
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
daeecc42386e58b5ee392845cb12775ae3dc4e82 | 2,487 | md | Markdown | docs/standard/cross-platform/windowsruntimestreamextensions-asrandomaccessstream-method.md | sheng-jie/docs.zh-cn-1 | e825f92bb3665ff8e05a0d627bb65a9243b39992 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/standard/cross-platform/windowsruntimestreamextensions-asrandomaccessstream-method.md | sheng-jie/docs.zh-cn-1 | e825f92bb3665ff8e05a0d627bb65a9243b39992 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/standard/cross-platform/windowsruntimestreamextensions-asrandomaccessstream-method.md | sheng-jie/docs.zh-cn-1 | e825f92bb3665ff8e05a0d627bb65a9243b39992 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: WindowsRuntimeStreamExtensions.AsRandomAccessStream(System.IO.Stream) 方法
ms.date: 03/30/2017
ms.technology: dotnet-standard
dev_langs:
- csharp
- vb
api_name:
- System.IO.WindowsRuntimeStreamExtensions.AsRandomAccessStream
api_location:
- System.Runtime.WindowsRuntime.dll
ms.assetid: dcc72283-caed-49ee-b45d-ccaf94e97129
author: mairaw
ms.author: mairaw
ms.openlocfilehash: 16f878abc11589fe62f78d941b367d82d7b49e1c
ms.sourcegitcommit: 11f11ca6cefe555972b3a5c99729d1a7523d8f50
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/03/2018
ms.locfileid: "32768510"
---
# <a name="windowsruntimestreamextensionsasrandomaccessstreamsystemiostream-method"></a>WindowsRuntimeStreamExtensions.AsRandomAccessStream(System.IO.Stream) 方法
[在 .NET Framework 4.5.1 和更高版本中受支持]
将指定的流转换为随机访问流。
**Namespace:** <xref:System.IO?displayProperty=nameWithType>
**程序集:** System.Runtime.WindowsRuntime (在 system.runtime.windowsruntime.dll 中)
## <a name="syntax"></a>语法
```csharp
[CLSCompliantAttribute(false)]
public static IRandomAccessStream AsRandomAccessStream(Stream stream)
```
```vb
'Declaration
<ExtensionAttribute> _
<CLSCompliantAttribute(False)> _
Public Shared Function AsRandomAccessStream ( _
stream As Stream) As IRandomAccessStream
```
#### <a name="parameters"></a>参数
`stream`
类型:<xref:System.IO.Stream?displayProperty=nameWithType>
要转换的流。
## <a name="return-value"></a>返回值
类型: [Windows.Storage.Streams.RandomAccessStream](http://msdn.microsoft.com/library/windows/apps/windows.storage.streams.randomaccessstream.aspx)
A[!INCLUDE[wrt](../../../includes/wrt-md.md)]随机访问流,它表示转换后的流。
## <a name="exceptions"></a>异常
|例外|条件|
|---------------|---------------|
|<xref:System.NotSupportedException>|要转换的流不支持查找。|
## <a name="remarks"></a>备注
此扩展方法仅在开发 Windows 应用商店应用时可用。 利用此方法,可以在 Windows 应用商店应用中轻松使用流。 要转换的 .NET Framework 流必须支持查找。 有关更多信息,请参见 <xref:System.IO.Stream.Seek%2A?displayProperty=nameWithType> 方法。
> [!IMPORTANT]
> 此 API 在 .NET Framework 4.5.1 和更高版本中受支持,但在 4.5 版中不受支持。
## <a name="version-information"></a>版本信息
**适用于 Windows 应用商店应用的.NET**
受支持:Windows 8.1
## <a name="see-also"></a>请参阅
<!--zz <xref:System.IO.WindowsRuntimeStreamExtensions>--> `System.IO.WindowsRuntimeStreamExtensions`
[如何:在 .NET Framework 流和 Windows 运行时流之间进行转换](../../../docs/standard/io/how-to-convert-between-dotnet-streams-and-winrt-streams.md)
| 33.16 | 168 | 0.725372 | yue_Hant | 0.792977 |
daf0b135d687e843ffcbc8c94e4d0d76cf4b9e86 | 1,637 | md | Markdown | CONTRIBUTING.md | rept/chartkick.js | 29d99acc596a642eaa14c6fdc71adf867225cae6 | [
"MIT"
] | null | null | null | CONTRIBUTING.md | rept/chartkick.js | 29d99acc596a642eaa14c6fdc71adf867225cae6 | [
"MIT"
] | null | null | null | CONTRIBUTING.md | rept/chartkick.js | 29d99acc596a642eaa14c6fdc71adf867225cae6 | [
"MIT"
] | null | null | null | # Contributing
First, thanks for wanting to contribute. You’re awesome! :heart:
## Questions
Use [Stack Overflow](https://stackoverflow.com/) with the tag `chartkick`.
## Feature Requests
Create an issue. Start the title with `[Idea]`.
## Issues
Think you’ve discovered an issue?
1. Search existing issues to see if it’s been reported.
2. Try the `master` branch to make sure it hasn’t been fixed.
If the above steps don’t help, create an issue. Include:
- Recreate the problem by forking [this gist](https://gist.github.com/ankane/2e92c0ff9c138db7bf482209920466bf). Include a link to your gist and the output in the issue.
- For exceptions, include the complete backtrace.
## Pull Requests
Fork the project and create a pull request. A few tips:
- New features should be added to Chart.js at the very least.
- Keep changes to a minimum. If you have multiple features or fixes, submit multiple pull requests.
- Follow the existing style. The code should read like it’s written by a single person.
Feel free to open an issue to get feedback on your idea before spending too much time on it.
Also, note that we aren’t currently accepting new chart types.
## Dev Setup
To get started with development and testing:
```sh
git clone https://github.com/ankane/chartkick.js.git
cd chartkick.js
yarn
yarn build
# start web server
yarn global add serve
serve
```
And visit [http://localhost:5000/examples](http://localhost:5000/examples) in your browser.
---
This contributing guide is released under [CCO](https://creativecommons.org/publicdomain/zero/1.0/) (public domain). Use it for your own project without attribution.
| 28.719298 | 168 | 0.758705 | eng_Latn | 0.993929 |
daf0d294d13160e09c0e85452650d7334ca589f0 | 907 | md | Markdown | README.md | GryderArt/CRISPRtoolkit | e5a342b217bb31550f326b2278dac8d278d98fad | [
"CC0-1.0"
] | 1 | 2021-09-27T10:15:17.000Z | 2021-09-27T10:15:17.000Z | README.md | GryderArt/CRISPRtoolkit | e5a342b217bb31550f326b2278dac8d278d98fad | [
"CC0-1.0"
] | null | null | null | README.md | GryderArt/CRISPRtoolkit | e5a342b217bb31550f326b2278dac8d278d98fad | [
"CC0-1.0"
] | null | null | null | # CRISPRtoolkit
Code used to handle pooled CRISPR data (buildMatrix_and_plotCRISPR.R) and design followup sgRNAs by generating cutsite locations as BED coordinate (sgRNA_to_bed.sh).
# Achilles CRISPR data analysis script
R-script for analyzing and making figures (plotAchillesCRISPR_20Q1.R) from Achilles DepMap datasets. Updated to 20Q1.
Data freely available from: https://depmap.org/portal/download/all/
1. CERES Rank dot plots
<a href="https://github.com/GryderArt/CRISPRtoolkit/blob/master/"><img src="example_plots/CERES_RankDots.png" width="700"/></a>
2. Achilles ranked box plots per tumor type
<a href="https://github.com/GryderArt/CRISPRtoolkit/blob/master/"><img src="example_plots/PAX3_RankedBoxes.png" width="700"/></a>
3. Heatmap, genes vs. tumor types
<a href="https://github.com/GryderArt/CRISPRtoolkit/blob/master/"><img src="example_plots/AchillesHeatMap.png" width="300"/></a>
| 43.190476 | 165 | 0.777288 | kor_Hang | 0.34516 |
daf2003e57b1626719f95052189d36c31e1403c3 | 678 | md | Markdown | readme.md | twistezo/netflix-subtitles-styler | bbb31d4a7f6b907b0aef3db9f284c80a1b224ab8 | [
"MIT"
] | 3 | 2019-12-23T20:54:33.000Z | 2022-03-23T11:42:13.000Z | readme.md | twistezo/netflix-subtitles-styler | bbb31d4a7f6b907b0aef3db9f284c80a1b224ab8 | [
"MIT"
] | 3 | 2019-03-14T09:30:03.000Z | 2019-04-11T15:31:33.000Z | readme.md | twistezo/netflix-subtitles-styler | bbb31d4a7f6b907b0aef3db9f284c80a1b224ab8 | [
"MIT"
] | 3 | 2019-07-29T10:50:37.000Z | 2021-01-02T02:41:17.000Z | ## Netflix subtitles styler
### Description
Google Chrome browser extension for manipulate styles of Netflix subtitles.
### Features
Netflix subtitles:
- change vertical position from bottom
- change font size
- change font color
- remove background shadow
Extension:
- autoload while Netflix website is on active tab
- store input data in browser Local Storage
- form validation
### Tools
Chrome-API, JavaScript
### Usage
Currently extension is not in Chrome Webstore so for using:
- download repository
- go to `chrome://extensions/` in browser
- click `Load unpacked`, select folder and that's it
### Latest version
<img src="https://i.imgur.com/kt6CeVw.png">
| 18.324324 | 75 | 0.752212 | eng_Latn | 0.902975 |
daf22fd14b9264f2538484cef42404f29069ac30 | 20,152 | md | Markdown | docs/api/DataApi.md | Jasmine0729/PI-Web-API-Client-Python | 1fe1d6da7743c7771056b4c283c8e04f8635a14f | [
"Apache-2.0"
] | 2 | 2019-07-03T21:29:16.000Z | 2021-05-31T15:26:10.000Z | docs/api/DataApi.md | rbechalany/PI-Web-API-Client-Python | 1fe1d6da7743c7771056b4c283c8e04f8635a14f | [
"Apache-2.0"
] | null | null | null | docs/api/DataApi.md | rbechalany/PI-Web-API-Client-Python | 1fe1d6da7743c7771056b4c283c8e04f8635a14f | [
"Apache-2.0"
] | 3 | 2019-07-03T21:36:51.000Z | 2020-05-21T19:26:08.000Z | # DataApi
Method | HTTP request | Description
------------ | ------------- | -------------
[**get_recorded_values**](DataApi.md#get_recorded_values) | Returns a pandas dataframe with compressed values for the requested time range from the source provider.
[**get_interpolated_values**](DataApi.md#get_interpolated_values) | Retrieves a pandas dataframe with interpolated values over the specified time range at the specified sampling interval.
[**get_plot_values**](DataApi.md#get_plot_values*) | Retrieves a pandas dataframe with values over the specified time range suitable for plotting over the number of intervals (typically represents pixels).
[**get_summary_values**](DataApi.md#get_summary_values*) | Returns a data frame with the summary over the specified time range for the stream.
[**get_multiple_recorded_values**](DataApi.md#get_multiple_recorded_values) | Returns an array of pandas dataframe with recorded values of the specified streams.
[**get_multiple_interpolated_values**](DataApi.md#get_multiple_interpolated_values) | Returns a dataframe with interpolated values of the specified streams over the specified time range at the specified sampling interval.
[**get_multiple_plot_values**](DataApi.md#get_multiple_plot_values) | Returns a pandas dataframe with values of the specified streams over the specified time range suitable for plotting over the number of intervals (typically represents pixels).
# **get_recorded_values**
> get_recorded_values('path', 'boundary_type', 'desired_units', 'end_time', 'filter_expression', 'include_filtered_values', 'max_count', 'selected_fields', 'start_time', 'time_zone')
Returns a pandas dataframe with compressed values for the requested time range from the source provider.
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| The path of the stream (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required]
**boundary_type** | **str**| An optional value that determines how the times and values of the returned end points are determined. The default is 'Inside'.. | [optional]
**desired_units** | **str**| The name or abbreviation of the desired units of measure for the returned value, as found in the UOM database associated with the attribute. If not specified for an attribute, the attribute's default unit of measure is used. If the underlying stream is a point, this value may not be specified, as points are not associated with a unit of measure.. | [optional]
**end_time** | **str**| An optional end time. The default is '*' for element attributes and points. For event frame attributes, the default is the event frame's end time, or '*' if that is not set. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**filter_expression** | **str**| An optional string containing a filter expression. Expression variables are relative to the data point. Use '.' to reference the containing attribute. The default is no filtering.. | [optional]
**include_filtered_values** | **bool**| Specify 'true' to indicate that values which fail the filter criteria are present in the returned data at the times where they occurred with a value set to a 'Filtered' enumeration value with bad status. Repeated consecutive failures are omitted.. | [optional]
**max_count** | **int**| The maximum number of values to be returned. The default is 1000.. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d' for element attributes and points. For event frame attributes, the default is the event frame's start time, or '*-1d' if that is not set.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_interpolated_values**
> get_interpolated_values('path', 'desired_units', 'end_time', 'filter_expression', 'include_filtered_values', 'interval', 'selected_fields', 'start_time', 'time_zone')
Retrieves a pandas dataframe with interpolated values over the specified time range at the specified sampling interval.
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| The path of the stream (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required]
**desired_units** | **str**| The name or abbreviation of the desired units of measure for the returned value, as found in the UOM database associated with the attribute. If not specified for an attribute, the attribute's default unit of measure is used. If the underlying stream is a point, this value may not be specified, as points are not associated with a unit of measure.. | [optional]
**end_time** | **str**| An optional end time. The default is '*' for element attributes and points. For event frame attributes, the default is the event frame's end time, or '*' if that is not set. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**filter_expression** | **str**| An optional string containing a filter expression. Expression variables are relative to the data point. Use '.' to reference the containing attribute. If the attribute does not support filtering, the filter will be ignored. The default is no filtering.. | [optional]
**include_filtered_values** | **bool**| Specify 'true' to indicate that values which fail the filter criteria are present in the returned data at the times where they occurred with a value set to a 'Filtered' enumeration value with bad status. Repeated consecutive failures are omitted.. | [optional]
**interval** | **str**| The sampling interval, in AFTimeSpan format.. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d' for element attributes and points. For event frame attributes, the default is the event frame's start time, or '*-1d' if that is not set.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_plot_values**
> get_plot_values**('path', 'desired_units', 'end_time', 'intervals', 'selected_fields', 'start_time', 'time_zone')
Retrieves a pandas dataframe with values over the specified time range suitable for plotting over the number of intervals (typically represents pixels).
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **str**| The path of the stream (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required]
**desired_units** | **str**| The name or abbreviation of the desired units of measure for the returned value, as found in the UOM database associated with the attribute. If not specified for an attribute, the attribute's default unit of measure is used. If the underlying stream is a point, this value may not be specified, as points are not associated with a unit of measure.. | [optional]
**end_time** | **str**| An optional end time. The default is '*' for element attributes and points. For event frame attributes, the default is the event frame's end time, or '*' if that is not set. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**intervals** | **int**| The number of intervals to plot over. Typically, this would be the number of horizontal pixels in the trend. The default is '24'. For each interval, the data available is examined and significant values are returned. Each interval can produce up to 5 values if they are unique, the first value in the interval, the last value, the highest value, the lowest value and at most one exceptional point (bad status or digital state).. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d' for element attributes and points. For event frame attributes, the default is the event frame's start time, or '*-1d' if that is not set.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_summary_values**
> get_summary_values('path', 'calculation_basis', 'end_time', 'filter_expression', 'sample_interval', 'sample_type', 'selected_fields', 'start_time', 'summary_duration', 'summary_type', 'time_type', 'time_zone')
Returns a data frame with the summary over the specified time range for the stream.
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **list[str]**| The paths of multiple streams (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required]
**calculation_basis** | **str**| Specifies the method of evaluating the data over the time range. The default is 'TimeWeighted'.. | [optional]
**end_time** | **str**| An optional end time. The default is '*' for element attributes and points. For event frame attributes, the default is the event frame's end time, or '*' if that is not set. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**filter_expression** | **str**| A string containing a filter expression. Expression variables are relative to the attribute. Use '.' to reference the containing attribute.. | [optional]
**sample_interval** | **str**| When the sampleType is Interval, sampleInterval specifies how often the filter expression is evaluated when computing the summary for an interval.. | [optional]
**sample_type** | **str**| Defines the evaluation of an expression over a time range. The default is 'ExpressionRecordedValues'.. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d' for element attributes and points. For event frame attributes, the default is the event frame's start time, or '*-1d' if that is not set.. | [optional]
**summary_duration** | **str**| The duration of each summary interval. If specified in hours, minutes, seconds, or milliseconds, the summary durations will be evenly spaced UTC time intervals. Longer interval types are interpreted using wall clock rules and are time zone dependent.. | [optional]
**summary_type** | **list[str]**| Specifies the kinds of summaries to produce over the range. The default is 'Total'. Multiple summary types may be specified by using multiple instances of summaryType.. | [optional]
**time_type** | **str**| Specifies how to calculate the timestamp for each interval. The default is 'Auto'.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
[**PIItemsSummaryValue**](../models/PIItemsSummaryValue.md)
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_multiple_recorded_values**
> get_multiple_recorded_values('path', 'boundary_type', 'end_time', 'filter_expression', 'include_filtered_values', 'max_count', 'selected_fields', 'start_time', 'time_zone')
Returns recorded values of the specified streams.
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **list[str]**| The paths of multiple streams (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required]
**boundary_type** | **str**| An optional value that determines how the times and values of the returned end points are determined. The default is 'Inside'.. | [optional]
**end_time** | **str**| An optional end time. The default is '*'. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**filter_expression** | **str**| An optional string containing a filter expression. Expression variables are relative to the data point. Use '.' to reference the containing attribute. The default is no filtering.. | [optional]
**include_filtered_values** | **bool**| Specify 'true' to indicate that values which fail the filter criteria are present in the returned data at the times where they occurred with a value set to a 'Filtered' enumeration value with bad status. Repeated consecutive failures are omitted.. | [optional]
**max_count** | **int**| The maximum number of values to be returned. The default is 1000.. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d'.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Array of Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_multiple_interpolated_values**
> get_multiple_interpolated_values('path', 'end_time', 'filter_expression', 'include_filtered_values', 'interval', 'selected_fields', 'start_time', 'time_zone')
Returns interpolated values of the specified streams over the specified time range at the specified sampling interval.
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **list[str]**| The paths of multiple streams (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required
**end_time** | **str**| An optional end time. The default is '*'. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**filter_expression** | **str**| An optional string containing a filter expression. Expression variables are relative to the data point. Use '.' to reference the containing attribute. If the attribute does not support filtering, the filter will be ignored. The default is no filtering.. | [optional]
**include_filtered_values** | **bool**| Specify 'true' to indicate that values which fail the filter criteria are present in the returned data at the times where they occurred with a value set to a 'Filtered' enumeration value with bad status. Repeated consecutive failures are omitted.. | [optional]
**interval** | **str**| The sampling interval, in AFTimeSpan format.. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d'.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
# **get_multiple_plot_values**
> get_multiple_plot_values('path', 'end_time', 'intervals', 'selected_fields', 'start_time', 'time_zone')
Returns values of attributes for the specified streams over the specified time range suitable for plotting over the number of intervals (typically represents pixels).
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**path** | **list[str]**| The paths of multiple streams (for a PI Point use "pi:\\servername\pointname" or "af:\\afservername\database\element|attribute" for an attribute). | [required
**end_time** | **str**| An optional end time. The default is '*'. Note that if endTime is earlier than startTime, the resulting values will be in time-descending order.. | [optional]
**intervals** | **int**| The number of intervals to plot over. Typically, this would be the number of horizontal pixels in the trend. The default is '24'. For each interval, the data available is examined and significant values are returned. Each interval can produce up to 5 values if they are unique, the first value in the interval, the last value, the highest value, the lowest value and at most one exceptional point (bad status or digital state).. | [optional]
**selected_fields** | **str**| List of fields to be returned in the response, separated by semicolons (;). If this parameter is not specified, all available fields will be returned.. | [optional]
**start_time** | **str**| An optional start time. The default is '*-1d'.. | [optional]
**time_zone** | **str**| The time zone in which the time string will be interpreted. This parameter will be ignored if a time zone is specified in the time string. If no time zone is specified in either places, the PI Web API server time zone will be used.. | [optional]
### Return type
Pandas Dataframe
[[Back to top]](#) [[Back to API list]](../../DOCUMENTATION.md#documentation-for-api-endpoints) [[Back to Model list]](../../DOCUMENTATION.md#documentation-for-models) [[Back to DOCUMENTATION]](../../DOCUMENTATION.md)
| 97.825243 | 467 | 0.72767 | eng_Latn | 0.986946 |
daf2c2feb06fc528bfe84cb4295b6400e3eb919a | 17,032 | md | Markdown | content/latest/blog/e-commerce-at-the-speed-of-amp.md | nurse/ampdocs | 28f5bac7d00ea42ae48371dfe3c0262b27cd3828 | [
"Apache-2.0"
] | null | null | null | content/latest/blog/e-commerce-at-the-speed-of-amp.md | nurse/ampdocs | 28f5bac7d00ea42ae48371dfe3c0262b27cd3828 | [
"Apache-2.0"
] | null | null | null | content/latest/blog/e-commerce-at-the-speed-of-amp.md | nurse/ampdocs | 28f5bac7d00ea42ae48371dfe3c0262b27cd3828 | [
"Apache-2.0"
] | null | null | null | ---
class: post-blog post-detail
type: Blog
$title: "E-commerce at the speed of AMP"
id: e-commerce-at-the-speed-of-amp
author: Lisa Wang
role: Product Manager, AMP Project
origin: "https://amphtml.wordpress.com/2017/09/06/e-commerce-at-the-speed-of-amp/amp/"
excerpt: "Early results for e-commerce companies that are investing in Accelerated Mobile Pages (AMP) are showing that the format is paying off in terms of conversions, speed, bounce rates and mobile acquisition costs. Brazil-based Fastcommerce’s clients are seeing a 15% lift in conversions on mobile as compared to non-AMP pages across their 2M AMP pages  WompMobile […]"
avatar: http://1.gravatar.com/avatar/42ecb1ea497ca9d0ffe1e406cae70e27?s=96&d=identicon&r=G
date_data: 2017-09-06T06:21:14-07:00
$date: September 6, 2017
$parent: /content/latest/list-blog.html
$path: /latest/blog/{base}/
$localization:
path: /{locale}/latest/blog/{base}/
components:
- social-share
- carousel
- anim
inlineCSS: .amp-wp-inline-329fdb7771c10d07df9eb73273c95a60{font-weight:400;}.amp-wp-inline-a6ec8840dd8107f0c4f9cbd7d00cece0{text-align:center;}
---
<div class="amp-wp-article-content">
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Early results for e-commerce companies that are investing in Accelerated Mobile Pages (AMP) are showing that the format is paying off in terms of conversions, speed, bounce rates and mobile acquisition costs.</span></p>
<ul><li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Brazil-based </span><a href="https://www.ampproject.org/case-studies/fastcommerce/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Fastcommerce’s</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> clients are seeing a </span><b>15% lift in conversions</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> on mobile as compared to non-AMP pages across their 2M AMP pages</span></span> </li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/case-studies/wompmobile/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">WompMobile</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> creates effective mobile experiences for e-commerce websites and saw a </span><b>105% increase in conversion rates</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and a</span><b> 31% decrease in bounce rates with AMP pages</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">.</span></span> </li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/case-studies/wego/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Wego.com</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">, the largest travel marketplace in the Middle East and Asia Pacific, saw a </span><b>95% increase in partner conversion rates</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and a </span><b><b>3x increase in ad conversions after creating AMP versions of key landing pages.</b></b> </li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">AMP drives close to half the mobile traffic of French organic retailer </span><a href="https://www.ampproject.org/case-studies/greenweez/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Greenweez</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and from January to March 2017, they saw an </span><b>80% increase in mobile conversion rates</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and </span><b>66% decrease in mobile acquisition costs</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">. </span><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> </span></li>
</ul><p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">We’ve seen that </span><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">AMP brings an </span><b>almost-instant page load</b><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> that makes it ideal for the first user interaction with your site. But there’s much more to an e-commerce experience than speed, and AMP is your ideal partner in this journey. For those of you that want to see similar success to Greenweez or Fastcommerce, we’d like to share an overview of all that is possible for e-commerce with AMP. </span></p>
<p><b>The Basics</b></p>
<p>Let’s start with the basics of your e-commerce site. Check out <a href="https://ampbyexample.com/introduction/amp_for_e-commerce_getting_started/">AMP for E-commerce Getting Started</a> on the AMPbyExample website. There you can find sandbox examples to start building product pages, product category pages, and checkout/payment flows. Provide your customers with everything they need to make a decision – <a href="https://ampbyexample.com/samples_templates/comment_section/preview/">reviews</a>, <a href="https://ampbyexample.com/advanced/image_galleries_with_amp-carousel/">photos</a>, <a href="https://ampbyexample.com/samples_templates/product_page/preview/">product customization</a>, and more.</p>
<amp-carousel width="600" height="480" type="slides" layout="responsive"><amp-img src="https://amphtml.files.wordpress.com/2017/09/myntra1.jpg?w=270" width="270" height="480" layout="responsive"></amp-img><amp-img src="https://amphtml.files.wordpress.com/2017/09/myntra2.gif?w=270" width="270" height="480" layout="responsive"></amp-img><amp-img src="https://amphtml.files.wordpress.com/2017/09/myntra3.gif?w=270" width="270" height="480" layout="responsive"></amp-img></amp-carousel><p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><i>Myntra, the largest online fashion player in India, saw a 60% improvement in speed and 40% reduction in bounce rates across their most important landing pages. By using amp-bind they also implemented sorting and filtering, and size selection on these pages to give their users a rich experience.</i></span></p>
<p>Some highlights of what AMP supports are:</p>
<ul><li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://ampbyexample.com/introduction/amp_for_e-commerce_getting_started/#dynamic-content"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Dynamic content</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">: To ensure your customers are always seeing the freshest information, amp-list and amp-bind can be used to fetch and render up-to-date content on your pages. </span></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://ampbyexample.com/introduction/amp_for_e-commerce_getting_started/#checkout-flow-and-payments"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Checkout/payments</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">: You can implement a </span><a href="https://ampbyexample.com/samples_templates/product_page/#product-page"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">shopping cart</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and initiate check-out flows directly from within your AMP pages. Whether you want to use the </span><a href="https://ampbyexample.com/advanced/payments_in_amp/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Payment Request API</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">, use </span><a href="https://ampbyexample.com/components/amp-form"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">amp-form</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">, or redirect users to a non-AMP page on your website is up to you. WompMobile </span><a href="https://www.youtube.com/watch?v=Em-tZ4WMMps&t=723"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">shared</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> their payment implementation at this year’s AMP Conf, which you can check out in the linked video. </span></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://ampbyexample.com/introduction/amp_for_e-commerce_getting_started/#personalization-and-login"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Personalization/log-in</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">: amp-list can be used to provide personalized content to your customers – whether in the form of recommended products or saving the state of their shopping cart. </span></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://ampbyexample.com/components/amp-experiment/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">A/B Testing</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">: To learn what works best for your users, you can use amp-experiment to conduct user experience experiments on your AMP pages. </span></li>
</ul><p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">For features that aren’t supported natively, you can use </span><a href="https://ampbyexample.com/components/amp-iframe/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">amp-iframe</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> to embed content and incorporate features like chat applications, maps, or other third party features. Or if you prefer, you can also hand off to a non-AMP page on your website. </span></p>
<p><b>amp-bind</b></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Many of these engaging and useful e-commerce experiences are made possible with amp-bind, an interactivity model which allows you to link user actions with different document states</span><i><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">. </span></i><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Back in July, we detailed many examples of the </span><a href="https://www.ampproject.org/latest/blog/amp-bind-brings-flexible-interactivity-to-amp-pages/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">new opportunities</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> amp-bind brings – here are some more of the key ones for e-commerce.</span></p>
<ul><li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/latest/blog/amp-bind-brings-flexible-interactivity-to-amp-pages/#product-color-and-size-selection"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Product color and size selection</span></a></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/latest/blog/amp-bind-brings-flexible-interactivity-to-amp-pages/#server-side-filter-and-sort"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Server-side filter & sort</span></a></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/latest/blog/amp-bind-brings-flexible-interactivity-to-amp-pages/#search-results-without-reload"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Search results without page reload</span></a></li>
<li class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"><a href="https://www.ampproject.org/latest/blog/amp-bind-brings-flexible-interactivity-to-amp-pages/#auto-suggest"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Search auto-suggest</span></a></li>
</ul><p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">In the example we built below, you can see filtering and sorting in action:</span></p>
<p><amp-anim class=" wp-image-1555 aligncenter amp-wp-enforced-sizes" src="https://amphtml.files.wordpress.com/2017/09/sort_filter.gif?w=282&h=501" alt="sort_filter" width="282" height="501" sizes="(min-width: 282px) 282px, 100vw"></amp-anim></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">And as we’ve mentioned, you will probably discover more capabilities than what we’ve identified. Explore the possibilities and </span><a href="https://groups.google.com/forum/#!forum/amphtml-discuss"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">share with the community</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> what you find. </span></p>
<p><b>AMP + PWA</b></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">When Wego, the largest travel marketplace in the Middle East, rebuilt their landing pages with AMP and their more interactive pages with PWA, they saw </span><a href="https://www.youtube.com/watch?v=_pmjBZi5zY0"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">tremendous improvements</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> in site performance. Their AMP pages saw more than a 10x increase in page speeds and a 12% increase in organic page visits. </span></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">While PWAs support engaging, app-like features, the Service Worker necessary for the PWA is unavailable the first time a user loads your site. AMP provides an ideal entry point to your site that allows the PWA to load behind the scenes. With their AMP + PWA implementation, Wego saw 95% more conversions and 26% more visitors to their site. </span></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">As you can see, e-commerce sites in particular can benefit from this combination: AMP dramatically speeds up the first page on your site and PWAs speed up the loading time for each subsequent click. This is especially useful when the conversion funnel spans multiple pages. </span></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">And as an added bonus, PWAs also support engaging, app-like features, such as add-to-homescreen buttons, push notifications, reliability in poor network conditions, and functionality even when the user is completely offline. </span></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">To learn more about how to implement an AMP + PWA site, check out our this </span><a href="https://www.youtube.com/watch?v=Yllbfu3JE2Y"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">video tutorial</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and </span><a href="https://www.ampproject.org/docs/guides/pwa-amp"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">guide</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">. </span></p>
<p><b>Analytics</b></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">amp-analytics supports both third-party analytics tools and your own in-house analytics solutions. You can find a list of all the third-party tools that have built in configurations for use with the amp-analytics component </span><a href="https://www.ampproject.org/docs/guides/analytics/analytics-vendors"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">here</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> – including Adobe Analytics, Google Analytics, Clicky Web Analytics, and more. For in-house implementations, check out our </span><a href="https://ampbyexample.com/components/amp-analytics/"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">AMP By Example on Analytics</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">. At AMP Conf earlier this year, companies like </span><a href="https://www.youtube.com/watch?v=wr2SfwCUI0M&t=692"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">eBay</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> and </span><a href="https://www.youtube.com/watch?v=xTn-Ph864EQ&t=842"><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Pinterest</span></a><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60"> also went into more details about how they incorporated analytics for AMP, so check out the linked videos to learn more.</span></p>
<p class="amp-wp-inline-a6ec8840dd8107f0c4f9cbd7d00cece0"><b>* * *</b></p>
<p><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">The AMP Project is committed to helping sites utilize the format’s lightening fast speeds for e-commerce. You can expect to see additional resources, like new e-commerce templates on AMPstart.com in the coming months. </span><b>Thanks to the AMP development community for your work and feedback. As always, please </b><a href="https://groups.google.com/forum/#!forum/amphtml-discuss"><b>let us know</b></a><b> if you have any issues or feature requests.</b></p>
<p><i><span class="amp-wp-inline-329fdb7771c10d07df9eb73273c95a60">Posted by Lisa Wang, Product Manager, AMP Project</span></i></p>
</div>
</div>
| 250.470588 | 1,500 | 0.788751 | eng_Latn | 0.607524 |
daf32e990c628b84bebb311e536d4251f902cf79 | 809 | md | Markdown | Sources/Mixer/README.md | phatblat/Cake | a826004f7149a122c91e1a2c658b0727be164c39 | [
"Apache-2.0"
] | 578 | 2019-03-02T17:19:39.000Z | 2022-01-12T05:05:06.000Z | Sources/Mixer/README.md | phatblat/Cake | a826004f7149a122c91e1a2c658b0727be164c39 | [
"Apache-2.0"
] | 16 | 2019-03-04T15:37:51.000Z | 2019-08-20T15:59:56.000Z | Sources/Mixer/README.md | phatblat/Cake | a826004f7149a122c91e1a2c658b0727be164c39 | [
"Apache-2.0"
] | 17 | 2019-03-03T06:23:01.000Z | 2022-01-12T05:05:07.000Z | Mixer is an independent Swift-Package because it builds its own copy
of SwiftPM (since libSwiftPM is not usable from an Xcode installation)
and 1. Cake cannot support c-packages yet; 2. adding SwiftPM as a
dependency kills clean builds (which we intend to fix); and 3. this
would be inefficient since we only need libSwiftPM for Mixer so really
we need Cake to support this more advanced use-case.
We have a subfolder `Base` that contains symlinks to our Cake base
module swift files. This is due to SwiftPM refusing to create modules
for directories that are below the `Package.swift` directory.
# Getting an Xcodeproj
In this directory:
swift package generate-xcodeproj --xcconfig-overrides .build/libSwiftPM.xcconfig
# Building Cake
Bootstrapping SwiftPM requires `ninja`:
brew install ninja | 36.772727 | 84 | 0.792336 | eng_Latn | 0.998792 |
daf36dc444b1e86ebe9562f57eaa39cdf091979e | 10,691 | md | Markdown | README.md | softasap/sa-secure-auditd | eb7b1e3174d2f7f968f6f35624a646f32909f841 | [
"BSD-3-Clause",
"MIT"
] | 7 | 2018-01-13T10:53:23.000Z | 2021-05-13T23:51:42.000Z | README.md | softasap/sa-secure-auditd | eb7b1e3174d2f7f968f6f35624a646f32909f841 | [
"BSD-3-Clause",
"MIT"
] | 4 | 2020-02-26T20:24:21.000Z | 2021-09-23T23:26:34.000Z | README.md | softasap/sa-secure-auditd | eb7b1e3174d2f7f968f6f35624a646f32909f841 | [
"BSD-3-Clause",
"MIT"
] | 5 | 2017-02-07T15:53:24.000Z | 2020-03-02T04:21:30.000Z | sa-secure-auditd
================
[](https://travis-ci.org/softasap/sa-secure-auditd)
Example of use: check box-example
Simple:
```YAML
custom_auditd_log_group: syslog # default root, change to other user if you plan to log messages
custom_auditd_props:
- {regexp: "^log_group =*", line: "log_group = {{auditd_log_group}}"}
custom_auditd_rules:
- "-D" # clean rules
- "-b 320" # no of bufs for messages
- "-f 1" # on failure 0 nothing, 1 dmesg, 2 kernel panic
- "-a exit,always -S unlink -S rmdir" # notify unlink rmdir
- "-w /etc/group -p wa" # group modification
- "-w /etc/passwd -p wa" # passwords modification
- "-w /etc/shadow -p wa"
- "-w /etc/sudoers -p wa"
- "-e 2" # prevent further changes to config
```
```YAML
- {
role: "sa-secure-auditd"
}
```
Advanced:
```YAML
- {
role: "sa-secure-auditd",
auditd_conf_props: "{{custom_auditd_props}}",
auditd_log_group: custom_auditd_log_group
}
```
Hint: viewing auditd reports
```bash
$ sudo journalctl --boot _TRANSPORT=audit
-- Logs begin at Thu 2016-01-05 09:20:01 CET. --
Jan 05 09:47:24 arsenic audit[3028]: USER_END pid=3028 uid=0 auid=1000 ses=3 subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 msg='op=PAM:session_close grantors=pam_keyinit,pam_limits,pam_keyinit,pam_limits,pam_systemd,pam_unix acct="root" exe="/usr/bin/sudo" hostname=? addr=? terminal=/dev/pts/4 res=success'
...
```
Or, perhaps
```bash
sudo journalctl -af _TRANSPORT=audit
```
STIG: Enterprise level auditing setup
-------------------------------------
Example of full audit.rules that correspond to
https://www.stigviewer.com/stig/red_hat_enterprise_linux_6/
```
## RHEL 6 Security Technical Implementation Guide
## Remove any existing rules
-D
## Buffer Size
-b 8192
## Failure Mode
-f 2
## Audit the audit logs
-w /var/log/audit/ -k auditlog
## Auditd configuration
-w /etc/audit/ -p wa -k auditconfig
-w /etc/libaudit.conf -p wa -k auditconfig
-w /etc/audisp/ -p wa -k audispconfig
## Monitor for use of audit management tools
-w /sbin/auditctl -p x -k audittools
-w /sbin/auditd -p x -k audittools
## Monitor AppArmor configuration changes
-w /etc/apparmor/ -p wa -k apparmor
-w /etc/apparmor.d/ -p wa -k apparmor
## Monitor usage of AppArmor tools
-w /sbin/apparmor_parser -p x -k apparmor_tools
-w /usr/sbin/aa-complain -p x -k apparmor_tools
-w /usr/sbin/aa-disable -p x -k apparmor_tools
-w /usr/sbin/aa-enforce -p x -k apparmor_tools
## Monitor Systemd configuration changes
-w /etc/systemd/ -p wa -k systemd
-w /lib/systemd/ -p wa -k systemd
## Monitor usage of systemd tools
-w /bin/systemctl -p x -k systemd_tools
-w /bin/journalctl -p x -k systemd_tools
## Special files
-a always,exit -F arch=b64 -S mknod -S mknodat -k specialfiles
## Mount operations
-a always,exit -F arch=b64 -S mount -S umount2 -k mount
## Changes to the time
-a always,exit -F arch=b64 -S adjtimex -S settimeofday -S clock_settime -k time
## Cron configuration & scheduled jobs
-w /etc/cron.allow -p wa -k cron
-w /etc/cron.deny -p wa -k cron
-w /etc/cron.d/ -p wa -k cron
-w /etc/cron.daily/ -p wa -k cron
-w /etc/cron.hourly/ -p wa -k cron
-w /etc/cron.monthly/ -p wa -k cron
-w /etc/cron.weekly/ -p wa -k cron
-w /etc/crontab -p wa -k cron
-w /var/spool/cron/crontabs/ -k cron
## User, group, password databases
-w /etc/group -p wa -k etcgroup
-w /etc/passwd -p wa -k etcpasswd
-w /etc/gshadow -k etcgroup
-w /etc/shadow -k etcpasswd
-w /etc/security/opasswd -k opasswd
## Monitor usage of passwd
-w /usr/bin/passwd -p x -k passwd_modification
## Monitor for use of tools to change group identifiers
-w /usr/sbin/groupadd -p x -k group_modification
-w /usr/sbin/groupmod -p x -k group_modification
-w /usr/sbin/addgroup -p x -k group_modification
-w /usr/sbin/useradd -p x -k user_modification
-w /usr/sbin/usermod -p x -k user_modification
-w /usr/sbin/adduser -p x -k user_modification
## Monitor module tools
-w /sbin/insmod -p x -k modules
-w /sbin/rmmod -p x -k modules
-w /sbin/modprobe -p x -k modules
## Login configuration and information
-w /etc/login.defs -p wa -k login
-w /etc/securetty -p wa -k login
-w /var/log/faillog -p wa -k login
-w /var/log/lastlog -p wa -k login
-w /var/log/tallylog -p wa -k login
## Network configuration
-w /etc/hosts -p wa -k hosts
-w /etc/network/ -p wa -k network
## System startup scripts
-w /etc/inittab -p wa -k init
-w /etc/init.d/ -p wa -k init
-w /etc/init/ -p wa -k init
## Library search paths
-w /etc/ld.so.conf -p wa -k libpath
## Local time zone
-w /etc/localtime -p wa -k localtime
## Time zone configuration
-w /etc/timezone -p wa -k timezone
## Kernel parameters
-w /etc/sysctl.conf -p wa -k sysctl
## Modprobe configuration
-w /etc/modprobe.conf -p wa -k modprobe
-w /etc/modprobe.d/ -p wa -k modprobe
-w /etc/modules -p wa -k modprobe
# Module manipulations.
-a always,exit -F arch=b64 -S init_module -S delete_module -k modules
## PAM configuration
-w /etc/pam.d/ -p wa -k pam
-w /etc/security/limits.conf -p wa -k pam
-w /etc/security/pam_env.conf -p wa -k pam
-w /etc/security/namespace.conf -p wa -k pam
-w /etc/security/namespace.init -p wa -k pam
## Postfix configuration
-w /etc/aliases -p wa -k mail
-w /etc/postfix/ -p wa -k mail
## SSH configuration
-w /etc/ssh/sshd_config -k sshd
## Changes to hostname
-a exit,always -F arch=b64 -S sethostname -k hostname
## Changes to issue
-w /etc/issue -p wa -k etcissue
-w /etc/issue.net -p wa -k etcissue
## Capture all failures to access on critical elements
-a exit,always -F arch=b64 -S open -F dir=/etc -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/bin -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/sbin -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/usr/bin -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/usr/sbin -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/var -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/home -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/root -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/srv -F success=0 -k unauthedfileaccess
-a exit,always -F arch=b64 -S open -F dir=/tmp -F success=0 -k unauthedfileaccess
## Monitor for use of process ID change (switching accounts) applications
-w /bin/su -p x -k priv_esc
-w /usr/bin/sudo -p x -k priv_esc
-w /etc/sudoers -p rw -k priv_esc
## Monitor usage of commands to change power state
-w /sbin/shutdown -p x -k power
-w /sbin/poweroff -p x -k power
-w /sbin/reboot -p x -k power
-w /sbin/halt -p x -k power
## Monitor admins accessing user files.
-a always,exit -F dir=/home/ -F uid=0 -C auid!=obj_uid -k admin_user_home
## Monitor changes and executions in /tmp and /var/tmp.
-w /tmp/ -p wxa -k tmp
-w /var/tmp/ -p wxa -k tmp
## Make the configuration immutable
-e 2
```
Few words about tooling you will use
------------------------------------
Kernel:
audit: hooks into the kernel to capture events and deliver them to auditd
Binaries:
auditd: daemon to capture events and store them (log file)
auditctl: client tool to configure auditd
audispd: daemon to multiplex events
aureport: reporting tool which reads from log file (auditd.log)
ausearch: event viewer (auditd.log)
autrace: using audit component in kernel to trace binaries
aulast: similar to last, but instaed using audit framework
aulastlog: similar to lastlog, also using audit framework instead
ausyscall: map syscall ID and name
auvirt: displaying audit information regarding virtual machines
Files:
audit.rules: used by auditctl to read what rules need to be used
auditd.conf: configuration file of auditd
Strategy: Excluding Events
--------------------------
The challenge with logging events, is to ensure that you log all important events, while avoiding logging the unneeded ones.
Logging large no of events might be not efficient and affect the performance of the Linux kernel.
To enhance the logging, we first need to determine what events often show up.
by executable
```shell
aureport -ts today -i -x --summary
Executable Summary Report
=================================
total file
=================================
1698 /bin/su
760 /usr/sbin/cron
87 /lib/systemd/systemd
75 /usr/sbin/sshd
41 /sbin/xtables-multi
30 /usr/bin/sudo
2 /lib/systemd/systemd-update-utmp
```
by syscall
```shell
aureport -ts today -i -s --summary
Syscall Summary Report
==========================
total syscall
==========================
2482 setsockopt
```
by event
```shell
aureport -ts today -i -e --summary
Event Summary Report
======================
total type
======================
23036 USER_START
22965 CRED_DISP
22965 USER_END
22952 CRED_ACQ
22948 USER_ACCT
14767 USER_AUTH
8113 LOGIN
2482 NETFILTER_CFG
2404 USER_ERR
1756 USER_LOGIN
360 SERVICE_START
300 SERVICE_STOP
88 USER_CMD
87 CRED_REFR
27 ANOM_ABEND
6 SYSTEM_RUNLEVEL
6 DAEMON_START
6 DAEMON_END
3 SYSTEM_SHUTDOWN
Possible Audit Record Types: https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/6/html/Security_Guide/sec-Audit_Record_Types.html
Ignoring events
---------------
Now we have idea, what type of messages we have on our system, we can filter out not needed events.
For that we have to make a rule, which matches and states the exclude of exit statement.
Note: The exit statement is used together with syscalls, for others we use exclude.
### Filter by message type
For example disabling all “CWD” (current working directory), we can use a rule like this:
```
-a exclude,always -F msgtype=CWD
```
ausearch tool will help you on examining
```
sudo ausearch -ts today -m CRED_ACQ
```
### Filter by multiple rules
Filter by multiple rules
We can combine multiple rules together, by using multiple -F parameters.
Up to 64 fields are parsed. -F expressions are concatenated via logical AND statement,
i.e. all fields have to be true, to trigger the action of the audit rule set.
```
-a exit,never -F arch=b32 -S fork -F success=0 -F path=/usr/lib/vmware-tools -F subj_type=initrc_t -F exit=-2
-a exit,never -F arch=b64 -S fork -F success=0 -F path=/usr/lib/vmware-tools -F subj_type=initrc_t -F exit=-2
```
Copyright and license
---------------------
Code licensed under the [BSD 3 clause] (https://opensource.org/licenses/BSD-3-Clause) or the [MIT License] (http://opensource.org/licenses/MIT).
Subscribe for roles updates at [FB] (https://www.facebook.com/SoftAsap/)
| 27.554124 | 320 | 0.699747 | eng_Latn | 0.570833 |
daf4086414bd1f877c386c21edb522a3d1ec1caf | 5,198 | md | Markdown | docs/framework/security/design-network.md | elfalem/architecture-center | 225774ee15c22a17c6ad10002b010e949538e5d7 | [
"CC-BY-4.0",
"MIT"
] | 4 | 2021-04-20T21:12:46.000Z | 2021-11-04T20:12:53.000Z | docs/framework/security/design-network.md | elfalem/architecture-center | 225774ee15c22a17c6ad10002b010e949538e5d7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/security/design-network.md | elfalem/architecture-center | 225774ee15c22a17c6ad10002b010e949538e5d7 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-11-04T12:50:12.000Z | 2021-11-22T20:36:35.000Z | ---
title: Network security strategies on Azure
description: Best practices for network security in Azure, including network segmentation, network management, containment strategy, and internet edge strategy.
author: PageWriter-MSFT
ms.date: 02/03/2021
ms.topic: conceptual
ms.service: architecture-center
ms.subservice: well-architected
ms.custom:
- article
---
# Network security
Protect assets by placing controls on network traffic originating in Azure, between on-premises and Azure hosted resources, and traffic to and from Azure. If security measures aren't in place attackers can gain access, for instance, by scanning across public IP ranges. Proper network security controls can provide defense-in-depth elements that help detect, contain, and stop attackers who gain entry into your cloud deployments.
## Checklist
**How have you secured the network of your workload?**
***
> [!div class="checklist"]
> - Segment your network footprint and create secure communication paths between segments. Align the network segmentation with overall enterprise segmentation strategy.
> - Design security controls that identify and allow or deny traffic, access requests, and application communication between segments.
> - Protect all public endpoints with Azure Front Door, Application Gateway, Azure Firewall, Azure DDoS Protection.
> - Mitigate DDoS attacks with DDoS **Standard** protection for critical workloads.
> - Prevent direct internet access of virtual machines.
> - Control network traffic between subnets (east-west) and application tiers (north-south).
> - Protect from data exfiltration attacks through a defense-in-depth approach with controls at each layer.
## In this section
Follow these questions to assess the workload at a deeper level. The recommendations in this section are based on using Azure Virtual Networking.
|Assessment|Description|
|---|---|
|[**How does the organization implement network segmentation to detect and contain adversary movement?**](design-network-segmentation.md)|Create segmentation in your network footprint to group the related assets and isolation. Align the network segmentation with the enterprise segmentation strategy.
|[**Should this workload be accessible from public IP addresses?**](design-network-connectivity.md)|Use native Azure networking feature to restrict access to individual application services. Explore multiple levels (such as IP filtering or firewall rules) to prevent application services from being accessed by unauthorized actors.|
|[**Are public endpoints of this workload protected?**](design-network-endpoints.md)|Use Azure Firewall to protect Azure Virtual Network resources. Web Application Firewall (WAF) mitigates the risk of an attacker being able to exploit commonly known security application vulnerabilities like cross-site scripting or SQL injection.|
|[**Is the traffic between subnets, Azure components and tiers of the workload managed and secured?**](design-network-flow.md)|Place controls between subnets of a VNet. Detect threats by allowing or denying ingress and egress traffic.|
## Azure security benchmark
The Azure Security Benchmark includes a collection of high-impact security recommendations you can use to help secure the services you use in Azure:
>  The questions in this section are aligned to the [Azure Security Benchmarks Network Security](/azure/security/benchmarks/security-controls-v2-network-security).
## Azure services
- [Azure Virtual Network](/azure/virtual-network/virtual-networks-overview)
- [Azure Firewall](/azure/firewall/overview)
- [Azure ExpressRoute](/azure/expressroute/)
- [Azure Private Link](/azure/private-link/)
## Reference architecture
Here are some reference architectures related to network security:
- [Hub-spoke network topology in Azure](../../reference-architectures/hybrid-networking/hub-spoke.yml)
- [Deploy highly available NVAs](../../reference-architectures/dmz/nva-ha.yml)
- [Windows N-tier application on Azure with SQL Server](../../reference-architectures/n-tier/n-tier-sql-server.yml)
- [Azure Kubernetes Service (AKS) production baseline](../../reference-architectures/containers/aks/secure-baseline-aks.yml)
## Next steps
Monitor the communication between segments. Use data to identify anomalies, set alerts, or block traffic to mitigate the risk of attackers crossing segmentation boundaries.
> [!div class="nextstepaction"]
> [Monitor identity, network, data risks](./monitor-identity-network.md)
## Related links
Combine network controls with application, identity, and other technical control types. This approach is effective in preventing, detecting, and responding to threats outside the networks you control. For more information, see these articles:
- [Applications and services security](design-apps-services.md)
- [Identity and access management considerations](design-identity.md)
- [Data protection](design-storage.md)
Ensure that resource grouping and administrative privileges align to the segmentation model. For more information, see [Administrative account security](design-admins.md).
> Go back to the main article: [Security](overview.md) | 66.641026 | 431 | 0.797999 | eng_Latn | 0.983742 |
daf4d8df3a8f8ecaae691a0abe94fd7b317bee67 | 4,657 | md | Markdown | add/metadata/System.ComponentModel.Design.Serialization/CodeDomDesignerLoader.meta.md | v-maudel/docs-1 | f849afb0bd9a505311e7aec32c544c3169edf1c5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | add/metadata/System.ComponentModel.Design.Serialization/CodeDomDesignerLoader.meta.md | v-maudel/docs-1 | f849afb0bd9a505311e7aec32c544c3169edf1c5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | add/metadata/System.ComponentModel.Design.Serialization/CodeDomDesignerLoader.meta.md | v-maudel/docs-1 | f849afb0bd9a505311e7aec32c544c3169edf1c5 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.System#ComponentModel#Design#Serialization#IDesignerSerializationService#Deserialize(System.Object)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.OnComponentRename(System.Object,System.String,System.String)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.Write(System.CodeDom.CodeCompileUnit)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.PerformFlush(System.ComponentModel.Design.Serialization.IDesignerSerializationManager)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.System#ComponentModel#Design#Serialization#INameCreationService#IsValidName(System.String)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.PerformLoad(System.ComponentModel.Design.Serialization.IDesignerSerializationManager)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.IsReloadNeeded
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.System#ComponentModel#Design#Serialization#INameCreationService#CreateName(System.ComponentModel.IContainer,System.Type)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.TypeResolutionService
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.OnBeginUnload
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.Dispose
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.System#ComponentModel#Design#Serialization#IDesignerSerializationService#Serialize(System.Collections.ICollection)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.CodeDomProvider
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.OnBeginLoad
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.OnEndLoad(System.Boolean,System.Collections.ICollection)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.Initialize
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.#ctor
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.System#ComponentModel#Design#Serialization#INameCreationService#ValidateName(System.String)
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
---
uid: System.ComponentModel.Design.Serialization.CodeDomDesignerLoader.Parse
ms.technology:
- "dotnet-standard"
author: "dotnet-bot"
ms.author: "dotnetcontent"
manager: "wpickett"
---
| 25.872222 | 190 | 0.786987 | yue_Hant | 0.239319 |
daf5ebdeeecaba046148f263da01926431add1bc | 7,820 | md | Markdown | src/content/osa0/osa0a.md | Granigan/fullstack-hy2019.github.io | b05ecf2c7a15a461d40e6a841fb66302c78c6cdf | [
"MIT"
] | null | null | null | src/content/osa0/osa0a.md | Granigan/fullstack-hy2019.github.io | b05ecf2c7a15a461d40e6a841fb66302c78c6cdf | [
"MIT"
] | null | null | null | src/content/osa0/osa0a.md | Granigan/fullstack-hy2019.github.io | b05ecf2c7a15a461d40e6a841fb66302c78c6cdf | [
"MIT"
] | null | null | null | ---
mainImage: ../../images/part-0.svg
part: 0
letter: a
---
<div class="content">
Kurssilla tutustutaan Javascriptilla tapahtuvaan moderniin websovelluskehitykseen. Pääpaino on React-kirjaston avulla toteutettavissa single page -sovelluksissa, ja niitä tukevissa Node.js:llä toteutetuissa REST-rajapinnoissa.
Kurssilla käsitellään myös sovellusten testaamista, konfigurointia ja suoritusympäristöjen hallintaa sekä NoSQL-tietokantoja.
### Oletetut esitiedot
Osallistujilta edellytetään vahvaa ohjelmointirutiinia, web-ohjelmoinnin ja tietokantojen perustuntemusta, git-versionhallintajärjestelmän peruskäytön hallintaa, kykyä pitkäjänteiseen työskentelyyn sekä valmiutta omatoimiseen tiedonhakuun ja ongelmanratkaisuun.
Osallistuminen ei kuitenkaan edellytä kurssilla käsiteltävien tekniikoiden tai Javascript-kielen hallintaa.
### Kurssimateriaali
Kurssimateriaali on tarkoitettu luettavaksi osa kerrallaan "alusta loppuun". Materiaalin seassa on tehtäviä, jotka on sijoiteltu siten, että kunkin tehtävän tekemiseen pitäsi olla riittävät tekniset valmiudet sitä edeltävässä materiaalissa. Voit siis tehdä tehtäviä sitä mukaan kun niitä tulee materiaalissa vastaan. Voi myös olla, että koko osan tehtävät kannattaa tehdä vasta sen jälkeen, kun olet ensin lukenut osan alusta loppuun kertaalleen. Useissa osissa tehtävät ovat samaa ohjelmaa laajentavia pienistä osista koostuvia kokonaisuuksia. Muutamia tehtävien ohjelmia kehitetään eteenpäin useamman osan aikana.
Materiaali perustuu muutamien osasta osaan vaihtuvien esimerkkiohjelmien asteittaiseen laajentamiseen. Materiaali toiminee parhaiten, jos kirjoitat samalla koodin myös itse ja teet koodiin myös pieniä modifikaatioita. Materiaalin käyttämien ohjelmien koodin eri vaiheiden tilanteita on tallennettu GitHubiin.
### Suoritustapa
Kurssi koostuu kahdeksasta osasta, joista ensimmäinen on historiallisista syistä numero nolla. Osat voi tulkita löyhästi ajatellen viikoiksi. Osia kuitenkin ilmestyy nopeampaa tahtia, ja suoritusnopeuskin on melko vapaa.
Materiaalissa osasta <i>n</i> osaan <i>n+1</i> eteneminen ei ole mielekästä ennen kuin riittävä osaaminen osan <i>n</i> asioista on saavutettu. Kurssilla sovelletaankin pedagogisin termein <i>tavoiteoppimista</i>, [engl. mastery learning](https://en.wikipedia.org/wiki/Mastery_learning) ja on tarkoitus, että etenet seuraavaan osaan vasta, kun riittävä määrä edellisen osan tehtävistä on tehty.
Oletuksena on, että teet kunkin osan tehtävistä <i>ainakin ne</i> jotka eivät ole merkattu tähdellä. Myös tähdellä merkatut tehtävät vaikuttavat arvosteluun, mutta niiden tekemättäjättäminen ei aiheuta liian suuria esteitä seuraavan osan (tähdellä merkkaamattomien) tehtävien tekemiseen.
Osien **deadlinet** ovat maanantaisin klo 23:59, poikkeuksena kaksi viimeistä osaa, joiden deadline on sunnuntai klo 23:59:
| osa | deadline |
| -------------- | :-------------------: |
| osa 0 ja osa 1 | ma 21.1. |
| osa 2 | ma 28.1. |
| osa 3 | ma 4.2. |
| osa 4 | ma 11.2. |
| osa 5 | ma 18.2. |
| osa 6 | su 3.3. |
| osa 7 | su 3.3. |
Tämän kurssin eri osiin jo tehtyjen palautusten ajankäyttöstatistiikan näet [tehtävien palautussovelluksesta](https://studies.cs.helsinki.fi/courses/#fullstack2019).
### Arvosteluperusteet
Kurssin oletusarvoinen laajuus on 5 opintopistettä. Arvosana määräytyy kaikkien tehtyjen tehtävien perusteella, myös tähdellä merkityt "vapaavalintaiset" tehtävät siis vaikuttavat arvosanaan. Noin 50% deadlineen mennessä tehdyistä tehtävistä tuo arvosanan 1 ja 80% arvosanan 5. Kurssin lopussa on koe, joka on suoritettava hyväksytysti. Koe ei kuitenkaan vaikuta arvosanaan.
Kurssilta on mahdollisuus ansaita lisäopintopisteitä. Jos teet 87.5% kurssin tehtävistä, saat yhden lisäopintopisteen. Tekemällä 95% tehtävistä saat 2 lisäopintopistettä.
### Arvosanarajat
Tarkemmat arvosanarajat määritellään siinä vaiheessa kun kurssin tehtävien yhteenlaskettu määrä on selvillä.
### Aiemmin suoritetun kurssin täydentäminen
Jos olet suorittanut kurssin vuonna 2018 alle 7 opintoviikon laajuisena, voit täydentää nyt suoritustasi. Käytännössä täydentäminen tapahtuu siten, että voit korvata tämän kurssin <i>osia</i> viime vuonna suorittamasi kurssin aikana palauttamillasi osilla. Eli jos olet suorittanut kurssin esim. avoimen yliopiston kautta kolmen opintopisteen laajuisena, voit korvata vanhan suorituksesi osilla 0-3 tämän kurssin osat 0-3.
Voit korvata ainoastaan kokonaisia osia, eli jos teit viime vuonna esim. 50% jonkin osan tehtävistä, et voi tällä kurssilla jatkaa samaa osaa. Viime vuotisten osien "hyväksiluku" tapahtuu tehtävien palautussovelluksella
### Tehtävien palauttaminen
Tehtävät palautetaan GitHubin kautta ja merkitsemällä tehdyt tehtävät [palautussovellukseen](https://studies.cs.helsinki.fi/courses/#fullstack2019).
Jos palautat eri osien tehtäviä samaan repositorioon, käytä järkevää hakemistojen nimentää. Voit toki tehdä jokaisen osan omaankin repositorioon, kaikki käy.
Tehtävät palautetaan **yksi osa kerrallaan**. Kun olet palauttanut osan tehtävät, et voi enää palauttaa saman osan tekemättä jättämiäsi tehtäviä.
GitHubiin palautettuja tehtäviä tarkastetaan [MOSS](https://theory.stanford.edu/~aiken/moss/)-plagiaattitunnistusjärjestelmän avulla. Jos GitHubista löytyy kurssin mallivastausten koodia tai useammalta opiskelijalta löytyy samaa koodia, käsitellään tilanne yliopiston [vilppikäytäntöjen](https://blogs.helsinki.fi/alakopsaa/opettajalle/epailen-opiskelijaa-vilpista-mita-tehda/) mukaan.
Suurin osa tehtävistä on moniosaisia, samaa ohjelmaa pala palalta rakentavia kokonaisuuksia. Tälläisissä tehtäväsarjoissa ohjelman lopullisen version palauttaminen riittää, voit toki halutessasi tehdä commitin jokaisen tehtävän jälkeisestä tilanteesta, mutta se ei ole välttämätöntä.
### Alkutoimet
Tällä kurssilla suositellaan Chrome-selaimen käyttöä, sillä se tarjoaa parhaan välineistön web-sovelluskehitystä ajatellen.
Kurssin tehtävät palautetaan GitHubiin, joten Git tulee olla asennettuna ja sitä on syytä osata käyttää. Ohjeita Gitin käyttämiseen löytyy muunmuassa [täältä](https://github.com/mluukkai/ohjelmistotekniikka2018/blob/master/tehtavat/viikko1.md#gitin-alkeet).
Asenna myös joku järkevä web-devausta tukeva tekstieditori, enemmän kuin suositeltava valinta on [Visual studio code](https://code.visualstudio.com/).
Älä koodaa nanolla, Notepadilla tai Geditillä. Myöskään NetBeans ei ole omimmillaan Web-devauksessa ja se on myös turhan raskas verrattuna esim. Visual Studio Codeen.
Asenna koneeseesi heti myös [Node.js](https://nodejs.org/en/). Materiaali on tehty versiolla 10.0, älä asenna mitään sitä vanhempaa versiota, kaiken tosin pitäisi toimia jos konellasi on Nodesta vähintään versio 8.0. Asennusohjeita on koottu [tänne](/asennusohjeita).
Noden myötä koneelle asentuu myös Node package manager [npm](https://www.npmjs.com/get-npm), jota tulemme tarvitsemaan kurssin aikana aktiivisesti. Tuoreen noden kera asentuu myös [npx](https://www.npmjs.com/package/npx), jota tarvitaan myös muutaman kerran.
### Typoja materiaalissa
Jos löydät kirjoitusvirheen tai jokin asia on ilmaistu epäselvästi tai kielioppisääntöjen vastaisesti, tee <i>pull request</i> repositoriossa <https://github.com/fullstack-hy2019/fullstack-hy2019.github.io> olevaan kurssimateriaaliin. Esim. tämän sivun markdown-muotoinen lähdekoodi löytyy repositorion alta osoitteesta <https://github.com/fullstack-hy2019/fullstack-hy2019.github.io/blob/source/src/content/osa0/osa0a.md>
Materiaalin jokaisen osan alalaidassa on linkki <em>Ehdota muutosta materiaalin sisältöön</em>, jota klikkaamalla pääset suoraan editoimaan sivun lähdekoodia.
</div>
| 81.458333 | 615 | 0.803197 | fin_Latn | 0.999987 |
daf6355a38ee86f0e4fc5950175a816d2e9b9549 | 7,395 | md | Markdown | articles/devtest/offer/how-to-sign-into-azure-with-github.md | ZetaPR/azure-docs.es-es | 0e2bf787d1d9ab12065fcb1091a7f13b96c6f8a2 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-03-12T23:37:16.000Z | 2021-03-12T23:37:16.000Z | articles/devtest/offer/how-to-sign-into-azure-with-github.md | ZetaPR/azure-docs.es-es | 0e2bf787d1d9ab12065fcb1091a7f13b96c6f8a2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/devtest/offer/how-to-sign-into-azure-with-github.md | ZetaPR/azure-docs.es-es | 0e2bf787d1d9ab12065fcb1091a7f13b96c6f8a2 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Inicio de sesión en Desarrollo/pruebas de Azure con sus credenciales de GitHub
description: Inicie sesión en una suscripción de crédito mensual de Azure individual con credenciales de GitHub.
author: jamestramel
ms.author: jametra
ms.date: 10/12/2021
ms.topic: how-to
ms.prod: visual-studio-windows
ms.custom: devtestoffer
ms.openlocfilehash: c4f918f0a344f67db03bb14fd907ad4aabdeaba1
ms.sourcegitcommit: 106f5c9fa5c6d3498dd1cfe63181a7ed4125ae6d
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 11/02/2021
ms.locfileid: "131090852"
---
# <a name="sign-into-your-monthly-azure-credit-subscription-and-visual-studio-using-your-github-credentials"></a>Inicio de sesión en una suscripción de crédito mensual de Azure y Visual Studio con sus credenciales de GitHub
En Microsoft, nos centramos en permitir a los desarrolladores que creen las mejores aplicaciones más rápido. Al proporcionar una variedad de productos y servicios, se cubren todas las fases del ciclo de vida de desarrollo de software, incluidas:
- IDE y herramientas DevOps
- Plataformas de datos y aplicaciones en la nube
- Sistemas operativos
- Inteligencia artificial
- Soluciones de IoT y mucho más
Nos centramos en los desarrolladores, tanto como personas que trabajan en equipos y organizaciones, y como miembros de comunidades de desarrolladores.
GitHub es una de las comunidades de desarrolladores más grandes. Para millones de desarrolladores de todo el mundo, su identidad de GitHub es un aspecto crítico de su vida digital. Al reconocerlo, nos complace anunciar mejoras que ayuden a los usuarios de GitHub a empezar a trabajar con nuestros servicios para desarrolladores, incluidos el crédito mensual de Azure para suscriptores de Visual Studio.
## <a name="your-github-credentials-can-now-log-you-in-to-microsoft-services"></a>Inicio de sesión en servicios de Microsoft con las credenciales de GitHub
Vamos a permitir que los desarrolladores inicien sesión con su cuenta de GitHub existente en los servicios en línea de Microsoft. Con las credenciales de GitHub, puede iniciar sesión a través de OAuth en cualquier lugar en el que lo haga con una cuenta personal de Microsoft, incluidas las suscripciones de crédito de Azure y Visual Studio.
Después de iniciar sesión en GitHub y autorizar la aplicación de Microsoft, se obtiene una nueva cuenta de Microsoft que está vinculada a la identidad de GitHub. Durante este proceso, también puede vincular una cuenta de Microsoft existente si tiene una.
## <a name="sign-in-to-azure-credit-subscription"></a>Inicio de sesión en la suscripción de crédito de Azure
[La suscripción de crédito de Azure para suscriptores de Visual Studio](https://azure.microsoft.com/pricing/member-offers/credit-for-visual-studio-subscribers) ofrece un conjunto de servicios para crear, implementar y administrar aplicaciones en sus plataformas y dispositivos preferidos. Use su crédito en Azure para los servicios de aprendizaje, desarrollo y pruebas, además de herramientas de colaboración y acceso a Azure DevOps Services.
La compatibilidad con la autenticación de GitHub facilita la experimentación con los servicios de Azure. Elija entre Virtual Machines, Websites, SQL Databases y Mobile Services. Use Windows Virtual Desktop para implementar y administrar rápidamente cientos de máquinas virtuales con fines de desarrollo y pruebas.
Para empezar a trabajar con la suscripción de crédito mensual de Azure con su cuenta de GitHub, seleccione "Iniciar sesión con GitHub" en cualquier [página de inicio de sesión de Microsoft](https://login.microsoftonline.com)


Si aún no ha activado el crédito, vaya a la página [Crédito mensual de Azure para suscriptores de Visual Studio](https://azure.microsoft.com/pricing/member-offers/credit-for-visual-studio-subscribers), seleccione "Activar su crédito" y luego "Iniciar sesión con GitHub" para empezar.


Una vez completado el proceso de inicio de sesión, se le mostrará la última organización de Azure Visual Studio que visitó. Si no ha usado nunca Azure Visual Studio y la suscripción de crédito, se encontrará en una nueva organización creada automáticamente.
## <a name="access-all-of-microsoft-online-services"></a>Acceso a todos los servicio en línea de Microsoft
Además de acceder a servicios como Desarrollo/pruebas de Azure, crédito mensual y Visual Studio, use su cuenta de GitHub para acceder a todos los servicios en línea de Microsoft, desde Excel Online a Xbox.
Al autenticarse con esos servicios, puede encontrar su cuenta de GitHub después de hacer clic en "Opciones de inicio de sesión".
## <a name="our-commitment-to-your-privacy"></a>Nuestro compromiso con su privacidad
La primera vez que use su cuenta de GitHub para iniciar sesión con Microsoft, GitHub le pedirá permiso para dar la información del perfil.
Si está de acuerdo, GitHub comparte las direcciones de correo electrónico de su cuenta GitHub y la información de perfil. Usaremos estos datos para comprobar si tiene una cuenta con nosotros. Si no la tiene, crearemos una cuenta. Conectar su identidad de GitHub a una identidad de Microsoft no proporciona a Microsoft acceso a los repositorios de GitHub. Las aplicaciones como Visual Studio solicitarán acceso a los repositorios si necesitan trabajar con el código. Deberá dar su consentimiento a esa solicitud por separado.
Aunque la cuenta de GitHub se use para iniciar sesión en su cuenta de Microsoft, son cuentas independientes. Una cuenta solo usa a la otra como método de inicio de sesión. Los cambios que realice en la cuenta de GitHub (como cambiar la contraseña o habilitar la autenticación en dos fases) no cambiarán su cuenta de Microsoft ni al revés. Administre las identidades de GitHub y de Microsoft en la [página de administración de cuenta](https://account.live.com/proofs/manage/). Solo tiene que buscar debajo de la pestaña de Seguridad.
## <a name="start-exploring-azure-visual-studio-and-monthly-credit-subscription-now"></a>Comience a explorar Azure Visual Studio y la suscripción de crédito mensual ahora
Vaya a la página [Crédito mensual de Azure para suscriptores de Visual Studio](https://azure.microsoft.com/pricing/member-offers/credit-for-visual-studio-subscribers/) y obtenga más información para empezar.
Si tiene alguna pregunta, consulte la [página de soporte técnico](https://support.microsoft.com/help/4501231/microsoft-account-link-your-github-account). Háganos saber lo que piensa en los comentarios a continuación. Como siempre, nos gustaría escuchar cualquier comentario o sugerencia que tenga.
| 97.302632 | 535 | 0.804327 | spa_Latn | 0.991561 |
daf7fbf2052dec968a44e4b40f56dba18af41b37 | 5,313 | md | Markdown | articles/cost-management-billing/manage/subscription-disabled.md | pmsousa/azure-docs.pt-pt | bc487beff48df00493484663c200e44d4b24cb18 | [
"CC-BY-4.0",
"MIT"
] | 15 | 2017-08-28T07:46:17.000Z | 2022-02-03T12:49:15.000Z | articles/cost-management-billing/manage/subscription-disabled.md | pmsousa/azure-docs.pt-pt | bc487beff48df00493484663c200e44d4b24cb18 | [
"CC-BY-4.0",
"MIT"
] | 407 | 2018-06-14T16:12:48.000Z | 2021-06-02T16:08:13.000Z | articles/cost-management-billing/manage/subscription-disabled.md | pmsousa/azure-docs.pt-pt | bc487beff48df00493484663c200e44d4b24cb18 | [
"CC-BY-4.0",
"MIT"
] | 17 | 2017-10-04T22:53:31.000Z | 2022-03-10T16:41:59.000Z | ---
title: Reativar uma subscrição do Azure desativada
description: Descreve quando pode ter uma subscrição do Azure desativada e como a reativar.
keywords: subscrição do azure desativada
author: bandersmsft
ms.reviewer: amberb
tags: billing
ms.service: cost-management-billing
ms.subservice: billing
ms.topic: how-to
ms.date: 03/30/2021
ms.author: banders
ms.openlocfilehash: 37093900bf49e8a7613e2e3f4311548675791ceb
ms.sourcegitcommit: 3f684a803cd0ccd6f0fb1b87744644a45ace750d
ms.translationtype: MT
ms.contentlocale: pt-PT
ms.lasthandoff: 04/02/2021
ms.locfileid: "106220888"
---
# <a name="reactivate-a-disabled-azure-subscription"></a>Reativar uma subscrição do Azure desativada
A sua subscrição do Azure pode ser desativada porque o crédito expirou, atingiu o limite de gastos, tem uma fatura em atraso, atingiu o limite do cartão de crédito ou porque a subscrição foi cancelada pelo Administrador de Conta. Veja qual a questão que se aplica a si e siga os passos neste artigo para reativar a subscrição.
## <a name="your-credit-is-expired"></a>O crédito expirou
Quando se inscreve numa conta gratuita do Azure, obtém uma subscrição free Trial, que lhe fornece crédito USD200 Azure na sua moeda de faturação durante 30 dias e 12 meses de serviços gratuitos. No final dos 30 dias, o Azure desativa a subscrição. A subscrição é desativada para o proteger de incorrer acidentalmente em custos devido a uma utilização que exceda o crédito e os serviços gratuitos incluídos na subscrição. Para continuar a utilizar os serviços do Azure, deve [atualizar a subscrição](upgrade-azure-subscription.md). Após a atualização, a subscrição ainda terá acesso aos serviços gratuitos durante 12 meses. Só é cobrado para utilização além dos limites de quantidade de serviço gratuito.
## <a name="you-reached-your-spending-limit"></a>Atingiu o limite de gastos
As subscrições do Azure com crédito, como a Avaliação Gratuita e o Visual Studio Enterprise, têm limites de gastos, Só pode utilizar serviços até ao crédito incluído. Quando o seu uso atinge o limite de gastos, o Azure desativa a sua subscrição durante o resto desse período de faturação. A subscrição é desativada para o proteger de incorrer acidentalmente em custos devido a uma utilização que exceda o crédito incluído na subscrição. Para eliminar o seu limite de gastos, consulte [Remover o limite de gastos no portal Azure](spending-limit.md#remove).
> [!NOTE]
> Se tiver uma subscrição de Avaliação Gratuita e remover o limite de gastos, a subscrição será convertida numa subscrição individual com tarifas pay as you go no final da Avaliação Gratuita. O crédito é mantido durante os 30 dias completos após a criação da subscrição. Também tem acesso a serviços gratuitos durante 12 meses.
Para monitorar e gerir a atividade de faturação do Azure, veja [Planear a gestão dos custos do Azure](../understand/plan-manage-costs.md).
## <a name="your-bill-is-past-due"></a>A fatura está em dívida
Para resolver um saldo vencido do passado, consulte um dos seguintes artigos:
- Para as subscrições do Microsoft Online Subscription Program, incluindo pay-as-you-go, consulte [o saldo devido do passado para a sua subscrição Azure depois de receber um e-mail do Azure](resolve-past-due-balance.md).
- Para as subscrições do Microsoft Customer Agreement, consulte [como pagar a sua conta para o Microsoft Azure](../understand/pay-bill.md).
## <a name="the-bill-exceeds-your-credit-card-limit"></a>A fatura excede o limite do cartão de crédito
Para resolver o problema, [mude para um cartão de crédito diferente.](change-credit-card.md) Ou, se estiver a representar uma empresa, pode [mudar para pagar por fatura](pay-by-invoice.md).
## <a name="the-subscription-was-accidentally-canceled"></a>A subscrição foi cancelada acidentalmente
Se for o Administrador de Conta e acidentalmente tiver cancelado uma subscrição pay-as-you-go, pode reativá-la no portal Azure.
1. Inicie sessão no [portal do Azure](https://portal.azure.com).
1. Vá a Subscrições e, em seguida, selecione a subscrição cancelada.
1. **Selecione Reativar**.
1. Confirme a reativação selecionando **OK**.
:::image type="content" source="./media/subscription-disabled/reactivate-sub.png" alt-text="Screenshot que mostra Confirmar a reativação" :::
Relativamente aos outros tipos de subscrições, [contacte o suporte](https://portal.azure.com/?#blade/Microsoft_Azure_Support/HelpAndSupportBlade) para reativar a subscrição.
## <a name="after-reactivation"></a>Após a reativação
Depois de a sua subscrição ser reativada, a criação ou gestão dos recursos poderá sofrer um atraso. Se o atraso ultrapassar os 30 minutos, contacte [o Suporte de Faturação Azure](https://go.microsoft.com/fwlink/?linkid=2083458) para obter assistência. A maioria dos recursos do Azure são retomados automaticamente e não requerem nenhuma ação. No entanto, recomendamos que verifique os recursos dos seus serviços do Azure e reinicie aqueles que não forem retomados automaticamente.
## <a name="need-help-contact-us"></a>Precisa de ajuda? Contacte-nos.
Se tiver dúvidas ou precisar de ajuda, [crie um pedido de suporte](https://go.microsoft.com/fwlink/?linkid=2083458).
## <a name="next-steps"></a>Passos seguintes
- Saiba como [Planear a gestão dos custos do Azure](../understand/plan-manage-costs.md).
| 75.9 | 703 | 0.790702 | por_Latn | 0.999246 |
daf84b47d63641c93874747d2a943778800eedb6 | 1,780 | md | Markdown | ssl/nginx.md | aminglinux/nginx | 0dac2dd57e1d30c18d942a54015226020bb14b4c | [
"Apache-2.0"
] | 6 | 2019-04-10T17:26:38.000Z | 2020-12-08T01:23:36.000Z | ssl/nginx.md | liuhangz1/nginx | c84e4052f237de0b0d8543a4d24f3757ea81e6e7 | [
"Apache-2.0"
] | null | null | null | ssl/nginx.md | liuhangz1/nginx | c84e4052f237de0b0d8543a4d24f3757ea81e6e7 | [
"Apache-2.0"
] | 21 | 2018-12-13T13:30:10.000Z | 2022-01-12T04:15:18.000Z | #### Nginx配置SSL
##### Nginx配置示例(单向)
```
cp /etc/pki/ca_test/server/server.* /usr/local/nginx/conf/
{
listen 443 ssl;
server_name www.aminglinux.com;
index index.html index.php;
root /data/wwwroot/aminglinux.com;
ssl on;
ssl_certificate server.crt;
ssl_certificate_key server.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ALL:!DH:!EXPORT:!RC4:+HIGH:+MEDIUM:!eNULL;
ssl_prefer_server_ciphers on;
...
}
```
##### 配置说明
```
1. 443端口为ssl监听端口。
2. ssl on表示打开ssl支持。
3. ssl_certificate指定crt文件所在路径,如果写相对路径,必须把该文件和nginx.conf文件放到一个目录下。
4. ssl_certificate_key指定key文件所在路径。
5. ssl_protocols指定SSL协议。
6. ssl_ciphers配置ssl加密算法,多个算法用:分隔,ALL表示全部算法,!表示不启用该算法,+表示将该算法排到最后面去。
7. ssl_prefer_server_ciphers 如果不指定默认为off,当为on时,在使用SSLv3和TLS协议时,服务器加密算法将优于客户端加密算法。
```
##### Nginx配置双向认证
```
cp /etc/pki/ca_test/root/ca.crt /usr/local/nginx/conf/
配置示例:
{
listen 443 ssl;
server_name www.aminglinux.com;
index index.html index.php;
root /data/wwwroot/aminglinux.com;
ssl on;
ssl_certificate server.crt;
ssl_certificate_key server.key;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ALL:!DH:!EXPORT:!RC4:+HIGH:+MEDIUM:!eNULL;
ssl_prefer_server_ciphers on;
ssl_client_certificate ca.crt; //这里的ca.crt是根证书公钥文件
ssl_verify_client on;
...
}
```
##### 客户端(浏览器)操作
```
如果不进行以下操作,浏览器会出现400错误。400 Bad Request(No required SSL certificate was sent)
首先需要将client.key转换为pfx(p12)格式
# cd /etc/pki/ca_test/client
# openssl pkcs12 -export -inkey client.key -in client.crt -out client.pfx //这一步需要输入一个自定义密码,一会在windows上安装的时候要用到,需要记一下。
然后将client.pfx拷贝到windows下,双击即可安装。
也可以直接curl测试:
curl -k --cert /etc/pki/ca_test/client/client.crt --key /etc/pki/ca_test/client/client.key https://www.aminglinux.com/index.html
``` | 28.253968 | 129 | 0.726966 | yue_Hant | 0.148893 |
daf85067aecdd3addd0fb851f00520fcc274529b | 7,108 | md | Markdown | index.md | Delawen/sevilladevelopers.github.io | 8b53d77689eb90d51a66737b354750d917326a0c | [
"MIT"
] | null | null | null | index.md | Delawen/sevilladevelopers.github.io | 8b53d77689eb90d51a66737b354750d917326a0c | [
"MIT"
] | null | null | null | index.md | Delawen/sevilladevelopers.github.io | 8b53d77689eb90d51a66737b354750d917326a0c | [
"MIT"
] | null | null | null | ---
layout : default
type : homepage
title : Sevilla Developers User Group
permalink : /
---
# ¿Qué es SevillaDevelopers?
**SevillaDevelopers**, o **svqdev** es una iniciativa colectiva para agrupar a las diferentes comunidades y grupos tecnológicos locales de nuestro entorno.
Es una herramienta para todas las comunidades que nos dota de una articulación común bajo la que podemos llegar más lejos y **aunar fuerzas** en la promoción del talento local. Todo ésto dentro del marco de los valores positivos del **aprendizaje colectivo** y buscando **una identidad común**: *un nosotros-nosotras que ponga el valor el activismo desplegado los últimos años en nuestro entorno directo respecto a la tecnología*.
> De una forma más directa: SevillaDevelopers es un iniciativa sin ánimo de lucro, abierta y horizontal que, a modo de paraguas, puede ayudarte a construir tu propia iniciativa facilitándote recursos, contactos, experiencias y por supuesto, la ayuda directa de compañeras y compañeros del sector.
## ¿Cómo lo hacemos?
1. Intentamos englobar a las comunidades tecnológicas que se encuentran localizadas en Sevilla y su provincia:
* [El grupo de usuarios de Java](https://www.meetup.com/es/SVQJUG/)
* [Geoinquietxs](https://www.meetup.com/es-ES/Geoinquietos-Sevilla/)
* [DrupalSevilla](https://groups.drupal.org/sevilla)
* [PHPSevilla](https://www.meetup.com/es/PHP-Sevilla/)
* [OWASP Sevilla](https://www.owasp.org/index.php/Sevilla)
* [Metodologías y gestión de proyectos](https://www.meetup.com/es-ES/gesprosev/)
* [Docker Sevilla](https://www.meetup.com/es-ES/Docker-Sevilla/)
* [Sevilla Salesforce Developer Group](https://trailblazercommunitygroups.com/sevilla-es-developers-group/)
* [Sevilla Ruby On Rails](https://www.meetup.com/es-ES/Sevilla-Ruby-On-Rails-Meetup/)
* [WordPress Sevilla](http://www.meetup.com/WordPress-Sevilla)
* [Sevilla Xamarin Developer Group](http://www.meetup.com/SevillaXamarinDevelopers)
* [Python Sevilla](http://www.meetup.com/Python-Sevilla/)
* [GDG Sevilla](http://www.meetup.com/GDGSevilla/)
* [Cartuja.NET](https://www.meetup.com/es-ES/Cartuja-NET/)
* [Sevilla R](https://sevillarusers.netlify.com/)
* [Sevilla JS](https://www.meetup.com/es-ES/sevilla-js/)
* [Sevilla QA](https://www.meetup.com/es-ES/sevillaQA)
* [Databeers Sevilla](https://www.meetup.com/es-ES/Databeers-Sevilla/)
* [Ethereum Sevilla](https://www.meetup.com/es-ES/Ethereum-Meetup-Sevilla/)
* [Ping a Programadoras!](https://pingprogramadoras.org/)
* [The Things Network Sevilla](https://www.thethingsnetwork.org/community/sevilla)
* [Sevilla Maker Society](https://www.meetup.com/es-ES/Maker-Society/)
* Y muchos otros que están todavía por nacer.
> Es obvio que en nuestro entorno se producen multitud de encuentros de diferentes formatos y objetivos y queremos ser un punto de encuentro colectivo para que todas y todos nos encontremos y conozcamos.
1. Impulsamos el conocimiento compartido y el aprendizaje. No importa el nivel que tengas *o creas tener*; **todos y todas sois bienvenidos**. Lo importante es encontrarnos, reconocernos y vincularnos.
1. Organizamos **citas periódicas de caracter transversal** donde nos reunamos y compartamos nuestras experiencias. De ahí nacen nuestras iniciativas SevillaDevelopers Conference (svqdc) y las futuras citas SevillaDevelopers-Lite.
1. Ofrecemos nuestros recursos, bases de datos, contactos y referencias que intentamos tener actualizados y disponibles para apoyar cualquier iniciativa. ¿Necesitas un lugar para organizar una quedada? tenemos algunas referencias útiles.
## ¿Dónde encontrarnos?
1. El sitio principal es el [grupo en Facebook](https://www.facebook.com/groups/sevilladevelopers/). Si no eres miembro, solicita acceso sin problemas.
La única razón por la que hay que pedir acceso es para evitar que se cuelen perfiles falsos. No necesitas tener *nivel*, ni estar trabajando como tal... Los únicos requisitos son:
* Tener ganas de aprender
* Ser una persona educada (no siendo un troll, respetando otras opiniones y tratar siempre de ayudar).
* Para arbitrar conflictos, nos apoyamos en este [Código de Conducta](http://berlincodeofconduct.org/es/).
Aquí puedes preguntar lo que quieras sin tener en cuenta *el nivel* de tu pregunta. Todos y todas hemos empezado alguna vez y sabemos que la única pregunta estúpida es la que no se hace. Eso si, usa el buscador antes para ver si alguien ya ha respondido tu pregunta.
1. Tambien estamos en Twitter en [@SevillaDevelope](https://twitter.com/SevillaDevelope)
1. Puedes añadir este [calendario](https://calendar.google.com/calendar/[email protected]&ctz=Europe/Madrid) donde aparecen todos los eventos de los que nos vamos enterando.
> Si quieres añadirlo a tu Google Calendar, usa esta direccion:
```
[email protected]
```
> Si coordinas alguna comunidad y quieres que vuestros eventos aparezcan en el calendario, [mándanos un correo](mailto://[email protected]) indicándonos la comunidad para que podamos darte permisos para que puedas subirlos.
## ¿Cómo colaborar?
* Pregunta lo que no sepas en el grupo.
* Comparte información que te parezca interesante y sea relevante para el grupo (es decir, por mucho que la última cadena de gatitos que te han pasado sea monísima, intenta no compartirla ^_^).
* Propón temas que te gustaria que se vieran en mayor profundidad.
* Si tienes una charla preparada y te gustaria darla pero no sabes donde ni cómo, dilo.
* Tanto si estás buscando empleo como si estás buscando profesionales, entra a nuestro grupo de ofertas de trabajo donde se publican oportunidades (El requisito fundamental para anunciantes es que se anote el salario y para el resto es del no comentar a no ser que te interese la oferta, para evitar ruido): [SevillaDevelopersJobs](https://www.facebook.com/groups/SevillaDevelopersJobs/)
* ¿Quieres mejorar la página? Haz un fork de [este repositorio](https://github.com/SevillaDevelopers/sevilladevelopers.github.io), haz los cambios necesarios en él y luego envia un *pull-request*
* El campo de las ideas está bien, pero el de la acción está aún mejor. Siempre necesitamos algo de ayuda para sacar adelante algún evento: organización, voluntariado, transporte, una regleta, un proyector... levanta la mano si tienes disponibilidad.
* ¿Hay algo que no esta cubierto en los puntos de arriba? Proponlo en el grupo.
## Cosas que hace la gente en Sevilla
Es importante promover y dar visibilidad a las actividades de las personas que forman parte de nuestra comunidad, así que hemos preparado una sección para promover nuestras diferentes aportaciones. Aquí iremos recopilando enlaces a:
* Proyectos de código abierto.
* Aplicaciones/productos en los que hayáis participado y queráis dar a conocer.
* Blogs en los que participas.
El único requisito (por ahora) es que este hecho por personas de aquí. Y en *personas de aquí* puntuan tanto las nacidas como las que viven. Somos tierra de acogida.
| 75.617021 | 430 | 0.773495 | spa_Latn | 0.985503 |
daf868cd3ebe2df5ff4f9ba379357ca4d409c65e | 61 | md | Markdown | add/metadata/System.Windows.Forms/RichTextBoxLanguageOptions.meta.md | kcpr10/dotnet-api-docs | b73418e9a84245edde38474bdd600bf06d047f5e | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-06-16T22:24:36.000Z | 2020-06-16T22:24:36.000Z | add/metadata/System.Windows.Forms/RichTextBoxLanguageOptions.meta.md | kcpr10/dotnet-api-docs | b73418e9a84245edde38474bdd600bf06d047f5e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | add/metadata/System.Windows.Forms/RichTextBoxLanguageOptions.meta.md | kcpr10/dotnet-api-docs | b73418e9a84245edde38474bdd600bf06d047f5e | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-04-08T14:42:27.000Z | 2019-04-08T14:42:27.000Z | ---
uid: System.Windows.Forms.RichTextBoxLanguageOptions
---
| 15.25 | 52 | 0.770492 | yue_Hant | 0.968676 |
daf8832c5c06bcee9177f8fd0ebc40f48fb2af05 | 49 | md | Markdown | README.md | daniiarabdiev/inferdata | 08832acd56c1071e48e24751f62029e395e6a291 | [
"MIT"
] | null | null | null | README.md | daniiarabdiev/inferdata | 08832acd56c1071e48e24751f62029e395e6a291 | [
"MIT"
] | null | null | null | README.md | daniiarabdiev/inferdata | 08832acd56c1071e48e24751f62029e395e6a291 | [
"MIT"
] | null | null | null | # Library for data type inference for ML projects | 49 | 49 | 0.816327 | eng_Latn | 0.911701 |
daf8d995dd90c66701cd9d786e9400980b6ad0c0 | 1,340 | md | Markdown | includes/webjobs-always-on-note.md | Artaggedon/azure-docs.es-es | 73e6ff211a5d55a2b8293a4dc137c48a63ed1369 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/webjobs-always-on-note.md | Artaggedon/azure-docs.es-es | 73e6ff211a5d55a2b8293a4dc137c48a63ed1369 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | includes/webjobs-always-on-note.md | Artaggedon/azure-docs.es-es | 73e6ff211a5d55a2b8293a4dc137c48a63ed1369 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: archivo de inclusión
description: archivo de inclusión
services: app-service
author: ggailey777
ms.service: app-service
ms.topic: include
ms.date: 06/26/2020
ms.author: glenga
ms.custom: include file
ms.openlocfilehash: c255be53a1809bf5dd3fc6b184852767dfec9c66
ms.sourcegitcommit: f28ebb95ae9aaaff3f87d8388a09b41e0b3445b5
ms.translationtype: HT
ms.contentlocale: es-ES
ms.lasthandoff: 03/29/2021
ms.locfileid: "96009691"
---
> [!NOTE]
> Una aplicación web puede agotar el tiempo de espera después de 20 minutos de inactividad. Solo las solicitudes a la aplicación web real pueden restablecer el temporizador. Al ver la configuración de la aplicación en Azure Portal o realizar solicitudes en el sitio de herramientas avanzadas (`https://<app_name>.scm.azurewebsites.net`), no se restablece el temporizador. Si configura la aplicación web para que ejecute trabajos web continuos o programados (desencadenador de temporizador), habilite la opción **AlwaysOn** en la página **Configuración** de Azure de la aplicación web para asegurarse de que los trabajos web se ejecuten de forma confiable. Esta característica solo está disponible en los [planes de tarifa](https://azure.microsoft.com/pricing/details/app-service/?ref=microsoft.com&utm_source=microsoft.com&utm_medium=docs&utm_campaign=visualstudio) Básico, Estándar y Premium.
| 67 | 893 | 0.814925 | spa_Latn | 0.898668 |
daf912b0a40a2d7a9ba4a19843d756005ac9211a | 45 | md | Markdown | README.md | thunderboltsid/sharedocs | d3a662c575930942487d0432a1936d9c56fa4b6a | [
"MIT"
] | null | null | null | README.md | thunderboltsid/sharedocs | d3a662c575930942487d0432a1936d9c56fa4b6a | [
"MIT"
] | 4 | 2017-04-22T14:58:08.000Z | 2017-04-22T15:31:57.000Z | README.md | thunderboltsid/shareDOT | d3a662c575930942487d0432a1936d9c56fa4b6a | [
"MIT"
] | null | null | null | # shareDOT
- `npm run build`
- `npm start` | 11.25 | 18 | 0.6 | eng_Latn | 0.899001 |
daf926ca5279915b404e02648f96ff600ada4fab | 11,502 | md | Markdown | docs/t-sql/statements/alter-server-audit-transact-sql.md | MemiyazaMiyazaki/sql-docs.ja-jp | 452d9a1fa796f60125d8bde47f95b67672ccef9f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/statements/alter-server-audit-transact-sql.md | MemiyazaMiyazaki/sql-docs.ja-jp | 452d9a1fa796f60125d8bde47f95b67672ccef9f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/t-sql/statements/alter-server-audit-transact-sql.md | MemiyazaMiyazaki/sql-docs.ja-jp | 452d9a1fa796f60125d8bde47f95b67672ccef9f | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-28T15:48:13.000Z | 2020-05-28T15:48:13.000Z | ---
title: ALTER SERVER AUDIT (Transact-SQL) | Microsoft Docs
ms.custom: ''
ms.date: 09/07/2018
ms.prod: sql
ms.prod_service: sql-database
ms.reviewer: ''
ms.technology: t-sql
ms.topic: language-reference
f1_keywords:
- ALTER_SERVER_AUDIT_TSQL
- ALTER SERVER AUDIT
dev_langs:
- TSQL
helpviewer_keywords:
- server audit [SQL Server]
- audits [SQL Server], specification
- ALTER SERVER AUDIT statement
ms.assetid: 63426d31-7a5c-4378-aa9e-afcf4f64ceb3
author: VanMSFT
ms.author: vanto
monikerRange: =azuresqldb-mi-current||>=sql-server-2016||=sqlallproducts-allversions||>=sql-server-linux-2017
ms.openlocfilehash: c4649a591f7261943d2d5393678f63888930c01f
ms.sourcegitcommit: 58158eda0aa0d7f87f9d958ae349a14c0ba8a209
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 03/30/2020
ms.locfileid: "73982035"
---
# <a name="alter-server-audit--transact-sql"></a>ALTER SERVER AUDIT (Transact-SQL)
[!INCLUDE[appliesto-ss-asdb-xxxx-xxx-md](../../includes/appliesto-ss-asdb-xxxx-xxx-md.md)]
[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] Audit 機能を使用して、サーバー監査オブジェクトを変更します。 詳しくは、「[SQL Server Audit (データベース エンジン)](../../relational-databases/security/auditing/sql-server-audit-database-engine.md)」を参照してください。
 [Transact-SQL 構文表記規則](../../t-sql/language-elements/transact-sql-syntax-conventions-transact-sql.md)
## <a name="syntax"></a>構文
```
ALTER SERVER AUDIT audit_name
{
[ TO { { FILE ( <file_options> [, ...n] ) } | APPLICATION_LOG | SECURITY_LOG } | URL]
[ WITH ( <audit_options> [ , ...n] ) ]
[ WHERE <predicate_expression> ]
}
| REMOVE WHERE
| MODIFY NAME = new_audit_name
[ ; ]
<file_options>::=
{
FILEPATH = 'os_file_path'
| MAXSIZE = { max_size { MB | GB | TB } | UNLIMITED }
| MAX_ROLLOVER_FILES = { integer | UNLIMITED }
| MAX_FILES = integer
| RESERVE_DISK_SPACE = { ON | OFF }
}
<audit_options>::=
{
QUEUE_DELAY = integer
| ON_FAILURE = { CONTINUE | SHUTDOWN | FAIL_OPERATION }
| STATE = = { ON | OFF }
}
<predicate_expression>::=
{
[NOT ] <predicate_factor>
[ { AND | OR } [NOT ] { <predicate_factor> } ]
[,...n ]
}
<predicate_factor>::=
event_field_name { = | < > | ! = | > | > = | < | < = } { number | ' string ' }
```
## <a name="arguments"></a>引数
TO { FILE | APPLICATION_LOG | SECURITY |URL}
監査ターゲットの場所を指定します。 オプションは、バイナリ ファイル、Windows アプリケーション ログ、または Windows セキュリティ ログです。
> [!IMPORTANT]
> Azure SQL Database マネージド インスタンスでは SQL 監査はサーバー レベルで動作し、Azure Blob Storage に `.xel` ファイルを格納します。
FILEPATH **= '** _os\_file\_path_ **'**
監査記録のパス。 ファイル名は、監査名と監査 GUID に基づいて生成されます。
MAXSIZE **=** _max\_size_
監査ファイルのサイズの上限を指定します。 *max_size* の値は、整数の後に **MB**、**GB**、**TB** を付けて指定するか、または **UNLIMITED** を指定します。 *max_size* に指定できる最小サイズは 2 **MB**、最大サイズは 2,147,483,647 **TB** です。 **UNLIMITED** を指定した場合、ファイルはディスクがいっぱいになるまで拡張されます。 2 MB 未満の値を指定すると、MSG_MAXSIZE_TOO_SMALL エラーが発生します。 既定値は **UNLIMITED** です。
MAX_ROLLOVER_FILES **=** _integer_ | **UNLIMITED**
ファイル システム内に保持するファイルの最大数を指定します。 MAX_ROLLOVER_FILES=0 が設定されている場合、作成されるロールオーバー ファイルの数は制限されません。 既定値は 0 です。 指定できるファイルの最大数は 2,147,483,647 です。
MAX_FILES =*integer*
作成できる監査ファイルの最大数を指定します。 制限に達しても、最初のファイルへのロールオーバーは行われません。 MAX_FILES の制限に達すると、追加の監査イベントを生成させるアクションは失敗し、エラーが発生します。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
RESERVE_DISK_SPACE **=** { ON | OFF }
このオプションは、ディスク上のファイルを MAXSIZE 値に事前に割り当てます。 MAXSIZE が UNLIMITED でない場合にのみ適用されます。 既定値は OFF です。
QUEUE_DELAY **=** _integer_
監査アクションの処理が強制されるまでの経過時間 (ミリ秒) を指定します。 値 0 は同期配信を表します。 クエリ遅延に設定可能な最小値は 1000 (1 秒) で、これが既定値です。 最大値は 2,147,483,647 (2,147,483.647 秒、つまり 24 日、20 時間、31 分、23.647 秒) です。 無効な数値を指定すると、MSG_INVALID_QUEUE_DELAY エラーが発生します。
ON_FAILURE **=** { CONTINUE | SHUTDOWN | FAIL_OPERATION}
[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] が監査ログに書き込むことができない場合に、ターゲットへのインスタンスの書き込みをエラーにするか、続行するか、停止するかを示します。
CONTINUE
[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] 操作を続行します。 監査レコードは保持されません。 監査はイベントのログ記録を試行し続け、エラー状態が解決されると、記録を再開します。 続行オプションを選択すると、セキュリティ ポリシーに違反する可能性がある、監査されない活動を許可する場合があります。 完全な監査を維持することより、[!INCLUDE[ssDE](../../includes/ssde-md.md)]の操作を続行することの方が重要である場合に、このオプションを使用します。
SHUTDOWN
[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] がなんらかの理由で監査ターゲットへのデータの書き込みに失敗した場合は、[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] のインスタンスを強制的にシャットダウンします。 `ALTER` ステートメントを実行しているログインには、[!INCLUDE[ssNoVersion](../../includes/ssnoversion-md.md)] 内での `SHUTDOWN` 権限が必要です。 実行中のログインから `SHUTDOWN` 権限が後で取り消された場合でも、シャットダウンの動作は継続します。 ユーザーがこの権限を持っていない場合は、ステートメントが失敗し、監査は変更されません。 監査エラーによってシステムのセキュリティまたは整合性が阻害される可能性がある場合に、このオプションを使用します。 詳細については、「[SHUTDOWN](../../t-sql/language-elements/shutdown-transact-sql.md)」を参照してください。
FAIL_OPERATION
監査イベントを発生させるデータベース アクションを失敗させます。 監査イベントを発生させないアクションは続行できますが、監査イベントを発生させることはできません。 監査はイベントのログ記録を試行し続け、エラー状態が解決されると、記録を再開します。 [!INCLUDE[ssDE](../../includes/ssde-md.md)]へのフル アクセスより、完全な監査の維持の方が重要である場合に、このオプションを使用します。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
STATE **=** { ON | OFF }
監査によるレコードの収集を有効または無効にします。 実行中の監査の状態を (ON から OFF に) 変更すると、監査が停止されたこと示す監査エントリ、監査を停止したプリンシパル、および監査が停止された時間が作成されます。
MODIFY NAME = *new_audit_name*
監査の名前を変更します。 他のオプションと組み合わせて使用することはできません。
predicate_expression
イベントを処理する必要があるかどうかを判定するために使用する述語式を指定します。 述語式は 3,000 文字に制限され、これにより文字列引数が制限されます。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
event_field_name
述語ソースを識別するイベント フィールドの名前を指定します。 監査フィールドについては、「[sys.fn_get_audit_file (Transact-SQL)](../../relational-databases/system-functions/sys-fn-get-audit-file-transact-sql.md)」で説明されています。 `file_name` と `audit_file_offset` 以外のすべてのフィールドは、監査できます。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
number
**decimal** を含む任意の数値型です。 制限として、使用可能な物理メモリの不足、または 64 ビット整数として表すのに大きすぎる数字が挙げられます。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
' string '
述語の比較に必要な ANSI 文字列または Unicode 文字列です。 述語比較関数に対しては、暗黙の文字列型変換は行われません。 無効な型を渡すとエラーになります。
**適用対象**: [!INCLUDE[ssSQL11](../../includes/sssql11-md.md)] 以降。
## <a name="remarks"></a>解説
ALTER AUDIT を呼び出すときは、TO 句、WITH 句、MODIFY NAME 句のうち少なくとも 1 つを指定する必要があります。
監査を変更する場合は、監査の状態を OFF オプションに設定する必要があります。 STATE=OFF 以外のオプションを使用して監査を有効にしているときに ALTER AUDIT を実行すると、MSG_NEED_AUDIT_DISABLED エラー メッセージが表示されます。
監査仕様の追加、変更、および削除は、監査を停止せずに実行できます。
監査を作成した後で、監査の GUID を変更することはできません。
**ALTER SERVER AUDIT** ステートメントはユーザー トランザクション内では使用できません。
## <a name="permissions"></a>アクセス許可
サーバー監査のプリンシパルを作成、変更、または削除するには、ALTER ANY SERVER AUDIT 権限または CONTROL SERVER 権限を持っている必要があります。
## <a name="examples"></a>例
### <a name="a-changing-a-server-audit-name"></a>A. サーバー監査の名前を変更する
次の例では、サーバー監査 `HIPAA_Audit` の名前を `HIPAA_Audit_Old` に変更します。
```
USE master
GO
ALTER SERVER AUDIT HIPAA_Audit
WITH (STATE = OFF);
GO
ALTER SERVER AUDIT HIPAA_Audit
MODIFY NAME = HIPAA_Audit_Old;
GO
ALTER SERVER AUDIT HIPAA_Audit_Old
WITH (STATE = ON);
GO
```
### <a name="b-changing-a-server-audit-target"></a>B. サーバー監査のターゲットを変更する
次の例では、`HIPAA_Audit` というサーバー監査を、ファイル ターゲットに変更します。
```
USE master
GO
ALTER SERVER AUDIT HIPAA_Audit
WITH (STATE = OFF);
GO
ALTER SERVER AUDIT HIPAA_Audit
TO FILE (FILEPATH ='\\SQLPROD_1\Audit\',
MAXSIZE = 1000 MB,
RESERVE_DISK_SPACE=OFF)
WITH (QUEUE_DELAY = 1000,
ON_FAILURE = CONTINUE);
GO
ALTER SERVER AUDIT HIPAA_Audit
WITH (STATE = ON);
GO
```
### <a name="c-changing-a-server-audit-where-clause"></a>C. サーバー監査 WHERE 句を変更する
次の例は、「[CREATE SERVER AUDIT (Transact-SQL)](../../t-sql/statements/create-server-audit-transact-sql.md)」の例 C で作成した WHERE 句を変更します。 新しい WHERE 句は、ユーザー定義イベントを 27 でフィルター選択します。
```sql
ALTER SERVER AUDIT [FilterForSensitiveData] WITH (STATE = OFF)
GO
ALTER SERVER AUDIT [FilterForSensitiveData]
WHERE user_defined_event_id = 27;
GO
ALTER SERVER AUDIT [FilterForSensitiveData] WITH (STATE = ON);
GO
```
### <a name="d-removing-a-where-clause"></a>D. WHERE 句を削除する
次の例では、WHERE 句の述語式を削除します。
```sql
ALTER SERVER AUDIT [FilterForSensitiveData] WITH (STATE = OFF)
GO
ALTER SERVER AUDIT [FilterForSensitiveData]
REMOVE WHERE;
GO
ALTER SERVER AUDIT [FilterForSensitiveData] WITH (STATE = ON);
GO
```
### <a name="e-renaming-a-server-audit"></a>E. サーバー監査の名前を変更する
次の例では、サーバー監査の名前を `FilterForSensitiveData` から `AuditDataAccess` に変更します。
```sql
ALTER SERVER AUDIT [FilterForSensitiveData] WITH (STATE = OFF)
GO
ALTER SERVER AUDIT [FilterForSensitiveData]
MODIFY NAME = AuditDataAccess;
GO
ALTER SERVER AUDIT [AuditDataAccess] WITH (STATE = ON);
GO
```
## <a name="see-also"></a>参照
[DROP SERVER AUDIT (Transact-SQL)](../../t-sql/statements/drop-server-audit-transact-sql.md)
[CREATE SERVER AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/create-server-audit-specification-transact-sql.md)
[ALTER SERVER AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/alter-server-audit-specification-transact-sql.md)
[DROP SERVER AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/drop-server-audit-specification-transact-sql.md)
[CREATE DATABASE AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/create-database-audit-specification-transact-sql.md)
[ALTER DATABASE AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/alter-database-audit-specification-transact-sql.md)
[DROP DATABASE AUDIT SPECIFICATION (Transact-SQL)](../../t-sql/statements/drop-database-audit-specification-transact-sql.md)
[ALTER AUTHORIZATION (Transact-SQL)](../../t-sql/statements/alter-authorization-transact-sql.md)
[sys.fn_get_audit_file (Transact-SQL)](../../relational-databases/system-functions/sys-fn-get-audit-file-transact-sql.md)
[sys.server_audits (Transact-SQL)](../../relational-databases/system-catalog-views/sys-server-audits-transact-sql.md)
[sys.server_file_audits (Transact-SQL)](../../relational-databases/system-catalog-views/sys-server-file-audits-transact-sql.md)
[sys.server_audit_specifications (Transact-SQL)](../../relational-databases/system-catalog-views/sys-server-audit-specifications-transact-sql.md)
[sys.server_audit_specification_details (Transact-SQL)](../../relational-databases/system-catalog-views/sys-server-audit-specification-details-transact-sql.md)
[sys.database_audit_specifications (Transact-SQL)](../../relational-databases/system-catalog-views/sys-database-audit-specifications-transact-sql.md)
[sys.database_audit_specification_details (Transact-SQL)](../../relational-databases/system-catalog-views/sys-database-audit-specification-details-transact-sql.md)
[sys.dm_server_audit_status (Transact-SQL)](../../relational-databases/system-dynamic-management-views/sys-dm-server-audit-status-transact-sql.md)
[sys.dm_audit_actions (Transact-SQL)](../../relational-databases/system-dynamic-management-views/sys-dm-audit-actions-transact-sql.md)
[サーバー監査およびサーバー監査の仕様を作成する](../../relational-databases/security/auditing/create-a-server-audit-and-server-audit-specification.md)
| 45.642857 | 530 | 0.71831 | yue_Hant | 0.798412 |
daf969963ba9cf5c7fdec0239037fa4e486ef5f2 | 523 | md | Markdown | README.md | lmkeston/empathy-development | c5985be4d200c521470767db52d6bd28fb5f71a3 | [
"CC-BY-4.0"
] | 5 | 2021-07-31T17:34:23.000Z | 2022-02-27T16:31:05.000Z | README.md | lmkeston/empathy-development | c5985be4d200c521470767db52d6bd28fb5f71a3 | [
"CC-BY-4.0"
] | 1 | 2020-02-24T16:16:20.000Z | 2020-02-25T18:29:15.000Z | README.md | lmkeston/empathy-development | c5985be4d200c521470767db52d6bd28fb5f71a3 | [
"CC-BY-4.0"
] | 3 | 2020-06-22T16:28:04.000Z | 2021-03-20T01:04:29.000Z | <p align="center"><img width="100" src="https://user-images.githubusercontent.com/38021615/74766565-2f197600-523a-11ea-9639-e22513cf6e6e.png"></p>
<p align="center">This page was created with help from <a href="https://lab.github.com/">GitHub Learning Lab</a></p>
- [Intro to Design Thinking](five-phases/)
- [Minimum Viable Product](mvp)
- [Empathize](empathy/)
- [Define & Ideate](define-and-ideate/)
- [Prototype & Test](prototype-and-test/)
This repository is licensed under [CC-by-4](LICENSE) (c) 2019 GitHub, Inc.
| 43.583333 | 146 | 0.720841 | yue_Hant | 0.421094 |
dafa688ca33bf3bd02e7658f2d6f52e59a2ec8cb | 17,893 | md | Markdown | src/commonmark/en/content/user/using-the-event-reports-app.md | Philip-Larsen-Donnelly/dhis2-markdown-docs | 852b5620792ea25f0d80695a30c28a3e018c4896 | [
"RSA-MD",
"Linux-OpenIB"
] | null | null | null | src/commonmark/en/content/user/using-the-event-reports-app.md | Philip-Larsen-Donnelly/dhis2-markdown-docs | 852b5620792ea25f0d80695a30c28a3e018c4896 | [
"RSA-MD",
"Linux-OpenIB"
] | null | null | null | src/commonmark/en/content/user/using-the-event-reports-app.md | Philip-Larsen-Donnelly/dhis2-markdown-docs | 852b5620792ea25f0d80695a30c28a3e018c4896 | [
"RSA-MD",
"Linux-OpenIB"
] | null | null | null | # Using the Event Reports app
<!--DHIS2-SECTION-ID:event_reports_app-->
## About the Event Reports app
<!--DHIS2-SECTION-ID:event_reports_about-->

With the **Event Report**s app you can analyse events in two types of
reports:
- Aggregated event reports: Pivot table-style analysis with aggregated
numbers of events
By selecting **Aggregated values** from the top-left menu you can
use the **Event Reports** app to create pivot tables with aggregated
numbers of events. An event report is always based on a program. You
can do analysis based on a range of dimensions. Each dimension can
have a corresponding filter. Dimensions can be selected from the
left-side menu. Similar to the pivot tables app, aggregated event
reports may be limited by the amount of RAM accessible by the
browser. If your requested table exceeds a set size, you will
recieve a warning prompt asking whether or not you want to continue.
- Individual event reports: Lists of events
By selecting **Events** from the top-left menu you can use the
**Event Reports** app to make searches or queries for events based
on a flexible set of criteria. The report will be displayed as a
table with one row per event. Each dimension can be used as a column
in the table or as a filter. Each dimension can have a criteria
(filter). Data elements of type option set allows for "in" criteria,
where multiple options can be selected. Numeric values can be
compared to filter values using greater than, equal or less than
operators.
## Create an event report
<!--DHIS2-SECTION-ID:event_reports_create-->
1. Open the **Event Reports** app.
2. Select **Aggregated values** or **Events**.
3. In the menu to the left, select the meta data you want to analyse.
4. Click **Layout** and arrange the dimensions.
You can keep the default selection if you want.
5. Click **Update**.
## Select dimension items
<!--DHIS2-SECTION-ID:event_reports_select_dimensions-->
An event report is always based on a program and you can do analysis
based on a range of dimensions. For programs with category combinations,
you can use program categories and category option group sets as
dimensions for tables and charts. Each dimension item can have a
corresponding filter.
1. Select data elements:
1. Click **Data**.
2. Select a program and a program stage.
The data elements associated with the selected program are
listed under **Available**. Each data element acts as a
dimension.
3. Select the data elements you need by double-clicking their
names.
Data elements can be filtered by type (Data elements, Program
attributes, Program indicators) and are prefixed to make them
easily recognizable.
After selecting a data element, it is visible under **Selected
data items**.
4. (Optional) For each data element, specify a filter with
operators such as "greater than", "in" or "equal" together with
a filter value.
2. Select periods.
1. Click **Periods**.
2. Select one or several periods.
You have three period options: relative periods, fixed periods
and start/end dates. You can combine fixed periods and relative
periods in the same chart. You cannot combine fixed periods and
relative periods with start/end dates in the same chart.
Overlapping periods are filtered so that they only appear once.
- Fixed periods: In the **Select period type** box, select a
period type. You can select any number of fixed periods from
any period type. Fixed periods can for example be "January
2014".
- Relative periods: In the lower part of the **Periods**
section, select as many relative periods as you like. The
names are relative to the current date. This means that if
the current month is March and you select **Last month**,
the month of February is included in the chart. Relative
periods has the advantage that it keeps the data in the
report up to date as time goes.
- Start/end dates: In the list under the **Periods** tab,
select **Start/end dates**. This period type lets you
specify flexible dates for the time span in the report.
3. Select organisation units.
1. Click **Organisation units**.
2. Click the gearbox icon.
3. Select a **Selection mode** and an organisation unit.
There are three different selection modes:
<table>
<caption>Selection modes</caption>
<colgroup>
<col style="width: 38%" />
<col style="width: 61%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Selection mode</p></th>
<th><p>Description</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p><strong>Select organisation units</strong></p></td>
<td><p>Lets you select the organisation units you want to appear in the chart from the organization tree.</p>
<p>Select <strong>User org unit</strong> to disable the organisation unit tree and only select the organisation unit that is related to your profile.</p>
<p>Select <strong>User sub-units</strong> to disable the organisation unit tree and only select the sub-units of the organisation unit that is related to your profile.</p>
<p>Select <strong>User sub-x2-units</strong> to disable the organisation unit tree and only select organisation units two levels down from the organisation unit that is related to your profile.</p>
<p>This functionality is useful for administrators to create a meaningful "system" favorite. With this option checked all users find their respective organisation unit when they open the favorite.</p></td>
</tr>
<tr class="even">
<td><p><strong>Select levels</strong></p></td>
<td><p>Lets you select all organisation units at one or more levels, for example national or district level.</p>
<p>You can also select the parent organisation unit in the tree, which makes it easy to select for example, all facilities inside one or more districts.</p></td>
</tr>
<tr class="odd">
<td><p><strong>Select groups</strong></p></td>
<td><p>Lets you select all organisation units inside one or several groups and parent organisation units at the same time, for example hospitals or chiefdoms.</p></td>
</tr>
</tbody>
</table>
4. Click **Update**.
## Select series, category and filter
<!--DHIS2-SECTION-ID:event_reports_select_series_category_filter-->
You can define which data dimension you want to appear as columns, rows
and filters in the pivot table. Each data element appears as individual
dimensions and can be placed on any of the axes.
> **Note**
>
> Data elements of continuous value types (real numbers/decimal numbers)
> can only be used as filters, and will automatically be positioned as
> filters in the layout dialog. The reason for this is that continuous
> number cannot be grouped into sensible ranges and used on columns and
> rows.
1. Click **Layout**.
2. Drag and drop the dimensions to the appropriate space.
3. Click **Update**.
## Change the display of your table
<!--DHIS2-SECTION-ID:event_reports_change_display-->
You can customize the display of an event report.
1. Click **Options**.
2. Set the options as required. Available options are different between
aggregated event reports and individual event reports.
<table style="width:100%;">
<caption>Event reports options</caption>
<colgroup>
<col style="width: 22%" />
<col style="width: 22%" />
<col style="width: 33%" />
<col style="width: 22%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Option</p></th>
<th><p>Description</p></th>
<th><p>Available for report type</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p><strong>Data</strong></p></td>
<td><p><strong>Show column totals</strong></p></td>
<td><p>Displays totals at the end of each column in the pivot table.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Show column sub-totals</strong></p></td>
<td><p>Displays sub-totals for each column in the pivot table.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Show row totals</strong></p></td>
<td><p>Displays totals at the end of each row in the pivot table.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Show row sub-totals</strong></p></td>
<td><p>Displays sub-totals for each row in the pivot table.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Show dimension labels</strong></p></td>
<td>Displays labels for dimensions.</td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Hide empty rows</strong></p></td>
<td><p>Hides empty rows in the pivot table.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Hide n/a data</strong></p></td>
<td><p>Hides data tagged as N/A from the chart.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Include only completed events</strong></p></td>
<td><p>Includes only completed events in the aggregation process. This is useful when you want for example to exclude partial events in indicator calculations.</p></td>
<td><p>Aggregated event report</p>
<p>Individual event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Limit</strong></p></td>
<td><p>Sets a limit of the maximum number of rows that you can display in the table, combined with a setting for showing top or bottom values.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Output type</strong></p></td>
<td><p>Defines the output type. The output types are <strong>Event</strong>, <strong>Enrollment</strong> and<strong>Tracked entity instance</strong>.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Program status</strong></p></td>
<td><p>Filters data based on the program status: <strong>All</strong>, <strong>Active</strong>, <strong>Completed</strong> or <strong>Cancelled</strong>.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Event status</strong></p></td>
<td><p>Filters data based on the event status: <strong>All</strong>, <strong>Active</strong>, <strong>Completed</strong>, <strong>Scheduled</strong>, <strong>Overdue</strong> or <strong>Skipped</strong>.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="odd">
<td><strong>Organisation units</strong></td>
<td><p><strong>Show hierarchy</strong></p></td>
<td><p>Includes the names of all parents of each organisation unit in labels.</p></td>
<td><p>Aggregated event report</p></td>
</tr>
<tr class="even">
<td><p><strong>Style</strong></p></td>
<td><p><strong>Display density</strong></p></td>
<td><p>Controls the size of the cells in the table. You can set it to <strong>Comfortable</strong>, <strong>Normal</strong> or <strong>Compact</strong>.</p>
<p><strong>Compact</strong> is useful when you want to fit large tables into the browser screen.</p></td>
<td><p>Aggregated event report</p>
<p>Individual event report</p></td>
</tr>
<tr class="odd">
<td></td>
<td><p><strong>Font size</strong></p></td>
<td><p>Controls the size of the table text font. You can set it to <strong>Large</strong>, <strong>Normal</strong> or <strong>Small</strong>.</p></td>
<td><p>Aggregated event report</p>
<p>Individual event report</p></td>
</tr>
<tr class="even">
<td></td>
<td><p><strong>Digit group separator</strong></p></td>
<td><p>Controls which character to separate groups of digits or "thousands". You can set it to <strong>Comma</strong>, <strong>Space</strong> or <strong>None</strong>.</p></td>
<td><p>Aggregated event report</p>
<p>Individual event report</p></td>
</tr>
</tbody>
</table>
3. Click **Update**.
## Download chart data source
<!--DHIS2-SECTION-ID:event_reports_download_report-->
You can download the data source behind an event report in HTML, JSON,
XML, Microsoft Excel or CSV formats.
1. Click **Download**.
2. Under **Plain data source**, click the format you want to download.
<table>
<caption>Available formats</caption>
<colgroup>
<col style="width: 27%" />
<col style="width: 72%" />
</colgroup>
<thead>
<tr class="header">
<th><p>Format</p></th>
<th><p>Description</p></th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td><p>HTML</p></td>
<td><p>Creates HTML table based on selected meta data</p></td>
</tr>
<tr class="even">
<td><p>JSON</p></td>
<td><p>Downloads data values in JSON format based on selected meta data</p></td>
</tr>
<tr class="odd">
<td><p>XML</p></td>
<td><p>Downloads data values in XML format based on selected meta data</p></td>
</tr>
<tr class="even">
<td><p>Microsoft Excel</p></td>
<td><p>Downloads data values in Microsoft Excel format based on selected meta data</p></td>
</tr>
<tr class="odd">
<td><p>CSV</p></td>
<td><p>Downloads data values in CSV format based on selected meta data</p></td>
</tr>
</tbody>
</table>
## Manage favorites
Saving your charts or pivot tables as favorites makes it easy to find
them later. You can also choose to share them with other users as an
interpretation or display them on the dashboard.
You view the details and interpretations of your favorites in the
**Pivot Table**, **Data Visualizer**, **Event Visualizer**, **Event
Reports** apps. Use the **Favorites** menu to manage your favorites.
### Open a favorite
1. Click **Favorites** \> **Open**.
2. Enter the name of a favorite in the search field, or click **Prev**
and **Next** to display favorites.
3. Click the name of the favorite you want to open.
### Save a favorite
1. Click **Favorites** \> **Save as**.
2. Enter a **Name** and a **Description** for your favorite.
3. Click **Save**.
### Rename a favorite
1. Click **Favorites** \> **Rename**.
2. Enter the new name for your favorite.
3. Click **Update**.
### Write an interpretation for a favorite
An interpretation is a link to a resource with a description of the data
at a given period. This information is visible in the **Dashboard** app.
To create an interpretation, you first need to create a favorite. If
you've shared your favorite with other people, the interpretation you
write is visible to those people.
1. Click **Favorites** \> **Write interpretation**.
2. In the text field, type a comment, question or interpretation. You
can also mention other users with '@username'. Start by typing '@'
plus the first letters of the username or real name and a mentioning
bar will display the available users. Mentioned users will receive
an internal DHIS2 message with the interpretation or comment. You
can see the interpretation in the **Dashboard** app.
3. Search for a user group that you want to share your favorite with,
then click the **+** icon.
4. Change sharing settings for the user groups you want to modify.
- **Can edit and view**: Everyone can view and edit the object.
- **Can view only**: Everyone can view the object.
- **None**: The public won't have access to the object. This
setting is only applicable to **Public access**.
5. Click **Share**.
### Subscribe to a favorite
When you are subscribed to a favorite, you receive internal messages
whenever another user likes/creates/updates an interpretation or
creates/update an interpretation comment of this favorite.
1. Open a favorite.
2. Click **\>\>\>** in the top right of the workspace.
3. Click on the upper-right bell icon to subscribe to this favorite.
### Create a link to a favorite
1. Click **Favorites** \> **Get link**.
2. Select one of the following:
- **Open in this app**: You get a URL for the favorite which you
can share with other users by email or chat.
- **Open in web api**: You get a URL of the API resource. By
default this is an HTML resource, but you can change the file
extension to ".json" or ".csv".
### Delete a favorite
1. Click **Favorites** \> **Delete**.
2. Click **OK**.
### View interpretations based on relative periods
To view interpretations for relative periods, such as a year ago:
1. Open a favorite with interpretations.
2. Click **\>\>\>** in the top right of the workspace.
3. Click an interpretation. Your chart displays the data and the date
based on when the interpretation was created.To view other
interpretations, click them.
## Visualize an event report as a chart
<!--DHIS2-SECTION-ID:event_reports_open_as_chart-->
When you have made an event report you can open it as a chart:
Click **Chart** \> **Open this chart as table**.
| 37.045549 | 223 | 0.658079 | eng_Latn | 0.98408 |
dafa8c257ea92838e6e0a3d1228e28309f678e79 | 1,551 | md | Markdown | treebanks/sah_yktdt/sah_yktdt-pos-CCONJ.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 204 | 2015-01-20T16:36:39.000Z | 2022-03-28T00:49:51.000Z | treebanks/sah_yktdt/sah_yktdt-pos-CCONJ.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 654 | 2015-01-02T17:06:29.000Z | 2022-03-31T18:23:34.000Z | treebanks/sah_yktdt/sah_yktdt-pos-CCONJ.md | vistamou/docs | 116b9c29e4218be06bf33b158284b9c952646989 | [
"Apache-2.0"
] | 200 | 2015-01-16T22:07:02.000Z | 2022-03-25T11:35:28.000Z | ---
layout: base
title: 'Statistics of CCONJ in UD_Yakut-YKTDT'
udver: '2'
---
## Treebank Statistics: UD_Yakut-YKTDT: POS Tags: `CCONJ`
There are 2 `CCONJ` lemmas (1%), 2 `CCONJ` types (1%) and 10 `CCONJ` tokens (4%).
Out of 12 observed tags, the rank of `CCONJ` is: 11 in number of lemmas, 11 in number of types and 8 in number of tokens.
The 10 most frequent `CCONJ` lemmas: <em>уонна, уоннa</em>
The 10 most frequent `CCONJ` types: <em>уонна, уоннa</em>
The 10 most frequent ambiguous lemmas:
The 10 most frequent ambiguous types:
## Morphology
The form / lemma ratio of `CCONJ` is 1.000000 (the average of all parts of speech is 1.278146).
The 1st highest number of forms (1) was observed with the lemma “уоннa”: <em>уоннa</em>.
The 2nd highest number of forms (1) was observed with the lemma “уонна”: <em>уонна</em>.
`CCONJ` does not occur with any features.
## Relations
`CCONJ` nodes are attached to their parents using 1 different relations: <tt><a href="sah_yktdt-dep-cc.html">cc</a></tt> (10; 100% instances)
Parents of `CCONJ` nodes belong to 5 different parts of speech: <tt><a href="sah_yktdt-pos-VERB.html">VERB</a></tt> (5; 50% instances), <tt><a href="sah_yktdt-pos-ADJ.html">ADJ</a></tt> (2; 20% instances), <tt><a href="sah_yktdt-pos-ADV.html">ADV</a></tt> (1; 10% instances), <tt><a href="sah_yktdt-pos-NOUN.html">NOUN</a></tt> (1; 10% instances), <tt><a href="sah_yktdt-pos-PROPN.html">PROPN</a></tt> (1; 10% instances)
10 (100%) `CCONJ` nodes are leaves.
The highest child degree of a `CCONJ` node is 0.
| 36.069767 | 420 | 0.691167 | eng_Latn | 0.769463 |
dafb21e2e9d9c2635334b3ec7c9328b71988fd89 | 3,591 | md | Markdown | _posts/设计模式/2018-07-26-设计模式25-中介者模式.md | zhenxing914/zhenxing914.github.io | eaeda740e5fba32736a424d6f15d0925986fd06b | [
"MIT"
] | null | null | null | _posts/设计模式/2018-07-26-设计模式25-中介者模式.md | zhenxing914/zhenxing914.github.io | eaeda740e5fba32736a424d6f15d0925986fd06b | [
"MIT"
] | null | null | null | _posts/设计模式/2018-07-26-设计模式25-中介者模式.md | zhenxing914/zhenxing914.github.io | eaeda740e5fba32736a424d6f15d0925986fd06b | [
"MIT"
] | 1 | 2016-09-09T07:02:02.000Z | 2016-09-09T07:02:02.000Z | ---
layout: post
title: "25-中介者模式"
categories: "设计模式"
tags: "设计模式 中介者模式"
author: "songzhx"
date: 2018-07-26 14:33:00
---
> **中介者模式(Mediator):**
>
> 用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显示地相互引用,从而使其耦合松散,而且可以肚子地改变它们之间的交互。

代码实例:
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public abstract class Mediator {
public abstract void send(String msg, Colleague colleage);
}
```
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public class ConcreteMediator extends Mediator {
private ConcreteColleague1 concreteColleague1 ;
private ConcreteColleague2 concreteColleague2;
public ConcreteColleague1 getConcreteColleague1() {
return concreteColleague1;
}
public void setConcreteColleague1(ConcreteColleague1 concreteColleague1) {
this.concreteColleague1 = concreteColleague1;
}
public ConcreteColleague2 getConcreteColleague2() {
return concreteColleague2;
}
public void setConcreteColleague2(ConcreteColleague2 concreteColleague2) {
this.concreteColleague2 = concreteColleague2;
}
@Override
public void send(String msg, Colleague colleage) {
if(colleage == concreteColleague1)
{
concreteColleague2.notifyMsg(msg);
}
else {
concreteColleague1.notifyMsg(msg);
}
}
}
```
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public abstract class Colleague {
protected Mediator mediator ;
public Colleague(Mediator mediator){
this.mediator = mediator;
}
abstract void send(String msg);
abstract void notifyMsg(String msg);
}
```
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public class ConcreteColleague1 extends Colleague{
public ConcreteColleague1(Mediator mediator) {
super(mediator);
}
@Override
void send(String msg ) {
mediator.send(msg ,this);
}
@Override
void notifyMsg(String msg) {
System.out.println("ConcreteColleague receive msg is :" + msg);
}
}
```
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public class ConcreteColleague2 extends Colleague {
public ConcreteColleague2(Mediator mediator) {
super(mediator);
}
@Override
void send(String msg) {
this.mediator.send(msg,this);
}
@Override
void notifyMsg(String msg) {
System.out.println("ConcreteColleague receive msg is : " + msg );
}
}
```
```java
package designpattern.ch25_mediator;
/**
* Created by song on 2018/7/26.
*/
public class Run {
public static void main(String[] args) {
ConcreteMediator mediator = new ConcreteMediator();
ConcreteColleague1 concreteColleague1 = new ConcreteColleague1(mediator);
ConcreteColleague2 concreteColleague2 = new ConcreteColleague2(mediator);
mediator.setConcreteColleague1(concreteColleague1);
mediator.setConcreteColleague2(concreteColleague2);
concreteColleague1.send("hello, i`m colleague1 .");
concreteColleague2.send("hello, i`m colleague2 .");
}
}
```
执行结果:
```java
ConcreteColleague receive msg is : hello, i`m colleague1 .
ConcreteColleague receive msg is : hello, i`m colleague2 .
```
[Github地址](https://github.com/zhenxing914/designpattern/tree/master/src/main/java/designpattern)
参考:大话设计模式
| 17.432039 | 96 | 0.681147 | eng_Latn | 0.616942 |
dafb906e94341a6fa0e48a8aafea6d6a09541d9e | 1,251 | md | Markdown | _posts/2019-09-02-Leetcode-LinkedList-21-Easy.md | Long-Py/Long-Py.github.io | 18f83fd4252932dca3faa6acefe8a9166500c1e7 | [
"MIT"
] | null | null | null | _posts/2019-09-02-Leetcode-LinkedList-21-Easy.md | Long-Py/Long-Py.github.io | 18f83fd4252932dca3faa6acefe8a9166500c1e7 | [
"MIT"
] | null | null | null | _posts/2019-09-02-Leetcode-LinkedList-21-Easy.md | Long-Py/Long-Py.github.io | 18f83fd4252932dca3faa6acefe8a9166500c1e7 | [
"MIT"
] | null | null | null | ---
layout: post
title: '21. Merge Two Sorted Lists'
subtitle: ''
date: 2019-09-02
categories: Leetcode
tags: Leetcode LinkedList
---
### [21\. Merge Two Sorted Lists](https://leetcode.com/problems/merge-two-sorted-lists/)
Difficulty: **Easy**
Topics: **Linked List**
Merge two sorted linked lists and return it as a new list. The new list should be made by splicing together the nodes of the first two lists.
**Example:**
```
Input: 1->2->4, 1->3->4
Output: 1->1->2->3->4->4
```
#### Solution
Language: **Python**
```python
# Definition for singly-linked list.
# class ListNode(object):
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution(object):
def mergeTwoLists(self, l1, l2):
"""
:type l1: ListNode
:type l2: ListNode
:rtype: ListNode
"""
dummy = ListNode(-1)
cur = dummy
while l1 and l2:
if l1.val < l2.val:
cur.next = ListNode(l1.val)
l1 = l1.next
else:
cur.next = ListNode(l2.val)
l2 = l2.next
cur = cur.next
if l1:
cur.next = l1
if l2:
cur.next = l2
return dummy.next
``` | 21.20339 | 141 | 0.547562 | eng_Latn | 0.726574 |
dafc096745baa2a202e1f823651d0ddf7f66c893 | 1,051 | md | Markdown | docs/csharp/misc/cs0159.md | adamsitnik/docs.pl-pl | c83da3ae45af087f6611635c348088ba35234d49 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/csharp/misc/cs0159.md | adamsitnik/docs.pl-pl | c83da3ae45af087f6611635c348088ba35234d49 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/csharp/misc/cs0159.md | adamsitnik/docs.pl-pl | c83da3ae45af087f6611635c348088ba35234d49 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Błąd kompilatora CS0159
ms.date: 07/20/2015
f1_keywords:
- CS0159
helpviewer_keywords:
- CS0159
ms.assetid: 9fde7ffa-aed7-4a9d-8f47-ea67bc9df9e4
ms.openlocfilehash: 1fdf776577a38c31847c38207ad7bfd786097401
ms.sourcegitcommit: 986f836f72ef10876878bd6217174e41464c145a
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 08/19/2019
ms.locfileid: "69600708"
---
# <a name="compiler-error-cs0159"></a>Błąd kompilatora CS0159
Brak etykiety "etykieta" w zakresie instrukcji goto
Etykieta, do której odwołuje się instrukcja [goto](../language-reference/keywords/goto.md) , nie została znaleziona w zakresie `goto` instrukcji.
Poniższy przykład generuje CS0159:
```csharp
// CS0159.cs
public class Class1
{
public static void Main()
{
int i = 0;
switch (i)
{
case 1:
goto case 3; // CS0159, case 3 label does not exist
case 2:
break;
}
goto NOWHERE; // CS0159, NOWHERE label does not exist
}
}
```
| 25.02381 | 148 | 0.67079 | pol_Latn | 0.830335 |
dafc60d1901d484e205585e8e2dd1dc797a164a7 | 2,939 | md | Markdown | source/_posts/tyson_fury_opens_up_on_challenging_mental_health_battle_during_coronavirus_pandemic.md | soumyadipdas37/finescoop.github.io | 0346d6175a2c36d4054083c144b7f8364db73f2f | [
"MIT"
] | null | null | null | source/_posts/tyson_fury_opens_up_on_challenging_mental_health_battle_during_coronavirus_pandemic.md | soumyadipdas37/finescoop.github.io | 0346d6175a2c36d4054083c144b7f8364db73f2f | [
"MIT"
] | null | null | null | source/_posts/tyson_fury_opens_up_on_challenging_mental_health_battle_during_coronavirus_pandemic.md | soumyadipdas37/finescoop.github.io | 0346d6175a2c36d4054083c144b7f8364db73f2f | [
"MIT"
] | 2 | 2021-09-18T12:06:26.000Z | 2021-11-14T15:17:34.000Z | ---
extends: _layouts.post
section: content
image: https://i.dailymail.co.uk/1s/2020/09/23/10/33519116-0-image-a-9_1600854239496.jpg
title: Tyson Fury opens up on challenging mental health battle during coronavirus pandemic
description: Tyson Fury has spoken about his mental health demons during the coronavirus pandemic and how he has been coping as the world continues to adapt.
date: 2020-09-23-10-47-41
categories: [latest, sports]
featured: true
---
Tyson Fury has spoken about his mental health demons during the coronavirus pandemic and how he has been coping as the world continues to adapt.
The current WBC heavyweight champion has struggled with depression throughout his career, and has been a long-term advocate for greater mental health discussion.
The 32-year-old has been unable to fight since defeating Deontay Wilder to win the WBC title in February. The highly-anticipated trilogy fight had been pencilled in for this year but that is now in severe doubt unless spectators can attend.
Tyson Fury has opened up about his mental health struggles during the coronavirus pandemic
Fury hasn't been able to fight since February - when he beat Deontay Wilder to win in Las Vegas
To keep himself fit and active during the pandemic, Fury has been working out twice a day - often sharing his routines on social media to spread positivity among his followers.
And speaking about how he has fared mentally during the pandemic, Fury opened up to describe it as 'challenging'.
'I found it challenging to say the least,' he told ITV's Good Morning Britain on Wednesday.
'But at least I've had the training in my life to keep me motivated and focused on what I'm about to achieve when given the chance.
'Like I've said many times, I train twice a day and 99 per cent of that is for me to keep my mental health on the straight and narrow path.
'It's been challenging but I'm been getting through it. I'm looking forward to when it all goes back to what we used to think was normal at one stage in our lives.'
The 'Gypsy King', like everyone, is looking forward to the world returning to normality in future
Boxing has returned in recent months with Fury's UK-based promoter Frank Warren holding fight cards without fans - but he has ruled out this possibility for Fury-Wilder III due to the sheer size of it.
'Not a fight of that magnitude [taking place without fans],' Warren told Good Morning Britain.
'Wilder and Fury was the highest grossing fight to ever take place in Vegas. We just can't lose that gate. It's a huge amount of money. We need the gate.
'Or we come up with a scenario where there is a huge site fee from a territory to take it, and we use it to promote their country.
'We are looking at those situations.'
Fury-Wilder III had been scheduled to take place this year before the Covid-19 pandemic hit
Fury's promoter Frank Warren says it will only happen with fans due to 'huge' gate receipts
| 59.979592 | 240 | 0.786322 | eng_Latn | 0.999839 |
dafc9a8c1d0b023a8f04c855d8a3de61c2be4efe | 4,953 | md | Markdown | README.md | fossabot/dataset-store | 8c0b46937834a72e1e3ad11bdab4c6795a8338c7 | [
"Apache-2.0"
] | null | null | null | README.md | fossabot/dataset-store | 8c0b46937834a72e1e3ad11bdab4c6795a8338c7 | [
"Apache-2.0"
] | null | null | null | README.md | fossabot/dataset-store | 8c0b46937834a72e1e3ad11bdab4c6795a8338c7 | [
"Apache-2.0"
] | null | null | null | # PlatIAgro Dataset Store
## Table of Contents
- [Introduction](#introduction)
- [Requirements](#requirements)
- [Quick Start](#quick-start)
- [Run Docker](#run-docker)
- [Run Local](#run-local)
- [Testing](#testing)
- [API](#api)
## Introduction
[](https://travis-ci.org/platiagro/dataset-store)
[](https://codecov.io/gh/platiagro/dataset-store/branch/master)
[](https://opensource.org/licenses/Apache-2.0)
[](https://gitter.im/platiagro/community?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge)
[](https://snyk.io/test/github/platiagro/dataset-store/master/?targetFile=package.json)
[](https://app.fossa.io/projects/git%2Bgithub.com%2Fmiguelfferraz%2Fdataset-store?ref=badge_shield)
PlatIAgro Dataset Store microservice.
## Requirements
The application can be run locally or in a docker container, the requirements for each setup are listed below.
### Local
- [Node.js](https://nodejs.org/)
### Docker
- [Docker CE](https://www.docker.com/get-docker)
- [Docker-Compose](https://docs.docker.com/compose/install/)
## Quick Start
Make sure you have all requirements installed on your computer, then you can run the server in a [docker container](#run-docker) or in your [local machine](#run-local).
**Firstly you need to create a .env file, see the .env.example.**
### Run Docker
Run it :
```bash
$ docker-compose up
```
_The default container port is 4000, you can change on docker-compose.yml_
### Run Local:
Run it :
```bash
$ npm install
$ npm run start
```
Or:
```bash
$ yarn
$ yarn start
```
## Testing
You can run the following command to test the project:
```bash
$ npm install
$ npm test
```
Or:
```bash
$ yarn
$ yarn test
```
To run tests with code coverage:
```bash
$ npm run test-coverage
```
Or:
```bash
$ yarn test-coverage
```
## API
API Reference with examples.
### Upload
**Upload Dataset and Header:** <br>
method: POST <br>
url: /datasets
With header:
```
curl -X POST \
http://localhost:3000/datasets/ \
-H 'Content-Type: multipart/form-data' \
-F dataset=@/l/disk0/mferraz/Documentos/platia/BigML_Dataset_Machine_Failure_ok.csv \
-F header=@/l/disk0/mferraz/Documentos/platia/feature_type_ok.txt \
-F experimentId=a2958bc1-a2c5-424f-bcb3-cf4701f4a423
```
Or:
```
curl -X POST \
http://localhost:3000/datasets/ \
-H 'Content-Type: multipart/form-data' \
-F dataset=@/l/disk0/mferraz/Documentos/platia/BigML_Dataset_Machine_Failure_ok.csv \
-F experimentId=a2958bc1-a2c5-424f-bcb3-cf4701f4a423
```
In this last case, the API will infer columns types.
### Datasets
**Get Dataset by ID:** <br>
method: GET <br>
url: /datasets/:datasetId
```
curl -X GET \
http://localhost:3000/datasets/2270d302-a4d8-449c-a9d0-8c47d1172641
```
### Headers
**Get Header by ID:** <br>
method: GET <br>
url: /headers/:headerId
```
curl -X GET \
http://localhost:3000/headers/9fd5ac4a-bddf-4a02-9f04-bb4810d963b3
```
### Columns
**Get columns from Header:** <br>
method: GET <br>
url: /headers/:headerId/columns
```
curl -X GET \
http://localhost:3000/headers/1a1b337f-f04e-4d17-8658-3420bc46dde2/columns/
```
**Update Column:** <br>
method: PATCH <br>
url: /headers/:headerId/columns/:columnId
```
curl -X PATCH \
http://localhost:3000/datasets/9d84c9d7-23d7-4977-b474-2d9dd5026c79/columns/a2958bc1-a2c5-424f-bcb3-cf4701f4a423 \
-d '{
"datatype": "DateTime"
}'
```
### Results
**Get Dataset table preview:** <br>
method: GET <br>
url: /results/:experimentId/dataset/:datasetId
```
curl -X GET \
http://localhost:3000/results/a2958bc1-a2c5-424f-bcb3-cf4701f4a423/dataset/c11e5412-3217-4912-aa2d-3f34a21d215d
```
**Get result table preview:** <br>
method: GET <br>
url: /results/:experimentId/:task/:headerId
```
curl -X GET \
http://localhost:3000/results/37abdc18-df28-4ab9-9f8d-9a6d2db1eb76/feature-temporal/6415aac6-a34f-4c5d-bf98-0853888a6c37
```
**Get plot:** <br>
method: GET <br>
url: /results/:experimentId/plot
```
curl -X GET \
http://localhost:3000/results/37abdc18-df28-4ab9-9f8d-9a6d2db1eb76/plot
```
**Get plot type:** <br>
method: GET <br>
url: /results/:experimentId/type
```
curl -X GET \
http://localhost:3000/results/37abdc18-df28-4ab9-9f8d-9a6d2db1eb76/type
```
## License
[](https://app.fossa.io/projects/git%2Bgithub.com%2Fmiguelfferraz%2Fdataset-store?ref=badge_large) | 23.037209 | 214 | 0.718151 | yue_Hant | 0.362723 |
dafd1548eb3de786454099c7f5b3742aa140069a | 4,158 | md | Markdown | markdowns/hello_world.md | rodburns/playground-eb8w0m4e | 4b14a5dce720a555c13d59c3a90f13a64d6c58db | [
"Apache-2.0"
] | null | null | null | markdowns/hello_world.md | rodburns/playground-eb8w0m4e | 4b14a5dce720a555c13d59c3a90f13a64d6c58db | [
"Apache-2.0"
] | null | null | null | markdowns/hello_world.md | rodburns/playground-eb8w0m4e | 4b14a5dce720a555c13d59c3a90f13a64d6c58db | [
"Apache-2.0"
] | null | null | null | # Hello World
This first exercise will guide you through the steps involved in writing your first SYCL application. In true first application fashion the aim will be to simply print "Hello World" to the console, however as this is SYCL you will be printing "Hello World" from the GPU.
## Including the SYCL Runtime
Everything you need to write a SYCL application is included in the header file `CL/sycl.hpp`.
1. Include the SYCL runtime header.
## Creating a Queue
In SYCL there are various different way to configure the devices available on our system however to make things easier SYCL provides defaults for the most common use cases, and the minimal object required to submit work is a `cl::sycl::queue`. A `cl::sycl::queue` can be default constructed; in which it case will ask the SYCL runtime to pick a device for you based on what's available in your system. There are other ways to ask SYCL to select a specific device based on your needs which we will cover in a later exercise, but for now this is all you need.
1. Default construct a `cl::sycl::queue` object called `myQueue`.
## Creating a Command Group
In SYCL a task is represented by what's called a command group. A command group contains a kernel function which can be executed on a device and any data dependencies that kernel function has. A command group is defined using a C++ function object (either a lambda function or a struct or class with a function call operator). The C++ function object must take a single parameter; a `cl::sycl::handler &`, which is used to link together data the kernel function and it's data depencies.
In this exercise we have provided the command group for you.
## Creating an Output Stream
In SYCL there are various objects which can be used to access data from within a kernel which are generally constructed within the scope of a command group. One of the simplest, which we are going to use in this exercise is a `cl::sycl::stream`. A `cl::sycl::stream` is a buffer output stream, behaving similarly to `std::ostream`, with the main difference being that it does not output to the console directly and instead buffers the output until after the kernel function is finished executing. A `cl::sycl::stream` must be constructed with three parameters, the maximum size of the buffer in bytes, the maximum length of a statement in bytes and the `cl::sycl::handler` associated with the command group scope it is created in.
1. Construct a `cl::sycl::stream` with a maximum buffer size of `1024`, a maximum statement length of `128` and the `cl::sycl::handler` provided by the command group function object.
## Defining a Kernel Function
In SYCL there are various ways to define a kernel function that will execute on a device depending on the kind of parallelism you want and the different features you require. The simplest of these is the `cl::sycl::handler::single_task` function, which takes a single parameter, being a C++ function object and executes that function object exactly once on the device. The C++ function object does not take any parameters, however it is important to note that if the function object is a lambda it must capture by value and if it is a struct or class it must define all members as value members.
In this exercise we have provided the kernel function for you.
## Outputing "Hello World"
From within the kernel function you can output to the `cl::sycl::stream` object using the `<<` operator as you would for `std::ostream` or `std::cout`.
1. Stream the text `Hello World` to the console from within the kernel function.
## Cleaning Up
One of the best features of SYCL is that it makes great use of C++ RAII (resource aquisition is initialisation), meaning that there is no explicit cleanup, everything is done via the SYCL object destructors. In this case the destructor of the `cl::sycl::stream` object will wait for the command group which is accessing it to complete and then ensure the buffer has been output to the console before returning.
# Run it!
@[Hello World from SYCL]({"stubs": ["src/exercises/hello_world.cpp"],"command": "sh /project/target/run.sh hello_world", "layout": "aside"})
| 86.625 | 730 | 0.774651 | eng_Latn | 0.999875 |
dafd181295c4d6475e9710d835c47c8540b04da3 | 933 | md | Markdown | collections/_traducoes/console/mega-drive/outrun-2019-(ripman).md | leomontenegro6/romhackersbr.github.io | 6819d18b194c467f9b85533337f13e599d6dab59 | [
"MIT"
] | 1 | 2021-08-30T14:42:15.000Z | 2021-08-30T14:42:15.000Z | collections/_traducoes/console/mega-drive/outrun-2019-(ripman).md | leomontenegro6/romhackersbr.github.io | 6819d18b194c467f9b85533337f13e599d6dab59 | [
"MIT"
] | null | null | null | collections/_traducoes/console/mega-drive/outrun-2019-(ripman).md | leomontenegro6/romhackersbr.github.io | 6819d18b194c467f9b85533337f13e599d6dab59 | [
"MIT"
] | null | null | null | ---
title: " OutRun 2019 (ripman)"
system: "Mega Drive"
platform: "Console"
game_title: "OutRun 2019"
game_category: "Esportes / Corrida de automóveis"
game_players: "1"
game_developer: "SIMS"
game_publisher: "Sega"
game_release_date: "??/??/1993"
patch_author: "ripman"
patch_group: "Nenhum"
patch_site: ""
patch_version: "1.0"
patch_release: "07/10/2017"
patch_type: "IPS"
patch_progress: "Textos"
patch_images: ["//img.romhackers.org/traducoes/%5BSMD%5D%20OutRun%202019%20-%20ripman%20-%201.png","//img.romhackers.org/traducoes/%5BSMD%5D%20OutRun%202019%20-%20ripman%20-%202.png","//img.romhackers.org/traducoes/%5BSMD%5D%20OutRun%202019%20-%20ripman%20-%203.png"]
---
Segundo o autor desta tradução, todos os textos do jogo foram traduzidos, mas não foram acentuados, e nenhuma mensagem em forma de gráfico foi editada.ATENÇÃO:Esta tradução deve ser aplicada na ROM OutRun 2019 (U) [!].bin, com CRC32 E32E17E2. | 46.65 | 268 | 0.740622 | por_Latn | 0.696713 |
dafd7de648fe17d038cdd6a6f6723c7fd26020c2 | 10,226 | md | Markdown | articles/iot-suite/iot-suite-connecting-devices-mbed.md | VinceSmith/azure-docs | 550bda5c2baf01ff16b9d109549388ffddddc1fd | [
"CC-BY-3.0"
] | 1 | 2019-06-02T17:00:22.000Z | 2019-06-02T17:00:22.000Z | articles/iot-suite/iot-suite-connecting-devices-mbed.md | VinceSmith/azure-docs | 550bda5c2baf01ff16b9d109549388ffddddc1fd | [
"CC-BY-3.0"
] | null | null | null | articles/iot-suite/iot-suite-connecting-devices-mbed.md | VinceSmith/azure-docs | 550bda5c2baf01ff16b9d109549388ffddddc1fd | [
"CC-BY-3.0"
] | 2 | 2017-02-18T05:45:54.000Z | 2019-12-21T21:23:13.000Z | ---
title: Connect a device using C on mbed | Microsoft Docs
description: Describes how to connect a device to the Azure IoT Suite preconfigured remote monitoring solution using an application written in C running on an mbed device.
services: ''
suite: iot-suite
documentationcenter: na
author: dominicbetts
manager: timlt
editor: ''
ms.assetid: 9551075e-dcf9-488f-943e-d0eb0e6260be
ms.service: iot-suite
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: na
ms.date: 01/04/2017
ms.author: dobett
---
# Connect your device to the remote monitoring preconfigured solution (mbed)
[!INCLUDE [iot-suite-selector-connecting](../../includes/iot-suite-selector-connecting.md)]
## Build and run the C sample solution
The following instructions describe the steps for connecting an [mbed-enabled Freescale FRDM-K64F][lnk-mbed-home] device to the remote monitoring solution.
### Connect the mbed device to your network and desktop machine
1. Connect the mbed device to your network using an Ethernet cable. This step is necessary because the sample application requires internet access.
2. See [Getting Started with mbed][lnk-mbed-getstarted] to connect your mbed device to your desktop PC.
3. If your desktop PC is running Windows, see [PC Configuration][lnk-mbed-pcconnect] to configure serial port access to your mbed device.
### Create an mbed project and import the sample code
1. In your web browser, go to the mbed.org [developer site](https://developer.mbed.org/). If you haven't signed up, you see an option to create an account (it's free). Otherwise, log in with your account credentials. Then click **Compiler** in the upper right-hand corner of the page. This action brings you to the *Workspace* interface.
2. Make sure the hardware platform you're using appears in the upper right-hand corner of the window, or click the icon in the right-hand corner to select your hardware platform.
3. Click **Import** on the main menu. Then click **Click here** to import from URL link next to the mbed globe logo.
![][6]
4. In the pop-up window, enter the link for the sample code https://developer.mbed.org/users/AzureIoTClient/code/remote_monitoring/ then click **Import**.
![][7]
5. You can see in the mbed compiler window that importing this project also imports various libraries. Some are provided and maintained by the Azure IoT team ([azureiot_common](https://developer.mbed.org/users/AzureIoTClient/code/azureiot_common/), [iothub_client](https://developer.mbed.org/users/AzureIoTClient/code/iothub_client/), [iothub_amqp_transport](https://developer.mbed.org/users/AzureIoTClient/code/iothub_amqp_transport/), [azure_uamqp](https://developer.mbed.org/users/AzureIoTClient/code/azure_uamqp/)), while others are third-party libraries available in the mbed libraries catalog.
![][8]
6. Open the remote_monitoring\remote_monitoring.c file and locate the following code in the file:
```
static const char* deviceId = "[Device Id]";
static const char* deviceKey = "[Device Key]";
static const char* hubName = "[IoTHub Name]";
static const char* hubSuffix = "[IoTHub Suffix, i.e. azure-devices.net]";
```
7. Replace [Device Id] and [Device Key], with your device data to enable the sample program to connect to your IoT hub. Use the IoT Hub Hostname to replace the [IoTHub Name] and [IoTHub Suffix, i.e. azure-devices.net] placeholders. For example, if your IoT Hub Hostname is **contoso.azure-devices.net**, **contoso** is the **hubName** and everything after it is the **hubSuffix**:
```
static const char* deviceId = "mydevice";
static const char* deviceKey = "mykey";
static const char* hubName = "contoso";
static const char* hubSuffix = "azure-devices.net";
```
![][9]
### Walk through the code
If you are interested in how the program works, this section describes some key parts of the sample code. If you only want to run the code, skip ahead to [Build and run the program](#buildandrun).
#### Defining the model
This sample uses the [serializer][lnk-serializer] library to define a model that specifies the messages the device can send to IoT Hub and receive from IoT Hub. In this sample, the **Contoso** namespace defines a **Thermostat** model that specifies:
- The **Temperature**, **ExternalTemperature**, and **Humidity** telemetry data.
- Metadata such as the device id, device properties.
- The commands that the device responds to:
```
BEGIN_NAMESPACE(Contoso);
DECLARE_STRUCT(SystemProperties,
ascii_char_ptr, DeviceID,
_Bool, Enabled
);
DECLARE_STRUCT(DeviceProperties,
ascii_char_ptr, DeviceID,
_Bool, HubEnabledState
);
DECLARE_MODEL(Thermostat,
/* Event data (temperature, external temperature and humidity) */
WITH_DATA(int, Temperature),
WITH_DATA(int, ExternalTemperature),
WITH_DATA(int, Humidity),
WITH_DATA(ascii_char_ptr, DeviceId),
/* Device Info - This is command metadata + some extra fields */
WITH_DATA(ascii_char_ptr, ObjectType),
WITH_DATA(_Bool, IsSimulatedDevice),
WITH_DATA(ascii_char_ptr, Version),
WITH_DATA(DeviceProperties, DeviceProperties),
WITH_DATA(ascii_char_ptr_no_quotes, Commands),
/* Commands implemented by the device */
WITH_ACTION(SetTemperature, int, temperature),
WITH_ACTION(SetHumidity, int, humidity)
);
END_NAMESPACE(Contoso);
```
Related to the model definition are the definitions for the **SetTemperature** and **SetHumidity** commands that the device responds to:
```
EXECUTE_COMMAND_RESULT SetTemperature(Thermostat* thermostat, int temperature)
{
(void)printf("Received temperature %d\r\n", temperature);
thermostat->Temperature = temperature;
return EXECUTE_COMMAND_SUCCESS;
}
EXECUTE_COMMAND_RESULT SetHumidity(Thermostat* thermostat, int humidity)
{
(void)printf("Received humidity %d\r\n", humidity);
thermostat->Humidity = humidity;
return EXECUTE_COMMAND_SUCCESS;
}
```
#### Connecting the model to the library
The functions **sendMessage** and **IoTHubMessage** are boilerplate code for sending telemetry from the device and connecting messages from IoT Hub to the command handlers.
#### The remote_monitoring_run function
The program's **main** function invokes the **remote_monitoring_run** function when the application starts to execute the device's behavior as an IoT Hub device client. This **remote_monitoring_run** function mostly consists of nested pairs of functions:
* **platform\_init** and **platform\_deinit** perform platform-specific initialization and shutdown operations.
* **serializer\_init** and **serializer\_deinit** initialize and de-initialize the serializer library.
* **IoTHubClient\_Create** and **IoTHubClient\_Destroy** create a client handle, **iotHubClientHandle**, using the device credentials for connecting to your IoT hub.
In the main section of the **remote_monitoring_run** function, the program performs the following operations using the **iotHubClientHandle** handle:
* Creates an instance of the Contoso thermostat model and sets up the message callbacks for the two commands.
* Sends information about the device itself, including the commands it supports, to your IoT hub using the serializer library. When the hub receives this message, it changes the device status in the dashboard from **Pending** to **Running**.
* Starts a **while** loop that sends temperature, external temperature, and humidity values to IoT Hub every second.
For reference, here is a sample **DeviceInfo** message sent to IoT Hub at startup:
```
{
"ObjectType":"DeviceInfo",
"Version":"1.0",
"IsSimulatedDevice":false,
"DeviceProperties":
{
"DeviceID":"mydevice01", "HubEnabledState":true
},
"Commands":
[
{"Name":"SetHumidity", "Parameters":[{"Name":"humidity","Type":"double"}]},
{ "Name":"SetTemperature", "Parameters":[{"Name":"temperature","Type":"double"}]}
]
}
```
For reference, here is a sample **Telemetry** message sent to IoT Hub:
```
{"DeviceId":"mydevice01", "Temperature":50, "Humidity":50, "ExternalTemperature":55}
```
For reference, here is a sample **Command** received from IoT Hub:
```
{
"Name":"SetHumidity",
"MessageId":"2f3d3c75-3b77-4832-80ed-a5bb3e233391",
"CreatedTime":"2016-03-11T15:09:44.2231295Z",
"Parameters":{"humidity":23}
}
```
<a id="buildandrun"/>
### Build and run the program
1. Click **Compile** to build the program. You can safely ignore any warnings, but if the build generates errors, fix them before proceeding.
2. If the build is successful, the mbed compiler website generates a .bin file with the name of your project and downloads it to your local machine. Copy the .bin file to the device. Saving the .bin file to the device causes the device to restart and run the program contained in the .bin file. You can manually restart the program at any time by pressing the reset button on the mbed device.
3. Connect to the device using an SSH client application, such as PuTTY. You can determine the serial port your device uses by checking Windows Device Manager.
![][11]
4. In PuTTY, click the **Serial** connection type. The device typically connects at 9600 baud, so enter 9600 in the **Speed** box. Then click **Open**.
5. The program starts executing. You may have to reset the board (press CTRL+Break or press the board's reset button) if the program does not start automatically when you connect.
![][10]
[!INCLUDE [iot-suite-visualize-connecting](../../includes/iot-suite-visualize-connecting.md)]
[6]: ./media/iot-suite-connecting-devices-mbed/mbed1.png
[7]: ./media/iot-suite-connecting-devices-mbed/mbed2a.png
[8]: ./media/iot-suite-connecting-devices-mbed/mbed3a.png
[9]: ./media/iot-suite-connecting-devices-mbed/suite6.png
[10]: ./media/iot-suite-connecting-devices-mbed/putty.png
[11]: ./media/iot-suite-connecting-devices-mbed/mbed6.png
[lnk-mbed-home]: https://developer.mbed.org/platforms/FRDM-K64F/
[lnk-mbed-getstarted]: https://developer.mbed.org/platforms/FRDM-K64F/#getting-started-with-mbed
[lnk-mbed-pcconnect]: https://developer.mbed.org/platforms/FRDM-K64F/#pc-configuration
[lnk-serializer]: https://azure.microsoft.com/documentation/articles/iot-hub-device-sdk-c-intro/#serializer
| 49.882927 | 599 | 0.75044 | eng_Latn | 0.960085 |
dafe2f60b7db440af3fb5d1594a4840127e31711 | 556 | md | Markdown | Read03.md | MohamadSheikhAlshabab/Steps_to_begin | c258fceda2e17e12fc2c306951b9522627988cf2 | [
"MIT"
] | null | null | null | Read03.md | MohamadSheikhAlshabab/Steps_to_begin | c258fceda2e17e12fc2c306951b9522627988cf2 | [
"MIT"
] | null | null | null | Read03.md | MohamadSheikhAlshabab/Steps_to_begin | c258fceda2e17e12fc2c306951b9522627988cf2 | [
"MIT"
] | null | null | null | # to start Django project
- 1 - mkdir name_folder
- 2 - cd name_folder
- 3 - poetry init -n
- 4 - poetry add django
- 5 - poetry add --dev black
- 6 - poetry shell
- 7 - django-admin startproject name_of_project . (just apply once)
- ..............................................................................................`^`
- ...................................................................................`| this dot is an important`
- 8 - python manage.py migrate
- 9 - python manage.py runserver
- 10 - python manage.py startapp name_of_app
| 37.066667 | 113 | 0.471223 | oci_Latn | 0.419544 |
dafeb8fa0d2a4aa20dffa349d404448abf8c041a | 1,420 | md | Markdown | docs/Plugins.md | championquizzer/skywalking-python | a9cf38a5a867a47e7f1ba3025846fb81b9e2dbf7 | [
"Apache-2.0"
] | null | null | null | docs/Plugins.md | championquizzer/skywalking-python | a9cf38a5a867a47e7f1ba3025846fb81b9e2dbf7 | [
"Apache-2.0"
] | null | null | null | docs/Plugins.md | championquizzer/skywalking-python | a9cf38a5a867a47e7f1ba3025846fb81b9e2dbf7 | [
"Apache-2.0"
] | null | null | null | # Supported Libraries
Library | Versions | Plugin Name
| :--- | :--- | :--- |
| [http.server](https://docs.python.org/3/library/http.server.html) | Python 3.5 ~ 3.8 | `sw_http_server` |
| [urllib.request](https://docs.python.org/3/library/urllib.request.html) | Python 3.5 ~ 3.8 | `sw_urllib_request` |
| [requests](https://requests.readthedocs.io/en/master/) | >= 2.9.0 < 2.15.0, >= 2.17.0 <= 2.24.0 | `sw_requests` |
| [Flask](https://flask.palletsprojects.com/en/1.1.x/) | >=1.0.4 <= 1.1.2 | `sw_flask` |
| [PyMySQL](https://pymysql.readthedocs.io/en/latest/) | 0.10.0 | `sw_pymysql` |
| [Django](https://www.djangoproject.com/) | >=2.0 <= 3.1 | `sw_django` |
| [redis-py](https://github.com/andymccurdy/redis-py/) | 3.5.3 | `sw_redis` |
| [kafka-python](https://kafka-python.readthedocs.io/en/master/) | 2.0.1 | `sw_kafka` |
| [tornado](https://www.tornadoweb.org/en/stable/) | 6.0.4 | `sw_tornado` |
| [pika](https://pika.readthedocs.io/en/stable/) | 1.1.0 | `sw_rabbitmq` |
| [pymongo](https://pymongo.readthedocs.io/en/stable/) | 3.11.0 | `sw_pymongo` |
| [elasticsearch](https://github.com/elastic/elasticsearch-py) | 7.9.0 | `sw_elasticsearch` |
| [urllib3](https://urllib3.readthedocs.io/en/latest/) | >= 1.25.9 <= 1.25.10 | `sw_urllib3` |
The column `Versions` only indicates that the versions are tested, if you found the newer versions are also supported, welcome to add the newer version into the table.
| 71 | 167 | 0.661268 | yue_Hant | 0.150534 |
dafeca465bf1f76f384b3043bb933c9e1974b569 | 2,102 | md | Markdown | roles/configure_jenkins/docs/credenciais.md | kamuridesu/devops-cicd-environment | f461a78e68b5dcf87560c2b740a6e947e7f46358 | [
"MIT"
] | null | null | null | roles/configure_jenkins/docs/credenciais.md | kamuridesu/devops-cicd-environment | f461a78e68b5dcf87560c2b740a6e947e7f46358 | [
"MIT"
] | null | null | null | roles/configure_jenkins/docs/credenciais.md | kamuridesu/devops-cicd-environment | f461a78e68b5dcf87560c2b740a6e947e7f46358 | [
"MIT"
] | 1 | 2022-03-30T18:41:33.000Z | 2022-03-30T18:41:33.000Z | ## Credenciais
1. Criando algumas `credenciais`
- Criar Chave privada e pública do Jenkins
- Passo 1: Acessar a vm do jenkins
```console
ssh -i keys/vagrant [email protected]
```
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-18.png">
</p>
- Passo 2: Acessar o container jenkins
```console
docker exec -it jenkins /bin/bash
```
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-19.png">
</p>
- Passo 3: Mudando para usuário `jenkins`
```console
su jenkins
```
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-20.png">
</p>
- Passo 4: Criar chaves ssh
```console
ssh-keygen
```
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-21.png">
</p>
- Passo 5: Copiando a chave privada e criando uma credencial no jenkins com ela.
```console
cat ~/.ssh/id_rsa
```
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-22.png">
</p>
- Manage Credentials
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-9.png">
</p>
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-10.png">
</p>
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-11.png">
</p>
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-12.png">
</p>
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-13.png">
</p>
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-23.png">
</p>
- [Colocar chave ssh pública do Jenkins no GitLab](../../configure_gitlab/docs/chavessh_user_jenkins.md)
- [Api Token Gitlab](../../configure_gitlab/docs/token.md)
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-16.png">
</p>
- [Api Token SonarQube](../../configure_sonar/docs/token.md)
<p align="center">
<img alt="Jenkins" src="../../../data/jenkins-images/jenkins-admin-28.png">
</p> | 23.098901 | 104 | 0.648906 | bos_Latn | 0.097704 |
daff4af71e73e494cd0d2809783ca6e14478c51f | 470 | md | Markdown | entries/opensr.md | Mailaender/opensourcegames | e3ffdfb848cc908680935dbb57420b19cddd45ff | [
"CC0-1.0"
] | null | null | null | entries/opensr.md | Mailaender/opensourcegames | e3ffdfb848cc908680935dbb57420b19cddd45ff | [
"CC0-1.0"
] | null | null | null | entries/opensr.md | Mailaender/opensourcegames | e3ffdfb848cc908680935dbb57420b19cddd45ff | [
"CC0-1.0"
] | null | null | null | # OpenSR
- Home: https://github.com/ObKo/OpenSR
- Inspiration: Space Rangers 2: Dominators
- State: beta, inactive since 2017
- Keyword: remake, content commercial + original required
- Code repository: https://github.com/ObKo/OpenSR.git (archived, @archived, @created 2011, @stars 68, @forks 10)
- Code language: C++
- Code license: GPL-3.0
- Code dependency: OpenAL, Qt
- Developer: Alexander Akulich, Kakadu, Konstantin Oblaukhov
## Building
- Build system: CMake
| 29.375 | 112 | 0.738298 | kor_Hang | 0.191149 |
daff74bf87b0038a2c79bd571bc7fa953b7e5300 | 821 | md | Markdown | snippets/CountBy.md | chuxuantinh/30-seconds-of-csharp | 80c1894ca868c634e7ebfa637a8684b1007c3863 | [
"CC0-1.0"
] | 139 | 2020-01-15T11:10:52.000Z | 2022-03-22T20:25:30.000Z | snippets/CountBy.md | thalicelopes/30-seconds-of-csharp | 34003a7ce73573aa4cdb3da4cba4a568d0097cba | [
"CC0-1.0"
] | 8 | 2019-12-18T17:14:38.000Z | 2021-04-02T08:35:43.000Z | snippets/CountBy.md | thalicelopes/30-seconds-of-csharp | 34003a7ce73573aa4cdb3da4cba4a568d0097cba | [
"CC0-1.0"
] | 34 | 2019-12-21T01:01:18.000Z | 2022-03-22T20:25:31.000Z | ---
title: CountBy
tags: array,list,lambda,intermediate
---
Groups the elements of a collection based on the given function and returns the count of elements in each group.
- Use `IEnumerable.GroupBy()` to create groups for each distinct value in the collection, after applying the provided function.
- Use `IEnumerable.ToDictionary()` to convert the result of the previous operation to a `Dictionary`.
```csharp
using System.Collections.Generic;
using System.Linq;
public static partial class _30s
{
public static Dictionary<R,int> CountBy<T,R>(IEnumerable<T> values, Func<T,R> map)
{
return values
.GroupBy(map)
.ToDictionary(v => v.Key, v => v.Count());
}
}
```
```csharp
var p = new[] {
new { a = 3, b = 2},
new { a = 2, b = 1}
};
_30s.CountBy(p, x => x.a); // { [3, 1], [2, 1] }
```
| 24.147059 | 127 | 0.667479 | eng_Latn | 0.906719 |
970047bafe43e3eacb5f7df4a5810cfb81db73d5 | 1,893 | md | Markdown | README.md | ezh/docker-logspout-sourcebased | 8d9de64658e7232c4ff7230be309e7c9a47e55ba | [
"MIT"
] | null | null | null | README.md | ezh/docker-logspout-sourcebased | 8d9de64658e7232c4ff7230be309e7c9a47e55ba | [
"MIT"
] | null | null | null | README.md | ezh/docker-logspout-sourcebased | 8d9de64658e7232c4ff7230be309e7c9a47e55ba | [
"MIT"
] | null | null | null | docker-logspout-sourcebased
=======================
[](https://travis-ci.org/ezh/docker-logspout-sourcebased) [](https://hub.docker.com/r/ezh1k/logspout/) [](https://github.com/ezh/docker-logspout-sourcebased/releases) [](https://github.com/ezh/docker-logspout-sourcebased/blob/master/LICENSE)
Docker compose source based logspout configuration
logspout build from source from https://github.com/gliderlabs/logspout
By default it builds the stable *logspout-3.1* if you use docker compose and latest unstable *master* if you build directly from Dockerfile.
[Hint #1](https://github.com/ezh/docker-logspout-sourcebased/blob/master/docker/Dockerfile#L19),
[Hint #2](https://github.com/ezh/docker-logspout-sourcebased/blob/master/docker-compose.yml#L8)
Image is based on `debian/jessie`, the same as an official Jenkis docker container.
Modules
-------
This container build with additional logspout modules:
* https://github.com/ezh/logspout-beat
* https://github.com/ezh/logspout-cloudwatch
* https://github.com/ezh/logspout-fluentd
* https://github.com/ezh/logspout-gelf
* https://github.com/ezh/logspout-kafka
* https://github.com/ezh/logspout-kinesis
* https://github.com/ezh/logspout-logentries-autowire
* https://github.com/ezh/logspout-logstash
* https://github.com/ezh/logspout-redis-logstash
* https://github.com/ezh/logspout-splunk
Execution
---------
logspout executed directly as PID 1 process.
Arguments
---------
You may set logspout version via `version` argument
Copyright
---------
Copyright © 2017 Alexey B. Aksenov/Ezh. All rights reserved.
| 42.066667 | 564 | 0.759113 | yue_Hant | 0.477152 |
970093a7e13ac04410ffdf988abd1d7ec4201b0a | 4,679 | md | Markdown | docs/framework/unmanaged-api/hosting/epolicyaction-enumeration.md | soelax/docs.de-de | 17beb71b6711590e35405a1086e6ac4eac24c207 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/hosting/epolicyaction-enumeration.md | soelax/docs.de-de | 17beb71b6711590e35405a1086e6ac4eac24c207 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/unmanaged-api/hosting/epolicyaction-enumeration.md | soelax/docs.de-de | 17beb71b6711590e35405a1086e6ac4eac24c207 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: EPolicyAction-Enumeration
ms.date: 03/30/2017
api_name:
- EPolicyAction
api_location:
- mscoree.dll
api_type:
- COM
f1_keywords:
- EPolicyAction
helpviewer_keywords:
- EPolicyAction enumeration [.NET Framework hosting]
ms.assetid: 72dd76ba-239e-45ac-9ded-318fb07d6c6d
topic_type:
- apiref
author: rpetrusha
ms.author: ronpet
ms.openlocfilehash: 80a0e8d37e834ea0a7623517e2e1228a79d9ea10
ms.sourcegitcommit: 6b308cf6d627d78ee36dbbae8972a310ac7fd6c8
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 01/23/2019
ms.locfileid: "54655711"
---
# <a name="epolicyaction-enumeration"></a>EPolicyAction-Enumeration
Beschreibt die Richtlinienaktionen, der Host kann für Vorgänge, die durch beschrieben festlegen [EClrOperation](../../../../docs/framework/unmanaged-api/hosting/eclroperation-enumeration.md) sowie durch beschriebene Fehler [EClrFailure](../../../../docs/framework/unmanaged-api/hosting/eclrfailure-enumeration.md).
## <a name="syntax"></a>Syntax
```
typedef enum {
eNoAction,
eThrowException,
eAbortThread,
eRudeAbortThread,
eUnloadAppDomain,
eRudeUnloadAppDomain,
eExitProcess,
eFastExitProcess,
eRudeExitProcess,
eDisableRuntime
} EPolicyAction;
```
## <a name="members"></a>Member
|Member|Beschreibung|
|------------|-----------------|
|`eAbortThread`|Gibt an, dass die common Language Runtime (CLR) den Thread ordnungsgemäß abgebrochen werden soll. Ein ordnungsgemäßer Abbruch beinhaltet versuchen der Ausführung alle `finally` Blöcke, alle `catch` Blöcke im Zusammenhang mit der Threadabbrüche und Finalizer.|
|`eDisableRuntime`|Gibt an, dass die CLR deaktiviert eingeben soll. Verwalteter Code kann keine weiteren des betroffenen Prozesses ausgeführt werden, und der CLR Threads blockiert.|
|`eExitProcess`|Gibt an, dass die CLR dem ordnungsgemäßen Beenden der Prozess, einschließlich der Ausführung von Finalizern und Bereinigung und protokollieren soll.|
|`eFastExitProcess`|Gibt an, dass die CLR den Prozess sofort beendet werden soll ohne Ausführung von Finalizern oder Bereinigung und Vorgänge. Jedoch ein wird die Benachrichtigung an den Debugger gesendet.|
|`eNoAction`|Gibt an, dass keine Aktion ausgeführt werden soll.|
|`eRudeAbortThread`|Gibt an, dass die CLR einen grobe Threadabbruch ausführen soll. Nur die `catch` und `finally` Blöcke gekennzeichnet mit <xref:System.EnterpriseServices.MustRunInClientContextAttribute> ausgeführt werden.|
|`eRudeExitProcess`|Gibt an, dass die CLR den Prozess beendet werden soll, ohne Ausführung von Finalizern oder Vorgänge protokollieren.|
|`eRudeUnloadAppDomain`|Gibt an, dass die CLR ein grobe Entladen durchführen, sollten die <xref:System.AppDomain>. Nur Finalizer mit markierten <xref:System.EnterpriseServices.MustRunInClientContextAttribute> ausgeführt werden. Auf ähnliche Weise alle Threads mit dieser <xref:System.AppDomain> in ihrem Stapel erhalten eine `ThreadAbortException`, sondern nur die `catch` und `finally` Blöcke gekennzeichnet mit <xref:System.EnterpriseServices.MustRunInClientContextAttribute> ausgeführt werden.|
|`eThrowException`|Gibt an, dass es sich bei der Bedingung, z. B. Out-of-Memory, Pufferüberlauf usw., entsprechende Ausnahme ausgelöst werden soll.|
|`eUnloadAppDomain`|Gibt an, dass die <xref:System.AppDomain> entladen werden soll. Die CLR versucht, die Finalizer ausgeführt.|
## <a name="remarks"></a>Hinweise
Der Host setzt Richtlinienaktionen durch Aufrufen der Methoden der der [ICLRPolicyManager](../../../../docs/framework/unmanaged-api/hosting/iclrpolicymanager-interface.md) Schnittstelle. Informationen über grobe und ordnungsgemäße Abbrüche finden Sie unter den [EClrOperation](../../../../docs/framework/unmanaged-api/hosting/eclroperation-enumeration.md) Enumeration.
## <a name="requirements"></a>Anforderungen
**Plattformen:** Weitere Informationen finden Sie unter [Systemanforderungen](../../../../docs/framework/get-started/system-requirements.md).
**Header:** MSCorEE.h
**Bibliothek:** MSCorEE.dll
**.NET Framework-Versionen:** [!INCLUDE[net_current_v20plus](../../../../includes/net-current-v20plus-md.md)]
## <a name="see-also"></a>Siehe auch
- [EClrFailure-Enumeration](../../../../docs/framework/unmanaged-api/hosting/eclrfailure-enumeration.md)
- [ICLRPolicyManager-Schnittstelle](../../../../docs/framework/unmanaged-api/hosting/iclrpolicymanager-interface.md)
- [IHostPolicyManager-Schnittstelle](../../../../docs/framework/unmanaged-api/hosting/ihostpolicymanager-interface.md)
- [Hosten von Enumerationen](../../../../docs/framework/unmanaged-api/hosting/hosting-enumerations.md)
| 59.987179 | 499 | 0.765762 | deu_Latn | 0.912126 |
9700ba29cd580116807cd450749832b6e6cdaef2 | 462 | md | Markdown | docs/usage/cli.md | datarootsio/databooks | 6ecbae09c7df8149ae3ab45a88e00f6ccea7d045 | [
"MIT"
] | 75 | 2021-12-20T11:50:48.000Z | 2022-03-31T19:57:26.000Z | docs/usage/cli.md | datarootsio/databooks | 6ecbae09c7df8149ae3ab45a88e00f6ccea7d045 | [
"MIT"
] | 26 | 2021-12-16T16:17:31.000Z | 2022-03-03T20:58:50.000Z | docs/usage/cli.md | datarootsio/databooks | 6ecbae09c7df8149ae3ab45a88e00f6ccea7d045 | [
"MIT"
] | 3 | 2021-12-16T15:26:15.000Z | 2022-03-02T10:04:34.000Z | # CLI tool
The most straightforward way to start using databooks is by using the terminal. It's the
default way of running the commands and how you've probably seen `databooks` being used
before. However, using the terminal can be error-prone and result in "dirty" notebooks
in your git repo. Check [CLI documentation](../CLI) for more information.
A safer alternative is to automate your databooks commands, by setting up CI in your
repo or pre-commit hooks.
| 46.2 | 88 | 0.785714 | eng_Latn | 0.99967 |
9700dffd08bd310ccbb44e44dca0700c6f8fa293 | 21 | md | Markdown | README.md | Carlows/trendbot-web-client | f5aaa0884230e62cc804fe7f91870539544a147b | [
"MIT"
] | null | null | null | README.md | Carlows/trendbot-web-client | f5aaa0884230e62cc804fe7f91870539544a147b | [
"MIT"
] | null | null | null | README.md | Carlows/trendbot-web-client | f5aaa0884230e62cc804fe7f91870539544a147b | [
"MIT"
] | null | null | null | # trendbot-web-client | 21 | 21 | 0.809524 | fra_Latn | 0.374808 |
97030431d5830e2e5214d3c31f11aabacf15fe3a | 11,866 | md | Markdown | oci-library/oci-hol/deploying-oci-streaming-service/deploying-oci-streaming-service.md | sgoil2019/learning-library | 91d4043b19c931b07ab6a0ac0d372b47207f5cd4 | [
"UPL-1.0"
] | null | null | null | oci-library/oci-hol/deploying-oci-streaming-service/deploying-oci-streaming-service.md | sgoil2019/learning-library | 91d4043b19c931b07ab6a0ac0d372b47207f5cd4 | [
"UPL-1.0"
] | null | null | null | oci-library/oci-hol/deploying-oci-streaming-service/deploying-oci-streaming-service.md | sgoil2019/learning-library | 91d4043b19c931b07ab6a0ac0d372b47207f5cd4 | [
"UPL-1.0"
] | null | null | null | # Deploying OCI Streaming Service
## Introduction
In this lab, we will create a compute instance, download a script to configure streaming service, publish and consume messages. The Oracle Cloud Infrastructure Streaming service provides a fully managed, scalable, and durable storage solution for ingesting continuous, high-volume streams of data that you can consume and process in real time. Streaming can be used for messaging, ingesting high-volume data such as application logs, operational telemetry, web Click-stream data, or other use cases in which data is produced and processed continually and sequentially in a publish-subscribe messaging model.
**Some Key points:**
*We recommend using Chrome or Edge as the broswer. Also set your browser zoom to 80%*
- All screenshots are examples ONLY.
- Do NOT use compartment name and other data from screenshots. Only use data (including compartment name) provided in the content section of the lab
- Mac OS Users should use command+C / command+V to copy and paste inside the OCI Console
- Login credentials are provided later in the guide (scroll down). Every User MUST keep these credentials handy.
**Cloud Tenant Name**
**User Name**
**Password**
**Compartment Name (Provided Later)**
*Note: OCI UI is being updated thus some screenshots in the instructions might be different than actual UI*
### Pre-Requisites
1. [OCI Training](https://cloud.oracle.com/en_US/iaas/training)
2. [Familiarity with OCI console](https://docs.us-phoenix-1.oraclecloud.com/Content/GSG/Concepts/console.htm)
3. [Overview of Networking](https://docs.us-phoenix-1.oraclecloud.com/Content/Network/Concepts/overview.htm)
4. [Familiarity with Compartment](https://docs.us-phoenix-1.oraclecloud.com/Content/GSG/Concepts/concepts.htm)
5. [Connecting to a compute instance](https://docs.us-phoenix-1.oraclecloud.com/Content/Compute/Tasks/accessinginstance.htm)
6. Completed *Generate SSH Keys* Lab in the Contens menu on the right
## **Step 1**: Sign in to OCI Console and create VCN
* **Tenant Name:** {{Cloud Tenant}}
* **User Name:** {{User Name}}
* **Password:** {{Password}}
* **Compartment:**{{Compartment}}
**Note:** OCI UI is being updated thus some screenshots in the instructions might be different than actual UI.
1. Sign in using your tenant name, user name and password. Use the login option under **Oracle Cloud Infrastructure**.

