
text
stringlengths 20
57.3k
| labels
class label 4
classes |
|---|---|
Title: Create Chinese language localization of Yellowbrick documentation.
Body: New repository is here: https://github.com/DistrictDataLabs/yellowbrick-docs-zh
Docs can be found at: http://www.scikit-yb.org/zh/latest/
@Juan0001 you've been added to the above repository and should have write access to it.
| 1medium
|
Title: Add support for a create_many_and_return method
Body: https://www.prisma.io/docs/orm/reference/prisma-client-reference#createmanyandreturn
| 1medium
|
Title: AttributeError: _hf_hook caused by delattr in hooks.remove_hook_from_module()
Body: ### System Info
```Shell
- `Accelerate` version: 1.4.0.dev0
- Platform: Linux-6.2.0-39-generic-x86_64-with-glibc2.39
- `accelerate` bash location: /workspaces/.venv_py311/bin/accelerate
- Python version: 3.11.11
- Numpy version: 1.26.3
- PyTorch version (GPU?): 2.5.1+rocm6.2 (True)
- System RAM: 1007.70 GB
- GPU type: AMD Instinct MI250X/MI250
- `Accelerate` default config:
Not found
```
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] One of the scripts in the examples/ folder of Accelerate or an officially supported `no_trainer` script in the `examples` folder of the `transformers` repo (such as `run_no_trainer_glue.py`)
- [X] My own task or dataset (give details below)
### Reproduction
When using the HunyuanVideo model via diffusers framework with the following script:
```
import torch
from diffusers import HunyuanVideoPipeline, HunyuanVideoTransformer3DModel
MODEL_ID = "hunyuanvideo-community/HunyuanVideo"
PROMPT = "A cat walks on the grass, realistic"
transformer = HunyuanVideoTransformer3DModel.from_pretrained(
MODEL_ID, subfolder="transformer", torch_dtype=torch.bfloat16
)
pipe = HunyuanVideoPipeline.from_pretrained(
MODEL_ID, transformer=transformer, torch_dtype=torch.float16
)
pipe.enable_model_cpu_offload()
pipe.vae.enable_tiling()
pipe.vae.enable_slicing()
pipe.transformer = torch.compile(pipe.transformer, mode="default")
# Warmup
_ = pipe(
prompt=PROMPT,
height=320,
width=512,
num_frames=61,
num_inference_steps=1,
max_sequence_length=256,
guidance_scale=0.0,
generator=torch.Generator(device="cuda").manual_seed(42),
)
# Inference
output = pipe(
prompt=PROMPT,
height=320,
width=512,
num_frames=61,
num_inference_steps=30,
max_sequence_length=256,
guidance_scale=0.0,
output_type="pil",
generator=torch.Generator(device="cuda").manual_seed(42),
)
```
Following error arises:
```
Traceback (most recent call last):
File "/workspaces/huvideo_diffusers_repro.py", line 21, in <module>
_ = pipe(
^^^^^
File "/workspaces/.venv_py311/lib/python3.11/site-packages/torch/utils/_contextlib.py", line 116, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "/workspaces/diffusers/src/diffusers/pipelines/hunyuan_video/pipeline_hunyuan_video.py", line 689, in __call__
self.maybe_free_model_hooks()
File "/workspaces/diffusers/src/diffusers/pipelines/pipeline_utils.py", line 1119, in maybe_free_model_hooks
self.enable_model_cpu_offload(device=getattr(self, "_offload_device", "cuda"))
File "/workspaces/diffusers/src/diffusers/pipelines/pipeline_utils.py", line 1050, in enable_model_cpu_offload
self.remove_all_hooks()
File "/workspaces/diffusers/src/diffusers/pipelines/pipeline_utils.py", line 1017, in remove_all_hooks
accelerate.hooks.remove_hook_from_module(model, recurse=True)
File "/workspaces/accelerate/src/accelerate/hooks.py", line 203, in remove_hook_from_module
delattr(module, "_hf_hook")
File "/workspaces/.venv_py311/lib/python3.11/site-packages/torch/nn/modules/module.py", line 2043, in __delattr__
super().__delattr__(name)
AttributeError: 'OptimizedModule' object has no attribute '_hf_hook'
```
When wrapping these two lines with `try ... except`, the run succeeds.
https://github.com/huggingface/accelerate/blob/main/src/accelerate/hooks.py#L203
https://github.com/huggingface/accelerate/blob/main/src/accelerate/hooks.py#L212
If we still log the exceptions, they produce:
```
Error: AttributeError – 'OptimizedModule' object has no attribute '_hf_hook'
Error: AttributeError – 'OptimizedModule' object has no attribute '_old_forward'
```
This indicates that there seems to be a logical error when using the following coding pattern:
```
if hasattr(object, attr):
delattr(object, attr)
```
Suggesting that even though `hasattr` returns True, there is no guarantee `delattr` will work as intended.
### Expected behavior
Successful run without errors when using torch.compile and cpu model offloading.
| 1medium
|
Title: [BUG] Ignoring nested schema examples
Body: ### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
### Describe the bug
When trying out examples in swagger 2.0 i see that the example values of nested objects are not considered
### To Reproduce
🚨 **Mandatory** 🚨: Steps to reproduce the behavior:
1. Run this command `st run -v --hypothesis-phases=explicit --validate-schema=true -c all -H "Authorization: Bearer root" --generation-allow-x00=False --hypothesis-verbosity=debug --base-url=http://localhost:8083 tree-openapi202.json --show-trace --dry-run`
2. See error
Please include a minimal API schema causing this issue:
minimal api schema attached (see Additional context section)
### Expected behavior
lets say we have a hypothetical tree object with related birds that live on the tree
```
tree:
name: birch
height: 25m
bird:
name: bird1
description: example-bird
```
Assume name fields are mandatory in tree, bird
Expect to see these examples.
1. `{ tree { name: birch }}` Minimal example with only required fields of only tree
2. `{ tree: { name: birch, bird: { name: bird1 }}` Minimum example with only required fields of tree, bird
3. `{ tree: { name: birch, height: 25m, bird: { name: bird1, description: example-bird }}` Maximum example with all fields populated
examples 2, 3 are missing in schemathesis
schemathesis never generates any example of bird under the tree whether or not we declare name fields as mandatory
note: dredd behavior is only example 3, greedy approach
### Environment
`platform Linux -- Python 3.9.18, schemathesis-3.33.0, hypothesis-6.103.5, hypothesis_jsonschema-0.23.1, jsonschema-4.22.0
`
### Additional context
this is the sample swagger doc used for testing
[tree-openapi20.json](https://github.com/user-attachments/files/16315777/tree-openapi20.json)
| 1medium
|
Title: Feature request: Check for AVX instruction set during install
Body: As of late last year TensorFlow requires the CPU to support the AVX instruction set. This is therefore required by the Precise wake word engine.
Currently there are no checks or warnings when installing Mycroft to indicate that this will be a problem. However a number of users have reported Precise failing and in the end it was identified that they were running on older or lower end hardware.
Mycroft could still be used with PocketSphinx as the wake word engine, however it would be better to notify the user such that they are a) aware of the reduced capability; and b) can choose whether or not to continue.
Advanced users may opt to build an older version of TensorFlow (v1.13) from source.
The simplest method (that I know of) to identify if AVX is supported is to check for avx in the cpuinfo flags eg:
`grep avx /proc/cpuinfo`
### Success criteria
- During installation CPUinfo is checked to confirm AVX support
- If available, installation silently continues
- If unavailable, information is provided to the user and the installation may be aborted
- If the user opts to continue installation, the PocketSphinx listener should be selected.
| 1medium
|
Title: Support creating assigned variable name based on another variable like `${${var}} = Keyword`
Body: Apparently, it is not possible do return values into nested variables in RF, for cases like:
```
${x${y}} = Keyword
${x}[a] = Keyword
```
These can be quite handy aswell while using FOR loops, to populate values inside, like:
```
FOR ${INDEX} IN RANGE 1 4
Keyword1 ${user${INDEX}-email} ${user${INDEX}-fullname} gender=${INDEX}
${short-id-${INDEX}} API - Get User ID ${user${INDEX}-fullname}
END
```
| 1medium
|
Title: Builtin types should be mapped to the builtins module
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently if a field name shadows a builtin type, e.g. `bool` then pyright will report unbound variables and potentially miss type errors in user code in certain configurations.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We can reduce the chance of this happening by mapping the types to the builtin module, for example:
```py
from builtins import bool as _bool
class Foo:
bool: _bool
```
| 1medium
|
Title: Optimize performance of GroupBy.nunique
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Now we implements GroupBy.nunique using GroupBy.transform, some optimizations could be applied to reduce intermediate data size.
| 1medium
|
Title: 'nan' output for CoherenceModel when calculating 'c_v'
Body: #### Problem description
I'm using LDA Multicore from gensim 3.8.3. I'm training on my train corpus and I'm able to evaluate the train corpus using the CoherenceModel within Gensim, to calculate the 'c_v' value. However, when I'm trying to calculate the 'c_v' over my test set, it throws the following warning:
/Users/xxx/env/lib/python3.7/site-packages/gensim/topic_coherence/direct_confirmation_measure.py:204: RuntimeWarning: divide by zero encountered in double_scalars
m_lr_i = np.log(numerator / denominator)
/Users/xxx/lib/python3.7/site-packages/gensim/topic_coherence/indirect_confirmation_measure.py:323: RuntimeWarning: invalid value encountered in double_scalars
return cv1.T.dot(cv2)[0, 0] / (_magnitude(cv1) * _magnitude(cv2))
Furthermore, the output value of the CoherenceModel is 'nan' for some of the topics and therefore I'm not able to evaluate my model on a heldout test set.
#### Steps/code/corpus to reproduce
I run the following code:
```python
coherence_model_lda = models.CoherenceModel(model=lda_model,
topics=topic_list,
corpus=corpus,
texts=texts,
dictionary=train_dictionary,
coherence=c_v,
topn=20
)
coherence_model_lda.get_coherence() = nan # output of aggregated cv value
coherence_model_lda.get_coherence_per_topic() = [0.4855137269180713, 0.3718866594914528, nan, nan, nan, 0.6782845928414825, 0.21638660621444444, 0.22337594485796397, 0.5975773184175942, 0.721341268732559, 0.5299883104816663, 0.5057903454344682, 0.5818051100304473, nan, nan, 0.30613393712342557, nan, 0.4104488627000527, nan, nan, 0.46028708148750963, nan, 0.394606654755219, 0.520685457293826, 0.5918440959767729, nan, nan, 0.4842068862650447, 0.9350644411891258, nan, nan, 0.7471151926054456, nan, nan, 0.5084926961568169, nan, nan, 0.4322957454944861, nan, nan, nan, 0.6460815758337844, 0.5810936860540964, 0.6636319471764807, nan, 0.6129884526648472, 0.48915614063099017, 0.4746167359622748, nan, 0.6826979166639224] # output of coherence value per topic
```
I've tried to increase the EPSILON value within:
gensim.topic_coherence.direct_confirmation_measure, however, this doesn't have any effect.
Furthermore, I've tried to change the input arguments (e.g. exclude the dictionary argument) but this also doesn't have any effect. I think the error has to do something with the fact that quite a large portion of the words within the test set is not available in the train set, however, the EPSILON value should be able to handle this.
#### Versions
```
python
Python 3.7.2 (default, Dec 2 2020, 09:47:26)
[Clang 9.0.0 (clang-900.0.39.2)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import platform; print(platform.platform())
Darwin-18.7.0-x86_64-i386-64bit
>>> import sys; print("Python", sys.version)
Python 3.7.2 (default, Dec 2 2020, 09:47:26)
[Clang 9.0.0 (clang-900.0.39.2)]
>>> import struct; print("Bits", 8 * struct.calcsize("P"))
Bits 64
>>> import numpy; print("NumPy", numpy.__version__)
NumPy 1.18.5
>>> import scipy; print("SciPy", scipy.__version__)
SciPy 1.5.2
>>> import gensim; print("gensim", gensim.__version__)
gensim 3.8.3
>>> from gensim.models import word2vec;print("FAST_VERSION", word2vec.FAST_VERSION)
```
| 1medium
|
Title: Provide a pytest plugin
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently, testing applications that use Prisma Client Python requires a fair bit of manual setup and non-obvious code paths, we can make this easier by providing a pytest plugin that automatically takes care of setting up and tearing down the database for you.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
`plugin`
```py
# consumers can define their own `prisma_client` fixture to add additional __init__ arguments
@pytest.fixture(scope='session')
def prisma_client() -> Client:
return Client()
@pytest.fixture()
{{ maybe_async_def }}prisma(prisma_client: Client) -> Iterator[Client]:
# cleanup
yield prisma_client
# teardown
# NOTE: there may be difficulties here due to scope mismatch, actual API is still TODO
```
`consumer`
```py
# tests that use model-based access must mark the test as using prisma
@pytest.mark.prisma
@pytest.mark.asyncio
async def test_foo() -> None:
user = await User.prisma().create({'name': 'Robert'})
assert user.name == 'Robert'
# tests that use the client fixture do not have to mark the test
@pytest.mark.asyncio
async def test_bar(prisma: Client) -> None:
user = await prisma.user.create({'name': 'Robert'})
assert user.name == 'Robert'
```
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
Code for truncating all tables in the database can be found in our own tests `conftest.py`:
https://github.com/RobertCraigie/prisma-client-py/blob/main/tests/conftest.py#L120-L124
| 1medium
|
Title: Update documentation dependencies
Body: Review the changes upgrading our documentation dependencies have on our built documentation. If approved, update deps in `requirements.txt` and `docs/requirements.txt` as follows:
```
## Documentation (uncomment to build documentation)
Sphinx>=1.7.4
sphinx-rtd-theme>=0.3.1
numpydoc>=0.8.0
```
| 1medium
|
Title: test_keep_alive_client_timeout failure
Body: While packaging sanic for the gentoo overlay guru I got this test failure:
```
=================================== FAILURES ===================================
________________________ test_keep_alive_client_timeout ________________________
@pytest.mark.skipif(
bool(environ.get("SANIC_NO_UVLOOP"))
or OS_IS_WINDOWS
or platform.system() != "Linux",
reason="Not testable with current client",
)
def test_keep_alive_client_timeout():
"""If the server keep-alive timeout is longer than the client
keep-alive timeout, client will try to create a new connection here."""
