
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
cbcf2fd16f24ea9d7a6b6520c336dae1d7060f5f
| 24,532 |
ipynb
|
Jupyter Notebook
|
03_CRS_Map_Projections.ipynb
|
reeshav-netizen/Geospatial-Fundamentals-in-Python
|
637e2d93f4763c9fdeeffc36d317396bdc9e16bf
|
[
"MIT"
] | 21 |
2019-12-01T03:22:51.000Z
|
2021-09-11T08:02:27.000Z
|
03_CRS_Map_Projections.ipynb
|
dongyi1996/Geospatial-Fundamentals-in-Python
|
0d9b61622b0ba2b1c5ec1f03c851ba36ae3a1282
|
[
"MIT"
] | 9 |
2020-11-17T20:58:27.000Z
|
2021-06-29T23:46:54.000Z
|
03_CRS_Map_Projections.ipynb
|
dongyi1996/Geospatial-Fundamentals-in-Python
|
0d9b61622b0ba2b1c5ec1f03c851ba36ae3a1282
|
[
"MIT"
] | 19 |
2019-06-29T22:16:28.000Z
|
2021-08-25T14:12:26.000Z
| 28.725995 | 303 | 0.582056 |
[
[
[
"# Lesson 3. Coordinate Reference Systems (CRS) & Map Projections\n\nBuilding off of what we learned in the previous notebook, we'll get to understand an integral aspect of geospatial data: Coordinate Reference Systems.\n\n- 3.1 California County Shapefile\n- 3.2 USA State Shapefile\n- 3.3 Plot the Two Together\n- 3.4 Coordinate Reference System (CRS)\n- 3.5 Getting the CRS\n- 3.6 Setting the CRS\n- 3.7 Transforming or Reprojecting the CRS\n- 3.8 Plotting States and Counties Togther\n- 3.9 Recap\n- **Exercise**: CRS Management\n\n<br>\n<font color='grey'>\n <b>Instructor Notes</b>\n\n- Datasets used\n - ‘notebook_data/california_counties/CaliforniaCounties.shp’\n - ‘notebook_data/us_states/us_states.shp’\n - ‘notebook_data/census/Places/cb_2018_06_place_500k.zip’\n\n- Expected time to complete\n - Lecture + Questions: 45 minutes\n - Exercises: 10 minutes\n</font>",
"_____no_output_____"
],
[
"### Import Libraries",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport geopandas as gpd\n\nimport matplotlib # base python plotting library\nimport matplotlib.pyplot as plt # submodule of matplotlib\n\n# To display plots, maps, charts etc in the notebook\n%matplotlib inline ",
"_____no_output_____"
]
],
[
[
"## 3.1 California County shapefile\nLet's go ahead and bring back in our California County shapefile. As before, we can read the file in using `gpd.read_file` and plot it straight away.",
"_____no_output_____"
]
],
[
[
"counties = gpd.read_file('notebook_data/california_counties/CaliforniaCounties.shp')\ncounties.plot(color='darkgreen')",
"_____no_output_____"
]
],
[
[
"Even if we have an awesome map like this, sometimes we want to have more geographical context, or we just want additional information. We're going to try **overlaying** our counties GeoDataFrame on our USA states shapefile.",
"_____no_output_____"
],
[
"## 3.2 USA State shapefile\n\nWe're going to bring in our states geodataframe, and let's do the usual operations to start exploring our data.",
"_____no_output_____"
]
],
[
[
"# Read in states shapefile\nstates = gpd.read_file('notebook_data/us_states/us_states.shp')",
"_____no_output_____"
],
[
"# Look at the first few rows\nstates.head()",
"_____no_output_____"
],
[
"# Count how many rows and columns we have\nstates.shape",
"_____no_output_____"
],
[
"# Plot our states data\nstates.plot()",
"_____no_output_____"
]
],
[
[
"You might have noticed that our plot extends beyond the 50 states (which we also saw when we executed the `shape` method). Let's double check what states we have included in our data.",
"_____no_output_____"
]
],
[
[
"states['STATE'].values",
"_____no_output_____"
]
],
[
[
"Beyond the 50 states we seem to have American Samoa, Puerto Rico, Guam, Commonwealth of the Northern Mariana Islands, and United States Virgin Islands included in this geodataframe. To make our map cleaner, let's limit the states to the contiguous states (so we'll also exclude Alaska and Hawaii).",
"_____no_output_____"
]
],
[
[
"# Define list of non-contiguous states\nnon_contiguous_us = [ 'American Samoa','Puerto Rico','Guam',\n 'Commonwealth of the Northern Mariana Islands',\n 'United States Virgin Islands', 'Alaska','Hawaii']\n# Limit data according to above list\nstates_limited = states.loc[~states['STATE'].isin(non_contiguous_us)]",
"_____no_output_____"
],
[
"# Plot it\nstates_limited.plot()",
"_____no_output_____"
]
],
[
[
"To prepare for our mapping overlay, let's make our states a nice, light grey color.",
"_____no_output_____"
]
],
[
[
"states_limited.plot(color='lightgrey', figsize=(10,10))",
"_____no_output_____"
]
],
[
[
"## 3.3 Plot the two together\n\nNow that we have both geodataframes in our environment, we can plot both in the same figure.\n\n**NOTE**: To do this, note that we're getting a Matplotlib Axes object (`ax`), then explicitly adding each our layers to it\nby providing the `ax=ax` argument to the `plot` method.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(10,10))\ncounties.plot(color='darkgreen',ax=ax)\nstates_limited.plot(color='lightgrey', ax=ax)",
"_____no_output_____"
]
],
[
[
"Oh no, what happened here?\n\n<img src=\"http://www.pngall.com/wp-content/uploads/2016/03/Light-Bulb-Free-PNG-Image.png\" width=\"20\" align=left > **Question** Without looking ahead, what do you think happened?\n\n",
"_____no_output_____"
]
],
[
[
"Your response here:\n\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"<br>\n<br>\nIf you look at the numbers we have on the x and y axes in our two plots, you'll see that the county data has much larger numbers than our states data. It's represented in some different type of unit other than decimal degrees! \n\nIn fact, that means if we zoom in really close into our plot we'll probably see the states data plotted. ",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfig, ax = plt.subplots(figsize=(10,10))\ncounties.plot(color='darkgreen',ax=ax)\nstates_limited.plot(color='lightgrey', ax=ax)\nax.set_xlim(-140,-50)\nax.set_ylim(20,50)",
"_____no_output_____"
]
],
[
[
"This is a key issue that you'll have to resolve time and time again when working with geospatial data!\n\nIt all revolves around **coordinate reference systems** and **projections**.",
"_____no_output_____"
],
[
"----------------------------\n\n## 3.4 Coordinate Reference Systems (CRS)",
"_____no_output_____"
],
[
"<img src=\"http://www.pngall.com/wp-content/uploads/2016/03/Light-Bulb-Free-PNG-Image.png\" width=\"20\" align=left > **Question** Do you have experience with Coordinate Reference Systems?",
"_____no_output_____"
]
],
[
[
"Your response here:\n\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"<br><br>As a refresher, a CRS describes how the coordinates in a geospatial dataset relate to locations on the surface of the earth. \n\nA `geographic CRS` consists of: \n- a 3D model of the shape of the earth (a **datum**), approximated as a sphere or spheroid (aka ellipsoid)\n- the **units** of the coordinate system (e.g, decimal degrees, meters, feet) and \n- the **origin** (i.e. the 0,0 location), specified as the meeting of the **equator** and the **prime meridian**( \n\nA `projected CRS` consists of\n- a geographic CRS\n- a **map projection** and related parameters used to transform the geographic coordinates to `2D` space.\n - a map projection is a mathematical model used to transform coordinate data\n\n### A Geographic vs Projected CRS\n<img src =\"https://www.e-education.psu.edu/natureofgeoinfo/sites/www.e-education.psu.edu.natureofgeoinfo/files/image/projection.gif\" height=\"100\" width=\"500\">",
"_____no_output_____"
],
[
"#### There are many, many CRSs\n\nTheoretically the number of CRSs is unlimited!\n\nWhy? Primariy, because there are many different definitions of the shape of the earth, multiplied by many different ways to cast its surface into 2 dimensions. Our understanding of the earth's shape and our ability to measure it has changed greatly over time.\n\n#### Why are CRSs Important?\n\n- You need to know the data about your data (or `metadata`) to use it appropriately.\n\n\n- All projected CRSs introduce distortion in shape, area, and/or distance. So understanding what CRS best maintains the characteristics you need for your area of interest and your analysis is important.\n\n\n- Some analysis methods expect geospatial data to be in a projected CRS\n - For example, `geopandas` expects a geodataframe to be in a projected CRS for area or distance based analyses.\n\n\n- Some Python libraries, but not all, implement dynamic reprojection from the input CRS to the required CRS and assume a specific CRS (WGS84) when a CRS is not explicitly defined.\n\n\n- Most Python spatial libraries, including Geopandas, require geospatial data to be in the same CRS if they are being analysed together.\n\n#### What you need to know when working with CRSs\n\n- What CRSs used in your study area and their main characteristics\n- How to identify, or `get`, the CRS of a geodataframe\n- How to `set` the CRS of geodataframe (i.e. define the projection)\n- Hot to `transform` the CRS of a geodataframe (i.e. reproject the data)",
"_____no_output_____"
],
[
"### Codes for CRSs commonly used with CA data\n\nCRSs are typically referenced by an [EPSG code](http://wiki.gis.com/wiki/index.php/European_Petroleum_Survey_Group). \n\nIt's important to know the commonly used CRSs and their EPSG codes for your geographic area of interest. \n\nFor example, below is a list of commonly used CRSs for California geospatial data along with their EPSG codes.\n\n##### Geographic CRSs\n-`4326: WGS84` (units decimal degrees) - the most commonly used geographic CRS\n\n-`4269: NAD83` (units decimal degrees) - the geographic CRS customized to best fit the USA. This is used by all Census geographic data.\n\n> `NAD83 (epsg:4269)` are approximately the same as `WGS84(epsg:4326)` although locations can differ by up to 1 meter in the continental USA and elsewhere up to 3m. That is not a big issue with census tract data as these data are only accurate within +/-7meters.\n##### Projected CRSs\n\n-`5070: CONUS NAD83` (units meters) projected CRS for mapping the entire contiguous USA (CONUS)\n\n-`3857: Web Mercator` (units meters) conformal (shape preserving) CRS used as the default in web mapping\n\n-`3310: CA Albers Equal Area, NAD83` (units meters) projected CRS for CA statewide mapping and spatial analysis\n\n-`26910: UTM Zone 10N, NAD83` (units meters) projected CRS for northern CA mapping & analysis\n\n-`26911: UTM Zone 11N, NAD83` (units meters) projected CRS for Southern CA mapping & analysis\n\n-`102641 to 102646: CA State Plane zones 1-6, NAD83` (units feet) projected CRS used for local analysis.\n\nYou can find the full CRS details on the website https://www.spatialreference.org",
"_____no_output_____"
],
[
"## 3.5 Getting the CRS\n\n### Getting the CRS of a gdf\n\nGeoPandas GeoDataFrames have a `crs` attribute that returns the CRS of the data.",
"_____no_output_____"
]
],
[
[
"counties.crs",
"_____no_output_____"
],
[
"states_limited.crs",
"_____no_output_____"
]
],
[
[
"As we can clearly see from those two printouts (even if we don't understand all the content!),\nthe CRSs of our two datasets are different! **This explains why we couldn't overlay them correctly!**",
"_____no_output_____"
],
[
"-----------------------------------------\nThe above CRS definition specifies \n- the name of the CRS (`WGS84`), \n- the axis units (`degree`)\n- the shape (`datum`),\n- and the origin (`Prime Meridian`, and the equator)\n- and the area for which it is best suited (`World`)\n\n> Notes:\n> - `geocentric` latitude and longitude assume a spherical (round) model of the shape of the earth\n> - `geodetic` latitude and longitude assume a spheriodal (ellipsoidal) model, which is closer to the true shape.\n> - `geodesy` is the study of the shape of the earth.",
"_____no_output_____"
],
[
"**NOTE**: If you print a `crs` call, Python will just display the EPSG code used to initiate the CRS object. Depending on your versions of Geopandas and its dependencies, this may or may not look different from what we just saw above.",
"_____no_output_____"
]
],
[
[
"print(states_limited.crs)",
"_____no_output_____"
]
],
[
[
"## 3.6 Setting the CRS\n\nYou can also set the CRS of a gdf using the `crs` attribute. You would set the CRS if is not defined or if you think it is incorrectly defined.\n\n> In desktop GIS terminology setting the CRS is called **defining the CRS**\n\nAs an example, let's set the CRS of our data to `None`",
"_____no_output_____"
]
],
[
[
"# first set the CRS to None\nstates_limited.crs = None",
"_____no_output_____"
],
[
"# Check it again\nstates_limited.crs",
"_____no_output_____"
]
],
[
[
"...hummm...\n\nIf a variable has a null value (None) then displaying it without printing it won't display anything!",
"_____no_output_____"
]
],
[
[
"# Check it again\nprint(states_limited.crs)",
"_____no_output_____"
]
],
[
[
"Now we'll set it back to its correct CRS.",
"_____no_output_____"
]
],
[
[
"# Set it to 4326\nstates_limited.crs = \"epsg:4326\"",
"_____no_output_____"
],
[
"# Show it\nstates_limited.crs",
"_____no_output_____"
]
],
[
[
"**NOTE**: You can set the CRS to anything you like, but **that doesn't make it correct**! This is because setting the CRS does not change the coordinate data; it just tells the software how to interpret it.",
"_____no_output_____"
],
[
"## 3.7 Transforming or Reprojecting the CRS\nYou can transform the CRS of a geodataframe with the `to_crs` method.\n\n\n> In desktop GIS terminology transforming the CRS is called **projecting the data** (or **reprojecting the data**)\n\nWhen you do this you want to save the output to a new GeoDataFrame.",
"_____no_output_____"
]
],
[
[
"states_limited_utm10 = states_limited.to_crs( \"epsg:26910\")",
"_____no_output_____"
]
],
[
[
"Now take a look at the CRS.",
"_____no_output_____"
]
],
[
[
"states_limited_utm10.crs",
"_____no_output_____"
]
],
[
[
"You can see the result immediately by plotting the data.",
"_____no_output_____"
]
],
[
[
"# plot geographic gdf\nstates_limited.plot();\nplt.axis('square');\n\n# plot utm gdf\nstates_limited_utm10.plot();\nplt.axis('square')",
"_____no_output_____"
],
[
"# Your thoughts here",
"_____no_output_____"
]
],
[
[
"<div style=\"display:inline-block;vertical-align:top;\">\n <img src=\"http://www.pngall.com/wp-content/uploads/2016/03/Light-Bulb-Free-PNG-Image.png\" width=\"30\" align=left > \n</div> \n<div style=\"display:inline-block;\">\n\n#### Questions\n</div>\n\n1. What two key differences do you see between the two plots above?\n1. Do either of these plotted USA maps look good?\n1. Try looking at the common CRS EPSG codes above and see if any of them look better for the whole country than what we have now. Then try transforming the states data to the CRS that you think would be best and plotting it. (Use the code cell two cells below.)",
"_____no_output_____"
]
],
[
[
"Your responses here:\n\n\n\n\n\n",
"_____no_output_____"
]
],
[
[
"# YOUR CODE HERE\n\n\n\n",
"_____no_output_____"
]
],
[
[
"**Double-click to see solution!**\n\n<!--\n#SOLUTION \nstates_limited_conus = states_limited.to_crs(\"epsg:5070\")\nstates_limited_conus.plot();\nplt.axis('square')\n-->",
"_____no_output_____"
],
[
"## 3.8 Plotting states and counties together\n\nNow that we know what a CRS is and how we can set them, let's convert our counties GeoDataFrame to match up with out states' crs.",
"_____no_output_____"
]
],
[
[
"# Convert counties data to NAD83 \ncounties_utm10 = counties.to_crs(\"epsg:26910\")",
"_____no_output_____"
],
[
"counties_utm10.plot()",
"_____no_output_____"
],
[
"# Plot it together!\nfig, ax = plt.subplots(figsize=(10,10))\nstates_limited_utm10.plot(color='lightgrey', ax=ax)\ncounties_utm10.plot(color='darkgreen',ax=ax)",
"_____no_output_____"
]
],
[
[
"Since we know that the best CRS to plot the contiguous US from the above question is 5070, let's also transform and plot everything in that CRS.",
"_____no_output_____"
]
],
[
[
"counties_conus = counties.to_crs(\"epsg:5070\")",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(10,10))\nstates_limited_conus.plot(color='lightgrey', ax=ax)\ncounties_conus.plot(color='darkgreen',ax=ax)",
"_____no_output_____"
]
],
[
[
"## 3.9 Recap\n\nIn this lesson we learned about...\n- Coordinate Reference Systems \n- Getting the CRS of a geodataframe\n - `crs`\n- Transforming/repojecting CRS\n - `to_crs`\n- Overlaying maps",
"_____no_output_____"
],
[
"## Exercise: CRS Management\n\nNow it's time to take a crack and managing the CRS of a new dataset. In the code cell below, write code to:\n\n1. Bring in the CA places data (`notebook_data/census/Places/cb_2018_06_place_500k.zip`)\n2. Check if the CRS is EPSG code 26910. If not, transform the CRS\n3. Plot the California counties and places together.\n\nTo see the solution, double-click the Markdown cell below.",
"_____no_output_____"
]
],
[
[
"# YOUR CODE HERE\n\n",
"_____no_output_____"
]
],
[
[
"## Double-click to see solution!\n\n<!--\n\n# SOLUTION\n\n# 1. Bring in the CA places data\ncalifornia_places = gpd.read_file('zip://notebook_data/census/Places/cb_2018_06_place_500k.zip')\ncalifornia_places.head()\n\n# 2. Check and transorm the CRS if needed\ncalifornia_places.crs\ncalifornia_places_utm10 = california_places.to_crs( \"epsg:26910\")\n\n# 3. Plot the California counties and places together\nfig, ax = plt.subplots(figsize=(10,10))\ncounties_utm10.plot(color='lightgrey', ax=ax)\ncalifornia_places_utm10 .plot(color='purple',ax=ax)\n\n-->",
"_____no_output_____"
],
[
"---\n<div style=\"display:inline-block;vertical-align:middle;\">\n<a href=\"https://dlab.berkeley.edu/\" target=\"_blank\"><img src =\"assets/images/dlab_logo.png\" width=\"75\" align=\"left\">\n</a>\n</div>\n\n<div style=\"display:inline-block;vertical-align:middle;\">\n <div style=\"font-size:larger\"> D-Lab @ University of California - Berkeley</div>\n <div> Team Geo<div>\n</div>\n \n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"raw",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"raw"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"raw"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbcf305980e03b1fbe9b172a159d72e8b48299f4
| 865,931 |
ipynb
|
Jupyter Notebook
|
05_support_vector_machines.ipynb
|
jtao/handson-ml2
|
52bec3d49b8c76b1131f6eea143f6825142de0f7
|
[
"Apache-2.0"
] | null | null | null |
05_support_vector_machines.ipynb
|
jtao/handson-ml2
|
52bec3d49b8c76b1131f6eea143f6825142de0f7
|
[
"Apache-2.0"
] | null | null | null |
05_support_vector_machines.ipynb
|
jtao/handson-ml2
|
52bec3d49b8c76b1131f6eea143f6825142de0f7
|
[
"Apache-2.0"
] | null | null | null | 295.136673 | 167,748 | 0.922117 |
[
[
[
"**Chapter 5 – Support Vector Machines**\n\n_This notebook contains all the sample code and solutions to the exercises in chapter 5._",
"_____no_output_____"
],
[
"<table align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/jtao/handson-ml2/blob/master/05_support_vector_machines.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Setup",
"_____no_output_____"
],
[
"First, let's import a few common modules, ensure MatplotLib plots figures inline and prepare a function to save the figures. We also check that Python 3.5 or later is installed (although Python 2.x may work, it is deprecated so we strongly recommend you use Python 3 instead), as well as Scikit-Learn ≥0.20.",
"_____no_output_____"
]
],
[
[
"# Python ≥3.5 is required\nimport sys\nassert sys.version_info >= (3, 5)\n\n# Scikit-Learn ≥0.20 is required\nimport sklearn\nassert sklearn.__version__ >= \"0.20\"\n\n# Common imports\nimport numpy as np\nimport os\n\n# to make this notebook's output stable across runs\nnp.random.seed(42)\n\n# To plot pretty figures\n%matplotlib inline\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nmpl.rc('axes', labelsize=14)\nmpl.rc('xtick', labelsize=12)\nmpl.rc('ytick', labelsize=12)\n\n# Where to save the figures\nPROJECT_ROOT_DIR = \".\"\nCHAPTER_ID = \"svm\"\nIMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, \"images\", CHAPTER_ID)\nos.makedirs(IMAGES_PATH, exist_ok=True)\n\ndef save_fig(fig_id, tight_layout=True, fig_extension=\"png\", resolution=300):\n path = os.path.join(IMAGES_PATH, fig_id + \".\" + fig_extension)\n print(\"Saving figure\", fig_id)\n if tight_layout:\n plt.tight_layout()\n plt.savefig(path, format=fig_extension, dpi=resolution)",
"_____no_output_____"
]
],
[
[
"# Large margin classification",
"_____no_output_____"
],
[
"The next few code cells generate the first figures in chapter 5. The first actual code sample comes after:",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVC\nfrom sklearn import datasets\n\niris = datasets.load_iris()\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = iris[\"target\"]\n\nsetosa_or_versicolor = (y == 0) | (y == 1)\nX = X[setosa_or_versicolor]\ny = y[setosa_or_versicolor]\n\n# SVM Classifier model\nsvm_clf = SVC(kernel=\"linear\", C=float(\"inf\"))\nsvm_clf.fit(X, y)",
"_____no_output_____"
],
[
"# Bad models\nx0 = np.linspace(0, 5.5, 200)\npred_1 = 5*x0 - 20\npred_2 = x0 - 1.8\npred_3 = 0.1 * x0 + 0.5\n\ndef plot_svc_decision_boundary(svm_clf, xmin, xmax):\n w = svm_clf.coef_[0]\n b = svm_clf.intercept_[0]\n\n # At the decision boundary, w0*x0 + w1*x1 + b = 0\n # => x1 = -w0/w1 * x0 - b/w1\n x0 = np.linspace(xmin, xmax, 200)\n decision_boundary = -w[0]/w[1] * x0 - b/w[1]\n\n margin = 1/w[1]\n gutter_up = decision_boundary + margin\n gutter_down = decision_boundary - margin\n\n svs = svm_clf.support_vectors_\n plt.scatter(svs[:, 0], svs[:, 1], s=180, facecolors='#FFAAAA')\n plt.plot(x0, decision_boundary, \"k-\", linewidth=2)\n plt.plot(x0, gutter_up, \"k--\", linewidth=2)\n plt.plot(x0, gutter_down, \"k--\", linewidth=2)\n\nfig, axes = plt.subplots(ncols=2, figsize=(10,2.7), sharey=True)\n\nplt.sca(axes[0])\nplt.plot(x0, pred_1, \"g--\", linewidth=2)\nplt.plot(x0, pred_2, \"m-\", linewidth=2)\nplt.plot(x0, pred_3, \"r-\", linewidth=2)\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"bs\", label=\"Iris versicolor\")\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"yo\", label=\"Iris setosa\")\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.legend(loc=\"upper left\", fontsize=14)\nplt.axis([0, 5.5, 0, 2])\n\nplt.sca(axes[1])\nplot_svc_decision_boundary(svm_clf, 0, 5.5)\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"bs\")\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"yo\")\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.axis([0, 5.5, 0, 2])\n\nsave_fig(\"large_margin_classification_plot\")\nplt.show()",
"Saving figure large_margin_classification_plot\n"
]
],
[
[
"# Sensitivity to feature scales",
"_____no_output_____"
]
],
[
[
"Xs = np.array([[1, 50], [5, 20], [3, 80], [5, 60]]).astype(np.float64)\nys = np.array([0, 0, 1, 1])\nsvm_clf = SVC(kernel=\"linear\", C=100)\nsvm_clf.fit(Xs, ys)\n\nplt.figure(figsize=(9,2.7))\nplt.subplot(121)\nplt.plot(Xs[:, 0][ys==1], Xs[:, 1][ys==1], \"bo\")\nplt.plot(Xs[:, 0][ys==0], Xs[:, 1][ys==0], \"ms\")\nplot_svc_decision_boundary(svm_clf, 0, 6)\nplt.xlabel(\"$x_0$\", fontsize=20)\nplt.ylabel(\"$x_1$ \", fontsize=20, rotation=0)\nplt.title(\"Unscaled\", fontsize=16)\nplt.axis([0, 6, 0, 90])\n\nfrom sklearn.preprocessing import StandardScaler\nscaler = StandardScaler()\nX_scaled = scaler.fit_transform(Xs)\nsvm_clf.fit(X_scaled, ys)\n\nplt.subplot(122)\nplt.plot(X_scaled[:, 0][ys==1], X_scaled[:, 1][ys==1], \"bo\")\nplt.plot(X_scaled[:, 0][ys==0], X_scaled[:, 1][ys==0], \"ms\")\nplot_svc_decision_boundary(svm_clf, -2, 2)\nplt.xlabel(\"$x'_0$\", fontsize=20)\nplt.ylabel(\"$x'_1$ \", fontsize=20, rotation=0)\nplt.title(\"Scaled\", fontsize=16)\nplt.axis([-2, 2, -2, 2])\n\nsave_fig(\"sensitivity_to_feature_scales_plot\")\n",
"Saving figure sensitivity_to_feature_scales_plot\n"
]
],
[
[
"# Sensitivity to outliers",
"_____no_output_____"
]
],
[
[
"X_outliers = np.array([[3.4, 1.3], [3.2, 0.8]])\ny_outliers = np.array([0, 0])\nXo1 = np.concatenate([X, X_outliers[:1]], axis=0)\nyo1 = np.concatenate([y, y_outliers[:1]], axis=0)\nXo2 = np.concatenate([X, X_outliers[1:]], axis=0)\nyo2 = np.concatenate([y, y_outliers[1:]], axis=0)\n\nsvm_clf2 = SVC(kernel=\"linear\", C=10**9)\nsvm_clf2.fit(Xo2, yo2)\n\nfig, axes = plt.subplots(ncols=2, figsize=(10,2.7), sharey=True)\n\nplt.sca(axes[0])\nplt.plot(Xo1[:, 0][yo1==1], Xo1[:, 1][yo1==1], \"bs\")\nplt.plot(Xo1[:, 0][yo1==0], Xo1[:, 1][yo1==0], \"yo\")\nplt.text(0.3, 1.0, \"Impossible!\", fontsize=24, color=\"red\")\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.annotate(\"Outlier\",\n xy=(X_outliers[0][0], X_outliers[0][1]),\n xytext=(2.5, 1.7),\n ha=\"center\",\n arrowprops=dict(facecolor='black', shrink=0.1),\n fontsize=16,\n )\nplt.axis([0, 5.5, 0, 2])\n\nplt.sca(axes[1])\nplt.plot(Xo2[:, 0][yo2==1], Xo2[:, 1][yo2==1], \"bs\")\nplt.plot(Xo2[:, 0][yo2==0], Xo2[:, 1][yo2==0], \"yo\")\nplot_svc_decision_boundary(svm_clf2, 0, 5.5)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.annotate(\"Outlier\",\n xy=(X_outliers[1][0], X_outliers[1][1]),\n xytext=(3.2, 0.08),\n ha=\"center\",\n arrowprops=dict(facecolor='black', shrink=0.1),\n fontsize=16,\n )\nplt.axis([0, 5.5, 0, 2])\n\nsave_fig(\"sensitivity_to_outliers_plot\")\nplt.show()",
"Saving figure sensitivity_to_outliers_plot\n"
]
],
[
[
"# Large margin *vs* margin violations",
"_____no_output_____"
],
[
"This is the first code example in chapter 5:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom sklearn import datasets\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.svm import LinearSVC\n\niris = datasets.load_iris()\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = (iris[\"target\"] == 2).astype(np.float64) # Iris virginica\n\nsvm_clf = Pipeline([\n (\"scaler\", StandardScaler()),\n (\"linear_svc\", LinearSVC(C=1, loss=\"hinge\", random_state=42)),\n ])\n\nsvm_clf.fit(X, y)",
"_____no_output_____"
],
[
"svm_clf.predict([[5.5, 1.7]])",
"_____no_output_____"
]
],
[
[
"Now let's generate the graph comparing different regularization settings:",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\nsvm_clf1 = LinearSVC(C=1, loss=\"hinge\", random_state=42)\nsvm_clf2 = LinearSVC(C=100, loss=\"hinge\", random_state=42)\n\nscaled_svm_clf1 = Pipeline([\n (\"scaler\", scaler),\n (\"linear_svc\", svm_clf1),\n ])\nscaled_svm_clf2 = Pipeline([\n (\"scaler\", scaler),\n (\"linear_svc\", svm_clf2),\n ])\n\nscaled_svm_clf1.fit(X, y)\nscaled_svm_clf2.fit(X, y)",
"/Users/jtao/miniconda3/envs/tf2/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.\n \"the number of iterations.\", ConvergenceWarning)\n"
],
[
"# Convert to unscaled parameters\nb1 = svm_clf1.decision_function([-scaler.mean_ / scaler.scale_])\nb2 = svm_clf2.decision_function([-scaler.mean_ / scaler.scale_])\nw1 = svm_clf1.coef_[0] / scaler.scale_\nw2 = svm_clf2.coef_[0] / scaler.scale_\nsvm_clf1.intercept_ = np.array([b1])\nsvm_clf2.intercept_ = np.array([b2])\nsvm_clf1.coef_ = np.array([w1])\nsvm_clf2.coef_ = np.array([w2])\n\n# Find support vectors (LinearSVC does not do this automatically)\nt = y * 2 - 1\nsupport_vectors_idx1 = (t * (X.dot(w1) + b1) < 1).ravel()\nsupport_vectors_idx2 = (t * (X.dot(w2) + b2) < 1).ravel()\nsvm_clf1.support_vectors_ = X[support_vectors_idx1]\nsvm_clf2.support_vectors_ = X[support_vectors_idx2]",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(ncols=2, figsize=(10,2.7), sharey=True)\n\nplt.sca(axes[0])\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"g^\", label=\"Iris virginica\")\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"bs\", label=\"Iris versicolor\")\nplot_svc_decision_boundary(svm_clf1, 4, 5.9)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.legend(loc=\"upper left\", fontsize=14)\nplt.title(\"$C = {}$\".format(svm_clf1.C), fontsize=16)\nplt.axis([4, 5.9, 0.8, 2.8])\n\nplt.sca(axes[1])\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"g^\")\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"bs\")\nplot_svc_decision_boundary(svm_clf2, 4, 5.99)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.title(\"$C = {}$\".format(svm_clf2.C), fontsize=16)\nplt.axis([4, 5.9, 0.8, 2.8])\n\nsave_fig(\"regularization_plot\")",
"Saving figure regularization_plot\n"
]
],
[
[
"# Non-linear classification",
"_____no_output_____"
]
],
[
[
"X1D = np.linspace(-4, 4, 9).reshape(-1, 1)\nX2D = np.c_[X1D, X1D**2]\ny = np.array([0, 0, 1, 1, 1, 1, 1, 0, 0])\n\nplt.figure(figsize=(10, 3))\n\nplt.subplot(121)\nplt.grid(True, which='both')\nplt.axhline(y=0, color='k')\nplt.plot(X1D[:, 0][y==0], np.zeros(4), \"bs\")\nplt.plot(X1D[:, 0][y==1], np.zeros(5), \"g^\")\nplt.gca().get_yaxis().set_ticks([])\nplt.xlabel(r\"$x_1$\", fontsize=20)\nplt.axis([-4.5, 4.5, -0.2, 0.2])\n\nplt.subplot(122)\nplt.grid(True, which='both')\nplt.axhline(y=0, color='k')\nplt.axvline(x=0, color='k')\nplt.plot(X2D[:, 0][y==0], X2D[:, 1][y==0], \"bs\")\nplt.plot(X2D[:, 0][y==1], X2D[:, 1][y==1], \"g^\")\nplt.xlabel(r\"$x_1$\", fontsize=20)\nplt.ylabel(r\"$x_2$ \", fontsize=20, rotation=0)\nplt.gca().get_yaxis().set_ticks([0, 4, 8, 12, 16])\nplt.plot([-4.5, 4.5], [6.5, 6.5], \"r--\", linewidth=3)\nplt.axis([-4.5, 4.5, -1, 17])\n\nplt.subplots_adjust(right=1)\n\nsave_fig(\"higher_dimensions_plot\", tight_layout=False)\nplt.show()",
"Saving figure higher_dimensions_plot\n"
],
[
"from sklearn.datasets import make_moons\nX, y = make_moons(n_samples=100, noise=0.15, random_state=42)\n\ndef plot_dataset(X, y, axes):\n plt.plot(X[:, 0][y==0], X[:, 1][y==0], \"bs\")\n plt.plot(X[:, 0][y==1], X[:, 1][y==1], \"g^\")\n plt.axis(axes)\n plt.grid(True, which='both')\n plt.xlabel(r\"$x_1$\", fontsize=20)\n plt.ylabel(r\"$x_2$\", fontsize=20, rotation=0)\n\nplot_dataset(X, y, [-1.5, 2.5, -1, 1.5])\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.datasets import make_moons\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import PolynomialFeatures\n\npolynomial_svm_clf = Pipeline([\n (\"poly_features\", PolynomialFeatures(degree=3)),\n (\"scaler\", StandardScaler()),\n (\"svm_clf\", LinearSVC(C=10, loss=\"hinge\", random_state=42))\n ])\n\npolynomial_svm_clf.fit(X, y)",
"/Users/jtao/miniconda3/envs/tf2/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.\n \"the number of iterations.\", ConvergenceWarning)\n"
],
[
"def plot_predictions(clf, axes):\n x0s = np.linspace(axes[0], axes[1], 100)\n x1s = np.linspace(axes[2], axes[3], 100)\n x0, x1 = np.meshgrid(x0s, x1s)\n X = np.c_[x0.ravel(), x1.ravel()]\n y_pred = clf.predict(X).reshape(x0.shape)\n y_decision = clf.decision_function(X).reshape(x0.shape)\n plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2)\n plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1)\n\nplot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5])\nplot_dataset(X, y, [-1.5, 2.5, -1, 1.5])\n\nsave_fig(\"moons_polynomial_svc_plot\")\nplt.show()",
"Saving figure moons_polynomial_svc_plot\n"
],
[
"from sklearn.svm import SVC\n\npoly_kernel_svm_clf = Pipeline([\n (\"scaler\", StandardScaler()),\n (\"svm_clf\", SVC(kernel=\"poly\", degree=3, coef0=1, C=5))\n ])\npoly_kernel_svm_clf.fit(X, y)",
"_____no_output_____"
],
[
"poly100_kernel_svm_clf = Pipeline([\n (\"scaler\", StandardScaler()),\n (\"svm_clf\", SVC(kernel=\"poly\", degree=10, coef0=100, C=5))\n ])\npoly100_kernel_svm_clf.fit(X, y)",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(ncols=2, figsize=(10.5, 4), sharey=True)\n\nplt.sca(axes[0])\nplot_predictions(poly_kernel_svm_clf, [-1.5, 2.45, -1, 1.5])\nplot_dataset(X, y, [-1.5, 2.4, -1, 1.5])\nplt.title(r\"$d=3, r=1, C=5$\", fontsize=18)\n\nplt.sca(axes[1])\nplot_predictions(poly100_kernel_svm_clf, [-1.5, 2.45, -1, 1.5])\nplot_dataset(X, y, [-1.5, 2.4, -1, 1.5])\nplt.title(r\"$d=10, r=100, C=5$\", fontsize=18)\nplt.ylabel(\"\")\n\nsave_fig(\"moons_kernelized_polynomial_svc_plot\")\nplt.show()",
"Saving figure moons_kernelized_polynomial_svc_plot\n"
],
[
"def gaussian_rbf(x, landmark, gamma):\n return np.exp(-gamma * np.linalg.norm(x - landmark, axis=1)**2)\n\ngamma = 0.3\n\nx1s = np.linspace(-4.5, 4.5, 200).reshape(-1, 1)\nx2s = gaussian_rbf(x1s, -2, gamma)\nx3s = gaussian_rbf(x1s, 1, gamma)\n\nXK = np.c_[gaussian_rbf(X1D, -2, gamma), gaussian_rbf(X1D, 1, gamma)]\nyk = np.array([0, 0, 1, 1, 1, 1, 1, 0, 0])\n\nplt.figure(figsize=(10.5, 4))\n\nplt.subplot(121)\nplt.grid(True, which='both')\nplt.axhline(y=0, color='k')\nplt.scatter(x=[-2, 1], y=[0, 0], s=150, alpha=0.5, c=\"red\")\nplt.plot(X1D[:, 0][yk==0], np.zeros(4), \"bs\")\nplt.plot(X1D[:, 0][yk==1], np.zeros(5), \"g^\")\nplt.plot(x1s, x2s, \"g--\")\nplt.plot(x1s, x3s, \"b:\")\nplt.gca().get_yaxis().set_ticks([0, 0.25, 0.5, 0.75, 1])\nplt.xlabel(r\"$x_1$\", fontsize=20)\nplt.ylabel(r\"Similarity\", fontsize=14)\nplt.annotate(r'$\\mathbf{x}$',\n xy=(X1D[3, 0], 0),\n xytext=(-0.5, 0.20),\n ha=\"center\",\n arrowprops=dict(facecolor='black', shrink=0.1),\n fontsize=18,\n )\nplt.text(-2, 0.9, \"$x_2$\", ha=\"center\", fontsize=20)\nplt.text(1, 0.9, \"$x_3$\", ha=\"center\", fontsize=20)\nplt.axis([-4.5, 4.5, -0.1, 1.1])\n\nplt.subplot(122)\nplt.grid(True, which='both')\nplt.axhline(y=0, color='k')\nplt.axvline(x=0, color='k')\nplt.plot(XK[:, 0][yk==0], XK[:, 1][yk==0], \"bs\")\nplt.plot(XK[:, 0][yk==1], XK[:, 1][yk==1], \"g^\")\nplt.xlabel(r\"$x_2$\", fontsize=20)\nplt.ylabel(r\"$x_3$ \", fontsize=20, rotation=0)\nplt.annotate(r'$\\phi\\left(\\mathbf{x}\\right)$',\n xy=(XK[3, 0], XK[3, 1]),\n xytext=(0.65, 0.50),\n ha=\"center\",\n arrowprops=dict(facecolor='black', shrink=0.1),\n fontsize=18,\n )\nplt.plot([-0.1, 1.1], [0.57, -0.1], \"r--\", linewidth=3)\nplt.axis([-0.1, 1.1, -0.1, 1.1])\n \nplt.subplots_adjust(right=1)\n\nsave_fig(\"kernel_method_plot\")\nplt.show()",
"Saving figure kernel_method_plot\n"
],
[
"x1_example = X1D[3, 0]\nfor landmark in (-2, 1):\n k = gaussian_rbf(np.array([[x1_example]]), np.array([[landmark]]), gamma)\n print(\"Phi({}, {}) = {}\".format(x1_example, landmark, k))",
"Phi(-1.0, -2) = [0.74081822]\nPhi(-1.0, 1) = [0.30119421]\n"
],
[
"rbf_kernel_svm_clf = Pipeline([\n (\"scaler\", StandardScaler()),\n (\"svm_clf\", SVC(kernel=\"rbf\", gamma=5, C=0.001))\n ])\nrbf_kernel_svm_clf.fit(X, y)",
"_____no_output_____"
],
[
"from sklearn.svm import SVC\n\ngamma1, gamma2 = 0.1, 5\nC1, C2 = 0.001, 1000\nhyperparams = (gamma1, C1), (gamma1, C2), (gamma2, C1), (gamma2, C2)\n\nsvm_clfs = []\nfor gamma, C in hyperparams:\n rbf_kernel_svm_clf = Pipeline([\n (\"scaler\", StandardScaler()),\n (\"svm_clf\", SVC(kernel=\"rbf\", gamma=gamma, C=C))\n ])\n rbf_kernel_svm_clf.fit(X, y)\n svm_clfs.append(rbf_kernel_svm_clf)\n\nfig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10.5, 7), sharex=True, sharey=True)\n\nfor i, svm_clf in enumerate(svm_clfs):\n plt.sca(axes[i // 2, i % 2])\n plot_predictions(svm_clf, [-1.5, 2.45, -1, 1.5])\n plot_dataset(X, y, [-1.5, 2.45, -1, 1.5])\n gamma, C = hyperparams[i]\n plt.title(r\"$\\gamma = {}, C = {}$\".format(gamma, C), fontsize=16)\n if i in (0, 1):\n plt.xlabel(\"\")\n if i in (1, 3):\n plt.ylabel(\"\")\n\nsave_fig(\"moons_rbf_svc_plot\")\nplt.show()",
"Saving figure moons_rbf_svc_plot\n"
]
],
[
[
"# Regression\n",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\nm = 50\nX = 2 * np.random.rand(m, 1)\ny = (4 + 3 * X + np.random.randn(m, 1)).ravel()",
"_____no_output_____"
],
[
"from sklearn.svm import LinearSVR\n\nsvm_reg = LinearSVR(epsilon=1.5, random_state=42)\nsvm_reg.fit(X, y)",
"_____no_output_____"
],
[
"svm_reg1 = LinearSVR(epsilon=1.5, random_state=42)\nsvm_reg2 = LinearSVR(epsilon=0.5, random_state=42)\nsvm_reg1.fit(X, y)\nsvm_reg2.fit(X, y)\n\ndef find_support_vectors(svm_reg, X, y):\n y_pred = svm_reg.predict(X)\n off_margin = (np.abs(y - y_pred) >= svm_reg.epsilon)\n return np.argwhere(off_margin)\n\nsvm_reg1.support_ = find_support_vectors(svm_reg1, X, y)\nsvm_reg2.support_ = find_support_vectors(svm_reg2, X, y)\n\neps_x1 = 1\neps_y_pred = svm_reg1.predict([[eps_x1]])",
"_____no_output_____"
],
[
"def plot_svm_regression(svm_reg, X, y, axes):\n x1s = np.linspace(axes[0], axes[1], 100).reshape(100, 1)\n y_pred = svm_reg.predict(x1s)\n plt.plot(x1s, y_pred, \"k-\", linewidth=2, label=r\"$\\hat{y}$\")\n plt.plot(x1s, y_pred + svm_reg.epsilon, \"k--\")\n plt.plot(x1s, y_pred - svm_reg.epsilon, \"k--\")\n plt.scatter(X[svm_reg.support_], y[svm_reg.support_], s=180, facecolors='#FFAAAA')\n plt.plot(X, y, \"bo\")\n plt.xlabel(r\"$x_1$\", fontsize=18)\n plt.legend(loc=\"upper left\", fontsize=18)\n plt.axis(axes)\n\nfig, axes = plt.subplots(ncols=2, figsize=(9, 4), sharey=True)\nplt.sca(axes[0])\nplot_svm_regression(svm_reg1, X, y, [0, 2, 3, 11])\nplt.title(r\"$\\epsilon = {}$\".format(svm_reg1.epsilon), fontsize=18)\nplt.ylabel(r\"$y$\", fontsize=18, rotation=0)\n#plt.plot([eps_x1, eps_x1], [eps_y_pred, eps_y_pred - svm_reg1.epsilon], \"k-\", linewidth=2)\nplt.annotate(\n '', xy=(eps_x1, eps_y_pred), xycoords='data',\n xytext=(eps_x1, eps_y_pred - svm_reg1.epsilon),\n textcoords='data', arrowprops={'arrowstyle': '<->', 'linewidth': 1.5}\n )\nplt.text(0.91, 5.6, r\"$\\epsilon$\", fontsize=20)\nplt.sca(axes[1])\nplot_svm_regression(svm_reg2, X, y, [0, 2, 3, 11])\nplt.title(r\"$\\epsilon = {}$\".format(svm_reg2.epsilon), fontsize=18)\nsave_fig(\"svm_regression_plot\")\nplt.show()",
"Saving figure svm_regression_plot\n"
],
[
"np.random.seed(42)\nm = 100\nX = 2 * np.random.rand(m, 1) - 1\ny = (0.2 + 0.1 * X + 0.5 * X**2 + np.random.randn(m, 1)/10).ravel()",
"_____no_output_____"
]
],
[
[
"**Note**: to be future-proof, we set `gamma=\"scale\"`, as this will be the default value in Scikit-Learn 0.22.",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVR\n\nsvm_poly_reg = SVR(kernel=\"poly\", degree=2, C=100, epsilon=0.1, gamma=\"scale\")\nsvm_poly_reg.fit(X, y)",
"_____no_output_____"
],
[
"from sklearn.svm import SVR\n\nsvm_poly_reg1 = SVR(kernel=\"poly\", degree=2, C=100, epsilon=0.1, gamma=\"scale\")\nsvm_poly_reg2 = SVR(kernel=\"poly\", degree=2, C=0.01, epsilon=0.1, gamma=\"scale\")\nsvm_poly_reg1.fit(X, y)\nsvm_poly_reg2.fit(X, y)",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(ncols=2, figsize=(9, 4), sharey=True)\nplt.sca(axes[0])\nplot_svm_regression(svm_poly_reg1, X, y, [-1, 1, 0, 1])\nplt.title(r\"$degree={}, C={}, \\epsilon = {}$\".format(svm_poly_reg1.degree, svm_poly_reg1.C, svm_poly_reg1.epsilon), fontsize=18)\nplt.ylabel(r\"$y$\", fontsize=18, rotation=0)\nplt.sca(axes[1])\nplot_svm_regression(svm_poly_reg2, X, y, [-1, 1, 0, 1])\nplt.title(r\"$degree={}, C={}, \\epsilon = {}$\".format(svm_poly_reg2.degree, svm_poly_reg2.C, svm_poly_reg2.epsilon), fontsize=18)\nsave_fig(\"svm_with_polynomial_kernel_plot\")\nplt.show()",
"Saving figure svm_with_polynomial_kernel_plot\n"
]
],
[
[
"# Under the hood",
"_____no_output_____"
]
],
[
[
"iris = datasets.load_iris()\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = (iris[\"target\"] == 2).astype(np.float64) # Iris virginica",
"_____no_output_____"
],
[
"from mpl_toolkits.mplot3d import Axes3D\n\ndef plot_3D_decision_function(ax, w, b, x1_lim=[4, 6], x2_lim=[0.8, 2.8]):\n x1_in_bounds = (X[:, 0] > x1_lim[0]) & (X[:, 0] < x1_lim[1])\n X_crop = X[x1_in_bounds]\n y_crop = y[x1_in_bounds]\n x1s = np.linspace(x1_lim[0], x1_lim[1], 20)\n x2s = np.linspace(x2_lim[0], x2_lim[1], 20)\n x1, x2 = np.meshgrid(x1s, x2s)\n xs = np.c_[x1.ravel(), x2.ravel()]\n df = (xs.dot(w) + b).reshape(x1.shape)\n m = 1 / np.linalg.norm(w)\n boundary_x2s = -x1s*(w[0]/w[1])-b/w[1]\n margin_x2s_1 = -x1s*(w[0]/w[1])-(b-1)/w[1]\n margin_x2s_2 = -x1s*(w[0]/w[1])-(b+1)/w[1]\n ax.plot_surface(x1s, x2, np.zeros_like(x1),\n color=\"b\", alpha=0.2, cstride=100, rstride=100)\n ax.plot(x1s, boundary_x2s, 0, \"k-\", linewidth=2, label=r\"$h=0$\")\n ax.plot(x1s, margin_x2s_1, 0, \"k--\", linewidth=2, label=r\"$h=\\pm 1$\")\n ax.plot(x1s, margin_x2s_2, 0, \"k--\", linewidth=2)\n ax.plot(X_crop[:, 0][y_crop==1], X_crop[:, 1][y_crop==1], 0, \"g^\")\n ax.plot_wireframe(x1, x2, df, alpha=0.3, color=\"k\")\n ax.plot(X_crop[:, 0][y_crop==0], X_crop[:, 1][y_crop==0], 0, \"bs\")\n ax.axis(x1_lim + x2_lim)\n ax.text(4.5, 2.5, 3.8, \"Decision function $h$\", fontsize=16)\n ax.set_xlabel(r\"Petal length\", fontsize=16, labelpad=10)\n ax.set_ylabel(r\"Petal width\", fontsize=16, labelpad=10)\n ax.set_zlabel(r\"$h = \\mathbf{w}^T \\mathbf{x} + b$\", fontsize=18, labelpad=5)\n ax.legend(loc=\"upper left\", fontsize=16)\n\nfig = plt.figure(figsize=(11, 6))\nax1 = fig.add_subplot(111, projection='3d')\nplot_3D_decision_function(ax1, w=svm_clf2.coef_[0], b=svm_clf2.intercept_[0])\n\nsave_fig(\"iris_3D_plot\")\nplt.show()",
"Saving figure iris_3D_plot\n"
]
],
[
[
"# Small weight vector results in a large margin",
"_____no_output_____"
]
],
[
[
"def plot_2D_decision_function(w, b, ylabel=True, x1_lim=[-3, 3]):\n x1 = np.linspace(x1_lim[0], x1_lim[1], 200)\n y = w * x1 + b\n m = 1 / w\n\n plt.plot(x1, y)\n plt.plot(x1_lim, [1, 1], \"k:\")\n plt.plot(x1_lim, [-1, -1], \"k:\")\n plt.axhline(y=0, color='k')\n plt.axvline(x=0, color='k')\n plt.plot([m, m], [0, 1], \"k--\")\n plt.plot([-m, -m], [0, -1], \"k--\")\n plt.plot([-m, m], [0, 0], \"k-o\", linewidth=3)\n plt.axis(x1_lim + [-2, 2])\n plt.xlabel(r\"$x_1$\", fontsize=16)\n if ylabel:\n plt.ylabel(r\"$w_1 x_1$ \", rotation=0, fontsize=16)\n plt.title(r\"$w_1 = {}$\".format(w), fontsize=16)\n\nfig, axes = plt.subplots(ncols=2, figsize=(9, 3.2), sharey=True)\nplt.sca(axes[0])\nplot_2D_decision_function(1, 0)\nplt.sca(axes[1])\nplot_2D_decision_function(0.5, 0, ylabel=False)\nsave_fig(\"small_w_large_margin_plot\")\nplt.show()",
"Saving figure small_w_large_margin_plot\n"
],
[
"from sklearn.svm import SVC\nfrom sklearn import datasets\n\niris = datasets.load_iris()\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = (iris[\"target\"] == 2).astype(np.float64) # Iris virginica\n\nsvm_clf = SVC(kernel=\"linear\", C=1)\nsvm_clf.fit(X, y)\nsvm_clf.predict([[5.3, 1.3]])",
"_____no_output_____"
]
],
[
[
"# Hinge loss",
"_____no_output_____"
]
],
[
[
"t = np.linspace(-2, 4, 200)\nh = np.where(1 - t < 0, 0, 1 - t) # max(0, 1-t)\n\nplt.figure(figsize=(5,2.8))\nplt.plot(t, h, \"b-\", linewidth=2, label=\"$max(0, 1 - t)$\")\nplt.grid(True, which='both')\nplt.axhline(y=0, color='k')\nplt.axvline(x=0, color='k')\nplt.yticks(np.arange(-1, 2.5, 1))\nplt.xlabel(\"$t$\", fontsize=16)\nplt.axis([-2, 4, -1, 2.5])\nplt.legend(loc=\"upper right\", fontsize=16)\nsave_fig(\"hinge_plot\")\nplt.show()",
"Saving figure hinge_plot\n"
]
],
[
[
"# Extra material",
"_____no_output_____"
],
[
"## Training time",
"_____no_output_____"
]
],
[
[
"X, y = make_moons(n_samples=1000, noise=0.4, random_state=42)\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"bs\")\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"g^\")",
"_____no_output_____"
],
[
"import time\n\ntol = 0.1\ntols = []\ntimes = []\nfor i in range(10):\n svm_clf = SVC(kernel=\"poly\", gamma=3, C=10, tol=tol, verbose=1)\n t1 = time.time()\n svm_clf.fit(X, y)\n t2 = time.time()\n times.append(t2-t1)\n tols.append(tol)\n print(i, tol, t2-t1)\n tol /= 10\nplt.semilogx(tols, times, \"bo-\")\nplt.xlabel(\"Tolerance\", fontsize=16)\nplt.ylabel(\"Time (seconds)\", fontsize=16)\nplt.grid(True)\nplt.show()",
"[LibSVM]0 0.1 0.2017989158630371\n[LibSVM]1 0.01 0.19569611549377441\n[LibSVM]2 0.001 0.23690319061279297\n[LibSVM]3 0.0001 0.41855812072753906\n[LibSVM]4 1e-05 0.7902979850769043\n[LibSVM]5 1.0000000000000002e-06 0.6455130577087402\n[LibSVM]6 1.0000000000000002e-07 0.7135508060455322\n[LibSVM]7 1.0000000000000002e-08 0.7550830841064453\n[LibSVM]8 1.0000000000000003e-09 0.8036937713623047\n[LibSVM]9 1.0000000000000003e-10 0.7757120132446289\n"
]
],
[
[
"## Linear SVM classifier implementation using Batch Gradient Descent",
"_____no_output_____"
]
],
[
[
"# Training set\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = (iris[\"target\"] == 2).astype(np.float64).reshape(-1, 1) # Iris virginica",
"_____no_output_____"
],
[
"from sklearn.base import BaseEstimator\n\nclass MyLinearSVC(BaseEstimator):\n def __init__(self, C=1, eta0=1, eta_d=10000, n_epochs=1000, random_state=None):\n self.C = C\n self.eta0 = eta0\n self.n_epochs = n_epochs\n self.random_state = random_state\n self.eta_d = eta_d\n\n def eta(self, epoch):\n return self.eta0 / (epoch + self.eta_d)\n \n def fit(self, X, y):\n # Random initialization\n if self.random_state:\n np.random.seed(self.random_state)\n w = np.random.randn(X.shape[1], 1) # n feature weights\n b = 0\n\n m = len(X)\n t = y * 2 - 1 # -1 if t==0, +1 if t==1\n X_t = X * t\n self.Js=[]\n\n # Training\n for epoch in range(self.n_epochs):\n support_vectors_idx = (X_t.dot(w) + t * b < 1).ravel()\n X_t_sv = X_t[support_vectors_idx]\n t_sv = t[support_vectors_idx]\n\n J = 1/2 * np.sum(w * w) + self.C * (np.sum(1 - X_t_sv.dot(w)) - b * np.sum(t_sv))\n self.Js.append(J)\n\n w_gradient_vector = w - self.C * np.sum(X_t_sv, axis=0).reshape(-1, 1)\n b_derivative = -self.C * np.sum(t_sv)\n \n w = w - self.eta(epoch) * w_gradient_vector\n b = b - self.eta(epoch) * b_derivative\n \n\n self.intercept_ = np.array([b])\n self.coef_ = np.array([w])\n support_vectors_idx = (X_t.dot(w) + t * b < 1).ravel()\n self.support_vectors_ = X[support_vectors_idx]\n return self\n\n def decision_function(self, X):\n return X.dot(self.coef_[0]) + self.intercept_[0]\n\n def predict(self, X):\n return (self.decision_function(X) >= 0).astype(np.float64)\n\nC=2\nsvm_clf = MyLinearSVC(C=C, eta0 = 10, eta_d = 1000, n_epochs=60000, random_state=2)\nsvm_clf.fit(X, y)\nsvm_clf.predict(np.array([[5, 2], [4, 1]]))",
"_____no_output_____"
],
[
"plt.plot(range(svm_clf.n_epochs), svm_clf.Js)\nplt.axis([0, svm_clf.n_epochs, 0, 100])",
"_____no_output_____"
],
[
"print(svm_clf.intercept_, svm_clf.coef_)",
"[-15.56761653] [[[2.28120287]\n [2.71621742]]]\n"
],
[
"svm_clf2 = SVC(kernel=\"linear\", C=C)\nsvm_clf2.fit(X, y.ravel())\nprint(svm_clf2.intercept_, svm_clf2.coef_)",
"[-15.51721253] [[2.27128546 2.71287145]]\n"
],
[
"yr = y.ravel()\nfig, axes = plt.subplots(ncols=2, figsize=(11, 3.2), sharey=True)\nplt.sca(axes[0])\nplt.plot(X[:, 0][yr==1], X[:, 1][yr==1], \"g^\", label=\"Iris virginica\")\nplt.plot(X[:, 0][yr==0], X[:, 1][yr==0], \"bs\", label=\"Not Iris virginica\")\nplot_svc_decision_boundary(svm_clf, 4, 6)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.title(\"MyLinearSVC\", fontsize=14)\nplt.axis([4, 6, 0.8, 2.8])\nplt.legend(loc=\"upper left\")\n\nplt.sca(axes[1])\nplt.plot(X[:, 0][yr==1], X[:, 1][yr==1], \"g^\")\nplt.plot(X[:, 0][yr==0], X[:, 1][yr==0], \"bs\")\nplot_svc_decision_boundary(svm_clf2, 4, 6)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.title(\"SVC\", fontsize=14)\nplt.axis([4, 6, 0.8, 2.8])\n",
"_____no_output_____"
],
[
"from sklearn.linear_model import SGDClassifier\n\nsgd_clf = SGDClassifier(loss=\"hinge\", alpha=0.017, max_iter=1000, tol=1e-3, random_state=42)\nsgd_clf.fit(X, y.ravel())\n\nm = len(X)\nt = y * 2 - 1 # -1 if t==0, +1 if t==1\nX_b = np.c_[np.ones((m, 1)), X] # Add bias input x0=1\nX_b_t = X_b * t\nsgd_theta = np.r_[sgd_clf.intercept_[0], sgd_clf.coef_[0]]\nprint(sgd_theta)\nsupport_vectors_idx = (X_b_t.dot(sgd_theta) < 1).ravel()\nsgd_clf.support_vectors_ = X[support_vectors_idx]\nsgd_clf.C = C\n\nplt.figure(figsize=(5.5,3.2))\nplt.plot(X[:, 0][yr==1], X[:, 1][yr==1], \"g^\")\nplt.plot(X[:, 0][yr==0], X[:, 1][yr==0], \"bs\")\nplot_svc_decision_boundary(sgd_clf, 4, 6)\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.title(\"SGDClassifier\", fontsize=14)\nplt.axis([4, 6, 0.8, 2.8])\n",
"[-12.52988101 1.94162342 1.84544824]\n"
]
],
[
[
"# Exercise solutions",
"_____no_output_____"
],
[
"## 1. to 7.",
"_____no_output_____"
],
[
"See appendix A.",
"_____no_output_____"
],
[
"# 8.",
"_____no_output_____"
],
[
"_Exercise: train a `LinearSVC` on a linearly separable dataset. Then train an `SVC` and a `SGDClassifier` on the same dataset. See if you can get them to produce roughly the same model._",
"_____no_output_____"
],
[
"Let's use the Iris dataset: the Iris Setosa and Iris Versicolor classes are linearly separable.",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets\n\niris = datasets.load_iris()\nX = iris[\"data\"][:, (2, 3)] # petal length, petal width\ny = iris[\"target\"]\n\nsetosa_or_versicolor = (y == 0) | (y == 1)\nX = X[setosa_or_versicolor]\ny = y[setosa_or_versicolor]",
"_____no_output_____"
],
[
"from sklearn.svm import SVC, LinearSVC\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.preprocessing import StandardScaler\n\nC = 5\nalpha = 1 / (C * len(X))\n\nlin_clf = LinearSVC(loss=\"hinge\", C=C, random_state=42)\nsvm_clf = SVC(kernel=\"linear\", C=C)\nsgd_clf = SGDClassifier(loss=\"hinge\", learning_rate=\"constant\", eta0=0.001, alpha=alpha,\n max_iter=1000, tol=1e-3, random_state=42)\n\nscaler = StandardScaler()\nX_scaled = scaler.fit_transform(X)\n\nlin_clf.fit(X_scaled, y)\nsvm_clf.fit(X_scaled, y)\nsgd_clf.fit(X_scaled, y)\n\nprint(\"LinearSVC: \", lin_clf.intercept_, lin_clf.coef_)\nprint(\"SVC: \", svm_clf.intercept_, svm_clf.coef_)\nprint(\"SGDClassifier(alpha={:.5f}):\".format(sgd_clf.alpha), sgd_clf.intercept_, sgd_clf.coef_)",
"LinearSVC: [0.28475098] [[1.05364854 1.09903804]]\nSVC: [0.31896852] [[1.1203284 1.02625193]]\nSGDClassifier(alpha=0.00200): [0.117] [[0.77714169 0.72981762]]\n"
]
],
[
[
"Let's plot the decision boundaries of these three models:",
"_____no_output_____"
]
],
[
[
"# Compute the slope and bias of each decision boundary\nw1 = -lin_clf.coef_[0, 0]/lin_clf.coef_[0, 1]\nb1 = -lin_clf.intercept_[0]/lin_clf.coef_[0, 1]\nw2 = -svm_clf.coef_[0, 0]/svm_clf.coef_[0, 1]\nb2 = -svm_clf.intercept_[0]/svm_clf.coef_[0, 1]\nw3 = -sgd_clf.coef_[0, 0]/sgd_clf.coef_[0, 1]\nb3 = -sgd_clf.intercept_[0]/sgd_clf.coef_[0, 1]\n\n# Transform the decision boundary lines back to the original scale\nline1 = scaler.inverse_transform([[-10, -10 * w1 + b1], [10, 10 * w1 + b1]])\nline2 = scaler.inverse_transform([[-10, -10 * w2 + b2], [10, 10 * w2 + b2]])\nline3 = scaler.inverse_transform([[-10, -10 * w3 + b3], [10, 10 * w3 + b3]])\n\n# Plot all three decision boundaries\nplt.figure(figsize=(11, 4))\nplt.plot(line1[:, 0], line1[:, 1], \"k:\", label=\"LinearSVC\")\nplt.plot(line2[:, 0], line2[:, 1], \"b--\", linewidth=2, label=\"SVC\")\nplt.plot(line3[:, 0], line3[:, 1], \"r-\", label=\"SGDClassifier\")\nplt.plot(X[:, 0][y==1], X[:, 1][y==1], \"bs\") # label=\"Iris versicolor\"\nplt.plot(X[:, 0][y==0], X[:, 1][y==0], \"yo\") # label=\"Iris setosa\"\nplt.xlabel(\"Petal length\", fontsize=14)\nplt.ylabel(\"Petal width\", fontsize=14)\nplt.legend(loc=\"upper center\", fontsize=14)\nplt.axis([0, 5.5, 0, 2])\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Close enough!",
"_____no_output_____"
],
[
"# 9.",
"_____no_output_____"
],
[
"_Exercise: train an SVM classifier on the MNIST dataset. Since SVM classifiers are binary classifiers, you will need to use one-versus-all to classify all 10 digits. You may want to tune the hyperparameters using small validation sets to speed up the process. What accuracy can you reach?_",
"_____no_output_____"
],
[
"First, let's load the dataset and split it into a training set and a test set. We could use `train_test_split()` but people usually just take the first 60,000 instances for the training set, and the last 10,000 instances for the test set (this makes it possible to compare your model's performance with others): ",
"_____no_output_____"
],
[
"**Warning:** since Scikit-Learn 0.24, `fetch_openml()` returns a Pandas `DataFrame` by default. To avoid this, we use `as_frame=False`.",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import fetch_openml\nmnist = fetch_openml('mnist_784', version=1, cache=True, as_frame=False)\n\nX = mnist[\"data\"]\ny = mnist[\"target\"].astype(np.uint8)\n\nX_train = X[:60000]\ny_train = y[:60000]\nX_test = X[60000:]\ny_test = y[60000:]",
"_____no_output_____"
]
],
[
[
"Many training algorithms are sensitive to the order of the training instances, so it's generally good practice to shuffle them first. However, the dataset is already shuffled, so we do not need to do it.",
"_____no_output_____"
],
[
"Let's start simple, with a linear SVM classifier. It will automatically use the One-vs-All (also called One-vs-the-Rest, OvR) strategy, so there's nothing special we need to do. Easy!\n\n**Warning**: this may take a few minutes depending on your hardware.",
"_____no_output_____"
]
],
[
[
"lin_clf = LinearSVC(random_state=42)\nlin_clf.fit(X_train, y_train)",
"/Users/jtao/miniconda3/envs/tf2/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.\n \"the number of iterations.\", ConvergenceWarning)\n"
]
],
[
[
"Let's make predictions on the training set and measure the accuracy (we don't want to measure it on the test set yet, since we have not selected and trained the final model yet):",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score\n\ny_pred = lin_clf.predict(X_train)\naccuracy_score(y_train, y_pred)",
"_____no_output_____"
]
],
[
[
"Okay, 89.5% accuracy on MNIST is pretty bad. This linear model is certainly too simple for MNIST, but perhaps we just needed to scale the data first:",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\nX_train_scaled = scaler.fit_transform(X_train.astype(np.float32))\nX_test_scaled = scaler.transform(X_test.astype(np.float32))",
"_____no_output_____"
]
],
[
[
"**Warning**: this may take a few minutes depending on your hardware.",
"_____no_output_____"
]
],
[
[
"lin_clf = LinearSVC(random_state=42)\nlin_clf.fit(X_train_scaled, y_train)",
"/Users/jtao/miniconda3/envs/tf2/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.\n \"the number of iterations.\", ConvergenceWarning)\n"
],
[
"y_pred = lin_clf.predict(X_train_scaled)\naccuracy_score(y_train, y_pred)",
"_____no_output_____"
]
],
[
[
"That's much better (we cut the error rate by about 25%), but still not great at all for MNIST. If we want to use an SVM, we will have to use a kernel. Let's try an `SVC` with an RBF kernel (the default).",
"_____no_output_____"
],
[
"**Note**: to be future-proof we set `gamma=\"scale\"` since it will be the default value in Scikit-Learn 0.22.",
"_____no_output_____"
]
],
[
[
"svm_clf = SVC(gamma=\"scale\")\nsvm_clf.fit(X_train_scaled[:10000], y_train[:10000])",
"_____no_output_____"
],
[
"y_pred = svm_clf.predict(X_train_scaled)\naccuracy_score(y_train, y_pred)",
"_____no_output_____"
]
],
[
[
"That's promising, we get better performance even though we trained the model on 6 times less data. Let's tune the hyperparameters by doing a randomized search with cross validation. We will do this on a small dataset just to speed up the process:",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import RandomizedSearchCV\nfrom scipy.stats import reciprocal, uniform\n\nparam_distributions = {\"gamma\": reciprocal(0.001, 0.1), \"C\": uniform(1, 10)}\nrnd_search_cv = RandomizedSearchCV(svm_clf, param_distributions, n_iter=10, verbose=2, cv=3)\nrnd_search_cv.fit(X_train_scaled[:1000], y_train[:1000])",
"Fitting 3 folds for each of 10 candidates, totalling 30 fits\n[CV] C=5.847490967837556, gamma=0.004375955271336425 .................\n"
],
[
"rnd_search_cv.best_estimator_",
"_____no_output_____"
],
[
"rnd_search_cv.best_score_",
"_____no_output_____"
]
],
[
[
"This looks pretty low but remember we only trained the model on 1,000 instances. Let's retrain the best estimator on the whole training set:",
"_____no_output_____"
],
[
"**Warning**: the following cell may take hours to run, depending on your hardware.",
"_____no_output_____"
]
],
[
[
"rnd_search_cv.best_estimator_.fit(X_train_scaled, y_train)",
"_____no_output_____"
],
[
"y_pred = rnd_search_cv.best_estimator_.predict(X_train_scaled)\naccuracy_score(y_train, y_pred)",
"_____no_output_____"
]
],
[
[
"Ah, this looks good! Let's select this model. Now we can test it on the test set:",
"_____no_output_____"
]
],
[
[
"y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled)\naccuracy_score(y_test, y_pred)",
"_____no_output_____"
]
],
[
[
"Not too bad, but apparently the model is overfitting slightly. It's tempting to tweak the hyperparameters a bit more (e.g. decreasing `C` and/or `gamma`), but we would run the risk of overfitting the test set. Other people have found that the hyperparameters `C=5` and `gamma=0.005` yield even better performance (over 98% accuracy). By running the randomized search for longer and on a larger part of the training set, you may be able to find this as well.",
"_____no_output_____"
],
[
"## 10.",
"_____no_output_____"
],
[
"_Exercise: train an SVM regressor on the California housing dataset._",
"_____no_output_____"
],
[
"Let's load the dataset using Scikit-Learn's `fetch_california_housing()` function:",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import fetch_california_housing\n\nhousing = fetch_california_housing()\nX = housing[\"data\"]\ny = housing[\"target\"]",
"_____no_output_____"
]
],
[
[
"Split it into a training set and a test set:",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)",
"_____no_output_____"
]
],
[
[
"Don't forget to scale the data:",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler\n\nscaler = StandardScaler()\nX_train_scaled = scaler.fit_transform(X_train)\nX_test_scaled = scaler.transform(X_test)",
"_____no_output_____"
]
],
[
[
"Let's train a simple `LinearSVR` first:",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import LinearSVR\n\nlin_svr = LinearSVR(random_state=42)\nlin_svr.fit(X_train_scaled, y_train)",
"/Users/jtao/miniconda3/envs/tf2/lib/python3.7/site-packages/sklearn/svm/_base.py:977: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.\n \"the number of iterations.\", ConvergenceWarning)\n"
]
],
[
[
"Let's see how it performs on the training set:",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_squared_error\n\ny_pred = lin_svr.predict(X_train_scaled)\nmse = mean_squared_error(y_train, y_pred)\nmse",
"_____no_output_____"
]
],
[
[
"Let's look at the RMSE:",
"_____no_output_____"
]
],
[
[
"np.sqrt(mse)",
"_____no_output_____"
]
],
[
[
"In this training set, the targets are tens of thousands of dollars. The RMSE gives a rough idea of the kind of error you should expect (with a higher weight for large errors): so with this model we can expect errors somewhere around $10,000. Not great. Let's see if we can do better with an RBF Kernel. We will use randomized search with cross validation to find the appropriate hyperparameter values for `C` and `gamma`:",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVR\nfrom sklearn.model_selection import RandomizedSearchCV\nfrom scipy.stats import reciprocal, uniform\n\nparam_distributions = {\"gamma\": reciprocal(0.001, 0.1), \"C\": uniform(1, 10)}\nrnd_search_cv = RandomizedSearchCV(SVR(), param_distributions, n_iter=10, verbose=2, cv=3, random_state=42)\nrnd_search_cv.fit(X_train_scaled, y_train)",
"[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n"
],
[
"rnd_search_cv.best_estimator_",
"_____no_output_____"
]
],
[
[
"Now let's measure the RMSE on the training set:",
"_____no_output_____"
]
],
[
[
"y_pred = rnd_search_cv.best_estimator_.predict(X_train_scaled)\nmse = mean_squared_error(y_train, y_pred)\nnp.sqrt(mse)",
"_____no_output_____"
]
],
[
[
"Looks much better than the linear model. Let's select this model and evaluate it on the test set:",
"_____no_output_____"
]
],
[
[
"y_pred = rnd_search_cv.best_estimator_.predict(X_test_scaled)\nmse = mean_squared_error(y_test, y_pred)\nnp.sqrt(mse)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbcf345731f6b57121c6be7951544251e28eb335
| 9,635 |
ipynb
|
Jupyter Notebook
|
00_cliente_api.ipynb
|
davidrodord56/py221
|
6790b03a43416bb32ff0c114ed278f8c1220e871
|
[
"MIT"
] | null | null | null |
00_cliente_api.ipynb
|
davidrodord56/py221
|
6790b03a43416bb32ff0c114ed278f8c1220e871
|
[
"MIT"
] | null | null | null |
00_cliente_api.ipynb
|
davidrodord56/py221
|
6790b03a43416bb32ff0c114ed278f8c1220e871
|
[
"MIT"
] | null | null | null | 30.490506 | 405 | 0.569486 |
[
[
[
"[](https://www.pythonista.io)",
"_____no_output_____"
],
[
"# Cliente de la API con requests.\n\nEn esta notebook se encuentra el código de un cliente capaz de consumir los servicios de los servidores creado en este curso.\n\nEs necesario que el servidor en la notebook se encuentre en ejecución.",
"_____no_output_____"
]
],
[
[
"!pip install requests PyYAML",
"Requirement already satisfied: requests in /home/oi/pythonista/lib/python3.9/site-packages (2.27.1)\r\nRequirement already satisfied: PyYAML in /home/oi/pythonista/lib/python3.9/site-packages (6.0)\r\nRequirement already satisfied: certifi>=2017.4.17 in /home/oi/pythonista/lib/python3.9/site-packages (from requests) (2021.10.8)\r\nRequirement already satisfied: charset-normalizer~=2.0.0 in /home/oi/pythonista/lib/python3.9/site-packages (from requests) (2.0.11)\r\nRequirement already satisfied: urllib3<1.27,>=1.21.1 in /home/oi/pythonista/lib/python3.9/site-packages (from requests) (1.26.8)\r\nRequirement already satisfied: idna<4,>=2.5 in /home/oi/pythonista/lib/python3.9/site-packages (from requests) (3.3)\r\n\u001b[33mWARNING: You are using pip version 21.3.1; however, version 22.0.3 is available.\r\nYou should consider upgrading via the '/home/oi/pythonista/bin/python -m pip install --upgrade pip' command.\u001b[0m\r\n"
],
[
"from requests import put, get, post, delete, patch\nimport yaml",
"_____no_output_____"
],
[
"# host=\"http://localhost:5000\"\nhost = \"https://py221-2111.uc.r.appspot.com\"",
"_____no_output_____"
]
],
[
[
"## Acceso a la raíz de la API.\n\nRegresará el listado completo de la base de datos en formato JSON.",
"_____no_output_____"
]
],
[
[
"with get(f'{host}/api/') as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"https://py221-2111.uc.r.appspot.com/api/\n404\nSin contenido JSON.\n"
]
],
[
[
"## Búsqueda por número de cuenta mediante GET.\n* Regresará los datos en formato JSON del registro cuyo campo 'Cuenta' coincida con el número que se ingrese en la ruta.\n* En caso de que no exista un registro con ese número de cuenta, regresará un mensaje 404.",
"_____no_output_____"
]
],
[
[
"with get(f'{host}/api/1231267') as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"## Creación de un nuevo registro mediante POST.\n* Creará un nuevo registro con la estructura de datos enviada en caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL y regresará los datos completos de dicho registro en formato JSON.\n* En caso de que exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 409.\n* En caso de que los datos no sean correctos, estén incompletos o no se apeguen a la estructura de datos, regresará un mensaje 400.",
"_____no_output_____"
]
],
[
[
" data ={'al_corriente': True,\n 'carrera': 'Sistemas',\n 'nombre': 'Laura',\n 'primer_apellido': 'Robles',\n 'promedio': 9.2,\n 'semestre': 1}",
"_____no_output_____"
],
[
"with post(f'{host}/api/1231268', json=data) as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"## Sustitución de un registro existente mediante PUT.\n\n* Sustituirá por completo un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL con los datos enviados y regresará los datos completos del nuevo registro en formato JSON.\n* En caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 404.\n* En caso de que los datos no sean correctos, no estén completos o no se apeguen a la estructura de datos, regresará un mensaje 400.\n\n",
"_____no_output_____"
]
],
[
[
" data = {'al_corriente': True,\n 'carrera': 'Sistemas',\n 'nombre': 'Laura',\n 'primer_apellido': 'Robles',\n 'segundo_apellido': 'Sánchez',\n 'promedio': 10,\n 'semestre': 2}",
"_____no_output_____"
],
[
"with put(f'{host}/api/1231268', json=data) as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"## Enmienda de un registro existente con el método ```PATCH```.",
"_____no_output_____"
]
],
[
[
"data = {'al_corriente': True,\n 'semestre': 10}",
"_____no_output_____"
],
[
"with patch(f'{host}/api/1231268', json=data) as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"## Eliminación de un registro existente mediante DELETE.\n* Eliminará un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL y regresará los datos completos del registro eliminado en formato JSON.\n* En caso de que no exista un registro cuyo contenido del campo 'Cuenta' coincida con el numero ingresado en la URL, regresará un mensaje 404.",
"_____no_output_____"
]
],
[
[
"with delete(f'{host}/api/1231268') as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(r.json())\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"## La documentación de *Swagger*.",
"_____no_output_____"
]
],
[
[
"with get('f'{host}/swagger/') as r:\n print(r.url)\n print(r.status_code)\n if r.headers['Content-Type'] == 'application/json':\n print(yaml.dump(r.json()))\n else:\n print(\"Sin contenido JSON.\")",
"_____no_output_____"
]
],
[
[
"<p style=\"text-align: center\"><a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\"><img alt=\"Licencia Creative Commons\" style=\"border-width:0\" src=\"https://i.creativecommons.org/l/by/4.0/80x15.png\" /></a><br />Esta obra está bajo una <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\">Licencia Creative Commons Atribución 4.0 Internacional</a>.</p>\n<p style=\"text-align: center\">© José Luis Chiquete Valdivieso. 2022.</p>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbcf3561e7e861fc00f773c39c3a53921d3a8f00
| 164,152 |
ipynb
|
Jupyter Notebook
|
inference-statistics/inference-statistics-course/notebooks/Intervalos_de_Confianza.ipynb
|
Elkinmt19/data-science-dojo
|
9e3d7ca8774474e1ad74138c7215ca3acdabf07c
|
[
"MIT"
] | 1 |
2022-01-14T03:16:23.000Z
|
2022-01-14T03:16:23.000Z
|
inference-statistics/inference-statistics-course/notebooks/Intervalos_de_Confianza.ipynb
|
Elkinmt19/data-engineer-dojo
|
15857ba5b72681e15c4b170f5a2505513e6d43ec
|
[
"MIT"
] | null | null | null |
inference-statistics/inference-statistics-course/notebooks/Intervalos_de_Confianza.ipynb
|
Elkinmt19/data-engineer-dojo
|
15857ba5b72681e15c4b170f5a2505513e6d43ec
|
[
"MIT"
] | null | null | null | 151.152855 | 25,424 | 0.86758 |
[
[
[
"**Estimación puntual**\n\n\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport scipy.stats as stats\nimport matplotlib.pyplot as plt\nimport random\nimport math",
"_____no_output_____"
],
[
"np.random.seed(2020)\npopulation_ages_1 = stats.poisson.rvs(loc = 18, mu = 35, size = 1500000)\npopulation_ages_2 = stats.poisson.rvs(loc = 18, mu = 10, size = 1000000)\npopulation_ages = np.concatenate((population_ages_1, population_ages_2))\n\nprint(population_ages_1.mean())\nprint(population_ages_2.mean())\nprint(population_ages.mean())",
"52.998824666666664\n27.999569\n42.9991224\n"
],
[
"pd.DataFrame(population_ages).hist(bins = 60, range = (17.5, 77.5), figsize = (10,10))",
"_____no_output_____"
],
[
"stats.skew(population_ages)",
"_____no_output_____"
],
[
"stats.kurtosis(population_ages)",
"_____no_output_____"
],
[
"np.random.seed(42)\nsample_ages = np.random.choice(population_ages, 500)\nprint(sample_ages.mean())",
"42.356\n"
],
[
"population_ages.mean() - sample_ages.mean()",
"_____no_output_____"
],
[
"population_races = ([\"blanca\"]*1000000) + ([\"negra\"]*500000) + ([\"hispana\"]*500000) + ([\"asiatica\"]*250000) + ([\"otros\"]*250000)",
"_____no_output_____"
],
[
"for race in set(population_races):\n print(\"Proporción de \"+race)\n print(population_races.count(race) / 2500000)",
"Proporción de blanca\n0.4\nProporción de hispana\n0.2\nProporción de otros\n0.1\nProporción de asiatica\n0.1\nProporción de negra\n0.2\n"
],
[
"random.seed(31)\nrace_sample = random.sample(population_races, 1000)",
"_____no_output_____"
],
[
"for race in set(race_sample):\n print(\"Proporción de \"+race)\n print(race_sample.count(race) / 1000)",
"Proporción de blanca\n0.379\nProporción de hispana\n0.201\nProporción de otros\n0.102\nProporción de asiatica\n0.101\nProporción de negra\n0.217\n"
],
[
"pd.DataFrame(population_ages).hist(bins = 60, range = (17.5, 77.5), figsize = (10,10))",
"_____no_output_____"
],
[
"pd.DataFrame(sample_ages).hist(bins = 60, range = (17.5, 77.5), figsize = (10,10))",
"_____no_output_____"
],
[
"np.random.sample(1988)\n\npoint_estimates = []\n\nfor x in range(200):\n sample = np.random.choice(population_ages, size = 500)\n point_estimates.append(sample.mean())\n\npd.DataFrame(point_estimates).plot(kind = \"density\", figsize = (9,9), xlim = (40, 46) )",
"_____no_output_____"
],
[
"np.array(point_estimates).mean()",
"_____no_output_____"
]
],
[
[
"**Si conocemos la desviación típica**",
"_____no_output_____"
]
],
[
[
"np.random.seed(10)\n\nn = 1000\nalpha = 0.05\n\nsample = np.random.choice(population_ages, size = n)\nsample_mean = sample.mean()\n\nz_critical = stats.norm.ppf(q = 1-alpha/2)\n\nsigma = population_ages.std()## sigma de la población\n\nsample_error = z_critical * sigma / math.sqrt(n)\n\nci = (sample_mean - sample_error, sample_mean + sample_error)\nci",
"_____no_output_____"
],
[
"np.random.seed(10)\n\nn = 1000\nalpha = 0.05\n\nintervals = []\nsample_means = []\n\nz_critical = stats.norm.ppf(q = 1-alpha/2)\n\nsigma = population_ages.std()## sigma de la población\n\nsample_error = z_critical * sigma / math.sqrt(n)\n\nfor sample in range(100):\n\n sample = np.random.choice(population_ages, size = n)\n sample_mean = sample.mean()\n sample_means.append(sample_mean)\n\n ci = (sample_mean - sample_error, sample_mean + sample_error)\n intervals.append(ci)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,10))\nplt.errorbar(x = np.arange(0.1, 100, 1), y = sample_means, yerr=[(top-bottom)/2 for top, bottom in intervals], fmt='o')\nplt.hlines(xmin = 0, xmax = 100, y = population_ages.mean(), linewidth=2.0, color=\"red\")",
"_____no_output_____"
]
],
[
[
"**Si la desviación típica no es conocida...**\n",
"_____no_output_____"
]
],
[
[
"np.random.seed(10)\n\nn = 25\nalpha = 0.05\n\nsample = np.random.choice(population_ages, size = n)\nsample_mean = sample.mean()\n\nt_critical = stats.t.ppf(q = 1-alpha/2, df = n-1)\n\nsample_sd = sample.std(ddof=1)## desviación estándar de la muestra\n\nsample_error = t_critical * sample_sd / math.sqrt(n)\n\nci = (sample_mean - sample_error, sample_mean + sample_error)\nci",
"_____no_output_____"
],
[
"stats.t.ppf(q = 1-alpha, df = n-1) - stats.norm.ppf(1-alpha)",
"_____no_output_____"
],
[
"stats.t.ppf(q = 1-alpha, df = 999) - stats.norm.ppf(1-alpha)",
"_____no_output_____"
],
[
"stats.t.interval(alpha = 0.95, df = 24, loc = sample_mean, scale = sample_sd/math.sqrt(n))",
"_____no_output_____"
]
],
[
[
"**Intervalo para la proporción poblacional**",
"_____no_output_____"
]
],
[
[
"alpha = 0.05\nn = 1000\nz_critical = stats.norm.ppf(q=1-alpha/2)\np_hat = race_sample.count(\"blanca\") / n\n\nsample_error = z_critical * math.sqrt((p_hat*(1-p_hat)/n))\n\nci = (p_hat - sample_error, p_hat + sample_error)\nci",
"_____no_output_____"
],
[
"stats.norm.interval(alpha = 0.95, loc = p_hat, scale = math.sqrt(p_hat*(1-p_hat)/n))",
"_____no_output_____"
]
],
[
[
"**Cómo interpretar el intervalo de confianza**",
"_____no_output_____"
]
],
[
[
"shape, scale = 2.0, 2.0 #mean = 4, std = 2*sqrt(2)\ns = np.random.gamma(shape, scale, 1000000)\n\nmu = shape*scale \nsigma = scale*np.sqrt(shape)",
"_____no_output_____"
],
[
"print(mu)\nprint(sigma)",
"4.0\n2.8284271247461903\n"
],
[
"meansample = []\nsample_size = 500\nfor i in range(0,50000):\n sample = random.choices(s, k=sample_size)\n meansample.append(sum(sample)/len(sample))\n\nplt.figure(figsize=(20,10))\nplt.hist(meansample, 200, density=True, color=\"lightblue\")\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(20,10))\nplt.hist(meansample, 200, density=True, color=\"lightblue\")\nplt.plot([mu,mu], [0, 3.5], 'k-', lw=4, color='green')\nplt.plot([mu-1.96*sigma/np.sqrt(sample_size), mu-1.96*sigma/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=2, color=\"navy\")\nplt.plot([mu+1.96*sigma/np.sqrt(sample_size), mu+1.96*sigma/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=2, color=\"navy\")\nplt.show()",
"_____no_output_____"
],
[
"sample_data = np.random.choice(s, size = sample_size)\nx_bar = sample_data.mean()\nss = sample_data.std()\n\nplt.figure(figsize=(20,10))\nplt.hist(meansample, 200, density=True, color=\"lightblue\")\nplt.plot([mu,mu], [0, 3.5], 'k-', lw=4, color='green')\nplt.plot([mu-1.96*sigma/np.sqrt(sample_size), mu-1.96*sigma/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=2, color=\"navy\")\nplt.plot([mu+1.96*sigma/np.sqrt(sample_size), mu+1.96*sigma/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=2, color=\"navy\")\nplt.plot([x_bar, x_bar], [0,3.5], 'k-', lw=2, color=\"red\")\nplt.plot([x_bar-1.96*ss/np.sqrt(sample_size), x_bar-1.96*ss/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=1, color=\"red\")\nplt.plot([x_bar+1.96*ss/np.sqrt(sample_size), x_bar+1.96*ss/np.sqrt(sample_size)], [0, 3.5], 'k-', lw=1, color=\"red\")\nplt.gca().add_patch(plt.Rectangle((x_bar-1.96*ss/np.sqrt(sample_size), 0), 2*(1.96*ss/np.sqrt(sample_size)), 3.5, fill=True, fc=(0.9, 0.1, 0.1, 0.15)))\nplt.show()",
"_____no_output_____"
],
[
"interval_list = []\nz_critical = 1.96 #z_0.975\nsample_size = 5000\nc = 0\nerror = z_critical*sigma/np.sqrt(sample_size)\n\nfor i in range(0,100):\n rs = random.choices(s, k=sample_size)\n mean = np.mean(rs)\n ub = mean + error\n lb = mean - error\n interval_list.append([lb, mean, ub])\n if ub >= mu and lb <= mu:\n c += 1 ",
"_____no_output_____"
],
[
"c",
"_____no_output_____"
],
[
"print(\"Número de intervalos de confianza que contienen el valor real de mu: \",c)\nplt.figure(figsize = (20, 10))\nplt.boxplot(interval_list)\nplt.plot([1,100], [mu, mu], 'k-', lw=2, color=\"red\")\nplt.show()",
"Número de intervalos de confianza que contienen el valor real de mu: 95\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbcf76bb58a396e1a40bf7d87c65d11734c0b33d
| 55,653 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/WebScrapingBasicToAdvanced-checkpoint.ipynb
|
Xwyzworms/WebScrapingBasic
|
f4b9224ef559511903c9a33e545cdb05bcdfc8b2
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/WebScrapingBasicToAdvanced-checkpoint.ipynb
|
Xwyzworms/WebScrapingBasic
|
f4b9224ef559511903c9a33e545cdb05bcdfc8b2
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/WebScrapingBasicToAdvanced-checkpoint.ipynb
|
Xwyzworms/WebScrapingBasic
|
f4b9224ef559511903c9a33e545cdb05bcdfc8b2
|
[
"MIT"
] | null | null | null | 43.717989 | 1,332 | 0.59844 |
[
[
[
"from urllib.request import urlopen\n\nhtml=urlopen('http://pythonscraping.com/pages/page1.html')\nprint(html.read())",
"b'<html>\\n<head>\\n<title>A Useful Page</title>\\n</head>\\n<body>\\n<h1>An Interesting Title</h1>\\n<div>\\nLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\\n</div>\\n</body>\\n</html>\\n'\n"
],
[
"from bs4 import BeautifulSoup\n\nhtml = urlopen(\"http://www.pythonscraping.com/pages/page1.html\")\nbs = BeautifulSoup(html.read())\nprint(bs)",
"<html>\n<head>\n<title>A Useful Page</title>\n</head>\n<body>\n<h1>An Interesting Title</h1>\n<div>\nLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n</div>\n</body>\n</html>\n\n"
],
[
"print(bs.h1)\nprint(bs.html.body.h1)\nprint(bs.body.h1)",
"<h1>An Interesting Title</h1>\n<h1>An Interesting Title</h1>\n<h1>An Interesting Title</h1>\n"
],
[
"html = urlopen(\"http://www.pythonscraping.com/pages/page1.html\")\n# lxml Has more advantage When parsing messy HTML < NO body / head section . unclosed tags. More faster\nbs = BeautifulSoup(html.read(),'lxml')\nprint(bs)",
"<html>\n<head>\n<title>A Useful Page</title>\n</head>\n<body>\n<h1>An Interesting Title</h1>\n<div>\nLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n</div>\n</body>\n</html>\n\n"
]
],
[
[
"## Sometimes we need to understand what is really going on when scraping and we need to done all those stuff by our hand ",
"_____no_output_____"
]
],
[
[
"html = urlopen(\"http://www.pythonscraping.com/pages/page1.html\")\n# 2 things could go wrong \n # page Not Found\n # Server is not found\nprint(html)\n# To handle the error we do this\nfrom urllib.error import HTTPError\nfrom urllib.error import URLError\ntry:\n html = urlopen(\"http://www.pythonscraping.com/pages/page1.html\")\nexcept HTTPError as e:\n print(e)\nexcept URLError as Ur:\n print(\"Server could not be found\")\nelse : \n bs = BeautifulSoup(html.read(),\"lxml\")\n try:\n badContent = bs.nonExistingTag.h1\n except AttributeError as ae :\n print(\"Tag Was not Found\")\n else :\n print(badContent)\n ",
"<http.client.HTTPResponse object at 0x00000201DE4810B8>\nTag Was not Found\n"
],
[
"from urllib.request import urlopen\nfrom urllib.error import HTTPError\nfrom bs4 import BeautifulSoup\n\ndef getTitle(url):\n try:\n html = urlopen(url)\n except HTTPError as e:\n return None\n \n try:\n bs = BeautifulSoup(html.read(), 'lxml')\n title = bs.body.h1\n except AttributeError as ae:\n return None\n \n return title\ntitle = getTitle(\"http://www.pythonscraping.com/pages/page1.html\")\nif (title == None):\n print(\"Title Could not found\")\nelse :\n print(title)",
"<h1>An Interesting Title</h1>\n"
],
[
"html = urlopen(\"http://www.pythonscraping.com/pages/page1.html\")\nbs = BeautifulSoup(html, \"lxml\")\nprint(bs)",
"<html>\n<head>\n<title>A Useful Page</title>\n</head>\n<body>\n<h1>An Interesting Title</h1>\n<div>\nLorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n</div>\n</body>\n</html>\n\n"
],
[
"from urllib.request import urlopen\nfrom bs4 import BeautifulSoup\n\nhtml = urlopen(\"http://www.pythonscraping.com/pages/warandpeace.html\")\nbs = BeautifulSoup(html, \"lxml\")\nnameListGreen = bs.findAll(\"span\", {\"class\" : [\"green\"]})\nstoryListRed = bs.findAll(\"span\" , {\"class\" : [\"red\"]})\n\nfor name in nameListGreen:\n print(name.get_text())\nfor name in storyListRed:\n print(name.get_text())\n",
"Anna\nPavlovna Scherer\nEmpress Marya\nFedorovna\nPrince Vasili Kuragin\nAnna Pavlovna\nSt. Petersburg\nthe prince\nAnna Pavlovna\nAnna Pavlovna\nthe prince\nthe prince\nthe prince\nPrince Vasili\nAnna Pavlovna\nAnna Pavlovna\nthe prince\nWintzingerode\nKing of Prussia\nle Vicomte de Mortemart\nMontmorencys\nRohans\nAbbe Morio\nthe Emperor\nthe prince\nPrince Vasili\nDowager Empress Marya Fedorovna\nthe baron\nAnna Pavlovna\nthe Empress\nthe Empress\nAnna Pavlovna's\nHer Majesty\nBaron\nFunke\nThe prince\nAnna\nPavlovna\nthe Empress\nThe prince\nAnatole\nthe prince\nThe prince\nAnna\nPavlovna\nAnna Pavlovna\nWell, Prince, so Genoa and Lucca are now just family estates of the\nBuonapartes. But I warn you, if you don't tell me that this means war,\nif you still try to defend the infamies and horrors perpetrated by\nthat Antichrist- I really believe he is Antichrist- I will have\nnothing more to do with you and you are no longer my friend, no longer\nmy 'faithful slave,' as you call yourself! But how do you do? I see\nI have frightened you- sit down and tell me all the news.\nIf you have nothing better to do, Count [or Prince], and if the\nprospect of spending an evening with a poor invalid is not too\nterrible, I shall be very charmed to see you tonight between 7 and 10-\nAnnette Scherer.\nHeavens! what a virulent attack!\nFirst of all, dear friend, tell me how you are. Set your friend's\nmind at rest,\nCan one be well while suffering morally? Can one be calm in times\nlike these if one has any feeling?\nYou are\nstaying the whole evening, I hope?\nAnd the fete at the English ambassador's? Today is Wednesday. I\nmust put in an appearance there,\nMy daughter is\ncoming for me to take me there.\nI thought today's fete had been canceled. I confess all these\nfestivities and fireworks are becoming wearisome.\nIf they had known that you wished it, the entertainment would\nhave been put off,\nDon't tease! Well, and what has been decided about Novosiltsev's\ndispatch? You know everything.\nWhat can one say about it?\nWhat has been decided? They have decided that\nBuonaparte has burnt his boats, and I believe that we are ready to\nburn ours.\nOh, don't speak to me of Austria. Perhaps I don't understand\nthings, but Austria never has wished, and does not wish, for war.\nShe is betraying us! Russia alone must save Europe. Our gracious\nsovereign recognizes his high vocation and will be true to it. That is\nthe one thing I have faith in! Our good and wonderful sovereign has to\nperform the noblest role on earth, and he is so virtuous and noble\nthat God will not forsake him. He will fulfill his vocation and\ncrush the hydra of revolution, which has become more terrible than\never in the person of this murderer and villain! We alone must\navenge the blood of the just one.... Whom, I ask you, can we rely\non?... England with her commercial spirit will not and cannot\nunderstand the Emperor Alexander's loftiness of soul. She has\nrefused to evacuate Malta. She wanted to find, and still seeks, some\nsecret motive in our actions. What answer did Novosiltsev get? None.\nThe English have not understood and cannot understand the\nself-abnegation of our Emperor who wants nothing for himself, but only\ndesires the good of mankind. And what have they promised? Nothing! And\nwhat little they have promised they will not perform! Prussia has\nalways declared that Buonaparte is invincible, and that all Europe\nis powerless before him.... And I don't believe a word that Hardenburg\nsays, or Haugwitz either. This famous Prussian neutrality is just a\ntrap. I have faith only in God and the lofty destiny of our adored\nmonarch. He will save Europe!\nI think,\nthat if you had been\nsent instead of our dear Wintzingerode you would have captured the\nKing of Prussia's consent by assault. You are so eloquent. Will you\ngive me a cup of tea?\nIn a moment. A propos,\nI am\nexpecting two very interesting men tonight, le Vicomte de Mortemart,\nwho is connected with the Montmorencys through the Rohans, one of\nthe best French families. He is one of the genuine emigres, the good\nones. And also the Abbe Morio. Do you know that profound thinker? He\nhas been received by the Emperor. Had you heard?\nI shall be delighted to meet them,\nBut tell me,\nis it true that the Dowager Empress wants Baron Funke\nto be appointed first secretary at Vienna? The baron by all accounts\nis a poor creature.\nBaron Funke has been recommended to the Dowager Empress by her\nsister,\nNow about your family. Do you know that since your daughter came\nout everyone has been enraptured by her? They say she is amazingly\nbeautiful.\nI often think,\nI often think how unfairly sometimes the\njoys of life are distributed. Why has fate given you two such splendid\nchildren? I don't speak of Anatole, your youngest. I don't like\nhim,\nTwo such charming children. And really you appreciate\nthem less than anyone, and so you don't deserve to have them.\nI can't help it,\nLavater would have said I\nlack the bump of paternity.\nDon't joke; I mean to have a serious talk with you. Do you know I\nam dissatisfied with your younger son? Between ourselves\nhe was mentioned at Her\nMajesty's and you were pitied....\nWhat would you have me do?\nYou know I did all\na father could for their education, and they have both turned out\nfools. Hippolyte is at least a quiet fool, but Anatole is an active\none. That is the only difference between them.\nAnd why are children born to such men as you? If you were not a\nfather there would be nothing I could reproach you with,\nI am your faithful slave and to you alone I can confess that my\nchildren are the bane of my life. It is the cross I have to bear. That\nis how I explain it to myself. It can't be helped!\n"
],
[
"alltags = set(tag.name for tag in bs.findAll())\nprint(alltags)",
"{'h1', 'h2', 'p', 'style', 'html', 'body', 'div', 'span', 'head'}\n"
],
[
"random = bs.findAll([\"body\",\"div\"])\n\nfor r in random:\n print(r.getText()) # Without Tags\n print(r) # With Tags\n break",
"\nWar and Peace\nChapter 1\n\n\"Well, Prince, so Genoa and Lucca are now just family estates of the\nBuonapartes. But I warn you, if you don't tell me that this means war,\nif you still try to defend the infamies and horrors perpetrated by\nthat Antichrist- I really believe he is Antichrist- I will have\nnothing more to do with you and you are no longer my friend, no longer\nmy 'faithful slave,' as you call yourself! But how do you do? I see\nI have frightened you- sit down and tell me all the news.\"\n\nIt was in July, 1805, and the speaker was the well-known Anna\nPavlovna Scherer, maid of honor and favorite of the Empress Marya\nFedorovna. With these words she greeted Prince Vasili Kuragin, a man\nof high rank and importance, who was the first to arrive at her\nreception. Anna Pavlovna had had a cough for some days. She was, as\nshe said, suffering from la grippe; grippe being then a new word in\nSt. Petersburg, used only by the elite.\n\nAll her invitations without exception, written in French, and\ndelivered by a scarlet-liveried footman that morning, ran as follows:\n\n\"If you have nothing better to do, Count [or Prince], and if the\nprospect of spending an evening with a poor invalid is not too\nterrible, I shall be very charmed to see you tonight between 7 and 10-\nAnnette Scherer.\"\n\n\"Heavens! what a virulent attack!\" replied the prince, not in the\nleast disconcerted by this reception. He had just entered, wearing\nan embroidered court uniform, knee breeches, and shoes, and had\nstars on his breast and a serene expression on his flat face. He spoke\nin that refined French in which our grandfathers not only spoke but\nthought, and with the gentle, patronizing intonation natural to a\nman of importance who had grown old in society and at court. He went\nup to Anna Pavlovna, kissed her hand, presenting to her his bald,\nscented, and shining head, and complacently seated himself on the\nsofa.\n\n\"First of all, dear friend, tell me how you are. Set your friend's\nmind at rest,\" said he without altering his tone, beneath the\npoliteness and affected sympathy of which indifference and even\nirony could be discerned.\n\n\"Can one be well while suffering morally? Can one be calm in times\nlike these if one has any feeling?\" said Anna Pavlovna. \"You are\nstaying the whole evening, I hope?\"\n\n\"And the fete at the English ambassador's? Today is Wednesday. I\nmust put in an appearance there,\" said the prince. \"My daughter is\ncoming for me to take me there.\"\n\n\"I thought today's fete had been canceled. I confess all these\nfestivities and fireworks are becoming wearisome.\"\n\n\"If they had known that you wished it, the entertainment would\nhave been put off,\" said the prince, who, like a wound-up clock, by\nforce of habit said things he did not even wish to be believed.\n\n\"Don't tease! Well, and what has been decided about Novosiltsev's\ndispatch? You know everything.\"\n\n\"What can one say about it?\" replied the prince in a cold,\nlistless tone. \"What has been decided? They have decided that\nBuonaparte has burnt his boats, and I believe that we are ready to\nburn ours.\"\n\nPrince Vasili always spoke languidly, like an actor repeating a\nstale part. Anna Pavlovna Scherer on the contrary, despite her forty\nyears, overflowed with animation and impulsiveness. To be an\nenthusiast had become her social vocation and, sometimes even when she\ndid not feel like it, she became enthusiastic in order not to\ndisappoint the expectations of those who knew her. The subdued smile\nwhich, though it did not suit her faded features, always played\nround her lips expressed, as in a spoiled child, a continual\nconsciousness of her charming defect, which she neither wished, nor\ncould, nor considered it necessary, to correct.\n\nIn the midst of a conversation on political matters Anna Pavlovna\nburst out:\n\n\"Oh, don't speak to me of Austria. Perhaps I don't understand\nthings, but Austria never has wished, and does not wish, for war.\nShe is betraying us! Russia alone must save Europe. Our gracious\nsovereign recognizes his high vocation and will be true to it. That is\nthe one thing I have faith in! Our good and wonderful sovereign has to\nperform the noblest role on earth, and he is so virtuous and noble\nthat God will not forsake him. He will fulfill his vocation and\ncrush the hydra of revolution, which has become more terrible than\never in the person of this murderer and villain! We alone must\navenge the blood of the just one.... Whom, I ask you, can we rely\non?... England with her commercial spirit will not and cannot\nunderstand the Emperor Alexander's loftiness of soul. She has\nrefused to evacuate Malta. She wanted to find, and still seeks, some\nsecret motive in our actions. What answer did Novosiltsev get? None.\nThe English have not understood and cannot understand the\nself-abnegation of our Emperor who wants nothing for himself, but only\ndesires the good of mankind. And what have they promised? Nothing! And\nwhat little they have promised they will not perform! Prussia has\nalways declared that Buonaparte is invincible, and that all Europe\nis powerless before him.... And I don't believe a word that Hardenburg\nsays, or Haugwitz either. This famous Prussian neutrality is just a\ntrap. I have faith only in God and the lofty destiny of our adored\nmonarch. He will save Europe!\"\n\nShe suddenly paused, smiling at her own impetuosity.\n\n\"I think,\" said the prince with a smile, \"that if you had been\nsent instead of our dear Wintzingerode you would have captured the\nKing of Prussia's consent by assault. You are so eloquent. Will you\ngive me a cup of tea?\"\n\n\"In a moment. A propos,\" she added, becoming calm again, \"I am\nexpecting two very interesting men tonight, le Vicomte de Mortemart,\nwho is connected with the Montmorencys through the Rohans, one of\nthe best French families. He is one of the genuine emigres, the good\nones. And also the Abbe Morio. Do you know that profound thinker? He\nhas been received by the Emperor. Had you heard?\"\n\n\"I shall be delighted to meet them,\" said the prince. \"But tell me,\"\nhe added with studied carelessness as if it had only just occurred\nto him, though the question he was about to ask was the chief motive\nof his visit, \"is it true that the Dowager Empress wants Baron Funke\nto be appointed first secretary at Vienna? The baron by all accounts\nis a poor creature.\"\n\nPrince Vasili wished to obtain this post for his son, but others\nwere trying through the Dowager Empress Marya Fedorovna to secure it\nfor the baron.\n\nAnna Pavlovna almost closed her eyes to indicate that neither she\nnor anyone else had a right to criticize what the Empress desired or\nwas pleased with.\n\n\"Baron Funke has been recommended to the Dowager Empress by her\nsister,\" was all she said, in a dry and mournful tone.\n\nAs she named the Empress, Anna Pavlovna's face suddenly assumed an\nexpression of profound and sincere devotion and respect mingled with\nsadness, and this occurred every time she mentioned her illustrious\npatroness. She added that Her Majesty had deigned to show Baron\nFunke, and again her face clouded over with sadness.\n\nThe prince was silent and looked indifferent. But, with the\nwomanly and courtierlike quickness and tact habitual to her, Anna\nPavlovna wished both to rebuke him (for daring to speak he had done of\na man recommended to the Empress) and at the same time to console him,\nso she said:\n\n\"Now about your family. Do you know that since your daughter came\nout everyone has been enraptured by her? They say she is amazingly\nbeautiful.\"\n\nThe prince bowed to signify his respect and gratitude.\n\n\"I often think,\" she continued after a short pause, drawing nearer\nto the prince and smiling amiably at him as if to show that\npolitical and social topics were ended and the time had come for\nintimate conversation- \"I often think how unfairly sometimes the\njoys of life are distributed. Why has fate given you two such splendid\nchildren? I don't speak of Anatole, your youngest. I don't like\nhim,\" she added in a tone admitting of no rejoinder and raising her\neyebrows. \"Two such charming children. And really you appreciate\nthem less than anyone, and so you don't deserve to have them.\"\n\nAnd she smiled her ecstatic smile.\n\n\"I can't help it,\" said the prince. \"Lavater would have said I\nlack the bump of paternity.\"\n\n\"Don't joke; I mean to have a serious talk with you. Do you know I\nam dissatisfied with your younger son? Between ourselves\" (and her\nface assumed its melancholy expression), \"he was mentioned at Her\nMajesty's and you were pitied....\"\n\nThe prince answered nothing, but she looked at him significantly,\nawaiting a reply. He frowned.\n\n\"What would you have me do?\" he said at last. \"You know I did all\na father could for their education, and they have both turned out\nfools. Hippolyte is at least a quiet fool, but Anatole is an active\none. That is the only difference between them.\" He said this smiling\nin a way more natural and animated than usual, so that the wrinkles\nround his mouth very clearly revealed something unexpectedly coarse\nand unpleasant.\n\n\"And why are children born to such men as you? If you were not a\nfather there would be nothing I could reproach you with,\" said Anna\nPavlovna, looking up pensively.\n\n\"I am your faithful slave and to you alone I can confess that my\nchildren are the bane of my life. It is the cross I have to bear. That\nis how I explain it to myself. It can't be helped!\"\n\nHe said no more, but expressed his resignation to cruel fate by a\ngesture. Anna Pavlovna meditated.\n\n\n<body>\n<h1>War and Peace</h1>\n<h2>Chapter 1</h2>\n<div id=\"text\">\n\"<span class=\"red\">Well, Prince, so Genoa and Lucca are now just family estates of the\nBuonapartes. But I warn you, if you don't tell me that this means war,\nif you still try to defend the infamies and horrors perpetrated by\nthat Antichrist- I really believe he is Antichrist- I will have\nnothing more to do with you and you are no longer my friend, no longer\nmy 'faithful slave,' as you call yourself! But how do you do? I see\nI have frightened you- sit down and tell me all the news.</span>\"\n<p></p>\nIt was in July, 1805, and the speaker was the well-known <span class=\"green\">Anna\nPavlovna Scherer</span>, maid of honor and favorite of the <span class=\"green\">Empress Marya\nFedorovna</span>. With these words she greeted <span class=\"green\">Prince Vasili Kuragin</span>, a man\nof high rank and importance, who was the first to arrive at her\nreception. <span class=\"green\">Anna Pavlovna</span> had had a cough for some days. She was, as\nshe said, suffering from la grippe; grippe being then a new word in\n<span class=\"green\">St. Petersburg</span>, used only by the elite.\n<p></p>\nAll her invitations without exception, written in French, and\ndelivered by a scarlet-liveried footman that morning, ran as follows:\n<p></p>\n\"<span class=\"red\">If you have nothing better to do, Count [or Prince], and if the\nprospect of spending an evening with a poor invalid is not too\nterrible, I shall be very charmed to see you tonight between 7 and 10-\nAnnette Scherer.</span>\"\n<p></p>\n\"<span class=\"red\">Heavens! what a virulent attack!</span>\" replied <span class=\"green\">the prince</span>, not in the\nleast disconcerted by this reception. He had just entered, wearing\nan embroidered court uniform, knee breeches, and shoes, and had\nstars on his breast and a serene expression on his flat face. He spoke\nin that refined French in which our grandfathers not only spoke but\nthought, and with the gentle, patronizing intonation natural to a\nman of importance who had grown old in society and at court. He went\nup to <span class=\"green\">Anna Pavlovna</span>, kissed her hand, presenting to her his bald,\nscented, and shining head, and complacently seated himself on the\nsofa.\n<p></p>\n\"<span class=\"red\">First of all, dear friend, tell me how you are. Set your friend's\nmind at rest,</span>\" said he without altering his tone, beneath the\npoliteness and affected sympathy of which indifference and even\nirony could be discerned.\n<p></p>\n\"<span class=\"red\">Can one be well while suffering morally? Can one be calm in times\nlike these if one has any feeling?</span>\" said <span class=\"green\">Anna Pavlovna</span>. \"<span class=\"red\">You are\nstaying the whole evening, I hope?</span>\"\n<p></p>\n\"<span class=\"red\">And the fete at the English ambassador's? Today is Wednesday. I\nmust put in an appearance there,</span>\" said <span class=\"green\">the prince</span>. \"<span class=\"red\">My daughter is\ncoming for me to take me there.</span>\"\n<p></p>\n\"<span class=\"red\">I thought today's fete had been canceled. I confess all these\nfestivities and fireworks are becoming wearisome.</span>\"\n<p></p>\n\"<span class=\"red\">If they had known that you wished it, the entertainment would\nhave been put off,</span>\" said <span class=\"green\">the prince</span>, who, like a wound-up clock, by\nforce of habit said things he did not even wish to be believed.\n<p></p>\n\"<span class=\"red\">Don't tease! Well, and what has been decided about Novosiltsev's\ndispatch? You know everything.</span>\"\n<p></p>\n\"<span class=\"red\">What can one say about it?</span>\" replied <span class=\"green\">the prince</span> in a cold,\nlistless tone. \"<span class=\"red\">What has been decided? They have decided that\nBuonaparte has burnt his boats, and I believe that we are ready to\nburn ours.</span>\"\n<p></p>\n<span class=\"green\">Prince Vasili</span> always spoke languidly, like an actor repeating a\nstale part. <span class=\"green\">Anna Pavlovna</span> Scherer on the contrary, despite her forty\nyears, overflowed with animation and impulsiveness. To be an\nenthusiast had become her social vocation and, sometimes even when she\ndid not feel like it, she became enthusiastic in order not to\ndisappoint the expectations of those who knew her. The subdued smile\nwhich, though it did not suit her faded features, always played\nround her lips expressed, as in a spoiled child, a continual\nconsciousness of her charming defect, which she neither wished, nor\ncould, nor considered it necessary, to correct.\n<p></p>\nIn the midst of a conversation on political matters <span class=\"green\">Anna Pavlovna</span>\nburst out:\n<p></p>\n\"<span class=\"red\">Oh, don't speak to me of Austria. Perhaps I don't understand\nthings, but Austria never has wished, and does not wish, for war.\nShe is betraying us! Russia alone must save Europe. Our gracious\nsovereign recognizes his high vocation and will be true to it. That is\nthe one thing I have faith in! Our good and wonderful sovereign has to\nperform the noblest role on earth, and he is so virtuous and noble\nthat God will not forsake him. He will fulfill his vocation and\ncrush the hydra of revolution, which has become more terrible than\never in the person of this murderer and villain! We alone must\navenge the blood of the just one.... Whom, I ask you, can we rely\non?... England with her commercial spirit will not and cannot\nunderstand the Emperor Alexander's loftiness of soul. She has\nrefused to evacuate Malta. She wanted to find, and still seeks, some\nsecret motive in our actions. What answer did Novosiltsev get? None.\nThe English have not understood and cannot understand the\nself-abnegation of our Emperor who wants nothing for himself, but only\ndesires the good of mankind. And what have they promised? Nothing! And\nwhat little they have promised they will not perform! Prussia has\nalways declared that Buonaparte is invincible, and that all Europe\nis powerless before him.... And I don't believe a word that Hardenburg\nsays, or Haugwitz either. This famous Prussian neutrality is just a\ntrap. I have faith only in God and the lofty destiny of our adored\nmonarch. He will save Europe!</span>\"\n<p></p>\nShe suddenly paused, smiling at her own impetuosity.\n<p></p>\n\"<span class=\"red\">I think,</span>\" said <span class=\"green\">the prince</span> with a smile, \"<span class=\"red\">that if you had been\nsent instead of our dear <span class=\"green\">Wintzingerode</span> you would have captured the\n<span class=\"green\">King of Prussia</span>'s consent by assault. You are so eloquent. Will you\ngive me a cup of tea?</span>\"\n<p></p>\n\"<span class=\"red\">In a moment. A propos,</span>\" she added, becoming calm again, \"<span class=\"red\">I am\nexpecting two very interesting men tonight, <span class=\"green\">le Vicomte de Mortemart</span>,\nwho is connected with the <span class=\"green\">Montmorencys</span> through the <span class=\"green\">Rohans</span>, one of\nthe best French families. He is one of the genuine emigres, the good\nones. And also the <span class=\"green\">Abbe Morio</span>. Do you know that profound thinker? He\nhas been received by <span class=\"green\">the Emperor</span>. Had you heard?</span>\"\n<p></p>\n\"<span class=\"red\">I shall be delighted to meet them,</span>\" said <span class=\"green\">the prince</span>. \"<span class=\"red\">But tell me,</span>\"\nhe added with studied carelessness as if it had only just occurred\nto him, though the question he was about to ask was the chief motive\nof his visit, \"<span class=\"red\">is it true that the Dowager Empress wants Baron Funke\nto be appointed first secretary at Vienna? The baron by all accounts\nis a poor creature.</span>\"\n<p></p>\n<span class=\"green\">Prince Vasili</span> wished to obtain this post for his son, but others\nwere trying through the <span class=\"green\">Dowager Empress Marya Fedorovna</span> to secure it\nfor <span class=\"green\">the baron</span>.\n<p></p>\n<span class=\"green\">Anna Pavlovna</span> almost closed her eyes to indicate that neither she\nnor anyone else had a right to criticize what <span class=\"green\">the Empress</span> desired or\nwas pleased with.\n<p></p>\n\"<span class=\"red\">Baron Funke has been recommended to the Dowager Empress by her\nsister,</span>\" was all she said, in a dry and mournful tone.\n<p></p>\nAs she named <span class=\"green\">the Empress</span>, <span class=\"green\">Anna Pavlovna's</span> face suddenly assumed an\nexpression of profound and sincere devotion and respect mingled with\nsadness, and this occurred every time she mentioned her illustrious\npatroness. She added that <span class=\"green\">Her Majesty</span> had deigned to show <span class=\"green\">Baron\nFunke</span>, and again her face clouded over with sadness.\n<p></p>\n<span class=\"green\">The prince</span> was silent and looked indifferent. But, with the\nwomanly and courtierlike quickness and tact habitual to her, <span class=\"green\">Anna\nPavlovna</span> wished both to rebuke him (for daring to speak he had done of\na man recommended to <span class=\"green\">the Empress</span>) and at the same time to console him,\nso she said:\n<p></p>\n\"<span class=\"red\">Now about your family. Do you know that since your daughter came\nout everyone has been enraptured by her? They say she is amazingly\nbeautiful.</span>\"\n<p></p>\n<span class=\"green\">The prince</span> bowed to signify his respect and gratitude.\n<p></p>\n\"<span class=\"red\">I often think,</span>\" she continued after a short pause, drawing nearer\nto the prince and smiling amiably at him as if to show that\npolitical and social topics were ended and the time had come for\nintimate conversation- \"<span class=\"red\">I often think how unfairly sometimes the\njoys of life are distributed. Why has fate given you two such splendid\nchildren? I don't speak of <span class=\"green\">Anatole</span>, your youngest. I don't like\nhim,</span>\" she added in a tone admitting of no rejoinder and raising her\neyebrows. \"<span class=\"red\">Two such charming children. And really you appreciate\nthem less than anyone, and so you don't deserve to have them.</span>\"\n<p></p>\nAnd she smiled her ecstatic smile.\n<p></p>\n\"<span class=\"red\">I can't help it,</span>\" said <span class=\"green\">the prince</span>. \"<span class=\"red\">Lavater would have said I\nlack the bump of paternity.</span>\"\n<p></p>\n\"<span class=\"red\">Don't joke; I mean to have a serious talk with you. Do you know I\nam dissatisfied with your younger son? Between ourselves</span>\" (and her\nface assumed its melancholy expression), \"<span class=\"red\">he was mentioned at Her\nMajesty's and you were pitied....</span>\"\n<p></p>\n<span class=\"green\">The prince</span> answered nothing, but she looked at him significantly,\nawaiting a reply. He frowned.\n<p></p>\n\"<span class=\"red\">What would you have me do?</span>\" he said at last. \"<span class=\"red\">You know I did all\na father could for their education, and they have both turned out\nfools. Hippolyte is at least a quiet fool, but Anatole is an active\none. That is the only difference between them.</span>\" He said this smiling\nin a way more natural and animated than usual, so that the wrinkles\nround his mouth very clearly revealed something unexpectedly coarse\nand unpleasant.\n<p></p>\n\"<span class=\"red\">And why are children born to such men as you? If you were not a\nfather there would be nothing I could reproach you with,</span>\" said <span class=\"green\">Anna\nPavlovna</span>, looking up pensively.\n<p></p>\n\"<span class=\"red\">I am your faithful slave and to you alone I can confess that my\nchildren are the bane of my life. It is the cross I have to bear. That\nis how I explain it to myself. It can't be helped!</span>\"\n<p></p>\nHe said no more, but expressed his resignation to cruel fate by a\ngesture. <span class=\"green\">Anna Pavlovna</span> meditated.\n</div>\n</body>\n"
],
[
"hlist = bs.findAll([\"h1\",\"h2\"])\nfor h in hlist:\n print(h)",
"<h1>War and Peace</h1>\n<h2>Chapter 1</h2>\n"
],
[
"hList = bs.findAll([\"h1\",\"h2\",\"h3\",\"h4\",\"h5\",\"h6\"])\nfor h in hList:\n print(h)",
"<h1>War and Peace</h1>\n<h2>Chapter 1</h2>\n"
],
[
"nameList =bs.findAll([\"span\"],text=\"the prince\")\nfor name in nameList:\n print(name)\n \nnameList = bs.find(class_=\"red\")\nnameList2 = bs.findAll(\"span\",{\"class\":\"green\"})\n\nprint(nameList)\nprint(nameList2)",
"<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"green\">the prince</span>\n<span class=\"red\">Well, Prince, so Genoa and Lucca are now just family estates of the\nBuonapartes. But I warn you, if you don't tell me that this means war,\nif you still try to defend the infamies and horrors perpetrated by\nthat Antichrist- I really believe he is Antichrist- I will have\nnothing more to do with you and you are no longer my friend, no longer\nmy 'faithful slave,' as you call yourself! But how do you do? I see\nI have frightened you- sit down and tell me all the news.</span>\n[<span class=\"green\">Anna\nPavlovna Scherer</span>, <span class=\"green\">Empress Marya\nFedorovna</span>, <span class=\"green\">Prince Vasili Kuragin</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">St. Petersburg</span>, <span class=\"green\">the prince</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">the prince</span>, <span class=\"green\">the prince</span>, <span class=\"green\">the prince</span>, <span class=\"green\">Prince Vasili</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">the prince</span>, <span class=\"green\">Wintzingerode</span>, <span class=\"green\">King of Prussia</span>, <span class=\"green\">le Vicomte de Mortemart</span>, <span class=\"green\">Montmorencys</span>, <span class=\"green\">Rohans</span>, <span class=\"green\">Abbe Morio</span>, <span class=\"green\">the Emperor</span>, <span class=\"green\">the prince</span>, <span class=\"green\">Prince Vasili</span>, <span class=\"green\">Dowager Empress Marya Fedorovna</span>, <span class=\"green\">the baron</span>, <span class=\"green\">Anna Pavlovna</span>, <span class=\"green\">the Empress</span>, <span class=\"green\">the Empress</span>, <span class=\"green\">Anna Pavlovna's</span>, <span class=\"green\">Her Majesty</span>, <span class=\"green\">Baron\nFunke</span>, <span class=\"green\">The prince</span>, <span class=\"green\">Anna\nPavlovna</span>, <span class=\"green\">the Empress</span>, <span class=\"green\">The prince</span>, <span class=\"green\">Anatole</span>, <span class=\"green\">the prince</span>, <span class=\"green\">The prince</span>, <span class=\"green\">Anna\nPavlovna</span>, <span class=\"green\">Anna Pavlovna</span>]\n"
]
],
[
[
"Objects on Beautiful soup\n- BeautifulSoup \n- Tag Objects List or Single value depends on (findAll and find)\n- NavigableString objs < Represent text within tags >\n- Comment obj < Represent the Comments>",
"_____no_output_____"
]
],
[
[
"# Navigating Treess\nhtml = urlopen(\"http://www.pythonscraping.com/pages/page3.html\")\nbs = BeautifulSoup(html,\"lxml\")\nprint(bs.html.head)\n",
"<head>\n<style>\nimg{\n\twidth:75px;\n}\ntable{\n\twidth:50%;\n}\ntd{\n\tmargin:10px;\n\tpadding:10px;\n}\n.wrapper{\n\twidth:800px;\n}\n.excitingNote{\n\tfont-style:italic;\n\tfont-weight:bold;\n}\n</style>\n</head>\n"
]
],
[
[
"In Beautiful Soup all treated as descendant , ya intinya descendant tuh kek Cucu dan seterunya lah\nexample :\nada ayah namanya badang\nanaknya rino\nrino nikah punya anak sambir\nnah si sambir ini disebut descendant\n\nbs.findAll juga sama makenya descendant juga ",
"_____no_output_____"
]
],
[
[
"#contoh descendant\nprint(bs.h1)\nprint(bs.html.h1)\nprint(bs.body.h1)\nprint(bs.findAll('img'))",
"<h1>Totally Normal Gifts</h1>\n<h1>Totally Normal Gifts</h1>\n<h1>Totally Normal Gifts</h1>\n[<img src=\"../img/gifts/logo.jpg\" style=\"float:left;\"/>, <img src=\"../img/gifts/img1.jpg\"/>, <img src=\"../img/gifts/img2.jpg\"/>, <img src=\"../img/gifts/img3.jpg\"/>, <img src=\"../img/gifts/img4.jpg\"/>, <img src=\"../img/gifts/img6.jpg\"/>]\n"
],
[
"# find children\nfor child in bs.find(\"table\", {\"id\" : \"giftList\"}).children:\n print(child)",
"\n\n<tr><th>\nItem Title\n</th><th>\nDescription\n</th><th>\nCost\n</th><th>\nImage\n</th></tr>\n\n\n<tr class=\"gift\" id=\"gift1\"><td>\nVegetable Basket\n</td><td>\nThis vegetable basket is the perfect gift for your health conscious (or overweight) friends!\n<span class=\"excitingNote\">Now with super-colorful bell peppers!</span>\n</td><td>\n$15.00\n</td><td>\n<img src=\"../img/gifts/img1.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift2\"><td>\nRussian Nesting Dolls\n</td><td>\nHand-painted by trained monkeys, these exquisite dolls are priceless! And by \"priceless,\" we mean \"extremely expensive\"! <span class=\"excitingNote\">8 entire dolls per set! Octuple the presents!</span>\n</td><td>\n$10,000.52\n</td><td>\n<img src=\"../img/gifts/img2.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift3\"><td>\nFish Painting\n</td><td>\nIf something seems fishy about this painting, it's because it's a fish! <span class=\"excitingNote\">Also hand-painted by trained monkeys!</span>\n</td><td>\n$10,005.00\n</td><td>\n<img src=\"../img/gifts/img3.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift4\"><td>\nDead Parrot\n</td><td>\nThis is an ex-parrot! <span class=\"excitingNote\">Or maybe he's only resting?</span>\n</td><td>\n$0.50\n</td><td>\n<img src=\"../img/gifts/img4.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift5\"><td>\nMystery Box\n</td><td>\nIf you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class=\"excitingNote\">Keep your friends guessing!</span>\n</td><td>\n$1.50\n</td><td>\n<img src=\"../img/gifts/img6.jpg\"/>\n</td></tr>\n\n\n"
],
[
"# Dealing with siblings\n# Jadi ini setiap masing masing masuk ke tr , lalu ambil seluruh child yang ada di tr \nfor sibling in bs.find(\"table\", {\"id\" : \"giftList\"}).tr.next_siblings:\n print(sibling)\n\nprint(\"\\n\\n\")\n",
"\n\n<tr class=\"gift\" id=\"gift1\"><td>\nVegetable Basket\n</td><td>\nThis vegetable basket is the perfect gift for your health conscious (or overweight) friends!\n<span class=\"excitingNote\">Now with super-colorful bell peppers!</span>\n</td><td>\n$15.00\n</td><td>\n<img src=\"../img/gifts/img1.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift2\"><td>\nRussian Nesting Dolls\n</td><td>\nHand-painted by trained monkeys, these exquisite dolls are priceless! And by \"priceless,\" we mean \"extremely expensive\"! <span class=\"excitingNote\">8 entire dolls per set! Octuple the presents!</span>\n</td><td>\n$10,000.52\n</td><td>\n<img src=\"../img/gifts/img2.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift3\"><td>\nFish Painting\n</td><td>\nIf something seems fishy about this painting, it's because it's a fish! <span class=\"excitingNote\">Also hand-painted by trained monkeys!</span>\n</td><td>\n$10,005.00\n</td><td>\n<img src=\"../img/gifts/img3.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift4\"><td>\nDead Parrot\n</td><td>\nThis is an ex-parrot! <span class=\"excitingNote\">Or maybe he's only resting?</span>\n</td><td>\n$0.50\n</td><td>\n<img src=\"../img/gifts/img4.jpg\"/>\n</td></tr>\n\n\n<tr class=\"gift\" id=\"gift5\"><td>\nMystery Box\n</td><td>\nIf you love suprises, this mystery box is for you! Do not place on light-colored surfaces. May cause oil staining. <span class=\"excitingNote\">Keep your friends guessing!</span>\n</td><td>\n$1.50\n</td><td>\n<img src=\"../img/gifts/img6.jpg\"/>\n</td></tr>\n\n\n\n\n\n"
],
[
"# Dealing with parents\n# Cara bacanya adalah : Get si parent dari pada tag yang dicari terus navigasi , ya gunain previous sibling \nfor parent in bs.find(\"img\",{\"src\" : \"../img/gifts/img1.jpg\"}).parent.previous_sibling.previous_sibling.next_sibling:\n print(parent)",
"\n$15.00\n\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cbcf7c201265f51022cd3715f3c6412da355d339
| 2,756 |
ipynb
|
Jupyter Notebook
|
python-scripts/data_analytics_learn/link_pandas/Ex_Files_Pandas_Data/Exercise Files/05_02/Final/Figures.ipynb
|
adityaka/misc_scripts
|
b28f71eb9b7eb429b44aeb9cb34f12355023125e
|
[
"BSD-3-Clause"
] | 1 |
2018-01-16T18:21:07.000Z
|
2018-01-16T18:21:07.000Z
|
python-scripts/data_analytics_learn/link_pandas/Ex_Files_Pandas_Data/Exercise Files/05_02/Final/Figures.ipynb
|
adityaka/misc_scripts
|
b28f71eb9b7eb429b44aeb9cb34f12355023125e
|
[
"BSD-3-Clause"
] | 1 |
2017-05-09T07:13:52.000Z
|
2017-06-12T05:24:08.000Z
|
python-scripts/data_analytics_learn/link_pandas/Ex_Files_Pandas_Data/Exercise Files/05_02/Final/.ipynb_checkpoints/Figures-checkpoint.ipynb
|
adityaka/misc_scripts
|
b28f71eb9b7eb429b44aeb9cb34f12355023125e
|
[
"BSD-3-Clause"
] | 1 |
2021-09-03T14:17:00.000Z
|
2021-09-03T14:17:00.000Z
| 18.496644 | 67 | 0.513425 |
[
[
[
"### Figures and Subplots\n- figure - container thats holds all elements of plot(s)\n- subplot - appears within a rectangular grid within a figure",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nplt.style.use('ggplot')",
"_____no_output_____"
],
[
"my_first_figure = plt.figure(\"My First Figure\")",
"_____no_output_____"
],
[
"subplot_1 = my_first_figure.add_subplot(2, 3, 1)\nsubplot_6 = my_first_figure.add_subplot(2, 3, 6)",
"_____no_output_____"
],
[
"plt.plot(np.random.rand(50).cumsum(), 'k--')\nplt.show()",
"_____no_output_____"
],
[
"subplot_2 = my_first_figure.add_subplot(2, 3, 2)\nplt.plot(np.random.rand(50), 'go')",
"_____no_output_____"
],
[
"subplot_6",
"_____no_output_____"
],
[
"plt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbcf8a1ca017409fdc81bfa1a090d4af80a5ab71
| 10,105 |
ipynb
|
Jupyter Notebook
|
week4/Seminar4.0_recap_approx_qlearning.ipynb
|
oleg-kachan/reinforcement_learning
|
8ba84c29f840bf860baad7a047158407a82d5409
|
[
"MIT"
] | 2 |
2020-11-24T17:56:30.000Z
|
2021-12-10T01:37:49.000Z
|
week4/Seminar4.0_recap_approx_qlearning.ipynb
|
oleg-kachan/reinforcement_learning
|
8ba84c29f840bf860baad7a047158407a82d5409
|
[
"MIT"
] | null | null | null |
week4/Seminar4.0_recap_approx_qlearning.ipynb
|
oleg-kachan/reinforcement_learning
|
8ba84c29f840bf860baad7a047158407a82d5409
|
[
"MIT"
] | 3 |
2017-04-01T11:48:37.000Z
|
2018-04-29T23:36:54.000Z
| 25.199501 | 269 | 0.55141 |
[
[
[
"# Approximate q-learning\n\nIn this notebook you will teach a lasagne neural network to do Q-learning.",
"_____no_output_____"
],
[
"__Frameworks__ - we'll accept this homework in any deep learning framework. For example, it translates to TensorFlow almost line-to-line. However, we recommend you to stick to theano/lasagne unless you're certain about your skills in the framework of your choice.",
"_____no_output_____"
]
],
[
[
"%env THEANO_FLAGS='floatX=float32'\nimport os\nif type(os.environ.get(\"DISPLAY\")) is not str or len(os.environ.get(\"DISPLAY\"))==0:\n !bash ../xvfb start\n %env DISPLAY=:1",
"_____no_output_____"
],
[
"import gym\nimport numpy as np, pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"env = gym.make(\"CartPole-v0\")\nenv.reset()\nn_actions = env.action_space.n\nstate_dim = env.observation_space.shape\n\nplt.imshow(env.render(\"rgb_array\"))",
"_____no_output_____"
]
],
[
[
"# Approximate (deep) Q-learning: building the network\n\nIn this section we will build and train naive Q-learning with theano/lasagne",
"_____no_output_____"
],
[
"First step is initializing input variables",
"_____no_output_____"
]
],
[
[
"import theano\nimport theano.tensor as T\n\n#create input variables. We'll support multiple states at once\n\n\ncurrent_states = T.matrix(\"states[batch,units]\")\nactions = T.ivector(\"action_ids[batch]\")\nrewards = T.vector(\"rewards[batch]\")\nnext_states = T.matrix(\"next states[batch,units]\")\nis_end = T.ivector(\"vector[batch] where 1 means that session just ended\")",
"_____no_output_____"
],
[
"import lasagne\nfrom lasagne.layers import *\n\n#input layer\nl_states = InputLayer((None,)+state_dim)\n\n\n<Your architecture. Please start with a single-layer network>\n\n\n#output layer\nl_qvalues = DenseLayer(<previous_layer>,num_units=n_actions,nonlinearity=None)",
"_____no_output_____"
]
],
[
[
"#### Predicting Q-values for `current_states`",
"_____no_output_____"
]
],
[
[
"#get q-values for ALL actions in current_states\npredicted_qvalues = get_output(l_qvalues,{l_states:current_states})",
"_____no_output_____"
],
[
"#compiling agent's \"GetQValues\" function\nget_qvalues = <compile a function that takes current_states and returns predicted_qvalues>",
"_____no_output_____"
],
[
"#select q-values for chosen actions\npredicted_qvalues_for_actions = predicted_qvalues[T.arange(actions.shape[0]),actions]",
"_____no_output_____"
]
],
[
[
"#### Loss function and `update`\nHere we write a function similar to `agent.update`.",
"_____no_output_____"
]
],
[
[
"#predict q-values for next states\npredicted_next_qvalues = get_output(l_qvalues,{l_states:<theano input with for states>})\n\n\n#Computing target q-values under \ngamma = 0.99\ntarget_qvalues_for_actions = <target Q-values using rewards and predicted_next_qvalues>\n\n#zero-out q-values at the end\ntarget_qvalues_for_actions = (1-is_end)*target_qvalues_for_actions\n\n#don't compute gradient over target q-values (consider constant)\ntarget_qvalues_for_actions = theano.gradient.disconnected_grad(target_qvalues_for_actions)",
"_____no_output_____"
],
[
"\n#mean squared error loss function\nloss = <mean squared between target_qvalues_for_actions and predicted_qvalues_for_actions>\n",
"_____no_output_____"
],
[
"#all network weights\nall_weights = get_all_params(l_qvalues,trainable=True)\n\n#network updates. Note the small learning rate (for stability)\nupdates = lasagne.updates.sgd(loss,all_weights,learning_rate=1e-4)",
"_____no_output_____"
],
[
"#Training function that resembles agent.update(state,action,reward,next_state) \n#with 1 more argument meaning is_end\ntrain_step = theano.function([current_states,actions,rewards,next_states,is_end],\n updates=updates)",
"_____no_output_____"
]
],
[
[
"### Playing the game",
"_____no_output_____"
]
],
[
[
"epsilon = 0.25 #initial epsilon\n\ndef generate_session(t_max=1000):\n \"\"\"play env with approximate q-learning agent and train it at the same time\"\"\"\n \n total_reward = 0\n s = env.reset()\n \n for t in range(t_max):\n \n #get action q-values from the network\n q_values = get_qvalues([s])[0] \n \n a = <sample action with epsilon-greedy strategy>\n \n new_s,r,done,info = env.step(a)\n \n #train agent one step. Note that we use one-element arrays instead of scalars \n #because that's what function accepts.\n train_step([s],[a],[r],[new_s],[done])\n \n total_reward+=r\n \n s = new_s\n if done: break\n \n return total_reward\n ",
"_____no_output_____"
],
[
"for i in range(100):\n \n rewards = [generate_session() for _ in range(100)] #generate new sessions\n \n epsilon*=0.95\n \n print (\"mean reward:%.3f\\tepsilon:%.5f\"%(np.mean(rewards),epsilon))\n\n if np.mean(rewards) > 300:\n print (\"You Win!\")\n break\n \n assert epsilon!=0, \"Please explore environment\"",
"_____no_output_____"
]
],
[
[
"### Video",
"_____no_output_____"
]
],
[
[
"epsilon=0 #Don't forget to reset epsilon back to initial value if you want to go on training",
"_____no_output_____"
],
[
"#record sessions\nimport gym.wrappers\nenv = gym.wrappers.Monitor(env,directory=\"videos\",force=True)\nsessions = [generate_session() for _ in range(100)]\nenv.close()\n#unwrap \nenv = env.env.env\n#upload to gym\n#gym.upload(\"./videos/\",api_key=\"<your_api_key>\") #you'll need me later\n\n#Warning! If you keep seeing error that reads something like\"DoubleWrapError\",\n#run env=gym.make(\"CartPole-v0\");env.reset();",
"_____no_output_____"
],
[
"#show video\nfrom IPython.display import HTML\nimport os\n\nvideo_names = list(filter(lambda s:s.endswith(\".mp4\"),os.listdir(\"./videos/\")))\n\nHTML(\"\"\"\n<video width=\"640\" height=\"480\" controls>\n <source src=\"{}\" type=\"video/mp4\">\n</video>\n\"\"\".format(\"./videos/\"+video_names[-1])) #this may or may not be _last_ video. Try other indices",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbcf948d9541f3b98ac502525100591acf890529
| 7,466 |
ipynb
|
Jupyter Notebook
|
home/trdb2/aip003.ipynb
|
zhs007/jupyternotebook.demo
|
64919dbc477a3b17f75fc9bf44e5368d7eb96581
|
[
"Apache-2.0"
] | null | null | null |
home/trdb2/aip003.ipynb
|
zhs007/jupyternotebook.demo
|
64919dbc477a3b17f75fc9bf44e5368d7eb96581
|
[
"Apache-2.0"
] | 8 |
2020-11-30T15:04:16.000Z
|
2021-03-07T04:16:40.000Z
|
home/trdb2/aip003.ipynb
|
zhs007/jupyternotebook.demo
|
64919dbc477a3b17f75fc9bf44e5368d7eb96581
|
[
"Apache-2.0"
] | null | null | null | 26.569395 | 208 | 0.502813 |
[
[
[
"均线定投",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom datetime import datetime\nimport trdb2py\nimport numpy as np\n\nisStaticImg = False\nwidth = 960\nheight = 768\n\npd.options.display.max_columns = None\npd.options.display.max_rows = None\n\ntrdb2cfg = trdb2py.loadConfig('./trdb2.yaml')",
"_____no_output_____"
],
[
"# 具体基金\nasset = 'jqdata.000300_XSHG|1d'\n# baselineasset = 'jrj.510310'\n# asset = 'jrj.110011'\n# baselineasset = 'jqdata.000300_XSHG|1d'\n\n# 起始时间,0表示从最开始算起\ntsStart = 0\ntsStart = int(trdb2py.str2timestamp('2013-05-01', '%Y-%m-%d'))\n\n# 结束时间,-1表示到现在为止\ntsEnd = -1\ntsEnd = int(trdb2py.str2timestamp('2020-12-31', '%Y-%m-%d'))\n\n# 初始资金池\nparamsinit = trdb2py.trading2_pb2.InitParams(\n money=10000,\n)\n\n# 买入参数,用全部的钱来买入(也就是复利)\nparamsbuy = trdb2py.trading2_pb2.BuyParams(\n perHandMoney=1,\n)\n\n# 买入参数,用全部的钱来买入(也就是复利)\nparamsbuy2 = trdb2py.trading2_pb2.BuyParams(\n perHandMoney=0.5,\n)\n\n# 卖出参数,全部卖出\nparamssell = trdb2py.trading2_pb2.SellParams(\n perVolume=1,\n)\n\nparamsaip = trdb2py.trading2_pb2.AIPParams(\n money=10000,\n type=trdb2py.trading2_pb2.AIPTT_MONTHDAY,\n day=1,\n)\n\n# 止盈参数,120%止盈\nparamstakeprofit = trdb2py.trading2_pb2.TakeProfitParams(\n perVolume=1,\n isOnlyProfit=True,\n# isFinish=True,\n)\n\n# 止盈参数,120%止盈\nparamstakeprofit1 = trdb2py.trading2_pb2.TakeProfitParams(\n perVolume=1,\n# isOnlyProfit=True,\n# isFinish=True,\n)\n\n# 卖出参数,全部卖出\nparamssell7 = trdb2py.trading2_pb2.SellParams(\n# perVolume=1,\n keepTime=7 * 24 * 60 * 60,\n)\n\nlststart = [1, 2, 3, 4, 5]\nlsttitle = ['周一', '周二', '周三', '周四', '周五']",
"_____no_output_____"
],
[
"def calcweekday2val2(wday, offday):\n if offday == 1:\n if wday == 5:\n return 3\n if offday == 2:\n if wday >= 4:\n return 4\n if offday == 3:\n if wday >= 3:\n return 5\n if offday == 4:\n if wday >= 2:\n return 6\n \n return offday\n",
"_____no_output_____"
],
[
"asset = 'jrj.110011'\n# asset = 'jqdata.000036_XSHG|1d'\n# asset = 'jqdata.000032_XSHG|1d'\nasset = 'jqdata.000300_XSHG|1d'\n\n# baseline \ns0 = trdb2py.trading2_pb2.Strategy(\n name=\"normal\",\n asset=trdb2py.str2asset(asset), \n)\n \nbuy0 = trdb2py.trading2_pb2.CtrlCondition(\n name='buyandhold',\n)\n\nparamsbuy = trdb2py.trading2_pb2.BuyParams(\n perHandMoney=1,\n)\n\nparamsinit = trdb2py.trading2_pb2.InitParams(\n money=10000,\n)\n\ns0.buy.extend([buy0])\ns0.paramsBuy.CopyFrom(paramsbuy)\ns0.paramsInit.CopyFrom(paramsinit) \np0 = trdb2py.trading2_pb2.SimTradingParams(\n assets=[trdb2py.str2asset(asset)],\n startTs=tsStart,\n endTs=tsEnd,\n strategies=[s0],\n title='沪深300',\n) \n\npnlBaseline = trdb2py.simTrading(trdb2cfg, p0)\ntrdb2py.showPNL(pnlBaseline, toImg=isStaticImg, width=width, height=height)",
"_____no_output_____"
],
[
"lstparams = []\n\nfor i in range(2, 181):\n buy0 = trdb2py.trading2_pb2.CtrlCondition(\n name='monthdayex',\n vals=[1],\n )\n \n buy1 = trdb2py.trading2_pb2.CtrlCondition(\n name='waittostart',\n vals=[i],\n )\n\n buy2 = trdb2py.trading2_pb2.CtrlCondition(\n name='indicatorsp',\n operators=['up'],\n strVals=['ta-sma.{}'.format(i)],\n ) \n \n sell0 = trdb2py.trading2_pb2.CtrlCondition(\n name='indicatorsp',\n operators=['downcross'],\n strVals=['ta-sma.{}'.format(i)],\n ) \n\n s0 = trdb2py.trading2_pb2.Strategy(\n name=\"normal\",\n asset=trdb2py.str2asset(asset),\n )\n \n# paramsaip = trdb2py.trading2_pb2.AIPParams(\n# money=10000,\n# type=trdb2py.trading2_pb2.AIPTT_WEEKDAY,\n# day=1,\n# )\n\n s0.buy.extend([buy0, buy1, buy2])\n s0.sell.extend([sell0]) \n s0.paramsBuy.CopyFrom(paramsbuy)\n s0.paramsSell.CopyFrom(paramssell)\n# s0.paramsInit.CopyFrom(paramsinit)\n s0.paramsAIP.CopyFrom(paramsaip)\n lstparams.append(trdb2py.trading2_pb2.SimTradingParams(\n assets=[trdb2py.str2asset(asset)],\n startTs=tsStart,\n endTs=tsEnd,\n strategies=[s0],\n title='{}定投'.format(i),\n ))\n \nlstaippnl = trdb2py.simTradings(trdb2cfg, lstparams, ignoreTotalReturn=1.5)\n\ntrdb2py.showPNLs(lstaippnl + [pnlBaseline], toImg=isStaticImg, width=width, height=height)",
"_____no_output_____"
]
],
[
[
"我们看到不管是每个月的几号买入,最终其实都差异不大",
"_____no_output_____"
]
],
[
[
"dfpnl1b = trdb2py.buildPNLReport(lstaippnl + [pnlBaseline])\n\ndfpnl1b[['title', 'maxDrawdown', 'maxDrawdownStart', 'maxDrawdownEnd', 'totalReturns', 'sharpe', 'annualizedReturns', 'annualizedVolatility', 'variance']].sort_values(by='totalReturns', ascending=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbcfb66403ebdef2b816e202f4211b861d5238d2
| 3,483 |
ipynb
|
Jupyter Notebook
|
BerghAlgorithms/src/OldFiles/interiorPoints.ipynb
|
nbenabla/destackification
|
f968381c9c722ecf3d286dc8809a3add4ab0f9e6
|
[
"MIT"
] | null | null | null |
BerghAlgorithms/src/OldFiles/interiorPoints.ipynb
|
nbenabla/destackification
|
f968381c9c722ecf3d286dc8809a3add4ab0f9e6
|
[
"MIT"
] | null | null | null |
BerghAlgorithms/src/OldFiles/interiorPoints.ipynb
|
nbenabla/destackification
|
f968381c9c722ecf3d286dc8809a3add4ab0f9e6
|
[
"MIT"
] | 1 |
2021-06-23T23:13:40.000Z
|
2021-06-23T23:13:40.000Z
| 21.90566 | 68 | 0.478898 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
cbcfd0bb7e583086229d0e98f0ccf22d5e581113
| 132,504 |
ipynb
|
Jupyter Notebook
|
hydra_openvino_pi.ipynb
|
dhruvsheth-ai/hydra-openvino-sensors
|
6373ace697e0db7a8bffe0e45875b2920a4475f1
|
[
"MIT"
] | 1 |
2020-10-05T03:31:10.000Z
|
2020-10-05T03:31:10.000Z
|
hydra_openvino_pi.ipynb
|
dhruvsheth-ai/hydra-openvino-sensors
|
6373ace697e0db7a8bffe0e45875b2920a4475f1
|
[
"MIT"
] | null | null | null |
hydra_openvino_pi.ipynb
|
dhruvsheth-ai/hydra-openvino-sensors
|
6373ace697e0db7a8bffe0e45875b2920a4475f1
|
[
"MIT"
] | null | null | null | 736.133333 | 128,165 | 0.953526 |
[
[
[
"<a href=\"https://colab.research.google.com/github/dhruvsheth-ai/hydra-openvino-sensors/blob/master/hydra_openvino_pi.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"**Install the latest OpenVino for Raspberry Pi OS package from Intel OpenVino Distribution Download**\nFor my case, I have Installed 2020.4 version.\n\n\n\n```\nl_openvino_toolkit_runtime_raspbian_p_2020.4.28\n```\n\nThis is the latest version available with the model zoo. Since the below code is executed on a Jupyter Notebook, terminal syntaxes may be different.\n",
"_____no_output_____"
]
],
[
[
"cd ~/Downloads/",
"_____no_output_____"
],
[
"!sudo mkdir -p /opt/intel/openvino",
"_____no_output_____"
],
[
"!sudo tar -xf l_openvino_toolkit_runtime_raspbian_p_<version>.tgz --strip 1 -C /opt/intel/openvino",
"_____no_output_____"
],
[
"!sudo apt install cmake",
"_____no_output_____"
],
[
"!echo \"source /opt/intel/openvino/bin/setupvars.sh\" >> ~/.bashrc",
"_____no_output_____"
]
],
[
[
"Your output on new terminal will be:\n\n\n```\n[setupvars.sh] OpenVINO environment initialized\n\n```\n\n",
"_____no_output_____"
]
],
[
[
"!sudo usermod -a -G users \"$(raspberry-pi)\"",
"_____no_output_____"
]
],
[
[
"The below are the USB rules for Intel Neural Compute Stick 2:",
"_____no_output_____"
]
],
[
[
"!sh /opt/intel/openvino/install_dependencies/install_NCS_udev_rules.sh",
"_____no_output_____"
]
],
[
[
"Once this is set up, move to the ```\nhydra-openvino-yolo.ipynb\n```\n file for running the model",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbcfd108fd52992e95bfbb138fc2a803c12d98f7
| 60,569 |
ipynb
|
Jupyter Notebook
|
CRIM_Data_Search_Collab.ipynb
|
RichardFreedman/Collab_Notebooks
|
3e0dbdddffd8cf73bc4c6ad3560d76120284066b
|
[
"Apache-2.0"
] | 1 |
2021-06-03T20:36:11.000Z
|
2021-06-03T20:36:11.000Z
|
CRIM_Data_Search_Collab.ipynb
|
RichardFreedman/Collab_Notebooks
|
3e0dbdddffd8cf73bc4c6ad3560d76120284066b
|
[
"Apache-2.0"
] | null | null | null |
CRIM_Data_Search_Collab.ipynb
|
RichardFreedman/Collab_Notebooks
|
3e0dbdddffd8cf73bc4c6ad3560d76120284066b
|
[
"Apache-2.0"
] | null | null | null | 33.389746 | 1,346 | 0.406247 |
[
[
[
"<a href=\"https://colab.research.google.com/github/RichardFreedman/CRIM_Collab_Notebooks/blob/main/CRIM_Data_Search.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import requests",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"# Markdown for descriptive text\n## level two\n### Structure notebook for various sections and TOC\nPlain text is just normal\n- list\n- list item with dashes\nor numbers\n\n1. this\n2. that\n3. another\n - Still other\n - Still more\n -And yet more\n \n \n\n\n\n",
"_____no_output_____"
],
[
"# Markdown vs Code\nPick Markdown for type of cell above. **Shift + return** to enter these\n# Formatting\nItalics is *before* **bold**\n\nEscape then B to create new cells (and pick cell types later)\n\n# Fill\nTab to auto fill within cell\n # Requests\nRequests in fact has several functions after the \".\" Like Get, or whatever\n\nRequests.get plus (), then Shift+Tab to see all the parameters that must be passed.\n\nResponse object allows you to extract what you need, like JSON\n\nFor Obs_1_json = response.json() we **need** the parenths to run the function\n\n# Dictionaries and Types\nDictionary= Key>Value Pairs (Key is MEI Links, value is the link)\n\nNote that Values can themselves contain dictionary\n\nPython Types\n\nDictionary (Pairs; can contain other Dictionaries)\nString (thing in a quote)\nList (always in square brackets, and can contain dictionaries and lists within them)\n\nindexing of items in a list start at ZERO\nlast item is \"-1\", etc\n\n# Get Key\nTo get an individual KEY from top level:\n\nObs_ema_1 = Obs_1_json[\"ema\"]\n\nThis allows you to dig deeper in nested lists or dictionaries. In this case piece is top level in JSON, the MEI link is next. The number allows you to pick from items IN a list: Obs_1_json[\"piece\"][\"mei_links\"][0]\n",
"_____no_output_____"
]
],
[
[
"Obs_1_url = \"https://crimproject.org/data/observations/1/\"",
"_____no_output_____"
],
[
"Obs_1_url",
"_____no_output_____"
],
[
"response = requests.get(Obs_1_url)",
"_____no_output_____"
],
[
"response",
"_____no_output_____"
],
[
"type(response)",
"_____no_output_____"
],
[
"Obs_1_json = response.json()",
"_____no_output_____"
],
[
"Obs_1_json",
"_____no_output_____"
],
[
"type(Obs_1_json)",
"_____no_output_____"
],
[
"example_list_1 = [5, 3, \"this\", \"that\"]",
"_____no_output_____"
],
[
"example_list_1[3]",
"_____no_output_____"
],
[
"Obs_1_json.keys()",
"_____no_output_____"
],
[
"Obs_ema_1 = Obs_1_json[\"ema\"]",
"_____no_output_____"
],
[
"Obs_ema_1",
"_____no_output_____"
],
[
"type(Obs_ema_1)",
"_____no_output_____"
],
[
"print(\"here is a print statement\")",
"here is a print statement\n"
],
[
"Obs_1_json[\"musical_type\"]",
"_____no_output_____"
],
[
"Obs_1_mt = Obs_1_json[\"musical_type\"]",
"_____no_output_____"
],
[
"Obs_1_mt",
"_____no_output_____"
],
[
"Obs_1_piece = Obs_1_json[\"piece\"]",
"_____no_output_____"
],
[
"Obs_1_piece",
"_____no_output_____"
],
[
"Obs_1_mei = Obs_1_piece[\"mei_links\"]",
"_____no_output_____"
],
[
"Obs_1_mei",
"_____no_output_____"
],
[
"len(Obs_1_mei)",
"_____no_output_____"
],
[
"Obs_1_mei[0]",
"_____no_output_____"
],
[
"Obs_1_json[\"piece\"][\"mei_links\"][0]",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Obs_1_json[\"ema\"]",
"_____no_output_____"
]
],
[
[
"# Loops\n",
"_____no_output_____"
]
],
[
[
"test_list = [1,5,2,5,6]",
"_____no_output_____"
],
[
"for i, observation_id in enumerate(test_list):\n # do stuff\n print(i, observation_id)",
"0 1\n1 5\n2 2\n3 5\n4 6\n"
],
[
"for number in range(1,10):\n print(number)",
"1\n2\n3\n4\n5\n6\n7\n8\n9\n"
],
[
"def myfunction():\n print(\"it is running\")",
"_____no_output_____"
],
[
"myfunction",
"_____no_output_____"
],
[
"myfunction()",
"it is running\n"
],
[
"def adder(num_1, num_2):\n return num_1 + num_2",
"_____no_output_____"
],
[
"adder(5,9)",
"_____no_output_____"
],
[
"def get_ema_for_observation_id(obs_id):\n # get Obs_1_url\n url = \"https://crimproject.org/data/observations/{}/\".format(obs_id)\n return url",
"_____no_output_____"
],
[
"def get_ema_for_observation_id(obs_id):\n # get Obs_1_ema\n my_ema_mei_dictionary = dict()\n url = \"https://crimproject.org/data/observations/{}/\".format(obs_id)\n response = requests.get(url)\n Obs_json = response.json()\n \n # Obs_ema = Obs_json[\"ema\"]\n \n my_ema_mei_dictionary[\"id\"]=Obs_json[\"id\"]\n my_ema_mei_dictionary[\"musical type\"]=Obs_json[\"musical_type\"]\n my_ema_mei_dictionary[\"int\"]=Obs_json[\"mt_fg_int\"]\n my_ema_mei_dictionary[\"tint\"]=Obs_json[\"mt_fg_tint\"]\n my_ema_mei_dictionary[\"ema\"]=Obs_json[\"ema\"]\n my_ema_mei_dictionary[\"mei\"]=Obs_json[\"piece\"][\"mei_links\"][0]\n my_ema_mei_dictionary[\"pdf\"]=Obs_json[\"piece\"][\"pdf_links\"][0]\n \n \n # Obs_piece = Obs_json[\"piece\"]\n # Obs_mei = Obs_piece[\"mei_links\"]\n \n print(f'Got: {obs_id}')\n \n # return {\"ema\":Obs_ema,\"mei\":Obs_mei}\n \n return my_ema_mei_dictionary\n",
"_____no_output_____"
],
[
"get_ema_for_observation_id(20)",
"Got: 20\n"
],
[
"output = get_ema_for_observation_id(20)",
"Got: 20\n"
],
[
"pd.Series(output).to_csv(\"output.csv\")",
"/Users/rfreedma/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:1: FutureWarning: The signature of `Series.to_csv` was aligned to that of `DataFrame.to_csv`, and argument 'header' will change its default value from False to True: please pass an explicit value to suppress this warning.\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"# this holds the output as a LIST of DICTS\nobs_data_list = []",
"_____no_output_____"
],
[
"# this is the list of IDs to call\n\nobs_call_list = [1,3,5,17,21]",
"_____no_output_____"
],
[
"# this is the LOOP that runs through the list aboe\n# for observ in obs_call_list:\n\nfor observ in range(1,11):\n call_list_output = get_ema_for_observation_id(observ)\n \n # the print command simply puts the output in the notebook terminal. \n #Later we will put it in the List of Dicts.\n \n # print(call_list_output)\n obs_data_list.append(call_list_output)\n ",
"Got: 1\nGot: 2\nGot: 3\nGot: 4\nGot: 5\nGot: 6\nGot: 7\nGot: 8\nGot: 9\nGot: 10\n"
],
[
"# list includes APPEND function that will allow us to add one item after each loop.\n# EX blank_list = [1,5,6] (note that these are in square brackets as LIST)\n# blank_list.append(89)\n# range would in parenths as in: range(1,11)\n# here we make a LIST object that contains the Range. \n# This allows it to iterate over the range\n# since the range could be HUGE We can ONLY append a number to a LIST!\n\nObs_range = list(range(1,11))\n",
"_____no_output_____"
],
[
"# blank_list.append(76)",
"_____no_output_____"
],
[
"blank_list",
"_____no_output_____"
],
[
"obs_data_list",
"_____no_output_____"
],
[
"pd.Series(obs_data_list).to_csv(\"obs_data_list.csv\")",
"/Users/rfreedma/opt/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:1: FutureWarning: The signature of `Series.to_csv` was aligned to that of `DataFrame.to_csv`, and argument 'header' will change its default value from False to True: please pass an explicit value to suppress this warning.\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"# Pandas DataFrame interprets the series of items in each Dict \n# as separate 'cells' (a tab structure)\nDF_output = pd.DataFrame(obs_data_list)",