2. From the OCI Services menu, Click **Virtual Cloud Networks** under Networking. Select the compartment assigned to you from the drop down menu on the left part of the screen under Networking and Click **Start VCN Wizard**.
**NOTE:** Ensure the correct Compartment is selected under COMPARTMENT list.
3. Click **VCN with Internet Connectivity** and click **Start VCN Wizard**.
4. Fill out the dialog box:
- **VCN NAME**: Provide a name
- **COMPARTMENT**: Ensure your compartment is selected
- **VCN CIDR BLOCK**: Provide a CIDR block (10.0.0.0/16)
- **PUBLIC SUBNET CIDR BLOCK**: Provide a CIDR block (10.0.1.0/24)
- **PRIVATE SUBNET CIDR BLOCK**: Provide a CIDR block (10.0.2.0/24)
- Click **Next**
5. Verify all the information and Click **Create**.
6. This will create a VCN with the following components.
*VCN, Public subnet, Private subnet, Internet gateway (IG), NAT gateway (NAT), Service gateway (SG)*
7. Click **View Virtual Cloud Network** to display your VCN details.
## **Step 2**: Create compute instance
1. Go to the OCI console. From OCI services menu, under **Compute**, click **Instances**.
2. Click Create Instance. Fill out the dialog box:
- **Name your instance**: Enter a name
- **Choose an operating system or image source**: Click **Change Image Source**. In the new window, Click **Oracle Images** Choose **Oracle Cloud Developer Image**. Scroll down, Accept the Agreement and Click **Select Image**

