atenció. La xarxa no es pagaria en diners, sinó en minuts.
## Democràcia a la xarxa
Una de les conseqüències que plataformes transversals, com Facebook o YouTube, agreguin les audiències és que la monetització del contingut també passa per les seves mans. Quan es tracta de diners, ells posen les normes. I les normes són ben senzilles: més visites generes, més calés t'endús. Un "clic", un "cèntim".
Però deixem per un moment de banda els (eternament discutits) incentius perversos que aquest model fomenta. Una seqüela encara més interessant d'aquest esquema és que en termes monetaris no existeix un vincle directe entre usuari i creador. Això significa que el meu "clic" val el mateix que el teu, encara que jo estigui disposat a pagar més pel fet de ser un incondicional d'aquest hipotètic creador.
Per tant, si un s'hi vol guanyar la vida, es veu incentivat a cercar el mínim comú denominador, el contingut més transversal possible, aquell que captarà més atenció. El fenomen del "click-bait" i els gats perseguint bales de llana. Un model de volum, de quantitat, per a les masses; un model que ens allunya del contingut reflexiu, enfocat i de qualitat.
## Fans 2.0
A Safareig n'hem parlat moltes vegades dels 1.000 fans. Una idea seductora que proposa que donat un mercat suficientment gran, els percentatges deixen de ser importants. L'estratègia és la següent: busca un tema que t'entusiasmi; canalitza aquesta energia per produir el millor contingut; i només necessitaràs 1.000 incondicionals disposats a pagar l'equivalent d'un Netflix per viure de la teva passió.
És per això que ara Substack és rellevant.
Per primera vegada la tecnologia ens permet connectar i donar suport directament al creador, sense intermediaris. Internet ja permet capitalitzar la irracionalitat humana i posar un "preu just" a la creativitat. Podem concloure que ara sí que existeixen les eines per fer realitat el somni dels 1.000 fans.
A poc a poc, aquestes dinàmiques de dependència s'estan invertint a les xarxes. Les audiències s'estan allunyant de les plataformes per acostar-se a les persones. D'alguna manera estem retornant el poder al poble, a creadors que s'adonen com, cada cop més, les plataformes depenen més d'ells i no al revés.
Aquest canvi és també una victòria per a la creativitat, que es manifesta de la mà de nous continguts que ja comencen a treure el cap. Formats de nínxol, impossibles de monetitzar en models transversals, ara poden fer-se un lloc i connectar directament amb la seva audiència. Curiosament ja no són els autors qui es preocupen de crear el contingut que agradarà a la plataforma. Si no que són les mateixes plataformes les qui vetllen per acontentar aquests nous ídols digitals.
Les conseqüències de tot plegat són ara per ara imprevisibles, de la mateixa manera que ho eren les de Facebook a principis del mil·lenni. Estem presenciant un moment històric amb la capacitat de redefinir, de nou, Internet. Més que mai, està literalment a les nostres mans donar suport i contribuir a la visió original de la xarxa: un espai sa, distribuït i creatiu — per a tothom.
| 117.754717 | 628 | 0.796827 | cat_Latn | 0.99989 |
117106dc824b2d7d2164f73ea90a61b73f1e5937 | 4,304 | md | Markdown | README.md | andj207/Tomo | 0379f714b0576a0d3c29ef39599a8783c1d5b881 | [
"MIT"
] | 122 | 2019-01-28T07:19:20.000Z | 2022-03-25T21:37:26.000Z | README.md | andj207/Tomo | 0379f714b0576a0d3c29ef39599a8783c1d5b881 | [
"MIT"
] | 3 | 2019-02-24T13:55:18.000Z | 2020-01-03T12:08:08.000Z | README.md | andj207/Tomo | 0379f714b0576a0d3c29ef39599a8783c1d5b881 | [
"MIT"
] | 13 | 2019-02-07T14:50:52.000Z | 2022-03-09T20:21:21.000Z | # Tomo
Tomo is a collection of fast image processing effects for Android.
Its main goal is to generate dynamic content for aesthetically pleasing apps.
The motivation behind this project can be read in [this blog post](https://medium.com/android-frontier/tomo-a-new-image-processing-library-for-android-344c59c9ee27).
## Showcase
In this demo app we showcase a cool adaptive background being generated using
the content of the screen:

## Using it
Add the snippet below in your root `build.gradle` at the end of repositories:
```
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
```
Then, add the dependency to your module:
```
dependencies {
compile 'com.github.AllanHasegawa:Tomo:x.y.z'
}
```
Latest release: [](https://jitpack.io/#AllanHasegawa/Tomo)
Initialize the library in your `Application` class:
```
class MyApp : Application {
override fun onCreate() {
Tomo.initialize(this)
...
}
}
```
Now you're ready to either apply the effects over `Bitmap`s or `ImageView`s:
```
val myBitmap: Bitmap = ...
val bitmapProcessed = Tomo.applyAdaptiveBackgroundGenerator(myBitmap, darkTheme = true)
val myImageView: ImageView = ...
Tomo.applyAdaptiveBackgroundGenerator(myImageView, darkTheme = true)
```
## Built-in effects
### Adaptive Background Generator
<table>
<tr>
<th rowspan="2">Source Image</th>
<th colspan="2">Adaptive Background Generator</th>
</tr>
<tr>
<th>Dark Theme</th>
<th>Light Theme</th>
</tr>
<tr>
<td><img width="100" src="/docs/tsunami_original.jpg?raw=true"></td>
<td><img width="100" src="/docs/tsunami_adp_bg_dark.png?raw=true"></td>
<td><img width="100" src="/docs/tsunami_adp_bg_light.png?raw=true"></td>
</tr>
<tr>
<td><img width="100" src="/docs/dali_original.jpg?raw=true"></td>
<td><img width="100" src="/docs/dali_adp_bg_dark.png?raw=true"></td>
<td><img width="100" src="/docs/dali_adp_bg_light.png?raw=true"></td>
</tr>
</table>
## Custom effects
Tomo comes equipped with a list of image transformations that can be
arranged in any order to build cool custom effects.
To transform a `Bitmap`, call `Tomo::applyCustomTransformation()`:
```kotlin
val newBitmap = Tomo.applyCustomTransformation(oldBitmap) {
// Scale to 1/10 of its size
resize(
newWidth = initialSize.width / 10,
newHeight = initialSize.height / 10
)
// Blur it
blur(radius = 25f)
// Clamp the value (from HSV)
valueClamp(
lowValue = 0.05f,
highValue = 0.3f,
saturationMultiplier = 1.3f,
saturationLowValue = 0f,
saturationHighValue = 1f
)
// Apply a noise overlay
grayNoise()
}
```
### `resize`
`resize`, as the name implies, lets you resize the bitmap.
### `blur`
`blur` applies a gaussian blur. It's maximum radius is `25f`.
### `valueClamp`
`valueClamp` clamps the value and the saturation of an image.
It can also scale the saturation.
### `grayNoise`
`grayNoise` applies a gray noise over the image.
### `rgbNoise`
`rgbNoise` assigns a random, close, RGB color to each pixel.
# License
```
Copyright 2019 Allan Yoshio Hasegawa
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
```
| 29.081081 | 460 | 0.707946 | eng_Latn | 0.634724 |
117219488c06c25e5a22057e99489de74dab26e1 | 497 | md | Markdown | README.md | jhyang12345/custom-http-server | 92ade6b728672ca6a36f8a79f424898eda60b85a | [
"MIT"
] | 5 | 2019-03-05T06:45:34.000Z | 2019-06-03T08:21:12.000Z | README.md | jhyang12345/custom-http-server | 92ade6b728672ca6a36f8a79f424898eda60b85a | [
"MIT"
] | 3 | 2021-03-09T00:53:17.000Z | 2022-02-12T06:31:28.000Z | README.md | jhyang12345/custom-http-server | 92ade6b728672ca6a36f8a79f424898eda60b85a | [
"MIT"
] | null | null | null | # custom-http-server: a command-line not-so-simple http server
`custom-http-server` is a simple, UI friendly version of the http-server package. It adds on to the basic functionality that http-server provides, and adds UI components to make it more user friendly.

# Alternating between list mode and grid mode
 | 62.125 | 200 | 0.782696 | eng_Latn | 0.72718 |
11724dc84e28487736e7bfc8e2a0509327af88f2 | 1,885 | md | Markdown | README.md | twifty/templar | f2e99fb78d8a7b6f1067cca82d30eaeb70554adf | [
"MIT"
] | 1 | 2020-05-03T18:07:13.000Z | 2020-05-03T18:07:13.000Z | README.md | twifty/templar | f2e99fb78d8a7b6f1067cca82d30eaeb70554adf | [
"MIT"
] | 1 | 2018-05-11T21:30:20.000Z | 2018-05-11T21:30:20.000Z | README.md | twifty/templar | f2e99fb78d8a7b6f1067cca82d30eaeb70554adf | [
"MIT"
] | null | null | null | # Templar
Adds the ability to use templates within the editor.
Template files can be written for any language with the ability to replace placeholder names with real values. Templates can also be grouped by project type or language, making them easier to find.
### Usage
Run the command `templar:manage-templates` or navigate to `Packages -> Templar -> Manage Templates` to create your templates.
The fields include:
* **Template Name**: The name which appears in the menus.
* **Name Prefix**: (optional) A file name prefix, which all new files using this template MUST use.
* **Name Postfix**: (optional) A file name postfix, which all new files using this template MUST use.
* **Project Type**: (optional) A simple group name. Using more than one group name will add the group as a submenu to the context menu.
* **File Extension**: (optional) The extension to give all new files.
Once a template has been created, it will be available from the context menu on the projects file tree.
### Advanced
A `templar` file can be configured from both the package settings and the root directory of a project. Both files will be loaded, but the projects file will take precedence over global. The file must be loadable by a `require` call and export a simple object. The keys of this object map to placeholders within the template. The values will be converted to strings and injected into the template. If a value is a javascript `function`, it will be called with an object containing all known placeholder values. This gives you full control over how the template is written.
A simple `templar.js` example:
```js
module.exports = {
author: 'Me',
namespace: function(props) {
return props.path.split('/').slice(1, -1).join('\\')
}
}
```
with a template:
```php
namespace {{ namespace }};
/**
* @author {{author}}
*/
abstract class Abstract{{ name }} {
//...
}
```
| 40.978261 | 571 | 0.737401 | eng_Latn | 0.998489 |
11725abe0be044c681518a37eb2d55866ef90173 | 34,588 | md | Markdown | docs/azure.md | karlmutch/studio-go-runner | b3072e3b9f0771a2caf017c02622709cce7338b0 | [
"Apache-2.0"
] | 1 | 2018-07-05T19:21:32.000Z | 2018-07-05T19:21:32.000Z | docs/azure.md | karlmutch/studio-go-runner | b3072e3b9f0771a2caf017c02622709cce7338b0 | [
"Apache-2.0"
] | 186 | 2018-12-19T02:17:19.000Z | 2021-09-23T01:08:42.000Z | docs/azure.md | karlmutch/studio-go-runner | b3072e3b9f0771a2caf017c02622709cce7338b0 | [
"Apache-2.0"
] | 10 | 2019-01-23T19:02:10.000Z | 2021-09-23T00:23:12.000Z | # Azure support for studio-go-runner
This document describes the Azure specific steps for the installation and use of the studio-go-runner within Azure.
Before using these instruction you should have an Azure account and have full access to its service principal. These instruction will guide you through the creation of a Kubernetes cluster using Microsoft specific tools. After completing them you will be able to use the kubectl and other generic tools for installation of the go runner.
This Go runner, and the Python runner found within the reference implementation of StudioML, have been tested on the Microsoft Azure cloud.
After completing the instructions in this document you may return to the main README.md file for further instructions.
<!--ts-->
Table of Contents
=================
* [Azure support for studio-go-runner](#azure-support-for-studio-go-runner)
* [Table of Contents](#table-of-contents)
* [Prerequisites](#prerequisites)
* [Planning](#planning)
* [Installation Prerequisites](#installation-prerequisites)
* [Automatted installation](#automatted-installation)
* ['The hard way' Installation](#the-hard-way-installation)
* [RabbitMQ Deployment](#rabbitmq-deployment)
* [Minio Deployment](#minio-deployment)
* [Compute cluster deployment](#compute-cluster-deployment)
* [Kubernetes and Azure](#kubernetes-and-azure)
* [Azure Kubernetes Private Image Registry deployments](#azure-kubernetes-private-image-registry-deployments)
* [Manifest and suggested deployment artifacts](#manifest-and-suggested-deployment-artifacts)
* [RabbitMQ Server](#rabbitmq-server)
* [Minio S3 Server](#minio-s3-server)
* [Workers](#workers)
* [Security Note](#security-note)
* [Software Manifest](#software-manifest)
* [CentOS and RHEL 7.0](#centos-and-rhel-70)
<!--te-->
## Prerequisites
The Azure installation process will generate a number of keys and other valuable data during the creation of cloud based compute resources that will need to be sequestered in some manner. In order to do this a long-lived host should be provisioned provisioned for use with the administration steps detailed within this document.
Your linux account should have an ssh key generated, see ssh-keygen man pages.
Azure can run Kubernetes as a platform for fleet management of machines and container orchestration using AKS supporting regions with machine types that have GPU resources. kubectl can be installed using instructions found at:
- kubectl https://kubernetes.io/docs/tasks/tools/install-kubectl/
Docker is also used to manage images from an administration machine. For Ubuntu the instructions can be found at the following location.
- Docker Ubuntu Installation, https://docs.docker.com/install/linux/docker-ce/ubuntu/#install-docker-engine---community
If the decision is made to use CentOS 7 then special accomodation needs to be made. These changes are described at the end of this document. In addition, the automatted scripts within the cloud directory are designed to deploy Ubuntu Azure master images. These will need modification when using CentOS.
Instructions on getting started with the azure tooling, at least Azure CLI 2.0.73, needed for operating your resources can be found as follows:
- AZ CLI https://github.com/Azure/azure-cli#installation
If you are a developer wishing to push workloads to the Azure Container Service you can find more information at, https://docs.microsoft.com/en-us/azure/container-registry/container-registry-get-started-docker-cli.
The Kubernetes eco-system has a customization tool known as kustomize that is used to adapt clusters to the exact requirements of customers. This tool can be installed using the following commands:
```shell
wget -O /usr/local/bin/kustomize https://github.com/kubernetes-sigs/kustomize/releases/download/kustomize%2Fv3.5.4/kustomize_kustomize.v3.5.4_linux_amd64
chmod +x /usr/local/bin/kustomize
export PATH=$PATH:/usr/local/bin
```
For the purposes of exchanging files with the S3 Minio server the minio client is available and can be installed using the following commands:
```shell
wget -O /usr/local/bin/mc https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x /usr/local/bin/mc
```
Now that the tooling is installed there are three major components for which installation occurs, a rabbitMQ server, a Minio S3 file server, and the compute cluster. The following sections detail these in order.
It is also worth noting that the requirements for the node pool network subnet can be have on IP addresses that are assigned, a subnet of sufficient size should be allocated for use by the node pools being used.. Each node within the node pool will be assigned a mnimum of 20 IPs unless efforts are made to restrict the creation of the node pool to bing done using the Azure command line tool.
## Planning
The Azure Kubernetes Service (AKS) has specific requirements in relation to networking that are critical to observe, this cannot be emphasized strongly enough. For information about the use of Azure CNI Networking please review, https://docs.microsoft.com/en-us/azure/aks/configure-azure-cni. Information about the use of bastion hosts to protect the cluster please see, https://docs.microsoft.com/en-us/azure/aks/operator-best-practices-network. For information about the network ports that need to be opened, please review, https://docs.microsoft.com/en-us/azure/aks/limit-egress-traffic.
## Installation Prerequisites
If Azure is being used then an Azure account will need and you need to authenticate with the account using the 'az login' command. This will also require access to a browser to complete the login:
```shell
$ az login --use-device-code
To sign in, use a web browser to open the page https://aka.ms/devicelogin and enter the code B.......D to authenticate.
```
You will now need to determine the Azure subscription id that will be used for all resources that are consumed within Azure. The current subscription ids available to you can be seen inside the Azure web portal or using the cmd line. Take care to choose the appropriate license. If you know you are using a default license then you can use the following command to save the subscription as a shell variable:
```shell
$ subscription_id=`az account list -otsv --query '[?isDefault].{subscriptionId: id}'`
```
If you have an Azure account with multiple subscriptions or you wish to change the default subscription you can use the az command to do so, for example:
```shell
$ az account list -otsv --all
AzureCloud ... True Visual Studio Ultimate with MSDN Enabled ...
AzureCloud ... False Pay-As-You-Go Warned ...
AzureCloud ... False Sentient AI Evaluation Enabled ...
$ az account set --subscription "Sentient AI Evaluation"
$ az account list -otsv --all
AzureCloud ... False Visual Studio Ultimate with MSDN Enabled ...
AzureCloud ... False Pay-As-You-Go Warned ...
AzureCloud ... True Sentient AI Evaluation Enabled ...
```
### Automatted installation
Installation of the RabbitMQ (rmq) queue server, and the minio S3 server, both being components within a StudioML deployment using runners, is included when using scripts found in this repositories cloud sub directory. If you wish to perform a ground up installation without checking out the studio-go-runner repository you can directly download the rmq and minio installation and run it using the following commands:
```shell
# The following command will create a temporary directory to run the install from and will move to it
cd `mktemp -d`
wget -O install_custom.sh https://raw.githubusercontent.com/leaf-ai/studio-go-runner/master/cloud/install.sh
wget -O README.md https://raw.githubusercontent.com/leaf-ai/studio-go-runner/master/cloud/README.md
```
You should now edit the installation file that was downloaded and follow the instructions included within it. After changes are written to disk you can now return to running the installation.
```shell
chmod +x ./install_custom.sh
./install_custom.sh
# Print the directory used to perform the installation
pwd
# Return to the users directory
cd -
```
More information can be found at, https://github.com/leaf-ai/studio-go-runner/blob/master/cloud/README.md.
### 'The hard way' Installation
Once the subscription ID is selected the next step is to generate for ourselves an identifier for use with Azure resource groups etc that identifies the current userand local host to prevent collisions. This can be done using rthe following commands:
```shell
uniq_id=`md5sum <(echo $subscription_id $(ip maddress show eth0)) | cut -f1 -d\ | cut -c1-8`
````
#### RabbitMQ Deployment
Azure has a prepackaged version of the Bitnami distribution of RabbitMQ available.
Before using the marketplace version you will need to retrieve your SSH public key and have it accessible when prompted.
```shell
cat $HOME/.ssh/id_rsa.pub
```
To begin the launch of this service use the Azure search bar to locate the Marketplace image, enter "RabbitMQ Certified by Bitnami" and click on the search result for marketplace.
Click on 'create' to move to the first configuration screen. Fill in the Resource group, and a Virtual Machine Name of your choice. Next select the Region to be (US) East US. It is also advised to change the machine type to be an A2\_v2.
At the bottom of this screen there are administration account details that should be filled in. Use a username of your choice and paste into the SSH Public Key field you public SSH key, shown above.
Begin moving through the configuration screens stopping in the management screen to turn off 'Auto-Shutdown' and then continue and finally use the Create button on the last screen to initialize the machine.
Once the deployment has completed a public IP address will be assigned by Azure and can be seen by going into the vnet interface attached to the machine and looking at the IP Configurations section. This can be found by clicking on the device listed inside the connected device pane of the vnet overview panel. Once you can see the public IP address of the screen take a note of that and then on the Configuration menu list item on the left side of the xx-ip configuration web page panel.
The ip configuration screen on Azure should now be used to set the public IP address assignment to Static in order that the machine is consistently available at the IP address it initially used. Press the save button which is displayed at the top left of the configuration panel.
Access to the web administration interface for this machine and also to the queue API interface should now be enabled in the network security group for the machine. To get to this screen return to the Azure web UI resource group you created and select the resource group to reveal the list of assets, in here you will see a network security group. Click on it and then the details screen will be shown. Choose the inbound security rules menu item on the left hand side of the details view and you will see an add option for each port that will be exposed. The add option will allow ports to be added, as you add the ports the only detail that usually needs changing is the port number in the 'Destination Port Ranges', and possibly the name of the rule to make things clear as to which port is being opened. Once these are entered press the Add button at the bottom of the panel.
You should open ports 15672, and 5672. The second port will require a priority to be set, add 1 to the default priority value inserted.
Three variables are required from the RabbitMQ install that will be used later, the IP Address of the server, and the user name, password pair. Commands later on within this document will refer to these values so you might want to record them as environment variables.
Access to the machine from the administration workstation can now be gained by using the ssh command bundled with your Ubuntu management workstation, for example:
```shell
ssh 40.117.178.107
The authenticity of host '40.117.178.107 (40.117.178.107)' can't be established.
ECDSA key fingerprint is SHA256:A9u3R6/pjKW37mvMrIq5ZJarx4TmHSmdUVTAuTPt9HY.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '40.117.178.107' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 16.04.6 LTS (GNU/Linux 4.15.0-1060-azure x86_64)
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
___ _ _ _
| _ |_) |_ _ _ __ _ _ __ (_)
| _ \ | _| ' \/ _` | ' \| |
|___/_|\__|_|_|\__,_|_|_|_|_|
*** Welcome to the Bitnami RabbitMQ 3.8.0-0 ***
*** Service accessible using hostname 40.117.178.107 , check out https://docs.bitnami.com/azure/infrastructure/rabbitmq/administration/connect-remotely/ ***
*** Documentation: https://docs.bitnami.com/azure/infrastructure/rabbitmq/ ***
*** https://docs.bitnami.com/azure/ ***
*** Bitnami Forums: https://community.bitnami.com/ ***
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
bitnami@rabbitMQ:~$
```
Instructions for obtaining the administration User ID can be found at https://docs.bitnami.com/azure/faq/get-started/find-credentials/.
```shell
export rabbit_host=40.117.178.107
export rabbit_user=user
export rabbit_password=password
```
You can now test access to the server by going to a browser and use the url, http://[the value of $rabbit_host]:15672. This will display a logon screen that you can enter the user name and the password into, thereby testing the access to the system.
#### Minio Deployment
To begin the launch of this service use the Azure search bar to locate the Marketplace image, enter "Ubuntu Server 18.04 LTS" and click on the search result for marketplace. Be sure that the one choosen is provided by Canonical and no other party. You will be able to identify the exact version by clicking on the "all results" option in the search results drop down panel. When using this option a list of all the matching images will be displayed with the vendor name underneath the icon.
Click on 'create' to move to the first configuration screen. Fill in the Resource group, and a Virtual Machine Name of your choice. Next select the Region to be (US) East US. The default machine type of D2s_v3 is appropriate until your requirements are fully known.
At the bottom of this screen there are administration account details that should be filled in. Use a username of your choice and paste into the SSH Public Key field you public SSH key, shown above.
Clicking next will take you to the Disks screen. You will need to use the Disks configuration screen to add an empty disk, "create and attach a disk", with 1TB of storage or more to hold any experiment data that is being generated. When prompted for the details of the disk use the "Storage Type" drop down to select an empty disk, "None"i, and change the size using the menus underneath that option.
Next move to the Networking screen and choose the "Public inbound ports" option to allow SSH to be exposed in order that you can SSH into this machine.
Continue moving through the configuration screens stopping in the management screen to turn off 'Auto-Shutdown' and then continue and finally use the Create button on the last screen to initialize the machine.
Once the deployment has completed a public IP address will be assigned by Azure and can be seen by going into the vnet interface attached to the machine and looking at the IP Configurations section. This can be found by clicking on the device listed inside the connected device pane of the vnet overview panel. Once you can see the public IP address of the screen take a note of that and then on the Configuration menu list item on the left side of the xx-ip configuration web page panel.
The ip configuration screen on Azure should now be used to set the public IP address assignment to Static in order that the machine is consistently available at the IP address it initially used. Press the save button which is displayed at the top left of the configuration panel.
Access to the web administration interface for this machine and also to the queue API interface should now be enabled in the network security group for the machine. To get to this screen return to the Azure web UI resource group you created and select the resource group to reveal the list of assets, in here you will see a network security group. Click on it and then the details screen will be shown. Choose the inbound security rules menu item on the left hand side of the details view and you will see an add option for each port that will be exposed. The add option will allow ports to be added, as you add the ports the only detail that usually needs changing is the port number in the 'Destination Port Ranges', and possibly the name of the rule to make things clear as to which port is being opened.
Following the above instruction you should now make the minio server port available for use through the network security group associated with the network interface, opening port 9000.
Access to the machine from the administration workstation can now be done, for example:
```shell
ssh 40.117.155.103
The authenticity of host '40.117.155.103 (40.117.155.103)' can't be established.
ECDSA key fingerprint is SHA256:j6XftRWhoyoLmlQtkfvtL5Mol0l2rQ3yAl0+QDo6EV4.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '40.117.155.103' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 5.0.0-1018-azure x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Thu Oct 17 00:26:33 UTC 2019
System load: 0.07 Processes: 128
Usage of /: 4.2% of 28.90GB Users logged in: 0
Memory usage: 4% IP address for eth0: 10.0.0.4
Swap usage: 0%
7 packages can be updated.
7 updates are security updates.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
kmutch@MinioServer:~$
```
The following commands should now be run to upgrade the OS to the latest patch levels:
```shell
sudo apt-get update
sudo apt-get upgrade
sudo useradd --system minio-user --shell /sbin/nologin
```
We now add the secondary 1TB storage allocated during machine creation using the fdisk command and then have the partition mounted automatically upon boot. The fdisk utility is menu driven so this is shown as an example. Most fields can be defaulted.
```shell
kmutch@MinioServer:~$ sudo fdisk /dev/sdc
Welcome to fdisk (util-linux 2.31.1).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table.
Created a new DOS disklabel with disk identifier 0xab23eb4b.
Command (m for help): n
Partition type
p primary (0 primary, 0 extended, 4 free)
e extended (container for logical partitions)
Select (default p): p
Partition number (1-4, default 1):
First sector (2048-2145386495, default 2048):
Last sector, +sectors or +size{K,M,G,T,P} (2048-2145386495, default 2145386495):
Created a new partition 1 of type 'Linux' and of size 1023 GiB.
Command (m for help): w
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.
kmutch@MinioServer:~$ sudo mkfs.ext4 /dev/sdc1
mke2fs 1.44.1 (24-Mar-2018)
Discarding device blocks: done
Creating filesystem with 268173056 4k blocks and 67043328 inodes
Filesystem UUID: e1af35dc-344b-45d6-aec6-8c39b1ad30d6
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Allocating group tables: done
Writing inode tables: done
Creating journal (262144 blocks): done
Writing superblocks and filesystem accounting information: done
kmutch@MinioServer:~$ sudo su
# mkdir /data
# id=`blkid /dev/sdc1 | cut -f2 -d\"`
# cat << EOF >> /etc/fstab
UUID=$id /data auto nosuid,nodev,nofail,x-gvfs-show 0 0
EOF
root@MinioServer:/home/kmutch# mount -a
```
The minio installation can now begin
```shell
sudo su
useradd --system minio-user --shell /sbin/nologin
wget -O /usr/local/bin/minio https://dl.minio.io/server/minio/release/linux-amd64/minio
chmod +x /usr/local/bin/minio
chown minio-user:minio-user /usr/local/bin/minio
mkdir /data/minio
mkdir /etc/minio
chown minio-user:minio-user /data/minio
chown minio-user:minio-user /etc/minio
cat << EOF >> /etc/default/minio
MINIO_VOLUMES="/data/minio/"
MINIO_OPTS="-C /etc/minio"
MINIO_ACCESS_KEY=229A0YHNJZ1DEXB80WFG
MINIO_SECRET_KEY=hsdiPjaZjd8DKD04HwW8GF0ZA9wPv8FCgYR88uqR
EOF
wget -O /etc/systemd/system/minio.service https://raw.githubusercontent.com/minio/minio-service/master/linux-systemd/minio.service
systemctl daemon-reload
systemctl enable minio
sudo service minio start
```
Once the minio server has been initiated information related to a generated access key and secret key will be generated for this installation. These values should be extracted and used to access the file server:
```shell
sudo cat /data/minio/.minio.sys/config/config.json| grep Key
"accessKey": "229A0YHNJZ1DEXB80WFG",
"secretKey": "hsdiPjaZjd8DKD04HwW8GF0ZA9wPv8FCgYR88uqR",
"routingKey": "",
```
These values should be recorded and kept in a safe location on the administration host for use by StudioML clients and experimenters. You also have the option of changing the values in this file to meet your own requirements and then restart the server. These values will be injected into your experiment host hocon configuration file.
```shell
export minio_access_key=229A0YHNJZ1DEXB80WFG
export minio_secret_key=hsdiPjaZjd8DKD04HwW8GF0ZA9wPv8FCgYR88uqR
```
If you wish to make use of the mc, minio client, to interact with the server you can add the minio host details to the mc configuration file to make access easier, please refer to the minio mc guide found at, https://docs.min.io/docs/minio-client-quickstart-guide.html.
```shell
mc config host add studio-s3 http://40.117.155.103:9000 ${minio_access_key} ${minio_secret_key}
mc mb studio-s3/mybucket
mc ls studio-s3
mc rm studio-s3/mybucket
```
Should you wish to examine the debug logging for your minio host the following command can be used:
```shell
sudo service minio status
```
## Compute cluster deployment
Once the main login has been completed you will be able to login to the container registry and other Azure services. Be aware that container registries are named in the global namespace for Azure.
If you need to create a registry then the following commands will do this for you:
```shell
export LOCATION=eastus
export azure_registry_name=leafai$uniq_id
export registry_resource_group=studioml-$uniq_id
export acr_principal=registry-acr-principal-$uniq_id
az group create --name $registry_resource_group --location $LOCATION
az acr create --name $azure_registry_name --resource-group $registry_resource_group --sku Basic
```
Create a new service principal and assign access, this process will auto generate a password for the role. The secret that is generated is only ever output once so a safe location should be found for it and it should be saved:
```shell
registryId=$(az acr show --name $azure_registry_name --query id --output tsv)
registrySecret=$(az ad sp create-for-rbac --name http://$acr_principal --scopes $registryId --role acrpull --query password --output tsv)
registryAppId=$(az ad sp show --id http://$acr_principal --query appId --output tsv)
az acr update -n $azure_registry_name --admin-enabled true
```
```shell
az acr login --name $azure_registry_name
Login Succeeded
```
Resource groups are an organizing abstraction within Azure so when using the az command line tools you will need to be aware of the resource group you are operating within.
```
az acr list --resource-group $registry_resource_group --query "[].{acrLoginServer:loginServer}" --output table
```
Pushing to Azure then becomes a process of tagging the image locally prior to the push to reflect the Azure login server, as follows:
```shell
docker pull leafai/azure-studio-go-runner:0.9.26-master-aaaagnjvnvh
docker tag leafai/azure-studio-go-runner:0.9.26-master-aaaagnjvnvh $azure_registry_name.azurecr.io/${azure_registry_name}/studio-go-runner:0.9.26-master-aaaagnjvnvh
docker push $azure_registry_name.azurecr.io/${azure_registry_name}/studio-go-runner:0.9.26-master-aaaagnjvnvh
```
The go runner build pipeline will push images to Azure ACR when run in a shell that has logged into Azure and acr together.
Azure image repositories can be queried using the CLI tool, for example:
```shell
az acr repository show-tags --name $azure_registry_name --repository ${azure_registry_name}/studio-go-runner --output table
```
More information about the compatibility of the registry between Azure and docker hub can be found at, https://docs.microsoft.com/en-us/azure/container-registry/container-registry-get-started-docker-cli.
### Kubernetes and Azure
The az aks CLI tool is used to create a Kubernetes cluster when hosting on Azure, this command set acts much like kops does for AWS. The following instructions will output a KUBECONFIG for downstream use by the Kubernetes tooling etc. The kubeconfig files will be generated for each region the service can be deployed to, when using the kubectl tools set your KUBECONFIG environment variable to point at the desired region. This will happen even if the region is specified using the --location command.
When handling multiple clusters the \_output directory will end up with multiple subdirectories, one for each cluster. The directories are auto-generated and so you will need to keep track of their names and the clusters they apply to. After using acs-engine deploy to generate and then deploy a cluster you should identify the directory that was created in your \_output area and then use that directory name in subsequent kubectl commands, when using the KUBECONFIG environment variable.
The example examples/azure/kubernetes.json file contains an empty Azure Client ID and secret. Before running this command you will need to create a service principal and extract client ID and secret for it, updating this file in turn. Those doing Azure account management and managing service principals might find the following helpful, https://github.com/Azure/aks-engine/blob/master/docs/topics/service-principals.md.
For information related to GPU workloads and k8s please review the following github page, https://github.com/Azure/aks-engine/blob/master/docs/topics/gpu.md. Using his methodology means not having to be concerned about spining up the nivida plugins and the like.
The command lines show here are using the JMESPath query language for json which you can read about here, http://jmespath.org/.
```shell
export k8s_resource_group=leafai-$uniq_id
export aks_cluster_group=leafai-cluster-$uniq_id
az group create --name $k8s_resource_group --location $LOCATION
az aks create --resource-group $k8s_resource_group --name $aks_cluster_group --node-vm-size Standard_NC6 --node-count 1
az aks get-credentials --resource-group $k8s_resource_group --name $aks_cluster_group
export KUBECONFIG=$HOME/.kube/config
kubectl create namespace gpu-resources
kubectl apply -f examples/azure/nvidia-device-plugin-ds-1.11.yaml
kubectl create secret docker-registry studioml-go-docker-key --docker-server=$azure_registry_name.azurecr.io --docker-username=$registryAppId --docker-password=$registrySecret [email protected]
```
```shell
cat << EOF > examples/azure/map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: studioml-env
data:
AMQP_URL: "amqp://${rabbit_user}:${rabbit_password}@${rabbit_host}:5672/"
EOF
cat << EOF > examples/azure/kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- deployment-1.13.yaml
patchesStrategicMerge:
- map.yaml
images:
- name: studioml/studio-go-runner
newName: ${azure_registry_name}.azurecr.io/${azure_registry_name}/studio-go-runner:0.9.26-master-aaaagnjvnvh
EOF
kubectl apply -f <(kustomize build examples/azure)
kubectl get pods
```
### Azure Kubernetes Private Image Registry deployments
In order to access private image repositories k8s requires authenticated access to the repository. In the following example we open access to the acr to the application created by the aks-engine. The azurecr.io credentials can also be saved as k8s secrets as an alternative to using Azure service principals. Using k8s secrets can be a little more error prone and opaque to the Azure platform so I tend to go with using Azure to do this. If you do wish to go with the k8s centric approach you can find more information at, https://kubernetes.io/docs/concepts/containers/images/#using-azure-container-registry-acr.
The following article shows how the Azure AKS cluster can be attached to the Azure Container Registry from which images are being served.
https://thorsten-hans.com/aks-and-acr-integration-revisited
az aks update --resource-group $k8s_resource_group --name $aks_cluster_group --attach-acr $registryId
A kubernetes cluster will now be installed and ready for the deployment of the studioml go runner. To continue please return to the base installation instructions.
# Manifest and suggested deployment artifacts
Current studio-go-runner, aka runner, is recommended to be deployed within Azure using the components from the following as a starting point:
RabbitMQ Server
---------------
https://hub.docker.com/layers/rabbitmq/library/rabbitmq/3.7.17-alpine/images/sha256-bc92e61664e10cd6dc7a9bba3d39a18a446552f9dc40d2eb68c19818556c3201
OSI Compliant
quay.io with a micro plan can be used for CVE scanning
The RabbitMQ Server will be deployed within the Azure account and resource group but outside of the Kubernetes cluster. The machine type is recommended to be DS12\_v2, $247 per month.
Minio S3 Server
---------------
The Minio server acts as the file distribution point for data processed by experiments. The entry point machine type is recommended to be D4s\_v3, $163.68 per month.
minio software can downloaded from dockerhub, the image is named minio/minio. Again quay.io is recommended for CVE scanning if desired.
Within Azure the minio server will typically be deployed using a standalone VM instance. Using the Azure CLI a host should be stood up with a fixed IP address to ensure that the machine remains available after restarts.
https://docs.microsoft.com/en-us/azure/virtual-network/virtual-networks-static-private-ip-arm-cli
The minio server is installed on Ubuntu typically however any OS can be used, for example CentOS, https://www.centosblog.com/install-configure-minio-object-storage-server-centos-linux/
On Ubuntu the following instructions can be used, https://linuxhint.com/install_minio_ubuntu_1804/.
```shell
```
Workers
-------
Kubernetes AKS Images and deployment details
AKS Base Image Distro w/ Ubuntu 18.04, April 2019
Workers, East US Region, availability currently limited to NC6, NC12, NV6, NV12 $700-$1,600 per month
Software deployed to the worker is the studio-go-runner. This software is available as open source and is provided also from the quay.io site. As of 9.20.0, sha256:...aec406105f91 there are no high-level vulnerabilities. This image can be pulled independently using, 'docker pull quay.io/leafai/studio-go-runner', the canonical URL is https://quay.io/repository/leafai/studio-go-runner/manifest/sha256:aec406105f917e150265442cb45794c67df0f8ee59450eb79cd904f09ded18d6.
Security Note
-------------
The Docker images being used within the solution are recommended, in high security situations, to be scanned independently for CVE's. A number of services are available for this purposes including quay.io that can be used as this is not provided by the open source studio.ml project. Suitable plans for managing enough docker repositories to deal with Studio.ML deployments typically cost in the $30 per month range from Quay.io, now Redhat Quay.io.
It is recommended that images intended for use within secured environments are first transferred into the Azure environment by performing docker pull operations from their original sources and then using docker tag, docker login, docker push operations then get transferred into the secured private registry of the Azure account holder. This is recommended to prevent tampering with images after scanning is performed and also to prevent version drift.
Software Manifest
-----------------
The runner is audited on a regular basis for Open Source compliance using SPDX tools. A total of 133 software packages are incorporated into the runner and are subject to source level security checking and alerting using github. The manifest file for this purpose is produced during builds and can be provided by request.
More information abouth the source scanning feature can be found at, https://help.github.com/en/articles/about-security-alerts-for-vulnerable-dependencies.
CentOS and RHEL 7.0
-------------------
Prior to running the Docker installation the containerd runtime requires the cgroups seline library and profiles to be installed using a archived repository for packages as follows:
```shell
yum install http://http://vault.centos.org/centos/7.6.1810/extras/x86_64/Packages/container-selinux-2.107-1.el7_6.noarch.rpm
````
Should you be using an alternative version of CentOS this server contains packages for many variants and versions of CentOS and can be browsed.
Copyright © 2019-2020 Cognizant Digital Business, Evolutionary AI. All rights reserved. Issued under the Apache 2.0 license.
| 61.109541 | 883 | 0.777611 | eng_Latn | 0.99278 |
117332469c5d8098e07c2431d73fa467936037bb | 3,894 | md | Markdown | CTF-Writeups/VulnHub/Fart_Knocker.md | koleksibot/Sofware-Tools | 8a67c34402e7c431bfcb15223d80570ed0aa258d | [
"Apache-2.0",
"CC-BY-4.0"
] | 12 | 2022-01-25T11:36:47.000Z | 2022-03-27T02:11:15.000Z | CTF-Writeups/VulnHub/Fart_Knocker.md | koleksibot/Sofware-Tools | 8a67c34402e7c431bfcb15223d80570ed0aa258d | [
"Apache-2.0",
"CC-BY-4.0"
] | 4 | 2022-02-14T00:22:53.000Z | 2022-02-24T16:35:26.000Z | CTF-Writeups/VulnHub/Fart_Knocker.md | koleksibot/Sofware-Tools | 8a67c34402e7c431bfcb15223d80570ed0aa258d | [
"Apache-2.0",
"CC-BY-4.0"
] | 24 | 2021-12-10T05:39:58.000Z | 2022-03-27T08:10:57.000Z | # VulnHub-Fart Knocker
## NMAP
```
Nmap scan report for Huhuhhhhhuhuhhh (192.168.43.108)
Host is up (0.00012s latency).
Not shown: 999 closed ports
PORT STATE SERVICE VERSION
80/tcp open http Apache httpd 2.4.7 ((Ubuntu))
|_http-server-header: Apache/2.4.7 (Ubuntu)
|_http-title: Site doesn't have a title (text/html).
MAC Address: 08:00:27:35:8B:64 (Oracle VirtualBox virtual NIC)
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 7.30 seconds
```
## PORT 80
On visiting the web page we had link named `Wooah` on clicking it prompt as to save or open a pacp file which is a wireshark file for analyzing packets
<img src="https://i.ibb.co/5MdMhDp/wireshark-analyze.png"/>
From the packets we can see that an IP was trying to connect with a port sequence of `7000,8000,9000,800`. So this looks like a port knocking scenario where you have to connect to number of ports in a sequence which will unlock a port for you to connect which is used to hide a port from connecting.
## Port Knocking
We can either use a for loop to conenct to certain port or we can use netcat to connect to these port sequence but a command `knock` can help us out in port knocking
<img src="https://i.ibb.co/jMxtVWR/port-knock.png"/>
Now we after port knocking run the nmap scan again immediately after running the knock command
<img src="https://i.ibb.co/HrNL75z/again-scan.png"/>
We can see that port 8888 is opened but in seconds it will be turned due to it's timeout configuration so run the knock command again and connect to this port using netcat or telnet
<img src="https://i.ibb.co/tcFBxtY/again-port-knock.png"/>
Visting the page we get
<img src="https://i.ibb.co/TrM44xt/burger-wordl.png"/>
<img src="https://i.ibb.co/bRK4Rvb/again-pcap.png"/>
We again get a prompt for opening or saving a pcap file let's do that an open it with wireshark
<img src="https://imgur.com/jYld7ct.png"/>
We can these packets here so follow the tcp stream of these packets
<img src="https://imgur.com/nmVLJLp.png"/>
On following it gives this message
```
eins drei drei sieben
```
Which on translating is in german which is translated to `1 3 3 7` which is the next sequence for port knock
<img src="https://imgur.com/RuxnE38.png"/>
On connecting with that port it gives us another page
<img src="https://imgur.com/Nz1bXJV.png"/>
<img src="https://imgur.com/WpkMqvB.png"/>
The heading gives us a hint `that base`
<img src="https://imgur.com/QhgjMM9.png"/>
Looks like another port which needs to be knocked
<img src="https://imgur.com/OceOfbd.png"/>
<img src="https://imgur.com/wyRWswt.png"/>
Connecting with any username will give you the ssh banner which has username and password
<img src="https://imgur.com/7Gx9epV.png"/>
But ssh was keep closing when we were loggin in with the correct creds but on giving the command /bin/bash I was able to get on the box
<img src="https://imgur.com/tIJlSOy.png"/>
I tried to stabilize the shell but bash not spawning in any way
<img src="https://imgur.com/r3QN2qe.png"/>
So ignoring to stabilize the shell let's enumerate the box using linpeas so I used `netcat` to transfer the file
<img src="https://imgur.com/uWuE8iv.png"/>
<img src="https://imgur.com/XoTtfjz.png"/>
Immediately it pointed that it is using an older version of linux kernel so we can look it up on exploit-db for any exploit available.
<img src="https://imgur.com/1gaGWBu.png"/>
This is the most common exploit of linux kernel which I have seen in alot of vulnerable machines
<img src="https://imgur.com/1rr7vgD.png"/>
Make sure to convert it into dos format because usually this is the error which occurs when running the binary , transfer the file to the machine , compile it then run it
<img src="https://imgur.com/32Wlfn4.png"/>
<img src="https://imgur.com/CwDDQNB.png"/> | 35.4 | 299 | 0.743708 | eng_Latn | 0.987736 |
1173442981d539d33fec20abef1d94270c21005f | 5,669 | md | Markdown | desktop-src/extensible-storage-engine/vistaapi-members.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 552 | 2019-08-20T00:08:40.000Z | 2022-03-30T18:25:35.000Z | desktop-src/extensible-storage-engine/vistaapi-members.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 1,143 | 2019-08-21T20:17:47.000Z | 2022-03-31T20:24:39.000Z | desktop-src/extensible-storage-engine/vistaapi-members.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 1,287 | 2019-08-20T05:37:48.000Z | 2022-03-31T20:22:06.000Z | ---
description: "Learn more about: VistaApi members"
title: VistaApi members (Microsoft.Isam.Esent.Interop.Vista)
TOCTitle: VistaApi members
ms:assetid: AllMembers.T:Microsoft.Isam.Esent.Interop.Vista.VistaApi
ms:mtpsurl: https://msdn.microsoft.com/library/microsoft.isam.esent.interop.vista.vistaapi_members(v=EXCHG.10)
ms:contentKeyID: 55104282
ms.date: 07/30/2014
ms.topic: article
---
# VistaApi members
Include protected members
Include inherited members
ESENT APIs that were first supported in Windows Vista.
The [VistaApi](./vistaapi-class.md) type exposes the following members.
## Methods
<table>
<thead>
<tr class="header">
<th> </th>
<th>Name</th>
<th>Description</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn335319(v=exchg.10).md">JetGetColumnInfo</a></td>
<td>Retrieves information about a column in a table.</td>
</tr>
<tr class="even">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351258(v=exchg.10).md">JetGetInstanceMiscInfo</a></td>
<td>Retrieves information about an instance.</td>
</tr>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn335320(v=exchg.10).md">JetGetRecordSize</a></td>
<td>Retrieves record size information from the desired location.</td>
</tr>
<tr class="even">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351264(v=exchg.10).md">JetGetThreadStats</a></td>
<td>Retrieves performance information from the database engine for the current thread. Multiple calls can be used to collect statistics that reflect the activity of the database engine on this thread between those calls.</td>
</tr>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351265(v=exchg.10).md">JetInit3</a></td>
<td>Initialize the ESENT database engine.</td>
</tr>
<tr class="even">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn335326(v=exchg.10).md">JetOpenTemporaryTable</a></td>
<td>Creates a temporary table with a single index. A temporary table stores and retrieves records just like an ordinary table created using JetCreateTableColumnIndex. However, temporary tables are much faster than ordinary tables due to their volatile nature. They can also be used to very quickly sort and perform duplicate removal on record sets when accessed in a purely sequential manner. Also see <a href="dn292231(v=exchg.10).md">JetOpenTempTable(JET_SESID, [], Int32, TempTableGrbit, JET_TABLEID, [])</a>, <a href="dn292233(v=exchg.10).md">JetOpenTempTable3(JET_SESID, [], Int32, JET_UNICODEINDEX, TempTableGrbit, JET_TABLEID, [])</a>.</td>
</tr>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351267(v=exchg.10).md">JetOSSnapshotEnd</a></td>
<td>Notifies the engine that the snapshot session finished.</td>
</tr>
<tr class="even">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351269(v=exchg.10).md">JetOSSnapshotGetFreezeInfo</a></td>
<td>Retrieves the list of instances and databases that are part of the snapshot session at any given moment.</td>
</tr>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn335341(v=exchg.10).md">JetOSSnapshotPrepareInstance</a></td>
<td>Selects a specific instance to be part of the snapshot session.</td>
</tr>
<tr class="even">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn335343(v=exchg.10).md">JetOSSnapshotTruncateLog</a></td>
<td>Enables log truncation for all instances that are part of the snapshot session.</td>
</tr>
<tr class="odd">
<td><img src="../images/dn292146.pubmethod(exchg.10).gif" title="Public method" alt="Public method" /><img src="../images/dn292146.static(exchg.10).gif" title="Static member" alt="Static member" /></td>
<td><a href="dn351271(v=exchg.10).md">JetOSSnapshotTruncateLogInstance</a></td>
<td>Truncates the log for a specified instance during a snapshot session.</td>
</tr>
</tbody>
</table>
Top
## See also
#### Reference
[VistaApi class](./vistaapi-class.md)
[Microsoft.Isam.Esent.Interop.Vista namespace](./microsoft.isam.esent.interop.vista-namespace.md)
| 56.69 | 647 | 0.727465 | eng_Latn | 0.39479 |
117428a2dd03e8b467ea336126a10a9fb3d015dc | 3,574 | md | Markdown | articles/hdinsight/interactive-query/interactive-query-troubleshoot-hive-logs-diskspace-full-headnodes.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/hdinsight/interactive-query/interactive-query-troubleshoot-hive-logs-diskspace-full-headnodes.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/hdinsight/interactive-query/interactive-query-troubleshoot-hive-logs-diskspace-full-headnodes.md | maiemy/azure-docs.it-it | b3649d817c2ec64a3738b5f05f18f85557d0d9b6 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Risoluzione dei problemi: spazio su disco riempito da log Apache Hive-Azure HDInsight'
description: Questo articolo fornisce le procedure per la risoluzione dei problemi da seguire quando Apache Hive i log riempiono lo spazio su disco nei nodi head di Azure HDInsight.
ms.service: hdinsight
ms.topic: troubleshooting
author: nisgoel
ms.author: nisgoel
ms.reviewer: jasonh
ms.date: 10/05/2020
ms.openlocfilehash: 107ec012bf2ff76ee1cbe4c5f8252566a5a16127
ms.sourcegitcommit: 7863fcea618b0342b7c91ae345aa099114205b03
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 11/03/2020
ms.locfileid: "93288925"
---
# <a name="scenario-apache-hive-logs-are-filling-up-the-disk-space-on-the-head-nodes-in-azure-hdinsight"></a>Scenario: i log di Apache Hive riempiono lo spazio su disco nei nodi head in Azure HDInsight
Questo articolo descrive le procedure per la risoluzione dei problemi e le possibili soluzioni per i problemi relativi allo spazio su disco insufficiente nei nodi head nei cluster HDInsight di Azure.
## <a name="issue"></a>Problema
In un cluster Apache Hive/LLAP, i log indesiderati occupano l'intero spazio su disco nei nodi head. Questa condizione può causare i problemi seguenti:
- L'accesso SSH non riesce perché non è rimasto spazio sul nodo head.
- Ambari genera un *errore http: 503 servizio non disponibile*.
- Il riavvio di HiveServer2 Interactive non riesce.
`ambari-agent`Quando si verifica il problema, i log includeranno le voci seguenti:
```
ambari_agent - Controller.py - [54697] - Controller - ERROR - Error:[Errno 28] No space left on device
```
```
ambari_agent - HostCheckReportFileHandler.py - [54697] - ambari_agent.HostCheckReportFileHandler - ERROR - Can't write host check file at /var/lib/ambari-agent/data/hostcheck.result
```
## <a name="cause"></a>Causa
Nelle configurazioni Advanced hive log4j la pianificazione dell'eliminazione predefinita corrente prevede l'eliminazione dei file più vecchi di 30 giorni, in base alla data dell'Ultima modifica.
## <a name="resolution"></a>Soluzione
1. Passare al riepilogo dei componenti hive nel portale di Ambari e selezionare la scheda **configs (configurazioni** ).
2. Passare alla `Advanced hive-log4j` sezione in **Impostazioni avanzate**.
3. Impostare il `appender.RFA.strategy.action.condition.age` parametro su un'età di propria scelta. In questo esempio l'età viene impostata su 14 giorni: `appender.RFA.strategy.action.condition.age = 14D`
4. Se non vengono visualizzate impostazioni correlate, aggiungere le impostazioni seguenti:
```
# automatically delete hive log
appender.RFA.strategy.action.type = Delete
appender.RFA.strategy.action.basePath = ${sys:hive.log.dir}
appender.RFA.strategy.action.condition.type = IfLastModified
appender.RFA.strategy.action.condition.age = 30D
appender.RFA.strategy.action.PathConditions.type = IfFileName
appender.RFA.strategy.action.PathConditions.regex = hive*.*log.*
```
5. Impostare `hive.root.logger` su `INFO,RFA` , come illustrato nell'esempio seguente. L'impostazione predefinita è `DEBUG` , che rende i log di grandi dimensioni.
```
# Define some default values that can be overridden by system properties
hive.log.threshold=ALL
hive.root.logger=INFO,RFA
hive.log.dir=${java.io.tmpdir}/${user.name}
hive.log.file=hive.log
```
6. Salvare le configurazioni e riavviare i componenti richiesti.
## <a name="next-steps"></a>Passaggi successivi
[!INCLUDE [troubleshooting next steps](../../../includes/hdinsight-troubleshooting-next-steps.md)]
| 47.653333 | 204 | 0.771684 | ita_Latn | 0.923073 |
11747039bc9c211f0de2d4bafa71ca8220800be2 | 18,855 | md | Markdown | powerquery-docs/power-query-ui.md | joefields/powerquery-docs | 12d6a82bc4b9d6b09e90b177ee592837c7a990f7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | powerquery-docs/power-query-ui.md | joefields/powerquery-docs | 12d6a82bc4b9d6b09e90b177ee592837c7a990f7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | powerquery-docs/power-query-ui.md | joefields/powerquery-docs | 12d6a82bc4b9d6b09e90b177ee592837c7a990f7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: The Power Query user interface
description: Learn about and how to use the various elements of the Power Query user interface
author: bezhan-msft
ms.topic: overview
ms.date: 5/28/2021
ms.author: dougklo
ms.reviewer: kvivek
localizationgroup: reference
---
# The Power Query user interface
With Power Query, you can connect to many different data sources and transform the data into the shape you want.
In this article, you'll learn how to create queries with Power Query by discovering:
- How the "Get Data" experience works in Power Query.
- How to use and take advantage of the Power Query user interface.
- How to perform common transformations like grouping and merging data.
If you're new to Power Query, you can [sign up for a free trial of Power BI](https://app.powerbi.com/signupredirect?pbi_source=web) before you begin. You can use Power BI dataflows to try out the Power Query Online experiences described in this article.
You can also [download Power BI Desktop for free](https://go.microsoft.com/fwlink/?LinkId=521662).
Examples in this article connect to and use the [Northwind OData feed](https://services.odata.org/V4/Northwind/Northwind.svc/).
```
https://services.odata.org/V4/Northwind/Northwind.svc/
```
## Connect to an OData feed
To start, locate the **OData** feed connector from the "Get Data" experience. You can select the **Other** category from the top, or search for **OData** in the search bar in the top-right corner.

Once you select this connector, the screen displays the connection settings and credentials.
- For **URL**, enter the URL to the Northwind OData feed shown in the previous section.
- For **On-premises data gateway**, leave as none.
- For **Authentication kind**, leave as anonymous.
Select the **Next** button.

The **Navigator** now opens, where you select the tables you want to connect to from the data source. Select the **Customers** table to load a preview of the data, and then select **Transform data**.

The dialog then loads the data from the Customers table into the Power Query editor.
The above experience of connecting to your data, specifying the authentication method, and selecting the specific object or table to connect to is called the **Get data** experience and is documented with further detail in the [Getting data](get-data-experience.md) article.
> [!NOTE]
> To learn more about the OData feed connector, see [OData feed](Connectors/ODataFeed.md).
## The Power Query editor user experience
The Power Query editor represents the Power Query user interface, where you can add or modify queries, manage queries by grouping or adding descriptions to query steps, or visualize your queries and their structure with different views. The Power Query user interface has five distinct components.
[  ](media/power-query-ui/pqui-user-interface.png#lightbox)
1. **Ribbon**: the ribbon navigation experience, which provides multiple tabs to add transforms, select options for your query, and access different ribbon buttons to complete various tasks.
2. **Queries pane**: a view of all your available queries.
3. **Current view**: your main working view, that by default, displays a preview of the data for your query. You can also enable the [diagram view](diagram-view.md) along with the data preview view. You can also switch between the [schema view](schema-view.md) and the data preview view while maintaining the diagram view.
4. **Query settings**: a view of the currently selected query with relevant information, such as query name, query steps, and various indicators.
5. **Status bar**: a bar displaying relevant important information about your query, such as execution time, total columns and rows, and processing status. This bar also contains buttons to change your current view.
> [!NOTE]
> The schema and diagram view are currently only available in Power Query Online.
## Using the Power Query editor
In this section, you'll begin transforming your data using Power Query. But before you start working on transforming the data, we'll discuss some of the UI panes that can be expanded or collapsed depending on their context. Selecting the appropriate panes lets you focus on the view that matters the most to you. We'll also discuss the different views that are available in the Power Query UI.
### The ribbon
The ribbon is the component where you'll find most of the transforms and actions that you can do in the Power Query editor. It has multiple tabs, whose values depend on the product integration. Each of the tabs provides specific buttons and options, some of which might be redundant across the whole Power Query experience. These buttons and options provide you with easy access to the transforms and actions that you may need.
[  ](media/power-query-ui/standard-ribbon.png#lightbox)
The Power Query interface is responsive and tries to adjust your screen resolution to show you the best experience. In scenarios where you'd like to see a compact version of the ribbon, there's also a collapse button at the bottom-right corner of the ribbon to help you switch to the compact ribbon.
[  ](media/power-query-ui/compact-ribbon.png#lightbox)
You can switch back to the standard ribbon view by simply clicking on the expand icon at the bottom-right corner of the ribbon
### Expand and collapse panes
You'll notice that throughout the Power Query user interface there are icons that help you collapse or expand certain views or sections. For example, there's an icon on the top right-hand corner of the Queries pane that collapses the queries pane when selected, and expands the pane when selected again.

### Switch between views
Apart from being able to collapse certain panes and sections in the Power Query user interface, you can also switch what views are displayed. To switch views, go to the **View** tab in the ribbon and you'll find the **Preview** and **Layout** groups, which control how the Power Query user interface will look.
You're encouraged to try all of these options to find the view and layout that you feel most comfortable working with. As an example, select **Schema view** from the ribbon.

The right side of the status bar also contains icons for the diagram, data, and schema views. You can use these icons to change between views. You can also use these icons to enable or disable the view of your choice.
[  ](media/power-query-ui/pqui-current-view-schema.png#lightbox)
### What is schema view
The schema view offers you a quick and straightforward way to interact only with the components of the schema for your table, such as the column names and data types. We recommend the schema view when you want to do schema-related actions, such as removing columns, renaming columns, changing column data types, reordering columns, or duplicating columns.
> [!NOTE]
> To learn more about schema view, see [Using Schema view](schema-view.md).
For example, in schema view, select the check mark next to the **Orders** and **CustomerDemographics** columns, and from the ribbon select the **Remove columns** action. This selection applies a transformation to remove these columns from your data.

### What is diagram view
You can now switch back to the data preview view and enable diagram view to see a more visual perspective of your data and query.

The diagram view helps you visualize how your query is structured and how it might interact with other queries in your project. Each step in your query has a distinct icon to help you recognize the transform that was used. There are also lines that connect steps to illustrate dependencies. Since both data preview view and diagram view are enabled, the diagram view displays on top of the data preview.
[  ](media/power-query-ui/pqui-data-preview-diagram-view.png#lightbox)
> [!NOTE]
> To learn more about diagram view, see [Diagram view](diagram-view.md).
### Begin transforming your data
With diagram view enabled, select the plus sign. You can search for a new transform to add to your query. Search for **Group by** and select the transform.

The **Group by** dialog then appears. You can set the **Group by** operation to group by the country and count the number of customer rows per country.
1. Keep the **Basic** radio button selected.
2. Select **Country** to group by.
3. Select **Customers** and **Count rows** as the column name and operation respectively.

Select **OK** to perform the operation. Your data preview refreshes to show the total number of customers by country.
An alternative way to launch the **Group by** dialog would be to use the **Group by** button in the ribbon or by right-clicking the **Country** column.
[  ](media/power-query-ui/pqui-group-by-alt.png#lightbox)
For convenience, transforms in Power Query can often be accessed from multiple places, so users can opt to use the experience they prefer.
## Adding a new query
Now that you have a query that provides the number of customers per country, you can add context to this data by finding the total number of suppliers for each territory.
First, you'll need to add the **Suppliers** data. Select **Get Data** and from the drop-down menu, and then select **OData**.

The OData connection experience reappears. Enter the connection settings as described in [Connect to an OData feed](#connect-to-an-odata-feed) to connect to the Northwind OData feed. In the **Navigator** experience, search for and select the **Suppliers** table.
[  ](media/power-query-ui/pqui-connect-to-odata-suppliers.png#lightbox)
Select **Create** to add the new query to the Power Query editor. The queries pane should now display both the **Customers** and the **Suppliers** query.
[  ](media/power-query-ui/pqui-customers-and-suppliers-query.png#lightbox)
Open the **Group by** dialog again, this time by selecting the **Group by** button on the ribbon under the **Transform** tab.

In the **Group by** dialog, set the **Group by** operation to group by the country and count the number of supplier rows per country.
1. Keep the **Basic** radio button selected.
2. Select **Country** to group by.
3. Select **Suppliers** and **Count rows** as the column name and operation respectively.

> [!NOTE]
> To learn more about the **Group by** transform, see [Grouping or summarizing rows](group-by.md).
## Referencing queries
Now that you have a query for customers and a query for suppliers, your next goal is to combine these queries into one. There are many ways to accomplish this, including using the **Merge** option in the **Customers** table, duplicating a query, or referencing a query. For this example, you'll create a reference by right-clicking the **Customers** table and selecting **Reference**, which effectively creates a new query that references the **Customers** query.

After creating this new query, change the name of the query to **Country Analysis** and disable the load of the **Customers** table by unmarking the **Enable load** option from the **Suppliers** query.
[  ](media/power-query-ui/pqui-disable-load.png#lightbox)
## Merging queries
A **merge queries** operation joins two existing tables together based on matching values from one or multiple columns. In this example, the goal is to join both the **Customers** and **Suppliers** tables into one table only for the countries that have both **Customers** and **Suppliers**.
Inside the **Country Analysis** query, select the **Merge queries** option from the **Home** tab in the ribbon.

A new dialog for the **Merge** operation appears. You can then select the query to merge with your current query. Select the **Suppliers** query and select the **Country** field from both queries. Finally, select the **Inner** join kind, as you only want the countries where you have **Customers** and **Suppliers** for this analysis.

After selecting the **OK** button, a new column is added to your **Country Analysis** query that contains the data from the **Suppliers** query. Select the icon next to the **Suppliers** field, which displays a menu where you can select which fields you want to expand. Select only the **Suppliers** field, and then select the **OK** button.

The result of this **expand** operation is a table with only 12 rows. Rename the **Suppliers.Suppliers** field to just **Suppliers** by double-clicking the field name and entering the new name.

> [!NOTE]
> To learn more about the **Merge queries** feature, see [Merge queries overview](merge-queries-overview.md).
## Applied steps
Every transformation that is applied to your query is saved as a step in the **Applied steps** section of the query settings pane. If you ever need to check how your query is transformed from step to step, you can select a step and preview how your query resolves at that specific point.
You can also right-click a query and select the **Properties** option to change the name of the query or add a description for the query. For example, right-click the **Merge queries** step from the **Country Analysis** query and change the name of the query to be **Merge with Suppliers** and the description to be **Getting data from the Suppliers query for Suppliers by Country**.

This change adds a new icon next to your step that you can hover over to read its description.

> [!NOTE]
> To learn more about **Applied steps**, see [Using the Applied Steps list](applied-steps.md).
Before moving on to the next section, disable the **Diagram view** to only see the **Data preview**.
## Adding a new column
With the data for customers and suppliers in a single table, you can now calculate the ratio of customers-to-suppliers for each country. Select the last step of the **Country Analysis** query, and then select both the **Customers** and **Suppliers** columns. In the **Add column tab** in the ribbon and inside the **From number** group, select **Standard**, and then **Divide (Integer)** from the dropdown.