"_____no_output_____"
],
[
"DF_output",
"_____no_output_____"
],
[
"DF_output.to_csv(\"obs_data_list.csv\")",
"_____no_output_____"
],
[
"# two = means check for equality\n# for 'contains' use str.contains(\"letter\")\n# can also use regex in this (for EMA range)\n# Filter_by_Type = (DF_output[\"musical type\"]==\"Fuga\") & (DF_output[\"id\"]==8)\nFilter_by_Type = DF_output[\"musical type\"].str.contains(\"Fuga\")\n\n# ",
"_____no_output_____"
],
[
"DF_output[Filter_by_Type]",
"_____no_output_____"
],
[
"# here is a string of text with numbers in it\n\nmy_num = 5\nf\"here is a string of text with numbers in it: {my_num}\"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbcfda76e9d7f61c71e02677d1d0031ee8b07976
| 73,974 |
ipynb
|
Jupyter Notebook
|
mailchimp_1.1.ipynb
|
nossas/bonde-mailchimp-scripts
|
ba34818102d1eaa2b32907b5929d5e8231216c9f
|
[
"MIT"
] | null | null | null |
mailchimp_1.1.ipynb
|
nossas/bonde-mailchimp-scripts
|
ba34818102d1eaa2b32907b5929d5e8231216c9f
|
[
"MIT"
] | null | null | null |
mailchimp_1.1.ipynb
|
nossas/bonde-mailchimp-scripts
|
ba34818102d1eaa2b32907b5929d5e8231216c9f
|
[
"MIT"
] | null | null | null | 52.688034 | 485 | 0.641077 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport datetime\nimport os\nimport glob, os\nimport time",
"_____no_output_____"
]
],
[
[
"O que vou fazer amanhã:\n- Abrir todos os bancos do granular activity/opens com o código que gera uma coluna com o nome do arquivo. \n- Ordenar por data e dropar duplicados, assim estimarei a data de envio do email (com a proxy da data da primeira abertura)\n- Terei um banco com todas as campanhas com o nome delas (nome do arquivo) no mesmo formato que no aggregated activity\n- Depois tenho que juntar todos os bancos do aggregated activity/opened e aggregated activity/not_opened\n- Criar uma coluna em cada um desses que especifíque se é de aberto ou fechado\n- Em seguida, concatenar opened com not opened\n- Mergir com o banco de campanhas\n- Ordenar por email e data de envio da campanha(descendente)!\n- Daí crio uma contagem que reseta com emails, onde o último email recebido pela pessoa é 1, o segundo 2, assim por diante...\n- Depois é apagar com filtros compostos: Se o email 1 (mais recente) é não aberto e o 2, 3,4 e 5",
"_____no_output_____"
]
],
[
[
"files = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/granular_activity/opens/*.csv')\n#df = pd.concat([pd.read_csv(fp, encoding='latin-1',nrows=1 ).assign(New=os.path.basename(fp) ) for fp in files], sort=False)\n# Não quero me confiar no nrows, que o pressuposto é que a primeira linha de cada arquivo é o timestamp da primeira abertura\ndf = pd.concat([pd.read_csv(fp, encoding='latin-1').assign(New=os.path.basename(fp) ) for fp in files], sort=False)\ndf = df.sort_values(['New', 'Timestamp'])\ndf = df[['New', 'Timestamp']].drop_duplicates('New')",
"_____no_output_____"
]
],
[
[
"Existem 6190 arquivos, mas só 4980 estão sendo lidos. Curiosamente, alguns deles são os que não tem. 2 horas pra descobrir que tudo isso era pq são arquivos vazios. A maior parte são testes ab de 100%, então óbvio que ninguém recebe o combo vencedor. Um caso que se eu fosse irresponsável, não ia dar em nada. Pq a perda não existe de vdd, é só a redução natural de categorias, já que algums não tem observações. O código abaixo (a versão limpa, claro), foi pra idenficcar isso.",
"_____no_output_____"
]
],
[
[
"#paths = pd.DataFrame({'caminhos':files})\n#paths['caminhos'] = paths['caminhos'].str[len('C:/Users/ander/Documents/Nossas_mailchimp/granular_activity/opens\\\\'):] #slicing\n\n#erros = pd.merge(df, paths, left_on='New', right_on='caminhos',how='outer', indicator=True)\n#erros[erros['_merge'] != 'both'].caminhos[5000]\n#df[df['New'].str.contains('340630_-pdm-solidariedade-nas-ruas-e-ilera-con')]",
"_____no_output_____"
]
],
[
[
"pd.read_csv('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/opened/308509_-rioacess-vel.csv',\n encoding='latin-1', usecols = [0,1,2,34, 36]).columns",
"_____no_output_____"
]
],
[
[
"files_opened = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/opened/*.csv')\nopened = pd.concat([pd.read_csv(fp, encoding='latin-1',usecols = [0,1,2]\n ).assign(New=os.path.basename(fp) ) for fp in files_opened], sort=False)",
"_____no_output_____"
],
[
"opended.shape",
"_____no_output_____"
],
[
"files_notopened = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/not_opened/*.csv')\nnot_opened = pd.concat([pd.read_csv(fp, encoding='latin-1',usecols = [0,1,2]\n ).assign(New=os.path.basename(fp) ) for fp in files_notopened], sort=False)",
"_____no_output_____"
],
[
"not_opened.shape",
"_____no_output_____"
],
[
"not_opened.to_csv('all_not_opened.csv', index=False)\nopended.to_csv('all_opened.csv', index=False)\ndf.to_csv('all_emails.csv', index=False)",
"_____no_output_____"
],
[
"s_nopened = not_opened.sample(frac=0.01)\ns_opened = opended.sample(frac=0.02)",
"_____no_output_____"
],
[
"s_opened.shape",
"_____no_output_____"
]
],
[
[
"### Dia 2 - Reiniciei o kernel e vou fazer as operações agora sem a memória pesada",
"_____no_output_____"
],
[
"open_1 = s_opened[['Email', 'Nome', 'Sobrenome', 'New']]\nopen_2 = s_opened[['Email Address', 'First Name', 'Last Name', 'New']]\nopen_3 = s_opened[['E-mail', 'First Name do eleitor', 'New']]\nopen_3['Sobrenome'] = ''\nopen_2.columns = ['Email', 'Nome', 'Sobrenome', 'New']\nopen_3.columns = ['Email', 'Nome', 'New', 'Sobrenome']\nopen_3 = open_3[['Email', 'Nome', 'Sobrenome', 'New']]\nopens = pd.concat([open_1, open_2, open_3])\n\nopens = opens.dropna(subset=['Email'])\nopens = opens.merge(df,on='New')\nopens['Atividade'] = 'abertura'",
"_____no_output_____"
],
[
"n_open_1 = s_nopened[['Email', 'Nome', 'Sobrenome', 'New']]\nn_open_2 = s_nopened[['Email Address', 'First Name', 'Last Name', 'New']]\nn_open_3 = s_nopened[['E-mail', 'First Name do eleitor', 'New']]\nn_open_3['Sobrenome'] = ''\nn_open_2.columns = ['Email', 'Nome', 'Sobrenome', 'New']\nn_open_3.columns = ['Email', 'Nome', 'New', 'Sobrenome']\nn_open_3 = open_3[['Email', 'Nome', 'Sobrenome', 'New']]\nn_opens = pd.concat([n_open_1, n_open_2, n_open_3])\n\nn_opens = n_opens.dropna(subset=['Email'])\nn_opens = n_opens.merge(df,on='New')\nn_opens['Atividade'] = 'não abertura'",
"_____no_output_____"
]
],
[
[
"start_time = time.time()\n#not_opened = pd.read_csv('all_not_opened.csv')\n#opened = pd.read_csv('all_opened.csv')\nemails = pd.read_csv('all_emails.csv')\nprint(\"--- %s seconds ---\" % (time.time() - start_time))",
"--- 0.1294398307800293 seconds ---\n"
]
],
[
[
"opens",
"_____no_output_____"
]
],
[
[
"open_1 = opened[['Email', 'Nome', 'Sobrenome', 'New']]\nopen_2 = opened[['Email Address', 'First Name', 'Last Name', 'New']]\nopen_3 = opened[['E-mail', 'First Name do eleitor', 'New']]\nopen_3['Sobrenome'] = ''\nopen_2.columns = ['Email', 'Nome', 'Sobrenome', 'New']\nopen_3.columns = ['Email', 'Nome', 'New', 'Sobrenome']\nopen_3 = open_3[['Email', 'Nome', 'Sobrenome', 'New']]\nopens = pd.concat([open_1, open_2, open_3])\n\nopens = opens.dropna(subset=['Email'])\nopens = opens.merge(emails,on='New')\nopens['Atividade'] = 'abertura'",
"C:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:6: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"recent_opens = opens.head(10000000)[opens.head(10000000)['Timestamp'] >'2019-01-01 12:12:48']\n## por algum motivo, quando eu uso head e não o banco inteiro, vai mais rápido.",
"_____no_output_____"
],
[
"recent_opens.to_csv('recent_opens.csv', index=False)",
"--- 13.886665105819702 seconds ---\n"
],
[
"# Já foi rodado\nn_opened = not_opened.merge(emails, on='New')",
"_____no_output_____"
],
[
"start_time = time.time()\n\nn_opened.to_csv('n_opened.csv', index=False)\n\nprint(\"--- %s seconds ---\" % (time.time() - start_time))",
"--- 1405.8530542850494 seconds ---\n"
]
],
[
[
"Recomeçar daqui: filtrar acima de 2019 e depois salvar (sábado). Na segunda volto e reorganizo, concateno com opens, ordeno e faço os cortes",
"_____no_output_____"
],
[
"Estratégia nova: impossível utilizar todas as linhas de não aberturas, então criei uma pasta só pros arquivos a partir de 2019.",
"_____no_output_____"
],
[
"Basicamnte recomecei tudo a partir daqui",
"_____no_output_____"
]
],
[
[
"start_time = time.time()\n\nfiles_notopened = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/not_opened_recentes/*.csv')\nn_opens = pd.concat([pd.read_csv(fp, encoding='latin-1',usecols = [0,1,2]\n ).assign(New=os.path.basename(fp) ) for fp in files_notopened], sort=False)\n\nprint(\"--- %s seconds ---\" % (time.time() - start_time))",
"--- 63.783284187316895 seconds ---\n"
],
[
"start_time = time.time()\n\nn_open_1 = n_opens[['Email', 'Nome', 'Sobrenome', 'New']].dropna(subset=['Email'])\nn_open_2 = n_opens[['Email Address', 'First Name', 'Last Name', 'New']].dropna(subset=['Email Address'])\nn_open_2.columns = ['Email', 'Nome', 'Sobrenome', 'New']\nn_opens = pd.concat([n_open_1, n_open_2])\n\n#n_opens = n_opens.dropna(subset=['Email'])\nn_opens = n_opens.merge(emails,on='New')\nn_opens['Atividade'] = 'não abertura'\n\nprint(\"--- %s seconds ---\" % (time.time() - start_time))",
"--- 14.82846474647522 seconds ---\n"
]
],
[
[
"Tática do opens abaixo. Mas pro n_opens, vai ser primeiro merge (já feito), depois corte de datas e só aí reorganizo e concateno. Depois, vou concatenar com o opens, reordenar e fazer os cortes",
"_____no_output_____"
]
],
[
[
"n_opens.to_csv('recent_n_opens.csv', index=False)",
"_____no_output_____"
],
[
"opens = pd.read_csv('recent_opens.csv')",
"_____no_output_____"
],
[
"opens.shape[0] + n_opens.shape[0]",
"_____no_output_____"
],
[
"type(all_activities['Timestamp'])",
"_____no_output_____"
],
[
"all_activities = pd.concat([opens, n_opens])\nall_activities = all_activities.sort_values(['Email','Timestamp'])\nall_activities.to_csv('all_recent_activities.csv', index=False)\nall_activities.to_json('all_recent_activities.json', index=False)",
"_____no_output_____"
]
],
[
[
"tirar média e desvio padrão do número de emails de cada um e do % de abertura de cada pessoa. Agora é só lazer.",
"_____no_output_____"
],
[
"porra, agora ainda vai ter que juntar com as inscrições de cada pessoa. Se é meu rio, ms, mapa..",
"_____no_output_____"
],
[
"## Recomeço aqui",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('all_recent_activities.csv')",
"_____no_output_____"
],
[
"files_notopened = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/not_opened_recentes/*.csv')\nn_opens = pd.concat([pd.read_csv(fp, encoding='latin-1'\n ).assign(New=os.path.basename(fp) ) for fp in files_notopened], sort=False)",
"C:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,20) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (9,11,14,15,19,20,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,15,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (20,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,15,19,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (20,25,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (9,11,15) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (11,14,15,24,25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,9,25,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15,19,20,21,23,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,14,15,20,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,14,15,20,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15,25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (24,25,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (11,14,15) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (14) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,15,20) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,16,19,20,21,22,23,24,25,26,27,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,9,10,19,20,24,25,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,19,21,22,23,24,25,26,27,28,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (3,5,6,9,10,11,14,15,16,17,19,20,21,22,23,24,25,26,27,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,16,19,20,21,22,27,28,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,14,15,20,21,22,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,16,17,19,20,21,22,23,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (3,4,5,6,9,10,11,14,15,16,17,19,20,21,22,23,24,25,26,27,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,14,15) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,16,19,20,21,22,23,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,19,20,21,22,23,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (6,9,10,11,14,15,20,21,22,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,19,20,21,22,23,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\n"
],
[
"n_opens = n_opens[['Email', 'Nome', 'Sobrenome', 'Inscrições', 'Interesses', 'Member Rating', 'New', 'Email Address',\n 'First Name', 'Last Name']].dropna(subset=['Inscrições'])",
"_____no_output_____"
],
[
"files_notopened = glob.glob('C:/Users/ander/Documents/Nossas_mailchimp/aggregate_activity/opened_recentes/*.csv')\nopens = pd.concat([pd.read_csv(fp, encoding='latin-1'\n ).assign(New=os.path.basename(fp) ) for fp in files_notopened], sort=False)",
"C:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,11,14,15,16,20,21,22,23,24,25,26,27,31,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,10,19,20,26,28) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,16,19,23,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (4,16,21,22,31,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (11,14,15,19,20) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (20,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,15) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,14,19,20,21,22,23,24,25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (20,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (3,4,5,6,9,10,11,15,16,17,18,19,20,21,22,23,24,25,26,27,28,31,33,34,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15,19,20,24,25,26,27) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,19,20,25,26) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (20,23) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,14,19,20,21,22,23,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (3,4,5,6,9,10,11,15,16,17,19,20,21,22,23,24,25,26,28,31,33,35) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,6,9,10,16,19,20,21,22,23,24,25,26,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3185: DtypeWarning: Columns (5,11,14,15,19,20,24,25,26,27,33) have mixed types. Specify dtype option on import or set low_memory=False.\n if (yield from self.run_code(code, result)):\n"
],
[
"opens = opens[['Email', 'Nome', 'Sobrenome', 'Inscrições', 'Interesses', 'Member Rating', 'New', 'Email Address',\n 'First Name', 'Last Name']].dropna(subset=['Inscrições'])",
"_____no_output_____"
],
[
"opens.Email.nunique()",
"_____no_output_____"
],
[
"n_opens = n_opens[['Email', 'Inscrições', 'Member Rating', 'New']].drop_duplicates('Email', keep='last')\nopens = opens[['Email', 'Inscrições', 'Member Rating', 'New']].drop_duplicates('Email', keep='last')\ninscricoes = pd.concat([n_opens, opens])",
"_____no_output_____"
],
[
"inscricoes.shape",
"_____no_output_____"
],
[
"inscricoes = inscricoes.merge(emails, on='New')",
"_____no_output_____"
],
[
"inscricoes = inscricoes.sort_values(['Email', 'Timestamp'])\ninscricoes = inscricoes.drop_duplicates(\"Email\")",
"_____no_output_____"
],
[
"inscricoes.columns = ['Email', 'Inscrições', 'Menber Rating', 'New', 'Timestamp']",
"_____no_output_____"
],
[
"df = df.merge(inscricoes[['Email', 'Inscrições', 'Menber Rating']], on='Email', how='outer', indicator=True)",
"_____no_output_____"
],
[
"df.to_csv('all_recent_activities_inscricoes.csv', index=False)",
"_____no_output_____"
],
[
"df = pd.read_csv('all_recent_activities_inscricoes.csv')\ndf = df.drop('_merge', axis=1)",
"_____no_output_____"
]
],
[
[
"Criar banco no nível do usuário",
"_____no_output_____"
]
],
[
[
"user_nopen = df[df['Atividade'] == 'não abertura'].groupby('Email', as_index=False).agg({'Atividade': \"count\"})\nuser_open = df[df['Atividade'] == 'abertura'].groupby('Email', as_index=False).agg({'Atividade': \"count\"})\nuser_geral = df.groupby('Email', as_index=False).agg({\"Timestamp\":\"first\",\"New\" : \"first\" ,\"Inscrições\":\"last\",\"Menber Rating\":\"last\"})\nuser_nopen.columns = ['Email','n_open']\nuser_open.columns = ['Email', 'open']\nuser_geral.columns = ['Email', 'First Email', 'New', 'Inscrições', 'Member Rating']\nuser = pd.merge(user_nopen, user_open, on='Email', how='outer', indicator=True)\nuser = user.merge(user_geral, on='Email')",
"_____no_output_____"
],
[
"#Taxa de abertura Geral\nuser.open.sum() /(user.open.sum() + user.n_open.sum()) ",
"_____no_output_____"
],
[
"user['Inscrições'] = user['Inscrições'].fillna('0')\nuser['corte'] = np.where((user['Inscrições'].str.contains('Meu Recife') |user['Inscrições'].str.contains('Minha Jampa') \n | user['Inscrições'].str.contains('Minha Campinas') | user['Inscrições'].str.contains('Minha Porto Alegre'))\n , \"imune\", \"elegível\")",
"_____no_output_____"
],
[
"imunes = user[user['corte'] == 'imune']\nuser = user[user['corte'] == 'elegível']",
"_____no_output_____"
],
[
"#user[user['Email'] =='[email protected]']",
"_____no_output_____"
],
[
"# Primeiras exclusões\nnunca_abriu = user[user['_merge'] =='left_only']\napagar_1 = nunca_abriu[nunca_abriu['n_open'] >= 3] # quem nunca abriu mesmo já recebendo mais de 3 emails\n# nunca abriu, recebeu menos que 2, mas é antigo\napagar_2 = nunca_abriu[(nunca_abriu['n_open'] < 3) & (nunca_abriu['First Email'] < '2019-07-01 00:00:01')]\n# pessoas que não abriram nenhum email, mas receberam 1 ou 2 e entraram há menos de 1 ano na base\nalerta = nunca_abriu[(nunca_abriu['n_open'] < 3) & (nunca_abriu['First Email'] > '2019-07-01 00:00:01')]",
"_____no_output_____"
],
[
"apagar_1.to_csv('nunca_abriu_1.csv')\napagar_2.to_csv('nunca_abriu_2.csv')\nalerta.to_csv('nunca_abriu_alerta.csv')",
"_____no_output_____"
],
[
"import pandas as pd\ndf = pd.read_csv('nunca_abriu_1.csv')",
"_____no_output_____"
],
[
"df['Member Rating'].value_counts(dropna=False)",
"_____no_output_____"
],
[
"apagar_1.shape\napagar_2.shape\nalerta.shape",
"_____no_output_____"
],
[
"nunca_abriu.n_open.sum()",
"_____no_output_____"
],
[
"df = df.merge(nunca_abriu[['Email']], on='Email', how='outer', indicator=True)",
"_____no_output_____"
],
[
"df = df[df['_merge'] != \"both\"]",
"_____no_output_____"
],
[
"df['corte'] = np.where((df['Inscrições'].str.contains('Meu Recife') |df['Inscrições'].str.contains('Minha Jampa') \n | df['Inscrições'].str.contains('Minha Campinas') | df['Inscrições'].str.contains('Minha Porto Alegre'))\n , \"imune\", \"elegível\")\ndf = df[df['corte'] == 'elegível']",
"_____no_output_____"
]
],
[
[
"CARALHO EU SEMPRE QUIS ESSE CÓDIGO (HACK PRA DROPAR DUPLICADOS MANTENDO N LINHAS)",
"_____no_output_____"
]
],
[
[
"df =df.sort_values(['Email', 'Timestamp'])",
"_____no_output_____"
],
[
"df['Inscrições'] = df['Inscrições'].fillna('0')",
"_____no_output_____"
],
[
"df_3 = df.groupby('Email').tail(3) #last 3 rows\ndf_5 = df.groupby('Email').tail(5) #last 5 rows\ndf_10 = df.groupby('Email').tail(10) #last 10 rows",
"_____no_output_____"
],
[
"df_3['abertura'] = np.where((df_3['Atividade'] =='abertura') ,1, 0)\ndf_3['não abertura'] = np.where((df_3['Atividade'] == 'não abertura'), 1, 0)\n\ndf_5['abertura'] = np.where((df_5['Atividade'] =='abertura') ,1, 0)\ndf_5['não abertura'] = np.where((df_5['Atividade'] == 'não abertura'), 1, 0)\n\ndf_10['abertura'] = np.where((df_10['Atividade'] =='abertura') ,1, 0)\ndf_10['não abertura'] = np.where((df_10['Atividade'] == 'não abertura'), 1, 0)",
"C:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"Entry point for launching an IPython kernel.\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n after removing the cwd from sys.path.\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:7: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n import sys\nC:\\Users\\ander\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:8: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"df_3 = df_3.groupby(['Email', 'Inscrições'],as_index=False).agg({'Atividade': \"count\", 'abertura': 'sum', 'não abertura':'sum'})\ndf_5 = df_5.groupby(['Email', 'Inscrições'],as_index=False).agg({'Atividade': \"count\", 'abertura': 'sum', 'não abertura':'sum'})\ndf_10=df_10.groupby(['Email', 'Inscrições'],as_index=False).agg({'Atividade': \"count\", 'abertura': 'sum', 'não abertura':'sum'})",
"_____no_output_____"
],
[
"apagar_3 = df_3[(df_3['Atividade'] == 3) & (df_3['não abertura'] == 3)]\napagar_5 = df_5[(df_5['Atividade'] == 5) & (df_5['não abertura'] == 5)]\napagar_10 = df_10[(df_10['Atividade'] == 10) & (df_10['não abertura'] == 10)]",
"_____no_output_____"
],
[
"apagar_3.to_csv('apagar_3.csv', index=False)\napagar_5.to_csv('apagar_5.csv', index=False)\napagar_10.to_csv('apagar_10.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbcff6e98de55b84dc7bedcfa382152ec550d9cd
| 67,663 |
ipynb
|
Jupyter Notebook
|
preprocessing_4.ipynb
|
rishabh1072/movie-recommendation-system
|
f1e92ab47f22c540e701e66ef2674ea78ef16994
|
[
"MIT"
] | null | null | null |
preprocessing_4.ipynb
|
rishabh1072/movie-recommendation-system
|
f1e92ab47f22c540e701e66ef2674ea78ef16994
|
[
"MIT"
] | null | null | null |
preprocessing_4.ipynb
|
rishabh1072/movie-recommendation-system
|
f1e92ab47f22c540e701e66ef2674ea78ef16994
|
[
"MIT"
] | null | null | null | 33.463403 | 173 | 0.41522 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport requests\nimport bs4 as bs\nimport urllib.request",
"_____no_output_____"
]
],
[
[
"## Extracting features of 2020 movies from Wikipedia",
"_____no_output_____"
]
],
[
[
"link = \"https://en.wikipedia.org/wiki/List_of_American_films_of_2020\"",
"_____no_output_____"
],
[
"source = urllib.request.urlopen(link).read()\nsoup = bs.BeautifulSoup(source,'lxml')",
"_____no_output_____"
],
[
"tables = soup.find_all('table',class_='wikitable sortable')",
"_____no_output_____"
],
[
"len(tables)",
"_____no_output_____"
],
[
"type(tables[0])",
"_____no_output_____"
],
[
"df1 = pd.read_html(str(tables[0]))[0]\ndf2 = pd.read_html(str(tables[1]))[0]\ndf3 = pd.read_html(str(tables[2]))[0]\ndf4 = pd.read_html(str(tables[3]).replace(\"'1\\\"\\'\",'\"1\"'))[0] ",
"_____no_output_____"
],
[
"df = df1.append(df2.append(df3.append(df4,ignore_index=True),ignore_index=True),ignore_index=True)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df_2020 = df[['Title','Cast and crew']]",
"_____no_output_____"
],
[
"df_2020",
"_____no_output_____"
],
[
"!pip install tmdbv3api",
"Collecting tmdbv3api\n Downloading https://files.pythonhosted.org/packages/fa/cb/72ca70a05b7364c2b41e6cf1f615729b0c99109a3be0e61e22d42859d48f/tmdbv3api-1.7.1-py2.py3-none-any.whl\nRequirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from tmdbv3api) (2.23.0)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->tmdbv3api) (2020.11.8)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->tmdbv3api) (2.10)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->tmdbv3api) (1.24.3)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->tmdbv3api) (3.0.4)\nInstalling collected packages: tmdbv3api\nSuccessfully installed tmdbv3api-1.7.1\n"
],
[
"from tmdbv3api import TMDb\nimport json\nimport requests\ntmdb = TMDb()\ntmdb.api_key = ''",
"_____no_output_____"
],
[
"from tmdbv3api import Movie\ntmdb_movie = Movie() \ndef get_genre(x):\n genres = []\n result = tmdb_movie.search(x)\n if not result:\n return np.NaN\n else:\n movie_id = result[0].id\n response = requests.get('https://api.themoviedb.org/3/movie/{}?api_key={}'.format(movie_id,tmdb.api_key))\n data_json = response.json()\n if data_json['genres']:\n genre_str = \" \" \n for i in range(0,len(data_json['genres'])):\n genres.append(data_json['genres'][i]['name'])\n return genre_str.join(genres)\n else:\n return np.NaN",
"_____no_output_____"
],
[
"df_2020['genres'] = df_2020['Title'].map(lambda x: get_genre(str(x)))",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"df_2020",
"_____no_output_____"
],
[
"def get_director(x):\n if \" (director)\" in x:\n return x.split(\" (director)\")[0]\n elif \" (directors)\" in x:\n return x.split(\" (directors)\")[0]\n else:\n return x.split(\" (director/screenplay)\")[0]",
"_____no_output_____"
],
[
"df_2020['director_name'] = df_2020['Cast and crew'].map(lambda x: get_director(str(x)))",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"def get_actor1(x):\n return ((x.split(\"screenplay); \")[-1]).split(\", \")[0])",
"_____no_output_____"
],
[
"df_2020['actor_1_name'] = df_2020['Cast and crew'].map(lambda x: get_actor1(str(x)))",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"def get_actor2(x):\n if len((x.split(\"screenplay); \")[-1]).split(\", \")) < 2:\n return np.NaN\n else:\n return ((x.split(\"screenplay); \")[-1]).split(\", \")[1])",
"_____no_output_____"
],
[
"df_2020['actor_2_name'] = df_2020['Cast and crew'].map(lambda x: get_actor2(str(x)))",
"_____no_output_____"
],
[
"def get_actor3(x):\n if len((x.split(\"screenplay); \")[-1]).split(\", \")) < 3:\n return np.NaN\n else:\n return ((x.split(\"screenplay); \")[-1]).split(\", \")[2])",
"_____no_output_____"
],
[
"df_2020['actor_3_name'] = df_2020['Cast and crew'].map(lambda x: get_actor3(str(x)))",
"_____no_output_____"
],
[
"df_2020",
"_____no_output_____"
],
[
"df_2020 = df_2020.rename(columns={'Title':'movie_title'})",
"_____no_output_____"
],
[
"new_df20 = df_2020.loc[:,['director_name','actor_1_name','actor_2_name','actor_3_name','genres','movie_title']]",
"_____no_output_____"
],
[
"new_df20",
"_____no_output_____"
],
[
"new_df20['comb'] = new_df20['actor_1_name'] + ' ' + new_df20['actor_2_name'] + ' '+ new_df20['actor_3_name'] + ' '+ new_df20['director_name'] +' ' + new_df20['genres']",
"_____no_output_____"
],
[
"new_df20.isna().sum()",
"_____no_output_____"
],
[
"new_df20 = new_df20.dropna(how='any')",
"_____no_output_____"
],
[
"new_df20.isna().sum()",
"_____no_output_____"
],
[
"new_df20['movie_title'] = new_df20['movie_title'].str.lower()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"new_df20",
"_____no_output_____"
],
[
"old_df = pd.read_csv('final_data.csv')",
"_____no_output_____"
],
[
"old_df",
"_____no_output_____"
],
[
"final_df = old_df.append(new_df20,ignore_index=True)",
"_____no_output_____"
],
[
"final_df",
"_____no_output_____"
],
[
"final_df.to_csv('main_data.csv',index=False)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbcffe44c4151636c7ececa6aa07729665333aeb
| 197,176 |
ipynb
|
Jupyter Notebook
|
Logistic Regression Classifier.ipynb
|
Ansu-John/Classification-Models
|
192e5ab0bd8d89a2127ab3f39734b9b01d537dd7
|
[
"MIT"
] | 1 |
2020-11-22T08:27:58.000Z
|
2020-11-22T08:27:58.000Z
|
Logistic Regression Classifier.ipynb
|
Ansu-John/Classification-Models
|
192e5ab0bd8d89a2127ab3f39734b9b01d537dd7
|
[
"MIT"
] | null | null | null |
Logistic Regression Classifier.ipynb
|
Ansu-John/Classification-Models
|
192e5ab0bd8d89a2127ab3f39734b9b01d537dd7
|
[
"MIT"
] | 1 |
2022-03-31T09:53:58.000Z
|
2022-03-31T09:53:58.000Z
| 52.636412 | 35,352 | 0.614842 |
[
[
[
"# Importing the libraries ",
"_____no_output_____"
]
],
[
[
"import numpy as np \nimport matplotlib.pyplot as plt \nimport pandas as pd \nimport seaborn as sns \n\nfrom sklearn.metrics import roc_curve, auc\nfrom sklearn.metrics import roc_auc_score,recall_score, precision_score, f1_score\nfrom sklearn.metrics import accuracy_score, confusion_matrix, classification_report, average_precision_score\n",
"_____no_output_____"
]
],
[
[
"# Load and Explore Data",
"_____no_output_____"
]
],
[
[
"dataset=pd.read_csv('weatherAUS.csv') \ndataset.head()",
"_____no_output_____"
],
[
"dataset.describe()",
"_____no_output_____"
],
[
"# find categorical variables\ncategorical = [var for var in dataset.columns if dataset[var].dtype=='O']\nprint('There are {} categorical variables : \\n'.format(len(categorical)), categorical)",
"There are 7 categorical variables : \n ['Date', 'Location', 'WindGustDir', 'WindDir9am', 'WindDir3pm', 'RainToday', 'RainTomorrow']\n"
],
[
"# view the categorical variables\ndataset[categorical].head()",
"_____no_output_____"
],
[
"# check and print categorical variables containing missing values\n\nnullCategorical = [var for var in categorical if dataset[var].isnull().sum()!=0]\nprint(dataset[nullCategorical].isnull().sum())",
"WindGustDir 9330\nWindDir9am 10013\nWindDir3pm 3778\nRainToday 1406\ndtype: int64\n"
]
],
[
[
"Number of labels: cardinality\n \nThe number of labels within a categorical variable is known as cardinality. A high number of labels within a variable is known as high cardinality. High cardinality may pose some serious problems in the machine learning model. So, I will check for high cardinality.",
"_____no_output_____"
]
],
[
[
"# check for cardinality in categorical variables\nfor var in categorical:\n print(var, ' contains ', len(dataset[var].unique()), ' labels')",
"Date contains 3436 labels\nLocation contains 49 labels\nWindGustDir contains 17 labels\nWindDir9am contains 17 labels\nWindDir3pm contains 17 labels\nRainToday contains 3 labels\nRainTomorrow contains 2 labels\n"
],
[
"# Feature Extraction",
"_____no_output_____"
],
[
"dataset['Date'].dtypes",
"_____no_output_____"
],
[
"# parse the dates, currently coded as strings, into datetime format\ndataset['Date'] = pd.to_datetime(dataset['Date'])",
"_____no_output_____"
],
[
"dataset['Date'].dtypes",
"_____no_output_____"
],
[
"# extract year from date\ndataset['Year'] = dataset['Date'].dt.year\n# extract month from date\ndataset['Month'] = dataset['Date'].dt.month\n# extract day from date\ndataset['Day'] = dataset['Date'].dt.day",
"_____no_output_____"
],
[
"dataset.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 142193 entries, 0 to 142192\nData columns (total 27 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Date 142193 non-null datetime64[ns]\n 1 Location 142193 non-null object \n 2 MinTemp 141556 non-null float64 \n 3 MaxTemp 141871 non-null float64 \n 4 Rainfall 140787 non-null float64 \n 5 Evaporation 81350 non-null float64 \n 6 Sunshine 74377 non-null float64 \n 7 WindGustDir 132863 non-null object \n 8 WindGustSpeed 132923 non-null float64 \n 9 WindDir9am 132180 non-null object \n 10 WindDir3pm 138415 non-null object \n 11 WindSpeed9am 140845 non-null float64 \n 12 WindSpeed3pm 139563 non-null float64 \n 13 Humidity9am 140419 non-null float64 \n 14 Humidity3pm 138583 non-null float64 \n 15 Pressure9am 128179 non-null float64 \n 16 Pressure3pm 128212 non-null float64 \n 17 Cloud9am 88536 non-null float64 \n 18 Cloud3pm 85099 non-null float64 \n 19 Temp9am 141289 non-null float64 \n 20 Temp3pm 139467 non-null float64 \n 21 RainToday 140787 non-null object \n 22 RISK_MM 142193 non-null float64 \n 23 RainTomorrow 142193 non-null object \n 24 Year 142193 non-null int64 \n 25 Month 142193 non-null int64 \n 26 Day 142193 non-null int64 \ndtypes: datetime64[ns](1), float64(17), int64(3), object(6)\nmemory usage: 29.3+ MB\n"
],
[
"# drop the original Date variable\ndataset.drop('Date', axis=1, inplace = True)\ndataset.head()",
"_____no_output_____"
]
],
[
[
"## Explore Categorical Variables",
"_____no_output_____"
]
],
[
[
"# Explore Location variable\ndataset.Location.unique()",
"_____no_output_____"
],
[
"# check frequency distribution of values in Location variable\ndataset.Location.value_counts()",
"_____no_output_____"
],
[
"# let's do One Hot Encoding of Location variable\n# get k-1 dummy variables after One Hot Encoding \npd.get_dummies(dataset.Location, drop_first=True).head()",
"_____no_output_____"
],
[
"# Explore WindGustDir variable\ndataset.WindGustDir.unique()",
"_____no_output_____"
],
[
"# check frequency distribution of values in WindGustDir variable\ndataset.WindGustDir.value_counts()",
"_____no_output_____"
],
[
"# let's do One Hot Encoding of WindGustDir variable\n# get k-1 dummy variables after One Hot Encoding \n# also add an additional dummy variable to indicate there was missing data\npd.get_dummies(dataset.WindGustDir, drop_first=True, dummy_na=True).head()",
"_____no_output_____"
],
[
"# sum the number of 1s per boolean variable over the rows of the dataset --> it will tell us how many observations we have for each category\npd.get_dummies(dataset.WindGustDir, drop_first=True, dummy_na=True).sum(axis=0)",
"_____no_output_____"
],
[
"# Explore WindDir9am variable\ndataset.WindDir9am.unique()",
"_____no_output_____"
],
[
"dataset.WindDir9am.value_counts()",
"_____no_output_____"
],
[
"pd.get_dummies(dataset.WindDir9am, drop_first=True, dummy_na=True).head()",
"_____no_output_____"
],
[
"# sum the number of 1s per boolean variable over the rows of the dataset -- it will tell us how many observations we have for each category\n\npd.get_dummies(dataset.WindDir9am, drop_first=True, dummy_na=True).sum(axis=0)",
"_____no_output_____"
],
[
"# Explore WindDir3pm variable\ndataset['WindDir3pm'].unique()",
"_____no_output_____"
],
[
"dataset['WindDir3pm'].value_counts()",
"_____no_output_____"
],
[
"pd.get_dummies(dataset.WindDir3pm, drop_first=True, dummy_na=True).head()",
"_____no_output_____"
],
[
"pd.get_dummies(dataset.WindDir3pm, drop_first=True, dummy_na=True).sum(axis=0)",
"_____no_output_____"
],
[
"# Explore RainToday variable\ndataset['RainToday'].unique()",
"_____no_output_____"
],
[
"dataset.RainToday.value_counts()",
"_____no_output_____"
],
[
"pd.get_dummies(dataset.RainToday, drop_first=True, dummy_na=True).head()",
"_____no_output_____"
],
[
"pd.get_dummies(dataset.RainToday, drop_first=True, dummy_na=True).sum(axis=0)",
"_____no_output_____"
]
],
[
[
"## Explore Numerical Variables",
"_____no_output_____"
]
],
[
[
"# find numerical variables\nnumerical = [var for var in dataset.columns if dataset[var].dtype!='O']\nprint('There are {} numerical variables : \\n'.format(len(numerical)), numerical)",
"There are 20 numerical variables : \n ['MinTemp', 'MaxTemp', 'Rainfall', 'Evaporation', 'Sunshine', 'WindGustSpeed', 'WindSpeed9am', 'WindSpeed3pm', 'Humidity9am', 'Humidity3pm', 'Pressure9am', 'Pressure3pm', 'Cloud9am', 'Cloud3pm', 'Temp9am', 'Temp3pm', 'RISK_MM', 'Year', 'Month', 'Day']\n"
],
[
"# view the numerical variables\ndataset[numerical].head()",
"_____no_output_____"
],
[
"# check missing values in numerical variables\ndataset[numerical].isnull().sum()",
"_____no_output_____"
],
[
"# view summary statistics in numerical variables to check for outliers\nprint(round(dataset[numerical].describe()),2)",
" MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustSpeed \\\ncount 141556.0 141871.0 140787.0 81350.0 74377.0 132923.0 \nmean 12.0 23.0 2.0 5.0 8.0 40.0 \nstd 6.0 7.0 8.0 4.0 4.0 14.0 \nmin -8.0 -5.0 0.0 0.0 0.0 6.0 \n25% 8.0 18.0 0.0 3.0 5.0 31.0 \n50% 12.0 23.0 0.0 5.0 8.0 39.0 \n75% 17.0 28.0 1.0 7.0 11.0 48.0 \nmax 34.0 48.0 371.0 145.0 14.0 135.0 \n\n WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm Pressure9am \\\ncount 140845.0 139563.0 140419.0 138583.0 128179.0 \nmean 14.0 19.0 69.0 51.0 1018.0 \nstd 9.0 9.0 19.0 21.0 7.0 \nmin 0.0 0.0 0.0 0.0 980.0 \n25% 7.0 13.0 57.0 37.0 1013.0 \n50% 13.0 19.0 70.0 52.0 1018.0 \n75% 19.0 24.0 83.0 66.0 1022.0 \nmax 130.0 87.0 100.0 100.0 1041.0 \n\n Pressure3pm Cloud9am Cloud3pm Temp9am Temp3pm RISK_MM \\\ncount 128212.0 88536.0 85099.0 141289.0 139467.0 142193.0 \nmean 1015.0 4.0 5.0 17.0 22.0 2.0 \nstd 7.0 3.0 3.0 6.0 7.0 8.0 \nmin 977.0 0.0 0.0 -7.0 -5.0 0.0 \n25% 1010.0 1.0 2.0 12.0 17.0 0.0 \n50% 1015.0 5.0 5.0 17.0 21.0 0.0 \n75% 1020.0 7.0 7.0 22.0 26.0 1.0 \nmax 1040.0 9.0 9.0 40.0 47.0 371.0 \n\n Year Month Day \ncount 142193.0 142193.0 142193.0 \nmean 2013.0 6.0 16.0 \nstd 3.0 3.0 9.0 \nmin 2007.0 1.0 1.0 \n25% 2011.0 3.0 8.0 \n50% 2013.0 6.0 16.0 \n75% 2015.0 9.0 23.0 \nmax 2017.0 12.0 31.0 2\n"
],
[
"# plot box plot to check outliers\nplt.figure(figsize=(10,15))\n\nplt.subplot(2, 2, 1)\nfig = sns.boxplot(y=dataset['Rainfall'])\nfig.set_ylabel('Rainfall')\n\nplt.subplot(2, 2, 2)\nfig = sns.boxplot(y=dataset[\"Evaporation\"])\nfig.set_ylabel('Evaporation')\n\nplt.subplot(2, 2, 3)\nfig = sns.boxplot(y=dataset['WindSpeed9am'])\nfig.set_ylabel('WindSpeed9am')\n\nplt.subplot(2, 2, 4)\nfig = sns.boxplot(y=dataset['WindSpeed3pm'])\nfig.set_ylabel('WindSpeed3pm')",
"_____no_output_____"
],
[
"# plot histogram to check distribution\nplt.figure(figsize=(10,15))\n\nplt.subplot(2, 2, 1)\nfig = dataset.Rainfall.hist(bins=10)\nfig.set_xlabel('Rainfall')\nfig.set_ylabel('RainTomorrow')\n\nplt.subplot(2, 2, 2)\nfig = dataset.Evaporation.hist(bins=10)\nfig.set_xlabel('Evaporation')\nfig.set_ylabel('RainTomorrow')\n\nplt.subplot(2, 2, 3)\nfig = dataset.WindSpeed9am.hist(bins=10)\nfig.set_xlabel('WindSpeed9am')\nfig.set_ylabel('RainTomorrow')\n\nplt.subplot(2, 2, 4)\nfig = dataset.WindSpeed3pm.hist(bins=10)\nfig.set_xlabel('WindSpeed3pm')\nfig.set_ylabel('RainTomorrow')",
"_____no_output_____"
],
[
"# find outliers for Rainfall variable\n\nIQR = dataset.Rainfall.quantile(0.75) - dataset.Rainfall.quantile(0.25)\nRainfall_Lower_fence = dataset.Rainfall.quantile(0.25) - (IQR * 3)\nRainfall_Upper_fence = dataset.Rainfall.quantile(0.75) + (IQR * 3)\nprint('Outliers are values < {lowerboundary} or > {upperboundary}'.format(lowerboundary=Rainfall_Lower_fence, upperboundary=Rainfall_Upper_fence))",
"Outliers are values < -2.4000000000000004 or > 3.2\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.Rainfall> Rainfall_Upper_fence) | (dataset.Rainfall< Rainfall_Lower_fence)]['Rainfall'].count()))",
"Number of outliers are 20462\n"
],
[
"# find outliers for Evaporation variable\n\nIQR = dataset.Evaporation.quantile(0.75) - dataset.Evaporation.quantile(0.25)\nEvaporation_Lower_fence = dataset.Evaporation.quantile(0.25) - (IQR * 3)\nEvaporation_Upper_fence = dataset.Evaporation.quantile(0.75) + (IQR * 3)\nprint('Outliers are values < {lowerboundary} or > {upperboundary}'.format(lowerboundary=Evaporation_Lower_fence, upperboundary=Evaporation_Upper_fence))",
"Outliers are values < -11.800000000000002 or > 21.800000000000004\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.Evaporation> Evaporation_Upper_fence) | (dataset.Evaporation< Evaporation_Lower_fence)]['Evaporation'].count()))",
"Number of outliers are 471\n"
],
[
"# find outliers for WindSpeed9am variable\n\nIQR = dataset.WindSpeed9am.quantile(0.75) - dataset.WindSpeed9am.quantile(0.25)\nWindSpeed9am_Lower_fence = dataset.WindSpeed9am.quantile(0.25) - (IQR * 3)\nWindSpeed9am_Upper_fence = dataset.WindSpeed9am.quantile(0.75) + (IQR * 3)\nprint('Outliers are values < {lowerboundary} or > {upperboundary}'.format(lowerboundary=WindSpeed9am_Lower_fence, upperboundary=WindSpeed9am_Upper_fence))",
"Outliers are values < -29.0 or > 55.0\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.WindSpeed9am> WindSpeed9am_Upper_fence) | (dataset.WindSpeed9am< WindSpeed9am_Lower_fence)]['WindSpeed9am'].count()))",
"Number of outliers are 107\n"
],
[
"# find outliers for WindSpeed3pm variable\n\nIQR = dataset.WindSpeed3pm.quantile(0.75) - dataset.WindSpeed3pm.quantile(0.25)\nWindSpeed3pm_Lower_fence = dataset.WindSpeed3pm.quantile(0.25) - (IQR * 3)\nWindSpeed3pm_Upper_fence = dataset.WindSpeed3pm.quantile(0.75) + (IQR * 3)\nprint('Outliers are values < {lowerboundary} or > {upperboundary}'.format(lowerboundary=WindSpeed3pm_Lower_fence, upperboundary=WindSpeed3pm_Upper_fence))",
"Outliers are values < -20.0 or > 57.0\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.WindSpeed3pm> WindSpeed3pm_Lower_fence) | (dataset.WindSpeed3pm< WindSpeed3pm_Upper_fence)]['WindSpeed3pm'].count()))",
"Number of outliers are 139563\n"
],
[
"def max_value(dataset, variable, top):\n return np.where(dataset[variable]>top, top, dataset[variable])\n\n\ndataset['Rainfall'] = max_value(dataset, 'Rainfall', Rainfall_Upper_fence)\ndataset['Evaporation'] = max_value(dataset, 'Evaporation', Evaporation_Upper_fence)\ndataset['WindSpeed9am'] = max_value(dataset, 'WindSpeed9am', WindSpeed9am_Upper_fence)\ndataset['WindSpeed3pm'] = max_value(dataset, 'WindSpeed3pm', 57)",
"_____no_output_____"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.Rainfall> Rainfall_Upper_fence) | (dataset.Rainfall< Rainfall_Lower_fence)]['Rainfall'].count()))",
"Number of outliers are 0\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.Evaporation> Evaporation_Upper_fence) | (dataset.Evaporation< Evaporation_Lower_fence)]['Evaporation'].count()))",
"Number of outliers are 0\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.WindSpeed9am> WindSpeed9am_Upper_fence) | (dataset.WindSpeed9am< WindSpeed9am_Lower_fence)]['WindSpeed9am'].count()))",
"Number of outliers are 0\n"
],
[
"print('Number of outliers are {}'. format(dataset[(dataset.WindSpeed3pm> WindSpeed3pm_Lower_fence) | (dataset.WindSpeed3pm< WindSpeed3pm_Upper_fence)]['WindSpeed3pm'].count()))",
"Number of outliers are 139563\n"
],
[
"# Replace NaN with default values",
"_____no_output_____"
],
[
"nullValues = [var for var in dataset.columns if dataset[var].isnull().sum()!=0]\nprint(dataset[nullValues].isnull().sum())",
"MinTemp 637\nMaxTemp 322\nRainfall 1406\nEvaporation 60843\nSunshine 67816\nWindGustDir 9330\nWindGustSpeed 9270\nWindDir9am 10013\nWindDir3pm 3778\nWindSpeed9am 1348\nWindSpeed3pm 2630\nHumidity9am 1774\nHumidity3pm 3610\nPressure9am 14014\nPressure3pm 13981\nCloud9am 53657\nCloud3pm 57094\nTemp9am 904\nTemp3pm 2726\nRainToday 1406\ndtype: int64\n"
],
[
"categorical = [var for var in nullValues if dataset[var].dtype=='O']",
"_____no_output_____"
],
[
"from sklearn.impute import SimpleImputer \ncategoricalImputer = SimpleImputer(missing_values=np.nan,strategy='constant') \ncategoricalImputer.fit(dataset[categorical]) \ndataset[categorical]=categoricalImputer.transform(dataset[categorical])\nprint(dataset.head())",
" Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir \\\n0 Albury 13.4 22.9 0.6 NaN NaN W \n1 Albury 7.4 25.1 0.0 NaN NaN WNW \n2 Albury 12.9 25.7 0.0 NaN NaN WSW \n3 Albury 9.2 28.0 0.0 NaN NaN NE \n4 Albury 17.5 32.3 1.0 NaN NaN W \n\n WindGustSpeed WindDir9am WindDir3pm ... Cloud9am Cloud3pm Temp9am \\\n0 44.0 W WNW ... 8.0 NaN 16.9 \n1 44.0 NNW WSW ... NaN NaN 17.2 \n2 46.0 W WSW ... NaN 2.0 21.0 \n3 24.0 SE E ... NaN NaN 18.1 \n4 41.0 ENE NW ... 7.0 8.0 17.8 \n\n Temp3pm RainToday RISK_MM RainTomorrow Year Month Day \n0 21.8 No 0.0 No 2008 12 1 \n1 24.3 No 0.0 No 2008 12 2 \n2 23.2 No 0.0 No 2008 12 3 \n3 26.5 No 1.0 No 2008 12 4 \n4 29.7 No 0.2 No 2008 12 5 \n\n[5 rows x 26 columns]\n"
],
[
"numerical = [var for var in dataset.columns if dataset[var].dtype!='O']",
"_____no_output_____"
],
[
"from sklearn.impute import SimpleImputer \nnumericalImputer = SimpleImputer(missing_values=np.nan,strategy='mean') \nnumericalImputer.fit(dataset[numerical]) \ndataset[numerical]=numericalImputer.transform(dataset[numerical])\nprint(dataset.head())",
" Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir \\\n0 Albury 13.4 22.9 0.6 5.404478 7.624853 W \n1 Albury 7.4 25.1 0.0 5.404478 7.624853 WNW \n2 Albury 12.9 25.7 0.0 5.404478 7.624853 WSW \n3 Albury 9.2 28.0 0.0 5.404478 7.624853 NE \n4 Albury 17.5 32.3 1.0 5.404478 7.624853 W \n\n WindGustSpeed WindDir9am WindDir3pm ... Cloud9am Cloud3pm Temp9am \\\n0 44.0 W WNW ... 8.000000 4.503167 16.9 \n1 44.0 NNW WSW ... 4.437189 4.503167 17.2 \n2 46.0 W WSW ... 4.437189 2.000000 21.0 \n3 24.0 SE E ... 4.437189 4.503167 18.1 \n4 41.0 ENE NW ... 7.000000 8.000000 17.8 \n\n Temp3pm RainToday RISK_MM RainTomorrow Year Month Day \n0 21.8 No 0.0 No 2008.0 12.0 1.0 \n1 24.3 No 0.0 No 2008.0 12.0 2.0 \n2 23.2 No 0.0 No 2008.0 12.0 3.0 \n3 26.5 No 1.0 No 2008.0 12.0 4.0 \n4 29.7 No 0.2 No 2008.0 12.0 5.0 \n\n[5 rows x 26 columns]\n"
]
],
[
[
"# Split data for model",
"_____no_output_____"
]
],
[
[
"x = dataset.drop(['RainTomorrow'], axis=1) # get all row data expect RainTomorrow\ny = dataset['RainTomorrow'] # get the RainTomorrow column depentant variable data for all rows",
"_____no_output_____"
],
[
"print(x.head())",
" Location MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustDir \\\n0 Albury 13.4 22.9 0.6 5.404478 7.624853 W \n1 Albury 7.4 25.1 0.0 5.404478 7.624853 WNW \n2 Albury 12.9 25.7 0.0 5.404478 7.624853 WSW \n3 Albury 9.2 28.0 0.0 5.404478 7.624853 NE \n4 Albury 17.5 32.3 1.0 5.404478 7.624853 W \n\n WindGustSpeed WindDir9am WindDir3pm ... Pressure3pm Cloud9am Cloud3pm \\\n0 44.0 W WNW ... 1007.1 8.000000 4.503167 \n1 44.0 NNW WSW ... 1007.8 4.437189 4.503167 \n2 46.0 W WSW ... 1008.7 4.437189 2.000000 \n3 24.0 SE E ... 1012.8 4.437189 4.503167 \n4 41.0 ENE NW ... 1006.0 7.000000 8.000000 \n\n Temp9am Temp3pm RainToday RISK_MM Year Month Day \n0 16.9 21.8 No 0.0 2008.0 12.0 1.0 \n1 17.2 24.3 No 0.0 2008.0 12.0 2.0 \n2 21.0 23.2 No 0.0 2008.0 12.0 3.0 \n3 18.1 26.5 No 1.0 2008.0 12.0 4.0 \n4 17.8 29.7 No 0.2 2008.0 12.0 5.0 \n\n[5 rows x 25 columns]\n"
],
[
"print(y[:10])",
"0 No\n1 No\n2 No\n3 No\n4 No\n5 No\n6 No\n7 No\n8 Yes\n9 No\nName: RainTomorrow, dtype: object\n"
]
],
[
[
"# Encoding categorical data",
"_____no_output_____"
]
],
[
[
"#encoding independent variable ",
"_____no_output_____"
],
[
"x = pd.get_dummies(x)\nprint(x.head())",
" MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustSpeed \\\n0 13.4 22.9 0.6 5.404478 7.624853 44.0 \n1 7.4 25.1 0.0 5.404478 7.624853 44.0 \n2 12.9 25.7 0.0 5.404478 7.624853 46.0 \n3 9.2 28.0 0.0 5.404478 7.624853 24.0 \n4 17.5 32.3 1.0 5.404478 7.624853 41.0 \n\n WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm ... WindDir3pm_SSE \\\n0 20.0 24.0 71.0 22.0 ... 0 \n1 4.0 22.0 44.0 25.0 ... 0 \n2 19.0 26.0 38.0 30.0 ... 0 \n3 11.0 9.0 45.0 16.0 ... 0 \n4 7.0 20.0 82.0 33.0 ... 0 \n\n WindDir3pm_SSW WindDir3pm_SW WindDir3pm_W WindDir3pm_WNW \\\n0 0 0 0 1 \n1 0 0 0 0 \n2 0 0 0 0 \n3 0 0 0 0 \n4 0 0 0 0 \n\n WindDir3pm_WSW WindDir3pm_missing_value RainToday_No RainToday_Yes \\\n0 0 0 1 0 \n1 1 0 1 0 \n2 1 0 1 0 \n3 0 0 1 0 \n4 0 0 1 0 \n\n RainToday_missing_value \n0 0 \n1 0 \n2 0 \n3 0 \n4 0 \n\n[5 rows x 123 columns]\n"
],
[
"## Encoding dependent variable ",
"_____no_output_____"
],
[
"# use LabelEncoder to replace purchased (dependent variable) with 0 and 1 \nfrom sklearn.preprocessing import LabelEncoder\ny= LabelEncoder().fit_transform(y)\nprint(y[:10])",
"[0 0 0 0 0 0 0 0 1 0]\n"
]
],
[
[
"# Splitting the dataset into training and test set ",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nx_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state = 0) # func returns train and test data. It takes dataset and then split size test_size =0.3 means 30% data is for test and rest for training and random_state \n",
"_____no_output_____"
],
[
"print(x_train.head())",
" MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustSpeed \\\n95444 13.0 21.0 3.2 5.404478 6.000000 31.000000 \n27932 19.5 22.8 3.2 5.404478 7.624853 35.000000 \n15097 21.0 33.4 0.0 5.404478 7.624853 39.984292 \n94607 10.3 19.8 3.2 2.800000 5.500000 54.000000 \n99888 15.5 25.3 0.2 5.404478 7.624853 31.000000 \n\n WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm ... \\\n95444 6.0 17.0 89.0 70.0 ... \n27932 13.0 0.0 99.0 83.0 ... \n15097 4.0 19.0 26.0 17.0 ... \n94607 9.0 20.0 78.0 50.0 ... \n99888 4.0 20.0 80.0 77.0 ... \n\n WindDir3pm_SSE WindDir3pm_SSW WindDir3pm_SW WindDir3pm_W \\\n95444 0 0 1 0 \n27932 0 0 0 0 \n15097 0 0 0 0 \n94607 0 0 0 0 \n99888 0 0 1 0 \n\n WindDir3pm_WNW WindDir3pm_WSW WindDir3pm_missing_value RainToday_No \\\n95444 0 0 0 0 \n27932 0 0 1 0 \n15097 0 0 0 1 \n94607 0 0 0 0 \n99888 0 0 0 1 \n\n RainToday_Yes RainToday_missing_value \n95444 1 0 \n27932 1 0 \n15097 0 0 \n94607 1 0 \n99888 0 0 \n\n[5 rows x 123 columns]\n"
],
[
"print(x_test.head())",
" MinTemp MaxTemp Rainfall Evaporation Sunshine WindGustSpeed \\\n86232 17.4 29.0 0.0 3.600000 11.100000 33.0 \n57576 6.8 14.4 0.8 0.800000 7.624853 46.0 \n124071 10.1 15.4 3.2 5.404478 7.624853 31.0 \n117955 14.4 33.4 0.0 8.000000 11.600000 41.0 \n133468 6.8 14.3 3.2 0.200000 7.300000 28.0 \n\n WindSpeed9am WindSpeed3pm Humidity9am Humidity3pm ... \\\n86232 11.0 19.0 63.0 61.0 ... \n57576 17.0 22.0 80.0 55.0 ... \n124071 13.0 9.0 70.0 61.0 ... \n117955 9.0 17.0 40.0 23.0 ... \n133468 15.0 13.0 92.0 47.0 ... \n\n WindDir3pm_SSE WindDir3pm_SSW WindDir3pm_SW WindDir3pm_W \\\n86232 0 0 0 0 \n57576 0 0 0 0 \n124071 1 0 0 0 \n117955 0 0 1 0 \n133468 0 0 0 0 \n\n WindDir3pm_WNW WindDir3pm_WSW WindDir3pm_missing_value \\\n86232 0 0 0 \n57576 0 0 0 \n124071 0 0 0 \n117955 0 0 0 \n133468 0 0 0 \n\n RainToday_No RainToday_Yes RainToday_missing_value \n86232 1 0 0 \n57576 1 0 0 \n124071 0 1 0 \n117955 1 0 0 \n133468 0 1 0 \n\n[5 rows x 123 columns]\n"
],
[
"print(y_train[:10])",
"[1 1 0 1 0 0 0 0 0 0]\n"
],
[
"print(y_test[:10])",
"[0 0 0 0 0 0 1 1 0 0]\n"
]
],
[
[
"# Feature scaling ",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import MinMaxScaler\nscaler = MinMaxScaler()\nx_train= scaler.fit_transform(x_train) \nx_test = scaler.transform(x_test)\nprint(x_train[:10,:])",
"[[0.50356295 0.48771267 1. ... 0. 1. 0. ]\n [0.65795724 0.52173913 1. ... 0. 1. 0. ]\n [0.6935867 0.7221172 0. ... 1. 0. 0. ]\n ...\n [0.74109264 0.80718336 0. ... 1. 0. 0. ]\n [0.66508314 0.68241966 0. ... 1. 0. 0. ]\n [0.59857482 0.66162571 0. ... 1. 0. 0. ]]\n"
],
[
"print(x_test[:10,:])",
"[[0.60807601 0.6389414 0. ... 1. 0. 0. ]\n [0.35629454 0.36294896 0.25 ... 1. 0. 0. ]\n [0.43467933 0.38185255 1. ... 0. 1. 0. ]\n ...\n [0.52256532 0.47069943 0. ... 1. 0. 0. ]\n [0.67458432 0.59546314 0.125 ... 1. 0. 0. ]\n [0.39667458 0.47258979 0. ... 1. 0. 0. ]]\n"
]
],
[
[
"# Build Model ",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression\nclassifier = LogisticRegression(solver='liblinear', random_state=0)\nclassifier.fit(x_train,y_train) ",
"_____no_output_____"
],
[
"#predicting the test set results\ny_pred = classifier.predict(x_test)",
"_____no_output_____"
]
],
[
[
"# Evaluate Model ",
"_____no_output_____"
]
],
[
[
"cm = confusion_matrix(y_test,y_pred)\nprint(cm)",
"[[32426 610]\n [ 3445 6177]]\n"
],
[
"cr = classification_report(y_test,y_pred)\nprint(cr)",
" precision recall f1-score support\n\n 0 0.90 0.98 0.94 33036\n 1 0.91 0.64 0.75 9622\n\n accuracy 0.90 42658\n macro avg 0.91 0.81 0.85 42658\nweighted avg 0.91 0.90 0.90 42658\n\n"
],
[
"accuracy_score(y_test,y_pred)",
"_____no_output_____"
],
[
"average_precision= average_precision_score(y_test,y_pred)\nprint(average_precision)",
"0.6650264570537755\n"
],
[
"recall_score(y_test,y_pred)",
"_____no_output_____"
],
[
"precision_score(y_test,y_pred)",
"_____no_output_____"
],
[
"f1_score(y_test,y_pred)",
"_____no_output_____"
],
[
"from sklearn.metrics import precision_recall_curve\nfrom sklearn.metrics import plot_precision_recall_curve",
"_____no_output_____"
],
[
"disp = plot_precision_recall_curve(classifier, x_test, y_test)\ndisp.ax_.set_title('2-class Precision-Recall curve: '\n 'AP={0:0.2f}'.format(average_precision))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd00a47d231cb5f45302905c106164b11570b85
| 49,699 |
ipynb
|
Jupyter Notebook
|
nbs/064_callback.PredictionDynamics.ipynb
|
Niklas-groiss-1/tsai
|
78bdcfb34515fcedd6e87a0a6911662397a8b954
|
[
"Apache-2.0"
] | 1 |
2022-01-02T18:21:27.000Z
|
2022-01-02T18:21:27.000Z
|
nbs/064_callback.PredictionDynamics.ipynb
|
Niklas-groiss-1/tsai
|
78bdcfb34515fcedd6e87a0a6911662397a8b954
|
[
"Apache-2.0"
] | 31 |
2021-12-01T23:08:51.000Z
|
2021-12-29T02:59:49.000Z
|
nbs/064_callback.PredictionDynamics.ipynb
|
Niklas-groiss-1/tsai
|
78bdcfb34515fcedd6e87a0a6911662397a8b954
|
[
"Apache-2.0"
] | 1 |
2022-03-13T16:47:04.000Z
|
2022-03-13T16:47:04.000Z
| 123.322581 | 30,398 | 0.813638 |
[
[
[
"# default_exp callback.PredictionDynamics",
"_____no_output_____"
]
],
[
[
"# PredictionDynamics\n\n> Callback used to visualize model predictions during training. ",
"_____no_output_____"
],
[
"This is an implementation created by Ignacio Oguiza ([email protected]) based on a [blog post](http://localhost:8888/?token=83bca9180c34e1c8991886445942499ee8c1e003bc0491d0) by Andrej Karpathy I read some time ago that I really liked. One of the things he mentioned was this: \n>\"**visualize prediction dynamics**. I like to visualize model predictions on a fixed test batch during the course of training. The “dynamics” of how these predictions move will give you incredibly good intuition for how the training progresses. Many times it is possible to feel the network “struggle” to fit your data if it wiggles too much in some way, revealing instabilities. Very low or very high learning rates are also easily noticeable in the amount of jitter.\" A. Karpathy\n",
"_____no_output_____"
]
],
[
[
"#export\nfrom fastai.callback.all import *\nfrom tsai.imports import *",
"_____no_output_____"
],
[
"# export\nclass PredictionDynamics(Callback):\n order, run_valid = 65, True\n\n def __init__(self, show_perc=1., figsize=(10,6), alpha=.3, size=30, color='lime', cmap='gist_rainbow', normalize=False, \n sensitivity=None, specificity=None):\n\n \"\"\"\n Args:\n show_perc: percent of samples from the valid set that will be displayed. Default: 1 (all).\n You can reduce it if the number is too high and the chart is too busy.\n alpha: level of transparency. Default:.3. 1 means no transparency.\n figsize: size of the chart. You may want to expand it if too many classes.\n size: size of each sample in the chart. Default:30. You may need to decrease it a bit if too many classes/ samples.\n color: color used in regression plots.\n cmap: color map used in classification plots.\n normalize: flag to normalize histograms displayed in binary classification.\n sensitivity: (aka recall or True Positive Rate) if you pass a float between 0. and 1. the sensitivity threshold will be plotted in the chart.\n Only used in binary classification.\n specificity: (or True Negative Rate) if you pass a float between 0. and 1. it will be plotted in the chart. Only used in binary classification.\n\n The red line in classification tasks indicate the average probability of true class.\n \"\"\"\n\n store_attr()\n\n def before_fit(self):\n self.run = not hasattr(self.learn, 'lr_finder') and not hasattr(self, \"gather_preds\")\n if not self.run:\n return\n self.cat = True if (hasattr(self.dls, \"c\") and self.dls.c > 1) else False\n if self.cat:\n self.binary = self.dls.c == 2\n if self.show_perc != 1:\n valid_size = len(self.dls.valid.dataset)\n self.show_idxs = np.random.choice(valid_size, int(round(self.show_perc * valid_size)), replace=False)\n\n # Prepare ground truth container\n self.y_true = []\n\n def before_epoch(self):\n # Prepare empty pred container in every epoch\n self.y_pred = []\n\n def after_pred(self):\n if self.training:\n return\n\n # Get y_true in epoch 0\n if self.epoch == 0:\n self.y_true.extend(self.y.cpu().flatten().numpy())\n\n # Gather y_pred for every batch\n if self.cat:\n if self.binary:\n y_pred = F.softmax(self.pred, -1)[:, 1].reshape(-1, 1).cpu()\n else:\n y_pred = torch.gather(F.softmax(self.pred, -1), -1, self.y.reshape(-1, 1).long()).cpu()\n else:\n y_pred = self.pred.cpu()\n self.y_pred.extend(y_pred.flatten().numpy())\n\n def after_epoch(self):\n # Ground truth\n if self.epoch == 0:\n self.y_true = np.array(self.y_true)\n if self.show_perc != 1:\n self.y_true = self.y_true[self.show_idxs]\n self.y_bounds = (np.min(self.y_true), np.max(self.y_true))\n self.min_x_bounds, self.max_x_bounds = np.min(self.y_true), np.max(self.y_true)\n\n self.y_pred = np.array(self.y_pred)\n if self.show_perc != 1:\n self.y_pred = self.y_pred[self.show_idxs]\n if self.cat:\n neg_thr = None\n pos_thr = None\n if self.specificity is not None: \n inp0 = self.y_pred[self.y_true == 0]\n neg_thr = np.sort(inp0)[-int(len(inp0) * (1 - self.specificity))]\n if self.sensitivity is not None: \n inp1 = self.y_pred[self.y_true == 1]\n pos_thr = np.sort(inp1)[-int(len(inp1) * self.sensitivity)]\n self.update_graph(self.y_pred, self.y_true, neg_thr=neg_thr, pos_thr=pos_thr)\n else:\n # Adjust bounds during validation\n self.min_x_bounds = min(self.min_x_bounds, np.min(self.y_pred))\n self.max_x_bounds = max(self.max_x_bounds, np.max(self.y_pred))\n x_bounds = (self.min_x_bounds, self.max_x_bounds)\n self.update_graph(self.y_pred, self.y_true, x_bounds=x_bounds, y_bounds=self.y_bounds)\n\n def update_graph(self, y_pred, y_true, x_bounds=None, y_bounds=None, neg_thr=None, pos_thr=None):\n if not hasattr(self, 'graph_fig'):\n self.df_out = display(\"\", display_id=True)\n if self.cat:\n self._cl_names = self.dls.vocab\n self._classes = L(self.dls.vocab.o2i.values())\n self._n_classes = len(self._classes)\n if self.binary:\n self.bins = np.linspace(0, 1, 101)\n else:\n _cm = plt.get_cmap(self.cmap)\n self._color = [_cm(1. * c/self._n_classes) for c in range(1, self._n_classes + 1)][::-1]\n self._h_vals = np.linspace(-.5, self._n_classes - .5, self._n_classes + 1)[::-1]\n self._rand = []\n for i, c in enumerate(self._classes):\n self._rand.append(.5 * (np.random.rand(np.sum(y_true == c)) - .5))\n self.graph_fig, self.graph_ax = plt.subplots(1, figsize=self.figsize)\n self.graph_out = display(\"\", display_id=True)\n self.graph_ax.clear()\n if self.cat:\n if self.binary:\n self.graph_ax.hist(y_pred[y_true == 0], bins=self.bins, density=self.normalize, color='red', label=self._cl_names[0],\n edgecolor='black', alpha=self.alpha)\n self.graph_ax.hist(y_pred[y_true == 1], bins=self.bins, density=self.normalize, color='blue', label=self._cl_names[1],\n edgecolor='black', alpha=self.alpha)\n self.graph_ax.axvline(.5, lw=1, ls='--', color='gray')\n if neg_thr is not None: \n self.graph_ax.axvline(neg_thr, lw=2, ls='--', color='red', label=f'specificity={(self.specificity):.3f}')\n if pos_thr is not None: \n self.graph_ax.axvline(pos_thr, lw=2, ls='--', color='blue', label=f'sensitivity={self.sensitivity:.3f}')\n self.graph_ax.set_xlabel(f'probability of class {self._cl_names[1]}', fontsize=12)\n self.graph_ax.legend()\n else:\n for i, c in enumerate(self._classes):\n self.graph_ax.scatter(y_pred[y_true == c], y_true[y_true == c] + self._rand[i], color=self._color[i],\n edgecolor='black', alpha=self.alpha, lw=.5, s=self.size)\n self.graph_ax.vlines(np.mean(y_pred[y_true == c]), i - .5, i + .5, color='r')\n self.graph_ax.vlines(.5, min(self._h_vals), max(self._h_vals), lw=.5)\n self.graph_ax.hlines(self._h_vals, 0, 1, lw=.5)\n self.graph_ax.set_ylim(min(self._h_vals), max(self._h_vals))\n self.graph_ax.set_yticks(self._classes)\n self.graph_ax.set_yticklabels(self._cl_names)\n self.graph_ax.set_ylabel('true class', fontsize=12)\n self.graph_ax.set_xlabel('probability of true class', fontsize=12)\n self.graph_ax.set_xlim(0, 1)\n self.graph_ax.set_xticks(np.linspace(0, 1, 11))\n self.graph_ax.grid(axis='x', color='gainsboro', lw=.2)\n else:\n self.graph_ax.scatter(y_pred, y_true, color=self.color, edgecolor='black', alpha=self.alpha, lw=.5, s=self.size)\n self.graph_ax.set_xlim(*x_bounds)\n self.graph_ax.set_ylim(*y_bounds)\n self.graph_ax.plot([*x_bounds], [*x_bounds], color='gainsboro')\n self.graph_ax.set_xlabel('y_pred', fontsize=12)\n self.graph_ax.set_ylabel('y_true', fontsize=12)\n self.graph_ax.grid(color='gainsboro', lw=.2)\n self.graph_ax.set_title(f'Prediction Dynamics \\nepoch: {self.epoch + 1}/{self.n_epoch}')\n self.df_out.update(pd.DataFrame(np.stack(self.learn.recorder.values)[-1].reshape(1,-1),\n columns=self.learn.recorder.metric_names[1:-1], index=[self.epoch]))\n self.graph_out.update(self.graph_ax.figure)\n if self.epoch == self.n_epoch - 1: \n plt.close(self.graph_ax.figure)",
"_____no_output_____"
],
[
"from tsai.basics import *\nfrom tsai.models.InceptionTime import *\ndsid = 'NATOPS'\nX, y, splits = get_UCR_data(dsid, split_data=False)\ncheck_data(X, y, splits, False)",
"X - shape: [360 samples x 24 features x 51 timesteps] type: memmap dtype:float32 isnan: 0\ny - shape: (360,) type: memmap dtype:<U3 n_classes: 6 (60 samples per class) ['1.0', '2.0', '3.0', '4.0', '5.0', '6.0'] isnan: False\nsplits - n_splits: 2 shape: [180, 180] overlap: False\n"
],
[
"tfms = [None, [Categorize()]]\nbatch_tfms = [TSStandardize(by_var=True)]\ndls = get_ts_dls(X, y, splits=splits, tfms=tfms, batch_tfms=batch_tfms)\nlearn = ts_learner(dls, InceptionTime, metrics=accuracy, cbs=PredictionDynamics()) \nlearn.fit_one_cycle(2, 3e-3)",
"_____no_output_____"
],
[
"#hide\nfrom tsai.imports import *\nfrom tsai.export import *\nnb_name = get_nb_name()\n# nb_name = \"064_callback.PredictionDynamics.ipynb\"\ncreate_scripts(nb_name);",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cbd00bba2fdbb75c0a996dc120e8d15991eec3c2
| 10,614 |
ipynb
|
Jupyter Notebook
|
Linear Algebra/(Week-3)IdentifyingSpecialMatrices.ipynb
|
rishabmallick/Mathematics-for-Machine-Learning
|
959a7513bd110f6c2255b2a460058147bdcd6beb
|
[
"MIT"
] | null | null | null |
Linear Algebra/(Week-3)IdentifyingSpecialMatrices.ipynb
|
rishabmallick/Mathematics-for-Machine-Learning
|
959a7513bd110f6c2255b2a460058147bdcd6beb
|
[
"MIT"
] | null | null | null |
Linear Algebra/(Week-3)IdentifyingSpecialMatrices.ipynb
|
rishabmallick/Mathematics-for-Machine-Learning
|
959a7513bd110f6c2255b2a460058147bdcd6beb
|
[
"MIT"
] | null | null | null | 32.658462 | 163 | 0.478142 |
[
[
[
"# Identifying special matrices\n## Instructions\nIn this assignment, you shall write a function that will test if a 4×4 matrix is singular, i.e. to determine if an inverse exists, before calculating it.\n\nYou shall use the method of converting a matrix to echelon form, and testing if this fails by leaving zeros that can’t be removed on the leading diagonal.\n\nDon't worry if you've not coded before, a framework for the function has already been written.\nLook through the code, and you'll be instructed where to make changes.\nWe'll do the first two rows, and you can use this as a guide to do the last two.\n\n### Matrices in Python\nIn the *numpy* package in Python, matrices are indexed using zero for the top-most column and left-most row.\nI.e., the matrix structure looks like this:\n```python\nA[0, 0] A[0, 1] A[0, 2] A[0, 3]\nA[1, 0] A[1, 1] A[1, 2] A[1, 3]\nA[2, 0] A[2, 1] A[2, 2] A[2, 3]\nA[3, 0] A[3, 1] A[3, 2] A[3, 3]\n```\nYou can access the value of each element individually using,\n```python\nA[n, m]\n```\nwhich will give the n'th row and m'th column (starting with zero).\nYou can also access a whole row at a time using,\n```python\nA[n]\n```\nWhich you will see will be useful when calculating linear combinations of rows.\n\nA final note - Python is sensitive to indentation.\nAll the code you should complete will be at the same level of indentation as the instruction comment.\n\n### How to submit\nEdit the code in the cell below to complete the assignment.\nOnce you are finished and happy with it, press the *Submit Assignment* button at the top of this notebook.\n\nPlease don't change any of the function names, as these will be checked by the grading script.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION\nimport numpy as np\n\n\n# Our function will go through the matrix replacing each row in order turning it into echelon form.\n# If at any point it fails because it can't put a 1 in the leading diagonal,\n# we will return the value True, otherwise, we will return False.\n# There is no need to edit this function.\ndef isSingular(A):\n B = np.array(A, dtype=np.float_) # Make B as a copy of A, since we're going to alter it's values.\n try:\n fixRowZero(B)\n fixRowOne(B)\n fixRowTwo(B)\n fixRowThree(B)\n except MatrixIsSingular:\n return True\n return False\n\n\n# This next line defines our error flag. For when things go wrong if the matrix is singular.\n# There is no need to edit this line.\nclass MatrixIsSingular(Exception): pass\n\n\n# For Row Zero, all we require is the first element is equal to 1.\n# We'll divide the row by the value of A[0, 0].\n# This will get us in trouble though if A[0, 0] equals 0, so first we'll test for that,\n# and if this is true, we'll add one of the lower rows to the first one before the division.\n# We'll repeat the test going down each lower row until we can do the division.\n# There is no need to edit this function.\ndef fixRowZero(A):\n if A[0, 0] == 0:\n A[0] = A[0] + A[1]\n if A[0, 0] == 0:\n A[0] = A[0] + A[2]\n if A[0, 0] == 0:\n A[0] = A[0] + A[3]\n if A[0, 0] == 0:\n raise MatrixIsSingular()\n A[0] = A[0] / A[0, 0]\n return A\n\n\n# First we'll set the sub-diagonal elements to zero, i.e. A[1,0].\n# Next we want the diagonal element to be equal to one.\n# We'll divide the row by the value of A[1, 1].\n# Again, we need to test if this is zero.\n# If so, we'll add a lower row and repeat setting the sub-diagonal elements to zero.\n# There is no need to edit this function.\ndef fixRowOne(A):\n A[1] = A[1] - A[1, 0] * A[0]\n if A[1, 1] == 0:\n A[1] = A[1] + A[2]\n A[1] = A[1] - A[1, 0] * A[0]\n if A[1, 1] == 0:\n A[1] = A[1] + A[3]\n A[1] = A[1] - A[1, 0] * A[0]\n if A[1, 1] == 0:\n raise MatrixIsSingular()\n A[1] = A[1] / A[1, 1]\n return A\n\n\n# This is the first function that you should complete.\n# Follow the instructions inside the function at each comment.\ndef fixRowTwo(A):\n # Insert code below to set the sub-diagonal elements of row two to zero (there are two of them).\n A[2] = A[2] - A[2, 0] * A[0]\n A[2] = A[2] - A[2, 1] * A[1]\n # Next we'll test that the diagonal element is not zero.\n if A[2, 2] == 0:\n # Insert code below that adds a lower row to row 2.\n A[2] = A[2] + A[3]\n # Now repeat your code which sets the sub-diagonal elements to zero.\n A[2] = A[2] - A[2, 0] * A[0]\n A[2] = A[2] - A[2, 1] * A[1]\n if A[2, 2] == 0:\n raise MatrixIsSingular()\n # Finally set the diagonal element to one by dividing the whole row by that element.\n A[2] = A[2] / A[2, 2]\n return A\n\n\n# You should also complete this function\n# Follow the instructions inside the function at each comment.\ndef fixRowThree(A):\n # Insert code below to set the sub-diagonal elements of row three to zero.\n A[3] = A[3] - A[3, 0] * A[0]\n A[3] = A[3] - A[3, 1] * A[1]\n A[3] = A[3] - A[3, 2] * A[2]\n # Complete the if statement to test if the diagonal element is zero.\n if A[3, 3] == 0:\n raise MatrixIsSingular()\n # Transform the row to set the diagonal element to one.\n A[3] = A[3] / A[3, 3]\n return A\n",
"_____no_output_____"
]
],
[
[
"## Test your code before submission\nTo test the code you've written above, run the cell (select the cell above, then press the play button [ ▶| ] or press shift-enter).\nYou can then use the code below to test out your function.\nYou don't need to submit this cell; you can edit and run it as much as you like.\n\nTry out your code on tricky test cases!",
"_____no_output_____"
]
],
[
[
"A = np.array([\n [2, 0, 0, 0],\n [0, 3, 0, 0],\n [0, 0, 4, 4],\n [0, 0, 5, 5]\n ], dtype=np.float_)\nisSingular(A)",
"_____no_output_____"
],
[
"A = np.array([\n [0, 7, -5, 3],\n [2, 8, 0, 4],\n [3, 12, 0, 5],\n [1, 3, 1, 3]\n ], dtype=np.float_)\nfixRowZero(A)",
"_____no_output_____"
],
[
"fixRowOne(A)",
"_____no_output_____"
],
[
"fixRowTwo(A)",
"_____no_output_____"
],
[
"fixRowThree(A)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cbd017c963bfabd61166aee1d956b7e6154fdba0
| 16,095 |
ipynb
|
Jupyter Notebook
|
label_roads.ipynb
|
carMartinez/city_perimeter_detect
|
6ea4e3e2f574f26a0c44a090f45617dd7cb456bb
|
[
"MIT"
] | null | null | null |
label_roads.ipynb
|
carMartinez/city_perimeter_detect
|
6ea4e3e2f574f26a0c44a090f45617dd7cb456bb
|
[
"MIT"
] | null | null | null |
label_roads.ipynb
|
carMartinez/city_perimeter_detect
|
6ea4e3e2f574f26a0c44a090f45617dd7cb456bb
|
[
"MIT"
] | null | null | null | 42.355263 | 668 | 0.606462 |
[
[
[
"# Label Roads",
"_____no_output_____"
],
[
"For machine learning, a set of road labels are needed for the downloaded aerial images. That is, for each aerial image, a mask image the same size is needed with each pixel having value 1 or 0 to indicate the prescense or abscense of a road. \n\n\n<table><tr><td><img src='/img/notebook/label_example_img.png'></td><td><img src='/img/notebook/label_example_label.png'></td></tr></table>\n\n\nHere, we use Open Street Map (OSM) data to create binary road masks for the aerial images as shown above. The OSM data is in the form of lines denoted by sequences of geographic coordinates, and the aerial images are georeferenced meaning each pixel can be mapped to a coordinate pair. Thus, assigning labels is relaively straightforward by mapping the road coordinates to the pixels in the images. There are two notable shortcomings of this approach:\n\n1. OSM data may sometimes be incomplete or inaccurate.\n2. OSM gives only the location of the center of the road and not the full extend of the road width. \n\nThe first issue is hard to correct, but with enough data a neural net can hopefully overcome the noise.\n\nThe second issue can be approached by assigning road labels more liberally. Rather than only assigning the centerline pixel as a road, one can label the adjacent neighboring pixels as roads as well. Methodical refinements of this procedure include expanding the neighborhood based on road type (e.g. highways have a larger neighborhood than residential streets) or by assigning a probability distribution to neighboring pixels rather than hard 1's. However, for this project, it is sufficient simply to expand the road labels by a fixed amount (this has already been applied in the example above). Compare the undilate (left) and dilated label examples below.\n\n<table><tr><td><img src='/img/web/labels_no_dilation.png'></td><td><img src='/img/web/labels_dilation.png'></td></tr></table>\n\nIn this rest of this notebook, a label image (i.e. a binary mask) is generated for each NAIP image downloaded previously. These images are of course the same size as the NAIP image and stored locally. Then, for the large city (Phoenix, AZ) which serves as the training and benchmark set, each image/mask pair is broken up into smaller tiles (say, 512x512x3 pixels) that will be fed as input to a neural net. These tilings are saved as datasets in the hdf5 format.",
"_____no_output_____"
]
],
[
[
"import rasterio\nimport fiona\nimport json\nimport h5py\nimport cv2\nimport os\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom sklearn.model_selection import train_test_split\nfrom rasterio.features import rasterize \nfrom helpers import make_tiles\nfrom pyproj import Proj\nfrom PIL import Image\n\n%matplotlib inline",
"/home/carlos/anaconda3/envs/geo/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
]
],
[
[
"First, we need to figure out which coordinate reference system (CRS) / projections we're working with. Different images may have different projections depending on their location, so the road coordinates need to be mapped with the correct projection. \n\nIt's a little overkill, but here we simply project all roads in Arizona for each CRS we find. If memory were a constrained resource, we could limit it to only roads within the cities that were downloaded, but the projections for a single state are managable.",
"_____no_output_____"
]
],
[
[
"from importlib import reload\nimport helpers\nreload(helpers)\nfrom helpers import make_tiles",
"_____no_output_____"
],
[
"with open('data/naip/download_info.json', 'r') as places_in:\n places = json.load(places_in)\n\n## Get all GeoTiff paths as a flat list\ntif_paths_in = [place_info['img_paths'] for _, place_info in places.items()]\ntif_paths_in = [path_in for paths_in in tif_paths_in for path_in in paths_in]\n\n## Get projections\nprojections = []\nfor tif_path_in in tif_paths_in:\n with rasterio.open(tif_path_in) as tif_in:\n projections.append(tif_in.crs['init'])\nprojections = list(set(projections))\n\nprint(projections) ",
"['epsg:26911', 'epsg:26912']\n"
],
[
"## Getting shapes for all roads in AZ\nshape_path = 'data/osm/arizona-latest-free_shp/gis.osm_roads_free_1.shp'\nroads_map = {} # Key is projection CRS, value is list of projected roads\nfor projection in projections:\n\n ## Get transformation\n proj = Proj(init = projection)\n \n ## Project road coordinates\n roads = []\n for i, feat in enumerate(fiona.open(shape_path, 'r')):\n lons, lats = zip(*feat['geometry']['coordinates'])\n xx, yy = proj(lons, lats)\n road = {'type': 'LineString','coordinates': list(zip(xx,yy))} # In meters\n roads.append(road)\n roads_map[projection] = roads\n\nprint('Found {} roads'.format(len(roads_map[projections[0]])))",
"Found 531899 roads\n"
]
],
[
[
"Next, loop through each image, get its CRS, and overlay the roads with the corresponding projection. A dilation from the OpenCV library is used to expand road labels.",
"_____no_output_____"
]
],
[
[
"## Save labels as .PNG images\n## Writing roads within bounds of a source geotiff.\nlabels_dir = 'data/naip/img/labels/'\nkernel = np.ones((3,3), np.uint8) # For label dilation\n\n## Make one output label per input image\nfor tif_path_in in tif_paths_in:\n labels_name_out = tif_path_in.split('/')[-1].replace('.tif', '_labels.png')\n labels_path_out = labels_dir + labels_name_out\n \n ## Skip if we've already made it\n if os.path.isfile(labels_path_out):\n continue\n \n with rasterio.open(tif_path_in) as tif_in:\n roads = roads_map[tif_in.crs['init']]\n\n ## Rasterize a mask\n labels = rasterize( \n roads, \n out_shape = tif_in.shape, \n transform = tif_in.transform,\n default_value = 1,\n fill = 0,\n all_touched=True\n )\n labels = cv2.dilate(labels, kernel, iterations = 2)\n \n labels_img = Image.fromarray(labels * 255)\n labels_img.save(labels_path_out)",
"_____no_output_____"
]
],
[
[
"The data from Phoenix is used as the train/test/dev sets and will be stored in a hdf5 file. Two helper functions will accomplish this. First, `make_tiles` takes an image and chunks it up into smaller sizes that can be input to the neural net. Further, we can specify if there should be any padding which there should be for the input image because the neural net reduces the size of the input. In this case, the padding comes from reflecting the edges of the input. We tile both the aerial image and the corresponding label image. The code is in `helpers.py`.\n\nThen, `make_hdf5_set` defined below takes a list of multiple aerial/label image pairs, splits each into tiles (called chunks in the code), and randomly assigns the tiles to the train/dev/test sets in specified proportions.",
"_____no_output_____"
]
],
[
[
"def make_hdf5_set(\n hdf5_path,\n img_paths,\n frac_train = .80,\n frac_dev = .10,\n frac_test = .10,\n train_input_name = 'X_train',\n train_label_name = 'Y_train',\n dev_input_name = 'X_dev',\n dev_label_name = 'Y_dev',\n test_input_name = 'X_test',\n test_label_name = 'Y_test'\n):\n assert frac_train + frac_dev + frac_test == 1\n \n with h5py.File(hdf5_path, 'w') as data:\n\n chunk_counter = 0\n for i,img_path in enumerate(img_paths):\n\n ## Chunk the image and corresponding labels\n labels_path = img_path.replace('download', 'labels').replace('.tif', '_labels.png')\n X_chunks, _, _ = make_tiles(img_path, pad = 64)\n labels_chunks, _, _ = make_tiles(labels_path)\n labels_chunks = labels_chunks / labels_chunks.max()\n labels_chunks = np.expand_dims(labels_chunks, 3).astype(np.int8)\n chunk_counter = chunk_counter + X_chunks.shape[0]\n\n ## Split into train/dev/test\n X_train, X_test, Y_train, Y_test = train_test_split(X_chunks, labels_chunks, test_size=frac_test, random_state=40)\n X_train, X_dev, Y_train, Y_dev = train_test_split(X_train, Y_train, train_size=frac_train/(frac_train+frac_dev), random_state=30)\n\n ## Add first chunks to dataset\n ## Should make the maxshape not so hardcoded\n if i == 0:\n dset_x_train = data.create_dataset(train_input_name, X_train.shape, maxshape = (None, 640, 640, 3), data=X_train)\n dset_x_dev = data.create_dataset(dev_input_name, X_dev.shape, maxshape = (None, 640, 640, 3), data=X_dev)\n dset_x_test = data.create_dataset(test_input_name, X_test.shape, maxshape = (None, 640, 640, 3), data=X_test)\n dset_y_train = data.create_dataset(train_label_name, Y_train.shape, maxshape = (None, 512, 512, 3), data=Y_train)\n dset_y_dev = data.create_dataset(dev_label_name, Y_dev.shape, maxshape = (None, 512, 512, 3), data=Y_dev)\n dset_y_test = data.create_dataset(test_label_name, Y_test.shape, maxshape = (None, 512, 512, 3), data=Y_test) \n\n ## Append new chunks to the dataset\n else:\n n_train_before_resize = dset_x_train.shape[0]\n n_train_after_resize = n_train_before_resize + X_train.shape[0]\n n_dev_before_resize = dset_x_dev.shape[0]\n n_dev_after_resize = n_dev_before_resize + X_dev.shape[0]\n n_test_before_resize = dset_x_test.shape[0]\n n_test_after_resize = n_test_before_resize + X_test.shape[0]\n\n dset_x_train.resize(n_train_after_resize, axis = 0)\n dset_y_train.resize(n_train_after_resize, axis = 0)\n dset_x_dev.resize(n_dev_after_resize, axis = 0)\n dset_y_dev.resize(n_dev_after_resize, axis = 0)\n dset_x_test.resize(n_test_after_resize, axis = 0)\n dset_y_test.resize(n_test_after_resize, axis = 0)\n\n dset_x_train[n_train_before_resize:] = X_train\n dset_y_train[n_train_before_resize:] = Y_train\n dset_x_dev[n_dev_before_resize:] = X_dev\n dset_y_dev[n_dev_before_resize:] = Y_dev\n dset_x_test[n_test_before_resize:] = X_test\n dset_y_test[n_test_before_resize:] = Y_test\n \n print('Saved {} input/output pairs to {}'.format(chunk_counter, hdf5_path))\n",
"_____no_output_____"
]
],
[
[
"Since the whole Phoenix dataset is rather large (~25GB HDF5 file), for development purposes we'll create a smaller set based on only a few input tiles that we manually specify. Then we'll do the same for the whole dataset.",
"_____no_output_____"
]
],
[
[
"img_paths = [\n 'm_3311117_ne_12_1_20150601',\n 'm_3311117_sw_12_1_20150529',\n 'm_3311117_nw_12_1_20150529',\n 'm_3311117_se_12_1_20150601',\n 'm_3311125_ne_12_1_20150601',\n 'm_3311125_nw_12_1_20150529',\n 'm_3311125_se_12_1_20150601',\n 'm_3311125_sw_12_1_20150529',\n 'm_3311133_ne_12_1_20150601',\n 'm_3311133_nw_12_1_20150529',\n 'm_3311133_se_12_1_20150601',\n 'm_3311133_sw_12_1_20150529'\n]\nimg_paths = ['data/naip/img/download/' + img_path + '.tif' for img_path in img_paths]\nhdf5_path = 'data/naip/hdf5/phoenix_subset.h5'\nmake_hdf5_set(hdf5_path, img_paths)",
"/home/carlos/anaconda3/envs/geo/lib/python3.6/site-packages/sklearn/model_selection/_split.py:2026: FutureWarning: From version 0.21, test_size will always complement train_size unless both are specified.\n FutureWarning)\n"
],
[
"img_paths = places['Phoenix']['img_paths']\nhdf5_path = 'data/naip/hdf5/phoenix.h5'\nmake_hdf5_set(hdf5_path, img_paths)",
"/home/carlos/anaconda3/envs/geo/lib/python3.6/site-packages/sklearn/model_selection/_split.py:2026: FutureWarning: From version 0.21, test_size will always complement train_size unless both are specified.\n FutureWarning)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd01c7791fd7ad9bd69837b03620cbed76f3eb8
| 11,347 |
ipynb
|
Jupyter Notebook
|
homework/Homework07.ipynb
|
Yijia17/sta-663-2021
|
e6484e3116c041b8c8eaae487eff5f351ff499c9
|
[
"MIT"
] | 18 |
2021-01-19T16:35:54.000Z
|
2022-01-01T02:12:30.000Z
|
homework/Homework07.ipynb
|
Yijia17/sta-663-2021
|
e6484e3116c041b8c8eaae487eff5f351ff499c9
|
[
"MIT"
] | null | null | null |
homework/Homework07.ipynb
|
Yijia17/sta-663-2021
|
e6484e3116c041b8c8eaae487eff5f351ff499c9
|
[
"MIT"
] | 24 |
2021-01-19T16:26:13.000Z
|
2022-03-15T05:10:14.000Z
| 44.673228 | 634 | 0.607297 |
[
[
[
"# Homework03: Topic Modeling with Latent Semantic Analysis",
"_____no_output_____"
],
[
"Latent Semantic Analysis (LSA) is a method for finding latent similarities between documents treated as a bag of words by using a low rank approximation. It is used for document classification, clustering and retrieval. For example, LSA can be used to search for prior art given a new patent application. In this homework, we will implement a small library for simple latent semantic analysis as a practical example of the application of SVD. The ideas are very similar to PCA. SVD is also used in recommender systems in an similar fashion (for an SVD-based recommender system library, see [Surpise](http://surpriselib.com). \n\nWe will implement a toy example of LSA to get familiar with the ideas. If you want to use LSA or similar methods for statistical language analysis, the most efficient Python libraries are probably [gensim](https://radimrehurek.com/gensim/) and [spaCy](https://spacy.io) - these also provide an online algorithm - i.e. the training information can be continuously updated. Other useful functions for processing natural language can be found in the [Natural Language Toolkit](http://www.nltk.org/).",
"_____no_output_____"
],
[
"**Note**: The SVD from scipy.linalg performs a full decomposition, which is inefficient since we only need to decompose until we get the first k singluar values. If the SVD from `scipy.linalg` is too slow, please use the `sparsesvd` function from the [sparsesvd](https://pypi.python.org/pypi/sparsesvd/) package to perform SVD instead. You can install in the usual way with \n```\n!pip install sparsesvd\n```\n\nThen import the following\n```python\nfrom sparsesvd import sparsesvd \nfrom scipy.sparse import csc_matrix \n```\n\nand use as follows\n```python\nsparsesvd(csc_matrix(M), k=10)\n```",
"_____no_output_____"
],
[
"**Exercise 1 (20 points)**. Calculating pairwise distance matrices.\n\nSuppose we want to construct a distance matrix between the rows of a matrix. For example, given the matrix \n\n```python\nM = np.array([[1,2,3],[4,5,6]])\n```\n\nthe distance matrix using Euclidean distance as the measure would be\n```python\n[[ 0.000 1.414 2.828]\n [ 1.414 0.000 1.414]\n [ 2.828 1.414 0.000]] \n```\nif $M$ was a collection of column vectors.\n\nWrite a function to calculate the pairwise-distance matrix given the matrix $M$ and some arbitrary distance function. Your functions should have the following signature:\n```\ndef func_name(M, distance_func):\n pass\n```\n\n0. Write a distance function for the Euclidean, squared Euclidean and cosine measures.\n1. Write the function using looping for M as a collection of row vectors.\n2. Write the function using looping for M as a collection of column vectors.\n3. Wrtie the function using broadcasting for M as a collection of row vectors.\n4. Write the function using broadcasting for M as a collection of column vectors. \n\nFor 3 and 4, try to avoid using transposition (but if you get stuck, there will be no penalty for using transposition). Check that all four functions give the same result when applied to the given matrix $M$.",
"_____no_output_____"
],
[
"**Exercise 2 (20 points)**. ",
"_____no_output_____"
],
[
"**Exercise 2 (20 points)**. Write 3 functions to calculate the term frequency (tf), the inverse document frequency (idf) and the product (tf-idf). Each function should take a single argument `docs`, which is a dictionary of (key=identifier, value=document text) pairs, and return an appropriately sized array. Convert '-' to ' ' (space), remove punctuation, convert text to lowercase and split on whitespace to generate a collection of terms from the document text.\n\n- tf = the number of occurrences of term $i$ in document $j$\n- idf = $\\log \\frac{n}{1 + \\text{df}_i}$ where $n$ is the total number of documents and $\\text{df}_i$ is the number of documents in which term $i$ occurs.\n\nPrint the table of tf-idf values for the following document collection\n\n```\ns1 = \"The quick brown fox\"\ns2 = \"Brown fox jumps over the jumps jumps jumps\"\ns3 = \"The the the lazy dog elephant.\"\ns4 = \"The the the the the dog peacock lion tiger elephant\"\n\ndocs = {'s1': s1, 's2': s2, 's3': s3, 's4': s4}\n```",
"_____no_output_____"
],
[
"**Exercise 3 (20 points)**. \n\n1. Write a function that takes a matrix $M$ and an integer $k$ as arguments, and reconstructs a reduced matrix using only the $k$ largest singular values. Use the `scipy.linagl.svd` function to perform the decomposition. This is the least squares approximation to the matrix $M$ in $k$ dimensions.\n\n2. Apply the function you just wrote to the following term-frequency matrix for a set of $9$ documents using $k=2$ and print the reconstructed matrix $M'$.\n```\nM = np.array([[1, 0, 0, 1, 0, 0, 0, 0, 0],\n [1, 0, 1, 0, 0, 0, 0, 0, 0],\n [1, 1, 0, 0, 0, 0, 0, 0, 0],\n [0, 1, 1, 0, 1, 0, 0, 0, 0],\n [0, 1, 1, 2, 0, 0, 0, 0, 0],\n [0, 1, 0, 0, 1, 0, 0, 0, 0],\n [0, 1, 0, 0, 1, 0, 0, 0, 0],\n [0, 0, 1, 1, 0, 0, 0, 0, 0],\n [0, 1, 0, 0, 0, 0, 0, 0, 1],\n [0, 0, 0, 0, 0, 1, 1, 1, 0],\n [0, 0, 0, 0, 0, 0, 1, 1, 1],\n [0, 0, 0, 0, 0, 0, 0, 1, 1]])\n```\n\n3. Calculate the pairwise correlation matrix for the original matrix M and the reconstructed matrix using $k=2$ singular values (you may use [scipy.stats.spearmanr](http://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.spearmanr.html) to do the calculations). Consider the fist 5 sets of documents as one group $G1$ and the last 4 as another group $G2$ (i.e. first 5 and last 4 columns). What is the average within group correlation for $G1$, $G2$ and the average cross-group correlation for G1-G2 using either $M$ or $M'$. (Do not include self-correlation in the within-group calculations.).",
"_____no_output_____"
],
[
"**Exercise 4 (40 points)**. Clustering with LSA\n\n1. Begin by loading a PubMed database of selected article titles using 'pickle'. With the following:\n```import pickle\ndocs = pickle.load(open('pubmed.pic', 'rb'))```\n\n Create a tf-idf matrix for every term that appears at least once in any of the documents. What is the shape of the tf-idf matrix? \n\n2. Perform SVD on the tf-idf matrix to obtain $U \\Sigma V^T$ (often written as $T \\Sigma D^T$ in this context with $T$ representing the terms and $D$ representing the documents). If we set all but the top $k$ singular values to 0, the reconstructed matrix is essentially $U_k \\Sigma_k V_k^T$, where $U_k$ is $m \\times k$, $\\Sigma_k$ is $k \\times k$ and $V_k^T$ is $k \\times n$. Terms in this reduced space are represented by $U_k \\Sigma_k$ and documents by $\\Sigma_k V^T_k$. Reconstruct the matrix using the first $k=10$ singular values.\n\n3. Use agglomerative hierarchical clustering with complete linkage to plot a dendrogram and comment on the likely number of document clusters with $k = 100$. Use the dendrogram function from [SciPy ](https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.cluster.hierarchy.dendrogram.html).\n\n4. Determine how similar each of the original documents is to the new document `data/mystery.txt`. Since $A = U \\Sigma V^T$, we also have $V = A^T U S^{-1}$ using orthogonality and the rule for transposing matrix products. This suggests that in order to map the new document to the same concept space, first find the tf-idf vector $v$ for the new document - this must contain all (and only) the terms present in the existing tf-idx matrix. Then the query vector $q$ is given by $v^T U_k \\Sigma_k^{-1}$. Find the 10 documents most similar to the new document and the 10 most dissimilar. ",
"_____no_output_____"
],
[
"**Notes on the Pubmed articles**\n\nThese were downloaded with the following script.\n\n```python\nfrom Bio import Entrez, Medline\nEntrez.email = \"YOUR EMAIL HERE\"\nimport cPickle\n\ntry:\n docs = cPickle.load(open('pubmed.pic'))\nexcept Exception, e:\n print e\n\n docs = {}\n for term in ['plasmodium', 'diabetes', 'asthma', 'cytometry']:\n handle = Entrez.esearch(db=\"pubmed\", term=term, retmax=50)\n result = Entrez.read(handle)\n handle.close()\n idlist = result[\"IdList\"]\n handle2 = Entrez.efetch(db=\"pubmed\", id=idlist, rettype=\"medline\", retmode=\"text\")\n result2 = Medline.parse(handle2)\n for record in result2:\n title = record.get(\"TI\", None)\n abstract = record.get(\"AB\", None)\n if title is None or abstract is None:\n continue\n docs[title] = '\\n'.join([title, abstract])\n print title\n handle2.close()\n cPickle.dump(docs, open('pubmed.pic', 'w'))\ndocs.values()\n```",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cbd01d673545f45befaa1eb8b9881941c9498309
| 530,035 |
ipynb
|
Jupyter Notebook
|
_notebooks/2020-08-31-pytorch_regression.ipynb
|
lucastiagooliveira/datascience
|
83e1378aac9e14133cb5309ca905869dea3098f9
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-08-31-pytorch_regression.ipynb
|
lucastiagooliveira/datascience
|
83e1378aac9e14133cb5309ca905869dea3098f9
|
[
"Apache-2.0"
] | 1 |
2022-02-26T09:53:05.000Z
|
2022-02-26T09:53:05.000Z
|
_notebooks/2020-08-31-pytorch_regression.ipynb
|
lucastiagooliveira/datascience
|
83e1378aac9e14133cb5309ca905869dea3098f9
|
[
"Apache-2.0"
] | null | null | null | 483.16773 | 497,400 | 0.933646 |
[
[
[
"# Pytorch Basics - Regressão Linear\n> Tutorial de como realizar um modelo de regressão linear no Pytorch.\n\n- toc: false \n- badges: true\n- comments: true\n- categories: [pytorch, regressaolinear]\n- image: images/pytorch.png",
"_____no_output_____"
],
[
"O objetivo desse breve trabalho é apresentar como é realizado um modelo de regressão linear utilizando pytorch. Muitas das vezes utiliza-se regressão linear como uma primeira hipotese, devido a sua simplicidade, antes de partir para modelos mais complexos.",
"_____no_output_____"
],
[
"## Carregando as bibliotecas necessárias",
"_____no_output_____"
]
],
[
[
"#Carregando o Pytorch\nimport torch\n\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## Carregando o conjunto de dados",
"_____no_output_____"
],
[
"Para carregar o bando de dados que está em .csv, utilizamos o pandas, o qual consegue ler um arquivo localmente ou em um nuvem (url deve ser do raw do .csv)",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('https://raw.githubusercontent.com/lucastiagooliveira/lucas_repo/master/Kaggle/Revisiting%20a%20Concrete%20Strength%20regression/datasets_31874_41246_Concrete_Data_Yeh.csv')",
"_____no_output_____"
]
],
[
[
"Mostrando as 5 primeiras linhas do dataframe carregado, isso é importante para verificarmos o se o dataframe está correto.",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
]
],
[
[
"Apresentando um resumo estatístico dos dataframe por coluna, tais como: quantidade de dados, média, desvio padrão, mínimo, primeiro ao terceiro quartil e valor máximo.",
"_____no_output_____"
]
],
[
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"## Plotando os gráficos de todas as váriaveis",
"_____no_output_____"
],
[
"Para visualização da relação entre as váriaveis é interessante fazer a visualização gráfica da relação entre as variáveis. Para isso usamos a função PairGrid da biblioteca Seaborn aliado com um scatterplot da biblioteca MatplotLib.",
"_____no_output_____"
]
],
[
[
"sns.set(style=\"darkgrid\")\ng = sns.PairGrid(df)\ng.map(plt.scatter)",
"_____no_output_____"
]
],
[
[
"## Correlação linear ",
"_____no_output_____"
],
[
"Para entendimento da correlação linear das variáveis entre si, temos a função \"built-in\" do Pandas que nos retorna o coeficiente de correlação que tem por padrão o método Pearson.",
"_____no_output_____"
]
],
[
[
"df.corr()",
"_____no_output_____"
]
],
[
[
"Escolhendo as variáveis que serão utilizadas para criação do modelo.",
"_____no_output_____"
]
],
[
[
"var_used = ['cement', 'superplasticizer', 'age', 'water']\ntrain = df[var_used]\ntarget = df['csMPa']",
"_____no_output_____"
]
],
[
[
"Tabela com somente as variáveis que serão utilizadas.",
"_____no_output_____"
]
],
[
[
"train.head()",
"_____no_output_____"
]
],
[
[
"Para iniciarmos um modelo temos que fazer a transformação da base de dados que está com o tipo de DataFrame para tensor, que é utilizado pelo Pytorch. Todavia, uma das maneiras de fazer essa transformação é antes fazer a transformação da base de dados para um vetor do Numpy e depois transformar para um tensor do Pytorch.\n\nObs.: Foi criado o vetor de uns para ser adicionado ao tensor dos parâmetros, pois essa coluna deverá multiplicar a constante da expressão (b), conforme o exemplo abaixo.\n\n Y = a*X + b",
"_____no_output_____"
]
],
[
[
"train = np.asarray(train)\na = np.ones((train.shape[0],1))\ntrain = torch.tensor(np.concatenate((train, a), axis=1))\ntarget = torch.tensor(np.asarray(target))\ntrain.shape",
"_____no_output_____"
]
],
[
[
"## Criando o modelo",
"_____no_output_____"
],
[
"Para iniciarmos precisamos criar uma função a qual definirá a equação da regressão linear a qual utilizará a função matmul para realizar a multiplicação entre os dois tensores dos parâmetros e variáveis dependentes.",
"_____no_output_____"
]
],
[
[
"def model(x,params):\n return torch.matmul(x, params)",
"_____no_output_____"
]
],
[
[
"Função que calcula o erro quadrático médio (MSE).\n\nPara saber mais sobre como é calculado acesso o link: https://pt.qwe.wiki/wiki/Mean_squared_error",
"_____no_output_____"
]
],
[
[
"def mse(pred, labels): return ((pred - labels)**2).mean()",
"_____no_output_____"
]
],
[
[
"Para iniciar o treino do modelo primeiramente temos que criar um tensor o qual receberá os valores dos parâmetros que serão atualizados a cada iteração, quedo assim precisamos utilizar o método requires_grad_ assim será possível calcular o gradiente desse tensor quando necessário.\n\nObserve que o tipo do objeto criado é torch.float64.",
"_____no_output_____"
]
],
[
[
"params = torch.randn(5,1, dtype=torch.float64).requires_grad_()\nparams.dtype",
"_____no_output_____"
]
],
[
[
"**Primeiro passo:** realizar as predições do modelo",
"_____no_output_____"
]
],
[
[
"pred = model(train, params)",
"_____no_output_____"
]
],
[
[
"**Segundo passo:** calcular como o nosso modelo performou, ou seja, calcular MSE para averiguação da performace do modelo.\n\nObserve que o modelo vai apresentar um erro acentuado, pois os parâmetros ainda não foram *treinados*.",
"_____no_output_____"
]
],
[
[
"loss = mse(pred, target)\nloss",
"_____no_output_____"
]
],
[
[
"**Terceiro passo:** realizar o gradiente descente.\n\nConceito do algoritmo de gradiente descendente: http://cursos.leg.ufpr.br/ML4all/apoio/Gradiente.html",
"_____no_output_____"
]
],
[
[
"loss.backward()\nparams.grad",
"_____no_output_____"
]
],
[
[
"**Quarto passo:** Atualização dos parâmetros, para isso utiliza-se o valor do gradiente por meio do algoritmo descendente e é escalado (multiplicado) pelo taxa de aprendizado (*learning rate*). \n\nApós a realização da atulização dos parâmetros deve-se resetar o gradiente.",
"_____no_output_____"
]
],
[
[
"lr = 1e-5\nparams.data -= lr * params.grad.data\nparams.grad = None",
"_____no_output_____"
]
],
[
[
"Primeira iteração realizada, pode-se observar o valor do erro do nosso modelo reduziu. A tendência é ocorrer uma diminuição até a cada iteração, até a estabilização do modelo.",
"_____no_output_____"
]
],
[
[
"pred = model(train, params)\nloss = mse(pred, target)\nloss",
"_____no_output_____"
]
],
[
[
"Foi criada uma função que realiza todos os passos acima realizados.",
"_____no_output_____"
]
],
[
[
"def step(train, target, params, lr = 1e-6):\n ## realizando as predições\n pred = model(train, params)\n \n ## caculando o erro\n loss = mse(pred, target)\n \n ## realizando o gradiente descendente\n loss.backward()\n \n ## atualizando os parâmtros\n params.data -= lr * params.grad.data\n \n ## reset do gradiente\n params.grad = None\n \n ## imprimindo na tela o erro\n print('Loss:',loss.item())\n \n ## retornado as predições e os parâmetros atuzalizados na ultima iteração\n return pred, params ",
"_____no_output_____"
]
],
[
[
"Criando um loop para realizar as itereções, é possível verificar a diminuição do erro a cada iteração, ou seja, se realizada mais iteração pode-se chegar a um resultado plausível (neste caso não cheramos a um, pois o modelo de regressão linear não é um modelo adequado para esses dados, somente como hipótese inicial).",
"_____no_output_____"
]
],
[
[
"for i in range(10): loss, params = step(train, target, params)",
"Loss: 4242.257680475658\nLoss: 4147.213642508007\nLoss: 4069.8103849910617\nLoss: 4002.831926761954\nLoss: 3942.1511473935216\nLoss: 3885.405335131498\nLoss: 3831.2396737957183\nLoss: 3778.8751298582406\nLoss: 3727.8616331660246\nLoss: 3677.9370952686463\n"
]
],
[
[
"Esté é o resultado dos parâmetros que serão utilizados para o modelo realizar futuras predições.",
"_____no_output_____"
]
],
[
[
"parameters = params\nparameters #parametros do modelo",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd021ef9608fadbe9e165a029a402e7af0d5912
| 80,066 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/disney_review_ETL-checkpoint.ipynb
|
Jhackmeyer/disneyland_review_analysis
|
3bcbd6908e275fe3966e146b5dd18d351fc3788d
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/disney_review_ETL-checkpoint.ipynb
|
Jhackmeyer/disneyland_review_analysis
|
3bcbd6908e275fe3966e146b5dd18d351fc3788d
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/disney_review_ETL-checkpoint.ipynb
|
Jhackmeyer/disneyland_review_analysis
|
3bcbd6908e275fe3966e146b5dd18d351fc3788d
|
[
"MIT"
] | null | null | null | 49.090129 | 17,460 | 0.649477 |
[
[
[
"## Import dependencies\nimport numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom getpass import getpass\nfrom sqlalchemy import create_engine \nimport psycopg2\nfrom sklearn.preprocessing import LabelEncoder",
"_____no_output_____"
],
[
"## Load the data\nfile_path = Path(\"Resources/DisneylandReviews.csv\")\ndisney_raw_df = pd.read_csv(file_path)",
"_____no_output_____"
],
[
"# Inspect data\ndisney_raw_df",
"_____no_output_____"
],
[
"# Inspect counts\ndisney_raw_df.count()",
"_____no_output_____"
],
[
"# Inspect data types\ndisney_raw_df.dtypes",
"_____no_output_____"
],
[
"# Check length of reviews\ndisney_raw_df[\"Review_Text\"].astype('str').str.split().str.len()",
"_____no_output_____"
],
[
"# Check first entry to confirm results\ndisney_raw_df[\"Review_Text\"].loc[0]",
"_____no_output_____"
],
[
"disney_raw_df[\"Review_Text\"].astype('str').str.len().loc[0]",
"_____no_output_____"
],
[
"# Add column for review lengths\ndisney_raw_df[\"Review_Words\"] = disney_raw_df[\"Review_Text\"].astype('str').str.split().str.len()\ndisney_raw_df[\"Review_Letters\"] = disney_raw_df[\"Review_Text\"].astype('str').str.len()",
"_____no_output_____"
],
[
"disney_raw_df.describe()",
"_____no_output_____"
],
[
"# Remove data with missing time values\ndisney_raw_df = disney_raw_df[disney_raw_df[\"Year_Month\"]!='missing']",
"_____no_output_____"
],
[
"# Split year/month column into two columns\ndisney_raw_df[[\"Year\", \"Month\"]] = disney_raw_df[\"Year_Month\"].str.split(pat=\"-\", expand = True)",
"C:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\pandas\\core\\frame.py:3191: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n self[k1] = value[k2]\n"
],
[
"disney_raw_df[\"Year_Month\"].value_counts()",
"_____no_output_____"
],
[
"# Check for nulls\ndisney_raw_df.isna().sum()",
"_____no_output_____"
],
[
"# Check unique locations\nlocations = disney_raw_df[\"Reviewer_Location\"].unique()\nsorted(locations)",
"_____no_output_____"
],
[
"# Replace locations with missing characters\ndisney_raw_df[\"Reviewer_Location\"] = disney_raw_df[\"Reviewer_Location\"].replace([\"Cura�ao\", \"C�te d'Ivoire\", \"�land Islands\"],[\"Curacao\", \"Cote d'Ivoire\", \"Aland Islands\"])",
"C:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
],
[
"# Check which disney parks were visited\ndisney_raw_df[\"Branch\"].unique()",
"_____no_output_____"
],
[
"# Come up with function for determining if reviewer was a local or tourist (in broad terms)\ndef tourist(row):\n if (row[\"Branch\"]==\"Disneyland_HongKong\") & (row[\"Reviewer_Location\"]==\"Hong Kong\"):\n return 0\n elif (row[\"Branch\"]==\"Disneyland_California\") & (row[\"Reviewer_Location\"]==\"United States\"):\n return 0 \n elif (row[\"Branch\"]==\"Disneyland_Paris\") & (row[\"Reviewer_Location\"]==\"France\"):\n return 0\n else:\n return 1",
"_____no_output_____"
],
[
"# Create tourism column: 1 is a reviewer from another country, 0 is a reviewer from the same country\ndisney_raw_df[\"Tourist\"] = disney_raw_df.apply(tourist, axis=1)",
"C:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
],
[
"# Check results\ndisney_raw_df[disney_raw_df[\"Tourist\"]==0]",
"_____no_output_____"
],
[
"# Check counts of tourist vs local\ndisney_raw_df[\"Tourist\"].value_counts()",
"_____no_output_____"
],
[
"# Change data types\ndisney_raw_df[\"Tourist\"] = disney_raw_df[\"Tourist\"].astype(int)\ndisney_raw_df[\"Month\"] = disney_raw_df[\"Month\"].astype(int)\ndisney_raw_df[\"Year\"] = disney_raw_df[\"Year\"].astype(int)\ndisney_raw_df[\"Year_Month\"] = pd.to_datetime(disney_raw_df[\"Year_Month\"])",
"C:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \nC:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n This is separate from the ipykernel package so we can avoid doing imports until\nC:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n after removing the cwd from sys.path.\nC:\\Anaconda\\envs\\mlenv\\lib\\site-packages\\ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"\n"
],
[
"disney_raw_df.dtypes",
"_____no_output_____"
],
[
"# Look at range of years\nsorted(disney_raw_df[\"Year\"].unique())",
"_____no_output_____"
],
[
"# Look for duplicate rows\ndisney_raw_df[\"Review_ID\"].duplicated().sum()",
"_____no_output_____"
],
[
"# Drop duplicate rows\ndisney_raw_df = disney_raw_df.drop_duplicates(subset=\"Review_ID\", keep=\"first\")",
"_____no_output_____"
],
[
"# We may have to bin locations; check number/distribution of unique entries\ndisney_raw_df[\"Reviewer_Location\"].value_counts()",
"_____no_output_____"
],
[
"# Create instance of labelencoder\nlabelencoder = LabelEncoder()\n# Encode categorical data\ndisney_raw_df[\"Branch_Encoded\"] = labelencoder.fit_transform(disney_raw_df[\"Branch\"])\ndisney_raw_df[\"Location_Encoded\"] = labelencoder.fit_transform(disney_raw_df[\"Reviewer_Location\"])",
"_____no_output_____"
],
[
"# View encoded branches\ndisney_raw_df.groupby([\"Branch_Encoded\", \"Branch\"]).size()",
"_____no_output_____"
],
[
"disney_raw_df.groupby([\"Tourist\", \"Branch\"]).size()",
"_____no_output_____"
],
[
"# View encoded locations\ndisney_raw_df.groupby([\"Location_Encoded\", \"Reviewer_Location\"]).size()",
"_____no_output_____"
],
[
"disney_clean_df = disney_raw_df",
"_____no_output_____"
],
[
"# Reset index\ndisney_clean_df.reset_index(inplace=True, drop=True)",
"_____no_output_____"
],
[
"## Now we upload our dataframe to SQL\n# Build the connection string\nprotocol = 'postgresql'\nuser = 'postgres'\nlocation = 'localhost'\nport = '5432'\ndb = 'disney_db'\npassword = getpass('Enter database password')",
"Enter database password········\n"
],
[
"# Store string as variable\ndb_string = f'{protocol}://{user}:{password}@{location}:{port}/{db}'",
"_____no_output_____"
],
[
"# Create database engine\nengine = create_engine(db_string)",
"_____no_output_____"
],
[
"# Send to database\ndisney_clean_df.to_sql(name='disneyland_reviews', con=engine, if_exists='replace')",
"_____no_output_____"
],
[
"# Export to csv\ndisney_clean_df.to_csv(\"Resources/disney_clean.csv\", index=False)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd026d9894dbed839a2a4ea396fc60e6863735b
| 10,010 |
ipynb
|
Jupyter Notebook
|
sideproject/yahoo stock.ipynb
|
kmkurumi/pythonProject
|
4262f227f1238d1b8c0368746a9fc30ea6a760f6
|
[
"MIT"
] | null | null | null |
sideproject/yahoo stock.ipynb
|
kmkurumi/pythonProject
|
4262f227f1238d1b8c0368746a9fc30ea6a760f6
|
[
"MIT"
] | null | null | null |
sideproject/yahoo stock.ipynb
|
kmkurumi/pythonProject
|
4262f227f1238d1b8c0368746a9fc30ea6a760f6
|
[
"MIT"
] | null | null | null | 36.137184 | 1,076 | 0.482517 |
[
[
[
"from bs4 import BeautifulSoup\nimport requests",
"_____no_output_____"
],
[
"class stock:\n def __init__(self,*stock_num):\n ",
"_____no_output_____"
],
[
"from bs4 import BeautifulSoup\nimport requests\nimport pymysql\nimport openpyxl\nfrom openpyxl.styles import Font\nimport gspread\nfrom oauth2client.service_account import ServiceAccountCredentials\nfrom selenium import webdriver\nfrom selenium.webdriver.support.ui import Select\nfrom webdriver_manager.chrome import ChromeDriverManager\nimport time\n\n\nclass Stock:\n def __init__(self, *stock_numbers):\n self.stock_numbers = stock_numbers\n\n def scrape(self):\n\n result = list()\n\n for stock_number in self.stock_numbers:\n\n response = requests.get(\n \"https://tw.stock.yahoo.com/q/q?s=\" + stock_number)\n soup = BeautifulSoup(response.text.replace(\"加到投資組合\", \"\"), \"lxml\")\n\n stock_date = soup.find(\n \"font\", {\"class\": \"tt\"}).getText().strip()[-9:] # 資料日期\n\n tables = soup.find_all(\"table\")[2] # 取得網頁中第三個表格\n tds = tables.find_all(\"td\")[0:11] # 取得表格中1到10格\n\n result.append((stock_date,) +\n tuple(td.getText().strip() for td in tds))\n return result\n\n def save(self, stocks):\n\n db_settings = {\n \"host\": \"127.0.0.1\",\n \"port\": 3306,\n \"user\": \"root\",\n \"password\": \"******\",\n \"db\": \"stock\",\n \"charset\": \"utf8\"\n }\n\n try:\n conn = pymysql.connect(**db_settings)\n\n with conn.cursor() as cursor:\n sql = \"\"\"INSERT INTO market(\n market_date,\n stock_name,\n market_time,\n final_price,\n buy_price,\n sell_price,\n ups_and_downs,\n lot,\n yesterday_price,\n opening_price,\n highest_price,\n lowest_price)\n VALUES(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)\"\"\"\n\n for stock in stocks:\n cursor.execute(sql, stock)\n conn.commit()\n\n except Exception as ex:\n print(\"Exception:\", ex)\n\n def export(self, stocks):\n wb = openpyxl.Workbook()\n sheet = wb.create_sheet(\"Yahoo股市\", 0)\n\n response = requests.get(\n \"https://tw.stock.yahoo.com/q/q?s=2451\")\n soup = BeautifulSoup(response.text, \"lxml\")\n\n tables = soup.find_all(\"table\")[2]\n ths = tables.find_all(\"th\")[0:11]\n titles = (\"資料日期\",) + tuple(th.getText() for th in ths)\n sheet.append(titles)\n\n for index, stock in enumerate(stocks):\n sheet.append(stock)\n\n if \"△\" in stock[6]:\n sheet.cell(row=index+2, column=7).font = Font(color='FF0000')\n elif \"▽\" in stock[6]:\n sheet.cell(row=index+2, column=7).font = Font(color='00A600')\n\n wb.save(\"yahoostock.xlsx\")\n\n def gsheet(self, stocks):\n scopes = [\"https://spreadsheets.google.com/feeds\"]\n\n credentials = ServiceAccountCredentials.from_json_keyfile_name(\n \"credentials.json\", scopes)\n\n client = gspread.authorize(credentials)\n\n sheet = client.open_by_key(\n \"YOUR GOOGLE SHEET KEY\").sheet1\n\n response = requests.get(\n \"https://tw.stock.yahoo.com/q/q?s=2451\")\n soup = BeautifulSoup(response.text, \"lxml\")\n\n tables = soup.find_all(\"table\")[2]\n ths = tables.find_all(\"th\")[0:11]\n titles = (\"資料日期\",) + tuple(th.getText() for th in ths)\n sheet.append_row(titles, 1)\n\n for stock in stocks:\n sheet.append_row(stock)\n\n def daily(self, year, month):\n browser = webdriver.Chrome(ChromeDriverManager().install())\n browser.get(\n \"https://www.twse.com.tw/zh/page/trading/exchange/STOCK_DAY_AVG.html\")\n\n select_year = Select(browser.find_element_by_name(\"yy\"))\n select_year.select_by_value(year) # 選擇傳入的年份\n\n select_month = Select(browser.find_element_by_name(\"mm\"))\n select_month.select_by_value(month) # 選擇傳入的月份\n\n stockno = browser.find_element_by_name(\"stockNo\") # 定位股票代碼輸入框\n\n result = []\n for stock_number in self.stock_numbers:\n stockno.clear() # 清空股票代碼輸入框\n stockno.send_keys(stock_number)\n stockno.submit()\n\n time.sleep(2)\n\n soup = BeautifulSoup(browser.page_source, \"lxml\")\n\n table = soup.find(\"table\", {\"id\": \"report-table\"})\n\n elements = table.find_all(\n \"td\", {\"class\": \"dt-head-center dt-body-center\"})\n\n data = (stock_number,) + tuple(element.getText()\n for element in elements)\n result.append(data)\n\n print(result)\n\n\nstock = Stock('2451', '2454', '2369') # 建立Stock物件\nstock.daily(\"2019\", \"7\") # 動態爬取指定的年月份中,股票代碼的每日收盤價\n\n# stock.gsheet(stock.scrape()) # 將爬取的股票當日行情資料寫入Google Sheet工作表\n# stock.export(stock.scrape()) # 將爬取的股票當日行情資料匯出成Excel檔案\n# stock.save(stock.scrape()) # 將爬取的股票當日行情資料存入MySQL資料庫中\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
cbd02c210c31e06dce3d2da9aa99ab328cb88317
| 14,137 |
ipynb
|
Jupyter Notebook
|
notebooks/docker_and_kubernetes/labs/2_intro_k8s.ipynb
|
acresende/asl-ml-immersion
|
914446de08c5c78a132d248e4a084ee18c8388b0
|
[
"Apache-2.0"
] | null | null | null |
notebooks/docker_and_kubernetes/labs/2_intro_k8s.ipynb
|
acresende/asl-ml-immersion
|
914446de08c5c78a132d248e4a084ee18c8388b0
|
[
"Apache-2.0"
] | null | null | null |
notebooks/docker_and_kubernetes/labs/2_intro_k8s.ipynb
|
acresende/asl-ml-immersion
|
914446de08c5c78a132d248e4a084ee18c8388b0
|
[
"Apache-2.0"
] | null | null | null | 37.498674 | 903 | 0.53406 |
[
[
[
"# Introduction to Kubernetes",
"_____no_output_____"
],
[
"**Learning Objectives**\n * Create GKE cluster from command line\n * Deploy an application to your cluster\n * Cleanup, delete the cluster ",
"_____no_output_____"
],
[
"## Overview\nKubernetes is an open source project (available on [kubernetes.io](kubernetes.io)) which can run on many different environments, from laptops to high-availability multi-node clusters; from public clouds to on-premise deployments; from virtual machines to bare metal.\n\nThe goal of this lab is to provide a short introduction to Kubernetes (k8s) and some basic functionality.",
"_____no_output_____"
],
[
"## Create a GKE cluster\n\nA cluster consists of at least one cluster master machine and multiple worker machines called nodes. Nodes are Compute Engine virtual machine (VM) instances that run the Kubernetes processes necessary to make them part of the cluster.\n\n**Note**: Cluster names must start with a letter and end with an alphanumeric, and cannot be longer than 40 characters.\n\nWe'll call our cluster `asl-cluster`.",
"_____no_output_____"
]
],
[
[
"import os\n\nCLUSTER_NAME = \"asl-cluster\"\nZONE = \"us-central1-a\"\n\nos.environ[\"CLUSTER_NAME\"] = CLUSTER_NAME\nos.environ[\"ZONE\"] = ZONE",
"_____no_output_____"
]
],
[
[
"We'll set our default compute zone to `us-central1-a` and use `gcloud container clusters create ...` to create the GKE cluster. Let's first look at all the clusters we currently have. ",
"_____no_output_____"
]
],
[
[
"!gcloud container clusters list",
"NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS\ncluster-1 us-central1-a 1.19.13-gke.1200 104.197.229.149 custom-2-4352 1.19.13-gke.1200 2 RUNNING\n\n\nTo take a quick anonymous survey, run:\n $ gcloud survey\n\n"
]
],
[
[
"**Exercise**\n\nUse `gcloud container clusters create` to create a new cluster using the `CLUSTER_NAME` we set above. This takes a few minutes...",
"_____no_output_____"
]
],
[
[
"%%bash\ngcloud container clusters create $CLUSTER_NAME --zone $ZONE",
"NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS\nasl-cluster us-central1-a 1.20.10-gke.301 35.225.26.255 e2-medium 1.20.10-gke.301 3 RUNNING\n"
]
],
[
[
"Now when we list our clusters again, we should see the cluster we created. ",
"_____no_output_____"
]
],
[
[
"!gcloud container clusters list",
"NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS\nasl-cluster us-central1-a 1.20.10-gke.301 35.225.26.255 e2-medium 1.20.10-gke.301 3 RUNNING\ncluster-1 us-central1-a 1.19.13-gke.1200 104.197.229.149 custom-2-4352 1.19.13-gke.1200 2 RUNNING\n"
]
],
[
[
"## Get authentication credentials and deploy and application\n\nAfter creating your cluster, you need authentication credentials to interact with it. Use `get-credentials` to authenticate the cluster.\n\n**Exercise**\n\nUse `gcloud container clusters get-credentials` to authenticate the cluster you created.",
"_____no_output_____"
]
],
[
[
"%%bash\ngcloud container clusters get-credentials $CLUSTER_NAME --zone $ZONE",
"Fetching cluster endpoint and auth data.\nkubeconfig entry generated for asl-cluster.\n"
]
],
[
[
"You can now deploy a containerized application to the cluster. For this lab, you'll run `hello-app` in your cluster.\n\nGKE uses Kubernetes objects to create and manage your cluster's resources. Kubernetes provides the [Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/) object for deploying stateless applications like web servers. [Service](https://kubernetes.io/docs/concepts/services-networking/service/) objects define rules and load balancing for accessing your application from the internet.",
"_____no_output_____"
],
[
"**Exercise**\n\nUse the `kubectl create` command to create a new Deployment `hello-server` from the `hello-app` container image. The `--image` flag to specify a container image to deploy. The `kubectl create` command pulls the example image from a Container Registry bucket. Here, use [gcr.io/google-samples/hello-app:1.0](gcr.io/google-samples/hello-app:1.0) to indicate the specific image version to pull. If a version is not specified, the latest version is used.",
"_____no_output_____"
]
],
[
[
"%%bash\nkubectl create deployment hello-server --image=gcr.io/google-samples/hello-app:1.0pp",
"deployment.apps/hello-server created\n"
]
],
[
[
"This Kubernetes command creates a Deployment object that represents `hello-server`. To create a Kubernetes Service, which is a Kubernetes resource that lets you expose your application to external traffic, run the `kubectl expose` command. \n\n**Exercise**\n\nUse the `kubectl expose` to expose the application. In this command, \n * `--port` specifies the port that the container exposes.\n * `type=\"LoadBalancer\"` creates a Compute Engine load balancer for your container.",
"_____no_output_____"
]
],
[
[
"%%bash\nkubectl expose deployment hello-server --type=LoadBalancer --port 8080",
"service/hello-server exposed\n"
]
],
[
[
"Use the `kubectl get service` command to inspect the `hello-server` Service.\n\n**Note**: It might take a minute for an external IP address to be generated. Run the previous command again if the `EXTERNAL-IP` column for `hello-server` status is pending.",
"_____no_output_____"
]
],
[
[
"!kubectl get service",
"NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE\nhello-server LoadBalancer 10.7.247.54 <pending> 8080:31631/TCP 3s\nkubernetes ClusterIP 10.7.240.1 <none> 443/TCP 9m12s\n"
]
],
[
[
"You can now view the application from your web browser, open a new tab and enter the following address, replacing `EXTERNAL IP` with the EXTERNAL-IP for `hello-server`:\n\n```bash\nhttp://[EXTERNAL_IP]:8080\n```\n\nYou should see a simple page which displays\n\n```bash\nHello, world!\nVersion: 1.0.0\nHostname: hello-server-5bfd595c65-7jqkn\n```",
"_____no_output_____"
],
[
"## Cleanup\n\nDelete the cluster using `gcloud` to free up those resources. Use the `--quiet` flag if you are executing this in a notebook. Deleting the cluster can take a few minutes. ",
"_____no_output_____"
],
[
"**Exercise**\n\nDelete the cluster. Use the `--quiet` flag since we're executing in a notebook.",
"_____no_output_____"
]
],
[
[
"%%bash\ngcloud container clusters --quiet delete ${CLUSTER_NAME} --zone $ZONE",
"Deleting cluster asl-cluster...\n...................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................done.\nDeleted [https://container.googleapis.com/v1/projects/qwiklabs-gcp-00-eeb852ce8ccb/zones/us-central1-a/clusters/asl-cluster].\n"
]
],
[
[
"Copyright 2020 Google LLC Licensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with the License. You may obtain a copy of the License at https://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd0382740092b146d2328eb5c9e0b76bde7c9ed
| 274 |
ipynb
|
Jupyter Notebook
|
notebooks/book1/10/iris_logreg.ipynb
|
igunduz/pyprobml
|
7bd674ac4b483c876859fb39e0ca5a940075490b
|
[
"MIT"
] | null | null | null |
notebooks/book1/10/iris_logreg.ipynb
|
igunduz/pyprobml
|
7bd674ac4b483c876859fb39e0ca5a940075490b
|
[
"MIT"
] | null | null | null |
notebooks/book1/10/iris_logreg.ipynb
|
igunduz/pyprobml
|
7bd674ac4b483c876859fb39e0ca5a940075490b
|
[
"MIT"
] | null | null | null | 17.125 | 103 | 0.576642 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
cbd03a5ada7da25831486cacf49fc2c758786cdc
| 29,903 |
ipynb
|
Jupyter Notebook
|
ToxicSpans_SemEval21.ipynb
|
iliasKatsabalos/toxic_spans
|
768acccc85a2cf41b8ed900f28900b764b9ad761
|
[
"CC0-1.0"
] | 47 |
2020-08-07T15:23:09.000Z
|
2022-03-24T11:55:11.000Z
|
ToxicSpans_SemEval21.ipynb
|
iliasKatsabalos/toxic_spans
|
768acccc85a2cf41b8ed900f28900b764b9ad761
|
[
"CC0-1.0"
] | 8 |
2020-10-27T12:15:20.000Z
|
2022-03-10T14:14:08.000Z
|
ToxicSpans_SemEval21.ipynb
|
iliasKatsabalos/toxic_spans
|
768acccc85a2cf41b8ed900f28900b764b9ad761
|
[
"CC0-1.0"
] | 20 |
2020-10-05T21:34:04.000Z
|
2022-03-30T08:36:46.000Z
| 50.172819 | 6,658 | 0.548641 |
[
[
[
"<a href=\"https://colab.research.google.com/github/ipavlopoulos/toxic_spans/blob/master/ToxicSpans_SemEval21.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Download the data and the code",
"_____no_output_____"
]
],
[
[
"from ast import literal_eval\nimport pandas as pd\nimport random",
"_____no_output_____"
],
[
"!git clone https://github.com/ipavlopoulos/toxic_spans.git\nfrom toxic_spans.evaluation.semeval2021 import f1",
"Cloning into 'toxic_spans'...\nremote: Enumerating objects: 205, done.\u001b[K\nremote: Counting objects: 100% (205/205), done.\u001b[K\nremote: Compressing objects: 100% (154/154), done.\u001b[K\nremote: Total 205 (delta 95), reused 145 (delta 49), pack-reused 0\u001b[K\nReceiving objects: 100% (205/205), 181.00 KiB | 5.32 MiB/s, done.\nResolving deltas: 100% (95/95), done.\n"
],
[
"tsd = pd.read_csv(\"toxic_spans/data/tsd_trial.csv\") \ntsd.spans = tsd.spans.apply(literal_eval)\ntsd.head(1)",
"_____no_output_____"
]
],
[
[
"### Run a random baseline\n* Returns random offsets as toxic per text",
"_____no_output_____"
]
],
[
[
"# make an example with a taboo word\ntaboo_word = \"fucking\"\ntemplate = f\"This is a {taboo_word} example.\"\n\n# build a random baseline (yields offsets at random)\nrandom_baseline = lambda text: [i for i, char in enumerate(text) if random.random()>0.5]\npredictions = random_baseline(template)\n\n# find the ground truth indices and print\ngold = list(range(template.index(taboo_word), template.index(taboo_word)+len(taboo_word)))\nprint(f\"Gold\\t\\t: {gold}\")\nprint(f\"Predicted\\t: {predictions}\")",
"Gold\t\t: [10, 11, 12, 13, 14, 15, 16]\nPredicted\t: [1, 5, 6, 9, 10, 11, 13, 16, 17, 21, 24]\n"
],
[
"tsd[\"random_predictions\"] = tsd.text.apply(random_baseline)\ntsd[\"f1_scores\"] = tsd.apply(lambda row: f1(row.random_predictions, row.spans), axis=1)\ntsd.head()",
"_____no_output_____"
],
[
"from scipy.stats import sem\n_ = tsd.f1_scores.plot(kind=\"box\")\nprint (f\"F1 = {tsd.f1_scores.mean():.2f} ± {sem(tsd.f1_scores):.2f}\")",
"F1 = 0.17 ± 0.01\n"
]
],
[
[
"### Prepare the text file with the scores\n* Name it as `spans-pred.txt`.\n* Align the scores with the rows.",
"_____no_output_____"
]
],
[
[
"# make sure that the ids match the ones of the scores\npredictions = tsd.random_predictions.to_list()\nids = tsd.index.to_list()\n\n# write in a prediction file named \"spans-pred.txt\"\nwith open(\"spans-pred.txt\", \"w\") as out:\n for uid, text_scores in zip(ids, predictions):\n out.write(f\"{str(uid)}\\t{str(text_scores)}\\n\")\n\n! head spans-pred.txt",
"0\t[0, 1, 2, 3, 5, 6, 8, 9, 10, 11, 12, 14, 15, 18, 21, 22, 24, 25, 28, 30, 31, 35, 36, 39, 40, 41, 43, 44, 45, 47, 48, 49, 50, 52, 57, 58, 61, 63, 68, 69, 70, 71, 72]\n1\t[2, 3, 5, 7, 8, 10, 11, 13, 17, 18, 19, 20, 21, 22, 25, 27, 28, 36, 37, 38, 39, 41, 44, 45, 46, 47, 48, 50, 51, 54, 55, 57, 58, 59, 65, 67, 68, 70, 71, 72, 75, 77, 79, 80, 83, 84, 86, 87, 88, 90, 92, 94, 95, 96, 97, 98, 104, 107, 108, 109, 110, 114, 115, 116, 117, 118, 119, 120, 124, 125, 126, 127, 132, 133, 134, 135, 136]\n2\t[3, 4, 7, 9, 10, 12, 17, 19, 23, 25, 28, 29, 30, 31, 32, 35, 36, 38, 44, 46, 47, 48, 50, 51, 52, 53, 56, 57, 59, 60, 64, 65, 66, 67, 68, 69, 74, 76, 78, 79, 80, 81, 83, 84, 85, 87, 88, 90, 92, 93, 94, 95, 96, 99, 100, 106, 108, 109, 111, 116, 117, 118, 119, 120, 121, 122, 123, 126, 133, 134, 135, 136, 138, 140, 142, 143, 144, 147, 155, 156, 158, 159, 160, 161, 164, 169, 170, 172, 173, 175, 176, 178, 179, 180, 183, 184, 185, 186]\n3\t[0, 2, 4, 5, 6, 7, 10, 14, 16, 17, 18, 19, 20, 21, 22, 25, 26, 28, 30, 32, 39, 41, 42, 45, 46, 49, 52, 56, 59, 62, 63, 68, 70, 71, 72, 73, 76, 79, 83, 84, 86, 87, 93, 95, 96, 98, 99, 100, 103, 104]\n4\t[1, 2, 3, 4, 5, 7, 15, 16, 18, 20, 21, 22, 23, 25, 26, 29, 36, 41, 44, 46, 47, 48, 49, 53, 56, 57, 58, 61, 62, 63, 64, 65, 66, 74, 75, 77, 80, 82, 86, 87, 89, 92, 94, 95, 96, 98, 100, 101, 102, 103, 105, 106, 109, 112, 113, 114, 116, 117, 119, 122, 123, 125, 127, 128, 129, 131, 136, 137, 140, 141, 142, 146, 147, 148, 149, 153, 154, 155, 157, 159, 160, 161, 162, 164, 165, 166, 167, 168, 169, 170, 173, 175, 183, 185, 187, 188, 191, 192, 193, 194, 196, 197, 198, 200, 204, 206, 207]\n5\t[0, 1, 2, 4, 5, 7, 8, 9, 12, 13, 18, 19, 23, 24, 25, 26, 28, 29, 31, 35, 37, 38, 42, 44, 47, 48, 49, 50, 51, 55, 60, 61, 62, 63, 67, 70, 71, 72, 73, 76, 77, 79, 81, 82, 83, 85, 87, 88, 89, 90, 98, 101, 103, 104, 105, 110, 111, 112, 114, 115]\n6\t[0, 10, 11, 12, 15, 17, 20, 25, 29, 31, 33, 34, 35, 36, 38, 40, 41, 48, 52, 53, 54, 55, 57, 59, 61, 63, 66, 68, 69, 72, 77, 78, 80, 81, 82, 83, 84, 87, 88, 90, 94, 95, 96, 98, 99, 100, 101, 104, 110, 111, 112, 114, 117, 119, 122, 123, 125, 126, 128, 130, 133, 134, 136, 138, 139, 140, 142, 143, 146, 148, 151, 152, 153, 154, 157, 158, 160, 161, 162, 163, 164, 167, 172, 173, 174, 175, 178, 179, 180, 185, 187, 188, 189, 193, 199, 201, 207, 208, 209, 210, 211, 212, 213, 217, 219, 220, 222, 223, 232, 233, 235, 238, 239, 242, 244, 248, 251, 256, 260, 261, 263, 269, 271, 272, 278, 279, 286, 287, 290, 291, 292, 293, 294, 297, 298, 299, 303, 304, 306, 308, 309, 315, 316, 318, 319, 320, 321, 322, 324, 325, 326, 328, 331, 333, 334, 335, 338, 341, 342, 343, 344, 347, 348, 349, 350, 356, 357, 361, 364, 369, 371, 372, 374, 375, 376, 377, 379, 382, 383, 385, 386, 387, 389, 391, 394, 397, 398, 402, 404, 406, 408, 410, 411, 413, 414, 416, 417, 419, 425, 426, 427, 429, 433, 438, 439, 440, 441, 443, 444, 445, 447, 448, 452, 453, 456, 457, 458, 459, 463, 464, 467, 470, 471, 472, 480, 481, 482, 483, 484, 485, 486, 489, 490, 491, 493, 494, 495, 496, 498, 501, 503, 506, 507, 508, 509, 510, 511, 516, 519, 520, 525, 527, 528, 529, 535, 536, 537, 539, 540, 541, 545, 548, 550, 551, 553, 557, 559, 561, 565, 568, 572, 573, 575, 576, 579, 582, 583, 584, 586, 587, 588, 594, 595, 600, 601, 606, 608, 609, 612, 613, 617, 620, 621, 622, 623, 627, 631, 633, 638]\n7\t[0, 1, 2, 5, 6, 7, 8, 9, 10, 12, 13, 18, 20, 21, 22, 24, 25, 28, 30, 31, 36, 37, 40, 42, 44, 47, 53, 57, 58, 60, 62, 64, 66, 67, 68, 69, 70, 75, 76, 77]\n8\t[0, 1, 2, 3, 4, 7, 8, 11, 13, 15, 17, 19, 20, 21, 22, 24, 25, 26, 28, 29, 31, 33, 38, 45, 46, 47, 48, 49, 50, 51, 53, 54, 57, 58, 59]\n9\t[0, 1, 2, 10, 11, 12, 14, 17, 19, 21, 23, 24, 27, 29, 30, 33, 35, 36, 38, 43, 48, 50, 53, 58, 60, 61, 62, 63, 65, 68, 69, 70, 72, 73, 74, 75, 76, 77, 78, 79, 81, 84, 86, 87, 88, 89, 90, 92, 93, 95, 96, 97, 98, 99, 100, 102, 107, 108, 110, 111, 112, 114, 115, 118, 119, 125, 130, 131, 134, 136, 137, 139, 140, 142, 144, 145, 146, 148, 149, 151, 153, 154, 155, 156, 157, 158, 160, 163, 164, 166, 167, 170, 171, 172, 174, 175, 177, 179, 182, 183, 188, 189, 192, 193, 194, 197, 198, 199, 200, 201, 202, 204, 205, 209, 210, 211, 212, 213, 214, 216, 217, 220, 221, 225, 226, 229, 232, 234, 235, 238, 239, 240, 241, 242, 244, 248, 249, 256, 259, 261, 264, 266, 267, 269, 270, 272, 276, 280, 282, 283, 285, 288, 289, 290, 292, 293, 295, 297, 298, 300, 302, 303]\n"
]
],
[
[
"### Zip the predictions\n* Take extra care to verify that only the predictions text file is included. \n* The text file should **not** be within any directory. \n* No other file should be included; the zip should only contain the txt file.\n",
"_____no_output_____"
]
],
[
[
"! zip -r random_predictions.zip ./spans-pred.* ",
" adding: spans-pred.txt (deflated 77%)\n"
]
],
[
[
"###### Check by unziping it: only a `spans-pred.txt` file should be created",
"_____no_output_____"
]
],
[
[
"! rm spans-pred.txt\n! unzip random_predictions.zip",
"Archive: random_predictions.zip\n inflating: spans-pred.txt \n"
]
],
[
[
"### Download the zip and submit it to be assessed",
"_____no_output_____"
]
],
[
[
"from google.colab import files\nfiles.download(\"random_predictions.zip\")",
"_____no_output_____"
]
],
[
[
"### When the submission is finished click the `Download output from scoring step`\n* The submission may take a while, so avoid late submissions.\n* Download the output_file.zip and see your score in the respective file.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd045c158445ab012e78beadd42c140215cae01
| 27,748 |
ipynb
|
Jupyter Notebook
|
neural_networks_gas_turbines_csv.ipynb
|
SAURABHMASLEKAR/xyz
|
71f80f63dce1b374912494108ab698301f68f077
|
[
"CC0-1.0"
] | null | null | null |
neural_networks_gas_turbines_csv.ipynb
|
SAURABHMASLEKAR/xyz
|
71f80f63dce1b374912494108ab698301f68f077
|
[
"CC0-1.0"
] | null | null | null |
neural_networks_gas_turbines_csv.ipynb
|
SAURABHMASLEKAR/xyz
|
71f80f63dce1b374912494108ab698301f68f077
|
[
"CC0-1.0"
] | null | null | null | 32.568075 | 248 | 0.340925 |
[
[
[
"<a href=\"https://colab.research.google.com/github/SAURABHMASLEKAR/xyz/blob/main/neural_networks_gas_turbines_csv.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n#Plot Tools\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport seaborn as sns\n#Model Building\nfrom sklearn.preprocessing import StandardScaler\nimport sklearn\nimport keras\nfrom keras.wrappers.scikit_learn import KerasRegressor\nfrom keras.models import Sequential\nfrom keras.layers import InputLayer,Dense\nimport tensorflow as tf\n#Model Validation\nfrom sklearn.model_selection import cross_val_score, KFold, train_test_split\nfrom sklearn.metrics import mean_squared_error",
"_____no_output_____"
],
[
"data=pd.read_csv('gas_turbines.csv')\ndata",
"_____no_output_____"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 15039 entries, 0 to 15038\nData columns (total 11 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 AT 15039 non-null float64\n 1 AP 15039 non-null float64\n 2 AH 15039 non-null float64\n 3 AFDP 15039 non-null float64\n 4 GTEP 15039 non-null float64\n 5 TIT 15039 non-null float64\n 6 TAT 15039 non-null float64\n 7 TEY 15039 non-null float64\n 8 CDP 15039 non-null float64\n 9 CO 15039 non-null float64\n 10 NOX 15039 non-null float64\ndtypes: float64(11)\nmemory usage: 1.3 MB\n"
],
[
"data.describe()",
"_____no_output_____"
],
[
"X = data.loc[:,['AT', 'AP', 'AH', 'AFDP', 'GTEP', 'TIT', 'TAT', 'CDP', 'CO','NOX']]\ny= data.loc[:,['TEY']]",
"_____no_output_____"
],
[
"scaler = StandardScaler()\nX = scaler.fit_transform(X)\ny = scaler.fit_transform(y)",
"_____no_output_____"
],
[
"def baseline_model():\n model = Sequential()\n model.add(Dense(10, input_dim=10, activation='tanh'))\n model.add(Dense(1))\n model.compile(loss='mean_squared_error', optimizer='adam')\n return model",
"_____no_output_____"
],
[
"estimator = KerasRegressor(build_fn=baseline_model, nb_epoch=50, batch_size=100, verbose=False)\nkfold = KFold(n_splits=10)\nresults = cross_val_score(estimator, X, y, cv=kfold)\nprint(\"Results: %.2f (%.2f) MSE\" % (results.mean(), results.std()))",
"Results: -0.14 (0.09) MSE\n"
],
[
"estimator.fit(X, y)\nprediction = estimator.predict(X)",
"_____no_output_____"
],
[
"prediction",
"_____no_output_____"
],
[
"a=scaler.inverse_transform(prediction)\na",
"_____no_output_____"
],
[
"b=scaler.inverse_transform(y)\nb",
"_____no_output_____"
],
[
"mean_squared_error(b,a)",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)",
"_____no_output_____"
],
[
"estimator.fit(X_train, y_train)\nprediction = estimator.predict(X_test)",
"_____no_output_____"
],
[
"prediction",
"_____no_output_____"
],
[
"c=scaler.inverse_transform(prediction)",
"_____no_output_____"
],
[
"d=scaler.inverse_transform(y_test)",
"_____no_output_____"
],
[
"mean_squared_error(d,c)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd046dac66d8ada35bbc504c0f4642e74a9ca6f
| 66,694 |
ipynb
|
Jupyter Notebook
|
02_Ngrams/.ipynb_checkpoints/00_TextAnalysis_basic-checkpoint.ipynb
|
aniellodesanto/Utah_5300
|
92cc6ffaa317ab3bcc6ccd5b439c8b9279b46a3e
|
[
"CC0-1.0"
] | null | null | null |
02_Ngrams/.ipynb_checkpoints/00_TextAnalysis_basic-checkpoint.ipynb
|
aniellodesanto/Utah_5300
|
92cc6ffaa317ab3bcc6ccd5b439c8b9279b46a3e
|
[
"CC0-1.0"
] | null | null | null |
02_Ngrams/.ipynb_checkpoints/00_TextAnalysis_basic-checkpoint.ipynb
|
aniellodesanto/Utah_5300
|
92cc6ffaa317ab3bcc6ccd5b439c8b9279b46a3e
|
[
"CC0-1.0"
] | 1 |
2022-01-21T05:44:04.000Z
|
2022-01-21T05:44:04.000Z
| 77.37123 | 11,996 | 0.761088 |
[
[
[
"# Counts, Frequencies, and Ngram Models\n\nBefore you proceed, make sure to run the cell below.\nThis will once again read in the cleaned up text files and store them as tokenized lists in the variables `hamlet`, `faustus`, and `mars`.\nIf you get an error, make sure that you did the previous notebook and that this notebook is in a folder containing the files `hamlex_clean.txt`, `faustus_clean.txt`, and `mars_clean.txt` (which should be the case if you did the previous notebook).",
"_____no_output_____"
]
],
[
[
"from google.colab import files\n\n\n#Import files\nupload1 = files.upload()\nupload2 = files.upload()\nupload3 = files.upload()\n\nhamlet_full = upload1['faustus_clean.txt'].decode('utf-8')\nfaustus_full = upload2['hamlet_clean.txt'].decode('utf-8')\nmars_full = upload3['mars_clean.txt'].decode('utf-8')\n\n",
"_____no_output_____"
],
[
"import re\ndef tokenize(the_string):\n \"\"\"Convert string to list of words\"\"\"\n return re.findall(r\"\\w+\", the_string)\n\n\n# define a variable for each token list\nhamlet = tokenize(hamlet_full)\nfaustus = tokenize(faustus_full)\nmars = tokenize(mars_full)",
"_____no_output_____"
]
],
[
[
"**Caution.**\nIf you restart the kernel at any point, make sure to run all these previous cells again so that the variables `hamlet`, `faustus`, and `mars` are defined.",
"_____no_output_____"
],
[
"## Counting words\n\nPython makes it very easy to count how often an element occurs in a list: the `collections` library provides a function `Counter` that does the counting for us.\nThe `Counter` function takes as its only argument a list (like the ones produced by `re.findall` for tokenization).\nIt then converts the list into a *Counter*.\nHere is what this looks like with a short example string.",
"_____no_output_____"
]
],
[
[
"import re\nfrom collections import Counter # this allows us to use Counter instead of collections.Counter\n\ntest_string = \"FTL is short for faster-than-light; we probably won't ever have space ships capable of FTL-travel.\"\n\n# tokenize the string\ntokens = re.findall(r\"\\w+\", str.lower(test_string))\nprint(\"The list of tokens:\", tokens)\n\n# add an empty line\nprint()\n\n# and now do the counting\ncounts = Counter(tokens)\nprint(\"Number of tokens for each word type:\", counts)",
"The list of tokens: ['ftl', 'is', 'short', 'for', 'faster', 'than', 'light', 'we', 'probably', 'won', 't', 'ever', 'have', 'space', 'ships', 'capable', 'of', 'ftl', 'travel']\n\nNumber of tokens for each word type: Counter({'ftl': 2, 'is': 1, 'short': 1, 'for': 1, 'faster': 1, 'than': 1, 'light': 1, 'we': 1, 'probably': 1, 'won': 1, 't': 1, 'ever': 1, 'have': 1, 'space': 1, 'ships': 1, 'capable': 1, 'of': 1, 'travel': 1})\n"
]
],
[
[
"Let's take a quick peak at what the counts looks like for each text.\nWe don't want to do this with something like `print(counts_hamlet)`, because the output would be so large that your browser might actually choke on it (it has happened to me sometimes).\nInstead, we will look at the 100 most common words.\nWe can do this with the function `Counter.most_common`, which takes two arguments: a Counter, and a positive number.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\n# construct the counters\ncounts_hamlet = Counter(hamlet)\ncounts_faustus = Counter(faustus)\ncounts_mars = Counter(mars)\n\nprint(\"Most common Hamlet words:\", Counter.most_common(counts_hamlet, 100))\nprint()\nprint(\"Most common Faustus words:\", Counter.most_common(counts_faustus, 100))\nprint()\nprint(\"Most common John Carter words:\", Counter.most_common(counts_mars, 100))",
"Most common Hamlet words: [('and', 509), ('the', 501), ('i', 400), ('of', 338), ('to', 333), ('that', 226), ('a', 212), ('in', 189), ('me', 187), ('faustus', 181), ('you', 176), ('my', 169), ('for', 161), ('thou', 154), ('d', 152), ('this', 146), ('not', 139), ('be', 137), ('is', 136), ('his', 134), ('with', 134), ('s', 117), ('what', 116), ('but', 114), ('it', 104), ('we', 98), ('will', 98), ('have', 97), ('all', 96), ('he', 93), ('as', 93), ('him', 92), ('now', 90), ('o', 85), ('thee', 79), ('shall', 78), ('then', 77), ('ll', 77), ('come', 76), ('your', 74), ('so', 72), ('are', 70), ('do', 67), ('thy', 66), ('see', 60), ('hell', 58), ('no', 54), ('on', 54), ('or', 51), ('may', 50), ('our', 48), ('soul', 48), ('if', 47), ('from', 46), ('an', 45), ('at', 44), ('by', 44), ('mephistophilis', 43), ('us', 42), ('these', 42), ('let', 42), ('am', 41), ('tell', 41), ('ay', 40), ('art', 39), ('was', 38), ('how', 38), ('they', 38), ('here', 37), ('sir', 36), ('make', 35), ('them', 35), ('into', 35), ('there', 34), ('go', 33), ('heaven', 33), ('where', 32), ('world', 32), ('lucifer', 32), ('lord', 31), ('doctor', 30), ('why', 30), ('god', 30), ('hath', 30), ('horse', 30), ('must', 29), ('some', 29), ('their', 29), ('would', 29), ('had', 29), ('can', 28), ('such', 28), ('devil', 28), ('take', 28), ('good', 27), ('upon', 27), ('more', 27), ('again', 27), ('one', 27), ('emperor', 26)]\n\nMost common Faustus words: [('the', 1060), ('and', 962), ('to', 728), ('of', 662), ('i', 623), ('you', 558), ('a', 525), ('my', 516), ('hamlet', 458), ('in', 434), ('it', 420), ('that', 405), ('is', 357), ('not', 314), ('this', 300), ('his', 295), ('d', 285), ('with', 266), ('but', 263), ('for', 252), ('your', 242), ('s', 235), ('me', 235), ('he', 231), ('as', 227), ('be', 222), ('lord', 221), ('what', 218), ('so', 198), ('king', 197), ('him', 194), ('have', 183), ('will', 170), ('do', 161), ('o', 155), ('we', 152), ('horatio', 150), ('no', 142), ('on', 136), ('are', 130), ('our', 119), ('if', 117), ('by', 117), ('all', 116), ('queen', 116), ('or', 114), ('shall', 114), ('good', 110), ('thou', 107), ('let', 105), ('come', 104), ('polonius', 104), ('laertes', 102), ('they', 98), ('now', 96), ('more', 96), ('there', 95), ('from', 95), ('t', 95), ('her', 91), ('how', 88), ('at', 86), ('was', 86), ('thy', 86), ('ophelia', 85), ('like', 84), ('most', 82), ('would', 81), ('know', 78), ('ll', 78), ('well', 77), ('sir', 75), ('tis', 74), ('them', 74), ('enter', 72), ('us', 71), ('may', 71), ('father', 70), ('go', 70), ('love', 68), ('rosencrantz', 68), ('did', 66), ('very', 66), ('hath', 64), ('speak', 63), ('then', 63), ('which', 63), ('why', 62), ('here', 62), ('first', 61), ('must', 60), ('give', 59), ('thee', 58), ('such', 58), ('their', 58), ('upon', 57), ('where', 57), ('man', 57), ('make', 56), ('th', 56)]\n\nMost common John Carter words: [('the', 4530), ('of', 2527), ('and', 2287), ('i', 1877), ('to', 1668), ('a', 1259), ('my', 951), ('in', 935), ('was', 822), ('that', 759), ('as', 725), ('me', 669), ('had', 659), ('with', 563), ('for', 526), ('it', 491), ('but', 436), ('which', 429), ('upon', 428), ('from', 419), ('his', 417), ('he', 381), ('her', 375), ('not', 374), ('you', 365), ('were', 337), ('at', 329), ('we', 317), ('they', 306), ('she', 293), ('by', 291), ('have', 274), ('their', 264), ('is', 261), ('on', 254), ('one', 254), ('this', 224), ('be', 216), ('would', 213), ('could', 208), ('so', 202), ('an', 197), ('all', 195), ('them', 193), ('him', 180), ('or', 176), ('dejah', 172), ('thoris', 172), ('than', 170), ('are', 170), ('no', 169), ('great', 161), ('been', 160), ('our', 158), ('before', 146), ('there', 144), ('then', 143), ('into', 140), ('other', 133), ('when', 131), ('who', 128), ('us', 128), ('your', 127), ('only', 121), ('toward', 121), ('sola', 121), ('little', 117), ('warriors', 117), ('did', 114), ('martian', 110), ('some', 107), ('out', 107), ('helium', 107), ('green', 105), ('two', 102), ('men', 100), ('these', 99), ('now', 98), ('about', 97), ('first', 97), ('s', 95), ('tars', 94), ('tarkas', 94), ('city', 92), ('after', 91), ('through', 91), ('what', 90), ('time', 89), ('more', 88), ('feet', 88), ('do', 87), ('where', 86), ('up', 85), ('man', 84), ('until', 81), ('over', 81), ('without', 80), ('down', 78), ('barsoom', 77), ('know', 76)]\n"
]
],
[
[
"**Exercise.**\nThe code below uses `import collections` instead of `from collections import Counter`.\nAs you can test for yourself, the code now produces various errors.\nFix the code so that the cell runs correctly.\nYou must not change the `import` statement.",
"_____no_output_____"
]
],
[
[