- **Availability Domain**: Select availability domain
- **Instance Type**: Select Virtual Machine
- **Instance Shape**: Select VM shape
**Under Configure Networking**
- **Virtual cloud network compartment**: Select your compartment
- **Virtual cloud network**: Choose the VCN
- **Subnet Compartment:** Choose your compartment.
- **Subnet:** Choose the Public Subnet under **Public Subnets**
- **Use network security groups to control traffic** : Leave un-checked
- **Assign a public IP address**: Check this option

- **Boot Volume:** Leave the default
- **Add SSH Keys:** Choose **Paste SSH Keys** and paste the Public Key saved earlier.
3. Click **Create**.
4. Wait for Instance to be in **Running** state. In Cloud Shell Terminal enter command:
```
<copy>cd .ssh</copy>
```
5. Enter **ls** and verify your SSH Key file exists.
6. Enter command:
```
<copy>bash</copy>
```
```
<copy>ssh -i <sshkeyname> opc@<PUBLIC_IP_OF_COMPUTE></copy>
```
**HINT:** If 'Permission denied error' is seen, ensure you are using '-i' in the ssh command. You MUST type the command, do NOT copy and paste ssh command.
7. Enter 'yes' when prompted for security message.

8. Verify opc@`<COMPUTE_INSTANCE_NAME>` appears on the prompt.
## **Step 3**: Download Script to configure Streaming service and Publish messages
1. In ssh session to compute instance, configure OCI CLI, Enter command:
```
<copy>
oci setup config
</copy>
```
2. Accept the default directory location. For user's OCID switch to OCI Console window. Click Human Icon and then your user name. In the user details page Click **copy** to copy the OCID. **Also note down your region name as shown in OCI Console window**. Paste the OCID in ssh session.

3. Repeat the step to find tenancy OCID (Human icon followed by Clicking Tenancy Name). Paste the Tenancy OCID in ssh session to compute instance followed by providing your region name (us-ashburn-1, us-phoenix-1 etc).
4. When asked for **Do you want to generate a new RSA key pair?** answer Y. For the rest of the questions accept default by pressing Enter.

5. **oci setup config** also generated an API key. We will need to upload this API key into our OCI account for authentication of API calls. Switch to ssh session to compute instance, to display the conent of API key Enter command:
```
<copy>
cat ~/.oci/oci_api_key_public.pem
</copy>
```
6. Hightligh and copy the content from ssh session. Switch to OCI Console, Click Human icon followed by your user name. In user details page Click **Add Public Key**. In the dialg box paste the public key content and Click **Add**.