This change creates a new column called **Integer-division** that you can rename to **Ratio**. This change is the final step of your query as you can see the customer-to-supplier ratio for the countries where the data has customers and suppliers.
## Data profiling
Another Power Query feature that can help you better understand your data is **Data Profiling**. By enabling the data profiling features, you'll get feedback about the data inside your query fields, such as value distribution, column quality, and more.
We recommended that you use this feature throughout the development of your queries, but you can always enable and disable the feature at your convenience. The following image shows all the data profiling tools enabled for your **Country Analysis** query.

> [!NOTE]
> To learn more about **Data profiling**, see [Using the data profiling tools](data-profiling-tools.md).
## The advanced editor
If you want to see the code that the Power Query editor is creating with each step, or want to create your own shaping code, you can use the advanced editor. To open the advanced editor, select the **View** tab on the ribbon, and then select **Advanced Editor**. A window appears, showing the existing query code.

You can directly edit the code in the **Advanced Editor** window. The editor indicates if your code is free of syntax errors. To close the window, select the **Done** or **Cancel** button.
## Summary
In this article, you created a series of queries with Power Query that provides a customer-to-supplier ratio analysis at the country level for the Northwind corporation.
You learned the components of the Power Query user interface, how to create new queries inside the query editor, reference queries, merge queries, understand the applied steps section, add new columns, and how to use the data profiling tools to better understand your data.
Power Query is a powerful tool used to connect to many different data sources and transform the data into the shape you want. The scenarios outlined in this article are examples to show how users can use Power Query to transform raw data into important actionable business insights.
| 69.319853 | 464 | 0.77083 | eng_Latn | 0.997302 |
1174849791f524d36626574fa2182ed8592433e5 | 3,160 | md | Markdown | Jekyll/Things-Need-To-Know/liquid-whitespace.md | zhongxiang117/zhongxiang117.github.io | 98828d0a9a4e0e02577547b537489d450182360e | [
"MIT"
] | null | null | null | Jekyll/Things-Need-To-Know/liquid-whitespace.md | zhongxiang117/zhongxiang117.github.io | 98828d0a9a4e0e02577547b537489d450182360e | [
"MIT"
] | null | null | null | Jekyll/Things-Need-To-Know/liquid-whitespace.md | zhongxiang117/zhongxiang117.github.io | 98828d0a9a4e0e02577547b537489d450182360e | [
"MIT"
] | null | null | null | ---
---
# Liquid Whitespace Control
official link: [`liquid-whitespace-control`](https://shopify.github.io/liquid/basics/whitespace/)
{% raw %}
it has a line:
> If you don’t want any of your tags to print whitespace, as a general rule you can add hyphens to both sides of all your tags (`{%-` and `-%}`):
however, it is not that much informative and clear, even with the help of their examples.
As a complementary, there are more examples:
# In Assignment
There are three examples.
## keep original
**input**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
{% assign song = "Hello" %} # assignment line
# after: empty-line-1
# after: empty-line-2
{{ song }}
```
**output**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
# assignment line
# after: empty-line-1
# after: empty-line-2
Hello # `song' is printed out in its original line
```
## left-side strip
**input**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
{%- assign song = "Hello" %} # assignment line
# after: empty-line-1
# after: empty-line-2
{{ song }}
```
**output**
```bash
# assignment line
# after: empty-line-1
# after: empty-line-2
Hello # printout without former whitespace
```
## right-side strip
**input**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
{% assign song = "Hello" -%} # assignment line
# after: empty-line-1
# after: empty-line-2
{{ song }}
```
**output**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
Hello # printout without latter whitespace or assignment line
```
```note
Attention: The `assignment-line` is also removed
```
## both-sides strip
**input**
```bash
# before: empty-line-1
# before: empty-line-2
# before: empty-line-3
{%- assign song = "Hello" -%} # assignment line
# after: empty-line-1
# after: empty-line-2
{{ song }}
```
**output**
```bash
Hello # printout without any whitespace
```
# in loop-control
its official link: [`liquid-loop-control`](https://shopify.github.io/liquid/tags/control-flow/)
```note
In total, it has three different types of loop control, in here, only the `if-elsif-else` control is talked. The mechanism for whitespace removing of the other two `case-when` & `unless-if` are similar with `if` control.
```

# important note
number of spaces in printout line dose not matter, for example:
**input**
```bash
{%- assign song = "Hello" -%}
{{ song }}
<!-- OR -->
{{ song }}
<!-- OR -->
{{ song }}
<!-- OR -->
{{song}}
```
**output**
all their results will be
```
Hello
```
{% endraw %} | 18.809524 | 220 | 0.563924 | eng_Latn | 0.981934 |
1174b60967754ddb26973454f6241e4c669244ea | 954 | md | Markdown | README.md | fortinet-solutions-cse/fortimailapi | ce868ce936628be1060f42b2dd5713b796f2fc65 | [
"Apache-2.0"
] | null | null | null | README.md | fortinet-solutions-cse/fortimailapi | ce868ce936628be1060f42b2dd5713b796f2fc65 | [
"Apache-2.0"
] | 1 | 2019-06-10T16:31:33.000Z | 2019-06-10T16:31:33.000Z | README.md | fortinet-solutions-cse/fortimailapi | ce868ce936628be1060f42b2dd5713b796f2fc65 | [
"Apache-2.0"
] | null | null | null | # FortiMail API Python
Python library to configure Fortinet's FortiMail devices (REST API)
To generate new version in PyPi do the following:
1. Submit all your changes including version update of ./setup.py to remote repo
2. Create a tag in the repo for this last commit
3. Push new tag into repo:
git push --tags
4. Create new package:
python setup.py sdist
5. Upload package:
twine upload dist/fortimailapi-0.x.x.tar.gz
Note: Ensure there is ~/.pypirc file with chmod 600 permissions and the following content:
[distutils]
index-servers =
pypi
pypitest
[pypi]
repository=https://upload.pypi.org/legacy/
username=your_user
password=your_password
[pypitest]
repository=https://testpypi.python.org/pypi
username=your_user
password=your_password
| 25.105263 | 90 | 0.620545 | eng_Latn | 0.847662 |
11750c65321b994c5ad4b9ae8fbbf027339ac0c1 | 1,445 | md | Markdown | README.md | vbkaisetsu/daachorse | a861b495d2da29777c144d225f40ce22ab8f95f1 | [
"Apache-2.0",
"MIT"
] | null | null | null | README.md | vbkaisetsu/daachorse | a861b495d2da29777c144d225f40ce22ab8f95f1 | [
"Apache-2.0",
"MIT"
] | null | null | null | README.md | vbkaisetsu/daachorse | a861b495d2da29777c144d225f40ce22ab8f95f1 | [
"Apache-2.0",
"MIT"
] | null | null | null | # 🐎 daachorse
Daac Horse: Double-Array Aho-Corasick
[](https://crates.io/crates/daachorse)
[](https://docs.rs/daachorse)
## Overview
A fast implementation of the Aho-Corasick algorithm using Double-Array Trie.
### Examples
```rust
use daachorse::DoubleArrayAhoCorasick;
let patterns = vec!["bcd", "ab", "a"];
let pma = DoubleArrayAhoCorasick::new(patterns).unwrap();
let mut it = pma.find_overlapping_iter("abcd");
let m = it.next().unwrap();
assert_eq!((0, 1, 2), (m.start(), m.end(), m.pattern()));
let m = it.next().unwrap();
assert_eq!((0, 2, 1), (m.start(), m.end(), m.pattern()));
let m = it.next().unwrap();
assert_eq!((1, 4, 0), (m.start(), m.end(), m.pattern()));
assert_eq!(None, it.next());
```
## Disclaimer
This software is developed by LegalForce, Inc.,
but not an officially supported LegalForce product.
## License
Licensed under either of
* Apache License, Version 2.0
([LICENSE-APACHE](LICENSE-APACHE) or http://www.apache.org/licenses/LICENSE-2.0)
* MIT license
([LICENSE-MIT](LICENSE-MIT) or http://opensource.org/licenses/MIT)
at your option.
## Contribution
Unless you explicitly state otherwise, any contribution intentionally submitted
for inclusion in the work by you, as defined in the Apache-2.0 license, shall be
dual licensed as above, without any additional terms or conditions.
| 26.272727 | 93 | 0.706574 | eng_Latn | 0.717912 |
11756636ca1391bdcb0432d8a13c079765da0045 | 1,824 | md | Markdown | docs/framework/unmanaged-api/hosting/getcorrequiredversion-function.md | eOkadas/docs.fr-fr | 64202ad620f9bcd91f4360ec74aa6d86e1d4ae15 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/hosting/getcorrequiredversion-function.md | eOkadas/docs.fr-fr | 64202ad620f9bcd91f4360ec74aa6d86e1d4ae15 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/hosting/getcorrequiredversion-function.md | eOkadas/docs.fr-fr | 64202ad620f9bcd91f4360ec74aa6d86e1d4ae15 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: GetCORRequiredVersion, fonction
ms.date: 03/30/2017
api_name:
- GetCORRequiredVersion
api_location:
- mscoree.dll
api_type:
- DLLExport
f1_keywords:
- GetCORRequiredVersion
helpviewer_keywords:
- GetCORRequiredVersion function [.NET Framework hosting]
ms.assetid: 1588fe7b-c378-4f4b-9c4b-48647f1119cc
topic_type:
- apiref
author: rpetrusha
ms.author: ronpet
ms.openlocfilehash: 8597b68b75d2b5f77f68fc13c3fb78bfdae46178
ms.sourcegitcommit: 7f616512044ab7795e32806578e8dc0c6a0e038f
ms.translationtype: MT
ms.contentlocale: fr-FR
ms.lasthandoff: 07/10/2019
ms.locfileid: "67736291"
---
# <a name="getcorrequiredversion-function"></a>GetCORRequiredVersion, fonction
Obtient le numéro de version de runtime (CLR) de langage commun requis.
Cette fonction a été déconseillée dans le .NET Framework 4.
## <a name="syntax"></a>Syntaxe
```cpp
HRESULT GetCORRequiredVersion (
[out] LPWSTR pbuffer,
[in] DWORD cchBuffer,
[out] DWORD *dwLength
);
```
## <a name="parameters"></a>Paramètres
`pbuffer`
[out] Une mémoire tampon qui contient une chaîne qui spécifie le numéro de version.
`cchBuffer`
[in] La taille, en octets, de la mémoire tampon.
`dwLength`
[out] Le nombre d’octets retournés dans la mémoire tampon.
## <a name="requirements"></a>Configuration requise
**Plateformes :** Consultez [Configuration requise](../../../../docs/framework/get-started/system-requirements.md).
**En-tête :** MSCorEE.h
**Bibliothèque :** MSCorEE.dll
**Versions du .NET Framework :** [!INCLUDE[net_current_v10plus](../../../../includes/net-current-v10plus-md.md)]
## <a name="see-also"></a>Voir aussi
- [Fonctions d’hébergement CLR dépréciées](../../../../docs/framework/unmanaged-api/hosting/deprecated-clr-hosting-functions.md)
| 28.952381 | 128 | 0.71875 | yue_Hant | 0.221926 |
1175a0151a8bba26de6ba93aa92c4c159a24e439 | 2,358 | md | Markdown | README.md | zzyyppqq/Android-info | f402873f7a004c191e76a836cdcd71d309ef6766 | [
"Apache-2.0"
] | null | null | null | README.md | zzyyppqq/Android-info | f402873f7a004c191e76a836cdcd71d309ef6766 | [
"Apache-2.0"
] | null | null | null | README.md | zzyyppqq/Android-info | f402873f7a004c191e76a836cdcd71d309ef6766 | [
"Apache-2.0"
] | null | null | null | # Android-info
> Android开发相关
>> - 网站
>>>1.[Android Weekly中文版](http://wiki.jikexueyuan.com/project/android-weekly/)
>>> [Android Weekly英文版](http://androidweekly.net/)
>>> Android Weekly 相当于是 Android 开发社区的实时通讯录,每周报道 Android 最新讯息,包括新的库、工具和博客等,只要你有 Email,就可以对其进行订阅,了解更多关于 Android 的消息。
>>>2.[Android Developers Blog 英文版](http://android-developers.blogspot.com/)
>>> Android Developers Blog
>>>3.[AndroidDevTools 中文版](http://www.androiddevtools.cn/)
>>> Android Dev Tools (官网地址:www.androiddevtools.cn)
收集整理Android开发所需的Android SDK、开发中用到的工具、Android开发教程、Android设计规范,免费的设计素材等。欢迎大家推荐自己在Android开发过程中用的好用的工具、学习开发教程、用到设计素材
>>>4.[Android Arsena 英文版(UI)](http://android-arsenal.com/)
>>> Android developer portal with tools, libraries, and apps
>>>5.[android-open-project 中文版(Trinea UI)](https://github.com/Trinea/android-open-project)
>>> android-open-project
>>>6.[appance 英文版(UI)](http://www.appance.com/category/android/)
>>> Android、iOS 、Windows Phone等开源项目
>>>7.[整理的Android开发资源(stormzhang)](http://www.stormzhang.com/android/2014/06/05/android-awesome-resources/)
>>> 整理的Android开发资源
>>>8.[codekk 中文版(UI)](http://a.codekk.com)
>>> codekk 源码解析 开源项目
>>>9.[Android学习之路 (stormzhang)](http://www.stormzhang.com/android/2014/07/07/learn-android-from-rookie/)
>>> Android学习之路
>>>10.[Android自定义控件实战 (Hongyang UI)](http://blog.csdn.net/lmj623565791/article/category/2680595)
>>> Android自定义控件实战
>>>11.[美团Android自动化之旅—生成渠道包 ](http://tech.meituan.com/mt-apk-packaging.html)
>>> 每当发新版本时,美团团购Android客户端会被分发到各个应用市场,比如豌豆荚,360手机助手等。为了统计这些市场的效果(活跃数,下单数等),需要有一种方法来唯一标识它们。
>>>12.[慕课网 (Video)](http://www.imooc.com/)
>>> 慕课网-国内最大的IT技能学习平台
>>>13.[Android开发者必备的42个网站](http://www.cnblogs.com/purediy/p/3498184.html)
>>> Android开发者必备的42个链接
>>>14.[quick-look-plugins](https://github.com/sindresorhus/quick-look-plugins)
>>> OSX系统 quick-look-plugins
>>>15.[dribbble](https://dribbble.com/shots/1945376-Search)
>>> 设计、动效相关
>>>16.[推荐几款实用的Android Studio 插件](http://jcodecraeer.com/a/anzhuokaifa/Android_Studio/2015/1009/3557.html)
>>> 推荐几款实用的Android Studio 插件
>>>17.[react-native环境配置](http://www.csdn.net/article/2015-09-24/2825787-react-native)
>>>18.[React-Native学习指南](https://github.com/ele828/react-native-guide)
>>>React-Native指南汇集了react-native学习资源与各类开源app
>>>19.[react-native](http://facebook.github.io/react-native/docs/view.html#content)
| 26.494382 | 114 | 0.739186 | yue_Hant | 0.712399 |
1176641a4fb1ce62c6760bde1d91e16c9cb33677 | 70 | md | Markdown | README.md | thomasio101/thomasio-auth-js-bcrypt | 1d3b82b378bfa43a21596fb9847e23b178a1af15 | [
"MIT"
] | null | null | null | README.md | thomasio101/thomasio-auth-js-bcrypt | 1d3b82b378bfa43a21596fb9847e23b178a1af15 | [
"MIT"
] | null | null | null | README.md | thomasio101/thomasio-auth-js-bcrypt | 1d3b82b378bfa43a21596fb9847e23b178a1af15 | [
"MIT"
] | null | null | null | # thomasio-auth-js-bcrypt
This project's documentation is coming soon! | 35 | 44 | 0.814286 | eng_Latn | 0.990217 |
117697c4424c7b138989000ff0fbc78942788ada | 10,482 | md | Markdown | blog/interact-apps.md | Moelf/abhishalya.github.io | 03440a535e64b794aba3866fbfbe30ab3588a206 | [
"MIT"
] | 8 | 2020-05-18T12:28:14.000Z | 2022-01-23T21:16:29.000Z | blog/interact-apps.md | Moelf/abhishalya.github.io | 03440a535e64b794aba3866fbfbe30ab3588a206 | [
"MIT"
] | 5 | 2019-01-08T06:31:20.000Z | 2020-10-18T15:07:23.000Z | blog/interact-apps.md | Moelf/abhishalya.github.io | 03440a535e64b794aba3866fbfbe30ab3588a206 | [
"MIT"
] | 4 | 2021-02-17T17:53:23.000Z | 2021-10-15T08:38:51.000Z | @def title = "Developing apps using Interact.jl"
@def published = "16 December 2019"
@def tags = ["julia", "code-in"]
# Developing apps using Interact.jl
I think many of you might think that it is quite impossible or hard to develop
a web-app in Julia. Well, you are wrong! Developing a web-app using Julia is
very much possible and is easy too. This post will give you a brief guide to
how you can develop you apps using
[Interact.jl](https://github.com/JuliaGizmos/Interact.jl) and
[WebIO](https://github.com/JuliaGizmos/WebIO.jl).
This blog post is also a submission to one of my Google Code-in tasks at Julia.
## Where are the docs?
Well, Interact is a great package but one of the things it lacks is the
proper documentation and examples which are really important which you try
to build your own app. The existing documentation is probably only good enough
for widgets but many of the functions are missing there. One of the reason is
Interact is build upon WebIO, CSSUtil and other packages where each one has its
own documentation. So if you don't find something in Interact chances are it
will be somewhere else. Just doing a Github search would get you to the source
:P
But hopefully, this post will give you all the basics you'll
need to know in order to successfully develop your app at one place.
This might not cover all there is but this should at least get you started.
## Getting Started
Before we move on to using these packages, we first need to make sure we have
everything we need.
Interact works with the following frontends:
- [Juno](https://junolab.org/) - A flexible IDE for the 21st century
- [IJulia](https://github.com/JuliaLang/IJulia.jl) - Jupyter notebooks
(and Jupyter Lab) for Julia
- [Blink](https://github.com/JunoLab/Blink.jl) - An Electron wrapper you can
use to make Desktop apps
- [Mux](https://github.com/JuliaWeb/Mux.jl) - A web server framework
You can use any one of these. I'll be working with IJulia and Mux here.
For IJulia, you need to make sure you have Jupyter notebook installed along
with nbextensions.
You can just do:
```
pip3 install jupyterlab --user
```
I avoid using `sudo pip` and you should too in my opinion.
Next, install the nbextensions
```
pip3 install jupyter_contrib_nbextensions
jupyter contrib nbextension install
```
And finally install the WebIO Jupyter notebook extension in REPL:
```
julia> ]
(v1.3) pkg> add WebIO
```
```julia
using WebIO
WebIO.install_jupyter_nbextension()
```
Now if everything is goes fine, you can move towards next step.
## Interact.jl - An example
Interact provides a
[set of widgets](https://juliagizmos.github.io/Interact.jl/latest/widgets/) you
can include in your app. Also, you can create you own
[custom widgets](https://juliagizmos.github.io/Interact.jl/latest/custom_widgets/)
if you want to. Here we will only focus on the available widgets.
So, here we will be trying to replicate the UI of the
[DiffEqOnline](https://app.juliadiffeq.org/sde) app. We can see that the UI
contains text input fields, numerical inputs and a dropdown menu. All of which
we can implement using the available widgets of Interact as follows:
```julia
# Textarea for the input equations (for multiline input)
input_eqn = Widgets.textarea(label = "Enter the system of differential equations here:",
value = "dx = a*x - b*x*y\ndy = -c*y + d*x*y")
# Textbox for the input parameters
input_param = Widgets.textbox(label = "Parameters:",
value = "a=1.5, b=1, c=3, d=1")
# Textarea for input noise (for multiline input)
input_noise = Widgets.textarea(label = "Input the noise function here:",
value = "dx = a*x\ndy = a*y")
# Textbox for the noise parameters
noise_param = Widgets.textbox(label = "Noise parameters:",
value = "a=0.25")
# Since we only accept numerical values for the time span we can
# use the spinbox. (we can also specify the range for spinboxes)
time_span_1 = Widgets.spinbox(label = "Time span:", value = 0)
time_span_2 = Widgets.spinbox(value = 10)
# Textbox for the initial conditions
initial_cond = Widgets.textbox(label = "Initial conditions:",
value = "1.0, 1.0")
# Textbox for the plotting variables
plotting_var = Widgets.textbox(label = "Plotting variables",
value = "[:x, :y]")
# To create a dropdown menu, we need a dict with the keys and associated values
# to select the options within it.
dict = Dict("SRIW1: Rossler's Strong Order 1.5 SRIW1 method" => 1,
"SRA1: Rossler's Strong Order 2.0 SRA1 method (for additive noise)" => 2)
plotting_var = Widgets.dropdown(label = "Solver:", dict, value = 2)
# Textbox for the graph name
graph_title = Widgets.textbox(label = "Graph title:",
value = "Stochastic Lotka-Volterra Equation")
# Creates a button with name "Solve it"
solve_but = button("Solve it")
```
Now, since we've got all the elements we needed, we can just create a UI element
by stacking them over one another.
We'll use `vbox` to vertically stack all the elements. You can use `hbox` to
horizontally stack elements. Also, to make it look better we will append a
horizontal line between each element and a vertical margin of 20px using
`hline()` and `vskip(20px)` respectively.
So, the final result should be something like this:
```julia
ui = vbox(vskip(20px), input_eqn, vskip(20px), hline(),
vskip(20px), input_param, vskip(20px), hline(),
vskip(20px), input_noise, vskip(20px), hline(),
vskip(20px), noise_param, vskip(20px), hline(),
vskip(20px), time_hor, vskip(20px), hline(),
vskip(20px), initial_cond, vskip(20px), hline(),
vskip(20px), plotting_var, vskip(20px), hline(),
vskip(20px), graph_title, vskip(20px), hline(),
vskip(20px), solve_but)
```
Now, if you're running all this code you'd see that the elements are already
styled. This is because Interact uses 'Bulma' CSS for the styling. We can
modify this, but it is a topic for some other post.
So far we've got the user-interface we needed. Now, how to record the values
and work with them. To understand that, we'll need to understand what
are `Observables`.
## Observables
Observables are like `Ref`s but you can listen to changes.
As an example:
```julia
using Observables
obv = Observable(0)
on(obv) do val
println("Value changed to: ", val)
end
```
So if we do:
```
obv[] = 10
```
Then the output will be:
```
Value changed to: 10
```
So, for the above example we need to construct an observable for each of the
elements we just created. I'll define a new function `make_observable` to do
this. But before that let's define a scope object to enclose the observables.
```julia
scope = Scope()
```
A `Scope` acts as a medium for bidirectional communication between Julia
and JavaScript. The primary method of communication is `Observables` which are
essentially wrappers around values that may change over time. A `Scope` may
contain several observables whose values can be updated and read from either
JavaScript or Julia.
So the `make_oservable` function will rely on a unique key which we will provide
for each of the elements we just constructed. So, in order to do that, we will
set an Observable object to each of the elements' value. What this will do is,
it will record the values of each of these elements. And we will trigger the
function which we want to run (the work to be done on the given values) on
a click of the `solve_but`.
So, to do this we might do something like this:
```julia
function makeobservable(key, val = get(dict, key, nothing))
scope[key] = Observable{Any}(val)
end
input_eqn = Widgets.textarea(label = "Enter the system of differential equations here:",
value = makeobservable("input_eqn"))
input_param = Widgets.textbox(label = "Parameters:",
value = makeobservable("input_param"))
input_noise = Widgets.textarea(label = "Input the noise function here:",
value = makeobservable("input_noise"))
# Do this for all elements in a similar way
```
Finally, for the button we need an observable for counting clicks. We can do
that like this:
```julia
clicks = scope["clicks"] = Observable{Any}(0)
```
Now, we need to provide some initial data for all of the elements. So, we will
construct a dict with the keys for each of the element and values set to the
initial values of their corresponding elements.
```julia
const init_dict = Dict(
"input_eqn" =>"dx = a*x - b*x*y\ndy = -c*y + d*x*y",
"input_param" =>"a=1.5, b=1, c=3, d=1",
"input_noise" => "dx = a*x\ndy = a*y",
"noise_param" => "a=0.25",
"time_span_1" => 0,
"time_span_2" => 10,
"initial_cond" => "1.0, 1.0",
"plotting_var" => "[:x, :y]",
"solver" => 1,
"graph_title" => "Stochastic Lotka-Volterra Equation",
)
```
Finally, we will construct a dict containing all of the form input elements like
this:
```julia
form_input = Observable{Dict}(dict)
form_input = makeobservable("form_input", init_dict)
```
Finally to update the `form_input` on the click, we can do something like this:
```julia
form_contents = Dict(key=> @js $(scope[key])[] for key in keys(init_dict))
onjs(clicks, @js () ->$form_input[] = $form_contents)
```
We will call the function we want to work with by sending the `form_input` as
an argument and appending the output to the `ui`.
To use Mux.jl to serve the web-page we can simple do:
```julia
]add Mux
using Mux
WebIO.webio_serve(page("/", req -> ui), 8488)
```
Here the number 8488 is the port number, you can use any port you want. After
this you can simply open the browser and redirect to `localhost:8488` or any
other port number you used and you should see the UI just created.
This completes the introductory blog post on how you can create a web-app
using Interact and WebIO. I hope it was helpful for you somewhat to make
your own apps. You can use all of the available documentation mentioned below
to get more details.
## Thanks
A huge thanks to [@sashi](https://github.com/shashi) and
[@logankilpatrick](https://github.com/logankilpatrick) for helping me out
throughout my tasks. :)
## References
1. https://juliagizmos.github.io/Interact.jl/latest/
2. https://juliagizmos.github.io/WebIO.jl/latest/
3. https://juliagizmos.github.io/Observables.jl/latest/
| 34.94 | 88 | 0.710551 | eng_Latn | 0.989114 |
1176a92d3a9f4fc2374d73c520f3e67369e897cf | 1,626 | md | Markdown | CHANGELOG.md | zxqfox/generator-bem-stub | cc50191f04745ed06286f3ac867d46dcc6c9e24b | [
"MIT"
] | null | null | null | CHANGELOG.md | zxqfox/generator-bem-stub | cc50191f04745ed06286f3ac867d46dcc6c9e24b | [
"MIT"
] | null | null | null | CHANGELOG.md | zxqfox/generator-bem-stub | cc50191f04745ed06286f3ac867d46dcc6c9e24b | [
"MIT"
] | null | null | null | History of changes
==================
0.3.0
-----
* Library [bem-components](http://bem.info/libs/bem-components/current/) was updated to `v2.0.0`.
* Updated other dependencies.
0.2.2
-----
* Fixed generation of file `.gitignore`.
0.2.1
-----
* Fixed generation of folders `*.bundles`.
* Updated [dependencies](https://github.com/bem/generator-bem-stub/commit/7113c13541c36ed510f259a5767747c12ef85624).
0.2.0
-----
* Fixed the work of the generator on Windows OS.
* Moved to using [enb-bem-techs](http://ru.bem.info/tools/bem/enb-bem-techs/) in generation of projects for assembler [ENB](https://github.com/enb-make/enb).
* Fixed the configuration of template engines for assembler [ENB](https://github.com/enb-make/enb).
* Fixed the generation of files `.gitignore` and `bower.json`.
* Removed technologies:
* ie6.css
* ie7.css
* [Roole](https://github.com/curvedmark/roole)
0.1.1
-----
* Fixed the generation of config for technolgy `node.js`.
0.1.0
-----
* Moved to using CSS preprocessor [Stylus](https://github.com/LearnBoost/stylus) as default in library [bem-components](http://bem.info/libs/bem-components/current/).
* Renamed option `no-deps` to `skip-install`.
* Refactored the questions to a user:
* Created the separate question about template engines for assembler [bem-tools](http://bem.info/tools/bem/bem-tools/).
* Created the separate question about [Autoprefixer](https://github.com/postcss/autoprefixer).
* Fixed the generation of file `bemjson.js`. It will be generated the same no matter what of kind assembler you use.
* Updated the versions of dependencies and libraries.
* Fixed bugs.
| 33.183673 | 166 | 0.722632 | eng_Latn | 0.716592 |
11784b8b1cbe6aaf3ada2dc50c6f78f3907742fa | 22,906 | md | Markdown | articles/security/security-azure-encryption-overview.md | mikaelkrief/azure-docs.fr-fr | 4cdd4a1518555b738f72dd53ba366849013f258c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/security/security-azure-encryption-overview.md | mikaelkrief/azure-docs.fr-fr | 4cdd4a1518555b738f72dd53ba366849013f258c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/security/security-azure-encryption-overview.md | mikaelkrief/azure-docs.fr-fr | 4cdd4a1518555b738f72dd53ba366849013f258c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Vue d’ensemble du chiffrement Azure | Microsoft Docs
description: En savoir plus sur les différentes options de chiffrement dans Azure
services: security
documentationcenter: na
author: Barclayn
manager: MBaldwin
editor: TomShinder
ms.assetid: ''
ms.service: security
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: na
ms.date: 08/18/2017
ms.author: barclayn
ms.openlocfilehash: 00c8b30b5351b7a6e4388b186fab70e3a3357ef4
ms.sourcegitcommit: b6319f1a87d9316122f96769aab0d92b46a6879a
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 05/20/2018
ms.locfileid: "34366305"
---
# <a name="azure-encryption-overview"></a>Vue d’ensemble du chiffrement Azure
Cet article fournit une vue d’ensemble de l’utilisation du chiffrement dans Microsoft Azure Document. Il couvre les principales zones de chiffrement, notamment le chiffrement au repos, le chiffrement en vol et la gestion des clés avec Azure Key Vault. Chaque section inclut des liens vers des informations plus détaillées.
## <a name="encryption-of-data-at-rest"></a>Chiffrement des données au repos
Les données au repos incluent des informations qui se trouvent dans un stockage persistant sur un support physique, sous n’importe quel format numérique. Il peut s’agir de fichiers sur un support magnétique ou optique, de données archivées et de sauvegardes de données. Microsoft Azure offre une variété de solutions de stockage de données en fonction des besoins, y compris le stockage sur fichier, disque, objet blob et table. Microsoft fournit également le chiffrement pour protéger [Azure SQL Database](../sql-database/sql-database-technical-overview.md), [Azure Cosmos DB](../cosmos-db/introduction.md) et Azure Data Lake.
Le chiffrement des données au repos est disponible pour les modèles de cloud SaaS (Software-as-a-Service), PaaS (Platform-as-a-Service) et IaaS (Infrastructure-as-a-Service). Cet article résume et fournit des ressources pour vous aider à utiliser les options de chiffrement Azure.
Pour accéder à une discussion plus détaillée du mode de chiffrement de données au repos dans Azure, consultez [Chiffrement au repos des données Azure](azure-security-encryption-atrest.md).
## <a name="azure-encryption-models"></a>Modèles de chiffrement Azure
Azure prend en charge plusieurs modèles de chiffrement, notamment le chiffrement côté serveur à l’aide de clés gérées par le service, de clés gérées par le client dans Key Vault, ou de clés gérées par le client sur du matériel contrôlé par le client. Avec le chiffrement côté client, vous pouvez gérer et stocker des clés localement ou dans un autre emplacement sûr.
### <a name="client-side-encryption"></a>chiffrement côté client
Le chiffrement côté client est effectué en dehors d’Azure. Il inclut :
- Les données chiffrées par une application qui s’exécute dans le centre de données du client ou par une application de service.
- Les données qui sont déjà chiffrées quand elles sont reçues par Azure.
Avec le chiffrement côté client, les fournisseurs de services cloud n’ont pas accès aux clés de chiffrement et ne peuvent pas déchiffrer ces données. Vous conservez un contrôle total des clés.
### <a name="server-side-encryption"></a>Chiffrement côté serveur
Les trois modèles de chiffrement côté serveur offrent différentes caractéristiques de gestion de clés, que vous pouvez choisir en fonction de vos besoins :
- **Clés gérées par le service** : ce modèle fournit une combinaison de contrôle et de fonctionnalités avec une faible surcharge.
- **Clés gérées par le client** : ce modèle vous permet de contrôler les clés, avec notamment la prise en charge de BYOK (Bring Your Own Keys), ou d’en générer de nouvelles.
- **Clés gérées par le service sur le matériel contrôlé par le client** : ce modèle vous permet de gérer les clés dans votre référentiel propriétaire, en dehors du contrôle de Microsoft. Cette caractéristique est appelée HYOK (Host Your Own Key). Toutefois, la configuration est complexe et la plupart des services Azure ne prennent pas en charge ce modèle.
### <a name="azure-disk-encryption"></a>Azure Disk Encryption
Vous pouvez protéger les machines virtuelles Windows et Linux à l’aide de [Azure Disk Encryption](azure-security-disk-encryption.md), qui utilise la technologie [Windows BitLocker](https://technet.microsoft.com/library/cc766295(v=ws.10).aspx) et Linux [DM-Crypt](https://en.wikipedia.org/wiki/Dm-crypt) pour protéger des disques du système d’exploitation et des disques de données avec un chiffrement de volume complet.
Les clés de chiffrement et les secrets sont sauvegardés dans votre abonnement [Azure Key Vault](../key-vault/key-vault-whatis.md). À l’aide du service Sauvegarde Azure, vous pouvez sauvegarder et restaurer des machines virtuelles chiffrées qui utilisent la configuration de clé de chiffrement à clé (KEK).
### <a name="azure-storage-service-encryption"></a>Chiffrement du service de stockage Azure
Les données au repos dans le stockage Blob Azure et les partages de fichiers Azure peuvent être chiffrées dans les scénarios côté serveur et côté client.
[Azure Storage Service Encryption](../storage/common/storage-service-encryption.md) (SSE) peut chiffrer automatiquement les données avant qu’elles ne soient stockées, et les déchiffre automatiquement quand vous les récupérez. Le processus est entièrement transparent pour les utilisateurs. Storage Service Encryption utilise le [chiffrement AES (Advanced Encryption Standard)](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard) 256 bits, qui est l’un des chiffrements par blocs les plus forts disponibles. AES gère le chiffrement, le déchiffrement et la gestion des clés en toute transparence.
### <a name="client-side-encryption-of-azure-blobs"></a>Chiffrement côté client des objets blob Azure
Vous pouvez effectuer le chiffrement côté client des objets blob Azure de différentes manières.
Vous pouvez utiliser la bibliothèque cliente de stockage Azure pour le package NuGet .NET afin de chiffrer les données dans vos applications clientes avant de les charger vers votre stockage Azure.
Pour en savoir plus et télécharger la bibliothèque cliente de stockage Azure pour le package NuGet .NET, consultez [Stockage Microsoft Azure 8.3.0](https://www.nuget.org/packages/WindowsAzure.Storage).
Quand vous utilisez le chiffrement côté client avec Key Vault, vos données sont chiffrées à l’aide d’une clé de chiffrement de contenu (CEK) symétrique à usage unique qui est générée par le SDK client de stockage Azure. La clé CEK est chiffrée à l’aide d’une clé de chiffrement de clé (KEK), qui peut être une clé symétrique ou une paire de clés asymétriques. Vous pouvez la gérer localement ou la stocker dans Key Vault. Les données chiffrées sont ensuite chargées vers Stockage Azure.
Pour en savoir plus sur le chiffrement côté client avec Key Vault et obtenir des instructions de démarrage pas à pas, consultez [Didacticiel : Chiffrement et déchiffrement d’objets blob dans Microsoft Azure Storage à l’aide d’Azure Key Vault](../storage/storage-encrypt-decrypt-blobs-key-vault.md).
Pour finir, vous pouvez également utiliser la bibliothèque cliente de stockage Azure pour Java afin d’effectuer un chiffrement côté client avant de charger des données vers le stockage Azure et de déchiffrer les données lors de leur téléchargement vers le client. La bibliothèque prend également en charge l’intégration à [Key Vault](https://azure.microsoft.com/services/key-vault/) pour la gestion des clés de compte de stockage.
### <a name="encryption-of-data-at-rest-with-azure-sql-database"></a>Chiffrement des données au repos avec Azure SQL Database
[Azure SQL Database](../sql-database/sql-database-technical-overview.md) est une base de données relationnelle à usage général dans Azure qui prend en charge des structures telles que les données relationnelles, JSON, les données spatiales et XML. SQL Database prend en charge le chiffrement côté serveur grâce à la fonctionnalité de chiffrement transparent des données (TDE) et le chiffrement côté client grâce à la fonction Always Encrypted.
#### <a name="transparent-data-encryption"></a>Chiffrement transparent des données
[TDE](https://docs.microsoft.com/sql/relational-databases/security/encryption/transparent-data-encryption-tde) est utilisé pour chiffrer les fichiers de données [SQL Server](https://www.microsoft.com/sql-server/sql-server-2016), [Azure SQL Database](../sql-database/sql-database-technical-overview.md) et [Azure SQL Data Warehouse](../sql-data-warehouse/sql-data-warehouse-overview-what-is.md) en temps réel à l’aide d’une clé de chiffrement de base de données (DEK) stockée dans l’enregistrement de démarrage de la base de données pour une disponibilité lors de la récupération.
TDE protège les données et les fichiers journaux, à l’aide d’algorithmes de chiffrement AES et 3DES (Triple Data Encryption Standard). Le chiffrement du fichier de base de données est effectué au niveau de la page. Les pages dans une base de données chiffrée sont chiffrées avant d’être écrites sur le disque, et sont déchiffrées quand elles sont lues en mémoire. TDE est désormais activé par défaut sur les nouvelles bases de données Azure SQL.
#### <a name="always-encrypted-feature"></a>Fonctionnalité Always Encrypted
Avec la fonctionnalité [Always Encrypted](https://docs.microsoft.com/sql/relational-databases/security/encryption/always-encrypted-database-engine) dans SQL Azure, vous pouvez chiffrer les données dans les applications clientes avant de les stocker dans Azure SQL Database. Vous pouvez également activer la délégation de l’administration locale de base de données à des tiers, et maintenir la séparation entre ceux qui possèdent et peuvent afficher les données et ceux qui les gèrent, mais qui ne doivent pas pouvoir y accéder.
#### <a name="cell-level-or-column-level-encryption"></a>Chiffrement au niveau des cellules ou au niveau des colonnes
Avec Azure SQL Database, vous pouvez appliquer un chiffrement symétrique à une colonne de données à l’aide de Transact-SQL. Cette approche porte le nom de [chiffrement au niveau des cellules ou chiffrement au niveau des colonnes](https://docs.microsoft.com/sql/relational-databases/security/encryption/encrypt-a-column-of-data) (CLE), car vous pouvez l’utiliser pour chiffrer les colonnes ou même des cellules de données spécifiques avec différentes clés de chiffrement. Cela vous offre la possibilité d’un chiffrement plus granulaire que le chiffrement transparent des données, qui chiffre les données dans les pages.
Le CLE dispose de fonctions intégrées que vous pouvez utiliser pour chiffrer les données à l’aide de clés symétriques ou asymétriques, de la clé publique d’un certificat ou d’une phrase secrète à l’aide de 3DES.
### <a name="cosmos-db-database-encryption"></a>Chiffrement de base de données Azure Cosmos DB
[Azure Cosmos DB](../cosmos-db/database-encryption-at-rest.md) est une base de données multi-modèles distribuée par Microsoft au niveau mondial. Les données utilisateur stockées dans le stockage non volatile (disques SSD) Cosmos DB sont chiffrées par défaut. Il n’existe aucun contrôle pour activer ou désactiver le chiffrement. Le chiffrement au repos est implémenté à l’aide d’un certain nombre de technologies de sécurité, notamment des systèmes de stockage de clés sécurisés, des réseaux chiffrés et des API de chiffrement. Les clés de chiffrement sont gérées par Microsoft et font l’objet d’une rotation par le biais de directives internes de Microsoft.
### <a name="at-rest-encryption-in-data-lake"></a>Chiffrement au repos dans Data Lake
[Azure Data Lake](../data-lake-store/data-lake-store-encryption.md) est un référentiel de l’entreprise pour tous les types de données collectées dans un seul emplacement avant toute définition formelle de spécifications ou schémas. Data Lake Store prend en charge « par défaut » un chiffrement transparent de données au repos défini lors de la création de votre compte. Par défaut, Azure Data Lake Store gère les clés pour vous, mais vous avez la possibilité de les gérer vous-même.
Trois types de clés sont utilisées dans le chiffrement et le déchiffrement des données : la clé de chiffrement principale (MEK), la clé de chiffrement de données (DEK) et la clé de chiffrement de blocs (BEK). La clé MEK permet de chiffrer la clé DEK, stockée sur un support persistant et a clé BEK est dérivée de la clé DEK et du bloc de données. Si vous gérez vos propres clés, vous pouvez procéder à la rotation de la clé MEK.
## <a name="encryption-of-data-in-transit"></a>Chiffrement des données en transit
Azure offre plusieurs mécanismes pour protéger la confidentialité des données lorsqu’elles transitent d’un emplacement à un autre.
### <a name="tlsssl-encryption-in-azure"></a>Chiffrement TLS/SSL dans Azure
Microsoft utilise le protocole [Transport Layer Security](https://en.wikipedia.org/wiki/Transport_Layer_Security) (TLS) pour protéger les données lorsqu’elles sont en déplacement entre les services cloud et les clients. Les centres de données Microsoft négocient une connexion TLS avec les systèmes clients qui se connectent aux services Azure. TLS fournit une authentification forte, la confidentialité et l’intégrité des messages (activation de la détection de falsification et d’interception des messages), l’interopérabilité, la flexibilité des algorithmes, ainsi que la facilité de déploiement et d’utilisation.
[Perfect Forward Secrecy](https://en.wikipedia.org/wiki/Forward_secrecy) (PFS) protège les connexions entre les systèmes clients des clients et les services cloud de Microsoft par des clés uniques. Les connexions utilisent également les longueurs de clés de chiffrement RSA de 2 048 bits. Cette combinaison rend difficile pour une personne l’interception et l’accès aux données en transit.
### <a name="azure-storage-transactions"></a>Transactions de stockage Azure
Si vous interagissez avec le stockage Azure via le portail Azure, toutes les transactions se produisent via HTTPS. L’API de stockage REST par le biais de HTTPS peut également être utilisée pour interagir avec le stockage Azure. Vous pouvez appliquer l’utilisation du protocole HTTPS quand vous appelez les API REST pour accéder aux objets dans les comptes de stockage en activant le transfert sécurisé requis pour le compte de stockage.
Les signatures d’accès partagé ([SAP](../storage/storage-dotnet-shared-access-signature-part-1.md)), qui peuvent être utilisées pour déléguer l’accès aux objets de stockage Azure, incluent une option pour spécifier que seul le protocole HTTPS est autorisé quand vous utilisez des signatures d’accès partagé. Cette approche garantit que toute personne envoyant des liens avec des jetons SAP utilise le protocole approprié.
[SMB 3.0](https://technet.microsoft.com/library/dn551363(v=ws.11).aspx#BKMK_SMBEncryption), qui est utilisé pour accéder à Azure File Shares, prend en charge le chiffrement et est disponible dans Windows Server 2012 R2, Windows 8, Windows 8.1 et Windows 10. Cela rend possible l’accès entre les régions et même l’accès sur le bureau.
Le chiffrement côté client chiffre les données avant qu’elles soient envoyées à votre instance Stockage Azure, afin qu’elles soient chiffrées quand elles transitent sur le réseau.
### <a name="smb-encryption-over-azure-virtual-networks"></a>Chiffrement SMB sur les réseaux virtuels Azure
En utilisant [SMB 3.0](https://support.microsoft.com/help/2709568/new-smb-3-0-features-in-the-windows-server-2012-file-server) sur des machines virtuelles qui exécutent Windows Server 2012 ou version ultérieure, vous pouvez sécuriser les transferts de données en chiffrant les données en transit sur des réseaux virtuels Azure. Le chiffrement des données offre une protection contre la falsification et les attaques d’écoute. Les administrateurs peuvent activer le chiffrement SMB pour l’ensemble du serveur ou juste des partages spécifiques.
Par défaut, une fois le chiffrement SMB activé pour un partage ou un serveur, seuls les clients SMB 3.0 sont autorisés à accéder aux partages chiffrés.
## <a name="in-transit-encryption-in-vms"></a>Chiffrement en transit sur des machines virtuelles
Les données en transit vers, à partir de et entre les machines virtuelles exécutant Windows sont chiffrées de différentes manières, en fonction de la nature de la connexion.
### <a name="rdp-sessions"></a>Sessions RDP
Vous pouvez vous connecter et ouvrir une session sur une machine virtuelle à l’aide du [protocole RDP (Remote Desktop Protocol)](https://msdn.microsoft.com/library/aa383015(v=vs.85).aspx) à partir d’un ordinateur client Windows ou d’un Mac avec un client RDP installé. Les données en transit sur le réseau dans les sessions RDP peuvent être protégées par le TLS.
Vous pouvez également utiliser le Bureau à distance pour vous connecter à une machine virtuelle Linux dans Azure.
### <a name="secure-access-to-linux-vms-with-ssh"></a>Sécuriser l’accès aux machines virtuelles Linux avec SSH
Pour la gestion à distance, vous pouvez utiliser [Secure Shell](../virtual-machines/linux/ssh-from-windows.md) (SSH) afin de vous connecter aux machines virtuelles Linux exécutées dans Azure. SSH est un protocole de connexion chiffré qui permet d’ouvrir des sessions en toute sécurité à travers des connexions non sécurisées. Il s’agit du protocole de connexion par défaut pour les machines virtuelles Linux hébergées dans Azure. En faisant appel à des clés SSH pour l’authentification, vous éliminez le besoin de mots de passe pour vous connecter. SSH utilise une paire de clés publique/privée (chiffrement asymétrique) pour l’authentification.
## <a name="azure-vpn-encryption"></a>Chiffrement VPN Azure
Vous pouvez vous connecter à Azure via un réseau privé virtuel qui crée un tunnel sécurisé pour protéger la confidentialité des données envoyées sur le réseau.
### <a name="azure-vpn-gateways"></a>Passerelles VPN Azure
Vous pouvez utiliser la [passerelle VPN Azure](../vpn-gateway/vpn-gateway-about-vpn-gateway-settings.md) pour envoyer un trafic chiffré entre votre réseau virtuel et votre emplacement local sur une connexion publique, ou pour envoyer un trafic entre des réseaux virtuels.
Les VPN de site à site utilisent [IPsec](https://en.wikipedia.org/wiki/IPsec) pour le chiffrement du transport. Les passerelles VPN Azure utilisent un ensemble de propositions par défaut. Vous pouvez configurer des passerelles VPN Azure pour utiliser une stratégie IPsec/IKE personnalisée avec des algorithmes de chiffrement spécifiques et des avantages clés, plutôt que des ensembles de stratégies Azure par défaut.
### <a name="point-to-site-vpns"></a>VPN point à site
Les VPN point à site permettent à des ordinateurs clients d’accéder à un réseau virtuel Azure. Le [protocole SSTP (Secure Socket Tunneling Protocol)](https://technet.microsoft.com/library/2007.06.cableguy.aspx) est utilisé pour créer le tunnel VPN. Il peut traverser des pare-feu (le tunnel apparaît en tant que connexion HTTPS). Vous pouvez utiliser votre propre autorité de certification racine interne d’infrastructure à clé publique pour la connectivité point à site.
Vous pouvez configurer une connexion VPN point à site à un réseau virtuel à l’aide du portail Azure avec l’authentification par certificat ou PowerShell.
Pour en savoir plus sur les connexions VPN de point à site à des réseaux virtuels Azure, consultez :
[Configurer une connexion point à site sur un réseau virtuel à l’aide d’une authentification par certificat Azure native : Portail Azure](../vpn-gateway/vpn-gateway-howto-point-to-site-resource-manager-portal.md)
[Configurer une connexion point à site à un réseau virtuel à l’aide de l’authentification par certificat Azure native : PowerShell](../vpn-gateway/vpn-gateway-howto-point-to-site-rm-ps.md)
### <a name="site-to-site-vpns"></a>VPN site à site
Vous pouvez utiliser une connexion de passerelle VPN de site à site pour connecter votre réseau local à un réseau virtuel Azure par le biais d’un tunnel VPN IPsec/IKE (IKEv1 ou IKEv2). Ce type de connexion nécessite un périphérique VPN local disposant d’une adresse IP publique exposée en externe.
Vous pouvez configurer une connexion VPN de site à site à un réseau virtuel à l’aide du portail Azure, de PowerShell ou d’Azure CLI.
Pour plus d'informations, consultez les pages suivantes :
[Créer une connexion de site à site dans le portail Azure](../vpn-gateway/vpn-gateway-howto-site-to-site-resource-manager-portal.md)
[Créer une connexion de site à site à l’aide de PowerShell](../vpn-gateway/vpn-gateway-create-site-to-site-rm-powershell.md)
[Créer un réseau virtuel avec une connexion VPN de site à site à l’aide de l’interface de ligne de commande](../vpn-gateway/vpn-gateway-howto-site-to-site-resource-manager-cli.md)
## <a name="in-transit-encryption-in-data-lake"></a>Chiffrement en transit dans Data Lake
Les données en transit (ou données en mouvement) sont également toujours chiffrées dans Data Lake Store. Outre le chiffrement des données avant leur stockage sur un support permanent, les données sont également toujours sécurisées en transit à l’aide du protocole HTTPS. HTTPS est le seul protocole pris en charge pour les interfaces REST Data Lake Store.
Pour en savoir plus sur le chiffrement des données en transit dans Data Lake, consultez [Chiffrement des données dans Azure Data Lake Store.](../data-lake-store/data-lake-store-encryption.md)
## <a name="key-management-with-key-vault"></a>Gestion des clés dans Key Vault
Sans protection appropriée et la gestion des clés, le chiffrement est rendu inutilisable. Key Vault est la solution recommandée de Microsoft qui permet de gérer et de contrôler l’accès aux clés de chiffrement utilisées par les services cloud. Les autorisations d’accès aux clés peuvent être attribuées aux services ou aux utilisateurs via des comptes Azure Active Directory.
Key Vault soulage les entreprises de la nécessité de configurer, de corriger et de tenir à jour des modules de sécurité matériels (HSM) et des logiciels de gestion de clés. Quand vous utilisez Key Vault, vous conservez le contrôle. Microsoft ne voit jamais vos clés, et les applications n’y ont pas accès directement. Vous pouvez également importer ou générer des clés dans les modules HSM.
## <a name="next-steps"></a>Étapes suivantes
- [Vue d’ensemble de la sécurité d’Azure](security-get-started-overview.md)
- [Vue d’ensemble de la sécurité réseau d’Azure](security-network-overview.md)
- [Vue d’ensemble de la sécurité des bases de données d’Azure](azure-database-security-overview.md)
- [Vue d’ensemble de la sécurité des machines virtuelles d’Azure](security-virtual-machines-overview.md)
- [Chiffrement des données au repos](azure-security-encryption-atrest.md)
- [Meilleures pratiques en matière de chiffrement et de sécurité des données](azure-security-data-encryption-best-practices.md)
| 108.559242 | 658 | 0.800271 | fra_Latn | 0.988742 |
1178cf5c9d6e082967110cf03bac1883b09be998 | 4,381 | md | Markdown | packages/comps/src/utils/README.md | lukaie/turbo | 0326048c8ce9470f0e8d6abe733011f1744cf81b | [
"MIT"
] | 18 | 2021-03-20T22:03:39.000Z | 2022-03-22T16:37:03.000Z | packages/comps/src/utils/README.md | lukaie/turbo | 0326048c8ce9470f0e8d6abe733011f1744cf81b | [
"MIT"
] | 678 | 2021-03-19T19:51:59.000Z | 2022-02-05T17:57:48.000Z | packages/comps/src/utils/README.md | lukaie/turbo | 0326048c8ce9470f0e8d6abe733011f1744cf81b | [
"MIT"
] | 15 | 2021-04-03T18:51:28.000Z | 2022-02-03T09:53:28.000Z | # Contract Interactions
Contract interactions occur in contract-calls.ts. There was an effort to keep them all in one place with data processing methods so that little shaping was needed in other parts of the UI. There are two types of contract calls:
- multicall
- calls using hardhard objects
## Getting user data
`getUserBalances` is the only place multicall is used. `ethereum-multicall` package is a modified version of the open source project with the same name. Locally there are modifications to fix issues with newer version of ethers.
User balances pulled:
- Amm liquidity provider tokens
- Pending rewards
- Market outcome shares
- USDC balance
- MATIC balance
- Allowances aka Approvals (only used in sportsbook)
## Getting market and amm data
`getMarketInfos` method is the integration point with react state called from `data.tsx`. Fetcher contracts are convenience contracts that help reduct the number of contract calls needed to pull all market and amm data. The helper contracts called `fetchers`. These fetchers pull down market and amm data, the data structure is made up of base properties that are common across all markets and specific market type properties.
Market types are:
- NFL, national football league.
- NBA, national baseball assoc.
- MMA, mixed martial arts (UFC)
- MLB, major league baseball
- CRYPTO, crypto currency price markets
- GROUPED, futures - multiple generic markets grouped together (not fully implemented)
Fetcher files and associated market types:
| File name | Description |
| ---- | ---- |
| `fetcher-sport.ts` | gets data for NFL, MMA, MLB and NBA markets |
| `fetcher-crypto.ts` | gets data for crypto markets |
| `fetcher-grouped.ts` | gets data for grouped markets |
Helpers are used to shape market type specific data:
| MARKET TYPE | FILE NAME |
------------- | --------------
| SPORTSLINK (used in older versions of the UI)| `derived-simple-sport-dailies`|
| CRYPTO | `derived-crypto-markets.ts`|
| MMA, MMALINK (used in older versions of the UI) | `derived-mma-dailies.ts`|
| MLB, NBA, NFL | `derived-nfl-dailies.ts`|
| GROUPED | `derived-grouped-data.ts`|
The shaped market and amm data is returned to data.tsx to be stored in state.
## Trading (buy, sell)
Trading has two aspects, the estimation and the actual contract call. Estimations are fast off chain calls, that tells the user the amount of market outcome shares they will get given USDC.
`doTrade` method in contract-calls.ts handels both buy and sell. Amm factory contract is called for the user to either buy (`buy`) or sell (`sellForCollateral`). The amm factory contract address is on the AmmExchange object for the market.
Minting complete sets `mintCompleteSets` is a way the user can convert USDC to market shares outcome tokens. The user can only mint complete sets before a market is resolved.
## Providing Liquidity
There are many aspects to Providing liquidity:
- estimations
- adding initial liquidity
- adding additional liquidity
- removing liquidity
Estimations uses static call on the contract to get estimations. This requires that the user has already approved the contracts. The UI indicates this to the user and the user has to sign a transaction to do the approval. Once the approvals are done, static calls can be used to estimate add liquidity and remove liquidity.
There is a helper method to get the rewards contract. `getRewardsContractAddress`.
```
const rewardContractAddress = getRewardsContractAddress(amm.marketFactoryAddress);
const rewardContract = rewardContractAddress ? getRewardContract(provider, rewardContractAddress, account) : null;
```
Usually Amm Factory contract would be called directly to add and remove liquidity. With rewards the master chef contract is the go-between. Methods in contract-calls still does support non-rewards add and remove liquidity.
| Method | Description |
| --- | --- |
| `createPool` | add initial liquidity |
| `addLiquidity` | add additional liquidity |
| `removeLiquidity` | remove liquidity |
## Rewards
Rewards contract "master chef" was added to track and disperse rewards to the liquidity provider. The master chef contract is a pass through to Amm Factory contract.
The user gets rewards for providing liquidity on markets, under specific circustances they get a bonus. `getUserBalances` adds calls to get pending rewards in the multicall. | 52.783133 | 427 | 0.7706 | eng_Latn | 0.996933 |
1179626585d536d18ad3362e6477a2b78898905f | 43,297 | md | Markdown | _posts/Learning/Review/2019-06-03-Machine learning.md | Wizna/Wizna.github.io | a806674a6e94b69458f4694f0124c13df8ba3b23 | [
"MIT"
] | 2 | 2020-10-01T02:56:34.000Z | 2021-01-10T10:19:24.000Z | _posts/Learning/Review/2019-06-03-Machine learning.md | Wizna/Wizna.github.io | a806674a6e94b69458f4694f0124c13df8ba3b23 | [
"MIT"
] | null | null | null | _posts/Learning/Review/2019-06-03-Machine learning.md | Wizna/Wizna.github.io | a806674a6e94b69458f4694f0124c13df8ba3b23 | [
"MIT"
] | 5 | 2020-10-01T02:56:39.000Z | 2020-10-03T17:51:44.000Z | 
* TOC
{:toc}
# Background
Just a review of machine learning for myself (really busy recently, so ...)
内容来自dive into deep learning, pattern recognition and machine learning, 网络。
# Basics
## Batch normalization
- Batch normalization: subtracting the batch mean and dividing by the batch standard deviation (2 trainable parameters for mean and standard deviation, mean->0, variance->1) to counter covariance shift (i.e. the distribution of input of training and testing are different) [Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift]( https://arxiv.org/pdf/1502.03167v3.pdf ) 也方便optimization,而且各feature之间不会有莫名的侧重,注意是每个feature dimension分开进行batch normalization
- batch normalization 经常被每一层分别使用。batch size不能为1(因为这时输出总为0)。
- [这里](https://github.com/ducha-aiki/caffenet-benchmark/blob/master/batchnorm.md)说BN放在activation之后会更好一些
- batch normalization的优点是可以用更大的学习速率,减少了训练时间,初始化不那么重要,结果更好,是某种程度的regularization
- batch normalization在train和predict表现不一样,predict时是用的training时根据所有training set估计的population mean和variance,实现上是计算动态的值,during training keeps running estimates of its computed mean and variance
## Layer normalization
- layer normalization和batch normalization类似,不过不是batch 那一维度(d=0)normalize,而是最后一个维度normalize, 作用是prevents the range of values in the layers from changing too much, which allows faster training and better generalization ability。
- batch normalization用在rnn上的话,得考虑不同sequence长度不同,而layer norm没有这个问题(one set of weight and bias shared over all time-steps)
- layer norm就是每个sample自己进行across feature 的layer层面的normalization,有自己的mean, variance。所以可以batch size为1, batch norm则是across minibatch 单个neuron来算
- MXNet's ndarray比numpy的要多2特点,1是有automatic differentiation,2是支持在GPU, and distributed cloud architectures上的asynchronous computation.
- broadcast就是复制来填充新的维度
- missing data比如NaN可以用imputation(填充一些数)或者deletion来处理
- 使用`x+=y`或者`z[:]=x`可以在老地方设置新ndarray,节约内存
- scalar, vector, matrix, tensor: 0-, 1-, 2-, n-dimension
- $L_{p}$ norm: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517120714786.png" alt="image-20200517120714786" style="zoom:80%;" />
- $L_{p}$norm的性质, for vectors in $C^{n}$ where $ 0 < r < p $:
- calculus微积分: integration, differentiation
- product rule: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517210613582.png" alt="image-20200517210613582" style="zoom:80%;" />
* quotient rule: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517210755705.png" alt="image-20200517210755705" style="zoom:80%;" />上面的是领导啊
* chain rule: 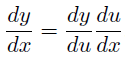
* matrix calculus: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517213215946.png" alt="image-20200517213215946" style="zoom:80%;" />[matrix calculus wiki](https://en.wikipedia.org/wiki/Matrix_calculus)
* A gradient is a vector whose components are the partial derivatives of a multivariate function
with respect to all its variables
* Bayes' Theorem: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517214155675.png" alt="image-20200517214155675" style="zoom:80%;" />
* <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200517222203691.png" alt="image-20200517222203691" style="zoom:80%;" />[推导](https://en.wikipedia.org/wiki/Variance)
* dot product: a scalar; cross product: a vector
* stochastic gradient descent: update in direction of negative gradient of minibatch<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200518114459580.png" alt="image-20200518114459580" style="zoom:80%;" />
* likelihood: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200518120658206.png" alt="image-20200518120658206" style="zoom:80%;" />
* 经常用negative log-likelihood来将maximize multiplication变成minimize sum
* minimizing squared error is equivalent to maximum likelihood estimation of a linear model under the assumption of additive Gaussian noise
* one-hot encoding: 1个1,其他补0
* entropy of a distribution p: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200518173223125.png" alt="image-20200518173223125" style="zoom:80%;" />
* cross-entropy is *asymmetric*: $H(p,q)=-\sum\limits_{x\in X}{p(x)\log q(x)}$
* minimize cross-entropy == maximize likelihood
* Kullback-Leibler divergence (也叫relative entropy或者information gain) is the difference between cross-entropy and entropy: <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200518174004941.png" alt="image-20200518174004941" style="zoom:80%;" />
* KL divergence is *asymmetric* and does not satisfy the [triangle inequality](https://en.wikipedia.org/wiki/Triangle_inequality)
* Jensen-Shannon divergence: ${{\rm {JSD}}}(P\parallel Q)={\frac {1}{2}}D(P\parallel M)+{\frac {1}{2}}D(Q\parallel M)$ where $M={\frac {1}{2}}(P+Q)$,这个JSD是symmetric的
* cross validation: split into k sets. do k experiments on (k-1 train, 1 validation), average the results
* forward propagation calculates and stores intermediate variables.
* 对于loss function $J$, 要计算偏导的$W$, $\frac{\partial J}{\partial W}=\frac{\partial J}{\partial O}*I^{T}+\lambda W$, 这里$O$是这个的output, $I$是这个的input,后面的term是regularization的导,这里也说明了为啥forward propagation要保留中间结果,此外注意activation function的导是elementwise multiplication,有些activation function对不同值的导得分别计算。training比prediction要占用更多内存
* Shift: distribution shift, covariate shift, label shift
* covariate shift correction: 后面说的只和feature $X$有关,和$y$是没有关系的。训练集来自$q(x)$,测试集来自$p(x)$,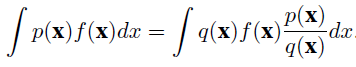,所以训练时给$X$一个weight $\frac{p(x)}{q(x)}$即可。经常是来一个混合数据集,训练一个分类器来估计这个weight,logistics分类器好算。
* label shift correction:和上面一样,加个importance weights,说白了调整一下输出
* concept shift correction:经常是缓慢的,所以就把新的数据集,再训练更新一下模型即可。
* 确实的数据,可以用这个feature的mean填充
* Logarithms are useful for relative loss.除法变减法
* 对于复杂模型,有block这个概念表示特定的结构,可以是1层,几层或者整个模型。只要写好参数和forward函数即可。
* 模型有时候需要,也可以,使不同层之间绑定同样的参数,这时候backpropagation的gradient是被分享那一层各自的和,比如a->b->b->c,就是第一个b和第二个b的和
* chain rule (probability): 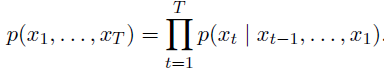
* cosine similarity,如果俩向量同向就是1 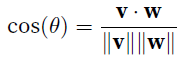
*
## Hyperparameters
* 一般layer width (node个数)取2的幂,计算高效
*
### Grid search
### Random search
## Transfer learning
- Chop off classification layers and replace with ones cater to ones' needs. Freeze pretrained layers during training. Enable training on batch normalization layers as well may get better results.
- [A Survey on Transfer Learning](https://www.cse.ust.hk/~qyang/Docs/2009/tkde_transfer_learning.pdf)
- 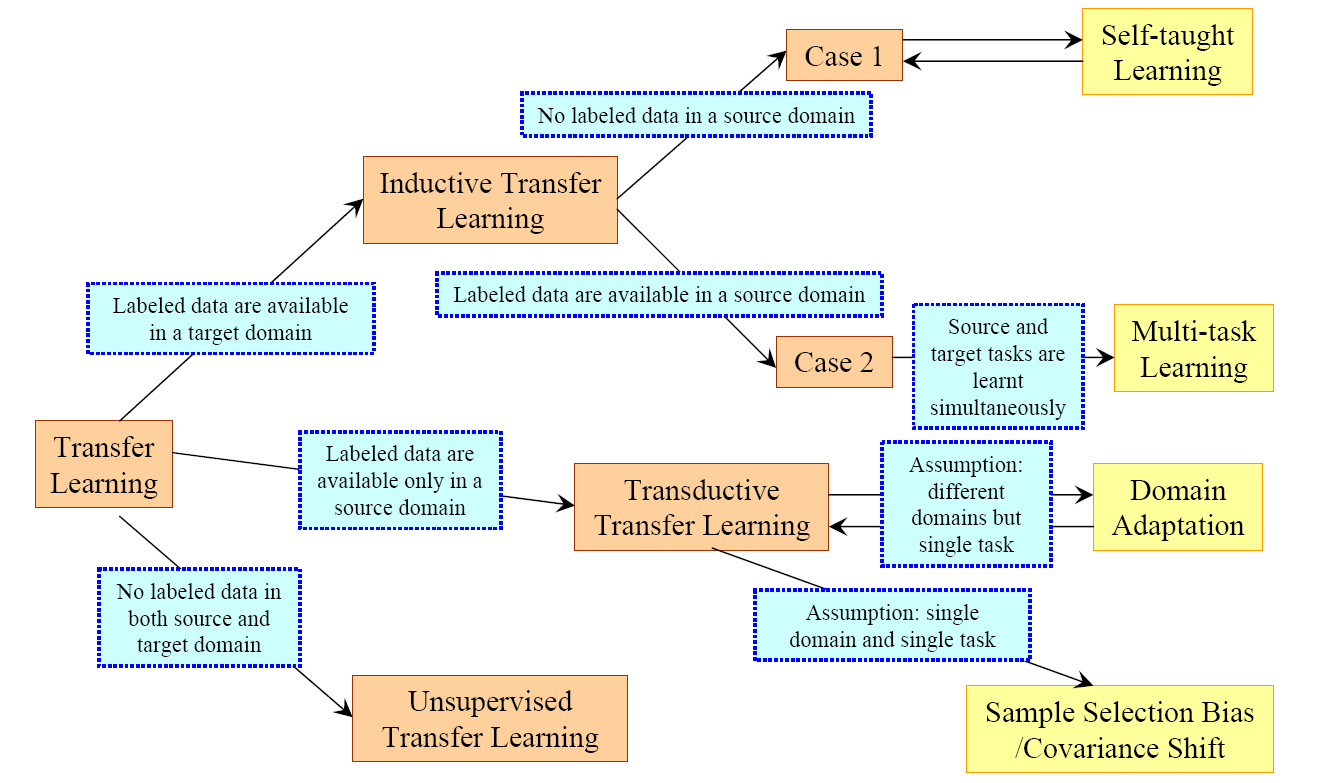
### One-shot learning
### Zero-shot learning
## Curriculum learning
## Objective function
### Mean absolute error
### Mean squared error
### Cross-entropy loss
- $loss(x,class)=-\log(\frac{exp(x[class])}{\Sigma_{j}exp(x[j])})=-x[class]+\log(\Sigma_{j}exp(x[j]))$
## Regularization
### Weight decay
* 即L2 regularization
* encourages weight values to decay towards zero, unless supported by the data.
* 这是q=2,ridge,让weights distribute evenly, driven to small values
* q=1的话,lasso, if `λ` is sufficiently large, some of the coefficients $w_{j}$ are driven to zero, leading to a sparse model,比如右边lasso的 $w_{1}$
<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200519133624932.png" alt="image-20200519133624932" style="zoom:50%;" />
*
### Dropout
* breaks up co-adaptation between layers
* in training, zeroing out each hidden unit with probability $p$, multiply by $\frac{1}{1-p}$ if kept, 这使得expected sum of weights, expected value of activation the same (这也是可以直接让p=0就用在test mode)
* in testing, no dropout
* 不同层可以不同dropout, a common trend is to set a lower dropout probability closer to the input layer
### Label smoothing
- Use not hard target 1 and 0, but a smoothed distribution. Subtract $\epsilon$ from target class, and assign that to all the classes based on a distribution (i.e. sum to 1). So the new smoothed version is $q \prime (k \mid x)=(1-\epsilon)\delta_{k,y}+\epsilon u(k)$ (x is the sample, y is the target class, u is the class distribution) [Rethinking the Inception Architecture for Computer Vision]( https://arxiv.org/pdf/1512.00567.pdf )
- hurts perplexity, but improves accuracy and BLEU score.
## Learning rate
### Pick learning rate
- Let the learning rate increase linearly (multiply same number) from small to higher over each mini-batch, calculate the loss for each rate, plot it (log scale on learning rate), pick the learning rate that gives the greatest decline (the going-down slope for loss) [Cyclical Learning Rates for Training Neural Networks]( https://arxiv.org/pdf/1506.01186.pdf )
### Warmup
- 对于区分度高的数据集,为了避免刚开始batches的data导致偏见,所以learning rate是线性从一个小的值增加到target 大小。https://stackoverflow.com/questions/55933867/what-does-learning-rate-warm-up-mean
- [Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour](https://arxiv.org/pdf/1706.02677.pdf)
### Differential learning rate
- Use different learning rate for different layers of the model, e.g. use smaller learning rate for transfer learning pretrained-layers, use a larger learning rate for the new classification layer
### Learning rate scheduling
- Start with a large learning rate, shrink after a number of iterations or after some conditions met (e.g. 3 epoch without improvement on loss)
## Initialization
* 求偏导,简单例子,对于一个很多层dense的模型,偏导就是连乘,eigenvalues范围广,特别大或者特别小,这个是log-space不能解决的
* Vanishing gradients: cause by比如用sigmoid做activation function,导数两头都趋于0,见图<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200520122630230.png" alt="image-20200520122630230" style="zoom:50%;" />
* Exploding gradients:比如100个~Normal(0,1)的数连乘,output炸了,gradient也炸了,一发update,model参数就毁了
* Symmetry:全连接的话,同一层所有unit没差,所以如果初始化为同一个值就废了
* 普通可用的初始化,比如Uniform(-0.07, 0.07)或者Normal(mean=0, std=0.01)
### Xavier initialization
* 为了满足variance经过一层后稳定,$\sigma^2$是某层$W$初始化后的的variance,对于forward propagation, 我们需要$n_{in}\sigma^2=1$,对于backward propagation,我们需要$n_{out}\sigma^2=1$,所以,选择满足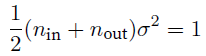
* 可以用mean是0,variance是$\sigma^2=\frac{2}{n_{in}+n_{out}}$的Gaussian distribution,也可以用uniform distribution $U(-\sqrt{\frac{6}{n_{in} + n_{out}}},\sqrt{\frac{6}{n_{in} + n_{out}}})$
* 注意到variance of uniform distribution $U(-a, a)$是$\int_{-a}^{a}(x-0)^2 \cdot f(x)dx=\int_{-a}^{a}x^2 \cdot \frac{1}{2a}dx=\frac{a^2}{3}$
## Optimizer
- Gradient descent: go along the gradient, not applicable to extremely large model (memory, time)
- `weight = weight - learning_rate * gradient`
- Stochastic gradient descent: pick a sample or a subset of data, go
- hessian matrix: a [square matrix](https://en.wikipedia.org/wiki/Square_matrix) of second-order [partial derivatives](https://en.wikipedia.org/wiki/Partial_derivative) of a scalar-valued function, it describes the local curvature of a function of many variables.![{\displaystyle \mathbf {H} ={\begin{bmatrix}{\dfrac {\partial ^{2}f}{\partial x_{1}^{2}}}&{\dfrac {\partial ^{2}f}{\partial x_{1}\,\partial x_{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{1}\,\partial x_{n}}}\\[2.2ex]{\dfrac {\partial ^{2}f}{\partial x_{2}\,\partial x_{1}}}&{\dfrac {\partial ^{2}f}{\partial x_{2}^{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{2}\,\partial x_{n}}}\\[2.2ex]\vdots &\vdots &\ddots &\vdots \\[2.2ex]{\dfrac {\partial ^{2}f}{\partial x_{n}\,\partial x_{1}}}&{\dfrac {\partial ^{2}f}{\partial x_{n}\,\partial x_{2}}}&\cdots &{\dfrac {\partial ^{2}f}{\partial x_{n}^{2}}}\end{bmatrix}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/614e3ddb8ba19b38bbfd8f554816904573aa65aa)
- hessian matrix is symmetric, hessian matrix of a function *f* is the [Jacobian matrix](https://en.wikipedia.org/wiki/Jacobian_matrix) of the [gradient](https://en.wikipedia.org/wiki/Gradient) of the function: **H**(*f*(**x**)) = **J**(∇*f*(**x**)).
- input k-dimensional vector and its output is a scalar:
- 1. eigenvalues of the functionʼs Hessian matrix at the zero-gradient position are all
positive: local minimum
2. eigenvalues of the functionʼs Hessian matrix at the zero-gradient position are all
negative: local maximum
3. eigenvalues of the functionʼs Hessian matrix at the zero-gradient position are negative
and positive: saddle point
- convex functions are those where the eigenvalues of the Hessian are never negative
- Jensenʼs inequality: $f$函数是convex的, 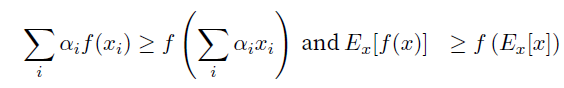
- convex函数没有local minima,不过可能有多个global minima或者没有global minima
-
### Stochastic gradient descent
- 就是相对于gradient descent 用所有training set的平均梯度,这里用random一个sample的梯度
- stochastic gradient $∇f_{i}(\textbf{x})$ is the unbiased estimate of gradient $∇f(\textbf{x})$.
-
### Momentum
- $\textbf{g}$ is gradient, $\textbf{v}$ is momentum, $\beta$ is between 0 and 1. 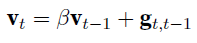
### Adagrad
- 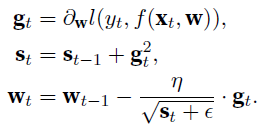
### Adam
- 和SGD相比,对initial learning rate不敏感
## Ensembles
- Combine multiple models' predictions to produce a final result (can be a collection of different checkpoints of a single model or models of different structures)
## Activations
### ReLU
* $ReLU(z)=max(z,0)$ <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200519004508856.png" alt="image-20200519004508856" style="zoom:50%;" />
* mitigates vanishing gradient,不过还是有dying ReLU的问题
### Leaky ReLU
- 以下用$x_{ji}$ to denote the input of $i$th channel in $j$th example
- 就是negative部分也有一个小斜率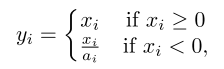
- $a_{i}$越大越接近ReLU,经验上可以取6~100
### PReLU
- parametric rectified linear unit,和leaky一样, 不过$a_{i}$ is learned in the training via back propagation
- may suffer from severe overfitting issue in small scale dataset
### RReLU
- Randomized Leaky Rectified Linear,就是把斜率从一个uniform $U(l,u)$里随机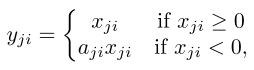
- test phase取固定值,也就是$\frac{l+u}{2}$
- 在小数据集上表现不错,经常是training loss比别人大,但是test loss更小
### Sigmoid
* sigmoid是一类s型曲线,这一类都可能saturated
* 代表:logit function, logistic function(logit的inverse function),hyperbolic tangent function
* logistic function值域 0 ~ 1 : $f(x)=\frac{1}{1+e^{-x}}$<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200519005935784.png" alt="image-20200519005935784" style="zoom: 50%;" />
* 求导$\frac{df}{dx}=f(x)(1-f(x))=f(x)f(-x)$[过程](https://en.wikipedia.org/wiki/Logistic_function#Derivative)
* 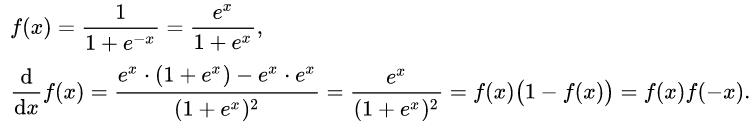
* tanh (hyperbolic tangent) function: $f(x)=\frac{1-e^{-2x}}{1+e^{-2x}}$<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200519011314832.png" alt="image-20200519011314832" style="zoom:50%;" />
* tanh形状和logistic相似,不过tanh是原点对称的$\frac{df}{dx}=1-f^{2}(x)$
*
### Softmax
* 计算<img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200518141705932.png" alt="image-20200518141705932" style="zoom:80%;" />
* softmax保证了each logit >=0且和为1
* 给softmax搭配cross entropy避免了exponential带来的数值overflow或者underflow问题
*
# Convolutional neural network
- 更准确地说法是cross correlation: 各自对应位置乘积的和
- convolution就是先上下,左右flip,然后同上
- channel (filter, feature map, kernel):可以有好多个,输入rgb可以看成3channel.有些简单的kernel比如检测edge,[1, -1]就把横线都去了
- padding: 填充使得产出的结果形状的大小和输入相同,经常kernel是奇数的边长,就是为了padding时可以上下左右一致
- stride:减小resolution,以及体积
- 对于多个channel,3层input,就需要3层kernel,然后3层各自convolution后,加一起,成为一层,如果输出想多层,就多写个这种3层kernel,input,output的层数就发生了变化。总的来说,kernel是4维的,长宽进出
- 1*1 convolutional layer == fully connected layer
- pooling: 常见的有maximum, average
- pooling减轻了模型对location的敏感性,并且spatial downsampling,减少参数
- pooling没有参数,输入输出channel数是一样的
- 每一层convolutional layer后面都有activation function
- feature map: 就是一个filter应用于前一层后的output
-
# Recurrent neural network
- May suffer vanishing or exploding gradient
- 可以用gradient clipping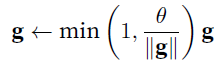gradient norm是在所有param上计算的
- Markov model: 一个first order markov model是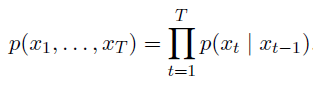
- if $x_{t}$只能取离散的值,那么有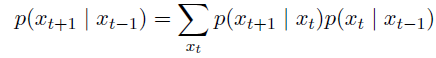
- autoregressive model:根据markov这样利用过去$\tau$个信息,计算下一位的条件概率
- latent autoregressive model:比如GRU, LSTM,更新一个latent state 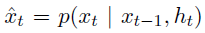
- tokenization: word or character or bpe
- vocabulary 映射到0-n的数字,包括一些特殊的token<unk>, <bos>, <eos>,<pad>
- RNN的参数并不随timestamp变化,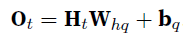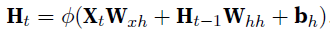
- error是softmax cross-entropy on each label
- perplexity: 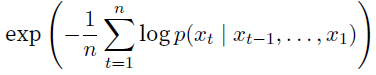
-
## GRU
- to deal with : 1. early observation is highly significant for predicting all future observations 2 , some symbols carry no pertinent observation (should skip) 3, logical break (reset internal states)
- reset gate $R_{t}$: 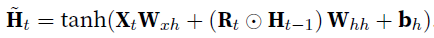capture short-term dependencies
- update gate $Z_{t}$: 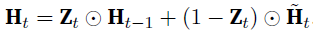capture long-term dependencies
-
## LSTM
- [Long short-term memory]( https://www.bioinf.jku.at/publications/older/2604.pdf )
- input gate
- forget gate
- output gate
- memory cell: entirely internal
- Can be bidirectional (just stack 2 lstm together, with input of opposite direction)
## Encoder-decoder
- a neural network design pattern, encoder -> state(several vector i.e. tensors) -> decoder
- An encoder is a network (FC, CNN, RNN, etc.) that takes the input, and outputs a feature
map, a vector or a tensor
- An decoder is a network (usually the same network structure as encoder) that takes the feature
vector from the encoder, and gives the best closest match to the actual input or intended
output.
- sequence-to-sequence model is based on encoder-decoder architecture, both encoder and decoder are RNNs
- 对于一个encoder-decoder模型,内部是这样的hidden state of the encoder is used directly to initialize the decoder hidden state to pass information
from the encoder to the decoder
-
# Computer vision
## Data augmentation
### general
- Mixup: superimpose e.g. 2 images together with a weight respectively e.g. 0.3, 0.7, classification loss modified to mean of the 2 class (with true labels not as 1s, but as 0.3, 0.7) [mixup: Beyond Empirical Risk Minimization]( https://arxiv.org/pdf/1710.09412.pdf )
### for image
- Change to RGB, HSV, YUV, LAB color spaces
- Change the brightness, contrast, saturation and hue: grayscale
- Affine transformation: horizontal or vertical flip, rotation, rescale, shear, translate
- Crop
### for text
- Back-translation for machine translation task, use a translator from opposite direction and generate (synthetic source data, monolingual target data) dataset
### for audio
- SoX effects
- Change to spectrograms, then apply time warping, frequency masking (randomly remove a set of frequencies), time masking [ SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition ]( https://arxiv.org/pdf/1904.08779.pdf )
## Pooling
-
# Natural language processing
- beam search: $ \mid Y \mid $这么多的词汇,很简单,就是每一层都挑前一层$k * \mid Y \mid $中挑最可能的k个。最后,收获的不是k个,而是$k * L$个,L是最长搜索的长度,e.g. a, a->b, a->b->c, 最后这些还用perplexity在candidates中来挑选一下最可能的。
- one-hot 不能很好的体现word之间的相似性,任意2个vector的cosine都是0
-
## Embeddings
- The technique of mapping words to vectors of real numbers is known as word embedding.
- word embedding可以给下游任务用,也可以直接用来找近义词或者类比(biggest = big + worst - bad)
- one-hot的维度是词汇量大小,sparse and high-dimensional,训练的embedding几维其实就是几个column,n个词汇,d维表示出来就是$n*d$的2维矩阵,所以很dense,一般就几百维
### Word2vec
- **Word2vec** is a group of related models that are used to produce [word embeddings](https://en.wikipedia.org/wiki/Word_embedding). These models are shallow, two-layer [neural networks](https://en.wikipedia.org/wiki/Neural_network) that are trained to reconstruct linguistic contexts of words. Word2vec takes as its input a large [corpus of text](https://en.wikipedia.org/wiki/Text_corpus) and produces a [vector space](https://en.wikipedia.org/wiki/Vector_space), typically of several hundred [dimensions](https://en.wikipedia.org/wiki/Dimensions), with each unique word in the [corpus](https://en.wikipedia.org/wiki/Corpus_linguistics) being assigned a corresponding vector in the space. [Word vectors](https://en.wikipedia.org/wiki/Word_vectors) are positioned in the vector space such that words that share common contexts in the corpus are located close to one another in the space.
- 训练时,会抑制那些出现频率高的词,比如the,所以出现频率越高,训练时某句中被dropout的概率越大
#### Skip-gram model
- central target word中间的word,而context word是central target word两侧window size以内的词
- 每个词有两个d维向量,一个$\textbf v_{i}$给central target word,一个$\textbf u_{i}$给context word
- 下标是在字典里的index,${0,1,...,\mid V\mid-1}$,其中$V$是vocabulary
- skip-gram不考虑复杂的,也无关距离,就是是不是context的一元条件概率,$w_{o}$是context word, $w_{c}$是target word。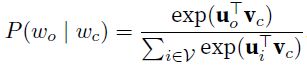
- $T$ is the length of text sequence, $m$ is window size, the joint probability of generating all context words given the central target word is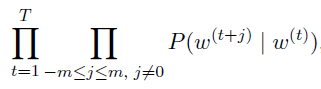
- 训练时候就是minimize上面这个probability的-log,然后对$\textbf u_{i}$, $\textbf v_{i}$各自求偏导来update
#### CBOW model
- skip-gram是给central target word下产生context word的概率,CBOW反过来,给context word,生成中间的target word
- 以下$\textbf u_{i}$是target word, $\textbf v_{i}$是context word,和skip-gram相反。windows size $m$,方式其实和skip-gram类似,不过因为context word很多,所以求平均向量来相乘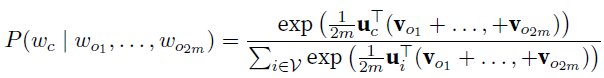
- 同样的,对于长度$T$的sequence,likelihood function如下
- 同样的,minimize -log
- 推荐的windows size是10 for skip-gram and 5 for CBOW
- 一般来说,central target word vector in the skip-gram model is generally used as the representation vector of a word,而CBOW用的是context word vector
#### Negative sampling
- 注意到上面skip-gram和CBOW我们每次softmax都要计算字典大小$\mid V \mid $这么多。所以用两种approximation的方法,negative sampling和hierarchical softmax
- 本质上这里就是换了一个loss function。多分类退化成了近似的二分类问题。
- [解释论文](https://arxiv.org/pdf/1402.3722.pdf),这个文章给了一种需要target word和context word不同vector的理由,因为自己和自己相近出现是很困难的,但是$v \cdot v$很小不符合逻辑。
- 不用conditional probability而用joint probability了,$D=1$指文本中有这个上下文,如果没有就是$D=0$,也就是negative samples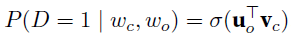
- 这里$\sigma$函数是sigmoid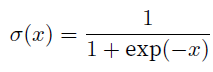个人认为主要好处是-log可以化简
- 老样子,对于长度$T$的文本,joint probability 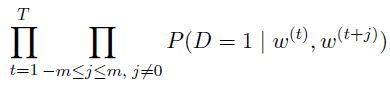
- 如果只是maximize这个,就都是相同的1了,所以需要negative samples
- 最后变成了如下,随机K个negative samples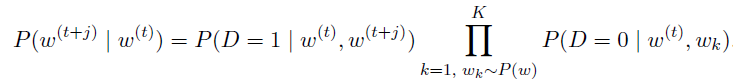
- 现在gradient计算跟$\mid V \mid $没关系了,和K线性相关
#### Hierarchical softmax
- 每个叶子节点是个word,$L(w)$是w的深度,$n(w,j)$是这个路径上$j^{th}$节点
- 改写成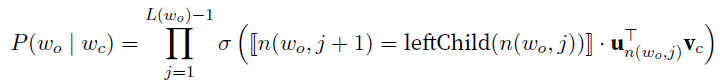
- 其中条件为真,$[\![x]\!]=1$,否则为$-1$
- 现在是$\log_{2}{\mid V \mid }$
### GloVe
- use square loss,数以$w_{i}$为central target word的那些context word的个数,比如某个word $w_{j}$,那么这个个数记为$x_{ij}$,注意到两个词互为context,所以$x_{ij}=x_{ji}$,这带来一个好处,2 vectors相等(实际中训练后俩vector因为初始化不一样,所以训练后不一样,取sum作为最后训练好的的embedding)
- 令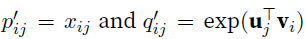,$p'$是我们的目标,$q'$是要训练的那俩vector,此外还有俩bias标量参数,一个给target word $b_{i}$, 一个给context word $c_{i}$. The weight function $h(x)$ is a monotone increasing function with the range [0; 1].
- loss function is 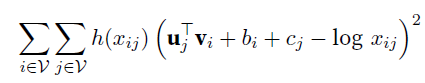
-
### Subword embedding
- 欧洲很多语言词性变化很多(morphology词态学),但是意思相近,简单的每个词对应某向量就浪费了这种信息。用subword embedding可以生成训练中没见过的词
#### fastText
- 给每个单词加上`<>`,然后按照character取长度3-6的那些subword,然后自己本身`<myself>`也是一个subword,这些subword都按照skip-gram训练词向量,最后central word vector $\textbf u_{w}$就是其所有subword的向量和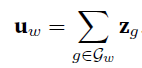
- 缺点是vocabulary变大很多
#### BPE
- Byte pair encoding: the most common pair of consecutive bytes of data is replaced with a byte that does not occur within that data, do this recursively [Neural Machine Translation of Rare Words with Subword Units]( https://arxiv.org/pdf/1508.07909.pdf )
- 从length=1的symbol是开始,也就是字母,greedy
## BERT (Bidirectional Encoder Representations from Transformers)
* 本质上word embedding是种粗浅的pretrain,而且word2vec, GloVe是context无关的,因为单词一词多义,所以context-sensitive的语言模型很有价值
* 在context-sensitive的语言模型中,ELMo是task-specific, GPT更好的一点就是它是task-agnostic(不可知的),不过GPT只是一侧context,从左到右,左边一样的话对应的vector就一样,不如ELMo,BERT天然双向context。在ELMo中,加的pretrained model被froze,不过GPT中所有参数都会被fine-tune.
* classification token `<cls>`,separation token `<sep>`
* The embeddings of the BERT input sequence are the sum of the token embeddings, segment embeddings, and positional embeddings这仨都是要训练的
* pretraining包含两个tasks,masked language modeling 和next sentence prediction
* masked language modeling就是mask某些词为`<mask>`,然后来预测这个token。loss可以是cross-entropy
* next sentence prediction则是判断两个句子是否是连着的,binary classification,也可用cross-entropy loss
* BERT可以被用于大量不同任务,加上fully-connected layer,这是要train的,而本身的pretrained parameters也要fine-tune。Parameters that are only related to pretraining loss will not be updated during finetuning,指的是按照masked language modelling loss和next sentence prediction loss训练的俩MLPs
* 一般是BERT representation of `<cls>`这个token被用来transform,比如扔到一个mlp中去输出个分数或类别
* 一般来说BERT不适合text generation,因为虽然可以全都`<mask>`,然后随便生成。但是不如GPT-2那种从左到右生成。
## ELMo (Embeddings from Language Models)
- each token is assigned a representation that is a function of the entire input sentence.
-
## GPT
-
## N-grams
- 语言模型language model: 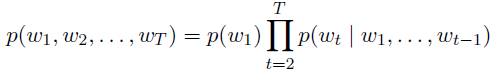
- Laplace smoothing (additive smoothing): 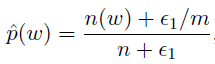,这里m是categories数量,所以估计值会在原本的概率和1/m的均匀分布之间,$\alpha$经常取0~1之间的数,如果是1的话,这个也叫做add-one smoothing
-
-
## Metrics
### BLEU
### TER
## Attention
- [Attention Is All You Need]( https://arxiv.org/pdf/1706.03762.pdf )
- Attention is a generalized pooling method with bias alignment over inputs.
- 参数少,速度快(可并行),效果好
- attention layer有个key-value pairs $\bf (k_{1}, v_{1})..(k_{n}, v_{n})$组成的memory,输入query $\bf{q}$,然后用score function $\alpha$计算query和key的相似度,然后输出对应的value作为output $\bf o$
- 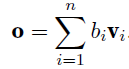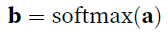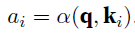
- 两种常见attention layer,都可以内含有dropout: dot product attention (multiplicative) and multilayer perceptron (additive) attention.前者score function就是点乘(要求query和keys的维度一样),后者则有个可训练的hidden layer的MLP,输出一个数
- dimension of the keys $d_{k}$, multiplicative attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code. Additive attention outperforms dot product attention without scaling for larger values of $d_{k}$ (所以原论文里用scaled dot product attention,给点乘后的结果乘了一个$\frac{1}{\sqrt{d_{k}}}$的参数)
- seq2seq with attention mechanism: encoder没变化。during the decoding, the decoder output from the previous timestep $t-1$ is used as the query. The output of the attention model is viewed as the context information, and such context is concatenated with the decoder input Dt. Finally, we feed the concatenation into the decoder.
- The decoder of the seq2seq with attention model passes three items from the encoder:
- 1. the encoder outputs of all timesteps: they are used as the attention layerʼs memory with
identical keys and values;
2. the hidden state of the encoderʼs final timestep: it is used as the initial decoderʼs hidden
state;
3. the encoder valid length: so the attention layer will not consider the padding tokens with
in the encoder outputs.
- transformer:主要是加了3个东西,
- 1. transformer block:包含两种sublayers,multi-head attention layer and position-wise feed-forward network layers
2. add and norm: a residual structure and a layer normalization,注意到右边式子括号中是residual,外面是layer norm 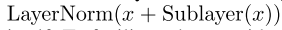
3. position encoding: 唯一add positional information的地方
- <img src="https://raw.githubusercontent.com/Wizna/play/master/image--000.png" alt="image--000" style="zoom: 25%;" />
- self-attention model is a normal attention model, with its query, its key, and its value being copied exactly the same from each item of the sequential inputs. output items of a self-attention layer can be computed in parallel. Self attention is a mechanism relating different positions of a single sequence in order to compute a representation of the sequence.
- multi-head attention: contain parallel self-attention layers (head), 可以是any attention (e.g. dot product attention, mlp attention) <img src="https://raw.githubusercontent.com/Wizna/play/master/image-20200808172837983.png" alt="image-20200808172837983" style="zoom:80%;" />
- 在transformer中multi-head attention用在了3处,1是encoder-decoder attention, queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder。2是self-attention in encoder,all of the keys, values and queries come from output of the previous layer in the encoder。3是self-attention in decoder, 类似
- position-wise feed-forward networks:3-d inputs with shape (batch size, sequence length, feature size), consists of two dense layers, equivalent to applying two $1*1$ convolution layers
- 这个feed-forward networks applied to each position separately and identically,不过当然不同层的参数不一样。本质式子就是俩线性变换夹了一个ReLU,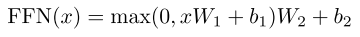
- add and norm: X as the original input in the residual network, and Y as the outputs from either the multi-head attention layer or the position-wise FFN network. In addition, we apply dropout on Y for regularization.
-
- position encoding: 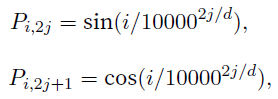$i$ refers to the order in the sentence, and $j$ refers to the
position along the embedding vector dimension, $d$是dimension of embedding。这个函数应该更容易把握relative positions,并且没有sequence长度限制,不过也可以用别的,比如learned ones ,一些解释https://www.zhihu.com/question/347678607
- [https://medium.com/@pkqiang49/%E4%B8%80%E6%96%87%E7%9C%8B%E6%87%82-attention-%E6%9C%AC%E8%B4%A8%E5%8E%9F%E7%90%86-3%E5%A4%A7%E4%BC%98%E7%82%B9-5%E5%A4%A7%E7%B1%BB%E5%9E%8B-e4fbe4b6d030](https://medium.com/@pkqiang49/一文看懂-attention-本质原理-3大优点-5大类型-e4fbe4b6d030)
* [A Decomposable Attention Model for Natural Language Inference](https://arxiv.org/pdf/1606.01933.pdf)这里提出一种结构,可以parameter少,还并行性好,结果还很好,3 steps: attending, comparing, aggregating.
## Unsupervised machine translation
- https://github.com/facebookresearch/MUSE
- [Word Translation Without Parallel Data](https://arxiv.org/pdf/1710.04087.pdf)
- [Unsupervised Machine Translation Using Monolingual Corpora Only](https://arxiv.org/pdf/1711.00043.pdf;Guillaume)
- starts with an unsupervised naïve translation model obtained by making word-by-word translation of sentences using a parallel dictionary learned in an unsupervised way
- train the encoder and decoder by reconstructing a sentence in a particular domain, given a noisy version (避免直接copy)of the same sentence in the same or in the other domain (重建或翻译)其中result of a translation with the model at the previous iteration in the case of the translation task.
- 此外还训练一个神经网络discriminator,encoder需要fool这个网络(让它判断不了输入语言ADVERSARIAL TRAINING)
# GAN
- [generative adversarial nets - paper](https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf)
- 本质是个minmax,$D$是discriminator, $G$ is generator. 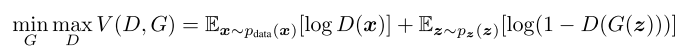
- $y$ is label, true 1 fake 0, $\textbf{x}$ is inputs, $D$ minimize 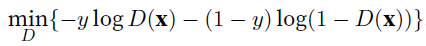
- $\textbf{z}$ is latent variable, 经常是random来生成data
- $G$ maximize 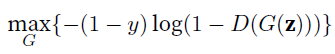 但是实现的时候,我们实际上是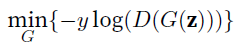, 特点是D的loss提供了training signal给G(当然,因为一个max,一个想min,所以把label由1变0)
- vanilla GAN couldn’t model all modes on a simple 2D dataset [VEEGAN: Reducing Mode Collapse in GANs using Implicit Variational Learning](https://arxiv.org/pdf/1705.07761.pdf)
-
# Reinforcement learning
-
# Recommender system
## Basics
- 召回即触发 (recall and trigger)
- multi-hot: 介于 label encoding 和 one-hot 之间 https://stats.stackexchange.com/questions/467633/what-exactly-is-multi-hot-encoding-and-how-is-it-different-from-one-hot
-
## CF (collaborative filtering)
- 头部效应明显,处理稀疏向量能力弱,泛化差
-
### UserCF
- Drawbacks: user num is much larger than item num, and storage of a similarity matix is expensive, grow by `O(n^2)`, sparse, especially for new users low rate
### ItemCF
- 一个用户 * 物品的`m*n`矩阵,物品相似度,根据正反馈物品推荐topk
- 相较而言,UserCF适合发现新热点,ItemCF适合稳定的兴趣点
## Matrix factorization
- MF is 1-st order of FM (factorization machine)
- 用更稠密的隐向量,利用了全局信息,一定程度上比CF更好的处理稀疏问题
- 说白了就是把`m*n` matrix factorized into `m*k` and `k*n`,k is the size of the hidden vector, the size is chosen by trade off generalization, calculation and expression capability
- When recommendation, just dot multiply the user vector with item vector
- 2 methods: SVD and gradient descent
- SVD needs co-occurrence matrix to be dense, however, it is very unlikely in the real case, so fill-in; Compution complexity `O(m*n^2)`
- Gradient descent objective function, where `K` is the set of user ratings
- $$
min_{q^{*},p^{*}}\Sigma_{(u,i) \in K}{(r_{ui} - q_{i}^{T}p_{u})}^{2}
$$
-
- to counter over-fitting, we can add regularization
- $$
\lambda(\lVert q_{i} \rVert^{2} + \lVert p_{u} \rVert^{2})
$$
- MF的空间复杂度降低为`(n+m)*k`
- drawbacks: 不方便加入用户,物品和context信息,同时在缺乏用户历史行为时也表现不佳
## 逻辑回归
- logistics regressio assumes dependent variable y obeys Bernoulli distribution偏心硬币, linear regression assumes y obeys gaussian distribution, 所以logistics regression更符合预测CTR (click through rate)要求
- 辛普森悖论,就是多一个维度时,都表现更好的a,在汇总数据后反而表现差,本质是维度不是均匀的。所以不能轻易合并高维数据,会损失信息
- 本质就是特征给个权重,相乘以后用非线性函数打个分,所以不具有特征交叉生成高维组合特征的能力
- POLY2:一种特征两两交叉的方法,给特征组合一个权重,不过只是治标,而且训练复杂度提升,大量交叉特征很稀疏,根本没有足够训练数据
- $$
\Phi POLY2(w,x)=\Sigma_{j_{1}=1}^{n-1}{\Sigma_{j_{2}=j_{1}+1}^{n}{w_{n(j_{1}, j_{2})}x_{j_{1}}x_{j_{2}}}}
$$
-
## Factorization machine
- 以下是FM的2阶版本
- $$
\Phi FM(w,x)=\Sigma_{j_{1}=1}^{n-1}{\Sigma_{j_{2}=j_{1}+1}^{n}{(w_{j_{1}}\cdot w_{j_{2}})x_{j_{1}}x_{j_{2}}}}
$$
- 每个特征学习一个latent vector, 隐向量的内积作为交叉特征的权重,权重参数数量从`n^2` -> `kn`
- FFM, 引入了field-aware特征域感知,表达能力更强
- $$
\Phi FFM(w,x)=\Sigma_{j_{1}=1}^{n-1}{\Sigma_{j_{2}=j_{1}+1}^{n}{(w_{j_{1},f_{2}}\cdot w_{j_{2},f_{1}})x_{j_{1}}x_{j_{2}}}}
$$
- 说白了就是特征变成一组,看菜吃饭
- 参数变成`n*f*k`,其中f是特征域个数,训练复杂度`kn^2`
- FM and FFM可以拓展到高维,不过组合爆炸,现实少用
## GBDT + LR
- GBDT就是构建新的离散特征向量的方法,LR就是logistics regression,和前者是分开的,不用梯度回传啥的
- GBDT就是gradient boosting decision tree,
## AutoRec
- AutoEncoder + CF的single hidden layer 的神经网络
- autoencoder 的objective function如下
- $$
\min_{\theta}\Sigma_{r\in S}{\lVert}r-h(r;\theta)\rVert_{2}^{2}
$$
- 重建函数 h 的参数量一般远小于输入向量的维度
- 经典的模型是3层,input, hidden and output
- $$
h(r;\theta)=f(W\cdot g(Vr + \mu)+b)
$$
- 其中f,g都是激活函数,而V,输入层到隐层的参数,W是隐层到输出层的参数矩阵
- 可以加上L2 norm,就用普通的提督反向传播就可以训练
## Deep Crossing
- 4 种 layers
- embedding layer: embedding一般是不会啊one-hot or multi-hot的稀疏响亮转换成稠密的向量,数值型feature可以不用embedding
- stacking layer: 把embeddign 和数值型特征连接到一起
- multiple residual units layer: 这个Res结构实现了feature的交叉重组,可以很深,所以就是deep crossing
- scoring layer: normally logistics for CTR predict or softmax for image classification
## NeuralCF
- https://paperswithcode.com/paper/neural-collaborative-filtering
- 利用神经网络来替代协同过滤的内积来进行特征交叉
-
## PNN
- 相对于 deep crossing 模型,就是把 stacking layer 换成 product layer,说白了就是更好的交叉特征
- IPNN,就是 inner product
- OPNN, 就是 outer product,其中外积操作会让模型复杂度从 M (向量的维度)变成 $M^{2}$,可以通过 superposition 来解决,这个操作相当于一个 average pooling,然后再进行外积互操作
- average pooling一般用在同类的 embedding 中,否则会模糊很重要的信息
-
## Wide & Deep
- Wide 主要是记忆,而 deep 则更好的泛化
- 单输入层的 Wide部分:已安装应用和曝光应用 2 个
- Deep 部分:全量特征
- 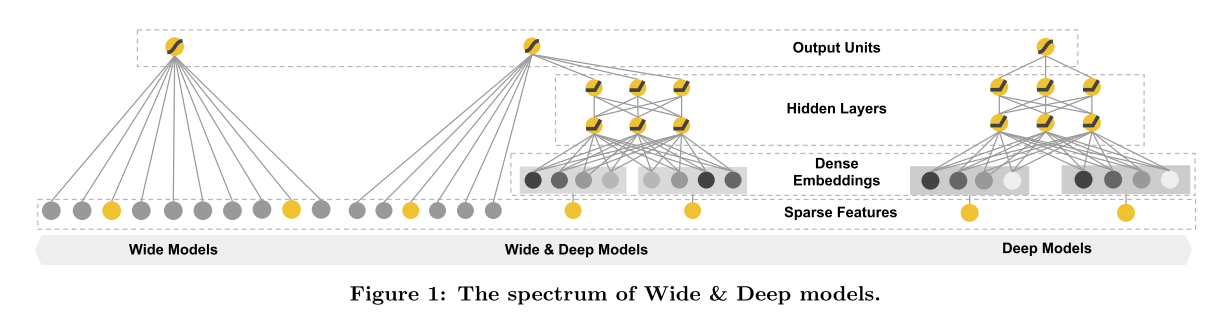
- Deep & cross:本质就是cross layer进行特征交叉,替代掉 wide 部分
## FNN, DeepFM, NFM
### FNN
- 本质在于 embedding 的改进,普通 embedding 训练非常慢
- embedding 训练收敛慢:
1. 参数数量大
2. 稀疏,只有非0特征连着的embedding会更新
- 使用 FM 模型训练好特征的隐向量来初始化 embedding 层,然后训练 embedding
### DeepFM
- FM 替换 wide
- FM 和 deep 共享相同的 embedding 层
## AFM, DIN
### AFM
- 注意力机制替代 sum pooling
- 给两两交叉特征层加一个 attention 然后输出 $f_{Att}{j(f_{PI}{(\epsilon)})=\Sigma_{(i,j)\in R_{x}}{a_{ij}(v_{i}\odot v_{j})x_{i}x_{j}}}$
- 注意力网络是单个全连接层加 softmax,要学习的就是 W, b, h
- $a\prime_{ij}=h^{T}ReLU(W(v_{i}\odot v_{j})x_{i}x_{j}+b)$
- $a_{ij}=\frac{\exp(a\prime_{ij})}{\Sigma_{(i,j)\in R_{x}}{\exp (a\prime_{ij})}}$
- 注意力网络跟大家一块训练即可
### DIN
- item特征组老样子,user特征组由 sum 变成 weighted sum,加上了 attention 的权重,本质就是加了个 attention unit
- attention unit:输入 2 embedding,计算 element-wise 减,这三者连接在一起,输入全连接层,然后单神经元输出一个 score
- attention 结构并不复杂,但是有效,应该是因为什么和什么相关的业务信息被attention表示了,比如item id和用户浏览过的item id发生作用,而不需要所有embedding都发生关系,那样训练困难,耗的资源多,逻辑上也不显然
## DIEN
- 本质是相对于 DIN 加了时间的序列
- 额外加了一个兴趣进化网络,分为三层,从低到高
1. behaviour layer
2. interest extraction layer
3. interest evolving layer
- interest extraction layer: 用的 GRU,这个没有RNN梯度消失的问题,也没有LSTM那么多参数,收敛速度更快
- interest evolving layer:主要是加上了 attention
## DRN
- 强化学习模型,好处是online
- Deep Q-Network,quality,给行动打分
- 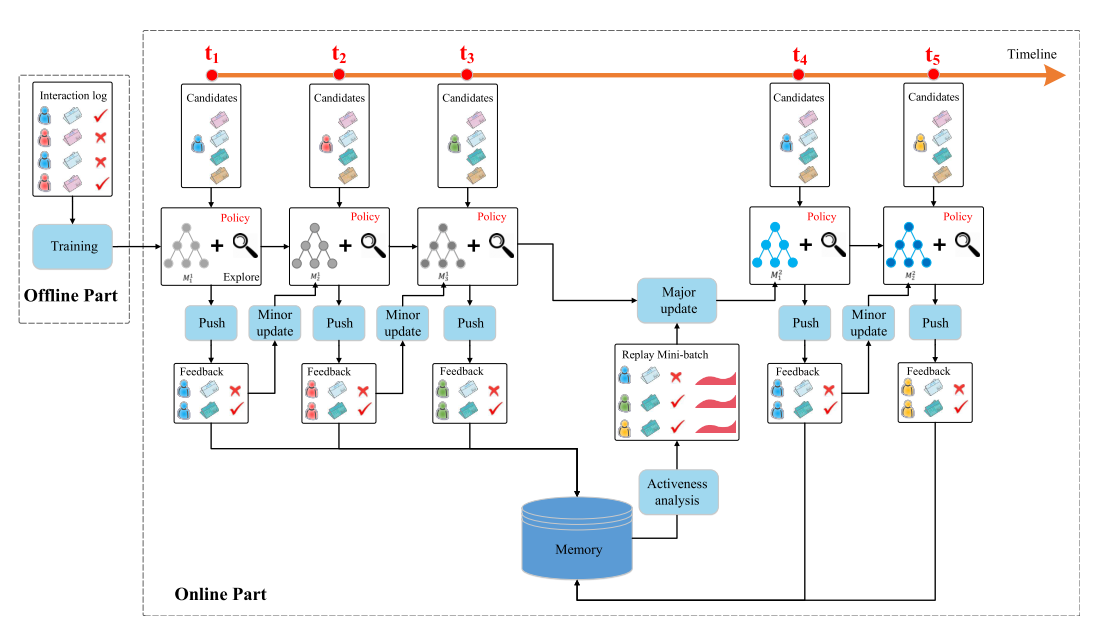
- 离线用历史数据训练一个初始化模型
- t1 -> t2 推送服务
- t2 微更新 (DBGDA)
- t4 主更新,就是重新训练
- t5 重复
- dueling bandit gradient descent algorithm:
1. 对于网络 Q 的参数$W$,增加一个随机的扰动,得到新的模型参数$\tilde{W}$,这个叫探索网络
2. 新老网络分别生成推荐结果$L$ $\tilde{L}$,然后俩进行 interleaving后推给用户
3. 好则用,不好则留,迭代
## Embeddings
- 主要用在3个方面
1. 网络中的 embedding 层,(和网络整体训练虽好,但是很多时候收敛太慢了,所以经常是 embedding 单独进行预训练)
2. embedding 和别的特征向量进行拼接
3. 通过 embedding 相似度直接进行召回 (这个要求的是 user, item的向量处于同一个向量空间,这样就可以直接搜索最近邻,不用进行点积运算,用locality sensitie hashing)
### Item2vec
- 和 word2vec 差不多,不过去掉了时间窗口(或者说markov),用用户历史记录序列中所有的item,两两有关
- 对于一个长度为K的用户历史记录 $w_{1},…,w_{K}$,objective function: $\frac{1}{K}\Sigma_{i=1}^{K}{\Sigma_{j\neq i}^{K}{\log p(w_{j}\lvert w_{i})}}$
- 主要是用于序列型数据
### Graph embedding
- 可以处理网络型数据
- 包含结构信息和局部相似性信息
#### DeepWalk
- 构建方法:
1. 用户行为序列构建有向图,多次连续出现的物品对,那么对应的边的权重被加强
2. 随机起始点,随机游走,产生物品序列,概率就是按照出边的权的比例来
3. 新的物品序列输入 word2vec,产生 embedding
#### Node2vec
- 网络具有:
1. 同质性 homophily,相近节点 embedding 相似,游走更偏 DFS,商品(同品类,同属性)
2. 结构性 structural equivalence,结构相似的节点 embedding 相似,游走更偏 BFS,商品(都是爆款,都是凑单)
- 调整超参数控制游走,可以产生不同侧重的 embedding,然后都用来后续训练
#### locality sensitive hashing 局部敏感哈希
- 本质是高维空间的点到低维空间的映射,满足高维相近低维也一定相近,但是远的也有一定的概率变成相近的
- 对于一个 k 维函数,让它计算一下和 k*m 矩阵的运算,就得到一个 m 维的向量,这个 矩阵其实就是 m 个hash 函数,对于生成的向量v,在它 m 个层面进行分桶($[\frac{v}{w}]$,就是除以桶的宽度然后取整),这样我们就知道了相近的点就是在各个维度相近的桶里,这样查找就会非常快
- 使用几个hash函数,这些hash函数是用 and, or都是工程上面的权衡
## Explore and exploit
- 推荐不能太过分,也要注意用户新兴趣的培养,多样性,同时对物品冷启也有好处
- 分3类:
1. 传统的:$\epsilon-Greedy$, Thompson Sampling (适用于偏心硬币,CTR) and UCB (upper confidence bound)
2. 个性化的:LinUCB
3. 模型的:DRN
## 工程实现
### 大数据
- 1. 批处理:HDFS + map reduce,延迟较大
2. 流计算:Storm, Flink,延迟小,灵活性大
3. lambda:批处理(离线处理) + 流计算(实时流),落盘前会进行合并和纠错校验
4. kappa:把批处理看作是时间窗口比较大的流处理,存储原始数据+数据重播
### 模型训练 (分布式)
- 1. Spark MLlib:全局广播,同步阻断式,慢,确保一致性
2. Parameter server:异步非阻断式,速度快,一致性有损(某个),多server,一致性hash,参数范围拉取和推送
### 上线部署
-
# Appendix
- 知识蒸馏:模型压缩,用小模型模拟 a pre-trained, larger model (or ensemble of models),引入一个变量softmax temperature $T$,$T$经常是1~20,$p_i = \frac{exp\left(\frac{z_i}{T}\right)}{\sum_{j} \exp\left(\frac{z_j}{T}\right)}$。两个新的超参数$\alpha, \beta$,其中$\beta$一般是$1-\alpha$,soft target包含的信息量更大。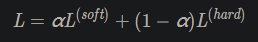
- 步骤:1、训练大模型:先用hard target,也就是正常的label训练大模型。
2、计算soft target:利用训练好的大模型来计算soft target。也就是大模型“软化后”再经过softmax的output。
3、训练小模型,在小模型的基础上再加一个额外的soft target的loss function,通过lambda来调节两个loss functions的比重。
4、预测时,将训练好的小模型按常规方式使用。
- Gaussian Mixture Model 和 K means:本质都可以做clustering,k means就是随便选几个点做cluster,然后hard assign那些点到某一个cluster,计算mean作为新cluster,不断EM optimization。gaussian mixture model则可以soft assign,某个点有多少概率属于这个cluster
-
- Glove vs word2vec, glove会更快点,easier to parallelize
- CopyNet
- Coverage机制 Seq2Seq token重复问题
- Boosting Bagging Stacking
- ```
# bagging
Given dataset D of size N.
For m in n_models:
Create new dataset D_i of size N by sampling with replacement from D.
Train model on D_i (and then predict)
Combine predictions with equal weight
# boosting,重视那些分错的
Init data with equal weights (1/N).
For m in n_model:
Train model on weighted data (and then predict)
Update weights according to misclassification rate.
Renormalize weights
Combine confidence weighted predictions
```
-
- 样本不均衡:上采样,下采样,调整权重
| 51.852695 | 989 | 0.774372 | eng_Latn | 0.560265 |
1179961a64a6797d9b0ce372638db2fbfda84ffc | 9,977 | md | Markdown | docs/guides/functions.md | roopesh83/terraform-provider-hsdp | 5bc38c8ca3337d96c1f539ccb47f7b52f6cfb4e1 | [
"MIT"
] | null | null | null | docs/guides/functions.md | roopesh83/terraform-provider-hsdp | 5bc38c8ca3337d96c1f539ccb47f7b52f6cfb4e1 | [
"MIT"
] | null | null | null | docs/guides/functions.md | roopesh83/terraform-provider-hsdp | 5bc38c8ca3337d96c1f539ccb47f7b52f6cfb4e1 | [
"MIT"
] | null | null | null | ---
page_title: "Working with hsdp_function"
---
# Working with hsdp_function
The `hsdp_function` resource is a higher level abstraction of the [HSDP Iron](https://www.hsdp.io/documentation/ironio-service-broker)
service. It uses an Iron service broker instance together with an (optional) function Gateway running in Cloud foundry. This combination
unlocks capabilities beyond the standard Iron services:
- No need to use Iron CLI to schedule tasks or upload code
- Manage Iron codes fully via Terraform
- **CRON** compatible scheduling of Docker workloads using Terraform, leapfrogging Iron.io scheduling capabilities
- Full control over the Docker container **ENVIRONMENT** variables, allowing easy workload configuration
- Automatic encryption of workload payloads
- Synchronously call a Docker workload running on an Iron Worker, with **streaming support**
- Asynchronously schedule a Docker workload with HTTP Callback support (POST output of workload)
- Function Gateway can be configured with Token auth (default)
- Optionally integrates with **HSDP IAM** for Organization RBAC access to functions
- Asynchronous jobs are scheduled and can take advantage of Iron autoscaling
- Designed to be **Iron agnostic**
# Configuring the backend
The execution plane is pluggable but at this time we only support the `siderite` backend type which utilizes the HSDP Iron services.
The `siderite` backend should be provisioned using the [siderite-backend](https://registry.terraform.io/modules/philips-labs/siderite-backend/cloudfoundry/latest) terraform module.
Example:
```hcl
module "siderite-backend" {
source = "philips-labs/siderite-backend/cloudfoundry"
version = "0.6.0"
cf_region = "eu-west"
cf_org_name = "my-cf-org"
cf_space = "myspace"
cf_user = var.cf_user
iron_plan = "large-encrypted-gpu"
}
```
> Iron service broker plan names can differ between CF regions so make sure the `iron_plan` you specify is available in the region
The module will provision an Iron service instance and deploy the function Gateway to the specified
Cloud foundry space. If no space is specified one will be created automatically.
> The (optional) Gateway app is very lean and is set up to use no more than 64MB RAM
# Defining your first function
With the above module in place you can continue defining a function:
```hcl
resource "hsdp_function" "cuda_test" {
name = "cuda-test"
docker_image = "philipslabs/hsdp-task-cuda-test:v0.0.4"
command = ["/app/cudatest"]
backend {
credentials = module.siderite_backend.credentials
}
}
```
When applied, the provider will perform the following actions:
- Create an iron `code` based on the specified docker image
- Create two (2) `schedules` in the Iron backend which use the `code`, one for sychronous calls and one for asychnronous calls
The `hsdp_function` resource will export a number of attributes:
| Name | Description |
|------|-------------|
| `async_endpoint` | The endpoint to trigger your function asychronously |
| `endpoint` | The endpoint to trigger your function synchronously |
| `auth_type` | The auth type conifguration of the API gateway |
| `token` | The security token to use for authenticating against the endpoints |
# Creating your own Docker function image
A `hsdp_function` compatible Docker image needs to adhere to a number of criteria. We use
a helper application called `siderite`. Siderite started as a convenience tool to ease Iron Worker usage. It now has a
`function` mode where it will look for an `/app/server` (configurable) and execute it. The server should start up and
listen on port `8080` for regular HTTP requests. The siderite binary will establish a connection to the gateway and wait
for synchronous requests to come in.
## Asynchronous function
In asychronous mode the Siderite helper will pull the payload from the Gateway and execute the request
(again by spawning `/app/server`). It will `POST` the response back to a URL specified in the original request Header called
`X-Callback-URL` header.
## Example Docker file
```dockerfile
FROM golang:1.16.5-alpine3.14 as builder
RUN apk add --no-cache git openssh gcc musl-dev
WORKDIR /src
COPY go.mod .
COPY go.sum .
# Get dependancies - will also be cached if we won't change mod/sum
RUN go mod download
# Build
COPY . .
RUN go build -o server .
FROM philipslabs/siderite:v0.8.0 AS siderite
FROM alpine:latest
RUN apk add --no-cache git openssh openssl bash postgresql-client
WORKDIR /app
COPY --from=siderite /app/siderite /app/siderite
COPY --from=builder /src/server /app
CMD ["/app/siderite","function"]
```
Notes:
- The above docker image builds a Go binary from source and copies it as `/app/server` in the final image
- You can use ANY programming language (even COBOL), as long as you produce an executable binary or script which spawns
listens on port `8080` after startup.
- We pull the `siderite` binary from the official `philipslabs/siderite` registry. Use a version tag for stability.
- The `CMD` statement should execute `/app/siderite function` as the main command
- If your function is always scheduled use `/app/siderite task` instead. This will automatically exit after a single run.
- Include any additional tools in your final image
## Example using curl:
```text
curl -v \
-X POST \
-H "Authorization: Token XXX" \
-H "X-Callback-URL: https://hook.bin/XYZ" \
https://hsdp-func-gateway-yyy.eu-west.philips-healthsuite.com/function/zzz
```
This would schedule the function to run. The result of the request will then be posted to `https://hook.bin/XYZ`. Calls
will be queued up and picked up by workers.
# Scheduling a function to run periodically (Task)
Enabling the gateway in the `siderite` backend unlocks full **CRON** compatible scheduling of `hsdp_function` resources.
It provides much finer control over scheduling behaviour compared to the standard Iron.io `run_every`
option. To achieve this the gateway runs an internal CRON scheduler which is driven by the provider managed schedule entries
in the Iron.io backend, syncing the config every few seconds.
```hcl
resource "hsdp_function" "cuda_test" {
name = "cuda-test"
docker_image = "philipslabs/hsdp-task-cuda-test:v0.0.5"
command = ["/app/cudatest"]
schedule = "14 15 * * * *"
timeout = 120
backend {
credentials = module.siderite_backend.credentials
}
}
```
The above example would queue your `hsdp_function` every day at exactly 3.14pm.
The following one would queue your function every Sunday morning at 5am:
```hcl
resource "hsdp_function" "cuda_test" {
name = "cuda-test"
docker_image = "philipslabs/hsdp-task-cuda-test:v0.0.4"
command = ["/app/cudatest"]
schedule = "0 5 * * * 0"
timeout = 120
backend {
credentials = module.siderite_backend.credentials
}
}
```
-> Even though you can specify an up-to-the-minute accurate schedule, your function is still queued on the
Iron cluster, so the exact start time is always determined by how busy the cluster is at that moment.
Finally, an example of using the Iron.io native scheduler:
```hcl
resource "hsdp_function" "cuda_test" {
name = "cuda-test"
docker_image = "philipslabs/hsdp-task-cuda-test:v0.0.5"
command = ["/app/cudatest"]
run_every = "20m"
start_at = "2021-01-01T07:00:00.00Z" # Start at 7am UTC
timeout = 120
backend {
credentials = module.siderite_backend.credentials
}
}
```
This will run your function every 20 minutes.
-> Always set a timeout value for your scheduled function. This sets a limit on the runtime for each invocation.
### cron field description
```text
1. Entry: Minute when the process will be started [0-60]
2. Entry: Hour when the process will be started [0-23]
3. Entry: Day of the month when the process will be started [1-28/29/30/31]
4. Entry: Month of the year when the process will be started [1-12]
5. Entry: Weekday when the process will be started [0-6] [0 is Sunday]
all x min = */x
```
## Function vs Task
The `hsdp_function` resource supports defining functions which are automatically executed
periodically i.e. `Tasks`. A Docker image which defines a task should use the following `CMD`:
```dockerfile
CMD ["/app/siderite","task"]
```
This ensures that after a single run the container exits gracefully instead of waiting to timeout.
## Naming convention
Please name and publish your `hsdp_function` compatible Docker images using a repository name starting with `hsdp-function-...`.
This will help others identify the primary usage pattern for your image.
If your image represents a task, please use the prefix `hsdp-task-...`
# Gateway authentication
The gateway supports a number of authentication methods which you can configure via the `auth_type` argument.
| Name | Description |
|------|-------------|
| `none` | Authentication disabled. Only recommended for testing |
| `token` | The default. Token based authentication |
| `iam` | [HSDP IAM](https://www.hsdp.io/documentation/identity-and-access-management-iam) based authentication |
## Token based authentication
The default authentication method is token based. The endpoint check the following HTTP header for the token
```http
Authorization: Token TOKENHERE
```
if the token matches up the request is allowed.
## IAM integration
The gateway also supports Role Based Access Control (RBAC) using HSDP IAM. The following values should be added to the
siderite backend module block:
```hcl
environment = {
AUTH_IAM_CLIENT_ID = "client_id_here"
AUTH_IAM_CLIENT_SECRET = "Secr3tH3rE"
AUTH_IAM_REGION = "eu-west"
AUTH_IAM_ENVIRONMENT = "prod"
AUTH_IAM_ORGS = "org-uuid1,org-uuid2"
AUTH_IAM_ROLES = "HSDP_FUNCTION"
}
```
With the above configuration the gateway will do a introspect call on the Bearer token and if the user/service has the
`HSDP_FUNCTION` role in either of the ORGs specified will be allowed to execute the function.
| 38.670543 | 180 | 0.748121 | eng_Latn | 0.989448 |
117a7357c3de218be6f468e8a45447a11c4adf85 | 51 | md | Markdown | README.md | Ksistof/crystal-clear-travel | 8af1213a91e1995d7cb3ab9a22f8320bab73b2aa | [
"CC-BY-4.0"
] | null | null | null | README.md | Ksistof/crystal-clear-travel | 8af1213a91e1995d7cb3ab9a22f8320bab73b2aa | [
"CC-BY-4.0"
] | null | null | null | README.md | Ksistof/crystal-clear-travel | 8af1213a91e1995d7cb3ab9a22f8320bab73b2aa | [
"CC-BY-4.0"
] | null | null | null | Visit our website --> http://crystalcleartravel.co/ | 51 | 51 | 0.764706 | kor_Hang | 0.548931 |
117ac8e6efbf213379575a59bf92cfbcf746bdd2 | 251 | md | Markdown | content/stories/20210304.md | JaWSnl/cleaning-clowns | 1a262bddea155b8427ac53dfd0d5b4e20f14090a | [
"MIT"
] | null | null | null | content/stories/20210304.md | JaWSnl/cleaning-clowns | 1a262bddea155b8427ac53dfd0d5b4e20f14090a | [
"MIT"
] | null | null | null | content/stories/20210304.md | JaWSnl/cleaning-clowns | 1a262bddea155b8427ac53dfd0d5b4e20f14090a | [
"MIT"
] | null | null | null |
---
title: "Nederland Bedankt: ‘cleaning clown’ Saskia Kruis-van Merrienboer"
date: 2021-03-04
publishdate: 2021-03-06
image: "/images/news-100x100.png"
---
https://maatschapwij.nu/blogs/nederland-bedankt-cleaning-clown-saskia-kruis-van-merrienboer/ | 27.888889 | 92 | 0.768924 | nld_Latn | 0.173489 |
117b2de2b2f0d402afadb3b7dce1745d249bae8b | 1,750 | md | Markdown | .github/ISSUE_TEMPLATE.md | tmpick/docker.github.io | d62a98d91779ffa1f776672b7c1f871c6de8e93d | [
"Apache-2.0"
] | 3,924 | 2016-09-23T21:04:18.000Z | 2022-03-30T21:57:00.000Z | .github/ISSUE_TEMPLATE.md | tmpick/docker.github.io | d62a98d91779ffa1f776672b7c1f871c6de8e93d | [
"Apache-2.0"
] | 12,149 | 2016-09-23T21:21:36.000Z | 2022-03-31T23:20:11.000Z | .github/ISSUE_TEMPLATE.md | tmpick/docker.github.io | d62a98d91779ffa1f776672b7c1f871c6de8e93d | [
"Apache-2.0"
] | 7,276 | 2016-09-23T21:13:39.000Z | 2022-03-31T07:50:40.000Z |
<!--
## READ ME FIRST
This repository is for reporting issues related to Docker Documentation. Before submitting a new issue, check whether the issue has already been reported. You can join the discussion using an emoji, or by adding a comment to an existing issue.
You can ask general questions and get community support through the Docker Community Slack - http://dockr.ly/slack. Personalized support is available through the Docker Pro, Team, and Business subscriptions. See https://www.docker.com/pricing for details.
-->
### Problem description
<!--
Briefly describe the problem that you found. A clear title and description helps us understand and address the issue quickly.
Report only documentation issues here. Report any product issues in the corresponding product repository.
If you are reporting a broken link issue, let us know how you arrived at the broken link; was it through a page on docs.docker.com, or from an external website?
-->
### Problem location
<!-- Help us find the problem quickly by choosing one of the following options: -->
- I saw a problem at the following URL: <Add URL>
- I couldn't find the information I wanted. I expected to find it near the following URL <Add the URL and briefly describe how we can improve the existing content>
- Other: <Add details that can help us understand the issue>
### Project version(s) affected
<!-- If this problem only affects specific versions of a project (like Docker
Engine 20.10, or Docker Desktop 4.2.0), tell us here. The fix may need to take that into account. -->
### Suggestions for a fix
<!--If you have specific ideas about how we can fix this issue, let us know. -->
<!-- To improve this template, edit the .github/ISSUE_TEMPLATE.md file -->
| 41.666667 | 255 | 0.756 | eng_Latn | 0.99909 |
117ba8af326d3cb1cd0468e06605fb4ecfa1d4b6 | 1,543 | md | Markdown | README.md | hejfelix/slinky-wrappers | 39eafb269eba87ce171efd240ed81bf9613ec640 | [
"MIT"
] | 10 | 2018-06-04T12:27:56.000Z | 2020-08-24T11:10:47.000Z | README.md | hejfelix/slinky-wrappers | 39eafb269eba87ce171efd240ed81bf9613ec640 | [
"MIT"
] | 2 | 2019-04-21T05:55:56.000Z | 2021-01-28T19:24:17.000Z | README.md | hejfelix/slinky-wrappers | 39eafb269eba87ce171efd240ed81bf9613ec640 | [
"MIT"
] | 4 | 2019-04-20T20:12:35.000Z | 2020-05-21T21:12:20.000Z | # *** HELP WANTED ***
The demo needs to be fleshed out. It serves as a sanity check / ad hoc test suite, but I don't have much time for this project since I became a dad. If you want to help, let me know!
# Demo
See the demo here: https://hejfelix.github.io/slinky-wrappers/
# Maven central
* React router 
* Semantic UI 
* Material UI 
## Installation
See in [build.sbt](build.sbt) how the demo project is set up using [scalajs-bundler](https://github.com/scalacenter/scalajs-bundler).
For a bigger example using material ui, please see this project: https://github.com/hejfelix/wishr
# slinky-wrappers
These are wrappers that I'm writing for my own projects. Currently, there's somewhat more support for Material UI than Semantic UI. There's an example using it here: https://github.com/hejfelix/wishr
There are some things which are very difficult to model using Scala's type system. Many of these problems could potentially be fixed by Dotty (singleton types, intersection-/union types, proper enums).
Furthermore, the intellij support is not (IMHO) amazing when using the @react macro. Hence, I'm not too busy with this project.
| 51.433333 | 202 | 0.773169 | eng_Latn | 0.94696 |
117bd96f9356ff28d6d1470a8a413fb4dd439390 | 4,953 | md | Markdown | infra-healthcheck/README.md | onap/integration-xtesting | a2b118029680f62e053211a9fd9443308286a31c | [
"Apache-2.0"
] | 1 | 2021-10-15T15:18:53.000Z | 2021-10-15T15:18:53.000Z | infra-healthcheck/README.md | onap/integration-xtesting | a2b118029680f62e053211a9fd9443308286a31c | [
"Apache-2.0"
] | null | null | null | infra-healthcheck/README.md | onap/integration-xtesting | a2b118029680f62e053211a9fd9443308286a31c | [
"Apache-2.0"
] | null | null | null | # infra-healthcheck
## Goal
This infra-healthcheck docker includes the test suites checking kubernetes and
healm charts of an ONAP deployment.
It includes 2 tests:
- onap-k8s: list pods, deployments, events, cm, ... For any faulty pod, it
collects the logs and the describe. The success criteria is 100% of the pods
are up and running
- onap-helm: list the helm charts. The success criteria is all the helm charts
are completed.
- nodeport_ingress: check that we have a 1:1 correspondance between nodeports
and ingress (run only when the env variable DEPLOY_SCENARIO includes ingress)
Please note that you will find another test (onap-k8s-teardown) in CI. It is exactly
the same than onap-k8s (status of the onap cluster) executed at the end of the
CI, after all the other tests. It allows to collect the logs of the components.
## Usage
### Configuration
Mandatory:
- The kubernetes configuration: usually hosted on the.kube/config of your
jumphost. It corresponds the kubernetes credentials and are needed to perform
the different operations. This file shall be copied in /root/.kube/config in
the docker.
Optional:
- The local result directory path: to store the results in your local
environement. It shall corresponds to the internal result docker path
/var/lib/xtesting/results
### Command
You can run this docker by typing:
```
docker run -v <the kube config>:/root/.kube/config -v
<result directory>:/var/lib/xtesting/results
nexus3.onap.org:10003/onap/xtesting-infra-healthcheck:master
```
Options:
- \-r: by default the reporting to the Database is not enabled. You need to
specify the -r option in the command line. Please note that in this case, you
must precise some env variables.
environment variables:
- Mandatory (if you want to report the results in the database):
- TEST_DB_URL: the url of the target Database with the env variable .
- NODE_NAME: the name of your test environement. It must be declared in the
test database (e.g. windriver-SB00)
- Optional:
- INSTALLER_TYPE: precise how your ONAP has been installed (e.g. kubespray-oom,
rke-oom)
- BUILD_TAG: a unique tag of your CI system. It can be usefull to get all the
tests of one CI run. It uses the regex (dai|week)ly-(.+?)-\[0-9]\* to find the
version (e.g. daily-elalto-123456789).
- DEPLOY_SCENARIO: your scenario deployment. ingress test run only if the
scenario includes 'ingress'
- ONAP_RELEASE: the name of the onap release in Helm. Default is "onap".
- ONAP_HELM_LOG_PATH: the path where to retrieve specific logs that helm
deploy has captured. you should add a volume if you want to retrieve them:
`-v <the user home dir>/.helm/plugins/deploy/cache/onap/logs:/onap_helm_logs`.
`/onap_helm_logs` is the default value.
The command becomes:
```
docker run -v <the kube config>:/root/.kube/config
-v <the user home dir>/.helm/plugins/deploy/cache/onap/logs:/onap_helm_logs
-v <result directory>:/var/lib/xtesting/results
nexus3.onap.org:10003/onap/xtesting-infra-healthcheck:master
/bin/bash -c "run_tests -r -t all"
```
Note that you can run only a subset of the tests and decide if you report the
results to the test BD or not.
The following commands are correct:
```
docker run -v <the kube config>:/root/.kube/config
-v <result directory>:/var/lib/xtesting/results
nexus3.onap.org:10003/onap/xtesting-infra-healthcheck:master
/bin/bash -c "run_tests -t onap-k8s"
```
```
docker run -v <the kube config>:/root/.kube/config
-v <the user home dir>/.helm/plugins/deploy/cache/onap/logs:/onap_helm_logs
-v <result directory>:/var/lib/xtesting/results
nexus3.onap.org:10003/onap/xtesting-infra-healthcheck:master
/bin/bash -c "run_tests -r -t onap-helm"
```
You can also run the docker in interactive mode, so you can run the tests from
inside the docker and directly modify the code of the test if you want.
```
docker run -it -v <the kube config>:/root/.kube/config
-v <the user home dir>/.helm/plugins/deploy/cache/onap/logs:/onap_helm_logs
-v <result directory>:/var/lib/xtesting/results
nexus3.onap.org:10003/onap/xtesting-infra-healthcheck:master bash
```
In this case you will get the bash prompt, you can run the test by typing in
the console
```
# run_tests -t onap-k8s
```
The code of the tests is in the docker. For python test, have a look at
/usr/lib/python3.8/site-packages. See the Dockerfile for more information.
### Output
```
+------------------+-------------+-------------------+----------+--------+
| TEST CASE | PROJECT | TIER | DURATION | RESULT |
+------------------+-------------+-------------------+----------+--------+
| onap-k8s | integration | infra-healthcheck | 00:06 | PASS |
| onap-helm | integration | infra-healthcheck | 00:01 | PASS |
| nodeport_ingress | security | security | 00:01 | FAIL |
+------------------+-------------+-------------------+----------+--------+
```
| 36.688889 | 84 | 0.700384 | eng_Latn | 0.976227 |
117c15a8ee559147ac524e7cccf633665309ea85 | 12,619 | md | Markdown | README.md | trasse/OpSeF-IV | ed7401996ebbd5231794574bef12e4ff92600b86 | [
"BSD-3-Clause"
] | 21 | 2020-05-01T02:08:42.000Z | 2021-06-09T02:49:14.000Z | README.md | trasse/OpSeF-IV | ed7401996ebbd5231794574bef12e4ff92600b86 | [
"BSD-3-Clause"
] | 5 | 2020-05-08T14:01:27.000Z | 2021-04-26T15:24:16.000Z | README.md | trasse/OpSeF-IV | ed7401996ebbd5231794574bef12e4ff92600b86 | [
"BSD-3-Clause"
] | 12 | 2020-05-27T12:05:54.000Z | 2022-02-09T15:14:57.000Z | ## Summary
Various pre-trained deep-learning models for the segmentation of biomedical images have been made available to users with little to no knowledge in machine learning. However, testing these tools individually is tedious and success is uncertain.
Here, we present OpSeF, a Python framework for deep-learning based semantic segmentation that was developed to promote the collaboration of biomedical user with experienced image-analysts. The performance of pre-trained models can be improved by using pre-processing to make the new input data more closely resemble the data the selected models were trained on. OpSeF assists analysts with the semi-automated exploration of different pre-processing parameters. OpSeF integrates in a single framework: scikit-image, a collection of Python algorithms for image processing, and three mechanistically distinct convolutional neural network (CNN) based segmentation methods, the U-Net implementation used in Cellprofiler 3.0, StarDist, and Cellpose. The optimization of parameters used for preprocessing and selection of a suitable model for segmentation form one functional unit. Even if sufficiently good results are not achievable with this approach, OpSeF results can inform the analysts in the selection of the most promising CNN-architecture in which the biomedical user might invest the effort of manually labeling training data.
We provide two generic non-microscopy image collections to illustrate common segmentation challenges. Further datasets exemplify the segmentation of a mono-layer of fluorescent cells, fluorescent tissue, cells in which various compartments have been stained with a single dye, as well as histological sections stained with one or two dyes. We provide Jupyter notebooks to support analysts in user training and as a template for the systematic search for the best combination of preprocessing and CNN-based segmentation. Results can be analyzed and visualized using matplotlib, pandas, scikit-image, and scikit-learn. They can be refined by object-selection based on their region properties, a biomedical-user-provided or an auto-generated mask. Additionally, results might be exported to AnnotatorJ for editing or classification in ImageJ. After refinement, the analyst can re-import results and further analyze them in OpSeF.
We encourage biomedical users to provide further image collections, analysts Jupyter notebooks, and pre-trained models. Thereby, OpSeF might soon become, both a “model store”, in which appropriate model might be identified with reasonable effort and a valuable resource for teaching biomedical user CNN-based segmentation.
## Technical description
OpSeF has been primarily developed for staff image analysts with solid knowledge in image analysis, thorough understating of the principles of machine learning, and ideally basic skills in Python.
The analysis pipeline consists of four principal sets of functions to *import and reshape* the data, to *pre-process* it, to *segment* objects, and to *analyze and classify* results.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M1.jpg" alt = "Paper Fig M1" style = "width: 500px;"/>
Currently, OpSeF can process individual tiff-files and the Leica “.lif” container file format. During *import and reshape,* the following options are available for tiff-input: *tile* in 2D and 3D, *scale*, and make *sub-stacks* . For lif-files, only the make *sub-stacks* option is supported.
Pre-processing is mainly based on scikit-image. It consists of a linear pipeline:
<img src="./Demo_Notebooks/Figures_Demo/Fig_M3.jpg" alt = "Paper Fig M3" style = "width: =500px;"/>
Images are filtered in 2D, background is removed, and then stacks are projected. Next, the following optional pre-processing operations might be performed: histogram adjustment, edge enhancement, and inversion of images.
Segmentation in cooperates the pre-trained U-Net implementation used in Cellprofiler 3.0, the StarDist 2D model and Cellpose.
Importantly, OpSeF is designed such that parameters for pre-processing and selection of the ideal model for segmentation are one functional unit.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M4.jpg" alt = "Paper Fig M4" style = "width: 400px;"/>
Left panel: Illustration of a processing pipeline, in which three different models are applied to data generated by four different pre-processing pipelines each. Right panel: Resulting images are classified into results that are correct; suffer from under- or over-segmentation or fail to detect objects.
## How to get started:
1) Clone repository
2) Download data from https://owncloud.gwdg.de/index.php/s/nSUqVXkkfUDPG5b
3) Setup environment
4) Execute OpSeF_IV_Configure_001.ipynb (only once after installation)
5) Open any "Basic" demo notebook
6) Define the path, where you put the data (see QuickStart.pdf) and execute notebook
7) Copy this file-path of the .pkl file (see QuickStart.pdf)
8) Open OpSeF_IV_Run_001.ipynb and point the variable file_path to the .pkl file generated in 7)
(see QuickStart.pdf)
Link to QuickStart.pdf:
[QuickStart.pdf](./Documentation/Quick_Start_OpSeF.pdf)
## Advanced Use:
#### Define your own project:
1) Copy an existing Demo Notebook
2) Organize all input data in one folder
*using .lif as input:*
root/myimage_container.lif
*using .tif as input:*
root/tiff/myimage1.tif (in case this folder is the direct input to the pre-processing pipeline)
root/tiff/myimage2.tif ...
root/tiff_raw_2D/myimage1.tif (if you want to make patches in 2D)
root/tiff_to_split/myimage1.tif (if you want ONLY create substacks, no binning or creation of patches)
root/tiff_raw/myimage1.tif (for all pipelines that start with patching or binning and use stacks)
3) Point Demo Notebook to this folder & give notebook a common name:
```python
input_def["root"] = "/home/trasse/Desktop/MLTestData/leaves"
input_def["dataset"] = "leaves"
```
4) Define input type
```python
input_def["input_type"] = ".tif"
```
5) Define first test run (give it a Run_ID, define pre-processing & which model to test)
```python
run_def["run_ID"] = "001" # give each run a new ID
#(unless you want to overwrite the old data)
run_def["pre_list"] = [["Median",3,50,"Max",False,run_def["clahe_prm"],"no",False],
["Median",3,50,"Max",True,run_def["clahe_prm"],"no",False],
["Median",3,50,"Max",False,run_def["clahe_prm"],"sobel",False],
["Median",3,50,"Max",False,run_def["clahe_prm"],"no",True]]
# For Cellpose
run_def["rescale_list"] = [0.2,0.4,0.6] # run1
# Define model
run_def["ModelType"] = ["CP_nuclei","CP_cyto","SD_2D_dsb2018","UNet_CP001"] # run1
```
6) Execute Run in OpSeF_IV_Run_001.ipynb (as described for the demo notebooks)
### Explore Post-Processing Options:
Segmented objects can be filtered by their region properties or a mask, results might be exported to AnnotatorJ and re-imported for further analysis. Blue arrows define the default processing pipeline, grey arrows feature available options. Dark Blue boxes are core components, light blue boxes are optional processing steps.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M5.jpg" alt = "Paper Fig M5" style = "width: 500px;"/>
Explore the Demo Notebook: OpSeF_IV_Setup_Advanced_Filter_Plot_CSV_to_Fiji_0001_SDB_EpiCells.
This notebook illustrates how results can be improved by simple filtering.
StarDist segmentation of the Multi-labeled Cells Datasets detected nuclei reliably but caused many false positive detections. These resembles the typical shape of cells but are larger than true nuclei. Orange arrows point at nuclei that were missed, the white arrow at two nuclei that were not split, the blue arrows at false positive detection that could not be removed by filtering.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M6_A.jpg" alt = "Paper Fig M6A" style = "width: 400px;"/>
Scatter plot of segmentation results shown in A. Left panel: Mean intensity plotted against area. Right panel: Circularity plotted against area. Blue Box illustrating parameter used to filter results.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M6_B.jpg" alt = "Paper Fig M6B" style = "width: 500px;"/>
Filtered Results. Orange arrows point at nuclei that were missed, the white arrow at two nuclei that were not split, the blue arrows at false positive detection that could not be removed by filtering.
<img src="./Demo_Notebooks/Figures_Demo/Fig_M6_C.jpg" alt = "Paper Fig M6C" style = "width: 400px;"/>
Explore the Demo Notebook:
OpSeF_IV_Setup_Advanced_User_Mask_Cluster_Plot_CSV_toFiji_0002dev_SkeletalMuscle_mask
This notebook illustrates the use of a user provided mask.
!! Execute the parameter from this Notebook in OpSeF_IV_Run_002_dev.ipynb !!
<img src="./Demo_Notebooks/Figures_Demo/Fig_Muscle_MaskD_E.jpg" alt = "Paper Fig MM_DE" style = "width: 500px;"/>
(D,E) Example for the use of a user provided mask to classify segmented objects. The segmentation results (false colored nuclei) are is superimposed onto the original image subjected to [median 3x3] preprocessing. All nuclei located in the green area assigned to Class 1, all others to Class 2. Red box indicates region shown enlarged in (E). From left to right in E: original image, nuclei assigned to class 1, nuclei assigned to class 2.
T-distributed Stochastic Neighbor Embedding (t-SNE) analysis and Principal component analysis (PCA) were used to whether there is a difference between the two classes. Nuclei are not clustered by their color-coded class (class 1 (purple), class 2 (yellow)).
To this aim the pc["Do_ClusterAnalysis"] has to be set to True and
```python
if pc["Do_ClusterAnalysis"]: # Define (below) which values will be included in the TSNE:
pc["Cluster_How"] = "Mask" # or "Mask"
```
<img src="./Demo_Notebooks/Figures_Demo/Fig_Muscle_Mask_FG.jpg" alt = "Paper Fig MM_FG" style = "width: 500px;"/>
(F) (t-SNE) analysis of nuclei assigned to class 1 (purple) or class 2 (yellow).
(G) PCA of nuclei assigned to class 1 (purple) or class 2 (yellow).
### Export to and Import from AnnotatorJ
AnnotatorJ is and ImageJ/Fiji plugin for semi-automatic object annotation using deep learning.
Please see the [AnnotatorJ repository](https://github.com/spreka/annotatorj) about the plugin and install instructions, specifically the [OpSeF import](https://github.com/spreka/annotatorj#opsef-import) and the [general usage](https://github.com/spreka/annotatorj#how-to-annotate) sections.
See details in the [documentation](https://github.com/spreka/annotatorj/blob/master/AnnotatorJ_documentation.pdf) too.
### Further Information:
Documentation of naming schemes used:
guide_to_folder_structure_and_file_naming.txt
Documentation of main variables used:
guide_to_variables.txt
Further Questions:
see FAQ :
[FAQ](./Documentation/FAQ.pdf)
Guide how to create masks for classification:
Guide_user_provided_masks.txt
## Common Issues
## Why & How to Contribute
Many ML-based segmentation tools can be classified as "developer to end-user" solution. The number of parameter accessible to the end-user is very limited. Often these tools are promoted with statements such as "no knowledge in machine learning required".
OpSeF follows a different approach. Using it without basic knowledge in machine learning and the desire to dive deeper into possibilities for optimization will most likely lead to frustration (and is thus discouraged).
OpSeF is designed as "image analyst to image analyst" project.
OpSeF allows for straightforward integration of large number of pre-trained model. We hope that OpSeF will be widely accepted as frame-work through which novel model can be made available to other image analysts.
At current OpSeF-IV is still at the prove of concept stage and contains currently only four pre-trained model & the to-do list is long.
It will reach it's full potential only by being transformed into a community project.
Thus, if you lack a feature, please try to add it yourself.
Please find the current to-do list here:
[To Do](./To_Do/to_do.txt)
Please consider to solve one of these tasks.
If you train new model, please make them available in OpSeF.
Hopefully, we will publish the OpSeF-XL update (with 40 pre-trained model instead of 4) within a year as a community paper.
Please contribute new Demo_Notebooks & teaching material.
If you get stuck please e-mail me & I will try to troubleshoot.
Then please consider to multiply you knowledge by volunteering to help other analysts in using and developing OpSeF.
| 53.92735 | 1,131 | 0.778509 | eng_Latn | 0.991468 |
117dbcbc66961d767b60841e97f616675abad5fe | 6,368 | md | Markdown | README.md | lgardenhire/Merlin-1 | 7e2ddb15f684a747a84083e99f673315f054c02d | [
"Apache-2.0"
] | null | null | null | README.md | lgardenhire/Merlin-1 | 7e2ddb15f684a747a84083e99f673315f054c02d | [
"Apache-2.0"
] | null | null | null | README.md | lgardenhire/Merlin-1 | 7e2ddb15f684a747a84083e99f673315f054c02d | [
"Apache-2.0"
] | null | null | null | ## [NVIDIA Merlin](https://github.com/NVIDIA-Merlin)
NVIDIA Merlin is an open source library designed to accelerate recommender systems on NVIDIA’s GPUs. It enables data scientists, machine learning engineers, and researchers to build high-performing recommenders at scale. Merlin includes tools to address common ETL, training, and inference challenges. Each stage of the Merlin pipeline is optimized to support hundreds of terabytes of data, which is all accessible through easy-to-use APIs. With Merlin, better predictions and increased click-through rates (CTRs) are within reach. For more information, see [NVIDIA Merlin](https://developer.nvidia.com/nvidia-merlin).
### Benefits
NVIDIA Merlin is a scalable and accelerated solution, making it easy to build recommender systems from end to end. With NVIDIA Merlin, you can:
* transform GPU-accelerated data (ETL) for preprocessing and engineering features, which scales beyond larger than memory datasets sizes.
* accelerate existing training pipelines in TensorFlow, PyTorch, or FastAI by leveraging optimized, custom-built data loaders.
* scale large deep learning recommender models by enabling larger than memory embedding tables.
* deploy data transformations and trained models to production with only a few lines of code.
The goal is to provide a scalable, accelerated and easy-to-use solution to build recommender systems end-to-end.
### Components of NVIDIA Merlin
NVIDIA Merlin is a collection of open source libraries:
* NVTabular
* HugeCTR
* Triton Inference Server
<p align="center">
<img src='https://developer.nvidia.com/sites/default/files/akamai/merlin/recommender-systems-dev-web-850.svg' width="65%">
</p>
**[NVTabular](https://github.com/NVIDIA/NVTabular)**:<br>
NVTabular is a feature engineering and preprocessing library for tabular data. NVTabular is essentially the ETL component of the Merlin ecosystem. It is designed to quickly and easily manipulate terabyte-size datasets that are used to train deep learning based recommender systems. NVTabular offers a high-level API that can be used to define complex data transformation workflows. NVTabular is also capable of transformation speed-ups that can be 100 times to 1,000 times faster than transformations taking place on optimized CPU clusters. With NVTabular, you can:
- prepare datasets quickly and easily for experimentation so that more models can be trained.
- process datasets that exceed GPU and CPU memory without having to worry about scale.
- focus on what to do with the data and not how to do it by using abstraction at the operation level.
**[NVTabular data loaders](https://github.com/NVIDIA/NVTabular)**:<br>
NVTabular provides seamless integration with common deep learning frameworks, such as TensorFlow, PyTorch, and HugeCTR. When training deep learning recommender system models, data loading can be a bottleneck. Therefore, we’ve developed custom, highly-optimized data loaders to accelerate existing TensorFlow and PyTorch training pipelines. The NVTabular data loaders can lead to a speed-up that is 9 times faster than the same training pipeline used with the GPU. With the NVTabular data loaders, you can:
- remove bottlenecks from data loading by processing large chunks of data at a time instead of item by item.
- process datasets that don’t fit within the GPU or CPU memory by streaming from the disk.
- prepare batches asynchronously into the GPU to avoid CPU-GPU communication.
- integrate easily into existing TensorFlow or PyTorch training pipelines by using a similar API.
**[HugeCTR](https://github.com/NVIDIA/HugeCTR)**:<br>
HugeCTR is a GPU-accelerated framework designed to distribute training across multiple GPUs and nodes and estimate click-through rates. HugeCTR contains optimized data loaders that can be used to prepare batches with GPU-acceleration. In addition, HugeCTR is capable of scaling large deep learning recommendation models. The neural network architectures often contain large embedding tables that represent hundreds of millions of users and items. These embedding tables can easily exceed the CPU/GPU memory. HugeCTR provides strategies for scaling large embedding tables beyond available memory. With HugeCTR, you can:
- scale embedding tables over multiple GPUs or multi nodes.
- load a subset of an embedding table into the GPU in a coarse grained, on-demand manner during the training stage.
**[Triton](https://github.com/triton-inference-server/server):**<br>
NVTabular and HugeCTR both support the Triton Inference Server to provide GPU-accelerated inference. The Triton Inference Server is open source inference serving software that can be used to simplify the deployment of trained AI models from any framework to production. With Triton, you can:
- deploy NVTabular ETL workflows and trained deep learning models to production with a few lines of code.
- deploy an ensemble of NVTabular ETL and trained deep learning models to ensure that same data transformations are applied in production.
- deploy models concurrently on GPUs to maximize utilization.
- enable low latency inferencing in real time or batch inferencing to maximize GPU/CPU utilization.
- scale the production environment with Kubernetes for orchestration, metrics, and auto-scaling using a Docker container.
### Examples
A collection of [end-to-end examples](./examples/) is available within this repository in the form of Jupyter notebooks. The examples demonstrate how to:
- download and prepare the dataset.
- use preprocessing and engineering features.
- train deep learning recommendation models with TensorFlow, PyTorch, FastAI, or HugeCTR.
- deploy the models to production.
These examples are based on different datasets and provide a wide range of real-world use cases.
### Resources
For more information about NVIDIA Merlin and its components, see the following:
- [NVTabular GitHub](https://github.com/NVIDIA/NVTabular)
- [HugeCTR GitHub](https://github.com/NVIDIA/HugeCTR)
- [NVTabular API Documentation](https://nvidia.github.io/NVTabular/main/Introduction.html)
- [HugeCTR User Guide](https://github.com/NVIDIA/HugeCTR/blob/master/docs/hugectr_user_guide.md)
- [HugeCTR Python API](https://github.com/NVIDIA/HugeCTR/blob/master/docs/python_interface.md)
- [NVTabular Accelerated Training Documentation](https://nvidia.github.io/NVTabular/main/training/index.html)
| 89.690141 | 618 | 0.805433 | eng_Latn | 0.989927 |
117dc7ccbd72eab6857039ef019dda714de1cf46 | 19,531 | md | Markdown | content/docs/v3/native/hotspot/index.md | pythondev0101/ionic-legacy-docs | 6d5482f4406ea63610850cebe3d6a03861f6dee4 | [
"Apache-2.0"
] | 6 | 2019-09-09T10:04:07.000Z | 2021-05-19T12:14:05.000Z | content/docs/v3/native/hotspot/index.md | pythondev0101/ionic-legacy-docs | 6d5482f4406ea63610850cebe3d6a03861f6dee4 | [
"Apache-2.0"
] | 2 | 2020-04-30T02:05:26.000Z | 2020-06-18T15:05:26.000Z | content/docs/v3/native/hotspot/index.md | pythondev0101/ionic-legacy-docs | 6d5482f4406ea63610850cebe3d6a03861f6dee4 | [
"Apache-2.0"
] | 251 | 2019-06-19T09:42:12.000Z | 2022-03-30T04:42:04.000Z | ---
layout: "fluid/docs_base"
version: "4.20.0"
versionHref: "/docs/native"
path: ""
category: native
id: "hotspot"
title: "Hotspot"
header_sub_title: "Class in module "
doc: "Hotspot"
docType: "class"
---
<h1 class="api-title">Hotspot<span class="beta" title="beta">β</span></h1>
<a class="improve-v2-docs" href="http://github.com/ionic-team/ionic-native/edit/master/src/@ionic-native/plugins/hotspot/index.ts#L101">
Improve this doc
</a>
<p class="beta-notice">
This plugin is still in beta stage and may not work as expected. Please
submit any issues to the <a target="_blank"
href="https://github.com/hypery2k/cordova-hotspot-plugin/issues">plugin repo</a>.
</p>
<p>A Cordova plugin for managing Hotspot networks on Android.</p>
<p>Requires Cordova plugin: <code>cordova-plugin-hotspot</code>. For more info, please see the <a href="https://github.com/hypery2k/cordova-hotspot-plugin">Hotspot plugin docs</a>.</p>
<p>Repo:
<a href="https://github.com/hypery2k/cordova-hotspot-plugin">
https://github.com/hypery2k/cordova-hotspot-plugin
</a>
</p>
<h2><a class="anchor" name="installation" href="#installation"></a>Installation</h2>
<ol class="installation">
<li>Install the Cordova and Ionic Native plugins:<br>
<pre><code class="nohighlight">$ ionic cordova plugin add cordova-plugin-hotspot
$ npm install --save @ionic-native/hotspot@4
</code></pre>
</li>
<li><a href="https://ionicframework.com/docs/native/#Add_Plugins_to_Your_App_Module">Add this plugin to your app's module</a></li>
</ol>
<h2><a class="anchor" name="platforms" href="#platforms"></a>Supported platforms</h2>
<ul>
<li>Android</li>
</ul>
<h2><a class="anchor" name="usage" href="#usage"></a>Usage</h2>
<pre><code class="lang-typescript">import { Hotspot, HotspotNetwork } from '@ionic-native/hotspot';
constructor(private hotspot: Hotspot) { }
...
this.hotspot.scanWifi().then((networks: Array<HotspotNetwork>) => {
console.log(networks);
});
</code></pre>
<h2><a class="anchor" name="instance-members" href="#instance-members"></a>Instance Members</h2>
<h3><a class="anchor" name="isAvailable" href="#isAvailable"></a><code>isAvailable()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="toggleWifi" href="#toggleWifi"></a><code>toggleWifi()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="createHotspot" href="#createHotspot"></a><code>createHotspot(SSID, mode, password)</code></h3>
Configures and starts hotspot with SSID and Password
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
SSID</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID of your new Access Point</p>
</td>
</tr>
<tr>
<td>
mode</td>
<td>
<code>string</code>
</td>
<td>
<p>encryption mode (Open, WEP, WPA, WPA_PSK)</p>
</td>
</tr>
<tr>
<td>
password</td>
<td>
<code>string</code>
</td>
<td>
<p>password for your new Access Point</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> - Promise to call once hotspot is started, or reject upon failure
</div><h3><a class="anchor" name="startHotspot" href="#startHotspot"></a><code>startHotspot()</code></h3>
Turns on Access Point
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code> - true if AP is started
</div><h3><a class="anchor" name="configureHotspot" href="#configureHotspot"></a><code>configureHotspot(SSID, mode, password)</code></h3>
Configures hotspot with SSID and Password
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
SSID</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID of your new Access Point</p>
</td>
</tr>
<tr>
<td>
mode</td>
<td>
<code>string</code>
</td>
<td>
<p>encryption mode (Open, WEP, WPA, WPA_PSK)</p>
</td>
</tr>
<tr>
<td>
password</td>
<td>
<code>string</code>
</td>
<td>
<p>password for your new Access Point</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> - Promise to call when hotspot is configured, or reject upon failure
</div><h3><a class="anchor" name="stopHotspot" href="#stopHotspot"></a><code>stopHotspot()</code></h3>
Turns off Access Point
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code> - Promise to turn off the hotspot, true on success, false on failure
</div><h3><a class="anchor" name="isHotspotEnabled" href="#isHotspotEnabled"></a><code>isHotspotEnabled()</code></h3>
Checks if hotspot is enabled
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> - Promise that hotspot is enabled, rejected if it is not enabled
</div><h3><a class="anchor" name="getAllHotspotDevices" href="#getAllHotspotDevices"></a><code>getAllHotspotDevices()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<Array<HotspotDevice>></code>
</div><h3><a class="anchor" name="connectToWifi" href="#connectToWifi"></a><code>connectToWifi(ssid, password)</code></h3>
Connect to a WiFi network
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ssid</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID to connect</p>
</td>
</tr>
<tr>
<td>
password</td>
<td>
<code>string</code>
</td>
<td>
<p>password to use</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> Promise that connection to the WiFi network was successfull, rejected if unsuccessful
</div><h3><a class="anchor" name="connectToWifiAuthEncrypt" href="#connectToWifiAuthEncrypt"></a><code>connectToWifiAuthEncrypt(ssid, password, authentication, encryption)</code></h3>
Connect to a WiFi network
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ssid</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID to connect</p>
</td>
</tr>
<tr>
<td>
password</td>
<td>
<code>string</code>
</td>
<td>
<p>Password to use</p>
</td>
</tr>
<tr>
<td>
authentication</td>
<td>
<code>string</code>
</td>
<td>
<p>Authentication modes to use (LEAP, SHARED, OPEN)</p>
</td>
</tr>
<tr>
<td>
encryption</td>
<td>
<code>string[]</code>
</td>
<td>
<p>Encryption modes to use (CCMP, TKIP, WEP104, WEP40)</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> Promise that connection to the WiFi network was successfull, rejected if unsuccessful
</div><h3><a class="anchor" name="addWifiNetwork" href="#addWifiNetwork"></a><code>addWifiNetwork(ssid, mode, password)</code></h3>
Add a WiFi network
