
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: Adding Example for FastApi OpenAPI documentation
Body: ## Problem
Currently for my pydantic models, I use the example field to document FastAPI:
` = Field(..., example="This is my example for SwaggerUI")`
## Suggested solution
Would it be possible through comment in the schema.prisma to add these examples?
## Alternatives
Open to any solution.
## Additional context
I want to completely remove my custom pydantic object definitions and rely on your generated models and partials (which I find amazing!)
| 1medium
|
Title: [Call for contributions] help us improve LoKr, LoHa, and other LyCORIS
Body: Originally reported by @bghira in https://github.com/huggingface/peft/issues/1931.
Our LoKr, LoHA, and other LyCORIS modules are outdated and could benefit from your help quite a bit. The following is a list of things that need modifications and fixing:
- [ ] fixed rank dropout implementation
- [ ] fixed maths (not multiplying against the vector, but only the scalar)
- [ ] full matrix tuning
- [ ] 1x1 convolutions
- [ ] quantised LoHa/LoKr
- [ ] weight-decomposed LoHa/LoKr
So, if you are interested, feel free to take one of these up at a time and open PRs. Of course, we will be with you for the PRs, learning from them and provide guidance as needed.
Please mention this issue when opening PRs and tag @BenjaminBossan and myself.
| 1medium
|
Title: Incorrect CBOW implementation in Gensim leads to inferior performance
Body: #### Problem description
According to this article https://aclanthology.org/2021.insights-1.1.pdf:
<img width="636" alt="Screen Shot 2021-11-09 at 15 47 21" src="https://user-images.githubusercontent.com/610412/140945923-7d279468-a9e9-41b4-b7c2-919919832bc5.png">
#### Steps/code/corpus to reproduce
I haven't tried to verify / reproduce. Gensim's goal is to follow the original C implementation faithfully, which it does. So this is not a bug per se, more a question of "how whether / how much we want to deviate from the reference implementation". I'm in favour if the result is unambiguous better (more accurate, faster, no downsides).
#### Versions
All versions since the beginning of word2vec in Gensim.
| 1medium
|
Title: Manifold Feature Engineering
Body: 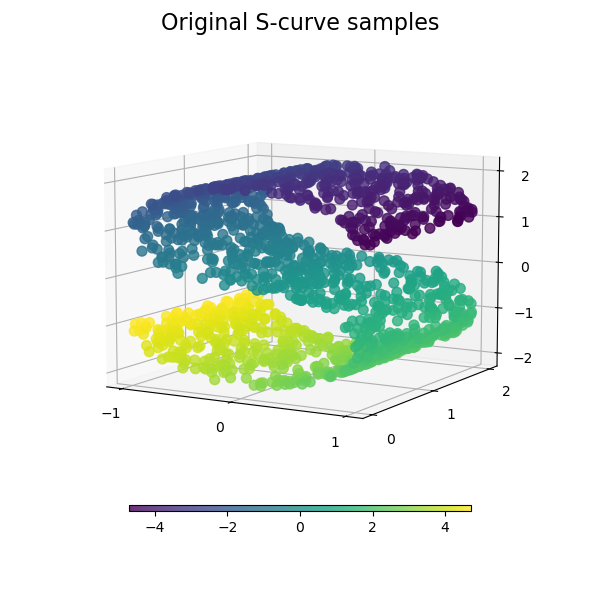
Currently we have a t-SNE visualizer for text, but we can create a general manifold learning visualizer for projecting high dimensional data into 2 dimensions that respect non-linear effects (unlike our current decomposition methods.
### Proposal/Issue
The visualizer would take as hyperparameters:
- The color space of the original data (either by class or more specifically for each point)
- The manifold method (string or estimator)
It would be fit to training data.
The visualizer would display the representation in 2D space, as well as the training time and any other associated metrics.
### Code Snippet
- Code snippet found here: [Plot Compare Manifold Methods](http://scikit-learn.org/stable/auto_examples/manifold/plot_compare_methods.html)
### Background
- [Comparison of Manifold Algorithms (sklearn docs)](http://scikit-learn.org/stable/modules/manifold.html#manifold)
This investigation started with self-organizing maps (SOMS) visualization:
- http://blog.yhat.com/posts/self-organizing-maps-2.html
- https://stats.stackexchange.com/questions/210446/how-does-one-visualize-the-self-organizing-map-of-n-dimensional-data
| 1medium
|
Title: [BUG] --report flag without arguments is broken.
Body: **Checklist**
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
**Describe the bug**
When running from the CLI with the --report flag an error is thrown. When adding any arguments like true or 1, a file with that name is created. I would like a report on schemathesis.io to be generated.
**To Reproduce**
Steps to reproduce the behavior:
Run a valid schemathesis command with the --report flag
The error received is the following:
```
Traceback (most recent call last):
File "/home/docker/.local/bin/st", line 8, in <module>
sys.exit(schemathesis())
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1157, in __call__
return self.main(*args, **kwargs)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1078, in main
rv = self.invoke(ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1686, in invoke
sub_ctx = cmd.make_context(cmd_name, args, parent=ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 943, in make_context
self.parse_args(ctx, args)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 1408, in parse_args
value, args = param.handle_parse_result(ctx, opts, args)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2400, in handle_parse_result
value = self.process_value(ctx, value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2356, in process_value
value = self.type_cast_value(ctx, value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2344, in type_cast_value
return convert(value)
File "/home/docker/.local/lib/python3.8/site-packages/click/core.py", line 2316, in convert
return self.type(value, param=self, ctx=ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 83, in __call__
return self.convert(value, param, ctx)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 712, in convert
lazy = self.resolve_lazy_flag(value)
File "/home/docker/.local/lib/python3.8/site-packages/click/types.py", line 694, in resolve_lazy_flag
if os.fspath(value) == "-":
TypeError: expected str, bytes or os.PathLike object, not object
```
**Expected behavior**
--report with no flags should upload a report to schemathesis.io
**Environment (please complete the following information):**
- OS: Debian WSL
- Python version: 3.8.10
- Schemathesis version: 3.19.5
- Spec version: 3.0.3
| 1medium
|
Title: connect() fails if /etc/os-release is not available
Body: ## Bug description
App fails if `/etc/os-release` is missing.
## How to reproduce
```
sudo mv /etc/os-release /etc/os-release.old
#start app
````
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: Cloud Linux OS (4.18.0-372.19.1.lve.el8.x86_64)
- Database: SQLite]
- Python version: 3.0
- Prisma version:
```
INFO: Waiting for application startup.
cat: /etc/os-release: No such file or directory
ERROR: Traceback (most recent call last):
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/starlette/routing.py", line 671, in lifespan
async with self.lifespan_context(app):
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/starlette/routing.py", line 566, in __aenter__
await self._router.startup()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/starlette/routing.py", line 648, in startup
await handler()
File "/home/wodorec1/wodore/tests/prisma/main.py", line 13, in startup
await prisma.connect()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/client.py", line 252, in connect
await self.__engine.connect(
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/engine/query.py", line 128, in connect
self.file = file = self._ensure_file()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/engine/query.py", line 116, in _ensure_file
return utils.ensure(BINARY_PATHS.query_engine)
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/engine/utils.py", line 72, in ensure
name = query_engine_name()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/engine/utils.py", line 36, in query_engine_name
return f'prisma-query-engine-{platform.check_for_extension(platform.binary_platform())}'
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/binaries/platform.py", line 56, in binary_platform
distro = linux_distro()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/binaries/platform.py", line 23, in linux_distro
distro_id, distro_id_like = _get_linux_distro_details()
File "/home/wodorec1/virtualenv/wodore/tests/prisma/3.9/lib/python3.9/site-packages/prisma/binaries/platform.py", line 37, in _get_linux_distro_details
process = subprocess.run(
File "/opt/alt/python39/lib64/python3.9/subprocess.py", line 528, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['cat', '/etc/os-release']' returned non-zero exit status 1.
```
| 1medium
|
Title: Consider renaming root `OR` query to `ANY`
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
The root `OR` part of a query can be confusing: https://news.ycombinator.com/item?id=30416531#30422118
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Replace the `OR` field with an `ANY` field, for example:
```py
posts = await client.post.find_many(
where={
'OR': [
{'title': {'contains': 'prisma'}},
{'content': {'contains': 'prisma'}},
]
}
)
```
Becomes:
```py
posts = await client.post.find_many(
where={
'ANY': [
{'title': {'contains': 'prisma'}},
{'content': {'contains': 'prisma'}},
]
}
)
```
If we decide to go with this (or similar), the `OR` field should be deprecated first and then removed in a later release.
| 1medium
|
Title: Change "alpha" parameter to "opacity"
Body: In working on issue #558, it's becoming clear that there is potential for naming confusion and collision around our use of `alpha` to mean the opacity/translucency (e.g. in the matplotlib sense), since in scikit-learn, `alpha` is often used to reference other things, such as the regularization hyperparameter, e.g.
```
oz = ResidualsPlot(Lasso(alpha=0.1), alpha=0.7)
```
As such, we should probably change our `alpha` to something like `opacity`. This update will impact a lot of the codebase and docs, and therefore has the potential to be disruptive, so I propose waiting until things are a bit quieter.
| 1medium
|
Title: Remove old datasets code and rewire with new datasets.load_* api
Body: As a follow up to reworking the datasets API, we need to go through and remove redundant old code in these locations:
- [x] `yellowbrick/download.py`
- [ ] `tests/dataset.py`
Part of this will be a requirement to rewire tests and examples as needed. Likely also there might be slight transformations of data in code that will have to happen
@DistrictDataLabs/team-oz-maintainers
| 1medium
|
Title: Add typing to all modules under `robot.api`
Body: Currently, the `@keyword` and `@library` functions exposed through the `robot.api` module have no annotations. This limits the type-checking that tools like mypy and Pylance / pyright can perform, in turn limiting what types of issues language servers can detect.
Adding annotations to these functions (and, ultimately, all public-facing interfaces of the Robot Framework) would enable better IDE / tool integration.
Note that the improvements with regards to automatic type conversion also closely relate to this issue since the framework uses the signatures of methods decorated with the `@keyword` decorator to attempt automatic type conversion, while the missing annotations limit static analysis of the decorated methods.
| 1medium
|
Title: [BUG] Optimization that compacts multiple filters into `eval` generates unexpected node in graph
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Optimization that compacts multiple filters into eval generates unexpected node in graph.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```python
@enter_mode(build=True)
def test_arithmetic_query(setup):
df1 = md.DataFrame(raw, chunk_size=10)
df2 = md.DataFrame(raw2, chunk_size=10)
df3 = df1.merge(df2, on='A', suffixes=('', '_'))
df3['K'] = df4 = df3["A"] * (1 - df3["B"])
graph = TileableGraph([df3.data])
next(TileableGraphBuilder(graph).build())
records = optimize(graph)
opt_df4 = records.get_optimization_result(df4.data)
assert opt_df4.op.expr == "(`A`) * ((1) - (`B`))"
assert len(graph) == 5 # for now len(graph) is 6
assert len([n for n in graph if isinstance(n.op, DataFrameEval)]) == 1 # and 2 evals exist
```
| 1medium
|
Title: Allow ModelVisualizers to wrap Pipeline objects
Body: **Describe the solution you'd like**
Our model visualizers expect to wrap classifiers, regressors, or clusters in order to visualize the model under the hood; they even do checks to ensure the right estimator is passed in. Unfortunately in many cases, passing a pipeline object as the model in question does not allow the visualizer to work, even though the model is acceptable as a pipeline, e.g. it is a classifier for classification score visualizers (more on this below). This is primarily because the Pipeline wrapper masks the attributes needed by the visualizer.
I propose that we modify the [`ModelVisualizer `](https://github.com/DistrictDataLabs/yellowbrick/blob/develop/yellowbrick/base.py#L274) to change the `ModelVisualizer.estimator` attribute to a `@property` - when setting the estimator property, we can perform a check to ensure that the Pipeline has a `final_estimator` attribute (e.g. that it is not a transformer pipeline). When getting the estimator property, we can return the final estimator instead of the entire Pipeline. This should ensure that we can use pipelines in our model visualizers.
**NOTE** however that we will still have to `fit()`, `predict()`, and `score()` on the entire pipeline, so this is a bit more nuanced than it seems on first glance. There will probably have to be `is_pipeline()` checking and other estimator access utilities.
**Is your feature request related to a problem? Please describe.**
Consider the following, fairly common code:
```python
from sklearn.pipeline import Pipeline
from sklearn.neural_network import MLPClassifier
from sklearn.feature_extraction.text import TfidfVectorizer
from yellowbrick.classifier import ClassificationReport
model = Pipeline([
('tfidf', TfidfVectorizer()),
('mlp', MLPClassifier()),
])
oz = ClassificationReport(model)
oz.fit(X_train, y_train)
oz.score(X_test, y_test)
oz.poof()
```
This seems to be a valid model for a classification report, unfortunately the classification report is not able to access the MLPClassiifer's `classes_` attribute since the Pipeline doesn't know how to pass that on to the final estimator.
I think the original idea for the `ScoreVisualizers` was that they would be inside of Pipelines, e.g.
```python
model = Pipeline([
('tfidf', TfidfVectorizer()),
('clf', ClassificationReport(MLPClassifier())),
])
model.fit(X, y)
model.score(X_test, y_test)
model.named_steps['clf'].poof()
```
But this makes it difficult to use more than one visualizer; e.g. ROCAUC visualizer and CR visualizer.
**Definition of Done**
- [ ] Update `ModelVisualizer` class with pipeline helpers
- [ ] Ensure current tests pass
- [ ] Add test to all model visualizer subclasses to pass in a pipeline as the estimator
- [ ] Add documentation about using visualizers with pipelines
| 1medium
|
Title: Provide a JSON Schema generator
Body: ## Problem
This would be useful as a real world example of a custom Prisma generator.
It could also help find any features we could add that would make building custom Prisma generators easier.
## Additional context
This has already been implemented in TypeScript: https://github.com/valentinpalkovic/prisma-json-schema-generator
| 1medium
|
Title: Allow removing tags using `-tag` syntax also in `Test Tags`
Body: `Test Tags` from `*** Settings ***` and `[Tags]` from Test Case behave differently when removing tags: while it is possible to remove tags with Test Case's `[Tag] -something`, Settings `Test Tags -something` introduces a new tag `-something`.
Running tests with these robot files (also [attached](https://github.com/user-attachments/files/17566740/TagsTest.zip)):
* `__init__.robot`:
```
*** Settings ***
Test Tags something
```
* `-SomethingInSettings.robot`:
```
*** Settings ***
Test Tags -something
*** Test Cases ***
-Something In Settings
Should Be Empty ${TEST TAGS}
```
* `-SomethingInTestCase.robot`:
```
*** Test Cases ***
-Something In Test Case
[Tags] -something
Should Be Empty ${TEST TAGS}
```
gives the following output:
```
> robot .
==============================================================================
TagsTest
==============================================================================
TagsTest.-SomethingInSettings
==============================================================================
-Something In Settings | FAIL |
'['-something', 'something']' should be empty.
------------------------------------------------------------------------------
TagsTest.-SomethingInSettings | FAIL |
1 test, 0 passed, 1 failed
==============================================================================
TagsTest.-SomethingInTestCase
==============================================================================
-Something In Test Case | PASS |
------------------------------------------------------------------------------
TagsTest.-SomethingInTestCase | PASS |
1 test, 1 passed, 0 failed
==============================================================================
TagsTest | FAIL |
2 tests, 1 passed, 1 failed
==============================================================================
```
(https://forum.robotframework.org/t/removing-tags-from-the-test-tags-setting/7513/6?u=romanliv confirms this as an issue to be fixed)
| 1medium
|
Title: Add fail-safe for downloading binaries.
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Whenever I wish to run the prisma command after installation, it will download binaries. Whenever I CTRL+C the task through the download process. It will cause me to not be able to download the binaries in the future unless there is a new update OR if I install NodeJS. It always frustrates me whenever this happens, so I have to wait till it does install in the future.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
I suggest adding a fail-safe for the downloading binaries, as if it is cancelled whilst the binaries are being downloaded, it will lead to the issue that the binaries haven't been downloaded.
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
I haven't currently considered anything else, sorry!
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
Issue #665.
| 1medium
|
Title: Word2vec: loss tally maxes at 134217728.0 due to float32 limited-precision
Body:
<!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that do not include relevant information and context will be closed without an answer. Thanks!
-->
#### Cumulative loss of word2vec maxes out at 134217728.0
I'm training a word2vec model with 2,793,404 sentences / 33,499,912 words, vocabulary size 162,253 (words with at least 5 occurrences).
Expected behaviour: with `compute_loss=True`, gensim's word2vec should compute the loss in the expected way.
Actual behaviour: the cumulative loss seems to be maxing out at `134217728.0`:
Building vocab...
Vocab done. Training model for 120 epochs, with 16 workers...
Loss after epoch 1: 16162246.0 / cumulative loss: 16162246.0
Loss after epoch 2: 11594642.0 / cumulative loss: 27756888.0
[ - snip - ]
Loss after epoch 110: 570688.0 / cumulative loss: 133002056.0
Loss after epoch 111: 564448.0 / cumulative loss: 133566504.0
Loss after epoch 112: 557848.0 / cumulative loss: 134124352.0
Loss after epoch 113: 93376.0 / cumulative loss: 134217728.0
Loss after epoch 114: 0.0 / cumulative loss: 134217728.0
Loss after epoch 115: 0.0 / cumulative loss: 134217728.0
And it stays at `134217728.0` thereafter. The value `134217728.0` is of course exactly `128*1024*1024`, which does not seem like a coincidence.
