
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a1ac8376adbb19964003cff3036bb96a9220aba
| 16,795 |
ipynb
|
Jupyter Notebook
|
notebooks/clases/6_modelos_preentrenados.ipynb
|
phuijse/INFO257
|
2fd55bd3115e8f8a4124d80e326a11e4938baf33
|
[
"CC0-1.0"
] | 6 |
2020-06-26T19:22:21.000Z
|
2022-01-26T22:02:01.000Z
|
notebooks/clases/6_modelos_preentrenados.ipynb
|
phuijse/INFO257
|
2fd55bd3115e8f8a4124d80e326a11e4938baf33
|
[
"CC0-1.0"
] | null | null | null |
notebooks/clases/6_modelos_preentrenados.ipynb
|
phuijse/INFO257
|
2fd55bd3115e8f8a4124d80e326a11e4938baf33
|
[
"CC0-1.0"
] | 6 |
2020-07-01T18:49:53.000Z
|
2022-02-16T20:58:01.000Z
| 34.700413 | 214 | 0.540935 |
[
[
[
"%matplotlib notebook\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"# Utilizando un modelo pre-entrenado\n\n[`torchvision.models`](https://pytorch.org/vision/stable/models.html) ofrece una serie de modelos famosos de la literatura de *deep learning*\n\nPor defecto el modelo se carga con pesos aleatorios\n\nSi indicamos `pretrained=True` se descarga un modelo entrenado\n\nSe pueden escoger modelos para clasificar, localizar y segmentar\n\n## Modelo para clasificar imágenes\n\ntorchvision tiene una basta cantidad de modelos para clasificar incluyendo distintas versiones de VGG, ResNet, AlexNet, GoogLeNet, DenseNet, entre otros\n\nCargaremos un modelo [resnet18](https://arxiv.org/pdf/1512.03385.pdf) [pre-entrenado](https://pytorch.org/docs/stable/torchvision/models.html#torchvision.models.resnet18) en [ImageNet](http://image-net.org/) ",
"_____no_output_____"
]
],
[
[
"from torchvision import models\n\nmodel = models.resnet18(pretrained=True, progress=True)\nmodel.eval()",
"_____no_output_____"
]
],
[
[
"Los modelos pre-entrenados esperan imágenes con\n- tres canales (RGB)\n- al menos 224x224 píxeles\n- píxeles entre 0 y 1 (float)\n- normalizadas con \n\n normalize = torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225])\n\n",
"_____no_output_____"
]
],
[
[
"img",
"_____no_output_____"
],
[
"from PIL import Image\nimport torch\nfrom torchvision import transforms\n\nimg = Image.open(\"img/dog.jpg\")\n\nmy_transform = transforms.Compose([transforms.Resize(256),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize(mean=(0.485, 0.456, 0.406), \n std=(0.229, 0.224, 0.225))])\n\n# Las clases con probabilidad más alta son\nprobs = torch.nn.Softmax(dim=1)(model.forward(my_transform(img).unsqueeze(0)))\n\nbest = probs.argsort(descending=True)\ndisplay(best[0, :10], \n probs[0, best[0, :10]])",
"_____no_output_____"
]
],
[
[
"¿A qué corresponde estas clases?\n\nClases de ImageNet: https://gist.github.com/ageitgey/4e1342c10a71981d0b491e1b8227328b\n",
"_____no_output_____"
],
[
"## Modelo para detectar entidades en imágenes\n\nAdicional a los modelos de clasificación torchvision también tiene modelos para\n- Detectar entidades en una imagen: Faster RCNN\n- Hacer segmentación por instancia: Mask RCNN\n- Hacer segmentación semántica: FCC, DeepLab\n- Clasificación de video \n\nA continuación probaremos la [Faster RCNN](https://arxiv.org/abs/1506.01497) para hace detección\n\nEste modelo fue pre-entrenado en la base de datos [COCO](https://cocodataset.org/)\n\nEl modelo retorna un diccionario con\n- 'boxes': Los bounding box de las entidades\n- 'labels': La etiqueta de la clase más probable de la entidad\n- 'score': La probabilidad de la etiqueta",
"_____no_output_____"
]
],
[
[
"model = models.detection.fasterrcnn_resnet50_fpn(pretrained=True)\nmodel.eval()\n\ntransform = transforms.ToTensor()\nimg = Image.open(\"img/pelea.jpg\") # No require normalización de color\nimg_tensor = transform(img)\n\nresult = model(img_tensor.unsqueeze(0))[0]\n\ndef filter_results(result, threshold=0.9):\n mask = result['scores'] > threshold\n bbox = result['boxes'][mask].detach().cpu().numpy()\n lbls = result['labels'][mask].detach().cpu().numpy()\n return bbox, lbls",
"_____no_output_____"
],
[
"from PIL import ImageFont, ImageDraw\n#fnt = ImageFont.truetype(\"arial.ttf\", 20) \n\nlabel2name = {1: 'persona', 2: 'bicicleta', 3: 'auto', 4: 'moto', \n 8: 'camioneta', 18: 'perro'}\n\ndef draw_rectangles(img, bbox, lbls):\n draw = ImageDraw.Draw(img)\n for k in range(len(bbox)):\n if lbls[k] in label2name.keys():\n draw.rectangle(bbox[k], fill=None, outline='white', width=2)\n draw.text([int(d) for d in bbox[k][:2]], label2name[lbls[k]], fill='white')\n\nbbox, lbls = filter_results(result)\nimg = Image.open(\"img/pelea.jpg\")\ndraw_rectangles(img, bbox, lbls)\ndisplay(img)",
"_____no_output_____"
]
],
[
[
"# Transferencia de Aprendizaje\n\n\nA continuación usaremos la técnicas de transferencia de aprendizaje para aprender un clasificador de imágenes para un fragmento de la base de datos food 5k\n\nEl objetivo es clasificar si la imagen corresponde a comida o no\n\nGuardamos las imagenes con la siguiente estructura de carpetas",
"_____no_output_____"
]
],
[
[
"!ls img/food5k/\n!ls img/food5k/train\n!ls img/food5k/valid",
"_____no_output_____"
]
],
[
[
"Con esto podemos usar `torchvision.datasets.ImageFolder` para crear los dataset de forma muy sencilla\n\nDado que usaremos un modelo preentrenado debemos transformar entregar las imágenes en tamaño 224x224 y con color normalizado\n\nUsaremos también aumentación de datos en el conjunto de entrenamiento",
"_____no_output_____"
]
],
[
[
"from torchvision import datasets\n\ntrain_transforms = transforms.Compose([transforms.RandomRotation(30),\n transforms.RandomResizedCrop(224),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406],\n [0.229, 0.224, 0.225])])\n\nvalid_transforms = transforms.Compose([transforms.Resize(255),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406],\n [0.229, 0.224, 0.225])])\n\ntrain_dataset = datasets.ImageFolder('img/food5k/train', transform=train_transforms)\nvalid_dataset = datasets.ImageFolder('img/food5k/valid', transform=valid_transforms)\ntrain_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)\nvalid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=256, shuffle=False)\n\nfor image, label in train_loader:\n break\n \nfig, ax = plt.subplots(1, 6, figsize=(9, 2), tight_layout=True)\nfor i in range(6):\n ax[i].imshow(image[i].permute(1,2,0).numpy())\n ax[i].axis('off')\n ax[i].set_title(label[i].numpy())",
"_____no_output_____"
]
],
[
[
"Usaremos el modelo ResNet18\n",
"_____no_output_____"
]
],
[
[
"model = models.resnet18(pretrained=True, progress=True)\n# model = models.squeezenet1_1(pretrained=True, progress=True)\ndisplay(model)",
"_____no_output_____"
]
],
[
[
"En este caso re-entrenaremos sólo la última capa: `fc`\n\nLas demás capas las congelaremos\n\nPara congelar una capa simplemente usamos `requires_grad=False` en sus parámetros\n\nCuando llamemos `backward` no se calculará gradiente para estas capas",
"_____no_output_____"
]
],
[
[
"#Congelamos todos los parámetros\nfor param in model.parameters(): \n param.requires_grad = False\n\n# La reemplazamos por una nueva capa de salida\nmodel.fc = torch.nn.Linear(model.fc.in_features , 2) # Para resnet\n#model.classifier = torch.nn.Sequential(torch.nn.Dropout(p=0.5, inplace=False), \n# torch.nn.Conv2d(512, 2, kernel_size=(1, 1), stride=(1, 1)),\n# torch.nn.ReLU(inplace=True),\n# torch.nn.AdaptiveAvgPool2d(output_size=(1, 1))) # Para Squeezenet\n\ncriterion = torch.nn.CrossEntropyLoss()\noptimizer = torch.optim.Adam(model.parameters(), lr=1e-3)\n\nfor epoch in range(10):\n for x, y in train_loader:\n optimizer.zero_grad()\n yhat = model.forward(x)\n loss = criterion(yhat, y)\n loss.backward()\n optimizer.step()\n\n epoch_loss = 0.0\n for x, y in valid_loader:\n yhat = model.forward(x)\n loss = criterion(yhat, y)\n epoch_loss += loss.item()\n print(f\"{epoch}, {epoch_loss:0.4f}, {torch.sum(yhat.argmax(dim=1) == y).item()/100}\")",
"_____no_output_____"
],
[
"targets, predictions = [], []\nfor mbdata, label in valid_loader:\n logits = model.forward(mbdata)\n predictions.append(logits.argmax(dim=1).detach().numpy())\n targets.append(label.numpy())\npredictions = np.concatenate(predictions)\ntargets = np.concatenate(targets)\n\nfrom sklearn.metrics import confusion_matrix, classification_report\n\ncm = confusion_matrix(targets, predictions)\ndisplay(cm)\n\nprint(classification_report(targets, predictions))",
"_____no_output_____"
]
],
[
[
"¿Cómo se compara lo anterior a entrenar una arquitectura convolucional desde cero?\n\nA modo de ejemplo se adapta la arquitectura Lenet5 para aceptar imágenes a color de 224x224 ¿Cuánto desempeño se obtiene entrenando la misma cantidad de épocas?",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nclass Lenet5(nn.Module):\n \n def __init__(self):\n super(type(self), self).__init__()\n # La entrada son imágenes de 3x224x224\n self.features = nn.Sequential(nn.Conv2d(3, 6, 5),\n nn.ReLU(),\n nn.MaxPool2d(3),\n nn.Conv2d(6, 16, 5),\n nn.ReLU(),\n nn.MaxPool2d(3), \n nn.Conv2d(16, 32, 5),\n nn.ReLU(),\n nn.MaxPool2d(3))\n \n self.classifier = nn.Sequential(nn.Linear(32*6*6, 120),\n nn.ReLU(),\n nn.Linear(120, 84),\n nn.ReLU(),\n nn.Linear(84, 2))\n\n def forward(self, x):\n z = self.features(x)\n #print(z.shape)\n # Esto es de tamaño Mx16x5x5\n z = z.view(-1, 32*6*6)\n # Esto es de tamaño Mx400\n return self.classifier(z)\n \nmodel = Lenet5()\ncriterion = torch.nn.CrossEntropyLoss()\noptimizer = torch.optim.Adam(model.parameters(), lr=1e-3)\n\nfor epoch in range(10):\n for x, y in train_loader:\n optimizer.zero_grad()\n yhat = model.forward(x)\n loss = criterion(yhat, y)\n loss.backward()\n optimizer.step()\n\n epoch_loss = 0.0\n for x, y in valid_loader:\n yhat = model.forward(x)\n loss = criterion(yhat, y)\n epoch_loss += loss.item()\n print(f\"{epoch}, {epoch_loss:0.4f}, {torch.sum(yhat.argmax(dim=1) == y).item()/100}\")",
"_____no_output_____"
],
[
"targets, predictions = [], []\nfor mbdata, label in valid_loader:\n logits = model.forward(mbdata)\n predictions.append(logits.argmax(dim=1).detach().numpy())\n targets.append(label.numpy())\npredictions = np.concatenate(predictions)\ntargets = np.concatenate(targets)\n\nfrom sklearn.metrics import confusion_matrix, classification_report\n\ncm = confusion_matrix(targets, predictions)\ndisplay(cm)\n\nprint(classification_report(targets, predictions))",
"_____no_output_____"
]
],
[
[
"# Resumen\n\nAspectos a considerar durante el entrenamiento de redes neuronales\n- Arquitecturas: cantidad y organización de capas, funciones de activación\n- Funciones de costo, optimizadores y sus parámetros (tasa de aprendizaje, momentum)\n- Verificar convergencia y sobreajuste:\n - Checkpoint: Guardar el último modelo y el con menor costo de validación\n - Early stopping: Detener el entrenamiento si el error de validación no disminuye en un cierto número de épocas\n- Inicialización de los parámetros: Probar varios entrenamientos desde inicios aleatorios distintos\n- Si el modelo se sobreajusta pronto\n - Disminuir complejidad\n - Incorporar regularización: Aumentación de datos, decaimiento de pesos, Dropout\n- Si quiero aprovechar un modelo preentrenado\n - Transferencia de aprendizaje\n - [Zoológico de modelos](https://modelzoo.co/)\n - [Papers with code](https://paperswithcode.com/)\n\nEstrategia agil\n> Desarrolla rápido e itera: Empieza simple. Propón una solución, impleméntala, entrena y evalua. Analiza las fallas, modifica e intenta de nuevo\n\nMucho exito en sus desarrollos futuros!",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a1acfd113f8baad340960ead65f95b1a066e5a7
| 191,577 |
ipynb
|
Jupyter Notebook
|
Chapters/01_Chapter01.ipynb
|
saketkc/pyFLGLM
|
9bb6342e97e4d28a8303e149846726a198c78156
|
[
"BSD-2-Clause"
] | null | null | null |
Chapters/01_Chapter01.ipynb
|
saketkc/pyFLGLM
|
9bb6342e97e4d28a8303e149846726a198c78156
|
[
"BSD-2-Clause"
] | null | null | null |
Chapters/01_Chapter01.ipynb
|
saketkc/pyFLGLM
|
9bb6342e97e4d28a8303e149846726a198c78156
|
[
"BSD-2-Clause"
] | 1 |
2020-07-31T17:09:03.000Z
|
2020-07-31T17:09:03.000Z
| 153.877108 | 59,990 | 0.802727 |
[
[
[
"<a href=\"https://colab.research.google.com/github/saketkc/pyFLGLM/blob/master/Chapters/01_Chapter01.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"## Chapter 1 - Introduction to Linear and Generalized Linear Models",
"_____no_output_____"
]
],
[
[
"import warnings\n\nimport pandas as pd\nimport proplot as plot\nimport seaborn as sns\nimport statsmodels.api as sm\nimport statsmodels.formula.api as smf\nfrom patsy import dmatrices\nfrom scipy import stats\n\nwarnings.filterwarnings(\"ignore\")\n%pylab inline\n\n\nplt.rcParams[\"axes.labelweight\"] = \"bold\"\nplt.rcParams[\"font.weight\"] = \"bold\"",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"crabs_df = pd.read_csv(\"../data/Crabs.tsv.gz\", sep=\"\\t\")\ncrabs_df.head()",
"_____no_output_____"
]
],
[
[
"This data comes from a study of female horseshoe crabs (citation unknown). During spawning session, the females migrate to the shore to brred. The males then attach themselves to females' posterior spine while the females\nburrows into the sand and lays cluster of eggs. The fertilization of eggs happens externally in the sand beneath the pair. During this spanwing, multulpe males may cluster the pair and may also fertilize the eggs. These males are called satellites.\n\n**crab**: observation index\n\n**y**: Number of satellites attached\n\n**weight**: weight of the female crab\n\n**color**: color of the female \n\n**spine**:condition of female's spine\n",
"_____no_output_____"
]
],
[
[
"print((crabs_df[\"y\"].mean(), crabs_df[\"y\"].var()))",
"(2.9190751445086707, 9.912017744320465)\n"
],
[
"sns.distplot(crabs_df[\"y\"], kde=False, color=\"slateblue\")",
"_____no_output_____"
],
[
"pd.crosstab(index=crabs_df[\"y\"], columns=\"count\")",
"_____no_output_____"
],
[
"formula = \"\"\"y ~ 1\"\"\"\nresponse, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_pois = sm.GLM(\n response, predictors, family=sm.families.Poisson(link=sm.families.links.identity())\n).fit()\nprint(fit_pois.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 172\nModel Family: Poisson Df Model: 0\nLink Function: identity Scale: 1.0000\nMethod: IRLS Log-Likelihood: -494.04\nDate: Mon, 22 Jun 2020 Deviance: 632.79\nTime: 23:43:22 Pearson chi2: 584.\nNo. Iterations: 3 \nCovariance Type: nonrobust \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nIntercept 2.9191 0.130 22.472 0.000 2.664 3.174\n==============================================================================\n"
]
],
[
[
"Fitting a Poisson distribution with a GLM containing only an iontercept and using identity link function gives the estimate of intercept which is essentially the mean of `y`. But poisson has the same mean as its variance. The sample variance of 9.92 suggests that a poisson fit is not appropriate here.",
"_____no_output_____"
],
[
"### Linear Model Using Weight to Predict Satellite Counts",
"_____no_output_____"
]
],
[
[
"print((crabs_df[\"weight\"].mean(), crabs_df[\"weight\"].var()))",
"(2.437190751445087, 0.33295809712326924)\n"
],
[
"print(crabs_df[\"weight\"].quantile(q=[0, 0.25, 0.5, 0.75, 1]))",
"0.00 1.20\n0.25 2.00\n0.50 2.35\n0.75 2.85\n1.00 5.20\nName: weight, dtype: float64\n"
],
[
"fig, ax = plt.subplots(figsize=(5, 5))\nax.scatter(crabs_df[\"weight\"], crabs_df[\"y\"])\nax.set_xlabel(\"weight\")\nax.set_ylabel(\"y\")",
"_____no_output_____"
]
],
[
[
"The plot shows that there is no clear trend in relation between y (number of satellites) and weight.",
"_____no_output_____"
],
[
"### Fit a LM vs GLM (Gaussian)",
"_____no_output_____"
]
],
[
[
"formula = \"\"\"y ~ weight\"\"\"\nfit_weight = smf.ols(formula=formula, data=crabs_df).fit()\nprint(fit_weight.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: y R-squared: 0.136\nModel: OLS Adj. R-squared: 0.131\nMethod: Least Squares F-statistic: 27.00\nDate: Mon, 22 Jun 2020 Prob (F-statistic): 5.75e-07\nTime: 23:43:22 Log-Likelihood: -430.70\nNo. Observations: 173 AIC: 865.4\nDf Residuals: 171 BIC: 871.7\nDf Model: 1 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nIntercept -1.9911 0.971 -2.050 0.042 -3.908 -0.074\nweight 2.0147 0.388 5.196 0.000 1.249 2.780\n==============================================================================\nOmnibus: 38.273 Durbin-Watson: 1.750\nProb(Omnibus): 0.000 Jarque-Bera (JB): 58.768\nSkew: 1.188 Prob(JB): 1.73e-13\nKurtosis: 4.584 Cond. No. 12.6\n==============================================================================\n\nWarnings:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
],
[
"response, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_weight2 = sm.GLM(response, predictors, family=sm.families.Gaussian()).fit()\nprint(fit_weight2.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 171\nModel Family: Gaussian Df Model: 1\nLink Function: identity Scale: 8.6106\nMethod: IRLS Log-Likelihood: -430.70\nDate: Mon, 22 Jun 2020 Deviance: 1472.4\nTime: 23:43:22 Pearson chi2: 1.47e+03\nNo. Iterations: 3 \nCovariance Type: nonrobust \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nIntercept -1.9911 0.971 -2.050 0.040 -3.894 -0.088\nweight 2.0147 0.388 5.196 0.000 1.255 2.775\n==============================================================================\n"
]
],
[
[
"Thus OLS and a GLM using Gaussian family and identity link are one and the same.",
"_____no_output_____"
],
[
"### Plotting the linear fit",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.scatter(crabs_df[\"weight\"], crabs_df[\"y\"])\nline = fit_weight2.params[0] + fit_weight2.params[1] * crabs_df[\"weight\"]\n\nax.plot(crabs_df[\"weight\"], line, color=\"#f03b20\")",
"_____no_output_____"
]
],
[
[
"### Comparing Mean Numbers of Satellites by Crab Color",
"_____no_output_____"
]
],
[
[
"crabs_df[\"color\"].value_counts()",
"_____no_output_____"
]
],
[
[
"color:\n 1 = medium light, \n 2 = medium, \n 3 = medium dark, \n 4 = dark\n",
"_____no_output_____"
]
],
[
[
"crabs_df.groupby(\"color\").agg([\"mean\", \"var\"])[[\"y\"]]",
"_____no_output_____"
]
],
[
[
"Majority of the crabs are of medoum color and the mean response also decreases as the color gets darker.",
"_____no_output_____"
],
[
"If we fit a linear model between $y$ and $color$ using `sm.ols`, color is treated as a quantitative variable:",
"_____no_output_____"
]
],
[
[
"mod = smf.ols(formula=\"y ~ color\", data=crabs_df)\nres = mod.fit()\nprint(res.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: y R-squared: 0.036\nModel: OLS Adj. R-squared: 0.031\nMethod: Least Squares F-statistic: 6.459\nDate: Mon, 22 Jun 2020 Prob (F-statistic): 0.0119\nTime: 23:43:23 Log-Likelihood: -440.18\nNo. Observations: 173 AIC: 884.4\nDf Residuals: 171 BIC: 890.7\nDf Model: 1 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nIntercept 4.7461 0.757 6.274 0.000 3.253 6.239\ncolor -0.7490 0.295 -2.542 0.012 -1.331 -0.167\n==============================================================================\nOmnibus: 38.876 Durbin-Watson: 1.780\nProb(Omnibus): 0.000 Jarque-Bera (JB): 59.793\nSkew: 1.207 Prob(JB): 1.04e-13\nKurtosis: 4.570 Cond. No. 9.39\n==============================================================================\n\nWarnings:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
]
],
[
[
"**Let's treat color as a qualitative variable:**",
"_____no_output_____"
]
],
[
[
"mod = smf.ols(formula=\"y ~ C(color)\", data=crabs_df)\nres = mod.fit()\nprint(res.summary())",
" OLS Regression Results \n==============================================================================\nDep. Variable: y R-squared: 0.040\nModel: OLS Adj. R-squared: 0.023\nMethod: Least Squares F-statistic: 2.323\nDate: Mon, 22 Jun 2020 Prob (F-statistic): 0.0769\nTime: 23:43:23 Log-Likelihood: -439.89\nNo. Observations: 173 AIC: 887.8\nDf Residuals: 169 BIC: 900.4\nDf Model: 3 \nCovariance Type: nonrobust \n=================================================================================\n coef std err t P>|t| [0.025 0.975]\n---------------------------------------------------------------------------------\nIntercept 4.0833 0.899 4.544 0.000 2.310 5.857\nC(color)[T.2] -0.7886 0.954 -0.827 0.409 -2.671 1.094\nC(color)[T.3] -1.8561 1.014 -1.831 0.069 -3.857 0.145\nC(color)[T.4] -2.0379 1.117 -1.824 0.070 -4.243 0.167\n==============================================================================\nOmnibus: 37.294 Durbin-Watson: 1.779\nProb(Omnibus): 0.000 Jarque-Bera (JB): 55.871\nSkew: 1.179 Prob(JB): 7.38e-13\nKurtosis: 4.479 Cond. No. 9.31\n==============================================================================\n\nWarnings:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
]
],
[
[
"This is equivalent to doing a GLM fit with a gaussian family and identity link:",
"_____no_output_____"
]
],
[
[
"formula = \"\"\"y ~ C(color)\"\"\"\nresponse, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_color = sm.GLM(response, predictors, family=sm.families.Gaussian()).fit()\nprint(fit_color.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 169\nModel Family: Gaussian Df Model: 3\nLink Function: identity Scale: 9.6884\nMethod: IRLS Log-Likelihood: -439.89\nDate: Mon, 22 Jun 2020 Deviance: 1637.3\nTime: 23:43:23 Pearson chi2: 1.64e+03\nNo. Iterations: 3 \nCovariance Type: nonrobust \n=================================================================================\n coef std err z P>|z| [0.025 0.975]\n---------------------------------------------------------------------------------\nIntercept 4.0833 0.899 4.544 0.000 2.322 5.844\nC(color)[T.2] -0.7886 0.954 -0.827 0.408 -2.658 1.080\nC(color)[T.3] -1.8561 1.014 -1.831 0.067 -3.843 0.131\nC(color)[T.4] -2.0379 1.117 -1.824 0.068 -4.227 0.151\n=================================================================================\n"
]
],
[
[
"If we instead do a poisson fit:",
"_____no_output_____"
]
],
[
[
"formula = \"\"\"y ~ C(color)\"\"\"\nresponse, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_color2 = sm.GLM(\n response, predictors, family=sm.families.Poisson(link=sm.families.links.identity)\n).fit()\nprint(fit_color2.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 169\nModel Family: Poisson Df Model: 3\nLink Function: identity Scale: 1.0000\nMethod: IRLS Log-Likelihood: -482.22\nDate: Mon, 22 Jun 2020 Deviance: 609.14\nTime: 23:43:23 Pearson chi2: 584.\nNo. Iterations: 3 \nCovariance Type: nonrobust \n=================================================================================\n coef std err z P>|z| [0.025 0.975]\n---------------------------------------------------------------------------------\nIntercept 4.0833 0.583 7.000 0.000 2.940 5.227\nC(color)[T.2] -0.7886 0.612 -1.288 0.198 -1.989 0.412\nC(color)[T.3] -1.8561 0.625 -2.969 0.003 -3.081 -0.631\nC(color)[T.4] -2.0379 0.658 -3.096 0.002 -3.328 -0.748\n=================================================================================\n"
]
],
[
[
"And we get the same estimates as when using Gaussian family with identity link! Because the ML estimates for the poisson distirbution is also the sample mean if there is a single predictor. But the standard values are much smaller. Because the errors here are heteroskedastic while the gaussian version assume homoskesdasticity.",
"_____no_output_____"
],
[
"### Using both qualitative and quantitative variables",
"_____no_output_____"
]
],
[
[
"formula = \"\"\"y ~ weight + C(color)\"\"\"\nresponse, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_weight_color = sm.GLM(response, predictors, family=sm.families.Gaussian()).fit()\nprint(fit_weight_color.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 168\nModel Family: Gaussian Df Model: 4\nLink Function: identity Scale: 8.6370\nMethod: IRLS Log-Likelihood: -429.44\nDate: Mon, 22 Jun 2020 Deviance: 1451.0\nTime: 23:43:23 Pearson chi2: 1.45e+03\nNo. Iterations: 3 \nCovariance Type: nonrobust \n=================================================================================\n coef std err z P>|z| [0.025 0.975]\n---------------------------------------------------------------------------------\nIntercept -0.8232 1.355 -0.608 0.543 -3.479 1.832\nC(color)[T.2] -0.6181 0.901 -0.686 0.493 -2.384 1.148\nC(color)[T.3] -1.2404 0.966 -1.284 0.199 -3.134 0.653\nC(color)[T.4] -1.1882 1.070 -1.110 0.267 -3.286 0.910\nweight 1.8662 0.402 4.645 0.000 1.079 2.654\n=================================================================================\n"
],
[
"formula = \"\"\"y ~ weight + C(color)\"\"\"\nresponse, predictors = dmatrices(formula, crabs_df, return_type=\"dataframe\")\nfit_weight_color2 = sm.GLM(\n response, predictors, family=sm.families.Poisson(link=sm.families.links.identity())\n).fit()\nprint(fit_weight_color2.summary())",
" Generalized Linear Model Regression Results \n==============================================================================\nDep. Variable: y No. Observations: 173\nModel: GLM Df Residuals: 168\nModel Family: Poisson Df Model: 4\nLink Function: identity Scale: 1.0000\nMethod: IRLS Log-Likelihood: nan\nDate: Mon, 22 Jun 2020 Deviance: 534.33\nTime: 23:43:23 Pearson chi2: 529.\nNo. Iterations: 100 \nCovariance Type: nonrobust \n=================================================================================\n coef std err z P>|z| [0.025 0.975]\n---------------------------------------------------------------------------------\nIntercept -0.9930 0.736 -1.349 0.177 -2.436 0.450\nC(color)[T.2] -0.8442 0.615 -1.374 0.170 -2.049 0.360\nC(color)[T.3] -1.4320 0.629 -2.278 0.023 -2.664 -0.200\nC(color)[T.4] -1.2248 0.658 -1.861 0.063 -2.515 0.065\nweight 2.0086 0.173 11.641 0.000 1.670 2.347\n=================================================================================\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4a1ada0848ad3d6e4f663eaaf86d45da01532590
| 8,156 |
ipynb
|
Jupyter Notebook
|
docs/tutorials/notebooks/Load_LocData.ipynb
|
super-resolution/Locan
|
94ed7759f7d7ceddee7c7feaabff80010cfedf30
|
[
"BSD-3-Clause"
] | 8 |
2021-11-25T20:05:49.000Z
|
2022-03-27T17:45:00.000Z
|
docs/tutorials/notebooks/Load_LocData.ipynb
|
super-resolution/Locan
|
94ed7759f7d7ceddee7c7feaabff80010cfedf30
|
[
"BSD-3-Clause"
] | 4 |
2021-12-15T22:39:20.000Z
|
2022-03-11T17:35:34.000Z
|
docs/tutorials/notebooks/Load_LocData.ipynb
|
super-resolution/Locan
|
94ed7759f7d7ceddee7c7feaabff80010cfedf30
|
[
"BSD-3-Clause"
] | 1 |
2022-03-22T19:53:13.000Z
|
2022-03-22T19:53:13.000Z
| 23.104816 | 284 | 0.575405 |
[
[
[
"# Tutorial about loading localization data from file",
"_____no_output_____"
]
],
[
[
"from pathlib import Path\n\nimport locan as lc",
"_____no_output_____"
],
[
"lc.show_versions(system=False, dependencies=False, verbose=False)",
"_____no_output_____"
]
],
[
[
"Localization data is typically provided as text or binary file with different formats depending on the fitting software. Locan provides functions for loading various localization files. \n\nAll available functions can be looked up in the [API documentation](https://locan.readthedocs.io/en/latest/source/generated/locan.locan_io.locdata.html#module-locan.locan_io.locdata).",
"_____no_output_____"
],
[
"In locan there are functions availabel to deal with file types according to the constant enum `FileType`:",
"_____no_output_____"
]
],
[
[
"list(lc.FileType._member_names_)",
"_____no_output_____"
]
],
[
[
"Currently the following io functions are available:",
"_____no_output_____"
]
],
[
[
"[name for name in dir(lc.locan_io) if not name.startswith(\"__\")]",
"_____no_output_____"
]
],
[
[
"Throughout this manual it might be helpful to use pathlib to provide path information. In all cases a string path is also usable.",
"_____no_output_____"
],
[
"## Load rapidSTORM data file",
"_____no_output_____"
],
[
"Here we identify some data in the test_data directory and provide a path using pathlib (a pathlib object is returned by `lc.ROOT_DIR`):",
"_____no_output_____"
]
],
[
[
"path = lc.ROOT_DIR / 'tests/test_data/rapidSTORM_dstorm_data.txt'\nprint(path, '\\n')",
"_____no_output_____"
]
],
[
[
"The data is then loaded from a rapidSTORM localization file. The file header is read to provide correct property names. The number of localisations to be read can be limited by *nrows*",
"_____no_output_____"
]
],
[
[
"dat = lc.load_rapidSTORM_file(path=path, nrows=1000)",
"_____no_output_____"
]
],
[
[
"Print information about the data: ",
"_____no_output_____"
]
],
[
[
"print('Data head:')\nprint(dat.data.head(), '\\n')\nprint('Summary:')\ndat.print_summary()\nprint('Properties:')\nprint(dat.properties)",
"_____no_output_____"
]
],
[
[
"Column names are exchanged with standard locan property names according to the following mapping. If no mapping is defined a warning is issued and the original column name is kept.",
"_____no_output_____"
]
],
[
[
"lc.RAPIDSTORM_KEYS",
"_____no_output_____"
]
],
[
[
"## Load Zeiss Elyra data file",
"_____no_output_____"
],
[
"The Elyra super-resolution microscopy system from Zeiss uses as slightly different file format. Elyra column names are exchanged with locan property names upon loading the data.",
"_____no_output_____"
]
],
[
[
"path_Elyra = lc.ROOT_DIR / 'tests/test_data/Elyra_dstorm_data.txt'\nprint(path_Elyra, '\\n')",
"_____no_output_____"
],
[
"dat_Elyra = lc.load_Elyra_file(path=path_Elyra, nrows=1000)",
"_____no_output_____"
],
[
"print('Data head:')\nprint(dat_Elyra.data.head(), '\\n')\nprint('Summary:')\ndat_Elyra.print_summary()\nprint('Properties:')\nprint(dat_Elyra.properties)",
"_____no_output_____"
]
],
[
[
"## Localization data from a custom text file",
"_____no_output_____"
],
[
"Other custom text files can be read with a function that wraps the pandas.read_table() method.",
"_____no_output_____"
]
],
[
[
"path_csv = lc.ROOT_DIR / 'tests/test_data/five_blobs.txt'\nprint(path_csv, '\\n')",
"_____no_output_____"
]
],
[
[
"Here data is loaded from a comma-separated-value file. Column names are read from the first line and a warning is given if the naming does not comply with locan conventions. Column names can also be provided as *column*. The separater, e.g. a tab '\\t' can be provided as *sep*.",
"_____no_output_____"
]
],
[
[
"dat_csv = lc.load_txt_file(path=path_csv, sep=',', columns=None, nrows=100)",
"_____no_output_____"
],
[
"print('Data head:')\nprint(dat_csv.data.head(), '\\n')\nprint('Summary:')\ndat_csv.print_summary()\nprint('Properties:')\nprint(dat_csv.properties)",
"_____no_output_____"
]
],
[
[
"## Load localization data file",
"_____no_output_____"
],
[
"A general function for loading localization data is provided. Targeting specific localization file formats is done through the `file_format` parameter.",
"_____no_output_____"
]
],
[
[
"path = lc.ROOT_DIR / 'tests/test_data/rapidSTORM_dstorm_data.txt'\nprint(path, '\\n')",
"_____no_output_____"
],
[
"dat = lc.load_locdata(path=path, file_type=lc.FileType.RAPIDSTORM, nrows=1000)",
"_____no_output_____"
],
[
"dat.print_summary()",
"_____no_output_____"
]
],
[
[
"The file type can be specified by using the enum class `FileType` and use tab control to make a choice.",
"_____no_output_____"
]
],
[
[
"lc.FileType.__members__",
"_____no_output_____"
],
[
"lc.FileType.RAPIDSTORM",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1ae53d284f8c435a2df8c50d2f0c3ab4aa3ffe
| 34,163 |
ipynb
|
Jupyter Notebook
|
notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | 1 |
2021-11-02T07:05:50.000Z
|
2021-11-02T07:05:50.000Z
|
notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | null | null | null |
notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb
|
diemtvu/vertex-ai-samples
|
92506526dc3e246e16dfa71cb552d3ffabde1f73
|
[
"Apache-2.0"
] | null | null | null | 34.895812 | 313 | 0.525978 |
[
[
[
"# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Vertex Pipelines: AutoML tabular regression pipelines using google-cloud-pipeline-components\n\n<table align=\"left\">\n <td>\n <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Colab logo\"> Run in Colab\n </a>\n </td>\n <td>\n <a href=\"https://github.com/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\">\n View on GitHub\n </a>\n </td>\n <td>\n <a href=\"https://console.cloud.google.com/ai/platform/notebooks/deploy-notebook?download_url=https://github.com/GoogleCloudPlatform/vertex-ai-samples/notebooks/official/pipelines/google_cloud_pipeline_components_automl_tabular.ipynb\">\n Open in Google Cloud Notebooks\n </a>\n </td>\n</table>\n<br/><br/><br/>",
"_____no_output_____"
],
[
"## Overview\n\nThis notebook shows how to use the components defined in [`google_cloud_pipeline_components`](https://github.com/kubeflow/pipelines/tree/master/components/google-cloud) to build an AutoML tabular regression workflow on [Vertex Pipelines](https://cloud.google.com/vertex-ai/docs/pipelines).",
"_____no_output_____"
],
[
"### Dataset\n\nThe dataset used for this tutorial is the [California Housing dataset from the 1990 Census](https://developers.google.com/machine-learning/crash-course/california-housing-data-description)\n\nThe dataset predicts the median house price.",
"_____no_output_____"
],
[
"### Objective\n\nIn this tutorial, you create an AutoML tabular regression using a pipeline with components from `google_cloud_pipeline_components`.\n\nThe steps performed include:\n\n- Create a `Dataset` resource.\n- Train an AutoML `Model` resource.\n- Creates an `Endpoint` resource.\n- Deploys the `Model` resource to the `Endpoint` resource.\n\nThe components are [documented here](https://google-cloud-pipeline-components.readthedocs.io/en/latest/google_cloud_pipeline_components.aiplatform.html#module-google_cloud_pipeline_components.aiplatform).",
"_____no_output_____"
],
[
"### Costs\n\nThis tutorial uses billable components of Google Cloud:\n\n* Vertex AI\n* Cloud Storage\n\nLearn about [Vertex AI\npricing](https://cloud.google.com/vertex-ai/pricing) and [Cloud Storage\npricing](https://cloud.google.com/storage/pricing), and use the [Pricing\nCalculator](https://cloud.google.com/products/calculator/)\nto generate a cost estimate based on your projected usage.",
"_____no_output_____"
],
[
"### Set up your local development environment\n\nIf you are using Colab or Google Cloud Notebook, your environment already meets all the requirements to run this notebook. You can skip this step.\n\nOtherwise, make sure your environment meets this notebook's requirements. You need the following:\n\n- The Cloud Storage SDK\n- Git\n- Python 3\n- virtualenv\n- Jupyter notebook running in a virtual environment with Python 3\n\nThe Cloud Storage guide to [Setting up a Python development environment](https://cloud.google.com/python/setup) and the [Jupyter installation guide](https://jupyter.org/install) provide detailed instructions for meeting these requirements. The following steps provide a condensed set of instructions:\n\n1. [Install and initialize the SDK](https://cloud.google.com/sdk/docs/).\n\n2. [Install Python 3](https://cloud.google.com/python/setup#installing_python).\n\n3. [Install virtualenv](Ihttps://cloud.google.com/python/setup#installing_and_using_virtualenv) and create a virtual environment that uses Python 3.\n\n4. Activate that environment and run `pip3 install Jupyter` in a terminal shell to install Jupyter.\n\n5. Run `jupyter notebook` on the command line in a terminal shell to launch Jupyter.\n\n6. Open this notebook in the Jupyter Notebook Dashboard.\n",
"_____no_output_____"
],
[
"## Installation\n\nInstall the latest version of Vertex SDK for Python.",
"_____no_output_____"
]
],
[
[
"import os\n\n# Google Cloud Notebook\nif os.path.exists(\"/opt/deeplearning/metadata/env_version\"):\n USER_FLAG = \"--user\"\nelse:\n USER_FLAG = \"\"\n\n! pip3 install --upgrade google-cloud-aiplatform $USER_FLAG",
"_____no_output_____"
]
],
[
[
"Install the latest GA version of *google-cloud-storage* library as well.",
"_____no_output_____"
]
],
[
[
"! pip3 install -U google-cloud-storage $USER_FLAG",
"_____no_output_____"
]
],
[
[
"Install the latest GA version of *google-cloud-pipeline-components* library as well.",
"_____no_output_____"
]
],
[
[
"! pip3 install $USER kfp google-cloud-pipeline-components --upgrade",
"_____no_output_____"
]
],
[
[
"### Restart the kernel\n\nOnce you've installed the additional packages, you need to restart the notebook kernel so it can find the packages.",
"_____no_output_____"
]
],
[
[
"import os\n\nif not os.getenv(\"IS_TESTING\"):\n # Automatically restart kernel after installs\n import IPython\n\n app = IPython.Application.instance()\n app.kernel.do_shutdown(True)",
"_____no_output_____"
]
],
[
[
"Check the versions of the packages you installed. The KFP SDK version should be >=1.6.",
"_____no_output_____"
]
],
[
[
"! python3 -c \"import kfp; print('KFP SDK version: {}'.format(kfp.__version__))\"\n! python3 -c \"import google_cloud_pipeline_components; print('google_cloud_pipeline_components version: {}'.format(google_cloud_pipeline_components.__version__))\"",
"_____no_output_____"
]
],
[
[
"## Before you begin\n\n### GPU runtime\n\nThis tutorial does not require a GPU runtime.\n\n### Set up your Google Cloud project\n\n**The following steps are required, regardless of your notebook environment.**\n\n1. [Select or create a Google Cloud project](https://console.cloud.google.com/cloud-resource-manager). When you first create an account, you get a $300 free credit towards your compute/storage costs.\n\n2. [Make sure that billing is enabled for your project.](https://cloud.google.com/billing/docs/how-to/modify-project)\n\n3. [Enable the Vertex AI APIs, Compute Engine APIs, and Cloud Storage.](https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component,storage-component.googleapis.com)\n\n4. [The Google Cloud SDK](https://cloud.google.com/sdk) is already installed in Google Cloud Notebook.\n\n5. Enter your project ID in the cell below. Then run the cell to make sure the\nCloud SDK uses the right project for all the commands in this notebook.\n\n**Note**: Jupyter runs lines prefixed with `!` as shell commands, and it interpolates Python variables prefixed with `$`.",
"_____no_output_____"
]
],
[
[
"PROJECT_ID = \"[your-project-id]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if PROJECT_ID == \"\" or PROJECT_ID is None or PROJECT_ID == \"[your-project-id]\":\n # Get your GCP project id from gcloud\n shell_output = ! gcloud config list --format 'value(core.project)' 2>/dev/null\n PROJECT_ID = shell_output[0]\n print(\"Project ID:\", PROJECT_ID)",
"_____no_output_____"
],
[
"! gcloud config set project $PROJECT_ID",
"_____no_output_____"
]
],
[
[
"#### Region\n\nYou can also change the `REGION` variable, which is used for operations\nthroughout the rest of this notebook. Below are regions supported for Vertex AI. We recommend that you choose the region closest to you.\n\n- Americas: `us-central1`\n- Europe: `europe-west4`\n- Asia Pacific: `asia-east1`\n\nYou may not use a multi-regional bucket for training with Vertex AI. Not all regions provide support for all Vertex AI services.\n\nLearn more about [Vertex AI regions](https://cloud.google.com/vertex-ai/docs/general/locations)",
"_____no_output_____"
]
],
[
[
"REGION = \"us-central1\" # @param {type: \"string\"}",
"_____no_output_____"
]
],
[
[
"#### Timestamp\n\nIf you are in a live tutorial session, you might be using a shared test account or project. To avoid name collisions between users on resources created, you create a timestamp for each instance session, and append the timestamp onto the name of resources you create in this tutorial.",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\n\nTIMESTAMP = datetime.now().strftime(\"%Y%m%d%H%M%S\")",
"_____no_output_____"
]
],
[
[
"### Authenticate your Google Cloud account\n\n**If you are using Google Cloud Notebook**, your environment is already authenticated. Skip this step.\n\n**If you are using Colab**, run the cell below and follow the instructions when prompted to authenticate your account via oAuth.\n\n**Otherwise**, follow these steps:\n\nIn the Cloud Console, go to the [Create service account key](https://console.cloud.google.com/apis/credentials/serviceaccountkey) page.\n\n**Click Create service account**.\n\nIn the **Service account name** field, enter a name, and click **Create**.\n\nIn the **Grant this service account access to project** section, click the Role drop-down list. Type \"Vertex\" into the filter box, and select **Vertex Administrator**. Type \"Storage Object Admin\" into the filter box, and select **Storage Object Admin**.\n\nClick Create. A JSON file that contains your key downloads to your local environment.\n\nEnter the path to your service account key as the GOOGLE_APPLICATION_CREDENTIALS variable in the cell below and run the cell.",
"_____no_output_____"
]
],
[
[
"# If you are running this notebook in Colab, run this cell and follow the\n# instructions to authenticate your GCP account. This provides access to your\n# Cloud Storage bucket and lets you submit training jobs and prediction\n# requests.\n\nimport os\nimport sys\n\n# If on Google Cloud Notebook, then don't execute this code\nif not os.path.exists(\"/opt/deeplearning/metadata/env_version\"):\n if \"google.colab\" in sys.modules:\n from google.colab import auth as google_auth\n\n google_auth.authenticate_user()\n\n # If you are running this notebook locally, replace the string below with the\n # path to your service account key and run this cell to authenticate your GCP\n # account.\n elif not os.getenv(\"IS_TESTING\"):\n %env GOOGLE_APPLICATION_CREDENTIALS ''",
"_____no_output_____"
]
],
[
[
"### Create a Cloud Storage bucket\n\n**The following steps are required, regardless of your notebook environment.**\n\nWhen you initialize the Vertex SDK for Python, you specify a Cloud Storage staging bucket. The staging bucket is where all the data associated with your dataset and model resources are retained across sessions.\n\nSet the name of your Cloud Storage bucket below. Bucket names must be globally unique across all Google Cloud projects, including those outside of your organization.",
"_____no_output_____"
]
],
[
[
"BUCKET_NAME = \"gs://[your-bucket-name]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if BUCKET_NAME == \"\" or BUCKET_NAME is None or BUCKET_NAME == \"gs://[your-bucket-name]\":\n BUCKET_NAME = \"gs://\" + PROJECT_ID + \"aip-\" + TIMESTAMP",
"_____no_output_____"
]
],
[
[
"**Only if your bucket doesn't already exist**: Run the following cell to create your Cloud Storage bucket.",
"_____no_output_____"
]
],
[
[
"! gsutil mb -l $REGION $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"Finally, validate access to your Cloud Storage bucket by examining its contents:",
"_____no_output_____"
]
],
[
[
"! gsutil ls -al $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"#### Service Account\n\n**If you don't know your service account**, try to get your service account using `gcloud` command by executing the second cell below.",
"_____no_output_____"
]
],
[
[
"SERVICE_ACCOUNT = \"[your-service-account]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if (\n SERVICE_ACCOUNT == \"\"\n or SERVICE_ACCOUNT is None\n or SERVICE_ACCOUNT == \"[your-service-account]\"\n):\n # Get your GCP project id from gcloud\n shell_output = !gcloud auth list 2>/dev/null\n SERVICE_ACCOUNT = shell_output[2].strip()\n print(\"Service Account:\", SERVICE_ACCOUNT)",
"_____no_output_____"
]
],
[
[
"#### Set service account access for Vertex Pipelines\n\nRun the following commands to grant your service account access to read and write pipeline artifacts in the bucket that you created in the previous step -- you only need to run these once per service account.",
"_____no_output_____"
]
],
[
[
"! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.objectCreator $BUCKET_NAME\n\n! gsutil iam ch serviceAccount:{SERVICE_ACCOUNT}:roles/storage.objectViewer $BUCKET_NAME",
"_____no_output_____"
]
],
[
[
"### Set up variables\n\nNext, set up some variables used throughout the tutorial.\n### Import libraries and define constants",
"_____no_output_____"
]
],
[
[
"import google.cloud.aiplatform as aip",
"_____no_output_____"
]
],
[
[
"#### Vertex AI constants\n\nSetup up the following constants for Vertex AI:\n\n- `API_ENDPOINT`: The Vertex AI API service endpoint for `Dataset`, `Model`, `Job`, `Pipeline` and `Endpoint` services.",
"_____no_output_____"
]
],
[
[
"# API service endpoint\nAPI_ENDPOINT = \"{}-aiplatform.googleapis.com\".format(REGION)",
"_____no_output_____"
]
],
[
[
"#### Vertex Pipelines constants\n\nSetup up the following constants for Vertex Pipelines:",
"_____no_output_____"
]
],
[
[
"PIPELINE_ROOT = \"{}/pipeline_root/cal_housing\".format(BUCKET_NAME)",
"_____no_output_____"
]
],
[
[
"Additional imports.",
"_____no_output_____"
]
],
[
[
"import kfp\nfrom google_cloud_pipeline_components import aiplatform as gcc_aip",
"_____no_output_____"
]
],
[
[
"## Initialize Vertex SDK for Python\n\nInitialize the Vertex SDK for Python for your project and corresponding bucket.",
"_____no_output_____"
]
],
[
[
"aip.init(project=PROJECT_ID, staging_bucket=BUCKET_NAME)",
"_____no_output_____"
]
],
[
[
"## Define AutoML tabular regression model pipeline that uses components from `google_cloud_pipeline_components`\n\nNext, you define the pipeline.\n\nCreate and deploy an AutoML tabular regression `Model` resource using a `Dataset` resource.",
"_____no_output_____"
]
],
[
[
"TRAIN_FILE_NAME = \"california_housing_train.csv\"\n! gsutil cp gs://aju-dev-demos-codelabs/sample_data/california_housing_train.csv {PIPELINE_ROOT}/data/\n\ngcs_csv_path = f\"{PIPELINE_ROOT}/data/{TRAIN_FILE_NAME}\"\n\n\[email protected](name=\"automl-tab-training-v2\")\ndef pipeline(project: str = PROJECT_ID):\n\n dataset_create_op = gcc_aip.TabularDatasetCreateOp(\n project=project, display_name=\"housing\", gcs_source=gcs_csv_path\n )\n\n training_op = gcc_aip.AutoMLTabularTrainingJobRunOp(\n project=project,\n display_name=\"train-automl-cal_housing\",\n optimization_prediction_type=\"regression\",\n optimization_objective=\"minimize-rmse\",\n column_transformations=[\n {\"numeric\": {\"column_name\": \"longitude\"}},\n {\"numeric\": {\"column_name\": \"latitude\"}},\n {\"numeric\": {\"column_name\": \"housing_median_age\"}},\n {\"numeric\": {\"column_name\": \"total_rooms\"}},\n {\"numeric\": {\"column_name\": \"total_bedrooms\"}},\n {\"numeric\": {\"column_name\": \"population\"}},\n {\"numeric\": {\"column_name\": \"households\"}},\n {\"numeric\": {\"column_name\": \"median_income\"}},\n {\"numeric\": {\"column_name\": \"median_house_value\"}},\n ],\n dataset=dataset_create_op.outputs[\"dataset\"],\n target_column=\"median_house_value\",\n )\n\n deploy_op = gcc_aip.ModelDeployOp( # noqa: F841\n model=training_op.outputs[\"model\"],\n project=project,\n machine_type=\"n1-standard-4\",\n )",
"_____no_output_____"
]
],
[
[
"## Compile the pipeline\n\nNext, compile the pipeline.",
"_____no_output_____"
]
],
[
[
"from kfp.v2 import compiler # noqa: F811\n\ncompiler.Compiler().compile(\n pipeline_func=pipeline,\n package_path=\"tabular regression_pipeline.json\".replace(\" \", \"_\"),\n)",
"_____no_output_____"
]
],
[
[
"## Run the pipeline\n\nNext, run the pipeline.",
"_____no_output_____"
]
],
[
[
"DISPLAY_NAME = \"cal_housing_\" + TIMESTAMP\n\njob = aip.PipelineJob(\n display_name=DISPLAY_NAME,\n template_path=\"tabular regression_pipeline.json\".replace(\" \", \"_\"),\n pipeline_root=PIPELINE_ROOT,\n)\n\njob.run()",
"_____no_output_____"
]
],
[
[
"Click on the generated link to see your run in the Cloud Console.\n\n<!-- It should look something like this as it is running:\n\n<a href=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" target=\"_blank\"><img src=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" width=\"40%\"/></a> -->\n\nIn the UI, many of the pipeline DAG nodes will expand or collapse when you click on them. Here is a partially-expanded view of the DAG (click image to see larger version).\n\n<a href=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" target=\"_blank\"><img src=\"https://storage.googleapis.com/amy-jo/images/mp/automl_tabular_classif.png\" width=\"40%\"/></a>",
"_____no_output_____"
],
[
"# Cleaning up\n\nTo clean up all Google Cloud resources used in this project, you can [delete the Google Cloud\nproject](https://cloud.google.com/resource-manager/docs/creating-managing-projects#shutting_down_projects) you used for the tutorial.\n\nOtherwise, you can delete the individual resources you created in this tutorial -- *Note:* this is auto-generated and not all resources may be applicable for this tutorial:\n\n- Dataset\n- Pipeline\n- Model\n- Endpoint\n- Batch Job\n- Custom Job\n- Hyperparameter Tuning Job\n- Cloud Storage Bucket",
"_____no_output_____"
]
],
[
[
"delete_dataset = True\ndelete_pipeline = True\ndelete_model = True\ndelete_endpoint = True\ndelete_batchjob = True\ndelete_customjob = True\ndelete_hptjob = True\ndelete_bucket = True\n\ntry:\n if delete_model and \"DISPLAY_NAME\" in globals():\n models = aip.Model.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n model = models[0]\n aip.Model.delete(model)\n print(\"Deleted model:\", model)\nexcept Exception as e:\n print(e)\n\ntry:\n if delete_endpoint and \"DISPLAY_NAME\" in globals():\n endpoints = aip.Endpoint.list(\n filter=f\"display_name={DISPLAY_NAME}_endpoint\", order_by=\"create_time\"\n )\n endpoint = endpoints[0]\n endpoint.undeploy_all()\n aip.Endpoint.delete(endpoint.resource_name)\n print(\"Deleted endpoint:\", endpoint)\nexcept Exception as e:\n print(e)\n\nif delete_dataset and \"DISPLAY_NAME\" in globals():\n if \"tabular\" == \"tabular\":\n try:\n datasets = aip.TabularDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.TabularDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"tabular\" == \"image\":\n try:\n datasets = aip.ImageDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.ImageDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"tabular\" == \"text\":\n try:\n datasets = aip.TextDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.TextDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\n if \"tabular\" == \"video\":\n try:\n datasets = aip.VideoDataset.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n dataset = datasets[0]\n aip.VideoDataset.delete(dataset.resource_name)\n print(\"Deleted dataset:\", dataset)\n except Exception as e:\n print(e)\n\ntry:\n if delete_pipeline and \"DISPLAY_NAME\" in globals():\n pipelines = aip.PipelineJob.list(\n filter=f\"display_name={DISPLAY_NAME}\", order_by=\"create_time\"\n )\n pipeline = pipelines[0]\n aip.PipelineJob.delete(pipeline.resource_name)\n print(\"Deleted pipeline:\", pipeline)\nexcept Exception as e:\n print(e)\n\nif delete_bucket and \"BUCKET_NAME\" in globals():\n ! gsutil rm -r $BUCKET_NAME",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a1ae6fb5d733935cf97b9279164962b71d93ec5
| 224,668 |
ipynb
|
Jupyter Notebook
|
Section-05-Oversampling/05-02-SMOTE.ipynb
|
bkiselgof/machine-learning-imbalanced-data
|
a5a4b8613411e42c041c103b72394b53c9fa0d62
|
[
"BSD-3-Clause"
] | null | null | null |
Section-05-Oversampling/05-02-SMOTE.ipynb
|
bkiselgof/machine-learning-imbalanced-data
|
a5a4b8613411e42c041c103b72394b53c9fa0d62
|
[
"BSD-3-Clause"
] | null | null | null |
Section-05-Oversampling/05-02-SMOTE.ipynb
|
bkiselgof/machine-learning-imbalanced-data
|
a5a4b8613411e42c041c103b72394b53c9fa0d62
|
[
"BSD-3-Clause"
] | 1 |
2021-07-16T02:37:51.000Z
|
2021-07-16T02:37:51.000Z
| 684.963415 | 77,876 | 0.953086 |
[
[
[
"# SMOTE\n\nCreates new samples by interpolation of samples of the minority class and any of its k nearest neighbours (also from the minority class). K is typically 5.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\nfrom sklearn.datasets import make_blobs\nfrom imblearn.over_sampling import SMOTE",
"_____no_output_____"
]
],
[
[
"## Create data\n\nhttps://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_blobs.html\n\nWe will create 2 classes, one majority one minority, clearly separated to facilitate the demonstration.",
"_____no_output_____"
]
],
[
[
"# Configuration options\nblobs_random_seed = 42\ncenters = [(0, 0), (5, 5)]\ncluster_std = 1.5\nnum_features_for_samples = 2\nnum_samples_total = 1600\n\n# Generate X\nX, y = make_blobs(\n n_samples=num_samples_total,\n centers=centers,\n n_features=num_features_for_samples,\n cluster_std=cluster_std)\n\n# transform arrays to pandas formats\nX = pd.DataFrame(X, columns=['VarA', 'VarB'])\ny = pd.Series(y)\n\n# create an imbalancced Xset\n# (make blobs creates same number of obs per class\n# we need to downsample manually)\nX = pd.concat([\n X[y == 0],\n X[y == 1].sample(200, random_state=42)\n], axis=0)\n\ny = y.loc[X.index]\n\n# display size\nX.shape, y.shape",
"_____no_output_____"
],
[
"sns.scatterplot(\n data=X, x=\"VarA\", y=\"VarB\", hue=y, alpha=0.5\n)\n\nplt.title('Toy dataset')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## SMOTE\n\nhttps://imbalanced-learn.org/stable/generated/imblearn.over_sampling.SMOTE.html",
"_____no_output_____"
]
],
[
[
"sm = SMOTE(\n sampling_strategy='auto', # samples only the minority class\n random_state=0, # for reproducibility\n k_neighbors=5,\n n_jobs=4\n)\n\nX_res, y_res = sm.fit_resample(X, y)",
"_____no_output_____"
],
[
"# size of original data\n\nX.shape, y.shape",
"_____no_output_____"
],
[
"# size of undersampled data\n\nX_res.shape, y_res.shape",
"_____no_output_____"
],
[
"# number of minority class observations\n\ny.value_counts(), y_res.value_counts()",
"_____no_output_____"
],
[
"# plot of original data\n\nsns.scatterplot(\n data=X, x=\"VarA\", y=\"VarB\", hue=y,alpha=0.5\n)\n\nplt.title('Original dataset')\nplt.show()",
"_____no_output_____"
],
[
"# plot of original data\n\nsns.scatterplot(\n data=X_res, x=\"VarA\", y=\"VarB\", hue=y_res, alpha=0.5\n)\n\nplt.title('Over-sampled dataset')\nplt.show()",
"_____no_output_____"
]
],
[
[
"There are now new observations that differ from the original ones. ",
"_____no_output_____"
],
[
"**HOMEWORK**\n\n- Test SMOTE in one of the datasets from imbalanced-learn and make some plots of variables highlighting the minority class to play and visualize the outcome better. \n\n- Change the parameter strategy and k_neighbor in the current notebook to attain different proportions of minority class and different new samples. Explore their distributions.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a1af1c83c42e97208186524ccb017af3b5d4c3b
| 4,179 |
ipynb
|
Jupyter Notebook
|
problem_#8.ipynb
|
KuniXl/daily_coding_problems
|
d0ce990ee7942abd7ee1577a562c7ba58d500c28
|
[
"MIT"
] | null | null | null |
problem_#8.ipynb
|
KuniXl/daily_coding_problems
|
d0ce990ee7942abd7ee1577a562c7ba58d500c28
|
[
"MIT"
] | null | null | null |
problem_#8.ipynb
|
KuniXl/daily_coding_problems
|
d0ce990ee7942abd7ee1577a562c7ba58d500c28
|
[
"MIT"
] | null | null | null | 23.744318 | 117 | 0.430725 |
[
[
[
"# Daily Coding Problem #8",
"_____no_output_____"
],
[
"A unival tree (which stands for \"universal value\") is a tree where all nodes under it have the same value.\n\nGiven the root to a binary tree, count the number of unival subtrees.\n\nFor example, the following tree has 5 unival subtrees:",
"_____no_output_____"
]
],
[
[
"tree = \"\"\" \n 0\n / \\\\\n 1 0\n / \\\\\n 1 0\n / \\\\\n 1 1\"\"\"",
"_____no_output_____"
],
[
"class Node:\n def __init__(self, val, left=None, right=None):\n self.val = val\n self.left = left\n self.right = right\n\ndef count_unival_subtrees_helper(subroot):\n if subroot == None:\n return 0, None\n \n left = subroot.left\n right = subroot.right\n \n count, val = count_unival_subtrees_helper(left)\n count2, val2 = count_unival_subtrees_helper(right)\n count = count + count2\n \n if subroot.left == None and subroot.right == None:\n #print(\"+1\")\n return 1+count, subroot.val\n \n if not (subroot.left and subroot.right):\n if subroot.val == val or subroot.val == val2:\n #print(\"+1\")\n return count+1, subroot.val\n else:\n #print(\"+0\")\n return count, None\n \n if val == val2 == subroot.val:\n #print(\"+1\")\n return 1 + count, subroot.val\n \n return count, None\n\ndef count_unival_subtrees(root):\n return count_unival_subtrees_helper(root)[0]\n \ntree = \"\"\" \n 0\n / \\\\\n 1 0\n / \\\\\n 1 0\n / \\\\\n 1 1\"\"\"\n\n_root = Node(val=0, left=Node(val=1),\n right=Node(val=0, left=Node(val=1, left=Node(val=1), right=Node(val=1)), right=Node(val=0)))\nprint(tree, '\\nNum of unival subtrees: ' + str(count_unival_subtrees(_root)))",
" \n 0\n / \\\n 1 0\n / \\\n 1 0\n / \\\n 1 1 \nNum of unival subtrees: 5\n"
],
[
"tree = \"\"\" \n 1\n \\\\\n 1\n / \\\\\n 1 1\n / \\\\\n 1 1\"\"\"\n_root = Node(val=1,\n right=Node(val=1, left=Node(val=1, left=Node(val=1), right=Node(val=1)), right=Node(val=1)))\nprint(tree, '\\nNum of unival subtrees: ' + str(count_unival_subtrees(_root)))",
" \n 1\n \\\n 1\n / \\\n 1 1\n / \\\n 1 1 \nNum of unival subtrees: 6\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a1af379e84f9c357df90a393e1a27b97ca8c9bd
| 211,827 |
ipynb
|
Jupyter Notebook
|
analysis/census/.ipynb_checkpoints/census data-checkpoint.ipynb
|
amckennafoster/seattle-littlefreelibrary
|
2a5d888d55d0d53b8d4ea1d2df3c974df30bdfb3
|
[
"MIT"
] | null | null | null |
analysis/census/.ipynb_checkpoints/census data-checkpoint.ipynb
|
amckennafoster/seattle-littlefreelibrary
|
2a5d888d55d0d53b8d4ea1d2df3c974df30bdfb3
|
[
"MIT"
] | null | null | null |
analysis/census/.ipynb_checkpoints/census data-checkpoint.ipynb
|
amckennafoster/seattle-littlefreelibrary
|
2a5d888d55d0d53b8d4ea1d2df3c974df30bdfb3
|
[
"MIT"
] | null | null | null | 43.416069 | 14,796 | 0.563375 |
[
[
[
"# Pull census data for the neighborhoods in Seattle\nUse this link to find tables: https://api.census.gov/data/2018/acs/acs5/variables.html",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport censusdata\nimport csv\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport scipy\nfrom scipy import stats",
"_____no_output_____"
],
[
"sample = censusdata.search('acs5', 2018,'concept', 'household income')",
"_____no_output_____"
],
[
"print(sample[0])",
"('B19001A_001E', 'HOUSEHOLD INCOME IN THE PAST 12 MONTHS (IN 2018 INFLATION-ADJUSTED DOLLARS) (WHITE ALONE HOUSEHOLDER)', 'Estimate!!Total')\n"
],
[
"sample = censusdata.search('acs5', 2018,'concept', 'population')",
"_____no_output_____"
],
[
"print(sample[:5])",
"[('B00001_001E', 'UNWEIGHTED SAMPLE COUNT OF THE POPULATION', 'Estimate!!Total'), ('B01003_001E', 'TOTAL POPULATION', 'Estimate!!Total'), ('B05006PR_001E', 'PLACE OF BIRTH FOR THE FOREIGN-BORN POPULATION IN PUERTO RICO', 'Estimate!!Total'), ('B05006PR_002E', 'PLACE OF BIRTH FOR THE FOREIGN-BORN POPULATION IN PUERTO RICO', 'Estimate!!Total!!Europe'), ('B05006PR_003E', 'PLACE OF BIRTH FOR THE FOREIGN-BORN POPULATION IN PUERTO RICO', 'Estimate!!Total!!Europe!!Northern Europe')]\n"
],
[
"states = censusdata.geographies(censusdata.censusgeo([('state', '*')]), 'acs5', 2018)",
"_____no_output_____"
],
[
"print(states['Washington'])",
"Summary level: 040, state:53\n"
],
[
"counties = censusdata.geographies(censusdata.censusgeo([('state', '53'), ('county', '*')]), 'acs5', 2018)",
"_____no_output_____"
],
[
"print(counties['King County, Washington'])",
"Summary level: 050, state:53> county:033\n"
]
],
[
[
"## Collect Population Data for King County",
"_____no_output_____"
]
],
[
[
"data = censusdata.download('acs5', 2018,\n censusdata.censusgeo([('state', '53'),\n ('county', '033'),\n ('tract', '*')]),\n ['B01003_001E'])",
"_____no_output_____"
],
[
"df = data",
"_____no_output_____"
],
[
"df = df.reset_index()\ndf = df.rename(columns={\"index\": \"tract\", \"B01003_001E\":\"pop\"})\ndf.head()",
"_____no_output_____"
],
[
"#convert object type to string\ndf['tract']= df['tract'].astype(str)",
"_____no_output_____"
],
[
"#Split out uneeded info\ndf[['tract']] = df['tract'].str.split(',').str[0] #Get the first value\ndf[['tract']] = df['tract'].str.split(' ').str[2] #Remove the words so only tract number remains",
"_____no_output_____"
],
[
"#convert object type to float\ndf['tract']= df['tract'].astype(float)",
"_____no_output_____"
],
[
"#There may be missing values listed as -666666. Delete those.\ndf = df[df['B01003_001E'] >= 0]\ndf.head()",
"_____no_output_____"
],
[
"df = df.sort_values(by=['tract'])\ndf.head()",
"_____no_output_____"
],
[
"df.to_csv('pop-by-tract.csv', mode = 'w', index=False)",
"_____no_output_____"
]
],
[
[
"## Collect income data for King County",
"_____no_output_____"
]
],
[
[
"data = censusdata.download('acs5', 2018,\n censusdata.censusgeo([('state', '53'),\n ('county', '033'),\n ('tract', '*')]),\n ['B19013_001E'])",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"data['tract']=data.index",
"_____no_output_____"
],
[
"df = data",
"_____no_output_____"
],
[
"#convert object type to string\ndf['tract']= df['tract'].astype(str)",
"_____no_output_____"
],
[
"#Split out uneeded info\ndf[['tract']] = df['tract'].str.split(',').str[0] #Get the first value\ndf[['tract']] = df['tract'].str.split(' ').str[2] #Remove the words so only tract number remains",
"_____no_output_____"
],
[
"#convert object type to float\ndf['tract']= df['tract'].astype(float)",
"_____no_output_____"
],
[
"#There may be missing values listed as -666666. Delete those.\ndf = df[df['B19013_001E'] >= 0]\ndf.head()",
"_____no_output_____"
],
[
"df.to_csv('seattle-census-tract-acs5-2018.csv', mode = 'w', index=False)",
"_____no_output_____"
],
[
"#Open the full tract file if needed\ndf = pd.read_csv('seattle-census-tract-acs5-2018.csv',encoding='utf-8')",
"_____no_output_____"
]
],
[
[
"### Regression for income and LFLs per population for all of Seattle\nThis merges population and lfl number data for tracts with the income data",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"#Open the file if needed\ndfinc = pd.read_csv('seattle-census-tract-acs5-2018.csv',encoding='utf-8')\nlflvtract = pd.read_csv('census-tracts-lfl-counts.csv',encoding='utf-8')\npop = pd.read_csv('pop-by-tract.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the population dataframe\ndfregr = pd.merge(dfinc, pop, on='tract', how='inner')\ndfregr.head()",
"_____no_output_____"
],
[
"#Merge with the lfl number dataset\ndfregr = pd.merge(dfregr, lflvtract, on='tract', how='inner')\ndfregr.head()",
"_____no_output_____"
],
[
"dfregr['lflperpop'] = dfregr['numlfls']/dfregr['pop']",
"_____no_output_____"
],
[
"#In case there are any negative values\ndfregr = dfregr[dfregr['household_income'] >= 0]",
"_____no_output_____"
],
[
"ax = sns.scatterplot(x=\"household_income\", y=\"lflperpop\", data=dfregr)\nax.set(ylim=(0, 0.005))",
"_____no_output_____"
],
[
"x = dfregr[['household_income']]\ny = dfregr[['lflperpop']]",
"_____no_output_____"
],
[
"model = LinearRegression().fit(x, y)\nr_sq = model.score(x, y)\nprint('coefficient of determination:', r_sq)\nprint('intercept:', model.intercept_)\nprint('slope:', model.coef_)",
"coefficient of determination: 0.22804078863785715\nintercept: [-0.00018629]\nslope: [[7.64326001e-09]]\n"
]
],
[
[
"### Check for Normality",
"_____no_output_____"
]
],
[
[
"#Create list of values to check - standardized number of lfls\nlflperpop = dfregr['lflperpop']",
"_____no_output_____"
],
[
"plt.hist(lflperpop)\nplt.show()",
"_____no_output_____"
],
[
"#Create list of values to check - income\nincome = dfregr['household_income']",
"_____no_output_____"
],
[
"plt.hist(income)\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Because the number of lfls is not normally distributed, use Spearman's correlation coefficien\nhttps://www.ncbi.nlm.nih.gov/pmc/articles/PMC3576830/#:~:text=In%20summary%2C%20correlation%20coefficients%20are,otherwise%20use%20Spearman's%20correlation%20coefficient.",
"_____no_output_____"
]
],
[
[
"#Spearmans Correlation for all variables in the table\ndfregr.corr(method='spearman')",
"_____no_output_____"
]
],
[
[
"household_income vs lflperpop is what we're interested in. 0.5 is considered moderate correlation. So moderate positive correlation",
"_____no_output_____"
],
[
"### Use SciPy to calculate spearman with p value for trend",
"_____no_output_____"
]
],
[
[
"#The %.3f' sets the number of decimal places\ncoef, p = stats.spearmanr(dfregr['household_income'],dfregr['lflperpop'])\nprint('Spearmans correlation coefficient: %.3f' % coef,' p-value: %.3f' % p)",
"Spearmans correlation coefficient: 0.502 p-value: 0.000\n"
]
],
[
[
"## Collect diversity numbers",
"_____no_output_____"
]
],
[
[
"sample = censusdata.search('acs5', 2018,'concept', 'families')\nprint(sample[0])",
"('B05009_001E', 'AGE AND NATIVITY OF OWN CHILDREN UNDER 18 YEARS IN FAMILIES AND SUBFAMILIES BY NUMBER AND NATIVITY OF PARENTS', 'Estimate!!Total')\n"
],
[
"# This gets data for total, white, african american, american indian, asian, hawaiian, other, and three combineation categories.\n#https://api.census.gov/data/2016/acs/acs5/groups/B02001.html\ndivdata = censusdata.download('acs5', 2016,\n censusdata.censusgeo([('state', '53'),\n ('county', '033'),\n ('tract', '*')]),\n ['B02001_001E',\n 'B02001_002E', \n 'B02001_003E',\n 'B02001_004E',\n 'B02001_005E',\n 'B02001_006E',\n 'B02001_007E',\n 'B02001_008E',\n 'B02001_009E',\n 'B02001_010E'])",
"_____no_output_____"
],
[
"divdata.head()",
"_____no_output_____"
],
[
"#Create a new dataframe in case something gets messed up\ndf = divdata\n\n#Rename columns and parse index\ndf['tract']=df.index\n#convert object type to string\ndf['tract']= df['tract'].astype(str)\n#Split out uneeded info\ndf[['tract']] = df['tract'].str.split(',').str[0] #Get the first value\ndf[['tract']] = df['tract'].str.split(' ').str[2] #Remove the words so only tract number remains\n#convert object type to float\ndf['tract']= df['tract'].astype(float)\ndf.rename(columns={'B02001_001E':'tot','B02001_002E':'wh',\n 'B02001_003E':'afam',\n 'B02001_004E':'amin',\n 'B02001_005E':'as',\n 'B02001_006E':'hw',\n 'B02001_007E':'ot',\n 'B02001_008E':'combo1',\n 'B02001_009E':'combo2',\n 'B02001_010E':'combo3'}, inplace=True)\n\n#Drop any rows that have a zero for tot column\ndf.drop(df[df['tot'] == 0].index, inplace = True) \n\ndf.head()",
"_____no_output_____"
],
[
"df = df.reset_index()\ndf = df.drop(columns=['index'])\ndf.head()",
"_____no_output_____"
]
],
[
[
"#### Calculate simpsons index (gini index is 1-simpsons)\nSimpsons is the sum of the squared category proportions. Lower value is more diverse. Gini-Simpsons, higher value more diverse",
"_____no_output_____"
]
],
[
[
"def simpsons(row):\n return (row['wh'] / row['tot'])**2 + (row['afam'] / row['tot'])**2 + (row['amin'] / row['tot'])**2 + (row['as'] / row['tot'])**2 + (row['hw'] / row['tot'])**2 + (row['ot'] / row['tot'])**2 + (row['combo1'] / row['tot'])**2 + (row['combo2'] / row['tot'])**2 + (row['combo3'] / row['tot'])**2\n\ndf['simpsons'] = df.apply(simpsons, axis=1)\ndf['gini-simp'] = 1 - df['simpsons']\ndf.head()",
"_____no_output_____"
],
[
"#Save file as csv\ndf.to_csv('diversity-seattle-census-tract-acs5-2018.csv', mode = 'w', index=False)",
"_____no_output_____"
]
],
[
[
"## Education Levels",
"_____no_output_____"
]
],
[
[
"data = censusdata.download('acs5', 2018,\n censusdata.censusgeo([('state', '53'),\n ('county', '033'),\n ('tract', '*')]),\n ['B06009_005E', 'B06009_006E'])",
"_____no_output_____"
],
[
"data['tract']=data.index\ndf = data",
"_____no_output_____"
],
[
"df['collegePlus'] = df['B06009_005E'] + df['B06009_006E']\ndf.drop(columns=['B06009_005E','B06009_006E'], inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"#convert object type to string\ndf['tract']= df['tract'].astype(str)",
"_____no_output_____"
],
[
"#Split out uneeded info\ndf[['tract']] = df['tract'].str.split(',').str[0] #Get the first value\ndf[['tract']] = df['tract'].str.split(' ').str[2] #Remove the words so only tract number remains",
"_____no_output_____"
],
[
"#convert object type to float\ndf['tract']= df['tract'].astype(float)",
"_____no_output_____"
],
[
"#There may be missing values listed as -666666. Delete those.\ndf = df[df['collegePlus'] >= 0]\ndf.head()",
"_____no_output_____"
],
[
"df = df.reset_index()\ndf = df.drop(columns=['index'])\ndf.head()",
"_____no_output_____"
],
[
"df.to_csv('seattle-census-tract-acs5-2018-edu.csv', mode = 'w', index=False)",
"_____no_output_____"
],
[
"#Open the edu tract file if needed\n#dfedu = df\ndfedu = pd.read_csv('seattle-census-tract-acs5-2018-edu.csv',encoding='utf-8')",
"_____no_output_____"
]
],
[
[
"## Calculate correlation between number of lfls per pop and education level",
"_____no_output_____"
]
],
[
[
"#Open census tract csv with the counts of lfls\n#I used QGIS to make a csv with the number of lfls per area for each census tract\nlflvtract = pd.read_csv('census-tracts-lfl-counts.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the lfl number dataset\ndfedulfl = pd.merge(lflvtract, dfedu, on='tract', how='inner')\ndfedulfl.head()",
"_____no_output_____"
],
[
"#Open the population data\npop = pd.read_csv('pop-by-tract.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the population dataframe\ndfedulfl = pd.merge(dfedulfl, pop, on='tract', how='inner')\ndfedulfl.head()",
"_____no_output_____"
],
[
"dfedulfl['lflperpop']=dfedulfl['numlfls']/dfedulfl['pop']",
"_____no_output_____"
],
[
"ax = sns.scatterplot(x=\"collegePlus\", y=\"lflperpop\", data=dfedulfl)\nax.set(ylim=(0, 0.005))",
"_____no_output_____"
],
[
"#Create list of values to check\nedu = dfedulfl['collegePlus']",
"_____no_output_____"
],
[
"plt.hist(edu)\nplt.show()",
"_____no_output_____"
],
[
"#Create list of values to check - income\nlflperpop = dfedulfl['lflperpop']",
"_____no_output_____"
],
[
"plt.hist(lflperpop)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Neither are normal most likely so use Spearman's",
"_____no_output_____"
]
],
[
[
"dfedulfl.corr(method='spearman')",
"_____no_output_____"
]
],
[
[
"A value of 0.15 is very weakly positively correlated",
"_____no_output_____"
]
],
[
[
"#Use SciPy\n#The %.3f' sets the number of decimal places\ncoef, p = stats.spearmanr(dfedulfl['collegePlus'],dfedulfl['lflperpop'])\nprint('Spearmans correlation coefficient: %.3f' % coef,' p-value: %.3f' % p)",
"Spearmans correlation coefficient: 0.147 p-value: 0.088\n"
]
],
[
[
"## Calculate correlation between number of lfls per pop and diversity",
"_____no_output_____"
]
],
[
[
"#Open census tract csv with the counts of lfls\n#I used QGIS to make a csv with the number of lfls per area for each census tract\nlflvtract = pd.read_csv('census-tracts-lfl-counts.csv',encoding='utf-8')\n\n#Open the diversity tract file if needed\ndfdiv = pd.read_csv('diversity-seattle-census-tract-acs5-2018.csv',encoding='utf-8')\n\n#Open the population data if needed\npop = pd.read_csv('pop-by-tract.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the lfl number dataset\ndfdivlfl = pd.merge(lflvtract, dfdiv, on='tract', how='inner')\ndfdivlfl.head()",
"_____no_output_____"
],
[
"#Merge with the population dataframe\ndfdivlfl = pd.merge(dfdivlfl, pop, on='tract', how='inner')\ndfdivlfl.head()",
"_____no_output_____"
],
[
"#Calculate lfls per pop.\ndfdivlfl['lflperpop']=dfdivlfl['numlfls']/dfdivlfl['pop']\n#Take only the useful columns (here tot is the total number included in diversity calculation)\ndfdivlfl = dfdivlfl[['tract','tot','gini-simp','pop','lflperpop']].copy()",
"_____no_output_____"
],
[
"#Create list of values to check\ndiv = dfdivlfl['gini-simp']\nplt.hist(div)\nplt.show()",
"_____no_output_____"
],
[
"#Not normal so use Spearman's\ndfdivlfl.corr(method='spearman')",
"_____no_output_____"
]
],
[
[
"gini-simp is moderately and negatively (-0.5) correlated with lfls per population by tract. Suggesting as diversity decreases, the number of lfls increase",
"_____no_output_____"
]
],
[
[
"#Use SciPy\n#The %.3f' sets the number of decimal places\ncoef, p = stats.spearmanr(dfdivlfl['gini-simp'],dfdivlfl['lflperpop'])\nprint('Spearmans correlation coefficient: %.3f' % coef,' p-value: %.3f' % p)",
"Spearmans correlation coefficient: -0.505 p-value: 0.000\n"
]
],
[
[
"## Calculate average median income for the study neighborhoods",
"_____no_output_____"
],
[
"#### I manually listed what census tracts match the neighborhood boundaries (Seattle's community reporting areas).\nI also got the population by census tract from here: https://www.census.gov/geographies/reference-files/2010/geo/2010-centers-population.html (divide the six number code by 100 to get the tract number",
"_____no_output_____"
]
],
[
[
"#Open census tract csv\nhoodtracts = pd.read_csv('censustracts-neighborhoods.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Open the median data if it's not already open\nmedians = pd.read_csv('seattle-census-tract-acs5-2018.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge the dataframes\ndflfl = pd.merge(hoodtracts, medians, on='tract', how='inner')\ndflfl.head()",
"_____no_output_____"
],
[
"#Open the population data\npop = pd.read_csv('pop-by-tract.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the population dataframe\ndflfl = pd.merge(dflfl, pop, on='tract', how='inner')\ndflfl.head()",
"_____no_output_____"
],
[
"#Open census tract csv with the counts of lfls\n#I used QGIS to make a csv with the number of lfls per area for each census tract. However, sq km column may be incorrect!!!\nlflvtract = pd.read_csv('census-tracts-lfl-counts.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the lfl number dataset\ndflfl = pd.merge(lflvtract, dflfl, on='tract', how='inner')\ndflfl.head()",
"_____no_output_____"
],
[
"dflfl['lflperpop'] = dflfl['numlfls']/dflfl['pop']",
"_____no_output_____"
],
[
"dflfl.head()",
"_____no_output_____"
],
[
"#Save file as csv\ndflfl.to_csv('census-compiled-data.csv', mode = 'w', index=False)",
"_____no_output_____"
],
[
"ax = sns.scatterplot(x=\"household_income\", y=\"lflperpop\", data=dflfl)\nax.set(ylim=(0, 0.005))",
"_____no_output_____"
]
],
[
[
"#### I used this site for the linear regression: https://realpython.com/linear-regression-in-python/#python-packages-for-linear-regression\n\nThe following is a regression only for neighborhoods in the study!",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"#Open the file if needed\ndflfl = pd.read_csv('census-compiled-data.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"x = dflfl[['household_income']]\ny = dflfl[['lflperpop']]",
"_____no_output_____"
],
[
"model = LinearRegression().fit(x, y)\nr_sq = model.score(x, y)\nprint('coefficient of determination:', r_sq)\nprint('intercept:', model.intercept_)\nprint('slope:', model.coef_)",
"coefficient of determination: 0.12185556404062636\nintercept: [9.16328386e-05]\nslope: [[7.57601413e-09]]\n"
]
],
[
[
"# Examine lfls and neighborhoods",
"_____no_output_____"
]
],
[
[
"#Open the census compiled data if needed\ndflfl = pd.read_csv('census-compiled-data.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"dflflhood = dflfl.groupby('neighborhood').agg({'household_income': ['mean'], 'pop': ['sum'], 'numlfls':['sum']})\n# rename columns\ndflflhood.columns = ['avg-median-income', 'pop', 'numlfls']\n\n# reset index to get grouped columns back\ndflflhood = dflflhood.reset_index()",
"_____no_output_____"
],
[
"dflflhood.head(8)",
"_____no_output_____"
]
],
[
[
"#### Diversity",
"_____no_output_____"
]
],
[
[
"#If necessary. Open census tract csv with the counts of lfls\n#I used QGIS to make a csv with the number of lfls per area for each census tract\nlflvtract = pd.read_csv('censustracts-neighborhoods.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#open up the diversity data\ndfdiv = pd.read_csv('diversity-seattle-census-tract-acs5-2018.csv',encoding='utf-8')",
"_____no_output_____"
],
[
"#Merge with the lfl number dataset\ndflfldiv = pd.merge(dfdiv, lflvtract, on='tract', how='inner')\ndflfldiv = dflfldiv.drop(columns=['simpsons','gini-simp'])\ndflfldiv.head()",
"_____no_output_____"
],
[
"dflfldiv = dflfldiv.groupby('neighborhood').agg({'tot': ['sum'], 'wh': ['sum'], 'afam':['sum'], 'amin':['sum'], 'as':['sum'], 'hw':['sum'], 'ot':['sum'], 'combo1':['sum'], 'combo2':['sum'], 'combo3':['sum']})\n# rename columns\ndflfldiv.columns = ['tot', 'wh', 'afam', 'amin', 'as', 'hw', 'ot', 'combo1', 'combo2', 'combo3']\n\n# reset index to get grouped columns back\ndflfldiv = dflfldiv.reset_index()",
"_____no_output_____"
],
[
"dflfldiv.head(8)",
"_____no_output_____"
],
[
"#Calculate Simpsons and gini\ndef simpsons(row):\n return (row['wh'] / row['tot'])**2 + (row['afam'] / row['tot'])**2 + (row['amin'] / row['tot'])**2 + (row['as'] / row['tot'])**2 + (row['hw'] / row['tot'])**2 + (row['ot'] / row['tot'])**2 + (row['combo1'] / row['tot'])**2 + (row['combo2'] / row['tot'])**2 + (row['combo3'] / row['tot'])**2\n\ndflfldiv['simpsons'] = dflfldiv.apply(simpsons, axis=1)\ndflfldiv['gini-simp'] = 1 - dflfldiv['simpsons']\ndflfldiv.head(8)",
"_____no_output_____"
],
[
"#Save file as csv\ndflfldiv.to_csv('census-lflhood-compiled-data.csv', mode = 'w', index=False)",
"_____no_output_____"
],
[
"#Merge diversity and income tables\ndfsocioecon = pd.merge(dflflhood, dflfldiv, on='neighborhood', how='inner')\ndfsocioecon.head()",
"_____no_output_____"
],
[
"#Save file\ndfsocioecon.to_csv('socioeconomic-by-neighborhood.csv', mode = 'w', index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1afcc7a5427af30d71ac84a4ad64acdadec98f
| 479,646 |
ipynb
|
Jupyter Notebook
|
percent_bachelors.ipynb
|
garethhay/playing_with_matplotlib
|
b9dd3178a5f83297690d3a110f25194336bcc4db
|
[
"MIT"
] | null | null | null |
percent_bachelors.ipynb
|
garethhay/playing_with_matplotlib
|
b9dd3178a5f83297690d3a110f25194336bcc4db
|
[
"MIT"
] | null | null | null |
percent_bachelors.ipynb
|
garethhay/playing_with_matplotlib
|
b9dd3178a5f83297690d3a110f25194336bcc4db
|
[
"MIT"
] | null | null | null | 825.552496 | 160,812 | 0.948946 |
[
[
[
"# Playing with Matplotlib\n\n\nPlease note I am making no assumptions nor any conclusions as I have not studied this data, it's actual original source, the source I got it from or even looked at most of the dataset itself. It is just some data to make graphs with and part of a tutorial.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\n#Demo used a direct link to the hosted file but a) slower and b) someone else's bandwidth\nwomen_majors = pd.read_csv('percent_bachelors.csv', encoding='utf-8')\n\nunder_20 = women_majors.loc[0, women_majors.loc[0] < 20]\nprint(under_20)",
"Agriculture 4.229798\nArchitecture 11.921005\nBusiness 9.064439\nComputer Science 13.600000\nEngineering 0.800000\nPhysical Sciences 13.800000\nName: 0, dtype: float64\n"
]
],
[
[
"## Calling Matplotlib ... magic\n\n[Literally](https://ipython.readthedocs.io/en/stable/interactive/plotting.html#id1) referred to as magic. Then again [Clarke's Third Law](https://en.wikipedia.org/wiki/Clarke%27s_three_laws).\n\nCalling it with the `inline` backend so the output (graphs) are shown under the code block that produced them",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Let us make a default graph\n\nSo we are going to use the year column for the x axis and results of the under_20 index labels. \n\nfigsize requires a tuple and formats the size of the figure in inches, width followed by height.",
"_____no_output_____"
]
],
[
[
"under_20_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))\nprint(\"Type is :\", type(under_20_graph))",
"Type is : <class 'matplotlib.axes._subplots.AxesSubplot'>\n"
]
],
[
[
"## Matplotlib refers to parts of a graph as below:\n\n\nSource: [Matplotlib.org](Matplotlib.org)",
"_____no_output_____"
],
[
"## Making it look like 538's style\n\nfivethirtyeight seems to be a US website and below is the google description:\n\n> Nate Silver's FiveThirtyEight uses statistical analysis — hard numbers — to tell compelling stories about elections, politics, sports, science, economics and ...\n\nA backend of the style is [here](https://github.com/matplotlib/matplotlib/blob/38be7aeaaac3691560aeadafe46722dda427ef47/lib/matplotlib/mpl-data/stylelib/fivethirtyeight.mplstyle) on github and the author of the style sheet discusses it [here](https://dataorigami.net/blogs/napkin-folding/17543615-replicating-538s-plot-styles-in-matplotlib) in a blog post.",
"_____no_output_____"
]
],
[
[
"import matplotlib.style as style\nprint(style.available)\n\nstyle.use('fivethirtyeight')\nwomen_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))",
"['bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark-palette', 'seaborn-dark', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'seaborn', 'Solarize_Light2', 'tableau-colorblind10', '_classic_test']\n"
]
],
[
[
"## Further work to do\n\n- [ ] Add a title and a subtitle.\n- [ ] Remove the block-style legend, and add labels near the relevant plot lines. We’ll also have to make the grid lines transparent around these labels.\n- [ ] Add a signature bottom bar which mentions the author of the graph and the source of the data.\n- Add a couple of other small adjustments:\n - [ ] increase the font size of the tick labels;\n - [ ] add a “%” symbol to one of the major tick labels of the y-axis;\n - [ ] remove the x-axis label;\n - [ ] bold the horizontal grid line at y = 0;\n - [ ] add an extra grid line next to the tick labels of the y-axis;\n - [ ] increase the lateral margins of the figure.\n \nGoing to assign the graph to fte_graph and start working on this list",
"_____no_output_____"
]
],
[
[
"fte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8))",
"_____no_output_____"
]
],
[
[
"# Matplotlib gotcha\n\nText is positioned based on the x and y coords of the generated graph so finish playing with those first\n\nAlso you need to have all the variables you are going to use on the graph in the same code block. Spacing them out as I have here doesn't produce a graph but makes it easier to learn.",
"_____no_output_____"
],
[
"## Custom tick labels\n\n- [x] increase the font size of the tick labels;\n\n`tick_params()` is a method for modifying the ticks.\n- `axis` defines which axis to work on\n- `which` are we working on the major or minor ticks\n- `labelsize` font size\n\n\n - [x] add a “%” symbol to one of the major tick labels of the y-axis;\n\n`set_yticklabels(labels = [list])`\n- there is also a `get_yticks()`\n- using some empty spaces in all the percentages that don't have the sign so they align",
"_____no_output_____"
]
],
[
[
"fte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)\nfte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])",
"_____no_output_____"
]
],
[
[
"## Make the y = 0 line bold\n\n- [x] bold the horizontal grid line at y = 0;\n\nThe title is a little bit of a lie as what we are actually going to do is add a new horizontal line at y = 0 which will be over the top of the other one. \n\n`axhline()` is the method for this and we are going to use the below arguements (doc for method is [here](https://matplotlib.org/api/_as_gen/matplotlib.axes.Axes.axhline.html?highlight=axhline#matplotlib.axes.Axes.axhline))\n - `y` where on the y axis we want the line\n - `color` what color we want the line\n - `linewidth` how wide we want the line\n - `alpha` how transparent we want the line or can be used to drop the color intensity",
"_____no_output_____"
]
],
[
[
"fte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)",
"_____no_output_____"
]
],
[
[
"## Add an extra vertical line\n\n- [x] add an extra grid line next to the tick labels of the y-axis;\n\nTo add the additional grid line near to the labels on the y axis we are going to extend the x axis range using `set_xlim()`\n\n`set_xlim()` we are going to use 2 simple and self explanatory parameters:\n- `left` where we want the start\n- `right` where we want the end ",
"_____no_output_____"
]
],
[
[
"fte_graph.set_xlim(left = 1969, right = 2011)",
"_____no_output_____"
]
],
[
[
"## Generating a sig bar\n\n- [x] remove the x-axis label;\n- [x] Add a signature bottom bar which mentions the author of the graph and the source of the data.\n\n### Removing the x axis label\n\n`set_visible(False)` we are going to use this method on the x axis label. \n\n### Generate the sig\n\nThis is slightly messy as it requires some testing on position but at the same time works nicely when it is sorted. Between the Author and Source details you will need to pad with spaces.\n\nWe are going to set the background of a text area to the grey required and the text colour to the actual graphs background colour. The \"white space\" of spacing will actually be the selected background colour.\n\nThe method is `text()`\n- `x` coord \n- `y` coord\n- `s` the string you want to use`\n- `fontsize` \n- `color` text colour\n- `backgroundcolor` ",
"_____no_output_____"
]
],
[
[
"fte_graph.xaxis.label.set_visible(False)\nfte_graph.text(x = 1965.8, y = -7, s = 'In your general direction Source: National Center for Education Statistics', fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')",
"_____no_output_____"
]
],
[
[
"We could also do things with multple lines of text as per below:\n\n`fte_graph.text(x = 1967.1, y = -6.5,\n s = '________________________________________________________________________________________________________________',\n color = 'grey', alpha = .7)\n\nfte_graph.text(x = 1966.1, y = -9,\n s = ' ©DATAQUEST Source: National Center for Education Statistics ',\n fontsize = 14, color = 'grey', alpha = .7)`",
"_____no_output_____"
],
[
"## Adding a title and a subtitle\n\n- [x] Add a title and a subtitle.\n\nApparently Matplotlib's inbuilt `title()` and `subtitle()` methods do not allow much control over the positioning there for it can be simpler to use the `text()` method. This will need some finesing into the final location but allows a lot of precision.\n\n`weight` can be used within the `text()` method to make text bold.\n\nText inside `text()` doesn't wordwrap you need to use `\\n` when you want it to move onto a new line ",
"_____no_output_____"
]
],
[
[
"fte_graph.text(x = 1966.65, y = 62.7, s = \"Some title for this graph that is interesting\", fontsize = 26, weight = \"bold\", alpha = .75)\nfte_graph.text(x = 1966.65, y = 57, s = \"A sub title text that goes on and on and on so hopefuly it will\\nword wrap onto the second line and look awesome\", fontsize = 19, alpha = .85)\n",
"_____no_output_____"
]
],
[
[
"## Colourblind friendly colours\n\n\nSource: [Points of View: Color blindness by Bang Wong](http://www.nature.com/nmeth/journal/v8/n6/full/nmeth.1618.html#ref1)\n\nWe need to declare all the colours we want the graph to use. We are going to use the above colours as they are more friendly to people with colourblindness but we are not going to use the yellow as reading yellow on white or grey is generally difficult.\n\nWe then need to modify the `plot()` to include the arguement `color =` assigned to whatever we call the colours variable.\n- One odd thing is for this color arguement (not text) we need to pass the colours as floats between 0 - 1. Hence the `[230/255,159/255,0]`\n- Needs to be passed as a list of lists",