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ssid</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID of network</p>
</td>
</tr>
<tr>
<td>
mode</td>
<td>
<code>string</code>
</td>
<td>
<p>Authentication mode of (Open, WEP, WPA, WPA_PSK)</p>
</td>
</tr>
<tr>
<td>
password</td>
<td>
<code>string</code>
</td>
<td>
<p>Password for network</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> Promise that adding the WiFi network was successfull, rejected if unsuccessful
</div><h3><a class="anchor" name="removeWifiNetwork" href="#removeWifiNetwork"></a><code>removeWifiNetwork(ssid)</code></h3>
Remove a WiFi network
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ssid</td>
<td>
<code>string</code>
</td>
<td>
<p>SSID of network</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<void></code> Promise that removing the WiFi network was successfull, rejected if unsuccessful
</div><h3><a class="anchor" name="isConnectedToInternet" href="#isConnectedToInternet"></a><code>isConnectedToInternet()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="isConnectedToInternetViaWifi" href="#isConnectedToInternetViaWifi"></a><code>isConnectedToInternetViaWifi()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="isWifiOn" href="#isWifiOn"></a><code>isWifiOn()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="isWifiSupported" href="#isWifiSupported"></a><code>isWifiSupported()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="isWifiDirectSupported" href="#isWifiDirectSupported"></a><code>isWifiDirectSupported()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code>
</div><h3><a class="anchor" name="scanWifi" href="#scanWifi"></a><code>scanWifi()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<Array<HotspotNetwork>></code>
</div><h3><a class="anchor" name="scanWifiByLevel" href="#scanWifiByLevel"></a><code>scanWifiByLevel()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<Array<HotspotNetwork>></code>
</div><h3><a class="anchor" name="startWifiPeriodicallyScan" href="#startWifiPeriodicallyScan"></a><code>startWifiPeriodicallyScan()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<any></code>
</div><h3><a class="anchor" name="stopWifiPeriodicallyScan" href="#stopWifiPeriodicallyScan"></a><code>stopWifiPeriodicallyScan()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<any></code>
</div><h3><a class="anchor" name="getNetConfig" href="#getNetConfig"></a><code>getNetConfig()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<HotspotNetworkConfig></code>
</div><h3><a class="anchor" name="getConnectionInfo" href="#getConnectionInfo"></a><code>getConnectionInfo()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<HotspotConnectionInfo></code>
</div><h3><a class="anchor" name="pingHost" href="#pingHost"></a><code>pingHost()</code></h3>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<string></code>
</div><h3><a class="anchor" name="getMacAddressOfHost" href="#getMacAddressOfHost"></a><code>getMacAddressOfHost(ip)</code></h3>
Gets MAC Address associated with IP Address from ARP File
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ip</td>
<td>
<code>string</code>
</td>
<td>
<p>IP Address that you want the MAC Address of</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<string></code> - A Promise for the MAC Address
</div><h3><a class="anchor" name="isDnsLive" href="#isDnsLive"></a><code>isDnsLive(ip)</code></h3>
Checks if IP is live using DNS
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ip</td>
<td>
<code>string</code>
</td>
<td>
<p>IP Address you want to test</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code> - A Promise for whether the IP Address is reachable
</div><h3><a class="anchor" name="isPortLive" href="#isPortLive"></a><code>isPortLive(ip)</code></h3>
Checks if IP is live using socket And PORT
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ip</td>
<td>
<code>string</code>
</td>
<td>
<p>IP Address you want to test</p>
</td>
</tr>
</tbody>
</table>
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code> - A Promise for whether the IP Address is reachable
</div><h3><a class="anchor" name="isRooted" href="#isRooted"></a><code>isRooted()</code></h3>
Checks if device is rooted
<div class="return-value" markdown="1">
<i class="icon ion-arrow-return-left"></i>
<b>Returns:</b> <code>Promise<boolean></code> - A Promise for whether the device is rooted
</div>
<h2><a class="anchor" name="HotspotConnectionInfo" href="#HotspotConnectionInfo"></a>HotspotConnectionInfo</h2>
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
SSID
</td>
<td>
<code>string</code>
</td>
<td>
<p>The service set identifier (SSID) of the current 802.11 network.</p>
</td>
</tr>
<tr>
<td>
BSSID
</td>
<td>
<code>string</code>
</td>
<td>
<p>The basic service set identifier (BSSID) of the current access point.</p>
</td>
</tr>
<tr>
<td>
linkSpeed
</td>
<td>
<code>string</code>
</td>
<td>
<p>The current link speed in Mbps</p>
</td>
</tr>
<tr>
<td>
IPAddress
</td>
<td>
<code>string</code>
</td>
<td>
<p>The IP Address</p>
</td>
</tr>
<tr>
<td>
networkID
</td>
<td>
<code>string</code>
</td>
<td>
<p>Each configured network has a unique small integer ID, used to identify the network when performing operations on the supplicant.</p>
</td>
</tr>
</tbody>
</table>
<h2><a class="anchor" name="HotspotNetwork" href="#HotspotNetwork"></a>HotspotNetwork</h2>
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
SSID
</td>
<td>
<code>string</code>
</td>
<td>
<p>Human readable network name</p>
</td>
</tr>
<tr>
<td>
BSSID
</td>
<td>
<code>string</code>
</td>
<td>
<p>MAC Address of the access point</p>
</td>
</tr>
<tr>
<td>
frequency
</td>
<td>
<code>number</code>
</td>
<td>
<p>The primary 20 MHz frequency (in MHz) of the channel over which the client is communicating with the access point.</p>
</td>
</tr>
<tr>
<td>
level
</td>
<td>
<code>number</code>
</td>
<td>
<p>The detected signal level in dBm, also known as the RSSI.</p>
</td>
</tr>
<tr>
<td>
timestamp
</td>
<td>
<code>number</code>
</td>
<td>
<p>Timestamp in microseconds (since boot) when this result was last seen.</p>
</td>
</tr>
<tr>
<td>
capabilities
</td>
<td>
<code>string</code>
</td>
<td>
<p>Describes the authentication, key management, and encryption schemes supported by the access point.</p>
</td>
</tr>
</tbody>
</table>
<h2><a class="anchor" name="HotspotNetworkConfig" href="#HotspotNetworkConfig"></a>HotspotNetworkConfig</h2>
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
deviceIPAddress
</td>
<td>
<code>string</code>
</td>
<td>
<p>Device IP Address</p>
</td>
</tr>
<tr>
<td>
deviceMacAddress
</td>
<td>
<code>string</code>
</td>
<td>
<p>Device MAC Address</p>
</td>
</tr>
<tr>
<td>
gatewayIPAddress
</td>
<td>
<code>string</code>
</td>
<td>
<p>Gateway IP Address</p>
</td>
</tr>
<tr>
<td>
gatewayMacAddress
</td>
<td>
<code>string</code>
</td>
<td>
<p>Gateway MAC Address</p>
</td>
</tr>
</tbody>
</table>
<h2><a class="anchor" name="HotspotDevice" href="#HotspotDevice"></a>HotspotDevice</h2>
<table class="table param-table" style="margin:0;">
<thead>
<tr>
<th>Param</th>
<th>Type</th>
<th>Details</th>
</tr>
</thead>
<tbody>
<tr>
<td>
ip
</td>
<td>
<code>string</code>
</td>
<td>
<p>Hotspot IP Address</p>
</td>
</tr>
<tr>
<td>
mac
</td>
<td>
<code>string</code>
</td>
<td>
<p>Hotspot MAC Address</p>
</td>
</tr>
</tbody>
</table>
| 20.515756 | 198 | 0.593518 | eng_Latn | 0.289637 |
117dccd01e253c1f67222ddd2b8a9d35e87837fe | 4,338 | md | Markdown | docs/framework/wcf/feature-details/workflow-control-endpoint.md | kakkun61/docs.ja-jp | 1b866afaf766b040dfc17aefdafb2a1220e53c95 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/workflow-control-endpoint.md | kakkun61/docs.ja-jp | 1b866afaf766b040dfc17aefdafb2a1220e53c95 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/workflow-control-endpoint.md | kakkun61/docs.ja-jp | 1b866afaf766b040dfc17aefdafb2a1220e53c95 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: ワークフロー コントロール エンドポイント
ms.date: 03/30/2017
ms.assetid: 1b883334-1590-4fbb-b0d6-65197efe0700
ms.openlocfilehash: ecc0946833db578c524ce7e4579024bd4cd46fd0
ms.sourcegitcommit: bc293b14af795e0e999e3304dd40c0222cf2ffe4
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 11/26/2020
ms.locfileid: "96266897"
---
# <a name="workflow-control-endpoint"></a>ワークフロー コントロール エンドポイント
ワークフロー コントロール エンドポイントは、開発者が管理操作を呼び出して、<xref:System.ServiceModel.Activities.WorkflowServiceHost> を使用してホストされているワークフロー インスタンスをリモート制御できるようにします。 この機能を使用すると、一時停止、再開、終了などの管理操作をプログラムで実行することができます。
> [!WARNING]
> トランザクション内でワークフローコントロールエンドポイントを使用していて、制御されているワークフローにアクティビティが含まれている場合 <xref:System.Activities.Statements.Persist> 、ワークフローインスタンスは、トランザクションがタイムアウトするまでブロックします。
## <a name="workflow-instance-management"></a>ワークフロー インスタンスの管理
[!INCLUDE[netfx_current_long](../../../../includes/netfx-current-long-md.md)] は、<xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> と呼ばれる新しいコントラクトを定義します。 このコントラクトは、<xref:System.ServiceModel.Activities.WorkflowServiceHost> でホストされるワークフロー インスタンスをリモート制御する一連の管理操作を定義します。 <xref:System.ServiceModel.Activities.WorkflowControlEndpoint> は、<xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> コントラクトの実装を提供する標準のエンドポイントです。 <xref:System.ServiceModel.Activities.WorkflowControlClient> は、管理操作を <xref:System.ServiceModel.Activities.WorkflowControlEndpoint> に送信するために使用するクラスです。
ワークフロー インスタンスには、次の状態があります。
アクティブ
完了した状態に達する前の、一時停止の状態でないときのワークフロー インスタンスの状態です。 この状態にあるときのワークフロー インスタンスは、アプリケーション メッセージを実行し、処理します。
Suspended
この状態にある間は、まだ実行が開始されていないアクティビティや、部分的に実行されているアクティビティがある場合でも、ワークフロー インスタンスは実行されません。
完了
ワークフロー インスタンスの最終的な状態です。 この状態に達した後は、ワークフロー インスタンスは実行できません。
## <a name="iworkflowinstancemanagement"></a>IWorkflowInstanceManagement
<xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> インターフェイスでは、同期バージョンおよび非同期バージョンで、一連の管理操作が定義されます。 トランザクション処理されたバージョンでは、トランザクションに対応するバインディングを使用する必要があります。 次の表は、サポートされる管理操作の一覧を示します。
|管理操作|Description|
|-----------------------|-----------------|
|中止|ワークフロー インスタンスの実行を強制的に停止します。|
|キャンセル|ワークフロー インスタンスをアクティブ状態または一時停止状態から完了状態に移行します。|
|実行|ワークフロー インスタンスに実行する機会を提供します。|
|[中断]|ワークフロー インスタンスをアクティブ状態から一時停止状態に移行します。|
|Terminate|ワークフロー インスタンスをアクティブ状態または一時停止状態から完了状態に移行します。|
|Unsuspend|ワークフロー インスタンスを一時停止状態からアクティブ状態に移行します。|
|TransactedCancel|クライアントからフローされた、またはローカルに作成されたトランザクションの下で Cancel 操作を実行します。 システムでワークフロー インスタンスの永続状態が維持される場合は、ワークフロー インスタンスが、この操作の実行中に持続している必要があります。|
|TransactedRun|クライアントからフローされた、またはローカルに作成されたトランザクションの下で Run 操作を実行します。 システムでワークフロー インスタンスの永続状態が維持される場合は、ワークフロー インスタンスが、この操作の実行中に持続している必要があります。|
|TransactedSuspend|クライアントからフローされた、またはローカルに作成されたトランザクションの下で Suspend 操作を実行します。 システムでワークフロー インスタンスの永続状態が維持される場合は、ワークフロー インスタンスが、この操作の実行中に持続している必要があります。|
|TransactedTerminate|クライアントからフローされた、またはローカルに作成されたトランザクションの下で Terminate 操作を実行します。 システムでワークフロー インスタンスの永続状態が維持される場合は、ワークフロー インスタンスが、この操作の実行中に持続している必要があります。|
|TransactedUnsuspend|クライアントからフローされた、またはローカルに作成されたトランザクションの下で Unsuspend 操作を実行します。 システムでワークフロー インスタンスの永続状態が維持される場合は、ワークフロー インスタンスが、この操作の実行中に持続している必要があります。|
<xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> コントラクトは、新しいワークフロー インスタンスを作成する手段を提供せず、既存のワークフロー インスタンスを管理する手段のみを提供します。 新しいワークフローインスタンスをリモートで作成する方法の詳細については、「 [ワークフローサービスホストの機能拡張](workflow-service-host-extensibility.md)」を参照してください。
## <a name="workflowcontrolendpoint"></a>WorkflowControlEndpoint
<xref:System.ServiceModel.Activities.WorkflowControlEndpoint> は、固定コントラクト <xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> を持つ標準のエンドポイントです。 <xref:System.ServiceModel.Activities.WorkflowServiceHost> インスタンスにこのエンドポイントが追加されると、このエンドポイントを使用して、ホスト インスタンスによってホストされる任意のワークフロー インスタンスにコマンド操作を送信できます。 標準エンドポイントの詳細については、「 [標準エンドポイント](standard-endpoints.md)」を参照してください。
## <a name="workflowcontrolclient"></a>WorkflowControlClient
<xref:System.ServiceModel.Activities.WorkflowControlClient> は、<xref:System.ServiceModel.Activities.WorkflowControlEndpoint> の <xref:System.ServiceModel.Activities.WorkflowServiceHost> に制御メッセージを送信できるようにするクラスです。 このクラスには、トランザクション処理された操作を除き、<xref:System.ServiceModel.Activities.IWorkflowInstanceManagement> コントラクトでサポートされる各操作用のメソッドが格納されています。 <xref:System.ServiceModel.Activities.WorkflowControlClient> では、アンビエント トランザクションを使用して、トランザクション処理された操作を使用する必要があるかどうかが判断されます。
| 71.114754 | 589 | 0.843476 | yue_Hant | 0.656059 |
117df114a3d7cca4d061c9de0a52dd9139b5446d | 3,272 | md | Markdown | stable/helm-release-pruner/README.md | yasintahaerol/charts-1 | 837d33e387dddec31c3cac9aea821270f1aaf7aa | [
"Apache-2.0"
] | 78 | 2019-07-11T07:59:18.000Z | 2022-03-31T16:54:16.000Z | stable/helm-release-pruner/README.md | yasintahaerol/charts-1 | 837d33e387dddec31c3cac9aea821270f1aaf7aa | [
"Apache-2.0"
] | 247 | 2019-07-12T06:47:07.000Z | 2022-03-28T16:10:12.000Z | stable/helm-release-pruner/README.md | yasintahaerol/charts-1 | 837d33e387dddec31c3cac9aea821270f1aaf7aa | [
"Apache-2.0"
] | 93 | 2019-07-11T08:10:53.000Z | 2022-03-17T19:05:37.000Z | # Helm Release Pruner Chart
This chart deploys a cronjob that purges stale Helm releases and associated namespaces. Releases are selected based on regex patterns for release name and namespace along with a Bash `date` command date string to define the stale cutoff date and time.
One use-case for this chart is purging ephemeral release releases after a period of inactivity.
## Example usage values file
The following values will purge all releases matching `^feature-.+-web$`
in namespace matching `^feature-.+` older than 7 days. It will also only
keep the 10 newest releases.
`job.dryRun` can be toggled to output matches without deleting anything.
```
job:
schedule: "0 */4 * * *"
dryRun: False
pruneProfiles:
- olderThan: "7 days ago"
helmReleaseFilter: "^feature-.+-web$"
namespaceFilter: "^feature-.+"
maxReleasesToKeep: 10
```
## Upgrading
### v3.0.0
This version is only compatible with Helm3. Update to this once you have upgraded helm.
In addition, this version moves the image to the Fairwinds repository in Quay. See the values section for the new location.
### v1.0.0
Chart version 1.0.0 introduced RBacDefinitions with rbac-manager to manage access. This is disabled by default. If enabled with the `rbac_manager.enabled`, the release should be purged and re-installed to ensure helm manages the resources.
## Values
| Key | Type | Default | Description |
|-----|------|---------|-------------|
| image.repository | string | `"quay.io/fairwinds/helm-release-pruner"` | Repo for image that the job runs on |
| image.tag | string | `"v3.2.0"` | The image tag to use |
| image.pullPolicy | string | `"Always"` | The image pull policy. We do not recommend changing this |
| job.backoffLimit | int | `3` | The backoff limit for the job |
| job.restartPolicy | string | `"Never"` | |
| job.schedule | string | `"0 */4 * * *"` | The schedule for the cronjob to run on |
| job.dryRun | bool | `true` | If true, will only log candidates for removal and not remove them |
| job.debug | bool | `false` | If true, will enable debug logging |
| job.serviceAccount.create | bool | `true` | If true, a service account will be created for the job to use |
| job.serviceAccount.name | string | `"ExistingServiceAccountName"` | The name of a pre-existing service account to use if job.serviceAccount.create is false |
| job.listSecretsRole.create | bool | `true` | If true, a cluster role will be created for the job to list helm releases |
| job.listSecretsRole.name | string | `"helm-release-pruner-list-secrets"` | Name of a cluster role granting list secrets permission |
| job.resources.limits.cpu | string | `"25m"` | |
| job.resources.limits.memory | string | `"32Mi"` | |
| job.resources.requests.cpu | string | `"25m"` | |
| job.resources.requests.memory | string | `"32M"` | |
| pruneProfiles | list | `[]` | Filters to use to find purge candidates. See example usage in values.yaml for details |
| rbac_manager.enabled | bool | `false` | If true, creates an RbacDefinition to manage access |
| rbac_manager.namespaceLabel | string | `""` | Label to match namespaces to grant access to |
| fullnameOverride | string | `""` | A template override for fullname |
| nameOverride | string | `""` | A template override for name |
| 51.125 | 251 | 0.711797 | eng_Latn | 0.985868 |
117e2cbfa4fa80a5f1b47a958f8cff9844d32d26 | 177 | md | Markdown | user/plugins/sitemap/CHANGELOG.md | ygunayer/yalingunayer.com | 3bdb64287eaaa2c7d9a7a419774ab5c8e817ea6a | [
"MIT"
] | null | null | null | user/plugins/sitemap/CHANGELOG.md | ygunayer/yalingunayer.com | 3bdb64287eaaa2c7d9a7a419774ab5c8e817ea6a | [
"MIT"
] | null | null | null | user/plugins/sitemap/CHANGELOG.md | ygunayer/yalingunayer.com | 3bdb64287eaaa2c7d9a7a419774ab5c8e817ea6a | [
"MIT"
] | null | null | null | # v1.3.0
## 02/25/2015
1. [](#new)
* Added `ignores` list to allow certain routes to be left out of sitemap
# v1.2.0
## 11/30/2014
1. [](#new)
* ChangeLog started...
| 14.75 | 76 | 0.587571 | eng_Latn | 0.838407 |
117f739065641cd2735ebdf230c403c7255f983d | 1,002 | md | Markdown | docs/csharp/language-reference/keywords/conversion-keywords.md | TyounanMOTI/docs.ja-jp | 72947e02a15d5396c2ee514246023a4ab24abc77 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-01-29T12:31:08.000Z | 2019-01-29T12:31:08.000Z | docs/csharp/language-reference/keywords/conversion-keywords.md | TyounanMOTI/docs.ja-jp | 72947e02a15d5396c2ee514246023a4ab24abc77 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/csharp/language-reference/keywords/conversion-keywords.md | TyounanMOTI/docs.ja-jp | 72947e02a15d5396c2ee514246023a4ab24abc77 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 変換キーワード (C# リファレンス)
ms.date: 07/20/2015
helpviewer_keywords:
- conversions [C#], keywords
- type conversion [C#], keywords
- types [C#], conversion keywords
ms.assetid: 8683ff14-5289-4efe-b4f5-1e6a075918ab
ms.openlocfilehash: 34175f1bda169a9def9e3146214a6d5cd4d258e7
ms.sourcegitcommit: fb78d8abbdb87144a3872cf154930157090dd933
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 09/29/2018
ms.locfileid: "47230931"
---
# <a name="conversion-keywords-c-reference"></a>変換キーワード (C# リファレンス)
ここでは、型変換で使用されるキーワードについて説明します。
- [explicit](../../../csharp/language-reference/keywords/explicit.md)
- [implicit](../../../csharp/language-reference/keywords/implicit.md)
- [operator](../../../csharp/language-reference/keywords/operator.md)
## <a name="see-also"></a>参照
- [C# リファレンス](../../../csharp/language-reference/index.md)
- [C# プログラミング ガイド](../../../csharp/programming-guide/index.md)
- [C# のキーワード](../../../csharp/language-reference/keywords/index.md)
| 33.4 | 73 | 0.709581 | eng_Latn | 0.110425 |
117f8ab01aa56104b5ca5fe8885d30e02b854bdb | 1,086 | md | Markdown | _posts/tool/etc-profile.md | tonyfeng9891220/tonyfeng9891220.github.io | ad7587131ddbd9f1d3aac2eebe15d84f2e51e049 | [
"MIT"
] | 2 | 2017-03-29T09:08:51.000Z | 2017-05-07T11:40:13.000Z | _posts/tool/etc-profile.md | gomaster-me/gomaster-me.github.io | ad7587131ddbd9f1d3aac2eebe15d84f2e51e049 | [
"MIT"
] | null | null | null | _posts/tool/etc-profile.md | gomaster-me/gomaster-me.github.io | ad7587131ddbd9f1d3aac2eebe15d84f2e51e049 | [
"MIT"
] | 1 | 2017-03-29T09:08:53.000Z | 2017-03-29T09:08:53.000Z | ---
layout: post
title: 环境变量
category: 工具
tags: 工具
keywords: 算法,排序,Sort,Algorithm
---
环境变量
~/.bash_profile
```
export JDK_HOME=$(/usr/libexec/java_home)
export SCALA_HOME="/usr/local/share/scala"
export SPARK_HOME="/Users/zhaocongcong/apps/spark-1.6.2-bin-hadoop2.6"
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH
export PATH=$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PYTHONPATH:$PATH
alias wcf='ls -l |grep "^-"|wc -l'
```
~/.zshrc
```
export PATH="$HOME/.jenv/bin:$PATH"
eval "$(jenv init -)"
export AWS_ACCESS_KEY_ID=AKIAOTXKEG4QQCKAYTAQ
export AWS_SECRET_ACCESS_KEY=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
#export JDK_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_101.jdk/Contents/Home"
export JDK_HOME=$(/usr/libexec/java_home)
export SCALA_HOME="/usr/local/share/scala"
export SPARK_HOME="/Users/zhaocongcong/apps/spark-1.6.2-bin-hadoop2.6"
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.9-src.zip:$PYTHONPATH
export PATH=$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PYTHONPATH:$JDK_HOME:$PATH
```
| 31.941176 | 88 | 0.775322 | yue_Hant | 0.672091 |
11802a4b6cdd98d5e2ef43f2261ab9f0f54a0903 | 6,746 | md | Markdown | orange3/CONTRIBUTING.md | rgschmitz1/BioDepot-workflow-builder | f74d904eeaf91ec52ec9b703d9fb38e9064e5a66 | [
"MIT"
] | 54 | 2017-01-08T17:21:49.000Z | 2021-11-02T08:46:07.000Z | orange3/CONTRIBUTING.md | Synthia-3/BioDepot-workflow-builder | 4ee93abe2d79465755e82a145af3b6a6e1e79fd4 | [
"MIT"
] | 22 | 2017-03-28T06:03:14.000Z | 2021-07-28T05:43:55.000Z | orange3/CONTRIBUTING.md | Synthia-3/BioDepot-workflow-builder | 4ee93abe2d79465755e82a145af3b6a6e1e79fd4 | [
"MIT"
] | 21 | 2017-01-26T21:12:09.000Z | 2022-01-31T21:34:59.000Z | Contributing
============
Thanks for taking the time to contribute to Orange!
Please submit contributions in accordance with the flow explained in the
[GitHub Guides].
[GitHub Guides]: https://guides.github.com/
Installing for development
--------------------------
See the relevant section in the [README file].
[README file]: https://github.com/biolab/orange3
Reporting bugs
--------------
Please report bugs according to established [bug reporting guidelines].
At least, include a method to reproduce the bug (if consistently
reproducible) and a screenshot (if applicable).
[bug reporting guidelines]: https://www.google.com/search?q=reporting+bugs
Coding style
------------
Roughly conform to [PEP-8] style guide for Python code. Whenever PEP-8 is
undefined, adhere to [Google Python Style Guide].
In addition, we add the following guidelines:
* Only ever `import *` to make objects available in another namespace,
preferably in *\_\_init\_\_.py*. Everywhere else use explicit object
imports.
* Use [Napoleon]-compatible (e.g. NumPy style) docstrings, preferably with
[tests].
* When instantiating Qt widgets, pass static property values as
[keyword args to the constructor] instead of calling separate property
setters later. For example, do:
view = QListView(alternatingRowColors=True,
selectionMode=QAbstractItemView.ExtendedSelection)
instead of:
view = QListView()
view.setAlternatingRowColors(True)
view.setSelectionMode(QAbstractItemView.ExtendedSelection)
* Each Orange widget module, or better still, each Python module (within
reason) should have a `__name__ == '__main__'`-fenced code block that
shows/tests the gist of that module in a user-friendly way.
* Core library objects should represent (`__repr__`) themselves in accordance
with the following statement from [Python data model documentation]:
> If at all possible, \[the string returned by `__repr__`\] should look like
> a valid Python expression that could be used to recreate an object with
> the same value (given an appropriate environment).
To that end, use [`Orange.util.Reprable`] when possible.
Please ensure your commits pass code quality assurance by executing:
pip install -r requirements-dev.txt
python setup.py lint
[PEP-8]: https://www.python.org/dev/peps/pep-0008/
[Google Python Style Guide]: https://google.github.io/styleguide/pyguide.html
[Napoleon]: http://www.sphinx-doc.org/en/stable/ext/napoleon.html
[keyword args to the constructor]: http://pyqt.sourceforge.net/Docs/PyQt5/qt_properties.html
[Python data model documentation]: https://docs.python.org/3/reference/datamodel.html#object.__repr__
[`Orange.util.Reprable`]: https://github.com/biolab/orange3/search?q="class+Reprable"&type=Code
Human Interface Guidelines
--------------------------
For UI design, conform to the [OS X Human Interface Guidelines].
In a nutshell, use title case for titles, push buttons, menu titles
and menu options. Elsewhere, use sentence case. Use title case for
combo box options where the item is imperative (e.g. Initialize with Method)
and sentence case otherwise.
[OS X Human Interface Guidelines]: https://developer.apple.com/library/mac/documentation/UserExperience/Conceptual/OSXHIGuidelines/TerminologyWording.html
Testing
-------
[tests]: #tests
If you contribute new code, write [unit tests] for it in _Orange/tests_ or
_Orange/widgets/*/tests_, as appropriate. Ensure the tests pass by running:
python setup.py test
Additionally, check that the tests for widgets pass:
python -m unittest -v Orange.widgets.tests \
Orange.canvas.report.tests
If testing on GNU/Linux, perhaps install _xvfb_ package and prefix the above
command with `xvfb-run `.
Prefer [doctests] for public APIs. Note, we unit-test doctests with
`NORMALIZE_WHITESPACE` and `ELLIPSIS` options enabled, so you can use them
implicitly.
[unit tests]: https://en.wikipedia.org/wiki/Unit_testing
[doctests]: https://en.wikipedia.org/wiki/Doctest
Environment variables
---------------------
Set these environment variables for value-added behavior:
* `ORANGE_DEBUG=1` - general developing and debugging. Influences stuff like
DOM Inspector in QWebView right-click menu, etc.
* `ORANGE_DEPRECATIONS_ERROR=1` - whether warnings of type
`OrangeDeprecationWarning` should be raised as exceptions.
Commit messages
---------------
Make a separate commit for each logical change you introduce. We prefer
short commit messages with descriptive titles. For a general format see
[Commit Guidelines]. E.g.:
> io: Fix reader for XYZ file format
>
> The reader didn't work correctly in such-and-such case.
The commit title (first line) should concisely explain _WHAT_ is the change.
If the reasons for the change aren't reasonably obvious, also explain the
_WHY_ and _HOW_ in the commit body.
The commit title should start with a tag which concisely conveys what
Python package, module, or class the introduced change pertains to.
**ProTip**: Examine project's [commit history] to see examples of commit
messages most probably acceptable to that project.
[Commit Guidelines]: http://git-scm.com/book/ch5-2.html#Commit-Guidelines
[commit history]: https://github.com/biolab/orange3/commits/master
Pull requests
-------------
Implement new features in separate topic branches:
git checkout master
git checkout -b my-new-feature # spin a branch off of current branch
When you are asked to make changes to your pull request, and you add the
commits that implement those changes, squash commits that fit together.
E.g., if your pull request looks like this:
d43ef09 Some feature I made
b803d26 reverts part of previous commit
77d5ad3 Some other bugfix
9e30343 Another new feature
1d5b3bc fix typo (in previous commit)
interactively rebase the commits onto the master branch:
git rebase --interactive master
and mark `fixup` or `squash` the commits that are just minor patches on
previous commits (interactive rebase also allows you to reword and reorder
commits). The resulting example pull request should look clean:
b432f18 some_module: Some feature I made
85d5a0a other.module: Some other bugfix
439e303 OWSomeWidget: Another new feature
Read more [about squashing commits].
[about squashing commits]: https://www.google.com/search?q=git+squash+commits
Documentation
-------------
Documentation in located in doc folder. It is split into three parts:
data-mining-library (scripting api), development (development guides),
and visual-programming (widget help files). You can build it with:
cd doc/<part>
make html
# Now open build/html/index.html to see it
| 35.135417 | 154 | 0.748147 | eng_Latn | 0.965456 |
11806bb902aa3eb1e4636a4430267c32af54f800 | 20,939 | md | Markdown | playlists/cumulative/37i9dQZF1DWYN0zdqzbEwl.md | masudissa0210/spotify-playlist-archive | a1a4a94af829378c9855040d905e04080c581acb | [
"MIT"
] | null | null | null | playlists/cumulative/37i9dQZF1DWYN0zdqzbEwl.md | masudissa0210/spotify-playlist-archive | a1a4a94af829378c9855040d905e04080c581acb | [
"MIT"
] | null | null | null | playlists/cumulative/37i9dQZF1DWYN0zdqzbEwl.md | masudissa0210/spotify-playlist-archive | a1a4a94af829378c9855040d905e04080c581acb | [
"MIT"
] | null | null | null | [pretty](/playlists/pretty/37i9dQZF1DWYN0zdqzbEwl.md) - cumulative - [plain](/playlists/plain/37i9dQZF1DWYN0zdqzbEwl) - [githistory](https://github.githistory.xyz/mackorone/spotify-playlist-archive/blob/main/playlists/plain/37i9dQZF1DWYN0zdqzbEwl)
### [Rock en Español](https://open.spotify.com/playlist/63Igemtn2mMuN2LhnHm574)
> Legendarios del rock en español\. Cover: Maná
| Title | Artist(s) | Album | Length | Added | Removed |
|---|---|---|---|---|---|
| [A un minuto de ti](https://open.spotify.com/track/7HlULtRMJSTzorUMebka0f) | [Mikel Erentxun](https://open.spotify.com/artist/7thnnayFyJnVOAJrpe5wMC) | [Naufragios](https://open.spotify.com/album/16RM2JFvsvSSSlylWmxhSV) | 3:53 | 2022-01-01 | |
| [Afuera](https://open.spotify.com/track/3pJfnBjO3kjudEchcPEDxS) | [Caifanes](https://open.spotify.com/artist/1GImnM7WYVp95431ypofy9) | [El Nervio Del Volcan](https://open.spotify.com/album/2mPZNQNgW1zrkIPyL9XJcf) | 4:48 | 2022-01-01 | |
| [Amargo Adiós](https://open.spotify.com/track/4mQwxVqjcHdUEfwSWEOopx) | [Inspector](https://open.spotify.com/artist/4OiCK9NnTWhakDIG57uBUA) | [Video Rola](https://open.spotify.com/album/68LCD69EOv3P1Pdk8OI4Ew) | 3:49 | 2022-01-01 | |
| [Amnesia](https://open.spotify.com/track/7fcK4YURteFjgPMslwGDpY) | [Inspector](https://open.spotify.com/artist/4OiCK9NnTWhakDIG57uBUA) | [The Gringo Guide To Rock En Español](https://open.spotify.com/album/4nGZyu9iNUNBDqq92ZiyR9) | 4:01 | 2022-01-01 | |
| [Amor Clandestino](https://open.spotify.com/track/5etssK2rpk4SnHWWD1Q6xn) | [Maná](https://open.spotify.com/artist/7okwEbXzyT2VffBmyQBWLz) | [Drama Y Luz](https://open.spotify.com/album/1sqgDb8MhdXgKAdGGLny9g) | 4:51 | 2022-01-01 | |
| [Arrullo De Estrellas](https://open.spotify.com/track/1p4rYrxjVkj6v2eMzRhLfA) | [Zoé](https://open.spotify.com/artist/6IdtcAwaNVAggwd6sCKgTI) | [Programaton](https://open.spotify.com/album/3UZ0vtpq3mGcr4J0kjveSD) | 4:12 | 2022-01-01 | |
| [Así Es la Vida](https://open.spotify.com/track/3ge3q3Hz0KWhQX5EAQcwEy) | [Elefante](https://open.spotify.com/artist/5oYHL2SijkMY52gKIhYJNb) | [Lo Que Andábamos Buscando \(Special Para CEV\)](https://open.spotify.com/album/5v3tEjfsPvLN3aDawSSx7h) | 5:09 | 2022-01-01 | |
| [Aun](https://open.spotify.com/track/1JTewgSxH7jQjolSwCn69u) | [Coda](https://open.spotify.com/artist/3qX79XCeQcRJdmlrcZZVIy) | [Veinte Para Las Doce](https://open.spotify.com/album/4hiYI3znWcf5uPUxfKVKeI) | 4:54 | 2022-01-01 | |
| [Aunque no sea conmigo](https://open.spotify.com/track/0dRY4OrSY53yUjVgfgne1W) | [Bunbury](https://open.spotify.com/artist/4uqzzJg3ww5eH7IgGV7DMT), [Andrés Calamaro](https://open.spotify.com/artist/3tAICgiSR5PfYY4B8qsoAU) | [Hijos del pueblo](https://open.spotify.com/album/69JZWukakNJGpGhJILhyTl) | 3:32 | 2022-01-01 | |
| [Beber de Tu Sangre](https://open.spotify.com/track/3Gr4OWY7lAXAq7PpgUbctG) | [Los Amantes De Lola](https://open.spotify.com/artist/7IwYwKG6VacXOThKHvPgUc) | [Rock En Espanol \- Lo Mejor De Los Amantes De Lola](https://open.spotify.com/album/38l9gB9jzOiWkQaR36ZhUG) | 4:36 | 2022-01-01 | |
| [Bolero Falaz](https://open.spotify.com/track/6sayXgNAqCmfUAqGAxP4xA) | [Aterciopelados](https://open.spotify.com/artist/3MqjsWDLhq8SyY6N3PE8yW) | [Lo Esencial](https://open.spotify.com/album/1imzv4Lfobnw8htp6XHGvd) | 3:45 | 2022-01-01 | |
| [Chau](https://open.spotify.com/track/7EWbEYuEDzr55hHtJZtonj) | [No Te Va Gustar](https://open.spotify.com/artist/4ZDoy7AWNgQVmX7T0u0B1j), [Julieta Venegas](https://open.spotify.com/artist/2QWIScpFDNxmS6ZEMIUvgm) | [Chau](https://open.spotify.com/album/43JH3qZu6rXGBqegyUq9J4) | 5:20 | 2022-01-01 | |
| [Clavado En Un Bar](https://open.spotify.com/track/78DVpEWwmJFC25KGz8fJuE) | [Maná](https://open.spotify.com/artist/7okwEbXzyT2VffBmyQBWLz) | [Sueños Líquidos](https://open.spotify.com/album/7ydFJUb1tmZPd6p4xIe10V) | 5:10 | 2022-01-01 | |
| [Como te extraño mi amor](https://open.spotify.com/track/6hFHsQWB7HdVrSe7efRR82) | [Café Tacvba](https://open.spotify.com/artist/09xj0S68Y1OU1vHMCZAIvz) | [Avalancha de éxitos](https://open.spotify.com/album/33iiSdb0XhQI0dSstspDls) | 3:34 | 2022-01-01 | |
| [Cuando Pase El Temblor \- Remasterizado 2007](https://open.spotify.com/track/3uMYq07Kj5m564OQwdSCrD) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [Nada Personal \(Remastered\)](https://open.spotify.com/album/0hyq754QnaKHYpH32QnWqs) | 3:49 | 2022-01-01 | |
| [De Música Ligera](https://open.spotify.com/track/4bzmedNeY5Ky9EiG6O4jlG) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [De Musica Ligera](https://open.spotify.com/album/0JrtFONTXgFV9Y96npZq7a) | 3:36 | 2022-01-01 | 2022-01-07 |
| [De Música Ligera \- Remasterizado 2007](https://open.spotify.com/track/2lpIh6Gr6HYjg1CFBaucS5) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [Canción Animal \(Remastered\)](https://open.spotify.com/album/3GoSlKTNcVOp1ZxE5OOXeN) | 3:32 | 2022-01-01 | |
| [Desde Que](https://open.spotify.com/track/4QLfVqOrpBOJra53EhlEX0) | [Liquits](https://open.spotify.com/artist/6gtggUV7CgB7b7bCpWa6PC) | [Jardin](https://open.spotify.com/album/38SjCB7KnLKUgyEBjRfGmC) | 3:38 | 2022-01-01 | |
| [Devuélveme a mi chica](https://open.spotify.com/track/1Wrzhfa5bNlqvsnCztz190) | [Hombres G](https://open.spotify.com/artist/60uh2KYYSCqAgJNxcU4DA0) | [Hombres G \(Edición 30 Aniversario\)](https://open.spotify.com/album/2iMF2NlOZMfBTdHyubrg6y) | 3:14 | 2022-01-01 | |
| [El ataque de las chicas cocodrilo](https://open.spotify.com/track/3quyxN3SapEsojxk1Uw10K) | [Hombres G](https://open.spotify.com/artist/60uh2KYYSCqAgJNxcU4DA0) | [La Cagaste..\. Burt Lancaster](https://open.spotify.com/album/6clqMga4PMBcBlWCR6idis) | 3:04 | 2022-01-01 | |
| [El Duelo](https://open.spotify.com/track/3XHg42QOqlevRU7jXRkAKk) | [La Ley](https://open.spotify.com/artist/1ZVoRDO29AlDXiMkRLMZSK) | [Invisible](https://open.spotify.com/album/5aocKknfljbM7XK3PWPVRi) | 3:14 | 2022-01-01 | 2022-01-09 |
| [El Esqueleto](https://open.spotify.com/track/1Z05BEFLTKxdp9xSjUnPGX) | [Victimas Del Doctor Cerebro](https://open.spotify.com/artist/6Z112eJxKl1E3nAbYZBr7M) | [Victimas Del Doctor Cerebro](https://open.spotify.com/album/4dcFGAgSnvjUK2fBUWoWSv) | 3:41 | 2022-01-01 | 2022-01-06 |
| [El Microbito](https://open.spotify.com/track/78Yoe3YYGLWYRIFp5YDPS6) | [Fobia](https://open.spotify.com/artist/3SqzxvGCKGJ9PYKXXPwjQS) | [Rock En Español \- Lo Mejor De Fobia](https://open.spotify.com/album/4qiTo13u4cRnHCAjxpQpzW) | 2:41 | 2022-01-01 | |
| [El Son del Dolor](https://open.spotify.com/track/4Uaa3LEapHkSeVwJcCTvTP) | [Cuca](https://open.spotify.com/artist/14xs9RNQa8MHRS7YU8Bzfk) | [G](https://open.spotify.com/album/0aqVqyNoU64e3CC7j7Z0pQ) | 4:02 | 2022-01-01 | |
| [En algún lugar](https://open.spotify.com/track/3UIENhLRdFIOuRan92cAQu) | [Duncan Dhu](https://open.spotify.com/artist/2MLHBMApNE5h8wIufiTPs7) | [El Grito Del Tiempo](https://open.spotify.com/album/53ysLjWIelVJ47Si7ouHB3) | 3:55 | 2022-01-01 | |
| [En El Muelle De San Blas](https://open.spotify.com/track/0mvocLIWUnT10znvIXwHGr) | [Maná](https://open.spotify.com/artist/7okwEbXzyT2VffBmyQBWLz) | [Sueños Líquidos](https://open.spotify.com/album/7ydFJUb1tmZPd6p4xIe10V) | 5:52 | 2022-01-01 | |
| [Eres](https://open.spotify.com/track/6kdCN6gTWLcLxmLXoUcwuI) | [Café Tacvba](https://open.spotify.com/artist/09xj0S68Y1OU1vHMCZAIvz) | [Cuatro Caminos](https://open.spotify.com/album/3ifA4OUPiT92YB4vYtAdVh) | 4:27 | 2022-01-01 | |
| [Es Por Ti](https://open.spotify.com/track/3UYYwbchCP47jl2Q9tAhMc) | [Inspector](https://open.spotify.com/artist/4OiCK9NnTWhakDIG57uBUA) | [Inspector](https://open.spotify.com/album/3q5bV5Fq3XEzbW5a0mAfcB) | 3:35 | 2022-01-01 | |
| [Esa noche](https://open.spotify.com/track/2jggaUpOvn2G6Pv2HCEU6m) | [Café Tacvba](https://open.spotify.com/artist/09xj0S68Y1OU1vHMCZAIvz) | [Re](https://open.spotify.com/album/7EJ5pXrSqqfybKyfbvlz84) | 3:26 | 2022-01-01 | 2022-01-09 |
| [Estrechez De Corazón](https://open.spotify.com/track/4oR2kX5BI50GBnQGRdRRsM) | [Los Prisioneros](https://open.spotify.com/artist/2mSHY8JOR0nRi3mtHqVa04) | [Coleccion Suprema](https://open.spotify.com/album/62mYqA8S00dcrD42jmml86) | 4:58 | 2022-01-01 | |
| [Flaca](https://open.spotify.com/track/1p7m9H4H8s0Y7SgRm7j3ED) | [Andrés Calamaro](https://open.spotify.com/artist/3tAICgiSR5PfYY4B8qsoAU) | [Alta Suciedad](https://open.spotify.com/album/44D07i1Lk0zFtWHRARMih6) | 4:37 | 2022-01-01 | |
| [Frente a frente \(feat\. Tulsa\)](https://open.spotify.com/track/73KNzyiG6xM6xguaLe4ICj) | [Bunbury](https://open.spotify.com/artist/4uqzzJg3ww5eH7IgGV7DMT), [Tulsa](https://open.spotify.com/artist/2gtVnbrVpID8VrotZPOg2a) | [Las Consecuencias](https://open.spotify.com/album/5xLCQx2sfojdolO0HQm4Et) | 3:53 | 2022-01-01 | |
| [Héroe de leyenda](https://open.spotify.com/track/6pAvXn45z0sktftypuEEzt) | [Heroes Del Silencio](https://open.spotify.com/artist/3qAPxVwIQRBuz5ImPUxpZT) | [El Mar No Cesa\- Edición Especial](https://open.spotify.com/album/1ybmfBatQowYBzowJxE74Y) | 4:08 | 2022-01-01 | 2022-01-08 |
| [Irresponsables](https://open.spotify.com/track/0dsViRiDTIuexAL42Nc1Kh) | [Babasónicos](https://open.spotify.com/artist/2F9pvj94b52wGKs0OqiNi2) | [Infame](https://open.spotify.com/album/7FYLw9fTOiYnJFbFk2Mntn) | 2:36 | 2022-01-01 | |
| [Kumbala](https://open.spotify.com/track/5EfHXTq8UPCFyPDvCNIKMm) | [Maldita Vecindad Y Los Hijos Del 5to\. Patio](https://open.spotify.com/artist/6WvDtNFHOWHfiNy8NVHujT) | [El Circo](https://open.spotify.com/album/5VJ9cWdT6Kv9UawePqLhCI) | 4:27 | 2022-01-01 | |
| [La chispa adecuada \(Bendecida 3\)](https://open.spotify.com/track/4vkSJSyPddHwL7v3l1cuRf) | [Heroes Del Silencio](https://open.spotify.com/artist/3qAPxVwIQRBuz5ImPUxpZT) | [Avalancha](https://open.spotify.com/album/3AikSptzlt3YvobRSMqL68) | 5:27 | 2022-01-01 | 2022-01-09 |
| [La chispa adecuada \(feat\. León Larregui\) \- MTV Unplugged](https://open.spotify.com/track/5vnAu12wplLvx1XH01PwRH) | [Bunbury](https://open.spotify.com/artist/4uqzzJg3ww5eH7IgGV7DMT), [León Larregui](https://open.spotify.com/artist/4ClsVDy2g7RKSSlvq8cF6d) | [MTV Unplugged\. El Libro De Las Mutaciones](https://open.spotify.com/album/3AO4YRY9r2gQL6GWLtdm7h) | 4:51 | 2022-01-01 | 2022-01-09 |
| [La Célula Que Explota](https://open.spotify.com/track/5mB0MGsRfKZALHrXjnktCK) | [Caifanes](https://open.spotify.com/artist/1GImnM7WYVp95431ypofy9) | [El Diablito](https://open.spotify.com/album/2cGrlR3OJwtQXUa4aQJRCV) | 3:35 | 2022-01-01 | |
| [La Dosis Perfecta](https://open.spotify.com/track/7IgC0NgE7WFerGSGtimXYA) | [Panteon Rococo](https://open.spotify.com/artist/11mqrDSFRRz8g0Wb3syJj5) | [A la Izquierda de la Tierra](https://open.spotify.com/album/6kuC8istEXp5B3n9cmiAlP) | 4:15 | 2022-01-01 | |
| [La flaca](https://open.spotify.com/track/1MrZ8hGkUWMmT816wPaMgE) | [Jarabe De Palo](https://open.spotify.com/artist/5B6H1Dq77AV1LZWrbNsuH5) | [La Flaca \- Edición 10º Aniversario](https://open.spotify.com/album/52SGUmWz4rcauYwTKIJzBp) | 4:21 | 2022-01-01 | |
| [La Guitarra \- MTV Unplugged](https://open.spotify.com/track/6ShvfmU4urNlBry7O9Vt0t) | [Los Auténticos Decadentes](https://open.spotify.com/artist/3HrbmsYpKjWH1lzhad7alj) | [La Guitarra \(Mtv Unplugged\)](https://open.spotify.com/album/1qadbNYJMqz4a1ttQ5FYJr) | 4:02 | 2022-01-01 | 2022-01-09 |
| [La ingrata](https://open.spotify.com/track/19ScoKGqnfUggyqOVQjsoH) | [Café Tacvba](https://open.spotify.com/artist/09xj0S68Y1OU1vHMCZAIvz) | [Re](https://open.spotify.com/album/7EJ5pXrSqqfybKyfbvlz84) | 3:32 | 2022-01-01 | 2022-01-07 |
| [La Lola](https://open.spotify.com/track/5hyq5k3Do9gW3HGvDg5ZEJ) | [Café Quijano](https://open.spotify.com/artist/2ECP3nWC88LaFz4oQzTo3Z) | [La Extraordinaria Paradoja Del Sonido Quijano](https://open.spotify.com/album/5PvhfeSnVId3ZknKo9ztID) | 3:17 | 2022-01-01 | |
| [La Muralla Verde](https://open.spotify.com/track/1qvY1z3Wm3sAYeHfPTnrbI) | [Los Enanitos Verdes](https://open.spotify.com/artist/4TK1gDgb7QKoPFlzRrBRgR) | [Originales \- 20 Exitos](https://open.spotify.com/album/3AWurTYrtIfp7HwHg48DxV) | 2:41 | 2022-01-01 | |
| [La pachanga](https://open.spotify.com/track/0bIye27QbOvSrTAmCViX5O) | [Vilma Palma e Vampiros](https://open.spotify.com/artist/5VQCk9RiLwri99OgOT34kq) | [Lo Mejor de Vilma Palma](https://open.spotify.com/album/04ezQVYrGNcXyrBUl42NZi) | 4:41 | 2022-01-01 | |
| [La Planta](https://open.spotify.com/track/2GggG2lQVYuus2aeAybe8M) | [Caos](https://open.spotify.com/artist/7aTwbcPoqJOzeEh96WHxrp) | [La Vida Gacha](https://open.spotify.com/album/46qlKidNmBw0FSJzFpb8LM) | 4:05 | 2022-01-01 | |
| [Lamento Boliviano](https://open.spotify.com/track/6Pur3hWy6Nzc27ilmsp5HA) | [Los Enanitos Verdes](https://open.spotify.com/artist/4TK1gDgb7QKoPFlzRrBRgR) | [Big Bang](https://open.spotify.com/album/3y63u5vmuMugqI8lfuUY3a) | 3:42 | 2022-01-01 | |
| [Las piedras rodantes](https://open.spotify.com/track/1gd7Q7mxviLWkG5HgvAMAc) | [El Tri](https://open.spotify.com/artist/3HgZDevp7GspkLUAa5cKne) | [Una rola para los minusválidos](https://open.spotify.com/album/1gk6tISd64foZA1eWwDnNg) | 3:18 | 2022-01-01 | |
| [Las piedras rodantes](https://open.spotify.com/track/5cINxgu1v3fvyngsKwtz2F) | [El Tri](https://open.spotify.com/artist/3HgZDevp7GspkLUAa5cKne) | [Las Clasicas Rock Pop en Espanol](https://open.spotify.com/album/1U0V7DcnyILGqhtYjwfgqi) | 3:18 | 2022-01-01 | 2022-01-09 |
| [Lo noto \- Versión CD](https://open.spotify.com/track/1k3Y0fhjdYKjfPSacDJm0p) | [Hombres G](https://open.spotify.com/artist/60uh2KYYSCqAgJNxcU4DA0) | [Peligrosamente Juntos](https://open.spotify.com/album/7eBwifbtzfdnn9NhcUaC8d) | 4:19 | 2022-01-01 | |
| [Lobo\-hombre en París](https://open.spotify.com/track/3M1H1CWjrSq7nxABHc8EXv) | [La Unión](https://open.spotify.com/artist/2Ax9wZpdlg4r2zkc3pcI8U) | [Grandes Exitos](https://open.spotify.com/album/7bYD4tCxzQOzGZmKBKtT3m) | 3:53 | 2022-01-01 | |
| [Loco \(Tu Forma de Ser\) \[Ft\. Rubén Albarrán\] \- MTV Unplugged](https://open.spotify.com/track/0639sfoRA7sW4fGS1EzcQu) | [Los Auténticos Decadentes](https://open.spotify.com/artist/3HrbmsYpKjWH1lzhad7alj), [Rubén Albarrán](https://open.spotify.com/artist/7M75Am5m6J934JSviUOGz0) | [Fiesta Nacional \(Mtv Unplugged\)](https://open.spotify.com/album/72XWQY6SO3b4M01tHYsIM7) | 4:09 | 2022-01-01 | |
| [Locos](https://open.spotify.com/track/31bHlrnZN0T7wYCQHmM8Y1) | [León Larregui](https://open.spotify.com/artist/4ClsVDy2g7RKSSlvq8cF6d) | [Locos](https://open.spotify.com/album/0HmsvxZrBylm6a7dz2IqrY) | 2:58 | 2022-01-01 | |
| [Love](https://open.spotify.com/track/5tyznRXlcIx0XlQ7S8iCMW) | [Zoé](https://open.spotify.com/artist/6IdtcAwaNVAggwd6sCKgTI) | [Rocanlover](https://open.spotify.com/album/45fpjQkEMNvYJn5SGPcCSX) | 3:23 | 2022-01-01 | |
| [Lucha De Gigantes](https://open.spotify.com/track/43GjYlBkIaEW2laq9D4Rr0) | [Nacha Pop](https://open.spotify.com/artist/1CdLG4i1rTEOsex2UE0jCH) | [Amores Perros \(Soundtrack\)](https://open.spotify.com/album/4ERQo3lv0nHNBZtJjW0doY) | 3:59 | 2022-01-01 | |
| [Mentira](https://open.spotify.com/track/5Em7MA991Gn3yhheaul0CX) | [La Ley](https://open.spotify.com/artist/1ZVoRDO29AlDXiMkRLMZSK) | [La Ley MTV Unplugged](https://open.spotify.com/album/0QkgxSUu5hG0yMkmVXBFKi) | 4:48 | 2022-01-01 | |
| [Mentiras](https://open.spotify.com/track/5ISbI7uonHP3Qx6OloertA) | [Los Amigos Invisibles](https://open.spotify.com/artist/5x3mrCTZmkoTXURN7pWdGN) | [Commercial](https://open.spotify.com/album/6UTNGpgi32axo5ilCMPhCF) | 3:21 | 2022-01-01 | |
| [Mentirosa](https://open.spotify.com/track/2AW8HXB5U4QA0ZmApbRM0B) | [Elefante](https://open.spotify.com/artist/5oYHL2SijkMY52gKIhYJNb) | [Elefante](https://open.spotify.com/album/42Fc71rqB9qZAb84q0Hs3U) | 4:04 | 2022-01-01 | |
| [Mirala Miralo](https://open.spotify.com/track/6GCNUmk7L7OWtpvSk0fWOg) | [Alejandra Guzman](https://open.spotify.com/artist/7Hf9AwMO37bSdxHb0FBGmO) | [Libre](https://open.spotify.com/album/5Zb5uLdHzmnIbOBy4zvVwW) | 4:00 | 2022-01-01 | 2022-01-09 |
| [Mujer Amante \- Vivo](https://open.spotify.com/track/5O5PY5HJNPxD7KyqU0SEhH) | [Rata Blanca](https://open.spotify.com/artist/632M26jlmnCrL8CqD5i7Kd) | [XX Aniversario En Vivo \- Magos, Espadas Y Rosas](https://open.spotify.com/album/7dbk5SnWgnt485vlCizXBE) | 6:17 | 2022-01-01 | |
| [Ni tú ni nadie](https://open.spotify.com/track/5IBTgDoYh2dADud6zwJD4L) | [Alaska Y Dinarama](https://open.spotify.com/artist/2mDlFcPtgXtLF1gEshEInh) | [Sinfonía del rock](https://open.spotify.com/album/026fbLeWC67db00wbSa7Nl) | 3:36 | 2022-01-01 | |
| [Obsesión](https://open.spotify.com/track/1l0mEM93oZMERzBmOCuiHe) | [Miguel Mateos](https://open.spotify.com/artist/02Nbktg6lCJiazPM6YYTMz) | [Lo Esencial](https://open.spotify.com/album/7zrwTOHJUTWDJBSED3mhbD) | 4:05 | 2022-01-01 | 2022-01-04 |
| [Oye Mi Amor](https://open.spotify.com/track/5EJ2THuhAapEIeQOtXUQ0x) | [Maná](https://open.spotify.com/artist/7okwEbXzyT2VffBmyQBWLz) | [¿Dónde Jugarán Los Niños?](https://open.spotify.com/album/2G0I22upYkTLYxfoAHiwBK) | 4:23 | 2022-01-01 | |
| [Para No Verte Más](https://open.spotify.com/track/19CmuECYssqkPWANF4nLWM) | [La Mosca Tse\-Tse](https://open.spotify.com/artist/60nua3AsVSfADZtg5Hdz3W) | [Visperas De Carnaval](https://open.spotify.com/album/4vIw5XspQuPt04VHX5oK5W) | 3:11 | 2022-01-01 | |
| [Persiana Americana](https://open.spotify.com/track/7JZP7kQsuFFWOrtAI7uNiW) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [Originales \- 20 Exitos](https://open.spotify.com/album/75LbseLsPdTkMO9oUD9J8n) | 4:50 | 2022-01-01 | 2022-01-08 |
| [Persiana Americana \- Remasterizado 2007](https://open.spotify.com/track/5wCUdBsdubZ3ZFoJoRsMrY) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [Me Verás Volver \(Hits & Más\)](https://open.spotify.com/album/0IkprxBZTCQhSry1AsDxcb) | 4:52 | 2022-01-01 | 2022-01-07 |
| [Pobre soñador](https://open.spotify.com/track/6UjxBtLPznyXztlMAFrtOW) | [El Tri](https://open.spotify.com/artist/3HgZDevp7GspkLUAa5cKne) | [25 años](https://open.spotify.com/album/1nscC8n3kewpA9DAHybQ9L) | 3:50 | 2022-01-01 | |
| [Sabor a Chocolate](https://open.spotify.com/track/29OzJTIOTjCgR7fLyEXY7u) | [Elefante](https://open.spotify.com/artist/5oYHL2SijkMY52gKIhYJNb) | [Lo Que Andábamos Buscando \(Special Para CEV\)](https://open.spotify.com/album/5v3tEjfsPvLN3aDawSSx7h) | 3:51 | 2022-01-01 | |
| [Santa Lucia \- Remastered 2005](https://open.spotify.com/track/5bycn7SuJzYnxte0W54mNX) | [Miguel Ríos](https://open.spotify.com/artist/1dpnxi6xgoB2kaRYnnoatZ) | [Rocanrol Bumerang](https://open.spotify.com/album/1YIw799VStxgysT27cUGwp) | 3:44 | 2022-01-01 | |
| [Sin Documentos](https://open.spotify.com/track/6eOT73H5zfEwTCe1Y0FDCc) | [Los Rodriguez](https://open.spotify.com/artist/3XkJyJgJDxnjdQgH0zfT8K) | [Sin Documentos](https://open.spotify.com/album/1o4bpii08vZJWZUAmn6H1t) | 4:45 | 2022-01-01 | 2022-01-05 |
| [Te Lo Pido por Favor](https://open.spotify.com/track/6iRkrVOhCjgKFB2cBWnx4M) | [Jaguares](https://open.spotify.com/artist/1RgXxY6uzWo9cjYYwwgVGq) | [El Primer Instinto](https://open.spotify.com/album/7BDdocfgBjmh5bw2VKA6JL) | 3:26 | 2022-01-01 | |
| [Te quiero](https://open.spotify.com/track/6tu2FHuKL9C8pwNrityweQ) | [Hombres G](https://open.spotify.com/artist/60uh2KYYSCqAgJNxcU4DA0) | [Las baladas \(Los singles vol II\)](https://open.spotify.com/album/2lsc9HZQaNf3gT7lIys2vN) | 3:45 | 2022-01-01 | |
| [Tren Al Sur](https://open.spotify.com/track/5nvS1vouQkX0HxOohfqCoS) | [Los Prisioneros](https://open.spotify.com/artist/2mSHY8JOR0nRi3mtHqVa04) | [Coleccion Suprema](https://open.spotify.com/album/62mYqA8S00dcrD42jmml86) | 5:38 | 2022-01-01 | 2022-01-04 |
| [Triste canción](https://open.spotify.com/track/3nNv67yimyA65gV5EQQtAK) | [El Tri](https://open.spotify.com/artist/3HgZDevp7GspkLUAa5cKne) | [Clasicas para Rockear](https://open.spotify.com/album/1udzt4QE3PY1KvUinZ5xiw) | 5:43 | 2022-01-01 | |
| [Trátame Suavemente \- Remasterizado 2007](https://open.spotify.com/track/65DBZofI0b79kfHTcWWDuU) | [Soda Stereo](https://open.spotify.com/artist/7An4yvF7hDYDolN4m5zKBp) | [Soda Stereo \(Remastered\)](https://open.spotify.com/album/3i4nU0OIi7gMmXDEhG9ZRt) | 3:20 | 2022-01-01 | |
| [Vasos Vacíos](https://open.spotify.com/track/6iCmg8Ntj6kBDmtoAiFVWf) | [Los Fabulosos Cadillacs](https://open.spotify.com/artist/2FS22haX3FYbyOsUAkuYqZ) | [Vasos Vacios](https://open.spotify.com/album/7fOv9NQRH5UWZq0EfUk1YE) | 4:38 | 2022-01-01 | |
| [Venezia](https://open.spotify.com/track/1wncA7mz0ntqvZ8UzFokGk) | [Hombres G](https://open.spotify.com/artist/60uh2KYYSCqAgJNxcU4DA0) | [Hombres G \(Edición 30 Aniversario\)](https://open.spotify.com/album/2iMF2NlOZMfBTdHyubrg6y) | 4:30 | 2022-01-01 | 2022-01-09 |
| [Viento](https://open.spotify.com/track/6QJCZyJv1fhkCyZA3lRoAD) | [Caifanes](https://open.spotify.com/artist/1GImnM7WYVp95431ypofy9) | [Caifanes](https://open.spotify.com/album/7oNSmwtmqu8EvnD3cv2HOr) | 3:56 | 2022-01-01 | 2022-01-06 |
\*This playlist was first scraped on 2022-01-02. Prior content cannot be recovered. | 237.943182 | 402 | 0.753856 | yue_Hant | 0.459285 |
1181cd84de1270319d3903f6c85e780688b6e080 | 3,125 | md | Markdown | docs/framework/wcf/feature-details/how-to-use-multiple-security-tokens-of-the-same-type.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/how-to-use-multiple-security-tokens-of-the-same-type.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/wcf/feature-details/how-to-use-multiple-security-tokens-of-the-same-type.md | novia713/docs.es-es | 0b2af23819b4104ec1d4e6ed4fc5c547de1f73d5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 'Cómo: Utilizar múltiples tokens de seguridad del mismo tipo'
ms.date: 03/30/2017
ms.assetid: cf179f48-4ed4-4caa-86a5-ef8eecc231cd
author: BrucePerlerMS
ms.openlocfilehash: 9d1dab0f4da82e4db96471f0a8cf25c32bd5eced
ms.sourcegitcommit: fb78d8abbdb87144a3872cf154930157090dd933
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 09/26/2018
ms.locfileid: "47198922"
---
# <a name="how-to-use-multiple-security-tokens-of-the-same-type"></a>Cómo: Utilizar múltiples tokens de seguridad del mismo tipo
- En [!INCLUDE[dnprdnshort](../../../../includes/dnprdnshort-md.md)] 3.0, un mensaje de cliente solo contenía un token de un tipo dado. Ahora, los mensajes de cliente pueden contener múltiples tokens de un tipo. En este tema se muestra cómo incluir múltiples tokens del mismo tipo en un mensaje de cliente.
- Tenga en cuenta que no se puede configurar un servicio de esta manera: un servicio puede contener sólo un token auxiliar.
### <a name="to-use-multiple-security-tokens-of-the-same-type"></a>Utilizar múltiples tokens de seguridad del mismo tipo
1. Cree una colección vacía de elementos de enlace para rellenarla.
[!code-csharp[C_CustomBinding#9](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#9)]
2. Cree <xref:System.ServiceModel.Channels.SecurityBindingElement> llamando a <xref:System.ServiceModel.Channels.SecurityBindingElement.CreateMutualCertificateBindingElement%2A>.
[!code-csharp[C_CustomBinding#10](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#10)]
3. Cree una colección <xref:System.ServiceModel.Security.Tokens.SupportingTokenParameters>.
[!code-csharp[C_CustomBinding#11](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#11)]
4. Agregue tokens SAML a la colección.
[!code-csharp[C_CustomBinding#12](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#12)]
5. Agregue la colección a <xref:System.ServiceModel.Channels.SecurityBindingElement>.
[!code-csharp[C_CustomBinding#13](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#13)]
6. Agregue elementos de enlace a la colección de elementos de enlace.
[!code-csharp[C_CustomBinding#14](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#14)]
7. Devuelva un nuevo enlace personalizado creado a partir de la colección de elementos de enlace.
[!code-csharp[C_CustomBinding#15](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#15)]
## <a name="example"></a>Ejemplo
Lo siguiente es el método completo descrito por el procedimiento anterior.
[!code-csharp[C_CustomBinding#7](../../../../samples/snippets/csharp/VS_Snippets_CFX/c_custombinding/cs/c_custombinding.cs#7)]
## <a name="see-also"></a>Vea también
[Arquitectura de seguridad](https://msdn.microsoft.com/library/16593476-d36a-408d-808c-ae6fd483e28f)
| 56.818182 | 310 | 0.75168 | spa_Latn | 0.621774 |
11822f239c15d666d0fe0f6aa97e0c683a37dd4b | 2,853 | md | Markdown | README.md | Shubham0Rajput/How-to-Intial-Deploy-to-heroku | 9306600c51680401ff457f10cbd761ea1b910987 | [
"MIT"
] | 1 | 2020-03-16T16:35:15.000Z | 2020-03-16T16:35:15.000Z | README.md | Shubham0Rajput/How-to-Intial-Deploy-to-heroku | 9306600c51680401ff457f10cbd761ea1b910987 | [
"MIT"
] | null | null | null | README.md | Shubham0Rajput/How-to-Intial-Deploy-to-heroku | 9306600c51680401ff457f10cbd761ea1b910987 | [
"MIT"
] | 3 | 2020-07-25T12:44:31.000Z | 2021-06-21T09:48:27.000Z | # How-to-Intial-Deploy-to-heroku
Intially I was not able to push a simple bot to heroku, but yeah googling a lot made it work!
## Very Initial Steps [NOOB Steps]
1. Install Telegram :)
2. Create a telegram bot by talking to [Bot Father](https://t.me/botfather)
3. Install python in your computer, if you are on windows follow [this](https://www.python.org/downloads/windows/)
4. Install git, follow [this](https://git-scm.com/download/win)
5. Install Heroku account [here](https://signup.heroku.com/login)
6. Install Heroku CLI from [here](https://devcenter.heroku.com/articles/heroku-cli)
7. Install editor of your choice, I preffer [Atom](https://atom.io)
### Step 0 [Optional]:
- Just git clone this repository and start working by editing the code
```shell
git clone https://github.com/Shubham0Rajput/How-to-Intial-Deploy-to-heroku.git
cd telegram-bot-heroku-deploy
- Or follow steps below!
### Step 1:
- Create your bot like we have bot.py and write any python code that is intially working on your local machine!
### Step 2:
- Make a folder like *telegram-bot* and put *bot.py* in the folder
### Step 3:
- Make a blank python file named
```shell
__init__.py
### Step 4:
- Make a *Procfile* this should be without any extension like .txt, you can go to view -> tick file name extensions and remove any extension
```shell
worker: python bot.py
- Write this in Procfile by using notepad or any editor of your choice! Here bot.py is your python code!
### Step 5:
- Now we have to make a *requirements.txt* through which heroku will install the dependencies to make our bot work!
- What to add in requirements.txt
- Mine looks like this:
```shell
future>=0.16.0
certifi
tornado>=5.1
cryptography
python-telegram-bot
Add anything which you have included in the python code!
### Step 6:
- Change directory to where you have made these files
- now in git bash CLI, intialize a git
```shell
git init
### Step 7:
- Now install heroku CLI
- Next
```shell
heroku login
heroku create app_name
- If you have already created app then select it:
```shell
heroku git:remote -a app_name
- Or else continue:
```shell
git add -f bot.py Procfile requirements.txt __init__.py
- ```shell
git commit -m "Added Files"
- Push files to heroku:
```shell
git push heroku master
- If it is not working then try this one:
```shell
git push heroku master --force
### At this point your bot should be running, you can check by
- ```shell
heroku ps
If it is not running then we have to reset dynos:
- ```shell
heroku ps:scale worker=0
- ```shell
heroku ps:scale worker=1
Now it should be running fine! Enjoy :)
### If you are trying to lazy which you should not! (Deploying to Heroku)
Choose App name and deploy!
Follow from Step 7 and edit bot.py with your token!
And finally deploy!
| 32.420455 | 140 | 0.715738 | eng_Latn | 0.988296 |
11824ed5f2131d3ddb86ccb80c0127c904ac4b59 | 4,523 | md | Markdown | docs/visual-basic/programming-guide/language-features/procedures/how-to-protect-a-procedure-argument-against-value-changes.md | ichengzi/docs.zh-cn | d227f2c5c114a40a4b99d232084cd086593fe21a | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/programming-guide/language-features/procedures/how-to-protect-a-procedure-argument-against-value-changes.md | ichengzi/docs.zh-cn | d227f2c5c114a40a4b99d232084cd086593fe21a | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/programming-guide/language-features/procedures/how-to-protect-a-procedure-argument-against-value-changes.md | ichengzi/docs.zh-cn | d227f2c5c114a40a4b99d232084cd086593fe21a | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 如何:防止过程参数的值被更改
ms.date: 07/20/2015
helpviewer_keywords:
- procedures [Visual Basic], arguments
- procedures [Visual Basic], parameters
- procedure arguments
- arguments [Visual Basic], passing by reference
- Visual Basic code, procedures
- arguments [Visual Basic], ByVal
- arguments [Visual Basic], passing by value
- procedure parameters
- procedures [Visual Basic], calling
- arguments [Visual Basic], ByRef
- arguments [Visual Basic], changing value
ms.assetid: d2b7c766-ce16-4d2c-8d79-3fc0e7ba2227
ms.openlocfilehash: 36092eb597b5b20e1da42cd9d15ab8633636cfb1
ms.sourcegitcommit: 17ee6605e01ef32506f8fdc686954244ba6911de
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/22/2019
ms.locfileid: "74344863"
---
# <a name="how-to-protect-a-procedure-argument-against-value-changes-visual-basic"></a>如何:防止过程自变量的值被更改 (Visual Basic)
If a procedure declares a parameter as [ByRef](../../../../visual-basic/language-reference/modifiers/byref.md), Visual Basic gives the procedure code a direct reference to the programming element underlying the argument in the calling code. This permits the procedure to change the value underlying the argument in the calling code. In some cases the calling code might want to protect against such a change.
You can always protect an argument from change by declaring the corresponding parameter [ByVal](../../../../visual-basic/language-reference/modifiers/byval.md) in the procedure. If you want to be able to change a given argument in some cases but not others, you can declare it `ByRef` and let the calling code determine the passing mechanism in each call. It does this by enclosing the corresponding argument in parentheses to pass it by value, or not enclosing it in parentheses to pass it by reference. For more information, see [How to: Force an Argument to Be Passed by Value](./how-to-force-an-argument-to-be-passed-by-value.md).
## <a name="example"></a>示例
The following example shows two procedures that take an array variable and operate on its elements. The `increase` procedure simply adds one to each element. The `replace` procedure assigns a new array to the parameter `a()` and then adds one to each element. However, the reassignment does not affect the underlying array variable in the calling code.
[!code-vb[VbVbcnProcedures#35](~/samples/snippets/visualbasic/VS_Snippets_VBCSharp/VbVbcnProcedures/VB/Class1.vb#35)]
[!code-vb[VbVbcnProcedures#38](~/samples/snippets/visualbasic/VS_Snippets_VBCSharp/VbVbcnProcedures/VB/Class1.vb#38)]
[!code-vb[VbVbcnProcedures#37](~/samples/snippets/visualbasic/VS_Snippets_VBCSharp/VbVbcnProcedures/VB/Class1.vb#37)]
The first `MsgBox` call displays "After increase(n): 11, 21, 31, 41". Because the array `n` is a reference type, `increase` can change its members, even though the passing mechanism is `ByVal`.
The second `MsgBox` call displays "After replace(n): 11, 21, 31, 41". Because `n` is passed `ByVal`, `replace` cannot modify the variable `n` in the calling code by assigning a new array to it. When `replace` creates the new array instance `k` and assigns it to the local variable `a`, it loses the reference to `n` passed in by the calling code. When it changes the members of `a`, only the local array `k` is affected. Therefore, `replace` does not increment the values of array `n` in the calling code.
## <a name="compiling-the-code"></a>编译代码
The default in Visual Basic is to pass arguments by value. However, it is good programming practice to include either the [ByVal](../../../../visual-basic/language-reference/modifiers/byval.md) or [ByRef](../../../../visual-basic/language-reference/modifiers/byref.md) keyword with every declared parameter. This makes your code easier to read.
## <a name="see-also"></a>请参阅
- [过程](./index.md)
- [过程参数和自变量](./procedure-parameters-and-arguments.md)
- [如何:将自变量传递给过程](./how-to-pass-arguments-to-a-procedure.md)
- [按值和按引用传递自变量](./passing-arguments-by-value-and-by-reference.md)
- [可修改和不可修改自变量之间的差异](./differences-between-modifiable-and-nonmodifiable-arguments.md)
- [通过值传递自变量和通过引用传递自变量之间的差异](./differences-between-passing-an-argument-by-value-and-by-reference.md)
- [如何:更改过程自变量的值](./how-to-change-the-value-of-a-procedure-argument.md)
- [如何:强制通过值传递自变量](./how-to-force-an-argument-to-be-passed-by-value.md)
- [按位置和按名称传递自变量](./passing-arguments-by-position-and-by-name.md)
- [值类型和引用类型](../../../../visual-basic/programming-guide/language-features/data-types/value-types-and-reference-types.md)
| 79.350877 | 637 | 0.762989 | eng_Latn | 0.939929 |
11827545b67b5f2e0058b5697a6bee834d74d5aa | 2,192 | md | Markdown | hugo/content/flexmatch/lab23/_index.en.md | nkwangjun/aws-gamelift-sample | c675868ef16944944b656d6e045bb37d6206c7a1 | [
"Apache-2.0"
] | 131 | 2018-03-28T19:25:51.000Z | 2022-03-13T12:47:07.000Z | hugo/content/flexmatch/lab23/_index.en.md | nkwangjun/aws-gamelift-sample | c675868ef16944944b656d6e045bb37d6206c7a1 | [
"Apache-2.0"
] | 7 | 2018-11-06T01:54:49.000Z | 2021-11-12T00:11:24.000Z | hugo/content/flexmatch/lab23/_index.en.md | nkwangjun/aws-gamelift-sample | c675868ef16944944b656d6e045bb37d6206c7a1 | [
"Apache-2.0"
] | 37 | 2018-03-28T19:25:52.000Z | 2022-03-12T15:27:19.000Z | ---
title: S3 Web Hosting
url: /flexmatch/lab23
weight: 40
pre: "<b>2-3. </b>"
---
### Leaderboard with S3 Web Hosting<br/><br/>
Previously we made database, API to handle user data and game result with API Gateway and Lambda function.
In this page, we are going to make static web site that S3 host. We can make Ranking board easily with this static web page with Lambda function that we made before.
1. Move to S3 service and create S3 bucket for web site. Creating bucket, uncheck *Block all public access* to allow public object.

2. There is web directory in the given source code. You can find main.js in this folder. Open main.js from Text editor.
3. Edit API Endpoint in source code. Modify URL to Invoke URL of API Gateway that we made previously.

4. Save modified main.js and upload all files in web directory to the S3 bucket that we made.
5. Give Public read access permission to objects.
6. Click Properties tab in bucket. Enable Static website hosting on this bucket.
7. Put index.html on Index document and click "Save" button.

8. When your files are uploaded, you are able to check web page on Static website hosting endpoint.
9. You should configure CORS on API Gateway. You can check Ranking board data from web page by this endpoint.
10. Move back to API Gateway, click "Actions" button and enable CORS option. (If it is disabled)
11. Configuring CORS. Set Access-Control-Allow-Origin to your static website URL. (In this HoL, it is OK to configure * for your comfort)

12. Click "Enable CORS" button.
13. If it is completed, you are able to find OPTIONS in your resource tab.
14. Click "Deploy API" button to deploy it prod stage.
You are able to check its data from API endpoint or this web page.
Web page made on this section will be used for ranking leaderboard like below.

**Now, it is time to make Game Server! :)**
---
<p align="center">
© 2020 Amazon Web Services, Inc. 또는 자회사, All rights reserved.
</p>
| 35.934426 | 165 | 0.734945 | eng_Latn | 0.968288 |
1182b468f7fc5d038d70706f791ff04d10c17656 | 2,269 | md | Markdown | README.md | jpchato/vegan-cosmetics | ca0c0caa9f01c5b152de2638d918bcaec3dd5085 | [
"MIT"
] | null | null | null | README.md | jpchato/vegan-cosmetics | ca0c0caa9f01c5b152de2638d918bcaec3dd5085 | [
"MIT"
] | null | null | null | README.md | jpchato/vegan-cosmetics | ca0c0caa9f01c5b152de2638d918bcaec3dd5085 | [
"MIT"
] | null | null | null | # vegan-cosmetics
* Jesse Pena, Corey Marchand, Vij Rangarajan
* Check cosmetics for vegan ingredients
## Title
* Looking for vegan cosmetics
### User Story sentence
* I want to be able to find all vegan cosmetics from WalMart. I want to be able to arrange the results in a specific order and save it in a file.
### Feature Tasks
* Find a working API for WalMart to get cosmetics with ingredients
### Acceptance Tests
* Successfully retrieve cosmetics
* Successfully review ingredients and sieve the data
* Successfully find vegan ingredients
## Title
* Data storage
### User Story sentence
* As a user I want to have the data retrieved saved to a file(.txt)
### Feature Tasks
* Traverse the api and save unique vegan cosmetic data
### Acceptance Tests
* Successfully find unique vegan cosmetic data
* Save vegan cosmetic data
## Title
* User Input
### User Story sentence
* As a user I want to be able to input a cosmetic and get search results (eyeliner, lipstick, foundation, etc.)
### Feature Tasks
* Create an input interface for the user to type in their search query
### Acceptance Tests
* Have an interface for the user to select products
## Title
* Data retrieval
### User Story sentence
* As a user I want to retrieve vegan cosmetic data from the storage (.txt file)
### Feature Tasks
* Traverse the text file and extract saved vegan cosmetic data and return it
### Acceptance Tests
* Successfully traverse the file
* Search for a particular cosmetic
* Pull out the particular cosmetic's information
## Title
* Looking for vegan cosmetics in a web page without an API
### User Story sentence
* As a user I want to scrape provided urls for vegan cosmetics
### Feature Tasks
* Scrape the provided the web page for vegan cosmetics
### Acceptance Tests
* Successfully retrieve cosmetics
* Successfully review ingredients and sieve the data
* Successfully find vegan ingredients
## Title
* Save personalized search results to .txt file
### User Story sentence
* As a user I want to save the results of my searches to a separate a .txt file
### Feature Tasks
* Save results of personalized searches to a separate .txt file
### Acceptance Tests
* Successfully create new .txt file with personalized search results
## Domain Model
* https://ibb.co/SsFPVPW
| 33.367647 | 145 | 0.762891 | eng_Latn | 0.974653 |
1183728819eaa2535926ba25dfcc148d44b91751 | 1,413 | md | Markdown | docs/pt/frontend/structure/setup.md | lhsazevedo/devitools-docs | 1aa7231a6855b5f2be70a487a4ce2e0e1dab92f0 | [
"MIT"
] | 3 | 2020-06-20T19:05:17.000Z | 2020-12-30T23:23:37.000Z | docs/pt/frontend/structure/setup.md | lhsazevedo/devitools-docs | 1aa7231a6855b5f2be70a487a4ce2e0e1dab92f0 | [
"MIT"
] | 12 | 2020-06-28T17:45:10.000Z | 2022-02-27T06:58:12.000Z | docs/pt/frontend/structure/setup.md | lhsazevedo/devitools-docs | 1aa7231a6855b5f2be70a487a4ce2e0e1dab92f0 | [
"MIT"
] | 1 | 2020-12-30T17:03:42.000Z | 2020-12-30T17:03:42.000Z | ---
description: >-
Para poder configurar a estrutura existe uma pasta que centraliza o que é
parametrizável dentro do projeto
---
# Setup
A pasta `src/settings` possui vários arquivos de configuração. Através deles é possível configurar uma série de recursos que veremos a seguir.
## `components.js`
Configura os componentes da aplicação de um modo geral. Através dele podemos aplicar configurações à todos os campos de texto do sistema, por exemplo.
## `date.js`
Lida com os formatos e configurações de datas que são suportadas
## `field.js`
Constitui uma fábrica de construção de campos com todas as propriedades que um campo deve possuir.
## `http.js`
Instância de cliente HTTP para realizar conexões na API base da aplicação. Possui interceptadores e será alterado para passar `headers` e modificar as configurações básicas de conexão.
## `local.js`
É a instância de cliente HTTP para fazer requests para o próprio projeto. Ele cria um cliente que aponta para a URL na qual o projeto está disponível no navegador.
## `report.js`
Representa as configurações que podem ser feitas para executar os relatórios.
## `rest.js`
Possui recursos para adaptar a comunicação da classe `Rest` com as respostas que as APIs retornam.
## `schema.js`
Agrupa as principais propriedades que podemos alterar na construção do `schema` e conversão de um `field` em um componente [`Vue`](https://vuejs.org).
| 32.860465 | 184 | 0.772116 | por_Latn | 0.999976 |
1183e97bb10bc6739519c2e626965e5319b109f7 | 3,205 | md | Markdown | _posts/2018-04-12-Implementing Let's Encrypt SSL in Cpanel.md | hethkar/hethkar.github.io | 1c90346a7fe9f3c8af2e0aeb50c4ab7aa20b1260 | [
"MIT"
] | null | null | null | _posts/2018-04-12-Implementing Let's Encrypt SSL in Cpanel.md | hethkar/hethkar.github.io | 1c90346a7fe9f3c8af2e0aeb50c4ab7aa20b1260 | [
"MIT"
] | null | null | null | _posts/2018-04-12-Implementing Let's Encrypt SSL in Cpanel.md | hethkar/hethkar.github.io | 1c90346a7fe9f3c8af2e0aeb50c4ab7aa20b1260 | [
"MIT"
] | null | null | null | ---
layout: post
title: 'How to install Lets Encrypt SSL for your websites in Cpanel'
subtitle: post 3
---
# How to install Let's Encrypt SSL for your websites in Cpanel
Go to the Security Sectiom of your Cpanel
You will find a SSL/TLS option under Security.
In the SSL/TLS page you will have the following sections.
### Private Keys (KEY)
Generate, view, upload, or delete your private keys.
### Certificate Signing Requests (CSR)
Generate, view, or delete SSL certificate signing requests.
### Certificates (CRT)
Generate, view, upload, or delete SSL certificates.
### Install and Manage SSL for your site (HTTPS)
Manage SSL sites.
First you will need generate a private key and CSR
Click the `Generate, view, or delete SSL certificate signing requests.` under CSR section.
The first field is the `Key` with a drop down menu.
You can generate your private key here
Option- Generate a new 2,048 bit key. (or if you have generated any private keys before it will be displayed in the drop down menu)
Next field is the Domains text box.
Here you will have to give your domain name for which you will be getting your SSL certificate from Let's Encrypt.
When it comes to Let's Encrypt if you want to have your SSL certificate for www.example.com , then you will have to mention www.example.com (with www included) in the
Domains text box, else if you don't want the www then you can just add your domain name as example.com .
Fill the rest of the fields.
Your CSR will be generated once you fill all mandatory fields and click on Generate button.
Copy of you CSR.
Go to https://zerossl.com/
Click on Online Tools
Go to FREE SSL Certificate Wizard
(Free SSL certificates trusted by all major browsers issued in minutes.)
Start the wizard.
You can give your email in the email field. This will be helpful as you will receive notifications about the certificate expiration date, though it is optional.
Paste the generated CSR in the right column.
Check the HTTP verification Check box.
Check the Accept ZeroSSL TOS , Accept Let's Encrypt SA (pdf) Check boxes.
On the left column a Let's Ecnrypt Key will be generated ( which you can copy and keep it with you as it will be needed when we want to renew the certificate )
Click on Next
Here you will get
The name for the file you will have to create .
location where you have to create. (public_html/.well-known/acme-challenge/filehere)
contents that file should have.
Once you have create you can open the link in a new tab and check if you're able to view the contents of the file from the website.
In the third step you will get you certificate generated.
You can copy your certicate and download it as well.
Installing the Certificate in the cPanel.
In the cPanel click on `Manage SSL sites.` under Install and Manage SSL for your site (HTTPS) .
Select your domain under the domain drop-down menu.
Paste your certificate under - Certificate: (CRT)
Once you paste your CRT, an autofill button will show up on the side - which will fill the rest of the sections.
Then click on the Install Certificate button which will the install the certificate.
It will take sometime for the Certificate to reflect on the website.
| 35.21978 | 167 | 0.770671 | eng_Latn | 0.998332 |
118421924b5150deec49e6705f153efa95abdda5 | 1,829 | md | Markdown | CHANGELOG.md | cltatman/releasy | 794dbbf920758f1e11c7fe35d04b4d676051c7e4 | [
"MIT"
] | 33 | 2016-12-13T06:43:47.000Z | 2021-12-28T06:58:20.000Z | CHANGELOG.md | cltatman/releasy | 794dbbf920758f1e11c7fe35d04b4d676051c7e4 | [
"MIT"
] | 5 | 2017-01-07T07:22:46.000Z | 2021-09-27T14:11:20.000Z | CHANGELOG.md | cltatman/releasy | 794dbbf920758f1e11c7fe35d04b4d676051c7e4 | [
"MIT"
] | 4 | 2017-04-25T16:28:30.000Z | 2021-09-23T14:08:58.000Z | Releasy Change Log
==================
v0.3.0
------
* _Project#file_ and _Project#exposed_files_ no longer require the argument to be an array (can take multiple arguments instead).
* Handles 7-ZIP not being found better (always gives error message).
* Removed support for the :github deployer, since they've stopped hosting files.
v0.2.2
------
* Added new deployers: :rsync and :local
* Removed 7z installation dependency on Windows (included 7za.exe in gem).
* Fixes for Ruby 1.8.7
* :osx_app build - Change directory into application directory before running app.
* :osx_app build - Add BINARY to list of "fake" encodings.
v0.2.0
------
* Name changed from "relapse" to "releasy" because of universal dislike and/or confusion about it :)
* Warning: API changed significantly from v0.1.0 because it was dreadful :D
* Allowed outputs to be configured separately from the project.
* Included gems in osx-app more safely, so that no files will be missing.
* Added `:exe` archive format (Windows self-extractor, used on any OS).
* Added `:dmg` archive format (OS X self-extractor, used on OS X only).
* Added `:windows_wrapped` output (windows folder made from a RubyInstaller archive, used on OSX/Linux).
* Allowed project and outputs to have archive formats (when called on Project, affecting all outputs).
* Archive formats can have a different `#extension` set.
* Output formats can have a different `#folder_suffix` set.
* No longer require Innosetup to be installed in order to create `:windows_folder` output.
* Added command, 'releasy install-sfx' that installs the self-extractor package for 7z, to enable :exe archiving (non-Windows only).
* Lots of other things fixes, refactors and additions, that I lost track of :$
v0.1.0
------
* First public release as "relapse" | 45.725 | 134 | 0.72608 | eng_Latn | 0.993179 |
11849928ed67cdafdf4fb2e58d093a140a8b2e73 | 2,290 | md | Markdown | wdk-ddi-src/content/netdma/nf-netdma-netdmainterruptdpc.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/netdma/nf-netdma-netdmainterruptdpc.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | wdk-ddi-src/content/netdma/nf-netdma-netdmainterruptdpc.md | jesweare/windows-driver-docs-ddi | a6e73cac25d8328115822ec266dabdf87d395bc7 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-12-08T21:34:31.000Z | 2021-12-08T21:34:31.000Z | ---
UID: NF:netdma.NetDmaInterruptDpc
title: NetDmaInterruptDpc function (netdma.h)
description: The NetDmaInterruptDpc function notifies the NetDMA interface that a DMA transfer deferred procedure call (DPC) has completed on a DMA channel.
old-location: netvista\netdmainterruptdpc.htm
tech.root: netvista
ms.assetid: 93d7e4dd-70ee-4490-bffd-9b07511ee9fe
ms.date: 05/02/2018
keywords: ["NetDmaInterruptDpc function"]
ms.keywords: NetDmaInterruptDpc, NetDmaInterruptDpc function [Network Drivers Starting with Windows Vista], netdma/NetDmaInterruptDpc, netdma_ref_112a0d48-213e-4b5c-a776-11d5dcb83e1b.xml, netvista.netdmainterruptdpc
req.header: netdma.h
req.include-header: Netdma.h
req.target-type: Universal
req.target-min-winverclnt: Supported for NetDMA 1.0 drivers in Windows Vista.
req.target-min-winversvr:
req.kmdf-ver:
req.umdf-ver:
req.ddi-compliance:
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib:
req.dll:
req.irql: DISPATCH_LEVEL
targetos: Windows
req.typenames:
f1_keywords:
- NetDmaInterruptDpc
- netdma/NetDmaInterruptDpc
topic_type:
- APIRef
- kbSyntax
api_type:
- HeaderDef
api_location:
- netdma.h
api_name:
- NetDmaInterruptDpc
---
# NetDmaInterruptDpc function
## -description
<div class="alert"><b>Note</b> The NetDMA interface is not supported
in Windows 8 and later.</div><div> </div>The
<b>NetDmaInterruptDpc</b> function notifies the NetDMA interface that a DMA transfer deferred procedure call
(DPC) has completed on a DMA channel.
## -parameters
### -param NetDmaChannelHandle
[in]
A handle that identifies the DMA channel. The DMA provider driver received this handle from NetDMA
in a call to the
<a href="/windows-hardware/drivers/ddi/netdma/nc-netdma-dma_channel_allocate_handler">
ProviderAllocateDmaChannel</a> function.
### -param DmaDescriptor
[in, optional]
A pointer to the last DMA descriptor that was processed.
## -returns
None.
## -remarks
DMA providers call the
<b>NetDmaInterruptDpc</b> function in their DPC handler.
## -see-also
<a href="/windows-hardware/drivers/ddi/netdma/nc-netdma-dma_channel_allocate_handler">ProviderAllocateDmaChannel</a> | 28.271605 | 216 | 0.749782 | eng_Latn | 0.468907 |
1184c982d972a8175f841d0c32e601fa08dfdbf8 | 9,277 | md | Markdown | docs/MAQS_7/Base/SoftAsserts.md | CoryJHolland/MAQS | a0bce596972f9a00051b75ceda1e19a973873a59 | [
"MIT"
] | 52 | 2017-02-24T19:42:07.000Z | 2022-02-22T12:09:58.000Z | docs/MAQS_7/Base/SoftAsserts.md | CoryJHolland/MAQS | a0bce596972f9a00051b75ceda1e19a973873a59 | [
"MIT"
] | 730 | 2017-02-24T14:37:35.000Z | 2022-03-28T11:01:52.000Z | docs/MAQS_7/Base/SoftAsserts.md | CoryJHolland/MAQS | a0bce596972f9a00051b75ceda1e19a973873a59 | [
"MIT"
] | 27 | 2017-04-06T16:51:56.000Z | 2022-03-05T11:01:32.000Z | # <img src="resources/maqslogo.ico" height="32" width="32"> Soft Assert
## Overview
Soft Asserts are a collection of assertions. When a soft assert is called it will determine the results of a condition, along with a name for the soft assert, and a failure message, and save that to a collection of Soft Asserts. It will also save the results of that Soft Assert to the log.
To call a Soft Assert using another assertion library in a test simply write
```csharp
// Simple
SoftAssert.Assert(() => Assert.IsTrue(shouldBeTrue, "Expected true"));
// More complex
SoftAssert.Assert(() => Assert.ThrowsException<StackOverflowException>(DoSomethingBadFunc));
```
If the success of a test is dependent on the results of the assertions, then the method
```csharp
SoftAssert.FailTestIfAssertFailed();
```
will be called, and if any previous SoftAsserts have been determined to have failed, it will throw an exception with the failed assert names, and the failure messages associated with those names.
The test will also write to the log with the end results of the Soft Assert collection.
## Uses
Soft Asserts are commonly used when collecting large amounts of data that needs to be evaluated without affecting the results of a test. In unit testing, Asserts will throw an exception if their condition fails. With Soft Asserts multiple assertions may be made, and stored, to be evaluated later. They make aggregate that assertion data into one place to be evaluated.
## Soft Assert Conditionals
### Assert(Action)
Assert will consume any standard assert. If the consumed assertion fails it will store that assert as a failure. If the the consumed assertion does not fail it will store that result as a success.
#### Written as
```csharp
SoftAssert.Assert(() => Assert.IsTrue(shouldBeTrue, "Expected true"));
```
#### Examples
```csharp
// Results in a true assertion
SoftAssert.Assert(() => Assert.IsTrue(true, "True assertion"));
// Results in a false assertion
SoftAssert.Assert(() => Assert.IsFalse(true, "False assertion"));
// Throws assertion
SoftAssert.Assert(() => Assert.ThrowsException<StackOverflowException>(DoSomethingBadFunc));
```
Assert will check the provided assertion function. If an assertion exception is thrown it will store that assert as a failure. If no assertion exception is thrown it will store that result as a success.
#### Pass in multiple asserts
```csharp
// Results in a false assertion
SoftAssert.Assert(() =>
{
Assert.IsTrue(true, "True assertion");
Assert.IsFalse(false, "True assertion"));
});
// Results in a false assertion, Only the first two asserts run
SoftAssert.Assert(() =>
{
Assert.IsTrue(true, "True assertion");
Assert.IsTrue(false, "False assertion"));
Assert.IsTrue(false, "False assertion"));
});
```
Assert can also combine multiple asserts together. If a single assertion exception is thrown it will store that assert as a failure. On the first failure the method will no invoke any more lines of code, so be sure to use multiple Assert methods if certain items must be checked. If no assertion exception is thrown it will store that result as a success.
### IsTrue(conditional) - ***DEPRECATED (will remove in version 6)***
IsTrue will evaluate the condition. If the condition is true it will store that assert as a success. If the condition is false it will store that result as a failure.
#### Written as
```csharp
SoftAssert.IsTrue(bool conditional, string softAssertName);
```
#### Examples
```csharp
// Results in a true assertion
SoftAssert.IsTrue(true, "True assertion");
// Results in a false assertion
SoftAssert.IsTrue(false, "False assertion");
```
IsTrue will evaluate the condition. If the condition is false it will store that assert as a success. If the condition is true it will store that result as a failure.
### IsFalse(conditional) - ***DEPRECATED (will remove in version 6)***
IsFalse will evaluate the condition. If the condition is true it will store that assert as a failure. If the condition is false it will store that result as a success.
#### Written as
```csharp
SoftAssert.IsFalse(bool conditional, string softAssertName);
```
#### Examples
```csharp
// Results in a true assertion
SoftAssert.IsFalse(false, "True assertion");
// Results in a false assertion
SoftAssert.IsFalse(true, "False assertion");
```
### AreEqual(string 1, string 2) - ***DEPRECATED (will remove in version 6)***
AreEqual will evaluate if both inputs are equal. If they are not equal it will store that assert as a failure. If they are equal it will store that assert as a success.
#### Written as
```csharp
SoftAssert.AreEqual(string expectedResult, string actualResult, string softAssertName);
```
#### Examples
```csharp
// Results in a true assertion
SoftAssert.AreEqual("1", "1", "True assertion");
// Results in a false assertion
SoftAssert.AreEqual("2", "1", "False assertion");
```
#### Example Output
```
Soft Assert 'True assertion' passed. Expected Value = '1', Actual Value = '1'.
Soft Assert 'False assertion' failed. Expected Value = '2', Actual Value = '1'
```
## Expected Soft Asserts
Expected soft asserts allow you to include a list of soft asserts which must be run in order for a test to pass. This helps assure that all expected soft asserts are run.
### SoftAssertExpectedAsserts(Attribute)
The SoftAssertExpectedAsserts attribute allows you to add the expected asserts to your test method as an attribute.
#### Written as
```csharp
[SoftAssertExpectedAsserts("one", "two")]
```
#### Examples
```csharp
[TestMethod]
[SoftAssertExpectedAsserts("one", "two")]
public void TEST()
{
this.SoftAssert.Assert(() => Assert.IsTrue(buttonOne.Enabled), "one");
this.SoftAssert.Assert(() => Assert.IsTrue(buttonTwo.Enabled), "two");
// Will fail is soft assert one and two have not been run
this.SoftAssert.FailTestIfAssertFailed();
}
```
### AddExpectedAsserts(Action)
The AddExpectedAsserts function allows you to add the expected asserts within your tests code.
#### Written as
```csharp
this.SoftAssert.AddExpectedAsserts("one");
```
#### Examples
```csharp
[TestMethod]
public void TEST()
{
this.SoftAssert.AddExpectedAsserts("one");
this.SoftAssert.AddExpectedAsserts("two");
this.SoftAssert.Assert(() => Assert.IsTrue(buttonOne.Enabled), "one");
this.SoftAssert.Assert(() => Assert.IsTrue(buttonTwo.Enabled), "two");
// Will fail is soft assert one and two have not been run
this.SoftAssert.FailTestIfAssertFailed();
}
```
## Soft Assert Collection Handling
After assertions have been made, and the soft assert collection has been filled with the results of those assertions, comes options on how to handle the results of that collection.
### Fail the Test if Any Soft Assert Failed
If the results of a collection of Soft Asserts would fail a test due to the tests conditions, then the FailTestIfAssertFailed method would be called. The method will throw an exception with any Soft Asserts that failed, and it will write to the log with the final results.
#### Example
```csharp
// Checks the Soft Assert collection, fails the test if a soft assert failed
SoftAssert.FailTestIfAssertFailed();
```
#### Example output
```
ERROR: SoftAssert.AreEqual failed for . Expected '2' but got '1'. False assertion
Total number of Asserts: 6. Passed Asserts = 3 Failed Asserts = 3
```
### Send All Soft Assert Data to the Log
If the results of a test aren’t dependent on the results of the collection of SoftAsserts, the method LogFinalAssertData may be called. The method will write to the log the results of the Soft Assert collection, giving a record of any failed or passed results. Failed soft asserts will be written as warnings.
#### Example
```csharp
// Writes the final assert data to the log without affecting the results of the test
SoftAssert.LogFinalAssertData();
```
#### Example output
```
WARNING: Soft Assert 'False assertion' failed. Expected Value = '2', Actual Value = '1'.
Total number of Asserts: 6. Passed Asserts = 3 Failed Asserts = 3
```
### Check If a Soft Assert Failed
If the results of a test aren’t dependent on the results of the collection of SoftAsserts but they may influence some future behavior of the test, DidSoftAssertFail may be called. The method will returns a Boolean of either true, there were no failures, or false, there were failures.
#### Example
```csharp
// Will return true if no asserts failed, false if any asserts failed
bool softAssertResults = SoftAssert.DidSoftAssertsFail();
```
### Did the User Check for Failed Asserts
If any of the previous Soft Assert handler methods are called, it will set a property, that by default is faulse, to true. DidUserCheck will return the value of that property. At the end of a test the DidUserCheck method is called, if a SoftAssert conditional has been created since the last time the user checked the results of the Soft Assert collection, it will write to the log that the user has not checked the results. It won’t affect the results of the test, but it will provide additional information to the log.
#### Example
```csharp
// Will return true if LogFinalData, FailTestIfAssertFailed, or DidSoftAssertFail was called
bool didUserCheck = SoftAssert.DidUserCheck();
``` | 42.949074 | 523 | 0.748841 | eng_Latn | 0.990575 |
11852fadc8a393c441e1fe1748a81faacfedc99b | 185 | md | Markdown | README.md | henriksommerfeld/food | 0f00f9a187c2fc2aa0dc2b2b764e811b2cdd80ed | [
"MIT"
] | null | null | null | README.md | henriksommerfeld/food | 0f00f9a187c2fc2aa0dc2b2b764e811b2cdd80ed | [
"MIT"
] | 1 | 2020-04-25T10:25:17.000Z | 2020-04-25T10:25:17.000Z | README.md | henriksommerfeld/food | 0f00f9a187c2fc2aa0dc2b2b764e811b2cdd80ed | [
"MIT"
] | null | null | null | # Recipe Collection
## Installation
`npm ci`
## Run
`npm start`
## Unit tests
`npm run test:unit`
## Integration tests
`npm run test:cypress:ci`
[1]: https://www.gatsbyjs.org/
| 9.25 | 30 | 0.659459 | kor_Hang | 0.442415 |
11859e805a3a5d7fee29c349a082f2b561459bdc | 2,070 | md | Markdown | docs/en/StaticExporter.md | nickspiel/silverstripe-staticpublisher | 0ebd8c7c0b4e2d677d420738f88d84983f7488f1 | [
"BSD-3-Clause"
] | null | null | null | docs/en/StaticExporter.md | nickspiel/silverstripe-staticpublisher | 0ebd8c7c0b4e2d677d420738f88d84983f7488f1 | [
"BSD-3-Clause"
] | null | null | null | docs/en/StaticExporter.md | nickspiel/silverstripe-staticpublisher | 0ebd8c7c0b4e2d677d420738f88d84983f7488f1 | [
"BSD-3-Clause"
] | 1 | 2019-10-07T17:10:47.000Z | 2019-10-07T17:10:47.000Z | # Static Exporter
## Introduction
StaticExporter allows you to export a static copy of your website either as a
tar.gz archive or to a separate folder. It does this by saving every page and
other registered URL to the file system. You can then server the exported
website on your production server or use it as a back up system.
## Requirements
- Unix filesystem
- Tar installed
<div class="warning" markdown='1'>
This has not been tested on Windows
</div>
## Usage
There are three ways the StaticExporter can be invoked depending on your use
case.
### GUI
If you're logged into your site as an administrator or your website is in
development mode, you can access the GUI for generating the export at:
http://yoursite.com/StaticExporter/. The GUI allows you to select a few
configuration options then will generate a tar.gz archive of the website.
### StaticExporterTask
Accessing http://yoursite.com/dev/tasks/StaticExporterTask will generate the
export of the website and save it to a folder on your filesystem. Unlike the
GUI option this does not allow you to configure options in the browser, instead
it relies on the developer setting the options via statics or through GET
parameters.
### Sake
To generate the export via command line ([sake](/framework/en/topics/commandline.md))
sake dev/tasks/StaticExporterTask
## Options
Both the StaticExporterTask and Sake task take the following GET params. The
GUI method only allows you to customize the baseurl path.
* baseurl - (string) Base URL for the published site
* symlink - (false|true) Copy the assets directory into the export or, simply
symlink to the original assets folder. If you're deploying to a separate
server ensure this is set to false.
* quiet - (false|true) Output progress of the export.
* path - (string) server path to generate export to.
Note that the path directory will be populated with the new exported files.
This script does not empty the directory first so you may which to remove the
folder (`rm -rf cache && sake dev/tasks/StaticExporterTask path=cache`)
| 34.5 | 85 | 0.775362 | eng_Latn | 0.996928 |
1185fcad3386e04714b8cf9fb88526e9416a0551 | 1,089 | md | Markdown | docs/LV_client/utilities/mono_replace_ego_pose.md | andresgonzalez2/monodrive-documentation | e459e803fc1ef6f87beaf2b1b6fea21f92ed6467 | [
"MIT"
] | 7 | 2020-06-11T21:35:15.000Z | 2021-04-19T03:45:33.000Z | docs/LV_client/utilities/mono_replace_ego_pose.md | andresgonzalez2/monodrive-documentation | e459e803fc1ef6f87beaf2b1b6fea21f92ed6467 | [
"MIT"
] | 126 | 2020-03-03T22:30:40.000Z | 2021-07-30T16:08:24.000Z | docs/LV_client/utilities/mono_replace_ego_pose.md | andresgonzalez2/monodrive-documentation | e459e803fc1ef6f87beaf2b1b6fea21f92ed6467 | [
"MIT"
] | 4 | 2018-09-11T09:52:10.000Z | 2019-09-26T06:35:41.000Z | # mono_replace_ego_pose.vi
<p class="img_container">
<img class="lg_img" src="../mono_replace_ego_pose.png"/>
</p>
### Description
Replaces the pose for the ego vehicle on a specific frame and outputs the JSON corresponding to the frame with the new settings.
For technical support contact us at <b>[email protected]</b>
### Inputs
- **Ego pose:** Values to replace the pose of the ego vehicle on a specific frame.
- **Frame number:** Frame number to obtain from the list of frames
- **Frames:** List with all the frames from the trajectory file
- **error in (Error Cluster):** Accepts error information wired from previously called VIs. This information can be used to decide if any functionality should be bypassed in the event of errors from other VIs.
### Outputs
- **Frame:** Frame on JSON format with the new pose for the ego vehicle
- **error out (Error Cluster):** Accepts error information wired from previously called VIs. This information can be used to decide if any functionality should be bypassed in the event of errors from other VIs.
<p> </p>
| 36.3 | 211 | 0.743802 | eng_Latn | 0.996435 |
118631f22638d3e925a47cfc4601cd7e0d6552e2 | 5,109 | md | Markdown | README.md | kirillmukhin/spaceduck-terminal | d3759801d79802b2ff935ae055ee9b55d7adffe8 | [
"MIT"
] | null | null | null | README.md | kirillmukhin/spaceduck-terminal | d3759801d79802b2ff935ae055ee9b55d7adffe8 | [
"MIT"
] | null | null | null | README.md | kirillmukhin/spaceduck-terminal | d3759801d79802b2ff935ae055ee9b55d7adffe8 | [
"MIT"
] | null | null | null | # Spaceduck terminal theme 🚀🦆
A intergalactic space theme for your terminal! This is the spaceduck repo for terminal themes. If you're looking for other applications here's the link to the [spaceduck home](https://github.com/pineapplegiant/spaceduck).
<center>
<img src="./img/iTerm.png" alt="Terminal screenshot of iTerm2 terminal with neofetch program ran">
</center>
**Color Disclaimer:**
I've personally swapped the yellow and purple colors in most terminal themes.
This is a personal preference as I've found it to render the colorscheme how I like since Spaceduck is dark purple oriented. Feel free to change the colorscheme locally to be more semantically correct! I'm open to change the repo here if any bugs are found however.
Take a look at [this thread](https://github.com/pineapplegiant/spaceduck-terminal/pull/2) to see the visual differences at this change.
## Currently Ported Terminals
- [Iterm2](#iterm2)
- [Terminal.app MacOS](#terminalapp-macos)
- [Alacritty](#alacritty)
- [Kitty](#kitty)
- [Windows Terminal](#windows-terminal)
- [Tmux](#tmux)
- [Konsole](#konsole)
- [Termux](#termux)
## Iterm2
To get the theme into [Iterm](https://iterm2.com/), download the `spaceduck.itermcolors` file and [import it into your settings](https://iterm2colorschemes.com/).
## Terminal.app MacOS
To get the theme into the [Mac Terminal app](<https://en.wikipedia.org/wiki/Terminal_(macOS)>), download the `spaceduck.terminal` file and import it into your settings.
## Alacritty
The color scheme for [Alacritty](https://github.com/alacritty/alacritty) is in the `spaceduck.yml` file or you can copy it here!
```YAML
# Space Duck
colors:
# Default colors
primary:
background: '#0f111b'
foreground: '#ecf0c1'
# Normal colors
normal:
black: '#000000'
red: '#e33400'
green: '#5ccc96'
yellow: '#b3a1e6'
blue: '#00a3cc'
magenta: '#f2ce00'
cyan: '#7a5ccc'
white: '#686f9a'
# Bright colors
bright:
black: '#686f9a'
red: '#e33400'
green: '#5ccc96'
yellow: '#b3a1e6'
blue: '#00a3cc'
magenta: '#f2ce00'
cyan: '#7a5ccc'
white: '#f0f1ce'
```
## Kitty
The Color theme for [Kitty](https://sw.kovidgoyal.net/kitty/) is in the `spaceduck.conf` file or you can copy it here!
```YAML
background #0f111b
foreground #ecf0c1
cursor #ecf0c1
selection_background #686f9a
color0 #000000
color8 #686f9a
color1 #e33400
color9 #e33400
color2 #5ccc96
color10 #5ccc96
color3 #b3a1e6
color11 #b3a1e6
color4 #00a3cc
color12 #00a3cc
color5 #f2ce00
color13 #f2ce00
color6 #7a5ccc
color14 #7a5ccc
color7 #686f9a
color15 #f0f1ce
selection_foreground #ffffff
```
## Windows Terminal
Color theme is in the `spaceduck_windowsterminal.json` file or you can copy it here! Put it in your [Windows Terminal](https://docs.microsoft.com/en-us/windows/terminal/customize-settings/profile-settings) settings.json
```JSON
"schemes": [
{
"name": "SpaceDuck",
"foreground": "#ecf0c1",
"background": "#0f111b",
"black": "#000000",
"red": "#e33400",
"green": "#5ccc96",
"yellow": "#b3a1e6",
"blue": "#00a3cc",
"purple": "#f2ce00",
"cyan": "#7a5ccc",
"white": "#686f9a",
"brightBlack": "#686f9a",
"brightRed": "#e33400",
"brightGreen": "#5ccc96",
"brightYellow": "#b3a1e6",
"brightBlue": "#00a3cc",
"brightPurple": "#f2ce00",
"brightCyan": "#7a5ccc",
"brightWhite": "#f0f1ce"
}
```
## Tmux
You can go ahead and check out [readme for tmux here](./tmux/README.md).
But if you're too lazy to click the link you can put this in your tmux.conf for an easy spaceduck themed bottom bar:
```tmux
# Basic color support setting
set-option -g default-terminal "screen-256color"
# Default bar color
set-option -g status-style bg='#1b1c36',fg='#ecf0c1'
# Active Pane
set -g pane-active-border-style "fg=#5ccc96"
# Inactive Pane
set -g pane-border-style "fg=#686f9a"
# Active window
set-option -g window-status-current-style bg='#686f9a',fg='#ffffff'
# Message
set-option -g message-style bg='#686f9a',fg='#ecf0c1'
set-option -g message-command-style bg='#686f9a',fg='#ecf0c1'
# When Commands are run
set -g message-style "fg=#0f111b,bg=#686f9a"
```
## Konsole
Copy `spaceduck.colorscheme` to the `.local/share/konsole/`. After that run `konsoleprofile colors="spaceduck"` OR in Konsole's settings navigate to `Configure Konsole...` > `Profiles` > Select your active profile e.g. `Shell (Default)` > `Edit...` > `Appearence` > Find and select `SpaceDuck` in the `Color scheme & font` > Press `Apply`.
## Termux
Copy `spaceduck.properties` file to the `~/.termux/` and rename it to `colors.properties`. After that exit Termux's session and launch it again.
Note: if you have Termux:Styling plugin installed - changing color scheme with it will overwrite `colors.properties` file with selected theme.
| 31.152439 | 339 | 0.667254 | eng_Latn | 0.803489 |
1186ad7091bcc87264e76b4abe23a42801db6916 | 69 | md | Markdown | README.md | sag754/CodeLab1-sag754-HW3 | 484032a249d7c4feb3a477c638734ce08e782683 | [
"Unlicense"
] | null | null | null | README.md | sag754/CodeLab1-sag754-HW3 | 484032a249d7c4feb3a477c638734ce08e782683 | [
"Unlicense"
] | null | null | null | README.md | sag754/CodeLab1-sag754-HW3 | 484032a249d7c4feb3a477c638734ce08e782683 | [
"Unlicense"
] | null | null | null | # CodeLab1-sag754-HW3
Assignment that generates a file to save data.
| 23 | 46 | 0.797101 | eng_Latn | 0.95433 |
1186af27760ef5be96047193423b55a029805199 | 1,903 | md | Markdown | articles/virtual-machines/virtual-machines-linux-infrastructure-subscription-accounts-guidelines.md | lettucebo/azure-content-zhtw | f9aa6105a8900d47dbf27a51fd993c44a9af5b63 | [
"CC-BY-3.0"
] | null | null | null | articles/virtual-machines/virtual-machines-linux-infrastructure-subscription-accounts-guidelines.md | lettucebo/azure-content-zhtw | f9aa6105a8900d47dbf27a51fd993c44a9af5b63 | [
"CC-BY-3.0"
] | null | null | null | articles/virtual-machines/virtual-machines-linux-infrastructure-subscription-accounts-guidelines.md | lettucebo/azure-content-zhtw | f9aa6105a8900d47dbf27a51fd993c44a9af5b63 | [
"CC-BY-3.0"
] | null | null | null | <properties
pageTitle="訂用帳戶和帳戶指導方針 | Microsoft Azure"
description="了解 Azure 上訂用帳戶和帳戶的關鍵設計和實作指導方針。"
documentationCenter=""
services="virtual-machines-linux"
authors="iainfoulds"
manager="timlt"
editor=""
tags="azure-resource-manager"/>
<tags
ms.service="virtual-machines-linux"
ms.workload="infrastructure-services"
ms.tgt_pltfrm="vm-linux"
ms.devlang="na"
ms.topic="article"
ms.date="09/08/2016"
ms.author="iainfou"/>
# 訂用帳戶和帳戶指導方針
[AZURE.INCLUDE [virtual-machines-linux-infrastructure-guidelines-intro](../../includes/virtual-machines-linux-infrastructure-guidelines-intro.md)]
本文著重於了解在環境和使用者群增加的情況下,管理訂用帳戶和帳戶的方法。
## 訂用帳戶和帳戶的實作指導方針
决策:
- 您需要裝載 IT 工作負載或基礎結構的是哪種訂用帳戶與帳戶的組合?
- 如何分解階層以使其符合您的組織?
工作:
- 將您的邏輯組織階層定義為您想從訂用帳戶層級管理它的方式。
- 若要符合此邏輯階層,請定義所需的帳戶及每個帳戶下的訂用帳戶。
- 使用您的命名慣例來建立訂用帳戶與帳戶的組合。
## 訂用帳戶與帳戶
若要使用 Azure,您需要一個以上的 Azure 訂用帳戶。虛擬機器 (VM) 或虛擬網路等資源存在於這些訂用帳戶中。
- 企業客戶通常會有 Enterprise 註冊,這是階層中最上層的資源,而且會與一或多個帳戶相關聯。
- 對於消費者與不具 Enterprise 註冊的客戶來說,最上層的資源是帳戶。
- 訂用帳戶會關聯至帳戶,而且每個帳戶可以有一或多個訂用帳戶。Azure 會在訂用帳戶層級記錄計費資訊。
由於帳戶/訂用帳戶關係中有兩個階層層級的限制,因此,請務必將帳戶和訂用帳戶的命名慣例與計費需求保持一致。舉例來說,如果有一家全球性公司使用 Azure,他們可能選擇針對每個區域擁有一個帳戶,並在區域層級管理訂用帳戶:

例如,您可以使用下列結構:

如果某個區域決定擁有一個以上與特定群組相關聯的訂用帳戶,則命名慣例必須包括在帳戶或訂用帳戶名稱上為額外資料進行編碼的方式。這個組織允許訊息傳遞計費資料在計費報告期間產生新的階層層級:

組織應看起來如下:

我們會透過可下載的檔案,針對單一帳戶或企業合約中的所有帳戶提供詳細的計費資訊。
## 後續步驟
[AZURE.INCLUDE [virtual-machines-linux-infrastructure-guidelines-next-steps](../../includes/virtual-machines-linux-infrastructure-guidelines-next-steps.md)]
<!---HONumber=AcomDC_0914_2016--> | 26.430556 | 157 | 0.771939 | yue_Hant | 0.853273 |
1186fc224a0d116567053bb3ba584ca4eb6ec819 | 1,596 | md | Markdown | getting-started/cluster/setup-aks.md | forkkit/dapr-docs | 86031e1c500e909fcccb682d8f7e13a803dfb943 | [
"MIT"
] | 7 | 2019-12-25T08:10:03.000Z | 2022-01-05T13:10:39.000Z | getting-started/cluster/setup-aks.md | forkkit/dapr-docs | 86031e1c500e909fcccb682d8f7e13a803dfb943 | [
"MIT"
] | null | null | null | getting-started/cluster/setup-aks.md | forkkit/dapr-docs | 86031e1c500e909fcccb682d8f7e13a803dfb943 | [
"MIT"
] | 11 | 2020-03-23T15:49:38.000Z | 2022-01-17T02:55:27.000Z |
# Set up an Azure Kubernetes Service cluster
## Prerequisites
- [Docker](https://docs.docker.com/install/)
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/)
- [Azure CLI](https://docs.microsoft.com/en-us/cli/azure/install-azure-cli?view=azure-cli-latest)
## Deploy an Azure Kubernetes Service cluster
This guide walks you through installing an Azure Kubernetes Service cluster. If you need more information, refer to [Quickstart: Deploy an Azure Kubernetes Service (AKS) cluster using the Azure CLI](https://docs.microsoft.com/en-us/azure/aks/kubernetes-walkthrough)
1. Login to Azure
```bash
az login
```
2. Set the default subscription
```bash
az account set -s [your_subscription_id]
```
3. Create a resource group
```bash
az group create --name [your_resource_group] --location [region]
```
4. Create an Azure Kubernetes Service cluster
Use 1.13.x or newer version of Kubernetes with `--kubernetes-version`
```bash
az aks create --resource-group [your_resource_group] --name [your_aks_cluster_name] --node-count 2 --kubernetes-version 1.14.6 --enable-addons http_application_routing --enable-rbac --generate-ssh-keys
```
5. Get the access credentials for the Azure Kubernetes cluster
```bash
az aks get-credentials -n [your_aks_cluster_name] -g [your_resource_group]
```
## (optional) Install Helm v3
1. [Install Helm v3 client](https://helm.sh/docs/intro/install/)
> **Note:** The latest Dapr helm chart no longer supports Helm v2. Please migrate from helm v2 to helm v3 by following [this guide](https://helm.sh/blog/migrate-from-helm-v2-to-helm-v3/).
| 31.294118 | 265 | 0.752506 | eng_Latn | 0.424235 |
11873ae0fbeabc2a91a09e576268e4005cac4894 | 6,381 | md | Markdown | README.md | sammarth-k/commatables.js | 9ec426c82b630702094ac577ab234796c8186684 | [
"MIT"
] | 1 | 2021-05-03T03:17:19.000Z | 2021-05-03T03:17:19.000Z | README.md | sammarth-k/commatables.js | 9ec426c82b630702094ac577ab234796c8186684 | [
"MIT"
] | null | null | null | README.md | sammarth-k/commatables.js | 9ec426c82b630702094ac577ab234796c8186684 | [
"MIT"
] | null | null | null | The docs are currently being written. Please check back soon for all the docs
- [Download](#article1)
- [Link2](#article2)
- [Link3](#article3)
- [Link4](#article4)
- [Link5](#article5)
Docs
----
#### Downloading commatables.js {#article1}
##### Method 1: CDN
html
<!--CSS Packages-->
<link rel="stylesheet" href="https://cdn.jsdelivr.net/gh/sammarth-k/[email protected]/commastyles.min.css">
<!--JavaScript Packages-->
<script src="https://cdn.jsdelivr.net/gh/sammarth-k/[email protected]/commatables.min.js"></script>
<!--You only need to add this if you want to use csv/txt files-->
<script src="https://cdn.jsdelivr.net/gh/jquery/[email protected]/dist/jquery.min.js"></script>
##### Method 2: Download Package via GitHub
You can visit [this
page](https://github.com/sammarth-k/commatables.js/releases) to download
a `.zip` or `tar.gz` file with the source code.
* * * * *
#### Usage {#article2}
To use commatables.js, you need to link the JavaScript and CSS file in
your document. To use the `csv2tab` feature you must add JQuery
right below the `commatables.js` file. Make sure you do this step as it
is shown here to prevent any error in generating tables.
<script src="path/commatables.js"></script>
<script src="path/jquery.js"></script>
Make sure you add this at the end of the document, before the `</body>`
At the beginning of your document, you want to add your stylesheet, as
so:
<head>
<link rel="stylesheet" href="path/commastyles.css">
</head>
Next, inside the body you have to create a `<div>` with the class
`commatable` (this class is essential for the script to find all your
CommaTables).
``` {.}
<div class="commatable"></div>
```
After that, you want to create your first table. To do so, you can use
**",", ";" and "|"** as your delimiters for columns and go to the next
line for a new row. Don't worry, whitespace on either ends of your rows
or cells won't affect the output since the script removes all whitespace
with the `trim()`.\
Your CommaTable should be created as follows:
``` {.} html
<div class="commatable">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
The output will be as shown:
Yikes, that doesn't look too good. Don't worry, we have a CSS library
dedicated to commatables.js. In the next section, you will see how to
create beatiful tables with responsive design.
#### Using the CSS {#article3}
In this section, we will look at how to use the CSS library to make your
CommaTables look amazing. All the examples used have been made using
commatables.js and the commastyles CSS library.
Let's start by looking at the default style we get when we use the
library:
``` {.}
<div class="commatable">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
Output:
<img src="assets/docs1.png">
<br>
<br>
Right away you see that our table now looks much cleaner. In fact, it's
also responsive. In the following example, you can see how the table
adapts to the given constraints.
<div class="commatable"><div class="ct-scroll"><table><thead><tr><th>Header 1</th><th>Header 2</th><th>Header 3</th><th>Header 4</th><th>Header 5</th><th>Header 6</th><th>Header 7</th><th>Header 8</th><th>Header 9</th><th>Header 10</th></tr></thead><tbody><tr><td>Col 1</td><td>Col 2</td><td>Col 3</td><td>Col 4</td><td>Col 5</td><td>Col 6</td><td>Col 7</td><td>Col 8</td><td>Col 9</td><td>Col 10</td></tr></tbody></table></div></div>
You can try changing your window size to see how the table responds. You
also don't worry about your text overflowing since whitespace is set to
`nowrap` in the CSS.
Let's now look at some of the different styles of tables we can create
with the CSS Library. For these examples, we will be using the `coral`
theme.
##### Adding Color to CommaTables
To add colors and themes to your CommaTable, you need to specify the
theme name as a class of the `div` your CommaTable is being generated
in.
``` {.}
<div class="commatable coral">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
Output:
<div class="commatable coral"><div class="ct-scroll"><table><thead><tr><th>Header 1</th><th>Header 2</th><th>Header 3</th></tr></thead><tbody><tr><td>Col 1</td><td>Col 2</td><td>Col 3</td></tr><tr><td>Col 1</td><td>Col 2</td><td>Col 3</td></tr></tbody></table></div></div>
Header 1, Header 2, Header 3 Col 1, Col 2, Col 3 Col 1, Col 2, Col 3
That definitely looks much better, but that's not all we can do!
##### Borders
You can add borders to your table using the `bordered` class. This
avoids any conflict with the Bootstrap `border` class.
``` {.}
<div class="commatable coral bordered">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
Output:
Header 1, Header 2, Header 3 Col 1, Col 2, Col 3 Col 1, Col 2, Col 3
```js script
// execute me
```
##### Columns
Next, we are going to add columns to the table:
``` {.}
<div class="commatable coral bordered columns">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
Output:
Header 1, Header 2, Header 3 Col 1, Col 2, Col 3 Col 1, Col 2, Col 3
##### Stripes
One of the best table styles is the `striped` style wherein you have the
theme color as your header background and a slightly lighter shade of it
as your stripes.
``` {.}
<div class="commatable coral striped">
Header 1, Header 2, Header 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
Col 1, Col 2, Col 3
</div>
```
Output:
Header 1, Header 2, Header 3 Col 1, Col 2, Col 3 Col 1, Col 2, Col 3 Col
1, Col 2, Col 3 Col 1, Col 2, Col 3
| 28.36 | 434 | 0.609309 | eng_Latn | 0.963619 |
11875016e294750556e83ac603feb2062bcfb31d | 2,142 | md | Markdown | dynamicsax2012-technet/savecommercelistserviceresponse-constructor-microsoft-dynamics-commerce-runtime-services-messages.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 9 | 2019-01-16T13:55:51.000Z | 2021-11-04T20:39:31.000Z | dynamicsax2012-technet/savecommercelistserviceresponse-constructor-microsoft-dynamics-commerce-runtime-services-messages.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 265 | 2018-08-07T18:36:16.000Z | 2021-11-10T07:15:20.000Z | dynamicsax2012-technet/savecommercelistserviceresponse-constructor-microsoft-dynamics-commerce-runtime-services-messages.md | MicrosoftDocs/DynamicsAX2012-technet | 4e3ffe40810e1b46742cdb19d1e90cf2c94a3662 | [
"CC-BY-4.0",
"MIT"
] | 32 | 2018-08-09T22:29:36.000Z | 2021-08-05T06:58:53.000Z | ---
title: SaveCommerceListServiceResponse Constructor (Microsoft.Dynamics.Commerce.Runtime.Services.Messages)
TOCTitle: SaveCommerceListServiceResponse Constructor
ms:assetid: M:Microsoft.Dynamics.Commerce.Runtime.Services.Messages.SaveCommerceListServiceResponse.#ctor(Microsoft.Dynamics.Commerce.Runtime.DataModel.CommerceList)
ms:mtpsurl: https://technet.microsoft.com/library/microsoft.dynamics.commerce.runtime.services.messages.savecommercelistserviceresponse.savecommercelistserviceresponse(v=AX.60)
ms:contentKeyID: 62205871
author: Khairunj
ms.date: 05/18/2015
mtps_version: v=AX.60
f1_keywords:
- Microsoft.Dynamics.Commerce.Runtime.Services.Messages.SaveCommerceListServiceResponse.#ctor
dev_langs:
- CSharp
- C++
- VB
---
# SaveCommerceListServiceResponse Constructor
[!INCLUDE[archive-banner](includes/archive-banner.md)]
Initializes a new instance of the [SaveCommerceListServiceResponse](savecommercelistserviceresponse-class-microsoft-dynamics-commerce-runtime-services-messages.md) class.
**Namespace:** [Microsoft.Dynamics.Commerce.Runtime.Services.Messages](microsoft-dynamics-commerce-runtime-services-messages-namespace.md)
**Assembly:** Microsoft.Dynamics.Commerce.Runtime.Services.Messages (in Microsoft.Dynamics.Commerce.Runtime.Services.Messages.dll)
## Syntax
``` vb
'Declaration
Public Sub New ( _
commerceList As CommerceList _
)
'Usage
Dim commerceList As CommerceList
Dim instance As New SaveCommerceListServiceResponse(commerceList)
```
``` csharp
public SaveCommerceListServiceResponse(
CommerceList commerceList
)
```
``` c++
public:
SaveCommerceListServiceResponse(
CommerceList^ commerceList
)
```
#### Parameters
- commerceList
Type: [Microsoft.Dynamics.Commerce.Runtime.DataModel.CommerceList](commercelist-class-microsoft-dynamics-commerce-runtime-datamodel.md)
## See Also
#### Reference
[SaveCommerceListServiceResponse Class](savecommercelistserviceresponse-class-microsoft-dynamics-commerce-runtime-services-messages.md)
[Microsoft.Dynamics.Commerce.Runtime.Services.Messages Namespace](microsoft-dynamics-commerce-runtime-services-messages-namespace.md)
| 31.970149 | 176 | 0.821195 | yue_Hant | 0.664447 |
118782dcd187468bef3132a44a141bd82fee7a86 | 35,630 | md | Markdown | source/docs/documentation/Iris/iris_widget_prog_guide/Content/ImageGallery_Properties.md | kumari-h/volt-mx-docs | 7b361299d49abedd1162cbb1640bad0cd04d3140 | [
"Apache-2.0"
] | null | null | null | source/docs/documentation/Iris/iris_widget_prog_guide/Content/ImageGallery_Properties.md | kumari-h/volt-mx-docs | 7b361299d49abedd1162cbb1640bad0cd04d3140 | [
"Apache-2.0"
] | null | null | null | source/docs/documentation/Iris/iris_widget_prog_guide/Content/ImageGallery_Properties.md | kumari-h/volt-mx-docs | 7b361299d49abedd1162cbb1640bad0cd04d3140 | [
"Apache-2.0"
] | null | null | null | ---
layout: "documentation"
category: "iris_widget_prog_guide"
---
ImageGallery - Basic Properties
-------------------------------
The basic properties for ImageGallery widget are:
* * *
[](javascript:void(0);)[accessibilityConfig Property](javascript:void(0);)
* * *
Enables you to control accessibility behavior and alternative text for the widget.
For more information on using accessibility features in your app, see the [Accessibility]({{ site.baseurl }}/docs/documentation/Iris/iris_user_guide/Content/Accessibility_Overview.html) appendix in the Volt MX IrisUser Guide.
Syntax
accessibilityConfig
Type
Object
Read/Write
Read + Write
Remarks
* The accessibilityConfig property is enabled for all the widgets which are supported under the Flex Layout.
> **_Note:_** From Volt MX Iris V9 SP2 GA version, you can provide i18n keys as values to all the attributes used inside the `accessibilityConfig` property. Values provided in the i18n keys take precedence over values provided in `a11yLabel`, `a11yValue`, and `a11yHint` fields.
The accessibilityConfig property is a JavaScript object which can contain the following key-value pairs.
| Key | Type | Description | ARIA Equivalent |
| --- | --- | --- | --- |
| a11yIndex | Integer with no floating or decimal number. | This is an optional parameter. Specifies the order in which the widgets are focused on a screen. | For all widgets, this parameter maps to the `aria-index`, `index`, or `taborder` properties. |
| a11yLabel | String | This is an optional parameter. Specifies alternate text to identify the widget. Generally the label should be the text that is displayed on the screen. | For all widgets, this parameter maps to the `aria-labelledby` property of ARIA in HTML. > **_Note:_** For the Image widget, this parameter maps to the **alt** attribute of ARIA in HTML. |
| a11yValue | String | This is an optional parameter. Specifies the descriptive text that explains the action associated with the widget. On the Android platform, the text specified for a11yValue is prefixed to the a11yHint. | This parameter is similar to the a11yLabel parameter. If the a11yValue is defined, the value of a11yValue is appended to the value of a11yLabel. These values are separated by a space. |
| a11yHint | String | This is an optional parameter. Specifies the descriptive text that explains the action associated with the widget. On the Android platform, the text specified for a11yValue is prefixed to the a11yHint. | For all widgets, this parameter maps to the `aria-describedby` property of ARIA in HTML. |
| a11yHidden | Boolean | This is an optional parameter. Specifies if the widget should be ignored by assistive technology. The default option is set to _false_. This option is supported on iOS 5.0 and above, Android 4.1 and above, and SPA | For all widgets, this parameter maps to the `aria-hidden` property of ARIA in HTML. |
| a11yARIA | Object | This is an optional parameter. For each widget, the key and value provided in this object are added as the attribute and value of the HTML tags respectively. Any values provided for attributes such as `aria-labelledby` and `aria-describedby` using this attribute, takes precedence over values given in `a11yLabel` and `a11yHint` fields. When a widget is provided with the following key value pair or attribute using the a11yARIA object, the tabIndex of the widget is automatically appended as zero.`{"role": "main"}``aria-label` | This parameter is only available on the Desktop Web platform. |
Android limitations
* If the results of the concatenation of a11y fields result in an empty string, then `accessibilityConfig` is ignored and the text that is on widget is read out.
* The soft keypad does not gain accessibility focus during the right/left swipe gesture when the keypad appears.
SPA/Desktop Web limitations
* When `accessibilityConfig` property is configured for any widget, the `tabIndex` attribute is added automatically to the `accessibilityConfig` property.
* The behavior of accessibility depends on the Web browser, Web browser version, Voice Over Assistant, and Voice Over Assistant version.
* Currently SPA/Desktop web applications support only a few ARIA tags. To achieve more accessibility features, use the attribute a11yARIA. The corresponding tags will be added to the DOM as per these configurations.
Example 1
This example uses the button widget, but the principle remains the same for all widgets that have an accessibilityConfig property.
{% highlight voltMx %}//This is a generic property that is applicable for various widgets.
//Here, we have shown how to use the accessibilityConfig Property for button widget.
/*You need to make a corresponding use of the accessibilityConfig property for other applicable widgets.*/
Form1.myButton.accessibilityConfig = {
"a11yLabel": "Label",
"a11yValue": "Value",
"a11yHint": "Hint"
};
{% endhighlight %}
Example 2
This example uses the button widget to implement internationalization in `accessibilityConfig` property, but the principle remains the same for all widgets.
{% highlight voltMx %}/*Sample code to implement internationalization in accessibilityConfig property in Native platform.*/
Form1.myButton.accessibilityConfig = {
"a11yLabel": voltmx.i18n.getLocalizedString("key1")
};
/*Sample code to implement internationalization in accessibilityConfig property in Desktop Web platform.*/
Form1.myButton.accessibilityConfig = {
"a11yLabel": "voltmx.i18n.getLocalizedString(\"key3\")"
};
{% endhighlight %}
Platform Availability
* Available in the IDE
* iOS, Android, SPA, and Desktop Web
* * *
[](javascript:void(0);)[anchorPoint Property](javascript:void(0);)
* * *
Specifies the anchor point of the widget bounds rectangle using the widget's coordinate space.
Syntax
anchorPoint
Type
JSObject
Read/Write
Read + Write
Remarks
The value for this property is a JavaScript dictionary object with the keys "x" and "y". The values for the "x" and "y" keys are floating-point numbers ranging from 0 to 1. All geometric manipulations to the widget occur about the specified point. For example, applying a rotation transform to a widget with the default anchor point causes the widget to rotate around its center.
The default value for this property is center ( {"x":0.5, "y":0.5} ), that represents the center of the widgets bounds rectangle. The behavior is undefined if the values are outside the range zero (0) to one (1).
Example
{% highlight voltMx %}Form1.widget1.anchorPoint = {
"x": 0.5,
"y": 0.5
};
{% endhighlight %}
Platform Availability
* iOS, Android, Windows, and SPA
* * *
[](javascript:void(0);)[data Property](javascript:void(0);)
* * *
Represents the JSObject to represent the images to be rendered in ImageGallery. The format of the JSObject consists of an array of two elements:
* \[0\] is the array of objects with hashes
* \[1\] is the key's key in the data hash of \[0\]
Example
{% highlight voltMx %}formname.widgetname.data=
[
[{"imagekey":"image1.png"},
{"imagekey":"image2.png"},
{"imagekey":"imagen.png"}]
];
{% endhighlight %}
Syntax
data
Type
Array
Read/Write
Yes - (Read and Write)
Platform Availability
Available in the IDE
Available on all platforms
* * *
[](javascript:void(0);)[enableCache Property](javascript:void(0);)
* * *
The property enables you to improve the performance of Positional Dimension Animations.
Syntax
enableCache
Type
Boolean
Read/Write
Read + Write
Remarks
The default value for this property is true.
> **_Note:_** When the property is used, application consumes more memory. The usage of the property enables tradeoff between performance and visual quality of the content. Use the property cautiously.
Example
{% highlight voltMx %}Form1.widgetID.enableCache = true;
{% endhighlight %}
Platform Availability
* Available in the IDE.
* Windows
* * *
[](javascript:void(0);)[focusSkin Property](javascript:void(0);)
* * *
Specifies the look and feel of the widget when in focus.
Syntax
focusSkin
Type
String
Read/Write
Yes - (Read and Write)
Remarks
You must be aware of the following:
On J2ME non-touch devices, if you do not specify the Focus skin, it is not possible to identify the focus change between the widgets.
Mobile Web does not support this property, instead browser specific focus will be applied.
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with focusSkin: "gradroundfocusbtn"
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
**focusSkin: "gradroundfocusbtn"**};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//Reading the focusSkin of ImageGallery
alert("ImageGallery focusSkin is ::"+imgGallery.focusSkin);
{% endhighlight %}
Platform Availability
Available in the IDE
Available on all platforms..
* * *
[](javascript:void(0);)[hoverSkin Property](javascript:void(0);)
* * *
Specifies the look and feel of a widget when the cursor hovers on the widget.
Syntax
hoverSkin
Type
String
Read/Write
Yes - (Read and Write)
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with hoverSkin:"hskin"
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
selectedIndex:3, spaceBetweenImages: 50};
var imgGalLayout = {containerWeight:100};
var imgGalPSP = {**hoverSkin:"hskin"**};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available on Windows Tablet.
* * *
[](javascript:void(0);)[id Property](javascript:void(0);)
* * *
id is a unique identifier of ImageGallery consisting of alpha numeric characters. Every ImageGallery should have a unique id within a Form.
Syntax
id
Type
String - \[Mandatory\]
Read/Write
Yes - (Read only)
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with ID:"imgGallery"
var imgGalBasic = { **id: "imgGallery"**, isVisible: true};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//Reading the ID of ImageGallery
alert("ImageGallery id is ::"+imgGallery.id);
{% endhighlight %}
Platform Availability
Available in the IDE
Available on all platforms.
* * *
[](javascript:void(0);)[imageWhenFailed Property](javascript:void(0);)
* * *
Specifies the image to be displayed when the remote resource is not available. This image is taken from the resources folder.
Syntax
imageWhenFailed
Type
String
Read/Write
No
Example
{% highlight voltMx %}//Defining the properties for ImageGallery with imageWhenFailed: "AppIcon.png".
//Image with the same name should be in resources folder.
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
imageWhileDownloading: "ApplicationIcon.png",
imageWhenFailed: "AppIcon.png"};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
{% endhighlight %}
Platform Availability
Not available in the IDE.
Available on all platforms except and Windows Desktop platforms.
* * *
[](javascript:void(0);)[imageWhileDownloading Property](javascript:void(0);)
* * *
Specifies the image to be displayed when the remote source is still being downloaded. This image is taken from the resources folder.
Syntax
imageWhileDownloading
Type
String
Read/Write
No
Example
{% highlight voltMx %}//Defining the properties for ImageGallery with imageWhileDownloading: "ApplicationIcon.png".
//Image with the same name should be in resources folder.
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
imageWhileDownloading: "ApplicationIcon.png"};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
{% endhighlight %}
Platform Availability
Available in the IDE.
Available on all platforms., BlackBerry 10, and Windows Desktop platforms.
* * *
[](javascript:void(0);)[info Property](javascript:void(0);)
* * *
A custom JSObject with the key value pairs that a developer can use to store the context with the widget. This will help in avoiding the globals to most part of the programming.
Syntax
info
Type
JSObject
Read/Write
Yes - (Read and Write)
Remarks
This is a **non-Constructor** property. You cannot set this property through widget constructor. But you can read and write data to it.
Info property can hold any JSObject. After assigning the JSObject to info property, the JSObject should not be modified. For example,
{% highlight voltMx %}var inf = {a: 'hello'};
widget.info = inf; //works
widget.info.a = 'hello world';
/*This will not update the widget info a property to Hello world.
widget.info.a will have old value as hello.*/
{% endhighlight %}
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with info property.
var imgGalBasic = { id: "imgGallery",isVisible: true};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
**imgGallery.info = {key:"ImageGal"};**
//Reading the info of ImageGallery
alert("ImageGallery info is ::"+imgGallery.info);
{% endhighlight %}
Platform Availability
Not available in the IDE.
Available on all platforms.
* * *
[](javascript:void(0);)[isVisible Property](javascript:void(0);)
* * *
This property controls the visibility of a widget on the form.
Syntax
isVisible
Type
Boolean
Read/Write
Yes - (Read and Write)
Remarks
The default value for this property is true. If set to _false,_ the widget is not displayed. If set to _true,_ the widget is displayed.
You can set the visibility of a widget dynamically from code using the setVisibility method.
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with isVisible: true
var imgGalBasic = { id: "imgGallery", **isVisible: true**};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//Reading the Visibility of ImageGallery
alert("ImageGallery Visibility is ::"+imgGallery.isVisible);
{% endhighlight %}
Platform Availability
Available in the IDE.
Available on all platforms.
* * *
[](javascript:void(0);)[itemsPerRow Property](javascript:void(0);)
* * *
Specifies the number of images to be displayed per row in an ImageGallery at a time.
Syntax
itemsPerRow
Type
Number
Read/Write
No
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with sitemsPerRow:3
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
selectedIndex:3, spaceBetweenImages: 50};
var imgGalLayout = {containerWeight:100};
var imgGalPSP = {**itemsPerRow:3**};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available only on Server side Mobile Web (advanced) platform.
* * *
[](javascript:void(0);)[navigationBarPosition Property](javascript:void(0);)
* * *
Specifies the position of the navigation bar for the ImageGallery. The pageview indicator either appears on the top or bottom of the ImageGallery.
Syntax
navigationBarPosition
Type
String
Read/Write
No
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with navigationBarPosition:"Bottom"
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
selectedIndex:3, spaceBetweenImages: 50};
var imgGalLayout = {containerWeight:100};
var imgGalPSP = {itemsPerRow:3, **navigationBarPosition:"Bottom"**};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available only on Server side Mobile Web (advanced) platform.
* * *
[](javascript:void(0);)[noofRowsPerPage Property](javascript:void(0);)
* * *
Specifies the number of rows to be displayed in each page.
Syntax
noofRowsPerPage
Type
Number
Read/Write
Yes - (Read and Write)
Remarks
This property is displayed only when [viewType](#viewType) is set to _IMAGE\_GALLERY\_VIEW\_TYPE\_PAGEVIEW_.
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with noofRowsPerPage:4.
var imgGalBasic={id:"imagegallery1",
isVisible:true,
skin:"imgGalskin",
focusSkin:"imgGalFSkin",
text:"Click Here",
**toolTip:"sample text"**};
var imgGalLayout={containerWeight:100,
padding:[5,5,5,5],
margin:[5,5,5,5],
hExpand:true,
vExpand:false,
displayText:true};
var imgGalPSP={viewType: constants.IMAGE_GALLERY_VIEW_TYPE_PAGEVIEW, **viewConfig: {noofRowsPerPage:4**}};
//Creating the ImageGallery.
var imagegallery1 = new voltmx.ui.ImageGallery(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available on Desktop Web.
* * *
[](javascript:void(0);)[retainContentAlignment Property](javascript:void(0);)
* * *
This property is used to retain the content alignment property value, as it was defined.
> **_Note:_** Locale-level configurations take priority when invalid values are given to this property, or if it is not defined.
The mirroring widget layout properties should be defined as follows.
{% highlight voltMx %}function getIsFlexPositionalShouldMirror(widgetRetainFlexPositionPropertiesValue) {
return (isI18nLayoutConfigEnabled &&
localeLayoutConfig[defaultLocale]
["mirrorFlexPositionalProperties"] == true &&
!widgetRetainFlexPositionPropertiesValue);
}
{% endhighlight %}
The following table illustrates how widgets consider Local flag and Widget flag values.
| Properties | Local Flag Value | Widget Flag Value | Action |
| --- | --- | --- | --- |
| Mirror/retain FlexPositionProperties | true | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | true | false | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | true | not specified | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | false | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | false | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | false | not specified | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | not specified | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | not specified | Use the Design/Model-specific default layout. |
Syntax
retainContentAlignment
Type
Boolean
Read/Write
No (only during widget-construction time)
Example
{% highlight voltMx %}//This is a generic property that is applicable for various widgets.
//Here, we have shown how to use the retainContentAlignment property for Button widget.
/*You need to make a corresponding use of the
retainContentAlignment property for other applicable widgets.*/
var btn = new voltmx.ui.Button({
"focusSkin": "defBtnFocus",
"height": "50dp",
"id": "myButton",
"isVisible": true,
"left": "0dp",
"skin": "defBtnNormal",
"text": "text always from top left",
"top": "0dp",
"width": "260dp",
"zIndex": 1
}, {
"contentAlignment": constants.CONTENT_ALIGN_TOP_LEFT,
"displayText": true,
"padding": [0, 0, 0, 0],
"paddingInPixel": false,
"retainFlexPositionProperties": false,
"retainContentAlignment": true
}, {});
{% endhighlight %}
Platform Availability
* Available in IDE
* Windows, iOS, Android, and SPA
* * *
[](javascript:void(0);)[retainFlexPositionProperties Property](javascript:void(0);)
* * *
This property is used to retain flex positional property values as they were defined. The flex positional properties are left, right, and padding.
> **_Note:_** Locale-level configurations take priority when invalid values are given to this property, or if it is not defined.
The mirroring widget layout properties should be defined as follows.
{% highlight voltMx %}function getIsFlexPositionalShouldMirror(widgetRetainFlexPositionPropertiesValue) {
return (isI18nLayoutConfigEnabled &&
localeLayoutConfig[defaultLocale]
["mirrorFlexPositionalProperties"] == true &&
!widgetRetainFlexPositionPropertiesValue);
}
{% endhighlight %}
The following table illustrates how widgets consider Local flag and Widget flag values.
| Properties | Local Flag Value | Widget Flag Value | Action |
| --- | --- | --- | --- |
| Mirror/retain FlexPositionProperties | true | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | true | false | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | true | not specified | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | false | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | false | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | false | not specified | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | not specified | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | not specified | Use the Design/Model-specific default layout. |
Syntax
retainFlexPositionProperties
Type
Boolean
Read/Write
No (only during widget-construction time)
Example
{% highlight voltMx %}//This is a generic property that is applicable for various widgets.
//Here, we have shown how to use the retainFlexPositionProperties property for Button widget.
/*You need to make a corresponding use of the
retainFlexPositionProperties property for other applicable widgets.*/
var btn = new voltmx.ui.Button({
"focusSkin": "defBtnFocus",
"height": "50dp",
"id": "myButton",
"isVisible": true,
"left": "0dp",
"skin": "defBtnNormal",
"text": "always left",
"top": "0dp",
"width": "260dp",
"zIndex": 1
}, {
"contentAlignment": constants.CONTENT_ALIGN_CENTER,
"displayText": true,
"padding": [0, 0, 0, 0],
"paddingInPixel": false,
"retainFlexPositionProperties": true,
"retainContentAlignment": false
}, {});
{% endhighlight %}
Platform Availability
* Available in IDE
* Windows, iOS, Android, and SPA
* * *
[](javascript:void(0);)[retainFlowHorizontalAlignment Property](javascript:void(0);)
* * *
This property is used to convert Flow Horizontal Left to Flow Horizontal Right.
> **_Note:_** Locale-level configurations take priority when invalid values are given to this property, or if it is not defined.
The mirroring widget layout properties should be defined as follows.
{% highlight voltMx %}function getIsFlexPositionalShouldMirror(widgetRetainFlexPositionPropertiesValue) {
return (isI18nLayoutConfigEnabled &&
localeLayoutConfig[defaultLocale]
["mirrorFlexPositionalProperties"] == true &&
!widgetRetainFlexPositionPropertiesValue);
}
{% endhighlight %}
The following table illustrates how widgets consider Local flag and Widget flag values.
| Properties | Local Flag Value | Widget Flag Value | Action |
| --- | --- | --- | --- |
| Mirror/retain FlexPositionProperties | true | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | true | false | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | true | not specified | Use Mirror FlexPositionProperties since locale-level Mirror is true. |
| Mirror/retain FlexPositionProperties | false | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | false | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | false | not specified | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | true | Use the designed layout from widget for all locales. Widget layout overrides everything else. |
| Mirror/retain FlexPositionProperties | not specified | false | Use the Design/Model-specific default layout. |
| Mirror/retain FlexPositionProperties | not specified | not specified | Use the Design/Model-specific default layout. |
Syntax
retainFlowHorizontalAlignment
Type
Boolean
Read/Write
No (only during widget-construction time)
Example
{% highlight voltMx %}//This is a generic property that is applicable for various widgets.
//Here, we have shown how to use the retainFlowHorizontalAlignment property for Button widget.
/*You need to make a corresponding use of the
retainFlowHorizontalAlignment property for other applicable widgets. */
var btn = new voltmx.ui.Button({
"focusSkin": "defBtnFocus",
"height": "50dp",
"id": "myButton",
"isVisible": true,
"left": "0dp",
"skin": "defBtnNormal",
"text": "always left",
"top": "0dp",
"width": "260dp",
"zIndex": 1
}, {
"contentAlignment": constants.CONTENT_ALIGN_CENTER,
"displayText": true,
"padding": [0, 0, 0, 0],
"paddingInPixel": false,
"retainFlexPositionProperties": true,
"retainContentAlignment": false,
"retainFlowHorizontalAlignment ": false
}, {});
{% endhighlight %}
Platform Availability
* Available in IDE
* Windows, iOS, Android, and SPA
* * *
[](javascript:void(0);)[selectedIndex Property](javascript:void(0);)
* * *
Indicates the currently selected image in the ImageGallery. The index is with respect to the order in which data is set with [data](#data) property. Programmatically setting the _selectedIndex_ will not make any visible differences in the row, however it will bring the row at the index into the view able area on the screen. Setting it to _null/nil_ clears the selection state.
Syntax
selectedIndex
Type
Number
Read/Write
Yes - (Read and Write)
Remarks
On Windows Phone platform, you cannot write data to this property.
If data contains the sections then the _selectedIndex_ indicates the selected row index within the section.
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with selectedIndex:3 (setSelectedIndex)
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
imageWhileDownloading: "ApplicationIcon.png",
imageWhenFailed: "AppIcon.png",
**selectedIndex:3**};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//getSelectedIndex
alert("Selected Index:"+imgGallery.selectedIndex);
{% endhighlight %}
Platform Availability
Not available in the IDE.
Available on all platforms..
* * *
[](javascript:void(0);)[selectedItem Property](javascript:void(0);)
* * *
Returns the selected data object (input array) corresponding to the selected image of the ImageGallery. If no image is selected, _null/nil_ is returned.
Syntax
selectedItem
Type
JSObject
Read/Write
Read only
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with selectedIndex:3 (setSelectedIndex)
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
imageWhileDownloading: "ApplicationIcon.png",
imageWhenFailed: "AppIcon.png",
selectedIndex:3};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//getSelectedItem
**alert("selected Item:"+imgGallery.selectedItem);**
{% endhighlight %}
Platform Availability
Not available in the IDE
Available on all platforms..
* * *
[](javascript:void(0);)[skin Property](javascript:void(0);)
* * *
Specifies the look and feel of the ImageGallery when not in focus.
Syntax
skin
Type
String
Read/Write
Yes - (Read and Write)
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with skin: "gradroundfocusbtn"
var imgGalBasic = { id: "imgGallery",
isVisible: true,
**skin: "gradroundfocusbtn"**};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
//Reading the skin of ImageGallery
alert("ImageGallery skin is ::"+imgGallery.skin);
{% endhighlight %}
Platform Availability
Available in the IDE
Available on all platforms..
[](javascript:void(0);)[spaceBetweenImages Property](javascript:void(0);)
* * *
Specifies the space between the images in the ImageGallery.
Syntax
spaceBetweenImages
Type
Number
Read/Write
No
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with spaceBetweenImages: 50
var imgGalBasic = { id: "imgGallery",
isVisible: true,
skin: "gradroundfocusbtn",
focusSkin: "gradroundfocusbtn",
imageWhileDownloading: "ApplicationIcon.png",
imageWhenFailed: "AppIcon.png",
selectedIndex:3, **spaceBetweenImages: 50**};
var imgGalLayout = {containerWeight:100};
//Creating the ImageGallery.
var imgGallery = new voltmx.ui.ImageGallery2(imgGalBasic,imgGalLayout,{});
{% endhighlight %}
Platform Availability
Available in the IDE.
Available on all platforms., and Windows Phone platforms.
* * *
[](javascript:void(0);)[transform Property](javascript:void(0);)
* * *
Contains an animation transformation that can be used to animate the widget.
Syntax
transform
Type
JSObject
Read/Write
Read + Write
Remarks
This property is set to the identify transform by default. Any transformations applied to the widget occur relative to the widget's anchor point. The transformation contained in this property must be created using the [voltmx.ui.makeAffineTransform]({{ site.baseurl }}/docs/documentation/Iris/iris_api_dev_guide/content/voltmx.ui_functions.html#makeAffi) function.
Example
This example uses the button widget, but the principle remains the same for all widgets that have a transform property.
{% highlight voltMx %}//Animation sample
var newTransform = voltmx.ui.makeAffineTransform();
newTransform.translate3D(223, 12, 56);
//translates by 223 xAxis,12 in yAxis,56 in zAxis
widget.transform = newTransform;
{% endhighlight %}
Platform Availability
* iOS, Android, Windows, and SPA
* * *
[](javascript:void(0);)[viewType Property](javascript:void(0);)
* * *
Specifies the appearance of the Image Gallery as Default view or Page view.
Syntax
viewType
Type
Number
Read/Write
Yes - (Read and Write)
Remarks
The default value for this property is IMAGE\_GALLERY\_VIEW\_TYPE\_DEFAULT.
You can select one of the following available views:
* _IMAGE\_GALLERY\_VIEW\_TYPE\_DEFAULT_ - This is the default selection and if this option is unchanged, the appearance of the image gallery remains unchanged.
* _IMAGE\_GALLERY\_VIEW\_TYPE\_PAGEVIEW_ - The images appears as a pageview. When this option is selected, the [noofRowsPerPage](#viewConf) is displayed.
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with viewType:IMAGE_GALLERY_VIEW_TYPE_DEFAULT.
var imgGalBasic={id:"imagegallery1",
isVisible:true,
skin:"imgGalskin",
focusSkin:"imgGalFSkin",
text:"Click Here",
toolTip:"sample text"};
var imgGalLayout={containerWeight:100,
padding:[5,5,5,5],
margin:[5,5,5,5],
hExpand:true,
vExpand:false,
displayText:true};
var imgGalPSP={**viewType: constants.IMAGE_GALLERY_VIEW_TYPE_DEFAULT** };
//Creating the ImageGallery.
var imagegallery1 = new voltmx.ui.ImageGallery(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available on Desktop Web.
* * *
[](javascript:void(0);)[viewConfig Property](javascript:void(0);)
* * *
Specifies the view configuration parameters when the [viewType](#viewType) is set as IMAGE\_GALLERY\_VIEW\_TYPE\_PAGEVIEW for Desktop Web platform.
Syntax
viewConfig
Type
JSObject
Read/Write
Yes - (Read and Write)
Example
{% highlight voltMx %}
//Defining the properties for ImageGallery with viewConfig:noofRowsPerPage.
var imgGalBasic={id:"imagegallery1",
isVisible:true,
skin:"imgGalskin",
focusSkin:"imgGalFSkin",
text:"Click Here",
toolTip:"sample text"};
var imgGalLayout={containerWeight:100,
padding:[5,5,5,5],
margin:[5,5,5,5],
hExpand:true,
vExpand:false,
displayText:true};
var imgGalPSP={viewType: constants.IMAGE_GALLERY_VIEW_TYPE_PAGEVIEW,
**viewConfig: {noofRowsPerPage: 5**} };
//Creating the ImageGallery.
var imagegallery1 = new voltmx.ui.ImageGallery(imgGalBasic,imgGalLayout,imgGalPSP);
{% endhighlight %}
Platform Availability
Available in the IDE.
This property is available on Desktop Web.
* * *
| 28.572574 | 616 | 0.755571 | eng_Latn | 0.926817 |
1187b7a7990edeca7932418da66a8a2b558d1552 | 3,784 | md | Markdown | docs/data-sources/java-heap-profiler.md | melodylail/perfetto | 4a9b683ccbbb7f1d3d16645671e960dae6a8a352 | [
"Apache-2.0"
] | null | null | null | docs/data-sources/java-heap-profiler.md | melodylail/perfetto | 4a9b683ccbbb7f1d3d16645671e960dae6a8a352 | [
"Apache-2.0"
] | null | null | null | docs/data-sources/java-heap-profiler.md | melodylail/perfetto | 4a9b683ccbbb7f1d3d16645671e960dae6a8a352 | [
"Apache-2.0"
] | null | null | null | # Memory: Java heap profiler
NOTE: The Java heap profiler requires Android 11 or higher
See the [Memory Guide](/docs/case-studies/memory.md#java-hprof) for getting
started with Java heap profiling.
Conversely from the [Native heap profiler](native-heap-profiler.md), the Java
heap profiler reports full retention graphs of managed objects but not
call-stacks. The information recorded by the Java heap profiler is of the form:
_Object X retains object Y, which is N bytes large, through its class member
named Z_.
## UI
Heap graph dumps are shown as flamegraphs in the UI after clicking on the
diamond in the _"Heap Profile"_ track of a process. Each diamond corresponds to
a heap dump.