#### Steps to reproduce
My code is as follows:
class MyLossCalculator(CallbackAny2Vec):
def __init__(self):
self.epoch = 1
self.losses = []
self.cumu_losses = []
def on_epoch_end(self, model):
cumu_loss = model.get_latest_training_loss()
loss = cumu_loss if self.epoch <= 1 else cumu_loss - self.cumu_losses[-1]
print(f"Loss after epoch {self.epoch}: {loss} / cumulative loss: {cumu_loss}")
self.epoch += 1
self.losses.append(loss)
self.cumu_losses.append(cumu_loss)
def train_and_check(my_sentences, my_epochs, my_workers=8):
print(f"Building vocab...")
my_model: Word2Vec = Word2Vec(sg=1, compute_loss=True, workers=my_workers)
my_model.build_vocab(my_sentences)
print(f"Vocab done. Training model for {my_epochs} epochs, with {my_workers} workers...")
loss_calc = MyLossCalculator()
trained_word_count, raw_word_count = my_model.train(my_sentences, total_examples=my_model.corpus_count, compute_loss=True,
epochs=my_epochs, callbacks=[loss_calc])
loss = loss_calc.losses[-1]
print(trained_word_count, raw_word_count, loss)
loss_df = pd.DataFrame({"training loss": loss_calc.losses})
loss_df.plot(color="blue")
# print(f"Calculating accuracy...")
# acc, details = my_model.wv.evaluate_word_analogies(questions_file, case_insensitive=True)
# print(acc)
return loss_calc, my_model
The data is a news article corpus in Finnish; I'm not at liberty to share all of it (and anyway it's a bit big), but it looks like one would expect:
[7]: df.head(2)
[7]: [Row(file_and_id='data_in_json/2018/04/0001.json.gz%%3-10169118', index_in_file='853', headline='Parainen pyristelee pois lastensuojelun kriisistä: irtisanoutuneiden tilalle houkutellaan uusia sosiaalityöntekijöitä paremmilla työeduilla', publication_date='2018-04-20 11:59:35+03:00', publication_year='2018', publication_month='04', sentence='hän tiesi minkälaiseen tilanteeseen tulee', lemmatised_sentence='hän tietää minkälainen tilanne tulla', source='yle', rnd=8.436637410902392e-08),
Row(file_and_id='data_in_xml/arkistosiirto2018.zip%%arkistosiirto2018/102054668.xml', index_in_file=None, headline='*** Tiedote/SDP: Medialle tiedoksi: SDP:n puheenjohtaja Antti Rinteen puhe puoluevaltuuston kokouksessa ***', publication_date='2018-04-21T12:51:44', publication_year='2018', publication_month='04', sentence='me haluamme jättää hallitukselle välikysymyksen siitä miksi nuorten ihmisten tulevaisuuden uskoa halutaan horjuttaa miksi epävarmuutta ja näköalattomuutta sekä pelkoa tulevaisuuden suhteen halutaan lisätä', lemmatised_sentence='me haluta jättää hallitus välikysymys se miksi nuori ihminen tulevaisuus usko haluta horjuttaa miksi epävarmuus ja näköalattomuus sekä pelko tulevaisuus suhteen haluta lisätä', source='stt', rnd=8.547760445010155e-07)]
sentences = list(map(lambda r: r["lemmatised_sentence"].split(" "), df.select("lemmatised_sentence").collect()))
[18]: sentences[0]
[18]: ['hän', 'tietää', 'minkälainen', 'tilanne', 'tulla']
#### Versions
The output of:
```python
import platform; print(platform.platform())
import sys; print("Python", sys.version)
import numpy; print("NumPy", numpy.__version__)
import scipy; print("SciPy", scipy.__version__)
import gensim; print("gensim", gensim.__version__)
from gensim.models import word2vec;print("FAST_VERSION", word2vec.FAST_VERSION)
```
is:
Windows-10-10.0.18362-SP0
Python 3.7.3 | packaged by conda-forge | (default, Jul 1 2019, 22:01:29) [MSC v.1900 64 bit (AMD64)]
NumPy 1.17.3
SciPy 1.3.1
gensim 3.8.1
FAST_VERSION 1
Finally, I'm not the only one who has encountered this issue. I found the following related links:
https://groups.google.com/forum/#!topic/gensim/IH5-nWoR_ZI
https://stackoverflow.com/questions/59823688/gensim-word2vec-model-loss-becomes-0-after-few-epochs
I'm not sure if this is only a display issue and the training continues normally even after the cumulative loss reaches its "maximum", or if the training in fact stops at that point. The trained word vectors seem reasonably ok, judging by `my_model.wv.evaluate_word_analogies()`, though they do need more training than this.
| 1medium
|
Title: Add optional typed base classes for listener API
Body: Issue #4567 proposes adding a base class for the dynamic library API and having similar base classes for the listener API would be convenient as well. The usage would be something like this:
```python
from robot.api.interfaces import ListenerV3
class Listener(ListenerV3):
...
```
The base class should have all available listener methods with documentation and appropriate type information. We should have base classes both for listener v2 and for v3 and they should have `ROBOT_LISTENER_API_VERSION` set accordingly.
Similarly as #4567, this would be easy to implement and could be done already in RF 6.1. We mainly need to agree on naming and where to import these base classes.
| 1medium
|
Title: [BUG] Failed to create Mars DataFrame when mars object exists in a list
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Failed to create Mars DataFrame when mars object exists in a list.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```
In [1]: import mars
In [2]: mars.new_session()
Web service started at http://0.0.0.0:24172
Out[2]: <mars.deploy.oscar.session.SyncSession at 0x7f8ada249370>
In [3]: import mars.dataframe as md
In [5]: s = md.Series([1, 2, 3])
In [6]: df2 = md.DataFrame({'a': [s.sum()]})
100%|█████████████████████████████████████| 100.0/100 [00:00<00:00, 1592.00it/s]
In [7]: df2
Out[7]: DataFrame <op=DataFrameDataSource, key=5a704fd6d6ab7aee6f31d874c2f11347>
In [12]: df2.execute()
0%| | 0/100 [00:00<?, ?it/s]Failed to run subtask 00lm3BBKMBsieIow3LtlHrwv on band numa-0
Traceback (most recent call last):
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 331, in internal_run_subtask
subtask_info.result = await self._retry_run_subtask(
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 420, in _retry_run_subtask
return await _retry_run(subtask, subtask_info, _run_subtask_once)
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 107, in _retry_run
raise ex
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 67, in _retry_run
return await target_async_func(*args)
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 373, in _run_subtask_once
return await asyncio.shield(aiotask)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/api.py", line 68, in run_subtask_in_slot
return await ref.run_subtask.options(profiling_context=profiling_context).send(
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 183, in send
future = await self._call(actor_ref.address, message, wait=False)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 61, in _call
return await self._caller.call(
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/core.py", line 95, in call
await client.send(message)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/communication/base.py", line 258, in send
return await self.channel.send(message)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/communication/socket.py", line 73, in send
buffers = await serializer.run()
File "/Users/qinxuye/Workspace/mars/mars/serialization/aio.py", line 80, in run
return self._get_buffers()
File "/Users/qinxuye/Workspace/mars/mars/serialization/aio.py", line 37, in _get_buffers
headers, buffers = serialize(self._obj)
File "/Users/qinxuye/Workspace/mars/mars/serialization/core.py", line 363, in serialize
gen_result = gen_serializer.serialize(gen_to_serial, context)
File "/Users/qinxuye/Workspace/mars/mars/serialization/core.py", line 72, in wrapped
return func(self, obj, context)
File "/Users/qinxuye/Workspace/mars/mars/serialization/core.py", line 151, in serialize
return {}, pickle_buffers(obj)
File "/Users/qinxuye/Workspace/mars/mars/serialization/core.py", line 88, in pickle_buffers
buffers[0] = cloudpickle.dumps(
File "/Users/qinxuye/miniconda3/envs/mars3.8/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py", line 73, in dumps
cp.dump(obj)
File "/Users/qinxuye/miniconda3/envs/mars3.8/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py", line 563, in dump
return Pickler.dump(self, obj)
TypeError: cannot pickle 'weakref' object
100%|█████████████████████████████████████| 100.0/100 [00:00<00:00, 3581.29it/s]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-12-fe40b754f95d> in <module>
----> 1 df2.execute()
~/Workspace/mars/mars/core/entity/tileables.py in execute(self, session, **kw)
460
461 def execute(self, session=None, **kw):
--> 462 result = self.data.execute(session=session, **kw)
463 if isinstance(result, TILEABLE_TYPE):
464 return self
~/Workspace/mars/mars/core/entity/executable.py in execute(self, session, **kw)
96
97 session = _get_session(self, session)
---> 98 return execute(self, session=session, **kw)
99
100 def _check_session(self, session: SessionType, action: str):
~/Workspace/mars/mars/deploy/oscar/session.py in execute(tileable, session, wait, new_session_kwargs, show_progress, progress_update_interval, *tileables, **kwargs)
1777 session = get_default_or_create(**(new_session_kwargs or dict()))
1778 session = _ensure_sync(session)
-> 1779 return session.execute(
1780 tileable,
1781 *tileables,
~/Workspace/mars/mars/deploy/oscar/session.py in execute(self, tileable, show_progress, *tileables, **kwargs)
1575 fut = asyncio.run_coroutine_threadsafe(coro, self._loop)
1576 try:
-> 1577 execution_info: ExecutionInfo = fut.result(
1578 timeout=self._isolated_session.timeout
1579 )
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440 else:
441 raise TimeoutError()
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in __get_result(self)
386 def __get_result(self):
387 if self._exception:
--> 388 raise self._exception
389 else:
390 return self._result
~/Workspace/mars/mars/deploy/oscar/session.py in _execute(session, wait, show_progress, progress_update_interval, cancelled, *tileables, **kwargs)
1757 # set cancelled to avoid wait task leak
1758 cancelled.set()
-> 1759 await execution_info
1760 else:
1761 return execution_info
~/Workspace/mars/mars/deploy/oscar/session.py in wait()
100
101 async def wait():
--> 102 return await self._aio_task
103
104 self._future_local.future = fut = asyncio.run_coroutine_threadsafe(
~/Workspace/mars/mars/deploy/oscar/session.py in _run_in_background(self, tileables, task_id, progress, profiling)
905 )
906 if task_result.error:
--> 907 raise task_result.error.with_traceback(task_result.traceback)
908 if cancelled:
909 return
~/Workspace/mars/mars/services/scheduling/worker/execution.py in internal_run_subtask(self, subtask, band_name)
329
330 batch_quota_req = {(subtask.session_id, subtask.subtask_id): calc_size}
--> 331 subtask_info.result = await self._retry_run_subtask(
332 subtask, band_name, subtask_api, batch_quota_req
333 )
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run_subtask(self, subtask, band_name, subtask_api, batch_quota_req)
418 # any exceptions occurred.
419 if subtask.retryable:
--> 420 return await _retry_run(subtask, subtask_info, _run_subtask_once)
421 else:
422 try:
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
105 )
106 else:
--> 107 raise ex
108
109
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
65 while True:
66 try:
---> 67 return await target_async_func(*args)
68 except (OSError, MarsError) as ex:
69 if subtask_info.num_retries < subtask_info.max_retries:
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _run_subtask_once()
371 subtask_api.run_subtask_in_slot(band_name, slot_id, subtask)
372 )
--> 373 return await asyncio.shield(aiotask)
374 except asyncio.CancelledError as ex:
375 # make sure allocated slots are traced
~/Workspace/mars/mars/services/subtask/api.py in run_subtask_in_slot(self, band_name, slot_id, subtask)
66 ProfilingContext(task_id=subtask.task_id) if enable_profiling else None
67 )
---> 68 return await ref.run_subtask.options(profiling_context=profiling_context).send(
69 subtask
70 )
~/Workspace/mars/mars/oscar/backends/context.py in send(self, actor_ref, message, wait_response, profiling_context)
181 ):
182 detect_cycle_send(message, wait_response)
--> 183 future = await self._call(actor_ref.address, message, wait=False)
184 if wait_response:
185 result = await self._wait(future, actor_ref.address, message)
~/Workspace/mars/mars/oscar/backends/context.py in _call(self, address, message, wait)
59 self, address: str, message: _MessageBase, wait: bool = True
60 ) -> Union[ResultMessage, ErrorMessage, asyncio.Future]:
---> 61 return await self._caller.call(
62 Router.get_instance_or_empty(), address, message, wait=wait
63 )
~/Workspace/mars/mars/oscar/backends/core.py in call(self, router, dest_address, message, wait)
93 with Timer() as timer:
94 try:
---> 95 await client.send(message)
96 except ConnectionError:
97 try:
~/Workspace/mars/mars/oscar/backends/communication/base.py in send(self, message)
256 @implements(Channel.send)
257 async def send(self, message):
--> 258 return await self.channel.send(message)
259
260 @implements(Channel.recv)
~/Workspace/mars/mars/oscar/backends/communication/socket.py in send(self, message)
71 compress = self.compression or 0
72 serializer = AioSerializer(message, compress=compress)
---> 73 buffers = await serializer.run()
74
75 # write buffers
~/Workspace/mars/mars/serialization/aio.py in run(self)
78
79 async def run(self):
---> 80 return self._get_buffers()
81
82
~/Workspace/mars/mars/serialization/aio.py in _get_buffers(self)
35
36 def _get_buffers(self):
---> 37 headers, buffers = serialize(self._obj)
38
39 def _is_cuda_buffer(buf): # pragma: no cover
~/Workspace/mars/mars/serialization/core.py in serialize(obj, context)
361 gen_to_serial = gen.send(last_serial)
362 gen_serializer = _serial_dispatcher.get_handler(type(gen_to_serial))
--> 363 gen_result = gen_serializer.serialize(gen_to_serial, context)
364 if isinstance(gen_result, types.GeneratorType):
365 # when intermediate result still generator, push its contexts
~/Workspace/mars/mars/serialization/core.py in wrapped(self, obj, context)
70 else:
71 context[id(obj)] = obj
---> 72 return func(self, obj, context)
73
74 return wrapped
~/Workspace/mars/mars/serialization/core.py in serialize(self, obj, context)
149 @buffered
150 def serialize(self, obj, context: Dict):
--> 151 return {}, pickle_buffers(obj)
152
153 def deserialize(self, header: Dict, buffers: List, context: Dict):
~/Workspace/mars/mars/serialization/core.py in pickle_buffers(obj)
86 buffers.append(memoryview(x))
87
---> 88 buffers[0] = cloudpickle.dumps(
89 obj,
90 buffer_callback=buffer_cb,
~/miniconda3/envs/mars3.8/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py in dumps(obj, protocol, buffer_callback)
71 file, protocol=protocol, buffer_callback=buffer_callback
72 )
---> 73 cp.dump(obj)
74 return file.getvalue()
75
~/miniconda3/envs/mars3.8/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py in dump(self, obj)
561 def dump(self, obj):
562 try:
--> 563 return Pickler.dump(self, obj)
564 except RuntimeError as e:
565 if "recursion" in e.args[0]:
TypeError: cannot pickle 'weakref' object
```
| 1medium
|
Title: Propose using `$var` syntax if evaluation IF or WHILE condition using `${var}` fails
Body: A common error when evaluating expressions with IF or otherwise is using something like
```
IF ${x} == 'expected'
Keyword
END
```
when the variable `${x}` contains a string. Normal variables are resolved _before_ evaluating the expression, so if `${x}` contains a string `value`, the evaluated expression will be `value == 'expected'`. Evaluating it fails because `value` isn't quoted, it's thus considered a variable in Python, and no such variable exists. The resulting error is this:
> Evaluating IF condition failed: Evaluating expression 'value == 'expected'' failed: NameError: name 'value' is not defined nor importable as module
One solution to this problem is quoting the variable like `'${x}' == 'expected'`, but that doesn't work if the variable value contains quotes or newlines. A better solution is using the special `$var` syntax like `$x == 'value'` that makes the variable available in the Python evaluation namespace (#2040). All this is explained in the [User Guide](http://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#evaluating-expressions), but there are many users who don't know about this and struggle with the syntax.
Because this is a such a common error, we should make the error more informative if the expression contains "normal" variables. We could, for example, show also the original expression and recommend quoting or using the "special" variable syntax. Possibly it could look like this:
> Evaluating IF condition failed: Evaluating expression 'value == 'expected'' failed: NameError: name 'value' is not defined nor importable as module
> The original expression was '${x} == 'expected''. Try using the '$var' syntax like '$x == 'expected'' to avoid resolving variables before the expression is evaluated. See the Evaluating expression appendix in the User Guide for more details.
There are few problems implementing this:
1. Variables are solved before the [evaluate_expression](https://github.com/robotframework/robotframework/blob/master/src/robot/variables/evaluation.py#L31) is called so this function doesn't know the original expression nor did it contain variables. This information needs to be passed to it, but in same cases (at least with inline Python evaluation) it isn't that easy.
2. It's not easy to detect when exactly this extra information should be included into the error. Including it always when evaluating the expression fails can add confusion when the error isn't related to variables. It would probably better to include it only if evaluation fails for a NameError, but also in that case you could have an expression like `'${x}' == value` where the variable likely isn't a problem. We could try some heuristics to see what causes the error, but that's probably too much work compared to including the extra info in some cases where it's not needed.
3. Coming up with a good but somewhat short error message isn't easy. I'm not totally happy with the above, but I guess it would be better than nothing.
Because this extra info is added only if evaluation fails, this should be a totally backwards compatible change. It would be nice to include it already into RF 6.1, but that release is already about to be late and this isn't that easy to implement, so RF 6.2 is probably a better target. If someone is interested to look at this, including it already into RF 6.1 ought to be possible.
| 1medium
|
Title: Stacked bar plots helper function
Body: Create a helper function in the `yellowbrick.draw` module that can create a stacked bar chart from a 2D array on the specified axes. This function should have the following basic signature:
```python
def bar_stack(data, ax=None, labels=None, ticks=None, colors=None, **kwargs):
"""
An advanced bar chart plotting utility that can draw bar and stacked bar charts from
data, wrapping calls to the specified matplotlib.Axes object.
Parameters
----------
data : 2D array-like
The data associated with the bar chart where the columns represent each bar
and the rows represent each stack in the bar chart. A single bar chart would
be a 2D array with only one row, a bar chart with three stacks per bar would
have a shape of (3, b).
ax : matplotlib.Axes, default: None
The axes object to draw the barplot on, uses plt.gca() if not specified.
labels : list of str, default: None
The labels for each row in the bar stack, used to create a legend.
ticks : list of str, default: None
The labels for each bar, added to the x-axis for a vertical plot, or the y-axis
for a horizontal plot.
colors : array-like, default: None
Specify the colors of each bar, each row in the stack, or every segment.
kwargs : dict
Additional keyword arguments to pass to ``ax.bar``.
"""
```
This is just a base signature and should be further refined as we dig into the work. Once this helper function is created, the following visualizers should be updated to use it:
- [ ] `PosTagVisualizer`
- [ ] `FeatureImportances`
- [ ] `ClassPredictionError`
(@DistrictDataLabs/team-oz-maintainers please feel free to add other visualizers above as needed)
**Describe the solution you'd like**
A helper function to create stacked bar plot. (See #510 and #847, #771 )
**Is your feature request related to a problem? Please describe.**
This can be useful for `ClassPredictionError`, `FeatureImportances`, and future stacked bar plot.
| 1medium
|
Title: [Documentation]: More FastAPI examples and clearer ASGI/WSGI sections
Body: Our documentation currently falls short in providing comprehensive examples for FastAPI and ASGI. This gap has led to user confusion. Additionally, the WSGI & ASGI topics are combined in a way that muddles the information.
### Proposed Changes
- Add more FastAPI examples across the "Python" documentation section to cater to a broader audience and use cases.
- Promote the use of `call_and_validate` throughout the documentation for consistency.
