
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
jlippold/tweakCompatible | 340425466 | Title: `Cercube for YouTube` working on iOS 11.3.1
Question:
username_0: ```
{
"packageId": "me.alfhaily.cercube",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "me.alfhaily.cercube",
"deviceId": "iPhone6,2",
"url": "http://cydia.saurik.com/package/me.alfhaily.cercube/",
"iOSVersion": "11.3.1",
"packageVersionIndexed": true,
"packageName": "Cercube for YouTube",
"category": "Tweaks",
"repository": "BigBoss",
"name": "Cercube for YouTube",
"packageIndexed": true,
"packageStatusExplaination": "This package version has been marked as Working based on feedback from users in the community. The current positive rating is 100% with 6 working reports.",
"id": "me.alfhaily.cercube",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.0.7",
"shortDescription": "Download YouTube videos and more!",
"latest": "4.2.2.5",
"author": "<NAME>",
"packageStatus": "Working"
},
"base64": "<KEY>",
"chosenStatus": "working",
"notes": ""
}
``` |
Pokecube-Development/Pokecube-Issues-and-Wiki | 585634858 | Title: Sound issue
Question:
username_0: Issue Description:
Clipping sound
What happens:
When pokemon are attacking/being attacked at a distance a tiny short clipped sound is played (this may be due to lag or may be due distance from the battle I have not fully discovered why this occurs.)
What you expected to happen:
Clean sound
Steps to reproduce:
1. Within visual range of a pokemon battle but not close enough to hear the sounds
2. May also require artificial latency to reproduce (sorry its not quite clear to whats causing it)
3.
____
Affected Versions (Do *not* use "latest"): Replace with a list of all mods you have in.
- Pokecube AIO: 2.0.5
- Minecraft: 1.15.2
- Forge: 31.1.27<issue_closed>
Status: Issue closed |
WormBase/db-migration | 227653631 | Title: Document manual steps at the end of the migration
Question:
username_0: * Missing from documentation (after step 8):
9. `azanium backup-db`
10. Transfer backed-up database to AWS S3
10.1 Setting `$FROM_URI` and `$TO_URI`:
`FROM_URI="file:///wormbase/datomic-db-backups/$LATEST_DATE/$WS_RELEASE"`
`TO_URI="datomic:ddb://us-east-1/$WS_RELEASE/wormbase"`
10.2 Ensuring use of correct version of datomic-pro
10.3 `cd $DATOMIC_PRO_HOME && ./bin/datomic backup-db "$FROM_URI" "$TO_URI"`<issue_closed>
Status: Issue closed |
litmuschaos/litmus | 550392727 | Title: (feat): Using Gitlab remote templates
Question:
username_0: This Issue is for the feature request in Gitlab pipeline of litmus-e2e:
**_What it is about?_**
- Adding the remote template feature for different experiments running in the Gitlab pipeline.
**_Why and how?_**
- Using the Gitlab templates for every experiment in the pipeline is a good practice in both aspects coding and understanding as by using the templates the logics would be written separately and called in the jobs.
Status: Issue closed
Answers:
username_0: PR to fix this issue - https://github.com/mayadata-io/gitlab-remote-templates/pull/1 |
PaulSonOfLars/gotgbot | 613928009 | Title: Get chat users list
Question:
username_0: Hi! How to get chat users list? It is needed for saving id and username of users in database.
Answers:
username_1: Bots can't get the list of users in a chat. This is a bot API limitation, I can't do anything about it. You need to store the data as they speak.
Status: Issue closed
username_0: Okay, thank you for the answer! |
sebgroup/react-components | 500754803 | Title: CRUD-pattern (new pattern)
Question:
username_0: **Pattern (sep 2019)**
A pattern that describes a uniform way for the user to add both soft and hard properties. This two-step pattern is especially useful in pages where the user has to manually update values.
A white card triggers a slide-out. Use is the same behaviour for all devices.
**Details**
See the measurements (etc) in Design Library:
https://designlibrary.sebgroup.com/patterns/crud/#usage
Design library identifier: component-crud

Any questions or feedback? /Ulrika, <EMAIL>
Answers:
username_1: @username_0 ... I think we need more details about this component. We're not sure how this component should behave. The only screenshots you have provided are mobile only. We don't know the behaviour when it's rendered in a desktop browser.
username_2: I have developed this component separately in my project. Please let me know if there is a need for it and I will add it to this repo. |
eslint/eslint | 234457928 | Title: ESLint requires trailing comma for function parameters.
Question:
username_0: **Tell us about your environment**
* **ESLint Version:** v3.19.0
* **Node Version:** v6.10.0
* **npm Version:** 5.0.3
**What parser (default, Babel-ESLint, etc.) are you using?**
default
**Please show your full configuration:**
```
{
"extends": "eslint-config-airbnb-base",
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
},
"globals": {
"ga": true,
},
"env": {
"browser": true,
"node": true,
"es6": true,
"jquery": true,
},
}
```
**What did you do? Please include the actual source code causing the issue.**
```js
function extract(a, b, c) {
console.log(c);
}
extract(
'style-loader',
[
'css?sourceMap',
'postcss',
'sass?sourceMap',
],
{
publicPath: '../',
} //👈 ESLint error: Missing trailing comma on the last function parameter.
);
```
**What did you expect to happen?**
ESLint should not check trailing comma for function parameter.
**What actually happened? Please include the actual, raw output from ESLint.**
➜ demo git:(dev) ✗ eslint eslint-test.js
/Users/tonni/Projects/demo/eslint-test.js
2:3 warning Unexpected console statement no-console
14:4 error Missing trailing comma comma-dangle
✖ 2 problems (1 error, 1 warning)
Answers:
username_1: Thanks for the report, but this is working as intended -- you are extending the `airbnb-base` configuration, which requires trailing commas for function arguments.
Also see: https://github.com/eslint/eslint/issues/8513, https://github.com/eslint/eslint/issues/7851, https://github.com/eslint/eslint/issues/7749, https://github.com/eslint/eslint/issues/7571.
username_0: 👍 Thanks for your excellent explanation, closing it. @username_1
Status: Issue closed
|
cout970/Magneticraft-API-and-Issues | 120082360 | Title: Pumpjack issues
Question:
username_0: I think the one which causes server TPS to nosedive when it depletes all oil source blocks has been fixed so I'll leave that one out (although I did just type it in here lol)
We are seeing 2 issues on our server which need addressing but we do run cauldron so not sure if one of them is related.
1) - pickaxing pumpjacks doesn't always drop the pumpjack in the world, sometimes they just disappear. Some of the guys on our server have mentioned they are getting them to drop if they pick the block which has the oil outlets on it. I tried with a vanilla iron pick always on that block and have lost 7 of them now. Not sure if this is related to Cauldron.
2) - large surface oil pools, if you get a large pool the pumpjack is not draining all the surface oil , needs to look further out.
Answers:
username_1: Fixed drop problems (probably). And oil searching needs a lot of work,
username_2: Found the same issue with 0.6.0-beta2. Pumpjack does not drop at all. kinda frustrating when playing a pack like Cthulhu Awakens, where the recipe has been made more expensive.
username_3: Has this been fixed? Players from a Civilization server are reporting this pumps keeps disappearing when broken.
username_4: Are you all using 0.6.1-final? it should be fixed in it. if it is fixed for you please let me know so I can close this :)
Status: Issue closed
username_0: I've not had an issue with 0.6.1 final, these are all fixed |
adobe-research/node-theseus | 171702560 | Title: Question: how hard would it be to interface theseus with another editor?
Question:
username_0: I used to work a lot with brackets, and I still think it's the most comfortable editor for HTML and CSS, but there's better node.js support elsewhere. I was wondering if there's a fundamental reason why theseus is only supporting brackets, other than it being enough.
Answers:
username_1: It's pretty easy to integrate node-theseus with other editors. I tried to [document the node-theseus protocol](http://adobe-research.github.io/fondue/) completely enough that someone could do just that.
The node-theseus protocol is basically a simple JSON-based RPC layer over WebSockets. Most of the work is done on the fondue side (because that's where the data is), so the data you get via the protocol is processed enough to be usable straight away.
If the editor you're targeting is also written in JavaScript, you should have no problem. I wrote [a simple example with d3](https://github.com/username_1/node-theseus-d3) that you might use as a base. I also wrote [a little profiler](https://github.com/username_1/fondue-profile) and [the start of a browser-based debugger](https://github.com/username_1/theseus-browser), but those last two projects have probably bit rot. I think they were based on experimental modifications of fondue, but the basic infrastructure will be the same.
It only took me a few hours to write a C++ client for node-theseus recently (using [nlohmann/json](https://github.com/nlohmann/json) and [zaphoyd/websocketpp](https://github.com/zaphoyd/websocketpp)), so supporting additional langauges should be no problem.
Let me know if I can help! The documentation is a direct result of other people asking for assistance integrating with their projects. :)
Status: Issue closed
|
GoogleChrome/lighthouse | 332108303 | Title: DevTools Error: FAILED_DOCUMENT_REQUEST
Question:
username_0: **Initial URL**: http://localhost:8000/
**Chrome Version**: 66.0.3359.181
**Error Message**: FAILED_DOCUMENT_REQUEST
**Stack Trace**:
```
LHError: FAILED_DOCUMENT_REQUEST
at Function.getPageLoadError (chrome-devtools://devtools/remote/serve_file/@<KEY>/audits2_worker/audits2_worker_module.js:917:27)
at pass.then._ (chrome-devtools://devtools/remote/serve_file/@<KEY>/audits2_worker/audits2_worker_module.js:922:270)
``` |
ikedaosushi/tech-news | 610044807 | Title: Jetson Nanoで動く深層強化学習を使ったラジコン向け自動運転ソフトウェアの紹介 - masato-ka's diary
Question:
username_0: Jetson Nanoで動く深層強化学習を使ったラジコン向け自動運転ソフトウェアの紹介 - masato-ka's diary<br>
<br>
https://ift.tt/3aL45AE |
intersystems-community/Global-Masters | 820034004 | Title: Badges for Votes - changes
Question:
username_0: **Posts Votes:**
dc_v50_postvotes
dc_v100_postvotes
dc_v500_postvotes
dc_v1000_postvotes
правила подсчета:
Awarded when your posts (articles, questions, discussions, announcements) gathered 50 / 100 / 500 / 1000 votes in sum on DC.
Posts must not be deleted; they must be published.
Posts from the Developer Community Feedback group are not counted.
**Comments Votes:**
dc_a50_answervotes
dc_a100_answervotes
dc_a500_answervotes
dc_a1000_answervotes
правила подсчета:
Awarded when your comments (любые комменты) gather 50 / 100 / 500 / 1000 votes in sum on DC.
Deleted answers are not counted
Answers at the Developer Community Feedback group are not counted.
@MakarovS96<issue_closed>
Status: Issue closed |
samvera-labs/avalon-bundle | 327762157 | Title: Create a rubocop cop to ensure necessary files have license headers
Question:
username_0: A rubocop cop would allow us to easily check that each new file gets a license header as part of the normal build process. It also gives us a standard place to record which files should and shouldn't have license headers via rubocop's config file.
I did a prototype here: https://github.com/samvera-labs/avalon-bundle/commit/a8784600ca0ef34d4c6010acdd2198cde83bf8fb This prototype would need to be altered to work properly and not be so brittle but proved the approach to be viable. It might also be best to more this to the `license_header` gem.
### Description
Create a gem similar to Bixby because we have multiple repositories we need to run this over
- [ ] the cop should detect when the license is not present (and in the correct format)
- [ ] the cop should autocorrect the license when appriorate (rubocop -a), so that way in the future we just update the gem and the `bundle install && bundle exec rubocop` to update the license
- Put this new gem in the gemfile
Related to #29.
Answers:
username_1: This can wait an be re-evaluated later. This is a before release type thing (formal release).
Status: Issue closed
|
MaybeShewill-CV/CRNN_Tensorflow | 488422393 | Title: 怎么提高预测速度
Question:
username_0: 将训练好的模型封装了一个服务,当sequence_length为70时,一张图片速度要2秒,请问应该怎样优化速度?
Answers:
username_1: @username_0 如果是gpu的话 第一次使用的时候需要warm up 可以多测试一些数据后再统计效率:)
Status: Issue closed
username_2: 您好!我也遇到了一样的问题,我把tf.nn.ctc_beam_search_decoder中的参数beam_width调整成了1,处理一张图片的时间就在0.5s以内了,您也可以试一下!
但是我没有深究这个参数的作用,我测试了几张图片,对结果貌似是没有影响的.....期待您的反馈 |
NervJS/taro | 877149243 | Title: Taro.uploadFile 设置 header 不生效
Question:
username_0: <!-- 请不要删除自动生成的 Issue 标签 -->
<!-- 请不要删除自动生成的 Issue 标签 -->
### 相关平台
H5
**浏览器版本: Chrome 90**
**使用框架: React**
### 复现步骤
```
const uploadTask = Taro.uploadFile({
url: `/openapi/${query}`,
filePath: files[0],
name: 'file',
formData: {
user: 'test',
},
header: { token: '123', abc: 'abc' },
success: function(res) {
var data = res.data
//do something
return data
},
})
uploadTask.progress(res => {
console.log('上传进度', res.progress)
console.log('已经上传的数据长度', res.totalBytesSent)
console.log('预期需要上传的数据总长度', res.totalBytesExpectedToSend)
})
uploadTask.abort() // 取消上传任务
```
### 期望结果
headers 显示 token
### 实际结果
```
Accept: */*
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6,ko;q=0.5,ja;q=0.4
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 1354
Content-Type: multipart/form-data; boundary=----WebKitFormBoundarypnWFAxyBMAiBz5zp
DNT: 1
Host: 10.0.2.135:10086
Origin: http://10.0.2.135:10086
Pragma: no-cache
Referer: http://10.0.2.135:10086/
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1
```
### 环境信息
```
👽 Taro v3.1.4
Taro CLI 3.1.4 environment info:
System:
[Truncated]
Shell: 5.8 - /bin/zsh
Binaries:
Node: 12.16.3 - ~/.nvm/versions/node/v12.16.3/bin/node
Yarn: 1.22.4 - ~/.nvm/versions/node/v12.16.3/bin/yarn
npm: 7.6.3 - ~/.nvm/versions/node/v12.16.3/bin/npm
npmPackages:
@tarojs/cli: 3.1.4 => 3.1.4
@tarojs/components: 3.1.4 => 3.1.4
@tarojs/mini-runner: 3.1.4 => 3.1.4
@tarojs/react: 3.1.4 => 3.1.4
@tarojs/runtime: 3.1.4 => 3.1.4
@tarojs/taro: 3.1.4 => 3.1.4
@tarojs/webpack-runner: 3.1.4 => 3.1.4
babel-preset-taro: 3.1.4 => 3.1.4
eslint-config-taro: 3.1.4 => 3.1.4
react: ^17.0.0 => 17.0.2
taro-ui: ^3.0.0-alpha.10 => 3.0.0-alpha.10
```
<!-- generated by taro-issues. 请勿修改或删除此行注释 --><!--labels=T-h5,V-3,F-react--><issue_closed>
Status: Issue closed |
cfpb/hmda-frontend | 545929122 | Title: Parser isn't reading LEIs with spaces
Question:
username_0: Short description explaining the high-level reason for the new issue.
Parser isn't reading LEIs with spaces as incorrect. When there is a space in the LEI in the LAR line, the parser doesn't note this as a formatting error. But it notes it in the S/V edits. It should be a parser error. This does however work with ULIs.
## Current behavior

## Expected behavior

## Steps to replicate behavior (include URLs)
1. File to test: [Bank1_is not NA (lowercase).txt](https://github.com/cfpb/hmda-frontend/files/4027697/Bank1_is.not.NA.lowercase.txt)
## Screenshots
Answers:
username_1: The [FFVT](https://ffiec.cfpb.gov/tools/file-format-verification) also considers the format of the provided test file correct, so this may be a validation that needs to be added on the backend.
The [FFVT](https://ffiec.cfpb.gov/tools/file-format-verification) does not identify a format error when there is a space in the ULI, so it could be using different parsing logic.
@username_2 @BarakStout @PatrickHSI could you please check if the backend is currently looking for spaces in the LEI and ULI fields of LAR rows during file format verification of a filing submission?
Observations:
- A space in a LAR LEI uploads without error and does not trigger a parse error but shows up as a syntactical edit.
- A space in a LAR ULI fails during upload with the following status
```json
{
"code": -1,
"message":"An error occurred while submitting the data.",
"description":"Please re-upload your file."
}
```
username_2: This appears to be a backend issue. Ticket with PR here: https://github.com/cfpb/hmda-platform/pull/3408
username_3: Closing since this is tracked in cfpb/hmda-platform#3408
Status: Issue closed
|
refined-bitbucket/refined-bitbucket | 709952429 | Title: Plugin not working in pull request screen
Question:
username_0: I've tried it in a commit diff and it works well. However inside a pull request screen, there is no syntax highlighting.
Answers:
username_1: The syntax highlighting is only implemented in the old pull request experience, not the new one.
Status: Issue closed
|
julianlam/nodebb-plugin-session-sharing | 264499909 | Title: Can you make register override ?
Question:
username_0: I see that you have login override. Can you make register override ? It will be a great option
Answers:
username_1: Hi there, you can do this by forcing all users to go to the login override. Simply disable user registration
Status: Issue closed
username_1: Let me know if this doesn't work for you...
username_2: I am having a similar issue with this with regard to admin users.
I have "Revaluate" set. With normal (non-admin) users, it works great. When I log out from the main site and shared session cookie is deleted, the user is likewise logged out of NodeBB. However, when I do the same with an admin user, I can confirm that the shared session cookie is deleted, but the person is NOT logged out of NodeBB. The only way I have found to log out such a person is by logging in someone else.
I am using NodeBB v1.10.2.
username_1: Hi @username_2 -- this is by design, we didn't want the admin user to be logged out because occasionally they may run into situations where they accidentally change some session-sharing option, and then they get logged out and can't log back in to fix it :grimacing:
Did you need to log out admins as well?
username_1: Bypass located here:
https://github.com/username_1/nodebb-plugin-session-sharing/blob/ae5bd15cbe3cb5a68dce34e87a8fecd94a5c4008/library.js#L495-L498
username_2: Yes I need to be able to log out admins as well.
Here is the problematic scenario:
- Admin is on a shared computer
- Admin logs in via my main site login page (not NodeBB)
- Admin navigates to the forum, and is automatically logged in
- Admin navigates back to the main site and logs out there, thinking he/she is logged out of the entire site, including forum
- Someone else navigates to the forum on this computer and discovers they are logged in as this admin.
username_1: Makes sense. I will see about adding an option to toggle this bypass on and off via the ACP.
username_1: Tracked in #67
username_2: Much appreciated.
username_3: Hey is someone else still facing same issue ?
Revalidatie is enabled.
Registration is disabled.
Login page is set to the other app's login url.
Shared Cookie is deleted through the other website.
(even I don't see the cookie (named token) in the inspector on both website after it has been deleted)
The nodebb is still logged in ...
username_1: Admin account stays logged in, just in case.
username_3: Forgot to mention ... not logged in as admin ...
username_3: <img width="1439" alt="Screenshot 2021-07-30 at 6 35 21 PM" src="https://user-images.githubusercontent.com/23694746/127661081-ccdadad0-8147-42ef-8dfe-1f6714a441b8.png">
As you acn see I have already deleted the token cookie but still it is logged in based on the express.sid cookie ...
Revalidate is turned on but seems it is not taking that cookie into account after it is logged in..
username_3: Yes I am certain re-validate is checked in admin panel ...
/debug/session generated the token for test user ... even my other app generated token were letting me login ..
but deleting or expiring the cookie was not logging it out ... It kept logged in even after deleting / expiring the cookie ..
(I even tried deleting the shared cookie from the inspector manually .. it still kept logged in) |
a14n/dart-google-maps | 458932683 | Title: StreetViewPanorama.controls array can't be indexed using ControlPosition enum
Question:
username_0: This code leads to the following error:
google.maps.GMap map;
...
var topRightControls = map.streetView.controls[ControlPosition.TOP_RIGHT];
Error:
The argument type 'ControlPosition' can't be assigned to the parameter type 'int'. #argument_type_not_assignable
I believe lib/src/core/street_view/street_view_panorama.dart should replace lines 57-66 with simply:
Controls controls;
Status: Issue closed
Answers:
username_1: Thanks for the report.
Fix available in version 3.3.4. |
dhall-lang/dhall-haskell | 474709097 | Title: `//` for recursive records?
Question:
username_0: For a [“recursive record” as defined in the Wiki](https://github.com/dhall-lang/dhall-lang/wiki/How-to-translate-recursive-code-to-Dhall#recursive-record), is it possible to implement the equivalent of the // operator/function?
(I asked this in the #dhall Slack channel where @MonoidMusician and @sellout offered some high-level ideas but I think I need further help)
Answers:
username_0: Wrong repo, sorry about that. Opened as https://github.com/dhall-lang/dhall-lang/issues/681
Status: Issue closed
|
societe-generale/github-crawler | 361732107 | Title: new FileContentParser : number of XML elements
Question:
username_0: ## Summary
It would be interesting to get a new parser that counts the number of elements under a certain xpath.