"_____no_output_____"
]
],
[
[
"colours = [[0,0,0], [230/255,159/255,0], [86/255,180/255,233/255], [0,158/255,115/255],\n [213/255,94/255,0], [0,114/255,178/255]]",
"_____no_output_____"
]
],
[
[
"## Remove the legend and place labels directly on the lines in the same colour\n\n- [x] Remove the block-style legend, and add labels near the relevant plot lines. We’ll also have to make the grid lines transparent around these labels.\n\nTo remove the standard legend we add `legend = False` to the `plot()`.\n\nTo make the text labels easier to read we will set their background to the main background colour which will effectively make the grid lines disappear around the labels.\n\nLastly we will use the `rotation` parameter so the text lines up nicely with the lines. ",
"_____no_output_____"
]
],
[
[
"#Defining our colour set\ncolours = [[0,0,0], [230/255,159/255,0], [86/255,180/255,233/255], [0,158/255,115/255],\n [213/255,94/255,0], [0,114/255,178/255]]\n#Set the graph name and the data it is going to plot\nfte_graph = women_majors.plot(x = 'Year', y = under_20.index, figsize = (12,8), color = colours, legend = False)\n#Place some text in the correct position to be a title with weighing and larger size\nfte_graph.text(x = 1966.65, y = 62.7, s = \"Some title for this graph that is interesting\", fontsize = 26, weight = \"bold\", alpha = .75)\n#Place some text in the correct position to be a subtitle\nfte_graph.text(x = 1966.65, y = 57, s = \"A sub title text that goes on and on and on so hopefuly it will\\nword wrap onto the second line and look awesome\", fontsize = 19, alpha = .85)\n#Place some text in the correct position and colour to generate a sig bar\nfte_graph.text(x = 1965.8, y = -7, s = ' In your general direction Source: National Center for Education Statistics ', fontsize = 14, color = '#f0f0f0', backgroundcolor = 'grey')\n#Widen the x axis\nfte_graph.set_xlim(left = 1969, right = 2011)\n#Make the x axis label invisible\nfte_graph.xaxis.label.set_visible(False)\n#Put a bold line over y = 0\nfte_graph.axhline(y = 0, color = 'black', linewidth = 1.3, alpha = .7)\n#Making the axis labels larger\nfte_graph.tick_params(axis = 'both', which = 'major', labelsize = 18)\n#Changing the x axis tick labels\nfte_graph.set_yticklabels(labels = [-10, '0 ', '10 ', '20 ', '30 ', '40 ', '50%'])\n#Line labels\nfte_graph.text(x = 1994, y = 44, s = 'Agriculture', color = colours[0], weight = 'bold', rotation = 33,\n backgroundcolor = '#f0f0f0')\nfte_graph.text(x = 1985, y = 42.2, s = 'Architecture', color = colours[1], weight = 'bold', rotation = 18,\n backgroundcolor = '#f0f0f0')\nfte_graph.text(x = 2004, y = 51, s = 'Business', color = colours[2], weight = 'bold', rotation = -5,\n backgroundcolor = '#f0f0f0')\nfte_graph.text(x = 2001, y = 30, s = 'Computer Science', color = colours[3], weight = 'bold', rotation = -42.5,\n backgroundcolor = '#f0f0f0')\nfte_graph.text(x = 1987, y = 11.5, s = 'Engineering', color = colours[4], weight = 'bold',\n backgroundcolor = '#f0f0f0')\nfte_graph.text(x = 1976, y = 25, s = 'Physical Sciences', color = colours[5], weight = 'bold', rotation = 27,\n backgroundcolor = '#f0f0f0')\n",
"_____no_output_____"
]
],
[
[
"# So this is as per tutorial\n\nThanks to [Dataquest.io](https://www.dataquest.io) for the blog post tutorial",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1b0d7442382723fe54a6e3d46efa2559aa4b8d
| 11,924 |
ipynb
|
Jupyter Notebook
|
aiml50/source/seer_pipeline.ipynb
|
Mikhail2k15/ignite-learning-paths-training-aiml
|
6c99e90c71dd74ff8573e940d3a3899b718bad57
|
[
"CC-BY-4.0",
"MIT"
] | 203 |
2019-10-07T10:44:09.000Z
|
2021-11-08T09:21:17.000Z
|
aiml50/source/seer_pipeline.ipynb
|
Mikhail2k15/ignite-learning-paths-training-aiml
|
6c99e90c71dd74ff8573e940d3a3899b718bad57
|
[
"CC-BY-4.0",
"MIT"
] | 53 |
2019-10-08T15:15:04.000Z
|
2020-11-23T16:29:39.000Z
|
aiml50/source/seer_pipeline.ipynb
|
Mikhail2k15/ignite-learning-paths-training-aiml
|
6c99e90c71dd74ff8573e940d3a3899b718bad57
|
[
"CC-BY-4.0",
"MIT"
] | 210 |
2019-10-04T14:41:49.000Z
|
2021-11-04T23:05:22.000Z
| 5,962 | 11,923 | 0.696243 |
[
[
[
"import azureml\nfrom azureml.core import Workspace, Experiment, Datastore, Environment\nfrom azureml.core.runconfig import RunConfiguration\nfrom azureml.data.datapath import DataPath, DataPathComputeBinding\nfrom azureml.data.data_reference import DataReference\nfrom azureml.core.compute import ComputeTarget, AmlCompute\nfrom azureml.core.compute_target import ComputeTargetException\nfrom azureml.pipeline.core import Pipeline, PipelineData, PipelineParameter\nfrom azureml.pipeline.steps import PythonScriptStep, EstimatorStep\nfrom azureml.widgets import RunDetails\nfrom azureml.train.estimator import Estimator\nimport os\n\nprint(\"Azure ML SDK Version: \", azureml.core.VERSION)",
"_____no_output_____"
]
],
[
[
"# Setup Variables",
"_____no_output_____"
]
],
[
[
"os.environ['STORAGE_ACCOUNT_KEY'] = 'YourAccountKeyHere'",
"_____no_output_____"
],
[
"datastorename='seerdata'\ndatastorepath='hardware'\ncontainername='seer-container'\nstorageaccountname='aiml50setupstorage'\nstorageaccountkey=os.environ.get('STORAGE_ACCOUNT_KEY')\ncomputetarget='twtcluster'",
"_____no_output_____"
]
],
[
[
"# Register/Reference a Datastore",
"_____no_output_____"
]
],
[
[
"# workspace\nws = Workspace.from_config(\n path='./azureml-config.json')\nprint(ws.datastores)",
"{'workspaceblobstore': <azureml.data.azure_storage_datastore.AzureBlobDatastore object at 0x7f926c220630>, 'workspacefilestore': <azureml.data.azure_storage_datastore.AzureFileDatastore object at 0x7f926c228048>, 'damoseerdata': <azureml.data.azure_storage_datastore.AzureBlobDatastore object at 0x7f926c228550>}\n"
],
[
"# See if that datastore already exists and unregister it if so\ntry:\n datastore = ws.datastores[datastorename]\n print ('Unregistering existing datastore')\n datastore.unregister()\nexcept:\n print ('Data store doesn\\'t exist, no need to remove')\nfinally:\n # register the datastore\n datastore = Datastore.register_azure_blob_container(workspace=ws,\n datastore_name=datastorename,\n container_name=containername,\n account_name=storageaccountname,\n account_key=storageaccountkey,\n create_if_not_exists=True)\n\nprint('Datastore registered: ', datastore)",
"_____no_output_____"
],
[
"# data\ndatastore = ws.datastores['seerdata']\ndatareference = DataReference(datastore=datastore, \n data_reference_name=\"seerdata\", \n path_on_datastore=datastorepath)\n",
"<azureml.data.azure_storage_datastore.AzureBlobDatastore object at 0x7f926c220278>\nAmlCompute(workspace=Workspace.create(name='damo-mlworkspace', subscription_id='bc202ec2-54ef-4576-b7fb-a961c983398e', resource_group='damo-aiml'), name=damoseercompute, id=/subscriptions/bc202ec2-54ef-4576-b7fb-a961c983398e/resourceGroups/damo-aiml/providers/Microsoft.MachineLearningServices/workspaces/damo-mlworkspace/computes/damoseercompute, type=AmlCompute, provisioning_state=Succeeded, location=australiaeast, tags=None)\n"
]
],
[
[
"# Create Compute Resources",
"_____no_output_____"
]
],
[
[
"try:\n cpu_cluster = ComputeTarget(workspace=ws, name=computetarget)\n print('Found existing cluster, use it.')\nexcept ComputeTargetException:\n compute_config = AmlCompute.provisioning_configuration(\n vm_size='STANDARD_NC6', \n min_nodes=1, \n max_nodes=4)\n cpu_cluster = ComputeTarget.create(ws, computetarget, compute_config)\n\ncpu_cluster.wait_for_completion(show_output=True)\ncompute = ws.compute_targets[computetarget]\n\nprint('Compute registered: ', compute)",
"_____no_output_____"
]
],
[
[
"# Define Pipeline!\n\nThe following will be created and then run:\n\n 1. Pipeline Parameters\n 2. Data Process Step\n 3. Training Step\n 4. Model Registration Step\n 5. Pipeline registration\n 6. Submit the pipeline for execution\n",
"_____no_output_____"
],
[
"## Pipeline Parameters\nWe need to tell the Pipeline what it needs to learn to see!",
"_____no_output_____"
]
],
[
[
"datapath = DataPath(datastore=datastore, path_on_datastore=datastorepath)\ndata_path_pipeline_param = (PipelineParameter(name=\"data\", \n default_value=datapath), \n DataPathComputeBinding(mode='mount'))\nprint(data_path_pipeline_param)\n\n# Configuration for data prep and training steps\ndataprepEnvironment = Environment.from_pip_requirements('dataprepenv', 'requirements-dataprepandtraining.txt')\ndataprepRunConfig = RunConfiguration()\ndataprepRunConfig.environment = dataprepEnvironment",
"(<azureml.pipeline.core.graph.PipelineParameter object at 0x7f926c23e320>, <azureml.data.datapath.DataPathComputeBinding object at 0x7f926c23e358>)\n"
]
],
[
[
"## Data Process Step",
"_____no_output_____"
]
],
[
[
"seer_tfrecords = PipelineData(\n \"tfrecords_set\",\n datastore=datastore,\n is_directory=True\n)\n\nprepStep = PythonScriptStep(\n 'parse.py',\n source_directory='.',\n name='Data Preparation',\n compute_target=compute,\n arguments=[\"--source_path\", data_path_pipeline_param, \"--target_path\", seer_tfrecords],\n runconfig=dataprepRunConfig,\n inputs=[data_path_pipeline_param],\n outputs=[seer_tfrecords]\n)\n\nprint(prepStep)",
"<azureml.pipeline.steps.python_script_step.PythonScriptStep object at 0x7f926c2205f8>\n"
]
],
[
[
"## Training Step",
"_____no_output_____"
]
],
[
[
"seer_training = PipelineData(\n \"train\",\n datastore=datastore,\n is_directory=True\n)\n\ntrain = Estimator(source_directory='.',\n compute_target=compute,\n entry_script='train.py',\n pip_requirements_file='requirements-dataprepandtraining.txt')\n\ntrainStep = EstimatorStep(\n name='Model Training',\n estimator=train,\n estimator_entry_script_arguments=[\"--source_path\", seer_tfrecords, \n \"--target_path\", seer_training,\n \"--epochs\", 5,\n \"--batch\", 10,\n \"--lr\", 0.001],\n inputs=[seer_tfrecords],\n outputs=[seer_training],\n compute_target=compute\n)\n\nprint(trainStep)",
"WARNING - 'gpu_support' is no longer necessary; AzureML now automatically detects and uses nvidia docker extension when it is available. It will be removed in a future release.\nWARNING - 'gpu_support' is no longer necessary; AzureML now automatically detects and uses nvidia docker extension when it is available. It will be removed in a future release.\n"
]
],
[
[
"# Register Model Step",
"_____no_output_____"
]
],
[
[
"registerEnvironment = Environment.from_pip_requirements('registerenv', 'requirements-registration.txt')\nregisterRunConfig = RunConfiguration()\nregisterRunConfig.environment = registerEnvironment\n\nseer_model = PipelineData(\n \"model\",\n datastore=datastore,\n is_directory=True\n)\n\nregisterStep = PythonScriptStep(\n 'register.py',\n source_directory='.',\n name='Model Registration',\n arguments=[\"--source_path\", seer_training, \n \"--target_path\", seer_model],\n inputs=[seer_training],\n outputs=[seer_model],\n compute_target=compute,\n runconfig=registerRunConfig\n)\n\nprint(registerStep)",
"<azureml.pipeline.steps.python_script_step.PythonScriptStep object at 0x7f926c23ebe0>\n"
]
],
[
[
"## Create and publish the Pipeline",
"_____no_output_____"
]
],
[
[
"pipeline = Pipeline(workspace=ws, steps=[prepStep, trainStep, registerStep])\n\npublished_pipeline = pipeline.publish(\n name=\"Seer Pipeline\", \n description=\"Transfer learned image classifier. Uses folders as labels.\")",
"WARNING - 'gpu_support' is no longer necessary; AzureML now automatically detects and uses nvidia docker extension when it is available. It will be removed in a future release.\nWARNING - 'gpu_support' is no longer necessary; AzureML now automatically detects and uses nvidia docker extension when it is available. It will be removed in a future release.\nWARNING - 'gpu_support' is no longer necessary; AzureML now automatically detects and uses nvidia docker extension when it is available. It will be removed in a future release.\n"
],
[
"# Submit the pipeline to be run\npipeline_run = Experiment(ws, 'seer',).submit(published_pipeline)\nprint('Run created with ID: ', pipeline_run.id)\n\nRunDetails(pipeline_run).show()",
"Run created with ID: 7103c1bc-807a-4e25-8874-e578511eb035\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1b1c16e8a9f9a3c4433c95f9af345c2392d634
| 679,414 |
ipynb
|
Jupyter Notebook
|
Wolt_Data_Science_Assignment_2022.ipynb
|
KNurmik/Wolt-Data-Science-Assignment-2022
|
889e1a9526ad453609f99e7cf5d90a198a83cee9
|
[
"MIT"
] | null | null | null |
Wolt_Data_Science_Assignment_2022.ipynb
|
KNurmik/Wolt-Data-Science-Assignment-2022
|
889e1a9526ad453609f99e7cf5d90a198a83cee9
|
[
"MIT"
] | null | null | null |
Wolt_Data_Science_Assignment_2022.ipynb
|
KNurmik/Wolt-Data-Science-Assignment-2022
|
889e1a9526ad453609f99e7cf5d90a198a83cee9
|
[
"MIT"
] | null | null | null | 583.187983 | 86,866 | 0.939931 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom datetime import datetime, timedelta\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import OneHotEncoder\n\nimport torch\nimport torch.nn as nn \nimport torch.nn.functional as F \nimport torch.optim as optim\nfrom torch.utils.data import Dataset, DataLoader\nfrom tqdm.auto import tqdm\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\nplt.rcParams[\"figure.figsize\"] = (13, 7)",
"_____no_output_____"
]
],
[
[
"# Wolt Data Science Assignment 2022\n### Karl Hendrik Nurmeots\n\n# Introduction\n\nHey! Thank you for taking the time to read through my assignment submission!\n\nIn this assignment I will be exploring the provided Wolt orders data and developing models to forecast the number of orders per hour for the next 24 hours based on the preceding 48 hours. As Wolt is a platform that connects thousands of restaurants and vendors with thousands of customers by involving thousands of drivers, it is a big logistical challenge that could greatly benefit from having accurate predictions for the number of orders.\n\nI begin by analyzing the Wolt orders dataset using visualizations that produce insights into how this problem should be modeled. Then, I propose a seq2seq recurrent neural network model for solving the problem and evaluate its performance. I improve the model further by adding additional, non-time series features to the model. Finally, I explain a bit about what motivates me to work at Wolt and how my past experiences make me a great candidate for the position.",
"_____no_output_____"
],
[
"# Data Preparation",
"_____no_output_____"
]
],
[
[
"#### Data Preparation\ndf = pd.read_csv('https://raw.githubusercontent.com/woltapp/data-science-summer-intern-2022/master/orders_autumn_2020.csv')\ndf.columns = ['timestamp', 'delivery_delay', 'item_count', 'user_lat', 'user_long', 'venue_lat', 'venue_long',\n 'delivery_estimate', 'delivery_actual', 'cloud_coverage', 'temperature', 'wind_speed', 'precipitation']\ndf.timestamp = pd.to_datetime(df.timestamp)\n\n# Timestamps are given with minute-precision, so round all timestamps down to their hour\ndf.timestamp = df.timestamp.apply(lambda x: datetime(x.year, x.month, x.day, x.hour, 0))\n\n# Group by timestamp\ngb = df.groupby('timestamp').agg({'timestamp': 'count'})\ngb.columns = ['orders']\n\n# There may be hours where no orders were placed, so generate all hours from Aug 1 to Sept 30 and join with data\nhours = pd.Series(pd.date_range(start=datetime(2020, 8, 1), end=datetime(2020, 9, 30, 23), freq='1H'))\ngb = gb.merge(hours.rename('hours'), how='right', left_index=True, right_on='hours')\ngb = gb.set_index('hours')\n\n# Replace NaN orders with 0\n#### Here I am assuming that there is no reason for data to be missing besides no orders being made:\n#### if this was not assumed, it might be better to replace the missing values with something like -1\n#### so that the models can learn that these particular datapoints contain no useful information\ngb.orders = gb.orders.fillna(0)\n\ngb['hour'] = gb.index.hour\ngb['weekday'] = gb.index.weekday",
"_____no_output_____"
]
],
[
[
"# Exploratory Data Analysis\n\nIn this section my goal is to visually analyze the data to understand its behaviour, and what aspects of the data the forecasting models should understand.",
"_____no_output_____"
]
],
[
[
"# Beginning date for graph\ndate = datetime(2020, 8, 1)\n\ntemp = gb[(gb.index >= date) & (date + timedelta(days=7) > gb.index)]\n\nplt.plot(temp.index, temp.orders)\nplt.title(f\"Number of Orders per Hour: {date.date()} to {(date + timedelta(days=7)).date()}\", fontsize=20)\nplt.ylabel('No. of orders', fontsize=16)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looking at the first week of the dataset a clear pattern emerges: most days in this week display two distinct peaks in the number of orders, although some days also showcase a third peak. ",
"_____no_output_____"
]
],
[
[
"dates = [datetime(2020, 8, 1), datetime(2020, 8, 15), datetime(2020, 9, 1), datetime(2020, 9, 15)]\n\nfig, axs = plt.subplots(2, 2, sharey=True)\nfor i in range(len(axs.flatten())):\n ax = axs.flatten()[i]\n date = dates[i]\n temp = gb[(gb.index >= date) & (date + timedelta(days=1) > gb.index)]\n\n ax.plot(temp.index.hour, temp.orders)\n if i in (0, 2):\n ax.set_ylabel('No. of orders', fontsize=12)\n ax.set_title(str(date.date()))\nplt.suptitle('Number of Orders per Hour', fontsize=16)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looking at four days separately we see that some days do not follow the previously observed bimodality at all. The peaks in these days also occur at different times. September 1, 2020 is a particularly anomalyous day as it displays a completely different pattern from most other days in the dataset.\n\nIt is clear that this time series data is somewhat complex and we want to model it by using techniques that can obtain a good understanding of how the data behaves.",
"_____no_output_____"
]
],
[
[
"temp = gb.groupby('hour').agg({'orders': 'sum'})\nplt.bar(temp.index, temp.orders)\nplt.xticks(np.arange(24))\nplt.xlabel(\"Hour\", fontsize=12)\nplt.ylabel(\"No. of Orders\", fontsize=12)\nplt.title(\"Total Orders per Hour of the Day\", fontsize=16)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looking at the distribution of orders per hour of the day we once again see the bimodal pattern observed earlier. This shows that, on average, the first peak of orders occurs at 09:00, and the second peak tends to occur at 15:00.\n\nWith more time, I would dig deeper into how the distribution of orders differs across different weekdays, especially weekends. Taking holidays and otherwise significant days of the year into account could also yield valuable information. These insights could be useful in improving the models that follow. ",
"_____no_output_____"
],
[
"# Modeling\n\nIf I was solving this problem while working for Wolt and if I had more time, I would approach the problem by first trying out simple models and then seeing if more complicated ones can improve on the results. A great baseline model for time series forecasting is simply using the past 48 hours' data as the prediction for the next 24: if the patterns in the data have little variation, this super simple model can be a surprisingly tough baseline to beat. Other simple models to try on this problem would be linear regression and ARIMA.\n\nHowever, for this assignment for the sake of saving time I will break my principle and jump directly to the cool stuff - recurrent neural networks (RNNs). RNNs are great at modeling complex patterns and behaviours in temporal data, and as such make a strong candidate for solving this problem.\n\nFor this problem I will be using the following seq2seq RNN model:\n\n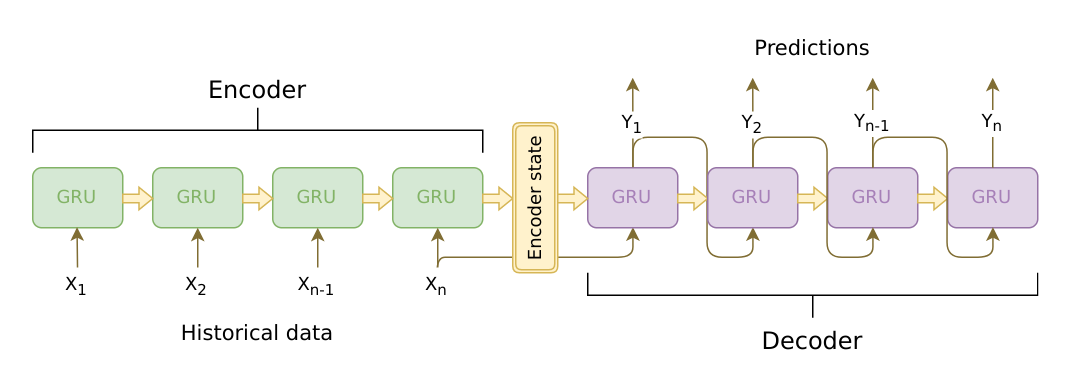\n\n[Image credit](https://www.kaggle.com/c/web-traffic-time-series-forecasting/discussion/43795)\n\nWhile writing together this model would usually take a fair bit of time and testing, I am able to do this quickly because I initially created this model with a friend as part of [a time series school project](https://github.com/KNurmik/Spain-Electricity-Load-Timeseries-Analysis). We have licensed the model such that anyone is able to use it for any purpose, including commercial purposes. I have a good idea that this model will work not only because of the school project we did, but also because I was able to adapt this model with great success for a time series problem I solved at my most recent summer internship at MindTitan, where I used this model to forecast customer satisfaction metrics for over 500,000 Elisa Eesti mobile internet users. As I have built up my [public GitHub portfolio](https://github.com/KNurmik) over time, I often find myself referring back to my earlier work and saving myself a lot of time and effort. \n\nAgain, I will use the past 48h worth of orders data to predict the following 24h. The model will take as input, for every observation, an array of 48 historical datapoints and output the predicted 24 future ones.\n\nI have split the data into training, validation and testing sets with roughly a 80%/10%/10% split where all of the training data chronologically precedes the validation data, which itself precedes the testing data. This way the model does not have any knowledge of the data that will be used for testing and we get the best understanding of how the model behaves when facing before-unseen data.\n\nAs is standard practice for ensuring numerical stability, all of the data is normalized based on the training data mean and standard deviation.\n\nThe model will use mean squared error as its loss function as this is a natural choice for regression tasks.\n\nWhen training, the model state with the best validation loss will be saved and used for evaluation on the test set later. ",
"_____no_output_____"
]
],
[
[
"# Model-specific data preparation\n\npredict_interval = 24\nhistory_interval = 48\ntrim = predict_interval + history_interval\n\n# Create N x (24+24) array where every row is one observation of 24h of history + 24h of target data\nindices = np.stack([np.arange(i, trim+i) for i in range(gb.shape[0] - trim + 1)])\ndata = np.stack([gb.orders.iloc[indices[i]] for i in range(indices.shape[0])])\n\nX = data[:, :history_interval]\ny = data[:, history_interval:]\n\n# Train-test-validation split (rougly 80%/10%/10%)\nX_train = X[:1100]\ny_train = y[:1100]\nX_val = X[1100:1250]\ny_val = y[1100:1250]\nX_test = X[1250:]\ny_test = y[1250:]\ny_test_unnorm = y_test.copy()\n# Mean-std normalization\nnorm_mean = X_train.mean()\nnorm_std = X_train.std()\n\ndef normalize(arr):\n return (arr - norm_mean) / norm_std\n\nvars = [X_train, y_train, X_val, y_val, X_test, y_test]\nfor var in vars:\n var[:] = normalize(var)\n\n\n# PyTorch data preparation\nclass WoltDataset(Dataset): \n def __init__(self, X, y):\n\n self.X = X\n self.y = y \n\n def __getitem__(self, idx):\n return self.X[idx, :], self.y[idx, :]\n\n def __len__(self):\n return self.X.shape[0]\n\n def unscale(self, X):\n return (X * norm_std) + norm_mean\n\ntrain_dataset = WoltDataset(X_train, y_train)\nval_dataset = WoltDataset(X_val, y_val)\ntest_dataset = WoltDataset(X_test, y_test)",
"_____no_output_____"
]
],
[
[
"I played around with the hyperparameters below and kept the ones that gave me the best validation results. With more time it may be worthwhile to set up a grid search to find the best possible hyperparameters.",
"_____no_output_____"
]
],
[
[
"# Hyperparameters\nBATCH_SIZE = 32\nEPOCHS = 25\nLR = 1e-3\nHIDDEN_SIZE = 256\n\ntrain_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE)\nval_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE)\ntest_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE)",
"_____no_output_____"
],
[
"class WoltEncoder(nn.Module):\n\n def __init__(self, hidden_size):\n super().__init__()\n self.gru = nn.GRU(input_size=1, hidden_size=hidden_size,\n batch_first= True)\n \n def forward(self, x):\n\n out, hidden = self.gru(x)\n return out, hidden.squeeze(0)\n\n\nclass WoltDecoder(nn.Module):\n\n def __init__(self, hidden_size):\n super().__init__()\n self.grucell = nn.GRUCell(input_size=1, hidden_size=hidden_size)\n\n self.fc = nn.Sequential(\n nn.Linear(in_features=hidden_size, out_features=hidden_size),\n nn.LeakyReLU(),\n nn.Linear(in_features=hidden_size, out_features=1)\n )\n\n def forward(self, y, hidden):\n\n ht = self.grucell(y, hidden)\n out = self.fc(ht)\n return out, ht\n\n\nclass WoltEncoderDecoder(nn.Module):\n\n def __init__(self, hidden_size, output_size):\n super().__init__()\n self.encoder = WoltEncoder(hidden_size)\n self.decoder = WoltDecoder(hidden_size)\n self.output_size = output_size\n\n def forward(self, x):\n\n encoder_out, hidden = self.encoder(x) # [batchsize, hidden_size]\n N = x.shape[0]\n outputs = torch.empty(N, self.output_size)\n curr = x[:, -1]\n for i in range(self.output_size):\n curr, hidden = self.decoder(curr, hidden)\n outputs[:, i] = curr.view(-1)\n\n return outputs",
"_____no_output_____"
],
[
"model = WoltEncoderDecoder(HIDDEN_SIZE, predict_interval)\noptimizer = optim.AdamW(model.parameters(), lr=LR)\ncriterion = nn.MSELoss()\nmodel = model.to(device)",
"_____no_output_____"
],
[
"train_losses = []\nval_losses = []\n\nbest_model = model.state_dict()\nbest_val_loss = np.inf\n\nfor epoch in range(EPOCHS):\n #t = tqdm(train_dataloader, desc=f\"Epoch: {epoch}\") # Uncomment and comment out the next line to get cool progress bars!\n t = train_dataloader\n cost = 0\n # Training\n for i, (prev, target) in enumerate(t):\n pred = model(prev.unsqueeze(-1).float().to(device))\n loss = criterion(pred, target.float())\n loss.backward()\n\n optimizer.step()\n optimizer.zero_grad()\n cost += float(loss.item() * prev.shape[0])\n\n train_losses.append(cost/len(train_dataset))\n\n # Validation\n with torch.no_grad():\n val_cost = 0\n for prev, target in val_dataloader:\n pred = model(prev.unsqueeze(-1).float().to(device))\n loss = criterion(pred, target.float())\n\n val_cost += float(loss.item() * prev.shape[0])\n val_loss = val_cost/len(val_dataset)\n val_losses.append(val_loss)\n\n # Keep model with best validation loss\n if val_loss < best_val_loss:\n best_model = model.state_dict()\n best_val_loss = val_loss",
"_____no_output_____"
],
[
"plt.plot(train_losses, label='Train')\nplt.plot(val_losses, label='Validation')\nplt.title(\"Loss over time\", fontsize=16)\nplt.xlabel(\"Epoch\", fontsize=12)\nplt.ylabel(\"Loss\", fontsize=12)\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"It does not seem like the model has completely converged, but it is close to doing so - given the limited time, it is an adequate outcome. With more time it might be a good idea to set up an adaptive learning rate and early stopping, and let the model train for longer for optimal results.",
"_____no_output_____"
],
[
"# Evaluation\n\nFor evaluation of the model I will primarily rely on qualitative visual analysis as the ideal model would perfectly capture the bimodal patterns that were observed previously. Root Mean Squared Error (RMSE) will be used to evaluate the model from a quantitative perspective.",
"_____no_output_____"
]
],
[
[
"# Restore best model state and run it on the test set\ntorch.cuda.empty_cache()\nmodel.load_state_dict(best_model)\nmodel.eval()\nX_test_tensor = torch.FloatTensor(test_dataset.X).unsqueeze(-1).to(device)\nwith torch.no_grad():\n rnn_pred = model(X_test_tensor)\nrnn_pred = rnn_pred.detach().cpu().numpy()",
"_____no_output_____"
],
[
"predicted = test_dataset.unscale(rnn_pred[0, :])\npredicted[predicted < 0] = 0\n\nplt.plot(np.arange(history_interval+1), np.r_[test_dataset.unscale(test_dataset.X[0, :]), test_dataset.unscale(test_dataset.y[0, 0])], label=\"Input\")\nplt.plot(np.arange(history_interval, history_interval + predict_interval), test_dataset.unscale(test_dataset.y[0, :]), label=\"True\", c=\"green\")\nplt.plot(np.arange(history_interval, history_interval + predict_interval), predicted, label=\"Predicted\", c=\"red\")\nplt.title(\"Predicted Orders\", fontsize=15)\nplt.xlabel(\"Hour\", fontsize=12)\nplt.ylabel(\"No. of Orders\", fontsize=12)\nplt.legend()\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"The above graph looks at the first observation in the test set more closely. Clearly, the model has correctly learned about the bimodal structure in the daily data and makes a good guess about when the peaks happen, but it does not do a great job of predicting the correct values for the peaks.",
"_____no_output_____"
]
],
[
[
"def plot_predictions(true, pred, time, is_scaled=False, \n std=norm_std, mean=norm_mean):\n\n if not is_scaled: \n pred = (pred * std) + mean\n pred[pred < 0] = 0\n rmse = np.sqrt((np.sum((true[:, time] - pred[:, time])**2)) / true.shape[0])\n\n plt.plot(true[:, time], label=\"True\")\n plt.plot(pred[:, time], label=\"Pred\")\n plt.suptitle(f\"Predictions {time+1} hour(s) in the future\", fontsize=15)\n plt.title('Root mean squared error: {}'.format(round(rmse, 3)))\n plt.legend()\n plt.xlabel(\"Timestep\")\n plt.ylabel(\"No. of Orders\")",
"_____no_output_____"
],
[
"plot_predictions(y_test_unnorm, rnn_pred, 0)",
"_____no_output_____"
]
],
[
[
"Here, the model's predictions for the entire test set are shown when considering the model's predictions one hour into the future. Again we see that the model does a good job in predicting the average number of orders per day, but does not exactly capture the daily two peak values.",
"_____no_output_____"
]
],
[
[
"plot_predictions(y_test_unnorm, rnn_pred, 23)",
"_____no_output_____"
]
],
[
[
"When evaluating the model for predictions 24 hours into the future, its performance is expectedly worse, but not overly so: these predictions are not much worse than for 1 hour into the future. The same problem of not capturing peaks well remains an issue.\n\nOverall, I would say these results are promising for a first prototype model. The model has learned the patterns in the data and does a decent job understanding if a given day will have more or fewer total orders. As there are usually 20 to 50 orders in a given hour, having an RMSE of 5 to 6 orders is not too bad either as it would likely still allow for informed business decisions to be made, but obviously a model with a smaller error is desireable.\n\nThis model would probably not work as well when used on time periods further away from the training data - the total amount and distribution of orders is likely different at various parts of the year, so a model that has only seen how the data behaves in August and September might not generalize well to other time periods. This issue could be largely mitigated by using more data - a year's worth at least to ensure the model understands yearly seasonal patterns. ",
"_____no_output_____"
],
[
"# Extending the Model\n\nAs mentioned earlier, it is likely that the distributions of orders share similarities across the same weekdays. The current model does not have direct access to what day the target data belongs to, but it may be able to make a guess based on the input data. Still, we can feed the weekday info into the model in hopes of improving it.\n\nTo do so, we will take the weekday info for the first day of the 48 hours of data that is fed into the model - this is sufficient for the model to know what days it is given and what day it will predict. The weekday information is one-hot encoded. Then, when the encoder produces its hidden state output, the hidden state along with the one-hot weekday information is sent through a fully connected layer to produce a new hidden state that contains the weekday information. This state is then passed to the decoder as previously.\n\nThe below code is largely the same as the code above. Any differences are pointed out by comments.",
"_____no_output_____"
]
],
[
[
"predict_interval = 24\nhistory_interval = 48\ntrim = predict_interval + history_interval\n\nindices = np.stack([np.arange(i, trim+i) for i in range(gb.shape[0] - trim + 1)])\ndata = np.stack([gb.orders.iloc[indices[i]] for i in range(indices.shape[0])])\n\n# Fetch weekday data for each observation and one-hot encode it\nweekday = np.stack([gb.weekday.iloc[indices[i][0]] for i in range(indices.shape[0])])\nenc = OneHotEncoder()\nweekday = enc.fit_transform(weekday.reshape(-1, 1)).toarray()\n\nX = data[:, :history_interval]\ny = data[:, history_interval:]\n\nX_train = X[:1100]\ny_train = y[:1100]\nweekday_train = weekday[:1100]\nX_val = X[1100:1250]\ny_val = y[1100:1250]\nweekday_val = weekday[1100:1250]\nX_test = X[1250:]\ny_test = y[1250:]\nweekday_test = weekday[1250:]\ny_test_unnorm = y_test.copy()\n\nnorm_mean = X_train.mean()\nnorm_std = X_train.std()\n\ndef normalize(arr):\n return (arr - norm_mean) / norm_std\n\nvars = [X_train, y_train, X_val, y_val, X_test, y_test]\nfor var in vars:\n var[:] = normalize(var)\n\nclass WoltDataset(Dataset): \n def __init__(self, X, y, additional):\n\n self.X = X\n self.y = y \n # Include matrix of additional information in the dataset\n self.additional = additional\n\n def __getitem__(self, idx):\n return self.X[idx, :], self.y[idx, :], self.additional[idx, :]\n\n def __len__(self):\n return self.X.shape[0]\n\n def unscale(self, X):\n return (X * norm_std) + norm_mean\n\ntrain_dataset = WoltDataset(X_train, y_train, weekday_train)\nval_dataset = WoltDataset(X_val, y_val, weekday_val)\ntest_dataset = WoltDataset(X_test, y_test, weekday_test)",
"_____no_output_____"
],
[
"BATCH_SIZE = 32\nEPOCHS = 50\nLR = 1e-4\nHIDDEN_SIZE = 256\n\ntrain_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE)\nval_dataloader = DataLoader(val_dataset, batch_size=BATCH_SIZE)\ntest_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE)",
"_____no_output_____"
],
[
"class WoltEncoderDecoder_additional(nn.Module):\n\n def __init__(self, hidden_size, output_size, additional_size):\n super().__init__()\n self.encoder = WoltEncoder(hidden_size)\n self.decoder = WoltDecoder(hidden_size)\n self.output_size = output_size\n # Additional fully connected layer to add weekday information\n self.fc = nn.Sequential(\n nn.Linear(hidden_size + additional_size, hidden_size),\n nn.LeakyReLU()\n )\n\n def forward(self, x, additional):\n\n encoder_out, hidden = self.encoder(x)\n # Add weekday information to time series data to produce new hidden state\n hidden = self.fc(torch.cat((hidden, additional), dim=1))\n N = x.shape[0]\n outputs = torch.empty(N, self.output_size)\n curr = x[:, -1]\n for i in range(self.output_size):\n curr, hidden = self.decoder(curr, hidden)\n outputs[:, i] = curr.view(-1)\n\n return outputs",
"_____no_output_____"
],
[
"model = WoltEncoderDecoder_additional(HIDDEN_SIZE, predict_interval, weekday.shape[1])\noptimizer = optim.AdamW(model.parameters(), lr=LR)\ncriterion = nn.MSELoss()\nmodel = model.to(device)",
"_____no_output_____"
],
[
"train_losses = []\nval_losses = []\n\nbest_model = model.state_dict()\nbest_val_loss = np.inf\n\nfor epoch in range(EPOCHS):\n #t = tqdm(train_dataloader, desc=f\"Epoch: {epoch}\") # Uncomment and comment out the next line to get cool progress bars!\n t = train_dataloader\n cost = 0\n # Training\n for i, (prev, target, additional) in enumerate(t):\n pred = model(prev.unsqueeze(-1).float().to(device), additional.float().to(device))\n loss = criterion(pred, target.float())\n loss.backward()\n\n optimizer.step()\n optimizer.zero_grad()\n cost += float(loss.item() * prev.shape[0])\n\n train_losses.append(cost/len(train_dataset))\n\n # Validation\n with torch.no_grad():\n val_cost = 0\n for prev, target, additional in val_dataloader:\n pred = model(prev.unsqueeze(-1).float().to(device), additional.float().to(device))\n loss = criterion(pred, target.float())\n\n val_cost += float(loss.item() * prev.shape[0])\n val_loss = val_cost/len(val_dataset)\n val_losses.append(val_loss)\n\n # Keep model with best validation loss\n if val_loss < best_val_loss:\n best_model = model.state_dict()\n best_val_loss = val_loss",
"_____no_output_____"
],
[
"plt.plot(train_losses, label='Train')\nplt.plot(val_losses, label='Validation')\nplt.title(\"Loss over time\", fontsize=16)\nplt.xlabel(\"Epoch\", fontsize=12)\nplt.ylabel(\"Loss\", fontsize=12)\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"It seems that just like the last model, this one hasn't fully converged and could likewise benefit from an adaptive learning rate and more training.",
"_____no_output_____"
]
],
[
[
"# Restore best model state and run it on the test set\ntorch.cuda.empty_cache()\nmodel.load_state_dict(best_model)\nmodel.eval()\nX_test_tensor = torch.FloatTensor(test_dataset.X).unsqueeze(-1).to(device)\nwith torch.no_grad():\n rnn_pred = model(X_test_tensor, torch.FloatTensor(weekday_test).to(device))\nrnn_pred = rnn_pred.detach().cpu().numpy()",
"_____no_output_____"
],
[
"predicted = test_dataset.unscale(rnn_pred[0, :])\npredicted[predicted < 0] = 0\n\nplt.plot(np.arange(history_interval+1), np.r_[test_dataset.unscale(test_dataset.X[0, :]), test_dataset.unscale(test_dataset.y[0, 0])], label=\"Input\")\nplt.plot(np.arange(history_interval, history_interval + predict_interval), test_dataset.unscale(test_dataset.y[0, :]), label=\"True\", c=\"green\")\nplt.plot(np.arange(history_interval, history_interval + predict_interval), predicted, label=\"Predicted\", c=\"red\")\nplt.title(\"Predicted Orders\", fontsize=15)\nplt.xlabel(\"Hour\", fontsize=12)\nplt.ylabel(\"No. of Orders\", fontsize=12)\nplt.legend()\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"For this instance, the results do not differ much from the simpler model - the model still doesn't capture the peaks very well.",
"_____no_output_____"
]
],
[
[
"plot_predictions(y_test_unnorm, rnn_pred, 0)",
"_____no_output_____"
]
],
[
[
"On various runs I was able to obtain results that both beat and fail to beat the simpler model. On average, however, it seems that this model is a slight improvement, but randomization has a large part in the results.\n\nThe issue of not capturing the daily peaks correctly is more complicated to fix than just adding little additional information, clearly.",
"_____no_output_____"
]
],
[
[
"plot_predictions(y_test_unnorm, rnn_pred, 23)",
"_____no_output_____"
]
],
[
[
"A bit surprisingly, this model tends to perform significantly worse than the simpler one on predictions 24 hours into the future. It might be worth reconsidering the way the additional weekdays information is incorporated into the model.\n\nOverall, it is clear that this model can be improved upon. It would greatly benefit from having lots more training data. Feeding more additional non-time series data into the model can only do good as well. However, even just the additional weekday information made training the model significantly slower - there is definitely a tradeoff between predictive performance and runtime performance here.\n\nIt is also important to note that this model has been trained to predict a complete day from 00:00 to 23:59. It would likely not work as well if it had to predict, say, Wednesday 12:00 to Thursday 11:59. To allow for this, we could feed the clock hour information of one or many datapoints to the model as well.",
"_____no_output_____"
],
[
"# My Background\n\n### Why Wolt?\n\nI am looking for an opportunity where I can put my data science skills to practice to deliver impactful business value and benefit stakeholders. An ideal role would allow me to directly communicate with stakeholders to then produce the most suitable solution together with my peers. \n\nData science is central to Wolt's operations, so I am very thrilled about the idea of working as part of Wolt's data science team. What really excites me about working at Wolt is the thought of what a huge logistical challenge Wolt's operations must be, and how much data science could be used to solve these challenges. Wolt's data science team is world class - I feel I would have so much to learn from them while hopefully also benefitting the team back through my own unique knowledge and experiences.\n\n### My Education\n\nI am currently finishing up my Data Science Honours BSc degree at the University of Toronto, which is often ranked in the top 10 universities in the world in the field of computer science. As this is a four-year degree program, it is comparable to a BSc+MSc obtained in Europe. I feel confident in my skills in most of the common data science paradigms, but my strongest interests are in deep learning and its uses in regression, classification and computer vision. Currently, I am focusing a large part of my effort to improving my natural language processing skills and knowledge. At Wolt, I do not have a particular problem I would want to solve or a particular technique I would want to use. What is most important to me is that I get to take on tasks that produce genuinely useful value and impact for Wolt, its partners, and its customers, using whatever tools necessary to get the job done.\n\n### My Professional Experience\n\nNearly all of the things I have studied in school I have already put to use in industry through the numerous internships I have had. I have solved problems with great success in domains completely different from each other such as insurance, renewable energy, telecommunications, and virology. For solving these problems, I have relied on vastly different techniques, ranging from deep learning to plain linear regression to simple visualization analysis. What was common between all of these experiences was the process of communicating with stakeholders to understand what is most important, and translating the issues brought up into data science problems. What I would bring to Wolt is a great ability to understand business needs and how data science can be best used to satisfy them. I have built up my skills and knowledge in a way that allows me to always find suitable tools to solve whatever problem may arise.\n\n### My Extracurriculars\n\nWhen data science isn't on my mind, I really enjoy playing chess, going swimming and working out, playing and watching football, and playing video games. In Toronto, I am also an active member in the local Estonian community where I frequently volunteer by helping host events through any way possible: bartending, lifting stuff backstage or hosting livestreams.\n\n### ----------------------------------------------------------\n\nThanks again for checking out my assignment submission! I hope to hear back from you soon!\n\n#### - Karl",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a1b36802bc8c24385b6ce8fbdc878f20f096dfe
| 318,360 |
ipynb
|
Jupyter Notebook
|
tutorial/source/stable.ipynb
|
bcjonescbt/pyro
|
1bc46ddd4485a18434bf1c5c128a8b020b46c559
|
[
"Apache-2.0"
] | null | null | null |
tutorial/source/stable.ipynb
|
bcjonescbt/pyro
|
1bc46ddd4485a18434bf1c5c128a8b020b46c559
|
[
"Apache-2.0"
] | null | null | null |
tutorial/source/stable.ipynb
|
bcjonescbt/pyro
|
1bc46ddd4485a18434bf1c5c128a8b020b46c559
|
[
"Apache-2.0"
] | 1 |
2020-04-24T01:18:03.000Z
|
2020-04-24T01:18:03.000Z
| 599.548023 | 110,632 | 0.942904 |
[
[
[
"# Levy Stable models of Stochastic Volatility\n\nThis tutorial demonstrates inference using the Levy [Stable](http://docs.pyro.ai/en/stable/distributions.html#stable) distribution through a motivating example of a non-Gaussian stochastic volatilty model.\n\nInference with stable distribution is tricky because the density `Stable.log_prob()` is not defined. In this tutorial we demonstrate two approaches to inference: (i) using the [poutine.reparam](http://docs.pyro.ai/en/latest/poutine.html#pyro.poutine.handlers.reparam) effect to transform models in to a tractable form, and (ii) using the likelihood-free loss [EnergyDistance](http://docs.pyro.ai/en/latest/inference_algos.html#pyro.infer.energy_distance.EnergyDistance) with SVI.\n\n\n#### Summary\n\n- [Stable.log_prob()](http://docs.pyro.ai/en/stable/distributions.html#stable) is undefined.\n- Stable inference requires either reparameterization or a likelihood-free loss.\n- Reparameterization:\n - The [poutine.reparam()](http://docs.pyro.ai/en/latest/poutine.html#pyro.poutine.handlers.reparam) handler can transform models using various [strategies](http://docs.pyro.ai/en/latest/infer.reparam.html).\n - The [StableReparam](http://docs.pyro.ai/en/latest/infer.reparam.html#pyro.infer.reparam.stable.StableReparam) strategy can be used for Stable distributions in SVI or HMC.\n - The [LatentStableReparam](http://docs.pyro.ai/en/latest/infer.reparam.html#pyro.infer.reparam.stable.LatentStableReparam) strategy is a little cheaper, but cannot be used for likelihoods.\n - The [DiscreteCosineReparam](http://docs.pyro.ai/en/latest/infer.reparam.html#pyro.infer.reparam.discrete_cosine.DiscreteCosine) strategy improves geometry in batched latent time series models.\n- Likelihood-free loss with SVI:\n - The [EnergyDistance](http://docs.pyro.ai/en/latest/inference_algos.html#pyro.infer.energy_distance.EnergyDistance) loss allows stable distributions in the guide and in model likelihoods.\n\n#### Table of contents\n\n- [Daily S&P data](#data)\n- [Fitting a single distribution to log returns](#fitting) using `EnergyDistance`\n- [Modeling stochastic volatility](#modeling) using `poutine.reparam`",
"_____no_output_____"
],
[
"## Daily S&P 500 data <a class=\"anchor\" id=\"data\"></a>\n\nThe following daily closing prices for the S&P 500 were loaded from [Yahoo finance](https://finance.yahoo.com/quote/%5EGSPC/history/).",
"_____no_output_____"
]
],
[
[
"import math\nimport os\nimport torch\nimport pyro\nimport pyro.distributions as dist\nfrom matplotlib import pyplot\nfrom torch.distributions import constraints\n\nfrom pyro import poutine\nfrom pyro.contrib.examples.finance import load_snp500\nfrom pyro.infer import EnergyDistance, Predictive, SVI, Trace_ELBO\nfrom pyro.infer.autoguide import AutoDiagonalNormal\nfrom pyro.infer.reparam import DiscreteCosineReparam, StableReparam\nfrom pyro.optim import ClippedAdam\nfrom pyro.ops.tensor_utils import convolve\n\n%matplotlib inline\nassert pyro.__version__.startswith('1.3.0')\npyro.enable_validation(True)\nsmoke_test = ('CI' in os.environ)",
"_____no_output_____"
],
[
"df = load_snp500()\ndates = df.Date.to_numpy()\nx = torch.tensor(df[\"Close\"]).float()\nx.shape",
"_____no_output_____"
],
[
"pyplot.figure(figsize=(9, 3))\npyplot.plot(x)\npyplot.yscale('log')\npyplot.ylabel(\"index\")\npyplot.xlabel(\"trading day\")\npyplot.title(\"S&P 500 from {} to {}\".format(dates[0], dates[-1]));\n",
"_____no_output_____"
]
],
[
[
"Of interest are the log returns, i.e. the log ratio of price on two subsequent days.",
"_____no_output_____"
]
],
[
[
"pyplot.figure(figsize=(9, 3))\nr = (x[1:] / x[:-1]).log()\npyplot.plot(r, \"k\", lw=0.1)\npyplot.title(\"daily log returns\")\npyplot.xlabel(\"trading day\");",
"_____no_output_____"
],
[
"pyplot.figure(figsize=(9, 3))\npyplot.hist(r, bins=200)\npyplot.yscale('log')\npyplot.ylabel(\"count\")\npyplot.xlabel(\"daily log returns\")\npyplot.title(\"Empirical distribution. mean={:0.3g}, std={:0.3g}\".format(r.mean(), r.std()));",
"_____no_output_____"
]
],
[
[
"## Fitting a single distribution to log returns <a class=\"anchor\" id=\"fitting\"></a>\n\nLog returns appear to be heavy-tailed. First let's fit a single distribution to the returns. To fit the distribution, we'll use a likelihood free statistical inference algorithm [EnergyDistance](http://docs.pyro.ai/en/latest/inference_algos.html#pyro.infer.energy_distance.EnergyDistance), which matches fractional moments of observed data and can handle data with heavy tails.",
"_____no_output_____"
]
],
[
[
"def model():\n stability = pyro.param(\"stability\", torch.tensor(1.9),\n constraint=constraints.interval(0, 2))\n skew = 0.\n scale = pyro.param(\"scale\", torch.tensor(0.1), constraint=constraints.positive)\n loc = pyro.param(\"loc\", torch.tensor(0.))\n with pyro.plate(\"data\", len(r)):\n return pyro.sample(\"r\", dist.Stable(stability, skew, scale, loc), obs=r)",
"_____no_output_____"
],
[
"%%time\npyro.clear_param_store()\npyro.set_rng_seed(1234567890)\nnum_steps = 1 if smoke_test else 201\noptim = ClippedAdam({\"lr\": 0.1, \"lrd\": 0.1 ** (1 / num_steps)})\nsvi = SVI(model, lambda: None, optim, EnergyDistance())\nlosses = []\nfor step in range(num_steps):\n loss = svi.step()\n losses.append(loss)\n if step % 20 == 0:\n print(\"step {} loss = {}\".format(step, loss))\n\nprint(\"-\" * 20)\npyplot.figure(figsize=(9, 3))\npyplot.plot(losses)\npyplot.yscale(\"log\")\npyplot.ylabel(\"loss\")\npyplot.xlabel(\"SVI step\")\nfor name, value in sorted(pyro.get_param_store().items()):\n if value.numel() == 1:\n print(\"{} = {:0.4g}\".format(name, value.squeeze().item()))",
"step 0 loss = 8.961664199829102\nstep 20 loss = 4.8506011962890625\nstep 40 loss = 1.5543489456176758\nstep 60 loss = 1.7787070274353027\nstep 80 loss = 1.4140945672988892\nstep 100 loss = 1.3671720027923584\nstep 120 loss = 1.287503719329834\nstep 140 loss = 1.2791334390640259\nstep 160 loss = 1.2810490131378174\nstep 180 loss = 1.2784368991851807\nstep 200 loss = 1.2823134660720825\n--------------------\nloc = 0.0003696\nscale = 0.00872\nstability = 1.977\nCPU times: user 15.6 s, sys: 521 ms, total: 16.1 s\nWall time: 2.38 s\n"
],
[
"samples = poutine.uncondition(model)().detach()\npyplot.figure(figsize=(9, 3))\npyplot.hist(samples, bins=200)\npyplot.yscale(\"log\")\npyplot.xlabel(\"daily log returns\")\npyplot.ylabel(\"count\")\npyplot.title(\"Posterior predictive distribution\");\n",
"_____no_output_____"
]
],
[
[
"This is a poor fit, but that was to be expected since we are mixing all time steps together: we would expect this to be a scale-mixture of distributions (Normal, or Stable), but are modeling it as a single distribution (Stable in this case).",
"_____no_output_____"
],
[
"## Modeling stochastic volatility <a class=\"anchor\" id=\"modeling\"></a>\n\nWe'll next fit a stochastic volatility model.\nLet's begin with a constant volatility model where log price $p$ follows Brownian motion\n\n$$\n \\log p_t = \\log p_{t-1} + w_t \\sqrt h\n$$\n\nwhere $w_t$ is a sequence of standard white noise. We can rewrite this model in terms of the log returns $r_t=\\log(p_t\\,/\\,p_{t-1})$:\n\n$$\n r_t = w_t \\sqrt h\n$$\n\nNow to account for [volatility clustering](https://en.wikipedia.org/wiki/Volatility_clustering) we can generalize to a stochastic volatility model where volatility $h$ depends on time $t$. Among the simplest such models is one where $h_t$ follows geometric Brownian motion\n\n$$\n \\log h_t = \\log h_{t-1} + \\sigma v_t\n$$\n\nwhere again $v_t$ is a sequence of standard white noise. The entire model thus consists of a geometric Brownian motion $h_t$ that determines the diffusion rate of another geometric Brownian motion $p_t$:\n\n$$\n \\log h_t = \\log h_{t-1} + \\sigma v_t \\\\\n \\log p_t = \\log p_{t-1} + w_t \\sqrt h_t\n$$\n\nUsually $v_1$ and $w_t$ are both Gaussian. We will generalize to a Stable distribution for $w_t$, learning three parameters (stability, skew, and location), but still scaling by $\\sqrt h_t$.\n\nOur Pyro model will sample the increments $v_t$ and record the computation of $\\log h_t$ via [pyro.deterministic](http://docs.pyro.ai/en/stable/primitives.html#pyro.deterministic). Note that there are many ways of implementing this model in Pyro, and geometry can vary depending on implementation. The following version seems to have good geometry, when combined with reparameterizers.",
"_____no_output_____"
]
],
[
[
"def model(data):\n # Note we avoid plates because we'll later reparameterize along the time axis using\n # DiscreteCosineReparam, breaking independence. This requires .unsqueeze()ing scalars.\n h_0 = pyro.sample(\"h_0\", dist.Normal(0, 1)).unsqueeze(-1)\n sigma = pyro.sample(\"sigma\", dist.LogNormal(0, 1)).unsqueeze(-1)\n v = pyro.sample(\"v\", dist.Normal(0, 1).expand(data.shape).to_event(1))\n log_h = pyro.deterministic(\"log_h\", h_0 + sigma * v.cumsum(dim=-1))\n sqrt_h = log_h.mul(0.5).exp().clamp(min=1e-8, max=1e8)\n\n # Observed log returns, assumed to be a Stable distribution scaled by sqrt(h).\n r_loc = pyro.sample(\"r_loc\", dist.Normal(0, 1e-2)).unsqueeze(-1)\n r_skew = pyro.sample(\"r_skew\", dist.Uniform(-1, 1)).unsqueeze(-1)\n r_stability = pyro.sample(\"r_stability\", dist.Uniform(0, 2)).unsqueeze(-1)\n pyro.sample(\"r\", dist.Stable(r_stability, r_skew, sqrt_h, r_loc * sqrt_h).to_event(1),\n obs=data)",
"_____no_output_____"
]
],
[
[
"We use two reparameterizers: [StableReparam](http://docs.pyro.ai/en/latest/infer.reparam.html#pyro.infer.reparam.stable.StableReparam) to handle the `Stable` likelihood (since `Stable.log_prob()` is undefined), and [DiscreteCosineReparam](http://docs.pyro.ai/en/latest/infer.reparam.html#pyro.infer.reparam.discrete_cosine.DiscreteCosineReparam) to improve geometry of the latent Gaussian process for `v`. We'll then use `reparam_model` for both inference and prediction.",
"_____no_output_____"
]
],
[
[
"reparam_model = poutine.reparam(model, {\"v\": DiscreteCosineReparam(),\n \"r\": StableReparam()})",
"_____no_output_____"
],
[
"%%time\npyro.clear_param_store()\npyro.set_rng_seed(1234567890)\nnum_steps = 1 if smoke_test else 1001\noptim = ClippedAdam({\"lr\": 0.05, \"betas\": (0.9, 0.99), \"lrd\": 0.1 ** (1 / num_steps)})\nguide = AutoDiagonalNormal(reparam_model)\nsvi = SVI(reparam_model, guide, optim, Trace_ELBO())\nlosses = []\nfor step in range(num_steps):\n loss = svi.step(r) / len(r)\n losses.append(loss)\n if step % 50 == 0:\n median = guide.median()\n print(\"step {} loss = {:0.6g}\".format(step, loss))\n\nprint(\"-\" * 20)\nfor name, (lb, ub) in sorted(guide.quantiles([0.325, 0.675]).items()):\n if lb.numel() == 1:\n lb = lb.detach().squeeze().item()\n ub = ub.detach().squeeze().item()\n print(\"{} = {:0.4g} ± {:0.4g}\".format(name, (lb + ub) / 2, (ub - lb) / 2))\n\npyplot.figure(figsize=(9, 3))\npyplot.plot(losses)\npyplot.ylabel(\"loss\")\npyplot.xlabel(\"SVI step\")\npyplot.xlim(0, len(losses))\npyplot.ylim(min(losses), 20)",
"step 0 loss = 80.7915\nstep 50 loss = 2.49764\nstep 100 loss = 6.18623\nstep 150 loss = -1.42891\nstep 200 loss = -2.48601\nstep 250 loss = -2.75234\nstep 300 loss = -2.80716\nstep 350 loss = -2.64854\nstep 400 loss = -2.93349\nstep 450 loss = -2.90964\nstep 500 loss = -2.93564\nstep 550 loss = -2.98376\nstep 600 loss = -3.01648\nstep 650 loss = -3.01208\nstep 700 loss = -3.04329\nstep 750 loss = -3.03045\nstep 800 loss = -3.04258\nstep 850 loss = -3.06856\nstep 900 loss = -3.05272\nstep 950 loss = -3.06414\nstep 1000 loss = -3.06487\n--------------------\nh_0 = 0.3713 ± 0.01079\nr_loc = 0.05134 ± 0.002976\nr_skew = 0.0001597 ± 0.0002002\nr_stability = 1.92 ± 0.001772\nsigma = 0.2373 ± 0.000313\nCPU times: user 38.1 s, sys: 6.95 s, total: 45.1 s\nWall time: 45.1 s\n"
]
],
[
[
"It appears the log returns exhibit very little skew, but exhibit a stability parameter slightly but significantly less than 2. This contrasts the usual Normal model corresponding to a Stable distribution with skew=0 and stability=2. We can now visualize the estimated volatility:",
"_____no_output_____"
]
],
[
[
"fig, axes = pyplot.subplots(2, figsize=(9, 5), sharex=True)\npyplot.subplots_adjust(hspace=0)\naxes[1].plot(r, \"k\", lw=0.2)\naxes[1].set_ylabel(\"log returns\")\naxes[1].set_xlim(0, len(r))\n\n# We will pull out median log returns using the autoguide's .median() and poutines.\nwith torch.no_grad():\n pred = Predictive(reparam_model, guide=guide, num_samples=20, parallel=True)(r)\nlog_h = pred[\"log_h\"]\naxes[0].plot(log_h.median(0).values, lw=1)\naxes[0].fill_between(torch.arange(len(log_h[0])),\n log_h.kthvalue(2, dim=0).values,\n log_h.kthvalue(18, dim=0).values,\n color='red', alpha=0.5)\naxes[0].set_ylabel(\"log volatility\")\n\nstability = pred[\"r_stability\"].median(0).values.item()\naxes[0].set_title(\"Estimated index of stability = {:0.4g}\".format(stability))\naxes[1].set_xlabel(\"trading day\");",
"_____no_output_____"
]
],
[
[
"Observe that volatility roughly follows areas of large absolute log returns. Note that the uncertainty is underestimated, since we have used an approximate `AutoDiagonalNormal` guide. For more precise uncertainty estimates, one could use [HMC](http://docs.pyro.ai/en/stable/mcmc.html#hmc) or [NUTS](http://docs.pyro.ai/en/stable/mcmc.html#nuts) inference.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1b5170ca8167e8ce372812556652df64a6ea4c
| 4,838 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Send mail-checkpoint.ipynb
|
ShahariarRabby/Mail_Server
|
8da7139a18a2b9c34d4cffe69e6b2b1e4b1cf7fa
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Send mail-checkpoint.ipynb
|
ShahariarRabby/Mail_Server
|
8da7139a18a2b9c34d4cffe69e6b2b1e4b1cf7fa
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Send mail-checkpoint.ipynb
|
ShahariarRabby/Mail_Server
|
8da7139a18a2b9c34d4cffe69e6b2b1e4b1cf7fa
|
[
"MIT"
] | 1 |
2018-12-14T16:14:50.000Z
|
2018-12-14T16:14:50.000Z
| 30.620253 | 178 | 0.558702 |
[
[
[
"### Send email Clint\n#### Importing all dependency",
"_____no_output_____"
]
],
[
[
"# ! /usr/bin/python\nimport smtplib\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom email.header import Header\nfrom email.utils import formataddr\nimport getpass\n",
"_____no_output_____"
]
],
[
[
"#### User Details Function",
"_____no_output_____"
]
],
[
[
"def user():\n# ORG_EMAIL = \"@gmail.com\"\n# FROM_EMAIL = \"ypur mail\" + ORG_EMAIL\n# FROM_PWD = \"yourpss\"\n FROM_EMAIL = raw_input(\"insert Email : \")\n FROM_PWD = getpass.getpass(\"input : \")\n return FROM_EMAIL,FROM_PWD",
"_____no_output_____"
]
],
[
[
"### Login function\nIn this function we call user details function and get the user name and password, Than we use those details for IMAP login.\n** SMTP is Simple Mail Transfer Protocol**",
"_____no_output_____"
]
],
[
[
"def login():\n gmail_user, gmail_pwd = user() #calling the user function for get user details\n smtpserver = smtplib.SMTP(\"smtp.gmail.com\",587) #Declaring gmail SMTP server address and port \n smtpserver.starttls() #Starting tls service, Transport Layer Security (TLS) are cryptographic protocols that provide communications security over a computer network.\n smtpserver.login(gmail_user, gmail_pwd) #Login to Gmail server using TLS\n print 'Login successful'\n return smtpserver",
"_____no_output_____"
]
],
[
[
"### Send mail function. \nThis function takes 5 argument. 1. Login Data. 2. To Email 3. From Email 4. HTML format massage 5. Normal text \n\n**The HTML message, is best and preferred.**",
"_____no_output_____"
]
],
[
[
"# text = \"Hi!\\n5633222222222222222http://www.python.org\"\n# html = \"\"\"\\\n# <html>\n# <head></head>\n# <body>\n# <p>Hi!<br>\n# How are you?<br>\n \n# Here is the <a href=\"http://www.python.org\">link</a> you wanted.\n# </p>\n# </body>\n# </html>\n# \"\"\"\ndef Send_Mail(smtpserver,TO_EMAIL,text=None,html=None,subject='Subject missing',FROM_EMAIL='Shahariar'):\n# Create message container - the correct MIME type is multipart/alternative.\n msg = MIMEMultipart('alternative') # In turn, use text/plain and text/html parts within the multipart/alternative part.\n msg['Subject'] = subject #Subject of the message\n msg['From'] = formataddr((str(Header(FROM_EMAIL, 'utf-8')), FROM_EMAIL)) #Adding custom Sender Name\n msg['To'] = TO_EMAIL #Assining Reciver email\n\n part1 = MIMEText(text, 'plain') #adding text part of mail\n part2 = MIMEText(html, 'html') #Adding HTMLpart of mail\n\n # Attach parts into message container.\n # According to RFC 2046, the last part of a multipart message, in this case\n # the HTML message, is best and preferred.\n msg.attach(part1) #attach Plain text\n msg.attach(part2) #attach HTML text\n\n # sendmail function takes 3 arguments: sender's address, recipient's address\n # and message to send - here it is sent as one string.\n try:\n smtpserver.sendmail(FROM_EMAIL, TO_EMAIL, msg.as_string())\n print \" Message Send\"\n smtpserver.quit() #stopping server\n except Exception:\n print Exception\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1b57a8a3ebc858ef3998f8deefed89c07ad20f
| 3,384 |
ipynb
|
Jupyter Notebook
|
part1 - setup YOLO.ipynb
|
Gaurav14cs17/Yolo_model
|
981d26aa9e96ca3c66d9d84712846804dd137be6
|
[
"MIT"
] | null | null | null |
part1 - setup YOLO.ipynb
|
Gaurav14cs17/Yolo_model
|
981d26aa9e96ca3c66d9d84712846804dd137be6
|
[
"MIT"
] | null | null | null |
part1 - setup YOLO.ipynb
|
Gaurav14cs17/Yolo_model
|
981d26aa9e96ca3c66d9d84712846804dd137be6
|
[
"MIT"
] | null | null | null | 24.70073 | 121 | 0.54344 |
[
[
[
"# what is YOLO v2 (aka YOLO 9000)\n\nYOLO9000 is a high speed, real time detection algorithm that can detect on <b>OVER 9000!</b> (object categories)\n\n- you can read more about it here (https://arxiv.org/pdf/1612.08242.pdf)\n- watch a talk on it here (https://www.youtube.com/watch?v=NM6lrxy0bxs)\n- and another talk here (https://www.youtube.com/watch?v=4eIBisqx9_g)",
"_____no_output_____"
],
[
"# Step1 - Requirements\n\n- <b>Python 3.5 or 3.6</b>. Anaconda (install tutorial https://www.youtube.com/watch?v=T8wK5loXkXg)\n- <b>Tensorflow</b> (tutorial GPU verions https://www.youtube.com/watch?v=RplXYjxgZbw&t=91s)\n- <b>openCV</b> (https://www.lfd.uci.edu/~gohlke/pythonlibs/)",
"_____no_output_____"
],
[
"# Step2 - Download the Darkflow repo\n\n- https://github.com/thtrieu/darkflow\n- extract the files somewhere locally",
"_____no_output_____"
],
[
"# Step3 - Build the library\n\n- open an ```cmd``` window and type\n\n```python\npython setup.py build_ext --inplace\n```\n\nOR\n\n```python\npip install -e .\n```",
"_____no_output_____"
],
[
"# Step 4 - Download a weights file\n\n- Download the YOLOv2 608x608 weights file here (https://pjreddie.com/darknet/yolov2/)\n- NOTE: there are other weights files you can try if you like\n- create a ```bin``` folder within the ```darkflow-master``` folder\n- put the weights file in the bin folder",
"_____no_output_____"
],
[
"# Processing a video file\n\n- move the video file into the ``darkflow-master```\n- from there, open a ```cmd``` window\n- use the command\n\n```python\npython flow --model cfg/yolo.cfg --load bin/yolov2.weights --demo videofile.mp4 --gpu 1.0 --saveVideo\n```\n\n```videofile.mp4``` is the name of your video.\n\nNOTE: if you do not have the GPU version of tensorflow, leave off the ```--gpu 1.0```\n\n```--saveVideo``` indicates to save a name video file, which has the boxes around objects",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a1b57b4a4cd3f199d2661d002a96397762a374e
| 232,301 |
ipynb
|
Jupyter Notebook
|
healthy_versus_severe.ipynb
|
waldeyr/Pedro_RED_SPL
|
cbb50520969a2bb0322eca326d0dfe25b620ff80
|
[
"MIT"
] | null | null | null |
healthy_versus_severe.ipynb
|
waldeyr/Pedro_RED_SPL
|
cbb50520969a2bb0322eca326d0dfe25b620ff80
|
[
"MIT"
] | null | null | null |
healthy_versus_severe.ipynb
|
waldeyr/Pedro_RED_SPL
|
cbb50520969a2bb0322eca326d0dfe25b620ff80
|
[
"MIT"
] | 1 |
2021-12-06T04:59:39.000Z
|
2021-12-06T04:59:39.000Z
| 148.815503 | 182,516 | 0.833724 |
[
[
[
"# healthy versus severe",
"_____no_output_____"
]
],
[
[
"import re\nimport numpy as np \nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport pydotplus\nfrom IPython.display import Image \nfrom six import StringIO\nimport matplotlib.image as mpimg\n#%pylab inline\n\nfrom sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, plot_tree, export_graphviz\nfrom sklearn import preprocessing, metrics\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report, confusion_matrix, mean_squared_error\n\n#!pip install biopython\nfrom Bio import Entrez\nfrom Bio import SeqIO",
"_____no_output_____"
],
[
"url = \"healthy_versus_severe/healthy.csv\"\nhealthy = pd.read_csv(url, sep='\\t')\nhealthy['type'] = 'healthy'\nhealthy.shape[0]",
"_____no_output_____"
],
[
"healthy.sample(n=2)",
"_____no_output_____"
],
[
"healthy.columns",
"_____no_output_____"
],
[
"url = \"healthy_versus_severe/severe.csv\"\nsevere = pd.read_csv(url, sep=',' )\nsevere['type'] = 'severe'\nsevere.shape[0]",
"_____no_output_____"
],
[
"severe.sample(n=2)",
"_____no_output_____"
],
[
"severe.columns",
"_____no_output_____"
],
[
"df = pd.concat([healthy, severe], ignore_index=True)",
"_____no_output_____"
],
[
"df.tail()",
"_____no_output_____"
],
[
"def getChromossome( ncbi_id ):\n if \"chr\" in ncbi_id: \n return ncbi_id\n else:\n Entrez.email = \"[email protected]\"\n with Entrez.efetch( db=\"nucleotide\", rettype=\"gb\", id=ncbi_id ) as handle:\n record = SeqIO.read(handle, \"gb\")\n for f in record.features:\n if f.qualifiers['chromosome'][0]:\n return \"chr\" + str(f.qualifiers['chromosome'][0])\n else:\n return ncbi_id\n \ndf['Region'] = df['Region'].apply(lambda x: getChromossome(x))",
"_____no_output_____"
],
[
"def setRegion(Region):\n if Region == 'chrX': return 23 # chromossome X\n if Region == 'chrY': return 24 # chromossome Y\n if Region == 'chrM': return 25 # Mitochondrial\n return re.sub('chr', '', Region)\n\ndf['Region'] = df['Region'].apply(lambda x: setRegion(str(x)))",
"_____no_output_____"
],
[
"df = df.fillna(int(0)) # all NaN fields are strings type, so they will be factorize later and the zero will be a category",
"_____no_output_____"
],
[
"df.Region = pd.factorize(df.Region, na_sentinel=None)[0]\ndf.subs = pd.factorize(df.subs, na_sentinel=None)[0]\ndf.defSubs = pd.factorize(df.defSubs, na_sentinel=None)[0]\ndf.sym = pd.factorize(df.sym, na_sentinel=None)[0]\ndf.ensembl_id = pd.factorize(df.ensembl_id, na_sentinel=None)[0]\ndf.type = pd.factorize(df.type, na_sentinel=None)[0]\ndf.genetic_var = pd.factorize(df.genetic_var, na_sentinel=None)[0]\ndf.most_severe_cons = pd.factorize(df.most_severe_cons, na_sentinel=None)[0]\ndf.aa_change = pd.factorize(df.aa_change, na_sentinel=None)[0]\ndf.codons_change = pd.factorize(df.codons_change, na_sentinel=None)[0]\ndf.all_cons = pd.factorize(df.all_cons, na_sentinel=None)[0]\ndf.most_severe_cons = pd.factorize(df.most_severe_cons, na_sentinel=None)[0]",
"_____no_output_____"
],
[
"df = df.drop(['Unnamed: 0'], axis=1)",
"_____no_output_____"
],
[
"df.tail()",
"_____no_output_____"
],
[
"y = df['type'].values",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"X = df.drop(['type'], axis=1)",
"_____no_output_____"
],
[
"X.columns",
"_____no_output_____"
],
[
"X.dtypes",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size = 0.1, shuffle = True, random_state = 1)",
"_____no_output_____"
],
[
"arvore = DecisionTreeClassifier(criterion='entropy', max_depth=10, min_samples_leaf=30, random_state=0)",
"_____no_output_____"
],
[
"modelo= arvore.fit(X_treino, y_treino)",
"_____no_output_____"
],
[
"%pylab inline\nprevisao = arvore.predict(X_teste)\nnp.sqrt(mean_squared_error(y_teste, previsao))\npylab.figure(figsize=(25,20))\nplot_tree(arvore, feature_names=X_treino.columns)",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"# Aplicando mo modelo gerado na base de testes\ny_predicoes = modelo.predict(X_teste)\n\n# Avaliação do modelo\nprint(f\"Acurácia da árvore: {metrics.accuracy_score(y_teste, y_predicoes)}\")\nprint(classification_report(y_teste, y_predicoes))",
"Acurácia da árvore: 1.0\n precision recall f1-score support\n\n 0 1.00 1.00 1.00 173\n 1 1.00 1.00 1.00 117\n\n accuracy 1.00 290\n macro avg 1.00 1.00 1.00 290\nweighted avg 1.00 1.00 1.00 290\n\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1b5f474da37ed17ee165abe36c486098d83047
| 20,039 |
ipynb
|
Jupyter Notebook
|
notebooks/tfagents01.ipynb
|
bmwant/chemister
|
fbefcc9f548acc69966b6fbe19c4486f471fb390
|
[
"MIT"
] | null | null | null |
notebooks/tfagents01.ipynb
|
bmwant/chemister
|
fbefcc9f548acc69966b6fbe19c4486f471fb390
|
[
"MIT"
] | 1 |
2020-04-29T23:35:21.000Z
|
2020-04-29T23:35:21.000Z
|
notebooks/tfagents01.ipynb
|
bmwant/chemister
|
fbefcc9f548acc69966b6fbe19c4486f471fb390
|
[
"MIT"
] | null | null | null | 31.11646 | 1,356 | 0.575777 |
[
[
[
"import base64\nimport imageio\nimport IPython\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport PIL.Image\nimport pyvirtualdisplay\nimport tensorflow as tf",
"_____no_output_____"
],
[
"from tf_agents.agents.dqn import dqn_agent",
"_____no_output_____"
],
[
"from tf_agents.agents.dqn import q_network",
"_____no_output_____"
],
[
"from tf_agents.drivers import dynamic_step_driver\nfrom tf_agents.environments import suite_gym\nfrom tf_agents.environments import tf_py_environment\nfrom tf_agents.environments import trajectory\nfrom tf_agents.metrics import metric_utils, tf_metrics\nfrom tf_agents.policies import random_tf_policy\nfrom tf_agents.replay_buffers import tf_uniform_replay_buffer\nfrom tf_agents.utils import common",
"_____no_output_____"
],
[
"tf.compat.v1.enable_v2_behavior()",
"_____no_output_____"
],
[
"display = pyvirtualdisplay.Display(visible=0, size=(1400, 900)).start()",
"_____no_output_____"
],
[
"# hyperparameters\nenv_name = 'CartPole-v0'\nnum_iterations = 20000\ninitial_collect_steps = 1000\ncollect_steps_per_iteration = 1\nreplay_buffer_capacity = 100000\nfc_layer_params = (100,)\n\nbatch_size = 64\nlearning_rate = 1e-3\nlog_interval = 200\nnum_eval_episodes = 10\neval_interval = 1000",
"_____no_output_____"
],
[
"env = suite_gym.load(env_name)",
"_____no_output_____"
],
[
"env.reset()",
"_____no_output_____"
],
[
"# PIL.Image.fromarray(env.render())",
"_____no_output_____"
],
[
"env.time_step_spec().observation",
"_____no_output_____"
],
[
"env.action_spec()",
"_____no_output_____"
],
[
"time_step = env.reset()",
"_____no_output_____"
],
[
"time_step",
"_____no_output_____"
],
[
"action = 1",
"_____no_output_____"
],
[
"next_time_step = env.step(action)",
"_____no_output_____"
],
[
"next_time_step",
"_____no_output_____"
],
[
"train_py_env = suite_gym.load(env_name)\neval_py_env = suite_gym.load(env_name)\n\ntrain_env = tf_py_environment.TFPyEnvironment(train_py_env)\neval_env = tf_py_environment.TFPyEnvironment(eval_py_env)",
"_____no_output_____"
],
[
"q_net = q_network.QNetwork(\n train_env.observation_spec(),\n train_env.action_spec(),\n fc_layer_params=fc_layer_params,\n)",
"_____no_output_____"
],
[
"optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=learning_rate)\n\ntrain_step_counter = tf.Variable(0)\n\ntf_agent = dqn_agent.DqnAgent(\n train_env.time_step_spec(),\n train_env.action_spec(),\n q_network=q_net,\n optimizer=optimizer,\n train_step_counter=train_step_counter,\n td_errors_loss_fn=dqn_agent.element_wise_squared_loss,\n)\ntf_agent.initialize()",
"_____no_output_____"
],
[
"eval_policy = tf_agent.policy",
"_____no_output_____"
],
[
"collect_policy = tf_agent.collect_policy",
"_____no_output_____"
],
[
"eval_policy",
"_____no_output_____"
],
[
"collect_policy",
"_____no_output_____"
],
[
"random_policy = random_tf_policy.RandomTFPolicy(train_env.time_step_spec(),\n train_env.action_spec())",
"_____no_output_____"
],
[
"def compute_avg_return(environment, policy, num_episodes=10): total_return = 0.0 \n for _ in range(num_episodes):\n time_step = environment.reset()\n episode_return = 0.0\n while not time_step.is_last():\n action_step = policy.action(time_step)\n time_step = environment.step(action_step.action)\n episode_return += time_step.reward\n total_return += episode_return\n avg_return = total_return / num_episodes\n return avg_return.numpy()[0]\n\ncompute_avg_return(eval_env, random_policy, num_eval_episodes)",
"_____no_output_____"
],
[
"replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(\n data_spec=tf_agent.collect_data_spec,\n batch_size=train_env.batch_size,\n max_length=replay_buffer_capacity\n)",
"_____no_output_____"
],
[
"def collect_step(environment, policy):\n time_step = environment.current_time_step()\n action_step = policy.action(time_step)\n next_time_step = environment.step(action_step.action)\n traj = trajectory.from_transition(time_step, action_step, next_time_step)\n replay_buffer.add_batch(traj)\n \nfor _ in range(initial_collect_steps):\n collect_step(train_env, random_policy)",
"_____no_output_____"
],
[
"dataset = replay_buffer.as_dataset(\n num_parallel_calls=3, sample_batch_size=batch_size, num_steps=2\n).prefetch(3)\n\niterator = iter(dataset)",
"_____no_output_____"
],
[
"%%time\n\ntf_agent.train = common.function(tf_agent.train)\n\ntf_agent.train_step_counter.assign(0)\n\navg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)\nreturns = [avg_return]\n\nfor _ in range(num_iterations):\n for _ in range(collect_steps_per_iteration):\n collect_step(train_env, tf_agent.collect_policy)\n \n experience, unused_info = next(iterator)\n train_loss = tf_agent.train(experience)\n \n step = tf_agent.train_step_counter.numpy()\n \n if step % log_interval == 0:\n print('step = {0}: loss = {1}'.format(step, train_loss.loss))\n \n if step % eval_interval == 0:\n avg_return = compute_avg_return(eval_env, tf_agent.policy, num_eval_episodes)\n print('step = {0}: Average Return = {1}'.format(step, avg_return))\n returns.append(avg_return)",
"step = 200: loss = 21.531078338623047\nstep = 400: loss = 56.50679397583008\nstep = 600: loss = 35.09357452392578\nstep = 800: loss = 32.73316192626953\nstep = 1000: loss = 34.38996887207031\nstep = 1000: Average Return = 198.39999389648438\nstep = 1200: loss = 82.58395385742188\nstep = 1400: loss = 132.54940795898438\nstep = 1600: loss = 124.92987823486328\nstep = 1800: loss = 47.248104095458984\nstep = 2000: loss = 30.976490020751953\nstep = 2000: Average Return = 59.29999923706055\nstep = 2200: loss = 336.6656188964844\nstep = 2400: loss = 105.05303955078125\nstep = 2600: loss = 30.639545440673828\nstep = 2800: loss = 99.55473327636719\nstep = 3000: loss = 602.5145263671875\nstep = 3000: Average Return = 61.400001525878906\nstep = 3200: loss = 32.09312438964844\nstep = 3400: loss = 646.1357421875\nstep = 3600: loss = 47.03107833862305\nstep = 3800: loss = 961.888671875\nstep = 4000: loss = 95.11054992675781\nstep = 4000: Average Return = 57.20000076293945\nstep = 4200: loss = 362.79473876953125\nstep = 4400: loss = 140.62449645996094\nstep = 4600: loss = 905.238037109375\nstep = 4800: loss = 791.81201171875\nstep = 5000: loss = 181.74420166015625\nstep = 5000: Average Return = 130.3000030517578\nstep = 5200: loss = 497.1757507324219\nstep = 5400: loss = 24.086318969726562\nstep = 5600: loss = 269.3563232421875\nstep = 5800: loss = 1143.132080078125\nstep = 6000: loss = 62.71086120605469\nstep = 6000: Average Return = 67.0\nstep = 6200: loss = 70.08395385742188\nstep = 6400: loss = 363.80535888671875\nstep = 6600: loss = 241.85345458984375\nstep = 6800: loss = 24.111295700073242\nstep = 7000: loss = 344.10174560546875\nstep = 7000: Average Return = 141.0\nstep = 7200: loss = 38.8997802734375\nstep = 7400: loss = 99.18739318847656\nstep = 7600: loss = 17.61404037475586\nstep = 7800: loss = 600.5834350585938\nstep = 8000: loss = 414.26959228515625\nstep = 8000: Average Return = 157.0\nstep = 8200: loss = 20.02684783935547\nstep = 8400: loss = 14.123218536376953\nstep = 8600: loss = 28.89373016357422\nstep = 8800: loss = 80.52288055419922\nstep = 9000: loss = 419.2340087890625\nstep = 9000: Average Return = 193.1999969482422\nstep = 9200: loss = 256.67510986328125\nstep = 9400: loss = 14.947534561157227\nstep = 9600: loss = 395.34228515625\nstep = 9800: loss = 589.22509765625\nstep = 10000: loss = 13.257735252380371\nstep = 10000: Average Return = 200.0\nstep = 10200: loss = 407.9547424316406\nstep = 10400: loss = 17.292442321777344\nstep = 10600: loss = 324.16363525390625\nstep = 10800: loss = 1717.2098388671875\nstep = 11000: loss = 49.145320892333984\nstep = 11000: Average Return = 200.0\nstep = 11200: loss = 514.08447265625\nstep = 11400: loss = 63.01993179321289\nstep = 11600: loss = 1021.0872802734375\nstep = 11800: loss = 964.418701171875\nstep = 12000: loss = 37.91742706298828\nstep = 12000: Average Return = 200.0\nstep = 12200: loss = 1242.521240234375\nstep = 12400: loss = 1746.5631103515625\nstep = 12600: loss = 248.897216796875\nstep = 12800: loss = 151.05337524414062\nstep = 13000: loss = 1101.4449462890625\nstep = 13000: Average Return = 200.0\nstep = 13200: loss = 438.28411865234375\nstep = 13400: loss = 248.16860961914062\nstep = 13600: loss = 29.330703735351562\nstep = 13800: loss = 730.8961181640625\nstep = 14000: loss = 45.49745178222656\nstep = 14000: Average Return = 200.0\nstep = 14200: loss = 3136.896728515625\nstep = 14400: loss = 1149.354736328125\nstep = 14600: loss = 1478.6949462890625\nstep = 14800: loss = 749.9140625\nstep = 15000: loss = 651.131591796875\nstep = 15000: Average Return = 200.0\nstep = 15200: loss = 72.52986145019531\nstep = 15400: loss = 71.09382629394531\nstep = 15600: loss = 53.930023193359375\nstep = 15800: loss = 67.3087158203125\nstep = 16000: loss = 107.1379165649414\nstep = 16000: Average Return = 200.0\nstep = 16200: loss = 2509.5419921875\nstep = 16400: loss = 1555.0823974609375\nstep = 16600: loss = 1803.7117919921875\nstep = 16800: loss = 56.22900390625\nstep = 17000: loss = 4349.1904296875\nstep = 17000: Average Return = 200.0\nstep = 17200: loss = 2455.945556640625\nstep = 17400: loss = 135.10093688964844\nstep = 17600: loss = 3655.994384765625\nstep = 17800: loss = 110.10887145996094\nstep = 18000: loss = 166.3095703125\nstep = 18000: Average Return = 200.0\nstep = 18200: loss = 58.304779052734375\nstep = 18400: loss = 71.43017578125\nstep = 18600: loss = 74.11643981933594\nstep = 18800: loss = 5936.5693359375\nstep = 19000: loss = 110.1064453125\nstep = 19000: Average Return = 200.0\nstep = 19200: loss = 426.91748046875\nstep = 19400: loss = 989.296142578125\nstep = 19600: loss = 144.06837463378906\nstep = 19800: loss = 88.01036071777344\nstep = 20000: loss = 126.41265106201172\nstep = 20000: Average Return = 200.0\nCPU times: user 2min 53s, sys: 7.51 s, total: 3min\nWall time: 2min 39s\n"
],
[
"steps = range(0, num_iterations+1, eval_interval)\nplt.plot(steps, returns)\nplt.ylabel('Average Return')\nplt.xlabel('Step')\nplt.ylim(top=250)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1b609d665d8857c377f6c2c79c2a1502e7f904
| 29,900 |
ipynb
|
Jupyter Notebook
|
day4.ipynb
|
klaruszek/dw_matrix_car
|
38b2c3441b283ae93d6992a89e3819b3d10638a0
|
[
"MIT"
] | null | null | null |
day4.ipynb
|
klaruszek/dw_matrix_car
|
38b2c3441b283ae93d6992a89e3819b3d10638a0
|
[
"MIT"
] | null | null | null |
day4.ipynb
|
klaruszek/dw_matrix_car
|
38b2c3441b283ae93d6992a89e3819b3d10638a0
|
[
"MIT"
] | null | null | null | 29,900 | 29,900 | 0.60495 |
[
[
[
"!pip install --upgrade tables\n!pip install eli5\n!pip install xgboost",
"Collecting tables\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/ed/c3/8fd9e3bb21872f9d69eb93b3014c86479864cca94e625fd03713ccacec80/tables-3.6.1-cp36-cp36m-manylinux1_x86_64.whl (4.3MB)\n\u001b[K |████████████████████████████████| 4.3MB 2.8MB/s \n\u001b[?25hRequirement already satisfied, skipping upgrade: numpy>=1.9.3 in /usr/local/lib/python3.6/dist-packages (from tables) (1.17.5)\nRequirement already satisfied, skipping upgrade: numexpr>=2.6.2 in /usr/local/lib/python3.6/dist-packages (from tables) (2.7.1)\nInstalling collected packages: tables\n Found existing installation: tables 3.4.4\n Uninstalling tables-3.4.4:\n Successfully uninstalled tables-3.4.4\nSuccessfully installed tables-3.6.1\nCollecting eli5\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/97/2f/c85c7d8f8548e460829971785347e14e45fa5c6617da374711dec8cb38cc/eli5-0.10.1-py2.py3-none-any.whl (105kB)\n\u001b[K |████████████████████████████████| 112kB 2.7MB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.9.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (1.17.5)\nRequirement already satisfied: graphviz in /usr/local/lib/python3.6/dist-packages (from eli5) (0.10.1)\nRequirement already satisfied: jinja2 in /usr/local/lib/python3.6/dist-packages (from eli5) (2.11.1)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from eli5) (1.4.1)\nRequirement already satisfied: attrs>16.0.0 in /usr/local/lib/python3.6/dist-packages (from eli5) (19.3.0)\nRequirement already satisfied: tabulate>=0.7.7 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.8.6)\nRequirement already satisfied: scikit-learn>=0.18 in /usr/local/lib/python3.6/dist-packages (from eli5) (0.22.1)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from eli5) (1.12.0)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.6/dist-packages (from jinja2->eli5) (1.1.1)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn>=0.18->eli5) (0.14.1)\nInstalling collected packages: eli5\nSuccessfully installed eli5-0.10.1\nRequirement already satisfied: xgboost in /usr/local/lib/python3.6/dist-packages (0.90)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from xgboost) (1.17.5)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from xgboost) (1.4.1)\n"
],
[
"import pandas as pd\nimport numpy as np\n\nfrom sklearn.dummy import DummyRegressor\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\n\nimport xgboost as xgb\n\nfrom sklearn.metrics import mean_absolute_error as mean\nfrom sklearn.model_selection import cross_val_score, KFold\n\nimport eli5\nfrom eli5.sklearn import PermutationImportance",
"_____no_output_____"
],
[
"cd '/content/drive/My Drive/Colab Notebook/dw_matrix/matrix_2/dw_matrix_car'",
"/content/drive/My Drive/Colab Notebook/dw_matrix/matrix_2/dw_matrix_car\n"
],
[
"df = df = pd.read_hdf('data/car.h5')\ndf.shape",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"##Feature Engineering",
"_____no_output_____"
]
],
[
[
"\n\nSUFFIX_CAT ='__cat'\nfor feat in df.columns:\n if isinstance(df[feat][0],list): continue\n\n factorize_values = df[feat].factorize()[0]\n if SUFFIX_CAT in feat:\n df[feat] = factorize_values\n else:\n df[feat + SUFFIX_CAT] = factorize_values\n\n",
"_____no_output_____"
],
[
"cat_feats = [x for x in df.columns if SUFFIX_CAT in x ]\ncat_feats = [x for x in cat_feats if 'price' not in x ]\nlen(cat_feats)",
"_____no_output_____"
],
[
"def run_model(model, feats):\n X = df[feats].values\n y = df['price_value'].values\n\n scores = cross_val_score(model, X, y, cv=3, scoring='neg_mean_absolute_error')\n return np.mean(scores),np.std(scores)\n\n",
"_____no_output_____"
]
],
[
[
"##Decision Tree",
"_____no_output_____"
]
],
[
[
"run_model (DecisionTreeRegressor(max_depth=5), cat_feats)",
"_____no_output_____"
]
],
[
[
"##Random Forest",
"_____no_output_____"
]
],
[
[
"model=RandomForestRegressor(max_depth=5, n_estimators=50)\nrun_model (model, cat_feats)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"##XGBoost",
"_____no_output_____"
]
],
[
[
"xgb_params = {\n 'max_depth' : 5,\n 'n_estimators' : 50,\n 'learning_rate' :0.1,\n 'seed':0\n}\n\nrun_model (xgb.XGBRegressor(**xgb_params), cat_feats)",
"[17:54:32] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[17:54:52] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[17:55:12] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"m = xgb.XGBRegressor(max_depth=5, n_estimators=50, learning_rate=0.1, seed=0)\nm.fit(X,y)\n\nimp = PermutationImportance(m, random_state=0).fit(X,y)\neli5.show_weights(imp, feature_names= cat_feats)",
"[17:55:45] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"len(cat_feats)",
"_____no_output_____"
],
[
"feats = ['param_napęd__cat', 'param_rok-produkcji__cat', 'param_stan__cat', 'param_skrzynia-biegów__cat', 'param_faktura-vat__cat', 'param_moc__cat', 'param_marka-pojazdu__cat','feature_kamera-cofania__cat', 'param_typ__cat', 'param_pojemność-skokowa__cat', 'seller_name__cat', 'feature_wspomaganie-kierownicy__cat', 'param_model-pojazdu__cat', 'param_wersja__cat','param_kod-silnika__cat', 'feature_system-start-stop__cat', 'feature_asystent-pasa-ruchu__cat', 'feature_czujniki-parkowania-przednie__cat', 'feature_łopatki-zmiany-biegów__cat', 'feature_regulowane-zawieszenie__cat']\n\nlen(feats)",
"_____no_output_____"
],
[
"run_model (xgb.XGBRegressor(**xgb_params), feats)",
"[18:07:48] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:07:53] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:07:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"df['param_rok-produkcji'] = df['param_rok-produkcji'].map(lambda x: -1 if str(x) == 'None' else int(x))\n\nfeats = ['param_napęd__cat', 'param_rok-produkcji', 'param_stan__cat', 'param_skrzynia-biegów__cat', 'param_faktura-vat__cat', 'param_moc__cat', 'param_marka-pojazdu__cat','feature_kamera-cofania__cat', 'param_typ__cat', 'param_pojemność-skokowa__cat', 'seller_name__cat', 'feature_wspomaganie-kierownicy__cat', 'param_model-pojazdu__cat', 'param_wersja__cat','param_kod-silnika__cat', 'feature_system-start-stop__cat', 'feature_asystent-pasa-ruchu__cat', 'feature_czujniki-parkowania-przednie__cat', 'feature_łopatki-zmiany-biegów__cat', 'feature_regulowane-zawieszenie__cat']\nrun_model (xgb.XGBRegressor(**xgb_params),feats)\n",
"[18:09:09] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:09:13] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:09:17] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"#df['param_moc'] = df['param_moc'].map(lambda x: -1 if str(x) == 'None' else int(x.split(' ')[0]))\n\ndf['param_rok-produkcji'] = df['param_rok-produkcji'].map(lambda x: -1 if str(x) == 'None' else int(x))\n\nfeats = ['param_napęd__cat', 'param_rok-produkcji', 'param_stan__cat', 'param_skrzynia-biegów__cat', 'param_faktura-vat__cat', 'param_moc', 'param_marka-pojazdu__cat','feature_kamera-cofania__cat', 'param_typ__cat', 'param_pojemność-skokowa__cat', 'seller_name__cat', 'feature_wspomaganie-kierownicy__cat', 'param_model-pojazdu__cat', 'param_wersja__cat','param_kod-silnika__cat', 'feature_system-start-stop__cat', 'feature_asystent-pasa-ruchu__cat', 'feature_czujniki-parkowania-przednie__cat', 'feature_łopatki-zmiany-biegów__cat', 'feature_regulowane-zawieszenie__cat']\nrun_model (xgb.XGBRegressor(**xgb_params),feats)\n",
"[18:14:44] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:14:48] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:14:52] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"df['param_pojemność-skokowa'] = df['param_pojemność-skokowa'].map(lambda x: -1 if str(x) == 'None' else int( str(x).split('cm')[0].replace(' ', '')))\n\nfeats = ['param_napęd__cat', 'param_rok-produkcji', 'param_stan__cat', 'param_skrzynia-biegów__cat', 'param_faktura-vat__cat', 'param_moc', 'param_marka-pojazdu__cat','feature_kamera-cofania__cat', 'param_typ__cat', 'param_pojemność-skokowa', 'seller_name__cat', 'feature_wspomaganie-kierownicy__cat', 'param_model-pojazdu__cat', 'param_wersja__cat','param_kod-silnika__cat', 'feature_system-start-stop__cat', 'feature_asystent-pasa-ruchu__cat', 'feature_czujniki-parkowania-przednie__cat', 'feature_łopatki-zmiany-biegów__cat', 'feature_regulowane-zawieszenie__cat']\nrun_model (xgb.XGBRegressor(**xgb_params),feats)",
"[18:33:03] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:33:07] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n[18:33:11] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1b6dad75e16d474969ef9e9c7e1ff437b7a100
| 18,292 |
ipynb
|
Jupyter Notebook
|
CaliforniaGeostats.ipynb
|