- Create separate sub-sections for ASGI and WSGI under the "Python" section to eliminate confusion and provide targeted guidance.
| 1medium
|
Title: Add support for middleware
Body: [https://www.prisma.io/docs/concepts/components/prisma-client/middleware](https://www.prisma.io/docs/concepts/components/prisma-client/middleware)
```py
client = Client()
async def logging_middleware(params: MiddlewareParams, next: NextMiddleware) -> MiddlewareResult:
log.info('Running %s query on %s', params.action, params.model)
yield await next(params)
log.info('Successfully ran %s query on %s ', params.action, params.model)
async def foo_middleware(params: MiddlewareParams, next: NextMiddleware) -> MiddlewareResult:
...
result = await next(params)
...
return result
client.use(logging_middleware, foo_middleware)
```
### Should Support
* Yielding result
* Returning result
| 1medium
|
Title: Using aggregation instead of transform to perform `df.groupby().nunique()`
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Now, `df.groupby().nunique()` would be delegated to `transform` to perform execution, it will be a shuffle operation which is very time consuming, we can delegate it to `aggregation` which is way more optimized.
| 1medium
|
Title: [BUG] NameError raised when comparing string inside agg function.
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
NameError raised when comparing string inside agg function.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```
In [3]: import mars.dataframe as md
In [4]: df = md.DataFrame({'a': ['1', '2', '3'], 'b': ['a1', 'a2', 'a1']})
In [5]: df.groupby('a', as_index=False)['b'].agg(lambda x: (x == "a1").sum()).ex
...: ecute()
0%| | 0/100 [00:00<?, ?it/s]Failed to run subtask aRWmQqEgc5OymCkUZLYRcTb9 on band numa-0
Traceback (most recent call last):
File "/Users/xuyeqin/Workspace/mars/mars/services/scheduling/worker/execution.py", line 315, in internal_run_subtask
subtask_info.result = await self._retry_run_subtask(
File "/Users/xuyeqin/Workspace/mars/mars/services/scheduling/worker/execution.py", line 404, in _retry_run_subtask
return await _retry_run(subtask, subtask_info, _run_subtask_once)
File "/Users/xuyeqin/Workspace/mars/mars/services/scheduling/worker/execution.py", line 91, in _retry_run
raise ex
File "/Users/xuyeqin/Workspace/mars/mars/services/scheduling/worker/execution.py", line 66, in _retry_run
return await target_async_func(*args)
File "/Users/xuyeqin/Workspace/mars/mars/services/scheduling/worker/execution.py", line 357, in _run_subtask_once
return await asyncio.shield(aiotask)
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/api.py", line 66, in run_subtask_in_slot
return await ref.run_subtask.options(profiling_context=profiling_context).send(
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/context.py", line 186, in send
return self._process_result_message(result)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/context.py", line 70, in _process_result_message
raise message.error.with_traceback(message.traceback)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/pool.py", line 520, in send
result = await self._run_coro(message.message_id, coro)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/pool.py", line 319, in _run_coro
return await coro
File "/Users/xuyeqin/Workspace/mars/mars/oscar/api.py", line 115, in __on_receive__
return await super().__on_receive__(message)
File "mars/oscar/core.pyx", line 373, in __on_receive__
raise ex
File "mars/oscar/core.pyx", line 367, in mars.oscar.core._BaseActor.__on_receive__
return await self._handle_actor_result(result)
File "mars/oscar/core.pyx", line 252, in _handle_actor_result
task_result = await coros[0]
File "mars/oscar/core.pyx", line 295, in _run_actor_async_generator
with debug_async_timeout('actor_lock_timeout',
File "mars/oscar/core.pyx", line 297, in mars.oscar.core._BaseActor._run_actor_async_generator
async with self._lock:
File "mars/oscar/core.pyx", line 301, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await gen.athrow(*res)
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/worker/runner.py", line 118, in run_subtask
result = yield self._running_processor.run(subtask)
File "mars/oscar/core.pyx", line 306, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await self._handle_actor_result(res)
File "mars/oscar/core.pyx", line 226, in _handle_actor_result
result = await result
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/context.py", line 186, in send
return self._process_result_message(result)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/context.py", line 70, in _process_result_message
raise message.error.with_traceback(message.traceback)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/pool.py", line 520, in send
result = await self._run_coro(message.message_id, coro)
File "/Users/xuyeqin/Workspace/mars/mars/oscar/backends/pool.py", line 319, in _run_coro
return await coro
File "/Users/xuyeqin/Workspace/mars/mars/oscar/api.py", line 115, in __on_receive__
return await super().__on_receive__(message)
File "mars/oscar/core.pyx", line 373, in __on_receive__
raise ex
File "mars/oscar/core.pyx", line 367, in mars.oscar.core._BaseActor.__on_receive__
return await self._handle_actor_result(result)
File "mars/oscar/core.pyx", line 252, in _handle_actor_result
task_result = await coros[0]
File "mars/oscar/core.pyx", line 295, in _run_actor_async_generator
with debug_async_timeout('actor_lock_timeout',
File "mars/oscar/core.pyx", line 297, in mars.oscar.core._BaseActor._run_actor_async_generator
async with self._lock:
File "mars/oscar/core.pyx", line 301, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await gen.athrow(*res)
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/worker/processor.py", line 596, in run
result = yield self._running_aio_task
File "mars/oscar/core.pyx", line 306, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await self._handle_actor_result(res)
File "mars/oscar/core.pyx", line 226, in _handle_actor_result
result = await result
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/worker/processor.py", line 457, in run
await self._execute_graph(chunk_graph)
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/worker/processor.py", line 209, in _execute_graph
await to_wait
File "/Users/xuyeqin/Workspace/mars/mars/lib/aio/_threads.py", line 36, in to_thread
return await loop.run_in_executor(None, func_call)
File "/Users/xuyeqin/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/core/mode.py", line 77, in _inner
return func(*args, **kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/services/subtask/worker/processor.py", line 177, in _execute_operand
return execute(ctx, op)
File "/Users/xuyeqin/Workspace/mars/mars/core/operand/core.py", line 487, in execute
result = executor(results, op)
File "/Users/xuyeqin/Workspace/mars/mars/core/custom_log.py", line 94, in wrap
return func(cls, ctx, op)
File "/Users/xuyeqin/Workspace/mars/mars/utils.py", line 1128, in wrapped
result = func(cls, ctx, op)
File "/Users/xuyeqin/Workspace/mars/mars/dataframe/groupby/aggregation.py", line 1050, in execute
cls._execute_map(ctx, op)
File "/Users/xuyeqin/Workspace/mars/mars/dataframe/groupby/aggregation.py", line 854, in _execute_map
pre_df = func(pre_df, gpu=op.is_gpu())
File "<string>", line 3, in expr_function
NameError: name 'a1' is not defined
0%| | 0/100 [00:00<?, ?it/s]
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-5-3a632fccd78f> in <module>
----> 1 df.groupby('a', as_index=False)['b'].agg(lambda x: (x == "a1").sum()).execute()
~/Workspace/mars/mars/core/entity/tileables.py in execute(self, session, **kw)
460
461 def execute(self, session=None, **kw):
--> 462 result = self.data.execute(session=session, **kw)
463 if isinstance(result, TILEABLE_TYPE):
464 return self
~/Workspace/mars/mars/core/entity/executable.py in execute(self, session, **kw)
96
97 session = _get_session(self, session)
---> 98 return execute(self, session=session, **kw)
99
100 def _check_session(self, session: SessionType, action: str):
~/Workspace/mars/mars/deploy/oscar/session.py in execute(tileable, session, wait, new_session_kwargs, show_progress, progress_update_interval, *tileables, **kwargs)
1771 session = get_default_or_create(**(new_session_kwargs or dict()))
1772 session = _ensure_sync(session)
-> 1773 return session.execute(
1774 tileable,
1775 *tileables,
~/Workspace/mars/mars/deploy/oscar/session.py in execute(self, tileable, show_progress, *tileables, **kwargs)
1571 fut = asyncio.run_coroutine_threadsafe(coro, self._loop)
1572 try:
-> 1573 execution_info: ExecutionInfo = fut.result(
1574 timeout=self._isolated_session.timeout
1575 )
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440 else:
441 raise TimeoutError()
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in __get_result(self)
386 def __get_result(self):
387 if self._exception:
--> 388 raise self._exception
389 else:
390 return self._result
~/Workspace/mars/mars/deploy/oscar/session.py in _execute(session, wait, show_progress, progress_update_interval, cancelled, *tileables, **kwargs)
1722 while not cancelled.is_set():
1723 try:
-> 1724 await asyncio.wait_for(
1725 asyncio.shield(execution_info), progress_update_interval
1726 )
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in wait_for(fut, timeout, loop)
481
482 if fut.done():
--> 483 return fut.result()
484 else:
485 fut.remove_done_callback(cb)
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in _wrap_awaitable(awaitable)
682 that will later be wrapped in a Task by ensure_future().
683 """
--> 684 return (yield from awaitable.__await__())
685
686 _wrap_awaitable._is_coroutine = _is_coroutine
~/Workspace/mars/mars/deploy/oscar/session.py in wait()
100
101 async def wait():
--> 102 return await self._aio_task
103
104 self._future_local.future = fut = asyncio.run_coroutine_threadsafe(
~/Workspace/mars/mars/deploy/oscar/session.py in _run_in_background(self, tileables, task_id, progress, profiling)
901 )
902 if task_result.error:
--> 903 raise task_result.error.with_traceback(task_result.traceback)
904 if cancelled:
905 return
~/Workspace/mars/mars/services/scheduling/worker/execution.py in internal_run_subtask(self, subtask, band_name)
313
314 batch_quota_req = {(subtask.session_id, subtask.subtask_id): calc_size}
--> 315 subtask_info.result = await self._retry_run_subtask(
316 subtask, band_name, subtask_api, batch_quota_req
317 )
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run_subtask(self, subtask, band_name, subtask_api, batch_quota_req)
402 # any exceptions occurred.
403 if subtask.retryable:
--> 404 return await _retry_run(subtask, subtask_info, _run_subtask_once)
405 else:
406 return await _run_subtask_once()
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
89 ex,
90 )
---> 91 raise ex
92
93
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
64 while True:
65 try:
---> 66 return await target_async_func(*args)
67 except (OSError, MarsError) as ex:
68 if subtask_info.num_retries < subtask_info.max_retries:
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _run_subtask_once()
355 subtask_api.run_subtask_in_slot(band_name, slot_id, subtask)
356 )
--> 357 return await asyncio.shield(aiotask)
358 except asyncio.CancelledError as ex:
359 # make sure allocated slots are traced
~/Workspace/mars/mars/services/subtask/api.py in run_subtask_in_slot(self, band_name, slot_id, subtask)
64 else None
65 )
---> 66 return await ref.run_subtask.options(profiling_context=profiling_context).send(
67 subtask
68 )
~/Workspace/mars/mars/oscar/backends/context.py in send(self, actor_ref, message, wait_response, profiling_context)
184 if wait_response:
185 result = await self._wait(future, actor_ref.address, message)
--> 186 return self._process_result_message(result)
187 else:
188 return future
~/Workspace/mars/mars/oscar/backends/context.py in _process_result_message(message)
68 return message.result
69 else:
---> 70 raise message.error.with_traceback(message.traceback)
71
72 async def _wait(self, future: asyncio.Future, address: str, message: _MessageBase):
~/Workspace/mars/mars/oscar/backends/pool.py in send()
518 raise ActorNotExist(f"Actor {actor_id} does not exist")
519 coro = self._actors[actor_id].__on_receive__(message.content)
--> 520 result = await self._run_coro(message.message_id, coro)
521 processor.result = ResultMessage(
522 message.message_id,
~/Workspace/mars/mars/oscar/backends/pool.py in _run_coro()
317 self._process_messages[message_id] = asyncio.tasks.current_task()
318 try:
--> 319 return await coro
320 finally:
321 self._process_messages.pop(message_id, None)
~/Workspace/mars/mars/oscar/api.py in __on_receive__()
113 Message shall be (method_name,) + args + (kwargs,)
114 """
--> 115 return await super().__on_receive__(message)
116
117
~/Workspace/mars/mars/oscar/core.pyx in __on_receive__()
371 debug_logger.exception('Got unhandled error when handling message %r'
372 'in actor %s at %s', message, self.uid, self.address)
--> 373 raise ex
374
375
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor.__on_receive__()
365 raise ValueError(f'call_method {call_method} not valid')
366
--> 367 return await self._handle_actor_result(result)
368 except Exception as ex:
369 if _log_unhandled_errors:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
250 # asyncio.wait as it introduces much overhead
251 if len(coros) == 1:
--> 252 task_result = await coros[0]
253 if extract_tuple:
254 result = task_result
~/Workspace/mars/mars/oscar/core.pyx in _run_actor_async_generator()
293 res = None
294 while True:
--> 295 with debug_async_timeout('actor_lock_timeout',
296 'async_generator %r hold lock timeout', gen):
297 async with self._lock:
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
295 with debug_async_timeout('actor_lock_timeout',
296 'async_generator %r hold lock timeout', gen):
--> 297 async with self._lock:
298 if not is_exception:
299 res = await gen.asend(res)
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
299 res = await gen.asend(res)
300 else:
--> 301 res = await gen.athrow(*res)
302 try:
303 if _log_cycle_send:
~/Workspace/mars/mars/services/subtask/worker/runner.py in run_subtask()
116 self._running_processor = self._last_processor = processor
117 try:
--> 118 result = yield self._running_processor.run(subtask)
119 finally:
120 self._running_processor = None
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
304 message_trace = pop_message_trace()
305
--> 306 res = await self._handle_actor_result(res)
307 is_exception = False
308 except:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
224
225 if inspect.isawaitable(result):
--> 226 result = await result
227 elif is_async_generator(result):
228 result = (result,)
~/Workspace/mars/mars/oscar/backends/context.py in send()
184 if wait_response:
185 result = await self._wait(future, actor_ref.address, message)
--> 186 return self._process_result_message(result)
187 else:
188 return future
~/Workspace/mars/mars/oscar/backends/context.py in _process_result_message()
68 return message.result
69 else:
---> 70 raise message.error.with_traceback(message.traceback)
71
72 async def _wait(self, future: asyncio.Future, address: str, message: _MessageBase):
~/Workspace/mars/mars/oscar/backends/pool.py in send()
518 raise ActorNotExist(f"Actor {actor_id} does not exist")
519 coro = self._actors[actor_id].__on_receive__(message.content)
--> 520 result = await self._run_coro(message.message_id, coro)
521 processor.result = ResultMessage(
522 message.message_id,
~/Workspace/mars/mars/oscar/backends/pool.py in _run_coro()
317 self._process_messages[message_id] = asyncio.tasks.current_task()
318 try:
--> 319 return await coro
320 finally:
321 self._process_messages.pop(message_id, None)
~/Workspace/mars/mars/oscar/api.py in __on_receive__()
113 Message shall be (method_name,) + args + (kwargs,)
114 """
--> 115 return await super().__on_receive__(message)
116
117
~/Workspace/mars/mars/oscar/core.pyx in __on_receive__()
371 debug_logger.exception('Got unhandled error when handling message %r'
372 'in actor %s at %s', message, self.uid, self.address)
--> 373 raise ex
374
375
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor.__on_receive__()
365 raise ValueError(f'call_method {call_method} not valid')
366
--> 367 return await self._handle_actor_result(result)
368 except Exception as ex:
369 if _log_unhandled_errors:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
250 # asyncio.wait as it introduces much overhead
251 if len(coros) == 1:
--> 252 task_result = await coros[0]
253 if extract_tuple:
254 result = task_result
~/Workspace/mars/mars/oscar/core.pyx in _run_actor_async_generator()
293 res = None
294 while True:
--> 295 with debug_async_timeout('actor_lock_timeout',
296 'async_generator %r hold lock timeout', gen):
297 async with self._lock:
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
295 with debug_async_timeout('actor_lock_timeout',
296 'async_generator %r hold lock timeout', gen):
--> 297 async with self._lock:
298 if not is_exception:
299 res = await gen.asend(res)
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
299 res = await gen.asend(res)
300 else:
--> 301 res = await gen.athrow(*res)
302 try:
303 if _log_cycle_send:
~/Workspace/mars/mars/services/subtask/worker/processor.py in run()
594 self._running_aio_task = asyncio.create_task(processor.run())
595 try:
--> 596 result = yield self._running_aio_task
597 raise mo.Return(result)
598 finally:
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
304 message_trace = pop_message_trace()
305
--> 306 res = await self._handle_actor_result(res)
307 is_exception = False
308 except:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
224
225 if inspect.isawaitable(result):
--> 226 result = await result
227 elif is_async_generator(result):
228 result = (result,)
~/Workspace/mars/mars/services/subtask/worker/processor.py in run()
455 try:
456 # execute chunk graph
--> 457 await self._execute_graph(chunk_graph)
458 finally:
459 # unpin inputs data
~/Workspace/mars/mars/services/subtask/worker/processor.py in _execute_graph()
207
208 try:
--> 209 await to_wait
210 logger.debug(
211 "Finish executing operand: %s," "chunk: %s, subtask id: %s",
~/Workspace/mars/mars/lib/aio/_threads.py in to_thread()
34 ctx = contextvars.copy_context()
35 func_call = functools.partial(ctx.run, func, *args, **kwargs)
---> 36 return await loop.run_in_executor(None, func_call)
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py in run()
55
56 try:
---> 57 result = self.fn(*self.args, **self.kwargs)
58 except BaseException as exc:
59 self.future.set_exception(exc)
~/Workspace/mars/mars/core/mode.py in _inner()
75 def _inner(*args, **kwargs):
76 with enter_mode(**mode_name_to_value):
---> 77 return func(*args, **kwargs)
78
79 else:
~/Workspace/mars/mars/services/subtask/worker/processor.py in _execute_operand()
175 self, ctx: Dict[str, Any], op: OperandType
176 ): # noqa: R0201 # pylint: disable=no-self-use
--> 177 return execute(ctx, op)
178
179 async def _execute_graph(self, chunk_graph: ChunkGraph):
~/Workspace/mars/mars/core/operand/core.py in execute()
485 # The `UFuncTypeError` was introduced by numpy#12593 since v1.17.0.
486 try:
--> 487 result = executor(results, op)
488 succeeded = True
489 return result
~/Workspace/mars/mars/core/custom_log.py in wrap()
92
93 if custom_log_dir is None:
---> 94 return func(cls, ctx, op)
95
96 log_path = os.path.join(custom_log_dir, op.key)
~/Workspace/mars/mars/utils.py in wrapped()
1126
1127 try:
-> 1128 result = func(cls, ctx, op)
1129 finally:
1130 with AbstractSession._lock:
~/Workspace/mars/mars/dataframe/groupby/aggregation.py in execute()
1048 pd.set_option("mode.use_inf_as_na", op.use_inf_as_na)
1049 if op.stage == OperandStage.map:
-> 1050 cls._execute_map(ctx, op)
1051 elif op.stage == OperandStage.combine:
1052 cls._execute_combine(ctx, op)
~/Workspace/mars/mars/dataframe/groupby/aggregation.py in _execute_map()
852 pre_df = in_data if cols is None else in_data[cols]
853 try:
--> 854 pre_df = func(pre_df, gpu=op.is_gpu())
855 except TypeError:
856 pre_df = pre_df.transform(_wrapped_func)
~/Workspace/mars/mars/dataframe/reduction/core.py in expr_function()
NameError: name 'a1' is not defined
```
| 1medium
|
Title: Audit usage of `Any` throughout the code base
Body: Currently there are a couple of places that we use `Any` when we should instead use a more accurate type or just fallback to `object`. For example, the `DataError` class, https://github.com/RobertCraigie/prisma-client-py/blob/5fe90fa3e09918f289aab573cdce79985c21d1ad/src/prisma/errors.py#L59
Other places for improvement:
- `QueryBuilder.method_format` should use a `Literal` type
| 1medium
|
Title: Make it possible for custom converters to get access to the library
Body: Custom converters are a handy feature added in RF 5.0 (#4088). It would be convenient if converters would be able to access the library they are attached to. This would allow conversion to be dependent on the state of the library or the automated application. For example, we web testing library could automatically check does a locator string (id, xpath, css, ...) match any object on the page and pass a reference to the object to the keyword.