## Type of Issue
<!-- This issue is a -->
<!-- put an `x` the boxe that apply. -->
It is a :
- [ ] bug
- [x] request
- [ ] question regarding the documentation
## Motivation
It would be helpful for example to know quickly the number of modules in a multi-module Maven project
## Expected Behavior
provide the Xpath under which to count nested elements. Count only the XML elements. return "not found" if xpath doesn't exist
## Steps to Reproduce (for bugs)
<!--- Please provide a link to a live example or steps to -->
<!-- reproduice this behavior -->
## Your Environment
<!--- If you're reporting a bug, include as many relevant details about the environment you experienced the bug in -->
* Version used: 1.0.8
* OS and version:
* Version of libs used:<issue_closed>
Status: Issue closed |
dbeaver/dbeaver | 624339424 | Title: Allow to see PostgreSQL REFCURSOR results in editor
Question:
username_0: **Is your feature request related to a problem? Please describe.**
I always wanted to see the results of a cursor returned from a function in PostgreSQL instead of just "<unnamed portal 1>"
**Describe the solution you'd like**
I would like to be able to double click "<unnamed portal 1>" in the query results and that a popup window would open with the cursor data (all columns an values).
**Describe alternatives you've considered**
Fetching the cursor manually in an anonymous block and printing its' values requires writing custom code.
**Additional context**
Answers:
username_1: Yeah, we had to fix it a long time ago.
In fact we already have ref cursors support for Oracle and PostgreSQL.
It works only in manual commit mode. Currently you can see cursor contents by <kbd>shift+enter</kbd> (it will be opened in popup dialog).
But we definitely need to show it in panel viewer + have ability to reuse cursor.
Like this:

Status: Issue closed
username_2: verified |
connell-class/revassess | 634924902 | Title: Tier 3 Test 1 asserts single result but returns List
Question:
username_0: **Describe the bug**
Tier 3 Test 1 asserts single result but returns List
java.lang.AssertionError: expected:<10> but was:<org.hibernate.query.internal.NativeQueryImpl@67ab1c47>
**To Reproduce**
Steps to reproduce the behavior:
1. Go to RevassessTier3\src\test\java\com\tier3\answers\Answer1Tests.java
2. Run as Junit Test
**Possible solution**
Replace
RevassessTier3\src\test\java\com\tier3\answers\Answer1Tests.java
Line 25
assertEquals(10,sess.createNativeQuery("select * from abs(-10)", Integer.class));
with
assertEquals(10,sess.createNativeQuery("select * from abs(-10)").getSingleResult());
Answers:
username_1: fixed
Status: Issue closed
|
serverless/serverless | 207710950 | Title: Error: spawn java ENOENT
Question:
username_0: <!--
1. If you have a question and not a bug/feature request please ask it at http://forum.serverless.com
2. Please check if an issue already exists so there are no duplicates
3. Check out and follow our Guidelines: https://github.com/serverless/serverless/blob/master/CONTRIBUTING.md
4. Fill out the whole template so we have a good overview on the issue
5. Do not remove any section of the template. If something is not applicable leave it empty but leave it in the Issue
6. Please follow the template, otherwise we'll have to ask you to update it
-->
# This is a (Bug Report)
## Description
Everytime I try to start serverless using the below command I get the same error. My JDK is updated to 1.8 and JAVA_HOME is set to that. I can't figure out how to fix this issue?
For bug reports:
* What went wrong?
Trying to run this command: sls dynamodb start --stage local -P 8001
* What did you expect should have happened?
local dynamodb to start running
* What was the config you used?
* What stacktrace or error message from your provider did you see?
events.js:160
throw er; // Unhandled 'error' event
^
Error: spawn java ENOENT
at exports._errnoException (util.js:1022:11)
at Process.ChildProcess._handle.onexit (internal/child_process.js:193:32)
at onErrorNT (internal/child_process.js:359:16)
at _combinedTickCallback (internal/process/next_tick.js:74:11)
at process._tickDomainCallback (internal/process/next_tick.js:122:9)
For feature proposals:
* What is the use case that should be solved. The more detail you describe this in the easier it is to understand for us.
* If there is additional config how would it look
Similar or dependent issues:
* #12345
## Additional Data
* ***Serverless Framework Version you're using***:
1.7
* ***Operating System***:
macOS Sierra
* ***Stack Trace***:
Error: spawn java ENOENT
at exports._errnoException (util.js:1022:11)
at Process.ChildProcess._handle.onexit (internal/child_process.js:193:32)
at onErrorNT (internal/child_process.js:359:16)
at _combinedTickCallback (internal/process/next_tick.js:74:11)
at process._tickDomainCallback (internal/process/next_tick.js:122:9)
* ***Provider Error messages***:
events.js:160
throw er; // Unhandled 'error' event
^
Answers:
username_1: Have you tried running `sls dynamodb install`? This downloads the DynamoDb libs you need.
Status: Issue closed
username_2: `sls dynamodb install` solved this issue for me. Thanks!
username_3: I have this same issue,
i'm on a mac, my java_home path is set and i've run `sls dynamodb install`
still getting this error
username_4: Same here in a docker environment (circleCI)
username_5: I fixed this to install java in alpine image:
apk --update add openjdk7-jre
But still can't start the dynamodb-local and serverless-offline in container.
@username_4
Did you try to start local dynamodb and serverless offline in container successfully?
username_4: Hey @username_5 ,
Yes, i've been able to do it successfully => https://github.com/username_4/circleci-node8-sls-jre
You can use this image in your circleCI build, or you can also get it from hub.docker, use it as a base image, and install your app with it.
I've been able to start local dynamodb + serverless offline with it.
Ping me if you need more information.
username_5: Thanks, @username_4 👍
I used your image and successfully start local dynamodb and serverless offline in the container. Furtherly, I add features to build and push the new `image:tag` with latest serverless release.
```
$ docker run --rm -it -v $(pwd):/opt/app -v ~/.aws:/root/.aws -v ~/.ssh:/root/.ssh svls/serverless:1.24.1 bash
bash-4.3# sls plugin install -n serverless-dynamodb-local
bash-4.3# sls plugin install -n serverless-offline
bash-4.3# sls dynamodb install
bash-4.3# sls offline start -r us-east-2 --noTimeout --corsDisallowCredentials false &
bash-4.3# npm run test
```
https://github.com/serverless-lambda/docker-serverless
username_4: @username_5 for running test locally with sls offline, I use:
```bash
bash# sls offline start --exec "npm run test"
```
Which method do you think it's better?
username_6: Got the same error, and fixed it: I forgot to install Java ;)
Fetch JDK from http://www.oracle.com/technetwork/java/javase/downloads/jdk10-downloads-4416644.html , install it and don't forget to restart your cmd on Windows.
username_7: java version "10.0.2" 2018-07-17
Java(TM) SE Runtime Environment 18.3 (build 10.0.2+13)
Java HotSpot(TM) 64-Bit Server VM 18.3 (build 10.0.2+13, mixed mode)
```
On ubuntu I have OpenJDK v1.8.0 installed:
```
$ java -version
openjdk version "1.8.0_181"
OpenJDK Runtime Environment (build 1.8.0_181-8u181-b13-0ubuntu0.16.04.1-b13)
OpenJDK 64-Bit Server VM (build 25.181-b13, mixed mode
```
username_8: `sudo apt install default-jdk` helped me for ubuntu. (user `sudo apt install default-jre` for mint) |
gcivil-nyu-org/spring2020-cs-gy-9223-class | 587922901 | Title: User can add new sensor
Question:
username_0: **User story**
As a user I can easily add a new sensor without having to manually write code so I can focus on other things.
**Acceptance criteria**
-Sensor is added and can be viewed
- Sensor can contain multiple fields with differnt data types
-Adding sensor does not cause any problems
**Definition of Done**
User can easily add sensor<issue_closed>
Status: Issue closed |
notgiven688/webminerpool | 360547903 | Title: About the Cryptonight V2
Question:
username_0: I'v tested today and i confirm that is slower then the V1
Is there anyone who has tried it before?
Answers:
username_1: Did you check the cv_v2 branch? Did you compile it yourself? The current cn_v2 branch is slower for v0 and v1 because of some compiler troubles which I already fixed - will update the branch soon. The cn_v2 version is slower because of the additional SQRT and 64bit DIVISION operations. Not much we can do about that - I think.
username_0: Yes compiled and tested on killallasics, i get almost 15% slower :(
username_1: It is expected that cnv2 runs slower, also with other miner programs. The problem is that especially code without cpu intrinsics suffer.
username_1: @username_0
Probably we can cast here to double and do a floating point division which should be faster.
https://github.com/username_1/webminerpool/blob/66f1379dbabd3a44483704e7ba3fa1deaf587a35/hash_cn/webassembly/cryptonight.c#L98
I will test it later.
username_0: @username_1
I really hope it will work ,that will really help
and thanks for your effort
username_1: `const uint64_t aa = (uint64_t)((double)dividend / (double)divisor); `
Indeed speeds up the calculations around 1-2% but fails some corner cases..
Status: Issue closed
|
tadashi-aikawa/jumeaux | 314383423 | Title: final/notify add-on
Question:
username_0: - [ ] Create this
- [ ] Make [final/slack] deprecated
- [ ] Create issue to be [final/slack] deprecated
[final/slack]: https://username_0.github.io/jumeaux/ja/addons/final/#slack
Answers:
username_0: Support since 0.65.0
Status: Issue closed
|
dart-lang/build | 269355859 | Title: LibraryBuilder: generate `y.dart` from input `x.dart`
Question:
username_0: I'm trying to create `test/src/foo_nullable.dart` given `test/src/foo.dart`
But I seem to only be able to generate `test/src/foo.nullable.dart`
Intentional? I'd love to have a bit more flexibility here...
`#ThingsIShouldKnow`
Related to https://github.com/dart-lang/build/issues/552
Answers:
username_1: Isn't this pkg/source_gen?
username_0: I hit this just using Builders – so I don't *think* so...
username_2: No, this is not possible today. We intentionally limited the files you can output to only changing extensions on the primary input.
We want to use only configuration driven output possibilities so that we can find outputs in Skylark without writing custom code for each builder.
What is the use case for being able to output to a different file basename?
username_0: I have some file `x.dart` and I'd like to treat it like a template to generate 3 other flavors.
`x_nullable.dart`, `x_nullable_custom_classes.dart`, `x_custom_classes.dart`
I can do all of this with extensions, obviously – just starts feeling a bit weird.
...more curious than anything
username_2: This would be possible today. We say "extension" but the way it's implemented is "postfix" so you could configure a builder to have `buildExtensions' as `{ '.dart': [ '_nullable.dart', '_custom_classes.dart']}`
Similarly if you had a use case you could go from `_test.dart` to `_harness.dart` or similar.
Status: Issue closed
username_2: This would be possible today. We say "extension" but the way it's implemented is "postfix" so you could configure a builder to have `buildExtensions' as `{ '.dart': [ '_nullable.dart', '_custom_classes.dart']}`
Similarly if you had a use case you could go from `_test.dart` to `_harness.dart` or similar.
username_2: I'm trying to create `test/src/foo_nullable.dart` given `test/src/foo.dart`
But I seem to only be able to generate `test/src/foo.nullable.dart`
Intentional? I'd love to have a bit more flexibility here...
`#ThingsIShouldKnow`
Related to https://github.com/dart-lang/build/issues/552
username_3: We have also had requests to generate files in a separate directory. This matters less when you are setting `writeToCache: true`, which will become more common soon, but I think it is still a valid use case we will want to eventually support, and we should be able to do it in a generic fashion that works across build systems without custom code per builder.
username_2: Interesting, the `example/` use case is pretty compelling, I'm having a hard time coming up with a configuration we could use that would work for that without being overly specific to that use case.
The types of directory moves I can imagine are:
1. Move from one top-level directory to another (`lib/something/foo.dart` to `example/something/foo.example.dart`)
2. Move to a sibling directory (`lib/something/foo.dart` to `lib/different/foo.dart`)
3. Move to a sub directory (`lib/something/foo.dart` to `lib/something/sub/foo.dart`)
Describing each of these without only configuration metadata could be tough.
username_2: I think we would most likely want the `example/` use case to be solved with `example/$example$` like our other [magic placeholder](https://github.com/dart-lang/build/pull/746) files. I don't think we want to go down a path of allowing an arbitrary number of assets to be mirrored in a separate directory tree.
We can reopen if we find a compelling use case, but for now I'm going to close this as not planned and we can file a separate issue for `$example$` if and when we need it.
Status: Issue closed
|
venveo/serverless-sharp | 595413185 | Title: Custom alias / domain + domain certificate for Cloudfront Distribution
Question:
username_0: Is this not yet supported at the moment?
If not, I'm interested in seeing if I can spend some time to add this option to the stack. Would be nice to have beautiful domains for image CDNs I was thinking ;-)
Answers:
username_0: https://github.com/venveo/serverless-sharp/pull/48
username_1: Thanks again! Added for next release!
Status: Issue closed
username_0: @username_1 np. :-) Please note that when custom domain is used, the region will have to be us-east-1 because that is the only way certificates can be made automatically (cloudfront certificates will have to be us-east-1 in order to be binded).
username_1: @username_0 Good catch! I'm working on refactoring the docs, so I'll be sure to include a note of that. |
zocteam/website | 442805444 | Title: Governance promo video
Question:
username_0: Would like to integrate this video into the website somewhere... https://youtu.be/HTMAkn7R6mE
Answers:
username_1: video is unavailable

username_0: Can alternatively be grabbed from here: https://mega.nz/#!2xkEhaxA!NmNRxug-bGvQXxfvo2WjtptBMqU0ZafcnyBQpg0z4Z8
Status: Issue closed
|
Esri/military-tools-geoprocessing-toolbox | 332068550 | Title: NumberFeatures tool does not label feature correctly when new feature class is created
Question:
username_0: _From @kgonzago on June 7, 2018 19:44_
6/13: Tasks remaining
- [ ] Add tool to MT toolbox
- [ ] Test from MT build
- [ ] Doc GRG toolset topic - add Number Features to table
- [ ] MT What's new (added the tool to GRG toolset)
When creating a new feature layer (feature class) during the Number Feature tool process, the tool:
1. Creates a new feature class in the project GDB
2. Adds it as a feature layer to the TOC
3. Applies the appropriate layer file for symbology
But, the features are not labeled at all. Somehow the layer file is preventing it from labeling.
## Expected Behavior
Features should be labeled in the newly created feature layer
## Current Behavior
Run tool on:

Get result:

Features are not labeled.
## Possible Solution
Update LYRX file to provide labels as well as symbology.
## Steps to Reproduce (for bugs)
1. Open the Clearing Operations solution
2. Open the Number features tool
3. Choose to number the NewLocations feature layer
4. Specify a new output feature class
5. Run the tool.
6. The new layer is added to the map. It has the correct symbology, but the features are not labeled.
7. Turn on labels - for some reason, even when you turn on labels they don't display (though sometimes they do. @kgonzago and @ACueva saw it not working, then I (BB) tried again on my own ArcGIS Pro 2.1.0 machine and I could manually apply labels and have them display).
## Context
<!--- How has this issue affected you? What are you trying to accomplish? -->
<!--- Providing context helps us come up with a solution that is most useful in the real world -->
## Your Environment
<!--- Include as many relevant details about the environment you experienced the bug in -->
* Version used:
* Environment name and version (e.g. Chrome 39, node.js 5.4):
* Operating System and version (desktop or mobile):
* Link to your project:
Win10, ArcGIS Pro 2.1.
Win8, ArcGIS Pro 2.1.0 (BB)
_Copied from original issue: Esri/solutions-geoprocessing-toolbox#677_
Answers:
username_0: _From @username_1 on June 12, 2018 18:22_
I ran this on Pro 2.2.12776(Beta2) and setting the symbology/labeling on the output layer using a lyrx file seems to be now working correctly for setting the labels. So **this issue is dependent on Pro 2.2 final**:

There is just a small code change needed ([here](https://github.com/Esri/solutions-geoprocessing-toolbox/blob/dev/clearing_operations/scripts/NumberFeaturesTool.py#L93)) to check whether in Pro or ArcMap because a Pro .lyrx file is needed to make the GP output labeling work (a 10.X .lyr file doesn't work for this labeling scenario)
Moving/migrating NumberFeatures tool opened with issue: https://github.com/Esri/military-tools-geoprocessing-toolbox/issues/339
FYI @username_2 @username_3 @username_4 @ACueva
username_0: _From @username_3 on June 12, 2018 18:26_
@username_1 - cool! So, an if product == ArcMap use lyr, if product == Pro use lyrx check here is all it would need?
username_0: _From @username_1 on June 12, 2018 18:40_
@username_3 - that is correct. There is an [existing method/utility](https://github.com/Esri/solutions-geoprocessing-toolbox/blob/dev/clearing_operations/scripts/Utilities.py#L41) for this - though its behavior is not consistent if run from arcpy outside of the Pro/ArcMap - since it returns: 1. Pro 2. ArcMap 3. Other (standalone arcpy but could be Pro or ArcMap python) - so we may need to add a method
username_1: Addressed/added/migrated from [previous clearing ops toolbox](https://github.com/Esri/solutions-geoprocessing-toolbox/tree/dev/clearing_operations) in PR #342
This should work as well as it did in the [previous clearing ops repo/toolbox](https://github.com/Esri/solutions-geoprocessing-toolbox/tree/dev/clearing_operations) - though more rigorous testing of this [may reveal new issues - ex.](https://github.com/Esri/military-tools-geoprocessing-toolbox/issues/339#issuecomment-396974424)
username_2: Symbology is missing from output in ArcMap and ArcGIS Pro
username_1: @username_2 - can you provide some additional info/repro steps or step me through
The issue might be the one mentioned here: https://github.com/Esri/military-tools-geoprocessing-toolbox/issues/339#issuecomment-396974424 that the exact field names **"Number" and "Purpose"** must exist in the input+output feature class because the layer files are set to use those fields.
Also Pro should be version 2.2.12776(Beta2) or later.
Example: ArcMap no symbols or labels with missing fields:

username_1: I found another way to repro @username_2 's [reported issue above](https://github.com/Esri/military-tools-geoprocessing-toolbox/issues/341#issuecomment-397469457) - if you don't supply an "Output Numbered Features" parameter - the symbology will also not be applied.
This has to do with the peculiar design of this tool that allows the input parameter to **sometimes** be used as the output parameter if no ouput parameter is supplied. The ouput is empty in this case so GP does not apply the symbology.
I think we have had similar problems with this tool design before https://github.com/Esri/solutions-geoprocessing-toolbox/issues/607 - https://github.com/Esri/solutions-geoprocessing-toolbox/issues/607#issuecomment-331572977

username_1: Just to summarize when labeling should work
Setting Labeling / Layer Symbology on the output only works currently with the NumberFeatures tool when:
1. An output parameter "Output Numbered Features" parameter is set
2. The field names "Number" and "Purpose" exist in the input
3. If in Pro, using 2.2.12776(Beta2) or later
These limitations were present in the previous ClearingOps toolset/template - but we are likely finding them as a result of just doing more testing *outside of* the template
username_2: With the information above I am going to verify the statements of @username_1
username_2: based on all the testing I have done I do not think that labels from gp tools work in ArcGIS Pro 2.2. I have tested this in

I would like to move this out of the sprint if someone else cannot get the labels to work correctly. @username_4 and @ACueva.
username_3: @username_2 - I think we can include logic to test whether or not the Purpose field is present and populated and choose which LYRX file to apply.
username_4: On Pro 2.2 final the tool is not labeling for me, either upon immediate output or by trying to turn labeling off then back on. I confirmed the "Number" field is present in the input and a "Purpose" field is present in the input. I also tried making sure the purpose field had non-null text values in it. Also I made sure to use an output named differently than the input. I confirmed that the output which is not labeling does have values in the number field and the label class expression is {Number]. In the label expression I tried to switch between all four languages in the label expression as well, also no luck. I attempted to switch and label by some other field, such as "Purpose" which I also calculated values, and still no labels at all.
username_2: @username_3 will try and use the old layer file that only populates simple symbology (yellow boxes with labels). If that does not work we will move on and not tackle this issue during this release.
username_3: I think I've got it working correctly now.
https://github.com/Esri/military-tools-geoprocessing-toolbox/pull/347
Had to add a feature class to the featuresetsWebMerc.gdb and point the symbology LYRX file to it in order for Pro to apply the symbology.
@username_2 - please test.
Status: Issue closed
|
planetarypy/pvl | 90711204 | Title: Write docs
Question:
username_0: Please add a simple example of opening a file containing a label and then extracting some sample information from that label for both a PDS3 image (Pancam?) and the sample `pattern.cub`.
As you have done elsewhere, write a short example in the readme, but more complete examples in the actual Sphinx docs.
Once those easy tasks are done then try doing the following things:
* Writing out a label using `encode`
* Modifying a label
* Adding an entry
* changing an entry
* Writing out the modified label
* Creating a label from scratch
Answers:
username_0: Note that some of the additional tasks above may be difficult, for example, creating a label from scratch. It might be possible but likely not easy, we will probably need to make some helper methods to improve this task and possibly others (like modifying label). The point of asking you to try it now is to expose and document those rough spots.
username_0: FYI there is an example of using `pvl.load` here: https://github.com/planetarypy/planetaryimage/blob/master/planetaryimage/image.py Note that `pvl.load` is renamed to `load_label` in this example just to be explicit about whats being loaded. This is not necessary for documentation purposes.