LeonardoQZ/handson-ml2
|
65071140656c2e4c890a49857c9a7399201f20fa
|
[
"Apache-2.0"
] | null | null | null |
CaliforniaGeostats.ipynb
|
LeonardoQZ/handson-ml2
|
65071140656c2e4c890a49857c9a7399201f20fa
|
[
"Apache-2.0"
] | null | null | null |
CaliforniaGeostats.ipynb
|
LeonardoQZ/handson-ml2
|
65071140656c2e4c890a49857c9a7399201f20fa
|
[
"Apache-2.0"
] | null | null | null | 29.937807 | 510 | 0.506014 |
[
[
[
"<a href=\"https://colab.research.google.com/github/LeonardoQZ/handson-ml2/blob/master/CaliforniaGeostats.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# California Housing with Geostatistics",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nfrom sklearn.datasets import fetch_california_housing\nfrom pandas.plotting import scatter_matrix",
"_____no_output_____"
]
],
[
[
"# Load, inspect and cleanup the data",
"_____no_output_____"
]
],
[
[
"housing_dataset = fetch_california_housing()\nprint(housing_dataset['DESCR'])",
"_____no_output_____"
],
[
"source_columns = housing_dataset['feature_names'] + ['target']\nhousing_df = pd.DataFrame(data= np.c_[housing_dataset['data'], housing_dataset['target']],\n columns= source_columns)",
"_____no_output_____"
],
[
"housing_df.describe()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nhousing_df.plot(kind=\"scatter\", x=\"Longitude\", y=\"Latitude\", alpha=0.4,\n s=housing_df[\"Population\"]/100, label=\"population\", figsize=(10,7),\n c=\"target\", cmap=plt.get_cmap(\"jet\"), colorbar=True,\n sharex=False)\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"There is clearly clipping in the target data. It would make sense to remove the maximum value from the analysis.\n\nWe will re-index to have simple range compatible with downstream transformations.",
"_____no_output_____"
]
],
[
[
"fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12, 6))\nhousing_df['target'].hist(bins=100, ax=axes[0])\nclipped_indexes = housing_df[ housing_df['target'].ge(5) ].index\nhousing_clipped_df = housing_df.drop(index=clipped_indexes).reset_index()\nhousing_clipped_df['target'].hist(bins=100, ax=axes[1]);",
"_____no_output_____"
],
[
"housing_clipped_df.info()\nhousing_clipped_df.describe()",
"_____no_output_____"
]
],
[
[
"# Define training set with stratified sampling",
"_____no_output_____"
],
[
"Before doing anything else let us split the data into train and test set. What kind of sampling to use is a non trivial question. There is high correlation between the median income and the target price. ",
"_____no_output_____"
]
],
[
[
"scatter_matrix(housing_clipped_df[['MedInc', 'target']], figsize=(12, 8));",
"_____no_output_____"
]
],
[
[
"We want to guarantee that the test set is representative of the income distribution. In practical terms we would want estimation errors from populations of very high income have acceptable confidence intervals. To achieve this we can stratify our sampling by breaking up the dataset into discrete median income categories. The estimation error of statistics on each of this categories will be smaller if we randomly sample independently from them than if we randomly sample without stratification.\n\nLet us compare strata by Geron, Pew Research with proportional quantile and decile stratification to quantify estimation errors.",
"_____no_output_____"
]
],
[
[
"income_category_geron, income_geron_bins = pd.cut(housing_clipped_df[\"MedInc\"],\n bins=[0., 1.5, 3.0, 4.5, 6., np.inf], retbins=True,\n labels=[1, 2, 3, 4, 5])\nincome_category_pew, income_pew_bins = pd.cut(housing_clipped_df[\"MedInc\"],\n bins=[0., 3.1, 4.2, 12.6, 18.8, np.inf], retbins=True,\n labels=[1, 2, 3, 4, 5])\nincome_category_quartiles, income_quartile_bins = pd.qcut(\n housing_clipped_df[\"MedInc\"], 4, retbins=True,\n labels=[str(i+1) for i in range(4)])\nincome_category_deciles, income_decile_bins = pd.qcut(\n housing_clipped_df[\"MedInc\"], 10, retbins=True,\n labels=[str(i+1) for i in range(10)])\n\nfig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 6))\nincome_category_geron.hist(bins=10, ax=axes[0,0])\nincome_category_pew.hist(bins=10, ax=axes[0,1])\nincome_category_quartiles.hist(bins=10, ax=axes[1,0])\nincome_category_deciles.hist(bins=10, ax=axes[1,1])\nplt.show()",
"_____no_output_____"
],
[
"income_categories = pd.DataFrame({\n 'Geron' : income_category_geron,\n 'Pew' : income_category_pew,\n 'Quartiles' : income_category_quartiles,\n 'Deciles' : income_category_deciles\n})\nincome_categories.describe()",
"_____no_output_____"
],
[
"housing_categorized = housing_clipped_df.copy()\nhousing_categorized[income_categories.keys()] = income_categories\n",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import StratifiedShuffleSplit\n\ntrain_set_random, test_set_random = train_test_split(housing_categorized, test_size=0.2, random_state=42)\nsplit = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)",
"_____no_output_____"
],
[
"train_sets = {\"Random\" : train_set_random }\ntest_sets = {\"Random\" : test_set_random }\nfor key in income_categories:\n for train_index, test_index in split.split(housing_categorized, housing_categorized[key]):\n train_sets[key] = housing_categorized.loc[train_index]\n test_sets[key] = housing_categorized.loc[test_index]\n",
"_____no_output_____"
],
[
"def generateCategoryComparison(income_categories):\n comparison = {}\n for cat in income_categories:\n overall = f\"Overall {cat}\"\n random = f\"Random {cat}\"\n stratified = f\"Stratified {cat}\"\n randErr = f\"RandErr {cat}\"\n stratErr = f\"StratErr {cat}\"\n compare_props = pd.DataFrame({\n overall : housing_categorized[cat].value_counts() / len(housing_categorized),\n random : train_sets['Random'][cat].value_counts() / len(train_sets['Random']),\n stratified : train_sets[cat][cat].value_counts() / len(train_sets[cat])\n }).sort_index()\n compare_props[randErr] = 100*np.abs(compare_props[random]/compare_props[overall] - 1)\n compare_props[stratErr] = 100*np.abs(compare_props[stratified]/compare_props[overall] - 1)\n comparison[cat] = compare_props\n return comparison",
"_____no_output_____"
],
[
"cat_comparison = generateCategoryComparison(income_categories)\n",
"_____no_output_____"
],
[
"cat_comparison",
"_____no_output_____"
]
],
[
[
"The Income stratification model of Pew Research gives the lowest sampling bias errors but on this particular dataset there are no units with a median in category 5 and very fey in 4. Let us adapt a bit the category.",
"_____no_output_____"
]
],
[
[
"income_strata, income_strata_bins = pd.cut(housing_clipped_df[\"MedInc\"],\n bins=[0., 3.1, 4.2, 7.5, 9.3, np.inf], retbins=True,\n labels=[1, 2, 3, 4, 5])\nhousing_categorized[\"Strata\"] = income_strata\ntrain_set_random, test_set_random = train_test_split(housing_categorized, test_size=0.2, random_state=42)\ntrain_sets['Random']=train_set_random\ntest_sets['Random']=test_set_random",
"_____no_output_____"
],
[
"for train_index, test_index in split.split(housing_categorized, housing_categorized[\"Strata\"]):\n train_sets[\"Strata\"] = housing_categorized.loc[train_index]\n test_sets[\"Strata\"] = housing_categorized.loc[test_index]",
"_____no_output_____"
],
[
"cat_comparison_final = generateCategoryComparison(['Pew', 'Strata'])",
"_____no_output_____"
],
[
"cat_comparison_final",
"_____no_output_____"
],
[
"income_strata.value_counts()",
"_____no_output_____"
]
],
[
[
"This seems a good starting point for our train and test dataset. Let us make a copy with the categories removed.",
"_____no_output_____"
]
],
[
[
"train_set = train_sets['Strata'].copy()\ntest_set = test_sets['Strata'].copy()\ntrain_set.drop(income_categories, axis=1, inplace=True)\ntrain_set.drop('Strata', axis=1, inplace=True)\ntest_set.drop(income_categories, axis=1, inplace=True)\ntest_set.drop('Strata', axis=1, inplace=True)\n",
"_____no_output_____"
]
],
[
[
"# Visualization",
"_____no_output_____"
],
[
"Let us get a birds eye view of the correlations in the data",
"_____no_output_____"
]
],
[
[
"\nscatter_matrix(train_set, figsize=(12, 8));",
"_____no_output_____"
],
[
"correlations = train_set.corr()\nprint(correlations[\"target\"].sort_values(ascending=False))",
"_____no_output_____"
]
],
[
[
"Maybe combining some of the features in a sensible way we can find other correlations",
"_____no_output_____"
]
],
[
[
"rooms_per_capita = train_set['AveRooms']/train_set['Population']\nbedroom_ratio = train_set['AveBedrms']/train_set['AveRooms']\n",
"_____no_output_____"
],
[
"correlations_xtra = housing_df.corr()\nprint(correlations_xtra[\"target\"].sort_values(ascending=False))\n\ncorr_threshold = 0.15\nhigh_corr = correlations_xtra[\"target\"].sort_values(ascending=False).abs().ge(corr_threshold)\nhigh_corr_cols=list(high_corr[high_corr].keys())",
"_____no_output_____"
],
[
"scatter_matrix(housing_df[high_corr_cols], figsize=(12, 8));",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedShuffleSplit\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a1b8510e6319f7c7b897416be67463e4712b360
| 6,420 |
ipynb
|
Jupyter Notebook
|
JupyterNotebooks/Labs/Lab 3.ipynb
|
ryan-gonfiantini/CMPT-120L-902-21S
|
e5807251e26ce422ce0c70f99ac62661b5881c18
|
[
"MIT"
] | null | null | null |
JupyterNotebooks/Labs/Lab 3.ipynb
|
ryan-gonfiantini/CMPT-120L-902-21S
|
e5807251e26ce422ce0c70f99ac62661b5881c18
|
[
"MIT"
] | null | null | null |
JupyterNotebooks/Labs/Lab 3.ipynb
|
ryan-gonfiantini/CMPT-120L-902-21S
|
e5807251e26ce422ce0c70f99ac62661b5881c18
|
[
"MIT"
] | null | null | null | 26.204082 | 186 | 0.540966 |
[
[
[
"# Lab Three\nRyan Gonfiantini\n---\n\nFor this lab we're going to be making and using a bunch of functions. \n\nOur Goals are:\n- Searching our Documentation\n- Using built in functions\n- Making our own functions\n- Combining functions\n- Structuring solutions",
"_____no_output_____"
]
],
[
[
"# For the following built in functions we didn't touch on them in class. I want you to look for them in the python documentation and implement them.",
"_____no_output_____"
],
[
"# I want you to find a built in function to SWAP CASE on a string. Print it.\n\n# For example the string \"HeY thERe HowS iT GoING\" turns into \"hEy THerE hOWs It gOing\"\nsample_string = \"HeY thERe HowS iT GoING\"\nprint(sample_string.swapcase()) ",
"hEy THerE hOWs It gOing\n"
],
[
"# I want you to find a built in function to CENTER a string and pad the sides with 4 dashes(-) a side. Print it.\n\n# For example the string \"Hey There\" becomes \"----Hey There----\"\n\nsample_string = \"Hey There\"\nprint(sample_string.center(17,\"-\"))",
"----Hey There----\n"
],
[
"# I want you to find a built in function to PARTITION a string. Print it.\n\n# For example the string \"abcdefg.hijklmnop\" would come out to be [\"abcdefg\",\".\",\"hijklmnop\"]\n\nsample_string = \"abcdefg.hijklmnop\"\nprint(sample_string.partition(\".\"))",
"('abcdefg', '.', 'hijklmnop')\n"
],
[
"# I want you to write a function that will take in a number and raise it to the power given. \n\n# For example if given the numbers 2 and 3. The math that the function should do is 2^3 and should print out or return 8. Print the output.\n\ndef power(number, exponent) -> int:\n return number ** exponent\nproblem_one = power(2,3)\nprint(problem_one)",
"8\n"
],
[
"# I want you to write a function that will take in a list and see how many times a given number is in the list. \n\n# For example if the array given is [2,3,5,2,3,6,7,8,2] and the number given is 2 the function should print out or return 3. Print the output.\narray = [2,3,5,2,3,6,7,8,2]\ndef number_list(array, target):\n count = 0 \n for number in array:\n if number == target:\n count += 1\n return count\nproblem_two = number_list(array, 2)\nprint(problem_two)",
"3\n"
],
[
"# Use the functions given to create a slope function. The function should be named slope and have 4 parameters.\n\n# If you don't remember the slope formula is (y2 - y1) / (x2 - x1) If this doesn't make sense look up `Slope Formula` on google.\n\ndef division(x, y):\n return x / y\n\ndef subtraction(x, y):\n return x - y\n\ndef slope(x1, x2, y1, y2):\n return division(subtraction(y2,y1), subtraction(x2, x1))\nslope_function = slope(5, 3, 10, 4)\nprint(slope_function)\n",
"3.0\n"
],
[
"# Use the functions given to create a distance function. The function should be named function and have 4 parameters.\n\n# HINT: You'll need a built in function here too. You'll also be able to use functions written earlier in the notebook as long as you've run those cells.\n\n# If you don't remember the distance formula it is the square root of the following ((x2 - x1)^2 + (y2 - y1)^2). If this doesn't make sense look up `Distance Formula` on google.\n\nimport math\n\ndef addition(x, y):\n return x + y\n\ndef distance(x1, x2, y1, y2):\n left_side = power(subtraction(x2, x1), 2)\n right_side = power(subtraction(y2, y1), 2)\n both_sides = addition(left_side, right_side)\n\n return math.sqrt(both_sides)\nprint(distance(10, 4, 5, 3))\n",
"6.324555320336759\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1b8d85993ae4f7bf2b750fc5ac1ffd027d6a0f
| 7,299 |
ipynb
|
Jupyter Notebook
|
code/chapter06_RNN/6.7_gru.ipynb
|
gao-lex/Dive-into-DL-PyTorch
|
a8ae6e964e2bcab156302ee4bd4ae560dcf6277f
|
[
"Apache-2.0"
] | 92 |
2019-09-18T14:58:53.000Z
|
2022-03-25T07:27:17.000Z
|
code/chapter06_RNN/6.7_gru.ipynb
|
sin-en-2009/ShusenTang-Dive-into-DL-PyTorch
|
fadb89502f95a14b59ed578353ac2a27789d3efa
|
[
"Apache-2.0"
] | 2 |
2021-05-20T12:16:47.000Z
|
2021-09-28T00:17:13.000Z
|
code/chapter06_RNN/6.7_gru.ipynb
|
sin-en-2009/ShusenTang-Dive-into-DL-PyTorch
|
fadb89502f95a14b59ed578353ac2a27789d3efa
|
[
"Apache-2.0"
] | 35 |
2019-09-19T02:06:18.000Z
|
2022-01-15T07:13:23.000Z
| 29.431452 | 126 | 0.544595 |
[
[
[
"# 6.7 门控循环单元(GRU)\n## 6.7.2 读取数据集",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch\nfrom torch import nn, optim\nimport torch.nn.functional as F\n\nimport sys\nsys.path.append(\"..\") \nimport d2lzh_pytorch as d2l\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n\n(corpus_indices, char_to_idx, idx_to_char, vocab_size) = d2l.load_data_jay_lyrics()\nprint(torch.__version__, device)",
"1.0.0 cpu\n"
]
],
[
[
"## 6.7.3 从零开始实现\n### 6.7.3.1 初始化模型参数",
"_____no_output_____"
]
],
[
[
"num_inputs, num_hiddens, num_outputs = vocab_size, 256, vocab_size\nprint('will use', device)\n\ndef get_params():\n def _one(shape):\n ts = torch.tensor(np.random.normal(0, 0.01, size=shape), device=device, dtype=torch.float32)\n return torch.nn.Parameter(ts, requires_grad=True)\n def _three():\n return (_one((num_inputs, num_hiddens)),\n _one((num_hiddens, num_hiddens)),\n torch.nn.Parameter(torch.zeros(num_hiddens, device=device, dtype=torch.float32), requires_grad=True))\n \n W_xz, W_hz, b_z = _three() # 更新门参数\n W_xr, W_hr, b_r = _three() # 重置门参数\n W_xh, W_hh, b_h = _three() # 候选隐藏状态参数\n \n # 输出层参数\n W_hq = _one((num_hiddens, num_outputs))\n b_q = torch.nn.Parameter(torch.zeros(num_outputs, device=device, dtype=torch.float32), requires_grad=True)\n return nn.ParameterList([W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q])",
"will use cpu\n"
]
],
[
[
"### 6.7.3.2 定义模型",
"_____no_output_____"
]
],
[
[
"def init_gru_state(batch_size, num_hiddens, device):\n return (torch.zeros((batch_size, num_hiddens), device=device), )",
"_____no_output_____"
],
[
"def gru(inputs, state, params):\n W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params\n H, = state\n outputs = []\n for X in inputs:\n Z = torch.sigmoid(torch.matmul(X, W_xz) + torch.matmul(H, W_hz) + b_z)\n R = torch.sigmoid(torch.matmul(X, W_xr) + torch.matmul(H, W_hr) + b_r)\n H_tilda = torch.tanh(torch.matmul(X, W_xh) + R * torch.matmul(H, W_hh) + b_h)\n H = Z * H + (1 - Z) * H_tilda\n Y = torch.matmul(H, W_hq) + b_q\n outputs.append(Y)\n return outputs, (H,)",
"_____no_output_____"
]
],
[
[
"### 6.7.3.3 训练模型并创作歌词",
"_____no_output_____"
]
],
[
[
"num_epochs, num_steps, batch_size, lr, clipping_theta = 160, 35, 32, 1e2, 1e-2\npred_period, pred_len, prefixes = 40, 50, ['分开', '不分开']",
"_____no_output_____"
],
[
"d2l.train_and_predict_rnn(gru, get_params, init_gru_state, num_hiddens,\n vocab_size, device, corpus_indices, idx_to_char,\n char_to_idx, False, num_epochs, num_steps, lr,\n clipping_theta, batch_size, pred_period, pred_len,\n prefixes)",
"epoch 40, perplexity 149.477598, time 1.08 sec\n - 分开 我不不你 我想你你的爱我 你不你的让我 你不你的让我 你不你的让我 你不你的让我 你不你的让我 你\n - 不分开 我想你你的让我 你不你的让我 你不你的让我 你不你的让我 你不你的让我 你不你的让我 你不你的让我\nepoch 80, perplexity 31.689210, time 1.10 sec\n - 分开 我想要你 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不\n - 不分开 我想要你 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不要再想 我不\nepoch 120, perplexity 4.866115, time 1.08 sec\n - 分开 我想要这样牵着你的手不放开 爱过 让我来的肩膀 一起好酒 你来了这节秋 后知后觉 我该好好生活 我\n - 不分开 你已经不了我不要 我不要再想你 我不要再想你 我不要再想你 不知不觉 我跟了这节奏 后知后觉 又过\nepoch 160, perplexity 1.442282, time 1.51 sec\n - 分开 我一定好生忧 唱着歌 一直走 我想就这样牵着你的手不放开 爱可不可以简简单单没有伤害 你 靠着我的\n - 不分开 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好生活 我该好好生活\n"
]
],
[
[
"## 6.7.4 简洁实现",
"_____no_output_____"
]
],
[
[
"lr = 1e-2\ngru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens)\nmodel = d2l.RNNModel(gru_layer, vocab_size).to(device)\nd2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,\n corpus_indices, idx_to_char, char_to_idx,\n num_epochs, num_steps, lr, clipping_theta,\n batch_size, pred_period, pred_len, prefixes)",
"epoch 40, perplexity 1.022157, time 1.02 sec\n - 分开手牵手 一步两步三步四步望著天 看星星 一颗两颗三颗四颗 连成线背著背默默许下心愿 看远方的星是否听\n - 不分开暴风圈来不及逃 我不能再想 我不能再想 我不 我不 我不能 爱情走的太快就像龙卷风 不能承受我已无处\nepoch 80, perplexity 1.014535, time 1.04 sec\n - 分开始想像 爸和妈当年的模样 说著一口吴侬软语的姑娘缓缓走过外滩 消失的 旧时光 一九四三 在回忆 的路\n - 不分开始爱像 不知不觉 你已经离开我 不知不觉 我跟了这节奏 后知后觉 又过了一个秋 后知后觉 我该好好\nepoch 120, perplexity 1.147843, time 1.04 sec\n - 分开都靠我 你拿着球不投 又不会掩护我 选你这种队友 瞎透了我 说你说 分数怎么停留 所有回忆对着我进攻\n - 不分开球我有多烦恼多 牧草有没有危险 一场梦 我面对我 甩开球我满腔的怒火 我想揍你已经很久 别想躲 说你\nepoch 160, perplexity 1.018370, time 1.05 sec\n - 分开爱上你 那场悲剧 是你完美演出的一场戏 宁愿心碎哭泣 再狠狠忘记 你爱过我的证据 让晶莹的泪滴 闪烁\n - 不分开始 担心今天的你过得好不好 整个画面是你 想你想的睡不著 嘴嘟嘟那可爱的模样 还有在你身上香香的味道\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1ba0959567c7c4323f108d059c44fdd9592135
| 9,427 |
ipynb
|
Jupyter Notebook
|
00-python-setup/Getting Started.ipynb
|
fmi-faim/py_course
|
16edd5f5498f0c02cfa757f6f5704b5f0831a733
|
[
"MIT"
] | 1 |
2022-01-13T11:13:22.000Z
|
2022-01-13T11:13:22.000Z
|
00-python-setup/Getting Started.ipynb
|
fmi-faim/py_course
|
16edd5f5498f0c02cfa757f6f5704b5f0831a733
|
[
"MIT"
] | null | null | null |
00-python-setup/Getting Started.ipynb
|
fmi-faim/py_course
|
16edd5f5498f0c02cfa757f6f5704b5f0831a733
|
[
"MIT"
] | null | null | null | 28.480363 | 349 | 0.583112 |
[
[
[
"# The JupyterLab Interface\n\nThe JupyterLab interface consists of a main work area containing tabs of documents and activities, a collapsible left sidebar, and a menu bar. The left sidebar contains a file browser, the list of running terminals and kernels, the table of contents, and the extension manager.\n\n\n\nJupyterLab sessions always reside in a workspace. Workspaces contain the state of JupyterLab: the files that are currently open, the layout of the application areas and tabs, etc.\n\nReference: [https://jupyterlab.readthedocs.io/en/latest/user/interface.html](https://jupyterlab.readthedocs.io/en/latest/user/interface.html)",
"_____no_output_____"
],
[
"# Notebook\n\nCurrently you are looking at a Jupyter Notebook. A Jupyter Notebook is an interactive environment for writing and running ocde. The notebook is capable of running code in a wide range of languages. However, each notebook is associated with a single kernel. This notebook is associated with the IPython kernel, therefore it runs Python code.\n\nReference: [https://github.com/jupyter/notebook/blob/6.1.x/docs/source/examples/Notebook/Running%20Code.ipynb](https://github.com/jupyter/notebook/blob/6.1.x/docs/source/examples/Notebook/Running%20Code.ipynb)",
"_____no_output_____"
],
[
"## Notebook Cell Types\nIn a Jupyter Notebook we can have text cells and code cells. \nIn text cells we can write markdown ([Markdown cheat sheet](https://www.markdownguide.org/cheat-sheet/)).\nIn code cells we can write program code which is executed by the IPython kernel associated with the notebook.\n\nCode cells have brackets `[ ]:` in front of them:\n* `[ ]:` means that the cell is empty.\n* `[*]:` means that the cell is currently being executed.\n* `[1]:` here the number indicates the execution step in the notebook. This execution step is updated everytime the cell is executed.\n\nTo render a text cell or execute a code cell you can press the run button in the toolbar above or press `Shift-Enter` on your keyboard.",
"_____no_output_____"
]
],
[
[
"2 + 2",
"_____no_output_____"
],
[
"# If we want to write text in a code cell we have to comment it out with '#'.\n\n# Next we asign some variables.\na = 2\nb = 2\nc = a + b",
"_____no_output_____"
],
[
"print(\"a is\", a)\nprint(\"b is\", b)\nprint(\"a + b =\", c)",
"_____no_output_____"
]
],
[
[
"# Displaying an Image",
"_____no_output_____"
]
],
[
[
"# import packages\nfrom tifffile import imread\nfrom matplotlib import pyplot as plt",
"_____no_output_____"
],
[
"img = imread('imgs/t000.tif')",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 10))\nplt.imshow(img, cmap='gray')",
"_____no_output_____"
]
],
[
[
"# Python Basics",
"_____no_output_____"
],
[
"## If Statement\nThe if statement allows us to branch code and act on different conditions.\nThe statement has the following logic:\n```\nif condition_0:\n code_0\nelif condition_1:\n code_1\nelse:\n code_2\n```\n`code_0` is executed if `condition_0` holds true. If `condition_0` is false `condition_1` is evaluated and `code_1` is executed if `condition_1` is true. If both conditions evaluate to false `code_2` is executed. \n\n__Note:__ `elif` and `else` are optional.\n",
"_____no_output_____"
]
],
[
[
"# Assign value to number\nnumber = 3\n\n# Test if the number is negative, zero or positive\nif number < 0:\n print(\"{} is a negative number.\".format(number))\nelif number == 0:\n print(\"The number is zero.\")\nelse:\n print(\"{} is a positive number.\".format(number))\n\n# The following code is outside of the if statement and always executed.\nprint(\"Done\")",
"_____no_output_____"
]
],
[
[
"## Functions\nIn Python we can define functions which can be reused in our code. It is good practice to define a function if we want to reuse the same code multiple times!",
"_____no_output_____"
]
],
[
[
"def categorize_number(number):\n \"\"\"\n Prints to standard output if the number is negative, zero or positive.\n \n Parameter:\n ----------\n number: The number to categorize.\n \"\"\"\n if number < 0:\n print(\"{} is a negative number.\".format(number))\n elif number == 0:\n print(\"The number is zero.\")\n else:\n print(\"{} is a positive number.\".format(number))",
"_____no_output_____"
],
[
"categorize_number(number=-2)",
"_____no_output_____"
]
],
[
[
"## Lists\nIn python we can easily define a list.",
"_____no_output_____"
]
],
[
[
"numbers = [-1, 0, 1, 2]",
"_____no_output_____"
],
[
"type(numbers)",
"_____no_output_____"
]
],
[
[
"## For Loop\nIf we want to apply some code (e.g. a function) to all elements of a list we can use a for loop.",
"_____no_output_____"
]
],
[
[
"for number in numbers:\n print(\"Currently processing number = {}.\".format(number))\n categorize_number(number)",
"_____no_output_____"
]
],
[
[
"## Range\nA typical usecase is that we want to get all numbers from 0 up to a given number e.g. 100. Luckely we don't have to type all 100 numbers into a list to iterate over them. We can just use the `range`-function which is part of Python.",
"_____no_output_____"
]
],
[
[
"for i in range(100):\n categorize_number(number=i)",
"_____no_output_____"
],
[
"import this",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1ba7a4ce460821828a8554f0a8a6f3845a1e08
| 45,573 |
ipynb
|
Jupyter Notebook
|
Linear Regression.ipynb
|
annalizaantonio/DeepLearning
|
1aa3ac8e019f5a80d5859a063dba4cefad42fbaf
|
[
"MIT"
] | null | null | null |
Linear Regression.ipynb
|
annalizaantonio/DeepLearning
|
1aa3ac8e019f5a80d5859a063dba4cefad42fbaf
|
[
"MIT"
] | null | null | null |
Linear Regression.ipynb
|
annalizaantonio/DeepLearning
|
1aa3ac8e019f5a80d5859a063dba4cefad42fbaf
|
[
"MIT"
] | 1 |
2019-10-02T19:23:41.000Z
|
2019-10-02T19:23:41.000Z
| 102.181614 | 18,780 | 0.854497 |
[
[
[
"<div style=\"width: 100%; overflow: hidden;\">\n <div style=\"width: 150px; float: left;\"> <img src=\"data/D4Sci_logo_ball.png\" alt=\"Data For Science, Inc\" align=\"left\" border=\"0\"> </div>\n <div style=\"float: left; margin-left: 10px;\"> <h1>Deep Learning From Scratch</h1>\n<h2>Linear Regression</h2>\n <p>Bruno Gonçalves<br/>\n <a href=\"http://www.data4sci.com/\">www.data4sci.com</a><br/>\n @bgoncalves, @data4sci</p></div>\n</div>",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\nimport watermark\n\n%load_ext watermark\n%matplotlib inline",
"_____no_output_____"
],
[
"%watermark -i -n -v -m -g -iv",
"watermark 1.8.1\nnumpy 1.16.2\nmatplotlib 3.1.0\nTue Sep 24 2019 2019-09-24T09:28:48-04:00\n\nCPython 3.7.3\nIPython 6.2.1\n\ncompiler : Clang 4.0.1 (tags/RELEASE_401/final)\nsystem : Darwin\nrelease : 18.7.0\nmachine : x86_64\nprocessor : i386\nCPU cores : 8\ninterpreter: 64bit\nGit hash : 46e8ada9ae78bc5ab280631b85d64d9ea1891da7\n"
],
[
"data = np.array(np.loadtxt(\"data/Anscombe1.dat\"))",
"_____no_output_____"
],
[
"print(data)",
"[[10. 8.04]\n [ 8. 6.95]\n [13. 7.58]\n [ 9. 8.81]\n [11. 8.33]\n [14. 9.96]\n [ 6. 7.24]\n [ 4. 4.26]\n [12. 10.84]\n [ 7. 4.82]\n [ 5. 5.68]]\n"
],
[
"X = data[:, 0].reshape(-1, 1)\ny = data[:, 1].reshape(-1, 1)",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"plt.plot(X, y, '*')\nplt.xlabel('X')\nplt.ylabel('y')\nplt.gcf().set_size_inches(11, 8)",
"_____no_output_____"
]
],
[
[
"Get matrix dimensions and add the bias column",
"_____no_output_____"
]
],
[
[
"M, N = X.shape\nX = np.concatenate((np.ones((M, 1)), X), axis=1) #Add x0",
"_____no_output_____"
],
[
"print(X)",
"[[ 1. 10.]\n [ 1. 8.]\n [ 1. 13.]\n [ 1. 9.]\n [ 1. 11.]\n [ 1. 14.]\n [ 1. 6.]\n [ 1. 4.]\n [ 1. 12.]\n [ 1. 7.]\n [ 1. 5.]]\n"
]
],
[
[
"Set the training parameters and initialize the weight matrix",
"_____no_output_____"
]
],
[
[
"alpha = 0.01\nepsilon = 0.12\n\nweights = 2*np.random.rand(N+1, 1)*epsilon - epsilon\ncount = 0",
"_____no_output_____"
]
],
[
[
"## Training Procedure",
"_____no_output_____"
]
],
[
[
"oldJ = 0\nerr = 1\n\nJs = []\n\nwhile err > 1e-6:\n Hs = np.dot(X, weights)\n deltas = alpha/M*np.dot(X.T, (Hs-y))\n\n count += 1\n weights -= deltas\n\n J = np.sum(np.power(Hs-y, 2.))/(2*M)\n Js.append(J)\n err = np.abs(oldJ-J)\n oldJ = J\n \n if count % 100 == 0:\n print(count, J, err, weights.flatten())\n\nprint(count, J, err, weights.flatten())",
"100 1.0156121187233378 0.000850294716994604 [0.33867803 0.76362272]\n200 0.9392871281862785 0.0006839027618601445 [0.61324329 0.7364354 ]\n300 0.8778979759499936 0.0005500716143855833 [0.85948297 0.71205287]\n400 0.8285219067782602 0.0004424295350546892 [1.08031928 0.69018576]\n500 0.788808111782883 0.0003558516534383216 [1.27837296 0.67057458]\n600 0.7568658057348 0.00028621597163347445 [1.45599438 0.6529866 ]\n700 0.7311742062342188 0.00023020711475285616 [1.61529145 0.63721308]\n800 0.7105101288221294 0.00018515848497269172 [1.7581546 0.62306684]\n900 0.6938897508155676 0.0001489253040438676 [1.88627924 0.61038 ]\n1000 0.6805217712260517 0.00011978249977417921 [2.00118588 0.599002 ]\n1100 0.669769736691388 9.634257485158226e-05 [2.10423814 0.58879781]\n1200 0.6611217397476118 7.748954769304373e-05 [2.196659 0.57964635]\n1300 0.6541660467670455 6.232582024046085e-05 [2.27954523 0.57143899]\n1400 0.6485714952015851 5.012944305782252e-05 [2.35388049 0.56407835]\n1500 0.6440717268383123 4.0319743110361905e-05 [2.42054694 0.55747707]\n1600 0.640452506408185 3.2429677757184194e-05 [2.48033572 0.55155681]\n1700 0.6375415217831182 2.6083598711257316e-05 [2.53395639 0.54624732]\n1800 0.6352001801458864 2.0979367319928777e-05 [2.58204526 0.54148559]\n1900 0.6333170095461422 1.6873969654884746e-05 [2.62517303 0.53721509]\n2000 0.6318023516887206 1.3571946549606473e-05 [2.66385152 0.53338517]\n2100 0.6305840932763592 1.091608773295949e-05 [2.69853974 0.52995036]\n2200 0.6296042326748277 8.779946999215582e-06 [2.72964933 0.5268699 ]\n2300 0.6288161184383956 7.061822073883839e-06 [2.7575495 0.52410724]\n2400 0.6281822282210567 5.6799125335293965e-06 [2.78257134 0.52162959]\n2500 0.6276723823268161 4.568425266526788e-06 [2.80501179 0.51940755]\n2600 0.6272623068456619 3.6744420426337854e-06 [2.82513718 0.51741474]\n2700 0.6269324779657126 2.9554000647857848e-06 [2.84318632 0.51562753]\n2800 0.6266671924389065 2.3770655349641956e-06 [2.85937342 0.51402469]\n2900 0.626453819944831 1.911903780627e-06 [2.87389057 0.51258721]\n3000 0.6262822017575282 1.5377683174611079e-06 [2.88691005 0.51129802]\n3100 0.6261441670856248 1.236846446817097e-06 [2.89858638 0.51014184]\n3198 0.6260351358497136 9.99153387470919e-07 [2.90885967 0.50912458]\n"
],
[
"plt.loglog(Js)",
"_____no_output_____"
],
[
"weights.flatten()",
"_____no_output_____"
],
[
"plt.plot(X.T[1], y, '*', label='points')\nplt.plot(X.T[1], np.dot(X, weights.flatten()), 'r-', label='y = %2.2f + %2.2f x' % tuple(weights.flatten()))\nplt.xlabel('X')\nplt.ylabel('y')\nplt.legend()\nplt.gcf().set_size_inches(11, 8)",
"_____no_output_____"
]
],
[
[
"<div style=\"width: 100%; overflow: hidden;\">\n <img src=\"data/D4Sci_logo_full.png\" alt=\"Data For Science, Inc\" align=\"center\" border=\"0\" width=300px> \n</div>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a1ba8b40dabfe441c4455cb3f4184b976f3c31d
| 86,490 |
ipynb
|
Jupyter Notebook
|
code/14_Investigate_CellularHeterogeneity.ipynb
|
menchelab/Perturbome
|
c93aeb2d42a1900f5060322732dd97f8eb8db7bd
|
[
"MIT"
] | 5 |
2019-11-15T19:58:31.000Z
|
2021-12-08T19:30:10.000Z
|
code/14_Investigate_CellularHeterogeneity.ipynb
|
mcaldera/Perturbome
|
82c752f90f7100865c09cfea0f1fe96deffe2ed9
|
[
"MIT"
] | 1 |
2020-01-06T21:23:57.000Z
|
2020-01-07T14:06:21.000Z
|
code/14_Investigate_CellularHeterogeneity.ipynb
|
mcaldera/Perturbome
|
82c752f90f7100865c09cfea0f1fe96deffe2ed9
|
[
"MIT"
] | 4 |
2019-11-26T07:34:49.000Z
|
2022-02-22T06:41:43.000Z
| 39.710744 | 414 | 0.472448 |
[
[
[
"# Check Cell Population Heterogeneity",
"_____no_output_____"
],
[
"## Libraries",
"_____no_output_____"
]
],
[
[
"import MySQLdb\nimport pandas\nimport numpy as np\nfrom matplotlib import pylab as plt\nimport os\nimport seaborn as sns\nfrom scipy.stats import mannwhitneyu as mw\nfrom scipy import stats\nimport operator\nfrom sklearn.preprocessing import StandardScaler,RobustScaler\nfrom sklearn.decomposition import PCA\nfrom scipy import stats\nimport operator",
"_____no_output_____"
]
],
[
[
"## Routine Functions",
"_____no_output_____"
]
],
[
[
"def ensure_dir(file_path):\n '''\n Function to ensure a file path exists, else creates the path\n\n :param file_path:\n :return:\n '''\n directory = os.path.dirname(file_path)\n if not os.path.exists(directory):\n os.makedirs(directory)\n",
"_____no_output_____"
],
[
"# Effect size\ndef cohen_d(x, y):\n nx = len(x)\n ny = len(y)\n dof = nx + ny - 2\n return (np.mean(x) - np.mean(y)) / np.sqrt(\n ((nx - 1) * np.std(x, ddof=1) ** 2 + (ny - 1) * np.std(y, ddof=1) ** 2) / dof)\n",
"_____no_output_____"
],
[
"# Some Easy Outlier detection\ndef reject_outliers_2(data, m=6.):\n d = np.abs(data - np.median(data))\n mdev = np.median(d)\n s = d / (mdev if mdev else 1.)\n #return s < m\n return [data[i] for i in range(0, len(data)) if s[i] < m]\n",
"_____no_output_____"
]
],
[
[
"## Load list of significant perturbations\n- Load all significant perturbations\n- Load drug decay\n- Load list of images that are excluded \n- Load list of features to investigate",
"_____no_output_____"
],
[
"### Significant perturbations",
"_____no_output_____"
]
],
[
[
"#Save significant perturbations\nsignificant_perturbations = []\n\n#open the file indicating which drug perturbations are significant in a matter of mahalanobis distance to DMSO\nfp = open('../data/Investigate_CellularHeterogeneity/Single_Perturbation_Significance.csv')\nfp.next()\n\n#go through whole file\nfor line in fp:\n \n #split row\n tmp = line.strip().split(',')\n \n #check if mahalanobis distance large than 7\n try:\n batch1_significance = float(tmp[1])\n batch2_significance = float(tmp[3])\n\n if batch1_significance > 7:\n significant_perturbations.append((tmp[0]+'_Batch1',batch1_significance))\n\n if batch2_significance > 7:\n significant_perturbations.append((tmp[0]+'_Batch2',batch2_significance))\n except:\n continue\n \n#sort all perturbations and take the top 10\nsignificant_perturbations.sort(key = operator.itemgetter(1), reverse = True)\nsignificant_perturbations = significant_perturbations[0:10]\n\n\nprint significant_perturbations",
"[('CLOUD112_Batch2', 18.37538233940767), ('CLOUD057_Batch2', 17.949603639959136), ('CLOUD077_Batch2', 17.925072455942466), ('CLOUD089_Batch2', 17.47079522868084), ('CLOUD115_Batch2', 17.248539756395267), ('CLOUD129_Batch2', 17.10830389505952), ('CLOUD103_Batch2', 16.74349834279324), ('CLOUD053_Batch2', 16.71700833717189), ('CLOUD117_Batch2', 16.605844984937995), ('CLOUD031_Batch2', 16.54152648493228)]\n"
]
],
[
[
"### Drug Decay",
"_____no_output_____"
]
],
[
[
"# Both thresholds need to be true to set a drug as decayed during experiment; threshold_decay is steepness and threshold_MaxDifference absolute difference\nthreshold_decay = 0.05\nthreshold_MaxDifference = 0.3\n\n\n# Load all the drug decay regressions\n# Created by checking the single drug responses over the different plates (there is a temporal context between plate 1 and 123)\n# One is interested both in the decay as well as the maximum change e.g. if gradient between 0.1 to 0.2, still ok\n# Create a dic that tells about the status of drug decay i.e. True if drug WORKED CORRECTLY\npath = '../data/Investigate_CellularHeterogeneity/DrugDecay_Combined.csv'\nfp = open(path)\nfp.next()\ndrug_decay = {}\nbatch1_Failed = 0\nbatch2_Failed = 0\nfor line in fp:\n tmp = line.strip().split(',')\n \n batch1_decay = float(tmp[1])\n batch1_diff = float(tmp[2])\n \n batch2_decay = float(tmp[3])\n batch2_diff = float(tmp[4])\n \n \n batch1_Status = True\n if batch1_decay >= threshold_decay and batch1_diff >= threshold_MaxDifference:\n batch1_Status = False\n batch1_Failed += 1\n \n batch2_Status = True\n if batch2_decay >= threshold_decay and batch2_diff >= threshold_MaxDifference:\n batch2_Status = False\n batch2_Failed += 1\n \n \n drug_decay[tmp[0]] = {'Batch1':batch1_Status,'Batch2':batch2_Status}\nfp.close()\n\nprint 'Number of drugs that decayed in batch1: %d' %batch1_Failed\nprint 'Number of drugs that decayed in batch2: %d' %batch2_Failed",
"Number of drugs that decayed in batch1: 6\nNumber of drugs that decayed in batch2: 2\n"
]
],
[
[
"### Load selected features",
"_____no_output_____"
]
],
[
[
"selected_Features = []\nfp = open('../data/Investigate_CellularHeterogeneity/Selected_Features.csv')\nfor line in fp:\n selected_Features.append(line.strip()[7:])\n \nprint 'Number of features: %d' %len(selected_Features)",
"Number of features: 78\n"
]
],
[
[
"### Load Problematic Images",
"_____no_output_____"
]
],
[
[
"problematic_images = {'Batch1':[],'Batch2':[]}\n\nbatches = ['1','2']\nfor batch_ in batches:\n fp = open('../data/Investigate_CellularHeterogeneity/BadImages/Batch'+batch_+'.csv','r')\n for line in fp:\n tmp = line.strip().split(',')\n problematic_images['Batch'+batch_].append(tmp[0])",
"_____no_output_____"
]
],
[
[
"## Actual Analysis",
"_____no_output_____"
],
[
"### Load corresponding images",
"_____no_output_____"
]
],
[
[
"# establish link\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n###########\n# DRUGS # \n########### \n\n#this will contain all the image numbers that are associated with a specific drug (only singles!)\nImage_Number_For_Drugs = {}\n\n#go through the list of all significant perturbers\nfor entry in significant_perturbations:\n drug,batch_ = entry[0].split('_')\n batch_ = batch_[5]\n \n # check if the drug is not decayed\n if drug_decay[drug]['Batch'+batch_] == True:\n\n #SQL string\n string = 'select ImageNumber,Image_Metadata_Plate from DPN1018Batch'+batch_+'Per_Image where Image_Metadata_ID_A like \"'+drug+'\" and Image_Metadata_ID_B like \"DMSO\";'\n\n #Extract data via pandas\n ImageNumbers = pandas.read_sql(string, con=db)\n\n #go through all rows\n for line in ImageNumbers.iterrows():\n \n #extract ImageNumber and PlateNumber\n Drug_ImageNumber = line[1][0]\n Drug_PlateNumber = line[1][1]\n\n #add to dictionary\n if entry[0] not in Image_Number_For_Drugs:\n Image_Number_For_Drugs[entry[0]] = {Drug_PlateNumber:[Drug_ImageNumber]}\n elif Drug_PlateNumber not in Image_Number_For_Drugs[entry[0]]:\n Image_Number_For_Drugs[entry[0]][Drug_PlateNumber] = [Drug_ImageNumber]\n else:\n Image_Number_For_Drugs[entry[0]][Drug_PlateNumber].append(Drug_ImageNumber)\n###########\n# DMSO # \n########### \n \n# this will contain imagenumbers for DMSO \nImage_Number_For_DMSO = {} \nfor batch_ in ['1','2']:\n\n #SQL string\n string = 'select ImageNumber,Image_Metadata_Plate from DPN1018Batch'+batch_+'Per_Image where Image_Metadata_ID_A like \"DMSO\" and Image_Metadata_ID_B like \"None\";'\n \n #Extract data via pandas\n ImageNumbers = pandas.read_sql(string, con=db)\n\n #go through all rows\n for line in ImageNumbers.iterrows():\n \n #extract ImageNumber and PlateNumber\n Drug_ImageNumber = line[1][0]\n Drug_PlateNumber = line[1][1]\n\n #add to dictionary\n if batch_ not in Image_Number_For_DMSO:\n Image_Number_For_DMSO[batch_] = {Drug_PlateNumber:[Drug_ImageNumber]}\n elif Drug_PlateNumber not in Image_Number_For_DMSO[batch_]:\n Image_Number_For_DMSO[batch_][Drug_PlateNumber] = [Drug_ImageNumber]\n else:\n Image_Number_For_DMSO[batch_][Drug_PlateNumber].append(Drug_ImageNumber)\n\ndb.close()",
"_____no_output_____"
]
],
[
[
"### Defintions\n- drug colors\n- feature colors",
"_____no_output_____"
]
],
[
[
"# define color code for individual significant drugs (static)\ndrug_colors = {'CLOUD031':'#8dd3c7','CLOUD053':'#ffffb3','CLOUD057':'#bebada','CLOUD089':'#fb8072','CLOUD112':'#80b1d3','CLOUD117':'#fdb462','CLOUD077':'#b3de69','CLOUD103':'#fccde5',\n 'CLOUD115':'#c51b8a','CLOUD129':'#bc80bd','DMSO':'grey'}\n\nfeature_colors = {'AreaShape':'#D53D48', #red\n 'Intensity':'#BDCA27', 'RadialDistribution':'#BDCA27', #green\n 'Other':'grey', #grey\n 'Texture':'#F8B301', #orange\n 'Granularity':'#3AB9D1'} #blue\n\n\n\n#create the string for selecting all features\nselected_feature_string = ','.join(selected_Features)",
"_____no_output_____"
],
[
"## EXTRACT DMSO\n####\n\n# Establish connections\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n#define plate and batch\nplate = 1315101\nbatch_ = '2'\n\n# create SQL string\nimages_dmso = Image_Number_For_DMSO[batch_][plate]\nimageNumberString_dmso = ','.join([str(x) for x in images_dmso])\nstring = 'select ImageNumber,ObjectNumber,'+selected_feature_string+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n\n# Extract only selected features (all DMSO cells)\nDMSO_allFeatures = pandas.read_sql(string, con=db)\nDMSO_allFeatures['Label'] = 'DMSO'\n\nDMSO_allFeatures = DMSO_allFeatures.dropna()\n\ndb.close()",
"_____no_output_____"
],
[
"DMSO_allFeatures.head()",
"_____no_output_____"
],
[
"## EXTRACT Drugs\n####\n\n# Establish connections\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n# Get all drugs for a choosen plate\nimages_drugs = []\nimage_to_drug = {}\nfor key in Image_Number_For_Drugs:\n for current_plate in Image_Number_For_Drugs[key]:\n if current_plate == plate:\n images_drugs.extend(Image_Number_For_Drugs[key][current_plate])\n for img in Image_Number_For_Drugs[key][current_plate]:\n image_to_drug[img] = key.split('_')[0]\n\n# Create SQL string\nimageNumberString_drug = ','.join([str(x) for x in images_drugs])\nstring = 'select ImageNumber,ObjectNumber,'+selected_feature_string+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n\n# Extract only selected features (all DMSO cells)\nDrug_allFeatures = pandas.read_sql(string, con=db)\nDrug_allFeatures['Label'] = 'Drug'\nfor key in image_to_drug:\n Drug_allFeatures.loc[Drug_allFeatures['ImageNumber'] == key,['Label']] = image_to_drug[key]\n\nDrug_allFeatures = Drug_allFeatures.dropna()\n\ndb.close()",
"_____no_output_____"
],
[
"Drug_allFeatures.head()",
"_____no_output_____"
]
],
[
[
"#### Perform Scaling pooled scaling",
"_____no_output_____"
]
],
[
[
"DMSO_and_Drugs = pandas.concat([DMSO_allFeatures,Drug_allFeatures])\nDMSO_and_Drugs_allFeatures_scaled = DMSO_and_Drugs.copy()\n\n\n#scaler = RobustScaler()\nscaler = StandardScaler()\nDMSO_and_Drugs_allFeatures_scaled[selected_Features] = scaler.fit_transform(DMSO_and_Drugs[selected_Features])\nDMSO_and_Drugs_allFeatures_scaled.head()",
"/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/sklearn/preprocessing/data.py:625: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.\n return self.partial_fit(X, y)\n/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/sklearn/base.py:462: DataConversionWarning: Data with input dtype int64, float64 were all converted to float64 by StandardScaler.\n return self.fit(X, **fit_params).transform(X)\n"
]
],
[
[
"### Plot results for DMSO and selected drugs (Distributions)",
"_____no_output_____"
]
],
[
[
"sns.set_style(\"whitegrid\", {'axes.grid' : False})\n\nmake_plots = True\n\n#check that folder exists\nensure_dir('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/DMSO/')\n#sns.set()\n\n\nis_normal = 0\n#go through all selected features\nfor f in selected_Features:\n \n #extract DMSO values for this specific feature\n feature_values = DMSO_and_Drugs_allFeatures_scaled.loc[DMSO_and_Drugs_allFeatures_scaled['Label'] == 'DMSO'][f].values\n \n #Test for normality are essentiality useless (for small datasets chance of not enough power, while for large dataset everything gets rejected as non normal)\n \n pvals = []\n for i in range(0,1000):\n pval_normal = stats.normaltest(np.random.choice(feature_values,50))[1]\n pvals.append(pval_normal)\n #pval_normal2 = stats.shapiro(feature_values)[1]\n \n if np.mean(pvals) >= 0.05:\n is_normal += 1\n \n \n if make_plots:\n plt.hist(feature_values,bins=100, color='grey',density=True)\n plt.title(f + 'Normal: %.2f' % np.mean(pvals))\n plt.savefig('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/DMSO/'+f+'.pdf')\n plt.close()\n\nprint len(selected_Features)\nprint is_normal",
"78\n30\n"
],
[
"ensure_dir('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/Drugs/')\n\n# Find drugs name\nall_drugs = list(set(image_to_drug.values()))\n\n#go through all selected features\nfor f in selected_Features:\n \n #extract the DMSO values\n feature_values_DMSO = DMSO_and_Drugs_allFeatures_scaled.loc[DMSO_and_Drugs_allFeatures_scaled['Label'] == 'DMSO'][f].values\n for drug in all_drugs:\n \n #extract drug values\n feature_values = DMSO_and_Drugs_allFeatures_scaled.loc[DMSO_and_Drugs_allFeatures_scaled['Label'] == drug][f].values\n\n #overlay the two distributions\n plt.hist(feature_values_DMSO,bins='doane', color='grey', alpha=0.5, density=True)\n plt.hist(feature_values,bins='doane', color=drug_colors[drug], alpha=0.5, density=True)\n plt.savefig('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/Drugs/'+f+'_'+drug+'.pdf')\n plt.close()",
"_____no_output_____"
],
[
"#colors for features\nfeature_type_colors = []\ncompartment_type_colors = []\n\n# contains KS results\nfeature_results = []\n\n# contains percentile results\nfeature_results_effect = []\nfor f in selected_Features:\n \n compartment,featuretype,_ = f.split('_')[0:3]\n \n \n if featuretype in feature_colors.keys():\n feature_type_colors.append(feature_colors[featuretype])\n else:\n feature_type_colors.append(feature_colors['Other'])\n \n if compartment == 'Cells':\n compartment_type_colors.append('#a6611a')\n else:\n compartment_type_colors.append('#018571')\n \n #Get DMSO values for specific feature \n feature_values_DMSO = DMSO_and_Drugs_allFeatures_scaled.loc[DMSO_and_Drugs_allFeatures_scaled['Label'] == 'DMSO'][f].values\n\n\n #Define the top5 , top95 percentiles\n low_5 = np.percentile(feature_values_DMSO,5)\n top_95 = np.percentile(feature_values_DMSO,95)\n \n #temporary results (each row contains one feature - all drugs)\n tmp = []\n tmp2 = []\n \n #go through all drugs\n for drug in all_drugs:\n \n # Get Drug values for specific feature\n feature_values_drug = DMSO_and_Drugs_allFeatures_scaled.loc[DMSO_and_Drugs_allFeatures_scaled['Label'] == drug][f].values\n \n #Number of significant cells\n tmp2.append(len([x for x in feature_values_drug if x < low_5 or x > top_95])/float(len(feature_values_drug)))\n \n #Compare curves\n tmp.append(stats.ks_2samp(feature_values_drug,feature_values_DMSO)[0])\n\n #add results to overall results lists\n feature_results.append(tmp)\n feature_results_effect.append(tmp2)",
"_____no_output_____"
],
[
"#sns.set()\nsns.clustermap(data=feature_results, xticklabels=all_drugs,yticklabels=selected_Features, row_colors=[feature_type_colors,compartment_type_colors])\n#sns.set(font_scale=0.5)\nplt.savefig('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/Clustermap_KS_Test.pdf')\nplt.close()",
"_____no_output_____"
],
[
"#sns.set()\nsns.clustermap(data=feature_results_effect, xticklabels=all_drugs,yticklabels=selected_Features, row_colors=[feature_type_colors,compartment_type_colors])\nsns.set(font_scale=5.5)\nplt.savefig('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/Clustermap_Percentiles.pdf')\nplt.close()",
"_____no_output_____"
],
[
"sns.set()\nplt.scatter(feature_results,feature_results_effect)\nplt.plot([0,1],[0,1],ls='--',c='grey')\nplt.xlabel('Penetrance')\nplt.ylabel('Effect')\nplt.savefig('../results/Investigate_CellularHeterogeneity/Penetrance_PooledScaled/Penetrance_vs_Effect.pdf')\nplt.close()",
"_____no_output_____"
]
],
[
[
"### Make PCA (all features)",
"_____no_output_____"
]
],
[
[
"db = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\nplate = 1315101\nbatch_ = '2'\n\nimages_dmso = Image_Number_For_DMSO[batch_][plate]\nimageNumberString_dmso = ','.join([str(x) for x in images_dmso])\nstring = 'select * from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\nDMSO_allFeatures = pandas.read_sql(string, con=db)\nDMSO_allFeatures['Label'] = 'DMSO'\n\nfor entry in list(Image_Number_For_Drugs.keys()):\n print entry\n drug,batch_ = entry.split('_')\n batch_ = batch_[5]\n \n \n images_drug = Image_Number_For_Drugs[entry][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n \n\n \n string = 'select * from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n drug_allFeatures = pandas.read_sql(string, con=db)\n drug_allFeatures['Label'] = 'Drug'\n\n # Put both dataframes together\n DMSO_drug_allFeatures = pandas.concat([drug_allFeatures,DMSO_allFeatures])\n to_remove = [x for x in DMSO_drug_allFeatures.columns if 'Location' in x or 'Center' in x]\n DMSO_drug_allFeatures = DMSO_drug_allFeatures.drop(to_remove, axis=1)\n DMSO_drug_allFeatures = DMSO_drug_allFeatures.dropna()\n \n\n\n y = DMSO_drug_allFeatures['Label'].values\n x = DMSO_drug_allFeatures.iloc[:,3:-1].values\n # Standardizing the features\n x = StandardScaler().fit_transform(x)\n\n pca = PCA(n_components=2)\n Drug_DMSO_Fit = pca.fit_transform(x)\n\n\n pca_drug = []\n pca_DMSO = []\n for label,element in zip(y,list(Drug_DMSO_Fit)):\n\n if label == 'Drug':\n pca_drug.append(element)\n else:\n pca_DMSO.append(element)\n\n pca_drug = np.array(pca_drug)\n pca_DMSO = np.array(pca_DMSO)\n\n\n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/')\n #plt.scatter(pca_drug[:,0],pca_drug[:,1], alpha=0.4)\n #plt.scatter(pca_DMSO[:,0],pca_DMSO[:,1], alpha=0.4)\n #plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/Scatter_AllFeatures.pdf')\n #plt.show()\n #plt.close()\n\n\n upper = 99.5\n lower = 0.5\n x_min = min([np.percentile(pca_drug[:,0],lower),np.percentile(pca_DMSO[:,0],lower)])\n x_max = max([np.percentile(pca_drug[:,0],upper),np.percentile(pca_DMSO[:,0],upper)])\n y_min = min([np.percentile(pca_drug[:,1],lower),np.percentile(pca_DMSO[:,1],lower)])\n y_max = max([np.percentile(pca_drug[:,1],upper),np.percentile(pca_DMSO[:,1],upper)])\n\n #bw = 1.5\n sns.kdeplot(pca_drug[:,0],pca_drug[:,1],shade_lowest=False, alpha=0.5)\n sns.kdeplot(pca_DMSO[:,0],pca_DMSO[:,1],shade_lowest=False, alpha=0.5)\n plt.xlim([x_min,x_max])\n plt.ylim([y_min,y_max])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/ContourPlot_AllFeatures.pdf')\n plt.close()\n\n\n\n sns.jointplot(pca_drug[:,0],pca_drug[:,1], kind='kde', bw = 'scott', color=drug_colors[drug], shade_lowest=False, alpha=0.5, xlim=[x_min,x_max], ylim=[y_min,y_max])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/JoinPlot_Drug_AllFaetures.pdf')\n plt.close()\n\n sns.jointplot(pca_DMSO[:,0],pca_DMSO[:,1], kind='kde', bw = 'scott', color=\"#D4D4D4\", shade_lowest=False,alpha=0.5, xlim=[x_min,x_max], ylim=[y_min,y_max])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/JoinPlot_DMSO_AllFaetures.pdf')\n plt.close()\n \n ",
"CLOUD112_Batch2\nCLOUD057_Batch2\nCLOUD089_Batch2\nCLOUD031_Batch2\nCLOUD053_Batch2\nCLOUD117_Batch2\nCLOUD103_Batch2\nCLOUD115_Batch2\nCLOUD077_Batch2\nCLOUD129_Batch2\n"
]
],
[
[
"### Make Violin plot selected features",
"_____no_output_____"
]
],
[
[
"db = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n\n#features = ['Cells_Intensity_StdIntensity_MitoTracker','Cells_Granularity_1_BetaTubulin','Nuclei_AreaShape_MaximumRadius','Cells_AreaShape_MaxFeretDiameter']\nfeatures = selected_Features\n\nplate = 1315101\n#batch_ = 2\n\ndrug_feature_results_to_plot = {}\nfor entry in Image_Number_For_Drugs:\n drug,batch_ = entry.split('_')\n batch_ = batch_[5]\n drug_feature_results_to_plot[entry] = {} \n print drug\n \n \n images_drug = Image_Number_For_Drugs[entry][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n\n images_dmso = Image_Number_For_DMSO[batch_][plate]\n imageNumberString_dmso = ','.join([str(x) for x in images_dmso])\n \n \n for feature in features:\n \n \n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/')\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n result_drug = list(pandas.read_sql(string, con=db)[feature].values)\n result_drug = reject_outliers_2([x for x in result_drug if str(x) != 'nan'],6)\n\n\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n result_dmso = list(pandas.read_sql(string, con=db)[feature].values)\n result_dmso = reject_outliers_2([x for x in result_dmso if str(x) != 'nan'],6)\n\n drug_feature_results_to_plot[entry][feature] = {'Drug':result_drug, 'DMSO':result_dmso}\n\ndb.close()",
"CLOUD112\nCLOUD057\nCLOUD089\nCLOUD031\nCLOUD053\nCLOUD117\nCLOUD103\nCLOUD115\nCLOUD077\nCLOUD129\n"
],
[
"#drug_colors = {'CLOUD031':'#8dd3c7','CLOUD053':'#ffffb3','CLOUD057':'#bebada','CLOUD089':'#fb8072','CLOUD112':'#80b1d3','CLOUD117':'#fdb462','CLOUD077':'#b3de69','CLOUD103':'#fccde5',\n# 'CLOUD115':'#d9d9d9','CLOUD129':'#bc80bd','DMSO':'grey',}\n\nfor feature in features:\n \n data = []\n drug_names = []\n \n\n for entry in list(Image_Number_For_Drugs.keys()):\n drug,batch_ = entry.split('_')\n \n drug_names.append((drug,np.median(drug_feature_results_to_plot[entry][feature]['Drug'])))\n data.append((drug_feature_results_to_plot[entry][feature]['Drug'],np.median(drug_feature_results_to_plot[entry][feature]['Drug'])))\n \n #print data\n data.sort(key = operator.itemgetter(1))\n drug_names.sort(key = operator.itemgetter(1))\n\n data = [x[0] for x in data]\n drug_names = [x[0] for x in drug_names]\n \n \n data.append(drug_feature_results_to_plot[entry][feature]['DMSO'])\n drug_names.append('DMSO')\n \n Percent_95 = np.percentile(drug_feature_results_to_plot[entry][feature]['DMSO'],90)\n Percent_5 = np.percentile(drug_feature_results_to_plot[entry][feature]['DMSO'],10)\n my_pal = {0: drug_colors[drug_names[0]], 1: drug_colors[drug_names[1]], 2:drug_colors[drug_names[2]],\n 3:drug_colors[drug_names[3]],4:drug_colors[drug_names[4]],5:drug_colors[drug_names[5]],\n 6:drug_colors[drug_names[6]],7:drug_colors[drug_names[7]],8:drug_colors[drug_names[8]]\n ,9:drug_colors[drug_names[9]],10:drug_colors[drug_names[10]]}\n\n #sns.violinplot(data=data,scale='width',bw='scott', palette='Paired', orient='h')\n sns.violinplot(data=data,scale='width',bw='scott', palette=my_pal, orient='h')\n plt.axvline(Percent_95,ls='--',color='grey')\n plt.axvline(Percent_5,ls='--',color='grey')\n plt.yticks(range(0,len(data)+1),drug_names, fontsize=5)\n plt.ylabel('Treatment', fontsize=5)\n plt.xticks(fontsize=5)\n plt.xlabel(feature, fontsize=5)\n #sns.swarmplot(data=data)\n plt.savefig('../results/Investigate_CellularHeterogeneity/Final/'+str(feature)+'_Violin.pdf')\n \n #plt.show()\n plt.close()\n \n ",
"_____no_output_____"
]
],
[
[
"### Analyse Features for selected Drugs",
"_____no_output_____"
]
],
[
[
"fp_out = open('../results/Investigate_CellularHeterogeneity/Result_Overview.csv','w')\nfp_out.write('Batch,Drug,Plate,Feature,Cohens\"D,Abs(CohenD),Coefficient_Variation,KS_Normality,MW_PVal\\n')\n\n#selected_Features = ['Cells_Intensity_StdIntensity_MitoTracker','Cells_Granularity_12_BetaTubulin','Nuclei_AreaShape_MaximumRadius','Cells_AreaShape_MaxFeretDiameter']\nselected_Features = ['Cells_AreaShape_FormFactor','Nuclei_AreaShape_MaxFeretDiameter','Cells_Granularity_1_BetaTubulin','Nuclei_Granularity_8_DAPI','Cells_Intensity_StdIntensity_MitoTracker','Nuclei_Intensity_IntegratedIntensity_DAPI']\n\n\n\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n#print Image_Number_For_Drugs\nfor entry in Image_Number_For_Drugs:\n print entry\n drug,batch_ = entry.split('_')\n batch_ = batch_[5]\n \n #plates = list(Image_Number_For_Drugs[entry].keys())\n plates = [1315101]\n \n for plate in plates:\n images_drug = Image_Number_For_Drugs[entry][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n\n images_dmso = Image_Number_For_DMSO[batch_][plate]\n imageNumberString_dmso = ','.join([str(x) for x in images_dmso])\n\n for feature in selected_Features:\n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/')\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n \n \n result_drug = list(pandas.read_sql(string, con=db)[feature].values)\n result_drug = reject_outliers_2([x for x in result_drug if str(x) != 'nan'],6)\n\n\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n result_dmso = list(pandas.read_sql(string, con=db)[feature].values)\n result_dmso = reject_outliers_2([x for x in result_dmso if str(x) != 'nan'],6)\n\n #sns.violinplot(data=[result_drug,result_dmso],bw=0.5, cut=50)\n #plt.show()\n cd = cohen_d(result_drug,result_dmso)\n mw_Pval = min([1,mw(result_drug,result_dmso)[1] * (len(selected_Features) * len(list(Image_Number_For_Drugs[entry])) * 2)])\n\n coev_var = np.std(result_drug)/np.mean(result_drug)\n #KS_Normality = stats.kstest(result_drug, 'norm')[1]\n KS_Normality = stats.shapiro(result_drug)[1]\n\n fp_out.write(batch_+','+drug+','+str(plate)+','+feature+','+str(cd)+','+str(abs(cd))+','+str(coev_var)+','+str(KS_Normality)+','+str(mw_Pval)+'\\n')\n #continue\n\n #bins = 14 prettier\n plt.hist(result_drug, bins = 20, color = drug_colors[drug], alpha=0.3, density=True)\n plt.hist(result_dmso, bins = 20, color = 'grey', alpha=0.3,density=True)\n plt.xlim([min([np.percentile(result_drug,1),np.percentile(result_dmso,1)]),max([np.percentile(result_drug,99),np.percentile(result_dmso,99)])])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Hist.pdf')\n #plt.show()\n plt.close()\n\n\n plt.boxplot([result_drug,result_dmso], whis = 1.5, showfliers = True)\n plt.xticks([1,2],[drug,'DMSO'])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Box.pdf')\n #plt.show()\n plt.close()\n\n \ndb.close()",
"CLOUD112_Batch2\nCLOUD057_Batch2\nCLOUD089_Batch2\nCLOUD031_Batch2\nCLOUD053_Batch2\nCLOUD117_Batch2\nCLOUD103_Batch2\nCLOUD115_Batch2\nCLOUD077_Batch2\nCLOUD129_Batch2\n"
]
],
[
[
"### Load actual cells",
"_____no_output_____"
]
],
[
[
"fp_out = open('../results/Investigate_CellularHeterogeneity/Result_Overview.csv','w')\nfp_out.write('Batch,Drug,Plate,Feature,Cohens\"D,Abs(CohenD),Coefficient_Variation,KS_Normality,MW_PVal\\n')\n\n#selected_Features = ['Cells_Intensity_StdIntensity_MitoTracker','Cells_Granularity_12_BetaTubulin','Nuclei_AreaShape_MaximumRadius','Cells_AreaShape_MaxFeretDiameter']\n\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n#print Image_Number_For_Drugs\nfor entry in Image_Number_For_Drugs:\n print entry\n drug,batch_ = entry.split('_')\n batch_ = batch_[5]\n \n plates = list(Image_Number_For_Drugs[entry].keys())\n #print plates\n \n for plate in plates:\n images_drug = Image_Number_For_Drugs[entry][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n\n images_dmso = Image_Number_For_DMSO[batch_][plate]\n imageNumberString_dmso = ','.join([str(x) for x in images_dmso])\n\n for feature in selected_Features:\n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/')\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n \n \n result_drug = list(pandas.read_sql(string, con=db)[feature].values)\n result_drug = reject_outliers_2([x for x in result_drug if str(x) != 'nan'],6)\n\n\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n result_dmso = list(pandas.read_sql(string, con=db)[feature].values)\n result_dmso = reject_outliers_2([x for x in result_dmso if str(x) != 'nan'],6)\n\n #sns.violinplot(data=[result_drug,result_dmso],bw=0.5, cut=50)\n #plt.show()\n cd = cohen_d(result_drug,result_dmso)\n mw_Pval = min([1,mw(result_drug,result_dmso)[1] * (len(selected_Features) * len(list(Image_Number_For_Drugs[entry])) * 2)])\n\n coev_var = np.std(result_drug)/np.mean(result_drug)\n #KS_Normality = stats.kstest(result_drug, 'norm')[1]\n KS_Normality = stats.shapiro(result_drug)[1]\n\n fp_out.write(batch_+','+drug+','+str(plate)+','+feature+','+str(cd)+','+str(abs(cd))+','+str(coev_var)+','+str(KS_Normality)+','+str(mw_Pval)+'\\n')\n #continue\n\n #bins = 14 prettier\n plt.hist(result_drug, bins = 20, color = '#3AB9D1', alpha=0.3, density=True)\n plt.hist(result_dmso, bins = 20, color = 'grey', alpha=0.3,density=True)\n plt.xlim([min([np.percentile(result_drug,1),np.percentile(result_dmso,1)]),max([np.percentile(result_drug,99),np.percentile(result_dmso,99)])])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Hist.pdf')\n #plt.show()\n plt.close()\n\n\n plt.boxplot([result_drug,result_dmso], whis = 1.5, showfliers = True)\n plt.xticks([1,2],[drug,'DMSO'])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Box.pdf')\n #plt.show()\n plt.close()\n\n \ndb.close()",
"CLOUD112_Batch2\nCLOUD057_Batch2\nCLOUD089_Batch2\nCLOUD031_Batch2\nCLOUD053_Batch2\nCLOUD117_Batch2\nCLOUD103_Batch2\nCLOUD115_Batch2\nCLOUD077_Batch2\nCLOUD129_Batch2\n"
]
],
[
[
"### Choose specific features / plate",
"_____no_output_____"
]
],
[
[
"db = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\n\nfeatures = ['Cells_Intensity_StdIntensity_MitoTracker','Cells_Granularity_12_BetaTubulin','Nuclei_AreaShape_MaximumRadius','Cells_AreaShape_MaxFeretDiameter']\nplate = 1315111\n#batch_ = 2\n\ndrug_feature_results_to_plot = {}\nfor entry in Image_Number_For_Drugs:\n drug,batch_ = entry.split('_')\n batch_ = batch_[5]\n drug_feature_results_to_plot[entry] = {} \n print drug\n \n \n images_drug = Image_Number_For_Drugs[entry][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n\n images_dmso = Image_Number_For_DMSO[batch_][plate]\n imageNumberString_dmso = ','.join([str(x) for x in images_dmso])\n \n \n for feature in features:\n \n \n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/')\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n result_drug = list(pandas.read_sql(string, con=db)[feature].values)\n result_drug = reject_outliers_2([x for x in result_drug if str(x) != 'nan'],6)\n\n\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018Batch'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n result_dmso = list(pandas.read_sql(string, con=db)[feature].values)\n result_dmso = reject_outliers_2([x for x in result_dmso if str(x) != 'nan'],6)\n\n drug_feature_results_to_plot[entry][feature] = {'Drug':result_drug, 'DMSO':result_dmso}\n\ndb.close()",
"CLOUD112\nCLOUD077\nCLOUD115\nCLOUD057\nCLOUD089\n"
],
[
"\n\nfor feature in features:\n \n data = []\n drug_names = []\n for entry in list(Image_Number_For_Drugs.keys()):\n drug,batch_ = entry.split('_')\n drug_names.append(drug)\n data.append(drug_feature_results_to_plot[entry][feature]['Drug'])\n \n data.append(drug_feature_results_to_plot[entry][feature]['DMSO'])\n drug_names.append('DMSO')\n \n Percent_95 = np.percentile(drug_feature_results_to_plot[entry][feature]['DMSO'],95)\n Percent_5 = np.percentile(drug_feature_results_to_plot[entry][feature]['DMSO'],5)\n\n sns.violinplot(data=data,scale='width')\n plt.axhline(Percent_95,ls='--',color='grey')\n plt.axhline(Percent_5,ls='--',color='grey')\n plt.xticks(range(0,len(data)+1),drug_names, fontsize=5)\n plt.xlabel('Treatment')\n plt.ylabel(feature)\n #sns.swarmplot(data=data)\n plt.savefig('../results/Investigate_CellularHeterogeneity/Final/'+str(feature)+'_Violin.pdf')\n \n #plt.show()\n plt.close()\n \n ",
"/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/scipy/stats/stats.py:1633: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
],
[
"Image_Number_For_Drugs = {'Batch1':{},'Batch2':{}}\n\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\nbatches = ['1','2']\nfor batch_ in batches:\n for drug in significant_perturbations['Batch'+batch_]:\n\n \n if drug == 'DMSO':\n string = 'select ImageNumber,Image_Metadata_Plate from DPN1018Batch'+batch_+'Per_Image where Image_Metadata_ID_A like \"DMSO\" and Image_Metadata_ID_B like \"None\";'\n ImageNumbers = pandas.read_sql(string, con=db)\n \n for line in ImageNumbers.iterrows():\n Drug_ImageNumber = line[1][0]\n Drug_PlateNumber = line[1][1]\n \n if drug not in Image_Number_For_Drugs['Batch'+batch_]:\n Image_Number_For_Drugs['Batch'+batch_][drug] = {Drug_PlateNumber:[Drug_ImageNumber]}\n elif Drug_PlateNumber not in Image_Number_For_Drugs['Batch'+batch_][drug]:\n Image_Number_For_Drugs['Batch'+batch_][drug][Drug_PlateNumber] = [Drug_ImageNumber]\n else:\n Image_Number_For_Drugs['Batch'+batch_][drug][Drug_PlateNumber].append(Drug_ImageNumber)\n\n \n elif drug_decay[drug]['Batch'+batch_] == True:\n \n string = 'select ImageNumber,Image_Metadata_Plate from DPN1018Batch'+batch_+'Per_Image where Image_Metadata_ID_A like \"'+drug+'\" and Image_Metadata_ID_B like \"DMSO\";'\n\n ImageNumbers = pandas.read_sql(string, con=db)\n #print(ImageNumbers)\n\n for line in ImageNumbers.iterrows():\n Drug_ImageNumber = line[1][0]\n Drug_PlateNumber = line[1][1]\n \n if drug not in Image_Number_For_Drugs['Batch'+batch_]:\n Image_Number_For_Drugs['Batch'+batch_][drug] = {Drug_PlateNumber:[Drug_ImageNumber]}\n elif Drug_PlateNumber not in Image_Number_For_Drugs['Batch'+batch_][drug]:\n Image_Number_For_Drugs['Batch'+batch_][drug][Drug_PlateNumber] = [Drug_ImageNumber]\n else:\n Image_Number_For_Drugs['Batch'+batch_][drug][Drug_PlateNumber].append(Drug_ImageNumber)\n\ndb.close()",
"_____no_output_____"
],
[
"fp_out = open('../results/Investigate_CellularHeterogeneity/Result_Overview.csv','w')\nfp_out.write('Batch,Drug,Plate,Feature,Cohens\"D,Abs(CohenD),Coefficient_Variation,KS_Normality,MW_PVal\\n')\n\n\ndb = MySQLdb.connect(\"menchelabdb.int.cemm.at\",\"root\",\"cqsr4h\",\"ImageAnalysisDDI\" )\n\nfor batch_ in Image_Number_For_Drugs:\n print batch_\n for drug in Image_Number_For_Drugs[batch_]:\n \n \n for plate in list(Image_Number_For_Drugs[batch_][drug])[0:1]:\n images_drug = Image_Number_For_Drugs[batch_][drug][plate]\n imageNumberString_drug = ','.join([str(x) for x in images_drug])\n \n images_dmso = Image_Number_For_Drugs[batch_]['DMSO'][plate]\n imageNumberString_dmso = ','.join([str(x) for x in images_dmso])\n \n \n for feature in selected_Features[0:2]:\n ensure_dir('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/')\n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_drug+');'\n result_drug = list(pandas.read_sql(string, con=db)[feature].values)\n result_drug = [x for x in result_drug if str(x) != 'nan']\n \n \n string = 'select ImageNumber,ObjectNumber,'+feature+' from DPN1018'+batch_+'Per_Object where ImageNumber in ('+imageNumberString_dmso+');'\n result_dmso = list(pandas.read_sql(string, con=db)[feature].values)\n result_dmso = [x for x in result_dmso if str(x) != 'nan']\n \n #sns.violinplot(data=[result_drug,result_dmso],bw=0.5, cut=50)\n #plt.show()\n cd = cohen_d(result_drug,result_dmso)\n mw_Pval = min([1,mw(result_drug,result_dmso)[1] * (len(selected_Features) * len(list(Image_Number_For_Drugs[batch_][drug])) * 2)])\n\n coev_var = np.std(result_drug)/np.mean(result_drug)\n #KS_Normality = stats.kstest(result_drug, 'norm')[1]\n KS_Normality = stats.shapiro(result_drug)[1]\n \n fp_out.write(batch_+','+drug+','+str(plate)+','+feature+','+str(cd)+','+str(abs(cd))+','+str(coev_var)+','+str(KS_Normality)+','+str(mw_Pval)+'\\n')\n #continue\n \n #bins = 14 prettier\n plt.hist(result_drug, bins = 20, color = '#3AB9D1', alpha=0.3, density=True)\n plt.hist(result_dmso, bins = 20, color = 'grey', alpha=0.3,density=True)\n plt.xlim([min([np.percentile(result_drug,1),np.percentile(result_dmso,1)]),max([np.percentile(result_drug,99),np.percentile(result_dmso,99)])])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Hist.pdf')\n #plt.show()\n plt.close()\n \n \n plt.boxplot([result_drug,result_dmso], whis = 1.5, showfliers = False)\n plt.xticks([1,2],[drug,'DMSO'])\n plt.savefig('../results/Investigate_CellularHeterogeneity/'+drug+'/'+feature+'/'+str(plate)+'_Box.pdf')\n #plt.show()\n plt.close()\nfp_out.close()",
"Batch2\nBatch1\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a1bb76b6857b9d65ff1f97e2e186028f8cf2b2a
| 36,058 |
ipynb
|
Jupyter Notebook
|
notebooks/02.5-make-projection-dfs/batsong-umap.ipynb
|
xingjeffrey/avgn_paper
|
412e95dabc7b7b13a434b85cc54a21c06efe4e2b
|
[
"MIT"
] | null | null | null |
notebooks/02.5-make-projection-dfs/batsong-umap.ipynb
|
xingjeffrey/avgn_paper
|
412e95dabc7b7b13a434b85cc54a21c06efe4e2b
|
[
"MIT"
] | null | null | null |
notebooks/02.5-make-projection-dfs/batsong-umap.ipynb
|
xingjeffrey/avgn_paper
|
412e95dabc7b7b13a434b85cc54a21c06efe4e2b
|
[
"MIT"
] | null | null | null | 87.307506 | 25,656 | 0.828887 |
[
[
[
"%load_ext autoreload\n%autoreload 2\n%env CUDA_DEVICE_ORDER=PCI_BUS_ID\n%env CUDA_VISIBLE_DEVICES=2",
"env: CUDA_DEVICE_ORDER=PCI_BUS_ID\nenv: CUDA_VISIBLE_DEVICES=2\n"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom tqdm.autonotebook import tqdm\nimport pandas as pd\nfrom cuml.manifold.umap import UMAP as cumlUMAP\nfrom avgn.utils.paths import DATA_DIR, most_recent_subdirectory, ensure_dir\nfrom avgn.signalprocessing.create_spectrogram_dataset import flatten_spectrograms",
"/mnt/cube/tsainbur/conda_envs/tpy3/lib/python3.6/site-packages/tqdm/autonotebook/__init__.py:14: TqdmExperimentalWarning: Using `tqdm.autonotebook.tqdm` in notebook mode. Use `tqdm.tqdm` instead to force console mode (e.g. in jupyter console)\n \" (e.g. in jupyter console)\", TqdmExperimentalWarning)\n"
]
],
[
[
"### load data",
"_____no_output_____"
]
],
[
[
"DATASET_ID = 'batsong_segmented'\ndf_loc = DATA_DIR / 'syllable_dfs' / DATASET_ID / 'fruitbat.pickle'",
"_____no_output_____"
],
[
"syllable_df = pd.read_pickle(df_loc)",
"_____no_output_____"
],
[
"syllable_df[:3]",
"_____no_output_____"
],
[
"np.shape(syllable_df.spectrogram.values[0])",
"_____no_output_____"
]
],
[
[
"### project",
"_____no_output_____"
]
],
[
[
"specs = list(syllable_df.spectrogram.values)\nspecs = [i/np.max(i) for i in tqdm(specs)]\nspecs_flattened = flatten_spectrograms(specs)\nnp.shape(specs_flattened)",
"_____no_output_____"
],
[
"cuml_umap = cumlUMAP()\nembedding = cuml_umap.fit_transform(specs_flattened)",
"/mnt/cube/tsainbur/conda_envs/tpy3/lib/python3.6/site-packages/ipykernel_launcher.py:1: UserWarning: Parameter should_downcast is deprecated, use convert_dtype in fit, fit_transform and transform methods instead. \n \"\"\"Entry point for launching an IPython kernel.\n/mnt/cube/tsainbur/conda_envs/tpy3/lib/python3.6/site-packages/ipykernel_launcher.py:2: UserWarning: Parameter should_downcast is deprecated, use convert_dtype in fit, fit_transform and transform methods instead. \n \n"
],
[
"syllable_df['umap'] = list(embedding)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nax.scatter(embedding[:,0], embedding[:,1], s=1, color='k', alpha = 0.005)\nax.set_xlim([-8,8])\nax.set_ylim([-8,8])",
"_____no_output_____"
]
],
[
[
"### Save",
"_____no_output_____"
]
],
[
[
"ensure_dir(DATA_DIR / 'embeddings' / DATASET_ID / 'full')",
"_____no_output_____"
],
[
"syllable_df.to_pickle(DATA_DIR / 'embeddings' / DATASET_ID / 'full.pickle')",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1bc2951324ca8ee1a2fa8017666a3de1238a64
| 864,669 |
ipynb
|
Jupyter Notebook
|
TimeSeries Forecast.ipynb
|
Data-drone/timeseries_mlflow
|
b3102b7c967489fb602a33393fd76c48842a0451
|
[
"MIT"
] | null | null | null |
TimeSeries Forecast.ipynb
|
Data-drone/timeseries_mlflow
|
b3102b7c967489fb602a33393fd76c48842a0451
|
[
"MIT"
] | null | null | null |
TimeSeries Forecast.ipynb
|
Data-drone/timeseries_mlflow
|
b3102b7c967489fb602a33393fd76c48842a0451
|
[
"MIT"
] | null | null | null | 253.494283 | 100,536 | 0.916041 |
[
[
[
"# Time Series Forecasting on NYC_Taxi\n\nw MLFlow\n\n- Objectives\n - Leverage ML FLow to build some time series models\n\n- Simple Forecast of aggregate daily data to start\n- Later will need to look at splitting out the datasets into different spots",
"_____no_output_____"
]
],
[
[
"%load_ext autotime",
"time: 185 µs (started: 2021-08-03 12:37:16 +00:00)\n"
],
[
"from setup import start_spark, extract_data\n\nsparksesh = start_spark()",
"_____no_output_____"
],
[
"from tseries.taxi_daily import TaxiDaily",
"_____no_output_____"
],
[
"taxi_daily = TaxiDaily(sparksesh)\ntaxi_daily.load_data()",
"_____no_output_____"
]
],
[
[
"# Settings for MLflow",
"_____no_output_____"
]
],
[
[
"# credentials for storing our model artifacts\n# mlflow needs these to be set whenever it is being called\nos.environ['AWS_ACCESS_KEY_ID'] = os.environ.get('MINIO_ACCESS_KEY')\nos.environ['AWS_SECRET_ACCESS_KEY'] = os.environ.get('MINIO_SECRET_KEY')\nos.environ['MLFLOW_S3_ENDPOINT_URL'] = 'http://minio:9000'",
"time: 377 µs (started: 2021-08-03 12:37:32 +00:00)\n"
]
],
[
[
"# Create Our Train Set",
"_____no_output_____"
]
],
[
[
"taxi_daily.dataset.agg(F.min(F.col('pickup_date')), F.max(F.col('pickup_date'))).collect()",
"_____no_output_____"
],
[
"taxi_daily.dataset.printSchema()",
"root\n |-- pickup_date: date (nullable = true)\n |-- total_rides: long (nullable = false)\n |-- total_takings: double (nullable = true)\n\ntime: 7.91 ms (started: 2021-08-03 12:37:46 +00:00)\n"
]
],
[
[
"Lets take 2 years to start",
"_____no_output_____"
]
],
[
[
"starting_dataset = taxi_daily.dataset.filter(\"pickup_date < '2015-09-01'\")",
"time: 15.4 ms (started: 2021-08-03 12:37:46 +00:00)\n"
],
[
"train, val = starting_dataset.filter(\"pickup_date < '2015-08-01'\").toPandas(), \\\n starting_dataset.filter(\"pickup_date >= '2015-08-01'\").toPandas()",
"time: 38.3 s (started: 2021-08-03 12:37:46 +00:00)\n"
]
],
[
[
"## Forecasting the Dataframe",
"_____no_output_____"
]
],
[
[
"import prophet\nimport pandas as pd\nfrom prophet import Prophet\nfrom prophet.diagnostics import cross_validation\nfrom prophet.diagnostics import performance_metrics\nimport mlflow",
"time: 2.09 s (started: 2021-08-03 12:38:24 +00:00)\n"
]
],
[
[
"There was an error in the hostname resolution hence switch to ip",
"_____no_output_____"
]
],
[
[
"#mlflow.delete_experiment('1')",
"time: 189 µs (started: 2021-08-03 12:38:27 +00:00)\n"
],
[
"mlflow.set_tracking_uri(\"http://192.168.64.21:5000/\")\ntracking_uri = mlflow.get_tracking_uri()\nprint(\"Current tracking uri: {}\".format(tracking_uri))",
"Current tracking uri: http://192.168.64.21:5000/\ntime: 3.03 ms (started: 2021-08-03 12:38:27 +00:00)\n"
],
[
"### Quick test on creating experiments\nfrom mlflow.exceptions import RestException\n\ntry:\n mlflow.create_experiment(\n name='taxi_daily_forecast'\n )\nexcept RestException:\n print('already_created')",
"already_created\ntime: 618 ms (started: 2021-08-03 12:38:27 +00:00)\n"
],
[
"experiment = mlflow.get_experiment(15)\nexperiment.artifact_location",
"_____no_output_____"
],
[
"# Build an evaluation function\nimport numpy as np\nfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score\n\ndef eval_metrics(actual, pred):\n rmse = np.sqrt(mean_squared_error(actual, pred))\n mae = mean_absolute_error(actual, pred)\n r2 = r2_score(actual, pred)\n return rmse, mae, r2",
"time: 253 ms (started: 2021-08-03 12:38:27 +00:00)\n"
],
[
"# To save models to mlflow we need to write a python wrapper \n# to make sure that it performs as mlflow expects\nimport mlflow.pyfunc\n\nclass ProphetModel(mlflow.pyfunc.PythonModel):\n \n def __init__(self, model):\n \n self.model = model\n super().__init__()\n \n def load_context(self, context):\n from prophet import Prophet\n return\n \n def predict(self, context, model_input):\n future = self.model.make_future_dataframe(periods=model_input['periods'][0])\n return self.model.predict(future)",
"time: 333 µs (started: 2021-08-03 12:38:27 +00:00)\n"
]
],
[
[
"44 seconds for training by default \\\n3.62 seconds with processes parallelisation \\\n13 seconds after we add the toPandas conversion here and run with parallelisation",
"_____no_output_____"
]
],
[
[
"train_prophet = train[['pickup_date', 'total_rides']]\ntrain_prophet.columns = ['ds', 'y']\n#train_prophet.head(10)\n\nval_prophet = val[['pickup_date', 'total_rides']]\nval_prophet.columns = ['ds', 'y']\n#val_prophet.head(10)",
"time: 7.96 ms (started: 2021-08-03 12:38:27 +00:00)\n"
],
[
"%time\n\nrolling_window = 0.1\n\nconda_env = {\n 'channels': ['conda-forge'],\n 'dependencies': [{\n 'pip': [\n 'prophet=={0}'.format(prophet.__version__)\n ]\n }],\n \"name\": \"prophetenv\"\n}\n\nwith mlflow.start_run(experiment_id=15):\n m = prophet.Prophet(daily_seasonality=True)\n # need to adjust the fit function to suit\n m.fit(train_prophet)\n \n # cross validation is the thingy that is generating our different train sets\n # tqdm is glitchy with my setup so disabling for now\n df_cv = cross_validation(m, initial=\"28 days\", period=\"7 days\", horizon=\"14 days\", \n disable_tqdm=True, parallel=\"processes\")\n df_p = performance_metrics(df_cv, rolling_window=rolling_window)\n \n mlflow.log_param(\"rolling_window\", rolling_window)\n mlflow.log_metric(\"rmse\", df_p.loc[0, \"rmse\"])\n mlflow.log_metric(\"mae\", df_p.loc[0, \"mae\"])\n mlflow.log_metric(\"mape\", df_p.loc[0, \"mape\"])\n \n print(\" CV: {}\".format(df_cv.head()))\n print(\" Perf: {}\".format(df_p.head()))\n \n mlflow.pyfunc.log_model(\"model\", conda_env=conda_env, python_model=ProphetModel(m))\n print(\n \"Logged model with URI: runs:/{run_id}/model\".format(\n run_id=mlflow.active_run().info.run_id\n )\n )",
"CPU times: user 1 µs, sys: 1 µs, total: 2 µs\nWall time: 6.68 µs\n"
]
],
[
[
"# Prophet Diagnostics",
"_____no_output_____"
]
],
[
[
"# Python\nfrom prophet.plot import plot_cross_validation_metric\nfig = plot_cross_validation_metric(df_cv, metric='mape')",
"/opt/conda/envs/spark/lib/python3.8/site-packages/prophet/plot.py:539: FutureWarning: casting timedelta64[ns] values to int64 with .astype(...) is deprecated and will raise in a future version. Use .view(...) instead.\n x_plt = df_none['horizon'].astype('timedelta64[ns]').astype(np.int64) / float(dt_conversions[i])\n/opt/conda/envs/spark/lib/python3.8/site-packages/prophet/plot.py:540: FutureWarning: casting timedelta64[ns] values to int64 with .astype(...) is deprecated and will raise in a future version. Use .view(...) instead.\n x_plt_h = df_h['horizon'].astype('timedelta64[ns]').astype(np.int64) / float(dt_conversions[i])\n"
]
],
[
[
"We aren't seeing many differences with longer horizons",
"_____no_output_____"
]
],
[
[
"future = m.make_future_dataframe(periods=len(val_prophet))",
"time: 1.27 ms (started: 2021-08-03 12:38:35 +00:00)\n"
],
[
"forecast = m.predict(future)",
"time: 1.85 s (started: 2021-08-03 12:38:35 +00:00)\n"
],
[
"fig = m.plot_components(forecast)",
"_____no_output_____"
]
],
[
[
"# Testing out Uber Orbit",
"_____no_output_____"
]
],
[
[
"from orbit.models.dlt import DLTFull\nfrom orbit.diagnostics.plot import plot_predicted_data",
"time: 382 ms (started: 2021-08-03 12:38:38 +00:00)\n"
],
[
"dlt = DLTFull(\n response_col='y', date_col='ds',\n #regressor_col=['trend.unemploy', 'trend.filling', 'trend.job'],\n seasonality=7,\n)",
"time: 391 µs (started: 2021-08-03 12:38:38 +00:00)\n"
],
[
"dlt.fit(df=train_prophet)\n\n# outcomes data frame\npredicted_df = dlt.predict(df=val_prophet)",
"WARNING:pystan:Maximum (flat) parameter count (1000) exceeded: skipping diagnostic tests for n_eff and Rhat.\nTo run all diagnostics call pystan.check_hmc_diagnostics(fit)\n"
],
[
"plot_predicted_data(\n training_actual_df=train_prophet, predicted_df=predicted_df,\n date_col=dlt.date_col, actual_col=dlt.response_col,\n test_actual_df=val_prophet\n)",
"_____no_output_____"
]
],
[
[
"# Testing sktime",
"_____no_output_____"
]
],
[
[
"from sktime.performance_metrics.forecasting import mean_absolute_percentage_error",
"time: 11.4 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"from sktime.utils.plotting import plot_series\nimport numpy as np",
"time: 50.6 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"print(\"min: {0}, max {1}\".format(min(train.pickup_date), max(train.pickup_date)))\nprint(\"min: {0}, max {1}\".format(min(val.pickup_date), max(val.pickup_date)))",
"min: 2013-08-01, max 2015-07-31\nmin: 2015-08-01, max 2015-08-31\ntime: 959 µs (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"train_tr = pd.date_range(min(train.pickup_date), max(train.pickup_date))\nval_tr = pd.date_range(min(val.pickup_date), max(val.pickup_date))\n\nassert len(train) == len(train_tr)\nassert len(val) == len(val_tr)",
"time: 6.7 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"train_skt_df = pd.Series(train['total_rides'].values.astype('float'), index=train_tr)\nval_skt_df = pd.Series(val['total_rides'].values, index=val_tr)",
"time: 3.61 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"plot_series(train_skt_df)",
"_____no_output_____"
],
[
"plot_series(val_skt_df)",
"_____no_output_____"
],
[
"# test pandas\n#pd.PeriodIndex(pd.date_range(\"2020-01-01\", periods=30, freq=\"D\"))\nfrom sktime.forecasting.base import ForecastingHorizon\n\n#fh = ForecastingHorizon(test_sktime.index, is_relative=False)\nfh_period = ForecastingHorizon(\n val_skt_df.index, is_relative=False\n)",
"time: 140 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"from sktime.forecasting.naive import NaiveForecaster\n\nbasic_forecaster = NaiveForecaster(strategy=\"last\")\nforecaster = NaiveForecaster(strategy=\"last\")",
"time: 3.82 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"forecaster.fit(train_skt_df)",
"_____no_output_____"
],
[
"# stuck here for now\npreds = forecaster.predict(fh_period)",
"time: 8.31 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"fig, ax = plot_series(val_skt_df, preds, labels=[\"y\", \"y_pred\"])",
"_____no_output_____"
],
[
"mean_absolute_percentage_error(preds, val_skt_df)",
"_____no_output_____"
],
[
"from sktime.forecasting.theta import ThetaForecaster",
"time: 17.6 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"# theta forecasting\nth_forecaster = ThetaForecaster(sp=7)\nth_forecaster.fit(train_skt_df)\n\nalpha = 0.05\ny_pred, y_pred_ints = th_forecaster.predict(fh_period, return_pred_int=True, alpha=alpha)",
"time: 11.5 ms (started: 2021-08-03 12:38:46 +00:00)\n"
],
[
"fig, ax = plot_series(val_skt_df, y_pred, labels=[\"y\", \"y_pred\"])\nax.fill_between(\n ax.get_lines()[-1].get_xdata(),\n y_pred_ints[\"lower\"],\n y_pred_ints[\"upper\"],\n alpha=0.2,\n color=ax.get_lines()[-1].get_c(),\n label=f\"{1 - alpha}% prediction intervals\",\n)\nax.legend();",
"_____no_output_____"
],
[
"mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
],
[
"from sktime.forecasting.ets import AutoETS",
"time: 4.87 ms (started: 2021-08-03 12:38:47 +00:00)\n"
],
[
"et_forecaster = AutoETS(auto=True, sp=7, n_jobs=-1)\net_forecaster.fit(train_skt_df)\ny_pred = et_forecaster.predict(fh_period)",
"time: 1.67 s (started: 2021-08-03 12:38:47 +00:00)\n"
],
[
"plot_series(train_skt_df, val_skt_df, y_pred, labels=[\"y_train\", \"y_test\", \"y_pred\"])\n#mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
],
[
"mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
],
[
"from sktime.forecasting.arima import AutoARIMA",
"time: 103 ms (started: 2021-08-03 12:38:48 +00:00)\n"
],
[
"ar_forecaster = AutoARIMA(sp=7, suppress_warnings=True)\nar_forecaster.fit(train_skt_df)\ny_pred = ar_forecaster.predict(fh_period)",
"time: 56 s (started: 2021-08-03 12:38:49 +00:00)\n"
],
[
"plot_series(train_skt_df, val_skt_df, y_pred, labels=[\"y_train\", \"y_test\", \"y_pred\"])\n#mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
],
[
"mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
],
[
"from sktime.forecasting.tbats import TBATS",
"time: 18.2 ms (started: 2021-08-03 12:39:45 +00:00)\n"
],
[
"tbats_forecaster = TBATS(sp=7, use_trend=True, use_box_cox=True)\ntbats_forecaster.fit(train_skt_df)\ny_pred = tbats_forecaster.predict(fh_period)",
"time: 1min 12s (started: 2021-08-03 12:39:45 +00:00)\n"
],
[
"plot_series(train_skt_df, val_skt_df, y_pred, labels=[\"y_train\", \"y_test\", \"y_pred\"])",
"_____no_output_____"
],
[
"mean_absolute_percentage_error(y_pred, val_skt_df)",
"_____no_output_____"
]
],
[
[
"# Pytorch - Forecasting",
"_____no_output_____"
]
],
[
[
"from pytorch_forecasting import Baseline, NBeats, TimeSeriesDataSet\nfrom pytorch_forecasting.data import NaNLabelEncoder, TorchNormalizer\nimport pytorch_lightning as pl\nfrom pytorch_lightning.callbacks import EarlyStopping\nimport torch",
"time: 1.06 s (started: 2021-08-03 12:40:57 +00:00)\n"
]
],
[
[
"We need to regig this:\n- need to merge the two datasets and split it by the time index\n- time index must be integer, cannot use date times etc\n",
"_____no_output_____"
]
],
[
[
"torch_train = train[['pickup_date', 'total_rides']].copy()\ntorch_train['group'] = 'Only'\ntorch_train['time_idx'] = torch_train.index.astype('int')",
"time: 2.03 ms (started: 2021-08-03 12:40:58 +00:00)\n"
],
[
"max(torch_train['time_idx'])",
"_____no_output_____"
],
[
"torch_val = val[['pickup_date', 'total_rides']].copy()\ntorch_val['group'] = 'Only'\ntorch_val.index = pd.RangeIndex(start=max(torch_train['time_idx'])+1, stop=max(torch_train['time_idx'])+len(torch_val)+1)\ntorch_val['time_idx'] = torch_val.index.astype('int')",
"time: 6.67 ms (started: 2021-08-03 12:40:58 +00:00)\n"
],
[
"merged = pd.concat([torch_train, torch_val])\nmerged.head()",
"_____no_output_____"
],
[
"torch_train.total_rides.head(2)",
"_____no_output_____"
],
[
"# create dataset and dataloaders\nmax_encoder_length = 60\nmax_prediction_length = len(val_skt_df)\ntraining_cutoff = 730\n\ncontext_length = max_encoder_length\nprediction_length = max_prediction_length\n\ntraining = TimeSeriesDataSet(\n merged[lambda x: x.time_idx < training_cutoff],\n time_idx=\"time_idx\",\n target=\"total_rides\",\n target_normalizer=TorchNormalizer(),\n #categorical_encoders={\"group\": NaNLabelEncoder().fit(torch_train.group)},\n group_ids=[\"group\"],\n # only unknown variable is \"value\" - and N-Beats can also not take any additional variables\n time_varying_unknown_reals=[\"total_rides\"],\n max_encoder_length=context_length,\n max_prediction_length=prediction_length,\n)\n\nvalidation = TimeSeriesDataSet.from_dataset(training, merged, min_prediction_idx=training_cutoff)\nbatch_size = 128\ntrain_dataloader = training.to_dataloader(train=True, batch_size=batch_size, num_workers=0)\nval_dataloader = validation.to_dataloader(train=False, batch_size=batch_size, num_workers=0)",
"time: 405 ms (started: 2021-08-03 12:40:58 +00:00)\n"
],
[
"training.target_normalizer",
"_____no_output_____"
],
[
"pl.seed_everything(42)\ntrainer = pl.Trainer(gradient_clip_val=0.01)\nnet = NBeats.from_dataset(training, learning_rate=3e-2, weight_decay=1e-2, \n widths=[32, 512], backcast_loss_ratio=0.1)",
"INFO:pytorch_lightning.utilities.seed:Global seed set to 42\nINFO:pytorch_lightning.utilities.distributed:GPU available: False, used: False\nINFO:pytorch_lightning.utilities.distributed:TPU available: False, using: 0 TPU cores\nINFO:pytorch_lightning.utilities.distributed:IPU available: False, using: 0 IPUs\n"
],
[
"# find optimal learning rate\nres = trainer.tuner.lr_find(net, train_dataloader=train_dataloader, \n val_dataloaders=val_dataloader, min_lr=1e-5)\nprint(f\"suggested learning rate: {res.suggestion()}\")\nfig = res.plot(show=True, suggest=True)\nfig.show()\nnet.hparams.learning_rate = res.suggestion()",
"/opt/conda/envs/spark/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:818: LightningDeprecationWarning: `trainer.tune(train_dataloader)` is deprecated in v1.4 and will be removed in v1.6. Use `trainer.tune(train_dataloaders)` instead. HINT: added 's'\n rank_zero_deprecation(\nINFO:pytorch_lightning.core.lightning:\n | Name | Type | Params\n-----------------------------------------------\n0 | loss | MASE | 0 \n1 | logging_metrics | ModuleList | 0 \n2 | net_blocks | ModuleList | 1.7 M \n-----------------------------------------------\n1.7 M Trainable params\n0 Non-trainable params\n1.7 M Total params\n6.919 Total estimated model params size (MB)\n/opt/conda/envs/spark/lib/python3.8/site-packages/pytorch_lightning/trainer/data_loading.py:105: UserWarning: The dataloader, val dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 32 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.\n rank_zero_warn(\nINFO:pytorch_lightning.utilities.seed:Global seed set to 42\n/opt/conda/envs/spark/lib/python3.8/site-packages/pytorch_lightning/trainer/data_loading.py:105: UserWarning: The dataloader, train dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 32 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.\n rank_zero_warn(\n/opt/conda/envs/spark/lib/python3.8/site-packages/pytorch_lightning/trainer/data_loading.py:322: UserWarning: The number of training samples (5) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.\n rank_zero_warn(\n"
],
[
"early_stop_callback = EarlyStopping(monitor=\"val_loss\", min_delta=1e-4, patience=10, verbose=False, mode=\"min\")\ntrainer = pl.Trainer(\n max_epochs=100,\n gpus=0,\n weights_summary=\"top\",\n gradient_clip_val=0.01,\n callbacks=[early_stop_callback],\n limit_train_batches=30,\n)\n\n\nnet = NBeats.from_dataset(\n training,\n learning_rate=4e-3,\n log_interval=10,\n log_val_interval=1,\n weight_decay=1e-2,\n widths=[32, 512],\n backcast_loss_ratio=1.0,\n)\n\ntrainer.fit(\n net,\n train_dataloader=train_dataloader,\n val_dataloaders=val_dataloader,\n)",