A simple way to support this would be passing the library instance to the converter along with the value to be converted:
```python
def converter(value, library):
...
```
For backwards compatibility reasons we cannot make the second argument mandatory and needing to use it in cases where it's not needed wouldn't be convenient in general. We can, however, easily check does the converter accept one or two arguments and pass it the library instance only in the latter case.
| 1medium
|
Title: Script to autogenerate images in docs
Body: Currently in our `docs` folder, we have code that generates png files to be used in the generated docs. It would be helpful to have a script to generate images and save them in the appropriate folder location.
related to: https://github.com/DistrictDataLabs/yellowbrick/issues/38
| 1medium
|
Title: Maximize whitespace with feature-reordering optimization in ParallelCoordinates and RadViz
Body: Both `RadViz` and `ParallelCoordinates` would benefit from increased whitespace/increased transparency that is achieved simply by recording the columns around the circle in `RadViz` and along the horizontal in `ParallelCoordinates`. Potentially some optimization technique would allow us to discover the best feature ordering/subset of features to display.
### Proposal/Issue
- [ ] enhance `RadViz`/`ParallelCoordinates` to specify the ordering of the features
- [ ] create a function/method to compute the amount of whitespace or alpha transparency in the figure
- [ ] implement an optimization method (Hill Climbing, Simulated Annealing, etc.) to maximize the whitespace/alpha transparency using feature orders as individual search points.
| 1medium
|
Title: Request: Add Flash Attention 2.0 Support for ViTMAEForPreTraining
Body: Hi Hugging Face team!
I am currently working on pre-training a Foundation Model using ViTMAEForPreTraining, and I was hoping to use Flash Attention 2.0 to speed up training and reduce memory usage. However, when I attempted to enable Flash Attention, I encountered the following error:
`ValueError: ViTMAEForPreTraining does not support Flash Attention 2.0 yet.
Please request to add support where the model is hosted, on its model hub page: https://huggingface.co//discussions/new
or in the Transformers GitHub repo: https://github.com/huggingface/transformers/issues/new`
Since MAE pre-training is heavily dependent on the attention mechanism, adding Flash Attention support would be a valuable enhancement—especially for larger ViT models and high-resolution datasets, like Landsat data we are working with.
**Feature Request**
- Please add support for Flash Attention 2.0 to ViTMAEForPreTraining.
- This would help make MAE pre-training more efficient in terms of speed and memory consumption.
**Why This Matters**
- Many users working with large imagery datasets (like remote sensing, medical imaging, etc.) would greatly benefit from this.
- Flash Attention has already proven useful in other ViT variants, so bringing this to MAE feels like a natural next step.
**Environment Details**
- Transformers version: v4.41.0.dev0
- PyTorch version: 2.5.1
- Running on multi-GPU with NCCL backend
| 1medium
|
Title: [FEATURE] graphql not required handling
Body: Currently when fields in graphql schemas are not required, schemathesis can send `null` to them.
According to the graphql specs this is valid and it is useful to find bugs.
But sometimes it would be easier to not send null values
Is there a way to turn the null value sending behavior off? It would be nice to have a simple switch for it
| 1medium
|
Title: [BUG] index out of range when using Mars with XGBOOST
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
IndexError: list assignment index out of range
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
Python 3.7.7 on ray docker 1.9
2. The version of Mars you use
0.9.0a2
3. Versions of crucial packages, such as numpy, scipy and pandas
pip install xgboost
pip install "xgboost_ray"
pip install lightgbm
4. Full stack of the error.
(base) ray@eb0b527fa9ea:~/ray/ray$ python main.py
2022-02-16 12:39:47,496 WARNING ray.py:301 -- Ray is not started, start the local ray cluster by `ray.init`.
2022-02-16 12:39:50,168 INFO services.py:1340 -- View the Ray dashboard at http://127.0.0.1:8265
2022-02-16 12:39:51,580 INFO driver.py:34 -- Setup cluster with {'ray://ray-cluster-1645043987/0': {'CPU': 8}, 'ray://ray-cluster-1645043987/1': {'CPU': 8}, 'ray://ray-cluster-1645043987/2': {'CPU': 8}, 'ray://ray-cluster-1645043987/3': {'CPU': 8}}
2022-02-16 12:39:51,581 INFO driver.py:36 -- Creating placement group ray-cluster-1645043987 with bundles [{'CPU': 8}, {'CPU': 8}, {'CPU': 8}, {'CPU': 8}].
2022-02-16 12:39:51,716 INFO driver.py:50 -- Create placement group success.
2022-02-16 12:39:52,978 INFO ray.py:479 -- Create supervisor on node ray://ray-cluster-1645043987/0/0 succeeds.
2022-02-16 12:39:53,230 INFO ray.py:489 -- Start services on supervisor ray://ray-cluster-1645043987/0/0 succeeds.
2022-02-16 12:40:07,025 INFO ray.py:498 -- Create 4 workers and start services on workers succeeds.
2022-02-16 12:40:07,036 WARNING ray.py:510 -- Web service started at http://0.0.0.0:46910
0%| | 0/100 [00:00<?, ?it/s]
Traceback (most recent call last):
File "main.py", line 69, in <module>
main()
File "main.py", line 35, in main
df_train, df_test = _load_data(n_samples, n_features, n_classes, test_size=0.2)
File "main.py", line 25, in _load_data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=shuffle_seed)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/learn/model_selection/_split.py", line 145, in train_test_split
session=session, **(run_kwargs or dict())
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/entity/executable.py", line 221, in execute
ret = execute(*self, session=session, **kw)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/deploy/oscar/session.py", line 1779, in execute
**kwargs,
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/deploy/oscar/session.py", line 1574, in execute
timeout=self._isolated_session.timeout
File "/home/ray/anaconda3/lib/python3.7/concurrent/futures/_base.py", line 435, in result
return self.__get_result()
File "/home/ray/anaconda3/lib/python3.7/concurrent/futures/_base.py", line 384, in __get_result
raise self._exception
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/deploy/oscar/session.py", line 1725, in _execute
asyncio.shield(execution_info), progress_update_interval
File "/home/ray/anaconda3/lib/python3.7/asyncio/tasks.py", line 442, in wait_for
return fut.result()
File "/home/ray/anaconda3/lib/python3.7/asyncio/tasks.py", line 630, in _wrap_awaitable
return (yield from awaitable.__await__())
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/deploy/oscar/session.py", line 102, in wait
return await self._aio_task
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/deploy/oscar/session.py", line 903, in _run_in_background
raise task_result.error.with_traceback(task_result.traceback)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 57, in inner
return await func(processor, *args, **kwargs)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 336, in get_next_stage_processor
chunk_graph = await self._get_next_chunk_graph(self._chunk_graph_iter)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 266, in _get_next_chunk_graph
chunk_graph = await fut
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/lib/aio/_threads.py", line 36, in to_thread
return await loop.run_in_executor(None, func_call)
File "/home/ray/anaconda3/lib/python3.7/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 261, in next_chunk_graph
return next(chunk_graph_iter)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/preprocessor.py", line 158, in tile
for chunk_graph in chunk_graph_builder.build():
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 272, in build
yield from self._build()
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 266, in _build
graph = next(tile_iterator)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/preprocessor.py", line 75, in __iter__
to_update_tileables = self._iter()
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 204, in _iter
visited,
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 113, in _tile
need_process = next(tile_handler)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 84, in _tile_handler
tiled_tileables = yield from handler.tile(tiled_tileables)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/entity/tileables.py", line 79, in tile
tiled_result = yield from tile_handler(op)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/learn/utils/shuffle.py", line 217, in tile
inp = yield from cls._safe_rechunk(inp, ax_nsplit)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/learn/utils/shuffle.py", line 144, in _safe_rechunk
return (yield from recursive_tile(tileable.rechunk(ax_nsplit)))
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/tensor/rechunk/rechunk.py", line 103, in rechunk
chunk_size = get_nsplits(tensor, chunk_size, tensor.dtype.itemsize)
File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/tensor/rechunk/core.py", line 34, in get_nsplits
chunk_size[idx] = c
IndexError: list assignment index out of range
(RayMainPool pid=5574) Unexpected error happens in <function TaskProcessor.get_next_stage_processor at 0x7f276f2458c0>
(RayMainPool pid=5574) Traceback (most recent call last):
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 57, in inner
(RayMainPool pid=5574) return await func(processor, *args, **kwargs)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 336, in get_next_stage_processor
(RayMainPool pid=5574) chunk_graph = await self._get_next_chunk_graph(self._chunk_graph_iter)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 266, in _get_next_chunk_graph
(RayMainPool pid=5574) chunk_graph = await fut
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/lib/aio/_threads.py", line 36, in to_thread
(RayMainPool pid=5574) return await loop.run_in_executor(None, func_call)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/concurrent/futures/thread.py", line 57, in run
(RayMainPool pid=5574) result = self.fn(*self.args, **self.kwargs)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/processor.py", line 261, in next_chunk_graph
(RayMainPool pid=5574) return next(chunk_graph_iter)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/preprocessor.py", line 158, in tile
(RayMainPool pid=5574) for chunk_graph in chunk_graph_builder.build():
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 272, in build
(RayMainPool pid=5574) yield from self._build()
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 266, in _build
(RayMainPool pid=5574) graph = next(tile_iterator)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/services/task/supervisor/preprocessor.py", line 75, in __iter__
(RayMainPool pid=5574) to_update_tileables = self._iter()
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 204, in _iter
(RayMainPool pid=5574) visited,
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 113, in _tile
(RayMainPool pid=5574) need_process = next(tile_handler)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/graph/builder/chunk.py", line 84, in _tile_handler
(RayMainPool pid=5574) tiled_tileables = yield from handler.tile(tiled_tileables)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/core/entity/tileables.py", line 79, in tile
(RayMainPool pid=5574) tiled_result = yield from tile_handler(op)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/learn/utils/shuffle.py", line 217, in tile
(RayMainPool pid=5574) inp = yield from cls._safe_rechunk(inp, ax_nsplit)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/learn/utils/shuffle.py", line 144, in _safe_rechunk
(RayMainPool pid=5574) return (yield from recursive_tile(tileable.rechunk(ax_nsplit)))
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/tensor/rechunk/rechunk.py", line 103, in rechunk
(RayMainPool pid=5574) chunk_size = get_nsplits(tensor, chunk_size, tensor.dtype.itemsize)
(RayMainPool pid=5574) File "/home/ray/anaconda3/lib/python3.7/site-packages/mars/tensor/rechunk/core.py", line 34, in get_nsplits
(RayMainPool pid=5574) chunk_size[idx] = c
(RayMainPool pid=5574) IndexError: list assignment index out of range
5. Minimized code to reproduce the error.
```python
import logging
import ray
import mars
import numpy as np
import mars.dataframe as md
from mars.learn.model_selection import train_test_split
from mars.learn.datasets import make_classification
from xgboost_ray import RayDMatrix, RayParams, train, predict
logger = logging.getLogger(__name__)
logging.basicConfig(format=ray.ray_constants.LOGGER_FORMAT, level=logging.INFO)
def _load_data(n_samples: int,
n_features:int,
n_classes: int,
test_size: float = 0.1,
shuffle_seed: int = 42):
n_informative = int(n_features * 0.5)
n_redundant = int(n_features * 0.2)
# generate dataset
X, y = make_classification(n_samples=n_samples, n_features=n_features, n_classes=n_classes, n_informative=n_informative, n_redundant=n_redundant, random_state=shuffle_seed)
X, y = md.DataFrame(X), md.DataFrame({"labels": y})
X.columns = ['feature-' + str(i) for i in range(n_features)]
# split dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=shuffle_seed)
return md.concat([X_train, y_train], axis=1), md.concat([X_test, y_test], axis=1)
def main(*args):
n_samples, n_features, worker_num, worker_cpu, num_shards = 10 ** 4, 20, 4, 8, 10
ray_params = RayParams(num_actors=10, cpus_per_actor=1)
# setup mars
mars.new_ray_session(worker_num=worker_num, worker_cpu=worker_cpu, worker_mem=1 * 1024 ** 3)
n_classes = 10
df_train, df_test = _load_data(n_samples, n_features, n_classes, test_size=0.2)
print(df_train)
print(df_test)
# convert mars DataFrame to Ray dataset
ds_train = md.to_ray_dataset(df_train, num_shards=num_shards)
ds_test = md.to_ray_dataset(df_test, num_shards=num_shards)
train_set = RayDMatrix(data=ds_train, label="labels")
test_set = RayDMatrix(data=ds_test, label="labels")
evals_result = {}
params = {
'nthread': 1,
'objective': 'multi:softmax',
'eval_metric': ['mlogloss', 'merror'],
'num_class': n_classes,
'eta': 0.1,
'seed': 42
}
bst = train(
params=params,
dtrain=train_set,
num_boost_round=200,
evals=[(train_set, 'train')],
evals_result=evals_result,
verbose_eval=100,
ray_params=ray_params
)
# predict on a test set.
pred = predict(bst, test_set, ray_params=ray_params)
precision = (ds_test.dataframe['labels'].to_pandas() == pred).astype(int).sum() / ds_test.dataframe.shape[0]
logger.info("Prediction Accuracy: %.4f", precision)
if __name__ == "__main__":
main()
```
**Expected behavior**
train_test_split would fail and emit "IndexError: list assignment index out of range".
**Additional context**
Add any other context about the problem here.
| 1medium
|
Title: add Flash Attention Support for Helsinki-NLP/opus models
Body: ### Feature request
I would like to propose adding support for flash attention to the Helsinki-NLP/opus models in the Hugging Face library. Judging by what I am seeing [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/marian/modeling_marian.py), it seems not implemented.
### Motivation
**performance gains:** adding flash attention would allow for significant speedups
### Your contribution
I am happy to help test the implementation if needed. Thank you for considering this enhancement, and I look forward to the discussion!
| 1medium
|
Title: [FEATURE] More control over explicit test example sources
Body: ### Is your feature request related to a problem? Please describe
Right now if OpenAPI endpoint has an example under `requestBody` AND request schema has an example value for each field, Schemathesis generates 2 separate requests with different payloads but the same request parameters. This is problematic for endpoints that create resources and accept resource IDs via request parameters, for example:
```
POST /book/{book_id}
```
because the 2nd request typically fails to create the resource due to the ID clash (that is part of the request path and doesn't change from example to example).
### Describe the solution you'd like
Ideally, something like this might take care of a wide range of needs:
- New CLI flag `--explicit-example-count` with values:
- `single` - at most one explicit request per operation may be performed
- `multiple` (default) - more than one request per operation may be performed
- New CLI flag `--explicit-example-source` with values:
- `all`
- `operation` - only examples defined under operation's `requestBody > content > {type} > example/examples` are used
- `schema` - only example(s) constructed from the operation's request schema's individual field examples (not sure if more than one example can be constructed from the schema definition)
This approach can be later extended to allow filtering by example name when using [`examples` with named values](https://swagger.io/specification/#media-type-object).
### Describe alternatives you've considered
1. Removing either operation example or field example
- Not ideal option as both example types typically play role when rendering the API docs from OpenAPI schema. If possible we'd like to keep both field-level examples and operation-level examples
2. Use hooks
- Could work but would significantly increase the complexity of the API testing. Currently we rely on the "create" operation test to set up test data that is later used by "read", "update" and "delete" operation tests. If we started using hooks to delete each created record after the test case completed, we'd then also need to start setting up the test data for "read", "update" and "delete"operation tests.
| 1medium
|
Title: [ENH] deconcatenate_column to preserve the original column location
Body: # Brief Description
<!-- Please provide a brief description of what you'd like to propose. -->
I would like to propose an enhancement to `deconcatenate_column` for preserving the original column position.
The current implementation will append the deconcatenated columns to the right of the original dataframe. In this way, the relative positions of the columns are not preserved.
I'd like to have a boolean kwarg that allows users to preserve the original column order.
# Example API
```python
df = (pd.DataFrame(...).
deconcatenate_column(..., preserve_position=True)
```
| 1medium
|
Title: Support accessing the DMMF at runtime
Body: ## Problem
Using typescript, I some times have to map all the schema with the following code:
```
async function generatePrismaVariablesDescriptions(): Promise<any> {
const a = {};
//return Prisma.dmmf.datamodel.models;
Prisma.dmmf.datamodel.models.map((model) => {
//a[model.name] = {};
model.fields.map((b) => {
a[b.name] = b.isList ? b.type.toString() + '[]' : b.type.toString();
});
});
return a;
}
```
It is unfortunate that right now this method is not implemented.
## Suggested solution
Add similar method to python library.
| 1medium
|
Title: Adapting Whisper to the new loss_function attribute
Body: @ArthurZucker @muellerzr Following up on #35838, #34191, #34198, #34283
I would like to help bring in Whisper into this. I see it was not included in the last #35875 round of fixes related to the loss function bug fix (grad acc.) nor the new global "loss_function" attr. Being an encodec model derived from Bart code in many places around loss and decoder input token handling - I suspect Bart would also benefit from such attention.
So - Would like to help with the following missing support:
## It does not accept kwargs
In 'forward' (For Conditional Gen) - Seems straight-forward to follow @muellerzr work and implement considering test passing. Anything special to consider there?
## I does not use the global "loss_function" attr (introduced with #34191)
I find that the closest Loss implementation would be ForMaskedLMLoss since seems like the shifted labels are expected from how the existing loss is calc'd
https://github.com/huggingface/transformers/blob/d4a6b4099bc163a44335aca2dd25355fc16fa248/src/transformers/models/whisper/modeling_whisper.py#L1787-L1791
### Some background on the above
I find this was derived from the Bart implementation, which forced the user to either provide `decoder_input_ids` or derived them from labels by shifting them to the right as part of the denoising pre-training task type - this lead to a situation where labels are expected to be left shifted compared to the logits which is properly served by the above loss calculation.