There are also simpler examples here:
https://github.com/planetarypy/pvl/blob/master/tests/test_decoder.py
Note there is both:
* `load` - which loads from file
* `loads` - which parses a label from a string.
The `load` form is probably going to be the most common.
username_1: Do you want the label from scratch to be based on an image without a label or from random information?
username_0: I would start by trying to recreate a very simple but valid label. Like `tiny1.lbl` in https://github.com/planetarypy/pvl/tree/master/tests/data/pds3 and then try making increasingly complex labels.
Status: Issue closed
username_0: Great start! |
MicrosoftDocs/feedback | 420820849 | Title: no serach result for short term like "GC"
Question:
username_0: **Describe the bug**
docs.microsoft.com/en-us/dotnet/api/ shows no result for short term like "GC"
**To Reproduce**
Steps to reproduce the behavior:
search **GC** on https://docs.microsoft.com/en-us/dotnet/api/
https://docs.microsoft.com/en-us/dotnet/api/?term=GC
**Expected behavior**
**Desktop (please complete the following information):**
- OS: win 10
- Browser: chrome
Answers:
username_1: @username_2 do you have a minimum of 3 letters for the API browser search?
username_2: Yes. You do need to use at least 3 letters but if you are looking for items in a two letter class name you can also type a . after GC and get results that way.
Status: Issue closed
username_0: @username_2
Thank you for your workaround.
I think lifting 'at least 3 letters` restriction for some well-known terms like GC/IO would provide better experience.
But I'm OK with your workaround.
So closing. |
fiveisprime/iron-cache | 116988858 | Title: No function for client.get()
Question:
username_0: I get the following while trying to get from a cache. Using IronWorker fine but notice this isn't an official repository. Is it no longer supported?
```
var cache = new ironcache.Client()
```
```
TypeError: cache.get is not a function
at File.store (/worker/lib/File.js:112:13)
at throw (native)
at onRejected (/worker/node_modules/co/index.js:81:24)
at /worker/node_modules/superagent/lib/node/index.js:1036:11
at Request.callback (/worker/node_modules/superagent/lib/node/index.js:797:3)
at IncomingMessage.<anonymous> (/worker/node_modules/superagent/lib/node/index.js:990:12)
at emitNone (events.js:72:20)
at IncomingMessage.emit (events.js:166:7)
at endReadableNT (_stream_readable.js:903:12)
at doNTCallback2 (node.js:439:9)
```
Status: Issue closed
Answers:
username_0: I get the following while trying to get from a cache. Using IronWorker fine but notice this isn't an official repository. Is it no longer supported?
```
var cache = new ironcache.Client()
```
```
TypeError: cache.get is not a function
at File.store (/worker/lib/File.js:112:13)
at throw (native)
at onRejected (/worker/node_modules/co/index.js:81:24)
at /worker/node_modules/superagent/lib/node/index.js:1036:11
at Request.callback (/worker/node_modules/superagent/lib/node/index.js:797:3)
at IncomingMessage.<anonymous> (/worker/node_modules/superagent/lib/node/index.js:990:12)
at emitNone (events.js:72:20)
at IncomingMessage.emit (events.js:166:7)
at endReadableNT (_stream_readable.js:903:12)
at doNTCallback2 (node.js:439:9)
```
Status: Issue closed
|
acceptbitcoincash/acceptbitcoincash | 328781180 | Title: Other porn site accepting BCH! (hush-hush.com)
Question:
username_0: Hey! I'm searching porn sites accepting BCH and I found this one
---------------
- name: Hush-Hush
url: http://www.hush-hush.com/
img: http://www.hush-hush.com/images/logo-trans.png
twitter: HHgalleries
facebook:
region:
country:
city:
bch: yes
btc: yes
othercrypto: yes
doc:
```<issue_closed>
Status: Issue closed |
dotnet/interactive | 561508234 | Title: PowerShell Notebook - Can't import Pester
Question:
username_0: #### Describe the bug
I tried to run one of my Azure Data Studio PowerShell notebooks into a PowerShell Notebook using .NET Jupyter. It worked fine until I tried to import my dbachecks module which uses Pester. I then created a new Notebook and tried to just run some Pester
The error I receive is
````
Describe: The 'Describe' command was found in the module 'Pester', but the module could not be loaded. For more information, run 'Import-Module Pester'.
````
When I try to just import Pester by itself using any of my available versions even 3.4.0 I get
````
Get-Command: C:\Users\mrrob\Documents\PowerShell\Modules\pester\4.9.0\Pester.psm1
Line |
94 | $script:SafeCommands['Get-CimInstance'] = Get-Command -Name Get-CimInstance -Module CimCmdlets @safeCommandLookupParameters
| ^ The term 'Get-CimInstance' is not recognized as the name of a
| cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included,
| verify that the path is correct and try again.
Import-Module: The module to process 'Pester.psm1', listed in field 'ModuleToProcess/RootModule' of module manifest 'C:\Users\mrrob\Documents\PowerShell\Modules\pester\4.9.0\pester.psd1' was not processed because no valid module was found in any module directory.
````
output of Get-Module Pester -ListAvailable
````
Directory: C:\Users\mrrob\Documents\PowerShell\Modules
ModuleType Version PreRelease Name PSEdition ExportedCommands
---------- ------- ---------- ---- --------- ----------------
Script 4.9.0 Pester Desk {Describe, Context, It, Should…}
Script 4.8.1 Pester Desk {Describe, Context, It, Should…}
Directory: C:\Program Files\WindowsPowerShell\Modules
ModuleType Version PreRelease Name PSEdition ExportedCommands
---------- ------- ---------- ---- --------- ----------------
Script 4.8.1 Pester Desk {Describe, Context, It, Should…}
Script 3.4.0 Pester Desk {Describe, Context, It, Should…}
````
#### Did this error occur while using `dotnet interactive`?
- [ X] .NET Jupyter Notebook
#### Screenshots
If applicable, add screenshots to help explain your problem.
#### Please complete the following:
- OS
- [X ] Windows 10
- [ ] macOS
- [ ] Linux (Please specify distro)
- [ ] iOS
- [ ] Android
- Browser
- [X ] Chrome
- [ X] Edge
- [ ] Safari
- Frontend
- [ ] Jupyter notebook
- [X ] Jupyter lab
- [ ] nteract
Answers:
username_0: {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# This is a new Notebook\n",
"\n",
"That has been written in .NET Interactive\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"<pre></pre>\r\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"<pre>Name Value</pre>\r\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"<pre>---- -----</pre>\r\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"<pre>PSVersion 7.0.0-rc.1</pre>\r\n"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"text/html": [
"<pre>PSEdition Core</pre>\r\n"
]
},
"metadata": {},
"output_type": "display_data"
[Truncated]
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": ".NET (PowerShell)",
"language": "PowerShell",
"name": ".net-powershell"
},
"language_info": {
"file_extension": ".ps1",
"mimetype": "text/x-powershell",
"name": "PowerShell",
"pygments_lexer": "powershell",
"version": "7.0"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
username_0: The notebook can be seen
https://gist.github.com/username_0/545b9c353c609ff5bb1bff4b6ccb57cd
username_1: This seems to be an issue with splatting in PowerShell when also providing named parameters:

username_1: A bit of a twist in how this is being done in the kernel, is likely going to be the issue:

username_2: @username_1 I am seeing, I see it in your screenshot as well, do you have any fix for that?
```powershell
Import-Module: The module to process 'Pester.psm1', listed in field 'ModuleToProcess/RootModule' of module manifest '...\Documents\PowerShell\Modules\pester\4.9.0\pester.psd1' was not processed because no valid module was found in any module directory.
```
username_1: I go by this, but then checking the Exported Commands and it is there:

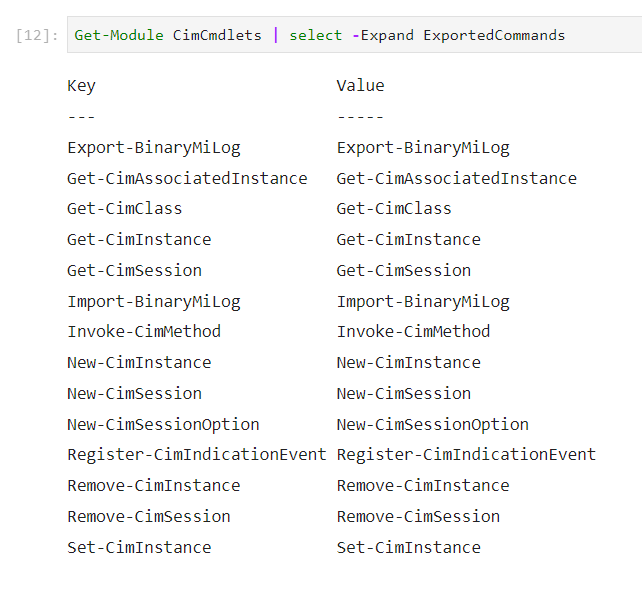
username_1: ...but even changing the psm1 to this line of the module it still fails, so I think the implicit remoting is the issue:
```
$script:SafeCommands['Get-CimInstance'] = Get-Command -Name Get-CimInstance -Module CimCmdlets -CommandType Cmdlet -ErrorAction Stop -All
```
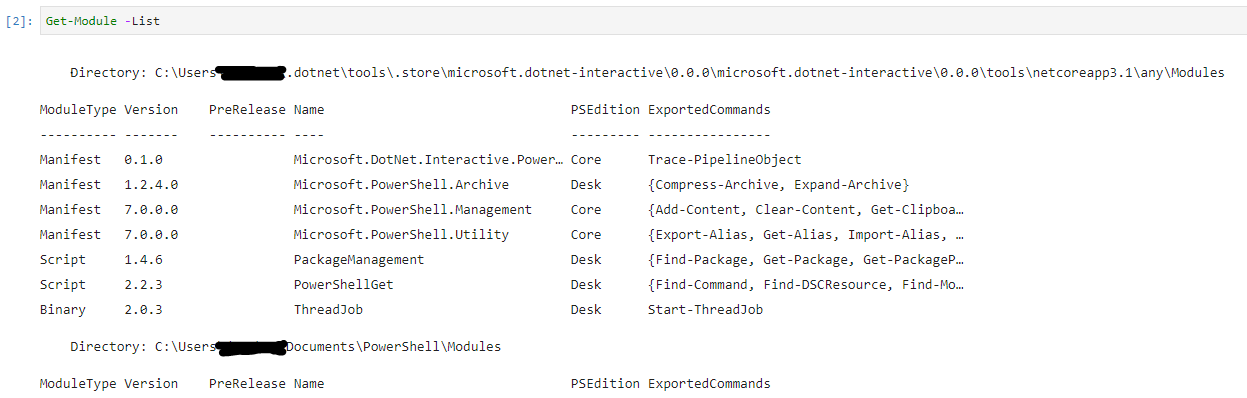
username_1: This is indeed the remoting issue because I just caught that the kernel is importing the Windows PowerShell version of the CimCmdlets module (note the version is `1.0.0.0` which is Windows release). The version matched to PowerShell 7 is version 7.0.0.0

username_3: @username_1 Thanks for reporting this! Yes, it was the CimCmdlets module from the system32 module path that got imported (via the `WinCompat` feature added in PS7). This is because currently the PS kernel don't ship all the built-in modules along with it ...
The built-in modules are not published anywhere and are platform specific, it's hard for an application that host powershell to ship them along. We have the issue https://github.com/PowerShell/PowerShell/issues/11783 to track this work.
username_1: @username_3 maybe I'm missing something...
While it is true that not all modules are going to be shipped with PowerShell CIM cmdlets are not one of them, they are indeed shipped with the versions of PowerShell (both 6 and 7). You can find the DLL, `Microsoft.Management.Infrastructure.CimCmdlets.dll`, located in the root directory of each version of PowerShell:

username_3: Yes, indeed.
What I meant is that not all built-in modules (literally the module folders) that come with PowerShell (6/7) out-of-box are currently shipped along with the PowerShell Jupyter kernel.
The following 7 modules are what the PowerShell Jupyter kernel currently ship, and we only have the `Utility` and `Management` built-in modules, no `CimCmdlets`.
We are working on get this fixed.
Status: Issue closed
username_0: Of course it can be resolved by importing from the local PowerShell Core
username_0: #### Describe the bug
I tried to run one of my Azure Data Studio PowerShell notebooks into a PowerShell Notebook using .NET Jupyter. It worked fine until I tried to import my dbachecks module which uses Pester. I then created a new Notebook and tried to just run some Pester
The error I receive is
````
Describe: The 'Describe' command was found in the module 'Pester', but the module could not be loaded. For more information, run 'Import-Module Pester'.
````
When I try to just import Pester by itself using any of my available versions even 3.4.0 I get
````
Get-Command: C:\Users\mrrob\Documents\PowerShell\Modules\pester\4.9.0\Pester.psm1
Line |
94 | $script:SafeCommands['Get-CimInstance'] = Get-Command -Name Get-CimInstance -Module CimCmdlets @safeCommandLookupParameters
| ^ The term 'Get-CimInstance' is not recognized as the name of a
| cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included,
| verify that the path is correct and try again.
Import-Module: The module to process 'Pester.psm1', listed in field 'ModuleToProcess/RootModule' of module manifest 'C:\Users\mrrob\Documents\PowerShell\Modules\pester\4.9.0\pester.psd1' was not processed because no valid module was found in any module directory.
````
output of Get-Module Pester -ListAvailable
````
Directory: C:\Users\mrrob\Documents\PowerShell\Modules
ModuleType Version PreRelease Name PSEdition ExportedCommands
---------- ------- ---------- ---- --------- ----------------
Script 4.9.0 Pester Desk {Describe, Context, It, Should…}
Script 4.8.1 Pester Desk {Describe, Context, It, Should…}
Directory: C:\Program Files\WindowsPowerShell\Modules
ModuleType Version PreRelease Name PSEdition ExportedCommands
---------- ------- ---------- ---- --------- ----------------
Script 4.8.1 Pester Desk {Describe, Context, It, Should…}
Script 3.4.0 Pester Desk {Describe, Context, It, Should…}
````
#### Did this error occur while using `dotnet interactive`?
- [ X] .NET Jupyter Notebook
#### Screenshots
If applicable, add screenshots to help explain your problem.
#### Please complete the following:
- OS
- [X ] Windows 10
- [ ] macOS
- [ ] Linux (Please specify distro)
- [ ] iOS
- [ ] Android
- Browser
- [X ] Chrome
- [ X] Edge
- [ ] Safari
- Frontend
- [ ] Jupyter notebook
- [X ] Jupyter lab
- [ ] nteract
username_0: That was a mistake that everyone at PowerShell Saturday Hamburg saw!!
Please re-open
Status: Issue closed
username_3: @username_0 The PR #189 brought in `CimCmdlets` and other built-in modules for the PowerShell kernel, so importing Pester should work fine now. |
byuitechops/module-publish-settings | 294882417 | Title: README: module-publish-settings
Question:
username_0: Please get the new README.md from the [Child Template](https://github.com/byuitechops/child-template/blob/master/README.md) and fill it out for your child module. Push it to your child module's repository.
If you have questions, ask Zach, Daniel, or Josh.<issue_closed>
Status: Issue closed |
lh3/minimap2 | 1101081595 | Title: [E::sam_parse1] query name too long
Question:
username_0: 12 12 12 12
```
Status: Issue closed
Answers:
username_1: ```
<(samples/NA19240/hifiasm/NA19240.asm.bp.hap2.p_ctg.fasta.gz)
```
Remove `<()`.
username_1: Then you can generate SAM first and then see if there are long query names. The error report is from samtools.
username_0: Thanks. Generated intermediate SAM file and query names were still only 11 characters. Bug in samtools 1.10, fixed by 1.12. |
cclib/cclib | 41575132 | Title: NMR and EPR attributes
Question:
username_0: Just to start the discussion....
Taking a look at the Gaussian NMR page, I see there are options for different gauge origins and methods. Do we parse all of them, similar to how we handle atomic charges? That is, a dictionary with the various origins/methods as keys? Or just the most common? I think NWChem and GAMESS only support the GIAO method
Are there other print options (e.g. eigenvectors) that would be useful?
Answers:
username_1: I'm looking to start parsing the NMR section of ORCA, and was hoping we could get some sort of consensus on what should be parsed. ORCA 4 only supports GIAO. While there are other methods, such as IGLO (available in ORCA 3), they are generally not recommended, so I don't know if we need a separate method flag. I know very little about NMR and what is important, but my talks with a developer of the NMR module in ORCA suggested that just parsing the isotropic and anisotropic should be sufficient.
I would propose that nmr be a tuple of two numpy arrays `(isotropic, anisotropic)`. However, it could also be a dictionary wherein `isotropic`, `anisotropic`, `shielding_tensor`, etc. are keys. Thoughts?
Here is a sample of all the data ORCA prints out for and NMR computation (He atom).
```
---------------
CHEMICAL SHIFTS
---------------
Note: using conversion factor for au to ppm alpha^2/2 = 26.625677252
Doing GIAO para- and diamagnetic shielding integrals analytically ...done
Doing remaining GIAO terms numerically ...done
--------------
Nucleus 0He:
--------------
Diamagnetic contribution to the shielding tensor (ppm) :
59.949 0.000 -0.000
0.000 59.949 0.000
-0.000 0.000 59.949
Paramagnetic contribution to the shielding tensor (ppm):
-0.000 0.000 0.000
0.000 -0.000 -0.000
0.000 -0.000 -0.000
Total shielding tensor (ppm):
59.949 0.000 0.000
0.000 59.949 -0.000
0.000 -0.000 59.949
Diagonalized sT*s matrix:
sDSO 59.949 59.949 59.949 iso= 59.949
sPSO -0.000 -0.000 -0.000 iso= -0.000
--------------- --------------- ---------------
Total 59.949 59.949 59.949 iso= 59.949
--------------------------
CHEMICAL SHIELDING SUMMARY (ppm)
--------------------------
Nucleus Element Isotropic Anisotropy
------- ------- ------------ ------------
0 He 59.949 0.000
```
username_2: I'll think about the structure once 1.5.2 is out, but I can comment on the first part. In practice, one is interested only in GIAO for the gauge problem because of absolute accuracy problems and poor/slow convergence with respect to the basis set for the other methods. In principle, one could choose IGLO, each individual nucleus, or a common origin. The g-tensor is less sensitive to the choice of gauge origin, so historically the choice is a common origin, usually the center of electronic charge. For hyperfine tensors, each nucleus is usually the center. I'm not sure about ISSC or ZFS tensors. If we'd like a common appearance for each of these, then there needs to be some flexibility for specifying the gauge origin.
More advanced (and for 2.0) is the choice of spin-orbit operator. @ghutchis also mentioned to me some time ago that the tensor orientation may be desirable for visualization, say in Avogadro.
I generally prefer dictionaries over tuples due to the descriptiveness.
username_3: Pushing back to v1.5.3 |
Clinical-Genomics/scout | 900388722 | Title: Dropdown height is a tad too small
Question:
username_0: I've just noticed this:

Sorry I didn't realize sooner when I reviewed yesterday @moedarrah!
Answers:
username_0: This could be easily fixed by assigning a custom style class only to the dropdowns present on the variants filters.
Status: Issue closed
|
DavidTanner/nodecredstash | 216820854 | Title: Allow passing custom endpoints into underlying AWS clients
Question:
username_0: To facilitate talking to a local dynamoDB instance, we need the ability to pass in a different endpoint parameters to KMS and DynamoDB. Because the same `awsOpts` param is shared for dynamo and KMS, it's not possible to change the endpoint.
I would propose two new items added to the high-level configuration (not `awsOpts`): `dynamoEndpoint` and `kmsEndpoint` that get merged into the respective `awsOpts` objects.
Answers:
username_1: Can you submit a pull request with said functionality and a test?
Status: Issue closed
|
aws/aws-xray-sdk-node | 274398492 | Title: Feature Request: Capturing additional SQL Query information
Question:
username_0: The current MySQL instrumentation only captures the url and query type of each query made.
It would be nice to update the instrumentation to also capture the actual query being run.
Obviously there would be privacy concerns attached to this, since you probably don't want to log out every query.
I'm happy to implement this if I can get some direction from the core team as to how you want to handle this.
I was thinking you can provide a predicate as part of the options initialising the instrumentation. This predicate that would be given the query being run, and return whether or not this query should log the query being run.
I came to look for this after seeing this forum thread: https://forums.aws.amazon.com/thread.jspa?messageID=809685
Answers:
username_1: Hi username_0,
Due to the sensitive nature of the data and information that could be captured, we have plans to address this issue internally. We are still discussing on how to handle best to handle this to get most value out of it, while still being safe and protecting our customer's potentially sensitive data and prevent unintentionally leaking data due to misconfiguration. We do intend to address this in the next calendar year.