"INFO:pytorch_lightning.utilities.distributed:GPU available: False, used: False\nINFO:pytorch_lightning.utilities.distributed:TPU available: False, using: 0 TPU cores\nINFO:pytorch_lightning.utilities.distributed:IPU available: False, using: 0 IPUs\n/opt/conda/envs/spark/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:531: LightningDeprecationWarning: `trainer.fit(train_dataloader)` is deprecated in v1.4 and will be removed in v1.6. Use `trainer.fit(train_dataloaders)` instead. HINT: added 's'\n rank_zero_deprecation(\nINFO:pytorch_lightning.core.lightning:\n | Name | Type | Params\n-----------------------------------------------\n0 | loss | MASE | 0 \n1 | logging_metrics | ModuleList | 0 \n2 | net_blocks | ModuleList | 1.7 M \n-----------------------------------------------\n1.7 M Trainable params\n0 Non-trainable params\n1.7 M Total params\n6.919 Total estimated model params size (MB)\n"
],
[
"best_model_path = trainer.checkpoint_callback.best_model_path\nbest_model = NBeats.load_from_checkpoint(best_model_path)",
"time: 26.9 ms (started: 2021-08-03 12:41:27 +00:00)\n"
],
[
"actuals = torch.cat([y[0] for x, y in iter(val_dataloader)])\npredictions = best_model.predict(val_dataloader)\n(actuals - predictions).abs().mean()",
"_____no_output_____"
],
[
"raw_predictions, x = best_model.predict(val_dataloader, mode=\"raw\", return_x=True)",
"time: 4.37 ms (started: 2021-08-03 12:41:27 +00:00)\n"
],
[
"best_model.plot_prediction(x, raw_predictions, idx=0, add_loss_to_title=True);",
"_____no_output_____"
],
[
"# we are only forecasting 1 series so idx is just 0\n#for idx in range(10): # plot 10 examples\n# best_model.plot_prediction(x, raw_predictions, idx=idx, add_loss_to_title=True);",
"time: 200 µs (started: 2021-08-03 12:41:27 +00:00)\n"
]
],
[
[
"# GluonTS\n\nrequires pandas at least 1.2 ",
"_____no_output_____"
]
],
[
[
"pd.__version__",
"_____no_output_____"
],
[
"from gluonts.dataset.common import ListDataset\nimport matplotlib.pyplot as plt",
"time: 52.9 ms (started: 2021-08-03 12:41:27 +00:00)\n"
],
[
"print(train_skt_df.values.shape)\nprint(val_skt_df.values.shape)",
"(730,)\n(31,)\ntime: 299 µs (started: 2021-08-03 12:41:27 +00:00)\n"
],
[
"# train dataset: cut the last window of length \"prediction_length\", add \"target\" and \"start\" fields\ntrain_ds = ListDataset(\n [{'target': train_skt_df.values.astype(int), 'start':train_skt_df.index[0].to_pydatetime() }],\n freq=\"1D\"\n)\n# test dataset: use the whole dataset, add \"target\" and \"start\" fields\ntest_ds = ListDataset(\n [{'target': val_skt_df.values.astype(int), 'start': val_skt_df.index[0].to_pydatetime() }],\n freq=\"1D\"\n)",
"time: 3.17 ms (started: 2021-08-03 12:41:27 +00:00)\n"
],
[
"#type(train_skt_df.index[0])\ntype(train_skt_df.index[0].to_pydatetime())\ntrain_skt_df.index[0].to_pydatetime()\n#train_skt_df.values",
"_____no_output_____"
],
[
"from gluonts.model.simple_feedforward import SimpleFeedForwardEstimator\nfrom gluonts.mx import Trainer",
"INFO:gluonts.mx.context:Using CPU\n"
],
[
"estimator = SimpleFeedForwardEstimator(\n num_hidden_dimensions=[10],\n prediction_length=len(val_skt_df),\n context_length=100,\n freq=\"D\",\n trainer=Trainer(\n ctx=\"cpu\",\n epochs=20,\n learning_rate=1e-3,\n num_batches_per_epoch=100\n )\n)",
"time: 788 µs (started: 2021-08-03 12:41:28 +00:00)\n"
],
[
"predictor = estimator.train(training_data=train_ds)",
"/home/jovyan/.local/lib/python3.8/site-packages/gluonts/dataset/common.py:323: FutureWarning: The 'freq' argument in Timestamp is deprecated and will be removed in a future version.\n timestamp = pd.Timestamp(string, freq=freq)\n/home/jovyan/.local/lib/python3.8/site-packages/gluonts/dataset/common.py:326: FutureWarning: Timestamp.freq is deprecated and will be removed in a future version\n if isinstance(timestamp.freq, Tick):\n/home/jovyan/.local/lib/python3.8/site-packages/gluonts/dataset/common.py:328: FutureWarning: Timestamp.freq is deprecated and will be removed in a future version\n timestamp.floor(timestamp.freq), timestamp.freq\n/home/jovyan/.local/lib/python3.8/site-packages/gluonts/dataset/common.py:327: FutureWarning: The 'freq' argument in Timestamp is deprecated and will be removed in a future version.\n return pd.Timestamp(\nINFO:gluonts.trainer:Start model training\nINFO:gluonts.trainer:Epoch[0] Learning rate is 0.001\n\n 0%| | 0/100 [00:00<?, ?it/s]\u001b[A/home/jovyan/.local/lib/python3.8/site-packages/gluonts/transform/split.py:36: FutureWarning: Timestamp.freq is deprecated and will be removed in a future version\n return _shift_timestamp_helper(ts, ts.freq, offset)\nINFO:gluonts.trainer:Number of parameters in SimpleFeedForwardTrainingNetwork: 31343\n/home/jovyan/.local/lib/python3.8/site-packages/gluonts/transform/split.py:36: FutureWarning: Timestamp.freq is deprecated and will be removed in a future version\n return _shift_timestamp_helper(ts, ts.freq, offset)\nWARNING:gluonts.trainer:Batch [11] of Epoch[0] gave NaN loss and it will be ignored\n100%|██████████| 100/100 [00:00<00:00, 237.58it/s, epoch=1/20, avg_epoch_loss=13.1]\nINFO:gluonts.trainer:Epoch[0] Elapsed time 0.423 seconds\nINFO:gluonts.trainer:Epoch[0] Evaluation metric 'epoch_loss'=13.113495\nINFO:gluonts.trainer:Epoch[1] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 295.84it/s, epoch=2/20, avg_epoch_loss=12.6]\nINFO:gluonts.trainer:Epoch[1] Elapsed time 0.340 seconds\nINFO:gluonts.trainer:Epoch[1] Evaluation metric 'epoch_loss'=12.556725\nINFO:gluonts.trainer:Epoch[2] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 287.54it/s, epoch=3/20, avg_epoch_loss=12.4]\nINFO:gluonts.trainer:Epoch[2] Elapsed time 0.349 seconds\nINFO:gluonts.trainer:Epoch[2] Evaluation metric 'epoch_loss'=12.447299\nINFO:gluonts.trainer:Epoch[3] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 280.00it/s, epoch=4/20, avg_epoch_loss=12.4]\nINFO:gluonts.trainer:Epoch[3] Elapsed time 0.359 seconds\nINFO:gluonts.trainer:Epoch[3] Evaluation metric 'epoch_loss'=12.390138\nINFO:gluonts.trainer:Epoch[4] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 271.89it/s, epoch=5/20, avg_epoch_loss=12.3]\nINFO:gluonts.trainer:Epoch[4] Elapsed time 0.370 seconds\nINFO:gluonts.trainer:Epoch[4] Evaluation metric 'epoch_loss'=12.338418\nINFO:gluonts.trainer:Epoch[5] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 253.58it/s, epoch=6/20, avg_epoch_loss=12.3]\nINFO:gluonts.trainer:Epoch[5] Elapsed time 0.396 seconds\nINFO:gluonts.trainer:Epoch[5] Evaluation metric 'epoch_loss'=12.317996\nINFO:gluonts.trainer:Epoch[6] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 275.03it/s, epoch=7/20, avg_epoch_loss=12.3]\nINFO:gluonts.trainer:Epoch[6] Elapsed time 0.366 seconds\nINFO:gluonts.trainer:Epoch[6] Evaluation metric 'epoch_loss'=12.299467\nINFO:gluonts.trainer:Epoch[7] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 277.79it/s, epoch=8/20, avg_epoch_loss=12.3]\nINFO:gluonts.trainer:Epoch[7] Elapsed time 0.362 seconds\nINFO:gluonts.trainer:Epoch[7] Evaluation metric 'epoch_loss'=12.260821\nINFO:gluonts.trainer:Epoch[8] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 278.62it/s, epoch=9/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[8] Elapsed time 0.361 seconds\nINFO:gluonts.trainer:Epoch[8] Evaluation metric 'epoch_loss'=12.208560\nINFO:gluonts.trainer:Epoch[9] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 287.02it/s, epoch=10/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[9] Elapsed time 0.350 seconds\nINFO:gluonts.trainer:Epoch[9] Evaluation metric 'epoch_loss'=12.211030\nINFO:gluonts.trainer:Epoch[10] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 292.83it/s, epoch=11/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[10] Elapsed time 0.343 seconds\nINFO:gluonts.trainer:Epoch[10] Evaluation metric 'epoch_loss'=12.214475\nINFO:gluonts.trainer:Epoch[11] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 300.41it/s, epoch=12/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[11] Elapsed time 0.334 seconds\nINFO:gluonts.trainer:Epoch[11] Evaluation metric 'epoch_loss'=12.193407\nINFO:gluonts.trainer:Epoch[12] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 295.57it/s, epoch=13/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[12] Elapsed time 0.340 seconds\nINFO:gluonts.trainer:Epoch[12] Evaluation metric 'epoch_loss'=12.186590\nINFO:gluonts.trainer:Epoch[13] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 279.38it/s, epoch=14/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[13] Elapsed time 0.360 seconds\nINFO:gluonts.trainer:Epoch[13] Evaluation metric 'epoch_loss'=12.150931\nINFO:gluonts.trainer:Epoch[14] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 297.05it/s, epoch=15/20, avg_epoch_loss=12.2]\nINFO:gluonts.trainer:Epoch[14] Elapsed time 0.338 seconds\nINFO:gluonts.trainer:Epoch[14] Evaluation metric 'epoch_loss'=12.168311\nINFO:gluonts.trainer:Epoch[15] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 286.76it/s, epoch=16/20, avg_epoch_loss=12.1]\nINFO:gluonts.trainer:Epoch[15] Elapsed time 0.350 seconds\nINFO:gluonts.trainer:Epoch[15] Evaluation metric 'epoch_loss'=12.141259\nINFO:gluonts.trainer:Epoch[16] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 263.51it/s, epoch=17/20, avg_epoch_loss=12.1]\nINFO:gluonts.trainer:Epoch[16] Elapsed time 0.381 seconds\nINFO:gluonts.trainer:Epoch[16] Evaluation metric 'epoch_loss'=12.134287\nINFO:gluonts.trainer:Epoch[17] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 285.82it/s, epoch=18/20, avg_epoch_loss=12.1]\nINFO:gluonts.trainer:Epoch[17] Elapsed time 0.352 seconds\nINFO:gluonts.trainer:Epoch[17] Evaluation metric 'epoch_loss'=12.136528\nINFO:gluonts.trainer:Epoch[18] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 273.46it/s, epoch=19/20, avg_epoch_loss=12.1]\nINFO:gluonts.trainer:Epoch[18] Elapsed time 0.367 seconds\nINFO:gluonts.trainer:Epoch[18] Evaluation metric 'epoch_loss'=12.108441\nINFO:gluonts.trainer:Epoch[19] Learning rate is 0.001\n\n100%|██████████| 100/100 [00:00<00:00, 295.07it/s, epoch=20/20, avg_epoch_loss=12.1]\nINFO:gluonts.trainer:Epoch[19] Elapsed time 0.341 seconds\nINFO:gluonts.trainer:Epoch[19] Evaluation metric 'epoch_loss'=12.111146\nINFO:root:Computing averaged parameters.\nINFO:root:Loading averaged parameters.\nINFO:gluonts.trainer:End model training\n"
],
[
"from gluonts.evaluation import make_evaluation_predictions",
"time: 10.2 ms (started: 2021-08-03 12:41:35 +00:00)\n"
],
[
"forecast_it, ts_it = make_evaluation_predictions(\n dataset=test_ds, # test dataset\n predictor=predictor, # predictor\n num_samples=100, # number of sample paths we want for evaluation\n)",
"time: 1.59 ms (started: 2021-08-03 12:41:35 +00:00)\n"
],
[
"forecasts = list(forecast_it)\ntss = list(ts_it)\nts_entry = tss[0]\nforecast_entry = forecasts[0]",
"time: 10.9 ms (started: 2021-08-03 12:41:35 +00:00)\n"
],
[
"def plot_prob_forecasts(ts_entry, forecast_entry):\n plot_length = 150\n prediction_intervals = (50.0, 90.0)\n legend = [\"observations\", \"median prediction\"] + [f\"{k}% prediction interval\" for k in prediction_intervals][::-1]\n\n fig, ax = plt.subplots(1, 1, figsize=(10, 7))\n ts_entry[-plot_length:].plot(ax=ax) # plot the time series\n forecast_entry.plot(prediction_intervals=prediction_intervals, color='g')\n plt.grid(which=\"both\")\n plt.legend(legend, loc=\"upper left\")\n plt.show()",
"time: 463 µs (started: 2021-08-03 12:41:35 +00:00)\n"
],
[
"plot_prob_forecasts(ts_entry, forecast_entry)",
"_____no_output_____"
]
],
[
[
"# Statsmodels",
"_____no_output_____"
]
],
[
[
"import statsmodels.api as sm",
"time: 237 µs (started: 2021-08-03 12:41:35 +00:00)\n"
],
[
"mod = sm.tsa.SARIMAX(train['total_rides'], order=(1, 0, 0), trend='c')\n# Estimate the parameters\nres = mod.fit()\n\nprint(res.summary())",
" SARIMAX Results \n==============================================================================\nDep. Variable: total_rides No. Observations: 730\nModel: SARIMAX(1, 0, 0) Log Likelihood -8852.172\nDate: Tue, 03 Aug 2021 AIC 17710.343\nTime: 13:18:26 BIC 17724.122\nSample: 0 HQIC 17715.659\n - 730 \nCovariance Type: opg \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nintercept 1.58e+05 8020.434 19.698 0.000 1.42e+05 1.74e+05\nar.L1 0.6724 0.017 39.522 0.000 0.639 0.706\nsigma2 1.974e+09 0.118 1.68e+10 0.000 1.97e+09 1.97e+09\n===================================================================================\nLjung-Box (L1) (Q): 24.30 Jarque-Bera (JB): 392.03\nProb(Q): 0.00 Prob(JB): 0.00\nHeteroskedasticity (H): 0.85 Skew: -1.03\nProb(H) (two-sided): 0.21 Kurtosis: 5.95\n===================================================================================\n\nWarnings:\n[1] Covariance matrix calculated using the outer product of gradients (complex-step).\n[2] Covariance matrix is singular or near-singular, with condition number 3.71e+25. Standard errors may be unstable.\ntime: 64.8 ms (started: 2021-08-03 13:18:26 +00:00)\n"
]
],
[
[
"## Stopping Spark Session",
"_____no_output_____"
]
],
[
[
"spark.stop()",
"time: 438 ms (started: 2021-08-03 13:41:57 +00:00)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1bc9d13bf8bf814d04dca24b495fe174d4d348
| 260,138 |
ipynb
|
Jupyter Notebook
|
notebooks/uncategorized/largescale_example.ipynb
|
J-Garcke-SCAI/jaxkern
|
9de7ebf52fe2d186d316350a6692b2ecc0885adc
|
[
"MIT"
] | 7 |
2020-09-28T07:39:16.000Z
|
2022-03-11T14:09:41.000Z
|
notebooks/uncategorized/largescale_example.ipynb
|
J-Garcke-SCAI/jaxkern
|
9de7ebf52fe2d186d316350a6692b2ecc0885adc
|
[
"MIT"
] | 5 |
2020-09-25T01:25:57.000Z
|
2020-10-09T16:15:49.000Z
|
notebooks/uncategorized/largescale_example.ipynb
|
J-Garcke-SCAI/jaxkern
|
9de7ebf52fe2d186d316350a6692b2ecc0885adc
|
[
"MIT"
] | 2 |
2021-05-25T21:59:58.000Z
|
2022-01-11T07:23:32.000Z
| 256.041339 | 40,844 | 0.912254 |
[
[
[
"# Large Scale Kernel Ridge Regression",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.insert(0, '/Users/eman/Documents/code_projects/kernellib')\nsys.path.insert(0, '/home/emmanuel/code/kernellib')",
"_____no_output_____"
],
[
"import numpy as np\nfrom kernellib.large_scale import RKSKernelRidge, KernelRidge as RKernelRidge\nfrom kernellib.utils import estimate_sigma, r_assessment\nfrom sklearn.model_selection import GridSearchCV\nimport matplotlib.pyplot as plt\n\n%matplotlib inline\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"#### Sample Data",
"_____no_output_____"
]
],
[
[
"seed = 123\nrng = np.random.RandomState(seed)\nn_train, n_test = 10000, 1000\nd_dimensions = 1\nnoise = 0.1\n\nxtrain = rng.randn(n_train, d_dimensions)\nytrain = np.sin(xtrain) + noise * rng.randn(n_train, d_dimensions)\n\nxtest = rng.randn(n_test, d_dimensions)\nytest = np.sin(xtest) + noise * rng.randn(n_test, d_dimensions)\n\n# training\nn_components = 10\nalpha = 1e-3\n\nsigma = estimate_sigma(xtrain)",
"_____no_output_____"
]
],
[
[
"## Random Kitchen Sinks Regression",
"_____no_output_____"
],
[
"In this method, I implement the Random Kitchen Sinks algorithm found [here](https://people.eecs.berkeley.edu/~brecht/kitchensinks.html) and [here](https://people.eecs.berkeley.edu/~brecht/kitchensinks.html). I don't try and transform the problem into a matrix approximation and then fit it into the KRR framework. This is largely because the RKS algorithm that they implement use complex values that need to be present in solving and transforming the data. If the complex values are taken out before the transformation, the results are garbage. Furthermore, some experiments that I ran (see below) show that the RKS as a transformer do not approximate the kernel matrix very well. So therefore, this algorithm comes as is. It's a shame that you cannot write the function as a transformer but the phenomenal results that you obtain make it worth it in my opinion.",
"_____no_output_____"
]
],
[
[
"rks_model = RKSKernelRidge(n_components=n_components, alpha=alpha, sigma=sigma, \n random_state=seed)\nrks_model.fit(xtrain, ytrain)\ny_pred = rks_model.predict(xtest)\nr_assessment(y_pred, ytest, verbose=1);",
" mae mse r2 rmse\nResults 0.079758 0.009984 0.976223 0.099922\n"
],
[
"%timeit rks_model.fit(xtrain, ytrain);\n%timeit rks_model.predict(xtest);",
"3.38 ms ± 186 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n278 µs ± 14.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = rks_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Random Kitchen Sinks Approximation')\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Cross Validation Compatibility",
"_____no_output_____"
]
],
[
[
"sigmaMin = np.log10(sigma*0.1);\nsigmaMax = np.log10(sigma*10);\nsigmas = np.logspace(sigmaMin,sigmaMax,20);\n\nparam_grid = {\n 'n_components': [1, 5, 10, 25],\n 'alpha': [1e0, 1e-1, 1e-2, 1e-3],\n 'sigma': sigmas\n}\n\nn_jobs = 24\ncv = 3\n\nrks_grid_model = GridSearchCV(RKSKernelRidge(random_state=seed),\n param_grid=param_grid, n_jobs=n_jobs, cv=cv, \n verbose=1)\nrks_grid_model.fit(xtrain, ytrain);",
"Fitting 3 folds for each of 320 candidates, totalling 960 fits\n"
],
[
"y_pred = rks_grid_model.predict(xtest)\nr_assessment(y_pred, ytest)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = rks_grid_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Random Kitchen Sinks Approximation w/ Grid Search')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Nystrom Approximation",
"_____no_output_____"
]
],
[
[
"approximation = 'nystrom'\nnys_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n sigma=sigma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation)\nnys_model.fit(xtrain, ytrain);\ny_pred = nys_model.predict(xtest)\nr_assessment(y_pred, ytest, verbose=1);",
" mae mse r2 rmse\nResults 0.080484 0.010232 0.97562 0.101152\n"
],
[
"%timeit nys_model.fit(xtrain, ytrain);\n%timeit nys_model.predict(xtest);",
"1.95 ms ± 104 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n279 µs ± 35.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = nys_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Nystrom Approximation')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Nystrom w/ Grid Search",
"_____no_output_____"
]
],
[
[
"\nsigmaMin = np.log10(sigma*0.1);\nsigmaMax = np.log10(sigma*10);\nsigmas = np.logspace(sigmaMin,sigmaMax,20);\n\nparam_grid = {\n 'kernel': ['rbf'],\n 'n_components': [1, 5, 10, 25],\n 'alpha': [1e0, 1e-1, 1e-2, 1e-3],\n 'sigma': sigmas\n}\nn_jobs = 24\ncv = 3\n\nnys_grid_model = GridSearchCV(RKernelRidge(random_state=seed,\n approximation=approximation),\n param_grid=param_grid, n_jobs=n_jobs, cv=cv, \n verbose=1)\nnys_grid_model.fit(xtrain, ytrain);",
"Fitting 3 folds for each of 320 candidates, totalling 960 fits\n"
],
[
"r_assessment(y_pred, ytest, verbose=1);\nprint('Best sigma:', nys_grid_model.best_estimator_.sigma)\nprint('Best alpha:',nys_grid_model.best_estimator_.alpha)\nprint('Best Number of features:', nys_grid_model.best_estimator_.n_components)\nprint('Best Kernel:', nys_grid_model.best_estimator_.kernel)",
" mae mse r2 rmse\nResults 0.079583 0.009968 0.97625 0.099838\nBest sigma: 1.1288378916846888\nBest alpha: 0.1\nBest Number of features: 10\nBest Kernel: rbf\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = nys_grid_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Nystrom Approximation w/ Grid Search')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Randomized Nystrom Matrix Approximation",
"_____no_output_____"
]
],
[
[
"approximation = 'rnystrom'\nk_rank = 10\nrnys_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n sigma=sigma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation,\n k_rank=k_rank)\nrnys_model.fit(xtrain, ytrain);\ny_pred = rnys_model.predict(xtest)\nr_assessment(y_pred, ytest, verbose=1);",
" mae mse r2 rmse\nResults 0.080322 0.010202 0.975668 0.101003\n"
],
[
"%timeit rnys_model.fit(xtrain, ytrain);\n%timeit rnys_model.predict(xtest);",
"2.44 ms ± 347 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n301 µs ± 52.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = rnys_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Randomized Nystrom Approximation')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Random Fourier Features Approximation",
"_____no_output_____"
]
],
[
[
"approximation = 'rff'\nrff_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n sigma=sigma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation)\nrff_model.fit(xtrain, ytrain);\ny_pred = rff_model.predict(xtest)\nr_assessment(y_pred, ytest, verbose=1);",
" mae mse r2 rmse\nResults 0.079697 0.009976 0.976239 0.099879\n"
],
[
"%timeit rff_model.fit(xtrain, ytrain);\n%timeit rff_model.predict(xtest);",
"5.5 ms ± 328 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n80.5 µs ± 4.23 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = rff_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Random Fourier Features')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Fast Food",
"_____no_output_____"
]
],
[
[
"approximation = 'fastfood'\nfastfood_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n sigma=sigma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation,\n trade_off='mem')\nfastfood_model.fit(xtrain, ytrain);\ny_pred = fastfood_model.predict(xtest)\nr_assessment(y_pred, ytest, verbose=1);",
" mae mse r2 rmse\nResults 0.079583 0.009968 0.97625 0.099838\n"
],
[
"%timeit fastfood_model.fit(xtrain, ytrain);\n%timeit fastfood_model.predict(xtest);",
"4.8 ms ± 224 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n524 µs ± 72.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)\n"
],
[
"fig, ax = plt.subplots()\n\nxplot = np.linspace(xtrain.min(), xtest.max(), 100)[:, np.newaxis]\nyplot = fastfood_model.predict(xplot)\n\nax.scatter(xtrain, ytrain, color='r', label='Training Data')\nax.plot(xplot, yplot, color='k', linewidth=2, label='Predictions')\nax.legend()\nax.set_title('Fast Food')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Timing Comparison",
"_____no_output_____"
],
[
"#### Number of Features",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import make_low_rank_matrix\nimport seaborn; seaborn.set()",
"/home/emmanuel/.conda/envs/sci_py36/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88\n return f(*args, **kwds)\n"
],
[
"m_range = (2 ** (np.arange(12.3, 20))).astype(int)\nprint(m_range.shape, m_range.min(), m_range.max())",
"(8,) 5042 645474\n"
],
[
"from sklearn.datasets import make_regression",
"_____no_output_____"
],
[
"print(t1.average, t1.stdev)",
"0.46411639344712186 0.002118701198427\n"
],
[
"%%time \nt_rks = list()\nt_nys = list()\nt_rnys = list()\nt_rbf = list()\nt_rff = list()\n\n# training\nn_components = 50\nalpha = 1e-3\ngamma = 1.0\n\nfor m in m_range:\n xtrain, ytrain = make_regression(n_samples=m, n_features=2000,\n n_informative=200, n_targets=1,\n effective_rank=50, noise=0.2, \n random_state=seed)\n print(xtrain.shape)\n # -------------------------------\n # Random Kitchen Sinks)\n # -------------------------------\n rks_model = RKSKernelRidge(n_components=n_components, alpha=alpha, \n gamma=gamma, random_state=seed)\n t1 = %timeit -oq rks_model.fit(xtrain, ytrain)\n \n # ------------------------------\n # Nystrom\n # ------------------------------\n approximation = 'nystrom'\n nys_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n gamma=gamma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation)\n t2 = %timeit -oq nys_model.fit(xtrain, ytrain);\n\n # ----------------------------\n # Randomized Nystrom\n # ----------------------------\n approximation = 'rnystrom'\n k_rank = n_components\n rnys_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n gamma=gamma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation,\n k_rank=k_rank)\n t3 = %timeit -oq rnys_model.fit(xtrain, ytrain);\n \n # -----------------------------------\n # RBF Sampler (Random Kitchen Sinks)\n # -----------------------------------\n approximation = 'rks'\n rks_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n gamma=gamma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation)\n t4 = %timeit -oq rks_model.fit(xtrain, ytrain); \n \n # -----------------------------\n # Random Fourier Features\n # -----------------------------\n approximation = 'rff'\n rff_model = RKernelRidge(n_components=n_components,\n alpha=alpha,\n gamma=gamma,\n kernel='rbf',\n random_state=seed,\n approximation=approximation)\n t5 = %timeit -oq rff_model.fit(xtrain, ytrain); \n \n t_rks.append(t1.best)\n t_nys.append(t2.best)\n t_rnys.append(t3.best)\n t_rbf.append(t4.best)\n t_rff.append(t5.best)\n \n\n \n ",
"(5042, 2000)\n(10085, 2000)\n(20171, 2000)\n(40342, 2000)\n(80684, 2000)\n(161368, 2000)\n(322737, 2000)\n(645474, 2000)\nCPU times: user 2h 4min 38s, sys: 4h 15min 33s, total: 6h 20min 11s\nWall time: 34min 36s\n"
],
[
"\n\nplt.loglog(m_range, t_rks, label='Random Kitchen Sinks')\nplt.loglog(m_range, t_rff, label='Random Fourier Features')\nplt.loglog(m_range, t_nys, label='Nystrom')\nplt.loglog(m_range, t_rnys, label='Randomized Nystrom')\nplt.loglog(m_range, t_rbf, label='RBF Sampler')\nplt.legend(loc='upper left')\nplt.xlabel('Number of Elements')\nplt.ylabel('Execution Time (secs)');\n\n",
"_____no_output_____"
],
[
"plt.plot(m_range, t_rks, label='Random Kitchen Sinks')\nplt.plot(m_range, t_rff, label='Random Fourier Features')\nplt.plot(m_range, t_nys, label='Nystrom')\nplt.plot(m_range, t_rnys, label='Randomized Nystrom')\nplt.plot(m_range, t_rbf, label='RBF Sampler')\nplt.legend(loc='upper left')\nplt.xlabel('Number of Elements')\nplt.ylabel('Execution Time (secs)');\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1bce458abfe5aad5f6b5eccc6fd48c8c02cab5
| 2,042 |
ipynb
|
Jupyter Notebook
|
applications/3DGAN/test_dataset.ipynb
|
NickleDave/generative-neural-nets-tutorial-scipy2020
|
74bed76687867ae07205bbf5c7836deecb165597
|
[
"MIT"
] | 1 |
2020-06-24T05:53:13.000Z
|
2020-06-24T05:53:13.000Z
|
applications/3DGAN/utils/test_dataset.ipynb
|
NickleDave/generative-neural-nets-tutorial-scipy2020
|
74bed76687867ae07205bbf5c7836deecb165597
|
[
"MIT"
] | 11 |
2020-03-02T10:02:26.000Z
|
2021-02-02T22:31:47.000Z
|
applications/3DGAN/utils/test_dataset.ipynb
|
NickleDave/generative-neural-nets-tutorial-scipy2020
|
74bed76687867ae07205bbf5c7836deecb165597
|
[
"MIT"
] | null | null | null | 25.525 | 263 | 0.580313 |
[
[
[
"from torch.utils.data import DataLoader\nfrom utils.ObjectData import ObjectDataset\nfrom utils.utils import save_plot_voxels\nimport numpy as np",
"shapely.geometry.Polygon not available!\nTraceback (most recent call last):\n File \"/home/pablo/miniconda3/lib/python3.6/site-packages/trimesh/creation.py\", line 22, in <module>\n from shapely.geometry import Polygon\nModuleNotFoundError: No module named 'shapely'\n"
],
[
"ob = ObjectDataset(\"data/test_toilet.csv\", side_len=64)\nloader = DataLoader(ob, batch_size=10, shuffle=False)",
"_____no_output_____"
],
[
"for batch_ndx, sample in enumerate(loader):\n save_plot_voxels(sample, \"./toilet\", 0)\n break",
"/home/pablo/miniconda3/lib/python3.6/site-packages/scipy/ndimage/interpolation.py:605: UserWarning: From scipy 0.13.0, the output shape of zoom() is calculated with round() instead of int() - for these inputs the size of the returned array has changed.\n \"the returned array has changed.\", UserWarning)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a1bce5eb8822ba4cbb7884efdca548dc8438e9e
| 287,348 |
ipynb
|
Jupyter Notebook
|
labo/ML0120EN-4.1-Review-RBMMNIST.ipynb
|
camara94/Cognitive-Deep-Learning-with-TensorFlow
|
0658e0f41836bfcca5ad8f1558c6bfc1ee1516a0
|
[
"MIT"
] | 1 |
2022-02-12T18:07:26.000Z
|
2022-02-12T18:07:26.000Z
|
labo/ML0120EN-4.1-Review-RBMMNIST.ipynb
|
camara94/Cognitive-Deep-Learning-with-TensorFlow
|
0658e0f41836bfcca5ad8f1558c6bfc1ee1516a0
|
[
"MIT"
] | null | null | null |
labo/ML0120EN-4.1-Review-RBMMNIST.ipynb
|
camara94/Cognitive-Deep-Learning-with-TensorFlow
|
0658e0f41836bfcca5ad8f1558c6bfc1ee1516a0
|
[
"MIT"
] | null | null | null | 157.623697 | 111,164 | 0.83268 |
[
[
[
"<a href=\"https://www.skills.network/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01\"><img src=\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DL0120ENedX/labs/Template%20for%20Instructional%20Hands-on%20Labs/images/IDSNlogo.png\" width=\"400px\" align=\"center\"></a>\n\n<h1 align=\"center\"><font size=\"5\">RESTRICTED BOLTZMANN MACHINES</font></h1>\n",
"_____no_output_____"
],
[
"<h3>Introduction</h3>\n<b>Restricted Boltzmann Machine (RBM):</b> RBMs are shallow neural nets that learn to reconstruct data by themselves in an unsupervised fashion. \n\n<h4>Why are RBMs important?</h4>\nAn RBM are a basic form of autoencoder. It can automatically extract <b>meaningful</b> features from a given input.\n\n<h4>How does it work?</h4>\nRBM is a 2 layer neural network. Simply, RBM takes the inputs and translates those into a set of binary values that represents them in the hidden layer. Then, these numbers can be translated back to reconstruct the inputs. Through several forward and backward passes, the RBM will be trained, and a trained RBM can reveal which features are the most important ones when detecting patterns. \n\n<h4>What are the applications of an RBM?</h4>\nRBM is useful for <a href='http://www.cs.utoronto.ca/~hinton/absps/netflixICML.pdf?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01'> Collaborative Filtering</a>, dimensionality reduction, classification, regression, feature learning, topic modeling and even <b>Deep Belief Networks</b>.\n\n<h4>Is RBM a generative or Discriminative model?</h4>\nRBM is a generative model. Let me explain it by first, see what is different between discriminative and generative models: \n\n<b>Discriminative:</b> Consider a classification problem where we want to learn to distinguish between Sedan cars (y = 1) and SUV cars (y = 0), based on some features of cars. Given a training set, an algorithm like logistic regression tries to find a straight line, or <i>decision boundary</i>, that separates the suv and sedan.\n\n<b>Generative:</b> looking at cars, we can build a model of what Sedan cars look like. Then, looking at SUVs, we can build a separate model of what SUV cars look like. Finally, to classify a new car, we can match the new car against the Sedan model, and match it against the SUV model, to see whether the new car looks more like the SUV or Sedan.\n\nGenerative Models specify a probability distribution over a dataset of input vectors. We can carry out both supervised and unsupervised tasks with generative models:\n\n<ul>\n <li>In an unsupervised task, we try to form a model for $P(x)$, where $P$ is the probability given $x$ as an input vector.</li>\n <li>In the supervised task, we first form a model for $P(x|y)$, where $P$ is the probability of $x$ given $y$(the label for $x$). For example, if $y = 0$ indicates that a car is an SUV, and $y = 1$ indicates that a car is a sedan, then $p(x|y = 0)$ models the distribution of SUV features, and $p(x|y = 1)$ models the distribution of sedan features. If we manage to find $P(x|y)$ and $P(y)$, then we can use <b>Bayes rule</b> to estimate $P(y|x)$, because: \n $$p(y|x) = \\frac{p(x|y)p(y)}{p(x)}$$</li>\n</ul>\nNow the question is, can we build a generative model, and then use it to create synthetic data by directly sampling from the modeled probability distributions? Lets see. \n",
"_____no_output_____"
],
[
"<h2>Table of Contents</h2>\n<ol>\n <li><a href=\"https://#ref1\">Initialization</a></li>\n <li><a href=\"https://#ref2\">RBM layers</a></li>\n <li><a href=\"https://#ref3\">What RBM can do after training?</a></li>\n <li><a href=\"https://#ref4\">How to train the model?</a></li>\n <li><a href=\"https://#ref5\">Learned features</a></li>\n</ol>\n<p></p>\n</div>\n<br>\n\n<hr>\n",
"_____no_output_____"
],
[
"<a id=\"ref1\"></a>\n\n<h3>Initialization</h3>\n\nFirst, we have to load the utility file which contains different utility functions that are not connected\nin any way to the networks presented in the tutorials, but rather help in\nprocessing the outputs into a more understandable way.\n",
"_____no_output_____"
]
],
[
[
"import urllib.request\nwith urllib.request.urlopen(\"https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-DL0120EN-SkillsNetwork/labs/Week4/data/utils.py\") as url:\n response = url.read()\ntarget = open('utils.py', 'w')\ntarget.write(response.decode('utf-8'))\ntarget.close()",
"_____no_output_____"
]
],
[
[
"<h2>Installing TensorFlow </h2>\n\nWe will installing TensorFlow version 2.2.0 and its required prerequistes. Also installing pillow\\...\n",
"_____no_output_____"
]
],
[
[
"!pip install grpcio==1.24.3\n!pip install tensorflow==2.2.0\n!pip install pillow==8.1.0",
"Collecting grpcio==1.24.3\n Downloading grpcio-1.24.3-cp37-cp37m-manylinux2010_x86_64.whl (2.2 MB)\n |████████████████████████████████| 2.2 MB 7.6 MB/s \n\u001b[?25hRequirement already satisfied: six>=1.5.2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from grpcio==1.24.3) (1.16.0)\nInstalling collected packages: grpcio\n Attempting uninstall: grpcio\n Found existing installation: grpcio 1.42.0\n Uninstalling grpcio-1.42.0:\n Successfully uninstalled grpcio-1.42.0\nSuccessfully installed grpcio-1.24.3\nCollecting tensorflow==2.2.0\n Downloading tensorflow-2.2.0-cp37-cp37m-manylinux2010_x86_64.whl (516.2 MB)\n |████████████████████████████████| 516.2 MB 562 bytes/s | 18.5 MB 2.7 MB/s eta 0:03:08 | 27.1 MB 5.5 MB/s eta 0:01:303 MB 5.6 MB/s eta 0:01:25 | 67.7 MB 5.7 MB/s eta 0:01:195 MB 7.2 MB/s eta 0:01:002 MB 5.7 MB/s eta 0:01:16|█████▊ | 92.1 MB 5.7 MB/s eta 0:01:15|█████▉ | 93.5 MB 5.7 MB/s eta 0:01:15MB/s eta 0:01:12 | 112.3 MB 10.3 MB/s eta 0:00:404 | 136.4 MB 5.6 MB/s eta 0:01:09 | 138.8 MB 5.6 MB/s eta 0:01:08 | 139.7 MB 5.6 MB/s eta 0:01:08 1:08 | 145.2 MB 2.6 MB/s eta 0:02:21 0 |██████████▎ | 166.7 MB 5.6 MB/s eta 0:01:03 | 170.4 MB 5.8 MB/s eta 0:01:01 |██████████▉ | 174.2 MB 5.8 MB/s eta 0:01:00 | 196.4 MB 10.5 MB/s eta 0:00:31 | 197.9 MB 10.5 MB/s eta 0:00:31 | 199.8 MB 10.5 MB/s eta 0:00:31/s eta 0:00:30��████ | 208.9 MB 10.5 MB/s eta 0:00:307 MB/s eta 0:01:53 | 234.1 MB 5.7 MB/s eta 0:00:50 �█████████▋ | 235.4 MB 5.7 MB/s eta 0:00:50 | 236.5 MB 5.7 MB/s eta 0:00:49 .7 MB/s eta 0:00:49 .7 MB/s eta 0:00:49 ��█████████ | 257.8 MB 7.4 MB/s eta 0:00:36 �███████████████ | 258.2 MB 7.4 MB/s eta 0:00:36 0:00:35 | 259.4 MB 7.4 MB/s eta 0:00:35 260.0 MB 7.4 MB/s eta 0:00:35 |████████████████▎ | 263.1 MB 5.7 MB/s eta 0:00:45 ��███████████▍ | 263.6 MB 5.7 MB/s eta 0:00:45 ��████████████████▍ | 281.1 MB 5.5 MB/s eta 0:00:43 ███▌ | 281.5 MB 5.5 MB/s eta 0:00:43 | 283.6 MB 1.3 MB/s eta 0:02:57 MB 1.3 MB/s eta 0:02:56 MB/s eta 0:02:56 �███████████▊ | 285.7 MB 1.3 MB/s eta 0:02:56 0:02:55 | 286.6 MB 1.3 MB/s eta 0:02:55 ██████▊ | 302.5 MB 5.5 MB/s eta 0:00:39 2.7 MB 5.5 MB/s eta 0:00:39 █████████████████▊ | 302.9 MB 5.5 MB/s eta 0:00:39 �████▉ | 303.1 MB 5.5 MB/s eta 0:00:39 �███████████████▉ | 303.4 MB 5.5 MB/s eta 0:00:39 ��██▉ | 303.6 MB 5.5 MB/s eta 0:00:39 |███████████████████ | 306.1 MB 2.4 MB/s eta 0:01:26 | 307.5 MB 2.4 MB/s eta 0:01:26 |███████████████████ | 307.7 MB 2.4 MB/s eta 0:01:26 |███████████████████▏ | 309.4 MB 2.4 MB/s eta 0:01:25 ��██████████████████▏ | 309.6 MB 2.4 MB/s eta 0:01:25 ��████████████████▎ | 310.2 MB 2.4 MB/s eta 0:01:25 ��██████████████████▍ | 328.6 MB 58.5 MB/s eta 0:00:04 | 330.3 MB 58.5 MB/s eta 0:00:04�███████▌ | 330.5 MB 58.5 MB/s eta 0:00:04��██████████████████▌ | 330.7 MB 58.5 MB/s eta 0:00:04███████████████▌ | 331.2 MB 58.5 MB/s eta 0:00:04 | 332.1 MB 58.5 MB/s eta 0:00:04��██████████████████▋ | 332.9 MB 397 kB/s eta 0:07:41 ▊ | 333.8 MB 397 kB/s eta 0:07:39 | 334.3 MB 397 kB/s eta 0:07:38 | 340.3 MB 397 kB/s eta 0:07:23 �████████▍ | 344.4 MB 5.2 MB/s eta 0:00:34 �████████▋ | 348.9 MB 5.2 MB/s eta 0:00:33 MB 5.2 MB/s eta 0:00:33 ��█▊ | 350.3 MB 5.2 MB/s eta 0:00:33 ██████████▊ | 350.6 MB 5.2 MB/s eta 0:00:33 �████████▉ | 352.6 MB 871 kB/s eta 0:03:08 3:07 �█████████ | 354.9 MB 871 kB/s eta 0:03:05 ��███████████████████▏ | 357.2 MB 871 kB/s eta 0:03:03 ████████████████▏ | 357.4 MB 871 kB/s eta 0:03:03 ��████████████████████▏ | 358.5 MB 871 kB/s eta 0:03:01 ��█████████████████████ | 372.2 MB 5.6 MB/s eta 0:00:26 █▍ | 376.7 MB 7.4 MB/s eta 0:00:19 █▌ | 378.9 MB 7.4 MB/s eta 0:00:19 █▊ | 383.5 MB 7.4 MB/s eta 0:00:18 �████████████████▉ | 383.9 MB 7.4 MB/s eta 0:00:18 ██ | 386.7 MB 2.7 MB/s eta 0:00:48 █████▊ | 398.4 MB 5.7 MB/s eta 0:00:21 ��███ | 403.3 MB 5.7 MB/s eta 0:00:20 ��████████████████▏ | 405.3 MB 5.7 MB/s eta 0:00:20 |█████████████████████████▏ | 405.8 MB 5.7 MB/s eta 0:00:20 ██████▎ | 407.3 MB 5.7 MB/s eta 0:00:19 ��████████████████▍ | 409.9 MB 2.7 MB/s eta 0:00:40 ██████▍ | 410.1 MB 2.7 MB/s eta 0:00:40 �████████▏ | 454.2 MB 5.6 MB/s eta 0:00:12 |████████████████████████████▍ | 457.5 MB 2.6 MB/s eta 0:00:23 |████████████████████████████▍ | 458.2 MB 2.6 MB/s eta 0:00:23 |████████████████████████████▍ | 458.5 MB 2.6 MB/s eta 0:00:23 �████████▋ | 461.6 MB 2.6 MB/s eta 0:00:21 |████████████████████████████▋ | 462.0 MB 2.6 MB/s eta 0:00:21 ��███████████████████▏ | 471.3 MB 5.4 MB/s eta 0:00:09 ��███████████████████▍ | 474.1 MB 5.4 MB/s eta 0:00:08 7 MB 7.3 MB/s eta 0:00:05 �█████████████████████████▉ | 480.5 MB 7.3 MB/s eta 0:00:05 ��█████████████▉ | 480.6 MB 7.3 MB/s eta 0:00:05 ��███████████████████▉ | 481.6 MB 7.3 MB/s eta 0:00:05 ████████▉ | 481.7 MB 7.3 MB/s eta 0:00:05 9 MB 7.3 MB/s eta 0:00:05 ��█████████████████ | 482.2 MB 7.3 MB/s eta 0:00:05 █████████ | 484.0 MB 739 kB/s eta 0:00:44 �█████████████████████████████ | 484.4 MB 739 kB/s eta 0:00:44 |██████████████████████████████▉ | 496.9 MB 7.2 MB/s eta 0:00:03 ██████████████████████████████ | 501.9 MB 7.2 MB/s eta 0:00:02 █▏| 502.2 MB 7.2 MB/s eta 0:00:02 02 MB 851 kB/s eta 0:00:15 �█████████████▎| 505.1 MB 851 kB/s eta 0:00:14 ��█████████████████████▎| 505.3 MB 851 kB/s eta 0:00:13 ��█▍| 505.7 MB 851 kB/s eta 0:00:13 ██████████▍| 505.9 MB 851 kB/s eta 0:00:13 �██████████████████▍| 506.0 MB 851 kB/s eta 0:00:12 ��██████████████████████████▍| 506.2 MB 851 kB/s eta 0:00:12 0:12 ��██████▍| 506.6 MB 851 kB/s eta 0:00:12 \n\u001b[?25hRequirement already satisfied: astunparse==1.6.3 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.6.3)\nRequirement already satisfied: h5py<2.11.0,>=2.10.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (2.10.0)\nRequirement already satisfied: absl-py>=0.7.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.0.0)\nRequirement already satisfied: protobuf>=3.8.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (3.19.1)\nRequirement already satisfied: keras-preprocessing>=1.1.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.1.2)\nRequirement already satisfied: grpcio>=1.8.6 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.24.3)\nRequirement already satisfied: numpy<2.0,>=1.16.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.21.4)\nRequirement already satisfied: opt-einsum>=2.3.2 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (3.3.0)\nRequirement already satisfied: scipy==1.4.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.4.1)\nRequirement already satisfied: google-pasta>=0.1.8 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (0.2.0)\nRequirement already satisfied: gast==0.3.3 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (0.3.3)\nCollecting tensorboard<2.3.0,>=2.2.0\n Downloading tensorboard-2.2.2-py3-none-any.whl (3.0 MB)\n |████████████████████████████████| 3.0 MB 49.5 MB/s ██████████▍ | 1.1 MB 49.5 MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: wheel>=0.26 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (0.37.0)\nCollecting tensorflow-estimator<2.3.0,>=2.2.0\n Downloading tensorflow_estimator-2.2.0-py2.py3-none-any.whl (454 kB)\n |████████████████████████████████| 454 kB 59.4 MB/s \n\u001b[?25hRequirement already satisfied: wrapt>=1.11.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.13.3)\nRequirement already satisfied: six>=1.12.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.16.0)\nRequirement already satisfied: termcolor>=1.1.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorflow==2.2.0) (1.1.0)\nCollecting tensorboard-plugin-wit>=1.6.0\n Downloading tensorboard_plugin_wit-1.8.1-py3-none-any.whl (781 kB)\n |████████████████████████████████| 781 kB 6.8 MB/s \n\u001b[?25hRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (0.4.6)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (1.35.0)\nRequirement already satisfied: markdown>=2.6.8 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (3.3.6)\nRequirement already satisfied: werkzeug>=0.11.15 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (2.0.1)\nRequirement already satisfied: setuptools>=41.0.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (59.4.0)\nRequirement already satisfied: requests<3,>=2.21.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (2.26.0)\nRequirement already satisfied: rsa<5,>=3.1.4 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (4.8)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (4.2.4)\nRequirement already satisfied: pyasn1-modules>=0.2.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from google-auth<2,>=1.6.3->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (0.2.8)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (1.3.1)\nRequirement already satisfied: importlib-metadata>=4.4 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from markdown>=2.6.8->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (4.8.2)\nRequirement already satisfied: certifi>=2017.4.17 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests<3,>=2.21.0->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (2021.10.8)\nRequirement already satisfied: urllib3<1.27,>=1.21.1 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests<3,>=2.21.0->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (1.26.7)\nRequirement already satisfied: idna<4,>=2.5 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests<3,>=2.21.0->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (3.1)\nRequirement already satisfied: charset-normalizer~=2.0.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests<3,>=2.21.0->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (2.0.8)\nRequirement already satisfied: typing-extensions>=3.6.4 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (4.0.1)\nRequirement already satisfied: zipp>=0.5 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (3.6.0)\nRequirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (0.4.8)\nRequirement already satisfied: oauthlib>=3.0.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard<2.3.0,>=2.2.0->tensorflow==2.2.0) (3.2.0)\nInstalling collected packages: tensorboard-plugin-wit, tensorflow-estimator, tensorboard, tensorflow\n Attempting uninstall: tensorflow-estimator\n Found existing installation: tensorflow-estimator 2.1.0\n Uninstalling tensorflow-estimator-2.1.0:\n Successfully uninstalled tensorflow-estimator-2.1.0\n Attempting uninstall: tensorboard\n Found existing installation: tensorboard 2.1.1\n Uninstalling tensorboard-2.1.1:\n Successfully uninstalled tensorboard-2.1.1\n Attempting uninstall: tensorflow\n Found existing installation: tensorflow 2.2.0rc0\n Uninstalling tensorflow-2.2.0rc0:\n Successfully uninstalled tensorflow-2.2.0rc0\nSuccessfully installed tensorboard-2.2.2 tensorboard-plugin-wit-1.8.1 tensorflow-2.2.0 tensorflow-estimator-2.2.0\nRequirement already satisfied: pillow==8.1.0 in /home/jupyterlab/conda/envs/python/lib/python3.7/site-packages (8.1.0)\n"
]
],
[
[
"<b>Notice:</b> This notebook has been created with TensorFlow version 2.2, and might not work with other versions. Therefore we check:\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom IPython.display import Markdown, display\n\ndef printmd(string):\n display(Markdown('# <span style=\"color:red\">'+string+'</span>'))\n\n\nif not tf.__version__ == '2.2.0':\n printmd('<<<<<!!!!! ERROR !!!! please upgrade to TensorFlow 2.2.0, or restart your Kernel (Kernel->Restart & Clear Output)>>>>>')",
"_____no_output_____"
]
],
[
[
"Now, we load in all the packages that we use to create the net including the TensorFlow package:\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\n\nfrom PIL import Image\nfrom utils import tile_raster_images\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"<hr>\n",
"_____no_output_____"
],
[
"<a id=\"ref2\"></a>\n\n<h3>RBM layers</h3>\n\nAn RBM has two layers. The first layer of the RBM is called the <b>visible</b> (or input layer). Imagine that our toy example, has only vectors with 7 values, so the visible layer must have $V=7$ input nodes.\nThe second layer is the <b>hidden</b> layer, which has $H$ neurons in our case. Each hidden node takes on values of either 0 or 1 (i.e., $h_i = 1$ or $h_i$ = 0), with a probability that is a logistic function of the inputs it receives from the other $V$ visible units, called for example, $p(h_i = 1)$. For our toy sample, we'll use 2 nodes in the hidden layer, so $H = 2$.\n\n<center><img src=\"https://ibm.box.com/shared/static/eu26opvcefgls6vnwuo29uwp0nudmokh.png\" alt=\"RBM Model\" style=\"width: 400px;\"></center>\n",
"_____no_output_____"
],
[
"Each node in the first layer also has a <b>bias</b>. We will denote the bias as $v\\_{bias}$, and this single value is shared among the $V$ visible units.\n\nThe <b>bias</b> of the second is defined similarly as $h\\_{bias}$, and this single value among the $H$ hidden units.\n",
"_____no_output_____"
]
],
[
[
"v_bias = tf.Variable(tf.zeros([7]), tf.float32)\nh_bias = tf.Variable(tf.zeros([2]), tf.float32)",
"2022-02-10 14:44:15.207273: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory\n2022-02-10 14:44:15.207345: E tensorflow/stream_executor/cuda/cuda_driver.cc:313] failed call to cuInit: UNKNOWN ERROR (303)\n2022-02-10 14:44:15.207395: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:156] kernel driver does not appear to be running on this host (jupyterlab-ldamaro98): /proc/driver/nvidia/version does not exist\n2022-02-10 14:44:15.208010: I tensorflow/core/platform/cpu_feature_guard.cc:143] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n2022-02-10 14:44:15.348430: I tensorflow/core/platform/profile_utils/cpu_utils.cc:102] CPU Frequency: 2095145000 Hz\n2022-02-10 14:44:15.367511: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f30f0000b20 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n2022-02-10 14:44:15.367555: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n"
]
],
[
[
"We have to define weights among the input layer and hidden layer nodes. In the weight matrix, the number of rows are equal to the input nodes, and the number of columns are equal to the output nodes. We define a tensor $\\mathbf{W}$ of shape = (7,2), where the number of visible neurons = 7, and the number of hidden neurons = 2.\n",
"_____no_output_____"
]
],
[
[
"W = tf.constant(np.random.normal(loc=0.0, scale=1.0, size=(7, 2)).astype(np.float32))",
"_____no_output_____"
]
],
[
[
"<hr>\n",
"_____no_output_____"
],
[
"<a id=\"ref3\"></a>\n\n<h3>What RBM can do after training?</h3>\nThink of RBM as a model that has been trained based on images of a dataset of many SUV and sedan cars. Also, imagine that the RBM network has only two hidden nodes, where one node encodes the weight and, and the other encodes the size. \nIn a sense, the different configurations represent different cars, where one is an SUV and the other is Sedan. In a training process, through many forward and backward passes, the RBM adjust its weights to send a stronger signal to either the SUV node (0, 1) or the sedan node (1, 0) in the hidden layer, given the pixels of images. Now, given an SUV in hidden layer, which distribution of pixels should we expect? RBM can give you 2 things. First, it encodes your images in hidden layer. Second, it gives you the probability of observing a case, given some hidden values.\n\n<h3>The Inference Process</h3>\n\nRBM has two phases:\n\n<ul>\n <li>Forward Pass</li> \n <li>Backward Pass or Reconstruction</li>\n</ul>\n\n<b>Phase 1) Forward pass:</b>\n\nInput one training sample (one image) $\\mathbf{x}$ through all visible nodes, and pass it to all hidden nodes. Processing happens in each node in the hidden layer. This computation begins by making stochastic decisions about whether to transmit that input or not (i.e. to determine the state of each hidden layer). First, the probability vector is computed using the input feature vector $\\mathbf{x}$, the weight matrix $\\mathbf{W}$, and the bias term $h\\_{bias}$, as\n\n$$p({h_j}|\\mathbf x)= \\sigma( \\sum\\_{i=1}^V W\\_{ij} x_i + h\\_{bias} )$$,\n\nwhere $\\sigma(z) = (1+e^{-z})^{-1}$ is the logistic function.\n\nSo, what does $p({h_j})$ represent? It is the <b>probability distribution</b> of the hidden units. That is, RBM uses inputs $x_i$ to make predictions about hidden node activations. For example, imagine that the hidden node activation values are \\[0.51 0.84] for the first training item. It tells you that the conditional probability for each hidden neuron for Phase 1 is:\n\n$$p(h\\_{1} = 1|\\mathbf{v}) = 0.51$$\n$$p(h\\_{2} = 1|\\mathbf{v}) = 0.84$$\n\nAs a result, for each row in the training set, vector of probabilities is generated. In TensorFlow, this is referred to as a `tensor` with a shape of (1,2).\n\nWe then turn unit $j$ with probability $p(h\\_{j}|\\mathbf{v})$, and turn it off with probability $1 - p(h\\_{j}|\\mathbf{v})$ by generating a uniform random number vector $\\mathbf{\\xi}$, and comparing it to the activation probability as\n\n<center>If $\\xi_j>p(h_{j}|\\mathbf{v})$, then $h_j=1$, else $h_j=0$.</center>\n\nTherefore, the conditional probability of a configuration of $\\mathbf{h}$ given $\\mathbf{v}$ (for a training sample) is:\n\n$$p(\\mathbf{h} \\mid \\mathbf{v}) = \\prod\\_{j=1}^H p(h_j \\mid \\mathbf{v})$$\n\nwhere $H$ is the number of hidden units.\n",
"_____no_output_____"
],
[
"Before we go further, let's look at a toy example for one case out of all input. Assume that we have a trained RBM, and a very simple input vector, such as \\[1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0].\\\nLet's see what the output of forward pass would look like:\n",
"_____no_output_____"
]
],
[
[
"X = tf.constant([[1.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0]], tf.float32)\n\nv_state = X\nprint (\"Input: \", v_state)\n\nh_bias = tf.constant([0.1, 0.1])\nprint (\"hb: \", h_bias)\nprint (\"w: \", W)\n\n# Calculate the probabilities of turning the hidden units on:\nh_prob = tf.nn.sigmoid(tf.matmul(v_state, W) + h_bias) #probabilities of the hidden units\nprint (\"p(h|v): \", h_prob)\n\n# Draw samples from the distribution:\nh_state = tf.nn.relu(tf.sign(h_prob - tf.random.uniform(tf.shape(h_prob)))) #states\nprint (\"h0 states:\", h_state)",
"Input: tf.Tensor([[1. 0. 0. 1. 0. 0. 0.]], shape=(1, 7), dtype=float32)\nhb: tf.Tensor([0.1 0.1], shape=(2,), dtype=float32)\nw: tf.Tensor(\n[[ 5.6035370e-01 -2.4774437e-01]\n [ 2.2297132e-01 9.3255501e-04]\n [ 1.9474676e+00 1.3033114e-01]\n [ 3.6674735e-01 1.9553826e+00]\n [-2.6839716e-02 1.0360655e+00]\n [-9.7221518e-03 -8.0420983e-01]\n [ 1.0748338e+00 6.9351502e-02]], shape=(7, 2), dtype=float32)\np(h|v): tf.Tensor([[0.73635346 0.85907626]], shape=(1, 2), dtype=float32)\nh0 states: tf.Tensor([[1. 1.]], shape=(1, 2), dtype=float32)\n"
]
],
[
[
"<b>Phase 2) Backward Pass (Reconstruction):</b>\nThe RBM reconstructs data by making several forward and backward passes between the visible and hidden layers.\n\nSo, in the second phase (i.e. reconstruction phase), the samples from the hidden layer (i.e. $\\mathbf h$) becomes the input in the backward pass. The same weight matrix and visible layer biases are used to passed to the sigmoid function. The reproduced output is a reconstruction which is an approximation of the original input.\n",
"_____no_output_____"
]
],
[
[
"vb = tf.constant([0.1, 0.2, 0.1, 0.1, 0.1, 0.2, 0.1])\nprint (\"b: \", vb)\nv_prob = tf.nn.sigmoid(tf.matmul(h_state, tf.transpose(W)) + vb)\nprint (\"p(vi∣h): \", v_prob)\nv_state = tf.nn.relu(tf.sign(v_prob - tf.random.uniform(tf.shape(v_prob))))\nprint (\"v probability states: \", v_state)",
"b: tf.Tensor([0.1 0.2 0.1 0.1 0.1 0.2 0.1], shape=(7,), dtype=float32)\np(vi∣h): tf.Tensor(\n[[0.6017134 0.604417 0.898238 0.9184993 0.7519848 0.35116276\n 0.77629167]], shape=(1, 7), dtype=float32)\nv probability states: tf.Tensor([[1. 1. 0. 1. 1. 1. 1.]], shape=(1, 7), dtype=float32)\n"
]
],
[
[
"RBM learns a probability distribution over the input, and then, after being trained, the RBM can generate new samples from the learned probability distribution. As you know, <b>probability distribution</b>, is a mathematical function that provides the probabilities of occurrence of different possible outcomes in an experiment.\n\nThe (conditional) probability distribution over the visible units v is given by\n\n$$p(\\mathbf{v} \\mid \\mathbf{h}) = \\prod\\_{i=1}^V p(v_i \\mid \\mathbf{h}),$$\n\nwhere,\n\n$$p(v_i \\mid \\mathbf{h}) = \\sigma\\left(\\sum\\_{j=1}^H W\\_{ji} h_j + v\\_{bias} \\right)$$\n\nso, given current state of hidden units and weights, what is the probability of generating \\[1. 0. 0. 1. 0. 0. 0.] in reconstruction phase, based on the above <b>probability distribution</b> function?\n",
"_____no_output_____"
]
],
[
[
"inp = X\nprint(\"input X:\" , inp.numpy())\n\nprint(\"probablity vector:\" , v_prob[0].numpy())\nv_probability = 1\n\nfor elm, p in zip(inp[0],v_prob[0]) :\n if elm ==1:\n v_probability *= p\n else:\n v_probability *= (1-p)\n\nprint(\"probability of generating X: \" , v_probability.numpy())",
"input X: [[1. 0. 0. 1. 0. 0. 0.]]\nprobablity vector: [0.6017134 0.604417 0.898238 0.9184993 0.7519848 0.35116276\n 0.77629167]\nprobability of generating X: 0.000800918\n"
]
],
[
[
"How similar are vectors $\\mathbf{x}$ and $\\mathbf{v}$? Of course, the reconstructed values most likely will not look anything like the input vector, because our network has not been trained yet. Our objective is to train the model in such a way that the input vector and reconstructed vector to be same. Therefore, based on how different the input values look to the ones that we just reconstructed, the weights are adjusted.\n",
"_____no_output_____"
],
[
"<hr>\n",
"_____no_output_____"
],
[
"<h2>MNIST</h2>\n",
"_____no_output_____"
],
[
"We will be using the MNIST dataset to practice the usage of RBMs. The following cell loads the MNIST dataset.\n",
"_____no_output_____"
]
],
[
[
"#loading training and test data\nmnist = tf.keras.datasets.mnist\n(trX, trY), (teX, teY) = mnist.load_data()\n\n# showing an example of the Flatten class and operation\nfrom tensorflow.keras.layers import Flatten\nflatten = Flatten(dtype='float32')\ntrX = flatten(trX/255.0)\ntrY = flatten(trY/255.0)",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz\n11493376/11490434 [==============================] - 1s 0us/step\n"
]
],
[
[
"Lets look at the dimension of the images.\n",
"_____no_output_____"
],
[
"MNIST images have 784 pixels, so the visible layer must have 784 input nodes. For our case, we'll use 50 nodes in the hidden layer, so i = 50.\n",
"_____no_output_____"
]
],
[
[
"vb = tf.Variable(tf.zeros([784]), tf.float32)\nhb = tf.Variable(tf.zeros([50]), tf.float32)",
"_____no_output_____"
]
],
[
[
"Let $\\mathbf W$ be the Tensor of 784x50 (784 - number of visible neurons, 50 - number of hidden neurons) that represents weights between the neurons.\n",
"_____no_output_____"
]
],
[
[
"W = tf.Variable(tf.zeros([784,50]), tf.float32)",
"_____no_output_____"
]
],
[
[
"Lets define the visible layer:\n",
"_____no_output_____"
]
],
[
[
"v0_state = tf.Variable(tf.zeros([784]), tf.float32)\n\n#testing to see if the matrix product works\ntf.matmul( [v0_state], W)",
"_____no_output_____"
]
],
[
[
"Now, we can define hidden layer:\n",
"_____no_output_____"
]
],
[
[
"#computing the hidden nodes probability vector and checking shape\nh0_prob = tf.nn.sigmoid(tf.matmul([v0_state], W) + hb) #probabilities of the hidden units\nprint(\"h0_state shape: \" , tf.shape(h0_prob))\n\n#defining a function to return only the generated hidden states \ndef hidden_layer(v0_state, W, hb):\n h0_prob = tf.nn.sigmoid(tf.matmul([v0_state], W) + hb) #probabilities of the hidden units\n h0_state = tf.nn.relu(tf.sign(h0_prob - tf.random.uniform(tf.shape(h0_prob)))) #sample_h_given_X\n return h0_state\n\n\nh0_state = hidden_layer(v0_state, W, hb)\nprint(\"first 15 hidden states: \", h0_state[0][0:15])",
"h0_state shape: tf.Tensor([ 1 50], shape=(2,), dtype=int32)\nfirst 15 hidden states: tf.Tensor([1. 1. 0. 1. 1. 1. 1. 0. 0. 1. 1. 0. 1. 0. 1.], shape=(15,), dtype=float32)\n"
]
],
[
[
"Now, we define reconstruction part:\n",
"_____no_output_____"
]
],
[
[
"def reconstructed_output(h0_state, W, vb):\n v1_prob = tf.nn.sigmoid(tf.matmul(h0_state, tf.transpose(W)) + vb) \n v1_state = tf.nn.relu(tf.sign(v1_prob - tf.random.uniform(tf.shape(v1_prob)))) #sample_v_given_h\n return v1_state[0]\n\nv1_state = reconstructed_output(h0_state, W, vb)\nprint(\"hidden state shape: \", h0_state.shape)\nprint(\"v0 state shape: \", v0_state.shape)\nprint(\"v1 state shape: \", v1_state.shape)",
"hidden state shape: (1, 50)\nv0 state shape: (784,)\nv1 state shape: (784,)\n"
]
],
[
[
"<h3>What is the objective function?</h3>\n\n<b>Goal</b>: Maximize the likelihood of our data being drawn from that distribution\n\n<b>Calculate error:</b>\\\nIn each epoch, we compute the \"error\" as a sum of the squared difference between step 1 and step n,\ne.g the error shows the difference between the data and its reconstruction.\n\n<b>Note:</b> tf.reduce_mean computes the mean of elements across dimensions of a tensor.\n",
"_____no_output_____"
]
],
[
[
"def error(v0_state, v1_state):\n return tf.reduce_mean(tf.square(v0_state - v1_state))\n\nerr = tf.reduce_mean(tf.square(v0_state - v1_state))\nprint(\"error\" , err.numpy())",
"error 0.50382656\n"
]
],
[
[
"<a id=\"ref4\"></a>\n\n<h3>Training the Model</h3>\n<b>Warning...</b> The following part is math-heavy, but you can skip it if you just want to run the cells in the next section.\n\nAs mentioned, we want to give a high probability to the input data we train on. So, in order to train an RBM, we have to maximize the product of probabilities assigned to all rows $\\mathbf{v}$ (images) in the training set $\\mathbf{V}$ (a matrix, where each row of it is treated as a visible vector $\\mathbf{v}$)\n\n$$\\arg \\max_W \\prod\\_{\\mathbf{v}\\in\\mathbf{V}\\_T} p(\\mathbf{v})$$\n\nwhich is equivalent to maximizing the expectation of the log probability, given as\n\n$$\\arg\\max_W\\left\\[ \\mathbb{E} \\left(\\prod\\_{\\mathbf v\\in \\mathbf V}\\text{log} \\left(p(\\mathbf v)\\right) \\right) \\right].$$\n\nSo, we have to update the weights $W\\_{ij}$ to increase $p(\\mathbf{v})$ for all $\\mathbf{v}$ in our training data during training. So we have to calculate the derivative:\n\n$$\\frac{\\partial \\log p(\\mathbf v)}{\\partial W\\_{ij}}$$\n\nThis cannot be easily done by typical <b>gradient descent (SGD)</b>, so we can use another approach, which has 2 steps:\n\n<ol>\n <li>Gibbs Sampling</li>\n <li>Contrastive Divergence</li>\n</ol> \n\n<h3>Gibbs Sampling</h3> \n\n<h4>Gibbs Sampling Step 1</h4> \nGiven an input vector $\\mathbf{v}$, we are using $p(\\mathbf{h}|\\mathbf{v})$ to predict the hidden values $\\mathbf{h}$. \n $$p({h_j}|\\mathbf v)= \\sigma\\left(\\sum_{i=1}^V W_{ij} v_i + h_{bias} \\right)$$\nThe samples are generated from this distribution by generating the uniform random variate vector $\\mathbf{\\xi} \\sim U[0,1]$ of length $H$ and comparing to the computed probabilities as\n\n<center>If $\\xi_j>p(h_{j}|\\mathbf{v})$, then $h_j=1$, else $h_j=0$.</center>\n\n<h4>Gibbs Sampling Step 2</h4> \nThen, knowing the hidden values, we use $p(\\mathbf v| \\mathbf h)$ for reconstructing of new input values v. \n\n$$p({v_i}|\\mathbf h)= \\sigma\\left(\\sum\\_{j=1}^H W^{T}*{ij} h_j + v*{bias} \\right)$$\n\nThe samples are generated from this distribution by generating a uniform random variate vector $\\mathbf{\\xi} \\sim U\\[0,1]$ of length $V$ and comparing to the computed probabilities as\n\n<center>If $\\xi_i>p(v_{i}|\\mathbf{h})$, then $v_i=1$, else $v_i=0$.</center>\n\nLet vectors $\\mathbf v_k$ and $\\mathbf h_k$ be for the $k$th iteration. In general, the $kth$ state is generrated as:\n\n<b>Iteration</b> $k$:\n\n$$\\mathbf v\\_{k-1} \\Rightarrow p(\\mathbf h\\_{k-1}|\\mathbf v\\_{k-1})\\Rightarrow \\mathbf h\\_{k-1}\\Rightarrow p(\\mathbf v\\_{k}|\\mathbf h\\_{k-1})\\Rightarrow \\mathbf v_k$$\n\n<h3>Contrastive Divergence (CD-k)</h3>\nThe update of the weight matrix is done during the Contrastive Divergence step. \n\nVectors v0 and vk are used to calculate the activation probabilities for hidden values h0 and hk. The difference between the outer products of those probabilities with input vectors v0 and vk results in the update matrix:\n\n$$\\Delta \\mathbf W_k =\\mathbf v_k \\otimes \\mathbf h_k - \\mathbf v\\_{k-1} \\otimes \\mathbf h\\_{k-1}$$\n\nContrastive Divergence is actually matrix of values that is computed and used to adjust values of the $\\mathbf W$ matrix. Changing $\\mathbf W$ incrementally leads to training of the $\\mathbf W$ values. Then, on each step (epoch), $\\mathbf W$ is updated using the following:\n\n$$\\mathbf W_k = \\mathbf W\\_{k-1} + \\alpha \\* \\Delta \\mathbf W_k$$\n\nReconstruction steps:\n\n<ul>\n <li> Get one data point from data set, like <i>x</i>, and pass it through the following steps:</li>\n\n<b>Iteration</b> $k=1$:\n\nSampling (starting with input image)\n$$\\mathbf x = \\mathbf v\\_0 \\Rightarrow p(\\mathbf h\\_0|\\mathbf v\\_0)\\Rightarrow \\mathbf h\\_0 \\Rightarrow p(\\mathbf v\\_1|\\mathbf h\\_0)\\Rightarrow \\mathbf v\\_1$$\\\nfollowed by the CD-k step\n$$\\Delta \\mathbf W\\_1 =\\mathbf v\\_1 \\otimes \\mathbf h\\_1 - \\mathbf v\\_{0} \\otimes \\mathbf h\\_{0}$$\\\n$$\\mathbf W\\_1 = \\mathbf W\\_{0} + \\alpha \\* \\Delta \\mathbf W\\_1$$\n\n<li> $\\mathbf v_1$ is the reconstruction of $\\mathbf x$ sent to the next iteration).</li>\n\n<b>Iteration</b> $k=2$:\n\nSampling (starting with $\\mathbf v\\_1$)\n\n$$\\mathbf v\\_1 \\Rightarrow p(\\mathbf h\\_1|\\mathbf v\\_1)\\Rightarrow \\mathbf h\\_1\\Rightarrow p(\\mathbf v\\_2|\\mathbf h\\_1)\\Rightarrow \\mathbf v\\_2$$\n\nfollowed by the CD-k step\n$$\\Delta \\mathbf W\\_2 =\\mathbf v\\_2 \\otimes \\mathbf h\\_2 - \\mathbf v\\_{1} \\otimes \\mathbf h\\_{1}$$\\\n$$\\mathbf W\\_2 = \\mathbf W\\_{1} + \\alpha \\* \\Delta \\mathbf W\\_2$$\n\n<li> $\\mathbf v_2$ is the reconstruction of $\\mathbf v_1$ sent to the next iteration).</li> \n\n<b>Iteration</b> $k=K$:\n\nSampling (starting with $\\mathbf v\\_{K-1}$)\n\n$$\\mathbf v\\_{K-1} \\Rightarrow p(\\mathbf h\\_{K-1}|\\mathbf v\\_{K-1})\\Rightarrow \\mathbf h\\_{K-1}\\Rightarrow p(\\mathbf v_K|\\mathbf h\\_{K-1})\\Rightarrow \\mathbf v_K$$\n\nfollowed by the CD-k step\n$$\\Delta \\mathbf W_K =\\mathbf v_K \\otimes \\mathbf h_K - \\mathbf v\\_{K-1} \\otimes \\mathbf h\\_{K-1}$$\\\n$$\\mathbf W_K = \\mathbf W\\_{K-1} + \\alpha \\* \\Delta \\mathbf W_K$$\n\n<b>What is $\\alpha$?</b>\\\nHere, alpha is some small step size, and is also known as the \"learning rate\".\n",
"_____no_output_____"
],
[
"$K$ is adjustable, and good performance can be achieved with $K=1$, so that we just take one set of sampling steps per image.\n",
"_____no_output_____"
]
],
[
[
"h1_prob = tf.nn.sigmoid(tf.matmul([v1_state], W) + hb)\nh1_state = tf.nn.relu(tf.sign(h1_prob - tf.random.uniform(tf.shape(h1_prob)))) #sample_h_given_X",
"_____no_output_____"
]
],
[
[
"Lets look at the error of the first run:\n",
"_____no_output_____"
]
],
[
[
"print(\"error: \", error(v0_state, v1_state))",
"error: tf.Tensor(0.50382656, shape=(), dtype=float32)\n"
],
[
"#Parameters\nalpha = 0.01\nepochs = 1\nbatchsize = 200\nweights = []\nerrors = []\nbatch_number = 0\nK = 1\n\n#creating datasets\ntrain_ds = \\\n tf.data.Dataset.from_tensor_slices((trX, trY)).batch(batchsize)\n\nfor epoch in range(epochs):\n for batch_x, batch_y in train_ds:\n batch_number += 1\n for i_sample in range(batchsize): \n for k in range(K):\n v0_state = batch_x[i_sample]\n h0_state = hidden_layer(v0_state, W, hb)\n v1_state = reconstructed_output(h0_state, W, vb)\n h1_state = hidden_layer(v1_state, W, hb)\n\n delta_W = tf.matmul(tf.transpose([v0_state]), h0_state) - tf.matmul(tf.transpose([v1_state]), h1_state)\n W = W + alpha * delta_W\n\n vb = vb + alpha * tf.reduce_mean(v0_state - v1_state, 0)\n hb = hb + alpha * tf.reduce_mean(h0_state - h1_state, 0) \n\n v0_state = v1_state\n\n if i_sample == batchsize-1:\n err = error(batch_x[i_sample], v1_state)\n errors.append(err)\n weights.append(W)\n print ( 'Epoch: %d' % epoch, \n \"batch #: %i \" % batch_number, \"of %i\" % int(60e3/batchsize), \n \"sample #: %i\" % i_sample,\n 'reconstruction error: %f' % err)\n\n",
"Epoch: 0 batch #: 1 of 300 sample #: 199 reconstruction error: 0.181490\nEpoch: 0 batch #: 2 of 300 sample #: 199 reconstruction error: 0.226618\nEpoch: 0 batch #: 3 of 300 sample #: 199 reconstruction error: 0.113937\nEpoch: 0 batch #: 4 of 300 sample #: 199 reconstruction error: 0.129773\nEpoch: 0 batch #: 5 of 300 sample #: 199 reconstruction error: 0.096787\nEpoch: 0 batch #: 6 of 300 sample #: 199 reconstruction error: 0.197378\nEpoch: 0 batch #: 7 of 300 sample #: 199 reconstruction error: 0.083072\nEpoch: 0 batch #: 8 of 300 sample #: 199 reconstruction error: 0.121209\nEpoch: 0 batch #: 9 of 300 sample #: 199 reconstruction error: 0.091759\nEpoch: 0 batch #: 10 of 300 sample #: 199 reconstruction error: 0.169959\nEpoch: 0 batch #: 11 of 300 sample #: 199 reconstruction error: 0.098664\nEpoch: 0 batch #: 12 of 300 sample #: 199 reconstruction error: 0.138917\nEpoch: 0 batch #: 13 of 300 sample #: 199 reconstruction error: 0.059987\nEpoch: 0 batch #: 14 of 300 sample #: 199 reconstruction error: 0.100662\nEpoch: 0 batch #: 15 of 300 sample #: 199 reconstruction error: 0.106688\nEpoch: 0 batch #: 16 of 300 sample #: 199 reconstruction error: 0.113345\nEpoch: 0 batch #: 17 of 300 sample #: 199 reconstruction error: 0.078019\nEpoch: 0 batch #: 18 of 300 sample #: 199 reconstruction error: 0.126737\nEpoch: 0 batch #: 19 of 300 sample #: 199 reconstruction error: 0.164385\nEpoch: 0 batch #: 20 of 300 sample #: 199 reconstruction error: 0.112205\nEpoch: 0 batch #: 21 of 300 sample #: 199 reconstruction error: 0.090184\nEpoch: 0 batch #: 22 of 300 sample #: 199 reconstruction error: 0.088593\nEpoch: 0 batch #: 23 of 300 sample #: 199 reconstruction error: 0.109174\nEpoch: 0 batch #: 24 of 300 sample #: 199 reconstruction error: 0.125464\nEpoch: 0 batch #: 25 of 300 sample #: 199 reconstruction error: 0.089876\nEpoch: 0 batch #: 26 of 300 sample #: 199 reconstruction error: 0.099287\nEpoch: 0 batch #: 27 of 300 sample #: 199 reconstruction error: 0.110949\nEpoch: 0 batch #: 28 of 300 sample #: 199 reconstruction error: 0.086431\nEpoch: 0 batch #: 29 of 300 sample #: 199 reconstruction error: 0.099625\nEpoch: 0 batch #: 30 of 300 sample #: 199 reconstruction error: 0.079735\nEpoch: 0 batch #: 31 of 300 sample #: 199 reconstruction error: 0.097096\nEpoch: 0 batch #: 32 of 300 sample #: 199 reconstruction error: 0.103483\nEpoch: 0 batch #: 33 of 300 sample #: 199 reconstruction error: 0.064805\nEpoch: 0 batch #: 34 of 300 sample #: 199 reconstruction error: 0.070953\nEpoch: 0 batch #: 35 of 300 sample #: 199 reconstruction error: 0.073705\nEpoch: 0 batch #: 36 of 300 sample #: 199 reconstruction error: 0.088685\nEpoch: 0 batch #: 37 of 300 sample #: 199 reconstruction error: 0.062073\nEpoch: 0 batch #: 38 of 300 sample #: 199 reconstruction error: 0.076285\nEpoch: 0 batch #: 39 of 300 sample #: 199 reconstruction error: 0.090906\nEpoch: 0 batch #: 40 of 300 sample #: 199 reconstruction error: 0.121743\nEpoch: 0 batch #: 41 of 300 sample #: 199 reconstruction error: 0.087402\nEpoch: 0 batch #: 42 of 300 sample #: 199 reconstruction error: 0.069751\nEpoch: 0 batch #: 43 of 300 sample #: 199 reconstruction error: 0.126709\nEpoch: 0 batch #: 44 of 300 sample #: 199 reconstruction error: 0.067819\nEpoch: 0 batch #: 45 of 300 sample #: 199 reconstruction error: 0.070431\nEpoch: 0 batch #: 46 of 300 sample #: 199 reconstruction error: 0.035988\nEpoch: 0 batch #: 47 of 300 sample #: 199 reconstruction error: 0.045632\nEpoch: 0 batch #: 48 of 300 sample #: 199 reconstruction error: 0.028342\nEpoch: 0 batch #: 49 of 300 sample #: 199 reconstruction error: 0.108962\nEpoch: 0 batch #: 50 of 300 sample #: 199 reconstruction error: 0.049843\nEpoch: 0 batch #: 51 of 300 sample #: 199 reconstruction error: 0.062721\nEpoch: 0 batch #: 52 of 300 sample #: 199 reconstruction error: 0.032359\nEpoch: 0 batch #: 53 of 300 sample #: 199 reconstruction error: 0.124875\nEpoch: 0 batch #: 54 of 300 sample #: 199 reconstruction error: 0.053970\nEpoch: 0 batch #: 55 of 300 sample #: 199 reconstruction error: 0.099540\nEpoch: 0 batch #: 56 of 300 sample #: 199 reconstruction error: 0.057506\nEpoch: 0 batch #: 57 of 300 sample #: 199 reconstruction error: 0.046444\nEpoch: 0 batch #: 58 of 300 sample #: 199 reconstruction error: 0.070986\nEpoch: 0 batch #: 59 of 300 sample #: 199 reconstruction error: 0.035508\nEpoch: 0 batch #: 60 of 300 sample #: 199 reconstruction error: 0.091428\nEpoch: 0 batch #: 61 of 300 sample #: 199 reconstruction error: 0.073954\nEpoch: 0 batch #: 62 of 300 sample #: 199 reconstruction error: 0.083024\nEpoch: 0 batch #: 63 of 300 sample #: 199 reconstruction error: 0.064170\nEpoch: 0 batch #: 64 of 300 sample #: 199 reconstruction error: 0.094896\nEpoch: 0 batch #: 65 of 300 sample #: 199 reconstruction error: 0.068793\nEpoch: 0 batch #: 66 of 300 sample #: 199 reconstruction error: 0.054303\nEpoch: 0 batch #: 67 of 300 sample #: 199 reconstruction error: 0.042512\nEpoch: 0 batch #: 68 of 300 sample #: 199 reconstruction error: 0.071066\nEpoch: 0 batch #: 69 of 300 sample #: 199 reconstruction error: 0.096237\nEpoch: 0 batch #: 70 of 300 sample #: 199 reconstruction error: 0.097814\nEpoch: 0 batch #: 71 of 300 sample #: 199 reconstruction error: 0.061144\nEpoch: 0 batch #: 72 of 300 sample #: 199 reconstruction error: 0.074871\nEpoch: 0 batch #: 73 of 300 sample #: 199 reconstruction error: 0.085258\nEpoch: 0 batch #: 74 of 300 sample #: 199 reconstruction error: 0.089072\nEpoch: 0 batch #: 75 of 300 sample #: 199 reconstruction error: 0.042035\nEpoch: 0 batch #: 76 of 300 sample #: 199 reconstruction error: 0.072229\nEpoch: 0 batch #: 77 of 300 sample #: 199 reconstruction error: 0.101394\nEpoch: 0 batch #: 78 of 300 sample #: 199 reconstruction error: 0.110132\nEpoch: 0 batch #: 79 of 300 sample #: 199 reconstruction error: 0.114004\nEpoch: 0 batch #: 80 of 300 sample #: 199 reconstruction error: 0.031516\nEpoch: 0 batch #: 81 of 300 sample #: 199 reconstruction error: 0.058057\nEpoch: 0 batch #: 82 of 300 sample #: 199 reconstruction error: 0.045137\nEpoch: 0 batch #: 83 of 300 sample #: 199 reconstruction error: 0.082767\nEpoch: 0 batch #: 84 of 300 sample #: 199 reconstruction error: 0.063767\nEpoch: 0 batch #: 85 of 300 sample #: 199 reconstruction error: 0.053461\nEpoch: 0 batch #: 86 of 300 sample #: 199 reconstruction error: 0.070853\nEpoch: 0 batch #: 87 of 300 sample #: 199 reconstruction error: 0.069413\nEpoch: 0 batch #: 88 of 300 sample #: 199 reconstruction error: 0.026721\nEpoch: 0 batch #: 89 of 300 sample #: 199 reconstruction error: 0.073464\nEpoch: 0 batch #: 90 of 300 sample #: 199 reconstruction error: 0.081772\nEpoch: 0 batch #: 91 of 300 sample #: 199 reconstruction error: 0.062217\nEpoch: 0 batch #: 92 of 300 sample #: 199 reconstruction error: 0.065483\nEpoch: 0 batch #: 93 of 300 sample #: 199 reconstruction error: 0.102462\nEpoch: 0 batch #: 94 of 300 sample #: 199 reconstruction error: 0.100790\nEpoch: 0 batch #: 95 of 300 sample #: 199 reconstruction error: 0.059578\nEpoch: 0 batch #: 96 of 300 sample #: 199 reconstruction error: 0.035403\nEpoch: 0 batch #: 97 of 300 sample #: 199 reconstruction error: 0.110947\nEpoch: 0 batch #: 98 of 300 sample #: 199 reconstruction error: 0.094116\nEpoch: 0 batch #: 99 of 300 sample #: 199 reconstruction error: 0.062313\nEpoch: 0 batch #: 100 of 300 sample #: 199 reconstruction error: 0.099484\nEpoch: 0 batch #: 101 of 300 sample #: 199 reconstruction error: 0.078899\nEpoch: 0 batch #: 102 of 300 sample #: 199 reconstruction error: 0.085088\nEpoch: 0 batch #: 103 of 300 sample #: 199 reconstruction error: 0.073663\nEpoch: 0 batch #: 104 of 300 sample #: 199 reconstruction error: 0.065980\nEpoch: 0 batch #: 105 of 300 sample #: 199 reconstruction error: 0.061742\nEpoch: 0 batch #: 106 of 300 sample #: 199 reconstruction error: 0.103281\nEpoch: 0 batch #: 107 of 300 sample #: 199 reconstruction error: 0.137282\nEpoch: 0 batch #: 108 of 300 sample #: 199 reconstruction error: 0.062694\nEpoch: 0 batch #: 109 of 300 sample #: 199 reconstruction error: 0.103292\nEpoch: 0 batch #: 110 of 300 sample #: 199 reconstruction error: 0.051278\nEpoch: 0 batch #: 111 of 300 sample #: 199 reconstruction error: 0.101042\nEpoch: 0 batch #: 112 of 300 sample #: 199 reconstruction error: 0.041656\nEpoch: 0 batch #: 113 of 300 sample #: 199 reconstruction error: 0.070708\nEpoch: 0 batch #: 114 of 300 sample #: 199 reconstruction error: 0.064345\nEpoch: 0 batch #: 115 of 300 sample #: 199 reconstruction error: 0.061236\nEpoch: 0 batch #: 116 of 300 sample #: 199 reconstruction error: 0.062725\nEpoch: 0 batch #: 117 of 300 sample #: 199 reconstruction error: 0.035495\nEpoch: 0 batch #: 118 of 300 sample #: 199 reconstruction error: 0.078127\nEpoch: 0 batch #: 119 of 300 sample #: 199 reconstruction error: 0.115260\nEpoch: 0 batch #: 120 of 300 sample #: 199 reconstruction error: 0.076486\nEpoch: 0 batch #: 121 of 300 sample #: 199 reconstruction error: 0.046469\nEpoch: 0 batch #: 122 of 300 sample #: 199 reconstruction error: 0.085336\nEpoch: 0 batch #: 123 of 300 sample #: 199 reconstruction error: 0.060311\nEpoch: 0 batch #: 124 of 300 sample #: 199 reconstruction error: 0.069637\nEpoch: 0 batch #: 125 of 300 sample #: 199 reconstruction error: 0.060998\nEpoch: 0 batch #: 126 of 300 sample #: 199 reconstruction error: 0.090099\nEpoch: 0 batch #: 127 of 300 sample #: 199 reconstruction error: 0.079671\nEpoch: 0 batch #: 128 of 300 sample #: 199 reconstruction error: 0.061979\nEpoch: 0 batch #: 129 of 300 sample #: 199 reconstruction error: 0.059338\nEpoch: 0 batch #: 130 of 300 sample #: 199 reconstruction error: 0.065500\nEpoch: 0 batch #: 131 of 300 sample #: 199 reconstruction error: 0.047281\nEpoch: 0 batch #: 132 of 300 sample #: 199 reconstruction error: 0.056105\nEpoch: 0 batch #: 133 of 300 sample #: 199 reconstruction error: 0.058116\nEpoch: 0 batch #: 134 of 300 sample #: 199 reconstruction error: 0.100014\nEpoch: 0 batch #: 135 of 300 sample #: 199 reconstruction error: 0.102046\nEpoch: 0 batch #: 136 of 300 sample #: 199 reconstruction error: 0.109627\nEpoch: 0 batch #: 137 of 300 sample #: 199 reconstruction error: 0.070912\nEpoch: 0 batch #: 138 of 300 sample #: 199 reconstruction error: 0.085497\nEpoch: 0 batch #: 139 of 300 sample #: 199 reconstruction error: 0.092873\nEpoch: 0 batch #: 140 of 300 sample #: 199 reconstruction error: 0.088141\nEpoch: 0 batch #: 141 of 300 sample #: 199 reconstruction error: 0.067634\nEpoch: 0 batch #: 142 of 300 sample #: 199 reconstruction error: 0.069824\nEpoch: 0 batch #: 143 of 300 sample #: 199 reconstruction error: 0.049749\nEpoch: 0 batch #: 144 of 300 sample #: 199 reconstruction error: 0.064737\nEpoch: 0 batch #: 145 of 300 sample #: 199 reconstruction error: 0.101700\nEpoch: 0 batch #: 146 of 300 sample #: 199 reconstruction error: 0.109317\nEpoch: 0 batch #: 147 of 300 sample #: 199 reconstruction error: 0.057240\nEpoch: 0 batch #: 148 of 300 sample #: 199 reconstruction error: 0.084088\nEpoch: 0 batch #: 149 of 300 sample #: 199 reconstruction error: 0.044632\nEpoch: 0 batch #: 150 of 300 sample #: 199 reconstruction error: 0.043975\nEpoch: 0 batch #: 151 of 300 sample #: 199 reconstruction error: 0.097628\nEpoch: 0 batch #: 152 of 300 sample #: 199 reconstruction error: 0.095164\nEpoch: 0 batch #: 153 of 300 sample #: 199 reconstruction error: 0.058381\nEpoch: 0 batch #: 154 of 300 sample #: 199 reconstruction error: 0.074643\nEpoch: 0 batch #: 155 of 300 sample #: 199 reconstruction error: 0.057561\nEpoch: 0 batch #: 156 of 300 sample #: 199 reconstruction error: 0.067769\nEpoch: 0 batch #: 157 of 300 sample #: 199 reconstruction error: 0.091483\nEpoch: 0 batch #: 158 of 300 sample #: 199 reconstruction error: 0.080274\nEpoch: 0 batch #: 159 of 300 sample #: 199 reconstruction error: 0.059987\nEpoch: 0 batch #: 160 of 300 sample #: 199 reconstruction error: 0.077406\nEpoch: 0 batch #: 161 of 300 sample #: 199 reconstruction error: 0.083710\nEpoch: 0 batch #: 162 of 300 sample #: 199 reconstruction error: 0.116410\nEpoch: 0 batch #: 163 of 300 sample #: 199 reconstruction error: 0.045444\nEpoch: 0 batch #: 164 of 300 sample #: 199 reconstruction error: 0.065845\nEpoch: 0 batch #: 165 of 300 sample #: 199 reconstruction error: 0.089978\nEpoch: 0 batch #: 166 of 300 sample #: 199 reconstruction error: 0.060230\nEpoch: 0 batch #: 167 of 300 sample #: 199 reconstruction error: 0.104887\nEpoch: 0 batch #: 168 of 300 sample #: 199 reconstruction error: 0.047541\nEpoch: 0 batch #: 169 of 300 sample #: 199 reconstruction error: 0.033204\nEpoch: 0 batch #: 170 of 300 sample #: 199 reconstruction error: 0.070523\nEpoch: 0 batch #: 171 of 300 sample #: 199 reconstruction error: 0.032166\nEpoch: 0 batch #: 172 of 300 sample #: 199 reconstruction error: 0.047005\nEpoch: 0 batch #: 173 of 300 sample #: 199 reconstruction error: 0.079492\nEpoch: 0 batch #: 174 of 300 sample #: 199 reconstruction error: 0.103791\nEpoch: 0 batch #: 175 of 300 sample #: 199 reconstruction error: 0.077465\nEpoch: 0 batch #: 176 of 300 sample #: 199 reconstruction error: 0.047142\nEpoch: 0 batch #: 177 of 300 sample #: 199 reconstruction error: 0.046551\nEpoch: 0 batch #: 178 of 300 sample #: 199 reconstruction error: 0.114609\nEpoch: 0 batch #: 179 of 300 sample #: 199 reconstruction error: 0.078421\nEpoch: 0 batch #: 180 of 300 sample #: 199 reconstruction error: 0.069796\nEpoch: 0 batch #: 181 of 300 sample #: 199 reconstruction error: 0.090841\nEpoch: 0 batch #: 182 of 300 sample #: 199 reconstruction error: 0.091087\nEpoch: 0 batch #: 183 of 300 sample #: 199 reconstruction error: 0.115371\nEpoch: 0 batch #: 184 of 300 sample #: 199 reconstruction error: 0.064118\nEpoch: 0 batch #: 185 of 300 sample #: 199 reconstruction error: 0.076465\nEpoch: 0 batch #: 186 of 300 sample #: 199 reconstruction error: 0.089709\nEpoch: 0 batch #: 187 of 300 sample #: 199 reconstruction error: 0.058879\nEpoch: 0 batch #: 188 of 300 sample #: 199 reconstruction error: 0.133649\nEpoch: 0 batch #: 189 of 300 sample #: 199 reconstruction error: 0.089536\nEpoch: 0 batch #: 190 of 300 sample #: 199 reconstruction error: 0.067580\nEpoch: 0 batch #: 191 of 300 sample #: 199 reconstruction error: 0.102757\nEpoch: 0 batch #: 192 of 300 sample #: 199 reconstruction error: 0.124256\nEpoch: 0 batch #: 193 of 300 sample #: 199 reconstruction error: 0.089608\nEpoch: 0 batch #: 194 of 300 sample #: 199 reconstruction error: 0.091259\nEpoch: 0 batch #: 195 of 300 sample #: 199 reconstruction error: 0.047594\nEpoch: 0 batch #: 196 of 300 sample #: 199 reconstruction error: 0.049549\nEpoch: 0 batch #: 197 of 300 sample #: 199 reconstruction error: 0.043850\nEpoch: 0 batch #: 198 of 300 sample #: 199 reconstruction error: 0.084267\nEpoch: 0 batch #: 199 of 300 sample #: 199 reconstruction error: 0.074712\nEpoch: 0 batch #: 200 of 300 sample #: 199 reconstruction error: 0.103321\nEpoch: 0 batch #: 201 of 300 sample #: 199 reconstruction error: 0.083940\nEpoch: 0 batch #: 202 of 300 sample #: 199 reconstruction error: 0.025342\nEpoch: 0 batch #: 203 of 300 sample #: 199 reconstruction error: 0.092757\nEpoch: 0 batch #: 204 of 300 sample #: 199 reconstruction error: 0.051605\nEpoch: 0 batch #: 205 of 300 sample #: 199 reconstruction error: 0.020350\nEpoch: 0 batch #: 206 of 300 sample #: 199 reconstruction error: 0.066208\nEpoch: 0 batch #: 207 of 300 sample #: 199 reconstruction error: 0.085209\nEpoch: 0 batch #: 208 of 300 sample #: 199 reconstruction error: 0.054745\nEpoch: 0 batch #: 209 of 300 sample #: 199 reconstruction error: 0.032346\nEpoch: 0 batch #: 210 of 300 sample #: 199 reconstruction error: 0.113093\nEpoch: 0 batch #: 211 of 300 sample #: 199 reconstruction error: 0.096846\nEpoch: 0 batch #: 212 of 300 sample #: 199 reconstruction error: 0.084237\nEpoch: 0 batch #: 213 of 300 sample #: 199 reconstruction error: 0.091394\nEpoch: 0 batch #: 214 of 300 sample #: 199 reconstruction error: 0.111412\nEpoch: 0 batch #: 215 of 300 sample #: 199 reconstruction error: 0.025961\nEpoch: 0 batch #: 216 of 300 sample #: 199 reconstruction error: 0.102458\nEpoch: 0 batch #: 217 of 300 sample #: 199 reconstruction error: 0.089194\nEpoch: 0 batch #: 218 of 300 sample #: 199 reconstruction error: 0.069017\nEpoch: 0 batch #: 219 of 300 sample #: 199 reconstruction error: 0.076313\nEpoch: 0 batch #: 220 of 300 sample #: 199 reconstruction error: 0.051142\nEpoch: 0 batch #: 221 of 300 sample #: 199 reconstruction error: 0.085557\nEpoch: 0 batch #: 222 of 300 sample #: 199 reconstruction error: 0.080849\nEpoch: 0 batch #: 223 of 300 sample #: 199 reconstruction error: 0.071102\nEpoch: 0 batch #: 224 of 300 sample #: 199 reconstruction error: 0.060800\nEpoch: 0 batch #: 225 of 300 sample #: 199 reconstruction error: 0.083759\nEpoch: 0 batch #: 226 of 300 sample #: 199 reconstruction error: 0.132004\nEpoch: 0 batch #: 227 of 300 sample #: 199 reconstruction error: 0.088325\nEpoch: 0 batch #: 228 of 300 sample #: 199 reconstruction error: 0.064410\nEpoch: 0 batch #: 229 of 300 sample #: 199 reconstruction error: 0.067922\nEpoch: 0 batch #: 230 of 300 sample #: 199 reconstruction error: 0.031927\nEpoch: 0 batch #: 231 of 300 sample #: 199 reconstruction error: 0.025444\nEpoch: 0 batch #: 232 of 300 sample #: 199 reconstruction error: 0.078067\nEpoch: 0 batch #: 233 of 300 sample #: 199 reconstruction error: 0.070510\nEpoch: 0 batch #: 234 of 300 sample #: 199 reconstruction error: 0.063471\nEpoch: 0 batch #: 235 of 300 sample #: 199 reconstruction error: 0.073271\nEpoch: 0 batch #: 236 of 300 sample #: 199 reconstruction error: 0.084065\nEpoch: 0 batch #: 237 of 300 sample #: 199 reconstruction error: 0.089104\nEpoch: 0 batch #: 238 of 300 sample #: 199 reconstruction error: 0.093152\nEpoch: 0 batch #: 239 of 300 sample #: 199 reconstruction error: 0.033167\nEpoch: 0 batch #: 240 of 300 sample #: 199 reconstruction error: 0.097091\nEpoch: 0 batch #: 241 of 300 sample #: 199 reconstruction error: 0.085161\nEpoch: 0 batch #: 242 of 300 sample #: 199 reconstruction error: 0.080054\nEpoch: 0 batch #: 243 of 300 sample #: 199 reconstruction error: 0.070885\nEpoch: 0 batch #: 244 of 300 sample #: 199 reconstruction error: 0.091522\nEpoch: 0 batch #: 245 of 300 sample #: 199 reconstruction error: 0.077524\nEpoch: 0 batch #: 246 of 300 sample #: 199 reconstruction error: 0.078981\nEpoch: 0 batch #: 247 of 300 sample #: 199 reconstruction error: 0.041408\nEpoch: 0 batch #: 248 of 300 sample #: 199 reconstruction error: 0.077941\nEpoch: 0 batch #: 249 of 300 sample #: 199 reconstruction error: 0.051463\nEpoch: 0 batch #: 250 of 300 sample #: 199 reconstruction error: 0.099801\nEpoch: 0 batch #: 251 of 300 sample #: 199 reconstruction error: 0.047861\nEpoch: 0 batch #: 252 of 300 sample #: 199 reconstruction error: 0.071527\nEpoch: 0 batch #: 253 of 300 sample #: 199 reconstruction error: 0.056395\nEpoch: 0 batch #: 254 of 300 sample #: 199 reconstruction error: 0.033149\nEpoch: 0 batch #: 255 of 300 sample #: 199 reconstruction error: 0.053642\nEpoch: 0 batch #: 256 of 300 sample #: 199 reconstruction error: 0.078130\nEpoch: 0 batch #: 257 of 300 sample #: 199 reconstruction error: 0.085226\nEpoch: 0 batch #: 258 of 300 sample #: 199 reconstruction error: 0.078745\nEpoch: 0 batch #: 259 of 300 sample #: 199 reconstruction error: 0.064764\nEpoch: 0 batch #: 260 of 300 sample #: 199 reconstruction error: 0.096383\nEpoch: 0 batch #: 261 of 300 sample #: 199 reconstruction error: 0.033897\nEpoch: 0 batch #: 262 of 300 sample #: 199 reconstruction error: 0.059891\nEpoch: 0 batch #: 263 of 300 sample #: 199 reconstruction error: 0.070884\nEpoch: 0 batch #: 264 of 300 sample #: 199 reconstruction error: 0.076846\nEpoch: 0 batch #: 265 of 300 sample #: 199 reconstruction error: 0.056853\nEpoch: 0 batch #: 266 of 300 sample #: 199 reconstruction error: 0.036399\nEpoch: 0 batch #: 267 of 300 sample #: 199 reconstruction error: 0.053595\nEpoch: 0 batch #: 268 of 300 sample #: 199 reconstruction error: 0.019813\nEpoch: 0 batch #: 269 of 300 sample #: 199 reconstruction error: 0.087437\nEpoch: 0 batch #: 270 of 300 sample #: 199 reconstruction error: 0.061348\nEpoch: 0 batch #: 271 of 300 sample #: 199 reconstruction error: 0.057498\nEpoch: 0 batch #: 272 of 300 sample #: 199 reconstruction error: 0.046255\nEpoch: 0 batch #: 273 of 300 sample #: 199 reconstruction error: 0.050070\nEpoch: 0 batch #: 274 of 300 sample #: 199 reconstruction error: 0.052301\nEpoch: 0 batch #: 275 of 300 sample #: 199 reconstruction error: 0.092943\nEpoch: 0 batch #: 276 of 300 sample #: 199 reconstruction error: 0.076873\nEpoch: 0 batch #: 277 of 300 sample #: 199 reconstruction error: 0.061354\nEpoch: 0 batch #: 278 of 300 sample #: 199 reconstruction error: 0.054438\nEpoch: 0 batch #: 279 of 300 sample #: 199 reconstruction error: 0.039391\nEpoch: 0 batch #: 280 of 300 sample #: 199 reconstruction error: 0.083421\nEpoch: 0 batch #: 281 of 300 sample #: 199 reconstruction error: 0.069057\nEpoch: 0 batch #: 282 of 300 sample #: 199 reconstruction error: 0.103020\nEpoch: 0 batch #: 283 of 300 sample #: 199 reconstruction error: 0.068260\nEpoch: 0 batch #: 284 of 300 sample #: 199 reconstruction error: 0.046181\nEpoch: 0 batch #: 285 of 300 sample #: 199 reconstruction error: 0.073459\nEpoch: 0 batch #: 286 of 300 sample #: 199 reconstruction error: 0.079612\nEpoch: 0 batch #: 287 of 300 sample #: 199 reconstruction error: 0.059040\nEpoch: 0 batch #: 288 of 300 sample #: 199 reconstruction error: 0.029798\nEpoch: 0 batch #: 289 of 300 sample #: 199 reconstruction error: 0.082036\nEpoch: 0 batch #: 290 of 300 sample #: 199 reconstruction error: 0.107877\nEpoch: 0 batch #: 291 of 300 sample #: 199 reconstruction error: 0.118987\nEpoch: 0 batch #: 292 of 300 sample #: 199 reconstruction error: 0.059433\nEpoch: 0 batch #: 293 of 300 sample #: 199 reconstruction error: 0.060507\nEpoch: 0 batch #: 294 of 300 sample #: 199 reconstruction error: 0.092895\nEpoch: 0 batch #: 295 of 300 sample #: 199 reconstruction error: 0.065533\nEpoch: 0 batch #: 296 of 300 sample #: 199 reconstruction error: 0.032091\nEpoch: 0 batch #: 297 of 300 sample #: 199 reconstruction error: 0.125060\nEpoch: 0 batch #: 298 of 300 sample #: 199 reconstruction error: 0.055163\nEpoch: 0 batch #: 299 of 300 sample #: 199 reconstruction error: 0.052081\nEpoch: 0 batch #: 300 of 300 sample #: 199 reconstruction error: 0.072876\n"