try:
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
client = ReuseableSanicTestClient(keep_alive_app_client_timeout, loop)
headers = {"Connection": "keep-alive"}
_, response = client.get("/1", headers=headers, request_keepalive=1)
assert response.status == 200
assert response.text == "OK"
loop.run_until_complete(aio_sleep(2))
_, response = client.get("/1", request_keepalive=1)
> assert ReusableSanicConnectionPool.last_reused_connection is None
E assert <AsyncHTTPConnection [HTTP/1.1, IDLE]> is None
E + where <AsyncHTTPConnection [HTTP/1.1, IDLE]> = ReusableSanicConnectionPool.last_reused_connection
_ = <Request: GET /1>
client = <test_keep_alive_timeout.ReuseableSanicTestClient object at 0x7f64c594a970>
headers = {'Connection': 'keep-alive'}
loop = <uvloop.Loop running=False closed=False debug=False>
response = <Response [200 OK]>
tests/test_keep_alive_timeout.py:266: AssertionError
----------------------------- Captured stdout call -----------------------------
[2021-06-28 13:42:18 +0200] [70] [INFO] Goin' Fast @ http://127.0.0.1:42101
[2021-06-28 13:42:18 +0200] - (sanic.access)[INFO][127.0.0.1:55528]: GET http://127.0.0.1:42101/1 200 2
[2021-06-28 13:42:20 +0200] - (sanic.access)[INFO][127.0.0.1:55528]: GET http://127.0.0.1:42101/1 200 2
------------------------------ Captured log call -------------------------------
INFO sanic.root:app.py:1236 Goin' Fast @ http://127.0.0.1:42101
INFO sanic.access:http.py:443
INFO sanic.access:http.py:443
```
Full log here: https://799023.bugs.gentoo.org/attachment.cgi?id=719724
https://bugs.gentoo.org/799023
| 1medium
|
Title: Execution fails if standard streams are not available
Body: My Python programs rely on the robot framework, and when I package and run them using a wrapper like pyinstaller, an error is reported here if the packaging parameter console is set to False
robot\running\outputcapture.py 47L
` def _release_and_log(self):
stdout, stderr = self._release()
if stdout:
LOGGER.log_output(stdout)
if stderr:
LOGGER.log_output(stderr)
sys.__stderr__.write(console_encode(stderr, stream=sys.__stderr__))`
The error message is
`sys.__stderr__.write(console_encode(stderr, stream=sys.stderr))
AttributeError: 'NoneType' object has no attribute 'write'`
| 1medium
|
Title: Add support for removing a registered Client
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
While it is not standard practice to create multiple Prisma Client's in production code, it could be very useful to be able to "unregister" a Client instance in unit tests. We already provide a context manager solution in the form of:
```py
from prisma.testing import reset_client
with reset_client():
...
```
However a context manager is not always an elegant solution.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add a corresponding `deregister` function.
| 1medium
|
Title: Some Doc2Vec vectors remain untrained, with either giant #s of docvecs or small contrived corpuses
Body: Investigating the user report at <https://groups.google.com/d/msg/gensim/XbH5Sr6RBcI/w5-AIwpSAwAJ>, I ran with a (much-smaller) version of the synthetic-corpus there, & reproduced similarly inexplicable results, with doc-vectors that *should* have received at least *some* training-adjustment showing no change after an epoch of training.
To demonstrate:
```python
import logging
logging.root.setLevel(level=logging.INFO)
from gensim.models.doc2vec import TaggedDocument
from gensim.models import Doc2Vec
import numpy as np
import inspect
class DummyTaggedDocuments(object):
def __init__(self, count=1001, shared_word=True, doc_word=True, digit_words=False):
self.count = count
self.shared_word = shared_word
self.doc_word = doc_word
self.digit_words = digit_words
def __iter__(self):
for i in range(self.count):
words = []
if self.shared_word:
words += ['shared']
if self.doc_word:
words += ['doc_'+str(i)]
if self.digit_words:
words += str(i)
tags = [i]
if i == self.count - 1:
logging.info("yielding last DummyTaggedDocument %i", i)
yield TaggedDocument(words=words, tags=tags)
def test_d2v_docvecs_trained(doc_args={}, d2v_args={}):
"""Demo bug in Doc2Vec (& more?) as of gensim 3.8.1 with sample>0"""
docs = DummyTaggedDocuments(**doc_args)
d2v_model = Doc2Vec(**d2v_args)
d2v_model.build_vocab(docs, progress_per=100000)
starting_vecs = d2v_model.docvecs.vectors_docs.copy()
d2v_model.train(docs, total_examples=d2v_model.corpus_count, epochs=d2v_model.epochs, report_delay=5)
unchanged = np.all(starting_vecs==d2v_model.docvecs.vectors_docs, axis=1)
unchanged_indexes = np.argwhere(unchanged)
return (len(unchanged_indexes), list(unchanged_indexes))
test_d2v_docvecs_trained(d2v_args=dict(min_count=0, sample=0.01, vector_size=4, epochs=1, workers=1))
```
The return value of this test method should, for the given parameters, be a count of 0 unchanged vectors, and and empty-list of unchanged vector indexes. But in a typical run I'm getting instead:
```
(12,
[array([0]),
array([1]),
array([4]),
array([6]),
array([9]),
array([11]),
array([13]),
array([14]),
array([15]),
array([30]),
array([33]),
array([80])])
```
Though this is an artificial dataset, with peculiar 2-word documents, which will often only be 1-word documents (after frequent-word-downsampling of the term shared by all documents) – every document should be at least 1 word long, and thus get at least some training in any single epoch. The logging output regarding sampling accurately reports what the effects *should* be (at this sampling level):
```
INFO:gensim.models.doc2vec:collected 1002 word types and 1001 unique tags from a corpus of 1001 examples and 2002 words
INFO:gensim.models.word2vec:Loading a fresh vocabulary
INFO:gensim.models.word2vec:effective_min_count=0 retains 1002 unique words (100% of original 1002, drops 0)
INFO:gensim.models.word2vec:effective_min_count=0 leaves 2002 word corpus (100% of original 2002, drops 0)
INFO:gensim.models.word2vec:deleting the raw counts dictionary of 1002 items
INFO:gensim.models.word2vec:sample=0.01 downsamples 1 most-common words
INFO:gensim.models.word2vec:downsampling leaves estimated 1162 word corpus (58.1% of prior 2002)
```
I get similar evidence of unchanged vectors in `dm=0` (PV-DBOW) mode. However, running more epochs usually drives the number of unchanged vectors to 0.
Turning off downsampling with `sample=0` ensures all vectors show some update, implying some error in the downsampling is involved. Essentially, that strongly implies something going wrong in the code at or around:
https://github.com/RaRe-Technologies/gensim/blob/3d6596112f8f1fc0e839a32c5a00ef3d7365c264/gensim/models/doc2vec_inner.pyx#L344
But, a manual check of the precalculated `sample_int` values for all-but-the-most-frequent word suggests they're where they should be: a value that the random-int is never higher-than, and thus a value that should result in the corresponding words never being down-sampled.
I may not have time to dig deeper anytime soon, so placing this recipe-to-reproduce & key observations so far here.
Notably, `Word2Vec` & `FastText` may be using similar sampling logic – so even though there's not yet a sighting there, similar issues may exist.
(Separately, I somewhat doubt this sample-related anomaly, whatever its cause, is necessarily related to actual original problem of the user in the thread referenced – which seemed only present in extremely large corpuses, likely with real many-word texts, over a normal number of repeated epochs, and perhaps only in the "very tail-end" doc-vectors.)
| 1medium
|
Title: Add backend for xarray
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
We can implement a xarray backend in Mars, refer to https://xarray.pydata.org/en/stable/internals/how-to-add-new-backend.html .
| 1medium
|
Title: Extend ColorMap with target type detection and color resolution
Body: **Describe the solution you'd like**
The [`yellowbrick.style.colors.ColorMap`](https://github.com/DistrictDataLabs/yellowbrick/blob/develop/yellowbrick/style/colors.py#L124) object is one of the most underutilized objects in our code base and it solves many of the color issues we have such as #325 #327 #244 #556 #70 #73 #399. Now that #588 and #73 are solved in #676, I propose that we extend this object with target type detection and color resolution so that it can be used more meaningfully. The new implementation should do the following:
1. Operate as a function or dictionary that returns a color for a value.
2. Should be able to return both categorical and continuous color scales.
3. Should be able to accept a palette or cmap name, or a list of colors and resolve them.
4. Should be able to detect the target type and determine continuous or discrete colors
**Is your feature request related to a problem? Please describe.**
Our color handling is inconsistent at best. A number of visualizers such as RadViz, ParallelCoordinates, PCA, TSNE, etc. only allow for discrete/categorical colors when they could benefit from continuous colors for regression problems. The `resolve_colors` function only works for discrete values, the use of palette names and cmap names is also inconsistent. By creating a single color determination object across all of Yellowbrick, we'll have an easier time managing colorization in our plots.
**Examples**
Categorical colors with color maps/names:
```python
colors = ColorMap(colors='Set1', names=['a', 'b', 'c'])
colors['a'] # 'red'
colors[0] # 'red'
colors = ColorMap(colors='Blues', n_colors=2)
colors['a']
colors[0]
colors['b'] # raises KeyError
```
Continuous colors
```python
colors = ColorMap(colors='Jet', minv=0.0, maxv=12.0)
colors[0.3]
colors[1.2]
```
Learning and transforming colors like an estimator
```python
colors = ColorMap(colors='RdBuGn').fit(y)
colors.target_type_ # 'continuous'
colors.transform(y) # list of colors returned
colors = ColorMap().fit(y)
colors.target_type_ # 'discrete'
colors.transform(y) # ['r', 'b', 'g', 'r', 'g', 'r', ...]
```
| 1medium
|
Title: Support dynamic connection string arguments
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Prisma supports configuration through the datasource url, e.g.
```prisma
datasource db {
provider = "sqlite"
url = "file:dev.db?connection_limit=10"
}
```
Will create a connection pool with 10 connections.
We should support configuring options like this from python.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add arguments to either the `Client` constructor or the `connect` method, e.g.
```py
client = Client(connection_limit=5)
```
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
This is purely QOL, users can just add the arguments to the connection string themselves.
| 1medium
|
Title: Make list of languages in Libdoc's default language selection dynamic
Body: Libdoc got localization support in RF 7.2 (#3676) and it's possible to specify the default language from the command line. The list of available languages to be selected is currently hard-coded and missed languages what were added late in RF 7.2 release cycle. The list was updated in RF 7.2.1 (#5317), but it is still hard-coded so we need to remember to keep it updated when new languages are added. Let's make it list dynamic so that it's created based on the available languages automatically so we can forget about that.
| 1medium
|
Title: Make Neuraxle compatible with Yellowbrick
Body: **Describe the solution you'd like**
It would be cool to create a NeuraxleWrapper that would wrap any Neuraxle step or pipeline, just like how Neuraxle adapts scikit-learn steps into its core using [SKLearnWrapper](https://github.com/Neuraxio/Neuraxle/blob/1425d584817fa6b03ee303ae8815bb7e45418cb7/neuraxle/steps/sklearn.py#L39).
**Is your feature request related to a problem? Please describe.**
Related:
- https://github.com/Neuraxio/Neuraxle/issues/340
- https://github.com/Neuraxio/Neuraxle/issues/342 (this suggested solution would avoid you to have to add Neuraxle to your requirements.txt if you do the same)
**Examples**
1. Neuraxle steps and pipeline don't directly inherit from sklearn steps, however they almost have the same API
2. Neuraxle steps and pipeline don't have a score method. Thus the NeuraxleWrapper could have such a method, being optionnally provided a metric to use at the construction of the wrapper or with a set_metric method on the wrapper.
@alxkolm
| 1medium
|
Title: Add tests for all supported database providers
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We currently do not run integration tests on all of the database providers we support as Prisma tests them themselves, however we should still run our own tests as there may be database specific functionality that causes errors with our client.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add new integration tests for all supported database providers: https://www.prisma.io/docs/reference/database-reference/supported-databases
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
For potential contributors: https://prisma-client-py.readthedocs.io/en/stable/contributing/contributing/#integration-tests
Please only submit pull requests with *one* database provider at a time. Thank you :)
| 1medium
|
Title: Support disabling HTTP connection pooling
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Some frameworks (e.g. Flask Async) are incompatible with global asynchronous HTTP connection pooling as they spawn workers in separate threads with their own event loop. As the connection pool is tied to the event loop it was started in the aforementioned behaviour can lead to confusing event loop errors.
This makes it impossible to use Prisma Client Python with such frameworks as the alternative solution (apart from monkeypatching) is to connect to the database separately on each worker thread however this has severe performance and database connection limit concerns.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We *could* support local HTTP connection pooling such that each event loop gets its own HTTP connection pool however I do not know how well this would work in practice:
- Performance concerns with rapidly opening and closing a connection pool - would it be better to not use a connection pool?
- Increased memory usage
- Scalability concerns
As such I think that the best solution (at least in the short term) is to add an option to disable HTTP connection pooling entirely while we figure out whether or not local HTTP connection pooling would be a viable solution.
```py
client = Client(
http={
'use_pool': False,
},
)
```
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
See this discussion: https://github.com/RobertCraigie/prisma-client-py/issues/224#issuecomment-1034015273
| 1medium
|
Title: [BUG] Custom Auth caching ignores scopes
Body: **Checklist**
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
**Describe the bug**
When implementing custom auth, I'm using the scopes provided by the security schema to request an access token with the required scopes.
When a request to a different endpoint that requires different scopes is made, schemathesis uses the token with the wrong scopes.