The native size of certain objects is represented as an extra child node in the
flamegraph, prefixed with "[native]". The extra node counts as an extra object.
This is available only on Android T+.
## SQL
Information about the Java Heap is written to the following tables:
* [`heap_graph_class`](/docs/analysis/sql-tables.autogen#heap_graph_class)
* [`heap_graph_object`](/docs/analysis/sql-tables.autogen#heap_graph_object)
* [`heap_graph_reference`](/docs/analysis/sql-tables.autogen#heap_graph_reference)
`native_size` (available only on Android T+) is extracted from the related
`libcore.util.NativeAllocationRegistry` and is not included in `self_size`.
For instance, to get the bytes used by class name, run the following query.
As-is this query will often return un-actionable information, as most of the
bytes in the Java heap end up being primitive arrays or strings.
```sql
select c.name, sum(o.self_size)
from heap_graph_object o join heap_graph_class c on (o.type_id = c.id)
where reachable = 1 group by 1 order by 2 desc;
```
|name |sum(o.self_size) |
|--------------------|--------------------|
|java.lang.String | 2770504|
|long[] | 1500048|
|int[] | 1181164|
|java.lang.Object[] | 624812|
|char[] | 357720|
|byte[] | 350423|
We can use `experimental_flamegraph` to normalize the graph into a tree, always
taking the shortest path to the root and get cumulative sizes.
Note that this is **experimental** and the **API is subject to change**.
From this we can see how much memory is being held by each type of object
For that, we need to find the timestamp and upid of the graph.
```sql
select distinct graph_sample_ts, upid from heap_graph_object
```
graph_sample_ts | upid |
--------------------|--------------------|
56785646801 | 1 |
We can then use them to get the flamegraph data.
```sql
select name, cumulative_size
from experimental_flamegraph(56785646801, 1, 'graph')
order by 2 desc;
```
| name | cumulative_size |
|------|-----------------|
|java.lang.String|1431688|
|java.lang.Class<android.icu.text.Transliterator>|1120227|
|android.icu.text.TransliteratorRegistry|1119600|
|com.android.systemui.statusbar.phone.StatusBarNotificationPresenter$2|1086209|
|com.android.systemui.statusbar.phone.StatusBarNotificationPresenter|1085593|
|java.util.Collections$SynchronizedMap|1063376|
|java.util.HashMap|1063292|
## TraceConfig
The Java heap profiler is configured through the
[JavaHprofConfig](/docs/reference/trace-config-proto.autogen#JavaHprofConfig)
section of the trace config.
```protobuf
data_sources {
config {
name: "android.java_hprof"
java_hprof_config {
process_cmdline: "com.google.android.inputmethod.latin"
dump_smaps: true
}
}
}
```
| 35.037037 | 82 | 0.703224 | eng_Latn | 0.970238 |
118837d2328fc436a13c8f5ea928d20cef9d31a4 | 595 | md | Markdown | src/pages/blog/2019-08-17-g-roll-seminar-with-alex-masterskya.md | dax8it/atjiujitsu04 | 153216e824b37872235b637a71946abd549f850a | [
"MIT"
] | null | null | null | src/pages/blog/2019-08-17-g-roll-seminar-with-alex-masterskya.md | dax8it/atjiujitsu04 | 153216e824b37872235b637a71946abd549f850a | [
"MIT"
] | 3 | 2021-03-09T17:28:39.000Z | 2021-09-21T03:27:44.000Z | src/pages/blog/2019-08-17-g-roll-seminar-with-alex-masterskya.md | dax8it/atjiujitsu04 | 153216e824b37872235b637a71946abd549f850a | [
"MIT"
] | null | null | null | ---
templateKey: blog-post
title: G-Roll Seminar with Alex Masterskya
date: 2019-08-31T16:00:00.000Z
description: Learning how to do the G-Roll
featuredpost: true
featuredimage: /img/dsc6904.jpg
tags:
- Seminar
- bjj
- jiujitsu
- nyc
---
### Thank you to everyone who joined us during Alex Masterskya, G-Roll Seminar. We hope you all learned something new and different from someone else's perspective.
**AUGUST 31, 2019**