Whisper, inherited that, but has a more involved input id prefixing scheme. the model is hardly the place to grab the "decoder start token id" which is required to accomplish the "shift right" of labels and get the `decoder_input_ids`, and anyway - for Whisper this prefix during inference is critical to determining the task and control over that is properly reflected in other args. (language, task, notimestamps etc)
Thus, proper collators suggested by @sanchit-gandhi in his [great guidance](https://huggingface.co/blog/fine-tune-whisper) and the work on Distill-Whisper have explicitly specified both `labels` and `decoder_input_ids` that worked around the auto (now unusable) "label shift righting". (See code [here](https://github.com/huggingface/distil-whisper/blob/cc96130f6e4cc74cab4545f3c6e7e5c204ced871/training/run_distillation.py#L460-L464))
Or otherwise "cooked" the labels to contain all but the first "decode start token id" as a hack. (More at #27384) and even the Collator code in the popular blog post about Whisper FT does:
```
# if bos token is appended in previous tokenization step,
# cut bos token here as it's append later anyways
if (labels[:, 0] == self.decoder_start_token_id).all().cpu().item():
labels = labels[:, 1:]
```
Which of course is a workaround to mitigate that Bart heritage.
WDYT @sanchit-gandhi, Did I get this right?
Anyway - this is why the `ForCausalLMLoss` probably won't be a fit - it will shift the labels left to match against logits positions.
Would like to know if that proper loss then to use is `ForMaskedLMLoss` or maybe a new `ForConditionalGenerationLMLoss` actually. Personally, I think a new one should exist, that does exactly what `ForMaskedLMLoss` with some shared implementation for both.
Also, as an aside I would love to see the Bart derived "decode_input_ids from labels" logic adapted to Whisper - but not sure I have the experience to know how.
## Grad acc loss bug still applies to Whisper
As it is implemented now - you can (thankfully) customize the loss calc using "compute_loss_func" which was introduced in #34198 - and this is mandatory for anyone who want to avoid the grad acc loss described [here](https://huggingface.co/blog/gradient_accumulation) and fixed in many PR's around the above mentioned efforts.
This is actually an open bug for Whisper which did not enjoy the common `fixed_cross_entropy` injection onto other models.
Thanks guys for all the great documentation on this, so much easier to try and contribute back!
| 1medium
|
Title: Run load tests
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We have not yet tested how well Prisma Client Python scales. Scalability is a core concern with ORMs / database clients.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Use [Locust](https://locust.io/) to write tests.
We should also include these tests in CI so that we can fail checks if there are any regressions and upload the results so they can be viewed on GitHub pages.
| 1medium
|
Title: [BUG] df.loc[:, [fields]] triggered unnecessary iterative tiling
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
df.loc[:, [fields]] triggered unnecessary iterative tiling.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```python
from mars.core import tile
df2 = df[df['x'] < 1]
loc_df = df2.loc[:, ['y', 'x']]
tiled_loc_df = tile(loc_df) # cannot run
```
| 1medium
|
Title: Fields nested within a list are not correctly serialised
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
The following query passes type checks and should work but it fails at runtime as the `startswith` field is not transformed to the internal `startsWith` field.
```py
await client.user.find_first(
where={
"AND": [
{"name": {"contains": "house"}},
{
"OR": [
{"name": {"startswith": "40"}},
{"name": {"contains": ", 40"}},
]
},
]
}
)
```
## How to reproduce
<!--
Steps to reproduce the behavior:
1. Go to '...'
2. Change '....'
3. Run '....'
4. See error
-->
Run the above query.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
No errors.
## Prisma information
<!-- Your Prisma schema, Prisma Client Python queries, ...
Do not include your database credentials when sharing your Prisma schema! -->
Internal test schema.
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: <!--[e.g. Mac OS, Windows, Debian, CentOS, ...]--> Mac OS
- Database: <!--[PostgreSQL, MySQL, MariaDB or SQLite]--> SQLite
- Python version: <!--[Run `python -V` to see your Python version]--> 3.9.9
| 1medium
|
Title: Raise a warning on multiple rapid connections / disconnections
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently an easy mistake to make is to use the client's context manager feature on every database query e.g.
```py
async with client:
user = await User.prisma().find_unique(
where={
'id' user_id,
},
)
```
This is a mistake when used in anything other than a small seed script as it will create a connection pool and connect to the database only to close the pool and disconnect immediately afterwards. This is very inefficient and should only be done once per application runtime.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
I believe this mistake is easy to make as the initial `connect()` must be called explicitly by the user and sometimes it is not very obvious where to do this. (#103 will solve this).
We should update the documentation for connecting with the context manager with a big warning saying not to use this repeatedly in actual applications.
We should also consider raising a warning if many calls to `connect()` and `disconnect()` are encountered. There should also be an easy way to disable these checks, maybe a new client parameter?
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
Encountered this pattern while reading through open source code:
https://github.com/shydiscord/shy-dashboard/blob/f708c3a70d9e3aaa60f6bae693bf649d27883ea0/shy-dashboard/server/blueprints/api.py
| 1medium
|
Title: Improve support for usage within multiprocessing environments
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently you cannot create a connection to the database & then pass the connected `Prisma` instance to a new process.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Support instantiating `Prisma` from a "settings" object which would be a simple object / dictionary holding the relevant information to point the engine to an already existing process.
```py
def handle(settings: PrismaSettings) -> None:
my_prisma = Prisma.from_settings(settings)
user = my_prisma.user.find_first()
print('user', user)
db = Prisma()
db.connect()
settings = db.get_settings()
if __name__ == '__main__':
p = multiprocessing.Process(target=shared_handle, args=[settings])
p.start()
p.join()
````
I'm not sure I particularly like the `settings` name though 🤷
| 1medium
|
Title: Result model: Add `message` to keywords and control structures and remove `doc` from controls
Body: Currently some control structures in the result model have a `doc` attribute that's represented in output.xml as a `<doc>` element. This attribute is used for storing information about removing or flattening items using `--flattenkeywords` and `--removekeywords` options. It's a rather strange attribute because it's not possible to set documentation for control structures in data. It's also also inconsistent that only some of the control structures have it.
On the other hand, control structures don't have a `message` attribute that would contain their possible failure message, they only have `status`. Keywords have in practice don't have `message` either. They do have the attribute, it is only used with teardowns to make possible to see the error message if a suite teardown fails.
To fix the above issues, we have decided to do the following:
- Add `message` to all keywords and control structures and always store the possible failure message in it.
- Use `message` also for storing information about flattening or removing items.
- Remove `doc` from control structures.
The main benefit of these changes is making the result model simpler and more consistent. It is important in general, but it gets even more important now that we are adding JSON serialization support to it (#4847) and that format will likely be used also by external tools.
The `doc` attribute that control structures currently have won't be directly removed, but it will be deprecated as part of #4846. Old output.xml files with possible `<doc>` elements with control structures will still be supported. Whatever content `<doc>` contains will be added to `message`.
| 1medium
|
Title: Integrate paddlepaddle or Mindspore
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
I want to integrate paddlepaddle and mindspore , any hint ?
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
I want to integrate paddlepaddle and mindspore , any hint ?
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
I want to integrate paddlepaddle and mindspore , any hint ?
**Additional context**
Add any other context or screenshots about the feature request here.
| 1medium
|
Title: Ensure multi schema models work
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Prisma added [preview feature support](https://github.com/prisma/prisma/issues/1122#issuecomment-1231773471) for `multiSchema` in `v4.3.0`, we should make sure this works for Prisma Client Python.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Write tests. I suspect this will already be supported.
| 1medium
|
Title: Regarding additional feature on Incremental SVD over available SVD_COMPRESSED method.
Body: Hi, @hendrikmakait and other teams members,
I am working on implementation of DeepLearning Models using SVD specifically SVD_Compressed method available in Dask using dask.array.linalg.svd_compressed especially using CuPy to compute larger SVD matrix on GPUs. But there is a problem I am facing while implementing this. While Computing SVD on larger matrix which are not possible to get loaded fully on GPU memory at a time, we require something called incremental SVD in addition to SVD_Compressed. I know this is possible to be done and not too tough to be implemented if we already have SVD_Compressed running on GPU already. By this what I actually require to do is Distributed Streaming SVD computation on larger dataset which is available on Storage but not fully loaded on GPU.
| 1medium
|
Title: In a Jupyter notebook, no display when poof is in a separate cell
Body: if visualizer.poof() is called in a separate cell, no visualization appears, as the empty plot has already been rendered in the call for fit(). Workaround is to access visualizer.ax.get_figure().
### Issue
For extra detail, see demo notebook linked in Background section
### Code Snippet
Tested using the bike share data set from the YB intro
In one cell:
```
visualizer = Rank1D()
visualizer.fit(X,y)
visualizer.transform(X)
```
In a separate cell:
`visualizer.poof()`
### Background
Demo notebook
https://gist.github.com/fdion/d645e164f6969d269aff681efa31ef96
| 1medium
|
Title: [ENH] Add ability to flag null values in columns
Body: # Brief Description
Hello everyone, I'd like to suggest a new method (I'll tentatively call it `flag_nulls`) that adds a new column to the dataframe to indicate if there are null values in the row.
If you are preparing a dataframe for machine learning or something, it's important to fill in the null values with something. However, the fact that the data is null could, in fact, be its own feature--for example, if someone is submitting an insurance claim and they haven't provided important information about themselves, that might be a flag that the claim is fraudulent.
# Example API
```python
# flag null values in columns
df.flag_nulls(column_name='null_flag', columns=None)
# column_name gives the name of the new column we generate
# columns is a list of the columns that we check for null values. If columns is None, we use all the columns
df1 = pd.DataFrame({'a': [1, 2, None, 4], 'b': [5.0, None, 7.0, 8.0]}
print df1.flag_nulls()
```
a | b | null_flag
---|---|---
1 | 5.0 | 0
2 | None | 1
None | 7.0 | 1
4 | 8.0 | 0
```python
print df1.flag_nulls(columns=['a'])
```
a | b | null_flag
---|---|---
1 | 5.0 | 0
2 | None | 0
None | 7.0 | 1
4 | 8.0 | 0
```python
print df1.flag_nulls(columns=['a'], column_name='flag')
```
a | b | flag
---|---|---
1 | 5.0 | 0
2 | None | 0
None | 7.0 | 1
4 | 8.0 | 0
# Notes
- Computerphile [agrees with me](https://www.youtube.com/watch?v=oCQbC818KKU) on this strategy as well ;)
- I would like to work on this issue if that's acceptable.
| 1medium
|
Title: Invalid string representation for bytes outside ASCII range
Body: Currently output from `Should be Equal` as well as `Should Contain` for bytes is not useful.
Consider following tests:
```robot
*** Test Cases ***
Test Should be Equal
${binary1Var} = Convert To Bytes \x00\x01\x02\xA0\xB0
${binary2Var} = Convert To Bytes abc
Should Be Equal ${binary1Var} ${binary2Var}
Test Should Contain
${binary1Var} = Convert To Bytes \x00\x01\x02\xA0\xB0
${item} = Convert To Bytes \xC0
Should Contain ${binary1Var} ${item}
```
output is:
```
==============================================================================
Test Should be Equal | FAIL |
☺☻\xa0\xb0 != abc
------------------------------------------------------------------------------
Test Should Contain | FAIL |
'☺☻\xa0\xb0' does not contain '\xc0'
------------------------------------------------------------------------------
Test | FAIL |
2 tests, 0 passed, 2 failed
==============================================================================
```
it would be better to have `b'\x00\x01\x02\xa0\xb0'` instead of `☺☻\xa0\xb0`
inside log some values are invisible:

| 1medium
|
Title: Add support for filtering by null values
Body: I couldn't find anything in documentation how filtering fields with null works.
I got it working with this:
```
await db.profile.find_many(where={"NOT": [{"first_name": "null"}]})
```
I don't know if this is the correct way. Because it would also filter a profile with the first_name "null".
| 1medium
|
Title: Perform syntax check after client generation
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
It is possible that the generator will generate invalid python code leading to the user having to uninstall and reinstall the prisma package
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Either parse the rendered files with an AST parser or import them after generation, if erroneous, remove the rendered files
| 1medium
|
Title: Deserialize raw query types into richer python types
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We currently deserialize raw query fields into types that are different than what the core ORM uses, e.g. `Decimal` becomes `float` instead of `decimal.Decimal`, this was implemented this way for backwards compatibility reasons.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We should use types that are nicer to work with:
- [ ] `datetime.datetime` for `DateTime` fields
- [ ] `decimal.Decimal` for `Decimal` fields
- [ ] `prisma.Base64` for `Bytes` fields
| 1medium
|
Title: Improve error message for http timeouts
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
The current error message when a HTTP timeout error is raised doesn't provide any details on how to fix the issue.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add more context to the error message.
| 1medium
|
Title: [BUG] Error is just ignored in `Actor.__pre_destroy__`
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
For now, error is just ignored in `Actor.__pre_destroy__`, if error occurs, it's just ignored.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```python
class ActorCannotDestroy(mo.Actor):
async def __pre_destroy__(self):
raise ValueError('Cannot destroy')
@pytest.mark.asyncio
async def test_error_in_pre_destroy(actor_pool_context):
pool = actor_pool_context
a = await mo.create_actor(ActorCannotDestroy, address=pool.external_address)
with pytest.raises(ValueError, match='Cannot destroy'): # no error raised
await mo.destroy_actor(a)
```
**Expected behavior**
Error can be raised in `Actor.__pre_destroy__`.
| 1medium
|
Title: [BUG] `mars.tensor.array_equal` raises error when input tensor's dtype is string
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
`mars.tensor.array_equal` raises error when input tensor's dtype is string.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```
In [12]: import mars
In [13]: import mars.tensor as mt
In [14]: mars.new_session()
Web service started at http://0.0.0.0:58497
Out[14]: <mars.deploy.oscar.session.SyncSession at 0x7ff688137880>
In [15]: a = mt.array(['a', 'b', 'c'])
In [16]: b = mt.array(['a', 'b', 'c'])
In [17]: mt.array_equal(a, b).execute()
0%| | 0/100 [00:00<?, ?it/s]Failed to run subtask G2H9d9WnwZFwUMDFKUweND1j on band numa-0
Traceback (most recent call last):
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 332, in internal_run_subtask
subtask_info.result = await self._retry_run_subtask(
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 433, in _retry_run_subtask
return await _retry_run(subtask, subtask_info, _run_subtask_once)
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 107, in _retry_run
raise ex
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 67, in _retry_run
return await target_async_func(*args)
File "/Users/qinxuye/Workspace/mars/mars/services/scheduling/worker/execution.py", line 375, in _run_subtask_once
return await asyncio.shield(aiotask)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/api.py", line 68, in run_subtask_in_slot
return await ref.run_subtask.options(profiling_context=profiling_context).send(
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 189, in send
return self._process_result_message(result)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 70, in _process_result_message
raise message.as_instanceof_cause()
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/pool.py", line 542, in send
result = await self._run_coro(message.message_id, coro)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/pool.py", line 333, in _run_coro
return await coro
File "/Users/qinxuye/Workspace/mars/mars/oscar/api.py", line 115, in __on_receive__
return await super().__on_receive__(message)
File "mars/oscar/core.pyx", line 506, in __on_receive__
raise ex
File "mars/oscar/core.pyx", line 500, in mars.oscar.core._BaseActor.__on_receive__
return await self._handle_actor_result(result)
File "mars/oscar/core.pyx", line 385, in _handle_actor_result
task_result = await coros[0]
File "mars/oscar/core.pyx", line 428, in _run_actor_async_generator
async with self._lock:
File "mars/oscar/core.pyx", line 430, in mars.oscar.core._BaseActor._run_actor_async_generator
'async_generator %r hold lock timeout', gen):
File "mars/oscar/core.pyx", line 434, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await gen.athrow(*res)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/worker/runner.py", line 118, in run_subtask
result = yield self._running_processor.run(subtask)
File "mars/oscar/core.pyx", line 439, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await self._handle_actor_result(res)
File "mars/oscar/core.pyx", line 359, in _handle_actor_result
result = await result
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 189, in send
return self._process_result_message(result)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/context.py", line 70, in _process_result_message
raise message.as_instanceof_cause()
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/pool.py", line 542, in send
result = await self._run_coro(message.message_id, coro)
File "/Users/qinxuye/Workspace/mars/mars/oscar/backends/pool.py", line 333, in _run_coro
return await coro
File "/Users/qinxuye/Workspace/mars/mars/oscar/api.py", line 115, in __on_receive__
return await super().__on_receive__(message)
File "mars/oscar/core.pyx", line 506, in __on_receive__
raise ex
File "mars/oscar/core.pyx", line 500, in mars.oscar.core._BaseActor.__on_receive__
return await self._handle_actor_result(result)
File "mars/oscar/core.pyx", line 385, in _handle_actor_result
task_result = await coros[0]
File "mars/oscar/core.pyx", line 428, in _run_actor_async_generator
async with self._lock:
File "mars/oscar/core.pyx", line 430, in mars.oscar.core._BaseActor._run_actor_async_generator
'async_generator %r hold lock timeout', gen):
File "mars/oscar/core.pyx", line 434, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await gen.athrow(*res)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/worker/processor.py", line 610, in run
result = yield self._running_aio_task
File "mars/oscar/core.pyx", line 439, in mars.oscar.core._BaseActor._run_actor_async_generator
res = await self._handle_actor_result(res)
File "mars/oscar/core.pyx", line 359, in _handle_actor_result
result = await result
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/worker/processor.py", line 457, in run
await self._execute_graph(chunk_graph)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/worker/processor.py", line 220, in _execute_graph
await to_wait
File "/Users/qinxuye/Workspace/mars/mars/lib/aio/_threads.py", line 36, in to_thread
return await loop.run_in_executor(None, func_call)
File "/Users/qinxuye/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/Users/qinxuye/Workspace/mars/mars/core/mode.py", line 77, in _inner
return func(*args, **kwargs)
File "/Users/qinxuye/Workspace/mars/mars/services/subtask/worker/processor.py", line 188, in _execute_operand
return execute(ctx, op)
File "/Users/qinxuye/Workspace/mars/mars/core/operand/core.py", line 489, in execute
raise TypeError(str(e)).with_traceback(sys.exc_info()[2]) from None
File "/Users/qinxuye/Workspace/mars/mars/core/operand/core.py", line 485, in execute
result = executor(results, op)
File "/Users/qinxuye/Workspace/mars/mars/tensor/arithmetic/core.py", line 165, in execute
ret = cls._execute_cpu(op, xp, lhs, rhs, **kw)
File "/Users/qinxuye/Workspace/mars/mars/tensor/arithmetic/core.py", line 142, in _execute_cpu
return cls._get_func(xp)(lhs, rhs, **kw)
TypeError: [address=127.0.0.1:41564, pid=5771] ufunc 'equal' did not contain a loop with signature matching types (dtype('<U1'), dtype('<U1')) -> dtype('bool')
100%|█████████████████████████████████████| 100.0/100 [00:00<00:00, 1990.45it/s]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-17-629343032f46> in <module>
----> 1 mt.array_equal(a, b).execute()
~/Workspace/mars/mars/core/entity/tileables.py in execute(self, session, **kw)
460
461 def execute(self, session=None, **kw):
--> 462 result = self.data.execute(session=session, **kw)
463 if isinstance(result, TILEABLE_TYPE):
464 return self
~/Workspace/mars/mars/core/entity/executable.py in execute(self, session, **kw)
96
97 session = _get_session(self, session)
---> 98 return execute(self, session=session, **kw)
99
100 def _check_session(self, session: SessionType, action: str):
~/Workspace/mars/mars/deploy/oscar/session.py in execute(tileable, session, wait, new_session_kwargs, show_progress, progress_update_interval, *tileables, **kwargs)
1801 session = get_default_or_create(**(new_session_kwargs or dict()))
1802 session = _ensure_sync(session)
-> 1803 return session.execute(
1804 tileable,
1805 *tileables,
~/Workspace/mars/mars/deploy/oscar/session.py in execute(self, tileable, show_progress, *tileables, **kwargs)
1599 fut = asyncio.run_coroutine_threadsafe(coro, self._loop)
1600 try:
-> 1601 execution_info: ExecutionInfo = fut.result(
1602 timeout=self._isolated_session.timeout
1603 )
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440 else:
441 raise TimeoutError()
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in __get_result(self)
386 def __get_result(self):
387 if self._exception:
--> 388 raise self._exception
389 else:
390 return self._result
~/Workspace/mars/mars/deploy/oscar/session.py in _execute(session, wait, show_progress, progress_update_interval, cancelled, *tileables, **kwargs)
1781 # set cancelled to avoid wait task leak
1782 cancelled.set()
-> 1783 await execution_info
1784 else:
1785 return execution_info
~/Workspace/mars/mars/deploy/oscar/session.py in wait()
102
103 async def wait():
--> 104 return await self._aio_task
105
106 self._future_local.future = fut = asyncio.run_coroutine_threadsafe(
~/Workspace/mars/mars/deploy/oscar/session.py in _run_in_background(self, tileables, task_id, progress, profiling)
916 )
917 if task_result.error:
--> 918 raise task_result.error.with_traceback(task_result.traceback)
919 if cancelled:
920 return
~/Workspace/mars/mars/services/scheduling/worker/execution.py in internal_run_subtask(self, subtask, band_name)
330
331 batch_quota_req = {(subtask.session_id, subtask.subtask_id): calc_size}
--> 332 subtask_info.result = await self._retry_run_subtask(
333 subtask, band_name, subtask_api, batch_quota_req
334 )
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run_subtask(self, subtask, band_name, subtask_api, batch_quota_req)
431 # any exceptions occurred.