**To Reproduce**
Steps to reproduce the behavior:
1. Add a hook implementing custom auth that looks like the sample below
```py
@schemathesis.auth()
class OAuth2Bearer:
@staticmethod
def get_scopes_from_ctx(context: AuthContext) -> frozenset[str, ...] | None:
security = context.operation.definition.get("security", [])
if not security:
return None
scopes = security[0][context.operation.get_security_requirements()[0]]
if not scopes:
return None
return frozenset(scopes)
def get(self, context: AuthContext) -> str | None:
if not (scopes := self.get_scopes_from_ctx(context)):
return None
token_endpoint = f"{context.operation.base_url}{TOKEN_ENDPOINT}"
# request token with required scopes for context
response = requests.post(token_endpoint, data={"scopes": scopes, ...})
data = response.json()
assert response.status_code == 200, data
return data["access_token"]
def set(self, case: Case, data: str, context: AuthContext) -> None:
case.headers = case.headers or {}
if not data:
return
case.headers["Authorization"] = f"Bearer {data}"
```
2. Run schemathesis on a schema with 2 endpoints that have different security scopes
```yaml
openapi: 3.0.3
info:
title: Cats Schema
description: Cats Schema
version: 1.0.0
contact:
email: [email protected]
servers:
- url: https://cats.cat
tags:
- name: cat
paths:
/v1/cats:
get:
description: List cats
operationId: listCats
tags:
- cat
responses:
"200":
description: List of cats
content:
application/json:
schema:
type: object
properties:
name:
type: string
security:
- oAuthBearer: ["list"]
post:
description: Create a a cat
operationId: createCat
tags:
- cat
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/Cat'
responses:
"200":
description: Newly created cat
content:
application/json:
schema:
$ref: '#/components/schemas/Cat'
security:
- oAuthBearer: ["create"]
components:
schemas:
Cat:
required:
- name
type: object
properties:
name:
type: string
example: Macavity
securitySchemes:
oAuthBearer:
type: oauth2
flows:
clientCredentials:
tokenUrl: /oauth/token
scopes:
list: "List cats"
create: "Create cats"
```
**Expected behavior**
As documented in the schema, the different endpoints have different security scopes.
Therefore, I'd expect the custom auth implementation to be called again with the different authentication context to request an access token with the right scopes.
**Environment (please complete the following information):**
N/A, but will provide anyway
- OS: Linux or macOS
- Python version: 3.9.2
- Schemathesis version: 3.19.7
- Spec version: 3.0.3
**Additional context**
I've bodged around it by returning the scopes from `Auth.get`, and comparing the scopes in the `Auth.set` context to the ones for the token. This obviously means that every request that requires different scopes to the original access token will end up hitting the authentication API, but it means I stop getting 403s from my application server!
```py
def get(self, context: AuthContext) -> _AuthData:
# ommitted for brevity
response = requests.post(...)
data = response.json()
assert response.status_code == 200, data
return scopes, data["access_token"]
def set(self, case: Case, data: _AuthData, context: AuthContext) -> None:
case.headers = case.headers or {}
if not data:
return
scopes, access_token = data
required_scopes = self.get_scopes_from_ctx(context)
if not required_scopes.issubset(scopes):
scopes, access_token = self.get(context)
case.headers["Authorization"] = f"Bearer {access_token}"
```
| 1medium
|
Title: Mark private modules and functions as private
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently we do not have a strict public API contract i.e. the public modules, classes and functions we provide are not treated any differently than the private ones. We should easily and correctly indicate to users which parts of our API are public not.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We should rename all modules and functions to indicate that they are private (e.g. `prisma.binaries` -> `prisma._binaries`) and then export all public modules, classes and functions in the base package.
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
This is what Encode do with https://github.com/encode/httpx
| 1medium
|
Title: Improve error message formatting
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We currently do not do any formatting for error tracebacks, formatting them nicely would increase readability and developer experience.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
I do not think we should completely remove raw tracebacks but we should improve the formatting for our error messages, we are already working on this with #60 but that is blocked by a pydantic bug and does not cover *all* error messages.
```
prisma.errors.MissingRequiredValueError: Failed to validate the query: `Unable to match input value to any allowed input type for the field. Parse errors: [Query parsing/validation error at `Mutation.createOnePost.data.PostCreateInput.published`: A value is required but not set., Query parsing/validation error at `Mutation.createOnePost.data.PostUncheckedCreateInput.published`: A value is required but not set.]` at `Mutation.createOnePost.data`
```
Format proposal is still work in progress.
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
https://twitter.com/willmcgugan/status/1489565889611677701
| 1medium
|
Title: CI Tests fail due to NLTK download first byte timeout
Body: **NLTK Downloader**
Here is a sample of an NLTK download in progress:
> [nltk_data] | Downloading package twitter_samples to
[nltk_data] | C:\Users\appveyor\AppData\Roaming\nltk_data...
[nltk_data] | Unzipping corpora\twitter_samples.zip.
[nltk_data] | Downloading package omw to
[nltk_data] | C:\Users\appveyor\AppData\Roaming\nltk_data...
[nltk_data] | Error downloading 'omw' from
[nltk_data] | <https://raw.githubusercontent.com/nltk/nltk_data
[nltk_data] | /gh-pages/packages/corpora/omw.zip>: HTTP Error
[nltk_data] | 503: first byte timeout
Error installing package. Retry? [n/y/e]
There is a related issue:
https://github.com/nltk/nltk/issues/1647
Could cached NLTK downloads provide the necessary NLTK data with sufficient freshness?
<!-- This line alerts the Yellowbrick maintainers, feel free to use this
@ address to alert us directly in follow up comments -->
@DistrictDataLabs/team-oz-maintainers
| 1medium
|
Title: Add comparison tables against other ORMs
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
When evaluating what ORM to use for your project it is not clear what tradeoffs / advantages you would get from choosing Prisma over another ORM. We should make this easy to figure out.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add a comparison table to the README / docs stating what features are / are not supported.
| 1medium
|
Title: More concise reports on network & config errors
Body: If there are e.g. connection errors, then the report is quite meh:
```
==================================== ERRORS ====================================
_______________________________ GET /api/failure _______________________________
requests.exceptions.ConnectionError: HTTPConnectionPool(host='127.0.0.1', port=1): Max retries exceeded with url: /api/failure (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f23fb0c4890>: Failed to establish a new connection: [Errno 111] Connection refused'))
requests.exceptions.ConnectionError: HTTPConnectionPool(host='127.0.0.1', port=1): Max retries exceeded with url: /api/failure (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f23fb0953d0>: Failed to establish a new connection: [Errno 111] Connection refused'))
_______________________________ GET /api/success _______________________________
requests.exceptions.ConnectionError: HTTPConnectionPool(host='127.0.0.1', port=1): Max retries exceeded with url: /api/success (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f23fb05f710>: Failed to establish a new connection: [Errno 111] Connection refused'))
requests.exceptions.ConnectionError: HTTPConnectionPool(host='127.0.0.1', port=1): Max retries exceeded with url: /api/success (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f23fb244d90>: Failed to establish a new connection: [Errno 111] Connection refused'))
Add this option to your command line parameters to see full tracebacks: --show-errors-tracebacks
Need more help?
Join our Discord server: https://discord.gg/R9ASRAmHnA
=================================== SUMMARY ====================================
```
I could be much more concise. Similarly, errors like `SerializationNotPossible` could be much better too
| 1medium
|
Title: Add log messages to result model that is build during execution and available to listeners
Body: In the new ListenerV3, it would be nice if result.messages were already populated in end_test and end_keyword.
Currently, the messages have to be collected using log_message to be used in end_test and end_keyword.
An example workaround looks like this:
```
def start_body_item(self, data, result):
self.body_items.append(result)
def log_message(self, message: Message):
result_msg = result.Message(
message=message.message,
html=message.html,
level=message.level,
timestamp=message.timestamp,
parent=message.parent,
)
if self.body_items:
self.body_items[-1].body.append(result_msg)
def end_body_item(self, data, result):
self.body_items.pop()
```
| 1medium
|
Title: [INF] Support Pyspark but not require it?
Body: I'm trying to catch up on the `pyspark` conversation. But I was wondering if we were supporting `pyspark`, but not requiring it @ericmjl , @zjpoh ?
I updated my local `pyjanitor` and had to download `pyspark` as the requirements changed, and it was about `215MB`. I think that's fine if it's required for development, but might not expected for users that only anticipate using `pandas`. I believe `rdkit` is currently optional for those users that will use it (maybe something else too), and I think that could be a good idea here too.
Again, I haven't looked through the entire `pyspark` conversation and changes yet.
| 1medium
|
Title: Implements `cluster.AffinityPropagation` algorithm
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
`cluster.AffinityPropagation` can be introduced, sklearn version is https://scikit-learn.org/stable/modules/generated/sklearn.cluster.AffinityPropagation.html
| 1medium
|
Title: Resolve relative paths from the schema location
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently, relative paths for partial type generators are resolved based on the current working directory, this can make it annoying as the client can only be generated from one specific directory.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Resolve paths relative to the location of the prisma schema file.
| 1medium
|
Title: Storing different documents in weaviate does not work because the index_name is not inferred from the BaseDoc subclass' name
Body: Storing two different types of documents in weaviate does not work.
I dont understand the API design here, is this intentional?
for example, lets assume I want to do a multilingual search, and have to use different embedding models to achieve this, or lets take the example from the documentation and add a different class, this will result in an error.
Example:
```python
import numpy as np
from pydantic import Field
from docarray import BaseDoc, DocList
from docarray.typing import NdArray
from docarray.index.backends.weaviate import WeaviateDocumentIndex
# Define a document schema
class Document(BaseDoc):
text: str
embedding: NdArray[2] = Field(
dims=2, is_embedding=True
) # Embedding column -> vector representation of the document
file: NdArray[100] = Field(dims=100)
# define a book schema
class Book(BaseDoc):
title: str
embedding: NdArray = Field( is_embedding=True)
# Make a list of 3 docs to index
docs = DocList[Document]([
Document(
text="Hello world", embedding=np.array([1, 2]), file=np.random.rand(100), id="1"
),
Document(
text="Hello world, how are you?",
embedding=np.array([3, 4]),
file=np.random.rand(100),
id="2",
),
Document(
text="Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut",
embedding=np.array([5, 6]),
file=np.random.rand(100),
id="3",
),
])
books = DocList[Book]([
Book(
title="Harry Potter", embedding=np.array([1, 2,3]), id="1"
),
Book(
title="Lords of the rings", embedding=np.array([3, 4,5]), id="2"
),
])
batch_config = {
"batch_size": 20,
"dynamic": False,
"timeout_retries": 3,
"num_workers": 1,
}
runtimeconfig = WeaviateDocumentIndex.RuntimeConfig(batch_config=batch_config)
dbconfig = WeaviateDocumentIndex.DBConfig(
host="http://localhost:8080"
)
store = WeaviateDocumentIndex[Document](db_config=dbconfig)
store.configure(runtimeconfig) # Batch settings being passed on
store.index(docs)
store = WeaviateDocumentIndex[Book](db_config=dbconfig)
store.configure(runtimeconfig) # Batch settings being passed on
store.index(books)
```
This gives:
```
---------------------------------------------------------------------------
UnexpectedStatusCodeException Traceback (most recent call last)
[/tmp/ipykernel_22411/2065625298.py](https://vscode-remote+ssh-002dremote-002baimwel-002dec2.vscode-resource.vscode-cdn.net/tmp/ipykernel_22411/2065625298.py) in ()
56 runtimeconfig = WeaviateDocumentIndex.RuntimeConfig(batch_config=batch_config)
57
---> 58 store = WeaviateDocumentIndex[Book](db_config=dbconfig)
59 store.configure(runtimeconfig) # Batch settings being passed on
60 store.index(docs)
[~/isco-labeling-tool/.venv/lib/python3.9/site-packages/docarray/index/backends/weaviate.py](https://vscode-remote+ssh-002dremote-002baimwel-002dec2.vscode-resource.vscode-cdn.net/home/ec2-user/isco-labeling-tool/notebooks/~/isco-labeling-tool/.venv/lib/python3.9/site-packages/docarray/index/backends/weaviate.py) in __init__(self, db_config, **kwargs)
110 self._set_embedding_column()
111 self._set_properties()
--> 112 self._create_schema()
113
114 def _set_properties(self) -> None:
[~/isco-labeling-tool/.venv/lib/python3.9/site-packages/docarray/index/backends/weaviate.py](https://vscode-remote+ssh-002dremote-002baimwel-002dec2.vscode-resource.vscode-cdn.net/home/ec2-user/isco-labeling-tool/notebooks/~/isco-labeling-tool/.venv/lib/python3.9/site-packages/docarray/index/backends/weaviate.py) in _create_schema(self)
217 )
218 else:
--> 219 self._client.schema.create_class(schema)
220
221 @dataclass
[~/isco-labeling-tool/.venv/lib/python3.9/site-packages/weaviate/schema/crud_schema.py](https://vscode-remote+ssh-002dremote-002baimwel-002dec2.vscode-resource.vscode-cdn.net/home/ec2-user/isco-labeling-tool/notebooks/~/isco-labeling-tool/.venv/lib/python3.9/site-packages/weaviate/schema/crud_schema.py) in create_class(self, schema_class)
180 # validate the class before loading
...
--> 708 raise UnexpectedStatusCodeException("Create class", response)
709
710 def _create_classes_with_primitives(self, schema_classes_list: list) -> None:
UnexpectedStatusCodeException: Create class! Unexpected status code: 422, with response body: {'error': [{'message': "Name 'Document' already used as a name for an Object class"}]}.
```
This happens because in `docarray/index/backends/weaviate.py` on line 210:
```
schema["class"] = self._db_config.index_name
```
So the class that is being added to weaviate (the table) is named after the _db_config's index_name, instead of the name of the schema class.
One can solve this in this (quite hacky) manner:
```
dbconfig = WeaviateDocumentIndex.DBConfig(
host="http://localhost:8080",
index_name=books.doc_type.__name__
)
store = WeaviateDocumentIndex[Book](db_config=dbconfig)
store.configure(runtimeconfig) # Batch settings being passed on
store.index(books)
```
or use the `Book.__name__` property.