Thanks,
Sandra
username_2: Has there been anything further on this? Without the SQL query data, I don't really get much value out of instrumenting PostgreSQL. I think the configuration proposals in the forums are sensible - it at least gives people the option on turning on query/parameter capture.
username_3: Any Updates @username_1 ? Is there a plan for this?
username_4: @username_3 Still on the roadmap and being prioritized against other items. PRs are welcome.
username_5: @username_4 / @username_1 : Any updates on this enhancement request. We see a lot of value of including our sqls while instrumenting our PostgreSQL DB roundtrips and as @username_2 points, there is not much value instrumenting DB round trips without the sql info. It looks like customers have been waiting for this feature for 3 years now.
username_6: Hi @username_5,
We are sorry this feature hasn't been prioritized yet. We're continuing to work on how best to capture these queries in a secure manner. |
scala/bug | 220096896 | Title: Private constructors and methods are compiled to public visibility when accessed from a companion object
Question:
username_0: Private constructors and methods are compiled to public visibility when a companion object access them. This should arguably be the "most private" possible. While the Scala compiler should (and likely does, I didn't test it) enforce the visibility restrictions, when interoperating with Java, it would be preferable to have something other than public visibility here.
Per <NAME>, the issue could be solvable by emitting an appropriate static forwarder in the class.
Example with expected results (no companion object):
```scala
class Private private(x: Int) {
private[this] val y = x
private def yValue = y
}
```
javap -p output with private constructor and method:
```scala
public class Private implements scala.ScalaObject {
private final int y;
private int yValue();
private Private(int);
}
```
This is expected.
However, adding the companion object as follows results in the private constructor and method being generated as public.
```scala
object Private {
def main(args: Array[String]) {
val p = new Private(7)
p.yValue
}
}
```
javap -p output with public constructor and method:
```scala
public class Private implements scala.ScalaObject {
private final int y;
public static final void main(java.lang.String[]);
public final int Private$$yValue();
public Private(int);
}
``` |
google/play-services-plugins | 487871192 | Title: Strict Version Matcher Gradle Plugin: Release tag 1.2.0 is missing
Question:
username_0: I am missing the release tag (and a [changelog](https://github.com/google/play-services-plugins/issues/40)) for version 1.2.0 of the _Strict Version Matcher Gradle Plugin_ which is already available via the Google Maven repository and [advertised in release notes of Google Play Services](https://developers.google.com/android/guides/releases#june_27_2019).
- [ ] Please tag your commits and push them as soon as you release new versions.
Answers:
username_0: Meanwhile, [version 1.2.1 has been released](https://developers.google.com/android/guides/releases#november_19_2019) at November 19, 2019.
I kindly ask you to add a detailed CHANGELOG and the corresponding tags to this repository. It appears to abandoned otherwise. :skull: |
smith-chem-wisc/MetaMorpheus | 1046738430 | Title: File was not found in the dictionary
Question:
username_0: I get an error, noting that the run has failed, with the error that one of the files was not found in the dictionary.
I re-ran only that file, and it was okay.
What does that error means?
Answers:
username_1: I'm not sure. If you see the error again, could you please paste the full error message or a screenshot into the issue here?
Otherwise, I believe there is an option to report the error to the metamorpheus email. Did you click that button to send the error report?
Which files is it complaining about? Please share an example of the files that reproduce the error.
Thanks!
username_1: Thank you for reporting the issue. Please reopen another if you encounter it again.
Status: Issue closed
|
EasyNetQ/EasyNetQ | 180687948 | Title: Crash Binding or Create Queue
Question:
username_0: Hi, I have a exception when I try to bind a queue to my exchange.
My topology is:
1) 2 VHost each with
send
Client -> Ex_cli -> routing Key1 -> Ex_Srv-> permanent Queue -> Server
receive
Client <- temporary Queue <- Ex_cli <- routing Key2 <- Ex_Srv<- Server
Server create the two topologies:
I doing this for a strong isolation between the client side and server side
The Client connect to VLogin/Ex_Cli, then create exclusive/temporary Queue on Ex_Cli, start the consumeur on queue and send Msg with reply (I use advence bus)
When server received the login message (and after validate credential), he reply a message to the client that contain all informations to connect to VBusiness and start processing with.
The Client close the IBus and create a new one with new parameter.
After I use my RPC to send messages in a loop.
Some time after 200 or 1000 or 10000 messages, I received a crash when I try to create the binding on Queue used to consume the reply and rarely when I try to create the Queue. (queue name Q_<ClientGuid>_<COUNTER>)
try
{
queue = _bus.Advanced.QueueDeclare(
name: queueName,
passive: false,
durable: false,
exclusive: true,
autoDelete: true
); <==== Exception happen here rarely
}
catch (Exception ex)
{
_log.ErrorFormat(ex, "Unable to create Queue Name{0}", queueName);
}
try
{
binding = _bus.Advanced.Bind(_exchange, queue, replyToRoutingKey); <==== Exception happen here frequently
}
catch (Exception ex)
{
_log.ErrorFormat(ex, "Unable to open BUS Topology QueueName{0}", queueName);
}
The Rabbit MQ log
Error on AMQP connection <0.5590.192> ([::1]:52399 -> [::1]:33704, vhost: 'VHDEMO', user: 'BHCClient', state: running), channel 3:
operation basic.ack caused a connection exception channel_error: "expected 'channel.open'"
Exception catch on Binding:
The AMQP operation was interrupted: AMQP close-reason, initiated by Peer, code=504, text="CHANNEL_ERROR - expected 'channel.open'", classId=60, methodId=80, cause=
Stack:
à EasyNetQ.Producer.ClientCommandDispatcherSingleton.Invoke(Action`1 channelAction)
à EasyNetQ.Producer.ClientCommandDispatcher.Invoke(Action`1 channelAction)
à EasyNetQ.RabbitAdvancedBus.Bind(IExchange exchange, IQueue queue, String routingKey)
à Network.RabbitMQBus.createQueueConsume(String queueName, String replyToRoutingKey, Action`3 callBackConsume) dans f:\OpalNetwork-RabbitMQV2\sources\technical\Network\RabbitMQSBus\RabbitMQBus.cs:ligne 523
I've try to find a solution, but unable to found any things.
I use the last nugget package and use a single thread (so no race on my side).
Have you some idea that can help me to understand what happen ?
Thanks in advance
Answers:
username_0: I close the subject, I make a work around with less overhead (240/s => 920/s)
Status: Issue closed
|
grid-js/gridjs | 1097060058 | Title: Import server-side data example
Question:
username_0: The live results on this template, https://gridjs.io/docs/examples/server/, fails with the error "An error happened while fetching the data". The console reports this error, "[Grid.js] [ERROR]: TypeError: data.map is not a function".
I believe the problem is in this line of the example code:
then: data => data.map(card => [card.name, card.lang, card.released_at, card.artist])
I think it should read:
then: data => data.results.map(card => [card.name, card.lang, card.released_at, card.artist]) |
argoproj/argo-cd | 819114953 | Title: Cluster cache requires manual refresh
Question:
username_0: If you are trying to resolve an environment-specific issue or have a one-off question about the edge case that does not require a feature then please consider asking a question in argocd slack [channel](https://argoproj.github.io/community/join-slack).
Checklist:
* [x] I've searched in the docs and FAQ for my answer: https://bit.ly/argocd-faq.
* [x] I've included steps to reproduce the bug.
* [x] I've pasted the output of `argocd version`.
**Describe the bug**
I synced a helm App that installed CRDs to the local cluster. Helm Apps that rely on helm's built-in `.Capabilities` object did not render those custom resources. I waited ~20 hours and the resources still did not render. I manually invalidated the cluster cache via the UI. Then I hard refreshed the helm Apps. Helm then properly rendered the custom resources.
This is an issue for us because we regularly spin up new clusters and want to use ArgoCD to bootstrap them. AFAICT, there is no way to invalidate the cluster state cache via the CLI, so we're stuck with an extra manual step on cluster bootstrap.
**To Reproduce**
I'm not certain all of these steps are required. I can say these steps reliably reproduce the issue in my environment.
I'll try to pare down the steps later.
* Start with a clean EKS cluster. We run k8s 1.18 latest.
* Install ArgoCD via the helm chart.
* Install a cluster autoscaler App and sync it. Here's the App used to reproduce:
```yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cluster-autoscaler-sandbox-1
namespace: argocd
finalizers: # will cascade deletion of this Application to its resources
- resources-finalizer.argocd.argoproj.io
spec:
destination:
namespace: kube-system
server: "https://kubernetes.default.svc"
project: default
source:
repoURL: "https://kubernetes.github.io/autoscaler"
chart: cluster-autoscaler-chart
targetRevision: 1.0.0
helm:
version: v3
releaseName: cluster-autoscaler
values: |
autoDiscovery:
clusterName: sandbox-1
enabled: true
awsRegion: us-west-2
cloudProvider: aws
fullnameOverride: cluster-autoscaler
replicaCount: 1
serviceMonitor:
enabled: true
namespace: kube-system
```
* Install a kube-prometheus-stack App and sync it. Here's the one used to reproduce:
```yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
[Truncated]
argocd: v1.8.3+0f9c684
BuildDate: 2021-01-21T22:19:20Z
GitCommit: <PASSWORD>
GitTreeState: clean
GoVersion: go1.14.12
Compiler: gc
Platform: linux/amd64
argocd-server: v1.8.3+0f9c684
BuildDate: 2021-01-21T22:20:39Z
GitCommit: <PASSWORD>
GitTreeState: clean
GoVersion: go1.14.12
Compiler: gc
Platform: linux/amd64
Ksonnet Version: v0.13.1
Kustomize Version: v3.8.1 2020-07-16T00:58:46Z
Helm Version: v3.4.1+gc4e7485
Kubectl Version: v1.17.8
Jsonnet Version: v0.17.0
```
Status: Issue closed
Answers:
username_1: Reopening since second issue (manifest caching) is still not resolved. First is fixed by https://github.com/argoproj/gitops-engine/pull/247
username_1: If you are trying to resolve an environment-specific issue or have a one-off question about the edge case that does not require a feature then please consider asking a question in argocd slack [channel](https://argoproj.github.io/community/join-slack).
Checklist:
* [x] I've searched in the docs and FAQ for my answer: https://bit.ly/argocd-faq.
* [x] I've included steps to reproduce the bug.
* [x] I've pasted the output of `argocd version`.
**Describe the bug**
I synced a helm App that installed CRDs to the local cluster. Helm Apps that rely on helm's built-in `.Capabilities` object did not render those custom resources. I waited ~20 hours and the resources still did not render. I manually invalidated the cluster cache via the UI. Then I hard refreshed the helm Apps. Helm then properly rendered the custom resources.
This is an issue for us because we regularly spin up new clusters and want to use ArgoCD to bootstrap them. AFAICT, there is no way to invalidate the cluster state cache via the CLI, so we're stuck with an extra manual step on cluster bootstrap.
**To Reproduce**
I'm not certain all of these steps are required. I can say these steps reliably reproduce the issue in my environment.
I'll try to pare down the steps later.
* Start with a clean EKS cluster. We run k8s 1.18 latest.
* Install ArgoCD via the helm chart.
* Install a cluster autoscaler App and sync it. Here's the App used to reproduce:
```yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: cluster-autoscaler-sandbox-1
namespace: argocd
finalizers: # will cascade deletion of this Application to its resources
- resources-finalizer.argocd.argoproj.io
spec:
destination:
namespace: kube-system
server: "https://kubernetes.default.svc"
project: default
source:
repoURL: "https://kubernetes.github.io/autoscaler"
chart: cluster-autoscaler-chart
targetRevision: 1.0.0
helm:
version: v3
releaseName: cluster-autoscaler
values: |
autoDiscovery:
clusterName: sandbox-1
enabled: true
awsRegion: us-west-2
cloudProvider: aws
fullnameOverride: cluster-autoscaler
replicaCount: 1
serviceMonitor:
enabled: true
namespace: kube-system
```
* Install a kube-prometheus-stack App and sync it. Here's the one used to reproduce:
```yaml
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
[Truncated]
argocd: v1.8.3+0f9c684
BuildDate: 2021-01-21T22:19:20Z
GitCommit: <PASSWORD>
GitTreeState: clean
GoVersion: go1.14.12
Compiler: gc
Platform: linux/amd64
argocd-server: v1.8.3+0f9c684
BuildDate: 2021-01-21T22:20:39Z
GitCommit: <PASSWORD>
GitTreeState: clean
GoVersion: go1.14.12
Compiler: gc
Platform: linux/amd64
Ksonnet Version: v0.13.1
Kustomize Version: v3.8.1 2020-07-16T00:58:46Z
Helm Version: v3.4.1+gc4e7485
Kubectl Version: v1.17.8
Jsonnet Version: v0.17.0
```
username_2: @username_0 Could you please tell me how to manually invalid cluster cache from UI? |
OpenZeppelin/openzeppelin-contracts | 509121866 | Title: ERC20 Approval event conformance
Question:
username_0: But current ERC20 implementation emits `Approval` event on every `allowance` change. Is there any practical reason for this or just a bug?
Original discussion started here: https://github.com/makerdao/dss/issues/76
Answers:
username_1: This has been discussed extensively in the past, and was a concious design decision. You can read more about the motivation on this issue (and associated PR): https://github.com/OpenZeppelin/openzeppelin-contracts/issues/707. The short version is that not emitting those events makes it impossible to reconstruct the state from events only.
Is this causing any issues in your application?
username_0: @username_1 that makes sense 👌
Status: Issue closed
|
linuxdeepin/developer-center | 299673197 | Title: Deepin Image Viewer no longer working ...
Question:
username_0: Linking the Issue from [here](https://github.com/linuxdeepin/com.deepin.ImageViewer/issues/1) ...
Answers:
username_1: Please try to launch it from terminal and paste the output here.
username_0: here you go ...
```
$ flatpak run com.deepin.ImageViewer
save old XDG_CONFIG_HOME: "/home/muz/.var/app/com.deepin.ImageViewer/config"
set XDG_CONFIG_HOME "/home/muz/.config"
set XDG_CONFIG_HOME "/home/muz/.var/app/com.deepin.ImageViewer/config"
"dtkwidget2" can not find qm files
"deepin-image-viewer" can not find qm files
Setting file: "/home/muz/.config/deepin/deepin-image-viewer/config.conf"
2018-02-25, 11:21:08.944 [Debug ] [main.cpp main 55] LogFile: "/home/muz/.var/app/com.deepin.ImageViewer/cache/deepin/deepin-image-viewer/deepin-image-viewer.log"
2018-02-25, 11:21:08.945 [Debug ] [main.cpp main 60] Deepin Image Viewer is defaultImage!
2018-02-25, 11:21:08.978 [Debug ] [dbmanager.cpp DBManager::checkDatabase 767] database is exist!
2018-02-25, 11:21:09.098 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformWindow 102] createPlatformWindow QWidgetWindow(0x1a4e7a0, name="QMainWindowClassWindow") Qt::WindowType(Window) QWindow(0x0)
2018-02-25, 11:21:09.110 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformBackingStore 162] createPlatformBackingStore deepin_platform_plugin::DFrameWindow(0x1ac67a0) Qt::WindowType(Window) QWindow(0x0)
2018-02-25, 11:21:09.111 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformWindow 102] createPlatformWindow deepin_platform_plugin::DFrameWindow(0x1ac67a0) Qt::WindowType(Window) QWindow(0x0)
2018-02-25, 11:21:09.143 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformBackingStore 162] createPlatformBackingStore QWidgetWindow(0x1a4e7a0, name="QMainWindowClassWindow") Qt::WindowType(Window) QWindow(0x0)
2018-02-25, 11:21:09.156 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformWindow 102] createPlatformWindow QWidgetWindow(0x1e67b40, name="CountLabelWindow") Qt::WindowType(Window) QWindow(0x0)
2018-02-25, 11:21:09.158 [Debug ] [dplatformintegration.cpp deepin_platform_plugin::DPlatformIntegration::createPlatformBackingStore 162] createPlatformBackingStore QWidgetWindow(0x1e67b40, name="CountLabelWindow") Qt::WindowType(Window) QWindow(0x0)
```
username_2: Any updates on this? I'm having the same issue, 7 months later.
`deepin-image-viewer twente_tick1.png
"dtkwidget2" can not find qm files
"deepin-image-viewer" can not find qm files
Setting file: "/home/kaden/.config/deepin/deepin-image-viewer/config.conf"
2018-09-04, 15:50:16.382 [Debug ] [ 0] LogFile: "/home/kaden/.cache/deepin/deepin-image-viewer/deepin-image-viewer.log"
2018-09-04, 15:50:16.382 [Debug ] [ 0] Deepin Image Viewer is defaultImage!
2018-09-04, 15:50:16.731 [Debug ] [ 0] database is exist!
thread '<unnamed>' panicked at 'assertion failed: rectangle.x1 >= rectangle.x0', rsvg_internals/src/surface_utils/iterators.rs:72:9
note: Run with `RUST_BACKTRACE=1` for a backtrace.
fatal runtime error: failed to initiate panic, error 5
[1] 26865 abort (core dumped) deepin-image-viewer twente_tick1.png
`
username_3: I am also the same getting the same thing, `dtkwidget2 can not find qm files`
username_4: Sorry, this issue will be closed soon. If it is necessary to discuss it again, please create a new issue.
Status: Issue closed
|
Azure/Communication | 856071372 | Title: I upgraded my ACS lib to beta.9 and i have some issues.
Question:
username_0: **Describe the bug**
I upgraded ACS to beta.9 and i couldn't get remoteParticipant, actually like this;
i have two device for testing. First of all i entered with first device in meeting and for example one min later i entered with second device. First device gets all remoteParticipant(second device infos like displayName) but my second device couldn't get remoteParticipant(first device infos like displayName).
i am using this code about that.
`call.addOnRemoteParticipantsUpdatedListener(p -> onParticipantUpdated(call.getRemoteParticipants()));`
But onParticipantUpdated method doesn't call my first device.
Thanks.
Ozan
Answers:
username_1: Can you also update to beta.10 and let us know if the issue persists? Thanks
username_0: @username_1 hi,
Actually i am trying to do one to one meeting , not possible more than two person being in a call. İ am using GroupCallLocator like this.
` private void joinGroupMeeting() {
joinButtonState(true);
Log.i("DEBUG:", "joinGroupMeeting Method runnnig");
GroupCallLocator groupCallContext = new GroupCallLocator(UUID.fromString(groupId));
JoinCallOptions joinCallOptions = new JoinCallOptions();
call = agent.join(this, groupCallContext, joinCallOptions);
call.addOnStateChangedListener(p -> callStateChanged(call.getState()));
}`
username_0: hi, i updated sdk to 1.0.0 but still like this.
username_1: @username_0, can you share a full snippet of code where you're trying to do this? From what we see, this should be working, so the issue might be in a different layer. Sharing a snippet or the logs from the device would help debug this. ty
username_0: Sure,
```
private void joinGroupMeeting() {
GroupCallLocator groupCallContext = new GroupCallLocator(UUID.fromString(groupId));
JoinCallOptions joinCallOptions = new JoinCallOptions();
call = agent.join(this, groupCallContext, joinCallOptions);
call.addOnStateChangedListener(this::onCallStateChanged);
}
```
onCallStateChanged() method working and when my call state is CONNECTED;
I am calling method for setting ui.
`call.addOnRemoteParticipantsUpdatedListener(this::onParticipantsUpdated);`
if remoteParticipants count 0 or null , below code is working for update ui.
```
if (call.getRemoteParticipants().size() == 0) {
currentMeetingUILogic("setCurrentVideoScreenUI");
}
```
```
private void currentMeetingUILogic(String tag) {
Log.i("DEBUG:", "currentMeetingUILogic Method runnnig " + tag);
if (mRemoteParticipant != null) {
if (mRemoteParticipant.isMuted()) {
getBinding().imgCurrentIsmuted.setVisibility(View.VISIBLE);
} else {
getBinding().imgCurrentIsmuted.setVisibility(View.GONE);
}
if (mRemoteParticipant.getVideoStreams().size() != 0) {
Log.i("DEBUG:", "There is camera open.");
remoteRendererDispose();
getRemoteCamera();
getBinding().clCurrentMeetingUnvideo.setVisibility(View.GONE);
getBinding().clCurrentMeetingNoone.setVisibility(View.GONE);
getBinding().clCurrentMeetingContainer.setVisibility(View.VISIBLE);
getBinding().txtCurrentNameSurnameLong.setVisibility(View.VISIBLE);
getBinding().txtCurrentNameSurnameLong.setText(mRemoteParticipant.getDisplayName());
} else {
Log.i("DEBUG:", "there is camera closed. ");
remoteRendererDispose();
getBinding().clCurrentMeetingNoone.setVisibility(View.GONE);
getBinding().clCurrentMeetingContainer.setVisibility(View.GONE);
getBinding().clCurrentMeetingUnvideo.setVisibility(View.VISIBLE);
getBinding().txtCurrentNameSurnameLong.setVisibility(View.VISIBLE);
getBinding().txtCurrentNameSurnameLong.setText(mRemoteParticipant.getDisplayName());
getBinding().txtCurrentNameSurnameShort.setText(convertNameFullToShort(mRemoteParticipant.getDisplayName()));
}
} else {
Log.i("DEBUG:", "there is no one");
remoteRendererDispose();
getBinding().clCurrentMeetingUnvideo.setVisibility(View.GONE);
getBinding().clCurrentMeetingContainer.setVisibility(View.GONE);
getBinding().clCurrentMeetingNoone.setVisibility(View.VISIBLE);
getBinding().imgCurrentIsmuted.setVisibility(View.GONE);
getBinding().txtCurrentNameSurnameLong.setVisibility(View.GONE);
}
}
```
But onParticipantsUpdated() method not calling when i did above scenario.