7. Download and Install pip utility which will be used to install additional software. Enter command:
```
<copy>
sudo curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
</copy>
```
followed by
```
<copy>
sudo python get-pip.py
</copy>
```
8. Install a virtual enviornement. This is being done so we have a clean environment to execute our python script that will create and publish messages to OCI streaming service. Enter command:
```
<copy>
sudo pip install virtualenv
</copy>
```
9. Now create a virtual environment, Enter command:
```
<copy>
bash
virtualenv <Environment_Name>
</copy>
```
For example **virtualenv stream\_env**.
Now initialize the virtual enviornment, Enter command:
**NOTE** : Below command assumes that the enviornment name is 'stream-env'
```
<copy>
cd /home/opc/stream_env/bin
</copy>
```
```
<copy>
source ~/stream_env/bin/activate
</copy>
```
10. Once your virtual environment is active, oci can be installed using pip, Enter command:
```
<copy>
pip install oci
</copy>
```

11. Now download the main script file though first we will remove the existing file, Enter Command:
```
<copy>
cd /home/opc
</copy>
```
```
<copy>
rm stream_example.py
</copy>
```
```
<copy>
wget https://raw.githubusercontent.com/oracle/learning-library/master/oci-library/oci-hol/deploying-oci-streaming-service/files/stream_example.py
</copy>
```
12. Now download a dependent script file though first we will remove the existing file, Enter Command:
```
<copy>
cd /home/opc/stream_env/lib/python2.7/site-packages/oci/streaming/
</copy>
```
```
<copy>
rm stream_admin_client_composite_operations.py
</copy>
```
```
<copy>
wget https://raw.githubusercontent.com/oracle/learning-library/master/oci-library/oci-hol/deploying-oci-streaming-service/files/stream_admin_client_composite_operations.py
</copy>
```
13. Our setup is now ready. Before running the script switch to OCI Console window, from the main menu Click **Compartments** under **Identity**. Click your compartment name and copy the OCID of the compartment. (Just as was done for user OCID earlier).
14. Switch to ssh session and run the script, Enter command:
```
<copy>
bash
python ~/stream_example.py <COMPARTMENT_OCID>
</copy>
```
For example :
python ~/stream\_example.py ocid1.compartment.oc1..aaaaaaaada2gaukcqoagqoshxq2pyt6cdsj2mhnrz3p5nke33ljx2bp476wq
15. Follow the prompts of the script. The script will create Streaming service called **SdkExampleStream**. It will publish 100 messages, create 2 groups on the compute and read those messages. Finally it will delete the streaming service. **You will be prompted to hit enter after verifying each step**.
## **Step 4**: Delete the resources
1. Switch to OCI console window.
2. If your Compute instance is not displayed, From OCI services menu Click **Instances** under **Compute**.
3. Locate compute instance, Click Action icon and then **Terminate**.

4. Make sure Permanently delete the attached Boot Volume is checked, Click **Terminate Instance**. Wait for instance to fully Terminate.

5. From OCI services menu Click **Virtual Cloud Networks** under Networking, list of all VCNs will appear.
6. Locate your VCN , Click Action icon and then **Terminate**. Click **Terminate All** in the Confirmation window. Click **Close** once VCN is deleted.