Anyway, my proposed solution would be to use the name of the class, and not some undocumented name in the db_config, this behaviour is quite unexpected tbh.
| 1medium
|
Title: Enable auto-styling checks in Azure pipeline
Body: I've replaced the single quotes by double quotes. It seems the auto styling does not run over the scripts so I missed it.
_Originally posted by @mphirke in https://github.com/ericmjl/pyjanitor/pull/714_
Looks like we need to double-check that `black` formats the `scripts/` directory.
| 1medium
|
Title: Chunks of `df.groupby().apply(func)` can be auto merged if the func is actually an aggregation func
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Chunks of `df.groupby().apply(func)` can be auto merged if the func is actually an aggregation func.
```
In [1]: import pandas as pd; import numpy as np
In [3]: import mars
In [4]: mars.new_session()
Web service started at http://0.0.0.0:60764
Out[4]: <mars.deploy.oscar.session.SyncSession at 0x7fa7826dd670>
In [6]: import mars.dataframe as md
In [10]: def f(df):
...: return df.sum()
In [19]: pdf = pd.DataFrame({'a': rs.randint(2, size=20_0000), 'b': rs.rand(20_0
...: 000)})
In [20]: df = md.DataFrame(pdf, chunk_size=1_0000).execute()
100%|██████████████████████████████████████| 100.0/100 [00:00<00:00, 440.41it/s]
In [21]: %time df.groupby('a', as_index=False).apply(f).sort_values('a').execute
...: ()
100%|███████████████████████████████████████| 100.0/100 [00:02<00:00, 38.95it/s]
CPU times: user 1.83 s, sys: 150 ms, total: 1.98 s
Wall time: 2.58 s
Out[21]:
a b
0 0.0 49795.075985
0 100326.0 50159.168985
In [22]: %time df.groupby('a', as_index=False).apply(f).rebalance(num_partitions
...: =1).sort_values('a').execute()
100%|███████████████████████████████████████| 100.0/100 [00:01<00:00, 60.80it/s]
CPU times: user 1.19 s, sys: 94 ms, total: 1.29 s
Wall time: 1.66 s
Out[22]:
a b
0 0.0 49795.075985
0 100326.0 50159.168985
```
Here we manually call rebalance to merge the chunks, and the performance's elevation can be observable.
| 1medium
|
Title: HTTP Client next steps
Body: I'm happy to see that #66 got merged! Great work @RobertCraigie
A couple of thoughts I was having from that PR:
- The HTTP client implementations could be private so that if in the future you migrate to Rust bindings or make other changes, they are not breaking changes.
- If the HTTP client is private, and since only HTTPX is being used now, the generic HTTP abstraction layer could be removed (just to simplify the code, no changes for users) and just rely on HTTPX's interfaces.
- Since there are no longer extra dependencies, client generator configuration could be simplified further by removing the `interface` option and generating both sync and async clients every time (simpler codebase, simpler for users, only con is some extra code that may not be used). Taking this a step further, some things could be moved from code generation to hardcoded real code (which makes it more testable). Alternatively, you could keep the option, but just make the default "both", which makes things simpler for users, but not really any simpler for the project.
| 1medium
|
Title: Test minimum dependency versions
Body: Currently we only test our dependencies on their latest versions, we should also run tests on the minimum version to ensure our metadata is up to date.
| 1medium
|
Title: Variables containing mutable values are resolved incorrectly in some cases
Body: I met a weird problem.
robot file `cases.robot` like this
```
*** Settings ***
Test Setup set os ip
Library Collections
*** Variables ***
&{linux_host1} mid=12345
&{linux_host2} mid=67890
@{list_a} ${linux_host1} ${linux_host2}
@{host_b} ${linux_host1} ${linux_host2}
*** Test Cases ***
case-a
FOR ${j} IN @{list_a}
LOG ${j}
LOG ${j}[os_ip]
END
case-b
FOR ${i} IN @{host_b}
LOG ${i}
LOG ${i}[os_ip]
END
*** Keywords ***
set os ip
Set to Dictionary ${linux_host1} os_ip=192.168.1.1
Set to Dictionary ${linux_host2} os_ip=192.168.1.2
Log ${linux_host1}
Log ${linux_host2}
```
run it, case-a passed, but case-b failed.
```
$ robot -d /tmp/ cases.robot
==============================================================================
Cases
==============================================================================
case-a | PASS |
------------------------------------------------------------------------------
case-b | FAIL |
Dictionary '${i}' has no key 'os_ip'.
------------------------------------------------------------------------------
Cases | FAIL |
2 tests, 1 passed, 1 failed
==============================================================================
Output: /tmp/output.xml
Log: /tmp/log.html
Report: /tmp/report.html
```
If change the variable `host_b` to `list_b`, both case passed.
```
*** Settings ***
Test Setup set os ip
Library Collections
*** Variables ***
&{linux_host1} mid=12345
&{linux_host2} mid=67890
@{list_a} ${linux_host1} ${linux_host2}
@{list_b} ${linux_host1} ${linux_host2}
*** Test Cases ***
case-a
FOR ${j} IN @{list_a}
log ${j}
LOG ${j}[os_ip]
END
case-b
FOR ${i} IN @{list_b}
log ${i}
LOG ${i}[os_ip]
END
*** Keywords ***
set os ip
Set to Dictionary ${linux_host1} os_ip=192.168.1.1
Set to Dictionary ${linux_host2} os_ip=192.168.1.2
Log ${linux_host1}
Log ${linux_host2}
```
```
==============================================================================
Cases
==============================================================================
case-a | PASS |
------------------------------------------------------------------------------
case-b | PASS |
------------------------------------------------------------------------------
Cases | PASS |
2 tests, 2 passed, 0 failed
==============================================================================
Output: /tmp/output.xml
Log: /tmp/log.html
Report: /tmp/report.html
```
robotframework version:
```
robotframework 7.0.1
robotframework-pythonlibcore 4.4.1
```
python 3.10.12
os: ubuntu 22.04
| 1medium
|
Title: Add alpha support for other scatter visualizers
Body: **Describe the solution you'd like**
In follow up to @peterespinosa's [recent PR](https://github.com/DistrictDataLabs/yellowbrick/pull/554), we should add an `alpha` (translucency) param to the scatter visualizers that don't currently have one.
**Is your feature request related to a problem? Please describe.**
The following visualizers need an `alpha` parameter:
- PCADecomposition
- PredictionError
- ResidualsPlot (implements a default alpha)
- text.TSNE (implements a default alpha)
see discussion in #475
| 1medium
|
Title: Radviz colors - Support Colormap and colors arguments
Body: Currently Radviz does not support adding a custom color palette.
Here's the segment of code to change / improve :
https://github.com/DistrictDataLabs/yellowbrick/blob/c5b2346c03ba5b8aaadf6a4037b1939e9f3063a2/yellowbrick/features/radviz.py#L176-L183
| 1medium
|
Title: Initial GraalPython support
Body: GraalPython from https://github.com/oracle/graalpython seems to work well enough so that official support for RobotFramework would be useful.
GraalPython allows for better testing of JVM based APIs, given that GraalPython itself runs on JVM and supports inheriting from Java classes, in a similar way as Jython did in RF 4.
The upcoming release 25 of GraalPython seems to have fixed outstanding issues the prevented running RFs own regression tests.
Using the early access release:
https://github.com/graalvm/graal-languages-ea-builds/releases/download/graalpy-25.0.0-ea.09/graalpy-25.0.0-ea.09-linux-amd64.tar.gz
On RedHat 9.5 I got 6768 tests, 6622 passed, 146 failed
**Notes on running the RF acceptance tests with GraalPython:**
Assumes graal-python unpacked in current dir, as well as robotframework source:
Create a virtual env with GraalPy:
./graalpy-25.0.0-dev-linux-amd64/bin/python -m venv genv
source genv/bin/activate
pip install -r robotframework/atest/requirements.txt # If gcc, patch, libxml2-devel and libxslt-devel are installed, lxml should compile for fine for GraalPy
deactivate
Run with CPython virtual env, where robotframework/atest/requirements-run.txt have been installed (jsonschema failed to install for GraalPy)
cd robotframework
python atest/run.py --interpreter ../genv/bin/python
Note that graalpython startup is slow and many tests are very short, so this make cumulative execution time for the tests slow.
| 1medium
|
Title: Use `assing`, not `variable`, with FOR and TRY/EXCEPT model objects when referring to assigned variables
Body: # FOR
After tokenising the assigned variable is of type `VARIABLE` with FOR loops but shall be `ASSIGN`:
Example:
```robot
FOR ${i} IN RANGE 10 # ${i} is: token.type == "VARIABLE"
Log ${i}
END
```
Here is an assignment happening as in:
```robot
${i} Set Variable 1
```
Therefore `VARIABLE` would be considered "wrong" here.
# TRY/EXCEPT
Similar situation is with EXCEPT AS variables. they are also `VARIABLE`
Example:
```robot
TRY
Fail failure message
EXCEPT AS ${error} # ${error} is: token.type == "VARIABLE"
Log my error ${error}
END
```
Should also be `ASSIGN` after the AS
Cheers
| 1medium
|
Title: Provide a TypedDict for every model
Body: ### Discussed in https://github.com/RobertCraigie/prisma-client-py/discussions/838
<div type='discussions-op-text'>
<sup>Originally posted by **NixBiks** November 20, 2023</sup>
Does there exist a generated `TypedDict` which represents a table as they look in the database?
I've been looking in `prisma.types` but no luck.
E.g. for I'd like something like
```py
from typing import Literal, Optional, TypedDict
LogLevel = Literal["NOTSET", "DEBUG", "INFO", "WARNING", "ERROR", "CRITICAL"]
class LogInDB(TypedDict):
id: int
level: LogLevel
message: str
worker_id: Optional[str]
```
for a schema like this
```prisma
enum LogLevel {
NOTSET
DEBUG
INFO
WARNING
ERROR
CRITICAL
}
model Log {
id BigInt @id @default(autoincrement())
level LogLevel
message String
worker_id String?
}
```
</div>
| 1medium
|
Title: JointPlotVisualizer produces different visualizations depending on how the figure and axes objects are defined
Body: **Describe the bug**
JointPlotVisualizer produces different visualizations depending on how the figure and axes objects are defined.
If the figure and axes are defined in the following manner:
_, ax = plt.subplots()
visualizer = JointPlotVisualizer(ax=ax, feature=feature, target=target, joint_plot="hex")
The results are as follows:
1) feature and target labels are displayed in the image
2) the tick labels are displayed only on the left and bottom axes
3) there are issues with the tick label values
On the other hand, if the figure and axes are defined as such:
fig = plt.figure()
ax = fig.add_subplot()
The results are as follows:
1) the feature and target labels are not displayed
2) the tick labels show up in all the axes
3) the tick label values are displayed with more meaningful values
Refer to the following jupyter notebook to see a demonstration of the differences:
https://github.com/pdamodaran/yellowbrick/blob/develop/examples/pdamodaran/JointPlot_Examples.ipynb
NOTE: any fixes to this issue should be considered in conjunction with the following issues:
https://github.com/DistrictDataLabs/yellowbrick/issues/434
https://github.com/DistrictDataLabs/yellowbrick/issues/214
| 1medium
|
Title: [BUG] Filtering failed when scaler is pd.Timestamp
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Filtering failed when scaler is pd.Timestamp.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```
In [1]: import mars.dataframe as md
In [2]: df = md.DataFrame({'a': ['a', 'b', 'c'], 'b': [md.Timestamp('2022-1-1'),
...: md.Timestamp('2022-1-2'), md.Timestamp('2022-1-3')]})
In [3]: df[df.b < md.Timestamp('2022-1-3')].execute()
Unexpected error happens in <function TaskProcessor.optimize at 0x7feea8b979d0>
Traceback (most recent call last):
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/processor.py", line 57, in inner
return await func(processor, *args, **kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/processor.py", line 131, in optimize
return await asyncio.to_thread(self._preprocessor.optimize)
File "/Users/xuyeqin/Workspace/mars/mars/lib/aio/_threads.py", line 36, in to_thread
return await loop.run_in_executor(None, func_call)
File "/Users/xuyeqin/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/preprocessor.py", line 127, in optimize
self.tileable_optimization_records = optimize_tileable_graph(
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/core.py", line 36, in optimize
return TileableOptimizer.optimize(tileable_graph)
File "/Users/xuyeqin/Workspace/mars/mars/core/mode.py", line 77, in _inner
return func(*args, **kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/core.py", line 265, in optimize
if rule.match(op):
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py", line 65, in match
_, expr = self._extract_eval_expression(op.outputs[0])
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py", line 111, in _extract_eval_expression
result = cls._extract_binary(tileable)
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py", line 148, in _extract_binary
rhs_tileable, rhs_expr = cls._extract_eval_expression(op.rhs)
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py", line 105, in _extract_eval_expression
elif isinstance(tileable.op, DataFrameUnaryUfunc):
AttributeError: 'Timestamp' object has no attribute 'op'
0%| | 0/100 [00:00<?, ?it/s]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-3-a7387f7228a9> in <module>
----> 1 df[df.b < md.Timestamp('2022-1-3')].execute()
~/Workspace/mars/mars/core/entity/tileables.py in execute(self, session, **kw)
460
461 def execute(self, session=None, **kw):
--> 462 result = self.data.execute(session=session, **kw)
463 if isinstance(result, TILEABLE_TYPE):
464 return self
~/Workspace/mars/mars/core/entity/executable.py in execute(self, session, **kw)
96
97 session = _get_session(self, session)
---> 98 return execute(self, session=session, **kw)
99
100 def _check_session(self, session: SessionType, action: str):
~/Workspace/mars/mars/deploy/oscar/session.py in execute(tileable, session, wait, new_session_kwargs, show_progress, progress_update_interval, *tileables, **kwargs)
1771 session = get_default_or_create(**(new_session_kwargs or dict()))
1772 session = _ensure_sync(session)
-> 1773 return session.execute(
1774 tileable,
1775 *tileables,
~/Workspace/mars/mars/deploy/oscar/session.py in execute(self, tileable, show_progress, *tileables, **kwargs)
1571 fut = asyncio.run_coroutine_threadsafe(coro, self._loop)
1572 try:
-> 1573 execution_info: ExecutionInfo = fut.result(
1574 timeout=self._isolated_session.timeout
1575 )
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440 else:
441 raise TimeoutError()
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in __get_result(self)
386 def __get_result(self):
387 if self._exception:
--> 388 raise self._exception
389 else:
390 return self._result
~/Workspace/mars/mars/deploy/oscar/session.py in _execute(session, wait, show_progress, progress_update_interval, cancelled, *tileables, **kwargs)
1722 while not cancelled.is_set():
1723 try:
-> 1724 await asyncio.wait_for(
1725 asyncio.shield(execution_info), progress_update_interval
1726 )
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in wait_for(fut, timeout, loop)
481
482 if fut.done():
--> 483 return fut.result()
484 else:
485 fut.remove_done_callback(cb)
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in _wrap_awaitable(awaitable)
682 that will later be wrapped in a Task by ensure_future().