]
],
[
[
"Let's take a look at the errors at the end of each batch:\n",
"_____no_output_____"
]
],
[
[
"plt.plot(errors)\nplt.xlabel(\"Batch Number\")\nplt.ylabel(\"Error\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"What is the final weight matrix $W$ after training?\n",
"_____no_output_____"
]
],
[
[
"print(W.numpy()) # a weight matrix of shape (50,784)",
"[[-0.5399998 -0.17 -0.6099997 ... -0.5199998 -0.5399998\n -0.5199998 ]\n [-0.46999982 -0.14999999 -0.69999963 ... -0.4999998 -0.5399998\n -0.57999974]\n [-0.4899998 -0.23000003 -0.6099997 ... -0.41999987 -0.3999999\n -0.5499998 ]\n ...\n [-0.46999982 -0.19000001 -0.6199997 ... -0.43999985 -0.3999999\n -0.5099998 ]\n [-0.42999986 -0.09999999 -0.6299997 ... -0.4899998 -0.4999998\n -0.6199997 ]\n [-0.5099998 -0.23000003 -0.6199997 ... -0.4899998 -0.5099998\n -0.5399998 ]]\n"
]
],
[
[
"<a id=\"ref5\"></a>\n\n<h3>Learned features</h3> \n",
"_____no_output_____"
],
[
"We can take each hidden unit and visualize the connections between that hidden unit and each element in the input vector. In our case, we have 50 hidden units. Lets visualize those.\n",
"_____no_output_____"
],
[
"Let's plot the current weights: <b>tile_raster_images</b> helps in generating an easy to grasp image from a set of samples or weights. It transforms the <b>uw</b> (with one flattened image per row of size 784), into an array (of size $28\\times28$) in which images are reshaped and laid out like tiles on a floor.\n",
"_____no_output_____"
]
],
[
[
"tile_raster_images(X=W.numpy().T, img_shape=(28, 28), tile_shape=(5, 10), tile_spacing=(1, 1))\nimport matplotlib.pyplot as plt\nfrom PIL import Image\n%matplotlib inline\nimage = Image.fromarray(tile_raster_images(X=W.numpy().T, img_shape=(28, 28) ,tile_shape=(5, 10), tile_spacing=(1, 1)))\n### Plot image\nplt.rcParams['figure.figsize'] = (18.0, 18.0)\nimgplot = plt.imshow(image)\nimgplot.set_cmap('gray') ",
"_____no_output_____"
]
],
[
[
"Each tile in the above visualization corresponds to a vector of connections between a hidden unit and visible layer's units.\n",
"_____no_output_____"
],
[
"Let's look at one of the learned weights corresponding to one of hidden units for example. In this particular square, the gray color represents weight = 0, and the whiter it is, the more positive the weights are (closer to 1). Conversely, the darker pixels are, the more negative the weights. The positive pixels will increase the probability of activation in hidden units (after multiplying by input/visible pixels), and negative pixels will decrease the probability of a unit hidden to be 1 (activated). So, why is this important? So we can see that this specific square (hidden unit) can detect a feature (e.g. a \"/\" shape) and if it exists in the input.\n",
"_____no_output_____"
]
],
[
[
"from PIL import Image\nimage = Image.fromarray(tile_raster_images(X =W.numpy().T[10:11], img_shape=(28, 28),tile_shape=(1, 1), tile_spacing=(1, 1)))\n### Plot image\nplt.rcParams['figure.figsize'] = (4.0, 4.0)\nimgplot = plt.imshow(image)\nimgplot.set_cmap('gray') ",
"_____no_output_____"
]
],
[
[
"Let's look at the reconstruction of an image now. Imagine that we have a destructed image of figure 3. Lets see if our trained network can fix it:\n\nFirst we plot the image:\n",
"_____no_output_____"
]
],
[
[
"!wget -O destructed3.jpg https://ibm.box.com/shared/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg\nimg = Image.open('destructed3.jpg')\nimg",
"--2022-02-10 15:01:53-- https://ibm.box.com/shared/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg\nResolving ibm.box.com (ibm.box.com)... 107.152.26.197\nConnecting to ibm.box.com (ibm.box.com)|107.152.26.197|:443... connected.\nHTTP request sent, awaiting response... 301 Moved Permanently\nLocation: /public/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg [following]\n--2022-02-10 15:01:54-- https://ibm.box.com/public/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg\nReusing existing connection to ibm.box.com:443.\nHTTP request sent, awaiting response... 301 Moved Permanently\nLocation: https://ibm.ent.box.com/public/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg [following]\n--2022-02-10 15:01:54-- https://ibm.ent.box.com/public/static/vvm1b63uvuxq88vbw9znpwu5ol380mco.jpg\nResolving ibm.ent.box.com (ibm.ent.box.com)... 107.152.29.201\nConnecting to ibm.ent.box.com (ibm.ent.box.com)|107.152.29.201|:443... connected.\nHTTP request sent, awaiting response... 302 Found\nLocation: https://public.boxcloud.com/d/1/b1!3DcaJylnJDjGVyf7LpxI7A55oXBcTovr7MZyDzSKOT3Nn9FGYazVQEfnZl5L8M1MtJ4zPHPtdf-Jzs6ozhItz1WMQdVdmZDlfI8BN3QKY-tVbrc-J3ywrbq7HbQ_9Ywb_PMoinByDypK6LNbV9VEJfPqczIJHiYGL3NVai5BEJ42fhnLU04NTf1BSMEJnyjMZV8V_wXfB6jdNjgk8SqYKDxRIntp2j6Prasy_hSmFtGIG8KC5OhusReHQhUbWz9yVU-ANpe3-5SPLczlooJZTT2IFcrNlXBsh8a6wfxRDcvtoJreRhMnkaG5cKqaACIp6rIyz0zguRIx0Tnh84Xi5KNrrAjOVC3ofNj5BEJBXb6HZMP8LDRXOMsJVesyEfjBZlT-cbykA8S2Q6ysAUnYIc99MW97KQ4awklVy-i6khej9YD4JH-0LGNbPnZqq-aTcePjhuFEQq-tzfFJqp3VKYWnUfP4GX-oEc3ohMDEjlvHzu92omyZEVUsRC9PBg_yxhaVvj-LSvxCl05gQQsB8YSub22ncyltOiRMEKT8KFNBm8xfj4TmavIKVwgvtRvBGKQ9zwWKLF3ArK-BSb_WB3kvf67Arwo4Pu8maybClujl_UjVEnmAFK2cudPWoq8L6uZtR_GwZmXwACXG8dS2VkU0920ttQmtQlZxSHD5Bnp8NQh7S836rClJRBP58MXdPKF9w-PafZQ6h2IDcL4f1qj67cPiGAr_CiQwawWrRWYnuMvTDfO1IWNgzg3ck0L-ZC3stv65enoqg1IdPrs6mwhbNAug_XAGzMvP03B48AqrBGk9FUAEQsKoWRlJP1WOcB-JAM26kJHWZ2mOnuDEZwTH6t-_WYNxu2qStJqKY0Qyntv5cIrQbhtDQJUcXQH_0485wF_vJLNEcuj6FT5i-TGCite87mv5wg8Y8k7YK0SG5eA8BhQxTAJkmEbq1jxgC9ZSN5w02IaXUzRVXfI8GerKERKD01NwkwLs4DcUHtclvNXpcFNjj9GJSAuYXi5IfdW67E7jxm9RE01YaDsKNaoOfrst1DDnqPni2LwnvvurKquQhC9XwIXKZRQ7-0PPul_sYeEMTKCTLGx-cpXxRNrU0D9RRoDWYVxhrPYdm6EtXzeXdpg29HiEMMtw-UW68VPH7-mqOxIMUnszk-RdZ5Ovs3Unx7nv5R_RuZ7gXL9NCPTjfgVLkUWC0QwIvaMg4lXPznpLU_Ut_pAdZ-w3gp1cTIwrx4p6Rt928Ye4hK5iLZXTSbT31fGNWlrVeOGDCpezt_7Yci6rV1sKNlkhQGi96fgEtef5HuvBCFtPRQWeDFiFh-w4Fvf5jRdfsTsJM23a1kH3ialcZ2XlqnK-1-qvdm58UAvNAF2YEB1QZVqcOxSO0Wjxt6JFQo5pIEs6d7JRX0cxKRwzNN_XsSkB0WJaH8NmNb5TjcuvzQWyou9yQA8_A1ElDnbtzfVeB7E./download [following]\n--2022-02-10 15:01:55-- https://public.boxcloud.com/d/1/b1!3DcaJylnJDjGVyf7LpxI7A55oXBcTovr7MZyDzSKOT3Nn9FGYazVQEfnZl5L8M1MtJ4zPHPtdf-Jzs6ozhItz1WMQdVdmZDlfI8BN3QKY-tVbrc-J3ywrbq7HbQ_9Ywb_PMoinByDypK6LNbV9VEJfPqczIJHiYGL3NVai5BEJ42fhnLU04NTf1BSMEJnyjMZV8V_wXfB6jdNjgk8SqYKDxRIntp2j6Prasy_hSmFtGIG8KC5OhusReHQhUbWz9yVU-ANpe3-5SPLczlooJZTT2IFcrNlXBsh8a6wfxRDcvtoJreRhMnkaG5cKqaACIp6rIyz0zguRIx0Tnh84Xi5KNrrAjOVC3ofNj5BEJBXb6HZMP8LDRXOMsJVesyEfjBZlT-cbykA8S2Q6ysAUnYIc99MW97KQ4awklVy-i6khej9YD4JH-0LGNbPnZqq-aTcePjhuFEQq-tzfFJqp3VKYWnUfP4GX-oEc3ohMDEjlvHzu92omyZEVUsRC9PBg_yxhaVvj-LSvxCl05gQQsB8YSub22ncyltOiRMEKT8KFNBm8xfj4TmavIKVwgvtRvBGKQ9zwWKLF3ArK-BSb_WB3kvf67Arwo4Pu8maybClujl_UjVEnmAFK2cudPWoq8L6uZtR_GwZmXwACXG8dS2VkU0920ttQmtQlZxSHD5Bnp8NQh7S836rClJRBP58MXdPKF9w-PafZQ6h2IDcL4f1qj67cPiGAr_CiQwawWrRWYnuMvTDfO1IWNgzg3ck0L-ZC3stv65enoqg1IdPrs6mwhbNAug_XAGzMvP03B48AqrBGk9FUAEQsKoWRlJP1WOcB-JAM26kJHWZ2mOnuDEZwTH6t-_WYNxu2qStJqKY0Qyntv5cIrQbhtDQJUcXQH_0485wF_vJLNEcuj6FT5i-TGCite87mv5wg8Y8k7YK0SG5eA8BhQxTAJkmEbq1jxgC9ZSN5w02IaXUzRVXfI8GerKERKD01NwkwLs4DcUHtclvNXpcFNjj9GJSAuYXi5IfdW67E7jxm9RE01YaDsKNaoOfrst1DDnqPni2LwnvvurKquQhC9XwIXKZRQ7-0PPul_sYeEMTKCTLGx-cpXxRNrU0D9RRoDWYVxhrPYdm6EtXzeXdpg29HiEMMtw-UW68VPH7-mqOxIMUnszk-RdZ5Ovs3Unx7nv5R_RuZ7gXL9NCPTjfgVLkUWC0QwIvaMg4lXPznpLU_Ut_pAdZ-w3gp1cTIwrx4p6Rt928Ye4hK5iLZXTSbT31fGNWlrVeOGDCpezt_7Yci6rV1sKNlkhQGi96fgEtef5HuvBCFtPRQWeDFiFh-w4Fvf5jRdfsTsJM23a1kH3ialcZ2XlqnK-1-qvdm58UAvNAF2YEB1QZVqcOxSO0Wjxt6JFQo5pIEs6d7JRX0cxKRwzNN_XsSkB0WJaH8NmNb5TjcuvzQWyou9yQA8_A1ElDnbtzfVeB7E./download\nResolving public.boxcloud.com (public.boxcloud.com)... 107.152.29.200\nConnecting to public.boxcloud.com (public.boxcloud.com)|107.152.29.200|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 24383 (24K) [image/jpeg]\nSaving to: ‘destructed3.jpg’\n\ndestructed3.jpg 100%[===================>] 23.81K --.-KB/s in 0s \n\n2022-02-10 15:01:56 (128 MB/s) - ‘destructed3.jpg’ saved [24383/24383]\n\n"
]
],
[
[
"Now let's pass this image through the neural net:\n",
"_____no_output_____"
]
],
[
[
"# convert the image to a 1d numpy array\nsample_case = np.array(img.convert('I').resize((28,28))).ravel().reshape((1, -1))/255.0\n\nsample_case = tf.cast(sample_case, dtype=tf.float32)",
"_____no_output_____"
]
],
[
[
"Feed the sample case into the network and reconstruct the output:\n",
"_____no_output_____"
]
],
[
[
"hh0_p = tf.nn.sigmoid(tf.matmul(sample_case, W) + hb)\nhh0_s = tf.round(hh0_p)\n\nprint(\"Probability nodes in hidden layer:\" ,hh0_p)\nprint(\"activated nodes in hidden layer:\" ,hh0_s)\n\n# reconstruct\nvv1_p = tf.nn.sigmoid(tf.matmul(hh0_s, tf.transpose(W)) + vb)\n\nprint(vv1_p)\n#rec_prob = sess.run(vv1_p, feed_dict={ hh0_s: hh0_s_val, W: prv_w, vb: prv_vb})",
"Probability nodes in hidden layer: tf.Tensor(\n[[9.9997497e-01 4.7241755e-10 9.9702585e-01 7.3435638e-07 7.6033171e-09\n 4.2033195e-04 9.1960710e-12 9.9979067e-01 3.3435543e-05 2.7897738e-12\n 9.9988925e-01 3.6613822e-02 1.7746564e-18 1.0887554e-04 2.3263600e-01\n 1.0000000e+00 9.4463474e-01 1.5011649e-13 8.1828535e-03 9.6892416e-02\n 3.3659230e-13 6.1337680e-02 9.9998176e-01 5.9688091e-04 1.0000000e+00\n 4.5131173e-12 1.4443225e-17 9.9251807e-01 1.1124051e-17 1.0471284e-14\n 1.8083754e-10 1.4272264e-13 9.9773395e-01 9.9988174e-01 8.5801389e-08\n 8.8268161e-02 6.7739592e-08 1.0000000e+00 5.4949794e-07 4.7360962e-07\n 1.0000000e+00 1.9219140e-05 2.9944122e-02 5.7255611e-06 1.0000000e+00\n 1.7656744e-02 5.2564610e-06 7.3587525e-01 9.9928826e-01 4.4816848e-02]], shape=(1, 50), dtype=float32)\nactivated nodes in hidden layer: tf.Tensor(\n[[1. 0. 1. 0. 0. 0. 0. 1. 0. 0. 1. 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 1. 0.\n 1. 0. 0. 1. 0. 0. 0. 0. 1. 1. 0. 0. 0. 1. 0. 0. 1. 0. 0. 0. 1. 0. 0. 1.\n 1. 0.]], shape=(1, 50), dtype=float32)\ntf.Tensor(\n[[2.27302313e-04 3.52829695e-04 4.14073467e-04 3.52829695e-04\n 3.22550535e-04 4.05788422e-04 3.70979309e-04 4.71472740e-04\n 2.86012888e-04 3.82244587e-04 3.22550535e-04 2.72125006e-04\n 4.69297171e-04 3.31014395e-04 5.13911247e-04 2.72989273e-04\n 3.70919704e-04 4.66793776e-04 4.26650047e-04 3.19212675e-04\n 3.03685665e-04 3.39001417e-04 4.48524952e-04 2.34186649e-04\n 3.86089087e-04 4.18126583e-04 2.34186649e-04 5.15937805e-04\n 4.18126583e-04 4.81009483e-04 4.57525253e-04 2.51203775e-04\n 3.95625830e-04 3.68654728e-04 3.63200903e-04 4.38868999e-04\n 3.98963690e-04 5.09858131e-04 5.13762236e-04 9.84996557e-04\n 7.21812248e-04 5.14477491e-04 5.33461571e-04 5.51700592e-04\n 7.89493322e-04 1.48081779e-03 5.64366579e-04 3.52650881e-04\n 5.12331724e-04 4.13596630e-04 4.10526991e-04 2.21282244e-04\n 4.39614058e-04 4.62144613e-04 5.64396381e-04 3.89933586e-04\n 2.56210566e-04 4.90754843e-04 4.35292721e-04 2.37137079e-04\n 5.34385443e-04 4.13775444e-04 4.02212143e-04 4.18156385e-04\n 3.56465578e-04 3.45617533e-04 2.91824341e-04 2.99036503e-04\n 3.27616930e-04 6.67929649e-04 9.68724489e-04 5.42789698e-04\n 5.94913960e-04 1.94579363e-04 1.60425901e-04 1.94072723e-04\n 1.09807865e-04 2.81870365e-04 5.71936369e-04 5.67615032e-04\n 6.00308180e-04 4.52637672e-04 2.64048576e-04 3.32355499e-04\n 4.71472740e-04 3.93837690e-04 3.98486853e-04 4.30494547e-04\n 3.94403934e-04 4.66763973e-04 9.29325819e-04 4.70072031e-04\n 2.53945589e-04 2.69681215e-04 6.23703003e-04 9.91284847e-04\n 2.52676010e-03 6.34613633e-03 6.31421804e-03 3.10775638e-03\n 2.22811103e-03 2.12687254e-03 2.21881270e-03 6.74992800e-04\n 3.76015902e-04 3.94016504e-04 4.54574823e-04 5.13672829e-04\n 4.64707613e-04 5.56826591e-04 2.41935253e-04 3.82244587e-04\n 2.48700380e-04 5.41210175e-04 4.59879637e-04 3.98099422e-04\n 7.19457865e-04 9.94294882e-04 7.76946545e-04 9.01162624e-04\n 1.52951479e-03 3.14411521e-03 7.17982650e-03 1.62982941e-02\n 4.99598086e-02 9.38280225e-02 1.92165434e-01 2.60024369e-01\n 1.90620899e-01 9.56359804e-02 3.66342366e-02 1.41244531e-02\n 3.24803591e-03 1.60598755e-03 3.04335356e-03 4.82657552e-03\n 1.16598606e-03 1.34712458e-03 5.70297241e-04 3.99053097e-04\n 3.13013792e-04 5.05685806e-04 4.50223684e-04 4.05132771e-04\n 1.15114450e-03 1.05780363e-03 1.78122520e-03 4.95004654e-03\n 1.76149011e-02 4.83056903e-02 1.61921352e-01 3.64930362e-01\n 5.67875624e-01 6.82772577e-01 8.30930769e-01 8.25347304e-01\n 9.19121444e-01 7.64762521e-01 4.19089973e-01 9.64420736e-02\n 3.11861038e-02 9.24938917e-03 1.44470036e-02 1.02522671e-02\n 2.97933817e-03 1.89507008e-03 1.55967474e-03 4.47243452e-04\n 3.32355499e-04 3.65614891e-04 4.83155251e-04 6.69151545e-04\n 1.20335817e-03 2.55706906e-03 5.52245975e-03 8.22553039e-03\n 5.42855263e-02 1.54458851e-01 5.07513523e-01 8.12303305e-01\n 9.04079795e-01 9.24115717e-01 9.14169788e-01 9.50802684e-01\n 9.49593663e-01 8.68327022e-01 6.87396646e-01 4.48357046e-01\n 1.72508180e-01 5.48420250e-02 1.69291794e-02 1.46861970e-02\n 5.86006045e-03 3.64828110e-03 1.94081664e-03 4.32789326e-04\n 3.58045101e-04 5.54084778e-04 7.79956579e-04 1.89593434e-03\n 2.93508172e-03 4.55895066e-03 7.26038218e-03 1.94054544e-02\n 6.44418597e-02 3.87215048e-01 6.32435024e-01 8.38723779e-01\n 8.16669226e-01 8.70843649e-01 8.84720325e-01 8.84334624e-01\n 7.10601747e-01 6.88454270e-01 4.95795578e-01 5.03324509e-01\n 4.60244924e-01 2.22653747e-01 1.15567595e-01 3.49720418e-02\n 8.79654288e-03 2.42322683e-03 1.73416734e-03 5.03122807e-04\n 2.90244818e-04 3.56078148e-04 1.17608905e-03 1.62678957e-03\n 1.40476227e-03 2.40406394e-03 9.10276175e-03 3.72380018e-02\n 5.99771142e-02 3.08849275e-01 6.46746516e-01 5.36984801e-01\n 3.66021454e-01 2.31858820e-01 1.99925244e-01 1.07155859e-01\n 2.22846657e-01 2.36077726e-01 3.30450773e-01 7.19815850e-01\n 6.82338655e-01 6.35782421e-01 1.84720695e-01 8.22519362e-02\n 1.92878246e-02 5.21954894e-03 2.26944685e-03 4.15414572e-04\n 5.87284565e-04 4.65393066e-04 9.38385725e-04 2.00513005e-03\n 2.95472145e-03 2.57685781e-03 4.47127223e-03 2.12655365e-02\n 8.78953934e-02 2.49187231e-01 2.75862664e-01 2.18917608e-01\n 4.49330807e-02 1.37972534e-02 8.45861435e-03 3.32101583e-02\n 5.41933775e-02 2.26766974e-01 4.70867515e-01 7.85092473e-01\n 9.01893377e-01 7.70193577e-01 3.13818693e-01 5.21448851e-02\n 1.09755397e-02 1.02825165e-02 1.12012029e-03 3.74138355e-04\n 2.67297029e-04 6.69926405e-04 6.58959150e-04 1.86672807e-03\n 1.99335814e-03 1.61033869e-03 3.21000814e-03 1.23727024e-02\n 4.55994904e-02 9.20078158e-02 1.41209424e-01 2.48919725e-02\n 1.19393170e-02 6.01318479e-03 7.59378076e-03 4.69455719e-02\n 1.46020919e-01 3.92638683e-01 6.35528922e-01 9.30243850e-01\n 9.14440989e-01 7.59441614e-01 1.64613336e-01 2.63007581e-02\n 4.08551097e-03 2.26306915e-03 9.03338194e-04 5.68747520e-04\n 5.62191010e-04 5.65916300e-04 1.38351321e-03 1.00481510e-03\n 2.27755308e-03 3.03852558e-03 2.76228786e-03 7.26997852e-03\n 1.24763250e-02 1.26079917e-02 1.32868886e-02 4.12827730e-03\n 5.70929050e-03 1.92090869e-02 7.23392367e-02 3.10022086e-01\n 5.34373283e-01 7.95318127e-01 8.56837809e-01 9.21992898e-01\n 8.84986460e-01 3.94415230e-01 3.18199694e-02 7.56514072e-03\n 1.25244260e-03 2.78750062e-03 1.29801035e-03 5.25563955e-04\n 2.71826982e-04 8.74787569e-04 9.24259424e-04 1.03908777e-03\n 6.53892756e-04 2.45010853e-03 2.04741955e-03 3.94317508e-03\n 5.83404303e-03 1.42873526e-02 3.47257257e-02 2.41055489e-02\n 9.93375778e-02 4.65636760e-01 8.21901441e-01 8.79901350e-01\n 8.04153502e-01 8.59464467e-01 8.62536907e-01 8.84799361e-01\n 6.69855118e-01 2.23025650e-01 8.34438205e-03 3.46451998e-04\n 2.29537487e-04 7.64280558e-04 5.31792641e-04 3.33994627e-04\n 2.59846449e-04 4.52816486e-04 6.56187534e-04 6.49422407e-04\n 8.82416964e-04 2.07534432e-03 3.27900052e-03 4.26468253e-03\n 1.06754899e-02 3.85966301e-02 9.04878676e-02 5.54852009e-01\n 7.71918058e-01 9.63203669e-01 9.81788993e-01 9.46859360e-01\n 9.51530814e-01 8.22838187e-01 8.50785136e-01 7.78206110e-01\n 4.75591362e-01 4.95963991e-02 4.24468517e-03 4.02361155e-04\n 1.66088343e-04 6.41226768e-04 5.90145588e-04 7.44968653e-04\n 5.97834587e-04 4.07665968e-04 5.55962324e-04 1.36759877e-03\n 2.18832493e-03 2.81506777e-03 1.81734562e-03 7.45388865e-03\n 1.15833580e-02 1.08309358e-01 3.90661418e-01 8.99943352e-01\n 9.75361586e-01 9.84647989e-01 9.78643954e-01 9.56582010e-01\n 9.18265283e-01 9.07121062e-01 8.52295041e-01 7.07843959e-01\n 1.37472332e-01 1.06498301e-02 7.17043877e-04 3.19004059e-04\n 1.45524740e-04 6.73443079e-04 5.94437122e-04 6.43461943e-04\n 4.58061695e-04 3.96430492e-04 7.58349895e-04 2.43508816e-03\n 4.21926379e-03 3.72219086e-03 5.75563312e-03 9.49171185e-03\n 5.43771386e-02 4.66119051e-02 3.96965384e-01 7.38621235e-01\n 9.04244065e-01 9.19233799e-01 8.56392562e-01 6.65863395e-01\n 7.50565529e-01 8.65838885e-01 7.57837713e-01 3.41662526e-01\n 2.89898813e-02 5.19889593e-03 7.46905804e-04 3.04371119e-04\n 1.41829252e-04 2.91228294e-04 5.09321690e-04 3.54856253e-04\n 3.94880772e-04 3.41117382e-04 4.55617905e-04 5.21731377e-03\n 7.48741627e-03 4.09203768e-03 1.52638853e-02 2.06738412e-02\n 1.89343095e-02 4.05204892e-02 9.52870846e-02 1.41196817e-01\n 2.90679634e-01 3.24181765e-01 1.60367072e-01 2.53952444e-01\n 5.94778478e-01 6.78152859e-01 4.93400931e-01 1.29337996e-01\n 1.70793235e-02 1.93974376e-03 4.68522310e-04 4.58240509e-04\n 2.08169222e-04 2.18600035e-04 6.38127327e-04 3.72439623e-04\n 3.45885754e-04 4.14431095e-04 1.46469474e-03 9.01371241e-03\n 2.23727822e-02 1.75180435e-02 5.36440611e-02 7.37976134e-02\n 2.95174718e-02 3.31636369e-02 2.91396379e-02 1.67565048e-02\n 2.38878727e-02 3.54267359e-02 1.09297633e-01 2.85597444e-01\n 4.51890618e-01 7.18234599e-01 3.28572392e-01 1.07702702e-01\n 1.19043291e-02 1.88899040e-03 1.96921825e-03 8.22573900e-04\n 6.96212053e-04 5.31882048e-04 7.23421574e-04 3.12238932e-04\n 3.45498323e-04 4.06056643e-04 2.94134021e-03 2.82437205e-02\n 6.75210357e-02 5.50577641e-02 1.88012213e-01 8.01627636e-02\n 2.99791098e-02 3.01206112e-02 1.91561580e-02 8.38005543e-03\n 7.11283088e-03 2.97648013e-02 1.25469923e-01 2.87721038e-01\n 4.25985634e-01 5.24165332e-01 2.96806991e-01 1.28775001e-01\n 1.61702931e-02 5.25459647e-03 1.75982714e-03 1.06900930e-03\n 1.28757954e-03 9.44405794e-04 6.95407391e-04 5.40167093e-04\n 3.15010548e-04 4.46230173e-04 6.43640757e-03 9.71334577e-02\n 1.47175223e-01 2.75208503e-01 3.03874850e-01 2.18278140e-01\n 2.00899780e-01 9.46939588e-02 3.21725607e-02 1.30921006e-02\n 1.64348483e-02 4.20061052e-02 1.52247995e-01 2.37855941e-01\n 6.63707018e-01 4.53107804e-01 1.90085649e-01 1.23454928e-01\n 1.68903470e-02 3.52373719e-03 2.49752402e-03 2.00694799e-03\n 3.09380889e-03 8.74489546e-04 9.56594944e-04 2.81661749e-04\n 2.74896622e-04 4.07338142e-04 1.31787658e-02 1.40392065e-01\n 3.27759802e-01 4.18480337e-01 6.35175109e-01 4.59587067e-01\n 4.75218713e-01 1.97299808e-01 6.75213337e-02 3.01073194e-02\n 2.67401040e-02 6.39799833e-02 1.27722114e-01 4.86516207e-01\n 7.40751207e-01 6.70646369e-01 2.68432140e-01 5.42255342e-02\n 1.03321075e-02 2.68429518e-03 1.99413300e-03 3.26678157e-03\n 3.17120552e-03 2.47782469e-03 9.15676355e-04 5.35607338e-04\n 2.34812498e-04 4.30345535e-04 8.00657272e-03 1.88935697e-01\n 4.39892918e-01 6.18519664e-01 8.19978833e-01 7.82863975e-01\n 4.91616815e-01 1.92952752e-01 7.17013478e-02 4.66679633e-02\n 1.28840446e-01 2.17190713e-01 4.97518390e-01 8.30015838e-01\n 8.56384039e-01 6.09405696e-01 1.04537368e-01 2.45152414e-02\n 8.48838687e-03 2.88760662e-03 2.16090679e-03 3.16450000e-03\n 5.37556410e-03 2.95150280e-03 6.58273697e-04 3.37451696e-04\n 5.16951084e-04 4.70072031e-04 4.00525331e-03 8.78701508e-02\n 3.16625178e-01 6.62086427e-01 8.62921357e-01 8.78114462e-01\n 7.58351564e-01 4.19796109e-01 3.15263569e-01 2.47760594e-01\n 3.85287344e-01 6.02063239e-01 8.30330372e-01 8.72356236e-01\n 7.43137479e-01 2.55553663e-01 2.57110000e-02 5.21141291e-03\n 4.42942977e-03 3.68362665e-03 2.39565969e-03 4.07859683e-03\n 3.73312831e-03 1.35105848e-03 4.52637672e-04 3.45259905e-04\n 4.90754843e-04 4.05788422e-04 1.10733509e-03 2.76482105e-02\n 1.31316185e-01 2.89220244e-01 7.94250488e-01 8.66750538e-01\n 8.85633111e-01 7.78180361e-01 8.41718197e-01 8.32074523e-01\n 7.20373511e-01 5.73360026e-01 5.17806828e-01 6.45586252e-01\n 2.37174064e-01 4.23887372e-02 1.73519254e-02 6.52512908e-03\n 5.28997183e-03 1.63930655e-03 1.69411302e-03 1.86726451e-03\n 1.98829174e-03 4.23699617e-04 4.11331654e-04 3.12954187e-04\n 6.89327717e-04 4.09960747e-04 4.24623489e-04 2.77909636e-03\n 1.67279541e-02 1.86984271e-01 3.58257949e-01 5.62932670e-01\n 4.36818004e-01 6.39780104e-01 4.61275280e-01 3.59469295e-01\n 2.82323986e-01 1.68582946e-01 9.39218700e-02 7.66445994e-02\n 2.96495557e-02 1.03892088e-02 4.46903706e-03 1.72320008e-03\n 1.72215700e-03 6.32107258e-04 7.20143318e-04 5.94884157e-04\n 5.25206327e-04 5.91605902e-04 2.64286995e-04 3.56376171e-04\n 2.80380249e-04 4.26679850e-04 3.92466784e-04 4.66972589e-04\n 1.46251917e-03 1.44755840e-03 8.17117095e-03 7.66134262e-03\n 6.11206889e-03 1.70406401e-02 1.04832053e-02 1.75053179e-02\n 6.02090359e-03 2.26837397e-03 2.01287866e-03 1.81061029e-03\n 3.27876210e-03 1.14515424e-03 8.20964575e-04 9.73135233e-04\n 3.39537859e-04 4.43488359e-04 3.97235155e-04 5.08278608e-04\n 5.39600849e-04 3.86238098e-04 3.47375870e-04 5.26249409e-04\n 3.29017639e-04 3.35633755e-04 2.53677368e-04 3.19600105e-04\n 5.98192215e-04 1.84929371e-03 3.46001983e-03 1.31168962e-03\n 5.42074442e-04 5.38617373e-04 1.21888518e-03 1.80569291e-03\n 4.71621752e-04 2.89767981e-04 1.82896852e-04 2.26557255e-04\n 4.94331121e-04 3.63498926e-04 8.89241695e-04 6.11186028e-04\n 3.05414200e-04 3.79800797e-04 3.99082899e-04 5.72472811e-04\n 3.24606895e-04 2.62290239e-04 5.15818596e-04 3.86089087e-04\n 5.31584024e-04 6.30021095e-04 4.71472740e-04 4.52965498e-04\n 3.62545252e-04 3.70949507e-04 2.67922878e-04 6.32792711e-04\n 7.66098499e-04 1.52447820e-03 2.00417638e-03 1.01265311e-03\n 4.38570976e-04 5.18977642e-04 2.46822834e-04 3.02016735e-04\n 5.68658113e-04 1.03080273e-03 4.92423773e-04 4.52369452e-04\n 3.13133001e-04 3.05980444e-04 3.56435776e-04 3.22103500e-04\n 2.77608633e-04 5.00649214e-04 3.89933586e-04 2.88903713e-04]], shape=(1, 784), dtype=float32)\n"
]
],
[
[
"Here we plot the reconstructed image:\n",
"_____no_output_____"
]
],
[
[
"img = Image.fromarray(tile_raster_images(X=vv1_p.numpy(), img_shape=(28, 28),tile_shape=(1, 1), tile_spacing=(1, 1)))\nplt.rcParams['figure.figsize'] = (4.0, 4.0)\nimgplot = plt.imshow(img)\nimgplot.set_cmap('gray') ",
"_____no_output_____"
]
],
[
[
"<hr>\n\n## Want to learn more?\n\nAlso, you can use **Watson Studio** to run these notebooks faster with bigger datasets.**Watson Studio** is IBM’s leading cloud solution for data scientists, built by data scientists. With Jupyter notebooks, RStudio, Apache Spark and popular libraries pre-packaged in the cloud, **Watson Studio** enables data scientists to collaborate on their projects without having to install anything. Join the fast-growing community of **Watson Studio** users today with a free account at [Watson Studio](https://cocl.us/ML0120EN_DSX).This is the end of this lesson. Thank you for reading this notebook, and good luck on your studies.\n",
"_____no_output_____"
],
[
"### Thanks for completing this lesson!\n\nNotebook created by: <a href = \"https://ca.linkedin.com/in/saeedaghabozorgi?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01\">Saeed Aghabozorgi</a>\n\nUpdated to TF 2.X by <a href=\"https://ca.linkedin.com/in/nilmeier?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01\"> Jerome Nilmeier</a><br />\n",
"_____no_output_____"
],
[
"### References:\n\n[https://en.wikipedia.org/wiki/Restricted_Boltzmann_machine](https://en.wikipedia.org/wiki/Restricted_Boltzmann_machine?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01)\\\n[http://deeplearning.net/tutorial/rbm.html](http://deeplearning.net/tutorial/rbm.html?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01)\\\n[http://www.cs.utoronto.ca/\\~hinton/absps/netflixICML.pdf](http://www.cs.utoronto.ca/\\~hinton/absps/netflixICML.pdf?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01)<br>\n<http://imonad.com/rbm/restricted-boltzmann-machine/>\n",
"_____no_output_____"
],
[
"<hr>\n\nCopyright © 2018 [Cognitive Class](https://cocl.us/DX0108EN_CC). This notebook and its source code are released under the terms of the [MIT License](https://bigdatauniversity.com/mit-license/?utm_medium=Exinfluencer&utm_source=Exinfluencer&utm_content=000026UJ&utm_term=10006555&utm_id=NA-SkillsNetwork-Channel-SkillsNetworkCoursesIBMDeveloperSkillsNetworkDL0120ENSkillsNetwork20629446-2021-01-01).\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a1bceaaa4f1b295632f98ff15c0529788f70070
| 265,626 |
ipynb
|
Jupyter Notebook
|
20200812_testing/.ipynb_checkpoints/simulation-checkpoint.ipynb
|
dongxulee/lifeCycle
|
2b4a74dbd64357d00b29f7d946a66afcba747cc6
|
[
"MIT"
] | null | null | null |
20200812_testing/.ipynb_checkpoints/simulation-checkpoint.ipynb
|
dongxulee/lifeCycle
|
2b4a74dbd64357d00b29f7d946a66afcba747cc6
|
[
"MIT"
] | null | null | null |
20200812_testing/.ipynb_checkpoints/simulation-checkpoint.ipynb
|
dongxulee/lifeCycle
|
2b4a74dbd64357d00b29f7d946a66afcba747cc6
|
[
"MIT"
] | null | null | null | 287.163243 | 65,724 | 0.921657 |
[
[
[
"### Simulation Part ",
"_____no_output_____"
]
],
[
[
"%pylab inline\nfrom scipy.interpolate import interpn\nfrom helpFunctions import surfacePlot\nimport numpy as np\nfrom multiprocessing import Pool\nfrom functools import partial\nimport warnings\nimport math\nwarnings.filterwarnings(\"ignore\")\nnp.printoptions(precision=2)",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"# time line\nT_min = 0\nT_max = 70\nT_R = 45\n# discounting factor\nbeta = 1/(1+0.02)\n# utility function parameter \ngamma = 2\n# relative importance of housing consumption and non durable consumption \nalpha = 0.8\n# parameter used to calculate the housing consumption \nkappa = 0.3\n# depreciation parameter \ndelta = 0.025\n# housing parameter \nchi = 0.3\n# uB associated parameter\nB = 2\n# # minimum consumption \n# c_bar = 3\n# constant cost \nc_h = 20.0\n# All the money amount are denoted in thousand dollars\nearningShock = [0.8,1.2]\n# Define transition matrix of economical states\n# GOOD -> GOOD 0.8, BAD -> BAD 0.6\nPs = np.array([[0.6, 0.4],[0.2, 0.8]])\n# current risk free interest rate\nr_b = np.array([0.01 ,0.03])\n# stock return depends on current and future econ states\n# r_k = np.array([[-0.2, 0.15],[-0.15, 0.2]])\nr_k = np.array([[-0.15, 0.20],[-0.15, 0.20]])\n# expected return on stock market\n# r_bar = 0.0667\nr_bar = 0.02\n# probability of survival\nPa = np.load(\"prob.npy\")\n# deterministic income\ndetEarning = np.load(\"detEarning.npy\")\n# probability of employment transition Pe[s, s_next, e, e_next]\nPe = np.array([[[[0.3, 0.7], [0.1, 0.9]], [[0.25, 0.75], [0.05, 0.95]]],\n [[[0.25, 0.75], [0.05, 0.95]], [[0.2, 0.8], [0.01, 0.99]]]])\n# tax rate before and after retirement\ntau_L = 0.2\ntau_R = 0.1\n# constant state variables: Purchase value 250k, down payment 50k, mortgage 200k, interest rate 3.6%,\n# 55 payment period, 8.4k per period. One housing unit is roughly 1 square feet. Housing price 0.25k/sf \n\n# some variables associate with 401k amount\nNt = [np.sum(Pa[t:]) for t in range(T_max-T_min)]\nDt = [np.ceil(((1+r_bar)**N - 1)/(r_bar*(1+r_bar)**N)) for N in Nt]\n\n# wealth discretization \nws = np.array([10,25,50,75,100,125,150,175,200,250,500,750,1000,1500,3000])\nw_grid_size = len(ws)\n# 401k amount discretization \nns = np.array([1, 5, 10, 15, 25, 40, 65, 100, 150, 300, 400,1000])\nn_grid_size = len(ns)\n# Mortgage amount, * 0.25 is the housing price per unit\nMs = np.array([50, 100, 150, 200, 350])*0.25\nM_grid_size = len(Ms)\n# Improvement amount \ngs = np.array([0,25,50,75,100])\ng_grid_size = len(gs)\npoints = (ws,ns,Ms,gs)\n# housing unit\nH = 400\n# mortgate rate \nrh = 0.036\n# mortgate payment \nm = 3\n# housing price constant \npt = 250/1000\n# 30k rent 1000 sf\npr = 30/1000\n\nxgrid = np.array([[w, n, M, g_lag, e, s] \n for w in ws\n for n in ns\n for M in Ms\n for g_lag in gs \n for e in [0,1]\n for s in [0,1]\n ]).reshape((w_grid_size, n_grid_size,M_grid_size,g_grid_size,2,2,6))",
"_____no_output_____"
],
[
"import quantecon as qe\nimport timeit\nfrom sklearn.neighbors import KNeighborsRegressor as KN\nmc = qe.MarkovChain(Ps)\n\n#Vgrid = np.load(\"Vgrid_i.npy\")\ncgrid = np.load(\"cgrid_i.npy\")\nbgrid = np.load(\"bgrid_i.npy\")\nkgrid = np.load(\"kgrid_i.npy\")\nigrid = np.load(\"igrid_i.npy\")\nqgrid = np.load(\"qgrid_i.npy\")\n\ndef action(t, x):\n w, n, M, g_lag, e, s = x\n c = interpn(points, cgrid[:,:,:,:,e,s,t], x[:4], method = \"nearest\", bounds_error = False, fill_value = None)[0]\n b = interpn(points, bgrid[:,:,:,:,e,s,t], x[:4], method = \"nearest\", bounds_error = False, fill_value = None)[0]\n k = interpn(points, kgrid[:,:,:,:,e,s,t], x[:4], method = \"nearest\", bounds_error = False, fill_value = None)[0]\n i = interpn(points, igrid[:,:,:,:,e,s,t], x[:4], method = \"nearest\", bounds_error = False, fill_value = None)[0]\n q = interpn(points, qgrid[:,:,:,:,e,s,t], x[:4], method = \"nearest\", bounds_error = False, fill_value = None)[0]\n return (c,b,k,i,q)\n\n#Define the earning function, which applies for both employment and unemployment, good econ state and bad econ state \ndef y(t, x):\n w, n, M, g_lag, e, s = x\n if t <= T_R:\n welfare = 5\n return detEarning[t] * earningShock[int(s)] * e + (1-e) * welfare\n else:\n return detEarning[t]\n\n#Define the evolution of the amount in 401k account \ndef gn(t, n, x, s_next):\n w, n, M, g_lag, e, s = x\n if t <= T_R and e == 1:\n # if the person is employed, then 5 percent of his income goes into 401k \n i = 0.05\n n_cur = n + y(t, x) * i\n elif t <= T_R and e == 0:\n # if the perons is unemployed, then n does not change \n n_cur = n\n else:\n # t > T_R, n/discounting amount will be withdraw from the 401k \n n_cur = n - n/Dt[t]\n return (1+r_k[int(s), s_next])*n_cur \n\n\ndef transition(x, a, t, s_next):\n '''\n Input: state and action and time\n Output: possible future states and corresponding probability \n '''\n w, n, M, g_lag, e, s = x\n c,b,k,i,q = a\n # variables used to collect possible states and probabilities\n x_next = []\n prob_next = []\n M_next = M*(1+rh) - m\n if q == 1:\n g = (1-delta)*g_lag + i\n else:\n g = (1-delta)*g_lag\n \n w_next = b*(1+r_b[int(s)]) + k*(1+r_k[int(s), s_next])\n n_next = gn(t, n, x, s_next)\n if t >= T_R:\n e_next = 0\n return [w_next, n_next, M_next, g, s_next, e_next]\n else:\n for e_next in [0,1]:\n x_next.append([w_next, n_next, M_next, g, s_next, e_next])\n prob_next.append(Pe[int(s),s_next,int(e),e_next])\n return x_next[np.random.choice(2, 1, p = prob_next)[0]]",
"_____no_output_____"
],
[
"'''\n Start with: \n Ms = 800 * 0.25\n w = 20\n n = 0\n g_lag = 0\n e = 1\n s = 1\n 1000 agents for 1 economy, 100 economies. \n \n use numpy array to contain the variable change:\n \n wealth, rFund, Mortgage, hImprov, employment, sState, salary, consumption, hConsumption, bond, stock, improve, hPercentage, life. Shape: (T_max-T_min, numAgents*numEcons)\n'''\nx0 = [20, 0, 80, 0, 1, 1]\n\nnumAgents = 1000\nnumEcons = 500",
"_____no_output_____"
],
[
"import random as rd\nEconStates = [mc.simulate(ts_length=T_max - T_min, init=0) for _ in range(numEcons)]\ndef simulation(i):\n track = np.zeros((T_max - T_min,14))\n econState = EconStates[i//numAgents]\n alive = True\n x = x0\n for t in range(len(econState)-1):\n if rd.random() > Pa[t]:\n alive = False\n if alive:\n track[t, 0] = x[0]\n track[t, 1] = x[1]\n track[t, 2] = x[2]\n track[t, 3] = x[3]\n track[t, 4] = x[4]\n track[t, 5] = x[5]\n track[t, 6] = y(t,x)\n a = action(t, x)\n track[t, 7] = a[0]\n track[t, 9] = a[1]\n track[t, 10] = a[2]\n track[t, 11] = a[3]\n track[t, 12] = a[4]\n track[t, 13] = 1\n # calculate housing consumption\n if a[4] == 1:\n h = H + (1-delta)*x[3] + a[3]\n Vh = (1+kappa)*h\n else:\n h = H + (1-delta)*x[3]\n Vh = (1-kappa)*(h-(1-a[4])*H)\n track[t, 8] = Vh\n s_next = econState[t+1]\n x = transition(x, a, t, s_next) \n return track",
"_____no_output_____"
],
[
"%%time\npool = Pool()\nagentsHistory = pool.map(simulation, list(range(numAgents*numEcons)))\npool.close()",
"CPU times: user 13.2 s, sys: 7.79 s, total: 21 s\nWall time: 36min 21s\n"
],
[
"len(agentsHistory)",
"_____no_output_____"
],
[
"np.save(\"agents\", np.array(agentsHistory))",
"_____no_output_____"
],
[
"agents = np.load(\"agents.npy\")",
"_____no_output_____"
],
[
"wealth = np.zeros((T_max-T_min, numAgents*numEcons))\nrFund = np.zeros((T_max-T_min, numAgents*numEcons))\nMortgage = np.zeros((T_max-T_min, numAgents*numEcons))\nhImprove = np.zeros((T_max-T_min, numAgents*numEcons))\nemployment = np.zeros((T_max-T_min, numAgents*numEcons))\nsState = np.zeros((T_max-T_min, numAgents*numEcons))\nsalary = np.zeros((T_max-T_min, numAgents*numEcons))\nconsumption = np.zeros((T_max-T_min, numAgents*numEcons))\nhConsumption = np.zeros((T_max-T_min, numAgents*numEcons))\nbond = np.zeros((T_max-T_min, numAgents*numEcons))\nstock = np.zeros((T_max-T_min, numAgents*numEcons))\nimprove = np.zeros((T_max-T_min, numAgents*numEcons))\nhPer = np.zeros((T_max-T_min, numAgents*numEcons))\nlife = np.zeros((T_max-T_min, numAgents*numEcons))",
"_____no_output_____"
],
[
"def separateAttributes(agents):\n for i in range(numAgents*numEcons):\n wealth[:,i] = agents[i][:,0]\n rFund[:,i] = agents[i][:,1]\n Mortgage[:,i] = agents[i][:,2]\n hImprove[:,i] = agents[i][:,3]\n employment[:,i] = agents[i][:,4]\n sState[:,i] = agents[i][:,5]\n salary[:,i] = agents[i][:,6]\n consumption[:,i] = agents[i][:,7]\n hConsumption[:,i] = agents[i][:,8]\n bond[:,i] = agents[i][:,9]\n stock[:,i] = agents[i][:,10]\n improve[:,i] = agents[i][:,11]\n hPer[:,i] = agents[i][:,12]\n life[:,i] = agents[i][:,13]\nseparateAttributes(agents)",
"_____no_output_____"
],
[
"np.save(\"wealth\", wealth)\nnp.save(\"rFund\", rFund)\nnp.save(\"Mortgage\", Mortgage)\nnp.save(\"hImprov\", hImprove)\nnp.save(\"employment\", employment)\nnp.save(\"sState\", sState)\nnp.save(\"salary\", salary)\nnp.save(\"consumption\", consumption)\nnp.save(\"hConsumption\", hConsumption)\nnp.save(\"bond\", bond)\nnp.save(\"stock\", stock)\nnp.save(\"improve\", improve)\nnp.save(\"hPer\", hPer)\nnp.save(\"life\", life)",
"_____no_output_____"
]
],
[
[
"### Summary Plot",
"_____no_output_____"
]
],
[
[
"wealth = np.load(\"wealth.npy\")\nrFund = np.load(\"rFund.npy\")\nMortgage = np.load(\"Mortgage.npy\")\nhImprove = np.load(\"hImprov.npy\")\nemployment = np.load(\"employment.npy\")\nsState = np.load(\"sState.npy\")\nsalary = np.load(\"salary.npy\")\nconsumption = np.load(\"consumption.npy\")\nhConsumption = np.load(\"hConsumption.npy\")\nbond = np.load(\"bond.npy\")\nstock = np.load(\"stock.npy\")\nimprove = np.load(\"improve.npy\")\nhPer = np.load(\"hPer.npy\")\nlife = np.load(\"life.npy\")",
"_____no_output_____"
],
[
"# Population during the entire simulation period\nplt.plot(np.mean(life, axis = 1))",
"_____no_output_____"
],
[
"def quantileForPeopleWholive(attribute, quantiles = [0.25, 0.5, 0.75]):\n qList = []\n for i in range(69):\n if len(np.where(life[i,:] == 1)[0]) == 0:\n qList.append(np.array([0] * len(quantiles)))\n else:\n qList.append(np.quantile(attribute[i, np.where(life[i,:] == 1)], q = quantiles))\n return np.array(qList)\n \ndef meanForPeopleWholive(attribute):\n means = []\n for i in range(69):\n if len(np.where(life[i,:] == 1)[0]) == 0:\n means.append(np.array([0]))\n else:\n means.append(np.mean(attribute[i, np.where(life[i,:] == 1)]))\n return np.array(means)",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of housing consumption \nplt.plot(quantileForPeopleWholive(hConsumption))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of wealth\nplt.plot(quantileForPeopleWholive(wealth))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of 401k amount \nplt.plot(quantileForPeopleWholive(rFund))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of Mortgage amount\nplt.plot(quantileForPeopleWholive(Mortgage))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of housing improvement\nplt.plot(quantileForPeopleWholive(hImprove))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of consumption \nplt.plot(quantileForPeopleWholive(consumption))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of bond\nplt.plot(quantileForPeopleWholive(bond))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of stock\nplt.plot(quantileForPeopleWholive(stock))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of housing improvement at this one episode \nplt.plot(quantileForPeopleWholive(improve))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of house occupation p, is p == 1 means no renting out \nplt.plot(quantileForPeopleWholive(hPer))",
"_____no_output_____"
],
[
"# plot the 0.25, 0.5, 0.75 quantiles of wealth\nplt.figure(figsize = [14,8])\nplt.plot(meanForPeopleWholive(wealth), label = \"wealth\")\n# plt.plot(meanForPeopleWholive(rFund), label = \"rFund\")\nplt.plot(meanForPeopleWholive(consumption), label = \"Consumption\")\nplt.plot(meanForPeopleWholive(bond), label = \"Bond\")\nplt.plot(meanForPeopleWholive(stock), label = \"Stock\")\n#plt.plot(meanForPeopleWholive(rFund), label = \"401k\")\nplt.legend()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1beeb5587a5c2617b31a8281c7602970d52e53
| 232,953 |
ipynb
|
Jupyter Notebook
|
diffphys-code-burgers.ipynb
|
zzzuuaa/pbdl-book
|
5ae6a742ec2cfcf2154f935349e5b0322e3bde1f
|
[
"Apache-2.0"
] | 1 |
2022-02-28T16:30:39.000Z
|
2022-02-28T16:30:39.000Z
|
diffphys-code-burgers.ipynb
|
zzzuuaa/pbdl-book
|
5ae6a742ec2cfcf2154f935349e5b0322e3bde1f
|
[
"Apache-2.0"
] | null | null | null |
diffphys-code-burgers.ipynb
|
zzzuuaa/pbdl-book
|
5ae6a742ec2cfcf2154f935349e5b0322e3bde1f
|
[
"Apache-2.0"
] | null | null | null | 390.860738 | 38,492 | 0.929166 |
[
[
[
"# Burgers Optimization with a Differentiable Physics Gradient\n\nTo illustrate the process of computing gradients in a _differentiable physics_ (DP) setting, we target the same inverse problem (the reconstruction task) used for the PINN example in {doc}`physicalloss-code`. The choice of DP as a method has some immediate implications: we start with a discretized PDE, and the evolution of the system is now fully determined by the resulting numerical solver. Hence, the only real unknown is the initial state. We will still need to re-compute all the states between the initial and target state many times, just now we won't need an NN for this step. Instead, we can rely on our discretized model. \n\nAlso, as we choose an initial discretization for the DP approach, the unknown initial state consists of the sampling points of the involved physical fields, and we can simply represent these unknowns as floating point variables. Hence, even for the initial state we do not need to set up an NN. Thus, our Burgers reconstruction problem reduces to a gradient-based optimization without any NN when solving it with DP. Nonetheless, it's a very good starting point to illustrate the process.\n\nFirst, we'll set up our discretized simulation. Here we can employ phiflow, as shown in the overview section on _Burgers forward simulations_. \n[[run in colab]](https://colab.research.google.com/github/tum-pbs/pbdl-book/blob/main/diffphys-code-burgers.ipynb)\n\n\n## Initialization\n\nphiflow directly gives us a sequence of differentiable operations, provided that we don't use the _numpy_ backend.\nThe important step here is to include `phi.tf.flow` instad of `phi.flow` (for _pytorch_ you could use `phi.torch.flow`).\n\nSo, as a first step, let's set up some constants, and initialize a `velocity` field with zeros, and our constraint at $t=0.5$ (step 16), now as a `CenteredGrid` in phiflow. Both are using periodic boundary conditions (via `extrapolation.PERIODIC`) and a spatial discretization of $\\Delta x = 1/128$.\n",
"_____no_output_____"
]
],
[
[
"#!pip install --upgrade --quiet phiflow\nfrom phi.tf.flow import *\n\nN = 128\nDX = 2/N\nSTEPS = 32\nDT = 1/STEPS\nNU = 0.01/(N*np.pi)\n\n# allocate velocity grid\nvelocity = CenteredGrid(0, extrapolation.PERIODIC, x=N, bounds=Box[-1:1])\n\n# and a grid with the reference solution \nREFERENCE_DATA = math.tensor([0.008612174447657694, 0.02584669669548606, 0.043136357266407785, 0.060491074685516746, 0.07793926183951633, 0.0954779141740818, 0.11311894389663882, 0.1308497114054023, 0.14867023658641343, 0.1665634396808965, 0.18452263429574314, 0.20253084411376132, 0.22057828799835133, 0.23865132431365316, 0.25673879161339097, 0.27483167307082423, 0.2929182325574904, 0.3109944766354339, 0.3290477753208284, 0.34707880794585116, 0.36507311960102307, 0.38303584302507954, 0.40094962955534186, 0.4188235294008765, 0.4366357052408043, 0.45439856841363885, 0.4720845505219581, 0.4897081943759776, 0.5072391070000235, 0.5247011051514834, 0.542067187709797, 0.5593576751669057, 0.5765465453632126, 0.5936507311857876, 0.6106452944663003, 0.6275435911624945, 0.6443221318186165, 0.6609900633731869, 0.67752574922899, 0.6939334022562877, 0.7101938106059631, 0.7263049537163667, 0.7422506131457406, 0.7580207366534812, 0.7736033721649875, 0.7889776974379873, 0.8041371279965555, 0.8190465276590387, 0.8337064887158392, 0.8480617965162781, 0.8621229412131242, 0.8758057344502199, 0.8891341984763013, 0.9019806505391214, 0.9143881632159129, 0.9261597966464793, 0.9373647624856912, 0.9476871303793314, 0.9572273019669029, 0.9654367940878237, 0.9724097482283165, 0.9767381835635638, 0.9669484658390122, 0.659083299684951, -0.659083180712816, -0.9669485121167052, -0.9767382069792288, -0.9724097635533602, -0.9654367970450167, -0.9572273263645859, -0.9476871280825523, -0.9373647681120841, -0.9261598056102645, -0.9143881718456056, -0.9019807055316369, -0.8891341634240081, -0.8758057205293912, -0.8621229450911845, -0.8480618138204272, -0.833706571569058, -0.8190466131476127, -0.8041372124868691, -0.7889777195422356, -0.7736033858767385, -0.758020740007683, -0.7422507481169578, -0.7263049162371344, -0.7101938950789042, -0.6939334061553678, -0.677525822052029, -0.6609901538934517, -0.6443222327338847, -0.6275436932970322, -0.6106454472814152, -0.5936507836778451, -0.5765466491708988, -0.5593578078967361, -0.5420672759411125, -0.5247011730988912, -0.5072391580614087, -0.4897082914472909, -0.47208460952428394, -0.4543985995006753, -0.4366355580500639, -0.41882350871539187, -0.40094955631843376, -0.38303594105786365, -0.36507302109186685, -0.3470786936847069, -0.3290476440540586, -0.31099441589505206, -0.2929180880304103, -0.27483158663081614, -0.2567388003912687, -0.2386513127155433, -0.22057831776499126, -0.20253089403524566, -0.18452269630486776, -0.1665634500729787, -0.14867027528284874, -0.13084990929476334, -0.1131191325854089, -0.09547794429803691, -0.07793928430794522, -0.06049114408297565, -0.0431364527809777, -0.025846763281087953, -0.00861212501518312] , math.spatial('x'))\nSOLUTION_T16 = CenteredGrid( REFERENCE_DATA, extrapolation.PERIODIC, x=N, bounds=Box[-1:1])",
"_____no_output_____"
]
],
[
[
"We can verify that the fields of our simulation are now backed by TensorFlow.",
"_____no_output_____"
]
],
[
[
"type(velocity.values.native())",
"_____no_output_____"
]
],
[
[
"## Gradients\n\nThe `record_gradients` function of phiflow triggers the generation of a gradient tape to compute gradients of a simulation via `math.gradients(loss, values)`.\n\nTo use it for the Burgers case we need to specify a loss function: we want the solution at $t=0.5$ to match the reference data. Thus we simply compute an $L^2$ difference between step number 16 and our constraint array as `loss`. Afterwards, we evaluate the gradient of the initial velocity state `velocity` with respect to this loss.",
"_____no_output_____"
]
],
[
[
"velocities = [velocity]\n\nwith math.record_gradients(velocity.values):\n\n for time_step in range(STEPS):\n v1 = diffuse.explicit(1.0*velocities[-1], NU, DT, substeps=1)\n v2 = advect.semi_lagrangian(v1, v1, DT)\n velocities.append(v2)\n\n loss = field.l2_loss(velocities[16] - SOLUTION_T16)*2./N # MSE\n\n grad = math.gradients(loss, velocity.values)\n\nprint('Loss: %f' % (loss))",
"WARNING:tensorflow:From /Users/thuerey/miniconda3/envs/tf/lib/python3.8/site-packages/tensorflow/python/ops/math_grad.py:297: setdiff1d (from tensorflow.python.ops.array_ops) is deprecated and will be removed after 2018-11-30.\nInstructions for updating:\nThis op will be removed after the deprecation date. Please switch to tf.sets.difference().\nLoss: 0.382915\n"
]
],
[
[
"Because we're only constraining time step 16, we could actually omit steps 17 to 31 in this setup. They don't have any degrees of freedom and are not constrained in any way. However, for fairness regarding a comparison with the previous PINN case, we include them.\n\nNote that we've done a lot of calculations here: first the 32 steps of our simulation, and then another 16 steps backwards from the loss. They were recorded by the gradient tape, and used to backpropagate the loss to the initial state of the simulation.\n\nNot surprisingly, because we're starting from zero, there's also a significant initial error of ca. 0.38 for the 16th simulation step.\n\nSo what do we get as a gradient here? It has the same dimensions as the velocity, and we can easily visualize it:\nStarting from the zero state for `velocity` (shown in blue), the first gradient is shown as a green line below. If you compare it with the solution it points in the opposite direction, as expected. The solution is much larger in magnitude, so we omit it here (see the next graph).\n",
"_____no_output_____"
]
],
[
[
"import pylab as plt\n\nfig = plt.figure().gca()\npltx = np.linspace(-1,1,N)\n\n# first gradient\nfig.plot(pltx, grad.numpy('x') , lw=2, color='green', label=\"Gradient\") \nfig.plot(pltx, velocity.values.numpy('x'), lw=2, color='mediumblue', label=\"u at t=0\")\nplt.xlabel('x'); plt.ylabel('u'); plt.legend();\n\n# some (optional) other fields to plot:\n#fig.plot(pltx, (velocities[16]).values.numpy('x') , lw=2, color='cyan', label=\"u at t=0.5\") \n#fig.plot(pltx, (SOLUTION_T16).values.numpy('x') , lw=2, color='red', label=\"solution at t=0.5\") \n#fig.plot(pltx, (velocities[16] - SOLUTION_T16).values.numpy('x') , lw=2, color='blue', label=\"difference at t=0.5\") \n",
"_____no_output_____"
]
],
[
[
"This gives us a \"search direction\" for each velocity variable. Based on a linear approximation, the gradient tells us how to change each of them to increase the loss function (gradients _always_ point \"upwards\"). Thus, we can use the gradient to run an optimization and find an initial state `velocity` that minimizes our loss.\n\n",
"_____no_output_____"
],
[
"## Optimization \n\nEquipped with the gradient we can run a gradient descent optimization. Below, we're using a learning rate of `LR=5`, and we're re-evaluating the loss for the updated state to track convergence. \n\nIn the following code block, we're additionally saving the gradients in a list called `grads`, such that we can visualize them later on. For a regular optimization we could of course discard the gradient after performing an update of the velocity.\n",
"_____no_output_____"
]
],
[
[
"LR = 5.\n\ngrads=[]\nfor optim_step in range(5):\n velocities = [velocity]\n with math.record_gradients(velocity.values):\n for time_step in range(STEPS):\n v1 = diffuse.explicit(1.0*velocities[-1], NU, DT)\n v2 = advect.semi_lagrangian(v1, v1, DT)\n velocities.append(v2)\n\n loss = field.l2_loss(velocities[16] - SOLUTION_T16)*2./N # MSE\n print('Optimization step %d, loss: %f' % (optim_step,loss))\n\n grads.append( math.gradients(loss, velocity.values) )\n\n velocity = velocity - LR * grads[-1]\n\n",
"Optimization step 0, loss: 0.382915\nOptimization step 1, loss: 0.326882\nOptimization step 2, loss: 0.281032\nOptimization step 3, loss: 0.242804\nOptimization step 4, loss: 0.210666\n"
]
],
[
[
"\nNow we can check well the 16th state of the simulation actually matches the target after the 5 update steps. This is what the loss measures, after all. The next graph shows the constraints (i.e. the solution we'd like to obtain) in green, and the reconstructed state after the initial state `velocity` (which we updated five times via the gradient by now) was updated 16 times by the solver. \n\n",
"_____no_output_____"
]
],
[
[
"fig = plt.figure().gca()\n\n# target constraint at t=0.5\nfig.plot(pltx, SOLUTION_T16.values.numpy('x'), lw=2, color='forestgreen', label=\"Reference\") \n\n# optimized state of our simulation after 16 steps\nfig.plot(pltx, velocities[16].values.numpy('x'), lw=2, color='mediumblue', label=\"Simulated velocity\")\n\nplt.xlabel('x'); plt.ylabel('u'); plt.legend(); plt.title(\"After 5 Optimization Steps at t=0.5\");",
"_____no_output_____"
]
],
[
[
"This seems to be going in the right direction! It's definitely not perfect, but we've only computed 5 GD update steps so far. The two peaks with a positive velocity on the left side of the shock and the negative peak on the right side are starting to show.\n\nThis is a good indicator that the backpropagation of gradients through all of our 16 simulated steps is behaving correctly, and that it's driving the solution in the right direction. The graph above only hints at how powerful the setup is: the gradient that we obtain from each of the simulation steps (and each operation within them) can easily be chained together into more complex sequences. In the example above, we're backpropagating through all 16 steps of the simulation, and we could easily enlarge this \"look-ahead\" of the optimization with minor changes to the code.\n\n",
"_____no_output_____"
],
[
"## More optimization steps\n\nBefore moving on to more complex physics simulations, or involving NNs, let's finish the optimization task at hand, and run more steps to get a better solution.\n\n",
"_____no_output_____"
]
],
[
[
"import time\nstart = time.time()\n\nfor optim_step in range(45):\n velocities = [velocity]\n with math.record_gradients(velocity.values):\n for time_step in range(STEPS):\n v1 = diffuse.explicit(1.0*velocities[-1], NU, DT)\n v2 = advect.semi_lagrangian(v1, v1, DT)\n velocities.append(v2)\n\n loss = field.l2_loss(velocities[16] - SOLUTION_T16)*2./N # MSE\n if optim_step%5==0: \n print('Optimization step %d, loss: %f' % (optim_step,loss))\n\n grad = math.gradients(loss, velocity.values)\n\n velocity = velocity - LR * grad\n\nend = time.time()\nprint(\"Runtime {:.2f}s\".format(end-start))",
"Optimization step 0, loss: 0.183476\nOptimization step 5, loss: 0.096224\nOptimization step 10, loss: 0.054792\nOptimization step 15, loss: 0.032819\nOptimization step 20, loss: 0.020334\nOptimization step 25, loss: 0.012852\nOptimization step 30, loss: 0.008185\nOptimization step 35, loss: 0.005186\nOptimization step 40, loss: 0.003263\nRuntime 56.25s\n"
]
],
[
[
"Thinking back to the PINN version from {doc}`diffphys-code-burgers`, we have a much lower error here after only 50 steps (by ca. an order of magnitude), and the runtime is also lower (roughly by a factor of 1.5 to 2). This behavior stems fro\n\nLet's plot again how well our solution at $t=0.5$ (blue) matches the constraints (green) now:",
"_____no_output_____"
]
],
[
[
"fig = plt.figure().gca()\nfig.plot(pltx, SOLUTION_T16.values.numpy('x'), lw=2, color='forestgreen', label=\"Reference\") \nfig.plot(pltx, velocities[16].values.numpy('x'), lw=2, color='mediumblue', label=\"Simulated velocity\")\nplt.xlabel('x'); plt.ylabel('u'); plt.legend(); plt.title(\"After 50 Optimization Steps at t=0.5\");",
"_____no_output_____"
]
],
[
[
"Not bad. But how well is the initial state recovered via backpropagation through the 16 simulation steps? This is what we're changing, and because it's only indirectly constrained via the observation later in time there is more room to deviate from a desired or expected solution.\n\nThis is shown in the next plot: ",
"_____no_output_____"
]
],
[
[
"fig = plt.figure().gca()\npltx = np.linspace(-1,1,N)\n\n# ground truth state at time=0 , move down\nINITIAL_GT = np.asarray( [-np.sin(np.pi * x) for x in np.linspace(-1+DX/2,1-DX/2,N)] ) # 1D numpy array\nfig.plot(pltx, INITIAL_GT.flatten() , lw=2, color='forestgreen', label=\"Ground truth initial state\") # ground truth initial state of sim\nfig.plot(pltx, velocity.values.numpy('x'), lw=2, color='mediumblue', label=\"Optimized initial state\") # manual\nplt.xlabel('x'); plt.ylabel('u'); plt.legend(); plt.title(\"Initial State After 50 Optimization Steps\");\n",
"_____no_output_____"
]
],
[
[
"Naturally, this is a tougher task: the optimization receives direct feedback what the state at $t=0.5$ should look like, but due to the non-linear model equation, we typically have a large number of solutions that exactly or numerically very closely satisfy the constraints. Hence, our minimizer does not necessarily find the exact state we started from (we can observe some numerical oscillations from the diffusion operator here with the default settings). However, the solution is still quite close in this Burgers scenario.\n\nBefore measuring the overall error of the reconstruction, let's visualize the full evolution of our system over time as this also yields the solution in the form of a numpy array that we can compare to the other versions:",
"_____no_output_____"
]
],
[
[
"import pylab\n\ndef show_state(a):\n a=np.expand_dims(a, axis=2)\n for i in range(4):\n a = np.concatenate( [a,a] , axis=2)\n a = np.reshape( a, [a.shape[0],a.shape[1]*a.shape[2]] )\n fig, axes = pylab.subplots(1, 1, figsize=(16, 5))\n im = axes.imshow(a, origin='upper', cmap='inferno')\n pylab.colorbar(im) \n \n# get numpy versions of all states \nvels = [ x.values.numpy('x,vector') for x in velocities] \n# concatenate along vector/features dimension\nvels = np.concatenate(vels, axis=-1) \n\n# save for comparison with other methods\nimport os; os.makedirs(\"./temp\",exist_ok=True)\nnp.savez_compressed(\"./temp/burgers-diffphys-solution.npz\", np.reshape(vels,[N,STEPS+1])) # remove batch & channel dimension\n\nshow_state(vels)",
"_____no_output_____"
]
],
[
[
"## Physics-informed vs. differentiable physics reconstruction\n\nNow we have both versions, the one with the PINN, and the DP version, so let's compare both reconstructions in more detail. (Note: The following cells expect that the Burgers-forward and PINN notebooks were executed in the same environment beforehand.)\n\nLet's first look at the solutions side by side. The code below generates an image with 3 versions, from top to bottom: the \"ground truth\" (GT) solution as given by the regular forward simulation, in the middle the PINN reconstruction, and at the bottom the differentiable physics version.\n",
"_____no_output_____"
]
],
[
[
"# note, this requires previous runs of the forward-sim & PINN notebooks in the same environment\nsol_gt=npfile=np.load(\"./temp/burgers-groundtruth-solution.npz\")[\"arr_0\"] \nsol_pi=npfile=np.load(\"./temp/burgers-pinn-solution.npz\")[\"arr_0\"] \nsol_dp=npfile=np.load(\"./temp/burgers-diffphys-solution.npz\")[\"arr_0\"] \n\ndivider = np.ones([10,33])*-1. # we'll sneak in a block of -1s to show a black divider in the image\nsbs = np.concatenate( [sol_gt, divider, sol_pi, divider, sol_dp], axis=0)\n\nprint(\"\\nSolutions Ground Truth (top), PINN (middle) , DiffPhys (bottom):\")\nshow_state(np.reshape(sbs,[N*3+20,33,1]))\n",
"\nSolutions Ground Truth (top), PINN (middle) , DiffPhys (bottom):\n"
]
],
[
[
"It's quite clearly visible here that the PINN solution (in the middle) recovers the overall shape of the solution, hence the temporal constraints are at least partially fulfilled. However, it doesn't manage to capture the amplitudes of the GT solution very well.\n\nThe reconstruction from the optimization with a differentiable solver (at the bottom) is much closer to the ground truth thanks to an improved flow of gradients over the whole course of the sequence. In addition, it can leverage the grid-based discretization for both forward as well as backward passes, and in this way provide a more accurate signal to the unknown initial state. It is nonetheless visible that the reconstruction lacks certain \"sharper\" features of the GT version, e.g., visible in the bottom left corner of the solution image.\n\nLet's quantify these errors over the whole sequence:",
"_____no_output_____"
]
],
[
[
"err_pi = np.sum( np.abs(sol_pi-sol_gt)) / (STEPS*N)\nerr_dp = np.sum( np.abs(sol_dp-sol_gt)) / (STEPS*N)\nprint(\"MAE PINN: {:7.5f} \\nMAE DP: {:7.5f}\".format(err_pi,err_dp))\n\nprint(\"\\nError GT to PINN (top) , DiffPhys (bottom):\")\nshow_state(np.reshape( np.concatenate([sol_pi-sol_gt, divider, sol_dp-sol_gt],axis=0) ,[N*2+10,33,1]))",
"MAE PINN: 0.23281 \nMAE DP: 0.06382\n\nError GT to PINN (top) , DiffPhys (bottom):\n"
]
],
[
[
"That's a pretty clear result: the PINN error is almost 4 times higher than the one from the Differentiable Physics (DP) reconstruction.\n\nThis difference also shows clearly in the jointly visualized image at the bottom: the magnitudes of the errors of the DP reconstruction are much closer to zero, as indicated by the purple color above.\n\nA simple direct reconstruction problem like this one is always a good initial test for a DP solver. It can be tested independently before moving on to more complex setups, e.g., coupling it with an NN. If the direct optimization does not converge, there's probably still something fundamentally wrong, and there's no point involving an NN. \n\nNow we have a first example to show similarities and differences of the two approaches. In the next section, we'll present a discussion of the findings so far, before moving to more complex cases in the following chapter.\n\n\n## Next steps\n\nAs with the PINN version, there's variety of things that can be improved and experimented with using the code above:\n\n* You can try to adjust the training parameters to further improve the reconstruction.\n* As for the PINN case, you can activate a different optimizer, and observe the changing (not necessarily improved) convergence behavior.\n* Vary the number of steps, or the resolution of the simulation and reconstruction.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1bf3531478d242425445b08d25fe27d6150f66
| 107,380 |
ipynb
|
Jupyter Notebook
|
ipynb/GM12878_RNAPII-superenhancer_graph_path_analysis_20200824.ipynb
|
TheJacksonLaboratory/human-chromatin-folding-dynamics
|
db854a22c828b159bbdbc585be67c2928c4a4988
|
[
"MIT"
] | null | null | null |
ipynb/GM12878_RNAPII-superenhancer_graph_path_analysis_20200824.ipynb
|
TheJacksonLaboratory/human-chromatin-folding-dynamics
|
db854a22c828b159bbdbc585be67c2928c4a4988
|
[
"MIT"
] | null | null | null |
ipynb/GM12878_RNAPII-superenhancer_graph_path_analysis_20200824.ipynb
|
TheJacksonLaboratory/human-chromatin-folding-dynamics
|
db854a22c828b159bbdbc585be67c2928c4a4988
|
[
"MIT"
] | 1 |
2021-07-10T12:01:21.000Z
|
2021-07-10T12:01:21.000Z
| 68.921694 | 54,080 | 0.718402 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport random\nfrom pyBedGraph import BedGraph\nfrom pybedtools import BedTool\nimport scipy.stats\nfrom scipy.stats import gaussian_kde as kde\nfrom matplotlib.colors import Normalize\nfrom matplotlib import cm\nfrom collections import Counter\nimport networkx as nx",
"_____no_output_____"
],
[
"def modLog(num, denom):\n if num==0 or denom==0:\n return 0\n else:\n return float(format(np.log2(num/denom), '.4f'))\n\ndef ShannonEnt(probList):\n \"\"\"Compute entropy for a list of probabilities.\"\"\"\n if sum(probList)!=1: ## input is count or frequency instead of probability\n probList = [i/sum(probList) for i in probList]\n entropy = sum([x*modLog(1,x) for x in probList])\n return float(format(entropy, '.6f'))\n\ndef normShannonEnt(probList):\n \"\"\"Compute normalized entropy for a list of probabilities.\"\"\"\n if sum(probList) != 1: ## input is count or frequency instead of probability\n probList = [i/sum(probList) for i in probList]\n entropy = sum([x*modLog(1,x) for x in probList])/np.log2(len(probList))\n if len(probList) == 1:\n entropy = 0\n return float(format(entropy, '.6f'))",
"_____no_output_____"
],
[
"def read_regionfile(directory, file_name):\n with open(directory + file_name) as f:\n gems = {}\n for line in f:\n tmp = line.strip().split(\"\\t\")\n gemid = tmp[4]\n if gemid in gems.keys():\n gems[gemid].append(tmp[5:])\n else:\n gems[gemid] = [tmp[5:]]\n return gems # all fragments within a complex w/ same GEM ID",
"_____no_output_____"
],
[
"def read_raidfile(directory, file_name):\n with open(directory + file_name) as f:\n raids = {}\n for line in f:\n tmp = line.strip().split(\"\\t\")\n tmp[1] = int(tmp[1])\n tmp[2] = int(tmp[2])\n raids[tmp[3]] = tmp[0:3]\n return raids",
"_____no_output_____"
],
[
"def read_elementsfile(directory, file_name):\n with open(directory + file_name) as f:\n elements = {}\n ebyraid = {}\n for line in f:\n tmp = line.strip().split(\"\\t\")\n eid = tmp[5]\n raidid = tmp[17]\n tmp[1] = int(tmp[1])\n tmp[2] = int(tmp[2])\n if tmp[4] != \".\":\n tmp.append(tmp[4]) # super-enhancer\n tmp.append('SE')\n else:\n if tmp[12] != '.' and float(tmp[13])>1: # active promoter\n tmp.append(tmp[12]) # add gene name\n tmp.append('P')\n else:\n tmp.append('E')\n tmp.append('E')\n if eid in elements.keys():\n elements[eid].append(tmp)\n else:\n elements[eid] = tmp\n if raidid in ebyraid.keys():\n ebyraid[raidid].append(eid)\n else:\n ebyraid[raidid] = [eid]\n sebyraid = dict([(key, list(dict.fromkeys([elements[x][4] for x in val if elements[x][4]!=\".\"]))) for key, val in ebyraid.items()])\n elements_se = {}\n for k,v in elements.items():\n if v[3] != \".\":\n if v[4] in elements_se.keys():\n elements_se[v[4]].append(v[5])\n else:\n elements_se[v[4]] = [v[5]]\n return elements, ebyraid, sebyraid, elements_se",
"_____no_output_____"
],
[
"def read_loopfile(directory, file_name):\n with open(directory + file_name) as f:\n loops = {}\n for line in f:\n tmp = line.strip().split(\"\\t\")\n lid = tmp[10]\n rid = tmp[16]\n petcnt = int(tmp[6])\n lpair = lid+\",\"+rid\n if lpair in loops.keys():\n loops[lpair] += petcnt\n else:\n loops[lpair] = petcnt\n return loops",
"_____no_output_____"
],
[
"def get_lpbyse(loops, elements):\n lpby1se = {}\n lpby2se = {}\n for key, val in loops.items():\n lanc = key.split(\",\")[0]\n lse = elements[lanc][4]\n lgene = elements[lanc][12]\n ltpm = elements[lanc][13]\n ranc = key.split(\",\")[1]\n rse = elements[ranc][4]\n rgene = elements[ranc][12]\n rtpm = elements[ranc][13]\n dist = elements[ranc][1]-elements[lanc][2]\n list2add = [lanc, lse, lgene, ltpm, ranc, rse, rgene, rtpm, val, dist]\n if lse=='.' and rse != \".\": # only 1 se; Right anchor overlaps SE\n if rse in lpby1se.keys(): \n lpby1se[rse].append(list2add)\n else:\n lpby1se[rse] = [list2add]\n if lse!='.' and rse==\".\": # only 1 se; Left anchor overlaps SE\n if lse in lpby1se.keys(): \n lpby1se[lse].append(list2add)\n else:\n lpby1se[lse] = [list2add]\n if lse!='.' and rse!='.' and lse != rse: # 2 se\n concat = lse+';'+rse\n if concat in lpby2se.keys(): \n lpby2se[concat].append(list2add)\n else:\n lpby2se[concat] = [list2add]\n return lpby1se, lpby2se",
"_____no_output_____"
],
[
"def plot_boxplot(dataset, dlabel, clr, tit, ylab, fig_name):\n fig = plt.figure(figsize = (8,6))\n medianprops = dict(linewidth = 3, color=clr)\n i=0\n boxprops = dict(linewidth = 1.5)\n toplot = [np.asarray([]) for i in range(len(dataset))]\n for d in dataset:\n #medianprops = dict(linewidth = 3, color=colcode[i])\n datax = toplot\n datax[i] = np.asarray(dataset[i])\n plt.boxplot(datax, widths = 0.6, medianprops = medianprops, boxprops = boxprops)\n i +=1\n plt.xticks([i for i in range(1, len(dataset)+1)], dlabel, fontsize = 18)\n plt.yticks(fontsize = 18)\n plt.ylabel(ylab, fontsize = 18)\n #plt.ylim(bottom=2.5)\n plt.title(tit, fontsize = 18)\n plt.savefig(fig_name+'.pdf', dpi=150, bbox_inches=\"tight\")\n plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def get_nodes(cldict):\n nodes = list(dict.fromkeys(list(cldict.values())))\n nodecolors = []\n nodecoldict = {}\n for x in nodes:\n if x.split(\"-\")[1][0] == \"S\": # is super-enhancer\n nodecolors.append(\"darkorchid\")\n nodecoldict[x] = \"darkorchid\"\n elif x.split(\"-\")[1][0] == \"E\": # is intermediate element and is enhancer\n nodecolors.append(\"orange\")\n nodecoldict[x] = \"orange\"\n elif x.split(\"-\")[1][0] == \"G\": # is target gene\n nodecolors.append(\"green\")\n nodecoldict[x] = \"green\"\n elif x.split(\"-\")[1][0] == \"O\": # is intermediate element and is other super-enhancer \n nodecolors.append(\"darkorchid\")\n nodecoldict[x] = \"darkorchid\"\n elif x.split(\"-\")[1][0] == \"P\": # is intermediate element and is promoter\n nodecolors.append(\"green\")\n nodecoldict[x] = \"green\"\n return nodes, nodecolors, nodecoldict",
"_____no_output_____"
],
[
"def get_graph(cldict, compbycl):\n G = nx.Graph()\n nodes, nodecolors, nodecoldict = get_nodes(cldict)\n G.add_nodes_from(nodes)\n compbyclpair = {}\n edgetriplet = []\n for key, val in compbycl.items():\n vert = key.split(\",\")\n left = vert[0]\n right = vert[-1]\n edgetriplet.append([left, right, val])\n if left != right: # exclude self-loops\n pair = left+\",\"+right\n if pair in compbyclpair.keys():\n compbyclpair[pair] += val\n else:\n compbyclpair[pair] = val\n for k,v in compbyclpair.items():\n l = k.split(\",\")[0]\n r = k.split(\",\")[1]\n G.add_weighted_edges_from([(l,r,v)])\n return nodes, nodecolors, nodecoldict, G, edgetriplet",
"_____no_output_____"
],
[
"def get_compbychr(rnapiir):\n compbychr = {}\n for k, v in rnapiir.items():\n tmp = [x[5] for x in v if x[5] != \".\"]\n chrom = [x[0] for x in v if x[5] != \".\"]\n if len(tmp) > 1: # at least 2 fragments overlapping elements\n if chrom[0] in compbychr.keys():\n compbychr[chrom[0]].append(tmp)\n else:\n compbychr[chrom[0]] = [tmp]\n return compbychr",
"_____no_output_____"
],
[
"def get_compcnt(se, target, elements_se, elements, compbychr):\n cnt = 0\n selist = elements_se[se]\n sedict = dict.fromkeys(selist, 0)\n chrom = elements[target][0]\n for x in compbychr[chrom]:\n if target in x:\n for y in selist:\n if y in x:\n cnt += 1\n sedict[y] += 1\n return cnt, sedict",
"_____no_output_____"
],
[
"def get_target(lpby1se, elements_se, elements, compbychr):\n setarget = {}\n for k, v in lpby1se.items():\n for x in v:\n if x[1] == \".\" and x[3] != \".\" or x[5] == \".\" and x[7] != \".\":\n if x[1] == \".\":\n target = x[0]\n tpm = float(x[3])\n elif x[5] == \".\":\n target = x[4]\n tpm = float(x[7])\n cmpcnt, sedict = get_compcnt(k, target, elements_se, elements, compbychr)\n if x[9] > 150000 and x[9] < 6000000 and cmpcnt > 0 and tpm > 1: # distance > 150 kb & < 6 Mbps\n if k in setarget.keys():\n if setarget[k][0][1] == \".\":\n currtpm = float(setarget[k][0][3])\n else:\n currtpm = float(setarget[k][0][7])\n if currtpm < tpm: # if expression is lower, replace\n setarget[k] = [x]\n else:\n setarget[k] = [x]\n return setarget",
"_____no_output_____"
],
[
"def se2target_elements(setarget, elements, elements_se, compbychr):\n elist = list(elements.keys())\n for k, v in setarget.items():\n if v[0][1] == \".\": # right super enhancer\n end = elements_se[v[0][5]][-1]\n start = v[0][0]\n target = start\n elif v[0][5] == \".\": # left super enhancer\n start = elements_se[v[0][1]][0]\n end = v[0][4]\n target = end\n startindx = elist.index(start)\n endindx = elist.index(end)\n path = []\n for i in range(startindx, endindx+1):\n tmp = elements[elist[i]]\n if tmp[4] != \".\" or tmp[2]-tmp[1] > 628: # either super-enhancer constituents or peak > 628 bp\n path.append(elist[i])\n clusters = []\n dum = [path[0]]\n for j in range(len(path)-1):\n nextstart = elements[path[j+1]][1]\n currend = elements[path[j]][2]\n nextse = elements[path[j+1]][4]\n currse = elements[path[j]][4]\n if nextstart-currend < 3000 or currse == nextse and currse != \".\": # either nearby or same SE ID\n dum.append(path[j+1])\n else:\n clusters.append(dum)\n dum = [path[j+1]]\n clusters.append(dum)\n cnt, sedict = get_compcnt(k, target, elements_se, elements, compbychr)\n setarget[k].append(path)\n setarget[k].append(clusters)\n setarget[k].append(sedict)\n setarget[k].append(cnt)\n return setarget",
"_____no_output_____"
],
[
"def extract_compbyelm(tlist, elements, compbychr):\n extracted = []\n chrom = elements[tlist[0]][0]\n for x in compbychr[chrom]:\n boolean = [i in tlist for i in x] # for each fragment, indicate if overlaps with elements of interest\n true_elm = [x[j] for j in range(len(boolean)) if boolean[j]==True]\n if len(true_elm) > 1:\n extracted.append(\",\".join(true_elm))\n return extracted",
"_____no_output_____"
],
[
"def get_compcntedges(G):\n alledges = list(G.edges.data())\n se2gene = 0\n se2enh = 0\n se2prom = 0\n enh2gene = 0\n enh2enh = 0\n enh2prom = 0\n prom2prom = 0\n prom2gene = 0\n for x in alledges:\n left = x[0].split(\"-\")[1][0]\n right = x[1].split(\"-\")[1][0]\n pair = [left, right]\n if \"S\" in pair and \"E\" in pair:\n se2enh += x[2]['weight']\n elif \"S\" in pair and \"G\" in pair:\n se2gene += x[2]['weight']\n elif \"S\" in pair and \"P\" in pair:\n se2prom += x[2]['weight']\n elif \"G\" in pair and \"E\" in pair:\n enh2gene += x[2]['weight']\n elif pair[0]==\"E\" and pair[1]==\"E\":\n enh2enh += x[2]['weight']\n elif \"E\" in pair and \"P\" in pair:\n enh2prom += x[2]['weight']\n elif pair[0]==\"P\" and pair[1]==\"P\":\n prom2prom += x[2]['weight']\n elif \"P\" in pair and \"G\" in pair:\n prom2gene += x[2]['weight']\n tot = sum([x[2]['weight'] for x in alledges])\n return se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot",
"_____no_output_____"
],
[
"def get_cldict(test, elements): # test is one of setarget\n if test[0][1] != \".\": # SE on left\n sepos = \"L\"\n gene = test[0][6]+\"; \"+test[0][7]+\"; \" + str(test[0][9])\n seid = test[0][1]\n elif test[0][5] != \".\": # SE on right\n sepos = \"R\"\n gene = test[0][2] + \"; \" + test[0][3] + \"; \" + str(test[0][9])\n seid = test[0][5]\n cldict = {}\n for i in range(len(test[2])):\n #print(i)\n states = [elements[y][19] for y in test[2][i]]\n if 'SE' in states:\n label = 'OSE'\n elif 'P' in states:\n label = 'P'\n else: \n label = 'E'\n for x in test[2][i]:\n if sepos == \"L\" and i == 0: # left-most element & super-enhancer\n cldict[x] = \"CL\" + str(i) + \"-\" + seid\n if sepos == \"L\" and i == len(test[2])-1: # left-most element & target gene\n cldict[x] = \"CL\" + str(i) + \"-G; \" + gene\n if sepos == \"R\" and i == len(test[2])-1: # right-most element & super-enhancer\n cldict[x] = \"CL\" + str(i) + \"-\" + seid\n if sepos == \"R\" and i == 0: # right-most element & target gene\n cldict[x] = \"CL\" + str(i) + \"-G; \" + gene\n elif i != 0 and i != len(test[2])-1: ## intermediate elements\n cldict[x] = \"CL\" + str(i) + \"-\" + label + str(i-1)\n return cldict",
"_____no_output_____"
],
[
"def get_summ_se2otherfrags(compbycl_dict):\n se2g_summ = [] # 1 frag in SE, 2, 3, 4, 5 to target gene\n se2p_summ = [] # 1 frag in SE, 2, 3, 4, 5 to promoter (intermediate element)\n se2e_summ = [] # 1 frag in SE, 2, 3, 4, 5 to enhancer (intermediate element)\n se2o_summ = [] # 1 frag in SE, 2, 3, 4, 5 to other super-enhancer (intermediate element)\n for key, val in compbycl_dict.items():\n tcounts = val\n secntlistg = [0, 0, 0, 0, 0]\n secntlistp = [0, 0, 0, 0, 0]\n secntliste = [0, 0, 0, 0, 0]\n secntlisto = [0, 0, 0, 0, 0]\n for k, v in tcounts.items():\n frags = k.split(\",\")\n fannot = [x.split(\"-\")[1][0] for x in frags]\n #print(fannot)\n secnt = len([x for x in fannot if x=='S'])\n gcnt = len([x for x in fannot if x=='G'])\n ecnt = len([x for x in fannot if x=='E'])\n pcnt = len([x for x in fannot if x=='P'])\n ocnt = len([x for x in fannot if x=='O'])\n if secnt > 0:\n if gcnt > 0:\n secntlistg[secnt-1] += v\n if pcnt > 0:\n secntlistp[secnt-1] += v\n if ecnt > 0:\n secntliste[secnt-1] += v\n if ocnt > 0:\n secntlisto[secnt-1] += v\n if sum(secntlistg)>0:\n se2g_summ.append([x/sum(secntlistg) for x in secntlistg])\n if sum(secntlistp)>0:\n se2p_summ.append([x/sum(secntlistp) for x in secntlistp])\n if sum(secntliste)>0:\n se2e_summ.append([x/sum(secntliste) for x in secntliste])\n if sum(secntlisto)>0:\n se2o_summ.append([x/sum(secntlisto) for x in secntlisto])\n return se2g_summ, se2p_summ, se2e_summ, se2o_summ",
"_____no_output_____"
],
[
"def plot_graph(nodes, nodecolors, G, ind, seid, coord, sedict, dist, cntse2g):\n se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot = get_compcntedges(G)\n plt.figure(figsize=(12, 12))\n #colors = range(len(list(G.edges)))\n edges,weights = zip(*nx.get_edge_attributes(G,'weight').items())\n nx.draw_circular(G, nodelist = nodes, with_labels=True, font_weight='bold', node_color=nodecolors, edge_color=weights, edge_cmap = plt.cm.Reds, width = 3)\n tit = \"super-enhancer_graphs_plot\"+str(ind) +\"_\"+ coord.split(\":\")[0]+\"-\"+coord.split(\":\")[1] + \"_\"+seid + \"_\" + str(len(nodes)) + \"nodes\"\n plt.title(seid+\"; \"+str(len(nodes)) + \" nodes; \" +\"\\n\"+ coord + \" (\" + str(dist) + \" bps)\" +\n \"\\n\" + str(cntse2g) + \" complexes from SE to gene \\n\"+ str(sedict) + \"\\n\" + \n \"SE to gene: \" + str(se2gene)+ \" complexes \\n\" +\n \"SE to enhancer: \" + str(se2enh) + \" complexes \\n\" + \n \"SE to prom: \" + str(se2prom)+ \" complexes \\n\" +\n \"Enhancer to gene: \" + str(enh2gene) + \" complexes \\n\" + \n \"Enh to Enh: \" + str(enh2enh) + \" complexes \\n\" + \n \"Enh to prom: \" + str(enh2prom) + \" complexes \\n\" +\n \"Prom to prom: \" + str(prom2prom) + \" complexes \\n\" +\n \"Prom to gene: \" + str(prom2gene) + \" complexes \\n\" +\n \"Total: \" + str(tot) +\" complexes\", fontsize=14)\n plt.savefig(directory+tit+'.png', dpi=300, bbox_inches='tight')\n #plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def position_MultiPartiteGraph( Graph, Parts , n_enh):\n # Graph is a networkX Graph object, where the nodes have attribute 'agentType' with part name as a value\n # Parts is a list of names for the parts (to be shown as columns)\n # returns list of dictionaries with keys being networkX Nodes, values being x,y coordinates for plottingxPos = {}\n xPos = {}\n yPos = {}\n for index1, agentType in enumerate(Parts):\n if agentType == 'SE':\n xPos[agentType] = index1\n yPos[agentType] = int(n_enh/2)\n elif agentType == 'Target':\n xPos[agentType] = index1\n yPos[agentType] = int(n_enh/2)\n else:\n xPos[agentType] = index1\n yPos[agentType] = 0\n\n pos = {}\n for node, attrDict in Graph.nodes(data=True):\n agentType = attrDict['agentType']\n # print ('node: %s\\tagentType: %s' % (node, agentType))\n # print ('\\t(x,y): (%d,%d)' % (xPos[agentType], yPos[agentType]))\n pos[node] = (xPos[agentType], yPos[agentType])\n yPos[agentType] += 1\n\n return pos",
"_____no_output_____"
],
[
"def plot_tripartite(G, nodes, tit):\n TG = nx.Graph()\n TG.add_nodes_from([x for x in nodes if x.split(\"-\")[1][0]==\"S\"], agentType='SE') # Add the node attribute \"bipartite\"\n TG.add_nodes_from([x for x in nodes if x.split(\"-\")[1][0]!=\"S\" and x.split(\"-\")[1][0]!=\"G\"], agentType='Enh')\n TG.add_nodes_from([x for x in nodes if x.split(\"-\")[1][0]==\"G\"], agentType='Target')\n\n for x in G.edges.data():\n TG.add_weighted_edges_from([(x[0], x[1], x[2]['weight'])])\n edges,weights = zip(*nx.get_edge_attributes(TG,'weight').items())\n nx.draw(TG,pos=position_MultiPartiteGraph(TG, ['SE', 'Enh', 'Target'], len(nodes)-2), nodelist = nodes, with_labels=True, font_weight='bold', node_color=nodecolors, edge_color=weights, edge_cmap = plt.cm.Reds, width = 3)\n plt.savefig(directory+tit+'.png', dpi=300, bbox_inches='tight')\n #plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def get_clbed(cllist, cldict, elements): # cllist is setarget[k][2]\n bed = []\n for x in cllist:\n chrom = elements[x[0]][0]\n start = elements[x[0]][1]\n end = elements[x[-1]][2]\n eid = cldict[x[0]]\n bed.append([chrom, start, end, eid])\n return bed",
"_____no_output_____"
],
[
"def plot_barchart(x, y, ylab, clr, tit, fig_name):\n fig = plt.figure(figsize = (18,6))\n plt.bar(x, y, width = 0.7, color = clr)\n plt.xticks(fontsize = 18)\n plt.yticks(fontsize = 18)\n plt.ylabel(ylab, fontsize = 18)\n plt.title(tit, fontsize = 18)\n plt.savefig(fig_name+'.png', dpi=150, bbox_inches=\"tight\")\n #plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def plot_aggregate(obsProb, xlimit, obsCol, obsColDark, fig_title, fig_name):\n obsProb_adj = obsProb\n obsProbMean = list(np.average(np.array(obsProb_adj), axis = 0))\n print([round(x,3) for x in obsProbMean])\n ## plotting begins\n x = np.arange(0,xlimit)\n fig = plt.figure(figsize = (10,5))\n ax = fig.add_subplot(111)\n std1 = np.std(np.array([x[:xlimit] for x in obsProb_adj]), axis = 0)\n #rects1 = ax.bar(x, obsProbMean[:xlimit], width = 0.35, color = obsCol, align = 'center', yerr = std1)\n rects1 = ax.bar(x, obsProbMean[:xlimit], width = 0.6, color = obsCol, align = 'center')\n plt.title(fig_title + \"\\n\"+\"Prob: \"+ \", \".join([str(round(x,3)) for x in obsProbMean]), fontsize = 17)\n plt.xlabel(\"Categories\", fontsize = 16)\n plt.ylabel(\"Proportion of \\n RNAPII ChIA-Drop complexes\", fontsize = 16)\n plt.xticks(np.arange(9),[\"SS\", \"ES\",\"PS\", \"GS\", \"EP\", \"PP\", \"GP\", \"EG\", \"EE\"], fontsize=16)\n plt.yticks(fontsize = 15)\n plt.savefig(directory+fig_name+'.png', dpi=300, bbox_inches='tight')\n plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def get_summ_9categories(edgetrip_dict): \n summ_raw = {} # 0: within SE, 1: SE2enh, 2: Enh2Enh, 3: Enh2Gene, 4: SE2gene\n for k, v in edgetrip_dict.items():\n tmpdict = dict.fromkeys([\"SS\",\"ES\", \"PS\", \"GS\", \"EP\", \"PP\", \"GP\", \"EG\", \"EE\"], 0)\n for x in v:\n e1 = x[0].split(\"-\")[1][0]\n e2 = x[1].split(\"-\")[1][0]\n tstr = ''.join(sorted([e1, e2]))\n if tstr in tmpdict.keys():\n tmpdict[tstr] += x[2]\n summ_raw[k] = list(tmpdict.values())\n summ_normalized = []\n for x in list(summ_raw.values()):\n tot = sum(x)\n if tot > 0:\n summ_normalized.append([y/tot for y in x])\n return summ_raw, summ_normalized",
"_____no_output_____"
],
[
"def compute_degree_cent(g_dict):\n ## compute degree centrality \n se_deg = []\n tg_deg = []\n enh_deg = []\n prom_deg = []\n ose_deg = []\n for k, v in g_dict.items():\n G = v\n degrees = G.degree(weight = 'weight')\n tot = sum([d for n,d in degrees])\n N = len(degrees)\n if tot > 0:\n for n,d in degrees:\n if n.split(\"-\")[1][0] == \"S\": # is super-enhancer\n #se_deg.append(d/(N-1))\n se_deg.append(d/(tot))\n elif n.split(\"-\")[1][0] == \"E\": # is enhancer\n #enh_deg.append(d/(N-1))\n enh_deg.append(d/(tot))\n elif n.split(\"-\")[1][0] == \"G\": # is target gene\n #tg_deg.append(d/(N-1))\n tg_deg.append(d/(tot))\n elif n.split(\"-\")[1][0] == \"P\": # is promoter\n #prom_deg.append(d/(N-1))\n prom_deg.append(d/(tot))\n elif n.split(\"-\")[1][0] == \"O\": # is other super-enhancer\n #ose_deg.append(d/(N-1))\n ose_deg.append(d/(tot))\n return se_deg, ose_deg, enh_deg, prom_deg, tg_deg",
"_____no_output_____"
],
[
"def get_clcoord(cldict, elements):\n clcoord = {}\n for k,v in cldict.items():\n chrom = elements[k][0]\n start = elements[k][1]\n end = elements[k][2]\n if v in clcoord.keys():\n if clcoord[v][1] > start:\n clcoord[v][1] = start\n if clcoord[v][2] < end:\n clcoord[v][2] = end\n else:\n clcoord[v] = [chrom, start, end]\n return clcoord",
"_____no_output_____"
],
[
"def plot_1hist(x1,bin_lims, lab1, clr1, tit, xlab, fig_name):\n bin_centers = 0.5*(bin_lims[:-1]+bin_lims[1:])\n bin_widths = bin_lims[1:]-bin_lims[:-1]\n hist1, _ = np.histogram(x1, bins=bin_lims)\n\n ##normalizing\n hist1b = hist1/np.max(hist1)\n\n fig, (ax2) = plt.subplots(nrows = 1, ncols = 1, figsize=(8, 6))\n ax2.bar(bin_centers, hist1b, width = bin_widths, align = 'center', label = lab1, color = clr1, alpha = 0.2)\n ax2.legend(loc = 'upper right', fontsize = 18) \n plt.title(tit, fontsize = 18)\n plt.xlabel(xlab, fontsize = 18)\n plt.ylabel(\"Relative Proportion\", fontsize = 18)\n plt.savefig(fig_name+'.pdf', dpi=300)\n plt.show()",
"_____no_output_____"
],
[
"#plot_linear(G, nodes, cldict, ind, seid, coord, sedict, dist, cntse2g)",
"_____no_output_____"
],
[
"def get_linear_positions(clcoord):\n left = min([x[1] for x in list(clcoord.values())])\n right = max([x[2] for x in list(clcoord.values())])\n span = right - left\n positions = {}\n for k,v in clcoord.items():\n positions[k] = [int((v[1]+v[2])/2)-left, 0]\n return positions ",
"_____no_output_____"
],
[
"def plot_linear(G, nodes, cldict, ind, seid, coord, sedict, dist, cntse2g):\n clcoord = get_clcoord(cldict, elements)\n positions = get_linear_positions(clcoord)\n maxdeg = max([d[1] for d in G.degree(weight = 'weight')])\n nodesizes = [int(d[1]*1000/maxdeg) for d in G.degree(weight = 'weight')]\n LG = nx.MultiDiGraph()\n LG.add_nodes_from(nodes)\n maxweight = max([x[2]['weight'] for x in G.edges.data()])\n #Reds = cm.get_cmap('Reds', maxweight)\n for x in G.edges.data():\n radius = (int(x[1].split(\"-\")[0].split(\"CL\")[1])-int(x[0].split(\"-\")[0].split(\"CL\")[1]))/(3*len(nodes))\n #ecol = Reds(x[2]['weight'])\n ecol = 'navy'\n #if x[2]['weight'] >= 1 and x[2]['weight'] <= 20: # 1-20 complexes\n # width = x[2]['weight']/4\n #elif x[2]['weight'] >= 21 and x[2]['weight'] <= 30: #21-30 complexes\n # width = 6\n #elif x[2]['weight'] >= 31: # >= 31 complexes\n # width = 7\n #width = x[2]['weight']*5/maxweight\n width = min(x[2]['weight']*8/maxweight, 7)\n if x[0].split(\"-\")[1][0] == \"S\" or x[1].split(\"-\")[1][0] == \"S\":\n radius = -radius\n LG.add_edge(x[0], x[1], weight = x[2]['weight'], rad=radius, width = width, col = ecol)\n\n plt.figure(figsize=(15, 18))\n edges,weights = zip(*nx.get_edge_attributes(LG,'weight').items())\n nx.draw_networkx_nodes(LG, pos = positions, nodelist = nodes, node_size = nodesizes, node_shape='o', with_labels=True, font_weight='bold', node_color=nodecolors)\n #nx.draw_networkx_labels(LG,pos,font_size=16)\n \n for edge in LG.edges(data=True):\n nx.draw_networkx_edges(LG, positions, edge_color = edge[2][\"col\"], arrowstyle=\"-\", width = edge[2][\"width\"], edgelist=[(edge[0],edge[1])], connectionstyle=f'arc3, rad = {edge[2][\"rad\"]}')\n \n se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot = get_compcntedges(G)\n \n tit = \"super-enhancer_linear-graphs_plot\"+str(ind) +\"_\"+ coord.split(\":\")[0]+\"-\"+coord.split(\":\")[1] + \"_\"+seid + \"_\" + str(len(nodes)) + \"nodes\"\n plt.title(seid+\"; \"+str(len(nodes)) + \" nodes; \" +\"\\n\"+ coord + \" (\" + str(dist) + \" bps)\" +\n \"\\n\" + \"Color bar max: \" + str(maxweight) + \"\\n\" + nodes[0] +\"\\n\" +nodes[-1] +\n \"\\n\" + str(cntse2g) + \" complexes from SE to gene \\n\"+ str(sedict) + \"\\n\" + \n \"SE to gene: \" + str(se2gene)+ \" complexes \\n\" +\n \"SE to enhancer: \" + str(se2enh) + \" complexes \\n\" + \n \"SE to prom: \" + str(se2prom)+ \" complexes \\n\" +\n \"Enhancer to gene: \" + str(enh2gene) + \" complexes \\n\" + \n \"Enh to Enh: \" + str(enh2enh) + \" complexes \\n\" + \n \"Enh to prom: \" + str(enh2prom) + \" complexes \\n\" +\n \"Prom to prom: \" + str(prom2prom) + \" complexes \\n\" +\n \"Prom to gene: \" + str(prom2gene) + \" complexes \\n\" +\n \"Total: \" + str(tot) +\" complexes\", fontsize=14)\n plt.savefig(directory+tit+'.png', dpi=300, bbox_inches='tight')\n #plt.show()\n plt.close()",
"_____no_output_____"
],
[
"def write_result(directory, out_list, out_name):\n with open(directory+out_name, 'a') as file1:\n for i in range(len(out_list)):\n file1.write('\\t'.join(map(str, out_list[i])) + '\\n')\n file1.close()",
"_____no_output_____"
],
[
"directory='/Users/kimm/Desktop/GM12878_files/'\ncohesin_rfile='GM12878-cohesin-pooled_comp_FDR_0.2_PASS.RNAPII-peaksoverlap.region'\nrnapii_rfile='GM12878-RNAPII-pooledv2_comp_FDR_0.2_PASS.RNAPII-peaksoverlap.region'\nelements_file='RNAPII-ChIA-PET-drop_peaks_merge500bp-superenhancer_const_chromHMM_ENCFF879KFK_RAID_20200729.bed'\nloop_file='LHG0035N_0035V_0045V.e500.clusters.cis.BE5.RNAPIIpeak.bothpksupport.bedpe'\nraid_file='GM12878_RAID_20200627.bed'",
"_____no_output_____"
],
[
"raids = read_raidfile(directory, raid_file)",
"_____no_output_____"
],
[
"loops = read_loopfile(directory, loop_file)",
"_____no_output_____"
],
[
"rnapiir = read_regionfile(directory, rnapii_rfile)",
"_____no_output_____"
],
[
"compbychr = get_compbychr(rnapiir)",
"_____no_output_____"
],
[
"elements, ebyraid, sebyraid, elements_se = read_elementsfile(directory, elements_file) # elements, elem. by RAID, super-enh by RAID",
"_____no_output_____"
],
[
"lpby1se, lpby2se = get_lpbyse(loops, elements)",
"_____no_output_____"
],
[
"setarget = get_target(lpby1se, elements_se, elements, compbychr)",
"_____no_output_____"
],
[
"len(setarget)",
"_____no_output_____"
],
[
"setarget = se2target_elements(setarget, elements, elements_se, compbychr)",
"_____no_output_____"
],
[
"ind = 0\nsumm_dict = {}\nedgetrip_dict = {}\ng_dict = {}\ncompbycl_dict = {}\nintermprom = []\nbed = []\ntable = [] # SE ID, target, TPM, span, coord, # interm. P, # interm. E, # interm. OSE, \n # se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot\nfor k, v in setarget.items():\n #print(k)\n if v[0][5] == k: # left target\n gene = v[0][2]\n tpm = float(v[0][3])\n elif v[0][1] == k: # right target\n gene = v[0][6]\n tpm = float(v[0][7])\n extracted = Counter(extract_compbyelm(v[1], elements, compbychr))\n cldict = get_cldict(v, elements)\n compbycl = {}\n for k2, v2 in extracted.items():\n klist = k2.split(\",\")\n cstr = \",\".join([cldict[x] for x in klist])\n if cstr in compbycl.keys():\n compbycl[cstr] += v2\n else:\n compbycl[cstr] = v2\n bed.extend(get_clbed(v[2], cldict, elements))\n nodes, nodecolors, nodecoldict, G, edgetriplet = get_graph(cldict, compbycl)\n se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot = get_compcntedges(G)\n summ_dict[k] = [se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene]\n edgetrip_dict[k] = edgetriplet\n g_dict[k] = G\n compbycl_dict[k] = compbycl\n chrom = elements[v[1][0]][0]\n start = elements[v[1][0]][1]\n end = elements[v[1][-1]][2]\n dist = end-start\n seid = k\n sedict = v[3]\n cntse2g = v[4]\n coord = chrom +\":\" + str(start)+\"-\"+str(end)\n elmstates = [x.split(\"-\")[1][0] for x in nodes]\n genelist = []\n for i in range(1,len(v[2])-1):\n genelist.extend([elements[y][12] for y in v[2][i] if elements[y][19]==\"P\"])\n genelistp = list(dict.fromkeys(sorted(genelist))) # list of intermediary promoter gene names\n for x in genelistp:\n intermprom.append([k, gene, tpm, dist, coord, x])\n tmptable = [k, gene, tpm, dist, coord] \n tmptable.append(len([x for x in elmstates if x==\"P\"]))\n tmptable.append(len([x for x in elmstates if x==\"E\"]))\n tmptable.append(len([x for x in elmstates if x==\"O\"]))\n tmptable.extend([se2gene, se2enh, se2prom, enh2gene, enh2enh, enh2prom, prom2prom, prom2gene, tot])\n table.append(tmptable)\n del tmptable\n if tot > 0:\n #plot_graph(nodes, nodecolors, G, ind, seid, coord, sedict, dist, cntse2g)\n tit = \"super-enhancer_tripartite_graphs_plot\"+str(ind) +\"_\"+ coord.split(\":\")[0]+\"-\"+coord.split(\":\")[1] + \"_\"+seid + \"_\" + str(len(nodes)) + \"nodes\"\n #plot_tripartite(G, nodes, tit)\n #plot_linear(G, nodes, cldict, ind, seid, coord, sedict, dist, cntse2g)\n ind += 1\n del G",