"import collections\n\n# construct the counters\ncounts_hamlet = Counter(hamlet)\ncounts_faustus = Counter(faustus)\ncounts_mars = Counter(mars)\n\nprint(\"Most common Hamlet words:\", Counter.most_common(counts_hamlet, 100))\nprint()\nprint(\"Most common Faustus words:\", Counter.most_common(counts_faustus, 100))\nprint()\nprint(\"Most common John Carter words:\", Counter.most_common(counts_mars, 100))",
"_____no_output_____"
]
],
[
[
"Python's output for `Counter.most_common` doesn't look too bad, but it is a bit convoluted.\nWe can use the function `pprint` from the `pprint` library to have each word on its own line.\nThe name *pprint* is short for *pretty-print*.",
"_____no_output_____"
]
],
[
[
"from pprint import pprint # we want to use pprint instead of pprint.pprint\nfrom collections import Counter\n\n# construct the counters\ncounts_hamlet = Counter(hamlet)\ncounts_faustus = Counter(faustus)\ncounts_mars = Counter(mars)\n\n# we have to split lines now because pprint cannot take multiple arguments like print\nprint(\"Most common Hamlet words:\")\npprint(Counter.most_common(counts_hamlet, 100))\nprint()\nprint(\"Most common Faustus words:\")\npprint(Counter.most_common(counts_faustus, 100))\nprint()\nprint(\"Most common John Carter words:\")\npprint(Counter.most_common(counts_mars, 100))",
"_____no_output_____"
]
],
[
[
"**Exercise.**\nWhat is the difference between the following two pieces of code?\nHow do they differ in their output, and why?",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\ncounts = Counter(hamlet[:50])\nprint(counts)",
"Counter({'in': 4, 'the': 4, 'of': 4, 'where': 2, 'nor': 2, 'not': 1, 'marching': 1, 'fields': 1, 'thrasymene': 1, 'mars': 1, 'did': 1, 'mate': 1, 'warlike': 1, 'carthagens': 1, 'sporting': 1, 'dalliance': 1, 'love': 1, 'courts': 1, 'kings': 1, 'state': 1, 'is': 1, 'overturn': 1, 'd': 1, 'pomp': 1, 'proud': 1, 'audacious': 1, 'deeds': 1, 'intends': 1, 'our': 1, 'muse': 1, 'to': 1, 'vaunt': 1, 'her': 1, 'heavenly': 1, 'verse': 1, 'only': 1, 'this': 1, 'gentles': 1, 'we': 1})\n"
],
[
"from collections import Counter\n\ncount = Counter(hamlet)\nprint(Counter.most_common(count, 50))",
"[('and', 509), ('the', 501), ('i', 400), ('of', 338), ('to', 333), ('that', 226), ('a', 212), ('in', 189), ('me', 187), ('faustus', 181), ('you', 176), ('my', 169), ('for', 161), ('thou', 154), ('d', 152), ('this', 146), ('not', 139), ('be', 137), ('is', 136), ('his', 134), ('with', 134), ('s', 117), ('what', 116), ('but', 114), ('it', 104), ('we', 98), ('will', 98), ('have', 97), ('all', 96), ('he', 93), ('as', 93), ('him', 92), ('now', 90), ('o', 85), ('thee', 79), ('shall', 78), ('then', 77), ('ll', 77), ('come', 76), ('your', 74), ('so', 72), ('are', 70), ('do', 67), ('thy', 66), ('see', 60), ('hell', 58), ('no', 54), ('on', 54), ('or', 51), ('may', 50)]\n"
]
],
[
[
"## A problem\n\nIf you look at the lists of 100 most common words for each text, you'll notice that they are fairly similar.\nFor instance, all of them have *a*, *the*, and *to* among the most frequent ones.\nThat's not a peculiarity of these few texts, it's a general property of English texts.\nThis is because of **Zipf's law**: ranking words by their frequency, the n-th word will have a relative frequency of 1/n.\nSo the most common word is twice as frequent as the second most common one, three times more frequent than the third most common one, and so on.\nAs a result, a handful of words make up over 50% of all words in a text.\n\nZipf's law means that word frequencies in a text give rise to a peculiar shape that we might call the Zipf dinosaur.\n\n\nA super-high neck, followed by a very long tail.\nFor English texts, the distribution usually resembles the one below, and that's even though this graph only shows the most common words.\n\n\n",
"_____no_output_____"
]
],
[
[
"from IPython.display import HTML\n\n# Youtube\nHTML('<iframe width=\"560\" height=\"315\" src=\"https://www.youtube.com/embed/fCn8zs912OE\" frameborder=\"0\" allowfullscreen></iframe>')\n",
"_____no_output_____"
]
],
[
[
"There is precious little variation between English texts with respect to which words are at the top.\nThese common but uninformative words are called **stop words**.\nIf we want to find any interesting differences between *Hamlet*, *Doctor Faustus*, and *Princess of Mars*, we have to filter out all these stop words.\nThat's not something we can do by hand, but our existing box of tricks doesn't really seem to fit either.\nWe could use a regular expression to delete all these words from the string before it even gets tokenized.\nBut that's not the best solution:\n\n1. A minor mistake in the regular expression might accidentally delete many things we want to keep.\n Odds are that this erroneous deletion would go unnoticed, possibly invalidating our stylistic analysis.\n1. There's hundreds of stop words, so the regular expression would be very long.\n Ideally, our code should be compact and easy to read.\n A super-long regular expression is the opposite of that, and it's no fun to type either.\n And of course, the longer a regular expression, the higher the chance that you make a typo (which takes us back to point 1).\n1. While regular expressions are fast, they are not as fast as most of the operations Python can perform on lists and counters.\n If there is an easy alternative to a regular expression, that alternative is worth exploring.\n\nAlright, so if regexes aren't the best solution, what's the alternative?\nWhy, it's simple: 0.",
"_____no_output_____"
],
[
"## Changing counts\n\nThe values in a Python counter can be changed very easily.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\nfrom pprint import pprint\n\n# define a test counter and show its values\ntest = Counter([\"John\", \"said\", \"that\", \"Mary\", \"said\", \"that\", \"Bill\", \"stinks\"])\npprint(test)\n\n# 'that' is a stop word; set its count to 0\ntest[\"that\"] = 0\npprint(test)",
"Counter({'said': 2, 'that': 2, 'John': 1, 'Mary': 1, 'Bill': 1, 'stinks': 1})\nCounter({'said': 2, 'John': 1, 'Mary': 1, 'Bill': 1, 'stinks': 1, 'that': 0})\n"
]
],
[
[
"The code above uses the new notation `test['that']`.\n\nCounters are a subclass of dictionaries, so `test[\"that\"]` points to the value for `\"that\"` in the counter `test`.\nWe also say that `\"that\"` is a **key** that points to a specific **value**.\nThe line\n\n```python\ntest[\"that\"] = 0\n```\n\nintstructs Python to set the value for the key `\"that\"` to `0`.",
"_____no_output_____"
],
[
"**Exercise.**\nLook at the code cell below.\nFor each line, add a comment that briefly describes what it does (for instance, *set value of 'that' to 0*).\nIf the line causes an error, fix the error and add two commments:\n\n1. What caused the error?\n1. What does the corrected line do?\n\nYou might want to use `pprint` to look at how the counter changes after each line.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\n# define a test counter and show its values\ntest = Counter([\"John\", \"said\", \"that\", \"Mary\", \"said\", \"that\", \"Bill\", \"stinks\"])\n\ntest[\"that\"] = 0 # set value of 'that' to 0\ntest[\"Mary\"] = test[\"that\"]\ntest[John] = 10\ntest[\"said\"] = test[\"John' - 'said\"]\ntest[\"really\"] = 0",
"_____no_output_____"
]
],
[
[
"Since we can change the values of keys in counters, stop words become very easy to deal with.\nRecall that the problem with stop words is not so much that they occur in the counter, but that they make up the large majority of high frequency words.\nOur intended fix was to delete them from the counter.\nBut instead, we can just set the count of each stop word to 0.\nThen every stop word is still technically contained by the counter, but since its frequency is 0 it will no longer show up among the most common words, which is what we really care about.\n\nAlright, let's do that.",
"_____no_output_____"
],
[
"**Exercise.**\nTogether with this notebook you found a figure which shows you the most common stop words of English (except for *whale*, you can ignore that one).\nExtend the code below so that the count for each one of the stop words listed in the figure is set to 0.\nCompare the output before and after stop word removal and ask yourself whether there has been significant progress.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\n# construct the counters\ncounts_hamlet = Counter(hamlet)\n# output with stop words\nprint(\"Most common Hamlet words before clean-up:\\n\", Counter.most_common(counts_hamlet, 25))\n\n# set stop word counts to 0\n# put your code here\n\n# output without stop words\nprint(\"Most common Hamlet words after clean-up:\\n\", Counter.most_common(counts_hamlet, 25))",
"_____no_output_____"
]
],
[
[
"Okay, this is an improvement, but it's really tedious.\nYou have to write the same code over and over again, changing only the key.\nAnd you aren't even done yet, there's still many more stop words to be removed.\nBut don't despair, you don't have to add another 100 lines of code.\nNo, repetitive tasks like that are exactly why programming languages have **`for` loops**.",
"_____no_output_____"
],
[
"With a `for`-loop, setting the counts of stop words to 0 becomes a matter of just a few lines.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\n# construct the counters\ncounts_hamlet = Counter(hamlet)\ncounts_faustus = Counter(faustus)\ncounts_mars = Counter(mars)\n\nstopwords = [\"the\", \"of\", \"and\", \"a\", \"to\", \"in\",\n \"that\", \"his\", \"it\", \"he\", \"but\", \"as\",\n \"is\", \"with\", \"was\", \"for\", \"all\", \"this\",\n \"at\", \"while\", \"by\", \"not\", \"from\", \"him\",\n \"so\", \"be\", \"one\", \"you\", \"there\", \"now\",\n \"had\", \"have\", \"or\", \"were\", \"they\", \"which\",\n \"like\"]\n\nfor word in stopwords:\n counts_hamlet[word] = 0\n counts_faustus[word] = 0\n counts_mars[word] = 0",
"_____no_output_____"
]
],
[
[
"Okay, now we can finally compare the three texts based on their unigram counts.\nYou can use the `Counter.most_common` function to see which words are most common in each text.\nWe can also compare the overall frequency distribution.\nThe code below will plot the counters, giving you a graphical representation of the frequency distribution, similar to the Zipf figures above.\n\n(Don't worry about what any of the code below does.\nJust run the cell and look at the pretty output.)",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\n# import relevant matplotlib code\nimport matplotlib.pyplot as plt\n\n# figsize(20, 10)\nplt.figure(figsize=(20,10))\n# the lines above are needed for Jupyter to display the plots in your browser\n# do not remove them\n\n# a little bit of preprocessing so that the data is ordered by frequency\ndef plot_preprocess(the_counter, n):\n \"\"\"format data for plotting n most common items\"\"\"\n sorted_list = sorted(the_counter.items(), key=lambda x: x[1], reverse=True)[:n]\n words, counts = zip(*sorted_list)\n return words, counts\n\n\nfor text in [counts_hamlet, counts_faustus, counts_mars]:\n # you can change the max words value to look at more or fewer words in one plot\n max_words = 10\n words = plot_preprocess(text, max_words)[0]\n counts = plot_preprocess(text, max_words)[1]\n plt.bar(range(len(counts)), counts, align=\"center\")\n plt.xticks(range(len(words)), words)\n plt.show()",
"_____no_output_____"
]
],
[
[
"So there you have it.\nYour first, fairly simple quantitative analysis of writing style.\nYou can compare the three texts among several dimensions:\n\n1. What are the most common words in each text?\n1. Are the distributions very different?\n Perhaps one of them keeps repeating the same words over and over, whereas another author varies their vocabulary more and thus has a smoother curve that's not as much tilted towards the left?\n ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd0543632ca6fb38b515f2ea081a8827840f774
| 129,585 |
ipynb
|
Jupyter Notebook
|
doc/example/petab_import.ipynb
|
LarsFroehling/pyPESTO
|
f9f4a526c0f34cda2c2670b7d61d4f9872a8e368
|
[
"BSD-3-Clause"
] | null | null | null |
doc/example/petab_import.ipynb
|
LarsFroehling/pyPESTO
|
f9f4a526c0f34cda2c2670b7d61d4f9872a8e368
|
[
"BSD-3-Clause"
] | null | null | null |
doc/example/petab_import.ipynb
|
LarsFroehling/pyPESTO
|
f9f4a526c0f34cda2c2670b7d61d4f9872a8e368
|
[
"BSD-3-Clause"
] | null | null | null | 220.382653 | 82,900 | 0.910676 |
[
[
[
"# Model import using the Petab format",
"_____no_output_____"
],
[
"In this notebook, we illustrate how to use [pyPESTO](https://github.com/icb-dcm/pypesto.git) together with [PEtab](https://github.com/petab-dev/petab.git) and [AMICI](https://github.com/icb-dcm/amici.git). We employ models from the [benchmark collection](https://github.com/benchmarking-initiative/benchmark-models-petab), which we first download:",
"_____no_output_____"
]
],
[
[
"import pypesto\nimport amici\nimport petab\n\nimport os\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n%matplotlib inline\n\n!git clone --depth 1 https://github.com/Benchmarking-Initiative/Benchmark-Models-PEtab.git tmp/benchmark-models || (cd tmp/benchmark-models && git pull)\n\nfolder_base = \"tmp/benchmark-models/Benchmark-Models/\"",
"fatal: destination path 'tmp/benchmark-models' already exists and is not an empty directory.\nAlready up to date.\n"
]
],
[
[
"## Import",
"_____no_output_____"
],
[
"### Manage PEtab model",
"_____no_output_____"
],
[
"A PEtab problem comprises all the information on the model, the data and the parameters to perform parameter estimation. We import a model as a `petab.Problem`.",
"_____no_output_____"
]
],
[
[
"# a collection of models that can be simulated\n\n#model_name = \"Zheng_PNAS2012\"\nmodel_name = \"Boehm_JProteomeRes2014\"\n#model_name = \"Fujita_SciSignal2010\"\n#model_name = \"Sneyd_PNAS2002\"\n#model_name = \"Borghans_BiophysChem1997\"\n#model_name = \"Elowitz_Nature2000\"\n#model_name = \"Crauste_CellSystems2017\"\n#model_name = \"Lucarelli_CellSystems2018\"\n#model_name = \"Schwen_PONE2014\"\n#model_name = \"Blasi_CellSystems2016\"\n\n# the yaml configuration file links to all needed files\nyaml_config = os.path.join(folder_base, model_name, model_name + '.yaml')\n\n# create a petab problem\npetab_problem = petab.Problem.from_yaml(yaml_config)",
"_____no_output_____"
]
],
[
[
"### Import model to AMICI",
"_____no_output_____"
],
[
"The model must be imported to pyPESTO and AMICI. Therefore, we create a `pypesto.PetabImporter` from the problem, and create an AMICI model.",
"_____no_output_____"
]
],
[
[
"importer = pypesto.PetabImporter(petab_problem)\n\nmodel = importer.create_model()\n\n# some model properties\nprint(\"Model parameters:\", list(model.getParameterIds()), '\\n')\nprint(\"Model const parameters:\", list(model.getFixedParameterIds()), '\\n')\nprint(\"Model outputs: \", list(model.getObservableIds()), '\\n')\nprint(\"Model states: \", list(model.getStateIds()), '\\n')",
"Model parameters: ['Epo_degradation_BaF3', 'k_exp_hetero', 'k_exp_homo', 'k_imp_hetero', 'k_imp_homo', 'k_phos', 'ratio', 'specC17', 'noiseParameter1_pSTAT5A_rel', 'noiseParameter1_pSTAT5B_rel', 'noiseParameter1_rSTAT5A_rel'] \n\nModel const parameters: [] \n\nModel outputs: ['pSTAT5A_rel', 'pSTAT5B_rel', 'rSTAT5A_rel'] \n\nModel states: ['STAT5A', 'STAT5B', 'pApB', 'pApA', 'pBpB', 'nucpApA', 'nucpApB', 'nucpBpB'] \n\n"
]
],
[
[
"### Create objective function",
"_____no_output_____"
],
[
"To perform parameter estimation, we need to define an objective function, which integrates the model, data, and noise model defined in the PEtab problem.",
"_____no_output_____"
]
],
[
[
"import libsbml\nconverter_config = libsbml.SBMLLocalParameterConverter()\\\n .getDefaultProperties()\npetab_problem.sbml_document.convert(converter_config)\n\nobj = importer.create_objective()\n\n# for some models, hyperparamters need to be adjusted\n#obj.amici_solver.setMaxSteps(10000)\n#obj.amici_solver.setRelativeTolerance(1e-7)\n#obj.amici_solver.setAbsoluteTolerance(1e-7)",
"_____no_output_____"
]
],
[
[
"We can request variable derivatives via `sensi_orders`, or function values or residuals as specified via `mode`. Passing `return_dict`, we obtain the direct result of the AMICI simulation.",
"_____no_output_____"
]
],
[
[
"ret = obj(petab_problem.x_nominal_scaled, mode='mode_fun', sensi_orders=(0,1), return_dict=True)\nprint(ret)",
"{'fval': 138.22199677513575, 'grad': array([ 2.20386015e-02, 5.53227506e-02, 5.78886452e-03, 5.40656415e-03,\n -4.51595809e-05, 7.91163446e-03, 0.00000000e+00, 1.07840959e-02,\n 2.40378735e-02, 1.91919657e-02, 0.00000000e+00]), 'hess': array([[ 2.11105595e+03, 5.89390039e-01, 1.07159910e+02,\n 2.81393973e+03, 8.94333861e-06, -7.86055092e+02,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 5.89390039e-01, 1.91513744e-03, -1.72774945e-01,\n 7.12558479e-01, -3.69774927e-08, -3.20531692e-01,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 1.07159910e+02, -1.72774945e-01, 6.99839693e+01,\n 1.61497679e+02, 7.16323554e-06, -8.83572656e+01,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 2.81393973e+03, 7.12558479e-01, 1.61497679e+02,\n 3.76058352e+03, 8.40044683e-06, -1.04136909e+03,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 8.94333861e-06, -3.69774927e-08, 7.16323554e-06,\n 8.40044683e-06, 2.86438192e-10, -2.24927732e-04,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [-7.86055092e+02, -3.20531692e-01, -8.83572656e+01,\n -1.04136909e+03, -2.24927732e-04, 9.29902113e+02,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00],\n [ 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00, 0.00000000e+00,\n 0.00000000e+00, 0.00000000e+00]]), 'res': array([], dtype=float64), 'sres': array([], shape=(0, 11), dtype=float64), 'rdatas': [<amici.numpy.ReturnDataView object at 0x7f7802f86610>]}\n"
]
],
[
[
"The problem defined in PEtab also defines the fixing of parameters, and parameter bounds. This information is contained in a `pypesto.Problem`.",
"_____no_output_____"
]
],
[
[
"problem = importer.create_problem(obj)",
"_____no_output_____"
]
],
[
[
"In particular, the problem accounts for the fixing of parametes.",
"_____no_output_____"
]
],
[
[
"print(problem.x_fixed_indices, problem.x_free_indices)",
"[6, 10] [0, 1, 2, 3, 4, 5, 7, 8, 9]\n"
]
],
[
[
"The problem creates a copy of he objective function that takes into account the fixed parameters. The objective function is able to calculate function values and derivatives. A finite difference check whether the computed gradient is accurate:",
"_____no_output_____"
]
],
[
[
"objective = problem.objective\nret = objective(petab_problem.x_nominal_free_scaled, sensi_orders=(0,1))\nprint(ret)",
"(138.22199677513575, array([ 2.20386015e-02, 5.53227506e-02, 5.78886452e-03, 5.40656415e-03,\n -4.51595809e-05, 7.91163446e-03, 1.07840959e-02, 2.40378735e-02,\n 1.91919657e-02]))\n"
],
[
"eps = 1e-4\n\ndef fd(x):\n grad = np.zeros_like(x)\n j = 0\n for i, xi in enumerate(x):\n mask = np.zeros_like(x)\n mask[i] += eps\n valinc, _ = objective(x+mask, sensi_orders=(0,1))\n valdec, _ = objective(x-mask, sensi_orders=(0,1))\n grad[j] = (valinc - valdec) / (2*eps)\n j += 1\n return grad\n\nfdval = fd(petab_problem.x_nominal_free_scaled)\nprint(\"fd: \", fdval)\nprint(\"l2 difference: \", np.linalg.norm(ret[1] - fdval))",
"fd: [0.02493368 0.05309659 0.00530587 0.01291083 0.00587754 0.01473653\n 0.01078279 0.02403657 0.01919066]\nl2 difference: 0.012310244824532144\n"
]
],
[
[
"### In short",
"_____no_output_____"
],
[
"All of the previous steps can be shortened by directly creating an importer object and then a problem:",
"_____no_output_____"
]
],
[
[
"importer = pypesto.PetabImporter.from_yaml(yaml_config)\nproblem = importer.create_problem()",
"_____no_output_____"
]
],
[
[
"## Run optimization",
"_____no_output_____"
],
[
"Given the problem, we can perform optimization. We can specify an optimizer to use, and a parallelization engine to speed things up.",
"_____no_output_____"
]
],
[
[
"optimizer = pypesto.ScipyOptimizer()\n\n# engine = pypesto.SingleCoreEngine()\nengine = pypesto.MultiProcessEngine()\n\n# do the optimization\nresult = pypesto.minimize(problem=problem, optimizer=optimizer,\n n_starts=10, engine=engine)",
"Engine set up to use up to 4 processes in total. The number was automatically determined and might not be appropriate on some systems.\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 38.1195 and h = 5.55541e-06, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 38.119511:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 88.9211 and h = 2.14177e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 88.921131:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 88.9211 and h = 2.14177e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 88.921131:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 88.9211 and h = 2.14177e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 88.921131:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 145.551 and h = 1.32433e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 145.550813:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 145.551 and h = 1.32433e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 145.550813:\nAMICI failed to integrate the forward problem\n\n[Warning] AMICI:CVODES:CVode:ERR_FAILURE: AMICI ERROR: in module CVODES in function CVode : At t = 145.551 and h = 1.32433e-05, the error test failed repeatedly or with |h| = hmin. \n[Warning] AMICI:simulation: AMICI forward simulation failed at t = 145.550813:\nAMICI failed to integrate the forward problem\n\n"
]
],
[
[
"## Visualize",
"_____no_output_____"
],
[
"The results are contained in a `pypesto.Result` object. It contains e.g. the optimal function values.",
"_____no_output_____"
]
],
[
[
"result.optimize_result.get_for_key('fval')",
"_____no_output_____"
]
],
[
[
"We can use the standard pyPESTO plotting routines to visualize and analyze the results.",
"_____no_output_____"
]
],
[
[
"import pypesto.visualize\n\nref = pypesto.visualize.create_references(x=petab_problem.x_nominal_scaled, fval=obj(petab_problem.x_nominal_scaled))\n\npypesto.visualize.waterfall(result, reference=ref, scale_y='lin')\npypesto.visualize.parameters(result, reference=ref)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd073d55967b516cce03d8dbeb17e93633548ef
| 77,353 |
ipynb
|
Jupyter Notebook
|
deep_learning_TensorFlow.ipynb
|
AlyssonBatista/Codigos-python
|
41f9d96245cf6063f0e50f6f52cacca04feae31c
|
[
"MIT"
] | null | null | null |
deep_learning_TensorFlow.ipynb
|
AlyssonBatista/Codigos-python
|
41f9d96245cf6063f0e50f6f52cacca04feae31c
|
[
"MIT"
] | null | null | null |
deep_learning_TensorFlow.ipynb
|
AlyssonBatista/Codigos-python
|
41f9d96245cf6063f0e50f6f52cacca04feae31c
|
[
"MIT"
] | null | null | null | 230.217262 | 57,477 | 0.883586 |
[
[
[
"<a href=\"https://colab.research.google.com/github/AlyssonBatista/Codigos-python/blob/main/deep_learning_TensorFlow.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Curso de Deep Learning com TensorFlow",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nfrom tensorflow import keras",
"_____no_output_____"
],
[
"# uma camada de entrada \nmodel = keras.Sequential([keras.layers.Dense(units=1,input_shape=[1])]) #units é a quantida de neurônios e imput shape é o formato dos dados de entrada\nmodel.compile(optimizer='sgd',loss='mean_squared_error')\n\nxs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)\nys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)# y = (2 * x) - 1\n\nmodel.fit(xs,ys,epochs=600)\n\nprint(model.predict([10.0]))",
"_____no_output_____"
]
],
[
[
"## Classificação de imagens \n",
"_____no_output_____"
]
],
[
[
"# TensorFlow e tf.keras\nimport tensorflow as tf\nfrom tensorflow import keras\n\n# Librariesauxiliares\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nprint(tf.__version__)\n\n'''\nLabel\tClasse\n0\tCamisetas/Top (T-shirt/top)\n1\tCalça (Trouser)\n2\tSuéter (Pullover)\n3\tVestidos (Dress)\n4\tCasaco (Coat)\n5\tSandálias (Sandal)\n6\tCamisas (Shirt)\n7\tTênis (Sneaker)\n8\tBolsa (Bag)\n9\tBotas (Ankle boot)\n'''\n\n\ndef main():\n fashion_mnist = keras.datasets.fashion_mnist\n (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\n\n print(train_images.shape)\n print(len(train_labels))\n print(train_labels)\n print(test_images.shape)\n print(len(test_labels))\n class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']\n\n plt.figure()\n plt.imshow(train_images[0])\n plt.colorbar()\n plt.grid(False)\n plt.show()\n\n train_images = train_images / 255.0\n test_images = test_images / 255.0\n plt.figure(figsize=(10, 10))\n for i in range(25):\n plt.subplot(5, 5, i + 1)\n plt.xticks([])\n plt.yticks([])\n plt.grid(False)\n plt.imshow(train_images[i], cmap=plt.cm.binary)\n plt.xlabel(class_names[train_labels[i]])\n plt.show()\n\n\nif __name__ == \"__main__\":\n main()",
"2.8.0\n(60000, 28, 28)\n60000\n[9 0 0 ... 3 0 5]\n(10000, 28, 28)\n10000\n"
],
[
"import keras\n\n\ndef main():\n fashion_mnist = keras.datasets.fashion_mnist\n (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()\n print(train_images)\n print(train_labels)\n print(test_images)\n print(test_labels)\n\n\nif __name__ == \"__main__\":\n main()",
"[[[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n ...\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]]\n[9 0 0 ... 3 0 5]\n[[[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n ...\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]\n\n [[0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n ...\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]\n [0 0 0 ... 0 0 0]]]\n[9 2 1 ... 8 1 5]\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd083a76db107332f033fd8768f1fee3c165492
| 9,022 |
ipynb
|
Jupyter Notebook
|
notebooks/basics/pytorch_intro/main.ipynb
|
AIMed-Team/edu-content
|
d5d274ee2a04c60b5099d1e361c9189f7fda2314
|
[
"MIT"
] | null | null | null |
notebooks/basics/pytorch_intro/main.ipynb
|
AIMed-Team/edu-content
|
d5d274ee2a04c60b5099d1e361c9189f7fda2314
|
[
"MIT"
] | null | null | null |
notebooks/basics/pytorch_intro/main.ipynb
|
AIMed-Team/edu-content
|
d5d274ee2a04c60b5099d1e361c9189f7fda2314
|
[
"MIT"
] | null | null | null | 30.173913 | 762 | 0.598759 |
[
[
[
"import numpy as np\nimport torch\nfrom torch import nn\nfrom torch.nn import functional as F\nfrom torchvision import transforms, datasets",
"_____no_output_____"
]
],
[
[
"**NOTE**: it is recommended to watch [this link](https://drive.google.com/file/d/1jARX0gjNZwpkcMloOnE8HmngIYDQ6sIB/view?usp=sharing) about \"Intoduction of how to code in Pytorch\" instructed by Rassa Ghavami beforehand.",
"_____no_output_____"
],
[
"### What is Tensor?\ntensor is mostly same as numpy array (even its applications like broadcasting operation, indexing, slicing and etc), except for it brings us the opportunity to run operations on faster hardwares like GPU. let's see some tensor defintion",
"_____no_output_____"
]
],
[
[
"arr = torch.zeros((256, 256), dtype=torch.int32)\n\n# tensors are defined by default at CPU\nprint(arr.device)\n\n# keep 'size', 'dtype' and 'device' same as arr, but fill with 1\narr2 = torch.ones_like(arr)\n\n# keep 'dtype' and 'device' same as arr, but fill data arbitrarily\narr3 = arr.new_tensor([[1, 2], [3, 4]])",
"_____no_output_____"
]
],
[
[
"in order to feed tensors to deep-learning models, they should follow a customary shape form; `B C H W` for 4D tensors where `B` is batch size, `C` is channel dimension and `H W` are spatial dimensions.",
"_____no_output_____"
],
[
"#### Device determination\nfirst we need to determine which device all torch tensors (including the input, learning weights and etc) are going to be allocated. basically, GPU is the first priority.",
"_____no_output_____"
]
],
[
[
"device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')",
"_____no_output_____"
]
],
[
[
"#### Pseudo random generation\nit is often recommended to generate **pseudo** random numbers as it provides fair comparison between different configs of deep learning model(s). torch provides this by `torch.manual_seed`.",
"_____no_output_____"
]
],
[
[
"np.random.seed(12345)\n\n# same seed on all devices; both CPU and CUDA\ntorch.manual_seed(12345)",
"_____no_output_____"
]
],
[
[
"## Build a CNN model\nfrom now on, you will learn how to build and train a CNN model.\n\npytorch models are defined as python classes inherited from `torch.nn.Module`. two functions are essential for model creation:\n1. learning weights (parameters) and network layers are defined within `__init__()`.\n2. forwarding procedure of the model is developed within `forward()`.\n\nso let's create a multi-classification CNN model (with ten ground-truth labels) containing the following layers: `Conv` -> `ReLU` -> `Batchnorm` -> `Conv` -> `ReLU` -> `Batchnorm` -> `Adaptive average pooling` -> `dropout` -> `fully connected`. suppose the input has only one channel and `forward()` will only return output of the model.",
"_____no_output_____"
]
],
[
[
"class Model(nn.Module):\n \n def __init__(self):\n super().__init__()\n # your code here\n\n def forward(self, x: torch.Tensor) -> torch.Tensor:\n # your code here \n \n return x",
"_____no_output_____"
]
],
[
[
"#### set model device\nPreviously, we have determined which device (GPU or CPU) is going to be used, although it has not been allocated yet to parameters of the model. Pytorch `.to(device)` Api provides this for us.",
"_____no_output_____"
]
],
[
[
"model = Model()\n\nmodel.to(device)",
"_____no_output_____"
]
],
[
[
"#### Model phases\nthere are two phases for a Pytorch model: `.train()` and `.eval()`. models are by default at `.train()` phase, however the difference between these two is that in `eval()` phase, some layers change their behavior during inference; for instance dropout will be deactivated and batch normalization will not update estimated mean and variance and they will be used only for normalization, hence please note **`.eval()` will not block parameters to be updated**. therefore during evaluation, besides `model.eval()` we should assure that back propagation is temporarily deactivated and this is possible by `torch.no_grad()`. indeed disabling the gradient calculation enables us to use bigger batch sizes as it speeds up the computation and reduces memory usage.",
"_____no_output_____"
],
[
"## Data processing\nBefore training, we need to prepare and process our dataset which is MNIST here.",
"_____no_output_____"
],
[
"#### Data transformation\nPIL images should first be transformed to torch tensors. `torchvision.transforms.Compose` provides a pipeline of transforms. in the following 'converting to tensors' is only applied.",
"_____no_output_____"
]
],
[
[
"transform = transforms.Compose([\n transforms.ToTensor()\n])",
"_____no_output_____"
]
],
[
[
"#### Download data\nas evaluation is not purpose of this notebook, you only need to load **train** set of MNIST dataset using `torchvision.datasets.MNIST`.",
"_____no_output_____"
]
],
[
[
"# your code here\ntrain = None",
"_____no_output_____"
]
],
[
[
"#### Data loader\ndefine train loader using `torch.utils.data.DataLoader`.",
"_____no_output_____"
]
],
[
[
"batch_size = 32\n\n# your code here\ntrain_loader = None",
"_____no_output_____"
]
],
[
[
"## Training\nhere we are going to develop training process of MNIST classification.",
"_____no_output_____"
],
[
"#### Optimizer\ndefine your optimizer, use `torch.optim`.",
"_____no_output_____"
]
],
[
[
"# your code here\noptimizer = None",
"_____no_output_____"
]
],
[
[
"#### Procedure\nimplement the procedure of training in the following cell. please note **evaluation is not purpose of this notebook**, therefore only report the training loss changes which ought to be descending in general. consider cross entropy as loss function and compute it without using pre-defined APIs. \nthe backpropagation consists of three sub-parts: \n1. gradient computation\n2. updating learning parameters\n3. removing current computed gradients for next iteration\n\nfortunately we don't need to implement them from sctrach as pytorch provides APIs for them.",
"_____no_output_____"
]
],
[
[
"num_epochs = 3\nnum_iters = len(train_loader)\ntrain_losses = np.zeros((num_epochs, num_iters), dtype=np.float32) \n\nfor epoch in range(num_epochs):\n for it, (X, y) in enumerate(train_loader):\n ## forward model\n \n ## compute loss\n \n ## backpropagation",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd08ba4bf0ea1e8ff6fc14170a68e74dc27f598
| 97,385 |
ipynb
|
Jupyter Notebook
|
eda_notebooks/top_charts_eda.ipynb
|
daphne-yang/spotify-visualizations
|
0932aa467526a1c83755d692473db5737c0dcff3
|
[
"MIT"
] | null | null | null |
eda_notebooks/top_charts_eda.ipynb
|
daphne-yang/spotify-visualizations
|
0932aa467526a1c83755d692473db5737c0dcff3
|
[
"MIT"
] | null | null | null |
eda_notebooks/top_charts_eda.ipynb
|
daphne-yang/spotify-visualizations
|
0932aa467526a1c83755d692473db5737c0dcff3
|
[
"MIT"
] | null | null | null | 71.501468 | 13,502 | 0.462864 |
[
[
[
"# Top Charts Exploratory Data Analysis",
"_____no_output_____"
],
[
"## Loading Dependencies",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom collections import Counter\nimport altair as alt\nimport nltk\nimport regex as re",
"_____no_output_____"
]
],
[
[
"## Loading in Data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('cleaned_data/all_top_songs_with_genres_nolist.csv')\n# preview of dataframe\ndf.head()",
"_____no_output_____"
]
],
[
[
"## Cleaning Up List of Genres",
"_____no_output_____"
]
],
[
[
"# cleaning up the genres column on copy of dataframe\ndf_ = df.copy()\ndf_['genre'] = df_['genre'].str.split(\", \")\n",
"_____no_output_____"
],
[
"# add all values to a list to generate a unique list of values\ngenres_list = []\nfor idx, value in enumerate(df_['genre']):\n genres_list.extend(value)",
"_____no_output_____"
]
],
[
[
"### Adding in Columns for genres",
"_____no_output_____"
]
],
[
[
"df_['pop'] = df.genre.str.contains('pop')==True\ndf_['rb'] = df.genre.str.contains('r-b')==True\ndf_['rap'] = df.genre.str.contains('rap')==True\ndf_['rock'] = df.genre.str.contains('rock')==True\ndf_['non-music'] = df.genre.str.contains('non-music')==True\ndf_['country'] = df.genre.str.contains('country')==True\ndf_['no_genre'] = df.genre.str.contains('m')==True",
"_____no_output_____"
],
[
"df_['pop'] = df_['pop'].astype(int)\ndf_['rb'] = df_['rb'].astype(int)\ndf_['rap'] = df_['rap'].astype(int)\ndf_['rock'] = df_['rock'].astype(int)\ndf_['non-music'] = df_['non-music'].astype(int)\ndf_['country'] = df_['country'].astype(int)\ndf_['no_genre'] = df_['no_genre'].astype(int)\ndf_.head()",
"_____no_output_____"
],
[
"### Saving to CSV\ndf_.to_csv('cleaned_data/OHE_all_top_songs.csv', index=False)",
"_____no_output_____"
],
[
"df_[df_['non-music'] == 1]['artist']",
"_____no_output_____"
],
[
"# drop non-music and bc they are all either having another genre or missing a genre\ndf_ = df_.drop(columns=['non-music'])",
"_____no_output_____"
],
[
"missing_genres = []\nfor i in range(len(df_.artist)):\n if sum(df_.iloc[i,6:11]) > 0:\n item = 0\n missing_genres.append(item)\n else:\n item = 1\n missing_genres.append(item)",
"_____no_output_____"
],
[
"df_['no_genre'] = missing_genres",
"_____no_output_____"
]
],
[
[
"## Visualizations",
"_____no_output_____"
]
],
[
[
"genre_frequencies = dict(Counter(genres_list))\ngenre_frequencies",
"_____no_output_____"
],
[
"genre_frequencies_df = pd.DataFrame.from_records([genre_frequencies])\ngenre_frequencies_df = genre_frequencies_df.rename(index={0:'counts'}).T.reset_index().rename(columns={'index':'genres'})\ngenre_frequencies_df = genre_frequencies_df[genre_frequencies_df['genres'].isin(['r-b', 'pop', 'rap', 'rock', 'country'])]\ngenre_frequencies_df.to_csv('cleaned_data/genre_song_counts.csv', index = False)",
"_____no_output_____"
],
[
"bars = alt.Chart(data=genre_frequencies_df).mark_bar().encode(\nx= 'genres',\ny = 'counts',\ncolor = 'genres'\n)\ntext = bars.mark_text(\n align='center',\n # baseline='top',\n dy=-10 \n).encode(\n text='counts:Q',\n)\n\n(bars + text).properties(height=500, width = 400,title = \"Frequency of Genres on Top 200 Charts\").configure_range(\n category={'scheme': 'tableau10'}\n)",
"_____no_output_____"
]
],
[
[
"There seem to be data that is labeled as non-music which is strange because there shouldn't be any labeled non-music. If there is another genre listed, remove non-music",
"_____no_output_____"
],
[
"# Keyword Extraction of all Genres",
"_____no_output_____"
]
],
[
[
"### Importing More Dependencies\nfrom resources.word_extraction.text_cleaning import lem_stem_text\nfrom resources.word_extraction.stopwords import remove_stopw, get_stopwords\nfrom resources.analyze import find_keywords, find_instances",
"_____no_output_____"
],
[
"df_['cleaned_lyrics'] = df_['lyrics'].str.replace('[^\\w\\s]','')\ndf_['cleaned_lyrics'] = df_['cleaned_lyrics'].str.replace('missing lyrics','')\ndf_['cleaned_lyrics'] = df_['cleaned_lyrics'].apply(remove_stopw)\ndf_['cleaned_lyrics'] = df_['cleaned_lyrics'].apply(lem_stem_text)\ndf_['cleaned_lyrics'] = df_.cleaned_lyrics.str.strip().str.split(' ')",
"_____no_output_____"
],
[
"df_",
"_____no_output_____"
],
[
"## getting a list of all lemmed and stemmed keywords without stopwords\nlyrics_wordlist = df_['cleaned_lyrics'].tolist()\nwords_list = []\nfor i in lyrics_wordlist:\n words_list.extend(i)\nlen(words_list)",
"_____no_output_____"
],
[
"# Creating a DataFrame of the Word Counts\nlyric_word_frequencies = pd.DataFrame.from_dict(Counter(words_list), orient = 'index').reset_index()\nlyric_word_frequencies = lyric_word_frequencies.rename(columns={'index':'word', 0:'count'})\nlyric_word_frequencies = lyric_word_frequencies.sort_values(by = \"count\", ascending = False)\nlyric_word_frequencies",
"_____no_output_____"
],
[
"lyric_word_frequencies.head(20)",
"_____no_output_____"
],
[
"lyric_word_frequencies.to_csv('cleaned_data/lyric_word_frequencies.csv', index = False)",
"_____no_output_____"
],
[
"top_100 = lyric_word_frequencies[:100]\ntop_100",
"_____no_output_____"
]
],
[
[
"## Top Words by Genre",
"_____no_output_____"
]
],
[
[
"pd.Series(genres_list).unique()",
"_____no_output_____"
],
[
"pop = df_[df_['pop'] == 1]\nrb = df_[df_['rb'] == 1]\nrap = df_[df_['rap'] == 1]\nrock = df_[df_['rock'] == 1]\ncountry = df_[df_['country'] == 1]\nm = df_[df_['no_genre'] == 1]",
"_____no_output_____"
],
[
"def top_lyrics(df, dfname):\n '''Function to find the top lyric unigrams based on a df containing lyrics'''\n ## getting a list of all lemmed and stemmed keywords without stopwords\n lyrics_wordlist = df['cleaned_lyrics'].tolist()\n words_list = []\n for i in lyrics_wordlist:\n words_list.extend(i)\n len(words_list)\n # Creating a DataFrame of the Word Counts\n lyric_word_frequencies = pd.DataFrame.from_dict(Counter(words_list), orient = 'index').reset_index()\n lyric_word_frequencies = lyric_word_frequencies.rename(columns={'index':'word', 0:'count'})\n lyric_word_frequencies = lyric_word_frequencies.sort_values(by = \"count\", ascending = False)\n lyric_word_frequencies['genre'] = dfname\n return lyric_word_frequencies",
"_____no_output_____"
],
[
"rb_lyrics = top_lyrics(rb, 'r-b')[:15]\nrb_lyrics",
"_____no_output_____"
],
[
"pop_lyrics = top_lyrics(pop, 'pop')[:15]",
"_____no_output_____"
],
[
"country_lyrics = top_lyrics(country, 'country')[:15]",
"_____no_output_____"
],
[
"rock_lyrics = top_lyrics(rock, 'rock')[:15]",
"_____no_output_____"
],
[
"rap_lyrics = top_lyrics(rap, 'rap')[:15]",
"_____no_output_____"
],
[
"full_lyrics = pd.concat([pop_lyrics,country_lyrics,rock_lyrics,rap_lyrics,rb_lyrics])\nfull_lyrics",
"_____no_output_____"
],
[
"full_lyrics.to_csv('cleaned_data/lyric_frequencies/top15_all_genres_lyric_frequencies.csv', index = False)",
"_____no_output_____"
]
],
[
[
"## Top Songs By Genre ",
"_____no_output_____"
],
[
"I forgot to get the top songs by genre streams so I am re importing the top 200 files and the previously created OHE (one-hot-encoded) df to create a new df with the streams",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"## OTHER MISC DATA CLEANING \ndf1 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2017_weekly_all_locations_top200.csv')\ndf2 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2018_weekly_all_locations_top200.csv')\ndf3 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2019_weekly_all_locations_top200.csv')\ndf4 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2020_weekly_all_locations_top200.csv')\ndf = pd.concat([df1, df2, df3, df4])\ndf['streams'] = df['streams'].str.replace(\",\", '').astype(int)\nglobal_df = df[df['country_chart'].str.contains(\"Global\")]\nglobal_df_total = global_df.groupby([\"track\", 'spotify_link']).sum().reset_index()\nlyrics_df = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/OHE_all_top_songs.csv')\nmerged_df = pd.merge(lyrics_df, global_df_total, \"inner\", on = \"track\")\nmerged_df = merged_df.rename(columns={'streams': \"total_streams\"})\nmerged_df",
"_____no_output_____"
],
[
"pop = merged_df[merged_df['pop'] == 1][['track', 'artist', 'total_streams', 'spotify_link']].reset_index(drop=True).sort_values(by=['total_streams'], ascending = False)[:11]\npop['genre'] = 'pop'\nrb = merged_df[merged_df['rb'] == 1][['track', 'artist', 'total_streams', 'spotify_link']].reset_index(drop=True).sort_values(by=['total_streams'], ascending = False)[:11]\nrb['genre'] = 'r-b'\nrap = merged_df[merged_df['rap'] == 1][['track', 'artist', 'total_streams', 'spotify_link']].reset_index(drop=True).sort_values(by=['total_streams'], ascending = False)[:13]\nrap['genre'] = 'rap'\nrock = merged_df[merged_df['rock'] == 1][['track', 'artist', 'total_streams', 'spotify_link']].reset_index(drop=True).sort_values(by=['total_streams'], ascending = False)[:13]\nrock['genre'] = 'rock'\ncountry = merged_df[merged_df['country'] == 1][['track', 'artist', 'total_streams', 'spotify_link']].reset_index(drop=True).sort_values(by=['total_streams'], ascending = False)[:12]\ncountry['genre'] = 'country'\ndf_output = pd.concat([pop, rb, rap, rock, country])",
"_____no_output_____"
],
[
"df_output",
"_____no_output_____"
],
[
"df_output.iloc[59][3]",
"_____no_output_____"
],
[
"# Change all links to embed links\ndf_output.to_csv('../cleaned_data/top10_by_genre_all_time.csv', index = False)",
"_____no_output_____"
]
],
[
[
"### Creating All Topic Songs With Years ",
"_____no_output_____"
]
],
[
[
"import pandas as pd \n\ndf1 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2017_weekly_all_locations_top200.csv')\ndf1['year'] = '2017'\ndf2 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2018_weekly_all_locations_top200.csv')\ndf2['year'] = '2018'\ndf3 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2019_weekly_all_locations_top200.csv')\ndf3['year'] = '2019'\ndf4 = pd.read_csv('/Users/daphneyang/Desktop/5YMIDS_SP21/w209/spotify-visualizations/cleaned_data/2020_weekly_all_locations_top200.csv')\ndf4['year'] = '2020'",
"_____no_output_____"
],
[
"df = pd.concat([df1, df2, df3, df4])\n\nall_locations_df_max = df.groupby([\"track\", 'artist','country_chart', 'year']).max().reset_index()[['track','artist',\"year\", 'streams', \"country_chart\",'spotify_link']]\n\nall_locations_df_max",
"_____no_output_____"
],
[
"all_locations_df_max.to_csv(\"cleaned_data/2017_2020_all_locations_max_streams.csv\", index = False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd0903cca08d3e1b81ce5aa5549495f7ff8aa8e
| 104,016 |
ipynb
|
Jupyter Notebook
|
tutorials/quickstart.ipynb
|
tempoCollaboration/OQuPy
|
a389a161991a59259e5df47d8e0f405fcac75fe5
|
[
"Apache-2.0"
] | 13 |
2022-02-15T12:33:17.000Z
|
2022-03-31T10:01:57.000Z
|
tutorials/quickstart.ipynb
|
tempoCollaboration/OQuPy
|
a389a161991a59259e5df47d8e0f405fcac75fe5
|
[
"Apache-2.0"
] | 11 |
2022-02-16T07:35:46.000Z
|
2022-03-24T18:22:12.000Z
|
tutorials/quickstart.ipynb
|
tempoCollaboration/OQuPy
|
a389a161991a59259e5df47d8e0f405fcac75fe5
|
[
"Apache-2.0"
] | 2 |
2022-02-17T01:23:55.000Z
|
2022-02-17T08:51:57.000Z
| 133.525032 | 14,156 | 0.872837 |
[
[
[
"# Quickstart\nA quick introduction on how to use the OQuPy package to compute the dynamics of a quantum system that is possibly strongly coupled to a structured environment. We illustrate this by applying the TEMPO method to the strongly coupled spin boson model.",
"_____no_output_____"
],
[
"**Contents:**\n\n* Example - The spin boson model\n * 1. The model and its parameters\n * 2. Create system, correlations and bath objects\n * 3. TEMPO computation",
"_____no_output_____"
],
[
"First, let's import OQuPy and some other packages we are going to use",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.insert(0,'..')\n\nimport oqupy\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"and check what version of tempo we are using.",
"_____no_output_____"
]
],
[
[
"oqupy.__version__",
"_____no_output_____"
]
],
[
[
"Let's also import some shorthands for the spin Pauli operators and density matrices.",
"_____no_output_____"
]
],
[
[
"sigma_x = oqupy.operators.sigma(\"x\")\nsigma_y = oqupy.operators.sigma(\"y\")\nsigma_z = oqupy.operators.sigma(\"z\")\nup_density_matrix = oqupy.operators.spin_dm(\"z+\")\ndown_density_matrix = oqupy.operators.spin_dm(\"z-\")",
"_____no_output_____"
]
],
[
[
"-------------------------------------------------\n## Example - The spin boson model\nAs a first example let's try to reconstruct one of the lines in figure 2a of [Strathearn2018] ([Nat. Comm. 9, 3322 (2018)](https://doi.org/10.1038/s41467-018-05617-3) / [arXiv:1711.09641v3](https://arxiv.org/abs/1711.09641)). In this example we compute the time evolution of a spin which is strongly coupled to an ohmic bath (spin-boson model). Before we go through this step by step below, let's have a brief look at the script that will do the job - just to have an idea where we are going:",
"_____no_output_____"
]
],
[
[
"Omega = 1.0\nomega_cutoff = 5.0\nalpha = 0.3\n\nsystem = oqupy.System(0.5 * Omega * sigma_x)\ncorrelations = oqupy.PowerLawSD(alpha=alpha,\n zeta=1,\n cutoff=omega_cutoff,\n cutoff_type='exponential')\nbath = oqupy.Bath(0.5 * sigma_z, correlations)\ntempo_parameters = oqupy.TempoParameters(dt=0.1, dkmax=30, epsrel=10**(-4))\n\ndynamics = oqupy.tempo_compute(system=system,\n bath=bath,\n initial_state=up_density_matrix,\n start_time=0.0,\n end_time=15.0,\n parameters=tempo_parameters)\nt, s_z = dynamics.expectations(0.5*sigma_z, real=True)\n\nplt.plot(t, s_z, label=r'$\\alpha=0.3$')\nplt.xlabel(r'$t\\,\\Omega$')\nplt.ylabel(r'$<S_z>$')\nplt.legend()",
"--> TEMPO computation:\n100.0% 150 of 150 [########################################] 00:00:14\nElapsed time: 14.9s\n"
]
],
[
[
"### 1. The model and its parameters \nWe consider a system Hamiltonian\n$$ H_{S} = \\frac{\\Omega}{2} \\hat{\\sigma}_x \\mathrm{,}$$\na bath Hamiltonian\n$$ H_{B} = \\sum_k \\omega_k \\hat{b}^\\dagger_k \\hat{b}_k \\mathrm{,}$$\nand an interaction Hamiltonian\n$$ H_{I} = \\frac{1}{2} \\hat{\\sigma}_z \\sum_k \\left( g_k \\hat{b}^\\dagger_k + g^*_k \\hat{b}_k \\right) \\mathrm{,}$$\nwhere $\\hat{\\sigma}_i$ are the Pauli operators, and the $g_k$ and $\\omega_k$ are such that the spectral density $J(\\omega)$ is\n$$ J(\\omega) = \\sum_k |g_k|^2 \\delta(\\omega - \\omega_k) = 2 \\, \\alpha \\, \\omega \\, \\exp\\left(-\\frac{\\omega}{\\omega_\\mathrm{cutoff}}\\right) \\mathrm{.} $$\nAlso, let's assume the initial density matrix of the spin is the up state\n$$ \\rho(0) = \\begin{pmatrix} 1 & 0 \\\\ 0 & 0 \\end{pmatrix} $$\nand the bath is initially at zero temperature.",
"_____no_output_____"
],
[
"For the numerical simulation it is advisable to choose a characteristic frequency and express all other physical parameters in terms of this frequency. Here, we choose $\\Omega$ for this and write:\n \n* $\\Omega = 1.0 \\Omega$\n* $\\omega_c = 5.0 \\Omega$\n* $\\alpha = 0.3$",
"_____no_output_____"
]
],
[
[
"Omega = 1.0\nomega_cutoff = 5.0\nalpha = 0.3",
"_____no_output_____"
]
],
[
[
"### 2. Create system, correlations and bath objects",
"_____no_output_____"
],
[
"#### System\n$$ H_{S} = \\frac{\\Omega}{2} \\hat{\\sigma}_x \\mathrm{,}$$",
"_____no_output_____"
]
],
[
[
"system = oqupy.System(0.5 * Omega * sigma_x)",
"_____no_output_____"
]
],
[
[
"#### Correlations\n$$ J(\\omega) = 2 \\, \\alpha \\, \\omega \\, \\exp\\left(-\\frac{\\omega}{\\omega_\\mathrm{cutoff}}\\right) $$",
"_____no_output_____"
],
[
"Because the spectral density is of the standard power-law form,\n$$ J(\\omega) = 2 \\alpha \\frac{\\omega^\\zeta}{\\omega_c^{\\zeta-1}} X(\\omega,\\omega_c) $$\nwith $\\zeta=1$ and $X$ of the type ``'exponential'`` we define the spectral density with:",
"_____no_output_____"
]
],
[
[
"correlations = oqupy.PowerLawSD(alpha=alpha,\n zeta=1,\n cutoff=omega_cutoff,\n cutoff_type='exponential')",
"_____no_output_____"
]
],
[
[
"#### Bath\nThe bath couples with the operator $\\frac{1}{2}\\hat{\\sigma}_z$ to the system.",
"_____no_output_____"
]
],
[
[
"bath = oqupy.Bath(0.5 * sigma_z, correlations)",
"_____no_output_____"
]
],
[
[
"### 3. TEMPO computation\nNow, that we have the system and the bath objects ready we can compute the dynamics of the spin starting in the up state, from time $t=0$ to $t=5\\,\\Omega^{-1}$",
"_____no_output_____"
]
],
[
[
"dynamics_1 = oqupy.tempo_compute(system=system,\n bath=bath,\n initial_state=up_density_matrix,\n start_time=0.0,\n end_time=5.0,\n tolerance=0.01)",
"../oqupy/tempo/tempo.py:833: UserWarning: Estimating parameters for TEMPO computation. No guarantee that resulting TEMPO computation converges towards the correct dynamics! Please refer to the TEMPO documentation and check convergence by varying the parameters for TEMPO manually.\n warnings.warn(GUESS_WARNING_MSG, UserWarning)\nWARNING: Estimating parameters for TEMPO computation. No guarantee that resulting TEMPO computation converges towards the correct dynamics! Please refer to the TEMPO documentation and check convergence by varying the parameters for TEMPO manually.\n"
]
],
[
[
"and plot the result:",
"_____no_output_____"
]
],
[
[
"t_1, z_1 = dynamics_1.expectations(0.5*sigma_z, real=True)\nplt.plot(t_1, z_1, label=r'$\\alpha=0.3$')\nplt.xlabel(r'$t\\,\\Omega$')\nplt.ylabel(r'$<S_z>$')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"Yay! This looks like the plot in figure 2a [Strathearn2018].",
"_____no_output_____"
],
[
"Let's have a look at the above warning. It said:\n\n```\nWARNING: Estimating parameters for TEMPO calculation. No guarantie that resulting TEMPO calculation converges towards the correct dynamics! Please refere to the TEMPO documentation and check convergence by varying the parameters for TEMPO manually.\n```\nWe got this message because we didn't tell the package what parameters to use for the TEMPO computation, but instead only specified a `tolerance`. The package tries it's best by implicitly calling the function `oqupy.guess_tempo_parameters()` to find parameters that are appropriate for the spectral density and system objects given.",
"_____no_output_____"
],
[
"#### TEMPO Parameters",
"_____no_output_____"
],
[
"There are **three key parameters** to a TEMPO computation:\n\n* `dt` - Length of a time step $\\delta t$ - It should be small enough such that a trotterisation between the system Hamiltonian and the environment it valid, and the environment auto-correlation function is reasonably well sampled.\n \n* `dkmax` - Number of time steps $K \\in \\mathbb{N}$ - It must be large enough such that $\\delta t \\times K$ is larger than the neccessary memory time $\\tau_\\mathrm{cut}$.\n\n* `epsrel` - The maximal relative error $\\epsilon_\\mathrm{rel}$ in the singular value truncation - It must be small enough such that the numerical compression (using tensor network algorithms) does not truncate relevant correlations.",
"_____no_output_____"
],
[
"To choose the right set of initial parameters, we recommend to first use the `oqupy.guess_tempo_parameters()` function and then check with the helper function `oqupy.helpers.plot_correlations_with_parameters()` whether it satisfies the above requirements:",
"_____no_output_____"
]
],
[
[
"parameters = oqupy.guess_tempo_parameters(system=system,\n bath=bath,\n start_time=0.0,\n end_time=5.0,\n tolerance=0.01)\nprint(parameters)",
"../oqupy/tempo/tempo.py:833: UserWarning: Estimating parameters for TEMPO computation. No guarantee that resulting TEMPO computation converges towards the correct dynamics! Please refer to the TEMPO documentation and check convergence by varying the parameters for TEMPO manually.\n warnings.warn(GUESS_WARNING_MSG, UserWarning)\nWARNING: Estimating parameters for TEMPO computation. No guarantee that resulting TEMPO computation converges towards the correct dynamics! Please refer to the TEMPO documentation and check convergence by varying the parameters for TEMPO manually.\n"
],
[
"fig, ax = plt.subplots(1,1)\noqupy.helpers.plot_correlations_with_parameters(bath.correlations, parameters, ax=ax)",
"_____no_output_____"
]
],
[
[
"In this plot you see the real and imaginary part of the environments auto-correlation as a function of the delay time $\\tau$ and the sampling of it corresponding the the chosen parameters. The spacing and the number of sampling points is given by `dt` and `dkmax` respectively. We can see that the auto-correlation function is close to zero for delay times larger than approx $2 \\Omega^{-1}$ and that the sampling points follow the curve reasonably well. Thus this is a reasonable set of parameters.",
"_____no_output_____"
],
[
"We can choose a set of parameters by hand and bundle them into a `TempoParameters` object,",
"_____no_output_____"
]
],
[
[
"tempo_parameters = oqupy.TempoParameters(dt=0.1, dkmax=30, epsrel=10**(-4), name=\"my rough parameters\")\nprint(tempo_parameters)",
"----------------------------------------------\nTempoParameters object: my rough parameters\n __no_description__\n dt = 0.1 \n dkmax = 30 \n epsrel = 0.0001 \n add_correlation_time = None \n\n"
]
],
[
[
"and check again with the helper function:",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(1,1)\noqupy.helpers.plot_correlations_with_parameters(bath.correlations, tempo_parameters, ax=ax)",
"_____no_output_____"
]
],
[
[
"We could feed this object into the `oqupy.tempo_compute()` function to get the dynamics of the system. However, instead of that, we can split up the work that `oqupy.tempo_compute()` does into several steps, which allows us to resume a computation to get later system dynamics without having to start over. For this we start with creating a `Tempo` object:",
"_____no_output_____"
]
],
[
[
"tempo = oqupy.Tempo(system=system,\n bath=bath,\n parameters=tempo_parameters,\n initial_state=up_density_matrix,\n start_time=0.0)",
"_____no_output_____"
]
],
[
[
"We can start by computing the dynamics up to time $5.0\\,\\Omega^{-1}$,",
"_____no_output_____"
]
],
[
[
"tempo.compute(end_time=5.0)",
"--> TEMPO computation:\n100.0% 50 of 50 [########################################] 00:00:03\nElapsed time: 3.4s\n"
]
],
[
[
"then get and plot the dynamics of expecatation values,",
"_____no_output_____"
]
],
[
[
"dynamics_2 = tempo.get_dynamics()\nplt.plot(*dynamics_2.expectations(0.5*sigma_z, real=True), label=r'$\\alpha=0.3$')\nplt.xlabel(r'$t\\,\\Omega$')\nplt.ylabel(r'$<S_z>$')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"then continue the computation to $15.0\\,\\Omega^{-1}$,",
"_____no_output_____"
]
],
[
[
"tempo.compute(end_time=15.0)",
"--> TEMPO computation:\n100.0% 100 of 100 [########################################] 00:00:12\nElapsed time: 12.8s\n"
]
],
[
[
"and then again get and plot the dynamics of expecatation values.",
"_____no_output_____"
]
],
[
[
"dynamics_2 = tempo.get_dynamics()\nplt.plot(*dynamics_2.expectations(0.5*sigma_z, real=True), label=r'$\\alpha=0.3$')\nplt.xlabel(r'$t\\,\\Omega$')\nplt.ylabel(r'$<S_z>$')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"Finally, we note: to validate the accuracy the result **it vital to check the convergence of such a simulation by varying all three computational parameters!** For this we recommend repeating the same simulation with slightly \"better\" parameters (smaller `dt`, larger `dkmax`, smaller `epsrel`) and to consider the difference of the result as an estimate of the upper bound of the accuracy of the simulation.",
"_____no_output_____"
],
[
"-------------------------------------------------",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd095be9c734df26b353b5f10cfa9e92d8476b0
| 672,345 |
ipynb
|
Jupyter Notebook
|
data_crawler & data/.ipynb_checkpoints/WordCloudTextAnalysis-checkpoint.ipynb
|
wewewexiao2008/Oxford-Group-Project
|
0cbc1d9abd99f6e9cb309545e9279fd115a8d86a
|
[
"MIT"
] | null | null | null |
data_crawler & data/.ipynb_checkpoints/WordCloudTextAnalysis-checkpoint.ipynb
|
wewewexiao2008/Oxford-Group-Project
|
0cbc1d9abd99f6e9cb309545e9279fd115a8d86a
|
[
"MIT"
] | null | null | null |
data_crawler & data/.ipynb_checkpoints/WordCloudTextAnalysis-checkpoint.ipynb
|
wewewexiao2008/Oxford-Group-Project
|
0cbc1d9abd99f6e9cb309545e9279fd115a8d86a
|
[
"MIT"
] | null | null | null | 1,769.328947 | 195,120 | 0.95873 |
[
[
[
"import jieba\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom wordcloud import (WordCloud, get_single_color_func,STOPWORDS)\nimport re",
"_____no_output_____"
],
[
"class SimpleGroupedColorFunc(object):\n \"\"\"Create a color function object which assigns EXACT colors\n to certain words based on the color to words mapping\n \"\"\"\n\n def __init__(self, color_to_words, default_color):\n self.word_to_color = {word: color\n for (color, words) in color_to_words.items()\n for word in words}\n\n self.default_color = default_color\n\n def __call__(self, word, **kwargs):\n return self.word_to_color.get(word, self.default_color)\n\n\nclass GroupedColorFunc(object):\n \"\"\"Create a color function object which assigns DIFFERENT SHADES of\n specified colors to certain words based on the color to words mapping.\n Uses wordcloud.get_single_color_func\n \"\"\"\n\n def __init__(self, color_to_words, default_color):\n self.color_func_to_words = [\n (get_single_color_func(color), set(words))\n for (color, words) in color_to_words.items()]\n\n self.default_color_func = get_single_color_func(default_color)\n\n def get_color_func(self, word):\n \"\"\"Returns a single_color_func associated with the word\"\"\"\n try:\n color_func = next(\n color_func for (color_func, words) in self.color_func_to_words\n if word in words)\n except StopIteration:\n color_func = self.default_color_func\n\n return color_func\n\n def __call__(self, word, **kwargs):\n return self.get_color_func(word)(word, **kwargs)\n \n",
"_____no_output_____"
],
[
"def content_preprocess(csv):\n# preprocess: extract comment content\n df = pd.read_csv(csv)\n preprocessed_data = df[['评论']]\n# Index and columns are not saved\n preprocessed_data.to_csv('content4wordcloud.csv',header = 0,index = 0)\n\ncontent_preprocess('douban_comment.csv')\n# content_preprocess('douban_comment.csv')\n\ndef word_cloud_creation(filename):\n '''create word cloud and split the words'''\n text = open(filename, encoding = 'utf-8', errors = 'ignore').read()\n word_list = jieba.cut(text, cut_all = True)\n wl = ' '.join(word_list)\n return wl\n\nstoptext1 = open('stopword.txt',encoding='utf-8').read()\nstopwords = stoptext1.split('\\n')\nstoptext2 = open('stopword2.txt',encoding='utf-8').read()\nstopwords = stopwords+stoptext2.split('\\n')\nstopwords = stopwords+['一部','这部','看过','真的','感觉','一种']\n\n\ndef word_cloud_setting():\n wc = WordCloud(max_words=500, collocations = False,repeat = True,background_color='white',scale=1.5, stopwords=stopwords,height = 1080, width = 1920, font_path = 'C:\\Windows\\Fonts\\simsun.ttc')\n return wc\n\ndef word_cloud_implementation(wl,wc):\n '''Generate word cloud and display'''\n my_words = wc.generate(wl)\n plt.imshow(my_words)\n plt.axis('off')\n wc.to_file('word_cloud.png')\n plt.show()\n\n\nwl = word_cloud_creation('content4wordcloud.csv')\nwc = word_cloud_setting()\n\n\nword_cloud_implementation(wl,wc)\n",
"_____no_output_____"
],
[
"# This Part: Emphasize what's most focused and professional\ncolor_to_words = {\n # words below will be colored with a single color function\n# focus on the film itself\n 'red': ['电影', '导演', '故事', '剧情', '配乐', '剧本', '表演','角色','镜头', '音乐','主角','观众','片子'],\n# talk about something else or feeling/attitude\n 'green': ['真的', '感觉','精彩','感动','喜欢','特别','人生', '世界', '生活','人性','经典']\n}\n\n# Words that are not in any of the color_to_words values\n# will be colored with a grey single color function\ndefault_color = 'grey'\n\n# Create a color function with single tone\n# grouped_color_func = SimpleGroupedColorFunc(color_to_words, default_color)\n\n# Create a color function with multiple tones\ngrouped_color_func = GroupedColorFunc(color_to_words, default_color)\n\n# Apply our color function\nwc.recolor(color_func=grouped_color_func)\nwc.to_file('word_cloud_emphasized.png')\nplt.figure()\nplt.imshow(wc, interpolation=\"bilinear\")\nplt.axis(\"off\")\nplt.show()",
"_____no_output_____"
],
[
"df = pd.read_csv('imdb_movie_review_info.csv')\npreprocessed_data = df[['userReview']]\npreprocessed_data",
"_____no_output_____"
],
[
"\ndef content_preprocess(csv):\n# preprocess: extract comment content\n df = pd.read_csv(csv)\n preprocessed_data = df[['userReview']]\n# Index and columns are not saved\n preprocessed_data.to_csv('content4wordcloud.csv',header = 0,index = 0)\n\ncontent_preprocess('imdb_movie_review_info.csv')\n# content_preprocess('douban_comment.csv')\n\ndef word_cloud_creation(filename):\n '''create word cloud and split the words'''\n text = open(filename, encoding = 'utf-8', errors = 'ignore').read()\n# word_list = jieba.cut(text, cut_all = True)\n wl = ''.join(text)\n wl = re.sub('<.*?>','',wl)\n wl = re.sub('the','',wl)\n# wl = re.sub('this')\n return wl\n\nstoptext1 = open('stopword.txt',encoding='utf-8').read()\nstopwords = stoptext1.split('\\n')\nstoptext2 = open('stopword2.txt',encoding='utf-8').read()\nstopwords = stopwords+stoptext2.split('\\n')\nstopwords = stopwords+['wa','a','i','time','make','watch']\n\n\ndef word_cloud_setting():\n# stopwords = ['当然','所以','另外','不过','so','that','what','me','to','so','of','it','and','the','in','you','but','will','with','但是','最后','还有']\n wc = WordCloud(max_words=500, collocations = False,repeat = True,background_color='white',scale=1.5, stopwords=stopwords,height = 1080, width = 1920, font_path = 'C:\\Windows\\Fonts\\simsun.ttc')\n return wc\n\ndef word_cloud_implementation(wl,wc):\n '''Generate word cloud and display'''\n my_words = wc.generate(wl)\n plt.imshow(my_words)\n plt.axis('off')\n wc.to_file('word_cloud_imdb.png')\n plt.show()\n\n\nwl = word_cloud_creation('content4wordcloud.csv')\nwc = word_cloud_setting()\n\n\nword_cloud_implementation(wl,wc)\n",
"_____no_output_____"
],
[
"# This Part: Emphasize what's most focused and professional\ncolor_to_words = {\n # words below will be colored with a single color function\n 'red': ['movie', 'film', 'character', 'performance', 'story', 'shot','actor','scene', 'director','plot','acting'],\n# talk about something else or feeling/attitude\n 'green': ['life', 'people','good','like','bad','love', 'great', 'feel','world','excellent','perfect','real','classic']\n}\n\n# Words that are not in any of the color_to_words values\n# will be colored with a grey single color function\ndefault_color = 'grey'\n\n# Create a color function with multiple tones\ngrouped_color_func = GroupedColorFunc(color_to_words, default_color)\n\n# Apply our color function\nwc.recolor(color_func=grouped_color_func)\nwc.to_file('word_cloud_emphasized_imdb.png')\nplt.figure()\nplt.imshow(wc, interpolation=\"bilinear\")\nplt.axis(\"off\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"In this part, we will find out what people tend to talk about in the movie reviews on douban and imdb separately. We're doing this by WordCloud which is a fascinating approach for us to figure out what's frequently occurs in people's reviews. By WordCloud, the most frequent words would be larger than other words. We can instantly see what we should pay attention to. Here is the two wordclouds figures of the reviews of each top250 movies on imdb and douban. We chose the top100 rated reviews which are basically positive. They can tell us what on earth people love about the movies. \n\nOf course, stopwords list must be added to filter out some meaningless words for example, 'the', 'than', 'that'. \n\nI noticed that people on douban may be customed to make a comment that is more based on self-feelings and experience, while people on imdb tend to talk about the movie itself. To see this feature more clearly, I have marked the words concerned about the movies **red** and the words about self experience and emotional feelings **green**. Basically, red words are more objective and green words are more subjective.\n\nSo I chose these words:\n\nIndeed, if you take a closer look, you will find that many comments on douban are more likely to talk about world, life, and whether they like the movie, which makes the clouds greener. However, imdb users tend to talk about performance, character, scenes.(red) I can't help wondering if this suggest that Chinese people and English-speaking world have a difference in thinking pattern or way of describing a thing. We Chinese like to focus on ourselves' life and feeling while the English-speaking community may prefer start from something about the movies. \n\nWell, this could also be the result of the difference in grammar. But I figure that this might not be the main reason.\n\nMoreover, Chinese seldom use simple words like '赞,棒great' to directly express their feelings('好good' is in the stopwords, 'like' as well), though they start with something that's not closely related to the movies.(world, life) We prefer to say a movie is '感人touching', or '真实close to reality' if we think they are very good. On the other hand, imdb users describe a movie with 'excellent', 'perfect'. They use these words as the highest praise.\n\nFor further research on reviews, my teammate Haoyun has done some research on prediction about genres by reviews.\n\n\n\ndouban:\n\n 'red': '电影', '导演', '故事', '剧情', '配乐', '剧本', '表演','角色','镜头', '音乐','主角','观众','片子'\n \n meaning: movie, director, story, plot, soundtrack, script, performance, character, shot, music, main character, audience, film(another)\n \n 'green': '真的', '感觉','精彩','感动','喜欢','特别','人生', '世界', '生活','人性','经典','现实'\n \n meaning: really, feel, excellent, touching, like, special(particularly), life, world, living(daily), humanity, classic, reality\n \nimdb:\n \n 'red': 'movie', 'film', 'character', 'performance', 'story', 'shot','actor','scene', 'director','plot','acting'\n \n 'green': 'life', 'people','good','like','bad','love', 'great', 'feel','world','excellent','perfect','real'",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
cbd0ae61a1193a1186c7b0f77271b7bbbc6011aa
| 43,539 |
ipynb
|
Jupyter Notebook
|
11_ltpy_atmospheric_composition_overview.ipynb
|
federicofierli1/LTPy_Notebooks_satellite_copernicus
|
7b8f3b2a9bea335d982f01bb686679b37f9a3c49
|
[
"MIT"
] | 4 |
2020-09-05T19:57:55.000Z
|
2021-04-22T16:08:17.000Z
|
11_ltpy_atmospheric_composition_overview.ipynb
|
federicofierli1/LTPy_Notebooks_satellite_copernicus
|
7b8f3b2a9bea335d982f01bb686679b37f9a3c49
|
[
"MIT"
] | null | null | null |
11_ltpy_atmospheric_composition_overview.ipynb
|
federicofierli1/LTPy_Notebooks_satellite_copernicus
|
7b8f3b2a9bea335d982f01bb686679b37f9a3c49
|
[
"MIT"
] | null | null | null | 40.728718 | 579 | 0.640828 |
[
[
[
"<img src='./img/EU-Copernicus-EUM_3Logos.png' alt='Logo EU Copernicus EUMETSAT' align='right' width='50%'></img>\n<br>",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"<a href=\"./index_ltpy.ipynb\"><< Index</a><span style=\"float:right;\"><a href=\"./12_ltpy_WEkEO_harmonized_data_access_api.ipynb\">12 - WEkEO Harmonized Data Access API >></a></span>",
"_____no_output_____"
],
[
"# 1.1 Atmospheric composition data - Overview and data access",
"_____no_output_____"
],
[
"This module gives an overview of the following atmospheric composition data services:\n* [EUMETSAT AC SAF - The EUMETSAT Satellite Application Facility on Atmospheric Composition Monitoring](#ac_saf)\n* [Copernicus Sentinel-5 Precursor (Sentinel-5P)](#sentinel_5p)\n* [Copernicus Sentinel-3](#sentinel3)\n* [Copernicus Atmosphere Monitoring Service (CAMS)](#cams)",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"## <a id=\"ac_saf\"></a>EUMETSAT AC SAF - The EUMETSAT Satellite Application Facility on Atmospheric Composition Monitoring",
"_____no_output_____"
],
[
"<span style=float:left><img src='./img/ac_saf_logo.png' alt='Logo EU Copernicus EUMETSAT' align='left' width='90%'></img></span>\n\nThe [EUMETSAT Satellite Application Facility on Atmospheric Composition Monitoring (EUMETSAT AC SAF)](http://acsaf.org/) is one of eight EUMETSAT Satellite Application Facilities (SAFs). <br>\n\nSAFs generate and disseminate operational EUMETSAT products and services and are an integral part of the distributed EUMETSAT Application Ground Segment. \n\nAC SAF processes data on ozone, other trace gases, aerosols and ultraviolet data, obtained from satellite instrumentation.",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### Available AC SAF products",
"_____no_output_____"
],
[
"AC-SAF offers three different product types: <br>\n\n|<font size='+0.2'><center>[Near real-time products](#nrt)</center></font> | <font size='+0.2'><center>[Offline products](#offline)</center></font> | <font size='+0.2'><center>[Data records](#records)</center></font> |\n|-----|-----|------|\n<img src='./img/nrt_no2_example.png' alt='Near-real time product - NO2' align='middle' width='60%'></img>|<img src='./img/offline_ozone_example.png' alt='Logo EU Copernicus EUMETSAT' align='middle' width='60%'></img>|<img src='./img/ac_saf_level3.png' alt='Logo EU Copernicus EUMETSAT' align='middle' width='100%'></img>|\n\n<br>\nNear real-time and offline products are often refered as Level 2 data. Data records are refered as Level 3 data. \n\nAC SAF products are sensed from two instruments onboard the Metop satellites:\n* [Global Ozone Monitoring Experiment-2 (GOME-2) instrument](https://acsaf.org/gome-2.html) <br>\nGOME-2 can measure a range of atmospheric trace constituents, with the emphasis on global ozone distributions. Furthermore, cloud properties and intensities of ultraviolet radiation are retrieved. These data are crucial for monitoring the atmospheric composition and the detection of pollutants. <br>\n\n* [Infrared Atmospheric Sounding Interferometer (IASI) instrument](https://acsaf.org/iasi.html)\n\nThe [Metop satellites](https://acsaf.org/metop.html) is a series of three satellites that were launched in October 2006 (Metop-A), September 2012 (Metop-B) and November 2018 (Metop-C) respectively.\n\nAll AC SAF products are disseminated under the [AC SAF Data policy](https://acsaf.org/data_policy.html).",
"_____no_output_____"
],
[
"<br> ",
"_____no_output_____"
],
[
"#### <a id=\"nrt\"></a>Near-real time (NRT) products",
"_____no_output_____"
],
[
"NRT products are Level 2 products and are available to users in 3 hours from sensing at the latest and available for the past two months. NRT products are disseminated in HDF5 format.\n\n| <img width=100>NRT Product type name</img> | Description | Unit | <img width=80>Satellite</img> | Instrument |\n| ---- | ----- | ----- | ---- | -----|\n| Total Ozone (O<sub>3</sub>) column | NRT total ozone column product provided information about vertical column densities of ozone in the atmosphere | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 |\n| Total and tropospheric NO<sub>2</sub> columns | NRT total and tropospheric NO2 column products provide information about vertical column densities of nitrogen dioxide in the atmosphere. | molecules/cm2 | Metop-A<br>Metop-B | GOME-2 |\n| Total SO<sub>2</sub> column | NRT total SO2 column product provides information about vertical column densities of the sulfur dioxide in the atmosphere. | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 \n| Total HCHO column | NRT HCHO column product provides information about vertical column densities of formaldehyde in the atmosphere. | molecules/cm2 | Metop-A<br>Metop-B | GOME-2 |\n| High-resolution vertical ozone profile | NRT high-resolution vertical ozone profile product provides an ozone profile from the GOME-2 nadir scanning mode. | Partial ozone columns in Dobson Units in 40 layers from the surface up to 0.001 hPa| Metop-A<br>Metop-B | GOME-2 |\n| Global tropospheric ozone column | The global tropospheric ozone column product provides information about vertical column densities of ozone in the troposphere, <br>from the surface to the tropopause and from the surface to 500 hPa (∼5km). | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 |",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"#### <a id=\"offline\"></a>Offline products",
"_____no_output_____"
],
[
"Offline products are Level 2 products and are available to users in 15 days of sensing. Typical delay is 2-3 days. Offline products are disseminated in HDF5 format.\n\n| Offline Product type name | Description | Unit | <img width=80>Satellite</img> | Instrument | <img width=150px>Time period</img> |\n| ---- | ----- | ----- | ---- | -----|----|\n| Total Ozone (O<sub>3</sub>) column | Offline total ozone column product provided information about vertical column densities of ozone in the atmosphere | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |\n| Total and tropospheric NO<sub>2</sub> columns | Offline total and tropospheric NO2 column products provide information about vertical column densities of nitrogen dioxide in the atmosphere. | molecules/cm2 | Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |\n| Total SO<sub>2</sub> column | Offline total SO2 column product provides information about vertical column densities of the sulfur dioxide in the atmosphere. | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |\n| Total HCHO column | Offline HCHO column product provides information about vertical column densities of formaldehyde in the atmosphere. | molecules/cm2 | Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |\n| High-resolution vertical ozone profile | Offline high-resolution vertical ozone profile product provides an ozone profile from the GOME-2 nadir scanning mode. | Partial ozone columns in Dobson Units in 40 layers from the surface up to 0.001 hPa| Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |\n| Global tropospheric ozone column | The offline global tropospheric ozone column product provides information about vertical column densities of ozone in the troposphere, from the surface to the tropopause and and from the surface to 500 hPa (∼5km). | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 | 1 Jan 2008 - almost NRT<br>13 Dec 2012 - almost NRT |",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"#### <a id=\"records\"></a>Data records",
"_____no_output_____"
],
[
"Data records are reprocessed, gridded Level 3 data. Data records are monthly aggregated products, regridded on a regular latitude-longitude grid. Data records are disseminated in NetCDF format.\n\n| Data record name | Description | Unit | <img width=80>Satellite</img> | Instrument | <img width=150>Time period</img> |\n| ---- | ----- | ----- | ---- | -----|----|\n| Reprocessed **tropospheric O<sub>3</sub>** column data record for the Tropics | Tropospheric ozone column data record for the Tropics provides long-term information <br>about vertical densities of ozone in the atmosphere for the tropics. | Dobson Units (DU) | Metop-A<br>Metop-B | GOME-2 | Jan 2007- Dec 2018<br>Jan 2013- Jun 2019 |\n| Reprocessed **total column and tropospheric NO<sub>2</sub>** data record | Total and tropospheric NO2 column data record provides long-term information about vertical column densities of nitrogen dioxide in the atmosphere. | molecules/cm2 | Metop-A<br>Metop-B | GOME-2 | Jan 2007 - Nov 2017<br>Jan 2013 - Nov 2017 |\n| Reprocessed **total H<sub>2</sub>O column** data record | Total H2O column data record provides long-term information about vertical column densities of water vapour in the atmosphere. | kg/m2 | Metop-A<br>Metop-B | GOME-2 | Jan 2007 - Nov 2017<br>Jan 2013 - Nov 2017 |",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id=\"ac_saf_access\"></a>How to access AC SAF products",
"_____no_output_____"
],
[
"AC SAF products can be accessed via different dissemination channels. There are channels where Level 2 and Level 3 are available for download. Other sources allow to browse through images and maps of the data. This is useful to see for what dates e.g. Level 2 data were sensed.",
"_____no_output_____"
],
[
"#### DLR ftp server",
"_____no_output_____"
],
[
"All near-real time, offline and reprocessed total column data are available at [DLR's ATMOS FTP-server](https://atmos.eoc.dlr.de/products/). Accessing data is a two step process:\n1. [Register](https://acsaf.org/registration_form.html) as a user of AC SAF products\n2. [Log in](https://atmos.eoc.dlr.de/products/)( (with the user name and password that is emailed to you after registration)\n\nOnce logged in, you find data folders for GOME-2 products from Metop-A in the directory *'gome2a/'* and GOME-2 products from Metop-B in the directory: *'gome2b/'* respectively. In each GOME-2 directory, you find the following sub-directories: <br> \n* **`near_real_time/`**, \n* **`offline/`**, and\n* **`level3/`**. \n\n<br>\n\n\n<div style='text-align:center;'>\n<figure><img src='./img/dlr_ftp_directory.png' width='50%'/>\n <figcaption><i>Example of the directory structure of DLR's ATMOS FTP-server</i></figcaption>\n</figure>\n</div>\n ",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"#### EUMETSAT Data Centre",
"_____no_output_____"
],
[
"The EUMETSAT Data Centre provides a long-term archive of data and generated products from EUMETSAT, which can be ordered online. Ordering data is a two step process:\n1. [Create an account](https://eoportal.eumetsat.int/userMgmt/register.faces) at the EUMETSAT Earth Observation Portal\n2. [Log in](https://eoportal.eumetsat.int/userMgmt/login.faces) (with the user name and password that is emailed to you after registration)\n\nOnce succesfully logged in, go to (1) Data Centre. You will be re-directed to (2) the User Services Client. Type in *'GOME'* as search term and you can get a list of all available GOME-2 products.",
"_____no_output_____"
],
[
"\n\n<div style='text-align:center;'>\n<figure><img src='./img/eumetsat_data_centre.png' width='50%' />\n <figcaption><i>Example of the directory structure of EUMETSAT's Data Centre</i></figcaption>\n</figure>\n</div>",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"#### Web-based services",
"_____no_output_____"
],
[
"There are two web-based services, [DLR's ATMOS webserver](https://atmos.eoc.dlr.de/app/missions/gome2) and the [TEMIS service by KNMI](http://temis.nl/index.php) that offer access to GOME-2/MetOp browse products. These services are helpful to see the availability of data for specific days, especially for AC SAF Level-2 parameters.",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"| <font size='+0.2'>[DLR's ATMOS webserver](https://atmos.eoc.dlr.de/app/missions/gome2)</font> | <font size='+0.2'>[TEMIS - Tropospheric Emission Monitoring Internet Service](http://temis.nl/index.php)</font> |\n| - | - |\n| <br>ATMOS (Atmospheric ParameTers Measured by in-Orbit Spectrosocopy is a webserver operated by DLR's Remote Sensing Technology Institute (IMF). The webserver provides access to browse products from GOME-2/Metop Products, both in NRT and offline mode. <br><br> | <br>TEMIS is a web-based service to browse and download atmospheric satellite data products maintained by KNMI. The data products consist mainly of tropospheric trace gases and aerosol concentrations, but also UV products, cloud information and surface albedo climatologies are provided. <br><br> |\n| <center><img src='./img/atmos_service.png' width='70%'></img></center> | <center><img src='./img/temis_service.png' width='70%'></img></center> |",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"## <a id=\"sentinel_5p\"></a>Copernicus Sentinel-5 Precursor (Sentinel-5P)",
"_____no_output_____"
],
[
"[Sentinel-5 Precursor (Sentinel-5P)](https://sentinels.copernicus.eu/web/sentinel/missions/sentinel-5p) is the first Copernicus mission dedicated to monitoring our atmosphere. The satellite carries the state-of-the-art TROPOMI instrument to map a multitude of trace gases.\n\nSentinel-5P was developed to reduce data gaps between the ENVISAT satellite - in particular the Sciamachy instrument - and the launch of Sentinel-5, and to complement GOME-2 on MetOp. In the future, both the geostationary Sentinel-4 and polar-orbiting Sentinel-5 missions will monitor the composition of the atmosphere for Copernicus Atmosphere Services. Both missions will be carried on meteorological satellites operated by [EUMETSAT](https://eumetsat.int).",
"_____no_output_____"
],
[
"### Available data products and trace gas information",
"_____no_output_____"
],
[
"<span style=float:right><img src='./img/sentinel_5p_data_products.jpg' alt='Sentinel-5p data prodcuts' align='right' width='90%'></img></span>\nData products from Sentinel-5P’s Tropomi instrument are distributed to users at two levels:\n* `Level-1B`: provides geo-located and radiometrically corrected top of the atmosphere Earth radiances in all spectral bands, as well as solar irradiances.\n* `Level-2`: provides atmospheric geophysical parameters.\n\n`Level-2` products are disseminated within three hours after sensing. This `near-real-time`(NRT) services disseminates the following products:\n* `Ozone`\n* `Sulphur dioxide`\n* `Nitrogen dioxide`\n* `Formaldehyde`\n* `Carbon monoxide`\n* `Vertical profiles of ozone` and\n* `Cloud / Aerosol distributions`\n\n`Level-1B` products are disseminated within 12 hours after sensing. \n\n`Methane`, `tropospheric ozone` and `corrected total nitrogen dioxide columns` are available withing 5 days after sensing.\n\n",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id=\"sentinel5p_access\"></a>How to access Sentinel-5P data",
"_____no_output_____"
],
[
"Sentinel-5P data can be accessed via different dissemination channels. The data is accessible via the `Copernicus Open Access Hub` and `EUMETSAT's EUMETCast`.",
"_____no_output_____"
],
[
"#### Copernicus Open Access Hub",
"_____no_output_____"
],
[
"Sentinel-5P data is available for browsing and downloading via the [Copernicus Open Access Hub](https://scihub.copernicus.eu/). The Copernicus Open Access Hub provides complete, free and open access to Sentinel-1, Sentinel-2, Sentinel-3 and Sentinel-5P data.",
"_____no_output_____"
],
[
"\n<div style='text-align:center;'>\n<figure><img src='./img/open_access_hub.png' alt='Sentinel-5p data products' align='middle' width='50%'/>\n <figcaption><i>Interface of the Copernicus Open Access Hub and the Sentinel-5P Pre-Operations Data Hub</i></figcaption>\n</figure>\n</div>",
"_____no_output_____"
],
[
"#### EUMETSAT's EUMETCast",
"_____no_output_____"
],
[
"Since August 2019, Sentinel-5p `Level 1B` and `Level 2` are as well available on EUMETSAT's EUMETCast:\n* **Level 1B** products will be distributed on EUMETCast Terrestrial\n* **Level 2** products are distributed on EUMETCast Europe, High Volume Service Transponder 2 (HVS-2)\n\nSentinel-5P data on EUMETCast can be accessed via [EUMETSAT's Earth Observation Portal (EOP)](https://eoportal.eumetsat.int/userMgmt/login.faces).",
"_____no_output_____"
],
[
"#### TEMIS",
"_____no_output_____"
],
[
"[TEMIS - Tropospheric Emission Monitoring Internet Service](http://temis.nl/airpollution/no2.html) provides access to selected Sentinel-5P parameters, e.g. `NO`<sub>2</sub>.",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"## <a id='sentinel3'></a>Copernicus Sentinel-3 - Ocean and Land Colour (OLCI)",
"_____no_output_____"
],
[
"<span style=float:right><img src='./img/sentinel3.png' alt='Sentinel-5p data prodcuts' align='right' width='90%'></img></span>\nThe Sentinel-3 is the Copernicus mission to monitor and measure sea surface topography, sea and land surface temperature and ocean and land surface.\n\nThe Sentinel-3 mission carries five different instruments aboard the satellites: and offers four differnt data product types:\n- [Ocean and Land Colour Instrument (OLCI)](https://sentinel.esa.int/web/sentinel/missions/sentinel-3/data-products/olci)\n- [Sea and Land Surface Temperature Radiometer (SLSTR)](https://sentinel.esa.int/web/sentinel/missions/sentinel-3/data-products/slstr)\n- [Synergy](https://sentinel.esa.int/web/sentinel/missions/sentinel-3/data-products/synergy), and\n- [Altimetry](https://sentinel.esa.int/web/sentinel/missions/sentinel-3/data-products/altimetry).\n\nThe Sentinel-3 OLCI mission supports maritime monitoring, land mapping and monitoring, atmospheric monitoring and climate change monitoring. ",
"_____no_output_____"
],
[
"### Available OLCI data products",
"_____no_output_____"
],
[
"OLCI product types are divided in three main categories:\n\n- #### Level-1B products\nTwo different Level-1B products can be obtained: \n - OL_1_EFR - output during EO processing mode for Full Resolution\n - OL_1_ERR -output during EO processing mode for Reduced Resolution\n\n The Level-1B products in EO processing mode contain calibrated, ortho-geolocated and spatially re-sampled Top Of Atmosphere (TOA) radiances for [21 OLCI spectral bands](https://sentinel.esa.int/web/sentinel/user-guides/sentinel-3-olci/resolutions/radiometric). In Full Resolution products (i.e. at native instrument spatial resolution), these parameters are provided for each re-gridded pixel on the product image and for each removed pixel. In Reduced Resolution products (i.e. at a resolution four times coarser), the parameters are only provided on the product grid.\n\n- #### Level-2 Land products and Water products\nThe level-2 land product provides land and atmospheric geophysical parameters. The Level-2 water product provides water and atmospheric geophysical parameters. All products are computed for full and reduced resolution:\n - OL_2_LFR - Land Full Resolution\n - OL_2_LRR - Land Reduced Resolution\n\n\nThere are two timeframes for the delivery of the products:\n- **Near-Real-Time (NRT)**: delivered to the users less than three hours after acquisition of the data by the sensor\n- **Non-Time Critical (NTC)**: delivered no later than one month after acquisition or from long-term archives. Typically, the product is available within 24 or 48 hours.\n\nThe data is disseminated in .zip archive containing free-standing `NetCDF4` product files.\n",
"_____no_output_____"
],
[
"### How to access Sentinel-3 data",
"_____no_output_____"
],
[
"Sentinel-3 data can be accessed via different dissemination channels. The data is accessible via the `Copernicus Open Access Hub` and `WEkEO's Harmonized Data Access API`.",
"_____no_output_____"
],
[
"#### Copernicus Open Access Hub\nSentinel-3 data is available for browsing and downloading via the Copernicus Open Access Hub. The Copernicus Open Access Hub provides complete, free and open access to Sentinel-1, Sentinel-2, Sentinel-3 and Sentinel-5P data. See the an example of the Copernicus Open Access Hub interface [here](#sentinel5p_access).",
"_____no_output_____"
],
[
"#### WEkEO's Harmonized Data Access API",
"_____no_output_____"
],
[
"<span style=float:left><img src='./img/wekeo_logo2.png' alt='Logo WEkEO' align='center' width='90%'></img></span>\n[WEkEO](https://www.wekeo.eu/) is the EU Copernicus DIAS (Data and Information Access Service) reference service for environmental data, virtual processing environments and skilled user support.\n\nWEkEO offers access to a variety of data, including different parameters sensored from Sentinel-1, Sentinel-2 and Sentinel-3. It further offers access to climate reanalysis and seasonal forecast data.\n\nThe [Harmonized Data Access (HDA) API](https://www.wekeo.eu/documentation/using_jupyter_notebooks), a REST interface, allows users to subset and download datasets from WEkEO. \n\nPlease see [here](./12_ltpy_WEkEO_harmonized_access_api.ipynb) a practical example how you can retrieve Sentinel-3 data from WEkEO using the Harmonized Data Access API.",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"## <a id=\"cams\"></a>Copernicus Atmosphere Monitoring Service (CAMS)",
"_____no_output_____"
],
[
"<span style=float:left><img src='./img/cams_logo_2.png' alt='Copernicus Atmosphere Monitoring Service' align='left' width='95%'></img></span>\n\n[The Copernicus Atmosphere Monitoring Service (CAMS)](https://atmosphere.copernicus.eu/) provides consistent and quality-controlled information related to `air pollution and health`, `solar energy`, `greenhouse gases` and `climate forcing`, everywhere in the world.\n\nCAMS is one of six services that form [Copernicus, the European Union's Earth observation programme](https://www.copernicus.eu/en).\n\nCAMS is implemented by the [European Centre for Medium-Range Weather Forecasts (ECMWF)](http://ecmwf.int/) on behalf of the European Commission. ECMWF is an independent intergovernmental organisation supported by 34 states. It is both a research institute and a 24/7 operational service, producing and disseminating numerical weather predictions to its member states. ",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### Available data products",
"_____no_output_____"
],
[
"CAMS offers four different data product types:\n\n|<font size='+0.2'><center>[CAMS Global <br>Reanalysis](#cams_reanalysis)</center></font></img> | <font size='+0.2'><center>[CAMS Global Analyses <br>and Forecasts](#cams_an_fc)</center></font> | <img width=30><font size='+0.2'><center>[CAMS Global Fire Assimilation System (GFAS)](#cams_gfas)</center></font></img> | <img width=30><font size='+0.2'><center>[CAMS Greenhouse Gases Flux Inversions](#cams_greenhouse_flux)</center></font></img> |\n|-----|-----|------|------|\n<img src='./img/cams_reanalysis.png' alt='CAMS reanalysis' align='middle' width='100%'></img>|<img src='./img/cams_forecast.png' alt='CAMS Forecast' align='middle' width='100%'></img>|<img src='./img/cams_gfas.png' alt='CAMS GFAS' align='middle' width='100%'></img>|<img src='./img/cams_greenhouse_fluxes.png' alt='CAMS greenhous flux inversions' align='middle' width='100%'></img>|\n",
"_____no_output_____"
],
[
"#### <a id=\"cams_reanalysis\"></a>CAMS Global Reanalysis",
"_____no_output_____"
],
[
"CAMS reanalysis data set provides consistent information on aerosols and reactive gases from 2003 to 2017. CAMS global reanalysis dataset has a global horizontal resolution of approximately 80 km and a refined temporal resolution of 3 hours. CAMS reanalysis are available in GRIB and NetCDF format.\n\n| Parameter family | Time period | <img width=80>Spatial resolution</img> | Temporal resolution |\n| ---- | ----- | ----- | -----|\n| [CAMS global reanalysis of total aerosol optical depth<br> at multiple wavelengths](https://atmosphere.copernicus.eu/catalogue#/product/urn:x-wmo:md:int.ecmwf::copernicus:cams:prod:rean:black-carbon-aod_dust-aod_organic-carbon-aod_sea-salt-aod_sulphate-aod_total-aod_warning_multiple_species:pid469) | 2003-2017 | ~80km | 3-hourly |\n| [CAMS global reanalysis of aerosol concentrations](https://atmosphere.copernicus.eu/catalogue#/product/urn:x-wmo:md:int.ecmwf::copernicus:cams:prod:rean:black-carbon-concentration_dust-concentration_organic-carbon-concentration_pm1_pm10_pm2.5_sea-salt-concentration_sulfates-concentration_warning_multiple_species:pid467) | 2003-2017 | ~80km | 3-hourly |\n| [CAMS global reanalysis chemical species](https://atmosphere.copernicus.eu/catalogue#/product/urn:x-wmo:md:int.ecmwf::copernicus:cams:prod:rean:ald2_c10h16_c2h4_c2h5oh_c2h6_c2o3_c3h6_c3h8_c5h8_ch3coch3_ch3cocho_ch3o2_ch3oh_ch3ooh_ch4_co_dms_h2o2_hcho_hcooh_hno3_ho2_ho2no2_mcooh_msa_n2o5_nh2_nh3_nh4_no_no2_no3_no3_a_nox_o3_oh_ole_onit_pan_par_pb_rooh_ror_ra_so2_so4_warning_multiple_species:pid468) | 2003-2017 | ~80km | 3-hourly |",
"_____no_output_____"
],
[
"#### <a id=\"cams_an_fc\"></a>CAMS Global analyses and forecasts",
"_____no_output_____"
],
[
"CAMS daily global analyses and forecast data set provides daily global forecasts of atmospheric composition parameters up to five days in advance. CAMS analyses and forecast data are available in GRIB and NetCDF format. \n\nThe forecast consists of 56 reactive trace gases in the troposphere, stratospheric ozone and five different types of aersol (desert dust, sea salt, organic matter, black carbon and sulphate).\n\n| Parameter family | Time period | <img width=80>Spatial resolution</img> | Forecast step |\n| ---- | ----- | ----- | -----|\n| CAMS global forecasts of aerosol optical depths | Jul 2012- 5 days in advance | ~40km | 3-hour |\n| CAMS global forecasts of aerosols | Jul 2012 - 5 days in advance | ~40km | 3-hour |\n| CAMS global forecasts of chemical species | Jul 2012- 5 days in advance | ~40km | 3-hour |\n| CAMS global forecasts of greenhouse gases | Jul 2012- 5 days in advance | ~9km | 3-hour |",
"_____no_output_____"
],
[
"#### <a id=\"cams_gfas\"></a>CAMS Global Fire Assimiliation System (GFAS)",
"_____no_output_____"
],
[
"CAMS GFAS assimilated fire radiative power (FRP) observations from satellite-based sensors to produce daily estimates of wildfire and biomass burning emissions. The GFAS output includes spatially gridded Fire Radiative Power (FRP), dry matter burnt and biomass burning emissions for a large set of chemical, greenhouse gas and aerosol species. CAMS GFAS data are available in GRIB and NetCDF data.\n\nA full list of CAMS GFAS parameters can be found in the [CAMS Global Fire Assimilation System (GFAS) data documentation](https://atmosphere.copernicus.eu/sites/default/files/2018-05/CAMS%20%20Global%20Fire%20Assimilation%20System%20%28GFAS%29%20data%20documentation.pdf).\n\n| Parameter family | Time period | <img width=80>Spatial resolution</img> | Temporal resolution |\n| ---- | ----- | ----- | ---- |\n| CAMS GFAS analysis surface parameters | Jan 2003 - present | ~11km | daily |\n| CAMS GFAS gridded satellite parameters | Jan 2003 - present | ~11km | daily |",
"_____no_output_____"
],
[
"#### <a id=\"cams_greenhouse_flux\"></a>CAMS Greenhouse Gases Flux Inversions",
"_____no_output_____"
],
[
"CAMS Greenhouse Gases Flux Inversion reanalysis describes the variations, in space and in time, of the surface sources and sinks (fluxes) of the three major greenhouse gases that are directly affected by human activities: `carbon dioxide (CO2)`, `methane (CH4)` and `nitrous oxide (N2O)`. CAMS Greenhouse Gases Flux data is available in GRIB and NetCDF format.\n\n| Parameter | Time period | <img width=80>Spatial resolution</img> | Frequency | Quantity |\n| ---- | ----- | ----- | ---- | -----|\n| Carbon Dioxide | Jan 1979 - Dec 2018 | ??? | 3 hourly<br>Monthly average | Concentration<br>Surface flux<br> Total colum |\n| Methane | Jan 1990 - Dec 2017 | ??? | 6-hourly<br>Daily average<br>Monthly average | Concentration<br>Surface flux<br>Total column\n| Nitrous Oxide | Jan 1995 - Dec 2017 | ???| 3-hourly<br>Monthly average | Concentration<br>Surface flux |",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id=\"cams_access\"></a>How to access CAMS data",
"_____no_output_____"
],
[
"CAMS data can be accessed in two different ways: `ECMWF data archive` and `CAMS data catalogue of data visualizations`. A more detailed description of the different data access platforms can be found [here](https://confluence.ecmwf.int/display/CKB/Access+to+CAMS+global+forecast+data).",
"_____no_output_____"
],
[
"#### ECMWF data archive",
"_____no_output_____"
],
[
"ECMWF's data archive is called Meteorological and Archival Retrieval System (MARS) and provides access to ECMWF Public Datasets. The following CAMS data can be accessed through the ECMWF MARS archive: `CAMS reanalysis`, `CAMS GFAS data` (older than one day), and `CAMS global analyses and forecasts` (older than five days).\n\nThe archive can be accessed in two ways: \n* via the [web interface](https://apps.ecmwf.int/datasets/) and \n* via the [ECMWF Web API](https://confluence.ecmwf.int/display/WEBAPI/Access+ECMWF+Public+Datasets).\n\nSubsequently, an example is shown how a MARS request can be executed within Python and data in either GRIB or netCDF can be downloaded on-demand.",
"_____no_output_____"
],
[
"#### 1. Register for an ECMWF user account",
"_____no_output_____"
],
[
"- Self-register at https://apps.ecmwf.int/registration/\n- Login at https://apps.ecmwf.int/auth/login",
"_____no_output_____"
],
[
"#### 2. Install the `ecmwfapi` python library",
"_____no_output_____"
],
[
"`pip install ecmwf-api-client`",
"_____no_output_____"
],
[
"#### 3. Retrieve your API key",
"_____no_output_____"
],
[
"You can retrieve your API key at https://api.ecmwf.int/v1/key/. Add the `url`, `key` and `email` information, when you define the `ECMWFDataServer` (see below).\n",
"_____no_output_____"
],
[
"#### 3. Execute a MARS request and download data as `netCDF` file",
"_____no_output_____"
],
[
"Below, you see the principle of a `data retrieval` request. You can use the web interface to browse through the datasets. At the end, there is the option to let generate the `data retrieval` request for the API.\n\nAdditionally, you can have a look [here](./cams_ecmwfapi_example_requests.ipynb) at some example requests for different CAMS parameters.\n\n**NOTE**: per default, ECMWF data is stored on a grid with longitudes going from 0 to 360 degrees. It can be reprojected to a regular geographic latitude-longitude grid, by setting the keyword argument `area` and `grid`. Per default, data is retrieved in `GRIB`. If you wish to retrieve the data in `netCDF`, you have to specify it by using the keyword argument `format`.\n\nThe example requests `Organic Matter Aerosol Optical Depth at 550 nm` forecast data for 3 June 2019 in `NetCDF`.",
"_____no_output_____"
]
],
[
[
"#!/usr/bin/env python\nfrom ecmwfapi import ECMWFDataServer\nserver = ECMWFDataServer(url=\"https://api.ecmwf.int/v1\", key=\"XXXXXXXXXXXXXXXX\", email=\"XXXXXXXXXXXXXXXX\")\n\n# Retrieve data in NetCDF format\nserver.retrieve({\n \"class\": \"mc\",\n \"dataset\": \"cams_nrealtime\",\n \"date\": \"2019-06-03/to/2019-06-03\",\n \"expver\": \"0001\",\n \"levtype\": \"sfc\",\n \"param\": \"210.210\",\n \"step\": \"3\",\n \"stream\": \"oper\",\n \"time\": \"00:00:00\",\n \"type\": \"fc\",\n \"format\": \"netcdf\",\n \"area\": \"90/-180/-90/180\",\n \"grid\": \"0.4/0.4\",\n \"target\": \"test.nc\"\n})",
"_____no_output_____"
]
],
[
[
"#### CAMS data catalogue of data visualizations",
"_____no_output_____"
],
[
"CAMS provides an extensive [catalogue of data visualizations](https://atmosphere.copernicus.eu/data) in the form of maps and charts. Products are updated daily and are available for selected parameters of `CAMS daily analyses and forecasts`.",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"## Further information",
"_____no_output_____"
],
[
"* [EUMETSAT AC SAF - The EUMETSAT Application Facility on Atmospheric Composition Monitoring](https://acsaf.org/index.html)\n* [AC SAF Data policy](https://acsaf.org/data_policy.html)\n* [AC SAF Algorithm Theoretical Basis Documents (atbds)](https://acsaf.org/atbds.html)\n\n\n* [DLR's ATMOS webserver](https://atmos.eoc.dlr.de/app/missions/gome2)\n* [TEMIS - Tropospheric Emission Monitoring Internet Service](http://temis.nl/index.php)\n\n\n* [Copernicus Open Access Hub](https://scihub.copernicus.eu/)\n* [EUMETSAT Earth Observation Portal](https://eoportal.eumetsat.int/userMgmt/login.faces)\n* [Sentinel-5P Mission information](https://sentinels.copernicus.eu/web/sentinel/missions/sentinel-5p)\n\n\n* [Sentinel-3 Mission information](https://sentinel.esa.int/web/sentinel/missions/sentinel-3)\n* [Sentinel-3 OLCI User Guide](https://sentinel.esa.int/web/sentinel/user-guides/sentinel-3-olci)\n* [WEkEO](https://www.wekeo.eu/)\n\n\n* [Copernicus Atmosphere Monitoring Service](https://atmosphere.copernicus.eu/)\n* [ECMWF Web Interface](https://apps.ecmwf.int/datasets/)\n* [ECMWF Web API](https://confluence.ecmwf.int/display/WEBAPI/Access+ECMWF+Public+Datasets)\n* [CAMS catalogue of data visualizations](https://atmosphere.copernicus.eu/data)\n* [CAMS Service Product Portfolio](https://atmosphere.copernicus.eu/sites/default/files/2018-12/CAMS%20Service%20Product%20Portfolio%20-%20July%202018.pdf)",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"<a href=\"./index_ltpy.ipynb\"><< Index</a><span style=\"float:right;\"><a href=\"./12_ltpy_WEkEO_harmonized_data_access_api.ipynb\">12 - WEkEO Harmonized Data Access API >></a></span>",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"<p style=\"text-align:left;\">This project is licensed under the <a href=\"./LICENSE\">MIT License</a> <span style=\"float:right;\"><a href=\"https://gitlab.eumetsat.int/eumetlab/atmosphere/atmosphere\">View on GitLab</a> | <a href=\"https://training.eumetsat.int/\">EUMETSAT Training</a> | <a href=mailto:[email protected]>Contact</a></span></p>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cbd0b469e273e4cda324e0a7354dff6f87726c6c
| 36,875 |
ipynb
|
Jupyter Notebook
|
EcoFOCI_Moorings/EcoFOCI_erddap_DataVarSubset.ipynb
|
NOAA-PMEL/EcoFOCI_Jupyter_Notebooks
|
9fd2385ed68c2decd03aa6167d0b86189704b4d9
|
[
"MIT"
] | 3 |
2017-03-23T16:52:44.000Z
|
2022-03-08T16:53:29.000Z
|
EcoFOCI_Moorings/EcoFOCI_erddap_DataVarSubset.ipynb
|
NOAA-PMEL/EcoFOCI_Jupyter_Notebooks
|
9fd2385ed68c2decd03aa6167d0b86189704b4d9
|
[
"MIT"
] | null | null | null |
EcoFOCI_Moorings/EcoFOCI_erddap_DataVarSubset.ipynb
|
NOAA-PMEL/EcoFOCI_Jupyter_Notebooks
|
9fd2385ed68c2decd03aa6167d0b86189704b4d9
|
[
"MIT"
] | 2 |
2017-03-30T22:01:25.000Z
|
2019-10-17T17:30:29.000Z
| 84.575688 | 13,572 | 0.772692 |
[
[
[
"from erddapy import ERDDAP\nimport pandas as pd\nimport numpy as np\n",
"_____no_output_____"
],
[
"## settings (move to yaml file for routines)\n\nserver_url = 'http://akutan.pmel.noaa.gov:8080/erddap'\nmaxdepth = 0 #keep all data above this depth\nsite_str = 'M8'\nregion = 'bs'\nsubstring = ['bs8','bs8'] #search substring useful for M2\nprelim=[]\n\n#this elimnates bad salinity but \ndata_QC = True\n",
"_____no_output_____"
],
[
"e = ERDDAP(server=server_url)\ndf = pd.read_csv(e.get_search_url(response='csv', search_for=f'datasets_Mooring AND {region}'))\n#print(df['Dataset ID'].values)",
"_____no_output_____"
],
[
"from requests.exceptions import HTTPError\n\ndfs = {}\n\nfor dataset_id in sorted(df['Dataset ID'].values):\n if ('1hr' in dataset_id):\n continue\n if any(x in dataset_id for x in substring) and not any(x in dataset_id for x in prelim) and ('final' in dataset_id):\n\n print(dataset_id)\n try:\n d = ERDDAP(server=server_url,\n protocol='tabledap',\n response='csv'\n )\n d.dataset_id=dataset_id\n d.variables = ['latitude',\n 'longitude',\n 'depth',\n 'Chlorophyll_Fluorescence',\n 'time',\n 'timeseries_id']\n d.constraints = {'depth>=':maxdepth}\n except HTTPError:\n print('Failed to generate url {}'.format(dataset_id))\n\n try:\n df_m = d.to_pandas(\n index_col='time (UTC)',\n parse_dates=True,\n skiprows=(1,) # units information can be dropped.\n )\n df_m.sort_index(inplace=True)\n df_m.columns = [x[1].split()[0] for x in enumerate(df_m.columns)]\n\n dfs.update({dataset_id:df_m})\n except:\n pass\n if any(x in dataset_id for x in prelim) and ('preliminary' in dataset_id):\n print(dataset_id)\n try:\n d = ERDDAP(server=server_url,\n protocol='tabledap',\n response='csv'\n )\n d.dataset_id=dataset_id\n d.variables = ['latitude',\n 'longitude',\n 'depth',\n 'Chlorophyll_Fluorescence',\n 'time',\n 'timeseries_id']\n d.constraints = {'depth>=':maxdepth}\n except HTTPError:\n print('Failed to generate url {}'.format(dataset_id))\n\n try:\n df_m = d.to_pandas(\n index_col='time (UTC)',\n parse_dates=True,\n skiprows=(1,) # units information can be dropped.\n )\n df_m.sort_index(inplace=True)\n df_m.columns = [x[1].split()[0] for x in enumerate(df_m.columns)]\n\n #using preliminary for unfinished datasets - very simple qc\n if data_QC:\n\n #overwinter moorings\n if '17bs2c' in dataset_id:\n df_m=df_m['2017-10-3':'2018-5-1']\n if '16bs2c' in dataset_id:\n df_m=df_m['2016-10-6':'2017-4-26']\n if '17bsm2a' in dataset_id:\n df_m=df_m['2017-4-28':'2017-9-22']\n if '18bsm2a' in dataset_id:\n df_m=df_m['2018-4-30':'2018-10-01']\n \n if '17bs8a' in dataset_id:\n df_m=df_m['2017-9-30':'2018-10-1']\n if '18bs8a' in dataset_id:\n df_m=df_m['2018-10-12':'2019-9-23'] \n\n if '16bs4b' in dataset_id:\n df_m=df_m['2016-9-26':'2017-9-24']\n if '17bs4b' in dataset_id:\n df_m=df_m['2017-9-30':'2018-10-1']\n if '18bs4b' in dataset_id:\n df_m=df_m['2018-10-12':'2018-9-23'] \n \n if '13bs5a' in dataset_id:\n df_m=df_m['2013-8-18':'2014-10-16']\n if '14bs5a' in dataset_id:\n df_m=df_m['2014-10-16':'2015-9-24']\n if '16bs5a' in dataset_id:\n df_m=df_m['2016-9-26':'2017-9-24']\n if '17bs5a' in dataset_id:\n df_m=df_m['2017-9-30':'2018-10-1']\n if '18bs5a' in dataset_id:\n df_m=df_m['2018-10-12':'2018-9-23'] \n dfs.update({dataset_id:df_m})\n except:\n pass",
"datasets_Mooring_05bs8a_final\ndatasets_Mooring_05bs8b_final\ndatasets_Mooring_06bs8a_final\ndatasets_Mooring_07bs8a_final\ndatasets_Mooring_08bs8a_final\ndatasets_Mooring_09bs8a_final\ndatasets_Mooring_10bs8a_final\ndatasets_Mooring_11bs8a_final\ndatasets_Mooring_12bs8a_final\ndatasets_Mooring_13bs8a_final\ndatasets_Mooring_14bs8a_final\ndatasets_Mooring_15bs8a_final\ndatasets_Mooring_16bs8a_final\ndatasets_Mooring_17bs8a_final\ndatasets_Mooring_18bs8a_final\n"
],
[
"df_merged=pd.DataFrame()\nfor dataset_id in dfs.keys():\n df_merged = df_merged.append(dfs[dataset_id])",
"_____no_output_____"
],
[
"df_merged.describe()",
"_____no_output_____"
],
[
"df_merged = df_merged.dropna()",
"_____no_output_____"
],
[
"import matplotlib as mpl\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"plt.scatter(df_merged.index, y=df_merged['depth'], s=10, c=df_merged['Chlorophyll_Fluorescence'], vmin=0, vmax=10, cmap='inferno')",
"_____no_output_____"
],
[
"plt.plot(df_merged.index, df_merged['Chlorophyll_Fluorescence'])",
"_____no_output_____"
],
[
"df_merged.to_csv(f'{site_str}_nearsfc_chlor.csv')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd0b9ac0eb768fc0b4a762c62dc4d5cbf1c167d
| 72,529 |
ipynb
|
Jupyter Notebook
|
regression/src/linear_regression.ipynb
|
deeplearninghsw/dlhsw-examples
|
49ae49b4fdc668c547cbc813e9a93cf17b36977d
|
[
"MIT"
] | null | null | null |
regression/src/linear_regression.ipynb
|
deeplearninghsw/dlhsw-examples
|
49ae49b4fdc668c547cbc813e9a93cf17b36977d
|
[
"MIT"
] | null | null | null |
regression/src/linear_regression.ipynb
|
deeplearninghsw/dlhsw-examples
|
49ae49b4fdc668c547cbc813e9a93cf17b36977d
|
[
"MIT"
] | null | null | null | 168.280742 | 24,278 | 0.89469 |
[
[
[
"import numpy as np\r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\nimport tensorflow as tf\r\n\r\nfrom utils.plotting import plot_dataset\r\nfrom tensorflow.keras import layers\r\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"# Load Dataset\r\ndf = pd.read_csv('data/ex.csv')\r\n\r\ndataset = df.copy()\r\n\r\nX = dataset.values\r\nx_cords = dataset['x'].values\r\ny_cords = dataset['y'].values",
"_____no_output_____"
],
[
"plot_dataset(x_cords, y_cords, 'Full Dataset')",
"_____no_output_____"
]
],
[
[
"### Split the data into train and test\n\nNow split the dataset into a training set and a test set.\nUse the test set in the final evaluation of the model.\n\n### Split features from labels\nSeparate the target value, the \"label\", from the features. This label is the value that you will train the model to predict.",
"_____no_output_____"
]
],
[
[
"# Train Test Split\r\nx_train, x_test, y_train, y_test = train_test_split(x_cords, y_cords, test_size=0.20, random_state=np.random.seed(6))\r\n\r\nX = np.stack((x_test, y_test), axis=1)",
"_____no_output_____"
]
],
[
[
"### Linear regression\n\nBefore building a DNN model, start with a linear regression.\nOne Variable\n\nStart with a single-variable linear regression, to predict `y` from `x`.\n\nTraining a model with `tf.keras` typically starts by defining the model architecture.\n\nIn this case use a `keras.Sequential` model. This model represents a sequence of steps. In this case there are two steps:\n\n- Normalize the input `x`.\n- Apply a linear transformation $(y = mx+b)$ to produce 1 output using `layers.Dense`.\n\nThe number of inputs can either be set by the `input_shape` argument, or automatically when the model is run for the first time.\n\nFirst create the horsepower `Normalization` layer:",
"_____no_output_____"
]
],
[
[
"# Build the sequential model\r\nmodel = tf.keras.Sequential([\r\n layers.Dense(1, input_dim=1)\r\n])\r\n\r\nmodel.summary()\r\n",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 1) 2 \n=================================================================\nTotal params: 2\nTrainable params: 2\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"This model will predict `y` from `x`.\n\nRun the untrained model on the first 10 `x` values. The output won't be good, but you'll see that it has the expected shape, (10,1):\n\n\n",
"_____no_output_____"
]
],
[
[
"model.predict(x_cords[:10])\r\nprint(model.predict(x_cords[:10]))\r\n",
"[[-0.7740608 ]\n [ 0.01136162]\n [ 0.01525406]\n [ 0.2661238 ]\n [-0.40301794]\n [-1.3150793 ]\n [-0.16705588]\n [ 0.25874162]\n [-0.1916014 ]\n [-0.03244563]]\n"
]
],
[
[
"Once the model is built, configure the training procedure using the `Model.compile()` method. The most important arguments to compile are the `loss` and the `optimizer` since these define what will be optimized (`mean_absolute_error`) and how (using the `optimizers.Adam`).",
"_____no_output_____"
]
],
[
[
"model.compile(\r\n optimizer=tf.optimizers.Adam(lr=1e-3),\r\n loss='logcosh')",
"C:\\ProgramData\\Anaconda3\\envs\\examples\\lib\\site-packages\\keras\\optimizer_v2\\optimizer_v2.py:355: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.\n warnings.warn(\n"
]
],
[
[
"Once the training is configured, use `Model.fit()` to execute the training:",
"_____no_output_____"
]
],
[
[
"%%time\r\nhistory = model.fit(\r\n x_train, y_train,\r\n epochs=100,\r\n validation_split=0.2,\r\n verbose=0)",
"Wall time: 4.03 s\n"
]
],
[
[
"Visualize the model's training progress using the stats stored in the history object.",
"_____no_output_____"
]
],
[
[
"hist = pd.DataFrame(history.history)\r\nhist['epoch'] = history.epoch\r\nhist.tail()\r\n",
"_____no_output_____"
],
[
"def plot_loss(history):\r\n plt.plot(history.history['loss'], label='loss')\r\n plt.plot(history.history['val_loss'], label='val_loss')\r\n plt.ylim([0, 1])\r\n plt.xlabel('Epoch')\r\n plt.ylabel('Error [Y]')\r\n plt.legend()\r\n plt.grid(True)\r\n\r\nplot_loss(history)\r\n",
"_____no_output_____"
],
[
"test_results = model.evaluate(\r\n x_test, y_test, verbose=0)\r\n\r\nx = tf.linspace(-4.0, 4.0, 9)\r\ny = model.predict(x)\r\n\r\ndef plot_model(x, y):\r\n plt.scatter(x_train, y_train, label='Data')\r\n plt.plot(x, y, color='k', label='Predictions')\r\n plt.xlabel('x')\r\n plt.ylabel('y')\r\n plt.legend()\r\n\r\nplot_model(x,y)\r\n\r\nprint(f\"Loss: {test_results}\")",
"Loss: 0.3650756776332855\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd0cfc0943211cbec113b575708f151ef69e42e
| 316,102 |
ipynb
|
Jupyter Notebook
|
CNS_CDF.ipynb
|
pik-copan/pydrf
|
998072d655331ca6669c71bb6df665292e8972e7
|
[
"BSD-3-Clause"
] | 1 |
2021-10-01T09:01:30.000Z
|
2021-10-01T09:01:30.000Z
|
CNS_CDF.ipynb
|
pik-copan/pydrf
|
998072d655331ca6669c71bb6df665292e8972e7
|
[
"BSD-3-Clause"
] | null | null | null |
CNS_CDF.ipynb
|
pik-copan/pydrf
|
998072d655331ca6669c71bb6df665292e8972e7
|
[
"BSD-3-Clause"
] | 1 |
2021-10-01T09:02:54.000Z
|
2021-10-01T09:02:54.000Z
| 172.922319 | 210,851 | 0.850071 |
[
[
[
"### Plot Comulative Distribution Of Sportive Behavior Over Time",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib notebook\nfrom sensible_raw.loaders import loader\nfrom world_viewer.cns_world import CNSWorld\nfrom world_viewer.synthetic_world import SyntheticWorld\nfrom world_viewer.glasses import Glasses\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import LogNorm, PowerNorm\nimport math\n\nimport pandas as pd\nimport numpy as np\n#import dask.dataframe as dd\nimport time\nimport seaborn as sns\n",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"# load data and restict timeseries\n# data from \"PreprocessOpinions/FitnessAsBehavior.ipynb\"\ndata = pd.read_pickle(\"data/op_fitness.pkl\")\n#data.reset_index(inplace=True)\nopinion = \"op_fitness\"\ndata = data[data.time >= CNSWorld.CNS_TIME_BEGIN]\ndata = data[data.time <= CNSWorld.CNS_TIME_END]\ndata.head()",
"_____no_output_____"
],
[
"# calc cummulative distribution function\ndef cdf_from_data(data, cdfx):\n size_data = len(data)\n y_values = []\n for i in cdfx:\n # all the values in data less than the ith value in x_values\n temp = data[data <= i]\n # fraction of that value with respect to the size of the x_values\n value = temp.size / size_data\n # pushing the value in the y_values\n y_values.append(value)\n # return both x and y values \n return pd.DataFrame({'x':cdfx, 'cdf':y_values}).set_index(\"x\")\n\ncdfx = np.linspace(start=0,stop=4,num=400)\n\ncdf = data.groupby(\"time\")[opinion + \"_abs\"].apply(lambda d: cdf_from_data(d, cdfx))#",
"_____no_output_____"
],
[
"# load cdf if previously calculated\n#cdf = pd.read_pickle(\"tmp/cdf_fitness.pkl\")",
"_____no_output_____"
],
[
"# plot cdf as heatmap (fig.: 3.3)\n\nfig, ax = plt.subplots(1,1)\n\nnum_ticks = 5\n# the index of the position of yticks\nyticks = np.linspace(0, len(cdfx)-1, num_ticks, dtype=np.int)\n# the content of labels of these yticks\nyticklabels = [round(cdfx[idx]) for idx in yticks]\n\ncmap = sns.cubehelix_palette(60, hue=0.05, rot=0, light=0.9, dark=0, as_cmap=True)\n\nax = sns.heatmap(df2, cmap=cmap, xticklabels=80, yticklabels=yticklabels, vmin=0.4, vmax=1, cbar_kws={'label': 'cumulative distribution function'})#, norm=LogNorm(vmin=0.1, vmax=1))#, , cbar_kws={\"ticks\": cbar_ticks})\n#ax.hlines([300], *ax.get_xlim(), linestyles=\"dashed\")\nax.set_yticks(yticks)\nax.invert_yaxis()\nplt.xticks(rotation=70)\nplt.yticks(rotation=0)\nplt.ylabel(r\"$\\bar b(t)$\")\n#ax.set_yscale('log')\n\n#sns.heatmap(cdf.cdf, annot=False)\nfig.savefig(\"test.png\" , dpi=600, bbox_inches='tight')",
"_____no_output_____"
],
[
"# plot cdf for singe timestep\n\nfig, ax = plt.subplots(1,1)\nax.plot(cdf.loc[\"2014-02-09\"].reset_index().x, 1-cdf.loc[\"2014-11-30\",\"cdf\"].values)\nax.set_yscale('log')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd0dde82ed26f6e41d892a7afb7be0eb3d24ec7
| 339,138 |
ipynb
|
Jupyter Notebook
|
docs/Tutorial_AB_Joins.ipynb
|
stumpy-dev/stumpy
|
589630e0308529d000fe9c06504ee7e4f759bc0b
|
[
"BSD-3-Clause"
] | null | null | null |
docs/Tutorial_AB_Joins.ipynb
|
stumpy-dev/stumpy
|
589630e0308529d000fe9c06504ee7e4f759bc0b
|
[
"BSD-3-Clause"
] | null | null | null |
docs/Tutorial_AB_Joins.ipynb
|
stumpy-dev/stumpy
|
589630e0308529d000fe9c06504ee7e4f759bc0b
|
[
"BSD-3-Clause"
] | null | null | null | 909.217158 | 116,432 | 0.953544 |
[
[
[
"# Finding Conserved Patterns Across Two Time Series \n\n## AB-Joins\n\nThis tutorial is adapted from the [Matrix Profile I](https://www.cs.ucr.edu/~eamonn/PID4481997_extend_Matrix%20Profile_I.pdf) paper and replicates Figures 9 and 10.\n\nPreviously, we had introduced a concept called [time series motifs](https://stumpy.readthedocs.io/en/latest/Tutorial_STUMPY_Basics.html), which are conserved patterns found within a single time series, $T$, that can be discovered by computing its [matrix profile](https://stumpy.readthedocs.io/en/latest/Tutorial_The_Matrix_Profile.html) using STUMPY. This process of computing a matrix profile with one time series is commonly known as a \"self-join\" since the subsequences within time series $T$ are only being compared with itself. However, what do you do if you have two time series, $T_{A}$ and $T_{B}$, and you want to know if there are any subsequences in $T_{A}$ that can also be found in $T_{B}$? By extension, a motif discovery process involving two time series is often referred to as an \"AB-join\" since all of the subsequences within time series $T_{A}$ are compared to all of the subsequences in $T_{B}$. \n\nIt turns out that \"self-joins\" can be trivially generalized to \"AB-joins\" and the resulting matrix profile, which annotates every subsequence in $T_{A}$ with its nearest subsequence neighbor in $T_{B}$, can be used to identify similar (or unique) subsequences across any two time series. Additionally, as long as $T_{A}$ and $T_{B}$ both have lengths that are greater than or equal to the subsequence length, $m$, there is no requirement that the two time series must be the same length. \n\nIn this short tutorial we will demonstrate how to find a conserved pattern across two independent time series using STUMPY.\n\n## Getting Started\n\nLet's import the packages that we'll need to load, analyze, and plot the data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport stumpy\nimport pandas as pd\nimport numpy as np\nfrom IPython.display import IFrame\nimport matplotlib.pyplot as plt\n\nplt.style.use('stumpy.mplstyle')",
"_____no_output_____"
]
],
[
[
"## Finding Similarities in Music Using STUMPY\n\nIn this tutorial we are going to analyze two songs, “Under Pressure” by Queen and David Bowie as well as “Ice Ice Baby” by Vanilla Ice. For those who are unfamiliar, in 1990, Vanilla Ice was alleged to have sampled the bass line from \"Under Pressure\" without crediting the original creators and the copyright claim was later settled out of court. Have a look at this short video and see if you can hear the similarities between the two songs:",
"_____no_output_____"
]
],
[
[
"IFrame(width=\"560\", height=\"315\", src=\"https://www.youtube.com/embed/HAA__AW3I1M\")",
"_____no_output_____"
]
],
[
[
"The two songs certainly share some similarities! But, before we move forward, imagine if you were the judge presiding over this court case. What analysis result would you need to see in order to be convinced, beyond a shadow of a doubt, that there was wrongdoing?",
"_____no_output_____"
],
[
"## Loading the Music Data\n\nTo make things easier, instead of using the raw music audio from each song, we're only going to use audio that has been pre-converted to a single frequency channel (i.e., the 2nd MFCC channel sampled at 100Hz).",
"_____no_output_____"
]
],
[
[
"queen_df = pd.read_csv(\"https://zenodo.org/record/4294912/files/queen.csv?download=1\")\nvanilla_ice_df = pd.read_csv(\"https://zenodo.org/record/4294912/files/vanilla_ice.csv?download=1\")\n\nprint(\"Length of Queen dataset : \" , queen_df.size)\nprint(\"Length of Vanilla ice dataset : \" , vanilla_ice_df.size)",
"Length of Queen dataset : 24289\nLength of Vanilla ice dataset : 23095\n"
]
],
[
[
"## Visualizing the Audio Frequencies\n\nIt was very clear in the earlier video that there are strong similarities between the two songs. However, even with this prior knowledge, it's incredibly difficult to spot the similarities (below) due to the sheer volume of the data: ",
"_____no_output_____"
]
],
[
[
"fig, axs = plt.subplots(2, sharex=True, gridspec_kw={'hspace': 0})\nplt.suptitle('Can You Spot The Pattern?', fontsize='30')\n\naxs[0].set_title('Under Pressure', fontsize=20, y=0.8)\naxs[1].set_title('Ice Ice Baby', fontsize=20, y=0)\n\naxs[1].set_xlabel('Time')\n\naxs[0].set_ylabel('Frequency')\naxs[1].set_ylabel('Frequency')\n\nylim_lower = -25\nylim_upper = 25\naxs[0].set_ylim(ylim_lower, ylim_upper)\naxs[1].set_ylim(ylim_lower, ylim_upper)\n\naxs[0].plot(queen_df['under_pressure'])\naxs[1].plot(vanilla_ice_df['ice_ice_baby'], c='orange')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Performing an AB-Join with STUMPY\n\nFortunately, using the `stumpy.stump` function, we can quickly compute the matrix profile by performing an AB-join and this will help us easily identify and locate the similar subsequence(s) between these two songs:",
"_____no_output_____"
]
],
[
[
"m = 500\nqueen_mp = stumpy.stump(T_A = queen_df['under_pressure'], \n m = m,\n T_B = vanilla_ice_df['ice_ice_baby'],\n ignore_trivial = False)",
"_____no_output_____"
]
],
[
[
"Above, we call `stumpy.stump` by specifying our two time series `T_A = queen_df['under_pressure']` and `T_B = vanilla_ice_df['ice_ice_baby']`. Following the original published work, we use a subsequence window length of `m = 500` and, since this is not a self-join, we set `ignore_trivial = False`. The resulting matrix profile, `queen_mp`, essentially serves as an annotation for `T_A` so, for every subsequence in `T_A`, we find its closest subsequence in `T_B`. \n\nAs a brief reminder of the matrix profile data structure, each row of `queen_mp` corresponds to each subsequence within `T_A`, the first column in `queen_mp` records the matrix profile value for each subsequence in `T_A` (i.e., the distance to its nearest neighbor in `T_B`), and the second column in `queen_mp` keeps track of the index location of the nearest neighbor subsequence in `T_B`. \n\nOne additional side note is that AB-joins are not symmetrical in general. That is, unlike a self-join, the order of the input time series matter. So, an AB-join will produce a different matrix profile than a BA-join (i.e., for every subsequence in `T_B`, we find its closest subsequence in `T_A`).\n\n## Visualizing the Matrix Profile\n\nJust as we've done [in the past](https://stumpy.readthedocs.io/en/latest/Tutorial_STUMPY_Basics.html), we can now look at the matrix profile, `queen_mp`, computed from our AB-join:",
"_____no_output_____"
]
],
[
[
"queen_motif_index = queen_mp[:, 0].argmin()\n\nplt.xlabel('Subsequence')\nplt.ylabel('Matrix Profile')\n\nplt.scatter(queen_motif_index, \n queen_mp[queen_motif_index, 0],\n c='red',\n s=100)\n\nplt.plot(queen_mp[:,0])\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Now, to discover the global motif (i.e., the most conserved pattern), `queen_motif_index`, all we need to do is identify the index location of the lowest distance value in the `queen_mp` matrix profile (see red circle above).",
"_____no_output_____"
]
],
[
[
"queen_motif_index = queen_mp[:, 0].argmin()\nprint(f'The motif is located at index {queen_motif_index} of \"Under Pressure\"')",
"The motif is located at index 904 of \"Under Pressure\"\n"
]
],
[
[
"In fact, the index location of its nearest neighbor in \"Ice Ice Baby\" is stored in `queen_mp[queen_motif_index, 1]`:",
"_____no_output_____"
]
],
[
[
"vanilla_ice_motif_index = queen_mp[queen_motif_index, 1]\nprint(f'The motif is located at index {vanilla_ice_motif_index} of \"Ice Ice Baby\"')",
"The motif is located at index 288 of \"Ice Ice Baby\"\n"
]
],
[
[
"## Overlaying The Best Matching Motif\n\nAfter identifying the motif and retrieving the index location from each song, let's overlay both of these subsequences and see how similar they are to each other: ",
"_____no_output_____"
]
],
[
[
"plt.plot(queen_df.iloc[queen_motif_index : queen_motif_index + m].values, label='Under Pressure')\nplt.plot(vanilla_ice_df.iloc[vanilla_ice_motif_index:vanilla_ice_motif_index+m].values, label='Ice Ice Baby')\n\nplt.xlabel('Time')\nplt.ylabel('Frequency')\n\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"Wow, the resulting overlay shows really strong correlation between the two subsequences! Are you convinced?\n\n## Summary\n\nAnd that's it! In just a few lines of code, you learned how to compute a matrix profile for two time series using STUMPY and identified the top-most conserved behavior between them. While this tutorial has focused on audio data, there are many further applications such as detecting imminent mechanical issues in sensor data by comparing to known experimental or historical failure datasets or finding matching movements in commodities or stock prices, just to name a few.\n\nYou can now import this package and use it in your own projects. Happy coding!\n\n## Resources\n\n[Matrix Profile I](https://www.cs.ucr.edu/~eamonn/PID4481997_extend_Matrix%20Profile_I.pdf)\n\n[STUMPY Documentation](https://stumpy.readthedocs.io/en/latest/)\n\n[STUMPY Matrix Profile Github Code Repository](https://github.com/TDAmeritrade/stumpy)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd0e389f63be201cabf5363d73996158f5d71fd
| 396,541 |
ipynb
|
Jupyter Notebook
|
code/python/.ipynb_checkpoints/testing visualizations of books-checkpoint.ipynb
|
morethanbooks/XML-TEI-Bible
|
eb42b0ff37ad0049e84f01eb55ec786c8b4a54ea
|
[
"CC-BY-4.0"
] | 18 |
2016-10-05T15:38:49.000Z
|
2021-11-09T08:43:16.000Z
|
code/python/.ipynb_checkpoints/testing visualizations of books-checkpoint.ipynb
|
morethanbooks/XML-TEI-Bible
|
eb42b0ff37ad0049e84f01eb55ec786c8b4a54ea
|
[
"CC-BY-4.0"
] | null | null | null |
code/python/.ipynb_checkpoints/testing visualizations of books-checkpoint.ipynb
|
morethanbooks/XML-TEI-Bible
|
eb42b0ff37ad0049e84f01eb55ec786c8b4a54ea
|
[
"CC-BY-4.0"
] | 2 |
2020-12-22T10:27:29.000Z
|
2021-04-16T12:00:42.000Z
| 319.533441 | 82,162 | 0.902013 |
[
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport numpy as np",
"_____no_output_____"
],
[
"quantitative_data = pd.read_csv(\"../../resulting data/quantitative_data.csv\", sep=\"\\t\", index_col=0)",
"_____no_output_____"
],
[
"quantitative_data.head()",
"_____no_output_____"
],
[
"quantitative_data.describe()",
"_____no_output_____"
],
[
"quantitative_data.plot.box(rot=90, figsize=(15,5))",
"_____no_output_____"
],
[
"quantitative_data.plot(kind=\"bar\", x=\"code\", y=\"verses\", color=\"green\",figsize=(10,5))",
"_____no_output_____"
],
[
"relative_quantitative_data = quantitative_data.copy().plot.bar(rot=90, figsize=(15,5), x=\"code\")",
"_____no_output_____"
],
[
"relative_quantitative_data = quantitative_data.copy()\n\nfor column in relative_quantitative_data.columns:\n if(relative_quantitative_data[column].dtype == np.float64 or relative_quantitative_data[column].dtype == np.int64):\n relative_quantitative_data[column] = relative_quantitative_data[column]/quantitative_data[\"verses\"]\n else:\n relative_quantitative_data[column]\n \n",
"_____no_output_____"
],
[
"relative_quantitative_data.head()",
"_____no_output_____"
],
[
"relative_quantitative_data.plot.box(rot=90, figsize=(15,5))",
"_____no_output_____"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"diff pers\",\"diff orgs\", \"diff plas\"], figsize=(18,5), title=\"Amount of different entities in each book of the Bible (relative to amount of verses)\")",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"pers\",\"orgs\", \"plas\"], figsize=(20,5))",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"qs-oral\", \"qs-written\",\"qs-prayer\"], figsize=(20,5))",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"qs-written\", \"qs-soCalled\",\"qs-prayer\",\"qs-song\",\"qs-idea\",], figsize=(20,5))",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"qs-dream\",\"qs-oath\"], figsize=(20,5))\n\n",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"qs_columns = [\"qs-dream\",\"qs-oath\",\"qs-written\", \"qs-soCalled\",\"qs-song\",\"qs-idea\",\"qs-oral\", \"qs-prayer\"]\nsorted(qs_columns)",
"_____no_output_____"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"qs-oral\", \"qs-written\",\"qs-prayer\"], figsize=(20,5))",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"relative_quantitative_data.plot(kind=\"bar\", x=\"code\", y=[\"qs-oral\", \"qs-written\",\"qs-prayer\"], figsize=(20,5))",
"/usr/local/lib/python3.4/dist-packages/pandas/plotting/_core.py:1716: UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access\n series.name = label\n"
],
[
"quantitative_data.plot.scatter(x=\"verses\",y=\"pericopes\")",
"_____no_output_____"
],
[
"quantitative_data.plot.scatter(x=\"diff orgs\",y=\"diff plas\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd0e45102b96ccbfcd30368c17c892cde4c310d
| 76,562 |
ipynb
|
Jupyter Notebook
|
ipynb/deprecated/examples/android/benchmarks/Android_PCMark.ipynb
|
Binse-Park/lisa_ARM
|
aa7767654c95bb2cc0a2dddecd5b82a7fcf5c746
|
[
"Apache-2.0"
] | 159 |
2016-01-25T11:08:39.000Z
|
2022-03-28T05:20:41.000Z
|
ipynb/deprecated/examples/android/benchmarks/Android_PCMark.ipynb
|
Binse-Park/lisa_ARM
|
aa7767654c95bb2cc0a2dddecd5b82a7fcf5c746
|
[
"Apache-2.0"
] | 656 |
2016-01-25T11:16:56.000Z
|
2022-03-23T16:03:28.000Z
|
ipynb/deprecated/examples/android/benchmarks/Android_PCMark.ipynb
|
Binse-Park/lisa_ARM
|
aa7767654c95bb2cc0a2dddecd5b82a7fcf5c746
|
[
"Apache-2.0"
] | 116 |
2016-01-25T12:06:31.000Z
|
2022-03-28T08:43:28.000Z
| 136.474153 | 59,098 | 0.853766 |
[
[
[
"# PCMark benchmark on Android",
"_____no_output_____"
],
[
"The goal of this experiment is to run benchmarks on a Pixel device running Android with an EAS kernel and collect results. The analysis phase will consist in comparing EAS with other schedulers, that is comparing *sched* governor with:\n\n - interactive\n - performance\n - powersave\n - ondemand\n \nThe benchmark we will be using is ***PCMark*** (https://www.futuremark.com/benchmarks/pcmark-android). You will need to **manually install** the app on the Android device in order to run this Notebook.\n\nWhen opinening PCMark for the first time you will need to Install the work benchmark from inside the app.",
"_____no_output_____"
]
],
[
[
"import logging\nfrom conf import LisaLogging\nLisaLogging.setup()",
"2016-12-12 13:09:13,035 INFO : root : Using LISA logging configuration:\n2016-12-12 13:09:13,035 INFO : root : /home/vagrant/lisa/logging.conf\n"
],
[
"%pylab inline\n\nimport copy\nimport os\nfrom time import sleep\nfrom subprocess import Popen\nimport pandas as pd\n\n# Support to access the remote target\nimport devlib\nfrom env import TestEnv\n\n# Support for trace events analysis\nfrom trace import Trace\n\n# Suport for FTrace events parsing and visualization\nimport trappy",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"## Test environment setup\n\nFor more details on this please check out **examples/utils/testenv_example.ipynb**.",
"_____no_output_____"
],
[
"In case more than one Android device are conencted to the host, you must specify the ID of the device you want to target in `my_target_conf`. Run `adb devices` on your host to get the ID. Also, you have to specify the path to your android sdk in ANDROID_HOME.",
"_____no_output_____"
]
],
[
[
"# Setup a target configuration\nmy_target_conf = {\n \n # Target platform and board\n \"platform\" : 'android',\n\n # Add target support\n \"board\" : 'pixel',\n \n # Device ID\n \"device\" : \"HT6670300102\",\n \n \"ANDROID_HOME\" : \"/home/vagrant/lisa/tools/android-sdk-linux/\",\n \n # Define devlib modules to load\n \"modules\" : [\n 'cpufreq' # enable CPUFreq support\n ],\n}",
"_____no_output_____"
],
[
"my_tests_conf = {\n\n # Folder where all the results will be collected\n \"results_dir\" : \"Android_PCMark\",\n\n # Platform configurations to test\n \"confs\" : [\n {\n \"tag\" : \"pcmark\",\n \"flags\" : \"ftrace\", # Enable FTrace events\n \"sched_features\" : \"ENERGY_AWARE\", # enable EAS\n },\n ],\n}",
"_____no_output_____"
],
[
"# Initialize a test environment using:\n# the provided target configuration (my_target_conf)\n# the provided test configuration (my_test_conf)\nte = TestEnv(target_conf=my_target_conf, test_conf=my_tests_conf)\ntarget = te.target",
"2016-12-08 17:14:32,454 INFO : TestEnv : Using base path: /home/vagrant/lisa\n2016-12-08 17:14:32,455 INFO : TestEnv : Loading custom (inline) target configuration\n2016-12-08 17:14:32,456 INFO : TestEnv : Loading custom (inline) test configuration\n2016-12-08 17:14:32,457 INFO : TestEnv : External tools using:\n2016-12-08 17:14:32,458 INFO : TestEnv : ANDROID_HOME: /home/vagrant/lisa/tools/android-sdk-linux/\n2016-12-08 17:14:32,458 INFO : TestEnv : CATAPULT_HOME: /home/vagrant/lisa/tools/catapult\n2016-12-08 17:14:32,459 INFO : TestEnv : Loading board:\n2016-12-08 17:14:32,460 INFO : TestEnv : /home/vagrant/lisa/libs/utils/platforms/pixel.json\n2016-12-08 17:14:32,462 INFO : TestEnv : Devlib modules to load: [u'bl', u'cpufreq']\n2016-12-08 17:14:32,463 INFO : TestEnv : Connecting Android target [HT6670300102]\n2016-12-08 17:14:32,463 INFO : TestEnv : Connection settings:\n2016-12-08 17:14:32,464 INFO : TestEnv : {'device': 'HT6670300102'}\n2016-12-08 17:14:32,562 INFO : android : ls command is set to ls -1\n2016-12-08 17:14:33,287 INFO : TestEnv : Initializing target workdir:\n2016-12-08 17:14:33,288 INFO : TestEnv : /data/local/tmp/devlib-target\n2016-12-08 17:14:35,211 INFO : TestEnv : Topology:\n2016-12-08 17:14:35,213 INFO : TestEnv : [[0, 1], [2, 3]]\n2016-12-08 17:14:35,471 INFO : TestEnv : Loading default EM:\n2016-12-08 17:14:35,472 INFO : TestEnv : /home/vagrant/lisa/libs/utils/platforms/pixel.json\n2016-12-08 17:14:35,475 WARNING : TestEnv : Wipe previous contents of the results folder:\n2016-12-08 17:14:35,475 WARNING : TestEnv : /home/vagrant/lisa/results/Android_PCMark\n2016-12-08 17:14:35,476 INFO : TestEnv : Set results folder to:\n2016-12-08 17:14:35,476 INFO : TestEnv : /home/vagrant/lisa/results/Android_PCMark\n2016-12-08 17:14:35,476 INFO : TestEnv : Experiment results available also in:\n2016-12-08 17:14:35,477 INFO : TestEnv : /home/vagrant/lisa/results_latest\n"
]
],
[
[
"## Support Functions",
"_____no_output_____"
],
[
"This set of support functions will help us running the benchmark using different CPUFreq governors.",
"_____no_output_____"
]
],
[
[
"def set_performance():\n target.cpufreq.set_all_governors('performance')\n\ndef set_powersave():\n target.cpufreq.set_all_governors('powersave')\n\ndef set_interactive():\n target.cpufreq.set_all_governors('interactive')\n\ndef set_sched():\n target.cpufreq.set_all_governors('sched')\n\ndef set_ondemand():\n target.cpufreq.set_all_governors('ondemand')\n \n for cpu in target.list_online_cpus():\n tunables = target.cpufreq.get_governor_tunables(cpu)\n target.cpufreq.set_governor_tunables(\n cpu,\n 'ondemand',\n **{'sampling_rate' : tunables['sampling_rate_min']}\n )",
"_____no_output_____"
],
[
"# CPUFreq configurations to test\nconfs = {\n 'performance' : {\n 'label' : 'prf',\n 'set' : set_performance,\n },\n #'powersave' : {\n # 'label' : 'pws',\n # 'set' : set_powersave,\n #},\n 'interactive' : {\n 'label' : 'int',\n 'set' : set_interactive,\n },\n #'sched' : {\n # 'label' : 'sch',\n # 'set' : set_sched,\n #},\n #'ondemand' : {\n # 'label' : 'odm',\n # 'set' : set_ondemand,\n #}\n}\n\n# The set of results for each comparison test\nresults = {}",
"_____no_output_____"
],
[
"#Check if PCMark si available on the device\n\ndef check_packages(pkgname):\n try:\n output = target.execute('pm list packages -f | grep -i {}'.format(pkgname))\n except Exception:\n raise RuntimeError('Package: [{}] not availabe on target'.format(pkgname))\n\n# Check for specified PKG name being available on target\ncheck_packages('com.futuremark.pcmark.android.benchmark')",
"_____no_output_____"
],
[
"# Function that helps run a PCMark experiment\n\ndef pcmark_run(exp_dir):\n # Unlock device screen (assume no password required)\n target.execute('input keyevent 82')\n # Start PCMark on the target device\n target.execute('monkey -p com.futuremark.pcmark.android.benchmark -c android.intent.category.LAUNCHER 1')\n # Wait few seconds to make sure the app is loaded\n sleep(5)\n \n # Flush entire log\n target.clear_logcat()\n \n # Run performance workload (assume screen is vertical)\n target.execute('input tap 750 1450')\n # Wait for completion (10 minutes in total) and collect log\n log_file = os.path.join(exp_dir, 'log.txt')\n # Wait 5 minutes\n sleep(300)\n # Start collecting the log\n with open(log_file, 'w') as log:\n logcat = Popen(['adb logcat', 'com.futuremark.pcmandroid.VirtualMachineState:*', '*:S'],\n stdout=log,\n shell=True)\n # Wait additional two minutes for benchmark to complete\n sleep(300)\n\n # Terminate logcat\n logcat.kill()\n\n # Get scores from logcat\n score_file = os.path.join(exp_dir, 'score.txt')\n os.popen('grep -o \"PCMA_.*_SCORE .*\" {} | sed \"s/ = / /g\" | sort -u > {}'.format(log_file, score_file))\n \n # Close application\n target.execute('am force-stop com.futuremark.pcmark.android.benchmark')\n \n return score_file",
"_____no_output_____"
],
[
"# Function that helps run PCMark for different governors\n\ndef experiment(governor, exp_dir):\n os.system('mkdir -p {}'.format(exp_dir));\n\n logging.info('------------------------')\n logging.info('Run workload using %s governor', governor)\n confs[governor]['set']()\n\n ### Run the benchmark ###\n score_file = pcmark_run(exp_dir)\n \n # Save the score as a dictionary\n scores = dict()\n with open(score_file, 'r') as f:\n lines = f.readlines()\n for l in lines:\n info = l.split()\n scores.update({info[0] : float(info[1])})\n \n # return all the experiment data\n return {\n 'dir' : exp_dir,\n 'scores' : scores,\n }",