683 """
--> 684 return (yield from awaitable.__await__())
685
686 _wrap_awaitable._is_coroutine = _is_coroutine
~/Workspace/mars/mars/deploy/oscar/session.py in wait()
100
101 async def wait():
--> 102 return await self._aio_task
103
104 self._future_local.future = fut = asyncio.run_coroutine_threadsafe(
~/Workspace/mars/mars/deploy/oscar/session.py in _run_in_background(self, tileables, task_id, progress, profiling)
901 )
902 if task_result.error:
--> 903 raise task_result.error.with_traceback(task_result.traceback)
904 if cancelled:
905 return
~/Workspace/mars/mars/services/task/supervisor/processor.py in inner(processor, *args, **kwargs)
55 async def inner(processor: "TaskProcessor", *args, **kwargs):
56 try:
---> 57 return await func(processor, *args, **kwargs)
58 except: # noqa: E722 # nosec # pylint: disable=bare-except # pragma: no cover
59 if log_when_error:
~/Workspace/mars/mars/services/task/supervisor/processor.py in optimize(self)
129 # optimization, run it in executor,
130 # since optimization may be a CPU intensive operation
--> 131 return await asyncio.to_thread(self._preprocessor.optimize)
132
133 @_record_error
~/Workspace/mars/mars/lib/aio/_threads.py in to_thread(func, *args, **kwargs)
34 ctx = contextvars.copy_context()
35 func_call = functools.partial(ctx.run, func, *args, **kwargs)
---> 36 return await loop.run_in_executor(None, func_call)
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py in run(self)
55
56 try:
---> 57 result = self.fn(*self.args, **self.kwargs)
58 except BaseException as exc:
59 self.future.set_exception(exc)
~/Workspace/mars/mars/services/task/supervisor/preprocessor.py in optimize(self)
125 if self._config.optimize_tileable_graph:
126 # enable optimization
--> 127 self.tileable_optimization_records = optimize_tileable_graph(
128 self.tileable_graph
129 )
~/Workspace/mars/mars/optimization/logical/tileable/core.py in optimize(tileable_graph)
34
35 def optimize(tileable_graph: TileableGraph) -> OptimizationRecords:
---> 36 return TileableOptimizer.optimize(tileable_graph)
~/Workspace/mars/mars/core/mode.py in _inner(*args, **kwargs)
75 def _inner(*args, **kwargs):
76 with enter_mode(**mode_name_to_value):
---> 77 return func(*args, **kwargs)
78
79 else:
~/Workspace/mars/mars/optimization/logical/core.py in optimize(cls, graph)
263 # maybe removed during optimization
264 continue
--> 265 if rule.match(op):
266 optimized = True
267 rule.apply(op)
~/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py in match(self, op)
63 @implements(OptimizationRule.match)
64 def match(self, op: OperandType) -> bool:
---> 65 _, expr = self._extract_eval_expression(op.outputs[0])
66 return expr is not None
67
~/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py in _extract_eval_expression(cls, tileable)
109 result = None, None
110 else:
--> 111 result = cls._extract_binary(tileable)
112 else:
113 result = None, None
~/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py in _extract_binary(cls, tileable)
146 if lhs_tileable is not None:
147 cls._add_collapsable_predecessor(tileable, op.lhs)
--> 148 rhs_tileable, rhs_expr = cls._extract_eval_expression(op.rhs)
149 if rhs_tileable is not None:
150 cls._add_collapsable_predecessor(tileable, op.rhs)
~/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py in _extract_eval_expression(cls, tileable)
103 if cls._is_select_dataframe_column(tileable):
104 result = cls._extract_column_select(tileable)
--> 105 elif isinstance(tileable.op, DataFrameUnaryUfunc):
106 result = cls._extract_unary(tileable)
107 elif isinstance(tileable.op, DataFrameBinopUfunc):
AttributeError: 'Timestamp' object has no attribute 'op'
```
| 1medium
|
Title: Add support for lazy connections
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently, defining multiple event handlers using a framework that doesn't support a callback like `on_startup()` is annoying as you have to check if the client is connected or not before making a query.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Refactor the internal engine connection to be lazy, i.e. whenever a query is made, connect to the database before running the query.
| 1medium
|
Title: Improving Quick Start Documentation
Body: **Quick Start Documentation**
In the walk through part of the documentation, correlation between actual temperature and feels like temperature were analysed. The author mentioned that it was intuitive to prioritize the feature 'feels like' over 'temp'. But for the reader, it is bit hard to understand the reason behind author's decision on feature selection from the plot.
Expectation:
Could add some more details on why 'feels like' is better than 'temp' when we train machine learning models.
### Background
https://www.datascience.com/blog/introduction-to-correlation-learn-data-science-tutorials
https://newonlinecourses.science.psu.edu/stat501/node/346/
| 1medium
|
Title: Provide helper methods for usage with third party frameworks
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently if someone wants to use Prisma Python with a framework like FastAPI for example they have to write this boilerplate:
```py
app = FastAPI()
prisma = Client(auto_register=True)
@app.on_event('startup') # type: ignore
async def startup() -> None:
await prisma.connect()
@app.on_event('shutdown') # type: ignore
async def shutdown() -> None:
if prisma.is_connected():
await prisma.disconnect()
```
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We could improve this experience by providing a method to do this for users:
```py
from prisma.ext.fastapi import register_prisma
app = FastAPI()
register_prisma(app)
# or
prisma = Client(auto_register=True)
register_prisma(app, prisma)
```
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
A full list of third party frameworks is yet to be decided on however they could just be implemented on a per-request basis.
| 1medium
|
Title: Sana Controlnet Support
Body: **Is your feature request related to a problem? Please describe.**
The first controlnet for Sana has appeared, so the feature is to add the sana controlnet to the diffusers pipeline https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_controlnet.md
**Describe the solution you'd like.**
Be able to use the sana controlnet
**Describe alternatives you've considered.**
Using the sana repo
| 1medium
|
Title: [FEATURE] Corpus for input values
Body: ### Is your feature request related to a problem? Please describe
Sometimes the user wants to test a large set of specific values to ensure corner cases are always covered.
### Describe the solution you'd like
A way to load such a corpus conveniently. The corpus format is not yet clear but at first glance, it could be done on the Open API parameters basis, i.e. they are named so it could be just a mapping `param => [variant_A, variant_B, ...]`. It would also correspond to a CSV file structure, where each column will have values for each parameter.
However, it is unclear how to deal with other parameters, e.g. inside `components` - the user may want to cover some specific properties of objects nested inside `components`.
Possible Python API:
```python
from schemathesis.corpus import Entry
schema.corpus.add(
Entry.from_path(
path="#/components/User/name",
values=["a", "b", "c"],
filter=... # Use values only in some specific API operation
),
Entry.named(
# All `user_id` parameters
name="user_id",
values=["42", "43", "44"]
),
)
```
CLI:
```
st run --corpus-path=...
```
However, it is unclear how such a file should be structured.
### Describe alternatives you've considered
Currently, it is not super convenient to do so. The closest equivalent is the `add_examples` hook, but it requires constructing examples manually. Alternatively, the user may modify their API schema which is not feasible for a large set of values.
### Additional context
Discussed privately in Discord - maybe JMeter's input values could be a source of inspiration for this.
| 1medium
|
Title: Add legend option to PCA visualizer
Body: The ``PCADecomposition`` allows us to set the color of the different entries. It would be cool to add a legend to describe the coloring.
### Proposal/Issue
The ``DataVisualizer`` class supports creating legends, but it requires that ``y`` is passed into ``.fit``. Admittedly, PCA doesn't require labels, but sometimes you have them. I would love to label the colorings in PCA. Could the constructor accept a ``legend`` parameter that is similar to the ``color`` parameter, but accepts labels?
| 1medium
|
Title: Extend partial model creation to support renaming fields
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Currently if you want to have a separation of concerns between your database and your application layer then you need to manually define a new model, e.g.
```py
from pydantic import BaseModel
class UserSchema(BaseModel):
id: str
name: str
```
This separation of concerns is important because renaming a database field shouldn't break anything that doesn't directly interface with the database.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add a new argument to `create_partial` to rename fields, e.g.
```py
User.create_partial(
rename={
'name': 'user_name',
},
)
```
This would then generate a partial model that looks like this:
```py
from pydantic import BaseModel
class UserSchema(BaseModel):
...
user_name: str = Field(alias='name')
```
| 1medium
|
Title: Move binaries outside of `/tmp` by default
Body: ## Problem
Currently, the downloaded binaries are placed in /tmp/ on Linux. However, /tmp/ directory is cleared on boot everytime.
## Suggested solution
Placing the binaries in /var/tmp/ on Linux. See [Temporary folder](https://en.wikipedia.org/wiki/Temporary_folder).
## Alternatives
Placing the binaries in site-packages/prisma/
| 1medium
|
Title: Keep "lifecycle log" in models
Body: ## Why
When Gensim users report issues with models, we have trouble deciding what they actually did, what version they used, etc. They're often confused themselves.
This leads to protracted communication => increased support effort => slower issue resolution and more annoyance all around. Not good.
## What
Keep an internal "lifecycle log" inside each model. This could be as simple as an internal list-of-strings attribute, e.g. `word2vec.lifecycle = ["init() created on 2020-06-20 15:49:03 UTC with Gensim 3.8.3 on Python 3.6", "train() called on 2020-06-20 15:49:04 UTC", "load() called on 2020-06-29 8:7:58 UTC", …]`. We would serialize this log on `save()`, and ask users to provide its value when investigating an issue.
We probably want to keep this simple and human-readable, both in the API and log content. Not to over-engineer to start with – not attempting a full model recreation from the log or anything, I can see how this could turn into a rabbit hole.
*Originally conceived by @gojomo in https://github.com/RaRe-Technologies/gensim/pull/2698#issuecomment-646929210.*
| 1medium
|
Title: Add official support for the windows platform
Body: ## Context
I haven't tested windows support in a while but apart from some internal changes required to make tests pass, the biggest blocker is https://github.com/prisma/prisma/issues/10270, however we can fix this ourselves.
| 1medium
|
Title: Improving generalization of LoRA with wise-ft
Body: ### Feature request
Include the [wise-ft](https://arxiv.org/abs/2109.01903) method in `LoraModel` models.
### Motivation
Wise-ft interpolates between the weights $W_{base}$ of a base model and the weights $W_{ft}$ of a finetuned model using the following formula:
$$W_{wise} = (1-\alpha) * W_{base} + \alpha * W_{ft} \tag{1}$$
where $\alpha \in [0,1]$. This approach effectively balances the trade-off between the zero-shot capabilities of the base model ($\alpha=0$) and the task-specific performance of the finetuned model ($\alpha=1$). It is particulary well suited when there is a distribution shift between the training data used for fine-tuning, and the test data used during inference.
For LoRA, as $W_{ft} = W_{base} + W_{delta}$, we can rewrite the formula (1) as:
$$W_{wise} = W_{base} + \alpha * W_{delta} \tag{2}$$
Note that the formula above does not apply wise-ft correctly to DoRA, as for DoRA, $W_{ft} = m_{dora} * (W_{base} + W_{delta})$.
We successfully applied this method to win the 5 tracks of the [Amazon KDD Cup 2024](https://www.aicrowd.com/challenges/amazon-kdd-cup-2024-multi-task-online-shopping-challenge-for-llms/leaderboards), achieving performance improvements of up to 1.5%. In this competition, no training data was provided, hence there was a distribution shift between the training data built by the participants and the hidden test data used for evaluation.
### Your contribution
There are several ways to implement wise-ft for LoRA adapters:
1. (no code) Update the configuration of the adapters and rescale the parameter `lora_alpha` by `α * lora_alpha` (which is not an int anymore)
2. (no code) Rescale the adapter weights by $\sqrt{\alpha}$ if no bias is used, as $W_{delta} = W_A \cdot W_B$. We did that in KDD cup.
3. Add a new attribute to the `LoraLayer` layers to update the scaling parameter of the adapters
4. Add a new method in the `LoraModel` class that updates the `scaling` parameter of the LoRA adapters as follow:
```python
for module in self.model.modules():
if isinstance(module, LoraLayer):
module.scaling = dict((k, v * alpha) for k, v in module.scaling.items())
# might be better to redefined scaling = lora_alpha / r OR sqrt(r) * alpha ? How to access use_rslora ?
```
5. Add a new argument to the `merge` method of `LoraLayer` and to the `merge_and_unload` method of `LoraModel` to apply wise-ft when merging the adapters.
The advantage of methods 3. and 5. would be to properly apply wise-ft to DoRA models as well (similar to the formula (1)).
I believe wise-ft can be applied to many use cases where the user knows there might be a shift between the training and test distributions or a need to recover the zero-shot capabilities of the base model.
| 1medium
|
Title: pyjanitor version of .assign() or mutate()
Body: Currently there are a few different pyjanitor functions to deal with adding/modifying columns.
- add_column() allows you to add a column, but doesn't accept lambda functions like join_apply()
- transform_column() allows you to transform an existing column, but also doesn't accept lambda functions.
- join_apply() accepts lambda functions, but doesn't allow you to transform an existing column. It also has an API that is slightly different from all other column editing functions. join_apply() uses (func, column_name) as opposed to (column_name, func).