432 if subtask.retryable:
--> 433 return await _retry_run(subtask, subtask_info, _run_subtask_once)
434 else:
435 try:
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
105 )
106 else:
--> 107 raise ex
108
109
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _retry_run(subtask, subtask_info, target_async_func, *args)
65 while True:
66 try:
---> 67 return await target_async_func(*args)
68 except (OSError, MarsError) as ex:
69 if subtask_info.num_retries < subtask_info.max_retries:
~/Workspace/mars/mars/services/scheduling/worker/execution.py in _run_subtask_once()
373 subtask_api.run_subtask_in_slot(band_name, slot_id, subtask)
374 )
--> 375 return await asyncio.shield(aiotask)
376 except asyncio.CancelledError as ex:
377 try:
~/Workspace/mars/mars/services/subtask/api.py in run_subtask_in_slot(self, band_name, slot_id, subtask)
66 ProfilingContext(task_id=subtask.task_id) if enable_profiling else None
67 )
---> 68 return await ref.run_subtask.options(profiling_context=profiling_context).send(
69 subtask
70 )
~/Workspace/mars/mars/oscar/backends/context.py in send(self, actor_ref, message, wait_response, profiling_context)
187 if wait_response:
188 result = await self._wait(future, actor_ref.address, message)
--> 189 return self._process_result_message(result)
190 else:
191 return future
~/Workspace/mars/mars/oscar/backends/context.py in _process_result_message(message)
68 return message.result
69 else:
---> 70 raise message.as_instanceof_cause()
71
72 async def _wait(self, future: asyncio.Future, address: str, message: _MessageBase):
~/Workspace/mars/mars/oscar/backends/pool.py in send()
540 raise ActorNotExist(f"Actor {actor_id} does not exist")
541 coro = self._actors[actor_id].__on_receive__(message.content)
--> 542 result = await self._run_coro(message.message_id, coro)
543 processor.result = ResultMessage(
544 message.message_id,
~/Workspace/mars/mars/oscar/backends/pool.py in _run_coro()
331 self._process_messages[message_id] = asyncio.tasks.current_task()
332 try:
--> 333 return await coro
334 finally:
335 self._process_messages.pop(message_id, None)
~/Workspace/mars/mars/oscar/api.py in __on_receive__()
113 Message shall be (method_name,) + args + (kwargs,)
114 """
--> 115 return await super().__on_receive__(message)
116
117
~/Workspace/mars/mars/oscar/core.pyx in __on_receive__()
504 debug_logger.exception('Got unhandled error when handling message %r '
505 'in actor %s at %s', message, self.uid, self.address)
--> 506 raise ex
507
508
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor.__on_receive__()
498 raise ValueError(f'call_method {call_method} not valid')
499
--> 500 return await self._handle_actor_result(result)
501 except Exception as ex:
502 if _log_unhandled_errors:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
383 # asyncio.wait as it introduces much overhead
384 if len(coros) == 1:
--> 385 task_result = await coros[0]
386 if extract_tuple:
387 result = task_result
~/Workspace/mars/mars/oscar/core.pyx in _run_actor_async_generator()
426 res = None
427 while True:
--> 428 async with self._lock:
429 with debug_async_timeout('actor_lock_timeout',
430 'async_generator %r hold lock timeout', gen):
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
428 async with self._lock:
429 with debug_async_timeout('actor_lock_timeout',
--> 430 'async_generator %r hold lock timeout', gen):
431 if not is_exception:
432 res = await gen.asend(res)
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
432 res = await gen.asend(res)
433 else:
--> 434 res = await gen.athrow(*res)
435 try:
436 if _log_cycle_send:
~/Workspace/mars/mars/services/subtask/worker/runner.py in run_subtask()
116 try:
117 self._running_processor = self._last_processor = processor
--> 118 result = yield self._running_processor.run(subtask)
119 finally:
120 self._running_processor = None
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
437 message_trace = pop_message_trace()
438
--> 439 res = await self._handle_actor_result(res)
440 is_exception = False
441 except:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
357
358 if inspect.isawaitable(result):
--> 359 result = await result
360 elif is_async_generator(result):
361 result = (result,)
~/Workspace/mars/mars/oscar/backends/context.py in send()
187 if wait_response:
188 result = await self._wait(future, actor_ref.address, message)
--> 189 return self._process_result_message(result)
190 else:
191 return future
~/Workspace/mars/mars/oscar/backends/context.py in _process_result_message()
68 return message.result
69 else:
---> 70 raise message.as_instanceof_cause()
71
72 async def _wait(self, future: asyncio.Future, address: str, message: _MessageBase):
~/Workspace/mars/mars/oscar/backends/pool.py in send()
540 raise ActorNotExist(f"Actor {actor_id} does not exist")
541 coro = self._actors[actor_id].__on_receive__(message.content)
--> 542 result = await self._run_coro(message.message_id, coro)
543 processor.result = ResultMessage(
544 message.message_id,
~/Workspace/mars/mars/oscar/backends/pool.py in _run_coro()
331 self._process_messages[message_id] = asyncio.tasks.current_task()
332 try:
--> 333 return await coro
334 finally:
335 self._process_messages.pop(message_id, None)
~/Workspace/mars/mars/oscar/api.py in __on_receive__()
113 Message shall be (method_name,) + args + (kwargs,)
114 """
--> 115 return await super().__on_receive__(message)
116
117
~/Workspace/mars/mars/oscar/core.pyx in __on_receive__()
504 debug_logger.exception('Got unhandled error when handling message %r '
505 'in actor %s at %s', message, self.uid, self.address)
--> 506 raise ex
507
508
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor.__on_receive__()
498 raise ValueError(f'call_method {call_method} not valid')
499
--> 500 return await self._handle_actor_result(result)
501 except Exception as ex:
502 if _log_unhandled_errors:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
383 # asyncio.wait as it introduces much overhead
384 if len(coros) == 1:
--> 385 task_result = await coros[0]
386 if extract_tuple:
387 result = task_result
~/Workspace/mars/mars/oscar/core.pyx in _run_actor_async_generator()
426 res = None
427 while True:
--> 428 async with self._lock:
429 with debug_async_timeout('actor_lock_timeout',
430 'async_generator %r hold lock timeout', gen):
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
428 async with self._lock:
429 with debug_async_timeout('actor_lock_timeout',
--> 430 'async_generator %r hold lock timeout', gen):
431 if not is_exception:
432 res = await gen.asend(res)
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
432 res = await gen.asend(res)
433 else:
--> 434 res = await gen.athrow(*res)
435 try:
436 if _log_cycle_send:
~/Workspace/mars/mars/services/subtask/worker/processor.py in run()
608 self._running_aio_task = asyncio.create_task(processor.run())
609 try:
--> 610 result = yield self._running_aio_task
611 logger.info("Finished subtask: %s", subtask.subtask_id)
612 raise mo.Return(result)
~/Workspace/mars/mars/oscar/core.pyx in mars.oscar.core._BaseActor._run_actor_async_generator()
437 message_trace = pop_message_trace()
438
--> 439 res = await self._handle_actor_result(res)
440 is_exception = False
441 except:
~/Workspace/mars/mars/oscar/core.pyx in _handle_actor_result()
357
358 if inspect.isawaitable(result):
--> 359 result = await result
360 elif is_async_generator(result):
361 result = (result,)
~/Workspace/mars/mars/services/subtask/worker/processor.py in run()
455 try:
456 # execute chunk graph
--> 457 await self._execute_graph(chunk_graph)
458 finally:
459 # unpin inputs data
~/Workspace/mars/mars/services/subtask/worker/processor.py in _execute_graph()
218
219 try:
--> 220 await to_wait
221 logger.debug(
222 "Finish executing operand: %s," "chunk: %s, subtask id: %s",
~/Workspace/mars/mars/lib/aio/_threads.py in to_thread()
34 ctx = contextvars.copy_context()
35 func_call = functools.partial(ctx.run, func, *args, **kwargs)
---> 36 return await loop.run_in_executor(None, func_call)
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py in run()
55
56 try:
---> 57 result = self.fn(*self.args, **self.kwargs)
58 except BaseException as exc:
59 self.future.set_exception(exc)
~/Workspace/mars/mars/core/mode.py in _inner()
75 def _inner(*args, **kwargs):
76 with enter_mode(**mode_name_to_value):
---> 77 return func(*args, **kwargs)
78
79 else:
~/Workspace/mars/mars/services/subtask/worker/processor.py in _execute_operand()
186 self, ctx: Dict[str, Any], op: OperandType
187 ): # noqa: R0201 # pylint: disable=no-self-use
--> 188 return execute(ctx, op)
189
190 async def _execute_graph(self, chunk_graph: ChunkGraph):
~/Workspace/mars/mars/core/operand/core.py in execute()
487 return result
488 except UFuncTypeError as e: # pragma: no cover
--> 489 raise TypeError(str(e)).with_traceback(sys.exc_info()[2]) from None
490 except NotImplementedError:
491 for op_cls in type(op).__mro__:
~/Workspace/mars/mars/core/operand/core.py in execute()
483 # The `UFuncTypeError` was introduced by numpy#12593 since v1.17.0.
484 try:
--> 485 result = executor(results, op)
486 succeeded = True
487 return result
~/Workspace/mars/mars/tensor/arithmetic/core.py in execute()
163 ret = cls._execute_gpu(op, xp, lhs, rhs, **kw)
164 else:
--> 165 ret = cls._execute_cpu(op, xp, lhs, rhs, **kw)
166 ctx[op.outputs[0].key] = _handle_out_dtype(ret, op.dtype)
167
~/Workspace/mars/mars/tensor/arithmetic/core.py in _execute_cpu()
140 if kw.get("out") is not None:
141 kw["out"] = np.asarray(kw["out"])
--> 142 return cls._get_func(xp)(lhs, rhs, **kw)
143
144 @classmethod
TypeError: [address=127.0.0.1:41564, pid=5771] ufunc 'equal' did not contain a loop with signature matching types (dtype('<U1'), dtype('<U1')) -> dtype('bool')
```
The reason is that we hand over a == b to `mt.equal(a, b)`, but for numpy, np.equal cannot handle string dtype, but == can.
```
In [6]: a = np.array(['a', 'b', 'c'])
In [7]: b = np.array(['a', 'b', 'c'])
In [8]: a == b
Out[8]: array([ True, True, True])
In [9]: np.equal(a, b)
---------------------------------------------------------------------------
UFuncTypeError Traceback (most recent call last)
<ipython-input-9-76fd4efa5344> in <module>
----> 1 np.equal(a, b)
UFuncTypeError: ufunc 'equal' did not contain a loop with signature matching types (dtype('<U1'), dtype('<U1')) -> dtype('bool')
```
| 1medium
|
Title: Support (> 10000)-token texts in `infer_vector()`
Body: As `infer_vector()` uses the same optimized Cython functions as training behind-the-scenes, it also suffers from the same fixed-token-buffer size as training, where texts with more than 10000 tokens have all overflow tokens ignored.
But, this might be easier to fix for inference, as the it could be easy to call the training functions with a mini-batch that just reuses the same temporary candidate vector-in-training.
(And in fact, thinking about this makes me wonder if we should just auto-chunk documents during training, too – perhaps with a warning to the user the 1st time this happens. Previously, I'd wanted to fix this limitation by using `alloca()` to replace our fixed 10000-slot on-stack arrays with variable-length on-stack arrays - which worked in my tests, and perhaps even offered a memory-compactness advantage/speedup for all the cases where texts were *smaller* than 10000 tokens – but, `alloca()` isn't guaranteed to be available everywhere, even though in practice it seems to be everywhere we support.)
| 1medium
|
Title: Add support for filtering by `in` and `not_in` for `Bytes` types
Body: Prisma added support for this in v3.6.0
| 1medium
|
Title: Precision-Recall Curve does not show class labels
Body: **Describe the bug**
When labels are passed into the `PrecisionRecallCurve` the visualization is not drawn correctly.
**To Reproduce**
```python
from yellowbrick.classifier import PrecisionRecallCurve
from yellowbrick.dataset import load_game
from sklearn.preprocessing import LabelEncoder
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split as tts
# Load the dataset and label encode the target
data = load_game()
X = data.iloc[:, data.columns != 'outcome']
y = LabelEncoder().fit_transform(data['outcome'])
# Create train test splits
X_train, X_test, y_train, y_test = tts(X, y, test_size=0.2, shuffle=True)
oz = PrecisionRecallCurve(
MultinomialNB(), per_class=True, iso_f1_curves=True, fill_area=False,
micro=False, classes=["loss", "draw", "win"]
)
oz.fit(X_train, y_train)
oz.score(X_test, y_test)
oz.poof()
```
**Dataset**
I used the game multi-label dataset from the UCI Machine Learning repository, as wrangled by the yellowbrick datasets module.
**Expected behavior**
When the target, `y` is label encoded (e.g. via the `LabelEncoder`) to classes 0, 1, and 2 and class names are passed in via the `classes` param of the visualizer, the legend should display the class names. However, in this case the visualization does not appear at all:

**Traceback**
No exception is raised, however, the following warning is issued:
```
/Users/benjamin/.pyenv/versions/3.6.2/envs/yellowbrick3/lib/python3.6/site-packages/numpy/lib/arraysetops.py:522: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
mask |= (ar1 == a)
/Users/benjamin/.pyenv/versions/3.6.2/envs/yellowbrick3/lib/python3.6/site-packages/sklearn/metrics/ranking.py:444: RuntimeWarning: invalid value encountered in true_divide
recall = tps / tps[-1]
objc[46460]: Class FIFinderSyncExtensionHost is implemented in both /System/Library/PrivateFrameworks/FinderKit.framework/Versions/A/FinderKit (0x7fffb473cc90) and /System/Library/PrivateFrameworks/FileProvider.framework/OverrideBundles/FinderSyncCollaborationFileProviderOverride.bundle/Contents/MacOS/FinderSyncCollaborationFileProviderOverride (0x12814ecd8). One of the two will be used. Which one is undefined.
```
**Desktop (please complete the following information):**
- OS: macOS High Sierra 10.13.6
- Python Version 3.6.2
- Yellowbrick Version 0.9 develop
**Additional context**
This was a known bug during development but was left in as a rare case.
| 1medium
|
Title: Add explicit command line option to limit which files are parsed
Body: When execution just some tests from a big directory structure, parsing only relevant files instead of the whole structure makes parsing faster. We don't currently have any explicit option for limiting parsing like that, but when the `--suite` option is used files not matching the specified suite are ignored. This functionality won't work too well in the future, though, if we make it possible to change the suite name using the `Name` setting (#4583). It's also likely that not too many users know about this functionality and the underlying logic to convert file and directory names to suite names for matching purposes is also rather complicated.
A good way to solve all the above problems is adding a separate command line option or options for controlling what files to parse. Once we have such functionality, we can remove the current performance optimization from `--suite`, a separate option makes the feature easier to discover, and also the code gets simpler. There are some design decisions to be made, though:
- What should the option be named? I was thinking `--includefiles`, but it has the same prefix as `--include` which would mean that shortened usages like `--incl` that used to be unique wouldn't work anymore. Perhaps `--parsefiles` or just `--files` would be better.
- Should the value be a literal value or should we accept glob patterns? I believe supporting patterns is a good idea.
- Should the value be just a file name or a relative or absolute path to it? I see benefits with both so possibly we could support both usages.
- Should the value include file extension? I believe it should be allowed but preferably not required. If that gets too complicated, always requiring it is probably better.
- Should there be separate option for excluding files? It would make some use cases easier, but I'm not sure is that worth the added complexity.
- Should this option affect only files or also directories? If the option would match a directory, we could automatically include all files under it, recursively. On the other hand, just matching files would be easier to implement and explain.
- Should we have separate options for matching files and directories? That's probably too much, especially if we'd have separate options for including and excluding. If directories are considered important, probably better to implement this so that the same option work with both files and directories.