```
private void onParticipantsUpdated(ParticipantsUpdatedEvent args) {
List<RemoteParticipant> remoteParticipants = args.getAddedParticipants();
.....
.....
}
```
thanks.
Ozan
username_1: @username_0, we noticed there is a potential issue with the SDK when used with App targeting SDK Version 30. As a temporary fix, while we sort this out on our end, can you make sure to target SDK version 29 for now. To do so, in your module level `build.gradle`, make sure `targetSdkVersion` is set to 29 and let us know how that goes. Thank you.
username_0: I am already using target sdk 29.
username_1: which devices are you using for the testing?
username_0: Samsung Galaxy A50
Android OS Version = 10
Samsung Galaxy S8
Android OS Version = 9
username_1: How are you attempting to end the call? Which API are you using?
username_0: its a little complicated. I'll tell you right now.
this code my close realtime comminucation's method end button.
```
@Override
public void onClickedCurrentCloseAll() {
//stopCall();
willCloseCommunication = true;
intent(MainActivity.class);
finish();
}
```
so i killing activity with finish and running onDestroy() method.
```
@Override
protected void onDestroy() {
Log.i("DEBUG:", "onDestroy method running.");
super.onDestroy();
clickLaggerDispose();
stopCall();
}
```
```
private void stopCall() {
Log.i("DEBUG:", "stopCall method running.");
if (call != null) {
try {
durationMeeting(false);
localRendererDispose();
remoteRendererDispose();
call.stopVideo(this, currentVideoStream).get();
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
call.hangUp(new HangUpOptions());
}
}
```
but it doesn't always give an error.
I noticed something else. When i switch camera , the image is going off on the other device.
```
@Override
public void onClickedSwitchCamera() {
if (deviceManager.getCameras().size() >= 2) {
if (desiredCamera.getId().equals(deviceManager.getCameras().get(0).getId())) {
desiredCamera = deviceManager.getCameras().get(1);
} else {
desiredCamera = deviceManager.getCameras().get(0);
}
try {
if (getBinding().clPreMeetingScreen.getVisibility() == View.VISIBLE) {
previewVideoStream.switchSource(desiredCamera).get();
} else if (getBinding().clCurrentMeetingScreen.getVisibility() == View.VISIBLE) {
currentVideoStream.switchSource(desiredCamera).get();
}
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
} else {
showDialog(ErrorDialogFragment.newInstance(getString(R.string.avs_not_yet_camera_count), getString(R.string.sm_error_dialog_button_text), true, DialogButtonActionType.JustDismiss.getValue()));
}
}
```
thats my switch camera code.
thanks.
username_1: Can you make sure you await the result of the `hangup(..)` CompletableFuture using `call.hangUp(new HangUpOptions()).get();` and let us know whether this works better?
username_0: actually i am not sure what's different.
username_1: @username_0, this should be fixed on the latest version. Please give it a try and let us know if the issue persists.
Status: Issue closed
|
11902804/MADDIGITAL-TEAM6 | 820839411 | Title: Bekijken hoe uart pinnen lezen raspberry
Answers:
username_1: https://www.raspberrypi.org/documentation/configuration/uart.md
username_1: We kunnen de de UART uitlezen op de rasberry. W

e kunnen ook data die we vanaf de raspberry sturen ook ontvangen op de ESP.
Status: Issue closed
|
jtablesaw/tablesaw | 1179332581 | Title: A table imported via read().csv() cannot be exported to json
Question:
username_0: Hey everyone, first at all thanks for this great project. I have a table like the following in CSV format
```
Username, Identifier,First name,Last name
booker12,9012,Rachel,Booker
grey07,2070,Laura,Grey
johnson81,4081,Craig,Johnson
jenkins46,9346,Mary,Jenkins
smith79,5079,Jamie,Smith
```
and I am reading it into a table via `read().csv()`. This works great, now I do a series of operations and I would like to export this table without headers as JSON.
If I do `table.write().toString("json")` it works but I get the headers and it is a Map instead of a List. To fix this I would like to use
```
table.write().usingOptions(JsonWriteOptions.builder(writer).asObjects(false).header(false).build())
```
but I get `Void` (I am using kotlin so technically I get `Unit`) instead of the expected result and I not figure it out why. I got the code from https://github.com/jtablesaw/tablesaw/issues/450#issuecomment-519686728 and if I use the provided example it works. Is this a bug or expected behaviour? Thanks a lot
Answers:
username_0: Ok, yesterday I was an idiot. Instead of calling `writer.toString()` I extected `table.write().usingOptions(JsonWriteOptions.builder(writer).asObjects(false).header(false).build())` to return the string directly. Of course it does not return anything so it absolutely right that I get `Void` out. Sorry for wasting your time
Status: Issue closed
|
EvictionLab/eviction-lab-etl | 344147594 | Title: Census API changes
Question:
username_0: Figure out if any of the changes to the Census API impact the current setup and adjust if they do
Answers:
username_1: Had to adjust method for fetching 2010 block groups (using tracts) and reduce the frequency of queries. Fixed in #102
Status: Issue closed
|
openstreetmap/iD | 413198625 | Title: Display preset in issue message
Question:
username_0: I came across an issue which said "<name of railway line> crosses Foot Path". I was confused at first until I realised the first part was referring to a railway line.
It seems the object name replaces the preset name in the issue message. I think it would be a good idea to display both, to tell users what type of object is causing an issue?
For example: Rail (<name of railway line>) crosses Foot Path (name of path) would be better IMO
Answers:
username_0: Whoops, seems like my examples got messed up - I had put the railway line name in angled brackets:
"Rail (name of railway line) crosses Foot Path (name of path)" or "Primary Road (ref) crosses Path (name)"
In your example it is currently Contra Costa County Road 120 crosses Concord Subdivision. I think a new/casual mapper seeing this might be confused about what this means without the road/rail.
The other reason I suggested this is because you could have the exact opposite problem, where your issue message is too short. For example two features which don't have a name but have a ref, e.g. "A1 crosses M2" and be confused about what exactly the problem is, or what it is referring to?
Status: Issue closed
username_2: Lets close this.. Since clicking on the message takes you to the issue, and hovering the message will highlight the things, the user can clearly see what kind of features they are by looking, and doesn't need any extra guidance in the message. |
geosolutions-it/MapStore2 | 275674344 | Title: Fix waffle bot interaction with PRs
Question:
username_0: ### Description
When i create a PR at the moment wafflebot adds these labels:

while it is enough the "pending review" label
### Please indicate if this issue is related to a bug or a new feature request
- [x] New Feature
### In case of New Feature (otherwise remove this paragraph)
*Acceptance Criteria - AC*
- When creating a PR it should add only "pending review" label and move it under the pending review column in the kanban
Status: Issue closed
Answers:
username_1: not needed after latest kanban updates |
alanxz/rabbitmq-c | 408736434 | Title: Segfault when using amqp-consume with --exchange and no routing key set.
Question:
username_0: I'm using amqp-tools 0.8.0-1+b3 from Debian stable.
`amqp-consume --url amqp://hohoho:lalala@localhost:1234/parapapapapa --exchange sialalala --no-ack -- true` crashes, while ` amqp-consume --url amqp://hohoho:lalala@localhost:1234/parapapapapa --exchange sialalala -r "" --no-ack -- true` does not.
```
gdb --args amqp-consume --url amqp://hohoho:lalala@localhost:1234/parapapapapa --exchange sialalala --no-ack -- true
GNU gdb (Debian 7.12-6) 7.12.0.20161007-git
Copyright (C) 2016 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from amqp-consume...(no debugging symbols found)...done.
(gdb) run
Starting program: /usr/bin/amqp-consume --url amqp://hohoho:lalala@localhost:1234/parapapapapa --exchange sialalala --no-ack --no-ack -- true
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Server provided queue name: amq.gen-C2xLagOP7YxxBrbgi7syBw
Program received signal SIGSEGV, Segmentation fault.
strlen () at ../sysdeps/x86_64/strlen.S:106
106 ../sysdeps/x86_64/strlen.S: No such file or directory.
(gdb) bt
#0 strlen () at ../sysdeps/x86_64/strlen.S:106
#1 0x00007ffff6b6f3ae in __GI___strdup (s=0x0) at strdup.c:41
#2 0x000055555555662f in ?? ()
#3 0x00007ffff6b0f2e1 in __libc_start_main (main=0x555555556160, argc=8, argv=0x7fffffffe098, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>, stack_end=0x7fffffffe088)
at ../csu/libc-start.c:291
#4 0x0000555555556baa in _start ()
```
Based on output and stacktrace I guess it's breaking here:
https://github.com/alanxz/rabbitmq-c/blob/a65c64c0efd883f3e200bd8831ad3ca066ea523c/tools/consume.c#L114 |
desktop/desktop | 308333506 | Title: not getting path for git.exe
Question:
username_0: <!--
First and foremost, we’d like to thank you for taking the time to contribute to our project. Before submitting your issue, please follow these steps:
1. Familiarize yourself with our contributing guide:
* https://github.com/desktop/desktop/blob/master/CONTRIBUTING.md#contributing-to-github-desktop
2. Check if your issue (and sometimes workaround) is in the known-issues doc:
* https://github.com/desktop/desktop/blob/master/docs/known-issues.md
3. Make sure your issue isn’t a duplicate of another issue
4. If you have made it to this step, go ahead and fill out the template below
-->
## Description
<!--
Provide a detailed description of the behavior you're seeing or the behavior you'd like to see **below** this comment.
-->
## Version
<!--
Place the version of GitHub Desktop you have installed **below** this comment. This is displayed under the 'About GitHub Desktop' menu item. If you are running from source, include the commit by running `git rev-parse HEAD` from the local repository.
-->
* GitHub Desktop:
<!--
Place the version of your operating system **below** this comment. The operating system you are running on may also help with reproducing the issue. If you are on macOS, launch 'About This Mac' and write down the OS version listed. If you are on Windows, open 'Command Prompt' and attach the output of this command: 'cmd /c ver'
-->
* Operating system:
## Steps to Reproduce
<!--
List the steps to reproduce your issue **below** this comment
ex,
1. `step 1`
2. `step 2`
3. `and so on…`
-->
### Expected Behavior
<!-- What you expected to happen -->
### Actual Behavior
<!-- What actually happens -->
## Additional Information
<!--
Place any additional information, configuration, or data that might be necessary to reproduce the issue **below** this comment.
If you have screen shots or gifs that demonstrate the issue, please include them.
If the issue involves a specific public repository, including the information about it will make it easier to recreate the issue.
If you are dealing with a performance issue or regression, attaching a Timeline profile of the task will help the developers understand the runtime behavior of the application on your machine.
https://github.com/desktop/desktop/blob/master/docs/contributing/timeline-profile.md
-->
### Logs
<!--
Attach your log file (You can simply drag your file here to insert it) to this issue. Please make sure the generated link to your log file is **below** this comment section otherwise it will not appear when you submit your issue.
macOS logs location: `~/Library/Application Support/GitHub Desktop/logs/*.desktop.production.log`
Windows logs location: `%APPDATA%\GitHub Desktop\logs\*.desktop.production.log`
The log files are organized by date, so see if anything was generated for today's date.
-->
Answers:
username_1: Thanks for reaching out!
We require the template to be filled out when submitting all issues. We do this so that we can be certain we have all the information we need to address your submission efficiently. This allows the maintainers to spend more time fixing bugs, implementing enhancements, and reviewing and merging pull requests.
Thanks for understanding and meeting us halfway 😀
username_2: Closing this issue due to inactivity. @username_0 if you're able to fill out the template we're happy to revisit this issue.
Status: Issue closed
|
CDrummond/lms-material | 776566336 | Title: Music folder view
Question:
username_0: Is there any way to still access the music folder view?
My albums are stored as:
Root
/ | \
FLAC ALAC Non FLAC
So often I like browsing the in FLAC folder to ensure I am playing the highest quality, when I have some albums which are also in MP3 / OGG other formats.
Answers:
username_1: Yes. Browse modes come from LMS. To configure which are shown in Material, use its settings dialog - in this dialog next to 'My Music' is a cog icon, click that.
Status: Issue closed
username_0: Thanks super helpful. |
datalad/datalad | 248171331 | Title: Provide nuitka-based binary packages
Question:
username_0: @username_1 made a nuitka-based binary build work. thanks!
Based on that we could provide self-contained binary packages in RPM, tar (etc) format to give users an easy way to deploy on *NIX-based infrastructure. Some should be possible for Windows -- maybe even with an MSI installer, or whatever is the method of today on windows.
Answers:
username_0: I tried the nuitka branch and could build a package in ~30min. It resulted in a tarball of about 120MB size. It looks like this bundles everything (incl. Git and git-annex).
I suspect that the build setup on windows would require some adjustments to achieve the same bundling approach.
Looks good AFAICS.
username_0: Where there any updates on this one over the past few weeks?
username_0: Also see https://twitter.com/NeuroStats/status/916733507296043009 -- non-root deployment of Git/annex is another use case for this.
username_1: There was! Kay did some fixes, and actually I built one yesterday! Only on Jessie for now, and we needed to do it in as old as we could, eg wheezy.
We need a tiny patch, but in general seems to work... I will share more later today so you could also check it out
username_0: Awesome!
username_1: you could check out http://onerussian.com/tmp/datalad-linux_0.9.1+git67-g1c55ab3.tgz, just wget , tar -xzf, and then point PATH to the bin/ within extracted directory
- it probably wouldn't work on elderly CentOS 6.9 or so since this one is build on jessie... need to reboot smaug with some kernel tweeks to be able to go back to wheezy docker
- any discovery logic relying on glob on the code (e.g. our plugins, datalad test without specifying explicit test submodule, or patoolib archivers support, and there was something in scrapy) wouldn't yet work
but otherwise seems to work more or less for basic operations (tried on search/get/uninstall)
I have now initiated a PR for the review etc https://github.com/datalad/datalad/pull/1889
username_0: Downloaded. Will check this morning.
username_0: Works as advertized. Great job everybody involved!
Status: Issue closed
username_0: We have the mature #1889 with the actual progress. |
glushchenko/fsnotes | 754720555 | Title: Setting for image upload directory (preferably with filename prefix)
Question:
username_0: <!-- NOTE: ignoring this template will lead to your issue being dealt with more slowly -->
**Describe your feature request**
It would be nice for there to be a setting that allows users to specify where images are placed when they are dragged and dropped into the md editor (drag and drop is awesome, so thanks for that!).
So by default images are placed in assets/. If I specify `${filename}.assets/` then it will automatically create the directory and store it there instead. Or `pictures/` to store in a pictures directory, etc.
**Additional context**
This is for MacOS.
Answers:
username_1: I strongly agree. For Markdown files, the images are currently places in the folder `i` which feels unconventional. Choosing how images are saved would be great! How [Typora](https://typora.io) handles this could be a great example:
<img width="712" alt="Screen Shot 2021-01-22 at 19 38 30" src="https://user-images.githubusercontent.com/3275148/105531314-69f91900-5ce9-11eb-93df-cd5c39576109.png">
Here's the piece of code that deals with images/files, but I don't know enough about macOS development to be able to implement this myself:
https://github.com/glushchenko/fsnotes/blob/master/FSNotes/Helpers/ImagesProcessor.swift#L210-L254 |
trufflesuite/ganache | 797414333 | Title: System Error when running Ganache 2.5.4 on win32
Question:
username_0: <!-- Please give us as much detail as you can about what you were doing at the time of the error, and any other relevant information -->
PLATFORM: win32
GANACHE VERSION: 2.5.4
EXCEPTION:
```
Error: ENOENT: no such file or directory, open 'C:\Users\mohammad.asif\AppData\Roaming\Ganache\workspaces\MyFirstEthBlockChain\chaindata\ContractCache'
at Object.openSync (fs.js:440:3)
at Object.func (electron/js2c/asar.js:140:31)
at Object.func [as openSync] (electron/js2c/asar.js:140:31)
at Object.readFileSync (fs.js:342:35)
at Object.fs.readFileSync (electron/js2c/asar.js:542:40)
at Object.fs.readFileSync (electron/js2c/asar.js:542:40)
at Proxy.getItem (C:\Program Files\WindowsApps\GanacheUI_2.5.4.0_x64__5dg5pnz03psnj\app\resources\app.asar\node_modules\node-localstorage\LocalStorage.js:237:19)
at JsonStorage_JsonStorage.getFromStorage (C:\Program Files\WindowsApps\GanacheUI_2.5.4.0_x64__5dg5pnz03psnj\app\resources\app.asar\webpack:\src\main\types\json\JsonStorage.js:18:42)
at JsonStorage_JsonStorage.getAll (C:\Program Files\WindowsApps\GanacheUI_2.5.4.0_x64__5dg5pnz03psnj\app\resources\app.asar\webpack:\src\main\types\json\JsonStorage.js:44:17)
at new ContractCache_ContractCache (C:\Program Files\WindowsApps\GanacheUI_2.5.4.0_x64__5dg5pnz03psnj\app\resources\app.asar\webpack:\src\integrations\ethereum\main\types\contracts\ContractCache.js:10:28)
``` |
skydive-project/skydive | 784896058 | Title: Cluster connectivity view in multicluster
Question:
username_0: Here am with 2 GCP clusters along with nsm ,after installing skydive in each cluster. I created 1 vm instance,i run skydive in analyzer mode along with both cluster skydive analyzer pod ip.through UI i got topology view that contains cluster with nodes without any link and also both cluster are peered in GCP that also not covered in UI.
I don't know how to show the connectivity within cluster and also other cluster.please let me solve this issue. |
cilium/cilium | 307437242 | Title: NFS mount broken in developer VM
Question:
username_0: When attempting to run the dev VM via `RELOAD=1 IPV4=1 NFS=1 MEMORY=5120 ./contrib/vagrant/start.sh`, I hit the following error on Ubuntu 17.10:
```
==> runtime1: Machine booted and ready!
==> runtime1: Checking for guest additions in VM...
==> runtime1: Setting hostname...
==> runtime1: Configuring and enabling network interfaces...
==> runtime1: Exporting NFS shared folders...
==> runtime1: Preparing to edit /etc/exports. Administrator privileges will be required...
==> runtime1: Mounting NFS shared folders...
The following SSH command responded with a non-zero exit status.
Vagrant assumes that this means the command failed!
mount -o vers=3,udp 192.168.34.1:/home/joe/work/src/github.com/cilium/cilium /home/vagrant/go/src/github.com/cilium/cilium
Stdout from the command:
Stderr from the command:
mount.nfs: requested NFS version or transport protocol is not supported
```
I attempted to change the vagrant VM image back to version 32, but this doesn't seem to fix the issue. I'm not sure when this was last working.
Answers:
username_1: try cleaning up your `/etc/exports`, and check if your NFS-utils version is `< 2.x`
username_0: `/etc/exports` is clean, nfs-utils is v1.3 in both host and VM.
username_0: PEBKAC, `/etc/exports` wasn't clean. Clearing that file out fixed the issue for me. Thanks @username_1 !
Status: Issue closed
|
broadinstitute/cromwell | 164550417 | Title: Reflect Backend Abort Status more accurately
Question:
username_0: As FireCloud ( @cbirger ) , I often abort workflows. Although JES currently makes a best effort to abort calls, sometimes those calls fail to abort. I would like to know through the cromwell call/workflow status the difference between "definitely aborted" and "unknown abort status".
The reason this is important is that if I know the status is "unknown" I know that I might be at risk for being billed for machines I don't want and should take further action.
</end of PO comment>
Technically this might require a little research and specifically work on JES. Ideally:
1. We change our overall workflow status to aborting
2. When we cancel a JES operation, the status of that operation will reflect reality.
3. We can poll that operation until it reaches a terminal state (e.g. cancelled). This may actually just be for us to keep running the workflow like normal and just add canceled to the list of terminal states).
4. Once all tasks are in a terminal state, the workflow status is Aborted
Question will be... if JES fails to terminate a job, should we change it's status to something like 'LOST' or 'UNKNOWN' after N minutes, or should we wait indefinitely. Since it's a best effort cancellation in JES we should handle this case
Answers:
username_1: @username_0 From what I understand, it is still a frequent problem that P.API does not abort workflows even though Cromwell asked.
@username_2 do you have an idea about the effort involved to make this fix?
@abaumann Do we have any data (from FC) with how often this is happening?
username_2: This doc predates that "we should fix aborts" google doc and is effectively a subset of that. I say effectively in that the specifics of what this ticket are asking for might be different from that doc, but that doc should be the authoritative one of the two.
Status: Issue closed
username_1: In that case I'm closing this in favor of the [Google Doc](https://docs.google.com/document/d/1B0FElJXOp4IP-v24C62CLsC0JQMbQPjaIrjOwnDqko8/edit). |
UoSGamesGroups/first-semester-l4-5-group-20 | 191782359 | Title: As a designer, find a suitable sound effect for when the overload goes off
Question:
username_0: 1. Find a sound effect (copyright free of course) that we can use for when the player activates the overload ability. This needs to be short and obvious. This one can be quite loud since it is effectively an explosion of sorts.
2. Produce a document in Word (or similar software) that contains a Harvard style reference for the sound file. Please keep all the references for all music and sound effects in the same document.