In general as I've been using pyjanitor I assumed there would be something along the lines of:
```python
df.mutate('a_plus_b', lambda x: x.a + x.b)
```
Is there a way to either add lambda functionality to add_column() and transform_column(), or add a function like mutate() that does this?
| 1medium
|
Title: Add library, resource file and variable file import related methods to listener version 3
Body: Listener version 3 was initially implemented in RF 3.0 (#1208). It didn't have `start/end_keyword` methods nor methods related to library, resource file and variable file imports because implementing them would have been too big task. It finally got keyword and control structure related methods in RF 7.0 (#3296), but it still lacks methods related to library, resource file and variable file imports.
Listener version 2 has methods `library_import`, `resource_import` and `variables_import`, and we probably should use same name with listener version 3 as well. With listener version 2 all these methods the name of the imported thing and a dictionary containing other information as arguments. With listener version 3 we want to pass the real model objects instead similarly as we do with `start/end` methods. Listeners should be able to modify at least resource files but preferably also libraries and variable files.
The good news is that implementing `start/end_keyword` methods required refactoring also library and resource file related model objects and they both ought to be in good enough shape to be used directly. With variable files we don't have such a good model object yet, but creating one shouldn't be too complicated. If it turns out to be hard, just adding methods for libraries and resource files and delaying adding methods for variable files is fine as well.
I consider this pretty high priority because after that listener version 3 can handle everything that listener version 2 can.
---
**UPDATE:** We won't create model objects representing variable files in RF 7.1, but the variable file related method will be added anyway. It will simply get a dictionary with same information as the listener v2 method, and the dictionary will be replaced with a proper object later when such an object is available. That change is covered by #5116.
| 1medium
|
Title: os_is_like in deb_setup.sh fails when multiple likes are specified
Body: In dev_setup.sh we use the [os_is_like](https://github.com/MycroftAI/mycroft-core/blob/dev/dev_setup.sh#L262) function to check the ID_LIKE field in `/etc/os-release`
The function currently only handle single entries like
`ID_LIKE=debian`
but in some cases this may list multiple os's. For example KDE Neon has a field like this
`ID_LIKE="ubuntu debian"`
The function should be updated to handle multiple distributions listed in the ID_LIKE field like above.
| 1medium
|
Title: [Feature request] Please add from_single_file support in SanaTransformer2DModel to support first Sana Apache licensed model
Body: **Is your feature request related to a problem? Please describe.**
We all know Sana model is very good but unfortunately the LICENSE is restrictive.
Recently a Sana finetuned model is released under Apache LICENSE. Unfortunately SanaTransformer2DModel does not support from_single_file to use it
**Describe the solution you'd like.**
```python
import torch
from diffusers import SanaPipeline
from diffusers import SanaTransformer2DModel
model_path = "Efficient-Large-Model/Sana_1600M_1024px_MultiLing"
dtype = torch.float16
transformer = SanaTransformer2DModel.from_single_file (
"Swarmeta-AI/Twig-v0-alpha/Twig-v0-alpha-1.6B-2048x-fp16.pth",
torch_dtype=dtype,
)
pipe = SanaPipeline.from_pretrained(
pretrained_model_name_or_path=model_path,
transformer=transformer,
torch_dtype=dtype,
use_safetensors=True,
)
pipe.to("cuda")
pipe.enable_model_cpu_offload()
pipe.enable_vae_slicing()
pipe.enable_vae_tiling()
inference_params = {
"prompt": "rose flower",
"negative_prompt": "",
"height": 1024,
"width": 1024,
"guidance_scale": 4.0,
"num_inference_steps": 20,
}
image = pipe(**inference_params).images[0]
image.save("sana.png")
```
```
(venv) C:\aiOWN\diffuser_webui>python sana_apache.py
Traceback (most recent call last):
File "C:\aiOWN\diffuser_webui\sana_apache.py", line 6, in <module>
transformer = SanaTransformer2DModel.from_single_file (
AttributeError: type object 'SanaTransformer2DModel' has no attribute 'from_single_file'
```
**Describe alternatives you've considered.**
No alternatives available as far as I know
**Additional context.**
N.A.
| 1medium
|
Title: gensim.similarities.Similarity merges results from shards incorrectly (LSI model)
Body: If "num_best" is used, `gensim.similarities.Similarity` runs the query against each of the shards (MatrixSimilarity objects) and then merges the results.
MatrixSimilarity uses `matutils.full2sparse_clipped()` to pick "num_best" results which sorts by the absolute value.
gensim.similarities.Similarity on the other hand, just uses `heapq.nlargest` (in `__getitem__`) to merge the results from each of the shards. So negative sims are either pushed down the list or cut off completely.
| 1medium
|
Title: Consistent enum formatting in 3.11+
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
https://github.com/python/cpython/issues/100458
https://blog.pecar.me/python-enum#there-be-dragons
reported here: https://discord.com/channels/933860922039099444/933860923117043718/1179537662235906048
## How to reproduce
<!--
Steps to reproduce the behavior:
1. Go to '...'
2. Change '....'
3. Run '....'
4. See error
-->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Prisma information
<!-- Your Prisma schema, Prisma Client Python queries, ...
Do not include your database credentials when sharing your Prisma schema! -->
```prisma
```
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: <!--[e.g. Mac OS, Windows, Debian, CentOS, ...]-->
- Database: <!--[PostgreSQL, MySQL, MariaDB or SQLite]-->
- Python version: <!--[Run `python -V` to see your Python version]-->
- Prisma version:
<!--[Run `prisma py version` to see your Prisma version and paste it between the ´´´]-->
```
```
| 1medium
|
Title: Enhance PCA Decomposition
Body: We should enhance the `PCADecomposition` visualizer to provide many of the features the `Manifold` visualizer provides, including things like:
- [ ] Color points by class with a legend (See #458)
- [ ] Color points by heatmap for continuous y and add a colorbar
- [ ] Add alpha parameter (see #475)
- [ ] Add random state to pass to PCA
- [ ] Allow user to pass in a PCA transformer/pipeline
- [ ] Update tests with better random data sets (more points; see manifold tests)
- [ ] Include explained variance/noise variance (or explained variance ratio) in chart
- [ ] Enhance biplots documentation
See also #455 as another enhancement that might not be related to this enhancement.
| 1medium
|
Title: [ENH] Include a featurization function for protein sequences
Body: # Brief Description
I would like to propose a function that featurizes protein sequences according to the following baseline featurizations:
- MW
- pKa
- T-features
- One-hot encoding
This proposed function would accept a column of strings, find the appropriate strings to featurize, and then return a featurization matrix (akin to how morgans are computed).
# Example API
```python
# Return a protein sequence featurization matrix using the “longest” sequence as the reference sequence.
import janitor.biology
df.sequence_features(sequence_column=‘prot_seq’, featurization_type=‘t’, sequence_length=“longest”)
# Featurize using MW, but only take most common sequence.
## By using “most_common_only”, any sequence not equal to the most common length is discarded.
df.sequence_features(sequence_column=‘prot_seq’, featurization_type=‘mw’, sequence_length=‘most_common_only’)
## By using “most_common_max”, any sequence greater than the most common length is discarded, while those less than the most common length are right-padded with the * symbol
df.sequence_features(sequence_column=“prot_seq”, featurization_type=“pka”, sequence_length=“most_common_max”)
```
| 1medium
|
Title: Make quick methods primetime
Body: After the visualizer audit we believe that the quick methods are ready to be made prime time.
Quick methods must:
1. Have a function signature identical to the Visualizer constructor with additional data for fit/score
2. Call `finalize()` and not `poof()`/`show()`
3. Return the fitted visualizer instance
4. Some visualizers must also insure that they call transform/fit_transform/score
For each visualizer found in the list below we must:
- [x] refactor the quick method to the new API
- [x] document the quick method
- [x] ensure there is an associated test or tests for the quick method
See #600 for more details on this issue
- [x] class_prediction_error
- [x] classification_report
- [x] confusion_matrix
- [x] precision_recall_curve
- [x] roc_auc
- [x] discrimination_threshold
- [x] alphas
- [x] cooks_distance
- [x] prediction_error
- [x] residuals_plot
- [x] kelbow_visualizer
- [x] intercluster_distance
- [x] silhouette_visualizer
- [x] balanced_binning_reference
- [x] class_balance
- [x] feature_correlation
- [x] cv_scores
- [x] learning_curve
- [x] validation_curve
- [ ] explained_variance_visualizer
- [x] feature_importances
- [x] rank1d
- [x] rank2d
- [x] rfecv
- [x] joint_plot
- [x] mainfold_embedding
- [x] pca_decomposition
- [x] parallel_coordinates
- [x] radviz
- [x] dispersion
- [x] freqdist
- [x] postag
- [x] tsne
- [x] umap
- [ ] gridsearch_color_plot
| 1medium
|
Title: Add "natural" sorting to pyjanitor
Body: # Brief Description
I would like to propose adding natural sorting to pyjanitor, as implemented in [natsort](https://github.com/SethMMorton/natsort).
To be clear, this would not be a reimplementation, but rather a wrapping of the functions available there.
# Example API
```python
df.natural_sort(column_names=['col1'], **natsort_kwargs)
```
# Skeleton Implementation
Still thinking about this, but it probably will need to involve indexing in the process.
| 1medium
|
Title: Support argument conversion with `Should Be Equal`
Body: to compare bytes returned from keyword it is necessary to create variable using Convert To Bytes and then compare using `Should be equal`
```robot
*** Keywords ***
Keyword returning bytes
${return} = Convert To Bytes \x1\x2
[Return] ${return}
*** Test Cases ***
Test
${bytes_result} = Keyword returning bytes
${expected_result} = Convert To Bytes \x1\x2\x3
Should be Equal ${bytes_result} ${expected_result}
```
it would be easier to have possibility to have direct way to compare it directly.
It could be done by adding `Should be Equal as Bytes` similar to `Should be Equal as Numbers` or as @pekkaklarck suggested in #5041 by adding `type` argument to `Should be Equal` -> `type=bytes`
| 1medium
|
Title: Add Q-Q plot to the yellowbrick.regressor.residuals class
Body: You already have a histogram feature for the `ResidulaPlot` method.
It will be immensely helpful to add a standard normality check method to the parent `yellowbrick.regressor.residuals` class like Q-Q plot.
Your functional interface is gearing up to be similar to statistical languages like **R** where you can throw the fitted model inside a function to generate more insight - mostly a visualization or a statistical score.
[Q-Q plot](https://en.wikipedia.org/wiki/Q%E2%80%93Q_plot) ability will be one of such basic statistical insights that can add value.
| 1medium
|
Title: [BUG] Coalesce returns a Series, instead of a dataframe
Body: # Brief Description
the [coalesce](https://pyjanitor.readthedocs.io/reference/janitor.functions/janitor.coalesce.html) function returns a Series, instead of a dataframe. Also, it may be more performant to use `bfill`, `ffill`, compared to the combination of `functools.reduce` and `combine_first`. Also, it would be nice to have a default value, in the event that there are still null values.
# System Information
- Operating system: /Linux/
- Python version (required): 3.9
# Minimally Reproducible Code
```python
df=pd.DataFrame({'s1':[np.nan,np.nan,6,9,9],'s2':[np.nan,8,7,9,9]})
s1 s2
0 NaN NaN
1 NaN 8.0
2 6.0 7.0
3 9.0 9.0
4 9.0 9.0
df.coalesce(['s1', 's2'],'col3') # returns a Series, instead of assigning to the dataframe.
col3
0 NaN
1 8.0
2 6.0
3 9.0
4 9.0
```
| 1medium
|
Title: Implement catchable WebsocketClosed
Body: See #2220
In v21.9, a new `WebsocketClosed` exception was added.
While you can to do the following:
```python
@app.websocker("/")
async def handler(request, ws):
try:
...
except asyncio.CancelledError:
print("connection closed")
```
We would like to add support for this pattern:
```python
@app.websocker("/")
async def handler(request, ws):
try:
...
except sanic.exceptions.WebsocketClosed:
print("connection closed")
```
| 1medium
|
Title: Visualizer for Missing Values Patterns
Body: It would be great to visualize missing data in a meaningful format that is easy to understand the patterns around it.
### Proposal/Issue
A basic implementation of the visualizer would include on the x axis, the labels / features and the y access would include a bar chart of the number of instances of a missing values.
A more advanced implementation of this would still have the x axis be the labels / features, but the range would be some type of order - either the index location or perhaps a datetime. Each missing value would be shown in a meaningful way potentially similar to this [visualization in this blog post](https://blogs.sas.com/content/iml/2017/11/29/visualize-patterns-missing-values.html):

| 1medium
|
Title: Provide a FastAPI admin panel
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Frameworks like Django provide an admin panel that users can customise to suit their needs and to easily add database records. This is a highly desirable feature.
Prisma already provides the [Prisma Studio](https://www.prisma.io/studio) application which while incredibly helpful and useful for browsing your data, it does not provide the customisability and utility that an admin panel can. It also cannot be easily exposed on your website which I would argue is one of the main benefits of an admin panel.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
While it would be better to provide a framework agnostic ASGI compatible app, this will result in increased implementation complexity and in my opinion it would be more beneficial to initially create an app that is only compatible with FastAPI.
We should provide a FastAPI app that can then be mounted into consumers own FastAPI application, e.g.
```py
from fastapi import FastAPI
from prisma.ext.fastapi.admin import admin_app
app = FastAPI()
app.mount("/admin", admin_app)
```
There are a lot of implementation details left to bikeshed but it could follow a similar pattern to https://github.com/fastapi-admin/fastapi-admin and make use of https://github.com/tabler/tabler.
Goals:
- Highly configurable
- Type safe
- Clean UI
To bikeshed:
- How to register and define resources
- How to handle authentication
- How to support custom dashboard homepage
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered. -->
We *could* try and integrate Prisma with the existing FastAPI admin panel but it was not designed to work with multiple ORMs and this would be a difficult task. It would be easier to implement this ourselves, this would also means that we'd be able to tailor it specifically for Prisma Python.