"_____no_output_____"
]
],
[
[
"## Run PCMark and collect scores",
"_____no_output_____"
]
],
[
[
"# Run the benchmark in all the configured governors\nfor governor in confs:\n test_dir = os.path.join(te.res_dir, governor)\n res = experiment(governor, test_dir)\n results[governor] = copy.deepcopy(res)",
"2016-12-08 17:14:43,080 INFO : root : ------------------------\n2016-12-08 17:14:43,081 INFO : root : Run workload using performance governor\n2016-12-08 17:24:50,386 INFO : root : ------------------------\n2016-12-08 17:24:50,387 INFO : root : Run workload using interactive governor\n"
]
],
[
[
"After running the benchmark for the specified governors we can show and plot the scores:",
"_____no_output_____"
]
],
[
[
"# Create results DataFrame\ndata = {}\nfor governor in confs:\n data[governor] = {}\n for score_name, score in results[governor]['scores'].iteritems():\n data[governor][score_name] = score\n\ndf = pd.DataFrame.from_dict(data)\ndf",
"_____no_output_____"
],
[
"df.plot(kind='bar', rot=45, figsize=(16,8),\n title='PCMark scores vs SchedFreq governors');",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd0f023bb842c7185a5949fcea5422853a21baf
| 181,602 |
ipynb
|
Jupyter Notebook
|
Basics/#7 Exploratory Data Analysis(EDA).ipynb
|
nikkkhil067/Machine-Learning
|
13f456eaee6232fdb6f3515c08f1cc229474497d
|
[
"MIT"
] | null | null | null |
Basics/#7 Exploratory Data Analysis(EDA).ipynb
|
nikkkhil067/Machine-Learning
|
13f456eaee6232fdb6f3515c08f1cc229474497d
|
[
"MIT"
] | null | null | null |
Basics/#7 Exploratory Data Analysis(EDA).ipynb
|
nikkkhil067/Machine-Learning
|
13f456eaee6232fdb6f3515c08f1cc229474497d
|
[
"MIT"
] | null | null | null | 55.791705 | 16,104 | 0.657069 |
[
[
[
"import numpy as numpy\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n%matplotlib inline ",
"_____no_output_____"
],
[
"train = pd.read_csv('titanic_train.csv')",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
]
],
[
[
"### Missing Data ",
"_____no_output_____"
]
],
[
[
"train.isnull()",
"_____no_output_____"
],
[
"sns.heatmap(train.isnull(),yticklabels=False,cbar=False,cmap='viridis')",
"_____no_output_____"
]
],
[
[
"Roughly 20 percent of the Age data is missing. The proportion of Age missing is likely small enough for reasonable replacement with some form of imputation. Looking at the Cabin column, it looks like we are just missing too much of that data to do something useful with at a basic level. We'll probably drop this later, or change it to another feature like \"Cabin Known: 1 or 0\"",
"_____no_output_____"
]
],
[
[
"sns.set_style('whitegrid')\nsns.countplot(x='Survived',data=train)",
"_____no_output_____"
],
[
"sns.set_style('whitegrid')\nsns.countplot(x='Survived',hue='Sex',data=train,palette='RdBu_r')",
"_____no_output_____"
],
[
"sns.set_style('whitegrid')\nsns.countplot(x='Survived',hue='Pclass',data=train,palette='rainbow')",
"_____no_output_____"
],
[
"sns.distplot(train['Age'].dropna(),kde=False,color='darkred',bins=40)",
"c:\\users\\nikhil gupta\\appdata\\local\\programs\\python\\python38\\lib\\site-packages\\seaborn\\distributions.py:2557: FutureWarning: `distplot` is a deprecated function and will be removed in a future version. Please adapt your code to use either `displot` (a figure-level function with similar flexibility) or `histplot` (an axes-level function for histograms).\n warnings.warn(msg, FutureWarning)\n"
],
[
"train['Age'].hist(bins=30,color='darkred',alpha=0.3)",
"_____no_output_____"
],
[
"sns.countplot(x='SibSp',data=train)",
"_____no_output_____"
],
[
"train['Fare'].hist(color='green',bins=40,figsize=(8,4))",
"_____no_output_____"
]
],
[
[
"### Cufflinks for plots ",
"_____no_output_____"
]
],
[
[
"import cufflinks as cf\ncf.go_offline()",
"_____no_output_____"
],
[
"train['Fare'].iplot(kind='hist',bins=30,color='green')",
"_____no_output_____"
]
],
[
[
"### Data Cleaning\nWe want to fill in missing age data instead of just dropping the missing age data rows. One way to do this is by filling in the mean age of all the passengers (imputation). However we can be smarter about this and check the average age by passenger class. ",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(12, 7))\nsns.boxplot(x='Pclass',y='Age',data=train,palette='winter')",
"_____no_output_____"
]
],
[
[
"We can see the wealthier passengers in the higher classes tend to be older, which makes sense. We'll use these average age values to impute based on Pclass for Age.",
"_____no_output_____"
]
],
[
[
"def impute_age(cols):\n Age = cols[0]\n Pclass = cols[1]\n \n if pd.isnull(Age):\n\n if Pclass == 1:\n return 37\n\n elif Pclass == 2:\n return 29\n\n else:\n return 24\n\n else:\n return Age",
"_____no_output_____"
]
],
[
[
"Now apply that function!",
"_____no_output_____"
]
],
[
[
"train['Age'] = train[['Age','Pclass']].apply(impute_age,axis=1)",
"_____no_output_____"
]
],
[
[
" Now let's check that heat map again!",
"_____no_output_____"
]
],
[
[
"sns.heatmap(train.isnull(),yticklabels=False,cbar=False,cmap='viridis')",
"_____no_output_____"
]
],
[
[
"Great! Let's go ahead and drop the Cabin column and the row in Embarked that is NaN.",
"_____no_output_____"
]
],
[
[
"train.drop('Cabin',axis=1,inplace=True)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"train.dropna(inplace=True)",
"_____no_output_____"
]
],
[
[
"### Converting Categorical Features¶\nWe'll need to convert categorical features to dummy variables using pandas! Otherwise our machine learning algorithm won't be able to directly take in those features as inputs.",
"_____no_output_____"
]
],
[
[
"train.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 889 entries, 0 to 890\nData columns (total 11 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 PassengerId 889 non-null int64 \n 1 Survived 889 non-null int64 \n 2 Pclass 889 non-null int64 \n 3 Name 889 non-null object \n 4 Sex 889 non-null object \n 5 Age 889 non-null float64\n 6 SibSp 889 non-null int64 \n 7 Parch 889 non-null int64 \n 8 Ticket 889 non-null object \n 9 Fare 889 non-null float64\n 10 Embarked 889 non-null object \ndtypes: float64(2), int64(5), object(4)\nmemory usage: 83.3+ KB\n"
],
[
"pd.get_dummies(train['Embarked'],drop_first=True).head()",
"_____no_output_____"
],
[
"sex = pd.get_dummies(train['Sex'],drop_first=True)\nembark = pd.get_dummies(train['Embarked'],drop_first=True)",
"_____no_output_____"
],
[
"train.drop(['Sex','Embarked','Name','Ticket'],axis=1,inplace=True)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"train = pd.concat([train,sex,embark],axis=1)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd1018171980546f3bf888add730efa1410eeba
| 7,406 |
ipynb
|
Jupyter Notebook
|
chatbotproject/chatbot_project.ipynb
|
rlalastjd782/rlalastjd782.github.io
|
7d708dd233991b5ebab9d39d7d3cf8969acbe27c
|
[
"MIT"
] | null | null | null |
chatbotproject/chatbot_project.ipynb
|
rlalastjd782/rlalastjd782.github.io
|
7d708dd233991b5ebab9d39d7d3cf8969acbe27c
|
[
"MIT"
] | null | null | null |
chatbotproject/chatbot_project.ipynb
|
rlalastjd782/rlalastjd782.github.io
|
7d708dd233991b5ebab9d39d7d3cf8969acbe27c
|
[
"MIT"
] | null | null | null | 49.704698 | 262 | 0.55131 |
[
[
[
"<a href=\"https://colab.research.google.com/github/rlalastjd782/rlalastjd782.github.io/blob/main/chatbotproject/chatbot_project.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import re\nimport requests\nfrom bs4 import BeautifulSoup\nimport pandas as pd\n\n# url 따오기\n\n# 판례\n\n# 뒷자리\nnumlist2= []\nfor num in range(3,600):\n num = format(num,'05')\n numlist2.append(num)\n\n# 앞자리\n\nnumlist = []\nfor num in range(1,25):\n num = format(num,'03')\n numlist.append(num)\n\n# url 코드\nurls = []\nfor i in numlist:\n for j in numlist2:\n url = \"https://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-{0}-{1}\".format(i,j)\n urls.append(url)\n\n#print(urls[0:10])\ndata = []\nfor url in urls[0:15] :\n print(url)\n webpage = requests.get(url)\n #print(webpage.text)\n soup = BeautifulSoup(webpage.content, \"html.parser\")\n dt = soup.select_one(\"#print_page\").text\n dt = dt.replace(\"\\n\", \"\")\n data.append(dt)\n#print(data) \n#data.strip()\n#print(data[1])\ndf = pd.DataFrame({\n 'data' : data,\n 'url' : url\n})\n\nprint(df)",
"https://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00003\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00004\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00005\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00006\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00007\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00008\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00009\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00010\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00011\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00012\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00013\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00014\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00015\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00016\nhttps://www.klac.or.kr/legalinfo/counselView.do?folderId=000&scdFolderId=&pageIndex=1&searchCnd=0&searchWrd=&caseId=case-001-00017\n data \\\n0 구분노동 > 근로일반제목회사분할로 퇴직금 일괄수령 후 재입사 형식 취한 경우 계속근... \n1 구분노동 > 근로일반제목학습지판매위탁 상담교사도 근로기준법상의 근로자인지질문저는 학... \n2 구분노동 > 근로일반제목대학병원의 전공의가 근로기준법상의 근로자에 해당하는지질문저는... \n3 구분노동 > 근로일반제목학교법인이 운영하는 대학교의 시간강사가 근로자인지질문대학교에... \n4 구분노동 > 근로일반제목자기소유 버스로 사업주의 회원 운송을 하면 근로기준법상 근로... \n5 구분노동 > 근로일반제목외국인회사의 경우에도 근로기준법이 적용되는지질문저는 외국인이... \n6 구분노동 > 근로일반제목산업기술연수생도 근로기준법상 근로자인지질문중국인 乙은 국내 ... \n7 구분노동 > 근로일반제목경리부장 겸 상무이사의 경우 근로기준법상의 근로자에 해당되는... \n8 구분노동 > 근로일반제목실업자도 노동조합 및 노동관계조정법상의 근로자에 해당되는지질... \n9 구분노동 > 근로일반제목아파트관리업자와 근로계약한 자의 입주자대표회의에 대한 임금청... \n10 구분노동 > 근로일반제목파견근로자의 사용사업자에 대한 근로자지위확인질문저희는 A발전... \n11 구분노동 > 근로일반제목골프장 캐디가 근로기준법상 근로자에 해당하는지 여부질문골프장... \n12 구분노동 > 근로일반제목화물운송회사와 화물자동차운전용역계약을 체결한 운송기사의 근로... \n13 구분노동 > 근로일반제목근로기준법이 적용되는 상시 5인 이상의 근로자를 사용하는 사... \n14 구분노동 > 임금 및 퇴직금제목상시4인 이하 근로자를 사용하는 사업장에 근무한 사람... \n\n url \n0 https://www.klac.or.kr/legalinfo/counselView.d... \n1 https://www.klac.or.kr/legalinfo/counselView.d... \n2 https://www.klac.or.kr/legalinfo/counselView.d... \n3 https://www.klac.or.kr/legalinfo/counselView.d... \n4 https://www.klac.or.kr/legalinfo/counselView.d... \n5 https://www.klac.or.kr/legalinfo/counselView.d... \n6 https://www.klac.or.kr/legalinfo/counselView.d... \n7 https://www.klac.or.kr/legalinfo/counselView.d... \n8 https://www.klac.or.kr/legalinfo/counselView.d... \n9 https://www.klac.or.kr/legalinfo/counselView.d... \n10 https://www.klac.or.kr/legalinfo/counselView.d... \n11 https://www.klac.or.kr/legalinfo/counselView.d... \n12 https://www.klac.or.kr/legalinfo/counselView.d... \n13 https://www.klac.or.kr/legalinfo/counselView.d... \n14 https://www.klac.or.kr/legalinfo/counselView.d... \n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
cbd1019a6e53a15959d68d4fdd0f4297d938f7ce
| 48,628 |
ipynb
|
Jupyter Notebook
|
examples/SlowBgpUpdates/ExampleAnalysisOfSlowBgpUpdatesUsingJupyter.ipynb
|
aristanetworks/pcapinspect
|
ce6016f189d2ac70e3c5b257963caef701e638b4
|
[
"MIT"
] | 2 |
2022-02-14T13:01:20.000Z
|
2022-02-14T16:54:33.000Z
|
examples/SlowBgpUpdates/ExampleAnalysisOfSlowBgpUpdatesUsingJupyter.ipynb
|
aristanetworks/pcapinspect
|
ce6016f189d2ac70e3c5b257963caef701e638b4
|
[
"MIT"
] | null | null | null |
examples/SlowBgpUpdates/ExampleAnalysisOfSlowBgpUpdatesUsingJupyter.ipynb
|
aristanetworks/pcapinspect
|
ce6016f189d2ac70e3c5b257963caef701e638b4
|
[
"MIT"
] | null | null | null | 196.080645 | 25,940 | 0.910031 |
[
[
[
"# Analysis with PcapInspect of .pcap file showing slow sending of BGP updates\nThis notebook was developed interactively in [Jupyter](https://jupyter.org/).\n\nUnfortunately, the .pcap file processed in this example can't be shared externally. In this investigation, an observation was made that after software upgrade of an Arista switch, some other peers started taking a very long time to deliver BGP Update messages.\n\nOf course, the rate at which the peer sent routes was mostly the responsibility of the peer's BGP implementation. However, it was possible that the Arista device wasn’t processing fast enough and consequently sending the peer a reduced TCP window size, which _would_ slow it down.\n\nUsing PcapInspect, we generate a bunch of statistics and data extracted from the .pcap, but the most interesting view is that provided by the plots shown near the end.",
"_____no_output_____"
]
],
[
[
"# Grab output from matplotlib and display the graphics in Jupyter. For other options, see\n# https://medium.com/@1522933668924/using-matplotlib-in-jupyter-notebooks-comparing-methods-and-some-tips-python-c38e85b40ba1\n%matplotlib inline\n\nimport sys\nsys.path.append(\"../..\") # Hack to get PcapInspect and other modules\nimport PcapInspect",
"_____no_output_____"
],
[
"pcapInspect = PcapInspect.PcapInspect('SlowBgpUpdates.pcap', stopAnalysisTime=300)",
"_____no_output_____"
],
[
"pcapInspect.plugins[ 'BgpPlugin' ].findEor('10.0.0.100', 'Peer')",
"Peer EOR is in frame 1463 at 283.864007\n"
],
[
"pcapInspect.doDeltaAnalysis('10.0.0.100', 'Peer')",
"\nPeer frame time deltas\n All:\n Average frame time delta: 0.365216 (861 frames)\n Minimum delta 0.000004 at 46.820134 (frame 103)\n Maximum delta 9.575227 at 298.687969 (frame 1467)\n BGP:\n Average frame time delta: 0.403773 (762 frames)\n Minimum delta 0.000004 at 46.820134 (frame 103)\n Maximum delta 9.575227 at 298.687969 (frame 1467)\n BGP Update:\n Average frame time delta: 0.396430 (754 frames)\n Minimum delta 0.000004 at 46.820134 (frame 103)\n Maximum delta 9.575227 at 298.687969 (frame 1467)\n TCP ACK:\n Average frame time delta: 0.365216 (861 frames)\n Minimum delta 0.000004 at 46.820134 (frame 103)\n Maximum delta 9.575227 at 298.687969 (frame 1467)\n"
],
[
"pcapInspect.doDeltaAnalysis( '10.0.0.101', 'Arista' )",
"\nArista frame time deltas\n All:\n Average frame time delta: 0.031403 (629 frames)\n Minimum delta 0.000006 at 46.820114 (frame 100)\n Maximum delta 8.052363 at 308.569725 (frame 1471)\n BGP:\n Average frame time delta: 0.957338 (18 frames)\n Minimum delta 0.000012 at 15.892623 (frame 49)\n Maximum delta 8.052363 at 308.569725 (frame 1471)\n BGP Update:\n Average frame time delta: 0.666116 (4 frames)\n Minimum delta 0.377759 at 15.786946 (frame 47)\n Maximum delta 0.871378 at 14.168419 (frame 39)\n TCP ACK:\n Average frame time delta: 0.031403 (629 frames)\n Minimum delta 0.000006 at 46.820114 (frame 100)\n Maximum delta 8.052363 at 308.569725 (frame 1471)\n"
],
[
"winSizePlotData = pcapInspect.doWindowSizeAnalysis( '10.0.0.101', 'Arista' )\nframeAndBytePlotData = pcapInspect.doFrameAndByteCount( '10.0.0.100', 'Peer' )",
"\nAll Arista TCP Window Size:\n Minimum window size 128 at 212.469297 (frame 1027)\n Maximum window size 29312 at 0.001436 (frame 3)\n\nCounting frames, msgs & bytes\n All Peer frames:\n endOfLastTimeSlot: 298.687970, lastFrameTime: 298.687969, timeSlotWidth: 3.733600\n"
]
],
[
[
"# The issue appears to be with the peer\nAs can be seen by comparing the 2 graphics below, after a while, the Arista device settles down to a fairly steady window size of 16k. There are some brief dips associated with out-of-order arrival of TCP packets, but it's generally steady. In spite of this, there is a ~100 second gap where the peer appears to be transmitting very little data. This kind of insight is very difficult to get looking at individual frames (after filtering, the PCAP contained about 1500 frames).\n\n",
"_____no_output_____"
]
],
[
[
"plotter = PcapInspect.Plotter()\nplotter.plot( winSizePlotData, 'lines' )",
"_____no_output_____"
],
[
"imageNameTemplate = pcapInspect.directory + 'Sender' +'_%s_count_' + pcapInspect.baseFilename + '.png'\nplotData = frameAndBytePlotData[ 'byte' ]\nplotData[ 'imageName' ] = imageNameTemplate % 'byte'\nplotter.plot( plotData, 'boxes' )",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd1060170919b53161a546cc79439a6713db7ee
| 3,957 |
ipynb
|
Jupyter Notebook
|
code/compile_facs_data.ipynb
|
bfurtwa/RETICLE
|
80bfd8e337725b6e22779d060a330c92ccd37e0c
|
[
"MIT"
] | null | null | null |
code/compile_facs_data.ipynb
|
bfurtwa/RETICLE
|
80bfd8e337725b6e22779d060a330c92ccd37e0c
|
[
"MIT"
] | null | null | null |
code/compile_facs_data.ipynb
|
bfurtwa/RETICLE
|
80bfd8e337725b6e22779d060a330c92ccd37e0c
|
[
"MIT"
] | null | null | null | 30.674419 | 336 | 0.515795 |
[
[
[
"### Notebook to compile the facs data table from the FlowJo output (+IndexSort plugin).\n.fcs files were gated in FlowJo and well location was preserved using the IndexSort plugin. Bi-exponential transform was applied and the FACS data was exported as the transformed 'channel' tables. To preserve the well location, also the un-transformed 'scale' tables were exported. These tables are beeing merged in this notebook.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport os",
"_____no_output_____"
],
[
"plates = ['8227_INX_celltype_P1_003',\n '8227_INX_celltype_P2_004',\n '8227_INX_celltype_P3_005']\n\npath = '../data/facs_data/'",
"_____no_output_____"
],
[
"# get all csv files in channel and scale folder\nfiles = [f for f in os.listdir(path+'channel/') if f.endswith(\".csv\")]\nfcs = ['_'.join(x.split('_')[1:-1]) for x in files]\ndata = pd.DataFrame({'file': files, 'fcs': fcs, 'plate': [plates.index(p) for p in fcs]}).set_index('file')\ndfs_channel = [pd.DataFrame() for i in range(len(plates))]\n\nfor f in files:\n fj = pd.read_csv(path+'channel/{}'.format(f))\n dfs_channel[data.loc[f, 'plate']] = dfs_channel[data.loc[f, 'plate']].append(fj)\n\ndfs_scale = [pd.DataFrame() for i in range(len(plates))]\nfor f in files:\n fj = pd.read_csv(path+'scale/{}'.format(f))\n dfs_scale[data.loc[f, 'plate']] = dfs_scale[data.loc[f, 'plate']].append(fj)\n\n# replace the index columns with the non-transformed values from scale\nfor i in range(len(dfs_channel)):\n dfs_channel[i].loc[:, ['IdxCol', 'IdxRow', 'Time']] = dfs_scale[i].loc[:, ['IdxCol', 'IdxRow', 'Time']]\n\n# transform row index in letter and make Well column. Somehow, the IdxRow index from FJ is reversed\nfor i in range(len(dfs_channel)):\n dfs_channel[i][\"IdxRow\"] = dfs_channel[i][\"IdxRow\"].apply(\n lambda x: [\n \"A\",\n \"B\",\n \"C\",\n \"D\",\n \"E\",\n \"F\",\n \"G\",\n \"H\",\n \"I\",\n \"J\",\n \"K\",\n \"L\",\n \"M\",\n \"N\",\n \"O\",\n \"P\",\n ][-x]\n )\n dfs_channel[i][\"Well\"] = dfs_channel[i][\"IdxRow\"] + dfs_channel[i][\"IdxCol\"].astype(str)\n dfs_channel[i] = dfs_channel[i].rename(columns={'IdxRow': 'Row', 'IdxCol': 'Column'})\n\n# save one table for each plate\n[dfs_channel[i].to_csv(path+'facs_data_P{}.txt'.format(i+1), sep='\\t', index=False) for i in range(len(dfs_channel))]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd10dd0c76b668e4bacf346ff9afb0034124364
| 76,102 |
ipynb
|
Jupyter Notebook
|
keras-study/dive-into-keras.ipynb
|
BAlmeidaS/deep-learning
|
3f6ab21cf08dcaaa4ed1cacb9e8c5642ab89db52
|
[
"MIT"
] | null | null | null |
keras-study/dive-into-keras.ipynb
|
BAlmeidaS/deep-learning
|
3f6ab21cf08dcaaa4ed1cacb9e8c5642ab89db52
|
[
"MIT"
] | null | null | null |
keras-study/dive-into-keras.ipynb
|
BAlmeidaS/deep-learning
|
3f6ab21cf08dcaaa4ed1cacb9e8c5642ab89db52
|
[
"MIT"
] | null | null | null | 34.765646 | 98 | 0.458083 |
[
[
[
"import numpy as np\n\nfrom keras.models import Sequential\nfrom keras.utils import np_utils\nfrom keras.layers.core import Dense, Activation\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"Using TensorFlow backend.\n"
],
[
"X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)\ny = np.array([[0], [0], [0], [1]], dtype=np.float32)\ny = np_utils.to_categorical(y)\n\nmodel = Sequential()\n\nmodel.add(Dense(32, input_dim=X.shape[1]))\n\nmodel.add(Activation('softmax'))\n\nmodel.add(Dense(2))\n\nmodel.add(Activation('sigmoid'))\n\ny",
"_____no_output_____"
],
[
"model.compile(loss=\"categorical_crossentropy\", optimizer=\"adam\", metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_25 (Dense) (None, 32) 96 \n_________________________________________________________________\nactivation_25 (Activation) (None, 32) 0 \n_________________________________________________________________\ndense_26 (Dense) (None, 2) 66 \n_________________________________________________________________\nactivation_26 (Activation) (None, 2) 0 \n=================================================================\nTotal params: 162\nTrainable params: 162\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"model.fit(X, y, nb_epoch=1000, verbose=2)",
"Epoch 1/1000\n - 0s - loss: 0.6963 - acc: 0.2500\nEpoch 2/1000\n - 0s - loss: 0.6957 - acc: 0.2500\nEpoch 3/1000\n - 0s - loss: 0.6952 - acc: 0.2500\nEpoch 4/1000\n - 0s - loss: 0.6946 - acc: 0.2500\nEpoch 5/1000\n - 0s - loss: 0.6941 - acc: 0.2500\nEpoch 6/1000\n - 0s - loss: 0.6935 - acc: 0.2500\nEpoch 7/1000\n - 0s - loss: 0.6930 - acc: 0.7500\nEpoch 8/1000\n - 0s - loss: 0.6925 - acc: 0.7500\nEpoch 9/1000\n - 0s - loss: 0.6919 - acc: 0.7500\nEpoch 10/1000\n - 0s - loss: 0.6914 - acc: 0.7500\nEpoch 11/1000\n - 0s - loss: 0.6908 - acc: 0.7500\nEpoch 12/1000\n - 0s - loss: 0.6903 - acc: 0.7500\nEpoch 13/1000\n - 0s - loss: 0.6897 - acc: 0.7500\nEpoch 14/1000\n - 0s - loss: 0.6892 - acc: 0.7500\nEpoch 15/1000\n - 0s - loss: 0.6887 - acc: 0.7500\nEpoch 16/1000\n - 0s - loss: 0.6881 - acc: 0.7500\nEpoch 17/1000\n - 0s - loss: 0.6876 - acc: 0.7500\nEpoch 18/1000\n - 0s - loss: 0.6871 - acc: 0.7500\nEpoch 19/1000\n - 0s - loss: 0.6865 - acc: 0.7500\nEpoch 20/1000\n - 0s - loss: 0.6860 - acc: 0.7500\nEpoch 21/1000\n - 0s - loss: 0.6855 - acc: 0.7500\nEpoch 22/1000\n - 0s - loss: 0.6850 - acc: 0.7500\nEpoch 23/1000\n - 0s - loss: 0.6844 - acc: 0.7500\nEpoch 24/1000\n - 0s - loss: 0.6839 - acc: 0.7500\nEpoch 25/1000\n - 0s - loss: 0.6834 - acc: 0.7500\nEpoch 26/1000\n - 0s - loss: 0.6829 - acc: 0.7500\nEpoch 27/1000\n - 0s - loss: 0.6824 - acc: 0.7500\nEpoch 28/1000\n - 0s - loss: 0.6818 - acc: 0.7500\nEpoch 29/1000\n - 0s - loss: 0.6813 - acc: 0.7500\nEpoch 30/1000\n - 0s - loss: 0.6808 - acc: 0.7500\nEpoch 31/1000\n - 0s - loss: 0.6803 - acc: 0.7500\nEpoch 32/1000\n - 0s - loss: 0.6798 - acc: 0.7500\nEpoch 33/1000\n - 0s - loss: 0.6793 - acc: 0.7500\nEpoch 34/1000\n - 0s - loss: 0.6788 - acc: 0.7500\nEpoch 35/1000\n - 0s - loss: 0.6783 - acc: 0.7500\nEpoch 36/1000\n - 0s - loss: 0.6778 - acc: 0.7500\nEpoch 37/1000\n - 0s - loss: 0.6772 - acc: 0.7500\nEpoch 38/1000\n - 0s - loss: 0.6767 - acc: 0.7500\nEpoch 39/1000\n - 0s - loss: 0.6762 - acc: 0.7500\nEpoch 40/1000\n - 0s - loss: 0.6757 - acc: 0.7500\nEpoch 41/1000\n - 0s - loss: 0.6752 - acc: 0.7500\nEpoch 42/1000\n - 0s - loss: 0.6748 - acc: 0.7500\nEpoch 43/1000\n - 0s - loss: 0.6743 - acc: 0.7500\nEpoch 44/1000\n - 0s - loss: 0.6738 - acc: 0.7500\nEpoch 45/1000\n - 0s - loss: 0.6733 - acc: 0.7500\nEpoch 46/1000\n - 0s - loss: 0.6728 - acc: 0.7500\nEpoch 47/1000\n - 0s - loss: 0.6723 - acc: 0.7500\nEpoch 48/1000\n - 0s - loss: 0.6718 - acc: 0.7500\nEpoch 49/1000\n - 0s - loss: 0.6713 - acc: 0.7500\nEpoch 50/1000\n - 0s - loss: 0.6708 - acc: 0.7500\nEpoch 51/1000\n - 0s - loss: 0.6703 - acc: 0.7500\nEpoch 52/1000\n - 0s - loss: 0.6699 - acc: 0.7500\nEpoch 53/1000\n - 0s - loss: 0.6694 - acc: 0.7500\nEpoch 54/1000\n - 0s - loss: 0.6689 - acc: 0.7500\nEpoch 55/1000\n - 0s - loss: 0.6684 - acc: 0.7500\nEpoch 56/1000\n - 0s - loss: 0.6679 - acc: 0.7500\nEpoch 57/1000\n - 0s - loss: 0.6675 - acc: 0.7500\nEpoch 58/1000\n - 0s - loss: 0.6670 - acc: 0.7500\nEpoch 59/1000\n - 0s - loss: 0.6665 - acc: 0.7500\nEpoch 60/1000\n - 0s - loss: 0.6661 - acc: 0.7500\nEpoch 61/1000\n - 0s - loss: 0.6656 - acc: 0.7500\nEpoch 62/1000\n - 0s - loss: 0.6651 - acc: 0.7500\nEpoch 63/1000\n - 0s - loss: 0.6646 - acc: 0.7500\nEpoch 64/1000\n - 0s - loss: 0.6642 - acc: 0.7500\nEpoch 65/1000\n - 0s - loss: 0.6637 - acc: 0.7500\nEpoch 66/1000\n - 0s - loss: 0.6633 - acc: 0.7500\nEpoch 67/1000\n - 0s - loss: 0.6628 - acc: 0.7500\nEpoch 68/1000\n - 0s - loss: 0.6623 - acc: 0.7500\nEpoch 69/1000\n - 0s - loss: 0.6619 - acc: 0.7500\nEpoch 70/1000\n - 0s - loss: 0.6614 - acc: 0.7500\nEpoch 71/1000\n - 0s - loss: 0.6610 - acc: 0.7500\nEpoch 72/1000\n - 0s - loss: 0.6605 - acc: 0.7500\nEpoch 73/1000\n - 0s - loss: 0.6601 - acc: 0.7500\nEpoch 74/1000\n - 0s - loss: 0.6596 - acc: 0.7500\nEpoch 75/1000\n - 0s - loss: 0.6591 - acc: 0.7500\nEpoch 76/1000\n - 0s - loss: 0.6587 - acc: 0.7500\nEpoch 77/1000\n - 0s - loss: 0.6582 - acc: 0.7500\nEpoch 78/1000\n - 0s - loss: 0.6578 - acc: 0.7500\nEpoch 79/1000\n - 0s - loss: 0.6574 - acc: 0.7500\nEpoch 80/1000\n - 0s - loss: 0.6569 - acc: 0.7500\nEpoch 81/1000\n - 0s - loss: 0.6565 - acc: 0.7500\nEpoch 82/1000\n - 0s - loss: 0.6560 - acc: 0.7500\nEpoch 83/1000\n - 0s - loss: 0.6556 - acc: 0.7500\nEpoch 84/1000\n - 0s - loss: 0.6551 - acc: 0.7500\nEpoch 85/1000\n - 0s - loss: 0.6547 - acc: 0.7500\nEpoch 86/1000\n - 0s - loss: 0.6543 - acc: 0.7500\nEpoch 87/1000\n - 0s - loss: 0.6538 - acc: 0.7500\nEpoch 88/1000\n - 0s - loss: 0.6534 - acc: 0.7500\nEpoch 89/1000\n - 0s - loss: 0.6530 - acc: 0.7500\nEpoch 90/1000\n - 0s - loss: 0.6525 - acc: 0.7500\nEpoch 91/1000\n - 0s - loss: 0.6521 - acc: 0.7500\nEpoch 92/1000\n - 0s - loss: 0.6517 - acc: 0.7500\nEpoch 93/1000\n - 0s - loss: 0.6512 - acc: 0.7500\nEpoch 94/1000\n - 0s - loss: 0.6508 - acc: 0.7500\nEpoch 95/1000\n - 0s - loss: 0.6504 - acc: 0.7500\nEpoch 96/1000\n - 0s - loss: 0.6500 - acc: 0.7500\nEpoch 97/1000\n - 0s - loss: 0.6495 - acc: 0.7500\nEpoch 98/1000\n - 0s - loss: 0.6491 - acc: 0.7500\nEpoch 99/1000\n - 0s - loss: 0.6487 - acc: 0.7500\nEpoch 100/1000\n - 0s - loss: 0.6483 - acc: 0.7500\nEpoch 101/1000\n - 0s - loss: 0.6479 - acc: 0.7500\nEpoch 102/1000\n - 0s - loss: 0.6474 - acc: 0.7500\nEpoch 103/1000\n - 0s - loss: 0.6470 - acc: 0.7500\nEpoch 104/1000\n - 0s - loss: 0.6466 - acc: 0.7500\nEpoch 105/1000\n - 0s - loss: 0.6462 - acc: 0.7500\nEpoch 106/1000\n - 0s - loss: 0.6458 - acc: 0.7500\nEpoch 107/1000\n - 0s - loss: 0.6454 - acc: 0.7500\nEpoch 108/1000\n - 0s - loss: 0.6449 - acc: 0.7500\nEpoch 109/1000\n - 0s - loss: 0.6445 - acc: 0.7500\nEpoch 110/1000\n - 0s - loss: 0.6441 - acc: 0.7500\nEpoch 111/1000\n - 0s - loss: 0.6437 - acc: 0.7500\nEpoch 112/1000\n - 0s - loss: 0.6433 - acc: 0.7500\nEpoch 113/1000\n - 0s - loss: 0.6429 - acc: 0.7500\nEpoch 114/1000\n - 0s - loss: 0.6425 - acc: 0.7500\nEpoch 115/1000\n - 0s - loss: 0.6421 - acc: 0.7500\nEpoch 116/1000\n - 0s - loss: 0.6417 - acc: 0.7500\nEpoch 117/1000\n - 0s - loss: 0.6413 - acc: 0.7500\nEpoch 118/1000\n - 0s - loss: 0.6409 - acc: 0.7500\nEpoch 119/1000\n - 0s - loss: 0.6405 - acc: 0.7500\nEpoch 120/1000\n - 0s - loss: 0.6401 - acc: 0.7500\nEpoch 121/1000\n - 0s - loss: 0.6397 - acc: 0.7500\nEpoch 122/1000\n - 0s - loss: 0.6393 - acc: 0.7500\nEpoch 123/1000\n - 0s - loss: 0.6389 - acc: 0.7500\nEpoch 124/1000\n - 0s - loss: 0.6385 - acc: 0.7500\nEpoch 125/1000\n - 0s - loss: 0.6381 - acc: 0.7500\nEpoch 126/1000\n - 0s - loss: 0.6377 - acc: 0.7500\nEpoch 127/1000\n - 0s - loss: 0.6373 - acc: 0.7500\nEpoch 128/1000\n - 0s - loss: 0.6370 - acc: 0.7500\nEpoch 129/1000\n - 0s - loss: 0.6366 - acc: 0.7500\nEpoch 130/1000\n - 0s - loss: 0.6362 - acc: 0.7500\nEpoch 131/1000\n - 0s - loss: 0.6358 - acc: 0.7500\nEpoch 132/1000\n - 0s - loss: 0.6354 - acc: 0.7500\nEpoch 133/1000\n - 0s - loss: 0.6350 - acc: 0.7500\nEpoch 134/1000\n - 0s - loss: 0.6346 - acc: 0.7500\nEpoch 135/1000\n - 0s - loss: 0.6343 - acc: 0.7500\nEpoch 136/1000\n - 0s - loss: 0.6339 - acc: 0.7500\nEpoch 137/1000\n - 0s - loss: 0.6335 - acc: 0.7500\nEpoch 138/1000\n - 0s - loss: 0.6331 - acc: 0.7500\nEpoch 139/1000\n - 0s - loss: 0.6327 - acc: 0.7500\nEpoch 140/1000\n - 0s - loss: 0.6324 - acc: 0.7500\nEpoch 141/1000\n - 0s - loss: 0.6320 - acc: 0.7500\nEpoch 142/1000\n - 0s - loss: 0.6316 - acc: 0.7500\nEpoch 143/1000\n - 0s - loss: 0.6312 - acc: 0.7500\nEpoch 144/1000\n - 0s - loss: 0.6309 - acc: 0.7500\nEpoch 145/1000\n - 0s - loss: 0.6305 - acc: 0.7500\nEpoch 146/1000\n - 0s - loss: 0.6301 - acc: 0.7500\nEpoch 147/1000\n - 0s - loss: 0.6297 - acc: 0.7500\nEpoch 148/1000\n - 0s - loss: 0.6294 - acc: 0.7500\nEpoch 149/1000\n - 0s - loss: 0.6290 - acc: 0.7500\nEpoch 150/1000\n - 0s - loss: 0.6286 - acc: 0.7500\nEpoch 151/1000\n - 0s - loss: 0.6283 - acc: 0.7500\nEpoch 152/1000\n - 0s - loss: 0.6279 - acc: 0.7500\nEpoch 153/1000\n - 0s - loss: 0.6275 - acc: 0.7500\nEpoch 154/1000\n - 0s - loss: 0.6272 - acc: 0.7500\nEpoch 155/1000\n - 0s - loss: 0.6268 - acc: 0.7500\nEpoch 156/1000\n - 0s - loss: 0.6264 - acc: 0.7500\nEpoch 157/1000\n - 0s - loss: 0.6261 - acc: 0.7500\nEpoch 158/1000\n - 0s - loss: 0.6257 - acc: 0.7500\nEpoch 159/1000\n - 0s - loss: 0.6253 - acc: 0.7500\nEpoch 160/1000\n - 0s - loss: 0.6250 - acc: 0.7500\nEpoch 161/1000\n - 0s - loss: 0.6246 - acc: 0.7500\nEpoch 162/1000\n - 0s - loss: 0.6243 - acc: 0.7500\nEpoch 163/1000\n - 0s - loss: 0.6239 - acc: 0.7500\nEpoch 164/1000\n - 0s - loss: 0.6236 - acc: 0.7500\nEpoch 165/1000\n - 0s - loss: 0.6232 - acc: 0.7500\nEpoch 166/1000\n - 0s - loss: 0.6228 - acc: 0.7500\nEpoch 167/1000\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
cbd1143428f97fd709cbb6c69188de43891661c2
| 43,605 |
ipynb
|
Jupyter Notebook
|
notebooks/Clustering.ipynb
|
lvreynoso/ds2.1-classwork
|
2d6b8b9abd1c1338381ce06325ec04389380f77a
|
[
"MIT"
] | null | null | null |
notebooks/Clustering.ipynb
|
lvreynoso/ds2.1-classwork
|
2d6b8b9abd1c1338381ce06325ec04389380f77a
|
[
"MIT"
] | 2 |
2019-09-15T06:11:04.000Z
|
2021-05-18T04:23:47.000Z
|
notebooks/Clustering.ipynb
|
lvreynoso/ds2.1-classwork
|
2d6b8b9abd1c1338381ce06325ec04389380f77a
|
[
"MIT"
] | 1 |
2019-09-11T19:02:04.000Z
|
2019-09-11T19:02:04.000Z
| 81.504673 | 14,632 | 0.780713 |
[
[
[
"from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import adjusted_rand_score\n\ndocuments = ['This is the first sentence.',\n 'This one is the second sentence.',\n 'And this is the third one.',\n 'Is this the first sentence?']\n\nvectorizer = CountVectorizer()\nX = vectorizer.fit_transform(documents)\n\n# X.torray() is BoW\nprint(X.toarray())",
"[[0 1 1 0 0 1 1 0 1]\n [0 0 1 1 1 1 1 0 1]\n [1 0 1 1 0 0 1 1 1]\n [0 1 1 0 0 1 1 0 1]]\n"
],
[
"# Get the unique words\nprint(vectorizer.get_feature_names())\n# the above array represents the number of times each feature name\n# appears in the sentence",
"['and', 'first', 'is', 'one', 'second', 'sentence', 'the', 'third', 'this']\n"
],
[
"# supervised learning vs unsupervised learning\n#\n# supervised learning includes linear regression, logistic regression, support vector machine\n# this is called supervised because it infers a function from labeled training data \n# consisting of a set of training examples\n#\n# unsupervised learning includes principal component analysis and clustering\n# unsupervised learning attempts to find previously unknown patterns in data, without preexisting labels",
"_____no_output_____"
],
[
"from figures import plot_kmeans_interactive\n\nplot_kmeans_interactive()",
"_____no_output_____"
],
[
"from sklearn.datasets.samples_generator import make_blobs\nimport matplotlib.pyplot as plt\n\nX, y = make_blobs(n_samples=300, centers=4,\n random_state=0, cluster_std=0.60)\n\nplt.scatter(X[:, 0], X[:, 1])",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\n\nkm = KMeans(n_clusters=4)\nkm.fit(X)\nprint(km.cluster_centers_)",
"[[ 1.98258281 0.86771314]\n [-1.58438467 2.83081263]\n [ 0.94973532 4.41906906]\n [-1.37324398 7.75368871]]\n"
],
[
"import numpy as np\nfrom scipy.spatial import distance\n\ndistortions = []\nK = range(1, 10)\nfor k in K:\n km = KMeans(n_clusters=k)\n km.fit(X)\n distortions.append(sum(np.min(distance.cdist(X, km.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])\n\n# Plot the elbow\nplt.plot(K, distortions, 'bx-')\nplt.xlabel('k')\nplt.ylabel('Distortion')\nplt.title('The Elbow Method showing the optimal k')\nplt.show()",
"_____no_output_____"
],
[
"def optimal(dist_arr):\n best_delta = 0\n optimal = 0\n for index, val in enumerate(dist_arr):\n k = index + 1\n delta_slope = 0\n if index > 0 and index < len(dist_arr) - 1:\n prev_slope = dist_arr[index-1] - dist_arr[index]\n next_slope = dist_arr[index] - dist_arr[index+1]\n delta_slope = abs(prev_slope - next_slope)\n if delta_slope > best_delta:\n best_delta = delta_slope\n optimal = k\n return optimal",
"_____no_output_____"
],
[
"optimal(distortions)",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import adjusted_rand_score\n\ndocuments = [\"This little kitty came to play when I was eating at a restaurant.\",\n \"Merley has the best squooshy kitten belly.\",\n \"Google Translate app is incredible.\",\n \"If you open 100 tab in google you get a smiley face.\",\n \"Best cat photo I've ever taken.\",\n \"Climbing ninja cat.\",\n \"Impressed with google map feedback.\",\n \"Key promoter extension for Google Chrome.\"]",
"_____no_output_____"
],
[
"# vec = CountVectorizer()\nvec = TfidfVectorizer(stop_words='english')\nJ = vec.fit_transform(documents)\nprint(J.toarray()) # this matrix is called a \"bag of words\"",
"[[0. 0. 0. 0. 0.40824829 0.\n 0. 0. 0.40824829 0. 0. 0.\n 0. 0. 0. 0. 0. 0.40824829\n 0.40824829 0. 0. 0. 0. 0.\n 0.40824829 0. 0.40824829 0. 0. 0.\n 0. 0. 0. ]\n [0. 0. 0.46114911 0.38647895 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0.46114911 0.\n 0. 0. 0.46114911 0. 0. 0.\n 0. 0. 0. 0. 0.46114911 0.\n 0. 0. 0. ]\n [0. 0.54216208 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0.34377441 0. 0.54216208 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.54216208 0. ]\n [0.4302495 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0.4302495 0.\n 0.27281282 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0.4302495 0.\n 0. 0. 0. 0.4302495 0. 0.4302495\n 0. 0. 0. ]\n [0. 0. 0. 0.39932256 0. 0.39932256\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.4764742\n 0. 0. 0. 0. 0. 0.\n 0.4764742 0. 0.4764742 ]\n [0. 0. 0. 0. 0. 0.5098139\n 0. 0.60831315 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0.60831315 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. ]\n [0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.54216208\n 0.34377441 0.54216208 0. 0. 0. 0.\n 0. 0.54216208 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. ]\n [0. 0. 0. 0. 0. 0.\n 0.47661984 0. 0. 0.47661984 0. 0.\n 0.30221535 0. 0. 0.47661984 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0.47661984 0. 0. 0. 0.\n 0. 0. 0. ]]\n"
],
[
"print(vec.get_feature_names())",
"['100', 'app', 'belly', 'best', 'came', 'cat', 'chrome', 'climbing', 'eating', 'extension', 'face', 'feedback', 'google', 'impressed', 'incredible', 'key', 'kitten', 'kitty', 'little', 'map', 'merley', 'ninja', 'open', 'photo', 'play', 'promoter', 'restaurant', 'smiley', 'squooshy', 'tab', 'taken', 'translate', 've']\n"
],
[
"print(J.shape)",
"(8, 33)\n"
],
[
"model = KMeans(n_clusters=2, init='k-means++')\nmodel.fit(J)",
"_____no_output_____"
],
[
"Y = vec.transform([\"chrome browser to open.\"])\nprint('Y:')\nprint(Y.toarray())\nprediction = model.predict(Y)\nprint(prediction)",
"Y:\n[[0. 0. 0. 0. 0. 0.\n 0.70710678 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0.70710678 0.\n 0. 0. 0. 0. 0. 0.\n 0. 0. 0. ]]\n[1]\n"
],
[
"Y = vec.transform([\"My cat is hungry.\"])\nprediction = model.predict(Y)\nprint(prediction)",
"[0]\n"
],
[
"model.get_params()",
"_____no_output_____"
],
[
"# beautiful\nfor index, sentence in enumerate(documents):\n print(sentence)\n print(model.predict(J[index]))",
"This little kitty came to play when I was eating at a restaurant.\n[0]\nMerley has the best squooshy kitten belly.\n[0]\nGoogle Translate app is incredible.\n[1]\nIf you open 100 tab in google you get a smiley face.\n[1]\nBest cat photo I've ever taken.\n[0]\nClimbing ninja cat.\n[0]\nImpressed with google map feedback.\n[1]\nKey promoter extension for Google Chrome.\n[1]\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd135982f8863c24de949784e9702ccfda4a096
| 6,842 |
ipynb
|
Jupyter Notebook
|
Excercise-3-CNN-on-Fashion-MNIST-Question.ipynb
|
snalahi/Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Learning
|
390b113b03c3d1c15366a281a8a0078d9ccef326
|
[
"MIT"
] | 1 |
2021-05-29T21:04:01.000Z
|
2021-05-29T21:04:01.000Z
|
Excercise-3-CNN-on-Fashion-MNIST-Question.ipynb
|
snalahi/Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Learning
|
390b113b03c3d1c15366a281a8a0078d9ccef326
|
[
"MIT"
] | null | null | null |
Excercise-3-CNN-on-Fashion-MNIST-Question.ipynb
|
snalahi/Introduction-to-TensorFlow-for-Artificial-Intelligence-Machine-Learning-and-Deep-Learning
|
390b113b03c3d1c15366a281a8a0078d9ccef326
|
[
"MIT"
] | null | null | null | 34.555556 | 515 | 0.531716 |
[
[
[
"## Exercise 3\nIn the videos you looked at how you would improve Fashion MNIST using Convolutions. For your exercise see if you can improve MNIST to 99.8% accuracy or more using only a single convolutional layer and a single MaxPooling 2D. You should stop training once the accuracy goes above this amount. It should happen in less than 20 epochs, so it's ok to hard code the number of epochs for training, but your training must end once it hits the above metric. If it doesn't, then you'll need to redesign your layers.\n\nI've started the code for you -- you need to finish it!\n\nWhen 99.8% accuracy has been hit, you should print out the string \"Reached 99.8% accuracy so cancelling training!\"\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom os import path, getcwd, chdir\n\n# DO NOT CHANGE THE LINE BELOW. If you are developing in a local\n# environment, then grab mnist.npz from the Coursera Jupyter Notebook\n# and place it inside a local folder and edit the path to that location\npath = f\"{getcwd()}/../tmp2/mnist.npz\"",
"_____no_output_____"
],
[
"config = tf.ConfigProto()\nconfig.gpu_options.allow_growth = True\nsess = tf.Session(config=config)",
"_____no_output_____"
],
[
"# GRADED FUNCTION: train_mnist_conv\ndef train_mnist_conv():\n # Please write your code only where you are indicated.\n # please do not remove model fitting inline comments.\n\n # YOUR CODE STARTS HERE\n \n class myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n # Quick solution for \"older\" tensorflow to get rid of TypeError: Use 'acc' instead of 'accuracy'\n # The version of tf used here is 1.14.0 (old) \n if(logs.get('acc') >= 0.998):\n print('\\nReached 99.8% accuracy so cancelling training!')\n self.model.stop_training = True\n \n # YOUR CODE ENDS HERE\n\n mnist = tf.keras.datasets.mnist\n (training_images, training_labels), (test_images, test_labels) = mnist.load_data(path=path)\n # YOUR CODE STARTS HERE\n \n training_images=training_images.reshape(60000, 28, 28, 1)\n training_images=training_images / 255.0\n callbacks = myCallback()\n\n # YOUR CODE ENDS HERE\n\n model = tf.keras.models.Sequential([\n # YOUR CODE STARTS HERE\n \n tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),\n tf.keras.layers.MaxPooling2D(2, 2),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(128, activation='relu'),\n tf.keras.layers.Dense(10, activation='softmax')\n \n # YOUR CODE ENDS HERE\n ])\n\n model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])\n # model fitting\n history = model.fit(\n # YOUR CODE STARTS HERE\n training_images, training_labels, epochs=30, callbacks=[callbacks]\n # YOUR CODE ENDS HERE\n )\n # model fitting\n return history.epoch, history.history['acc'][-1]\n\n",
"_____no_output_____"
],
[
"_, _ = train_mnist_conv()",
"Epoch 1/30\n60000/60000 [==============================] - 12s 205us/sample - loss: 0.1335 - acc: 0.9589\nEpoch 2/30\n60000/60000 [==============================] - 12s 201us/sample - loss: 0.0462 - acc: 0.9858\nEpoch 3/30\n60000/60000 [==============================] - 12s 200us/sample - loss: 0.0291 - acc: 0.9908\nEpoch 4/30\n60000/60000 [==============================] - 12s 205us/sample - loss: 0.0189 - acc: 0.9938\nEpoch 5/30\n60000/60000 [==============================] - 13s 218us/sample - loss: 0.0143 - acc: 0.9954\nEpoch 6/30\n60000/60000 [==============================] - 14s 235us/sample - loss: 0.0093 - acc: 0.9967\nEpoch 7/30\n60000/60000 [==============================] - 14s 230us/sample - loss: 0.0072 - acc: 0.9976\nEpoch 8/30\n60000/60000 [==============================] - 14s 234us/sample - loss: 0.0066 - acc: 0.9978\nEpoch 9/30\n59648/60000 [============================>.] - ETA: 0s - loss: 0.0051 - acc: 0.9981\nReached 99.8% accuracy so cancelling training!\n60000/60000 [==============================] - 13s 223us/sample - loss: 0.0052 - acc: 0.9981\n"
],
[
"# Now click the 'Submit Assignment' button above.\n# Once that is complete, please run the following two cells to save your work and close the notebook",
"_____no_output_____"
],
[
"%%javascript\n<!-- Save the notebook -->\nIPython.notebook.save_checkpoint();",
"_____no_output_____"
],
[
"%%javascript\nIPython.notebook.session.delete();\nwindow.onbeforeunload = null\nsetTimeout(function() { window.close(); }, 1000);",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd13e796b06c934bf90501c1fdb494e80550677
| 355,476 |
ipynb
|
Jupyter Notebook
|
notebooks/archive/Reproducibility-and-Standards/reproducible-distribution.ipynb
|
sys-bio/network-modeling-summer-school-2021
|
9215861074466c045bdbbe06046c13a388f34c79
|
[
"MIT"
] | 2 |
2021-07-23T16:25:49.000Z
|
2021-08-03T12:47:02.000Z
|
notebooks/archive/Reproducibility-and-Standards/reproducible-distribution.ipynb
|
sys-bio/network-modeling-summer-school-2021
|
9215861074466c045bdbbe06046c13a388f34c79
|
[
"MIT"
] | null | null | null |
notebooks/archive/Reproducibility-and-Standards/reproducible-distribution.ipynb
|
sys-bio/network-modeling-summer-school-2021
|
9215861074466c045bdbbe06046c13a388f34c79
|
[
"MIT"
] | null | null | null | 355,476 | 355,476 | 0.923151 |
[
[
[
"# Distributing standardized COMBINE archives with Tellurium\n\n<div align='center'><img src=\"https://raw.githubusercontent.com/vporubsky/tellurium-libroadrunner-tutorial/master/tellurium-and-libroadrunner.png\" width=\"60%\" style=\"padding: 20px\"></div>\n<div align='center' style='font-size:100%'>\nVeronica L. Porubsky, BS\n<div align='center' style='font-size:100%'>Sauro Lab PhD Student, Department of Bioengineering<br>\nHead of Outreach, <a href=\"https://reproduciblebiomodels.org/dissemination-and-training/seminar/\">Center for Reproducible Biomedical Modeling</a><br>\nUniversity of Washington, Seattle, WA USA\n</div>\n<hr>",
"_____no_output_____"
],
[
"To facilitate design and comprehension of their models, modelers should use standard systems biology formats for\nmodel descriptions, simulation experiments, and to distribute stand-alone archives which can regenerate the modeling study. We will discuss three of these standards - the Systems Biology Markup Language (SBML), the Simulation Experiment Description Markup Language (SED-ML), and the COMBINE archive/ inline Open Modeling EXchange format (OMEX) format.\n",
"_____no_output_____"
],
[
"## TOC\n* [Links to relevant resources](#relevant-resources)\n* [Packages and Constants](#standardized-formats-packages-and-constants)\n* [Import and export capabilities with Tellurium](#import-export)\n* [Importing SBML directly from the BioModels Database for simulation](#import-from-biomodels)\n* [Exporting SBML or Antimony models](#export-to-sbml-or-antimony)\n* [Writing SED-ML with PhraSED-ML](#writing-phrasedml)\n* [Exporting SED-ML](#exporting-sedml)\n* [Generating a COMBINE archive](#combine-archive)\n* [Exercises](#exercises)",
"_____no_output_____"
],
[
"# Links to relevant resources <a class=\"anchor\" id=\"relevant-resources\"></a>\n\n<a href=\"http://model.caltech.edu/\">SBML specification</a><br>\n<a href=\"http://sbml.org/SBML_Software_Guide/SBML_Software_Matrix\">SBML tool support</a><br>\n<a href=\"https://sed-ml.org/\">SED-ML specification</a><br>\n<a href=\"https://sed-ml.org/showcase.html\">SED-ML tool support</a><br>\n<a href=\"http://phrasedml.sourceforge.net/phrasedml__api_8h.html\">PhraSED-ML documentation</a><br>\n<a href=\"http://phrasedml.sourceforge.net/Tutorial.html\">PhraSED-ML tutorial</a><br>\n<a href=\"https://tellurium.readthedocs.io/en/latest/\">Tellurium documentation</a><br>\n<a href=\"https://libroadrunner.readthedocs.io/en/latest/\">libRoadRunner documentation</a><br>\n<a href=\"https://tellurium.readthedocs.io/en/latest/antimony.html\">Antimony documentation</a><br>\n<a href=\"http://copasi.org/Download/\">COPASI download</a><br>\n\n\n",
"_____no_output_____"
],
[
"# Packages and constants <a class=\"anchor\" id=\"standardized-formats-packages-and-constants\"></a>\n",
"_____no_output_____"
]
],
[
[
"!pip install tellurium -q",
"\u001b[K |████████████████████████████████| 118 kB 6.7 MB/s \n\u001b[K |████████████████████████████████| 3.1 MB 30.4 MB/s \n\u001b[K |████████████████████████████████| 2.5 MB 40.5 MB/s \n\u001b[K |████████████████████████████████| 3.2 MB 49.7 MB/s \n\u001b[K |████████████████████████████████| 36.7 MB 14 kB/s \n\u001b[K |████████████████████████████████| 14.9 MB 100 kB/s \n\u001b[K |████████████████████████████████| 6.2 MB 28.9 MB/s \n\u001b[K |████████████████████████████████| 28.5 MB 24 kB/s \n\u001b[K |████████████████████████████████| 2.0 MB 46.3 MB/s \n\u001b[K |████████████████████████████████| 5.8 MB 21.1 MB/s \n\u001b[K |████████████████████████████████| 5.6 MB 36.0 MB/s \n\u001b[K |████████████████████████████████| 16.6 MB 46 kB/s \n\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\ndatascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.\nalbumentations 0.1.12 requires imgaug<0.2.7,>=0.2.5, but you have imgaug 0.2.9 which is incompatible.\u001b[0m\n\u001b[?25h"
],
[
"import tellurium as te\nimport phrasedml",
"_____no_output_____"
]
],
[
[
"# Import and export capabilities with Tellurium <a class=\"anchor\" id=\"import-export\"></a>\n\nModels can be imported from the BioModels Database, given the appropriate BioModel ID using a standard URL format to programmatically access the model of interest. \n\nWe will use this model of respiratory oscillations in Saccharomyces cerevisae by <a href=\"https://www.ebi.ac.uk/biomodels/BIOMD0000000090\">Jana Wolf et al. (2001)</a> </div> as an example:\n<br>\n\n<div align='center'><img src=\"https://raw.githubusercontent.com/vporubsky/tellurium-libroadrunner-tutorial/master/wolf_publication.PNG\" width=\"65%\" style=\"padding: 20px\"></div>\n<br>\n<div align='center'><img src=\"https://raw.githubusercontent.com/vporubsky/tellurium-libroadrunner-tutorial/master/wolf_network.PNG\" width=\"65%\" style=\"padding: 20px\"></div>",
"_____no_output_____"
],
[
"# Importing SBML directly from the BioModels Database for simulation <a class=\"anchor\" id=\"import-from-biomodels\"></a>\n\nSBML is a software data format for describing computational biological models. Markup languages allow you to separate annotations and documentation about the content from the content itself, using standardized tags. So the model and annotations are stored in a single file, but tools that support SBML are designed to interpret these to perform tasks. SBML is independent of any particular software tool and is broadly applicable to the modeling domain. It is open and free, and widely supported. Tools might allow for writing the model, simulating the model, visualizing the network, etc.\n\nWe will demonstrate how Tellurium supports import and export of SBML model files.",
"_____no_output_____"
]
],
[
[
"# Import an SBML model from the BioModels Database using a url\nwolf = te.loadSBMLModel(\"https://www.ebi.ac.uk/biomodels/model/download/BIOMD0000000090.2?filename=BIOMD0000000090_url.xml\")\nwolf.simulate(0, 200, 1000)\nwolf.plot(figsize = (15, 10), xtitle = 'Time', ytitle = 'Concentration')",
"_____no_output_____"
]
],
[
[
"# Exporting SBML or Antimony models <a class=\"anchor\" id=\"export-to-sbml-or-antimony\"></a>",
"_____no_output_____"
]
],
[
[
"# Export the model you just accessed from BioModels to the current directory as an SBML string\nwolf.reset()\nwolf.exportToSBML('Wolf2001_Respiratory_Oscillations.xml', current = True)",
"_____no_output_____"
],
[
"# You can also export the model to the current directory as an Antimony string\n# Let's take a look at the string first\nprint(wolf.getCurrentAntimony())",
"// Created by libAntimony v2.12.0\nmodel *Wolf2001_Respiratory_Oscillations()\n\n // Compartments and Species:\n compartment c0, c1, c2;\n species $sul_ex in c0, $eth_ex in c0, $oxy_ex in c0, oxy in c2, $H2O in c2;\n species A3c in c1, aps in c1, $PPi in c1, pap in c1, sul in c1, eth in c1;\n species $A2c in c1, hyd in c1, cys in c1, N2 in c1, $N1 in c1, aco in c1;\n species oah in c1, S1 in c2, $S2 in c2, $C1 in c2, $C2 in c2, $A2m in c2;\n species A3m in c2, $Ho in c1, $Hm in c2;\n\n // Assignment Rules:\n A2c := Ac - A3c;\n N1 := N - N2;\n S2 := S - S1;\n A2m := Am - A3m;\n\n // Reactions:\n v1: $sul_ex => sul; c0*k_v0/(1 + (cys/Kc)^n);\n v13: $eth_ex => eth; c0*k_v13;\n v2: sul + A3c => aps + $PPi; c1*k2*sul*A3c;\n v10: $oxy_ex => oxy; c0*k_v10;\n v14: oxy => $oxy_ex; c2*k14*oxy;\n v3: aps + A3c => pap + $A2c; c1*k3*aps*A3c;\n v4: pap + 3 N2 => hyd + 3 $N1; c1*k4*pap*N2;\n v5: hyd + oah => cys; c1*k5*hyd*oah;\n v6: cys => ; c1*k6*cys;\n v7: eth + 2 $N1 => aco + 2 N2; c1*k7*eth*N1;\n v15: aco => oah; c1*k15*aco;\n v17: hyd => ; c1*k17*hyd;\n v18: oah => ; c1*k18*oah;\n v8: $S2 + aco => S1; c2*k8*aco*S2;\n v9: S1 + 4 $N1 => $S2 + 4 N2; c2*k9*S1*N1;\n v11a: $C1 + $Hm + N2 => $C2 + $Ho + $N1; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v11a2: $C2 + oxy => $C1 + $H2O; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v16: $A2c + A3m => $A2m + A3c; c2*k16*A3m*A2c;\n v11b: $Ho + $A2m => $Hm + A3m; (c2*3*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m)))*A2m/(Ka + A2m);\n vLEAK: $Ho => $Hm; 0;\n v12: A3c => $A2c; c1*k12*A3c;\n\n // Species initializations:\n sul_ex = 0;\n eth_ex = 0;\n oxy_ex = 0;\n oxy = 7/c2;\n oxy has substance_per_volume;\n H2O = 0;\n A3c = 1.5/c1;\n A3c has substance_per_volume;\n aps = 0.5/c1;\n aps has substance_per_volume;\n PPi = 0;\n pap = 0.4/c1;\n pap has substance_per_volume;\n sul = 0.4/c1;\n sul has substance_per_volume;\n eth = 4/c1;\n eth has substance_per_volume;\n A2c has substance_per_volume;\n hyd = 0.5/c1;\n hyd has substance_per_volume;\n cys = 0.3/c1;\n cys has substance_per_volume;\n N2 = 2/c1;\n N2 has substance_per_volume;\n N1 has substance_per_volume;\n aco = 0.3/c1;\n aco has substance_per_volume;\n oah = 1.5/c1;\n oah has substance_per_volume;\n S1 = 1.5/c2;\n S1 has substance_per_volume;\n S2 has substance_per_volume;\n C1 = 0;\n C2 = 0;\n A2m has substance_per_volume;\n A3m = 1.5/c2;\n A3m has substance_per_volume;\n Ho = 0;\n Hm = 0;\n\n // Compartment initializations:\n c0 = 1;\n c1 = 1;\n c2 = 1;\n\n // Variable initializations:\n Ac = 2;\n N = 2;\n S = 2;\n Am = 2;\n k_v0 = 1.6;\n k2 = 0.2;\n k3 = 0.2;\n k4 = 0.2;\n k5 = 0.1;\n k6 = 0.12;\n k7 = 10;\n k8 = 10;\n k9 = 10;\n k_v10 = 80;\n k11 = 10;\n k12 = 5;\n k_v13 = 4;\n k14 = 10;\n k15 = 5;\n k16 = 10;\n k17 = 0.02;\n k18 = 1;\n n = 4;\n m = 4;\n Ka = 1;\n Kc = 0.1;\n a = 0.1;\n Kh = 0.5;\n\n // Other declarations:\n const c0, c1, c2, Ac, N, S, Am, k_v0, k2, k3, k4, k5, k6, k7, k8, k9, k_v10;\n const k11, k12, k_v13, k14, k15, k16, k17, k18, n, m, Ka, Kc, a, Kh;\n\n // Unit definitions:\n unit substance = mole;\n unit substance_per_volume = mole / litre;\n\n // Display Names:\n c0 is \"external\";\n c1 is \"cytosol\";\n c2 is \"mitochondria\";\n sul_ex is \"SO4_ex\";\n eth_ex is \"EtOH_ex\";\n oxy_ex is \"O2_ex\";\n oxy is \"O2\";\n A3c is \"ATP\";\n aps is \"APS\";\n pap is \"PAPS\";\n sul is \"SO4\";\n eth is \"EtOH\";\n A2c is \"ADP\";\n hyd is \"H2S\";\n cys is \"CYS\";\n N2 is \"NADH\";\n N1 is \"NAD\";\n aco is \"AcCoA\";\n oah is \"OAH\";\n A2m is \"ADP_mit\";\n A3m is \"ATP_mit\";\n v11a is \"vET1\";\n v11a2 is \"vET2\";\n v11b is \"vSYNT\";\n\n // CV terms:\n c0 hypernym \"http://identifiers.org/obo.go/GO:0005576\"\n c1 hypernym \"http://identifiers.org/obo.go/GO:0005829\"\n c2 hypernym \"http://identifiers.org/obo.go/GO:0005739\"\n sul_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n oxy_ex identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n oxy identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n H2O identity \"http://identifiers.org/obo.chebi/CHEBI:15377\"\n A3c identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n aps identity \"http://identifiers.org/obo.chebi/CHEBI:17709\"\n PPi identity \"http://identifiers.org/obo.chebi/CHEBI:18361\"\n pap identity \"http://identifiers.org/obo.chebi/CHEBI:17980\"\n sul identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n A2c identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n hyd identity \"http://identifiers.org/obo.chebi/CHEBI:16136\"\n cys identity \"http://identifiers.org/obo.chebi/CHEBI:17561\"\n N2 identity \"http://identifiers.org/obo.chebi/CHEBI:16908\"\n N1 identity \"http://identifiers.org/obo.chebi/CHEBI:15846\"\n aco identity \"http://identifiers.org/obo.chebi/CHEBI:15351\"\n oah identity \"http://identifiers.org/obo.chebi/CHEBI:16288\"\n S1 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n S2 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n C1 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n C2 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n A2m identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n A3m identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n Ho identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n Hm identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n v1 hypernym \"http://identifiers.org/obo.go/GO:0015381\"\n v13 hypernym \"http://identifiers.org/obo.go/GO:0015850\"\n v2 identity \"http://identifiers.org/ec-code/2.7.7.4\"\n v3 identity \"http://identifiers.org/ec-code/2.7.1.25\"\n v3 hypernym \"http://identifiers.org/obo.go/GO:0004020\"\n v4 version \"http://identifiers.org/ec-code/1.8.4.8\",\n \"http://identifiers.org/ec-code/1.8.1.2\"\n v5 version \"http://identifiers.org/ec-code/4.4.1.1\",\n \"http://identifiers.org/ec-code/4.2.1.22\",\n \"http://identifiers.org/ec-code/2.5.1.49\"\n v7 version \"http://identifiers.org/ec-code/6.2.1.1\",\n \"http://identifiers.org/ec-code/1.2.1.3\",\n \"http://identifiers.org/ec-code/1.1.1.1\"\n v15 identity \"http://identifiers.org/ec-code/2.3.1.31\"\n v8 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v9 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v11a identity \"http://identifiers.org/obo.go/GO:0015990\"\n v11a parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a2 version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 identity \"http://identifiers.org/obo.go/GO:0006123\"\n v16 identity \"http://identifiers.org/obo.go/GO:0005471\"\n v11b parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11b hypernym \"http://identifiers.org/obo.go/GO:0006119\"\n v11b version \"http://identifiers.org/obo.go/GO:0002082\"\n vLEAK hypernym \"http://identifiers.org/obo.go/GO:0006810\"\n v12 hypernym \"http://identifiers.org/obo.go/GO:0006200\"\nend\n\nWolf2001_Respiratory_Oscillations is \"Wolf2001_Respiratory_Oscillations\"\n\nWolf2001_Respiratory_Oscillations model_entity_is \"http://identifiers.org/biomodels.db/MODEL9728951048\"\nWolf2001_Respiratory_Oscillations model_entity_is \"http://identifiers.org/biomodels.db/BIOMD0000000090\"\nWolf2001_Respiratory_Oscillations description \"http://identifiers.org/pubmed/11423122\"\nWolf2001_Respiratory_Oscillations taxon \"http://identifiers.org/taxonomy/4932\"\nWolf2001_Respiratory_Oscillations hypernym \"http://identifiers.org/obo.go/GO:0019379\"\n\n"
],
[
"# Edit the Antimony string of Wolf et al.:\n# Update model name for ease of use with PhraSED-ML\n# Remove model name annotatations -- causes error with SED-ML export\nwolf = te.loada(\"\"\"\n// Created by libAntimony v2.12.0\nmodel wolf\n\n // Compartments and Species:\n compartment c0, c1, c2;\n species $sul_ex in c0, $eth_ex in c0, $oxy_ex in c0, oxy in c2, $H2O in c2;\n species A3c in c1, aps in c1, $PPi in c1, pap in c1, sul in c1, eth in c1;\n species $A2c in c1, hyd in c1, cys in c1, N2 in c1, $N1 in c1, aco in c1;\n species oah in c1, S1 in c2, $S2 in c2, $C1 in c2, $C2 in c2, $A2m in c2;\n species A3m in c2, $Ho in c1, $Hm in c2;\n\n // Assignment Rules:\n A2c := Ac - A3c;\n N1 := N - N2;\n S2 := S - S1;\n A2m := Am - A3m;\n\n // Reactions:\n v1: $sul_ex => sul; c0*k_v0/(1 + (cys/Kc)^n);\n v13: $eth_ex => eth; c0*k_v13;\n v2: sul + A3c => aps + $PPi; c1*k2*sul*A3c;\n v10: $oxy_ex => oxy; c0*k_v10;\n v14: oxy => $oxy_ex; c2*k14*oxy;\n v3: aps + A3c => pap + $A2c; c1*k3*aps*A3c;\n v4: pap + 3 N2 => hyd + 3 $N1; c1*k4*pap*N2;\n v5: hyd + oah => cys; c1*k5*hyd*oah;\n v6: cys => ; c1*k6*cys;\n v7: eth + 2 $N1 => aco + 2 N2; c1*k7*eth*N1;\n v15: aco => oah; c1*k15*aco;\n v17: hyd => ; c1*k17*hyd;\n v18: oah => ; c1*k18*oah;\n v8: $S2 + aco => S1; c2*k8*aco*S2;\n v9: S1 + 4 $N1 => $S2 + 4 N2; c2*k9*S1*N1;\n v11a: $C1 + $Hm + N2 => $C2 + $Ho + $N1; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v11a2: $C2 + oxy => $C1 + $H2O; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v16: $A2c + A3m => $A2m + A3c; c2*k16*A3m*A2c;\n v11b: $Ho + $A2m => $Hm + A3m; (c2*3*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m)))*A2m/(Ka + A2m);\n vLEAK: $Ho => $Hm; 0;\n v12: A3c => $A2c; c1*k12*A3c;\n\n // Species initializations:\n sul_ex = 0;\n eth_ex = 0;\n oxy_ex = 0;\n oxy = 7/c2;\n oxy has substance_per_volume;\n H2O = 0;\n A3c = 1.5/c1;\n A3c has substance_per_volume;\n aps = 0.5/c1;\n aps has substance_per_volume;\n PPi = 0;\n pap = 0.4/c1;\n pap has substance_per_volume;\n sul = 0.4/c1;\n sul has substance_per_volume;\n eth = 4/c1;\n eth has substance_per_volume;\n A2c has substance_per_volume;\n hyd = 0.5/c1;\n hyd has substance_per_volume;\n cys = 0.3/c1;\n cys has substance_per_volume;\n N2 = 2/c1;\n N2 has substance_per_volume;\n N1 has substance_per_volume;\n aco = 0.3/c1;\n aco has substance_per_volume;\n oah = 1.5/c1;\n oah has substance_per_volume;\n S1 = 1.5/c2;\n S1 has substance_per_volume;\n S2 has substance_per_volume;\n C1 = 0;\n C2 = 0;\n A2m has substance_per_volume;\n A3m = 1.5/c2;\n A3m has substance_per_volume;\n Ho = 0;\n Hm = 0;\n\n // Compartment initializations:\n c0 = 1;\n c1 = 1;\n c2 = 1;\n\n // Variable initializations:\n Ac = 2;\n N = 2;\n S = 2;\n Am = 2;\n k_v0 = 1.6;\n k2 = 0.2;\n k3 = 0.2;\n k4 = 0.2;\n k5 = 0.1;\n k6 = 0.12;\n k7 = 10;\n k8 = 10;\n k9 = 10;\n k_v10 = 80;\n k11 = 10;\n k12 = 5;\n k_v13 = 4;\n k14 = 10;\n k15 = 5;\n k16 = 10;\n k17 = 0.02;\n k18 = 1;\n n = 4;\n m = 4;\n Ka = 1;\n Kc = 0.1;\n a = 0.1;\n Kh = 0.5;\n\n // Other declarations:\n const c0, c1, c2, Ac, N, S, Am, k_v0, k2, k3, k4, k5, k6, k7, k8, k9, k_v10;\n const k11, k12, k_v13, k14, k15, k16, k17, k18, n, m, Ka, Kc, a, Kh;\n\n // Unit definitions:\n unit substance = mole;\n unit substance_per_volume = mole / litre;\n\n // Display Names:\n c0 is \"external\";\n c1 is \"cytosol\";\n c2 is \"mitochondria\";\n sul_ex is \"SO4_ex\";\n eth_ex is \"EtOH_ex\";\n oxy_ex is \"O2_ex\";\n oxy is \"O2\";\n A3c is \"ATP\";\n aps is \"APS\";\n pap is \"PAPS\";\n sul is \"SO4\";\n eth is \"EtOH\";\n A2c is \"ADP\";\n hyd is \"H2S\";\n cys is \"CYS\";\n N2 is \"NADH\";\n N1 is \"NAD\";\n aco is \"AcCoA\";\n oah is \"OAH\";\n A2m is \"ADP_mit\";\n A3m is \"ATP_mit\";\n v11a is \"vET1\";\n v11a2 is \"vET2\";\n v11b is \"vSYNT\";\n\n // CV terms:\n c0 hypernym \"http://identifiers.org/obo.go/GO:0005576\"\n c1 hypernym \"http://identifiers.org/obo.go/GO:0005829\"\n c2 hypernym \"http://identifiers.org/obo.go/GO:0005739\"\n sul_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n oxy_ex identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n oxy identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n H2O identity \"http://identifiers.org/obo.chebi/CHEBI:15377\"\n A3c identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n aps identity \"http://identifiers.org/obo.chebi/CHEBI:17709\"\n PPi identity \"http://identifiers.org/obo.chebi/CHEBI:18361\"\n pap identity \"http://identifiers.org/obo.chebi/CHEBI:17980\"\n sul identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n A2c identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n hyd identity \"http://identifiers.org/obo.chebi/CHEBI:16136\"\n cys identity \"http://identifiers.org/obo.chebi/CHEBI:17561\"\n N2 identity \"http://identifiers.org/obo.chebi/CHEBI:16908\"\n N1 identity \"http://identifiers.org/obo.chebi/CHEBI:15846\"\n aco identity \"http://identifiers.org/obo.chebi/CHEBI:15351\"\n oah identity \"http://identifiers.org/obo.chebi/CHEBI:16288\"\n S1 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n S2 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n C1 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n C2 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n A2m identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n A3m identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n Ho identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n Hm identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n v1 hypernym \"http://identifiers.org/obo.go/GO:0015381\"\n v13 hypernym \"http://identifiers.org/obo.go/GO:0015850\"\n v2 identity \"http://identifiers.org/ec-code/2.7.7.4\"\n v3 identity \"http://identifiers.org/ec-code/2.7.1.25\"\n v3 hypernym \"http://identifiers.org/obo.go/GO:0004020\"\n v4 version \"http://identifiers.org/ec-code/1.8.4.8\",\n \"http://identifiers.org/ec-code/1.8.1.2\"\n v5 version \"http://identifiers.org/ec-code/4.4.1.1\",\n \"http://identifiers.org/ec-code/4.2.1.22\",\n \"http://identifiers.org/ec-code/2.5.1.49\"\n v7 version \"http://identifiers.org/ec-code/6.2.1.1\",\n \"http://identifiers.org/ec-code/1.2.1.3\",\n \"http://identifiers.org/ec-code/1.1.1.1\"\n v15 identity \"http://identifiers.org/ec-code/2.3.1.31\"\n v8 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v9 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v11a identity \"http://identifiers.org/obo.go/GO:0015990\"\n v11a parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a2 version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 identity \"http://identifiers.org/obo.go/GO:0006123\"\n v16 identity \"http://identifiers.org/obo.go/GO:0005471\"\n v11b parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11b hypernym \"http://identifiers.org/obo.go/GO:0006119\"\n v11b version \"http://identifiers.org/obo.go/GO:0002082\"\n vLEAK hypernym \"http://identifiers.org/obo.go/GO:0006810\"\n v12 hypernym \"http://identifiers.org/obo.go/GO:0006200\"\nend\n\"\"\")\n\n# Export SBML and Antimony versions of the updated model to current working directory\nwolf.exportToAntimony('wolf_antimony.txt')\nwolf.exportToSBML('wolf.xml')",
"_____no_output_____"
],
[
"# Let's work with the species 'oxy'(CHEBI ID: 15379) - or dioxygen - going forward \nwolf.simulate(0, 100, 1000, ['time', 'oxy']) # note that specific species can be selected for recording concentrations over the timecourse\nwolf.plot(figsize = (10, 6), xtitle = 'Time', ytitle = 'Concentration')",
"_____no_output_____"
]
],
[
[
"# Writing SED-ML with PhraSED-ML <a class=\"anchor\" id=\"writing-phrasedml\"></a>\n\nSED-ML encodes the information required by the minimal information about a simiulation experiment guidelines (MIASE) to enable reproduction of simulation experiments in a computer-readable format.\n\nThe specification includes:\n* selection of experimental data for the experiment\n* models used for the experiement\n* which simulation to run on which models\n* which results to pass to output\n* how results should be output\n\nPhraSED-ML is a language and a library that provide a text-based way to read, summarize, and create SED-ML files as part of the greater Tellurium modeling environment we have discussed. ",
"_____no_output_____"
]
],
[
[
"# Write phraSED-ML string specifying the simulation study\nwolf_phrasedml = '''\n // Set model\n wolf = model \"wolf.xml\" # model_id = model source_model\n\n // Deterministic simulation\n det_sim = simulate uniform(0, 500, 1000) # sim_id = simulate simulation_type\n wolf_det_sim = run det_sim on wolf # task_id = run sim_id on model_id\n plot \"Wolf et al. dynamics (Model ID: BIOMD0000000090)\" time vs oxy # plot title_name x vs y\n'''\n\n# Generate SED-ML string from the phraSED-ML string\nwolf.resetAll()\nwolf_sbml = wolf.getSBML()\nphrasedml.setReferencedSBML(\"wolf.xml\", wolf_sbml)\nwolf_sedml = phrasedml.convertString(wolf_phrasedml)\n\nprint(wolf_sedml)",
"<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!-- Created by phraSED-ML version v1.1.1 with libSBML version 5.19.1. -->\n<sedML xmlns=\"http://sed-ml.org/sed-ml/level1/version3\" level=\"1\" version=\"3\">\n <listOfModels>\n <model id=\"wolf\" language=\"urn:sedml:language:sbml.level-3.version-1\" source=\"wolf.xml\"/>\n </listOfModels>\n <listOfSimulations>\n <uniformTimeCourse id=\"det_sim\" initialTime=\"0\" outputStartTime=\"0\" outputEndTime=\"500\" numberOfPoints=\"1000\">\n <algorithm kisaoID=\"KISAO:0000019\"/>\n </uniformTimeCourse>\n </listOfSimulations>\n <listOfTasks>\n <task id=\"wolf_det_sim\" modelReference=\"wolf\" simulationReference=\"det_sim\"/>\n </listOfTasks>\n <listOfDataGenerators>\n <dataGenerator id=\"plot_0_0_0\" name=\"time\">\n <math xmlns=\"http://www.w3.org/1998/Math/MathML\">\n <ci> time </ci>\n </math>\n <listOfVariables>\n <variable id=\"time\" symbol=\"urn:sedml:symbol:time\" taskReference=\"wolf_det_sim\" modelReference=\"wolf\"/>\n </listOfVariables>\n </dataGenerator>\n <dataGenerator id=\"plot_0_0_1\" name=\"oxy\">\n <math xmlns=\"http://www.w3.org/1998/Math/MathML\">\n <ci> oxy </ci>\n </math>\n <listOfVariables>\n <variable id=\"oxy\" target=\"/sbml:sbml/sbml:model/sbml:listOfSpecies/sbml:species[@id='oxy']\" taskReference=\"wolf_det_sim\" modelReference=\"wolf\"/>\n </listOfVariables>\n </dataGenerator>\n </listOfDataGenerators>\n <listOfOutputs>\n <plot2D id=\"plot_0\" name=\"Wolf et al. dynamics (Model ID: BIOMD0000000090)\">\n <listOfCurves>\n <curve id=\"plot_0__plot_0_0_0__plot_0_0_1\" logX=\"false\" xDataReference=\"plot_0_0_0\" logY=\"false\" yDataReference=\"plot_0_0_1\"/>\n </listOfCurves>\n </plot2D>\n </listOfOutputs>\n</sedML>\n\n"
]
],
[
[
"# Exporting SED-ML <a class=\"anchor\" id=\"exporting-sedml\"></a>",
"_____no_output_____"
]
],
[
[
"# Save the SED-ML simulation experiment to your current working directory\nte.saveToFile('wolf_sedml.xml', wolf_sedml)\n\n# Load and run SED-ML script\nte.executeSEDML('wolf_sedml.xml')",
"_____no_output_____"
]
],
[
[
"# Generating a COMBINE archive <a class=\"anchor\" id=\"combine-archive\"></a>\n\nCOMBINE archives package SBML models and SED-ML simulation experiment descriptions together to ensure complete modeling studies or experiments can be exchangesd between software tools. Tellurium provides the inline Open Modeling EXchange format (OMEX) to edit contents of COMBINE archives in a human-readable format. Inline OMEX is essentially an Antimony description of the model joined to the PhraSED-ML experiment description.\n",
"_____no_output_____"
]
],
[
[
"# Read Antimony model into a string\nwolf_antimony = te.readFromFile('wolf_antimony.txt')\n\n\n# create an inline OMEX string\nwolf_inline_omex = '\\n'.join([wolf_antimony, wolf_phrasedml])\nprint(wolf_inline_omex)\n",
"// Created by libAntimony v2.12.0\nmodel *wolf()\n\n // Compartments and Species:\n compartment c0, c1, c2;\n species $sul_ex in c0, $eth_ex in c0, $oxy_ex in c0, oxy in c2, $H2O in c2;\n species A3c in c1, aps in c1, $PPi in c1, pap in c1, sul in c1, eth in c1;\n species $A2c in c1, hyd in c1, cys in c1, N2 in c1, $N1 in c1, aco in c1;\n species oah in c1, S1 in c2, $S2 in c2, $C1 in c2, $C2 in c2, $A2m in c2;\n species A3m in c2, $Ho in c1, $Hm in c2;\n\n // Assignment Rules:\n A2c := Ac - A3c;\n N1 := N - N2;\n S2 := S - S1;\n A2m := Am - A3m;\n\n // Reactions:\n v1: $sul_ex => sul; c0*k_v0/(1 + (cys/Kc)^n);\n v13: $eth_ex => eth; c0*k_v13;\n v2: sul + A3c => aps + $PPi; c1*k2*sul*A3c;\n v10: $oxy_ex => oxy; c0*k_v10;\n v14: oxy => $oxy_ex; c2*k14*oxy;\n v3: aps + A3c => pap + $A2c; c1*k3*aps*A3c;\n v4: pap + 3 N2 => hyd + 3 $N1; c1*k4*pap*N2;\n v5: hyd + oah => cys; c1*k5*hyd*oah;\n v6: cys => ; c1*k6*cys;\n v7: eth + 2 $N1 => aco + 2 N2; c1*k7*eth*N1;\n v15: aco => oah; c1*k15*aco;\n v17: hyd => ; c1*k17*hyd;\n v18: oah => ; c1*k18*oah;\n v8: $S2 + aco => S1; c2*k8*aco*S2;\n v9: S1 + 4 $N1 => $S2 + 4 N2; c2*k9*S1*N1;\n v11a: $C1 + $Hm + N2 => $C2 + $Ho + $N1; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v11a2: $C2 + oxy => $C1 + $H2O; c2*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m));\n v16: $A2c + A3m => $A2m + A3c; c2*k16*A3m*A2c;\n v11b: $Ho + $A2m => $Hm + A3m; (c2*3*k11*N2*oxy/((a*N2 + oxy)*(1 + (hyd/Kh)^m)))*A2m/(Ka + A2m);\n vLEAK: $Ho => $Hm; 0;\n v12: A3c => $A2c; c1*k12*A3c;\n\n // Species initializations:\n sul_ex = 0;\n eth_ex = 0;\n oxy_ex = 0;\n oxy = 7/c2;\n oxy has substance_per_volume;\n H2O = 0;\n A3c = 1.5/c1;\n A3c has substance_per_volume;\n aps = 0.5/c1;\n aps has substance_per_volume;\n PPi = 0;\n pap = 0.4/c1;\n pap has substance_per_volume;\n sul = 0.4/c1;\n sul has substance_per_volume;\n eth = 4/c1;\n eth has substance_per_volume;\n A2c has substance_per_volume;\n hyd = 0.5/c1;\n hyd has substance_per_volume;\n cys = 0.3/c1;\n cys has substance_per_volume;\n N2 = 2/c1;\n N2 has substance_per_volume;\n N1 has substance_per_volume;\n aco = 0.3/c1;\n aco has substance_per_volume;\n oah = 1.5/c1;\n oah has substance_per_volume;\n S1 = 1.5/c2;\n S1 has substance_per_volume;\n S2 has substance_per_volume;\n C1 = 0;\n C2 = 0;\n A2m has substance_per_volume;\n A3m = 1.5/c2;\n A3m has substance_per_volume;\n Ho = 0;\n Hm = 0;\n\n // Compartment initializations:\n c0 = 1;\n c1 = 1;\n c2 = 1;\n\n // Variable initializations:\n Ac = 2;\n N = 2;\n S = 2;\n Am = 2;\n k_v0 = 1.6;\n Kc = 0.1;\n n = 4;\n k_v13 = 4;\n k2 = 0.2;\n k_v10 = 80;\n k14 = 10;\n k3 = 0.2;\n k4 = 0.2;\n k5 = 0.1;\n k6 = 0.12;\n k7 = 10;\n k15 = 5;\n k17 = 0.02;\n k18 = 1;\n k8 = 10;\n k9 = 10;\n k11 = 10;\n a = 0.1;\n Kh = 0.5;\n m = 4;\n k16 = 10;\n Ka = 1;\n k12 = 5;\n\n // Other declarations:\n const c0, c1, c2, Ac, N, S, Am, k_v0, Kc, n, k_v13, k2, k_v10, k14, k3;\n const k4, k5, k6, k7, k15, k17, k18, k8, k9, k11, a, Kh, m, k16, Ka, k12;\n\n // Unit definitions:\n unit substance_per_volume = mole / litre;\n unit substance = mole;\n\n // Display Names:\n c0 is \"external\";\n c1 is \"cytosol\";\n c2 is \"mitochondria\";\n sul_ex is \"SO4_ex\";\n eth_ex is \"EtOH_ex\";\n oxy_ex is \"O2_ex\";\n oxy is \"O2\";\n A3c is \"ATP\";\n aps is \"APS\";\n pap is \"PAPS\";\n sul is \"SO4\";\n eth is \"EtOH\";\n A2c is \"ADP\";\n hyd is \"H2S\";\n cys is \"CYS\";\n N2 is \"NADH\";\n N1 is \"NAD\";\n aco is \"AcCoA\";\n oah is \"OAH\";\n A2m is \"ADP_mit\";\n A3m is \"ATP_mit\";\n v11a is \"vET1\";\n v11a2 is \"vET2\";\n v11b is \"vSYNT\";\n\n // CV terms:\n c0 hypernym \"http://identifiers.org/obo.go/GO:0005576\"\n c1 hypernym \"http://identifiers.org/obo.go/GO:0005829\"\n c2 hypernym \"http://identifiers.org/obo.go/GO:0005739\"\n sul_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth_ex identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n oxy_ex identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n oxy identity \"http://identifiers.org/obo.chebi/CHEBI:15379\"\n H2O identity \"http://identifiers.org/obo.chebi/CHEBI:15377\"\n A3c identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n aps identity \"http://identifiers.org/obo.chebi/CHEBI:17709\"\n PPi identity \"http://identifiers.org/obo.chebi/CHEBI:18361\"\n pap identity \"http://identifiers.org/obo.chebi/CHEBI:17980\"\n sul identity \"http://identifiers.org/obo.chebi/CHEBI:16189\"\n eth identity \"http://identifiers.org/obo.chebi/CHEBI:16236\"\n A2c identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n hyd identity \"http://identifiers.org/obo.chebi/CHEBI:16136\"\n cys identity \"http://identifiers.org/obo.chebi/CHEBI:17561\"\n N2 identity \"http://identifiers.org/obo.chebi/CHEBI:16908\"\n N1 identity \"http://identifiers.org/obo.chebi/CHEBI:15846\"\n aco identity \"http://identifiers.org/obo.chebi/CHEBI:15351\"\n oah identity \"http://identifiers.org/obo.chebi/CHEBI:16288\"\n S1 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n S2 parthood \"http://identifiers.org/obo.go/GO:0030062\"\n C1 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n C2 hypernym \"http://identifiers.org/obo.go/GO:0005746\"\n A2m identity \"http://identifiers.org/obo.chebi/CHEBI:16761\"\n A3m identity \"http://identifiers.org/obo.chebi/CHEBI:15422\"\n Ho identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n Hm identity \"http://identifiers.org/obo.chebi/CHEBI:24636\"\n v1 hypernym \"http://identifiers.org/obo.go/GO:0015381\"\n v13 hypernym \"http://identifiers.org/obo.go/GO:0015850\"\n v2 identity \"http://identifiers.org/ec-code/2.7.7.4\"\n v3 identity \"http://identifiers.org/ec-code/2.7.1.25\"\n v3 hypernym \"http://identifiers.org/obo.go/GO:0004020\"\n v4 version \"http://identifiers.org/ec-code/1.8.4.8\",\n \"http://identifiers.org/ec-code/1.8.1.2\"\n v5 version \"http://identifiers.org/ec-code/4.4.1.1\",\n \"http://identifiers.org/ec-code/4.2.1.22\",\n \"http://identifiers.org/ec-code/2.5.1.49\"\n v7 version \"http://identifiers.org/ec-code/6.2.1.1\",\n \"http://identifiers.org/ec-code/1.2.1.3\",\n \"http://identifiers.org/ec-code/1.1.1.1\"\n v15 identity \"http://identifiers.org/ec-code/2.3.1.31\"\n v8 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v9 parthood \"http://identifiers.org/obo.go/GO:0006099\"\n v11a identity \"http://identifiers.org/obo.go/GO:0015990\"\n v11a parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11a2 version \"http://identifiers.org/obo.go/GO:0002082\"\n v11a2 identity \"http://identifiers.org/obo.go/GO:0006123\"\n v16 identity \"http://identifiers.org/obo.go/GO:0005471\"\n v11b parthood \"http://identifiers.org/obo.go/GO:0042775\"\n v11b hypernym \"http://identifiers.org/obo.go/GO:0006119\"\n v11b version \"http://identifiers.org/obo.go/GO:0002082\"\n vLEAK hypernym \"http://identifiers.org/obo.go/GO:0006810\"\n v12 hypernym \"http://identifiers.org/obo.go/GO:0006200\"\nend\n\n\n // Set model\n wolf = model \"wolf.xml\" # model_id = model source_model\n\n // Deterministic simulation\n det_sim = simulate uniform(0, 500, 1000) # sim_id = simulate simulation_type\n wolf_det_sim = run det_sim on wolf # task_id = run sim_id on model_id\n plot \"Wolf et al. dynamics (Model ID: BIOMD0000000090)\" time vs oxy # plot title_name x vs y\n\n"
],
[
"# export to a COMBINE archive\nte.exportInlineOmex(wolf_inline_omex, 'wolf.omex')",
"_____no_output_____"
]
],
[
[
"# Exercises <a class=\"anchor\" id=\"exercises\"></a>",
"_____no_output_____"
],
[
"## Exercise 1:\n\nDownload the <a href=\"http://www.ebi.ac.uk/biomodels-main/BIOMD0000000010 \"> Kholodenko 2000 model</a> of ultrasensitivity and negative feedback oscillations in the MAPK cascade from the BioModels Database, and upload to your workspace. Simulate and plot simulation results for the model.\n\n<div align='center'><img src=\"https://raw.githubusercontent.com/vporubsky/tellurium-libroadrunner-tutorial/master/kholodenko_publication.PNG\" width=\"75%\"></div>\n",
"_____no_output_____"
]
],
[
[
"# Write your solution here",
"_____no_output_____"
]
],
[
[
"## Exercise 1 Solution:",
"_____no_output_____"
]
],
[
[
"# Solution\nr = te.loadSBMLModel(\n \"https://www.ebi.ac.uk/biomodels/model/download/BIOMD0000000010?filename=BIOMD0000000010_url.xml\")\nr.simulate(0, 5000, 1000)\nr.plot()",
"_____no_output_____"
]
],
[
[
"# Acknowledgements\n<br>\n<div align='left'><img src=\"https://raw.githubusercontent.com/vporubsky/tellurium-libroadrunner-tutorial/master/acknowledgments.png\" width=\"80%\"></div>",
"_____no_output_____"
],
[
"<br>\n<html>\n <head>\n </head>\n <body>\n <h1>Bibliography</h1>\n <ol>\n <li>\n <p>K. Choi et al., <cite>Tellurium: An extensible python-based modeling environment for systems and synthetic biology</cite>, Biosystems, vol. 171, pp. 74–79, Sep. 2018.</p>\n </li>\n <li>\n <p>E. T. Somogyi et al., <cite>libRoadRunner: a high performance SBML simulation and analysis library.,</cite>, Bioinformatics, vol. 31, no. 20, pp. 3315–21, Oct. 2015.</p>\n <li>\n <p>L. P. Smith, F. T. Bergmann, D. Chandran, and H. M. Sauro, <cite>Antimony: a modular model definition language</cite>, Bioinformatics, vol. 25, no. 18, pp. 2452–2454, Sep. 2009.</p>\n </li>\n <li>\n <p>K. Choi, L. P. Smith, J. K. Medley, and H. M. Sauro, <cite>phraSED-ML: a paraphrased, human-readable adaptation of SED-ML</cite>, J. Bioinform. Comput. Biol., vol. 14, no. 06, Dec. 2016.</p>\n </li>\n <li>\n <p> B.N. Kholodenko, O.V. Demin, G. Moehren, J.B. Hoek, <cite>Quantification of short term signaling by the epidermal growth factor receptor.</cite>, J Biol Chem., vol. 274, no. 42, Oct. 1999.</p>\n </li>\n </ol>\n </body>\n</html>\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd13fa06f350b6a7e8747a9c2c8e80e882cd9d0
| 25,341 |
ipynb
|
Jupyter Notebook
|
site/ko/tutorials/keras/classification.ipynb
|
nic-fp/docs
|
a3dff9a33f832e6fd53b3ace6337c854ce707431
|
[
"Apache-2.0"
] | 3 |
2020-01-09T02:58:22.000Z
|
2020-09-11T09:02:01.000Z
|
site/ko/tutorials/keras/classification.ipynb
|
nic-fp/docs
|
a3dff9a33f832e6fd53b3ace6337c854ce707431
|
[
"Apache-2.0"
] | 1 |
2020-01-11T03:55:25.000Z
|
2020-01-11T03:55:25.000Z
|
site/ko/tutorials/keras/classification.ipynb
|
nic-fp/docs
|
a3dff9a33f832e6fd53b3ace6337c854ce707431
|
[
"Apache-2.0"
] | 2 |
2020-01-15T21:50:31.000Z
|
2020-01-15T21:56:30.000Z
| 24.389798 | 295 | 0.530326 |
[
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# 첫 번째 신경망 훈련하기: 기초적인 분류 문제",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/keras/classification\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />TensorFlow.org에서 보기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/ko/tutorials/keras/classification.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />구글 코랩(Colab)에서 실행하기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/ko/tutorials/keras/classification.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />깃허브(GitHub) 소스 보기</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도\n불구하고 [공식 영문 문서](https://www.tensorflow.org/?hl=en)의 내용과 일치하지 않을 수 있습니다.\n이 번역에 개선할 부분이 있다면\n[tensorflow/docs](https://github.com/tensorflow/docs) 깃헙 저장소로 풀 리퀘스트를 보내주시기 바랍니다.\n문서 번역이나 리뷰에 참여하려면\n[[email protected]](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-ko)로\n메일을 보내주시기 바랍니다.",
"_____no_output_____"
],
[
"이 튜토리얼에서는 운동화나 셔츠 같은 옷 이미지를 분류하는 신경망 모델을 훈련합니다. 상세 내용을 모두 이해하지 못해도 괜찮습니다. 여기서는 완전한 텐서플로(TensorFlow) 프로그램을 빠르게 살펴 보겠습니다. 자세한 내용은 앞으로 배우면서 더 설명합니다.\n\n여기에서는 텐서플로 모델을 만들고 훈련할 수 있는 고수준 API인 [tf.keras](https://www.tensorflow.org/guide/keras)를 사용합니다.",
"_____no_output_____"
]
],
[
[
"try:\n # Colab only\n %tensorflow_version 2.x\nexcept Exception:\n pass\n",
"_____no_output_____"
],
[
"from __future__ import absolute_import, division, print_function, unicode_literals, unicode_literals\n\n# tensorflow와 tf.keras를 임포트합니다\nimport tensorflow as tf\nfrom tensorflow import keras\n\n# 헬퍼(helper) 라이브러리를 임포트합니다\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nprint(tf.__version__)",
"_____no_output_____"
]
],
[
[
"## 패션 MNIST 데이터셋 임포트하기",
"_____no_output_____"
],
[
"10개의 범주(category)와 70,000개의 흑백 이미지로 구성된 [패션 MNIST](https://github.com/zalandoresearch/fashion-mnist) 데이터셋을 사용하겠습니다. 이미지는 해상도(28x28 픽셀)가 낮고 다음처럼 개별 옷 품목을 나타냅니다:\n\n<table>\n <tr><td>\n <img src=\"https://tensorflow.org/images/fashion-mnist-sprite.png\"\n alt=\"Fashion MNIST sprite\" width=\"600\">\n </td></tr>\n <tr><td align=\"center\">\n <b>그림 1.</b> <a href=\"https://github.com/zalandoresearch/fashion-mnist\">패션-MNIST 샘플</a> (Zalando, MIT License).<br/> \n </td></tr>\n</table>\n\n패션 MNIST는 컴퓨터 비전 분야의 \"Hello, World\" 프로그램격인 고전 [MNIST](http://yann.lecun.com/exdb/mnist/) 데이터셋을 대신해서 자주 사용됩니다. MNIST 데이터셋은 손글씨 숫자(0, 1, 2 등)의 이미지로 이루어져 있습니다. 여기서 사용하려는 옷 이미지와 동일한 포맷입니다.\n\n패션 MNIST는 일반적인 MNIST 보다 조금 더 어려운 문제이고 다양한 예제를 만들기 위해 선택했습니다. 두 데이터셋은 비교적 작기 때문에 알고리즘의 작동 여부를 확인하기 위해 사용되곤 합니다. 코드를 테스트하고 디버깅하는 용도로 좋습니다.\n\n네트워크를 훈련하는데 60,000개의 이미지를 사용합니다. 그다음 네트워크가 얼마나 정확하게 이미지를 분류하는지 10,000개의 이미지로 평가하겠습니다. 패션 MNIST 데이터셋은 텐서플로에서 바로 임포트하여 적재할 수 있습니다:",
"_____no_output_____"
]
],
[
[
"fashion_mnist = keras.datasets.fashion_mnist\n\n(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()",
"_____no_output_____"
]
],
[
[
"load_data() 함수를 호출하면 네 개의 넘파이(NumPy) 배열이 반환됩니다:\n\n* `train_images`와 `train_labels` 배열은 모델 학습에 사용되는 *훈련 세트*입니다.\n* `test_images`와 `test_labels` 배열은 모델 테스트에 사용되는 *테스트 세트*입니다.\n\n이미지는 28x28 크기의 넘파이 배열이고 픽셀 값은 0과 255 사이입니다. *레이블*(label)은 0에서 9까지의 정수 배열입니다. 이 값은 이미지에 있는 옷의 *클래스*(class)를 나타냅니다:\n\n<table>\n <tr>\n <th>레이블</th>\n <th>클래스</th>\n </tr>\n <tr>\n <td>0</td>\n <td>T-shirt/top</td>\n </tr>\n <tr>\n <td>1</td>\n <td>Trouser</td>\n </tr>\n <tr>\n <td>2</td>\n <td>Pullover</td>\n </tr>\n <tr>\n <td>3</td>\n <td>Dress</td>\n </tr>\n <tr>\n <td>4</td>\n <td>Coat</td>\n </tr>\n <tr>\n <td>5</td>\n <td>Sandal</td>\n </tr>\n <tr>\n <td>6</td>\n <td>Shirt</td>\n </tr>\n <tr>\n <td>7</td>\n <td>Sneaker</td>\n </tr>\n <tr>\n <td>8</td>\n <td>Bag</td>\n </tr>\n <tr>\n <td>9</td>\n <td>Ankle boot</td>\n </tr>\n</table>\n\n각 이미지는 하나의 레이블에 매핑되어 있습니다. 데이터셋에 *클래스 이름*이 들어있지 않기 때문에 나중에 이미지를 출력할 때 사용하기 위해 별도의 변수를 만들어 저장합니다:",
"_____no_output_____"
]
],
[
[
"class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',\n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']",
"_____no_output_____"
]
],
[
[
"## 데이터 탐색\n\n모델을 훈련하기 전에 데이터셋 구조를 살펴보죠. 다음 코드는 훈련 세트에 60,000개의 이미지가 있다는 것을 보여줍니다. 각 이미지는 28x28 픽셀로 표현됩니다:",
"_____no_output_____"
]
],
[
[
"train_images.shape",
"_____no_output_____"
]
],
[
[
"비슷하게 훈련 세트에는 60,000개의 레이블이 있습니다:",
"_____no_output_____"
]
],
[
[
"len(train_labels)",
"_____no_output_____"
]
],
[
[
"각 레이블은 0과 9사이의 정수입니다:",
"_____no_output_____"
]
],
[
[
"train_labels",
"_____no_output_____"
]
],
[
[
"테스트 세트에는 10,000개의 이미지가 있습니다. 이 이미지도 28x28 픽셀로 표현됩니다:",
"_____no_output_____"
]
],
[
[
"test_images.shape",
"_____no_output_____"
]
],
[
[
"테스트 세트는 10,000개의 이미지에 대한 레이블을 가지고 있습니다:",
"_____no_output_____"
]
],
[
[
"len(test_labels)",
"_____no_output_____"
]
],
[
[
"## 데이터 전처리\n\n네트워크를 훈련하기 전에 데이터를 전처리해야 합니다. 훈련 세트에 있는 첫 번째 이미지를 보면 픽셀 값의 범위가 0~255 사이라는 것을 알 수 있습니다:",
"_____no_output_____"
]
],
[
[
"plt.figure()\nplt.imshow(train_images[0])\nplt.colorbar()\nplt.grid(False)\nplt.show()",
"_____no_output_____"
]
],
[
[
"신경망 모델에 주입하기 전에 이 값의 범위를 0~1 사이로 조정하겠습니다. 이렇게 하려면 255로 나누어야 합니다. *훈련 세트*와 *테스트 세트*를 동일한 방식으로 전처리하는 것이 중요합니다:",
"_____no_output_____"
]
],
[
[
"train_images = train_images / 255.0\n\ntest_images = test_images / 255.0",
"_____no_output_____"
]
],
[
[
"*훈련 세트*에서 처음 25개 이미지와 그 아래 클래스 이름을 출력해 보죠. 데이터 포맷이 올바른지 확인하고 네트워크 구성과 훈련할 준비를 마칩니다.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid(False)\n plt.imshow(train_images[i], cmap=plt.cm.binary)\n plt.xlabel(class_names[train_labels[i]])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 모델 구성\n\n신경망 모델을 만들려면 모델의 층을 구성한 다음 모델을 컴파일합니다.",
"_____no_output_____"
],
[
"### 층 설정\n\n신경망의 기본 구성 요소는 *층*(layer)입니다. 층은 주입된 데이터에서 표현을 추출합니다. 아마도 문제를 해결하는데 더 의미있는 표현이 추출될 것입니다.\n\n대부분 딥러닝은 간단한 층을 연결하여 구성됩니다. `tf.keras.layers.Dense`와 같은 층들의 가중치(parameter)는 훈련하는 동안 학습됩니다.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n keras.layers.Flatten(input_shape=(28, 28)),\n keras.layers.Dense(128, activation='relu'),\n keras.layers.Dense(10, activation='softmax')\n])",
"_____no_output_____"
]
],
[
[
"이 네트워크의 첫 번째 층인 `tf.keras.layers.Flatten`은 2차원 배열(28 x 28 픽셀)의 이미지 포맷을 28 * 28 = 784 픽셀의 1차원 배열로 변환합니다. 이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘립니다. 이 층에는 학습되는 가중치가 없고 데이터를 변환하기만 합니다.\n\n픽셀을 펼친 후에는 두 개의 `tf.keras.layers.Dense` 층이 연속되어 연결됩니다. 이 층을 밀집 연결(densely-connected) 또는 완전 연결(fully-connected) 층이라고 부릅니다. 첫 번째 `Dense` 층은 128개의 노드(또는 뉴런)를 가집니다. 두 번째 (마지막) 층은 10개의 노드의 *소프트맥스*(softmax) 층입니다. 이 층은 10개의 확률을 반환하고 반환된 값의 전체 합은 1입니다. 각 노드는 현재 이미지가 10개 클래스 중 하나에 속할 확률을 출력합니다.\n\n### 모델 컴파일\n\n모델을 훈련하기 전에 필요한 몇 가지 설정이 모델 *컴파일* 단계에서 추가됩니다:\n\n* *손실 함수*(Loss function)-훈련 하는 동안 모델의 오차를 측정합니다. 모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 합니다.\n* *옵티마이저*(Optimizer)-데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정합니다.\n* *지표*(Metrics)-훈련 단계와 테스트 단계를 모니터링하기 위해 사용합니다. 다음 예에서는 올바르게 분류된 이미지의 비율인 *정확도*를 사용합니다.",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"## 모델 훈련\n\n신경망 모델을 훈련하는 단계는 다음과 같습니다:\n\n1. 훈련 데이터를 모델에 주입합니다-이 예에서는 `train_images`와 `train_labels` 배열입니다.\n2. 모델이 이미지와 레이블을 매핑하는 방법을 배웁니다.\n3. 테스트 세트에 대한 모델의 예측을 만듭니다-이 예에서는 `test_images` 배열입니다. 이 예측이 `test_labels` 배열의 레이블과 맞는지 확인합니다.\n\n훈련을 시작하기 위해 `model.fit` 메서드를 호출하면 모델이 훈련 데이터를 학습합니다:",
"_____no_output_____"
]
],
[
[
"model.fit(train_images, train_labels, epochs=5)",
"_____no_output_____"
]
],
[
[
"모델이 훈련되면서 손실과 정확도 지표가 출력됩니다. 이 모델은 훈련 세트에서 약 0.88(88%) 정도의 정확도를 달성합니다.",
"_____no_output_____"
],
[
"## 정확도 평가\n\n그다음 테스트 세트에서 모델의 성능을 비교합니다:",
"_____no_output_____"
]
],
[
[
"test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)\n\nprint('\\n테스트 정확도:', test_acc)",
"_____no_output_____"
]
],
[
[
"테스트 세트의 정확도가 훈련 세트의 정확도보다 조금 낮습니다. 훈련 세트의 정확도와 테스트 세트의 정확도 사이의 차이는 *과대적합*(overfitting) 때문입니다. 과대적합은 머신러닝 모델이 훈련 데이터보다 새로운 데이터에서 성능이 낮아지는 현상을 말합니다.",
"_____no_output_____"
],
[
"## 예측 만들기\n\n훈련된 모델을 사용하여 이미지에 대한 예측을 만들 수 있습니다.",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(test_images)",
"_____no_output_____"
]
],
[
[
"여기서는 테스트 세트에 있는 각 이미지의 레이블을 예측했습니다. 첫 번째 예측을 확인해 보죠:",
"_____no_output_____"
]
],
[
[
"predictions[0]",
"_____no_output_____"
]
],
[
[
"이 예측은 10개의 숫자 배열로 나타납니다. 이 값은 10개의 옷 품목에 상응하는 모델의 신뢰도(confidence)를 나타냅니다. 가장 높은 신뢰도를 가진 레이블을 찾아보죠:",
"_____no_output_____"
]
],
[
[
"np.argmax(predictions[0])",
"_____no_output_____"
]
],
[
[
"모델은 이 이미지가 앵클 부츠(`class_name[9]`)라고 가장 확신하고 있습니다. 이 값이 맞는지 테스트 레이블을 확인해 보죠:",
"_____no_output_____"
]
],
[
[
"test_labels[0]",
"_____no_output_____"
]
],
[
[
"10개 클래스에 대한 예측을 모두 그래프로 표현해 보겠습니다:",
"_____no_output_____"
]
],
[
[
"def plot_image(i, predictions_array, true_label, img):\n predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]\n plt.grid(False)\n plt.xticks([])\n plt.yticks([])\n\n plt.imshow(img, cmap=plt.cm.binary)\n\n predicted_label = np.argmax(predictions_array)\n if predicted_label == true_label:\n color = 'blue'\n else:\n color = 'red'\n\n plt.xlabel(\"{} {:2.0f}% ({})\".format(class_names[predicted_label],\n 100*np.max(predictions_array),\n class_names[true_label]),\n color=color)\n\ndef plot_value_array(i, predictions_array, true_label):\n predictions_array, true_label = predictions_array[i], true_label[i]\n plt.grid(False)\n plt.xticks([])\n plt.yticks([])\n thisplot = plt.bar(range(10), predictions_array, color=\"#777777\")\n plt.ylim([0, 1])\n predicted_label = np.argmax(predictions_array)\n\n thisplot[predicted_label].set_color('red')\n thisplot[true_label].set_color('blue')",
"_____no_output_____"
]
],
[
[
"0번째 원소의 이미지, 예측, 신뢰도 점수 배열을 확인해 보겠습니다.",
"_____no_output_____"
]
],
[
[
"i = 0\nplt.figure(figsize=(6,3))\nplt.subplot(1,2,1)\nplot_image(i, predictions, test_labels, test_images)\nplt.subplot(1,2,2)\nplot_value_array(i, predictions, test_labels)\nplt.show()",
"_____no_output_____"
],
[
"i = 12\nplt.figure(figsize=(6,3))\nplt.subplot(1,2,1)\nplot_image(i, predictions, test_labels, test_images)\nplt.subplot(1,2,2)\nplot_value_array(i, predictions, test_labels)\nplt.show()",
"_____no_output_____"
]
],
[
[
"몇 개의 이미지의 예측을 출력해 보죠. 올바르게 예측된 레이블은 파란색이고 잘못 예측된 레이블은 빨강색입니다. 숫자는 예측 레이블의 신뢰도 퍼센트(100점 만점)입니다. 신뢰도 점수가 높을 때도 잘못 예측할 수 있습니다.",
"_____no_output_____"
]
],
[
[
"# 처음 X 개의 테스트 이미지와 예측 레이블, 진짜 레이블을 출력합니다\n# 올바른 예측은 파랑색으로 잘못된 예측은 빨강색으로 나타냅니다\nnum_rows = 5\nnum_cols = 3\nnum_images = num_rows*num_cols\nplt.figure(figsize=(2*2*num_cols, 2*num_rows))\nfor i in range(num_images):\n plt.subplot(num_rows, 2*num_cols, 2*i+1)\n plot_image(i, predictions, test_labels, test_images)\n plt.subplot(num_rows, 2*num_cols, 2*i+2)\n plot_value_array(i, predictions, test_labels)\nplt.show()",
"_____no_output_____"
]
],
[
[
"마지막으로 훈련된 모델을 사용하여 한 이미지에 대한 예측을 만듭니다.",
"_____no_output_____"
]
],
[
[
"# 테스트 세트에서 이미지 하나를 선택합니다\nimg = test_images[0]\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"`tf.keras` 모델은 한 번에 샘플의 묶음 또는 *배치*(batch)로 예측을 만드는데 최적화되어 있습니다. 하나의 이미지를 사용할 때에도 2차원 배열로 만들어야 합니다:",
"_____no_output_____"
]
],
[
[
"# 이미지 하나만 사용할 때도 배치에 추가합니다\nimg = (np.expand_dims(img,0))\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"이제 이 이미지의 예측을 만듭니다:",
"_____no_output_____"
]
],
[
[
"predictions_single = model.predict(img)\n\nprint(predictions_single)",
"_____no_output_____"
],
[
"plot_value_array(0, predictions_single, test_labels)\n_ = plt.xticks(range(10), class_names, rotation=45)",
"_____no_output_____"
]
],
[
[
"`model.predict`는 2차원 넘파이 배열을 반환하므로 첫 번째 이미지의 예측을 선택합니다:",
"_____no_output_____"
]
],
[
[
"np.argmax(predictions_single[0])",
"_____no_output_____"
]
],
[
[
"이전과 마찬가지로 모델의 예측은 레이블 9입니다.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd14d773958813e4f48f0adc7ae4994ade16add
| 8,948 |
ipynb
|
Jupyter Notebook
|
sessions/examples/02 - Python machine learning - clustering.ipynb
|
NudlerLab/biodata
|
42fabdade0d942a7ad7cad294ad969279ff7dd7b
|
[
"MIT"
] | null | null | null |
sessions/examples/02 - Python machine learning - clustering.ipynb
|
NudlerLab/biodata
|
42fabdade0d942a7ad7cad294ad969279ff7dd7b
|
[
"MIT"
] | null | null | null |
sessions/examples/02 - Python machine learning - clustering.ipynb
|
NudlerLab/biodata
|
42fabdade0d942a7ad7cad294ad969279ff7dd7b
|
[
"MIT"
] | 1 |
2018-10-26T17:46:24.000Z
|
2018-10-26T17:46:24.000Z
| 30.22973 | 283 | 0.553532 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport os\n\nfrom plotnine import *",
"_____no_output_____"
]
],
[
[
"## Overview\n* select 5'UTRs longer than 80 nt\n* count reads aligned to these UTRs (pysam)\n* plot utr reads -bcm vs utr reads + bcm\n* select UTRs with increased number of reads upon addition of BCM (clustering?)\n* compare selected UTRs with genes upregulated in the stationary phase as discovered by DESeq2\n* compare selected UTRs with small RNA binding sites (pybedtools?)",
"_____no_output_____"
],
[
"### Sample table and barcodes",
"_____no_output_____"
]
],
[
[
"# Sample titles with corresponding barcodes\nsamples = {\n 's9': ['ATCACG', 'ACAGTG'],\n 's9+bcm': ['CGATGT', 'GCCAAT'],\n 's17': ['TTAGGC', 'GATCAG'],\n 's17+bcm': ['TGACCA', 'TAGCTT'],\n 's19': ['CAGATC','GGCTAC'],\n 's19+bcm': ['ACTTGA', 'CTTGTA']\n}\n\n# Barcodes\nbarcodes = ['ATCACG', 'ACAGTG', 'CGATGT', 'GCCAAT', 'TTAGGC', 'GATCAG', 'TGACCA', 'TAGCTT', 'CAGATC','GGCTAC', 'ACTTGA', 'CTTGTA']",
"_____no_output_____"
]
],
[
[
"### Load counts for genes, calculate counts in UTRs longer than 80 nt\n\nGene counts were obtained using `htseq` program against the standard NC_000913 .GFF file The was I calculate reads in UTRs here is not strand-specific. So the numbers can be confounded if there is a transcript going in the opposite direction. We can solve this later if needed.",
"_____no_output_____"
]
],
[
[
"dfm = pd.read_csv('../../data/dfm.csv', sep='\\t')\ndfm",
"_____no_output_____"
]
],
[
[
"### Normalize counts for feature length, log-transform, and take means for replicates\n\nPseudo-counts (+1) are added during UTR reads counting to make sure we can log-transform the data.",
"_____no_output_____"
]
],
[
[
"id_vars = ['TSS','TU_name','coord_5','coord_3','gene', 'UTR_length']\nvalue_vars = ['s9','s17','s19','s9+bcm','s17+bcm','s19+bcm']\n\ndfn = dfm.copy()\n\n# Normalize counts by gene and utr length\ndef norm_orf(barcode, rec):\n return float(rec[barcode] / abs(rec['first_gene_5'] - rec['first_gene_3']))\n\ndef norm_utr(barcode, rec):\n return float(rec['utr_{0}'.format(barcode)] / rec['UTR_length'])\n\nfor barcode in barcodes:\n dfn['orf_{0}'.format(barcode)] = dfn.apply(lambda rec: norm_orf(barcode, rec), axis=1)\n dfn['utr_{0}'.format(barcode)] = dfn.apply(lambda rec: norm_utr(barcode, rec), axis=1)\n\n \ndf = dfn[id_vars].copy()\n# Take means across replicates according to the samples dict\nfor sample, bcs in samples.items():\n df['orf_{0}'.format(sample)] = np.log10(dfn[['orf_{0}'.format(b) for b in list(bcs)]].mean(axis=1))\n df['utr_{0}'.format(sample)] = np.log10(dfn[['utr_{0}'.format(b) for b in list(bcs)]].mean(axis=1))\ndf",
"_____no_output_____"
]
],
[
[
"### Plot wild type with vs without BCM\n\nTwo clusters are apparent. We are after the UTRs that are upregulated by the addition of BCM (cloud of points in the left part of the plot along y=0 line and in general (significantly) above y=x line).\n\nBTW, the point size is the length of UTR. No (apparent) correlation here.",
"_____no_output_____"
]
],
[
[
"(ggplot(df, aes(x='utr_s9', y='utr_s9+bcm', size='UTR_length'))\n + geom_point(size=0.5, alpha=0.1)\n + geom_abline(slope=1, intercept=0, size=.5, color='#586e75')\n)",
"_____no_output_____"
],
[
"(ggplot(df, aes(x='utr_s9', y='utr_s19', size='UTR_length'))\n + geom_point(size=0.5, alpha=0.1)\n + geom_abline(slope=1, intercept=0, size=0.5, color='#586e75')\n)",
"_____no_output_____"
]
],
[
[
"### Clustering\n\nNow we need a way to split the points the way we want. Let's try a bunch of clustering algorithms from `scikit-learn.`",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import euclidean_distances\nfrom sklearn.neighbors import kneighbors_graph\nfrom sklearn import cluster\nfrom sklearn import mixture\n\nX = df[['utr_s9', 'utr_s9+bcm']].to_numpy()\nX = StandardScaler().fit_transform(X)\n\nbandwidth = cluster.estimate_bandwidth(X, quantile=0.3)\nconnectivity = kneighbors_graph(X, n_neighbors=20)\nconnectivity = 0.05 * (connectivity + connectivity.T)\n#distances = euclidean_distances(X)\n\ngmm = mixture.GaussianMixture(n_components=2, covariance_type='full')\n\nms = cluster.MeanShift(bandwidth=bandwidth, bin_seeding=True)\ntwo_means = cluster.MiniBatchKMeans(n_clusters=2, batch_size=200)\nkmeans = cluster.KMeans(n_clusters=2)\nward = cluster.AgglomerativeClustering(n_clusters=2, linkage='ward', connectivity=connectivity)\nspectral = cluster.SpectralClustering(n_clusters=2, n_neighbors=20, eigen_solver='arpack', affinity='nearest_neighbors')\ndbscan = cluster.DBSCAN(eps=.5)\naffinity_propagation = cluster.AffinityPropagation(damping=.95, preference=-200)\naverage_linkage = cluster.AgglomerativeClustering(linkage='average', affinity='cityblock', n_clusters=2, connectivity=connectivity)\n\nfor name, alg in [\n ('MiniBatchKMeans', two_means),\n ('KMeans', kmeans),\n ('AffinityPropagation', affinity_propagation),\n ('MeanShift', ms),\n ('GMM', gmm),\n ('SpectralClustering', spectral),\n ('Ward', ward),\n ('AgglomerativeClustering', average_linkage),\n ('DBSCAN', dbscan)\n ]:\n alg.fit(X)\n if hasattr(alg, 'labels_'):\n df['label'] = alg.labels_.astype(np.int32)\n else:\n df['label'] = alg.predict(X)\n \n p = ggplot(df, aes(x='utr_s9', y='utr_s9+bcm', color='label')) \\\n + geom_point(size=0.5, alpha=0.5) \\\n + ggtitle(name) \\\n + geom_abline(slope=1, intercept=0, size=0.5, color='#586e75')\n print(p)",
"_____no_output_____"
],
[
"X = df.as_matrix",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd155c4f6d9955bcfc71b62d4cb90671bc8c1f7
| 301,200 |
ipynb
|
Jupyter Notebook
|
LSTM.ipynb
|
KennyCandy/CNNRNN
|
b22f408db3ce043eb773a1af54c660a9d7ec4df7
|
[
"MIT"
] | null | null | null |
LSTM.ipynb
|
KennyCandy/CNNRNN
|
b22f408db3ce043eb773a1af54c660a9d7ec4df7
|
[
"MIT"
] | null | null | null |
LSTM.ipynb
|
KennyCandy/CNNRNN
|
b22f408db3ce043eb773a1af54c660a9d7ec4df7
|
[
"MIT"
] | null | null | null | 321.108742 | 182,264 | 0.907364 |
[
[
[
"# LSTM for Human Activity Recognition\n\nHuman activity recognition using smartphones dataset and an LSTM RNN. Classifying the type of movement amongst six categories:\n- WALKING,\n- WALKING_UPSTAIRS,\n- WALKING_DOWNSTAIRS,\n- SITTING,\n- STANDING,\n- LAYING.\n\n\n## Video dataset overview\n\nFollow this link to see a video of the 6 activities recorded in the experiment with one of the participants:\n\n<a href=\"http://www.youtube.com/watch?feature=player_embedded&v=XOEN9W05_4A\n\" target=\"_blank\"><img src=\"http://img.youtube.com/vi/XOEN9W05_4A/0.jpg\" \nalt=\"Video of the experiment\" width=\"400\" height=\"300\" border=\"10\" /></a>\n<a href=\"https://youtu.be/XOEN9W05_4A\"><center>[Watch video]</center></a>\n\n## Details about input data\n\nI will be using an LSTM on the data to learn (as a cellphone attached on the waist) to recognise the type of activity that the user is doing. The dataset's description goes like this:\n\n> The sensor signals (accelerometer and gyroscope) were pre-processed by applying noise filters and then sampled in fixed-width sliding windows of 2.56 sec and 50% overlap (128 readings/window). The sensor acceleration signal, which has gravitational and body motion components, was separated using a Butterworth low-pass filter into body acceleration and gravity. The gravitational force is assumed to have only low frequency components, therefore a filter with 0.3 Hz cutoff frequency was used. \n\nThat said, I will use the almost raw data: only the gravity effect has been filtered out of the accelerometer as a preprocessing step for another 3D feature as an input to help learning. \n\n## What is an RNN?\n\nAs explained in [this article](http://karpathy.github.io/2015/05/21/rnn-effectiveness/), an RNN takes many input vectors to process them and output other vectors. It can be roughly pictured like in the image below, imagining each rectangle has a vectorial depth and other special hidden quirks in the image below. **In our case, the \"many to one\" architecture is used**: we accept time series of feature vectors (one vector per time step) to convert them to a probability vector at the output for classification. Note that a \"one to one\" architecture would be a standard feedforward neural network. \n\n<img src=\"http://karpathy.github.io/assets/rnn/diags.jpeg\" />\n\nAn LSTM is an improved RNN. It is more complex, but easier to train, avoiding what is called the vanishing gradient problem and the exploding gradient problem. \n\n\n## Results \n\nScroll on! Nice visuals awaits. ",
"_____no_output_____"
],
[
"# All Includes\n\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport tensorflow as tf # Version r0.10\nfrom sklearn import metrics\n\nimport os",
"_____no_output_____"
],
[
"# Useful Constants\n\n# Those are separate normalised input features for the neural network\nINPUT_SIGNAL_TYPES = [\n \"body_acc_x_\",\n \"body_acc_y_\",\n \"body_acc_z_\",\n \"body_gyro_x_\",\n \"body_gyro_y_\",\n \"body_gyro_z_\",\n \"total_acc_x_\",\n \"total_acc_y_\",\n \"total_acc_z_\"\n]\n\n# Output classes to learn how to classify\nLABELS = [\n \"WALKING\", \n \"WALKING_UPSTAIRS\", \n \"WALKING_DOWNSTAIRS\", \n \"SITTING\", \n \"STANDING\", \n \"LAYING\"\n]",
"_____no_output_____"
]
],
[
[
"## Let's start by downloading the data: ",
"_____no_output_____"
]
],
[
[
"# Note: Linux bash commands start with a \"!\" inside those \"ipython notebook\" cells\n\nDATA_PATH = \"data/\"\n\n!pwd && ls\nos.chdir(DATA_PATH)\n!pwd && ls\n\n!python download_dataset.py\n\n!pwd && ls\nos.chdir(\"..\")\n!pwd && ls\n\nDATASET_PATH = DATA_PATH + \"UCI HAR Dataset/\"\nprint(\"\\n\" + \"Dataset is now located at: \" + DATASET_PATH)",
"_____no_output_____"
]
],
[
[
"## Preparing dataset:",
"_____no_output_____"
]
],
[
[
"TRAIN = \"train/\"\nTEST = \"test/\"\n\n\n# Load \"X\" (the neural network's training and testing inputs)\n\ndef load_X(X_signals_paths):\n X_signals = []\n \n for signal_type_path in X_signals_paths:\n file = open(signal_type_path, 'rb')\n # Read dataset from disk, dealing with text files' syntax\n X_signals.append(\n [np.array(serie, dtype=np.float32) for serie in [\n row.replace(' ', ' ').strip().split(' ') for row in file\n ]]\n )\n file.close()\n \n return np.transpose(np.array(X_signals), (1, 2, 0))\n\nX_train_signals_paths = [\n DATASET_PATH + TRAIN + \"Inertial Signals/\" + signal + \"train.txt\" for signal in INPUT_SIGNAL_TYPES\n]\nX_test_signals_paths = [\n DATASET_PATH + TEST + \"Inertial Signals/\" + signal + \"test.txt\" for signal in INPUT_SIGNAL_TYPES\n]\n\nX_train = load_X(X_train_signals_paths)\nX_test = load_X(X_test_signals_paths)\n\n\n# Load \"y\" (the neural network's training and testing outputs)\n\ndef load_y(y_path):\n file = open(y_path, 'rb')\n # Read dataset from disk, dealing with text file's syntax\n y_ = np.array(\n [elem for elem in [\n row.replace(' ', ' ').strip().split(' ') for row in file\n ]], \n dtype=np.int32\n )\n file.close()\n \n # Substract 1 to each output class for friendly 0-based indexing \n return y_ - 1\n\ny_train_path = DATASET_PATH + TRAIN + \"y_train.txt\"\ny_test_path = DATASET_PATH + TEST + \"y_test.txt\"\n\ny_train = load_y(y_train_path)\ny_test = load_y(y_test_path)",
"_____no_output_____"
]
],
[
[
"## Additionnal Parameters:\n\nHere are some core parameter definitions for the training. \n\nThe whole neural network's structure could be summarised by enumerating those parameters and the fact an LSTM is used. ",
"_____no_output_____"
]
],
[
[
"# Input Data \n\ntraining_data_count = len(X_train) # 7352 training series (with 50% overlap between each serie)\ntest_data_count = len(X_test) # 2947 testing series\nn_steps = len(X_train[0]) # 128 timesteps per series\nn_input = len(X_train[0][0]) # 9 input parameters per timestep\n\n\n# LSTM Neural Network's internal structure\n\nn_hidden = 32 # Hidden layer num of features\nn_classes = 6 # Total classes (should go up, or should go down)\n\n\n# Training \n\nlearning_rate = 0.0025\nlambda_loss_amount = 0.0015\ntraining_iters = training_data_count * 300 # Loop 300 times on the dataset\nbatch_size = 1500\ndisplay_iter = 30000 # To show test set accuracy during training\n\n\n# Some debugging info\n\nprint \"Some useful info to get an insight on dataset's shape and normalisation:\"\nprint \"(X shape, y shape, every X's mean, every X's standard deviation)\"\nprint (X_test.shape, y_test.shape, np.mean(X_test), np.std(X_test))\nprint \"The dataset is therefore properly normalised, as expected, but not yet one-hot encoded.\"",
"Some useful info to get an insight on dataset's shape and normalisation:\n(X shape, y shape, every X's mean, every X's standard deviation)\n((2947, 128, 9), (2947, 1), 0.099147044, 0.39534995)\nThe dataset is therefore properly normalised, as expected, but not yet one-hot encoded.\n"
]
],
[
[
"## Utility functions for training:",
"_____no_output_____"
]
],
[
[
"def LSTM_RNN(_X, _weights, _biases):\n # Function returns a tensorflow LSTM (RNN) artificial neural network from given parameters. \n # Moreover, two LSTM cells are stacked which adds deepness to the neural network. \n # Note, some code of this notebook is inspired from an slightly different \n # RNN architecture used on another dataset: \n # https://tensorhub.com/aymericdamien/tensorflow-rnn\n\n # (NOTE: This step could be greatly optimised by shaping the dataset once\n # input shape: (batch_size, n_steps, n_input)\n _X = tf.transpose(_X, [1, 0, 2]) # permute n_steps and batch_size\n # Reshape to prepare input to hidden activation\n _X = tf.reshape(_X, [-1, n_input]) \n # new shape: (n_steps*batch_size, n_input)\n \n # Linear activation\n _X = tf.nn.relu(tf.matmul(_X, _weights['hidden']) + _biases['hidden'])\n # Split data because rnn cell needs a list of inputs for the RNN inner loop\n _X = tf.split(0, n_steps, _X) \n # new shape: n_steps * (batch_size, n_hidden)\n\n # Define two stacked LSTM cells (two recurrent layers deep) with tensorflow\n lstm_cell_1 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)\n lstm_cell_2 = tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True)\n lstm_cells = tf.nn.rnn_cell.MultiRNNCell([lstm_cell_1, lstm_cell_2], state_is_tuple=True)\n # Get LSTM cell output\n outputs, states = tf.nn.rnn(lstm_cells, _X, dtype=tf.float32)\n\n # Get last time step's output feature for a \"many to one\" style classifier, \n # as in the image describing RNNs at the top of this page\n lstm_last_output = outputs[-1]\n \n # Linear activation\n return tf.matmul(lstm_last_output, _weights['out']) + _biases['out']\n\n\ndef extract_batch_size(_train, step, batch_size):\n # Function to fetch a \"batch_size\" amount of data from \"(X|y)_train\" data. \n \n shape = list(_train.shape)\n shape[0] = batch_size\n batch_s = np.empty(shape)\n\n for i in range(batch_size):\n # Loop index\n index = ((step-1)*batch_size + i) % len(_train)\n batch_s[i] = _train[index] \n\n return batch_s\n\n\ndef one_hot(y_):\n # Function to encode output labels from number indexes \n # e.g.: [[5], [0], [3]] --> [[0, 0, 0, 0, 0, 1], [1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0]]\n \n y_ = y_.reshape(len(y_))\n n_values = np.max(y_) + 1\n return np.eye(n_values)[np.array(y_, dtype=np.int32)] # Returns FLOATS",
"_____no_output_____"
]
],
[
[
"## Let's get serious and build the neural network:",
"_____no_output_____"
]
],
[
[
"# Graph input/output\nx = tf.placeholder(tf.float32, [None, n_steps, n_input])\ny = tf.placeholder(tf.float32, [None, n_classes])\n\n# Graph weights\nweights = {\n 'hidden': tf.Variable(tf.random_normal([n_input, n_hidden])), # Hidden layer weights\n 'out': tf.Variable(tf.random_normal([n_hidden, n_classes], mean=1.0))\n}\nbiases = {\n 'hidden': tf.Variable(tf.random_normal([n_hidden])),\n 'out': tf.Variable(tf.random_normal([n_classes]))\n}\n\npred = LSTM_RNN(x, weights, biases)\n\n# Loss, optimizer and evaluation\nl2 = lambda_loss_amount * sum(\n tf.nn.l2_loss(tf_var) for tf_var in tf.trainable_variables()\n) # L2 loss prevents this overkill neural network to overfit the data\ncost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) + l2 # Softmax loss\noptimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer\n\ncorrect_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))\naccuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))",
"_____no_output_____"
]
],
[
[
"## Hooray, now train the neural network:",
"_____no_output_____"
]
],
[
[
"# To keep track of training's performance\ntest_losses = []\ntest_accuracies = []\ntrain_losses = []\ntrain_accuracies = []\n\n# Launch the graph\nsess = tf.InteractiveSession(config=tf.ConfigProto(log_device_placement=True))\ninit = tf.initialize_all_variables()\nsess.run(init)\n\n# Perform Training steps with \"batch_size\" amount of example data at each loop\nstep = 1\nwhile step * batch_size <= training_iters:\n batch_xs = extract_batch_size(X_train, step, batch_size)\n batch_ys = one_hot(extract_batch_size(y_train, step, batch_size))\n\n # Fit training using batch data\n _, loss, acc = sess.run(\n [optimizer, cost, accuracy],\n feed_dict={\n x: batch_xs, \n y: batch_ys\n }\n )\n train_losses.append(loss)\n train_accuracies.append(acc)\n \n # Evaluate network only at some steps for faster training: \n if (step*batch_size % display_iter == 0) or (step == 1) or (step * batch_size > training_iters):\n \n # To not spam console, show training accuracy/loss in this \"if\"\n print \"Training iter #\" + str(step*batch_size) + \\\n \": Batch Loss = \" + \"{:.6f}\".format(loss) + \\\n \", Accuracy = {}\".format(acc)\n \n # Evaluation on the test set (no learning made here - just evaluation for diagnosis)\n loss, acc = sess.run(\n [cost, accuracy], \n feed_dict={\n x: X_test,\n y: one_hot(y_test)\n }\n )\n test_losses.append(loss)\n test_accuracies.append(acc)\n print \"PERFORMANCE ON TEST SET: \" + \\\n \"Batch Loss = {}\".format(loss) + \\\n \", Accuracy = {}\".format(acc)\n\n step += 1\n\nprint \"Optimization Finished!\"\n\n# Accuracy for test data\n\none_hot_predictions, accuracy, final_loss = sess.run(\n [pred, accuracy, cost],\n feed_dict={\n x: X_test,\n y: one_hot(y_test)\n }\n)\n\ntest_losses.append(final_loss)\ntest_accuracies.append(accuracy)\n\nprint \"FINAL RESULT: \" + \\\n \"Batch Loss = {}\".format(final_loss) + \\\n \", Accuracy = {}\".format(accuracy)",
"Training iter #1500: Batch Loss = 3.074432, Accuracy = 0.100666671991\nPERFORMANCE ON TEST SET: Batch Loss = 2.64702987671, Accuracy = 0.224635243416\nTraining iter #30000: Batch Loss = 1.388876, Accuracy = 0.713999986649\nPERFORMANCE ON TEST SET: Batch Loss = 1.42781305313, Accuracy = 0.678316831589\nTraining iter #60000: Batch Loss = 1.243671, Accuracy = 0.755333304405\nPERFORMANCE ON TEST SET: Batch Loss = 1.33201026917, Accuracy = 0.725822806358\nTraining iter #90000: Batch Loss = 1.026985, Accuracy = 0.858666718006\nPERFORMANCE ON TEST SET: Batch Loss = 1.29318606853, Accuracy = 0.784526586533\nTraining iter #120000: Batch Loss = 0.950223, Accuracy = 0.88666665554\nPERFORMANCE ON TEST SET: Batch Loss = 1.19165813923, Accuracy = 0.818459331989\nTraining iter #150000: Batch Loss = 0.821248, Accuracy = 0.934666633606\nPERFORMANCE ON TEST SET: Batch Loss = 1.1244571209, Accuracy = 0.840515732765\nTraining iter #180000: Batch Loss = 0.852562, Accuracy = 0.895999968052\nPERFORMANCE ON TEST SET: Batch Loss = 1.09874331951, Accuracy = 0.85985738039\nTraining iter #210000: Batch Loss = 0.975475, Accuracy = 0.886000037193\nPERFORMANCE ON TEST SET: Batch Loss = 1.00003457069, Accuracy = 0.87852036953\nTraining iter #240000: Batch Loss = 0.778386, Accuracy = 0.943333387375\nPERFORMANCE ON TEST SET: Batch Loss = 1.01710581779, Accuracy = 0.87852036953\nTraining iter #270000: Batch Loss = 0.687293, Accuracy = 0.942666709423\nPERFORMANCE ON TEST SET: Batch Loss = 0.985704541206, Accuracy = 0.885646343231\nTraining iter #300000: Batch Loss = 0.648103, Accuracy = 0.974000036716\nPERFORMANCE ON TEST SET: Batch Loss = 1.01484704018, Accuracy = 0.873769819736\nTraining iter #330000: Batch Loss = 0.759852, Accuracy = 0.948000073433\nPERFORMANCE ON TEST SET: Batch Loss = 0.960080265999, Accuracy = 0.871394515038\nTraining iter #360000: Batch Loss = 0.739065, Accuracy = 0.923333406448\nPERFORMANCE ON TEST SET: Batch Loss = 0.955386519432, Accuracy = 0.880556344986\nTraining iter #390000: Batch Loss = 0.721678, Accuracy = 0.932666659355\nPERFORMANCE ON TEST SET: Batch Loss = 0.999629855156, Accuracy = 0.860875368118\nTraining iter #420000: Batch Loss = 0.629302, Accuracy = 0.953333437443\nPERFORMANCE ON TEST SET: Batch Loss = 0.959317803383, Accuracy = 0.874109148979\nTraining iter #450000: Batch Loss = 0.611473, Accuracy = 0.955333292484\nPERFORMANCE ON TEST SET: Batch Loss = 0.913493096828, Accuracy = 0.884628295898\nTraining iter #480000: Batch Loss = 0.610332, Accuracy = 0.942000031471\nPERFORMANCE ON TEST SET: Batch Loss = 0.95140516758, Accuracy = 0.874109148979\nTraining iter #510000: Batch Loss = 0.596108, Accuracy = 0.972666740417\nPERFORMANCE ON TEST SET: Batch Loss = 0.912526726723, Accuracy = 0.87987780571\nTraining iter #540000: Batch Loss = 0.644551, Accuracy = 0.932000041008\nPERFORMANCE ON TEST SET: Batch Loss = 0.915139496326, Accuracy = 0.877841830254\nTraining iter #570000: Batch Loss = 0.631275, Accuracy = 0.92933344841\nPERFORMANCE ON TEST SET: Batch Loss = 0.892684578896, Accuracy = 0.878181099892\nTraining iter #600000: Batch Loss = 0.616123, Accuracy = 0.933333277702\nPERFORMANCE ON TEST SET: Batch Loss = 0.905649662018, Accuracy = 0.874109208584\nTraining iter #630000: Batch Loss = 0.518553, Accuracy = 0.983333408833\nPERFORMANCE ON TEST SET: Batch Loss = 0.877397477627, Accuracy = 0.872751891613\nTraining iter #660000: Batch Loss = 0.517939, Accuracy = 0.971333324909\nPERFORMANCE ON TEST SET: Batch Loss = 0.873089075089, Accuracy = 0.882931649685\nTraining iter #690000: Batch Loss = 0.501185, Accuracy = 0.980666697025\nPERFORMANCE ON TEST SET: Batch Loss = 0.880154192448, Accuracy = 0.873769879341\nTraining iter #720000: Batch Loss = 0.554758, Accuracy = 0.951333403587\nPERFORMANCE ON TEST SET: Batch Loss = 0.843538284302, Accuracy = 0.881574392319\nTraining iter #750000: Batch Loss = 0.563906, Accuracy = 0.938666701317\nPERFORMANCE ON TEST SET: Batch Loss = 0.896262228489, Accuracy = 0.867322564125\nTraining iter #780000: Batch Loss = 0.464500, Accuracy = 0.967333436012\nPERFORMANCE ON TEST SET: Batch Loss = 0.871921360493, Accuracy = 0.874787867069\nTraining iter #810000: Batch Loss = 0.482101, Accuracy = 0.952000081539\nPERFORMANCE ON TEST SET: Batch Loss = 0.856980860233, Accuracy = 0.87682390213\nTraining iter #840000: Batch Loss = 0.505377, Accuracy = 0.938666701317\nPERFORMANCE ON TEST SET: Batch Loss = 0.790416657925, Accuracy = 0.884628295898\nTraining iter #870000: Batch Loss = 0.458924, Accuracy = 0.972000002861\nPERFORMANCE ON TEST SET: Batch Loss = 0.793853282928, Accuracy = 0.879877686501\nTraining iter #900000: Batch Loss = 0.418589, Accuracy = 0.984000086784\nPERFORMANCE ON TEST SET: Batch Loss = 0.887957155704, Accuracy = 0.870376586914\nTraining iter #930000: Batch Loss = 1.169172, Accuracy = 0.695999979973\nPERFORMANCE ON TEST SET: Batch Loss = 0.910101830959, Accuracy = 0.783169269562\nTraining iter #960000: Batch Loss = 0.606064, Accuracy = 0.891333341599\nPERFORMANCE ON TEST SET: Batch Loss = 0.852943599224, Accuracy = 0.829317867756\nTraining iter #990000: Batch Loss = 0.470464, Accuracy = 0.961333394051\nPERFORMANCE ON TEST SET: Batch Loss = 0.724700808525, Accuracy = 0.865965306759\nTraining iter #1020000: Batch Loss = 0.437445, Accuracy = 0.969333350658\nPERFORMANCE ON TEST SET: Batch Loss = 0.706804692745, Accuracy = 0.897522866726\nTraining iter #1050000: Batch Loss = 0.416014, Accuracy = 0.974000096321\nPERFORMANCE ON TEST SET: Batch Loss = 0.682184875011, Accuracy = 0.903970062733\nTraining iter #1080000: Batch Loss = 0.453880, Accuracy = 0.972000002861\nPERFORMANCE ON TEST SET: Batch Loss = 0.672256708145, Accuracy = 0.907702565193\nTraining iter #1110000: Batch Loss = 0.471102, Accuracy = 0.938666701317\nPERFORMANCE ON TEST SET: Batch Loss = 0.727611303329, Accuracy = 0.895826101303\nTraining iter #1140000: Batch Loss = 0.464602, Accuracy = 0.942666709423\nPERFORMANCE ON TEST SET: Batch Loss = 0.7117882967, Accuracy = 0.892772197723\nTraining iter #1170000: Batch Loss = 0.399398, Accuracy = 0.957333445549\nPERFORMANCE ON TEST SET: Batch Loss = 0.662129640579, Accuracy = 0.894129574299\nTraining iter #1200000: Batch Loss = 0.465797, Accuracy = 0.940666735172\nPERFORMANCE ON TEST SET: Batch Loss = 0.679540455341, Accuracy = 0.884967684746\nTraining iter #1230000: Batch Loss = 0.479665, Accuracy = 0.938666641712\nPERFORMANCE ON TEST SET: Batch Loss = 0.683512926102, Accuracy = 0.881913661957\nTraining iter #1260000: Batch Loss = 0.390101, Accuracy = 0.977333366871\nPERFORMANCE ON TEST SET: Batch Loss = 0.628258824348, Accuracy = 0.901255488396\nTraining iter #1290000: Batch Loss = 0.420251, Accuracy = 0.94000005722\nPERFORMANCE ON TEST SET: Batch Loss = 0.648212552071, Accuracy = 0.899898052216\nTraining iter #1320000: Batch Loss = 0.432608, Accuracy = 0.95066678524\nPERFORMANCE ON TEST SET: Batch Loss = 0.610033810139, Accuracy = 0.904648661613\nTraining iter #1350000: Batch Loss = 0.403986, Accuracy = 0.938666701317\nPERFORMANCE ON TEST SET: Batch Loss = 0.70320302248, Accuracy = 0.886325001717\nTraining iter #1380000: Batch Loss = 0.358220, Accuracy = 0.968666732311\nPERFORMANCE ON TEST SET: Batch Loss = 0.613206148148, Accuracy = 0.898540854454\nTraining iter #1410000: Batch Loss = 0.341404, Accuracy = 0.973999977112\nPERFORMANCE ON TEST SET: Batch Loss = 0.648775041103, Accuracy = 0.886664271355\nTraining iter #1440000: Batch Loss = 0.368336, Accuracy = 0.97000002861\nPERFORMANCE ON TEST SET: Batch Loss = 0.598120570183, Accuracy = 0.905666589737\nTraining iter #1470000: Batch Loss = 0.390903, Accuracy = 0.956666707993\nPERFORMANCE ON TEST SET: Batch Loss = 0.66110599041, Accuracy = 0.889039635658\nTraining iter #1500000: Batch Loss = 0.400978, Accuracy = 0.939333379269\nPERFORMANCE ON TEST SET: Batch Loss = 0.724209189415, Accuracy = 0.880217075348\nTraining iter #1530000: Batch Loss = 0.323776, Accuracy = 0.965999960899\nPERFORMANCE ON TEST SET: Batch Loss = 0.634877681732, Accuracy = 0.894468903542\nTraining iter #1560000: Batch Loss = 0.336838, Accuracy = 0.959333360195\nPERFORMANCE ON TEST SET: Batch Loss = 0.655008435249, Accuracy = 0.879877746105\nTraining iter #1590000: Batch Loss = 0.363266, Accuracy = 0.944666743279\nPERFORMANCE ON TEST SET: Batch Loss = 0.632539153099, Accuracy = 0.894129574299\nTraining iter #1620000: Batch Loss = 0.315511, Accuracy = 0.976666688919\nPERFORMANCE ON TEST SET: Batch Loss = 0.684278428555, Accuracy = 0.887003660202\nTraining iter #1650000: Batch Loss = 0.328709, Accuracy = 0.952000081539\nPERFORMANCE ON TEST SET: Batch Loss = 0.639604568481, Accuracy = 0.90057682991\nTraining iter #1680000: Batch Loss = 0.376681, Accuracy = 0.934000015259\nPERFORMANCE ON TEST SET: Batch Loss = 0.628734171391, Accuracy = 0.890057504177\nTraining iter #1710000: Batch Loss = 0.373600, Accuracy = 0.945999979973\nPERFORMANCE ON TEST SET: Batch Loss = 0.588403463364, Accuracy = 0.905666649342\nTraining iter #1740000: Batch Loss = 0.304719, Accuracy = 0.969333350658\nPERFORMANCE ON TEST SET: Batch Loss = 0.807882368565, Accuracy = 0.86732262373\nTraining iter #1770000: Batch Loss = 0.484144, Accuracy = 0.916666686535\nPERFORMANCE ON TEST SET: Batch Loss = 0.787532448769, Accuracy = 0.833050489426\nTraining iter #1800000: Batch Loss = 0.328061, Accuracy = 0.961333394051\nPERFORMANCE ON TEST SET: Batch Loss = 0.552209913731, Accuracy = 0.890396952629\nTraining iter #1830000: Batch Loss = 0.361723, Accuracy = 0.953333318233\nPERFORMANCE ON TEST SET: Batch Loss = 0.49697381258, Accuracy = 0.909399271011\nTraining iter #1860000: Batch Loss = 0.381517, Accuracy = 0.934666693211\nPERFORMANCE ON TEST SET: Batch Loss = 0.513538181782, Accuracy = 0.919239759445\nTraining iter #1890000: Batch Loss = 0.316621, Accuracy = 0.954666733742\nPERFORMANCE ON TEST SET: Batch Loss = 0.512967705727, Accuracy = 0.912113904953\nTraining iter #1920000: Batch Loss = 0.300370, Accuracy = 0.960000038147\nPERFORMANCE ON TEST SET: Batch Loss = 0.529131948948, Accuracy = 0.902273356915\nTraining iter #1950000: Batch Loss = 0.306562, Accuracy = 0.956666707993\nPERFORMANCE ON TEST SET: Batch Loss = 0.530484378338, Accuracy = 0.909399271011\nTraining iter #1980000: Batch Loss = 0.318665, Accuracy = 0.954666733742\nPERFORMANCE ON TEST SET: Batch Loss = 0.521255552769, Accuracy = 0.916185855865\nTraining iter #2010000: Batch Loss = 0.423832, Accuracy = 0.949333369732\nPERFORMANCE ON TEST SET: Batch Loss = 0.508657217026, Accuracy = 0.910417318344\nTraining iter #2040000: Batch Loss = 0.335710, Accuracy = 0.950000107288\nPERFORMANCE ON TEST SET: Batch Loss = 0.591941297054, Accuracy = 0.885646283627\nTraining iter #2070000: Batch Loss = 0.335933, Accuracy = 0.933333337307\nPERFORMANCE ON TEST SET: Batch Loss = 0.495988607407, Accuracy = 0.906345367432\nTraining iter #2100000: Batch Loss = 0.271547, Accuracy = 0.986000061035\nPERFORMANCE ON TEST SET: Batch Loss = 0.500951290131, Accuracy = 0.908720612526\nTraining iter #2130000: Batch Loss = 0.278299, Accuracy = 0.970666706562\nPERFORMANCE ON TEST SET: Batch Loss = 0.508447647095, Accuracy = 0.91856110096\nTraining iter #2160000: Batch Loss = 0.270260, Accuracy = 0.963999986649\nPERFORMANCE ON TEST SET: Batch Loss = 0.505264401436, Accuracy = 0.919239759445\nTraining iter #2190000: Batch Loss = 0.273257, Accuracy = 0.968666732311\nPERFORMANCE ON TEST SET: Batch Loss = 0.504503488541, Accuracy = 0.914149820805\nOptimization Finished!\nFINAL RESULT: Batch Loss = 0.510438203812, Accuracy = 0.914149880409\n"
]
],
[
[
"## Training is good, but having visual insight is even better:\n\nOkay, let's plot this simply in the notebook for now.",
"_____no_output_____"
]
],
[
[
"# (Inline plots: )\n%matplotlib inline\n\nfont = {\n 'family' : 'Bitstream Vera Sans',\n 'weight' : 'bold',\n 'size' : 18\n}\nmatplotlib.rc('font', **font)\n\nwidth = 12\nheight = 12\nplt.figure(figsize=(width, height))\n\nindep_train_axis = np.array(range(batch_size, (len(train_losses)+1)*batch_size, batch_size))\nplt.plot(indep_train_axis, np.array(train_losses), \"b--\", label=\"Train losses\")\nplt.plot(indep_train_axis, np.array(train_accuracies), \"g--\", label=\"Train accuracies\")\n\nindep_test_axis = np.array(range(batch_size, len(test_losses)*display_iter, display_iter)[:-1] + [training_iters])\nplt.plot(indep_test_axis, np.array(test_losses), \"b-\", label=\"Test losses\")\nplt.plot(indep_test_axis, np.array(test_accuracies), \"g-\", label=\"Test accuracies\")\n\nplt.title(\"Training session's progress over iterations\")\nplt.legend(loc='upper right', shadow=True)\nplt.ylabel('Training Progress (Loss or Accuracy values)')\nplt.xlabel('Training iteration')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## And finally, the multi-class confusion matrix and metrics!",
"_____no_output_____"
]
],
[
[
"# Results\n\npredictions = one_hot_predictions.argmax(1)\n\nprint \"Testing Accuracy: {}%\".format(100*accuracy)\n\nprint \"\"\nprint \"Precision: {}%\".format(100*metrics.precision_score(y_test, predictions, average=\"weighted\"))\nprint \"Recall: {}%\".format(100*metrics.recall_score(y_test, predictions, average=\"weighted\"))\nprint \"f1_score: {}%\".format(100*metrics.f1_score(y_test, predictions, average=\"weighted\"))\n\nprint \"\"\nprint \"Confusion Matrix:\"\nconfusion_matrix = metrics.confusion_matrix(y_test, predictions)\nprint confusion_matrix\nnormalised_confusion_matrix = np.array(confusion_matrix, dtype=np.float32)/np.sum(confusion_matrix)*100\n\nprint \"\"\nprint \"Confusion matrix (normalised to % of total test data):\"\nprint normalised_confusion_matrix\nprint (\"Note: training and testing data is not equally distributed amongst classes, \"\n \"so it is normal that more than a 6th of the data is correctly classifier in the last category.\")\n\n# Plot Results: \nwidth = 12\nheight = 12\nplt.figure(figsize=(width, height))\nplt.imshow(\n normalised_confusion_matrix, \n interpolation='nearest', \n cmap=plt.cm.rainbow\n)\nplt.title(\"Confusion matrix \\n(normalised to % of total test data)\")\nplt.colorbar()\ntick_marks = np.arange(n_classes)\nplt.xticks(tick_marks, LABELS, rotation=90)\nplt.yticks(tick_marks, LABELS)\nplt.tight_layout()\nplt.ylabel('True label')\nplt.xlabel('Predicted label')\nplt.show()",
"Testing Accuracy: 91.4149880409%\n\nPrecision: 91.5553217851%\nRecall: 91.4149983034%\nf1_score: 91.4338139477%\n\nConfusion Matrix:\n[[467 21 0 0 8 0]\n [ 6 451 14 0 0 0]\n [ 4 2 414 0 0 0]\n [ 1 7 0 396 87 0]\n [ 1 1 0 74 456 0]\n [ 0 27 0 0 0 510]]\n\nConfusion matrix (normalised to % of total test data):\n[[ 15.84662342 0.71258909 0. 0. 0.2714625 0. ]\n [ 0.20359688 15.30369854 0.47505939 0. 0. 0. ]\n [ 0.13573125 0.06786563 14.04818439 0. 0. 0. ]\n [ 0.03393281 0.2375297 0. 13.43739319 2.95215464 0. ]\n [ 0.03393281 0.03393281 0. 2.51102829 15.47336292 0. ]\n [ 0. 0.91618598 0. 0. 0. 17.30573463]]\nNote: training and testing data is not equally distributed amongst classes, so it is normal that more than a 6th of the data is correctly classifier in the last category.\n"
],
[
"sess.close()",
"_____no_output_____"
]
],
[
[
"## Conclusion\n\nOutstandingly, **the accuracy is of 91%**! \n\nThis means that the neural networks is almost always able to correctly identify the movement type! Remember, the phone is attached on the waist and each series to classify has just a 128 sample window of two internal sensors (a.k.a. 2.56 seconds at 50 FPS), so those predictions are extremely accurate.\n\nI specially did not expect such good results for guessing between \"WALKING\" \"WALKING_UPSTAIRS\" and \"WALKING_DOWNSTAIRS\" as a cellphone. Thought, it is still possible to see a little cluster on the matrix between those 3 classes. This is great.\n\nIt is also possible to see that it was hard to do the difference between \"SITTING\" and \"STANDING\". Those are seemingly almost the same thing from the point of view of a device placed on the belly, according to how the dataset was gathered. \n\nI also tried my code without the gyroscope, using only the two 3D accelerometer's features (and not changing the training hyperparameters), and got an accuracy of 87%.\n\n\n## Improvements\n\nIn [another repo of mine](https://github.com/guillaume-chevalier/HAR-stacked-residual-bidir-LSTMs), the accuracy is pushed up to 94% using a special deep bidirectional architecture, and this architecture is tested on another dataset. If you want to learn more about deep learning, I have built a list of ressources that I found to be useful [here](https://github.com/guillaume-chevalier/awesome-deep-learning-resources). \n\n\n## References\n\nThe [dataset](https://archive.ics.uci.edu/ml/datasets/Human+Activity+Recognition+Using+Smartphones) can be found on the UCI Machine Learning Repository. \n\n> Davide Anguita, Alessandro Ghio, Luca Oneto, Xavier Parra and Jorge L. Reyes-Ortiz. A Public Domain Dataset for Human Activity Recognition Using Smartphones. 21th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, ESANN 2013. Bruges, Belgium 24-26 April 2013.\n\nIf you want to cite my work, you can point to the URL of the GitHub repository: \n> https://github.com/guillaume-chevalier/LSTM-Human-Activity-Recognition\n\n## Connect with me\n\n- https://ca.linkedin.com/in/chevalierg \n- https://twitter.com/guillaume_che\n- https://github.com/guillaume-chevalier/",
"_____no_output_____"
]
],
[
[
"# Let's convert this notebook to a README as the GitHub project's title page:\n!jupyter nbconvert --to markdown LSTM.ipynb\n!mv LSTM.md README.md",
"[NbConvertApp] Converting notebook LSTM.ipynb to markdown\n[NbConvertApp] Support files will be in LSTM_files/\n[NbConvertApp] Making directory LSTM_files\n[NbConvertApp] Making directory LSTM_files\n[NbConvertApp] Writing 31631 bytes to LSTM.md\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd1643df914dd9abaebd4e3eb84be3f03da93f7
| 2,263 |
ipynb
|
Jupyter Notebook
|
index.ipynb
|
jackiey99/slowai
|
bb2e8ff34df4f1809325d8e37d1ee5c568e83294
|
[
"Apache-2.0"
] | null | null | null |
index.ipynb
|
jackiey99/slowai
|
bb2e8ff34df4f1809325d8e37d1ee5c568e83294
|
[
"Apache-2.0"
] | 2 |
2021-09-28T05:42:42.000Z
|
2022-02-26T10:04:21.000Z
|
index.ipynb
|
jackiey99/slowai
|
bb2e8ff34df4f1809325d8e37d1ee5c568e83294
|
[
"Apache-2.0"
] | null | null | null | 16.639706 | 81 | 0.486522 |
[
[
[
"#hide\nfrom your_lib.core import *",
"_____no_output_____"
]
],
[
[
"# Project name here\n\n> Summary description here.",
"_____no_output_____"
],
[
"This file will become your README and also the index of your documentation.",
"_____no_output_____"
],
[
"## Install",
"_____no_output_____"
],
[
"`pip install your_project_name`",
"_____no_output_____"
],
[
"## How to use",
"_____no_output_____"
],
[
"Fill me in please! Don't forget code examples:",
"_____no_output_____"
]
],
[
[
"1+1",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\n",
"_____no_output_____"
],
[
"from nbdev.export import *\nnotebook2script()",
"Converted 00_core.ipynb.\nConverted index.ipynb.\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd1797389bc8fe2e4c63767452d707497aca3bc
| 3,282 |
ipynb
|
Jupyter Notebook
|
delphes/uncertainty_calibration.ipynb
|
luqiang21/particleflow
|
a78ca76fd0b58fce0dc12ca307e3d3fe0be351ef
|
[
"Apache-2.0"
] | 12 |
2019-09-29T21:24:18.000Z
|
2022-02-22T13:20:38.000Z
|
delphes/uncertainty_calibration.ipynb
|
luqiang21/particleflow
|
a78ca76fd0b58fce0dc12ca307e3d3fe0be351ef
|
[
"Apache-2.0"
] | 39 |
2019-10-03T18:21:01.000Z
|
2021-12-07T11:58:57.000Z
|
delphes/uncertainty_calibration.ipynb
|
luqiang21/particleflow
|
a78ca76fd0b58fce0dc12ca307e3d3fe0be351ef
|
[
"Apache-2.0"
] | 19 |
2019-09-29T21:24:27.000Z
|
2022-03-31T12:17:04.000Z
| 22.175676 | 138 | 0.515844 |
[
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"#Only run this once!\n!rm -f pred.npz.bz2 pred.npz\n!wget https://jpata.web.cern.ch/jpata/2101.08578/v1/pred.npz.bz2\n!bzip2 -d pred.npz.bz2",
"_____no_output_____"
],
[
"fi = np.load(\"pred.npz\")\nygen = fi[\"ygen\"]\nycand = fi[\"ycand\"]\nypred = fi[\"ypred\"]\nypred_raw = fi[\"ypred_raw\"]",
"_____no_output_____"
],
[
"ygen.shape",
"_____no_output_____"
]
],
[
[
"We have 100 events, up to 5120 particles in each event, 7 features per particle. We have 3 types of data matrices for each event:\n- ygen - ground truth from the generator\n- ypred - prediction from the MLPF model\n- ycand - prediction from the standard DelphesPF algorithm",
"_____no_output_____"
]
],
[
[
"#features are (particle ID, charge, pT, eta, sin phi, cos phi, energy)\nygen[0, 0]",
"_____no_output_____"
],
[
"#Same for the prediction\nypred[0, 0]",
"_____no_output_____"
],
[
"#particle ID (type is)\n#0 - no particle\n#1 - charged hadron\n#2 - neutral hadron\n#3 - photon\n#4 - electron\n#5 - muon\nnp.unique(ygen[:, :, 0], return_counts=True)",
"_____no_output_____"
],
[
"#We also have the raw logits for the multiclass ID prediction\nypred_raw.shape",
"_____no_output_____"
],
[
"#Ground truth vs model prediction particles\nplt.figure(figsize=(10,10))\n\n\nev = ygen[0, :]\nmsk = ev[:, 0]!=0\nplt.scatter(ev[msk, 3], np.arctan2(ev[msk, 4], ev[msk, 5]), s=2*ev[msk, 2], marker=\"o\", alpha=0.5)\n\nev = ypred[0, :]\nmsk = ev[:, 0]!=0\nplt.scatter(ev[msk, 3], np.arctan2(ev[msk, 4], ev[msk, 5]), s=2*ev[msk, 2], marker=\"s\", alpha=0.5)\n\nplt.xlabel(\"eta\")\nplt.ylabel(\"phi\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cbd17d80b999c8c378cba4b6f9b9811dd7241609
| 35,411 |
ipynb
|
Jupyter Notebook
|
workflow/notebooks/make_data/clause_clusters.ipynb
|
CambridgeSemiticsLab/BH_time_collocations
|
2d1864b6e9cd26624c769ee1e970d69d19da7fbf
|
[
"CC-BY-4.0"
] | 5 |
2019-06-19T19:42:21.000Z
|
2021-04-20T22:43:45.000Z
|
workflow/notebooks/make_data/clause_clusters.ipynb
|
CambridgeSemiticsLab/BHTenseAndAspect
|
2d1864b6e9cd26624c769ee1e970d69d19da7fbf
|
[
"CC-BY-4.0"
] | 2 |
2020-02-25T10:19:40.000Z
|
2020-03-13T15:29:01.000Z
|
workflow/notebooks/make_data/clause_clusters.ipynb
|
CambridgeSemiticsLab/BH_time_collocations
|
2d1864b6e9cd26624c769ee1e970d69d19da7fbf
|
[
"CC-BY-4.0"
] | null | null | null | 44.319149 | 9,920 | 0.520177 |
[
[
[
"# Build Clause Clusters with Book Boundaries",
"_____no_output_____"
]
],
[
[
"from tf.app import use\nbhsa = use('bhsa')\nF, E, T, L = bhsa.api.F, bhsa.api.E, bhsa.api.T, bhsa.api.L",
"_____no_output_____"
],
[
"from pathlib import Path",
"_____no_output_____"
],
[
"# divide texts evenly into slices of 50 clauses\n\ndef cluster_clauses(N):\n \n clusters = []\n\n for book in F.otype.s('book'):\n \n clauses = list(L.d(book,'clause'))\n cluster = []\n\n for i, clause in enumerate(clauses):\n \n i += 1\n \n cluster.append(clause)\n\n # create cluster of 50\n if (i and i % N == 0):\n clusters.append(cluster)\n cluster = []\n\n # deal with final uneven clusters\n elif i == len(clauses):\n if (len(cluster) / N) < 0.6:\n clusters[-1].extend(cluster) # add to last cluster\n else:\n clusters.append(cluster) # keep as cluster\n \n return {\n clause:i+1 for i,clust in enumerate(clusters)\n for clause in clust\n }",
"_____no_output_____"
],
[
"cluster_50 = cluster_clauses(50)\ncluster_10 = cluster_clauses(10)",
"_____no_output_____"
]
],
[
[
"## Map Book-names to clause clusters",
"_____no_output_____"
]
],
[
[
"# map book names for visualizing\n\n# map grouped book names\nbook_map = {\n 'Genesis':'Gen',\n 'Exodus':'Exod',\n 'Leviticus':'Lev',\n 'Numbers':'Num',\n 'Deuteronomy':'Deut',\n 'Joshua':'Josh',\n 'Judges':'Judg',\n '1_Samuel':'Sam',\n '2_Samuel':'Sam',\n '1_Kings':'Kgs',\n '2_Kings':'Kgs',\n 'Isaiah':'Isa',\n 'Jeremiah':'Jer',\n 'Ezekiel':'Ezek',\n# 'Hosea':'Hos',\n# 'Joel':'Joel',\n# 'Amos':'Amos',\n# 'Obadiah':'Obad',\n# 'Jonah':'Jonah',\n# 'Micah':'Mic',\n# 'Nahum':'Nah',\n# 'Habakkuk':'Hab',\n# 'Zephaniah':'Zeph',\n# 'Haggai':'Hag',\n# 'Zechariah':'Zech',\n# 'Malachi':'Mal',\n 'Psalms':'Pss',\n 'Job':'Job',\n 'Proverbs':'Prov',\n# 'Ruth':'Ruth',\n# 'Song_of_songs':'Song',\n# 'Ecclesiastes':'Eccl',\n# 'Lamentations':'Lam',\n# 'Esther':'Esth',\n# 'Daniel':'Dan',\n# 'Ezra':'Ezra',\n# 'Nehemiah':'Neh',\n '1_Chronicles':'Chr',\n '2_Chronicles':'Chr'\n}\n# book of 12\nfor book in ('Hosea', 'Joel', 'Amos', 'Obadiah',\n 'Jonah', 'Micah', 'Nahum', 'Habakkuk',\n 'Zephaniah', 'Haggai', 'Zechariah',\n 'Malachi'): \n book_map[book] = 'Twelve'\n\n# Megilloth\nfor book in ('Ruth', 'Lamentations', 'Ecclesiastes', \n 'Esther', 'Song_of_songs'): \n book_map[book] = 'Megil'\n\n# Dan-Neh\nfor book in ('Ezra', 'Nehemiah', 'Daniel'): \n book_map[book] = 'Dan-Neh'",
"_____no_output_____"
],
[
"clustertypes = [cluster_50, cluster_10]\n\nbookmaps = []\n\nfor clust in clustertypes:\n bookmap = {'Gen':1}\n prev_book = 'Gen'\n for cl in clust:\n book = T.sectionFromNode(cl)[0]\n mbook = book_map.get(book, book)\n if prev_book != mbook:\n bookmap[mbook] = clust[cl]\n prev_book = mbook\n bookmaps.append(bookmap) ",
"_____no_output_____"
]
],
[
[
"# Export",
"_____no_output_____"
]
],
[
[
"import json",
"_____no_output_____"
],
[
"data = {\n '50': {\n 'clusters': cluster_50,\n 'bookbounds': bookmaps[0],\n },\n '10': {\n 'clusters': cluster_10,\n 'bookbounds': bookmaps[1]\n },\n}\n\noutpath = Path('/Users/cody/github/CambridgeSemiticsLab/time_collocations/results/cl_clusters')\nif not outpath.exists():\n outpath.mkdir()\n\nwith open(outpath.joinpath('clusters.json'), 'w') as outfile:\n json.dump(data, outfile)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd182bd936616758e5ae1cac7a1fd84a4c1e204
| 11,359 |
ipynb
|
Jupyter Notebook
|
d2l/chapter_computer-vision/transposed-conv.ipynb
|
atlasbioinfo/myDLNotes_Pytorch
|
fada6ab56af340cd5ec6cc4dfd5e749af16a6ed4
|
[
"MIT"
] | null | null | null |
d2l/chapter_computer-vision/transposed-conv.ipynb
|
atlasbioinfo/myDLNotes_Pytorch
|
fada6ab56af340cd5ec6cc4dfd5e749af16a6ed4
|
[
"MIT"
] | null | null | null |
d2l/chapter_computer-vision/transposed-conv.ipynb
|
atlasbioinfo/myDLNotes_Pytorch
|
fada6ab56af340cd5ec6cc4dfd5e749af16a6ed4
|
[
"MIT"
] | null | null | null | 22.993927 | 167 | 0.491857 |
[
[
[
"# 转置卷积\n:label:`sec_transposed_conv`\n\n到目前为止,我们所见到的卷积神经网络层,例如卷积层( :numref:`sec_conv_layer`)和汇聚层( :numref:`sec_pooling`),通常会减少下采样输入图像的空间维度(高和宽)。\n然而如果输入和输出图像的空间维度相同,在以像素级分类的语义分割中将会很方便。\n例如,输出像素所处的通道维可以保有输入像素在同一位置上的分类结果。 \n\n为了实现这一点,尤其是在空间维度被卷积神经网络层缩小后,我们可以使用另一种类型的卷积神经网络层,它可以增加上采样中间层特征图的空间维度。\n在本节中,我们将介绍 \n*转置卷积*(transposed convolution) :cite:`Dumoulin.Visin.2016`, \n用于扭转下采样导致的空间尺寸减小。\n",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn\nfrom d2l import torch as d2l\n",
"_____no_output_____"
]
],
[
[
"## 基本操作\n\n让我们暂时忽略通道,从基本的转置卷积开始,设步幅为1且没有填充。\n假设我们有一个$n_h \\times n_w$的输入张量和一个$k_h \\times k_w$的卷积核。\n以步幅为1滑动卷积核窗口,每行$n_w$次,每列$n_h$次,共产生$n_h n_w$个中间结果。\n每个中间结果都是一个$(n_h + k_h - 1) \\times (n_w + k_w - 1)$的张量,初始化为0。\n为了计算每个中间张量,输入张量中的每个元素都要乘以卷积核,从而使所得的$k_h \\times k_w$张量替换中间张量的一部分。\n请注意,每个中间张量被替换部分的位置与输入张量中元素的位置相对应。\n最后,所有中间结果相加以获得最终结果。 \n\n例如, :numref:`fig_trans_conv` 解释了如何为$2\\times 2$的输入张量计算卷积核为$2\\times 2$的转置卷积。 \n\n\n:label:`fig_trans_conv`\n\n我们可以对输入矩阵`X`和卷积核矩阵 `K`(**实现基本的转置卷积运算**)`trans_conv`。\n",
"_____no_output_____"
]
],
[
[
"def trans_conv(X, K):\n h, w = K.shape\n Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))\n for i in range(X.shape[0]):\n for j in range(X.shape[1]):\n Y[i: i + h, j: j + w] += X[i, j] * K\n return Y",
"_____no_output_____"
]
],
[
[
"与通过卷积核“减少”输入元素的常规卷积(在 :numref:`sec_conv_layer` 中)相比,转置卷积通过卷积核“广播”输入元素,从而产生大于输入的输出。\n我们可以通过 :numref:`fig_trans_conv` 来构建输入张量 `X` 和卷积核张量 `K` 从而[**验证上述实现输出**]。\n此实现是基本的二维转置卷积运算。\n",
"_____no_output_____"
]
],
[
[
"X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])\nK = torch.tensor([[0.0, 1.0], [2.0, 3.0]])\ntrans_conv(X, K)",
"_____no_output_____"
]
],
[
[
"或者,当输入`X`和卷积核`K`都是四维张量时,我们可以[**使用高级API获得相同的结果**]。\n",
"_____no_output_____"
]
],
[
[
"X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)\ntconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)\ntconv.weight.data = K\ntconv(X)",
"_____no_output_____"
]
],
[
[
"## [**填充、步幅和多通道**]\n\n与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。\n例如,当将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。\n",
"_____no_output_____"
]
],
[
[
"tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)\ntconv.weight.data = K\ntconv(X)",
"_____no_output_____"
]
],
[
[
"在转置卷积中,步幅被指定为中间结果(输出),而不是输入。\n使用 :numref:`fig_trans_conv` 中相同输入和卷积核张量,将步幅从1更改为2会增加中间张量的高和权重,因此输出张量在 :numref:`fig_trans_conv_stride2` 中。 \n\n\n:label:`fig_trans_conv_stride2`\n\n以下代码可以验证 :numref:`fig_trans_conv_stride2` 中步幅为2的转置卷积的输出。\n",
"_____no_output_____"
]
],
[
[
"tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)\ntconv.weight.data = K\ntconv(X)",
"_____no_output_____"
]
],
[
[
"对于多个输入和输出通道,转置卷积与常规卷积以相同方式运作。\n假设输入有 $c_i$ 个通道,且转置卷积为每个输入通道分配了一个 $k_h\\times k_w$ 的卷积核张量。\n当指定多个输出通道时,每个输出通道将有一个 $c_i\\times k_h\\times k_w$ 的卷积核。 \n\n同样,如果我们将 $\\mathsf{X}$ 代入卷积层 $f$ 来输出 $\\mathsf{Y}=f(\\mathsf{X})$ ,并创建一个与 $f$ 具有相同的超参数、但输出通道数量是 $\\mathsf{X}$ 中通道数的转置卷积层 $g$,那么 $g(Y)$ 的形状将与 $\\mathsf{X}$ 相同。\n下面的示例可以解释这一点。\n",
"_____no_output_____"
]
],
[
[