This feature should be implemented before RF 7 where we'd like to change `--suite` so that it doesn't affect parsing. That would give users who need the performance optimization time to update their scripts.
| 1medium
|
Title: [INF] Implement utils pytest mark
Body: # Brief Description
When updating the tests for #510, I noticed that `test_check_columns` had a `pytest.mark.utils` decorator but, when running the code, `utils` was not a a valid mark. I updated the `pytest.ini` file to have it, but AFAICT `test_check_columns` is the only package that uses it. We should expand this mark to all utilities tests, and make sure that there's no missing documentation, etc. associated with the new mark.
| 1medium
|
Title: Nicer error handling with mishandled responses
Body: ```python
@app.get("/")
async def handler(request):
response1 = await request.respond(headers={"one": "one"})
response2 = await request.respond(headers={"two": "two"})
await response1.send("One")
await response2.send("Two")
await response1.eof()
await response2.send("???")
await response2.eof()
```
```
$ curl localhost:9999 -i
HTTP/1.1 200 OK
one: one
transfer-encoding: chunked
connection: keep-alive
content-type: None
OneTwo
```
```
[2021-08-17 15:14:06 +0300] [368537] [ERROR] Exception occurred while handling uri: 'http://localhost:9999/'
Traceback (most recent call last):
File "handle_request", line 83, in handle_request
"""
File "/tmp/p.py", line 21, in handler
await response2.send("???")
File "/home/adam/Projects/Sanic/sanic/sanic/response.py", line 122, in send
await self.stream.send(data, end_stream=end_stream)
TypeError: 'NoneType' object is not callable
```
Two things here:
1. When we create the second response, there is no indication to the user that this is somewhat useless. The headers here are ignored, although you can continue sending from it. As seen in example.
2. When `send` is called after the `eof`, there should be a nicer error than `NoneType` that does not explain what happened to the stream.
| 1medium
|
Title: Add client option to log SQL queries
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Performance issues with ORMs can be hard to debug, we should add an option to log generated SQL queries.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Don't know how this would be implemented as it seems like we'd have to spawn a new thread to capture and then filter the output from the query engine as the query engine logs contain a lot of noise that we don't want to send to users.
| 1medium
|
Title: Consider refactoring Base64 API
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
It is not obvious how `Base64` objects should be constructed, it would be a very easy mistake to construct the object like so:
```py
data = Base64(b'my binary data')
# when it should be
data = Base64(base64.b64encode(b'my binary data'))
# or
data = Base64.encode(b'my binary data')
```
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
One solution to this would be to disable construction through `__init__` and instead require a classmethod to be used, the API would then look like this:
```py
data = Base64.from_data(b'my binary data')
data = Base64.from_b64(base64.b64encode(b'my binary data'))
```
We would then deprecate the previous API and remove it in a later release.
| 1medium
|
Title: Create target package for supervised target visualizers
Body: For supervised machine learning, there is some independent analysis that must be conducted on the target vector; for example label encoding, "bucketization", etc.
For visualizers:
- move the class balance here without requiring a model, fit, or score
- perform detection of sequential or categorical data (and associated colors)
- plot feature/target correlations in this package
| 1medium
|
Title: Scripts to Regenerate Tutorial and Quickstart Documentation Images
Body: In the documentation, the tutorial and quickstart need a script that can autogenerate the images similar to how they are done in the `doc/api/` section. The code to generate the images is located in the rst files and can be simple extracted and moved into a py file.
These scripts can live right alongside their .rst compatriots.
| 1medium
|
Title: Add internal tests against a clean installation
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We need to add additional safeguards for using the package pre-generation to avoid issues like #182
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Work in progress.
| 1medium
|
Title: guvectorize does not check contiguity, breaks indexing
Body: numba 0.59.0
- [x] I have tried using the latest released version of Numba (most recent is
visible in the release notes
(https://numba.readthedocs.io/en/stable/release-notes-overview.html).
- [x] I have included a self contained code sample to reproduce the problem.
i.e. it's possible to run as 'python bug.py'.
I just started working with numba and I'm in awe of the ease of use and the enormous performance improvement! But this one issue had me stumped for quite some time, as it occurred deep inside my code.
```
import numba
import numpy as np
@numba.guvectorize(['void(int64[::1])'], '(n)')
def foo(arr):
print('Array:', arr)
print('Iterated:')
for i in range(len(arr)):
print(i, arr[i])
# This one works fine:
# foo(np.array([1, 2, 3], dtype=np.int64))
foo(np.broadcast_to(np.array([4]), (3,)))
```
This prints:
```
Array: [4 4 4]
Iterated:
4
0
32
```
I would expect an exception to be raised, because there is no matching signature. The passed array is not contiguous, because it has a stride of 0.
Instead, only the first element is printed correctly; the other two are garbage. I suspect this happens because the array is assumed to be contiguous, so the stride is ignored.
| 1medium
|
Title: Support item assignment with lists and dicts like `${x}[key] = Keyword`
Body: These aren't currently supported:
```
${dict} = Create Dictionary key=initial
${dict}[key] = Set Variable new
${list} = Create List one two
${list}[0] = Set Variable new
```
Especially setting dictionary items would be useful, but there certainly are cases where setting list items is convenient as well. In fact, this syntax should work with any object that has `__setitem__`.
Things to take into account:
- It should be possible to specify the key/index as a variable like `${x}[${y}]`.
- It should be possible to give list indices as strings and as integers.
- Lists should support slices.
- Error message should be clear if the item is immutable (tuple, string, immutable mapping, ...).
This would be a convenient feature, but because it's possible to manipulate lists and dicts with Collections keywords I don't consider this high priority. See also #4545 that proposes supporting `${x${y}} = Keyword` and also contained this enhancement in it initially.
| 1medium
|
Title: Remove deprecated constructs from Libdoc spec files
Body: `datatypes` were deprecated in favor of more generic `typedocs` in RF 5.0 (#4160) and in RF 6.1 there were argument type related changes (#4538). We have preserved old data in specs for backwards compatibility reasons but now it's time remove it. The main motivation is making specs simpler and smaller.
Libdoc can read old specs. That support can still be preserved.
| 1medium
|
Title: Support DataFrame indexing with mars Tensor
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Currently the following snippets causes error, which is quite surprising for users coming from Pandas background:
```python
import mars.dataframe as md
import mars.tensor as mt
df = md.DataFrame(mt.random.randn(10, 4))
df.loc[df.index].execute()
```
It will be nice to support indexing with Mars Tensor as well.
Thank you !
| 1medium
|
Title: User-agent parser / accessor on Request
Body: ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
The user-agent string is notoriously difficult to decipher. Suggesting to have `request.user_agent` with properties for browser and OS (in contrast to `request.header.user_agent` which is the raw header), alike to how we return the Accept header parsed. This would be useful for logging/statistics as well as to workaround certain browser incompatibilities that are otherwise not possible to test for strictly server-side.
### Describe the solution you'd like
There are various ways to approach this, ranging from just returning the UA string but with the compatibility cruft removed (i.e. the way it should be if Internet wasn't broken), to providing separate accessors for browser, browser-version, platform, etc.
### Additional context
https://pypi.org/project/httpagentparser/
https://github.com/pallets/werkzeug/blob/main/src/werkzeug/user_agent.py
| 1medium
|
Title: Output a warning when an unknown config option is present
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Someone may misspell a config option and not realise until they don't get the behaviour that they want. This would be confusing
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We can avoid the whole confusion mentioned above by outputting a warning indicating that the option is unknown.
We shouldn't raise an error as it isn't really a fatal error and shouldn't block someone from deploying or using the client.
| 1medium
|
Title: New `robot:flatten` tag for "flattening" keyword structures
Body: Introduction
------------
With nested keyword structures, especially with recursive keyword calls and with WHILE and FOR loops, the log file can get hard do understand with many different nesting levels. Such nested structures also increase output.xml size, because even a simple keyword like
```robotframework
*** Keywords ***
Keyword
Log Robot
Log Framework
```
creates this much content:
```xml
<kw name="Keyword">
<kw name="Log" library="BuiltIn">
<arg>Robot</arg>
<doc>Logs the given message with the given level.</doc>
<msg timestamp="20230103 20:06:36.663" level="INFO">Robot</msg>
<status status="PASS" starttime="20230103 20:06:36.663" endtime="20230103 20:06:36.663"/>
</kw>
<kw name="Log" library="BuiltIn">
<arg>Framework</arg>
<doc>Logs the given message with the given level.</doc>
<msg timestamp="20230103 20:06:36.663" level="INFO">Framework</msg>
<status status="PASS" starttime="20230103 20:06:36.663" endtime="20230103 20:06:36.664"/>
</kw>
<status status="PASS" starttime="20230103 20:06:36.663" endtime="20230103 20:06:36.664"/>
</kw>
```
We have had `--flattenkeywords` option for "flattening" such structures since RF 2.8.2 (#1551) and it works great. When a keyword is flattened, its child keywords and control structures are removed otherwise, but all their messages are preserved. It doesn't affect output.xml generated during execution, but flattening happens when output.xml files are parsed and can save huge amounts of memory. When `--flattenkeywords` is used with Rebot, it is possible to create a new flattened output.xml. For example, the above structure is converted into this if `Keyowrd` is flattened:
```
<kw name="Keyword">
<doc>_*Content flattened.*_</doc>
<msg timestamp="20230103 20:06:36.663" level="INFO">Robot</msg>
<msg timestamp="20230103 20:06:36.663" level="INFO">Framework</msg>
<status status="PASS" starttime="20230103 20:06:36.663" endtime="20230103 20:06:36.664"/>
</kw>
```
Proposal
--------
Flattening works based on keyword names and based on tags, but it needs to be activated separately from the command line. This issue proposes adding new built-in tag `robot:flatten` that activates this behavior automatically. Removing top level keywords from tests and leaving only their messages doesn't make sense, so `robot:flatten` should be usable only as a keyword tag.
This functionality should work already during execution so that flattened keywords and control structures are never written to output.xml file. This avoid output.xml file growing big and is likely to also enhance the performance a bit.
Open questions
---------------
There are some open questions related to the design still:
- [x] Should `start/end_keyword` listener methods be called with flattened keywords? I believe not, but I don't feel too strongly about this.
- [x] Should we add *Content flattened* to keyword documentation like we do with `--flattenkeywords`? I believe not. There's the `robot:flatten` tag to indicate that anyway.
- [x] Should `--flattenkeywords` be changed to work during execution as well? I believe yes, but that requires a separate issue.
- [x] Should automatic TRACE level logging of arguments and return values of flattened keywords be disabled? I believe yes, but this isn't high priority.
Possible future enhancements
------------------------------
`--flattenkeywords` allows flattening WHILE or FOR loops or all loop iterations. Something like that would be convenient with built-in tags as well. We could consider something like `robot:flatten:while` and `robot:flatten:iteration` to support that, but I believe that's something that can wait until future versions.
Another alternative would be allowing tags with control structures as shown in the example below. This would require parser and model changes but could also have other use cases. That's certainly out of the scope of RF 6.1, though.
```robotframework
*** Keywords ***
Keyword
WHILE True
[Tags] robot:flatten
Nested
END
```
| 1medium
|
Title: Allow listeners to change execution status
Body: Listeners using the v3 API can set the status and message of each executed keyword and a control structure, but these changes do not affect the actual test execution. For example, changing keyword status from PASS to FAIL changes the status of the keyword in the log file, but subsequent keywords are executed normally as if the keyword would PASS. Similarly, changing keyword status from FAIL to PASS changes keyword status in the log file, but the failure still propagates and the test fails.
We should enhance the execution logic so that if the test status or message is altered by listeners, that change is taken into account. This would allow failing or skipping test, suppressing failures and so on.
| 1medium
|
Title: Automatic argument conversion and validation for `Literal`
Body: Look at this moment:
```py
def foo(a: Literal[1, 2, 3]): ...
```
```robot
Something
foo 1
```
Currently, robot will send a `"1"` to this function, which is invalid, I would expect robot to convert the string to an int.
- #4630
| 1medium
|
Title: Make `FOR IN ZIP` loop behavior if lists have different lengths configurable
Body: Robot `FOR IN ZIP` loop behaves like Python's [zip](https://docs.python.org/3/library/functions.html#zip) so that if lists lengths aren't the same, items from the longest one are ignored. For example, the following loop would be executed only twice:
```robotframework
*** Variables ***
@{ANIMALS} dog cat horse cow elephant
@{ELÄIMET} koira kissa
*** Test Cases ***
Example
FOR ${en} ${fi} IN ZIP ${ANIMALS} ${ELÄIMET}
Log ${en} is ${fi} in Finnish
END
```
This behavior can cause problems when iterating over items received from the automated system. For example, the following test would pass regardless how many things `Get something` returns as long as the returned items match the expected values. The example even succeeds if `Get something` nothing.
```robotframework
*** Test Cases ***
Example
Validate something expected 1 expected 2 expected 3
*** Keywords ****
Validate something
[Arguments] @{expected}
@{actual} = Get something
FOR ${act} ${exp} IN ZIP ${actual} ${expected}
Validate one thing ${act} ${exp}
END
```
To avoid the above example failing if `Get something` returns more or less values than expected, a separate check needs to be added. Because there's no ready-made keyword for checking are list lengths equal (`Lists should be equal` keyword doesn't work here), the validation needs to use something bit more complicated like this:
```
Should be equal ${{len($actual)}} ${{len($expected)}}
```
For a real life example see [this example](https://github.com/robotframework/robotframework/blob/f7ee913622e60c0cf630e1580c2bb58c57100187/atest/robot/running/if/invalid_if.robot#L119) from out acceptance tests. Tests also contain various `FOR IN ZIP` usages where this particular issue could cause problems.
This same underlying issues has caused problems with Python's `zip` as well. Starting from Python 3.10 (see [PEP 619](https://peps.python.org/pep-0618/) `zip` has new `strict` parameter that can be used like `zip(actual, expected, strict=True)`. It causes a `ValueError` to be raised if iterated lists have different lengths. Related to this, Python also has separate [itertools.zip_longest](https://docs.python.org/3/library/itertools.html#itertools.zip_longest) that goes through all items in all lists so that if certain list has less value than others, value specified with the `fillvalue` argument is used instead.
My proposal is that we add new `mode` configuration option to `FOR IN ZIP` loops. The motivation is that we could have three values `shortest`, `strict` and `longest` emulating Python's behavior with `zip(...)`, `zip(..., strict=True=`), and `zip_longest(...)`, respectively. This was also [considered with Python](https://peps.python.org/pep-0618/#add-several-modes-to-switch-between), but they decided to go with a Boolean option `strict` partly because they already have a separate `zip_longest`.
Another reason `mode` wasn't used with Python is that to properly support the `longest` case, it would require adding `fillvalue` that doesn't make sense with other modes. That's a valid concern in our case as well, but I don't consider it too big a problem. We don't at the moment support the `longest` case at all, so this would instead be a nice enhancement and a lot better syntax than separate `FOR IN ZIP LONGEST` would be.
| 1medium
|
Title: Support type aliases in formats `'list[int]'` and `'int | float'` in argument conversion
Body: Our argument conversion typically uses actual types like `int`, `list[int]` and `int | float`, but we also support type aliases as strings like `'int'` or `'integer'`. The motivation for type aliases is to support types returned, for example, by dynamic libraries wrapping code using other languages. Such libraries can simply return type names as strings instead of mapping them to actual Python types.
There are two limitations with type aliases, though:
- It isn't possible to represent types with nested types like `'list[int]'`. Aliases always map to a single concrete type, not to nested types.
- Unions cannot be represented using "Python syntax" like `'int | float'`. It is possible to use a tuple like `('int', 'float')`, though, so this is mainly an inconvenience.
Implementing this enhancement requires two things:
- Support for parsing strings like `'list[int]'` and `'int | float'`. Results could be newish [TypeInfo](https://github.com/robotframework/robotframework/blob/6e6f3a595d800ff43e792c4a7c582e7bf6abc131/src/robot/running/arguments/argumentspec.py#L183) objects that were added to make Libdoc handle nested types properly (#4538). Probably we could add a new `TypeInfo.from_string` class method.
- Enhance type conversion to work with `TypeInfo`. Currently these objects are only used by Libdoc.
In addition to helping with libraries wrapping non-Python code, this enhancement would allow us to create argument converters based on Libdoc spec files. That would probably be useful for external tools such as editor plugins.
| 1medium
|
Title: Support Werkzeug 3.0+
Body: Currently, it is pinned to `<3.0`, but it will be nice to support both
| 1medium
|
Title: Include tzinfo in returned datetime instances
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
As far as I am aware, all Prisma DateTimes are in UTC. We should represent this on model's datetime objects too.
| 1medium
|
Title: IBM Watson STT not working
Body: The IBM STT interface is not currently working as IBM have changed their authentication mechanism.
The existing implementation uses the [SpeechRecognition Python package](https://github.com/Uberi/speech_recognition) which has not been updated to use the new API key.
The simplest fix would be to implement a new StreamingSTT class within Mycroft and not use the SR package for this service.
IBM STT Docs:
https://cloud.ibm.com/apidocs/speech-to-text/speech-to-text
| 1medium
|
Title: Argument list too long when connecting to a database with a large schema
Body: ## Bug description
The query engine cannot spawn the query engine child process when the schema is too large.
The error is coming from that line https://github.com/RobertCraigie/prisma-client-py/blob/main/src/prisma/generator/templates/engine/query.py.jinja#L106. When the schema is too large, it's content will be truncated by the OS and the engine will fail to start. The following patch will circumvent the issue by passing the path to the schema instead of it's content:
```
env = os.environ.copy()
env.update(
# PRISMA_DML=self.dml,
RUST_LOG='error',
RUST_LOG_FORMAT='json',
PRISMA_CLIENT_ENGINE_TYPE='binary',
)
if os.environ.get('PRISMA_DML_PATH'):
env.update(PRISMA_DML_PATH=os.environ.get('PRISMA_DML_PATH'))
else:
env.update(PRISMA_DML=self.dml)
```
## How to reproduce
Steps to reproduce the behavior:
1. Generate a prisma.schema file with a large number of tables and fields
2. Generate the prisma client
3. Connect to the database
4. See error:
```
Traceback (most recent call last):
File "...", line 239, in <module>
app = CashflowLoader(args.process_date)
File "...", line 35, in __init__
self.db.connect()
File ".../venv/lib/python3.9/site-packages/prisma/client.py", line 3657, in connect
self.__engine.connect(
File ".../venv/lib/python3.9/site-packages/prisma/engine/query.py", line 110, in connect
self.spawn(file, timeout=timeout, datasources=datasources)
File ".../venv/lib/python3.9/site-packages/prisma/engine/query.py", line 152, in spawn
self.process = subprocess.Popen(
File ".../lib/python3.9/subprocess.py", line 951, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File ".../lib/python3.9/subprocess.py", line 1821, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
OSError: [Errno 7] Argument list too long: '/tmp/prisma/binaries/engines/efdf9b1183dddfd4258cd181a72125755215ab7b/prisma-query-engine-debian-openssl-1.1.x'
```
## Expected behavior
No error should be reported and the connexion should be established with the database.