## Additional Context
[Laravel Nova](https://nova.laravel.com/) looks like a good solution to build ideas from.
https://twitter.com/taylorotwell/status/1508870009703079942?t=Mt9R_x2Jh0k2mSs01_kZ5w&s=19
| 1medium
|
Title: Enhance reporting errors and warnings in parsing model tokens
Body: The parsing model supports setting errors for individual tokens, but there are two problems with the current approach:
1. Errors (typically syntax errors) aren't separated from warnings (typically deprecations). This caused a problem when deprecating singular section headers (#4432) and the code reporting the warning as part of execution needed to know [what errors can occur in different contexts](https://github.com/robotframework/robotframework/blob/d007855fea4957031cb952c4157fa36dfb3b7228/src/robot/running/builder/transformers.py#L516) to handle the problem. With the planned deprecation of the pipe-separated format (#5203) this is likely even a bigger problem, because there's no single context where pipes can be used.
2. It isn't easy to recognize if the same error/warning occurs multiple times in same file. This requires comparing messages, but because they typically contain some variables parts, they cannot be compared directly. Searching for a certain sub-string is also problematic, because error messages can change.
My proposal for solving both of the above problems is adding new `errno` attribute to to the `Token` objects with the following semantics:
1. `errno` is an integer representing an error code.
2. Each error and warning has a different code.
3. Codes have constant names like `ERR_SINGULAR_HEADER_DEPRECATED` stored as attributes of the `Token` class.
4. Errors and warnings have different ranges so that it is easy to separate them. We could, for example, use negative values with warnings and positive with errors. Zero would mean no error/warning.
| 1medium
|
Title: [ENH] Method for adding functionality to GroupBy
Body: It would be nice to be able to add functionality to the Pandas `GroupBy` objects: `GroupBy`, `DataFrameGroupBy`, `SeriesGroupBy`. There's no convenient accessor interface to do this, but maybe there's a way to reliably monkeypatch them. This would allow us to create nifty aggregation / apply functions and avoid the `.groupby(...).apply()` route for tasks we may encounter routinely. It could also potentially open up opportunities to speed up such operations... `.groupby().apply()` can often be slow for large numbers of groups.
| 1medium
|
Title: Support `merge_small_files` for `md.read_parquet` etc
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
For reading data op like `md.read_parquet` and `md.read_csv`, if too many small files exist, a lot of chunks would be created, and the upcoming computation could be extremely slow. Thus I suggest to add a `merge_small_files` argument to these functions to enable auto optimization on merging small files.
**Describe the solution you'd like**
Sample a few input chunks, e.g. 10 chunks, get `k = 128M / {size of the largest chunk}`, if greater than 2, try to merge small chunks every k chunks.
| 1medium
|
Title: [ENH] Speed up pyjanitor operations with swifter integration?
Body: Found this interesting package: https://github.com/jmcarpenter2/swifter.
In the name of squeezing out a bit more speed when pyjanitor uses `apply()`-oriented operations, maybe this could be a way to implement this under-the-hood.
| 1medium
|
Title: Add tests for examples
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
As of the time of writing, the FastAPI example will raise warnings as FastAPI internally recreates model types, this would be annoying for users to disable.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add a new workflow to test examples (examples will also have to be rewritten to include tests).
| 1medium
|
Title: Add support for CockroachDB
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
We already have pretty good support for CockroachDB but there is one blind spot, the `push` operation for arrays is not supported.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
We need to disable generating this type.
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
https://github.com/prisma/prisma/issues/13892
| 1medium
|
Title: Refine handling and display of the `X-Schemathesis-TestCaseId` header
Body: The `X-Schemathesis-TestCaseId` header is currently displayed as part of the reproduction command. This inclusion is misleading because the ID in the generated command was not actually sent during testing. As a result, it can't be used for searching through logs based on this ID.
- Remove `X-Schemathesis-TestCaseId` from the CLI output for the reproduction command.
- Retain `X-Schemathesis-TestCaseId` only in VCR cassettes for traceability.
- Document how this header behaves and why it could be useful
- Modify the ID format to use an alphabet with more than just hexadecimal characters for better readability and shorter length.
| 1medium
|
Title: Gatherplot Feature Visualizer
Body: Gatherplots could be a useful feature analysis tool for Yellowbrick, as they enable users to more easily visualize patterns in large datasets by stacking overlapping points.
### Proposal
It would be interesting to implement a `GatherPlot` visualizer in the Yellowbrick API to address the problem of overplotting of data points when visualizing large datasets in a scatterplot. Instead of overlapping, data points that map to the same position are stacked together.
### Background
- [*Gatherplots: Generalized Scatterplots for Nominal Data*
by Deokgun Park, Sung-Hee Kim, Niklas Elmqvist](https://arxiv.org/abs/1708.08033)
- http://www.gatherplot.org/ by @intuinno
| 1medium
|
Title: [BUG] Optimization of filter-setitem failed
Body: <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Optimization of filter-setitem failed.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version
2. The version of Mars you use
3. Versions of crucial packages, such as numpy, scipy and pandas
4. Full stack of the error.
5. Minimized code to reproduce the error.
```
In [13]: df = md.DataFrame(mt.random.rand(10, 4, chunk_size=4), columns=list('ab
...: cd'))
In [14]: df['e'] = df['a'] * df['b'] - 2
In [15]: df['f'] = df['e'] * 2 - df['c']
In [16]: df.groupby('a').sum().execute()
Unexpected error happens in <function TaskProcessor.optimize at 0x7ff2c31a1280>
Traceback (most recent call last):
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/processor.py", line 57, in inner
return await func(processor, *args, **kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/processor.py", line 131, in optimize
return await asyncio.to_thread(self._preprocessor.optimize)
File "/Users/xuyeqin/Workspace/mars/mars/lib/aio/_threads.py", line 36, in to_thread
return await loop.run_in_executor(None, func_call)
File "/Users/xuyeqin/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py", line 57, in run
result = self.fn(*self.args, **self.kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/services/task/supervisor/preprocessor.py", line 127, in optimize
self.tileable_optimization_records = optimize_tileable_graph(
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/core.py", line 36, in optimize
return TileableOptimizer.optimize(tileable_graph)
File "/Users/xuyeqin/Workspace/mars/mars/core/mode.py", line 77, in _inner
return func(*args, **kwargs)
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/core.py", line 271, in optimize
rule.apply(op)
File "/Users/xuyeqin/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py", line 260, in apply
self._graph.add_edge(in_tileable, new_node)
File "mars/core/graph/core.pyx", line 93, in mars.core.graph.core.DirectedGraph.add_edge
File "mars/core/graph/core.pyx", line 100, in mars.core.graph.core.DirectedGraph._add_edge
KeyError: 'Node DataFrame(op=DataFrameSetitem) does not exist in the directed graph'
0%| | 0/100 [00:00<?, ?it/s]
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-16-aafe9450034d> in <module>
----> 1 df.groupby('a').sum().execute()
~/Workspace/mars/mars/core/entity/tileables.py in execute(self, session, **kw)
460
461 def execute(self, session=None, **kw):
--> 462 result = self.data.execute(session=session, **kw)
463 if isinstance(result, TILEABLE_TYPE):
464 return self
~/Workspace/mars/mars/core/entity/executable.py in execute(self, session, **kw)
96
97 session = _get_session(self, session)
---> 98 return execute(self, session=session, **kw)
99
100 def _check_session(self, session: SessionType, action: str):
~/Workspace/mars/mars/deploy/oscar/session.py in execute(tileable, session, wait, new_session_kwargs, show_progress, progress_update_interval, *tileables, **kwargs)
1771 session = get_default_or_create(**(new_session_kwargs or dict()))
1772 session = _ensure_sync(session)
-> 1773 return session.execute(
1774 tileable,
1775 *tileables,
~/Workspace/mars/mars/deploy/oscar/session.py in execute(self, tileable, show_progress, *tileables, **kwargs)
1571 fut = asyncio.run_coroutine_threadsafe(coro, self._loop)
1572 try:
-> 1573 execution_info: ExecutionInfo = fut.result(
1574 timeout=self._isolated_session.timeout
1575 )
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in result(self, timeout)
437 raise CancelledError()
438 elif self._state == FINISHED:
--> 439 return self.__get_result()
440 else:
441 raise TimeoutError()
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/_base.py in __get_result(self)
386 def __get_result(self):
387 if self._exception:
--> 388 raise self._exception
389 else:
390 return self._result
~/Workspace/mars/mars/deploy/oscar/session.py in _execute(session, wait, show_progress, progress_update_interval, cancelled, *tileables, **kwargs)
1722 while not cancelled.is_set():
1723 try:
-> 1724 await asyncio.wait_for(
1725 asyncio.shield(execution_info), progress_update_interval
1726 )
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in wait_for(fut, timeout, loop)
481
482 if fut.done():
--> 483 return fut.result()
484 else:
485 fut.remove_done_callback(cb)
~/miniconda3/envs/mars3.8/lib/python3.8/asyncio/tasks.py in _wrap_awaitable(awaitable)
682 that will later be wrapped in a Task by ensure_future().
683 """
--> 684 return (yield from awaitable.__await__())
685
686 _wrap_awaitable._is_coroutine = _is_coroutine
~/Workspace/mars/mars/deploy/oscar/session.py in wait()
100
101 async def wait():
--> 102 return await self._aio_task
103
104 self._future_local.future = fut = asyncio.run_coroutine_threadsafe(
~/Workspace/mars/mars/deploy/oscar/session.py in _run_in_background(self, tileables, task_id, progress, profiling)
901 )
902 if task_result.error:
--> 903 raise task_result.error.with_traceback(task_result.traceback)
904 if cancelled:
905 return
~/Workspace/mars/mars/services/task/supervisor/processor.py in inner(processor, *args, **kwargs)
55 async def inner(processor: "TaskProcessor", *args, **kwargs):
56 try:
---> 57 return await func(processor, *args, **kwargs)
58 except: # noqa: E722 # nosec # pylint: disable=bare-except # pragma: no cover
59 if log_when_error:
~/Workspace/mars/mars/services/task/supervisor/processor.py in optimize(self)
129 # optimization, run it in executor,
130 # since optimization may be a CPU intensive operation
--> 131 return await asyncio.to_thread(self._preprocessor.optimize)
132
133 @_record_error
~/Workspace/mars/mars/lib/aio/_threads.py in to_thread(func, *args, **kwargs)
34 ctx = contextvars.copy_context()
35 func_call = functools.partial(ctx.run, func, *args, **kwargs)
---> 36 return await loop.run_in_executor(None, func_call)
~/miniconda3/envs/mars3.8/lib/python3.8/concurrent/futures/thread.py in run(self)
55
56 try:
---> 57 result = self.fn(*self.args, **self.kwargs)
58 except BaseException as exc:
59 self.future.set_exception(exc)
~/Workspace/mars/mars/services/task/supervisor/preprocessor.py in optimize(self)
125 if self._config.optimize_tileable_graph:
126 # enable optimization
--> 127 self.tileable_optimization_records = optimize_tileable_graph(
128 self.tileable_graph
129 )
~/Workspace/mars/mars/optimization/logical/tileable/core.py in optimize(tileable_graph)
34
35 def optimize(tileable_graph: TileableGraph) -> OptimizationRecords:
---> 36 return TileableOptimizer.optimize(tileable_graph)
~/Workspace/mars/mars/core/mode.py in _inner(*args, **kwargs)
75 def _inner(*args, **kwargs):
76 with enter_mode(**mode_name_to_value):
---> 77 return func(*args, **kwargs)
78
79 else:
~/Workspace/mars/mars/optimization/logical/core.py in optimize(cls, graph)
269 if rule.match(op):
270 optimized = True
--> 271 rule.apply(op)
272 if optimized:
273 cls._replace_inputs(graph, records)
~/Workspace/mars/mars/optimization/logical/tileable/arithmetic_query.py in apply(self, op)
258
259 self._replace_node(node, new_node)
--> 260 self._graph.add_edge(in_tileable, new_node)
261 self._records.append_record(
262 OptimizationRecord(node, new_node, OptimizationRecordType.replace)
~/Workspace/mars/mars/core/graph/core.pyx in mars.core.graph.core.DirectedGraph.add_edge()
~/Workspace/mars/mars/core/graph/core.pyx in mars.core.graph.core.DirectedGraph._add_edge()
KeyError: 'Node DataFrame(op=DataFrameSetitem) does not exist in the directed graph'
```
| 1medium
|
Title: Newlines should not be scaped when using setting usetex=True
Body: The documentation mentions this behavior, but only as a passing note in the middle of the tutorial.
https://github.com/matplotlib/matplotlib/blob/f94fce68abe66f29e3045d0d4f20ccd0effa6767/galleries/users_explain/text/usetex.py#L87-L94
When passing slightly complex latex code to matplotlib, a user might be tempted to use multi-line strings, and the error that matplotlib produces is quite cryptic. For example,
```python
ax.annotate(text=r"""\begin{tabular}{cc}
a & b \\
c & d
\end{tabular}""", xy=(0.5,0.5), xycoords="figure fraction", xytext=(0,0))
```
produces
```
RuntimeError: latex was not able to process the following string: b'\\\\begin{tabular}{cc} '
```
I think it would be better to fix this behavior, but if not, it would be nice to give more visibility to it or include it in the [troubleshooting](https://github.com/matplotlib/matplotlib/blob/f94fce68abe66f29e3045d0d4f20ccd0effa6767/lib/matplotlib/text.py#L1282-L1297) at the end of the same page, at least.
| 1medium
|
Title: Could not connect to the Query Engine due to OSError [Errno 99]
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
A user has encountered this error:
```
OSError: [Errno 99] Cannot assign requested address
File "httpcore/_exceptions.py", line 10, in map_exceptions
yield
File "httpcore/backends/sync.py", line 94, in connect_tcp
sock = socket.create_connection(
File "socket.py", line 844, in create_connection
raise err
File "socket.py", line 832, in create_connection
sock.connect(sa)
```
## How to reproduce
<!--
Steps to reproduce the behavior:
1. Go to '...'
2. Change '....'
3. Run '....'
4. See error
-->
Not currently reproducible. Theorised cause is a race condition between us picking a port to use & the query engine actually using it.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
This should not crash.
| 1medium
|
Title: Let query engine determine free port
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
There is a race condition between when we choose a port to run the query engine on & another process using that port while the query engine is starting up.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Pass in `--port=0` and parse the log message.