"_____no_output_____"
],
[
"write_result(directory, table, \"GM12878_RNAPII_superenhancer_summarytable_20200824.txt\")",
"_____no_output_____"
],
[
"# check weight counts\nfor k in edgetrip_dict.keys():\n edgedict_sum = sum([x[2] for x in edgetrip_dict[k] if x[0] != x[1]])\n graph_sum = sum([y['weight'] for y in [x[2] for x in g_dict[k].edges.data()]])\n if edgedict_sum != graph_sum:\n print(k)",
"_____no_output_____"
],
[
"se2g_summ, se2p_summ, se2e_summ, se2o_summ = get_summ_se2otherfrags(compbycl_dict)",
"_____no_output_____"
],
[
"print(\"SE to other SE:\")\nfor i in range(5):\n print(str(i+1)+ \" frag in SE: \" + str(round(np.mean([x[i] for x in se2p_summ])*100, 3))+ \" %\")",
"SE to other SE:\n1 frag in SE: 96.169 %\n2 frag in SE: 3.482 %\n3 frag in SE: 0.349 %\n4 frag in SE: 0.0 %\n5 frag in SE: 0.0 %\n"
],
[
"se2f_summ = se2g_summ\nse2f_summ.extend(se2p_summ)\nse2f_summ.extend(se2e_summ)\nse2f_summ.extend(se2o_summ)",
"_____no_output_____"
],
[
"len(se2f_summ)",
"_____no_output_____"
],
[
"print(\"SE to other functional elements:\")\nfor i in range(5):\n print(str(i+1)+ \" frag in SE: \" + str(round(np.mean([x[i] for x in se2f_summ])*100, 3))+ \" %\")",
"SE to other functional elements:\n1 frag in SE: 96.53 %\n2 frag in SE: 3.257 %\n3 frag in SE: 0.206 %\n4 frag in SE: 0.002 %\n5 frag in SE: 0.004 %\n"
],
[
"totcnt = 0\nfor k,v in compbycl_dict.items():\n tcounts = v\n for k1,v1 in tcounts.items():\n totcnt += v1",
"_____no_output_____"
],
[
"totcnt",
"_____no_output_____"
],
[
"se2f_raw = [0,0,0,0] # 1 frag in SE, 2, 3, 4, 5 to target gene\nfor key, val in compbycl_dict.items():\n tcounts = val\n for k, v in tcounts.items():\n frags = k.split(\",\")\n fannot = [x.split(\"-\")[1][0] for x in frags]\n #print(fannot)\n secnt = len([x for x in fannot if x=='S'])\n gcnt = len([x for x in fannot if x=='G'])\n ecnt = len([x for x in fannot if x=='E'])\n pcnt = len([x for x in fannot if x=='P'])\n ocnt = len([x for x in fannot if x=='O'])\n fcnt = gcnt + ecnt + pcnt + ocnt\n if fcnt > 0:\n if secnt == 1:\n se2f_raw[0] += v\n elif secnt == 2:\n se2f_raw[1] += v\n elif secnt == 3:\n se2f_raw[2] += v\n elif secnt > 3:\n se2f_raw[3] += v",
"_____no_output_____"
],
[
"se2f_raw",
"_____no_output_____"
],
[
"sum(se2f_raw)",
"_____no_output_____"
],
[
"summ_raw, summ_normalized = get_summ_9categories(edgetrip_dict)",
"_____no_output_____"
],
[
"## plot degrees for each SE \nfor k, v in g_dict.items():\n G = v\n degrees = G.degree(weight = 'weight')\n degpair = sorted([[n,d] for n,d in degrees], key=lambda x: int(x[0].split(\"-\")[0].split(\"CL\")[1]))\n plot_barchart([x[0].split(\"-\")[1] for x in degpair], [x[1] for x in degpair], \"Degrees\", \"#590059\", k + \": degrees\", directory+k+\"_degrees_barchart_20200820\")",
"_____no_output_____"
],
[
"se_deg, ose_deg, enh_deg, prom_deg, tg_deg = compute_degree_cent(g_dict)",
"_____no_output_____"
],
[
"tit = \"Normalized degrees RNAPII ChIA-Drop \\n\" + \\\n\"SE: n = \" + str(len(se_deg))+ \"; mean = \" + str(round(np.mean(se_deg), 2)) + \"; median = \" + str(round(np.median(se_deg), 2)) + \"\\n\" \\\n\"Other SE: n = \" + str(len(ose_deg))+ \"; mean = \" + str(round(np.mean(ose_deg), 2)) + \"; median = \" + str(round(np.median(ose_deg), 2)) + \"\\n\" \\\n\"Enhancers: n = \" + str(len(enh_deg))+ \"; mean = \" + str(round(np.mean(enh_deg), 2)) + \"; median = \" + str(round(np.median(enh_deg), 2)) + \"\\n\" \\\n\"Promoters: n = \" + str(len(prom_deg))+ \"; mean = \" + str(round(np.mean(prom_deg), 2)) + \"; median = \" + str(round(np.median(prom_deg), 2)) + \"\\n\" \\\n\"Target gene: n = \" + str(len(tg_deg))+ \"; mean = \" + str(round(np.mean(tg_deg), 2)) + \"; median = \" + str(round(np.median(tg_deg), 2)) + \"\\n\" \\",
"_____no_output_____"
],
[
"plot_boxplot([se_deg, ose_deg, enh_deg, prom_deg, tg_deg], [\"SE\", \"Other SE\", \"Enh\", \"Prom\", \"Target Gene\"], \"#590059\", tit, \"Normalized degrees\", \"GM12878_RNAPII_SE_degree_centrality_normby-nEdges_boxplot_20200824\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1bf442fe90aa44b958ac71edb5a892f4d4c3b2
| 52,074 |
ipynb
|
Jupyter Notebook
|
notebooks/misc/mix_PPCA_celeba_training.ipynb
|
karm-patel/pyprobml
|
af8230a0bc0d01bb0f779582d87e5856d25e6211
|
[
"MIT"
] | null | null | null |
notebooks/misc/mix_PPCA_celeba_training.ipynb
|
karm-patel/pyprobml
|
af8230a0bc0d01bb0f779582d87e5856d25e6211
|
[
"MIT"
] | 1 |
2022-03-27T04:59:50.000Z
|
2022-03-27T04:59:50.000Z
|
notebooks/misc/mix_PPCA_celeba_training.ipynb
|
karm-patel/pyprobml
|
af8230a0bc0d01bb0f779582d87e5856d25e6211
|
[
"MIT"
] | 2 |
2022-03-26T11:52:36.000Z
|
2022-03-27T05:17:48.000Z
| 73.13764 | 9,936 | 0.756193 |
[
[
[
"### Source:\n1) https://github.com/eitanrich/torch-mfa \n\n2) https://github.com/eitanrich/gans-n-gmms\n\n",
"_____no_output_____"
],
[
"### Getting: CelebA Dataset",
"_____no_output_____"
]
],
[
[
"!wget -q https://raw.githubusercontent.com/sayantanauddy/vae_lightning/main/data.py",
"_____no_output_____"
]
],
[
[
"### Getting helper functions ",
"_____no_output_____"
]
],
[
[
"!wget -q https://raw.githubusercontent.com/probml/pyprobml/master/scripts/mfa_celeba_helpers.py",
"_____no_output_____"
]
],
[
[
"### Get the Kaggle api token and upload it to colab. Follow the instructions [here](https://github.com/Kaggle/kaggle-api#api-credentials).\n",
"_____no_output_____"
]
],
[
[
"!pip install kaggle",
"Requirement already satisfied: kaggle in /usr/local/lib/python3.7/dist-packages (1.5.12)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from kaggle) (4.41.1)\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from kaggle) (2.23.0)\nRequirement already satisfied: certifi in /usr/local/lib/python3.7/dist-packages (from kaggle) (2021.5.30)\nRequirement already satisfied: python-dateutil in /usr/local/lib/python3.7/dist-packages (from kaggle) (2.8.1)\nRequirement already satisfied: six>=1.10 in /usr/local/lib/python3.7/dist-packages (from kaggle) (1.15.0)\nRequirement already satisfied: python-slugify in /usr/local/lib/python3.7/dist-packages (from kaggle) (5.0.2)\nRequirement already satisfied: urllib3 in /usr/local/lib/python3.7/dist-packages (from kaggle) (1.24.3)\nRequirement already satisfied: text-unidecode>=1.3 in /usr/local/lib/python3.7/dist-packages (from python-slugify->kaggle) (1.3)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->kaggle) (2.10)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->kaggle) (3.0.4)\n"
],
[
"from google.colab import files\n\nuploaded = files.upload()",
"_____no_output_____"
],
[
"!mkdir /root/.kaggle",
"_____no_output_____"
],
[
"!cp kaggle.json /root/.kaggle/kaggle.json",
"_____no_output_____"
],
[
"!chmod 600 /root/.kaggle/kaggle.json",
"_____no_output_____"
]
],
[
[
"### Train and saving the checkpoint",
"_____no_output_____"
]
],
[
[
"!pip install torchvision",
"Requirement already satisfied: torchvision in /usr/local/lib/python3.7/dist-packages (0.10.0+cu102)\nRequirement already satisfied: numpy in /usr/local/lib/python3.7/dist-packages (from torchvision) (1.19.5)\nRequirement already satisfied: torch==1.9.0 in /usr/local/lib/python3.7/dist-packages (from torchvision) (1.9.0+cu102)\nRequirement already satisfied: pillow>=5.3.0 in /usr/local/lib/python3.7/dist-packages (from torchvision) (7.1.2)\nRequirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch==1.9.0->torchvision) (3.7.4.3)\n"
],
[
"!pip install pytorch-lightning",
"Collecting pytorch-lightning\n Downloading pytorch_lightning-1.4.1-py3-none-any.whl (915 kB)\n\u001b[K |████████████████████████████████| 915 kB 9.3 MB/s \n\u001b[?25hRequirement already satisfied: tqdm>=4.41.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (4.41.1)\nRequirement already satisfied: numpy>=1.17.2 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (1.19.5)\nCollecting pyDeprecate==0.3.1\n Downloading pyDeprecate-0.3.1-py3-none-any.whl (10 kB)\nCollecting tensorboard!=2.5.0,>=2.2.0\n Downloading tensorboard-2.4.1-py3-none-any.whl (10.6 MB)\n\u001b[K |████████████████████████████████| 10.6 MB 57.8 MB/s \n\u001b[?25hCollecting fsspec[http]!=2021.06.0,>=2021.05.0\n Downloading fsspec-2021.7.0-py3-none-any.whl (118 kB)\n\u001b[K |████████████████████████████████| 118 kB 56.2 MB/s \n\u001b[?25hRequirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (3.7.4.3)\nCollecting future>=0.17.1\n Downloading future-0.18.2.tar.gz (829 kB)\n\u001b[K |████████████████████████████████| 829 kB 50.8 MB/s \n\u001b[?25hCollecting PyYAML>=5.1\n Downloading PyYAML-5.4.1-cp37-cp37m-manylinux1_x86_64.whl (636 kB)\n\u001b[K |████████████████████████████████| 636 kB 55.9 MB/s \n\u001b[?25hCollecting torchmetrics>=0.4.0\n Downloading torchmetrics-0.4.1-py3-none-any.whl (234 kB)\n\u001b[K |████████████████████████████████| 234 kB 65.0 MB/s \n\u001b[?25hRequirement already satisfied: packaging>=17.0 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (21.0)\nRequirement already satisfied: torch>=1.6 in /usr/local/lib/python3.7/dist-packages (from pytorch-lightning) (1.9.0+cu102)\nCollecting aiohttp\n Downloading aiohttp-3.7.4.post0-cp37-cp37m-manylinux2014_x86_64.whl (1.3 MB)\n\u001b[K |████████████████████████████████| 1.3 MB 50.8 MB/s \n\u001b[?25hRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2.23.0)\nRequirement already satisfied: pyparsing>=2.0.2 in /usr/local/lib/python3.7/dist-packages (from packaging>=17.0->pytorch-lightning) (2.4.7)\nRequirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (0.4.4)\nRequirement already satisfied: google-auth<2,>=1.6.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.32.1)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.0.1)\nRequirement already satisfied: grpcio>=1.24.3 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.34.1)\nRequirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (57.2.0)\nRequirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (0.12.0)\nRequirement already satisfied: protobuf>=3.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (3.17.3)\nRequirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (0.36.2)\nRequirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.15.0)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (3.3.4)\nRequirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.7/dist-packages (from tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.8.0)\nRequirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (4.7.2)\nRequirement already satisfied: cachetools<5.0,>=2.0.0 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (4.2.2)\nRequirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.7/dist-packages (from google-auth<2,>=1.6.3->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (0.2.8)\nRequirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.7/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (1.3.0)\nRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from markdown>=2.6.8->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (4.6.1)\nRequirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.7/dist-packages (from pyasn1-modules>=0.2.1->google-auth<2,>=1.6.3->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (0.4.8)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2.10)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (1.24.3)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (2021.5.30)\nRequirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.7/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (3.1.1)\nCollecting async-timeout<4.0,>=3.0\n Downloading async_timeout-3.0.1-py3-none-any.whl (8.2 kB)\nRequirement already satisfied: attrs>=17.3.0 in /usr/local/lib/python3.7/dist-packages (from aiohttp->fsspec[http]!=2021.06.0,>=2021.05.0->pytorch-lightning) (21.2.0)\nCollecting multidict<7.0,>=4.5\n Downloading multidict-5.1.0-cp37-cp37m-manylinux2014_x86_64.whl (142 kB)\n\u001b[K |████████████████████████████████| 142 kB 74.1 MB/s \n\u001b[?25hCollecting yarl<2.0,>=1.0\n Downloading yarl-1.6.3-cp37-cp37m-manylinux2014_x86_64.whl (294 kB)\n\u001b[K |████████████████████████████████| 294 kB 60.1 MB/s \n\u001b[?25hRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->markdown>=2.6.8->tensorboard!=2.5.0,>=2.2.0->pytorch-lightning) (3.5.0)\nBuilding wheels for collected packages: future\n Building wheel for future (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for future: filename=future-0.18.2-py3-none-any.whl size=491070 sha256=6b8f7d5812f120bbde2518947439a9de2f7af615d60c0b95913b271cfa684b33\n Stored in directory: /root/.cache/pip/wheels/56/b0/fe/4410d17b32f1f0c3cf54cdfb2bc04d7b4b8f4ae377e2229ba0\nSuccessfully built future\nInstalling collected packages: multidict, yarl, async-timeout, fsspec, aiohttp, torchmetrics, tensorboard, PyYAML, pyDeprecate, future, pytorch-lightning\n Attempting uninstall: tensorboard\n Found existing installation: tensorboard 2.5.0\n Uninstalling tensorboard-2.5.0:\n Successfully uninstalled tensorboard-2.5.0\n Attempting uninstall: PyYAML\n Found existing installation: PyYAML 3.13\n Uninstalling PyYAML-3.13:\n Successfully uninstalled PyYAML-3.13\n Attempting uninstall: future\n Found existing installation: future 0.16.0\n Uninstalling future-0.16.0:\n Successfully uninstalled future-0.16.0\n\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\ntensorflow 2.5.0 requires tensorboard~=2.5, but you have tensorboard 2.4.1 which is incompatible.\u001b[0m\nSuccessfully installed PyYAML-5.4.1 aiohttp-3.7.4.post0 async-timeout-3.0.1 fsspec-2021.7.0 future-0.18.2 multidict-5.1.0 pyDeprecate-0.3.1 pytorch-lightning-1.4.1 tensorboard-2.4.1 torchmetrics-0.4.1 yarl-1.6.3\n"
],
[
"import sys, os\nimport torch\nfrom torchvision.datasets import CelebA, MNIST\nimport torchvision.transforms as transforms\nfrom pytorch_lightning import LightningDataModule, LightningModule, Trainer\nfrom torch.utils.data import DataLoader, random_split\nimport numpy as np\nfrom matplotlib import pyplot as plt\nfrom imageio import imwrite\nfrom packaging import version\nfrom mfa_celeba_helpers import *\nfrom data import CelebADataset, CelebADataModule\n\n\"\"\"\nMFA model training (data fitting) example.\nNote that actual EM (and SGD) training code are part of the MFA class itself.\n\"\"\"\n\n\ndef main(argv):\n assert version.parse(torch.__version__) >= version.parse(\"1.2.0\")\n\n dataset = argv[1] if len(argv) == 2 else \"celeba\"\n print(\"Preparing dataset and parameters for\", dataset, \"...\")\n\n if dataset == \"celeba\":\n image_shape = [64, 64, 3] # The input image shape\n n_components = 300 # Number of components in the mixture model\n n_factors = 10 # Number of factors - the latent dimension (same for all components)\n batch_size = 1000 # The EM batch size\n num_iterations = 30 # Number of EM iterations (=epochs)\n feature_sampling = 0.2 # For faster responsibilities calculation, randomly sample the coordinates (or False)\n mfa_sgd_epochs = 0 # Perform additional training with diagonal (per-pixel) covariance, using SGD\n init_method = \"rnd_samples\" # Initialize each component from few random samples using PPCA\n trans = transforms.Compose(\n [\n CropTransform((25, 50, 25 + 128, 50 + 128)),\n transforms.Resize(image_shape[0]),\n transforms.ToTensor(),\n ReshapeTransform([-1]),\n ]\n )\n train_set = CelebADataset(root=\"./data\", split=\"train\", transform=trans, download=True)\n test_set = CelebADataset(root=\"./data\", split=\"test\", transform=trans, download=True)\n elif dataset == \"mnist\":\n image_shape = [28, 28] # The input image shape\n n_components = 50 # Number of components in the mixture model\n n_factors = 6 # Number of factors - the latent dimension (same for all components)\n batch_size = 1000 # The EM batch size\n num_iterations = 30 # Number of EM iterations (=epochs)\n feature_sampling = False # For faster responsibilities calculation, randomly sample the coordinates (or False)\n mfa_sgd_epochs = 0 # Perform additional training with diagonal (per-pixel) covariance, using SGD\n init_method = \"kmeans\" # Initialize by using k-means clustering\n trans = transforms.Compose([transforms.ToTensor(), ReshapeTransform([-1])])\n train_set = MNIST(root=\"./data\", train=True, transform=trans, download=True)\n test_set = MNIST(root=\"./data\", train=False, transform=trans, download=True)\n else:\n assert False, \"Unknown dataset: \" + dataset\n\n device = torch.device(\"cuda\") if torch.cuda.is_available() else torch.device(\"cpu\")\n model_dir = \"./models/\" + dataset\n os.makedirs(model_dir, exist_ok=True)\n figures_dir = \"./figures/\" + dataset\n os.makedirs(figures_dir, exist_ok=True)\n model_name = \"c_{}_l_{}_init_{}\".format(n_components, n_factors, init_method)\n\n print(\"Defining the MFA model...\")\n model = MFA(\n n_components=n_components, n_features=np.prod(image_shape), n_factors=n_factors, init_method=init_method\n ).to(device=device)\n\n print(\"EM fitting: {} components / {} factors / batch size {} ...\".format(n_components, n_factors, batch_size))\n ll_log = model.batch_fit(\n train_set, test_set, batch_size=batch_size, max_iterations=num_iterations, feature_sampling=feature_sampling\n )\n\n if mfa_sgd_epochs > 0:\n print(\"Continuing training using SGD with diagonal (instead of isotropic) noise covariance...\")\n model.isotropic_noise = False\n ll_log_sgd = model.sgd_mfa_train(\n train_set, test_size=256, max_epochs=mfa_sgd_epochs, feature_sampling=feature_sampling\n )\n ll_log += ll_log_sgd\n\n print(\"Saving the model...\")\n torch.save(model.state_dict(), os.path.join(model_dir, \"model_\" + model_name + \".pth\"))\n\n print(\"Visualizing the trained model...\")\n model_image = visualize_model(model, image_shape=image_shape, end_component=10)\n imwrite(os.path.join(figures_dir, \"model_\" + model_name + \".jpg\"), model_image)\n\n print(\"Generating random samples...\")\n rnd_samples, _ = model.sample(100, with_noise=False)\n mosaic = samples_to_mosaic(rnd_samples, image_shape=image_shape)\n imwrite(os.path.join(figures_dir, \"samples_\" + model_name + \".jpg\"), mosaic)\n\n print(\"Plotting test log-likelihood graph...\")\n plt.plot(ll_log, label=\"c{}_l{}_b{}\".format(n_components, n_factors, batch_size))\n plt.grid(True)\n plt.savefig(os.path.join(figures_dir, \"training_graph_\" + model_name + \".jpg\"))\n print(\"Done\")\n\n\nif __name__ == \"__main__\":\n main(sys.argv)",
"Preparing dataset and parameters for celeba ...\nDownloading dataset. Please while while the download and extraction processes complete\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a1c0f18c5145cd4660323473c2c351268710f57
| 7,933 |
ipynb
|
Jupyter Notebook
|
chapters/chapter_8/8_5_NMT/8_5_nmt_munging.ipynb
|
Jochen-M/pytorch_nlp
|
75ffbe60d1a9c383981396f346c6dcbabbb9e5d7
|
[
"Apache-2.0"
] | 1 |
2019-11-21T13:07:41.000Z
|
2019-11-21T13:07:41.000Z
|
chapters/chapter_8/8_5_NMT/8_5_nmt_munging.ipynb
|
Jochen-M/pytorch_nlp
|
75ffbe60d1a9c383981396f346c6dcbabbb9e5d7
|
[
"Apache-2.0"
] | null | null | null |
chapters/chapter_8/8_5_NMT/8_5_nmt_munging.ipynb
|
Jochen-M/pytorch_nlp
|
75ffbe60d1a9c383981396f346c6dcbabbb9e5d7
|
[
"Apache-2.0"
] | null | null | null | 27.449827 | 100 | 0.436531 |
[
[
[
"from argparse import Namespace\nfrom nltk.tokenize import word_tokenize\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"args = Namespace(\n source_data_path=\"data/nmt/eng-fra.txt\",\n output_data_path=\"data/nmt/simplest_eng_fra.csv\",\n perc_train=0.7,\n perc_val=0.15,\n perc_test=0.15,\n seed=1337\n)\n\nassert args.perc_test > 0 and (args.perc_test + args.perc_val + args.perc_train == 1.0)",
"_____no_output_____"
],
[
"with open(args.source_data_path) as fp:\n lines = fp.readlines()\n \nlines = [line.replace(\"\\n\", \"\").lower().split(\"\\t\") for line in lines]",
"_____no_output_____"
],
[
"data = []\nfor english_sentence, french_sentence in lines:\n data.append({\"english_tokens\": word_tokenize(english_sentence, language=\"english\"),\n \"french_tokens\": word_tokenize(french_sentence, language=\"french\")})",
"_____no_output_____"
],
[
"filter_phrases = (\n (\"i\", \"am\"), (\"i\", \"'m\"), \n (\"he\", \"is\"), (\"he\", \"'s\"),\n (\"she\", \"is\"), (\"she\", \"'s\"),\n (\"you\", \"are\"), (\"you\", \"'re\"),\n (\"we\", \"are\"), (\"we\", \"'re\"),\n (\"they\", \"are\"), (\"they\", \"'re\")\n)\n",
"_____no_output_____"
],
[
"data_subset = {phrase: [] for phrase in filter_phrases}\nfor datum in data:\n key = tuple(datum['english_tokens'][:2])\n if key in data_subset:\n data_subset[key].append(datum)",
"_____no_output_____"
],
[
"counts = {k: len(v) for k,v in data_subset.items()}\ncounts, sum(counts.values())",
"_____no_output_____"
],
[
"np.random.seed(args.seed)\n\ndataset_stage3 = []\nfor phrase, datum_list in sorted(data_subset.items()):\n np.random.shuffle(datum_list)\n n_train = int(len(datum_list) * args.perc_train)\n n_val = int(len(datum_list) * args.perc_val)\n\n for datum in datum_list[:n_train]:\n datum['split'] = 'train'\n \n for datum in datum_list[n_train:n_train+n_val]:\n datum['split'] = 'val'\n \n for datum in datum_list[n_train+n_val:]:\n datum['split'] = 'test'\n \n dataset_stage3.extend(datum_list) ",
"_____no_output_____"
],
[
"# here we pop and assign into the dictionary, thus modifying in place\nfor datum in dataset_stage3:\n datum['source_language'] = \" \".join(datum.pop('english_tokens'))\n datum['target_language'] = \" \".join(datum.pop('french_tokens'))",
"_____no_output_____"
],
[
"nmt_df = pd.DataFrame(dataset_stage3)",
"_____no_output_____"
],
[
"nmt_df.head()",
"_____no_output_____"
],
[
"nmt_df.to_csv(args.output_data_path)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1c118257fd101edbe2db2843b93e0b60f78c8b
| 88,015 |
ipynb
|
Jupyter Notebook
|
Aqua_Modis_Explorer.ipynb
|
OceanAtlas/incubator
|
656e5e172533dd75415867bf853d00fec2f66307
|
[
"BSD-2-Clause"
] | null | null | null |
Aqua_Modis_Explorer.ipynb
|
OceanAtlas/incubator
|
656e5e172533dd75415867bf853d00fec2f66307
|
[
"BSD-2-Clause"
] | null | null | null |
Aqua_Modis_Explorer.ipynb
|
OceanAtlas/incubator
|
656e5e172533dd75415867bf853d00fec2f66307
|
[
"BSD-2-Clause"
] | null | null | null | 187.265957 | 51,080 | 0.889564 |
[
[
[
"import netCDF4\nimport numpy as np\nimport pandas as pd\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport matplotlib.cm as cm \nfrom matplotlib.colors import LinearSegmentedColormap\nimport csv, sys, pdb, time, math\nimport xarray as xr",
"_____no_output_____"
],
[
"file = \"/Users/oz/Downloads/A20182132018243.L3m_MO_CHL_chlor_a_4km.nc\"",
"_____no_output_____"
],
[
"rootgrp = netCDF4.Dataset(file, \"r\", format=\"NETCDF4\")",
"_____no_output_____"
],
[
"print(rootgrp.data_model)\nprint(rootgrp.dimensions)\n\nprint(rootgrp.variables)\nprint(len(rootgrp.dimensions.get(\"lat\")))\nprint(len(rootgrp.dimensions.get(\"lon\")))",
"NETCDF4\nOrderedDict([('lat', <class 'netCDF4._netCDF4.Dimension'>: name = 'lat', size = 4320\n), ('lon', <class 'netCDF4._netCDF4.Dimension'>: name = 'lon', size = 8640\n), ('rgb', <class 'netCDF4._netCDF4.Dimension'>: name = 'rgb', size = 3\n), ('eightbitcolor', <class 'netCDF4._netCDF4.Dimension'>: name = 'eightbitcolor', size = 256\n)])\nOrderedDict([('chlor_a', <class 'netCDF4._netCDF4.Variable'>\nfloat32 chlor_a(lat, lon)\n long_name: Chlorophyll Concentration, OCI Algorithm\n units: mg m^-3\n standard_name: mass_concentration_of_chlorophyll_in_sea_water\n _FillValue: -32767.0\n valid_min: 0.001\n valid_max: 100.0\n reference: Hu, C., Lee Z., and Franz, B.A. (2012). Chlorophyll-a algorithms for oligotrophic oceans: A novel approach based on three-band reflectance difference, J. Geophys. Res., 117, C01011, doi:10.1029/2011JC007395.\n display_scale: log\n display_min: 0.01\n display_max: 20.0\nunlimited dimensions: \ncurrent shape = (4320, 8640)\nfilling on), ('lat', <class 'netCDF4._netCDF4.Variable'>\nfloat32 lat(lat)\n long_name: Latitude\n units: degrees_north\n standard_name: latitude\n _FillValue: -999.0\n valid_min: -90.0\n valid_max: 90.0\nunlimited dimensions: \ncurrent shape = (4320,)\nfilling on), ('lon', <class 'netCDF4._netCDF4.Variable'>\nfloat32 lon(lon)\n long_name: Longitude\n units: degrees_east\n standard_name: longitude\n _FillValue: -999.0\n valid_min: -180.0\n valid_max: 180.0\nunlimited dimensions: \ncurrent shape = (8640,)\nfilling on), ('palette', <class 'netCDF4._netCDF4.Variable'>\nuint8 palette(rgb, eightbitcolor)\nunlimited dimensions: \ncurrent shape = (3, 256)\nfilling on, default _FillValue of 255 ignored\n)])\n4320\n8640\n"
],
[
"aVar = rootgrp.variables.get('chlor_a') # a Variable Object\nprint(aVar)",
"<class 'netCDF4._netCDF4.Variable'>\nfloat32 chlor_a(lat, lon)\n long_name: Chlorophyll Concentration, OCI Algorithm\n units: mg m^-3\n standard_name: mass_concentration_of_chlorophyll_in_sea_water\n _FillValue: -32767.0\n valid_min: 0.001\n valid_max: 100.0\n reference: Hu, C., Lee Z., and Franz, B.A. (2012). Chlorophyll-a algorithms for oligotrophic oceans: A novel approach based on three-band reflectance difference, J. Geophys. Res., 117, C01011, doi:10.1029/2011JC007395.\n display_scale: log\n display_min: 0.01\n display_max: 20.0\nunlimited dimensions: \ncurrent shape = (4320, 8640)\nfilling on\n"
],
[
"# get lat dimension\ntheLatDim = rootgrp.dimensions.get(\"lat\")\nlatSize = theLatDim.size\nprint(latSize)\n\n# the lon dimensions\nlonSize = rootgrp.dimensions.get(\"lon\").size\nprint(lonSize)\n\ngrid = np.zeros((latSize, lonSize))\n\nlatGrid = np.zeros((latSize))\nlonGrid = np.zeros((lonSize))\nltVar = rootgrp.variables.get('lat')\nlnVar = rootgrp.variables.get('lon')\n\nfor lt in range(latSize):\n latGrid[lt] = ltVar[lt]\n# print(ltVar[lt], \"\\t\", end=\"\\n\")\nfor ln in range(lonSize):\n lonGrid[ln] = lnVar[ln]\n# print(lnVar[ln], end=\"\")\n\n#iterate the netcdf array at the surface (0)\n# for lt in range(latSize):\n# for ln in range(lonSize):\n# print(aVar[lt, ln], end=\"\")\n# print()",
"4320\n8640\n"
],
[
"chlor_a_ds = xr.open_dataset(file)",
"_____no_output_____"
],
[
"print(chlor_a_ds)",
"<xarray.Dataset>\nDimensions: (eightbitcolor: 256, lat: 4320, lon: 8640, rgb: 3)\nCoordinates:\n * lat (lat) float32 89.979164 89.9375 89.89583 ... -89.93751 -89.97918\n * lon (lon) float32 -179.97917 -179.9375 ... 179.93752 179.97917\nDimensions without coordinates: eightbitcolor, rgb\nData variables:\n chlor_a (lat, lon) float32 ...\n palette (rgb, eightbitcolor) uint8 ...\nAttributes:\n product_name: A20182132018243.L3m_MO_CHL_chlor_a_4km.nc\n instrument: MODIS\n title: MODISA Level-3 Standard Mapped Image\n project: Ocean Biology Processing Group (NASA/G...\n platform: Aqua\n temporal_range: month\n processing_version: 2018.0\n date_created: 2018-10-09T21:47:08.000Z\n history: l3mapgen par=A20182132018243.L3m_MO_CH...\n l2_flag_names: ATMFAIL,LAND,HILT,HISATZEN,STRAYLIGHT,...\n time_coverage_start: 2018-08-01T01:00:00.000Z\n time_coverage_end: 2018-09-01T02:25:00.000Z\n start_orbit_number: 86396\n end_orbit_number: 86849\n map_projection: Equidistant Cylindrical\n latitude_units: degrees_north\n longitude_units: degrees_east\n northernmost_latitude: 90.0\n southernmost_latitude: -90.0\n westernmost_longitude: -180.0\n easternmost_longitude: 180.0\n geospatial_lat_max: 90.0\n geospatial_lat_min: -90.0\n geospatial_lon_max: 180.0\n geospatial_lon_min: -180.0\n grid_mapping_name: latitude_longitude\n latitude_step: 0.041666668\n longitude_step: 0.041666668\n sw_point_latitude: -89.979164\n sw_point_longitude: -179.97917\n geospatial_lon_resolution: 4.6383123\n geospatial_lat_resolution: 4.6383123\n geospatial_lat_units: degrees_north\n geospatial_lon_units: degrees_east\n spatialResolution: 4.64 km\n number_of_lines: 4320\n number_of_columns: 8640\n measure: Mean\n suggested_image_scaling_minimum: 0.01\n suggested_image_scaling_maximum: 20.0\n suggested_image_scaling_type: LOG\n suggested_image_scaling_applied: No\n _lastModified: 2018-10-09T21:47:08.000Z\n Conventions: CF-1.6 ACDD-1.3\n institution: NASA Goddard Space Flight Center, Ocea...\n standard_name_vocabulary: CF Standard Name Table v36\n naming_authority: gov.nasa.gsfc.sci.oceandata\n id: A20182132018243.L3b_MO_CHL.nc/L3/A2018...\n license: http://science.nasa.gov/earth-science/...\n creator_name: NASA/GSFC/OBPG\n publisher_name: NASA/GSFC/OBPG\n creator_email: [email protected]\n publisher_email: [email protected]\n creator_url: http://oceandata.sci.gsfc.nasa.gov\n publisher_url: http://oceandata.sci.gsfc.nasa.gov\n processing_level: L3 Mapped\n cdm_data_type: grid\n identifier_product_doi_authority: http://dx.doi.org\n identifier_product_doi: 10.5067/AQUA/MODIS/L3M/CHL/2018\n keywords: Earth Science > Oceans > Ocean Chemist...\n keywords_vocabulary: NASA Global Change Master Directory (G...\n data_bins: 16353084\n data_minimum: 0.006072768\n data_maximum: 99.716034\n"
],
[
"chlor_da = chlor_a_ds['chlor_a'].values",
"_____no_output_____"
],
[
"print(chlor_da.shape)\nlatVals = chlor_a_ds['lat'].values\nlonVals = chlor_a_ds['lon'].values\nprint(latVals)\nprint(lonVals)",
"(4320, 8640)\n[ 89.979164 89.9375 89.89583 ... -89.895836 -89.93751 -89.97918 ]\n[-179.97917 -179.9375 -179.89584 ... 179.89583 179.93752 179.97917]\n"
],
[
"chlor_a_ds['chlor_a'].plot.imshow(vmin=0.0, vmax=30.0)",
"_____no_output_____"
],
[
"latVals = chlor_a_ds['lat'].values",
"_____no_output_____"
],
[
"print(latVals)",
"[ 89.979164 89.9375 89.89583 ... -89.895836 -89.93751 -89.97918 ]\n"
],
[
"plt.imshow(chlor_da, extent=(lonVals.min(), lonVals.max(), latVals.min(), latVals.max()),\n interpolation='nearest', cmap=cm.gist_rainbow) #LRBT\nplt.show()",
"_____no_output_____"
],
[
"lapush_da = chlor_a_ds['chlor_a'].sel(lat=[47.97], lon=[-125.37], method='nearest')",
"_____no_output_____"
],
[
"lapush_da",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1c28bf11c2d699c0ba8102a623b10be8918182
| 35,653 |
ipynb
|
Jupyter Notebook
|
intro-to-pytorch/Part 4 - Fashion-MNIST (Solution).ipynb
|
NalinDadhich/PyTorch
|
5eec09daa15a7c394129774bbe04c0d7a4c0c024
|
[
"MIT"
] | null | null | null |
intro-to-pytorch/Part 4 - Fashion-MNIST (Solution).ipynb
|
NalinDadhich/PyTorch
|
5eec09daa15a7c394129774bbe04c0d7a4c0c024
|
[
"MIT"
] | 5 |
2019-12-16T21:50:49.000Z
|
2022-02-10T00:16:44.000Z
|
intro-to-pytorch/Part 4 - Fashion-MNIST (Solution).ipynb
|
NalinDadhich/PyTorch
|
5eec09daa15a7c394129774bbe04c0d7a4c0c024
|
[
"MIT"
] | null | null | null | 146.720165 | 24,056 | 0.88318 |
[
[
[
"# Classifying Fashion-MNIST\n\nNow it's your turn to build and train a neural network. You'll be using the [Fashion-MNIST dataset](https://github.com/zalandoresearch/fashion-mnist), a drop-in replacement for the MNIST dataset. MNIST is actually quite trivial with neural networks where you can easily achieve better than 97% accuracy. Fashion-MNIST is a set of 28x28 greyscale images of clothes. It's more complex than MNIST, so it's a better representation of the actual performance of your network, and a better representation of datasets you'll use in the real world.\n\n<img src='assets/fashion-mnist-sprite.png' width=500px>\n\nIn this notebook, you'll build your own neural network. For the most part, you could just copy and paste the code from Part 3, but you wouldn't be learning. It's important for you to write the code yourself and get it to work. Feel free to consult the previous notebooks though as you work through this.\n\nFirst off, let's load the dataset through torchvision.",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torchvision import datasets, transforms\nimport helper\n\n# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n# Download and load the training data\ntrainset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)\n\n# Download and load the test data\ntestset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/', download=True, train=False, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"Here we can see one of the images.",
"_____no_output_____"
]
],
[
[
"image, label = next(iter(trainloader))\nhelper.imshow(image[0,:]);",
"_____no_output_____"
]
],
[
[
"## Building the network\n\nHere you should define your network. As with MNIST, each image is 28x28 which is a total of 784 pixels, and there are 10 classes. You should include at least one hidden layer. We suggest you use ReLU activations for the layers and to return the logits or log-softmax from the forward pass. It's up to you how many layers you add and the size of those layers.",
"_____no_output_____"
]
],
[
[
"from torch import nn, optim\nimport torch.nn.functional as F",
"_____no_output_____"
],
[
"# TODO: Define your network architecture here\nclass Classifier(nn.Module):\n def __init__(self):\n super().__init__()\n self.fc1 = nn.Linear(784, 256)\n self.fc2 = nn.Linear(256, 128)\n self.fc3 = nn.Linear(128, 64)\n self.fc4 = nn.Linear(64, 10)\n \n def forward(self, x):\n # make sure input tensor is flattened\n x = x.view(x.shape[0], -1)\n \n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = F.relu(self.fc3(x))\n x = F.log_softmax(self.fc4(x), dim=1)\n \n return x",
"_____no_output_____"
]
],
[
[
"# Train the network\n\nNow you should create your network and train it. First you'll want to define [the criterion](http://pytorch.org/docs/master/nn.html#loss-functions) (something like `nn.CrossEntropyLoss` or `nn.NLLLoss`) and [the optimizer](http://pytorch.org/docs/master/optim.html) (typically `optim.SGD` or `optim.Adam`).\n\nThen write the training code. Remember the training pass is a fairly straightforward process:\n\n* Make a forward pass through the network to get the logits \n* Use the logits to calculate the loss\n* Perform a backward pass through the network with `loss.backward()` to calculate the gradients\n* Take a step with the optimizer to update the weights\n\nBy adjusting the hyperparameters (hidden units, learning rate, etc), you should be able to get the training loss below 0.4.",
"_____no_output_____"
]
],
[
[
"# TODO: Create the network, define the criterion and optimizer\nmodel = Classifier()\ncriterion = nn.NLLLoss()\noptimizer = optim.Adam(model.parameters(), lr=0.003)",
"_____no_output_____"
],
[
"# TODO: Train the network here\nepochs = 5\n\nfor e in range(epochs):\n running_loss = 0\n for images, labels in trainloader:\n log_ps = model(images)\n loss = criterion(log_ps, labels)\n \n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n \n running_loss += loss.item()\n else:\n print(f\"Training loss: {running_loss/len(trainloader)}\")",
"Training loss: 283.4510831311345\nTraining loss: 274.7842669263482\nTraining loss: 267.907463490963\nTraining loss: 258.2156918346882\nTraining loss: 251.79347000271082\n"
],
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport helper\n\n# Test out your network!\n\ndataiter = iter(testloader)\nimages, labels = dataiter.next()\nimg = images[1]\n\n# TODO: Calculate the class probabilities (softmax) for img\nps = torch.exp(model(img))\n\n# Plot the image and probabilities\nhelper.view_classify(img, ps, version='Fashion')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a1c3db6eb0ff59031773b0b768c782a9fb098b2
| 61,493 |
ipynb
|
Jupyter Notebook
|
common-voice-small/main.ipynb
|
py-lidbox/examples
|
789c5ceb02653999653cd025eded58f43ab1adc8
|
[
"MIT"
] | 2 |
2020-12-10T10:44:55.000Z
|
2021-04-12T10:57:06.000Z
|
common-voice-small/main.ipynb
|
py-lidbox/examples
|
789c5ceb02653999653cd025eded58f43ab1adc8
|
[
"MIT"
] | 4 |
2020-11-04T18:09:32.000Z
|
2022-01-29T19:08:13.000Z
|
common-voice-small/main.ipynb
|
py-lidbox/examples
|
789c5ceb02653999653cd025eded58f43ab1adc8
|
[
"MIT"
] | 2 |
2021-05-05T03:40:13.000Z
|
2021-12-10T06:39:46.000Z
| 37.133454 | 300 | 0.601695 |
[
[
[
"# Automatically reload imported modules that are changed outside this notebook\n%load_ext autoreload\n%autoreload 2\n\n# More pixels in figures\nimport matplotlib.pyplot as plt\n%matplotlib inline\nplt.rcParams[\"figure.dpi\"] = 200\n\n# Init PRNG with fixed seed for reproducibility\nimport numpy as np\nnp_rng = np.random.default_rng(1)\n\nimport tensorflow as tf\ntf.random.set_seed(np_rng.integers(0, tf.int64.max))",
"_____no_output_____"
]
],
[
[
"# Common Voice spoken language identification with a neural network\n\n**2020-11-08**\n\n\nThis example is a thorough, but simple walk-through on how to do everything from loading mp3-files containing speech to preprocessing and transforming the speech data into something we can feed to a neural network classifier.\nDeep learning based speech analysis is a vast research topic and there are countless techniques that could possibly be applied to improve the results of this example.\nThis example tries to avoid going into too much detail into these techniques and instead focuses on getting an end-to-end classification pipeline up and running with a small dataset.\n\n## Data\n\nThis example uses open speech data downloaded from the [Mozilla Common Voice](https://commonvoice.mozilla.org/en/datasets) project.\nSee the readme file for downloading the data.\nIn addition to the space needed for the downloaded data, you will need at least 10 GiB of free disk space for caching (can be disabled).",
"_____no_output_____"
]
],
[
[
"import urllib.parse\nfrom IPython.display import display, Markdown\n\n\nlanguages = \"\"\"\n et\n mn\n ta\n tr\n\"\"\".split()\n\nlanguages = sorted(l.strip() for l in languages)\n\ndisplay(Markdown(\"### Languages\"))\ndisplay(Markdown('\\n'.join(\"* `{}`\".format(l) for l in languages)))\n\nbcp47_validator_url = 'https://schneegans.de/lv/?tags='\ndisplay(Markdown(\"See [this tool]({}) for a description of the BCP-47 language codes.\"\n .format(bcp47_validator_url + urllib.parse.quote('\\n'.join(languages)))))",
"_____no_output_____"
]
],
[
[
"## Loading the metadata\n\nWe start by preprocessing the Common Voice metadata files.\n\nUpdate `datadir` and `workdir` to match your setup.\nAll output will be written to `workdir`.",
"_____no_output_____"
]
],
[
[
"import os\n\n\nworkdir = \"/data/exp/cv4\"\ndatadir = \"/mnt/data/speech/common-voice/downloads/2020/cv-corpus\"\n\nprint(\"work dir:\", workdir)\nprint(\"data source dir:\", datadir)\n\nos.makedirs(workdir, exist_ok=True)\nassert os.path.isdir(datadir), datadir + \" does not exist\"",
"_____no_output_____"
]
],
[
[
"Common Voice metadata is distributed as `tsv` files and all audio samples are mp3-files under `clips`.",
"_____no_output_____"
]
],
[
[
"dirs = sorted((f for f in os.scandir(datadir) if f.is_dir()), key=lambda f: f.name)\n\nprint(datadir)\nfor d in dirs:\n if d.name in languages:\n print(' ', d.name)\n for f in os.scandir(d):\n print(' ', f.name)\n\nmissing_languages = set(languages) - set(d.name for d in dirs)\nassert missing_languages == set(), \"missing languages: {}\".format(missing_languages)",
"_____no_output_____"
]
],
[
[
"There's plenty of metadata, but it seems that the train-dev-test split has been predefined so lets use that.\n\n[pandas](https://pandas.pydata.org/pandas-docs/stable/index.html) makes it easy to read, filter, and manipulate metadata in tables.\nLets try to preprocess all metadata here so we don't have to worry about it later.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom IPython.display import display, Markdown\n\n\n# Lexicographic order of labels as a fixed index target to label mapping\ntarget2lang = tuple(sorted(languages))\nlang2target = {lang: target for target, lang in enumerate(target2lang)}\n\nprint(\"lang2target:\", lang2target)\nprint(\"target2lang:\", target2lang)\n\n\ndef expand_metadata(row):\n \"\"\"\n Update dataframe row by generating a unique utterance id,\n expanding the absolute path to the mp3 file,\n and adding an integer target for the label.\n \"\"\"\n row.id = \"{:s}_{:s}\".format(\n row.path.split(\".mp3\", 1)[0].split(\"common_voice_\", 1)[1],\n row.split)\n row.path = os.path.join(datadir, row.lang, \"clips\", row.path)\n row.target = lang2target[row.lang]\n return row\n\n\ndef tsv_to_lang_dataframe(lang, split):\n \"\"\"\n Given a language and dataset split (train, dev, test),\n load the Common Voice metadata tsv-file from disk into a pandas.DataFrame.\n Preprocess all rows by dropping unneeded columns and adding new metadata.\n \"\"\"\n df = pd.read_csv(\n os.path.join(datadir, lang, split + \".tsv\"),\n sep='\\t',\n # We only need these columns from the metadata\n usecols=(\"client_id\", \"path\", \"sentence\"))\n # Add language label as column\n df.insert(len(df.columns), \"lang\", lang)\n # Add split name to every row for easier filtering\n df.insert(len(df.columns), \"split\", split)\n # Add placeholders for integer targets and utterance ids generated row-wise\n df.insert(len(df.columns), \"target\", -1)\n df.insert(len(df.columns), \"id\", \"\")\n # Create new metadata columns\n df = df.transform(expand_metadata, axis=1)\n return df\n\n\nsplit_names = (\"train\", \"dev\", \"test\")\n\n# Concatenate metadata for all 4 languages into a single table for each split\nsplits = [pd.concat([tsv_to_lang_dataframe(lang, split) for lang in target2lang])\n for split in split_names]\n\n# Concatenate split metadata into a single table, indexed by utterance ids\nmeta = (pd.concat(splits)\n .set_index(\"id\", drop=True, verify_integrity=True)\n .sort_index())\ndel splits\n\nfor split in split_names:\n display(Markdown(\"### \" + split))\n display(meta[meta[\"split\"]==split])",
"_____no_output_____"
]
],
[
[
"### Checking that all splits are disjoint by speaker\n\nTo ensure our neural network will learn what language is being spoken and not who is speaking, we want to test it on data that does not have any voices present in the training data.\nThe `client_id` should correspond to a unique, pseudonymized identifier for every speaker.\n\nLets check all splits are disjoint by speaker id.",
"_____no_output_____"
]
],
[
[
"def assert_splits_disjoint_by_speaker(meta):\n split2spk = {split: set(meta[meta[\"split\"]==split].client_id.to_numpy())\n for split in split_names}\n\n for split, spk in split2spk.items():\n print(\"split {} has {} speakers\".format(split, len(spk)))\n\n print()\n print(\"asserting all are disjoint\")\n assert split2spk[\"train\"] & split2spk[\"test\"] == set(), \"train and test, mutual speakers\"\n assert split2spk[\"train\"] & split2spk[\"dev\"] == set(), \"train and dev, mutual speakers\"\n assert split2spk[\"dev\"] & split2spk[\"test\"] == set(), \"dev and test, mutual speakers\"\n print(\"ok\")\n\n\nassert_splits_disjoint_by_speaker(meta)",
"_____no_output_____"
]
],
[
[
"We can see that none of the speakers are in two or more dataset splits.\nWe also see that the test set has a lot of unique speakers who are not in the training set.\nThis is good because we want to test that our neural network classifier knows how to classify input from unknown speakers.\n\n### Checking that all audio files exist",
"_____no_output_____"
]
],
[
[
"for uttid, row in meta.iterrows():\n assert os.path.exists(row[\"path\"]), row[\"path\"] + \" does not exist\"\nprint(\"ok\")",
"_____no_output_____"
]
],
[
[
"## Balancing the language distribution\n\nLets see how many samples we have per language.",
"_____no_output_____"
]
],
[
[
"import seaborn as sns\n\n\nsns.set(rc={'figure.figsize': (8, 6)})\nax = sns.countplot(\n x=\"split\",\n order=split_names,\n hue=\"lang\",\n hue_order=target2lang,\n data=meta)\nax.set_title(\"Total amount of audio samples\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"We can see that the amount of samples with Mongolian, Tamil, and Turkish speech are quite balanced, but we have significantly larger amounts of Estonian speech.\nMore data is of course always better, but if there is too much of one label compared to the others, our neural network might overfit on this label.\n\nBut these are only the counts of audio files, how much speech do we have in total per language?\nWe need to read every file to get a reliable answer.\nSee also [SoX](http://sox.sourceforge.net/Main/HomePage) for a good command line tool.",
"_____no_output_____"
]
],
[
[
"import miniaudio\n\n\nmeta[\"duration\"] = np.array([\n miniaudio.mp3_get_file_info(path).duration for path in meta.path], np.float32)\nmeta",
"_____no_output_____"
],
[
"def plot_duration_distribution(data):\n sns.set(rc={'figure.figsize': (8, 6)})\n \n ax = sns.boxplot(\n x=\"split\",\n order=split_names,\n y=\"duration\",\n hue=\"lang\",\n hue_order=target2lang,\n data=data)\n ax.set_title(\"Median audio file duration in seconds\")\n plt.show()\n\n ax = sns.barplot(\n x=\"split\",\n order=split_names,\n y=\"duration\",\n hue=\"lang\",\n hue_order=target2lang,\n data=data,\n ci=None,\n estimator=np.sum)\n ax.set_title(\"Total amount of audio in seconds\")\n plt.show()\n\n\nplot_duration_distribution(meta)",
"_____no_output_____"
]
],
[
[
"The median length of Estonian samples is approx. 2.5 seconds greater compared to Turkish samples, which have the shortest median length.\nWe can also see that the total amount of Estonian speech is much larger compared to other languages in our datasets.\nNotice also the significant amount of outliers with long durations in the Tamil and Turkish datasets.\n\nLets do simple random oversampling for the training split using this approach:\n\n1. Select the target language according to maximum total amount of speech in seconds (Estonian).\n2. Compute differences in total durations between the target language and the three other languages.\n3. Compute median signal length by language.\n4. Compute sample sizes by dividing the duration deltas with median signal lengths, separately for each language.\n5. Draw samples with replacement from the metadata separately for each language.\n6. Merge samples with rest of the metadata and verify there are no duplicate ids.",
"_____no_output_____"
]
],
[
[
"def random_oversampling(meta):\n groupby_lang = meta[[\"lang\", \"duration\"]].groupby(\"lang\")\n \n total_dur = groupby_lang.sum()\n target_lang = total_dur.idxmax()[0]\n print(\"target lang:\", target_lang)\n print(\"total durations:\")\n display(total_dur)\n \n total_dur_delta = total_dur.loc[target_lang] - total_dur\n print(\"total duration delta to target lang:\")\n display(total_dur_delta)\n \n median_dur = groupby_lang.median()\n print(\"median durations:\")\n display(median_dur)\n \n sample_sizes = (total_dur_delta / median_dur).astype(np.int32)\n print(\"median duration weighted sample sizes based on total duration differences:\")\n display(sample_sizes)\n \n samples = []\n \n for lang in groupby_lang.groups:\n sample_size = sample_sizes.loc[lang][0]\n sample = (meta[meta[\"lang\"]==lang]\n .sample(n=sample_size, replace=True, random_state=np_rng.bit_generator)\n .reset_index()\n .transform(update_sample_id, axis=1))\n samples.append(sample)\n\n return pd.concat(samples).set_index(\"id\", drop=True, verify_integrity=True)\n\n\ndef update_sample_id(row):\n row[\"id\"] = \"{}_copy_{}\".format(row[\"id\"], row.name)\n return row\n\n \n# Augment training set metadata\nmeta = pd.concat([random_oversampling(meta[meta[\"split\"]==\"train\"]), meta]).sort_index()\n\nassert not meta.isna().any(axis=None), \"NaNs in metadata after augmentation\"\nplot_duration_distribution(meta)\nassert_splits_disjoint_by_speaker(meta)\nmeta",
"_____no_output_____"
]
],
[
[
"Speech data augmentation is a common research topic.\nThere are [better](https://www.isca-speech.org/archive/interspeech_2015/papers/i15_3586.pdf) ways to augment data than the simple duplication of metadata rows we did here.\nOne approach (which we won't be doing here) which is easy to implement and might work well is to take copies of signals and make them randomly a bit faster or slower.\nFor example, draw randomly speed ratios from `[0.9, 1.1]` and resample the signal by multiplying its sample rate with the random ratio.",
"_____no_output_____"
],
[
"## Inspecting the audio\n\nLets take a look at the speech data and listen to a few randomly picked samples from each label.\nWe pick 2 random samples for each language from the training set.",
"_____no_output_____"
]
],
[
[
"samples = (meta[meta[\"split\"]==\"train\"]\n .groupby(\"lang\")\n .sample(n=2, random_state=np_rng.bit_generator))\nsamples",
"_____no_output_____"
]
],
[
[
"Then lets read the mp3-files from disk, plot the signals, and listen to the audio.",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, Audio, HTML\nimport scipy.signal\n\n\ndef read_mp3(path, resample_rate=16000):\n if isinstance(path, bytes):\n # If path is a tf.string tensor, it will be in bytes\n path = path.decode(\"utf-8\")\n \n f = miniaudio.mp3_read_file_f32(path)\n \n # Downsample to target rate, 16 kHz is commonly used for speech data\n new_len = round(len(f.samples) * float(resample_rate) / f.sample_rate)\n signal = scipy.signal.resample(f.samples, new_len)\n \n # Normalize to [-1, 1]\n signal /= np.abs(signal).max()\n \n return signal, resample_rate\n\n\ndef embed_audio(signal, rate):\n display(Audio(data=signal, rate=rate, embed=True, normalize=False))\n\n \ndef plot_signal(data, figsize=(6, 0.5), **kwargs):\n ax = sns.lineplot(data=data, lw=0.1, **kwargs)\n ax.set_axis_off()\n ax.margins(0)\n plt.gcf().set_size_inches(*figsize)\n plt.show()\n\n \ndef plot_separator():\n display(HTML(data=\"<hr style='border: 2px solid'>\"))\n\n \nfor sentence, lang, clip_path in samples[[\"sentence\", \"lang\", \"path\"]].to_numpy():\n signal, rate = read_mp3(clip_path)\n plot_signal(signal)\n print(\"length: {} sec\".format(signal.size / rate))\n print(\"lang:\", lang)\n print(\"sentence:\", sentence)\n embed_audio(signal, rate)\n plot_separator()",
"_____no_output_____"
]
],
[
[
"One of the most challenging aspects of the Mozilla Common Voice dataset is that the audio quality varies greatly: different microphones, background noise, user is speaking close to the device or far away etc.\nIt is difficult to ensure that a neural network will learn to classify different languages as opposed to classifying distinct acoustic artefacts from specific microphones.\nThere's a [vast amount of research](https://www.isca-speech.org/archive/Interspeech_2020/) being done on developing techniques for solving these kind of problems.\nHowever, these are well out of scope for this simple example and we won't be studying them here.\n\n\n## Spectral representations\n\nIt is usually not possible (at least not yet in 2020) to detect languages directly from the waveform.\nInstead, the [fast Fourier transform](https://en.wikipedia.org/wiki/Short-time_Fourier_transform) (FFT) is applied on small, overlapping windows of the signal to get a 2-dimensional representation of energies in different frequency bands.\nSee [this](https://wiki.aalto.fi/display/ITSP/Spectrogram+and+the+STFT) for further details.\n\nHowever, output from the FFT is usually not usable directly and must be refined.\nLets begin by selecting the first signal from our random sample and extract the power spectrogram.\n\n### Power spectrogram",
"_____no_output_____"
]
],
[
[
"from lidbox.features.audio import spectrograms\n\n\ndef plot_spectrogram(S, cmap=\"viridis\", figsize=None, **kwargs):\n if figsize is None:\n figsize = S.shape[0]/50, S.shape[1]/50\n ax = sns.heatmap(S.T, cbar=False, cmap=cmap, **kwargs)\n ax.invert_yaxis()\n ax.set_axis_off()\n ax.margins(0)\n plt.gcf().set_size_inches(*figsize)\n plt.show()\n\n \nsample = samples[[\"sentence\", \"lang\", \"path\"]].to_numpy()[0]\nsentence, lang, clip_path = sample\n\nsignal, rate = read_mp3(clip_path)\nplot_signal(signal)\n\npowspec = spectrograms([signal], rate)[0]\n\nplot_spectrogram(powspec.numpy())",
"_____no_output_____"
]
],
[
[
"This representation is very sparse, with zeros everywhere except in the lowest frequency bands.\nThe main problem here is that relative differences between energy values are very large, making it different to compare large changes in energy.\nThese differences can be reduced by mapping the values onto a logarithmic scale.\n\nThe [decibel-scale](https://en.wikipedia.org/wiki/Decibel) is a common choice.\nWe will use the maximum value of `powspec` as the reference power ($\\text{P}_0$).\n\n### Decibel-scale spectrogram",
"_____no_output_____"
]
],
[
[
"from lidbox.features.audio import power_to_db\n\n\ndbspec = power_to_db([powspec])[0]\nplot_spectrogram(dbspec.numpy())",
"_____no_output_____"
]
],
[
[
"This is an improvement, but the representation is still rather sparse.\nWe also see that most speech information is in the lower bands, with a bit of energy in the higher frequencies.\nA common approach is to \"squeeze together\" the y-axis of all frequency bands by using a different scale, such as the [Mel-scale](https://en.wikipedia.org/wiki/Mel_scale).\nLets \"squeeze\" the current 256 frequency bins into 40 Mel-bins.",
"_____no_output_____"
],
[
"### Log-scale Mel-spectrogram\n\n**Note** that we are scaling different things here.\nThe Mel-scale warps the frequency bins (y-axis), while the logarithm is used to reduce relative differences between individual spectrogram values (pixels).",
"_____no_output_____"
]
],
[
[
"from lidbox.features.audio import linear_to_mel\n\n\ndef logmelspectrograms(signals, rate):\n powspecs = spectrograms(signals, rate)\n melspecs = linear_to_mel(powspecs, rate, num_mel_bins=40)\n return tf.math.log(melspecs + 1e-6)\n \n\nlogmelspec = logmelspectrograms([signal], rate)[0]\nplot_spectrogram(logmelspec.numpy())",
"_____no_output_____"
]
],
[
[
"One common normalization technique is frequency channel standardization, i.e. normalization of rows to zero mean and unit variance.",
"_____no_output_____"
]
],
[
[
"from lidbox.features import cmvn\n\nlogmelspec_mv = cmvn([logmelspec])[0]\nplot_spectrogram(logmelspec_mv.numpy())",
"_____no_output_____"
]
],
[
[
"Or only mean-normalization if you think the variances contain important information.",
"_____no_output_____"
]
],
[
[
"logmelspec_m = cmvn([logmelspec], normalize_variance=False)[0]\nplot_spectrogram(logmelspec_m.numpy())",
"_____no_output_____"
]
],
[
[
"## Cepstral representations\n\nAnother common representation are the Mel-frequency cepstral coefficients (MFCC), which are obtained by applying the [discrete cosine transform](https://en.wikipedia.org/wiki/Discrete_cosine_transform) on the log-scale Mel-spectrogram.\n\n### MFCC",
"_____no_output_____"
]
],
[
[
"def plot_cepstra(X, figsize=None):\n if not figsize:\n figsize = (X.shape[0]/50, X.shape[1]/20)\n plot_spectrogram(X, cmap=\"RdBu_r\", figsize=figsize)\n\n \nmfcc = tf.signal.mfccs_from_log_mel_spectrograms([logmelspec])[0]\nplot_cepstra(mfcc.numpy())",
"_____no_output_____"
]
],
[
[
"Most of the information is concentrated in the lower coefficients.\nIt is common to drop the 0th coefficient and select a subset starting at 1, e.g. 1 to 20.\nSee [this post](http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/) for more details.",
"_____no_output_____"
]
],
[
[
"mfcc = mfcc[:,1:21]\nplot_cepstra(mfcc.numpy())",
"_____no_output_____"
]
],
[
[
"Now we have a very compact representation, but most of the variance is still in the lower coefficients and overshadows the smaller changes in higher coefficients.\nWe can normalize the MFCC matrix row-wise by standardizing each row to zero mean and unit variance.\nThis is commonly called cepstral mean and variance normalization (CMVN).\n\n### MFCC + CMVN",
"_____no_output_____"
]
],
[
[
"mfcc_cmvn = cmvn([mfcc])[0]\nplot_cepstra(mfcc_cmvn.numpy())",
"_____no_output_____"
]
],
[
[
"### Which one is best?\n\nSpeech feature extraction is a large, active research topic and it is impossible to choose one representation that would work well in all situations.\nCommon choices in state-of-the-art spoken language identification are log-scale Mel-spectrograms and MFCCs, with different normalization approaches.\nFor example, [here](https://github.com/swshon/dialectID_e2e) is an experiment in Arabic dialect identification, where log-scale Mel-spectra (referred to as FBANK) produced slightly better results compared to MFCCs.\n\nIt is not obvious when to choose which representation, or if we should even use the FFT at all.\nYou can read [this post](https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html) for a more detailed discussion.\n\n## Voice activity detection\n\nIt is common for speech datasets to contain audio samples with short segments of silence or sounds that are not speech.\nSince these are usually irrelevant for making a language classification decision, we would prefer to discard such segments.\nThis is called voice activity detection (VAD) and it is another large, active research area.\n[Here](https://wiki.aalto.fi/pages/viewpage.action?pageId=151500905) is a brief overview of VAD. \n\nNon-speech segments can be either noise or silence. \nSeparating non-speech noise from speech is non-trivial but possible, for example with [neural networks](https://www.isca-speech.org/archive/Interspeech_2019/pdfs/1354.pdf).\nSilence, on the other hand, shows up as zeros in our speech representations, since these segments contain lower energy values compared to segments with speech.\nSuch non-speech segments are therefore easy to detect and discard, for example by comparing the energy of the segment to the average energy of the whole sample.\n\nIf the samples in our example do not contain much background noise, a simple energy-based VAD technique should be enough to drop all silent segments.\nWe'll use the [root mean square](https://en.wikipedia.org/wiki/Root_mean_square) (RMS) energy to detect short silence segments.\n`lidbox` has a simple energy-based VAD function, which we will use as follows:\n\n1. Divide the signal into non-overlapping 10 ms long windows.\n2. Compute RMS of each window.\n3. Reduce all window RMS values by averaging to get a single mean RMS value.\n4. Set a decision threshold at 0.1 for marking silence windows. In other words, if the window RMS is less than 0.1 of the mean RMS, mark the window as silence.\n",
"_____no_output_____"
]
],
[
[
"from lidbox.features.audio import framewise_rms_energy_vad_decisions\nimport matplotlib.patches as patches\n\n\nsentence, lang, clip_path = sample\nsignal, rate = read_mp3(clip_path)\n\nwindow_ms = tf.constant(10, tf.int32)\nwindow_frame_length = (window_ms * rate) // 1000\n\n# Get binary VAD decisions for each 10 ms window\nvad_1 = framewise_rms_energy_vad_decisions(\n signal=signal,\n sample_rate=rate,\n frame_step_ms=window_ms,\n strength=0.1)\n\n# Plot unfiltered signal\nsns.set(rc={'figure.figsize': (6, 0.5)})\nax = sns.lineplot(data=signal, lw=0.1, legend=None)\nax.set_axis_off()\nax.margins(0)\n\n# Plot shaded area over samples marked as not speech (VAD == 0)\nfor x, is_speech in enumerate(vad_1.numpy()):\n if not is_speech:\n rect = patches.Rectangle(\n (x*window_frame_length, -1),\n window_frame_length,\n 2,\n linewidth=0,\n color='gray',\n alpha=0.2)\n ax.add_patch(rect)\nplt.show()\n\nprint(\"lang:\", lang)\nprint(\"sentence: '{}'\".format(sentence))\nembed_audio(signal, rate)\n\n# Partition the signal into 10 ms windows to match the VAD decisions\nwindows = tf.signal.frame(signal, window_frame_length, window_frame_length)\n# Filter signal with VAD decision == 1 (remove gray areas)\nfiltered_signal = tf.reshape(windows[vad_1], [-1])\n\nplot_signal(filtered_signal)\nprint(\"dropped {:d} out of {:d} frames, leaving {:.3f} of the original signal\".format(\n signal.shape[0] - filtered_signal.shape[0],\n signal.shape[0],\n filtered_signal.shape[0]/signal.shape[0]))\nembed_audio(filtered_signal, rate)",
"_____no_output_____"
]
],
[
[
"The filtered signal has less silence, but some of the pauses between words sound too short and unnatural.\nWe would prefer not to remove small pauses that normally occur between words, so lets say all pauses shorter than 300 ms should not be filtered out.\nLets also move all VAD code into a function.",
"_____no_output_____"
]
],
[
[
"def remove_silence(signal, rate):\n window_ms = tf.constant(10, tf.int32)\n window_frames = (window_ms * rate) // 1000\n \n # Get binary VAD decisions for each 10 ms window\n vad_1 = framewise_rms_energy_vad_decisions(\n signal=signal,\n sample_rate=rate,\n frame_step_ms=window_ms,\n # Do not return VAD = 0 decisions for sequences shorter than 300 ms\n min_non_speech_ms=300,\n strength=0.1)\n \n # Partition the signal into 10 ms windows to match the VAD decisions\n windows = tf.signal.frame(signal, window_frames, window_frames)\n # Filter signal with VAD decision == 1\n return tf.reshape(windows[vad_1], [-1])\n\n\nsentence, lang, clip_path = sample\nsignal, rate = read_mp3(clip_path)\n\nfiltered_signal = remove_silence(signal, rate)\nplot_signal(filtered_signal)\n\nprint(\"dropped {:d} out of {:d} frames, leaving {:.3f} of the original signal\".format(\n signal.shape[0] - filtered_signal.shape[0],\n signal.shape[0],\n filtered_signal.shape[0]/signal.shape[0]))\n\nprint(\"lang:\", lang)\nprint(\"sentence: '{}'\".format(sentence))\nembed_audio(filtered_signal, rate)",
"_____no_output_____"
]
],
[
[
"We dropped some silence segments but left most of the speech intact, perhaps this is enough for our example.\n\nAlthough this VAD approach is simple and works ok for our data, it will not work for speech data with non-speech sounds in the background like music or noise.\nFor such data we might need more powerful VAD filters such as neural networks that have been trained on a speech vs non-speech classification task with large amounts of different noise.\n\nBut lets not add more complexity to our example.\nWe'll use the RMS based filter for all other signals too.",
"_____no_output_____"
],
[
"## Comparison of representations\n\nLets extract these features for all signals in our random sample.",
"_____no_output_____"
]
],
[
[
"for sentence, lang, clip_path in samples[[\"sentence\", \"lang\", \"path\"]].to_numpy():\n signal_before_vad, rate = read_mp3(clip_path)\n signal = remove_silence(signal_before_vad, rate)\n \n logmelspec = logmelspectrograms([signal], rate)[0]\n logmelspec_mvn = cmvn([logmelspec], normalize_variance=False)[0]\n \n mfcc = tf.signal.mfccs_from_log_mel_spectrograms([logmelspec])[0]\n mfcc = mfcc[:,1:21]\n mfcc_cmvn = cmvn([mfcc])[0]\n \n plot_width = logmelspec.shape[0]/50\n plot_signal(signal.numpy(), figsize=(plot_width, .6))\n print(\"VAD: {} -> {} sec\".format(\n signal_before_vad.size / rate,\n signal.numpy().size / rate))\n print(\"lang:\", lang)\n print(\"sentence:\", sentence)\n embed_audio(signal.numpy(), rate)\n \n plot_spectrogram(logmelspec_mvn.numpy(), figsize=(plot_width, 1.2))\n plot_cepstra(mfcc_cmvn.numpy(), figsize=(plot_width, .6))\n \n plot_separator()",
"_____no_output_____"
]
],
[
[
"## Loading the samples to a `tf.data.Dataset` iterator\n\nOur dataset is relatively small (2.5 GiB) and we might be able to read all files into signals and keep them in main memory.\nHowever, most speech datasets are much larger due to the amount of data needed for training neural network models that would be of any practical use.\nWe need some kind of lazy iteration or streaming solution that views only one part of the dataset at a time.\nOne such solution is to represent the dataset as a [TensorFlow iterator](https://www.tensorflow.org/api_docs/python/tf/data/Dataset), which evaluates its contents only when they are needed, similar to the [MapReduce](https://en.wikipedia.org/wiki/MapReduce) programming model for big data.\n\nThe downside with lazy iteration or streaming is that we lose the capability of doing random access by row id.\nHowever, this shouldn't be a problem since we can always keep the whole metadata table in memory and do random access on its rows whenever needed.\n\nAnother benefit of TensorFlow dataset iterators is that we can map arbitrary [`tf.function`](https://www.tensorflow.org/api_docs/python/tf/function)s over the dataset and TensorFlow will automatically parallelize the computations and place them on different devices, such as the GPU.\nThe core architecture of `lidbox` has been organized around the `tf.data.Dataset` API, leaving all the heavy lifting for TensorFlow to handle.\n\nBut before we load all our speech data, lets warmup with our small random sample of 8 rows.",
"_____no_output_____"
]
],
[
[
"samples",
"_____no_output_____"
]
],
[
[
"Lets load it into a `tf.data.Dataset`.",
"_____no_output_____"
]
],
[
[
"def metadata_to_dataset_input(meta): \n # Create a mapping from column names to all values under the column as tensors\n return {\n \"id\": tf.constant(meta.index, tf.string),\n \"path\": tf.constant(meta.path, tf.string),\n \"lang\": tf.constant(meta.lang, tf.string),\n \"target\": tf.constant(meta.target, tf.int32),\n \"split\": tf.constant(meta.split, tf.string),\n }\n\n\nsample_ds = tf.data.Dataset.from_tensor_slices(metadata_to_dataset_input(samples))\nsample_ds",
"_____no_output_____"
]
],
[
[
"All elements produced by the `Dataset` iterator are `dict`s of (string, Tensor) pairs, where the string denotes the metadata type.\n\nAlthough the `Dataset` object is primarily for automating large-scale data processing pipelines, it is easy to extract all elements as `numpy`-values:",
"_____no_output_____"
]
],
[
[
"for x in sample_ds.as_numpy_iterator():\n display(x)",
"_____no_output_____"
]
],
[
[
"### Reading audio files\n\nLets load the signals by [mapping](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#map) a file reading function for each element over the whole dataset.\nWe'll add a `tf.data.Dataset` function wrapper on top of `read_mp3`, which we defined earlier.\nTensorFlow will infer the input and output values of the wrapper as tensors from the type signature of dataset elements.\nWe must use `tf.numpy_function` if we want to allow calling the non-TensorFlow function `read_mp3` also from\ninside the graph environment.\nIt might not be as efficient as using TensorFlow ops but reading a file would have a lot of latency anyway so this is not such a big hit for performance.\nBesides, we can always hide the latency by reading several files in parallel.",
"_____no_output_____"
]
],
[
[
"def read_mp3_wrapper(x):\n signal, sample_rate = tf.numpy_function(\n # Function\n read_mp3,\n # Argument list\n [x[\"path\"]],\n # Return value types\n [tf.float32, tf.int64])\n return dict(x, signal=signal, sample_rate=tf.cast(sample_rate, tf.int32))\n\n\nfor x in sample_ds.map(read_mp3_wrapper).as_numpy_iterator():\n print(\"id: {}\".format(x[\"id\"].decode(\"utf-8\")))\n print(\"signal.shape: {}, sample rate: {}\".format(x[\"signal\"].shape, x[\"sample_rate\"]))\n print()",
"_____no_output_____"
]
],
[
[
"### Removing silence and extracting features\n\nOrganizing all preprocessing steps as functions that can be mapped over the `Dataset` object allows us to represent complex transformations easily.",
"_____no_output_____"
]
],
[
[
"def remove_silence_wrapper(x):\n return dict(x, signal=remove_silence(x[\"signal\"], x[\"sample_rate\"]))\n\n\ndef batch_extract_features(x):\n with tf.device(\"GPU\"):\n signals, rates = x[\"signal\"], x[\"sample_rate\"]\n logmelspecs = logmelspectrograms(signals, rates[0])\n logmelspecs_smn = cmvn(logmelspecs, normalize_variance=False)\n mfccs = tf.signal.mfccs_from_log_mel_spectrograms(logmelspecs)\n mfccs = mfccs[...,1:21]\n mfccs_cmvn = cmvn(mfccs)\n return dict(x, logmelspec=logmelspecs_smn, mfcc=mfccs_cmvn)\n\n\nfeatures_ds = (sample_ds.map(read_mp3_wrapper)\n .map(remove_silence_wrapper)\n .batch(1)\n .map(batch_extract_features)\n .unbatch())\n\nfor x in features_ds.as_numpy_iterator():\n print(x[\"id\"])\n for k in (\"signal\", \"logmelspec\", \"mfcc\"):\n print(\"{}.shape: {}\".format(k, x[k].shape))\n print()",
"_____no_output_____"
]
],
[
[
"### Inspecting dataset contents in TensorBoard\n\n`lidbox` has a helper function for dumping element information into [`TensorBoard`](https://www.tensorflow.org/tensorboard) summaries.\nThis converts all 2D features into images, writes signals as audio summaries, and extracts utterance ids.",
"_____no_output_____"
]
],
[
[
"import lidbox.data.steps as ds_steps\n\n\ncachedir = os.path.join(workdir, \"cache\")\n\n_ = ds_steps.consume_to_tensorboard(\n # Rename logmelspec as 'input', these will be plotted as images\n ds=features_ds.map(lambda x: dict(x, input=x[\"logmelspec\"])),\n summary_dir=os.path.join(cachedir, \"tensorboard\", \"data\", \"sample\"),\n config={\"batch_size\": 1, \"image_size_multiplier\": 4})",
"_____no_output_____"
]
],
[
[
"Open a terminal and launch TensorBoard to view the summaries written to `$wrkdir/cache/tensorboard/dataset/sample`:\n```\ntensorboard --logdir /data/exp/cv4/cache/tensorboard\n```\nThen open the url in a browser and inspect the contents.\nYou can leave the server running, since we'll log the training progress to the same directory.",
"_____no_output_____"
],
[
"## Loading all data\n\nWe'll now begin loading everything from disk and preparing a pipeline from mp3-filepaths to neural network input.\nWe'll use the autotune feature of `tf.data` to allow TensorFlow figure out automatically how much of the pipeline should be split up into parallel calls.",
"_____no_output_____"
]
],
[
[
"import lidbox.data.steps as ds_steps\n\nTF_AUTOTUNE = tf.data.experimental.AUTOTUNE\n\n\ndef signal_is_not_empty(x):\n return tf.size(x[\"signal\"]) > 0\n \n\ndef pipeline_from_metadata(data, shuffle=False):\n if shuffle:\n # Shuffle metadata to get an even distribution of labels\n data = data.sample(frac=1, random_state=np_rng.bit_generator)\n ds = (\n # Initialize dataset from metadata\n tf.data.Dataset.from_tensor_slices(metadata_to_dataset_input(data))\n # Read mp3 files from disk in parallel\n .map(read_mp3_wrapper, num_parallel_calls=TF_AUTOTUNE)\n # Apply RMS VAD to drop silence from all signals\n .map(remove_silence_wrapper, num_parallel_calls=TF_AUTOTUNE)\n # Drop signals that VAD removed completely\n .filter(signal_is_not_empty)\n # Extract features in parallel\n .batch(1)\n .map(batch_extract_features, num_parallel_calls=TF_AUTOTUNE)\n .unbatch()\n )\n return ds\n\n\n# Mapping from dataset split names to tf.data.Dataset objects\nsplit2ds = {\n split: pipeline_from_metadata(meta[meta[\"split\"]==split], shuffle=split==\"train\")\n for split in split_names\n}",
"_____no_output_____"
]
],
[
[
"### Testing pipeline performance\n\nNote that we only constructed the pipeline with all steps we want to compute.\nAll TensorFlow ops are computed only when elements are requested from the iterator.\n\nLets iterate over the training dataset from first to last element to ensure the pipeline will not be a performance bottleneck during training.",
"_____no_output_____"
]
],
[
[
"_ = ds_steps.consume(split2ds[\"train\"], log_interval=2000)",
"_____no_output_____"
]
],
[
[
"### Caching pipeline state\n\nWe can [cache](https://www.tensorflow.org/api_docs/python/tf/data/Dataset#cache) the iterator state as a single binary file at arbitrary stages.\nThis allows us to automatically skip all steps that precede the call to `tf.Dataset.cache`.\n\nLets cache the training dataset and iterate again over all elements to fill the cache.\n**Note** that you will still be storing all data on the disk (4.6 GiB new data), so this optimization is a space-time tradeoff.",
"_____no_output_____"
]
],
[
[
"os.makedirs(os.path.join(cachedir, \"data\"))\n\nsplit2ds[\"train\"] = split2ds[\"train\"].cache(os.path.join(cachedir, \"data\", \"train\"))\n_ = ds_steps.consume(split2ds[\"train\"], log_interval=2000)",
"_____no_output_____"
]
],
[
[
"If we iterate over the dataset again, TensorFlow should read all elements from the cache file.",
"_____no_output_____"
]
],
[
[
"_ = ds_steps.consume(split2ds[\"train\"], log_interval=2000)",
"_____no_output_____"
]
],
[
[
"As a side note, if your training environment has fast read-write access to a file system configured for reading and writing very large files, this optimization can be a very significant performance improvement.\n\n**Note** also that all usual problems related to cache invalidation apply.\nWhen caching extracted features and metadata to disk, be extra careful in your experiments to ensure you are not interpreting results computed on data from some outdated cache.\n\n### Dumping a few batches to TensorBoard \n\nLets extract 100 first elements of every split to TensorBoard.",
"_____no_output_____"
]
],
[
[
"for split, ds in split2ds.items():\n _ = ds_steps.consume_to_tensorboard(\n ds.map(lambda x: dict(x, input=x[\"logmelspec\"])),\n os.path.join(cachedir, \"tensorboard\", \"data\", split),\n {\"batch_size\": 1,\n \"image_size_multiplier\": 2,\n \"num_batches\": 100},\n exist_ok=True)",
"_____no_output_____"
]
],
[
[
"## Training a supervised, neural network language classifier\n\nWe have now configured an efficient data pipeline and extracted some data samples to summary files for TensorBoard.\nIt is time to train a classifier on the data.\n\n### Drop metadata from dataset\n\nDuring training, we only need a tuple of model input and targets.\nWe can therefore drop everything else from the dataset elements just before training starts.\nThis is also a good place to decide if we want to train on MFCCs or Mel-spectra.",
"_____no_output_____"
]
],
[
[
"model_input_type = \"logmelspec\"\n\ndef as_model_input(x):\n return x[model_input_type], x[\"target\"]\n\n\ntrain_ds_demo = list(split2ds[\"train\"]\n .map(as_model_input)\n .shuffle(100)\n .take(6)\n .as_numpy_iterator())\n\nfor input, target in train_ds_demo:\n print(input.shape, target2lang[target])\n if model_input_type == \"mfcc\":\n plot_cepstra(input)\n else:\n plot_spectrogram(input)\n plot_separator()",
"_____no_output_____"
]
],
[
[
"### Asserting all input is valid\n\nSince the training dataset is cached, we can quickly iterate over all elements and check that we don't have any NaNs or negative targets.",
"_____no_output_____"
]
],
[
[
"def assert_finite(x, y):\n tf.debugging.assert_all_finite(x, \"non-finite input\")\n tf.debugging.assert_non_negative(y, \"negative target\")\n return x, y\n\n_ = ds_steps.consume(split2ds[\"train\"].map(as_model_input).map(assert_finite), log_interval=5000)",
"_____no_output_____"
]
],
[
[
"It is also easy to compute stats on the dataset elements.\nFor example finding global minimum and maximum values of the inputs.",
"_____no_output_____"
]
],
[
[
"x_min = split2ds[\"train\"].map(as_model_input).reduce(\n tf.float32.max,\n lambda acc, elem: tf.math.minimum(acc, tf.math.reduce_min(elem[0])))\n\nx_max = split2ds[\"train\"].map(as_model_input).reduce(\n tf.float32.min,\n lambda acc, elem: tf.math.maximum(acc, tf.math.reduce_max(elem[0])))\n\nprint(\"input tensor global minimum: {}, maximum: {}\".format(x_min.numpy(), x_max.numpy()))",
"_____no_output_____"
]
],
[
[
"### Selecting a model architecture\n\n`lidbox` provides a small set of neural network model architectures out of the box.\nMany of these architectures have good results in the literature for different datasets.\nThese models have been implemented in Keras, so you could replace the model we are using here with anything you want.\n\nThe [\"x-vector\"](http://danielpovey.com/files/2018_odyssey_xvector_lid.pdf) architecture has worked well in speaker and language identification so lets create an untrained Keras x-vector model.\nOne of its core features is learning fixed length vector representations (x-vectors) for input of arbitrary length.\nThese vectors are extracted from the first fully connected layer (`segment1`), without activation.\nThis opens up opportunities for doing all kinds of statistical analysis on these vectors, but that's out of scope for our example.\n\nWe'll try to regularize the network by adding frequency [channel dropout](https://dl.acm.org/doi/abs/10.1016/j.patrec.2017.09.023) with probability 0.8.\nIn other words, during training we set input rows randomly to zeros with probability 0.8.\nThis might avoid overfitting the network on frequency channels containing noise that is irrelevant for deciding the language.",
"_____no_output_____"
]
],
[
[
"import lidbox.models.xvector as xvector\n\n\ndef create_model(num_freq_bins, num_labels):\n model = xvector.create([None, num_freq_bins], num_labels, channel_dropout_rate=0.8)\n model.compile(\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5))\n return model\n\n\nmodel = create_model(\n num_freq_bins=20 if model_input_type == \"mfcc\" else 40,\n num_labels=len(target2lang))\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"### Channel dropout demo\n\nHere's what happens to the input during training.",
"_____no_output_____"
]
],
[
[
"channel_dropout = tf.keras.layers.SpatialDropout1D(model.get_layer(\"channel_dropout\").rate)\n\nfor input, target in train_ds_demo:\n print(input.shape, target2lang[target])\n input = channel_dropout(tf.expand_dims(input, 0), training=True)[0].numpy()\n if model_input_type == \"mfcc\":\n plot_cepstra(input)\n else:\n plot_spectrogram(input)\n plot_separator()",
"_____no_output_____"
]
],
[
[
"### Training the classifier\n\nThe validation set is needed after every epoch, so we might as well cache it.\n**Note** that this writes 2.5 GiB of additional data to disk the first time the validation set is iterated over, i.e. at the end of epoch 1.\nAlso, we can't use batches since our input is of different lengths (perhaps with [ragged tensors](https://www.tensorflow.org/versions/r2.3/api_docs/python/tf/data/experimental/dense_to_ragged_batch)).",
"_____no_output_____"
]
],
[
[
"callbacks = [\n # Write scalar metrics and network weights to TensorBoard\n tf.keras.callbacks.TensorBoard(\n log_dir=os.path.join(cachedir, \"tensorboard\", model.name),\n update_freq=\"epoch\",\n write_images=True,\n profile_batch=0,\n ),\n # Stop training if validation loss has not improved from the global minimum in 10 epochs\n tf.keras.callbacks.EarlyStopping(\n monitor='val_loss',\n patience=10,\n ),\n # Write model weights to cache everytime we get a new global minimum loss value\n tf.keras.callbacks.ModelCheckpoint(\n os.path.join(cachedir, \"model\", model.name),\n monitor='val_loss',\n save_weights_only=True,\n save_best_only=True,\n verbose=1,\n ),\n]\n\ntrain_ds = split2ds[\"train\"].map(as_model_input).shuffle(1000)\ndev_ds = split2ds[\"dev\"].cache(os.path.join(cachedir, \"data\", \"dev\")).map(as_model_input)\n\nhistory = model.fit(\n train_ds.batch(1),\n validation_data=dev_ds.batch(1),\n callbacks=callbacks,\n verbose=2,\n epochs=100)",
"_____no_output_____"
]
],
[
[
"## Evaluating the classifier\n\n\nLets run all test set samples through our trained model by loading the best weights from the cache.",
"_____no_output_____"
]
],
[
[
"from lidbox.util import predict_with_model\n\n\ntest_ds = split2ds[\"test\"].map(lambda x: dict(x, input=x[\"logmelspec\"])).batch(1)\n\n_ = model.load_weights(os.path.join(cachedir, \"model\", model.name))\nutt2pred = predict_with_model(model, test_ds)\n\ntest_meta = meta[meta[\"split\"]==\"test\"]\nassert not test_meta.join(utt2pred).isna().any(axis=None), \"missing predictions\"\ntest_meta = test_meta.join(utt2pred)\ntest_meta",
"_____no_output_____"
]
],
[
[
"### Average detection cost ($\\text{C}_\\text{avg}$)\n\nThe de facto standard metric for evaluating spoken language classifiers might be the *average detection cost* ($\\text{C}_\\text{avg}$), which has been refined to its current form during past [language recognition competitions](https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=925272).\n`lidbox` provides this metric as a `tf.keras.Metric` subclass.\nScikit-learn provides other commonly used metrics so there is no need to manually compute those.",
"_____no_output_____"
]
],
[
[
"from lidbox.util import classification_report\nfrom lidbox.visualize import draw_confusion_matrix\n\n\ntrue_sparse = test_meta.target.to_numpy(np.int32)\n\npred_dense = np.stack(test_meta.prediction)\npred_sparse = pred_dense.argmax(axis=1).astype(np.int32)\n\nreport = classification_report(true_sparse, pred_dense, lang2target)\n\nfor m in (\"avg_detection_cost\", \"avg_equal_error_rate\", \"accuracy\"):\n print(\"{}: {:.3f}\".format(m, report[m]))\n \nlang_metrics = pd.DataFrame.from_dict({k: v for k, v in report.items() if k in lang2target})\nlang_metrics[\"mean\"] = lang_metrics.mean(axis=1)\ndisplay(lang_metrics.T)\n\nfig, ax = draw_confusion_matrix(report[\"confusion_matrix\"], lang2target)",
"_____no_output_____"
]
],
[
[
"## Conclusions\n\nThis was an example on deep learning based simple spoken language identification of 4 different languages from the Mozilla Common Voice free speech datasets.\nWe managed to train a model that adequately recognizes languages spoken by the test set speakers.\n\nHowever, there is clearly room for improvement.\nWe did simple random oversampling to balance the language distribution in the training set, but perhaps there are better ways to do this.\nWe also did not tune optimization hyperparameters or try different neural network architectures or layer combinations.\nIt might also be possible to increase robustness by audio feature engineering, such as [random FIR filtering](https://www.isca-speech.org/archive/Interspeech_2018/abstracts/1047.html) to simulate microphone differences.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1c41241f61951aa15e438a5fa070daf3f5f3b8
| 128,214 |
ipynb
|
Jupyter Notebook
|
DataAnalysis/kaggle_bike-sharing-demand_rf.ipynb
|
jgj9883/Unsupervised-learning
|
6578a61bb4a542917ea7035e38c928ae138edc6f
|
[
"MIT"
] | null | null | null |
DataAnalysis/kaggle_bike-sharing-demand_rf.ipynb
|
jgj9883/Unsupervised-learning
|
6578a61bb4a542917ea7035e38c928ae138edc6f
|
[
"MIT"
] | null | null | null |
DataAnalysis/kaggle_bike-sharing-demand_rf.ipynb
|
jgj9883/Unsupervised-learning
|
6578a61bb4a542917ea7035e38c928ae138edc6f
|
[
"MIT"
] | null | null | null | 114.784244 | 49,592 | 0.848768 |
[
[
[
"### Load Dataset",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# 노트북 안에 그래프를 그리기 위해\n%matplotlib inline\n\n# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처\nmpl.rcParams['axes.unicode_minus'] = False\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"train = pd.read_csv(\"data/Bike Sharing Demand/train.csv\", parse_dates=[\"datetime\"])\ntrain.shape",
"_____no_output_____"
],
[
"test = pd.read_csv(\"data/Bike Sharing Demand/test.csv\", parse_dates=[\"datetime\"])\ntest.shape",
"_____no_output_____"
]
],
[
[
"### Feature Engineering",
"_____no_output_____"
]
],
[
[
"train[\"year\"] = train[\"datetime\"].dt.year\ntrain[\"month\"] = train[\"datetime\"].dt.month\ntrain[\"day\"] = train[\"datetime\"].dt.day\ntrain[\"hour\"] = train[\"datetime\"].dt.hour\ntrain[\"minute\"] = train[\"datetime\"].dt.minute\ntrain[\"second\"] = train[\"datetime\"].dt.second\ntrain[\"dayofweek\"] = train[\"datetime\"].dt.dayofweek\ntrain.shape",
"_____no_output_____"
],
[
"test[\"year\"] = test[\"datetime\"].dt.year\ntest[\"month\"] = test[\"datetime\"].dt.month\ntest[\"day\"] = test[\"datetime\"].dt.day\ntest[\"hour\"] = test[\"datetime\"].dt.hour\ntest[\"minute\"] = test[\"datetime\"].dt.minute\ntest[\"second\"] = test[\"datetime\"].dt.second\ntest[\"dayofweek\"] = test[\"datetime\"].dt.dayofweek\ntest.shape",
"_____no_output_____"
],
[
"# widspeed 풍속에 0 값이 가장 많다. => 잘못 기록된 데이터를 고쳐 줄 필요가 있음\nfig, axes = plt.subplots(nrows=2)\nfig.set_size_inches(18,10)\n\nplt.sca(axes[0])\nplt.xticks(rotation=30, ha='right')\naxes[0].set(ylabel='Count',title=\"train windspeed\")\nsns.countplot(data=train, x=\"windspeed\", ax=axes[0])\n\nplt.sca(axes[1])\nplt.xticks(rotation=30, ha='right')\naxes[1].set(ylabel='Count',title=\"test windspeed\")\nsns.countplot(data=test, x=\"windspeed\", ax=axes[1])",
"_____no_output_____"
],
[
"# 풍속의 0값에 특정 값을 넣어준다.\n# 평균을 구해 일괄적으로 넣어줄 수도 있지만, 예측의 정확도를 높이는 데 도움이 될것 같진 않다.\n# train.loc[train[\"windspeed\"] == 0, \"windspeed\"] = train[\"windspeed\"].mean()\n# test.loc[train[\"windspeed\"] == 0, \"windspeed\"] = train[\"windspeed\"].mean()",
"_____no_output_____"
],
[
"# 풍속이 0인것과 아닌 것의 세트를 나누어 준다.\ntrainWind0 = train.loc[train['windspeed'] == 0]\ntrainWindNot0 = train.loc[train['windspeed'] != 0]\nprint(trainWind0.shape)\nprint(trainWindNot0.shape)",
"(1313, 19)\n(9573, 19)\n"
],
[
"# 그래서 머신러닝으로 예측을 해서 풍속을 넣어주도록 한다.\nfrom sklearn.ensemble import RandomForestClassifier\n\ndef predict_windspeed(data):\n \n # 풍속이 0인것과 아닌 것을 나누어 준다.\n dataWind0 = data.loc[data['windspeed'] == 0]\n dataWindNot0 = data.loc[data['windspeed'] != 0]\n \n # 풍속을 예측할 피처를 선택한다.\n wCol = [\"season\", \"weather\", \"humidity\", \"month\", \"temp\", \"year\", \"atemp\"]\n\n # 풍속이 0이 아닌 데이터들의 타입을 스트링으로 바꿔준다.\n dataWindNot0[\"windspeed\"] = dataWindNot0[\"windspeed\"].astype(\"str\")\n\n # 랜덤포레스트 분류기를 사용한다.\n rfModel_wind = RandomForestClassifier()\n\n # wCol에 있는 피처의 값을 바탕으로 풍속을 학습시킨다.\n rfModel_wind.fit(dataWindNot0[wCol], dataWindNot0[\"windspeed\"])\n\n # 학습한 값을 바탕으로 풍속이 0으로 기록 된 데이터의 풍속을 예측한다.\n wind0Values = rfModel_wind.predict(X = dataWind0[wCol])\n\n # 값을 다 예측 후 비교해 보기 위해\n # 예측한 값을 넣어 줄 데이터 프레임을 새로 만든다.\n predictWind0 = dataWind0\n predictWindNot0 = dataWindNot0\n\n # 값이 0으로 기록 된 풍속에 대해 예측한 값을 넣어준다.\n predictWind0[\"windspeed\"] = wind0Values\n\n # dataWindNot0 0이 아닌 풍속이 있는 데이터프레임에 예측한 값이 있는 데이터프레임을 합쳐준다.\n data = predictWindNot0.append(predictWind0)\n\n # 풍속의 데이터타입을 float으로 지정해 준다.\n data[\"windspeed\"] = data[\"windspeed\"].astype(\"float\")\n\n data.reset_index(inplace=True)\n data.drop('index', inplace=True, axis=1)\n \n return data",
"_____no_output_____"
],
[
"# 0값을 조정한다.\ntrain = predict_windspeed(train)\n# test = predict_windspeed(test)\n\n# widspeed 의 0값을 조정한 데이터를 시각화\nfig, ax1 = plt.subplots()\nfig.set_size_inches(18,6)\n\nplt.sca(ax1)\nplt.xticks(rotation=30, ha='right')\nax1.set(ylabel='Count',title=\"train windspeed\")\nsns.countplot(data=train, x=\"windspeed\", ax=ax1)",
"_____no_output_____"
]
],
[
[
"### Feature Selection\n##### 신호와 잡음을 구분해야 한다.\n##### 피처가 많다고 해서 무조건 좋은 성능을 내지 않는다.\n##### 피처를 하나씩 추가하고 변경해 가면서 성능이 좋지 않은 피처는 제거하도록 한다.",
"_____no_output_____"
]
],
[
[