| 18.030303 | 164 | 0.692437 | eng_Latn | 0.545646 |
1188a8b222739014d66954c51a3ba196c313d718 | 13,184 | md | Markdown | docs/gitbook/tutorials/appmesh-progressive-delivery.md | Freydal/flagger | 358391bfde9c90821e52f17471733a2476a65b07 | [
"Apache-2.0"
] | 369 | 2018-10-09T20:11:50.000Z | 2019-03-19T19:27:02.000Z | docs/gitbook/tutorials/appmesh-progressive-delivery.md | Freydal/flagger | 358391bfde9c90821e52f17471733a2476a65b07 | [
"Apache-2.0"
] | 96 | 2018-10-25T14:01:26.000Z | 2019-03-20T15:57:26.000Z | docs/gitbook/tutorials/appmesh-progressive-delivery.md | Freydal/flagger | 358391bfde9c90821e52f17471733a2476a65b07 | [
"Apache-2.0"
] | 25 | 2018-11-15T18:55:39.000Z | 2019-03-19T07:12:57.000Z | # App Mesh Canary Deployments
This guide shows you how to use App Mesh and Flagger to automate canary deployments.
You'll need an EKS cluster (Kubernetes >= 1.16) configured with App Mesh,
you can find the installation guide [here](https://docs.flagger.app/install/flagger-install-on-eks-appmesh).
## Bootstrap
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
then creates a series of objects (Kubernetes deployments, ClusterIP services,
App Mesh virtual nodes and services).
These objects expose the application on the mesh and drive the canary analysis and promotion.
The only App Mesh object you need to create by yourself is the mesh resource.
Create a mesh called `global`:
```bash
cat << EOF | kubectl apply -f -
apiVersion: appmesh.k8s.aws/v1beta2
kind: Mesh
metadata:
name: global
spec:
namespaceSelector:
matchLabels:
appmesh.k8s.aws/sidecarInjectorWebhook: enabled
EOF
```
Create a test namespace with App Mesh sidecar injection enabled:
```bash
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: test
labels:
appmesh.k8s.aws/sidecarInjectorWebhook: enabled
EOF
```
Create a deployment and a horizontal pod autoscaler:
```bash
kubectl apply -k https://github.com/fluxcd/flagger//kustomize/podinfo?ref=main
```
Deploy the load testing service to generate traffic during the canary analysis:
```bash
helm upgrade -i flagger-loadtester flagger/loadtester \
--namespace=test \
--set appmesh.enabled=true \
--set "appmesh.backends[0]=podinfo" \
--set "appmesh.backends[1]=podinfo-canary"
```
Create a canary definition:
```yaml
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
annotations:
# Enable Envoy access logging to stdout.
appmesh.flagger.app/accesslog: enabled
name: podinfo
namespace: test
spec:
# App Mesh API reference
provider: appmesh:v1beta2
# deployment reference
targetRef:
apiVersion: apps/v1
kind: Deployment
name: podinfo
# the maximum time in seconds for the canary deployment
# to make progress before it is rollback (default 600s)
progressDeadlineSeconds: 60
# HPA reference (optional)
autoscalerRef:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
name: podinfo
service:
# container port
port: 9898
# App Mesh ingress timeout (optional)
timeout: 15s
# App Mesh retry policy (optional)
retries:
attempts: 3
perTryTimeout: 5s
retryOn: "gateway-error,client-error,stream-error"
# App Mesh URI settings
match:
- uri:
prefix: /
rewrite:
uri: /
# define the canary analysis timing and KPIs
analysis:
# schedule interval (default 60s)
interval: 1m
# max number of failed metric checks before rollback
threshold: 5
# max traffic percentage routed to canary
# percentage (0-100)
maxWeight: 50
# canary increment step
# percentage (0-100)
stepWeight: 5
# App Mesh Prometheus checks
metrics:
- name: request-success-rate
# minimum req success rate (non 5xx responses)
# percentage (0-100)
thresholdRange:
min: 99
interval: 1m
- name: request-duration
# maximum req duration P99
# milliseconds
thresholdRange:
max: 500
interval: 30s
# testing (optional)
webhooks:
- name: acceptance-test
type: pre-rollout
url: http://flagger-loadtester.test/
timeout: 30s
metadata:
type: bash
cmd: "curl -sd 'test' http://podinfo-canary.test:9898/token | grep token"
- name: load-test
url: http://flagger-loadtester.test/
timeout: 5s
metadata:
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
```
Save the above resource as podinfo-canary.yaml and then apply it:
```bash
kubectl apply -f ./podinfo-canary.yaml
```
After a couple of seconds Flagger will create the canary objects:
```bash
# applied
deployment.apps/podinfo
horizontalpodautoscaler.autoscaling/podinfo
canary.flagger.app/podinfo
# generated Kubernetes objects
deployment.apps/podinfo-primary
horizontalpodautoscaler.autoscaling/podinfo-primary
service/podinfo
service/podinfo-canary
service/podinfo-primary
# generated App Mesh objects
virtualnode.appmesh.k8s.aws/podinfo-canary
virtualnode.appmesh.k8s.aws/podinfo-primary
virtualrouter.appmesh.k8s.aws/podinfo
virtualrouter.appmesh.k8s.aws/podinfo-canary
virtualservice.appmesh.k8s.aws/podinfo
virtualservice.appmesh.k8s.aws/podinfo-canary
```
After the bootstrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test`
will be routed to the primary pods.
During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
App Mesh blocks all egress traffic by default.
If your application needs to call another service, you have to create an App Mesh virtual service for it
and add the virtual service name to the backend list.
```yaml
service:
port: 9898
backends:
- backend1
- arn:aws:appmesh:eu-west-1:12345678910:mesh/my-mesh/virtualService/backend2
```
## Setup App Mesh Gateway (optional)
In order to expose the podinfo app outside the mesh you can use the App Mesh Gateway.
Deploy the App Mesh Gateway behind an AWS NLB:
```bash
helm upgrade -i appmesh-gateway eks/appmesh-gateway \
--namespace test
```
Find the gateway public address:
```bash
export URL="http://$(kubectl -n test get svc/appmesh-gateway -ojson | jq -r ".status.loadBalancer.ingress[].hostname")"
echo $URL
```
Wait for the NLB to become active:
```bash
watch curl -sS $URL
```
Create a gateway route that points to the podinfo virtual service:
```yaml
cat << EOF | kubectl apply -f -
apiVersion: appmesh.k8s.aws/v1beta2
kind: GatewayRoute
metadata:
name: podinfo
namespace: test
spec:
httpRoute:
match:
prefix: "/"
action:
target:
virtualService:
virtualServiceRef:
name: podinfo
EOF
```
Open your browser and navigate to the ingress address to access podinfo UI.
## Automated canary promotion
A canary deployment is triggered by changes in any of the following objects:
* Deployment PodSpec (container image, command, ports, env, resources, etc)
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
Trigger a canary deployment by updating the container image:
```bash
kubectl -n test set image deployment/podinfo \
podinfod=ghcr.io/stefanprodan/podinfo:6.0.1
```
Flagger detects that the deployment revision changed and starts a new rollout:
```text
kubectl -n test describe canary/podinfo
Status:
Canary Weight: 0
Failed Checks: 0
Phase: Succeeded
Events:
New revision detected! Scaling up podinfo.test
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
Pre-rollout check acceptance-test passed
Advance podinfo.test canary weight 5
Advance podinfo.test canary weight 10
Advance podinfo.test canary weight 15
Advance podinfo.test canary weight 20
Advance podinfo.test canary weight 25
Advance podinfo.test canary weight 30
Advance podinfo.test canary weight 35
Advance podinfo.test canary weight 40
Advance podinfo.test canary weight 45
Advance podinfo.test canary weight 50
Copying podinfo.test template spec to podinfo-primary.test
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
Routing all traffic to primary
Promotion completed! Scaling down podinfo.test
```
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
During the analysis the canary’s progress can be monitored with Grafana.
The App Mesh dashboard URL is
[http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo](http://localhost:3000/d/flagger-appmesh/appmesh-canary?refresh=10s&orgId=1&var-namespace=test&var-primary=podinfo-primary&var-canary=podinfo).
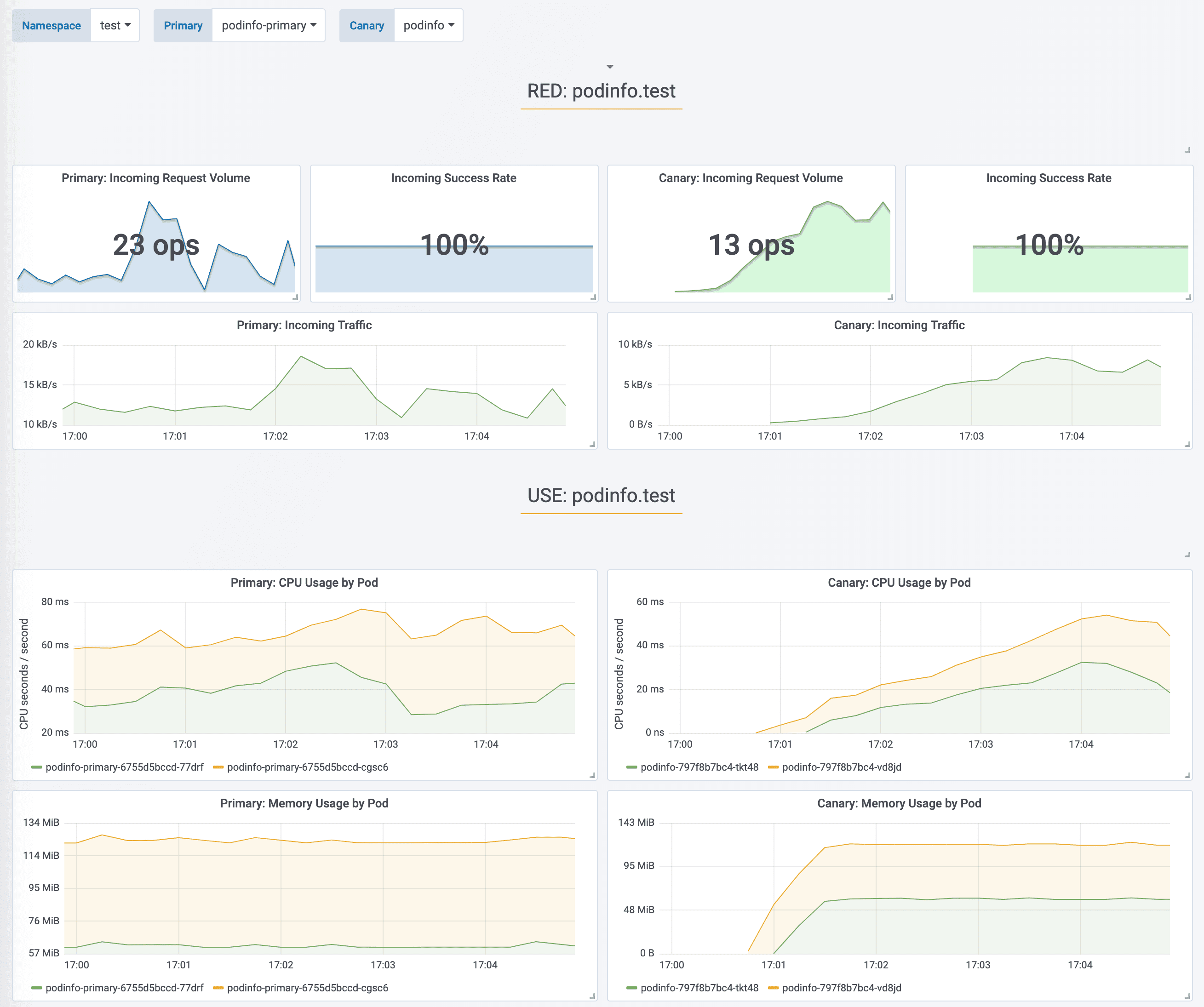
You can monitor all canaries with:
```bash
watch kubectl get canaries --all-namespaces
NAMESPACE NAME STATUS WEIGHT
test podinfo Progressing 15
prod frontend Succeeded 0
prod backend Failed 0
```
If you’ve enabled the Slack notifications, you should receive the following messages:

## Automated rollback
During the canary analysis you can generate HTTP 500 errors or high latency to test if Flagger pauses the rollout.
Trigger a canary deployment:
```bash
kubectl -n test set image deployment/podinfo \
podinfod=ghcr.io/stefanprodan/podinfo:6.0.2
```
Exec into the load tester pod with:
```bash
kubectl -n test exec -it deploy/flagger-loadtester bash
```
Generate HTTP 500 errors:
```bash
hey -z 1m -c 5 -q 5 http://podinfo-canary.test:9898/status/500
```
Generate latency:
```bash
watch -n 1 curl http://podinfo-canary.test:9898/delay/1
```
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
the canary is scaled to zero and the rollout is marked as failed.
```text
kubectl -n appmesh-system logs deploy/flagger -f | jq .msg
New revision detected! progressing canary analysis for podinfo.test
Pre-rollout check acceptance-test passed
Advance podinfo.test canary weight 5
Advance podinfo.test canary weight 10
Advance podinfo.test canary weight 15
Halt podinfo.test advancement success rate 69.17% < 99%
Halt podinfo.test advancement success rate 61.39% < 99%
Halt podinfo.test advancement success rate 55.06% < 99%
Halt podinfo.test advancement request duration 1.20s > 0.5s
Halt podinfo.test advancement request duration 1.45s > 0.5s
Rolling back podinfo.test failed checks threshold reached 5
Canary failed! Scaling down podinfo.test
```
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded,
or if the analysis reached the maximum number of failed checks:
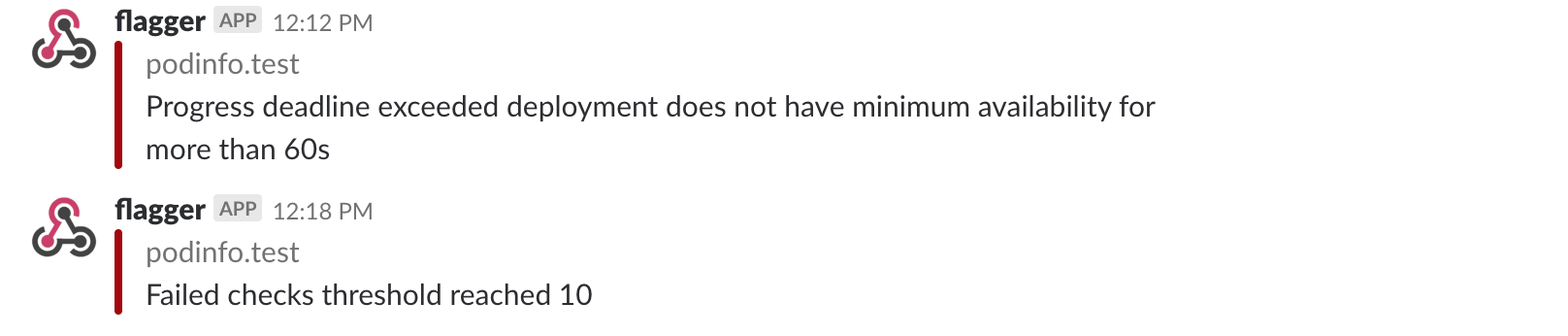
## A/B Testing
Besides weighted routing, Flagger can be configured to route traffic to the canary based on HTTP match conditions.
In an A/B testing scenario, you'll be using HTTP headers or cookies to target a certain segment of your users.
This is particularly useful for frontend applications that require session affinity.
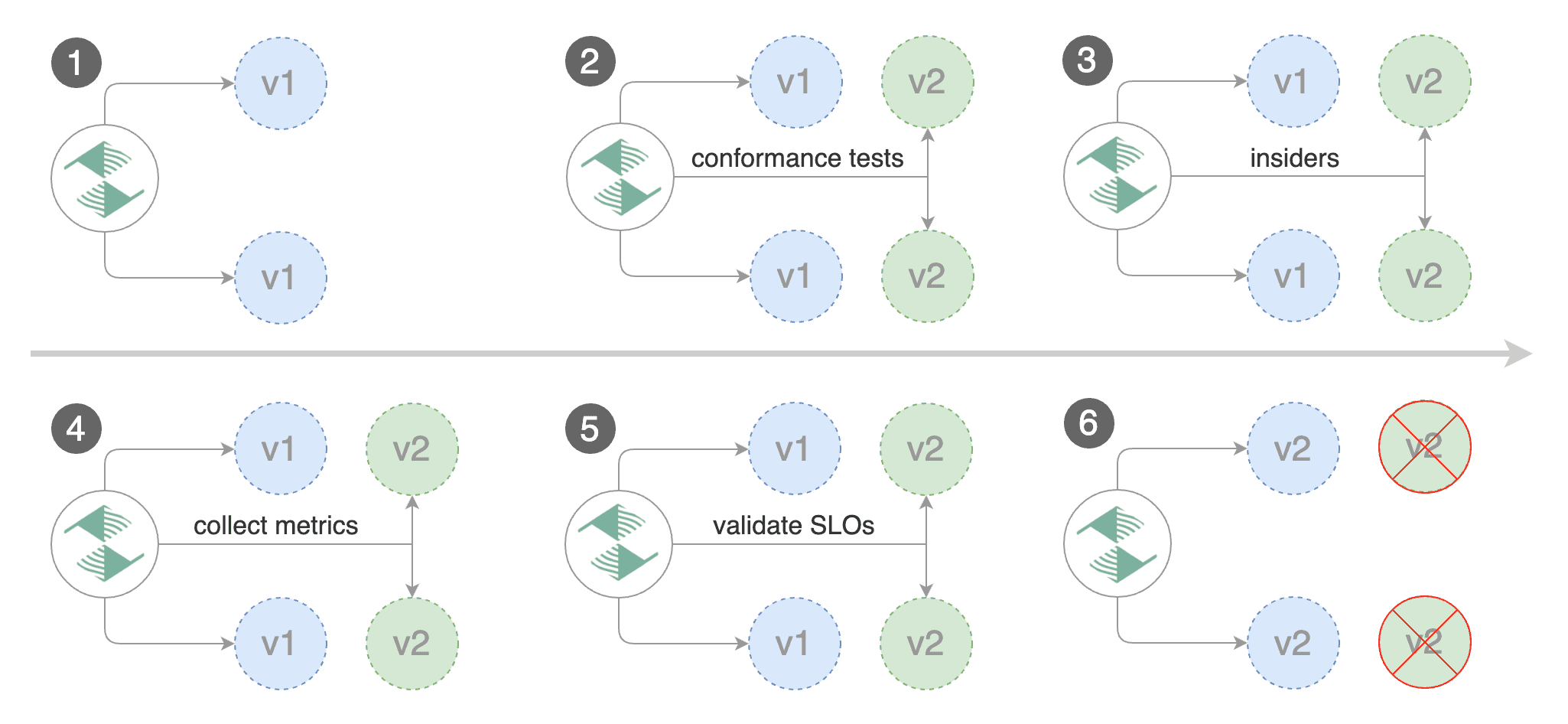
Edit the canary analysis, remove the max/step weight and add the match conditions and iterations:
```yaml
analysis:
interval: 1m
threshold: 5
iterations: 10
match:
- headers:
x-canary:
exact: "insider"
webhooks:
- name: load-test
url: http://flagger-loadtester.test/
metadata:
cmd: "hey -z 1m -q 10 -c 2 -H 'X-Canary: insider' http://podinfo.test:9898/"
```
The above configuration will run an analysis for ten minutes targeting users that have a `X-Canary: insider` header.
You can also use a HTTP cookie, to target all users with a `canary` cookie set to `insider` the match condition should be:
```yaml
match:
- headers:
cookie:
regex: "^(.*?;)?(canary=insider)(;.*)?$"
webhooks:
- name: load-test
url: http://flagger-loadtester.test/
metadata:
cmd: "hey -z 1m -q 10 -c 2 -H 'Cookie: canary=insider' http://podinfo.test:9898/"
```
Trigger a canary deployment by updating the container image:
```bash
kubectl -n test set image deployment/podinfo \
podinfod=ghcr.io/stefanprodan/podinfo:6.0.3
```
Flagger detects that the deployment revision changed and starts the A/B test:
```text
kubectl -n appmesh-system logs deploy/flagger -f | jq .msg
New revision detected! progressing canary analysis for podinfo.test
Advance podinfo.test canary iteration 1/10
Advance podinfo.test canary iteration 2/10
Advance podinfo.test canary iteration 3/10
Advance podinfo.test canary iteration 4/10
Advance podinfo.test canary iteration 5/10
Advance podinfo.test canary iteration 6/10
Advance podinfo.test canary iteration 7/10
Advance podinfo.test canary iteration 8/10
Advance podinfo.test canary iteration 9/10
Advance podinfo.test canary iteration 10/10
Copying podinfo.test template spec to podinfo-primary.test
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
Routing all traffic to primary
Promotion completed! Scaling down podinfo.test
```
The above procedure can be extended with
[custom metrics](../usage/metrics.md) checks,
[webhooks](../usage/webhooks.md),
[manual promotion](../usage/webhooks.md#manual-gating) approval and
[Slack or MS Teams](../usage/alerting.md) notifications.
| 30.308046 | 285 | 0.74507 | eng_Latn | 0.821113 |
1188da26901cd8689690095d4d41486e672c7fde | 96 | md | Markdown | app/service/bbq/common/CONTRIBUTORS.md | 78182648/blibli-go | 7c717cc07073ff3397397fd3c01aa93234b142e3 | [
"MIT"
] | 22 | 2019-04-27T06:44:41.000Z | 2022-02-04T16:54:14.000Z | app/service/bbq/common/CONTRIBUTORS.md | YouthAge/blibli-go | 7c717cc07073ff3397397fd3c01aa93234b142e3 | [
"MIT"
] | null | null | null | app/service/bbq/common/CONTRIBUTORS.md | YouthAge/blibli-go | 7c717cc07073ff3397397fd3c01aa93234b142e3 | [
"MIT"
] | 34 | 2019-05-07T08:22:27.000Z | 2022-03-25T08:14:56.000Z | # Owner
luxiaowei
jiangdongqi
# Author
luxiaowei
jiangdongqi
# Reviewer
luxiaowei
jiangdongqi
| 8 | 11 | 0.822917 | kor_Hang | 0.522798 |
11895ad3a110ca0a084f1ceb65be6cd51d39f9b5 | 9,498 | md | Markdown | docs/ComponentValidationResultDTO.md | faceless7171/nifi-go-client | dee97a370368a1b4bfe9d25b7dbfff79da993780 | [
"Apache-2.0"
] | 3 | 2020-08-07T14:58:21.000Z | 2021-02-20T15:40:44.000Z | docs/ComponentValidationResultDTO.md | faceless7171/nifi-go-client | dee97a370368a1b4bfe9d25b7dbfff79da993780 | [
"Apache-2.0"
] | 1 | 2021-07-19T08:05:26.000Z | 2021-11-04T22:36:17.000Z | docs/ComponentValidationResultDTO.md | faceless7171/nifi-go-client | dee97a370368a1b4bfe9d25b7dbfff79da993780 | [
"Apache-2.0"
] | 2 | 2021-06-07T17:35:26.000Z | 2021-07-19T11:22:34.000Z | # ComponentValidationResultDTO
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**ProcessGroupId** | Pointer to **string** | The UUID of the Process Group that this component is in | [optional]
**Id** | Pointer to **string** | The UUID of this component | [optional]
**ReferenceType** | Pointer to **string** | The type of this component | [optional]
**Name** | Pointer to **string** | The name of this component. | [optional]
**State** | Pointer to **string** | The scheduled state of a processor or reporting task referencing a controller service. If this component is another controller service, this field represents the controller service state. | [optional]
**ActiveThreadCount** | Pointer to **int32** | The number of active threads for the referencing component. | [optional]
**ValidationErrors** | Pointer to **[]string** | The validation errors for the component. | [optional]
**CurrentlyValid** | Pointer to **bool** | Whether or not the component is currently valid | [optional]
**ResultsValid** | Pointer to **bool** | Whether or not the component will be valid if the Parameter Context is changed | [optional]
**ResultantValidationErrors** | Pointer to **[]string** | The validation errors that will apply to the component if the Parameter Context is changed | [optional]
## Methods
### NewComponentValidationResultDTO
`func NewComponentValidationResultDTO() *ComponentValidationResultDTO`
NewComponentValidationResultDTO instantiates a new ComponentValidationResultDTO object
This constructor will assign default values to properties that have it defined,
and makes sure properties required by API are set, but the set of arguments
will change when the set of required properties is changed
### NewComponentValidationResultDTOWithDefaults
`func NewComponentValidationResultDTOWithDefaults() *ComponentValidationResultDTO`
NewComponentValidationResultDTOWithDefaults instantiates a new ComponentValidationResultDTO object
This constructor will only assign default values to properties that have it defined,
but it doesn't guarantee that properties required by API are set
### GetProcessGroupId
`func (o *ComponentValidationResultDTO) GetProcessGroupId() string`
GetProcessGroupId returns the ProcessGroupId field if non-nil, zero value otherwise.
### GetProcessGroupIdOk
`func (o *ComponentValidationResultDTO) GetProcessGroupIdOk() (*string, bool)`
GetProcessGroupIdOk returns a tuple with the ProcessGroupId field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetProcessGroupId
`func (o *ComponentValidationResultDTO) SetProcessGroupId(v string)`
SetProcessGroupId sets ProcessGroupId field to given value.
### HasProcessGroupId
`func (o *ComponentValidationResultDTO) HasProcessGroupId() bool`
HasProcessGroupId returns a boolean if a field has been set.
### GetId
`func (o *ComponentValidationResultDTO) GetId() string`
GetId returns the Id field if non-nil, zero value otherwise.
### GetIdOk
`func (o *ComponentValidationResultDTO) GetIdOk() (*string, bool)`
GetIdOk returns a tuple with the Id field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetId
`func (o *ComponentValidationResultDTO) SetId(v string)`
SetId sets Id field to given value.
### HasId
`func (o *ComponentValidationResultDTO) HasId() bool`
HasId returns a boolean if a field has been set.
### GetReferenceType
`func (o *ComponentValidationResultDTO) GetReferenceType() string`
GetReferenceType returns the ReferenceType field if non-nil, zero value otherwise.
### GetReferenceTypeOk
`func (o *ComponentValidationResultDTO) GetReferenceTypeOk() (*string, bool)`
GetReferenceTypeOk returns a tuple with the ReferenceType field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetReferenceType
`func (o *ComponentValidationResultDTO) SetReferenceType(v string)`
SetReferenceType sets ReferenceType field to given value.
### HasReferenceType
`func (o *ComponentValidationResultDTO) HasReferenceType() bool`
HasReferenceType returns a boolean if a field has been set.
### GetName
`func (o *ComponentValidationResultDTO) GetName() string`
GetName returns the Name field if non-nil, zero value otherwise.
### GetNameOk
`func (o *ComponentValidationResultDTO) GetNameOk() (*string, bool)`
GetNameOk returns a tuple with the Name field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetName
`func (o *ComponentValidationResultDTO) SetName(v string)`
SetName sets Name field to given value.
### HasName
`func (o *ComponentValidationResultDTO) HasName() bool`
HasName returns a boolean if a field has been set.
### GetState
`func (o *ComponentValidationResultDTO) GetState() string`
GetState returns the State field if non-nil, zero value otherwise.
### GetStateOk
`func (o *ComponentValidationResultDTO) GetStateOk() (*string, bool)`
GetStateOk returns a tuple with the State field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetState
`func (o *ComponentValidationResultDTO) SetState(v string)`
SetState sets State field to given value.
### HasState
`func (o *ComponentValidationResultDTO) HasState() bool`
HasState returns a boolean if a field has been set.
### GetActiveThreadCount
`func (o *ComponentValidationResultDTO) GetActiveThreadCount() int32`
GetActiveThreadCount returns the ActiveThreadCount field if non-nil, zero value otherwise.
### GetActiveThreadCountOk
`func (o *ComponentValidationResultDTO) GetActiveThreadCountOk() (*int32, bool)`
GetActiveThreadCountOk returns a tuple with the ActiveThreadCount field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetActiveThreadCount
`func (o *ComponentValidationResultDTO) SetActiveThreadCount(v int32)`
SetActiveThreadCount sets ActiveThreadCount field to given value.
### HasActiveThreadCount
`func (o *ComponentValidationResultDTO) HasActiveThreadCount() bool`
HasActiveThreadCount returns a boolean if a field has been set.
### GetValidationErrors
`func (o *ComponentValidationResultDTO) GetValidationErrors() []string`
GetValidationErrors returns the ValidationErrors field if non-nil, zero value otherwise.
### GetValidationErrorsOk
`func (o *ComponentValidationResultDTO) GetValidationErrorsOk() (*[]string, bool)`
GetValidationErrorsOk returns a tuple with the ValidationErrors field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetValidationErrors
`func (o *ComponentValidationResultDTO) SetValidationErrors(v []string)`
SetValidationErrors sets ValidationErrors field to given value.
### HasValidationErrors
`func (o *ComponentValidationResultDTO) HasValidationErrors() bool`
HasValidationErrors returns a boolean if a field has been set.
### GetCurrentlyValid
`func (o *ComponentValidationResultDTO) GetCurrentlyValid() bool`
GetCurrentlyValid returns the CurrentlyValid field if non-nil, zero value otherwise.
### GetCurrentlyValidOk
`func (o *ComponentValidationResultDTO) GetCurrentlyValidOk() (*bool, bool)`
GetCurrentlyValidOk returns a tuple with the CurrentlyValid field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetCurrentlyValid
`func (o *ComponentValidationResultDTO) SetCurrentlyValid(v bool)`
SetCurrentlyValid sets CurrentlyValid field to given value.
### HasCurrentlyValid
`func (o *ComponentValidationResultDTO) HasCurrentlyValid() bool`
HasCurrentlyValid returns a boolean if a field has been set.
### GetResultsValid
`func (o *ComponentValidationResultDTO) GetResultsValid() bool`
GetResultsValid returns the ResultsValid field if non-nil, zero value otherwise.
### GetResultsValidOk
`func (o *ComponentValidationResultDTO) GetResultsValidOk() (*bool, bool)`
GetResultsValidOk returns a tuple with the ResultsValid field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetResultsValid
`func (o *ComponentValidationResultDTO) SetResultsValid(v bool)`
SetResultsValid sets ResultsValid field to given value.
### HasResultsValid
`func (o *ComponentValidationResultDTO) HasResultsValid() bool`
HasResultsValid returns a boolean if a field has been set.
### GetResultantValidationErrors
`func (o *ComponentValidationResultDTO) GetResultantValidationErrors() []string`
GetResultantValidationErrors returns the ResultantValidationErrors field if non-nil, zero value otherwise.
### GetResultantValidationErrorsOk
`func (o *ComponentValidationResultDTO) GetResultantValidationErrorsOk() (*[]string, bool)`
GetResultantValidationErrorsOk returns a tuple with the ResultantValidationErrors field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetResultantValidationErrors
`func (o *ComponentValidationResultDTO) SetResultantValidationErrors(v []string)`
SetResultantValidationErrors sets ResultantValidationErrors field to given value.
### HasResultantValidationErrors
`func (o *ComponentValidationResultDTO) HasResultantValidationErrors() bool`
HasResultantValidationErrors returns a boolean if a field has been set.
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
| 32.639175 | 237 | 0.783955 | eng_Latn | 0.590749 |
11896df6c896bac0f237497596260f4446f0f2b8 | 2,449 | md | Markdown | catalog/azure/storage/README.md | muchemwal/dataops-infra | 16a169daa89773f02f196f37d2fe0fba5ee1e2d1 | [
"MIT"
] | 12 | 2020-02-29T03:54:54.000Z | 2020-12-03T08:16:04.000Z | catalog/azure/storage/README.md | muchemwal/dataops-infra | 16a169daa89773f02f196f37d2fe0fba5ee1e2d1 | [
"MIT"
] | 99 | 2019-12-08T19:54:30.000Z | 2020-12-27T01:30:58.000Z | catalog/azure/storage/README.md | muchemwal/dataops-infra | 16a169daa89773f02f196f37d2fe0fba5ee1e2d1 | [
"MIT"
] | 30 | 2020-02-27T20:58:37.000Z | 2020-10-30T14:13:52.000Z | ---
parent: Infrastructure Catalog
title: Azure Storage
nav_exclude: false
---
# Azure Storage
[`source = "git::https://github.com/slalom-ggp/dataops-infra/tree/main/catalog/azure/storage?ref=main"`](https://github.com/slalom-ggp/dataops-infra/tree/main/catalog/azure/storage)
## Overview
Deploys Storage Containers, Queue Storage, and Table Storage within a storage
account.
## Requirements
No requirements.
## Providers
No provider.
## Required Inputs
The following input variables are required:
### name\_prefix
Description: Standard `name_prefix` module input.
Type: `string`
### resource\_tags
Description: Standard `resource_tags` module input.
Type: `map(string)`
### storage\_account\_name
Description: The name of the Storage Account to be created.
Type: `string`
## Optional Inputs
The following input variables are optional (have default values):
### container\_names
Description: Names of Storage Containers to be created.
Type: `list(string)`
Default: `[]`
### table\_storage\_names
Description: Names of Tables to be created.
Type: `list(string)`
Default: `[]`
### queue\_storage\_names
Description: Names of Queues to be created.
Type: `list(string)`
Default: `[]`
### container\_access\_type
Description: The access level configured for the Storage Container(s). Possible values are blob, container or private.
Type: `string`
Default: `"private"`
## Outputs
The following outputs are exported:
### summary
Description: Summary of resources created by this module.
### storage\_container\_names
Description: The Storage Container name value(s) of the newly created container(s).
### table\_storage\_names
Description: The Table Storage name value(s) of the newly created table(s).
### queue\_storage\_names
Description: The Queue Storage name value(s) of the newly created table(s).
---------------------
## Source Files
_Source code for this module is available using the links below._
* [main.tf](https://github.com/slalom-ggp/dataops-infra/tree/main//catalog/azure/storage/main.tf)
* [outputs.tf](https://github.com/slalom-ggp/dataops-infra/tree/main//catalog/azure/storage/outputs.tf)
* [variables.tf](https://github.com/slalom-ggp/dataops-infra/tree/main//catalog/azure/storage/variables.tf)
---------------------
_**NOTE:** This documentation was auto-generated using
`terraform-docs` and `s-infra` from `slalom.dataops`.
Please do not attempt to manually update this file._
| 20.931624 | 181 | 0.737036 | eng_Latn | 0.780646 |
118a3964edbe8fc6a22a860e25b2ceaf33853c9c | 1,494 | md | Markdown | teaching.md | Daniel-Pailanir/Daniel-Pailanir.github.io | ff669b387d53cda05c63b9eccedf998508ccb218 | [
"MIT"
] | null | null | null | teaching.md | Daniel-Pailanir/Daniel-Pailanir.github.io | ff669b387d53cda05c63b9eccedf998508ccb218 | [
"MIT"
] | null | null | null | teaching.md | Daniel-Pailanir/Daniel-Pailanir.github.io | ff669b387d53cda05c63b9eccedf998508ccb218 | [
"MIT"
] | null | null | null | ---
layout: page
title: Teaching
full-width: true
subtitle: Below you will find material that can help you !!
---
### TEACHING ASSISTANT
Here is a compilation of exercises that I did as a teacher's assistant:
#### [_University of Santiago of Chile_](https://fae.usach.cl/) - UNDEGRADUATE
- ECO Principles of Microeconomics: [Ayudantía 1](../pdf/principles_micro/ayudantia_1_sol.pdf), [Ayudantía 2](../pdf/principles_micro/ayudantia_2_sol.pdf), [Ayudantía 3](../pdf/principles_micro/ayudantia_3_sol.pdf), [Ayudantía 4](../pdf/principles_micro/ayudantia_4_sol.pdf), [Ayudantía 5](../pdf/principles_micro/ayudantia_5_sol.pdf), [Ayudantía 6](../pdf/principles_micro/ayudantia_6_sol.pdf) y [Ayudantía 7](../pdf/principles_micro/ayudantia_7_sol.pdf).
- ECO Microeconomics I: [Guía I](../pdf/microeconomics/Guia-I-Solucion.pdf), [Guía II](../pdf/microeconomics/Guia-II-Solucion.pdf), [Guía III](../pdf/microeconomics/Guia-III-Solucion.pdf) y [Guía IV](../pdf/microeconomics/Guia-IV-Solucion.pdf).
- ECO Macroeconomics II: [Ayudantía 1](../pdf/macroeconomics/ayudantia_1_sol.pdf), [Ayudantía 2](../pdf/macroeconomics/ayudantia_2_sol.pdf), [Ayudantía 3](../pdf/macroeconomics/ayudantia_3_sol.pdf), [Ayudantía 4](../pdf/macroeconomics/ayudantia_4_sol.pdf), [Ayudantía 5](../pdf/macroeconomics/ayudantia_5_sol.pdf), [Ayudantía 6](../pdf/macroeconomics/ayudantia_6_sol.pdf) y [Ayudantía 7](../pdf/macroeconomics/ayudantia_7_sol.pdf).
{: .box-note}
**Note:** This material is only available in Spanish
| 74.7 | 456 | 0.757697 | ast_Latn | 0.28357 |
118a5ed3b849593e6d3fd75b08e2abb4ea8bdbaa | 294 | md | Markdown | README.md | bookbot-kids/image_compression | a536da063282bb8363b6faa35d51fa18f1df77c1 | [
"Apache-2.0"
] | null | null | null | README.md | bookbot-kids/image_compression | a536da063282bb8363b6faa35d51fa18f1df77c1 | [
"Apache-2.0"
] | null | null | null | README.md | bookbot-kids/image_compression | a536da063282bb8363b6faa35d51fa18f1df77c1 | [
"Apache-2.0"
] | null | null | null | # image_compression
An image compression dart package
## How to build binary file:
- [jpegoptim](https://github.com/tjko/jpegoptim) Run following commands
```
./configure
make
make strip
make install
```
- [zopfli](https://github.com/google/zopfli) Run:
```
make zopflipng
``` | 18.375 | 71 | 0.690476 | eng_Latn | 0.295397 |
118ab397b908e04ff56d7f4173755149660c918f | 3,511 | md | Markdown | README.md | jsetton/craigslist-renew | c66adfef5d285078a4220e2b1d4e40fbcf6677ae | [
"MIT"
] | 12 | 2019-10-06T17:34:56.000Z | 2022-02-17T01:25:00.000Z | README.md | calexil/craigslist-renew | c66adfef5d285078a4220e2b1d4e40fbcf6677ae | [
"MIT"
] | 1 | 2021-05-24T20:30:47.000Z | 2021-05-24T22:17:23.000Z | README.md | calexil/craigslist-renew | c66adfef5d285078a4220e2b1d4e40fbcf6677ae | [
"MIT"
] | 3 | 2019-10-25T20:35:43.000Z | 2021-05-23T02:13:46.000Z | # craigslist-renew
This is a simple python script that will auto-renew all your active Craigslist posts. It can also notify you when a post expires.
## Requirements
This project depends on the following python modules:
* `beautifulsoup4`
* `html5lib`
* `PyYAML`
* `selenium`
Use the python package manager to install them:
```
pip3 install -r requirements.txt
```
## Usage
Create a yaml config file with the following content:
```yaml
---
#
# Required parameters
#
email: <craigslist login>
password: <craigslist password>
notify: <comma separated list of emails>
#
# Optional parameters
#
# specify sender email address
from: <sender email address>
# specify smtp server settings (defaults to using sendmail command if omitted)
smtp:
server: <host:port>
username: <mail username>
password: <mail password>
# set to 1 to suppress notification emails on renewal
no_success_mail: <1|0>
# set to 1 to renew all posts available for renewal
# By default, only the first expired post gets renewed on each run
renew_all: <1|0>
# specify path for logging actions taken
logfile: <path-to-logfile>
# specify selenium webdriver local path or remote url (defaults to using chromedriver in local path if omitted)
webdriver: <path-to-webdriver>
# specify the list of your current postings for expiration notifications
postings:
- title: My post
area: nyc
- title: Another post
area: nyc
```
Then just schedule the script in cron to run at the schedule you want. Depending on the category and location, craigslist posts can be renewed about once every few days, so running the script every few hours should be more than sufficient:
```cron
0 */2 * * * /path/to/craigslist-renew.py /path/to/config.yml
```
You can only renew a post so many times before it expires, so to get notified about expired posts, make sure you have configured the `postings` parameter in your configuration and add the following (daily) cronjob:
```cron
0 21 * * * /path/to/craigslist-renew.py --expired /path/to/config.yml
```
## Docker Image
[](https://hub.docker.com/r/jsetton/craigslist-renew).
### Supported tags
By default, the chromedriver package is included as local webdriver. If you rather use a [Selenium Grid](https://www.selenium.dev/docs/site/en/grid/) server instead, use the `remote` tag. If going with the latter, make sure to specify the remote url in the config file.
| Tags | Description |
| :---------------: | ------------------------ |
| `latest`, `local` | Local webdriver support |
| `remote` | Remote webdriver support |
### Run commands
Make sure that the configuration file `config.yml` is in the directory you are running the commands below or specify the proper directory path in the volume parameter. The log file path should be set to `/data/<logfile>` in the configuration file, if specified.
#### Renew posts
```bash
docker run --rm -v $(pwd):/data jsetton/craigslist-renew
```
#### Check expired posts
```bash
docker run --rm -v $(pwd):/data jsetton/craigslist-renew --expired
```
## Kubernetes CronJob
To deploy this script as a [Kubernetes CronJob](https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/)
### Create ConfMap
``` bash
kubectl create configmap craigslist-renew-config --from-file=config.yml
```
### Apply the Job
Adjust `kubernetes/cronjob.yaml` cron schedule, defaults to every odd day.
``` bash
kubectl apply -f kubernetes/cronjob.yaml
```
| 31.348214 | 269 | 0.727998 | eng_Latn | 0.983517 |
118bd753f6cfc8c0f1db1817dddc1136d3dd5043 | 2,178 | md | Markdown | vendor/taskphp/taskphp/docs/http_client.md | lamack/treeH5 | 4a645d416dca70f275e15a7ac9cea4b3b95f3229 | [
"FSFAP"
] | 1 | 2021-04-28T06:48:15.000Z | 2021-04-28T06:48:15.000Z | vendor/taskphp/taskphp/docs/http_client.md | lamack/treeH5 | 4a645d416dca70f275e15a7ac9cea4b3b95f3229 | [
"FSFAP"
] | null | null | null | vendor/taskphp/taskphp/docs/http_client.md | lamack/treeH5 | 4a645d416dca70f275e15a7ac9cea4b3b95f3229 | [
"FSFAP"
] | null | null | null | ## http请求客户端类Client使用说明
http请求客户端类Client使用说明,支持CURL和Socket,默认使用 CURL,当手动指定useCurl或者curl扩展没有安装时, 会使用Socket目前支持get和post两种请求方式 。
## 详细使用说明
```php
use core\lib\http\Client;
```
1. 基本 get 请求:
```php
$http = new Http(); // 实例化对象
$result = $http->get('http://weibo.com/at/comment');
```
2. 基本 post 请求:
```php
$http = new Http(); // 实例化对象
$result = $http->post('http://someurl.com/post-new-article',array('title'=>$title, 'body'=>$body) );
```
3. 模拟登录 ( post 和 get 同时使用, 利用 cookie 存储状态 ) :
```php
$http = new Http(); // 实例化对象
$http->setCookiepath(substr(md5($username), 0, 10)); // 设置 cookie, 如果是多个用户请求的话
// 提交 post 数据
$loginData = $http->post('http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.3.19)', array('username'=>$username, 'loginPass'=>$password) );
$result = $http->get('http://weibo.com/at/comment');
```
4. 利用 initialize 函数设置多个 config 信息
```php
$httpConfig['method'] = 'GET';
$httpConfig['target'] = 'http://www.somedomain.com/index.html';
$httpConfig['referrer'] = 'http://www.somedomain.com';
$httpConfig['user_agent'] = 'My Crawler';
$httpConfig['timeout'] = '30';
$httpConfig['params'] = array('var1' => 'testvalue', 'var2' => 'somevalue');
$http = new Http();
$http->initialize($httpConfig);
$http->execute();
$result = $http->result;
```
5. 复杂的设置:
```php
$http = new Http();
$http->useCurl(false); // 不使用 curl
$http->setMethod('POST'); // 使用 POST method
// 设置 POST 数据
$http->addParam('user_name' , 'yourusername');
$http->addParam('password' , 'yourpassword');
// Referrer
$http->setReferrer('https://yourproject.projectpath.com/login');
// 开始执行请求
$http->execute('https://yourproject.projectpath.com/login/authenticate');
$result = $http->getResult();
```
6. 获取开启了 basic auth 的请求
```php
$http = new Http();
// Set HTTP basic authentication realms
$http->setAuth('yourusername', 'yourpassword');
// 获取某个被保护的应用的 feed
$http->get('http://www.someblog.com/protected/feed.xml');
$result = $http->result;
``` | 30.25 | 154 | 0.593664 | yue_Hant | 0.775341 |
118c19441fce8efe38af3cd38d1fa51ab4f37e7b | 434 | md | Markdown | 01-Class-Content/13-MVC/01-Activities/03-SeinfeldApp/README.md | sharpzeb/bootcamp | 358aa123c946e41afde07822109a4d4614a44614 | [
"ADSL"
] | 8 | 2020-12-08T16:56:29.000Z | 2021-07-17T18:24:38.000Z | 01-Class-Content/13-MVC/01-Activities/03-SeinfeldApp/README.md | sharpzeb/bootcamp | 358aa123c946e41afde07822109a4d4614a44614 | [
"ADSL"
] | 1 | 2021-01-16T15:35:51.000Z | 2021-01-16T15:35:51.000Z | 01-Class-Content/13-MVC/01-Activities/03-SeinfeldApp/README.md | sharpzeb/bootcamp | 358aa123c946e41afde07822109a4d4614a44614 | [
"ADSL"
] | 6 | 2020-12-14T17:38:24.000Z | 2021-04-13T00:12:17.000Z | * **Instructions**
* Create a Node Application with Express and MySQL with three Express routes.
* Create a `/cast` route that will display all the actors and their data ordered by their id's.
* Create a `/coolness-chart` route that will display all the actors and their data ordered by their coolness points.
* Create a `/attitude-chart/:att` route that will display all the actors for a specific type of attitude.
| 43.4 | 120 | 0.737327 | eng_Latn | 0.9996 |
118d719e7fb45df3e7b1bcd9c1f246b20bb01f71 | 78 | md | Markdown | README.md | PacktPublishing/Data-Visualization-in-Stata | 1c8818b7a73c85fee97c507b33a1a573acd94494 | [
"MIT"
] | 1 | 2022-03-20T11:31:27.000Z | 2022-03-20T11:31:27.000Z | README.md | PacktPublishing/Data-Visualization-in-Stata | 1c8818b7a73c85fee97c507b33a1a573acd94494 | [
"MIT"
] | null | null | null | README.md | PacktPublishing/Data-Visualization-in-Stata | 1c8818b7a73c85fee97c507b33a1a573acd94494 | [
"MIT"
] | null | null | null | # Data-Visualization-in-Stata
Data Visualization in Stata, published by Packt
| 26 | 47 | 0.820513 | kor_Hang | 0.540276 |
118d7d32dc72d673c69408acd4c005c6e9bc0c26 | 3,668 | md | Markdown | data/readme_files/charulagrl.Data-Structures-and-Algorithms.md | DLR-SC/repository-synergy | 115e48c37e659b144b2c3b89695483fd1d6dc788 | [
"MIT"
] | 5 | 2021-05-09T12:51:32.000Z | 2021-11-04T11:02:54.000Z | data/readme_files/charulagrl.Data-Structures-and-Algorithms.md | DLR-SC/repository-synergy | 115e48c37e659b144b2c3b89695483fd1d6dc788 | [
"MIT"
] | null | null | null | data/readme_files/charulagrl.Data-Structures-and-Algorithms.md | DLR-SC/repository-synergy | 115e48c37e659b144b2c3b89695483fd1d6dc788 | [
"MIT"
] | 3 | 2021-05-12T12:14:05.000Z | 2021-10-06T05:19:54.000Z | # Data structures and algorithms
This repository contains the compilation of solution of commonly asked Data Strcuture and Algorithm interview questions.
It contains programs on the following topics:
## Data Structures
* [array](https://github.com/charulagrl/data-structures-and-algorithms/tree/master/data-structure-questions/array)
* [string](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/string)
* [linked list](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/linked_list)
* [binary tree](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/binary_tree)
* [binary search tree](https://github.com/charulagrl/data-structures-and-algorithms/tree/master/data-structure-questions/binary_search_tree)
* [graphs](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/graph)
## Algorithms
* [searching](https://github.com/charulagrl/data-structures-and-algorithms/tree/master/searching)
* [binary search](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/searching/binary_search.py)
* [ternary search](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/searching/ternary_search.py)
* [sorting](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/sorting)
* [bubble sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/bubble_sort.py)
* [insertion sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/insertion_sort.py)
* [selection sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/selection_sort.py)
* [merge sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/merge_sort.py)
* [quick sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/quick_sort.py)
* [heap sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/heap_sort.py)
* [bucket sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/bucket_sort.py)
* [counting sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/counting_sort.py)
* [radix sort](https://github.com/charulagrl/data-structures-and-algorithms/blob/master/sorting/radix_sort.py)
* [dynamic programming](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/dynamic_programming)
* [backtrack](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/backtrack)
## Cracking the Coding Interview
It contains:
* Chapter wise [solution](https://github.com/charulagrl/data-structures-and-algorithms/tree/master/cracking_the_coding_interview) to questions in the book [Cracking the Coding Interview](https://www.amazon.com/dp/0984782850/ref=pd_lpo_sbs_dp_ss_1?pf_rd_p=1944687622&pf_rd_s=lpo-top-stripe-1&pf_rd_t=201&pf_rd_i=098478280X&pf_rd_m=ATVPDKIKX0DER&pf_rd_r=6722W3709RPF696KQD17).
* [Chapter 1: Arrays & Strings](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/CrackingTheCodingInterview/array_and_string)
* [Chapter 2: Linked Lists](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/CrackingTheCodingInterview/linked_list)
* [Chapter 3: Stacks and Queues](https://github.com/charulagrl/Data-Structures-and-Algorithms/tree/master/CrackingTheCodingInterview/stack_and_queue)
* [Chapter 4: Trees and Graphs](https://github.com/charulagrl/data-structures-and-algorithms/tree/master/cracking_the_coding_interview/trees_and_graphs)
## Tests
python -m tests.searching_test
python -m tests.sorting_test
| 76.416667 | 374 | 0.808342 | yue_Hant | 0.219429 |
118d7de6ec3da6fec750660d8b1ad0d08ded3c4f | 710 | md | Markdown | doc/python_argument_flag/README.md | CodeLingoBot/learn | d7ea19cb9a887ec60435698b9e945a110163eea2 | [
"CC-BY-4.0"
] | 1,235 | 2015-09-08T20:21:49.000Z | 2022-03-28T10:54:28.000Z | doc/python_argument_flag/README.md | fengpf/learn | d7ea19cb9a887ec60435698b9e945a110163eea2 | [
"CC-BY-4.0"
] | 10 | 2015-09-08T23:16:52.000Z | 2021-12-15T01:15:13.000Z | doc/python_argument_flag/README.md | fengpf/learn | d7ea19cb9a887ec60435698b9e945a110163eea2 | [
"CC-BY-4.0"
] | 183 | 2015-09-08T14:46:09.000Z | 2022-03-06T07:03:31.000Z | [*back to contents*](https://github.com/gyuho/learn#contents)<br>
# Python: argument, flag
- [flag](#flag)
[↑ top](#python-argument-flag)
<br><br><br><br><hr>
#### flag
```python
#!/usr/bin/python -u
import sys
import getopt
usage = """
Usage:
./00_flag.py -i 8 -o hello -d 7 -f
"""
try:
opts, args = getopt.gnu_getopt(sys.argv[1:], "i:o:d:f")
except:
print usage
sys.exit(0)
if __name__ == "__main__":
o = {}
for opt, arg in opts:
o[opt] = arg
print '-f' in o
from pprint import pprint
pprint(o)
"""
./00_flag.py -i 8 -o hello -d 7 -f
True
{'-d': '7', '-f': '', '-i': '8', '-o': 'hello'}
"""
```
[↑ top](#python-argument-flag)
<br><br><br><br><hr>
| 13.653846 | 65 | 0.54507 | eng_Latn | 0.137295 |
118e4f79ff5d0f33f1fbe42e30c979aa55cb3b52 | 9,579 | md | Markdown | archived/2021-01-21/2021-01-21-参加了一场985相亲局.md | NodeBE4/teahouse | 4d31c4088cc871c98a9760cefd2d77e5e0dd7466 | [
"MIT"
] | 1 | 2020-09-16T02:05:27.000Z | 2020-09-16T02:05:27.000Z | archived/2021-01-21/2021-01-21-参加了一场985相亲局.md | NodeBE4/teahouse | 4d31c4088cc871c98a9760cefd2d77e5e0dd7466 | [
"MIT"
] | null | null | null | archived/2021-01-21/2021-01-21-参加了一场985相亲局.md | NodeBE4/teahouse | 4d31c4088cc871c98a9760cefd2d77e5e0dd7466 | [
"MIT"
] | null | null | null | ---
layout: post
title: "参加了一场985相亲局"
date: 2021-01-21T05:17:19.000Z
author: 洋流
from: https://matters.news/@yangliuyilia/%25E5%258F%2582%25E5%258A%25A0%25E4%25BA%2586%25E4%25B8%2580%25E5%259C%25BA985%25E7%259B%25B8%25E4%25BA%25B2%25E5%25B1%2580-bafyreid5g42eajsl7dpkmpujajqknkpxqnw6uyv5umfs27f6xhcezg6zey
tags: [ Matters ]
categories: [ Matters ]
---
<!--1611206239000-->
[参加了一场985相亲局](https://matters.news/@yangliuyilia/%25E5%258F%2582%25E5%258A%25A0%25E4%25BA%2586%25E4%25B8%2580%25E5%259C%25BA985%25E7%259B%25B8%25E4%25BA%25B2%25E5%25B1%2580-bafyreid5g42eajsl7dpkmpujajqknkpxqnw6uyv5umfs27f6xhcezg6zey)
------
<div>
<p>11月21日,北京初雪如约而至。在这个需要温暖与靠近的恋爱天气,我走进了798艺术区,参加了一场神秘的“985相亲局”。相信你早已对这个高端相亲局有所耳闻:名校毕业,精英圈子,高标准筛选机制,参与其中的单身青年男女,期待在这里遇到匹配的另一半,培养出更精英的后代。</p><p>正如主办方“陌上花开HIMMR”(以下简称“陌上”)对平台的定位:全国唯一一个专注国内985高校和海外名校在校生和校友的婚恋平台,旨在通过精准定位用户群体、提供优质高效的婚恋服务,致力为不愿将就的你找到最好的爱情。</p><p>从下午2点到5点,在历时3个小时的活动中,我与将近20位男士对话,与参加活动的100位男士错肩。离开“爱的博物馆”,最初参与时的兴奋已经荡然无存,疲惫不堪地看着微信里新加的7位男士,我不确定自己是否将会迎来最好的爱情和婚姻。但至少有一点逐渐清晰,在这场优秀与优秀的对峙中,唯一被消弭隐身的,就是爱情。</p><figure class="image"> <picture> <source type="image/webp" media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.webp" onerror="this.srcset='https://assets.matters.news/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.jpeg'"> <source media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.jpeg" onerror="this.srcset='https://assets.matters.news/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.jpeg'"> <source type="image/webp" srcset="https://assets.matters.news/processed/540w/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.webp"> <img src="https://assets.matters.news/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.jpeg" srcset="https://assets.matters.news/processed/540w/embed/4dd0c183-3770-4c60-a3cb-eee309c7c2a5.jpeg" loading="lazy" referrerpolicy="no-referrer"> </picture> <figcaption><span></span></figcaption></figure><p><br></p><p>一、走进壁垒森严的“985相亲局”</p><p>“爱的博物馆”餐厅位于北京798艺术园区北一街的拐角处。在纵横交错的园区找到这家餐厅并不难,下午两点钟,形单影只的青年男女冒着雨夹雪,撑着伞络绎不绝地汇聚在这里。“陌上花开”平台包场了餐厅,举办平台今年规模最大的线下高端相亲局。</p><p>在餐厅门口,每位参与者会拿到活动嘉宾信息表,被贴上与本人编号相对应的号码牌。手里这张细密的表格一面是100位男嘉宾的信息,另一面是100位女嘉宾的信息。除了昵称,出生日期和家乡,平台精准定位用户群体的高标准体现在表格上,是学历、毕业院校和职业。</p><p>在参与活动的200人中,硕士和博士占9成,嘉宾们无一例外是985名校毕业生或有QS世界大学排名前一百海外名校学历。优秀的更直观反映是他们从事的行业,近一半嘉宾在金融行业工作,除此之外,男嘉宾多来自互联网,咨询行业,也有央企和机关单位,女嘉宾多来自高校、科研院所和医院。</p><p>上下两层的餐厅被划分成不同的区域,除了占据大部分空间的“八分钟约会”,在餐厅包间内,嘉宾们可以自由组队玩“门萨桌游”等小游戏和狼人杀。抱着对“门萨”两字的莫名畏惧,我走向“八分钟约会区”,在一张六人圆桌旁小心地坐下,成为不能移动的三位女嘉宾的一员,等待着三位男嘉宾的落座和即将到来的闲聊8分钟。</p><p>更像是一场面试,桌旁的6位嘉宾轮流充当应聘者和面试官。男嘉宾首先说自己的编号,然后介绍自己的毕业院校、职业经历和职业内容,最后是爱好,通常是马拉松、网球、游泳等对健康有益的运动。桌上剩余的5人拿起表格,在纸张翻动的哗啦声里,心照不宣地扫动眼神,暗自衡量他的学校和职业。</p><p>与我同桌的一位女生是清华大学毕业的博士,含蓄地通过自我介绍展露自己的优秀后,就再无发言。相比她的沉默,1994年出生的小夏显得亲和。小夏硕士毕业于QS排名靠前的香港某大学,从事教育行业,看起来有些马虎,经常对应错男生的基本信息。多数女性参与者年纪介于1993-1988年之间,小夏年纪偏小,对每一位男嘉宾充满好奇,经常会追问他的爱好,毫不羞涩地展现她对其他行业的不了解。</p><p>小夏的天真让气氛活跃了不少。但八分钟还未到,听完三位女生的介绍后,有男嘉宾拿起大衣和手机,欠身礼貌地说了声,“不好意思我出去接个电话。”就再也没有回来。</p><p>尴尬开始弥漫,我很诧异在相亲局上没有人询问感情,就恋爱经历问了几个问题后,有位男嘉宾似乎感到被冒犯,嘟囔了说了句,“你是第一次参加吧。陌上的相亲局很少有人问这个。”便也起身离开了。</p><p>男嘉宾的接二离去让聊天陷入冰点。这桌散场后,我与小夏聊天,私下里的小夏有种不同于先前的理智。小夏懊恼地说,“我还是母胎单身,觉得这个年纪还没有谈过恋爱太失败了。尝试自己主动认识,朋友介绍,都没有合适的。工作的这两年开始有婚恋焦虑。也有很多人追我,但我觉得他们有所图,只想享受我的物质条件。”</p><p><br></p><p>恋爱经历空白的小夏期待着平台帮她筛选男生。对1991年出生的Kate来说,参加相亲局则是她唯一可以认识异性的机会。</p><p>Kate本科和硕士就读于一所西南著名的985高校,回到家乡北京后,又继续读了博士,现在在科研所上班。Kate高挑大方,外形出众,身高接近170cm。平日工作环境女多男少,身边优秀的男士几乎全都已婚。Kate坦言,“我比较看重外形和人品,男生至少要180以上吧。其他的相亲局我看不中的比较多,朋友介绍给我陌上,我就来了。”</p><p>“刚才8分钟加我的男生也很多,但是个子和年龄我都不是很满意。唉,上学的时候觉得180以上的很多啊,怎么现在这么难。”Kate语气失落,继而又燃起兴致,她拉着我的手亲昵地问,“你刚才有遇到长得帅的小哥哥吗?高不高?能带我认识一下吗?”</p><p>室内烘热,人声鼎沸。“八分钟约会”结束前的最后一桌,已经有男士不耐烦地玩起了手机。向三批男士反复介绍了自己的毕业院校和职业经历后,我仿佛经历了三次紧绷身心的无领导小组面试,有些喘不上气。在室外透气时,我遇到了同样有海外留学和工作经历的L。L在英国8年,在新加坡6年,目前在南方的一所大学教书。他衣着考究,古龙水味道闻起来平和沉稳。在与L的聊天中,我们谈起国外糟糕的气候,美食和交通,意外地发现我们在不同时刻登上了同一座不具名的山。气氛融洽,正当我为此雀跃时,他问了我的年龄,开始变得心猿意马。</p><p>“我想找个有海外生活背景,更开放包容的。我年纪已经不小了,但参加活动的女孩,年纪不是太大,就是太小。像你,看起来近两年不会结婚。”L生于1983年,是北京本地人,为了这场相亲会,他专门飞回来北京。但活动才刚刚过半,L回餐厅围上围巾,拿上长柄伞,留下一句“我还是有些失望”,便离开了。</p><p><br></p><p>二、势均力敌的爱情博弈</p><p>小夏告诉我,11月12日,她早早定好9点半的闹钟,抱着手机等着陌上公众号推送,抢一个线下报名的名额。通常情况下,陌上的线下活动报名很难,女生的名额放出后会在5分钟内被抢光,男生则不用抢,有时甚至需要主办方邀请才能凑够活动人数。</p><p>中国男女总性别比达到了104.45,通常情况下,人们普遍认知单身群体男多女少。但在陌上高端相亲平台,男女嘉宾的比例大约在3:7。相比于女生的投入和更外显的焦虑,有些男生显得很疏离。Ziv就是其中的一员。</p><p>活动开始后,Ziv仍不紧不慢地坐在沙发上,小口啜饮一杯花茶,没有参加8分钟约会,也没有组局玩游戏。多数时候,他一个人在二楼的栏杆处站着,俯身看着楼下围绕着桌子来回走动的男女神游。</p><p>与Ziv聊过后,我吃惊地发现,这种远距离观望并不源自他对这种场合的不适。相反,他早已在相亲活动身经百战。从2019年第一次参加陌上组织的七夕线下活动,这是他第四次参加“985”相亲局。至于其他相亲会,从2019年5月1日开始,他早已参加了不下50场。</p><p>虽然Ziv自嘲来自安徽小地方的自己是“小镇做题渣”,但与名校毕业,进入光鲜行业,年收入20万以上的多数参与者人生轨迹相似:从日本TOP2的大学研究生毕业后,Ziv在上海工作,2019年年初,他考进无数人梦寐以求的国企,搬到北京,在北京定居。被问到单身的原因,Ziv直言,“在婚恋市场上我还是很有竞争力的。只是我太挑了。”</p><p>“经济方面肯定得和我差不多,太差的我不会接触。”虽然31岁的Ziv目前仍是单身,但他并没有太重的焦虑感,“男生可以向下兼容,女生就不行,女生不想找比自己差的。比如我,普通本科我也可以接受,对我而言,找个漂亮的女生结婚不是很难的事情。但我还是比较主观,看中感觉。”</p><p>Ziv无法描述自己喜欢哪一种“感觉”的女生,但说到自己抗拒的类型,他温和的语气突然变得激烈,“我无法理解那种端着的女生。已经来参加相亲会了,就不要总等着男生联系你,要我每天迁就你,我会觉得太累了。”</p><p>“去年我就在陌上的活动加了一个女生,她比我还大,87年的。我回去给她发了3条微信,她都没有回复我。我就把她删除了。你猜怎么着,今天我又看到她了,她主动添加我为好友。在相亲群里,但凡有女生主动加人,只能说明一件事情——她真的着急了。”</p><p>三条未回复的消息带给Ziv的屈辱感,竟让他一年未能忘却。多数参与者与Ziv相似,他们优秀,且被动,一边焦虑一边挑剔,在意互惠和等价交换。展示完自己的高价值后,便把自己置于冷漠的高地,仿佛主动向下探就吃了亏,失去了自己在感情中的地位。</p><p>只有说起户口,Ziv会流露出罕见的不自信,“我最近喜欢一个女孩,她似乎很看重北京户口,我很怕她会因此拒绝我。”但片刻后,Ziv又恢复了自如,“不过户口也不重要,有户口买不起房也白搭。我已经打算在北京买房了,而且我买的起。”</p><p><br></p><p>即使是从未谈过恋爱的小夏,面对爱情也保持清醒。“要说我喜欢的类型,除了硬件上的学校好、家庭好,我喜欢性格阳光一些的,还有三观契合。”</p><p>除此之外,小夏仍期待着有个人能真心实意地为她付出,“我觉得经济条件是加分项,不是必要的。如果我足够喜欢他,就算他没有北京的户口,房子,收入不算高,我也觉得不是问题。因为户口和房子,我都有。”但小夏很快收回少女的期待,她直言不讳,“最看中的还是男生的学校背景和门当户对。”</p><p>在这场势均力敌的爱情博弈中,没有人愿意向下看。无论是像Ziv这样走出小镇在北京站稳脚跟的青年,抑或是家境良好受过高等教育的小夏。他们不希望自己拥有的一切因为配偶选择土崩瓦解,这是一个共识:不相互拖累是最低要求。相亲局中的人试图通过婚恋再次确认或提升自己在社会中的竞争位置,不管这个标签是财富、职业、户口、还是学习。</p><figure class="image"> <picture> <source type="image/webp" media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.webp" onerror="this.srcset='https://assets.matters.news/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.jpeg'"> <source media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.jpeg" onerror="this.srcset='https://assets.matters.news/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.jpeg'"> <source type="image/webp" srcset="https://assets.matters.news/processed/540w/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.webp"> <img src="https://assets.matters.news/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.jpeg" srcset="https://assets.matters.news/processed/540w/embed/daf9b89d-be66-49e3-890f-f2a212cb569f.jpeg" loading="lazy" referrerpolicy="no-referrer"> </picture> <figcaption><span></span></figcaption></figure><p><br></p><p>三、爱的绩效</p><p><br></p><p>陌上花开HIMMR的全称是“How I Met Mr. Right”,平台介绍是:致力为不愿将就的你找到最好的爱情。Mr. Right应该是什么样的人?最好的爱情是什么模样?平台和参与其中的男女嘉宾都说不清楚。</p><p>但至少有一点为平台和参与者认同,嘉宾优质和配对高效是通往最好爱情,寻找到对的人的最佳路径。</p><p>自2015年成立以来,陌上花开共计服务嘉宾超过 10000 人,脱单率超过 35%,效率远超其他婚恋平台。这种高效率的脱单离不开平台红娘的包装。</p><p>在陌上公众号发文称为“挂牌”,平台会发送男女嘉宾的信息,看到的任何人都可以发送自己的信息应征。只要购买金牌红娘的服务,红娘会帮你挖掘亮点,甄选发文素材,优化文字,选图P图,打造精致的挂牌贴。</p><p>能够挂牌的女孩们有相似的“凡尔赛”文案:父母是高知,彼此恩爱,家境殷实。虽然父母的要求严格培养全面,但家庭教育开明通达,所以女嘉宾不仅成绩优异,工作光鲜亮丽,更有小提琴、芭蕾、钢琴等多项才艺,从未缺失过温暖与爱。</p><p>线上的无暇与标签化在线下也同样适用。与姿态较高的Ziv不同,男嘉宾乔森主动,热情,深谙高效的重要性。在八分钟约会环节,乔森会用几个关键词介绍自己,“羽毛球、炒股、头条算法”,并就这几个关键字延伸,主导聊天的话题。</p><p>八分钟结束后,乔森熟练地打开微信面对面建群,把在座的6人都拉入群组。去年陌上的双十一活动,乔森给群里100位女生都发送了好友申请,通过的有30多个。今年,他只是加了和自己有过碰面的女生,最终通过的有十几人。在申请介绍里,乔森依旧备注自己的昵称和关键词:羽毛球、炒股、头条算法。</p><p>乔森说,“那样的环境一定要给自己贴标签,像很多女生介绍自己,我什么也记不得。虽然加了这么多人,但是我一个也对不上号,不知道谁是谁。”</p><p>乔森曾就职于业内最好的百度凤巢,后跳槽去另一家知名互联网公司。职业道路明朗化,拿到北京户口后,他开始积极地寻找爱情。工作日的白天,乔森忙到没有时间回复消息,我们只能趁晚上10点他下班后,才有完整的交流。</p><p>“全部的生活都被工作挤占了,还有时间谈恋爱吗?”乔森沉默了几秒,回复我说,“谈恋爱也并不一定花时间,周末还是可以一起出来玩嘛。”</p><p>乔森谈起先前的恋情,充斥着争吵,不理解和痛苦,耗尽他的时间和精力。去年分手后,乔森说自己仿佛终于解脱。提起爱情的模样,乔森说自己喜欢爱运动的高瘦女孩,不希望有消极的情绪,只想和简单的女孩一起快乐地玩。</p><p>在《爱欲之死》里,韩炳哲写道,“绩效原则已经统御了当今社会的所有生活领域,包括爱和性。”在乔森身上,可以看到这种“爱”的消退。积极地认识新的人,快速建立联系。但同时,爱被当成一种享受的形式被积极化:爱必须提供愉悦,并且要免于受到伤害、打击、攻击等负面行为的影响,如果一有问题出现,就会选择退却。</p><p>但爱并不是只有积极的一面。爱情可以让人更开阔,更完善,爱情也意味着暴露,撕裂,伤害,授予某人能摧毁自己的力量。就像哲学家列维纳斯所说, “爱不是一种可能性,它并不基于我们的努力和积极态度而存在,它可以没由来地打击我们,伤害我们。” </p><p>无论是讲究效率的平台运营和设置投放,还是拒绝爱的消极面的参与者,在绩效的洪流里,男女双方谈户口,年收,房子,家庭背景和兴趣爱好,唯一拒绝不谈的,就是爱的复杂性,就是爱本身。</p><figure class="image"> <picture> <source type="image/webp" media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.webp" onerror="this.srcset='https://assets.matters.news/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.jpeg'"> <source media="(min-width: 768px)" srcset="https://assets.matters.news/processed/1080w/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.jpeg" onerror="this.srcset='https://assets.matters.news/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.jpeg'"> <source type="image/webp" srcset="https://assets.matters.news/processed/540w/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.webp"> <img src="https://assets.matters.news/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.jpeg" srcset="https://assets.matters.news/processed/540w/embed/9ba71844-b329-40f7-910d-0b9ae2e047f1.jpeg" loading="lazy" referrerpolicy="no-referrer"> </picture> <figcaption><span></span></figcaption></figure><p><br></p><p>五点钟活动结束后,走出“爱的博物馆”,天已经全黑了。雪落在温度尚存的地面融化成一滩滩脏水,穿高跟鞋背着名牌包的姑娘们小心地避开可能溅起的泥点。看起来其貌不扬的男嘉宾开着跑车轰鸣离开,相见甚欢的男女们一起叫车相约共进晚餐。更多的人裹紧围巾,只身走向冷风中的望京南地铁站。</p><p>我与新认识的女孩莎莎一同走出大门,谨慎地询问她可以聊聊对婚恋的看法吗?1988年生的莎莎摆了摆手,苦涩地笑着同我告别,“这么多年,我已经没有什么好说的了。”</p><p><br></p><p>背后“爱的博物馆”里,粉色心形气球已经被工作人员撤开,墙壁上关于爱的关键字还在熠熠闪光,“荷尔蒙、多巴胺、自私、焦虑、疯狂、真心。”手机里弹出关于初雪的推送,是纳博科夫的句子,“你是否爱过一个人,她看起来就像圣诞节清晨的阳光,初雪以后松树枝上的小松鼠,雨天小路上溅到行人裤腿上的泥点,还有那些最美的玫瑰花。”真是美好的初雪之夜,我在“爱的博物馆”,见证了一场优质的失败。</p><p><br></p>
</div>
| 563.470588 | 8,951 | 0.811985 | yue_Hant | 0.397973 |
118e53700512bcb5f15d7180fe46d23b9f03d923 | 906 | md | Markdown | vendor/friendsofsymfony/jsrouting-bundle/CHANGELOG.md | pidurffi/Sitios | faf80a125883b4493f3e37cfbfe5af26ea63fa49 | [
"MIT"
] | null | null | null | vendor/friendsofsymfony/jsrouting-bundle/CHANGELOG.md | pidurffi/Sitios | faf80a125883b4493f3e37cfbfe5af26ea63fa49 | [
"MIT"
] | null | null | null | vendor/friendsofsymfony/jsrouting-bundle/CHANGELOG.md | pidurffi/Sitios | faf80a125883b4493f3e37cfbfe5af26ea63fa49 | [
"MIT"
] | null | null | null | # Changelog
## v2.1.1 - 2017-12-13
- Fix SF <4 compatibility ([#306](https://github.com/FriendsOfSymfony/FOSJsRoutingBundle/issues/306))
## v2.1.0 - 2017-12-13
- Add Symfony 4 compatibility ([#300](https://github.com/FriendsOfSymfony/FOSJsRoutingBundle/pull/300))
- Add JSON dump functionality ([#302](https://github.com/FriendsOfSymfony/FOSJsRoutingBundle/pull/302))
- Fix bug denormalizing empty routing collections from cache
- Update documentation for Symfony 3 ([#273](https://github.com/FriendsOfSymfony/FOSJsRoutingBundle/pull/273))
## v2.0.0 - 2017-11-08
- Add Symfony 3.* compatibility
- Added `--pretty-print` option to `fos:js-routing:dump`-command, making the resulting javascript pretty-printed
- Removed SF 2.1 backwards compatibility code
- Add automatic injection of `locale` parameter
- Added functionality to change the used router service
- Added normalizer classes
| 47.684211 | 113 | 0.752759 | yue_Hant | 0.349563 |
118eb884932396611b4967afa23298df4e7f6a96 | 18,058 | md | Markdown | site/sfguides/src/resource_optimization_billing_metrics/resource_optimization_billing_metrics.md | davidwhiting/sfquickstarts | 6590039cd5074b396ff99716a57ca7e3db469ecc | [
"Apache-2.0"
] | null | null | null | site/sfguides/src/resource_optimization_billing_metrics/resource_optimization_billing_metrics.md | davidwhiting/sfquickstarts | 6590039cd5074b396ff99716a57ca7e3db469ecc | [
"Apache-2.0"
] | null | null | null | site/sfguides/src/resource_optimization_billing_metrics/resource_optimization_billing_metrics.md | davidwhiting/sfquickstarts | 6590039cd5074b396ff99716a57ca7e3db469ecc | [
"Apache-2.0"
] | 1 | 2021-06-22T14:45:12.000Z | 2021-06-22T14:45:12.000Z | summary: This guide can be used to help customers setup and run queries pertaining to monitoring billing metrics that might help identify areas of over-consumption.
id: resource_optimization_billing_metrics
categories: Resource Optimization
environments: web
status: Published
feedback link: https://github.com/Snowflake-Labs/sfguides/issues
tags: Resource Optimization, Cost Optimization, Billing, Billing Metrics, Monitoring
authors: Matt Meredith
#Resource Optimization: Billing Metrics
<!-- -------------->
## Overview
This resource optimization guide represents one module of the four contained in the series. These guides are meant to help customers better monitor and manage their credit consumption. Helping our customers build confidence that their credits are being used efficiently is key to an ongoing successful partnership. In addition to this set of Snowflake Guides for Resource Optimization, Snowflake also offers community support as well as Training and Professional Services offerings. To learn more about the paid offerings, take a look at upcoming [education and training](https://www.snowflake.com/education-and-training/).
This [blog post](https://www.snowflake.com/blog/understanding-snowflakes-resource-optimization-capabilities/) can provide you with a better understanding of Snowflake's Resource Optimization capabilities.
### Billing Metrics
Billing queries are responsible for identifying total costs associated with the high level functions of the Snowflake Cloud Data Platform, which includes warehouse compute, snowpipe compute, and storage costs. If costs are noticeably higher in one category versus the others, you may want to evaluate what might be causing that.
These metrics also seek to identify those queries that are consuming the most amount of credits. From there, each of these queries can be analyze for their importance (do they need to be run as frequently, if at all) and explore if additional controls need to be in place to prevent excessive consumption (i.e. resource monitors, statement timeouts, etc.).
### What You’ll Learn
- how to identify and analyze Snowflake consumption across all services
- how to analyze most resource-intensive queries
- how to analyze serverless consumption
### What You’ll Need
- A [Snowflake](https://www.snowflake.com/) Account
- Access to view [Account Usage Data Share](https://docs.snowflake.com/en/sql-reference/account-usage.html#enabling-account-usage-for-other-roles)
### Related Materials
- Resource Optimization: Setup & Configuration
- Resource Optimization: Usage Monitoring
- Resource Optimization: Performance
## Query Tiers
Each query within the Resource Optimization Snowflake Guides will have a tier designation just to the right of its name as "(T*)". The following tier descriptions should help to better understand those designations.
### Tier 1 Queries
At its core, Tier 1 queries are essential to Resource Optimization at Snowflake and should be used by each customer to help with their consumption monitoring - regardless of size, industry, location, etc.
### Tier 2 Queries
Tier 2 queries, while still playing a vital role in the process, offer an extra level of depth around Resource Optimization and while they may not be essential to all customers and their workloads, it can offer further explanation as to any additional areas in which over-consumption may be identified.
### Tier 3 Queries
Finally, Tier 3 queries are designed to be used by customers that are looking to leave no stone unturned when it comes to optimizing their consumption of Snowflake. While these queries are still very helpful in this process, they are not as critical as the queries in Tier 1 & 2.
## Billing Metrics (T1)
###### Tier 1
#### Description:
Identify key metrics as it pertains to total compute costs from warehouses,
serverless features, and total storage costs.
#### How to Interpret Results:
Where are we seeing most of our costs coming from (compute, serverless, storage)? Are seeing excessive costs in any of those categories that are above expectations?
#### Primary Schema:
Account_Usage
#### SQL
```sql
/* These queries can be used to measure where costs have been incurred by
the different cost vectors within a Snowflake account including:
1) Warehouse Costs
2) Serverless Costs
3) Storage Costs
To accurately report the dollar amounts, make changes to the variables
defined on lines 17 to 20 to properly reflect your credit price, the initial
capacity purchased, when your contract started and the term (default 12 months)
If unsure, ask your Sales Engineer or Account Executive
*/
USE DATABASE SNOWFLAKE;
USE SCHEMA ACCOUNT_USAGE;
SET CREDIT_PRICE = 4.00; --edit this number to reflect credit price
SET TERM_LENGTH = 12; --integer value in months
SET TERM_START_DATE = '2019-01-01';
SET TERM_AMOUNT = 100000.00; --number(10,2) value in dollars
WITH CONTRACT_VALUES AS (
SELECT
$CREDIT_PRICE::decimal(10,2) as CREDIT_PRICE
,$TERM_AMOUNT::decimal(38,0) as TOTAL_CONTRACT_VALUE
,$TERM_START_DATE::timestamp as CONTRACT_START_DATE
,DATEADD(month,$TERM_LENGTH,$TERM_START_DATE)::timestamp as CONTRACT_END_DATE
),
PROJECTED_USAGE AS (
SELECT
CREDIT_PRICE
,TOTAL_CONTRACT_VALUE
,CONTRACT_START_DATE
,CONTRACT_END_DATE
,(TOTAL_CONTRACT_VALUE)
/
DATEDIFF(day,CONTRACT_START_DATE,CONTRACT_END_DATE) AS DOLLARS_PER_DAY
, (TOTAL_CONTRACT_VALUE/CREDIT_PRICE)
/
DATEDIFF(day,CONTRACT_START_DATE,CONTRACT_END_DATE) AS CREDITS_PER_DAY
FROM CONTRACT_VALUES
)
--COMPUTE FROM WAREHOUSES
SELECT
'WH Compute' as WAREHOUSE_GROUP_NAME
,WMH.WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,WMH.START_TIME
,WMH.END_TIME
,WMH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*WMH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY WMH
UNION ALL
--COMPUTE FROM SNOWPIPE
SELECT
'Snowpipe' AS WAREHOUSE_GROUP_NAME
,PUH.PIPE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,PUH.START_TIME
,PUH.END_TIME
,PUH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*PUH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.PIPE_USAGE_HISTORY PUH
UNION ALL
--COMPUTE FROM CLUSTERING
SELECT
'Auto Clustering' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,ACH.START_TIME
,ACH.END_TIME
,ACH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*ACH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.AUTOMATIC_CLUSTERING_HISTORY ACH
UNION ALL
--COMPUTE FROM MATERIALIZED VIEWS
SELECT
'Materialized Views' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,MVH.START_TIME
,MVH.END_TIME
,MVH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*MVH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.MATERIALIZED_VIEW_REFRESH_HISTORY MVH
UNION ALL
--COMPUTE FROM SEARCH OPTIMIZATION
SELECT
'Search Optimization' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME || '.' || SCHEMA_NAME || '.' || TABLE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,SOH.START_TIME
,SOH.END_TIME
,SOH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*SOH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.SEARCH_OPTIMIZATION_HISTORY SOH
UNION ALL
--COMPUTE FROM REPLICATION
SELECT
'Replication' AS WAREHOUSE_GROUP_NAME
,DATABASE_NAME AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,RUH.START_TIME
,RUH.END_TIME
,RUH.CREDITS_USED
,$CREDIT_PRICE
,($CREDIT_PRICE*RUH.CREDITS_USED) AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.REPLICATION_USAGE_HISTORY RUH
UNION ALL
--STORAGE COSTS
SELECT
'Storage' AS WAREHOUSE_GROUP_NAME
,'Storage' AS WAREHOUSE_NAME
,NULL AS GROUP_CONTACT
,NULL AS GROUP_COST_CENTER
,NULL AS GROUP_COMMENT
,SU.USAGE_DATE
,SU.USAGE_DATE
,NULL AS CREDITS_USED
,$CREDIT_PRICE
,((STORAGE_BYTES + STAGE_BYTES + FAILSAFE_BYTES)/(1024*1024*1024*1024)*23)/DA.DAYS_IN_MONTH AS DOLLARS_USED
,'ACTUAL COMPUTE' AS MEASURE_TYPE
from SNOWFLAKE.ACCOUNT_USAGE.STORAGE_USAGE SU
JOIN (SELECT COUNT(*) AS DAYS_IN_MONTH,TO_DATE(DATE_PART('year',D_DATE)||'-'||DATE_PART('month',D_DATE)||'-01') as DATE_MONTH FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.DATE_DIM GROUP BY TO_DATE(DATE_PART('year',D_DATE)||'-'||DATE_PART('month',D_DATE)||'-01')) DA ON DA.DATE_MONTH = TO_DATE(DATE_PART('year',USAGE_DATE)||'-'||DATE_PART('month',USAGE_DATE)||'-01')
UNION ALL
SELECT
NULL as WAREHOUSE_GROUP_NAME
,NULL as WAREHOUSE_NAME
,NULL as GROUP_CONTACT
,NULL as GROUP_COST_CENTER
,NULL as GROUP_COMMENT
,DA.D_DATE::timestamp as START_TIME
,DA.D_DATE::timestamp as END_TIME
,PU.CREDITS_PER_DAY AS CREDITS_USED
,PU.CREDIT_PRICE
,PU.DOLLARS_PER_DAY AS DOLLARS_USED
,'PROJECTED COMPUTE' AS MEASURE_TYPE
FROM PROJECTED_USAGE PU
JOIN SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.DATE_DIM DA ON DA.D_DATE BETWEEN PU.CONTRACT_START_DATE AND PU.CONTRACT_END_DATE
UNION ALL
SELECT
NULL as WAREHOUSE_GROUP_NAME
,NULL as WAREHOUSE_NAME
,NULL as GROUP_CONTACT
,NULL as GROUP_COST_CENTER
,NULL as GROUP_COMMENT
,NULL as START_TIME
,NULL as END_TIME
,NULL AS CREDITS_USED
,PU.CREDIT_PRICE
,PU.TOTAL_CONTRACT_VALUE AS DOLLARS_USED
,'CONTRACT VALUES' AS MEASURE_TYPE
FROM PROJECTED_USAGE PU
;
```
#### Screenshot