We don't currently parse any logs from the query engine so getting that setup will be the most challenging part here.
| 1medium
|
Title: MostInformativeFeatures visualizer
Body: **Is your feature request related to a problem? Please describe.**
This feature is motivated by the discussion in #510. The problem is how to visualize feature importance for multiple classes and/or instances. This requires solving two problems: 1. selecting the "most informative features" and 2. producing an appropriate visualization.
**Describe the solution you'd like**
MIFV = MostInformativeFeatures
MIFV().predict(X) would give a viz for the features most responsible for the prediction
MIFV().poof()/fit(X) would show a viz for the features
For both cases, the proposed visual is a heat map where one axis is class labels or data and the other axis represents features.
Questions/Issues:
* The estimators would have to (mathematically) support such a notion of feature importance.
* Top 10 features doesn't make sense if all the features are similar in strength.
* Does it make sense to numerically compare feature strengths over multiple classes?
| 1medium
|
Title: Scalar relational fields are not included in `create_many` input
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
The following query should be supported.
```py
await client.profile.create_many(
data=[
{'user_id': 'a', 'description': 'Foo'},
{'user_id': 'b', 'description': 'Foo 2'},
],
)
```
## How to reproduce
<!--
Steps to reproduce the behavior:
1. Go to '...'
2. Change '....'
3. Run '....'
4. See error
-->
Run pyright on the above query
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
No errors
## Prisma information
<!-- Your Prisma schema, Prisma Client Python queries, ...
Do not include your database credentials when sharing your Prisma schema! -->
Internal test schema
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: <!--[e.g. Mac OS, Windows, Debian, CentOS, ...]--> Mac OS
- Database: <!--[PostgreSQL, MySQL, MariaDB or SQLite]--> PostgreSQL
- Python version: <!--[Run `python -V` to see your Python version]--> 3.9.9
| 1medium
|
Title: Validation Curve
Body: Create validation curves to finish implementing the two types of validation curves in scikit-learn.
### Proposal/Issue
Scikit-learn provides two methods for diagnosing a model's sensitivity to bias vs variance as [validation curves](http://scikit-learn.org/stable/modules/learning_curve.html):
- [`learning_curve`](http://scikit-learn.org/stable/auto_examples/model_selection/plot_learning_curve.html)
- [`validation_curve`](http://scikit-learn.org/stable/auto_examples/model_selection/plot_validation_curve.html#sphx-glr-auto-examples-model-selection-plot-validation-curve-py)
We've already implemented the learning curve in #275 and is being moved to model selection in #377 -- to finish this up we should add the validation curve plot.
### Code Snippet
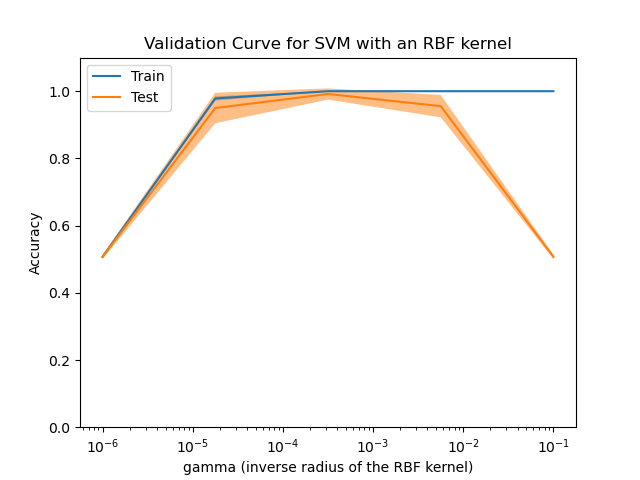
| 1medium
|
Title: Investigate Bolt to speed up Gensim and save memory
Body: I found https://github.com/dblalock/bolt: "*Bolt is an algorithm for compressing vectors of real-valued data and running mathematical operations directly on the compressed representations.*"
My understanding is that this saves a tremendous (10-200x) amount of space AND time, in case a static (fixed) dense matrix is being repeatedly multiplied by other vectors / matrices:
```python
# these are approximately equal (though the latter are shifted and scaled)
enc = bolt.Encoder(reduction='dot').fit(X)
[np.dot(X, q) for q in queries]
[enc.transform(q) for q in queries]
```
The cost of this fabulous speedup & space saving is (some) loss of precision – unclear how much.
This seems perfect for pretty much all trained Gensim models: in particular, KeyedVectors, LsiModel, and the Similarity classes.
**Task**: Investigate Bolt, see how difficult it would be to integrate, how stable, how robust. And how much will Bolt really save Gensim users in practice, in terms of faster query speed and (especially) smaller model memory.
| 1medium
|
Title: Add type information to `TestSuite` structure
Body: The `TestSuite` structure would benefit from more type hints that would allow IDEs to provide better completion support. That would help with writing code using the visitor API and listener API v3, especially if #4569 and #4568 are implemented.
For most parts adding type info ought to be pretty easy and at least those parts should preferably be done already in RF 6.1. It is possible that `TestSuite` code using our `@setter` is too dynamic to editors to understand and just adding type info to isn't enough. If that's the case, we need to consider changing such code so that it uses the standard `@property.setter` instead. That may be too big a task for RF 6.1, though.
| 1medium
|
Title: Publish cleanup script as a separate package to help resolve mismatched rendered files
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Sometimes (especially when upgrading) a user's installation can become corrupted somehow, it is difficult for them to fix this themselves. Uninstalling and reinstalling Prisma does not always seem to fix this issue forcing users to download and run the cleanup script that we use internally.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Add a new package that is installed by default so that it is easy to reset the current Prisma installation to its pre-generation state.
```
python -m prisma_cleanup
```
| 1medium
|
Title: Introduce type annotations
Body: Following @mpenkov's effort for smart_open in https://github.com/RaRe-Technologies/smart_open/pull/545, we could also introduce type annotations into Gensim.
The benefits are mild (nothing much gained), so this would be mostly for the documentation and CI.
Ticket only relevant once we drop py3.6, because without [PEP 585](https://www.python.org/dev/peps/pep-0585/) the annotations are too ugly and code-obfuscating, and PEP585 is py3.7+ only.
| 1medium
|
Title: Implements `{DataFrame,Series}.{combine,combine_first}`
Body: Mars lacks pandas API `combine` and `combine_first` to combine two source frames / series into one single result.
| 1medium
|
Title: Adapt to deprecation of `Int64Index` in pandas 1.4
Body: In pandas 1.4, `Index` is to replace `Int64Index`, `UInt64Index` and `FloatIndex`. The latter will be dropped in pandas 2.0. It is needed for Mars to adapt to this API change.
| 1medium
|
Title: `Json` fields cannot be used with type safe raw queries
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
You cannot pass a model that uses a `Json` field to `client.query_raw` as Pydantic expects the JSON data to be a string, however this gets deserialised at the database level.
## How to reproduce
<!--
Steps to reproduce the behavior:
1. Go to '...'
2. Change '....'
3. Run '....'
4. See error
-->
TODO
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
TODO
## Prisma information
<!-- Your Prisma schema, Prisma Client Python queries, ...
Do not include your database credentials when sharing your Prisma schema! -->
```prisma
```
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: <!--[e.g. Mac OS, Windows, Debian, CentOS, ...]-->
- Database: <!--[PostgreSQL, MySQL, MariaDB or SQLite]-->
- Python version: <!--[Run `python -V` to see your Python version]-->
- Prisma version:
<!--[Run `prisma py version` to see your Prisma version and paste it between the ´´´]-->
```
```
| 1medium
|
Title: Create with required relation is incorrectly typed
Body: <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional logging output.
-->
## Bug description
<!-- A clear and concise description of what the bug is. -->
The following code will pass type checks but will raise an error at runtime as user is a required relation
```py
Profile.prisma().create({'bio': 'My bio', 'country': 'Scotland'})
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Type checkers should report an error
## Prisma information
<!-- Your Prisma schema, Prisma Client Python queries, ...
Do not include your database credentials when sharing your Prisma schema! -->
Internal schema
## Environment & setup
<!-- In which environment does the problem occur -->
- OS: <!--[e.g. Mac OS, Windows, Debian, CentOS, ...]--> Mac OS
- Database: <!--[PostgreSQL, MySQL, MariaDB or SQLite]--> SQLite
- Python version: <!--[Run `python -V` to see your Python version]--> 3.9.9
| 1medium
|
Title: Export the config used to generate the client
Body: ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Due to how our data structures will change significantly given different config options, e.g. `recursive_type_depth = -1`. Anyone writing a library that makes use of Prisma Client Python cannot provide easy to understand errors if they rely on an option like recursive types.
## Suggested solution
<!-- A clear and concise description of what you want to happen. -->
Export the config class used to generate the client, e.g.
```py
CONFIG = Config(
interface='sync',
recursive_type_depth=5
engine_type=EngineType.binary,
partial_type_generator=None,
)
```
| 1medium
|
Title: Process: Test and keyword timeouts do not work when running processes on Windows
Body: I've noticed in scenarios where the [test case timeout](https://robotframework.org/robotframework/latest/RobotFrameworkUserGuide.html#timeouts) is employed that Windows hosts are not able to continue past the Process related keywords. It looks like this was alluded to in [2056#issuecomment-118502807](https://github.com/robotframework/robotframework/issues/2056#issuecomment-118502807).
#2061 touches upon the implications of timeouts on resources and [Terminate Process](https://robotframework.org/robotframework/latest/libraries/Process.html#Terminate%20Process) does note some behavioral distinctions for Windows but neither address if the Process keywords should be stopped, as seen on a Linux host, or can continue to block as seen on a Windows host.
I'll note that the comment above provides a sensible workaround by leveraging a variable for the process timeouts, just trying to qualify if this behavior is a bug, by design, or notable enough to document.
A reproducible case is outline below noting the behavioral difference in the `output.xml` snippets.
```
*** Settings ***
Library OperatingSystem
Library Process
*** Variables ***
${EXT} = ${{(platform.system() == "Windows" and ".exe") or ""}}
*** Test Cases ***
Build
VAR ${source} SEPARATOR=\n
... \#include <unistd.h>
... int main(void){ sleep(30); }
Remove File ./test${EXT}
${result} = Run Process
... gcc
... -O2
... -xc
... -
... -o
... test${EXT}
... stdin=${source}
Should Be Equal As Integers ${result.rc} 0
Validate
[Timeout] 10
File Should Exist ./test${EXT}
${result} = Run Process
... ./test${EXT}
... stdout=DEVNULL
... stderr=DEVNULL
... on_timeout=terminate
```
### Windows
`uv tool run --from "robotframework==7.2.2" --python "cpython==3.12.9" cmd /c "python -m platform && python -VV && robot --outputdir win Test.robot"`
```
Windows-11-10.0.22631-SP0
Python 3.12.9 (main, Feb 12 2025, 14:52:31) [MSC v.1942 64 bit (AMD64)]
==============================================================================
Test
==============================================================================
Build | PASS |
------------------------------------------------------------------------------
Validate | FAIL |
Test timeout 10 seconds exceeded.
------------------------------------------------------------------------------
Test | FAIL |
2 tests, 1 passed, 1 failed
==============================================================================
Output: D:\robot\win\output.xml
Log: D:\robot\win\log.html
Report: D:\robot\win\report.html
```
`win\output.xml`
```
<doc>Runs a process and waits for it to complete.</doc>
<status status="FAIL" start="2025-02-19T16:16:57.359796" elapsed="30.066544">Test timeout 10 seconds exceeded.</status>
```
### Linux
`wsl -d Ubuntu-22.04 -e bash -lc "uv tool run --from 'robotframework==7.2.2' --python 'cpython==3.12.9' bash -c 'python -m platform && python -VV && robot --outputdir ubu Test.robot'"`
```
Linux-5.15.167.4-microsoft-standard-WSL2-x86_64-with-glibc2.35
Python 3.12.9 (main, Feb 12 2025, 14:50:50) [Clang 19.1.6 ]
==============================================================================
Test
==============================================================================
Build | PASS |
------------------------------------------------------------------------------
Validate | FAIL |
Test timeout 10 seconds exceeded.
------------------------------------------------------------------------------
Test | FAIL |
2 tests, 1 passed, 1 failed
==============================================================================
Output: /mnt/d/robot/ubu/output.xml
Log: /mnt/d/robot/ubu/log.html
Report: /mnt/d/robot/ubu/report.html
```
`ubu/output.xml`
```
<doc>Runs a process and waits for it to complete.</doc>
<status status="FAIL" start="2025-02-19T16:18:25.446909" elapsed="9.995855">Test timeout 10 seconds exceeded.</status>
```
| 1medium
|
Title: Finish up CVScores visualizer
Body: CVScores is a new visualizer under yellowbrick/model_selection. Here are a couple things left to do and small enhancements:
- [x] Add documentation ([done](http://www.scikit-yb.org/en/develop/api/model_selection/cv.html))
- [x] Add test cases
- [x] Add a legend that labels the average cvscore dotted line with the numeric value of `self.cv_scores_mean_`
- [x] Adjust the ylim so that `CVScores` plots will be more easily comparable across different models.
| 1medium
|
Title: [DOC] Add info: how to sync forks
Body: # Brief Description of Fix
Currently, the docs do not provide instructions on how to sync up pyjanitor forks. This should be added as it is difficult for newcomers to know how to keep things updated.
# Relevant Context
- [This page should be edited](https://pyjanitor.readthedocs.io/contributing.html)
| 1medium
|
Title: Headers from Exceptions
Body: ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
Headers set on Exception objects not carried through on all renderers
### Code snippet
```py
raise Unauthorized(
"Auth required.",
headers={"foo": "bar"},
)
```
### Expected Behavior
Response should have:
```
Foo: bar
```
### How do you run Sanic?
Sanic CLI
### Operating System
all
### Sanic Version
23.3
### Additional context
_No response_
| 1medium
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.