"X = torch.rand(size=(1, 10, 16, 16))\nconv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)\ntconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)\ntconv(conv(X)).shape == X.shape",
"_____no_output_____"
]
],
[
[
"## [**与矩阵变换的联系**]\n:label:`subsec-connection-to-mat-transposition`\n\n转置卷积为何以矩阵变换命名呢?\n让我们首先看看如何使用矩阵乘法来实现卷积。\n在下面的示例中,我们定义了一个$3\\times 3$的输入`X`和$2\\times 2$卷积核`K`,然后使用`corr2d`函数计算卷积输出`Y`。\n",
"_____no_output_____"
]
],
[
[
"X = torch.arange(9.0).reshape(3, 3)\nK = torch.tensor([[1.0, 2.0], [3.0, 4.0]])\nY = d2l.corr2d(X, K)\nY",
"_____no_output_____"
]
],
[
[
"接下来,我们将卷积核`K`重写为包含大量0的稀疏权重矩阵`W`。\n权重矩阵的形状是($4$,$9$),其中非0元素来自卷积核`K`。\n",
"_____no_output_____"
]
],
[
[
"def kernel2matrix(K):\n k, W = torch.zeros(5), torch.zeros((4, 9))\n k[:2], k[3:5] = K[0, :], K[1, :]\n W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, k\n return W\n\nW = kernel2matrix(K)\nW",
"_____no_output_____"
]
],
[
[
"逐行连接输入`X`,获得了一个长度为9的矢量。\n然后,`W`的矩阵乘法和向量化的`X`给出了一个长度为4的向量。\n重塑它之后,可以获得与上面的原始卷积操作所得相同的结果`Y`:我们刚刚使用矩阵乘法实现了卷积。\n",
"_____no_output_____"
]
],
[
[
"Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)",
"_____no_output_____"
]
],
[
[
"同样,我们可以使用矩阵乘法来实现转置卷积。\n在下面的示例中,我们将上面的常规卷积$2 \\times 2$的输出`Y`作为转置卷积的输入。\n想要通过矩阵相乘来实现它,我们只需要将权重矩阵`W`的形状转置为$(9, 4)$。\n",
"_____no_output_____"
]
],
[
[
"Z = trans_conv(Y, K)\nZ == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3)",
"_____no_output_____"
]
],
[
[
"抽象来看,给定输入向量 $\\mathbf{x}$ 和权重矩阵 $\\mathbf{W}$,卷积的前向传播函数可以通过将其输入与权重矩阵相乘并输出向量 $\\mathbf{y}=\\mathbf{W}\\mathbf{x}$ 来实现。\n由于反向传播遵循链规则和 $\\nabla_{\\mathbf{x}}\\mathbf{y}=\\mathbf{W}^\\top$,卷积的反向传播函数可以通过将其输入与转置的权重矩阵 $\\mathbf{W}^\\top$ 相乘来实现。\n因此,转置卷积层能够交换卷积层的正向传播函数和反向传播函数:它的正向传播和反向传播函数将输入向量分别与 $\\mathbf{W}^\\top$ 和 $\\mathbf{W}$ 相乘。 \n\n\n## 小结\n\n* 与通过卷积核减少输入元素的常规卷积相反,转置卷积通过卷积核广播输入元素,从而产生形状大于输入的输出。\n* 如果我们将 $\\mathsf{X}$ 输入卷积层 $f$ 来获得输出 $\\mathsf{Y}=f(\\mathsf{X})$ 并创造一个与 $f$ 有相同的超参数、但输出通道数是 $\\mathsf{X}$ 中通道数的转置卷积层 $g$,那么 $g(Y)$ 的形状将与 $\\mathsf{X}$ 相同。\n* 我们可以使用矩阵乘法来实现卷积。转置卷积层能够交换卷积层的正向传播函数和反向传播函数。\n\n## 练习\n\n1. 在 :numref:`subsec-connection-to-mat-transposition` 中,卷积输入 `X` 和转置的卷积输出 `Z` 具有相同的形状。他们的数值也相同吗?为什么?\n1. 使用矩阵乘法来实现卷积是否有效率?为什么?\n",
"_____no_output_____"
],
[
"[Discussions](https://discuss.d2l.ai/t/3302)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd18b0f63d48a8960059889ef5fe9f3bf5fb6dd
| 166,296 |
ipynb
|
Jupyter Notebook
|
pymaceuticals_starter.ipynb
|
MattEgan660/Matplotlib-Challenge
|
6de8df8c1f13c630817e9e914573e8291cb21e9a
|
[
"ADSL"
] | null | null | null |
pymaceuticals_starter.ipynb
|
MattEgan660/Matplotlib-Challenge
|
6de8df8c1f13c630817e9e914573e8291cb21e9a
|
[
"ADSL"
] | null | null | null |
pymaceuticals_starter.ipynb
|
MattEgan660/Matplotlib-Challenge
|
6de8df8c1f13c630817e9e914573e8291cb21e9a
|
[
"ADSL"
] | null | null | null | 102.525277 | 19,696 | 0.803477 |
[
[
[
"### Analysis",
"_____no_output_____"
],
[
"1. From the tested treatments, Capomulina and Ramican show the largest reduction in tumor volume. Given how similar both treatments performed, further testing is necessary to determine which regimen will work the best. \n\n2. The correlation coefficient for mouse weight and average tumor volume is approximately .83 meaning we have a very strong linear relationship between these two variables. \n\n3. With an r-squared value of .6962, we know that approximately 70% variation from the mean is explained by our model. While this model provides a fairly strong capacity to predict tumor volume for a given weight, adding other variables like age, breed, and sex would likely increase its effectiveness.\n",
"_____no_output_____"
],
[
"### Import Depedencies and Read CSV Data",
"_____no_output_____"
]
],
[
[
"# Dependencies and Setup\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport scipy.stats as st\nimport numpy as np\n\n# Study data files\nmouse_metadata_path = \"Resources/Mouse_metadata.csv\"\nstudy_results_path = \"Resources/Study_results.csv\"\n\n# Read the mouse data and the study results\nmouse_metadata = pd.read_csv(mouse_metadata_path)\nstudy_results = pd.read_csv(study_results_path)\n\n# Combine the data into a single dataset\ncombined_data_df = pd.merge(mouse_metadata, study_results, on = 'Mouse ID')\n\n# Display the data table for preview\ncombined_data_df.head()",
"_____no_output_____"
],
[
"# Checking the number of mice.\nmouse_count1 = combined_data_df['Mouse ID'].nunique()\nmouse_count1",
"_____no_output_____"
],
[
"#check observation count \ncombined_data_df['Mouse ID'].count()",
"_____no_output_____"
],
[
"# Getting the duplicate mice by ID number that shows up for Mouse ID and Timepoint. \nduplicated_vals = combined_data_df[combined_data_df.duplicated(subset = ['Mouse ID', 'Timepoint'], keep = False)]\nduplicated_vals",
"_____no_output_____"
],
[
"# Create a clean DataFrame by dropping the duplicate mouse by its ID.\nclean_df = combined_data_df.drop_duplicates(subset = ['Mouse ID', 'Timepoint'], keep = False)\nclean_df.head()",
"_____no_output_____"
],
[
"# Checking the number of mice in the clean DataFrame.\nclean_mouse_count = clean_df['Mouse ID'].nunique()\nclean_mouse_count",
"_____no_output_____"
],
[
"#Check observation count on clean data\nclean_df['Mouse ID'].count()",
"_____no_output_____"
]
],
[
[
"## Summary Statistics",
"_____no_output_____"
]
],
[
[
"# Generate a summary statistics table of mean, median, variance, standard deviation, and SEM of the tumor volume for each regimen\n# Use groupby and summary statistical methods to calculate the following properties of each drug regimen: mean, median, variance, standard deviation, and SEM of the tumor volume. \n\n#Group Dataframe by Drug Regimen\nregimen_groups = clean_df.groupby(['Drug Regimen'])\n\n#Find mean for each regimen group\nregimen_mean = regimen_groups['Tumor Volume (mm3)'].mean()\n\n#Find median for each regimen group\nregimen_median = regimen_groups['Tumor Volume (mm3)'].median()\n\n#Find variance for each regimen group\nregimen_variance = regimen_groups['Tumor Volume (mm3)'].var()\n\n#Find standard deviation for each regimen group\nregimen_std = regimen_groups['Tumor Volume (mm3)'].std()\n\n#Find sem for each regimen group\nregimen_sem = regimen_groups['Tumor Volume (mm3)'].sem()\n",
"_____no_output_____"
],
[
"# Assemble the resulting series into a single summary dataframe.\nsummary_table = pd.DataFrame({\"Mean\": regimen_mean, \n \"Median\":regimen_median, \n \"Variance\":regimen_variance, \n \"Standard Deviation\": regimen_std, \n \"SEM\": regimen_sem})\n\nsummary_table",
"_____no_output_____"
],
[
"# Using the aggregation method, produce the same summary statistics in a single line\n\naggregate_df = clean_df.groupby('Drug Regimen').aggregate({\"Tumor Volume (mm3)\": ['mean', 'median', 'var', \n 'std', 'sem']})\n\naggregate_df",
"_____no_output_____"
]
],
[
[
"## Bar and Pie Charts",
"_____no_output_____"
]
],
[
[
"# Get value counts for each regimen\nregimen_count = clean_df['Drug Regimen'].value_counts()\n\n# Generate a bar plot showing the total number of measurements taken on each drug regimen using pandas.\nregimen_count = clean_df['Drug Regimen'].value_counts().plot.bar(width=0.5)\n\n# Set labels for axes\nregimen_count.set_xlabel(\"Drug Regimen\")\nregimen_count.set_ylabel(\"Number of Observations\")\nregimen_count.set_title(\"Treatment Regimen Observation Count\")\n",
"_____no_output_____"
],
[
"regimen_count",
"_____no_output_____"
],
[
"# Generate a bar plot showing the total number of measurements taken on each drug regimen using pyplot.\n\n# Determine number of data points\npy_regimen_count = clean_df['Drug Regimen'].value_counts()\n\n# Set X axis\nx_axis = np.arange(len(py_regimen_count))\n\n#Create bar plot\nplt.bar(x_axis, py_regimen_count, width = 0.5)\n\n# Set names for drug regimen groups\ntick_locations = [value for value in x_axis]\nplt.xticks(tick_locations, py_regimen_count.index.values)\n\n#Change orientation of x labels \nplt.xticks(rotation=90)\n\n# Add labels and title\nplt.xlabel(\"Drug Regimen\")\nplt.ylabel(\"Number of Observations\")\nplt.title('Treatment Regimen Observation Count')\n\n\n\n# Display results\nplt.show()",
"_____no_output_____"
],
[
"# Determine number of data points\npy_regimen_count = clean_df['Drug Regimen'].value_counts()\npy_regimen_count",
"_____no_output_____"
],
[
"# Generate a pie plot showing the distribution of female versus male mice using pandas\n\n# Find distribition of mice by sex\nsex_count = clean_df['Sex'].value_counts()\n\n# Generate Pie chart for sex distribution\nsex_distribution_chart = sex_count.plot.pie(startangle=90, title='Distribution by Sex', autopct=\"%1.1f%%\")\n\n\n# Hide Y label to improve presentation\nsex_distribution_chart.set_ylabel('')",
"_____no_output_____"
],
[
"# Generate a pie plot showing the distribution of female versus male mice using pyplot\n\n# Identify distribution of data by sex\npy_sex_distribution = clean_df['Sex'].value_counts()\n\n# Tell matplotlib to create a pie chart filled with corresponding percentages and displayed vertically\nplt.pie(py_sex_distribution, labels=py_sex_distribution.index.values, startangle=90, autopct=\"%1.1f%%\")\nplt.title('Distribution by Sex')\n\n# Display resulting plot\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Quartiles, Outliers and Boxplots",
"_____no_output_____"
]
],
[
[
"# Calculate the final tumor volume of each mouse across four of the treatment regimens: Capomulin, Ramicane, Infubinol, and Ceftamin\n# Start by getting the last (greatest) timepoint for each mouse\n# Merge this group df with the original dataframe to get the tumor volume at the last timepoint\n\nmaxtimept_df = pd.DataFrame(clean_df.groupby('Mouse ID')['Timepoint'].max()).reset_index().rename(columns={'Timepoint': 'Timepoint (Max)'})\n\nclean_max_df = pd.merge(clean_df, maxtimept_df, on='Mouse ID')\nclean_max_df.head()",
"_____no_output_____"
],
[
"regimens = ['Capomulin', 'Ramicane', 'Infubinol', 'Ceftamin']\nregimen_values = []\n\nfor regimen in regimens:\n # create dataframe with all regimens we are interested in \n selected_regimens_df = clean_max_df.loc[clean_max_df['Drug Regimen'] == regimen]\n \n # find last time point using max and store in another dataframe\n results_df= selected_regimens_df.loc[selected_regimens_df['Timepoint'] == selected_regimens_df['Timepoint (Max)']]\n \n # Get Tumor volume from clean_max_df dataframe\n values = results_df['Tumor Volume (mm3)']\n regimen_values.append(values)\n \n # Calculate Quartiles and IQR\n quartiles = values.quantile([0.25, 0.5, 0.75])\n upperquartile = quartiles[0.75]\n lowerquartile = quartiles[0.25]\n iqr = upperquartile - lowerquartile\n \n #print results\n print(f\" IQR for {regimen} is {iqr}\")\n \n \n #Find upper and lower bounds\n upper_bound = upperquartile + (1.5 * iqr)\n lower_bound = lowerquartile - (1.5 * iqr)\n print(f\"Upper Bound for {regimen}: {upper_bound}\")\n print(f\"Lower Bound for {regimen}: {lower_bound}\")\n \n \n # Find Outliers\n outliers_count = (values.loc[(clean_max_df['Tumor Volume (mm3)'] >= upper_bound) | \n (clean_max_df['Tumor Volume (mm3)'] <= lower_bound)]).count()\n \n print(f\" The {regimen} regimen has {outliers_count} outlier(s)\")",
" IQR for Capomulin is 7.781863460000004\nUpper Bound for Capomulin: 51.83201549\nLower Bound for Capomulin: 20.70456164999999\n The Capomulin regimen has 0 outlier(s)\n IQR for Ramicane is 9.098536719999998\nUpper Bound for Ramicane: 54.30681135\nLower Bound for Ramicane: 17.912664470000003\n The Ramicane regimen has 0 outlier(s)\n IQR for Infubinol is 11.477135160000003\nUpper Bound for Infubinol: 82.74144559000001\nLower Bound for Infubinol: 36.83290494999999\n The Infubinol regimen has 1 outlier(s)\n IQR for Ceftamin is 15.577752179999997\nUpper Bound for Ceftamin: 87.66645829999999\nLower Bound for Ceftamin: 25.355449580000002\n The Ceftamin regimen has 0 outlier(s)\n"
],
[
"# Generate a box plot of the final tumor volume of each mouse across four regimens of interest\n\n# Create Box Plot\nplt.boxplot(regimen_values)\n\n# Add Title and Labels\nplt.title('Tumor Volume by Drug')\nplt.ylabel(' Tumor Volume (mm3)')\nplt.xticks([1, 2, 3, 4], ['Capomulin', 'Ramicane', 'Infubinol', 'Ceftamin'])\n",
"_____no_output_____"
]
],
[
[
"## Line and Scatter Plots",
"_____no_output_____"
]
],
[
[
"# Generate a line plot of tumor volume vs. time point for a mouse treated with Capomulin\n\n# Isolate Capomulin regimen oberservations\nCapomulin_df = clean_df.loc[clean_df['Drug Regimen'] == 'Capomulin']\n\nCapomulin_mouse= Capomulin_df.loc[Capomulin_df['Mouse ID'] == \"b128\",:]\nCapomulin_mouse.head()\n\n#create chart\nplt.plot(Capomulin_mouse['Timepoint'], Capomulin_mouse['Tumor Volume (mm3)'], marker = 'o')\n\n# Add labels and title to plot\nplt.xlabel(\"Time (days)\")\nplt.ylabel(\"Tumor Volume (mm3)\")\nplt.title(\"Capomulin Treatment for Mouse b128\")\n\nplt.show()",
"_____no_output_____"
],
[
"# Generate a scatter plot of average tumor volume vs. mouse weight for the Capomulin regimen\n\n# Isolate Capomulin regimen oberservations\ncapomulin_df = clean_df.loc[clean_df['Drug Regimen'] == 'Capomulin']\n\n#create df with average tumor volumes\nAvg_Tumor_Vol = pd.DataFrame(capomulin_df.groupby('Mouse ID')['Tumor Volume (mm3)'].mean())\n\n# Merge with capomulin_df\nAverage_Tumor_Volume_df =pd.merge(capomulin_df, Avg_Tumor_Vol, on = 'Mouse ID', how = \"left\").rename(columns = {'Tumor Volume (mm3)_y' : 'Avg. Tumor Volume'})\nAverage_Tumor_Volume_df.head()\n\n# Define Variables for scatter plot \nx_axis = Average_Tumor_Volume_df['Weight (g)']\ny_axis = Average_Tumor_Volume_df['Avg. Tumor Volume']\n\n\n#Create scatter plot \nplt.scatter(x_axis, y_axis)\n\n# Add labels and title to plot\nplt.xlabel(\"Weight (g)\")\nplt.ylabel(\"Average Tumor Volume (mm3)\")\nplt.title('Average Tumor Volume by Weight')\n\n\n# Display plot\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"## Correlation and Regression",
"_____no_output_____"
]
],
[
[
"# Calculate the correlation coefficient and linear regression model \ncorrelation = st.pearsonr(x_axis, y_axis)\nprint(f\"\"\"The correlation between weight and average tumor volume in the Capomulin regimen is {round((correlation[0]), 4)}.\"\"\")",
"The correlation between weight and average tumor volume in the Capomulin regimen is 0.8344.\n"
],
[
"# For mouse weight and average tumor volume for the Capomulin regimen\n\n(slope, intercept, rvalue, pvalue, stderr) = st.linregress(x_axis, y_axis)\nregression_values = x_axis * slope + intercept\nlinear_equation = \"y = \" + str(round(slope,2)) + \"x + \" + str(round(intercept,2))\n\n# Plot linear regression on to the scatter plot\nplt.scatter(x_axis,y_axis)\nplt.plot(x_axis,regression_values,\"r-\")\n\n#apply labels and title\nplt.xlabel(\"Weight (g)\")\nplt.ylabel(\"Average Tumor Volume (mm3)\")\nplt.title('Average Tumor Volume by Weight')\n\n\n# Add linear equation to the scatterplot\nplt.annotate(linear_equation,(20,37), fontsize=15, color=\"black\")\n\n\n# Display plot\nplt.show()\n\n\n",
"_____no_output_____"
],
[
"# Calculate r squared to see how well our model predicts average tumor volume for a given weight\n\nrsquared = round((rvalue**2),4)\nrsquared",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd19469b808ad4ebbe87155fe90dc904f60d6a5
| 234,377 |
ipynb
|
Jupyter Notebook
|
content-draft/sell_in_may_part2.ipynb
|
Rgveda/alpha-scientist
|
f801b436ea5425cbbc1aa81729b2f22d227bbff9
|
[
"Apache-2.0"
] | 1 |
2020-12-28T07:04:54.000Z
|
2020-12-28T07:04:54.000Z
|
content-draft/sell_in_may_part2.ipynb
|
Rgveda/alpha-scientist
|
f801b436ea5425cbbc1aa81729b2f22d227bbff9
|
[
"Apache-2.0"
] | null | null | null |
content-draft/sell_in_may_part2.ipynb
|
Rgveda/alpha-scientist
|
f801b436ea5425cbbc1aa81729b2f22d227bbff9
|
[
"Apache-2.0"
] | null | null | null | 348.257058 | 33,022 | 0.922211 |
[
[
[
"## TODO\n* Add O2C and C2O seasonality\n* Look at diff symbols\n* Look at fund flows",
"_____no_output_____"
],
[
"## Key Takeaways\n* ...\n\n\nIn the [first post](sell_in_may.html) of this short series, we covered several seasonality patterns for large cap equities (i.e, SPY), most of which continue to be in effect. \n\nThe findings of that exercise sparked interest in what similar seasonal patterns may exist in other asset classes. This post will pick up where that post left off, looking at \"risk-off\" assets which exhibit low (or negative) correlation to equities. \n\n",
"_____no_output_____"
]
],
[
[
"\n## Replace this section of imports with your preferred\n## data download/access interface. This calls a \n## proprietary set of methods (ie they won't work for you)\n\nimport sys\nsys.path.append('/anaconda/')\nimport config\n\nsys.path.append(config.REPO_ROOT+'data/')\nfrom prices.eod import read\n\n####### Below here are standard python packages ######\nimport numpy as np\nimport pandas as pd\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom IPython import display\nimport seaborn as sns\n\nfrom IPython.core.display import HTML,Image\n\n\n## Load Data\nsymbols = ['SPY','IWM','AGG','LQD','IEF','MUB','GLD']\n#symbols = ['SPY','IWM','AGG','LQD','JNK','IEF']\nprices = read.get_symbols_close(symbols,adjusted=True)\nreturns = prices.pct_change()\nlog_ret = np.log(prices).diff()\n\n",
"_____no_output_____"
]
],
[
[
"### Month-of-year seasonality\n\nAgain, we'll start with month-of-year returns for several asset classes. Note that I'm making use of the seaborn library's excellent `clustermap()` method to both visually represent patterns in asset classes _and_ to group the assets by similarity (using Euclidean distance between the average monthly returns vectors of each column). \n\n_Note that the values plotted are z-score values (important for accurate clustering)_.",
"_____no_output_____"
]
],
[
[
"by_month = log_ret.resample('BM').sum()\nby_month[by_month==0.0] = None \n# because months prior to fund launch are summed to 0.0000\n\navg_monthly = by_month.groupby(by_month.index.month).mean()\n\nsns.clustermap(avg_monthly[symbols],row_cluster=False,z_score=True, metric='euclidean',\\\n cmap=sns.diverging_palette(10, 220, sep=20, n=7))\n## Notes: \n# should use either z_score =True or standard_scale = True for accurate clustering\n# Uses Euclidean distance as metric for determining cluster",
"_____no_output_____"
]
],
[
[
"Clearly, the seasonal patterns we saw in the [last post](sell_in_may.html) do not generalize across all instruments - which is a very good thing! IWM (small cap equities) do more or less mimic the SPY patterns, but the \"risk-off\" assets generally perform well in the summer months of July and August, when equities had faltered. \n\nWe might consider a strategy of shifting from risk-on (e.g., SPY) to risk-off (e.g., IEF) for June to September.",
"_____no_output_____"
]
],
[
[
"rotation_results = pd.Series(index=avg_monthly.index)\nrotation_results.loc[[1,2,3,4,5,10,11,12]] = avg_monthly['SPY']\nrotation_results.loc[[6,7,8,9]] = avg_monthly['IEF']\n#\nprint(\"Returns:\")\nprint(avg_monthly.SPY.sum())\nprint(rotation_results.sum())\nprint()\nprint(\"Sharpe:\")\nprint(avg_monthly.SPY.sum()/(by_month.std()['SPY']*12**0.5))\nprint(rotation_results.sum()/(rotation_results.std()*12**0.5))\n",
"Returns:\n0.09231732105877347\n0.11971481651504569\n\nSharpe:\n0.6495856298514646\n5.2988969815087055\n"
],
[
"avg_monthly.SPY.std()*12**0.5",
"_____no_output_____"
]
],
[
[
"\nNext, I'll plot the same for day-of-month. ",
"_____no_output_____"
]
],
[
[
"avg_day_of_month = log_ret.groupby(log_ret.index.day).mean()\nsns.clustermap(avg_day_of_month[symbols],row_cluster=False,z_score= True,metric='euclidean',\\\n cmap=sns.diverging_palette(10, 220, sep=20, n=7))",
"_____no_output_____"
]
],
[
[
"This is a bit messy, but I think the dominant pattern is weakness within all \"risk-off\" assets (treasurys, etc...) for the first 1/3 to 1/2 of the month, followed by a very strong end of month rally. \n\nFinally, plot a clustermap for day-of-week:",
"_____no_output_____"
]
],
[
[
"avg_day_of_week = log_ret.groupby(log_ret.index.weekday+1).mean()\nsns.clustermap(avg_day_of_week[symbols],row_cluster=False,z_score= True,metric='euclidean',\\\n cmap=sns.diverging_palette(10, 220, sep=20, n=7))",
"_____no_output_____"
]
],
[
[
"Again, a bit messy. However, the most consistent pattern is \"avoid Thursday\" for risk-off assets like AGG, LQD, and IEF. Anyone with a hypothesis as to why this might be, please do share!\n\n",
"_____no_output_____"
],
[
"### Observations\n* Clusters form about as you'd expect. The \"risk-off\" assets like Treasurys (IEF), munis (MUB), gold (GLD), and long volatility (VXX) tend to cluster together. The \"risk-on\" assets like SPY, EEM, IXUS, and JNK tend to cluster together.\n* Risk-off assets (Treasurys etc...) appear to follow the opposite of \"sell in May\", with weakness in November and December, when SPY and related were strongest.\n* Within day-of-month, there are some _very_ strong patterns for fixed income, with negative days at the beginning of month and positive days at end of month. \n* Day of week shows very strong clustering of risk-off assets (outperform on Fridays). There's an interesting clustering of underperformance on Mondays. This may be a false correlation since some of these funds have much shorter time histories than others and may be reflecting that",
"_____no_output_____"
]
],
[
[
"risk_off_symbols = ['IEF','MUB','AGG','LQD']\n\ndf = log_ret[symbols_1].mean(axis=1).dropna().to_frame(name='pct_chg')\nby_month = df.resample('BM').sum()\nby_month['month'] = by_month.index.month\n\ntitle='Avg Log Return (%): by Calendar Month \\nfor Risk-off Symbols {}'.format(risk_off_symbols)\ns = (by_month.groupby('month').pct_chg.mean()*100)\nmy_colors = ['r','r','r','r','g','g','g','g','g','g','r','r',]\nax = s.plot(kind='bar',color=my_colors,title=title)\nax.axhline(y=0.00, color='grey', linestyle='--', lw=2)",
"_____no_output_____"
]
],
[
[
"Wow, maybe there's some truth to this myth! It appears that there is a strong difference between the summer months (June to September) and the rest. \n\nFrom the above chart, it appears than we'd be well advised to sell on June 1st and buy back on September 30th. However, to follow the commonly used interpretation of selling on May 1st and repurchasing on Oct 31st. I'll group the data into those two periods and calculate the monthly average:",
"_____no_output_____"
]
],
[
[
"by_month['season'] = None\nby_month.loc[by_month.month.between(5,10),'season'] = 'may_oct'\nby_month.loc[~by_month.month.between(5,10),'season'] = 'nov_apr'\n\n(by_month.groupby('season').pct_chg.mean()*100).plot.bar\\\n(title='Avg Monthly Log Return (%): \\nMay-Oct vs Nov_Apr (1993-present)'\\\n ,color='grey')\n",
"_____no_output_____"
]
],
[
[
"A significant difference. The \"winter\" months are more than double the average return of the summer months. But has this anomaly been taken out of the market by genius quants and vampire squid? Let's look at this breakout by year:",
"_____no_output_____"
],
[
"Of these, the most interesting patterns, to me, are the day-of-week and day-of-month cycles. \n\n### Day of Week\nI'll repeat the same analysis pattern as developed in the prior post ([\"Sell in May\"](sell_in_may.html)), using a composite of four generally \"risk-off\" assets. You may choose create composites differently. ",
"_____no_output_____"
]
],
[
[
"risk_off_symbols = ['IEF','MUB','AGG','LQD']\n\ndf = log_ret[risk_off_symbols].mean(axis=1).dropna().to_frame(name='pct_chg')\n\nby_day = df\nby_day['day_of_week'] = by_day.index.weekday+ 1\n\nax = (by_day.groupby('day_of_week').pct_chg.mean()*100).plot.bar\\\n(title='Avg Daily Log Return (%): by Day of Week \\n for {}'.format(risk_off_symbols),color='grey')\nplt.show()\n\nby_day['part_of_week'] = None\nby_day.loc[by_day.day_of_week ==4,'part_of_week'] = 'thurs'\nby_day.loc[by_day.day_of_week !=4,'part_of_week'] = 'fri_weds'\n\n(by_day.groupby('part_of_week').pct_chg.mean()*100).plot.bar\\\n(title='Avg Daily Log Return (%): Mon vs Tue-Fri \\n for {}'.format(risk_off_symbols)\\\n ,color='grey')\n\ntitle='Avg Daily Log Return (%) by Part of Week\\nFour Year Moving Average\\n for {}'.format(risk_off_symbols)\nby_day['year'] = by_day.index.year\nax = (by_day.groupby(['year','part_of_week']).pct_chg.mean().unstack().rolling(4).mean()*100).plot()\nax.axhline(y=0.00, color='grey', linestyle='--', lw=2)\nax.set_title(title)\n\n",
"_____no_output_____"
]
],
[
[
"The \"avoid Thursday\" for risk-off assets seemed to be remarkably useful until about 4 years ago, when it ceased to work. I'll call this one busted. Moving on to day-of-month, and following the same grouping and averaging approach:",
"_____no_output_____"
]
],
[
[
"risk_off_symbols = ['IEF','MUB','AGG','LQD']\nby_day = log_ret[risk_off_symbols].mean(axis=1).dropna().to_frame(name='pct_chg')\nby_day['day_of_month'] = by_day.index.day \ntitle='Avg Daily Log Return (%): by Day of Month \\nFor: {}'.format(symbols_1)\nax = (by_day.groupby('day_of_month').pct_chg.mean()*100).plot.bar(xlim=(1,31),title=title,color='grey')\nax.axhline(y=0.00, color='grey', linestyle='--', lw=2)",
"_____no_output_____"
]
],
[
[
"Here we see the same pattern as appeared in the clustermap. I wonder if the end of month rally is being driven by the ex-div date, which I believe is usually the 1st of the month for these funds. \n\n_Note: this data is dividend-adjusted so there is no valid reason for this - just dividend harvesting and behavioral biases, IMO._",
"_____no_output_____"
]
],
[
[
"by_day['part_of_month'] = None\nby_day.loc[by_day.index.day <=10,'part_of_month'] = 'first_10d'\nby_day.loc[by_day.index.day >10,'part_of_month'] = 'last_20d'\n\n(by_day.groupby('part_of_month').pct_chg.mean()*100).plot.bar\\\n(title='Avg Daily Log Return (%): \\nDays 1-10 vs 11-31\\nfor risk-off assets {}'.format(risk_off_symbols)\\\n ,color='grey')\n\ntitle='Avg Daily Log Return (%) \\nDays 1-10 vs 11-31\\nfor risk-off assets {}'.format(risk_off_symbols)\nby_day['year'] = by_day.index.year\nax = (by_day.groupby(['year','part_of_month']).pct_chg.mean().unstack().rolling(4).mean()*100).plot(title=title)\nax.axhline(y=0.00, color='grey', linestyle='--', lw=2)",
"_____no_output_____"
]
],
[
[
"In contrast to the day-of-week anomaly, this day-of-month pattern seems to hold extremely well. It's also an extremely tradeable anomaly, considering that it requires only one round-trip per month. ",
"_____no_output_____"
]
],
[
[
"baseline = by_day.resample('A').pct_chg.sum()\nonly_last_20 = by_day[by_day.part_of_month=='last_20d'].resample('A').pct_chg.sum()\npd.DataFrame({'baseline':baseline,'only_last_20':only_last_20}).plot.bar()\nprint(pd.DataFrame({'baseline':baseline,'only_last_20':only_last_20}).mean())",
"baseline 0.043380\nonly_last_20 0.049227\ndtype: float64\n"
]
],
[
[
"Going to cash in the first 10 days of each month actually _increased_ annualized returns (log) by about 0.60%, while simultaneously lowering capital employed and volatility of returns. Of the seasonality anomalies we've reviewed in this post and the previous, this appears to be the most robust and low risk. \n\n\n\n## Conclusion\n... \n\nIf the future looks anything like the past (insert standard disclaimer about past performance...) then rules of thumb might be:\n* Sell on Labor Day and buy on Halloween - especially do this on election years! This assumes that you've got a productive use for the cash! \n* Do your buying at Friday's close, do your selling at Wednesday's close\n* Maximize your exposure at the end/beginning of months and during the early-middle part of the month, lighten up.\n* Remember that, in most of these anomalies, _total_ return would decrease by only participating in part of the market since any positive return is better than sitting in cash. Risk-adjusted returns would be significantly improved by only participating in the most favorable periods. It's for each investor to decide what's important to them. \n\nI had intended to extend this analysis to other asset classes, but will save that for a future post. I'd like to expand this to small caps, rest-of-world developed/emerging, fixed income, growth, value, etc... \n\n\n### One last thing...\n\nIf you've found this post useful, please follow [@data2alpha](https://twitter.com/data2alpha) on twitter and forward to a friend or colleague who may also find this topic interesting.\n\nFinally, take a minute to leave a comment below. Share your thoughts on this post or to offer an idea for future posts. Thanks for reading!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd1961446bdf2989f6c98816493c5f6926042cc
| 10,587 |
ipynb
|
Jupyter Notebook
|
api-book/_build/html/_sources/chapter-6-production-tools/JWT.ipynb
|
Eligijus112/api-book
|
e345598b6226eaef190caa016c199e9db2b697ff
|
[
"MIT"
] | null | null | null |
api-book/_build/html/_sources/chapter-6-production-tools/JWT.ipynb
|
Eligijus112/api-book
|
e345598b6226eaef190caa016c199e9db2b697ff
|
[
"MIT"
] | 21 |
2021-11-09T16:13:59.000Z
|
2022-01-16T12:57:27.000Z
|
api-book/chapter-6-production-tools/JWT.ipynb
|
Eligijus112/api-book
|
e345598b6226eaef190caa016c199e9db2b697ff
|
[
"MIT"
] | null | null | null | 31.792793 | 643 | 0.590252 |
[
[
[
"# JWT based authentification \n\nIn the API world, authentification is a process where we want to authenticate a user. In real world applications, only authenticated users can access the API. Additionaly, we may want to track how much does a specific user query an API. \n\nTo solve the complex issue of authentification, the current golden standart are the `JWT tokens`. \n\n`JWT` stands for JSON Web Token. \n\nThe high level graph of the process: \n\n",
"_____no_output_____"
],
[
"1) The user requests a token, sending over his credentials (username and password). \n\n2) The server checks the credentials and if they are correct, it generates a JWT token. The token gets sent back to the user. \n\n3) Every time the user makes a request to any of the APIs on a certain server, it has to include the JWT token. Only the JWT token is used to authenticate the user.\n\n# JWT token \n\nA JWT token is just a string that has three parts separated by dots:\n\n```\n<header>.<payload>.<signature> \n```\n\nAn example may look like this:\n\n`eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c` \n\nThats it, the above string is a JWT token that has alot of information encoded into it. There are many libraries that can be used both to create and to decode a JWT token. In the subsequent chapters we will use Python implementations of JWT authentification and go through the details of the JWT token system. \n\n# The authentification flow \n\nAll the code is in the `jwt-toke-example` directory. Be sure to run \n\n```\ndocker-compose up \n```\n\nTo spin up a PSQL server. \n\nAdditionaly, start the API from the same directory:\n\n```\nuvicorn app:app --port 8000\n```\n\n## Step 1: Requesting a token \n\n### User registration\n\nIn the JWT flow, we still cannot escape the good old username and password combination. We need to store this information somewhere in the server and every time a user requests a new token, we need to check if the user credentials are correct. For this, we need to create an endpoint for user registration and then for token generation. Because of this reason, the whole process of authentification ideally should be done via HTTPS and not HTTP. For the purpose of this tutorial, we will use HTTP, because the concepts are exactly the same. HTTPS only adds a layer of obfuscation and encodes the transactions between user and server. \n\nThe user database table is very straightforward. It contains the username, the password and the date it was created: ",
"_____no_output_____"
]
],
[
[
"!cat jwt-token-example/models.py",
"cat: jwt-token-example/models.py: No such file or directory\n"
]
],
[
[
"The endpoint for user creation is `/users/register`. To register we need to send a POST request with the following data:\n\n```\n {\n \"username\": <username>,\n \"password\": <password>\n }\n```",
"_____no_output_____"
]
],
[
[
"# Importing the request making lib \nimport requests\n\n# Making the request to the API to register the user \nresponse = requests.post(\n \"http://localhost:8000/users/register\", \n json={\"username\": \"eligijus\", \"password\": \"123456\"}\n)\n\nif response.status_code in [200, 201]:\n print(f\"Response: {response.json()}\")",
"Response: {'message': 'User already exists', 'user_id': 1}\n"
]
],
[
[
"Now that we have a registered user we can start implementing the logic of JWT token creation. \n\n## Step 2: Creating the JWT token \n\nThe library that creates the JWT token is called `pyjwt`. It is a Python library that can be used to create and decode JWT tokens. It is fully compliant with the [JSON Web Token standard](https://tools.ietf.org/html/rfc7519).\n\nThe token creation and inspection script is: ",
"_____no_output_____"
]
],
[
[
"!cat jwt-token-example/jwt_tokens.py",
"cat: jwt-token-example/jwt_tokens.py: No such file or directory\n"
]
],
[
[
"The logic of creating the token is in the `create_token()` function. Remember the JWT token structure: \n\n```\n<header>.<payload>.<signature>\n```\n\nThe `header` part encodes the algorithm and type needed to decode the token.\n\nThe `payload` part holds the dictionary of claims. The claims are the information that gets encoded into the token as a dictionary. \n\nThe `signature` part is the signature of the token. It is used to verify the token by the python library. The `_SECRET` constant is used to construct the signature. That it why it should be kept only as a runtime variable in the variable where no one can access it. \n\nLets query the endpoint `/token` using the credentials we used to register the user.",
"_____no_output_____"
]
],
[
[
"# Making the request to the API to get the token\nresponse = requests.post(\n \"http://localhost:8000/token\", \n json={\"username\": \"eligijus\", \"password\": \"123456\"}\n)\n\n# Extracting the token \ntoken = response.json().get('token')\n\n# Printing out the gotten token \nprint(f\"Token: {token}\")",
"Token: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJleHAiOjE2NDIzNDIzNTcsImlhdCI6MTY0MjMzODc1Nywic3ViIjoxfQ.vaJZQZMA_JqLEhgIZm6jxwnr1D9HkQs1OK9BWSwGOeM\n"
]
],
[
[
"The above token will be valid for 60 minutes and can be used to make requests to the API. If we make a request with a non existing user, we will get a `401 Unauthorized` error:",
"_____no_output_____"
]
],
[
[
"# Making the request to the API to get the token\nresponse = requests.post(\n \"http://localhost:8000/token\", \n json={\"username\": \"eligijus\", \"password\": \"12345\"}\n)\n\n# Printing out the status code \nprint(f\"Response code: {response.status_code}\")",
"Response code: 401\n"
]
],
[
[
"## Step 3: Using the JWT token \n\nEvery time a user makes a request to the API, we need to include the JWT token in the request. We will use the `Authorization` header to include the token and will send a GET request to our very well know number root calculating API. ",
"_____no_output_____"
]
],
[
[
"# Defining the parameteres to send \nnumber = 88\nn = 0.88\n\n# Making the request with the token \nresponse = requests.get(\n f\"http://localhost:8000/root?number={number}&n={n}\",\n headers={\"Authorization\": f\"{token}\"}\n)\n\n# Printing out the status code and the result \nprint(f\"Response code: {response.status_code}\")\nprint(f\"Root {n} of {number} is: {response.json()}\")",
"Response code: 200\nRoot 0.88 of 88 is: {'root': 51.42150122383022}\n"
]
],
[
[
"If we use a bad JWT code, a user does not exist in the database or the token has expired, we will get a 401 Unauthorized response error:",
"_____no_output_____"
]
],
[
[
"# Making the request with the token \nresponse = requests.get(\n f\"http://localhost:8000/root?number={number}&n={n}\",\n headers={\"Authorization\": \"Hello I am a really legit token\"}\n)\n\n# Printing out the status code and the result \nprint(f\"Response code: {response.status_code}\")\nprint(f\"Root {n} of {number} is: {response.json()}\")",
"Response code: 401\nRoot 0.88 of 88 is: {'message': 'Token is not valid'}\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd1cf67bd00014072116e17263af6173a600e5b
| 145,717 |
ipynb
|
Jupyter Notebook
|
notebooks/Episode 4.ipynb
|
lgatto/2016-11-17-cam
|
6fef0efe81f0658e18e06111a6e92cb567db1e79
|
[
"CC-BY-4.0"
] | 1 |
2016-11-14T11:08:53.000Z
|
2016-11-14T11:08:53.000Z
|
notebooks/Episode 4.ipynb
|
lgatto/2016-11-17-cam
|
6fef0efe81f0658e18e06111a6e92cb567db1e79
|
[
"CC-BY-4.0"
] | null | null | null |
notebooks/Episode 4.ipynb
|
lgatto/2016-11-17-cam
|
6fef0efe81f0658e18e06111a6e92cb567db1e79
|
[
"CC-BY-4.0"
] | null | null | null | 41.02393 | 93 | 0.395486 |
[
[
[
"## Combining DataFrames",
"_____no_output_____"
]
],
[
[
"import pandas as pd\narticles_df = pd.read_csv('articles.csv', dtype={'LanguageId':str})",
"_____no_output_____"
],
[
"articles_df[articles_df.LanguageId == '4']",
"_____no_output_____"
],
[
"articles_df = pd.read_csv('articles.csv', encoding='utf8')",
"_____no_output_____"
],
[
"articles_df = pd.read_csv('articles.csv', \n parse_dates=[['Year', 'Month', 'Day']], \n keep_date_col=True)",
"_____no_output_____"
],
[
"articles_df[['Year_Month_Day', 'Year', 'Month', 'Day']]",
"_____no_output_____"
],
[
"articles_df",
"_____no_output_____"
],
[
"articles_df = pd.read_csv('articles.csv', \n parse_dates={'Date': ['Year', 'Month', 'Day']}, \n keep_date_col=True)",
"_____no_output_____"
],
[
"articles_df[(articles_df.Date >= '2015-07-01') & (articles_df.Date < '2015-08-01')]",
"_____no_output_____"
],
[
"articles_df = pd.read_csv('articles.csv', \n parse_dates={'Date': ['Year', 'Month', 'Day']}, \n keep_date_col=True,\n usecols=['First_Author', 'Year', 'Month', 'Day'])",
"_____no_output_____"
],
[
"articles_df.drop(['Day', 'Month', 'Year'], axis=1)",
"_____no_output_____"
],
[
"articles_df.to_csv('ournew.csv', encoding='utf8')",
"_____no_output_____"
],
[
"new_df = pd.read_csv('ournew.csv', encoding='utf8', index_col=0)\nnew_df",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd1dca5732d99cfe01cb115eb3e780dae02446a
| 157,400 |
ipynb
|
Jupyter Notebook
|
Python_101-2022.ipynb
|
yarengozutok/hu-bby162-2022
|
6352a20c108abdb0a1c9efa86145cfc3a73d0d13
|
[
"MIT"
] | null | null | null |
Python_101-2022.ipynb
|
yarengozutok/hu-bby162-2022
|
6352a20c108abdb0a1c9efa86145cfc3a73d0d13
|
[
"MIT"
] | null | null | null |
Python_101-2022.ipynb
|
yarengozutok/hu-bby162-2022
|
6352a20c108abdb0a1c9efa86145cfc3a73d0d13
|
[
"MIT"
] | null | null | null | 29.338304 | 480 | 0.47791 |
[
[
[
"<a href=\"https://colab.research.google.com/github/yarengozutok/HU-BBY162-2022/blob/main/Python_101-2022.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"#Bölüm 00: Python'a Giriş",
"_____no_output_____"
],
[
"## Yazar Hakkında\n\nYaren Gözütok\n",
"_____no_output_____"
],
[
"##Çalışma Defteri Hakkında\n\nBu çalışma defteri Google'ın Jupyter Notebook platformuna benzer özellikler taşıyan Google Colab üzerinde oluşturulmuştur. Google Colab, herhangi bir altyapı düzenlemesine ihtiyaç duymadan Web tabanlı olarak Python kodları yazmanıza ve çalıştırmanıza imkan veren ücretsiz bir platformdur. Platform ile ilgili detaylı bilgiye [https://colab.research.google.com/notebooks/intro.ipynb](https://colab.research.google.com/notebooks/intro.ipynb) adresinden ulaşabilirsiniz.\n\nPython'a giriş seviyesinde 10 dersten oluşan bu çalışma defteri daha önce kodlama deneyimi olmayan öğrenenler için hazırlanmıştır. Etkileşimli yapısından dolayı hem konu anlatımlarının hem de çalıştırılabilir örneklerin bir arada olduğu bu yapı, sürekli olarak güncellenebilecek bir altyapıya sahiptir. Bu açıdan çalışma defterinin güncel sürümünü aşağıdaki adresten kontrol etmenizi tavsiye ederim.\n\nSürüm 1.0: [Python 101](https://github.com/orcunmadran/Python101/blob/main/Python_101.ipynb)\n\nİyi çalışmalar ve başarılar :)",
"_____no_output_____"
],
[
"## Kullanım Şartları\n\nBu çalışma defteri aşağıda belirtilen şartlar altında, katkıda bulunanlara Atıf vermek ve aynı lisansla paylaşmak kaydıyla ticari amaç dahil olmak üzere her şekilde dağıtabilir, paylaşabilir, üzerinde değişiklik yapılarak yeniden kullanılabilir.\n\n\n---\n\n\n\nBu çalışma defteri Jetbrains'in \"Introduction to Python\" dersi temel alınarak hazırlanmış ve Creative Commons [Atıf-AynıLisanslaPaylaş 4.0 Uluslararası Lisansı](http://creativecommons.org/licenses/by-sa/4.0/) ile lisanslanmıştır.\n\n---\n\n",
"_____no_output_____"
],
[
"# Bölüm 01: Giriş\n\nBu bölümde:\n\n* İlk bilgisayar programımız,\n* Yorumlar yer almaktadır.",
"_____no_output_____"
],
[
"## İlk Bilgisayar Programımız\nGeleneksel olarak herhangi bir programlama dilinde yazılan ilk program \"Merhaba Dünya!\"'dır.",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n\n```\nprint(\"Merhaba Dünya!\")\n```\n\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\nprint(\"Merhaba Dünya!\")",
"Merhaba Dünya!\n"
]
],
[
[
"**Görev:** Kendinizi dünyaya tanıtacak ilk bilgisayar programını yazın!",
"_____no_output_____"
]
],
[
[
"print(\"Merhaba Python\")",
"Merhaba Python\n"
]
],
[
[
"## Yorumlar\nPython'daki yorumlar # \"hash\" karakteriyle başlar ve fiziksel çizginin sonuna kadar uzanır. Yorum yapmak için kullanılan # \"hash\" karakteri kod satırlarını geçici olarak devre dışı bırakmak amacıyla da kullanılabilir. ",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n\n```\n# Bu ilk bilgisayar programım için ilk yorumum\nprint(\"# bu bir yorum değildir\")\nprint(\"Merhaba!\") # yorumlar kod satırının devamında da yapılabilir.\n#print(\"Bu kod geçici olarak devre dışı bırakılmıştır.\")\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\n# Bu ilk bilgisayar programım için ilk yorumum\nprint(\"# bu bir yorum değildir\")\nprint(\"Merhaba!\") # yorumlar kod satırının devamında da yapılabilir.\n# print(\"Bu kod geçici olarak devre dışı bırakılmıştır.\")\n\n#Python öğreniyorum\nprint(\"#Python öğreniyorum\")\n",
"# bu bir yorum değildir\nMerhaba!\n#Python öğreniyorum\n"
]
],
[
[
"**Görev:** Python kodunuza yeni bir yorum ekleyin, mevcut satıra yorum ekleyin, yazılmış olan bir kod satırını geçici olarak devre dışı bırakın!",
"_____no_output_____"
]
],
[
[
"print(\"Bu satırın devamına bir yorum ekleyin\") #Python öğreniyorum\n#print(\"Bu satırı devre dışı bırakın!\")",
"Bu satırın devamına bir yorum ekleyin\n"
]
],
[
[
"# Bölüm 02: Değişkenler\nBu bölümde:\n\n\n* Değişken nedir?,\n* Değişken tanımlama,\n* Değişken türleri,\n* Değişken türü dönüştürme,\n* Aritmetik operatörler,\n* Artıtılmış atama operatörleri,\n* Boolean operatörleri,\n* Karşılaştırma operatörleri yer almaktadır.\n\n",
"_____no_output_____"
],
[
"## Değişken Nedir?\nDeğişkenler değerleri depolamak için kullanılır. Böylece daha sonra bu değişkenler program içinden çağırılarak atanan değer tekrar ve tekrar kullanılabilir. Değişkenlere metinler ve / veya sayılar atanabilir. Sayı atamaları direkt rakamların yazılması ile gerçekleştirilirken, metin atamalarında metin tek tırnak içinde ( 'abc' ) ya da çift tırnak ( \"abc\" ) içinde atanır.\n\nDeğişkenler etiketlere benzer ve atama operatörü olarak adlandırılan eşittir ( = ) operatörü ile bir değişkene bir değer atanabilir. Bir değer ataması zincirleme şeklinde gerçekleştirilebilir. Örneğin: a = b = 2",
"_____no_output_____"
],
[
"**Örnek Uygulama 1**\n\nAşağıda bir \"zincir atama\" örneği yer almaktadır. Değer olarak atanan 2 hem \"a\" değişkenine, hem de \"b\" değişkenine atanmaktadır.\n\n```\na = b = 2\nprint(\"a = \" + str(a))\nprint(\"b = \" + str(b))\n```\n\n\"a\" ve \"b\" değişkenleri başka metinler ile birlikte ekrana yazdırılmak istendiğinde metin formatına çevrilmesi gerekmektedir. Bu bağlamda kullanılan \"str(a)\" ve \"str(b)\" ifadeleri eğitimin ilerleyen bölümlerinde anlatılacaktır.",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\na = b = 2\nprint(\"a = \" + str(a))\nprint(\"b = \" + str(b))\n\na = b = 5\nprint(\"a = \" + str(a))\nprint(\"b = \" + str(b))\n",
"a = 2\nb = 2\na = 5\nb = 5\n"
]
],
[
[
"**Örnek Uygulama 2**\n\n\n```\nadSoyad = \"Orçun Madran\"\nprint(\"Adı Soyadı: \" + adSoyad)\n```",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nadSoyad = \"Orçun Madran\"\nprint(\"Adı Soyadı: \" + adSoyad)\n\nAdSoyad = \"Yaren Gözütok\"\nprint(\"Adı Soyadı: \" + AdSoyad)\n",
"Adı Soyadı: Orçun Madran\nAdı Soyadı: Yaren Gözütok\n"
]
],
[
[
"**Görev:** \"eposta\" adlı bir değişken oluşturun. Oluşturduğunuz bu değişkene bir e-posta adresi atayın. Daha sonra atadığınız bu değeri ekrana yazdırın. Örneğin: \"E-posta: orcun[at]madran.net\"",
"_____no_output_____"
]
],
[
[
"# Ekrana e-posta yazdır\nEposta = \"[email protected]\"\nprint(\"E-Posta Adresi: \" + Eposta)",
"E-Posta Adresi: [email protected]\n"
]
],
[
[
"## Değişken Tanımlama\nDeğişken isimlerinde uyulması gereken bir takım kurallar vardır:\n\n\n* Rakam ile başlayamaz.\n* Boşluk kullanılamaz.\n* Alt tire ( _ ) haricinde bir noktalama işareti kullanılamaz.\n* Python içinde yerleşik olarak tanımlanmış anahtar kelimeler kullanılamaz (ör: print).\n* Python 3. sürümden itibaren latin dışı karakter desteği olan \"Unicode\" desteği gelmiştir. Türkçe karakterler değişken isimlerinde kullanılabilir. \n\n**Dikkat:** Değişken isimleri büyük-küçük harfe duyarlıdır. Büyük harfle başlanan isimlendirmeler genelde *sınıflar* için kullanılır. Değişken isimlerinin daha anlaşılır olması için deve notasyonu (camelCase) ya da alt tire kullanımı tavsiye edilir.\n",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n```\ndegisken = 1\nkullaniciAdi = \"orcunmadran\"\nkul_ad = \"rafet\"\n```\n\n",
"_____no_output_____"
],
[
"Henüz tanımlanmamış bir değişken kullanıldığında derleyicinin döndürdüğü hatayı kodu çalıştırarak gözlemleyin!",
"_____no_output_____"
]
],
[
[
"degisken1 = \"Veri\"\nprint(degisken2)\n",
"_____no_output_____"
]
],
[
[
"**Görev:** Tanımladığınız değişkeni ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"degisken3 = 'Yeni veri'\nprint(\"Değişkeni yaz: \" + degisken3)",
"_____no_output_____"
]
],
[
[
"## Değişken Türleri\nPython'da iki ana sayı türü vardır; tam sayılar ve ondalık sayılar.\n\n**Dikkat:** Ondalık sayıların yazımında Türkçe'de *virgül* (,) kullanılmasına rağmen, programlama dillerinin evrensel yazım kuralları içerisinde ondalık sayılar *nokta* (.) ile ifade edilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n```\ntamSayi = 5\nprint(type(tamSayi)) # tamSayi değişkeninin türünü yazdırır\n\nondalikSayi = 7.4\nprint(type(ondalikSayi) # ondalikSayi değişkeninin türünü yazdırır\n```",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ntamSayi = 5\nprint(type(tamSayi))\n\nondalikSayi = 7.4\nprint(type(ondalikSayi))",
"_____no_output_____"
]
],
[
[
"**Görev:** \"sayi\" değişkeninin türünü belirleyerek ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"sayi = 9.0\nprint(type(sayi))\n",
"_____no_output_____"
]
],
[
[
"## Değişken Türü Dönüştürme\nBir veri türünü diğerine dönüştürmenize izin veren birkaç yerleşik fonksiyon (built-in function) vardır. Bu fonksiyonlar (\"int()\", \"str()\", \"float()\") uygulandıkları değişkeni dönüştürerek yeni bir nesne döndürürler. ",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n```\nsayi = 6.5\nprint(type(sayi)) # \"sayi\" değişkeninin türünü ondalık olarak yazdırır\nprint(sayi)\n\nsayi = int(sayi) # Ondalık sayı olan \"sayi\" değişkenini tam sayıya dönüştürür\nprint(type(sayi))\nprint(sayi)\n\nsayi = float(sayi) # Tam sayı olan \"sayi\" değişkenini ondalık sayıya dönüştürür\nprint(type(sayi))\nprint(sayi)\n\nsayi = str(sayi) # \"sayi\" değişkeni artık düz metin halini almıştır\nprint(type(sayi))\nprint(sayi)\n```",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nsayi = 6.5\nprint(type(sayi))\nprint(sayi)\n \nsayi = int(sayi)\nprint(type(sayi))\nprint(sayi)\n \nsayi = float(sayi)\nprint(type(sayi))\nprint(sayi)\n \nsayi = str(sayi)\nprint(type(sayi))\nprint(sayi)\n",
"_____no_output_____"
]
],
[
[
"**Görev:** Ondalık sayıyı tam sayıya dönüştürün ve ekrana değişken türünü ve değeri yazdırın!",
"_____no_output_____"
]
],
[
[
"sayi = 3.14\nprint(type(sayi))\nprint(sayi)\n\nsayi = int(sayi)\nprint(type(sayi))\nprint(sayi)\n\nsayi = float(sayi)\nprint(type(sayi))\nprint(sayi)\n\nsayi= str(sayi)\nprint(type(sayi))\nprint(sayi)",
"_____no_output_____"
],
[
"Değer = input(\"Yaşınızı giriniz\")\nprint(Değer)\nprint(type(Değer))\nprint(2022 - int(Değer))",
"_____no_output_____"
],
[
"#Doğum Yılı Yazdırma Programı\n\nbulunduğumuzyıl = input(\"Bulunduğunuz yılı giriniz\")\nyaş = input(\"Yaşınızı giriniz\")\nprint(int(bulunduğumuzyıl)- int(yaş))",
"_____no_output_____"
],
[
"#Doğum Yılı Yazdırma Programı\n\n#Şimdiki yılı al\nsyil = input(\"İçinde bulunduğunuz yılı giriniz\")\n#Doğum tarihini al\ndtarih = input(\"Doğum tarihinizi giriniz\")\n\n#Dönüştürme işlemleri\nsyil = int(syil)\ndtarih = int(dtarih)\n\n#Yaşı hesapla\nyas = syil - dtarih\n\n#Yaşı ekrana yazdır\nprint(\"Yaşınız: \" + str(yas))\n",
"_____no_output_____"
]
],
[
[
"## Aritmetik Operatörler\nDiğer tüm programlama dillerinde olduğu gibi, toplama (+), çıkarma (-), çarpma (yıldız) ve bölme (/) operatörleri sayılarla kullanılabilir. Bunlarla birlikte Python'un üs (çift yıldız) ve mod (%) operatörleri vardır.\n\n**Dikkat:** Matematik işlemlerinde geçerli olan aritmetik operatörlerin öncelik sıralamaları (çarpma, bölme, toplama, çıkarma) ve parantezlerin önceliği kuralları Python içindeki matematiksel işlemler için de geçerlidir. \n",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n```\n# Toplama işlemi\nsayi = 7.0\nsonuc = sayi + 3.5\nprint(sonuc)\n\n# Çıkarma işlemi\nsayi = 200\nsonuc = sayi - 35\nprint(sonuc)\n\n# Çarpma işlemi\nsayi = 44\nsonuc = sayi * 10\nprint(sonuc)\n\n# Bölme işlemi\nsayi = 30\nsonuc = sayi / 3\nprint(sonuc)\n\n# Üs alma işlemi\nsayi = 30\nsonuc = sayi ** 3\nprint(sonuc)\n\n# Mod alma işlemi \nsayi = 35\nsonuc = sayi % 4\nprint(sonuc)\n```",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\n# Toplama işlemi\nsayi = 7.0\nsonuc = sayi + 3.5\nprint(sonuc)\n \n# Çıkarma işlemi\nsayi = 200\nsonuc = sayi - 35\nprint(sonuc)\n \n# Çarpma işlemi\nsayi = 44\nsonuc = sayi * 10\nprint(sonuc)\n \n# Bölme işlemi\nsayi = 30\nsonuc = sayi / 3\nprint(sonuc)\n \n# Üs alma işlemi\nsayi = 30\nsonuc = sayi ** 3\nprint(sonuc)\n \n# Mod alma işlemi \nsayi = 35\nsonuc = sayi % 4\nprint(sonuc)",
"_____no_output_____"
]
],
[
[
"**Görev:** Aşağıda değer atamaları tamamlanmış olan değişkenleri kullanarak ürünlerin peşin satın alınma bedelini TL olarak hesaplayınız ve ürün adı ile birlikte ekrana yazdırınız! İpucu: Ürün adını ve ürün bedelini tek bir satırda yazdırmak isterseniz ürün bedelini str() fonksiyonu ile düz metin değişken türüne çevirmeniz gerekir. ",
"_____no_output_____"
]
],
[
[
"urunAdi = \"Bisiklet\"\nurunBedeliAvro = 850\nkurAvro = 10\nurunAdet = input(\"Ürün adetini giriniz: \")\npesinAdetIndirimTL = 500\nbutce = 15000\n\nhesapla = ((urunBedeliAvro* int(urunAdet)) * kurAvro) - pesinAdetIndirimTL\nbutceTamam = butce > hesapla\n\nprint(hesapla)\n\nprint(\"Alışveriş bütçeme uygun mu?\" + str(butceTamam))",
"_____no_output_____"
],
[
"#Ürünlerin peşin satın alma bedelini TL olarak hesapla, ürün adı ile ekrana yazdır!\n\nurunAdı = \"Telefon\"\nurunBedeliAvro = 2000\nkurAvro = 15\nurunAdet = input(\"Ürün adetini giriniz: \")\npesinAdetindirimTL = 500\nbutce = 30000\n\nhesapla = ((urunBedeliAvro * int(urunAdet)) * kurAvro) - pesinAdetindirimTL\n\nbutceTamam = butce > hesapla\n\nprint(hesapla)\n\nprint(\"Alışveriş bütçeme uygun mu?\" + str(butceTamam))\n",
"_____no_output_____"
]
],
[
[
"## Artırılmış Atama Operatörleri\nArtırılmış atama, bir değişkenin mevcut değerine belirlenen değerin eklenerek ( += ) ya da çıkartılarak ( -= ) atanması işlemidir. \n",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nsayi = 8\nsayi += 4 # Mevcut değer olan 8'e 4 daha ekler.\nprint(sayi) \n\nsayi -= 6 # Mevcut değer olan 12'den 6 eksiltir.\nprint(\"Sayı = \" + str(sayi))\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama çalıştır\n\nsayi = 8\nsayi += 4\nprint(sayi) \n \nsayi -= 6 \nprint(\"Sayı = \" + str(sayi))",
"_____no_output_____"
]
],
[
[
"**Görev:** Artıtılmış atama operatörleri kullanarak \"sayi\" değişkenine 20 ekleyip, 10 çıkartarak değişkenin güncel değerini ekrana yazdırın! ",
"_____no_output_____"
]
],
[
[
"sayi = 55\nsayi += 20\nprint(sayi)\n\nsayi -= 10\nprint(\"Sayı = \" + str(sayi))",
"_____no_output_____"
]
],
[
[
"## Boolean Operatörleri\nBoolean, yalnızca **Doğru (True)** veya **Yanlış (False)** olabilen bir değer türüdür. Eşitlik (==) operatörleri karşılaştırılan iki değişkenin eşit olup olmadığını kontrol eder ve *True* ya da *False* değeri döndürür.",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n```\ndeger1 = 10\ndeger2 = 10\nesitMi = (deger1 == deger2) # Eşit olup olmadıkları kontrol ediliyor\nprint(esitMi) # Değişken \"True\" olarak dönüyor\n\ndeger1 = \"Python\"\ndeger2 = \"Piton\"\nesitMi = (deger1 == deger2) # Eşit olup olmadıkları kontrol ediliyor\nprint(esitMi) # Değişken \"False\" olarak dönüyor\n```",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama çalıştır\n\ndeger1 = 10\ndeger2 = 10\nesitMi = (deger1 == deger2) \nprint(esitMi) \n \ndeger1 = \"Python\"\ndeger2 = \"Piton\"\nesitMi = (deger1 == deger2)\nprint(esitMi)",
"_____no_output_____"
]
],
[
[
"**Görev:** Atamaları yapılmış olan değişkenler arasındaki eşitliği kontrol edin ve sonucu ekrana yazıdırın!",
"_____no_output_____"
]
],
[
[
"sifre = \"Python2020\"\n\nsifreTekrar = \"Piton2020\"\n\nsifrek = input(\"Şifrenizi giriniz: \")\n\n\nprint(sifrek==sifre)\n\n",
"_____no_output_____"
],
[
"#Kullanıcı adı ve şifre gir\n\nKullanıcıadı = \"yarengozutok\"\nSıfre = \"tavsan23\"\n\nKullanıcıadık = input(\"Kullanıcı adınızı giriniz: \")\nSıfrek = input(\"Şifrenizi giriniz: \")\n\nprint(Kullanıcıadık==Kullanıcıadı)\nprint(Sıfrek==Sıfre)",
"_____no_output_____"
]
],
[
[
"## Karşılaştırma Operatörleri\nPython'da, >=, <= , >, < vb. dahil olmak üzere birçok operatör bulunmaktadır. Python'daki tüm karşılaştırma operatörleri aynı önceliğe sahiptir. Karşılaştırma sonucunda boole değerleri (*True* ya da *False*) döner. Karşılaştırma operatörleri isteğe bağlı olarak arka arkaya da (zincirlenerek) kullanılabilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama:**\n\n```\ndeger1 = 5\ndeger2 = 7\ndeger3 = 9\n\nprint(deger1 < deger2 < deger3) # Sonuç \"True\" olarak dönecektir\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama çalıştır\n\ndeger1 = 5\ndeger2 = 7\ndeger3 = 9\n \nprint(deger1 < deger2 < deger3)",
"_____no_output_____"
]
],
[
[
"**Görev:** Aşağıda değer atamaları tamamlanmış olan değişkenleri kullanarak ürünlerin peşin satın alınma bedelini TL olarak hesaplayın. Toplam satın alma bedeli ile bütçenizi karşılaştırın. Satın alma bedelini ve bütçenizi ekrana yazdırın. Ödeme bütçenizi aşıyorsa ekrana \"False\", aşmıyorsa \"True\" yazdırın. ",
"_____no_output_____"
]
],
[
[
"urunAdi = \"Bisiklet\"\nurunBedeliAvro = 850\nkurAvro = 10\nurunAdet = 3\npesinAdetIndirimTL = 500\nbutce = 20000\n\nhesapla= ((urunBedeliAvro*urunAdet)*kurAvro)- pesinAdetIndirimTL\nbutceTamam = butce > hesapla\nprint(hesapla)\nprint(\"Alışveriş bütçeme uygun mu? \" + str(butceTamam))",
"_____no_output_____"
],
[
"yasLimiti = 13\nyas = int(input( \"Yaşınızı giriniz: \"))\nkontrol = yas >= yasLimiti\n\nprint(\"Youtube yayınlarını izleyebilir: \" + str(kontrol))",
"_____no_output_____"
]
],
[
[
"# Bölüm 03: Metin Katarları\n\nBu bölümde:\n\n* Birbirine bağlama,\n* Metin katarı çarpımı,\n* Metin katarı dizinleme,\n* Metin katarı negatif dizinleme,\n* Metin katarı dilimleme,\n* In operatörü,\n* Metin katarının uzunluğu,\n* Özel karakterlerden kaçma,\n* Basit metin katarı metodları,\n* Metin katarı biçimlendirme yer almaktadır.",
"_____no_output_____"
],
[
"## Birbirine Bağlama\nBirbirine bağlama artı (+) işlemini kullanarak iki metin katarının birleştirilmesi işlemine denir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndeger1 = \"Merhaba\"\ndeger2 = \"Dünya\"\n\nselamlama = deger1 + \" \" + deger2\nprint(selamlama) # Çıktı: Merhaba Dünya\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalışıtır\n\ndeger1 = \"Merhaba\"\ndeger2 = \"Dünya\"\n\nselamlama = deger1 + \" \" + deger2\nprint(selamlama)",
"_____no_output_____"
]
],
[
[
"**Görev:** *ad*, *soyad* ve *hitap* değişkenlerini tek bir çıktıda birleştirecek kodu yazın! ",
"_____no_output_____"
]
],
[
[
"hitap = \"Öğr. Gör.\"\nad = \"Orçun\"\nsoyad = \"Madran\"\n\nçıktı = hitap + ad + soyad\nprint(çıktı)\n\n# Çıktı: Öğr. Gör. Orçun Madran",
"_____no_output_____"
]
],
[
[
"## Metin Katarı Çarpımı\nPython, metin katarlarının çarpım sayısı kadar tekrar ettirilmesini desteklemektedir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Hadi! \"\nmetniCarp = metin * 4\nprint(metniCarp) # Çıktı: Hadi! Hadi! Hadi! Hadi! \n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nmetin = \"Hadi! \"\nmetniCarp = metin * 4\nprint(metniCarp)",
"_____no_output_____"
]
],
[
[
"**Görev:** Sizi sürekli bekleten arkadaşınızı uyarabilmek için istediğiniz sayıda \"Hadi!\" kelimesini ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"metin = \"Hadi! \"\nmetniCarp = metin*4\nprint(metniCarp)\n\n# Çıktı: Hadi! Hadi! Hadi! Hadi! ... Hadi!",
"_____no_output_____"
]
],
[
[
"##Metin Katarı Dizinleme\nKonumu biliniyorsa, bir metin katarındaki ilgili karaktere erişilebilir. Örneğin; str[index] metin katarındaki indeks numarasının karşılık geldiği karakteri geri döndürecektir. İndekslerin her zaman 0'dan başladığı unutulmamalıdır. İndeksler, sağdan saymaya başlamak için negatif sayılar da olabilir. -0, 0 ile aynı olduğundan, negatif indeksler -1 ile başlar.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python Programlama Dili\"\nprint(\"'h' harfini yakala: \" + metin[3]) # Çıktı: 'h' harfini yakala: h\"\n```\n",
"_____no_output_____"
]
],
[
[
"# örnek uygulama çalıştır\n\nmetin = \"Python Programlama Dili\"\nprint(\"'h'harfini yakala: \" + metin[3])",
"'h'harfini yakala: h\n"
]
],
[
[
"**Görev:** İndeks numarasını kullanarak metin katarındaki ikinci \"P\" harfini ekrana yazdırın!\n",
"_____no_output_____"
]
],
[
[
"\n#Çıktı = P\n\nmetin =\"Python Programlama Dili\"\nprint(metin[0])\n\n\n\n\n\n\n",
"P\n"
]
],
[
[
"## Metin Katarı Negatif Dizinleme\nMetin katarının sonlarında yer alan bir karaktere daha rahat erişebilmek için indeks numarası negatif bir değer olarak belirlenebilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python Programlama Dili\"\ndHarfi = metin[-4]\nprint(dHarfi) # Çıktı: D\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama çalıştır\n\nmetin = \"Python Programlama Dili\"\ndHarfi = metin[-4]\nprint(dHarfi)",
"D\n"
]
],
[
[
"**Görev:** Metin katarının sonunda yer alan \"i\" harfini ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"metin = \"Python Programlama Dili\"\nprint(metin[-1])\n#Çıktı: i",
"i\n"
]
],
[
[
"##Metin Katarı Dilimleme\nDilimleme, bir metin katarından birden çok karakter (bir alt katar oluşturmak) almak için kullanılır. Söz dizimi indeks numarası ile bir karaktere erişmeye benzer, ancak iki nokta üst üste işaretiyle ayrılmış iki indeks numarası kullanılır. Ör: str[ind1:ind2].\n\nNoktalı virgülün solundaki indeks numarası belirlenmezse ilk karakterden itibaren (ilk karakter dahil) seçimin yapılacağı anlamına gelir. Ör: str[:ind2]\n\nNoktalı virgülün sağındaki indeks numarası belirlenmezse son karaktere kadar (son karakter dahil) seçimin yapılacağı anlamına gelir. Ör: str[ind1:]",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python Programlama Dili\"\ndilimle = metin[:6] \nprint(dilimle) # Çıktı: Python\n\nmetin = \"Python Programlama Dili\" \nprint(metin[7:]) # Çıktı: Programlama Dili\n\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama çalıştır\n\nmetin = \"Python Programlama Dili\"\ndilimle = metin[:6] \nprint(dilimle)\n\nmetin = \"Python Programlama Dili\" \nprint(metin[7:])",
"Python\nProgramlama Dili\n"
]
],
[
[
"**Görev:** Metin katarını dilemleyerek katarda yer alan üç kelimeyi de ayrı ayrı (alt alta) ekrana yazdırın!.",
"_____no_output_____"
]
],
[
[
"# Çıktı:\n# Python\n# Programlama\n# Dili\n\nmetin = \"Python Programlama Dili\" \ndilimle = metin[:6]\nprint(dilimle)\n\nmetin = \"Python Programlama Dili\"\nprint(metin[7:])\n\nmetin2 = \"Python Programlama Dili\"\ndilimle2 = metin2[7:18]\nprint(dilimle2)\n",
"Python\nProgramlama Dili\nProgramlama\n"
],
[
"haber= \"But I must explain to you how all this mistaken idea of denouncing pleasure and praising pain was born and I will give you a complete account of the system\"\nprint(haber)\nozet = haber[:40] + \" devamı için tıklayınız...\"\nprint(ozet)",
"But I must explain to you how all this mistaken idea of denouncing pleasure and praising pain was born and I will give you a complete account of the system\nBut I must explain to you how all this m devamı için tıklayınız...\n"
],
[
"haber = \"But I must explain to you how all this mistaken idea of denouncing pleasure praising pain was born\"\nbaslangic = haber[:20]\nbitis = haber[-20:]\nprint(baslangic + \".......\" + bitis)",
"_____no_output_____"
]
],
[
[
"##In Operatörü\nBir metin katarının belirli bir harf ya da bir alt katar içerip içermediğini kontrol etmek için, in anahtar sözcüğü kullanılır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python Programlama Dili\"\nprint(\"Programlama\" in metin) # Çıktı: True\n```\n\n",
"_____no_output_____"
],
[
"**Görev:** Metin katarında \"Python\" kelimesinin geçip geçmediğini kontrol ederek ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"metin = \"Python Programlama Dili\"\narama = input(\"Arama yapılacak kelimeyi giriniz: \")\nsonuç = arama in metin\nprint(\"Aradığınız kelime var: \" + str(sonuç))\n",
"Arama yapılacak kelimeyi giriniz: p\nAradığınız kelime var: False\n"
]
],
[
[
"##Metin Katarının Uzunluğu\nBir metin katarının kaç karakter içerdiğini saymak için len() yerleşik fonksiyonu kullanılır. ",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python programlama dili\"\nprint(len(metin)) # Çıktı: 23\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nmetin = \"Python programlama dili\"\nprint(len(metin)) ",
"23\n"
],
[
"# 1-Bir girdiye > klavyeden\n# 2-Klavyeden girilen bilginin uzunluğunu hesapla\n# 3-Uzunluğu limit ile karşılaştır\n# 4-Sonucu ekrana yaz\n\n#Klavyeden girilen metnin 20 karakterden küçük ise false mesajı veren kod.\n\ngirilen = input(\"Metin giriniz: \")\nprint(girilen)\n\ngirilenKarakter = len(girilen)\nprint(girilenKarakter)\n\nkontrol = girilenKarakter > 10\nprint(kontrol)",
"_____no_output_____"
]
],
[
[
"**Görev:** Metin katarındaki cümlenin ilk yarısını ekrana yazdırın! Yazılan kod cümlenin uzunluğundan bağımsız olarak cümleyi ikiye bölmelidir.",
"_____no_output_____"
]
],
[
[
"metin = \"Python programlama dili, dünyada eğitim amacıyla en çok kullanılan programlama dillerinin başında gelir.\"\n\nprint(metin[:52])\n\n#yarısı = len(metin)/2\n\n#print(yarısı)\n\n\n\n\n\n# Çıktı: Python programlama dili, dünyada eğitim amacıyla en",
"Python programlama dili, dünyada eğitim amacıyla en \n"
]
],
[
[
"## Özel Karakterlerden Kaçma\nMetin katarları içerisinde tek ve çift tırnak kullanımı kimi zaman sorunlara yol açmaktadır. Bu karakterin metin katarları içerisinde kullanılabilmesi için \"Ters Eğik Çizgi\" ile birlikte kullanılırlar. \n\nÖrneğin: 'Önümüzdeki ay \"Ankara'da Python Eğitimi\" gerçekleştirilecek' cümlesindeki tek tırnak kullanımı soruna yol açacağından 'Önümüzdeki ay \"Ankara\\'da Python Eğitimi\" gerçekleştirilecek' şeklinde kullanılmalıdır.\n\n**İpucu:** Tek tırnaklı metin katarlarından kaçmak için çift tırnak ya da tam tersi kullanılabilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = 'Önümüzdeki ay \"Ankara\\'da Python Eğitimi\" gerçekleştirilecektir.'\nprint(metin) #Çıktı: Önümüzdeki ay \"Ankara'da Python Eğitimi\" gerçekleştirilecektir.\n\nmetin = 'Önümüzdeki ay \"Ankara'da Python Eğitimi\" gerçekleştirilecektir.'\nprint(metin) # Çıktı: Geçersiz söz dizimi hatası dönecektir. \n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nmetin = 'Önümüzdeki ay \"Ankara\\'da Python Eğitimi\" gerçekleştirilecektir.'\nprint(metin)",
"Önümüzdeki ay \"Ankara'da Python Eğitimi\" gerçekleştirilecektir.\n"
],
[
"# Örnek uygulamadaki hatayı gözlemle\n\nmetin = 'Önümüzdeki ay \"Ankara'da Python Eğitimi\" gerçekleştirilecektir.'\nprint(metin)",
"_____no_output_____"
]
],
[
[
"**Görev:** Metin katarındaki cümlede yer alan noktalama işaretlerinden uygun şekilde kaçarak cümleyi ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"metin = \"Bilimsel çalışmalarda 'Python' kullanımı Türkiye'de çok yaygınlaştı!\"\nprint(metin)",
"Bilimsel çalışmalarda 'Python' kullanımı Türkiye'de çok yaygınlaştı!\n"
]
],
[
[
"##Basit Metin Katarı Metodları\nPython içinde birçok yerleşik metin katarı fonksiyonu vardır. En çok kullanılan fonksiyonlardan bazıları olarak;\n\n* tüm harfleri büyük harfe dönüştüren *upper()*,\n* tüm harfleri küçük harfe dönüştüren *lower()*,\n* sadece cümlenin ilk harfini büyük hale getiren *capitalize()* sayılabilir.\n\n**İpucu:** Python'daki yerleşik fonksiyonların bir listesini görüntüleyebilmek için metin katarından sonra bir nokta (.) koyulur ve uygun olan fonksiyonlar arayüz tarafından otomatik olarak listelenir. Bu yardımcı işlevi tetiklemek için CTRL + Bolşuk tuş kombinasyonu da kullanılabilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nmetin = \"Python Programlama Dili\"\nprint(metin.lower()) # Çıktı: python programlama dili\nprint(metin.upper()) # Çıktı: PYTHON PROGRAMLAMA DILI\nprint(metin.capitalize()) # Çıktı: Python programlama dili\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nmetin = \"Python Programlama Dili\"\nprint(metin.lower())\nprint(metin.upper())\nprint(metin.capitalize())",
"python programlama dili\nPYTHON PROGRAMLAMA DILI\nPython programlama dili\n"
]
],
[
[
"**Görev:** *anahtarKelime* ve *arananKelime* değişkenlerinde yer alan metinler karşılaştırıldığında birbirlerine eşit (==) olmalarını sağlayın ve dönen değerin \"True\" olmasını sağlayın!",
"_____no_output_____"
]
],
[
[
"anahtarKelime = \"Makine Öğrenmesi\"\narananKelime = \"makine öğrenmesi\"\n\nprint(anahtarKelime.lower() == arananKelime) # Çıktı: True\nprint(anahtarKelime.lower())",
"True\nmakine öğrenmesi\n"
]
],
[
[
"##Metin Katarı Biçimlendirme\nBir metin katarından sonraki % operatörü, bir metin katarını değişkenlerle birleştirmek için kullanılır. % operatörü, bir metin katarıdanki % s öğesini, arkasından gelen değişkenle değiştirir. % d sembolü ise, sayısal veya ondalık değerler için yer tutucu olarak kullanılır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nadsoyad = \"Orçun Madran\"\ndogumTarihi = 1976\n\nprint(\"Merhaba, ben %s!\" % adsoyad) # Çıktı: Merhaba, ben Orçun Madran!\nprint(\"Ben %d doğumluyum\" % dogumTarihi) # Ben 1976 doğumluyum.\n\nad = \"Orçun\"\nsoyad = \"Madran\"\n\nprint(\"Merhaba, ben %s %s!\" % (ad, soyad)) # Çıktı: Merhaba, ben Orçun Madran!\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nadsoyad = \"Orçun Madran\"\ndogumTarihi = 1976\n\nprint(\"Merhaba, ben %s!\" % adsoyad)\nprint(\"Ben %d doğumluyum\" % dogumTarihi)",
"Merhaba, ben Orçun Madran!\nBen 1976 doğumluyum\n"
],
[
"# Örnek uygulamayı çalıştır\n\nad = \"Orçun\"\nsoyad = \"Madran\"\n\nprint(\"Merhaba, ben %s %s!\" % (ad, soyad))",
"Merhaba, ben Orçun Madran!\n"
]
],
[
[
"**Görev:** \"Merhaba Orçun Madran, bu dönemki dersiniz 'Programlama Dilleri'. Başarılar!\" cümlesini ekrana biçimlendirmeyi kullanarak (artı işaretini kullanmadan) yazdırın!",
"_____no_output_____"
]
],
[
[
"ad = \"Orçun\"\nsoyad = \"Madran\"\nders = \"Programlama Dilleri\"\nprint(\"Merhaba ben %s %s, bu dönemki dersiniz '%s'.Başarılar!\" % (ad, soyad, ders))\n\n# Çıktı: Merhaba Orçun Madran, bu dönemki dersiniz \"Programlama Dilleri\". Başarılar!",
"Merhaba ben Orçun Madran, bu dönemki dersiniz 'Programlama Dilleri'.Başarılar!\n"
]
],
[
[
"21 ŞUBAT 2022 PAZARTESİ (Buraya kadar geldik.)\n \n---\n\n",
"_____no_output_____"
]
],
[
[
"ad = \"Yaren\"\nsoyad = \"Gozutok\"\nders = \"Python\"\nprint(\"Merhaba ben %s %s, bu dönemki dersim '%s' . Başarılı olacağım!\" % (ad, soyad, ders))",
"Merhaba ben Yaren Gozutok, bu dönemki dersim 'Python' . Başarılı olacağım!\n"
]
],
[
[
"# Bölüm 04: Veri Yapılar\n\nBu bölümde:\n\n* Listeler,\n* Liste işlemleri,\n* Liste öğeleri,\n* Demetler (Tuples),\n* Sözlükler,\n* Sözlük değerleri ve anahtarları,\n* In anahtar kelimesinin kullanımı yer almaktadır.\n",
"_____no_output_____"
],
[
"## Listeler\nListe, birden fazla değeri tek bir değişken adı altında saklamak için kullanabileceğiniz bir veri yapısıdır. Bir liste köşeli parantez arasında virgülle ayrılmış değerler dizisi olarak yazılır. Ör: liste = [deger1, deger2].\n\nListeler farklı türden öğeler içerebilir, ancak genellikle listedeki tüm öğeler aynı türdedir. Metin katarları gibi listeler de dizine eklenebilir ve dilimlenebilir. (Bkz. Bölüm 3).",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"] # acikListe adında yeni bir liste oluşturur\n\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak']\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"]\nprint(acikListe)",
"_____no_output_____"
]
],
[
[
"**Görev 1:** acikListe içinde yer alan 3. liste öğesini ekrana yazıdırın! ",
"_____no_output_____"
]
],
[
[
"acikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"]\nprint(acikListe[2])\n",
"Açık Veri\n"
]
],
[
[
"**Görev 2:** acikListe içinde yer alan 4. ve 5. liste öğesini ekrana yazıdırın! ",
"_____no_output_____"
]
],
[
[
"acikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"]\nprint(acikListe[3:5])",
"['Açık Eğitim', 'Açık Kaynak']\n"
]
],
[
[
"## Liste İşlemleri\nappend() fonksiyonunu kullanarak ya da artırılmış atama operatörü ( += ) yardımıyla listenin sonuna yeni öğeler (değerler) eklenebilir. Listelerin içindeki öğeler güncellenebilir, yani liste[indeksNo] = yeni_deger kullanarak içeriklerini değiştirmek mümkündür.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"] # acikListe adında yeni bir liste oluşturur\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak']\n\nacikListe += [\"Açık Donanım\", \"Açık İnovasyon\"] # listeye iki yeni öğe ekler\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak', 'Açık Donanım', 'Açık İnovasyon']\n\nacikListe.append(\"Açık Veri Gazeteciliği\") # listeye yeni bir öğe ekler\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak', 'Açık Donanım', 'Açık İnovasyon', 'Açık Veri Gazeteciliği']\n\nacikListe[4] = \"Açık Kaynak Kod\" # listenin 5. öğesini değiştirir\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak Kod', 'Açık Donanım', 'Açık İnovasyon', 'Açık Veri Gazeteciliği']\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"]\nprint(acikListe)\n \nacikListe += [\"Açık Donanım\", \"Açık İnovasyon\"] \nprint(acikListe)\n \nacikListe.append(\"Açık Veri Gazeteciliği\")\nprint(acikListe)\n \nacikListe[4] = \"Açık Kaynak Kod\"\nprint(acikListe)",
"['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak']\n['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak', 'Açık Donanım', 'Açık İnovasyon']\n['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak', 'Açık Donanım', 'Açık İnovasyon', 'Açık Veri Gazeteciliği']\n['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak Kod', 'Açık Donanım', 'Açık İnovasyon', 'Açık Veri Gazeteciliği']\n"
],
[
"#Arkadaş Listesi\n\nListe = [\"Yaren\"]\nprint(Liste)\n\nyeni = input(\"Arkadaşının adı: \")\nListe.append(yeni)\n\nyeni = input(\"Arkadaşının adı: \")\nListe.append(yeni)\n\nprint(Liste)",
"['Yaren']\nArkadaşının adı: Bayezıt\nArkadaşının adı: Esin\n['Yaren', 'Bayezıt', 'Esin']\n"
],
[
"#Arkadaş Listesi\n\nliste = [\"Yaren Gozutok\"]\nad = input(\"Adınızı giriniz: \")\nsoyad = input(\"Soyadınızı giriniz: \")\nadsoyad = ad + \" \" + soyad\nliste.append(adsoyad)\nprint(liste)\nliste[0]= \"Yeni Arkadaş\"\n\nprint(liste)",
"Adınızı giriniz: Bayezıt\nSoyadınızı giriniz: Uyanır\n['Yaren Gozutok', 'Bayezıt Uyanır']\n['Yeni Arkadaş', 'Bayezıt Uyanır']\n"
]
],
[
[
"**Görev:** bilgiBilim adlı bir liste oluşturun. Bu listeye bilgi bilim disiplini ile ilgili 3 adet anahtar kelime ya da kavram ekleyin. Bu listeyi ekrana yazdırın. Listeye istediğiniz bir yöntem ile (append(), +=) 2 yeni öğe ekleyin. Ekrana listenin son durumunu yazdırın. Listenizdeki son öğeyi değiştirin. Listenin son halini ekrana yazıdırn.",
"_____no_output_____"
]
],
[
[
"#bilgiBilim\n\nliste = [\"Açık Erişim\", \"Açık Kaynak\", \"Açık Veri\"]\nprint(liste)\n\nyeni = input(\"Eklemek istediğiniz kelimeyi girin: \")\nliste.append(yeni)\n\nyeni = input(\"Eklemek istediğiniz kelimeyi girin: \")\nliste.append(yeni)\n\nprint(liste)",
"['Açık Erişim', 'Açık Kaynak', 'Açık Veri']\nEklemek istediğiniz kelimeyi girin: Kamu malı\nEklemek istediğiniz kelimeyi girin: açık lisans\n['Açık Erişim', 'Açık Kaynak', 'Açık Veri', 'Kamu malı', 'açık lisans']\n"
]
],
[
[
"## Liste Öğeleri",
"_____no_output_____"
],
[
"Liste öğelerini dilimleme (slice) yaparak da atamak mümkündür. Bu bir listenin boyutunu değiştirebilir veya listeyi tamamen temizleyebilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"] # acikListe adında yeni bir liste oluşturur\nprint(acikListe) # Çıktı: ['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak']\n\nacikListe[2:4] = [\"Açık İnovasyon\"] # \"Açık Veri\" ve \"Açık Eğitim\" öğelerinin yerine tek bir öğe ekler\nprint(acikListe) #Çıktı: [\"Açık Bilim\", \"Açık Erişim\", \"Açık İnovasyon\", \"Açık Kaynak\"]\n\nacikListe[:2] = [] # listenin ilk iki öğesini siler\nprint(acikListe) #Çıktı: [\"Açık İnovasyon\", \"Açık Kaynak\"]\n\nacikListe[:] = [] # listeyi temizler \nprint(acikListe) #Çıktı: []\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nacikListe = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Eğitim\", \"Açık Kaynak\"]\nprint(acikListe)\n\nacikListe[2:4] = [\"Açık İnovasyon\"]\nprint(acikListe)\n\nacikListe[:2] = []\nprint(acikListe)\n\nacikListe[:] = []\nprint(acikListe)",
"['Açık Bilim', 'Açık Erişim', 'Açık Veri', 'Açık Eğitim', 'Açık Kaynak']\n['Açık Bilim', 'Açık Erişim', 'Açık İnovasyon', 'Açık Kaynak']\n['Açık İnovasyon', 'Açık Kaynak']\n[]\n"
]
],
[
[
"**Görev:** Önceki görevde oluşturulan \"bilgiBilim\" adlı listenin istediğiniz öğesini silerek listenin güncel halini ekrana yazdırın. Listeyi tamamen temizleyerek listenin güncel halini ekrana yazdırın.",
"_____no_output_____"
]
],
[
[
"#bilgiBilim\nliste = [\"Açık Erişim\", \"Açık Kaynak\", \"Açık Veri\", \"Açık Lisans\", \"Kamu Malı\"]\nprint(liste)\n\nliste [2:4] = [\"Açık İnovasyon\"]\nprint(liste)\n\nliste [:2] = []\nprint(liste)\n\nliste[:] = []\nprint(liste)",
"['Açık Erişim', 'Açık Kaynak', 'Açık Veri', 'Açık Lisans', 'Kamu Malı']\n['Açık Erişim', 'Açık Kaynak', 'Açık İnovasyon', 'Kamu Malı']\n['Açık İnovasyon', 'Kamu Malı']\n[]\n"
]
],
[
[
"## Demetler (Tuples)",
"_____no_output_____"
],
[
"Demetler neredeyse listelerle aynı. Demetler ve listeler arasındaki tek önemli fark, demetlerin değiştirilememesidir. Demetlere öğe eklenmez, öğe değiştirilmez veya demetlerden öğe silinemez. Demetler, parantez içine alınmış bir virgül operatörü tarafından oluşturulur. Ör: demet = (\"deger1\", \"deger2\", \"deger3\"). Tek bir öğe demetinde (\"d\",) gibi bir virgül olmalıdır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nulkeKodlari = (\"TR\", \"US\", \"EN\", \"JP\")\nprint(ulkeKodlari) # Çıktı: ('TR', 'US', 'EN', 'JP')\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nulkeKodlari = (\"TR\", \"US\", \"EN\", \"JP\")\nprint(ulkeKodlari)",
"_____no_output_____"
]
],
[
[
"**Görev:** Kongre Kütüphanesi konu başlıkları listesinin kodlarından oluşan bir demet oluşturun ve ekrana yazdırın! Oluşturulan demet içindeki tek bir öğeyi ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"#konuBasliklari\nbaslıkkodları = (\"CB\", \"CC\", \"CT\")\nprint(baslıkkodları)\n\n\nprint(baslıkkodları[2])\n",
"('CB', 'CC', 'CT')\nCT\n"
]
],
[
[
"## Sözlükler\nSözlük, listeye benzer, ancak sözlük içindeki değerlere indeks numarası yerine bir anahtara ile erişilebilir. Bir anahtar herhangi bir metin katarı veya rakam olabilir. Sözlükler ayraç içine alınır. Ör: sozluk = {'anahtar1': \"değer1\", 'anahtar2': \"değer2\"}.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nadresDefteri = {\"Hacettepe Üniversitesi\": \"hacettepe.edu.tr\", \"ODTÜ\": \"odtu.edu.tr\", \"Bilkent Üniversitesi\": \"bilkent.edu.tr\"} # yeni bir sözlük oluşturur\nprint(adresDefteri) # Çıktı: {'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\n\nadresDefteri[\"Ankara Üniversitesi\"] = \"ankara.edu.tr\" #sözlüğe yeni bir öğe ekler\nprint(adresDefteri) # Çıktı: {'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr', 'Ankara Üniversitesi': 'ankara.edu.tr'}\n\ndel adresDefteri [\"Ankara Üniversitesi\"] #sözlükten belirtilen öğeyi siler\nprint(adresDefteri) # Çıktı: {'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nadresDefteri = {\"Hacettepe Üniversitesi\": \"hacettepe.edu.tr\", \"ODTÜ\": \"odtu.edu.tr\", \"Bilkent Üniversitesi\": \"bilkent.edu.tr\"}\nprint(adresDefteri)\n\nadresDefteri[\"Ankara Üniversitesi\"] = \"ankara.edu.tr\"\nprint(adresDefteri)\n\ndel adresDefteri [\"Ankara Üniversitesi\"]\nprint(adresDefteri)",
"{'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\n{'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr', 'Ankara Üniversitesi': 'ankara.edu.tr'}\n{'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\n"
]
],
[
[
"**Görev:** İstediğin herhangi bir konuda 5 öğeye sahip bir sözlük oluştur. Sözlüğü ekrana yazdır. Sözlükteki belirli bir öğeyi ekrana yazdır. Sözlükteki belirli bir öğeyi silerek sözlüğün güncel halini ekrana yazdır!",
"_____no_output_____"
]
],
[
[
"#Bilim Sözlüğü\n\nsozluk = {\"Açık Erişim\": \"Kamu Kaynakları...\" , \"Açık Veri\": \"Açık olarak...\"}\nprint(sozluk)\n\nsozluk[\"Açık İnovasyon\"] = \"Aİ.......\"\nprint(sozluk)\n\ndel sozluk[\"Açık Erişim\"]\nprint(sozluk)\nsozluk[\"Açık İnovasyon\"] = \"Aİ22.......\"\nprint(sozluk)\n\nprint(sozluk[\"Açık Veri\"])\n\n",
"{'Açık Erişim': 'Kamu Kaynakları...', 'Açık Veri': 'Açık olarak...'}\n{'Açık Erişim': 'Kamu Kaynakları...', 'Açık Veri': 'Açık olarak...', 'Açık İnovasyon': 'Aİ.......'}\n{'Açık Veri': 'Açık olarak...', 'Açık İnovasyon': 'Aİ.......'}\n{'Açık Veri': 'Açık olarak...', 'Açık İnovasyon': 'Aİ22.......'}\nAçık olarak...\n"
]
],
[
[
"## Sözlük Değerleri ve Anahtarları\nSözlüklerde values() ve keys() gibi birçok yararlı fonksiyon vardır. Bir sozlük adı ve ardından noktadan sonra çıkan listeyi kullanarak geri kalan fonksiyolar incelenebilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nadresDefteri = {\"Hacettepe Üniversitesi\": \"hacettepe.edu.tr\", \"ODTÜ\": \"odtu.edu.tr\", \"Bilkent Üniversitesi\": \"bilkent.edu.tr\"} # yeni bir sözlük oluşturur\nprint(adresDefteri) # Çıktı: {'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\n\nprint(adresDefteri.values()) # Çıktı: dict_values(['hacettepe.edu.tr', 'odtu.edu.tr', 'bilkent.edu.tr'])\n\nprint(adresDefteri.keys()) # Çıktı: dict_keys(['Hacettepe Üniversitesi', 'ODTÜ', 'Bilkent Üniversitesi'])\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nadresDefteri = {\"Hacettepe Üniversitesi\": \"hacettepe.edu.tr\", \"ODTÜ\": \"odtu.edu.tr\", \"Bilkent Üniversitesi\": \"bilkent.edu.tr\"}\nprint(adresDefteri)\n\nprint(adresDefteri.values())\n\nprint(adresDefteri.keys())",
"{'Hacettepe Üniversitesi': 'hacettepe.edu.tr', 'ODTÜ': 'odtu.edu.tr', 'Bilkent Üniversitesi': 'bilkent.edu.tr'}\ndict_values(['hacettepe.edu.tr', 'odtu.edu.tr', 'bilkent.edu.tr'])\ndict_keys(['Hacettepe Üniversitesi', 'ODTÜ', 'Bilkent Üniversitesi'])\n"
]
],
[
[
"**Görev:** İstediğin bir konuda istediğin öğe saysına sahip bir sözlük oluştur. Sözlükler ile ilgili farklı fonksiyoları dene. Sonuçları ekrana yazdır!",
"_____no_output_____"
]
],
[
[
"#yeniSozluk\n\nsozluk = {\"Açık Erişim\" : \"Kamu kaynakları...\", \"Açık Veri\": \"Açık verilere erişim...\"}\nprint(sozluk)\n\nprint(sozluk.values())\n\nprint(sozluk.keys())\n\n",
"{'Açık Erişim': 'Kamu kaynakları...', 'Açık Veri': 'Açık verilere erişim...'}\ndict_values(['Kamu kaynakları...', 'Açık verilere erişim...'])\ndict_keys(['Açık Erişim', 'Açık Veri'])\n"
]
],
[
[
"##In Anahtar Kelimesi\n\"In\" anahtar sözcüğü, bir listenin veya sözlüğün belirli bir öğe içerip içermediğini kontrol etmek için kullanılır. Daha önce metin katarlarındaki kullanıma benzer bir kullanımı vardır. \"In\" anahtar sözcüğü ile öğe kontrolü yapıldıktan sonra sonuç, öğe listede ya da sözlükte yer alıyorsa *True* yer almıyorsa *False* olarak geri döner.\n\n**Dikkat**: Aranan öğe ile liste ya da sözlük içinde yer alan öğelerin karşılaştırılması sırasında büyük-küçük harf duyarlılığı bulunmaktadır. Ör: \"Bilgi\" ve \"bilgi\" iki farklı öğe olarak değerlendirilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nbilgiKavramları = [\"indeks\", \"erişim\", \"koleksiyon\"] # yeni bir liste oluşturur\nprint(\"Erişim\" in bilgiKavramları) # Çıktı: False\n\nbilgiSozlugu = {\"indeks\": \"index\", \"erişim\": \"access\", \"koleksiyon\": \"collection\"} # yeni bir sozluk oluşturur\nprint(\"koleksiyon\" in bilgiSozlugu.keys()) # çıktı: True\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nbilgiKavramları = [\"indeks\", \"erişim\", \"koleksiyon\"]\nprint(\"Erişim\" in bilgiKavramları)\n\nbilgiSozlugu = {\"indeks\": \"index\", \"erişim\": \"access\", \"koleksiyon\": \"collection\"}\nprint(\"koleksiyon\" in bilgiSozlugu.keys())",
"False\nTrue\n"
]
],
[
[
"**Görev:** Bir liste ve bir sözlük oluşturun. Liste içinde istediğiniz kelimeyi aratın ve sonucunu ekrana yazdırın! Oluşturduğunuz sözlüğün içinde hem anahtar kelime (keys()) hem de değer (values()) kontrolü yaptırın ve sonucunu ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"#yeniListe\ndersler = [\"Bilgi Erişim\", \"Bilgi Hizmetleri\", \"Bilginin Düzenlenmesi\"]\nprint(\"Bilgi Hizmetleri\" in dersler)\n\n#yeniSozluk\nderssozlugu = {\"Bilgi Erişim\":\"Bilgiye kolay eriştirme...\", \"Bilginin Düzenlenmesi\": \"AACR ve Marc...\"}\nprint(derssozlugu.values())\nprint(derssozlugu.keys())\n",
"True\ndict_values(['Bilgiye kolay eriştirme...', 'AACR ve Marc...'])\ndict_keys(['Bilgi Erişim', 'Bilginin Düzenlenmesi'])\n"
]
],
[
[
"#Bölüm 05: Koşullu İfadeler\n\nBu bölümde:\n\n* Mantıksal operatörler,\n* If cümleciği,\n* Else ve elif kullanımı yer almatadır.",
"_____no_output_____"
],
[
"##Mantıksal Operatörler\nMantıksal operatörler ifadeleri karşılaştırır ve sonuçları *True* ya da *False* değerleriyle döndürür. Python'da üç tane mantıksal operatör bulunur:\n\n1. \"and\" operatörü: Her iki yanındaki ifadeler doğru olduğunda *True* değerini döndürür.\n2. \"or\" operatörü: Her iki tarafındaki ifadelerden en az bir ifade doğru olduğunda \"True\" değerini döndürür.\n3. \"not\" operatörü: İfadenin tam tersi olarak değerlendirilmesini sağlar.\n",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nkullaniciAdi = \"orcunmadran\"\nsifre = 123456\nprint(kullaniciAdi == \"orcunmadran\" and sifre == 123456) # Çıktı: True\n\nkullaniciAdi = \"orcunmadran\"\nsifre = 123456\nprint(kullaniciAdi == \"orcunmadran\" and not sifre == 123456) # Çıktı: False\n\ncepTel = \"05321234567\"\nePosta = \"[email protected]\"\nprint(cepTel == \"\" or ePosta == \"[email protected]\" ) # Çıktı: True\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nkullaniciAdi = \"orcunmadran\"\nsifre = 123456\nprint(kullaniciAdi == \"orcunmadran\" and sifre == 123456)\n\nkullaniciAdi = \"orcunmadran\"\nsifre = 123456\nprint(kullaniciAdi == \"orcunmadran\" and not sifre == 123456)\n\ncepTel = \"05321234567\"\nePosta = \"[email protected]\"\nprint(cepTel == \"\" or ePosta == \"[email protected]\" )",
"True\nFalse\nTrue\n"
]
],
[
[
"**Görev:** Klavyeden girilen kullanıcı adı ve şifrenin kayıtlı bulunan kullanıcı adı ve şifre ile uyuşup uyuşmadığını kontrol edin ve sonucu ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"#Sistemde yer alan bilgiler:\nsisKulAdi = \"yonetici\"\nsisKulSifre = \"bby162\"\n\n#Klavyeden girilen bilgiler:\ngirKulAdi = input(\"Kullanıcı Adı: \")\ngirKulSifre = input(\"Şifre: \")\n\n#Kontrol\nsonuc = sisKulAdi == girKulAdi and sisKulSifre == girKulSifre\n\n#Sonuç\nprint(sonuc)",
"Kullanıcı Adı: yonetici\nŞifre: bby162\nTrue\n"
],
[
"kuladı = \"yaren\"\nkulsifre = \"12345\"\n\ngirkuladı = input(\"Kullanıcı Adı: \")\ngirkulsifre = input(\"Şifre: \")\n\nsonuc = kuladı == girkuladı and kulsifre == girkulsifre\n\nprint(sonuc)",
"Kullanıcı Adı: yaren\nŞifre: 12345\nTrue\n"
]
],
[
[
"Birden fazla koşulu and ile birleştirebiliyoruz\n",
"_____no_output_____"
],
[
"28 ŞUBAT 2022 PAZARTESİ (Buraya kadar geldik.)\n",
"_____no_output_____"
],
[
"## If Cümleciği\n\"If\" anahtar sözcüğü, verilen ifadenin doğru olup olmadığını kontrol ettikten sonra belirtilen kodu çalıştıran bir koşullu ifade oluşturmak için kullanılır. Python'da kod bloklarının tanımlanması için girinti kullanır.",
"_____no_output_____"
],
[
"and ve or ile farklı kurgulanabiliyor.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nacikKavramlar = [\"bilim\", \"erişim\", \"veri\", \"eğitim\"]\nkavram = input(\"Bir açık kavramı yazın: \")\nif kavram in acikKavramlar:\n print(kavram + \" açık kavramlar listesinde yer alıyor!\")\n```\n\n",
"_____no_output_____"
],
[
": ile if cümleciği kapatılıyor.\nkendine ait olan alt satırların devreye girip girmemesini kontrol ediyor.",
"_____no_output_____"
]
],
[
[
"#Örnek derste\ndeger= 1\ndeger2= 2\nif deger == deger2:\n print(\"birbirine eşit\")\n\nif deger != deger2:\n print(\"birbirine eşit değil\")\n\n",
"birbirine eşit değil\n"
],
[
"#kendi örneğim\n\ndeger = 1453\ndeger2 = 1071\nif deger == deger2:\n print(\"birbirine eşit\")\n\nif deger != deger2:\n print(\"birbirine eşit değil\")",
"birbirine eşit değil\n"
],
[
"# Örnek uygulamayı çalıştır\n\nacikKavramlar = [\"bilim\", \"erişim\", \"veri\", \"eğitim\"]\nkavram = input(\"Bir açık kavramı yazın: \")\nif kavram in acikKavramlar:\n print(kavram + \" açık kavramlar listesinde yer alıyor!\")",
"Bir açık kavramı yazın: bilim\nbilim açık kavramlar listesinde yer alıyor!\n"
]
],
[
[
"**Görev:** \"acikSozluk\" içinde yer alan anahtarları (keys) kullanarak eğer klavyeden girilen anahtar kelime sözlükte varsa açıklamasını ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"acikSozluk = {\n \"Açık Bilim\" : \"Bilimsel bilgi kamu malıdır. Bilimsel yayınlara ve verilere açık erişim bir haktır.\" ,\n \"Açık Erişim\" : \"Kamu kaynakları ile yapılan araştırmalar sonucunda üretilen yayınlara ücretsiz erişim\" ,\n \"Açık Veri\" : \"Kamu kaynakları ile yapılan araştırma sonucunda üretilen verilere ücretsiz ve yeniden kullanılabilir biçimde erişim\" \n }\nanahtar = input(\"Anahtar Kelime: \")\nif anahtar in acikSozluk:\n print(anahtar + \" Açık sözlükte yer alıyor!\")\n\n#If",
"Anahtar Kelime: Açık Veri\nAçık Veri Açık sözlükte yer alıyor!\n"
]
],
[
[
"## Else ve Elif Kullanımı\n\"If\" cümleciği içinde ikinci bir ifadenin doğruluğunun kontrolü için \"Elif\" ifadesi kullanılır. Doğruluğu sorgulanan ifadelerden hiçbiri *True* döndürmediği zaman çalışacak olan kod bloğu \"Else\" altında yer alan kod bloğudur. ",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ngunler = [\"Pazartesi\", \"Çarşamba\", \"Cuma\"]\ngirilen = input(\"Gün giriniz: \")\nif girilen == gunler[0]:\n print(\"Programlama Dilleri\")\nelif girilen == gunler[1]:\n print(\"Kataloglama\")\nelif girilen == gunler[2]:\n print(\"Bilimsel İletişim\")\nelse :\n print(\"Kayıtlı bir gün bilgisi girmediniz!\")\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ngunler = [\"Pazartesi\", \"Çarşamba\", \"Cuma\"]\ngirilen = input(\"Gün giriniz: \")\nif girilen == gunler[0]:\n print(\"Programlama Dilleri\")\nelif girilen == gunler[1]:\n print(\"Kataloglama\")\nelif girilen == gunler[2]:\n print(\"Bilimsel İletişim\")\nelse :\n print(\"Kayıtlı bir gün bilgisi girmediniz!\")",
"Gün giriniz: Cuma\nBilimsel İletişim\n"
],
[
"gunler = [\"Pazartesi\", \"Salı\", \"Çarşamba\", \"Perşembe\"]\ngirilen = input(\"Gün giriniz: \")\nif girilen == gunler[0]:\n print(\"Programlama Dilleri\")\nelif girilen == gunler[1]:\n print(\"Türk Dili\")\nelif girilen == gunler[2]:\n print(\"Bilimsel İletişim ve Bilgi Erişim\")\nelif girilen == gunler[3]:\n print(\"Bilginin Düzenlenmesi\")\n\nelse :\n print(\"Kayıtlı bir gün girmediniz! \")",
"Gün giriniz: Salı\nTürk Dili\n"
]
],
[
[
"Elif birden fazla durum kontrol etmek için kullanılıyor.\n",
"_____no_output_____"
],
[
"**Görev:** Klavyeden girilen yaş bilgisini kullanarak ekrana aşağıdaki mesajları yazdır:\n\n* 21 yaş altı ve 64 yaş üstü kişilere: \"Sokağa çıkma yasağı bulunmaktadır!\"\n* Diğer tüm kişilere: \"Sokağa çıkma yasağı yoktur!\"\n* Klavyeden yaş harici bir bilgi girişi yapıldığında: \"Yaşınızı rakam olarak giriniz!\"",
"_____no_output_____"
]
],
[
[
"yas = int(input(\"Yaşınızı giriniz: \"))\nif yas < 21:\n print(\"Sokağa çıkma yasağı bulunmaktadır!\")\nelif yas > 64:\n print(\"Sokağa çıkma yasağı bulunmaktadır!\")\nelse:\n print(\"Sokağa çıkma yasağı yoktur!\")",
"_____no_output_____"
]
],
[
[
"7 MART PAZARTESİ (Buraya kadar geldik.)\n",
"_____no_output_____"
],
[
"# Bölüm 06: Döngüler\n\nBu bölümde:\n\n* for döngüsü,\n* Metin katarlarında for döngüsü kullanımı,\n* while döngüsü,\n* break anahtar kelimesi,\n* continue anahtar kelimesi yer almaktadır.\n\n",
"_____no_output_____"
],
[
"## for Döngüsü\nfor döngüleri belirli komut satırını ya da satırlarını yinelemek (tekrar etmek) için kullanılır. Her yinelemede, for döngüsünde tanımlanan değişken listedeki bir sonraki değere otomatik olarak atanacaktır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nfor i in range(5): # i değerine 0-4 arası indeks değerleri otomatik olarak atanır\n print(i) # Çıktı: Bu komut satırı toplam 5 kere tekrarlanır ve her satırda yeni i değeri yazdırılır\n\n\nkonular = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\"] # yeni bir liste oluşturur\n\nfor konu in konular:\n print(konu) #Çıktı: Her bir liste öğesi alt alta satırlara yazdırılır\n\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulmayı çalıştır\n\nfor i in range(5):\n print(i+1) #Sıfırı ekranda görmemek için +1 ekledik. ",
"1\n2\n3\n4\n5\n"
],
[
"#Ders örneği\nliste = []\nfor i in range(3):\n veri = input(\"Giriş yap: \")\n liste.append(veri)\n print(liste)",
"Giriş yap: y\n['y']\nGiriş yap: a\n['y', 'a']\nGiriş yap: r\n['y', 'a', 'r']\n"
],
[
"!range for sonraası indeks numarası atıyor\nrange kullanmadığımızda listenin elemanlarını ekliyor",
"_____no_output_____"
],
[
"# Örnek uygulmayı çalıştır\n\nkonular = [\"Açık Bilim\", \"Açık Erişim\", \"Açık Veri\", \"Açık Donanım\"]\n\nfor konu in konular:\n print(konu)",
"Açık Bilim\nAçık Erişim\nAçık Veri\nAçık Donanım\n"
]
],
[
[
"! Liste içindeki eleman sayısı kadar otomatik for döngüsü yapabilir.",
"_____no_output_____"
],
[
"**Görev:** Bir liste oluşturun. Liste öğelerini \"for\" döngüsü kullanarak ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"#liste\nliste = [\"elma\", \"armut\", \"kivi\", \"muz\"]\nfor yazdır in liste:\n print(yazdır)\n",
"elma\narmut\nkivi\nmuz\n"
]
],
[
[
"## Metin Katarlarında for Döngüsü Kullanımı\nMetin Katarları üzerinde gerçekleştirilebilecek işlemler Python'daki listelerle büyük benzerlik taşırlar. Metin Katarını oluşturan öğeler (harfler) liste elemanları gibi \"for\" döngüsü yardımıyla ekrana yazdırılabilir. ",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ncumle = \"Bisiklet hem zihni hem bedeni dinç tutar!\"\n\nfor harf in cumle: # Cümledeki her bir harfi ekrana satır satır yazdırır\n print(harf)\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ncumle = \"Bisiklet hem zihni, hem bedeni dinç tutar!\"\n \nfor harf in cumle:\n print(harf)",
"B\ni\ns\ni\nk\nl\ne\nt\n \nh\ne\nm\n \nz\ni\nh\nn\ni\n,\n \nh\ne\nm\n \nb\ne\nd\ne\nn\ni\n \nd\ni\nn\nç\n \nt\nu\nt\na\nr\n!\n"
]
],
[
[
"**Görev:** İçinde metin katarı bulunan bir değişken oluşturun. Bu değişkende yer alan her bir harfi bir satıra gelecek şekilde \"for\" döngüsü ile ekrana yazdırın!",
"_____no_output_____"
]
],
[
[
"#degisken\ncumle = \"Benim adım Yaren\"\nfor harf in cumle:\n print(harf)\n",
"B\ne\nn\ni\nm\n \na\nd\nı\nm\n \nY\na\nr\ne\nn\n"
]
],
[
[
"## while Döngüsü\n\"While\" döngüsü \"if\" cümleciğinin ifade şekline benzer. Koşul doğruysa döngüye bağlı kod satırı ya da satırları yürütülür (çalıştırılır). Temel fark, koşul doğru (True) olduğu olduğu sürece bağlı kod satırı ya da satırları çalışmaya devam eder.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndeger = 1\n\nwhile deger <= 10:\n print(deger) # Bu satır 10 kez tekrarlanacak\n deger += 1 # Bu satır da 10 kez tekrarlanacak\n\nprint(\"Program bitti\") # Bu satır sadece bir kez çalıştırılacak\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ndeger = 1\n\nwhile deger <= 10:\n print(deger)\n deger += 1\n \nprint(\"Program bitti\")",
"1\n2\n3\n4\n5\n6\n7\n8\n9\n10\nProgram bitti\n"
]
],
[
[
"## break Anahtar Kelimesi\nAsla bitmeyen döngüye sonsuz döngü adı verilir. Döngü koşulu daima doğru (True) olursa, böyle bir döngü sonsuz olur. \"Break\" anahtar kelimesi geçerli döngüden çıkmak için kullanılır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\nsayi = 0\n\nwhile True: # bu döngü sonsuz bir döngüdür\n print(sayi)\n sayi += 1\n if sayi >= 5:\n break # sayı değeri 5 olduğunda döngü otomatik olarak sonlanır\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek Uygulamayı çalıştır\n\nsayi = 0\n\nwhile True:\n print(sayi)\n sayi += 1\n if sayi >= 5:\n break",
"0\n1\n2\n3\n4\n"
]
],
[
[
"## continue Anahtar Kelimesi\n\"continue\" anahtar kelimesi, o anda yürütülen döngü için döngü içindeki kodun geri kalanını atlamak ve \"for\" veya \"while\" deyimine geri dönmek için kullanılır.",
"_____no_output_____"
],
[
"\n\n```\nfor i in range(5):\n if i == 3:\n continue # i değeri 3 olduğu anda altta yer alan \"print\" komutu atlanıyor.\n print(i)\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek Uygulamayı çalıştır\n\nfor i in range(5):\n if i == 3:\n continue\n print(i)",
"0\n1\n2\n4\n"
]
],
[
[
"Belirli bir kısmı atlamak için de kullanıyorduk.\n",
"_____no_output_____"
],
[
"**Görev: Tahmin Oyunu**\n\n\"while\" döngüsü kullanarak bir tahmin oyunu tasarla. Bu tahmin oyununda, önceden belirlenmiş olan kelime ile klavyeden girilen kelime karşılaştırılmalı, tahmin doğru ise oyun \"Bildiniz..!\" mesajı ile sonlanmalı, yanlış ise tahmin hakkı bir daha verilmeli.",
"_____no_output_____"
]
],
[
[
"#Tahmin Oyunu\nkelime = \"bilgi\"\ntahmin = \"\"",
"_____no_output_____"
],
[
"print(\"Kelime tahmin oyununa hoş geldiniz! \")\n\noyuncuismi = input(\"İsminizi giriniz: \")\n\nkelime = \"erişim\"\ntahmin = input(\"Tahmininizi giriniz: \" )\nwhile tahmin == kelime:\n print(\"Bildiniz\")\n break\nelse:\n print(\"Bilemediniz\")",
"Kelime tahmin oyununa hoş geldiniz! \nİsminizi giriniz: Yaren\nTahmininizi giriniz: kkk\nBilemediniz\n"
]
],
[
[
"# Bölüm 07: Fonksiyonlar",
"_____no_output_____"
],
[
"## Fonksiyon Tanımlama (Definition)\nFonksiyonlar, yazılan kodu faydalı bloklara bölmenin, daha okunabilir hale getirmenin ve tekrar kullanmaya yardımcı olmanın kullanışlı bir yoludur. Fonksiyonlar \"def\" anahtar sözcüğü ve ardından fonksiyonun adı kullanılarak tanımlanır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndef merhaba_dunya(): # fonksiyon tanımlama, isimlendirme\n print(\"Merhaba Dünya!\") #fonksiyona dahil kod satırları\n\nfor i in range(5):\n merhaba_dunya() # fonksiyon 5 kere çağırılacak\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ndef merhaba_dunya(): # fonksiyon tanımlama, isimlendirme\n print(\"Merhaba Dünya!\") #fonksiyona dahil kod satırları\n\nfor i in range(5):\n merhaba_dunya() # fonksiyon 5 kere çağırılacak",
"_____no_output_____"
]
],
[
[
"##Fonksiyolarda Parametre Kullanımı\nFonksiyon parametreleri, fonksiyon adından sonra parantez () içinde tanımlanır. Parametre, iletilen bağımsız değişken için değişken adı görevi görür.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndef foo(x): # x bir fonksiyon parametresidir\n print(\"x = \" + str(x))\n\nfoo(5) # 5 değeri fonksiyona iletilir ve değer olarak kullanılır.\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ndef foo(x):\n print(\"x = \" + str(x))\n\nfoo(5)",
"x = 5\n"
]
],
[
[
"**Görev:** *karsila* fonksiyonunun tetiklenmesi için gerekli kod ve parametleri ekle!",
"_____no_output_____"
]
],
[
[
"def karsila(kAd, kSoyad):\n print(\"Hoşgeldin, %s %s\" % (kAd, kSoyad))\n\n",
"_____no_output_____"
]
],
[
[
"##Return Değeri\nFonksiyonlar, \"return\" anahtar sözcüğünü kullanarak fonksiyon sonucunda bir değer döndürebilir. Döndürülen değer bir değişkene atanabilir veya sadece örneğin değeri yazdırmak için kullanılabilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndef iki_sayi_topla(a, b):\n return a + b # hesaplama işleminin sonucu değer olarak döndürülüyor\n\nprint(iki_sayi_topla(3, 12)) # ekrana işlem sonucu yazdırılacak\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ndef iki_sayi_topla(a, b):\n return a + b\n\nprint(iki_sayi_topla(3, 12))",
"15\n"
]
],
[
[
"##Varsayılan Parametreler\nBazen bir veya daha fazla fonksiyon parametresi için varsayılan bir değer belirtmek yararlı olabilir. Bu, ihtiyaç duyulan parametrelerden daha az argümanla çağrılabilen bir fonksiyon oluşturur.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n```\ndef iki_sayi_carp(a, b=2):\n return a * b\n\nprint(iki_sayi_carp(3, 47)) # verilen iki degeri de kullanır \nprint(iki_sayi_carp(3)) # verilmeyen 2. değer yerine varsayılanı kullanır\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\ndef iki_sayi_carp(a, b=2):\n return a * b\n\nprint(iki_sayi_carp(3, 47))\nprint(iki_sayi_carp(3))",
"141\n6\n"
]
],
[
[
"**Örnek Uygulama: Sayısal Loto**\n\nAşağıda temel yapısı aynı olan iki *sayısal loto* uygulaması bulunmaktadır: Fonksiyonsuz ve fonksiyonlu.\n\nİlk sayısal loto uygulamasında herhangi bir fonksiyon kullanımı yoktur. Her satırda 1-49 arası 6 adet sayının yer aldığı 6 satır oluşturur.\n\nİkinci sayısal loto uygulamsında ise *tahminEt* isimli bir fonksiyon yer almaktadır. Bu fonksiyon varsayılan parametrelere sahiptir ve bu parametreler fonksiyon çağırılırken değiştirilebilir. Böylece ilk uygulamadan çok daha geniş seçenekler sunabilir bir hale gelmiştir.\n\n",
"_____no_output_____"
]
],
[
[
"#Sayısal Loto örnek uygulama (fonksiyonsuz)\n\nfrom random import randint\ni = 0\nsecilenler = [0,0,0,0,0,0]\nfor rastgele in secilenler:\n while i < len(secilenler):\n secilen = randint(1, 49)\n if secilen not in secilenler:\n secilenler[i] = secilen\n i+=1\n print(sorted(secilenler))\n i=0",
"_____no_output_____"
],
[
"#Sayısal Loto örnek uygulama (fonksiyonlu)\n\nfrom random import randint\ndef tahminEt(rakam=6, satir=6, baslangic=1, bitis=49):\n i = 0\n secilenler = []\n for liste in range(rakam):\n secilenler.append(0)\n for olustur in range(satir):\n while i < len(secilenler):\n secilen = randint(baslangic, bitis)\n if secilen not in secilenler:\n secilenler[i] = secilen\n i+=1\n print(sorted(secilenler))\n i=0\ntahminEt(10,6,1,60)",
"_____no_output_____"
]
],
[
[
"**Görev:** Bu görev genel olarak fonksiyon bölümünü kapsamaktadır.\n\nDaha önce yapmış olduğunuz \"Adam Asmaca\" projesini (ya da aşağıda yer alan örneği) fonksiyonlar kullanarak oyun bittiğinde tekrar başlatmaya gerek duyulmadan yeniden oynanabilmesine imkan sağlayacak şekilde yeniden kurgulayın.\n\nOyunun farklı sekansları için farklı fonksiyonlar tanımlayarak oyunu daha optimize hale getirmeye çalışın.\n\nAşağıda bir adam asmaca oyununun temel özellikerine sahip bir örnek yer almaktadır.\n\n",
"_____no_output_____"
]
],
[
[
"#Fonksiyonsuz Adam Asmaca\n\nfrom random import choice\n\nadamCan = 3\n\nkelimeler = [\"bisiklet\", \"triatlon\", \"yüzme\", \"koşu\"]\nsecilenKelime = choice(kelimeler)\nprint(secilenKelime)\ndizilenKelime = []\nfor diz in secilenKelime:\n dizilenKelime.append(\"_\")\nprint(dizilenKelime)\n\nwhile adamCan > 0:\n girilenHarf = input(\"Bir harf giriniz: \")\n canKontrol = girilenHarf in secilenKelime\n if canKontrol == False:\n adamCan-=1\n i = 0\n for kontrol in secilenKelime:\n if secilenKelime[i] == girilenHarf:\n dizilenKelime[i] = girilenHarf\n i+=1\n print(dizilenKelime)\n print(\"Kalan can: \"+ str(adamCan))",
"yüzme\n['_', '_', '_', '_', '_']\nBir harf giriniz: y\n['y', '_', '_', '_', '_']\nKalan can: 3\nBir harf giriniz: ü\n['y', 'ü', '_', '_', '_']\nKalan can: 3\nBir harf giriniz: z\n['y', 'ü', 'z', '_', '_']\nKalan can: 3\nBir harf giriniz: m\n['y', 'ü', 'z', 'm', '_']\nKalan can: 3\nBir harf giriniz: e\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 3\nBir harf giriniz: k\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 2\nBir harf giriniz: l\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 1\nBir harf giriniz: m\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 1\nBir harf giriniz: e\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 1\nBir harf giriniz: s\n['y', 'ü', 'z', 'm', 'e']\nKalan can: 0\n"
],
[
"#Fonksiyonlu Adam Asmaca\n",
"_____no_output_____"
]
],
[
[
"# Bölüm 08: Sınıflar ve Nesneler\n\nBu bölümde:\n\n* Sınıf ve nesne tanımlama,\n* Değişkenlere erişim,\n* self parametresi,\n* init metodu yer almaktadır.",
"_____no_output_____"
],
[
"## Sınıf ve Nesne Tanımlama\nBir nesne değişkenleri ve fonksiyonları tek bir varlıkta birleştirir. Nesneler değişkenlerini ve fonksiyonlarını sınıflardan alır. Sınıflar bir anlamda nesnelerinizi oluşturmak için kullanılan şablonlardır. Bir nesneyi, fonksiyonların yanı sıra veri içeren tek bir veri yapısı olarak düşünebilirsiniz. Nesnelerin fonksiyonlarına yöntem (metod) denir.\n\n**İpucu:** Sınıf isimlerinin baş harfi büyük yazılarak Python içindeki diğer öğelerden (değişken, fonksiyon vb.) daha rahat ayırt edilmeleri sağlanır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n```\nclass BenimSinifim: # yeni bir sınıfın tanımlanması\n \n bsDegisken = 4 # sınıf içinde yer alan bir değişken\n\n def bsFonksiyon(self): #sınıf içinde yer alan bir fonksiyon\n print(\"Benim sınıfımın fonksiyonundan Merhaba!\")\n\nbenimNesnem = BenimSinifim()\n```\n\n",
"_____no_output_____"
],
[
"##Değişkenlere ve Fonksiyonlara Erişim\nSınıftan örneklenen bir nesnenin içindeki bir değişkene ya da fonksiyona erişmek için öncelikle nesnenin adı daha sonra ise değişkenin ya da fonkiyonun adı çağırılmalıdır (Ör: nesneAdi.degiskenAdi). Bir sınıfın farklı örnekleri (nesneleri) içinde tanımlanan değişkenlerin değerleri değiştirebilir.",
"_____no_output_____"
],
[
"**Örnek Uygulama 1**\n\n\n```\nclass BenimSinifim: # yeni bir sınıf oluşturur\n bsDegisken = 3 # sınıfın içinde bir değişken tanımlar\n def bsFonksiyon(self): #sınıfın içinde bir fonksiyon tanımlar\n print(\"Benim sınıfımın fonksiyonundan Merhaba!\")\n\nbenimNesnem = BenimSinifim() #sınıftan yeni bir nesne oluşturur\n\nfor i in range(benimNesnem.bsDegisken): # oluşturulan nesne üzerinden değişkene ve fonksiyona ulaşılır\n benimNesnem.bsFonksiyon()\n\nbenimNesnem.bsDegisken = 5 # sınıfın içinde tanımlanan değişkene yeni değer atanması\n\nfor i in range(benimNesnem.bsDegisken):\n benimNesnem.bsFonksiyon()\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama 1'i gözlemleyelim\n\nclass BenimSinifim: \n bsDegisken = 3\n def bsFonksiyon(self):\n print(\"Benim sınıfımın fonksiyonundan Merhaba!\")\n\nbenimNesnem = BenimSinifim()\n\nfor i in range(benimNesnem.bsDegisken):\n benimNesnem.bsFonksiyon()\n\nbenimNesnem.bsDegisken = 5\n\nfor i in range(benimNesnem.bsDegisken):\n benimNesnem.bsFonksiyon()",
"Benim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\nBenim sınıfımın fonksiyonundan Merhaba!\n"
]
],
[
[
"Programı yaz belirli bölümlerini tekrar lkullanma ihtiyacı sınıf. (Büyük parça)",
"_____no_output_____"
],
[
"**Örnek Uygulama 2**\n\n\n```\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n\nbisiklet1 = Bisiklet()\nbisiklet2 = Bisiklet()\n\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())\n\nbisiklet2.renk = \"Sarı\"\nbisiklet2.vites = 22\n\nprint(\"Bisiklet 2: \" + bisiklet2.ozellikler())\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulama 2'i gözlemleyelim\n\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n\nbisiklet1 = Bisiklet()\nbisiklet2 = Bisiklet()\n\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())\n\nbisiklet2.renk = \"Sarı\"\nbisiklet2.vites = 22\n\nprint(\"Bisiklet 2: \" + bisiklet2.ozellikler())",
"_____no_output_____"
]
],
[
[
"##self Parametresi\n\"self\" parametresi bir Python kuralıdır. \"self\", herhangi bir sınıf yöntemine iletilen ilk parametredir. Python, oluşturulan nesneyi belirtmek için self parametresini kullanır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\nAşağıdaki örnek uygulamada **Bisiklet** sınıfının değişkenleri olan *renk* ve *bisiklet*, sınıf içindeki fonksiyonda **self** parametresi ile birlikte kullanılmaktadır. Bu kullanım şekli sınıftan oluşturulan nesnelerin tanımlanmış değişkenlere ulaşabilmeleri için gereklidir.\n```\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamada \"self\" tanımlaması yapılmadığı zaman döndürülen hata kodunu inceleyin\n\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (renk, vites) #tanımlama eksik\n return ozellikDetay\n\nbisiklet1 = Bisiklet()\nbisiklet2 = Bisiklet()\n\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())\n\nbisiklet2.renk = \"Sarı\"\nbisiklet2.vites = 22\n\nprint(\"Bisiklet 2: \" + bisiklet2.ozellikler())",
"_____no_output_____"
]
],
[
[
"##__init__ Metodu\n__init__ fonksiyonu, oluşturduğu nesneleri başlatmak için kullanılır. init \"başlat\" ın kısaltmasıdır. __init__() her zaman yaratılan nesneye atıfta bulunan en az bir argüman alır: \"self\".\n",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\nAşağıdaki örnek uygulamada *sporDali* sınıfının içinde tanımlanan **init** fonksiyonu, sınıf oluşturulduğu anda çalışmaya başlamaktadır. Fonksiyonun ayrıca çağırılmasına gerek kalmamıştır.\n```\nclass sporDali:\n sporlar = [\"Yüzme\", \"Bisiklet\", \"Koşu\"]\n def __init__(self):\n for spor in self.sporlar:\n print(spor + \" bir triatlon branşıdır.\")\n\ntriatlon = sporDali()\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır\n\nclass sporDali:\n sporlar = [\"Yüzme\", \"Bisiklet\", \"Koşu\"]\n def __init__(self):\n for spor in self.sporlar:\n print(spor + \" bir triatlon branşıdır.\")\n\ntriatlon = sporDali()",
"Yüzme bir triatlon branşıdır.\nBisiklet bir triatlon branşıdır.\nKoşu bir triatlon branşıdır.\n"
],
[
"# Örnek uygulamayı > Duatlon\n\nclass sporDali:\n sporlar = [\"Yüzme\", \"Bisiklet\", \"Koşu\"]\n def __init__(self):\n for spor in self.sporlar:\n print(spor + \" bir triatlon branşıdır.\")\n\ntriatlon = sporDali()",
"Yüzme bir triatlon branşıdır.\nBisiklet bir triatlon branşıdır.\nKoşu bir triatlon branşıdır.\n"
]
],
[
[
"#Bölüm 09: Modüller ve Paketler",
"_____no_output_____"
],
[
"##Modülün İçe Aktarılması\nPython'daki modüller, Python tanımlarını (sınıflar, fonksiyonlar vb.) ve ifadelerini (değişkenler, listeler, sözlükler vb.) içeren .py uzantısına sahip Python dosyalarıdır.\n\nModüller, *import* anahtar sözcüğü ve uzantı olmadan dosya adı kullanılarak içe aktarılır. Bir modül, çalışan bir Python betiğine ilk kez yüklendiğinde, modüldeki kodun bir kez çalıştırılmasıyla başlatılır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n\n```\n#bisiklet.py adlı modülün içeriği\n\"\"\"\nBu modül içinde Bisiklet sınıfı yer almaktadır.\n\"\"\"\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n```\n\n\n\n```\n#bisikletler.py adlı Python dosyasının içeriği\n\nimport bisiklet\n\nbisiklet1 = bisiklet.Bisiklet()\n\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())\n\n```\n\n",
"_____no_output_____"
],
[
"**PyCharm Örneği**\n\n\n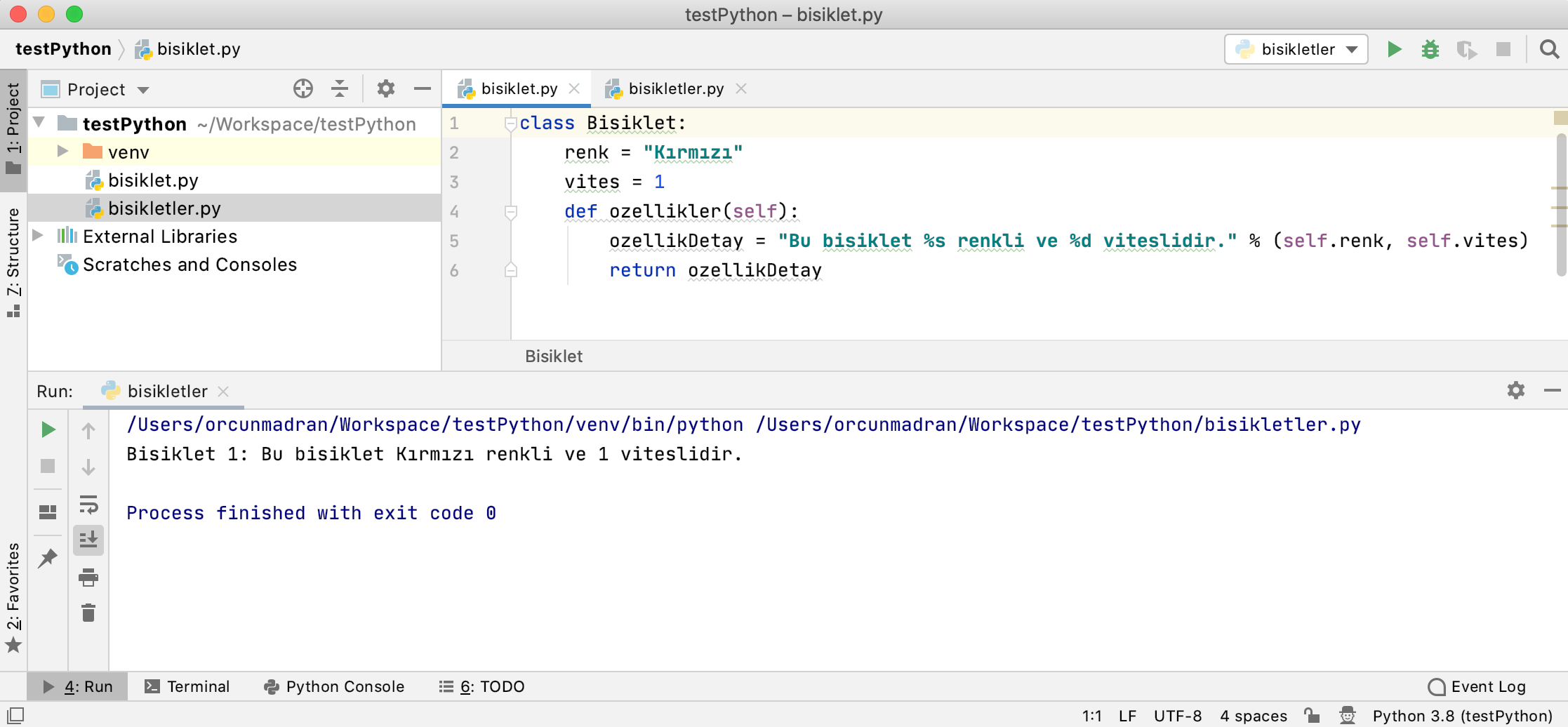 \n\nbisiklet.py\n\n\n\n---\n\n\n\n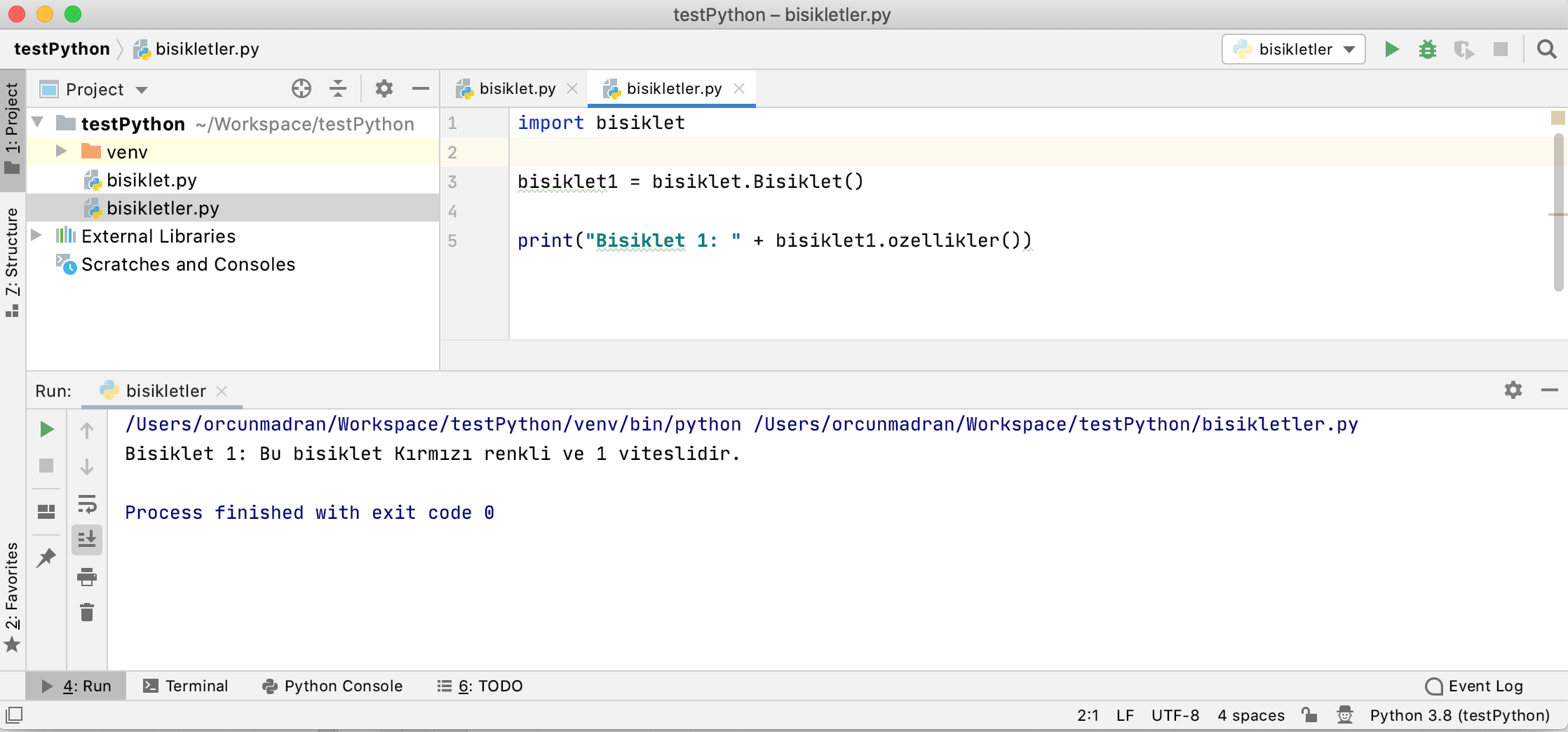\n\nbisikletler.py",
"_____no_output_____"
],
[
"##Colab'de Modülün İçe Aktarılması\n\nBir önceki bölümde (Modülün İçe Aktarılması) herhangi bir kişisel bilgisayarın sabit diski üzerinde çalışırken yerleşik olmayan (kendi yazdığımız) modülün içe aktarılması yer aldı.\n\nBu bölümde ise Colab üzerinde çalışırken yerleşik olmayan bir modülü nasıl içe aktarılacağı yer almakta.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\nAşağıda içeriği görüntülenen *bisiklet.py* adlı Python dosyası Google Drive içerisinde \"BBY162_Python_a_Giris.ipynb\" dosyasının ile aynı klasör içinde bulunmaktadır.\n\n```\n#bisiklet.py adlı modülün içeriği\n\"\"\"\nBu modül içinde Bisiklet sınıfı yer almaktadır.\n\"\"\"\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n```\n",
"_____no_output_____"
]
],
[
[
"# Google Drive'ın bir disk olarak görülmesi \nfrom google.colab import drive\ndrive.mount('gdrive') # bağlanan diskin 'gdrive' adı ile tanımlanması.\n\nimport sys # bağlanan diskin fiziksel yolunun tespit edilmesi ve bağlantı yoluna eklenmesi\nsys.path.append('/content/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/')\n\nimport bisiklet # bisiklet.py içerisindeki 'bisiklet' modülünün içe aktarılması\n\nbisiklet1 = bisiklet.Bisiklet()\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())",
"_____no_output_____"
]
],
[
[
"##Yerleşik Modüller (built-in)\nPython aşağıdaki bağlantıda yer alan standart modüllerle birlikte gelir. Bu modüllerin *import* anahtar kelimesi ile çağrılması yeterlidir. Ayrıca bu modüllerin yüklenmesine gerek yoktur.\n\n[Python Standart Modülleri](https://docs.python.org/3/library/)",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n```\nimport datetime\nprint(datetime.datetime.today())\n```\n\n",
"_____no_output_____"
]
],
[
[
"# Örnek uygulamayı çalıştır \n\nimport datetime\nprint(datetime.datetime.today())",
"2022-05-03 20:28:29.347449\n"
]
],
[
[
"##from import Kullanımı\nİçe aktarma ifadesinin bir başka kullanım şekli *from* anahtar kelimesinin kullanılmasıdır. *from* ifadesi ile modül adları paketin içinde alınarak direkt kullanıma hazır hale getirilir. Bu şekilde, içe aktarılan modül, modül_adı öneki olmadan doğrudan kullanılır.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n\n```\n#bisiklet.py adlı modülün içeriği\n\"\"\"\nBu modül içinde Bisiklet sınıfı yer almaktadır.\n\"\"\"\nclass Bisiklet:\n renk = \"Kırmızı\"\n vites = 1\n def ozellikler(self):\n ozellikDetay = \"Bu bisiklet %s renkli ve %d viteslidir.\" % (self.renk, self.vites)\n return ozellikDetay\n```\n",
"_____no_output_____"
]
],
[
[
"# Google Drive'ın bir disk olarak görülmesi \nfrom google.colab import drive\ndrive.mount('gdrive') # bağlanan diskin 'gdrive' adı ile tanımlanması.\n\nimport sys # bağlanan diskin fiziksel yolunun tespit edilmesi ve bağlantı yoluna eklenmesi\nsys.path.append('/content/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/')\n\nfrom bisiklet import Bisiklet # bisiklet.py içerisindeki 'bisiklet' sınıfının içe aktarılması\n\nbisiklet1 = Bisiklet() # bisiklet ön tanımlamasına gerek kalmadı\nprint(\"Bisiklet 1: \" + bisiklet1.ozellikler())",
"_____no_output_____"
]
],
[
[
"#Bölüm 10: Dosya İşlemleri",
"_____no_output_____"
],
[
"##Dosya Okuma\nPython, bilgisayarınızdaki bir dosyadan bilgi okumak ve yazmak için bir dizi yerleşik fonksiyona sahiptir. **open** fonksiyonu bir dosyayı açmak için kullanılır. Dosya, okuma modunda (ikinci argüman olarak \"r\" kullanılarak) veya yazma modunda (ikinci argüman olarak \"w\" kullanılarak) açılabilir. **open** fonksiyonu dosya nesnesini döndürür. Dosyanın saklanması için kapatılması gerekir.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\n\n```\n#Google Drive Bağlantısı\nfrom google.colab import drive\ndrive.mount('/gdrive')\n\ndosya = \"/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/metin.txt\"\n\nf = open(dosya, \"r\") \n\nfor line in f.readlines():\n print(line)\n\nf.close()\n```\n\nDosyanın sağlıklı şekilde okunabilmesi için Google Drive ile bağlantının kurulmuş olması ve okunacak dosyanın yolunun tam olarak belirtilmesi gerekmektedir.\n\n",
"_____no_output_____"
]
],
[
[
"#Google Drive Bağlantısı\nfrom google.colab import drive\ndrive.mount('/gdrive')\n\ndosya = \"/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/metin.txt\"\n\nf = open(dosya, \"r\") \n\nfor line in f.readlines():\n print(line)\n\nf.close()",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\n"
]
],
[
[
"##Dosya Yazma\nBir dosyayı ikinci argüman olarak \"w\" (yazma) kullanarak açarsanız, yeni bir boş dosya oluşturulur. Aynı ada sahip başka bir dosya varsa silineceğini unutmayın. Mevcut bir dosyaya içerik eklemek istiyorsanız \"a\" (ekleme) değiştiricisini kullanmalısınız.",
"_____no_output_____"
],
[
"**Örnek Uygulama**\n\nAşağıdaki örnekte dosya 'w' parametresi ile açıldığı için var olan dosyanın içindekiler silinir ve yeni veriler dosyaya yazılır. Dosyanın içindeki verilerin kalması ve yeni verilerin eklenmesi isteniyorsa dosya 'a' parametresi ile açılmalıdır.\n\n```\n#Google Drive Bağlantısı\nfrom google.colab import drive\ndrive.mount('/gdrive')\n \ndosya = \"/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/cikti.txt\"\n\nf = open(dosya, 'w') # Mevcut veriye ek veri yazılması için parametre: 'a'\nf.write(\"test\") # Her yeni verinin bir alt satıra yazdırılması \"test\\n\"\nf.close()\n```\n\nKod çalıştırıldıktan sonra eğer *cikti.txt* adında bir dosya yoksa otomatik olarak oluşturulur ve istenilen içerik yazılır.\n\n",
"_____no_output_____"
]
],
[
[
"#Google Drive Bağlantısı\nfrom google.colab import drive\ndrive.mount('/gdrive')\n \ndosya = \"/gdrive/My Drive/Colab Notebooks/BBY162 - Programlama ve Algoritmalar/cikti.txt\"\n\nf = open(dosya, 'w') # Mevcut veriye ek veri yazılması için parametre: 'a'\nf.write(\"test\") # Her yeni verinin bir alt satıra yazdırılması \"test\\n\"\nf.close()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
cbd1e514ae9fa238ca44329d89cd1cd330d9a4c3
| 21,795 |
ipynb
|
Jupyter Notebook
|
03_Grouping/Alcohol_Consumption/Exercise_Hossein.ipynb
|
hoseinkh/pandas_exercises
|
78bdde02e94a140a47d08f36c07fe3296d7e026d
|
[
"BSD-3-Clause"
] | null | null | null |
03_Grouping/Alcohol_Consumption/Exercise_Hossein.ipynb
|
hoseinkh/pandas_exercises
|
78bdde02e94a140a47d08f36c07fe3296d7e026d
|
[
"BSD-3-Clause"
] | null | null | null |
03_Grouping/Alcohol_Consumption/Exercise_Hossein.ipynb
|
hoseinkh/pandas_exercises
|
78bdde02e94a140a47d08f36c07fe3296d7e026d
|
[
"BSD-3-Clause"
] | null | null | null | 27.942308 | 133 | 0.342969 |
[
[
[
"# Ex - GroupBy",
"_____no_output_____"
],
[
"### Introduction:\n\nGroupBy can be summarized as Split-Apply-Combine.\n\nSpecial thanks to: https://github.com/justmarkham for sharing the dataset and materials.\n\nCheck out this [Diagram](http://i.imgur.com/yjNkiwL.png) \n### Step 1. Import the necessary libraries",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"### Step 2. Import the dataset from this [address](https://raw.githubusercontent.com/justmarkham/DAT8/master/data/drinks.csv). ",
"_____no_output_____"
],
[
"### Step 3. Assign it to a variable called drinks.",
"_____no_output_____"
]
],
[
[
"url = \"https://raw.githubusercontent.com/justmarkham/DAT8/master/data/drinks.csv\"\ndf = pd.read_csv(url)",
"_____no_output_____"
],
[
"df.head(5)",
"_____no_output_____"
]
],
[
[
"### Step 4. Which continent drinks more beer on average?",
"_____no_output_____"
]
],
[
[
"total_avg = df[\"beer_servings\"].mean()\ntotal_avg",
"_____no_output_____"
],
[
"df.groupby(\"continent\").mean()[df.groupby(\"continent\").mean()[\"beer_servings\"] > total_avg][\"beer_servings\"]\n",
"_____no_output_____"
]
],
[
[
"### Step 5. For each continent print the statistics for wine consumption.",
"_____no_output_____"
]
],
[
[
"df.groupby(\"continent\").describe()[\"wine_servings\"]",
"_____no_output_____"
]
],
[
[
"### Step 6. Print the mean alcohol consumption per continent for every column",
"_____no_output_____"
]
],
[
[
"df.groupby(\"continent\").mean()",
"_____no_output_____"
]
],
[
[
"### Step 7. Print the median alcohol consumption per continent for every column",
"_____no_output_____"
]
],
[
[
"df.groupby(\"continent\").median()",
"_____no_output_____"
]
],
[
[
"### Step 8. Print the mean, min and max values for spirit consumption.\n#### This time output a DataFrame",
"_____no_output_____"
]
],
[
[
"# overall\ndf[[\"spirit_servings\"]].describe().loc[[\"mean\", \"min\", \"max\"],:]",
"_____no_output_____"
],
[
"# by continent\ndf.groupby(\"continent\")[\"spirit_servings\"].describe().loc[:,[\"mean\", \"min\", \"max\"]]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd1ee2faf29baa1bf2bc70d0825ce8962d88037
| 8,089 |
ipynb
|
Jupyter Notebook
|
examples/preprocess/Preprocess.ipynb
|
yniad/chesslab-old
|
e3d5899bf868117b4d88b141d1563ee35c436b83
|
[
"MIT"
] | null | null | null |
examples/preprocess/Preprocess.ipynb
|
yniad/chesslab-old
|
e3d5899bf868117b4d88b141d1563ee35c436b83
|
[
"MIT"
] | null | null | null |
examples/preprocess/Preprocess.ipynb
|
yniad/chesslab-old
|
e3d5899bf868117b4d88b141d1563ee35c436b83
|
[
"MIT"
] | 1 |
2022-02-11T04:34:22.000Z
|
2022-02-11T04:34:22.000Z
| 23.58309 | 202 | 0.452837 |
[
[
[
"This notebook preprocess the data extracted from the chess database.\n\nTo run this notebook with all the 170 million of positions from the chess database is required at least 8GB of RAM (if you use a local machine, for some reason, I can't run it on google colab).\n\nI used a laptop with a SSD NVMe, Intel i7-9750h and 24GB RAM DDR4@2666Mhz \n\n",
"_____no_output_____"
]
],
[
[
"total_ram = 170e6*64/1024/1024/1024\nprint(\"If all data were loaded, it would take at least {:.1f} GB of RAM\".format(total_ram))",
"If all data were loaded, it would take at least 10.1 GB of RAM\n"
],
[
"#!pip install chesslab --upgrade",
"_____no_output_____"
],
[
"from chesslab_.preprocessing import preprocess",
"_____no_output_____"
],
[
"download=False",
"_____no_output_____"
],
[
"#https://drive.google.com/file/d/1XwH0reHwaOA0Tpt0ihJkP_XW99EUhlp9/view?usp=sharing\nif download:\n from chesslab.utils import download_7z\n path='./'\n file_id = '1XwH0reHwaOA0Tpt0ihJkP_XW99EUhlp9'\n download_7z(file_id,path)\nelse:\n path='D:/database/ccrl/'",
"_____no_output_____"
],
[
"block_size=1000000\nblocks=170\npath_files= path\nstart_name= 'chess'\nmin_elo= 2500\ndata_name= 'ccrl_states_elo2'\nlabels_name= 'ccrl_results_elo2'\nelo_filter= 1 #1 = mean, 2 = min\nnb_game_filter= 10 #0 no aplica el filtro\ndelete_duplicate=True\ndelete_draws= True\ndelete_both_winners = True\ndelete_eaten=True\nundersampling=False\n\n\npreprocess(\n block_size= block_size,\n blocks= blocks,\n path= path_files,\n start_name= start_name,\n min_elo= min_elo,\n data_name= data_name,\n labels_name= labels_name,\n elo_filter= elo_filter,\n nb_game_filter= nb_game_filter,\n delete_eaten=delete_eaten,\n delete_duplicate=delete_duplicate,\n delete_draws= delete_draws,\n delete_both_winners = delete_both_winners,\n undersampling=undersampling)",
"Reading blocks\nfile: 1\nfile: 2\nfile: 3\nfile: 4\nfile: 5\nfile: 6\nfile: 7\nfile: 8\nfile: 9\nfile: 10\nfile: 11\nfile: 12\nfile: 13\nfile: 14\nfile: 15\nfile: 16\nfile: 17\nfile: 18\nfile: 19\nfile: 20\nfile: 21\nfile: 22\nfile: 23\nfile: 24\nfile: 25\nfile: 26\nfile: 27\nfile: 28\nfile: 29\nfile: 30\nfile: 31\nfile: 32\nfile: 33\nfile: 34\nfile: 35\nfile: 36\nfile: 37\nfile: 38\nfile: 39\nfile: 40\nfile: 41\nfile: 42\nfile: 43\nfile: 44\nfile: 45\nfile: 46\nfile: 47\nfile: 48\nfile: 49\nfile: 50\nfile: 51\nfile: 52\nfile: 53\nfile: 54\nfile: 55\nfile: 56\nfile: 57\nfile: 58\nfile: 59\nfile: 60\nfile: 61\nfile: 62\nfile: 63\nfile: 64\nfile: 65\nfile: 66\nfile: 67\nfile: 68\nfile: 69\nfile: 70\nfile: 71\nfile: 72\nfile: 73\nfile: 74\nfile: 75\nfile: 76\nfile: 77\nfile: 78\nfile: 79\nfile: 80\nfile: 81\nfile: 82\nfile: 83\nfile: 84\nfile: 85\nfile: 86\nfile: 87\nfile: 88\nfile: 89\nfile: 90\nfile: 91\nfile: 92\nfile: 93\nfile: 94\nfile: 95\nfile: 96\nfile: 97\nfile: 98\nfile: 99\nfile: 100\nfile: 101\nfile: 102\nfile: 103\nfile: 104\nfile: 105\nfile: 106\nfile: 107\nfile: 108\nfile: 109\nfile: 110\nfile: 111\nfile: 112\nfile: 113\nfile: 114\nfile: 115\nfile: 116\nfile: 117\nfile: 118\nfile: 119\nfile: 120\nfile: 121\nfile: 122\nfile: 123\nfile: 124\nfile: 125\nfile: 126\nfile: 127\nfile: 128\nfile: 129\nfile: 130\nfile: 131\nfile: 132\nfile: 133\nfile: 134\nfile: 135\nfile: 136\nfile: 137\nfile: 138\nfile: 139\nfile: 140\nfile: 141\nfile: 142\nfile: 143\nfile: 144\nfile: 145\nfile: 146\nfile: 147\nfile: 148\nfile: 149\nfile: 150\nfile: 151\nfile: 152\nfile: 153\nfile: 154\nfile: 155\nfile: 156\nfile: 157\nfile: 158\nfile: 159\nfile: 160\nfile: 161\nfile: 162\nfile: 163\nfile: 164\nfile: 165\nfile: 166\nfile: 167\nfile: 168\nfile: 169\nfile: 170\n================================================================================\nSelecting 10 game states per game\ntotal of different games: 542058\ntotal of different states: 5420580\ntotal of different results: 5420580\n================================================================================\ndeleting duplicates\ntotal of different states: 4879605\ntotal of different results: 4879605\n================================================================================\ndeleting games with both winners\ntotal of different states: 4829155\ntotal of different results: 4829155\n================================================================================\nwhite total wins: 2844032\nblack total wins: 1985123\nIB=1.43\nsaving files\nfiles saved\nElapsed time: 48s = 0.8m\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd1f3b0df676cc3b9d55e557f29c116232c39c7
| 111,326 |
ipynb
|
Jupyter Notebook
|
AI for Medical Diagnosis/Week 1/C1W1_L3_Densenet.ipynb
|
amanchadha/ai-for-medicine-specialization
|
e68cc6f5ce5dd8980e9c433b78d5d5e7ad1ddea3
|
[
"MIT"
] | 1 |
2021-12-10T09:01:55.000Z
|
2021-12-10T09:01:55.000Z
|
AI for Medical Diagnosis/Week 1/C1W1_L3_Densenet.ipynb
|
amanchadha/ai-for-medicine-specialization
|
e68cc6f5ce5dd8980e9c433b78d5d5e7ad1ddea3
|
[
"MIT"
] | null | null | null |
AI for Medical Diagnosis/Week 1/C1W1_L3_Densenet.ipynb
|
amanchadha/ai-for-medicine-specialization
|
e68cc6f5ce5dd8980e9c433b78d5d5e7ad1ddea3
|
[
"MIT"
] | null | null | null | 84.019623 | 291 | 0.694519 |
[
[
[
"## AI for Medicine Course 1 Week 1 lecture exercises",
"_____no_output_____"
],
[
"<a name=\"densenet\"></a>\n# Densenet\n\nIn this week's assignment, you'll be using a pre-trained Densenet model for image classification. \n\nDensenet is a convolutional network where each layer is connected to all other layers that are deeper in the network\n- The first layer is connected to the 2nd, 3rd, 4th etc.\n- The second layer is connected to the 3rd, 4th, 5th etc.\n\nLike this:\n\n<img src=\"densenet.png\" alt=\"U-net Image\" width=\"400\" align=\"middle\"/>\n\nFor a detailed explanation of Densenet, check out the source of the image above, a paper by Gao Huang et al. 2018 called [Densely Connected Convolutional Networks](https://arxiv.org/pdf/1608.06993.pdf).\n\nThe cells below are set up to provide an exploration of the Keras densenet implementation that you'll be using in the assignment. Run these cells to gain some insight into the network architecture. ",
"_____no_output_____"
]
],
[
[
"# Import Densenet from Keras\nfrom keras.applications.densenet import DenseNet121\nfrom keras.layers import Dense, GlobalAveragePooling2D\nfrom keras.models import Model\nfrom keras import backend as K",
"Using TensorFlow backend.\n"
]
],
[
[
"For your work in the assignment, you'll be loading a set of pre-trained weights to reduce training time.",
"_____no_output_____"
]
],
[
[
"# Create the base pre-trained model\nbase_model = DenseNet121(weights='./nih/densenet.hdf5', include_top=False);",
"WARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\nInstructions for updating:\nIf using Keras pass *_constraint arguments to layers.\nWARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:4070: The name tf.nn.max_pool is deprecated. Please use tf.nn.max_pool2d instead.\n\nWARNING:tensorflow:From /opt/conda/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:4074: The name tf.nn.avg_pool is deprecated. Please use tf.nn.avg_pool2d instead.\n\n"
]
],
[
[
"View a summary of the model",
"_____no_output_____"
]
],
[
[
"# Print the model summary\nbase_model.summary()",