## Most Expensive Queries (T2)
###### Tier 2
#### Description:
This query orders the most expensive queries from the last 30 days. It takes into account the warehouse size, assuming that a 1 minute query on larger warehouse is more expensive than a 1 minute query on a smaller warehouse
#### How to Interpret Results:
This is an opportunity to evaluate expensive queries and take some action. The admin could:
-look at the query profile
-contact the user who executed the query
-take action to optimize these queries
#### Primary Schema:
Account_Usage
#### SQL
```sql
WITH WAREHOUSE_SIZE AS
(
SELECT WAREHOUSE_SIZE, NODES
FROM (
SELECT 'XSMALL' AS WAREHOUSE_SIZE, 1 AS NODES
UNION ALL
SELECT 'SMALL' AS WAREHOUSE_SIZE, 2 AS NODES
UNION ALL
SELECT 'MEDIUM' AS WAREHOUSE_SIZE, 4 AS NODES
UNION ALL
SELECT 'LARGE' AS WAREHOUSE_SIZE, 8 AS NODES
UNION ALL
SELECT 'XLARGE' AS WAREHOUSE_SIZE, 16 AS NODES
UNION ALL
SELECT '2XLARGE' AS WAREHOUSE_SIZE, 32 AS NODES
UNION ALL
SELECT '3XLARGE' AS WAREHOUSE_SIZE, 64 AS NODES
UNION ALL
SELECT '4XLARGE' AS WAREHOUSE_SIZE, 128 AS NODES
)
),
QUERY_HISTORY AS
(
SELECT QH.QUERY_ID
,QH.QUERY_TEXT
,QH.USER_NAME
,QH.ROLE_NAME
,QH.EXECUTION_TIME
,QH.WAREHOUSE_SIZE
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY QH
WHERE START_TIME > DATEADD(month,-2,CURRENT_TIMESTAMP())
)
SELECT QH.QUERY_ID
,'https://' || current_account() || '.snowflakecomputing.com/console#/monitoring/queries/detail?queryId='||QH.QUERY_ID AS QU
,QH.QUERY_TEXT
,QH.USER_NAME
,QH.ROLE_NAME
,QH.EXECUTION_TIME as EXECUTION_TIME_MILLISECONDS
,(QH.EXECUTION_TIME/(1000)) as EXECUTION_TIME_SECONDS
,(QH.EXECUTION_TIME/(1000*60)) AS EXECUTION_TIME_MINUTES
,(QH.EXECUTION_TIME/(1000*60*60)) AS EXECUTION_TIME_HOURS
,WS.WAREHOUSE_SIZE
,WS.NODES
,(QH.EXECUTION_TIME/(1000*60*60))*WS.NODES as RELATIVE_PERFORMANCE_COST
FROM QUERY_HISTORY QH
JOIN WAREHOUSE_SIZE WS ON WS.WAREHOUSE_SIZE = upper(QH.WAREHOUSE_SIZE)
ORDER BY RELATIVE_PERFORMANCE_COST DESC
LIMIT 200
;
```
## Average Cost per Query by Warehouse (T2)
###### Tier 2
#### Description:
This summarize the query activity and credit consumption per warehouse over the last month. The query also includes the ratio of queries executed to credits consumed on the warehouse
#### How to Interpret Results:
Highlights any scenarios where warehouse consumption is significantly out of line with the number of queries executed. Maybe auto-suspend needs to be adjusted or warehouses need to be consolidated.
#### Primary Schema:
Account_Usage
#### SQL
```sql
set credit_price = 4; --edit this value to reflect your credit price
SELECT
COALESCE(WC.WAREHOUSE_NAME,QC.WAREHOUSE_NAME) AS WAREHOUSE_NAME
,QC.QUERY_COUNT_LAST_MONTH
,WC.CREDITS_USED_LAST_MONTH
,WC.CREDIT_COST_LAST_MONTH
,CAST((WC.CREDIT_COST_LAST_MONTH / QC.QUERY_COUNT_LAST_MONTH) AS decimal(10,2) ) AS COST_PER_QUERY
FROM (
SELECT
WAREHOUSE_NAME
,COUNT(QUERY_ID) as QUERY_COUNT_LAST_MONTH
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE TO_DATE(START_TIME) >= TO_DATE(DATEADD(month,-1,CURRENT_TIMESTAMP()))
GROUP BY WAREHOUSE_NAME
) QC
JOIN (
SELECT
WAREHOUSE_NAME
,SUM(CREDITS_USED) as CREDITS_USED_LAST_MONTH
,SUM(CREDITS_USED)*($CREDIT_PRICE) as CREDIT_COST_LAST_MONTH
FROM SNOWFLAKE.ACCOUNT_USAGE.WAREHOUSE_METERING_HISTORY
WHERE TO_DATE(START_TIME) >= TO_DATE(DATEADD(month,-1,CURRENT_TIMESTAMP()))
GROUP BY WAREHOUSE_NAME
) WC
ON WC.WAREHOUSE_NAME = QC.WAREHOUSE_NAME
ORDER BY COST_PER_QUERY DESC
;
```
#### Screenshot