If you find a long sound file but somewhere in that sound file is a short sound effect you could crop out of it, then use Audacity to crop out that sound effect and delete the rest, but make sure you still reference the whole thing.
Estimated time - 1 hour
Answers:
username_1: researched music i found suitable for the sound needed for the task
1H
Status: Issue closed
|
ccxt/ccxt | 456487906 | Title: dx fetch_open_orders returns empty
Question:
username_0: dx fetch_open_orders returns empty where I have open orders
Request: POST https://acl.dx.exchange {'Content-Type': 'application/json-rpc', 'Authorization': 'XXX', 'User-Agent': 'python-requests/2.19.1', 'Accept-Encoding': 'gzip, deflate'} {"jsonrpc":"2.0","id":XXX,"method":"OrderManagement.OpenOrders","params":[{"pagination":{"limit":null,"offset":0},"instrumentId":1045}]}
Response: POST https://acl.dx.exchange 200 {'Date': 'Sat, 15 Jun 2019 01:39:50 GMT', 'Content-Type': 'application/json-rpc', 'Content-Length': '84', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Methods': 'GET, POST, OPTIONS', XXX {"id":"XXX+12","result":{"orders":[],"total":{"count":0}},"error":null}
[]
- OS:win10
- Programming Language version:py3.6.6
- CCXT version:1.18.698
- Exchange:dx
- Method:fetch_open_orders
Answers:
username_1: @username_0 can you plz provide more clues? 1045 = ETH/USDT, but they also have ETH/USD – are you sure there's no confusion?
username_0: Hi, strangely enough the 2+ days old order I wasnt able to get.
With new orders it worked but it has an error here:
line 345 in dx.py symbol = self.markets_by_id[order['instrumentId']]['symbol']
fails since order["instrument"] id will be an integer and wont work as an key, monkeypatched it to a string and it works.
so in python I think this works: symbol = self.markets_by_id[str(order['instrumentId'])]['symbol']
bit as it is generated somehow it has to be changed somewhere else.
Status: Issue closed
username_1: Thx for the clues, i've added the necessary fixes, and it should work without a monkey patch as of 1.18.709 (it will arrive in 15 minutes). Let us know if you have any issues with it.
username_2: @username_0 @username_1
Yes, sadly this is a limitation on the exchange side.
I think, they do this because there is no `get_order` method. |
sisoputnfrba/foro | 842682025 | Title: [TP0] Definiciones múltiples de `logger'
Question:
username_0: Muy buenas a todos.
Probé en hacer el `make` del Servidor en mi distribución personal y me encontré con el siguiente inconveniente:

Cada vez que ejecuto el `make` hace referencia a un `.o` distinto:

La distribución es arch-linux.
Pude hacerlo andar en la máquina virtual de la cátedra, pero opté en probarlo localmente para ver si podía mejorar la experiencia y performance de poder programar a la largo del cuatrimestre.
Muchas gracias 🙏🏻
Answers:
username_1: ¡Buenas!
Antes que nada, ¿podrías pasarnos en qué archivos tenés declarado `logger` así podemos contar con más contexto para poder ayudarte a encontrar el error?
username_0: Muy buenas @username_1
Pude solucionarlo con los siguientes pasos.
Originalmente `Servidor/utils.h` se encontraba como:

Lo que opté en hacer es sacar la declaración del logger hacia `Server/servidor.c`:

y dejé en `Servidor/utils.h` el extern del mismo:

username_2: Buenas!
Consulta rápida, en la vm de la catedra no te hizo falta agregar la variable en el .h para que salga andando de una?
Instalaste las commons en tu base de arch? Porque capaz por ahí arranca el problema.
Saludos.-
username_0: Muy buenas @username_2
Efectivamente, no me hizo falta. Hice el tp0 por primera vez en la vm y me anduvo a la primera 👍🏻
Sí, me aseguré de que las commons estén instaladas. De hecho probé el workflow del tp0 varias veces desinstalando/instalando las commons.
Saludos
username_2: Buenas!
Ahora con un poco mas de cafeina en el cuerpo se me ocurren algunas alternativas:
1. La versión de GCC es abismalmente diferente, en la VM esta instalado GCC 5.4.0, lo cual tambien puede ser que sea un factor que teniendo en cuenta como esta armado el repo este dándote problemas, lo que podrías hacer seria hacer un downgrade de la versión a la 5.4.0 y checkear si eso funciona.
2. Como el problema es que te dice que tenes múltiples definiciones de logger, eso puede venir de la mano de que vos tenes por un lado el logger en utils.h de la carpeta Servidor y por otro lado en tp0.c también tenes la variable logger y como estamos en versiones distintas de GCC, capaz que hay algún cambio relacionado a como compila los archivos que no estamos viendo y bueno, genera que encuentre 2 veces la definición de logger.
3. Como última opción, podes pasarte el detalle de un git diff a ver que cambio respecto al tp0
Por último, recién (de nuevo gracias a que estoy un poco mas despierto) me percato de que subiste *screenshots de tu código* y es algo que **les pedimos en el template de issue que no lo hagan**.
En este tipo de situaciones lo que tenés que hacer es hacer simple copy-paste de tu código y agregar el markdown para que sea código (si te interesa que se vea resaltado) ya que si no cualquiera que quiera usar el buscador no va a encontrar nada porque no busca en el texto en imágenes.
Saludos.-
username_0: Muchas gracias por las ideas.
No tuve éxito llevando a cabo el downgrade😢
Tendré presente para la próxima los requisitos del foro, pido disculpas.
Muchas gracias nuevamente 👍🏻
Status: Issue closed
|
rollup/plugins | 700314007 | Title: If the entry module is commonjs, the output don't have named export
Question:
username_0: <!--
⚡️ katchow! We 💛 issues.
🚨 Your issue will be CLOSED if:
- This template is removed
- Parts of this template are removed
👉🏽 Need help or tech support? Please don't open an issue!
Head to https://gitter.im/rollup/rollup or https://stackoverflow.com/questions/tagged/rollupjs
❤️ Rollup? Please consider supporting our collective:
👉 https://opencollective.com/rollup/donate
-->
- Rollup Plugin Name: @rollup/plugin-commonjs
- Rollup Plugin Version: 15.0.0
- Rollup Version: 2.26.11
- Operating System (or Browser): Chrome
- Node Version: 12.16.2
- Link to reproduction _(⚠️ read below)_: https://repl.it/@username_0/rollup-repro#dist/react.js
<!--
🚨 Issues WITHOUT a valid reproduction WILL BE CLOSED!
Please provide one by:
1. Using the REPL.it plugin reproduction template at https://repl.it/@rollup/rollup-plugin-repro
2. Provide a minimal repository link (Read https://git.io/fNzHA for instructions).
Please use NPM for installing dependencies!
These may take more time to triage than the other options.
3. Using the Rollup REPL at https://rollupjs.org/repl/
⚠️ ZIP Files are unsafe and maintainers will NOT download them.
-->
### Expected Behavior
I am trying to bundle react into esm. So that I can use it in browser's native esm envirenment.
I expect the output to have named export:
```
// dist/react.js
// ...
export { Component, useState, useEffect };
```
### Actual Behavior
The output only have a default export:
```
// dist/react.js
// ...
const React = { Component, useState, useEffect };
export default React;
```
### Additional Information
How can [jspm.dev](https://jspm.dev/react) build react into esm with named export? Isn't it using rollup too? @guybedford Can you share how you do it?
<!--
Most issues can be expressed or demonstrated through the REPL or a repository.
However, the situation may arise where some small code snippets also need to
be provided. In that situation, please add your code below using
Fenced Code Blocks (https://help.github.com/articles/creating-and-highlighting-code-blocks/)
-->
Answers:
username_0: As guybedford [replied in discord](https://discord.com/channels/570400367884501026/570400367884501032/754458375370178671), the named exports extraction done by [cjs-module-lexer](https://github.com/guybedford/cjs-module-lexer)
username_1: fwiw that discord link doesn't work for me
username_0: jspm discord invite link: https://discord.gg/dNRweUu
username_0: [I have created a rollup plugin to fix this](https://github.com/vitejs/vite/pull/825#issuecomment-695201499). In the options hook I replace cjs entry with a proxy entry module which re-export all named export from the original cjs entry.
@lukastaegert Do you think this fix can be done in the `@rollup/plugin-commonjs`?
username_2: Is this is something related --> https://github.com/pikapkg/snowpack/blob/4c66f9a12ea13ec59c3c59e2383464da510fa12b/esinstall/src/rollup-plugins/rollup-plugin-wrap-install-targets.ts#L23 Like how snowpack wraps the module with all the sub-modules that can be installed. |
GoogleCloudPlatform/gcp-service-broker | 259221601 | Title: Ability to configure AclEntry for CloudSQL Broker
Question:
username_0: https://github.com/GoogleCloudPlatform/gcp-service-broker/blob/master/brokerapi/brokers/cloudsql/broker.go
Line: 145
Assuming we want to restrict access, where would be the appropriate place to configure this? Env Var, Plan, ?
Answers:
username_1: I'd probably implement this as a parameter to provision
Status: Issue closed
|
DeltaML/model-buyer | 468403160 | Title: CI flow
Question:
username_0: **Is your feature request related to a problem? Please describe.**
Add CI tools.
**Describe the solution you'd like**
- Run CI flow with travis-ci.
- Protect branch master
- Need build docker image and push in Docker registry after push in master.
**Describe alternatives you've considered**
Make manually
**Additional context**
Use this example in others deltaml repositories<issue_closed>
Status: Issue closed |
XX-net/XX-Net | 95571922 | Title: xxnet
Question:
username_0: 最新版双击start快捷键,无法运行。。
win7 64位系统
虽然我的username_11.16.3还能看youtube 1080p。。我只是想测试下最新版
Answers:
username_0: 最新版双击start快捷键,无法运行。。
win7 64位系统
虽然我的username_11.16.3还能看youtube 1080p。。我只是想测试下最新版
username_0: 大佬,最新版中的扫描线程数跟首次读写量与后续读写量怎么突然改了
是看了我文章的话,还是改回去比较好。我整整看了1天的youtube
#分片下载模块
[autorange]
#下载线程数
threads = 16
#分片下载大小,服务端发现超出该值后,自动分片下载
maxsize = 1572864
#首次读写量
waitsize = 153600
#后续读写量
bufsize = 327680
新版本中的
threads = 8
maxsize = 1572864
waitsize = 52428
bufsize = 8192888
这样username_1 半小时会崩溃一次把 。。1.16.3中是这样
username_0: [autorange]
#下载线程数
threads = 16
#分片下载大小,服务端发现超出该值后,自动分片下载
maxsize = 1572864
#首次读写量
waitsize = 153600
#后续读写量
bufsize = 327680
这样设置比较好点
username_1: 恩,先放着,这个版本能挺多久看看再说
username_0: 很多人反映 软件无法启动
username_0: 双击start以后,vbs会出来。证书没出来。。username_1就更没出来。。。管理员模式也不行 |
jeremylong/DependencyCheck | 246421455 | Title: Error occurred connecting to the local database
Question:
username_0: Hi everyone!
I'm running dependency check as a part of a CI pipeline in a Jenkins instance and suddenly this connection error started to happen. This is the second time we see this local database, but in the first time the job went back to normal after a few hours.
Here's the plugin configuration. Note that I added **`<connectionString>`** after trying to solve this error based on #410
```
<plugin>
<groupId>org.owasp</groupId>
<artifactId>dependency-check-maven</artifactId>
<version>2.0.1</version>
<configuration>
<failBuildOnCVSS>8</failBuildOnCVSS>
<skipProvidedScope>true</skipProvidedScope>
<outputDirectory>${project.build.directory}/reports/owasp</outputDirectory>
<nuspecAnalyzerEnabled>false</nuspecAnalyzerEnabled>
<assemblyAnalyzerEnabled>false</assemblyAnalyzerEnabled>
<connectionString>jdbc:h2:file:%s;FILE_LOCK=FS;AUTOCOMMIT=ON;</connectionString>
</configuration>
<executions>
<execution>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
```
Here's the stacktrace that jenkins is outputting
```
[ERROR] Failed to execute goal org.owasp:dependency-check-maven:2.0.1:check (default-cli) on project default: An exception occurred connecting to the local database. Please see the log file for more details. Unable to connect to the database -> [Help 1]
org.apache.maven.lifecycle.LifecycleExecutionException: Failed to execute goal org.owasp:dependency-check-maven:2.0.1:check (default-cli) on project default: An exception occurred connecting to the local database. Please see the log file for more details.
at org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:216)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:153)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:145)
at org.apache.maven.lifecycle.internal.LifecycleModuleBuilder.buildProject(LifecycleModuleBuilder.java:116)
at org.apache.maven.lifecycle.internal.builder.multithreaded.MultiThreadedBuilder$1.call(MultiThreadedBuilder.java:188)
at org.apache.maven.lifecycle.internal.builder.multithreaded.MultiThreadedBuilder$1.call(MultiThreadedBuilder.java:184)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.maven.plugin.MojoExecutionException: An exception occurred connecting to the local database. Please see the log file for more details.
at org.owasp.dependencycheck.maven.CheckMojo.runCheck(CheckMojo.java:95)
at org.owasp.dependencycheck.maven.BaseDependencyCheckMojo.execute(BaseDependencyCheckMojo.java:514)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo(DefaultBuildPluginManager.java:132)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:208)
... 11 more
Caused by: org.owasp.dependencycheck.data.nvdcve.DatabaseException: Unable to connect to the database
at org.owasp.dependencycheck.data.nvdcve.ConnectionFactory.initialize(ConnectionFactory.java:164)
at org.owasp.dependencycheck.Engine.initializeEngine(Engine.java:129)
at org.owasp.dependencycheck.Engine.<init>(Engine.java:106)
at org.owasp.dependencycheck.maven.BaseDependencyCheckMojo.initializeEngine(BaseDependencyCheckMojo.java:881)
at org.owasp.dependencycheck.maven.CheckMojo.runCheck(CheckMojo.java:88)
... 14 more
[ERROR]
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
```
Is this a know bug our a maven issue? Couldn't find any fixes or documentation for this error.
If you need any more information please get in touch!
Thanks!
Answers:
username_1: Any chance you could add `-X` to the execution of mvn on the failing build and provide the additional details contained (related to dependency-check's execution)?
username_0: Here it is.
I omitted some private information but the whole execution is there
```
[INFO] Error stacktraces are turned on.
[DEBUG] Reading global settings from /opt/apache-maven/apache-maven-3.2.3/conf/settings.xml
[DEBUG] Reading user settings from /home/web/.m2/settings.xml
[DEBUG] Using local repository at /home/web/.m2/repository
[DEBUG] Using manager EnhancedLocalRepositoryManager with priority 10.0 for /home/web/.m2/repository
[INFO] Scanning for projects...
[DEBUG] Extension realms for project com.api:default:war:2.5-SNAPSHOT: (none)
[DEBUG] Looking up lifecyle mappings for packaging war from ClassRealm[plexus.core, parent: null]
[DEBUG] Extension realms for project com.api:defaultParent:pom:2.5-SNAPSHOT: (none)
[DEBUG] Looking up lifecyle mappings for packaging pom from ClassRealm[plexus.core, parent: null]
[DEBUG] Resolving plugin prefix dependency-check from [org.apache.maven.plugins, org.codehaus.mojo]
[DEBUG] Resolved plugin prefix dependency-check to org.owasp:dependency-check-maven from POM com.api:default:war:2.5-SNAPSHOT
[DEBUG] === REACTOR BUILD PLAN ================================================
[DEBUG] Project: com.api:default:war:2.5-SNAPSHOT
[DEBUG] Tasks: [dependency-check:check]
[DEBUG] Style: Regular
[DEBUG] =======================================================================
[INFO]
[INFO] Using the MultiThreadedBuilder implementation with a thread count of 128
[DEBUG] Scheduling: MavenProject: com.api:default:2.5-SNAPSHOT @ pom.xml
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building project
[INFO] ------------------------------------------------------------------------
[DEBUG] Resolving plugin prefix dependency-check from [org.apache.maven.plugins, org.codehaus.mojo]
[DEBUG] Resolved plugin prefix dependency-check to org.owasp:dependency-check-maven from POM com.api:default:war:2.5-SNAPSHOT
[DEBUG] Lifecycle default -> [validate, initialize, generate-sources, process-sources, generate-resources, process-resources, compile, process-classes, generate-test-sources, process-test-sources, generate-test-resources, process-test-resources, test-compile, process-test-classes, test, prepare-package, package, pre-integration-test, integration-test, post-integration-test, verify, install, deploy]
[DEBUG] Lifecycle clean -> [pre-clean, clean, post-clean]
[DEBUG] Lifecycle site -> [pre-site, site, post-site, site-deploy]
[DEBUG] === PROJECT BUILD PLAN ================================================
[DEBUG] Project: com.api:default:2.5-SNAPSHOT
[DEBUG] Dependencies (collect): []
[DEBUG] Dependencies (resolve): [compile+runtime]
[DEBUG] Repositories (dependencies): [spring.io (http://repo.spring.io/libs-release-remote, releases+snapshots), central (https://repo.maven.apache.org/maven2, releases)]
[DEBUG] Repositories (plugins) : [omitted]
[DEBUG] -----------------------------------------------------------------------
[DEBUG] Goal: org.owasp:dependency-check-maven:2.0.1:check (default-cli)
[DEBUG] Style: Regular
[DEBUG] Configuration: <?xml version="1.0" encoding="UTF-8"?>
<configuration>
<aggregate>${aggregate}</aggregate>
<archiveAnalyzerEnabled>${archiveAnalyzerEnabled}</archiveAnalyzerEnabled>
<assemblyAnalyzerEnabled>false</assemblyAnalyzerEnabled>
<autoUpdate>${autoUpdate}</autoUpdate>
<autoconfAnalyzerEnabled>${autoconfAnalyzerEnabled}</autoconfAnalyzerEnabled>
<bundleAuditAnalyzerEnabled>${bundleAuditAnalyzerEnabled}</bundleAuditAnalyzerEnabled>
<bundleAuditPath default-value="">${bundleAuditPath}</bundleAuditPath>
<centralAnalyzerEnabled>${centralAnalyzerEnabled}</centralAnalyzerEnabled>
<cmakeAnalyzerEnabled>${cmakeAnalyzerEnabled}</cmakeAnalyzerEnabled>
<cocoapodsAnalyzerEnabled>${cocoapodsAnalyzerEnabled}</cocoapodsAnalyzerEnabled>
<composerAnalyzerEnabled>${composerAnalyzerEnabled}</composerAnalyzerEnabled>
<connectionString default-value="">jdbc:h2:file:%s;FILE_LOCK=FS;AUTOCOMMIT=ON;</connectionString>
<connectionTimeout default-value="">${connectionTimeout}</connectionTimeout>
<cveUrl12Base default-value="">${cveUrl12Base}</cveUrl12Base>
<cveUrl12Modified default-value="">${cveUrl12Modified}</cveUrl12Modified>
<cveUrl20Base default-value="">${cveUrl20Base}</cveUrl20Base>
[Truncated]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: org.apache.maven.plugin.MojoExecutionException: An exception occurred connecting to the local database. Please see the log file for more details.
at org.owasp.dependencycheck.maven.CheckMojo.runCheck(CheckMojo.java:95)
at org.owasp.dependencycheck.maven.BaseDependencyCheckMojo.execute(BaseDependencyCheckMojo.java:514)
at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo(DefaultBuildPluginManager.java:132)
at org.apache.maven.lifecycle.internal.MojoExecutor.execute(MojoExecutor.java:208)
... 11 more
Caused by: org.owasp.dependencycheck.data.nvdcve.DatabaseException: Unable to connect to the database
at org.owasp.dependencycheck.data.nvdcve.ConnectionFactory.initialize(ConnectionFactory.java:164)
at org.owasp.dependencycheck.Engine.initializeEngine(Engine.java:129)
at org.owasp.dependencycheck.Engine.<init>(Engine.java:106)
at org.owasp.dependencycheck.maven.BaseDependencyCheckMojo.initializeEngine(BaseDependencyCheckMojo.java:881)
at org.owasp.dependencycheck.maven.CheckMojo.runCheck(CheckMojo.java:88)
... 14 more
[ERROR]
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/MojoExecutionException
```
username_2: I have just started to see the same exception with a Jenkins CI setup. The error is identical but on the `aggregate` goal.
```
org.owasp:dependency-check-maven:1.4.4.1:aggregate (default cli) on project xx: An exception occurred connecting to the local database. Please see the log file for more details. Unable to connect to the database -> [Help 1]
```
Unfortunately I'm unable to provide debug information, but thought it might be useful to know that someone else is experiencing the problem.
username_1: @username_2 are you also seeing:
```
Unable to connect to the database
org.h2.jdbc.JdbcSQLException: File corrupted while reading record: "146930 of 145738". Possible solution: use the recovery tool [90030-176]
at org.h2.message.DbException.getJdbcSQLException(DbException.java:344)
```
username_1: @username_0 if you delete the contents of `/home/web/dependency-check/1.4.3/cve-data/dc` and re-run the build - do you still get the error?
Status: Issue closed
|
fatih/vim-go | 451890688 | Title: Debugger breaks when stepping inside interface method call
Question:
username_0: ### What did you do? (required: The issue will be **closed** when not provided)
Set a breakpoint on the main function of https://github.com/username_0/delve_client_testing/blob/master/21autogen/main.go, started the debugger, used :GoDebugStep a bunch of times.