"# 연속형 feature와 범주형 feature \n# 연속형 feature = [\"temp\",\"humidity\",\"windspeed\",\"atemp\"]\n# 범주형 feature의 type을 category로 변경 해 준다.\ncategorical_feature_names = [\"season\",\"holiday\",\"workingday\",\"weather\",\n \"dayofweek\",\"month\",\"year\",\"hour\"]\n\nfor var in categorical_feature_names:\n train[var] = train[var].astype(\"category\")\n test[var] = test[var].astype(\"category\")",
"_____no_output_____"
],
[
"feature_names = [\"season\", \"weather\", \"temp\", \"atemp\", \"humidity\", \"windspeed\",\n \"year\", \"hour\", \"dayofweek\", \"holiday\", \"workingday\"]\n\nfeature_names",
"_____no_output_____"
],
[
"X_train = train[feature_names]\n\nprint(X_train.shape)\nX_train.head()",
"(10886, 11)\n"
],
[
"\nX_test = test[feature_names]\n\nprint(X_test.shape)\nX_test.head()",
"(6493, 11)\n"
],
[
"label_name = \"count\"\n\ny_train = train[label_name]\n\nprint(y_train.shape)\ny_train.head()",
"(10886,)\n"
]
],
[
[
"### Score",
"_____no_output_____"
],
[
"### RMSLE",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import make_scorer\n\ndef rmsle(predicted_values, actual_values):\n # 넘파이로 배열 형태로 바꿔준다.\n predicted_values = np.array(predicted_values)\n actual_values = np.array(actual_values)\n \n # 예측값과 실제 값에 1을 더하고 로그를 씌워준다.\n log_predict = np.log(predicted_values + 1)\n log_actual = np.log(actual_values + 1)\n \n # 위에서 계산한 예측값에서 실제값을 빼주고 제곱을 해준다.\n difference = log_predict - log_actual\n # difference = (log_predict - log_actual) ** 2\n difference = np.square(difference)\n \n # 평균을 낸다.\n mean_difference = difference.mean()\n \n # 다시 루트를 씌운다.\n score = np.sqrt(mean_difference)\n \n return score\n\nrmsle_scorer = make_scorer(rmsle)\nrmsle_scorer",
"_____no_output_____"
]
],
[
[
"### Cross Validation 교차 검증",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import KFold\nfrom sklearn.model_selection import cross_val_score\n\nk_fold = KFold(n_splits=10, shuffle=True, random_state=0)",
"_____no_output_____"
]
],
[
[
"### RandomForest",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestRegressor\n\nmax_depth_list = []\n\nmodel = RandomForestRegressor(n_estimators=100,\n n_jobs=-1,\n random_state=0)\nmodel",
"_____no_output_____"
],
[
"%time score = cross_val_score(model, X_train, y_train, cv=k_fold, scoring=rmsle_scorer)\nscore = score.mean()\n# 0에 근접할수록 좋은 데이터\nprint(\"Score= {0:.5f}\".format(score))",
"Wall time: 6.56 s\nScore= 0.33095\n"
]
],
[
[
"### Train",
"_____no_output_____"
]
],
[
[
"# 학습시킴, 피팅(옷을 맞출 때 사용하는 피팅을 생각함) - 피처와 레이블을 넣어주면 알아서 학습을 함\nmodel.fit(X_train, y_train)",
"_____no_output_____"
],
[
"# 예측\npredictions = model.predict(X_test)\n\nprint(predictions.shape)\npredictions[0:10]",
"(6493,)\n"
],
[
"# 예측한 데이터를 시각화 해본다. \nfig,(ax1,ax2)= plt.subplots(ncols=2)\nfig.set_size_inches(12,5)\nsns.distplot(y_train,ax=ax1,bins=50)\nax1.set(title=\"train\")\nsns.distplot(predictions,ax=ax2,bins=50)\nax2.set(title=\"test\")",
"_____no_output_____"
]
],
[
[
"### Submit",
"_____no_output_____"
]
],
[
[
"submission = pd.read_csv(\"data/Bike Sharing Demand/sampleSubmission.csv\")\nsubmission\n\nsubmission[\"count\"] = predictions\n\nprint(submission.shape)\nsubmission.head()",
"(6493, 2)\n"
],
[
"submission.to_csv(\"data/Score_{0:.5f}_submission.csv\".format(score), index=False)",
"_____no_output_____"
]
],
[
[
"### 참고\n\nEDA & Ensemble Model (Top 10 Percentile) | Kaggle\nHow to finish top 10 percentile in Bike Sharing Demand Competition In Kaggle? (part -1)\nHow to finish top 10 percentile in Bike Sharing Demand Competition In Kaggle? (part -2)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a1c41c47cf577c877c6e581a50b678dc5b797dd
| 30,102 |
ipynb
|
Jupyter Notebook
|
7.17.ipynb
|
cs1558789464/testBJ
|
d0184ccf65e554b44dffae896528886bbe60eb37
|
[
"Apache-2.0"
] | null | null | null |
7.17.ipynb
|
cs1558789464/testBJ
|
d0184ccf65e554b44dffae896528886bbe60eb37
|
[
"Apache-2.0"
] | null | null | null |
7.17.ipynb
|
cs1558789464/testBJ
|
d0184ccf65e554b44dffae896528886bbe60eb37
|
[
"Apache-2.0"
] | null | null | null | 21.094604 | 108 | 0.475018 |
[
[
[
"# 数学函数、字符串和对象\n## 本章介绍Python函数来执行常见的数学运算\n- 函数是完成一个特殊任务的一组语句,可以理解为一个函数相当于一个小功能,但是在开发中,需要注意一个函数的长度最好不要超过一屏\n- Python中的内置函数是不需要Import导入的\n<img src=\"../Photo/15.png\"></img>",
"_____no_output_____"
]
],
[
[
"a = -10\nprint(abs(a))\nmax",
"_____no_output_____"
],
[
"b = -10.1\nprint(abs(b))",
"_____no_output_____"
],
[
"c = 0\nprint(abs(c))",
"_____no_output_____"
],
[
"max(1, 2, 3, 4, 5)\n",
"_____no_output_____"
],
[
"min(1, 2, 3, 4, 5)",
"_____no_output_____"
],
[
"min(1, 2, 3, -4, 5)",
"_____no_output_____"
],
[
"for i in range(10):\n print(i)",
"_____no_output_____"
],
[
"pow(2, 4, 2) # 幂指数运算,第三个参数是取模运算",
"_____no_output_____"
],
[
"round(10.67, 1) # 一个参数就是四舍五入,保留小数位数\n",
"_____no_output_____"
],
[
"round(6.9)",
"_____no_output_____"
],
[
"round(8.123456,3)",
"_____no_output_____"
],
[
"import random\na = random.randint(0,1000)\nprint(\"随机数为\",a)\nprint(\"已经生成一个0-1000随机数\")\nprint(\"请输入你猜测的数字大小\")\nzz = int(input(\"please input a num : \" ))\nif a<zz:\n print(\"大了\")\nif a>zz:\n print(\"小了\")\nif a==zz:\n print(\"猜中了\")",
"_____no_output_____"
],
[
"import time\nstart = time.time()\nnum = 0\nfor i in range(1000000):\n num +=i\nend = time.time()\nprint(end - start)\n",
"_____no_output_____"
]
],
[
[
"## 尝试练习Python内置函数",
"_____no_output_____"
],
[
"## Python中的math模块提供了许多数学函数\n<img src=\"../Photo/16.png\"></img>\n<img src=\"../Photo/17.png\"></img>\n",
"_____no_output_____"
]
],
[
[
"#L = (yloga+(1-y)log(1-a))",
"_____no_output_____"
],
[
"import math\n#y=0\n#a=1\n",
"_____no_output_____"
],
[
"import math # 导入数学包\na1 = math.fabs(-2)\nprint(a1)\n\nprint(math.log(2.71828))\nprint(math.asin(1.0))",
"_____no_output_____"
],
[
"b1 = math.cos(math.radians(90)) # cos代入的是弧度值,very important!\nprint(b1)\nc1 = 3.1415926\nprint(math.degrees(c1))",
"_____no_output_____"
],
[
"math.sqrt(9)",
"_____no_output_____"
],
[
"math.sin(2 * math.pi)",
"_____no_output_____"
],
[
"math.cos(2 * math.pi)",
"_____no_output_____"
],
[
"min(2, 2, 1)",
"_____no_output_____"
],
[
"math.log(math.e ** 2)",
"_____no_output_____"
],
[
"math.exp(1)",
"_____no_output_____"
],
[
"max(2, 3, 4)",
"_____no_output_____"
],
[
"math.ceil(-2.5)",
"_____no_output_____"
],
[
"# 验证码系统\nfirst_num, second_num = 3, 4\nprint('验证码', first_num ,'+', second_num, '= ?')\nanswer = eval(input('写出结果: '))\n\nif answer == first_num + second_num:\n print('验证码正确')\nelse:\n print('验证码错误')\n",
"_____no_output_____"
],
[
"import random\nimport math\n\nfirst_num, second_num = 3, 4\nlist = ['+', '-', '*', '/']\nrandl = random.randint(0, 3)\nif list[randl]=='+':\n print('验证码', first_num ,'+', second_num, '= ?')\n right_answer = first_num + second_num\nelif list[randl]=='-':\n print('验证码', first_num ,'-', second_num, '= ?')\n right_answer = first_num - second_num\nelif list[randl]=='-':\n print('验证码', first_num ,'*', second_num, '= ?')\n right_answer = first_num * second_num\nelse:\n print('验证码', first_num ,'/', second_num, '= ?')\n right_answer = first_num / second_num\n \nanswer = eval(input('写出结果: '))\n\nif answer == right_answer:\n print('验证码正确')\nelse:\n print('验证码错误')",
"_____no_output_____"
],
[
"# 验证码系统\nimport random\nfirst_num = random.randint(0, 9)\nsecond_num = random.randint(0, 9)\nfuhao = random.randint(0, 3)\n\nif fuhao==0:\n print('验证码', first_num ,'+', second_num, '= ?')\n right_answer = first_num + second_num\nelif fuhao==1:\n print('验证码', first_num ,'-', second_num, '= ?')\n right_answer = first_num - second_num\nelif fuhao==2:\n print('验证码', first_num ,'*', second_num, '= ?')\n right_answer = first_num * second_num\nelse:\n print('验证码', first_num ,'/', second_num, '= ?')\n right_answer = first_num / second_num\n \nanswer = eval(input('写出结果: '))\n\nif answer == right_answer:\n print('验证码正确')\nelse:\n print('验证码错误')\n",
"_____no_output_____"
],
[
"import random\nlist = ['+', '-', '*', '/']\nc = random.sample(list, 1)\nprint(c)",
"_____no_output_____"
],
[
"import random\nimport math\n\nfirst_num = random.randint(0, 9)\nsecond_num = random.randint(0, 9)\nlist = ['+', '-', '*', '/']\nfuhao = random.sample(list, 1)\nif fuhao=='+':\n print('验证码', first_num ,'+', second_num, '= ?')\n right_answer = first_num + second_num\nelif fuhao=='-':\n print('验证码', first_num ,'-', second_num, '= ?')\n right_answer = first_num - second_num\nelif fuhao=='-':\n print('验证码', first_num ,'*', second_num, '= ?')\n right_answer = first_num * second_num\nelse:\n print('验证码', first_num ,'/', second_num, '= ?')\n right_answer = first_num / second_num\n \nanswer = eval(input('写出结果: '))\n\nif answer == right_answer:\n print('验证码正确')\nelse:\n print('验证码错误')",
"_____no_output_____"
],
[
"import PIL",
"_____no_output_____"
]
],
[
[
"## 两个数学常量PI和e,可以通过使用math.pi 和math.e调用",
"_____no_output_____"
]
],
[
[
"import math\nprint(math.pi)\nprint(math.e)",
"_____no_output_____"
]
],
[
[
"## EP:\n- 通过math库,写一个程序,使得用户输入三个顶点(x,y)返回三个角度\n- 注意:Python计算角度为弧度制,需要将其转换为角度\n<img src=\"../Photo/18.png\">",
"_____no_output_____"
]
],
[
[
"import math\nx1 = int(input(\"请输入A点x1坐标: \"))\ny1 = int(input(\"请输入A点y1坐标: \"))\nx2 = int(input(\"请输入B点x1坐标: \"))\ny2 = int(input(\"请输入B点y1坐标: \"))\nx3 = int(input(\"请输入C点x1坐标: \"))\ny3 = int(input(\"请输入C点y1坐标: \"))\nc = math.sqrt((x2-x1)**2+(y2-y1)**2)\nb = math.sqrt((x3-x1)**2+(y3-y1)**2)\na = math.sqrt((x3-x2)**2+(y3-y2)**2)\nA = math.degrees(math.acos((a*a-b*b-c*c)/(-2*b*c)))\nB = math.degrees(math.acos((b*b-a*a-c*c)/(-2*a*c)))\nprint(A)\n",
"_____no_output_____"
],
[
"import math\n\nx1, y1 = eval(input('输入A点坐标:'))\nx2, y2 = eval(input('输入B点坐标:'))\nx3, y3 = eval(input('输入C点坐标:'))\n\na = math.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)\nb = math.sqrt((x1 - x3) ** 2 + (y1 - y3) ** 2)\nc = math.sqrt((x2 - x3) ** 2 + (y2 - y3) ** 2)\n\nA = math.degrees(math.acos((a * a - b * b - c * c) / (-2 * b * c)))\nB = math.degrees(math.acos((b * b - a * a - c * c) / (-2 * a * c)))\nC = math.degrees(math.acos((c * c - b * b - a * a) / (-2 * a * b)))\n\nprint('三角形的三个角分别为', A, B, C)\n\n \n",
"_____no_output_____"
]
],
[
[
"## 字符串和字符\n- 在Python中,字符串必须是在单引号或者双引号内,在多段换行的字符串中可以使用“”“\n- 在使用”“”时,给予其变量则变为字符串,否则当多行注释使用",
"_____no_output_____"
]
],
[
[
"z = \"hhhhh我好帅\"\na = \"h\"\nfor i in z:\n print(i)\n count = 0\n print(a)\n if i == a:\n count+=1\nprint(count)\n ",
"_____no_output_____"
],
[
"a = 'joker'\nb = \"Kate\"\nc = \"\"\"在Python中,字符串必须是在单引号或者双引号内,在多段换行的字符串中可以使用“”“\n在使用”“”时,给予其变量则变为字符串,否则当多行注释使用\"\"\" #字符串有多行时,添加三个单引号或者三个双引号\n\n\"\"\"在Python中,字符串必须是在单引号或者双引号内,在多段换行的字符串中可以使用“”“\n在使用”“”时,给予其变量则变为字符串,否则当多行注释使用\"\"\" #三引号可以表示多行注释\n# 当6个引号没有赋值时,那么它是注释的作用\n# 6个引号的作用,多行文本\n\nprint(type(a), type(b), type(c))",
"_____no_output_____"
]
],
[
[
"## ASCII码与Unicode码\n- <img src=\"../Photo/19.png\"></img>\n- <img src=\"../Photo/20.png\"></img>\n- <img src=\"../Photo/21.png\"></img>",
"_____no_output_____"
],
[
"## 函数ord、chr\n- ord 返回ASCII码值\n- chr 返回字符",
"_____no_output_____"
]
],
[
[
"joker = 'A'\nord(joker)\nprint(ord('q'), ord('Z'))",
"_____no_output_____"
],
[
"print(chr(65))\nprint(chr(90))",
"_____no_output_____"
],
[
"import numpy as np\nnp.nonzero(1)",
"_____no_output_____"
],
[
"cs = \"[email protected]\"\nprint(\"加密后:\",end = '')\nfor i in cs:\n zz = ord(i) + 1\n print(str(zz),end = '')\n \n ",
"_____no_output_____"
]
],
[
[
"## EP:\n- 利用ord与chr进行简单邮箱加密",
"_____no_output_____"
]
],
[
[
"email = '[email protected]' # 邮箱加密过程\nj = 0\nfor i in email:\n text = ord(i) + 1\n re_text = chr(text)\n print(re_text)",
"n\nb\np\nn\nb\np\nd\ni\np\no\nh\nA\n2\n7\n4\n/\nd\np\nn\n"
],
[
"import hashlib\nstr1 = 'this is a test.'\nh1 = hashlib.md5()\nh1.update(str1.encode(encoding = 'utf-8'))\nprint('MD5加密之后为:', h1.hexdigest())",
"_____no_output_____"
]
],
[
[
"## 转义序列 \\\n- a = \"He said,\"Johon's program is easy to read\"\"\n- 转掉原来的意思\n- 一般情况下,只有当语句与默认语句相撞的时候,就需要转义",
"_____no_output_____"
]
],
[
[
"a = \"He said,\\\"Johon's program is easy to read\\\"\" #z正则表达式中常用转义字符\\\nprint(a)",
"_____no_output_____"
]
],
[
[
"## 高级print\n- 参数 end: 以什么方式结束打印\n- 默认换行打印",
"_____no_output_____"
]
],
[
[
"email = '[email protected]' # 邮箱加密过程\nj = 0\nfor i in email:\n text = ord(i) + 1\n re_text = chr(text)\n print(re_text, end = '')",
"_____no_output_____"
]
],
[
[
"## 函数str\n- 将类型强制转换成字符串类型\n- 其他一些以后会学到(list,set,tuple...)",
"_____no_output_____"
]
],
[
[
"a = 100.12\ntype(str(a))",
"_____no_output_____"
]
],
[
[
"## 字符串连接操作\n- 直接使用 “+” \n- join() 函数 ",
"_____no_output_____"
]
],
[
[
"a1 = 'www.baidu.com/image.page='\na2 = '1'\nfor i in range(0, 10):\n a2 = a1 + str(i)\n print(a2)",
"_____no_output_____"
],
[
" %time '' .join(('a','b'))",
"_____no_output_____"
],
[
"a = \"abc\"\nb = \"def\"\n%time print(a+b)",
"_____no_output_____"
],
[
"joint = '^'\n%time joint.join(('a', 'b', 'c', 'd')) # join的参数需要在一个元组之中",
"_____no_output_____"
],
[
"%time '*'.join(('a', 'b', 'c', 'd')) # join的参数需要在一个元组之中",
"_____no_output_____"
],
[
"%time 'A' + 'B' + 'C'",
"_____no_output_____"
]
],
[
[
"## EP:\n- 将 “Welcome” “to” \"Python\" 拼接\n- 将int型 100 与 “joker is a bad man” 拼接\n- 从控制台读取字符串\n> 输入一个名字返回夸奖此人是一个帅哥",
"_____no_output_____"
]
],
[
[
"a = \"Welcome\"\nb = \"to\"\nc = \"Python\"\nprint(''.join((a,'\\t',b,'\\t',c)))",
"_____no_output_____"
],
[
"a = 100\nb = \"jocker is a bad man\"\nprint('' .join((str(a),'\\t',b)))",
"_____no_output_____"
],
[
"text1 = ' '.join(('Welcome', 'to', 'Python'))\ni = 100\ntext2 = str(i)\ntext3 = ' '.join((text2, 'Joker is a bad man'))\nprint(text1, '\\n', text2 ,'\\n', text3)",
"_____no_output_____"
],
[
"name = input('输入名字:')\ntext = ' '.join((name, 'is a good boy.'))\nprint(text)",
"_____no_output_____"
]
],
[
[
"## 实例研究:最小数量硬币\n- 开发一个程序,让用户输入总金额,这是一个用美元和美分表示的浮点值,返回一个由美元、两角五分的硬币、一角的硬币、五分硬币、以及美分个数\n<img src=\"../Photo/22.png\"></img>",
"_____no_output_____"
]
],
[
[
"amount = eval(input('Enter an amount, for example 11.56: '))\nfenshuAmount = int(amount * 100)\ndollorAmount = fenshuAmount // 100\nremainDollorAmount = fenshuAmount % 100\njiaoAmount = remainDollorAmount // 25\nremainJiaoAmount = remainDollorAmount % 25\nfenAmount = remainJiaoAmount // 10\nremainFenAmount = remainJiaoAmount % 10\nfenAmount2 = remainFenAmount // 5\nremainFenAmount2 = remainFenAmount % 5\nfenFinalAmount = remainFenAmount2 \nprint('美元个数为',dollorAmount,'\\n', '两角五分硬币个数为',\n jiaoAmount, '\\n','一角个数为', fenAmount, '\\n','五美分个数为', fenAmount2,'\\n', '一美分个数为',fenFinalAmount)",
"_____no_output_____"
],
[
"amount = eval(input('Ennter an amount,for example 11.56:'))\nremainingAmount = int(amount * 100)\nprint(remainingAmount)\nnumberOfOneDollars = remainingAmount //100\nremainingAmount = remainingAmount % 100\nnumberOfQuarters = remainingAmount // 25\nremainingAmount = remainingAmount % 25\nnumberOfDimes = remainingAmount // 10\nremainingAmount = remainingAmount % 10\nnumberOfNickls = remainingAmount // 5\nremainingAmount = remainingAmount % 5\nnumberOfPenies = remainingAmount\nprint(numberOfOneDollars,numberOfQuarters,numberOfDimes,numberOfNickls,numberOfPenies)",
"_____no_output_____"
]
],
[
[
"- Python弱项,对于浮点型的处理并不是很好,但是处理数据的时候使用的是Numpy类型\n<img src=\"../Photo/23.png\"></img>",
"_____no_output_____"
]
],
[
[
"remainingAmount = eval(input('Ennter an amount,for example 11.56:'))\nprint(remainingAmount)\nnumberOfOneDollars = remainingAmount //100\nremainingAmount = remainingAmount % 100\nnumberOfQuarters = remainingAmount // 25\nremainingAmount = remainingAmount % 25\nnumberOfDimes = remainingAmount // 10\nremainingAmount = remainingAmount % 10\nnumberOfNickls = remainingAmount // 5\nremainingAmount = remainingAmount % 5\nnumberOfPenies = remainingAmount\nprint(numberOfOneDollars,numberOfQuarters,numberOfDimes,numberOfNickls,numberOfPenies)",
"_____no_output_____"
]
],
[
[
"## id与type\n- id 查看内存地址,在判断语句中将会使用\n- type 查看元素类型",
"_____no_output_____"
]
],
[
[
"a = 100\nid(a)",
"_____no_output_____"
],
[
"id(True)",
"_____no_output_____"
],
[
"100 == 100",
"_____no_output_____"
],
[
"112345678800000000 is '112345678800000000'",
"_____no_output_____"
],
[
"112345678800000000 is 112345678800000000",
"_____no_output_____"
],
[
"a = True\nb = False\nprint(id(a), id(b))\na is b\n",
"_____no_output_____"
]
],
[
[
"## 其他格式化语句见书",
"_____no_output_____"
],
[
"# Homework\n- 1\n<img src=\"../Photo/24.png\"><img>\n<img src=\"../Photo/25.png\"><img>",
"_____no_output_____"
]
],
[
[
"import math\nr = float(input(\"please input the r: \"))\ns = 2*r*math.sin(math.pi / 5)\narea = 5*s*s/(4*math.tan(math.pi / 5)) \nprint(round(area,2))",
"please input the r: 5.5\n71.92\n"
]
],
[
[
"- 2\n<img src=\"../Photo/26.png\"><img>",
"_____no_output_____"
]
],
[
[
"import math\nx1 = math.radians(float(input(\"please input the x1: \")))\ny1 = math.radians(float(input(\"please input the y1: \")))\nx2 = math.radians(float(input(\"please input the x2: \")))\ny2 = math.radians(float(input(\"please input the y2: \")))\nradius = 6371.01\nd = radius*math.acos(math.sin(x1)*math.sin(x2)+math.cos(x1)*math.cos(x2)*math.cos(y1-y2))\nprint(d)",
"please input the x1: 39.55\nplease input the y1: -116.25\nplease input the x2: 41.5\nplease input the y2: 87.37\n10691.79183231593\n"
]
],
[
[
"- 3\n<img src=\"../Photo/27.png\"><img>",
"_____no_output_____"
]
],
[
[
"import math\ns = float(input(\"please input the s\"))\narea = 5*s*s/(4*math.tan(math.pi/5))\nprint(area)",
"please input the s5.5\n52.044441367816255\n"
]
],
[
[
"- 4\n<img src=\"../Photo/28.png\"><img>",
"_____no_output_____"
]
],
[
[
"import math\nn = int(input(\"please input the n\"))\ns = float(input(\"please input the s\"))\narea = n*s*s/(4*math.tan(math.pi/n))\nprint(area)",
"please input the n5\nplease input the s6.5\n72.69017017488386\n"
]
],
[
[
"- 5\n<img src=\"../Photo/29.png\"><img>\n<img src=\"../Photo/30.png\"><img>",
"_____no_output_____"
]
],
[
[
"a = int(input(\"please input a asciinum: \"))\nprint(chr(a))",
"please input a asciinum: 69\nE\n"
]
],
[
[
"- 6\n<img src=\"../Photo/31.png\"><img>",
"_____no_output_____"
]
],
[
[
"name = input(\"please input ypur name: \")\nworked = float(input(\"please input you hours worked: \"))\npay = float(input(\"please input you hourly pay rate: \"))\nfederal = float(input(\"please input tax withholding: \"))\nstate = float(input(\"please input statx tax: \"))\nCross = worked * pay\nFederal = (worked * pay)*1/5\nState = (worked * pay)*9/100\ntotal = Federal + State\nPay = (worked*pay) - total\nprint(\"Employee Name: \"+name)\nprint(\"Hours Worked: \",worked)\nprint(\"Pay rate: \",pay)\nprint(\"Gross Pay: \",Cross)\nprint(\"Deductions:\")\nprint(\"Federal Withholding(20%): \",Federal )\nprint(\"State Withholding(9%): \",round(State,2))\nprint(\"Total Deduction: \",round(total,2))\nprint(\"Net Pay: \",round(Pay,2))",
"please input ypur name: smith\nplease input you hours worked: 10\nplease input you hourly pay rate: 9.75\nplease input tax withholding: 0.20\nplease input statx tax: 0.09\nEmployee Name: smith\nHours Worked: 10.0\nPay rate: 9.75\nGross Pay: 97.5\nDeductions:\nFederal Withholding(20%): 19.5\nState Withholding(9%): 8.78\nTotal Deduction: 28.27\nNet Pay: 69.22\n"
]
],
[
[
"- 7\n<img src=\"../Photo/32.png\"><img>",
"_____no_output_____"
]
],
[
[
"a = (input(\"please input a 4 number: \"))\nresult = a[::-1]\nprint(result)",
"please input a 4 number: 3125\n5213\n"
]
],
[
[
"- 8 进阶:\n> 加密一串文本,并将解密后的文件写入本地保存",
"_____no_output_____"
]
],
[
[
"a = 'abcd'\nfor i in a:\n text = ord(i) + 1\n re_text = chr(text)\n print(re_text,end = '')\noutputfile = open(\"day02.txt\",'w')\noutputfile.write(reves_text)\noutputfile.close()\n",
"bcde"
],
[
"\noutputfile = open(\"day02.txt\",'w')\noutputfile.write(reves_text)\noutputfile.close()",
"加密之后的信息为: nbpnbpdipohA274/dpn\n解密之后的信息为: [email protected]\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1c45183fa86d5f1928a057543ba8f399841b21
| 11,643 |
ipynb
|
Jupyter Notebook
|
site/ko/alpha/tutorials/quickstart/advanced.ipynb
|
kyleabeauchamp/docs
|
a5952bc17d89ed11a39e1124b362382f9064af65
|
[
"Apache-2.0"
] | 1 |
2019-06-06T19:49:12.000Z
|
2019-06-06T19:49:12.000Z
|
site/ko/alpha/tutorials/quickstart/advanced.ipynb
|
kyleabeauchamp/docs
|
a5952bc17d89ed11a39e1124b362382f9064af65
|
[
"Apache-2.0"
] | null | null | null |
site/ko/alpha/tutorials/quickstart/advanced.ipynb
|
kyleabeauchamp/docs
|
a5952bc17d89ed11a39e1124b362382f9064af65
|
[
"Apache-2.0"
] | 1 |
2020-04-20T18:08:01.000Z
|
2020-04-20T18:08:01.000Z
| 29.625954 | 259 | 0.492055 |
[
[
[
"##### Copyright 2019 The TensorFlow Authors.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# 텐서플로 2.0 시작하기: 전문가용",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/alpha/tutorials/quickstart/advanced\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />TensorFlow.org에서 보기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/ko/alpha/tutorials/quickstart/advanced.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />구글 코랩(Colab)에서 실행 하기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/ko/alpha/tutorials/quickstart/advanced.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />깃허브(GitHub) 소스 보기</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도\n불구하고 [공식 영문 문서](https://www.tensorflow.org/?hl=en)의 내용과 일치하지 않을 수 있습니다.\n이 번역에 개선할 부분이 있다면\n[tensorflow/docs](https://github.com/tensorflow/docs) 깃헙 저장소로 풀 리퀘스트를 보내주시기 바랍니다.\n문서 번역이나 리뷰에 참여하려면\n[[email protected]](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-ko)로\n메일을 보내주시기 바랍니다.",
"_____no_output_____"
],
[
"이 문서는 [구글 코랩](https://colab.research.google.com/notebooks/welcome.ipynb)(Colaboratory) 노트북 파일입니다. 파이썬 프로그램을 브라우저에서 직접 실행할 수 있기 때문에 텐서플로를 배우고 사용하기 좋은 도구입니다:\n\n1. 파이썬 런타임(runtime)에 연결하세요: 메뉴 막대의 오른쪽 상단에서 *CONNECT*를 선택하세요.\n2. 노트북의 모든 코드 셀(cell)을 실행하세요: *Runtime* > *Run all*을 선택하세요.\n\n더 많은 예제와 자세한 안내는 [텐서플로 튜토리얼](https://www.tensorflow.org/alpha/tutorials/)을 참고하세요.\n\n먼저 프로그램에 텐서플로 라이브러리를 임포트합니다:",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\n!pip install tensorflow-gpu==2.0.0-alpha0\nimport tensorflow as tf\n\nfrom tensorflow.keras.layers import Dense, Flatten, Conv2D\nfrom tensorflow.keras import Model",
"_____no_output_____"
]
],
[
[
"[MNIST 데이터셋](http://yann.lecun.com/exdb/mnist/)을 로드하여 준비합니다.",
"_____no_output_____"
]
],
[
[
"mnist = tf.keras.datasets.mnist\n\n(x_train, y_train), (x_test, y_test) = mnist.load_data()\nx_train, x_test = x_train / 255.0, x_test / 255.0\n\n# 채널 차원을 추가합니다.\nx_train = x_train[..., tf.newaxis]\nx_test = x_test[..., tf.newaxis]",
"_____no_output_____"
]
],
[
[
"tf.data를 사용하여 데이터셋을 섞고 배치를 만듭니다:",
"_____no_output_____"
]
],
[
[
"train_ds = tf.data.Dataset.from_tensor_slices(\n (x_train, y_train)).shuffle(10000).batch(32)\ntest_ds = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32)",
"_____no_output_____"
]
],
[
[
"케라스(Keras)의 [모델 서브클래싱(subclassing) API](https://www.tensorflow.org/guide/keras#model_subclassing)를 사용하여 `tf.keras` 모델을 만듭니다:",
"_____no_output_____"
]
],
[
[
"class MyModel(Model):\n def __init__(self):\n super(MyModel, self).__init__()\n self.conv1 = Conv2D(32, 3, activation='relu')\n self.flatten = Flatten()\n self.d1 = Dense(128, activation='relu')\n self.d2 = Dense(10, activation='softmax')\n\n def call(self, x):\n x = self.conv1(x)\n x = self.flatten(x)\n x = self.d1(x)\n return self.d2(x)\n\nmodel = MyModel()",
"_____no_output_____"
]
],
[
[
"훈련에 필요한 옵티마이저(optimizer)와 손실 함수를 선택합니다:",
"_____no_output_____"
]
],
[
[
"loss_object = tf.keras.losses.SparseCategoricalCrossentropy()\n\noptimizer = tf.keras.optimizers.Adam()",
"_____no_output_____"
]
],
[
[
"모델의 손실과 성능을 측정할 지표를 선택합니다. 에포크가 진행되는 동안 수집된 측정 지표를 바탕으로 최종 결과를 출력합니다.",
"_____no_output_____"
]
],
[
[
"train_loss = tf.keras.metrics.Mean(name='train_loss')\ntrain_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')\n\ntest_loss = tf.keras.metrics.Mean(name='test_loss')\ntest_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')",
"_____no_output_____"
]
],
[
[
"`tf.GradientTape`를 사용하여 모델을 훈련합니다:",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef train_step(images, labels):\n with tf.GradientTape() as tape:\n predictions = model(images)\n loss = loss_object(labels, predictions)\n gradients = tape.gradient(loss, model.trainable_variables)\n optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n\n train_loss(loss)\n train_accuracy(labels, predictions)",
"_____no_output_____"
]
],
[
[
"이제 모델을 테스트합니다:",
"_____no_output_____"
]
],
[
[
"@tf.function\ndef test_step(images, labels):\n predictions = model(images)\n t_loss = loss_object(labels, predictions)\n\n test_loss(t_loss)\n test_accuracy(labels, predictions)",
"_____no_output_____"
],
[
"EPOCHS = 5\n\nfor epoch in range(EPOCHS):\n for images, labels in train_ds:\n train_step(images, labels)\n\n for test_images, test_labels in test_ds:\n test_step(test_images, test_labels)\n\n template = '에포크: {}, 손실: {}, 정확도: {}, 테스트 손실: {}, 테스트 정확도: {}'\n print (template.format(epoch+1,\n train_loss.result(),\n train_accuracy.result()*100,\n test_loss.result(),\n test_accuracy.result()*100))",
"_____no_output_____"
]
],
[
[
"훈련된 이미지 분류기는 이 데이터셋에서 약 98%의 정확도를 달성합니다. 더 자세한 내용은 [TensorFlow 튜토리얼](https://www.tensorflow.org/alpha/tutorials/)을 참고하세요.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a1c696682d87e468f2e0e7ba799dad47b0e684c
| 59,356 |
ipynb
|
Jupyter Notebook
|
HowToApplyMorphologyToOneLabel.ipynb
|
aghayoor/SimpleITK-Notebook-Answers
|
4ec48f94f2f544585cc09da98d98f56d557d7aee
|
[
"Apache-2.0"
] | null | null | null |
HowToApplyMorphologyToOneLabel.ipynb
|
aghayoor/SimpleITK-Notebook-Answers
|
4ec48f94f2f544585cc09da98d98f56d557d7aee
|
[
"Apache-2.0"
] | null | null | null |
HowToApplyMorphologyToOneLabel.ipynb
|
aghayoor/SimpleITK-Notebook-Answers
|
4ec48f94f2f544585cc09da98d98f56d557d7aee
|
[
"Apache-2.0"
] | null | null | null | 139.990566 | 13,989 | 0.830144 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a1c72833ff01e055554bd2eec00c244f813ac7d
| 12,886 |
ipynb
|
Jupyter Notebook
|
examples/Trial/.ipynb_checkpoints/Darwin Supervised Classification Trial-checkpoint.ipynb
|
dharchibald/asteroid-classifier
|
dd9d3b6d12d7ecc0b773204b73c6d0cf12e0e15b
|
[
"Apache-2.0"
] | null | null | null |
examples/Trial/.ipynb_checkpoints/Darwin Supervised Classification Trial-checkpoint.ipynb
|
dharchibald/asteroid-classifier
|
dd9d3b6d12d7ecc0b773204b73c6d0cf12e0e15b
|
[
"Apache-2.0"
] | null | null | null |
examples/Trial/.ipynb_checkpoints/Darwin Supervised Classification Trial-checkpoint.ipynb
|
dharchibald/asteroid-classifier
|
dd9d3b6d12d7ecc0b773204b73c6d0cf12e0e15b
|
[
"Apache-2.0"
] | null | null | null | 25.772 | 660 | 0.555642 |
[
[
[
"<img src=\"https://cybersecurity-excellence-awards.com/wp-content/uploads/2017/06/366812.png\">",
"_____no_output_____"
],
[
"<h1><center>Darwin Supervised Classification Model Building </center></h1>",
"_____no_output_____"
],
[
"Prior to getting started, there are a few things you want to do:\n1. Set the dataset path.\n2. Enter your username and password to ensure that you're able to log in successfully\n\nOnce you're up and running, here are a few things to be mindful of:\n1. For every run, look up the job status (i.e. requested, failed, running, completed) and wait for job to complete before proceeding. \n2. If you're not satisfied with your model and think that Darwin can do better by exploring a larger search space, use the resume function.",
"_____no_output_____"
],
[
"## Import libraries",
"_____no_output_____"
]
],
[
[
"# Import necessary libraries\nimport warnings\nwarnings.filterwarnings(\"ignore\", message=\"numpy.dtype size changed\")\n%matplotlib inline\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom IPython.display import Image\nfrom time import sleep\nimport os\nimport numpy as np\nfrom sklearn.metrics import classification_report\n\nfrom amb_sdk.sdk import DarwinSdk",
"_____no_output_____"
]
],
[
[
"## Setup",
"_____no_output_____"
],
[
"**Login to Darwin**<br>\nEnter your registered username and password below to login to Darwin.",
"_____no_output_____"
]
],
[
[
"# Login\nds = DarwinSdk()\nds.set_url('https://amb-trial-api.sparkcognition.com/v1/')\nstatus, msg = ds.auth_login_user('username', 'password')\n\nif not status:\n print(msg)",
"_____no_output_____"
]
],
[
[
"**Data Path** <br>\nIn the cell below, set the path to your dataset, the default is Darwin's example datasets",
"_____no_output_____"
]
],
[
[
"path = '../../sets/'",
"_____no_output_____"
]
],
[
[
"## Data Upload and Clean",
"_____no_output_____"
],
[
"**Read dataset and view a file snippet**",
"_____no_output_____"
],
[
"After setting up the dataset path, the next step is to upload the dataset from your local device to the server. <br> In the cell below, you need to specify the dataset_name if you want to use your own data.",
"_____no_output_____"
]
],
[
[
"dataset_name = 'cancer_train.csv'\ndf = pd.read_csv(os.path.join(path, dataset_name))\ndf.head()",
"_____no_output_____"
]
],
[
[
"**Upload dataset to Darwin**",
"_____no_output_____"
]
],
[
[
"# Upload dataset\nstatus, dataset = ds.upload_dataset(os.path.join(path, dataset_name))\nif not status:\n print(dataset)",
"_____no_output_____"
]
],
[
[
"**Clean dataset**",
"_____no_output_____"
]
],
[
[
"# clean dataset\ntarget = \"Diagnosis\"\nstatus, job_id = ds.clean_data(dataset_name, target = target)\n\nif status:\n ds.wait_for_job(job_id['job_name'])\nelse:\n print(job_id)",
"_____no_output_____"
]
],
[
[
"## Create and Train Model ",
"_____no_output_____"
],
[
"We will now build a model that will learn the class labels in the target column.<br> In the default cancer dataset, the target column is \"Diagnosis\". <br> You will have to specify your own target name for your custom dataset. <br> You can also increase max_train_time for longer training.\n",
"_____no_output_____"
]
],
[
[
"model = target + \"_model0\"\nstatus, job_id = ds.create_model(dataset_names = dataset_name, \\\n model_name = model, \\\n max_train_time = '00:02')\nif status:\n ds.wait_for_job(job_id['job_name'])\nelse:\n print(job_id)",
"_____no_output_____"
]
],
[
[
"## Extra Training (Optional)\nRun the following cell for extra training, no need to specify parameters",
"_____no_output_____"
]
],
[
[
"# Train some more\nstatus, job_id = ds.resume_training_model(dataset_names = dataset_name,\n model_name = model,\n max_train_time = '00:05')\n \nif status:\n ds.wait_for_job(job_id['job_name'])\nelse:\n print(job_id)",
"_____no_output_____"
]
],
[
[
"## Analyze Model\nAnalyze model provides feature importance ranked by the model. <br> It indicates a general view of which features pose a bigger impact on the model",
"_____no_output_____"
]
],
[
[
"# Retrieve feature importance of built model\nstatus, artifact = ds.analyze_model(model)\nsleep(1)\nif status:\n ds.wait_for_job(artifact['job_name'])\nelse:\n print(artifact)\nstatus, feature_importance = ds.download_artifact(artifact['artifact_name'])",
"_____no_output_____"
]
],
[
[
"Show the 10 most important features of the model.",
"_____no_output_____"
]
],
[
[
"feature_importance[:10]",
"_____no_output_____"
]
],
[
[
"## Predictions\n**Perform model prediction on the the training dataset.**",
"_____no_output_____"
]
],
[
[
"status, artifact = ds.run_model(dataset_name, model)\nsleep(1)\nds.wait_for_job(artifact['job_name'])",
"_____no_output_____"
]
],
[
[
"Download predictions from Darwin's server.",
"_____no_output_____"
]
],
[
[
"status, prediction = ds.download_artifact(artifact['artifact_name'])\nprediction.head()",
"_____no_output_____"
]
],
[
[
"Create plots comparing predictions with actual target",
"_____no_output_____"
]
],
[
[
"unq = prediction[target].unique()[::-1]\np = np.zeros((len(prediction),))\na = np.zeros((len(prediction),))\nfor i,q in enumerate(unq):\n p += i*(prediction[target] == q).values\n a += i*(df[target] == q).values\n#Plot predictions vs actual\nplt.plot(a)\nplt.plot(p)\nplt.legend(['Actual','Predicted'])\nplt.yticks([i for i in range(len(unq))],[q for q in unq]);\nprint(classification_report(df[target], prediction[target]))",
"_____no_output_____"
]
],
[
[
"**Perform model prediction on a test dataset that wasn't used in training.** <br>\nUpload test dataset",
"_____no_output_____"
]
],
[
[
"test_data = 'cancer_test.csv'\nstatus, dataset = ds.upload_dataset(os.path.join(path, test_data))\nif not status:\n print(dataset)",
"_____no_output_____"
]
],
[
[
"clean test data",
"_____no_output_____"
]
],
[
[
"# clean test dataset\nstatus, job_id = ds.clean_data(test_data, target = target, model_name = model)\n\nif status:\n ds.wait_for_job(job_id['job_name'])\nelse:\n print(job_id)",
"_____no_output_____"
]
],
[
[
"Run model on test dataset.",
"_____no_output_____"
]
],
[
[
"status, artifact = ds.run_model(test_data, model)\nsleep(1)\nds.wait_for_job(artifact['job_name'])",
"_____no_output_____"
]
],
[
[
"Create plots comparing predictions with actual target",
"_____no_output_____"
]
],
[
[
"# Create plots comparing predictions with actual target\nstatus, prediction = ds.download_artifact(artifact['artifact_name'])\ndf = pd.read_csv(os.path.join(path,test_data))\nunq = prediction[target].unique()[::-1]\np = np.zeros((len(prediction),))\na = np.zeros((len(prediction),))\nfor i,q in enumerate(unq):\n p += i*(prediction[target] == q).values\n a += i*(df[target] == q).values\n#Plot predictions vs actual\nplt.plot(a)\nplt.plot(p)\nplt.legend(['Actual','Predicted'])\nplt.yticks([i for i in range(len(unq))],[q for q in unq]);\nprint(classification_report(df[target], prediction[target]))",
"_____no_output_____"
]
],
[
[
"## Find out which machine learning model did Darwin use:",
"_____no_output_____"
]
],
[
[
"status, model_type = ds.lookup_model_name(model)\nprint(model_type['description']['best_genome'])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1c8a0c7699f8383871a25e02f41c4324bbd1b6
| 13,975 |
ipynb
|
Jupyter Notebook
|
gene_data_exploration.ipynb
|
danhtaihoang/gene-prediction
|
5443f47f4f405da46294a085f593204d0a694f96
|
[
"MIT"
] | null | null | null |
gene_data_exploration.ipynb
|
danhtaihoang/gene-prediction
|
5443f47f4f405da46294a085f593204d0a694f96
|
[
"MIT"
] | null | null | null |
gene_data_exploration.ipynb
|
danhtaihoang/gene-prediction
|
5443f47f4f405da46294a085f593204d0a694f96
|
[
"MIT"
] | null | null | null | 27.188716 | 81 | 0.393417 |
[
[
[
"import numpy as np\nimport pandas as pd\n\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"np.random.seed(1)",
"_____no_output_____"
],
[
"# load data\n#df = np.loadtxt('../gene_sequence_data.txt',delimiter=',',dtype=np.str)\ndf = pd.read_csv('../gene_sequence_data.txt',sep= ',',header=None)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.columns = ['class', 'name', 'seq']",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df = df[['seq','class']]",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"#x1 = np.array([list(x[t]) for t in range(len(x))])\n# remove empty space\ndf['seq'] = df['seq'].str.strip()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"X = df['seq']",
"_____no_output_____"
],
[
"X = np.array([list(X[t]) for t in range(len(X))])",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"l,n = X.shape\nfor t in range(l):\n if len(np.unique(X[t,:])) > 4:\n print(t,len(np.unique(X[t,:])),np.unique(X[t,:]))",
"107 5 ['A' 'C' 'G' 'N' 'T']\n239 5 ['A' 'C' 'G' 'N' 'T']\n365 5 ['A' 'C' 'G' 'N' 'T']\n366 5 ['A' 'C' 'G' 'N' 'T']\n485 5 ['A' 'C' 'G' 'N' 'T']\n1247 5 ['A' 'C' 'D' 'G' 'T']\n1440 5 ['A' 'C' 'G' 'R' 'T']\n1441 5 ['A' 'C' 'G' 'S' 'T']\n1804 5 ['A' 'C' 'G' 'N' 'T']\n2069 5 ['A' 'C' 'G' 'N' 'T']\n2135 5 ['A' 'C' 'G' 'N' 'T']\n2578 5 ['A' 'C' 'D' 'G' 'T']\n2636 5 ['A' 'C' 'G' 'N' 'T']\n2637 5 ['A' 'C' 'G' 'N' 'T']\n2910 5 ['A' 'C' 'G' 'N' 'T']\n"
],
[
"# delete rows containing bad letters\nbad_letters = ['D','N','S','R']\nfor bad_letter in bad_letters:\n t = np.unique(np.where(X == bad_letter)[0])\n X = np.delete(X,t,axis=0)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1c93f29e0efe990ab242de90ea9fdea62a17b0
| 4,440 |
ipynb
|
Jupyter Notebook
|
AlDa/Sondierungsverfahren.ipynb
|
lyubadimitrova/cl-classes
|
00cb100a7b3aeb50c21c235710f3a73905fd5a77
|
[
"MIT"
] | null | null | null |
AlDa/Sondierungsverfahren.ipynb
|
lyubadimitrova/cl-classes
|
00cb100a7b3aeb50c21c235710f3a73905fd5a77
|
[
"MIT"
] | null | null | null |
AlDa/Sondierungsverfahren.ipynb
|
lyubadimitrova/cl-classes
|
00cb100a7b3aeb50c21c235710f3a73905fd5a77
|
[
"MIT"
] | null | null | null | 35.238095 | 207 | 0.45045 |
[
[
[
"# Hashing\n\n## Lineare Sondierung\nBei einer Kollision versuchen wir die nächste freie Stelle in unserer Hashtabelle zu suchen. Dieses Verhalten wird durch die Formel:<br> $h(k, i) = (h'(k) + i) \\bmod m$ mit $h'(k) = k \\bmod m$<br>\nm ist die Größe der Hashtabelle ausgedrückt.<br>\nIm ersten Durchlauf ist i = 0. Tritt eine Kollision auf, so berechnen wir einen neuen Schlüssel, in dem wir zum eigentlichen\nErgebnis der Hashfunktion h' i addieren. Hierdurch können aber Adressen entstehen, die größer sind als der Adressraum. Deshalb benötigen wir auch in h ein 'mod m'.\n<br>\nBeispielsequenz:<br>\n10, 22, 31, 4, 15, 28, 17, 88, 59 (9 Elemente) sollen in Hashtabelle mit m=11 eingefügt werden.<br>\n\n Rechnung:<br>\n Element 10: 10 mod 11 = 10 -> 10 kommt an Tabellenposition 10<br>\n Element 22: 22 mod 11 = 0 -> 22 kommt am Tabellenposition 0<br>\n Element 31: 31 mod 11 = 9 -> 31 kommt an Tabellenposition 9<br>\n Element 4: 4 mod 11 = 4 -> 4 kommt an Tabellenposition 4<br>\n Element 15: 15 mod 11 = 4 -> Kollision!<br>\n (h'(15) + 1) mod 11 = (4 + 1) mod 11 = 5 -> 15 kommt an Tabellenposition 5<br>\n ...<br>\n\n| adr | value | \n|-----|-------| \n| 0 | 22 | \n| 1 | 88 | \n| 2 | | \n| 3 | | \n| 4 | 4 | \n| 5 | 15 |\n| 6 | 28 |\n| 7 | 17 |\n| 8 | 59 |\n| 9 | 31 |\n| 10 | 10 |\n\n\n## Quadratische Sondierung\nHier benutzen wir stattdessen $h(k,i) = (h'(k) + c_{1}*i + c_{2}*i^{2}) \\bmod m$. h' ist das selbe wie beim linearen Sondieren.<br>\nWir rechnen wieder mit den Beispielzahlen von oben und wählen $c_{1} = 1$ und $c_{2} = 3$ (das ist willkürlich und kann frei gewählt werden)\n\nRechnung:<br>\nElement 10: 10 mod 11 = 11 -> 10 kommt an Tabellenposition\n...\nElement 5: 15 mod 11 = 4 -> Kollision! <br>\n(h'(15) + 1 + 3) mod 11 = (4 + 1 + 3) mod 11 = 8\n-> 15 kommt auf Position 8<br>\nElement 28: 28 mod 11 = 6 -> 28 kommt an Tabellenposition 6<br>\nElement 17: 17 mod 11 = 6 -> Kollision! <br>\n(h'(17) + 1 + 3) mod 11 = 10 -> Kollision! <br>\n(h'(17) + 2 + 12) mod 11 = 9 -> Kollision! <br>\n(h'(17) + 3 + 27) mod 11 = 3 -> 17 kommtauf Position 3 <br>\n...\n\n| adr | value | \n|-----|-------| \n| 0 | 22 | \n| 1 | | \n| 2 | 88 | \n| 3 | 17 | \n| 4 | 4 | \n| 5 | |\n| 6 | 28 |\n| 7 | 59 |\n| 8 | 17 |\n| 9 | 31 |\n| 10 | 10 |\n\n\n## Double Hashing\nHier setzen wir die Hashfunktion h aus zwei Hashfunktionen zusammensetzt. $h_{1}$ ist hierbei h' von oben.<br>\n$h(k,i)=(h_{1}(k) + h_{2}(k)*i) \\bmod m$<br>\n$h_{1}(k) = k \\bmod m$<br>\n$h_{2}(k) = 1 + (k \\bmod m-1)$<br>\nDie Rechnung erfolgt analog zu oben - nur dass wir bei Kollision eben das neue h(k, i) benutzen.\n\n| adr | value | \n|-----|-------| \n| 0 | 22 | \n| 1 | | \n| 2 | 59 | \n| 3 | 17 | \n| 4 | 4 | \n| 5 | 15 |\n| 6 | 28 |\n| 7 | 88 |\n| 8 | |\n| 9 | 31 |\n| 10 | 10 |",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4a1ca53effc95d8fa55ad4908c28e89372c6539a
| 18,112 |
ipynb
|
Jupyter Notebook
|
docs/_build/jupyter_execute/index.ipynb
|
amakelov/mandala
|
a9ec051ef730ada4eed216c62a07b033126e78d5
|
[
"Apache-2.0"
] | 9 |
2022-02-22T19:24:01.000Z
|
2022-03-23T04:46:41.000Z
|
docs/_build/jupyter_execute/index.ipynb
|
amakelov/mandala
|
a9ec051ef730ada4eed216c62a07b033126e78d5
|
[
"Apache-2.0"
] | null | null | null |
docs/_build/jupyter_execute/index.ipynb
|
amakelov/mandala
|
a9ec051ef730ada4eed216c62a07b033126e78d5
|
[
"Apache-2.0"
] | null | null | null | 47.663158 | 204 | 0.635435 |
[
[
[
"# Mandala: self-managing experiments\n## What is Mandala?\nMandala enables new, simpler patterns for working with complex and evolving\ncomputational experiments. \n\nIt eliminates low-level code and decisions for how to save, load, query,\ndelete and otherwise organize results. To achieve this, it lets computational\ncode \"manage itself\" by organizing and addressing its own data storage.\n\n```{admonition} Under construction\n:class: warning\nThis project is under active development\n```\n\n### Features at a glance\n- **concise**: code computations in pure Python (w/ control flow, collections,\n ...) -- results are automatically tracked and queriable\n- **iterate rapidly**: add/edit parameters/logic and rerun code -- past results\n are loaded on demand, and only new computations are executed\n- **pattern-match against Python code**: query across complex, branching\n projects by reusing computational code itself",
"_____no_output_____"
],
[
"### Quick start\n#### Installation\n```console\npip install git+https://github.com/amakelov/mandala\n```\n#### Recommended introductions\nTo build some understanding, check these out:\n- 2-minute introduction: [intro to self-managing code](2mins)\n- 10-minute introduction: [manage a small ML project](10mins)\n#### Minimal working examples\nIf you want to jump right into code, below are a few minimal, somewhat\ninteresting examples to play with and extend:",
"_____no_output_____"
]
],
[
[
"from typing import List\nfrom mandala.all import *\nset_logging_level('warning')\n\n# create a storage for results\nstorage = Storage(in_memory=True) # can also be persistent (on disk)\n\n@op(storage) # memoization decorator\ndef inc(x) -> int:\n return x + 1 \n\n@op(storage) \ndef mean(x:List[int]) -> float: \n # you can operate on / return collections of memoized results\n return sum(x) / len(x) \n\nwith run(storage): # calls inside `run` block are memoized\n nums = [inc(i) for i in range(5)]\n result = mean(nums) # memoization composes through lists without copying data\n print(f'Mean of 5 nums: {result}')\n\n# add logic/parameters directly on top of memoized code without re-doing past work\nwith run(storage, lazy=True):\n nums = [inc(i) for i in range(10)]\n result = mean(nums) \n\n# walk over chains of calls without loading intermediate data \n# to traverse storage and collect results flexibly\nwith run(storage, lazy=True):\n nums = [inc(i) for i in range(10)]\n result = mean(nums) \n print(f'Reference to mean of 10 nums: {result}')\n storage.attach(result) # load the value in-place \n print(f'Loaded mean of 10 nums: {result}')\n\n# pattern-match to memoized compositions of calls\nwith query(storage) as q: \n # this may not make sense unless you read the tutorials\n i = Query()\n inc_i = inc(i).named('inc_i')\n nums = MakeList(containing=inc_i, at_index=0).named('nums')\n result = mean(nums).named('result')\n df = q.get_table(inc_i, nums, result)\ndf",
"Mean of 5 nums: AtomRef(3.0, type=AtomType(float))\n"
]
],
[
[
"## Why Mandala?\n### Advantages\nCompared to other tools for tracking and managing computations, the features that\nmost set Mandala apart are the direct and concise patterns in which complex\nPython code can interact with its own storage. This manifests in several ways: \n- **Python code as interface to its own storage**: you just write the code to compute\n what you want to compute (freely using Python's control flow and collections),\n and directly add more parameters and logic to it over time. Mandala takes\n care of the rest:\n - **the organization of storage mirrors the structure of code**, and Mandala\n provides you with the tools to make maximum use of this --\n retracing memoized code with on-demand data loading, and declarative\n code-based pattern-matching.\n - this leads to **simple, intuitive and flexible ways to query and iterate on \n experiments**, even when their logic gets quite complex -- without any data\n organization efforts on your part.\n - it also allows you to **query relationships between any variables in your\n projects**, even when they are separated by many computational steps -- **without\n explicitly annotating these relationships**.\n- **refactor code and data will follow**: Mandala makes it easy to apply\n familiar software refactorings to code *without* losing the relationship to\n this code's existing results. This gives you high-level tools to manage the\n complexity of both the code and its data as the project grows. \n- **organize all results and their relationships**: Mandala manages all the\n artifacts produced by computations, not just a set of human-readable\n metrics. It lets you use pure Python idioms to\n - compute with **data structures with shared substructure**\n - **index and view data in multiple ways** and on multiple levels of analysis\n\n without storage duplication. This gives you much flexibility in manipulating\n the contents of storage to express your intent.\n\n### Comparisons\nMandala takes inspiration from many other programming tools and concepts. Below\nis an (incomplete but growing) list of comparisons with relevant tools:\n- [algebraicjulia](https://www.algebraicjulia.org/):\n [conjunctive](https://www.algebraicjulia.org/blog/post/2020/12/cset-conjunctive-queries/) [queries](https://www.algebraicjulia.org/blog/post/2020/11/sql-as-hypergraph/)\n are integral to Mandala's declarative interface, and are generalized in\n several ways to make them practical for complex experiments:\n - a single table of values is used to enable polymorphism\n - operations on lists/dicts are integrated with query construction\n - queries can use the hierarchical structure of computations\n - constraints can be partitioned (to avoid interaction) while using some\n shared base (to enable code reuse)\n - dynamic query generation can use conditionals to enable disjunctive\n queries, and even loops (though this quickly becomes inefficient)\n- [koji](https://arxiv.org/abs/1901.01908) and [content-addressable computation](https://research.protocol.ai/publications/ipfs-fan-a-function-addressable-computation-network/delarocha2021a.pdf):\n Mandala uses causal hashing to \n - ensure correct, deterministic and idempotent behavior;\n - avoid hashing large (or unhashable) Python objects;\n - avoid discrepancies between object hashes across library versions \n\n Mandala can be thought of as a single-node, Python-only implementation of\n general-purpose content-addressable computation with two extra features:\n - hierarchical organization of computation,\n - declarative queries\n- [funsies](https://github.com/aspuru-guzik-group/funsies) is a workflow engine\n for Python scripts that also uses causal hashing. Mandala differs by\n integrating more closely with Python (by using functions instead of scripts as\n the units of work), and thus enabling more fine-grained control and\n expressiveness over what gets computed and how. \n- [joblib.Memory](https://joblib.readthedocs.io/en/latest/memory.html#memory)\n implements persistent memoization for Python functions that overcomes some of\n the issues naive implementations have with large and complex Python objects.\n Mandala augments `joblib.Memory` in some key ways:\n - memoized calls can be queried/deleted declaratively\n - collections and memoized functions calling other memoized functions can\n reuse storage\n - you can modify and refactor memoized functions while retaining connection to\n memoized calls\n - you can avoid the latency of hashing large/complex objects \n- [incpy](https://dl.acm.org/doi/abs/10.1145/2001420.2001455?casa_token=ahM2UC4Uk-4AAAAA:9lZXVDS7nYEHzHPJk-UCTOAICGb2astAh2hrL00VB125nF6IGG90OwA-ujbe-cIg2hT4T1MOpbE2)\n augments the Python interpreter with automatic persistent memoization. Mandala\n also enables automatic persistent memoization, but it is different from\n `incpy` in some key ways:\n - uses decorators to explicitly designate memoized functions (which can be\n good or bad depending on your goals)\n - allows for lazy retracing of memoized calls\n - provides additional features like the ones mentioned in the comparison with\n `joblib.Memory`\n\n### Philosophy\nWhen can we declare data management for computational experiments a solved\nproblem? It's unclear how to turn this question into a measurable goal, but\nthere is a somewhat objective *lower bound* on how simple data management can\nget:\n\n> At the end of the day, we have to *at least* write down the (Python) code to express\n> the computations we want to run, *regardless* of data management concerns. \n> Can this be *all* the code we have to write, and *still* be able to achieve\n> the goals of data management?\n\nMandala aims to bring us to this idealized lower bound. It adopts the view that\nPython itself is flexible and expressive enough to capture our intentions about\nexperiments. There shouldn't be a ton of extra interfaces, concepts and syntax\nbetween your thoughts, their expression in code, and its results.\n\nBy mirroring the structure of computational code in the organization of data,\nand harmoniously extending Python's tools for capturing intention and managing\ncomplexity, we can achieve a more flexible, natural and immediate way to\ninteract with computations.\n\nThis echoes the design goals of some other tools. For example,\n[dask](https://dask.org) and [ray](https://ray.io) (both of which Mandala\nintegrates with) aim to let you write Python code the way you are used to, and\ntake care of parallelization for you.",
"_____no_output_____"
],
[
"## Limitations \nThis project is under active development, and not ready for production. Its goal\nso far has been to demonstrate that certain high-level programming patterns are\nviable by building a sufficiently useful working prototype. Limitations can be\nsummarized as follows:\n- it is easy to get started, but effective use in complex projects requires some\n getting used to;\n- much of the code does what it does in very simple and often inefficient ways;\n- interfaces and (more importantly) storage formats may change in backward\n incompatible ways.\n- bugs likely still exist;\n\nThat being said, Mandala is already quite usable in many practical situations.\nBelow is a detailed outline of current limitations you should be aware of if you\nconsider using this library in your work. \n\n### \"Missing\" features\nThere are some things you may be used to seeing in projects like this that\ncurrently don't exist:\n- **functions over scripts**: Mandala focuses on functions as the basic\n building blocks of experiments as opposed to Python scripts. There is no\n fundamental conceptual distinction between the two, but:\n - functions provide a better-behaved interface, especially when it comes to\n typing, refactoring, and hierarchical organization\n - using functions makes it much easier to use \n projects such as [ray](https://www.ray.io/) and [dask](https://dask.org/)\n alongside Mandala\n - if you don't need to do something extra complicated involving different\n Python processes or virtual environments, it is easy to wrap a script as a\n function that takes in some settings and resource descriptions (e.g., paths to\n input files) and returns other resource descriptions (e.g., paths to output\n files). However, the burden of refactoring the script's interface manually\n and organizing its input/output resources would still be on you. So, always\n use a function where you can.\n- **no integration with git**: version control data is not automatically\n included in Mandala's records at this point, thought this would be an easy\n addition. There are other programming patterns available for working with\n multiple versions of code.\n- **no GUI**: for now, the library leans heavily towards using computational\n code itself as a highly programmable interface to results, and visualization\n is left to other tools. \n\n### Acquiring best practices\nUsing some features effectively requires deeper understanding:\n- **declarative queries**: It's possible to create underconstrained\n pattern-matching queries which return a number of rows that grows\n multiplicatively with the numbers of rows of memoization tables of functions\n in the query. Such queries may take a very long time or run out of RAM even\n for moderately-sized projects (`sqlite` will usually complain about this at\n the start of the query).\n\n Certain ways to define and compose memoized functions promote such queries, so\n a good understanding of this issue may be needed depending on the project.\n- **deletions**: deleting anything from storage is subject to invariants that\n prevent the existence of \"mysterious\" objects (ones without a computational\n history tracing back to user inputs) from existing. This means that you must\n understand well how deletion works to avoid deleting more things than you\n really intend.\n\n### Performance\nThe library has not been optimized much for performance. A few things to keep in\nmind for now:\n- When using disk-based persistence, Mandala introduces an overhead of a few 10s\n of ms for each call to a memoized function, on top of any work to serialize\n inputs/outputs and run the function.\n- Storing and loading large collections can be slow (a list of 1000 integers\n already leads to a visible ~1s delay)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a1ca6d49eacf8951ad393de658802b72a97b268
| 1,565 |
ipynb
|
Jupyter Notebook
|
Association_rule_learning.ipynb
|
saurabhsingh1411/100-Days-Of-ML-Code
|
274366b4d256514235c51e45db934d29a8c3bdf2
|
[
"MIT"
] | null | null | null |
Association_rule_learning.ipynb
|
saurabhsingh1411/100-Days-Of-ML-Code
|
274366b4d256514235c51e45db934d29a8c3bdf2
|
[
"MIT"
] | null | null | null |
Association_rule_learning.ipynb
|
saurabhsingh1411/100-Days-Of-ML-Code
|
274366b4d256514235c51e45db934d29a8c3bdf2
|
[
"MIT"
] | null | null | null | 23.358209 | 260 | 0.470288 |
[
[
[
"<a href=\"https://colab.research.google.com/github/saurabhsingh1411/100-Days-Of-ML-Code/blob/master/Association_rule_learning.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"print(2+3)",
"5\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
]
] |
4a1cbed743ecc90614f38cabbea16dbf8fcf098a
| 584,015 |
ipynb
|
Jupyter Notebook
|
End to end simple and powerful dnn with leakyrelu (Gold medal).ipynb
|
Pythonash/Kaggle-eng-
|
8ca4f833b86ca5d99cb68fc7ce30cef0423abc60
|
[
"MIT"
] | null | null | null |
End to end simple and powerful dnn with leakyrelu (Gold medal).ipynb
|
Pythonash/Kaggle-eng-
|
8ca4f833b86ca5d99cb68fc7ce30cef0423abc60
|
[
"MIT"
] | null | null | null |
End to end simple and powerful dnn with leakyrelu (Gold medal).ipynb
|
Pythonash/Kaggle-eng-
|
8ca4f833b86ca5d99cb68fc7ce30cef0423abc60
|
[
"MIT"
] | null | null | null | 248.728705 | 306,586 | 0.876198 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Pythonash/Kaggle-eng-/blob/Brain/end_to_end_simple_and_powerful_dnn_with_leakyrelu.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Welcome to my notebook\n\nHi all, I have uploaded several notebooks for beginners who does not know how to participate in competition.\n\nNow, I will show you my end-to-end procedure which contains loading dataset, training model, and submitting the result.\n\nFurthermore, it will be helpful to you who want to use neural network with tensorflow and keras.\n\nmy notebook, version 2, acheived 0.146 score!\n\nHere, there are many chances to upgrade the model through handling hyper-parameter so that you can improve your score in leaderboard.\n\nIf you have any questions, please leave the comments.\n\n\n## **Knowledge can be improved by being shared.**\n\nPlease upvote!!\n\n\n## [You can learn more skills for handling dataset or neural network.]\n\n- [Parallel DNN and CNN network for beginners](https://www.kaggle.com/pythonash/parallel-dnn-and-cnn-network-for-beginners) - **Pawpularity Contest (silver medal)**\n\n- [Handling image and csv dataset at the same time](https://www.kaggle.com/pythonash/how-to-use-csv-and-img-at-the-same-time) - **Pawpularity Contest (bronze medal)**\n \n- [Image data handling without memory exploded](https://www.kaggle.com/pythonash/how-to-handle-dataset-for-beginners) - **Pawpularity Contest (bronze medal)**\n\n- [Data handling & Deep learning](https://www.kaggle.com/pythonash/how-to-handle-raw-dataset-and-analyze-with-dl) - **Titanic competition (best score!!, bronze medal)**\n\n- [Deep learning model with SeLU activation function](https://www.kaggle.com/pythonash/selu-activation-function-in-dl) - **Titanic competition (bronze medal)**\n\n- [Preparing a completed dataset with proper imputation method](https://www.kaggle.com/pythonash/making-completed-dataset) - **Titanic competition**\n \n \n \n### [More contents or information]\n\n## [Pythonash Github](https://github.com/pythonash)\n\n## [Pythonash blog](https://pythonash.github.io/ash)\n\n**Let's start!**",
"_____no_output_____"
],
[
"# Contents\n\n<a id=\"toc\"></a>\n- [1. Import Library](#1)\n- [2. Load dataset](#2)\n - [2.1 Dataset](#2.1) \n- [3. Model ](#3)\n - [3.1 KFold strategy](#3.1)\n- [4. Submit](#4)\n- [5. Review](#5)",
"_____no_output_____"
],
[
"<a id=\"1\"></a>\n# Import Library",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tensorflow as tf\nfrom sklearn.preprocessing import StandardScaler\nimport ubiquant\nfrom sklearn.model_selection import KFold\nfrom scipy.stats import pearsonr",
"_____no_output_____"
]
],
[
[
"<a id=\"2\"></a>\n# Load dataset\n\nAs you may know, this competition's dataset (18.55gb) is too large.\n\nSo, we will use another dataset is converted low memory (about 3.63gb).\n\nYou can see the description on [ubiquant-parquet](https://www.kaggle.com/c/ubiquant-market-prediction/discussion/301724) and add the data by searching as below:\n\nThank you for sharing!! @Rob Mulla\n\n**Click \" + Add data\" on upper right**\n\n\n\n**Next, search \"ubiquant\" and click add**\n\n\n\n\nAfter above procedures, load the parquet.\n\nsee the dataset.",
"_____no_output_____"
],
[
"<a id=\"2.1\"></a>\n# Dataset",
"_____no_output_____"
]
],
[
[
"df = pd.read_parquet('../input/ubiquant-parquet/train_low_mem.parquet')\ndf",
"_____no_output_____"
]
],
[
[
"## There is no missing value.",
"_____no_output_____"
]
],
[
[
"df.isnull().sum().sum()",
"_____no_output_____"
]
],
[
[
"## What is the shape of submission??",
"_____no_output_____"
]
],
[
[
"pd.read_parquet('../input/ubiquant-parquet/example_sample_submission.parquet')",
"_____no_output_____"
]
],
[
[
"## I will use all features\n\nIn fact, I have already done the EDA and some statistical approaches.\n\nBut I identified that the result would be good when all the data was used.\n\nOf course, although my approach might not be perfect, you will get robust score by tuning the hyper-parameter.",
"_____no_output_____"
],
[
"## Data columns",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
]
],
[
[
"## Use the features, f_0 ~ f_299.",
"_____no_output_____"
]
],
[
[
"f_col = df.drop(['row_id','time_id','investment_id','target'],axis=1).columns\nf_col",
"_____no_output_____"
]
],
[
[
"## We will convert \"investment_id\" column with StandardScaler in sklearn.\n\nSince \"f_#\" columns are similar to standard normal distribution, \"investment_id\" column will be converted for efficient training.\n\nTo apply the same criteria at test dataset, make the scaler and use it later.",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\nscaler.fit(pd.DataFrame(df['investment_id']))",
"_____no_output_____"
]
],
[
[
"## Make dataset function.\n\nThe test dataset will be given in last code cell by specific API.\n\nSo, we will use \"make dataset function\" efficiently.",
"_____no_output_____"
]
],
[
[
"def make_dataset(df):\n inv_df = df['investment_id']\n f_df = df[f_col]\n scaled_investment_id = scaler.transform(pd.DataFrame(inv_df))\n df['investment_id'] = scaled_investment_id\n data_x = pd.concat([df['investment_id'], f_df], axis=1)\n return data_x",
"_____no_output_____"
]
],
[
[
"## Change the data type\n\nNotebook memory has limit which is too small to use raw data.\n\nSo, change the data type to \"float16\".\n\nAnd divide the dataset into variables for input and output.",
"_____no_output_____"
],
[
"## Input variables",
"_____no_output_____"
]
],
[
[
"df=df.astype('float16')\ndf_x = make_dataset(df)\ndf_x",
"_____no_output_____"
]
],
[
[
"## Target variable",
"_____no_output_____"
]
],
[
[
"df_y = pd.DataFrame(df['target'])\ndf_y",
"_____no_output_____"
]
],
[
[
"## Delete raw data\n\nTo prevent notebook memory from exlporing, delete raw data.",
"_____no_output_____"
]
],
[
[
"del df",
"_____no_output_____"
]
],
[
[
"<a id=\"3\"></a>\n# Model\n\nWe will use a simple deep neural network.\n\nThe brief descriptions are as follows:\n\n## 1. Use LeakyReLU activation.\n\n- You can set a parpameter.\n\n## 2. Use BatchNormalization.\n\n- It is mainly used before activation function layer.\n\n## 3. Use Dropout.\n\n- You can change the raito.\n\n## 4. Use kernel_initializer with 'he_normal'.\n\n- 'he_normal' initializer strategy works well with derivatives of relu.\n\n## 5. Use ExponentialDecay scheduling.\n\n- It will be great for improving your performance.\n\n## 6. Use ModelCheckpoint.\n\n- To save your best performance, we will use ModelChechpoint in callbacks parameter.\n",
"_____no_output_____"
]
],
[
[
"def pythonash_model():\n inputs_ = tf.keras.Input(shape = [df_x.shape[1]])\n x = tf.keras.layers.Dense(64, kernel_initializer = 'he_normal')(inputs_)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n \n x = tf.keras.layers.Dense(128, kernel_initializer = 'he_normal')(leaky)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n \n x = tf.keras.layers.Dense(256, kernel_initializer = 'he_normal')(leaky)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n \n x = tf.keras.layers.Dense(512, kernel_initializer = 'he_normal')(leaky)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n \n x = tf.keras.layers.Dense(256, kernel_initializer = 'he_normal')(leaky)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n drop = tf.keras.layers.Dropout(0.4)(leaky)\n \n x = tf.keras.layers.Dense(128, kernel_initializer = 'he_normal')(drop)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n \n x = tf.keras.layers.Dense(8, kernel_initializer = 'he_normal')(leaky)\n batch = tf.keras.layers.BatchNormalization()(x)\n leaky = tf.keras.layers.LeakyReLU(0.1)(batch)\n drop = tf.keras.layers.Dropout(0.4)(leaky)\n \n outputs_ = tf.keras.layers.Dense(1)(drop)\n \n model = tf.keras.Model(inputs = inputs_, outputs = outputs_)\n \n rmse = tf.keras.metrics.RootMeanSquaredError()\n\n learning_sch = tf.keras.optimizers.schedules.ExponentialDecay(\n initial_learning_rate = 0.003,\n decay_steps = 9700,\n decay_rate = 0.98)\n adam = tf.keras.optimizers.Adam(learning_rate = learning_sch)\n \n model.compile(loss = 'mse', metrics = rmse, optimizer = adam)\n return model\n\npythonash_model().summary()",
"Model: \"model\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) [(None, 301)] 0 \n_________________________________________________________________\ndense (Dense) (None, 64) 19328 \n_________________________________________________________________\nbatch_normalization (BatchNo (None, 64) 256 \n_________________________________________________________________\nleaky_re_lu (LeakyReLU) (None, 64) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 128) 8320 \n_________________________________________________________________\nbatch_normalization_1 (Batch (None, 128) 512 \n_________________________________________________________________\nleaky_re_lu_1 (LeakyReLU) (None, 128) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 256) 33024 \n_________________________________________________________________\nbatch_normalization_2 (Batch (None, 256) 1024 \n_________________________________________________________________\nleaky_re_lu_2 (LeakyReLU) (None, 256) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 512) 131584 \n_________________________________________________________________\nbatch_normalization_3 (Batch (None, 512) 2048 \n_________________________________________________________________\nleaky_re_lu_3 (LeakyReLU) (None, 512) 0 \n_________________________________________________________________\ndense_4 (Dense) (None, 256) 131328 \n_________________________________________________________________\nbatch_normalization_4 (Batch (None, 256) 1024 \n_________________________________________________________________\nleaky_re_lu_4 (LeakyReLU) (None, 256) 0 \n_________________________________________________________________\ndropout (Dropout) (None, 256) 0 \n_________________________________________________________________\ndense_5 (Dense) (None, 128) 32896 \n_________________________________________________________________\nbatch_normalization_5 (Batch (None, 128) 512 \n_________________________________________________________________\nleaky_re_lu_5 (LeakyReLU) (None, 128) 0 \n_________________________________________________________________\ndense_6 (Dense) (None, 8) 1032 \n_________________________________________________________________\nbatch_normalization_6 (Batch (None, 8) 32 \n_________________________________________________________________\nleaky_re_lu_6 (LeakyReLU) (None, 8) 0 \n_________________________________________________________________\ndropout_1 (Dropout) (None, 8) 0 \n_________________________________________________________________\ndense_7 (Dense) (None, 1) 9 \n=================================================================\nTotal params: 362,929\nTrainable params: 360,225\nNon-trainable params: 2,704\n_________________________________________________________________\n"
]
],
[
[
"## Model graphic",
"_____no_output_____"
]
],
[
[
"tf.keras.utils.plot_model(pythonash_model(),show_shapes=True,expand_nested=True)",
"_____no_output_____"
]
],
[
[
"<a id=\"3.1\"></a>\n# KFold strategy\n\nKFold strategy is good at evaluating robust.\n\nFurthermore, using kfold is of use for training procedure and overfitting, because we have plenty of dataset.",
"_____no_output_____"
]
],
[
[
"kfold_generator = KFold(n_splits =5, shuffle=True, random_state = 2022)\nkfold_generator",
"_____no_output_____"
]
],
[
[
"## Model fitting\n\nWe can use KFold strategy by using \"for\" structure.",
"_____no_output_____"
]
],
[
[
"# Write your model name down in 'pythonash_model.h5'.\ncallbacks = tf.keras.callbacks.ModelCheckpoint('pythonash_model.h5', save_best_only = True)\nfor train_index, val_index in kfold_generator.split(df_x, df_y):\n # Split training dataset.\n train_x, train_y = df_x.iloc[train_index], df_y.iloc[train_index]\n # Split validation dataset.\n val_x, val_y = df_x.iloc[val_index], df_y.iloc[val_index]\n # Make tensor dataset.\n tf_train = tf.data.Dataset.from_tensor_slices((train_x, train_y)).shuffle(2022).batch(1024, drop_remainder=True).prefetch(1)\n tf_val = tf.data.Dataset.from_tensor_slices((val_x, val_y)).shuffle(2022).batch(1024, drop_remainder=True).prefetch(1)\n # Load model\n model = pythonash_model()\n # Model fitting\n \n ## I used 5 epochs for fast save.\n ## Change the epochs into more numbers.\n model.fit(tf_train, callbacks = callbacks, epochs = 5, #### change the epochs into more numbers.\n validation_data = (tf_val), shuffle=True)\n # Delete tensor dataset and model for avoiding memory exploring.\n del tf_train\n del tf_val\n del model",
"2022-02-17 06:51:06.216617: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1512903056 exceeds 10% of free system memory.\n2022-02-17 06:51:07.770172: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1512903056 exceeds 10% of free system memory.\n2022-02-17 06:51:09.174804: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 378225764 exceeds 10% of free system memory.\n2022-02-17 06:51:09.540961: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 378225764 exceeds 10% of free system memory.\n2022-02-17 06:51:09.967924: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1512903056 exceeds 10% of free system memory.\n"
]
],
[
[
"<a id=\"4\"></a>\n# Submit\n\nTo submit your result, follow the code given by [competetion overview evaluation](https://www.kaggle.com/c/ubiquant-market-prediction/overview/evaluation).\n\nIf you don't know how it works, just run the code as below:\n\n\n",
"_____no_output_____"
]
],
[
[
"best_model = tf.keras.models.load_model('pythonash_model.h5')\nenv = ubiquant.make_env() \niter_test = env.iter_test() \nfor (test_df, sample_prediction_df) in iter_test:\n test_df = make_dataset(test_df)\n sample_prediction_df['target'] = best_model.predict(test_df) \n env.predict(sample_prediction_df)",
"This version of the API is not optimized and should not be used to estimate the runtime of your code on the hidden test set.\n"
]
],
[
[
"<a id=\"5\"></a>\n# Review\n\nI want to share my experiences that I have tried to improve the performance.\n\n## 1. It might not be perfect to use more neurons.\n\n> I recommend you to stack more layers rather than using more neurons.\n\n## 2. Change the learning rate or LeakyReLU parameter.\n\n- When LeakyReLU was used with 0.4 and initial learning rate was 0.001, I achieved the score, 0.146.\n\n- LeakyReLU would be great rather than 'relu' or 'elu' in my notebook.\n\n- When LeakyReLU was used with 0.1 and initial learning rate was 0.001, I achieved the score, 0.147.\n\n## 3. To use both ModelCheckpoint and EarlyStopping at the same time makes the memory explore.\n\n\n## **It has done!!**\n\nIf this notebook is helpful to you, give me **upvotes!!**\n\nThank you for viewing.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1cbf9d48112c6631b34b171844f7fc48f28f3a
| 10,830 |
ipynb
|
Jupyter Notebook
|
src/triplet_processor.ipynb
|
MillionConcepts/m3-conversion
|
485c0cf6dcad12971c15fd728b194b465a82e713
|
[
"BSD-3-Clause"
] | 1 |
2022-02-14T09:22:46.000Z
|
2022-02-14T09:22:46.000Z
|
src/triplet_processor.ipynb
|
MillionConcepts/m3-conversion
|
485c0cf6dcad12971c15fd728b194b465a82e713
|
[
"BSD-3-Clause"
] | null | null | null |
src/triplet_processor.ipynb
|
MillionConcepts/m3-conversion
|
485c0cf6dcad12971c15fd728b194b465a82e713
|
[
"BSD-3-Clause"
] | null | null | null | 39.097473 | 104 | 0.606556 |
[
[
[
"# notebook for processing fully reduced m3 data \"triplets\"\nThis is a notebook for processing L0 / L1B / L2 triplets (i.e.,\nthe observations that got reduced).\n\n## general notes\n\nWe process the reduced data in triplets simply to improve the metadata on the\nL0 and L2 products. We convert L1B first to extract several attributes to fill\nout their metadata. This data is scratched to disk in\n[./directories/m3/m3_index.csv'](./directories/m3/m3_index.csv), because it\nalso serves as a useful user-facing index to the archive. A complete version\nof this index is provided in this repository, but this index was originally\ncreated during this conversion process, and will be recreated if you run it\nagain. This index is read into the ```m3_index variable``` below; its path is\nalso soft-coded in several ```m3_conversion``` classes, so make sure you\nchange that or feed them the correct path as an argument if you change this\nlocation.\n\nThis notebook does not apply programmatic rules to iterate over the file\nstructure of the mirrored archive. It uses an index that was partly manually\ngenerated:\n[/src/directories/m3/m3_data_mappings.csv](/src/directories/m3/m3_data_mappings.csv).\nThis was manually manipulated to manage several small idiosyncracies in the\nPDS3 archive.\n\n35 of the V3 L1B products in the PDS3 archive are duplicated: one copy in the\ncorrect month-by-year directory, one copy in some incorrect month-by-year\ndirectory. We pick the 'first' one in all cases (see the line\n```pds3_label_file = input_directory + group_files[product_type][0]``` below).\nEach pair's members have identical md5sums, so it *probably* doesn't matter\nwhich member of the pair we use.\n\n## performance tips\n\nThe most likely bottlenecks for this process are I/O throughput and CPU. We\nrecommend both using a high-throughput disk and parallelizing this, either\nusing ```pathos``` (vanilla Python ```multiprocessing``` will probably fail\nduring a pickling step) or simply by running multiple\ncopies of this notebook. If you do parallelize this process on a single\nmachine, note that working memory can suddenly catch you off-guard as a\nconstraint. While many of the M3 observational data files are small, some are\nover 4 GB, and the method presented here requires them to be completely loaded\ninto memory in order to convert them to FITS and strip the prefix tables from\nthe L0 files. When passed ```clean=True```, the ```m3_converter```\nobservational data writer class constructors aggressively delete data after\nusing it, but this still results in a pretty high -- and spiky -- working\nmemory burden.",
"_____no_output_____"
]
],
[
[
"import datetime as dt\nimport os\nfrom types import MappingProxyType\n\nfrom more_itertools import distribute\nimport pandas as pd\nimport sh\n\nfrom m3_bulk import basenamer, make_m3_triplet, \\\n m3_triplet_bundle_paths, crude_time_log, fix_end_object_tags\nfrom m3_conversion import M3L0Converter, M3L1BConverter, M3L2Converter\nfrom pvl.decoder import ParseError",
"_____no_output_____"
],
[
"\nm3_index = pd.read_csv('./directories/m3/m3_index.csv')\n\n# directory of file mappings, grouped into m3 basename clusters\nfile_mappings = pd.read_csv('./directories/m3/m3_data_mappings.csv')\nfile_mappings[\"basename\"] = file_mappings[\"filepath\"].apply(basenamer)\nbasename_groups = list(file_mappings.groupby(\"basename\"))\n\n# what kind of files does each pds4 product have?\n# paths to the locally-written versions are stored in the relevant attributes of \n# the associated PDSVersionConverter instance.\npds4_filetypes = MappingProxyType({\n 'l0': ('pds4_label_file', 'clock_file', 'fits_image_file'),\n 'l1b': ('pds4_label_file', 'loc_file', 'tim_file', 'rdn_file', 'obs_file'),\n 'l2': ('pds4_label_file', 'sup_file', 'rfl_file')\n})\n\n# root directories of PDS3 and PDS4 data sets respectively\ninput_directory = '/home/ubuntu/m3_input/'\noutput_directory = '/home/ubuntu/m3_output/'",
"_____no_output_____"
],
[
"# all the triplets: what we are converting here.\nreduced_groups = [group for group in basename_groups if len(group[1]) >= 3]\n\n# the\nedr_groups = [group for group in basename_groups if len(group[1]) == 1] # lonesome EDR images\n\ntriplet_product_types = ('l1b', 'l0', 'l2')\n\n# initialize our mapping of product types to\n# product-writer class constructors.\n# MappingProxyType is just a safety mechanism\n# to make sure constructors don't get messed with\nconverters = MappingProxyType({\n 'l0': M3L0Converter,\n 'l1b': M3L1BConverter,\n 'l2': M3L2Converter\n})\nwriters = {} # dict to hold instances of the converter classes",
"_____no_output_____"
],
[
"# initialize iteration, control execution in whatever way\n\n# this is a place to split your index up however you like\n# if you're parallelizing using multiple copies of this\n# notebook.\nchunk_ix_of_this_notebook = 0\ntotal_chunks = 40\nchunks = distribute(total_chunks, reduced_groups)\n# eagerly evaluate so we know how long it is,\n# and what all is in it if we have an error\nchunk = list(chunks[chunk_ix_of_this_notebook])\nlog_string = \"_\" + str(chunk_ix_of_this_notebook)\n\ngroup_enumerator = enumerate(chunk)",
"_____no_output_____"
],
[
"for ix, group in group_enumerator:\n\n print(ix, len(chunk))\n print(\"beginning product conversion\")\n triplet_start_time = dt.datetime.now()\n group_files = make_m3_triplet(group)\n # what are the correct output paths (relative to\n # the root of the pds4 bundle) for these products?\n bundle_paths = m3_triplet_bundle_paths(group)\n\n for product_type in triplet_product_types:\n # read the PDS3 product and perform file conversions \n pds3_label_file = input_directory + group_files[product_type][0]\n try: \n writers[product_type] = converters[product_type](\n pds3_label_file, suppress_warnings=True, clean=True\n )\n except ParseError: # fix broken END_OBJECT tags in some of the target-mode files \n print(\"fixing broken END_OBJECT tags\")\n temp_label_file = fix_end_object_tags(pds3_label_file)\n writers[product_type] = converters[product_type](\n temp_label_file, suppress_warnings=True, clean=True\n )\n os.remove(temp_label_file)\n # write PDS4 label and product files\n # don't actually need to shave the extra / here but...\n # this would be more safely rewritten with PyFilesystem\n # (see clem-conversion)\n output_path = output_directory + bundle_paths[product_type][1:] \n sh.mkdir(\"-p\", output_path)\n writers[product_type].write_pds4(output_path, write_product_files=True, clean=True) \n\n # occasionally (slow but very useful) spot-check with validate tool\n # note that this just invokes a one-line script at /usr/bin/validate\n # that links to the local install of the PDS Validate Tool; this\n # allows us to avoid throwing java stuff all over our environment\n if ix % 20 == 1:\n print(\"1-mod-20th triplet: running Validate Tool\")\n validate_results = sh.validate(\"-t\", writers[product_type].pds4_label_file)\n with open(\"validate_dump.txt\", \"a\") as file:\n file.write(validate_results.stdout.decode())\n print(\"validated successfully\")\n # log transfer crudely\n crude_time_log(\n \"m3_data_conversion_log\" + log_string + \".csv\",\n writers[product_type], \n str((dt.datetime.now() - triplet_start_time).total_seconds())\n )\n\n print(\n \"done with this triplet; total seconds \" \n + str((dt.datetime.now() - triplet_start_time).total_seconds())\n )",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a1cc35335788b1946bd2f773b0b8bc9c9b8301d
| 6,430 |
ipynb
|
Jupyter Notebook
|
examples/widgets.ipynb
|
westurner/jupyter-cadquery
|
7b5b2ffa4a79f6053ce3bec738063a5ff56e8fa2
|
[
"Apache-2.0"
] | null | null | null |
examples/widgets.ipynb
|
westurner/jupyter-cadquery
|
7b5b2ffa4a79f6053ce3bec738063a5ff56e8fa2
|
[
"Apache-2.0"
] | null | null | null |
examples/widgets.ipynb
|
westurner/jupyter-cadquery
|
7b5b2ffa4a79f6053ce3bec738063a5ff56e8fa2
|
[
"Apache-2.0"
] | null | null | null | 25.019455 | 99 | 0.450078 |
[
[
[
"import os\n\nfrom ipywidgets import Output, HBox, Layout\n\nimport jupyter_cadquery\n\nicon_path = os.path.join(os.path.dirname(jupyter_cadquery.__file__), \"icons\")",
"_____no_output_____"
]
],
[
[
"# ipywidgets",
"_____no_output_____"
]
],
[
[
"from ipywidgets import interact, interactive, fixed, interact_manual\nimport ipywidgets as widgets\n\ndef f(x):\n return x\n\ninteract(f, x=10);",
"_____no_output_____"
]
],
[
[
"# pythreejs",
"_____no_output_____"
]
],
[
[
"from pythreejs import *\n\nBoxGeometry(\n width=5,\n height=10,\n depth=15,\n widthSegments=5,\n heightSegments=10,\n depthSegments=15)\n",
"_____no_output_____"
]
],
[
[
"# Sidecar",
"_____no_output_____"
]
],
[
[
"from sidecar import Sidecar\nfrom ipywidgets import IntSlider\n\nsc = Sidecar(title='Sidecar Output')\nsl = IntSlider(description='Some slider')\nwith sc:\n display(sl)",
"_____no_output_____"
]
],
[
[
"# Image Button",
"_____no_output_____"
]
],
[
[
"from jupyter_cadquery.widgets import ImageButton\n\noutput = Output()\n\ndef handler(out):\n def f(b):\n with out:\n print(\"Pressed\", b.type)\n return f\n\ndef create_button(icon):\n button = ImageButton(\n width=36, \n height=28, \n image_path=\"%s/%s.png\" % (icon_path, icon),\n tooltip=\"Change view to %s\" % icon,\n type=icon\n )\n button.on_click(handler(output))\n return button\n\nbutton1 = create_button(\"fit\")\nbutton2 = create_button(\"isometric\")\n\n\nHBox([button1, button2, output])",
"_____no_output_____"
]
],
[
[
"# Tree View",
"_____no_output_____"
]
],
[
[
"from ipywidgets import Checkbox, Layout, HBox, Output\nfrom jupyter_cadquery.widgets import TreeView, UNSELECTED, SELECTED, MIXED, EMPTY, state_diff",
"_____no_output_____"
],
[
"tree = {\n 'type': 'node',\n 'name': 'Root',\n 'id': \"n1\",\n 'children': [\n {'type': 'leaf',\n 'name': 'Red box',\n 'id': \"R\",\n 'color': 'rgba(255, 0, 0, 0.6)'},\n {'type': 'node',\n 'name': 'Sub',\n 'id': \"n2\",\n 'children': [\n {'type': 'leaf',\n 'name': 'Green box',\n 'id': \"G\",\n 'color': 'rgba(0, 255, 0, 0.6)'},\n {'type': 'leaf',\n 'name': 'blue box',\n 'id': \"B\",\n 'color': 'rgba(0, 0, 255, 0.6)'}]},\n {'type': 'leaf',\n 'name': 'Yellow box',\n 'id': \"Y\",\n 'color': 'rgba(255, 255, 0, 0.6)'}\n]}\n\nstate = {\n \"R\": [EMPTY, UNSELECTED],\n \"G\": [UNSELECTED, SELECTED],\n \"B\": [SELECTED, UNSELECTED],\n \"Y\": [SELECTED, SELECTED]\n}\n\nimage_paths = [\n {UNSELECTED: \"%s/no_shape.png\" % icon_path, \n SELECTED: \"%s/shape.png\" % icon_path, \n MIXED: \"%s/mix_shape.png\" % icon_path, \n EMPTY: \"%s/empty.png\" % icon_path},\n {UNSELECTED: \"%s/no_mesh.png\" % icon_path, \n SELECTED: \"%s/mesh.png\" % icon_path, \n MIXED: \"%s/mix_mesh.png\" % icon_path, \n EMPTY: \"%s/empty.png\" % icon_path}\n]\n\nheight = \"300px\"\n\noutput = Output(layout=Layout(height=height, width=\"800px\", \n overflow_y=\"scroll\", overflow_x=\"scroll\"))\noutput.add_class(\"mac-scrollbar\")\n\ndef handler(out):\n def f(states):\n diff = state_diff(states.get(\"old\"), states.get(\"new\"))\n with out:\n #print(states.get(\"old\"))\n #print(states.get(\"new\"))\n print(diff)\n return f\n\nt = TreeView(image_paths=image_paths, tree=tree, state=state, \n layout=Layout(height=height, width=\"200px\", \n overflow_y=\"scroll\", overflow_x=\"scroll\"))\n\nt.add_class(\"mac-scrollbar\")\n\nt.observe(handler(output), \"state\")\nHBox([t, output])\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1ccd28ae07291d08a6ccde4b073271e7b089d0
| 264,497 |
ipynb
|
Jupyter Notebook
|
notebook/Measure Notebook.ipynb
|
Miki-Vaszily/assistant-improve-recommendations-notebook
|
ac1d975a5db314ec0be763984b009719c554b94d
|
[
"Apache-2.0"
] | null | null | null |
notebook/Measure Notebook.ipynb
|
Miki-Vaszily/assistant-improve-recommendations-notebook
|
ac1d975a5db314ec0be763984b009719c554b94d
|
[
"Apache-2.0"
] | null | null | null |
notebook/Measure Notebook.ipynb
|
Miki-Vaszily/assistant-improve-recommendations-notebook
|
ac1d975a5db314ec0be763984b009719c554b94d
|
[
"Apache-2.0"
] | null | null | null | 112.936379 | 52,838 | 0.803979 |
[
[
[
"# Measure Watson Assistant Performance ",
"_____no_output_____"
],
[
"\n\n## Introduction\n\nThis notebook demonstrates how to setup automated metrics that help you measure, monitor, and understand the behavior of your Watson Assistant system. As described in <a href=\"https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/raw/master/notebook/IBM%20Watson%20Assistant%20Continuous%20Improvement%20Best%20Practices.pdf\" target=\"_blank\" rel=\"noopener noreferrer\">Watson Assistant Continuous Improvement Best Practices</a>, this is the first step of your continuous improvement process. The goal of this step is to understand where your assistant is doing well vs where it isn’t and to potentially focus your improvement effort to one of the problem areas identified. We define two measures to achieve this goal: **Coverage** and **Effectiveness**.\n\n- **Coverage** is the portion of total user messages your assistant is attempting to respond to.\n\n- **Effectiveness** refers to how well your assistant is handling the conversations it is attempting to respond to.\n\nThe pre-requisite for running this notebook is Watson Assistant (formerly Watson Conversation). This notebook assumes familiarity with Watson Assistant and concepts such as workspaces, intents and training examples. \n\n### Programming language and environment\nSome familiarity with Python is recommended. This notebook runs on Python 3.5 with Default Python 3.5 XS environment.\n***",
"_____no_output_____"
],
[
"## Table of contents",
"_____no_output_____"
],
[
"1. [Configuration and setup](#setup)<br>\n 1.1 [Import and apply global CSS styles](#css)<br>\n 1.2 [Install required Python libraries](#python)<br>\n 1.3 [Import functions used in the notebook](#function)<br>\n2. [Load and format data](#load)<br>\n 2.1 [Option one: from a Watson Assistant instance](#load_remote)<br>\n 2.2 [Option two: from JSON files](#load_local)<br>\n 2.3 [Format the log data](#format_data)<br>\n3. [Define coverage and effectiveness metrics](#set_metrics)<br>\n 3.1 [Customize coverage](#set_coverage)<br>\n 3.2 [Customize effectiveness](#set_effectiveness)<br>\n4. [Calculate overall coverage and effectiveness](#overall)<br>\n 4.1 [Calculate overall metrics](#overall1)<br>\n 4.2 [Display overall results](#overall2)<br>\n5. [Analyze coverage](#msg_analysis)<br>\n 5.1 [Display overall coverage](#msg_analysis1)<br>\n 5.2 [Calculate coverage over time](#msg_analysis2)<br>\n6. [Analyze effectiveness](#conv_analysis)<br>\n 6.1 [Generate excel file and upload to our project](#conv_analysis1)<br>\n 6.2 [Plot breakdown by effectiveness graph](#conv_analysis2)<br>\n7. [Root cause analysis of non coverage](#root_cause)<br>\n8. [Abandoned and resolved intent analysis](#abandoned_resolved_intents)<br>\n 8.1 [Count of all started intents](#started_intents)<br>\n 8.2 [Analyze resolved intents](#resolved_intents)<br>\n 8.3 [Analyze abandoned intents](#abandoned_intents)<br>\n9. [Summary and next steps](#summary)<br>",
"_____no_output_____"
],
[
"<a id=\"setup\"></a>\n## 1. Configuration and Setup\n\nIn this section, we add data and workspace access credentials, import required libraries and functions.",
"_____no_output_____"
],
[
"### <a id=\"css\"></a> 1.1 Import and apply global CSS styles",
"_____no_output_____"
]
],
[
[
"from IPython.display import HTML\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/css/custom.css\nHTML(open('custom.css', 'r').read())",
" % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 348 100 348 0 0 348 0 0:00:01 --:--:-- 0:00:01 600\n"
]
],
[
[
"### <a id=\"python\"></a> 1.2 Install required Python libraries",
"_____no_output_____"
]
],
[
[
"# install watson-developer-cloud python SDK\n# After running this cell once, comment out the following code. Packages only need to be installed once.\n!pip3 install --upgrade \"watson-developer-cloud>=1.0,<2.0\";\n\n# Import required libraries\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport json\nfrom pandas.io.json import json_normalize\nfrom watson_developer_cloud import AssistantV1\nimport matplotlib.dates as mdates\nimport re\nfrom IPython.display import display",