"Model: \"densenet121\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) (None, None, None, 3 0 \n__________________________________________________________________________________________________\nzero_padding2d_1 (ZeroPadding2D (None, None, None, 3 0 input_1[0][0] \n__________________________________________________________________________________________________\nconv1/conv (Conv2D) (None, None, None, 6 9408 zero_padding2d_1[0][0] \n__________________________________________________________________________________________________\nconv1/bn (BatchNormalization) (None, None, None, 6 256 conv1/conv[0][0] \n__________________________________________________________________________________________________\nconv1/relu (Activation) (None, None, None, 6 0 conv1/bn[0][0] \n__________________________________________________________________________________________________\nzero_padding2d_2 (ZeroPadding2D (None, None, None, 6 0 conv1/relu[0][0] \n__________________________________________________________________________________________________\npool1 (MaxPooling2D) (None, None, None, 6 0 zero_padding2d_2[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_bn (BatchNormali (None, None, None, 6 256 pool1[0][0] \n__________________________________________________________________________________________________\nconv2_block1_0_relu (Activation (None, None, None, 6 0 conv2_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_conv (Conv2D) (None, None, None, 1 8192 conv2_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_bn (BatchNormali (None, None, None, 1 512 conv2_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block1_1_relu (Activation (None, None, None, 1 0 conv2_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block1_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block1_concat (Concatenat (None, None, None, 9 0 pool1[0][0] \n conv2_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_bn (BatchNormali (None, None, None, 9 384 conv2_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block2_0_relu (Activation (None, None, None, 9 0 conv2_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_conv (Conv2D) (None, None, None, 1 12288 conv2_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_bn (BatchNormali (None, None, None, 1 512 conv2_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block2_1_relu (Activation (None, None, None, 1 0 conv2_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block2_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block2_concat (Concatenat (None, None, None, 1 0 conv2_block1_concat[0][0] \n conv2_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_bn (BatchNormali (None, None, None, 1 512 conv2_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block3_0_relu (Activation (None, None, None, 1 0 conv2_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_conv (Conv2D) (None, None, None, 1 16384 conv2_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_bn (BatchNormali (None, None, None, 1 512 conv2_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block3_1_relu (Activation (None, None, None, 1 0 conv2_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block3_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block3_concat (Concatenat (None, None, None, 1 0 conv2_block2_concat[0][0] \n conv2_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_bn (BatchNormali (None, None, None, 1 640 conv2_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block4_0_relu (Activation (None, None, None, 1 0 conv2_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_conv (Conv2D) (None, None, None, 1 20480 conv2_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_bn (BatchNormali (None, None, None, 1 512 conv2_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block4_1_relu (Activation (None, None, None, 1 0 conv2_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block4_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block4_concat (Concatenat (None, None, None, 1 0 conv2_block3_concat[0][0] \n conv2_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_bn (BatchNormali (None, None, None, 1 768 conv2_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block5_0_relu (Activation (None, None, None, 1 0 conv2_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_conv (Conv2D) (None, None, None, 1 24576 conv2_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_bn (BatchNormali (None, None, None, 1 512 conv2_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block5_1_relu (Activation (None, None, None, 1 0 conv2_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block5_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block5_concat (Concatenat (None, None, None, 2 0 conv2_block4_concat[0][0] \n conv2_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_bn (BatchNormali (None, None, None, 2 896 conv2_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv2_block6_0_relu (Activation (None, None, None, 2 0 conv2_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_conv (Conv2D) (None, None, None, 1 28672 conv2_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_bn (BatchNormali (None, None, None, 1 512 conv2_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv2_block6_1_relu (Activation (None, None, None, 1 0 conv2_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv2_block6_2_conv (Conv2D) (None, None, None, 3 36864 conv2_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv2_block6_concat (Concatenat (None, None, None, 2 0 conv2_block5_concat[0][0] \n conv2_block6_2_conv[0][0] \n__________________________________________________________________________________________________\npool2_bn (BatchNormalization) (None, None, None, 2 1024 conv2_block6_concat[0][0] \n__________________________________________________________________________________________________\npool2_relu (Activation) (None, None, None, 2 0 pool2_bn[0][0] \n__________________________________________________________________________________________________\npool2_conv (Conv2D) (None, None, None, 1 32768 pool2_relu[0][0] \n__________________________________________________________________________________________________\npool2_pool (AveragePooling2D) (None, None, None, 1 0 pool2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_bn (BatchNormali (None, None, None, 1 512 pool2_pool[0][0] \n__________________________________________________________________________________________________\nconv3_block1_0_relu (Activation (None, None, None, 1 0 conv3_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_conv (Conv2D) (None, None, None, 1 16384 conv3_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_bn (BatchNormali (None, None, None, 1 512 conv3_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block1_1_relu (Activation (None, None, None, 1 0 conv3_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block1_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block1_concat (Concatenat (None, None, None, 1 0 pool2_pool[0][0] \n conv3_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_bn (BatchNormali (None, None, None, 1 640 conv3_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block2_0_relu (Activation (None, None, None, 1 0 conv3_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_conv (Conv2D) (None, None, None, 1 20480 conv3_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_bn (BatchNormali (None, None, None, 1 512 conv3_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block2_1_relu (Activation (None, None, None, 1 0 conv3_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block2_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block2_concat (Concatenat (None, None, None, 1 0 conv3_block1_concat[0][0] \n conv3_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_bn (BatchNormali (None, None, None, 1 768 conv3_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block3_0_relu (Activation (None, None, None, 1 0 conv3_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_conv (Conv2D) (None, None, None, 1 24576 conv3_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_bn (BatchNormali (None, None, None, 1 512 conv3_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block3_1_relu (Activation (None, None, None, 1 0 conv3_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block3_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block3_concat (Concatenat (None, None, None, 2 0 conv3_block2_concat[0][0] \n conv3_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_bn (BatchNormali (None, None, None, 2 896 conv3_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block4_0_relu (Activation (None, None, None, 2 0 conv3_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_conv (Conv2D) (None, None, None, 1 28672 conv3_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_bn (BatchNormali (None, None, None, 1 512 conv3_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block4_1_relu (Activation (None, None, None, 1 0 conv3_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block4_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block4_concat (Concatenat (None, None, None, 2 0 conv3_block3_concat[0][0] \n conv3_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_bn (BatchNormali (None, None, None, 2 1024 conv3_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block5_0_relu (Activation (None, None, None, 2 0 conv3_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_conv (Conv2D) (None, None, None, 1 32768 conv3_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_bn (BatchNormali (None, None, None, 1 512 conv3_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block5_1_relu (Activation (None, None, None, 1 0 conv3_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block5_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block5_concat (Concatenat (None, None, None, 2 0 conv3_block4_concat[0][0] \n conv3_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_bn (BatchNormali (None, None, None, 2 1152 conv3_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block6_0_relu (Activation (None, None, None, 2 0 conv3_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_conv (Conv2D) (None, None, None, 1 36864 conv3_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_bn (BatchNormali (None, None, None, 1 512 conv3_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block6_1_relu (Activation (None, None, None, 1 0 conv3_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block6_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block6_concat (Concatenat (None, None, None, 3 0 conv3_block5_concat[0][0] \n conv3_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_bn (BatchNormali (None, None, None, 3 1280 conv3_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block7_0_relu (Activation (None, None, None, 3 0 conv3_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_conv (Conv2D) (None, None, None, 1 40960 conv3_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_bn (BatchNormali (None, None, None, 1 512 conv3_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block7_1_relu (Activation (None, None, None, 1 0 conv3_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block7_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block7_concat (Concatenat (None, None, None, 3 0 conv3_block6_concat[0][0] \n conv3_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_bn (BatchNormali (None, None, None, 3 1408 conv3_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block8_0_relu (Activation (None, None, None, 3 0 conv3_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_conv (Conv2D) (None, None, None, 1 45056 conv3_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_bn (BatchNormali (None, None, None, 1 512 conv3_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block8_1_relu (Activation (None, None, None, 1 0 conv3_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block8_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block8_concat (Concatenat (None, None, None, 3 0 conv3_block7_concat[0][0] \n conv3_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_bn (BatchNormali (None, None, None, 3 1536 conv3_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block9_0_relu (Activation (None, None, None, 3 0 conv3_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_conv (Conv2D) (None, None, None, 1 49152 conv3_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_bn (BatchNormali (None, None, None, 1 512 conv3_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block9_1_relu (Activation (None, None, None, 1 0 conv3_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block9_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block9_concat (Concatenat (None, None, None, 4 0 conv3_block8_concat[0][0] \n conv3_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_bn (BatchNormal (None, None, None, 4 1664 conv3_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block10_0_relu (Activatio (None, None, None, 4 0 conv3_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_conv (Conv2D) (None, None, None, 1 53248 conv3_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_bn (BatchNormal (None, None, None, 1 512 conv3_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block10_1_relu (Activatio (None, None, None, 1 0 conv3_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block10_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block10_concat (Concatena (None, None, None, 4 0 conv3_block9_concat[0][0] \n conv3_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_bn (BatchNormal (None, None, None, 4 1792 conv3_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block11_0_relu (Activatio (None, None, None, 4 0 conv3_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_conv (Conv2D) (None, None, None, 1 57344 conv3_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_bn (BatchNormal (None, None, None, 1 512 conv3_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block11_1_relu (Activatio (None, None, None, 1 0 conv3_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block11_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block11_concat (Concatena (None, None, None, 4 0 conv3_block10_concat[0][0] \n conv3_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_bn (BatchNormal (None, None, None, 4 1920 conv3_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv3_block12_0_relu (Activatio (None, None, None, 4 0 conv3_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_conv (Conv2D) (None, None, None, 1 61440 conv3_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_bn (BatchNormal (None, None, None, 1 512 conv3_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv3_block12_1_relu (Activatio (None, None, None, 1 0 conv3_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv3_block12_2_conv (Conv2D) (None, None, None, 3 36864 conv3_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv3_block12_concat (Concatena (None, None, None, 5 0 conv3_block11_concat[0][0] \n conv3_block12_2_conv[0][0] \n__________________________________________________________________________________________________\npool3_bn (BatchNormalization) (None, None, None, 5 2048 conv3_block12_concat[0][0] \n__________________________________________________________________________________________________\npool3_relu (Activation) (None, None, None, 5 0 pool3_bn[0][0] \n__________________________________________________________________________________________________\npool3_conv (Conv2D) (None, None, None, 2 131072 pool3_relu[0][0] \n__________________________________________________________________________________________________\npool3_pool (AveragePooling2D) (None, None, None, 2 0 pool3_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_bn (BatchNormali (None, None, None, 2 1024 pool3_pool[0][0] \n__________________________________________________________________________________________________\nconv4_block1_0_relu (Activation (None, None, None, 2 0 conv4_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_conv (Conv2D) (None, None, None, 1 32768 conv4_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_bn (BatchNormali (None, None, None, 1 512 conv4_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block1_1_relu (Activation (None, None, None, 1 0 conv4_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block1_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block1_concat (Concatenat (None, None, None, 2 0 pool3_pool[0][0] \n conv4_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_bn (BatchNormali (None, None, None, 2 1152 conv4_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block2_0_relu (Activation (None, None, None, 2 0 conv4_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_conv (Conv2D) (None, None, None, 1 36864 conv4_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_bn (BatchNormali (None, None, None, 1 512 conv4_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block2_1_relu (Activation (None, None, None, 1 0 conv4_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block2_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block2_concat (Concatenat (None, None, None, 3 0 conv4_block1_concat[0][0] \n conv4_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_bn (BatchNormali (None, None, None, 3 1280 conv4_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block3_0_relu (Activation (None, None, None, 3 0 conv4_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_conv (Conv2D) (None, None, None, 1 40960 conv4_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_bn (BatchNormali (None, None, None, 1 512 conv4_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block3_1_relu (Activation (None, None, None, 1 0 conv4_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block3_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block3_concat (Concatenat (None, None, None, 3 0 conv4_block2_concat[0][0] \n conv4_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_bn (BatchNormali (None, None, None, 3 1408 conv4_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block4_0_relu (Activation (None, None, None, 3 0 conv4_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_conv (Conv2D) (None, None, None, 1 45056 conv4_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_bn (BatchNormali (None, None, None, 1 512 conv4_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block4_1_relu (Activation (None, None, None, 1 0 conv4_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block4_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block4_concat (Concatenat (None, None, None, 3 0 conv4_block3_concat[0][0] \n conv4_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_bn (BatchNormali (None, None, None, 3 1536 conv4_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block5_0_relu (Activation (None, None, None, 3 0 conv4_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_conv (Conv2D) (None, None, None, 1 49152 conv4_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_bn (BatchNormali (None, None, None, 1 512 conv4_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block5_1_relu (Activation (None, None, None, 1 0 conv4_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block5_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block5_concat (Concatenat (None, None, None, 4 0 conv4_block4_concat[0][0] \n conv4_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_bn (BatchNormali (None, None, None, 4 1664 conv4_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block6_0_relu (Activation (None, None, None, 4 0 conv4_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_conv (Conv2D) (None, None, None, 1 53248 conv4_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_bn (BatchNormali (None, None, None, 1 512 conv4_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block6_1_relu (Activation (None, None, None, 1 0 conv4_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block6_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block6_concat (Concatenat (None, None, None, 4 0 conv4_block5_concat[0][0] \n conv4_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_bn (BatchNormali (None, None, None, 4 1792 conv4_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block7_0_relu (Activation (None, None, None, 4 0 conv4_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_conv (Conv2D) (None, None, None, 1 57344 conv4_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_bn (BatchNormali (None, None, None, 1 512 conv4_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block7_1_relu (Activation (None, None, None, 1 0 conv4_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block7_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block7_concat (Concatenat (None, None, None, 4 0 conv4_block6_concat[0][0] \n conv4_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_bn (BatchNormali (None, None, None, 4 1920 conv4_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block8_0_relu (Activation (None, None, None, 4 0 conv4_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_conv (Conv2D) (None, None, None, 1 61440 conv4_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_bn (BatchNormali (None, None, None, 1 512 conv4_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block8_1_relu (Activation (None, None, None, 1 0 conv4_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block8_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block8_concat (Concatenat (None, None, None, 5 0 conv4_block7_concat[0][0] \n conv4_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_bn (BatchNormali (None, None, None, 5 2048 conv4_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block9_0_relu (Activation (None, None, None, 5 0 conv4_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_conv (Conv2D) (None, None, None, 1 65536 conv4_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_bn (BatchNormali (None, None, None, 1 512 conv4_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block9_1_relu (Activation (None, None, None, 1 0 conv4_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block9_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block9_concat (Concatenat (None, None, None, 5 0 conv4_block8_concat[0][0] \n conv4_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_bn (BatchNormal (None, None, None, 5 2176 conv4_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block10_0_relu (Activatio (None, None, None, 5 0 conv4_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_conv (Conv2D) (None, None, None, 1 69632 conv4_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_bn (BatchNormal (None, None, None, 1 512 conv4_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block10_1_relu (Activatio (None, None, None, 1 0 conv4_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block10_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block10_concat (Concatena (None, None, None, 5 0 conv4_block9_concat[0][0] \n conv4_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_bn (BatchNormal (None, None, None, 5 2304 conv4_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block11_0_relu (Activatio (None, None, None, 5 0 conv4_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_conv (Conv2D) (None, None, None, 1 73728 conv4_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_bn (BatchNormal (None, None, None, 1 512 conv4_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block11_1_relu (Activatio (None, None, None, 1 0 conv4_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block11_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block11_concat (Concatena (None, None, None, 6 0 conv4_block10_concat[0][0] \n conv4_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_bn (BatchNormal (None, None, None, 6 2432 conv4_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block12_0_relu (Activatio (None, None, None, 6 0 conv4_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_conv (Conv2D) (None, None, None, 1 77824 conv4_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_bn (BatchNormal (None, None, None, 1 512 conv4_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block12_1_relu (Activatio (None, None, None, 1 0 conv4_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block12_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block12_concat (Concatena (None, None, None, 6 0 conv4_block11_concat[0][0] \n conv4_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_bn (BatchNormal (None, None, None, 6 2560 conv4_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block13_0_relu (Activatio (None, None, None, 6 0 conv4_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_conv (Conv2D) (None, None, None, 1 81920 conv4_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_bn (BatchNormal (None, None, None, 1 512 conv4_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block13_1_relu (Activatio (None, None, None, 1 0 conv4_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block13_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block13_concat (Concatena (None, None, None, 6 0 conv4_block12_concat[0][0] \n conv4_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_bn (BatchNormal (None, None, None, 6 2688 conv4_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block14_0_relu (Activatio (None, None, None, 6 0 conv4_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_conv (Conv2D) (None, None, None, 1 86016 conv4_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_bn (BatchNormal (None, None, None, 1 512 conv4_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block14_1_relu (Activatio (None, None, None, 1 0 conv4_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block14_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block14_concat (Concatena (None, None, None, 7 0 conv4_block13_concat[0][0] \n conv4_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_bn (BatchNormal (None, None, None, 7 2816 conv4_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block15_0_relu (Activatio (None, None, None, 7 0 conv4_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_conv (Conv2D) (None, None, None, 1 90112 conv4_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_bn (BatchNormal (None, None, None, 1 512 conv4_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block15_1_relu (Activatio (None, None, None, 1 0 conv4_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block15_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block15_concat (Concatena (None, None, None, 7 0 conv4_block14_concat[0][0] \n conv4_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_bn (BatchNormal (None, None, None, 7 2944 conv4_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block16_0_relu (Activatio (None, None, None, 7 0 conv4_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_conv (Conv2D) (None, None, None, 1 94208 conv4_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_bn (BatchNormal (None, None, None, 1 512 conv4_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block16_1_relu (Activatio (None, None, None, 1 0 conv4_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block16_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block16_concat (Concatena (None, None, None, 7 0 conv4_block15_concat[0][0] \n conv4_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_bn (BatchNormal (None, None, None, 7 3072 conv4_block16_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block17_0_relu (Activatio (None, None, None, 7 0 conv4_block17_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_conv (Conv2D) (None, None, None, 1 98304 conv4_block17_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_bn (BatchNormal (None, None, None, 1 512 conv4_block17_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block17_1_relu (Activatio (None, None, None, 1 0 conv4_block17_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block17_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block17_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block17_concat (Concatena (None, None, None, 8 0 conv4_block16_concat[0][0] \n conv4_block17_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_bn (BatchNormal (None, None, None, 8 3200 conv4_block17_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block18_0_relu (Activatio (None, None, None, 8 0 conv4_block18_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_conv (Conv2D) (None, None, None, 1 102400 conv4_block18_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_bn (BatchNormal (None, None, None, 1 512 conv4_block18_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block18_1_relu (Activatio (None, None, None, 1 0 conv4_block18_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block18_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block18_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block18_concat (Concatena (None, None, None, 8 0 conv4_block17_concat[0][0] \n conv4_block18_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_bn (BatchNormal (None, None, None, 8 3328 conv4_block18_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block19_0_relu (Activatio (None, None, None, 8 0 conv4_block19_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_conv (Conv2D) (None, None, None, 1 106496 conv4_block19_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_bn (BatchNormal (None, None, None, 1 512 conv4_block19_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block19_1_relu (Activatio (None, None, None, 1 0 conv4_block19_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block19_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block19_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block19_concat (Concatena (None, None, None, 8 0 conv4_block18_concat[0][0] \n conv4_block19_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_bn (BatchNormal (None, None, None, 8 3456 conv4_block19_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block20_0_relu (Activatio (None, None, None, 8 0 conv4_block20_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_conv (Conv2D) (None, None, None, 1 110592 conv4_block20_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_bn (BatchNormal (None, None, None, 1 512 conv4_block20_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block20_1_relu (Activatio (None, None, None, 1 0 conv4_block20_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block20_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block20_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block20_concat (Concatena (None, None, None, 8 0 conv4_block19_concat[0][0] \n conv4_block20_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_bn (BatchNormal (None, None, None, 8 3584 conv4_block20_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block21_0_relu (Activatio (None, None, None, 8 0 conv4_block21_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_conv (Conv2D) (None, None, None, 1 114688 conv4_block21_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_bn (BatchNormal (None, None, None, 1 512 conv4_block21_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block21_1_relu (Activatio (None, None, None, 1 0 conv4_block21_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block21_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block21_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block21_concat (Concatena (None, None, None, 9 0 conv4_block20_concat[0][0] \n conv4_block21_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_bn (BatchNormal (None, None, None, 9 3712 conv4_block21_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block22_0_relu (Activatio (None, None, None, 9 0 conv4_block22_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_conv (Conv2D) (None, None, None, 1 118784 conv4_block22_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_bn (BatchNormal (None, None, None, 1 512 conv4_block22_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block22_1_relu (Activatio (None, None, None, 1 0 conv4_block22_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block22_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block22_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block22_concat (Concatena (None, None, None, 9 0 conv4_block21_concat[0][0] \n conv4_block22_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_bn (BatchNormal (None, None, None, 9 3840 conv4_block22_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block23_0_relu (Activatio (None, None, None, 9 0 conv4_block23_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_conv (Conv2D) (None, None, None, 1 122880 conv4_block23_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_bn (BatchNormal (None, None, None, 1 512 conv4_block23_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block23_1_relu (Activatio (None, None, None, 1 0 conv4_block23_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block23_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block23_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block23_concat (Concatena (None, None, None, 9 0 conv4_block22_concat[0][0] \n conv4_block23_2_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_bn (BatchNormal (None, None, None, 9 3968 conv4_block23_concat[0][0] \n__________________________________________________________________________________________________\nconv4_block24_0_relu (Activatio (None, None, None, 9 0 conv4_block24_0_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_conv (Conv2D) (None, None, None, 1 126976 conv4_block24_0_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_bn (BatchNormal (None, None, None, 1 512 conv4_block24_1_conv[0][0] \n__________________________________________________________________________________________________\nconv4_block24_1_relu (Activatio (None, None, None, 1 0 conv4_block24_1_bn[0][0] \n__________________________________________________________________________________________________\nconv4_block24_2_conv (Conv2D) (None, None, None, 3 36864 conv4_block24_1_relu[0][0] \n__________________________________________________________________________________________________\nconv4_block24_concat (Concatena (None, None, None, 1 0 conv4_block23_concat[0][0] \n conv4_block24_2_conv[0][0] \n__________________________________________________________________________________________________\npool4_bn (BatchNormalization) (None, None, None, 1 4096 conv4_block24_concat[0][0] \n__________________________________________________________________________________________________\npool4_relu (Activation) (None, None, None, 1 0 pool4_bn[0][0] \n__________________________________________________________________________________________________\npool4_conv (Conv2D) (None, None, None, 5 524288 pool4_relu[0][0] \n__________________________________________________________________________________________________\npool4_pool (AveragePooling2D) (None, None, None, 5 0 pool4_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_bn (BatchNormali (None, None, None, 5 2048 pool4_pool[0][0] \n__________________________________________________________________________________________________\nconv5_block1_0_relu (Activation (None, None, None, 5 0 conv5_block1_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_conv (Conv2D) (None, None, None, 1 65536 conv5_block1_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_bn (BatchNormali (None, None, None, 1 512 conv5_block1_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block1_1_relu (Activation (None, None, None, 1 0 conv5_block1_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block1_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block1_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block1_concat (Concatenat (None, None, None, 5 0 pool4_pool[0][0] \n conv5_block1_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_bn (BatchNormali (None, None, None, 5 2176 conv5_block1_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block2_0_relu (Activation (None, None, None, 5 0 conv5_block2_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_conv (Conv2D) (None, None, None, 1 69632 conv5_block2_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_bn (BatchNormali (None, None, None, 1 512 conv5_block2_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block2_1_relu (Activation (None, None, None, 1 0 conv5_block2_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block2_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block2_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block2_concat (Concatenat (None, None, None, 5 0 conv5_block1_concat[0][0] \n conv5_block2_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_bn (BatchNormali (None, None, None, 5 2304 conv5_block2_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block3_0_relu (Activation (None, None, None, 5 0 conv5_block3_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_conv (Conv2D) (None, None, None, 1 73728 conv5_block3_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_bn (BatchNormali (None, None, None, 1 512 conv5_block3_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block3_1_relu (Activation (None, None, None, 1 0 conv5_block3_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block3_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block3_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block3_concat (Concatenat (None, None, None, 6 0 conv5_block2_concat[0][0] \n conv5_block3_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_bn (BatchNormali (None, None, None, 6 2432 conv5_block3_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block4_0_relu (Activation (None, None, None, 6 0 conv5_block4_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_conv (Conv2D) (None, None, None, 1 77824 conv5_block4_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_bn (BatchNormali (None, None, None, 1 512 conv5_block4_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block4_1_relu (Activation (None, None, None, 1 0 conv5_block4_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block4_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block4_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block4_concat (Concatenat (None, None, None, 6 0 conv5_block3_concat[0][0] \n conv5_block4_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_bn (BatchNormali (None, None, None, 6 2560 conv5_block4_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block5_0_relu (Activation (None, None, None, 6 0 conv5_block5_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_conv (Conv2D) (None, None, None, 1 81920 conv5_block5_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_bn (BatchNormali (None, None, None, 1 512 conv5_block5_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block5_1_relu (Activation (None, None, None, 1 0 conv5_block5_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block5_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block5_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block5_concat (Concatenat (None, None, None, 6 0 conv5_block4_concat[0][0] \n conv5_block5_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_bn (BatchNormali (None, None, None, 6 2688 conv5_block5_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block6_0_relu (Activation (None, None, None, 6 0 conv5_block6_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_conv (Conv2D) (None, None, None, 1 86016 conv5_block6_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_bn (BatchNormali (None, None, None, 1 512 conv5_block6_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block6_1_relu (Activation (None, None, None, 1 0 conv5_block6_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block6_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block6_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block6_concat (Concatenat (None, None, None, 7 0 conv5_block5_concat[0][0] \n conv5_block6_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_bn (BatchNormali (None, None, None, 7 2816 conv5_block6_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block7_0_relu (Activation (None, None, None, 7 0 conv5_block7_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_conv (Conv2D) (None, None, None, 1 90112 conv5_block7_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_bn (BatchNormali (None, None, None, 1 512 conv5_block7_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block7_1_relu (Activation (None, None, None, 1 0 conv5_block7_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block7_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block7_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block7_concat (Concatenat (None, None, None, 7 0 conv5_block6_concat[0][0] \n conv5_block7_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_bn (BatchNormali (None, None, None, 7 2944 conv5_block7_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block8_0_relu (Activation (None, None, None, 7 0 conv5_block8_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_conv (Conv2D) (None, None, None, 1 94208 conv5_block8_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_bn (BatchNormali (None, None, None, 1 512 conv5_block8_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block8_1_relu (Activation (None, None, None, 1 0 conv5_block8_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block8_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block8_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block8_concat (Concatenat (None, None, None, 7 0 conv5_block7_concat[0][0] \n conv5_block8_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_bn (BatchNormali (None, None, None, 7 3072 conv5_block8_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block9_0_relu (Activation (None, None, None, 7 0 conv5_block9_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_conv (Conv2D) (None, None, None, 1 98304 conv5_block9_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_bn (BatchNormali (None, None, None, 1 512 conv5_block9_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block9_1_relu (Activation (None, None, None, 1 0 conv5_block9_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block9_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block9_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block9_concat (Concatenat (None, None, None, 8 0 conv5_block8_concat[0][0] \n conv5_block9_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_bn (BatchNormal (None, None, None, 8 3200 conv5_block9_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block10_0_relu (Activatio (None, None, None, 8 0 conv5_block10_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_conv (Conv2D) (None, None, None, 1 102400 conv5_block10_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_bn (BatchNormal (None, None, None, 1 512 conv5_block10_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block10_1_relu (Activatio (None, None, None, 1 0 conv5_block10_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block10_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block10_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block10_concat (Concatena (None, None, None, 8 0 conv5_block9_concat[0][0] \n conv5_block10_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_bn (BatchNormal (None, None, None, 8 3328 conv5_block10_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block11_0_relu (Activatio (None, None, None, 8 0 conv5_block11_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_conv (Conv2D) (None, None, None, 1 106496 conv5_block11_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_bn (BatchNormal (None, None, None, 1 512 conv5_block11_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block11_1_relu (Activatio (None, None, None, 1 0 conv5_block11_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block11_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block11_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block11_concat (Concatena (None, None, None, 8 0 conv5_block10_concat[0][0] \n conv5_block11_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_bn (BatchNormal (None, None, None, 8 3456 conv5_block11_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block12_0_relu (Activatio (None, None, None, 8 0 conv5_block12_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_conv (Conv2D) (None, None, None, 1 110592 conv5_block12_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_bn (BatchNormal (None, None, None, 1 512 conv5_block12_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block12_1_relu (Activatio (None, None, None, 1 0 conv5_block12_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block12_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block12_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block12_concat (Concatena (None, None, None, 8 0 conv5_block11_concat[0][0] \n conv5_block12_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_bn (BatchNormal (None, None, None, 8 3584 conv5_block12_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block13_0_relu (Activatio (None, None, None, 8 0 conv5_block13_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_conv (Conv2D) (None, None, None, 1 114688 conv5_block13_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_bn (BatchNormal (None, None, None, 1 512 conv5_block13_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block13_1_relu (Activatio (None, None, None, 1 0 conv5_block13_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block13_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block13_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block13_concat (Concatena (None, None, None, 9 0 conv5_block12_concat[0][0] \n conv5_block13_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_bn (BatchNormal (None, None, None, 9 3712 conv5_block13_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block14_0_relu (Activatio (None, None, None, 9 0 conv5_block14_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_conv (Conv2D) (None, None, None, 1 118784 conv5_block14_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_bn (BatchNormal (None, None, None, 1 512 conv5_block14_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block14_1_relu (Activatio (None, None, None, 1 0 conv5_block14_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block14_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block14_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block14_concat (Concatena (None, None, None, 9 0 conv5_block13_concat[0][0] \n conv5_block14_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_bn (BatchNormal (None, None, None, 9 3840 conv5_block14_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block15_0_relu (Activatio (None, None, None, 9 0 conv5_block15_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_conv (Conv2D) (None, None, None, 1 122880 conv5_block15_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_bn (BatchNormal (None, None, None, 1 512 conv5_block15_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block15_1_relu (Activatio (None, None, None, 1 0 conv5_block15_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block15_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block15_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block15_concat (Concatena (None, None, None, 9 0 conv5_block14_concat[0][0] \n conv5_block15_2_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_bn (BatchNormal (None, None, None, 9 3968 conv5_block15_concat[0][0] \n__________________________________________________________________________________________________\nconv5_block16_0_relu (Activatio (None, None, None, 9 0 conv5_block16_0_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_conv (Conv2D) (None, None, None, 1 126976 conv5_block16_0_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_bn (BatchNormal (None, None, None, 1 512 conv5_block16_1_conv[0][0] \n__________________________________________________________________________________________________\nconv5_block16_1_relu (Activatio (None, None, None, 1 0 conv5_block16_1_bn[0][0] \n__________________________________________________________________________________________________\nconv5_block16_2_conv (Conv2D) (None, None, None, 3 36864 conv5_block16_1_relu[0][0] \n__________________________________________________________________________________________________\nconv5_block16_concat (Concatena (None, None, None, 1 0 conv5_block15_concat[0][0] \n conv5_block16_2_conv[0][0] \n__________________________________________________________________________________________________\nbn (BatchNormalization) (None, None, None, 1 4096 conv5_block16_concat[0][0] \n__________________________________________________________________________________________________\nrelu (Activation) (None, None, None, 1 0 bn[0][0] \n==================================================================================================\nTotal params: 7,037,504\nTrainable params: 6,953,856\nNon-trainable params: 83,648\n__________________________________________________________________________________________________\n"
],
[
"# Print out the first five layers\nlayers_l = base_model.layers\n\nprint(\"First 5 layers\")\nlayers_l[0:5]",
"First 5 layers\n"
],
[
"# Print out the last five layers\nprint(\"Last 5 layers\")\nlayers_l[-6:-1]",
"Last 5 layers\n"
],
[
"# Get the convolutional layers and print the first 5\nconv2D_layers = [layer for layer in base_model.layers \n if str(type(layer)).find('Conv2D') > -1]\nprint(\"The first five conv2D layers\")\nconv2D_layers[0:5]",
"The first five conv2D layers\n"
],
[
"# Print out the total number of convolutional layers\nprint(f\"There are {len(conv2D_layers)} convolutional layers\")",
"There are 120 convolutional layers\n"
],
[
"# Print the number of channels in the input\nprint(\"The input has 3 channels\")\nbase_model.input",
"The input has 3 channels\n"
],
[
"# Print the number of output channels\nprint(\"The output has 1024 channels\")\nx = base_model.output\nx",
"The output has 1024 channels\n"
],
[
"# Add a global spatial average pooling layer\nx_pool = GlobalAveragePooling2D()(x)\nx_pool",
"_____no_output_____"
],
[
"# Define a set of five class labels to use as an example\nlabels = ['Emphysema', \n 'Hernia', \n 'Mass', \n 'Pneumonia', \n 'Edema']\nn_classes = len(labels)\nprint(f\"In this example, you want your model to identify {n_classes} classes\")",
"In this example, you want your model to identify 5 classes\n"
],
[
"# Add a logistic layer the same size as the number of classes you're trying to predict\npredictions = Dense(n_classes, activation=\"sigmoid\")(x_pool)\nprint(f\"Predictions have {n_classes} units, one for each class\")\npredictions",
"_____no_output_____"
],
[
"# Create an updated model\nmodel = Model(inputs=base_model.input, outputs=predictions)",
"_____no_output_____"
],
[
"# Compile the model\nmodel.compile(optimizer='adam',\n loss='categorical_crossentropy')\n# (You'll customize the loss function in the assignment!)",
"_____no_output_____"
]
],
[
[
"#### This has been a brief exploration of the Densenet architecture you'll use in this week's graded assignment!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
cbd1f877bbe1299660a8c2d3ed25d188c1abe321
| 28,993 |
ipynb
|
Jupyter Notebook
|
GoogleSheetsExample/goodPendulumMeausurementAnlysis.ipynb
|
PhysicsUofRAUI/some-kaggle-notebooks
|
6c6c01535ee0815d5c81e4d9bfad9be976a6ad73
|
[
"MIT"
] | null | null | null |
GoogleSheetsExample/goodPendulumMeausurementAnlysis.ipynb
|
PhysicsUofRAUI/some-kaggle-notebooks
|
6c6c01535ee0815d5c81e4d9bfad9be976a6ad73
|
[
"MIT"
] | null | null | null |
GoogleSheetsExample/goodPendulumMeausurementAnlysis.ipynb
|
PhysicsUofRAUI/some-kaggle-notebooks
|
6c6c01535ee0815d5c81e4d9bfad9be976a6ad73
|
[
"MIT"
] | null | null | null | 34.805522 | 1,006 | 0.417825 |
[
[
[
"# Set Up\nThe first 5 lines are importing libraries that will be needed later in the notebook. The next lines are setting up the connection to the google service account.\n\n# Getting a Google Service Account\nHere is another great tutorial on using Google Sheets and in the begining it shows the steps to create a google service account to use: https://www.twilio.com/blog/2017/02/an-easy-way-to-read-and-write-to-a-google-spreadsheet-in-python.html.\n\nAfter setting up the service account you have to share the google sheet with the service account so that it has permission to access it. Then all you have to do is add you client_secret.json file so that the service account can be authorized.\n\n# Drive Folder\nThe drive folder were the sheets discussed here can be found at: https://drive.google.com/drive/folders/1FoTM8DRPcfbevmKnmUQN1-LPvE4oE9hJ?usp=sharing.\n\nThe Google Sheets that end with 'Orig' is how the Google sheet looked before I ran this notebook and the Google Sheets that end with 'Calculations' is what it looks like after I have ran this notebook.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport csv\nimport gspread\nfrom oauth2client.service_account import ServiceAccountCredentials\n\nscope = ['https://spreadsheets.google.com/feeds',\n'https://www.googleapis.com/auth/drive']\ncreds = ServiceAccountCredentials.from_json_keyfile_name('client_secret.json', scope)\nclient = gspread.authorize(creds)",
"_____no_output_____"
]
],
[
[
"# Create Pandas Dataframes\nIn the next cell I will create two pandas dataframes each containing one of the two google sheets that I will connect to. \n\nThe first thing to do is to open the Google Sheets so that they can be manipulated. After the sheets are I opened I used the 'get_all_values()' function to get all of the data from that Google sheet. Now the 'get_all_values()' function returns a list of lists which is not my prefered data structure for doing math operations on. \n\nI decided to create a dataframe out of each of those list of lists. I set the columns of the dataframe to the first list in the list, and then all the other lists were set as the data.\n\nThe last thing I do in this cell is print out one of the finished dataframes.",
"_____no_output_____"
]
],
[
[
"# open the google sheets\npendulum_1 = client.open('pendulum1GoodMeasurementsCalculations').sheet1\n\npendulum_2 = client.open('pendulum2GoodMeasurementsCalculations').sheet1\n\n#read in the data from the spreadsheet\npendulum_1_data = pendulum_1.get_all_values()\n\npendulum_2_data = pendulum_2.get_all_values()\n\n# make a pandas dataframe out of the data\npendulum_1_df = pd.DataFrame(pendulum_1_data[1:], columns = pendulum_1_data[0])\n\npendulum_2_df = pd.DataFrame(pendulum_2_data[1:], columns = pendulum_2_data[0])\n\n\n# print out the data from one of the sheets as an example\npendulum_2_df",
"_____no_output_____"
]
],
[
[
"# Convert Strings to Numeric Values\nFor some reason the default data type of values read in from Google Sheets are strings. I can not do math operations on strings so the next cell converts the columns that I need to work with to numeric values. ",
"_____no_output_____"
]
],
[
[
"# Convert the Time and Counts columns to numeric values\npendulum_2_df['Time'] = pd.to_numeric(pendulum_2_df['Time'])\npendulum_2_df['Counts'] = pd.to_numeric(pendulum_2_df['Counts'])\n\npendulum_1_df['Time'] = pd.to_numeric(pendulum_1_df['Time'])\npendulum_1_df['Counts'] = pd.to_numeric(pendulum_1_df['Counts'])",
"_____no_output_____"
]
],
[
[
"# Do My Calculations\nThis data was originally for a lab I did in my last year of university, and the following cell is just copied from the notebook I used for it. \n\nThe lab was Kater's Pendulum and for that lab my lab partners and I had to count the number of times a pendulum passed in front of a sensor while timing how long that took. The first calculation is the period of each of the trials that were done. \n\nAfter getting the period for each trial I calculated the standard deviation and the mean of the those values. \n\nFinally I printed out those values.",
"_____no_output_____"
]
],
[
[
"# Calculate the period of each trial for each pendulum\npendulum_1_df['Period'] = pendulum_1_df['Time'] / (pendulum_1_df['Counts'] / 2)\n\npendulum_2_df['Period'] = pendulum_2_df['Time'] / (pendulum_2_df['Counts'] / 2)\n\n# calculate the standard deviation of each pendulum\nstd_period1 = pendulum_1_df.loc[:,\"Period\"].std()\n\nstd_period2 = pendulum_2_df.loc[:,\"Period\"].std()\n\n# Calculate the mean of each pendulum\nmean_period1 = pendulum_1_df.loc[:,\"Period\"].mean()\n\nmean_period2 = pendulum_2_df.loc[:,\"Period\"].mean()\n\n# print out the mean and error of each period\nprint(\"Period1: \" + str(mean_period1))\n\nprint(\"Period2: \" + str(mean_period2))\n\nprint(\"Period1 error: \" + str(std_period1/np.sqrt(50)))\n\nprint(\"Period2 error: \" + str(std_period2/np.sqrt(50)))",
"Period1: 1.90251632015529\nPeriod2: 1.9031536058307212\nPeriod1 error: 8.400437814259619e-05\nPeriod2 error: 0.000105541906951631\n"
]
],
[
[
"# Get a List of New Values\nIn the following cell I simply took the column that I want to add to Google sheets and made it into a list. ",
"_____no_output_____"
]
],
[
[
"# convert the Period columns to a list\nperiod_1 = pendulum_1_df['Period'].tolist()\n\nperiod_2 = pendulum_2_df['Period'].tolist()\n\nprint(period_1)",
"[1.9026582278481012, 1.9031012658227848, 1.9029113924050634, 1.9024683544303795, 1.9027215189873417, 1.9023417721518987, 1.9018987341772151, 1.9015189873417722, 1.9031012658227848, 1.9029113924050634, 1.9022784810126583, 1.9034810126582278, 1.9030379746835444, 1.9032911392405065, 1.9033333333333333, 1.9017610062893082, 1.9025625000000002, 1.9024683544303795, 1.902919254658385, 1.9030817610062891, 1.9027044025157231, 1.9025157232704402, 1.9027215189873417, 1.9027215189873417, 1.9021383647798742, 1.9019496855345914, 1.9027044025157231, 1.9024683544303795, 1.900943396226415, 1.9023270440251574, 1.9015189873417722, 1.9031012658227848, 1.9026582278481012, 1.9034810126582278, 1.9027215189873417, 1.9020886075949366, 1.9025316455696204, 1.9020886075949366, 1.9022784810126583, 1.9027672955974844, 1.9017499999999998, 1.902919254658385, 1.9027044025157231, 1.9021739130434783, 1.9025157232704402, 1.9032704402515723, 1.9022929936305735, 1.9021383647798742, 1.903076923076923, 1.9006962025316456]\n"
]
],
[
[
"# Updating Google Sheets\nIn the next two cells I update the google sheets with the new 'Period' column. I used the 'update_cell()' function to accomplish this.",
"_____no_output_____"
]
],
[
[
"# add the period column to the pendulum 1 Google Sheet\npendulum_1.update_cell(1, 7, 'Period')\nfor row_index, curr_period in enumerate(period_1):\n pendulum_1.update_cell(row_index + 2, 7, curr_period)",
"_____no_output_____"
],
[
"# add the period column to the pendulum 2 Google Sheet\npendulum_2.update_cell(1, 7, 'Period')\nfor row_index, curr_period in enumerate(period_2):\n pendulum_2.update_cell(row_index + 2, 7, curr_period)",
"_____no_output_____"
]
],
[
[
"# Adding Mean and Error\nTo finish off I added the mean and the error of the period distributions to the end of their respective google sheets.",
"_____no_output_____"
]
],
[
[
"# Add the mean and error in mean calculations to the google sheets.\npendulum_1.update_cell(52, 1, 'Period Mean')\npendulum_1.update_cell(52, 7, mean_period1)\npendulum_1.update_cell(53, 1, 'Error in Mean')\npendulum_1.update_cell(53, 7, std_period1/np.sqrt(50))\n\npendulum_2.update_cell(52, 1, 'Period Mean')\npendulum_2.update_cell(52, 7, mean_period2)\npendulum_2.update_cell(53, 1, 'Error in Mean')\npendulum_2.update_cell(53, 7, std_period2/np.sqrt(50))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd21a5b8f732b9fb54635e9dec91268eee190d8
| 750 |
ipynb
|
Jupyter Notebook
|
Action.ipynb
|
DeepFutures/deepfutures
|
7797b3be3fd69ff934314123a96ac2ba9370d00e
|
[
"Apache-2.0"
] | 2 |
2019-01-18T21:14:26.000Z
|
2019-12-12T10:23:09.000Z
|
Action.ipynb
|
DeepFutures/deepfutures
|
7797b3be3fd69ff934314123a96ac2ba9370d00e
|
[
"Apache-2.0"
] | 4 |
2018-02-01T03:44:12.000Z
|
2018-02-01T04:00:43.000Z
|
Action.ipynb
|
DeepFutures/deepfutures
|
7797b3be3fd69ff934314123a96ac2ba9370d00e
|
[
"Apache-2.0"
] | null | null | null | 19.230769 | 54 | 0.514667 |
[
[
[
"class Action(object):\n def __init__(self, isPass, isLong, bias):\n self.isPass = isPass\n self.isLong = isLong\n self.bias = bias",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
cbd22e227fe7ba06004754af4aa20ec863fe4eb0
| 250,183 |
ipynb
|
Jupyter Notebook
|
rscooler/FBT/warp/FRBT_test.ipynb
|
radiasoft/mcool
|
67f853093f2ff062b4271c77f52c0b146324a046
|
[
"Apache-2.0"
] | 1 |
2017-11-03T18:03:08.000Z
|
2017-11-03T18:03:08.000Z
|
rscooler/FBT/warp/FRBT_test.ipynb
|
radiasoft/rscooler
|
67f853093f2ff062b4271c77f52c0b146324a046
|
[
"Apache-2.0"
] | 1 |
2020-02-14T21:57:40.000Z
|
2020-02-14T21:57:40.000Z
|
rscooler/FBT/warp/FRBT_test.ipynb
|
radiasoft/mcool
|
67f853093f2ff062b4271c77f52c0b146324a046
|
[
"Apache-2.0"
] | null | null | null | 113.874829 | 131,929 | 0.7981 |
[
[
[
"Simple testing of FBT in Warp. Just transform beam in a drift. No solenoid included and no inverse transform.",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook",
"_____no_output_____"
],
[
"import sys\ndel sys.argv[1:]\nfrom warp import *",
"# Warp\n# Origin date: Fri, 15 Apr 2016 10:32:21 -0700\n# Local date: Fri, 15 Apr 2016 10:32:21 -0700\n# Commit hash: 557dfc1\n# /usr/local/lib/python2.7/site-packages/warp/warp.pyc\n# /usr/local/lib/python2.7/site-packages/warp/warpC.so\n# Tue May 10 13:38:16 2016\n# import warp time 0.53919506073 seconds\n# For more help, type warphelp()\n"
],
[
"from warp.data_dumping.openpmd_diag import particle_diag\nimport numpy as np\nimport os\nfrom copy import deepcopy\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"diagDir = 'diags/test/hdf5'\n\ndef cleanupPrevious(outputDirectory = diagDir):\n if os.path.exists(outputDirectory):\n files = os.listdir(outputDirectory)\n for file in files:\n if file.endswith('.h5'):\n os.remove(os.path.join(outputDirectory,file))\n\ncleanupPrevious()\n\ndef setup():\n\tpass",
"_____no_output_____"
],
[
"##########################################\n### Create Beam and Set its Parameters ###\n##########################################\n\ntop.lrelativ = True\ntop.relativity = 1\n\nbeam = Species(type=Electron, name='Electron') \nbeam.ekin = 55e6 #KE = 2.5 MeV\nderivqty() #Sets addition derived parameters (such as beam.vbeam)\n\ntop.emitx = 4.0*800e-6 / top.gammabar # geometric emittance: emit_full = 4 * emit_rms\ntop.emity = 4.0*1e-6 / top.gammabar\nbeam.a0 = sqrt(top.emitx * 5.0)\nbeam.b0 = sqrt(top.emity * 5.0)\nbeam.ap0 = -1 * top.emitx * 0.0 / beam.a0\nbeam.bp0 = -1 * top.emity * 0.0 / beam.b0\n\n\nbeam.vthz = 0 #Sets the longitudinal thermal velocity (see iop_lin_002)\nbeam.ibeam = 0 # beam.ibeam/(top.gammabar**2) #Set correct current for relativity (see iop_lin_002)\n\n\ntop.npmax = 10000\n\nw3d.distrbtn = \"Gaussian0\" \n\nw3d.cylinder = True #Set True if running without envelope solver",
"_____no_output_____"
],
[
"#####################\n### Setup Lattice ###\n#####################\n\n\nturnLength = 2.0e-3 #39.9682297148\nsteps = 2 #8000.\n\ntop.zlatstrt = 0#0. # z of lattice start (added to element z's on generate). \ntop.zlatperi = 10.0#turnLength # Lattice periodicity\n\ntop.dt = turnLength / steps / beam.vbeam \n\nstart = Marker()\ndrift1 = Drft(l=1e-3)\ntransform = Marker()\ndrift2 = Drft(l=1e-3)\nend = Marker()\n\ntransformLine = start + drift1 + transform + drift2 + end\n\nmadtowarp(transformLine)",
"_____no_output_____"
],
[
"def FRBT(beta=5.0, alpha=0.0):\n \"\"\" \n Transforms a matched flat beam to a round 'magnetized' beam.\n \"\"\"\n\n gamma = (1. - alpha**2) / beta\n\n R = np.zeros([6,6],dtype='float64')\n R[0,0] = 1. + alpha\n R[0,1] = beta\n R[0,2] = 1. - alpha\n R[0,3] = -beta\n\n R[1,0] = -gamma\n R[1,1] = 1. - alpha\n R[1,2] = gamma\n R[1,3] = 1. + alpha\n\n R[2,0] = 1. - alpha\n R[2,1] = -beta\n R[2,2] = 1. + alpha\n R[2,3] = beta\n\n R[3,0] = gamma\n R[3,1] = 1. + alpha\n R[3,2] = -gamma\n R[3,3] = 1. - alpha\n\n R[4,4] = 2.\n R[5,5] = 2.\n\n R = 0.5 * R\n \n x = {}\n\n norm = {}\n for i in range(6):\n for j in range(6):\n norm[i,j] = 1.0\n norm[0,1] = norm[0,3] = norm[2,1] = norm[2,3] = 1./top.pgroup.uzp\n norm[1,0] = norm[1,2] = top.pgroup.uzp\n norm[3,0] = norm[3,2] = top.pgroup.uzp\n\n x = {}\n x[0] = np.copy(top.pgroup.xp)\n x[1] = np.copy(top.pgroup.uxp)\n x[2] = np.copy(top.pgroup.yp)\n x[3] = np.copy(top.pgroup.uyp)\n x[4] = np.copy(top.pgroup.zp)\n x[5] = np.copy(top.pgroup.uzp)\n\n print x[0].shape\n\n holding = []\n\n for i in range(6):\n val = 0\n for j in range(6):\n val += R[i,j] * x[j] * norm[i,j]\n \n holding.append(val)\n\n\n top.pgroup.xp = holding[0]\n top.pgroup.uxp = holding[1]\n top.pgroup.yp = holding[2]\n top.pgroup.uyp = holding[3]\n top.pgroup.zp = holding[4]\n top.pgroup.uzp = holding[5]\n \n# print \"Transform!\"",
"_____no_output_____"
],
[
"################################\n### 3D Simulation Parameters ###\n################################\n\n\ntop.prwall = pr1 = 0.14\n\n#Set cells\nw3d.nx = 128\nw3d.ny = 128\nw3d.nz = 1\n\n\n\n#Set boundaries\nw3d.xmmin = -0.10\nw3d.xmmax = 0.10 \nw3d.ymmin = -0.10 \nw3d.ymmax = 0.10 \nw3d.zmmin = -2e-3\nw3d.zmmax = 2e-3\n\ntop.pboundxy = 0 # Absorbing Boundary for particles\n\ntop.ibpush = 2 # set type of pusher to vXB push without tan corrections\n ## 0:off, 1:fast, 2:accurate\n\ntop.fstype = -1",
"_____no_output_____"
],
[
"############################\n### Particle Diagnostics ###\n############################\n\ndiagP0 = particle_diag.ParticleDiagnostic( period=1, top=top, w3d=w3d,\n species= { species.name : species for species in listofallspecies },\n comm_world=comm_world, lparallel_output=False, write_dir = diagDir[:-4] )\n\ndiagP = particle_diag.ParticleDiagnostic( period=1, top=top, w3d=w3d,\n species= { species.name : species for species in listofallspecies },\n comm_world=comm_world, lparallel_output=False, write_dir = diagDir[:-4] )\n\ninstallbeforestep( diagP0.write )\ninstallafterstep( diagP.write )",
"_____no_output_____"
],
[
"#################################\n### Generate and Run PIC Code ###\n#################################\n\npackage(\"wxy\")\ngenerate()\nfieldsolve()\n\n\n#installafterstep(thin_lens_lattice)\n#Execute First Step\n\ninstallbeforestep(FRBT)\n\nstep(1)",
" *** particle simulation package WXY generating\n --- Resetting lattice array sizes\n --- Allocating space for particles\n --- Loading particles\n --- Setting charge density\n --- Allocating Win_Moments\n --- Allocating Z_Moments\n --- Allocating Lab_Moments\n --- Allocating history arrays\n Atomic number of ion = 5.4858E-04\n Charge state of ion = -1.0000E+00\n Initial X, Y emittances = 2.9457E-05, 3.6821E-08 m-rad\n Initial X,Y envelope radii = 1.2136E-02, 4.2908E-04 m\n Initial X,Y envelope angles = -0.0000E+00, -0.0000E+00 rad\n Input beam current = 0.0000E+00 amps\n Current density = 0.0000E+00 amps/m**2\n Charge density = 0.0000E+00 Coul/m**3\n Number density = -0.0000E+00\n Plasma frequency = 0.0000E+00 1/s\n times dt = 0.0000E+00\n times quad period = 0.0000E+00\n Plasma period = 6.2832E+36 s\n X-, Y-Thermal Velocities = 3.6382E+05, 1.2863E+04 m/s\n times dt = 1.2136E-06, 4.2908E-08 m\n times dt/dx, dt/dy (X, Y) = 7.7671E-04, 2.7461E-05\n X-, Y-Debye Wavelengths = 3.6382E+41, 1.2863E+40 m\n over dx, dy (X and Y) = 2.3284E+44, 8.2322E+42\n Longitudinal thermal velocity (rms) = 0.0000E+00 m/s\n times dt = 0.0000E+00 m\n times dt/dz = 0.0000E+00\n Longitudinal Debye wavelength = 0.0000E+00 m\n over dz = 0.0000E+00\n Beam velocity = 2.9978E+08 m/s\n over c = 9.9996E-01\n Kinetic energy = 5.5000E+07 eV\n Weight of simulation particles = 0.0000E+00\n Number of simulation particles = 10000\n Number of real particles = 0.0000E+00\n Total mass = 0.0000E+00 kg\n Total charge = -0.0000E+00 Coul\n Generalized perveance = 0.0000E+00\n Characteristic current = -1.7045E+04 amps\n Budker parameter = 0.0000E+00\n Timestep size dt = 3.3358E-12 s\n Tune length = 0.0000E+00\n Undep. X-, Y-Betatron frequencies = 6.2832E+36, 6.2832E+36 1/s\n Undep. X-, Y-Betatron periods = 0.0000E+00, 0.0000E+00 s\n Undep. X-, Y-Betatron wavelengths = 0.0000E+00, 0.0000E+00 m\n Dep. X-, Y-Betatron frequencies = 6.2832E+36, 6.2832E+36 1/s\n Dep. X-, Y-Betatron periods = 0.0000E+00, 0.0000E+00 s\n X-, Y-Tune Depressions (sigma/sigma0) = 0.0000E+00, 0.0000E+00\n Space charge wave velocity = 0.0000E+00 m/s\n Effective wall radius = 1.4142E-01 m\n Geometric factor = 8.2534E+00\n X-, Y-Emittance over Space charge forces = 6.0997E+30, 2.1566E+29\n Number of grid points in x = 128\n Number of grid points in y = 128\n Number of grid points in z = 0\n Grid spacing in x = 1.5625E-03 m\n Grid spacing in y = 1.5625E-03 m\n Grid spacing in z = 0.0000E+00 m\n Bend radius = 0.0000E+00 m\n Bending field = 0.0000E+00 T\n Bend length = 0.0000E+00 m\n Straight section length = 0.0000E+00 m\n Z at start of first bend = 0.0000E+00 m\nit = 0 time = 0.0000E+00 pz =-0.0000E+00 ese = 0.0000E+00 ek = 0.0000E+00 et = 0.0000E+00\n(10000,)\n *** particle simulation package WXY running\n"
],
[
"def readparticles(filename):\n \"\"\"\n Reads in openPMD compliant particle file generated by Warp's ParticleDiagnostic class.\n\n Parameters:\n filename (str): Path to a ParticleDiagnostic output file.\n Returns:\n particle_arrays (dict): Dictionary with entry for each species in the file that contains an array\n of the 6D particle coordinates.\n \"\"\"\n\n dims = ['momentum/x', 'position/y', 'momentum/y', 'position/z', 'momentum/z']\n particle_arrays = {}\n\n f = h5.File(filename, 'r')\n\n if f.attrs.get('openPMD') is None:\n print \"Warning!: Not an openPMD file. This may not work.\"\n\n step = f['data'].keys()[0]\n species_list = f['data/%s/particles' % step].keys()\n\n for species in species_list:\n parray = f['data/%s/particles/%s/position/x' % (step, species)]\n for dim in dims:\n parray = np.column_stack((parray, f['data/%s/particles/%s/' % (step, species) + dim]))\n\n particle_arrays[species] = parray\n\n return particle_arrays\n\ndef convertunits(particlearray):\n \"\"\"\n Putting particle coordinate data in good ol'fashioned accelerator units:\n x: m\n x': ux/uz\n y: m\n y': uy/uz\n z: m\n p: MeV/c\n\n \"\"\"\n dat = deepcopy(particlearray) # Don't copy by reference\n dat[:, 1] = dat[:, 1] / dat[:, 5]\n dat[:, 3] = dat[:, 3] / dat[:, 5]\n dat[:, 5] = dat[:, 5] / 5.344286E-22\n\n return dat\n",
"_____no_output_____"
],
[
"def svecplot(array):\n fig = plt.figure(figsize = (8,8))\n Q = plt.quiver(array[:,0],array[:,2],array[:,1],array[:,3])\n plt.quiverkey(Q,0.0, 0.92, 0.002, r'$2', labelpos='W')\n xmax = np.max(array[:,0])\n xmin = np.min(array[:,0])\n plt.xlim(1.5*xmin,1.5*xmax)\n plt.ylim(1.5*xmin,1.5*xmax)\n plt.show()",
"_____no_output_____"
],
[
"init = convertunits(readparticles('diags/test/hdf5/data00000000.h5')['Electron'])\nfin = convertunits(readparticles('diags/test/hdf5/data00000001.h5')['Electron'])",
"_____no_output_____"
],
[
"svecplot(init)\nplt.title(\"Initial Flat Beam\")\nplt.xlabel(\"x (m)\")\nplt.ylabel(\"y (m)\")",
"_____no_output_____"
],
[
"svecplot(fin)\nplt.title(\"Magnetized Beam after FRBT\")\nplt.xlabel(\"x (m)\")\nplt.ylabel(\"y (m)\")",
"_____no_output_____"
],
[
"def vortex_check(init):\n beta = 5.0\n alpha = 0\n gamma = (1 - alpha**2) / beta\n x1 = ((1+alpha) * init[0,0] + (beta) * init[0,1] + (1-alpha) * init[0,2] + (-beta) * init[0,3]) * 0.5\n x2 = ((-gamma) * init[0,0] + (1-alpha) * init[0,1] + (gamma) * init[0,2] + (1+alpha) * init[0,3]) * 0.5\n y1 = ((1-alpha) * init[0,0] + (-beta) * init[0,1] + (1+alpha) * init[0,2] + (beta) * init[0,3]) * 0.5\n y2 = ((gamma) * init[0,0] + (1+alpha) * init[0,1] + (-gamma) * init[0,2] + (1-alpha) * init[0,3]) * 0.5\n print x1, fin[0,0]\n print x2, fin[0,1]\n print y1, fin[0,2]\n print y2, fin[0,3]",
"_____no_output_____"
],
[
"def calc_emittance(array):\n xemit = np.sqrt(np.average(array[:,0]**2) * np.average(array[:,1]**2) - np.average(array[:,0] * array[:,1])**2 )\n yemit = np.sqrt(np.average(array[:,2]**2) * np.average(array[:,3]**2) - np.average(array[:,2] * array[:,3])**2 )\n \n return xemit,yemit",
"_____no_output_____"
],
[
"epsx0,epsy0 = calc_emittance(init)\nepsxf,epsyf = calc_emittance(fin)",
"_____no_output_____"
],
[
"print \"Initial:\\n x-emit: %s Initial y-emit: %s\" % (epsx0,epsy0)\nprint \"After Transform:\\n x-emit: %s y-emit: %s\" % (epsxf,epsyf)",
"Initial:\n x-emit: 7.31384527417e-06 Initial y-emit: 9.17185992956e-09\nAfter Transform:\n x-emit: 3.65810665997e-06 y-emit: 3.66491195757e-06\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd23046a5669597a6691d725eb8b09eb5182877
| 2,814 |
ipynb
|
Jupyter Notebook
|
Neruda.ipynb
|
alvagante/artificial-poet
|
665c25a37d5f360ff83213cee77ec226d86767d3
|
[
"MIT"
] | null | null | null |
Neruda.ipynb
|
alvagante/artificial-poet
|
665c25a37d5f360ff83213cee77ec226d86767d3
|
[
"MIT"
] | null | null | null |
Neruda.ipynb
|
alvagante/artificial-poet
|
665c25a37d5f360ff83213cee77ec226d86767d3
|
[
"MIT"
] | null | null | null | 24.469565 | 83 | 0.686567 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
cbd2344e1ea4836a0f032499fc16e645186e2fb9
| 419,523 |
ipynb
|
Jupyter Notebook
|
NY_city_offense_2013.ipynb
|
percevalve/test
|
3e5cd2d444b9c0145cd762b21469ded860918a28
|
[
"MIT"
] | null | null | null |
NY_city_offense_2013.ipynb
|
percevalve/test
|
3e5cd2d444b9c0145cd762b21469ded860918a28
|
[
"MIT"
] | null | null | null |
NY_city_offense_2013.ipynb
|
percevalve/test
|
3e5cd2d444b9c0145cd762b21469ded860918a28
|
[
"MIT"
] | null | null | null | 287.93617 | 92,016 | 0.926834 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport os\nfrom matplotlib import pyplot as plt\nimport numpy as np\nfrom sklearn import linear_model\nfrom sklearn.model_selection import train_test_split\nfrom matplotlib.mlab import PCA as mlabPCA\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.decomposition import PCA \n%matplotlib inline\npd.options.display.float_format = '{:.3f}'.format\n\n# Suppress annoying harmless error.\nimport warnings\nwarnings.filterwarnings(action=\"ignore\", module=\"scipy\", message=\"^internal gelsd\")",
"_____no_output_____"
],
[
"base = pd.read_excel('table_8_offenses_known_to_law_enforcement_new_york_by_city_2013.xls'\n ,encoding=\"latin1\"\n ,skiprows=4\n ,nrows=348)\nbase.columns = ['city', 'population', 'violent_crime','murder','rape_1', 'rape_2',\n 'robbery', 'aggravated', 'property', 'burglary',\n 'theft', 'motor', 'arson']",
"_____no_output_____"
]
],
[
[
"# Understanding the data\n\n## Correlations\n\nFirst let's look at the initial correlations to understand what we have",
"_____no_output_____"
]
],
[
[
"cmap = sns.diverging_palette(128, 240,as_cmap=True)\nplt.rcParams.update({'font.size': 12})\ndef show_corr(df):\n corr = df.corr()\n mask = np.zeros_like(corr, dtype=np.bool)\n mask[np.triu_indices_from(mask)] = True\n f, ax = plt.subplots(figsize=(11, 9))\n sns.heatmap(corr, mask=mask,cmap=cmap, center=0,annot=True,\n square=True, linewidths=.5, cbar_kws={\"shrink\": .5},fmt='.1f'\n );\nshow_corr(base)",
"_____no_output_____"
],
[
"display(base.head(3))\nprint(base.rape_1.unique())",
"_____no_output_____"
]
],
[
[
"We notice that all the variables are highly corraleted!\n\nThe assumption is that all variable are dependent on the population (the number are total number of crime per category, so there is a link between the population and all the crime numbers).\n\nWe also notice that the variable rape_1 is actually only N/A values",
"_____no_output_____"
]
],
[
[
"per_pop = base.copy()\nper_pop = per_pop.drop(['city','rape_1'],axis=1)\nfor col in ['violent_crime','murder', 'rape_2','robbery', 'aggravated', 'property', 'burglary','theft', 'motor']:\n per_pop[col] = per_pop[col]/per_pop.population",
"_____no_output_____"
],
[
"show_corr(per_pop)",
"_____no_output_____"
]
],
[
[
"That is much better !\n\nHaving the crime rates allows us to notice that there is a very high correlation between *property* crimes and *theft*, we could make a first model base on that !\n\nAlso, apart from *arson*, we can also see that there is very little correlation between the population of the city and the different crime rate, especially for the type of crime we are looking into : *property* and *theft*.",
"_____no_output_____"
]
],
[
[
"plt.scatter(per_pop.theft,per_pop.property,s=3)\nplt.title(\"Theft and Property crime (per population)\")",
"_____no_output_____"
]
],
[
[
"Indeed they seem very correlated graphically!\n\nWe notice there is an outlier : it seems to be aligned with the rest of the group, but we will need to make sure it does not have a disproportionate influence on the regression.",
"_____no_output_____"
]
],
[
[
"x = per_pop[['theft']]\ny = per_pop.property\nX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.2)\n# Instantiate our model.\nregr = linear_model.LinearRegression()\n\n# Fit our model to our data.\nregr.fit(X_train,y_train)\n\n# Display the attributes we calculated.\nprint('Coefficients: \\n', regr.coef_)\nprint('Intercept: \\n', regr.intercept_)\nprint(\"Train score:\",regr.score(X_train,y_train))\nprint(\"Test score:\",regr.score(X_test,y_test))\n# Plot outputs\nplt.scatter(X_test,y_test, color='black',s=2,label=\"Test values\")\nplt.scatter(X_test, regr.predict(X_test), color='red',s=1,label=\"Predicted values\")\nplt.legend()\nplt.show()",
"Coefficients: \n [1.18099717]\nIntercept: \n 0.0008224361899665626\nTrain score: 0.9687579043360584\nTest score: 0.9808555515374818\n"
],
[
"predicted = regr.predict(x)\nresidual = y - predicted\nplt.hist(residual,bins=30);\nplt.title(\"Residual histogram\")",
"_____no_output_____"
],
[
"plt.scatter(predicted, residual)\nplt.xlabel('Predicted')\nplt.ylabel('Residual')\nplt.axhline(y=0)\nplt.title('Residual vs. Predicted')\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\ncross_val_score(regr, x, y, cv=10)",
"_____no_output_____"
]
],
[
[
"# First regression discussion\n\nIndeed we are able to explain around 95% of the value of the Property crime per population.\n\nThe residual is almost normally distributed, but they are a couple of errors that are higher than expected further from 0.\n\nAlso the plot of the residual and expected show some heteroscedasticity.\n\nAs this is only our first regression with one variable, we will try to improve it with the other variables.\n\nWe also notice the outlier variable is visible on the graph and present a higher than expected error : this seems like it is related to the population, looking at the distribution of population there is only one city of more than 1 million inhabitant : this outlier might have a disproportionnate influence on the regression so we will take it out.\n\nAlso, **Arson** behave in a strange manner, with N/A that is linked to the way the crime are reported. The median value in 0, so we can safely replace N/A by 0, but we will recorded the value that are N/A with a categorical value.",
"_____no_output_____"
],
[
"# Second regression\n\nAs there are not many variable, and we already have a very good prediction with theft, let's look iteratively at the features, using the minimum of the cross validation test score.",
"_____no_output_____"
]
],
[
[
"for_reg = per_pop.sort_values(\"population\").reset_index().fillna(0)\ny = for_reg[[\"property\"]]\n\nfor col in ['population', 'violent_crime', 'murder', 'rape_2', 'robbery',\n 'aggravated', 'motor', 'arson',]:\n x = for_reg[['theft', 'burglary', col]]\n print(col,min(cross_val_score(regr, x, y, cv=15)))",
"population 0.6988700459160666\nviolent_crime 0.9954780632389395\nmurder 0.9952512586580933\nrape_2 0.993941873066868\nrobbery 0.9975899816013971\naggravated 0.9945121337653015\nmotor 1.0\narson 0.9816383298786536\n"
],
[
"x = for_reg[['theft', 'burglary', 'motor']]\ncross_val_score(regr, x, y, cv=35)",
"_____no_output_____"
],
[
"\ny = for_reg[[\"property\"]]\nx = for_reg[['theft', 'burglary',\"motor\"]]\nX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.10)\n# Instantiate our model.\nregr = linear_model.LinearRegression()\n\n# Fit our model to our data.\nregr.fit(X_train,y_train)\n\n# Display the attributes we calculated.\nprint('Coefficients: \\n', regr.coef_)\nprint('Intercept: \\n', regr.intercept_)\nprint(\"Train score:\",regr.score(X_train,y_train))\nprint(\"Test score:\",regr.score(X_test,y_test))\n# Plot outputs\nplt.scatter(X_test.theft,y_test, color='black',s=2,label=\"Test values\")\nplt.scatter(X_test.theft, regr.predict(X_test), color='red',s=1,label=\"Predicted values\")\nplt.legend()\nplt.show()",
"Coefficients: \n [[1. 1. 1.]]\nIntercept: \n [0.]\nTrain score: 1.0\nTest score: 1.0\n"
]
],
[
[
"# Getting the R2 score for the **Property Crime**\n\nThe regression was on the property crime per population, let's check the R2 for the actual R2 value.",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import r2_score\nfor_r2 = X_test.merge(for_reg[[\"population\"]],left_index=True, right_index=True)\n#r2_score((for_r2.population*y_test.T).T, for_r2.population*[x[0] for x in regr.predict(X_test)], multioutput='variance_weighted')",
"_____no_output_____"
]
],
[
[
"# Second regression conclusion\n\nThis result is very surprising, it really looks like a data leak ! It seems that Property = Theft + Burglary + Motor \n\nTo make it a little more interesting, let's look at the data without those 3 values and try to find a good prediction.\n\n",
"_____no_output_____"
],
[
"# Doing some PCA...",
"_____no_output_____"
]
],
[
[
"per_pop = base.copy()\nper_pop = per_pop.drop(['city','rape_1'],axis=1)\nfor col in ['violent_crime','murder', 'rape_2','robbery', 'aggravated', 'property', 'burglary','theft', 'motor']:\n per_pop[col] = per_pop[col]/per_pop.population",
"_____no_output_____"
],
[
"crime_pca = per_pop[['violent_crime','murder', 'rape_2','robbery', 'aggravated']].copy()\nsklearn_pca = PCA(n_components=5)\nX = StandardScaler().fit_transform(crime_pca)\nY_sklearn = sklearn_pca.fit_transform(X)",
"_____no_output_____"
],
[
"display(sklearn_pca.components_)\ndisplay(sklearn_pca.explained_variance_)",
"_____no_output_____"
],
[
"sum(sklearn_pca.explained_variance_ratio_[:3])",
"_____no_output_____"
],
[
"for i in range(5):\n per_pop[f\"pca_{i}\"] = Y_sklearn[:,i]\n\nper_pop[\"is_arson\"] = per_pop.arson.isna()\nper_pop = per_pop.fillna(0)\n#per_pop = per_pop.drop(['theft', 'burglary',\"motor\"],axis=1)",
"_____no_output_____"
],
[
"show_corr(per_pop)",
"_____no_output_____"
]
],
[
[
"# Third regression\n\n\n",
"_____no_output_____"
],
[
"## Very bad fit !",
"_____no_output_____"
]
],
[
[
"for_reg = per_pop[per_pop.population<1000000].sort_values(\"population\").reset_index()\n#for_reg = per_pop[~per_pop.arson.isna()].sort_values(\"population\").reset_index()\n\ny = for_reg[[\"property\"]]\nx = for_reg[['pca_0', 'pca_1', 'pca_2','is_arson','arson']]\nX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.40)\n# Instantiate our model.\nregr = linear_model.LinearRegression()\n\n# Fit our model to our data.\nregr.fit(X_train,y_train)\n\n# Display the attributes we calculated.\nprint('Coefficients: \\n', regr.coef_)\nprint('Intercept: \\n', regr.intercept_)\nprint(\"Train score:\",regr.score(X_train,y_train))\nprint(\"Test score:\",regr.score(X_test,y_test))\n# Plot outputs\n#plt.scatter(X_test.pca_0,y_test, color='black',s=2,label=\"Test values\")\n#plt.scatter(X_test.pca_0, regr.predict(X_test), color='red',s=1,label=\"Predicted values\")\n#plt.legend()\n#plt.show()",
"Coefficients: \n [[ 0.00583329 0.00226337 0.00507798 0. -0.00228573]]\nIntercept: \n [0.02148309]\nTrain score: 0.3473450441153516\nTest score: -3.5383435264011163\n"
],
[
"predicted_test = regr.predict(X_test)\npredicted_train = regr.predict(X_train)\n\nresidual_test = y_test - predicted_test\nresidual_train = y_train - predicted_train\n_,bins,_ = plt.hist(residual_test.property,color=\"red\",bins=15,alpha=0.6,density=True,label=\"Test residual\");\nplt.hist(residual_train.property,color=\"green\",bins=bins,alpha=0.3,density=True,label=\"Train residual\");\nplt.legend()\nplt.title(\"Residual histogram\");",
"_____no_output_____"
],
[
"plt.scatter(predicted_test, residual_test.property,s=10,label=\"Test\")\nplt.scatter(predicted_train, residual_train.property,s=15,alpha=0.5,label=\"Train\")\n\nplt.xlabel('Predicted')\nplt.ylabel('Residual')\nplt.axhline(y=0,color=\"red\")\nplt.title('Residual vs. Predicted')\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nfor_r2 = X_test.merge(for_reg[[\"population\"]],left_index=True, right_index=True)\nr2_score((for_r2.population*y_test.T).T, for_r2.population*[x[0] for x in regr.predict(X_test)], multioutput='variance_weighted')",
"_____no_output_____"
]
],
[
[
"Eventhoug we get a very bad score for the property crim rate, we still end up with a very high score for the number of property crime as it is dependant on the population mostly.\n\nBut looking at the test and train, we realize that the train has no 'is_arson', when the rest of the values are comparable.",
"_____no_output_____"
]
],
[
[
"sum(X_train.is_arson)",
"_____no_output_____"
],
[
"_,bins,_ = plt.hist(X_train.arson,density=True,alpha=0.5)\n_,bins,_ = plt.hist(X_test.arson,bins=bins,density=True,alpha=0.5)\n",
"_____no_output_____"
],
[
"per_pop.is_arson.unique()",
"_____no_output_____"
],
[
"_,bins,_ = plt.hist(per_pop[per_pop.is_arson==True].pca_0,bins=20,density=True,alpha=0.5,color=\"blue\");\nplt.hist(per_pop[per_pop.is_arson==False].pca_0,bins=bins,density=True,alpha=0.5,color=\"red\");\n",
"_____no_output_____"
],
[
"_,bins,_ = plt.hist(per_pop[per_pop.is_arson==True].pca_1,bins=20,density=True,alpha=0.5,color=\"blue\");\nplt.hist(per_pop[per_pop.is_arson==False].pca_1,bins=bins,density=True,alpha=0.5,color=\"red\");\n",
"_____no_output_____"
]
],
[
[
"## Controling the train and test are comparable\n\nThere is an overal difference between cities that report arson correctly and the others, we need to make sure the number of 'is_arson' is almost the same in train and test.",
"_____no_output_____"
]
],
[
[
"for_reg = per_pop[per_pop.population<1000000].sort_values(\"population\").reset_index()\n#for_reg = per_pop[~per_pop.arson.isna()].sort_values(\"population\").reset_index()\n\ny = for_reg[[\"property\"]]\nx = for_reg[['pca_0', 'pca_1',\"pca_2\"]]\nX_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.10)\n# Instantiate our model.\nregr = linear_model.LinearRegression()\n\n# Fit our model to our data.\nregr.fit(X_train,y_train)\n\n# Display the attributes we calculated.\nprint('Coefficients: \\n', regr.coef_)\nprint('Intercept: \\n', regr.intercept_)\nprint(\"Train score:\",regr.score(X_train,y_train))\nprint(\"Test score:\",regr.score(X_test,y_test))\n# Plot outputs\n#plt.scatter(X_test.pca_0,y_test, color='black',s=2,label=\"Test values\")\n#plt.scatter(X_test.pca_0, regr.predict(X_test), color='red',s=1,label=\"Predicted values\")\n#plt.legend()\n#plt.show()\ntest_arson = X_test.merge(for_reg[[\"is_arson\"]],left_index=True, right_index=True)\ntrain_arson = X_train.merge(for_reg[[\"is_arson\"]],left_index=True, right_index=True)\n\nprint(\"Check Arson train\",sum(train_arson.is_arson)/train_arson.shape[0])\nprint(\"Check Arson test\",sum(test_arson.is_arson)/test_arson.shape[0])",
"Coefficients: \n [[0.00401347 0.00375692 0.00232556]]\nIntercept: \n [0.01985029]\nTrain score: 0.30136373478732703\nTest score: 0.673643768307089\nCheck Arson train 0.46153846153846156\nCheck Arson test 0.45714285714285713\n"
],
[
"predicted_test = regr.predict(X_test)\npredicted_train = regr.predict(X_train)\n\nresidual_test = y_test - predicted_test\nresidual_train = y_train - predicted_train\n_,bins,_ = plt.hist(residual_test.property,color=\"red\",bins=15,alpha=0.6,density=True,label=\"Test residual\");\nplt.hist(residual_train.property,color=\"green\",bins=bins,alpha=0.3,density=True,label=\"Train residual\");\nplt.legend()\nplt.title(\"Residual histogram\");",
"_____no_output_____"
],
[
"plt.scatter(predicted_test, residual_test.property,s=10,label=\"Test\")\nplt.scatter(predicted_train, residual_train.property,s=15,alpha=0.5,label=\"Train\")\n\nplt.xlabel('Predicted')\nplt.ylabel('Residual')\nplt.axhline(y=0,color=\"red\")\nplt.title('Residual vs. Predicted')\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"plt.scatter(x.pca_0,y.property)",
"_____no_output_____"
],
[
"plt.scatter(x.pca_1,y.property)",
"_____no_output_____"
],
[
"plt.scatter(x.pca_2,y.property)",
"_____no_output_____"
],
[
"cross_val_score(regr, x, y, cv=5)",
"_____no_output_____"
],
[
"from sklearn.metrics import r2_score\nfor_r2 = X_test.merge(for_reg[[\"population\"]],left_index=True, right_index=True)\nr2_score((for_r2.population*y_test.T).T, for_r2.population*[x[0] for x in regr.predict(X_test)], multioutput='variance_weighted')",
"_____no_output_____"
]
],
[
[
"In the this final regression, we still have some outliers.",
"_____no_output_____"
]
],
[
[
"import statsmodels.formula.api as smf\nfrom statsmodels.sandbox.regression.predstd import wls_prediction_std\n",
"_____no_output_____"
],
[
"per_pop.columns",
"_____no_output_____"
],
[
"#per_pop = base.copy()\n#per_pop = per_pop.drop(['city','rape_1'],axis=1)\nfor col in ['violent_crime','murder', 'rape_2','robbery', 'aggravated', 'property', 'burglary','theft', 'motor']:\n base[col+\"_per_pop\"] = base[col]/base.population",
"_____no_output_____"
],
[
"base.columns",
"_____no_output_____"
],
[
"linear_formula = 'property_per_pop ~ violent_crime_per_pop+rape_2_per_pop'\n\n# Fit the model to our data using the formula.\nlm = smf.ols(formula=linear_formula, data=base).fit()",
"_____no_output_____"
],
[
"lm.params",
"_____no_output_____"
],
[
"lm.pvalues",
"_____no_output_____"
],
[
"lm.rsquared",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd23a48b75482d9b71e0ff0b25a65aec086271b
| 67,937 |
ipynb
|
Jupyter Notebook
|
8 - Microsoft Professional Capstone/Medical+Image+Analysis.ipynb
|
2series/Professional-In-Artificial-Intelligence
|
e9ae7735cfa416b4447acb5e869b70953eb364a5
|
[
"MIT"
] | 3 |
2019-02-04T06:15:13.000Z
|
2019-05-02T07:04:54.000Z
|
10. Capstone Project/Medical+Image+Analysis.ipynb
|
thomasxmeng/microsoft-professional-program-artificial-intelligence
|
4d28f8c3a5c263b2ae984bb41916b21ef5179531
|
[
"Apache-2.0"
] | null | null | null |
10. Capstone Project/Medical+Image+Analysis.ipynb
|
thomasxmeng/microsoft-professional-program-artificial-intelligence
|
4d28f8c3a5c263b2ae984bb41916b21ef5179531
|
[
"Apache-2.0"
] | 8 |
2018-08-04T21:17:32.000Z
|
2020-04-18T08:26:09.000Z
| 143.934322 | 50,810 | 0.851259 |
[
[
[
"### Deep learning for identifying the orientation Scanned images\n\nFirst we will load the train and test data and create a CTF file",
"_____no_output_____"
]
],
[
[
"import os\nfrom PIL import Image\nimport numpy as np\nimport itertools\nimport random\nimport time\nimport matplotlib.pyplot as plt\n\nimport cntk as C\n\n\ndef split_line(line):\n splits = line.strip().split(',')\n return (splits[0], int(splits[1]))\n\ndef load_labels_dict(labels_file):\n with open(labels_file) as f:\n return dict([split_line(line) for line in f.readlines()[1:]])\n\ndef load_data(data_dir, labels_dict):\n for f in os.listdir(data_dir):\n key = f[:-4]\n label = labels_dict[key]\n image = np.array(Image.open(os.path.join(data_dir, f)), dtype = np.int16).flatten()\n yield np.hstack([image, int(label)])\n \ndef write_to_ctf_file(generator, test_file_name, train_file_name, pct_train = 0.9, rng_seed = 0):\n random.seed(rng_seed)\n labels = [l for l in map(' '.join, np.eye(4, dtype = np.int16).astype(str))]\n with open(test_file_name, 'w') as testf:\n with open(train_file_name, 'w') as trainf:\n lines = 0\n for entry in generator:\n rand_num = random.random()\n formatted_line = '|labels {} |features {}\\n'.format(labels[int(entry[-1])], ' '.join(entry[:-1].astype(str)))\n if rand_num <= pct_train:\n trainf.write(formatted_line)\n else:\n testf.write(formatted_line)\n\n lines += 1\n if lines % 1000 == 0: \n print('Processed {} entries'.format(str(lines)))",
"_____no_output_____"
],
[
"train_data_dir = os.path.join('data', 'train')\nlabels_file = os.path.join('data', 'train_labels.csv')\n\ntrain_file = 'train_data.ctf'\ntest_file = 'test_data.ctf'\nall_data_file = 'all_data.ctf'\n\nlabels_dict = load_labels_dict(labels_file)\nif os.path.exists(train_file) and os.path.exists(test_file):\n print(\"Test and training CTF Files exists, not recreating them again\")\nelse:\n generator = load_data(train_data_dir, labels_dict)\n write_to_ctf_file(generator, test_file, train_file)\n \n \n#Created only to enable testing on entire test data to hoping to improve the submission score\nif os.path.exists(all_data_file):\n print(\"All data CTF Files exists, not recreating it again\")\nelse:\n generator = load_data(train_data_dir, labels_dict)\n labels = [l for l in map(' '.join, np.eye(4, dtype = np.int16).astype(str))]\n with open(all_data_file, 'w') as f:\n lines = 0\n for entry in generator:\n formatted_line = '|labels {} |features {}\\n'.format(labels[int(entry[-1])], ' '.join(entry[:-1].astype(str)))\n f.write(formatted_line)\n lines += 1\n if lines % 1000 == 0: \n print('Processed {} entries'.format(str(lines)))\n",
"Test and training CTF Files exists, not recreating them again\nAll data CTF Files exists, not recreating it again\n"
],
[
"np.random.seed(0)\nC.cntk_py.set_fixed_random_seed(1)\nC.cntk_py.force_deterministic_algorithms()\nnum_output_classes = 4\ninput_dim_model = (1, 64, 64)\n\ndef create_reader(file_path, is_training):\n print('Creating reader from file ' + file_path)\n ctf = C.io.CTFDeserializer(file_path, C.io.StreamDefs(\n labels = C.io.StreamDef(field='labels', shape = 4, is_sparse=False),\n features = C.io.StreamDef(field='features', shape = 64 * 64, is_sparse=False),\n ))\n \n return C.io.MinibatchSource(ctf, randomize = is_training, max_sweeps = C.io.INFINITELY_REPEAT if is_training else 1)",
"_____no_output_____"
],
[
"x = C.input_variable(input_dim_model)\ny = C.input_variable(num_output_classes)\n\ndef create_model(features):\n with C.layers.default_options(init = C.glorot_uniform(), activation = C.relu):\n h = features\n h = C.layers.Convolution2D(filter_shape=(5, 5), \n num_filters = 32, \n strides=(2, 2), \n pad=True, name='first_conv')(h)\n \n h = C.layers.MaxPooling(filter_shape = (5, 5), strides = (2, 2), name = 'pool1')(h)\n\n h = C.layers.Convolution2D(filter_shape=(5, 5), \n num_filters = 64,\n strides=(2, 2),\n pad=True, name='second_conv')(h)\n \n h = C.layers.MaxPooling(filter_shape = (3, 3), strides = (2, 2), name = 'pool2')(h)\n\n r = C.layers.Dense(num_output_classes, activation = None, name='classify')(h)\n return r",
"_____no_output_____"
],
[
"def print_training_progress(trainer, mb, frequency, verbose=1):\n training_loss = \"NA\"\n eval_error = \"NA\"\n\n if mb % frequency == 0:\n training_loss = trainer.previous_minibatch_loss_average\n eval_error = trainer.previous_minibatch_evaluation_average\n if verbose: \n print (\"Minibatch: {0}, Loss: {1:.4f}, Error: {2:.2f}%\".format(mb, training_loss, eval_error*100)) \n ",
"_____no_output_____"
],
[
"def train_test(train_reader, test_reader, model_func, num_sweeps_to_train_with=10):\n \n model = model_func(x/255)\n \n # Instantiate the loss and error function\n loss = C.cross_entropy_with_softmax(model, y)\n label_error = C.classification_error(model, y)\n \n # Initialize the parameters for the trainer\n minibatch_size = 64 \n num_samples_per_sweep = 60000\n num_minibatches_to_train = (num_samples_per_sweep * num_sweeps_to_train_with) / minibatch_size\n \n learning_rate = 0.1\n lr_schedule = C.learning_rate_schedule(learning_rate, C.UnitType.minibatch)\n learner = C.sgd(model.parameters, lr_schedule)\n \n trainer = C.Trainer(model, (loss, label_error), [learner])\n \n \n input_map={\n y : train_reader.streams.labels,\n x : train_reader.streams.features\n } \n \n training_progress_output_freq = 500\n \n \n start = time.time()\n\n for i in range(0, int(num_minibatches_to_train)): \n data=train_reader.next_minibatch(minibatch_size, input_map = input_map) \n trainer.train_minibatch(data)\n print_training_progress(trainer, i, training_progress_output_freq, verbose=1)\n \n \n print(\"Training took {:.1f} sec\".format(time.time() - start))\n \n \n test_input_map = {\n y : test_reader.streams.labels,\n x : test_reader.streams.features\n }\n \n test_minibatch_size = 64\n num_samples = 2000\n num_minibatches_to_test = num_samples // test_minibatch_size\n\n test_result = 0.0 \n for i in range(num_minibatches_to_test): \n data = test_reader.next_minibatch(test_minibatch_size, input_map=test_input_map) \n eval_error = trainer.test_minibatch(data)\n test_result = test_result + eval_error\n\n # Average of evaluation errors of all test minibatches\n print(\"Average test error: {0:.2f}%\".format(test_result*100 / num_minibatches_to_test))\n\n\n",
"_____no_output_____"
],
[
"def do_train_test(model, train_on_all_data = False): \n if train_on_all_data:\n reader_train = create_reader(all_data_file, True)\n else:\n reader_train = create_reader(train_file, True)\n \n reader_test = create_reader(test_file, False)\n train_test(reader_train, reader_test, model)",
"_____no_output_____"
],
[
"C.cntk_py.set_fixed_random_seed(1)\nC.cntk_py.force_deterministic_algorithms()\nmodel = create_model(x)\nprint('pool2 shape is ' + str(model.pool2.shape))\nC.logging.log_number_of_parameters(model)\ndo_train_test(model, train_on_all_data = False)\n\n#Test data not relevant here in case we use all data, the tests won't be out of sample\n#Just done as an attempt improve the submission score using all possible test data after we find the best model \n#that gave minimum error on validation set\n#Surprisingly, it didn't improve the score but reduced the score by a fraction.\n#do_train_test(model, train_on_all_data = True)",
"pool2 shape is (64, 3, 3)\nTraining 54404 parameters in 6 parameter tensors.\nCreating reader from file train_data.ctf\nCreating reader from file test_data.ctf\nMinibatch: 0, Loss: 1.4199, Error: 78.12%\nMinibatch: 500, Loss: 0.0753, Error: 1.56%\nMinibatch: 1000, Loss: 0.0280, Error: 0.00%\nMinibatch: 1500, Loss: 0.0063, Error: 0.00%\nMinibatch: 2000, Loss: 0.0069, Error: 0.00%\nMinibatch: 2500, Loss: 0.0154, Error: 1.56%\nMinibatch: 3000, Loss: 0.0024, Error: 0.00%\nMinibatch: 3500, Loss: 0.0089, Error: 0.00%\nMinibatch: 4000, Loss: 0.0015, Error: 0.00%\nMinibatch: 4500, Loss: 0.0031, Error: 0.00%\nMinibatch: 5000, Loss: 0.0121, Error: 0.00%\nMinibatch: 5500, Loss: 0.0013, Error: 0.00%\nMinibatch: 6000, Loss: 0.0006, Error: 0.00%\nMinibatch: 6500, Loss: 0.0010, Error: 0.00%\nMinibatch: 7000, Loss: 0.0006, Error: 0.00%\nMinibatch: 7500, Loss: 0.0003, Error: 0.00%\nMinibatch: 8000, Loss: 0.0001, Error: 0.00%\nMinibatch: 8500, Loss: 0.0006, Error: 0.00%\nMinibatch: 9000, Loss: 0.0002, Error: 0.00%\nTraining took 1720.1 sec\nAverage test error: 0.05%\n"
],
[
"#Accumulate and display the misclassified \n#TODO: FIX this\ntest_reader = create_reader(test_file, False)\nlabels = []\npredictions = []\nall_images = []\nfor i in range(0, 2000, 500): \n validation_data = test_reader.next_minibatch(500)\n features = validation_data[test_reader.streams.features].as_sequences()\n all_images += features\n l = validation_data[test_reader.streams.labels].as_sequences()\n labels += [np.argmax(i.flatten()) for i in l]\n images = [i.reshape(1, 64, 64) for i in features] \n preds = model(images)\n predictions += [np.argmax(i.flatten()) for i in preds]\n\n\npredictions = np.array(predictions)\nlabels = np.array(labels)\nmask = predictions != labels\nmismatch = np.array(all_images)[mask]\nexpected_label = labels[mask]\nmismatch_pred = predictions[mask]\nmismatch_images = np.array(all_images)[mask]",
"Creating reader from file test_data.ctf\n"
],
[
"%matplotlib inline\n\nfor i in range(len(expected_label)):\n fig = plt.figure(figsize = (8, 6))\n ax = fig.gca()\n ax.set_title('Expected label ' + str(expected_label[i]) + ', got label ' + str(mismatch_pred[i]))\n image = mismatch_images[i]\n plt.imshow(image.reshape(64, 64), cmap = 'gray')\n plt.axis('off')\n\n\n",
"_____no_output_____"
],
[
"submission_data_dir = os.path.join('data', 'test')\nsubmission_file = 'submission_data.ctf'\n\ndef file_to_ndarray(file_root, imfile):\n return (imfile[:-4], np.array(Image.open(os.path.join(file_root, imfile))).reshape((-1, 64, 64)))\n\nsubmission_images = [file_to_ndarray(submission_data_dir, f) for f in os.listdir(submission_data_dir)]\nsubmission_images = sorted(submission_images, key = lambda x: x[0])\ninput_images = [x[1].astype(np.float32) / 255 for x in submission_images]\n\nall_predictions = []\n\nsubmission_mini_batch_size = 50\n\nfor i in range(0, 20000, submission_mini_batch_size):\n predictions = model(input_images[i:(i + submission_mini_batch_size)])\n all_predictions.append(np.argmax(predictions, axis = 1))\n \nall_predictions = [item for sl in all_predictions for item in sl]\n\nwith open('submission.csv', 'w') as f:\n f.write('id,orientation\\n')\n for i in range(20000):\n f.write(submission_images[i][0] + \",\" + str(all_predictions[i]) + \"\\n\")\n",
"/root/anaconda3/envs/cntk-py35/lib/python3.5/site-packages/cntk/core.py:401: UserWarning: you provided the minibatch data as a list, but your corresponding input variable (uid \"Input3\") has only one dynamic axis (batch axis). To speed up graph execution, please convert the data beforehand into one NumPy array to speed up training.\n 'training.' % var.uid)\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd24c8f366e204200b64e3a2908580b769e15f2
| 662,033 |
ipynb
|
Jupyter Notebook
|
aa-example.ipynb
|
kasimte/adversarial-attacks-in-pytorch-example
|
71a3c82dad802c3bfb75d71ec4a2062d514afa0a
|
[
"MIT"
] | 8 |
2019-11-14T13:15:10.000Z
|
2021-07-28T02:31:05.000Z
|
aa-example.ipynb
|
kasimte/adversarial-attacks-in-pytorch-example
|
71a3c82dad802c3bfb75d71ec4a2062d514afa0a
|
[
"MIT"
] | null | null | null |
aa-example.ipynb
|
kasimte/adversarial-attacks-in-pytorch-example
|
71a3c82dad802c3bfb75d71ec4a2062d514afa0a
|
[
"MIT"
] | 4 |
2019-11-14T13:15:12.000Z
|
2020-10-19T16:53:20.000Z
| 156.545992 | 135,106 | 0.798394 |
[
[
[
"# Adversarial Attacks Example in PyTorch",
"_____no_output_____"
],
[
"## Import Dependencies\n\nThis section imports all necessary libraries, such as PyTorch.",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport torchvision\nfrom torchvision import datasets, transforms\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport math\n\nimport torch.backends.cudnn as cudnn\nimport os\nimport argparse",
"_____no_output_____"
]
],
[
[
"### GPU Check",
"_____no_output_____"
]
],
[
[
"device = 'cuda' if torch.cuda.is_available() else 'cpu'\nif torch.cuda.is_available():\n print(\"Using GPU.\")\nelse: \n print(\"Using CPU.\")",
"Using CPU.\n"
]
],
[
[
"## Data Preparation",
"_____no_output_____"
]
],
[
[
"# MNIST dataloader declaration\n\nprint('==> Preparing data..')\n\n# The standard output of the torchvision MNIST data set is [0,1] range, which\n# is what we want for later processing. All we need for a transform, is to \n# translate it to tensors.\n\n# We first download the train and test datasets if necessary and then load them into pytorch dataloaders.\nmnist_train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)\nmnist_test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor(), download=True)\n\n\nmnist_dataset_sizes = {'train' : mnist_train_dataset.__len__(), 'test' : mnist_test_dataset.__len__()} # a dictionary to keep both train and test datasets\n\nmnist_train_loader = torch.utils.data.DataLoader(\n dataset=mnist_train_dataset,\n batch_size=256,\n shuffle=True)\nmnist_test_loader = torch.utils.data.DataLoader(\n dataset=mnist_test_dataset,\n batch_size=1,\n shuffle=True)\n\nmnist_dataloaders = {'train' : mnist_train_loader ,'test' : mnist_test_loader} # a dictionary to keep both train and test loaders",
"\r0it [00:00, ?it/s]"
],
[
"# CIFAR10 dataloader declaration\n\nprint('==> Preparing data..')\n\n# The standard output of the torchvision CIFAR data set is [0,1] range, which\n# is what we want for later processing. All we need for a transform, is to \n# translate it to tensors.\n\n# we first download the train and test datasets if necessary and then load them into pytorch dataloaders\ncifar_train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transforms.ToTensor())\ncifar_train_loader = torch.utils.data.DataLoader(cifar_train_dataset, batch_size=128, shuffle=True, num_workers=2)\n\ncifar_test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transforms.ToTensor())\ncifar_test_loader = torch.utils.data.DataLoader(cifar_test_dataset, batch_size=100, shuffle=False, num_workers=2)\n\n# these are the output categories from the CIFAR dataset\nclasses = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')",
"\n0it [00:00, ?it/s]\u001b[A"
]
],
[
[
"## Model Definition\n\nWe used LeNet model to train against MNIST dataset because the dataset is not very complex and LeNet can easily reach a high accuracy to then demonstrate an ttack. For CIFAR10 dataset, however, we used the more complex DenseNet model to reach an accuracy of 90% to then attack.",
"_____no_output_____"
],
[
"### LeNet",
"_____no_output_____"
]
],
[
[
"# LeNet Model definition\nclass LeNet(nn.Module):\n def __init__(self):\n super(LeNet, self).__init__()\n self.conv1 = nn.Conv2d(1, 10, kernel_size=5)\n self.conv2 = nn.Conv2d(10, 20, kernel_size=5)\n self.conv2_drop = nn.Dropout2d()\n self.fc1 = nn.Linear(320, 50)\n self.fc2 = nn.Linear(50, 10)\n\n def forward(self, x):\n x = F.relu(F.max_pool2d(self.conv1(x), 2)) #first convolutional layer\n x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) #secon convolutional layer with dropout\n x = x.view(-1, 320) #making the data flat\n x = F.relu(self.fc1(x)) #fully connected layer\n x = F.dropout(x, training=self.training) #final dropout\n x = self.fc2(x) # last fully connected layer\n return F.log_softmax(x, dim=1) #output layer",
"_____no_output_____"
]
],
[
[
"This is the standard implementation of the DenseNet proposed in the following paper.\n[DenseNet paper](https://arxiv.org/abs/1608.06993)\n\nThe idea of Densely Connected Networks is that every layer is connected to all its previous layers and its succeeding ones, thus forming a Dense Block.\n\n\n\nThe implementation is broken to smaller parts, called a Dense Block with 5 layers. Each time there is a convolution operation of the previous layer, it is followed by concatenation of the tensors. This is allowed as the channel dimensions, height and width of the input stay the same after convolution with a kernel size 3×3 and padding 1.\nIn this way the feature maps produced are more diversified and tend to have richer patterns. Also, another advantage is better information flow during training.",
"_____no_output_____"
],
[
"### DenseNet",
"_____no_output_____"
]
],
[
[
"# This is a basic densenet model definition.\n\nclass Bottleneck(nn.Module):\n def __init__(self, in_planes, growth_rate):\n super(Bottleneck, self).__init__()\n self.bn1 = nn.BatchNorm2d(in_planes)\n self.conv1 = nn.Conv2d(in_planes, 4*growth_rate, kernel_size=1, bias=False)\n self.bn2 = nn.BatchNorm2d(4*growth_rate)\n self.conv2 = nn.Conv2d(4*growth_rate, growth_rate, kernel_size=3, padding=1, bias=False)\n\n def forward(self, x):\n out = self.conv1(F.relu(self.bn1(x)))\n out = self.conv2(F.relu(self.bn2(out)))\n out = torch.cat([out,x], 1)\n return out\n\n\nclass Transition(nn.Module):\n def __init__(self, in_planes, out_planes):\n super(Transition, self).__init__()\n self.bn = nn.BatchNorm2d(in_planes)\n self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=1, bias=False)\n\n def forward(self, x):\n out = self.conv(F.relu(self.bn(x)))\n out = F.avg_pool2d(out, 2)\n return out\n\n\nclass DenseNet(nn.Module):\n def __init__(self, block, nblocks, growth_rate=12, reduction=0.5, num_classes=10):\n super(DenseNet, self).__init__()\n self.growth_rate = growth_rate\n\n num_planes = 2*growth_rate\n self.conv1 = nn.Conv2d(3, num_planes, kernel_size=3, padding=1, bias=False)\n\n self.dense1 = self._make_dense_layers(block, num_planes, nblocks[0])\n num_planes += nblocks[0]*growth_rate\n out_planes = int(math.floor(num_planes*reduction))\n self.trans1 = Transition(num_planes, out_planes)\n num_planes = out_planes\n\n self.dense2 = self._make_dense_layers(block, num_planes, nblocks[1])\n num_planes += nblocks[1]*growth_rate\n out_planes = int(math.floor(num_planes*reduction))\n self.trans2 = Transition(num_planes, out_planes)\n num_planes = out_planes\n\n self.dense3 = self._make_dense_layers(block, num_planes, nblocks[2])\n num_planes += nblocks[2]*growth_rate\n out_planes = int(math.floor(num_planes*reduction))\n self.trans3 = Transition(num_planes, out_planes)\n num_planes = out_planes\n\n self.dense4 = self._make_dense_layers(block, num_planes, nblocks[3])\n num_planes += nblocks[3]*growth_rate\n\n self.bn = nn.BatchNorm2d(num_planes)\n self.linear = nn.Linear(num_planes, num_classes)\n\n def _make_dense_layers(self, block, in_planes, nblock):\n layers = []\n for i in range(nblock):\n layers.append(block(in_planes, self.growth_rate))\n in_planes += self.growth_rate\n return nn.Sequential(*layers)\n\n def forward(self, x):\n out = self.conv1(x)\n out = self.trans1(self.dense1(out))\n out = self.trans2(self.dense2(out))\n out = self.trans3(self.dense3(out))\n out = self.dense4(out)\n out = F.avg_pool2d(F.relu(self.bn(out)), 4)\n out = out.view(out.size(0), -1)\n out = self.linear(out)\n return out\n\n# This creates a densenet model with basic settings for cifar.\ndef densenet_cifar():\n return DenseNet(Bottleneck, [6,12,24,16], growth_rate=12)",
"_____no_output_____"
],
[
"#building model for MNIST data\nprint('==> Building the model for MNIST dataset..')\nmnist_model = LeNet().to(device)\nmnist_criterion = nn.CrossEntropyLoss()\nmnist_optimizer = optim.Adam(mnist_model.parameters(), lr=0.001)\nmnist_num_epochs= 20",
"==> Building the model for MNIST dataset..\n"
],
[
"#building model for CIFAR10\n# Model\nprint('==> Building the model for CIFAR10 dataset..')\n\n# initialize our datamodel\ncifar_model = densenet_cifar()\ncifar_model = cifar_model.to(device)\n\n\n# use cross entropy as our objective function, since we are building a classifier\ncifar_criterion = nn.CrossEntropyLoss()\n\n# use adam as an optimizer, because it is a popular default nowadays\n# (following the crowd, I know)\ncifar_optimizer = optim.Adam(cifar_model.parameters(), lr=0.1)\nbest_acc = 0 # save the best test accuracy\nstart_epoch = 0 # start from epoch 0\ncifar_num_epochs =20",
"==> Building the model for CIFAR10 dataset..\n"
]
],
[
[
"##Model Training",
"_____no_output_____"
]
],
[
[
"#Training for MNIST dataset\ndef train_mnist_model(model, data_loaders, dataset_sizes, criterion, optimizer, num_epochs, device):\n \n model = model.to(device)\n model.train() # set train mode\n \n \n \n # for each epoch\n for epoch in range(num_epochs):\n print('Epoch {}/{}'.format(epoch+1, num_epochs))\n \n running_loss, running_corrects = 0.0, 0\n \n # for each batch\n for inputs, labels in data_loaders['train']:\n inputs = inputs.to(device)\n labels =labels.to(device) \n\n \n \n # making sure all the gradients of parameter tensors are zero\n optimizer.zero_grad() # set gradient as 0\n \n # get the model output\n outputs = model(inputs)\n \n # get the prediction of model\n _, preds = torch.max(outputs, 1)\n \n # calculate loss of the output\n loss = criterion(outputs, labels)\n \n # backpropagation\n loss.backward()\n \n # update model parameters using optimzier\n optimizer.step()\n \n \n batch_loss_total = loss.item() * inputs.size(0) # total loss of the batch\n running_loss += batch_loss_total # cumluative sum of loss\n running_corrects += torch.sum(preds == labels.data) # cumulative sum of correct count\n \n #calculating the loss and accuracy for the epoch \n epoch_loss = running_loss / dataset_sizes['train']\n epoch_acc = running_corrects.double() / dataset_sizes['train']\n print('Train Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))\n print('-' * 10)\n \n \n # after tranining epochs, test epoch starts\n else:\n model.eval() # set test mode\n running_loss, running_corrects = 0.0, 0\n \n # for each batch\n for inputs, labels in data_loaders['test']:\n inputs = inputs.to(device)\n labels =labels.to(device)\n\n \n # same with the training part.\n outputs = model(inputs)\n _, preds = torch.max(outputs, 1)\n loss = criterion(outputs, labels)\n \n \n running_loss += loss.item() * inputs.size(0) # cumluative sum of loss\n running_corrects += torch.sum(preds == labels.data) # cumluative sum of corrects count\n \n #calculating the loss and accuracy\n test_loss = running_loss / dataset_sizes['test']\n test_acc = (running_corrects.double() / dataset_sizes['test']).item()\n print('<Test Loss: {:.4f} Acc: {:.4f}>'.format(test_loss, test_acc))\n ",
"_____no_output_____"
],
[
"train_mnist_model(mnist_model, mnist_dataloaders, mnist_dataset_sizes, mnist_criterion, mnist_optimizer, mnist_num_epochs, device)",
"Epoch 1/20\nTrain Loss: 0.1181 Acc: 0.9653\n----------\nEpoch 2/20\nTrain Loss: 0.1189 Acc: 0.9658\n----------\nEpoch 3/20\nTrain Loss: 0.1157 Acc: 0.9658\n----------\nEpoch 4/20\nTrain Loss: 0.1159 Acc: 0.9655\n----------\nEpoch 5/20\nTrain Loss: 0.1130 Acc: 0.9665\n----------\nEpoch 6/20\nTrain Loss: 0.1108 Acc: 0.9676\n----------\nEpoch 7/20\nTrain Loss: 0.1104 Acc: 0.9680\n----------\nEpoch 8/20\nTrain Loss: 0.1100 Acc: 0.9674\n----------\nEpoch 9/20\nTrain Loss: 0.1039 Acc: 0.9688\n----------\nEpoch 10/20\nTrain Loss: 0.1064 Acc: 0.9697\n----------\nEpoch 11/20\nTrain Loss: 0.1045 Acc: 0.9688\n----------\nEpoch 12/20\nTrain Loss: 0.1041 Acc: 0.9693\n----------\nEpoch 13/20\nTrain Loss: 0.1047 Acc: 0.9693\n----------\nEpoch 14/20\nTrain Loss: 0.1023 Acc: 0.9695\n----------\nEpoch 15/20\nTrain Loss: 0.1003 Acc: 0.9708\n----------\nEpoch 16/20\nTrain Loss: 0.1008 Acc: 0.9703\n----------\nEpoch 17/20\nTrain Loss: 0.0976 Acc: 0.9711\n----------\nEpoch 18/20\nTrain Loss: 0.0960 Acc: 0.9714\n----------\nEpoch 19/20\nTrain Loss: 0.0946 Acc: 0.9718\n----------\nEpoch 20/20\nTrain Loss: 0.0979 Acc: 0.9706\n----------\n<Test Loss: 0.0314 Acc: 0.9900>\n"
],
[
"# Training for CIFAR10 dataset\ndef train_cifar_model(model, train_loader, criterion, optimizer, num_epochs, device):\n \n print('\\nEpoch: %d' % num_epochs)\n model.train() #set the mode to train\n train_loss = 0\n correct = 0\n total = 0\n \n for batch_idx, (inputs, targets) in enumerate(train_loader):\n inputs, targets = inputs.to(device), targets.to(device)\n optimizer.zero_grad() # making sure all the gradients of parameter tensors are zero\n outputs = model(inputs) #forward pass the model againt the input\n loss = criterion(outputs, targets) #calculate the loss\n loss.backward() #back propagation\n optimizer.step() #update model parameters using the optimiser\n\n train_loss += loss.item() #cumulative sum of loss\n _, predicted = outputs.max(1) #the model prediction\n total += targets.size(0)\n correct += predicted.eq(targets).sum().item() #cumulative sume of corrects count\n if batch_idx % 100 == 0:\n #calculating and printig the loss and accuracy\n print('Loss: %.3f | Acc: %.3f%% (%d/%d)' % (train_loss/(batch_idx+1), 100.*correct/total, correct, total))\n\n#testing for CIFAR10 dataset\ndef test_cifar_model(model, test_loader, criterion, device, save=True):\n \"\"\"Tests the model.\n Taks the epoch number as a parameter.\n \"\"\"\n global best_acc\n model.eval() # set the mode to test\n test_loss = 0\n correct = 0\n total = 0\n with torch.no_grad():\n #similar to the train part\n for batch_idx, (inputs, targets) in enumerate(test_loader):\n inputs, targets = inputs.to(device), targets.to(device)\n outputs = model(inputs)\n loss = criterion(outputs, targets)\n\n test_loss += loss.item()\n _, predicted = outputs.max(1)\n total += targets.size(0)\n correct += predicted.eq(targets).sum().item()\n\n if batch_idx % 100 == 0:\n print('Loss: %.3f | Acc: %.3f%% (%d/%d) TEST' % (test_loss/(batch_idx+1), 100.*correct/total, correct, total))\n #calculating the accuracy\n acc = 100.*correct/total\n if acc > best_acc and save:\n best_acc = acc",
"_____no_output_____"
],
[
"\nfor epoch in range(start_epoch, start_epoch+cifar_num_epochs):\n train_cifar_model(cifar_model, cifar_train_loader, cifar_criterion, cifar_optimizer, epoch, device)\n test_cifar_model(cifar_model, cifar_test_loader, cifar_criterion, device)",
"\nEpoch: 0\nLoss: 0.251 | Acc: 90.625% (116/128)\nLoss: 0.228 | Acc: 91.747% (11861/12928)\nLoss: 0.237 | Acc: 91.581% (23562/25728)\nLoss: 0.239 | Acc: 91.539% (35268/38528)\nLoss: 0.665 | Acc: 78.000% (78/100) TEST\n\nEpoch: 1\nLoss: 0.165 | Acc: 96.875% (124/128)\nLoss: 0.207 | Acc: 92.845% (12003/12928)\nLoss: 0.221 | Acc: 92.269% (23739/25728)\nLoss: 0.230 | Acc: 91.873% (35397/38528)\nLoss: 0.467 | Acc: 87.000% (87/100) TEST\n\nEpoch: 2\nLoss: 0.224 | Acc: 90.625% (116/128)\nLoss: 0.199 | Acc: 92.907% (12011/12928)\nLoss: 0.218 | Acc: 92.370% (23765/25728)\nLoss: 0.219 | Acc: 92.281% (35554/38528)\nLoss: 0.566 | Acc: 84.000% (84/100) TEST\n\nEpoch: 3\nLoss: 0.227 | Acc: 91.406% (117/128)\nLoss: 0.193 | Acc: 93.309% (12063/12928)\nLoss: 0.198 | Acc: 93.148% (23965/25728)\nLoss: 0.209 | Acc: 92.740% (35731/38528)\nLoss: 0.487 | Acc: 84.000% (84/100) TEST\n\nEpoch: 4\nLoss: 0.114 | Acc: 97.656% (125/128)\nLoss: 0.185 | Acc: 93.502% (12088/12928)\nLoss: 0.195 | Acc: 93.089% (23950/25728)\nLoss: 0.211 | Acc: 92.515% (35644/38528)\nLoss: 0.665 | Acc: 81.000% (81/100) TEST\n\nEpoch: 5\nLoss: 0.165 | Acc: 96.875% (124/128)\nLoss: 0.167 | Acc: 94.137% (12170/12928)\nLoss: 0.177 | Acc: 93.816% (24137/25728)\nLoss: 0.185 | Acc: 93.532% (36036/38528)\nLoss: 0.674 | Acc: 83.000% (83/100) TEST\n\nEpoch: 6\nLoss: 0.123 | Acc: 96.094% (123/128)\nLoss: 0.169 | Acc: 94.075% (12162/12928)\nLoss: 0.183 | Acc: 93.493% (24054/25728)\nLoss: 0.184 | Acc: 93.449% (36004/38528)\nLoss: 0.598 | Acc: 81.000% (81/100) TEST\n\nEpoch: 7\nLoss: 0.107 | Acc: 96.875% (124/128)\nLoss: 0.153 | Acc: 94.462% (12212/12928)\nLoss: 0.161 | Acc: 94.150% (24223/25728)\nLoss: 0.172 | Acc: 93.901% (36178/38528)\nLoss: 0.680 | Acc: 82.000% (82/100) TEST\n\nEpoch: 8\nLoss: 0.231 | Acc: 92.188% (118/128)\nLoss: 0.142 | Acc: 94.848% (12262/12928)\nLoss: 0.151 | Acc: 94.683% (24360/25728)\nLoss: 0.160 | Acc: 94.321% (36340/38528)\nLoss: 0.585 | Acc: 85.000% (85/100) TEST\n\nEpoch: 9\nLoss: 0.146 | Acc: 95.312% (122/128)\nLoss: 0.151 | Acc: 94.756% (12250/12928)\nLoss: 0.163 | Acc: 94.314% (24265/25728)\nLoss: 0.161 | Acc: 94.383% (36364/38528)\nLoss: 0.536 | Acc: 85.000% (85/100) TEST\n\nEpoch: 10\nLoss: 0.130 | Acc: 95.312% (122/128)\nLoss: 0.120 | Acc: 95.692% (12371/12928)\nLoss: 0.134 | Acc: 95.138% (24477/25728)\nLoss: 0.143 | Acc: 94.874% (36553/38528)\nLoss: 0.413 | Acc: 90.000% (90/100) TEST\n\nEpoch: 11\nLoss: 0.124 | Acc: 95.312% (122/128)\nLoss: 0.134 | Acc: 95.336% (12325/12928)\nLoss: 0.131 | Acc: 95.464% (24561/25728)\nLoss: 0.140 | Acc: 95.092% (36637/38528)\nLoss: 0.587 | Acc: 84.000% (84/100) TEST\n\nEpoch: 12\nLoss: 0.099 | Acc: 97.656% (125/128)\nLoss: 0.125 | Acc: 95.537% (12351/12928)\nLoss: 0.131 | Acc: 95.359% (24534/25728)\nLoss: 0.140 | Acc: 95.094% (36638/38528)\nLoss: 0.440 | Acc: 90.000% (90/100) TEST\n\nEpoch: 13\nLoss: 0.105 | Acc: 97.656% (125/128)\nLoss: 0.128 | Acc: 95.444% (12339/12928)\nLoss: 0.129 | Acc: 95.503% (24571/25728)\nLoss: 0.136 | Acc: 95.307% (36720/38528)\nLoss: 0.521 | Acc: 85.000% (85/100) TEST\n\nEpoch: 14\nLoss: 0.058 | Acc: 97.656% (125/128)\nLoss: 0.114 | Acc: 96.047% (12417/12928)\nLoss: 0.118 | Acc: 95.861% (24663/25728)\nLoss: 0.124 | Acc: 95.619% (36840/38528)\nLoss: 0.766 | Acc: 84.000% (84/100) TEST\n\nEpoch: 15\nLoss: 0.149 | Acc: 95.312% (122/128)\nLoss: 0.118 | Acc: 95.862% (12393/12928)\nLoss: 0.125 | Acc: 95.631% (24604/25728)\nLoss: 0.128 | Acc: 95.463% (36780/38528)\nLoss: 0.833 | Acc: 80.000% (80/100) TEST\n\nEpoch: 16\nLoss: 0.066 | Acc: 98.438% (126/128)\nLoss: 0.103 | Acc: 96.156% (12431/12928)\nLoss: 0.104 | Acc: 96.210% (24753/25728)\nLoss: 0.118 | Acc: 95.751% (36891/38528)\nLoss: 0.511 | Acc: 90.000% (90/100) TEST\n\nEpoch: 17\nLoss: 0.025 | Acc: 99.219% (127/128)\nLoss: 0.098 | Acc: 96.597% (12488/12928)\nLoss: 0.115 | Acc: 96.043% (24710/25728)\nLoss: 0.125 | Acc: 95.743% (36888/38528)\nLoss: 0.674 | Acc: 85.000% (85/100) TEST\n\nEpoch: 18\nLoss: 0.074 | Acc: 96.875% (124/128)\nLoss: 0.097 | Acc: 96.566% (12484/12928)\nLoss: 0.105 | Acc: 96.311% (24779/25728)\nLoss: 0.115 | Acc: 96.026% (36997/38528)\nLoss: 0.691 | Acc: 85.000% (85/100) TEST\n\nEpoch: 19\nLoss: 0.128 | Acc: 96.094% (123/128)\nLoss: 0.092 | Acc: 96.651% (12495/12928)\nLoss: 0.104 | Acc: 96.319% (24781/25728)\nLoss: 0.111 | Acc: 96.107% (37028/38528)\nLoss: 0.744 | Acc: 85.000% (85/100) TEST\n"
]
],
[
[
"## Save and Reload the Model",
"_____no_output_____"
]
],
[
[
"# Mounting Google Drive\nfrom google.colab import auth\nauth.authenticate_user()\n\nfrom google.colab import drive\ndrive.mount('/content/gdrive')\n\ngdrive_dir = 'gdrive/My Drive/ml/' # update with your own path",
"_____no_output_____"
],
[
"# Save and reload the mnist_model\nprint('==> Saving model for MNIST..')\ntorch.save(mnist_model.state_dict(), gdrive_dir+'lenet_mnist_model.pth')\n\n#change the directory to load your own pretrained model\nprint('==> Loading saved model for MNIST..')\nmnist_model = LeNet().to(device)\nmnist_model.load_state_dict(torch.load(gdrive_dir+'lenet_mnist_model.pth'))\nmnist_model.eval()",
"_____no_output_____"
],
[
"# Save and reload the cifar_model\nprint('==> Saving model for CIFAR..')\ntorch.save(cifar_model.state_dict(), './densenet_cifar_model.pth')\n\n#change the directory to load your own pretrained model\nprint('==> Loading saved model for CIFAR..')\ncifar_model = densenet_cifar().to(device)\ncifar_model.load_state_dict(torch.load(gdrive_dir+'densenet_cifar_model.pth'))\ncifar_model.eval()",
"_____no_output_____"
]
],
[
[
"## Attack Definition\n\nWe used these two attack methods:\n\n* Fast Gradient Signed Method (FGSM)\n* Iterative Least Likely method (Iter.L.L.)",
"_____no_output_____"
]
],
[
[
"# Fast Gradient Singed Method attack (FGSM)\n#Model is the trained model for the target dataset\n#target is the ground truth label of the image\n#epsilon is the hyper parameter which shows the degree of perturbation\n\ndef fgsm_attack(model, image, target, epsilon):\n # Set requires_grad attribute of tensor. Important for Attack\n image.requires_grad = True\n\n # Forward pass the data through the model\n output = model(image)\n init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability(the prediction of the model)\n \n \n \n # If the initial prediction is already wrong, dont bother attacking\n if init_pred[0].item() != target[0].item():\n #if init_pred.item() != target.item():\n return image\n # Calculate the loss\n loss = F.nll_loss(output, target)\n # Zero all existing gradients\n model.zero_grad()\n # Calculate gradients of model in backward pass\n loss.backward()\n\n # Collect datagrad\n data_grad = image.grad.data\n \n # Collect the element-wise sign of the data gradient\n sign_data_grad = data_grad.sign()\n # Create the perturbed image by adjusting each pixel of the input image\n perturbed_image = image + epsilon*sign_data_grad\n # Adding clipping to maintain [0,1] range\n perturbed_image = torch.clamp(perturbed_image, 0, 1)\n \n # Return the perturbed image\n return perturbed_image",
"_____no_output_____"
],
[
"# Iterative least likely method\n\n# Model is the trained model for the target dataset\n# target is the ground truth label of the image\n# alpha is the hyper parameter which shows the degree of perturbation in each iteration, the value is borrowed from the refrenced paper [4] according to the report file\n# iters is the no. of iterations\n# no. of iterations can be set manually, otherwise (if iters==0) this function will take care of it\n\ndef ill_attack(model, image, target, epsilon, alpha, iters): \n\n # Forward passing the image through model one time to get the least likely labels\n output = model(image)\n ll_label = torch.min(output, 1)[1] # get the index of the min log-probability \n \n if iters == 0 :\n # In paper [4], min(epsilon + 4, 1.25*epsilon) is used as number of iterations\n iters = int(min(epsilon + 4, 1.25*epsilon))\n \n # In the original paper the images were in [0,255] range but here our data is in [0,1].\n # So we need to scale the epsilon value in a way that suits our data, which is dividing by 255.\n epsilon = epsilon/255\n \n for i in range(iters) : \n # Set requires_grad attribute of tensor. Important for Attack\n image.requires_grad = True\n \n # Forward pass the data through the model\n output = model(image)\n init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability(the model's prediction)\n \n # If the current prediction is already wrong, dont bother to continue\n if init_pred.item() != target.item():\n return image\n\n # Calculate the loss\n loss = F.nll_loss(output, ll_label) \n\n # Zero all existing gradients\n model.zero_grad()\n\n # Calculate gradients of model in backward pass\n loss.backward()\n\n # Collect datagrad\n data_grad = image.grad.data\n\n # Collect the element-wise sign of the data gradient\n sign_data_grad = data_grad.sign()\n # Create the perturbed image by adjusting each pixel of the input image\n perturbed_image = image - alpha*sign_data_grad\n \n \n # Updating the image for next iteration\n #\n # We want to keep the perturbed image in range [image-epsilon, image+epsilon] \n # based on the definition of the attack. However the value of image-epsilon \n # itself must not fall behind 0, as the data range is [0,1].\n # And the value of image+epsilon also must not exceed 1, for the same reason.\n # So we clip the perturbed image between the (image-epsilon) clipped to 0 and \n # (image+epsilon) clipped to 1.\n a = torch.clamp(image - epsilon, min=0) \n b = (perturbed_image>=a).float()*perturbed_image + (a>perturbed_image).float()*a\n c = (b > image+epsilon).float()*(image+epsilon) + (image+epsilon >= b).float()*b\n image = torch.clamp(c, max=1).detach_()\n \n return image",
"_____no_output_____"
]
],
[
[
"## Model Attack Design",
"_____no_output_____"
]
],
[
[
"# We used the same values as described in the reference paper [4] in the report.\n\nfgsm_epsilons = [0, .05, .1, .15, .2, .25, .3] # values for epsilon hyper-parameter for FGSM attack\nill_epsilons = [0, 2, 4, 8, 16] # values for epsilon hyper-parameter for Iter.L.L attack\n",
"\n170500096it [08:17, 267040.80it/s] \u001b[A"
],
[
"#This is where we test the effect of the attack on the trained model\n#model is the pretrained model on your dataset\n#test_loader contains the test dataset\n#other parameters are set based on the type of the attack\n\ndef attack_test(model, device, test_loader, epsilon, iters, attack='fgsm', alpha=1 ):\n\n # Accuracy counter. accumulates the number of correctly predicted exampels\n correct = 0\n adv_examples = [] # a list to save some of the successful adversarial examples for visualizing purpose\n orig_examples = [] # this list keeps the original image before manipulation corresponding to the images in adv_examples list for comparing purpose\n\n\n # Loop over all examples in test set\n for data, target in test_loader:\n\n # Send the data and label to the device\n data, target = data.to(device), target.to(device)\n # Forward pass the data through the model\n output = model(data)\n init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability (model prediction of the image)\n \n \n \n # Call the Attack\n if attack == 'fgsm':\n perturbed_data = fgsm_attack(model, data, target, epsilon=epsilon )\n else:\n perturbed_data = ill_attack(model, data, target, epsilon, alpha, iters)\n \n\n # Re-classify the perturbed image\n output = model(perturbed_data)\n\n # Check for success\n #target refers to the ground truth label\n #init_pred refers to the model prediction of the original image\n #final_pred refers to the model prediction of the manipulated image\n final_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability (model prediction of the perturbed image)\n if final_pred[0].item() == target[0].item(): #perturbation hasn't affected the classification\n correct += 1\n \n # Special case for saving 0 epsilon examples which is equivalent to no adversarial attack\n if (epsilon == 0) and (len(adv_examples) < 5):\n adv_ex = perturbed_data.squeeze().detach().cpu().numpy()\n orig_ex = data.squeeze().detach().cpu().numpy()\n adv_examples.append( (init_pred[0].item(), final_pred[0].item(), adv_ex) )\n orig_examples.append( (target[0].item(), init_pred[0].item(), orig_ex) )\n else:\n # Save some adv examples for visualization later\n if len(adv_examples) < 5:\n adv_ex = perturbed_data.squeeze().detach().cpu().numpy()\n orig_ex = data.squeeze().detach().cpu().numpy()\n adv_examples.append( (init_pred[0].item(), final_pred[0].item(), adv_ex) )\n orig_examples.append( (target[0].item(), init_pred[0].item(), orig_ex) )\n\n # Calculate final accuracy for this epsilon\n final_acc = correct/float(len(test_loader))\n print(\"Epsilon: {}\\tTest Accuracy = {} / {} = {}\".format(epsilon, correct, len(test_loader), final_acc))\n\n # Return the accuracy and an adversarial examples and their corresponding original images\n return final_acc, adv_examples, orig_examples",
"_____no_output_____"
]
],
[
[
"##Running the Attack for MNIST dataset",
"_____no_output_____"
]
],
[
[
"#FGSM attack\nmnist_fgsm_accuracies = [] #list to keep the model accuracy after attack for each epsilon value\nmnist_fgsm_examples = [] # list to collect adversarial examples returned from the attack_test function for every epsilon values\nmnist_fgsm_orig_examples = [] #list to collect original images corresponding the collected adversarial examples\n\n# Run test for each epsilon\nfor eps in fgsm_epsilons:\n acc, ex, orig = attack_test(mnist_model, device, mnist_test_loader, eps, attack='fgsm', alpha=1, iters=0)\n mnist_fgsm_accuracies.append(acc)\n mnist_fgsm_examples.append(ex)\n mnist_fgsm_orig_examples.append(orig)",
"Epsilon: 0\tTest Accuracy = 9900 / 10000 = 0.99\nEpsilon: 0.05\tTest Accuracy = 9375 / 10000 = 0.9375\nEpsilon: 0.1\tTest Accuracy = 8049 / 10000 = 0.8049\nEpsilon: 0.15\tTest Accuracy = 5992 / 10000 = 0.5992\nEpsilon: 0.2\tTest Accuracy = 4014 / 10000 = 0.4014\nEpsilon: 0.25\tTest Accuracy = 2601 / 10000 = 0.2601\nEpsilon: 0.3\tTest Accuracy = 1785 / 10000 = 0.1785\n"
],
[
"#Iterative_LL attack\nmnist_ill_accuracies = [] #list to keep the model accuracy after attack for each epsilon value\nmnist_ill_examples = [] # list to collect adversarial examples returned from the attack_test function for every epsilon values\nmnist_ill_orig_examples = [] #list to collect original images corresponding the collected adversarial examples\n\n# Run test for each epsilon\nfor eps in ill_epsilons:\n acc, ex, orig = attack_test(mnist_model, device, mnist_test_loader, eps, attack='ill', alpha=1, iters=0)\n mnist_ill_accuracies.append(acc)\n mnist_ill_examples.append(ex)\n mnist_ill_orig_examples.append(orig)",
"Epsilon: 0\tTest Accuracy = 9900 / 10000 = 0.99\nEpsilon: 2\tTest Accuracy = 9900 / 10000 = 0.99\nEpsilon: 4\tTest Accuracy = 9511 / 10000 = 0.9511\nEpsilon: 8\tTest Accuracy = 241 / 10000 = 0.0241\nEpsilon: 16\tTest Accuracy = 0 / 10000 = 0.0\n"
]
],
[
[
"##Visualizing the results for MNIST dataset",
"_____no_output_____"
]
],
[
[
"#Accuracy after attack vs epsilon\nplt.figure(figsize=(5,5))\nplt.plot(fgsm_epsilons, mnist_fgsm_accuracies, \"*-\")\nplt.yticks(np.arange(0, 1.1, step=0.1))\nplt.xticks(np.arange(0, .35, step=0.05))\nplt.title(\"FSGM Attack vs MNIST Model Accuracy vs Epsilon\")\nplt.xlabel(\"Epsilon\")\nplt.ylabel(\"Accuracy\")\nplt.show()",
"_____no_output_____"
],
[
"# Plot several examples vs their adversarial samples at each epsilon for fgms attack\ncnt = 0\nplt.figure(figsize=(8,20))\nfor i in range(len(fgsm_epsilons)):\n for j in range(2):\n cnt += 1\n plt.subplot(len(fgsm_epsilons),2,cnt)\n plt.xticks([], [])\n plt.yticks([], [])\n if j==0:\n plt.ylabel(\"Eps: {}\".format(fgsm_epsilons[i]), fontsize=14)\n \n orig,adv,ex = mnist_fgsm_orig_examples[i][0]\n plt.title(\"target \"+\"{} -> {}\".format(orig, adv)+ \" predicted\")\n plt.imshow(ex, cmap=\"gray\")\n else:\n orig,adv,ex = mnist_fgsm_examples[i][0]\n plt.title(\"predicted \"+\"{} -> {}\".format(orig, adv)+ \" attacked\")\n plt.imshow(ex, cmap=\"gray\")\n \nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"#Accuracy after attack vs epsilon\nplt.figure(figsize=(5,5))\nplt.plot(ill_epsilons, mnist_ill_accuracies, \"*-\", color='R')\nplt.yticks(np.arange(0, 1.1, step=0.1))\nplt.xticks(np.arange(0, 17, step=2))\nplt.title(\"Iterative Least Likely vs MNIST Model / Accuracy vs Epsilon\")\nplt.xlabel(\"Epsilon\")\nplt.ylabel(\"Accuracy\")\nplt.show()",
"_____no_output_____"
],
[
"# Plot several examples vs their adversarial samples at each epsilon for ill attack\ncnt = 0\nplt.figure(figsize=(8,20))\nfor i in range(len(ill_epsilons)):\n for j in range(2):\n cnt += 1\n plt.subplot(len(ill_epsilons),2,cnt)\n plt.xticks([], [])\n plt.yticks([], [])\n if j==0:\n plt.ylabel(\"Eps: {}\".format(ill_epsilons[i]), fontsize=14)\n \n orig,adv,ex = mnist_ill_orig_examples[i][0]\n plt.title(\"target \"+\"{} -> {}\".format(orig, adv)+ \" predicted\")\n plt.imshow(ex, cmap=\"gray\")\n else:\n orig,adv,ex = mnist_ill_examples[i][0]\n plt.title(\"predicted \"+\"{} -> {}\".format(orig, adv)+ \" attacked\")\n plt.imshow(ex, cmap=\"gray\")\n \nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"##Running the Attack for CIFAR10 dataset",
"_____no_output_____"
]
],
[
[
"#FGSM attack\ncifar_fgsm_accuracies = [] #list to keep the model accuracy after attack for each epsilon value\ncifar_fgsm_examples = [] # list to collect adversarial examples returned from the attack_test function for every epsilon values\ncifar_fgsm_orig_examples = [] #list to collect original images corresponding the collected adversarial examples\n\n# Run test for each epsilon\nfor eps in fgsm_epsilons:\n acc, ex, orig = attack_test(cifar_model, device, cifar_test_loader, eps, attack='fgsm', alpha=1, iters=0)\n cifar_fgsm_accuracies.append(acc)\n cifar_fgsm_examples.append(ex)\n cifar_fgsm_orig_examples.append(orig)",
"Epsilon: 0\tTest Accuracy = 88 / 100 = 0.88\nEpsilon: 0.05\tTest Accuracy = 10 / 100 = 0.1\nEpsilon: 0.1\tTest Accuracy = 12 / 100 = 0.12\nEpsilon: 0.15\tTest Accuracy = 14 / 100 = 0.14\nEpsilon: 0.2\tTest Accuracy = 17 / 100 = 0.17\nEpsilon: 0.25\tTest Accuracy = 10 / 100 = 0.1\nEpsilon: 0.3\tTest Accuracy = 8 / 100 = 0.08\n"
],
[
"#Iterative_LL attack\ncifar_ill_accuracies = [] #list to keep the model accuracy after attack for each epsilon value\ncifar_ill_examples = [] # list to collect adversarial examples returned from the attack_test function for every epsilon values\ncifar_ill_orig_examples = [] #list to collect original images corresponding the collected adversarial examples\n\n# Run test for each epsilon\nfor eps in ill_epsilons:\n acc, ex, orig = attack_test(cifar_model, device, cifar_test_loader, eps, attack='ill', alpha=1, iters=0)\n cifar_ill_accuracies.append(acc)\n cifar_ill_examples.append(ex)\n cifar_ill_orig_examples.append(orig)",
"Epsilon: 0\tTest Accuracy = 88 / 100 = 0.88\nEpsilon: 2\tTest Accuracy = 27 / 100 = 0.27\nEpsilon: 4\tTest Accuracy = 0 / 100 = 0.0\nEpsilon: 8\tTest Accuracy = 0 / 100 = 0.0\nEpsilon: 16\tTest Accuracy = 0 / 100 = 0.0\n"
]
],
[
[
"##Visualizing the results for CIFAR10 dataset",
"_____no_output_____"
]
],
[
[
"#Accuracy after attack vs epsilon\nplt.figure(figsize=(5,5))\nplt.plot(fgsm_epsilons, cifar_fgsm_accuracies, \"*-\")\nplt.yticks(np.arange(0, 1.1, step=0.1))\nplt.xticks(np.arange(0, .35, step=0.05))\nplt.title(\"FSGM Attack vs CIFAR Model Accuracy vs Epsilon\")\nplt.xlabel(\"Epsilon\")\nplt.ylabel(\"Accuracy\")\nplt.show()",
"_____no_output_____"
],
[
"# Plot several examples vs their adversarial samples at each epsilon for fgms attack\ncnt = 0\n# 8 is the separation between images\n# 20 is the size of the printed image\nplt.figure(figsize=(8,20))\nfor i in range(len(fgsm_epsilons)):\n for j in range(2):\n cnt += 1\n plt.subplot(len(fgsm_epsilons),2,cnt)\n plt.xticks([], [])\n plt.yticks([], [])\n if j==0:\n plt.ylabel(\"Eps: {}\".format(fgsm_epsilons[i]), fontsize=14)\n \n orig,adv,ex = cifar_fgsm_orig_examples[i][0]\n plt.title(\"target \"+\"{} -> {}\".format(classes[orig], classes[adv])+ \" predicted\")\n plt.imshow(ex[0].transpose(1,2,0), cmap=\"gray\")\n else:\n orig,adv,ex = cifar_fgsm_examples[i][0]\n plt.title(\"predicted \"+\"{} -> {}\".format(classes[orig], classes[adv])+ \" attacked\")\n plt.imshow(ex[0].transpose(1,2,0), cmap=\"gray\")\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"#Accuracy after attack vs epsilon\nplt.figure(figsize=(5,5))\nplt.plot(ill_epsilons, cifar_ill_accuracies, \"*-\", color='R')\nplt.yticks(np.arange(0, 1.1, step=0.1))\nplt.xticks(np.arange(0, 17, step=2))\nplt.title(\"Iterative Least Likely vs CIFAR Model / Accuracy vs Epsilon\")\nplt.xlabel(\"Epsilon\")\nplt.ylabel(\"Accuracy\")\nplt.show()",
"_____no_output_____"
],
[
"# Plot several examples vs their adversarial samples at each epsilon for iterative\n# least likely attack.\n\ncnt = 0\n# 8 is the separation between images\n# 20 is the size of the printed image\nplt.figure(figsize=(8,20))\nfor i in range(len(ill_epsilons)):\n for j in range(2):\n cnt += 1\n plt.subplot(len(ill_epsilons),2,cnt)\n plt.xticks([], [])\n plt.yticks([], [])\n if j==0:\n plt.ylabel(\"Eps: {}\".format(ill_epsilons[i]), fontsize=14)\n \n orig,adv,ex = cifar_ill_orig_examples[i][0]\n plt.title(\"target \"+\"{} -> {}\".format(classes[orig], classes[adv])+ \" predicted\")\n plt.imshow(ex[0].transpose(1,2,0), cmap=\"gray\")\n else:\n orig,adv,ex = cifar_ill_examples[i][0]\n plt.title(\"predicted \"+\"{} -> {}\".format(classes[orig], classes[adv])+ \" attacked\")\n plt.imshow(ex[0].transpose(1,2,0), cmap=\"gray\")\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cbd24d42f05b97c241f0a0e904629cefbd0c7918
| 20,971 |
ipynb
|
Jupyter Notebook
|
ch05/Feature_Engineering_Similarity.ipynb
|
oooooolr/blueprints-text
|
f1be13113cd8fa48e3e9e2e9b40324ff61b5f023
|
[
"Apache-2.0"
] | 97 |
2020-09-14T13:42:48.000Z
|
2022-03-27T16:03:11.000Z
|
ch05/Feature_Engineering_Similarity.ipynb
|
oooooolr/blueprints-text
|
f1be13113cd8fa48e3e9e2e9b40324ff61b5f023
|
[
"Apache-2.0"
] | 13 |
2021-05-09T12:20:19.000Z
|
2022-03-21T08:57:33.000Z
|
ch05/Feature_Engineering_Similarity.ipynb
|
oooooolr/blueprints-text
|
f1be13113cd8fa48e3e9e2e9b40324ff61b5f023
|
[
"Apache-2.0"
] | 49 |
2020-10-12T19:33:26.000Z
|
2022-03-28T17:38:57.000Z
| 22.191534 | 186 | 0.531925 |
[
[
[
"[**Blueprints for Text Analysis Using Python**](https://github.com/blueprints-for-text-analytics-python/blueprints-text) \nJens Albrecht, Sidharth Ramachandran, Christian Winkler\n\n**If you like the book or the code examples here, please leave a friendly comment on [Amazon.com](https://www.amazon.com/Blueprints-Text-Analytics-Using-Python/dp/149207408X)!**\n<img src=\"../rating.png\" width=\"100\"/>\n\n# Chapter 5:<div class='tocSkip'/>",
"_____no_output_____"
],
[
"# Feature Engineering and Syntactic Similarity",
"_____no_output_____"
],
[
"## Remark<div class='tocSkip'/>\n\nThe code in this notebook differs slightly from the printed book. \n\nSeveral layout and formatting commands, like `figsize` to control figure size or subplot commands are removed in the book.\n\nAll of this is done to simplify the code in the book and put the focus on the important parts instead of formatting.",
"_____no_output_____"
],
[
"## Setup<div class='tocSkip'/>\n\nSet directory locations. If working on Google Colab: copy files and install required libraries.",
"_____no_output_____"
]
],
[
[
"import sys, os\nON_COLAB = 'google.colab' in sys.modules\n\nif ON_COLAB:\n GIT_ROOT = 'https://github.com/blueprints-for-text-analytics-python/blueprints-text/raw/master'\n os.system(f'wget {GIT_ROOT}/ch05/setup.py')\n\n%run -i setup.py",
"_____no_output_____"
]
],
[
[
"## Load Python Settings<div class=\"tocSkip\"/>\n\nCommon imports, defaults for formatting in Matplotlib, Pandas etc.",
"_____no_output_____"
]
],
[
[
"%run \"$BASE_DIR/settings.py\"\n\n%reload_ext autoreload\n%autoreload 2\n%config InlineBackend.figure_format = 'png'",
"_____no_output_____"
]
],
[
[
"# Data preparation",
"_____no_output_____"
]
],
[
[
"sentences = [\"It was the best of times\", \n \"it was the worst of times\", \n \"it was the age of wisdom\", \n \"it was the age of foolishness\"]\n\ntokenized_sentences = [[t for t in sentence.split()] for sentence in sentences]\n\nvocabulary = set([w for s in tokenized_sentences for w in s])\n\nimport pandas as pd\n[[w, i] for i,w in enumerate(vocabulary)]",
"_____no_output_____"
]
],
[
[
"# One-hot by hand",
"_____no_output_____"
]
],
[
[
"def onehot_encode(tokenized_sentence):\n return [1 if w in tokenized_sentence else 0 for w in vocabulary]\n\nonehot = [onehot_encode(tokenized_sentence) for tokenized_sentence in tokenized_sentences]\n\nfor (sentence, oh) in zip(sentences, onehot):\n print(\"%s: %s\" % (oh, sentence))",
"_____no_output_____"
],
[
"pd.DataFrame(onehot, columns=vocabulary)",
"_____no_output_____"
],
[
"sim = [onehot[0][i] & onehot[1][i] for i in range(0, len(vocabulary))]\nsum(sim)",
"_____no_output_____"
],
[
"import numpy as np\nnp.dot(onehot[0], onehot[1])",
"_____no_output_____"
],
[
"np.dot(onehot, onehot[1])",
"_____no_output_____"
]
],
[
[
"## Out of vocabulary",
"_____no_output_____"
]
],
[
[
"onehot_encode(\"the age of wisdom is the best of times\".split())",
"_____no_output_____"
],
[
"onehot_encode(\"John likes to watch movies. Mary likes movies too.\".split())",
"_____no_output_____"
]
],
[
[
"## document term matrix",
"_____no_output_____"
]
],
[
[
"onehot",
"_____no_output_____"
]
],
[
[
"## similarities",
"_____no_output_____"
]
],
[
[
"import numpy as np\nnp.dot(onehot, np.transpose(onehot))",
"_____no_output_____"
]
],
[
[
"# scikit learn one-hot vectorization",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import MultiLabelBinarizer\nlb = MultiLabelBinarizer()\nlb.fit([vocabulary])\nlb.transform(tokenized_sentences)",
"_____no_output_____"
]
],
[
[
"# CountVectorizer",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\ncv = CountVectorizer()",
"_____no_output_____"
],
[
"more_sentences = sentences + [\"John likes to watch movies. Mary likes movies too.\",\n \"Mary also likes to watch football games.\"]\npd.DataFrame(more_sentences)",
"_____no_output_____"
],
[
"cv.fit(more_sentences)",
"_____no_output_____"
],
[
"print(cv.get_feature_names())",
"_____no_output_____"
],
[
"dt = cv.transform(more_sentences)",
"_____no_output_____"
],
[
"dt",
"_____no_output_____"
],
[
"pd.DataFrame(dt.toarray(), columns=cv.get_feature_names())",
"_____no_output_____"
],
[
"from sklearn.metrics.pairwise import cosine_similarity\ncosine_similarity(dt[0], dt[1])",
"_____no_output_____"
],
[
"len(more_sentences)",
"_____no_output_____"
],
[
"pd.DataFrame(cosine_similarity(dt, dt))",
"_____no_output_____"
]
],
[
[
"# TF/IDF",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfTransformer\ntfidf = TfidfTransformer()\ntfidf_dt = tfidf.fit_transform(dt)",
"_____no_output_____"
],
[
"pd.DataFrame(tfidf_dt.toarray(), columns=cv.get_feature_names())",
"_____no_output_____"
],
[
"pd.DataFrame(cosine_similarity(tfidf_dt, tfidf_dt))",
"_____no_output_____"
],
[
"headlines = pd.read_csv(ABCNEWS_FILE, parse_dates=[\"publish_date\"])\nheadlines.head()",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import TfidfVectorizer\ntfidf = TfidfVectorizer()\ndt = tfidf.fit_transform(headlines[\"headline_text\"])",
"_____no_output_____"
],
[
"dt",
"_____no_output_____"
],
[
"dt.data.nbytes",
"_____no_output_____"
],
[
"%%time\ncosine_similarity(dt[0:10000], dt[0:10000])",
"_____no_output_____"
]
],
[
[
"## Stopwords",
"_____no_output_____"
]
],
[
[
"from spacy.lang.en.stop_words import STOP_WORDS as stopwords\nprint(len(stopwords))\ntfidf = TfidfVectorizer(stop_words=stopwords)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\ndt",
"_____no_output_____"
]
],
[
[
"## min_df",
"_____no_output_____"
]
],
[
[
"tfidf = TfidfVectorizer(stop_words=stopwords, min_df=2)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\ndt",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(stop_words=stopwords, min_df=.0001)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\ndt",
"_____no_output_____"
]
],
[
[
"## max_df",
"_____no_output_____"
]
],
[
[
"tfidf = TfidfVectorizer(stop_words=stopwords, max_df=0.1)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\ndt",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(max_df=0.1)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\ndt",
"_____no_output_____"
]
],
[
[
"## n-grams",
"_____no_output_____"
]
],
[
[
"tfidf = TfidfVectorizer(stop_words=stopwords, ngram_range=(1,2), min_df=2)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\nprint(dt.shape)\nprint(dt.data.nbytes)\ntfidf = TfidfVectorizer(stop_words=stopwords, ngram_range=(1,3), min_df=2)\ndt = tfidf.fit_transform(headlines[\"headline_text\"])\nprint(dt.shape)\nprint(dt.data.nbytes)",
"_____no_output_____"
]
],
[
[
"## Lemmas",
"_____no_output_____"
]
],
[
[
"from tqdm.auto import tqdm\nimport spacy\nnlp = spacy.load(\"en\")\nnouns_adjectives_verbs = [\"NOUN\", \"PROPN\", \"ADJ\", \"ADV\", \"VERB\"]\nfor i, row in tqdm(headlines.iterrows(), total=len(headlines)):\n doc = nlp(str(row[\"headline_text\"]))\n headlines.at[i, \"lemmas\"] = \" \".join([token.lemma_ for token in doc])\n headlines.at[i, \"nav\"] = \" \".join([token.lemma_ for token in doc if token.pos_ in nouns_adjectives_verbs])",
"_____no_output_____"
],
[
"headlines.head()",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(stop_words=stopwords)\ndt = tfidf.fit_transform(headlines[\"lemmas\"].map(str))\ndt",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(stop_words=stopwords)\ndt = tfidf.fit_transform(headlines[\"nav\"].map(str))\ndt",
"_____no_output_____"
]
],
[
[
"## remove top 10,000",
"_____no_output_____"
]
],
[
[
"top_10000 = pd.read_csv(\"https://raw.githubusercontent.com/first20hours/google-10000-english/master/google-10000-english.txt\", header=None)\ntfidf = TfidfVectorizer(stop_words=set(top_10000.iloc[:,0].values))\ndt = tfidf.fit_transform(headlines[\"nav\"].map(str))\ndt",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(ngram_range=(1,2), stop_words=set(top_10000.iloc[:,0].values), min_df=2)\ndt = tfidf.fit_transform(headlines[\"nav\"].map(str))\ndt",
"_____no_output_____"
]
],
[
[
"## Finding document most similar to made-up document",
"_____no_output_____"
]
],
[
[
"tfidf = TfidfVectorizer(stop_words=stopwords, min_df=2)\ndt = tfidf.fit_transform(headlines[\"lemmas\"].map(str))\ndt",
"_____no_output_____"
],
[
"made_up = tfidf.transform([\"australia and new zealand discuss optimal apple size\"])",
"_____no_output_____"
],
[
"sim = cosine_similarity(made_up, dt)",
"_____no_output_____"
],
[
"sim[0]",
"_____no_output_____"
],
[
"headlines.iloc[np.argsort(sim[0])[::-1][0:5]][[\"publish_date\", \"lemmas\"]]",
"_____no_output_____"
]
],
[
[
"# Finding the most similar documents",
"_____no_output_____"
]
],
[
[
"# there are \"test\" headlines in the corpus\nstopwords.add(\"test\")\ntfidf = TfidfVectorizer(stop_words=stopwords, ngram_range=(1,2), min_df=2, norm='l2')\ndt = tfidf.fit_transform(headlines[\"headline_text\"])",
"_____no_output_____"
]
],
[
[
"### Timing Cosine Similarity",
"_____no_output_____"
]
],
[
[
"%%time\ncosine_similarity(dt[0:10000], dt[0:10000], dense_output=False)",
"_____no_output_____"
],
[
"%%time\nr = cosine_similarity(dt[0:10000], dt[0:10000])\nr[r > 0.9999] = 0\nprint(np.argmax(r))",
"_____no_output_____"
],
[
"%%time\nr = cosine_similarity(dt[0:10000], dt[0:10000], dense_output=False)\nr[r > 0.9999] = 0\nprint(np.argmax(r))",
"_____no_output_____"
]
],
[
[
"### Timing Dot-Product",
"_____no_output_____"
]
],
[
[
"%%time\nr = np.dot(dt[0:10000], np.transpose(dt[0:10000]))\nr[r > 0.9999] = 0\nprint(np.argmax(r))",
"_____no_output_____"
]
],
[
[
"## Batch",
"_____no_output_____"
]
],
[
[
"%%time\nbatch = 10000\nmax_sim = 0.0\nmax_a = None\nmax_b = None\nfor a in range(0, dt.shape[0], batch):\n for b in range(0, a+batch, batch):\n print(a, b)\n #r = np.dot(dt[a:a+batch], np.transpose(dt[b:b+batch]))\n r = cosine_similarity(dt[a:a+batch], dt[b:b+batch], dense_output=False)\n # eliminate identical vectors\n # by setting their similarity to np.nan which gets sorted out\n r[r > 0.9999] = 0\n sim = r.max()\n if sim > max_sim:\n # argmax returns a single value which we have to \n # map to the two dimensions \n (max_a, max_b) = np.unravel_index(np.argmax(r), r.shape)\n # adjust offsets in corpus (this is a submatrix)\n max_a += a\n max_b += b\n max_sim = sim",
"_____no_output_____"
],
[
"print(max_a, max_b)",
"_____no_output_____"
],
[
"print(max_sim)",
"_____no_output_____"
],
[
"pd.set_option('max_colwidth', -1)\nheadlines.iloc[[max_a, max_b]][[\"publish_date\", \"headline_text\"]]",
"_____no_output_____"
]
],
[
[
"# Finding most related words",
"_____no_output_____"
]
],
[
[
"tfidf_word = TfidfVectorizer(stop_words=stopwords, min_df=1000)\ndt_word = tfidf_word.fit_transform(headlines[\"headline_text\"])",
"_____no_output_____"
],
[
"r = cosine_similarity(dt_word.T, dt_word.T)\nnp.fill_diagonal(r, 0)",
"_____no_output_____"
],
[
"voc = tfidf_word.get_feature_names()\nsize = r.shape[0] # quadratic\nfor index in np.argsort(r.flatten())[::-1][0:40]:\n a = int(index/size)\n b = index%size\n if a > b: # avoid repetitions\n print('\"%s\" related to \"%s\"' % (voc[a], voc[b]))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cbd259d30b4be12295998648022b6cfd19f17737
| 4,880 |
ipynb
|
Jupyter Notebook
|
03-strings checkpoint.ipynb
|
SongulKizilay/PythonNotlarm
|
1f9de6815cbb76dec6caadea55639871284e1728
|
[
"MIT"
] | 1 |
2021-03-28T10:32:36.000Z
|
2021-03-28T10:32:36.000Z
|
03-strings checkpoint.ipynb
|
SongulKizilay/PythonNotlarm
|
1f9de6815cbb76dec6caadea55639871284e1728
|
[
"MIT"
] | null | null | null |
03-strings checkpoint.ipynb
|
SongulKizilay/PythonNotlarm
|
1f9de6815cbb76dec6caadea55639871284e1728
|
[
"MIT"
] | 1 |
2021-12-21T17:24:03.000Z