## Acknowledgements
*Congratulations! You have successfully completed the lab.*
- **Author** - Flavio Pereira, Larry Beausoleil
- **Adapted by** - Yaisah Granillo, Cloud Solution Engineer
- **Contributors** - Kamryn Vinson, QA Engineer Lead Intern | Arabella Yao, Product Manager Intern, DB Product Management
- **Last Updated By/Date** - Yaisah Granillo, June 2020
## See an issue?
Please submit feedback using this [form](https://apexapps.oracle.com/pls/apex/f?p=133:1:::::P1_FEEDBACK:1). Please include the *workshop name*, *lab* and *step* in your request. If you don't see the workshop name listed, please enter it manually. If you would like for us to follow up with you, enter your email in the *Feedback Comments* section.
| 38.032051 | 607 | 0.700405 | eng_Latn | 0.917305 |
9703097525c4c407414a26163253eb15e27811eb | 2,977 | md | Markdown | src/ru/2018-02-ay/10/05.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 68 | 2016-10-30T23:17:56.000Z | 2022-03-27T11:58:16.000Z | src/ru/2018-02-ay/10/05.md | PrJared/sabbath-school-lessons | 94a27f5bcba987a11a698e5e0d4279b81a68bc9a | [
"MIT"
] | 367 | 2016-10-21T03:50:22.000Z | 2022-03-28T23:35:25.000Z | src/ru/2018-02-ay/10/05.md | OsArts/Bible-study | cfcefde42e21795e217d192a8b7a703ebb7a6c01 | [
"MIT"
] | 109 | 2016-08-02T14:32:13.000Z | 2022-03-31T10:18:41.000Z | ---
title: Готов или нет?
date: 06/06/2018
---
**Практика**: Дан. 12:1; Откр. 13:14–17
Когда мы слышим упоминание Америки и Вавилона в одном контексте, речь обычно идет о «времени скорби». Часто при обсуждении данной темы люди испытывают сильный страх и падают духом, если им не предлагать конкретных практических советов, касающихся того, как пережить эти времена. Итак, когда время скорби наступит, что нам делать? Как жить в течение всего этого периода?
Будьте готовы. В Откр. 13 говорится, что тем, кто не имеет начертания зверя, нельзя будет что-либо продавать и покупать. Благодаря усилиям сатаны это поколение настолько поглощено охотой за материальным благополучием, что наша вера подвергается испытанию всякий раз, когда мы не в состоянии купить то, чего нам хочется просто так. Нам нужно научиться довольствоваться самым необходимым, прося Бога преобразовать наш разум так, чтобы потребительство не привело в тот период к нашему падению только из-за простой тяги к покупкам. Когда встает вопрос о необходимых для нас вещах, нам советуют научиться самим выращивать то, что пригодно в пищу, и самим шить себе одежду! Навыки и умения, которые, казалось бы, остались в далеком прошлом, могут помочь нам пережить трудные времена!
Изучайте. В той же самой главе рассказывается о том, что зверь будет способен обольщать живущих на земле своими чудесами. Мы часто думаем, что изучение этих чудес может помочь нам избежать обмана. Но как определить фальшивый бриллиант, если не знать отличительные характеристики настоящего камня? Да, надо исследовать, какую роль в событиях последнего времени будет играть Америка и какие действия она будет предпринимать, но нельзя пренебрегать и изучением характера Божьего. Достаточно лишь знать Его Самого и Его дела, чтобы суметь определить, какие из происходящих чудес являются фальшивкой.
Помните, Кто контролирует ситуацию. В Дан. 12:1 автор не только сообщает о том, что наступит время тяжкое, но и подчеркивает, что Михаил вступится за Свой народ и в этот страшный период принесет людям спасение. Поэтому мы не должны позволять себе думать о времени скорби со страхом и отчаянием, ведь Бог в том же самом стихе обещал, что все те, чьи имена будут записаны в книге жизни, спасутся.
Во 2 Петр. 1:19 говорится: «И притом мы имеем вернейшее пророческое слово; и вы хорошо делаете, что обращаетесь к нему, как к светильнику, сияющему в темном месте, доколе не начнет рассветать день и не взойдет утренняя звезда в сердцах ваших» (2 Петр. 1:19). Итак, пророчество необходимо изучать и применять в своей жизни. В результате Иисус поселится в нашем сердце. Это значит, что пророческие слова призваны произвести в человеке глобальные перемены, чтобы подготовить к исполнению этих самых слов.
**Дискуссия**
`1. Как еще можно подготовиться к этому периоду земной истории?`
`2. Как вы думаете, что мешает вам быть полностью к нему готовым?`
`3. Какие изменения произвело в вас изучение Слова Божьего?`
_Джон Ватта, Лондон, Англия_ | 114.5 | 777 | 0.802486 | rus_Cyrl | 0.996364 |
97036c44f072d684c9c1491a09b7e677e730b320 | 5,225 | md | Markdown | articles/site-recovery/hyper-v-vmm-secondary-support-matrix.md | Kraviecc/azure-docs.pl-pl | 4fffea2e214711aa49a9bbb8759d2b9cf1b74ae7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/hyper-v-vmm-secondary-support-matrix.md | Kraviecc/azure-docs.pl-pl | 4fffea2e214711aa49a9bbb8759d2b9cf1b74ae7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/site-recovery/hyper-v-vmm-secondary-support-matrix.md | Kraviecc/azure-docs.pl-pl | 4fffea2e214711aa49a9bbb8759d2b9cf1b74ae7 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Obsługa odzyskiwania po awarii macierzy z funkcją Hyper-V w dodatkowej lokacji programu VMM z Azure Site Recovery
description: Podsumowuje obsługę replikacji maszyny wirtualnej funkcji Hyper-V w chmurach programu VMM do lokacji dodatkowej z Azure Site Recovery.
author: rayne-wiselman
manager: carmonm
ms.service: site-recovery
ms.topic: conceptual
ms.date: 11/06/2019
ms.author: raynew
ms.openlocfilehash: af7baf413c9054ef3e5bf527851ac06c113cdce7
ms.sourcegitcommit: 829d951d5c90442a38012daaf77e86046018e5b9
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 10/09/2020
ms.locfileid: "86131166"
---
# <a name="support-matrix-for-disaster-recovery-of-hyper-v-vms-to-a-secondary-site"></a>Matryca obsługi odzyskiwania po awarii maszyn wirtualnych funkcji Hyper-V do lokacji dodatkowej
W tym artykule opisano, co jest obsługiwane w przypadku używania usługi [Azure Site Recovery](site-recovery-overview.md) do replikowania maszyn wirtualnych funkcji Hyper-V zarządzanych w chmurach System Center Virtual Machine Manager (VMM) do lokacji dodatkowej. Jeśli chcesz replikować maszyny wirtualne funkcji Hyper-V do platformy Azure, zapoznaj się z [tą matrycą obsługi](hyper-v-azure-support-matrix.md).
> [!NOTE]
> Replikację można przeprowadzić tylko w lokacji dodatkowej, gdy hosty funkcji Hyper-V są zarządzane w chmurach programu VMM.
## <a name="host-servers"></a>Serwery hosta
**System operacyjny** | **Szczegóły**
--- | ---
Windows Server 2012 z dodatkiem R2 | Na serwerach musi być uruchomionych najnowszych aktualizacji.
Windows Server 2016 | Chmury programu VMM 2016 z mieszaniną hostów z systemami Windows Server 2016 i 2012 R2 nie są obecnie obsługiwane.<br/><br/> Wdrożenia uaktualnione z programu System Center 2012 R2 VMM 2012 R2 do programu System Center 2016 nie są obecnie obsługiwane.
## <a name="replicated-vm-support"></a>Obsługa zreplikowanej maszyny wirtualnej
Poniższa tabela zawiera podsumowanie obsługi systemu operacyjnego dla maszyn replikowanych za pomocą Site Recovery. Każde obciążenie może być uruchomione w obsługiwanym systemie operacyjnym.
**Wersja systemu Windows** | **Funkcja Hyper-V (z programem VMM)**
--- | ---
Windows Server 2016 | Wszystkie systemy operacyjne gościa [obsługiwane przez funkcję Hyper-V](/windows-server/virtualization/hyper-v/Supported-Windows-guest-operating-systems-for-Hyper-V-on-Windows) w systemie Windows Server 2016
Windows Server 2012 z dodatkiem R2 | Wszystkie systemy operacyjne gościa [obsługiwane przez funkcję Hyper-V](/previous-versions/windows/it-pro/windows-server-2012-R2-and-2012/dn792027%28v%3dws.11%29) w systemie Windows Server 2012 R2
## <a name="linux-machine-storage"></a>Magazyn maszyny z systemem Linux
Można replikować tylko maszyny z systemem Linux z następującym magazynem:
- System plików (EXT3, ETX4, ReiserFS, XFS).
- Wielościeżkowe oprogramowanie — mapowanie urządzeń.
- Menedżer woluminów (LVM2).
- Serwery fizyczne z magazynem w usłudze HP CCISS Controller nie są obsługiwane.
- System plików ReiserFS jest obsługiwany tylko w systemie SUSE Linux Enterprise Server 11 z dodatkiem SP3.
## <a name="network-configuration---hostguest-vm"></a>Konfiguracja sieci-Host/maszyna wirtualna gościa
**Konfiguracja** | **Obsługiwał**
--- | ---
Hostowanie — Tworzenie zespołu kart interfejsu sieciowego | Tak
Host-sieć VLAN | Tak
Host-IPv4 | Tak
Host-IPv6 | Nie
Maszyna wirtualna gościa — Tworzenie zespołu kart interfejsu sieciowego | Nie
Maszyna wirtualna gościa — IPv4 | Tak
Maszyna wirtualna gościa — IPv6 | Nie
Maszyna wirtualna gościa — system Windows/Linux — statyczny adres IP | Tak
Maszyna wirtualna gościa — wiele kart sieciowych | Yes
## <a name="storage"></a>Magazyn
### <a name="host-storage"></a>Magazyn hosta
**Magazyn (Host)** | **Obsługiwał**
--- | ---
NFS | Nie dotyczy
SMB 3.0 | Tak
SIEĆ SAN (ISCSI) | Tak
Wiele ścieżek (MPIO) | Tak
### <a name="guest-or-physical-server-storage"></a>Magazyn Gości lub serwer fizyczny
**Konfiguracja** | **Obsługiwał**
--- | --- |
VMDK | Nie dotyczy
DYSK VHD/VHDX | Tak (do 16 dysków)
Maszyna wirtualna generacji 2 | Tak
Udostępniony dysk klastra | Nie
Zaszyfrowany dysk | Nie
UEFI| Nie dotyczy
NFS | Nie
SMB 3.0 | Nie
RDM | Nie dotyczy
Dysk > 1 TB | Tak
Wolumin z dyskiem rozłożonym > 1 TB<br/><br/> LVM | Tak
Miejsca do magazynowania | Tak
Gorące Dodawanie/usuwanie dysku | Nie
Wykluczanie dysku | Tak
Wiele ścieżek (MPIO) | Tak
## <a name="vaults"></a>Magazyny
**Akcja** | **Obsługiwał**
--- | ---
Przenoszenie magazynów między grupami zasobów (w ramach subskrypcji lub między subskrypcjami) | Nie
Przenoszenie magazynu, sieci, maszyn wirtualnych platformy Azure między grupami zasobów (w ramach subskrypcji lub między subskrypcjami) | Nie
## <a name="azure-site-recovery-provider"></a>Dostawca Azure Site Recovery
Dostawca koordynuje komunikację między serwerami programu VMM.
**Najnowsza** | **Aktualizacje**
--- | ---
5.1.19 ([dostępne z portalu](https://aka.ms/downloaddra) | [Najnowsze funkcje i poprawki](https://support.microsoft.com/kb/3155002)
## <a name="next-steps"></a>Następne kroki
[Replikowanie maszyn wirtualnych funkcji Hyper-V w chmurach programu VMM do lokacji dodatkowej](./hyper-v-vmm-disaster-recovery.md)
| 44.279661 | 410 | 0.770335 | pol_Latn | 0.998586 |
9703b3c1040b99380bdd404841b72526f5305238 | 34 | md | Markdown | README.md | alexsdeatherage/dev_portfolio | deb7c3354a406716bb4be061daf35bdf149c0e05 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | README.md | alexsdeatherage/dev_portfolio | deb7c3354a406716bb4be061daf35bdf149c0e05 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | README.md | alexsdeatherage/dev_portfolio | deb7c3354a406716bb4be061daf35bdf149c0e05 | [
"CC-BY-3.0",
"MIT"
] | null | null | null | # dev_portfolio
Portfolio Website
| 11.333333 | 17 | 0.852941 | eng_Latn | 0.368396 |
970506ef218b31d53d9a71ffc879b05e460c65cd | 753 | md | Markdown | docs/visual-basic/misc/bc31404.md | aedeny/docs | 584da79eedd480d86c7576bb403ed8d347160f6a | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-11-12T04:31:31.000Z | 2019-11-12T04:31:31.000Z | docs/visual-basic/misc/bc31404.md | aedeny/docs | 584da79eedd480d86c7576bb403ed8d347160f6a | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc31404.md | aedeny/docs | 584da79eedd480d86c7576bb403ed8d347160f6a | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-11-12T04:31:34.000Z | 2019-11-12T04:31:34.000Z | ---
title: "'<methodname>' cannot shadow a method declared 'MustOverride'"
ms.date: 07/20/2015
f1_keywords:
- "vbc31404"
- "bc31404"
helpviewer_keywords:
- "BC31404"
ms.assetid: 3e7bb4a0-14af-46ba-bc62-2234c16f1827
---
# '<methodname>' cannot shadow a method declared 'MustOverride'
A property or method with the `MustOverride` modifier and the same name is declared in a deriving class.
**Error ID:** BC31404
## To correct this error
1. Add the `Overrides` modifier to the overriding property or method in the derived class.
2. Remove the `MustOverride` modifier from the property or method in the base class.
## See also
- [MustOverride](../../visual-basic/language-reference/modifiers/mustoverride.md)
| 31.375 | 106 | 0.721116 | eng_Latn | 0.963806 |
9706b21991af03cce11dd3e31e8885576c9bb3bd | 5,643 | md | Markdown | _posts/2017-12-19-spring-security-16-security-object.md | shenkaige123/shenkaige123.github.io | 1b1ac07861ecc98270e0b816017b451a2a66f648 | [
"Apache-2.0"
] | 16 | 2018-12-14T04:52:58.000Z | 2022-03-27T16:27:39.000Z | _posts/2017-12-19-spring-security-16-security-object.md | sanmu1314/houbb.github.io | 375e9f4c519af3d64d112bce3b0d37891feb804c | [
"Apache-2.0"
] | 5 | 2019-11-07T12:22:17.000Z | 2022-02-16T03:54:28.000Z | _posts/2017-12-19-spring-security-16-security-object.md | sanmu1314/houbb.github.io | 375e9f4c519af3d64d112bce3b0d37891feb804c | [
"Apache-2.0"
] | 5 | 2016-05-08T14:08:08.000Z | 2021-04-23T09:08:46.000Z | ---
layout: post
title: Spring Security Authorization 安全对象实施
date: 2017-12-19 22:29:09 +0800
categories: [Spring]
tags: [spring, web-safe]
published: true
---
# 序言
前面我们学习了 [spring security 与 springmvc 的整合入门教程](https://www.toutiao.com/i6884852647480787459/)。
[spring secutity整合springboot入门](https://www.toutiao.com/item/6916894767628468747/)
[spring security 使用 maven 导入汇总](https://www.toutiao.com/item/6917240713151398403/)
[spring security 业界标准加密策略源码详解](https://www.toutiao.com/item/6917261378050982403/)
[Spring Security 如何预防CSRF跨域攻击?](https://www.toutiao.com/item/6917618373924995591/)
[Spring Security 安全响应头配置详解](https://www.toutiao.com/item/6918186604846842376/)
这一节我们来学习一下 spring security 的整体架构设计。
# 安全对象实施
## AOP联盟(方法调用)安全拦截器
在Spring Security 2.0之前,确保MethodInvocation的安全需要大量样板配置。
现在,推荐的方法安全性方法是使用名称空间配置。
这样,方法安全性基础结构bean会自动为您配置,因此您实际上不需要了解实施类。我们将仅简要介绍此处涉及的课程。
方法安全性是使用MethodSecurityInterceptor实施的,该方法可以保护MethodInvocation。
根据配置方法,拦截器可能特定于单个bean,也可能在多个bean之间共享。
拦截器使用MethodSecurityMetadataSource实例获取适用于特定方法调用的配置属性。
MapBasedMethodSecurityMetadataSource用于存储以方法名称作为键的配置属性(可以使用通配符),当使用 `<intercept-methods>` 或 `<protect-point>` 元素在应用程序上下文中定义属性时,将在内部使用该属性。
其他实现将用于处理基于注释的配置。
## 显式方法SecurityInterceptor配置
当然,您可以直接在应用程序上下文中配置MethodSecurityInterceptor,以与Spring AOP的代理机制之一配合使用:
```xml
<bean id="bankManagerSecurity" class=
"org.springframework.security.access.intercept.aopalliance.MethodSecurityInterceptor">
<property name="authenticationManager" ref="authenticationManager"/>
<property name="accessDecisionManager" ref="accessDecisionManager"/>
<property name="afterInvocationManager" ref="afterInvocationManager"/>
<property name="securityMetadataSource">
<sec:method-security-metadata-source>
<sec:protect method="com.mycompany.BankManager.delete*" access="ROLE_SUPERVISOR"/>
<sec:protect method="com.mycompany.BankManager.getBalance" access="ROLE_TELLER,ROLE_SUPERVISOR"/>
</sec:method-security-metadata-source>
</property>
</bean>
```
# AspectJ(JoinPoint)安全拦截器
AspectJ安全拦截器与上一节中讨论的AOP Alliance安全拦截器非常相似。
实际上,我们将仅讨论本节中的区别。
AspectJ拦截器被命名为AspectJSecurityInterceptor。
与依赖于Spring应用程序上下文通过代理编织在安全拦截器中的AOP Alliance安全拦截器不同,AspectJSecurityInterceptor通过AspectJ编译器进行编织。
在同一个应用程序中同时使用两种类型的安全拦截器并不少见,其中AspectJSecurityInterceptor用于域对象实例安全,而AOP Alliance MethodSecurityInterceptor用于服务层安全。
首先,让我们考虑如何在Spring应用程序上下文中配置AspectJSecurityInterceptor:
```xml
<bean id="bankManagerSecurity" class=
"org.springframework.security.access.intercept.aspectj.AspectJMethodSecurityInterceptor">
<property name="authenticationManager" ref="authenticationManager"/>
<property name="accessDecisionManager" ref="accessDecisionManager"/>
<property name="afterInvocationManager" ref="afterInvocationManager"/>
<property name="securityMetadataSource">
<sec:method-security-metadata-source>
<sec:protect method="com.mycompany.BankManager.delete*" access="ROLE_SUPERVISOR"/>
<sec:protect method="com.mycompany.BankManager.getBalance" access="ROLE_TELLER,ROLE_SUPERVISOR"/>
</sec:method-security-metadata-source>
</property>
</bean>
```
如您所见,除了类名外,AspectJSecurityInterceptor与AOP Alliance安全拦截器完全相同。
确实,这两个拦截器可以共享相同的securityMetadataSource,因为SecurityMetadataSource与java.lang.reflect.Method一起使用,而不是与AOP库特定的类一起使用。
当然,您的访问决策可以访问特定于AOP库的相关调用(即MethodInvocation或JoinPoint),因此在制定访问决策(例如方法参数)时可以考虑一系列附加条件。
接下来,您需要定义AspectJ方面。
例如:
```java
package org.springframework.security.samples.aspectj;
import org.springframework.security.access.intercept.aspectj.AspectJSecurityInterceptor;
import org.springframework.security.access.intercept.aspectj.AspectJCallback;
import org.springframework.beans.factory.InitializingBean;
public aspect DomainObjectInstanceSecurityAspect implements InitializingBean {
private AspectJSecurityInterceptor securityInterceptor;
pointcut domainObjectInstanceExecution(): target(PersistableEntity)
&& execution(public * *(..)) && !within(DomainObjectInstanceSecurityAspect);
Object around(): domainObjectInstanceExecution() {
if (this.securityInterceptor == null) {
return proceed();
}
AspectJCallback callback = new AspectJCallback() {
public Object proceedWithObject() {
return proceed();
}
};
return this.securityInterceptor.invoke(thisJoinPoint, callback);
}
public AspectJSecurityInterceptor getSecurityInterceptor() {
return securityInterceptor;
}
public void setSecurityInterceptor(AspectJSecurityInterceptor securityInterceptor) {
this.securityInterceptor = securityInterceptor;
}
public void afterPropertiesSet() throws Exception {
if (this.securityInterceptor == null)
throw new IllegalArgumentException("securityInterceptor required");
}
}
}
```
在上面的示例中,安全拦截器将应用于PersistableEntity的每个实例,这是一个未显示的抽象类(您可以使用喜欢的任何其他类或切入点表达式)。
对于那些好奇的人,需要使用AspectJCallback,因为proced(); 语句仅在around()主体内具有特殊含义。
当希望目标对象继续时,AspectJSecurityInterceptor会调用此匿名AspectJCallback类。
您将需要配置Spring以加载方面并将其与AspectJSecurityInterceptor关联。
实现此目的的bean声明如下所示:
```xml
<bean id="domainObjectInstanceSecurityAspect"
class="security.samples.aspectj.DomainObjectInstanceSecurityAspect"
factory-method="aspectOf">
<property name="securityInterceptor" ref="bankManagerSecurity"/>
</bean>
```
就是如此简单!
现在,您可以使用自己认为合适的任何方式(例如new Person();)从应用程序中的任何位置创建bean,并且将应用安全拦截器。
# 小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。
# 参考资料
[https://docs.spring.io/spring-security/site/docs/5.4.2/reference/html5/#features](https://docs.spring.io/spring-security/site/docs/5.4.2/reference/html5/#features)
* any list
{:toc} | 30.502703 | 164 | 0.793904 | yue_Hant | 0.506487 |
970708dfd9f651163381815c8450210eae24dbb2 | 6,020 | md | Markdown | README.md | njthanhtrang/14.-Model-View-Controller-MVC-Challenge-Tech-Blog | 8197e6818a50c93dc6e808f946c823b04fc685d7 | [
"Unlicense"
] | null | null | null | README.md | njthanhtrang/14.-Model-View-Controller-MVC-Challenge-Tech-Blog | 8197e6818a50c93dc6e808f946c823b04fc685d7 | [
"Unlicense"
] | null | null | null | README.md | njthanhtrang/14.-Model-View-Controller-MVC-Challenge-Tech-Blog | 8197e6818a50c93dc6e808f946c823b04fc685d7 | [
"Unlicense"
] | 1 | 2022-03-07T01:14:56.000Z | 2022-03-07T01:14:56.000Z | # 14.-Model-View-Controller-MVC-Challenge-Tech-Blog
## Description
This application is a CMS-style blog site that allows users to publish articles and blog posts and the latest technologies and comment on other developers' posts as well. This application follows the Model View Controller (MVC) architectural structure, uses Handlebars.js as the templating language, Sequelize as the ORM, and express-session npm package for authentication.
The user is presented with the homepage, which includes existing blog posts if any have been posted, navigation links for the homepage and the dashboard, and the option to log in.
Acceptance criteria include:
When clicking the homepage, the user is taken to the homepage.
When clicking on any other links in the navigation, the user is prompted to either sign up or sign in.
When signing up, the user is prompted to create a username and password.
When clicking on the sign-up button, user credentials are saved and the user is logged into the site.
When revisiting the site at a later time and choosing to sign in, the user is prompted to enter their username and password.
When signed in to the site, users see navigation links for the homepage, the dashboard, and the option to log out.
When clicking on the homepage option in the navigation, the user is taken to the homepage and presented with existing blog posts that include the post title and the date created.
When clicking on an existing blog post, the user is presented with the post title, contents, post creator’s username, and date created for that post and has the option to leave a comment.
When entering a comment and clicking on the submit button while signed in, the comment is saved and the post is updated to display the comment, the comment creator’s username, and the date created.
When clicking on the dashboard option in the navigation, the user is taken to the dashboard and presented with any blog posts already created and the option to add a new blog post.
When clicking on the button to add a new blog post, the user is prompted to enter both a title and contents for the blog post.
When clicking on the button to create a new blog post, the title and contents of the post are saved and the user is taken back to an updated dashboard with the new blog post.
When clicking on one of the existing posts in the dashboard, the user is able to delete or update the post and taken back to an updated dashboard.
When clicking on the logout option in the navigation, the user is signed out of the site.
When the user is idle on the site for more than a set time, the user is able to view comments but is prompted to log in again before they can add, update, or delete comments.
Future implementations include resizing the input area for a better UI experience.
## Table of Contents
If your README is very long, add a table of contents to make it easy for users to find what they need.
* [Installation](#installation)
* [Usage](#usage)
* [Packages](#packages)
* [Credits](#credits)
* [Questions](#questions)
* [License](#license)
## Installation
Clone the repository, navigate to the project folder on your CLI and run the following command to install Node.js:
```npm install```
## Usage
Run the following command on your CLI to run the application:
```node server.js```
Or, view the deployed application on Heroku at https://techblog302.herokuapp.com/.
<img width="1060" alt="Screen Shot 2021-07-08 at 10 56 36 AM" src="https://user-images.githubusercontent.com/77700824/124969108-2b2af700-dfdb-11eb-95cc-eefad746769a.png">
<img width="1057" alt="Screen Shot 2021-07-08 at 10 56 56 AM" src="https://user-images.githubusercontent.com/77700824/124969151-37af4f80-dfdb-11eb-8e38-05efe1e44d42.png">
<img width="1197" alt="Screen Shot 2021-07-08 at 11 34 20 AM" src="https://user-images.githubusercontent.com/77700824/124973495-71368980-dfe0-11eb-812a-91fb96a90aca.png">
## Packages
* express-handlebars https://www.npmjs.com/package/express-handlebars to use Handlebars.js for Views
* MySQL2 https://www.npmjs.com/package/mysql2 to connect to a MySQL database for Models
* Sequelize https://www.npmjs.com/package/sequelize to create an Express.js API for Controllers
* dotenv https://www.npmjs.com/package/dotenv to use environmental variables
* bcrypt https://www.npmjs.com/package/bcrypt to hash passwords
* express-session https://www.npmjs.com/package/express-session for authentication, storing session data on client side in a cookie. When idle on the site for more than a set time, the cookie expires and the user is required to log in again to start a new session.
* connect-session-sequelize https://www.npmjs.com/package/connect-session-sequelize for authentication
## Credits
Created by Jennifer Nguyen.
## Questions
For additional questions and information, please visit my [GitHub profile](github.com/njthanhtrang/)
or reach out via email at [email protected].
## License
MIT License
Copyright (c) [2021] [Jennifer Nguyen]
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
| 54.727273 | 373 | 0.786379 | eng_Latn | 0.989364 |
97075bc3209ecc19468db078a8865e5f22e46fbb | 2,186 | md | Markdown | docs/xquery/logical-expressions-xquery.md | roaming-debug/sql-docs.zh-cn | 6a1bc73995cfdbde269233c6342e136f32349419 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/xquery/logical-expressions-xquery.md | roaming-debug/sql-docs.zh-cn | 6a1bc73995cfdbde269233c6342e136f32349419 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/xquery/logical-expressions-xquery.md | roaming-debug/sql-docs.zh-cn | 6a1bc73995cfdbde269233c6342e136f32349419 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 逻辑表达式 (XQuery) |Microsoft Docs
description: 了解 XQuery 中支持的逻辑表达式。
ms.custom: ''
ms.date: 03/14/2017
ms.prod: sql
ms.prod_service: sql
ms.reviewer: ''
ms.technology: xml
ms.topic: language-reference
dev_langs:
- XML
helpviewer_keywords:
- logical operators [SQL Server], XQuery
- effective Boolean value [XQuery]
- logical expressions [XQuery]
- EBV
- expressions [XQuery], logical
ms.assetid: de94cd2e-2d48-49fb-9ebd-a2d90c79bf62
author: rothja
ms.author: jroth
ms.openlocfilehash: 44f05374320dc2d5c329ad234e62dd0c420bf22c
ms.sourcegitcommit: 917df4ffd22e4a229af7dc481dcce3ebba0aa4d7
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 02/10/2021
ms.locfileid: "100341850"
---
# <a name="logical-expressions-xquery"></a>逻辑表达式 (XQuery)
[!INCLUDE [SQL Server Azure SQL Database ](../includes/applies-to-version/sqlserver.md)]
XQuery 支持逻辑 **and** 和 **or** 运算符。
```
expression1 and expression2
expression1 or expression2
```
中的测试表达式 `expression1,``expression2` [!INCLUDE[ssNoVersion](../includes/ssnoversion-md.md)] 可以导致空序列、一个或多个节点的序列或单个布尔值。 根据结果,按照下列方式确定它们的有效布尔值:
- 如果测试表达式的结果是空序列,则表达式的结果为 False。
- 如果测试表达式的结果是单个布尔值,则此值便为表达式的结果。
- 如果测试表达式的结果是包含一个或多个节点的序列,则表达式的结果为 True。
- 否则,将引发静态错误。
然后,将逻辑 **and** 和 **or** 运算符应用于带有标准逻辑语义的表达式的结果布尔值。
下面的查询从产品目录中检索特定产品型号的前一小图片(<`Picture`> 元素)。 请注意,对于每一个产品说明文档,目录都可以存储具有不同属性(如大小和角度)的一个或多个产品图片。
```
SELECT CatalogDescription.query('
declare namespace PD="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription";
for $F in /PD:ProductDescription/PD:Picture[PD:Size="small"
and PD:Angle="front"]
return
$F
') as Result
FROM Production.ProductModel
where ProductModelID=19
```
结果如下:
```
<PD:Picture
xmlns:PD="https://schemas.microsoft.com/sqlserver/2004/07/adventure-works/ProductModelDescription">
<PD:Angle>front</PD:Angle>
<PD:Size>small</PD:Size>
<PD:ProductPhotoID>31</PD:ProductPhotoID>
</PD:Picture>
```
## <a name="see-also"></a>另请参阅
[XQuery 表达式](../xquery/xquery-expressions.md)
| 26.987654 | 142 | 0.697164 | yue_Hant | 0.512399 |
9707845f7359c0504cdfa32165b6d16ae9dd9638 | 625 | md | Markdown | _posts/2008-02-14-tips-gratis-telepon-umum.md | satriadewa2x/tasikisme | 5a74947735a465f8416a5673067f5fbf966d1173 | [
"MIT"
] | null | null | null | _posts/2008-02-14-tips-gratis-telepon-umum.md | satriadewa2x/tasikisme | 5a74947735a465f8416a5673067f5fbf966d1173 | [
"MIT"
] | null | null | null | _posts/2008-02-14-tips-gratis-telepon-umum.md | satriadewa2x/tasikisme | 5a74947735a465f8416a5673067f5fbf966d1173 | [
"MIT"
] | null | null | null | ---
id: 33
title: Tips Gratis Telepon Umum!
date: 2008-02-14T18:39:34+07:00
author: Nana
layout: post
guid: https://www.tasikisme.com/?p=7
permalink: /tips-gratis-telepon-umum/
categories:
- Tips
tags:
- Tips
---
Anda cari dulu telpon umumnya. Kalo trickini gagal, cari telp. Umum lain.
**Caranya** :
Angkat dulu gagang telp. Tekan tmbol angka 142 atau nomor free call apa saja. Kalau sudah bunyi nada stand by off,
lalu tekan angka 1111111111.. yang banyak dan dengan kecepatan konstan. Kalau sudah bunyi, Anda dial nomor tujuan lokal. Kalau belum berbunyi, coba lagi.
**Catatan** : Tidak semua telepon umum bisa. | 31.25 | 154 | 0.7408 | ind_Latn | 0.986393 |
9707ce756f4ba5eb25957cc59f60d48a58bef87f | 644 | md | Markdown | developers/tools/using-ganache/README.md | DanKinsella/docs-home | d6c386d8b2443594e973e2fc180bf8518a40290d | [
"MIT"
] | 34 | 2020-01-22T00:34:14.000Z | 2022-03-30T11:19:26.000Z | developers/tools/using-ganache/README.md | DanKinsella/docs-home | d6c386d8b2443594e973e2fc180bf8518a40290d | [
"MIT"
] | 31 | 2021-06-18T21:30:11.000Z | 2022-02-04T02:52:13.000Z | developers/tools/using-ganache/README.md | DanKinsella/docs-home | d6c386d8b2443594e973e2fc180bf8518a40290d | [
"MIT"
] | 65 | 2019-08-05T14:11:31.000Z | 2022-03-29T10:00:30.000Z | ---
description: This page describes how to use ganache-cli to connect to Harmony networks.
---
# Ganache
Install Ganache CLI
```
npm install -g ganache-cli
```
Load Harmony networks (local, testnet, mainnet) to ganache-cli. The command below loads
```
ganache-cli -f http://localhost:9500 --networkId 1666700000
or for testnet
ganache-cli -f https://api.s0.b.hmny.io --networkId 1666700000
or for mainnet
ganache-cli -f https://api.s0.t.hmny.io --networkId 1666600000
```
Use web3.js to interact with the ganache binded harmony network
```
const web3 = new Web3("http://127.0.0.1:8545");
web3.eth.getBlockNumber().then(console.log)
```
| 22.206897 | 87 | 0.729814 | eng_Latn | 0.610276 |
9708d0b3d623c2db627c3b192166df8a57387cf2 | 5,155 | md | Markdown | README.md | foss-cafe/terraform-helm-chart-release | 41cf04cfdd8616de1e34b2c3d9f1b6727287d2c4 | [
"Apache-2.0"
] | 1 | 2020-07-09T23:16:59.000Z | 2020-07-09T23:16:59.000Z | README.md | foss-cafe/terraform-helm-chart-release | 41cf04cfdd8616de1e34b2c3d9f1b6727287d2c4 | [
"Apache-2.0"
] | null | null | null | README.md | foss-cafe/terraform-helm-chart-release | 41cf04cfdd8616de1e34b2c3d9f1b6727287d2c4 | [
"Apache-2.0"
] | null | null | null | # Terraform Module for Helm Release
### Use as a Module
```terrraform
module "helmredis" {
source = "git::https://github.com/foss-cafe/terraform-helm-release.git/"
name = "my-redis-release"
repository = data.helm_repository.stable.metadata[0].name
chart = "redis"
chart_version = "6.0.1"
set = [{
name = "cluster.enabled"
value = "true"
},
{
name = "metrics.enabled"
value = "true"
}
]
set_string = [{
name = "service.annotations.prometheus\\.io/port"
value = "9127"
}
]
}
```
<!-- BEGINNING OF PRE-COMMIT-TERRAFORM DOCS HOOK -->
## Requirements
| Name | Version |
|------|---------|
| terraform | ~> 0.12.24 |
| helm | ~> 1.1.0 |
## Providers
| Name | Version |
|------|---------|
| helm | ~> 1.1.0 |
## Inputs
| Name | Description | Type | Default | Required |
|------|-------------|------|---------|:--------:|
| atomic | If set, installation process purges chart on fail. The wait flag will be set automatically if atomic is used. Defaults to true | `bool` | `true` | no |
| chart | Chart name to be installed | `string` | `null` | no |
| chart\_version | Specify the exact chart version to install. If this is not specified, the latest version is installed | `string` | `null` | no |
| cleanup\_on\_fail | Allow deletion of new resources created in this upgrade when upgrade fails. Defaults to false | `bool` | `true` | no |
| dependency\_update | Runs helm dependency update before installing the chart. Defaults to false. | `bool` | `false` | no |
| disable\_webhooks | Prevent hooks from running. Defauts to false | `bool` | `false` | no |
| force\_update | Force resource update through delete/recreate if needed. Defaults to false | `bool` | `false` | no |
| keyring | Location of public keys used for verification. Used only if verify is true. Defaults to /.gnupg/pubring.gpg in the location set by home | `string` | `"/.gnupg/pubring.gpg"` | no |
| max\_history | Maximum number of release versions stored per release. Defaults to 0 (no limit). | `number` | `0` | no |
| name | Release name | `string` | `null` | no |
| namespace | The namespace to install the release into. Defaults to default | `string` | `"default"` | no |
| recreate\_pods | Perform pods restart during upgrade/rollback. Defaults to false | `bool` | `false` | no |
| render\_subchart\_notes | If set, render subchart notes along with the parent. Defaults to true | `bool` | `true` | no |
| replace | Re-use the given name, even if that name is already used. This is unsafe in production. Defaults to false. | `bool` | `false` | no |
| repository | Repository where to locate the requested chart. If is an URL the chart is installed without installing the repository | `string` | `null` | no |
| repository\_ca\_file | The Repositories CA File | `string` | `null` | no |
| repository\_cert\_file | The repositories cert file | `string` | `null` | no |
| repository\_key\_file | The repositories cert key file | `string` | `null` | no |
| repository\_password | Password for HTTP basic authentication against the reposotory | `string` | `null` | no |
| repository\_username | Username for HTTP basic authentication against the repository | `string` | `null` | no |
| reset\_values | When upgrading, reset the values to the ones built into the chart. Defaults to false. | `bool` | `false` | no |
| reuse\_values | When upgrading, reuse the last release's values and merge in any overrides. If 'reset\_values' is specified, this is ignored. Defaults to false | `bool` | `false` | no |
| set | Value block with custom values to be merged with the values yaml. | `list(map(string))` | `[]` | no |
| set\_sensitive | Value block with custom sensitive values to be merged with the values yaml that won't be exposed in the plan's diff. | `list(map(string))` | `[]` | no |
| set\_string | Value block with custom STRING values to be merged with the values yaml. | `list(map(string))` | `[]` | no |
| skip\_crds | If set, no CRDs will be installed. By default, CRDs are installed if not already present. Defaults to false. | `bool` | `false` | no |
| timeout | Time in seconds to wait for any individual kubernetes operation. Defaults to 300 seconds. | `number` | `300` | no |
| values | List of values in raw yaml to pass to helm. Values will be merged, in order, as Helm does with multiple -f options | `list` | `[]` | no |
| verify | Verify the package before installing it. Defaults to false | `bool` | `false` | no |
| wait | Will wait until all resources are in a ready state before marking the release as successful. It will wait for as long as timeout. Defaults to true. | `bool` | `true` | no |
## Outputs
| Name | Description |
|------|-------------|
| chart | The name of the chart |
| name | Name is the name of the release |
| namespace | Namespace is the kubernetes namespace of the release |
| revision | Version is an int32 which represents the version of the release |
| status | Status of the release |
| version | A SemVer 2 conformant version string of the chart |
<!-- END OF PRE-COMMIT-TERRAFORM DOCS HOOK -->
## License
Apache 2 Licensed. See LICENSE for full details.
| 55.430108 | 191 | 0.671775 | eng_Latn | 0.976548 |
9708f39f9e57d53437de52e1a967dd326c9a62eb | 7,121 | md | Markdown | i18n/locales/ru-RU/hourofcode/promote/resources.md | pickettd/code-dot-org | 20a6b232178e4389e1189b3bdcf0dc87ba59ec90 | [
"Apache-2.0"
] | null | null | null | i18n/locales/ru-RU/hourofcode/promote/resources.md | pickettd/code-dot-org | 20a6b232178e4389e1189b3bdcf0dc87ba59ec90 | [
"Apache-2.0"
] | null | null | null | i18n/locales/ru-RU/hourofcode/promote/resources.md | pickettd/code-dot-org | 20a6b232178e4389e1189b3bdcf0dc87ba59ec90 | [
"Apache-2.0"
] | null | null | null | * * *
title: <%= hoc_s(:title_resources) %> layout: wide nav: promote_nav
* * *
<link rel="stylesheet" type="text/css" href="/css/promote-page.css" />
</link>
# Promote the Hour of Code
## Hosting an Hour of Code? [See the how-to guide](<%= resolve_url('/how-to') %>)
<%= view :promote_handouts %> <%= view :promote_videos %>
<a id="posters"></a>
## Повесьте эти плакаты у себя в школе
<%= view :promote_posters %>
<a id="social"></a>
## Разместите в социальных сетях:
[](/images/social-1.jpg) [](/images/social-2.jpg) [](/images/social-3.jpg)
<%= view :social_posters %>
<a id="logo"></a>
## Use the Hour of Code logo to spread the word
[ %>)](%= localized_image('/images/hour-of-code-logo.png') %)
[Download hi-res versions](http://images.code.org/share/hour-of-code-logo.zip)
**"Hour of Code" is trademarked. We don't want to prevent this usage, but we want to make sure it fits within a few limits:**
1. Любые ссылки на Час Программирования должны использоваться не как ваше собственное название, а как отсылка к Часу Программирования как общественному движению. Good example: "Participate in the Hour of Code™ at ACMECorp.com". Bad example: "Try Hour of Code by ACME Corp".
2. Use a "TM" superscript in the most prominent places you mention "Hour of Code", both on your web site and in app descriptions.
3. Включите в описание страницы абзац, включая ссылки на сайты Недели Образования в Информатике (CSEdWeek) и Code.org, содержащий следующую информацию:
*“The 'Hour of Code™' is a nationwide initiative by Computer Science Education Week[csedweek.org] and Code.org[code.org] to introduce millions of students to one hour of computer science and computer programming.”*
4. No use of "Hour of Code" in app names.
<a id="stickers"></a>
## Print these stickers to give to your students
(Stickers are 1" diameter, 63 per sheet)
[](/images/hour-of-code-stickers.pdf)
<a id="sample-emails"></a>
## Отправляйте эти письма, чтобы помочь рекламировать "Час кода"
<a id="email"></a>
## Попросите вашу школу, работодателя и друзей зарегистрироваться:
Компьютеры везде, но сейчас меньше школ учат информатике, чем 10 лет назад. Но есть и хорошие новости: мы можем это изменить. If you've heard about the Hour of Code before, you might know it made history. More than 100 million students have tried an Hour of Code.
With the Hour of Code, computer science has been on homepages of Google, MSN, Yahoo! и Disney. Over 100 partners joined together to support this movement. Last year, every Apple Store in the world hosted an Hour of Code and even President Obama wrote his first line of code as part of the campaign.
This year, let's make it even bigger. I’m asking you to join in for the Hour of Code 2015. Please get involved with an Hour of Code event during Computer Science Education Week, <%= campaign_date('full') %>.
Выступите с речью. Организуйте мероприятие. Предложите местной школе принять участие. Или попробуйте сами поучаствовать в "Часе Кода" - понять основы программирования полезно любому.
Get started at http://hourofcode.com/<%= @country %>
<a id="media-pitch"></a>
## Пригласите СМИ на ваше мероприятие:
**Subject line:** Local school joins mission to introduce students to computer science
Компьютеры везде, но сейчас школы учат информатике меньше чем 10 лет назад. Хорошая новость состоит в том, что мы собираемся изменить это.
With the Hour of Code, computer science has been on homepages of Google, MSN, Yahoo! и Disney. Over 100 partners joined together to support this movement. Last year, every Apple Store in the world hosted an Hour of Code and even President Obama wrote his first line of code as part of the campaign.
That’s why every one of the [X number] students at [SCHOOL NAME] are joining in on the largest learning event in history: The Hour of Code, during Dec. 7-13.
Я хочу пригласить вас посетить наше вводное собрание, и посмотреть на детей на мероприятии, которое состоится [DATE].
"Час Кода", организуемый некоммерческой организацией Code.org и более 100 другими, это признак того, что сегодняшнее поколение учеников готово приобретать критически важные для успеха в 21-м веке навыки. Пожалуйста, присоединяйтесь.
**Контакт:** [YOUR NAME], [TITLE], моб.: (212) 555-5555
**Когда:** [Дата и время вашего мероприятия]
**Где:** [Адрес и маршруты]
Буду рад возможности пообщаться.
<a id="parents"></a>
## Расскажите родителям о событии в вашей школе:
Уважаемые родители,
Мы живём в мире, окружённом технологиями. И мы знаем, что, какую бы область обучения ни выбрали наши ученики, их способность добиваться успеха будет всё больше зависеть от понимания того, как работает технология. Но только крошечная часть учеников обучается компьютерным технологиям, даже меньше, чем десять лет назад.
Вот почему вся наша школа присоединяется к крупнейшему в истории обучения событию: Часу Программирования, в рамках Недели Образования в Информатике (с 8 7-13). More than 100 million students worldwide have already tried an Hour of Code.
Час Программирования - это утверждение, что [ИМЯ ШКОЛЫ] готова к обучению основным навыкам XXI века. Чтобы продолжить привлекать учеников к программированию, мы хотим сделать наше мероприятие "Час Программирования" огромным. I encourage you to volunteer, reach out to local media, share the news on social media channels and consider hosting additional Hour of Code events in the community.
Это шанс изменить будущее образования в [НАЗВАНИЕ ГОРОДА].
See http://hourofcode.com/<%= @country %> for details, and help spread the word.
С уважением,
Ваш директор
<a id="politicians"></a>
## Пригласите местного политика на мероприятие в вашей школе:
Уважаемый [ФАМИЛИЯ Мэра/Губернатора/Депутата]:
Знаете ли Вы, что в сегодняшней экономике количество вакансий в сфере компьютерных технологий превышает число выпускников в отношении 3 к 1? А также, что компьютерные технологии являются основой для *каждой* сферы. Yet most of schools don’t teach it. Мы пытаемся изменить это в [НАЗВАНИЕ ШКОЛЫ].
Вот почему вся наша школа присоединяется к крупнейшему в истории обучения событию: Часу Программирования, в рамках Недели Образования в Информатике (с 8 7-13). More than 100 million students worldwide have already tried an Hour of Code.
Мы приглашаем Вас принять участие в нашем мероприятии под названием "Час Программирования" и выступить на нашем стартовом собрании. Оно будет проходить [ЧИСЛО, ВРЕМЯ, МЕСТО] и даст понять, что в [Название области или города] готовы обучать навыкам критики XXI века. Мы хотим быть уверенными в том, что наши ученики находятся в передних рядах создания технологии будущего, а не потребления.
Пожалуйста, свяжитесь со мной по [НОМЕР ТЕЛЕФОНА ИЛИ АДРЕС ЭЛ. ПОЧТЫ]. С нетерпением жду Ваше сообщение.
С уважением, [NAME], [TITLE]
<%= view :signup_button %> | 53.541353 | 390 | 0.761269 | rus_Cyrl | 0.667832 |
970a0354ae9d784a4e055d5fa73790e563588c58 | 835 | md | Markdown | README.md | mysocketio/kubernetes_controller | 22fe43cf3b2ca334a6ea064ab731d95ae7cc0df8 | [
"Apache-2.0"
] | 6 | 2021-01-15T18:54:57.000Z | 2022-03-25T05:37:23.000Z | README.md | mysocketio/kubernetes_controller | 22fe43cf3b2ca334a6ea064ab731d95ae7cc0df8 | [
"Apache-2.0"
] | 1 | 2021-04-18T13:30:12.000Z | 2021-04-18T13:30:12.000Z | README.md | mysocketio/kubernetes_controller | 22fe43cf3b2ca334a6ea064ab731d95ae7cc0df8 | [
"Apache-2.0"
] | 2 | 2021-02-22T00:57:27.000Z | 2021-12-14T20:15:56.000Z | # kubernetes_controller
Kubernetes controller for Mysocket.io
For details, also see this blog https://www.mysocket.io/post/global-load-balancing-with-kubernetes-and-mysocket
Make sure to update line 14,15 and 16 of mysocketd.yaml with the correct mysocket credentials.
Then deploy the controller:
```kubectl apply -f mysocketd.yaml```
After the controller is installed, simply add the following annotation to your _Service_ to make it globably available via mysocket.io
```
kind: Service
metadata:
annotations:
mysocket.io/enabled: "true"
```
keep an eye on the contoller log files:
```kubectl logs -n mysocket -f <mysocketd-pod>```
Things to keep in mind:
This is an MVP, it currently has the following know limitations:
1) only one contoller pod is running at a time.
2) the controller only picks up RSA keys for now
| 29.821429 | 134 | 0.77006 | eng_Latn | 0.993528 |
970ab14c236b50646e3db358f944b118387d43e4 | 1,974 | md | Markdown | ISSBA/README.md | hfzhang31/I-BAU_Adversarial_Unlearning_of-Backdoors_via_implicit_Hypergradient | 19195589caf6649a1c874aa0d3b6c708f9c3772f | [
"MIT"
] | null | null | null | ISSBA/README.md | hfzhang31/I-BAU_Adversarial_Unlearning_of-Backdoors_via_implicit_Hypergradient | 19195589caf6649a1c874aa0d3b6c708f9c3772f | [
"MIT"
] | null | null | null | ISSBA/README.md | hfzhang31/I-BAU_Adversarial_Unlearning_of-Backdoors_via_implicit_Hypergradient | 19195589caf6649a1c874aa0d3b6c708f9c3772f | [
"MIT"
] | null | null | null | # Invisible Backdoor Attack with Sample-Specific Triggers
## Environment
This project is developed with Python 3.6 on Ubuntu 18.04. Please run the following script to install the required packages
```shell
pip install -r requirements.txt
```
## Demo
Before running the code, please download the checkpoints from [Baidudisk](https://pan.baidu.com/s/1m5yRFQ4Wt7Km_56CIxzgsg) (code:o89z), and put them into `ckpt` folder.
1. Generating poisoned sample with sample-specific trigger.
```python
# TensorFlow
python encode_image.py \
--model_path=ckpt/encoder_imagenet \
--image_path=data/imagenet/org/n01770393_12386.JPEG \
--out_dir=data/imagenet/bd/
```
|  |  | 
|:--:| :--:| :--:|
| Benign image | Backdoor image | Trigger |
2. Runing `test.py` for testing benign and poisoned images.
```python
# PyTorch
python test.py
```
## Train
1. Download data from [Baidudisk](https://pan.baidu.com/s/1p_t5EJ91hkiyeYBFEZyfsg
)(code:oxgb) and unzip it to folder `datasets/`.
2. Run training script `bash train.sh`.
3. The files in checkpoint folder are as following:
```
--- args.json # Input arguments
|-- x_checkpoint.pth.tar # checkpoint
|-- x_model_best.pth.tar # best checkpoint
|-- x.txt # log file
```
## Defense
Comming soon...
## Citation
Please cite our paper in your publications if it helps your research:
```
@inproceedings{li_ISSBA_2021,
title={Invisible Backdoor Attack with Sample-Specific Triggers},
author={Li, Yuezun and Li, Yiming and Wu, Baoyuan and Li, Longkang and He, Ran and Lyu, Siwei},
booktitle={IEEE International Conference on Computer Vision (ICCV)},
year={2021}
}
```
## Notice
This repository is NOT for commecial use. It is provided "as it is" and we are not responsible for any subsequence of using this code.
| 32.9 | 168 | 0.710233 | eng_Latn | 0.895488 |
970af42efda54d8e8c48badd42c6028a5f875464 | 4,618 | md | Markdown | Samples/RazorPages/Readme.md | adam8797/RavenDB.Identity | 70ca50874c8705c1c520719850c670d4706c358b | [
"MIT"
] | null | null | null | Samples/RazorPages/Readme.md | adam8797/RavenDB.Identity | 70ca50874c8705c1c520719850c670d4706c358b | [
"MIT"
] | null | null | null | Samples/RazorPages/Readme.md | adam8797/RavenDB.Identity | 70ca50874c8705c1c520719850c670d4706c358b | [
"MIT"
] | null | null | null | # RavenDB.Identity Sample
This is a Razor Pages sample that shows how to use Raven.Identity.
There are four areas of interest:
1. [appsettings.json](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/appsettings.json) - where we configure our connection to Raven.
2. [AppUser.cs](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Models/AppUser.cs) - our user class containing any user data like FirstName and LastName.
3. [RavenSaveChangesAsyncFilter.cs](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Filters/RavenSaveChangesAsyncFilter.cs) - where we save changes to Raven after actions finish executing. This makes sense for a Razor Pages project. For an MVC or Web API project, use a RavenController base class instead.
4. [Startup.cs](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Startup.cs) - where we wire up everything.
More details below.
## 1. appsettings.json - connection to Raven
Our [appsettings.json file](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/appsettings.json) defines our connection to Raven. This is done using the [RavenDB.DependencyInjection](https://github.com/JudahGabriel/RavenDB.DependencyInjection/) package.
```json
"RavenSettings": {
"Urls": [
"http://live-test.ravendb.net"
],
"DatabaseName": "Raven.Identity.Sample.RazorPages",
"CertFilePath": "",
"CertPassword": ""
},
```
## 2. AppUser.cs - user class
We create our own [AppUser class](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Models/AppUser.cs) to hold user data:
```csharp
public class AppUser : Raven.Identity.IdentityUser
{
/// <summary>
/// The full name of the user.
/// </summary>
public string FullName { get; set; }
}
```
While this step isn't strictly necessary -- it's possible to skip AppUser and just use the built-in `Raven.Identity.IdentityUser` -- we recommend creating an AppUser class so you can extend your users with app-specific data.
## 3. RavenSaveChangesAsyncFilter
We need to `.SaveChangesAsync()` for anything to persist in Raven. Where should we do this?
While we could call `.SaveChangesAsync()` in the code-behind of every Razor page, that is tedious and error prone. Instead, we create a Razor action filter to save changes, [RaveSaveChangesAsyncFilter.cs](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Filters/RavenSaveChangesAsyncFilter.cs):
```csharp
/// <summary>
/// Razor Pages filter that saves any changes after the action completes.
/// </summary>
public class RavenSaveChangesAsyncFilter : IAsyncPageFilter
{
private readonly IAsyncDocumentSession dbSession;
public RavenSaveChangesAsyncFilter(IAsyncDocumentSession dbSession)
{
this.dbSession = dbSession;
}
public async Task OnPageHandlerSelectionAsync(PageHandlerSelectedContext context)
{
await Task.CompletedTask;
}
public async Task OnPageHandlerExecutionAsync(PageHandlerExecutingContext context, PageHandlerExecutionDelegate next)
{
var result = await next.Invoke();
// If there was no exception, and the action wasn't cancelled, save changes.
if (result.Exception == null && !result.Canceled)
{
await this.dbSession.SaveChangesAsync();
}
}
}
```
For MVC and Web API projects can use an action filter, or may alternately use a RavenController base class to accomplish the same thing.
## 4. Start.cs, wiring it all together
In [Startup.cs](https://github.com/JudahGabriel/RavenDB.Identity/blob/master/Samples/RazorPages/Startup.cs), we wire up all of the above steps:
```csharp
public void ConfigureServices(IServiceCollection services)
{
// Grab our RavenSettings object from appsettings.json.
services.Configure<RavenSettings>(Configuration.GetSection("RavenSettings"));
...
// Add an IDocumentStore singleton, with settings pulled from the RavenSettings.
services.AddRavenDbDocStore();
// Add a scoped IAsyncDocumentSession. For the sync version, use .AddRavenSession() instead.
// Note: Your code is responsible for calling .SaveChangesAsync() on this. This Sample does so via the RavenSaveChangesAsyncFilter.
services.AddRavenDbAsyncSession();
// Use Raven for our users
services.AddRavenDbIdentity<AppUser>();
...
// Call .SaveChangesAsync() after each action.
services
.AddMvc(o => o.Filters.Add<RavenSaveChangesAsyncFilter>())
.SetCompatibilityVersion(CompatibilityVersion.Version_2_2);
}
``` | 41.232143 | 338 | 0.757038 | eng_Latn | 0.419028 |
970c5ae8df57ab7870a50bcab14bc04a4ed08240 | 2,090 | md | Markdown | intune/reports-ref-current-user.md | yushinok/IntuneDocs.ja-jp | 68d9b9a5960c7c89308c98a79cbc0f1b2edf3bff | [
"CC-BY-4.0",
"MIT"
] | null | null | null | intune/reports-ref-current-user.md | yushinok/IntuneDocs.ja-jp | 68d9b9a5960c7c89308c98a79cbc0f1b2edf3bff | [
"CC-BY-4.0",
"MIT"
] | null | null | null | intune/reports-ref-current-user.md | yushinok/IntuneDocs.ja-jp | 68d9b9a5960c7c89308c98a79cbc0f1b2edf3bff | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 現在のユーザー - Intune データ ウェアハウス
titlesuffix: Microsoft Intune
description: Intune データ ウェアハウス API のエンティティ コレクションのユーザー カテゴリに関するリファレンス トピック。
keywords: Intune データ ウェアハウス
author: Erikre
ms.author: erikre
manager: dougeby
ms.date: 09/13/2018
ms.topic: article
ms.prod: ''
ms.service: microsoft-intune
ms.technology: ''
ms.assetid: C10E6752-E925-40AD-ABBF-6B621FB7AFC4
ms.reviewer: aanavath
ms.suite: ems
search.appverid: MET150
ms.custom: intune-classic
ms.openlocfilehash: b58f6f360cf034be11153a57227da42ed1e29388
ms.sourcegitcommit: 51b763e131917fccd255c346286fa515fcee33f0
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 11/20/2018
ms.locfileid: "52189777"
---
# <a name="reference-for-current-user-entity"></a>現在のユーザー エンティティのリファレンス
**現在のユーザー** カテゴリには、データ モデルのユーザー プロパティが含まれています。 **現在のユーザー** エンティティ コレクションは、現在アクティブなユーザーに限られています。 エンティティには、現在ライセンスが割り当てられているすべての Azure Active Directory ユーザーが含まれています。 ライセンスは、Intune ライセンス、ハイブリッド ライセンス、または Microsoft Office 365 ライセンスです。 ユーザーは削除されると、現在のユーザー コレクションに表示されなくなります。 ユーザー状態の変更の履歴を含むコレクションについては、「[ユーザー エンティティのリファレンス](reports-ref-user.md)」をご覧ください。
## <a name="current-user"></a>現在のユーザー
**Current User** エンティティには、社内のすべての Azure Active Directory (Azure AD) ユーザーと、割り当てられているライセンスが表示されます。
| プロパティ | 説明 | 例 |
|---------|------------|--------|
| UserKey |データ ウェアハウス内のユーザーを示す一意識別子 - 代理キー。 |123 |
| UserId |ユーザーを示す一意識別子 - UserKey と似ていますが、ナチュラル キーです。 |b66bc706-ffff-7437-0340-032819502773 |
| UserEmail |ユーザーの電子メール アドレス。 |[email protected] |
| UPN | ユーザーのユーザー プリンシパル名。 | [email protected] |
| DisplayName |ユーザーの表示名。 |John |
| IntuneLicensed |ユーザーに Intune のライセンスがあるかどうかを示します。 |真/偽 |
| StartDateInclusiveUTC |このユーザーがデータ ウェアハウスで作成されたときの UTC 日時。 |11/23/2016 12:00:00 AM |
| RowLastModifiedDateTimeUTC |このユーザーがデータ ウェアハウスで最後に変更されたときの UTC 日時。 |11/23/2016 12:00:00 AM |
## <a name="next-steps"></a>次の手順
- **ユーザー** エンティティ コレクションを使用して、ユーザー データを現在アクティブでないユーザーにまで拡張できます。 詳細については、「[ユーザー エンティティのリファレンス](reports-ref-user.md)」をご覧ください。
- データ ウェアハウスが Intune のユーザーの有効期間を追跡する方法の詳細については、「[Intune データ ウェアハウスのユーザー有効期間の表記](reports-ref-user-timeline.md)」をご覧ください。
| 42.653061 | 348 | 0.776555 | yue_Hant | 0.533373 |
970c6697f433e3786f5727f14e95a1292e519433 | 11,275 | md | Markdown | docs/mllib-migration-guides.md | coodoing/spark | 6cb75db9ab1a4f227069bec2763b89546b88b0ee | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | null | null | null | docs/mllib-migration-guides.md | coodoing/spark | 6cb75db9ab1a4f227069bec2763b89546b88b0ee | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | null | null | null | docs/mllib-migration-guides.md | coodoing/spark | 6cb75db9ab1a4f227069bec2763b89546b88b0ee | [
"BSD-3-Clause-Open-MPI",
"PSF-2.0",
"Apache-2.0",
"BSD-2-Clause",
"MIT",
"MIT-0",
"BSD-3-Clause-No-Nuclear-License-2014",
"BSD-3-Clause-Clear",
"PostgreSQL",
"BSD-3-Clause"
] | null | null | null | ---
layout: global
title: Old Migration Guides - spark.mllib
displayTitle: Old Migration Guides - spark.mllib
description: MLlib migration guides from before Spark SPARK_VERSION_SHORT
---
The migration guide for the current Spark version is kept on the [MLlib Programming Guide main page](mllib-guide.html#migration-guide).
## From 1.5 to 1.6
There are no breaking API changes in the `spark.mllib` or `spark.ml` packages, but there are
deprecations and changes of behavior.
Deprecations:
* [SPARK-11358](https://issues.apache.org/jira/browse/SPARK-11358):
In `spark.mllib.clustering.KMeans`, the `runs` parameter has been deprecated.
* [SPARK-10592](https://issues.apache.org/jira/browse/SPARK-10592):
In `spark.ml.classification.LogisticRegressionModel` and
`spark.ml.regression.LinearRegressionModel`, the `weights` field has been deprecated in favor of
the new name `coefficients`. This helps disambiguate from instance (row) "weights" given to
algorithms.
Changes of behavior:
* [SPARK-7770](https://issues.apache.org/jira/browse/SPARK-7770):
`spark.mllib.tree.GradientBoostedTrees`: `validationTol` has changed semantics in 1.6.
Previously, it was a threshold for absolute change in error. Now, it resembles the behavior of
`GradientDescent`'s `convergenceTol`: For large errors, it uses relative error (relative to the
previous error); for small errors (`< 0.01`), it uses absolute error.
* [SPARK-11069](https://issues.apache.org/jira/browse/SPARK-11069):
`spark.ml.feature.RegexTokenizer`: Previously, it did not convert strings to lowercase before
tokenizing. Now, it converts to lowercase by default, with an option not to. This matches the
behavior of the simpler `Tokenizer` transformer.
## From 1.4 to 1.5
In the `spark.mllib` package, there are no breaking API changes but several behavior changes:
* [SPARK-9005](https://issues.apache.org/jira/browse/SPARK-9005):
`RegressionMetrics.explainedVariance` returns the average regression sum of squares.
* [SPARK-8600](https://issues.apache.org/jira/browse/SPARK-8600): `NaiveBayesModel.labels` become
sorted.
* [SPARK-3382](https://issues.apache.org/jira/browse/SPARK-3382): `GradientDescent` has a default
convergence tolerance `1e-3`, and hence iterations might end earlier than 1.4.
In the `spark.ml` package, there exists one breaking API change and one behavior change:
* [SPARK-9268](https://issues.apache.org/jira/browse/SPARK-9268): Java's varargs support is removed
from `Params.setDefault` due to a
[Scala compiler bug](https://issues.scala-lang.org/browse/SI-9013).
* [SPARK-10097](https://issues.apache.org/jira/browse/SPARK-10097): `Evaluator.isLargerBetter` is
added to indicate metric ordering. Metrics like RMSE no longer flip signs as in 1.4.
## From 1.3 to 1.4
In the `spark.mllib` package, there were several breaking changes, but all in `DeveloperApi` or `Experimental` APIs:
* Gradient-Boosted Trees
* *(Breaking change)* The signature of the [`Loss.gradient`](api/scala/index.html#org.apache.spark.mllib.tree.loss.Loss) method was changed. This is only an issues for users who wrote their own losses for GBTs.
* *(Breaking change)* The `apply` and `copy` methods for the case class [`BoostingStrategy`](api/scala/index.html#org.apache.spark.mllib.tree.configuration.BoostingStrategy) have been changed because of a modification to the case class fields. This could be an issue for users who use `BoostingStrategy` to set GBT parameters.
* *(Breaking change)* The return value of [`LDA.run`](api/scala/index.html#org.apache.spark.mllib.clustering.LDA) has changed. It now returns an abstract class `LDAModel` instead of the concrete class `DistributedLDAModel`. The object of type `LDAModel` can still be cast to the appropriate concrete type, which depends on the optimization algorithm.
In the `spark.ml` package, several major API changes occurred, including:
* `Param` and other APIs for specifying parameters
* `uid` unique IDs for Pipeline components
* Reorganization of certain classes
Since the `spark.ml` API was an alpha component in Spark 1.3, we do not list all changes here.
However, since 1.4 `spark.ml` is no longer an alpha component, we will provide details on any API
changes for future releases.
## From 1.2 to 1.3
In the `spark.mllib` package, there were several breaking changes. The first change (in `ALS`) is the only one in a component not marked as Alpha or Experimental.
* *(Breaking change)* In [`ALS`](api/scala/index.html#org.apache.spark.mllib.recommendation.ALS), the extraneous method `solveLeastSquares` has been removed. The `DeveloperApi` method `analyzeBlocks` was also removed.
* *(Breaking change)* [`StandardScalerModel`](api/scala/index.html#org.apache.spark.mllib.feature.StandardScalerModel) remains an Alpha component. In it, the `variance` method has been replaced with the `std` method. To compute the column variance values returned by the original `variance` method, simply square the standard deviation values returned by `std`.
* *(Breaking change)* [`StreamingLinearRegressionWithSGD`](api/scala/index.html#org.apache.spark.mllib.regression.StreamingLinearRegressionWithSGD) remains an Experimental component. In it, there were two changes:
* The constructor taking arguments was removed in favor of a builder pattern using the default constructor plus parameter setter methods.
* Variable `model` is no longer public.
* *(Breaking change)* [`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree) remains an Experimental component. In it and its associated classes, there were several changes:
* In `DecisionTree`, the deprecated class method `train` has been removed. (The object/static `train` methods remain.)
* In `Strategy`, the `checkpointDir` parameter has been removed. Checkpointing is still supported, but the checkpoint directory must be set before calling tree and tree ensemble training.
* `PythonMLlibAPI` (the interface between Scala/Java and Python for MLlib) was a public API but is now private, declared `private[python]`. This was never meant for external use.
* In linear regression (including Lasso and ridge regression), the squared loss is now divided by 2.
So in order to produce the same result as in 1.2, the regularization parameter needs to be divided by 2 and the step size needs to be multiplied by 2.
In the `spark.ml` package, the main API changes are from Spark SQL. We list the most important changes here:
* The old [SchemaRDD](http://spark.apache.org/docs/1.2.1/api/scala/index.html#org.apache.spark.sql.SchemaRDD) has been replaced with [DataFrame](api/scala/index.html#org.apache.spark.sql.DataFrame) with a somewhat modified API. All algorithms in Spark ML which used to use SchemaRDD now use DataFrame.
* In Spark 1.2, we used implicit conversions from `RDD`s of `LabeledPoint` into `SchemaRDD`s by calling `import sqlContext._` where `sqlContext` was an instance of `SQLContext`. These implicits have been moved, so we now call `import sqlContext.implicits._`.
* Java APIs for SQL have also changed accordingly. Please see the examples above and the [Spark SQL Programming Guide](sql-programming-guide.html) for details.
Other changes were in `LogisticRegression`:
* The `scoreCol` output column (with default value "score") was renamed to be `probabilityCol` (with default value "probability"). The type was originally `Double` (for the probability of class 1.0), but it is now `Vector` (for the probability of each class, to support multiclass classification in the future).
* In Spark 1.2, `LogisticRegressionModel` did not include an intercept. In Spark 1.3, it includes an intercept; however, it will always be 0.0 since it uses the default settings for [spark.mllib.LogisticRegressionWithLBFGS](api/scala/index.html#org.apache.spark.mllib.classification.LogisticRegressionWithLBFGS). The option to use an intercept will be added in the future.
## From 1.1 to 1.2
The only API changes in MLlib v1.2 are in
[`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree),
which continues to be an experimental API in MLlib 1.2:
1. *(Breaking change)* The Scala API for classification takes a named argument specifying the number
of classes. In MLlib v1.1, this argument was called `numClasses` in Python and
`numClassesForClassification` in Scala. In MLlib v1.2, the names are both set to `numClasses`.
This `numClasses` parameter is specified either via
[`Strategy`](api/scala/index.html#org.apache.spark.mllib.tree.configuration.Strategy)
or via [`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree)
static `trainClassifier` and `trainRegressor` methods.
2. *(Breaking change)* The API for
[`Node`](api/scala/index.html#org.apache.spark.mllib.tree.model.Node) has changed.
This should generally not affect user code, unless the user manually constructs decision trees
(instead of using the `trainClassifier` or `trainRegressor` methods).
The tree `Node` now includes more information, including the probability of the predicted label
(for classification).
3. Printing methods' output has changed. The `toString` (Scala/Java) and `__repr__` (Python) methods used to print the full model; they now print a summary. For the full model, use `toDebugString`.
Examples in the Spark distribution and examples in the
[Decision Trees Guide](mllib-decision-tree.html#examples) have been updated accordingly.
## From 1.0 to 1.1
The only API changes in MLlib v1.1 are in
[`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree),
which continues to be an experimental API in MLlib 1.1:
1. *(Breaking change)* The meaning of tree depth has been changed by 1 in order to match
the implementations of trees in
[scikit-learn](http://scikit-learn.org/stable/modules/classes.html#module-sklearn.tree)
and in [rpart](http://cran.r-project.org/web/packages/rpart/index.html).
In MLlib v1.0, a depth-1 tree had 1 leaf node, and a depth-2 tree had 1 root node and 2 leaf nodes.
In MLlib v1.1, a depth-0 tree has 1 leaf node, and a depth-1 tree has 1 root node and 2 leaf nodes.
This depth is specified by the `maxDepth` parameter in
[`Strategy`](api/scala/index.html#org.apache.spark.mllib.tree.configuration.Strategy)
or via [`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree)
static `trainClassifier` and `trainRegressor` methods.
2. *(Non-breaking change)* We recommend using the newly added `trainClassifier` and `trainRegressor`
methods to build a [`DecisionTree`](api/scala/index.html#org.apache.spark.mllib.tree.DecisionTree),
rather than using the old parameter class `Strategy`. These new training methods explicitly
separate classification and regression, and they replace specialized parameter types with
simple `String` types.
Examples of the new, recommended `trainClassifier` and `trainRegressor` are given in the
[Decision Trees Guide](mllib-decision-tree.html#examples).
## From 0.9 to 1.0
In MLlib v1.0, we support both dense and sparse input in a unified way, which introduces a few
breaking changes. If your data is sparse, please store it in a sparse format instead of dense to
take advantage of sparsity in both storage and computation. Details are described below.
| 70.46875 | 374 | 0.776053 | eng_Latn | 0.978416 |
970c73f3aef07018eff4bcfb99bc6a438673f6f2 | 2,880 | md | Markdown | README.md | ahmads1990/Teaching | 66a32016e16551b98daf2d8ad5721a7f1b76e8c4 | [
"MIT"
] | 2 | 2021-11-04T02:33:01.000Z | 2021-11-04T02:34:15.000Z | README.md | ahmads1990/Teaching | 66a32016e16551b98daf2d8ad5721a7f1b76e8c4 | [
"MIT"
] | null | null | null | README.md | ahmads1990/Teaching | 66a32016e16551b98daf2d8ad5721a7f1b76e8c4 | [
"MIT"
] | null | null | null | <!-- # Teaching Materials for [Dr. Waleed A. Yousef](http://www.wy.helwan.edu.eg) -->
<!-- ## Spring 2019 -->
<!-- **Office Hours:** Wed. 12pm--4pm and by appointment (send an email). -->
<!-- **Courses:** -->
<!-- * [CS 496: Data Science IV (More Advanced Pattern Recognition)](PatternRecognition) -->
# All Courses #
**Courses On [Open-Course-Ware (recording completed)](http://www.youtube.com/fcihocw):**
* [MA 112: Discrete Mathematics I (logic, basics, and foundations)](DiscreteMathematics)
* [CS 214: Data Structures](DataStructures)
* [ST 121: Probability](Probability)
**Courses On [Open-Course-Ware (still recording)](http://www.youtube.com/fcihocw):**
* [ST 122: Statistics](Statistics)
* [MA 214: Linear Algebra](LinearAlgebra)
* [CS 221: Digital Design](DigitalDesign)
* [CS 495: Data Visualization](DataVisualization)
* [CS 395: Data Science I: metro-rider snapshots of 15-course field](DataScience)
* [CS 396: Data Science II (Pattern Recognition)](PatternRecognition)
* [CS 395: Optimization](Optimization)
**Other Courses:** (not recorded yet)
* [IT 441 (Digital Image Processing)](ImageProcessing)
* [CS 251 (Software Engineering I)](SoftwareEngineeringI)
# Citation #
Please, use the following citation when you use my lecture notes:
```
@Misc{Yousef2009LectureNotesComputerScience,
author = {Waleed A. Yousef},
title = {Lecture Notes in Computer Science: mathematics and intuition},
year = 2009,
url = {https://github.com/DrWaleedAYousef/Teaching}
}
```
<!-- ## Call for Graduation Projects, Fall 2019 (coming soon ISA) -->
<!-- For interested students in my graduation projects of 2016-2017, this is a list of the projects I am -->
<!-- going to supervise along with a list of [suggested readings](GP) -->
<!-- **1- CAD: Computer Aided Detection of breast cancer using Deep Learning** -->
<!-- The objective is to leverage the new "deep learning" approach of pattern recognition to -->
<!-- enhance the accuracy of the detection algorithms of breast cancer. The prerequisites courses -->
<!-- for joining this project are: probability, pattern recognition, and image processing. To know -->
<!-- about one of the CAD systems visits [LIBCAD](http://libcad.mesclabs.com). -->
<!-- **2- DV: Building a Grammar of Graphics for Data Visualization** -->
<!-- This is a continuation on 2 previous graduation projects (2015 and 2016). To know about data -->
<!-- visualization read (Chen, H{a}rdle, Unwin - 2008 - Handbook of data visualization). To know -->
<!-- one of the interactive data visualization systems visit, -->
<!-- e.g., [DVP](http://dvp.mesclabs.com). It is intended to continue on -->
<!-- the graduation project of this year (2106) to build a complete Grammar of Graphics data -->
<!-- visualization system (Wilkinson et al. - 2006 - The Grammar of Graphics). -->
| 42.352941 | 108 | 0.692014 | eng_Latn | 0.62902 |
970c9f155c08509e897d469c947c1b7b88b0143b | 8,870 | md | Markdown | help/release-notes/2020/april-2020.md | ktukker-adobe/experience-platform.en | 7c9b3f9b6404f6bb3937fcfbcdaf73bf23a3bb7d | [
"MIT"
] | null | null | null | help/release-notes/2020/april-2020.md | ktukker-adobe/experience-platform.en | 7c9b3f9b6404f6bb3937fcfbcdaf73bf23a3bb7d | [
"MIT"
] | null | null | null | help/release-notes/2020/april-2020.md | ktukker-adobe/experience-platform.en | 7c9b3f9b6404f6bb3937fcfbcdaf73bf23a3bb7d | [
"MIT"
] | null | null | null | ---
title: Adobe Experience Platform Release Notes
description: Experience Platform release notes April 8, 2020
doc-type: release notes
last-update: April 13, 2020
author: ens71067
keywords: release notes;
---
# Adobe Experience Platform release notes
**Release date: April 8, 2020**
New features in Adobe Experience Platform:
* [!DNL Intelligent Services](#intelligent)
Updates to existing features:
* [!DNL Experience Data Model (XDM)](#xdm)
* [!DNL Data Governance](#governance)
* [!DNL Destinations](#destinations)
* [!DNL Privacy Service](#privacy)
* [!DNL Sources](#sources)
## [!DNL Intelligent Services] {#intelligent}
[!DNL Intelligent Services] empower marketing analysts and practitioners to leverage the power of artificial intelligence and machine learning in customer experience use cases. This allows for marketing analysts to set up predictions specific to a company's needs using business-level configurations without the need for data science expertise. Additionally, marketing practitioners can activate predictions in Adobe Experience Cloud, Adobe Experience Platform, and 3rd party applications.
**Key features**
|Feature|Description|
|---|---|
| [!DNL Customer AI] | [!DNL Customer AI] provides marketers with the power to generate customer predictions at the individual level with explanations. With the help of influential factors, [!DNL Customer AI] can tell you what a customer is likely to do and why. Additionally, marketers can benefit from [!DNL Customer AI] predictions and insights to personalize customer experiences by serving the most appropriate offers and messaging. |
| [!DNL Attribution AI] | [!DNL Attribution AI] is a multi-channel, algorithmic attribution service that calculates the influence and incremental impact of customer interactions against specified outcomes. With [!DNL Attribution AI], marketers can measure and optimize marketing and advertising spend by understanding the impact of every individual customer interaction across each phase of the customers’ journeys.|
**Known issues**
* No known issues currently.
For more information on [!DNL Intelligent Services] and what it has to offer, see the [Intelligent Services overview](../../intelligent-services/home.md).
## [!DNL Experience Data Model] (XDM) System {#xdm}
Standardization and interoperability are key concepts behind [!DNL Experience Platform]. [!DNL Experience Data Model] (XDM), driven by Adobe, is an effort to standardize customer experience data and define schemas for customer experience management.
XDM is a publicly documented specification designed to improve the power of digital experiences. It provides common structures and definitions for any application to communicate with services on Adobe Experience Platform. By adhering to XDM standards, all customer experience data can be incorporated into a common representation delivering insights in a faster, more integrated way. You can gain valuable insights from customer actions, define customer audiences through segments, and use customer attributes for personalization purposes.
**New features**
| Feature | Description |
| --- | --- |
| Automatic alternate display info | The [!DNL Schema Registry] automatically applies the customized title and description values configured in the `alternateDisplayInfo` descriptor. |
| Scalar field restrictions | The [!DNL Schema Registry] does not allow more than 6000 scalar fields in a single schema. |
| Performance overhaul | The [!DNL Schema Registry] has been overhauled to perform and meet the demands of [!DNL Experience Platform] better. |
**Bug fixes**
* Updated XDM to XED converted to support a cleaner XED format for nested URI fields in standard XDM.
**Known issues**
* Known
## [!DNL Data Governance] {#governance}
Adobe Experience Platform [!DNL Data Governance] is a series of strategies and technologies used to manage customer data and ensure compliance with regulations, restrictions, and policies applicable to data usage. It plays a key role within [!DNL Experience Platform] at various levels, including cataloging, data lineage, data usage labeling, data access policies, and access control on data for marketing actions.
Getting started with data governance requires a thorough understanding of the regulations, contractual obligations, and corporate policies that apply to your customer data. From there, data can be classified by applying the appropriate data usage labels, and its use can be controlled through the definition of data usage policies.
The DULE framework simplifies and streamlines the process of categorizing data and creating data usage policies through the [!DNL Experience Platform] user interface and DULE [!DNL Policy Service] API.
**New features**
| Feature | Description |
| -----------| ---------- |
| Manage data usage policies in the UI | Data usage policies can now be managed within the _Policies_ workspace in the [!DNL Experience Platform] UI. See the [policy user guide](../../data-governance/policies/user-guide.md) for more information.|
**Known issues**
* None.
For more information, please see the [Data Governance overview](../../data-governance/home.md).
## Destinations {#destinations}
In [Adobe Real-time Customer Data Platform](../../rtcdp/overview.md), destinations are pre-built integrations with destination platforms that activate data to those partners in a seamless way.
**New destinations**
Adobe Real-time CDP now supports data activation to over fifty [!DNL Experience Cloud Launch] extensions, enabling analytics, personalization, and other use cases. See below for details:
|Documentation | Description|
|--- | ---|
|[Destination types and categories](/help/rtcdp/destinations/destination-types.md) | This article explains the difference between connections and extensions in the Adobe Real-time CDP interface and recommends when to use each of these destinations.|
|[Experience Platform Launch extensions](/help/rtcdp/destinations/experience-platform-launch-extensions.md) | This page explains what [!DNL Launch] extensions are, lists use cases for using them, and links to documentation for each [!DNL Launch] extension in Adobe Real-time CDP.|
For more information, please see the [Destinations overview](/help/rtcdp/destinations/destinations-overview.md).
## [!DNL Privacy Service] {#privacy}
New legal and organizational regulations are giving users the right to access or delete their personal data from your data stores upon request. Adobe Experience Platform [!DNL Privacy Service] provides a RESTful API and user interface to help you manage these data requests from your customers. With [!DNL Privacy Service], you can submit requests to access and delete private or personal customer data from Adobe Experience Cloud applications, facilitating automated compliance with legal and organizational privacy regulations.
**New features**
| Feature | Description |
| --- | --- |
| PDPA support | Privacy requests can now be created and tracked under the Personal Data Protection Act (PDPA) in Thailand. When making privacy requests in the API, the `regulation` array accepts the value "pdpa_tha". |
| Namespace types in the UI | You can now specify different namespace types in the Request Builder in the [!DNL Privacy Service] UI. See the [user guide](../../privacy-service/ui/user-guide.md) for more information. |
| Old endpoint deprecation | The old API endpoint (`data/privacy/gdpr`) has been deprecated. |
Known issues
* None
For more information about [!DNL Privacy Service], please start by reading the [Privacy Service overview](../../privacy-service/home.md).
## Sources {#sources}
Adobe Experience Platform can ingest data from external sources while allowing you to structure, label, and enhance that data using [!DNL Platform] services. You can ingest data from a variety of sources such as Adobe applications, cloud-based storage, third party software, and your CRM system.
[!DNL Experience Platform] provides a RESTful API and an interactive UI that lets you set up source connections for various data providers with ease. These source connections allow you to authenticate and connect to external storage systems and CRM services, set times for ingestion runs, and manage data ingestion throughput.
**New features**
| Feature | Description |
| ------- | ----------- |
| API and UI support for databases | New source connectors for [!DNL Apache Spark] (on HDInsights), [!DNL Azure Synapse Analytics], [!DNL Azure Table Storage], [!DNL Hive] (on HDInsights), and [!DNL Phoenix]. |
| API and UI support for payments-based applications| New source connectors for [!DNL PayPal]. |
| API and UI support for protocols-based applications | New source connectors for [!DNL Generic OData]. |
**Known issues**
* None
To learn more about sources, see the [sources overview](../../sources/home.md).
| 65.220588 | 539 | 0.77903 | eng_Latn | 0.987447 |
970d086aa2264470df1f43aae3907fb3272b571c | 2,618 | md | Markdown | docs/backup-restore/cchksgfiles-errcheckdbheaders-function.md | isabella232/office-developer-exchange-docs.ja-JP | d2d2f4e3861e8a3495b7c1acfe7f3784a246423f | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T18:53:49.000Z | 2020-05-19T18:53:49.000Z | docs/backup-restore/cchksgfiles-errcheckdbheaders-function.md | isabella232/office-developer-exchange-docs.ja-JP | d2d2f4e3861e8a3495b7c1acfe7f3784a246423f | [
"CC-BY-4.0",
"MIT"
] | 2 | 2021-12-08T02:37:43.000Z | 2021-12-08T02:37:59.000Z | docs/backup-restore/cchksgfiles-errcheckdbheaders-function.md | isabella232/office-developer-exchange-docs.ja-JP | d2d2f4e3861e8a3495b7c1acfe7f3784a246423f | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: CChkSGFiles.ErrCheckDbHeaders 関数
manager: sethgros
ms.date: 11/16/2014
ms.audience: Developer
ms.topic: overview
ms.prod: office-online-server
ms.localizationpriority: medium
api_name:
- ErrCheckDbHeaders
api_type:
- dllExport
ms.assetid: 75289cd2-35b1-4f75-a651-dce01f1ddda1
description: '最終更新日: 2013 年 2 月 22 日'
ms.openlocfilehash: 215a0d1126fce48b7e3800016619b0c52915312b
ms.sourcegitcommit: 54f6cd5a704b36b76d110ee53a6d6c1c3e15f5a9
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 09/24/2021
ms.locfileid: "59510471"
---
# <a name="cchksgfileserrcheckdbheaders-function"></a>CChkSGFiles.ErrCheckDbHeaders 関数
**適用対象: Exchange Server** 2003 |Exchange Server 2007 |Exchange Server 2010 |Exchange Server 2013
**ErrInit** 関数で指定されたデータベース ファイルのヘッダーを検証します。この関数は、指定されたデータベースごとのページ サイズとページ数も返します。
```cs
Vitual ERRErrCheckDbHeaders
(
ULONG * const pcbDbPageSize,
ULONG * const pcHeaderPagesPerDb,
ULONG const piDbErrorEncountered,
Const ULONGulFlags = NO_FLAGS
);
```
## <a name="parameters"></a>パラメーター
### <a name="pcbdbpagesize"></a>pcbDbPageSize
出力パラメーター。指定されたデータベースごとのページ サイズ (バイト単位)。
### <a name="pcheaderpagesperdb"></a>pcHeaderPagesPerDb
出力パラメーター。指定された各データベースの開始時のページ数。データベース エンジンによって、このページ数が内部使用のために予約されます。検証のために、**ErrCheckDbPages** 関数にヘッダー ページを渡しては *いけません*。
### <a name="pidberrorencountered"></a>piDbErrorEncountered
出力パラメーター。関数の戻り値がエラーを示している場合、このパラメーターは **ErrInit** 関数に渡した **rgwszDb[]** 配列のインデックスになります。インデックスで示された配列の要素は、エラーが発生したデータベースを表します。関数がエラー値を返さない場合、このパラメーターの値は無効になります。
### <a name="ulflags"></a>ulFlags
オプションの入力パラメーター。この値は、将来使用するために予約されています。渡された値は、0 (ゼロ) になります。
## <a name="return-value"></a>戻り値
この関数は [、CChkSGFiles.ERR 列挙からエラー コードを返します](cchksgfiles-err-enumeration.md)。
## <a name="remarks"></a>注釈
**ErrCheckDbHeaders** は、**ErrInit** によって登録したすべてのデータベースで、ログ署名とデータベース ページ サイズが同じであることを検証します。また、最小の **genMin** パラメーター値と、最大の **genMax** パラメーター値を使用することで、登録されたすべてのデータベースをクリーン シャットダウン状態にするために必要になるログ ファイルのセットを決定することもできます。
**piDbErrorEncountered** パラメーターは、ゼロ以外の **ErrCheckDbHeaders** の戻り値で示されるエラーが検出された場合にのみ設定されます。
この関数でエラーが発生すると、エラー イベントが Windows エラー イベント ログに追加されます。
**ErrCheckDbHeaders** は、**ErrInit** を呼び出した後にのみ呼び出せるようになり、**ErrCheckDbPages** および **ErrCheckLogs** を呼び出す前に呼び出す必要があります。
マルチスレッド アプリケーションで CHKSGFILES を使用している場合は、シングル スレッド部分で **ErrCheckDbHeaders** 関数を呼び出す必要があります。また **、CCheckSGFiles** オブジェクトごとに 1 回だけ呼び出す必要があります。
## <a name="requirements"></a>要件
Exchange 2013 には、CHKSGFILES API の 64 ビット バージョンだけが含まれています。
アプリケーションを実行しているアカウントには、確認するデータベースとログ ファイルに対する読み取りアクセス許可が必要です。
| 32.725 | 214 | 0.773491 | yue_Hant | 0.803237 |
970d1ca1956d81193185ed67c5058708bfc47893 | 1,657 | md | Markdown | _posts/2004-2-18-2004-02-18.md | gt-2003-2017/gt-2003-2017.github.io | d9b4154d35ecccbe063e9919c7e9537a84c6d56e | [
"MIT"
] | null | null | null | _posts/2004-2-18-2004-02-18.md | gt-2003-2017/gt-2003-2017.github.io | d9b4154d35ecccbe063e9919c7e9537a84c6d56e | [
"MIT"
] | null | null | null | _posts/2004-2-18-2004-02-18.md | gt-2003-2017/gt-2003-2017.github.io | d9b4154d35ecccbe063e9919c7e9537a84c6d56e | [
"MIT"
] | null | null | null | 느헤미야 9:16 - 9:21
2004년 02월 18일 (수)
연하여 주시는 은혜
느헤미야 9:16 - 9:21 / 새찬송가 82 장
9:16 저희와 우리 열조가 교만히 하고 목을 굳게 하여 주의 명령을 듣지 아니하고
17 거역하며 주께서 저희 가운데 행하신 기사를 생각지 아니하고 목을 굳게 하며 패역하여 스스로 한 두목을 세우고 종 되었던 땅으로 돌아가고자 하였사오나 오직 주는 사유하시는 하나님이시라 은혜로우시며 긍휼히 여기시며 더디 노하시며 인자가 풍부하시므로 저희를 버리지 아니하셨나이다
18 또 저희가 송아지를 부어 만들고 이르기를 이는 곧 너희를 인도하여 애굽에서 나오게 하신 하나님이라 하여 크게 설만하게 하였사오나
19 주께서는 연하여 긍휼을 베푸사 저희를 광야에 버리지 아니하시고 낮에는 구름 기둥으로 길을 인도하시며 밤에는 불 기둥으로 그 행할 길을 비취사 떠나게 아니하셨사오며
20 또 주의 선한 신을 주사 저희를 가르치시며 주의 만나로 저희 입에 끊어지지 않게 하시고 저희의 목마름을 인하여 물을 주시사
21 사십 년 동안을 들에서 기르시되 결핍함이 없게 하시므로 그 옷이 해어지지 아니하였고 발이 부릍지 아니하였사오며
입술의 말씀
21 For forty years you sustained them in the desert; they lacked nothing, their clothes did not wear out nor did their feet become swollen.
해석도움
설만함과 사유하심
하나님의 이 놀라운 구원과 인도와 공급을 체험한 이스라엘 백성들은 그럼에도 불구하고 하나님 앞에 무례하고 방자히 행했습니다. 하나님은 그들을 감찰하시고 들으셨지만 그들은 교만하여 하나님의 계명에 귀를 기울이지 않았고(16) 거역하여 주께서 행하신 기사를 생각지 아니했습니다(17). 도리어 그들은 하나님의 은혜를 멸시하고 종 되었던 땅 이집트로 되돌아가기를 도모했으며 하나님의 은혜를 우상에게로 돌리고자 했습니다. 찬양자들은 심판 받을 수 밖에 없는 이 같은 큰 죄가 용서 받을 수 있는 것은, 오직 하나님의 성품에서 기인한다고 노래합니다. “오직 주는 사유하시는 하나님이시라(17)”는 고백은 용서하시는 것이 그분의 고유의 성품이라는 뜻입니다. 참으로 하나님에게는 언제나 죄인을 용서하실 준비가 되어 있는 것입니다.
연하여 주시는 은혜
이스라엘은 거듭해서(18) 범죄하지만, 하나님은 연하여(19) 긍휼을 베푸셨습니다. 찬양자들은 하나님께서 구름기둥과 불기둥을 치우지 않으셨다는 사실을 노래하고 있습니다(19/비교 12). 이것은 그들이 죄 가운데 방황하며 멸망하도록 방치하실 수 있었음에도 불구하고 크신 긍휼을 베푸사 계속 인도하셨음을 고백하는 것입니다. 뿐만 아니라 하나님은 주의 선한 신을 모세를 비롯한 많은 장로들에게 부어 주시어 백성들에게 생명에 이르는 말씀을 더욱 풍성하게 가르치게 하셨습니다(20전/민11:17). 찬양자들은 또한 그들의 범죄에도 불구하고 만나와 음료의 기적이 계속되었다는 것에 대해 다시금 언급하고 있습니다(20후/비교15). 하나님은 실패한 그들을 이처럼 먹이시고 입히시되 그들의 옷이 해어지지 않고 그들의 발이 부르트지 않을 정도로 세밀하게 길러주셨습니다. 이와 같은 큰 사랑과 배려가, 바로 우리가 받고 있는 사랑입니다. | 53.451613 | 459 | 0.727218 | kor_Hang | 1.00001 |
970d616f03c43b2ff81d594f7c053eb45459a885 | 1,365 | md | Markdown | AlchemyInsights/office-apps-icons-shortcuts-white-blank-duplicate.md | isabella232/OfficeDocs-AlchemyInsights-pr.pl-PL | 621d5519261e87dafaff1a0b3d7379f37e226bf6 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T19:07:24.000Z | 2020-05-19T19:07:24.000Z | AlchemyInsights/office-apps-icons-shortcuts-white-blank-duplicate.md | isabella232/OfficeDocs-AlchemyInsights-pr.pl-PL | 621d5519261e87dafaff1a0b3d7379f37e226bf6 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2022-02-09T06:52:18.000Z | 2022-02-09T06:52:35.000Z | AlchemyInsights/office-apps-icons-shortcuts-white-blank-duplicate.md | isabella232/OfficeDocs-AlchemyInsights-pr.pl-PL | 621d5519261e87dafaff1a0b3d7379f37e226bf6 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-10-09T20:27:31.000Z | 2019-10-09T20:27:31.000Z | ---
title: Microsoft 365 ikony/skróty aplikacji białe, puste lub zduplikowane
ms.author: pebaum
author: pebaum
manager: scotv
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Normal
ms.collection: Adm_O365
ms.custom:
- "2530"
- "9000572"
ms.openlocfilehash: 965a3a3e9769694666a961531ac55b31b1da4b7c64eb4700199df8cbcf2152d7
ms.sourcegitcommit: b5f7da89a650d2915dc652449623c78be6247175
ms.translationtype: MT
ms.contentlocale: pl-PL
ms.lasthandoff: 08/05/2021
ms.locfileid: "54065186"
---
# <a name="office-app-icons-or-shortcuts-are-white-blank-or-duplicate"></a>aplikacja pakietu Office lub skróty są białe, puste lub zduplikowane
Jeśli aplikacja pakietu Office są puste lub białe, spróbuj [naprawić Office aplikacji](https://support.office.com/article/repair-an-office-application-7821d4b6-7c1d-4205-aa0e-a6b40c5bb88b). Aby usunąć zduplikowane aplikacja pakietu Office, zobacz skróty [Office pozostają po Office odinstalowywania.](https://support.office.com/article/office-shortcuts-remain-after-office-uninstall-cc04b8e2-6e91-4c10-94af-9359e595d565)
Aby uzyskać więcej informacji, [Office ikony są puste](https://support.office.com/article/office-icons-are-blank-after-installing-office-from-the-microsoft-store-7cdaebde-93d5-4873-b767-d9ddc0474d59)po zainstalowaniu Office z Microsoft Store. | 52.5 | 420 | 0.824908 | pol_Latn | 0.812367 |
970e09160094bac0558bc83d260babd939e0a44c | 36 | md | Markdown | _my_date/2017-09.md | transblinkgift/transblinkgift.github.io | 7c2c546c519cf59d8ac1772f78d70aa271854b5a | [
"MIT"
] | null | null | null | _my_date/2017-09.md | transblinkgift/transblinkgift.github.io | 7c2c546c519cf59d8ac1772f78d70aa271854b5a | [
"MIT"
] | null | null | null | _my_date/2017-09.md | transblinkgift/transblinkgift.github.io | 7c2c546c519cf59d8ac1772f78d70aa271854b5a | [
"MIT"
] | null | null | null | ---
slug: 2017-09
name: Sep 2017
--- | 9 | 14 | 0.583333 | eng_Latn | 0.356534 |
970e3e5356a756a35dab2b6909a7027c5caded4f | 604 | md | Markdown | pages/blog/official.md | AmiyaBot/Amiya-Bot-pages | c3f5dd7f79b82741e4d2b2e4dd12a98464219e7d | [
"MIT"
] | 5 | 2021-12-11T06:55:12.000Z | 2021-12-26T02:54:31.000Z | pages/blog/official.md | AmiyaBot/Amiya-Bot-pages | c3f5dd7f79b82741e4d2b2e4dd12a98464219e7d | [
"MIT"
] | 1 | 2021-12-15T14:57:08.000Z | 2021-12-18T17:34:39.000Z | pages/blog/official.md | AmiyaBot/Amiya-Bot-pages | c3f5dd7f79b82741e4d2b2e4dd12a98464219e7d | [
"MIT"
] | 2 | 2021-12-15T13:41:11.000Z | 2021-12-15T13:54:44.000Z | ---
title: Amiya的测试工坊
---
::: tip 我还没加入?<br>
点击链接加入QQ频道 [Amiya的测试工坊](https://qun.qq.com/qqweb/qunpro/share?_wv=3&_wwv=128&appChannel=share&inviteCode=1W4sJux&appChannel=share&businessType=9&from=181074&biz=ka&shareSource=5)
:::
欢迎加入 Amiya 的测试工坊,Amiya 的测试工坊是 AmiyaBot 项目的集结地。<br>
你可以在里面和各位志同道合的《明日方舟》游戏爱好者交流,也可以反馈项目 BUG,或加入开发组等...
### Amiya 有什么功能?
请阅读 [《功能指引》](/blog/function/)
### 想支持 Amiya 的运营?
Amiya-Bot 项目将一直坚持,且呼吁所有使用 Amiya-Bot 源码搭建的作者们**免费**提供使用。<br>
如果你想支持 Amiya-Bot 项目,给各位作者打赏一杯咖啡,或者给本项目 [GitHub](https://github.com/AmiyaBot/Amiya-Bot) 一颗 star,都可以带给阿米娅项目前行下去的动力。<br>
打赏请备注"阿米娅"
<sponsors/>
| 26.26087 | 178 | 0.746689 | yue_Hant | 0.967021 |
970e4e87f36c26d4e0080ef2511a111a4bf51945 | 29,455 | md | Markdown | content/news/214-jun-july-dev.md | joebass85/lbry.com | adede340bce634f2868cb8c9edfa1bbcdbab87f3 | [
"MIT"
] | 1 | 2020-04-05T07:29:41.000Z | 2020-04-05T07:29:41.000Z | content/news/214-jun-july-dev.md | joebass85/lbry.com | adede340bce634f2868cb8c9edfa1bbcdbab87f3 | [
"MIT"
] | null | null | null | content/news/214-jun-july-dev.md | joebass85/lbry.com | adede340bce634f2868cb8c9edfa1bbcdbab87f3 | [
"MIT"
] | null | null | null | ---
author: tom-zarebczan
title: 'Development Update for June/July 2019'
date: '2019-07-31 09:00:00'
cover: 'geometry-cover.jpg'
category: community-update
---
Welcome to the June/July 2019 LBRY Development update! In this post we’ll show you what we’ve been up to and review our progress since our [last update in March](https://lbry.com/news/feb-19-update). We apologize for the gap in updates as the team was working extremely hard on getting our latest release out (and we’ve got an awesome app to show for it!). In the future, we’ll be providing shorter, more regular updates, regardless of our app / SDK release schedule. Sit tight, there’s lots to talk about below including updates from the Apps(Desktop + Mobile), SDK and blockchain teams!
To read previous updates, please visit our [Development and Community Update archive](https://lbry.io/news/category/community-update).
If you want to see a condensed view of what we have completed recently and what’s planned for LBRY, check out our [Roadmap](https://lbry.io/roadmap).
# In This Update {#dev-updates}
* [Desktop App Quick Recap](#summary-desktop)
* [SDK Quick Recap](#summary-sdk)
* [LBRY Desktop - Deep Dives and Next Steps](#app)
* [LBRY Desktop - New Supports Feature](#supports)
* [LBRY Desktop - File Download Options Coming Soon](#streaming)
* [LBRY for Android Updates](#android)
* [LBRY.tv Updates](#web)
* [Open.LBRY.com Redesign](#open)
* [LBRY SDK Download Upgrades and Progress](#sdk)
* [YouTube Sync Transfers](#youtube)
* [Blockchain Upstream Updates and Progress](#blockchain)
* [2019 Roadmap Update](#2019)
### Desktop App Quick Recap {#summary-desktop}
Since our last development update, the app had a few minor updates leading up to the recent [0.34 Erikson release](https://github.com/lbryio/lbry-desktop/releases/tag/v0.34.0) which showcased a brand new layout, customizable homepage, new Account Overview section, channel editing, comments, video lengths, and much more! After Darwin, we shifted focus to consolidate the desktop and web versions of LBRY into a single codebase -- a huge effort! We’ve launched the web preview at [beta.lbry.tv](https://beta.lbry.tv) which you can explore today. The app team also made modifications to support the evolving LBRY SDK which had significant and breaking API changes. This paved the way for the current release which includes tagging and discovery changes.
Erikson is a ***huge step*** in the direction that LBRY ultimately wants to go - giving the community control to determine what content is discoverable and how to find it through our newly customizable home page and tagging system. LBRY no longer curates homepage content and instead it is user controlled based on selecting tags and channels of interest. The content is segmented into three main areas -- Trending/Top/New. You can read all about how these sections work in our new [Trending FAQ](https://lbry.com/faq/trending). Our goal is for quality content to easily discoverable, when ranked by LBC tips and supports ([new experimental setting in this release](#supports)), by anyone on the network (fans, curators, etc).
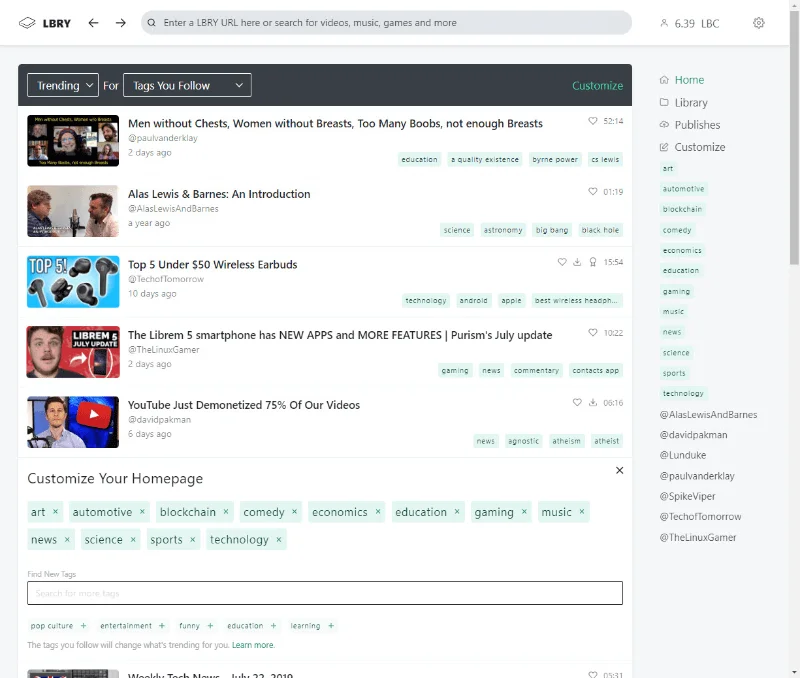
### SDK Quick Recap {#summary-sdk}
On the SDK side of the house, the major release was [version 0.38.0](https://github.com/lbryio/lbry-sdk/releases/tag/v0.38.0) and subsequent patches up to version 0.38.5 which are in the current app release. Since our last update, four versions have passed with each iteration building additional features to enable the Desktop app’s customizable views released recently. In order to calculate trending data and do complex searches using tags ( and also "not_tags" and "not_channels" to facilitate filtering), the entire backend wallet server had to be re-written from scratch to implement how the blockchain layer works, but added to an easy to consume database, along with the logic for performing the [trending calculations](https://lbry.com/faq/trending) mentioned earlier.
Reading and storing the data was the first large undertaking, but one that proved to be even a bigger challenge was making all the queries performant. With each click of the app, the SDK searches through over a million pieces of content, across various data points, in LIGHTNING fast times of under 100-200 milliseconds. You can read more about the challenges and details in the [SDK updates](#sdk) section below.
### LBRY Desktop - Deep Dive and Next Steps {#app}
The release of [App E - Erikson](https://github.com/lbryio/lbry-desktop/releases/tag/v0.34.0) is one of the biggest and boldest releases of LBRY yet - it comes packed with new features including a tag-based, customizable homepage, publisher ability to tag content, channel editing (simplistic first pass), first non-English language options (special thanks to the Polish and Indonesian translators - Madiator2019 and Chris45!!), comments alpha (not decentralized -- stored on LBRY servers), option for support own/others’ content, short URLs (instead of the long string of characters/numbers after the #), a one click zipping tool for wallet backups, content sharing integration with [beta.lbry.tv](https://beta.lbry.tv), and a groovy loading animation. The release also includes a UI overhaul including a new sidebar, Overview page, Account/Settings menu, and light/dark quick switch. See, we told you the wait since the last update was worth it! Instead of content being curated by LBRY, the homepage is now driven by tags, channels followed, and the [Top/Trending ranking algorithms](https://lbry.com/faq/trending) using the LBRY protocol. This makes content discovery an even playing field for all as the rules are out in the open, as opposed to YouTube’s hidden algorithms. Having the ability to see new content published on LBRY via the “New” option on the homepage is also a huge step forward as it showcases the new content being uploaded every minute.
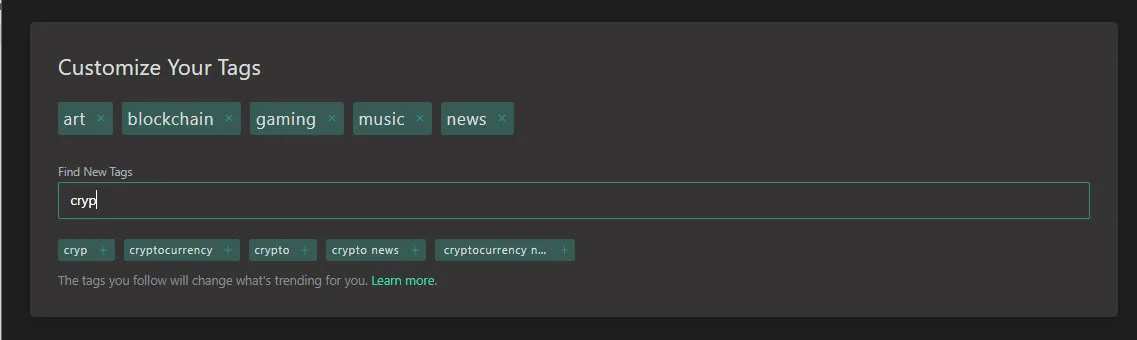
#### Publishing and URLs
Publishers who previously uploaded on LBRY will need to edit their content to take advantage of the new features including tags and video lengths (content has to be re-uploaded if it was published before ~April 2019). Both edits and new publishes can be customized with tags, metadata such as file size, content length, and dimensions will be pulled in and stored with your claim data automatically. You’ll also notice that content is now correctly sorted on channel pages in the app. This is due to the addition of a release time field in the SDK which allows us to sort the content based on when it was actually published, instead of when it was last updated on LBRY.
You’ll also notice shorter URLs throughout the app. These replace the long URLs you’re used to and are first come first serve at [LBRY claim names](https://lbry.com/faq/naming) (i.e. if you try to publish lbry://one or other popular vanity claim names, you may be left with a URL like lbry://one#123 instead of lbry://one#1). We’ve also added the ability to use more characters in your LBRY URLs - you can pretty much use anything you want besides spaces and `=&#:$@%?;/\\"<>%{}|^~[\`. This includes emoji support! (Check out `lbry://♒`)
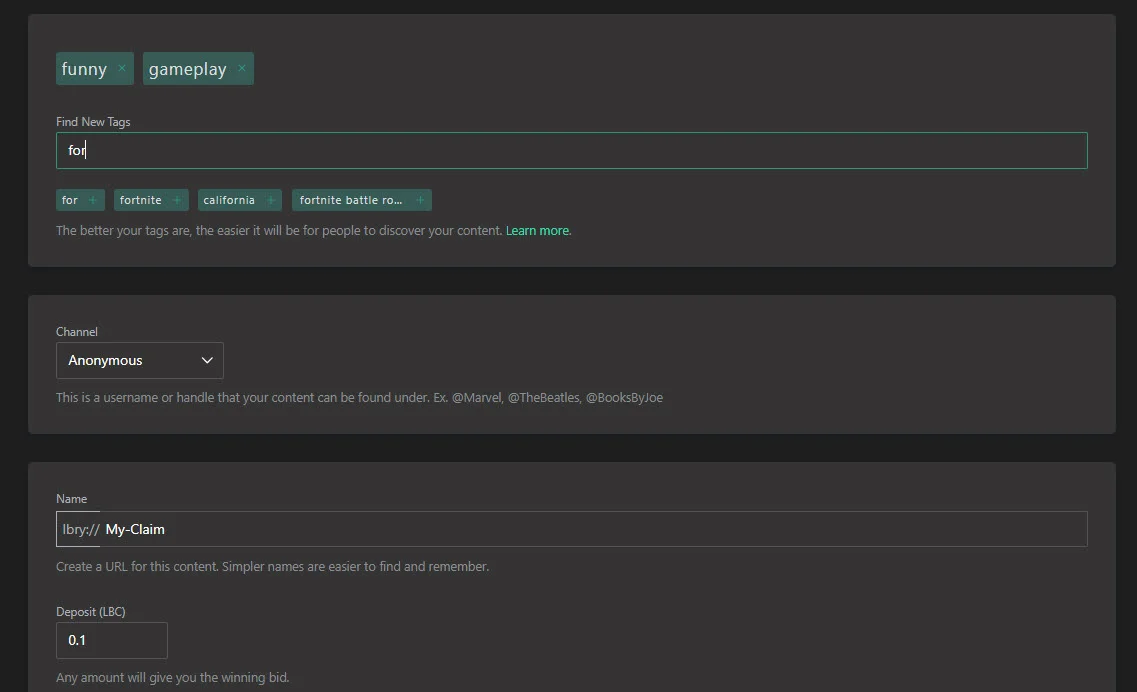
#### Subscriptions, Tags and Channels
The subscriptions area is now easier to access from either the `Channels you Follow` drop down on the homepage, or by each specific channel in the right hand side bar. Each tag you follow is also listed above the channels and has their own Trending/Top/New pages as well. You can also navigate to these tags (even ones you don’t follow), by clicking them throughout the app (i.e. on the homepage next to other tags, or on a related video you are exploring). Once you access a tag you don’t have in your list, you have the option to follow it, adding it to your sidebar.
These tags can be managed from the Customize option in the sidebar or homepage Customize button. Here, you can also search for new tags and see the list of channels you follow.
Recommended channels are now shown by clicking the `Find New Channels` button to the right of `Channels you Follow`. You’ll also notice that content is greyed out to show it’s already been viewed. We’re hoping to bring back unread counts for Subscriptions (and maybe tags too?) in a future release.
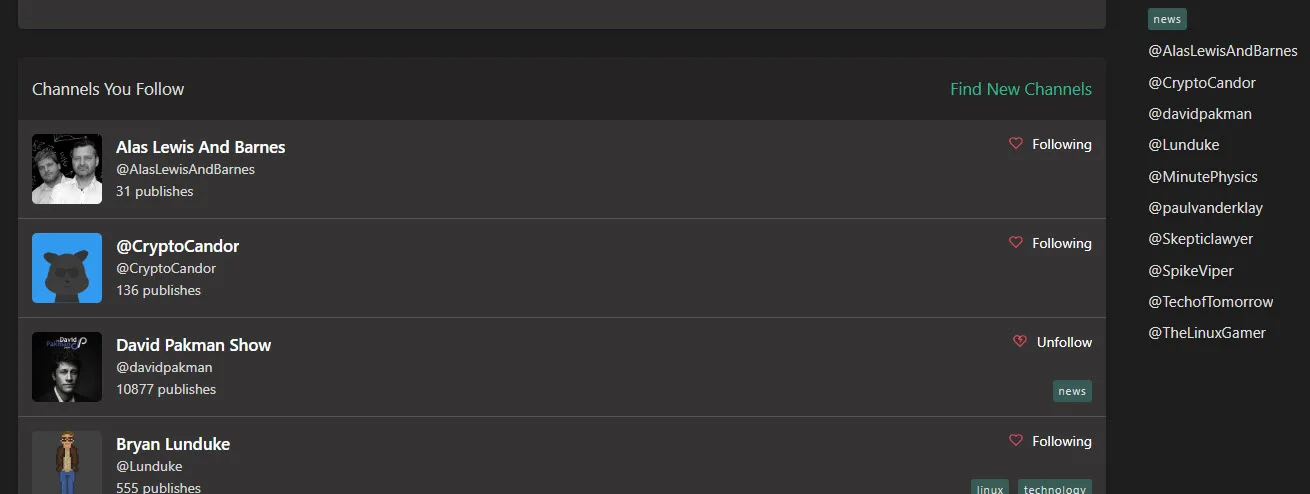
#### Community Voting and Channel Editing
To allow users to participate easier in the trending/ranking process, we added a new experimental setting for supports([read more below](#supports)). This allows users to help promote their favorite content by depositing LBC, which can be withdrawn at anytime.
Understanding that creators want to manage their channel profiles, we included the first version of the channel edit page. This is accessed by clicking your channel from the Publishes page. We’ll be adding a `My Channels` section soon along with a way to create your profile when creating a channel (removing this from the Publish flow). The profiles go along nicely with the new channel hover feature that displays the thumbnail, tags, and number of publishes.
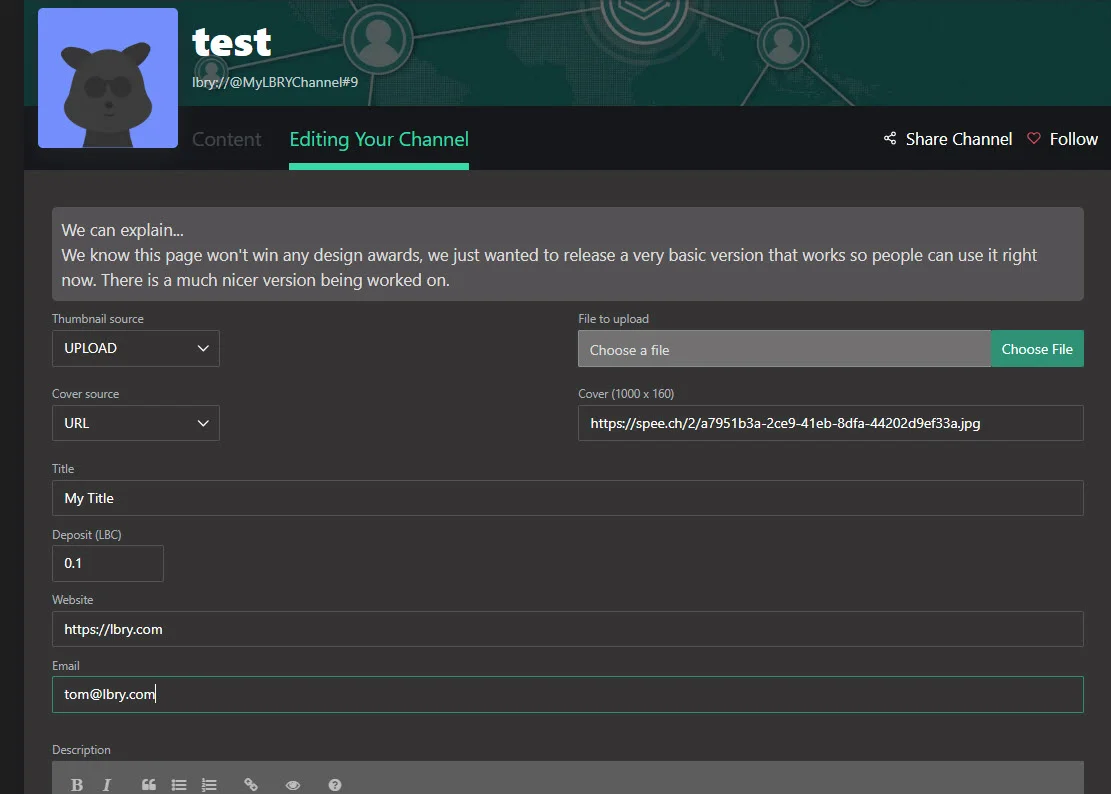
#### Commenting Alpha on LBRY
Rounding off the feature set, we added the first releases of Commenting and Language options -- all thanks to community contributions! The Commenting Alpha earns its name as it comes with a basic feature set -- creating anonymous/channel based comments, and viewing them. There are no delete or moderation features yet (if you have ideas, leave them [here](https://github.com/lbryio/lbry-desktop/issues/2598)). Since these comments are not decentralized but are stored on LBRY servers, please alert us to any that need attention through the report button on the claim.
We’ll be using the alpha to work through the UI design on the app, and nail down the API required on the SDK. Our longer term goal with comments is to put them on the blockchain, but we’re still waiting for support metadata features to be enabled at that layer - this will allow things like channel signing of supports/tips, and information like which tags are accurate/not, suggested edits, building a web of trust, and more!
#### Next Steps and Coming Soon
The next steps on the Desktop app will be to allow further customization of the homepage by enabling the blocking of channels and tags so that users can be in full control of what they don’t want to see as well. We’ll be adding a `My Channels` page so users can access their channels more readily and a way to create those channels directly from a better version of today’s edit page page (and separating this flow from the Publish page where channel creation exists today).
We are also in the middle of upgrading the video player to support [streaming](#streaming) (not live streaming!) which will give users the ability to turn off saving files (and hosted content too, but that will make LBRY sad!). The next bigger feature on the radar is cross device syncing so that users can have the same account between their devices, including [Android](#android) which currently supports it.
### LBRY Desktop - New Supports Feature {#supports}
A new experimental feature, which can be enabled on the Settings page of the app,
was added to allow supporting content. Some of you may be aware of supports already because you’ve tried them via the SDK, so this will make your life easier to be able to do them in app. For those that are new - supports are very similar to [tipping](https://lbry.com/faq/tipping) on LBRY, but the LBC deposit stays in your own wallet and can be removed at any time (see the Wallet page / trash can icon to remove / add LBC back to your balance). Publishers will also see the Support option by default on their own content (previously the tip button was hidden). While the support is active, it is no longer part of your balance and instead the LBC is used to help other users discover the content you supported and/or secure its [vanity name](https://lbry.com/faq/naming). The discovery comes through the new homepage and affecting the way the claim is ranked in the Trending and Top calculations - the more LBC that’s tipped and supported, the higher the content can rank up.
The new feature now allows anyone in the community to support their favorite content, without having to give up any LBC (as you would normally with tips). Supports do help the creators as well by possibly having more users take a peek, but please consider sending them a tip if you are really enjoying their content! Once more users become accustomed to this feature, we’ll enable it without the experimental setting.
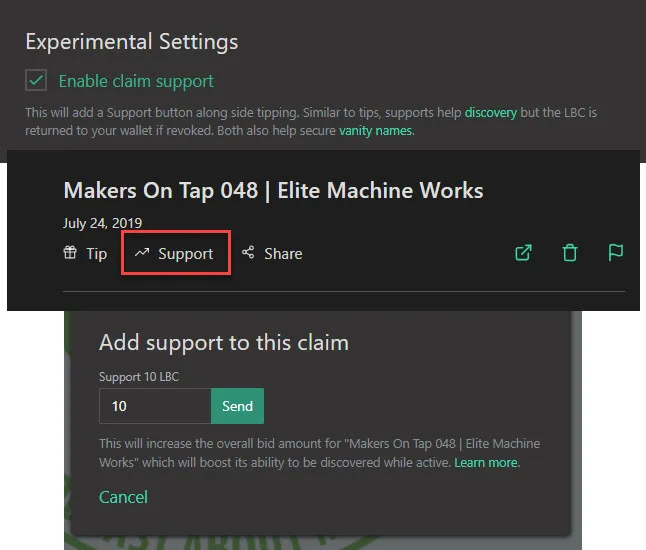
### LBRY Desktop - File Download Options Coming Soon {#streaming}
A common concern we have from users is that not everyone wants to store all the content they view on their PCs and we’ve listened. The SDK now provides a way to stream content from our decentralized network without having to save any data to the user’s computer. Our [Android](#android) app is already taking advantage of this technology and was a test bed before we implemented it on the desktop app (currently a work in progress and we expect to ship within a couple weeks). This would work the typical video formats you see it the LBRY app (H264 MP4s), as well as audio files, and images. There are some plugins we’ll be experimenting with to see if we can support additional video types (download may be required). There will be two on/off settings available - Saving Files and Saving Blobs (hosted data).
By turning off Saving Files, video/audio content will not save the output file anymore when content is watched. If you disable Saving Blobs, the hosted chunks of data (required to help the network seed content) will also not be saved. We will continue to strongly encourage the saving of Blobs (disabling it will make LBRY sad, but we understand that users should have a choice). These settings will only work going forward - so if you downloaded something and then turned it off, that will only take effect for new downloads. We’ll also give users a setting for max number of connections so that higher bandwidth users can take advantage of using more peers on the network to stream/download content faster.
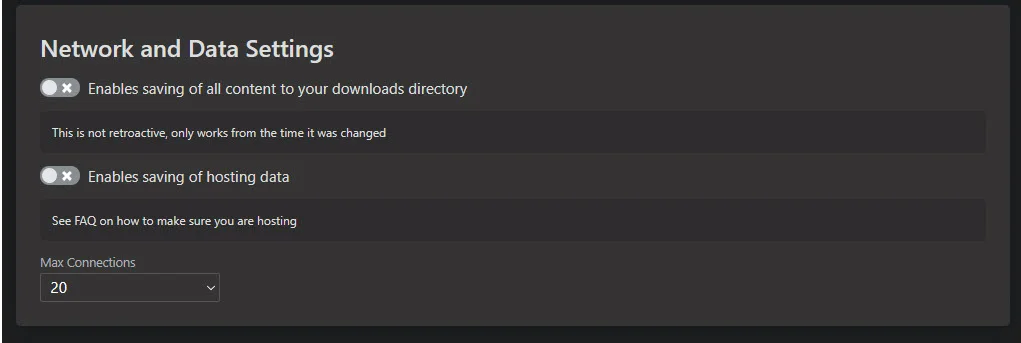
### LBRY for Android Updates {#android}
Since our last update, the Android app has evolved from its alpha state and into a fully released Beta on the [Google Play Store](https://lbry.com/get#android)!!. The main new features include viewing content without saving files, horizontal scrolling on the homepage, channel profiles, wallet syncing/encryption, and redesigned first run experience. The first run experience revamp was also important as it introduced the cross device feature for new users, and also allow account-less access if needed (there’s an option to skip on the first screen). Being able to view content without saving it is super important, especially on mobile platforms, which is why we decided to implement our Range Request streaming solution here first (and let the Android devs work out the kinks!).
The latest release defaults to streaming mode, and does not have options for saving content locally yet nor can content be removed from the Library section after its streamed - both features to come in a future release. We also ditched the vertical browsing on the home page as horizontal scrolling is more intuitive and you can see more categories without having to scroll down 10 items.
The Android beta also featured the first implementation of our Cross Device Sync which allows users to backup their encrypted wallets on LBRY’s servers. When a user goes through the setup process, they are asked for a password to secure their account . A blank password can be used and will still be encrypted locally/on our servers, but this is not recommended if storing larger amounts of LBC. Existing users can also take advantage of this feature by turning it on from the Wallet page. Currently there is no recovery method if a password is lost but we plan to support one in the future. Once this is enabled on lbry.tv and the desktop, the users’ accounts will merge and they’ll have a seamless experience between devices.
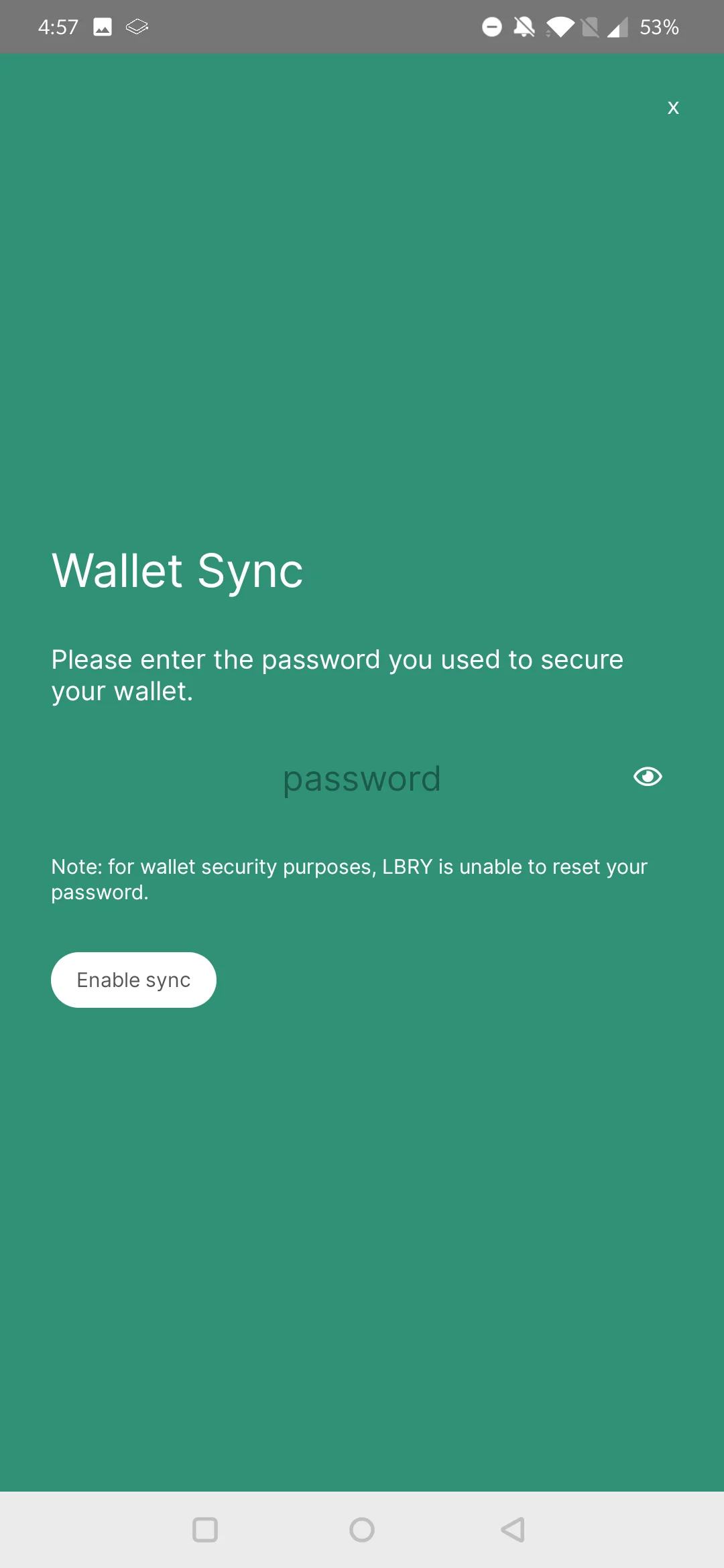
Next up for the Android app is to bring the discovery/tagging/trending tools we see in the Desktop app / lbry.tv. They will work in a very similar fashion where the Top/New/Trending options will be available, along with a customizable list of tags. The tags will be shown in a similar fashion to the horizontal scroll mechanism on the current curated homepage. After this, the goal is to profile the performance of the app since we’re fully aware of the UI lockups and other slowness while using various parts of the app. This will help smooth out the Android app experience to go along with the new lightning fast discovery solution.
### LBRY.tv Updates {#web}
Over the last few months, we’ve been running a view only pilot of [beta.lbry.tv](https://beta.lbry.tv) which means you can view free content, but none of the publishing or account (LBC) related features are enabled. This allows us to test the scalability of LBRY on the Web, while working in the background to develop the rest of the feature set. Users are also able to sign up with their email to save their subscriptions and be signed up for the mailing list.
Currently, the app is up to speed with the Desktop app which includes the customizable homepage, discovery, and tagging features. You will find links to lbry.tv from the share button in the app, or you can simply share them from your browser (such as https://beta.lbry.tv/@bitcoinandfriends/a). We are also finishing up a feature that will show thumbnail preview when links to channels/content are shared - this should be available in the next few days.
Internally we are finishing up / testing the accounts and rewards related features, and hope to have a full release in the next couple of months. The wallet will be a custodial solution where LBRY helps users manage their keys. Initially these wallets will be separate from any local Desktop/Android app ones, but the plan is to enable a way for users to sync all their wallets across devices, including lbry.tv.
Want to be the first to know when it’s fully operational? Sign up for the mailing list at [lbry.tv](https://lbry.tv).
### Open.LBRY.com Redesign {#open}
Our hyperlinking / sharing website, [open.lbry.com](https://open.lbry.com) received a design overhaul and new settings for opening in app vs on [beta.lbry.tv](https://beta.lbry.tv). There is a countdown timer, along with the two options, and a link to download the LBRY app if the user has not done so already. Users can also choose to remember their setting so it’s instantly performed the next time they use the open site. Open.lbry.com links are the best way to share LBRY URLs currently. As next steps, we are exploring adding these options directly into beta.lbry.tv and enabling thumbnails for content previews.
### SDK Download Upgrades and Progress {#sdk}
The main focus of SDK development over the last few months has been all the discovery features we’ve outlined so far in this update. None of this would be possible without a huge undertaking to create and improve our wallet server functionality, trending calculations, and APIs to support searching and customizing tag data. The wallet server is the main database the LBRY SDK connects to in order to resolve claims, publish, validate data, and create transactions. This large undertaking required us to basically re-write this entire component so that data from the LBRY blockchain could be saved, validated, and retrieved extremely fast.
For the release, we deployed about 9 wallet servers around the world to provide a good quality connection and experience for app users. We’ll be making the documentation easier for anyone to run their own wallet servers so that the community can start contributing more to the decentralization of the network and potentially getting fees for relaying transactions.
Prior to this update, every time the app would request a URL to be resolved or a channel to viewed, the wallet server would simply pass the call onto LBRYcrd (full blockchain node) for processing/retrieval. This was no longer possible if we wanted to save trending data, along with all the tag, and other metadata that could be accessed by simple SQL query. To accomplish this, the team first had to process all the blockchain data into a database, saving all new claims, updates, and channels, along with other pieces of information like how tips/supports are being added/removed over time, compared to all other claims, in order to produce Z-score trending calculations. This processing would take place from block 0 on a clean start, and then continue processing each and every block that was written to the LBRY network.
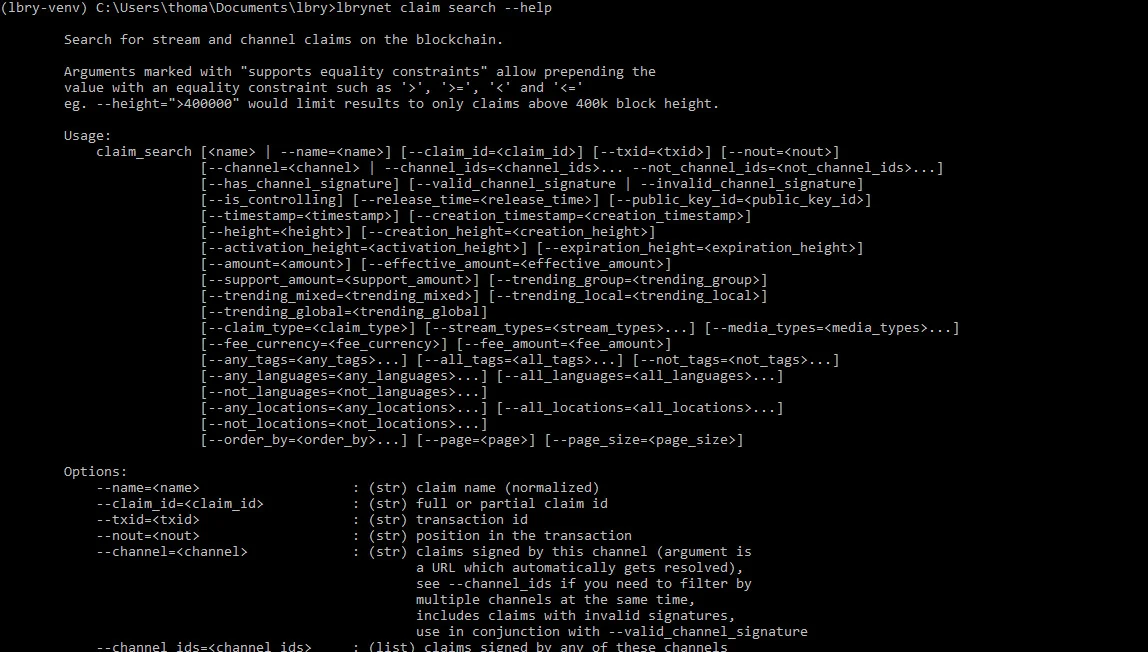
We decided to go with a popular Z-score algorithm which calculates changes about once a day, over a 7 day period, to get a sense of how content on LBRY is performing against each other in order to paint a picture of what’s considered to be trending. What proved to be one of the most difficult parts of this overhaul was making the queries (at least the common ones that the app would use) performant on a large and growing claim database. This involved breaking down slow queries to understand where the most time was being spent, creating special indexes to help with fast lookups, and writing the monitoring/testing tools to help the team experiment and gather feedback.
We were able to get all of the queries, including ANY number of tags, while excluding mature tags, and sorting/filtering on various slices of data like release time, effective amount, and trending calculations, down to under 200ms, with many being under 100ms, and simple resolve calls under 30ms (all round trip on a good connection). There is still some work to be done to optimize other queries that the app and other projects may want to use, i.e. showing free content only, or certain types of content. Give the claim search a shot via the [CLI tools!](https://lbry.com/faq/how-to-cli)
Next steps for the SDK will include making the new wallet servers more robust/easy for anyone in the community to run, supporting wallet sync where multiple accounts are treated as one (i.e. mobile + desktop + lbrytv), providing additional balances for tips received/active supports/LBC in claims, and reposting of content to any channel (i.e similar to re-tweets - curated channels with other creator’s content, where the monetization goes to the original publisher).
### YouTube Sync Transfers {#youtube}
The last gap in our YouTube sync process is the ability to send channels, claims, and certificate data to creators who are using the app with their own wallets. We know this has been confusing for many YouTubers because their content is synced but they don’t have access to it in the app. Without the solution in place, we’ve been handling this manually for creators who want to get control be sending them the synced wallet files, and we’ve setup a new request process for this [on our website](https://lbry.com/claim-wallet).
This process is tedious for both ourselves and creators, so we’re currently developing the automated solution that will allow YouTubers to click a single button in the apps in order to import their channel (can be used to publish new content right away) and then start the updating process to move the claim and channel claim to their local wallet address. During this time, we’ll also grab their address so we know where to publish newly posted content to. This process will also support the case where a creator has multiple synced channels. Any tips accumulated will be added back as supports on the creator’s channel claim to help boost their rankings in discovery. We’ll be sending an email to all creators once this process is up and running - thank you to everyone for their patience while we worked through this last critical feature.
### Blockchain Upstream Updates and Progress {#blockchain}
Since our last update, the LBRY blockchain went through [an upgrade](https://lbry.io/news/hf1903) on March 24 which enabled more characters to be used in claim naming, and making sure they are normalized when competing for vanity URLs. Since then, the team has been focused on bringing our code base up to speed with Bitcoin 0.17 and also including enhancements to optimize memory usage of the claimtrie. You can see the latest release notes about all the changes for [upstream merge](https://github.com/lbryio/lbrycrd/releases/tag/v0.17.1.0) and [memory improvements](https://github.com/lbryio/lbrycrd/releases/tag/v0.17.2.0) on GitHub. Typical memory usage while running LBRYcrd went from about 4.5GB to roughly 2/2.5 GB depending on API usage.
The upstream changes also mean LBRY can enable Segregated Witness (SegWit) on the network which is part of Bitcoin Core’s vision in scaling the blockchain which we currently share. This allows running 2nd layer networks like Lightning in order to enable super fast transactions, including purchases of content and hopefully be the backbone of our vision for data markets (hosts have to be online for both data transfers and Lighting, so it seems to be a match made in heaven). We plan to enable this later this year and experiment with trustless purchasing of LBRY content / blobs.
Another long awaited feature of the upstream merge is HD wallets, which allow you to backup a single master key to regenerate addresses from as opposed to saving the entire wallet.dat file (this is possible if you start a fresh lbrycrd or backup/remove your current wallet.dat). *Please note:* Master private keys are currently not cross compatible between the SDK and LBRYcrd wallet (this will result in 2 different sets of addresses).
The next steps in this area include the fork to upgrade with SegWit and add the ability to add metadata with support transactions (will allow signing by channels, rating, comments, edit suggestions).
### 2019 Roadmap Update {#2019}
We’ve successfully accomplished a number of roadmap items fully, while others are partially complete and ongoing efforts. Fully completed (but the improvements never really stop, right?) are:
* **Technical Community** - completed with the launch of [lbry.tech](https://lbry.com)
* **Android 1.0** - the [Android](#android) app made it out of the unreleased state on the app store (missing full parity with desktop app, but some features are ahead!)
* **Community Swarms** - are [fully operational around the globe](https://lbry.com/news/comm-update)
* **Discovery** - was enabled through the latest SDK and Desktop releases, coming to Android soon
Partially completed/still in progress are:
* **Commenting** - we released a centralized alpha only, Creator Features where we added channel metadata/edit features, but still lacking on reporting/verifying
* **Creator Partnerships** - in progress and will be announced later this year
* **LBRY on the Web** - is up at [beta.lbry.tv](https://beta.lbry.tv) but is missing account features
* **Multi-Device Experience** - the wallet syncing process was enabled on Android, but currently in progress on Desktop
* **Internationalization** - enabled in the last Desktop release but needs to be expanded to more languages/apps
* **Protocol Performance** - we’ve met some of the targets like resolution time and failure rate but still lacking on startup and downloading times
# Want to Develop on the LBRY ecosystem?
All of our code is open source and available on [GitHub](https://github.com/lbryio). Are you a developer and want to find out more? Check out our [contributing guide](https://lbry.tech/contribute) and our [LBRY App specific contributing document](https://github.com/lbryio/lbry-app/blob/master/CONTRIBUTING.md). Make sure you have turned on the Developer option in your email preferences (see app overview page), or sign up at [lbry.tech](https://lbry.tech). We also have a [LBRY Discourse Forum](https://discourse.lbry.io) where developers can interact with the team and ask questions across all our different projects.
If you aren’t part of our Discord community yet, [join us](https://chat.lbry.com) anytime and say hello!
Our community allows LBRYians to interact with the team directly and for us to engage users in order to grow the LBRY platform. Also follow us on [Twitter](https://twitter.com/lbryio), [Facebook](https://facebook.com/lbryio), [Reddit](https://www.reddit.com/r/lbry), [BitcoinTalk](https://bitcointalk.org/index.php?topic=5116826.new#new), and [Telegram](https://t.me/lbryofficial).
[Back to **top**](#dev-updates)
We’ve got a special bonus for readers of this update, enjoy some LBC via this code (while supplies last!): `dev-update-jun-ztaxc`
Thanks for supporting LBRY - stay tuned for more news and updates! And if you haven’t downloaded the [LBRY app](https://lbry.io/get?auto=1) yet, what are you waiting for?
| 153.411458 | 1,461 | 0.784519 | eng_Latn | 0.999437 |
970f57dfefe67af50786b5239159dd184f65ccd5 | 250 | md | Markdown | _videos/2015-07-25-disneyland-edition.md | marcialwushu/jekyll-video | b353a3bd9614828b32d71f4a6d03a38828a37bb9 | [
"MIT"
] | 1 | 2021-07-08T02:58:18.000Z | 2021-07-08T02:58:18.000Z | _videos/2015-07-25-disneyland-edition.md | marcialwushu/jekyll-video | b353a3bd9614828b32d71f4a6d03a38828a37bb9 | [
"MIT"
] | 3 | 2020-04-22T01:50:38.000Z | 2021-02-28T20:16:40.000Z | _videos/2015-07-25-disneyland-edition.md | marcialwushu/MyYouTubeDocList | 19980561b0abc9b0bcb4a8549fcbff0f6bb9a201 | [
"MIT"
] | null | null | null | ---
title: Toda a Verdade - Webcams, Ver e Ser Visto - SIC Noticias
youtube_id: llNCoHqN0_A
date: 2015-07-25
tags: [VidCon, Disney]
---
Novo Canal, [https://www.youtube.com/channel/UC80M...](https://www.youtube.com/channel/UC80Mw5G_AT520Juq4fdfvog)
| 31.25 | 113 | 0.736 | kor_Hang | 0.210253 |
970fdf2ce0bbce4d9e72d061418d91fe76ab6777 | 12,312 | md | Markdown | articles/app-service-mobile/app-service-mobile-xamarin-android-get-started-offline-data.md | SunnyDeng/azure-content-dede | edb0ac8eec176b64971ec219274a4a922dd00fec | [
"CC-BY-3.0"
] | 2 | 2020-08-29T21:10:59.000Z | 2021-07-25T10:13:02.000Z | articles/app-service-mobile/app-service-mobile-xamarin-android-get-started-offline-data.md | SunnyDeng/azure-content-dede | edb0ac8eec176b64971ec219274a4a922dd00fec | [
"CC-BY-3.0"
] | null | null | null | articles/app-service-mobile/app-service-mobile-xamarin-android-get-started-offline-data.md | SunnyDeng/azure-content-dede | edb0ac8eec176b64971ec219274a4a922dd00fec | [
"CC-BY-3.0"
] | null | null | null | <properties
pageTitle="Aktivieren der Offlinesynchronisierung für Ihre Azure Mobile App (Xamarin Android)"
description="Erfahren Sie, wie Sie mobile App Service-Apps verwenden, um Offlinedaten in Ihrer Xamarin Android-Anwendung zwischenzuspeichern und zu synchronisieren."
documentationCenter="xamarin"
authors="wesmc7777"
manager="dwrede"
editor=""
services="app-service\mobile"/>
<tags
ms.service="app-service-mobile"
ms.workload="mobile"
ms.tgt_pltfrm="mobile-xamarin-android"
ms.devlang="dotnet"
ms.topic="article"
ms.date="08/22/2015"
ms.author="wesmc"/>
# Aktivieren der Offlinesynchronisierung für Ihre mobile Xamarin.Android-App
[AZURE.INCLUDE [app-service-mobile-selector-offline](../../includes/app-service-mobile-selector-offline.md)]
[AZURE.INCLUDE [app-service-mobile-note-mobile-services](../../includes/app-service-mobile-note-mobile-services.md)]
## Übersicht
In diesem Lernprogramm wird die Funktion zur Offlinesynchronisierung von Azure Mobile Apps für Xamarin.Android eingeführt. Offlinesynchronisierung ermöglicht Endbenutzern die Interaktion mit einer mobilen App – Anzeigen, Hinzufügen und Ändern von Daten –, auch wenn keine Netzwerkverbindung vorhanden ist. Änderungen werden in einer lokalen Datenbank gespeichert. Sobald das Gerät wieder online ist, werden diese Änderungen mit dem Remotedienst synchronisiert.
In diesem Lernprogramm aktualisieren Sie das Clientprojekt aus dem Lernprogramm [Erstellen einer Xamarin Android-App] zur Unterstützung der Offlinefunktionen von Azure Mobile Apps. Wenn Sie das heruntergeladene Schnellstart-Serverprojekt nicht verwenden, müssen Sie Ihrem Projekt die Datenzugriffs-Erweiterungspakete hinzufügen. Weitere Informationen zu Servererweiterungspaketen finden Sie unter [Work with the .NET backend server SDK for Azure Mobile Apps](app-service-mobile-dotnet-backend-how-to-use-server-sdk.md) (in englischer Sprache).
Weitere Informationen zur Offlinesynchronisierungsfunktion finden Sie im Thema [Offlinedatensynchronisierung in Azure Mobile Apps].
## Anforderungen
* Visual Studio 2013
* Visual Studio mit [Xamarin-Erweiterung] **oder** [Xamarin Studio]
* Abschluss des Lernprogramms [Erstellen einer Xamarin Android-App]. Dieses Lernprogramm verwendet die fertige App, die in diesem Lernprogramm behandelt wird.
## Überprüfen des Clientcodes für die Synchronisierung
Das Xamarin-Clientprojekt, das Sie heruntergeladen haben, nachdem Sie das Lernprogramm [Erstellen einer Xamarin Android-App] abgeschlossen haben, enthält bereits Code zur Unterstützung der Offlinesynchronisierung mithilfe einer lokalen SQLite-Datenbank. Dies ist eine kurze Übersicht darüber, was bereits im Code des Lernprogramms enthalten ist. Eine grundlegende Übersicht über die Funktion finden Sie unter [Offlinedatensynchronisierung in Azure Mobile Apps].
* Bevor Tabellenvorgänge durchgeführt werden können, muss der lokale Speicher initialisiert werden. Die lokale Datenbank wird initialisiert, wenn `ToDoActivity.InitLocalStoreAsync()` von `ToDoActivity.OnCreate()` ausgeführt wird. Dadurch wird eine neue lokale SQLite-Datenbank mit der `MobileServiceSQLiteStore`-Klasse erstellt, die vom Azure Mobile Apps-Client-SDK bereitgestellt wird.
Die `DefineTable`-Methode erstellt eine Tabelle im lokalen Speicher, die mit den Feldern im bereitgestellten Typ übereinstimmt (in diesem Fall `ToDoItem`). Der Typ muss nicht alle Spalten der Remotedatenbank enthalten. Es ist möglich, nur eine Teilmenge der Spalten zu speichern. // ToDoActivity.cs
private async Task InitLocalStoreAsync()
{
// new code to initialize the SQLite store
string path = Path.Combine(System.Environment.GetFolderPath(System.Environment.SpecialFolder.Personal), localDbFilename);
if (!File.Exists(path))
{
File.Create(path).Dispose();
}
var store = new MobileServiceSQLiteStore(path);
store.DefineTable<ToDoItem>();
// Uses the default conflict handler, which fails on conflict
// To use a different conflict handler, pass a parameter to InitializeAsync. For more details, see http://go.microsoft.com/fwlink/?LinkId=521416
await client.SyncContext.InitializeAsync(store);
}
* Das `toDoTable`-Mitglied von `ToDoActivity` ist vom Typ `IMobileServiceSyncTable` und nicht vom Typ `IMobileServiceTable`. Dies leitet alle Erstellen-, Lesen-, Aktualisieren- und Löschtabellenvorgänge (CRUD) an die lokale Datenbank.
Sie legen fest, wann diese Änderungen per Pushvorgang an das Azure Mobile App-Back-End durch Aufrufen von `IMobileServiceSyncContext.PushAsync()` mit dem Synchronisierungskontext für die Clientverbindung übertragen werden. Der Synchronisierungskontext hilft dabei, Tabellenbeziehungen durch das Nachverfolgen und Übertragen von Änderungen in allen Tabellen beizubehalten, die eine Clientanwendung geändert hat, wenn `PushAsync` aufgerufen wird.
Der bereitgestellte Code ruft `ToDoActivity.SyncAsync()` zum Synchronisieren ab, wenn die TodoItem-Liste aktualisiert wird oder ein TodoItem hinzugefügt wird oder abgeschlossen ist. So synchronisiert er nach jeder lokalen Änderung durch Ausführen eines Pushvorgangs auf den Synchronisierungskontext und eines Pullvorgangs auf der Synchronisierungstabelle. Es ist jedoch zu beachten, dass bei einem Pullvorgang auf einer Tabelle mit ausstehenden lokalen Updates, die durch den Kontext verfolgt werden, dieser Pullvorgang zunächst automatisch einen Kontextpush ausführt. So können Sie in diesen Fällen (Elemente aktualisieren, hinzufügen und abschließen) den expliziten `PushAsync`-Aufruf auslassen. Er ist überflüssig.
Im bereitgestellten Code werden alle Datensätze in der `TodoItem`-Remotetabelle abgefragt, es ist aber auch möglich, Datensätze durch Übergeben einer Abfrage-ID und Abfrage an `PushAsync` zu filtern. Weitere Informationen finden Sie im Abschnitt *Inkrementelle Synchronisierung* in [Offlinedatensynchronisierung in Azure Mobile Apps].
<!-- Need updated conflict handling info : `InitializeAsync` uses the default conflict handler, which fails whenever there is a conflict. To provide a custom conflict handler, see the tutorial [Handling conflicts with offline support for Mobile Services].
--> // ToDoActivity.cs
private async Task SyncAsync()
{
try {
await client.SyncContext.PushAsync();
await toDoTable.PullAsync("allTodoItems", toDoTable.CreateQuery()); // query ID is used for incremental sync
} catch (Java.Net.MalformedURLException) {
CreateAndShowDialog (new Exception ("There was an error creating the Mobile Service. Verify the URL"), "Error");
} catch (Exception e) {
CreateAndShowDialog (e, "Error");
}
}
## Ausführen der Client-App
Führen Sie die Clientanwendung mindestens einmal aus, um die lokale Datenbank zu füllen. Im nächsten Abschnitt simulieren Sie ein Offlineszenario und ändern die Daten im lokalen Speicher, während die App offline ist.
## Aktualisieren des Synchronisierungsverhaltens der Client-App
In diesem Abschnitt ändern Sie die Client-App, um ein Offlineszenario mithilfe einer ungültigen Anwendungs-URL für Ihr Back-End zu simulieren. Beim Hinzufügen oder Ändern von Datenelementen werden diese Änderungen im lokalen Speicher gespeichert, aber nicht mit dem Back-End-Datenspeicher synchronisiert, bis die Verbindung wiederhergestellt ist.
1. Ändern Sie am Anfang von `ToDoActivity.cs` die Initialisierung von `applicationURL` und `gatewayURL`, um auf ungültige URLs zu verweisen:
const string applicationURL = @"https://your-service.azurewebsites.xxx/";
const string gatewayURL = @"https://your-gateway.azurewebsites.xxx";
2. Aktualisieren Sie `ToDoActivity.SyncAsync`, sodass `MobileServicePushFailedException` abgefangen und einfach ignoriert werden, vorausgesetzt, Sie sind offline.
private async Task SyncAsync()
{
try {
await client.SyncContext.PushAsync();
await toDoTable.PullAsync("allTodoItems", toDoTable.CreateQuery()); // query ID is used for incremental sync
} catch (Java.Net.MalformedURLException) {
CreateAndShowDialog (new Exception ("There was an error creating the Mobile Service. Verify the URL"), "Error");
} catch (MobileServicePushFailedException)
{
// Not reporting this exception. Assuming the app is offline for now
}
catch (Exception e) {
CreateAndShowDialog (e, "Error");
}
}
3. Erstellen Sie die App, und führen Sie sie aus. Wenn Sie ein Ausnahmedialogfeld mit der Namensauflösungsausnahme erhalten, schließen Sie es. Wenn Sie einige neue Todo-Elemente hinzufügen, können Sie feststellen, dass sich die App so verhält, als wäre sie verbunden. Das liegt daran, dass `MobileServicePushFailedException` ohne Anzeige des Dialogfelds verarbeitet wird.
4. Die neu hinzugefügten Elemente sind nur im lokalen Speicher vorhanden, bis sie per Push an das mobile Back-End übertragen werden können. Schließen Sie die App, und starten Sie sie neu, um zu überprüfen, ob die neuen Elemente dauerhaft im lokalen Speicher gespeichert wurden.
5. (Optional) Verwenden Sie Visual Studio zum Anzeigen der Azure SQL-Datenbanktabelle, um festzustellen, ob sich die Daten in der Back-End-Datenbank nicht geändert haben.
Öffnen Sie den **Server-Explorer** in Visual Studio. Navigieren Sie zu der Datenbank in **Azure** -> **SQL-Datenbanken**. Klicken Sie mit der rechten Maustaste auf Ihre Datenbank, und wählen Sie **In SQL Server-Objekt-Explorer öffnen** aus. Jetzt können nach Ihrer SQL-Datenbanktabelle und seinen Inhalten suchen.
6. (Optional) Verwenden Sie ein REST-Tool wie Fiddler oder Postman, um Ihr mobiles Back-End mit einer GET-Abfrage in Form von `https://your-mobile-app-backend-name.azurewebsites.net/tables/TodoItem` abzufragen.
## Aktualisieren der Client-App, um erneut eine Verbindung mit dem mobilen Back-End herzustellen
In diesem Abschnitt stellen Sie erneut eine Verbindung zwischen der App und dem mobilen Back-End her, um zu simulieren, dass die App wieder im Onlinezustand ist. Wenn Sie die Aktualisierungsbewegung durchführen, werden Daten mit Ihrem mobilen Back-End synchronisiert.
1. Öffnen Sie `ToDoActivity.cs`. Korrigieren Sie die `applicationURL` und die `gatewayURL`, um auf die richtigen URLs zu verweisen.
2. Erstellen Sie die App erneut, und führen Sie sie aus. Die App versucht, sich nach dem Start mit dem Azure Mobile App-Back-End zu synchronisieren. Stellen Sie sicher, dass keine Ausnahmedialogfelder erstellt werden.
3. (Optional) Zeigen Sie die aktualisierten Daten mithilfe von SQL Server-Objekt-Explorer oder einem REST-Tool wie Fiddler an. Beachten Sie, dass die Daten zwischen der Azure Mobile App-Back-End-Datenbank und dem lokalen Speicher synchronisiert wurden.
Beachten Sie, dass die Daten zwischen der Datenbank und dem lokalen Speicher synchronisiert wurden und die Elemente enthalten, die Sie offline hinzugefügt haben.
## Zusätzliche Ressourcen
* [Offlinedatensynchronisierung in Azure Mobile Apps]
* [Cloud Cover: Offlinesynchronisierung in Azure Mobile Services] (Hinweis: Im Video geht es zwar um Mobile Services, aber die Offlinesynchronisierung in Azure Mobile Apps funktioniert auf ähnliche Weise.)
<!-- ##Summary
[AZURE.INCLUDE [mobile-services-offline-summary-csharp](../../includes/mobile-services-offline-summary-csharp.md)]
## Next steps
* [Handling conflicts with offline support for Mobile Services]
* [How to use the Xamarin Component client for Azure Mobile Services]
-->
<!-- Images -->
<!-- URLs. -->
[Erstellen einer Xamarin Android-App]: ../app-service-mobile-xamarin-android-get-started.md
[Offlinedatensynchronisierung in Azure Mobile Apps]: ../app-service-mobile-offline-data-sync.md
[How to use the Xamarin Component client for Azure Mobile Services]: ../partner-xamarin-mobile-services-how-to-use-client-library.md
[Xamarin Studio]: http://xamarin.com/download
[Xamarin-Erweiterung]: http://xamarin.com/visual-studio
[Cloud Cover: Offlinesynchronisierung in Azure Mobile Services]: http://channel9.msdn.com/Shows/Cloud+Cover/Episode-155-Offline-Storage-with-Donna-Malayeri
<!---HONumber=Nov15_HO1--> | 69.954545 | 718 | 0.780133 | deu_Latn | 0.985558 |
9711d34ac51c6fb3b77fa6c0fad0d22df91da3ab | 2,971 | md | Markdown | docs/framework/winforms/controls/how-to-display-time-with-the-datetimepicker-control.md | paularuiz22/docs | 56a652c21770cad32dfcf128f8977d341d106332 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-12-17T08:15:14.000Z | 2019-12-17T08:15:14.000Z | docs/framework/winforms/controls/how-to-display-time-with-the-datetimepicker-control.md | paularuiz22/docs | 56a652c21770cad32dfcf128f8977d341d106332 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/framework/winforms/controls/how-to-display-time-with-the-datetimepicker-control.md | paularuiz22/docs | 56a652c21770cad32dfcf128f8977d341d106332 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "How to: Display Time with the DateTimePicker Control"
ms.date: "03/30/2017"
dev_langs:
- "csharp"
- "vb"
helpviewer_keywords:
- "time [Windows Forms], displaying in DateTimePicker control"
- "examples [Windows Forms], DateTimePicker control"
- "DateTimePicker control [Windows Forms], displaying time"
ms.assetid: 0c1c8b40-1b50-4301-a90c-39516775ccb1
---
# How to: Display Time with the DateTimePicker Control
If you want your application to enable users to select a date and time, and to display that date and time in the specified format, use the <xref:System.Windows.Forms.DateTimePicker> control. The following procedure shows how to use the <xref:System.Windows.Forms.DateTimePicker> control to display the time.
### To display the time with the DateTimePicker control
1. Set the <xref:System.Windows.Forms.DateTimePicker.Format%2A> property to <xref:System.Windows.Forms.DateTimePickerFormat.Time>
[!code-csharp[System.Windows.Forms.DateTimePickerTimeOnly#2](~/samples/snippets/csharp/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/CS/Form1.cs#2)]
[!code-vb[System.Windows.Forms.DateTimePickerTimeOnly#2](~/samples/snippets/visualbasic/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/VB/Form1.vb#2)]
2. Set the <xref:System.Windows.Forms.DateTimePicker.ShowUpDown%2A> property for the <xref:System.Windows.Forms.DateTimePicker> to `true`.
[!code-csharp[System.Windows.Forms.DateTimePickerTimeOnly#3](~/samples/snippets/csharp/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/CS/Form1.cs#3)]
[!code-vb[System.Windows.Forms.DateTimePickerTimeOnly#3](~/samples/snippets/visualbasic/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/VB/Form1.vb#3)]
## Example
The following code sample shows how to create a <xref:System.Windows.Forms.DateTimePicker> that enables users to choose a time only.
[!code-csharp[System.Windows.Forms.DateTimePickerTimeOnly#1](~/samples/snippets/csharp/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/CS/Form1.cs#1)]
[!code-vb[System.Windows.Forms.DateTimePickerTimeOnly#1](~/samples/snippets/visualbasic/VS_Snippets_Winforms/System.Windows.Forms.DateTimePickerTimeOnly/VB/Form1.vb#1)]
## Compiling the Code
This example requires:
- References to the System, System.Data, System.Drawing and System.Windows.Forms assemblies.
For information about building this example from the command line for Visual Basic or Visual C#, see [Building from the Command Line](../../../visual-basic/reference/command-line-compiler/building-from-the-command-line.md) or [Command-line Building With csc.exe](../../../csharp/language-reference/compiler-options/command-line-building-with-csc-exe.md). You can also build this example in Visual Studio by pasting the code into a new project.
## See also
- [DateTimePicker Control](datetimepicker-control-windows-forms.md)
| 67.522727 | 446 | 0.781218 | yue_Hant | 0.646558 |
9712545473a9d077ce9c9a6da6c08955fb9b4e8d | 4,025 | md | Markdown | _publications/2018-01-17-mean-landslide-geometries-inferred-from-a-global-database-of-earthquake-and-non-earthquake-triggered-landslides.md | copyme/copyme.github.io | 112c2a9eac8ca155224d86d390d5cf701e16db6b | [
"MIT"
] | null | null | null | _publications/2018-01-17-mean-landslide-geometries-inferred-from-a-global-database-of-earthquake-and-non-earthquake-triggered-landslides.md | copyme/copyme.github.io | 112c2a9eac8ca155224d86d390d5cf701e16db6b | [
"MIT"
] | null | null | null | _publications/2018-01-17-mean-landslide-geometries-inferred-from-a-global-database-of-earthquake-and-non-earthquake-triggered-landslides.md | copyme/copyme.github.io | 112c2a9eac8ca155224d86d390d5cf701e16db6b | [
"MIT"
] | null | null | null | ---
title: "Mean Landslide Geometries Inferred From a Global Database of Earthquake- and Non-earthquake-Triggered Landslides"
collection: publications
permalink: /publication/2018-01-17-mean-landslide-geometries-inferred-from-a-global-database-of-earthquake-and-non-earthquake-triggered-landslides
excerpt: '
**Author(s):** G. Domej, C. Bourdeau, L. Lenti, S. Martino, K. Pluta
**Abstract:** Ranging in size from very small to tremendous, landslides often cause loss of life and
damage to infrastructure, property and the environment. They are triggered by a variety and
combinations of causes among which the role of water and seismic shaking have the most serious
consequences. In this regard, seismic wave amplification due to topography as well as to the
impedance contrast between the landslide mass and its underlying bedrock are of particular interest.
Therefore, high resolution reconstruction of the lateral confinement of the landslide mass and the
exact measurement of the mechanical properties are a necessity. A global chronological database was
created to study and compare 2D and 3D geometries of landslides, i.e. of landslides properly sliding
on a rupture surface. It contains 277 seismically and non-seismically induced landslides whose
rupture masses were measured in all available details allowing for statistical analyses of their
shapes and to create numerical models thereupon based. Detailed studies reveal that values of
distinct geometrical parameters have different statistical behaviors. As for dimension related
parameters, occurrence frequencies follow decreasing exponential distributions and mean values
progressively increase with landslide magnitude. In contrast, occurrence frequencies of
shape-related parameters follow normal distributions and mean values are constant throughout
different landslide magnitudes. Dimensions and shapes of landslides are thus to be regarded in a
precise and distinctive manner when analyzing seismically induced slope displacements.
**File(s)**: [**Article (PDF)**](../files/ijege-17_02-domej-et-alii.pdf),
[**BibTeX**](../files/DOMEJ_IJEGE_17.bib)'
date: 2017-12-31
venue: 'Italian Journal of Engineering Geology and Environment'
---
**Author(s):** G. Domej, C. Bourdeau, L. Lenti, S. Martino, K. Pluta
**Abstract:** Ranging in size from very small to tremendous, landslides often cause loss of life and
damage to infrastructure, property and the environment. They are triggered by a variety and
combinations of causes among which the role of water and seismic shaking have the most serious
consequences. In this regard, seismic wave amplification due to topography as well as to the
impedance contrast between the landslide mass and its underlying bedrock are of particular interest.
Therefore, high resolution reconstruction of the lateral confinement of the landslide mass and the
exact measurement of the mechanical properties are a necessity. A global chronological database was
created to study and compare 2D and 3D geometries of landslides, i.e. of landslides properly sliding
on a rupture surface. It contains 277 seismically and non-seismically induced landslides whose
rupture masses were measured in all available details allowing for statistical analyses of their
shapes and to create numerical models thereupon based. Detailed studies reveal that values of
distinct geometrical parameters have different statistical behaviors. As for dimension related
parameters, occurrence frequencies follow decreasing exponential distributions and mean values
progressively increase with landslide magnitude. In contrast, occurrence frequencies of
shape-related parameters follow normal distributions and mean values are constant throughout
different landslide magnitudes. Dimensions and shapes of landslides are thus to be regarded in a
precise and distinctive manner when analyzing seismically induced slope displacements.
**File(s)**: [**Article (PDF)**](../files/ijege-17_02-domej-et-alii.pdf),
[**BibTeX**](../files/DOMEJ_IJEGE_17.bib)
| 68.220339 | 146 | 0.817143 | eng_Latn | 0.996953 |
9712d02eb0a25beb56225fce6b06005d3f90b8df | 3,222 | md | Markdown | README.md | marius-cornescu/docker-hadoop-secure | 01b4fc1a80c23249a98c8390e07aef8dc38cb09c | [
"MIT"
] | null | null | null | README.md | marius-cornescu/docker-hadoop-secure | 01b4fc1a80c23249a98c8390e07aef8dc38cb09c | [
"MIT"
] | null | null | null | README.md | marius-cornescu/docker-hadoop-secure | 01b4fc1a80c23249a98c8390e07aef8dc38cb09c | [
"MIT"
] | null | null | null | # Apache Hadoop 2.7.1 Docker image with Kerberos enabled
[](https://hub.docker.com/r/knappek/hadoop-secure)
[](LICENSE.md)
This project is a fork from [sequenceiq hadoop-docker](https://github.com/sequenceiq/hadoop-docker)
and extends it with Kerberos enabled. With docker-compose 2 containers get
created, one with MIT KDC installed and one with a single node kerberized
Hadoop cluster.
The Docker image is also available on [Docker Hub](https://hub.docker.com/r/knappek/hadoop-secure/).
Versions
--------
* JDK8
* Hadoop 2.7.7
* Maven 3.5.0
Default Environment Variables
-----------------------------
| Name | Value | Description |
| ---- | ---- | ---- |
| `KRB_REALM` | `EXAMPLE.COM` | The Kerberos Realm, more information [here](https://web.mit.edu/kerberos/krb5-1.12/doc/admin/conf_files/krb5_conf.html#) |
| `DOMAIN_REALM` | `example.com` | The Kerberos Domain Realm, more information [here](https://web.mit.edu/kerberos/krb5-1.12/doc/admin/conf_files/krb5_conf.html#) |
| `KERBEROS_ADMIN` | `admin/admin` | The KDC admin user |
| `KERBEROS_ADMIN_PASSWORD` | `admin` | The KDC admin password |
| `KERBEROS_ROOT_USER_PASSWORD` | `password` | The password of the Kerberos principal `root` which maps to the OS root user |
You can simply define these variables in the `docker-compose.yml`.
Run image
---------
Clone the [Github project](https://github.com/Knappek/docker-hadoop-secure) and run
```
docker-compose up -d
```
Usage
-----
Get the container name with `docker ps` and login to the container with
```
docker exec -it <container-name> /bin/bash
```
To obtain a Kerberos ticket, execute
```
kinit
```
where you will get prompted to enter your password. Afterwards you can use `hdfs` CLI like
```
hdfs dfs -ls /
```
Known issues
------------
### Unable to obtain Kerberos password
#### Error
docker-compose up fails for the first time with the error
```
Login failure for nn/[email protected] from keytab /etc/security/keytabs/nn.service.keytab: javax.security.auth.login.LoginException: Unable to obtain password from user
```
#### Solution
Stop the containers with `docker-compose down` and start again with `docker-compose up -d`.
### JDK 8
Make sure you use download a JDK version that is still available. Old versions can be deprecated by Oracle and thus the download link won't be able anymore.
Get the latest JDK8 Download URL with
```
curl -s https://lv.binarybabel.org/catalog-api/java/jdk8.json
```
### Java Keystore
If the Keystroe has been expired, then create a new `keystore.jks`:
1. create private key
```
openssl genrsa -des3 -out server.key 1024
```
2. create csr
```
openssl req -new -key server.key -out server.csr`
```
3. remove passphrase in key
```
cp server.key server.key.org
openssl rsa -in server.key.org -out server.key
```
3. create self-signed cert
```
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
```
4. create JKS and import certificate
```
keytool -import -keystore keystore.jks -alias CARoot -file server.crt`
```
| 25.571429 | 181 | 0.716636 | eng_Latn | 0.786825 |
97139593a17afbb1a70089012598f789b9ad77d3 | 10 | md | Markdown | README.md | Baoanxia/study | 477af802ee2f0de7dabf1d9992c9046b6f8bf71d | [
"MIT"
] | null | null | null | README.md | Baoanxia/study | 477af802ee2f0de7dabf1d9992c9046b6f8bf71d | [
"MIT"
] | null | null | null | README.md | Baoanxia/study | 477af802ee2f0de7dabf1d9992c9046b6f8bf71d | [
"MIT"
] | null | null | null | # study
无
| 3.333333 | 7 | 0.6 | eng_Latn | 0.867485 |
971482d70d8cff779c089d7345b53a932a1179fd | 15,214 | md | Markdown | windows/security/threat-protection/microsoft-defender-antivirus/prevent-changes-to-security-settings-with-tamper-protection.md | dbyrdaquent/windows-itpro-docs | 62de4272662d184377ee74e67a5568833f931c1e | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-06-12T20:32:34.000Z | 2020-06-12T20:32:34.000Z | windows/security/threat-protection/microsoft-defender-antivirus/prevent-changes-to-security-settings-with-tamper-protection.md | blouis84/windows-itpro-docs | ded5a5914367e9a7a1c3eb955517114e23e4a707 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows/security/threat-protection/microsoft-defender-antivirus/prevent-changes-to-security-settings-with-tamper-protection.md | blouis84/windows-itpro-docs | ded5a5914367e9a7a1c3eb955517114e23e4a707 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Protect security settings with tamper protection
ms.reviewer:
manager: dansimp
description: Use tamper protection to prevent malicious apps from changing important security settings.
keywords: malware, defender, antivirus, tamper protection
search.product: eADQiWindows 10XVcnh
ms.pagetype: security
ms.prod: w10
ms.mktglfcycl: manage
ms.sitesec: library
ms.pagetype: security
ms.localizationpriority: medium
audience: ITPro
author: denisebmsft
ms.author: deniseb
ms.custom: nextgen
---
# Protect security settings with tamper protection
**Applies to:**
- Windows 10
## Overview
During some kinds of cyber attacks, bad actors try to disable security features, such as anti-virus protection, on your machines. They do this to get easier access to your data, to install malware, or to otherwise exploit your data, identity, and devices. Tamper protection helps prevent this from occurring.
With tamper protection, malicious apps are prevented from taking actions such as:
- Disabling virus and threat protection
- Disabling real-time protection
- Turning off behavior monitoring
- Disabling antivirus (such as IOfficeAntivirus (IOAV))
- Disabling cloud-delivered protection
- Removing security intelligence updates
### How it works
Tamper protection essentially locks Microsoft Defender Antivirus and prevents your security settings from being changed through apps and methods such as:
- Configuring settings in Registry Editor on your Windows machine
- Changing settings through PowerShell cmdlets
- Editing or removing security settings through group policies
Tamper protection doesn't prevent you from viewing your security settings. And, tamper protection doesn't affect how third-party antivirus apps register with the Windows Security app. If your organization is using Windows 10 Enterprise E5, individual users can't change the tamper protection setting; this is managed by your security team.
### What do you want to do?
1. Turn tamper protection on <br/>
- [For an individual machine, use Windows Security](#turn-tamper-protection-on-or-off-for-an-individual-machine).
- [For your organization, use Intune](#turn-tamper-protection-on-or-off-for-your-organization-using-intune).
2. [View information about tampering attempts](#view-information-about-tampering-attempts).
3. [Review your security recommendations](#review-your-security-recommendations).
4. [Browse the frequently asked questions](#view-information-about-tampering-attempts).
## Turn tamper protection on (or off) for an individual machine
> [!NOTE]
> Tamper protection blocks attempts to modify Microsoft Defender Antivirus settings through the registry.
>
> To help ensure that tamper protection doesn’t interfere with third-party security products or enterprise installation scripts that modify these settings, go to **Windows Security** and update **Security intelligence** to version 1.287.60.0 or later. (See [Security intelligence updates](https://www.microsoft.com/wdsi/definitions).)
>
> Once you’ve made this update, tamper protection will continue to protect your registry settings, and will also log attempts to modify them without returning errors.
If you are a home user, or you are not subject to settings managed by a security team, you can use the Windows Security app to turn tamper protection on or off. You must have appropriate admin permissions on your machine to do this.
1. Click **Start**, and start typing *Defender*. In the search results, select **Windows Security**.
2. Select **Virus & threat protection** > **Virus & threat protection settings**.
3. Set **Tamper Protection** to **On** or **Off**.
Here's what you see in the Windows Security app:

## Turn tamper protection on (or off) for your organization using Intune
If you are part of your organization's security team, and your subscription includes [Intune](https://docs.microsoft.com/intune/fundamentals/what-is-intune), you can turn tamper protection on (or off) for your organization in the Microsoft 365 Device Management portal ([https://aka.ms/intuneportal](https://aka.ms/intuneportal)).
> [!NOTE]
> The ability to manage tamper protection in Intune is rolling out now; if you don't have it yet, you should very soon, assuming your organization has [Microsoft Defender Advanced Threat Protection](../microsoft-defender-atp/whats-new-in-microsoft-defender-atp.md) (Microsoft Defender ATP) and that you meet the prerequisites listed below.
You must have appropriate [permissions](../microsoft-defender-atp/assign-portal-access.md), such as global admin, security admin, or security operations, to perform the following task.
1. Make sure your organization meets all of the following requirements to manage tamper protection using Intune:
- Your organization must have [Microsoft Defender ATP E5](https://www.microsoft.com/microsoft-365/windows/microsoft-defender-atp) (this is included in [Microsoft 365 E5](https://docs.microsoft.com/microsoft-365/enterprise/microsoft-365-overview)).
- Your organization uses [Intune to manage devices](https://docs.microsoft.com/intune/fundamentals/what-is-device-management). ([Intune licenses](https://docs.microsoft.com/intune/fundamentals/licenses) are required; this is included in Microsoft 365 E5.)
- Your Windows machines must be running Windows 10 OS [1709](https://docs.microsoft.com/windows/release-information/status-windows-10-1709), [1803](https://docs.microsoft.com/windows/release-information/status-windows-10-1803), [1809](https://docs.microsoft.com/windows/release-information/status-windows-10-1809-and-windows-server-2019) or later. (See [Windows 10 release information](https://docs.microsoft.com/windows/release-information/) for more details about releases.)
- You must be using Windows security with [security intelligence](https://www.microsoft.com/wdsi/definitions) updated to version 1.287.60.0 (or above).
- Your machines must be using anti-malware platform version 4.18.1906.3 (or above) and anti-malware engine version 1.1.15500.X (or above). ([Manage Microsoft Defender Antivirus updates and apply baselines](manage-updates-baselines-microsoft-defender-antivirus.md).)
2. Go to the Microsoft 365 Device Management portal ([https://devicemanagement.microsoft.com](https://devicemanagement.microsoft.com)) and sign in with your work or school account.
3. Select **Device configuration** > **Profiles**.
4. Create a profile as follows:
- Platform: **Windows 10 and later**
- Profile type: **Endpoint protection**
- Category: **Microsoft Defender Security Center**
- Tamper Protection: **Enabled**

5. Assign the profile to one or more groups.
Here's what you see in the Windows Security app:

### Are you using Windows OS 1709, 1803, or 1809?
If you are using Windows 10 OS [1709](https://docs.microsoft.com/windows/release-information/status-windows-10-1709), [1803](https://docs.microsoft.com/windows/release-information/status-windows-10-1803), or [1809](https://docs.microsoft.com/windows/release-information/status-windows-10-1809-and-windows-server-2019), you won't see **Tamper Protection** in the Windows Security app. In this case, you can use PowerShell to determine whether tamper protection is enabled.
#### Use PowerShell to determine whether tamper protection is turned on
1. Open the Windows PowerShell app.
2. Use the [Get-MpComputerStatus](https://docs.microsoft.com/powershell/module/defender/get-mpcomputerstatus?view=win10-ps) PowerShell cmdlet.
3. In the list of results, look for `IsTamperProtected`. (A value of *true* means tamper protection is enabled.)
## View information about tampering attempts
Tampering attempts typically indicate bigger cyberattacks. Bad actors try to change security settings as a way to persist and stay undetected. If you're part of your organization's security team, you can view information about such attempts, and then take appropriate actions to mitigate threats.
When a tampering attempt is detected, an alert is raised in the [Microsoft Defender Security Center](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/portal-overview) ([https://securitycenter.windows.com](https://securitycenter.windows.com)).

Using [endpoint detection and response](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/overview-endpoint-detection-response) and [advanced hunting](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/advanced-hunting-overview) capabilities in Microsoft Defender ATP, your security operations team can investigate and address such attempts.
## Review your security recommendations
Tamper protection integrates with [Threat & Vulnerability Management](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/next-gen-threat-and-vuln-mgt) capabilities. [Security recommendations](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/tvm-security-recommendation) include making sure tamper protection is turned on. For example, you can search on *tamper*, as shown in the following image:

In the results, you can select **Turn on Tamper Protection** to learn more and turn it on.