### What did you expect to happen?
End up inside main.IfaceImpl.Method.
### What happened instead?
Stuck inside an empty buffer.
### Configuration (**MUST** fill this out):
#### vim-go version:
#### `vimrc` you used to reproduce (use a *minimal* vimrc with other plugins disabled; do not link to a 2,000 line vimrc):
<details><summary>vimrc</summary><br><pre>
</pre></details>
#### Vim version (first three lines from `:version`):
<!-- :version -->
```
VIM - Vi IMproved 8.1 (2018 May 18, compiled May 27 2019 13:46:23)
Included patches: 1-1408
Modified by <EMAIL>
```
#### Go version (`go version`):
<!-- go version -->
go version go1.12.4 linux/amd64
#### Go environment
not relevant
Status: Issue closed
Answers:
username_1: I am unable to duplicate this with the current version of vim-go. There have been several improvements to vim-go and to delve since this issue was originally created; it's possible that any root cause was resolved by the many changes since this issue was reported. |
aboutyou/dart_packages | 786939870 | Title: How to refresh a token
Question:
username_0: Can any one please explain how can we refresh the token in the application side.
The first token we got is valid for only one day.
Answers:
username_1: @username_0 That depends on your server setup. For common languages (Go, PHP, etc.) there exist community-made SDKs to handle this for you.
Broadly speaking you need to convert the "first token" (authorization grant token) into a _refresh token_ right away (from you servers to Apple's). Then one is supposed to validate that the refresh token is "still in good standing" with Apple once a day.
The API in question is htusername_1s://developer.apple.com/documentation/sign_in_with_apple/generate_and_validate_tokens, but as said above, it's probably fastest to rely on an existing and proven SDK to handle this for you.
username_2: Is there an easy way to plug this into Firebase's refresh token functionality? |
rust-lang/cargo | 1068702814 | Title: Default install to --locked when used with --path
Question:
username_0: ### Problem
As a rust developer that eats his own dogfood, I often `cargo build --release` to test some things then `cargo install --path .` to deploy an application on the local machine. This invariably results in a complete from-scratch rebuild because cargo ignores the lock file. Can I please suggest that when used in combination with `--path` (perhaps only for local filesystem paths?) that `cargo install` should default to `--locked`?
* It's far faster
* It's the element of least surprise, since a user would expect to install what they just built and something totally different
* For potential contributors to git projects where the user clones the directory and then uses `cargo install` rather than installing from crates.io or from a git path (to cache build dependencies, to prevent downloading a huge git repo each time, etc, etc) this can often result in breakage because git master is working/passing _with the lock file_ but the user/dev gets a completely different output because the lock file is ignored, potentially causing build issues and a maintenance nightmare for project owners.
### Proposed Solution
When `cargo install --path` is used with a local path, it should by default respect the presence of any lock files.
### Notes
_No response_
Answers:
username_1: I'm not going to claim that the current behavior is intuitive. But this is a duplicate of #9436 and #7169, so let's continue the conversation where the history and arguments have been expressed.
Status: Issue closed
username_0: Thanks. I didn’t find anything relevant when I searched. |
bogdal/django-gcm | 124035118 | Title: django-gcm issue with sending message
Question:
username_0: I have followed the django-gcm documentation to setup gcm for my project. I was experiencing problems while sending message to gcm registered device, I was able to send something to the gcm registered device but on the android device it was coming as null. Here is the link I am following
http://django-gcm.readthedocs.org/en/latest/sending_messages.html
so I changed this line
my_phone.send_message('my test message', collapse_key='something')
to
my_phone.send_message({'message':'my test message'}, collapse_key='something')
and it got working fine for me and I am receiving a proper message so I am suggesting a little change in the documentation so that others won't get into problems.
Answers:
username_1: Fixed in #40
Status: Issue closed
|
cerner/terra-clinical | 227794878 | Title: Fallback text for icons in ActionHeader buttons
Question:
username_0: ### Description of Issue
The icons used in the action header buttons need to have fallback text in case the icons fail to load.
Answers:
username_1: @username_0 What are the cases where the icons fail to load?
username_0: @username_1 This was a change that was made recently in our legacy component. Looking back at the issue, it was with font icons failing to load. I'm not sure if this could still happen with svg icons.
Status: Issue closed
username_2: Closed with #50 |
Altinn/altinn-studio | 395538119 | Title: Misleading logout process
Question:
username_0: **Describe the bug**
When looking at service to another organization, the logout button is located under the name of that organization.
This makes me wonder what the logout will do. Do I logout myself? Or that organization?
**To Reproduce**
Steps to reproduce the behavior:
1. log in
2. View the service of another organization
3. Click on the name of the organization in the top menu
**Expected behavior**
Logout connected to my user, not organization
**Screenshots**

**Desktop (please complete the following information):**
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**Smartphone (please complete the following information):**
- Device: [e.g. iPhone6]
- OS: [e.g. iOS8.1]
- Browser [e.g. stock browser, safari]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
Status: Issue closed
Answers:
username_0: Duplicate of #1313, closing this |
gluon-lang/gluon_language-server | 679867219 | Title: Deadlock problems still exist in version 0.17
Question:
username_0: Try this code copied from https://github.com/gluon-lang/gluon/issues/842.
```
type Digit a =
| One a
| Two a a
| Three a a a
| Four a a a a
type Node b =
| Node2 b b
| Node3 b b b
type FingerTree c =
| Empty
| Single c
| Deep (Digit c) (FingerTree (Node c)) (Digit c)
type View d =
| Nil
| View d (FingerTree d)
rec let viewl xs : FingerTree e -> View e =
match xs with
| Empty -> Nil
| Single x -> View x Empty
| Deep (One a) deeper suffix ->
match viewl deeper with
| View (Node2 b c) rest -> View a (Deep (Two b c) rest suffix)
| View (Node3 b c d) rest -> View a (Deep (Three b c d) rest suffix)
| Nil ->
match suffix with
| One w -> View a (Single w)
| Two w x -> View a (Deep (One w) Empty (One x))
| Three w x y -> View a (Deep (Two w x) Empty (One y))
| Four w x y z -> View a (Deep (Three w x y) Empty (One z))
| Deep (Two a b) deeper suffix -> View a (Deep (One b) deeper suffix)
| Deep (Three a b c) deeper suffix -> View a (Deep (Two b c) deeper suffix)
| Deep (Four a b c d) deeper suffix -> View a (Deep (Three b c d) deeper suffix)
viewl
```
Find this line `type View d =`, modify the `d` to `a`, save the file. If nothing happens, modify `a` back to `d`, save. Repeat this procedure for a few times and the LSP would lock up.
Based on the experiences of my attempts to find out the problems, this probably happens here:
https://github.com/gluon-lang/gluon_language-server/blob/5465972e5e41481accc8cb14ddef1b470cd1f7c8/src/diagnostics.rs#L340-L342
But I didn't find out who is blocking it. |
bolt/core | 718197642 | Title: Support 'standard' Symfony .env options
Question:
username_0: At the moment Bolt 4 only supports one file for environment variables configuration: .env
Symfony supports overriding/extending .env based on the environment (.env.prod / env.test), and allows additional .local suffix for local changes not meant to be checked in to version control. This is really convenient.
See:
https://symfony.com/doc/current/configuration.html#configuring-environment-variables-in-env-files
https://symfony.com/doc/current/configuration.html#overriding-environment-values-via-env-local
I'd think supporting this wouldn't make anyone's existing config to break, but it will enable lots of developers with Symfony experience to use env files like they are used to.
How can you help?
-------------------------------
I can create a pull request, It looks like this could even be a 1 line change.
Answers:
username_0: Hmm, I just noticed:
```
// The check is to ensure we don't use .env in production
if (! isset($_SERVER['APP_ENV'])) {
```
This doesn't means this change will still work, and I don't see the setting of APP_ENV in the documentation. But it needs a second look - maybe it's only the comment that needs a change, like:
```
// The check is to ensure you can completely disable Dotenv loading by setting APP_ENV externally.
if (! isset($_SERVER['APP_ENV'])) {
```
Then it would be correct again. I've marked the PR as 'Draft' for the moment.
Status: Issue closed
|
ResearchComputing/RCAMP | 134638320 | Title: Allow users to associate other people with their projects
Question:
username_0: I see this as a list of strings, so random names and email addresses can be included; but we could later infer allocation membership by parsing these strings.
Answers:
username_1: If we require that they provide a list of e-mails, we could later send account request links to the emails provided.
username_0: Requiring an email address is not onerous, fair enough, and I'd be totally ok with this implementation; but I think even better would be if we *detect* the presence of an email address in an otherwise freetext input, and enable/disable a "send an account invitation" button dynamically based on that.
Status: Issue closed
username_0: review pending #76
username_0: I see this as a list of strings, so random names and email addresses can be included; but we could later infer allocation membership by parsing these strings.
username_0: As implemented, it looks like this doesn't support arbitrary people being associated with a project, which *is* what is described as the desired feature. In the interest of minimum-viable, though, I'm going to create a new issue to track that additional enhancement for __future__, and decide that this is sufficient for now.
Status: Issue closed
|
Azure/azure-sdk-for-java | 1006301147 | Title: [BUG][azure-spring-boot-starter-servicebus-jms][qpid] Message end in DLQ after MaxDeliveryCountExceeded even when message is processed without error/exception
Question:
username_0: This issue is related to azure support tickets
**TrackingID#2109220050000347** and **Ticket-number #11091792** detailed logs are attached in first ticket.
**Describe the bug**
We are consuming messages from servicebus (SB). While we don't see the spikes in SB everything works well. However when there's spike (a lot of incoming messages msgcount > 10k) messages are being retried and then put to DLQ with reason **MaxDeliveryCountExceeded**.
It seems like message commit is not processed correctly in servicebus and/or the commit is not delivered to SB and we don't see any error in client library.
***Exception or Stack Trace***
no stacktrace, no exception
**To Reproduce**
Steps to reproduce the behavior: that's a question to you, but probably put > 10k messages to SB and try to process them.
***Code Snippet***
Here in archivingUsageTrackingService we are sending message to another topic.
```java
@JmsListener(destination = "${azure.servicebus.queues.usageActivity}", containerFactory = JMS_FACTORY_NAME)
public void consume(UsageMessage usageMessage) {
log.info("UsageMessage received: {}", usageMessage);
usageTrackingService.processUsageMessage(usageMessage);
archivingUsageTrackingService.trackErsUsage(usageMessage);
}
```
Following is the config for queue/topic factories
```java
@Bean
public JmsListenerContainerFactory<?> fiscalJmsFactory(ConnectionFactory connectionFactory,
DefaultJmsListenerContainerFactoryConfigurer configurer) {
if (connectionFactory instanceof CachingConnectionFactory) {
CachingConnectionFactory cachingConnectionFactory = (CachingConnectionFactory) connectionFactory;
cachingConnectionFactory.setCacheProducers(false);
}
DefaultJmsListenerContainerFactory factory = new DfDefaultJmsListenerContainerFactory();
factory.setErrorHandler(t -> log.error("Unable to process JMS message", t));
factory.setExceptionListener(t -> log.error("Unable to process JMS message", t));
factory.setMessageConverter(jacksonJmsMessageConverter());
configurer.configure(factory, connectionFactory);
return factory;
}
@Bean
@ConditionalOnProperty(prefix = "df.azure.servicebus", name = "enableJmsTopic", havingValue = "true")
public JmsListenerContainerFactory<?> fiscalJmsTopicFactory(ConnectionFactory connectionFactory,
DefaultJmsListenerContainerFactoryConfigurer configurer) {
if (connectionFactory instanceof CachingConnectionFactory) {
CachingConnectionFactory cachingConnectionFactory = (CachingConnectionFactory) connectionFactory;
cachingConnectionFactory.setCacheProducers(false);
}
DefaultJmsListenerContainerFactory factory = new DfDefaultJmsListenerContainerFactory();
factory.setErrorHandler(t -> log.error("Unable to process JMS message", t));
factory.setExceptionListener(t -> log.error("Unable to process JMS message", t));
factory.setMessageConverter(jacksonJmsMessageConverter());
factory.setSubscriptionDurable(true);
configurer.configure(factory, connectionFactory);
return factory;
}
```
[Truncated]
**Expected behavior**
Whenever message is processed without any error it should be removed from SB queue and not moved to DLQ. **OR** when message couldn't be removed from queue because of any reason, we should see some error in client library.
**Screenshots**
Spike:

**Setup (please complete the following information):**
- OS: kubernetes
- Library/Libraries: azure-spring-boot-starter-servicebus-jms 3.7.0
- Java version: 11
- App Server/Environment: tomcat 9.0.52
- Frameworks: spring-boot 2.5.4
**Information Checklist**
Kindly make sure that you have added all the following information above and checkoff the required fields otherwise we will treat the issuer as an incomplete report
- [x] Bug Description Added
- [x] Repro Steps Added
- [x] Setup information Added
Answers:
username_1: 
And here you can see that there is some correlation between number of incoming messages and client errors. But our microservice always processes only one message concurrently and we have maximal 7 instances of this microservice. So we concurrently process only 7 messages. Our application does not have any high usage of resources during these peeks. When we resend these messages into the same queue then these messages are normally processed on the first attempt. And as you can see there is almost no user error only during these peeks. And our application is "pretty" fast because it is able to process all messages 10 times during 10min but it is not able to acknowledge them.
username_2: Hi @username_1 and @username_0 , thanks for your reporting. This is due to the default prefetch count of 1000 is used, and with your configuration of max-delivery-count and lock-duratition, the prefetched messages cannot be consumed before the configuration expire, so they are dead lettered. We will fix this soon by providing a configuration option of prefetch.
username_1: @username_2 Can you give us more details? Because I do not understand what you mean by prefetch. If I understand correctly the issue is in your library am I right? Is there the issue in `qpid-proton-j` or `qpid-jms` or ` spring-jms` or an Service Bus library or directly in Service Bus? Is there any workaround because we have to resend everyday thousands of messages so it is not ok for us. Increasing number of max delivery count does not help only restarting our application helped to process some messages I have already tested it on our testing environment.

Can you provide any date/milestone/plan when when it should be fixed? Why isn't there any error in logs?
username_2: @username_1 do you use the Service Bus Standard tier? I can reproduce your issue in standard tier but not the premium tier, and that's because in the [JmsConnectionFactory](https://github.com/Azure/azure-sdk-for-java/blob/81313a476b758f2d725bec9f70354612f6f881d9/sdk/spring/azure-spring-boot/src/main/java/com/azure/spring/autoconfigure/jms/NonPremiumServiceBusJMSAutoConfiguration.java#L27) of standard tier, we use the default prefetch count as 1000, which is defined in [Client configuration - Apache Qpid™](https://qpid.apache.org/releases/qpid-jms-0.55.0/docs/index.html) , that value controls how many messages the remote peer can send to the client and be held in a prefetch buffer for each consumer instance. And in your case, during the spike the consumer cannot process all the 1000 messages within the lock duration, then the lock will expire and the message will be dead lettered after retry over max-delivery-count.
So this issue could be resolved by configuring prefetch count as you need, for example , setting it as 0 means a pull consumer. But now our library doesn't support setting this. For a quick workaround, you could modify our bean of [jmsConnectionFactory](https://github.com/Azure/azure-sdk-for-java/blob/81313a476b758f2d725bec9f70354612f6f881d9/sdk/spring/azure-spring-boot/src/main/java/com/azure/spring/autoconfigure/jms/NonPremiumServiceBusJMSAutoConfiguration.java#L27) by a bean post processor and set the prefetch policy of it. For example,
```
@Component
public class AzureServiceBusBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof JmsConnectionFactory) {
JmsConnectionFactory jmsConnectionFactory = (JmsConnectionFactory) bean;
JmsDefaultPrefetchPolicy policy = new JmsDefaultPrefetchPolicy();
policy.setAll(0); // you should adjust the number according to the consuming capiblity of your application
jmsConnectionFactory.setPrefetchPolicy(policy);
}
return bean;
}
}
```
We plan to fix this in next month before our release in next month.
username_1: @username_2 Yes we use standard tier. I will test it we do not need to wait for your fix because we use our modified connection factory anyway. You can implement it as an general customizer which customize JmsConnectionFactory in the factory bean merhod. The strange thing is that it starts if there is more than 10 000 messages and then all communication with the queue in Azure Service Bus is completely dead locked until moving some messages to DLQ. You can see it in my graph that when it reached this limit then it was not able to acknowledge any message for 6hours (there was set max delivery count to 500). I still do not understand why if there is less than 10k messages this issue is not there and I can see it even if I have 7 or 3 client applications. It looks like there is some limitation directly in Azure Services Bus. Does premium tier use completely different library or API (I know it supports JMS 2.0).
username_2: @username_1 for premium tier we rely on another library of [com.microsoft.azure:azure-servicebus-jms:0.0.7](https://github.com/Azure/azure-servicebus-jms) for the connection factory, which sets the default value of prefetch as 0.
For the phenomanon in your case, could you share your configuration of the lock duration? And how long does it take for your client to consume one message? Also in the picture you provided, how many client applications were there in 6pm and when you adjusted the max dilivery count?
username_1: @username_2 There were 2-3 instances so I would say 3 because it scales fast. Lock duration is 1 min. And one message is processed in a few milliseconds (I checked randomly a few messages and it is +-4ms). In the second repetition it would be faster. So if I count correct then 10ms (per message) x 1000 messages = 10s so it should be ok and there is huge space to 1 min. I increased max delivery count at +- 6:50pm (I have already marked it in my graph). You can se that from +-7pm when it reached a limit then no message was acknowledged until 3am. But if you set prefetch to 0 then it would be pretty slow. I had to already disable producer caching so it is next slow down regarding Azure Services Bus.
username_2: @username_1 One of the possible reasons for the dead-locking is that, there is one message being consumed over the lock duration(1min), then it causes consuming-time * max-delivery-count of dead locking , because your client rotates in fetching it from SB and then consuming for 500 times. You could check if that's the reason by checking the longest consuming time of all messages and see if there are ones over your lock-duration. If so, perhaps you could consider add custom consuming logic for those messages instead of dealing with them directly. And just increasing max-diliverty-count might not be a good solution for it might expand some small issues.
username_1: @username_2 No it is impossible because I sent completely the same message (i change only created date) for testing 20 000 times and therefore the logic do the same thing all the time.
username_1: @username_2 Change prefetch policy to 0 works like a charm in my tests 👍. Can you set it as default value?
username_3: @username_2 Could you ping me internally, thanks
username_4: Hi @username_1 and @username_0, can you use command `ulimit -a` to see the number of file descriptors in the machine? I think it may because of the limit of the number of file descriptors, if so you can increase the number.
Also, I will change the code to set the default prefetch count as 0, and if time is enought I will also expose a parameter to set the prefetch count, and then I will release the library this month.
username_4: @username_1 we have release [azure-spring-boot-starter-servicebus-jms3.10.0](https://search.maven.org/artifact/com.azure.spring/azure-spring-boot-starter-servicebus-jms/3.10.0/jar), the parameter list is [here](https://github.com/Azure/azure-sdk-for-java/tree/main/sdk/spring/azure-spring-boot-starter-servicebus-jms#configuration-options). |
Intel-Media-SDK/MediaSDK | 894207418 | Title: MFXVideoENCODE_Reset failed when encoder is inited with mfxExtAvcTemporalLayers
Question:
username_0: Hi, I use MediaSDK to do h264 encoder and want do dynamci format change of mfxVideoENCODE by calling MFXVideoENCODE_Reset function but I have following problems
If I init mfxVideoENCODE without setting mfxExtAvcTemporalLayers, I can successfully call MFXVideoENCODE_Reset to dynamic change bitrate, profile, frame size etc during encoding
If I init mfxVideoENCODE with setting mfxExtAvcTemporalLayers like "{0,1,0,0,0,0,0,0}" or "{0,1,2,0,0,0,0,0}" or "{0,1,2,4,0,0,0,0}", MFXVideoENCODE_Reset always return MFX_ERR_INVALID_VIDEO_PARAM, no matter what new encoder paramter I set
So how to dynamic change encoder format when temporal layer is enabled? thanks
Answers:
username_1: Hi @DenWolf can you take a look?
username_2: Hi @username_0,
In general, MFXVideoENCODE_Reset should work with Temporal Layers feature.
Returning error status “MFX_ERR_INVALID_VIDEO_PARAM” means that something is wrong with Encoding parameters set at all (maybe not related to Temporal Layers directly).
Below are several tips what should be tried/checked:
First of all, presented programming of “mfxExtAvcTemporalLayers” like "{0,1,0,0,0,0,0,0}" or "{0,1,2,0,0,0,0,0}" or "{0,1,2,4,0,0,0,0}" is not correct – it should be "{1,0,0,0,0,0,0,0}" or "{1,2,0,0,0,0,0,0}" or "{1,2,4,0,0,0,0,0}".
Also, inside the “Reset” function there is the same full-parameters-scope checking as originally in “Init” function, so need to check correctness for all Reset parameters.
Then, better to clarify the reason/use-case of Reset calling – is it related to Temporal Layers setting change (ex: change number of layers) or just another encoding parameters (ex: resolution, bitrate, ..) – current information will be helpful.