|
2021-12-21T17:24:03.000Z
| 15.591054 | 80 | 0.447746 |
[
[
[
"my_string=\"helloworld\"",
"_____no_output_____"
],
[
"my_string",
"_____no_output_____"
],
[
"##Başlık",
"_____no_output_____"
],
[
"\"helloworld\"\n##Başlık",
"_____no_output_____"
],
[
"##indexing",
"_____no_output_____"
],
[
"my_string",
"_____no_output_____"
],
[
"my_string[0]",
"_____no_output_____"
]
],
[
[
"eğer string içinde bir sırayı çağırıyorsan [] kullan dizi gibi davranıyor",
"_____no_output_____"
]
],
[
[
"my_string[-1]",
"_____no_output_____"
]
],
[
[
"-1 son harfini alıyor ",
"_____no_output_____"
]
],
[
[
"my_string_2=\"12334567890\"",
"_____no_output_____"
]
],
[
[
"my_string_2[0]",
"_____no_output_____"
]
],
[
[
"my_string_2[2:]",
"_____no_output_____"
]
],
[
[
"1 ve 2 yi almadı [2:] 2. indexten başlat ve gerisini göster",
"_____no_output_____"
],
[
"##slicing",
"_____no_output_____"
],
[
"#slicing",
"_____no_output_____"
]
],
[
[
"my_string_2[4:]",
"_____no_output_____"
],
[
"my_string_2[:3]",
"_____no_output_____"
]
],
[
[
"3 den öncekileri yazar\n",
"_____no_output_____"
]
],
[
[
"#stopping index\n",
"_____no_output_____"
]
],
[
[
"my_string_2[1:5]",
"_____no_output_____"
]
],
[
[
"1 ve 5. eleman arasını getirir",
"_____no_output_____"
],
[
"### ",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"raw"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd263b5253e86751b141d22047fd36304c7a0f1
| 142,365 |
ipynb
|
Jupyter Notebook
|
examples/Acciones_v1.ipynb
|
DeisterStuff/investment
|
d54e7c9f8493f37e03ec47db105ca91d650078a3
|
[
"MIT"
] | null | null | null |
examples/Acciones_v1.ipynb
|
DeisterStuff/investment
|
d54e7c9f8493f37e03ec47db105ca91d650078a3
|
[
"MIT"
] | null | null | null |
examples/Acciones_v1.ipynb
|
DeisterStuff/investment
|
d54e7c9f8493f37e03ec47db105ca91d650078a3
|
[
"MIT"
] | null | null | null | 103.916058 | 38,528 | 0.826207 |
[
[
[
"#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport quandl\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport time\nimport datetime\nfrom datetime import datetime",
"_____no_output_____"
],
[
"#selected = ['WALMEX', 'GRUMAB', 'PE&OLES']\n# get adjusted closing prices of 5 selected companies with Quandl\nquandl.ApiConfig.api_key = 'Qa3CCQjeQQM2EZtv-rvh'\nselected = ['CNP', 'F', 'WMT', 'GE', 'TSLA']\ndata = quandl.get_table('WIKI/PRICES', ticker = selected,\n qopts = { 'columns': ['date', 'ticker', 'adj_close'] },\n date = { 'gte': '2014-1-1', 'lte': '2016-12-31' }, paginate=True)\n\n# reorganise data pulled by setting date as index with\n# columns of tickers and their corresponding adjusted prices\nclean = data.set_index('date')\ntable = clean.pivot(columns='ticker')",
"_____no_output_____"
],
[
"table",
"_____no_output_____"
],
[
"import yfinance as yf\n\nmsft = yf.Tickers(\"spy qqq\")",
"_____no_output_____"
],
[
"table = msft.history()['Close']\ntable",
"[*********************100%***********************] 2 of 2 completed\n"
],
[
"selected = [\"SPY\",\"QQQ\"]",
"_____no_output_____"
],
[
"\n\n# calculate daily and annual returns of the stocks\nreturns_daily = table.pct_change()\nreturns_annual = returns_daily.mean() * 250\n\n# get daily and covariance of returns of the stock\ncov_daily = returns_daily.cov()\ncov_annual = cov_daily * 250\n\n# empty lists to store returns, volatility and weights of imiginary portfolios\nport_returns = []\nport_volatility = []\nstock_weights = []\n\n# set the number of combinations for imaginary portfolios\nnum_assets = len(selected)\nnum_portfolios = 50000\n\n# populate the empty lists with each portfolios returns,risk and weights\nfor single_portfolio in range(num_portfolios):\n weights = np.random.random(num_assets)\n weights /= np.sum(weights)\n returns = np.dot(weights, returns_annual)\n volatility = np.sqrt(np.dot(weights.T, np.dot(cov_annual, weights)))\n port_returns.append(returns)\n port_volatility.append(volatility)\n stock_weights.append(weights)\n\n# a dictionary for Returns and Risk values of each portfolio\nportfolio = {'Returns': port_returns,\n 'Volatility': port_volatility}\n\n# extend original dictionary to accomodate each ticker and weight in the portfolio\nfor counter,symbol in enumerate(selected):\n portfolio[symbol+' Weight'] = [Weight[counter] for Weight in stock_weights]\n\n# make a nice dataframe of the extended dictionary\ndf = pd.DataFrame(portfolio)\n\n# get better labels for desired arrangement of columns\ncolumn_order = ['Returns', 'Volatility'] + [stock+' Weight' for stock in selected]\n\n# reorder dataframe columns\ndf = df[column_order]\n\n# plot the efficient frontier with a scatter plot\nplt.style.use('seaborn')\ndf.plot.scatter(x='Volatility', y='Returns', figsize=(10, 8), grid=True)\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"# }\n# # get adjusted closing prices of 5 selected companies with Quandl\n# quandl.ApiConfig.api_key = 'Qa3CCQjeQQM2EZtv-rvh'\n# selected = ['CNP', 'F', 'WMT', 'GE', 'TSLA']\n# data = quandl.get_table('WIKI/PRICES', ticker = selected,\n# qopts = { 'columns': ['date', 'ticker', 'adj_close'] },\n# date = { 'gte': '2014-1-1', 'lte': '2016-12-31' }, paginate=True)\n\n# # reorganise data pulled by setting date as index with\n# # columns of tickers and their corresponding adjusted prices\n# clean = data.set_index('date')\n# table = clean.pivot(columns='ticker')\n\n# calculate daily and annual returns of the stocks\nreturns_daily = table.pct_change()\nreturns_annual = returns_daily.mean() * 250\n\n# get daily and covariance of returns of the stock\ncov_daily = returns_daily.cov()\ncov_annual = cov_daily * 250\n\n# empty lists to store returns, volatility and weights of imiginary portfolios\nport_returns = []\nport_volatility = []\nsharpe_ratio = []\nstock_weights = []\n\n# set the number of combinations for imaginary portfolios\nnum_assets = len(selected)\nnum_portfolios = 50000\n\n#set random seed for reproduction's sake\nnp.random.seed(101)\n\n# populate the empty lists with each portfolios returns,risk and weights\nfor single_portfolio in range(num_portfolios):\n weights = np.random.random(num_assets)\n weights /= np.sum(weights)\n returns = np.dot(weights, returns_annual)\n volatility = np.sqrt(np.dot(weights.T, np.dot(cov_annual, weights)))\n sharpe = returns / volatility\n sharpe_ratio.append(sharpe)\n port_returns.append(returns)\n port_volatility.append(volatility)\n stock_weights.append(weights)\n\n# a dictionary for Returns and Risk values of each portfolio\nportfolio = {'Returns': port_returns,\n 'Volatility': port_volatility,\n 'Sharpe Ratio': sharpe_ratio}\n\n# extend original dictionary to accomodate each ticker and weight in the portfolio\nfor counter,symbol in enumerate(selected):\n portfolio[symbol+' Weight'] = [Weight[counter] for Weight in stock_weights]\n\n# make a nice dataframe of the extended dictionary\ndf = pd.DataFrame(portfolio)\n\n# get better labels for desired arrangement of columns\ncolumn_order = ['Returns', 'Volatility', 'Sharpe Ratio'] + [stock+' Weight' for stock in selected]\n\n# reorder dataframe columns\ndf = df[column_order]\n\n# plot frontier, max sharpe & min Volatility values with a scatterplot\nplt.style.use('seaborn-dark')\ndf.plot.scatter(x='Volatility', y='Returns', c='Sharpe Ratio',\n cmap='RdYlGn', edgecolors='black', figsize=(10, 8), grid=True)\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"# find min Volatility & max sharpe values in the dataframe (df)\nmin_volatility = df['Volatility'].min()\nmax_sharpe = df['Sharpe Ratio'].max()\n\n# use the min, max values to locate and create the two special portfolios\nsharpe_portfolio = df.loc[df['Sharpe Ratio'] == max_sharpe]\nmin_variance_port = df.loc[df['Volatility'] == min_volatility]\n\n# plot frontier, max sharpe & min Volatility values with a scatterplot\nplt.style.use('seaborn-dark')\ndf.plot.scatter(x='Volatility', y='Returns', c='Sharpe Ratio',\n cmap='RdYlGn', edgecolors='black', figsize=(10, 8), grid=True)\nplt.scatter(x=sharpe_portfolio['Volatility'], y=sharpe_portfolio['Returns'], c='red', marker='D', s=200)\nplt.scatter(x=min_variance_port['Volatility'], y=min_variance_port['Returns'], c='blue', marker='D', s=200 )\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"print(min_variance_port.T)",
" 17879\nReturns 0.045828\nVolatility 0.138552\nSharpe Ratio 0.330761\nCNP Weight 0.240327\nF Weight 0.104659\nWMT Weight 0.257760\nGE Weight 0.001487\nTSLA Weight 0.395767\n"
],
[
"print(sharpe_portfolio.T)",
" 31209\nReturns 0.116145\nVolatility 0.175045\nSharpe Ratio 0.663514\nCNP Weight 0.372890\nF Weight 0.008482\nWMT Weight 0.404987\nGE Weight 0.211450\nTSLA Weight 0.002190\n"
],
[
"from pandas_datareader import data\nimport pandas as pd\nfrom yahoo_finance import Share",
"_____no_output_____"
],
[
"# Define the instruments to download. We would like to see Apple, Microsoft and the S&P500 index.\ntickers = ['WALMEX','GMEXICOB','PE&OLES']\n\n# Define which online source one should use\ndata_source = 'google'\n\n# We would like all available data from 01/01/2000 until 12/31/2016.\nstart_date = '2015-01-16'\nend_date = '2018-01-16'\n\n# User pandas_reader.data.DataReader to load the desired data. As simple as that.\npanel_data = data.DataReader(tickers, data_source, start_date, end_date)\n\n# Getting just the adjusted closing prices. This will return a Pandas DataFrame\n# The index in this DataFrame is the major index of the panel_data.\nclose = panel_data.ix['Close']\n\n# Getting all weekdays between 01/01/2000 and 12/31/2016\nall_weekdays = pd.date_range(start=start_date, end=end_date, freq='B')\n\n# How do we align the existing prices in adj_close with our new set of dates?\n# All we need to do is reindex close using all_weekdays as the new indec\nclose= close.reindex(all_weekdays)\n",
"_____no_output_____"
],
[
"selected = ['WALMEX', 'GMEXICOB', 'PE&OLES']\n# get adjusted closing prices of 5 selected companies with Quandl\nquandl.ApiConfig.api_key = 'Qa3CCQjeQQM2EZtv-rvh'\ndata = quandl.get_table('WIKI/PRICES', ticker = selected,\n qopts = { 'columns': ['date', 'ticker', 'adj_close'] },\n date = { 'gte': '2015-01-16', 'lte': '2018-01-16' }, paginate=True)\n\n# reorganise data pulled by setting date as index with\n# columns of tickers and their corresponding adjusted prices\nclean = data.set_index('date')\ntable = close",
"_____no_output_____"
],
[
"table.head()",
"_____no_output_____"
],
[
"\n\n# calculate daily and annual returns of the stocks\nreturns_daily = table.pct_change()\nreturns_annual = returns_daily.mean() * 250\n\n# get daily and covariance of returns of the stock\ncov_daily = returns_daily.cov()\ncov_annual = cov_daily * 250\n\n# empty lists to store returns, volatility and weights of imiginary portfolios\nport_returns = []\nport_volatility = []\nstock_weights = []\n\n# set the number of combinations for imaginary portfolios\nnum_assets = len(selected)\nnum_portfolios = 50000\n\n# populate the empty lists with each portfolios returns,risk and weights\nfor single_portfolio in range(num_portfolios):\n weights = np.random.random(num_assets)\n weights /= np.sum(weights)\n returns = np.dot(weights, returns_annual)\n volatility = np.sqrt(np.dot(weights.T, np.dot(cov_annual, weights)))\n port_returns.append(returns)\n port_volatility.append(volatility)\n stock_weights.append(weights)\n\n# a dictionary for Returns and Risk values of each portfolio\nportfolio = {'Returns': port_returns,\n 'Volatility': port_volatility}\n\n# extend original dictionary to accomodate each ticker and weight in the portfolio\nfor counter,symbol in enumerate(selected):\n portfolio[symbol+' Weight'] = [Weight[counter] for Weight in stock_weights]\n\n# make a nice dataframe of the extended dictionary\ndf = pd.DataFrame(portfolio)\n\n# get better labels for desired arrangement of columns\ncolumn_order = ['Returns', 'Volatility'] + [stock+' Weight' for stock in selected]\n\n# reorder dataframe columns\ndf = df[column_order]\n\n# plot the efficient frontier with a scatter plot\nplt.style.use('seaborn')\ndf.plot.scatter(x='Volatility', y='Returns', figsize=(10, 8), grid=True)\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"\ntable = close\n\n# calculate daily and annual returns of the stocks\nreturns_daily = table.pct_change()\nreturns_annual = returns_daily.mean() * 250\n\n# get daily and covariance of returns of the stock\ncov_daily = returns_daily.cov()\ncov_annual = cov_daily * 250\n\n# empty lists to store returns, volatility and weights of imiginary portfolios\nport_returns = []\nport_volatility = []\nsharpe_ratio = []\nstock_weights = []\n\n# set the number of combinations for imaginary portfolios\nnum_assets = len(selected)\nnum_portfolios = 50000\n\n#set random seed for reproduction's sake\nnp.random.seed(101)\n\n# populate the empty lists with each portfolios returns,risk and weights\nfor single_portfolio in range(num_portfolios):\n weights = np.random.random(num_assets)\n weights /= np.sum(weights)\n returns = np.dot(weights, returns_annual)\n volatility = np.sqrt(np.dot(weights.T, np.dot(cov_annual, weights)))\n sharpe = returns / volatility\n sharpe_ratio.append(sharpe)\n port_returns.append(returns)\n port_volatility.append(volatility)\n stock_weights.append(weights)\n\n# a dictionary for Returns and Risk values of each portfolio\nportfolio = {'Returns': port_returns,\n 'Volatility': port_volatility,\n 'Sharpe Ratio': sharpe_ratio}\n\n# extend original dictionary to accomodate each ticker and weight in the portfolio\nfor counter,symbol in enumerate(selected):\n portfolio[symbol+' Weight'] = [Weight[counter] for Weight in stock_weights]\n\n# make a nice dataframe of the extended dictionary\ndf = pd.DataFrame(portfolio)\n\n# get better labels for desired arrangement of columns\ncolumn_order = ['Returns', 'Volatility', 'Sharpe Ratio'] + [stock+' Weight' for stock in selected]\n\n# reorder dataframe columns\ndf = df[column_order]\n\n# plot frontier, max sharpe & min Volatility values with a scatterplot\nplt.style.use('seaborn-dark')\ndf.plot.scatter(x='Volatility', y='Returns', c='Sharpe Ratio',\n cmap='RdYlGn', edgecolors='black', figsize=(10, 8), grid=True)\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"# find min Volatility & max sharpe values in the dataframe (df)\nmin_volatility = df['Volatility'].min()\nmax_sharpe = df['Sharpe Ratio'].max()\n\n# use the min, max values to locate and create the two special portfolios\nsharpe_portfolio = df.loc[df['Sharpe Ratio'] == max_sharpe]\nmin_variance_port = df.loc[df['Volatility'] == min_volatility]\n\n# plot frontier, max sharpe & min Volatility values with a scatterplot\nplt.style.use('seaborn-dark')\ndf.plot.scatter(x='Volatility', y='Returns', c='Sharpe Ratio',\n cmap='RdYlGn', edgecolors='black', figsize=(10, 8), grid=True)\nplt.scatter(x=sharpe_portfolio['Volatility'], y=sharpe_portfolio['Returns'], c='red', marker='D', s=200)\nplt.scatter(x=min_variance_port['Volatility'], y=min_variance_port['Returns'], c='blue', marker='D', s=200 )\nplt.xlabel('Volatility (Std. Deviation)')\nplt.ylabel('Expected Returns')\nplt.title('Efficient Frontier')\nplt.show()",
"_____no_output_____"
],
[
"print(min_variance_port.T)",
"_____no_output_____"
],
[
"print(sharpe_portfolio.T)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"close_original=close.copy()",
"_____no_output_____"
],
[
"close[selected[2]].plot()\nplt.title(selected[2])",
"_____no_output_____"
],
[
"close[selected[1]].plot()\nplt.title(selected[1])",
"_____no_output_____"
],
[
"close[selected[0]].plot()\nplt.title(selected[0])",
"_____no_output_____"
],
[
"close.GMEXICOB.plot()\nplt.title(selected[2])",
"_____no_output_____"
],
[
"for i in range(0,3):\n print selected[i]\n print close[selected[i]].describe()",
"_____no_output_____"
],
[
"for i in range(0,3):\n print selected[i]\n print \"precio del inicio\"\n print close[selected[i]][0]\n print \"precio actual\"\n print close[selected[i]][len(close)-1]\n print \"La media es: \"\n print close[selected[i]].mean()\n print \"La varianza es: \"\n print (close[selected[i]].std())**2\n print \"La volatilidad es: \"\n print close[selected[i]].std()\n print \"El rendimiento del portafolio es: \" + str(int((close[selected[i]][len(close1)-1]/close[selected[i]][0])*100)-100)+ \" %\"",
"_____no_output_____"
],
[
"close.cov()",
"_____no_output_____"
],
[
"close.corr()",
"_____no_output_____"
],
[
"for i in range(0,3):\n print selected[i]+ \" : \" +str(float(sharpe_portfolio[selected[i]+\" Weight\"]*2000000))",
"_____no_output_____"
],
[
"close1=DataFrame(close.copy())",
"_____no_output_____"
],
[
"close1.head()",
"_____no_output_____"
],
[
"close1['PORT']=float(sharpe_portfolio[selected[0]+\" Weight\"]*2000000)*close1[selected[0]]+float(sharpe_portfolio[selected[1]+\" Weight\"]*2000000)*close1[selected[1]]+float(sharpe_portfolio[selected[2]+\" Weight\"]*2000000)*close1[selected[2]]",
"_____no_output_____"
],
[
"close1.head()",
"_____no_output_____"
],
[
"print close1.PORT.describe()",
"_____no_output_____"
],
[
"print \"PORT\"\nprint \"La media es: \"\nprint close1.PORT.mean()\nprint \"La varianza es: \"\nprint (close1.PORT.std())**2\nprint \"La volatilidad es: \"\nprint close1.PORT.std()",
"_____no_output_____"
],
[
"print \"El rendimiento del portafolio es: \" + str(int((close1.PORT[len(close1)-1]/close1.PORT[0])*100)-100)+ \" %\"",
"_____no_output_____"
],
[
"close1.PORT[len(close1)-1]",
"_____no_output_____"
],
[
"close1.PORT[0]",
"_____no_output_____"
],
[
"close1.cov()",
"_____no_output_____"
],
[
"close1.corr()",
"_____no_output_____"
],
[
"close_original.head()",
"_____no_output_____"
],
[
"close_anual=close_original[close_original.index[datetime.date(close_original.index())>datetime.date(2017,3,16)]]",
"_____no_output_____"
],
[
"close_original['Fecha']=close_original.index",
"_____no_output_____"
],
[
"datetime.date(1943,3, 13)",
"_____no_output_____"
],
[
"close_original[close_original.Fecha]",
"_____no_output_____"
],
[
"now = datetime.datetime.now()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd2742b3c711f5113ee6d038580bd9c30b5f380
| 16,890 |
ipynb
|
Jupyter Notebook
|
examples/notebook/examples/clustering_sat.ipynb
|
personalcomputer/or-tools
|
2cb85b4eead4c38e1c54b48044f92087cf165bce
|
[
"Apache-2.0"
] | 1 |
2022-03-08T22:28:12.000Z
|
2022-03-08T22:28:12.000Z
|
examples/notebook/examples/clustering_sat.ipynb
|
personalcomputer/or-tools
|
2cb85b4eead4c38e1c54b48044f92087cf165bce
|
[
"Apache-2.0"
] | null | null | null |
examples/notebook/examples/clustering_sat.ipynb
|
personalcomputer/or-tools
|
2cb85b4eead4c38e1c54b48044f92087cf165bce
|
[
"Apache-2.0"
] | null | null | null | 80.813397 | 290 | 0.627768 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
cbd275299720bf6459aef5ae7abd7291b85b70d9
| 1,474 |
ipynb
|
Jupyter Notebook
|
Pratica1.ipynb
|
VitoriaCarvalho/MinicursoSINFO2021
|
98d6b6699b3ea0d9a3c00211bb74a37c455209d8
|
[
"MIT"
] | 3 |
2021-11-22T23:38:19.000Z
|
2021-11-23T20:13:59.000Z
|
Pratica1.ipynb
|
VitoriaCarvalho/MinicursoSINFO2021
|
98d6b6699b3ea0d9a3c00211bb74a37c455209d8
|
[
"MIT"
] | null | null | null |
Pratica1.ipynb
|
VitoriaCarvalho/MinicursoSINFO2021
|
98d6b6699b3ea0d9a3c00211bb74a37c455209d8
|
[
"MIT"
] | 1 |
2021-11-23T12:51:14.000Z
|
2021-11-23T12:51:14.000Z
| 21.057143 | 59 | 0.476934 |
[
[
[
"import cv2\nimport numpy as np",
"_____no_output_____"
],
[
"cap = cv2.VideoCapture(0)\n\nwhile cap.isOpened():\n \n ret, frame = cap.read()\n \n if not ret:\n break\n \n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n \n canny = cv2.Canny(gray, 50, 200)\n canny = np.dstack((canny, canny, canny))\n\n concat = np.hstack((frame, canny))\n \n cv2.imshow('frame', concat)\n \n key = cv2.waitKey(1)\n if key == ord('q'):\n break\n \ncap.release()\ncv2.destroyAllWindows()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
cbd276e69e8ff005770bfebeda18448c44f0813a
| 8,287 |
ipynb
|
Jupyter Notebook
|
90_workshops/202111_dust_training_school/dust_workshop_part2/day2/day2_assignment.ipynb
|
trivedi-c/atm_Practical3
|
1cd1e0bd263d274cada781d871ad37314ebe139e
|
[
"MIT"
] | null | null | null |
90_workshops/202111_dust_training_school/dust_workshop_part2/day2/day2_assignment.ipynb
|
trivedi-c/atm_Practical3
|
1cd1e0bd263d274cada781d871ad37314ebe139e
|
[
"MIT"
] | null | null | null |
90_workshops/202111_dust_training_school/dust_workshop_part2/day2/day2_assignment.ipynb
|
trivedi-c/atm_Practical3
|
1cd1e0bd263d274cada781d871ad37314ebe139e
|
[
"MIT"
] | null | null | null | 28.091525 | 314 | 0.585133 |
[
[
[
"<img src='../img/dust_banner.png' alt='Training school and workshop on dust' align='center' width='100%'></img>\n\n<br>",
"_____no_output_____"
],
[
"# Day 2 - Assignment",
"_____no_output_____"
],
[
"### About",
"_____no_output_____"
],
[
"> So far, we analysed Aerosol Optical Depth from different types of data (satellite, model-based and ground-based observations) for a single dust event. Let us now broaden our view and analyse the annual cycle in 2020 of Aerosol Optical Depth from AERONET and compare it with the CAMS global reanalysis data.",
"_____no_output_____"
],
[
"### Tasks",
"_____no_output_____"
],
[
"#### 1. Download and plot time-series of AERONET data for Santa Cruz, Tenerife in 2020\n * **Hint** \n * [AERONET - Example notebook](../../dust_workshop_part1/02_ground-based_observations/21_AERONET.ipynb)\n * you can select daily aggregates of the station observations by setting the `AVG` key to `AVG=20`\n * **Interpret the results:**\n * Have there been other times in 2020 with increased AOD values?\n * If yes, how could you find out if the increase in AOD is caused by dust? Try to find out by visualizing the AOD time-series together with another parameter from the AERONET data.\n * [MSG SEVIRI Dust RGB](https://sds-was.aemet.es/forecast-products/dust-observations/msg-2013-eumetsat) and [MODIS RGB](https://worldview.earthdata.nasa.gov/) quick looks might be helpful to get a more complete picture of other events that might have happened in 2020\n\n\n#### 2. Download CAMS global reanalysis (EAC4) and select 2020 time-series for *Santa Cruz, Tenerife*\n * **Hint**\n * [CAMS global forecast - Example notebook](../../dust_workshop_part1/03_model-based_data/32_CAMS_global_forecast_duaod_load_browse.ipynb) (**Note:** the notebook works with CAMS forecast data, but they have a similar data structure to the CAMS global reanalysis data)\n * [Data access](https://ads.atmosphere.copernicus.eu/cdsapp#!/dataset/cams-global-reanalysis-eac4?tab=form) with the following specifications:\n > Variable on single levels: `Dust aerosol optical depth at 550 nm` <br>\n > Date: `Start=2020-01-01`, `End=2020-12-31` <br>\n > Time: `[00:00, 03:00, 06:00, 09:00, 12:00, 15:00, 18:00, 21:00]` <br>\n > Restricted area: `N: 30., W: -20, E: 14, S: 20.` <br>\n >Format: `netCDF` <br>\n * With the xarray function `sel()` and keyword argument `method='nearest'` you can select data based on coordinate information\n * We also recommend you to transform your xarray.DataArray into a pandas.DataFrame with the function `to_dataframe()`\n \n\n#### 3. Visualize both time-series of CAMS reanalysis and AERONET daily aggregates in one plot\n * **Interpret the results:** What can you say about the annual cycle in 2020 of AOD in Santa Cruz, Tenerife?",
"_____no_output_____"
],
[
"### Module outline\n* [1 - Select latitude / longitude values for Santa Cruz, Tenerife](#select_lat_lon)\n* [2 - Download and plot time-series of AERONET data](#aeronet)\n* [3 - Download CAMS global reanalysis (EAC4) and select 2020 time-series for Santa Cruz, Tenerife](#cams_reanalysis)\n* [4 - Combine both annual time-series and visualize both in one plot](#visualize_annual_ts)\n",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"##### Load required libraries",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport os\nimport xarray as xr\nimport numpy as np\nimport netCDF4 as nc\nimport pandas as pd\n\nfrom IPython.display import HTML\n\nimport matplotlib.pyplot as plt\nimport matplotlib.colors\nfrom matplotlib.cm import get_cmap\nfrom matplotlib import animation\nimport cartopy.crs as ccrs\nfrom cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER\nimport cartopy.feature as cfeature\n\nfrom matplotlib.axes import Axes\nfrom cartopy.mpl.geoaxes import GeoAxes\nGeoAxes._pcolormesh_patched = Axes.pcolormesh\n\nimport wget\n\nimport warnings\nwarnings.simplefilter(action = \"ignore\", category = RuntimeWarning)",
"_____no_output_____"
]
],
[
[
"##### Load helper functions",
"_____no_output_____"
]
],
[
[
"%run ../functions.ipynb",
"_____no_output_____"
]
],
[
[
"<hr>",
"_____no_output_____"
],
[
"### <a id='select_lat_lon'></a>1. Select latitude / longitude values for Santa Cruz, Tenerife",
"_____no_output_____"
],
[
"You can see an overview of all available AERONET Site Names [here](https://aeronet.gsfc.nasa.gov/cgi-bin/draw_map_display_aod_v3?long1=-180&long2=180&lat1=-90&lat2=90&multiplier=2&what_map=4&nachal=1&formatter=0&level=3&place_code=10&place_limit=0).",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id='aeronet'></a>2. Download and plot time-series of AERONET data",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id='cams_reanalysis'></a> 3. Download CAMS global reanalysis (EAC4) and select 2020 time-series for Santa Cruz, Tenerife",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"### <a id='visualize_annual_ts'></a>4. Combine both annual time-series and visualize both in one plot",
"_____no_output_____"
],
[
"<br>",
"_____no_output_____"
],
[
"<hr>",
"_____no_output_____"
],
[
"<img src='../img/copernicus_logo.png' alt='Logo EU Copernicus' align='left' width='20%'><br><br><br><br>\n<p style=\"text-align:right;\">This project is licensed under the <a href=\"./LICENSE\">MIT License</a> and is developed under a Copernicus contract.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cbd28069e4eec93950a827352aacf4773b0d9ea6
| 9,520 |
ipynb
|
Jupyter Notebook
|
examples/generative/ipynb/pixelcnn.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | 3 |
2020-06-09T04:19:35.000Z
|
2020-06-23T15:38:31.000Z
|
examples/generative/ipynb/pixelcnn.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | null | null | null |
examples/generative/ipynb/pixelcnn.ipynb
|
w-hat/keras-io
|
cd2111799249d446836f7b966c3c3d004fe18830
|
[
"Apache-2.0"
] | 2 |
2020-11-19T17:52:50.000Z
|
2020-11-19T17:52:57.000Z
| 32.380952 | 110 | 0.55063 |
[
[
[
"# PixelCNN\n\n**Author:** [ADMoreau](https://github.com/ADMoreau)<br>\n**Date created:** 2020/05/17<br>\n**Last modified:** 2020/05/23<br>\n**Description:** PixelCNN implemented in Keras.",
"_____no_output_____"
],
[
"## Introduction\n\nPixelCNN is a generative model proposed in 2016 by van den Oord et al.\n(reference: [Conditional Image Generation with PixelCNN Decoders](https://arxiv.org/abs/1606.05328)).\nIt is designed to generate images (or other data types) iteratively,\nfrom an input vector where the probability distribution of prior elements dictates the\nprobability distribution of later elements. In the following example, images are generated\nin this fashion, pixel-by-pixel, via a masked convolution kernel that only looks at data\nfrom previously generated pixels (origin at the top left) to generate later pixels.\nDuring inference, the output of the network is used as a probability ditribution\nfrom which new pixel values are sampled to generate a new image\n(here, with MNIST, the pixels values are either black or white).\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom tqdm import tqdm\n",
"_____no_output_____"
]
],
[
[
"## Getting the Data\n",
"_____no_output_____"
]
],
[
[
"# Model / data parameters\nnum_classes = 10\ninput_shape = (28, 28, 1)\nn_residual_blocks = 5\n# The data, split between train and test sets\n(x, _), (y, _) = keras.datasets.mnist.load_data()\n# Concatenate all of the images together\ndata = np.concatenate((x, y), axis=0)\n# Round all pixel values less than 33% of the max 256 value to 0\n# anything above this value gets rounded up to 1 so that all values are either\n# 0 or 1\ndata = np.where(data < (0.33 * 256), 0, 1)\ndata = data.astype(np.float32)\n",
"_____no_output_____"
]
],
[
[
"## Create two classes for the requisite Layers for the model\n",
"_____no_output_____"
]
],
[
[
"# The first layer is the PixelCNN layer. This layer simply\n# builds on the 2D convolutional layer, but includes masking.\nclass PixelConvLayer(layers.Layer):\n def __init__(self, mask_type, **kwargs):\n super(PixelConvLayer, self).__init__()\n self.mask_type = mask_type\n self.conv = layers.Conv2D(**kwargs)\n\n def build(self, input_shape):\n # Build the conv2d layer to initialize kernel variables\n self.conv.build(input_shape)\n # Use the initialized kernel to create the mask\n kernel_shape = self.conv.kernel.get_shape()\n self.mask = np.zeros(shape=kernel_shape)\n self.mask[: kernel_shape[0] // 2, ...] = 1.0\n self.mask[kernel_shape[0] // 2, : kernel_shape[1] // 2, ...] = 1.0\n if self.mask_type == \"B\":\n self.mask[kernel_shape[0] // 2, kernel_shape[1] // 2, ...] = 1.0\n\n def call(self, inputs):\n self.conv.kernel.assign(self.conv.kernel * self.mask)\n return self.conv(inputs)\n\n\n# Next, we build our residual block layer.\n# This is just a normal residual block, but based on the PixelConvLayer.\nclass ResidualBlock(keras.layers.Layer):\n def __init__(self, filters, **kwargs):\n super(ResidualBlock, self).__init__(**kwargs)\n self.conv1 = keras.layers.Conv2D(\n filters=filters, kernel_size=1, activation=\"relu\"\n )\n self.pixel_conv = PixelConvLayer(\n mask_type=\"B\",\n filters=filters // 2,\n kernel_size=3,\n activation=\"relu\",\n padding=\"same\",\n )\n self.conv2 = keras.layers.Conv2D(\n filters=filters, kernel_size=1, activation=\"relu\"\n )\n\n def call(self, inputs):\n x = self.conv1(inputs)\n x = self.pixel_conv(x)\n x = self.conv2(x)\n return keras.layers.add([inputs, x])\n\n",
"_____no_output_____"
]
],
[
[
"## Build the model based on the original paper\n",
"_____no_output_____"
]
],
[
[
"inputs = keras.Input(shape=input_shape)\nx = PixelConvLayer(\n mask_type=\"A\", filters=128, kernel_size=7, activation=\"relu\", padding=\"same\"\n)(inputs)\n\nfor _ in range(n_residual_blocks):\n x = ResidualBlock(filters=128)(x)\n\nfor _ in range(2):\n x = PixelConvLayer(\n mask_type=\"B\",\n filters=128,\n kernel_size=1,\n strides=1,\n activation=\"relu\",\n padding=\"valid\",\n )(x)\n\nout = keras.layers.Conv2D(\n filters=1, kernel_size=1, strides=1, activation=\"sigmoid\", padding=\"valid\"\n)(x)\n\npixel_cnn = keras.Model(inputs, out)\nadam = keras.optimizers.Adam(learning_rate=0.0005)\npixel_cnn.compile(optimizer=adam, loss=\"binary_crossentropy\")\n\npixel_cnn.summary()\npixel_cnn.fit(\n x=data, y=data, batch_size=128, epochs=50, validation_split=0.1, verbose=2\n)\n",
"_____no_output_____"
]
],
[
[
"## Demonstration\n\nThe PixelCNN cannot generate the full image at once, and must instead generate each pixel in\norder, append the last generated pixel to the current image, and feed the image back into the\nmodel to repeat the process.\n",
"_____no_output_____"
]
],
[
[
"from IPython.display import Image, display\n\n# Create an empty array of pixels.\nbatch = 4\npixels = np.zeros(shape=(batch,) + (pixel_cnn.input_shape)[1:])\nbatch, rows, cols, channels = pixels.shape\n\n# Iterate the pixels because generation has to be done sequentially pixel by pixel.\nfor row in tqdm(range(rows)):\n for col in range(cols):\n for channel in range(channels):\n # Feed the whole array and retrieving the pixel value probabilities for the next\n # pixel.\n probs = pixel_cnn.predict(pixels)[:, row, col, channel]\n # Use the probabilities to pick pixel values and append the values to the image\n # frame.\n pixels[:, row, col, channel] = tf.math.ceil(\n probs - tf.random.uniform(probs.shape)\n )\n\n\ndef deprocess_image(x):\n # Stack the single channeled black and white image to rgb values.\n x = np.stack((x, x, x), 2)\n # Undo preprocessing\n x *= 255.0\n # Convert to uint8 and clip to the valid range [0, 255]\n x = np.clip(x, 0, 255).astype(\"uint8\")\n return x\n\n\n# Iterate the generated images and plot them with matplotlib.\nfor i, pic in enumerate(pixels):\n keras.preprocessing.image.save_img(\n \"generated_image_{}.png\".format(i), deprocess_image(np.squeeze(pic, -1))\n )\n\ndisplay(Image(\"generated_image_0.png\"))\ndisplay(Image(\"generated_image_1.png\"))\ndisplay(Image(\"generated_image_2.png\"))\ndisplay(Image(\"generated_image_3.png\"))\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd2900a54fccc2fd161c23d00b8637ac1165f66
| 2,819 |
ipynb
|
Jupyter Notebook
|
omnisharp-tracking-sln-for-csproj_for-linux/_03_Operators-and-Expressions/.vscode/script-as-jupiterNB.ipynb
|
VProfirov/vscode_extensions-and-solutions
|
73a06d43b30d6288d123769b05c3c45df852ca9e
|
[
"MIT"
] | null | null | null |
omnisharp-tracking-sln-for-csproj_for-linux/_03_Operators-and-Expressions/.vscode/script-as-jupiterNB.ipynb
|
VProfirov/vscode_extensions-and-solutions
|
73a06d43b30d6288d123769b05c3c45df852ca9e
|
[
"MIT"
] | null | null | null |
omnisharp-tracking-sln-for-csproj_for-linux/_03_Operators-and-Expressions/.vscode/script-as-jupiterNB.ipynb
|
VProfirov/vscode_extensions-and-solutions
|
73a06d43b30d6288d123769b05c3c45df852ca9e
|
[
"MIT"
] | null | null | null | 44.746032 | 1,080 | 0.649521 |
[
[
[
"# from pathlib import Path\nimport pathlib\n# file_path = __file__\n# file_path = '/home/vas/Documents/GitHub/vscode_extensions-and-solutions/omnisharp-tracking-sln-for-csproj_for-linux/_03_Operators-and-Expressions/.vscode/'\nfile_path = '/home/vas/Documents/GitHub/vscode_extensions-and-solutions/omnisharp-tracking-sln-for-csproj_for-linux/_03_Operators-and-Expressions/'\nparent_dir = pathlib.PurePath(file_path).parent[0]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
cbd2aa124fc15a902c5ff8a53e239541067938e4
| 92,865 |
ipynb
|
Jupyter Notebook
|
submodules/resource/d2l-zh/mxnet/chapter_convolutional-modern/batch-norm.ipynb
|
alphajayGithub/ai.online
|
3e440d88111627827456aa8672516eb389a68e98
|
[
"MIT"
] | null | null | null |
submodules/resource/d2l-zh/mxnet/chapter_convolutional-modern/batch-norm.ipynb
|
alphajayGithub/ai.online
|
3e440d88111627827456aa8672516eb389a68e98
|
[
"MIT"
] | null | null | null |
submodules/resource/d2l-zh/mxnet/chapter_convolutional-modern/batch-norm.ipynb
|
alphajayGithub/ai.online
|
3e440d88111627827456aa8672516eb389a68e98
|
[
"MIT"
] | null | null | null | 40.891678 | 207 | 0.498369 |
[
[
[
"# 批量规范化\n:label:`sec_batch_norm`\n\n训练深层神经网络是十分困难的,特别是在较短的时间内使他们收敛更加棘手。\n在本节中,我们将介绍*批量规范化*(batch normalization) :cite:`Ioffe.Szegedy.2015`,这是一种流行且有效的技术,可持续加速深层网络的收敛速度。\n再结合在 :numref:`sec_resnet`中将介绍的残差块,批量规范化使得研究人员能够训练100层以上的网络。\n\n## 训练深层网络\n\n为什么需要批量规范化层呢?让我们来回顾一下训练神经网络时出现的一些实际挑战。\n\n首先,数据预处理的方式通常会对最终结果产生巨大影响。\n回想一下我们应用多层感知机来预测房价的例子( :numref:`sec_kaggle_house`)。\n使用真实数据时,我们的第一步是标准化输入特征,使其平均值为0,方差为1。\n直观地说,这种标准化可以很好地与我们的优化器配合使用,因为它可以将参数的量级进行统一。\n\n第二,对于典型的多层感知机或卷积神经网络。当我们训练时,中间层中的变量(例如,多层感知机中的仿射变换输出)可能具有更广的变化范围:不论是沿着从输入到输出的层,跨同一层中的单元,或是随着时间的推移,模型参数的随着训练更新变幻莫测。\n批量规范化的发明者非正式地假设,这些变量分布中的这种偏移可能会阻碍网络的收敛。\n直观地说,我们可能会猜想,如果一个层的可变值是另一层的100倍,这可能需要对学习率进行补偿调整。\n\n第三,更深层的网络很复杂,容易过拟合。\n这意味着正则化变得更加重要。\n\n批量规范化应用于单个可选层(也可以应用到所有层),其原理如下:在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。\n接下来,我们应用比例系数和比例偏移。\n正是由于这个基于*批量*统计的*标准化*,才有了*批量规范化*的名称。\n\n请注意,如果我们尝试使用大小为1的小批量应用批量规范化,我们将无法学到任何东西。\n这是因为在减去均值之后,每个隐藏单元将为0。\n所以,只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。\n请注意,在应用批量规范化时,批量大小的选择可能比没有批量规范化时更重要。\n\n从形式上来说,用$\\mathbf{x} \\in \\mathcal{B}$表示一个来自小批量$\\mathcal{B}$的输入,批量规范化$\\mathrm{BN}$根据以下表达式转换$\\mathbf{x}$:\n\n$$\\mathrm{BN}(\\mathbf{x}) = \\boldsymbol{\\gamma} \\odot \\frac{\\mathbf{x} - \\hat{\\boldsymbol{\\mu}}_\\mathcal{B}}{\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}} + \\boldsymbol{\\beta}.$$\n:eqlabel:`eq_batchnorm`\n\n在 :eqref:`eq_batchnorm`中,$\\hat{\\boldsymbol{\\mu}}_\\mathcal{B}$是小批量$\\mathcal{B}$的样本均值,$\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}$是小批量$\\mathcal{B}$的样本标准差。\n应用标准化后,生成的小批量的平均值为0和单位方差为1。\n由于单位方差(与其他一些魔法数)是一个主观的选择,因此我们通常包含\n*拉伸参数*(scale)$\\boldsymbol{\\gamma}$和*偏移参数*(shift)$\\boldsymbol{\\beta}$,它们的形状与$\\mathbf{x}$相同。\n请注意,$\\boldsymbol{\\gamma}$和$\\boldsymbol{\\beta}$是需要与其他模型参数一起学习的参数。\n\n由于在训练过程中,中间层的变化幅度不能过于剧烈,而批量规范化将每一层主动居中,并将它们重新调整为给定的平均值和大小(通过$\\hat{\\boldsymbol{\\mu}}_\\mathcal{B}$和${\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}}$)。\n\n从形式上来看,我们计算出 :eqref:`eq_batchnorm`中的$\\hat{\\boldsymbol{\\mu}}_\\mathcal{B}$和${\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}}$,如下所示:\n\n$$\\begin{aligned} \\hat{\\boldsymbol{\\mu}}_\\mathcal{B} &= \\frac{1}{|\\mathcal{B}|} \\sum_{\\mathbf{x} \\in \\mathcal{B}} \\mathbf{x},\\\\\n\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}^2 &= \\frac{1}{|\\mathcal{B}|} \\sum_{\\mathbf{x} \\in \\mathcal{B}} (\\mathbf{x} - \\hat{\\boldsymbol{\\mu}}_{\\mathcal{B}})^2 + \\epsilon.\\end{aligned}$$\n\n请注意,我们在方差估计值中添加一个小的常量$\\epsilon > 0$,以确保我们永远不会尝试除以零,即使在经验方差估计值可能消失的情况下也是如此。估计值$\\hat{\\boldsymbol{\\mu}}_\\mathcal{B}$和${\\hat{\\boldsymbol{\\sigma}}_\\mathcal{B}}$通过使用平均值和方差的噪声(noise)估计来抵消缩放问题。\n你可能会认为这种噪声是一个问题,而事实上它是有益的。\n\n事实证明,这是深度学习中一个反复出现的主题。\n由于尚未在理论上明确的原因,优化中的各种噪声源通常会导致更快的训练和较少的过拟合:这种变化似乎是正则化的一种形式。\n在一些初步研究中, :cite:`Teye.Azizpour.Smith.2018`和 :cite:`Luo.Wang.Shao.ea.2018`分别将批量规范化的性质与贝叶斯先验相关联。\n这些理论揭示了为什么批量规范化最适应$50 \\sim 100$范围中的中等批量大小的难题。\n\n另外,批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。\n在训练过程中,我们无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。\n而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。\n\n现在,我们了解一下批量规范化在实践中是如何工作的。\n\n## 批量规范化层\n\n回想一下,批量规范化和其他层之间的一个关键区别是,由于批量规范化在完整的小批量上运行,因此我们不能像以前在引入其他层时那样忽略批量大小。\n我们在下面讨论这两种情况:全连接层和卷积层,他们的批量规范化实现略有不同。\n\n### 全连接层\n\n通常,我们将批量规范化层置于全连接层中的仿射变换和激活函数之间。\n设全连接层的输入为u,权重参数和偏置参数分别为$\\mathbf{W}$和$\\mathbf{b}$,激活函数为$\\phi$,批量规范化的运算符为$\\mathrm{BN}$。\n那么,使用批量规范化的全连接层的输出的计算详情如下:\n\n$$\\mathbf{h} = \\phi(\\mathrm{BN}(\\mathbf{W}\\mathbf{x} + \\mathbf{b}) ).$$\n\n回想一下,均值和方差是在应用变换的\"相同\"小批量上计算的。\n\n### 卷积层\n\n同样,对于卷积层,我们可以在卷积层之后和非线性激活函数之前应用批量规范化。\n当卷积有多个输出通道时,我们需要对这些通道的“每个”输出执行批量规范化,每个通道都有自己的拉伸(scale)和偏移(shift)参数,这两个参数都是标量。\n假设我们的小批量包含$m$个样本,并且对于每个通道,卷积的输出具有高度$p$和宽度$q$。\n那么对于卷积层,我们在每个输出通道的$m \\cdot p \\cdot q$个元素上同时执行每个批量规范化。\n因此,在计算平均值和方差时,我们会收集所有空间位置的值,然后在给定通道内应用相同的均值和方差,以便在每个空间位置对值进行规范化。\n\n### 预测过程中的批量规范化\n\n正如我们前面提到的,批量规范化在训练模式和预测模式下的行为通常不同。\n首先,将训练好的模型用于预测时,我们不再需要样本均值中的噪声以及在微批次上估计每个小批次产生的样本方差了。\n其次,例如,我们可能需要使用我们的模型对逐个样本进行预测。\n一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。\n可见,和暂退法一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的。\n\n## (**从零实现**)\n\n下面,我们从头开始实现一个具有张量的批量规范化层。\n",
"_____no_output_____"
]
],
[
[
"from mxnet import autograd, init, np, npx\nfrom mxnet.gluon import nn\nfrom d2l import mxnet as d2l\n\nnpx.set_np()\n\ndef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):\n # 通过autograd来判断当前模式是训练模式还是预测模式\n if not autograd.is_training():\n # 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差\n X_hat = (X - moving_mean) / np.sqrt(moving_var + eps)\n else:\n assert len(X.shape) in (2, 4)\n if len(X.shape) == 2:\n # 使用全连接层的情况,计算特征维上的均值和方差\n mean = X.mean(axis=0)\n var = ((X - mean) ** 2).mean(axis=0)\n else:\n # 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。\n # 这里我们需要保持X的形状以便后面可以做广播运算\n mean = X.mean(axis=(0, 2, 3), keepdims=True)\n var = ((X - mean) ** 2).mean(axis=(0, 2, 3), keepdims=True)\n # 训练模式下,用当前的均值和方差做标准化\n X_hat = (X - mean) / np.sqrt(var + eps)\n # 更新移动平均的均值和方差\n moving_mean = momentum * moving_mean + (1.0 - momentum) * mean\n moving_var = momentum * moving_var + (1.0 - momentum) * var\n Y = gamma * X_hat + beta # 缩放和移位\n return Y, moving_mean, moving_var",
"_____no_output_____"
]
],
[
[
"我们现在可以[**创建一个正确的`BatchNorm`层**]。\n这个层将保持适当的参数:拉伸`gamma`和偏移`beta`,这两个参数将在训练过程中更新。\n此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。\n\n撇开算法细节,注意我们实现层的基础设计模式。\n通常情况下,我们用一个单独的函数定义其数学原理,比如说`batch_norm`。\n然后,我们将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题。\n为了方便起见,我们并不担心在这里自动推断输入形状,因此我们需要指定整个特征的数量。\n不用担心,深度学习框架中的批量规范化API将为我们解决上述问题,我们稍后将展示这一点。\n",
"_____no_output_____"
]
],
[
[
"class BatchNorm(nn.Block):\n # num_features:完全连接层的输出数量或卷积层的输出通道数。\n # num_dims:2表示完全连接层,4表示卷积层\n def __init__(self, num_features, num_dims, **kwargs):\n super().__init__(**kwargs)\n if num_dims == 2:\n shape = (1, num_features)\n else:\n shape = (1, num_features, 1, 1)\n # 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0\n self.gamma = self.params.get('gamma', shape=shape, init=init.One())\n self.beta = self.params.get('beta', shape=shape, init=init.Zero())\n # 非模型参数的变量初始化为0和1\n self.moving_mean = np.zeros(shape)\n self.moving_var = np.ones(shape)\n\n def forward(self, X):\n # 如果X不在内存上,将moving_mean和moving_var\n # 复制到X所在显存上\n if self.moving_mean.ctx != X.ctx:\n self.moving_mean = self.moving_mean.copyto(X.ctx)\n self.moving_var = self.moving_var.copyto(X.ctx)\n # 保存更新过的moving_mean和moving_var\n Y, self.moving_mean, self.moving_var = batch_norm(\n X, self.gamma.data(), self.beta.data(), self.moving_mean,\n self.moving_var, eps=1e-12, momentum=0.9)\n return Y",
"_____no_output_____"
]
],
[
[
"## 使用批量规范化层的 LeNet\n\n为了更好理解如何[**应用`BatchNorm`**],下面我们将其应用(**于LeNet模型**)( :numref:`sec_lenet`)。\n回想一下,批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。\n",
"_____no_output_____"
]
],
[
[
"net = nn.Sequential()\nnet.add(nn.Conv2D(6, kernel_size=5),\n BatchNorm(6, num_dims=4),\n nn.Activation('sigmoid'),\n nn.AvgPool2D(pool_size=2, strides=2),\n nn.Conv2D(16, kernel_size=5),\n BatchNorm(16, num_dims=4),\n nn.Activation('sigmoid'),\n nn.AvgPool2D(pool_size=2, strides=2),\n nn.Dense(120),\n BatchNorm(120, num_dims=2),\n nn.Activation('sigmoid'),\n nn.Dense(84),\n BatchNorm(84, num_dims=2),\n nn.Activation('sigmoid'),\n nn.Dense(10))",
"_____no_output_____"
]
],
[
[
"和以前一样,我们将[**在Fashion-MNIST数据集上训练网络**]。\n这个代码与我们第一次训练LeNet( :numref:`sec_lenet`)时几乎完全相同,主要区别在于学习率大得多。\n",
"_____no_output_____"
]
],
[
[
"lr, num_epochs, batch_size = 1.0, 10, 256\ntrain_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)\nd2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())",
"loss 0.265, train acc 0.902, test acc 0.898\n17183.5 examples/sec on gpu(0)\n"
]
],
[
[
"让我们来看看从第一个批量规范化层中学到的[**拉伸参数`gamma`和偏移参数`beta`**]。\n",
"_____no_output_____"
]
],
[
[
"net[1].gamma.data().reshape(-1,), net[1].beta.data().reshape(-1,)",
"_____no_output_____"
]
],
[
[
"## [**简明实现**]\n\n除了使用我们刚刚定义的`BatchNorm`,我们也可以直接使用深度学习框架中定义的`BatchNorm`。\n该代码看起来几乎与我们上面的代码相同。\n",
"_____no_output_____"
]
],
[
[
"net = nn.Sequential()\nnet.add(nn.Conv2D(6, kernel_size=5),\n nn.BatchNorm(),\n nn.Activation('sigmoid'),\n nn.AvgPool2D(pool_size=2, strides=2),\n nn.Conv2D(16, kernel_size=5),\n nn.BatchNorm(),\n nn.Activation('sigmoid'),\n nn.AvgPool2D(pool_size=2, strides=2),\n nn.Dense(120),\n nn.BatchNorm(),\n nn.Activation('sigmoid'),\n nn.Dense(84),\n nn.BatchNorm(),\n nn.Activation('sigmoid'),\n nn.Dense(10))",
"_____no_output_____"
]
],
[
[
"下面,我们[**使用相同超参数来训练模型**]。\n请注意,通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。\n",
"_____no_output_____"
]
],
[
[
"d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())",
"loss 0.280, train acc 0.896, test acc 0.852\n33526.9 examples/sec on gpu(0)\n"
]
],
[
[
"## 争议\n\n直观地说,批量规范化被认为可以使优化更加平滑。\n然而,我们必须小心区分直觉和对我们观察到的现象的真实解释。\n回想一下,我们甚至不知道简单的神经网络(多层感知机和传统的卷积神经网络)为什么如此有效。\n即使在暂退法和权重衰减的情况下,它们仍然非常灵活,因此无法通过常规的学习理论泛化保证来解释它们是否能够泛化到看不见的数据。\n\n在提出批量规范化的论文中,作者除了介绍了其应用,还解释了其原理:通过减少*内部协变量偏移*(internal covariate shift)。\n据推测,作者所说的“内部协变量转移”类似于上述的投机直觉,即变量值的分布在训练过程中会发生变化。\n然而,这种解释有两个问题:\n1、这种偏移与严格定义的*协变量偏移*(covariate shift)非常不同,所以这个名字用词不当。\n2、这种解释只提供了一种不明确的直觉,但留下了一个有待后续挖掘的问题:为什么这项技术如此有效?\n本书旨在传达实践者用来发展深层神经网络的直觉。\n然而,重要的是将这些指导性直觉与既定的科学事实区分开来。\n最终,当你掌握了这些方法,并开始撰写自己的研究论文时,你会希望清楚地区分技术和直觉。\n\n随着批量规范化的普及,“内部协变量偏移”的解释反复出现在技术文献的辩论,特别是关于“如何展示机器学习研究”的更广泛的讨论中。\nAli Rahimi在接受2017年NeurIPS大会的“接受时间考验奖”(Test of Time Award)时发表了一篇令人难忘的演讲。他将“内部协变量转移”作为焦点,将现代深度学习的实践比作炼金术。\n他对该示例进行了详细回顾 :cite:`Lipton.Steinhardt.2018`,概述了机器学习中令人不安的趋势。\n此外,一些作者对批量规范化的成功提出了另一种解释:在某些方面,批量规范化的表现出与原始论文 :cite:`Santurkar.Tsipras.Ilyas.ea.2018`中声称的行为是相反的。\n\n然而,与机器学习文献中成千上万类似模糊的说法相比,内部协变量偏移没有更值得批评。\n很可能,它作为这些辩论的焦点而产生共鸣,要归功于目标受众对它的广泛认可。\n批量规范化已经被证明是一种不可或缺的方法。它适用于几乎所有图像分类器,并在学术界获得了数万引用。\n\n## 小结\n\n* 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。\n* 批量规范化在全连接层和卷积层的使用略有不同。\n* 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。\n* 批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。\n\n## 练习\n\n1. 在使用批量规范化之前,我们是否可以从全连接层或卷积层中删除偏置参数?为什么?\n1. 比较LeNet在使用和不使用批量规范化情况下的学习率。\n 1. 绘制训练和测试准确度的提高。\n 1. 你的学习率有多高?\n1. 我们是否需要在每个层中进行批量规范化?尝试一下?\n1. 你可以通过批量规范化来替换暂退法吗?行为会如何改变?\n1. 确定参数`beta`和`gamma`,并观察和分析结果。\n1. 查看高级API中有关`BatchNorm`的在线文档,以查看其他批量规范化的应用。\n1. 研究思路:想想你可以应用的其他“规范化”转换?你可以应用概率积分变换吗?全秩协方差估计可以么?\n",
"_____no_output_____"
],
[
"[Discussions](https://discuss.d2l.ai/t/1876)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd2e9f77e0ff448655abd8ce51d226f7515e70a
| 2,273 |
ipynb
|
Jupyter Notebook
|
notebooks/bpr_south.ipynb
|
daxsoule/BOTPT
|
1ace69005d00f276406dd91be8aae927b047f61a
|
[
"MIT"
] | null | null | null |
notebooks/bpr_south.ipynb
|
daxsoule/BOTPT
|
1ace69005d00f276406dd91be8aae927b047f61a
|
[
"MIT"
] | null | null | null |
notebooks/bpr_south.ipynb
|
daxsoule/BOTPT
|
1ace69005d00f276406dd91be8aae927b047f61a
|
[
"MIT"
] | null | null | null | 21.855769 | 116 | 0.528377 |
[
[
[
"import pandas as pd\nimport hvplot.pandas\nimport numpy as np\nimport matplotlib.dates as dates\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"import datetime\ndef dateparse (date_string):\n return datetime.datetime.strptime(date_string, '%m/%d/%Y %H:%M:%S')",
"_____no_output_____"
]
],
[
[
"### South 2013-2015",
"_____no_output_____"
]
],
[
[
"bpr_file = '/home/jovyan/data/bpr/Axial_Deformation/nemo2013-2015-BPR-South-1-15sec-driftcorr-detided-lpf.txt'",
"_____no_output_____"
],
[
"df_nemoS13 = pd.read_csv(bpr_file, parse_dates=True, date_parser=dateparse, index_col='Date',\n dtype = {'Date': object,'Depth': np.float64,\n 'Temp': np.float64, 'SpotlDetidedDepth': np.float64,\n 'LPFDetidedDepth': np.float64})",
"_____no_output_____"
],
[
"df_nemoS13.head()",
"_____no_output_____"
],
[
"df_nemoS13.hvplot.scatter(x='Date', y= 'RawDep', datashade=True, flip_yaxis=True)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cbd2ec92a0225aa27a2b1deb3af969a9b95f5c21
| 17,616 |
ipynb
|
Jupyter Notebook
|
_notebooks/2021-06-16-poleval-through-wav2vec2.ipynb
|
jimregan/notes
|
24e374d326b4e96b7d31d08a808f9f19fe473e76
|
[
"Apache-2.0"
] | 1 |
2021-08-25T08:08:45.000Z
|
2021-08-25T08:08:45.000Z
|
_notebooks/2021-06-16-poleval-through-wav2vec2.ipynb
|
jimregan/notes
|
24e374d326b4e96b7d31d08a808f9f19fe473e76
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2021-06-16-poleval-through-wav2vec2.ipynb
|
jimregan/notes
|
24e374d326b4e96b7d31d08a808f9f19fe473e76
|
[
"Apache-2.0"
] | null | null | null | 37.480851 | 123 | 0.485695 |
[
[
[
"# \"Poleval 2021 through wav2vec2\"\n> \"Trying for pronunciation recovery\"\n\n- toc: false\n- branch: master\n- comments: true\n- hidden: true\n- categories: [wav2vec2, poleval, colab]\n",
"_____no_output_____"
]
],
[
[
"%%capture\n!pip install gdown",
"_____no_output_____"
],
[
"!gdown https://drive.google.com/uc?id=1b6MyyqgA9D1U7DX3Vtgda7f9ppkxjCXJ",
"Downloading...\nFrom: https://drive.google.com/uc?id=1b6MyyqgA9D1U7DX3Vtgda7f9ppkxjCXJ\nTo: /content/poleval_wav.train.tar.gz\n2.14GB [00:38, 55.7MB/s]\n"
],
[
"%%capture\n!tar zxvf poleval_wav.train.tar.gz && rm poleval_wav.train.tar.gz",
"_____no_output_____"
],
[
"%%capture\n!pip install librosa webrtcvad",
"_____no_output_____"
],
[
"#collapse-hide\n# VAD wrapper is taken from PyTorch Speaker Verification:\n# https://github.com/HarryVolek/PyTorch_Speaker_Verification\n# Copyright (c) 2019, HarryVolek\n# License: BSD-3-Clause\n# based on https://github.com/wiseman/py-webrtcvad/blob/master/example.py\n# Copyright (c) 2016 John Wiseman\n# License: MIT\nimport collections\nimport contextlib\nimport numpy as np\nimport sys\nimport librosa\nimport wave\n\nimport webrtcvad\n\n#from hparam import hparam as hp\nsr = 16000\n\ndef read_wave(path, sr):\n \"\"\"Reads a .wav file.\n Takes the path, and returns (PCM audio data, sample rate).\n Assumes sample width == 2\n \"\"\"\n with contextlib.closing(wave.open(path, 'rb')) as wf:\n num_channels = wf.getnchannels()\n assert num_channels == 1\n sample_width = wf.getsampwidth()\n assert sample_width == 2\n sample_rate = wf.getframerate()\n assert sample_rate in (8000, 16000, 32000, 48000)\n pcm_data = wf.readframes(wf.getnframes())\n data, _ = librosa.load(path, sr)\n assert len(data.shape) == 1\n assert sr in (8000, 16000, 32000, 48000)\n return data, pcm_data\n \nclass Frame(object):\n \"\"\"Represents a \"frame\" of audio data.\"\"\"\n def __init__(self, bytes, timestamp, duration):\n self.bytes = bytes\n self.timestamp = timestamp\n self.duration = duration\n\n\ndef frame_generator(frame_duration_ms, audio, sample_rate):\n \"\"\"Generates audio frames from PCM audio data.\n Takes the desired frame duration in milliseconds, the PCM data, and\n the sample rate.\n Yields Frames of the requested duration.\n \"\"\"\n n = int(sample_rate * (frame_duration_ms / 1000.0) * 2)\n offset = 0\n timestamp = 0.0\n duration = (float(n) / sample_rate) / 2.0\n while offset + n < len(audio):\n yield Frame(audio[offset:offset + n], timestamp, duration)\n timestamp += duration\n offset += n\n\n\ndef vad_collector(sample_rate, frame_duration_ms,\n padding_duration_ms, vad, frames):\n \"\"\"Filters out non-voiced audio frames.\n Given a webrtcvad.Vad and a source of audio frames, yields only\n the voiced audio.\n Uses a padded, sliding window algorithm over the audio frames.\n When more than 90% of the frames in the window are voiced (as\n reported by the VAD), the collector triggers and begins yielding\n audio frames. Then the collector waits until 90% of the frames in\n the window are unvoiced to detrigger.\n The window is padded at the front and back to provide a small\n amount of silence or the beginnings/endings of speech around the\n voiced frames.\n Arguments:\n sample_rate - The audio sample rate, in Hz.\n frame_duration_ms - The frame duration in milliseconds.\n padding_duration_ms - The amount to pad the window, in milliseconds.\n vad - An instance of webrtcvad.Vad.\n frames - a source of audio frames (sequence or generator).\n Returns: A generator that yields PCM audio data.\n \"\"\"\n num_padding_frames = int(padding_duration_ms / frame_duration_ms)\n # We use a deque for our sliding window/ring buffer.\n ring_buffer = collections.deque(maxlen=num_padding_frames)\n # We have two states: TRIGGERED and NOTTRIGGERED. We start in the\n # NOTTRIGGERED state.\n triggered = False\n\n voiced_frames = []\n for frame in frames:\n is_speech = vad.is_speech(frame.bytes, sample_rate)\n\n if not triggered:\n ring_buffer.append((frame, is_speech))\n num_voiced = len([f for f, speech in ring_buffer if speech])\n # If we're NOTTRIGGERED and more than 90% of the frames in\n # the ring buffer are voiced frames, then enter the\n # TRIGGERED state.\n if num_voiced > 0.9 * ring_buffer.maxlen:\n triggered = True\n start = ring_buffer[0][0].timestamp\n # We want to yield all the audio we see from now until\n # we are NOTTRIGGERED, but we have to start with the\n # audio that's already in the ring buffer.\n for f, s in ring_buffer:\n voiced_frames.append(f)\n ring_buffer.clear()\n else:\n # We're in the TRIGGERED state, so collect the audio data\n # and add it to the ring buffer.\n voiced_frames.append(frame)\n ring_buffer.append((frame, is_speech))\n num_unvoiced = len([f for f, speech in ring_buffer if not speech])\n # If more than 90% of the frames in the ring buffer are\n # unvoiced, then enter NOTTRIGGERED and yield whatever\n # audio we've collected.\n if num_unvoiced > 0.9 * ring_buffer.maxlen:\n triggered = False\n yield (start, frame.timestamp + frame.duration)\n ring_buffer.clear()\n voiced_frames = []\n # If we have any leftover voiced audio when we run out of input,\n # yield it.\n if voiced_frames:\n yield (start, frame.timestamp + frame.duration)\n\n\ndef VAD_chunk(aggressiveness, path):\n audio, byte_audio = read_wave(path, sr)\n vad = webrtcvad.Vad(int(aggressiveness))\n frames = frame_generator(20, byte_audio, sr)\n frames = list(frames)\n times = vad_collector(sr, 20, 200, vad, frames)\n speech_times = []\n speech_segs = []\n for i, time in enumerate(times):\n start = np.round(time[0],decimals=2)\n end = np.round(time[1],decimals=2)\n j = start\n while j + .4 < end:\n end_j = np.round(j+.4,decimals=2)\n speech_times.append((j, end_j))\n speech_segs.append(audio[int(j*sr):int(end_j*sr)])\n j = end_j\n else:\n speech_times.append((j, end))\n speech_segs.append(audio[int(j*sr):int(end*sr)])\n return speech_times, speech_segs",
"_____no_output_____"
],
[
"#collapse-hide\n# Based on code from PyTorch Speaker Verification:\n# https://github.com/HarryVolek/PyTorch_Speaker_Verification\n# Copyright (c) 2019, HarryVolek\n# Additions Copyright (c) 2021, Jim O'Regan\n# License: MIT\nimport numpy as np\n\n# wav2vec2's max duration is 40 seconds, using 39 by default\n# to be a little safer\ndef vad_concat(times, segs, max_duration=39.0):\n \"\"\"\n Concatenate continuous times and their segments, where the end time\n of a segment is the same as the start time of the next\n Parameters:\n times: list of tuple (start, end)\n segs: list of segments (audio frames)\n max_duration: maximum duration of the resulting concatenated\n segments; the kernel size of wav2vec2 is 40 seconds, so\n the default max_duration is 39, to ensure the resulting\n list of segments will fit\n Returns:\n concat_times: list of tuple (start, end)\n concat_segs: list of segments (audio frames)\n \"\"\"\n absolute_maximum=40.0\n if max_duration > absolute_maximum:\n raise Exception('`max_duration` {:.2f} larger than kernel size (40 seconds)'.format(max_duration))\n # we take 0.0 to mean \"don't concatenate\"\n do_concat = (max_duration != 0.0)\n concat_seg = []\n concat_times = []\n seg_concat = segs[0]\n time_concat = times[0]\n for i in range(0, len(times)-1):\n can_concat = (times[i+1][1] - time_concat[0]) < max_duration\n if time_concat[1] == times[i+1][0] and do_concat and can_concat:\n seg_concat = np.concatenate((seg_concat, segs[i+1]))\n time_concat = (time_concat[0], times[i+1][1])\n else:\n concat_seg.append(seg_concat)\n seg_concat = segs[i+1]\n concat_times.append(time_concat)\n time_concat = times[i+1]\n else:\n concat_seg.append(seg_concat)\n concat_times.append(time_concat)\n return concat_times, concat_seg",
"_____no_output_____"
],
[
"def make_dataset(concat_times, concat_segs):\n starts = [s[0] for s in concat_times]\n ends = [s[1] for s in concat_times]\n return {'start': starts,\n 'end': ends,\n 'speech': concat_segs}",
"_____no_output_____"
],
[
"%%capture\n!pip install datasets",
"_____no_output_____"
],
[
"from datasets import Dataset\n\ndef vad_to_dataset(path, max_duration):\n t,s = VAD_chunk(3, path)\n if max_duration > 0.0:\n ct, cs = vad_concat(t, s, max_duration)\n dset = make_dataset(ct, cs)\n else:\n dset = make_dataset(t, s)\n return Dataset.from_dict(dset)",
"_____no_output_____"
],
[
"%%capture\n!pip install -q transformers",
"_____no_output_____"
],
[
"%%capture\nfrom transformers import Wav2Vec2Processor, Wav2Vec2ForCTC\n# load model and tokenizer\nprocessor = Wav2Vec2Processor.from_pretrained(\"mbien/wav2vec2-large-xlsr-polish\")\nmodel = Wav2Vec2ForCTC.from_pretrained(\"mbien/wav2vec2-large-xlsr-polish\")\nmodel.to(\"cuda\")",
"_____no_output_____"
],
[
"def speech_file_to_array_fn(batch):\n import torchaudio\n speech_array, sampling_rate = torchaudio.load(batch[\"path\"])\n batch[\"speech\"] = speech_array[0].numpy()\n batch[\"sampling_rate\"] = sampling_rate\n batch[\"target_text\"] = batch[\"sentence\"]\n return batch\ndef evaluate(batch):\n import torch\n inputs = processor(batch[\"speech\"], sampling_rate=16_000, return_tensors=\"pt\", padding=True)\n\n with torch.no_grad():\n logits = model(inputs.input_values.to(\"cuda\"), attention_mask=inputs.attention_mask.to(\"cuda\")).logits\n\n pred_ids = torch.argmax(logits, dim=-1)\n batch[\"pred_strings\"] = processor.batch_decode(pred_ids)\n return batch",
"_____no_output_____"
],
[
"import json\ndef process_wave(filename, duration):\n import json\n dataset = vad_to_dataset(filename, duration)\n result = dataset.map(evaluate, batched=True, batch_size=16)\n speechless = result.remove_columns(['speech'])\n d=speechless.to_dict()\n tlog = list()\n for i in range(0, len(d['end']) - 1):\n out = dict()\n out['start'] = d['start'][i]\n out['end'] = d['end'][i]\n out['transcript'] = d['pred_strings'][i]\n tlog.append(out)\n with open('{}.tlog'.format(filename), 'w') as outfile:\n json.dump(tlog, outfile) ",
"_____no_output_____"
],
[
"import glob\nfor f in glob.glob('/content/poleval_final_dataset_wav/train/*.wav'):\n print(f)\n process_wave(f, 10.0)",
"_____no_output_____"
],
[
"!find . -name '*tlog'|zip poleval-train.zip -@",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd2eee7e367bd45b4e23c5adb5c8ad4016ba6e5
| 50,680 |
ipynb
|
Jupyter Notebook
|
My_LS_DS_441_RNN_and_LSTM_Assignment.ipynb
|
wel51x/DS-Unit-4-Sprint-4-Deep-Learning
|
f914f138295b8168db3c3aff3aeb28b0cd49ea84
|
[
"MIT"
] | null | null | null |
My_LS_DS_441_RNN_and_LSTM_Assignment.ipynb
|
wel51x/DS-Unit-4-Sprint-4-Deep-Learning
|
f914f138295b8168db3c3aff3aeb28b0cd49ea84
|
[
"MIT"
] | null | null | null |
My_LS_DS_441_RNN_and_LSTM_Assignment.ipynb
|
wel51x/DS-Unit-4-Sprint-4-Deep-Learning
|
f914f138295b8168db3c3aff3aeb28b0cd49ea84
|
[
"MIT"
] | null | null | null | 79.435737 | 25,570 | 0.48528 |
[
[
[
"<a href=\"https://colab.research.google.com/github/wel51x/DS-Unit-4-Sprint-4-Deep-Learning/blob/master/My_LS_DS_441_RNN_and_LSTM_Assignment.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Lambda School Data Science - Recurrent Neural Networks and LSTM\n\n> \"Yesterday's just a memory - tomorrow is never what it's supposed to be.\" -- Bob Dylan",
"_____no_output_____"
],
[
"####have down-version numpy to get \"RNN/LSTM Sentiment Classification with Keras\" to work in colab",
"_____no_output_____"
]
],
[
[
"!pip install numpy==1.16.2\nimport numpy as np",
"Collecting numpy==1.16.2\n Using cached https://files.pythonhosted.org/packages/35/d5/4f8410ac303e690144f0a0603c4b8fd3b986feb2749c435f7cdbb288f17e/numpy-1.16.2-cp36-cp36m-manylinux1_x86_64.whl\n\u001b[31mERROR: datascience 0.10.6 has requirement folium==0.2.1, but you'll have folium 0.8.3 which is incompatible.\u001b[0m\n\u001b[31mERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.\u001b[0m\nInstalling collected packages: numpy\n Found existing installation: numpy 1.16.3\n Uninstalling numpy-1.16.3:\n Successfully uninstalled numpy-1.16.3\nSuccessfully installed numpy-1.16.2\n"
]
],
[
[
"### Forecasting\n\nForecasting - at it's simplest, it just means \"predict the future\":",
"_____no_output_____"
],
[
"# Assignment\n\n\n\nIt is said that [infinite monkeys typing for an infinite amount of time](https://en.wikipedia.org/wiki/Infinite_monkey_theorem) will eventually type, among other things, the complete works of Wiliam Shakespeare. Let's see if we can get there a bit faster, with the power of Recurrent Neural Networks and LSTM.\n\nThis text file contains the complete works of Shakespeare: https://www.gutenberg.org/files/100/100-0.txt\n\nUse it as training data for an RNN - you can keep it simple and train character level, and that is suggested as an initial approach.\n\nThen, use that trained RNN to generate Shakespearean-ish text. Your goal - a function that can take, as an argument, the size of text (e.g. number of characters or lines) to generate, and returns generated text of that size.\n\nNote - Shakespeare wrote an awful lot. It's OK, especially initially, to sample/use smaller data and parameters, so you can have a tighter feedback loop when you're trying to get things running. Then, once you've got a proof of concept - start pushing it more!",
"_____no_output_____"
]
],
[
[
"# Imports\nfrom random import random\nimport numpy as np\nimport requests",
"_____no_output_____"
],
[
"# TODO - Words, words, mere words, no matter from the heart.\n# Grab first ten\nr = requests.get('http://www.gutenberg.org/files/100/100-0.txt', verify=True)\nx = r.text.find('From')\ny = r.text.find('thine or thee.')\narticle_text = r.text[x : y+14]",
"_____no_output_____"
],
[
"chars = list(set(article_text)) # split and remove duplicate characters. convert to list.\n\nnum_chars = len(chars) # the number of unique characters\ntxt_data_size = len(article_text)\n\nprint(\"unique characters : \", num_chars)\nprint(\"txt_data_size : \", txt_data_size)",
"unique characters : 68\ntxt_data_size : 6561\n"
]
],
[
[
"#### one hot encode",
"_____no_output_____"
]
],
[
[
"char_to_int = dict((c, i) for i, c in enumerate(chars)) # \"enumerate\" retruns index and value. Convert it to dictionary\nint_to_char = dict((i, c) for i, c in enumerate(chars))\nprint(char_to_int)\nprint(\"----------------------------------------------------\")\nprint(int_to_char)\nprint(\"----------------------------------------------------\")\n# integer encode input data\ninteger_encoded = [char_to_int[i] for i in article_text] # \"integer_encoded\" is a list which has a sequence converted from an original data to integers.\nprint(integer_encoded)\nprint(\"----------------------------------------------------\")\nprint(\"data length : \", len(integer_encoded))",
"{'C': 0, 'j': 1, 'U': 2, 'l': 3, '\\n': 4, 'G': 5, 'H': 6, 'u': 7, 'A': 8, ',': 9, 'S': 10, 'B': 11, 'b': 12, 'f': 13, 'y': 14, 'c': 15, 't': 16, 'o': 17, 'v': 18, ':': 19, '?': 20, '8': 21, 'w': 22, 'a': 23, 'T': 24, 'p': 25, '4': 26, 'R': 27, '6': 28, 'h': 29, 'D': 30, 'O': 31, 'x': 32, 'L': 33, ')': 34, '2': 35, 'k': 36, '\\r': 37, '1': 38, 's': 39, 'z': 40, ' ': 41, '7': 42, 'm': 43, '’': 44, '9': 45, 'e': 46, '3': 47, '0': 48, 'M': 49, ';': 50, 'i': 51, 'Y': 52, 'q': 53, 'P': 54, '5': 55, 'F': 56, '.': 57, '(': 58, 'g': 59, '‘': 60, 'I': 61, 'W': 62, 'N': 63, 'n': 64, 'r': 65, 'd': 66, '-': 67}\n----------------------------------------------------\n{0: 'C', 1: 'j', 2: 'U', 3: 'l', 4: '\\n', 5: 'G', 6: 'H', 7: 'u', 8: 'A', 9: ',', 10: 'S', 11: 'B', 12: 'b', 13: 'f', 14: 'y', 15: 'c', 16: 't', 17: 'o', 18: 'v', 19: ':', 20: '?', 21: '8', 22: 'w', 23: 'a', 24: 'T', 25: 'p', 26: '4', 27: 'R', 28: '6', 29: 'h', 30: 'D', 31: 'O', 32: 'x', 33: 'L', 34: ')', 35: '2', 36: 'k', 37: '\\r', 38: '1', 39: 's', 40: 'z', 41: ' ', 42: '7', 43: 'm', 44: '’', 45: '9', 46: 'e', 47: '3', 48: '0', 49: 'M', 50: ';', 51: 'i', 52: 'Y', 53: 'q', 54: 'P', 55: '5', 56: 'F', 57: '.', 58: '(', 59: 'g', 60: '‘', 61: 'I', 62: 'W', 63: 'N', 64: 'n', 65: 'r', 66: 'd', 67: '-'}\n----------------------------------------------------\n[56, 65, 17, 43, 41, 13, 23, 51, 65, 46, 39, 16, 41, 15, 65, 46, 23, 16, 7, 65, 46, 39, 41, 22, 46, 41, 66, 46, 39, 51, 65, 46, 41, 51, 64, 15, 65, 46, 23, 39, 46, 9, 37, 4, 24, 29, 23, 16, 41, 16, 29, 46, 65, 46, 12, 14, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 65, 17, 39, 46, 41, 43, 51, 59, 29, 16, 41, 64, 46, 18, 46, 65, 41, 66, 51, 46, 9, 37, 4, 11, 7, 16, 41, 23, 39, 41, 16, 29, 46, 41, 65, 51, 25, 46, 65, 41, 39, 29, 17, 7, 3, 66, 41, 12, 14, 41, 16, 51, 43, 46, 41, 66, 46, 15, 46, 23, 39, 46, 9, 37, 4, 6, 51, 39, 41, 16, 46, 64, 66, 46, 65, 41, 29, 46, 51, 65, 41, 43, 51, 59, 29, 16, 41, 12, 46, 23, 65, 41, 29, 51, 39, 41, 43, 46, 43, 17, 65, 14, 19, 37, 4, 11, 7, 16, 41, 16, 29, 17, 7, 41, 15, 17, 64, 16, 65, 23, 15, 16, 46, 66, 41, 16, 17, 41, 16, 29, 51, 64, 46, 41, 17, 22, 64, 41, 12, 65, 51, 59, 29, 16, 41, 46, 14, 46, 39, 9, 37, 4, 56, 46, 46, 66, 44, 39, 16, 41, 16, 29, 14, 41, 3, 51, 59, 29, 16, 44, 39, 41, 13, 3, 23, 43, 46, 41, 22, 51, 16, 29, 41, 39, 46, 3, 13, 67, 39, 7, 12, 39, 16, 23, 64, 16, 51, 23, 3, 41, 13, 7, 46, 3, 9, 37, 4, 49, 23, 36, 51, 64, 59, 41, 23, 41, 13, 23, 43, 51, 64, 46, 41, 22, 29, 46, 65, 46, 41, 23, 12, 7, 64, 66, 23, 64, 15, 46, 41, 3, 51, 46, 39, 9, 37, 4, 24, 29, 14, 41, 39, 46, 3, 13, 41, 16, 29, 14, 41, 13, 17, 46, 9, 41, 16, 17, 41, 16, 29, 14, 41, 39, 22, 46, 46, 16, 41, 39, 46, 3, 13, 41, 16, 17, 17, 41, 15, 65, 7, 46, 3, 19, 37, 4, 24, 29, 17, 7, 41, 16, 29, 23, 16, 41, 23, 65, 16, 41, 64, 17, 22, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 44, 39, 41, 13, 65, 46, 39, 29, 41, 17, 65, 64, 23, 43, 46, 64, 16, 9, 37, 4, 8, 64, 66, 41, 17, 64, 3, 14, 41, 29, 46, 65, 23, 3, 66, 41, 16, 17, 41, 16, 29, 46, 41, 59, 23, 7, 66, 14, 41, 39, 25, 65, 51, 64, 59, 9, 37, 4, 62, 51, 16, 29, 51, 64, 41, 16, 29, 51, 64, 46, 41, 17, 22, 64, 41, 12, 7, 66, 41, 12, 7, 65, 51, 46, 39, 16, 41, 16, 29, 14, 41, 15, 17, 64, 16, 46, 64, 16, 9, 37, 4, 8, 64, 66, 9, 41, 16, 46, 64, 66, 46, 65, 41, 15, 29, 7, 65, 3, 9, 41, 43, 23, 36, 44, 39, 16, 41, 22, 23, 39, 16, 46, 41, 51, 64, 41, 64, 51, 59, 59, 23, 65, 66, 51, 64, 59, 19, 37, 4, 41, 41, 54, 51, 16, 14, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 9, 41, 17, 65, 41, 46, 3, 39, 46, 41, 16, 29, 51, 39, 41, 59, 3, 7, 16, 16, 17, 64, 41, 12, 46, 9, 37, 4, 41, 41, 24, 17, 41, 46, 23, 16, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 44, 39, 41, 66, 7, 46, 9, 41, 12, 14, 41, 16, 29, 46, 41, 59, 65, 23, 18, 46, 41, 23, 64, 66, 41, 16, 29, 46, 46, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 35, 37, 4, 37, 4, 62, 29, 46, 64, 41, 13, 17, 65, 16, 14, 41, 22, 51, 64, 16, 46, 65, 39, 41, 39, 29, 23, 3, 3, 41, 12, 46, 39, 51, 46, 59, 46, 41, 16, 29, 14, 41, 12, 65, 17, 22, 9, 37, 4, 8, 64, 66, 41, 66, 51, 59, 41, 66, 46, 46, 25, 41, 16, 65, 46, 64, 15, 29, 46, 39, 41, 51, 64, 41, 16, 29, 14, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 13, 51, 46, 3, 66, 9, 37, 4, 24, 29, 14, 41, 14, 17, 7, 16, 29, 44, 39, 41, 25, 65, 17, 7, 66, 41, 3, 51, 18, 46, 65, 14, 41, 39, 17, 41, 59, 23, 40, 46, 66, 41, 17, 64, 41, 64, 17, 22, 9, 37, 4, 62, 51, 3, 3, 41, 12, 46, 41, 23, 41, 16, 23, 16, 16, 46, 65, 46, 66, 41, 22, 46, 46, 66, 41, 17, 13, 41, 39, 43, 23, 3, 3, 41, 22, 17, 65, 16, 29, 41, 29, 46, 3, 66, 19, 37, 4, 24, 29, 46, 64, 41, 12, 46, 51, 64, 59, 41, 23, 39, 36, 46, 66, 9, 41, 22, 29, 46, 65, 46, 41, 23, 3, 3, 41, 16, 29, 14, 41, 12, 46, 23, 7, 16, 14, 41, 3, 51, 46, 39, 9, 37, 4, 62, 29, 46, 65, 46, 41, 23, 3, 3, 41, 16, 29, 46, 41, 16, 65, 46, 23, 39, 7, 65, 46, 41, 17, 13, 41, 16, 29, 14, 41, 3, 7, 39, 16, 14, 41, 66, 23, 14, 39, 50, 37, 4, 24, 17, 41, 39, 23, 14, 9, 41, 22, 51, 16, 29, 51, 64, 41, 16, 29, 51, 64, 46, 41, 17, 22, 64, 41, 66, 46, 46, 25, 41, 39, 7, 64, 36, 46, 64, 41, 46, 14, 46, 39, 9, 37, 4, 62, 46, 65, 46, 41, 23, 64, 41, 23, 3, 3, 67, 46, 23, 16, 51, 64, 59, 41, 39, 29, 23, 43, 46, 9, 41, 23, 64, 66, 41, 16, 29, 65, 51, 13, 16, 3, 46, 39, 39, 41, 25, 65, 23, 51, 39, 46, 57, 37, 4, 6, 17, 22, 41, 43, 7, 15, 29, 41, 43, 17, 65, 46, 41, 25, 65, 23, 51, 39, 46, 41, 66, 46, 39, 46, 65, 18, 44, 66, 41, 16, 29, 14, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 7, 39, 46, 9, 37, 4, 61, 13, 41, 16, 29, 17, 7, 41, 15, 17, 7, 3, 66, 39, 16, 41, 23, 64, 39, 22, 46, 65, 41, 60, 24, 29, 51, 39, 41, 13, 23, 51, 65, 41, 15, 29, 51, 3, 66, 41, 17, 13, 41, 43, 51, 64, 46, 37, 4, 10, 29, 23, 3, 3, 41, 39, 7, 43, 41, 43, 14, 41, 15, 17, 7, 64, 16, 9, 41, 23, 64, 66, 41, 43, 23, 36, 46, 41, 43, 14, 41, 17, 3, 66, 41, 46, 32, 15, 7, 39, 46, 9, 44, 37, 4, 54, 65, 17, 18, 51, 64, 59, 41, 29, 51, 39, 41, 12, 46, 23, 7, 16, 14, 41, 12, 14, 41, 39, 7, 15, 15, 46, 39, 39, 51, 17, 64, 41, 16, 29, 51, 64, 46, 57, 37, 4, 41, 41, 24, 29, 51, 39, 41, 22, 46, 65, 46, 41, 16, 17, 41, 12, 46, 41, 64, 46, 22, 41, 43, 23, 66, 46, 41, 22, 29, 46, 64, 41, 16, 29, 17, 7, 41, 23, 65, 16, 41, 17, 3, 66, 9, 37, 4, 41, 41, 8, 64, 66, 41, 39, 46, 46, 41, 16, 29, 14, 41, 12, 3, 17, 17, 66, 41, 22, 23, 65, 43, 41, 22, 29, 46, 64, 41, 16, 29, 17, 7, 41, 13, 46, 46, 3, 44, 39, 16, 41, 51, 16, 41, 15, 17, 3, 66, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 47, 37, 4, 37, 4, 33, 17, 17, 36, 41, 51, 64, 41, 16, 29, 14, 41, 59, 3, 23, 39, 39, 41, 23, 64, 66, 41, 16, 46, 3, 3, 41, 16, 29, 46, 41, 13, 23, 15, 46, 41, 16, 29, 17, 7, 41, 18, 51, 46, 22, 46, 39, 16, 9, 37, 4, 63, 17, 22, 41, 51, 39, 41, 16, 29, 46, 41, 16, 51, 43, 46, 41, 16, 29, 23, 16, 41, 13, 23, 15, 46, 41, 39, 29, 17, 7, 3, 66, 41, 13, 17, 65, 43, 41, 23, 64, 17, 16, 29, 46, 65, 9, 37, 4, 62, 29, 17, 39, 46, 41, 13, 65, 46, 39, 29, 41, 65, 46, 25, 23, 51, 65, 41, 51, 13, 41, 64, 17, 22, 41, 16, 29, 17, 7, 41, 64, 17, 16, 41, 65, 46, 64, 46, 22, 46, 39, 16, 9, 37, 4, 24, 29, 17, 7, 41, 66, 17, 39, 16, 41, 12, 46, 59, 7, 51, 3, 46, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 9, 41, 7, 64, 12, 3, 46, 39, 39, 41, 39, 17, 43, 46, 41, 43, 17, 16, 29, 46, 65, 57, 37, 4, 56, 17, 65, 41, 22, 29, 46, 65, 46, 41, 51, 39, 41, 39, 29, 46, 41, 39, 17, 41, 13, 23, 51, 65, 41, 22, 29, 17, 39, 46, 41, 7, 64, 46, 23, 65, 46, 66, 41, 22, 17, 43, 12, 37, 4, 30, 51, 39, 66, 23, 51, 64, 39, 41, 16, 29, 46, 41, 16, 51, 3, 3, 23, 59, 46, 41, 17, 13, 41, 16, 29, 14, 41, 29, 7, 39, 12, 23, 64, 66, 65, 14, 20, 37, 4, 31, 65, 41, 22, 29, 17, 41, 51, 39, 41, 29, 46, 41, 39, 17, 41, 13, 17, 64, 66, 41, 22, 51, 3, 3, 41, 12, 46, 41, 16, 29, 46, 41, 16, 17, 43, 12, 37, 4, 31, 13, 41, 29, 51, 39, 41, 39, 46, 3, 13, 67, 3, 17, 18, 46, 41, 16, 17, 41, 39, 16, 17, 25, 41, 25, 17, 39, 16, 46, 65, 51, 16, 14, 20, 37, 4, 24, 29, 17, 7, 41, 23, 65, 16, 41, 16, 29, 14, 41, 43, 17, 16, 29, 46, 65, 44, 39, 41, 59, 3, 23, 39, 39, 41, 23, 64, 66, 41, 39, 29, 46, 41, 51, 64, 41, 16, 29, 46, 46, 37, 4, 0, 23, 3, 3, 39, 41, 12, 23, 15, 36, 41, 16, 29, 46, 41, 3, 17, 18, 46, 3, 14, 41, 8, 25, 65, 51, 3, 41, 17, 13, 41, 29, 46, 65, 41, 25, 65, 51, 43, 46, 9, 37, 4, 10, 17, 41, 16, 29, 17, 7, 41, 16, 29, 65, 17, 7, 59, 29, 41, 22, 51, 64, 66, 17, 22, 39, 41, 17, 13, 41, 16, 29, 51, 64, 46, 41, 23, 59, 46, 41, 39, 29, 23, 3, 16, 41, 39, 46, 46, 9, 37, 4, 30, 46, 39, 25, 51, 16, 46, 41, 17, 13, 41, 22, 65, 51, 64, 36, 3, 46, 39, 41, 16, 29, 51, 39, 41, 16, 29, 14, 41, 59, 17, 3, 66, 46, 64, 41, 16, 51, 43, 46, 57, 37, 4, 41, 41, 11, 7, 16, 41, 51, 13, 41, 16, 29, 17, 7, 41, 3, 51, 18, 46, 41, 65, 46, 43, 46, 43, 12, 46, 65, 46, 66, 41, 64, 17, 16, 41, 16, 17, 41, 12, 46, 9, 37, 4, 41, 41, 30, 51, 46, 41, 39, 51, 64, 59, 3, 46, 41, 23, 64, 66, 41, 16, 29, 51, 64, 46, 41, 51, 43, 23, 59, 46, 41, 66, 51, 46, 39, 41, 22, 51, 16, 29, 41, 16, 29, 46, 46, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 26, 37, 4, 37, 4, 2, 64, 16, 29, 65, 51, 13, 16, 14, 41, 3, 17, 18, 46, 3, 51, 64, 46, 39, 39, 41, 22, 29, 14, 41, 66, 17, 39, 16, 41, 16, 29, 17, 7, 41, 39, 25, 46, 64, 66, 9, 37, 4, 2, 25, 17, 64, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 16, 29, 14, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 3, 46, 59, 23, 15, 14, 20, 37, 4, 63, 23, 16, 7, 65, 46, 44, 39, 41, 12, 46, 53, 7, 46, 39, 16, 41, 59, 51, 18, 46, 39, 41, 64, 17, 16, 29, 51, 64, 59, 41, 12, 7, 16, 41, 66, 17, 16, 29, 41, 3, 46, 64, 66, 9, 37, 4, 8, 64, 66, 41, 12, 46, 51, 64, 59, 41, 13, 65, 23, 64, 36, 41, 39, 29, 46, 41, 3, 46, 64, 66, 39, 41, 16, 17, 41, 16, 29, 17, 39, 46, 41, 23, 65, 46, 41, 13, 65, 46, 46, 19, 37, 4, 24, 29, 46, 64, 41, 12, 46, 23, 7, 16, 46, 17, 7, 39, 41, 64, 51, 59, 59, 23, 65, 66, 41, 22, 29, 14, 41, 66, 17, 39, 16, 41, 16, 29, 17, 7, 41, 23, 12, 7, 39, 46, 9, 37, 4, 24, 29, 46, 41, 12, 17, 7, 64, 16, 46, 17, 7, 39, 41, 3, 23, 65, 59, 46, 39, 39, 41, 59, 51, 18, 46, 64, 41, 16, 29, 46, 46, 41, 16, 17, 41, 59, 51, 18, 46, 20, 37, 4, 54, 65, 17, 13, 51, 16, 3, 46, 39, 39, 41, 7, 39, 7, 65, 46, 65, 41, 22, 29, 14, 41, 66, 17, 39, 16, 41, 16, 29, 17, 7, 41, 7, 39, 46, 37, 4, 10, 17, 41, 59, 65, 46, 23, 16, 41, 23, 41, 39, 7, 43, 41, 17, 13, 41, 39, 7, 43, 39, 41, 14, 46, 16, 41, 15, 23, 64, 39, 16, 41, 64, 17, 16, 41, 3, 51, 18, 46, 20, 37, 4, 56, 17, 65, 41, 29, 23, 18, 51, 64, 59, 41, 16, 65, 23, 13, 13, 51, 15, 41, 22, 51, 16, 29, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 23, 3, 17, 64, 46, 9, 37, 4, 24, 29, 17, 7, 41, 17, 13, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 16, 29, 14, 41, 39, 22, 46, 46, 16, 41, 39, 46, 3, 13, 41, 66, 17, 39, 16, 41, 66, 46, 15, 46, 51, 18, 46, 9, 37, 4, 24, 29, 46, 64, 41, 29, 17, 22, 41, 22, 29, 46, 64, 41, 64, 23, 16, 7, 65, 46, 41, 15, 23, 3, 3, 39, 41, 16, 29, 46, 46, 41, 16, 17, 41, 12, 46, 41, 59, 17, 64, 46, 9, 37, 4, 62, 29, 23, 16, 41, 23, 15, 15, 46, 25, 16, 23, 12, 3, 46, 41, 23, 7, 66, 51, 16, 41, 15, 23, 64, 39, 16, 41, 16, 29, 17, 7, 41, 3, 46, 23, 18, 46, 20, 37, 4, 41, 41, 24, 29, 14, 41, 7, 64, 7, 39, 46, 66, 41, 12, 46, 23, 7, 16, 14, 41, 43, 7, 39, 16, 41, 12, 46, 41, 16, 17, 43, 12, 46, 66, 41, 22, 51, 16, 29, 41, 16, 29, 46, 46, 9, 37, 4, 41, 41, 62, 29, 51, 15, 29, 41, 7, 39, 46, 66, 41, 3, 51, 18, 46, 39, 41, 16, 29, 44, 41, 46, 32, 46, 15, 7, 16, 17, 65, 41, 16, 17, 41, 12, 46, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 55, 37, 4, 37, 4, 24, 29, 17, 39, 46, 41, 29, 17, 7, 65, 39, 41, 16, 29, 23, 16, 41, 22, 51, 16, 29, 41, 59, 46, 64, 16, 3, 46, 41, 22, 17, 65, 36, 41, 66, 51, 66, 41, 13, 65, 23, 43, 46, 37, 4, 24, 29, 46, 41, 3, 17, 18, 46, 3, 14, 41, 59, 23, 40, 46, 41, 22, 29, 46, 65, 46, 41, 46, 18, 46, 65, 14, 41, 46, 14, 46, 41, 66, 17, 16, 29, 41, 66, 22, 46, 3, 3, 37, 4, 62, 51, 3, 3, 41, 25, 3, 23, 14, 41, 16, 29, 46, 41, 16, 14, 65, 23, 64, 16, 39, 41, 16, 17, 41, 16, 29, 46, 41, 18, 46, 65, 14, 41, 39, 23, 43, 46, 9, 37, 4, 8, 64, 66, 41, 16, 29, 23, 16, 41, 7, 64, 13, 23, 51, 65, 41, 22, 29, 51, 15, 29, 41, 13, 23, 51, 65, 3, 14, 41, 66, 17, 16, 29, 41, 46, 32, 15, 46, 3, 19, 37, 4, 56, 17, 65, 41, 64, 46, 18, 46, 65, 67, 65, 46, 39, 16, 51, 64, 59, 41, 16, 51, 43, 46, 41, 3, 46, 23, 66, 39, 41, 39, 7, 43, 43, 46, 65, 41, 17, 64, 37, 4, 24, 17, 41, 29, 51, 66, 46, 17, 7, 39, 41, 22, 51, 64, 16, 46, 65, 41, 23, 64, 66, 41, 15, 17, 64, 13, 17, 7, 64, 66, 39, 41, 29, 51, 43, 41, 16, 29, 46, 65, 46, 9, 37, 4, 10, 23, 25, 41, 15, 29, 46, 15, 36, 46, 66, 41, 22, 51, 16, 29, 41, 13, 65, 17, 39, 16, 41, 23, 64, 66, 41, 3, 7, 39, 16, 14, 41, 3, 46, 23, 18, 46, 39, 41, 53, 7, 51, 16, 46, 41, 59, 17, 64, 46, 9, 37, 4, 11, 46, 23, 7, 16, 14, 41, 17, 44, 46, 65, 67, 39, 64, 17, 22, 46, 66, 41, 23, 64, 66, 41, 12, 23, 65, 46, 64, 46, 39, 39, 41, 46, 18, 46, 65, 14, 41, 22, 29, 46, 65, 46, 19, 37, 4, 24, 29, 46, 64, 41, 22, 46, 65, 46, 41, 64, 17, 16, 41, 39, 7, 43, 43, 46, 65, 44, 39, 41, 66, 51, 39, 16, 51, 3, 3, 23, 16, 51, 17, 64, 41, 3, 46, 13, 16, 37, 4, 8, 41, 3, 51, 53, 7, 51, 66, 41, 25, 65, 51, 39, 17, 64, 46, 65, 41, 25, 46, 64, 16, 41, 51, 64, 41, 22, 23, 3, 3, 39, 41, 17, 13, 41, 59, 3, 23, 39, 39, 9, 37, 4, 11, 46, 23, 7, 16, 14, 44, 39, 41, 46, 13, 13, 46, 15, 16, 41, 22, 51, 16, 29, 41, 12, 46, 23, 7, 16, 14, 41, 22, 46, 65, 46, 41, 12, 46, 65, 46, 13, 16, 9, 37, 4, 63, 17, 65, 41, 51, 16, 41, 64, 17, 65, 41, 64, 17, 41, 65, 46, 43, 46, 43, 12, 65, 23, 64, 15, 46, 41, 22, 29, 23, 16, 41, 51, 16, 41, 22, 23, 39, 57, 37, 4, 41, 41, 11, 7, 16, 41, 13, 3, 17, 22, 46, 65, 39, 41, 66, 51, 39, 16, 51, 3, 3, 46, 66, 41, 16, 29, 17, 7, 59, 29, 41, 16, 29, 46, 14, 41, 22, 51, 16, 29, 41, 22, 51, 64, 16, 46, 65, 41, 43, 46, 46, 16, 9, 37, 4, 41, 41, 33, 46, 46, 39, 46, 41, 12, 7, 16, 41, 16, 29, 46, 51, 65, 41, 39, 29, 17, 22, 9, 41, 16, 29, 46, 51, 65, 41, 39, 7, 12, 39, 16, 23, 64, 15, 46, 41, 39, 16, 51, 3, 3, 41, 3, 51, 18, 46, 39, 41, 39, 22, 46, 46, 16, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 28, 37, 4, 37, 4, 24, 29, 46, 64, 41, 3, 46, 16, 41, 64, 17, 16, 41, 22, 51, 64, 16, 46, 65, 44, 39, 41, 65, 23, 59, 59, 46, 66, 41, 29, 23, 64, 66, 41, 66, 46, 13, 23, 15, 46, 9, 37, 4, 61, 64, 41, 16, 29, 46, 46, 41, 16, 29, 14, 41, 39, 7, 43, 43, 46, 65, 41, 46, 65, 46, 41, 16, 29, 17, 7, 41, 12, 46, 41, 66, 51, 39, 16, 51, 3, 3, 46, 66, 19, 37, 4, 49, 23, 36, 46, 41, 39, 22, 46, 46, 16, 41, 39, 17, 43, 46, 41, 18, 51, 23, 3, 50, 41, 16, 65, 46, 23, 39, 7, 65, 46, 41, 16, 29, 17, 7, 41, 39, 17, 43, 46, 41, 25, 3, 23, 15, 46, 9, 37, 4, 62, 51, 16, 29, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 16, 65, 46, 23, 39, 7, 65, 46, 41, 46, 65, 46, 41, 51, 16, 41, 12, 46, 41, 39, 46, 3, 13, 67, 36, 51, 3, 3, 46, 66, 19, 37, 4, 24, 29, 23, 16, 41, 7, 39, 46, 41, 51, 39, 41, 64, 17, 16, 41, 13, 17, 65, 12, 51, 66, 66, 46, 64, 41, 7, 39, 7, 65, 14, 9, 37, 4, 62, 29, 51, 15, 29, 41, 29, 23, 25, 25, 51, 46, 39, 41, 16, 29, 17, 39, 46, 41, 16, 29, 23, 16, 41, 25, 23, 14, 41, 16, 29, 46, 41, 22, 51, 3, 3, 51, 64, 59, 41, 3, 17, 23, 64, 50, 37, 4, 24, 29, 23, 16, 44, 39, 41, 13, 17, 65, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 16, 17, 41, 12, 65, 46, 46, 66, 41, 23, 64, 17, 16, 29, 46, 65, 41, 16, 29, 46, 46, 9, 37, 4, 31, 65, 41, 16, 46, 64, 41, 16, 51, 43, 46, 39, 41, 29, 23, 25, 25, 51, 46, 65, 41, 12, 46, 41, 51, 16, 41, 16, 46, 64, 41, 13, 17, 65, 41, 17, 64, 46, 9, 37, 4, 24, 46, 64, 41, 16, 51, 43, 46, 39, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 22, 46, 65, 46, 41, 29, 23, 25, 25, 51, 46, 65, 41, 16, 29, 23, 64, 41, 16, 29, 17, 7, 41, 23, 65, 16, 9, 37, 4, 61, 13, 41, 16, 46, 64, 41, 17, 13, 41, 16, 29, 51, 64, 46, 41, 16, 46, 64, 41, 16, 51, 43, 46, 39, 41, 65, 46, 13, 51, 59, 7, 65, 46, 66, 41, 16, 29, 46, 46, 19, 37, 4, 24, 29, 46, 64, 41, 22, 29, 23, 16, 41, 15, 17, 7, 3, 66, 41, 66, 46, 23, 16, 29, 41, 66, 17, 41, 51, 13, 41, 16, 29, 17, 7, 41, 39, 29, 17, 7, 3, 66, 39, 16, 41, 66, 46, 25, 23, 65, 16, 9, 37, 4, 33, 46, 23, 18, 51, 64, 59, 41, 16, 29, 46, 46, 41, 3, 51, 18, 51, 64, 59, 41, 51, 64, 41, 25, 17, 39, 16, 46, 65, 51, 16, 14, 20, 37, 4, 41, 41, 11, 46, 41, 64, 17, 16, 41, 39, 46, 3, 13, 67, 22, 51, 3, 3, 46, 66, 41, 13, 17, 65, 41, 16, 29, 17, 7, 41, 23, 65, 16, 41, 43, 7, 15, 29, 41, 16, 17, 17, 41, 13, 23, 51, 65, 9, 37, 4, 41, 41, 24, 17, 41, 12, 46, 41, 66, 46, 23, 16, 29, 44, 39, 41, 15, 17, 64, 53, 7, 46, 39, 16, 41, 23, 64, 66, 41, 43, 23, 36, 46, 41, 22, 17, 65, 43, 39, 41, 16, 29, 51, 64, 46, 41, 29, 46, 51, 65, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 42, 37, 4, 37, 4, 33, 17, 41, 51, 64, 41, 16, 29, 46, 41, 17, 65, 51, 46, 64, 16, 41, 22, 29, 46, 64, 41, 16, 29, 46, 41, 59, 65, 23, 15, 51, 17, 7, 39, 41, 3, 51, 59, 29, 16, 37, 4, 33, 51, 13, 16, 39, 41, 7, 25, 41, 29, 51, 39, 41, 12, 7, 65, 64, 51, 64, 59, 41, 29, 46, 23, 66, 9, 41, 46, 23, 15, 29, 41, 7, 64, 66, 46, 65, 41, 46, 14, 46, 37, 4, 30, 17, 16, 29, 41, 29, 17, 43, 23, 59, 46, 41, 16, 17, 41, 29, 51, 39, 41, 64, 46, 22, 67, 23, 25, 25, 46, 23, 65, 51, 64, 59, 41, 39, 51, 59, 29, 16, 9, 37, 4, 10, 46, 65, 18, 51, 64, 59, 41, 22, 51, 16, 29, 41, 3, 17, 17, 36, 39, 41, 29, 51, 39, 41, 39, 23, 15, 65, 46, 66, 41, 43, 23, 1, 46, 39, 16, 14, 9, 37, 4, 8, 64, 66, 41, 29, 23, 18, 51, 64, 59, 41, 15, 3, 51, 43, 12, 46, 66, 41, 16, 29, 46, 41, 39, 16, 46, 46, 25, 67, 7, 25, 41, 29, 46, 23, 18, 46, 64, 3, 14, 41, 29, 51, 3, 3, 9, 37, 4, 27, 46, 39, 46, 43, 12, 3, 51, 64, 59, 41, 39, 16, 65, 17, 64, 59, 41, 14, 17, 7, 16, 29, 41, 51, 64, 41, 29, 51, 39, 41, 43, 51, 66, 66, 3, 46, 41, 23, 59, 46, 9, 37, 4, 52, 46, 16, 41, 43, 17, 65, 16, 23, 3, 41, 3, 17, 17, 36, 39, 41, 23, 66, 17, 65, 46, 41, 29, 51, 39, 41, 12, 46, 23, 7, 16, 14, 41, 39, 16, 51, 3, 3, 9, 37, 4, 8, 16, 16, 46, 64, 66, 51, 64, 59, 41, 17, 64, 41, 29, 51, 39, 41, 59, 17, 3, 66, 46, 64, 41, 25, 51, 3, 59, 65, 51, 43, 23, 59, 46, 19, 37, 4, 11, 7, 16, 41, 22, 29, 46, 64, 41, 13, 65, 17, 43, 41, 29, 51, 59, 29, 43, 17, 39, 16, 41, 25, 51, 16, 15, 29, 41, 22, 51, 16, 29, 41, 22, 46, 23, 65, 14, 41, 15, 23, 65, 9, 37, 4, 33, 51, 36, 46, 41, 13, 46, 46, 12, 3, 46, 41, 23, 59, 46, 41, 29, 46, 41, 65, 46, 46, 3, 46, 16, 29, 41, 13, 65, 17, 43, 41, 16, 29, 46, 41, 66, 23, 14, 9, 37, 4, 24, 29, 46, 41, 46, 14, 46, 39, 41, 58, 13, 17, 65, 46, 41, 66, 7, 16, 46, 17, 7, 39, 34, 41, 64, 17, 22, 41, 15, 17, 64, 18, 46, 65, 16, 46, 66, 41, 23, 65, 46, 37, 4, 56, 65, 17, 43, 41, 29, 51, 39, 41, 3, 17, 22, 41, 16, 65, 23, 15, 16, 41, 23, 64, 66, 41, 3, 17, 17, 36, 41, 23, 64, 17, 16, 29, 46, 65, 41, 22, 23, 14, 19, 37, 4, 41, 41, 10, 17, 41, 16, 29, 17, 7, 9, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 17, 7, 16, 67, 59, 17, 51, 64, 59, 41, 51, 64, 41, 16, 29, 14, 41, 64, 17, 17, 64, 19, 37, 4, 41, 41, 2, 64, 3, 17, 17, 36, 46, 66, 41, 17, 64, 41, 66, 51, 46, 39, 16, 41, 7, 64, 3, 46, 39, 39, 41, 16, 29, 17, 7, 41, 59, 46, 16, 41, 23, 41, 39, 17, 64, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 21, 37, 4, 37, 4, 49, 7, 39, 51, 15, 41, 16, 17, 41, 29, 46, 23, 65, 9, 41, 22, 29, 14, 41, 29, 46, 23, 65, 44, 39, 16, 41, 16, 29, 17, 7, 41, 43, 7, 39, 51, 15, 41, 39, 23, 66, 3, 14, 20, 37, 4, 10, 22, 46, 46, 16, 39, 41, 22, 51, 16, 29, 41, 39, 22, 46, 46, 16, 39, 41, 22, 23, 65, 41, 64, 17, 16, 9, 41, 1, 17, 14, 41, 66, 46, 3, 51, 59, 29, 16, 39, 41, 51, 64, 41, 1, 17, 14, 19, 37, 4, 62, 29, 14, 41, 3, 17, 18, 44, 39, 16, 41, 16, 29, 17, 7, 41, 16, 29, 23, 16, 41, 22, 29, 51, 15, 29, 41, 16, 29, 17, 7, 41, 65, 46, 15, 46, 51, 18, 44, 39, 16, 41, 64, 17, 16, 41, 59, 3, 23, 66, 3, 14, 9, 37, 4, 31, 65, 41, 46, 3, 39, 46, 41, 65, 46, 15, 46, 51, 18, 44, 39, 16, 41, 22, 51, 16, 29, 41, 25, 3, 46, 23, 39, 7, 65, 46, 41, 16, 29, 51, 64, 46, 41, 23, 64, 64, 17, 14, 20, 37, 4, 61, 13, 41, 16, 29, 46, 41, 16, 65, 7, 46, 41, 15, 17, 64, 15, 17, 65, 66, 41, 17, 13, 41, 22, 46, 3, 3, 67, 16, 7, 64, 46, 66, 41, 39, 17, 7, 64, 66, 39, 9, 37, 4, 11, 14, 41, 7, 64, 51, 17, 64, 39, 41, 43, 23, 65, 65, 51, 46, 66, 41, 66, 17, 41, 17, 13, 13, 46, 64, 66, 41, 16, 29, 51, 64, 46, 41, 46, 23, 65, 9, 37, 4, 24, 29, 46, 14, 41, 66, 17, 41, 12, 7, 16, 41, 39, 22, 46, 46, 16, 3, 14, 41, 15, 29, 51, 66, 46, 41, 16, 29, 46, 46, 9, 41, 22, 29, 17, 41, 15, 17, 64, 13, 17, 7, 64, 66, 39, 37, 4, 61, 64, 41, 39, 51, 64, 59, 3, 46, 64, 46, 39, 39, 41, 16, 29, 46, 41, 25, 23, 65, 16, 39, 41, 16, 29, 23, 16, 41, 16, 29, 17, 7, 41, 39, 29, 17, 7, 3, 66, 39, 16, 41, 12, 46, 23, 65, 19, 37, 4, 49, 23, 65, 36, 41, 29, 17, 22, 41, 17, 64, 46, 41, 39, 16, 65, 51, 64, 59, 41, 39, 22, 46, 46, 16, 41, 29, 7, 39, 12, 23, 64, 66, 41, 16, 17, 41, 23, 64, 17, 16, 29, 46, 65, 9, 37, 4, 10, 16, 65, 51, 36, 46, 39, 41, 46, 23, 15, 29, 41, 51, 64, 41, 46, 23, 15, 29, 41, 12, 14, 41, 43, 7, 16, 7, 23, 3, 41, 17, 65, 66, 46, 65, 51, 64, 59, 50, 37, 4, 27, 46, 39, 46, 43, 12, 3, 51, 64, 59, 41, 39, 51, 65, 46, 9, 41, 23, 64, 66, 41, 15, 29, 51, 3, 66, 9, 41, 23, 64, 66, 41, 29, 23, 25, 25, 14, 41, 43, 17, 16, 29, 46, 65, 9, 37, 4, 62, 29, 17, 41, 23, 3, 3, 41, 51, 64, 41, 17, 64, 46, 9, 41, 17, 64, 46, 41, 25, 3, 46, 23, 39, 51, 64, 59, 41, 64, 17, 16, 46, 41, 66, 17, 41, 39, 51, 64, 59, 19, 37, 4, 41, 41, 62, 29, 17, 39, 46, 41, 39, 25, 46, 46, 15, 29, 3, 46, 39, 39, 41, 39, 17, 64, 59, 41, 12, 46, 51, 64, 59, 41, 43, 23, 64, 14, 9, 41, 39, 46, 46, 43, 51, 64, 59, 41, 17, 64, 46, 9, 37, 4, 41, 41, 10, 51, 64, 59, 39, 41, 16, 29, 51, 39, 41, 16, 17, 41, 16, 29, 46, 46, 9, 41, 60, 24, 29, 17, 7, 41, 39, 51, 64, 59, 3, 46, 41, 22, 51, 3, 16, 41, 25, 65, 17, 18, 46, 41, 64, 17, 64, 46, 44, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 45, 37, 4, 37, 4, 61, 39, 41, 51, 16, 41, 13, 17, 65, 41, 13, 46, 23, 65, 41, 16, 17, 41, 22, 46, 16, 41, 23, 41, 22, 51, 66, 17, 22, 44, 39, 41, 46, 14, 46, 9, 37, 4, 24, 29, 23, 16, 41, 16, 29, 17, 7, 41, 15, 17, 64, 39, 7, 43, 44, 39, 16, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 51, 64, 41, 39, 51, 64, 59, 3, 46, 41, 3, 51, 13, 46, 20, 37, 4, 8, 29, 9, 41, 51, 13, 41, 16, 29, 17, 7, 41, 51, 39, 39, 7, 46, 3, 46, 39, 39, 41, 39, 29, 23, 3, 16, 41, 29, 23, 25, 41, 16, 17, 41, 66, 51, 46, 9, 37, 4, 24, 29, 46, 41, 22, 17, 65, 3, 66, 41, 22, 51, 3, 3, 41, 22, 23, 51, 3, 41, 16, 29, 46, 46, 41, 3, 51, 36, 46, 41, 23, 41, 43, 23, 36, 46, 3, 46, 39, 39, 41, 22, 51, 13, 46, 9, 37, 4, 24, 29, 46, 41, 22, 17, 65, 3, 66, 41, 22, 51, 3, 3, 41, 12, 46, 41, 16, 29, 14, 41, 22, 51, 66, 17, 22, 41, 23, 64, 66, 41, 39, 16, 51, 3, 3, 41, 22, 46, 46, 25, 9, 37, 4, 24, 29, 23, 16, 41, 16, 29, 17, 7, 41, 64, 17, 41, 13, 17, 65, 43, 41, 17, 13, 41, 16, 29, 46, 46, 41, 29, 23, 39, 16, 41, 3, 46, 13, 16, 41, 12, 46, 29, 51, 64, 66, 9, 37, 4, 62, 29, 46, 64, 41, 46, 18, 46, 65, 14, 41, 25, 65, 51, 18, 23, 16, 46, 41, 22, 51, 66, 17, 22, 41, 22, 46, 3, 3, 41, 43, 23, 14, 41, 36, 46, 46, 25, 9, 37, 4, 11, 14, 41, 15, 29, 51, 3, 66, 65, 46, 64, 44, 39, 41, 46, 14, 46, 39, 9, 41, 29, 46, 65, 41, 29, 7, 39, 12, 23, 64, 66, 44, 39, 41, 39, 29, 23, 25, 46, 41, 51, 64, 41, 43, 51, 64, 66, 19, 37, 4, 33, 17, 17, 36, 41, 22, 29, 23, 16, 41, 23, 64, 41, 7, 64, 16, 29, 65, 51, 13, 16, 41, 51, 64, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 41, 66, 17, 16, 29, 41, 39, 25, 46, 64, 66, 37, 4, 10, 29, 51, 13, 16, 39, 41, 12, 7, 16, 41, 29, 51, 39, 41, 25, 3, 23, 15, 46, 9, 41, 13, 17, 65, 41, 39, 16, 51, 3, 3, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 41, 46, 64, 1, 17, 14, 39, 41, 51, 16, 50, 37, 4, 11, 7, 16, 41, 12, 46, 23, 7, 16, 14, 44, 39, 41, 22, 23, 39, 16, 46, 41, 29, 23, 16, 29, 41, 51, 64, 41, 16, 29, 46, 41, 22, 17, 65, 3, 66, 41, 23, 64, 41, 46, 64, 66, 9, 37, 4, 8, 64, 66, 41, 36, 46, 25, 16, 41, 7, 64, 7, 39, 46, 66, 41, 16, 29, 46, 41, 7, 39, 46, 65, 41, 39, 17, 41, 66, 46, 39, 16, 65, 17, 14, 39, 41, 51, 16, 19, 37, 4, 41, 41, 63, 17, 41, 3, 17, 18, 46, 41, 16, 17, 22, 23, 65, 66, 41, 17, 16, 29, 46, 65, 39, 41, 51, 64, 41, 16, 29, 23, 16, 41, 12, 17, 39, 17, 43, 41, 39, 51, 16, 39, 37, 4, 41, 41, 24, 29, 23, 16, 41, 17, 64, 41, 29, 51, 43, 39, 46, 3, 13, 41, 39, 7, 15, 29, 41, 43, 7, 65, 66, 44, 65, 17, 7, 39, 41, 39, 29, 23, 43, 46, 41, 15, 17, 43, 43, 51, 16, 39, 57, 37, 4, 37, 4, 37, 4, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 41, 38, 48, 37, 4, 37, 4, 56, 17, 65, 41, 39, 29, 23, 43, 46, 41, 66, 46, 64, 14, 41, 16, 29, 23, 16, 41, 16, 29, 17, 7, 41, 12, 46, 23, 65, 44, 39, 16, 41, 3, 17, 18, 46, 41, 16, 17, 41, 23, 64, 14, 37, 4, 62, 29, 17, 41, 13, 17, 65, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 23, 65, 16, 41, 39, 17, 41, 7, 64, 25, 65, 17, 18, 51, 66, 46, 64, 16, 57, 37, 4, 5, 65, 23, 64, 16, 41, 51, 13, 41, 16, 29, 17, 7, 41, 22, 51, 3, 16, 9, 41, 16, 29, 17, 7, 41, 23, 65, 16, 41, 12, 46, 3, 17, 18, 46, 66, 41, 17, 13, 41, 43, 23, 64, 14, 9, 37, 4, 11, 7, 16, 41, 16, 29, 23, 16, 41, 16, 29, 17, 7, 41, 64, 17, 64, 46, 41, 3, 17, 18, 44, 39, 16, 41, 51, 39, 41, 43, 17, 39, 16, 41, 46, 18, 51, 66, 46, 64, 16, 19, 37, 4, 56, 17, 65, 41, 16, 29, 17, 7, 41, 23, 65, 16, 41, 39, 17, 41, 25, 17, 39, 39, 46, 39, 39, 46, 66, 41, 22, 51, 16, 29, 41, 43, 7, 65, 66, 44, 65, 17, 7, 39, 41, 29, 23, 16, 46, 9, 37, 4, 24, 29, 23, 16, 41, 44, 59, 23, 51, 64, 39, 16, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 16, 29, 17, 7, 41, 39, 16, 51, 15, 36, 44, 39, 16, 41, 64, 17, 16, 41, 16, 17, 41, 15, 17, 64, 39, 25, 51, 65, 46, 9, 37, 4, 10, 46, 46, 36, 51, 64, 59, 41, 16, 29, 23, 16, 41, 12, 46, 23, 7, 16, 46, 17, 7, 39, 41, 65, 17, 17, 13, 41, 16, 17, 41, 65, 7, 51, 64, 23, 16, 46, 37, 4, 62, 29, 51, 15, 29, 41, 16, 17, 41, 65, 46, 25, 23, 51, 65, 41, 39, 29, 17, 7, 3, 66, 41, 12, 46, 41, 16, 29, 14, 41, 15, 29, 51, 46, 13, 41, 66, 46, 39, 51, 65, 46, 19, 37, 4, 31, 41, 15, 29, 23, 64, 59, 46, 41, 16, 29, 14, 41, 16, 29, 17, 7, 59, 29, 16, 9, 41, 16, 29, 23, 16, 41, 61, 41, 43, 23, 14, 41, 15, 29, 23, 64, 59, 46, 41, 43, 14, 41, 43, 51, 64, 66, 9, 37, 4, 10, 29, 23, 3, 3, 41, 29, 23, 16, 46, 41, 12, 46, 41, 13, 23, 51, 65, 46, 65, 41, 3, 17, 66, 59, 46, 66, 41, 16, 29, 23, 64, 41, 59, 46, 64, 16, 3, 46, 41, 3, 17, 18, 46, 20, 37, 4, 11, 46, 41, 23, 39, 41, 16, 29, 14, 41, 25, 65, 46, 39, 46, 64, 15, 46, 41, 51, 39, 41, 59, 65, 23, 15, 51, 17, 7, 39, 41, 23, 64, 66, 41, 36, 51, 64, 66, 9, 37, 4, 31, 65, 41, 16, 17, 41, 16, 29, 14, 41, 39, 46, 3, 13, 41, 23, 16, 41, 3, 46, 23, 39, 16, 41, 36, 51, 64, 66, 67, 29, 46, 23, 65, 16, 46, 66, 41, 25, 65, 17, 18, 46, 9, 37, 4, 41, 41, 49, 23, 36, 46, 41, 16, 29, 46, 46, 41, 23, 64, 17, 16, 29, 46, 65, 41, 39, 46, 3, 13, 41, 13, 17, 65, 41, 3, 17, 18, 46, 41, 17, 13, 41, 43, 46, 9, 37, 4, 41, 41, 24, 29, 23, 16, 41, 12, 46, 23, 7, 16, 14, 41, 39, 16, 51, 3, 3, 41, 43, 23, 14, 41, 3, 51, 18, 46, 41, 51, 64, 41, 16, 29, 51, 64, 46, 41, 17, 65, 41, 16, 29, 46, 46, 57]\n----------------------------------------------------\ndata length : 6561\n"
]
],
[
[
"#### hyperparameters",
"_____no_output_____"
]
],
[
[
"iteration = 500\nsequence_length = 40\nbatch_size = round((txt_data_size /sequence_length)+0.5) # = math.ceil\nhidden_size = 128 # size of hidden layer of neurons. \nlearning_rate = 1e-1\n\n# model parameters\n\nW_xh = np.random.randn(hidden_size, num_chars)*0.01 # weight input -> hidden. \nW_hh = np.random.randn(hidden_size, hidden_size)*0.01 # weight hidden -> hidden\nW_hy = np.random.randn(num_chars, hidden_size)*0.01 # weight hidden -> output\n\nb_h = np.zeros((hidden_size, 1)) # hidden bias\nb_y = np.zeros((num_chars, 1)) # output bias\n\nh_prev = np.zeros((hidden_size,1)) # h_(t-1)",
"_____no_output_____"
]
],
[
[
"#### Forward propagation",
"_____no_output_____"
]
],
[
[
"def forwardprop(inputs, targets, h_prev):\n \n # Since the RNN receives the sequence, the weights are not updated during one sequence.\n xs, hs, ys, ps = {}, {}, {}, {} # dictionary\n hs[-1] = np.copy(h_prev) # Copy previous hidden state vector to -1 key value.\n loss = 0 # loss initialization\n \n for t in range(len(inputs)): # t is a \"time step\" and is used as a key(dic). \n \n xs[t] = np.zeros((num_chars,1)) \n xs[t][inputs[t]] = 1\n hs[t] = np.tanh(np.dot(W_xh, xs[t]) + np.dot(W_hh, hs[t-1]) + b_h) # hidden state. \n ys[t] = np.dot(W_hy, hs[t]) + b_y # unnormalized log probabilities for next chars\n ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars. \n # Softmax. -> The sum of probabilities is 1 even without the exp() function, but all of the elements are positive through the exp() function.\n \n loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss). Efficient and simple code\n\n# y_class = np.zeros((num_chars, 1)) \n# y_class[targets[t]] =1\n# loss += np.sum(y_class*(-np.log(ps[t]))) # softmax (cross-entropy loss) \n\n return loss, ps, hs, xs",
"_____no_output_____"
]
],
[
[
"#### Backward propagation",
"_____no_output_____"
]
],
[
[
"def backprop(ps, inputs, hs, xs):\n\n dWxh, dWhh, dWhy = np.zeros_like(W_xh), np.zeros_like(W_hh), np.zeros_like(W_hy) # make all zero matrices.\n dbh, dby = np.zeros_like(b_h), np.zeros_like(b_y)\n dhnext = np.zeros_like(hs[0]) # (hidden_size,1) \n\n # reversed\n for t in reversed(range(len(inputs))):\n dy = np.copy(ps[t]) # shape (num_chars,1). \"dy\" means \"dloss/dy\"\n dy[targets[t]] -= 1 # backprop into y. After taking the soft max in the input vector, subtract 1 from the value of the element corresponding to the correct label.\n dWhy += np.dot(dy, hs[t].T)\n dby += dy \n dh = np.dot(W_hy.T, dy) + dhnext # backprop into h. \n dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity #tanh'(x) = 1-tanh^2(x)\n dbh += dhraw\n dWxh += np.dot(dhraw, xs[t].T)\n dWhh += np.dot(dhraw, hs[t-1].T)\n dhnext = np.dot(W_hh.T, dhraw)\n for dparam in [dWxh, dWhh, dWhy, dbh, dby]: \n np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients. \n \n return dWxh, dWhh, dWhy, dbh, dby",
"_____no_output_____"
]
],
[
[
"#### Training",
"_____no_output_____"
]
],
[
[
"%%time\n\ndata_pointer = 0\n\n# memory variables for Adagrad\nmWxh, mWhh, mWhy = np.zeros_like(W_xh), np.zeros_like(W_hh), np.zeros_like(W_hy)\nmbh, mby = np.zeros_like(b_h), np.zeros_like(b_y) \n\nfor i in range(iteration+1):\n h_prev = np.zeros((hidden_size,1)) # reset RNN memory\n data_pointer = 0 # go from start of data\n \n for b in range(batch_size):\n \n inputs = [char_to_int[ch] for ch in article_text[data_pointer:data_pointer+sequence_length]]\n targets = [char_to_int[ch] for ch in article_text[data_pointer+1:data_pointer+sequence_length+1]] # t+1 \n \n if (data_pointer+sequence_length+1 >= len(article_text) and b == batch_size-1): # processing of the last part of the input data. \n# targets.append(char_to_int[txt_data[0]]) # When the data doesn't fit, add the first char to the back.\n targets.append(char_to_int[\" \"]) # When the data doesn't fit, add space(\" \") to the back.\n\n\n # forward\n loss, ps, hs, xs = forwardprop(inputs, targets, h_prev)\n# print(loss)\n \n # backward\n dWxh, dWhh, dWhy, dbh, dby = backprop(ps, inputs, hs, xs) \n \n \n # perform parameter update with Adagrad\n for param, dparam, mem in zip([W_xh, W_hh, W_hy, b_h, b_y], \n [dWxh, dWhh, dWhy, dbh, dby], \n [mWxh, mWhh, mWhy, mbh, mby]):\n mem += dparam * dparam # elementwise\n param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update \n \n data_pointer += sequence_length # move data pointer\n \n if i % 25 == 0:\n print ('iter %d, loss: %f' % (i, loss)) # print progress",
"iter 0, loss: 1.013929\niter 25, loss: 0.020648\niter 50, loss: 0.006868\niter 75, loss: 0.007810\niter 100, loss: 0.006554\niter 125, loss: 0.006616\niter 150, loss: 0.004147\niter 175, loss: 0.003310\niter 200, loss: 0.002658\niter 225, loss: 0.002035\niter 250, loss: 0.001868\niter 275, loss: 0.001897\niter 300, loss: 0.001902\niter 325, loss: 0.001976\niter 350, loss: 0.001875\niter 375, loss: 0.001738\niter 400, loss: 0.001727\niter 425, loss: 0.002082\niter 450, loss: 0.002615\niter 475, loss: 0.002942\niter 500, loss: 0.002798\nCPU times: user 9min 50s, sys: 6min 5s, total: 15min 56s\nWall time: 8min 4s\n"
]
],
[
[
"#### Prediction",
"_____no_output_____"
]
],
[
[
"def predict(test_char, length):\n x = np.zeros((num_chars, 1)) \n x[char_to_int[test_char]] = 1\n ixes = []\n h = np.zeros((hidden_size,1))\n\n for t in range(length):\n h = np.tanh(np.dot(W_xh, x) + np.dot(W_hh, h) + b_h) \n y = np.dot(W_hy, h) + b_y\n p = np.exp(y) / np.sum(np.exp(y)) \n ix = np.random.choice(range(num_chars), p=p.ravel()) # ravel -> rank0\n # \"ix\" is a list of indexes selected according to the soft max probability.\n x = np.zeros((num_chars, 1)) # init\n x[ix] = 1 \n ixes.append(ix) # list\n txt = test_char + ''.join(int_to_char[i] for i in ixes)\n print ('----\\n %s \\n----' % (txt, ))",
"_____no_output_____"
],
[
"predict('S', 500)",
"----\n Se ouch withire anlost thou thae conglenesss in pleas’s thy dor thou thou used if frere times,\r\nThat coms hid self and dondd’st rears, way pef-loir anur (fots ar that not lise:\r\n To hile welf thou so nf he chere foud prey:\r\n Samest ent thou thom\r\nThath tind thou bece doth llor deoved wimm ‘Th plle spllf stilg conother mat sthinced Sar mear, in that in that of not.\r\n\r\n\r\nThe inine the will on rlove?\r\n That cone when’s:\r\nLied,\r\n Thap so dooked buciigg trakiglambcige on thou ridouts cof cor shaf \n----\n"
],
[
"predict('C', 750)",
"----\n Cail wime praild harice hipppiveeats or there hash cherideld with wilf thy on thou not spof bud the each doth ho fond ity \r\nRet,\r\nSo the gazlovang still thic not iwculo the worpcery to thy sone shat anus preredine unthry uns and,\r\nIft aft,\r\nBusurst to thide be is thane thou no dus tookchiss why kinde,\r\nThe still thet condd,\r\nSheausinother.\r\n Who non.\r\n\r\nMuse,\r\nThy so faill the eots datimuchise for shald to in that not be maplats in thou the rakmthine preage dor chou thou with co loy frat now buce stiets thou cong in thy lof musbllhise sond confourm’st no for rotfouglaving be my lr chil’s nd thee,\r\nThos what anojoy time his thy that thou not buy ming nlor dust,\r\n Lealt whath wilt:\r\nThif thou nots be do whe sorld k’s in welf kind,\r\n Nust de \n----\n"
]
],
[
[
"# Resources and Stretch Goals",
"_____no_output_____"
],
[
"## Stretch goals:\n- Refine the training and generation of text to be able to ask for different genres/styles of Shakespearean text (e.g. plays versus sonnets)\n- Train a classification model that takes text and returns which work of Shakespeare it is most likely to be from\n- Make it more performant! Many possible routes here - lean on Keras, optimize the code, and/or use more resources (AWS, etc.)\n- Revisit the news example from class, and improve it - use categories or tags to refine the model/generation, or train a news classifier\n- Run on bigger, better data\n\n## Resources:\n- [The Unreasonable Effectiveness of Recurrent Neural Networks](https://karpathy.github.io/2015/05/21/rnn-effectiveness/) - a seminal writeup demonstrating a simple but effective character-level NLP RNN\n- [Simple NumPy implementation of RNN](https://github.com/JY-Yoon/RNN-Implementation-using-NumPy/blob/master/RNN%20Implementation%20using%20NumPy.ipynb) - Python 3 version of the code from \"Unreasonable Effectiveness\"\n- [TensorFlow RNN Tutorial](https://github.com/tensorflow/models/tree/master/tutorials/rnn) - code for training a RNN on the Penn Tree Bank language dataset\n- [4 part tutorial on RNN](http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/) - relates RNN to the vanishing gradient problem, and provides example implementation\n- [RNN training tips and tricks](https://github.com/karpathy/char-rnn#tips-and-tricks) - some rules of thumb for parameterizing and training your RNN",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cbd2f7f3ceebd86e456b90e7f30d78486e7f962b
| 250,056 |
ipynb
|
Jupyter Notebook
|
notebooks/Coase.ipynb
|
jhconning/DevII
|
fc9c9e91dae79eea3e55beb67b2de01d8c375b04
|
[
"MIT"
] | null | null | null |
notebooks/Coase.ipynb
|
jhconning/DevII
|
fc9c9e91dae79eea3e55beb67b2de01d8c375b04
|
[
"MIT"
] | null | null | null |
notebooks/Coase.ipynb
|
jhconning/DevII
|
fc9c9e91dae79eea3e55beb67b2de01d8c375b04
|
[
"MIT"
] | null | null | null | 260.475 | 66,452 | 0.923241 |
[
[
[
"# Coase and Property\n\n> Coase, R. H. 1960. “The Problem of Social Cost.” *The Journal of Law and Economics* 3:1–44.\n\n> Coase, Ronald H. 1937. “The Nature of the Firm.” *Economica* 4 (16):386–405.",
"_____no_output_____"
],
[
"**Slideshow mode**: this notebook can be viewed as a slideshow by pressing Alt-R if run on a server.",
"_____no_output_____"
],
[
"## Coase (1960) The Problem of Social Cost\n\n### A rancher and wheat farmer.\n\nBoth are utilizing adjacent plots of land. No fence separates the lands. ",
"_____no_output_____"
],
[
"**The Wheat Farmer:** chooses a production method that delivers a maximum profit of $\\Pi_W =8$. \n- to keep this simple suppose this is the farmer's only production choice.",
"_____no_output_____"
],
[
"**The Rancher:** chooses herd size $x$ to maximize profits $\\Pi_C(x) = P \\cdot F(x) - c \\cdot x^2$\n\n- $P$ is cattle price and $c$ is the cost of feeding each animal. ",
"_____no_output_____"
],
[
"- The herd size $x^*$ that maximizes profits given by:\n\n$$P \\cdot F'(x^*) = c$$",
"_____no_output_____"
],
[
"**Example:** If $F(x) = x$, $c=\\frac{1}{2}$. \n\nThe FOC are $x^{*} = P_c$ \n\nWith $P_c=4$ and $c=\\frac{1}{2}$, the rancher's privately optimal herd size of $x^* = 4$",
"_____no_output_____"
],
[
"#### Missing Property Rights impose external costs\n\nWith no effective barrier separating the fields cattle sometimes strays into the wheat farmer's fields, damaging crops and reducing wheat farmer's profits.\n\nAssume that if the rancher keeps a herd size $x$ net profits in wheat are reduced from $\\Pi_W$ to:\n\n$$\\Pi_W(x) = \\Pi_W - d \\cdot x^2$$",
"_____no_output_____"
],
[
"**The external cost**\n\nSuppose $d=\\frac{1}{2}$\n\nAt the rancher's private optimum herd size of $x^*=4$, the farmer's profit is reduced from 8 to zero:\n\n$$\\begin{align}\n\\Pi_W(x) &= \\Pi_W - d \\cdot x^2 \\\\\n & = 8 - \\frac{1}{2} \\cdot 4^2 = 0\n \\end{align}$$",
"_____no_output_____"
]
],
[
[
"from coase import *\nfrom ipywidgets import interact, fixed",
"_____no_output_____"
]
],
[
[
"At private optimum Rancher earns \\$8 but imposes external costs that drive the farmer's earnings to zero.",
"_____no_output_____"
]
],
[
[
"coaseplot1()",
"_____no_output_____"
]
],
[
[
"Private and social marginal benefits and costs can be plotted to see deadweight loss (DWL) differently:",
"_____no_output_____"
]
],
[
[
"coaseplot2()",
"_____no_output_____"
]
],
[
[
"## The assignment of property rights (liability)",
"_____no_output_____"
],
[
"**Scenario 1:** Farmer is given the right to enjoin (i.e. limit or prohibit) cattle herding.\n\nIf the farmer enforces a prohibition on all cattle herding:\n\n- Rancher now earns \\$0. \n- Farmer earns \\$8. ",
"_____no_output_____"
],
[
"- But this is not efficient! Total output is smaller than it could be. \n- If transactions costs are low the two parties can bargain to a more efficient outcome.",
"_____no_output_____"
],
[
"**Scenario 1:** Farmer is given the right to enjoin (i.e. limit or prohibit) cattle herding.\n\nRancher reasons that if she were permitted to herd 2 cattle she'd earn $\\$6$ while imposing \\$2 in damage.\n - She could offer $\\$2$ in full compensation for damage, pocketing remaining \\$4 \n - or they could bargain over how to divide the gains to trade of \\$4 in other ways.",
"_____no_output_____"
],
[
"**Scenario 2:** Rancher is granted right to graze with impunity.\n\nFarmer reasons that if herd size could be reduced from 4 to 2\n- farm profits would rise from $\\$0$ to $\\$6$\n- rancher's profits would fall from $\\$8$ to $\\$6$",
"_____no_output_____"
],
[
"- So farmer could offer to fully compensate rancher for $\\$2$ loss and pocket remaining $\\$4$\n- or they could bargain to divide those gains to trade of $\\$4$ in other ways.",
"_____no_output_____"
],
[
"### Who causes the externality?\n\n- The rancher, because his cows trample the crops?\n- The farmer, for placing his field too close to the rancher?\n- Ronald Coase point is that there is no clear answer to this question.\n - Hence Pigouvian tax/subsidy 'solutions' are not obvious. Should we tax the rancher, or subsidize them to keep their herd size down? \n - 'Externality' problem is due to the non-assignment of property rights.",
"_____no_output_____"
],
[
"## The 'Coase Theorem'\n\n### With zero/low transactions costs\n\n- **The initial assignment of property rights does not matter for efficiency:** The parties traded to an efficient solution no matter who first got the rights. ",
"_____no_output_____"
],
[
"- **The 'emergence' of property rights**: Even with no initial third-party assignment of property rights, it should be in the interests of the parties to create such rights and negotiate/trade to an efficient outcome. ",
"_____no_output_____"
],
[
"- **The initial allocation does matter for the distribution of benefits between parties.** Legally tradable entitlements are valuable, generate income to those who can then sell.",
"_____no_output_____"
],
[
"### Coase Theorem: True, False or Tautology?\n\n> \"Costless bargaining is efficient tautologically; if I assume people can agree on socially efficient bargains, then of course they will... In the absence of property rights, a bargain *establishes* a contract between parties with novel rights that needn’t exist ex-ante.\"\nCooter (1990)\n\nIn the Farmer and Rancher example there was a missing market for legal entitlements. \n\nOnce the market is made complete (by an assumed third party) then the First Welfare Theorem applies: complete competitive markets will lead to efficient allocations, regardless of initial allocation of property rights. \n\nThe \"Coase Theorem\" makes legal entitlements tradable.",
"_____no_output_____"
],
[
"In this view insuring efficiency is matter or removing impediments to free exchange of legal entitlements. However, \n\n>\"The interesting case is when transaction costs make bargaining difficult. What you should take from Coase is that social efficiency can be enhanced by institutions (including the firm!) which allow socially efficient bargains to be reached by removing restrictive transaction costs, and particularly that the assignment of property rights to different parties can either help or hinder those institutions.\"\n\nGood further discussions from [D. Mcloskey](http://www.deirdremccloskey.com/docs/pdf/Article_306.pdf) and [here](https://afinetheorem.wordpress.com/2013/09/03/on-coases-two-famous-theorems/): \n ",
"_____no_output_____"
],
[
"## When initial rights allocations matters for efficiency\n\n- 'Coase Theorem' (Stigler) interpretation sweeps under the rug the complicated political question of who gets initial rights.\n - Parties may engage in costly conflict, expend real resources to try to establish control over initial allocation of rights.\n - The [Myerson Satterthaite theorem](https://en.wikipedia.org/wiki/Myerson%E2%80%93Satterthwaite_theorem) establishes that when parties are asymmetrically informed about each other's valuations (e.g. here about the value of damages or benefits) then efficient exchange may become difficult/impossible. Each party may try to extract rents by trying to \"hold-up\" the other. \n - Suppose we had many farmers and ranchers. It might be costly/difficult to bring all relevant ranchers and farmers together and to agree on bargain terms. \n- Coase himself thought transactions costs mattered and hence initial allocation mechanisms had to be thought through carefully (e.g. spectrum auctions). ",
"_____no_output_____"
],
[
"## A Coasian view of land market development\n\nSuppose there is an open field. In the absence of a land market whoever gets to the land first (possibly the more powerful in the the village) will prepare/clear land until the marginal value product of the last unit of land is equal to the clearing cost. We contrast two situations:\n\n(1) Open frontier: where land is still abundant\n\n(2) Land Scarcity.\n\nThere will be a misallocation in (2) shown by DWL in the diagram... but also an incentive for the parties to bargain to a more efficient outcome. A well functionining land market would also deliver that outcome. ",
"_____no_output_____"
],
[
"#### Abundant land environment\n\n$\\bar T$ units of land and $N$=2 households.\n\nLand clearing cost $c$. Frontier land not yet exhausted.\n\nMaximize profits at $P \\cdot F_T(T) = c$",
"_____no_output_____"
],
[
"Land demand for each farmer is given by $P\\cdot F_T(T_i) = r$. So for this production $P \\frac{1}{\\sqrt T_i} = r$ or $P \\frac{1}{\\sqrt T_i} = cl$ so we can write\n\n$$T^*_i(r) = (P/r)^2$$\n\nIf there is an open frontier the sum or demands falls short of total land supply and the marginal cost of land is the cost of clearing $r=c_l$. ",
"_____no_output_____"
],
[
"'Land scarcity' results on the other hand when there is an equilibrium price of land $r>c_l$ where $r$ is found from \n\n$$\\sum T^*_i(r) = \\bar T$$\n\nNow land rent $r-c$ can be charged on the right to access and use land. Trade in these legal entitlements can raise output and efficiency. But there may be conflict and a 'scramble' to establish those rights of first access. ",
"_____no_output_____"
],
[
"#### 'Customary' land rights\n\n- Suppose norm is that all in the village can use as much land as they can farm\n- Higher status individuals get allocation first\n- As long as land is abundant everyone gets the land they want\n- No \"land rent\" -- cannot charge rent above $c$ since villagers are free to clear at cost $c$",
"_____no_output_____"
]
],
[
[
"landmarket(P=5, cl = 3, title = 'Open Frontier')",
"_____no_output_____"
]
],
[
[
"### The closing of the frontier\n- Rising population or improving price or technology increases demand for land.\n- Suppose price at which product can be sold increases\n - demand for land increases.\n- Suppose total demandat clearing cost $c$ exceedsavailable land supply. \n - High-status individuals (who have first-access) leave less land available than is needed to satisfy remaining villagers demand.\n- Inefficient allocation of land\n - marginal products of land not equalized across households.\n - output would increase if we establish a market for trading land",
"_____no_output_____"
]
],
[
[
"landmarket(P=8, cl = 3, title = 'Land Scarcity')",
"_____no_output_____"
]
],
[
[
"We can solve for the equilibrium rental rate $r$ given environmental paramters including the price $P$, land endowment $\\bar T$, population size $N$ and technology parameters $A)",
"_____no_output_____"
],
[
"To do:\n(things to still do in this notebook)\n - indicate DWL on landmarket diagrams\n - create widget to see how diagram shifts with changing parameters",
"_____no_output_____"
]
],
[
[
"interact(landmarket, P=(4,10,0.2), cl = (0,5,0.5), \n title = fixed('Land'), A=fixed(1));",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
cbd30841fdf9066f7c53e9d660ef46ba5d868d7b
| 142,005 |
ipynb
|
Jupyter Notebook
|
tutorials/tune_cnn.ipynb
|
dmitryvinn/Ax-1
|
a94036392df64dce43223b73b701945daf2852dd
|
[
"MIT"
] | 1 |
2022-02-10T10:51:40.000Z
|
2022-02-10T10:51:40.000Z
|
tutorials/tune_cnn.ipynb
|
dmitryvinn/Ax-1
|
a94036392df64dce43223b73b701945daf2852dd
|
[
"MIT"
] | null | null | null |
tutorials/tune_cnn.ipynb
|
dmitryvinn/Ax-1
|
a94036392df64dce43223b73b701945daf2852dd
|
[
"MIT"
] | null | null | null | 185.385117 | 52,706 | 0.753804 |
[
[
[
"# Tune a CNN on MNIST\n\nThis tutorial walks through using Ax to tune two hyperparameters (learning rate and momentum) for a PyTorch CNN on the MNIST dataset trained using SGD with momentum.\n",
"_____no_output_____"
]
],
[
[
"import torch\nimport numpy as np\n\nfrom ax.plot.contour import plot_contour\nfrom ax.plot.trace import optimization_trace_single_method\nfrom ax.service.managed_loop import optimize\nfrom ax.utils.notebook.plotting import render, init_notebook_plotting\nfrom ax.utils.tutorials.cnn_utils import load_mnist, train, evaluate, CNN\n\ninit_notebook_plotting()",
"_____no_output_____"
],
[
"torch.manual_seed(12345)\ndtype = torch.float\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")",
"_____no_output_____"
]
],
[
[
"## 1. Load MNIST data\nFirst, we need to load the MNIST data and partition it into training, validation, and test sets.\n\nNote: this will download the dataset if necessary.",
"_____no_output_____"
]
],
[
[
"BATCH_SIZE = 512\ntrain_loader, valid_loader, test_loader = load_mnist(batch_size=BATCH_SIZE)",
"_____no_output_____"
]
],
[
[
"## 2. Define function to optimize\nIn this tutorial, we want to optimize classification accuracy on the validation set as a function of the learning rate and momentum. The function takes in a parameterization (set of parameter values), computes the classification accuracy, and returns a dictionary of metric name ('accuracy') to a tuple with the mean and standard error.",
"_____no_output_____"
]
],
[
[
"def train_evaluate(parameterization):\n net = CNN()\n net = train(net=net, train_loader=train_loader, parameters=parameterization, dtype=dtype, device=device)\n return evaluate(\n net=net,\n data_loader=valid_loader,\n dtype=dtype,\n device=device,\n )",
"_____no_output_____"
]
],
[
[
"## 3. Run the optimization loop\nHere, we set the bounds on the learning rate and momentum and set the parameter space for the learning rate to be on a log scale. ",
"_____no_output_____"
]
],
[
[
"best_parameters, values, experiment, model = optimize(\n parameters=[\n {\"name\": \"lr\", \"type\": \"range\", \"bounds\": [1e-6, 0.4], \"log_scale\": True},\n {\"name\": \"momentum\", \"type\": \"range\", \"bounds\": [0.0, 1.0]},\n ],\n evaluation_function=train_evaluate,\n objective_name='accuracy',\n)",
"[INFO 08-09 10:32:05] ax.modelbridge.dispatch_utils: Using Bayesian Optimization generation strategy. Iterations after 5 will take longer to generate due to model-fitting.\n[INFO 08-09 10:32:05] ax.service.managed_loop: Started full optimization with 20 steps.\n[INFO 08-09 10:32:05] ax.service.managed_loop: Running optimization trial 1...\n[INFO 08-09 10:32:40] ax.service.managed_loop: Running optimization trial 2...\n[INFO 08-09 10:33:03] ax.service.managed_loop: Running optimization trial 3...\n[INFO 08-09 10:33:26] ax.service.managed_loop: Running optimization trial 4...\n[INFO 08-09 10:33:50] ax.service.managed_loop: Running optimization trial 5...\n[INFO 08-09 10:34:13] ax.service.managed_loop: Running optimization trial 6...\n[INFO 08-09 10:34:41] ax.service.managed_loop: Running optimization trial 7...\n[INFO 08-09 10:35:11] ax.service.managed_loop: Running optimization trial 8...\n[INFO 08-09 10:35:48] ax.service.managed_loop: Running optimization trial 9...\n[INFO 08-09 10:36:26] ax.service.managed_loop: Running optimization trial 10...\n[INFO 08-09 10:37:04] ax.service.managed_loop: Running optimization trial 11...\n[INFO 08-09 10:37:40] ax.service.managed_loop: Running optimization trial 12...\n[INFO 08-09 10:38:25] ax.service.managed_loop: Running optimization trial 13...\n[INFO 08-09 10:39:11] ax.service.managed_loop: Running optimization trial 14...\n[INFO 08-09 10:39:54] ax.service.managed_loop: Running optimization trial 15...\n[INFO 08-09 10:40:38] ax.service.managed_loop: Running optimization trial 16...\n[INFO 08-09 10:41:35] ax.service.managed_loop: Running optimization trial 17...\n[INFO 08-09 10:42:21] ax.service.managed_loop: Running optimization trial 18...\n[INFO 08-09 10:43:07] ax.service.managed_loop: Running optimization trial 19...\n[INFO 08-09 10:43:50] ax.service.managed_loop: Running optimization trial 20...\n"
]
],
[
[
"We can introspect the optimal parameters and their outcomes:",
"_____no_output_____"
]
],
[
[
"best_parameters",
"_____no_output_____"
],
[
"means, covariances = values\nmeans, covariances",
"_____no_output_____"
]
],
[
[
"## 4. Plot response surface\n\nContour plot showing classification accuracy as a function of the two hyperparameters.\n\nThe black squares show points that we have actually run, notice how they are clustered in the optimal region.",
"_____no_output_____"
]
],
[
[
"render(plot_contour(model=model, param_x='lr', param_y='momentum', metric_name='accuracy'))",
"_____no_output_____"
]
],
[
[
"## 5. Plot best objective as function of the iteration\n\nShow the model accuracy improving as we identify better hyperparameters.",
"_____no_output_____"
]
],
[
[
"# `plot_single_method` expects a 2-d array of means, because it expects to average means from multiple \n# optimization runs, so we wrap out best objectives array in another array.\nbest_objectives = np.array([[trial.objective_mean*100 for trial in experiment.trials.values()]])\nbest_objective_plot = optimization_trace_single_method(\n y=np.maximum.accumulate(best_objectives, axis=1),\n title=\"Model performance vs. # of iterations\",\n ylabel=\"Classification Accuracy, %\",\n)\nrender(best_objective_plot)",
"_____no_output_____"
]
],
[
[
"## 6. Train CNN with best hyperparameters and evaluate on test set\nNote that the resulting accuracy on the test set might not be exactly the same as the maximum accuracy achieved on the evaluation set throughout optimization. ",
"_____no_output_____"
]
],
[
[
"data = experiment.fetch_data()\ndf = data.df\nbest_arm_name = df.arm_name[df['mean'] == df['mean'].max()].values[0]\nbest_arm = experiment.arms_by_name[best_arm_name]\nbest_arm",
"_____no_output_____"
],
[
"combined_train_valid_set = torch.utils.data.ConcatDataset([\n train_loader.dataset.dataset, \n valid_loader.dataset.dataset,\n])\ncombined_train_valid_loader = torch.utils.data.DataLoader(\n combined_train_valid_set, \n batch_size=BATCH_SIZE, \n shuffle=True,\n)",
"_____no_output_____"
],
[
"net = train(\n net=CNN(),\n train_loader=combined_train_valid_loader, \n parameters=best_arm.parameters,\n dtype=dtype,\n device=device,\n)\ntest_accuracy = evaluate(\n net=net,\n data_loader=test_loader,\n dtype=dtype,\n device=device,\n)",
"_____no_output_____"
],
[
"print(f\"Classification Accuracy (test set): {round(test_accuracy*100, 2)}%\")",
"Classification Accuracy (test set): 97.8%\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cbd30aac3eb3296a512d2333cbea8a863dd534f9
| 101,167 |
ipynb
|
Jupyter Notebook
|
cronjobs/transient_matching/light_transient_matching.ipynb
|
rknop/timedomain
|
d3e3c43dfbb9cadc150ea04024d9b4132cb9ca17
|
[
"MIT"
] | 1 |
2021-06-18T05:25:27.000Z
|
2021-06-18T05:25:27.000Z
|
cronjobs/transient_matching/light_transient_matching.ipynb
|
MatthewPortman/timedomain
|
b9c6c2e6804d7dde56311d9402769be545d505d0
|
[
"MIT"
] | null | null | null |
cronjobs/transient_matching/light_transient_matching.ipynb
|
MatthewPortman/timedomain
|
b9c6c2e6804d7dde56311d9402769be545d505d0
|
[
"MIT"
] | null | null | null | 49.15792 | 18,356 | 0.585883 |
[
[
[
"#import sys\n#!{sys.executable} -m pip install --user alerce",
"_____no_output_____"
]
],
[
[
"# light_transient_matching\n## Matches DESI observations to ALERCE and DECAM ledger objects\n\nThis code predominately takes in data from the ALERCE and DECAM ledger brokers and identifies DESI observations within 2 arcseconds of those objects, suspected to be transients. It then prepares those matches to be fed into our [CNN code](https://github.com/MatthewPortman/timedomain/blob/master/cronjobs/transient_matching/modified_cnn_classify_data_gradCAM.ipynb) which attempts to identify the class of these transients.\n\nThe main matching algorithm uses astropy's **match_coordinate_sky** to match 1-to-1 targets with the objects from the two ledgers. Wrapping functions handle data retrieval from both the ledgers as well as from DESI and prepare this data to be fed into **match_coordinate_sky**. Since ALERCE returns a small enough (pandas) dataframe, we do not need to precondition the input much. However, DECAM has many more objects to match so we use a two-stage process: an initial 2 degree match to tile RA's/DEC's and a second closer 1 arcsecond match to individual targets. \n\nAs the code is a work in progress, please forgive any redundancies. We are attempting to merge all of the above (neatly) into the same two or three matching/handling functions!",
"_____no_output_____"
]
],
[
[
"from astropy.io import fits\nfrom astropy.table import Table\nfrom astropy import units as u\nfrom astropy.time import Time\nfrom astropy.coordinates import SkyCoord, match_coordinates_sky, Angle\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom glob import glob\nimport sys\n\nimport sqlite3\nimport os\n\nfrom desispec.io import read_spectra, write_spectra\nfrom desispec.spectra import Spectra\n\n# Some handy global variables\nglobal db_filename\ndb_filename = '/global/cfs/cdirs/desi/science/td/daily-search/transients_search.db'\nglobal exposure_path\nexposure_path = os.environ[\"DESI_SPECTRO_REDUX\"]\nglobal color_band\ncolor_band = \"r\"\nglobal minDist\nminDist = {}\n\nglobal today\ntoday = Time.now()",
"_____no_output_____"
]
],
[
[
"## Necessary functions",
"_____no_output_____"
]
],
[
[
"# Grabbing the file names\ndef all_candidate_filenames(transient_dir: str):\n \n # This function grabs the names of all input files in the transient directory and does some python string manipulation\n # to grab the names of the input files with full path and the filenames themselves.\n\n try:\n filenames_read = glob(transient_dir + \"/*.fits\") # Hardcoding is hopefully a temporary measure.\n \n except:\n print(\"Could not grab/find any fits in the transient spectra directory:\")\n print(transient_dir)\n filenames_read = [] # Just in case\n #filenames_out = [] # Just in case\n raise SystemExit(\"Exiting.\")\n \n #else:\n #filenames_out = [s.split(\".\")[0] for s in filenames_read]\n #filenames_out = [s.split(\"/\")[-1] for s in filenames_read]\n #filenames_out = [s.replace(\"in\", \"out\") for s in filenames_out]\n \n return filenames_read #, filenames_out\n\n#path_to_transient = \"/global/cfs/cdirs/desi/science/td/daily-search/desitrip/out\"\n#print(all_candidate_filenames(path_to_transient)[1])",
"_____no_output_____"
],
[
"# From ALeRCE_ledgermaker https://github.com/alercebroker/alerce_client\n# I have had trouble importing this before so I copy, paste it, and modify it here.\n\n# I also leave these imports here because why not?\nimport requests\nfrom alerce.core import Alerce\nfrom alerce.exceptions import APIError\n\nalerce_client = Alerce()\n\n# Choose cone_radius of diameter of tile so that, whatever coord I choose for ra_in, dec_in, we cover the whole tile\ndef access_alerts(lastmjd_in=[], ra_in = None, dec_in = None, cone_radius = 3600*4.01, classifier='stamp_classifier', class_names=['SN', 'AGN']):\n if type(class_names) is not list:\n raise TypeError('Argument `class_names` must be a list.')\n \n dataframes = []\n if not lastmjd_in:\n date_range = 60\n lastmjd_in = [Time.now().mjd - 60, Time.now().mjd]\n print('Defaulting to a lastmjd range of', str(date_range), 'days before today.')\n \n #print(\"lastmjd:\", lastmjd_in)\n for class_name in class_names:\n data = alerce_client.query_objects(classifier=classifier,\n class_name=class_name, \n lastmjd=lastmjd_in,\n ra = ra_in,\n dec = dec_in,\n radius = cone_radius, # in arcseconds\n page_size = 5000,\n order_by='oid',\n order_mode='DESC', \n format='pandas')\n \n #if lastmjd is not None:\n # select = data['lastmjd'] >= lastmjd\n # data = data[select]\n \n dataframes.append(data)\n \n #print(pd.concat(dataframes).columns)\n return pd.concat(dataframes).sort_values(by = 'lastmjd')",
"_____no_output_____"
],
[
"# From https://github.com/desihub/timedomain/blob/master/too_ledgers/decam_TAMU_ledgermaker.ipynb\n# Function to grab decam data\nfrom bs4 import BeautifulSoup\nimport json\nimport requests\ndef access_decam_data(url, overwrite=False):\n \"\"\"Download reduced DECam transient data from Texas A&M.\n Cache the data to avoid lengthy and expensive downloads.\n \n Parameters\n ----------\n url : str\n URL for accessing the data.\n overwrite : bool\n Download new data and overwrite the cached data.\n \n Returns\n -------\n decam_transients : pandas.DataFrame\n Table of transient data.\n \"\"\"\n folders = url.split('/')\n thedate = folders[-1] if len(folders[-1]) > 0 else folders[-2]\n outfile = '{}.csv'.format(thedate)\n \n if os.path.exists(outfile) and not overwrite:\n # Access cached data.\n decam_transients = pd.read_csv(outfile)\n else:\n # Download the DECam data index.\n # A try/except is needed because the datahub SSL certificate isn't playing well with URL requests.\n try:\n decam_dets = requests.get(url, auth=('decam','tamudecam')).text\n except:\n requests.packages.urllib3.disable_warnings(requests.packages.urllib3.exceptions.InsecureRequestWarning)\n decam_dets = requests.get(url, verify=False, auth=('decam','tamudecam')).text\n \n # Convert transient index page into scrapable data using BeautifulSoup.\n soup = BeautifulSoup(decam_dets)\n \n # Loop through transient object summary JSON files indexed in the main transient page.\n # Download the JSONs and dump the info into a Pandas table.\n decam_transients = None\n j = 0\n\n for a in soup.find_all('a', href=True):\n if 'object-summary.json' in a:\n link = a['href'].replace('./', '')\n summary_url = url + link \n summary_text = requests.get(summary_url, verify=False, auth=('decam','tamudecam')).text\n summary_data = json.loads(summary_text)\n\n j += 1\n #print('Accessing {:3d} {}'.format(j, summary_url)) # Modified by Matt\n\n if decam_transients is None:\n decam_transients = pd.DataFrame(summary_data, index=[0])\n else:\n decam_transients = pd.concat([decam_transients, pd.DataFrame(summary_data, index=[0])])\n \n # Cache the data for future access.\n print('Saving output to {}'.format(outfile))\n decam_transients.to_csv(outfile, index=False)\n \n return decam_transients",
"_____no_output_____"
],
[
"# Function to read in fits table info, RA, DEC, MJD and targetid if so desired\n# Uses control parameter tile to determine if opening tile exposure file or not since headers are different\nimport logging\n\ndef read_fits_info(filepath: str, transient_candidate = True):\n \n '''\n if transient_candidate:\n hdu_num = 1\n else:\n hdu_num = 5\n '''\n # Disabling INFO logging temporarily to suppress INFO level output/print from read_spectra\n logging.disable(logging.INFO)\n try:\n spec_info = read_spectra(filepath).fibermap\n except:\n filename = filepath.split(\"/\")[-1]\n print(\"Could not open or use:\", filename)\n #print(\"In path:\", filepath)\n #print(\"Trying the next file...\")\n return np.array([]), np.array([]), 0, 0\n \n headers = ['TARGETID', 'TARGET_RA', 'TARGET_DEC', 'LAST_MJD']\n targ_info = {}\n for head in headers:\n try:\n targ_info[head] = spec_info[head].data\n except:\n if not head == 'LAST_MJD': print(\"Failed to read in\", head, \"data. Continuing...\")\n targ_info[head] = False\n \n # targ_id = spec_info['TARGETID'].data\n # targ_ra = spec_info['TARGET_RA'].data # Now it's a numpy array\n # targ_dec = spec_info['TARGET_DEC'].data\n # targ_mjd = spec_info['LAST_MJD'] #.data\n\n if np.any(targ_info['LAST_MJD']):\n targ_mjd = Time(targ_info['LAST_MJD'][0], format = 'mjd')\n elif transient_candidate:\n targ_mjd = filepath.split(\"/\")[-1].split(\"_\")[-2] #to grab the date\n targ_mjd = Time(targ_mjd, format = 'mjd') #.mjd\n else:\n print(\"Unable to determine observation mjd for\", filename)\n print(\"This target will not be considered.\")\n return np.array([]), np.array([]), 0, 0\n\n '''\n with fits.open(filepath) as hdu1:\n data_table = Table(hdu1[hdu_num].data) #columns\n \n targ_id = data_table['TARGETID']\n targ_ra = data_table['TARGET_RA'].data # Now it's a numpy array\n targ_dec = data_table['TARGET_DEC'].data\n #targ_mjd = data_table['MJD'][0] some have different versions of this so this is a *bad* idea... at least now I know the try except works!\n \n if tile:\n targ_mjd = hdu1[hdu_num].header['MJD-OBS']\n '''\n \n # if tile and not np.all(targ_mjd):\n # print(\"Unable to grab mjd from spectra, taking it from the filename...\")\n # targ_mjd = filepath.split(\"/\")[-1].split(\"_\")[-2] #to grab the date\n # #targ_mjd = targ_mjd[:4]+\"-\"+targ_mjd[4:6]+\"-\"+targ_mjd[6:] # Adding dashes for Time\n # targ_mjd = Time(targ_mjd, format = 'mjd') #.mjd\n \n # Re-enabling logging for future calls if necessary\n logging.disable(logging.NOTSET) \n \n return targ_info[\"TARGET_RA\"], targ_info[\"TARGET_DEC\"], targ_mjd, targ_info[\"TARGETID\"] #targ_ra, targ_dec, targ_mjd, targ_id",
"_____no_output_____"
]
],
[
[
"## Matching function\n\nMore or less the prototype to the later rendition used for DECAM. Will not be around in later versions of this notebook as I will be able to repurpose the DECAM code to do both. Planned obsolescence? \n\nIt may not be even worth it at this point... ah well!",
"_____no_output_____"
]
],
[
[
"# Prototype for the later, heftier matching function\n# Will be deprecated, please reference commentary in inner_matching later for operation notes\ndef matching(path_in: str, max_sep: float, tile = False, date_dict = {}): \n \n max_sep *= u.arcsec \n #max_sep = Angle(max_sep*u.arcsec)\n \n #if not target_ra_dec_date:\n # target_ras, target_decs, obs_mjds = read_fits_ra_dec(path_in, tile)\n #else:\n # target_ras, target_decs, obs_mjds = target_ra_dec_date\n \n #Look back 60 days from the DESI observations\n days_back = 60\n \n if not date_dict:\n print(\"No RA's/DEC's fed in. Quitting.\")\n return np.array([]), np.array([])\n \n all_trans_matches = []\n all_alerts_matches = []\n targetid_matches = []\n \n for obs_mjd, ra_dec in date_dict.items():\n \n # Grab RAs and DECs from input. \n target_ras = ra_dec[:, 0]\n target_decs = ra_dec[:, 1]\n target_ids = np.int64(ra_dec[:, 2])\n\n # Check for NaN's and remove which don't play nice with match_coordinates_sky\n nan_ra = np.isnan(target_ras)\n nan_dec = np.isnan(target_decs)\n\n if np.any(nan_ra) or np.any(nan_dec):\n print(\"NaNs found, removing them from array (not FITS) before match.\")\n #print(\"Original length (ra, dec): \", len(target_ras), len(target_decs))\n nans = np.logical_not(np.logical_and(nan_ra, nan_dec))\n target_ras = target_ras[nans] # Logic masking, probably more efficient\n target_decs = target_decs[nans]\n #print(\"Reduced length (ra, dec):\", len(target_ras), len(target_decs))\n \n # Some code used to test -- please ignore ******************\n # Feed average to access alerts, perhaps that will speed things up/find better results\n #avg_ra = np.average(target_ras)\n #avg_dec = np.average(target_decs)\n# coo_trans_search = SkyCoord(target_ras*u.deg, target_decs*u.deg)\n# #print(coo_trans_search)\n# idxs, d2d, _ = match_coordinates_sky(coo_trans_search, coo_trans_search, nthneighbor = 2)\n# # for conesearch in alerce\n# max_sep = np.max(d2d).arcsec + 2.1 # to expand a bit further than the furthest neighbor\n# ra_in = coo_trans_search[0].ra\n# dec_in = coo_trans_search[0].dec\n # Some code used to test -- please ignore ****************** \n \n #print([obs_mjd - days_back, obs_mjd])\n try:\n alerts = access_alerts(lastmjd_in = [obs_mjd - days_back, obs_mjd], \n ra_in = target_ras[0], \n dec_in = target_decs[0], #cone_radius = max_sep, \n class_names = ['SN']\n ) # Modified Julian Day .mjd\n except:\n #print(\"No SN matches (\"+str(days_back)+\" day range) for\", obs_mjd)\n #break\n continue\n \n # For each fits file, look at one month before the observation from Alerce\n # Not sure kdtrees matter\n # tree_name = \"kdtree_\" + str(obs_mjd - days_back)\n\n alerts_ra = alerts['meanra'].to_numpy()\n #print(\"Length of alerts: \", len(alerts_ra))\n alerts_dec = alerts['meandec'].to_numpy()\n\n # Converting to SkyCoord type arrays (really quite handy)\n coo_trans_search = SkyCoord(target_ras*u.deg, target_decs*u.deg)\n coo_alerts = SkyCoord(alerts_ra*u.deg, alerts_dec*u.deg)\n \n # Some code used to test -- please ignore ******************\n #ra_range = list(zip(*[(i, j) for i,j in zip(alerts_ra,alerts_dec) if (np.min(target_ras) < i and i < np.max(target_ras) and np.min(target_decs) < j and j < np.max(target_decs))]))\n #try: \n # ra_range = SkyCoord(ra_range[0]*u.deg, ra_range[1]*u.deg)\n #except:\n # continue\n #print(ra_range)\n #print(coo_trans_search)\n #idx_alerts, d2d_trans, d3d_trans = match_coordinates_sky(coo_trans_search, ra_range)\n #for i in coo_trans_search:\n #print(i.separation(ra_range[3]))\n #print(idx_alerts)\n #print(np.min(d2d_trans))\n #break\n # Some code used to test -- please ignore ******************\n \n idx_alerts, d2d_trans, d3d_trans = match_coordinates_sky(coo_trans_search, coo_alerts) \n\n # Filtering by maximum separation and closest match\n sep_constraint = d2d_trans < max_sep\n trans_matches = coo_trans_search[sep_constraint]\n alerts_matches = coo_alerts[idx_alerts[sep_constraint]]\n \n targetid_matches = target_ids[sep_constraint]\n \n #print(d2d_trans < max_sep)\n minDist[obs_mjd] = np.min(d2d_trans)\n\n # Adding everything to lists and outputting\n if trans_matches.size:\n all_trans_matches.append(trans_matches)\n all_alerts_matches.append(alerts_matches)\n sort_dist = np.sort(d2d_trans)\n #print(\"Minimum distance found: \", sort_dist[0])\n #print()\n #break\n #else:\n #print(\"No matches found...\\n\")\n #break\n\n return all_trans_matches, all_alerts_matches, targetid_matches",
"_____no_output_____"
]
],
[
[
"## Matching to ALERCE \nRuns a 5 arcsecond match of DESI to Alerce objects. Since everything is handled in functions, this part is quite clean.\n\nFrom back when I was going to use *if __name__ == \"__main__\":*... those were the days",
"_____no_output_____"
]
],
[
[
"# Transient dir\npath_to_transient = \"/global/cfs/cdirs/desi/science/td/daily-search/desitrip/out\"\n# Grab paths\npaths_to_fits = all_candidate_filenames(path_to_transient)\n#print(len(paths_to_fits))\n\ndesi_info_dict = {}\ntarget_ras, target_decs, obs_mjd, targ_ids = read_fits_info(paths_to_fits[0], transient_candidate = True)\ndesi_info_dict[obs_mjd] = np.column_stack((target_ras, target_decs, targ_ids))\n\n'''\nTo be used when functions are properly combined.\ninitial_check(ledger_df = None, ledger_type = '')\ncloser_check(matches_dict = {}, ledger_df = None, ledger_type = '', exclusion_list = [])\n'''\nfail_count = 0\n# Iterate through every fits file and grab all necessary info and plop it all together\nfor path in paths_to_fits[1:]:\n target_ras, target_decs, obs_mjd, targ_ids = read_fits_info(path, transient_candidate = True) \n\n if not obs_mjd: \n fail_count += 1\n continue\n\n #try:\n if obs_mjd in desi_info_dict.keys():\n np.append(desi_info_dict[obs_mjd], np.array([target_ras, target_decs, targ_ids]).T, axis = 0)\n else:\n desi_info_dict[obs_mjd] = np.column_stack((target_ras, target_decs, targ_ids))\n #desi_info_dict[obs_mjd].extend((target_ras, target_decs, targ_ids))\n #except:\n # continue\n #desi_info_dict[obs_mjd] = np.column_stack((target_ras, target_decs, targ_ids))\n #desi_info_dict[obs_mjd].append((target_ras, target_decs, targ_ids))\n#trans_matches, _ = matching(path, 5.0, (all_desi_ras, all_desi_decs, all_obs_mjd))\n\n# if trans_matches.size:\n# all_trans_matches.append(trans_matches)\n# all_alerts_matches.append(alerts_matches)",
"_____no_output_____"
],
[
"#print([i.mjd for i in sorted(desi_info_dict.keys())])\nprint(len(paths_to_fits))\nprint(len(desi_info_dict))\n#print(fail_count)",
"1213\n741\n"
]
],
[
[
"#print(len(desi_info_dict))\ntemp_dict = {a:b for a,b,c in zip(desi_info_dict.keys(), desi_info_dict.values(), range(len(desi_info_dict))) if c > 650}",
"_____no_output_____"
]
],
[
[
"# I was going to prepare everything by removing duplicate target ids but it's more trouble than it's worth and match_coordinates_sky can handle it\n# Takes quite a bit of time... not much more I can do to speed things up though since querying Alerce for every individual date is the hang-up.\n#print(len(paths_to_fits) - ledesi_info_dictfo_dict))\n#print(fail_count)\n\n#trans_matches, _, target_id_matches = matching(\"\", 2.0, date_dict = temp_dict)\ntrans_matches, _, target_id_matches = matching(\"\", 2.0, date_dict = desi_info_dict)\n\nprint(trans_matches)\nprint(target_id_matches)",
"[]\n[]\n"
],
[
"print(sorted(minDist.values())[:5])\n#for i in minDist.values():\n# print(i)",
"[<Angle 0.00233529 deg>, <Angle 0.00512101 deg>, <Angle 0.00519003 deg>, <Angle 0.00640351 deg>, <Angle 0.0124173 deg>]\n"
]
],
[
[
"## Matching to DECAM functions",
"_____no_output_____"
],
[
"Overwrite *read_fits_info* with older version to accommodate *read_spectra* error",
"_____no_output_____"
]
],
[
[
"# Read useful data from fits file, RA, DEC, target ID, and mjd as a leftover from previous use \ndef read_fits_info(filepath: str, transient_candidate = False):\n \n if transient_candidate:\n hdu_num = 1\n else:\n hdu_num = 5\n \n try:\n with fits.open(filepath) as hdu1:\n \n data_table = Table(hdu1[hdu_num].data) #columns\n \n targ_ID = data_table['TARGETID']\n targ_ra = data_table['TARGET_RA'].data # Now it's a numpy array\n targ_dec = data_table['TARGET_DEC'].data\n \n #targ_mjd = data_table['MJD'][0] some have different versions of this so this is a *bad* idea... at least now I know the try except works!\n \n # if transient_candidate: \n # targ_mjd = hdu1[hdu_num].header['MJD-OBS'] # This is a string\n # else:\n # targ_mjd = data_table['MJD'].data\n # targ_mjd = Time(targ_mjd[0], format = 'mjd')\n \n except:\n filename = filepath.split(\"/\")[-1]\n print(\"Could not open or use:\", filename)\n #print(\"In path:\", filepath)\n #print(\"Trying the next file...\")\n return np.array([]), np.array([]), np.array([])\n \n return targ_ra, targ_dec, targ_ID #targ_mjd, targ_ID",
"_____no_output_____"
],
[
"# Grabbing the frame fits files\ndef glob_frames(exp_d: str): \n \n # This function grabs the names of all input files in the transient directory and does some python string manipulation\n # to grab the names of the input files with full path and the filenames themselves.\n\n try:\n filenames_read = glob(exp_d + \"/cframe-\" + color_band + \"*.fits\") # Only need one of b, r, z\n # sframes not flux calibrated\n # May want to use tiles... coadd (will need later, but not now)\n except:\n try:\n filenames_read = glob(exp_d + \"/frame-\" + color_band + \"*.fits\") # Only need one of b, r, z\n except:\n print(\"Could not grab/find any fits in the exposure directory:\")\n print(exp_d)\n filenames_read = [] # Just in case\n #filenames_out = [] # Just in case\n raise SystemExit(\"Exitting.\")\n\n #else:\n #filenames_out = [s.split(\".\")[0] for s in filenames_read]\n #filenames_out = [s.split(\"/\")[-1] for s in filenames_read]\n #filenames_out = [s.replace(\"in\", \"out\") for s in filenames_out]\n \n return filenames_read #, filenames_out\n\n#path_to_transient = \"/global/cfs/cdirs/desi/science/td/daily-search/desitrip/out\"\n#print(all_candidate_filenames(path_to_transient)[1])",
"_____no_output_____"
]
],
[
[
"## Match handling routines\n\nThe two functions below perform data handling/calling for the final match step. \n\nThe first, **initial_check** grabs all the tile RAs and DECS from the exposures and tiles SQL table, does some filtering, and sends the necessary information to the matching function. Currently designed to handle ALERCE as well but work has to be done to make sure it operates correctly.",
"_____no_output_____"
]
],
[
[