## Prisma information
Create a large schema file
No specific queries required
## Environment & setup
- OS: Windows 11, Ubuntu 20.10
- Database: MariaDB
- Python version: 3.9.7
- Prisma version:
```
prisma : 3.13.0
prisma client python : 0.6.6
platform : debian-openssl-1.1.x
engines : efdf9b1183dddfd4258cd181a72125755215ab7b
install path : /mnt/c/Users/andrew/OneDrive/Git_Repos/e22/Benzaiten_repos/benzaiten-processes/venv/lib/python3.9/site-packages/prisma
installed extras : []
```
| 1medium
|
Title: Add `nunique` support for DataFrameGroupBy
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Support `df.groupby().nunique()` for returning DataFrame with counts of unique elements in each position.
| 1medium
|
Title: Keyword accepting embedded arguments cannot be used with variable containing characters used in keyword name
Body: Variable file, var.py:
```python
class myClass(object):
def __init__(self):
self.attr = '1/1/1'
obj = myClass()
```
Test file, test.robot:
```robotframework
*** Settings ***
Variables var.py
*** Test Cases ***
Example Test
Embedded Logging Of Object Attribute ${obj.attr}.200
*** Keywords ***
Embedded Logging Of Object Attribute ${obj_attr}.${value}
Log ${obj_attr}
Log ${value}
```
Note that the '.' is part of the keyword name, but it messes up the argument evaluation.
Output:
```
robot .\test.robot
==============================================================================
Test
==============================================================================
Example Test | FAIL |
Variable '${obj' was not closed properly.
------------------------------------------------------------------------------
Test | FAIL |
1 test, 0 passed, 1 failed
==============================================================================
```
Robot Framework 7.0.1 (Python 3.10.2 on win32)
| 1medium
|
Title: Support `[Setup]` with user keywords
Body: As per the discussion in #4745, this is a separate issue to add a `[Setup]` setting to user keywords.
The reason for wanting it in our usecase is to indicate a semantic differance between regular steps in a keyword and the Setup/Teardown. This differance is used by our system to define if a fail is a Setup failure (to be handled by the Test Framework team) and a DUT failure (to be handled by the test team).
Specifically this helps us when using Templates in a test case, as the template keyword could then have a Setup and Teardown that's excecuted once per run of the template instead of once for the whole testcase.
| 1medium
|
Title: Automatic probe for engine configuration
Body: If we can detect certain tested app behaviors like fails on the framework level due to the NULL bytes (I guess some web servers do it), then we may consider automatically re-configuring certain aspects of data generation in order to avoid failing on issues that are likely out of control for the user.
| 1medium
|
Title: Allow listeners to remove log messages by setting them to `None`
Body: ## Context
Issue #5089 proposed making it possible for listeners to remove log messages altogether by setting them to an empty string. It was not implemented for the following reasons:
- It turned out that there are valid reasons to log empty messages and removing them can cause undesired results especially with `Log Many`.
- The enhancement itself wasn't considered important enough.
One of the things PR #5084 proposed was adding a new log level above INFO to make it possible to easily remove most of the messages. As I commented the PR, I don't think a new hard-coded level is a good idea, but we could make it possible to add custom levels. That is quite a big task, though, and I started to think that listeners being able to remove messages would provide similar functionality.
## Proposal
Based on #5089 and #5084 it is convenient to be able to remove messages. This is my proposal how to do it without problems in #5089:
- Allow listeners to remove messages altogether by setting them to `None`. In practice these messages simply aren't written to output.xml and thus they won't end up to the log file either.
- For consistency, allow also model modifiers (`--pre-rebot-modifier`) to remove messages the same way.
- Make sure that everything logged normally is converted to strings. For example, `logger.info(None)` should log string `None` instead of the message being ignored.
This ought to be a safe change because the last point makes sure normal logging isn't affected. The only risk I see that if one model modifier sets `msg.message` to `None` and then another does something like `if 'xxx' in msg.message`, there's a TypeError. We could prevent this by not supporting this functionality with model modifiers. With them it's possible to remove messages also otherwise with something like `msg.parent.body.remove(msg)`, but `msg.message = None` is simpler and consistent with listeners.
| 1medium
|
Title: as_numba_type fails to parse tuples
Body: `numba.extending.as_numba_type()` currently fails to parse tuples that are passed to it in the python type hint style. This behavior seems to be caused by the type not being an instance of `typing._GenericAlias`. I have also replicated this for `list` and `dict`.
- [x] I have tried using the latest released version of Numba (most recent is
visible in the release notes
(https://numba.readthedocs.io/en/stable/release-notes-overview.html).
- [x] I have included a self contained code sample to reproduce the problem.
i.e. it's possible to run as 'python bug.py'.
python version: 3.10.16
numba version: 0.61.0
```
import numba as nb
py_type = tuple[float, float]
assert py_type.__origin__ is tuple
annotation = nb.extending.as_numba_type(py_type)
```
| 1medium
|
Title: Setting `PYTHONWARNDEFAULTENCODING` causes warnings
Body: If environment variable PYTHONWARNDEFAULTENCODING is set (and at least when running on MacOS), `_get_python_system_encoding()` from `robot/utils/encodingsniffer.py` in triggers following warning;
```
/Users/rasjani/src/duunit/energy-meter/venv/lib/python3.11/site-packages/robot/utils/encodingsniffer.py:59: EncodingWarning: UTF-8 Mode affects locale.getpreferredencoding(). Consider locale.getencoding() instead.
return locale.getpreferredencoding(False)
```
In this example, all i did was `import Browser` in the python repl.
| 1medium
|
Title: Document and communicate dropped support for win32
Body: The 0.57.x line of Numba is the last to support `win32` -- that is the Windows 32 bit platform as per the LLVM target identifier.
This means, that for 0.58 this drop in supported platforms must be communicated, that is to say:
* [ ] Find all occurrences of and remove win32 advert and descriptions in the documentation
* [ ] Remove any win32 specific hacks from ci config and recipes
* [ ] Mention this in the release notes
| 1medium
|
Title: Update the bad_values notebook to show use of update_where for fixing ranges
Body: # Brief Description
One issue I've run into trouble with when working with data is that I need to define a range of bad values - for example, sale price should always be > 0. It looks like the `update_where` function would be a good candidate
```python
df = jn.update_where(df['price'] < 0, 'price', None)
```
but it took me a bit of time to find this function for this use-case. I'd like to add a note to the `bad_values` notebook to show the usage of this function for addressing ranges of values.
As a specific example, we could note that longitude needs to be in a range [-180, 180] and latitude is in a range of [-90, 90]. And, since this is US data, we the latitude and longitude boundaries of the USA as tighter boundaries (19.50 to 64.86 lat, -161.76 to -68.01 long). If someone was keying in the values and misplaced a decimal somewhere, this could be an easy way to catch the problem.
If this is approved, I'd be happy to submit the fix.
| 1medium
|
Title: Add Sklearn pipeline test for more complicated Visualizers
Body: There are some visualizers that require additional work in order to write sklearn pipeline test. It is likely that the underlying visualizer needs to expose learned attributes needed to generate the visualizers. The following is an example using sklearn pipeline for the InterClusterDistanceMetric visualizer:
```
AttributeError: 'Pipeline' object has no attribute 'cluster_centers_'
```
See issues and PR
https://github.com/DistrictDataLabs/yellowbrick/issues/1253
https://github.com/DistrictDataLabs/yellowbrick/issues/1248
https://github.com/DistrictDataLabs/yellowbrick/pull/1249
Issue:
https://github.com/DistrictDataLabs/yellowbrick/issues/1257
PR:
https://github.com/DistrictDataLabs/yellowbrick/pull/1259
Issue:
https://github.com/DistrictDataLabs/yellowbrick/issues/1256
PR:
https://github.com/DistrictDataLabs/yellowbrick/pull/1262
- [ ] Decision Boundaries
- [ ] RFECV
- [ ] ValidationCurve
- [ ] Add a pipeline model input test and quick method test for feature importances
- [ ] Add a pipeline model input test and quick method test for alpha selection
- [ ] Add a pipeline model input test and quick method test for InterClusterDistanceMetric
- [ ] KElbowVisualizer
- [ ] SilhouetteVisualizer
- [ ] GridSearchColorPlot
Example
```
def test_within_pipeline(self):
"""
Test that visualizer can be accessed within a sklearn pipeline
"""
X, y = load_mushroom(return_dataset=True).to_numpy()
X = OneHotEncoder().fit_transform(X).toarray()
cv = StratifiedKFold(n_splits=2, shuffle=True, random_state=11)
model = Pipeline([
('minmax', MinMaxScaler()),
('cvscores', CVScores(BernoulliNB(), cv=cv))
])
model.fit(X, y)
model['cvscores'].finalize()
self.assert_images_similar(model['cvscores'], tol=2.0)
def test_within_pipeline_quickmethod(self):
"""
Test that visualizer quickmethod can be accessed within a
sklearn pipeline
"""
X, y = load_mushroom(return_dataset=True).to_numpy()
X = OneHotEncoder().fit_transform(X).toarray()
cv = StratifiedKFold(n_splits=2, shuffle=True, random_state=11)
model = Pipeline([
('minmax', MinMaxScaler()),
('cvscores', cv_scores(BernoulliNB(), X, y, cv=cv, show=False,
random_state=42))
])
self.assert_images_similar(model['cvscores'], tol=2.0)
def test_pipeline_as_model_input(self):
"""
Test that visualizer can handle sklearn pipeline as model input
"""
X, y = load_mushroom(return_dataset=True).to_numpy()
X = OneHotEncoder().fit_transform(X).toarray()
cv = StratifiedKFold(n_splits=2, shuffle=True, random_state=11)
model = Pipeline([
('minmax', MinMaxScaler()),
('nb', BernoulliNB())
])
oz = CVScores(model, cv=cv)
oz.fit(X, y)
oz.finalize()
self.assert_images_similar(oz, tol=2.0)
def test_pipeline_as_model_input_quickmethod(self):
"""
Test that visualizer can handle sklearn pipeline as model input
within a quickmethod
"""
X, y = load_mushroom(return_dataset=True).to_numpy()
X = OneHotEncoder().fit_transform(X).toarray()
cv = StratifiedKFold(n_splits=2, shuffle=True, random_state=11)
model = Pipeline([
('minmax', MinMaxScaler()),
('nb', BernoulliNB())
])
oz = cv_scores(model, X, y, show=False, cv=cv)
self.assert_images_similar(oz, tol=2.0)
```
<!-- If you have a question, note that you can email us via our listserve:
https://groups.google.com/forum/#!forum/yellowbrick -->
<!-- This line alerts the Yellowbrick maintainers, feel free to use this
@ address to alert us directly in follow up comments -->
@DistrictDataLabs/team-oz-maintainers
| 1medium
|
Title: Automate simple tests cases
Body: not for this pull request, but to ease development we could consider to somehow automate the old abstract methods (maybe with some decorators)
_Originally posted by @edgarriba in https://github.com/kornia/kornia/pull/2745#discussion_r1461614395_
just for the record, the old methods that we used in the base test class as abstracts were:
```python
def test_smoke(self, device, dtype):
# test the function with different parameters arguments, to check if the function at least runs with all the
# arguments allowed.
pass
def test_exception(self, device, dtype):
# tests the exceptions which can occur on your function
# example of how to properly test your exceptions
# with pytest.raises(<raised Error>) as errinfo:
# your_function(<set of parameters that raise the error>)
# assert '<msg of error>' in str(errinfo)
pass
def test_cardinality(self, device, dtype):
# test if with different parameters the shape of the output is the expected
pass
def test_feature_foo(self, device, dtype):
# test basic functionality
pass
def test_feature_bar(self, device, dtype):
# test another functionality
pass
def test_gradcheck(self, device):
# test the functionality gradients
# Uses `self.gradcheck(...)`
pass
```
| 1medium
|
Title: [ENH] Implement framework for adding xarray methods
Body: See PR #585 and general discussion #394
I've currently implemented two methods, one that wraps a numpy array with the metadata from an xarray dataarray [`dataarray.clone_using(numpy_array)`] (kind of like the xarray equivalent of `np.zeros_like`), and one that converts an axis which contains datetime coordinates to human-readable floats of the desired unit (`convert_datetime_to_number`).
It uses the same methodology to register methods as the rest of pyjanitor:
```python
@register_dataarray_method
def new_method(da: xr.DataArray, some_params) -> xr.DataArray:
do_stuff()
return dataarray
```
It also includes a `register_dataset_method` decorator. These can be `@decorator1 @decorator2` chained to register the method for both `xr.Dataset`s and `xr.DataArray`s.
```python
da = xr.DataArray(np.random.randint(0, 100, size=(512, 1024)), dims=['random_ax_1', 'random_ax_2'],
coords=dict(random_ax_1=np.linspace(0, 1, 512), random_ax_2=np.logspace(-2, 2, 1024)),
name='original')
da.clone_using(np.random.randn(512, 1024))
da.clone_using(np.random.randn(512, 1024), new_name='new_and_improved', use_coords=False)
(
da.assign_coords(
random_ax_1=1e9 * np.arange(512) * np.timedelta64(1, 'ns')
)
.convert_datetime_to_number('m', dim='random_ax_1')
)
```
| 1medium
|
Title: Add support for `connectOrCreate`
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
| 1medium
|
Title: Unnecessary access log when socket disconnects before sending any bytes
Body: **Describe the bug**
A socket connection request to server will cause following error:
```
[2021-08-30 10:29:31 +0800] - (sanic.access)[INFO][UNKNOWN]: NONE http:///* 503 666
[2021-08-30 10:29:31 +0800] [6386] [ERROR] Connection lost before response written @ ('127.0.0.1', 36214) <Request: NONE *>
```
why and how can i prevent that?
**Code snippet**
server.py
```
from sanic import Sanic
from sanic import text
app = Sanic.get_app("test", force_create=True)
@app.get("/")
async def response(request):
return text("ok")
if __name__ == "__main__":
app.run(host="0.0.0.0", port=9000, access_log=True, debug=True)
```
client.py
```
import socket
if __name__ == '__main__':
server_addr = ('localhost', 9000)
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket.connect(server_addr)
tcp_socket.close()
```
**Expected behavior**
no error msg
**Environment (please complete the following information):**
- OS: CentOS
- Version: 21.6.2
| 1medium
|
Title: Convert ScatterVisualizer to a mixin
Body: **Describe the solution you'd like**
Convert `ScatterVisualizer`, currently in contrib, into a YB mixin.
**Is your feature request related to a problem? Please describe.**
Besides `ScatterVisualizer` many YB visualizers implement some kind of scatterplot:
- [RadViz](https://github.com/DistrictDataLabs/yellowbrick/blob/bf5bd3f297ee6fdb589e457ecb0f954f085a5bf8/yellowbrick/features/radviz.py#L222)
- [Dispersion](https://github.com/DistrictDataLabs/yellowbrick/blob/25f1b9a6f3bdf1fa1a4cb88412b3ee095488d3ff/yellowbrick/text/dispersion.py#L106)
- [Manifold](https://github.com/DistrictDataLabs/yellowbrick/blob/75b0f6aa245f17844c1701383df0e02bc37875f4/yellowbrick/features/manifold.py#L388)
- [JointPlotVisualizer](https://github.com/DistrictDataLabs/yellowbrick/blob/9e8f76805132215aa77ee5a0a1ff20ca7034faf9/yellowbrick/features/jointplot.py#L247)
- [PCADecomposition](https://github.com/DistrictDataLabs/yellowbrick/blob/4d0483edd1468855df714f77bca1a0a93f01cbce/yellowbrick/features/pca.py#L157)
- [ResidualsPlot](https://github.com/DistrictDataLabs/yellowbrick/blob/718fc5b6f66a89527ee05f12de6dbe298b919e7f/yellowbrick/regressor/residuals.py#L173)
- [PredictionError](https://github.com/DistrictDataLabs/yellowbrick/blob/718fc5b6f66a89527ee05f12de6dbe298b919e7f/yellowbrick/regressor/residuals.py#L173)
- [TSNE](https://github.com/DistrictDataLabs/yellowbrick/blob/5ae6e320615ea32e6d1c201bdc9b551175c1e42b/yellowbrick/text/tsne.py#L336)
And it's likely that future visualizers may also require some form of scatterplot. In order to implement these in a more uniform and predictable way, it would be convenient to convert the current `ScatterVisualizer`, which was recently moved to contrib, into a YB mixin that could both serve as a base for the above visualizers and support future development.
See discussion in #475
| 1medium
|
Title: Color document boundaries (or classes) in dispersion plot
Body: **Describe the solution you'd like**
I work with text data a lot and am very excited about the new [`DispersionPlots`](http://www.scikit-yb.org/en/latest/api/text/dispersion.html)! As a future feature, it would be very useful to indicate document boundaries on the plot using a high perceptual contrast colormap, or perhaps a qualitative colormap to color the classes (when classes are available).
**Use case**
Adding document boundaries (or per-class document coloring) to the plot would enable me to visualize things like:
- n-grams that are very common in only a particular subset of the documents
- n-grams that are very common across all documents
- n-gram appearance vs. variance in document length
- n-gram appearance on a per-class basis (if classes are available)
Update
---------
@lwgray on August 24th, 2018
Issue #576 Doesn't completely resolve this issue thus it will remain open. However, #576 does add document boundaries to the dispersion plot
| 1medium
|
Title: [DOC] PyPI page has no project description
Body: # Brief Description of Fix
The PyPI page for `pyjanitor` has no project description. I'm not sure if it previously did, and was lost in a recent version update. I'm not sure how to fix it, but I assume it's something that @ericmjl would be able to change.
# Relevant Context
- [Link to PyPI page](https://pypi.org/project/pyjanitor/)
| 1medium
|
Title: Implements `sklearn.ensemble.RandomForestClassifier`
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Random forest classifier is widely used and should be introduced. The related scikit-learn API is https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier
| 1medium
|
Title: Libdoc: Show type information of embedded paramters
Body: When generating libdoc documentation, keywords with embedded arguments do not show the type hints.
This is a significant disadvantage to the "regular" parameter use case as in many cases the type information is clearer and more concise than free text would be.
For example.:
```
Write ${data} to ${destination}
Types.:
data = bytes
destination = socket.socket | io.RawIOBase
```
The types provide quite a bit of helpful information.
I believe that release 7.3 is going to touch the libdoc code base close to this to implement [libdoc markdown](https://github.com/robotframework/robotframework/issues/5304), therefore I think this would be a good fit.
| 1medium
|
Title: Prisma CLI and Client use different base paths for relative SQLite files
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
With this schema as `prisma/schema.prisma`:
```prisma
datasource db {
provider = "sqlite"
url = "file:dev.db"
}
model User {
id String @id @default(cuid())
name String
}
```
Running `prisma db push` creates a database file at `prisma/dev.db`.
Now running the client will error as the query engine uses the path relative to the working directory instead of the schema directory, e.g.
`main.py`
```python
import asyncio
from prisma import Prisma
from prisma.models import User
async def bar() -> None:
p = Prisma(auto_register=True)
await p.connect()
await User.prisma().create(data={'name': 'Robert'})
asyncio.run(bar())
```
Will use `dev.db` instead of `prisma/dev.db`.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The CLI and the Client should use the same database path.
| 1medium
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.