Also note: if application has called the Reset without IDR directly and actual Reset for the frame not in the Base Layer – returning error MFX_ERR_INVALID_VIDEO_PARAM is expected.
Thanks & Regards,
Kristina
username_2: Hi @username_0 - If you still have any questions, please, let me know and reopen this ticket.
Thanks & Regards,
Kristina
Status: Issue closed
|
timsneath/time | 614924976 | Title: Consider running all tests under one run
Question:
username_0: ...generates a nice comparison output
```
#!/bin/bash
mkdir -p {dart,go,java}
dart2native hello.dart -o dart/hello
go build -o go hello.go
javac -d java hello.java
hyperfine --warmup 3 --export-markdown 'results.md' \
'./hello.sh' \
'go/hello' \
'go run hello.go' \
'dart/hello' \
'dart hello.dart' \
'java -cp java HelloWorld' \
'node hello.js' \
'python3 hello.py' \
'ruby hello.rb'
```
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
|:---|---:|---:|---:|---:|
| `./hello.sh` | 2.0 ± 0.5 | 0.7 | 3.9 | 1.00 |
| `go/hello` | 3.6 ± 0.4 | 2.4 | 5.5 | 1.81 ± 0.53 |
| `go run hello.go` | 299.2 ± 13.0 | 279.4 | 316.6 | 152.36 ± 42.48 |
| `dart/hello` | 10.3 ± 0.9 | 8.6 | 14.5 | 5.23 ± 1.52 |
| `dart hello.dart` | 600.9 ± 12.8 | 586.0 | 621.2 | 306.02 ± 84.53 |
| `java -cp java HelloWorld` | 107.7 ± 2.7 | 103.5 | 114.0 | 54.83 ± 15.16 |
| `node hello.js` | 70.4 ± 2.6 | 65.9 | 76.8 | 35.85 ± 9.96 |
| `python3 hello.py` | 32.3 ± 2.3 | 27.6 | 37.8 | 16.46 ± 4.68 |
| `ruby hello.rb` | 54.9 ± 3.0 | 51.0 | 66.1 | 27.98 ± 7.86 |
Answers:
username_1: Fixed with `https://github.com/username_1/time/blob/master/compare.sh`
Status: Issue closed
|
jbtule/keyczar-dotnet | 237246854 | Title: Insecure storage of private key set
Question:
username_0: Storing the private key set in the file system is insecure.
Consideration should be given to separate this process into its own library and allow for different storage methods for the key sets to be injected into the library. Such as a Key Vault (HSM), database or other more secure stores.
Answers:
username_1: Yeah, I agree. The `IKeySet` interface needs rethinking. Right now GetKeyData(int version) requires returning serialized json. While in private projects I've written my own IKeySet for alternative storage and have made that work, i wouldn't say it's ideal. So definitely something to consider.
username_0: I have also been working on different storage methods.
I'm happy to assist in getting this implemented, could you share your work with me and I'll see what I can put together.
username_1: I've been making changes to Keyczar in PR #10 based on an old proposal for official keyczar, that never went anywhere as their project stalled. It's released as a 0.8.0-alpha1 on nuget. It de-emphasizes the filesystem api's, and makes it more obvious how to combine keyset types for better security, by creating two interfaces `IRootProviderKeySet` and `ILayeredKeySet`. All the existing KeySets have been converted to those two interfaces. I'm going to be creating some new azure based keystores and proxies to the key vault in this new project https://github.com/username_1/Keyzure |
Xabaril/AspNetCore.Diagnostics.HealthChecks | 410718843 | Title: healthchecks-ui does not display all the healthchecks if the list is too long or the screen resolution too low
Question:
username_0: 
From the 25 registered services, only 21 are displayed with a screen resolution of 1920x1080
Answers:
username_1: Hi @username_0
@username_2 can you check this?
username_2: I made some changes to the UI so right now you scan use scroll to view a large number of services, and added some extra bottom margin. I also changed the css minifying process so it does not overwrite the source file.

username_2: HealthChecks.UI version 2.2.15 is being built and will be available soon in NuGet. I close the issue but feel to reopen if you find some issue @username_0
Status: Issue closed
|
electron/electron | 181300188 | Title: openDevTools ignores options
Question:
username_0: * Electron version: 1.4.2
* Operating system: Windows (have not tried it yet on Mac and Linux)
`webContents.openDevTools([options])` ignores any options given and defaults to either the last dock state or, if there are no user preferences yet, it will default to the right.
Status: Issue closed
Answers:
username_0: The issue still persists in 1.4.4. According to the change log it was fixed with this release. The only `mode` option that has any effect on how the developer tools window is opened is `detach`. Every other `mode` option is still opens the developer tools attached to the right.
username_2: 160000 commit <PASSWORD> vendor/brightray
```
/cc @username_3
username_3: Yeah, apologies for this, the brightray submodule wasn't bumped after the fix there was merged so it didn't make it in 1.4.4, will be in 1.4.5 though (and is on master).
username_4: I still got this problem in version 1.7.6. Have any special parameters or setting required to support this options? |
docker/for-mac | 342968393 | Title: IT's not starting
Question:
username_0: <!--
Please, check https://docs.docker.com/docker-for-mac/troubleshoot/.
Issues without logs and details cannot be debugged, and will be closed.
Issues unrelated to Docker for Mac will be closed. In particular, see
- https://github.com/docker/compose/issues for docker-compose
- https://github.com/docker/machine/issues for docker-machine
- https://github.com/moby/moby/issues for Docker daemon
- https://github.com/docker/docker.github.io/issues for the documentation
-->
<!--
Replace `- [ ]` with `- [x]`, or click after having submitted the issue.
-->
- [ ] I have tried with the latest version of my channel (Stable or Edge)
- [ ] I have uploaded Diagnostics
- Diagnostics ID:
### Expected behavior
### Actual behavior
### Information
<!--
Please, help us understand the problem. For instance:
- Is it reproducible?
- Is the problem new?
- Did the problem appear with an update?
- A reproducible case if this is a bug, Dockerfiles FTW.
-->
- macOS Version:
### Diagnostic logs
<!-- Full output of the diagnostics from "Diagnose & Feedback" in the menu ... -->
```
Docker for Mac: version...
```
### Steps to reproduce the behavior
<!--
A reproducible case, Dockerfiles FTW.
-->
1. ...
2. ...
Answers:
username_1: Closing as there are no diagnostics or detailed info to investigate the issue
Status: Issue closed
|
OpenSecuritySummit/oss2018 | 331487780 | Title: Review written outcomes statuses
Question:
username_0: - Some organizers forget to change the outcomes status from `draft` to `review-content` or `done`.
- Is an outcome has been finished, the status has been changed to `done`.
- Review the outcomes status.
Answers:
username_0: I'm going over all outcomes to see if some outcomes with a content still have `draft` status.
Status: Issue closed
username_0: I went over all outcomes files under `\content\outcomes` folder and I changed the status from `draft` to `review-content` for all outcomes that content has been written. |
thoughtbot/paul_revere | 339768372 | Title: Namespace announcement model
Question:
username_0: I guess it would be better if the `announcement` model is being under a namespace. Otherwise, it would be conflicted the host app.
Answers:
username_1: Chances are that if your host app has defined a model named `Announcement`, you aren't using this gem, you are likely doing a lot more.
#own2cents
Status: Issue closed
username_2: I'm going to close this because I don't think we plan on making this change.
If someone else wants to, I think either direction of:
- Use an actual namespace for the model and table
- Make the model name configurable
...are worth exploring. |
TediCross/TediCross | 426210061 | Title: Duplicated mapping key
Question:
username_0: /home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:171
throw generateError(state, message);
^
YAMLException: duplicated mapping key at line 26, column -395:
bridges:
^
at generateError (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:165:10)
at throwError (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:171:9)
at storeMappingPair (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:320:7)
at readBlockMapping (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1083:9)
at composeNode (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1344:12)
at readDocument (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1504:3)
at loadDocuments (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1560:5)
at load (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1581:19)
at Object.safeLoad (/home/killua/TediCross/node_modules/js-yaml/lib/js-yaml/loader.js:1603:10)
at Object.<anonymous> (/home/killua/TediCross/main.js:56:31)
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] start: `node main.js`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] start script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
```
What am I missing? The settings.yaml is correctly formatted.
Answers:
username_1: Can you post your settings.yaml? Please censor out the tokens and secrets first.
Status: Issue closed
username_0: Well, my bad. I duplicated the keyword "bridges" by accident. |
Jobeso/react-native-story-share | 435839030 | Title: Example project doesn't work
Question:
username_0: Hello!
I wanted to try the example project you have included in this repository to see how the library works, but that app seems to not do anything. I just ran `yarn` and then `react-native run-android`, and it runs successfully, but when clicking the "share to instagram" button, I get an error:

Am I missing something or is this a bug?
Answers:
username_1: Seems to be a bug then. Maybe it's related to missing storage write permissions. I'll check it out.
username_1: Was a permissions problem indeed. With the newest version permissions are not necessary anymore. Please checkout the example project, should work now.
Status: Issue closed
|
gpbl/react-day-picker | 204325717 | Title: error on example
Question:
username_0: url: http://react-day-picker.js.org/examples/?localizedMoment
THe example is not working and on console, I see this error.
```
Uncaught TypeError: Cannot read property 'firstDayOfWeek' of null
at Object.l [as getFirstDayOfWeek] (MomentLocaleUtils.js:47)
at Object.l [as getFirstDayOfWeekFromProps] (Helpers.js:50)
at t.value (DayPicker.js:419)
at t.value (DayPicker.js:477)
at d._renderValidatedComponentWithoutOwnerOrContext (ReactCompositeComponent.js:799)
at d._renderValidatedComponent (ReactCompositeComponent.js:822)
at d._updateRenderedComponent (ReactCompositeComponent.js:746)
at d._performComponentUpdate (ReactCompositeComponent.js:724)
at d.updateComponent (ReactCompositeComponent.js:645)
at d.receiveComponent (ReactCompositeComponent.js:547)
```
Answers:
username_1: Thanks for the report! Going to fix it soon
Status: Issue closed
|
KhronosGroup/glTF-Project-Explorer | 1009896662 | Title: V2 Brainstorming
Question:
username_0: This is an issue to brainstorm what V2 should be and to discuss what features we want.
Answers:
username_1: Some topics are already addressed (or at least mentioned) on other issues:
- The project explorer should be applicable to other projects.
- This refers to projects that are "similar" to glTF (in that they specify standards or file formats), and where general resources (applications, tutorials, libraries) should be listed. One specific example is https://github.com/KhronosGroup/glTF-Project-Explorer/issues/85
- This _might_ also refer to "things that are not so similar to glTF", namely tutorials, videos, articles and presentations, as suggested in https://github.com/KhronosGroup/glTF-Project-Explorer/issues/88
It has to be decided where to draw the line - i.e. whether there are significant structural differences that require different structures to represent the two, or whether an "Entry" in such a project explorer instance can reasonably be generalized so that it can cover a WebApplication and a YouTube video, without introducing too many contortions on the implementation level...
- The search functionality should be improved (c.f. https://github.com/KhronosGroup/glTF-Project-Explorer/issues/119 ).
- For me, this is the biggest topic. I noticed that when I had been searching something, I did not use the search+filter at all, but instead, just used the CTRL+F browser search. That's not good. A large part of this could already be covered by not only taking the project _`title`_ into account, but also the _`description`_. An alternative would be to abandon the `task`, and instead, allow users to define `keywords` that are dedicatedly used as "search terms that should cause that project to show up". Some initial thoughts are in https://github.com/KhronosGroup/glTF-Project-Explorer/issues/111
- One could consider using the search functionality of an existing CMS. The goal cannot be to re-implement some "on-site Google search"
- One could consider some sort of auto-completion. For example, when the user types in `"C++` in the search field, it could offer some convenient, dropdown-like auto-completion with options like
[type:importer]
[type:exporter]
[type:viewer]
that can be used to "drill down" and refine the search, in an exploratory style
- A "find similar projects" functionality would be nice. For example, someone might type in the name (or manually select) an existing "C++ glTF loader library with MIT license", and then hit a button to receive a list of other projects that match these tags. Yes, it will be necessary to quantify the _difference_ between "MIT" and "BSD", and between "C" and "C++" (ouch!), but it could be a _really_ useful feature for people who are looking for alternatives.
- It might be interesting to have some sort of visualization of the ecosystem.
This was mentioned in https://github.com/KhronosGroup/glTF-Project-Explorer/issues/83 , but I wonder whether this will be an "integral part" of the explorer itself, or whether it could be a completely independent project that just pulls from the same database, or whether it will be a mix of both, namely a visualization that builds on top of some sort of search+filter API that the explorer offers (thus, keeping the explorer "standalone", and creating a "visualizer" that only depends on the explorer via a small, clean interface)
username_0: I don't have the user journeys completely typed up yet, but I do have the low-detail wire frames finished. There are 3 layouts presented here, one for the Basic Layout, the Detailed Info screen, and the Card Layout. For the Card Layout I've presented 3 variants to show how different repository links will be represented in the card list on the Basic Layout screen.
# Basic Layout

# Detailed Info Layout

# Card Layout



username_2: It would be great if the projects that are established enough to have their own logos/icons could display them as you've shown in the final wireframe above.
username_0: I really like that idea, and I've spent the past few days mulling it over and seeing what we can do. I've narrowed down the possibilities for implementation to two options:
1. We allow users to upload a 64x64 SVG image of their logo, that will be referenced in the data file. This is my favorite option, but I believe we may run into potential legal issues if we don't require that the logo be licensed as CC-0 or CC-BY.
2. We allow users to link to a 64x64 SVG image that is on their site. I do not like this option, as it opens users up to several potential vulnerabilities.
I can't make the next Tooling TSG meeting but perhaps on the 17th we could discuss more about these options.
username_2: I don't think we can expect people's trademarks to be available as CC-anything. But in cases where a trademark is used on a link to the legitimate website for the trademarked product, I believe it's often allowable (but standard disclaimer, I am not a lawyer). This permission may need to be obtained on a product-by-product basis, however.
username_0: I am not a lawyer either, but I think the issue is the potential storage of the files. I do think you're right that we can't expect trademarks to be available as creative commons licensed. Probably worth a discussion with a lawyer.
username_0: I just opened #139 which replaces the simple title search with an indexed search. I'm going to leave it open for a week for comments.
Next up is redoing the design a bit. In order to make things a bit easier I am going to do a little refactoring to use something like tailwindcss. This will also help to solve a few issues with specific browsers. Should be done sometime next week with that PR. |
DefinitelyTyped/DefinitelyTyped | 188893218 | Title: Definition Request: reactstrap
Question:
username_0: I'm currently building type definitions for this library as I use it, so I'll eventually finish the whole thing.
However, if anyone has already written some, please contribute (or just link to a repo) to cut down on duplicate work. I can help with test coverage.
Answers:
username_1: The definitions of reactstrap have already been made. #15357
This should be closed now.
username_2: @username_0 can you close this?
username_0: Yes! I missed the last message.
Status: Issue closed
|
cyu/rack-cors | 177513740 | Title: Rails 5 -
Question:
username_0: File config.ru:
`use Rack::Cors do
allow do
origins 'localhost:3000', '127.0.0.1:3000',
/\Ahttp:\/\/192\.168\.0\.\d{1,3}(:\d+)?\z/
# regular expressions can be used here
resource '/file/list_all/', :headers => 'x-domain-token'
resource '/file/at/*',
:methods => [:get, :post, :delete, :put, :patch, :options, :head],
:headers => 'x-domain-token',
:expose => ['Some-Custom-Response-Header'],
:max_age => 600
# headers to expose
end
allow do
origins '*'
resource '/public/*', :headers => :any, :methods => :get
end
end`
File config/application.rb:
`config.middleware.insert_before 0, Rack::Cors do
allow do
origins '*'
resource '*', :headers => :any, :methods => [:get, :post, :options]
end
end`
Middleware output:
`use Rack::Cors
use Rack::Sendfile
use ActionDispatch::Static
use ActionDispatch::Executor
use ActiveSupport::Cache::Strategy::LocalCache::Middleware
use Rack::Runtime
use Rack::MethodOverride
use ActionDispatch::RequestId
use Rails::Rack::Logger
use ActionDispatch::ShowExceptions
use ActionDispatch::DebugExceptions
use ActionDispatch::RemoteIp
use ActionDispatch::Callbacks
use ActionDispatch::Cookies
use ActionDispatch::Session::CookieStore
use ActionDispatch::Flash
use Rack::Head
use Rack::ConditionalGet
use Rack::ETag
use Warden::Manager
run Kabrabom::Application.routes`
Postman's plugin results:
`Accept:text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01
X-DevTools-Emulate-Network-Conditions-Client-Id:747d2432-8d59-43e3-aa3e-62baac1833ca,747d2432-8d59-43e3-aa3e-62baac1833ca
Origin:http://kabrabom.herokuapp.com
User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Referer:http://kabrabom.herokuapp.com/professional_professions/new?_sm_au_=iFVn48qbQPRVWLGM
Accept-Encoding:gzip, deflate, sdch, br
Accept-Language:pt-BR,pt;q=0.8,en-US;q=0.6,en;q=0.4`
Important: I am connected by my company's proxy.
I d really thankfull if you @username_5 can help me.
Thanks!!!
Answers:
username_1: Ok do you have any update on this question ?
I'm having the same issue right now :-)
username_2: Any response to this problem? :'(
username_3: I also ran into several problems configuring cors, but in the end it was not rack-cors, but my configuration that was wrong. CORs configuration is difficult because it is precise; if Access-Control-Allow-Origin is not being returned it's because your request did not match your configuration /precisely/.
Looking at your config.ru, I can already guess your problem:
```ruby
resource '/file/list_all/', :headers => 'x-domain-token'
resource '/file/at/*',
:methods => [:get, :post, :delete, :put, :patch, :options, :head],
:headers => 'x-domain-token',
:expose => ['Some-Custom-Response-Header'],
:max_age => 600
```
First try setting `:headers` to `:any`. I bet you are setting the `Content-Type` of your requests, right? Because if you are, and you don't specify that in `headers`, it won't match the request, and thus `Access-Control-Allow-Origin` will not be returned.
My suggested strategy: start from the absolutely most laxed settings (match all origins, match all headers, etc), and one by one make changes to the settings to restrict. When something doesn't work, you'll need you made a mistake when the request starts to fail.
username_4: any news?
username_5: @username_0 What URL are you trying to access? I'm guessing since http://kabrabom.herokuapp.com isn't in the first resource set that you're trying to access the /public/ resources right?
username_6: Im having trouble with sub domain origins being accepted by rack cors.
username_7: @username_0 Were you able to resolve your issue? Please tell me if you did, I am facing the same problem.
username_8: @username_0 were you able to find a fix? I've run into the same problem strangely because it worked perfectly the day before and suddenly, it's stopped.
username_5: I'm closing this issue because of inactivity from the original submitter.
If you're still having problems. Please create a new issue and provide the specifics.
Status: Issue closed
|
halcy/Mastodon.py | 483540225 | Title: Function to get your own user_id
Question:
username_0: Functions like ``account_followers`` require a user id, even when you want to lookup your own followers.
There seems to be no easy way to get your own id in Mastodon.py, so you need to find it using some workaround like reading the user dict from one of your own toots.
Can something like ``.account_info()`` be added, that returns the user dict for your own account?
Answers:
username_1: that function is account_verify_credentials. I am not fond of the name either. Docs could specifically point this out, I guess?
Sent from my iPhone
>
username_0: Indeed, that's what I was looking for.
What about adding it to the examples at the top of the docs? Quite a few functions need your own user id to work, so it might be a good idea to show a small example how it is used.
Maybe a two line example "read your follower list" could be added, that shows getting your account info and then using the id to fetch your follower list.
username_1: I'm considering just making the docs more clear, and possibly adding a function alias for this one thing like we have for reply, which needs updating anyways (oops), probably called "me()" or something.
Status: Issue closed
|
WarEmu/WarBugs | 118830552 | Title: Collection of some engineer bugs I found.
Question:
username_0: Morale 4 abilities are like whack a mole, once your morale is full and you can use the m4 ability they pop up and go back to not usable I pretty much had to spam my F4 key and left mouse button to activate it.
Napalm grenade and the tactic throwing arm (25% extra range on grenadier abilities) don't work together the tooltip says 81ft range but when I throw it at max range nothing happens and the ability starts the 30 second cooldown. Similar to most of the ground target abilities if you throw them out of range they do nothing and a cooldown starts.
The turret always looks in the direction of the engineer unless it has a target to attack its probably taking me as friendly target.
The Bugmans keg is missing the animation.
Sometimes the turret tooltip doesnt show its abilities.
Answers:
username_1: One report per problem, please.
Turret abilities disappearing is known, no need to report that.
Status: Issue closed
|
nickbabcock/Pfim | 426765612 | Title: Targa bottom / top right images
Question:
username_0: Images that are targa encoded with the orientation at the bottom right or top right seem very rare (ie: no program I've seen allows one to save in those formats), and these images are decoded differently depending on the program.



While paint.net (first image) and gimp (third image) decode the image how I would expect -- image glass (second image) defaults to decoding as bottom left, which is the current behavior of Pfim until I determine what is the correct coarse of action. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.