"def initial_check(ledger_df = None, ledger_type = ''):\n\n query_date_start = \"20210301\"\n \n #today = Time.now()\n smushed_YMD = today.iso.split(\" \")[0].replace(\"-\",\"\")\n \n query_date_end = smushed_YMD \n\n # Handy queries for debugging/useful info\n query2 = \"PRAGMA table_info(exposures)\"\n query3 = \"PRAGMA table_info(tiles)\"\n # Crossmatch across tiles and exposures to grab obsdate via tileid\n query_match = \"SELECT distinct tilera, tiledec, obsdate, obsmjd, expid, exposures.tileid from exposures INNER JOIN tiles ON exposures.tileid = tiles.tileid where obsdate BETWEEN \" + \\\n query_date_start + \" AND \" + query_date_end + \";\" \n \n '''\n Some handy code for debugging\n #cur.execute(query2)\n #row2 = cur.fetchall()\n #for i in row2:\n # print(i[:])\n\n '''\n \n # Querying sql and returning a data type called sqlite3 row, it's kind of like a namedtuple/dictionary\n conn = sqlite3.connect(db_filename)\n\n conn.row_factory = sqlite3.Row # https://docs.python.org/3/library/sqlite3.html#sqlite3.Row\n\n cur = conn.cursor()\n\n cur.execute(query_match)\n matches_list = cur.fetchall()\n cur.close()\n\n # I knew there was a way! THANK YOU!\n # https://stackoverflow.com/questions/11276473/append-to-a-dict-of-lists-with-a-dict-comprehension\n \n # Grabbing everything by obsdate from matches_list\n date_dict = {k['obsdate'] : list(filter(lambda x:x['obsdate'] == k['obsdate'], matches_list)) for k in matches_list}\n\n alert_matches_dict = {}\n\n all_trans_matches = []\n all_alerts_matches = []\n \n # Grabbing DECAM ledger if not already fed in\n if ledger_type.upper() == 'DECAM_TAMU':\n if ledger_df.empty:\n ledger_df = access_decam_data('https://datahub.geos.tamu.edu:8000/decam/LCData_Legacy/')\n\n # Iterating through the dates and checking each tile observed on each date\n # It is done in this way to cut down on calls to ALERCE since we go day by day\n # It's also a convenient way to organize things\n for date, row in date_dict.items():\n \n date_str = str(date)\n date_str = date_str[:4]+\"-\"+date_str[4:6]+\"-\"+date_str[6:] # Adding dashes for Time\n obs_mjd = Time(date_str).mjd\n\n # This method is *technically* safer than doing a double list comprehension with set albeit slower\n # The lists are small enough that speed shouldn't matter here\n unique_tileid = {i['tileid']: (i['tilera'], i['tiledec']) for i in row}\n exposure_ras, exposure_decs = zip(*unique_tileid.values())\n # Grabbing alerce ledger if not done already\n if ledger_type.upper() == 'ALERCE':\n if ledger_df.empty:\n ledger_df = access_alerts(lastmjd = obs_mjd - 28) # Modified Julian Day #.mjd\n elif ledger_type.upper() == 'DECAM_TAMU':\n pass\n else:\n print(\"Cannot use alerts broker/ledger provided. Stopping before match.\")\n return {}\n\n #Reatin tileid\n tileid_arr = np.array(list(unique_tileid.keys())) \n\n # Where the magic/matching happens\n trans_matches, alert_matches, trans_ids, alerts_ids, _ = \\\n inner_matching(target_ids_in = tileid_arr, target_ras_in = exposure_ras, target_decs_in = exposure_decs, obs_mjd_in = obs_mjd, \n path_in = '', max_sep = 1.8, sep_units = 'deg', ledger_df_in = ledger_df, ledger_type_in = ledger_type)\n \n # Add everything into one giant list for both\n if trans_matches.size:\n #print(date, \"-\", len(trans_matches), \"matches\")\n all_trans_matches.append(trans_matches)\n all_alerts_matches.append(alert_matches)\n else:\n #print(\"No matches on\", date)\n continue\n\n # Prepping output\n # Populating the dictionary by date (a common theme)\n # Each element in the dictionary thus contains the entire sqlite3 row (all info from sql tables with said headers)\n alert_matches_dict[date] = []\n\n for tup in trans_matches:\n ra = tup.ra.deg\n dec = tup.dec.deg\n match_rows = [i for i in row if (i['tilera'], i['tiledec']) == (ra, dec)] # Just rebuilding for populating, this shouldn't change/exclude anything\n alert_matches_dict[date].extend(match_rows)\n \n return alert_matches_dict",
"_____no_output_____"
]
],
[
[
"## closer_check\n**closer_check** is also a handling function but operates differently in that now it is checking individual targets. This *must* be run after **initial_check** because it takes as input the dictionary **initial_check** spits out. It then grabs all the targets from the DESI files and pipes that into the matching function but this time with a much more strict matching radius (in this case 2 arcseconds). \n\nIt then preps the data for output and writing.",
"_____no_output_____"
]
],
[
[
"def closer_check(matches_dict = {}, ledger_df = None, ledger_type = '', exclusion_list = []):\n all_exp_matches = {}\n \n if not matches_dict:\n print(\"No far matches fed in for nearby matching. Returning none.\")\n return {}\n \n # Again just in case the dataframe isn't fed in\n if ledger_type.upper() == 'DECAM_TAMU':\n \n id_head = 'ObjectID'\n ra_head = 'RA-OBJECT'\n dec_head = 'DEC-OBJECT'\n \n if ledger_df.empty:\n ledger_df = access_decam_data('https://datahub.geos.tamu.edu:8000/decam/LCData_Legacy/')\n \n count_flag=0\n # Iterating through date and all tile information for that date\n for date, row in matches_dict.items(): \n print(\"\\n\", date)\n if date in exclusion_list:\n continue\n\n # Declaring some things\n all_exp_matches[date] = []\n alert_exp_matches = []\n file_indices = {}\n\n all_targ_ras = np.array([])\n all_targ_decs = np.array([])\n all_targ_ids = np.array([])\n all_tileids = np.array([])\n all_petals = np.array([])\n\n # Iterating through each initial match tile for every date\n for i in row:\n # Grabbing the paths and iterating through them to grab the RA's/DEC's\n exp_paths = '/'.join((exposure_path, \"daily/exposures\", str(i['obsdate']), \"000\"+str(i['expid'])))\n #print(exp_paths)\n for path in glob_frames(exp_paths):\n #print(path)\n targ_ras, targ_decs, targ_ids = read_fits_info(path, transient_candidate = False)\n \n h=fits.open(path)\n tileid = h[0].header['TILEID']\n tileids = np.full(len(targ_ras),tileid).tolist()\n petal = path.split(\"/\")[-1].split(\"-\")[1][-1]\n petals = np.full(len(targ_ras),petal).tolist()\n\n # This is to retain the row to debug/check the original FITS file\n # And to pull the info by row direct if you feel so inclined\n all_len = len(all_targ_ras)\n new_len = len(targ_ras)\n if all_len:\n all_len -= 1\n file_indices[path] = (all_len, all_len + new_len) # The start and end index, modulo number\n else:\n file_indices[path] = (0, new_len) # The start and end index, modulo number\n\n if len(targ_ras) != len(targ_decs):\n print(\"Length of all ras vs. all decs do not match.\")\n print(\"Something went wrong!\")\n print(\"Continuing but not adding those to match...\")\n continue\n\n # All the ras/decs together!\n all_targ_ras = np.append(all_targ_ras, targ_ras)\n all_targ_decs = np.append(all_targ_decs, targ_decs)\n all_targ_ids = np.append(all_targ_ids, targ_ids)\n all_tileids = np.append(all_tileids, tileids)\n all_petals = np.append(all_petals, petals)\n\n date_mjd = str(date)[:4]+\"-\"+str(date)[4:6] + \"-\" + str(date)[6:] # Adding dashes for Time\n date_mjd = Time(date_mjd).mjd\n \n # Grabbing ALERCE just in case\n # Slow\n if ledger_type.upper() == 'ALERCE':\n \n id_head = 'oid'\n ra_head = 'meanra'\n dec_head = 'meandec'\n \n if ledger_df.empty:\n ledger_df = access_alerts(lastmjd_in = obs_mjd - 45) # Modified Julian Day #.mjd\n \n # Checking for NaNs, again doesn't play nice with match_coordinates_sky\n nan_ra = np.isnan(all_targ_ras)\n nan_dec = np.isnan(all_targ_decs)\n \n if np.any(nan_ra) or np.any(nan_dec):\n print(\"NaNs found, removing them from array before match.\")\n #print(\"Original length (ra, dec): \", len(target_ras), len(target_decs))\n nans = np.logical_not(np.logical_and(nan_ra, nan_dec))\n all_targ_ras = all_targ_ras[nans] # Logic masking, probably more efficient\n all_targ_decs = all_targ_decs[nans]\n all_targ_ids = all_targ_ids[nans]\n all_tileids = all_tileids[nans]\n all_petals = all_petals[nans]\n \n # Where the magic matching happens. This time with separation 2 arcseconds.\n # Will be cleaned up (eventually)\n alert_exp_matches, alerts_matches, targetid_exp_matches, id_alerts_matches, exp_idx = inner_matching(target_ids_in =all_targ_ids, \\\n target_ras_in = all_targ_ras, target_decs_in = all_targ_decs, obs_mjd_in = date_mjd, \n path_in = '', max_sep = 2, sep_units = 'arcsec', ledger_df_in = ledger_df, ledger_type_in = ledger_type)\n \n date_arr=np.full(alerts_matches.shape[0],date)\n #print(date_arr.shape,targetid_exp_matches.shape,alert_exp_matches.shape, id_alerts_matches.shape,alerts_matches.shape )\n info_arr_date=np.column_stack((date_arr,all_tileids[exp_idx],all_petals[exp_idx], targetid_exp_matches,alert_exp_matches.ra.deg,alert_exp_matches.dec.deg, \\\n id_alerts_matches,alerts_matches.ra.deg,alerts_matches.dec.deg ))\n all_exp_matches[date].append(info_arr_date)\n \n if count_flag==0: \n all_exp_matches_arr=info_arr_date\n count_flag=1\n else: \n #print(all_exp_matches_arr,info_arr_date)\n all_exp_matches_arr=np.concatenate((all_exp_matches_arr,info_arr_date))\n \n # Does not easily output to a csv since we have multiple results for each date\n # so uh... custom file output for me\n return all_exp_matches_arr",
"_____no_output_____"
]
],
[
[
"## inner_matching\n#### aka the bread & butter\n**inner_matching** is what ultimately does the final match and calls **match_coordinates_sky** with everything fed in. So really it doesn't do much other than take in all the goodies and make everyone happy.\n\nIt may still be difficult to co-opt for alerce matching but that may be a project for another time.",
"_____no_output_____"
]
],
[
[
"def inner_matching(target_ids_in = np.array([]), target_ras_in = np.array([]), target_decs_in = np.array([]), obs_mjd_in = '', path_in = '', max_sep = 2, sep_units = 'arcsec', ledger_df_in = None, ledger_type_in = ''): # to be combined with the other matching thing in due time\n \n # Figuring out the units\n if sep_units == 'arcsec':\n max_sep *= u.arcsec\n elif sep_units == 'arcmin':\n max_sep *= u.arcmin\n elif sep_units == 'deg':\n max_sep *= u.deg\n else:\n print(\"Separation unit specified is invalid for matching. Defaulting to arcsecond.\")\n max_sep *= u.arcsec\n \n if not np.array(target_ras_in).size:\n return np.array([]), np.array([])\n \n # Checking for NaNs, again doesn't play nice with match_coordinates_sky\n nan_ra = np.isnan(target_ras_in)\n nan_dec = np.isnan(target_decs_in)\n \n if np.any(nan_ra) or np.any(nan_dec):\n print(\"NaNs found, removing them from array before match.\")\n #print(\"Original length (ra, dec): \", len(target_ras), len(target_decs))\n nans = np.logical_not(np.logical_and(nan_ra, nan_dec))\n target_ras_in = target_ras_in[nans] # Logic masking, probably more efficient\n target_decs_in = target_decs_in[nans]\n target_ids_in = target_ids_in[nans]\n \n #print(\"Reduced length (ra, dec):\", len(target_ras), len(target_decs))\n\n # For quick matching if said kdtree actually does anything\n # Supposed to speed things up on subsequent runs *shrugs*\n tree_name = \"_\".join((\"kdtree\", ledger_type_in, str(obs_mjd_in)))\n \n # Selecting header string to use with the different alert brokers/ledgers\n if ledger_type_in.upper() == 'DECAM_TAMU':\n id_head = 'ObjectID'\n ra_head = 'RA-OBJECT'\n dec_head = 'DEC-OBJECT'\n \n elif ledger_type_in.upper() == 'ALERCE':\n id_head = 'oid' #Check this is how id is called!\n ra_head = 'meanra'\n dec_head = 'meandec'\n \n else:\n print(\"No ledger type specified. Quitting.\") \n # lofty goals\n # Will try to figure it out assuming it's a pandas dataframe.\")\n #print(\"Returning empty-handed for now until that is complete - Matthew P.\")\n return np.array([]), np.array([])\n \n # Convert df RA/DEC to numpy arrays\n alerts_id = ledger_df_in[id_head].to_numpy()\n alerts_ra = ledger_df_in[ra_head].to_numpy()\n alerts_dec = ledger_df_in[dec_head].to_numpy()\n\n # Convert everything to SkyCoord\n coo_trans_search = SkyCoord(target_ras_in*u.deg, target_decs_in*u.deg)\n coo_alerts = SkyCoord(alerts_ra*u.deg, alerts_dec*u.deg)\n\n # Do the matching! \n idx_alerts, d2d_trans, d3d_trans = match_coordinates_sky(coo_trans_search, coo_alerts, storekdtree = tree_name) # store tree to speed up subsequent results\n\n # Filter out the good stuff\n sep_constraint = d2d_trans < max_sep\n trans_matches = coo_trans_search[sep_constraint]\n trans_matches_ids = target_ids_in[sep_constraint]\n alerts_matches = coo_alerts[idx_alerts[sep_constraint]]\n alerts_matches_ids = alerts_id[idx_alerts[sep_constraint]]\n \n if trans_matches.size:\n print(len(trans_matches), \"matches with separation -\", max_sep)\n #sort_dist = np.sort(d2d_trans)\n #print(\"Minimum distance found: \", sort_dist[0])\n\n return trans_matches, alerts_matches, trans_matches_ids, alerts_matches_ids, sep_constraint",
"_____no_output_____"
]
],
[
[
"## Grab DECAM ledger as pandas dataframe",
"_____no_output_____"
]
],
[
[
"decam_transients = access_decam_data('https://datahub.geos.tamu.edu:8000/decam/LCData_Legacy/', overwrite = True) # If True, grabs a fresh batch",
"Saving output to LCData_Legacy.csv\n"
],
[
"decam_transients_agn = access_decam_data('https://datahub.geos.tamu.edu:8000/decam/LCData_Legacy_AGN/', overwrite = True) # If True, grabs a fresh batch",
"Saving output to LCData_Legacy_AGN.csv\n"
],
[
"decam_transients",
"_____no_output_____"
]
],
[
[
"## Run initial check (on tiles) and closer check (on targets)",
"_____no_output_____"
]
],
[
[
"init_matches_by_date = initial_check(ledger_df = decam_transients, ledger_type = 'DECAM_TAMU')",
"2 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n10 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n12 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n7 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n12 matches with separation - 1.8 deg\n10 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n"
],
[
"close_matches = closer_check(init_matches_by_date, ledger_df = decam_transients, ledger_type = 'DECAM_TAMU', exclusion_list = [])\nnp.save('matches_DECam',close_matches, allow_pickle=True)",
"\n 20210322\n8 matches with separation - 2.0 arcsec\n\n 20210402\n2 matches with separation - 2.0 arcsec\n\n 20210405\nNaNs found, removing them from array before match.\n24 matches with separation - 2.0 arcsec\n\n 20210406\nNaNs found, removing them from array before match.\n15 matches with separation - 2.0 arcsec\n\n 20210407\nNaNs found, removing them from array before match.\n33 matches with separation - 2.0 arcsec\n\n 20210408\nNaNs found, removing them from array before match.\n4 matches with separation - 2.0 arcsec\n\n 20210409\nNaNs found, removing them from array before match.\n7 matches with separation - 2.0 arcsec\n\n 20210410\nNaNs found, removing them from array before match.\n40 matches with separation - 2.0 arcsec\n\n 20210411\nNaNs found, removing them from array before match.\n\n 20210412\nNaNs found, removing them from array before match.\n5 matches with separation - 2.0 arcsec\n\n 20210413\nNaNs found, removing them from array before match.\n9 matches with separation - 2.0 arcsec\n\n 20210414\nNaNs found, removing them from array before match.\n9 matches with separation - 2.0 arcsec\n\n 20210415\nNaNs found, removing them from array before match.\n3 matches with separation - 2.0 arcsec\n\n 20210416\nNaNs found, removing them from array before match.\n20 matches with separation - 2.0 arcsec\n\n 20210417\nNaNs found, removing them from array before match.\n12 matches with separation - 2.0 arcsec\n\n 20210418\nNaNs found, removing them from array before match.\n6 matches with separation - 2.0 arcsec\n\n 20210419\nNaNs found, removing them from array before match.\n6 matches with separation - 2.0 arcsec\n\n 20210420\nNaNs found, removing them from array before match.\n4 matches with separation - 2.0 arcsec\n\n 20210428\nNaNs found, removing them from array before match.\n\n 20210429\nNaNs found, removing them from array before match.\n1 matches with separation - 2.0 arcsec\n\n 20210430\nNaNs found, removing them from array before match.\n33 matches with separation - 2.0 arcsec\n\n 20210501\nNaNs found, removing them from array before match.\n4 matches with separation - 2.0 arcsec\n\n 20210502\nNaNs found, removing them from array before match.\n46 matches with separation - 2.0 arcsec\n\n 20210503\nNaNs found, removing them from array before match.\n33 matches with separation - 2.0 arcsec\n\n 20210504\nNaNs found, removing them from array before match.\n35 matches with separation - 2.0 arcsec\n\n 20210505\nNaNs found, removing them from array before match.\n40 matches with separation - 2.0 arcsec\n\n 20210506\n32 matches with separation - 2.0 arcsec\n\n 20210507\n16 matches with separation - 2.0 arcsec\n\n 20210508\n30 matches with separation - 2.0 arcsec\n\n 20210509\n2 matches with separation - 2.0 arcsec\n\n 20210510\n22 matches with separation - 2.0 arcsec\n\n 20210511\n1 matches with separation - 2.0 arcsec\n\n 20210512\n9 matches with separation - 2.0 arcsec\n\n 20210513\n12 matches with separation - 2.0 arcsec\n\n 20210517\n8 matches with separation - 2.0 arcsec\n\n 20210518\n3 matches with separation - 2.0 arcsec\n\n 20210529\nNaNs found, removing them from array before match.\n13 matches with separation - 2.0 arcsec\n\n 20210530\n\n 20210531\n1 matches with separation - 2.0 arcsec\n\n 20210602\n5 matches with separation - 2.0 arcsec\n\n 20210604\n1 matches with separation - 2.0 arcsec\n\n 20210605\n\n 20210606\n\n 20210608\n3 matches with separation - 2.0 arcsec\n\n 20210609\n10 matches with separation - 2.0 arcsec\n\n 20210610\n2 matches with separation - 2.0 arcsec\n\n 20210611\n\n 20210612\n9 matches with separation - 2.0 arcsec\n\n 20210613\n5 matches with separation - 2.0 arcsec\n\n 20210627\n2 matches with separation - 2.0 arcsec\n\n 20210706\n\n 20210709\n"
],
[
"init_matches_agn_by_date = initial_check(ledger_df = decam_transients_agn, ledger_type = 'DECAM_TAMU')\nclose_matches_agn = closer_check(init_matches_agn_by_date, ledger_df = decam_transients_agn, ledger_type = 'DECAM_TAMU', exclusion_list = [])\nnp.save('matches_DECam_agn',close_matches_agn, allow_pickle=True)",
"2 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n10 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n12 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n7 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n9 matches with separation - 1.8 deg\n12 matches with separation - 1.8 deg\n10 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n8 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n6 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n5 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n4 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n3 matches with separation - 1.8 deg\n2 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n1 matches with separation - 1.8 deg\n\n 20210322\n\n 20210402\n\n 20210405\nNaNs found, removing them from array before match.\n24 matches with separation - 2.0 arcsec\n\n 20210406\nNaNs found, removing them from array before match.\n27 matches with separation - 2.0 arcsec\n\n 20210407\nNaNs found, removing them from array before match.\n27 matches with separation - 2.0 arcsec\n\n 20210408\nNaNs found, removing them from array before match.\n8 matches with separation - 2.0 arcsec\n\n 20210409\nNaNs found, removing them from array before match.\n10 matches with separation - 2.0 arcsec\n\n 20210410\nNaNs found, removing them from array before match.\n18 matches with separation - 2.0 arcsec\n\n 20210411\nNaNs found, removing them from array before match.\n\n 20210412\nNaNs found, removing them from array before match.\n6 matches with separation - 2.0 arcsec\n\n 20210413\nNaNs found, removing them from array before match.\n7 matches with separation - 2.0 arcsec\n\n 20210414\nNaNs found, removing them from array before match.\n4 matches with separation - 2.0 arcsec\n\n 20210415\nNaNs found, removing them from array before match.\n3 matches with separation - 2.0 arcsec\n\n 20210416\nNaNs found, removing them from array before match.\n8 matches with separation - 2.0 arcsec\n\n 20210417\nNaNs found, removing them from array before match.\n18 matches with separation - 2.0 arcsec\n\n 20210418\nNaNs found, removing them from array before match.\n5 matches with separation - 2.0 arcsec\n\n 20210419\nNaNs found, removing them from array before match.\n2 matches with separation - 2.0 arcsec\n\n 20210420\nNaNs found, removing them from array before match.\n3 matches with separation - 2.0 arcsec\n\n 20210428\nNaNs found, removing them from array before match.\n\n 20210429\nNaNs found, removing them from array before match.\n\n 20210430\nNaNs found, removing them from array before match.\n7 matches with separation - 2.0 arcsec\n\n 20210501\nNaNs found, removing them from array before match.\n2 matches with separation - 2.0 arcsec\n\n 20210502\nNaNs found, removing them from array before match.\n15 matches with separation - 2.0 arcsec\n\n 20210503\nNaNs found, removing them from array before match.\n10 matches with separation - 2.0 arcsec\n\n 20210504\nNaNs found, removing them from array before match.\n13 matches with separation - 2.0 arcsec\n\n 20210505\nNaNs found, removing them from array before match.\n9 matches with separation - 2.0 arcsec\n\n 20210506\n8 matches with separation - 2.0 arcsec\n\n 20210507\n5 matches with separation - 2.0 arcsec\n\n 20210508\n7 matches with separation - 2.0 arcsec\n\n 20210509\n1 matches with separation - 2.0 arcsec\n\n 20210510\n3 matches with separation - 2.0 arcsec\n\n 20210511\n8 matches with separation - 2.0 arcsec\n\n 20210512\n12 matches with separation - 2.0 arcsec\n\n 20210513\n1 matches with separation - 2.0 arcsec\n\n 20210517\n3 matches with separation - 2.0 arcsec\n\n 20210518\n6 matches with separation - 2.0 arcsec\n\n 20210529\nNaNs found, removing them from array before match.\n2 matches with separation - 2.0 arcsec\n\n 20210530\n6 matches with separation - 2.0 arcsec\n\n 20210531\n5 matches with separation - 2.0 arcsec\n\n 20210602\n9 matches with separation - 2.0 arcsec\n\n 20210604\n8 matches with separation - 2.0 arcsec\n\n 20210605\n\n 20210606\n\n 20210608\n3 matches with separation - 2.0 arcsec\n\n 20210609\n5 matches with separation - 2.0 arcsec\n\n 20210610\n2 matches with separation - 2.0 arcsec\n\n 20210611\n2 matches with separation - 2.0 arcsec\n\n 20210612\n2 matches with separation - 2.0 arcsec\n\n 20210613\n1 matches with separation - 2.0 arcsec\n\n 20210627\n\n 20210706\n\n 20210709\n"
],
[
"np.save('matches_DECam_agn',close_matches_agn, allow_pickle=True)",
"_____no_output_____"
]
],
[
[
"## A quick plot to see the distribution of target matches",
"_____no_output_____"
]
],
[
[
"plt.scatter(close_matches[:,4], close_matches[:,5],label='SN')\nplt.scatter(close_matches_agn[:,4], close_matches_agn[:,5],label='AGN')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"## End notes:\nDouble matches are to be expected, could be worthwhile to compare the spectra of both",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"raw"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cbd325c7aa0a05998dc8e96cffc745e46a94ea82
| 6,870 |
ipynb
|
Jupyter Notebook
|
notebooks/plot_cascade_decomposition.ipynb
|
pySTEPS/pysteps_tutorials
|
aeb7cf92603c9b72bf6e80d0870a10daac3a4923
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/plot_cascade_decomposition.ipynb
|
pySTEPS/pysteps_tutorials
|
aeb7cf92603c9b72bf6e80d0870a10daac3a4923
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/plot_cascade_decomposition.ipynb
|
pySTEPS/pysteps_tutorials
|
aeb7cf92603c9b72bf6e80d0870a10daac3a4923
|
[
"BSD-3-Clause"
] | 1 |
2022-03-08T08:10:11.000Z
|
2022-03-08T08:10:11.000Z
| 29.612069 | 99 | 0.552693 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\n# Cascade decomposition\n\nThis example script shows how to compute and plot the cascade decompositon of \na single radar precipitation field in pysteps.\n",
"_____no_output_____"
]
],
[
[
"from matplotlib import cm, pyplot as plt\nimport numpy as np\nimport os\nfrom pprint import pprint\nfrom pysteps.cascade.bandpass_filters import filter_gaussian\nfrom pysteps import io, rcparams\nfrom pysteps.cascade.decomposition import decomposition_fft\nfrom pysteps.utils import conversion, transformation\nfrom pysteps.visualization import plot_precip_field",
"_____no_output_____"
]
],
[
[
"## Read precipitation field\n\nFirst thing, the radar composite is imported and transformed in units\nof dB.\n\n",
"_____no_output_____"
]
],
[
[
"# Import the example radar composite\nroot_path = rcparams.data_sources[\"fmi\"][\"root_path\"]\nfilename = os.path.join(\n root_path, \"20160928\", \"201609281600_fmi.radar.composite.lowest_FIN_SUOMI1.pgm.gz\"\n)\nR, _, metadata = io.import_fmi_pgm(filename, gzipped=True)\n\n# Convert to rain rate\nR, metadata = conversion.to_rainrate(R, metadata)\n\n# Nicely print the metadata\npprint(metadata)\n\n# Plot the rainfall field\nplot_precip_field(R, geodata=metadata)\nplt.show()\n\n# Log-transform the data\nR, metadata = transformation.dB_transform(R, metadata, threshold=0.1, zerovalue=-15.0)",
"_____no_output_____"
]
],
[
[
"## 2D Fourier spectrum\n\nCompute and plot the 2D Fourier power spectrum of the precipitaton field.\n\n",
"_____no_output_____"
]
],
[
[
"# Set Nans as the fill value\nR[~np.isfinite(R)] = metadata[\"zerovalue\"]\n\n# Compute the Fourier transform of the input field\nF = abs(np.fft.fftshift(np.fft.fft2(R)))\n\n# Plot the power spectrum\nM, N = F.shape\nfig, ax = plt.subplots()\nim = ax.imshow(\n np.log(F ** 2), vmin=4, vmax=24, cmap=cm.jet, extent=(-N / 2, N / 2, -M / 2, M / 2)\n)\ncb = fig.colorbar(im)\nax.set_xlabel(\"Wavenumber $k_x$\")\nax.set_ylabel(\"Wavenumber $k_y$\")\nax.set_title(\"Log-power spectrum of R\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Cascade decomposition\n\nFirst, construct a set of Gaussian bandpass filters and plot the corresponding\n1D filters.\n\n",
"_____no_output_____"
]
],
[
[
"num_cascade_levels = 7\n\n# Construct the Gaussian bandpass filters\nfilter = filter_gaussian(R.shape, num_cascade_levels)\n\n# Plot the bandpass filter weights\nL = max(N, M)\nfig, ax = plt.subplots()\nfor k in range(num_cascade_levels):\n ax.semilogx(\n np.linspace(0, L / 2, len(filter[\"weights_1d\"][k, :])),\n filter[\"weights_1d\"][k, :],\n \"k-\",\n base=pow(0.5 * L / 3, 1.0 / (num_cascade_levels - 2)),\n )\nax.set_xlim(1, L / 2)\nax.set_ylim(0, 1)\nxt = np.hstack([[1.0], filter[\"central_wavenumbers\"][1:]])\nax.set_xticks(xt)\nax.set_xticklabels([\"%.2f\" % cf for cf in filter[\"central_wavenumbers\"]])\nax.set_xlabel(\"Radial wavenumber $|\\mathbf{k}|$\")\nax.set_ylabel(\"Normalized weight\")\nax.set_title(\"Bandpass filter weights\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Finally, apply the 2D Gaussian filters to decompose the radar rainfall field\ninto a set of cascade levels of decreasing spatial scale and plot them.\n\n",
"_____no_output_____"
]
],
[
[
"decomp = decomposition_fft(R, filter, compute_stats=True)\n\n# Plot the normalized cascade levels\nfor i in range(num_cascade_levels):\n mu = decomp[\"means\"][i]\n sigma = decomp[\"stds\"][i]\n decomp[\"cascade_levels\"][i] = (decomp[\"cascade_levels\"][i] - mu) / sigma\n\nfig, ax = plt.subplots(nrows=2, ncols=4)\n\nax[0, 0].imshow(R, cmap=cm.RdBu_r, vmin=-5, vmax=5)\nax[0, 1].imshow(decomp[\"cascade_levels\"][0], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[0, 2].imshow(decomp[\"cascade_levels\"][1], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[0, 3].imshow(decomp[\"cascade_levels\"][2], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[1, 0].imshow(decomp[\"cascade_levels\"][3], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[1, 1].imshow(decomp[\"cascade_levels\"][4], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[1, 2].imshow(decomp[\"cascade_levels\"][5], cmap=cm.RdBu_r, vmin=-3, vmax=3)\nax[1, 3].imshow(decomp[\"cascade_levels\"][6], cmap=cm.RdBu_r, vmin=-3, vmax=3)\n\nax[0, 0].set_title(\"Observed\")\nax[0, 1].set_title(\"Level 1\")\nax[0, 2].set_title(\"Level 2\")\nax[0, 3].set_title(\"Level 3\")\nax[1, 0].set_title(\"Level 4\")\nax[1, 1].set_title(\"Level 5\")\nax[1, 2].set_title(\"Level 6\")\nax[1, 3].set_title(\"Level 7\")\n\nfor i in range(2):\n for j in range(4):\n ax[i, j].set_xticks([])\n ax[i, j].set_yticks([])\nplt.tight_layout()\nplt.show()\n\n# sphinx_gallery_thumbnail_number = 4",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd32c977f8b2726b25c905579bdaee4df71767f
| 24,305 |
ipynb
|
Jupyter Notebook
|
site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb
|
RedContritio/docs-l10n
|
f69a7c0d2157703a26cef95bac34b39ac0250373
|
[
"Apache-2.0"
] | 1 |
2022-03-29T22:32:18.000Z
|
2022-03-29T22:32:18.000Z
|
site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb
|
RedContritio/docs-l10n
|
f69a7c0d2157703a26cef95bac34b39ac0250373
|
[
"Apache-2.0"
] | null | null | null |
site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb
|
RedContritio/docs-l10n
|
f69a7c0d2157703a26cef95bac34b39ac0250373
|
[
"Apache-2.0"
] | null | null | null | 28.594118 | 285 | 0.52195 |
[
[
[
"##### Copyright 2021 The TF-Agents Authors.\n",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# CheckpointerとPolicySaver\n\n<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://www.tensorflow.org/agents/tutorials/10_checkpointer_policysaver_tutorial\"> <img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\"> TensorFlow.org で表示</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb\"> <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\"> Google Colab で実行</a></td>\n <td><a target=\"_blank\" href=\"https://github.com/tensorflow/docs-l10n/blob/master/site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb\"> <img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\"> GitHub でソースを表示</a></td>\n <td><a href=\"https://storage.googleapis.com/tensorflow_docs/docs-l10n/site/ja/agents/tutorials/10_checkpointer_policysaver_tutorial.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\">ノートブックをダウンロード</a></td>\n</table>",
"_____no_output_____"
],
[
"## はじめに\n\n`tf_agents.utils.common.Checkpointer`は、ローカルストレージとの間でトレーニングの状態、ポリシーの状態、およびreplay_bufferの状態を保存/読み込むユーティリティです。\n\n`tf_agents.policies.policy_saver.PolicySaver`は、ポリシーのみを保存/読み込むツールであり、`Checkpointer`よりも軽量です。`PolicySaver`を使用すると、ポリシーを作成したコードに関する知識がなくてもモデルをデプロイできます。\n\nこのチュートリアルでは、DQNを使用してモデルをトレーニングし、次に`Checkpointer`と`PolicySaver`を使用して、状態とモデルをインタラクティブな方法で保存および読み込む方法を紹介します。`PolicySaver`では、TF2.0の新しいsaved_modelツールとフォーマットを使用することに注意してください。\n",
"_____no_output_____"
],
[
"## セットアップ",
"_____no_output_____"
],
[
"以下の依存関係をインストールしていない場合は、実行します。",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\n!sudo apt-get update\n!sudo apt-get install -y xvfb ffmpeg python-opengl\n!pip install pyglet\n!pip install 'imageio==2.4.0'\n!pip install 'xvfbwrapper==0.2.9'\n!pip install tf-agents",
"_____no_output_____"
],
[
"from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport base64\nimport imageio\nimport io\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport os\nimport shutil\nimport tempfile\nimport tensorflow as tf\nimport zipfile\nimport IPython\n\ntry:\n from google.colab import files\nexcept ImportError:\n files = None\nfrom tf_agents.agents.dqn import dqn_agent\nfrom tf_agents.drivers import dynamic_step_driver\nfrom tf_agents.environments import suite_gym\nfrom tf_agents.environments import tf_py_environment\nfrom tf_agents.eval import metric_utils\nfrom tf_agents.metrics import tf_metrics\nfrom tf_agents.networks import q_network\nfrom tf_agents.policies import policy_saver\nfrom tf_agents.policies import py_tf_eager_policy\nfrom tf_agents.policies import random_tf_policy\nfrom tf_agents.replay_buffers import tf_uniform_replay_buffer\nfrom tf_agents.trajectories import trajectory\nfrom tf_agents.utils import common\n\ntempdir = os.getenv(\"TEST_TMPDIR\", tempfile.gettempdir())",
"_____no_output_____"
],
[
"#@test {\"skip\": true}\n# Set up a virtual display for rendering OpenAI gym environments.\nimport xvfbwrapper\nxvfbwrapper.Xvfb(1400, 900, 24).start()",
"_____no_output_____"
]
],
[
[
"## DQNエージェント\n\n前のColabと同じように、DQNエージェントを設定します。 このColabでは、詳細は主な部分ではないので、デフォルトでは非表示になっていますが、「コードを表示」をクリックすると詳細を表示できます。",
"_____no_output_____"
],
[
"### ハイパーパラメーター",
"_____no_output_____"
]
],
[
[
"env_name = \"CartPole-v1\"\n\ncollect_steps_per_iteration = 100\nreplay_buffer_capacity = 100000\n\nfc_layer_params = (100,)\n\nbatch_size = 64\nlearning_rate = 1e-3\nlog_interval = 5\n\nnum_eval_episodes = 10\neval_interval = 1000",
"_____no_output_____"
]
],
[
[
"### 環境",
"_____no_output_____"
]
],
[
[
"train_py_env = suite_gym.load(env_name)\neval_py_env = suite_gym.load(env_name)\n\ntrain_env = tf_py_environment.TFPyEnvironment(train_py_env)\neval_env = tf_py_environment.TFPyEnvironment(eval_py_env)",
"_____no_output_____"
]
],
[
[
"### エージェント",
"_____no_output_____"
]
],
[
[
"#@title\nq_net = q_network.QNetwork(\n train_env.observation_spec(),\n train_env.action_spec(),\n fc_layer_params=fc_layer_params)\n\noptimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)\n\nglobal_step = tf.compat.v1.train.get_or_create_global_step()\n\nagent = dqn_agent.DqnAgent(\n train_env.time_step_spec(),\n train_env.action_spec(),\n q_network=q_net,\n optimizer=optimizer,\n td_errors_loss_fn=common.element_wise_squared_loss,\n train_step_counter=global_step)\nagent.initialize()",
"_____no_output_____"
]
],
[
[
"### データ収集",
"_____no_output_____"
]
],
[
[
"#@title\nreplay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(\n data_spec=agent.collect_data_spec,\n batch_size=train_env.batch_size,\n max_length=replay_buffer_capacity)\n\ncollect_driver = dynamic_step_driver.DynamicStepDriver(\n train_env,\n agent.collect_policy,\n observers=[replay_buffer.add_batch],\n num_steps=collect_steps_per_iteration)\n\n# Initial data collection\ncollect_driver.run()\n\n# Dataset generates trajectories with shape [BxTx...] where\n# T = n_step_update + 1.\ndataset = replay_buffer.as_dataset(\n num_parallel_calls=3, sample_batch_size=batch_size,\n num_steps=2).prefetch(3)\n\niterator = iter(dataset)",
"_____no_output_____"
]
],
[
[
"### エージェントのトレーニング",
"_____no_output_____"
]
],
[
[
"#@title\n# (Optional) Optimize by wrapping some of the code in a graph using TF function.\nagent.train = common.function(agent.train)\n\ndef train_one_iteration():\n\n # Collect a few steps using collect_policy and save to the replay buffer.\n collect_driver.run()\n\n # Sample a batch of data from the buffer and update the agent's network.\n experience, unused_info = next(iterator)\n train_loss = agent.train(experience)\n\n iteration = agent.train_step_counter.numpy()\n print ('iteration: {0} loss: {1}'.format(iteration, train_loss.loss))",
"_____no_output_____"
]
],
[
[
"### ビデオ生成",
"_____no_output_____"
]
],
[
[
"#@title\ndef embed_gif(gif_buffer):\n \"\"\"Embeds a gif file in the notebook.\"\"\"\n tag = '<img src=\"data:image/gif;base64,{0}\"/>'.format(base64.b64encode(gif_buffer).decode())\n return IPython.display.HTML(tag)\n\ndef run_episodes_and_create_video(policy, eval_tf_env, eval_py_env):\n num_episodes = 3\n frames = []\n for _ in range(num_episodes):\n time_step = eval_tf_env.reset()\n frames.append(eval_py_env.render())\n while not time_step.is_last():\n action_step = policy.action(time_step)\n time_step = eval_tf_env.step(action_step.action)\n frames.append(eval_py_env.render())\n gif_file = io.BytesIO()\n imageio.mimsave(gif_file, frames, format='gif', fps=60)\n IPython.display.display(embed_gif(gif_file.getvalue()))",
"_____no_output_____"
]
],
[
[
"### ビデオ生成\n\nビデオを生成して、ポリシーのパフォーマンスを確認します。",
"_____no_output_____"
]
],
[
[
"print ('global_step:')\nprint (global_step)\nrun_episodes_and_create_video(agent.policy, eval_env, eval_py_env)",
"_____no_output_____"
]
],
[
[
"## チェックポインタとPolicySaverのセットアップ\n\nCheckpointerとPolicySaverを使用する準備ができました。",
"_____no_output_____"
],
[
"### Checkpointer\n",
"_____no_output_____"
]
],
[
[
"checkpoint_dir = os.path.join(tempdir, 'checkpoint')\ntrain_checkpointer = common.Checkpointer(\n ckpt_dir=checkpoint_dir,\n max_to_keep=1,\n agent=agent,\n policy=agent.policy,\n replay_buffer=replay_buffer,\n global_step=global_step\n)",
"_____no_output_____"
]
],
[
[
"### Policy Saver",
"_____no_output_____"
]
],
[
[
"policy_dir = os.path.join(tempdir, 'policy')\ntf_policy_saver = policy_saver.PolicySaver(agent.policy)",
"_____no_output_____"
]
],
[
[
"### 1回のイテレーションのトレーニング",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\nprint('Training one iteration....')\ntrain_one_iteration()",
"_____no_output_____"
]
],
[
[
"### チェックポイントに保存",
"_____no_output_____"
]
],
[
[
"train_checkpointer.save(global_step)",
"_____no_output_____"
]
],
[
[
"### チェックポイントに復元\n\nチェックポイントに復元するためには、チェックポイントが作成されたときと同じ方法でオブジェクト全体を再作成する必要があります。",
"_____no_output_____"
]
],
[
[
"train_checkpointer.initialize_or_restore()\nglobal_step = tf.compat.v1.train.get_global_step()",
"_____no_output_____"
]
],
[
[
"また、ポリシーを保存して指定する場所にエクスポートします。",
"_____no_output_____"
]
],
[
[
"tf_policy_saver.save(policy_dir)",
"_____no_output_____"
]
],
[
[
"ポリシーの作成に使用されたエージェントまたはネットワークについての知識がなくても、ポリシーを読み込めるので、ポリシーのデプロイが非常に簡単になります。\n\n保存されたポリシーを読み込み、それがどのように機能するかを確認します。",
"_____no_output_____"
]
],
[
[
"saved_policy = tf.saved_model.load(policy_dir)\nrun_episodes_and_create_video(saved_policy, eval_env, eval_py_env)",
"_____no_output_____"
]
],
[
[
"## エクスポートとインポート\n\n以下は、後でトレーニングを続行し、再度トレーニングすることなくモデルをデプロイできるように、Checkpointer とポリシーディレクトリをエクスポート/インポートするのに役立ちます。\n\n「1回のイテレーションのトレーニング」に戻り、後で違いを理解できるように、さらに数回トレーニングします。 結果が少し改善し始めたら、以下に進みます。",
"_____no_output_____"
]
],
[
[
"#@title Create zip file and upload zip file (double-click to see the code)\ndef create_zip_file(dirname, base_filename):\n return shutil.make_archive(base_filename, 'zip', dirname)\n\ndef upload_and_unzip_file_to(dirname):\n if files is None:\n return\n uploaded = files.upload()\n for fn in uploaded.keys():\n print('User uploaded file \"{name}\" with length {length} bytes'.format(\n name=fn, length=len(uploaded[fn])))\n shutil.rmtree(dirname)\n zip_files = zipfile.ZipFile(io.BytesIO(uploaded[fn]), 'r')\n zip_files.extractall(dirname)\n zip_files.close()",
"_____no_output_____"
]
],
[
[
"チェックポイントディレクトリからzipファイルを作成します。",
"_____no_output_____"
]
],
[
[
"train_checkpointer.save(global_step)\ncheckpoint_zip_filename = create_zip_file(checkpoint_dir, os.path.join(tempdir, 'exported_cp'))",
"_____no_output_____"
]
],
[
[
"zipファイルをダウンロードします。",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\nif files is not None:\n files.download(checkpoint_zip_filename) # try again if this fails: https://github.com/googlecolab/colabtools/issues/469",
"_____no_output_____"
]
],
[
[
"10〜15回ほどトレーニングした後、チェックポイントのzipファイルをダウンロードし、[ランタイム]> [再起動してすべて実行]に移動してトレーニングをリセットし、このセルに戻ります。ダウンロードしたzipファイルをアップロードして、トレーニングを続けます。",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\nupload_and_unzip_file_to(checkpoint_dir)\ntrain_checkpointer.initialize_or_restore()\nglobal_step = tf.compat.v1.train.get_global_step()",
"_____no_output_____"
]
],
[
[
"チェックポイントディレクトリをアップロードしたら、「1回のイテレーションのトレーニング」に戻ってトレーニングを続けるか、「ビデオ生成」に戻って読み込まれたポリシーのパフォーマンスを確認します。",
"_____no_output_____"
],
[
"または、ポリシー(モデル)を保存して復元することもできます。Checkpointerとは異なり、トレーニングを続けることはできませんが、モデルをデプロイすることはできます。ダウンロードしたファイルはCheckpointerのファイルよりも大幅に小さいことに注意してください。",
"_____no_output_____"
]
],
[
[
"tf_policy_saver.save(policy_dir)\npolicy_zip_filename = create_zip_file(policy_dir, os.path.join(tempdir, 'exported_policy'))",
"_____no_output_____"
],
[
"#@test {\"skip\": true}\nif files is not None:\n files.download(policy_zip_filename) # try again if this fails: https://github.com/googlecolab/colabtools/issues/469",
"_____no_output_____"
]
],
[
[
"ダウンロードしたポリシーディレクトリ(exported_policy.zip)をアップロードし、保存したポリシーの動作を確認します。",
"_____no_output_____"
]
],
[
[
"#@test {\"skip\": true}\nupload_and_unzip_file_to(policy_dir)\nsaved_policy = tf.saved_model.load(policy_dir)\nrun_episodes_and_create_video(saved_policy, eval_env, eval_py_env)\n",
"_____no_output_____"
]
],
[
[
"## SavedModelPyTFEagerPolicy\n\nTFポリシーを使用しない場合は、`py_tf_eager_policy.SavedModelPyTFEagerPolicy`を使用して、Python envでsaved_modelを直接使用することもできます。\n\nこれは、eagerモードが有効になっている場合にのみ機能することに注意してください。",
"_____no_output_____"
]
],
[
[
"eager_py_policy = py_tf_eager_policy.SavedModelPyTFEagerPolicy(\n policy_dir, eval_py_env.time_step_spec(), eval_py_env.action_spec())\n\n# Note that we're passing eval_py_env not eval_env.\nrun_episodes_and_create_video(eager_py_policy, eval_py_env, eval_py_env)",
"_____no_output_____"
]
],
[
[
"## ポリシーを TFLite に変換する\n\n詳細については、「[TensorFlow Lite 推論](https://tensorflow.org/lite/guide/inference)」をご覧ください。",
"_____no_output_____"
]
],
[
[
"converter = tf.lite.TFLiteConverter.from_saved_model(policy_dir, signature_keys=[\"action\"])\nconverter.target_spec.supported_ops = [\n tf.lite.OpsSet.TFLITE_BUILTINS, # enable TensorFlow Lite ops.\n tf.lite.OpsSet.SELECT_TF_OPS # enable TensorFlow ops.\n]\ntflite_policy = converter.convert()\nwith open(os.path.join(tempdir, 'policy.tflite'), 'wb') as f:\n f.write(tflite_policy)",
"_____no_output_____"
]
],
[
[
"### TFLite モデルで推論を実行する",
"_____no_output_____"
]
],
[
[
"import numpy as np\ninterpreter = tf.lite.Interpreter(os.path.join(tempdir, 'policy.tflite'))\n\npolicy_runner = interpreter.get_signature_runner()\nprint(policy_runner._inputs)",
"_____no_output_____"
],
[
"policy_runner(**{\n '0/discount':tf.constant(0.0),\n '0/observation':tf.zeros([1,4]),\n '0/reward':tf.constant(0.0),\n '0/step_type':tf.constant(0)})",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cbd332409f089612bdaa82152e4545d3fb7af172
| 8,765 |
ipynb
|
Jupyter Notebook
|
reddit_randomness_scrape.ipynb
|
dwisdom0/reddit-randomness-notebooks
|
67e6feca5b1ff488d0f1ddffd98bca353f47674a
|
[
"MIT"
] | null | null | null |
reddit_randomness_scrape.ipynb
|
dwisdom0/reddit-randomness-notebooks
|
67e6feca5b1ff488d0f1ddffd98bca353f47674a
|
[
"MIT"
] | null | null | null |
reddit_randomness_scrape.ipynb
|
dwisdom0/reddit-randomness-notebooks
|
67e6feca5b1ff488d0f1ddffd98bca353f47674a
|
[
"MIT"
] | null | null | null | 8,765 | 8,765 | 0.618483 |
[
[
[
"# How random is `r/random`?\n\nThere's a limit of 0.5 req/s (1 request every 2 seconds)\n\n\n## What a good response looks like (status code 302)\n```\n$ curl https://www.reddit.com/r/random\n\n<html>\n <head>\n <title>302 Found</title>\n </head>\n <body>\n <h1>302 Found</h1>\n The resource was found at <a href=\"https://www.reddit.com/r/Amd/?utm_campaign=redirect&utm_medium=desktop&utm_source=reddit&utm_name=random_subreddit\">https://www.reddit.com/r/Amd/?utm_campaign=redirect&utm_medium=desktop&utm_source=reddit&utm_name=random_subreddit</a>;\nyou should be redirected automatically.\n\n\n </body>\n</html>\n```\n\n## What a bad response looks like (status code 429)\n```\n$ curl https://www.reddit.com/r/random\n\n<!doctype html>\n<html>\n <head>\n <title>Too Many Requests</title>\n <style>\n body {\n font: small verdana, arial, helvetica, sans-serif;\n width: 600px;\n margin: 0 auto;\n }\n\n h1 {\n height: 40px;\n background: transparent url(//www.redditstatic.com/reddit.com.header.png) no-repeat scroll top right;\n }\n </style>\n </head>\n <body>\n <h1>whoa there, pardner!</h1>\n\n\n\n<p>we're sorry, but you appear to be a bot and we've seen too many requests\nfrom you lately. we enforce a hard speed limit on requests that appear to come\nfrom bots to prevent abuse.</p>\n\n<p>if you are not a bot but are spoofing one via your browser's user agent\nstring: please change your user agent string to avoid seeing this message\nagain.</p>\n\n<p>please wait 4 second(s) and try again.</p>\n\n <p>as a reminder to developers, we recommend that clients make no\n more than <a href=\"http://github.com/reddit/reddit/wiki/API\">one\n request every two seconds</a> to avoid seeing this message.</p>\n </body>\n</html>\n```\n\n\n# What happens\nGET --> 302 (redirect) --> 200 (subreddit)\n\nI only want the name of the subreddit, so I don't need to follow the redirect.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport requests\n\nfrom time import sleep\nfrom tqdm import tqdm\nfrom random import random",
"_____no_output_____"
],
[
"def parse_http(req):\n \"\"\"\n Returns the name of the subreddit from a request\n\n If the status code isn't 302, returns \"Error\"\n \"\"\"\n if req.status_code != 302:\n return \"Error\"\n \n start_idx = req.text.index('/r/') + len('/r/')\n end_idx = req.text.index('?utm_campaign=redirect') - 1\n\n return req.text[start_idx:end_idx]\n\n ",
"_____no_output_____"
],
[
"sites = []\ncodes = []\n\nheaders = {\n 'User-Agent': 'Mozilla/5.0'\n}\n\n# Works for 10, 100 @ 3 seconds / request\n# Works for 10 @ 2 seconds / request\nfor _ in tqdm(range(1000), ascii=True):\n # Might have to mess with the User-Agent to look less like a bot\n # https://evanhahn.com/python-requests-library-useragent\n # Yeah the User-Agent says it's coming from python requests\n # Changing it fixed everything\n r = requests.get('https://www.reddit.com/r/random', \n headers=headers,\n allow_redirects=False)\n if r.status_code == 429:\n print(\"Got rate limit error\")\n sites.append(parse_http(r))\n codes.append(r.status_code)\n # Jitter the sleep a bit to throw off bot detection\n sleep(2 + random())\n\n",
"100%|##########| 1000/1000 [43:44<00:00, 2.62s/it]\n"
],
[
"#[print(code, site) for code, site in zip(codes, sites)];\nfor row in list(zip(codes, sites))[-10:]:\n print(row[0], row[1])",
"302 Documentaries\n302 MadeInAbyss\n302 starcitizen\n302 camphalfblood\n302 selfhosted\n302 MrRobot\n302 hajimenoippo\n302 Warthunder\n302 FifaCareers\n302 Pathfinder_Kingmaker\n"
],
[
"df = pd.DataFrame(list(zip(sites, codes)), columns=['subreddit', 'response_code'])\ndf.head()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1000 entries, 0 to 999\nData columns (total 2 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 subreddit 1000 non-null object\n 1 response_code 1000 non-null int64 \ndtypes: int64(1), object(1)\nmemory usage: 15.8+ KB\n"
],
[
"from time import time\nfname = 'reddit_randomness_' + str(int(time())) + '.csv'\ndf.to_csv(fname,index=False)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd335af4775a293ace704648224d8ad7947a7a6
| 3,843 |
ipynb
|
Jupyter Notebook
|
ds/notebooks/dev/13_run_autonuts.ipynb
|
nestauk/beis-indicators
|
d3133c2bd935a13ecfd6bc8f6e52c8d157477c7c
|
[
"MIT"
] | 4 |
2020-04-09T20:16:38.000Z
|
2022-03-25T11:36:30.000Z
|
ds/notebooks/dev/13_run_autonuts.ipynb
|
nestauk/beis-indicators
|
d3133c2bd935a13ecfd6bc8f6e52c8d157477c7c
|
[
"MIT"
] | 353 |
2019-11-06T11:26:51.000Z
|
2021-12-08T09:13:53.000Z
|
ds/notebooks/dev/13_run_autonuts.ipynb
|
nestauk/beis-indicators
|
d3133c2bd935a13ecfd6bc8f6e52c8d157477c7c
|
[
"MIT"
] | 1 |
2020-08-03T12:42:31.000Z
|
2020-08-03T12:42:31.000Z
| 25.450331 | 104 | 0.444965 |
[
[
[
"# Auto NUTS processing\n\nHere we relabel indicators using the nuts detector",
"_____no_output_____"
],
[
"## 0. Preamble",
"_____no_output_____"
]
],
[
[
"%run ../notebook_preamble.ipy",
"_____no_output_____"
],
[
"from beis_indicators.utils.nuts_utils import auto_nuts2_uk\n\nimport re",
"_____no_output_____"
],
[
"def test_dataset(data_source):\n '''\n This function finds, for a data source, the processed csvs, and performs autonuts detection\n \n For now it will simply print the inferred specification for each csv\n \n Args:\n -data source (str) is the folder storing indicators in /processed\n \n '''\n \n path = f'../../data/processed/{data_source}'\n \n csv_files = [x for x in os.listdir(path) if 'csv' in x]\n \n for x in csv_files:\n print(x)\n auton = auto_nuts2_uk(pd.read_csv(os.path.join(path,x)))\n \n print(set(auton['nuts_year_spec']))\n \n ",
"_____no_output_____"
],
[
"def nuts_test_processed():\n '''\n Finds all csv folders in the processed folder with a yaml file (ie merged indicators)\n Performs the test\n \n '''\n \n to_check = []\n \n for folder in os.listdir('../../data/processed/'):\n \n if os.path.isdir(f'../../data/processed/{folder}')==True:\n \n #We assume that folders with yamls have been processed\n yamls = [x for x in os.listdir(f'../../data/processed/{folder}') if '.yaml' in x]\n \n #This is not always the case though\n \n try:\n \n for x in yamls:\n\n csv = re.sub('.yaml','.csv',x)\n\n table = pd.read_csv(f'../../data/processed/{folder}/{csv}',index_col=None)\n \n #Remove unnecessary indices\n table = table[[x for x in table.columns if 'Unnamed' not in x]]\n\n #Autonuts\n autonuts = auto_nuts2_uk(table)\n \n #Save\n autonuts.to_csv(f'../../data/processed/{folder}/{csv}',index=False)\n\n print(autonuts.head())\n \n except:\n print('old schema')",
"_____no_output_____"
],
[
"nuts_test_processed()",
"_____no_output_____"
],
[
"?pd.read_csv",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd3463804b74a756daf48eb930bdedef7fa9fa4
| 475,278 |
ipynb
|
Jupyter Notebook
|
HuggingFace/Hands-on_Workshop/01_transformers_tour.ipynb
|
ee2110/Natural_Language_Processing-NLP-TensorFlow
|
e4697d28a7cfd694f6a231598cd939a9362a4e94
|
[
"MIT"
] | null | null | null |
HuggingFace/Hands-on_Workshop/01_transformers_tour.ipynb
|
ee2110/Natural_Language_Processing-NLP-TensorFlow
|
e4697d28a7cfd694f6a231598cd939a9362a4e94
|
[
"MIT"
] | null | null | null |
HuggingFace/Hands-on_Workshop/01_transformers_tour.ipynb
|
ee2110/Natural_Language_Processing-NLP-TensorFlow
|
e4697d28a7cfd694f6a231598cd939a9362a4e94
|
[
"MIT"
] | null | null | null | 39.178798 | 40,370 | 0.537868 |
[
[
[
"# A 🤗 tour of transformer applications",
"_____no_output_____"
],
[
"In this notebook we take a tour around transformers applications. The transformer architecture is very versatile and allows us to perform many NLP tasks with only minor modifications. For this reason they have been applied to a wide range of NLP tasks such as classification, named entity recognition, or translation.",
"_____no_output_____"
],
[
"## Pipeline",
"_____no_output_____"
],
[
"We experiment with models for these tasks using the high-level API called pipeline. The pipeline takes care of all preprocessing and returns cleaned up predictions. The pipeline is primarily used for inference where we apply fine-tuned models to new examples.",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/pipeline.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=800>",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\nYouTubeVideo('1pedAIvTWXk')",
"_____no_output_____"
]
],
[
[
"## Setup",
"_____no_output_____"
],
[
"Before we start we need to make sure we have the transformers library installed as well as the sentencepiece tokenizer which we'll need for some models.",
"_____no_output_____"
]
],
[
[
"%%capture\n!pip install transformers\n!pip install sentencepiece",
"_____no_output_____"
]
],
[
[
"Furthermore, we create a textwrapper to format long texts nicely.",
"_____no_output_____"
]
],
[
[
"import textwrap\nwrapper = textwrap.TextWrapper(width=80, break_long_words=False, break_on_hyphens=False)",
"_____no_output_____"
]
],
[
[
"## Classification",
"_____no_output_____"
],
[
"We start by setting up an example text that we would like to analyze with a transformer model. This looks like your standard customer feedback from a transformer:",
"_____no_output_____"
]
],
[
[
"text = \"\"\"Dear Amazon, last week I ordered an Optimus Prime action figure \\\nfrom your online store in Germany. Unfortunately, when I opened the package, \\\nI discovered to my horror that I had been sent an action figure of Megatron \\\ninstead! As a lifelong enemy of the Decepticons, I hope you can understand my \\\ndilemma. To resolve the issue, I demand an exchange of Megatron for the \\\nOptimus Prime figure I ordered. Enclosed are copies of my records concerning \\\nthis purchase. I expect to hear from you soon. Sincerely, Bumblebee.\"\"\"\n\nprint(wrapper.fill(text))",
"Dear Amazon, last week I ordered an Optimus Prime action figure from your online\nstore in Germany. Unfortunately, when I opened the package, I discovered to my\nhorror that I had been sent an action figure of Megatron instead! As a lifelong\nenemy of the Decepticons, I hope you can understand my dilemma. To resolve the\nissue, I demand an exchange of Megatron for the Optimus Prime figure I ordered.\nEnclosed are copies of my records concerning this purchase. I expect to hear\nfrom you soon. Sincerely, Bumblebee.\n"
]
],
[
[
"One of the most common tasks in NLP and especially when dealing with customer texts is _sentiment analysis_. We would like to know if a customer is satisfied with a service or product and potentially aggregate the feedback across all customers for reporting.",
"_____no_output_____"
],
[
"For text classification the model gets all the inputs and makes a single prediction as shown in the following example:",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/clf_arch.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=600>",
"_____no_output_____"
],
[
"We can achieve this by setting up a `pipeline` object which wraps a transformer model. When initializing we need to specify the task. Sentiment analysis is a subfield of text classification where a single label is given to a ",
"_____no_output_____"
]
],
[
[
"from transformers import pipeline\n\nsentiment_pipeline = pipeline('text-classification')",
"No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)\n"
]
],
[
[
"You can see a warning message: we did not specify in the pipeline which model we would like to use. In that case it loads a default model. The `distilbert-base-uncased-finetuned-sst-2-english` model is a small BERT variant trained on [SST-2](https://paperswithcode.com/sota/sentiment-analysis-on-sst-2-binary) which is a sentiment analysis dataset.",
"_____no_output_____"
],
[
"You'll notice that the first time you execute the model a download is executed. The model is downloaded from the 🤗 Hub! The second time the cached model will be used.",
"_____no_output_____"
],
[
"Now we are ready to run our example through pipeline and look at some predictions:",
"_____no_output_____"
]
],
[
[
"sentiment_pipeline(text)",
"_____no_output_____"
]
],
[
[
"The model predicts negative sentiment with a high confidence which makes sense. You can see that the pipeline returns a list of dicts with the predictions. We can also pass several texts at the same time in which case we would get several dicts in the list for each text one.",
"_____no_output_____"
],
[
"## Named entity recognition",
"_____no_output_____"
],
[
"Let's see if we can do something a little more sophisticated. Instead of just finding the overall sentiment let's see if we can extract named entities such as organizations, locations, or individuals from the text. This task is called named entity recognition (NER). Instead of predicting just a class for the whole text a class is predicted for each token, thus this task belongs to the category of token classification:",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/ner_arch.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=550>",
"_____no_output_____"
],
[
"Again, we just load a pipeline for the NER task without specifying a model. This will load a default BERT model that has been trained on the [CoNLL-2003](https://huggingface.co/datasets/conll2003).",
"_____no_output_____"
]
],
[
[
"ner_pipeline = pipeline('ner')",
"No model was supplied, defaulted to dbmdz/bert-large-cased-finetuned-conll03-english (https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english)\n"
]
],
[
[
"When we pass our text through the model we get a long list of dicts: each dict corresponds to one detected entity. Since multiple tokens can correspond to a a single entity we can apply an aggregation strategy that merges entities if the same class appears in consequtive tokens.",
"_____no_output_____"
]
],
[
[
"entities = ner_pipeline(text, aggregation_strategy=\"simple\")\nprint(entities)",
"[{'entity_group': 'ORG', 'score': 0.87900966, 'word': 'Amazon', 'start': 5, 'end': 11}, {'entity_group': 'MISC', 'score': 0.9908588, 'word': 'Optimus Prime', 'start': 36, 'end': 49}, {'entity_group': 'LOC', 'score': 0.9997547, 'word': 'Germany', 'start': 90, 'end': 97}, {'entity_group': 'MISC', 'score': 0.55656844, 'word': 'Mega', 'start': 208, 'end': 212}, {'entity_group': 'PER', 'score': 0.5902572, 'word': '##tron', 'start': 212, 'end': 216}, {'entity_group': 'ORG', 'score': 0.66969234, 'word': 'Decept', 'start': 253, 'end': 259}, {'entity_group': 'MISC', 'score': 0.498349, 'word': '##icons', 'start': 259, 'end': 264}, {'entity_group': 'MISC', 'score': 0.77536106, 'word': 'Megatron', 'start': 350, 'end': 358}, {'entity_group': 'MISC', 'score': 0.98785394, 'word': 'Optimus Prime', 'start': 367, 'end': 380}, {'entity_group': 'PER', 'score': 0.8120963, 'word': 'Bumblebee', 'start': 502, 'end': 511}]\n"
]
],
[
[
"Let's clean the outputs a bit up:",
"_____no_output_____"
]
],
[
[
"for entity in entities:\n print(f\"{entity['word']}: {entity['entity_group']} ({entity['score']:.2f})\")",
"Amazon: ORG (0.88)\nOptimus Prime: MISC (0.99)\nGermany: LOC (1.00)\nMega: MISC (0.56)\n##tron: PER (0.59)\nDecept: ORG (0.67)\n##icons: MISC (0.50)\nMegatron: MISC (0.78)\nOptimus Prime: MISC (0.99)\nBumblebee: PER (0.81)\n"
]
],
[
[
"It seems that the model found most of the named entities but was confused about the class of the transformer characters. This is no surprise since the original dataset probably did not contain many transformer characters. For this reason it makes sense to further fine-tune a model on your on dataset!",
"_____no_output_____"
],
[
"## Question-answering",
"_____no_output_____"
],
[
"We have now seen an example of text and token classification using transformers. However, there are more interesting tasks we can use transformers for. One of them is question-answering. In this task the model is given a question and a context and needs to find the answer to the question within the context. This problem can be rephrased into a classification problem: For each token the model needs to predict whether it is the start or the end of the answer. In the end we can extract the answer by looking at the span between the token with the highest start probability and highest end probability:",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/qa_arch.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=600>",
"_____no_output_____"
],
[
"You can imagine that this requires quite a bit of pre- and post-processing logic. Good thing that the pipeline takes care of all that!",
"_____no_output_____"
]
],
[
[
"qa_pipeline = pipeline(\"question-answering\")",
"No model was supplied, defaulted to distilbert-base-cased-distilled-squad (https://huggingface.co/distilbert-base-cased-distilled-squad)\n"
]
],
[
[
"This default model is trained on the canonical [SQuAD dataset](https://huggingface.co/datasets/squad). Let's see if we can ask it what the customer wants:",
"_____no_output_____"
]
],
[
[
"question = \"What does the customer want?\"\n\noutputs = qa_pipeline(question=question, context=text)\noutputs",
"_____no_output_____"
],
[
"question2 = \"How much the product?\"\n\noutputs2 = qa_pipeline(question=question2, context=text)\noutputs2",
"_____no_output_____"
]
],
[
[
"Awesome, that sounds about right!",
"_____no_output_____"
],
[
"## Summarization",
"_____no_output_____"
],
[
"Let's see if we can go beyond these natural language understanding tasks (NLU) where BERT excels and delve into the generative domain. Note that generation is much more expensive since we usually generate one token at a time and need to run this several times.",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/gen_steps.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=600>",
"_____no_output_____"
],
[
"A popular task involving generation is summarization. Let's see if we can use a transformer to generate a summary for us:",
"_____no_output_____"
]
],
[
[
"summarization_pipeline = pipeline(\"summarization\")",
"No model was supplied, defaulted to sshleifer/distilbart-cnn-12-6 (https://huggingface.co/sshleifer/distilbart-cnn-12-6)\n"
]
],
[
[
"This model is trained was trained on the [CNN/Dailymail dataset](https://huggingface.co/datasets/cnn_dailymail) to summarize news articles.",
"_____no_output_____"
]
],
[
[
"outputs = summarization_pipeline(text, max_length=45, clean_up_tokenization_spaces=True)\nprint(wrapper.fill(outputs[0]['summary_text']))",
" Bumblebee ordered an Optimus Prime action figure from your online store in\nGermany. Unfortunately, when I opened the package, I discovered to my horror\nthat I had been sent an action figure of Megatron instead.\n"
]
],
[
[
"## Translation",
"_____no_output_____"
],
[
"But what if there is no model in the language of my data? You can still try to translate the text. The Helsinki NLP team has provided over 1000 language pair models for translation. Here we load one that translates English to Japanese:",
"_____no_output_____"
]
],
[
[
"translator = pipeline(\"translation_en_to_ja\", model=\"Helsinki-NLP/opus-tatoeba-en-ja\")",
"_____no_output_____"
]
],
[
[
"Let's translate the a text to Japanese:",
"_____no_output_____"
]
],
[
[
"text = 'At the MLT workshop in Tokyo we gave an introduction about Transformers.'",
"_____no_output_____"
],
[
"outputs = translator(text, clean_up_tokenization_spaces=True)\nprint(wrapper.fill(outputs[0]['translation_text']))",
"東京のMLTワークショップで,トランスフォーマーについて紹介しました.\n"
]
],
[
[
"We can see that the text is clearly not perfectly translated, but the core meaning stays the same. Another cool application of translation models is data augmentation via backtranslation!",
"_____no_output_____"
],
[
"## Custom Model",
"_____no_output_____"
],
[
"As a last example let's have a look at a cool application showing the versatility of transformers: zero-shot classification. In zero-shot classification the model receives a text and a list of candidate labels and determines which labels are compatible with the text. Instead of having fixed classes this allows for flexible classification without any labelled data! Usually this is a good first baseline!",
"_____no_output_____"
]
],
[
[
"zero_shot_classifier = pipeline(\"zero-shot-classification\",\n model=\"vicgalle/xlm-roberta-large-xnli-anli\")",
"_____no_output_____"
]
],
[
[
"Let's have a look at an example:",
"_____no_output_____"
]
],
[
[
"text = '東京のMLTワークショップで,トランスフォーマーについて紹介しました.'\nclasses = ['Japan', 'Switzerland', 'USA']",
"_____no_output_____"
],
[
"zero_shot_classifier(text, classes)",
"_____no_output_____"
]
],
[
[
"This seems to have worked really well on this short example. Naturally, for longer and more domain specific examples this approach might suffer.",
"_____no_output_____"
],
[
"## More pipelines",
"_____no_output_____"
],
[
"There are many more pipelines that you can experiment with. Look at the following list for an overview:",
"_____no_output_____"
]
],
[
[
"from transformers import pipelines\nfor task in pipelines.SUPPORTED_TASKS:\n print(task)",
"audio-classification\nautomatic-speech-recognition\nfeature-extraction\ntext-classification\ntoken-classification\nquestion-answering\ntable-question-answering\nfill-mask\nsummarization\ntranslation\ntext2text-generation\ntext-generation\nzero-shot-classification\nconversational\nimage-classification\nobject-detection\n"
]
],
[
[
"Transformers not only work for NLP but can also be applied to other modalities. Let's have a look at a few.",
"_____no_output_____"
],
[
"### Computer vision",
"_____no_output_____"
],
[
"Recently, transformer models have also entered computer vision. Check out the DETR model on the [Hub](https://huggingface.co/facebook/detr-resnet-101-dc5):",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/object_detection.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=400>",
"_____no_output_____"
],
[
"### Audio",
"_____no_output_____"
],
[
"Another promising area is audio processing. Especially Speech2Text there have been some promising advancements recently. See for example the [wav2vec2 model](https://huggingface.co/facebook/wav2vec2-base-960h):",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/speech2text.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=400>",
"_____no_output_____"
],
[
"### Table QA",
"_____no_output_____"
],
[
"Finally, a lot of real world data is still in form of tables. Being able to query tables is very useful and with [TAPAS](https://huggingface.co/google/tapas-large-finetuned-wtq) you can do tabular question-answering:",
"_____no_output_____"
],
[
"<img src=\"https://github.com/huggingface/workshops/blob/main/machine-learning-tokyo/images/tapas.png?raw=1\" alt=\"Alt text that describes the graphic\" title=\"Title text\" width=400>",
"_____no_output_____"
],
[
"## Cache",
"_____no_output_____"
],
[
"Whenever we load a new model from the Hub it is cached on the machine you are running on. If you run these examples on Colab this is not an issue since the persistent storage will be cleaned after your session anyway. However, if you run this notebook on your laptop you might have just filled several GB of your hard drive. By default the cache is saved in the folder `~/.cache/huggingface/transformers`. Make sure to clear it from time to time if your hard drive starts to fill up.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
cbd356aa8d2a4aeed7c123b2c03a68553f3ceb36
| 2,258 |
ipynb
|
Jupyter Notebook
|
assignment-day_3.ipynb
|
vineeth98-vc/letsUpgrade
|
50dbadd8460f405a90a5748c3917eb3e5d992e70
|
[
"Apache-2.0"
] | null | null | null |
assignment-day_3.ipynb
|
vineeth98-vc/letsUpgrade
|
50dbadd8460f405a90a5748c3917eb3e5d992e70
|
[
"Apache-2.0"
] | null | null | null |
assignment-day_3.ipynb
|
vineeth98-vc/letsUpgrade
|
50dbadd8460f405a90a5748c3917eb3e5d992e70
|
[
"Apache-2.0"
] | null | null | null | 18.97479 | 163 | 0.473871 |
[
[
[
"#printing 1 to 200 prime numbers:",
"_____no_output_____"
],
[
"for num in range(1,200):\n count=0\n for i in range(num,0,-1):\n if(num%i==0):\n count+=1\n if(count==2):\n print(num ,end=\" \")",
"2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 "
],
[
"# USing if-else clause:",
"_____no_output_____"
],
[
"num=int(input())\nif(num<=1000):\n print(\"safe to land\")\nelif(num>1000 and num<=5000):\n print(\"come down to 1000 mtrs\")\nelse:\n print(\"turn around\")",
"9000\nturn around\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
cbd357375c8c1869fb51cc68e65ea1d9999a78c2
| 7,812 |
ipynb
|
Jupyter Notebook
|
src/puzzle/examples/puzzle_boat/4_warmup/titania.ipynb
|
PhilHarnish/forge
|
663f19d759b94d84935c14915922070635a4af65
|
[
"MIT"
] | 2 |
2020-08-18T18:43:09.000Z
|
2020-08-18T20:05:59.000Z
|
src/puzzle/examples/puzzle_boat/4_warmup/titania.ipynb
|
PhilHarnish/forge
|
663f19d759b94d84935c14915922070635a4af65
|
[
"MIT"
] | null | null | null |
src/puzzle/examples/puzzle_boat/4_warmup/titania.ipynb
|
PhilHarnish/forge
|
663f19d759b94d84935c14915922070635a4af65
|
[
"MIT"
] | null | null | null | 22.067797 | 200 | 0.501664 |
[
[
[
"# Titania = CLERK MOTEL\nOn Bumble, the Queen of Fairies and the Queen of Bees got together to find some other queens.\n\n* Given\n * Queen of Fairies\n * Queen of Bees\n* Solutions\n * C [Ellery Queen](https://en.wikipedia.org/wiki/Ellery_Queen) = TDDTNW M UPZTDO\n * L Queen of Hearts = THE L OF HEARTS\n * E Queen Elizabeth = E ELIZABETH II\n * R Steve McQueen = STEVE MC R MOVIES\n * K Queen Latifah = K LATIFAH ALBUMS\n * meta\n\n```\n C/M L/O\n E/T R/E\n K/L\n```",
"_____no_output_____"
]
],
[
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nLIT NPGRU IRL GWOLTNW\nLIT ENTTJ MPVVFU GWOLTNW\nLIT TEWYLFRU MNPOO GWOLTNW\nLIT OFRGTOT LCFU GWOLTNW\nLIT PNFEFU PV TZFD\n\"\"\", hint=\"cryptogram\", threshold=1)\n# LIT NPGRU IRL GWOLTNW\n# THE ROMAN HAT MYSTERY\n# LIT ENTTJ MPVVFU GWOLTNW\n# THE GREEK COFFIN MYSTERY\n# LIT TEWYLFRU MNPOO GWOLTNW\n# THE EGYPTIAN CROSS MYSTERY\n# LIT OFRGTOT LCFU GWOLTNW\n# THE SIAMESE TWIN MYSTERY\n# LIT PNFEFU PV TZFD\n# THE ORIGIN OF EVIL\n\n# TDDTNW M UPZTDO\n# ELLERY C NOVELS",
"WARNING\nMax fringe size was: 15112\n"
],
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nKQLECDP\nNDWSDNLSI\nZOMXFUSLDI\nLZZ BFPN PNDFQ NDMWI\nYOMRFUS KMQW\n\"\"\", hint=\"cryptogram\")\n# Queen of Hearts\n# THELOFHEARTS\n# PNDOLZNDMQPI\n# CROQUET\n# KQLECDP\n# HEDGEHOGS\n# NDWSDNLSI\n# FLAMINGOES\n# ZOMXFUSLDI\n# OFF WITH THEIR HEADS\n# LZZ BFPN PNDFQ NDMWI\n# BLAZING CARD\n# YOMRFUS KMQW",
"WARNING\nMax fringe size was: 7225\n"
],
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nZOXMNRBFGP DGQGXT\nXYIBNK\nDINRXT XFGIQTK\nQYRBTKL ITNBRNRB PYRGIXF\nYXTGR QNRTI\n\"\"\", hint=\"cryptogram\")\n# TQN?GZTLF\n# Queen Elizabeth\n# EELIZABETHII\n# \n# BUCKINGHAM PALACE\n# ZOXMNRBFGP DGQGXT\n# CORGIS\n# XYIBNK\n# PRINCE CHARLES \n# DINRXT XFGIQTK\n# LONGEST-REIGNING MONARCH\n# QYRBTKL ITNBRNRB PYRGIXF\n# OCEAN LINER\n# YXTGR QNRTI\n",
"WARNING\nMax fringe size was: 7225\n"
],
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nLUF ZTYSWDWMFSL VFQFS\nLUF YEFTL FVMTRF\nLUF LPXFEWSY WSDFESP\nRTRWJJPS\nLUF MWSMWSSTLW OWC\n\"\"\", hint=\"cryptogram\", threshold=1)\n# Steve McQueen\n# STEVEMCRMOVIES\n# VLFQFZMEZPQWFV\n# THE MAGNIFICENT SEVEN\n# LUF ZTYSWDWMFSL VFQFS\n# THE GREAT ESCAPE\n# LUF YEFTL FVMTRF\n# THE TOWERING INFERNO\n# LUF LPXFEWSY WSDFESP\n# PAPILLON\n# RTRWJJPS\n# THE CINCINNATI KID\n# LUF MWSMWSSTLW OWC\n",
"WARNING\nMax fringe size was: 3682\n"
],
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nHZRWPO FY Z BDBRZ\nIQZVL PODTH\nFPGOP DH RNO VFWPR\nRNO GZHZ FXOHB ZQIWU\nSOPBFHZ\n\"\"\", hint=\"cryptogram\", threshold=1)\n# Queen Latifah\n# LQZRDYZNZQIWUB\n# KLATIFAHALBUMS\n# NATURE OF A SISTA\n# HZRWPO FY Z BDBRZ\n# BLACK REIGN\n# IQZVL PODTH\n# ORDER IN THE COURT\n# FPGOP DH RNO VFWPR\n# THE DANA OVENS ALBUM\n# RNO GZHZ FXOHB ZQIWU\n# PERSONA\n# SOPBFHZ\n",
"WARNING\nMax fringe size was: 17839\n"
],
[
"import forge\nfrom puzzle.puzzlepedia import puzzlepedia\n\npuzzle = puzzlepedia.parse(\"\"\"\nLQZRDYZNZQIWUB\nPNDOLZNDMQPI\nTDDTNWMUPZTDO\nTTQNJGZTLFNN\nVLFQFZMEZPQWFV\n\"\"\", hint=\"cryptogram\")\n\n\n################\n# LQZRDYZNZQIWUB\n# KLATIFAHALBUMS = K / L\n################\n# PNDOLZNDMQPI\n# THELOFHEARTS = L / O\n################\n# TDDTNWMUPZTDO\n# ELLERYCNOVELS = C / M\n################\n# TTQNJGZTLFNN\n# EELIZABETHII = E / T\n################\n# VLFQFZMEZPQWFV\n# STEVEMCRMOVIES = R / E\n################\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd35ca3d7b948b135edbd01595c4a59d03f801b
| 2,042 |
ipynb
|
Jupyter Notebook
|
tour4_plastic_bond/bs_ep_ikh.ipynb
|
bmcs-group/bmcs_tutorial
|
4e008e72839fad8820a6b663a20d3f188610525d
|
[
"MIT"
] | null | null | null |
tour4_plastic_bond/bs_ep_ikh.ipynb
|
bmcs-group/bmcs_tutorial
|
4e008e72839fad8820a6b663a20d3f188610525d
|
[
"MIT"
] | null | null | null |
tour4_plastic_bond/bs_ep_ikh.ipynb
|
bmcs-group/bmcs_tutorial
|
4e008e72839fad8820a6b663a20d3f188610525d
|
[
"MIT"
] | null | null | null | 18.396396 | 120 | 0.507835 |
[
[
[
"%matplotlib widget\nfrom plastic_app.bs_model_explorer import BSModelExplorer",
"_____no_output_____"
],
[
"bs = BSModelExplorer(delta_s=2)\nbs.bs_model.trait_set(K=3, gamma=0)\nbs.n_steps=100",
"_____no_output_____"
],
[
"bs.interact()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
cbd35d4b271eba5172e7d061ef65a09c9d87a4e9
| 15,612 |
ipynb
|
Jupyter Notebook
|
examples/notebooks/contrasts.ipynb
|
bksahu/statsmodels
|
143410a8b3f7fc55536a10efd4015273b54335de
|
[
"BSD-3-Clause"
] | 20 |
2015-01-28T21:52:59.000Z
|
2022-01-24T01:24:26.000Z
|
examples/notebooks/contrasts.ipynb
|
bksahu/statsmodels
|
143410a8b3f7fc55536a10efd4015273b54335de
|
[
"BSD-3-Clause"
] | 7 |
2015-11-20T08:33:04.000Z
|
2020-07-24T19:34:39.000Z
|
examples/notebooks/contrasts.ipynb
|
bksahu/statsmodels
|
143410a8b3f7fc55536a10efd4015273b54335de
|
[
"BSD-3-Clause"
] | 28 |
2015-04-01T20:02:25.000Z
|
2021-07-03T00:09:28.000Z
| 28.541133 | 743 | 0.601012 |
[
[
[
"# Contrasts Overview",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function\nimport numpy as np\nimport statsmodels.api as sm",
"_____no_output_____"
]
],
[
[
"This document is based heavily on this excellent resource from UCLA http://www.ats.ucla.edu/stat/r/library/contrast_coding.htm",
"_____no_output_____"
],
[
"A categorical variable of K categories, or levels, usually enters a regression as a sequence of K-1 dummy variables. This amounts to a linear hypothesis on the level means. That is, each test statistic for these variables amounts to testing whether the mean for that level is statistically significantly different from the mean of the base category. This dummy coding is called Treatment coding in R parlance, and we will follow this convention. There are, however, different coding methods that amount to different sets of linear hypotheses.\n\nIn fact, the dummy coding is not technically a contrast coding. This is because the dummy variables add to one and are not functionally independent of the model's intercept. On the other hand, a set of *contrasts* for a categorical variable with `k` levels is a set of `k-1` functionally independent linear combinations of the factor level means that are also independent of the sum of the dummy variables. The dummy coding isn't wrong *per se*. It captures all of the coefficients, but it complicates matters when the model assumes independence of the coefficients such as in ANOVA. Linear regression models do not assume independence of the coefficients and thus dummy coding is often the only coding that is taught in this context.\n\nTo have a look at the contrast matrices in Patsy, we will use data from UCLA ATS. First let's load the data.",
"_____no_output_____"
],
[
"#### Example Data",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nurl = 'https://stats.idre.ucla.edu/stat/data/hsb2.csv'\nhsb2 = pd.read_table(url, delimiter=\",\")",
"_____no_output_____"
],
[
"hsb2.head(10)",
"_____no_output_____"
]
],
[
[
"It will be instructive to look at the mean of the dependent variable, write, for each level of race ((1 = Hispanic, 2 = Asian, 3 = African American and 4 = Caucasian)).",
"_____no_output_____"
]
],
[
[
"hsb2.groupby('race')['write'].mean()",
"_____no_output_____"
]
],
[
[
"#### Treatment (Dummy) Coding",
"_____no_output_____"
],
[
"Dummy coding is likely the most well known coding scheme. It compares each level of the categorical variable to a base reference level. The base reference level is the value of the intercept. It is the default contrast in Patsy for unordered categorical factors. The Treatment contrast matrix for race would be",
"_____no_output_____"
]
],
[
[
"from patsy.contrasts import Treatment\nlevels = [1,2,3,4]\ncontrast = Treatment(reference=0).code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
]
],
[
[
"Here we used `reference=0`, which implies that the first level, Hispanic, is the reference category against which the other level effects are measured. As mentioned above, the columns do not sum to zero and are thus not independent of the intercept. To be explicit, let's look at how this would encode the `race` variable.",
"_____no_output_____"
]
],
[
[
"hsb2.race.head(10)",
"_____no_output_____"
],
[
"print(contrast.matrix[hsb2.race-1, :][:20])",
"_____no_output_____"
],
[
"sm.categorical(hsb2.race.values)",
"_____no_output_____"
]
],
[
[
"This is a bit of a trick, as the `race` category conveniently maps to zero-based indices. If it does not, this conversion happens under the hood, so this won't work in general but nonetheless is a useful exercise to fix ideas. The below illustrates the output using the three contrasts above",
"_____no_output_____"
]
],
[
[
"from statsmodels.formula.api import ols\nmod = ols(\"write ~ C(race, Treatment)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"We explicitly gave the contrast for race; however, since Treatment is the default, we could have omitted this.",
"_____no_output_____"
],
[
"### Simple Coding",
"_____no_output_____"
],
[
"Like Treatment Coding, Simple Coding compares each level to a fixed reference level. However, with simple coding, the intercept is the grand mean of all the levels of the factors. Patsy doesn't have the Simple contrast included, but you can easily define your own contrasts. To do so, write a class that contains a code_with_intercept and a code_without_intercept method that returns a patsy.contrast.ContrastMatrix instance",
"_____no_output_____"
]
],
[
[
"from patsy.contrasts import ContrastMatrix\n\ndef _name_levels(prefix, levels):\n return [\"[%s%s]\" % (prefix, level) for level in levels]\n\nclass Simple(object):\n def _simple_contrast(self, levels):\n nlevels = len(levels)\n contr = -1./nlevels * np.ones((nlevels, nlevels-1))\n contr[1:][np.diag_indices(nlevels-1)] = (nlevels-1.)/nlevels\n return contr\n\n def code_with_intercept(self, levels):\n contrast = np.column_stack((np.ones(len(levels)),\n self._simple_contrast(levels)))\n return ContrastMatrix(contrast, _name_levels(\"Simp.\", levels))\n\n def code_without_intercept(self, levels):\n contrast = self._simple_contrast(levels)\n return ContrastMatrix(contrast, _name_levels(\"Simp.\", levels[:-1]))",
"_____no_output_____"
],
[
"hsb2.groupby('race')['write'].mean().mean()",
"_____no_output_____"
],
[
"contrast = Simple().code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
],
[
"mod = ols(\"write ~ C(race, Simple)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"### Sum (Deviation) Coding",
"_____no_output_____"
],
[
"Sum coding compares the mean of the dependent variable for a given level to the overall mean of the dependent variable over all the levels. That is, it uses contrasts between each of the first k-1 levels and level k In this example, level 1 is compared to all the others, level 2 to all the others, and level 3 to all the others.",
"_____no_output_____"
]
],
[
[
"from patsy.contrasts import Sum\ncontrast = Sum().code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
],
[
"mod = ols(\"write ~ C(race, Sum)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"This corresponds to a parameterization that forces all the coefficients to sum to zero. Notice that the intercept here is the grand mean where the grand mean is the mean of means of the dependent variable by each level.",
"_____no_output_____"
]
],
[
[
"hsb2.groupby('race')['write'].mean().mean()",
"_____no_output_____"
]
],
[
[
"### Backward Difference Coding",
"_____no_output_____"
],
[
"In backward difference coding, the mean of the dependent variable for a level is compared with the mean of the dependent variable for the prior level. This type of coding may be useful for a nominal or an ordinal variable.",
"_____no_output_____"
]
],
[
[
"from patsy.contrasts import Diff\ncontrast = Diff().code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
],
[
"mod = ols(\"write ~ C(race, Diff)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"For example, here the coefficient on level 1 is the mean of `write` at level 2 compared with the mean at level 1. Ie.,",
"_____no_output_____"
]
],
[
[
"res.params[\"C(race, Diff)[D.1]\"]\nhsb2.groupby('race').mean()[\"write\"][2] - \\\n hsb2.groupby('race').mean()[\"write\"][1]",
"_____no_output_____"
]
],
[
[
"### Helmert Coding",
"_____no_output_____"
],
[
"Our version of Helmert coding is sometimes referred to as Reverse Helmert Coding. The mean of the dependent variable for a level is compared to the mean of the dependent variable over all previous levels. Hence, the name 'reverse' being sometimes applied to differentiate from forward Helmert coding. This comparison does not make much sense for a nominal variable such as race, but we would use the Helmert contrast like so:",
"_____no_output_____"
]
],
[
[
"from patsy.contrasts import Helmert\ncontrast = Helmert().code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
],
[
"mod = ols(\"write ~ C(race, Helmert)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"To illustrate, the comparison on level 4 is the mean of the dependent variable at the previous three levels taken from the mean at level 4",
"_____no_output_____"
]
],
[
[
"grouped = hsb2.groupby('race')\ngrouped.mean()[\"write\"][4] - grouped.mean()[\"write\"][:3].mean()",
"_____no_output_____"
]
],
[
[
"As you can see, these are only equal up to a constant. Other versions of the Helmert contrast give the actual difference in means. Regardless, the hypothesis tests are the same.",
"_____no_output_____"
]
],
[
[
"k = 4\n1./k * (grouped.mean()[\"write\"][k] - grouped.mean()[\"write\"][:k-1].mean())\nk = 3\n1./k * (grouped.mean()[\"write\"][k] - grouped.mean()[\"write\"][:k-1].mean())",
"_____no_output_____"
]
],
[
[
"### Orthogonal Polynomial Coding",
"_____no_output_____"
],
[
"The coefficients taken on by polynomial coding for `k=4` levels are the linear, quadratic, and cubic trends in the categorical variable. The categorical variable here is assumed to be represented by an underlying, equally spaced numeric variable. Therefore, this type of encoding is used only for ordered categorical variables with equal spacing. In general, the polynomial contrast produces polynomials of order `k-1`. Since `race` is not an ordered factor variable let's use `read` as an example. First we need to create an ordered categorical from `read`.",
"_____no_output_____"
]
],
[
[
"hsb2['readcat'] = np.asarray(pd.cut(hsb2.read, bins=3))\nhsb2.groupby('readcat').mean()['write']",
"_____no_output_____"
],
[
"from patsy.contrasts import Poly\nlevels = hsb2.readcat.unique().tolist()\ncontrast = Poly().code_without_intercept(levels)\nprint(contrast.matrix)",
"_____no_output_____"
],
[
"mod = ols(\"write ~ C(readcat, Poly)\", data=hsb2)\nres = mod.fit()\nprint(res.summary())",
"_____no_output_____"
]
],
[
[
"As you can see, readcat has a significant linear effect on the dependent variable `write` but not a significant quadratic or cubic effect.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
cbd360d6438b56c5db6d23378b309fcdaa90dada
| 5,764 |
ipynb
|
Jupyter Notebook
|
examples/notebook/vendor_scheduling_sat.ipynb
|
arlm/or-tools
|
f3fd201e68cf75b7720ff5c3cadc599a1d02b54b
|
[
"Apache-2.0"
] | 2 |
2018-11-03T15:58:09.000Z
|
2019-11-24T17:15:48.000Z
|
examples/notebook/vendor_scheduling_sat.ipynb
|
arlm/or-tools
|
f3fd201e68cf75b7720ff5c3cadc599a1d02b54b
|
[
"Apache-2.0"
] | null | null | null |
examples/notebook/vendor_scheduling_sat.ipynb
|
arlm/or-tools
|
f3fd201e68cf75b7720ff5c3cadc599a1d02b54b
|
[
"Apache-2.0"
] | 2 |
2020-02-26T18:11:33.000Z
|
2020-12-02T07:44:34.000Z
| 37.921053 | 89 | 0.541985 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
cbd36994e18ca8046d689664ba0106437c74ca33
| 28,778 |
ipynb
|
Jupyter Notebook
|
notebooks/12_gym_tuto.ipynb
|
dbarbier/scikit-decide
|
6f43cde8f76a79ed71371da73e20b1293255442e
|
[
"MIT"
] | 27 |
2020-11-23T11:45:31.000Z
|
2022-03-22T08:08:00.000Z
|
notebooks/12_gym_tuto.ipynb
|
dbarbier/scikit-decide
|
6f43cde8f76a79ed71371da73e20b1293255442e
|
[
"MIT"
] | 94 |
2021-02-24T09:50:23.000Z
|
2022-02-27T10:07:15.000Z
|
notebooks/12_gym_tuto.ipynb
|
dbarbier/scikit-decide
|
6f43cde8f76a79ed71371da73e20b1293255442e
|
[
"MIT"
] | 12 |
2020-12-08T10:38:26.000Z
|
2021-10-01T09:17:04.000Z
| 31.904656 | 609 | 0.580826 |
[
[
[
"# Gym environment with scikit-decide tutorial: Continuous Mountain Car\n\nIn this notebook we tackle the continuous mountain car problem taken from [OpenAI Gym](https://gym.openai.com/), a toolkit for developing environments, usually to be solved by Reinforcement Learning (RL) algorithms.\n\nContinuous Mountain Car, a standard testing domain in RL, is a problem in which an under-powered car must drive up a steep hill. \n\n<div align=\"middle\">\n <video controls autoplay preload \n src=\"https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/MountainCarContinuous-v0/original.mp4\">\n </video>\n</div>\n\nNote that we use here the *continuous* version of the mountain car because \nit has a *shaped* or *dense* reward (i.e. not sparse) which can be used successfully when solving, as opposed to the other \"Mountain Car\" environments. \nFor reminder, a sparse reward is a reward which is null almost everywhere, whereas a dense or shaped reward has more meaningful values for most transitions.\n\nThis problem has been chosen for two reasons:\n - Show how scikit-decide can be used to solve Gym environments (the de-facto standard in the RL community),\n - Highlight that by doing so, you will be able to use not only solvers from the RL community (like the ones in [stable_baselines3](https://github.com/DLR-RM/stable-baselines3) for example), but also other solvers coming from other communities like genetic programming and planning/search (use of an underlying search graph) that can be very efficient.\n\nTherefore in this notebook we will go through the following steps:\n - Wrap a Gym environment in a scikit-decide domain;\n - Use a classical RL algorithm like PPO to solve our problem;\n - Give CGP (Cartesian Genetic Programming) a try on the same problem;\n - Finally use IW (Iterated Width) coming from the planning community on the same problem.",
"_____no_output_____"
]
],
[
[
"import os\nfrom time import sleep\nfrom typing import Callable, Optional\n\nimport gym\nimport matplotlib.pyplot as plt\nfrom IPython.display import clear_output\nfrom stable_baselines3 import PPO\n\nfrom skdecide import Solver\nfrom skdecide.hub.domain.gym import (\n GymDiscreteActionDomain,\n GymDomain,\n GymPlanningDomain,\n GymWidthDomain,\n)\nfrom skdecide.hub.solver.cgp import CGP\nfrom skdecide.hub.solver.iw import IW\nfrom skdecide.hub.solver.stable_baselines import StableBaseline\n\n# choose standard matplolib inline backend to render plots\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"When running this notebook on remote servers like with Colab or Binder, rendering of gym environment will fail as no actual display device exists. Thus we need to start a virtual display to make it work.",
"_____no_output_____"
]
],
[
[
"if \"DISPLAY\" not in os.environ:\n import pyvirtualdisplay\n\n _display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))\n _display.start()",
"_____no_output_____"
]
],
[
[
"## About Continuous Mountain Car problem",
"_____no_output_____"
],
[
"In this a problem, an under-powered car must drive up a steep hill. \nThe agent (a car) is started at the bottom of a valley. For any given\nstate the agent may choose to accelerate to the left, right or cease\nany acceleration.\n\n### Observations\n\n- Car Position [-1.2, 0.6]\n- Car Velocity [-0.07, +0.07]\n\n### Action\n- the power coefficient [-1.0, 1.0]\n\n\n### Goal\nThe car position is more than 0.45.\n\n### Reward\n\nReward of 100 is awarded if the agent reached the flag (position = 0.45) on top of the mountain.\nReward is decrease based on amount of energy consumed each step.\n\n### Starting State\nThe position of the car is assigned a uniform random value in [-0.6 , -0.4].\nThe starting velocity of the car is always assigned to 0.\n\n ",
"_____no_output_____"
],
[
"## Wrap Gym environment in a scikit-decide domain",
"_____no_output_____"
],
[
"We choose the gym environment we would like to use.",
"_____no_output_____"
]
],
[
[
"ENV_NAME = \"MountainCarContinuous-v0\"",
"_____no_output_____"
]
],
[
[
"We define a domain factory using `GymDomain` proxy available in scikit-decide which will wrap the Gym environment.",
"_____no_output_____"
]
],
[
[
"domain_factory = lambda: GymDomain(gym.make(ENV_NAME))",
"_____no_output_____"
]
],
[
[
"Here is a screenshot of such an environment. \n\nNote: We close the domain straight away to avoid leaving the OpenGL pop-up window open on local Jupyter sessions.",
"_____no_output_____"
]
],
[
[
"domain = domain_factory()\ndomain.reset()\nplt.imshow(domain.render(mode=\"rgb_array\"))\nplt.axis(\"off\")\ndomain.close()",
"_____no_output_____"
]
],
[
[
"## Solve with Reinforcement Learning (StableBaseline + PPO)\n\nWe first try a solver coming from the Reinforcement Learning community that is make use of OpenAI [stable_baselines3](https://github.com/DLR-RM/stable-baselines3), which give access to a lot of RL algorithms.\n\nHere we choose [Proximal Policy Optimization (PPO)](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html) solver. It directly optimizes the weights of the policy network using stochastic gradient ascent. See more details in stable baselines [documentation](https://stable-baselines3.readthedocs.io/en/master/modules/ppo.html) and [original paper](https://arxiv.org/abs/1707.06347). ",
"_____no_output_____"
],
[
"### Check compatibility\nWe check the compatibility of the domain with the chosen solver.",
"_____no_output_____"
]
],
[
[
"domain = domain_factory()\nassert StableBaseline.check_domain(domain)\ndomain.close()",
"_____no_output_____"
]
],
[
[
"### Solver instantiation",
"_____no_output_____"
]
],
[
[
"solver = StableBaseline(\n PPO, \"MlpPolicy\", learn_config={\"total_timesteps\": 10000}, verbose=True\n)",
"_____no_output_____"
]
],
[
[
"### Training solver on domain",
"_____no_output_____"
]
],
[
[
"GymDomain.solve_with(solver, domain_factory)",
"_____no_output_____"
]
],
[
[
"### Rolling out a solution\n\nWe can use the trained solver to roll out an episode to see if this is actually solving the problem at hand.\n\nFor educative purpose, we define here our own rollout (which will probably be needed if you want to actually use the solver in a real case). If you want to take a look at the (more complex) one already implemented in the library, see the `rollout()` function in [utils.py](https://github.com/airbus/scikit-decide/blob/master/skdecide/utils.py) module.\n\nBy default we display the solution in a matplotlib figure. If you need only to check wether the goal is reached or not, you can specify `render=False`. In this case, the rollout is greatly speed up and a message is still printed at the end of process specifying success or not, with the number of steps required.",
"_____no_output_____"
]
],
[
[
"def rollout(\n domain: GymDomain,\n solver: Solver,\n max_steps: int,\n pause_between_steps: Optional[float] = 0.01,\n render: bool = True,\n):\n \"\"\"Roll out one episode in a domain according to the policy of a trained solver.\n\n Args:\n domain: the maze domain to solve\n solver: a trained solver\n max_steps: maximum number of steps allowed to reach the goal\n pause_between_steps: time (s) paused between agent movements.\n No pause if None.\n render: if True, the rollout is rendered in a matplotlib figure as an animation;\n if False, speed up a lot the rollout.\n\n \"\"\"\n # Initialize episode\n solver.reset()\n observation = domain.reset()\n\n # Initialize image\n if render:\n plt.ioff()\n fig, ax = plt.subplots(1)\n ax.axis(\"off\")\n plt.ion()\n img = ax.imshow(domain.render(mode=\"rgb_array\"))\n display(fig)\n\n # loop until max_steps or goal is reached\n for i_step in range(1, max_steps + 1):\n if pause_between_steps is not None:\n sleep(pause_between_steps)\n\n # choose action according to solver\n action = solver.sample_action(observation)\n # get corresponding action\n outcome = domain.step(action)\n observation = outcome.observation\n\n # update image\n if render:\n img.set_data(domain.render(mode=\"rgb_array\"))\n fig.canvas.draw()\n clear_output(wait=True)\n display(fig)\n\n # final state reached?\n if outcome.termination:\n break\n\n # close the figure to avoid jupyter duplicating the last image\n if render:\n plt.close(fig)\n\n # goal reached?\n is_goal_reached = observation[0] >= 0.45\n if is_goal_reached:\n print(f\"Goal reached in {i_step} steps!\")\n else:\n print(f\"Goal not reached after {i_step} steps!\")\n\n return is_goal_reached, i_step",
"_____no_output_____"
]
],
[
[
"We create a domain for the roll out and close it at the end. If not closing it, an OpenGL popup windows stays open, at least on local Jupyter sessions.",
"_____no_output_____"
]
],
[
[
"domain = domain_factory()\ntry:\n rollout(\n domain=domain,\n solver=solver,\n max_steps=999,\n pause_between_steps=None,\n render=True,\n )\nfinally:\n domain.close()",
"_____no_output_____"
]
],
[
[
"We can see that PPO does not find a solution to the problem. This is mainly due to the way the reward is computed. Indeed negative reward accumulates as long as the goal is not reached, which encourages the agent to stop moving.\nEven if we increase the training time, it still occurs. (You can test that by increasing the parameter \"total_timesteps\" in the solver definition.)\n\nActually, typical RL algorithms like PPO are a good fit for domains with \"well-shaped\" rewards (guiding towards the goal), but can struggle in sparse or \"badly-shaped\" reward environment like Mountain Car Continuous. \n\nWe will see in the next sections that non-RL methods can overcome this issue.",
"_____no_output_____"
],
[
"### Cleaning up",
"_____no_output_____"
],
[
"Some solvers need proper cleaning before being deleted.",
"_____no_output_____"
]
],
[
[
"solver._cleanup()",
"_____no_output_____"
]
],
[
[
"Note that this is automatically done if you use the solver within a `with` statement. The syntax would look something like:\n\n```python\nwith solver_factory() as solver:\n MyDomain.solve_with(solver, domain_factory)\n rollout(domain=domain, solver=solver)\n```",
"_____no_output_____"
],
[
"## Solve with Cartesian Genetic Programming (CGP)\n\nCGP (Cartesian Genetic Programming) is a form of genetic programming that uses a graph representation (2D grid of nodes) to encode computer programs.\nSee [Miller, Julian. (2003). Cartesian Genetic Programming. 10.1007/978-3-642-17310-3.](https://www.researchgate.net/publication/2859242_Cartesian_Genetic_Programming) for more details.\n\nPros:\n+ ability to customize the set of atomic functions used by CPG (e.g. to inject some domain knowledge)\n+ ability to inspect the final formula found by CGP (no black box)\n\nCons:\n- the fitness function of CGP is defined by the rewards, so can be unable to solve in sparse reward scenarios",
"_____no_output_____"
],
[
"### Check compatibility\nWe check the compatibility of the domain with the chosen solver.",
"_____no_output_____"
]
],
[
[
"domain = domain_factory()\nassert CGP.check_domain(domain)\ndomain.close()",
"_____no_output_____"
]
],
[
[
"### Solver instantiation",
"_____no_output_____"
]
],
[
[
"solver = CGP(\"TEMP_CGP\", n_it=25, verbose=True)",
"_____no_output_____"
]
],
[
[
"### Training solver on domain",
"_____no_output_____"
]
],
[
[
"GymDomain.solve_with(solver, domain_factory)",
"_____no_output_____"
]
],
[
[
"### Rolling out a solution",
"_____no_output_____"
],
[
"We use the same roll out function as for PPO solver.",
"_____no_output_____"
]
],
[
[
"domain = domain_factory()\ntry:\n rollout(\n domain=domain,\n solver=solver,\n max_steps=999,\n pause_between_steps=None,\n render=True,\n )\nfinally:\n domain.close()",
"_____no_output_____"
]
],
[
[
"CGP seems doing well on this problem. Indeed the presence of periodic functions ($asin$, $acos$, and $atan$) in its base set of atomic functions makes it suitable for modelling this kind of pendular motion.",
"_____no_output_____"
],
[
"***Warning***: On some cases, it happens that CGP does not actually find a solution. As there is randomness here, this is not possible. Running multiple episodes can sometimes solve the problem. If you have bad luck, you will even have to train again the solver.",
"_____no_output_____"
]
],
[
[
"for i_episode in range(10):\n print(f\"Episode #{i_episode}\")\n domain = domain_factory()\n try:\n rollout(\n domain=domain,\n solver=solver,\n max_steps=999,\n pause_between_steps=None,\n render=False,\n )\n finally:\n domain.close()",
"_____no_output_____"
]
],
[
[
"### Cleaning up",
"_____no_output_____"
]
],
[
[
"solver._cleanup()",
"_____no_output_____"
]
],
[
[
"## Solve with Classical Planning (IW)\n\nIterated Width (IW) is a width based search algorithm that builds a graph on-demand, while pruning non-novel nodes. \n\nIn order to handle continuous domains, a state encoding specific to continuous state variables dynamically and adaptively discretizes the continuous state variables in such a way to build a compact graph based on intervals (rather than a naive grid of discrete point values). \n\nThe novelty measures discards intervals that are included in previously explored intervals, thus favoring to extend the state variable intervals. \n\nSee https://www.ijcai.org/proceedings/2020/578 for more details.",
"_____no_output_____"
],
[
"### Prepare the domain for IW\n\nWe need to wrap the Gym environment in a domain with finer charateristics so that IW can be used on it. More precisely, it needs the methods inherited from `GymPlanningDomain`, `GymDiscreteActionDomain` and `GymWidthDomain`. In addition, we will need to provide to IW a state features function to dynamically increase state variable intervals. For Gym domains, we use Boundary Extension Encoding (BEE) features as explained in the [paper](https://www.ijcai.org/proceedings/2020/578) mentioned above. This is implemented as `bee2_features()` method in `GymWidthDomain` that our domain class will inherit.",
"_____no_output_____"
]
],
[
[
"class D(GymPlanningDomain, GymWidthDomain, GymDiscreteActionDomain):\n pass\n\n\nclass GymDomainForWidthSolvers(D):\n def __init__(\n self,\n gym_env: gym.Env,\n set_state: Callable[[gym.Env, D.T_memory[D.T_state]], None] = None,\n get_state: Callable[[gym.Env], D.T_memory[D.T_state]] = None,\n termination_is_goal: bool = True,\n continuous_feature_fidelity: int = 5,\n discretization_factor: int = 3,\n branching_factor: int = None,\n max_depth: int = 1000,\n ) -> None:\n GymPlanningDomain.__init__(\n self,\n gym_env=gym_env,\n set_state=set_state,\n get_state=get_state,\n termination_is_goal=termination_is_goal,\n max_depth=max_depth,\n )\n GymDiscreteActionDomain.__init__(\n self,\n discretization_factor=discretization_factor,\n branching_factor=branching_factor,\n )\n GymWidthDomain.__init__(\n self, continuous_feature_fidelity=continuous_feature_fidelity\n )\n gym_env._max_episode_steps = max_depth",
"_____no_output_____"
]
],
[
[
"We redefine accordingly the domain factory.",
"_____no_output_____"
]
],
[
[
"domain4width_factory = lambda: GymDomainForWidthSolvers(gym.make(ENV_NAME))",
"_____no_output_____"
]
],
[
[
"### Check compatibility\nWe check the compatibility of the domain with the chosen solver.",
"_____no_output_____"
]
],
[
[
"domain = domain4width_factory()\nassert IW.check_domain(domain)\ndomain.close()",
"_____no_output_____"
]
],
[
[
"### Solver instantiation",
"_____no_output_____"
],
[
"As explained earlier, we use the Boundary Extension Encoding state features `bee2_features` so that IW can dynamically increase state variable intervals. In other domains, other state features might be more suitable.",
"_____no_output_____"
]
],
[
[
"solver = IW(\n state_features=lambda d, s: d.bee2_features(s),\n node_ordering=lambda a_gscore, a_novelty, a_depth, b_gscore, b_novelty, b_depth: a_novelty\n > b_novelty,\n parallel=False,\n debug_logs=False,\n domain_factory=domain4width_factory,\n)",
"_____no_output_____"
]
],
[
[
"### Training solver on domain",
"_____no_output_____"
]
],
[
[
"GymDomainForWidthSolvers.solve_with(solver, domain4width_factory)",
"_____no_output_____"
]
],
[
[
"### Rolling out a solution\n\n**Disclaimer:** This roll out can be a bit painful to look on local Jupyter sessions. Indeed, IW creates copies of the environment at each step which makes pop up then close a new OpenGL window each time.",
"_____no_output_____"
],
[
"We have to slightly modify the roll out function as observations for the new domain are now wrapped in a `GymDomainProxyState` to make them serializable. So to get access to the underlying numpy array, we need to look for `observation._state`.",
"_____no_output_____"
]
],
[
[
"def rollout_iw(\n domain: GymDomain,\n solver: Solver,\n max_steps: int,\n pause_between_steps: Optional[float] = 0.01,\n render: bool = False,\n):\n \"\"\"Roll out one episode in a domain according to the policy of a trained solver.\n\n Args:\n domain: the maze domain to solve\n solver: a trained solver\n max_steps: maximum number of steps allowed to reach the goal\n pause_between_steps: time (s) paused between agent movements.\n No pause if None.\n render: if True, the rollout is rendered in a matplotlib figure as an animation;\n if False, speed up a lot the rollout.\n\n \"\"\"\n # Initialize episode\n solver.reset()\n observation = domain.reset()\n\n # Initialize image\n if render:\n plt.ioff()\n fig, ax = plt.subplots(1)\n ax.axis(\"off\")\n plt.ion()\n img = ax.imshow(domain.render(mode=\"rgb_array\"))\n display(fig)\n\n # loop until max_steps or goal is reached\n for i_step in range(1, max_steps + 1):\n if pause_between_steps is not None:\n sleep(pause_between_steps)\n\n # choose action according to solver\n action = solver.sample_action(observation)\n # get corresponding action\n outcome = domain.step(action)\n observation = outcome.observation\n\n # update image\n if render:\n img.set_data(domain.render(mode=\"rgb_array\"))\n fig.canvas.draw()\n clear_output(wait=True)\n display(fig)\n\n # final state reached?\n if outcome.termination:\n break\n\n # close the figure to avoid jupyter duplicating the last image\n if render:\n plt.close(fig)\n\n # goal reached?\n is_goal_reached = observation._state[0] >= 0.45\n if is_goal_reached:\n print(f\"Goal reached in {i_step} steps!\")\n else:\n print(f\"Goal not reached after {i_step} steps!\")\n\n return is_goal_reached, i_step",
"_____no_output_____"
],
[
"domain = domain4width_factory()\ntry:\n rollout_iw(\n domain=domain,\n solver=solver,\n max_steps=999,\n pause_between_steps=None,\n render=True,\n )\nfinally:\n domain.close()",
"_____no_output_____"
]
],
[
[
"IW works especially well in mountain car. \n\nIndeed we need to increase the cinetic+potential energy to reach the goal, which comes to increase as much as possible the values of the state variables (position and velocity). This is exactly what IW is designed to do (trying to explore novel states, which means here with higher position or velocity). \n\nAs a consequence, IW can find an optimal strategy in a few seconds (whereas in most cases PPO and CGP can't find optimal strategies in the same computation time).",
"_____no_output_____"
],
[
"### Cleaning up",
"_____no_output_____"
]
],
[
[
"solver._cleanup()",
"_____no_output_____"
]
],
[
[
"## Conclusion",
"_____no_output_____"
],
[
"We saw that it is possible thanks to scikit-decide to apply solvers from different fields and communities (Reinforcement Learning, Genetic Programming, and Planning) on a OpenAI Gym Environment.\n\nEven though the domain used here is more classical for RL community, the solvers from other communities performed far better. In particular the IW algorithm was able to find an efficient solution in a very short time.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cbd37585891b05d635db95d39d37a9bb4eb3a8da
| 20,527 |
ipynb
|
Jupyter Notebook
|
docs/notebooks/Ubelt Demo.ipynb
|
SamuelLabrador/ubelt
|
fea384df978b558b5c2f3a48a597a0a345bdb814
|
[
"Apache-2.0"
] | null | null | null |
docs/notebooks/Ubelt Demo.ipynb
|
SamuelLabrador/ubelt
|
fea384df978b558b5c2f3a48a597a0a345bdb814
|
[
"Apache-2.0"
] | null | null | null |
docs/notebooks/Ubelt Demo.ipynb
|
SamuelLabrador/ubelt
|
fea384df978b558b5c2f3a48a597a0a345bdb814
|
[
"Apache-2.0"
] | null | null | null | 25.404703 | 147 | 0.511716 |
[
[
[
"Timing\n------\n\nQuickly time a single line.",
"_____no_output_____"
]
],
[
[
"import math\nimport ubelt as ub\ntimer = ub.Timer('Timer demo!', verbose=1)\nwith timer:\n math.factorial(100000)",
"\ntic('Timer demo!')\n...toc('Timer demo!')=0.1446s\n"
]
],
[
[
"Robust Timing and Benchmarking\n------------------------------\n\nEasily do robust timings on existing blocks of code by simply indenting\nthem. The quick and dirty way just requires one indent.",
"_____no_output_____"
]
],
[
[
"import math\nimport ubelt as ub\nfor _ in ub.Timerit(num=200, verbose=3):\n math.factorial(10000)",
"Timing for: 200 loops, best of 3\nTimed for: 200 loops, best of 3\n body took: 473.4 ms\n time per loop: best=1.938 ms, mean=2.208 ± 0.43 ms\n"
]
],
[
[
"Loop Progress\n-------------\n\n``ProgIter`` is a (mostly) drop-in alternative to\n```tqdm`` <https://pypi.python.org/pypi/tqdm>`__. \n*The advantage of ``ProgIter`` is that it does not use any python threading*,\nand therefore can be safer with code that makes heavy use of multiprocessing.\n\nNote: ProgIter is now a standalone module: ``pip intstall progiter``)",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\nimport math\nfor n in ub.ProgIter(range(7500)):\n math.factorial(n)",
" 7500/7500... rate=2151.77 Hz, eta=0:00:00, total=0:00:03, wall=22:29 ESTTT\n"
],
[
"import ubelt as ub\nimport math\nfor n in ub.ProgIter(range(7500), freq=2, adjust=False):\n math.factorial(n)\n \n# Note that forcing freq=2 all the time comes at a performance cost\n# The default adjustment algorithm causes almost no overhead",
" 7500/7500... rate=560.16 Hz, eta=0:00:00, total=0:00:06, wall=22:29 ESTTST\n"
],
[
">>> import ubelt as ub\n>>> def is_prime(n):\n... return n >= 2 and not any(n % i == 0 for i in range(2, n))\n>>> for n in ub.ProgIter(range(1000), verbose=2):\n>>> # do some work\n>>> is_prime(n)",
" 0/1000... rate=0 Hz, eta=?, total=0:00:00, wall=22:29 EST\n 1/1000... rate=109950.53 Hz, eta=0:00:00, total=0:00:00, wall=22:29 EST\n 257/1000... rate=209392.86 Hz, eta=0:00:00, total=0:00:00, wall=22:29 EST\n 642/1000... rate=142079.56 Hz, eta=0:00:00, total=0:00:00, wall=22:29 EST\n 1000/1000... rate=105135.94 Hz, eta=0:00:00, total=0:00:00, wall=22:29 EST\n"
]
],
[
[
"Caching\n-------\n\nCache intermediate results in a script with minimal boilerplate.",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\ncfgstr = 'repr-of-params-that-uniquely-determine-the-process'\ncacher = ub.Cacher('test_process', cfgstr)\ndata = cacher.tryload()\nif data is None:\n myvar1 = 'result of expensive process'\n myvar2 = 'another result'\n data = myvar1, myvar2\n cacher.save(data)\nmyvar1, myvar2 = data",
"_____no_output_____"
]
],
[
[
"Hashing\n-------\n\nThe ``ub.hash_data`` constructs a hash corresponding to a (mostly)\narbitrary ordered python object. A common use case for this function is\nto construct the ``cfgstr`` mentioned in the example for ``ub.Cacher``.\nInstead of returning a hex, string, ``ub.hash_data`` encodes the hash\ndigest using the 26 lowercase letters in the roman alphabet. This makes\nthe result easy to use as a filename suffix.",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\ndata = [('arg1', 5), ('lr', .01), ('augmenters', ['flip', 'translate'])]\nub.hash_data(data)",
"_____no_output_____"
],
[
"import ubelt as ub\ndata = [('arg1', 5), ('lr', .01), ('augmenters', ['flip', 'translate'])]\nub.hash_data(data, hasher='sha512', base='abc')",
"_____no_output_____"
]
],
[
[
"Command Line Interaction\n------------------------\n\nThe builtin Python ``subprocess.Popen`` module is great, but it can be a\nbit clunky at times. The ``os.system`` command is easy to use, but it\ndoesn't have much flexibility. The ``ub.cmd`` function aims to fix this.\nIt is as simple to run as ``os.system``, but it returns a dictionary\ncontaining the return code, standard out, standard error, and the\n``Popen`` object used under the hood.",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\ninfo = ub.cmd('cmake --version')\n# Quickly inspect and parse output of a \nprint(info['out'])",
"cmake version 3.11.0-rc2\n\nCMake suite maintained and supported by Kitware (kitware.com/cmake).\n\n"
],
[
"# The info dict contains other useful data\nprint(ub.repr2({k: v for k, v in info.items() if 'out' != k}))",
"{\n 'command': 'cmake --version',\n 'err': '',\n 'proc': <subprocess.Popen object at 0x7f1b36af80f0>,\n 'ret': 0,\n}\n"
],
[
"# Also possible to simultaniously capture and display output in realtime\ninfo = ub.cmd('cmake --version', tee=1)",
"cmake version 3.11.0-rc2\n\nCMake suite maintained and supported by Kitware (kitware.com/cmake).\n"
],
[
"# tee=True is equivalent to using verbose=1, but there is also verbose=2\ninfo = ub.cmd('cmake --version', verbose=2)",
"[ubelt.cmd] joncrall@calculex:~/Dropbox$ cmake --version\ncmake version 3.11.0-rc2\n\nCMake suite maintained and supported by Kitware (kitware.com/cmake).\n"
],
[
"# and verbose=3\ninfo = ub.cmd('cmake --version', verbose=3)",
"┌─── START CMD ───\n[ubelt.cmd] joncrall@calculex:~/Dropbox$ cmake --version\ncmake version 3.11.0-rc2\n\nCMake suite maintained and supported by Kitware (kitware.com/cmake).\n└─── END CMD ───\n"
]
],
[
[
"Cross-Platform Resource and Cache Directories\n---------------------------------------------\n\nIf you have an application which writes configuration or cache files,\nthe standard place to dump those files differs depending if you are on\nWindows, Linux, or Mac. UBelt offers a unified functions for determining\nwhat these paths are.\n\nThe ``ub.ensure_app_cache_dir`` and ``ub.ensure_app_resource_dir``\nfunctions find the correct platform-specific location for these files\nand ensures that the directories exist. (Note: replacing \"ensure\" with\n\"get\" will simply return the path, but not ensure that it exists)\n\nThe resource root directory is ``~/AppData/Roaming`` on Windows,\n``~/.config`` on Linux and ``~/Library/Application Support`` on Mac. The\ncache root directory is ``~/AppData/Local`` on Windows, ``~/.config`` on\nLinux and ``~/Library/Caches`` on Mac.\n",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\nprint(ub.shrinkuser(ub.ensure_app_cache_dir('my_app')))",
"~/.cache/my_app\n"
]
],
[
[
"Downloading Files\n-----------------\n\nThe function ``ub.download`` provides a simple interface to download a\nURL and save its data to a file.\n\nThe function ``ub.grabdata`` works similarly to ``ub.download``, but\nwhereas ``ub.download`` will always re-download the file,\n``ub.grabdata`` will check if the file exists and only re-download it if\nit needs to.\n\nNew in version 0.4.0: both functions now accepts the ``hash_prefix`` keyword\nargument, which if specified will check that the hash of the file matches the\nprovided value. The ``hasher`` keyword argument can be used to change which\nhashing algorithm is used (it defaults to ``\"sha512\"``).",
"_____no_output_____"
]
],
[
[
" >>> import ubelt as ub\n >>> url = 'http://i.imgur.com/rqwaDag.png'\n >>> fpath = ub.download(url, verbose=0)\n >>> print(ub.shrinkuser(fpath))",
"~/.cache/ubelt/rqwaDag.png\n"
],
[
" >>> import ubelt as ub\n >>> url = 'http://i.imgur.com/rqwaDag.png'\n >>> fpath = ub.grabdata(url, verbose=0, hash_prefix='944389a39')\n >>> print(ub.shrinkuser(fpath))",
"~/.cache/ubelt/rqwaDag.png\n"
],
[
"try:\n ub.grabdata(url, verbose=0, hash_prefix='not-the-right-hash')\nexcept Exception as ex:\n print('type(ex) = {!r}'.format(type(ex)))",
"hash_prefix = 'not-the-right-hash'\ngot = '944389a39dfb8fa9e3d075bc25416d56782093d5dca88a1f84cac16bf515fa12aeebbbebf91f1e31e8beb59468a7a5f3a69ab12ac1e3c1d1581e1ad9688b766f'\ntype(ex) = <class 'RuntimeError'>\n"
]
],
[
[
"# Dictionary Tools",
"_____no_output_____"
]
],
[
[
"import ubelt as ub\nitem_list = ['ham', 'jam', 'spam', 'eggs', 'cheese', 'bannana']\ngroupid_list = ['protein', 'fruit', 'protein', 'protein', 'dairy', 'fruit']\ngroups = ub.group_items(item_list, groupid_list)\nprint(ub.repr2(groups, nl=1))",
"{\n 'dairy': ['cheese'],\n 'fruit': ['jam', 'bannana'],\n 'protein': ['ham', 'spam', 'eggs'],\n}\n"
],
[
"import ubelt as ub\nitem_list = [1, 2, 39, 900, 1232, 900, 1232, 2, 2, 2, 900]\nub.dict_hist(item_list)",
"_____no_output_____"
],
[
"import ubelt as ub\nitems = [0, 0, 1, 2, 3, 3, 0, 12, 2, 9]\nub.find_duplicates(items, k=2)",
"_____no_output_____"
],
[
"import ubelt as ub\ndict_ = {'K': 3, 'dcvs_clip_max': 0.2, 'p': 0.1}\nsubdict_ = ub.dict_subset(dict_, ['K', 'dcvs_clip_max'])\nprint(subdict_)",
"OrderedDict([('K', 3), ('dcvs_clip_max', 0.2)])\n"
],
[
"import ubelt as ub\ndict_ = {1: 'a', 2: 'b', 3: 'c'}\nprint(list(ub.dict_take(dict_, [1, 2, 3, 4, 5], default=None)))",
"['a', 'b', 'c', None, None]\n"
],
[
"import ubelt as ub\ndict_ = {'a': [1, 2, 3], 'b': []}\nnewdict = ub.map_vals(len, dict_)\nprint(newdict)",
"{'a': 3, 'b': 0}\n"
],
[
"import ubelt as ub\nmapping = {0: 'a', 1: 'b', 2: 'c', 3: 'd'}\nub.invert_dict(mapping)",
"_____no_output_____"
],
[
"import ubelt as ub\nmapping = {'a': 0, 'A': 0, 'b': 1, 'c': 2, 'C': 2, 'd': 3}\nub.invert_dict(mapping, unique_vals=False)",
"_____no_output_____"
]
],
[
[
"AutoDict - Autovivification\n---------------------------\n\nWhile the ``collections.defaultdict`` is nice, it is sometimes more\nconvenient to have an infinitely nested dictionary of dictionaries.\n\n(But be careful, you may start to write in Perl) ",
"_____no_output_____"
]
],
[
[
">>> import ubelt as ub\n>>> auto = ub.AutoDict()\n>>> print('auto = {!r}'.format(auto))\n>>> auto[0][10][100] = None\n>>> print('auto = {!r}'.format(auto))\n>>> auto[0][1] = 'hello'\n>>> print('auto = {!r}'.format(auto))",
"auto = {}\nauto = {0: {10: {100: None}}}\nauto = {0: {1: 'hello', 10: {100: None}}}\n"
]
],
[
[
"String-based imports\n--------------------\n\nUbelt contains functions to import modules dynamically without using the\npython ``import`` statement. While ``importlib`` exists, the ``ubelt``\nimplementation is simpler to user and does not have the disadvantage of\nbreaking ``pytest``.\n\nNote ``ubelt`` simply provides an interface to this functionality, the\ncore implementation is in ``xdoctest``.",
"_____no_output_____"
]
],
[
[
">>> import ubelt as ub\n>>> module = ub.import_module_from_path(ub.truepath('~/code/ubelt/ubelt'))\n>>> print('module = {!r}'.format(module))\n>>> module = ub.import_module_from_name('ubelt')\n>>> print('module = {!r}'.format(module))\n\n>>> modpath = ub.util_import.__file__\n>>> print(ub.modpath_to_modname(modpath))\n>>> modname = ub.util_import.__name__\n>>> assert ub.truepath(ub.modname_to_modpath(modname)) == modpath",
"module = <module 'ubelt' from '/home/joncrall/code/ubelt/ubelt/__init__.py'>\nmodule = <module 'ubelt' from '/home/joncrall/code/ubelt/ubelt/__init__.py'>\nubelt.util_import\n"
]
],
[
[
"Horizontal String Concatenation\n-------------------------------\n\nSometimes its just prettier to horizontally concatenate two blocks of\ntext.",
"_____no_output_____"
]
],
[
[
" >>> import ubelt as ub\n >>> B = ub.repr2([[1, 2], [3, 4]], nl=1, cbr=True, trailsep=False)\n >>> C = ub.repr2([[5, 6], [7, 8]], nl=1, cbr=True, trailsep=False)\n >>> print(ub.hzcat(['A = ', B, ' * ', C]))",
"A = [[1, 2], * [[5, 6],\n [3, 4]] [7, 8]]\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd37f6ea938444cbcd45f725f1ef30db5011920
| 14,978 |
ipynb
|
Jupyter Notebook
|
examples/estimator/classifier/NuSVC/c/basics.pct.ipynb
|
karoka/sklearn-porter
|
f57b6d042c9ae18c6bb8c027362f9e40bfd34d63
|
[
"MIT"
] | 1,197 |
2016-08-30T14:49:34.000Z
|
2022-03-30T05:38:52.000Z
|
examples/estimator/classifier/NuSVC/c/basics.pct.ipynb
|
karoka/sklearn-porter
|
f57b6d042c9ae18c6bb8c027362f9e40bfd34d63
|
[
"MIT"
] | 80 |
2016-11-18T17:37:19.000Z
|
2022-03-25T12:41:40.000Z
|
examples/estimator/classifier/NuSVC/c/basics.pct.ipynb
|
karoka/sklearn-porter
|
f57b6d042c9ae18c6bb8c027362f9e40bfd34d63
|
[
"MIT"
] | 171 |
2016-08-25T20:05:27.000Z
|
2022-03-28T07:39:54.000Z
| 44.710448 | 3,339 | 0.464214 |
[
[
[
"# sklearn-porter\n\nRepository: [https://github.com/nok/sklearn-porter](https://github.com/nok/sklearn-porter)\n\n## NuSVC\n\nDocumentation: [sklearn.svm.NuSVC](http://scikit-learn.org/stable/modules/generated/sklearn.svm.NuSVC.html)",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('../../../../..')",
"_____no_output_____"
]
],
[
[
"### Load data",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import load_iris\n\niris_data = load_iris()\n\nX = iris_data.data\ny = iris_data.target\n\nprint(X.shape, y.shape)",
"((150, 4), (150,))\n"
]
],
[
[
"### Train classifier",
"_____no_output_____"
]
],
[
[
"from sklearn import svm\n\nclf = svm.NuSVC(gamma=0.001, kernel='rbf', random_state=0)\nclf.fit(X, y)",
"_____no_output_____"
]
],
[
[
"### Transpile classifier",
"_____no_output_____"
]
],
[
[
"from sklearn_porter import Porter\n\nporter = Porter(clf, language='c')\noutput = porter.export()\n\nprint(output)",
"#include <stdlib.h>\n#include <stdio.h>\n#include <math.h>\n\n#define N_FEATURES 4\n#define N_CLASSES 3\n#define N_VECTORS 104\n#define N_ROWS 3\n#define N_COEFFICIENTS 2\n#define N_INTERCEPTS 3\n#define KERNEL_TYPE 'r'\n#define KERNEL_GAMMA 0.001\n#define KERNEL_COEF 0.0\n#define KERNEL_DEGREE 3\n\ndouble vectors[104][4] = {{4.9, 3.0, 1.4, 0.2}, {4.6, 3.1, 1.5, 0.2}, {5.4, 3.9, 1.7, 0.4}, {5.0, 3.4, 1.5, 0.2}, {4.9, 3.1, 1.5, 0.1}, {5.4, 3.7, 1.5, 0.2}, {4.8, 3.4, 1.6, 0.2}, {5.7, 4.4, 1.5, 0.4}, {5.7, 3.8, 1.7, 0.3}, {5.1, 3.8, 1.5, 0.3}, {5.4, 3.4, 1.7, 0.2}, {5.1, 3.7, 1.5, 0.4}, {5.1, 3.3, 1.7, 0.5}, {4.8, 3.4, 1.9, 0.2}, {5.0, 3.0, 1.6, 0.2}, {5.0, 3.4, 1.6, 0.4}, {5.2, 3.5, 1.5, 0.2}, {4.7, 3.2, 1.6, 0.2}, {4.8, 3.1, 1.6, 0.2}, {5.4, 3.4, 1.5, 0.4}, {4.9, 3.1, 1.5, 0.2}, {5.1, 3.4, 1.5, 0.2}, {4.5, 2.3, 1.3, 0.3}, {5.0, 3.5, 1.6, 0.6}, {5.1, 3.8, 1.9, 0.4}, {4.8, 3.0, 1.4, 0.3}, {5.1, 3.8, 1.6, 0.2}, {5.3, 3.7, 1.5, 0.2}, {7.0, 3.2, 4.7, 1.4}, {6.4, 3.2, 4.5, 1.5}, {6.9, 3.1, 4.9, 1.5}, {5.5, 2.3, 4.0, 1.3}, {6.5, 2.8, 4.6, 1.5}, {5.7, 2.8, 4.5, 1.3}, {6.3, 3.3, 4.7, 1.6}, {4.9, 2.4, 3.3, 1.0}, {6.6, 2.9, 4.6, 1.3}, {5.2, 2.7, 3.9, 1.4}, {5.0, 2.0, 3.5, 1.0}, {5.9, 3.0, 4.2, 1.5}, {6.0, 2.2, 4.0, 1.0}, {6.1, 2.9, 4.7, 1.4}, {5.6, 2.9, 3.6, 1.3}, {6.7, 3.1, 4.4, 1.4}, {5.6, 3.0, 4.5, 1.5}, {5.8, 2.7, 4.1, 1.0}, {6.2, 2.2, 4.5, 1.5}, {5.6, 2.5, 3.9, 1.1}, {5.9, 3.2, 4.8, 1.8}, {6.1, 2.8, 4.0, 1.3}, {6.3, 2.5, 4.9, 1.5}, {6.1, 2.8, 4.7, 1.2}, {6.6, 3.0, 4.4, 1.4}, {6.8, 2.8, 4.8, 1.4}, {6.7, 3.0, 5.0, 1.7}, {6.0, 2.9, 4.5, 1.5}, {5.7, 2.6, 3.5, 1.0}, {5.5, 2.4, 3.8, 1.1}, {5.5, 2.4, 3.7, 1.0}, {5.8, 2.7, 3.9, 1.2}, {6.0, 2.7, 5.1, 1.6}, {5.4, 3.0, 4.5, 1.5}, {6.0, 3.4, 4.5, 1.6}, {6.7, 3.1, 4.7, 1.5}, {6.3, 2.3, 4.4, 1.3}, {5.6, 3.0, 4.1, 1.3}, {5.5, 2.5, 4.0, 1.3}, {5.5, 2.6, 4.4, 1.2}, {6.1, 3.0, 4.6, 1.4}, {5.8, 2.6, 4.0, 1.2}, {5.0, 2.3, 3.3, 1.0}, {5.6, 2.7, 4.2, 1.3}, {5.7, 3.0, 4.2, 1.2}, {5.7, 2.9, 4.2, 1.3}, {6.2, 2.9, 4.3, 1.3}, {5.1, 2.5, 3.0, 1.1}, {5.7, 2.8, 4.1, 1.3}, {5.8, 2.7, 5.1, 1.9}, {6.3, 2.9, 5.6, 1.8}, {4.9, 2.5, 4.5, 1.7}, {6.5, 3.2, 5.1, 2.0}, {6.4, 2.7, 5.3, 1.9}, {5.7, 2.5, 5.0, 2.0}, {5.8, 2.8, 5.1, 2.4}, {6.4, 3.2, 5.3, 2.3}, {6.5, 3.0, 5.5, 1.8}, {6.0, 2.2, 5.0, 1.5}, {5.6, 2.8, 4.9, 2.0}, {6.3, 2.7, 4.9, 1.8}, {6.2, 2.8, 4.8, 1.8}, {6.1, 3.0, 4.9, 1.8}, {7.2, 3.0, 5.8, 1.6}, {6.3, 2.8, 5.1, 1.5}, {6.1, 2.6, 5.6, 1.4}, {6.4, 3.1, 5.5, 1.8}, {6.0, 3.0, 4.8, 1.8}, {6.9, 3.1, 5.4, 2.1}, {6.9, 3.1, 5.1, 2.3}, {5.8, 2.7, 5.1, 1.9}, {6.7, 3.0, 5.2, 2.3}, {6.3, 2.5, 5.0, 1.9}, {6.5, 3.0, 5.2, 2.0}, {6.2, 3.4, 5.4, 2.3}, {5.9, 3.0, 5.1, 1.8}};\ndouble coefficients[2][104] = {{4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 0.0, 4.680538527007988, 0.0, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 4.680538527007988, 0.0, -0.0, -0.0, -0.0, -4.680538527007988, -0.0, -0.0, -0.0, -4.680538527007988, -0.0, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -0.0, -4.680538527007988, -0.0, -0.0, -4.680538527007988, -0.0, -4.680538527007988, -0.0, -4.680538527007988, -0.0, -0.0, -0.0, -0.0, -0.0, -0.0, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -0.0, -0.0, -0.0, -0.0, -0.0, -4.680538527007988, -4.680538527007988, -4.680538527007988, -0.0, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -4.680538527007988, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -0.0, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -0.0, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366, -2.1228182659346366}, {0.0, 0.0, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 0.0, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 2.1228182659346366, 47.52934177369389, 47.52934177369389, 47.52934177369389, 0.0, 47.52934177369389, 47.52934177369389, 47.52934177369389, 0.0, 47.52934177369389, 0.0, 0.0, 0.0, 0.0, 47.52934177369389, 0.0, 47.52934177369389, 47.52934177369389, 0.0, 47.52934177369389, 0.0, 47.52934177369389, 0.0, 47.52934177369389, 47.52934177369389, 47.52934177369389, 47.52934177369389, 47.52934177369389, 47.52934177369389, 0.0, 0.0, 0.0, 0.0, 47.52934177369389, 47.52934177369389, 47.52934177369389, 47.52934177369389, 47.52934177369389, 0.0, 0.0, 47.52934177369389, 47.52934177369389, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -0.0, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -47.52934177369389, -0.0, -47.52934177369389}};\ndouble intercepts[3] = {0.09572808365772528, 0.049757317370245795, -0.08418168966801846};\nint weights[3] = {28, 49, 27};\n\nint predict (double features[]) {\n int i, j, k, d, l;\n\n double kernels[N_VECTORS];\n double kernel;\n switch (KERNEL_TYPE) {\n case 'l':\n // <x,x'>\n for (i = 0; i < N_VECTORS; i++) {\n kernel = 0.;\n for (j = 0; j < N_FEATURES; j++) {\n kernel += vectors[i][j] * features[j];\n }\n kernels[i] = kernel;\n }\n break;\n case 'p':\n // (y<x,x'>+r)^d\n for (i = 0; i < N_VECTORS; i++) {\n kernel = 0.;\n for (j = 0; j < N_FEATURES; j++) {\n kernel += vectors[i][j] * features[j];\n }\n kernels[i] = pow((KERNEL_GAMMA * kernel) + KERNEL_COEF, KERNEL_DEGREE);\n }\n break;\n case 'r':\n // exp(-y|x-x'|^2)\n for (i = 0; i < N_VECTORS; i++) {\n kernel = 0.;\n for (j = 0; j < N_FEATURES; j++) {\n kernel += pow(vectors[i][j] - features[j], 2);\n }\n kernels[i] = exp(-KERNEL_GAMMA * kernel);\n }\n break;\n case 's':\n // tanh(y<x,x'>+r)\n for (i = 0; i < N_VECTORS; i++) {\n kernel = 0.;\n for (j = 0; j < N_FEATURES; j++) {\n kernel += vectors[i][j] * features[j];\n }\n kernels[i] = tanh((KERNEL_GAMMA * kernel) + KERNEL_COEF);\n }\n break;\n }\n\n int starts[N_ROWS];\n int start;\n for (i = 0; i < N_ROWS; i++) {\n if (i != 0) {\n start = 0;\n for (j = 0; j < i; j++) {\n start += weights[j];\n }\n starts[i] = start;\n } else {\n starts[0] = 0;\n }\n }\n\n int ends[N_ROWS];\n for (i = 0; i < N_ROWS; i++) {\n ends[i] = weights[i] + starts[i];\n }\n\n if (N_CLASSES == 2) {\n\n for (i = 0; i < N_VECTORS; i++) {\n kernels[i] = -kernels[i];\n }\n\n double decision = 0.;\n for (k = starts[1]; k < ends[1]; k++) {\n decision += kernels[k] * coefficients[0][k];\n }\n for (k = starts[0]; k < ends[0]; k++) {\n decision += kernels[k] * coefficients[0][k];\n }\n decision += intercepts[0];\n\n if (decision > 0) {\n return 0;\n }\n return 1;\n\n }\n\n double decisions[N_INTERCEPTS];\n double tmp;\n for (i = 0, d = 0, l = N_ROWS; i < l; i++) {\n for (j = i + 1; j < l; j++) {\n tmp = 0.;\n for (k = starts[j]; k < ends[j]; k++) {\n tmp += kernels[k] * coefficients[i][k];\n }\n for (k = starts[i]; k < ends[i]; k++) {\n tmp += kernels[k] * coefficients[j - 1][k];\n }\n decisions[d] = tmp + intercepts[d];\n d = d + 1;\n }\n }\n\n int votes[N_INTERCEPTS];\n for (i = 0, d = 0, l = N_ROWS; i < l; i++) {\n for (j = i + 1; j < l; j++) {\n votes[d] = decisions[d] > 0 ? i : j;\n d = d + 1;\n }\n }\n\n int amounts[N_CLASSES];\n for (i = 0, l = N_CLASSES; i < l; i++) {\n amounts[i] = 0;\n }\n for (i = 0; i < N_INTERCEPTS; i++) {\n amounts[votes[i]] += 1;\n }\n\n int classVal = -1;\n int classIdx = -1;\n for (i = 0; i < N_CLASSES; i++) {\n if (amounts[i] > classVal) {\n classVal = amounts[i];\n classIdx= i;\n }\n }\n return classIdx;\n\n}\n\nint main(int argc, const char * argv[]) {\n\n /* Features: */\n double features[argc-1];\n int i;\n for (i = 1; i < argc; i++) {\n features[i-1] = atof(argv[i]);\n }\n\n /* Prediction: */\n printf(\"%d\", predict(features));\n return 0;\n\n}\n\n"
]
],
[
[
"### Run classification in C",
"_____no_output_____"
]
],
[
[
"# Save model:\n# with open('nusvc.c', 'w') as f:\n# f.write(output)\n\n# Compile model:\n# $ gcc nusvc.c -std=c99 -lm -o nusvc\n\n# Run classification:\n# $ ./nusvc 1 2 3 4",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cbd38311b0d6e330919fe767693d60f307069565
| 7,019 |
ipynb
|
Jupyter Notebook
|
05_1_cross_validation_uni_class_cdc16/create_testing_sets_Jul_PM.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null |
05_1_cross_validation_uni_class_cdc16/create_testing_sets_Jul_PM.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null |
05_1_cross_validation_uni_class_cdc16/create_testing_sets_Jul_PM.ipynb
|
jingzbu/InverseVITraffic
|
c0d33d91bdd3c014147d58866c1a2b99fb8a9608
|
[
"MIT"
] | null | null | null | 24.456446 | 113 | 0.511754 |
[
[
[
"%run ../Python_files/util_data_storage_and_load.py",
"_____no_output_____"
],
[
"%run ../Python_files/load_dicts.py",
"_____no_output_____"
],
[
"%run ../Python_files/util.py",
"_____no_output_____"
],
[
"import numpy as np\nfrom numpy.linalg import inv",
"_____no_output_____"
],
[
"# load link flow data\n\nimport json\n\nwith open('../temp_files/link_day_minute_Jul_dict_JSON_adjusted.json', 'r') as json_file:\n link_day_minute_Jul_dict_JSON = json.load(json_file)",
"_____no_output_____"
],
[
"# week_day_Jul_list = [2, 3, 4, 5, 6, 9, 10, 11, 12, 13, 16, 17, 18, 19, 20, 23, 24, 25, 26, 27, 30, 31]\n\n# testing set 1\nweek_day_Jul_list_1 = [20, 23, 24, 25, 26, 27, 30, 31]\n\n# testing set 2\nweek_day_Jul_list_2 = [11, 12, 13, 16, 17, 18, 19]\n\n# testing set 3\nweek_day_Jul_list_3 = [2, 3, 4, 5, 6, 9, 10]",
"_____no_output_____"
],
[
"link_flow_testing_set_Jul_PM_1 = []\nfor link_idx in range(24):\n for day in week_day_Jul_list_1: \n key = 'link_' + str(link_idx) + '_' + str(day)\n link_flow_testing_set_Jul_PM_1.append(link_day_minute_Jul_dict_JSON[key] ['PM_flow'])\n \nlink_flow_testing_set_Jul_PM_2 = []\nfor link_idx in range(24):\n for day in week_day_Jul_list_2: \n key = 'link_' + str(link_idx) + '_' + str(day)\n link_flow_testing_set_Jul_PM_2.append(link_day_minute_Jul_dict_JSON[key] ['PM_flow'])\n \nlink_flow_testing_set_Jul_PM_3 = []\nfor link_idx in range(24):\n for day in week_day_Jul_list_3: \n key = 'link_' + str(link_idx) + '_' + str(day)\n link_flow_testing_set_Jul_PM_3.append(link_day_minute_Jul_dict_JSON[key] ['PM_flow'])",
"_____no_output_____"
],
[
"len(link_flow_testing_set_Jul_PM_1)",
"_____no_output_____"
],
[
"testing_set_1 = np.matrix(link_flow_testing_set_Jul_PM_1)\ntesting_set_1 = np.matrix.reshape(testing_set_1, 24, 8)\ntesting_set_1 = np.nan_to_num(testing_set_1)\ny = np.array(np.transpose(testing_set_1))\ny = y[np.all(y != 0, axis=1)]\ntesting_set_1 = np.transpose(y)\ntesting_set_1 = np.matrix(testing_set_1)\n\ntesting_set_2 = np.matrix(link_flow_testing_set_Jul_PM_2)\ntesting_set_2 = np.matrix.reshape(testing_set_2, 24, 7)\ntesting_set_2 = np.nan_to_num(testing_set_2)\ny = np.array(np.transpose(testing_set_2))\ny = y[np.all(y != 0, axis=1)]\ntesting_set_2 = np.transpose(y)\ntesting_set_2 = np.matrix(testing_set_2)\n\ntesting_set_3 = np.matrix(link_flow_testing_set_Jul_PM_3)\ntesting_set_3 = np.matrix.reshape(testing_set_3, 24, 7)\ntesting_set_3 = np.nan_to_num(testing_set_3)\ny = np.array(np.transpose(testing_set_3))\ny = y[np.all(y != 0, axis=1)]\ntesting_set_3 = np.transpose(y)\ntesting_set_3 = np.matrix(testing_set_3)",
"_____no_output_____"
],
[
"np.size(testing_set_1, 1), np.size(testing_set_3, 0)",
"_____no_output_____"
],
[
"testing_set_3[:,:1]",
"_____no_output_____"
],
[
"# write testing sets to file\n\nzdump([testing_set_1, testing_set_2, testing_set_3], '../temp_files/testing_sets_Jul_PM.pkz')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd38484ff54e92459af25b81b3fe7db09559269
| 12,418 |
ipynb
|
Jupyter Notebook
|
Monte_Carlo_Simulation_Example.ipynb
|
Granero0011/AB-Demo
|
6cd74321ba27813d37293e7e994b620c79eb6f9a
|
[
"MIT"
] | null | null | null |
Monte_Carlo_Simulation_Example.ipynb
|
Granero0011/AB-Demo
|
6cd74321ba27813d37293e7e994b620c79eb6f9a
|
[
"MIT"
] | null | null | null |
Monte_Carlo_Simulation_Example.ipynb
|
Granero0011/AB-Demo
|
6cd74321ba27813d37293e7e994b620c79eb6f9a
|
[
"MIT"
] | null | null | null | 44.669065 | 351 | 0.478982 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Granero0011/AB-Demo/blob/master/Monte_Carlo_Simulation_Example.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\n\nsns.set_style('whitegrid')",
"_____no_output_____"
],
[
"avg = 1\nstd_dev=.1\nnum_reps= 500\nnum_simulations= 1000",
"_____no_output_____"
],
[
"pct_to_target = np.random.normal(avg, std_dev, num_reps).round(2)",
"_____no_output_____"
],
[
"sales_target_values = [75_000, 100_000, 200_000, 300_000, 400_000, 500_000]\nsales_target_prob = [.3, .3, .2, .1, .05, .05]\nsales_target = np.random.choice(sales_target_values, num_reps, p=sales_target_prob)",
"_____no_output_____"
],
[
"df = pd.DataFrame(index=range(num_reps), data={'Pct_To_Target': pct_to_target,\n 'Sales_Target': sales_target})\n\ndf['Sales'] = df['Pct_To_Target'] * df['Sales_Target']",
"_____no_output_____"
],
[
"def calc_commission_rate(x):\n \"\"\" Return the commission rate based on the table:\n 0-90% = 2%\n 91-99% = 3%\n >= 100 = 4%\n \"\"\"\n if x <= .90:\n return .02\n if x <= .99:\n return .03\n else:\n return .04",
"_____no_output_____"
],
[
"df['Commission_Rate'] = df['Pct_To_Target'].apply(calc_commission_rate)\ndf['Commission_Amount'] = df['Commission_Rate'] * df['Sales']",
"_____no_output_____"
],
[
"# Define a list to keep all the results from each simulation that we want to analyze\nall_stats = []\n\n# Loop through many simulations\nfor i in range(num_simulations):\n\n # Choose random inputs for the sales targets and percent to target\n sales_target = np.random.choice(sales_target_values, num_reps, p=sales_target_prob)\n pct_to_target = np.random.normal(avg, std_dev, num_reps).round(2)\n\n # Build the dataframe based on the inputs and number of reps\n df = pd.DataFrame(index=range(num_reps), data={'Pct_To_Target': pct_to_target,\n 'Sales_Target': sales_target})\n\n # Back into the sales number using the percent to target rate\n df['Sales'] = df['Pct_To_Target'] * df['Sales_Target']\n\n # Determine the commissions rate and calculate it\n df['Commission_Rate'] = df['Pct_To_Target'].apply(calc_commission_rate)\n df['Commission_Amount'] = df['Commission_Rate'] * df['Sales']\n\n # We want to track sales,commission amounts and sales targets over all the simulations\n all_stats.append([df['Sales'].sum().round(0),\n df['Commission_Amount'].sum().round(0),\n df['Sales_Target'].sum().round(0)])",
"_____no_output_____"
],
[
"results_df = pd.DataFrame.from_records(all_stats, columns=['Sales',\n 'Commission_Amount',\n 'Sales_Target'])",
"_____no_output_____"
],
[
"results_df.describe().style.format('{:,}')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cbd388370915d7561133d3935f46556317500f1e
| 10,521 |
ipynb
|
Jupyter Notebook
|
notebooks/scrape-HH-by-keyword-selenium.ipynb
|
georgypv/jobs-scraper-selenium-kafka-mysql
|
c95640e9312622b80646ce93a8053a185f27f8de
|
[
"Apache-2.0"
] | null | null | null |
notebooks/scrape-HH-by-keyword-selenium.ipynb
|
georgypv/jobs-scraper-selenium-kafka-mysql
|
c95640e9312622b80646ce93a8053a185f27f8de
|
[
"Apache-2.0"
] | null | null | null |
notebooks/scrape-HH-by-keyword-selenium.ipynb
|
georgypv/jobs-scraper-selenium-kafka-mysql
|
c95640e9312622b80646ce93a8053a185f27f8de
|
[
"Apache-2.0"
] | null | null | null | 35.90785 | 136 | 0.512974 |
[
[
[
"import random\nimport os\nimport sys\nfrom time import sleep\nfrom datetime import datetime\nimport requests as rt\nimport numpy as np\n\nfrom bs4 import BeautifulSoup\n\nfrom selenium import webdriver\nfrom selenium.webdriver.chrome.options import Options\nfrom selenium.webdriver.common.keys import Keys\nfrom selenium.common.exceptions import NoSuchElementException,ElementNotInteractableException, ElementClickInterceptedException\n\n\nimport sqlalchemy as sa\nfrom sqlalchemy.orm import sessionmaker",
"_____no_output_____"
],
[
"def get_browser(driver_path=r'chromedriver/chromedriver.exe', headless=False):\n options = webdriver.ChromeOptions()\n if headless:\n options.add_argument('headless')\n options.add_argument('window-size=1200x600')\n browser = webdriver.Chrome(driver_path, options=options)\n return browser",
"_____no_output_____"
],
[
"def get_vacancies_on_page(browser): \n #close pop-up window with suggested region (if present)\n try:\n browser.find_element_by_class_name('bloko-icon_cancel').click()\n except (NoSuchElementException, ElementNotInteractableException):\n pass\n \n vacancy_cards = browser.find_elements_by_class_name('vacancy-serp-item ')\n \n return vacancy_cards\n \n \n ",
"_____no_output_____"
],
[
"def get_vacancy_info(card, browser, keyword, verbose=True):\n \n try:\n card.find_element_by_class_name('vacancy-serp-item__info')\\\n .find_element_by_tag_name('a')\\\n .send_keys(Keys.CONTROL + Keys.RETURN) #open new tab in Chrome\n\n sleep(2) #let it fully load\n #go to the last opened tab\n browser.switch_to.window(browser.window_handles[-1])\n \n basic_info = False\n while not basic_info:\n try:\n vacancy_title = browser.find_element_by_xpath('//div[@class=\"vacancy-title\"]//h1').text\n company_name = browser.find_element_by_xpath('//a[@class=\"vacancy-company-name\"]').text\n company_href_hh = browser.find_element_by_xpath('//a[@class=\"vacancy-company-name\"]').get_attribute('href')\n publish_time = browser.find_element_by_xpath('//p[@class=\"vacancy-creation-time\"]').text\n basic_info = True\n except:\n sleep(3)\n \n if verbose:\n print(\"Title: \", vacancy_title )\n print(\"Company: \", company_name )\n print(\"Company link: \", company_href_hh )\n print(\"Publish time: \", publish_time )\n\n try:\n salary = browser.find_element_by_xpath('//div[@class=\"vacancy-title\"]//p[@class=\"vacancy-salary\"]').text\n except NoSuchElementException :\n salary = 'не указано'\n \n \n try:\n emp_mode = browser.find_element_by_xpath('//p[@data-qa=\"vacancy-view-employment-mode\"]').text\n except NoSuchElementException :\n emp_mode = 'не указано'\n finally:\n emp_mode = emp_mode.strip().replace('\\n', ' ')\n \n \n try:\n exp = browser.find_element_by_xpath('//span[@data-qa=\"vacancy-experience\"]').text\n except NoSuchElementException :\n exp = 'не указано'\n finally: \n exp = exp.strip().replace('\\n', ' ')\n \n try:\n company_address = browser.find_element_by_xpath('//span[@data-qa=\"vacancy-view-raw-address\"]').text\n except NoSuchElementException:\n company_address = 'не указано'\n \n try:\n vacancy_description = browser.find_element_by_xpath('//div[@data-qa=\"vacancy-description\"]').text\n except NoSuchElementException:\n vacancy_description = 'не указано'\n finally:\n vacancy_description = vacancy_description.replace('\\n', ' ')\n \n try:\n vacancy_tags = browser.find_element_by_xpath('//div[@class=\"bloko-tag-list\"]').text\n except NoSuchElementException:\n vacancy_tags = 'не указано'\n finally:\n vacancy_tags = vacancy_tags.replace('\\n', ', ')\n \n if verbose: \n print(\"Salary: \", salary )\n print(\"Company address: \", company_address )\n print('Experience: ', exp)\n print('Employment mode: ', emp_mode)\n print(\"Vacancy description: \", vacancy_description[:50] )\n print(\"Vacancy tags: \", vacancy_tags)\n\n browser.close() #close tab\n browser.switch_to.window(browser.window_handles[0]) #switch to the first tab\n \n dt = str(datetime.now())\n \n vacancy_info = {'dt': dt,\n 'keyword': keyword,\n 'vacancy_title': vacancy_title,\n 'vacancy_salary': salary,\n 'vacancy_tags': vacancy_tags,\n 'vacancy_description': vacancy_description,\n 'vacancy_experience' : exp,\n 'employment_mode': emp_mode,\n 'company_name':company_name,\n 'company_link':company_href_hh,\n 'company_address':company_address,\n 'publish_place_and_time':publish_time}\n \n return vacancy_info\n \n\n except Exception as ex:\n print('Exeption while scraping info!')\n print(str(ex))\n return None\n ",
"_____no_output_____"
],
[
"def insert_data(data, engine, table_name, schema): \n metadata = sa.MetaData(bind=engine)\n table = sa.Table(table_name, metadata, autoload=True, schema=schema)\n con = engine.connect()\n try:\n con.execute(table.insert().values(data))\n except Exception as ex:\n print('Exception while inserting data!')\n print(str(ex))\n finally: \n con.close()\n",
"_____no_output_____"
],
[
"def scrape_HH(browser, keyword='Python', pages2scrape=3, table2save='HH_vacancies', verbose=True):\n url = f'https://hh.ru/search/vacancy?area=1&fromSearchLine=true&st=searchVacancy&text={keyword}&from=suggest_post'\n browser.get(url)\n while pages2scrape > 0:\n vacancy_cards = get_vacancies_on_page(browser=browser)\n for card in vacancy_cards:\n vacancy_info = get_vacancy_info(card, browser=browser, keyword=keyword, verbose=verbose)\n insert_data(data=vacancy_info, engine=engine, table_name=table2save)\n if verbose:\n print('Inserted row')\n try:\n #click to the \"Next\" button to load other vacancies\n browser.find_element_by_xpath('//a[@data-qa=\"pager-next\"]').click()\n print('Go to the next page')\n except (NoSuchElementException, ElementNotInteractableException):\n browser.close()\n break\n finally:\n pages2scrape -= 1\n \n",
"_____no_output_____"
],
[
"mysql_con = '' #add your connection to DB\nengine = sa.create_engine(mysql_con)\n\nbrowser = get_browser(driver_path=r'chromedriver/chromedriver.exe', headless=False)",
"_____no_output_____"
],
[
"scrape_HH(browser, keyword='Grafana', pages2scrape=15, verbose=False)",
"Go to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\nGo to the next page\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.