## AutoClustering Cost History (by Day by Object) (T3)
###### Tier 3
#### Description:
Full list of tables with auto-clustering and the volume of credits consumed via the service over the last 30 days, broken out by day.
#### How to Interpret Results:
Look for irregularities in the credit consumption or consistently high consumption
#### Primary Schema:
Account_Usage
#### SQL
```sql
SELECT TO_DATE(START_TIME) as DATE
,DATABASE_NAME
,SCHEMA_NAME
,TABLE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."AUTOMATIC_CLUSTERING_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
GROUP BY 1,2,3,4
ORDER BY 5 DESC
;
```
#### Screenshot

## Materialized Views Cost History (by Day by Object) (T3)
###### Tier 3
#### Description:
Full list of materialized views and the volume of credits consumed via the service over the last 30 days, broken out by day.
#### How to Interpret Results:
Look for irregularities in the credit consumption or consistently high consumption
#### Primary Schema:
Account_Usage
#### SQL
```sql
SELECT
TO_DATE(START_TIME) as DATE
,DATABASE_NAME
,SCHEMA_NAME
,TABLE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."MATERIALIZED_VIEW_REFRESH_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
GROUP BY 1,2,3,4
ORDER BY 5 DESC
;
```
## Search Optimization Cost History (by Day by Object) (T3)
###### Tier 3
#### Description:
Full list of tables with search optimization and the volume of credits consumed via the service over the last 30 days, broken out by day.
#### How to Interpret Results:
Look for irregularities in the credit consumption or consistently high consumption
#### Primary Schema:
Account_Usage
#### SQL
```sql
TSELECT
TO_DATE(START_TIME) as DATE
,DATABASE_NAME
,SCHEMA_NAME
,TABLE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."SEARCH_OPTIMIZATION_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
GROUP BY 1,2,3,4
ORDER BY 5 DESC
;
```
## Snowpipe Cost History (by Day by Object) (T3)
###### Tier 3
#### Description:
Full list of pipes and the volume of credits consumed via the service over the last 30 days, broken out by day.
#### How to Interpret Results:
Look for irregularities in the credit consumption or consistently high consumption
#### Primary Schema:
Account_Usage
#### SQL
```sql
SELECT
TO_DATE(START_TIME) as DATE
,PIPE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."PIPE_USAGE_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
GROUP BY 1,2
ORDER BY 3 DESC
;
```
## Replication Cost History (by Day by Object) (T3)
###### Tier 3
#### Description:
Full list of replicated databases and the volume of credits consumed via the replication service over the last 30 days, broken out by day.
#### How to Interpret Results:
Look for irregularities in the credit consumption or consistently high consumption
#### Primary Schema:
Account_Usage
#### SQL
```sql
SELECT
TO_DATE(START_TIME) as DATE
,DATABASE_NAME
,SUM(CREDITS_USED) as CREDITS_USED
FROM "SNOWFLAKE"."ACCOUNT_USAGE"."REPLICATION_USAGE_HISTORY"
WHERE START_TIME >= dateadd(month,-1,current_timestamp())
GROUP BY 1,2
ORDER BY 3 DESC
;
``` | 35.617357 | 624 | 0.722007 | yue_Hant | 0.754268 |
118ebce26c0d800c304f997d45035b9f11d494ad | 463 | md | Markdown | solutions/beecrowd/1001/problem.md | deniscostadsc/playground | 11fa8e2b708571940451f005e1f55af0b6e5764a | [
"MIT"
] | 18 | 2015-01-22T04:08:51.000Z | 2022-01-08T22:36:47.000Z | solutions/beecrowd/1001/problem.md | deniscostadsc/playground | 11fa8e2b708571940451f005e1f55af0b6e5764a | [
"MIT"
] | 4 | 2016-04-25T12:32:46.000Z | 2021-06-15T18:01:30.000Z | solutions/beecrowd/1001/problem.md | deniscostadsc/playground | 11fa8e2b708571940451f005e1f55af0b6e5764a | [
"MIT"
] | 25 | 2015-03-02T06:21:51.000Z | 2021-09-12T20:49:21.000Z | http://www.beecrowd.com.br/judge/problems/view/1001
# Extremely Basic
Read 2 variables, named $A$ and $B$ and make the sum of these two variables,
assigning its result to the variable $X$. Print $X$ as shown below. Print
endline after the result otherwise you will get “Presentation Error".
## Input
The input file will contain 2 integer numbers.
## Output
Print $X$ according to the following example, with a blank space before and
after the equal signal.
| 27.235294 | 76 | 0.758099 | eng_Latn | 0.998297 |
118f2df6d5604cb9bc0fd84d6300cbe6b1fef976 | 2,268 | md | Markdown | docs/vs-2015/ide/reference/upgrade-devenv-exe.md | drvoss/visualstudio-docs.ko-kr | 739317082fa0a67453bad9d3073fbebcb0aaa7fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/vs-2015/ide/reference/upgrade-devenv-exe.md | drvoss/visualstudio-docs.ko-kr | 739317082fa0a67453bad9d3073fbebcb0aaa7fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/vs-2015/ide/reference/upgrade-devenv-exe.md | drvoss/visualstudio-docs.ko-kr | 739317082fa0a67453bad9d3073fbebcb0aaa7fb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: -Upgrade(devenv.exe) | Microsoft Docs
ms.custom: ''
ms.date: 11/15/2016
ms.prod: visual-studio-dev14
ms.reviewer: ''
ms.suite: ''
ms.technology:
- vs-ide-general
ms.tgt_pltfrm: ''
ms.topic: article
helpviewer_keywords:
- /upgrade Devenv switch
- Devenv, /upgrade switch
- upgrade Devenv switch
ms.assetid: 3468045c-5cc9-4157-9a9d-622452145d27
caps.latest.revision: 22
author: gewarren
ms.author: gewarren
manager: ghogen
ms.openlocfilehash: 79a00da92ac2da6eb37fa1eef90fa112598d23f3
ms.sourcegitcommit: 9ceaf69568d61023868ced59108ae4dd46f720ab
ms.translationtype: MT
ms.contentlocale: ko-KR
ms.lasthandoff: 10/12/2018
ms.locfileid: "49264963"
---
# <a name="upgrade-devenvexe"></a>/Upgrade (devenv.exe)
[!INCLUDE[vs2017banner](../../includes/vs2017banner.md)]
솔루션 파일 및 모든 프로젝트 파일이나 지정한 프로젝트 파일을 이러한 파일의 현재 [!INCLUDE[vsprvs](../../includes/vsprvs-md.md)] 형식으로 업데이트합니다.
## <a name="syntax"></a>구문
```
devenv SolutionFile | ProjectFile /upgrade
```
## <a name="arguments"></a>인수
`SolutionFile`
전체 솔루션 및 해당 프로젝트를 업그레이드할 경우 필요합니다. 솔루션 파일의 경로 및 이름입니다. 솔루션 파일의 이름만 입력하거나 솔루션 파일의 전체 경로와 이름을 입력할 수 있습니다. 이름이 지정된 폴더나 파일이 아직 없으면 새로 만들어집니다.
`ProjectFile`
단일 프로젝트를 업그레이드할 경우 필요합니다. 솔루션 내에 있는 프로젝트 파일의 경로와 이름입니다. 프로젝트 파일의 이름만 입력하거나 프로젝트 파일의 전체 경로와 이름을 입력할 수 있습니다. 이름이 지정된 폴더나 파일이 아직 없으면 새로 만들어집니다.
## <a name="remarks"></a>설명
백업은 자동으로 만들어지고 현재 디렉터리에 생성된 Backup 디렉터리로 복사됩니다.
소스 제어 솔루션 또는 프로젝트는 업그레이드하기 전에 체크 아웃해야 합니다.
`/upgrade` 스위치를 사용해도 [!INCLUDE[vsprvs](../../includes/vsprvs-md.md)]가 시작되지 않습니다. 솔루션 또는 프로젝트의 개발 언어에 대한 업그레이드 보고서에서 업그레이드 결과를 확인할 수 없습니다. 오류 또는 사용 정보가 반환되지 않습니다. 프로젝트를 업그레이드 하는 방법은 [!INCLUDE[vsprvs](../../includes/vsprvs-md.md)]를 참조 하세요 [방법: 해결 실패 한 Visual Studio 프로젝트 업그레이드](../../porting/how-to-troubleshoot-unsuccessful-visual-studio-project-upgrades.md)합니다.
## <a name="example"></a>예제
이 예제에서는 [!INCLUDE[vsprvs](../../includes/vsprvs-md.md)] 솔루션에 대한 기본 폴더에서 “MyProject.sln”이라는 솔루션 파일을 업그레이드합니다.
```
devenv "MyProject.sln" /upgrade
```
## <a name="see-also"></a>참고 항목
[방법: 실패 한 Visual Studio 프로젝트 업그레이드 문제 해결](../../porting/how-to-troubleshoot-unsuccessful-visual-studio-project-upgrades.md)
[Devenv 명령줄 스위치](../../ide/reference/devenv-command-line-switches.md)
| 33.850746 | 364 | 0.704586 | kor_Hang | 0.999907 |
118f5e558ad38bd129edfdbbb748270a6d5f0173 | 11,163 | md | Markdown | content/howto/tutorials/build-an-employee-directory-app-beginner-4-add-pages-to-the-user-interface.md | ChrisdeG/docs | d35412bab3098b6b7f19b785496889d462e06496 | [
"CC-BY-4.0"
] | null | null | null | content/howto/tutorials/build-an-employee-directory-app-beginner-4-add-pages-to-the-user-interface.md | ChrisdeG/docs | d35412bab3098b6b7f19b785496889d462e06496 | [
"CC-BY-4.0"
] | null | null | null | content/howto/tutorials/build-an-employee-directory-app-beginner-4-add-pages-to-the-user-interface.md | ChrisdeG/docs | d35412bab3098b6b7f19b785496889d462e06496 | [
"CC-BY-4.0"
] | null | null | null | ---
title: "Build an Employee Directory App (Beginner) Step 4: Add Pages to the User Interface"
parent: "build-an-employee-directory-app-beginner"
description: "Presents details on add pages to your app's UI in the Web Modeler."
tags: ["build", "app", "developer portal", "web modeler"]
---
## 1 Introduction
This is the fourth how-to in this series on creating an employee directory in the Web Modeler. In this how-to, you will learn how to add pages to the app.
**This how-to will teach you how to do the following:**
* Create an overview page
* Create a detail page
* Connect pages to a domain model
* Use the Google Maps Widget
## 2 Prerequisites
Before starting with this how-to, make sure you have completed the following prerequisite:
* Complete the third how-to in this series: [How to Build an Employee Directory App (Beginner) Step 3: Publish and View Your App](build-an-employee-directory-app-beginner-3-publish-and-view-your-app)
## 3 Adding Pages to the User Interface
Pages define the user interface of your Mendix app. Each page consists of widgets such as buttons, list views, data grids and input elements. For example, the default home page comes with a header and a layout grid.
### 3.1 Adding an Employee Overview Page
Now that you have created a basic dashboard, you need to add a new page that can be opened from a dashboard item that reflects its purpose. To achieve this, follow these steps:
1. Select the top-left **BUTTON** image:

2. Click the **Icon** property and change it to **User**:

3. Select the top-left **Open Page** button and enter *Employees* for the **Caption** property:

4. Select the image you just changed to a user image and set the **On Click Action** property to **Page**:

5. Change the page property by clicking **Select page**:

6. To create a new page in the **Select Page** dialog box, do the following:<br>
a. Click **New page**.<br>
b. Change the title of the page to **Employees**.<br>
c. Select **Lists** > **Lists Default** for the template.

Well done — you've created your first page! Let's finish up some things before you start working on the new Employees page.
7. Select the **Home** page by clicking the **Pages** icon in the left menu bar.
8. Select the **Button** with the **Employees** caption.
9. Change the **On Click Action** property of the button by setting it to **Page**.
10. For the **Page** property of this button, select the page named **Employees**.
Great, you're done. Now you're ready to head over to the Employees page!
### 3.2 Editing the New Employees Page
A new page is based on a page template, which in this case is **Lists Default**, which you selected in a previous steps. The page template consists of several widgets for you to change.
To edit the widgets, follow these steps:
1. Open the **Employees** page by using the recent documents option:

2. Select the **TEXT** widget with **Title**:

3. Change the **Content** property to **Employees**.
4. Delete the **Text** widget with the subtitle.
5. Select the **CONTAINER** where the **Add** button is located:

6. Select the parent **Row** using the breadcrumb:

7. Change the **Row Layout** to *large left column & small right column* for all profiles:

### 3.3 Switching Building Blocks
If one of the available building blocks is more similar to your requirement than what is provided by default in page templates, you can easily make a replacement.
To switch building blocks, follow these steps:
1. Select the **LIST VIEW** widget and delete it:

2. Open the **Toolbox** and from **Lists**, drag the **List3** building block into the container.
At this point the page looks pretty nice, so you're ready to connect some data elements to it!
### 3.4 Creating and Connecting an Employee Data Structure to the Page
This page has several widgets to display records from your database. In Mendix, the structure of a database record is defined by an **Entity**.
To create the entity for an employee, follow these steps:
1. Select the **LIST VIEW**, which groups all the user cards together:

2. You want to create a new entity, so click the **Entity** property:

3. To create a new entity in the **Select Entity** dialog box, do the following:<br>
a. Click **New Entity**.<br>
b. Enter *Employee* for the **Name**.
4. Select the **TEXT** widget of the top user card and clear the **Content** property:

5. Click **Add parameter** for the **Content** property:

6. Create a new attribute in the **Select your attribute** dialog box (which will be added to the Employee entity) by doing the following:<br>
a. Enter *Name* for the attribute **Name**.<br>
b. Set the attribute **Type** to **String**.
7. In the subtitle **TEXT** widget, repeat steps 4-6 to add an attribute for **Email [String]**:

### 3.5 Adding an Input Employee Page
Now that you have created an entity representing the employees, you also need to populate that entity with data. The quickest way to add data to your app is to create an input page.
To add a page for inputting employees, follow these steps:
1. Select the **Add** button on the **Employees** page:

2. Select **Employee** for the **Entity** property of the button:

3. Click the **Page** property to open the **Select Page** dialog box.
4. Click **New page** and do the following:<br>
a. Enter *Employee* for the **Title** of the page.<br>
b. Select **Forms** > **Form Vertical** for the template:

### 3.6 Connecting the Input Page to the Employee Entity
The page you created consists of a set of text box widgets grouped together by a data view (a data view serves as the glue between page widgets and entities).
To connect the text box widgets to the Employee entity attributes, follow these steps:
1. Select the text box widget with the **Name** caption.
2. Click the icon in the data source header to select the containing data view.

3. Set the **Entity** property of the related data view to **Employee**.

4. Select the text box with the **Name** caption and connect it to the the **Name** attribute of the **Employee** entity.

5. Do the same thing for **Email**.
6. Add the following attributes to the entity for the remaining text box widgets:
* **Phone [String]**
* **Birthday [Date and Time]**
* **Bio [String]**
7. Go the **Design** properties category and toggle the **Full Width** property for the **Save** and **Cancel** buttons to improve the user experience:

### 3.7 Using the Google Maps widget
You can easily add rich widgets to your pages to greatly benefit the user experience.
To add the Google Maps widget to the page, follow these steps:
1. On the **Employee** page, open the **Toolbox**, make sure **Widgets** is selected, and search for the **Google Maps** widget:

3. Drag the **Google Maps** widget from the **Display** properties category onto the page below the **Bio** text box.
4. The Google Maps widget requires an **Address attribute** or both the **Latitude attribute** and **Longitude attribute**. So, search for "Text" in the **Toolbox** and drag the additional **Text Box** widget above the map.
5. Connect the new text box to a new attribute named **Address**:

6. Select the Google Maps widget, open the **Data source** properties category, and do the following:<br>
a. Set the **Locations Entity** to **Employee**.<br>
b. Set the **Address Attribute** to **Address**.
### 3.8 Connecting the List View On Click to a Page
The last thing you have to do is finish up the employees page. To connect a list view to this page, follow these steps:
1. Open the **Employees** page and then select the **LIST VIEW**:

2. Set the **On Click Action** to **Page** and select the **Employee** page (like you did for the **Add** button).
You're done! Time to view the effects of all your changes.
## 4 Viewing Your App
Update and view your app, just like you did in [How to Build an Employee Directory App (Beginner) Step 3: Publish and View Your App](build-an-employee-directory-app-beginner-3-publish-and-view-your-app).
You can now use your app to add and edit employees!
Continue on to the last part of this tutorial: [How to Build an Employee Directory App (Beginner) Step 5: Promote an Employee](build-an-employee-directory-app-beginner-5-add-employee-promotion-logic).
## 5 Related Content
* [How to Build an Employee Directory App (Beginner) Step 1: Create the App](build-an-employee-directory-app-beginner-1-create-the-app)
* [How to Build an Employee Directory App (Beginner) Step 2: Build a Dashboard Page](build-an-employee-directory-app-beginner-2-build-a-dashboard-page)
* [How to Build an Employee Directory App (Beginner) Step 3: Publish and View Your App](build-an-employee-directory-app-beginner-3-publish-and-view-your-app)
* [How to Build an Employee Directory App (Beginner) Step 5: Add Employee Promotion Logic](build-an-employee-directory-app-beginner-5-add-employee-promotion-logic)
| 46.319502 | 223 | 0.73439 | eng_Latn | 0.986456 |
118f7c2d0d6c28ed744c69d63346ed73f4d365ef | 1,418 | md | Markdown | desktop-src/direct3d9/linear-texture-filtering.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 552 | 2019-08-20T00:08:40.000Z | 2022-03-30T18:25:35.000Z | desktop-src/direct3d9/linear-texture-filtering.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 1,143 | 2019-08-21T20:17:47.000Z | 2022-03-31T20:24:39.000Z | desktop-src/direct3d9/linear-texture-filtering.md | velden/win32 | 94b05f07dccf18d4b1dbca13b19fd365a0c7eedc | [
"CC-BY-4.0",
"MIT"
] | 1,287 | 2019-08-20T05:37:48.000Z | 2022-03-31T20:22:06.000Z | ---
description: Direct3D uses a form of linear texture filtering called bilinear filtering.
ms.assetid: 'vs|directx_sdk|~\linear_texture_filtering.htm'
title: Linear Texture Filtering (Direct3D 9)
ms.topic: article
ms.date: 05/31/2018
---
# Linear Texture Filtering (Direct3D 9)
Direct3D uses a form of linear texture filtering called bilinear filtering. Like [Nearest-Point Sampling (Direct3D 9)](nearest-point-sampling.md), bilinear texture filtering first computes a texel address, which is usually not an integer address. Bilinear filtering then finds the texel whose integer address is closest to the computed address. In addition, the Direct3D rendering module computes a weighted average of the texels that are immediately above, below, to the left of, and to the right of the nearest sample point.
Select bilinear texture filtering by invoking the [**IDirect3DDevice9::SetSamplerState**](/windows/win32/api/d3d9helper/nf-d3d9helper-idirect3ddevice9-setsamplerstate) method. Set the value of the first parameter to the integer index number (0-7) of the texture for which you are selecting a texture filtering method. Pass D3DSAMP\_MAGFILTER, D3DSAMP\_MINFILTER, or D3DSAMP\_MIPFILTER for the second parameter to set the magnification, minification, or mipmapping filter. Pass D3DTEXF\_LINEAR in the third parameter.
## Related topics
<dl> <dt>
[Texture Filtering](texture-filtering.md)
</dt> </dl>
| 56.72 | 526 | 0.797602 | eng_Latn | 0.9872 |
118f93175be35d1fa6ba41b55ecbbd268083a37c | 5,730 | md | Markdown | apps/acai-cli/CHANGELOG.md | MartinHelmut/berries | f9b2d0f216a44af7c651e2b26de57df1b0d2630b | [
"MIT"
] | 8 | 2017-12-20T16:07:51.000Z | 2018-01-24T21:02:46.000Z | apps/acai-cli/CHANGELOG.md | MartinHelmut/berries | f9b2d0f216a44af7c651e2b26de57df1b0d2630b | [
"MIT"
] | 30 | 2017-12-21T16:09:53.000Z | 2018-12-20T16:53:08.000Z | apps/acai-cli/CHANGELOG.md | MartinHelmut/berries | f9b2d0f216a44af7c651e2b26de57df1b0d2630b | [
"MIT"
] | 3 | 2017-12-21T08:00:16.000Z | 2018-01-24T21:02:48.000Z | # Change Log
All notable changes to this project will be documented in this file.
See [Conventional Commits](https://conventionalcommits.org) for commit guidelines.
## [1.3.7](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2019-02-04)
**Note:** Version bump only for package @berries/acai-cli
## [1.3.6](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-12-21)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.3.5"></a>
## [1.3.5](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-09-09)
### Bug Fixes
* packages/acai-cli/.snyk & packages/acai-cli/package.json to reduce vulnerabilities ([af06210](https://github.com/MartinHelmut/berries/commit/af06210))
<a name="1.3.4"></a>
## [1.3.4](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-08-05)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.3.3"></a>
## [1.3.3](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-07-10)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.3.2"></a>
## [1.3.2](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-05-13)
### Bug Fixes
* update dependency ora to v2.1.0 ([07e7a76](https://github.com/MartinHelmut/berries/commit/07e7a76))
<a name="1.3.1"></a>
## [1.3.1](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-03-24)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.3.0"></a>
# [1.3.0](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-02-21)
### Features
* **website:** bootstrap basic berries documentation ([1a4ba37](https://github.com/MartinHelmut/berries/commit/1a4ba37))
<a name="1.2.0"></a>
# [1.2.0](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-02-17)
### Features
* **acai-cli:** support multiple file globs ([1a6ab7b](https://github.com/MartinHelmut/berries/commit/1a6ab7b))
<a name="1.1.4"></a>
## [1.1.4](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-02-08)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.1.3"></a>
## [1.1.3](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-30)
### Bug Fixes
* fix wrong branch resolution ([993c99b](https://github.com/MartinHelmut/berries/commit/993c99b))
<a name="1.1.2"></a>
## [1.1.2](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-30)
### Bug Fixes
* **acai-cli:** check if depth is defined and afterwards if integer ([e614688](https://github.com/MartinHelmut/berries/commit/e614688))
<a name="1.1.1"></a>
## [1.1.1](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-30)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.1.0"></a>
# [1.1.0](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-30)
### Bug Fixes
* **acai-cli:** ignore result list on empty hotspot list ([7af9d5a](https://github.com/MartinHelmut/berries/commit/7af9d5a))
* **acai-cli:** make bin file executable ([7094a65](https://github.com/MartinHelmut/berries/commit/7094a65))
* **acai-cli:** wrong default for branch name ([8a1013d](https://github.com/MartinHelmut/berries/commit/8a1013d))
### Features
* **acai-cli:** add flag to define branch ([d6f7152](https://github.com/MartinHelmut/berries/commit/d6f7152))
* **acai-cli:** add new format option for commit depth ([27e8fbe](https://github.com/MartinHelmut/berries/commit/27e8fbe))
<a name="1.0.4"></a>
## [1.0.4](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-21)
### Bug Fixes
* **acai-cli:** fix animated svg url ([14a871f](https://github.com/MartinHelmut/berries/commit/14a871f))
<a name="1.0.3"></a>
## [1.0.3](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-21)
### Bug Fixes
* **acai-cli:** add proper command name mapping ([d14e7c9](https://github.com/MartinHelmut/berries/commit/d14e7c9))
<a name="1.0.2"></a>
## [1.0.2](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-21)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.0.1"></a>
## [1.0.1](https://github.com/MartinHelmut/berries/compare/@berries/[email protected]...@berries/[email protected]) (2018-01-21)
**Note:** Version bump only for package @berries/acai-cli
<a name="1.0.0"></a>
# 1.0.0 (2018-01-21)
### Bug Fixes
* **acai-cli:** remove required property for cwd option ([dd20992](https://github.com/MartinHelmut/berries/commit/dd20992))
### Features
* **acai:** Add execution time property to scanner result ([0473ed7](https://github.com/MartinHelmut/berries/commit/0473ed7))
* **acai-cli:** Bootstraped new package ([9f83ffb](https://github.com/MartinHelmut/berries/commit/9f83ffb))
* **acai-cli:** Create acai command line tool ([2489d58](https://github.com/MartinHelmut/berries/commit/2489d58)), closes [#6](https://github.com/MartinHelmut/berries/issues/6) [#7](https://github.com/MartinHelmut/berries/issues/7) [#8](https://github.com/MartinHelmut/berries/issues/8)
| 28.79397 | 286 | 0.68918 | yue_Hant | 0.226936 |
118ff10847d9f283001ff5ed891b027053b14a79 | 3,301 | md | Markdown | README.md | TheRoryWillAim/Python-Selenium-Automation-System | e53d0d52fda26d29de6c8fa960bedf8a1b8e53b9 | [
"MIT"
] | 3 | 2020-11-08T12:01:22.000Z | 2021-06-02T06:52:59.000Z | README.md | TheRoryWillAim/Python-Selenium-Automation-System | e53d0d52fda26d29de6c8fa960bedf8a1b8e53b9 | [
"MIT"
] | null | null | null | README.md | TheRoryWillAim/Python-Selenium-Automation-System | e53d0d52fda26d29de6c8fa960bedf8a1b8e53b9 | [
"MIT"
] | null | null | null | # Python-Selenium-Automation-System
## Introduction
Like many other methodological innovations, Automation has grown over the years with technological advancements, however very few people take advantage of the libraries and methods available to automate their daily tasks. This paper explores the avenue of automation along with scraping data from the internet.
Our project aims to encourage and explore the world of automation through the use of two major programming languages and interfaces – Python and Selenium. It explores the most popular libraries implemented by python to perform automation and file manipulation in recent years which include the OS, XML, urlparse and getpass libraries. It also explores selenium which is a free (open-source) automated testing framework used to validate web applications across different browsers and platforms. It intends to create a tool-set driven by automation and web scraping.
We intend to implement and provide a tool set to users with the purpose of saving multiple webpages, documents and means to access files offline without the need to individually go and save each and every required page manually. The tool set also includes scripts that can be used to scrape weather data, top daily news as well as open multiple links through a simple script. This documentation will also cover our workflow methodologies, explore previous work in the field, provide a Software requirement specification documentation along with the design of the proposed system.
The objectives of the implementation are as follows:
• Implementation of a multiple-link opener that automates opening links one-by-one on a browser.
• Scraping the top news headlines from the google news webpage
• Scraping weather information from Open Weather Map
• Automate form fill-ups and logins through Facebook login automation
• Automatically download the desired number of images corresponding to the keyword and number of images required entered by the user.
• Provide a working interface to the user that works on menu-based selection with proper user sanitized inputs.
## Innovation
Work for most people nowadays involves using the internet on a daily basis, however people sometimes need offline web pages and images. They may require to do trivial tasks repeatedly such as open multiple links, download multiple images and so on. They may not have the time required to manually perform multiple searches and operations over the internet. We intend to provide a toolset that can help such people and other students that need to scrape data off the internet and automate their work. This can help improve their efficiency along with lessening their burden. It can also be used by tech enthusiasts to explore the upcoming field of automation through programming.
## Implementation
Run the following scripts in terminal of above code directory
• pip install virtualenv
• virtualenv env
• cd env/scripts
• activate.bat
• cd..
• cd..
• pip install selenium
• pip install urllib3
• pip install contextlib2
• pip install beautifulsoup4
• pip install pyowm==2.7.1
• pip install simple-image-download
• pip install Flask
• python index.py
## Contributors
- TheRoryWillAim(Mayank)
## License & copyright
Licensed under the [MIT License](LICENSE).
| 48.544118 | 678 | 0.805513 | eng_Latn | 0.999499 |
119042f1dec062777e13e0d7935e7fc146edca5c | 913 | md | Markdown | 22-Follow-Along-Link-Highlighter/README.md | Jishenshen/JavaSript30-Challenge | ee51c8c9e6aa94904855e8b4042bf3d51f926836 | [
"Xnet",
"X11"
] | null | null | null | 22-Follow-Along-Link-Highlighter/README.md | Jishenshen/JavaSript30-Challenge | ee51c8c9e6aa94904855e8b4042bf3d51f926836 | [
"Xnet",
"X11"
] | null | null | null | 22-Follow-Along-Link-Highlighter/README.md | Jishenshen/JavaSript30-Challenge | ee51c8c9e6aa94904855e8b4042bf3d51f926836 | [
"Xnet",
"X11"
] | null | null | null | # Day22 - Follow Along Links
第 22 天的练习是一个动画练习,当鼠标移动到锚点处,会有一个白色的色块移动到当前锚点所在的位置。
## css
1. 初始化问题:
```css
*,
*:before,
*:after {
-webkit-box-sizing: border-box;
-moz-box-sizing: border-box;
box-sizing: border-box;
}
```
是让所有的元素都使用 border-box ,并且包括 伪类 before, after 。并不是特殊的定义它们俩。before,after 默认的 display 是 inline, 但难免有人会把它变成 block 来用,这时候统一 box-sizing 会好操作一些。
## JavaScript
通过观察 HTML 代码结构,可以发现需要显示白色动画背景的都是 a 标签,因此首先获取到能够触发事件的 DOM 元素。
当处于动画时查看开发者工具,可以发现这个白色色块儿是一个相对于文档绝对定位的<span>,当我们的鼠标移动到<a>标签的时候,它的 top 和 left 随鼠标移动的位置的变化而动态变化,再加上我们对 CSS 的 highlight 类设置了 transition: all 0.2s;属性,因此会有动画的效果。
介绍一个比较新的 API,[object.getBoundingClientRect()](https://developer.mozilla.org/zh-CN/docs/Web/API/Element/getBoundingClientRect),这个方法返回元素的大小及其相对于视口的位置。返回值是一个 DOMRect 对象,该对象包含了一组用于描述边框的只读属性——left、top、right 和 bottom,单位为像素。除了 width 和 height 外的属性都是相对于视口的左上角位置而言的。具体可以下图所示的边界: getboundclient
| 36.52 | 283 | 0.764513 | yue_Hant | 0.48925 |
1190e929199853f5d0ff4c676e4daf970fe1600f | 3,352 | md | Markdown | README.md | mcantu-cloudinabox/enterprise-showcase | b7f70e43a8f9d1efd26509cc7315384daa632e4f | [
"MIT"
] | null | null | null | README.md | mcantu-cloudinabox/enterprise-showcase | b7f70e43a8f9d1efd26509cc7315384daa632e4f | [
"MIT"
] | null | null | null | README.md | mcantu-cloudinabox/enterprise-showcase | b7f70e43a8f9d1efd26509cc7315384daa632e4f | [
"MIT"
] | null | null | null | # enterprise-showcase
Showcase all the great work that your peers are working on and happily sharing internally.
`enterprise-showcase` is a static web site, hosted on *GitHub Pages* and generated through *GitHub Actions*. No need for a separate runtime or server, and you can fine tune how often you want the site to be generated.
## Features
- Browse every `internal` repository across all organizations of your GitHub Enterpise Account.
- Create collections of repositories so that you can highlight great projects.
- Easily extended so you can customize it to your needs
`enterprise-showcase` is built with GitHub Pages, GitHub Actions, [Nuxt.js](https://nuxtjs.org/) and [Vuetify](https://vuetifyjs.com/)
## Setup
- Fork this repository
- Enable GitHub Pages by setting `gh-pages` as the source branch

- Create a `GH_EA_TOKEN` secret and provide a Personal Access Token with `read:org` and `read:enterprise` permissions as the value (see [helaili/ea-repo-list](https://github.com/helaili/ea-repo-list) for more details).
- Configure the repository retrieval job by editing the `.github\workflows\repo-list.yml` and provide the name of your GitHub Enterprise Account
```yaml
steps:
- uses: actions/checkout@v2
- name: Get the repos
uses: helaili/ea-repo-list@master
with:
enterprise: <replace with GitHub Enteprise Account name>
outputFilename: repositories.json
token: ${{secrets.GH_EA_TOKEN}}
```
- Manually trigger a first repository list retrieval by starting the *Generate repository list* workflow. The Actions workflow should execute succesfully and you should get a freshly commited `repositories.json` file at the root of your repository.

- Create collections by creating a `.md` file per collection in `content/collections`. The *front matter* header allow you to set the collection title, description and list of repositories. The body of the document is available to provide a more detailed description of the collection.
```markdown
---
title: C.R.E.A.M.
description: Cheese Rules Everything Around Me
repositories:
- octocheese/camembert
- octocheese/roquefort
- amsterdam/gouda
- vermont/cheddar
---
# All of them!!!
We love them all
```
<img width="1383" alt="Screen Shot 2021-01-11 at 21 49 45" src="https://user-images.githubusercontent.com/2787414/104236613-2126a200-5457-11eb-9bef-f45e890886c5.png">
- The web site should be published to `https://<your org or account name>/enterprise-showcase/`. In case you renamed the repository, change `router.base` accordingly in the `nuxt.config.js` file. Remove this variable completely if you are publishing to your organization or account-level site (`<user>.github.io` or `<organization>.github.io`)
## Build Setup
```bash
# install dependencies
$ npm install
# serve with hot reload at localhost:3000
$ npm run dev
# build for production and launch server
$ npm run build
$ npm run start
# generate static project
$ npm run generate
```
For detailed explanation on how things work, check out [Nuxt.js docs](https://nuxtjs.org).
| 45.297297 | 343 | 0.760442 | eng_Latn | 0.979107 |
119196a91b85781368742de9034d67023ff37932 | 477 | md | Markdown | docs/api-reference/classes/NSProjectEventEntity/GetPublishType.md | stianol/crmscript | be1ad4f3a967aee2974e9dc7217255565980331e | [
"MIT"
] | null | null | null | docs/api-reference/classes/NSProjectEventEntity/GetPublishType.md | stianol/crmscript | be1ad4f3a967aee2974e9dc7217255565980331e | [
"MIT"
] | null | null | null | docs/api-reference/classes/NSProjectEventEntity/GetPublishType.md | stianol/crmscript | be1ad4f3a967aee2974e9dc7217255565980331e | [
"MIT"
] | null | null | null | ---
uid: crmscript_ref_NSProjectEventEntity_GetPublishType
title: Integer GetPublishType()
intellisense: NSProjectEventEntity.GetPublishType
keywords: NSProjectEventEntity, GetPublishType
so.topic: reference
---
# Integer GetPublishType()
Type of publishing action, 0 = Unknown, 1 = to external persons
**Returns:** Integer
- Enum: 0 = Undefined
- Enum: 1 = External
```crmscript
NSProjectEventEntity thing;
Integer publishType = thing.GetPublishType();
```
| 20.73913 | 63 | 0.761006 | eng_Latn | 0.361082 |
119219d82d8213079897909a9689ae178c7ef6d9 | 58 | md | Markdown | _posts/2014/2014-10-24-Small-Million-Mothertapes.md | taxihelms0/s1-arch | 0ef372717010dc36c1119f22a7e003c10442edc4 | [
"MIT"
] | null | null | null | _posts/2014/2014-10-24-Small-Million-Mothertapes.md | taxihelms0/s1-arch | 0ef372717010dc36c1119f22a7e003c10442edc4 | [
"MIT"
] | 1 | 2021-03-30T12:07:18.000Z | 2021-03-30T12:07:18.000Z | _posts/2014/2014-10-24-Small-Million-Mothertapes.md | taxihelms0/s1-arch | 0ef372717010dc36c1119f22a7e003c10442edc4 | [
"MIT"
] | null | null | null | ---
title: Small Million, Mothertapes
date: 2014-10-24
--- | 14.5 | 33 | 0.689655 | eng_Latn | 0.446465 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.