To learn more about Threat & Vulnerability Management, see [Threat & Vulnerability Management in Microsoft Defender Security Center](https://docs.microsoft.com/windows/security/threat-protection/microsoft-defender-atp/tvm-dashboard-insights#threat--vulnerability-management-in-microsoft-defender-security-center).
## Frequently asked questions
### To which Windows OS versions is configuring tamper protection is applicable?
Windows 10 OS [1709](https://docs.microsoft.com/windows/release-information/status-windows-10-1709), [1803](https://docs.microsoft.com/windows/release-information/status-windows-10-1803), [1809](https://docs.microsoft.com/windows/release-information/status-windows-10-1809-and-windows-server-2019), or later together with [Microsoft Defender Advanced Threat Protection E5](https://www.microsoft.com/microsoft-365/windows/microsoft-defender-atp).
### Is configuring tamper protection in Intune supported on servers?
No
### Will tamper protection have any impact on third party antivirus registration?
No. Third-party antivirus offerings will continue to register with the Windows Security application.
### What happens if Microsoft Defender Antivirus is not active on a device?
Tamper protection will not have any impact on such devices.
### How can I turn tamper protection on/off?
If you are a home user, see [Turn tamper protection on (or off) for an individual machine](#turn-tamper-protection-on-or-off-for-an-individual-machine).
If you are an organization using [Microsoft Defender ATP E5](https://www.microsoft.com/microsoft-365/windows/microsoft-defender-atp), you should be able to manage tamper protection in Intune similar to how you manage other endpoint protection features. See [Turn tamper protection on (or off) for your organization using Intune](#turn-tamper-protection-on-or-off-for-your-organization-using-intune).
### How does configuring tamper protection in Intune affect how I manage Microsoft Defender Antivirus through my group policy?
Your regular group policy doesn’t apply to tamper protection, and changes to Microsoft Defender Antivirus settings are ignored when tamper protection is on.
>[!NOTE]
>A small delay in Group Policy (GPO) processing may occur if Group Policy settings include values that control Microsoft Defender Antivirus features protected by tamper protection. To avoid any potential delays, we recommend that you remove settings that control Microsoft Defender Antivirus related behavior from GPO and simply allow tamper protection to protect Microsoft Defender Antivirus settings. <br><br>
> Sample Microsoft Defender Antivirus settings:<br>
> Turn off Microsoft Defender Antivirus <br>
> Computer Configuration\Administrative Templates\Windows Components\Windows Defender\
Value DisableAntiSpyware = 0 <br><br>
>Turn off real-time protection<br>
Computer Configuration\Administrative Templates\Windows Components\Microsoft Defender Antivirus\Real-time Protection\
Value DisableRealtimeMonitoring = 0
### For Microsoft Defender ATP E5, is configuring tamper protection in Intune targeted to the entire organization only?
Configuring tamper protection in Intune can be targeted to your entire organization as well as to specific devices and user groups.
### Can I configure Tamper Protection in Microsoft Endpoint Configuration Manager?
Currently we do not have support to manage Tamper Protection through Microsoft Endpoint Configuration Manager.
### I have the Windows E3 enrollment. Can I use configuring tamper protection in Intune?
Currently, configuring tamper protection in Intune is only available for customers who have [Microsoft Defender Advanced Threat Protection E5](https://www.microsoft.com/microsoft-365/windows/microsoft-defender-atp).
### What happens if I try to change Microsoft Defender ATP settings in Intune, Microsoft Endpoint Configuration Manager, and Windows Management Instrumentation when Tamper Protection is enabled on a device?
You won’t be able to change the features that are protected by tamper protection; such change requests are ignored.
### I’m an enterprise customer. Can local admins change tamper protection on their devices?
No. Local admins cannot change or modify tamper protection settings.
### What happens if my device is onboarded with Microsoft Defender ATP and then goes into an off-boarded state?
In this case, tamper protection status changes, and this feature is no longer applied.
### Will there be an alert about tamper protection status changing in the Microsoft Defender Security Center?
Yes. The alert is shown in [https://securitycenter.microsoft.com](https://securitycenter.microsoft.com) under **Alerts**.
In addition, your security operations team can use hunting queries, such as the following:
`DeviceAlertEvents | where Title == "Tamper Protection bypass"`
[View information about tampering attempts](#view-information-about-tampering-attempts).
### Will there be a group policy setting for tamper protection?
No.
## Related articles
[Help secure Windows PCs with Endpoint Protection for Microsoft Intune](https://docs.microsoft.com/intune/help-secure-windows-pcs-with-endpoint-protection-for-microsoft-intune)
[Get an overview of Microsoft Defender ATP E5](https://www.microsoft.com/microsoft-365/windows/microsoft-defender-atp)
[Better together: Microsoft Defender Antivirus and Microsoft Defender Advanced Threat Protection](why-use-microsoft-defender-antivirus.md)
| 64.194093 | 480 | 0.796832 | eng_Latn | 0.945384 |
97155fde4bc3c89fdd01381853266da71727808f | 499 | md | Markdown | shopping/area-farmers-markets.md | prplecake/veganmsp.com-jekyll | bb3690647d004eb2ca6d1b00b364131f3853f326 | [
"MIT"
] | null | null | null | shopping/area-farmers-markets.md | prplecake/veganmsp.com-jekyll | bb3690647d004eb2ca6d1b00b364131f3853f326 | [
"MIT"
] | null | null | null | shopping/area-farmers-markets.md | prplecake/veganmsp.com-jekyll | bb3690647d004eb2ca6d1b00b364131f3853f326 | [
"MIT"
] | null | null | null | ---
title: Area Farmer's Markets
permalink: /shopping/area-farmers-markets/
---
**Hopkins Farmers Market** – 07:30-12:00 – Saturdays, Mid-June through
October<br />
16 9th Avenue S., Hopkins, MN 55343<br />
<https://www.hopkinsfarmersmarket.com><br />
(952) 583-1930
**Hopkins Winter Farmers Market** – 09:00-12:00 – Saturdays, November
through Mid-December<br />
Hopkins Activity Center<br />
33 14th Avenue N., Hopkins, MN 55343<br />
<https://www.hopkinsfarmersmarket.com><br />
(952) 583-1930
| 27.722222 | 70 | 0.711423 | eng_Latn | 0.130394 |
97157d5a9b567cfd53026cd3cb91c2940ec2b2c4 | 660 | md | Markdown | _minecraft_en/item/001/Orange_Dye.md | game-z/game-z.github.io | c5d3a591b488cc4c9ffcb403b44327b9c45c8310 | [
"BSD-3-Clause"
] | null | null | null | _minecraft_en/item/001/Orange_Dye.md | game-z/game-z.github.io | c5d3a591b488cc4c9ffcb403b44327b9c45c8310 | [
"BSD-3-Clause"
] | null | null | null | _minecraft_en/item/001/Orange_Dye.md | game-z/game-z.github.io | c5d3a591b488cc4c9ffcb403b44327b9c45c8310 | [
"BSD-3-Clause"
] | null | null | null | ---
title: Orange Dye
layout: document
---
## Detail
|Kind|Content|
|---|---|
|Description|Orange Dye|
|Type|[Materials](Materials)|
|Production Tool|[Crafting Table](Crafting_Table)|
You can be created from flowers.
It can also be made into other colors by mixing dyes.
## Recipe
|Result|Materials|
|---|---|
|[Orange Dye](Orange_Dye)x1|[Orange Tulip](Orange_Tulip)x1|
|[Orange Dye](Orange_Dye)x2|[Rose Red](Rose_Red)x1,[Dandelion Yellow](Dandelion_Yellow)x1|
## Materials that can be crafted
[Orange Wool](Orange_Wool),
[Orange Concrete Powder](Orange_Concrete_Powder),
[Orange Shulker Box](Orange_Shulker_Box),
[Orange Terracotta](Orange_Terracotta),
| 22.758621 | 90 | 0.740909 | eng_Latn | 0.458605 |
97159db869ba270ccbfd5ae1d020c53b5d069334 | 2,560 | md | Markdown | README.md | fedota/fl-webserver | 8015f59445529edf13589d7c9339a6e48e58640f | [
"MIT"
] | null | null | null | README.md | fedota/fl-webserver | 8015f59445529edf13589d7c9339a6e48e58640f | [
"MIT"
] | 1 | 2022-02-10T15:02:06.000Z | 2022-02-10T15:02:06.000Z | README.md | fedota/fl-webserver | 8015f59445529edf13589d7c9339a6e48e58640f | [
"MIT"
] | null | null | null | # Webserver
Webserver for Fedota
## Overview
Webserver has the following responsibilities:
- Interface for problem setter and data organizations
- Manages database and stores uploaded files at appropriate locations
- Spawns FL infrastructure for a FL problem and tracks the status of round for FL problems
## Workflow
- Problem setter uses the Webserver to create the FL problem providing with description, data format, initial files required, client docker image link, etc.
- For storing uploaded files and files generated during a FL round, a common file storage is used with appropriate directory partitions and permissions to avoid inconsistencies as shown in [fedota-infra](https://github.com/fedota/fedota-infra#shared-file-storage-structure)
- With uploaded files placed at the appropriate location, the Webserver creates the FL, Coordinator and Selectors, for the problem and notes their addresses. The Coordinator and Selectors for a FL problem run in isolated namespaces.
- Data organization wishing to contribute in the training of the model with their local data use the instructions provided to run the client docker image with required arguments and makes a connection request to the respective selector. Data organizations should coordinate among themselves on when to run clients to ensure goal count is reached.
- Coordinator for a FL problem sends updates about the round to the Webserver which notes the changes.
### Setup
- Install dependencies: `pip install -r requirements.txt`
- Fedota migrations: `python manage.py makemigrations fedota`
- Migrate: `python manage.py migrate`
- Start webserver: `python manage.py runserver`
- Superuser : `python manage.py createsuperuser`
When running locally the selector and coordinator can share the /data directory for the model and checkpoint files as shown in the last section of [fedota-infra](https://github.com/fedota/fedota-infra) repo. Otherwise deploy the nfs-service and change the mount for the k8s/fl-pv.yaml as shown in the NFS section of fedota-infra repo.
### Themes
Default themes can be added using:
- `python manage.py loaddata admin_interface_theme_django.json`
- `python manage.py loaddata admin_interface_theme_bootstrap.json`
- `python manage.py loaddata admin_interface_theme_uswds.json`
- `python manage.py loaddata admin_interface_theme_foundation.json`
### Contribute
Fix code style issues before pushing:
`pre-commit run --all-files`
### TODO
- Add code to create the client docker image passing the selector address as a argument for the data holders to download | 67.368421 | 346 | 0.806641 | eng_Latn | 0.992794 |
97159faefc149f7229ea8c35723e797dad7f40ee | 1,159 | md | Markdown | _posts/react/2018-08-12-1passChi.md | edgewood1/edge.github.io | 095434327e077e03335087d56d30c6988984795f | [
"MIT"
] | null | null | null | _posts/react/2018-08-12-1passChi.md | edgewood1/edge.github.io | 095434327e077e03335087d56d30c6988984795f | [
"MIT"
] | null | null | null | _posts/react/2018-08-12-1passChi.md | edgewood1/edge.github.io | 095434327e077e03335087d56d30c6988984795f | [
"MIT"
] | null | null | null | ---
layout: post
published: true
categories: react
title: Passing to Child 1
---
To recap:
The parent renders the child component 4 times.
Each time, it assigns from its state the following values:
unique id, counter setting, and value.
The child handles design and functino of each button.
--------
In the parent, we rendered the child, assigning state variables.
In the child, data/varaibles that we pass down are saved in the 'this.props' variable.
So in the child, we set up the state to take the 'values' variable:
```javascript
class Child extends Component {
state = {
count: this.props.value
};
```
If, in the child, you console.log this.props...
```javascript
console.log('props', this.props);
```
You see 4 objects represented, one for each object in our parent's state.counters array:
```javascript
props {value: 4, selected: true}
props {value: 3, selected: true}
props {value: 2, selected: true}
props {value: 0, selected: true}
```
In the above, props will not show key because that is just the id
Props is actually an object from React.Component that lists all the attributes in the current component.
| 22.288462 | 105 | 0.718723 | eng_Latn | 0.997811 |
9715d651e4599e6b5e983f2d5c6a47fce8b75712 | 13,511 | md | Markdown | Library/PackageCache/[email protected]/Documentation~/universalrp-asset.md | mangelhoyos/Broken-Line | 021f8b658c904d16876bb4cee3bca86dd03c018d | [
"Apache-2.0"
] | 4 | 2021-06-02T19:03:51.000Z | 2021-10-02T19:47:05.000Z | URPScripts/[email protected]/Documentation~/universalrp-asset.md | UWA-MakeItSimple/Course-URP | ed6bb7abd0eae5cc6a991568be751747db0b2f09 | [
"MIT"
] | 7 | 2021-04-07T10:03:53.000Z | 2022-03-14T22:06:08.000Z | URPScripts/[email protected]/Documentation~/universalrp-asset.md | UWA-MakeItSimple/Course-URP | ed6bb7abd0eae5cc6a991568be751747db0b2f09 | [
"MIT"
] | 2 | 2021-12-06T13:56:23.000Z | 2021-12-06T13:56:37.000Z | # Universal Render Pipeline Asset
To use the Universal Render Pipeline (URP), you have to [create a URP Asset and assign the asset in the Graphics settings](configuring-universalrp-for-use.md).
The URP Asset controls several graphical features and quality settings for the Universal Render Pipeline. It is a scriptable object that inherits from ‘RenderPipelineAsset’. When you assign the asset in the Graphics settings, Unity switches from the built-in render pipeline to the URP. You can then adjust the corresponding settings directly in the URP, instead of looking for them elsewhere.
You can have multiple URP assets and switch between them. For example, you can have one with Shadows on and one with Shadows off. If you switch between the assets to see the effects, you don’t have to manually toggle the corresponding settings for shadows every time. You cannot, however, switch between HDRP/SRP and URP assets, as the
render pipelines are incompatible.
## UI overview
In the URP, you can configure settings for:
- [__General__](#general)
- [__Quality__](#quality)
- [__Lighting__](#lighting)
- [__Shadows__](#shadows)
- [__Post-processing__](#post-processing)
- [__Advanced__](#advanced)
- [__Adaptive Performance__](#adaptive-performance)
**Note:** If you have the experimental 2D Renderer enabled (menu: **Graphics Settings** > add the 2D Renderer Asset under **Scriptable Render Pipeline Settings**), some of the options related to 3D rendering in the URP Asset don't have any impact on your final app or game.
### General
The __General__ settings control the core part of the pipeline rendered frame.
| __Property__ | __Description__ |
| ----------------------- | ------------------------------------------------------------ |
| __Depth Texture__ | Enables URP to create a `_CameraDepthTexture`. URP then uses this [depth texture](https://docs.unity3d.com/Manual/SL-DepthTextures.html) by default for all Cameras in your Scene. You can override this for individual cameras in the [Camera Inspector](camera-component-reference.md). |
| __Opaque Texture__ | Enable this to create a `_CameraOpaqueTexture` as default for all cameras in your Scene. This works like the [GrabPass](https://docs.unity3d.com/Manual/SL-GrabPass.html) in the built-in render pipeline. The __Opaque Texture__ provides a snapshot of the scene right before URP renders any transparent meshes. You can use this in transparent Shaders to create effects like frosted glass, water refraction, or heat waves. You can override this for individual cameras in the [Camera Inspector](camera-component-reference.md). |
| __Opaque Downsampling__ | Set the sampling mode on the opaque texture to one of the following:<br/>__None__: Produces a copy of the opaque pass in the same resolution as the camera.<br/>__2x Bilinear__: Produces a half-resolution image with bilinear filtering.<br/>__4x Box__: Produces a quarter-resolution image with box filtering. This produces a softly blurred copy.<br/>__4x Bilinear__: Produces a quarter-resolution image with bi-linear filtering. |
| __Terrain Holes__ | If you disable this option, the URP removes all Terrain hole Shader variants when you build for the Unity Player, which decreases build time. |
### Quality
These settings control the quality level of the URP. This is where you can make performance better on lower-end hardware or make graphics look better on higher-end hardware.
**Tip:** If you want to have different settings for different hardware, you can configure these settings across multiple Universal Render Pipeline assets, and switch them out as needed.
| Property | Description |
| ---------------- | ------------------------------------------------------------ |
| __HDR__ | Enable this to allow rendering in High Dynamic Range (HDR) by default for every camera in your Scene. With HDR, the brightest part of the image can be greater than 1. This gives you a wider range of light intensities, so your lighting looks more realistic. With it, you can still see details and experience less saturation even with bright light. This is useful if you want a wide range of lighting or to use [bloom](https://docs.unity3d.com/Manual/PostProcessing-Bloom.html) effects. If you’re targeting lower-end hardware, you can disable this to skip HDR calculations and get better performance. You can override this for individual cameras in the Camera Inspector. |
| __MSAA__ | Use [Multi Sample Anti-aliasing](https://en.wikipedia.org/wiki/Multisample_anti-aliasing) by default for every Camera in your Scene while rendering. This softens edges of your geometry, so they’re not jagged or flickering. In the drop-down menu, select how many samples to use per pixel: __2x__, __4x__, or __8x__. The more samples you choose, the smoother your object edges are. If you want to skip MSAA calculations, or you don’t need them in a 2D game, select __Disabled__. You can override this for individual cameras in the Camera Inspector. |
| __Render Scale__ | This slider scales the render target resolution (not the resolution of your current device). Use this when you want to render at a smaller resolution for performance reasons or to upscale rendering to improve quality. This only scales the game rendering. UI rendering is left at the native resolution for the device. |
### Lighting
These settings affect the lights in your Scene.
If you disable some of these settings, the relevant [keywords](shader-stripping.md) are [stripped from the Shader variables](shading-model.md#shaderStripping). If there are settings that you know for certain you won’t use in your game or app, you can disable them to improve performance and reduce build time.
| Property | Description |
| --------------------- | ------------------------------------------------------------ |
| __Main Light__ | These settings affect the main [Directional Light](https://docs.unity3d.com/Manual/Lighting.html) in your Scene. You can select this by assigning it as a [Sun Source](https://docs.unity3d.com/Manual/GlobalIllumination.html) in the Lighting Inspector. If you don’t assign a sun source, the URP treats the brightest directional light in the Scene as the main light. You can choose between [Pixel Lighting](https://docs.unity3d.com/Manual/LightPerformance.html) and _None_. If you choose None, URP doesn’t render a main light, even if you’ve set a sun source. |
| __Cast Shadows__ | Check this box to make the main light cast shadows in your Scene. |
| __Shadow Resolution__ | This controls how large the shadow map texture for the main light is. High resolutions give sharper, more detailed shadows. If memory or rendering time is an issue, try a lower resolution. |
| __Additional Lights__ | Here, you can choose to have additional lights to supplement your main light. Choose between [Per Vertex](https://docs.unity3d.com/Manual/LightPerformance.html), [Per Pixel](https://docs.unity3d.com/Manual/LightPerformance.html), or __Disabled__. |
| __Per Object Limit__ | This slider sets the limit for how many additional lights can affect each GameObject. |
| __Cast Shadows__ | Check this box to make the additional lights cast shadows in your Scene. |
| __Shadow Resolution__ | This controls the size of the textures that cast directional shadows for the additional lights. This is a sprite atlas that packs up to 16 shadow maps. High resolutions give sharper, more detailed shadows. If memory or rendering time is an issue, try a lower resolution. |
### Shadows
These settings let you configure how shadows look and behave, and find a good balance between the visual quality and performance.

The **Shadows** section has the following properties.
| Property | Description |
| ---------------- | ----------- |
| __Max Distance__ | The maximum distance from the Camera at which Unity renders the shadows. Unity does not render shadows farther than this distance.<br/>__Note:__ This property is in metric units regardless of the value in the __Working Unit__ property. |
| __Working Unit__ | The unit in which Unity measures the shadow cascade distances. |
| __Cascade Count__ | The number of [shadow cascades](https://docs.unity3d.com/Manual/shadow-cascades.html). With shadow cascades, you can avoid crude shadows close to the Camera and keep the Shadow Resolution reasonably low. For more information, see the page [Shadow Cascades](https://docs.unity3d.com/Manual/shadow-cascades.html). Increasing the number of cascades reduces the performance. |
| Split 1 | The distance where cascade 1 ends and cascade 2 starts. |
| Split 2 | The distance where cascade 2 ends and cascade 3 starts. |
| Split 3 | The distance where cascade 3 ends and cascade 4 starts. |
| **Depth Bias** | Use this setting to reduce [shadow acne](https://docs.unity3d.com/Manual/ShadowPerformance.html). |
| **Normal Bias** | Use this setting to reduce [shadow acne](https://docs.unity3d.com/Manual/ShadowPerformance.html). |
| __Soft Shadows__ | Select this check box to enable extra processing of the shadow maps to give them a smoother look.<br/>When enabled, Unity uses the following shadow map filtering method:<br/>Desktop platforms: 5x5 tent filter, mobile platforms: 4 tap filter.<br/>**Performance impact**: high.<br/>When this option is disabled, Unity samples the shadow map once with the default hardware filtering. |
### Post-processing
This section allows you to fine-tune global post-processing settings.
| Property | Description |
| ---------------- | ------------------------------------------------------------ |
| __Grading Mode__ | Select the [color grading](https://docs.unity3d.com/Manual/PostProcessing-ColorGrading.html) mode to use for the Project.<br />• __High Dynamic Range__: This mode works best for high precision grading similar to movie production workflows. Unity applies color grading before tonemapping.<br />• __Low Dynamic Range__: This mode follows a more classic workflow. Unity applies a limited range of color grading after tonemapping. |
| __LUT Size__ | Set the size of the internal and external [look-up textures (LUTs)](https://docs.unity3d.com/Manual/PostProcessing-ColorGrading.html) that the Universal Render Pipeline uses for color grading. Higher sizes provide more precision, but have a potential cost of performance and memory use. You cannot mix and match LUT sizes, so decide on a size before you start the color grading process.<br />The default value, **32**, provides a good balance of speed and quality. |
### Advanced
This section allows you to fine-tune less commonly changed settings, which impact deeper rendering features and Shader combinations.
| Property | Description |
| -------------------------- | ------------------------------------------------------------ |
| __SRP Batcher__ | Check this box to enable the SRP Batcher. This is useful if you have many different Materials that use the same Shader. The SRP Batcher is an inner loop that speeds up CPU rendering without affecting GPU performance. When you use the SRP Batcher, it replaces the SRP rendering code inner loop. |
| __Dynamic Batching__ | Enable [Dynamic Batching](https://docs.unity3d.com/Manual/DrawCallBatching.html), to make the render pipeline automatically batch small dynamic objects that share the same Material. This is useful for platforms and graphics APIs that do not support GPU instancing. If your targeted hardware does support GPU instancing, disable __Dynamic Batching__. You can change this at run time. |
| __Mixed Lighting__ | Enable [Mixed Lighting](https://docs.unity3d.com/Manual/LightMode-Mixed.html), to tell the pipeline to include mixed lighting shader variants in the build. |
| __Debug Level__ | Set the level of debug information that the render pipeline generates. The values are:<br />**Disabled**: Debugging is disabled. This is the default.<br />**Profiling**: Makes the render pipeline provide detailed information tags, which you can see in the FrameDebugger. |
| __Shader Variant Log Level__ | Set the level of information about Shader Stripping and Shader Variants you want to display when Unity finishes a build. Values are:<br /> **Disabled**: Unity doesn’t log anything.<br />**Only Universal**: Unity logs information for all of the [URP Shaders](shaders-in-universalrp.md).<br />**All**: Unity logs information for all Shaders in your build.<br /> You can see the information in Console panel when your build has finished. |
### Adaptive Performance
This section is available if the Adaptive Performance package is installed in the project. The __Use Adaptive Performance__ property lets you enable the Adaptive Performance functionality.
| __Property__ | __Description__ |
| ----------------------- | ------------------------------------------------------------ |
| __Use Adaptive Performance__ | Select this check box to enable the Adaptive Performance functionality, which adjusts the rendering quality at runtime. |
| 108.959677 | 691 | 0.725779 | eng_Latn | 0.990679 |
9716cceceb55501807be027e9dc744800b3cc8e1 | 433 | md | Markdown | ClientApp/src/styles/readme.md | e-hermoso/OCPW-Automation-Map-Check | 85127cc13fd8bf3121cb1e3a41df0fa7b528b4c0 | [
"MIT"
] | null | null | null | ClientApp/src/styles/readme.md | e-hermoso/OCPW-Automation-Map-Check | 85127cc13fd8bf3121cb1e3a41df0fa7b528b4c0 | [
"MIT"
] | 7 | 2022-01-06T17:15:10.000Z | 2022-03-30T20:56:23.000Z | ClientApp/src/styles/readme.md | e-hermoso/OCPW-Automation-Map-Check | 85127cc13fd8bf3121cb1e3a41df0fa7b528b4c0 | [
"MIT"
] | null | null | null | # A Guide to the Styling of this App
*Please read me!*
---
## Quick Start
This app uses [BEM](http://getbem.com/) and [sass](https://sass-lang.com/) to make the code as modular as possible.
I recommend reading up on these if you are unfamiliar.
1.BEM
BEM stands for Block Element Modifier. It's a simple way to organize your styles.
The naming convention follows this pattern:
`.block {}`
`.block__element {}`
`.block--modifier {}` | 30.928571 | 115 | 0.722864 | eng_Latn | 0.970958 |
97173918e54f1fdaa27d86264901a95020b3fd12 | 2,784 | md | Markdown | README.md | KimDongEon/ONE | 3e2e9039ed2599b1d7a9ce1f1036b8218614860d | [
"Apache-2.0"
] | null | null | null | README.md | KimDongEon/ONE | 3e2e9039ed2599b1d7a9ce1f1036b8218614860d | [
"Apache-2.0"
] | null | null | null | README.md | KimDongEon/ONE | 3e2e9039ed2599b1d7a9ce1f1036b8218614860d | [
"Apache-2.0"
] | null | null | null | [](https://github.com/Samsung/ONE/releases)
[](https://nnfw.readthedocs.io/en/latest/?badge=latest)

[](https://gitter.im/Samsung/ONE)
# **ONE** (On-device Neural Engine)
A high-performance, on-device neural network inference framework.
## Goal
This project **ONE** aims at providing a high-performance, on-device neural network (NN) inference
framework that performs inference of a given NN model on processors, such as CPU, GPU, DSP or NPU.
We develop a runtime that runs on a Linux kernel-based OS platform such as Ubuntu, Tizen, or
Android, and a compiler toolchain to support NN models created using various NN training frameworks such
as Tensorflow or PyTorch in a unified form at runtime.
## Overview
- [Background](docs/overview/background.md)
- [Roadmap](docs/overview/roadmap.md)
- [Overall Architecture](docs/overview/overall-architecture.md)
## Getting started
- For the contribution, please refer to our [contribution guide](docs/howto/how-to-contribute.md).
- You can also find various how-to documents [here](docs/howto).
## Feature Request
You can suggest development of **ONE**'s features that are not yet available.
The functions requested so far can be checked in the [popular feature request](https://github.com/Samsung/ONE/issues?q=label%3AFEATURE_REQUEST+) list.
- If the feature you want is on the list, :+1: to the body of the issue. The feature with the most
:+1: is placed at the top of the list. When adding new features, we will prioritize them with this reference.
Of course, it is good to add an additional comment which describes your request in detail.
- For features not listed, [create a new issue](https://github.com/Samsung/ONE/issues/new).
Sooner or later, the maintainer will tag the `FEATURE_REQUEST` label and appear on the list.
We expect one of the most frequent feature requests would be the operator kernel implementation.
It is good to make a request, but it is better if you contribute by yourself. See the following guide,
[How to add a new operation](docs/howto/how-to-add-a-new-operation.md), for help.
We are looking forward to your participation.
Thank you in advance!
## How to Contact
- Please post questions, issues, or suggestions into [Issues](https://github.com/Samsung/ONE/issues). This is the best way to communicate with the developer.
- You can also have an open discussion with community members through [gitter.im](https://gitter.im/Samsung/ONE) channel.
| 50.618182 | 157 | 0.769397 | eng_Latn | 0.98664 |
97178edf320be13da2834cf0bda3b73b633be9a1 | 45,975 | md | Markdown | docs/PolicyV1alpha1Api.md | Arvinhub/client-python | d67df30f635231d68dc4c20b9b7e234c616c1e6a | [
"Apache-2.0"
] | 1 | 2021-06-16T02:57:18.000Z | 2021-06-16T02:57:18.000Z | docs/PolicyV1alpha1Api.md | Arvinhub/client-python | d67df30f635231d68dc4c20b9b7e234c616c1e6a | [
"Apache-2.0"
] | null | null | null | docs/PolicyV1alpha1Api.md | Arvinhub/client-python | d67df30f635231d68dc4c20b9b7e234c616c1e6a | [
"Apache-2.0"
] | null | null | null | # k8sclient.PolicyV1alpha1Api
All URIs are relative to *https://localhost*
Method | HTTP request | Description
------------- | ------------- | -------------
[**create_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#create_policy_v1alpha1_namespaced_pod_disruption_budget) | **POST** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets |
[**delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget) | **DELETE** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets |
[**delete_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#delete_policy_v1alpha1_namespaced_pod_disruption_budget) | **DELETE** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name} |
[**get_policy_v1alpha1_api_resources**](PolicyV1alpha1Api.md#get_policy_v1alpha1_api_resources) | **GET** /apis/policy/v1alpha1/ |
[**list_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#list_policy_v1alpha1_namespaced_pod_disruption_budget) | **GET** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets |
[**list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces**](PolicyV1alpha1Api.md#list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces) | **GET** /apis/policy/v1alpha1/poddisruptionbudgets |
[**patch_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#patch_policy_v1alpha1_namespaced_pod_disruption_budget) | **PATCH** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name} |
[**patch_policy_v1alpha1_namespaced_pod_disruption_budget_status**](PolicyV1alpha1Api.md#patch_policy_v1alpha1_namespaced_pod_disruption_budget_status) | **PATCH** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name}/status |
[**read_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#read_policy_v1alpha1_namespaced_pod_disruption_budget) | **GET** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name} |
[**read_policy_v1alpha1_namespaced_pod_disruption_budget_status**](PolicyV1alpha1Api.md#read_policy_v1alpha1_namespaced_pod_disruption_budget_status) | **GET** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name}/status |
[**replace_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#replace_policy_v1alpha1_namespaced_pod_disruption_budget) | **PUT** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name} |
[**replace_policy_v1alpha1_namespaced_pod_disruption_budget_status**](PolicyV1alpha1Api.md#replace_policy_v1alpha1_namespaced_pod_disruption_budget_status) | **PUT** /apis/policy/v1alpha1/namespaces/{namespace}/poddisruptionbudgets/{name}/status |
[**watch_policy_v1alpha1_namespaced_pod_disruption_budget**](PolicyV1alpha1Api.md#watch_policy_v1alpha1_namespaced_pod_disruption_budget) | **GET** /apis/policy/v1alpha1/watch/namespaces/{namespace}/poddisruptionbudgets/{name} |
[**watch_policy_v1alpha1_namespaced_pod_disruption_budget_list**](PolicyV1alpha1Api.md#watch_policy_v1alpha1_namespaced_pod_disruption_budget_list) | **GET** /apis/policy/v1alpha1/watch/namespaces/{namespace}/poddisruptionbudgets |
[**watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces**](PolicyV1alpha1Api.md#watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces) | **GET** /apis/policy/v1alpha1/watch/poddisruptionbudgets |
# **create_policy_v1alpha1_namespaced_pod_disruption_budget**
> V1alpha1PodDisruptionBudget create_policy_v1alpha1_namespaced_pod_disruption_budget(namespace, body, pretty=pretty)
create a PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.V1alpha1PodDisruptionBudget() # V1alpha1PodDisruptionBudget |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.create_policy_v1alpha1_namespaced_pod_disruption_budget(namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->create_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget**
> UnversionedStatus delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget(namespace, pretty=pretty, field_selector=field_selector, label_selector=label_selector, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
delete collection of PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget(namespace, pretty=pretty, field_selector=field_selector, label_selector=label_selector, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->delete_policy_v1alpha1_collection_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**UnversionedStatus**](UnversionedStatus.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **delete_policy_v1alpha1_namespaced_pod_disruption_budget**
> UnversionedStatus delete_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
delete a PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.V1DeleteOptions() # V1DeleteOptions |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.delete_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->delete_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**V1DeleteOptions**](V1DeleteOptions.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**UnversionedStatus**](UnversionedStatus.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **get_policy_v1alpha1_api_resources**
> UnversionedAPIResourceList get_policy_v1alpha1_api_resources()
get available resources
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
try:
api_response = api_instance.get_policy_v1alpha1_api_resources()
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->get_policy_v1alpha1_api_resources: %s\n" % e)
```
### Parameters
This endpoint does not need any parameter.
### Return type
[**UnversionedAPIResourceList**](UnversionedAPIResourceList.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: application/json, application/yaml, application/vnd.kubernetes.protobuf
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list_policy_v1alpha1_namespaced_pod_disruption_budget**
> V1alpha1PodDisruptionBudgetList list_policy_v1alpha1_namespaced_pod_disruption_budget(namespace, pretty=pretty, field_selector=field_selector, label_selector=label_selector, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
list or watch objects of kind PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.list_policy_v1alpha1_namespaced_pod_disruption_budget(namespace, pretty=pretty, field_selector=field_selector, label_selector=label_selector, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->list_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**V1alpha1PodDisruptionBudgetList**](V1alpha1PodDisruptionBudgetList.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf, application/json;stream=watch, application/vnd.kubernetes.protobuf;stream=watch
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces**
> V1alpha1PodDisruptionBudgetList list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces(field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
list or watch objects of kind PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces(field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->list_policy_v1alpha1_pod_disruption_budget_for_all_namespaces: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**V1alpha1PodDisruptionBudgetList**](V1alpha1PodDisruptionBudgetList.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf, application/json;stream=watch, application/vnd.kubernetes.protobuf;stream=watch
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **patch_policy_v1alpha1_namespaced_pod_disruption_budget**
> V1alpha1PodDisruptionBudget patch_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
partially update the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.UnversionedPatch() # UnversionedPatch |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.patch_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->patch_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**UnversionedPatch**](UnversionedPatch.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: application/json-patch+json, application/merge-patch+json, application/strategic-merge-patch+json
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **patch_policy_v1alpha1_namespaced_pod_disruption_budget_status**
> V1alpha1PodDisruptionBudget patch_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, body, pretty=pretty)
partially update status of the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.UnversionedPatch() # UnversionedPatch |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.patch_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->patch_policy_v1alpha1_namespaced_pod_disruption_budget_status: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**UnversionedPatch**](UnversionedPatch.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: application/json-patch+json, application/merge-patch+json, application/strategic-merge-patch+json
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read_policy_v1alpha1_namespaced_pod_disruption_budget**
> V1alpha1PodDisruptionBudget read_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, pretty=pretty, exact=exact, export=export)
read the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
exact = true # bool | Should the export be exact. Exact export maintains cluster-specific fields like 'Namespace' (optional)
export = true # bool | Should this value be exported. Export strips fields that a user can not specify. (optional)
try:
api_response = api_instance.read_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, pretty=pretty, exact=exact, export=export)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->read_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**exact** | **bool**| Should the export be exact. Exact export maintains cluster-specific fields like 'Namespace' | [optional]
**export** | **bool**| Should this value be exported. Export strips fields that a user can not specify. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **read_policy_v1alpha1_namespaced_pod_disruption_budget_status**
> V1alpha1PodDisruptionBudget read_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, pretty=pretty)
read status of the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.read_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->read_policy_v1alpha1_namespaced_pod_disruption_budget_status: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **replace_policy_v1alpha1_namespaced_pod_disruption_budget**
> V1alpha1PodDisruptionBudget replace_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
replace the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.V1alpha1PodDisruptionBudget() # V1alpha1PodDisruptionBudget |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.replace_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->replace_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **replace_policy_v1alpha1_namespaced_pod_disruption_budget_status**
> V1alpha1PodDisruptionBudget replace_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, body, pretty=pretty)
replace status of the specified PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
body = k8sclient.V1alpha1PodDisruptionBudget() # V1alpha1PodDisruptionBudget |
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
try:
api_response = api_instance.replace_policy_v1alpha1_namespaced_pod_disruption_budget_status(name, namespace, body, pretty=pretty)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->replace_policy_v1alpha1_namespaced_pod_disruption_budget_status: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**body** | [**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)| |
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
### Return type
[**V1alpha1PodDisruptionBudget**](V1alpha1PodDisruptionBudget.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **watch_policy_v1alpha1_namespaced_pod_disruption_budget**
> VersionedEvent watch_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
watch changes to an object of kind PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
name = 'name_example' # str | name of the PodDisruptionBudget
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.watch_policy_v1alpha1_namespaced_pod_disruption_budget(name, namespace, field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->watch_policy_v1alpha1_namespaced_pod_disruption_budget: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**name** | **str**| name of the PodDisruptionBudget |
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**VersionedEvent**](VersionedEvent.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf, application/json;stream=watch, application/vnd.kubernetes.protobuf;stream=watch
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **watch_policy_v1alpha1_namespaced_pod_disruption_budget_list**
> VersionedEvent watch_policy_v1alpha1_namespaced_pod_disruption_budget_list(namespace, field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
watch individual changes to a list of PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
namespace = 'namespace_example' # str | object name and auth scope, such as for teams and projects
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.watch_policy_v1alpha1_namespaced_pod_disruption_budget_list(namespace, field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->watch_policy_v1alpha1_namespaced_pod_disruption_budget_list: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**namespace** | **str**| object name and auth scope, such as for teams and projects |
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**VersionedEvent**](VersionedEvent.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf, application/json;stream=watch, application/vnd.kubernetes.protobuf;stream=watch
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
# **watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces**
> VersionedEvent watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces(field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
watch individual changes to a list of PodDisruptionBudget
### Example
```python
from __future__ import print_statement
import time
import k8sclient
from k8sclient.rest import ApiException
from pprint import pprint
# Configure API key authorization: BearerToken
k8sclient.configuration.api_key['authorization'] = 'YOUR_API_KEY'
# Uncomment below to setup prefix (e.g. Bearer) for API key, if needed
# k8sclient.configuration.api_key_prefix['authorization'] = 'Bearer'
# create an instance of the API class
api_instance = k8sclient.PolicyV1alpha1Api()
field_selector = 'field_selector_example' # str | A selector to restrict the list of returned objects by their fields. Defaults to everything. (optional)
label_selector = 'label_selector_example' # str | A selector to restrict the list of returned objects by their labels. Defaults to everything. (optional)
pretty = 'pretty_example' # str | If 'true', then the output is pretty printed. (optional)
resource_version = 'resource_version_example' # str | When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. (optional)
timeout_seconds = 56 # int | Timeout for the list/watch call. (optional)
watch = true # bool | Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. (optional)
try:
api_response = api_instance.watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces(field_selector=field_selector, label_selector=label_selector, pretty=pretty, resource_version=resource_version, timeout_seconds=timeout_seconds, watch=watch)
pprint(api_response)
except ApiException as e:
print("Exception when calling PolicyV1alpha1Api->watch_policy_v1alpha1_pod_disruption_budget_list_for_all_namespaces: %s\n" % e)
```
### Parameters
Name | Type | Description | Notes
------------- | ------------- | ------------- | -------------
**field_selector** | **str**| A selector to restrict the list of returned objects by their fields. Defaults to everything. | [optional]
**label_selector** | **str**| A selector to restrict the list of returned objects by their labels. Defaults to everything. | [optional]
**pretty** | **str**| If 'true', then the output is pretty printed. | [optional]
**resource_version** | **str**| When specified with a watch call, shows changes that occur after that particular version of a resource. Defaults to changes from the beginning of history. | [optional]
**timeout_seconds** | **int**| Timeout for the list/watch call. | [optional]
**watch** | **bool**| Watch for changes to the described resources and return them as a stream of add, update, and remove notifications. Specify resourceVersion. | [optional]
### Return type
[**VersionedEvent**](VersionedEvent.md)
### Authorization
[BearerToken](../README.md#BearerToken)
### HTTP request headers
- **Content-Type**: */*
- **Accept**: application/json, application/yaml, application/vnd.kubernetes.protobuf, application/json;stream=watch, application/vnd.kubernetes.protobuf;stream=watch
[[Back to top]](#) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to Model list]](../README.md#documentation-for-models) [[Back to README]](../README.md)
| 50.191048 | 267 | 0.761044 | eng_Latn | 0.81292 |
9717b9e2e131f297f34fe20e8fb892b2a5c116ad | 447 | md | Markdown | _posts/2019-09-11-shaking-off.md | C-Jeremy/Lagrange | 9d45e87788e1d19c91eab04cb42375cfd56419b4 | [
"MIT"
] | 2 | 2021-02-15T13:03:08.000Z | 2021-02-15T13:03:37.000Z | _posts/2019-09-11-shaking-off.md | C-Jeremy/Lagrange | 9d45e87788e1d19c91eab04cb42375cfd56419b4 | [
"MIT"
] | null | null | null | _posts/2019-09-11-shaking-off.md | C-Jeremy/Lagrange | 9d45e87788e1d19c91eab04cb42375cfd56419b4 | [
"MIT"
] | 1 | 2018-08-27T18:47:49.000Z | 2018-08-27T18:47:49.000Z | ---
title: Shaking Off
author: Jeremy
tags: [exams, routine]
permalink: /170
date: 2019-09-11
---
{: .centre-image }
It's okay, I'm making these students more resilient. They will thank me for this extra training!
| 37.25 | 249 | 0.771812 | eng_Latn | 0.916744 |
9717bdfe28fbea1d1f6b6a40df5a60689a695185 | 6,478 | md | Markdown | articles/databox-online/data-box-gateway-system-requirements.md | LeMuecke/azure-docs.de-de | a7b8103dcc7d5ec5b56b9b4bb348aecd2434afbd | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/databox-online/data-box-gateway-system-requirements.md | LeMuecke/azure-docs.de-de | a7b8103dcc7d5ec5b56b9b4bb348aecd2434afbd | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/databox-online/data-box-gateway-system-requirements.md | LeMuecke/azure-docs.de-de | a7b8103dcc7d5ec5b56b9b4bb348aecd2434afbd | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Systemanforderungen für Microsoft Azure Data Box Gateway | Microsoft-Dokumentation
description: In diesem Artikel erfahren Sie mehr über die Software- und Netzwerkanforderungen für Azure Data Box Gateway.
services: databox
author: alkohli
ms.service: databox
ms.subservice: gateway
ms.topic: article
ms.date: 05/08/2019
ms.author: alkohli
ms.openlocfilehash: aadaedfd2c9ecf544d142e42a0fbeb410324b7d8
ms.sourcegitcommit: 877491bd46921c11dd478bd25fc718ceee2dcc08
ms.translationtype: HT
ms.contentlocale: de-DE
ms.lasthandoff: 07/02/2020
ms.locfileid: "82562439"
---
# <a name="azure-data-box-gateway-system-requirements"></a>Systemanforderungen für Azure Data Box Gateway
In diesem Artikel werden wichtige Systemanforderungen für Ihre Microsoft Azure Data Box Gateway-Lösung und die Clients beschrieben, die mit Azure Data Box Gateway verbunden sind. Sie sollten die Informationen sorgfältig lesen, bevor Sie Data Box Gateway bereitstellen. Auch später sollten Sie während der Bereitstellung und beim nachfolgenden Betrieb bei Bedarf als Referenz darauf zurückgreifen.
Für das virtuelle Data Box Gateway-Gerät gelten die folgenden Systemanforderungen:
- **Softwareanforderungen für Hosts**: Beschreibt die unterstützten Plattformen, Browser für die lokale Webbenutzeroberfläche, SMB-Clients und alle zusätzlichen Anforderungen an Hosts, die sich mit dem Gerät verbinden.
- **Netzwerkanforderungen für das Gerät**: Liefert Informationen zu den Netzwerkanforderungen für den Betrieb des Geräts.
## <a name="specifications-for-the-virtual-device"></a>Spezifikationen für das virtuelle Gerät
Das dem Data Box Gateway zugrunde liegende Hostsystem ist in der Lage, die folgenden Ressourcen für die Bereitstellung Ihres virtuellen Geräts zuzuordnen:
| Spezifikationen | BESCHREIBUNG |
|---------------------------------------------------------|--------------------------|
| Virtuelle Prozessoren (Kerne) | Mindestens 4 |
| Arbeitsspeicher | Mindestens 8 GB|
| Verfügbarkeit|Einzelner Knoten|
| Datenträger| Betriebssystemdatenträger: 250 GB <br> Datenträger für Daten: Mindestens 2 TB, für schlanke Speicherzuweisung geeignet, muss durch SSD-Datenträger unterstützt werden|
| Netzwerkschnittstellen|Mindestens eine virtuelle Netzwerkschnittstelle|
## <a name="supported-os-for-clients-connected-to-device"></a>Unterstütztes Betriebssystem für Clients, die mit dem Gerät verbunden sind
[!INCLUDE [Supported OS for clients connected to device](../../includes/data-box-edge-gateway-supported-client-os.md)]
## <a name="supported-protocols-for-clients-accessing-device"></a>Unterstützte Protokolle für Clients, die auf das Gerät zugreifen
[!INCLUDE [Supported protocols for clients accessing device](../../includes/data-box-edge-gateway-supported-client-protocols.md)]
## <a name="supported-virtualization-platforms-for-device"></a>Unterstützte Virtualisierungsplattformen für das Gerät
| **Betriebssystem/-plattform** |**Versionen** |**Hinweise** |
|---------|---------|---------|
|Hyper-V | 2012 R2 <br> 2016 <br> 2019 | |
|VMware ESXi | 6.0 <br> 6,5 <br> 6.7 |VMware-Tools werden nicht unterstützt. |
## <a name="supported-storage-accounts"></a>Unterstützte Speicherkonten
[!INCLUDE [Supported storage accounts](../../includes/data-box-edge-gateway-supported-storage-accounts.md)]
## <a name="supported-storage-types"></a>Unterstützte Speichertypen
[!INCLUDE [Supported storage types](../../includes/data-box-edge-gateway-supported-storage-types.md)]
## <a name="supported-browsers-for-local-web-ui"></a>Unterstützte Browser für die lokale Webbenutzeroberfläche
[!INCLUDE [Supported browsers for local web UI](../../includes/data-box-edge-gateway-supported-browsers.md)]
## <a name="networking-port-requirements"></a>Anforderungen für den Netzwerkport
In der folgenden Tabelle sind die Ports aufgeführt, die in der Firewall für SMB-, Cloud- oder Verwaltungsdatenverkehr geöffnet werden müssen. In dieser Tabelle bezieht sich *ein* oder *eingehend* auf die Richtung, aus der eingehende Clientanforderungen auf das Gerät zugreifen. Entsprechend bezieht sich *aus* oder *ausgehend* auf die Richtung, in der das Data Box Gateway-Gerät Daten über die Bereitstellung hinaus an externe Ziele sendet: z.B. ausgehende Verbindungen mit dem Internet.
[!INCLUDE [Port configuration for device](../../includes/data-box-edge-gateway-port-config.md)]
## <a name="url-patterns-for-firewall-rules"></a>URL-Muster für Firewallregeln
Netzwerkadministratoren können häufig erweiterte, auf den URL-Mustern basierende Firewallregeln konfigurieren, die zum Filtern des eingehenden und ausgehenden Verkehrs verwendet werden. Ihr Data Box Gateway-Gerät und der Data Box Gateway-Dienst hängen von anderen Microsoft-Anwendungen wie Azure Service Bus, Azure Active Directory Access Control, Speicherkonten und Microsoft Update-Servern ab. Die URL-Muster, die diesen Anwendungen zugeordnet sind, können verwendet werden, um Firewallregeln zu konfigurieren. Es ist wichtig, zu verstehen, dass sich diese den Anwendungen zugeordneten URL-Muster ändern können. Das bedeutet, dass der Netzwerkadministrator die Firewallregeln für Ihr Data Box Gateway bei Bedarf überwachen und aktualisieren muss.
Es empfiehlt sich, die Firewallregeln für den ausgehenden Verkehr basierend auf den festen IP-Adressen für Data Box Gateway in den meisten Fällen recht locker festzulegen. Sie können jedoch die folgenden Informationen verwenden, um erweiterte Firewallregeln festzulegen, die erforderlich sind, um sichere Umgebungen zu erstellen.
> [!NOTE]
> - Die Geräte-IPs (Quell-IPs) sollten immer für alle cloudaktivierten Netzwerkschnittstellen eingerichtet sein.
> - Die Ziel-IPs sollten auf die [IP-Bereiche des Azure-Datencenters](https://www.microsoft.com/download/confirmation.aspx?id=41653) festgelegt werden.
[!INCLUDE [URL patterns for firewall](../../includes/data-box-edge-gateway-url-patterns-firewall.md)]
### <a name="url-patterns-for-azure-government"></a>URL-Muster für Azure Government
[!INCLUDE [Azure Government URL patterns for firewall](../../includes/data-box-edge-gateway-gov-url-patterns-firewall.md)]
## <a name="internet-bandwidth"></a>Internetbandbreite
[!INCLUDE [Internet bandwidth](../../includes/data-box-edge-gateway-internet-bandwidth.md)]
## <a name="next-step"></a>Nächster Schritt
* [Bereitstellen Ihres Azure Data Box-Gateways](data-box-gateway-deploy-prep.md)
| 64.78 | 748 | 0.772461 | deu_Latn | 0.96047 |
9717de0964ba39f504b83e73e64af540c9c4e9a0 | 18,380 | md | Markdown | articles/cloud-services/cloud-services-model-and-package.md | wreyesus/azure-content-eses-articles-app-service-web-app-service-web-staged-publishing-realworld-scenarios.md | addd81caca263120e230109b811593b939994ebb | [
"CC-BY-3.0"
] | null | null | null | articles/cloud-services/cloud-services-model-and-package.md | wreyesus/azure-content-eses-articles-app-service-web-app-service-web-staged-publishing-realworld-scenarios.md | addd81caca263120e230109b811593b939994ebb | [
"CC-BY-3.0"
] | null | null | null | articles/cloud-services/cloud-services-model-and-package.md | wreyesus/azure-content-eses-articles-app-service-web-app-service-web-staged-publishing-realworld-scenarios.md | addd81caca263120e230109b811593b939994ebb | [
"CC-BY-3.0"
] | null | null | null | <properties
pageTitle="Qué es un modelo y un paquete de servicio en la nube en Azure | Microsoft Azure"
description="Describe el modelo (.csdef, .cscfg) y el paquete (.cspkg) de servicio en la nube en Azure"
services="cloud-services"
documentationCenter=""
authors="Thraka"
manager="timlt"
editor=""/>
<tags
ms.service="cloud-services"
ms.workload="tbd"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="09/06/2016"
ms.author="adegeo"/>
# ¿Qué es el modelo de servicio en la nube y cómo se empaqueta?
Un servicio en la nube se crea a partir de tres componentes: la definición de servicio _(.csdef)_, la configuración de servicio _(.cscfg)_ y un paquete de servicio _(.cspkg)_. Los archivos **ServiceDefinition.csdef** y **ServiceConfig.cscfg** se basan ambos en XML y describen la estructura del servicio en la nube y cómo se configura; lo que se conoce en conjunto como modelo. **ServicePackage.cspkg** es un archivo ZIP que se genera a partir de **ServiceDefinition.csdef** y, entre otras cosas, contiene todas las dependencias necesarias basadas en archivos binarios. Azure crea un servicio en la nube a partir de **ServicePackage.cspkg** y **ServiceConfig.cscfg**.
Una vez que se ejecuta el servicio en la nube en Azure, puede volver a configurarlo mediante el archivo **ServiceConfig.cscfg**, pero no puede alterar la definición.
## ¿Sobre qué le gustaría saber más?
* Quiero saber más sobre los archivos [ServiceDefinition.csdef](#csdef) y [ServiceConfig.cscfg](#cscfg).
* Eso ya lo sé. Deme [algunos ejemplos](#next-steps) sobre lo que puedo configurar.
* Quiero crear el archivo [ServicePackage.cspkg](#cspkg).
* Estoy usando Visual Studio y quiero...
* [Crear un nuevo servicio en la nube][vs_create]
* [Volver a configurar un servicio en la nube existente][vs_reconfigure]
* [Implementar un proyecto de servicio en la nube][vs_deploy]
* [Escritorio remoto en una instancia de servicio en la nube][remotedesktop]
<a name="csdef"></a>
## ServiceDefinition.csdef
El archivo **ServiceDefinition.csdef** especifica los valores que usa Azure para configurar un servicio en la nube. El [esquema de definición de servicio de Azure (archivo .csdef)](https://msdn.microsoft.com/library/azure/ee758711.aspx) proporciona el formato permitido para un archivo de definición de servicio. En el ejemplo siguiente se muestra la configuración que se puede definir para los roles web y de trabajo:
```xml
<?xml version="1.0" encoding="utf-8"?>
<ServiceDefinition name="MyServiceName" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WebRole name="WebRole1" vmsize="Medium">
<Sites>
<Site name="Web">
<Bindings>
<Binding name="HttpIn" endpointName="HttpIn" />
</Bindings>
</Site>
</Sites>
<Endpoints>
<InputEndpoint name="HttpIn" protocol="http" port="80" />
<InternalEndpoint name="InternalHttpIn" protocol="http" />
</Endpoints>
<Certificates>
<Certificate name="Certificate1" storeLocation="LocalMachine" storeName="My" />
</Certificates>
<Imports>
<Import moduleName="Connect" />
<Import moduleName="Diagnostics" />
<Import moduleName="RemoteAccess" />
<Import moduleName="RemoteForwarder" />
</Imports>
<LocalResources>
<LocalStorage name="localStoreOne" sizeInMB="10" />
<LocalStorage name="localStoreTwo" sizeInMB="10" cleanOnRoleRecycle="false" />
</LocalResources>
<Startup>
<Task commandLine="Startup.cmd" executionContext="limited" taskType="simple" />
</Startup>
</WebRole>
<WorkerRole name="WorkerRole1">
<ConfigurationSettings>
<Setting name="DiagnosticsConnectionString" />
</ConfigurationSettings>
<Imports>
<Import moduleName="RemoteAccess" />
<Import moduleName="RemoteForwarder" />
</Imports>
<Endpoints>
<InputEndpoint name="Endpoint1" protocol="tcp" port="10000" />
<InternalEndpoint name="Endpoint2" protocol="tcp" />
</Endpoints>
</WorkerRole>
</ServiceDefinition>
```
Puede hacer referencia al [[esquema de definición de servicio]] para entender mejor el esquema XML que se usa aquí; sin embargo, a continuación se da una explicación rápida de algunos de los elementos:
**Sites** contiene las definiciones de sitios web o aplicaciones web que se hospedan en IIS7.
**InputEndpoints** contiene las definiciones de los extremos que se usan para ponerse en contacto con el servicio en la nube.
**InternalEndpoints** contiene las definiciones de los extremos que se usan en las instancias de rol para comunicarse entre sí.
**ConfigurationSettings** contiene las definiciones de configuración de las características de un rol concreto.
**Certificates** contiene las definiciones de los certificados que son necesarios para un rol. En el ejemplo de código anterior se muestra un certificado que se usa para la configuración de Azure Connect.
**LocalResources** contiene las definiciones de los recursos de almacenamiento local. Un recurso de almacenamiento local es un directorio reservado en el sistema de archivos de la máquina virtual en la que se ejecuta una instancia de un rol.
**Imports** contiene las definiciones de los módulos importados. El ejemplo de código anterior muestra los módulos de Conexión a Escritorio remoto y Azure Connect.
**Startup** contiene las tareas que se ejecutan cuando se inicia el rol. Las tareas se definen en un archivo ejecutable o .cmd.
<a name="cscfg"></a>
## ServiceConfiguration.cscfg
La configuración de los valores del servicio en la nube viene determinada por los valores del archivo **ServiceConfiguration.cscfg**. Especifique el número de instancias que desea implementar para cada rol en este archivo. Los valores de configuración que ha definido en el archivo de definición de servicio se agregan al archivo de configuración de servicio. Las huellas digitales de los certificados de administración que están asociados con el servicio en la nube también se agregan al archivo. El [esquema de configuración de servicio de Azure (archivo .cscfg)](https://msdn.microsoft.com/library/azure/ee758710.aspx) proporciona el formato permitido para un archivo de configuración de servicio.
El archivo de configuración de servicio no se empaqueta con la aplicación, sino que se carga en Azure como un archivo independiente y se usa para configurar el servicio en la nube. Puede cargar un nuevo archivo de configuración de servicio sin volver a implementar el servicio en la nube. Los valores de configuración del servicio en la nube pueden cambiarse mientras el servicio en la nube se está ejecutando. En el ejemplo siguiente se muestran los valores de configuración que se pueden definir para los roles web y de trabajo:
```xml
<?xml version="1.0"?>
<ServiceConfiguration serviceName="MyServiceName" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration">
<Role name="WebRole1">
<Instances count="2" />
<ConfigurationSettings>
<Setting name="SettingName" value="SettingValue" />
</ConfigurationSettings>
<Certificates>
<Certificate name="CertificateName" thumbprint="CertThumbprint" thumbprintAlgorithm="sha1" />
<Certificate name="Microsoft.WindowsAzure.Plugins.RemoteAccess.PasswordEncryption"
thumbprint="CertThumbprint" thumbprintAlgorithm="sha1" />
</Certificates>
</Role>
</ServiceConfiguration>
```
Puede hacer referencia al [esquema de configuración de servicio](https://msdn.microsoft.com/library/azure/ee758710.aspx) para comprender mejor el esquema XML que se usa aquí; sin embargo, a continuación se da una explicación rápida de los elementos:
**Instances** configura el número de instancias en ejecución para el rol. Para evitar la posibilidad de que el servicio en la nube deje de estar disponible durante las actualizaciones, es recomendable que implemente más de una instancia de los roles accesibles a través de web. Al hacerlo, estará siguiendo las instrucciones del [contrato de nivel de servicio (SLA) de Cálculo de Azure](http://azure.microsoft.com/support/legal/sla/), que garantiza la conectividad externa del 99,95 % para los roles accesibles a través de Internet cuando se implementan dos o más instancias de rol para un servicio.
**ConfigurationSettings** configura los valores de las instancias en ejecución de un rol. El nombre de los elementos `<Setting>` debe coincidir con las definiciones de configuración del archivo de definición de servicio.
**Certificates** configura los certificados usados por el servicio. En el ejemplo de código anterior se muestra cómo definir el certificado para el módulo RemoteAccess. El valor del atributo *thumbprint* debe establecerse en la huella digital del certificado que se va a usar.
<p/>
>[AZURE.NOTE] La huella digital del certificado puede agregarse al archivo de configuración mediante un editor de texto, o el valor se puede agregar en la pestaña el**Certificados** de la página **Propiedades** del rol en Visual Studio.
## Definición de los puertos de las instancias de rol
Azure permite un solo punto de entrada a un rol web. Esto significa que todo el tráfico se produce a través de una dirección IP. Puede configurar sus sitios web para que compartan un puerto configurando el encabezado host para dirigir la solicitud a la ubicación correcta. También puede configurar las aplicaciones para que escuchen en puertos conocidos de la dirección IP.
En el ejemplo siguiente se muestra la configuración de un rol web con un sitio web y una aplicación web. El sitio web se configura como la ubicación de entrada predeterminada en el puerto 80 y las aplicaciones web se configuran para recibir solicitudes de un encabezado host alternativo que se llama "mail.mysite.cloudapp.net".
```xml
<WebRole>
<ConfigurationSettings>
<Setting name="DiagnosticsConnectionString" />
</ConfigurationSettings>
<Endpoints>
<InputEndpoint name="HttpIn" protocol="http" <mark>port="80"</mark> />
<InputEndpoint name="Https" protocol="https" port="443" certificate="SSL"/>
<InputEndpoint name="NetTcp" protocol="tcp" port="808" certificate="SSL"/>
</Endpoints>
<LocalResources>
<LocalStorage name="Sites" cleanOnRoleRecycle="true" sizeInMB="100" />
</LocalResources>
<Site name="Mysite" packageDir="Sites\Mysite">
<Bindings>
<Binding name="http" endpointName="HttpIn" />
<Binding name="https" endpointName="Https" />
<Binding name="tcp" endpointName="NetTcp" />
</Bindings>
</Site>
<Site name="MailSite" packageDir="MailSite">
<Bindings>
<Binding name="mail" endpointName="HttpIn" <mark>hostheader="mail.mysite.cloudapp.net"</mark> />
</Bindings>
<VirtualDirectory name="artifacts" />
<VirtualApplication name="storageproxy">
<VirtualDirectory name="packages" packageDir="Sites\storageProxy\packages"/>
</VirtualApplication>
</Site>
</WebRole>
```
## Cambio de la configuración de un rol
Puede actualizar la configuración de su servicio en la nube mientras se ejecuta en Azure, sin necesidad de desconectarlo. Para cambiar la información de configuración, puede cargar un nuevo archivo de configuración, o editar el archivo de configuración existente y aplicarlo al servicio en ejecución. Pueden realizarse los siguientes cambios en la configuración de un servicio:
- **Cambiar los valores de configuración**: cuando los valores de una configuración cambian, una instancia de rol puede elegir aplicar el cambio mientras la instancia está en línea, o bien reciclar la instancia correctamente y aplicar el cambio mientras la instancia está sin conexión.
- **Cambiar la topología de servicio de las instancias de rol**: los cambios en la topología no afectan a las instancias en ejecución, excepto donde se vaya a eliminar una instancia. Por lo general, el resto de instancias no es necesario reciclarlas; sin embargo, puede decidir hacerlo en respuesta a un cambio en la topología.
- **Cambiar la huella digital del certificado**: solo puede actualizar un certificado cuando una instancia de rol está sin conexión. Si un certificado se agrega, elimina o cambia mientras la instancia de rol está en línea, Azure dejará la instancia sin conexión para actualizar el certificado y la volverá a poner en línea una vez completado el cambio.
### Control de los cambios de configuración con eventos de tiempo de ejecución de servicio
La [biblioteca de tiempo de ejecución de Azure](https://msdn.microsoft.com/library/azure/mt419365.aspx) incluye el espacio de nombres [Microsoft.WindowsAzure.ServiceRuntime](https://msdn.microsoft.com/library/azure/microsoft.windowsazure.serviceruntime.aspx), que proporciona clases para interactuar con el entorno de Azure desde el código que se ejecuta en una instancia de un rol. La clase [RoleEnvironment](https://msdn.microsoft.com/library/azure/microsoft.windowsazure.serviceruntime.roleenvironment.aspx) define los siguientes eventos que se producen antes y después de un cambio de configuración:
- **[Evento](https://msdn.microsoft.com/library/azure/microsoft.windowsazure.serviceruntime.roleenvironment.changing.aspx) Changing**: se produce antes de que el cambio de configuración se aplique a una instancia especificada de un rol, lo que le ofrece la oportunidad de dar de baja las instancias de rol, en caso necesario.
- **[Evento](https://msdn.microsoft.com/library/azure/microsoft.windowsazure.serviceruntime.roleenvironment.changed.aspx) Changed**: se produce después de que el cambio de configuración se aplica a una instancia especificada de un rol.
> [AZURE.NOTE] Dado que los cambios de certificado siempre ponen las instancias de un rol sin conexión, no producen los eventos RoleEnvironment.Changing o RoleEnvironment.Changed.
<a name="cspkg"></a>
## ServicePackage.cspkg
Para implementar una aplicación como un servicio en la nube de Azure, primero debe empaquetar la aplicación en el formato adecuado. Puede usar la herramienta de línea de comandos **CSPack** (que se instala con el [SDK de Azure](https://azure.microsoft.com/downloads/)) para crear el archivo de paquete como una alternativa a Visual Studio.
**CSPack** usa el contenido del archivo de configuración de servicio y del archivo de definición de servicio para definir el contenido del paquete. **CSPack** genera un archivo de paquete de aplicación (.cspkg) que puede cargar en Azure mediante el [Portal de Azure](cloud-services-how-to-create-deploy-portal.md#create-and-deploy). De forma predeterminada, el paquete se denomina `[ServiceDefinitionFileName].cspkg`, pero puede especificar un nombre diferente mediante la opción `/out` de **CSPack**.
**CSPack** generalmente se encuentra en `C:\Program Files\Microsoft SDKs\Azure\.NET SDK[sdk-version]\bin`.
>[AZURE.NOTE]
CSPack.exe (en Windows) está disponible cuando se ejecuta el acceso directo del **símbolo del sistema de Microsoft Azure** que se instala con el SDK.
>
>Ejecute el programa CSPack.exe por sí solo para ver documentación sobre todos los comandos y modificadores posibles.
<p />
>[AZURE.TIP]
Ejecute su servicio en la nube localmente en el **emulador de proceso de Microsoft Azure**, use la opción **/copyonly**. Esta opción copia los archivos binarios de la aplicación en un esquema de directorio desde el que se pueden ejecutar en el emulador de proceso.
### Comando de ejemplo para empaquetar un servicio en la nube
En el ejemplo siguiente se crea un paquete de aplicación que contiene la información de un rol web. El comando especifica el archivo de definición de servicio que se usará, el directorio donde se pueden encontrar los archivos binarios y el nombre del archivo de paquete.
cspack [DirectoryName][ServiceDefinition]
/role:[RoleName];[RoleBinariesDirectory]
/sites:[RoleName];[VirtualPath];[PhysicalPath]
/out:[OutputFileName]
Si la aplicación contiene un rol web y un rol de trabajo, se usa el siguiente comando:
cspack [DirectoryName][ServiceDefinition]
/out:[OutputFileName]
/role:[RoleName];[RoleBinariesDirectory]
/sites:[RoleName];[VirtualPath];[PhysicalPath]
/role:[RoleName];[RoleBinariesDirectory];[RoleAssemblyName]
Donde las variables se definen como de la manera siguiente:
| Variable | Valor |
| ------------------------- | ----- |
| [DirectoryName] | El subdirectorio bajo el directorio raíz del proyecto que contiene el archivo .csdef del proyecto de Azure.|
| [ServiceDefinition] | El nombre del archivo de definición de servicio. De forma predeterminada, este archivo se denomina ServiceDefinition.csdef. |
| [OutputFileName] | El nombre del archivo de paquete generado. Normalmente, se establece en el nombre de la aplicación. Si no se especifica ningún nombre de archivo, el paquete de aplicación se crea como [ApplicationName].cspkg.|
| [RoleName] | El nombre del rol, tal y como se define en el archivo de definición de servicio.|
| [RoleBinariesDirectory] | La ubicación de los archivos binarios para el rol.|
| [VirtualPath] | Los directorios físicos de cada ruta de acceso virtual definida en la sección Sites de la definición de servicio.|
| [PhysicalPath] | Los directorios físicos del contenido de cada ruta de acceso virtual definida en el nodo de sitio de la definición de servicio.|
| [RoleAssemblyName] | El nombre del archivo binario del rol.|
## Pasos siguientes
Voy a crear un paquete de servicio en la nube y quiero...
* [Configurar Escritorio remoto para una instancia de servicio en la nube][remotedesktop]
* [Implementar un proyecto de servicio en la nube][deploy]
Estoy usando Visual Studio y quiero...
* [Crear un nuevo servicio en la nube][vs_create]
* [Volver a configurar un servicio en la nube existente][vs_reconfigure]
* [Implementar un proyecto de servicio en la nube][vs_deploy]
* [Configurar Escritorio remoto para una instancia de servicio en la nube][vs_remote]
[deploy]: cloud-services-how-to-create-deploy-portal.md
[remotedesktop]: cloud-services-role-enable-remote-desktop.md
[vs_remote]: ../vs-azure-tools-remote-desktop-roles.md
[vs_deploy]: ../vs-azure-tools-cloud-service-publish-set-up-required-services-in-visual-studio.md
[vs_reconfigure]: ../vs-azure-tools-configure-roles-for-cloud-service.md
[vs_create]: ../vs-azure-tools-azure-project-create.md
<!---HONumber=AcomDC_0914_2016--> | 68.327138 | 700 | 0.764146 | spa_Latn | 0.984119 |
9718a4c3daf701a6e75b8d2a5972cdc813982983 | 4,965 | md | Markdown | public/assets/vendors/update/README.md | croize/myjejaringwebsite | 4ae4d02adff068697e5c3ec942b5c8d67abec9b9 | [
"MIT"
] | 2 | 2018-01-30T05:43:39.000Z | 2018-02-07T12:21:39.000Z | public/assets/vendors/update/README.md | croize/myjejaringwebsite | 4ae4d02adff068697e5c3ec942b5c8d67abec9b9 | [
"MIT"
] | null | null | null | public/assets/vendors/update/README.md | croize/myjejaringwebsite | 4ae4d02adff068697e5c3ec942b5c8d67abec9b9 | [
"MIT"
] | 3 | 2021-04-25T09:57:34.000Z | 2021-12-05T12:33:20.000Z | # update [](https://www.npmjs.com/package/update) [](https://travis-ci.org/update/update)
> Easily keep anything in your project up-to-date by installing the updaters you want to use and running `update` in the command line! Update the copyright date, licence type, ensure that a project uses your latest eslint or jshint configuration, remove deprecated package.json fields, or anything you can think of!
## CLI
### Install
Install globally with [npm](https://www.npmjs.com/)
```sh
$ npm i -g update
```
### Commands
```sh
$ update <command> [options]
```
**List updaters**
Choose from a list of updaters and tasks to run:
```sh
$ update list
```
**Run a specific updater**
The following would run updater `foo`:
```sh
$ update foo
# run updater "foo" with options
$ update foo --bar=baz
```
### tasks
_(TODO)_
### plugins
_(TODO)_
#### pipeline plugins
_(TODO)_
#### instance plugins
_(TODO)_
### middleware
A middleware is a function that exposes the following parameters:
* `file`: **{Object}** [vinyl](http://github.com/gulpjs/vinyl) file object
* `next`: **{Function}** must be called to continue on to the next file.
```js
function rename(file, next) {
file.path = 'foo/' + file.path;
next();
}
// example usage: prefix all `.js` file paths with `foo/`
app.onLoad(/\.js/, rename);
```
The `onStream` method is a custom [middleware](docs/middleware.md) handler that the `update`
```js
app.onStream(/lib\//, rename);
```
## API
### Install
Install with [npm](https://www.npmjs.com/):
```sh
$ npm i update --save
```
```js
var update = require('update');
```
## API
### [Update](index.js#L30)
Create an `update` application. This is the main function exported by the update module.
**Params**
* `options` **{Object}**
**Example**
```js
var Update = require('update');
var update = new Update();
```
## Related projects
* [assemble](https://www.npmjs.com/package/assemble): Assemble is a powerful, extendable and easy to use static site generator for node.js. Used… [more](https://www.npmjs.com/package/assemble) | [homepage](https://github.com/assemble/assemble)
* [boilerplate](https://www.npmjs.com/package/boilerplate): Tools and conventions for authoring and publishing boilerplates that can be generated by any build… [more](https://www.npmjs.com/package/boilerplate) | [homepage](http://boilerplates.io)
* [composer](https://www.npmjs.com/package/composer): API-first task runner with three methods: task, run and watch. | [homepage](https://github.com/jonschlinkert/composer)
* [generate](https://www.npmjs.com/package/generate): Fast, composable, highly extendable project generator with a user-friendly and expressive API. | [homepage](https://github.com/generate/generate)
* [scaffold](https://www.npmjs.com/package/scaffold): Conventions and API for creating declarative configuration objects for project scaffolds - similar in format… [more](https://www.npmjs.com/package/scaffold) | [homepage](https://github.com/jonschlinkert/scaffold)
* [templates](https://www.npmjs.com/package/templates): System for creating and managing template collections, and rendering templates with any node.js template engine.… [more](https://www.npmjs.com/package/templates) | [homepage](https://github.com/jonschlinkert/templates)
* [update](https://www.npmjs.com/package/update): Update | [homepage](https://github.com/jonschlinkert/update)
* [verb](https://www.npmjs.com/package/verb): Documentation generator for GitHub projects. Verb is extremely powerful, easy to use, and is used… [more](https://www.npmjs.com/package/verb) | [homepage](https://github.com/verbose/verb)
## Authoring
### Updaters
_(TODO)_
#### Tasks
_(TODO)_
#### Middleware
_(TODO)_
#### Plugins
> Updater plugins follow the same signature as gulp plugins
**Example**
```js
function myPlugin(options) {
return through.obj(function(file, enc, next) {
var str = file.contents.toString();
// do stuff to `file`
file.contents = new Buffer(file.contents);
next(null, file);
});
}
```
### Publish
1. Name your project following the convention: `updater-*`
2. Don't use dots in the name (e.g `.js`)
3. Make sure you add `updater` to the keywords in `package.json`
4. Tweet about your updater!
## Running tests
Install dev dependencies:
```sh
$ npm i -d && npm test
```
## Contributing
Pull requests and stars are always welcome. For bugs and feature requests, [please create an issue](https://github.com/jonschlinkert/update/issues/new).
## Author
**Jon Schlinkert**
* [github/jonschlinkert](https://github.com/jonschlinkert)
* [twitter/jonschlinkert](http://twitter.com/jonschlinkert)
## License
Copyright © 2016 [Jon Schlinkert](https://github.com/jonschlinkert)
Released under the MIT license.
***
_This file was generated by [verb](https://github.com/verbose/verb) on January 09, 2016._ | 26.837838 | 315 | 0.712387 | eng_Latn | 0.495434 |
9718d28aac1f13fc797e76bd3d865c3ec24f6fe9 | 1,871 | md | Markdown | sota-guides/Nettle Creek Bald (W4C_WM-027).md | k4kpk/k4kpk.github.io | 31c1ff28f1c7691c91e05bf31bbc100aeceda967 | [
"CC-BY-4.0"
] | null | null | null | sota-guides/Nettle Creek Bald (W4C_WM-027).md | k4kpk/k4kpk.github.io | 31c1ff28f1c7691c91e05bf31bbc100aeceda967 | [
"CC-BY-4.0"
] | 4 | 2020-08-25T22:13:01.000Z | 2021-06-30T16:45:38.000Z | sota-guides/Nettle Creek Bald (W4C_WM-027).md | k4kpk/k4kpk.github.io | 31c1ff28f1c7691c91e05bf31bbc100aeceda967 | [
"CC-BY-4.0"
] | null | null | null | ---
layout: sota-guide
---
SOTA Guide - Nettle Creek Bald, W4C/WM-027
#### Drive Guide - Nettle Creek Bald from Atlanta
* **Duration**: 3:00
* **Google Maps** URL from Atlanta (33.917, -84.3378): http://goo.gl/maps/ZALRL
* **Seasonal/Limited Access**:
* **Directions**:
* I-285 to I-85 North
* I-985 to GA-365 to US-441 North. Follow US-441 as it turns/exits.
* After you turn Left in Cherokee to parallel the river, it is 15.7 miles to the trailhead
* **Food**
* Last McDonalds:
* Dinner
#### Drive Guide - Nettle Creek Bald from Cowee Bald
* **Duration**: 1:50, 60 miles (actual 2014 drive time)
* **Google Maps**: http://goo.gl/maps/VHp0e
* **Directions**:
* Head away from gate and go 1.3
* Side road merges from R. Go straight 2.7
* Side road merges from L. Keep R and go 2.5
* S onto pavement and go 1.3
* S on Leatherman Gap Rd and go 1.2
* R on Cowee Creek Rd and go 1.5
* S on NC-28 S and go 2.0
* L on Sanderstown Rd (at Recycle Center) and go 3.2
* L on US-441 N and go 14.4
* S on US-74 W and go 7.4
* Bear R on US-441 N and go 5.1
* R on US-19 N and go 0.5
* L on US-441 N and go 15.7
* Park on Left. Small sign on L, "Thomas Divide Trail"
#### Drive Guide - Nettle Creek Bald from Clingman's Dome
* **Duration**: 0:25
* **Google Maps**: http://goo.gl/maps/p6AqR
#### Trail Guide
* **Duration**: 2.2 miles, 1:15 in, 1:00 out (comfortable); 1:05 in and 0:50 out really hurrying
* **Navigation**
* Follow Thomas Divide Trail south from the hairpin turn on US-441. (Leaves from behind the sign at the parking area)
* **Trailhead altitude**: 4642
* **Summit altitude**: 5180
* **GPS tracks/waypoints**:
* Trailhead: 35.58578,-83.39884
* Summit: 35.5666, -83.3819
#### Summit Guide
* Hang antenna from tree: yes
* Space to guy mast: yes
* Cell coverage: VZN=intermittent, AT&T not tested
| 30.672131 | 121 | 0.651523 | eng_Latn | 0.705177 |
97194c513389d62a09b002d8452ad78b571cb71c | 43 | md | Markdown | README.md | react-pure/react-pure | bcf78947b0205074bc37299abef667d592207dfa | [
"MIT"
] | null | null | null | README.md | react-pure/react-pure | bcf78947b0205074bc37299abef667d592207dfa | [
"MIT"
] | null | null | null | README.md | react-pure/react-pure | bcf78947b0205074bc37299abef667d592207dfa | [
"MIT"
] | null | null | null | # react-pure
React Components for Pure CSS
| 14.333333 | 29 | 0.790698 | eng_Latn | 0.760096 |
971973ced66cc75f9805d665af566f6fe3ac6d0a | 6,237 | md | Markdown | docs/concepts/09-serializing.md | McCarthyFinch/slate | c290edca41c2afdc08ab720123260cf7e3152f87 | [
"MIT"
] | null | null | null | docs/concepts/09-serializing.md | McCarthyFinch/slate | c290edca41c2afdc08ab720123260cf7e3152f87 | [
"MIT"
] | null | null | null | docs/concepts/09-serializing.md | McCarthyFinch/slate | c290edca41c2afdc08ab720123260cf7e3152f87 | [
"MIT"
] | null | null | null | # Serializing
Slate's data model has been built with serialization in mind. Specifically, its text nodes are defined in a way that makes them easier to read at a glance, but also easy to serialize to common formats like HTML and Markdown.
And, because Slate uses plain JSON for its data, you can write serialization logic very easily.
## Plaintext
For example, taking the value of an editor and returning plaintext:
```js
import { Node } from '@mccarthyfinch/slate'
const serialize = nodes => {
return nodes.map(n => Node.string(n)).join('\n')
}
```
Here we're taking the children nodes of an `Editor` as a `nodes` argument, and returning a plaintext representation where each top-level node is separated by a single `\n` new line character.
For an input of:
```js
const nodes = [
{
type: 'paragraph',
children: [{ text: 'An opening paragraph...' }],
},
{
type: 'quote',
children: [{ text: 'A wise quote.' }],
},
{
type: 'paragraph',
children: [{ text: 'A closing paragraph!' }],
},
]
```
You'd end up with:
```txt
An opening paragraph...
A wise quote.
A closing paragraph!
```
Notice how the quote block isn't distinguishable in any way, that's because we're talking about plaintext. But you can serialize the data to anything you want—it's just JSON after all.
## HTML
For example, here's a similar `serialize` function for HTML:
```js
import escapeHtml from 'escape-html'
import { Node, Text } from '@mccarthyfinch/slate'
const serialize = node => {
if (Text.isText(node)) {
return escapeHtml(node.text)
}
const children = node.children.map(n => serialize(n)).join('')
switch (node.type) {
case 'quote':
return `<blockquote><p>${children}</p></blockquote>`
case 'paragraph':
return `<p>${children}</p>`
case 'link':
return `<a href="${escapeHtml(node.url)}">${children}</a>`
default:
return children
}
}
```
This one is a bit more aware than the plaintext serializer above. It's actually _recursive_ so that it can keep iterating deeper through a node's children until it gets to the leaf text nodes. And for each node it receives, it converts it to an HTML string.
It also takes a single node as input instead of an array, so if you passed in an editor like:
```js
const editor = {
children: [
{
type: 'paragraph',
children: [
{ text: 'An opening paragraph with a ' },
{
type: 'link',
url: 'https://example.com',
children: [{ text: 'link' }],
},
{ text: ' in it.' },
],
},
{
type: 'quote',
children: [{ text: 'A wise quote.' }],
},
{
type: 'paragraph',
children: [{ text: 'A closing paragraph!' }],
},
],
// `Editor` objects also have other properties that are omitted here...
}
```
You'd receive back (line breaks added for legibility):
```html
<p>An opening paragraph with a <a href="https://example.com">link</a> in it.</p>
<blockquote><p>A wise quote.</p></blockquote>
<p>A closing paragraph!</p>
```
It's really that easy!
## Deserializing
Another common use case in Slate is doing the reverse—deserializing. This is when you have some arbitrary input and want to convert it into a Slate-compatible JSON structure. For example, when someone pastes HTML into your editor and you want to ensure it gets parsed with the proper formatting for your editor.
Slate has a built-in helper for this: the `slate-hyperscript` package.
The most common way to use `slate-hyperscript` is for writing JSX documents, for example when writing tests. You might use it like so:
```jsx
/** @jsx jsx */
import { jsx } from '@mccarthyfinch/slate-hyperscript'
const input = (
<fragment>
<element type="paragraph">A line of text.</element>
</fragment>
)
```
And the JSX feature of your compiler (Babel, TypeScript, etc.) would turn that `input` variable into:
```js
const input = [
{
type: 'paragraph',
children: [{ text: 'A line of text.' }],
},
]
```
This is great for test cases, or places where you want to be able to write a lot of Slate objects in a very readable form.
However! This doesn't help with deserialization.
But `slate-hyperscript` isn't only for JSX. It's just a way to build _trees of Slate content_. Which happens to be exactly what you want to do when you're deserializing something like HTML.
For example, here's a `deserialize` function for HTML:
```js
import { jsx } from '@mccarthyfinch/slate-hyperscript'
const deserialize = el => {
if (el.nodeType === 3) {
return el.textContent
} else if (el.nodeType !== 1) {
return null
}
const children = Array.from(el.childNodes).map(deserialize)
switch (el.nodeName) {
case 'BODY':
return jsx('fragment', {}, children)
case 'BR':
return '\n'
case 'BLOCKQUOTE':
return jsx('element', { type: 'quote' }, children)
case 'P':
return jsx('element', { type: 'paragraph' }, children)
case 'A':
return jsx(
'element',
{ type: 'link', url: el.getAttribute('href') },
children
)
default:
return el.textContent
}
}
```
It takes in an `el` HTML element object and returns a Slate fragment. So if you have an HTML string, you can parse and deserialize it like so:
```js
const html = '...'
const document = new DOMParser().parseFromString(html, 'text/html')
deserialize(document.body)
```
With this input:
```js
<p>An opening paragraph with a <a href="https://example.com">link</a> in it.</p>
<blockquote><p>A wise quote.</p></blockquote>
<p>A closing paragraph!</p>
```
You'd end up with this output:
```js
const fragment = [
{
type: 'paragraph',
children: [
{ text: 'An opening paragraph with a ' },
{
type: 'link',
url: 'https://example.com',
children: [{ text: 'link' }],
},
{ text: ' in it.' },
],
},
{
type: 'quote',
children: [
{
type: 'paragraph',
children: [{ text: 'A wise quote.' }],
},
],
},
{
type: 'paragraph',
children: [{ text: 'A closing paragraph!' }],
},
]
```
And just like the serializing function, you can extend it to fit your exact domain model's needs.
| 25.9875 | 311 | 0.641815 | eng_Latn | 0.971827 |
971978f0d51e537681d144c270b2d68e0432438a | 6,257 | md | Markdown | http/redirects.md | RekGRpth/everything-curl | c23de7d4e6bc69059485cdfcb691b5fb4b93baf5 | [
"CC-BY-4.0"
] | 1 | 2022-01-18T06:22:45.000Z | 2022-01-18T06:22:45.000Z | http/redirects.md | RekGRpth/everything-curl | c23de7d4e6bc69059485cdfcb691b5fb4b93baf5 | [
"CC-BY-4.0"
] | null | null | null | http/redirects.md | RekGRpth/everything-curl | c23de7d4e6bc69059485cdfcb691b5fb4b93baf5 | [
"CC-BY-4.0"
] | null | null | null | # HTTP redirects
The “redirect” is a fundamental part of the HTTP protocol. The concept was
present and is documented already in the first spec (RFC 1945), published in
1996, and it has remained well-used ever since.
A redirect is exactly what it sounds like. It is the server sending back an
instruction to the client instead of giving back the contents the client
wanted. The server says “go look over *here* instead for that thing you asked
for“.
Redirects are not all alike. How permanent is the redirect? What request
method should the client use in the next request?
All redirects also need to send back a `Location:` header with the new URI to
ask for, which can be absolute or relative.
## Permanent and temporary
Is the redirect meant to last or just remain valid for now? If you want a GET to
permanently redirect users to resource B with another GET, send
back a 301. It also means that the user-agent (browser) is meant to cache this
and keep going to the new URI from now on when the original URI is requested.
The temporary alternative is 302. Right now the server wants the client to
send a GET request to B, but it should not cache this but keep trying the
original URI when directed to it next time.
Note that both 301 and 302 will make browsers do a GET in the next request,
which possibly means changing the method if it started with a POST (and only if
POST). This changing of the HTTP method to GET for 301 and 302 responses is
said to be “for historical reasons”, but that’s still what browsers do so most
of the public web will behave this way.
In practice, the 303 code is similar to 302. It will not be cached and it will
make the client issue a GET in the next request. The differences between a 302
and 303 are subtle, but 303 seems to be more designed for an “indirect
response” to the original request rather than just a redirect.
These three codes were the only redirect codes in the HTTP/1.0 spec.
curl however, does not remember or cache any redirects at all so to it,
there's really no difference between permanent and temporary redirects.
## Tell curl to follow redirects
In curl's tradition of only doing the basics unless you tell it differently,
it does not follow HTTP redirects by default. Use the `-L, --location` to tell
it to do that.
When following redirects is enabled, curl will follow up to 50 redirects by
default. There's a maximum limit mostly to avoid the risk of getting caught in
endless loops. If 50 is not sufficient for you, you can change the maximum
number of redirects to follow with the `--max-redirs` option.
## GET or POST?
All three of these response codes, 301 and 302/303, will assume that the
client sends a GET to get the new URI, even if the client might have sent a
POST in the first request. This is important, at least if you do something
that does not use GET.
If the server instead wants to redirect the client to a new URI and wants it
to send the same method in the second request as it did in the first, like if
it first sent POST it’d like it to send POST again in the next request, the
server would use different response codes.
To tell the client “the URI you sent a POST to, is permanently redirected to B
where you should instead send your POST now and in the future”, the server
responds with a 308. And to complicate matters, the 308 code is only recently
defined (the [spec](https://tools.ietf.org/html/rfc7238#section-3) was
published in June 2014) so older clients may not treat it correctly! If so,
then the only response code left for you is…
The (older) response code to tell a client to send a POST also in the next
request but temporarily is 307. This redirect will not be cached by the client
though, so it’ll again post to A if requested to again. The 307 code was
introduced in HTTP/1.1.
Oh, and redirects work the same way in HTTP/2 as they do in HTTP/1.1.
| |Permanent | Temporary |
|---------------------|----------|-------------|
|Switch to GET | 301 | 302 and 303 |
|Keep original method | 308 | 307 |
### Decide what method to use in redirects
It turns out that there are web services out there in the world that want a
POST sent to the original URL, but are responding with HTTP redirects that use
a 301, 302 or 303 response codes and *still* want the HTTP client to send the
next request as a POST. As explained above, browsers won’t do that and neither
will curl—by default.
Since these setups exist, and they’re actually not terribly rare, curl offers
options to alter its behavior.
You can tell curl to not change the non-GET request method to GET after a 30x
response by using the dedicated options for that: `--post301`, `--post302` and
`--post303`. If you are instead writing a libcurl based application, you
control that behavior with the `CURLOPT_POSTREDIR` option.
## Redirecting to other host names
When you use curl you may provide credentials like user name and password for
a particular site, but since a HTTP redirect might move away to a different
host curl limits what it sends away to other hosts than the original within
the same transfer.
So if you want the credentials to also get sent to the following host names
even though they are not the same as the original—presumably because you
trust them and know that there's no harm in doing that—you can tell curl that
it is fine to do so by using the `--location-trusted` option.
# Non-HTTP redirects
Browsers support more ways to do redirects that sometimes make life
complicated to a curl user as these methods are not supported or recognized by
curl.
## HTML redirects
If the above was not enough, the web world also provides a method to redirect
browsers by plain HTML. See the example `<meta>` tag below. This is somewhat
complicated with curl since curl never parses HTML and thus has no knowledge
of these kinds of redirects.
<meta http-equiv="refresh" content="0; url=http://example.com/">
## JavaScript redirects
The modern web is full of JavaScript and as you know, JavaScript is a
language and a full run-time that allows code to execute in the browser when
visiting websites.
JavaScript also provides means for it to instruct the browser to move on to
another site—a redirect, if you will.
| 45.34058 | 80 | 0.764424 | eng_Latn | 0.999944 |
9719b4356338af504a21016fc92b9b1ad043e961 | 173 | md | Markdown | README.md | hoalby/FFmpeg-Build-Shell-Scripts | 3a65fcffff50344c920e686fa7ac6f2995384332 | [
"MIT"
] | 2 | 2019-05-05T17:17:13.000Z | 2021-03-26T13:34:02.000Z | README.md | hoalby/FFmpeg-Build-Shell-Scripts | 3a65fcffff50344c920e686fa7ac6f2995384332 | [
"MIT"
] | null | null | null | README.md | hoalby/FFmpeg-Build-Shell-Scripts | 3a65fcffff50344c920e686fa7ac6f2995384332 | [
"MIT"
] | 1 | 2021-03-26T13:34:05.000Z | 2021-03-26T13:34:05.000Z | # FFmpeg build shell scripts
## Environment
macOS 10.14</br>
Xcode 10.0
## Version
Lame 3.100</br>
FDK-AAC 0.1.6</br>
x264-snapshot-20181015-2245</br>
FFmpeg 4.0.2</br>
| 12.357143 | 32 | 0.682081 | kor_Hang | 0.184934 |
971ba60cf0a9c67819932f7b98e2d7eb420eebf0 | 1,034 | md | Markdown | _posts/2021-07-08-351745465.md | bookmana/bookmana.github.io | 2ed7b023b0851c0c18ad8e7831ece910d9108852 | [
"MIT"
] | null | null | null | _posts/2021-07-08-351745465.md | bookmana/bookmana.github.io | 2ed7b023b0851c0c18ad8e7831ece910d9108852 | [
"MIT"
] | null | null | null | _posts/2021-07-08-351745465.md | bookmana/bookmana.github.io | 2ed7b023b0851c0c18ad8e7831ece910d9108852 | [
"MIT"
] | null | null | null | ---
title: "중국 딜레마"
date: 2021-07-08 02:20:45
categories: [국내도서, 사회과학]
image: https://bimage.interpark.com/goods_image/5/4/6/5/351745465s.jpg
description: ● “2011년 초 재스민 혁명의 물결이 중동 곳곳을 뒤흔들던 때였다. 그해 3월 6일 모리화(재스민) 시위가 예고되어 있던 베이징 중심가 왕푸징으로 취재를 나갔다. 온라인에서 집회 장소라고 지목된 맥도널드와 케이에프시 매장 안의 많은 손님들은 이어폰을 귀에 꽂고 계속 주변을 살피는
---
## **정보**
- **ISBN : 9791160406177**
- **출판사 : 한겨레출판**
- **출판일 : 20210625**
- **저자 : 박민희**
------
## **요약**
● “2011년 초 재스민 혁명의 물결이 중동 곳곳을 뒤흔들던 때였다. 그해 3월 6일 모리화(재스민) 시위가 예고되어 있던 베이징 중심가 왕푸징으로 취재를 나갔다. 온라인에서 집회 장소라고 지목된 맥도널드와 케이에프시 매장 안의 많은 손님들은 이어폰을 귀에 꽂고 계속 주변을 살피는 사복경찰들이었다. 거리의 청소부들도 눈에 띄게 깔끔한 차림으로 쓰레기도 없는 도로를 빗자루로 계속 쓸면서 행인들이 모일 수 없게 했다. 공사를 하지 않는데도 거리 한가운데를 공사장 가림막으로 막았다. 살수차들은 물청소를 할 필요가 없어 보이는 거리를 계속 돌아다녔다. 모두가 연극을 하고 있었다. 시위는 없었고 권력의 불안함만 가득했다.” (6쪽) 중국은 왜 이 길을 가고 있을까중국의 발전 모델은 얼마나 지속 가능할까현대 중국...
------
“2011년 초 재스민 혁명의 물결이 중동 곳곳을 뒤흔들던 때였다. 그해 3월 6일 모리화(재스민) 시위가 예고되어 있던 베이징 중심가 왕푸징으로 취재를 나갔다. 온라인에서 집회 장소라고 지목된 맥도널드와 케이에프시 매장 안의 많은 손님들은 이어폰을 귀에 꽂고 계속 주변을 살피는...
------
중국 딜레마
------
| 28.722222 | 402 | 0.659574 | kor_Hang | 1.00001 |
971bd5f56c0e27bc7b71dee78733eb2a85cb5ca0 | 7,170 | md | Markdown | readme.md | UNIT-23/react-native-calendar-select | 6890ab5d50df45414300aa058e2a200b188c145e | [
"MIT"
] | null | null | null | readme.md | UNIT-23/react-native-calendar-select | 6890ab5d50df45414300aa058e2a200b188c145e | [
"MIT"
] | null | null | null | readme.md | UNIT-23/react-native-calendar-select | 6890ab5d50df45414300aa058e2a200b188c145e | [
"MIT"
] | null | null | null | ## react-native-calendar-select [](https://travis-ci.org/Tinysymphony/react-native-calendar-select) [](https://coveralls.io/github/Tinysymphony/react-native-calendar-select?branch=master)
A date picker component like Airbnb. You can select a date period from the calendar modal.
### Examples
#### Selection Types Example
<a href="#selectionType" id="selectionType"><img src="./screenshots/selectionTypeBtns.png" width="200"></a>
#### iOS Examples
<a href="#ios-en" id="ios-en"><img src="./screenshots/ios-en.gif" align="left" width="200"></a>
<a href="#ios-zh" id="ios-zh"><img src="./screenshots/ios-zh.gif" align="left" width="200"></a>
<a href="#ios-jp" id="ios-jp"><img src="./screenshots/ios-jp.gif" width="200"></a>
#### Android Examples
<a href="#a-en" id="a-en"><img src="./screenshots/a-en.gif" align="left" width="200"></a>
<a href="#a-zh" id="a-zh"><img src="./screenshots/a-zh.gif" align="left" width="200"></a>
<a href="#a-jp" id="a-jp"><img src="./screenshots/a-jp.gif" width="200"></a>
### Usage
> This component use `moment.js` to process date.
**install from npm**
```shell
npm install --save react-native-calendar-select
```
**import in project**
```js
import Calendar from "react-native-calendar-select"
```
```js
constructor (props) {
super(props);
this.state = {
startDate: new Date(2017, 6, 12),
endDate: new Date(2017, 8, 2)
};
this.confirmDate = this.confirmDate.bind(this);
this.openCalendar = this.openCalendar.bind(this);
}
// when confirm button is clicked, an object is conveyed to outer component
// contains following property:
// startDate [Date Object], endDate [Date Object]
// startMoment [Moment Object], endMoment [Moment Object]
confirmDate({startDate, endDate, startMoment, endMoment}) {
this.setState({
startDate,
endDate
});
}
openCalendar() {
this.calendar && this.calendar.open();
}
// in render function
render() {
// It's an optional property, I use this to show the structure of customI18n object.
let customI18n = {
'w': ['', 'Mon', 'Tues', 'Wed', 'Thur', 'Fri', 'Sat', 'Sun'],
'weekday': ['', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday'],
'text': {
'start': 'Check in',
'end': 'Check out',
'date': 'Date',
'save': 'Confirm',
'clear': 'Reset'
},
'date': 'DD / MM' // date format
};
// optional property, too.
let color = {
subColor: '#f0f0f0',
mainColor: "#f4995d"
};
return (
<View>
<Button title="Open Calendar" onPress={this.openCalendar}>
<Calendar
i18n="en"
ref={(calendar) => {this.calendar = calendar;}}
customI18n={customI18n}
color={color}
format="YYYYMMDD"
minDate="20170510"
maxDate="20180312"
startDate={this.state.startDate}
endDate={this.state.endDate}
onConfirm={this.confirmDate}
/>
</View>
);
}
```
### Properties
| Property | Type | Default | Description |
| ------------- | ----------------------------- | ------------ | ------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| i18n | String | 'en' | Language of the component, supports `en` / `zh` / `jp`. |
| dow | Number | 1 | Day of the week default is 'Monday' |
| customI18n | Object | {} | Customize text of the component, the structure of this object is shown in the example above. |
| color | Object | {} | Customize color. |
| format | string | 'YYYY-MM-DD' | Define date format, you can also pass Date Object or Moment Object as props. |
| minDate | String / Object | - | Min date of calendar |
| maxDate | String / Object | - | Max date of calendar |
| startDate | String / Object | null | Start date of selection |
| endDate | String / Object | null | End date of selection |
| onConfirm | Function | - | Callback function when the period is confirmed, receives an object as only parameter, contains `startDate` / `endDate` / `startMoment` / `endMoment` four property. |
| selectionType | enum(`manual`, `week`, `day`) | "manual" | Initial (optional) selection type can be one of `manual`, `week` and `day` |
| animationType | enum(`slide`, `fade`, `none`) | "slide" | Initial (optional) animation type can be one of `slide`, `fade` and `none` |
### Instance methods
| Method | Description |
| ------- | -------------------------------------------- |
| cancel | Cancel modification of state and close modal |
| close | Close select modal |
| open | Open select modal |
| clear | Reset state of component |
| confirm | Confirm selection and close modal |
### Color properties
| Prop | Description |
| ----------- | ----------------------------------------- |
| subColor | Sets the Text Color |
| mainColor | Sets the Background Color of the Calendar |
| borderColor | Sets the Color of the Calendar border |
LICENSE MIT
| 50.492958 | 404 | 0.439331 | eng_Latn | 0.613947 |
971d417e52aa6d9b6addff113c1bde6864d78fb0 | 5,418 | md | Markdown | _posts/2016-02-09-Objective-C_Runtime_2_Messaging_and_forwarding.md | zziking/zziking.github.com | 58ebd089ab4062ccd9f8688d643561833c34fe19 | [
"MIT"
] | null | null | null | _posts/2016-02-09-Objective-C_Runtime_2_Messaging_and_forwarding.md | zziking/zziking.github.com | 58ebd089ab4062ccd9f8688d643561833c34fe19 | [
"MIT"
] | null | null | null | _posts/2016-02-09-Objective-C_Runtime_2_Messaging_and_forwarding.md | zziking/zziking.github.com | 58ebd089ab4062ccd9f8688d643561833c34fe19 | [
"MIT"
] | null | null | null | ---
layout: post
title: Objective-C Runtime(二)OC的消息机制
fullview: true
category: iOS
tags: Runtime
keywords: Runtime,Messaging,Forwarding
---
在上一篇文章中,我们探讨了Objective-C的对象模型,在本文中我们来了解OC的一个强大的特性:消息机制,了解消息机制,可以让我们知道OC中调用一个方法会经历哪些过程。
# 消息传递(Messaging)
在C等语言中,调用一个方法就是执行内存中的一段代码,这在编译的时候就决定好了,所以没有动态的特性,而在Objective-C中,方法的调用会被编译成消息的发送,调用某个对象的方法,其实是在运行时给对象发送了一条消息, 例如,下面的代码是等价的:
```objc
[array insertObject:obj atIndex:0];
objc_msgSend(array, @selector(insertObject:atIndex:), foo, 0);
```
那么,runtime又是如何处理`objc_msgSend`发送的消息呢?从发送消息到最终的方法调用,这之间经历了一个怎样的过程?
`objc_msgSend`的源码是使用汇编写的,本人汇编渣,无法从源码角度去分析,不过从详尽的注释和相关的文档,我们可以一窥其面目,`objc_msgSend`会经过以下步骤:
1. 通过对象的`isa`指针找到对象所属的class
2. 在class的方法缓存`(objc_cache)`中查找方法,如果没有找到,则继续3、4步骤
3. 在class的`method_list`中查找方法
4. 如果class中没有找到方法,则继续往它的`super class`中查找, 直到查找到根类
5. 一旦找到方法,就去执行对应的方法实现(IMP),并把方法添加到方法缓存中
> ps,如果还不了解`isa`和OC的对象模型的,可以去看看我的上一篇文章:[Objective-C Runtime(一)对象模型及类与元类 ](http://zziking.github.io/ios/2016/02/08/Objective-C_Runtime_1_The_object_model.html)
在这个方法查找过程中,`runtime`引入了缓存机制,这是为了提高方法查找的效率,因为,如果调用的方法在根类中,那么每次方法调用都要沿着继承链去每个类的方法列表中查找一遍,效率无疑是低下的。这个方法缓存的实现,其实就是一个哈希表的存储,以`selector name`的哈希值为索引, 存储方法的实现(IMP),这样的查找效率较高,看到这里,可能有人会有疑问,既然每个`class`维护着一个方法缓存的哈希表,为什么还要维护一个方法列表`method list`呢?每次直接去哈希表里查找方法不是更快吗?
这其实是因为哈希表是一个无序表,而方法列表是一个有序列表,查找方法会顺着`method list`依次查找,这样就赋予了`category`一个特性:可以覆盖原本类的实现,而如果是使用哈希表,则无法保证顺序。关于`category`的原理和具体实现,将在后续的文章中探讨。
# 动态方法决议与消息转发
在上面的查找方法的过程中,如果最终没有查找到目标方法,会导致crash,但是在crash之前,`runtime`会给我们2次机会去挽救程序:
1. Dynamic Method Resolution
2. Message Forwarding
## Dynamic Method Resolution(动态方法决议)
第一个机会就是动态方法决议, 有时候,我们可能希望能动态地为一个方法提供具体实现,例如,我们使用`@dynamic`声明了一个属性:
```objc
@dynamic propertyName;
```
这会告诉编译器这个属性的`getter`和`setter`方法会动态的提供。
我们可以通过实现`+(BOOL)resolveInstanceMethod:` 和`+(BOOL)resolveClassMethod:`方法来动态地为selector生成方法的实现,这两个方法分别为实例方法和类方法提供了动态添加方法的可能。一个Objective-C的方法其实就是一个最少包含两个参数`(self, _cmd)`的C函数,我们可以使用`class_addMethod`来动态地给类添加方法:
```objc
void dynamicMethodIMP(id self, SEL _cmd) {
// implementation ....
}
+ (BOOL)resolveInstanceMethod:(SEL)aSEL
{
if (aSEL == @selector(resolveThisMethodDynamically)) {
class_addMethod([self class], aSEL, (IMP) dynamicMethodIMP, "v@:");
return YES;
}
return [super resolveInstanceMethod:aSEL];
}
```
> 注:上面`class_addMethod`的参数`v@:`详见[Type Encodings](https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Articles/ocrtTypeEncodings.html#//apple_ref/doc/uid/TP40008048-CH100-SW1)
在这里, 我们在`+(BOOL)resolveInstanceMethod:`中使用`class_addMethod`添加了对应selector`resolveThisMethodDynamically`函数的实现`void dynamicMethodIMP(id self, SEL _cmd)`,并返回YES,`runtime`就会重启一次消息的发送过程,调用动态添加的方法。
如果这个方法返回NO,或者没有动态地添加方法,`runtime`将进入下一步:**消息转发(Message Forwarding)**
## Message Forwarding(消息转发)
消息转发是`runtime`给我们第二次挽救程序的机会,消息转发分为两步:
1. 首先`runtime`会调用`-(id)forwardingTargetForSelector:(SEL)aSelector`方法,为selector寻找一个转发的目标对象,如果这个方法返回的不是nil或self,`runtime`会将消息发送给返回的目标对象,否则继续下一步
2. `runtime`会调用`-(NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector`方法来获得一个方法签名,这个方法签名记录了方法的参数和返回值等信息,如果这个方法返回nil, `runtime`会调用`doesNotRecognizeSelector:`,在这里将抛出`unrecognized selector exception`,程序Crash; 如果返回了一个方法签名,`runtime`会创建一个`NSInvocation`对象,并发送`-forwardInvocation`消息给目标对象。
`NSInvocation`实际上就是对一个消息的描述,包括selector和参数等信息, 我们可以利用这个invocation来实现调用其他对象的目标方法:
```objc
- (NSMethodSignature*)methodSignatureForSelector:(SEL)selector
{
NSMethodSignature* signature = [super methodSignatureForSelector:selector];
if (!signature) {
signature = [someOtherObject methodSignatureForSelector:selector];
}
return signature;
}
- (void)forwardInvocation:(NSInvocation *)anInvocation
{
if ([someOtherObject respondsToSelector:
[anInvocation selector]])
[anInvocation invokeWithTarget:someOtherObject];
else
[super forwardInvocation:anInvocation];
}
```
消息转发机制是OC非常强大的一个特性,利用它,我们可以实现很多扩展功能,例如,我在[利用OC的动态方法决议与消息转发机制实现多重代理](http://zziking.github.io/ios/2015/11/01/利用OC的动态方法决议与消息转发机制实现多重代理.html)一文中,实现了代理转发功能。还有,我们可以利用这个特性实现AOP(切面编程),为某个方法的调用设置拦截器,比如,log信息的记录使用AOP来实现可以降低代码的耦合度。
动态方法决议和消息转发可以用下图来表示:

# 总结
Objective-C中给一个对象发送消息会经过以下几个步骤:
1. 在对象的类中查找selector,如果找到了,执行对应函数的IMP,查找过程会使用缓存,并且沿着类的继承关系链查找
2. 如果没有找到,Runtime 会发送`+resolveInstanceMethod:`或者`+resolveClassMethod:`尝试去 resolve 这个消息
3. 如果 resolve 方法返回 NO,Runtime 就发送`-forwardingTargetForSelector:`允许你把这个消息转发给另一个对象
4. 如果没有新的目标对象返回, Runtime 就会发送`-methodSignatureForSelector:`和`-forwardInvocation:`消息。你可以发送`-invokeWithTarget:`消息来手动转发消息或者发送`-doesNotRecognizeSelector:`抛出异常。
# 参考链接
1. [How Messaging Works](https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Articles/ocrtHowMessagingWorks.html#//apple_ref/doc/uid/TP40008048-CH104-SW2)
2. [Dynamic Method Resolution](https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Articles/ocrtDynamicResolution.html#//apple_ref/doc/uid/TP40008048-CH102-SW1)
3. [Message Forwarding](https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/ObjCRuntimeGuide/Articles/ocrtForwarding.html#//apple_ref/doc/uid/TP40008048-CH105-SW1)
4. [ Objective-C Runtime](http://tech.glowing.com/cn/objective-c-runtime/) | 25.083333 | 290 | 0.782577 | yue_Hant | 0.881286 |
971dfb2cc2a011d7e28ca9c6aa8131b23c5fdd0e | 431 | md | Markdown | docs/_api-inspection/lastResponse.md | bsalex/fetch-mock | 3d10a0e43f667e7259e9fe77c3486bd3cea8378f | [
"MIT"
] | null | null | null | docs/_api-inspection/lastResponse.md | bsalex/fetch-mock | 3d10a0e43f667e7259e9fe77c3486bd3cea8378f | [
"MIT"
] | null | null | null | docs/_api-inspection/lastResponse.md | bsalex/fetch-mock | 3d10a0e43f667e7259e9fe77c3486bd3cea8378f | [
"MIT"
] | null | null | null | ---
title: .lastResponse(filter, options)
navTitle: .lastResponse()
position: 5.5
versionAdded: 9.10.0
description: |-
Returns the `Response` for the last call to `fetch` matching the given `filter` and `options`.
If `.lastResponse()` is called before fetch has been resolved then it will return `undefined`
{: .warning}
To obtain json/text responses await the `.json()/.text()` methods of the response
{: .info}
---
| 28.733333 | 97 | 0.703016 | eng_Latn | 0.977957 |
971e6bb685e3b17daa640ccf7080c6d1c8a5efd2 | 3,953 | md | Markdown | docs/extensibility/debugger/reference/debugref-info-flags.md | tommorris/visualstudio-docs.es-es | 651470ca234bb6db8391ae9f50ff23485896393c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/extensibility/debugger/reference/debugref-info-flags.md | tommorris/visualstudio-docs.es-es | 651470ca234bb6db8391ae9f50ff23485896393c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/extensibility/debugger/reference/debugref-info-flags.md | tommorris/visualstudio-docs.es-es | 651470ca234bb6db8391ae9f50ff23485896393c | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: DEBUGREF_INFO_FLAGS | Documentos de Microsoft
ms.custom: ''
ms.date: 11/04/2016
ms.technology:
- vs-ide-sdk
ms.topic: conceptual
f1_keywords:
- DEBUGREF_INFO_FLAGS
helpviewer_keywords:
- DEBUGREF_INFO_FLAGS enumeration
ms.assetid: 1b043327-302a-4f6d-b51d-f94f9d7c7f9d
author: gregvanl
ms.author: gregvanl
manager: douge
ms.workload:
- vssdk
ms.openlocfilehash: f5864b3503b19e8a473f45e4167aad835181da50
ms.sourcegitcommit: 6a9d5bd75e50947659fd6c837111a6a547884e2a
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 04/16/2018
ms.locfileid: "31108380"
---
# <a name="debugrefinfoflags"></a>DEBUGREF_INFO_FLAGS
Especifica qué información debe recuperar sobre un objeto de referencia de debug.
## <a name="syntax"></a>Sintaxis
```cpp
enum enum_DEBUGREF_INFO_FLAGS {
DEBUGREF_INFO_NAME = 0x00000001,
DEBUGREF_INFO_TYPE = 0x00000002,
DEBUGREF_INFO_VALUE = 0x00000004,
DEBUGREF_INFO_ATTRIB = 0x00000008,
DEBUGREF_INFO_REFTYPE = 0x00000010,
DEBUGREF_INFO_REF = 0x00000020,
DEBUGREF_INFO_VALUE_AUTOEXPAND = 0x00010000,
DEBUGREF_INFO_NONE = 0x00000000,
DEBUGREF_INFO_ALL = 0xffffffff
};
typedef DWORD DEBUGREF_INFO_FLAGS;
```
```csharp
public enum enum_DEBUGREF_INFO_FLAGS {
DEBUGREF_INFO_NAME = 0x00000001,
DEBUGREF_INFO_TYPE = 0x00000002,
DEBUGREF_INFO_VALUE = 0x00000004,
DEBUGREF_INFO_ATTRIB = 0x00000008,
DEBUGREF_INFO_REFTYPE = 0x00000010,
DEBUGREF_INFO_REF = 0x00000020,
DEBUGREF_INFO_VALUE_AUTOEXPAND = 0x00010000,
DEBUGREF_INFO_NONE = 0x00000000,
DEBUGREF_INFO_ALL = 0xffffffff
};
```
## <a name="members"></a>Miembros
DEBUGREF_INFO_NAME
Inicializar o utilizar el `bstrName` campo en la estructura.
DEBUGREF_INFO_TYPE
Inicializar o utilizar el `bstrType` campo en la estructura.
DEBUGREF_INFO_VALUE
Inicializar o utilizar el `bstrValue` campo en la estructura.
DEBUGREF_INFO_ATTRIB
Inicializar o utilizar el `dwAttrib` campo en la estructura.
DEBUGREF_INFO_REFTYPE
Inicializar o utilizar el `dwRefType` campo en la estructura.
DEBUGREF_INFO_REF
Inicializar o utilizar el `pReference` campo en la estructura.
DEBUGREF_INFO_VALUE_AUTOEXPAND
El campo de valor debe contener el valor auto y ampliado, si está disponible para este tipo de objeto.
DEBUGREF_INFO_NONE
Indica que no se establecen marcas.
DEBUGREF_INFO_ALL
Indica una máscara de las marcas.
## <a name="remarks"></a>Comentarios
Estas marcas se pasan a la [EnumChildren](../../../extensibility/debugger/reference/idebugreference2-enumchildren.md) y [GetReferenceInfo](../../../extensibility/debugger/reference/idebugreference2-getreferenceinfo.md) métodos para indicar qué campos de la [DEBUG_REFERENCE_INFO](../../../extensibility/debugger/reference/debug-reference-info.md) estructura deben inicializarse.
Utilizado para la `dwFields` miembro de la `DEBUG_REFERENCE_INFO` estructura para indicar qué campos se utilizan y válido cuando se devuelve la estructura.
Estos valores se pueden combinar con un bit a bit `OR`.
## <a name="requirements"></a>Requisitos
Encabezado: msdbg.h
Namespace: Microsoft.VisualStudio.Debugger.Interop
Ensamblado: Microsoft.VisualStudio.Debugger.Interop.dll
## <a name="see-also"></a>Vea también
[Enumeraciones](../../../extensibility/debugger/reference/enumerations-visual-studio-debugging.md)
[DEBUG_REFERENCE_INFO](../../../extensibility/debugger/reference/debug-reference-info.md)
[EnumChildren](../../../extensibility/debugger/reference/idebugreference2-enumchildren.md)
[GetReferenceInfo](../../../extensibility/debugger/reference/idebugreference2-getreferenceinfo.md) | 37.647619 | 381 | 0.71743 | spa_Latn | 0.292328 |
971f25a66cbb62a3f7819b70fe63a40ddcd5c511 | 1,587 | md | Markdown | docs/QuorumTxReceipt.md | Treize37/tatum | c96e3985beeff2c6490920985002705c5d156f30 | [
"MIT"
] | null | null | null | docs/QuorumTxReceipt.md | Treize37/tatum | c96e3985beeff2c6490920985002705c5d156f30 | [
"MIT"
] | null | null | null | docs/QuorumTxReceipt.md | Treize37/tatum | c96e3985beeff2c6490920985002705c5d156f30 | [
"MIT"
] | null | null | null | # Tatum::QuorumTxReceipt
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**block_hash** | **String** | Hash of the block where this transaction was in. | [optional]
**status** | **BOOLEAN** | TRUE if the transaction was successful, FALSE, if the EVM reverted the transaction. | [optional]
**block_number** | [**BigDecimal**](BigDecimal.md) | Block number where this transaction was in. | [optional]
**from** | **String** | Address of the sender. | [optional]
**transaction_hash** | **String** | Hash of the transaction. | [optional]
**to** | **String** | Address of the receiver. 'null' when its a contract creation transaction. | [optional]
**transaction_index** | [**BigDecimal**](BigDecimal.md) | Integer of the transactions index position in the block. | [optional]
**value** | **String** | Value transferred in wei. | [optional]
**gas_used** | [**BigDecimal**](BigDecimal.md) | The amount of gas used by this specific transaction alone. | [optional]
**cumulative_gas_used** | [**BigDecimal**](BigDecimal.md) | The total amount of gas used when this transaction was executed in the block. | [optional]
**contract_address** | **String** | The contract address created, if the transaction was a contract creation, otherwise null. | [optional]
**logs_bloom** | **String** | The bloom filter for the logs of the transaction. 'null' when its pending transaction. | [optional]
**logs** | [**Array<EthTxLogs>**](EthTxLogs.md) | Log events, that happened in this transaction. | [optional]
| 79.35 | 151 | 0.671078 | eng_Latn | 0.90635 |
971f381c5053d4c89b3b2b8006f936a663b9184b | 968 | md | Markdown | AlchemyInsights/cant-add-guests-to-a-team.md | isabella232/OfficeDocs-AlchemyInsights-pr.fi-FI | d4c2084ab362e84a16286d8b4e6a1e137b271ce6 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-19T19:06:30.000Z | 2020-09-17T11:26:00.000Z | AlchemyInsights/cant-add-guests-to-a-team.md | MicrosoftDocs/OfficeDocs-AlchemyInsights-pr.fi-FI | d98cfb244ae52a6624ec7fb9c7fc1092811bdfb7 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2022-02-09T06:50:18.000Z | 2022-02-09T06:50:31.000Z | AlchemyInsights/cant-add-guests-to-a-team.md | isabella232/OfficeDocs-AlchemyInsights-pr.fi-FI | d4c2084ab362e84a16286d8b4e6a1e137b271ce6 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-10-11T19:13:35.000Z | 2021-10-09T10:47:01.000Z | ---
title: Vierasta ei voida lisätä tiimiin
ms.author: pebaum
author: pebaum
manager: scotv
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Priority
ms.collection: Adm_O365
ms.custom:
- "9003558"
- "6657"
ms.openlocfilehash: 70f0ab311358c88b4817a810956942bf88d9444fa850a5216736eb657189d5a5
ms.sourcegitcommit: b5f7da89a650d2915dc652449623c78be6247175
ms.translationtype: MT
ms.contentlocale: fi-FI
ms.lasthandoff: 08/05/2021
ms.locfileid: "53996087"
---
# <a name="cant-add-guests-to-a-team"></a>Vierasta ei voida lisätä tiimiin
Kun haluat lisätä vieraan tiimiin, seuraavien asioiden on oltava tosia:
- Järjestelmänvalvoja on ottanut käyttöön Teamsin vieraskäytön.
- Olet tiimin omistaja.
- Lisättävä henkilö on organisaatiosi ulkopuolelta, esimerkiksi kumppani tai konsultti.
Katso lisätätietoja kohdasta, [Vieraan liittyminen tiimiin](https://docs.microsoft.com/MicrosoftTeams/guest-joins). | 32.266667 | 115 | 0.816116 | fin_Latn | 0.955066 |
97201435888e6e88c4b472aa10eb6b11ebd3ce88 | 404 | md | Markdown | posts/2017-02-25-personal-coding-flow.md | eynol/eynol.github.io | a4e0d0bd196febb0a89ddad20b1da23e8a7d2b21 | [
"MIT"
] | 1 | 2022-03-16T22:01:03.000Z | 2022-03-16T22:01:03.000Z | posts/2017-02-25-personal-coding-flow.md | eynol/eynol.github.io | a4e0d0bd196febb0a89ddad20b1da23e8a7d2b21 | [
"MIT"
] | 1 | 2022-03-16T14:22:03.000Z | 2022-03-16T14:22:03.000Z | posts/2017-02-25-personal-coding-flow.md | eynol/eynol.github.io | a4e0d0bd196febb0a89ddad20b1da23e8a7d2b21 | [
"MIT"
] | null | null | null | ---
title: 个人软件开发流程
title-en: Personal Coding Flow
date: 2017-02-25 12:33:48
layout: post
tags:
- Notes
---
根据软件的大小不同,软件开发的流程也不同。从最初学习编程到现在,软件开发的这个流程也越来复杂,对应的软件规模也越来越大。在此,总结一下2016年及以前软件开发的流程。因为软件开发的课程还在学习中,所以只能浅谈面向对象的方法。
# 面向过程
一开始学习编程的过程中,就是面向过程编程的,随性,没有文档。后来有了各种流程图,帮助我们理清思路,并且还有文档。
所以一开始是有什么需求,根据需求画出流程图(事件流,数据流),然后再编程。
# 面向对象
这个是需要我们从不同抽象层次来思考,适合大型应用和战略性的应用。
**以上两种方式各选一个来开发软件,便不会造成混乱的局面,全在控制中。**
| 22.444444 | 112 | 0.806931 | zho_Hans | 0.329406 |
9720b13efe81dc7279ad0dd54762328d1e19c667 | 1,791 | md | Markdown | src/components/Icon/README.en-US.md | ui-puzzles/rect | 634fdb9a2dcaee81f9cbf6c3ef294eaecea8f13b | [
"MIT"
] | 4 | 2021-10-31T01:34:09.000Z | 2022-03-02T12:39:37.000Z | src/components/Icon/README.en-US.md | ui-puzzles/rect | 634fdb9a2dcaee81f9cbf6c3ef294eaecea8f13b | [
"MIT"
] | 1 | 2022-03-31T07:10:02.000Z | 2022-03-31T07:10:02.000Z | src/components/Icon/README.en-US.md | ui-puzzles/rect | 634fdb9a2dcaee81f9cbf6c3ef294eaecea8f13b | [
"MIT"
] | 1 | 2022-03-31T02:32:47.000Z | 2022-03-31T02:32:47.000Z | ## API
Different button styles can be generated by setting Button properties. The recommended order is: type -> shape -> size -> loading -> disabled.
|Property|Description|Type|DefaultValue|
|---|---|---|---|
|htmlType|html button type|`'button' \| 'submit' \| 'reset'`|`button`|
|style|Additional style|`CSSProperties`|`-`|
|className|Additional css class|`string \| string[]`|`-`|
|type|A variety of button types are available: `primary`, `secondary`, `dashed`,`text`, `linear` and `default` which is the secondary.|`'default' \| 'primary' \| 'secondary' \| 'dashed' \| 'text' \| 'outline'`|`default`|
|status|Status of the button|`'warning' \| 'danger' \| 'success' \| 'default'`|`default`|
|size|Size of the button|`'mini' \| 'small' \| 'default' \| 'large'`|`default`|
|shape|Three button shapes are available: `circle`, `round` and `square`|`'circle' \| 'round' \| 'square'`|`square`|
|href|The button behaves like `<a>` with href as target url.|`string`|`-`|
|target|The target attribute of the link, which takes effect when href exists.|`string`|`-`|
|anchorProps|The native attribute of the link, which takes effect when href exists|`HTMLProps<HTMLAnchorElement>`|`-`|
|disabled|Whether to disable the button|`boolean`|`-`|
|loading|Whether the button is in the loading state|`boolean`|`-`|
|loadingFixedWidth|The width of the button remains unchanged on loading|`boolean`|`-`|
|icon|Icon of the button|`ReactNode`|`-`|
|iconOnly|Whether to show icon only, in which case the button width and height are equal. If `icon` is specified and there are no children, `iconOnly` defaults to `true`|`boolean`|`-`|
|long|Whether the width of the button should adapt to the container.|`boolean`|`-`|
|onClick|Callback fired when the button is clicked|`(e: Event) => void`|`-`|
## Change Log | 71.64 | 220 | 0.697376 | eng_Latn | 0.966073 |
9720d7928bc6d26da80006f74d65859f6e725858 | 9,810 | md | Markdown | _posts/2012-07-23-Throttling FSharp Events using the Reactive Extensions.md | jamessdixon/mathias-brandewinder.github.io | dfd34f551efd9a38d1585ff5fbd7a42006fb2121 | [
"MIT"
] | null | null | null | _posts/2012-07-23-Throttling FSharp Events using the Reactive Extensions.md | jamessdixon/mathias-brandewinder.github.io | dfd34f551efd9a38d1585ff5fbd7a42006fb2121 | [
"MIT"
] | null | null | null | _posts/2012-07-23-Throttling FSharp Events using the Reactive Extensions.md | jamessdixon/mathias-brandewinder.github.io | dfd34f551efd9a38d1585ff5fbd7a42006fb2121 | [
"MIT"
] | null | null | null | ---
layout: post
title: Throttling F# Events using the Reactive Extensions
tags:
- F#
- Rx
- Reactive
- Observable
- Bumblebee
- Throttling
---
Nothing fancy this week – just thought I would share some of what I learnt recently playing with the Reactive Extensions and F#.
Here is the context: my current week-ends project, [Bumblebee](http://bumblebee.codeplex.com/), is a Solver, which, given a Problem to solve, will search for solutions, and fire an event every time an improvement is found. I am currently working on using in in Azure, to hopefully scale out and tackle problems of a larger scale than what I can achieve on a single local machine. One problem I ran into, though, is that if multiple worker roles begin firing events every time a solution is found, the system will likely grind to a halt trying to cope with a gazillion messages (not to mention a potentially unpleasantly high bill), whereas I really don’t care about every single solution – I care about being notified about some improvements, not necessarily every single one. What I want is an ability to “throttle” the flow of events coming from my solver, to receive, say, the best one every 30 seconds.
For illustration purposes, here is a highly simplified version of the Bumblebee solver:
``` fsharp
type Generator() =
let intFound = new Event<int>()
member this.IntFound = intFound.Publish
member this.Start() =
Task.Factory.StartNew(fun () ->
printfn "Searching for numbers..."
for i in 0 .. 100 do
intFound.Trigger(i)
Thread.Sleep(500)
) |> ignore
```
<!--more-->
The Generator class exposes a Start method, which, once called, will “generate” numbers from 0 to 100 – just like the Solver would return solutions of improving quality over time.
Generator declares an event, intFound, which will be triggered when we found a new integer of interest, and which is exposed through IntFound, which consumers can then subscribe to. When we Start the generator, we spin a new Task, which will be running on its own thread, and will simply produce integers from 0 to 100, with a 500ms delay between solutions.
The syntax for declaring an event is refreshingly simple, and we can use it in a way similar to what we would do in C#, by adding a Handler to the event, for instance in a simple Console application like this:
``` fsharp
let Main =
let handler i = printfn "Simple handler: got %i" i
let generator = new Generator()
generator.IntFound.Add handler
generator.Start()
let wait = Console.ReadLine()
ignore ()
```
Create a handler that prints out an integer, hook it up to the event, and run the application – you should see something like this happening:

So far, nothing very thrilling.
However, there is more. Our event this.IntFound is an IEvent, which inherits from IObservable, and allows you to do all sort of fun stuff with your events, like transform and compose them into something more usable. Out-of-the-box, the F# Observable module provides a few useful functions. Instead of adding a handler to the event, let’s start by subscribing to the event:
``` fsharp
et Main =
let handler i = printfn "Simple handler: got %i" i
let generator = new Generator()
generator.IntFound.Add handler
let interval = new TimeSpan(0, 0, 5)
generator.IntFound
|> Observable.subscribe (fun e -> printfn "Observed %i" e)
|> ignore
generator.Start()
let wait = Console.ReadLine()
ignore ()
```
This is doing essentially the same thing as before – running this will produce something along these lines:

As you can see, we have now 2 subscribers to the event. However, this is just where the fun begins. We can start transforming our event in a few ways – for instance, we could decide to filter out integers that are odd, and transform the result by mapping integers to floats, multiplied by 3 (why not?):
``` fsharp
let Main =
let handler i = printfn "Simple handler: got %i" i
let generator = new Generator()
generator.IntFound.Add handler
let interval = new TimeSpan(0, 0, 5)
generator.IntFound
|> Observable.filter (fun e -> e % 2 = 0)
|> Observable.map (fun e -> (float)e * 3.0)
|> Observable.subscribe (fun e -> printfn "Observed %f" e)
|> ignore
generator.Start()
let wait = Console.ReadLine()
ignore ()
```
Still not the most thrilling thing ever, but it proves the point – from a sequence of Events that was returning integers, we managed to transform it into a fairly different sequence, all in a few lines of code:

The reason I was interested in Observables, though, is because a while back, I attended a [talk ](http://www.baynetug.org/DesktopModules/DetailXEvents.aspx?ItemID=462&mid=49), given by my good friend [Petar](https://twitter.com/petarvucetin), where he presented the [Reactive Extensions](http://msdn.microsoft.com/en-us/data/gg577609.aspx) (Rx) – and I remembered that Rx had a few nice utilities built-in to manage Observables, which would hopefully help me achieve my goal, throttling my sequence of events over time.
At that stage, I wasted a bit of time, trying first to figure out whether or not I needed Rx (the F# module already has a lot built in, so I was wondering if maybe it had all I needed…), then I got tripped up by figuring out what Rx method I needed, and how to make it work seamlessly with F# and the pipe-forward operator.
Needing some “throttling”, I rushed into the [`Throttle`](http://rxwiki.wikidot.com/101samples#toc29) method, which looked plausible enough; unfortunately, throttle wasn’t doing quite what I thought it would – from what I gather, it filters out any event that is followed by another event within a certain time window. I see how this would come handy in lots of scenarios (think typing in a Search Box – you don’t want to trigger a Search while the person it typing, so waiting until no typing occurs is a good idea), but what I really needed was [Sample](http://rxwiki.wikidot.com/101samples#toc28), which returns only the latest event that occurred by regular time window.
Now there is another small problem: [`Observable.Sample`](http://msdn.microsoft.com/en-us/library/ff707287(v=vs.92).aspx) takes in 2 arguments, the Observable to be sampled, and a sampling interval represented as a `TimeSpan`. The issue here is that because of the C#-style signature, we cannot directly use it with a pipe-forward. It’s simple enough to solve, though: create a small extension method, extending the Observable module with a composable function:
``` fsharp
module Observable =
let sample (interval: TimeSpan) (obs: IObservable<'a>) =
Observable.Sample(obs, interval)
```
And we are now set! Armed with our new sample function, we can now do the following:
``` fsharp
let Main =
let handler i = printfn "Simple handler: got %i" i
let generator = new Generator()
generator.IntFound.Add handler
let interval = new TimeSpan(0, 0, 5)
generator.IntFound
|> Observable.filter (fun e -> e % 2 = 0)
|> Observable.map (fun e -> (float)e * 3.0)
|> Observable.sample interval
|> Observable.subscribe (fun e -> printfn "Observed %f" e)
|> ignore
generator.Start()
let wait = Console.ReadLine()
ignore ()
```
We sample our event stream every 5 seconds, returning only the latest that occurred in that window. Running this produces the following:

As you can see, while the original handler is capturing an event every half second, our Observable is showing up every 10 events, that is, every 5 seconds, which is exactly what we expected – and I have now exactly what I need to “throttle” the solutions stream coming from Bumblebee.
That’s it for today – fairly simple stuff, but hopefully this illustrates how easy it is to work with events in F#, and what Observables add to the table, and maybe this will come in useful for someone!
Additional resources I found useful or interesting underway:
[Time Flies Like an Arrow in F#](http://weblogs.asp.net/podwysocki/archive/2010/03/28/time-flies-like-an-arrow-in-f-and-the-reactive-extensions-for-net.aspx)
[Reactive Programming: First Class Events in F#](http://tomasp.net/blog/reactive-i-fsevents.aspx)
[FSharp.Reactive](https://github.com/panesofglass/FSharp.Reactive)
Full code sample (F# console application, using Rx Extensions)
``` fsharp
open System
open System.Threading
open System.Threading.Tasks
open System.Reactive.Linq
type Generator() =
let intFound = new Event<int>()
[<CLIEvent>]
member this.IntFound = intFound.Publish
member this.Start() =
Task.Factory.StartNew(fun () ->
printfn "Searching for numbers..."
for i in 0 .. 100 do
intFound.Trigger(i)
Thread.Sleep(500)
) |> ignore
module Observable =
let sample (interval: TimeSpan) (obs: IObservable<'a>) =
Observable.Sample(obs, interval)
let Main =
let handler i = printfn "Simple handler: got %i" i
let generator = new Generator()
generator.IntFound.Add handler
let interval = new TimeSpan(0, 0, 5)
generator.IntFound
|> Observable.filter (fun e -> e % 2 = 0)
|> Observable.map (fun e -> (float)e * 3.0)
|> Observable.sample interval
|> Observable.subscribe (fun e -> printfn "Observed %f" e)
|> ignore
generator.Start()
let wait = Console.ReadLine()
ignore ()
```
| 45.841121 | 908 | 0.721407 | eng_Latn | 0.994374 |
9721e8f13cd09e36f24dbac10f2e45f233362fca | 185 | md | Markdown | README.md | NuroDev/bus-factor | 9e3378357b5d642e79f2bc89f2e882aa0cc956ec | [
"MIT"
] | null | null | null | README.md | NuroDev/bus-factor | 9e3378357b5d642e79f2bc89f2e882aa0cc956ec | [
"MIT"
] | null | null | null | README.md | NuroDev/bus-factor | 9e3378357b5d642e79f2bc89f2e882aa0cc956ec | [
"MIT"
] | null | null | null | # bus-factor
🚌 Bus factor estimation
[](https://github.com/nurodev/bus-factor/actions/workflows/ci.yml)
| 30.833333 | 145 | 0.756757 | kor_Hang | 0.169644 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.