"Requirement already up-to-date: watson-developer-cloud<2.0,>=1.0 in /usr/local/lib/python3.6/site-packages (1.7.1)\nRequirement already satisfied, skipping upgrade: service-identity>=17.0.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (17.0.0)\nRequirement already satisfied, skipping upgrade: pyOpenSSL>=16.2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.0.0)\nRequirement already satisfied, skipping upgrade: requests<3.0,>=2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (2.18.4)\nRequirement already satisfied, skipping upgrade: Twisted>=13.2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.4.0)\nRequirement already satisfied, skipping upgrade: autobahn>=0.10.9 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.6.1)\nRequirement already satisfied, skipping upgrade: python-dateutil>=2.5.3 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (2.6.1)\nRequirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (18.1.0)\nRequirement already satisfied, skipping upgrade: pyasn1-modules in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (0.2.2)\nRequirement already satisfied, skipping upgrade: pyasn1 in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (0.1.9)\nRequirement already satisfied, skipping upgrade: cryptography>=2.2.1 in /usr/local/lib/python3.6/site-packages (from pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (2.2.2)\nRequirement already satisfied, skipping upgrade: six>=1.5.2 in /usr/local/lib/python3.6/site-packages (from pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (1.11.0)\nRequirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (3.0.4)\nRequirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (2017.11.5)\nRequirement already satisfied, skipping upgrade: idna<2.7,>=2.5 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (2.6)\nRequirement already satisfied, skipping upgrade: urllib3<1.23,>=1.21.1 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (1.22)\nRequirement already satisfied, skipping upgrade: hyperlink>=17.1.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (18.0.0)\nRequirement already satisfied, skipping upgrade: incremental>=16.10.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (17.5.0)\nRequirement already satisfied, skipping upgrade: constantly>=15.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (15.1.0)\nRequirement already satisfied, skipping upgrade: Automat>=0.3.0 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (0.7.0)\nRequirement already satisfied, skipping upgrade: zope.interface>=4.4.2 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (4.5.0)\nRequirement already satisfied, skipping upgrade: txaio>=2.10.0 in /usr/local/lib/python3.6/site-packages (from autobahn>=0.10.9->watson-developer-cloud<2.0,>=1.0) (2.10.0)\nRequirement already satisfied, skipping upgrade: cffi>=1.7; platform_python_implementation != \"PyPy\" in /usr/local/lib/python3.6/site-packages (from cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (1.11.2)\nRequirement already satisfied, skipping upgrade: asn1crypto>=0.21.0 in /usr/local/lib/python3.6/site-packages (from cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (0.24.0)\nRequirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/site-packages (from zope.interface>=4.4.2->Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (39.0.1)\nRequirement already satisfied, skipping upgrade: pycparser in /usr/local/lib/python3.6/site-packages (from cffi>=1.7; platform_python_implementation != \"PyPy\"->cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (2.18)\n\u001b[33mWARNING: You are using pip version 19.1.1, however version 19.2.2 is available.\nYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\n"
]
],
[
[
"### <a id=\"function\"></a> 1.3 Import functions used in the notebook",
"_____no_output_____"
]
],
[
[
"# Import function module files\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/cos_op.py\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/watson_assistant_func.py\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/visualize_func.py\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/computation_func.py\n \n# Import the visualization related functions\nfrom visualize_func import make_pie\nfrom visualize_func import coverage_barh\nfrom visualize_func import width_bar\n\n# Import Cloud Object Storage related functions \nfrom cos_op import generate_link\nfrom cos_op import generate_excel_measure\n\n# Import Watson Assistant related functions\nfrom watson_assistant_func import get_logs_jupyter\n\n# Import Dataframe computation related functions\nfrom computation_func import get_effective_df\nfrom computation_func import get_coverage_df\nfrom computation_func import chk_is_valid_node\nfrom computation_func import format_data",
" % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 7240 100 7240 0 0 7240 0 0:00:01 --:--:-- 0:00:01 14280\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 6952 100 6952 0 0 6952 0 0:00:01 --:--:-- 0:00:01 14605-:--:-- --:--:-- --:--:-- 0\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 10166 100 10166 0 0 10166 0 0:00:01 --:--:-- 0:00:01 19933\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 15862 100 15862 0 0 15862 0 0:00:01 --:--:-- 0:00:01 31224\n"
]
],
[
[
"## <a id=\"load\"></a> 2. Load and format data ",
"_____no_output_____"
],
[
"### <a id=\"load_remote\"></a> 2.1 Option one: from a Watson Assistant instance\n\n#### 2.1.1 Add Watson Assistant configuration\n\nProvide your Watson Assistant credentials and the workspace id that you want to fetch data from. \n\n- For more information about obtaining Watson Assistant credentials, see [Service credentials for Watson services](https://console.bluemix.net/docs/services/watson/getting-started-credentials.html#creating-credentials).\n- API requests require a version parameter that takes a date in the format version=YYYY-MM-DD. For more information about version, see [Versioning](https://www.ibm.com/watson/developercloud/assistant/api/v1/curl.html?curl#versioning).\n",
"_____no_output_____"
]
],
[
[
"# Provide credentials to connect to assistant\ncreds = {'username':'YOUR_USERNAME',\n 'password':'YOUR_PASSWORD',\n 'version':'2018-05-03'}\n\n# Connect to Watson Assistant\nconversation = AssistantV1(username=creds['username'], \n password=creds['password'], \n version=creds['version'])\n\n# You only need to give api key and url to connect. If you can connect using this, you will not need the above code\n\n# conversation = AssistantV1(version='2019-04-28',\n# iam_apikey='',\n# url='')",
"_____no_output_____"
]
],
[
[
"#### 2.1.2 Fetch and load a workspace\n\nFetch the workspace for the workspace id given in `workspace_id` variable.",
"_____no_output_____"
]
],
[
[
"# Provide the workspace id you want to analyze\nworkspace_id = ''\n\nif len(workspace_id) > 0:\n # Fetch the worksapce info. for the input workspace id\n workspace = conversation.get_workspace(workspace_id = workspace_id, export=True)\n\n # Store the workspace details in a dataframe\n df_workspace = json_normalize(workspace)\n\n # Get all intents present in current version of workspace\n workspace_intents= [intent['intent'] for intent in df_workspace['intents'].values[0]] \n\n # Get all dialog nodes present in current version of workspace\n workspace_nodes= pd.DataFrame(df_workspace['dialog_nodes'].values[0])\n\n # Mark the workspace loaded\n workspace_loaded = True\nelse:\n workspace_loaded = False",
"_____no_output_____"
]
],
[
[
"#### 2.1.3 Fetch and load workspace logs\n\nFetch the logs for the workspace id given in `workspace_id` variable. Any necessary filter can be specified in the `filter` variable.<br>\nNote that if the logs were already fetched in a previous run, it will be read from the a cache file.",
"_____no_output_____"
]
],
[
[
"if len(workspace_id) > 0:\n # Filter to be applied while fetching logs, e.g., removing empty input 'meta.summary.input_text_length_i>0', 'response_timestamp>=2018-09-18'\n filter = 'meta.summary.input_text_length_i>0'\n\n # Send this info into the get_logs function\n workspace_creds={'sdk_object':conversation, 'ws_id':workspace['workspace_id'], 'ws_name':workspace['name']}\n\n # Fetch the logs for the workspace\n df = get_logs_jupyter(num_logs=10000, log_list=[], workspace_creds=workspace_creds, log_filter=filter)\n\n # Mark the logs loaded\n logs_loaded = True\nelse:\n logs_loaded = False ",
"_____no_output_____"
]
],
[
[
"### <a id=\"load_local\"></a> 2.2 Option two: from JSON files\n\n#### 2.2.1 Load a workspace JSON file",
"_____no_output_____"
]
],
[
[
"if not workspace_loaded:\n \n # The following code is for using demo workspace\n import requests\n print('Loading workspace data from Watson developer cloud Github repo ... ', end='')\n workspace_data = requests.get(\"https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/notebook/data/workspace.json\").text \n print('completed!')\n df_workspace = json_normalize(json.loads(workspace_data))\n \n # Specify a workspace JSON file\n # workspace_file = 'workspace.json'\n\n # Store the workspace details in a dataframe\n # df_workspace = json_normalize(json.load(open(workspace_file)))\n\n # Get all intents present in current version of workspace\n workspace_intents = [intent['intent'] for intent in df_workspace['intents'].values[0]] \n\n # Get all dialog nodes present in current version of workspace\n workspace_nodes = pd.DataFrame(df_workspace['dialog_nodes'].values[0])\nJupyter Notebook\nMeasure Notebook (autosaved) Current Kernel Logo \n\nPython 3\n\n File\n Edit\n View\n Insert\n Cell\n Kernel\n Widgets\n Help\n\nMeasure Watson Assistant Performance\n\noverall_measure.png\nIntroduction\n\nThis notebook demonstrates how to setup automated metrics that help you measure, monitor, and understand the behavior of your Watson Assistant system. As described in Watson Assistant Continuous Improvement Best Practices, this is the first step of your continuous improvement process. The goal of this step is to understand where your assistant is doing well vs where it isn’t and to potentially focus your improvement effort to one of the problem areas identified. We define two measures to achieve this goal: Coverage and Effectiveness.\n\n Coverage is the portion of total user messages your assistant is attempting to respond to.\n\n Effectiveness refers to how well your assistant is handling the conversations it is attempting to respond to.\n\nThe pre-requisite for running this notebook is Watson Assistant (formerly Watson Conversation). This notebook assumes familiarity with Watson Assistant and concepts such as workspaces, intents and training examples.\nProgramming language and environment\n\nSome familiarity with Python is recommended. This notebook runs on Python 3.5 with Default Python 3.5 XS environment.\nTable of contents\n\n Configuration and setup\n 1.1 Import and apply global CSS styles\n 1.2 Install required Python libraries\n 1.3 Import functions used in the notebook\n Load and format data\n 2.1 Option one: from a Watson Assistant instance\n 2.2 Option two: from JSON files\n 2.3 Format the log data\n Define coverage and effectiveness metrics\n 3.1 Customize coverage\n 3.2 Customize effectiveness\n Calculate overall coverage and effectiveness\n 4.1 Calculate overall metrics\n 4.2 Display overall results\n Analyze coverage\n 5.1 Display overall coverage\n 5.2 Calculate coverage over time\n Analyze effectiveness\n 6.1 Generate excel file and upload to our project\n 6.2 Plot breakdown by effectiveness graph\n Root cause analysis of non coverage\n Abandoned and resolved intent analysis\n 8.1 Count of all started intents\n 8.2 Analyze resolved intents\n 8.3 Analyze abandoned intents\n Summary and next steps\n\n1. Configuration and Setup\n\nIn this section, we add data and workspace access credentials, import required libraries and functions.\n1.1 Import and apply global CSS styles\n\nfrom IPython.display import HTML\n\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/css/custom.css\n\nHTML(open('custom.css', 'r').read())\n\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 348 100 348 0 0 348 0 0:00:01 --:--:-- 0:00:01 600\n\n1.2 Install required Python libraries\n\n# install watson-developer-cloud python SDK\n\n# After running this cell once, comment out the following code. Packages only need to be installed once.\n\n!pip3 install --upgrade \"watson-developer-cloud>=1.0,<2.0\";\n\n\n\n# Import required libraries\n\nimport pandas as pd\n\nimport matplotlib.pyplot as plt\n\nimport json\n\nfrom pandas.io.json import json_normalize\n\nfrom watson_developer_cloud import AssistantV1\n\nimport matplotlib.dates as mdates\n\nimport re\n\nfrom IPython.display import display\n\nRequirement already up-to-date: watson-developer-cloud<2.0,>=1.0 in /usr/local/lib/python3.6/site-packages (1.7.1)\nRequirement already satisfied, skipping upgrade: service-identity>=17.0.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (17.0.0)\nRequirement already satisfied, skipping upgrade: pyOpenSSL>=16.2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.0.0)\nRequirement already satisfied, skipping upgrade: requests<3.0,>=2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (2.18.4)\nRequirement already satisfied, skipping upgrade: Twisted>=13.2.0 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.4.0)\nRequirement already satisfied, skipping upgrade: autobahn>=0.10.9 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (18.6.1)\nRequirement already satisfied, skipping upgrade: python-dateutil>=2.5.3 in /usr/local/lib/python3.6/site-packages (from watson-developer-cloud<2.0,>=1.0) (2.6.1)\nRequirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (18.1.0)\nRequirement already satisfied, skipping upgrade: pyasn1-modules in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (0.2.2)\nRequirement already satisfied, skipping upgrade: pyasn1 in /usr/local/lib/python3.6/site-packages (from service-identity>=17.0.0->watson-developer-cloud<2.0,>=1.0) (0.1.9)\nRequirement already satisfied, skipping upgrade: cryptography>=2.2.1 in /usr/local/lib/python3.6/site-packages (from pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (2.2.2)\nRequirement already satisfied, skipping upgrade: six>=1.5.2 in /usr/local/lib/python3.6/site-packages (from pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (1.11.0)\nRequirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (3.0.4)\nRequirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (2017.11.5)\nRequirement already satisfied, skipping upgrade: idna<2.7,>=2.5 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (2.6)\nRequirement already satisfied, skipping upgrade: urllib3<1.23,>=1.21.1 in /usr/local/lib/python3.6/site-packages (from requests<3.0,>=2.0->watson-developer-cloud<2.0,>=1.0) (1.22)\nRequirement already satisfied, skipping upgrade: hyperlink>=17.1.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (18.0.0)\nRequirement already satisfied, skipping upgrade: incremental>=16.10.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (17.5.0)\nRequirement already satisfied, skipping upgrade: constantly>=15.1 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (15.1.0)\nRequirement already satisfied, skipping upgrade: Automat>=0.3.0 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (0.7.0)\nRequirement already satisfied, skipping upgrade: zope.interface>=4.4.2 in /usr/local/lib/python3.6/site-packages (from Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (4.5.0)\nRequirement already satisfied, skipping upgrade: txaio>=2.10.0 in /usr/local/lib/python3.6/site-packages (from autobahn>=0.10.9->watson-developer-cloud<2.0,>=1.0) (2.10.0)\nRequirement already satisfied, skipping upgrade: cffi>=1.7; platform_python_implementation != \"PyPy\" in /usr/local/lib/python3.6/site-packages (from cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (1.11.2)\nRequirement already satisfied, skipping upgrade: asn1crypto>=0.21.0 in /usr/local/lib/python3.6/site-packages (from cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (0.24.0)\nRequirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/site-packages (from zope.interface>=4.4.2->Twisted>=13.2.0->watson-developer-cloud<2.0,>=1.0) (39.0.1)\nRequirement already satisfied, skipping upgrade: pycparser in /usr/local/lib/python3.6/site-packages (from cffi>=1.7; platform_python_implementation != \"PyPy\"->cryptography>=2.2.1->pyOpenSSL>=16.2.0->watson-developer-cloud<2.0,>=1.0) (2.18)\nWARNING: You are using pip version 19.1.1, however version 19.2.2 is available.\nYou should consider upgrading via the 'pip install --upgrade pip' command.\n\n:0: UserWarning: You do not have a working installation of the service_identity module: 'cannot import name 'opentype''. Please install it from <https://pypi.python.org/pypi/service_identity> and make sure all of its dependencies are satisfied. Without the service_identity module, Twisted can perform only rudimentary TLS client hostname verification. Many valid certificate/hostname mappings may be rejected.\n\n1.3 Import functions used in the notebook\n\n# Import function module files\n\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/cos_op.py\n\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/watson_assistant_func.py\n\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/visualize_func.py\n\n!curl -O https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/src/main/python/computation_func.py\n\n \n\n# Import the visualization related functions\n\nfrom visualize_func import make_pie\n\nfrom visualize_func import coverage_barh\n\nfrom visualize_func import width_bar\n\n\n\n# Import Cloud Object Storage related functions \n\nfrom cos_op import generate_link\n\nfrom cos_op import generate_excel_measure\n\n\n\n# Import Watson Assistant related functions\n\nfrom watson_assistant_func import get_logs_jupyter\n\n\n\n# Import Dataframe computation related functions\n\nfrom computation_func import get_effective_df\n\nfrom computation_func import get_coverage_df\n\nfrom computation_func import chk_is_valid_node\n\nfrom computation_func import format_data\n\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 7240 100 7240 0 0 7240 0 0:00:01 --:--:-- 0:00:01 14280\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 6952 100 6952 0 0 6952 0 0:00:01 --:--:-- 0:00:01 14605-:--:-- --:--:-- --:--:-- 0\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 10166 100 10166 0 0 10166 0 0:00:01 --:--:-- 0:00:01 19933\n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 15862 100 15862 0 0 15862 0 0:00:01 --:--:-- 0:00:01 31224\n\n2. Load and format data\n2.1 Option one: from a Watson Assistant instance\n2.1.1 Add Watson Assistant configuration\n\nProvide your Watson Assistant credentials and the workspace id that you want to fetch data from.\n\n For more information about obtaining Watson Assistant credentials, see Service credentials for Watson services.\n API requests require a version parameter that takes a date in the format version=YYYY-MM-DD. For more information about version, see Versioning.\n\n# Provide credentials to connect to assistant\n\ncreds = {'username':'YOUR_USERNAME',\n\n 'password':'YOUR_PASSWORD',\n\n 'version':'2018-05-03'}\n\n\n\n# Connect to Watson Assistant\n\nconversation = AssistantV1(username=creds['username'], \n\n password=creds['password'], \n\n version=creds['version'])\n\n\n\n# You only need to give api key and url to connect. If you can connect using this, you will not need the above code\n\n\n\n# conversation = AssistantV1(version='2019-04-28',\n\n# iam_apikey='',\n\n# url='')\n\n2.1.2 Fetch and load a workspace\n\nFetch the workspace for the workspace id given in workspace_id variable.\n\n# Provide the workspace id you want to analyze\n\nworkspace_id = ''\n\n\n\nif len(workspace_id) > 0:\n\n # Fetch the worksapce info. for the input workspace id\n\n workspace = conversation.get_workspace(workspace_id = workspace_id, export=True)\n\n\n\n # Store the workspace details in a dataframe\n\n df_workspace = json_normalize(workspace)\n\n\n\n # Get all intents present in current version of workspace\n\n workspace_intents= [intent['intent'] for intent in df_workspace['intents'].values[0]] \n\n\n\n # Get all dialog nodes present in current version of workspace\n\n workspace_nodes= pd.DataFrame(df_workspace['dialog_nodes'].values[0])\n\n\n\n # Mark the workspace loaded\n\n workspace_loaded = True\n\nelse:\n\n workspace_loaded = False\n\n2.1.3 Fetch and load workspace logs\n\nFetch the logs for the workspace id given in workspace_id variable. Any necessary filter can be specified in the filter variable.\nNote that if the logs were already fetched in a previous run, it will be read from the a cache file.\n\nif len(workspace_id) > 0:\n\n # Filter to be applied while fetching logs, e.g., removing empty input 'meta.summary.input_text_length_i>0', 'response_timestamp>=2018-09-18'\n\n filter = 'meta.summary.input_text_length_i>0'\n\n\n\n # Send this info into the get_logs function\n\n workspace_creds={'sdk_object':conversation, 'ws_id':workspace['workspace_id'], 'ws_name':workspace['name']}\n\n\n\n # Fetch the logs for the workspace\n\n df = get_logs_jupyter(num_logs=10000, log_list=[], workspace_creds=workspace_creds, log_filter=filter)\n\n\n\n # Mark the logs loaded\n\n logs_loaded = True\n\nelse:\n\n logs_loaded = False \n\n2.2 Option two: from JSON files\n2.2.1 Load a workspace JSON file\n\nif not workspace_loaded:\n\n \n\n # The following code is for using demo workspace\n\n import requests\n\n print('Loading workspace data from Watson developer cloud Github repo ... ', end='')\n\n workspace_data = requests.get(\"https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/notebook/data/workspace.json\").text \n\n print('completed!')\n\n df_workspace = json_normalize(json.loads(workspace_data))\n\n \n\n # Specify a workspace JSON file\n\n # workspace_file = 'workspace.json'\n\n\n\n # Store the workspace details in a dataframe\n\n # df_workspace = json_normalize(json.load(open(workspace_file)))\n\n\n\n # Get all intents present in current version of workspace\n\n workspace_intents = [intent['intent'] for intent in df_workspace['intents'].values[0]] \n\n\n\n # Get all dialog nodes present in current version of workspace\n\n workspace_nodes = pd.DataFrame(df_workspace['dialog_nodes'].values[0])",
"Loading workspace data from Watson developer cloud Github repo ... completed!\n"
]
],
[
[
"#### 2.2.2 Load a log JSON file",
"_____no_output_____"
]
],
[
[
"if not logs_loaded:\n \n # The following code is for using demo logs\n import requests\n print('Loading demo log data from Watson developer cloud Github repo ... ', end='')\n log_raw_data = requests.get(\"https://raw.githubusercontent.com/watson-developer-cloud/assistant-improve-recommendations-notebook/master/notebook/data/sample_logs.json\").text\n print('completed!')\n df = pd.DataFrame.from_records(json.loads(log_raw_data))\n\n# # The following code is for loading your log file\n# # Specify a log JSON file\n# log_file = 'sample_logs.json'\n \n# # Create a dataframe for logs\n# df = pd.DataFrame.from_records(json.load(open(log_file)))",
"Loading demo log data from Watson developer cloud Github repo ... completed!\n"
]
],
[
[
"### <a id=\"format_data\"></a> 2.3 Format the log data",
"_____no_output_____"
]
],
[
[
"# Format the logs data from the workspace\ndf_formated = format_data(df)\n",
"_____no_output_____"
]
],
[
[
"<a id=\"set_metrics\"></a>\n## 3. Define effectiveness and coverage metrics\nAs described in Watson Assistant Continuous Improvement Best Practices, **Effectiveness** and **Coverage** are the two measures that provide a reliable understanding of your assistant’s overall performance. Both of the two measures are customizable based on your preferences. In this section, we provide a guideline for setting each of them.",
"_____no_output_____"
],
[
"### <a id=\"set_coverage\"></a> 3.1 Customize coverage\n\nCoverage measures your Watson Assistant system at the utterance level. You may include automated metrics that help identify utterences that your service is not answering. Example metrics include: \n\n- Confidence threshold\n- Dialog information\n\nFor Confidence threshold, you can set a threshold to include utterances with confidence values below this threshold. For more information regarding Confidence, see [Absolute scoring](https://console.bluemix.net/docs/services/conversation/intents.html#absolute-scoring-and-mark-as-irrelevant).\n\nFor Dialog information, you can specify what the notebook should look for in your logs to determine that a message is not covered by your assistant.\n\n- Use the node_ids list to include the identifiers of any dialog nodes you've used to model that a message is out of scope. \n- Similarly, use the node_names list to include any dialog nodes.\n- Use node_conditions for dialog conditions that indicate a message is out of scope.\n \nNote that these lists are treated as \"OR\" conditions - any occurrence of any of them will signify that a message is not covered. \n\n__Where to find node id, node name, and node condition__?\n\nYou can find the values of these variables from your workspace JSON file based on following mappings.\n\n- node id: `dialog_node`\n- node name: `title`\n- node condition: `conditions`\n\nYou can also find node name, and node condition in your workspace dialog editor. For more information, see [Dialog Nodes].(https://console.bluemix.net/docs/services/conversation/dialog-overview.html#dialog-nodes)\n\nBelow we provide example code for identifying coverage based on confidence and dialog node. ",
"_____no_output_____"
]
],
[
[
"#Specify the confidence threhold you want to look for in the logs\nconfidence_threshold = .20\n\n# Add coverage node ids, if any, to list\nnode_ids = ['node_1_1467910920863', 'node_1_1467919680248']\n\n# Add coverage node names, if any, to list\nnode_names = []\n\n# Add coverage node conditions, if any, to list\nnode_conditions = ['#out_of_scope || #off_topic', 'anything_else']\n\n# Check if the dialog nodes are present in the current version of workspace\ndf_coverage_nodes = chk_is_valid_node(node_ids, node_names, node_conditions, workspace_nodes)\ndf_coverage_nodes",
"_____no_output_____"
]
],
[
[
"### <a id=\"set_effectiveness\"></a> 3.2 Customize effectiveness\n\nEffectiveness measures your Watson Assistant system at the conversation level. You may include automated metrics that help identify problematic conversations. Example metrics include:\n\n- Escalations to live agent: conversations escalated to a human agent for quality reasons.\n- Poor NPS: conversations that received a poor NPS (Net Promoter Score), or other explicit user feedback.\n- Task not completed: conversations failed to complete the task the user was attempting.\n- Implicit feedback: conversations containing implicit feedback that suggests failure, such as links provided not being clicked. \n\nBelow we provide example code for identifying escalation based on intents and dialog information.",
"_____no_output_____"
],
[
"#### <a id=\"set_escalation_intent\"></a> 3.2.1 Specify intents to identify escalations\nIf you have specific intents that point to escalation or any other effectiveness measure, specify those in `chk_effective_intents` lists below. <br>\n**Note:** If you don't have specific intents to capture effectiveness, leave chk_effective_intents list empty.",
"_____no_output_____"
]
],
[
[
"# Add your escalation intents to the list\nchk_effective_intents=['connect_to_agent']\n\n# Store the intents in a dataframe\ndf_chk_effective_intents = pd.DataFrame(chk_effective_intents, columns = ['Intent'])\n\n# Add a 'valid' flag to the dataframe\ndf_chk_effective_intents['Valid']= True\n\n# Add count column for selected intents\ndf_chk_effective_intents['Count']= 0\n\n# Checking the validity of the specified intents. Look out for the `valid` column in the table displayed below.\nfor intent in chk_effective_intents:\n # Check if intent is present in workspace\n if intent not in workspace_intents:\n # If not present, mark it as 'not valid'\n df_chk_effective_intents.loc[df_chk_effective_intents['Intent']==intent,['Valid']] = False\n # Remove intent from the chk_effective_intents list \n chk_effective_intents.remove(intent)\n else:\n # Calculate number of times each intent is hit\n count = df_formated.loc[df_formated['response.top_intent_intent']==intent]['log_id'].nunique()\n df_chk_effective_intents.loc[df_chk_effective_intents['Intent']==intent,['Count']] = count\n# Display intents and validity\ndf_chk_effective_intents",
"_____no_output_____"
]
],
[
[
"#### <a id=\"set_escalation_dialog\"></a> 3.2.2 Specify dialog nodes to identify escalations\nIf you have specific dialog nodes that point to escalation or any other effectiveness measure, you can automated capture them based on three variables: node id, node name, and node condition.\n\n- Use the node_ids list to include the identifiers of any dialog nodes you've used to model that a message indicates an escalation. \n- Similarly, use the node_names list to include dialog nodes.\n- Use node_conditions for dialog conditions that indicate a message is out of scope.\n\nNote that these lists are treated as \"OR\" conditions - any occurrence of any of them will signify that a message is not covered. \n\n__Where to find node id, node name, and node condition__?\n\nYou can find the values of these variables from your workspace JSON file based on following mappings.\n\n- node id: `dialog_node`\n- node name: `title`\n- node condition: `conditions`\n\nYou can also find node name, and node condition in your workspace dialog editor. For more information, see [Dialog Nodes](https://console.bluemix.net/docs/services/conversation/dialog-overview.html#dialog-nodes).\n\n**Note:** If your assistant does not incorporate escalations and you do not have any other automated conversation-level quality metrics to identify problematic conversations (e.g., poor NPS, task not completed), you can simply track coverage and average confidence over a recent sample of your entire production logs. Leave an empty list for node_ids, node_names and node_conditions. ",
"_____no_output_____"
]
],
[
[
"# Add effectiveness node ids, if any, to list\nnode_ids = []\n\n# Add effectiveness node names, if any, to list\nnode_names = ['not_trained']\n\n# Add effectiveness node conditions, if any, to list\nnode_conditions = ['#connect_to_agent', '#answer_not_helpful']\n\n# If your assistant does not incorporate escalations and you do not have any other automated conversation-level quality metrics, uncomment lines below \n# node_ids = [] \n# node_names = [] \n# node_conditions = [] \n\n# Check if the dialog nodes are present in the current version of workspace\ndf_chk_effective_nodes = chk_is_valid_node(node_ids, node_names, node_conditions, workspace_nodes)\ndf_chk_effective_nodes",
"_____no_output_____"
]
],
[
[
"## 4. Calculate overall coverage and effectiveness<a id=\"overall\"></a>",
"_____no_output_____"
],
[
"The combination of effectiveness and coverage is very powerful for diagnostics.\nIf your effectiveness and coverage metrics are high, it means that your assistant is responding to most inquiries and responding well. If either effectiveness or coverage are low, the metrics provide you with the information you need to start improving your assistant. \n",
"_____no_output_____"
],
[
"### 4.1 Calculate overall metrics<a id=\"overall1\"></a>",
"_____no_output_____"
]
],
[
[
"df_formated_copy = df_formated.copy(deep = True)\n\n# Mark if a message is covered and store results in df_coverage dataframe\ndf_coverage = get_coverage_df(df_formated_copy , df_coverage_nodes, confidence_threshold)\n\n# Mark if a conversation is effective and store results in df_coverage dataframe\ndf_effective = get_effective_df(df_formated_copy, chk_effective_intents, df_chk_effective_nodes, filter_non_intent_node=True, workspace_nodes=workspace_nodes)\n\n# Calculate average confidence\navg_conf = float(\"{0:.2f}\".format(df_coverage[df_coverage['Covered']==True]['response.top_intent_confidence'].mean()*100))\n\n# Calculate coverage\ncoverage = float(\"{0:.2f}\".format((df_coverage['Covered'].value_counts().to_frame()['Covered'][True]/df_coverage['Covered'].value_counts().sum())*100))\n\n# Calculate effectiveness\neffective_perc = float(\"{0:.2f}\".format((df_effective.loc[df_effective['Escalated_conversation']==False]['response.context.conversation_id'].nunique()/df_effective['response.context.conversation_id'].nunique())*100)) \n\n# Plot pie graphs for coverage and effectiveness\ncoverage_pie = make_pie(coverage, \"Percent of total messages covered\")\neffective_pie = make_pie(effective_perc, 'Percent of non-escalated conversations')",
"_____no_output_____"
]
],
[
[
"Messages to be displayed with coverage and effectiveness metrics are given below",
"_____no_output_____"
]
],
[
[
"# Messages to be displayed with effectiveness and coverage\ncoverage_msg = '<h2>Coverage</h2></br>A message that is not covered would either be a \\\nmessage your assistant responded to with some form \\\nof “I’m not trained” or that it immediately handed over \\\nto a human agent without attempting to respond'\n\neffectiveness_msg = '<h2>Effectiveness</h2></br>This notebook provides a list of metrics customers \\\ncan use to assess how effective their assistant is at \\\nresponding to conversation and metrics '",
"_____no_output_____"
]
],
[
[
"### 4.2 Display overall results<a id=\"overall2\"></a>\n",
"_____no_output_____"
]
],
[
[
"# Display the coverage and effectiveness pie charts\nHTML('<tr><th colspan=\"4\"><div align=\"center\"><h2>Coverage and Effectiveness<hr/></h2></div></th></tr>\\\n<tr>\\\n <td style=\"width:500px\">{c_pie}</td>\\\n <td style=\"width:450px\"><div align=\"left\"> {c_msg} </div></td>\\\n <td style=\"width:500px\">{e_pie}</td>\\\n <td style=\"width:450px\"><div align=\"left\"> {e_msg} </div></td>\\\n</tr>'\n .format(c_pie=coverage_pie, c_msg = coverage_msg, e_pie = effective_pie, e_msg = effectiveness_msg))",
"_____no_output_____"
]
],
[
[
"Here, we can see our assistant's coverage and effectiveness. We will have to take a deeper look at both of these metrics to understand the nuances and decide where we should focus next. \n\nNote that the distinction between a user message and a conversation. A conversation in Watson Assistant represents a session of one or more messages from a user and the associated responses returned to the user from the assistant. A conversation includes a Conversation id for the purposes of grouping a sequence of messages and responses. ",
"_____no_output_____"
],
[
"<a id=\"msg_analysis\"></a>\n## 5. Analyze coverage\n\nHere, we take a deeper look at the Coverage of our Watson Assistant.",
"_____no_output_____"
],
[
"\n### 5.1 Display overall coverage<a id=\"msg_analysis1\"></a>\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline \n\n# Compute the number of conversations in the log\nconvs = df_coverage['response.context.conversation_id'].nunique()\n\n# Compute the number of messages in the log\nmsgs = df_coverage['response.context.conversation_id'].size\n\n#Display the results\nprint('Overall messages\\n', \"=\" * len('Overall messages'), '\\nTotal Conversations: ', convs, '\\nTotal Messages: ', msgs, '\\n\\n', sep = '')\n\n#Display the coverage bar chart\ndisplay(coverage_barh(coverage, avg_conf, 'Coverage & Average confidence', False))",
"Overall messages\n================\nTotal Conversations: 4319\nTotal Messages: 7706\n\n\n"
]
],
[
[
"Here, we see the percentage of messages covered and their average confidence. Now, let us take a look at the coverage over time.",
"_____no_output_____"
],
[
"\n### 5.2 Calculate coverage over time<a id=\"msg_analysis2\"></a>\n",
"_____no_output_____"
]
],
[
[
"# Make a copy of df_coverage dataframe\ndf_Tbot_raw1 = df_coverage.copy(deep=True)\n\n# Group by date and covered and compute the count\ncovered_counts = df_Tbot_raw1[['Date','Covered']].groupby(['Date','Covered']).agg({'Covered': 'count'})\n\n# Convert numbers to percentage\ncoverage_grp = covered_counts.groupby(level=0).apply(lambda x:round(100 * x / float(x.sum()),2)).rename(columns = {'Covered':'Coverage'}).reset_index()\n\n# Get only covered messages\ncoverage_time = coverage_grp[coverage_grp['Covered']==True].reset_index(drop = True)\n\n# Determine the number of xticks required\nxticks = [d for d in coverage_time['Date']]",
"_____no_output_____"
],
[
"# Plot the coverage over time graph\nfig, ax = plt.subplots(figsize=(30,8))\n\n# Format the date on x-axis\nax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))\nax.xaxis_date()\nax.set_xticks(xticks)\n# Rotate x-axis labels\nfor ax in fig.axes:\n plt.sca(ax)\n plt.xticks(rotation = 315)\n\n# Plot a line plot if there are more data points\nif len(coverage_time) >1:\n ax.plot_date(coverage_time['Date'], coverage_time['Coverage'], fmt = '-', color = '#4fa8f6', linewidth=6)\n# Plot a scatter plot if there is only one date on x-axis\nelse:\n ax.plot_date(coverage_time['Date'], coverage_time['Coverage'], color = '#4fa8f6', linewidth=6)\n\n# Set axis labels and title\nax.set_xlabel(\"Time\", fontsize=20, fontweight='bold')\nax.set_ylabel(\"Coverage %\", fontsize=20, fontweight='bold')\nax.set_title('Coverage over time', fontsize=25, fontweight = 'bold')\nax.tick_params(axis='both', labelsize=15)\n\n# Hide the right and top spines\nax.spines['right'].set_visible(False)\nax.spines['top'].set_visible(False)",
"_____no_output_____"
]
],
[
[
"**Note:** Compare the coverage over time with any major updates to your assistant, to see if the changes affected the performance.",
"_____no_output_____"
],
[
"<a id=\"conv_analysis\"></a>\n## 6. Analyze effectiveness",
"_____no_output_____"
],
[
"Here, we will take a deeper look at effectiveness of the assistant",
"_____no_output_____"
]
],
[
[
"# Get the escalated conversations\ndf_effective_true = df_effective.loc[df_effective['Escalated_conversation']==True]\n\n# Get the non-escalated conversations\ndf_not_effective = df_effective.loc[df_effective['Escalated_conversation']==False]\n\n# Calculate percentage of escalated conversations\nef_escalated = float(\"{0:.2f}\".format(100-effective_perc))\n\n# Calculate coverage and non-coverage in escalated conversations\nif len(df_effective_true) > 0:\n escalated_covered = float(\"{0:.2f}\".format((df_effective_true['Covered'].value_counts().to_frame()['Covered'][True]/df_effective_true['Covered'].value_counts().sum())*100))\n escalated_not_covered = float(\"{0:.2f}\".format(100- escalated_covered))\nelse:\n escalated_covered = 0\n escalated_not_covered = 0\n\n# Calculate coverage and non-coverage in non-escalated conversations\nif len(df_not_effective) > 0:\n not_escalated_covered = float(\"{0:.2f}\".format((df_not_effective['Covered'].value_counts().to_frame()['Covered'][True]/df_not_effective['Covered'].value_counts().sum())*100))\n not_escalated_not_covered = float(\"{0:.2f}\".format(100 - not_escalated_covered))\nelse:\n not_escalated_covered = 0\n not_escalated_not_covered = 0\n\n# Calculate average confidence of escalated conversations\nif len(df_effective_true) > 0:\n esc_avg_conf = float(\"{0:.2f}\".format(df_effective_true[df_effective_true['Covered']==True]['response.top_intent_confidence'].mean()*100))\nelse:\n esc_avg_conf = 0\n \n# Calculate average confidence of non-escalated conversations\nif len(df_not_effective) > 0:\n not_esc_avg_conf = float(\"{0:.2f}\".format(df_not_effective[df_not_effective['Covered']==True]['response.top_intent_confidence'].mean()*100))\nelse:\n not_esc_avg_conf = 0",
"_____no_output_____"
]
],
[
[
"### 6.1 Generate excel file and upload to our project<a id=\"conv_analysis1\"></a>",
"_____no_output_____"
]
],
[
[
"# Copy the effective dataframe\ndf_excel = df_effective.copy(deep=True)\n# Rename columns to generate excel\ndf_excel = df_excel.rename(columns={'log_id':'Log ID', 'response.context.conversation_id':'Conversation ID',\n 'response.timestamp':'Response Timestamp',\n 'request_input':'Utterance Text',\n 'response_text':'Response Text', 'response.top_intent_intent':'Detected top intent',\n 'response.top_intent_confidence':'Detected top intent confidence',\n 'Intent 2 intent': 'Intent 2', 'Intent 2 confidence':'Intent 2 Confidence', \n 'Intent 3 intent': 'Intent 3', 'Intent 3 confidence':'Intent 3 Confidence',\n 'response_entities':'Detected Entities', 'Escalated_conversation':'Escalated conversation?',\n 'Covered':'Covered?', 'Not Covered cause':'Not covered - cause',\n 'response.output.nodes_visited_s':'Dialog Flow', 'response_dialog_stack':'Dialog stack',\n 'response_dialog_request_counter':'Dialog request counter', 'response_dialog_turn_counter':'Dialog turn counter'\n })\n\nexisting_columns = ['Log ID', 'Conversation ID', 'Response Timestamp', 'Customer ID (must retain for delete)',\n 'Utterance Text', 'Response Text', 'Detected top intent', 'Detected top intent confidence',\n 'Intent 2', 'Intent 2 Confidence', 'Confidence gap (between 1 and 2)', 'Intent 3', 'Intent 3 Confidence',\n 'Detected Entities', 'Escalated conversation?', 'Covered?', 'Not covered - cause',\n 'Dialog Flow', 'Dialog stack', 'Dialog request counter', 'Dialog turn counter']\n# Add new columns for annotating problematic logs\nnew_columns_excel = ['Response Correct (Y/N)?', 'Response Helpful (Y/N)?', 'Root cause (Problem with Intent, entity, dialog)',\n 'Wrong intent? If yes, put the correct intent. Otherwise leave it blank', 'New intent needed? (A new intent. Otherwise leave blank)',\n 'Add Utterance to Training data (Y/N)', 'Entity missed? If yes, put the missed entity value. Otherwise leave it blank', 'New entity needed? If yes, put the entity name',\n 'New entity value? If yes, put the entity value', 'New dialog logic needed?', 'Wrong dialog node? If yes, put the node name. Otherwise leave it blank','No dialog node triggered']\n\n# Add the new columns to the dataframe\ndf_excel = df_excel.reindex(columns=[*existing_columns, *new_columns_excel], fill_value='')",
"_____no_output_____"
],
[
"# Set maximum sampling size\nSAMPLE_SIZE = 200\n\n# Set output filename\nall_file = 'All.xlsx'\nescalated_sample_file = 'Escalated_sample.xlsx'\nnon_escalated_sample_file = 'NotEscalated_sample.xlsx'\n\n# Generate all covered sample file\ndf_covered = df_excel[df_excel['Covered?']==True].reset_index(drop=True)\n\n# Generate all not covered sample file\ndf_not_covered = df_excel[df_excel['Covered?']==False].reset_index(drop=True)\n\n# Convert to Excel format and upload to COS\ngenerate_excel_measure([df_covered,df_not_covered], ['Covered', 'Not_Covered'], filename=all_file, project_io=None)\n\n# Generate escalated and covered sample file\ndf_escalated_true = df_excel.loc[df_excel['Escalated conversation?']==True]\ndf_escalated_covered = df_escalated_true[df_escalated_true['Covered?']==True]\nif len(df_escalated_covered) > 0:\n df_escalated_covered = df_escalated_covered.sample(n=min(len(df_escalated_covered), SAMPLE_SIZE), random_state=1).reset_index(drop=True)\n\n# Generate escalated but not covered sample file\ndf_escalated_not_covered = df_escalated_true[df_escalated_true['Covered?']==False]\nif len(df_escalated_not_covered) > 0:\n df_escalated_not_covered = df_escalated_not_covered.sample(n=min(len(df_escalated_not_covered), SAMPLE_SIZE), random_state=1).reset_index(drop=True)\n\n# Covert to Excel format and upload to COS\ngenerate_excel_measure([df_escalated_covered,df_escalated_not_covered], ['Covered', 'Not_Covered'], filename=escalated_sample_file, project_io=None)\n\n# Generate not escalated but covered sample file\ndf_not_escalated = df_excel.loc[df_excel['Escalated conversation?']==False]\ndf_not_escalated_covered = df_not_escalated[df_not_escalated['Covered?']==True]\nif len(df_not_escalated_covered) > 0:\n df_not_escalated_covered = df_not_escalated_covered.sample(n=min(len(df_not_escalated_covered), SAMPLE_SIZE), random_state=1).reset_index(drop=True)\n\n# Generate not escalated and not covered sample file\ndf_not_escalated_not_covered = df_not_escalated[df_not_escalated['Covered?']==False]\nif len(df_not_escalated_not_covered) > 0:\n df_not_escalated_not_covered = df_not_escalated_covered.sample(n=min(len(df_not_escalated_not_covered), SAMPLE_SIZE), random_state=1).reset_index(drop=True)\n \n# Covert to Excel format and upload to COS\ngenerate_excel_measure([df_not_escalated_covered,df_not_escalated_not_covered], ['Covered', 'Not_Covered'], filename=non_escalated_sample_file, project_io=None)",
"_____no_output_____"
]
],
[
[
"### 6.2 Plot breakdown by effectiveness graph<a id=\"conv_analysis2\"></a>",
"_____no_output_____"
]
],
[
[
"#### Get the links to the excels\nall_html_link = '<a href={} target=\"_blank\">All.xlsx</a>'.format(all_file)\nescalated_html_link = '<a href={} target=\"_blank\">Escalated_sample.xlsx</a>'.format(escalated_sample_file)\nnot_escalated_html_link = '<a href={} target=\"_blank\">NotEscalated_sample.xlsx</a>'.format(non_escalated_sample_file)\n\n# Embed the links in HTML table format\nlink_html = '<tr><th colspan=\"4\"><div align=\"left\"><a id=\"file_list\"></a>View the lists here: {} {} {}</div></th></tr>'.format(all_html_link, escalated_html_link, not_escalated_html_link)\n\nif 100-effective_perc > 0:\n escalated_bar = coverage_barh(escalated_covered, esc_avg_conf, '', True, 15, width_bar(100-effective_perc))\nelse:\n escalated_bar = ''\n\nif effective_perc > 0: \n non_escalated_bar = coverage_barh(not_escalated_covered, not_esc_avg_conf, '' , True , 15,width_bar(effective_perc))\nelse:\n non_escalated_bar = ''\n\n# Plot the results\nHTML('<tr><th colspan=\"4\"><div align=\"left\"><h2>Breakdown by effectiveness<hr/></h2></div></th></tr>\\\n'+ link_html + '<tr><td style= \"border-right: 1px solid black; border-bottom: 1px solid black; width : 400px\"><div align=\"left\"><strong>Effectiveness (Escalated) </br>\\\n<font size=\"5\">{ef_escalated}%</strong></font size></br></div></td>\\\n <td style=\"width:1000px; height=100;\">{one}</td></tr>\\\n<tr><td style= \"border-right: 1px solid black; border-bottom: 1px solid black; width : 400px;\"><div align=\"left\"><strong>Effectiveness (Not escalated) </br>\\\n<font size=\"5\">{effective_perc}%</strong></font size></br></div></td>\\\n <td style=\"width:1000px; height=100;border-bottom: 1px solid black;\">{two}</td>\\\n</tr>'.format(ef_escalated= ef_escalated,\n one = escalated_bar, \n effective_perc = effective_perc, \n two = non_escalated_bar)) \n",
"_____no_output_____"
]
],
[
[
"You can download all the analyzed data from `All.xlsx`. A sample of escalated and non-escalated conversations are available in `Escalated_sample.xlsx` and `NotEscalated_sample.xlsx` respectively.\n",
"_____no_output_____"
],
[
"<a id=\"root_cause\"></a>\n## 7. Root cause analysis of non coverage\nLets us take a look at the reasons for non-coverage of messages",
"_____no_output_____"
]
],
[
[
"# Count the causes for non-coverage and store results in dataframe\nnot_covered = pd.DataFrame(df_coverage['Not Covered cause'].value_counts().reset_index())\n# Name the columns in the dataframe\nnot_covered.columns = ['Messages', 'Total']\nnot_covered",
"_____no_output_____"
]
],
[
[
"<a id=\"abandoned_resolved_intents\"></a>\n## 8. Abandoned and resolved intent analysis\n\nWhen users engage in a conversation session, an assistant identifies the intent of each message from the user. Based on the logic flow defined in a dialog tree, the assistant communicates with users and performs actions. The assistant may succeed or fail to satisfy users' intent. One way to identify patterns of success or failure is by analyzing which intents most often lead to a dialog node associated with resolution, and which intents most often lead to users abandoning the session. Analyzing resolved and abandoned intents can help you identify issues in your assistant to improve, such as a problematic dialog flow or imprecise intents. In this section, we demonstrate a method of conducting intent analysis using context variables.\n\nWe introduce two context variables: `response_context_IntentStarted` and `response_context_IntentCompleted`. You will need to modify your dialog skill definition (workspace) to introduce these variables in your dialog flow. After you modify your dialog skill definition, your logs will be marked such that when users trigger a conversation with an intent, the assistant will use `response_context_IntentStarted` to record the intent. During the conversation, the assistant will use `response_context_IntentCompleted` to record if the intent is satisfied. Follow the steps below to add the context variables for an intent in your dialog skill definition.\n\n1. Open Dialog Overview page, see <a href=\"https://cloud.ibm.com/docs/services/assistant?topic=assistant-dialog-overview\" target=\"_blank\">Dialog Overview</a> for more information.\n2. Click the entry point node of the dialog node that is associated with the intent you want to analyze\n3. Open the context editor, see <a href=\"https://cloud.ibm.com/docs/services/assistant?topic=assistant-dialog-runtime#dialog-runtime-context-variables\" target=\"_blank\">Context Variables</a> for more information\n4. Add `response_context_IntentStarted` as a variable and \\[intent_name\\] as the value\n5. Follow the dialog flow to locate the satisfying node of the intent\n6. Open the context editor\n7. Add `response_context_IntentCompleted` as variable and \\[intent_name\\] as the value\n8. Repeat step 5-7 to mark all satisfying nodes of the intent if necessary\n\nThen repeat the above steps for every intent you want to analyze in this way.\n\nAfter completing the above steps, run the following code for intent analysis. Note that the analysis requires logs generated after the above changes. You will need to reload the updated workspace and logs.",
"_____no_output_____"
],
[
"### 8.1 Count of all started intents<a id=\"started_intents\"></a>",
"_____no_output_____"
]
],
[
[
"# Define context variables\nstart_intent_variable = 'response_context_IntentStarted'\n\nif start_intent_variable in df_formated:\n # Group dataframe by conversation_id and start_intent_variable\n df_intent_started = df_formated.groupby(['response.context.conversation_id', start_intent_variable]).count().reset_index()\n # Refactors data to show only columns of conversation_id and start_intent_variable\n df_intent_started = df_intent_started[['response.context.conversation_id', start_intent_variable]]\n\n # Count the number of conversation_ids with each start_intent_variable\n intent_started = df_intent_started[start_intent_variable].value_counts().reset_index()\n intent_started.columns = ['Intent', 'Count']\n display(HTML(intent_started.to_html()))\nelse:\n print('Cannot find \\'response_context_IntentStarted\\' and \\'response_context_IntentCompleted\\' in logs. Please check step 4 and make sure updated logs are reloaded.')\n",
"_____no_output_____"
]
],
[
[
"### 8.2 Analyze resolved intents<a id=\"resolved_intents\"></a>",
"_____no_output_____"
]
],
[
[
"end_intent_variable = 'response_context_IntentCompleted'\n\nif end_intent_variable in df_formated:\n\n # Group dataframe by conversation_id and end_intent_variable\n df_intent_completed = df_formated.groupby(['response.context.conversation_id',end_intent_variable]).count().reset_index()\n # Refactor data to show columns of conversation_id and end_intent_variable only\n df_intent_completed = df_intent_completed[['response.context.conversation_id',end_intent_variable]]\n # Count the number of conversation_ids with each end_intent_variable\n intent_completed = df_intent_completed[end_intent_variable].value_counts().reset_index()\n intent_completed.columns = ['Intent', 'Count']\n\n # Show counts of resolved intents\n intent_completed_title = '\\nCount of resolved intents in all conversations\\n'\n print(intent_completed_title, \"=\" * len(intent_completed_title),'', sep = '')\n display(HTML(intent_completed.to_html()))\n\n # Convert dataframe to a list\n res_intent_list = intent_completed.values.tolist()\n # Get list of started intents\n all_intent = df_intent_started[start_intent_variable].value_counts().reset_index().values.tolist()\n\n # Loop over resolved intents list. Each element contains a pair of intent and count\n data = []\n for pair_ab in res_intent_list:\n # Loop over each row of started intents. Each row contains a pair of intent and count\n for pair_all in all_intent:\n # Check if the intent name matches in started and resolved intents\n if pair_ab[0] == pair_all[0]:\n # Then acccesses the count from that matched intent, and calculate percentage\n perc = (pair_ab[1]/pair_all[1])*100\n # Add the matched intent name and percentage to data list\n data.append([pair_ab[0],perc])\n\n # Create a new dataframe with data list\n resolved_percentage = pd.DataFrame(data=data).reset_index(drop=True)\n\n # Format the dataframe, and orders data in descending order (shows highest percentage first)\n resolved_percentage.columns = ['Intent','Percentage']\n resolved_percentage.sort_values(ascending=False,inplace=True, by='Percentage')\n # Format the data in the percentage column to include '%', and 1 decimal point\n resolved_percentage['Percentage'] = resolved_percentage['Percentage'].apply(lambda x: \"{0:.1f}%\".format(x))\n resolved_percentage.reset_index(drop=True, inplace=True)\n\n # Show most resolved intents\n most_resolved_intents = \"\\nMost resolved intents (%)\\n\"\n print(most_resolved_intents, \"=\" * len(most_resolved_intents),'', sep = '')\n display(HTML(resolved_percentage.to_html()))\n\nelse:\n print('Cannot find \\'response_context_IntentStarted\\' and \\'response_context_IntentCompleted\\' in logs. Please check step 4 and make sure updated logs are reloaded.')\n",
"\nCount of resolved intents in all conversations\n================================================\n"
]
],
[
[
"### 8.3 Analyze abandoned intents<a id=\"abandoned_intents\"></a>",
"_____no_output_____"
]
],
[
[
"if start_intent_variable in df_formated and end_intent_variable in df_formated:\n\n # Create lists of started and end_intent_variable\n intent_complete_list = df_intent_completed.values.tolist()\n intent_started_list = df_intent_started.values.tolist()\n\n # Looping over completed intents list. Each element contains a pair of conversation id and end_intent_variable\n for pair in intent_complete_list:\n # Checks if any element is found in list of started intents\n if pair in intent_started_list:\n # If found, remove that pair from the list of started intents\n intent_started_list.remove(pair)\n\n # Create a new dataframe with updated dataset. \n # This updated dataset contains intents that have been started but not completed, thus categorised as abandoned\n df_intent_abandoned = pd.DataFrame(data=intent_started_list)\n\n # Group each pair (conversation id, intent abandoned), and show number of occurances of each abandoned intent\n final_intent_abandoned = df_intent_abandoned[1].value_counts().reset_index()\n final_intent_abandoned.columns = ['Intent','Count']\n\n # Show counts of abandoned intents\n intent_abandoned_title = '\\nCount of abandoned intents in all conversations\\n'\n print(intent_abandoned_title, \"=\" * len(intent_abandoned_title),'', sep = '')\n display(HTML(final_intent_abandoned.to_html()))\n\n # Convert dataframe to a list\n aban_intent_list = final_intent_abandoned.values.tolist()\n # Get list of started intents\n all_intent = df_intent_started[start_intent_variable].value_counts().reset_index().values.tolist()\n\n # Loop over resolved intents list. Each element contains a pair of intent and count\n data = []\n for pair_ab in aban_intent_list:\n # Loop over each row of started intents. Each row contains a pair of intent and count\n for pair_all in all_intent:\n # Check if the intent name matches in started and resolved intents\n if pair_ab[0] == pair_all[0]:\n # Then acccesse the count from that matched intent, and calculate percentage\n perc = (pair_ab[1]/pair_all[1])*100\n # Add the matched intent name and percentage to data list\n data.append([pair_ab[0],perc])\n\n # Create a new dataframe with data list\n abandoned_percentage = pd.DataFrame(data=data).reset_index(drop=True)\n\n # Format the dataframe, and orders data in descending order (shows highest percentage first)\n abandoned_percentage.columns = ['Intent','Percentage']\n abandoned_percentage.sort_values(ascending=False,inplace=True, by='Percentage')\n abandoned_percentage.reset_index(drop=True, inplace=True)\n\n # Format the data in the percentage column to include '%', and 1 decimal point\n abandoned_percentage['Percentage'] = abandoned_percentage['Percentage'].apply(lambda x: \"{0:.1f}%\".format(x))\n\n # Show most abandoned intents\n most_abandoned_intents = \"\\nMost abandoned intents (%)\\n\"\n print(most_abandoned_intents, \"=\" * len(most_abandoned_intents),'', sep = '')\n display(HTML(abandoned_percentage.to_html()))\n\nelse:\n print('Cannot find \\'response_context_IntentStarted\\' and \\'response_context_IntentCompleted\\' in logs. Please check step 4 and make sure updated logs are reloaded.')\n",
"\nCount of abandoned intents in all conversations\n=================================================\n"
]
],
[
[
"Finally, we generate an Excel file that lists all conversations for which there are abandoned and resolved intents for further analysis.",
"_____no_output_____"
]
],
[
[
"if df_intent_abandoned is not None and df_intent_completed is not None:\n \n # Rename columns\n df_intent_abandoned.columns = ['Conversation_id','Intent']\n df_intent_completed.columns = ['Conversation_id','Intent']\n\n # Generate excel file\n file_name = 'Abandoned_Resolved.xlsx'\n generate_excel_measure([df_intent_abandoned,df_intent_completed], ['Abandoned', 'Resolved'], filename= file_name, project_io=None)\n link_html = 'Abandoned and resolved intents: <b><a href={} target=\"_blank\">Abandoned_Resolved.xlsx</a></b>'.format(file_name)\n\n display(HTML(link_html))\n \nelse:\n print('Cannot find \\'response_context_IntentStarted\\' and \\'response_context_IntentCompleted\\' in logs. Please check step 4 and make sure updated logs are reloaded.')\n",
"_____no_output_____"
]
],
[
[
"<a id=\"summary\"></a>\n## 9. Summary and next steps\n\nThe metrics described above help you narrow your immediate focus of improvement. We suggest the following two strategies: \n\n- **Toward improving Effectiveness**\n\n We suggest focusing on a group of problematic conversations, e.g., escalated conversations, then performing a deeper analysis on these conversation as follows. <br>\n 1. Choose to download either the complete conversations ([All.xlsx](#file_list)), or sampled escalated conversations [Escalated_sample.xlsx](#file_list), or non-escalated conversations [NotEscalated_sample.xlsx](#file_list).<br>\n 2. Perform a manual assessment of these conversations.<br>\n 3. Analyze the results using our __Analyze Watson Assistant Effectiveness__ Jupyter Notebook.\n\n\n- **Toward improving Coverage**\n\n For utterances where an intent was found but no response was given. We suggest performing a deeper analysis to identify root causes, e.g., missing entities or lacking of dialog logic. \n\n For utterances where no intent was found, we suggest expanding intent coverage as follows.\n\n 1. Examine utterances from the production log, especially focus on the utterances that are below the confidence (0.2 by default).\n 2. If you set a confidence threshold significantly higher than 0.2, we suggest looking at utterances that are below but close to the threshold.\n 3. Once you select a collection of utterances, intent expansion, you can focus on intent expansion by two methods:\n - One-by-One: examine each utterance to either change to an existing intent or add a new intent.\n - Unsupervised Learning: perform semantic clustering to generate utterance clusters; examine each cluster to decide (1) adding utterances of an existing intent or (2) creating a new intent.\n\nFor more information, please check <a href=\"https://github.com/watson-developer-cloud/assistant-improve-recommendations-notebook/raw/master/notebook/IBM%20Watson%20Assistant%20Continuous%20Improvement%20Best%20Practices.pdf\" target=\"_blank\" rel=\"noopener noreferrer\">Watson Assistant Continuous Improvement Best Practices</a>.",
"_____no_output_____"
],
[
"### <a id=\"authors\"></a>Authors\n\n**Zhe Zhang**, Ph.D. in Computer Science, is an Advisory Software Engineer for IBM Watson AI. Zhe has a research background in Natural Language Processing, Sentiment Analysis, Text Mining, and Machine Learning. His research has been published at leading conferences and journals including ACL and EMNLP.\n\n**Sherin Varughese** is a Data Scientist for IBM Watson AI. Sherin has her graduate degree in Business Intelligence and Data Analytics and has experience in Data Analysis, Warehousing and Machine Learning.",
"_____no_output_____"
],
[
"### <a id=\"acknowledgement\"></a> Acknowledgement\n\nThe authors would like to thank the following members of the IBM Research and Watson Assistant teams for their contributions and reviews of the notebook: Matt Arnold, Adam Benvie, Kyle Croutwater, Eric Wayne.",
"_____no_output_____"
],
[
"Copyright © 2019 IBM. This notebook and its source code are released under the terms of the MIT License.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a1cda9c9c3b6488ef57eaf7ecc5d75dc2c87a43
| 118,552 |
ipynb
|
Jupyter Notebook
|
notebooks/a01.Requirement_Hardskills_Years_of_experience.ipynb
|
ok524/clap_fulfillment
|
b338f684c986897d27d16dc00831b31ca13c335d
|
[
"MIT"
] | null | null | null |
notebooks/a01.Requirement_Hardskills_Years_of_experience.ipynb
|
ok524/clap_fulfillment
|
b338f684c986897d27d16dc00831b31ca13c335d
|
[
"MIT"
] | null | null | null |
notebooks/a01.Requirement_Hardskills_Years_of_experience.ipynb
|
ok524/clap_fulfillment
|
b338f684c986897d27d16dc00831b31ca13c335d
|
[
"MIT"
] | null | null | null | 135.179019 | 3,704 | 0.737921 |
[
[
[
"import os\nimport sys\nimport re\nimport time\nimport json\n\nimport numpy as np\nimport pandas as pd\n\n# from vglib import vglib2\n# vg = vglib2.Vglib()\n# vg.function_add('basicsummary', 'BasicSummary')\n\nimport importlib\nimport util\nimportlib.reload(util)\nfrom util import *\n\n### Example\n# from vglib import vglib2\n# import importlib\n# importlib.reload(vglib2)\n# #from <file_module> import <Class/Function>\n# from vglib.vglib2 import Vglib",
"_____no_output_____"
],
[
"df = get_df()",
"_____no_output_____"
],
[
"df_token = load_tokens()",
"['Industry', 'Function', 'Personality', 'Language', 'Qualification (academic)', 'Qualifiaction (professional)', 'Software', 'Programing Language', 'Soft Skill', 'Hard Skill', 'xxx', 'salary range min', 'salary range max']\n"
],
[
"df_req = get_section_requirement(df, df_token)",
"\n\n\n### Has matches\nRequirements: Bachelor degree from Accounting and Finance or related disciplinePossess a minimum of 3 years' relevant experience in consolidation preferably with exposure from the manufacturing industryStraight Big 4 candidates will be consideredKnowledge of Oracle would be a plusStrong business analytical mindsetGood command of written and spoken English and Chinese (Mandarin)Strong learning capabilities and result-drivenOccasional travels would be requiredTo apply online please click the 'Apply' button below. For a confidential discussion about this role please contact Alison Lam on +852 3907 3945. For more Sales and Marketing opportunities please visit our website: https: //www.morganmckinley.com.hk/sales-marketing-jobs\n\n\n\n### Has matches\nRequirements: : Degree holder in Accounting, Finance or equivalent disciplines ACCA/CPA/AICPA/CICPA member qualification is required Minimum 5 years working experience gained in manufacturing industries with PRC background,State-owned enterprises working experience or audit firms Supervision experience is required Proficient in MS Office with excellent Excel skill is a required Advanced skills in ERP (SAP preferred) are required Proficient in both written and spoken English and Chinese, including Putonghua Detail-oriented, devoted, independent, and able to work under pressure Immediate available is preferred Interested parties please send detailed resume with salary expectations to us through JobsDB. Applicants are welcomed to visit our website: www.fongs.com for further information about the Company. We are an equal opportunity employer and welcome applications from all qualified candidates. Personal data collected by us relating to applications for the above job will be kept confidential and be used for recruitment related purposes only. Applicants not hearing from us within 6 weeks from their applications may consider their applications unsuccessful. Unless applicants advise us otherwise, we may refer suitable applicants to other vacancies within the Group.\n\n\n\n=== No matches, Show Original\nResponsible for financial & management accounts reporting and manage day-to-day accounting operations Conduct the overall preparation of month-end, quarterly, interim and annual management reports including budgeting, forecasting and closing Prepare consolidation accounting reports for purpose of financial accounting book closing & management accounting review Coordinate and complete annual audits Assist in formulating, implementing and monitoring internal and financial control policies Support Company Secretarial matters from the financial perspective Liaise with external auditors / consultants on interim / annual audit and tax filing Involve in Business Valuation and other ad-hoc assignments as required\n\n\n\n### Has matches\nRequirement 2 years of accounting experience (retail industry is an advantage) Proficiency in MS office (Word, Excel, etc.) Detail-minded, proactive & good integrity Fresh graduate will be considered Benefits Attractive Salary Medical benefits Education Allowance Discretionary bonus We offer an attractive remuneration package to successful candidate. Please send your resume with full details including previous job experiences, expected salary, current salary and available date to us.\n\n\n\n### Has matches\nRequirements: : Be fun-loving, energetic, positive and open-mind F.5 / HKDSE LCCI or Diploma /Certificate in Accounting is preferable 2 years' relevant working experience Experience in Yonyou accounting is an advantage Proactive, attention to details with good communication skills Proficient in PC skill of words and excel Others: Open and friendly working environment Free drink and snack\n\n\n\n### Has matches\nRequirements: : High Diploma /Degree holder with professional qualification in Accounting. Minimum 5 years' accounting experience, including full set of books. Strong sense of responsibility, self-motivated, well organized & mature. Proficiency in computer skills including MS Office. Candidates who are immediately available are preferred. Less experience and qualification may be considered as Accountant. We offer attractive salary and benefits for the right candidate. Interested parties, please send resume to by clicking 'Apply Now' Personal data collected will be used for recruitment purpose only.\n\n\n\n### Has matches\nRequirements: : : Bachelor Degree Holder in Accounting, Finance or other related discipline with professional qualifications such as HKICPA, ACCA or its equivalent Qualified Accountant with over 8 years’ relevant experience, including at least 3 years working experience in a listed company Extensive hands-on experience in financial reporting, internal control, financial analysis, budgeting, forecasting, accounting and taxation Familiar with accounting policies for HKFRS/IFRS Good command of written and spoken English Proficiency in using MS Word, Excel, and PowerPoint. Self-motivated, team player, can work under pressure and able to roll up sleeves to demonstrate and achieve solid results Interested party, please sends your application with full resume, stating present and expected salary, and quotes the reference (SGFA) by clicking \"Apply Now\". Only short-listed candidates will be notified. Applicants not invited for an interview within 6 weeks should consider their applicants unsuccessful. Personal data provided by job applicants will be used strictly for recruitment and selection.\n\n\n\n### Has matches\nRequirements: : LCC Higher or above. At least 5 years' solid experience and knowledge in accounting software Proficient in spoken and written English and Chinese Self-motivated, well organized, detailed-minded and a good team player Able to work independently and work under pressure Immediately available is preferred Benefits: Salary: HK$20K - HK$23K Year end bonus Alternative week work Bank holidays\n\n\n\n=== No matches, Show Original\nOur client, an international accounting services firm, is looking for an Senior Client Accounting Manager / Head of Client Accounting to join their dynamic client accounting services team. Responsibilities: Oversee client delivery staff ensuring a high quality of accounting services are provided Manage client issue escalations and day to day relationship management Support business development activities with the management team and sales Experience: Diploma or above in Accountancy required At least 5-8 years client accounting experience in CPA firms / accounting services firms with team management experience preferred Experience preparing financial statements for corporates and / or trusts is a must Experience liaising with external auditors and banks is essential Knowledge of Accounting Systems is an advantage Able to work under pressure and meet tight deadlines Fluent in writing and verbal communication skill, in English, Cantonese and Mandarin Personal Attributes: Attention to detail Good interpersonal skills with ability to evoke trust and openness in clients, colleagues and intermediaries Strong sense of responsibility, detail-oriented, independent and self-motivated Please kindly press Apply Now to proceed further We regret that only shortlisted candidates will be notified or contacted. Your interest will be treated with the strictest of confidence. We regret that only shortlisted candidates will be notified or contacted.\n\n\n\n### Has matches\nRequirements: : LCCI Intermediate level or above At least 2 years accounting experience Mature, detail-oriented and responsible Proficient in MYOB accounting system, MS Office and Chinese Word Processing Good command of both spoken and written English and Chinese Immediately available preferred We offer competitive remuneration package to the right candidate. Interested parties please send your resume, stating your availability current and expected salary by clicking “Apply Now”. Personal data will be used for recruitment purposes only.\n\n\n\n### Has matches\nRequirements: : Bachelor degree or above in Accounting or equivalent Minimum 5 years working experience, preferably in Chinese investment banks or brokerage firms Knowledge of Flex system is an advantage Good command of spoken and written Mandarin & Cantonese Strong sense of responsibilities, control mindset and able to work under pressure Interested parties, please send your resume in both \"English\" and \"Chinese\" with expected salary and date of available by clicking \"Apply Now\" button.\n\n\n\n=== No matches, Show Original\nNew head count is needed for the expanding business. The role will handle all the analysis duties and prepare various reports under the FP&A team.Client DetailsOur client is a reputable company in the FMCG industry, selling health and skincare products across Europe. With France as their headquarter, they have over 40 regional offices around the world and around 200 retail stores. To look after the APAC and new emerging markets, the company is now looking for a detail-minded Financial Analyst to join the team.Description Business partnering with different stakeholders in markets with budgeting and forecastingPrepare summary level reports on performance to executive leaders in GEM and French HQ office Forecast and actuals consolidation with variance analysis commentaryProvide value-added analysis and recommendations to support business decisionsBe a team player supporting the FP&A team with management reporting and financial planning process, along with other ad-hoc analysis ProfileBachelor degree or above3 years of analysis experienceQualifications of professional body is a plusExcellent analytical skillsStrong communication skillsProficiency in MS Office (Excel)Job Offer Competitive salary Package, double pay + discretionary bonus15 Annual LeavesFull coverage of medical and dental insuranceExcellent opportunity to enhance your CVTsim Sha TsuiTo apply online please click the 'Apply' button below. For a confidential discussion about this role please contact Sammi Mak on +852 2258 3545.\n\n\n\n### Has matches\nRequirements: : Degree holder + Good English 5-6 yrs A/C Payable or A/C Receivable exp Online purchase/payment card exp pref. Please call Ms. Lam at 2869-8638 / email: asianaim@biznetvigator. com to obtain an application form.\n\n\n\n### Has matches\nRequirements: F.5 & LCC inter or above, minimum 3 years’ experience in teller & cash/cheques handling with bookkeeping knowledge; Experience of providing clerical support to treasury accounting is an advantage; Meticulous, accurate and trustworthy; Reliable, mature and able to work independently; With good interpersonal interaction and can communicate well; Proficient in MS Excel & Word; Good command of spoken and written Chinese, English, & Putonghua. We offer 5.5 days: (Alternate Saturday), excellent career opportunities, attractive remuneration package and comprehensive staff benefits to the suitable candidate. Interested parties, please send your full resume with Current & Expected salary by clicking \"APPLY NOW\". (Personal data collected will be used for recruitment purpose only) Corporate website: www.roadking.com.hk\n\n\n\n### Has matches\nRequirements: Degree holder preferably in Accounting, Finance or related discipline. 1-2 years working experience preferably gained in the financial services industry. Fund administration experience would be an asset. Good written and verbal communication in English, Cantonese and Mandarin. A team-player with excellent working attitude; willing to take on multiple functions Detail minded with good problem solving skill and able to work independently under pressure. Knowledge of various financial instruments with direct working experience of Bloomberg terminal will be beneficial. We offer a competitive salary and benefits to the right candidates. Interested parties, please send your full resume with expected salary by clicking \"Apply Now\" Personal data provided by job applicants will be used for recruitment purposes only and will be treated in strict confidence.\n\n\n\n### Has matches\nRequirements: : Tertiary educated in Textile / Textile Chemistry / Mechanical Engineering or its equivalent Possess experience in dye house, machinery sales or textiles related is highly preferred Excellent communication and negotiation skills A good team player, self-motivated, result-oriented with positive working attitude Good command of written and spoken English, Mandarin and Chinese Familiar with MS Office and Chinese Word Processing Interested parties please send detailed resume and include salary expectation via e-mail: “Apply Now” to The Group Human Resources & Administration Manager. Applicants are welcomed to visit our website: http://www.fongs.com/ for further information about the Company. We are an equal opportunity employer and welcome applications from all qualified candidates. Personal data collected by us relating to applications for the above job will be kept confidential and be used for recruitment related purposes only. Applicants not hearing from us within 6 weeks from their applications may consider their applications unsuccessful. Unless applicants advise us otherwise, we may refer suitable applicants to other vacancies within the Group.\n\n\n\n### Has matches\nRequirements: : Bachelor degree in finance, accounting or related discipline Holder of CPA/CIA/ACCA/CICPA membership Minimum 5 years audit experience in listed company or PRC manufacturing business with experience in state-owned enterprises is definitely an advantage Familiar with PRC accounting & taxation regulation Good command of English & Chinese including Putonghua Strong in report writing skills Self-initiative, well organized, with strong analytical skill and attentive to details personality Knowledge in SAP system Willing to travel and occasionally work in PRC Immediately available preferred We offer attractive remuneration packages and a challenging environment for professionals who wish to advance their careers in a sophisticated and precision industry. Excellent career development opportunities. Interested parties please send detailed resumes with salary expectations to us through JobsDB. Applicants are welcomed to visit our website: www.fongs.com for further information about the Company. We are an equal opportunity employer and welcome applications from all qualified candidates. Personal data collected by us relating to applications for the above job will be kept confidential and be used for recruitment related purposes only. Applicants not hearing from us within 6 weeks from their applications may consider their applications unsuccessful. Unless applicants advise us otherwise, we may refer suitable applicants to other vacancies within the Group.\n\n\n\n### Has matches\nRequirements: Diploma in a science/medical related discipline( e.g bio-medical, bio-science, life-science, bio-engineering) Min 3 - 4 years related experience in a similar role with HA and Private Hospitals preferred. Good leadership and communication skills Do kindly send your CV over to Jefferson.lim@ onearw.com We regret that only shortlisted candidates will be notified or contacted. Your interest will be treated with the strictest of confidence. We regret that only shortlisted candidates will be notified or contacted.\n\n\n\n=== No matches, Show Original\nYou will: Identify and develop new business and achieve performance targets Assist in the formulation of sales and marketing strategies to launch, promote and sell the company products Develop and initiate marketing materials, plan campaigns for marketing promotion Work with product team closely to respond to rapid market changes Station in Singapore and have infrequent business trip to other SE Asian countries You should have/be: Degree holder or above Solid experience in programming and product management is an advantage Extensive network which helps efficient channel building Strong business insight with creative thinking Self-motivation and ability to work independently under pressure Passionate for continuous improvement and learning Excellent verbal and written communication skills Good command of both English and any one Asian language\n\n\n\n### Has matches\nRequirements: : Have at least 2 year’s hands-on experience in following skill sets: Oracle Database 11g or above; Oracle Report; Apache Tomcat; Java ; Digital signing and electronic certificate related technologies; SVN – Source Control PL/SQL; XML; and Microsoft Windows Server 2008 or above. Candidate with less experience will be considered for the Analyst Programmer role.\n\n\n\n=== No matches, Show Original\nJob Objectives: Several business trip to China main city (e.g. Shenzhen, Shanghai, Beijing, Chengdu,Guangzhou etc.) to hold seminars and meet with high net worth clients To explore Oversea Property, Asset Management and Risk Management solution to individual and corporate clients Assistant Regional Manager develop financial services in Mainland Global finance consultant Establish and maintain good relationship of our large chinese customers and prospects base To assist in business development, marketing and client seminar, recruitment activities People we are looking for: Bachelor degree holder or above in all disciplines, preferably with major in Business Administration, Finance, Accounting, Economics or relevant discipline. Excellent Interpersonal and communication skills as well as good command of both written and spoken English and Chinese (Mandarin & Cantonese) Candidates with IANG visa is welcomed Strong communication skills and trouble-shooting skills Offer and Benefit: One year salary package $15,000 plus 100% commission Intensive Quality Training Programme CFA, CFP or AFP examinations resources and support with individual sponsorship provided Fast track promotion to management level The information provided by applicants will be treated in strict confidence and used solely for recruitment purpose.\n\n\n\n=== No matches, Show Original\nOur Client, a Financial Management Service Provider, is currently looking for a high calibre Senior Backend Developer to join their company to cope with business expansion. The Job: Work in a team setting to develop and maintain the gini mobile app Work under agile methodology Own one or more components of the software stack, from design to implementation to monitoring and operations. Great communication skills Be a team player and willing to learn The Person: Bachelor's degree and above in relevant studies preferred Work Experience with 2-6 years experience in software development Familiar with: MySQL, Basic Infrastructure, Basic Javascript Familiarity with at least one backend/frontend framework Develop best practices Experienced with launching an app into the commercial market\n\n\n\n### Has matches\nRequirements: : Diploma holder in any Disciplines At least 5 years of customer service experience in the hospitality industry Experienced in Supervisory level is a plus With a can-do attitude and strong service mindset Confident and fluent in spoken English and Mandarin Willing to work on shift (Overnight shift is NOT required)\n\n\n\n### Has matches\nRequirements: : - Diploma or above in Business related disciplines - At least 1 year working experience - Detailed-mind and Good communication and interpersonal skills - Good command of spoken and written English and Mandarin Interested parties please send your full resume, expected salary and the earliest available date by click “Apply Now”. For more details, please visit our web site: http://www.lktechnology.com/en/index.html *L.K. Machinery International Ltd. is an equal opportunity employer. *Personal data collected will be used for recruitment purpose only.\n\n\n\n=== No matches, Show Original\nThe Human Resources Director is responsible for short and long term planning of the HR function. This means leading strategically and tactically in the areas of workforce planning, recruitment and staffing strategies, compensation & benefits, labour relations, and development initiatives.About the roleDirectly report to General Manager Lead a team and drive full spectrum HR functions including recruitment, employee relations, compensation & benefits, training & development, employee engagement, HR policy, and any HR related projects Conduct HR analysis and propose professional consultation to top managementTake an active role as HR consultant or coach to the business leaders on people matters Work closely with Corporate HR team to ensure the efficiency of HR initiatives About the personBachelor degree holder with human resources management or related discipline With 12 years or more of progressive Human Resource experience from sizeable platforms Strong leadership skills with good business acumen Excellent organisational, interpersonal, and planning skillsFluency of English, Cantonese, and Mandarin About the company Our client is one of the world-wide luxurious and prestige hotel group . Currently they are looking for an upcoming and elite HR leader for this 5-stars hotel brand.\n\n\n\n### Has matches\nRequirement F.5 / DSE or above At least 2 years or above working experience is preferred Fluency in spoken English, Cantonese and Mandarin Good computer knowledge and Chinese typing required Have good communication / interpersonal skill and phone manner, mature, polite, hardworking, responsible, independent and open-minded\n\n\n\n=== No matches, Show Original\n*月入高達 $50,000 至 $100,000* (底 薪 + 保 證 佣 金 + 額 外 獎 賞 ) 具三年或以上美容銷售經驗 積極、主動及良好顧客服務態度 工作地點: 太古城 / 銅鑼灣 / 尖沙咀 福利+其他獎金 每月6.5天休息日 婚假、恩恤假 年終花紅 進修津貼 加班補鐘 完善在職培訓 良好晉升機會 介紹新人獎金 自願性牙科計劃、醫療及住院福利 員工購物及美容療程優惠 申請方法: 應徵者請於辦公時間致電 3980 9817 或 3980 9819 約見面試或將個人履歷、要求待遇及聯絡電話 Whatsapp: 9018 0223 / WeChat: PhillipWainHR (資料只供招聘用途)\n\n\n\n### Has matches\nRequirements: : Degree in Accounting, Finance or related disciplinesA qualified member of ACCA/HKICPA or similar professional bodies is a PLUSMinimum 3 years of accounting or auditing experienceGood command in both spoken and written Chinese (Cantonese & Mandarin) and EnglishDetail-oriented, energetic, adaptable and proactive attitude, fast learnerThis is an excellent opportunity to join a leading international organization who is able to offer the right individual to the chance to impact the business. Interested individuals can apply now and send CV to Kelvin KO, or call +852 3972 6554 for more information. Only relevant candidates will be contacted.\n\n\n\n=== No matches, Show Original\nTHE COMPANY: Manufacturer and exporter: metal car parts focus in metal air filter Headquarters: Hong Kong Factory: Dongguan 1000 workers Main market: global automotive brands We are looking for ACCOUNTING MANAGER - with details as follows: THE JOB: Degree in Accounting / Finance related 10-15 years accounting / finance experience, of which minimum 4 years in manufacturers with factories in China Solid experience in reviewing China factory accounting Experience in leading China Accounting Teams is a plus Strong leadership and management skills Report to the Director Fully responsible for managing and reviewing Dongguan factory accounts Lead and monitor the work done by Dongguan Accounting Team Supervise 1 X Accountant in HK office (who also travel to China factory) Frequent Dongguan trip is required 13 months salary + performance bonus Medical benefits Office location: TST East Less experience will be considered as Senior Accountant TO APPLY for this job or similar jobs: For secure and confidential job application, please click the below link to get our email address. http://jpc.hk/confidential_apply.htm We provide free job hunting services to job seekers. To speed up our process, please do NOT send us download links. Personal data provided by job applicants will be used for recruitment purpose only. Your privacy is guaranteed. We will never give out, lease, or sell your personal information. JPC Recruiting Services was established in 1990. http://www.facebook.com/pages/JPC-Texson-Ltd/500356593325952\n\n\n\n### Has matches\nRequirements: : Degree or above 3-5 years experience of analyst or decision support roles Key responsibilities: Directly report to FP&A Manager Financial analysis Support the Finance Business Partner in gathering business input and create first drafts of budgets and forecasts, including supporting any reporting system submissions thereof Preparation and analysis of monthly financial performance reports enabling analysis of revenue, net sales, profitability and orderbook positions by team, panel, client and service. Operating cost reporting and analysis to support cost management and resourcing decisions Setting strategies and business unit targets with the business e.g. competitor analysis Please send in your full resume with last drawn, expected salary and availability to Bond West Application Email Address \"Click Here\" or via \"APPLY\" button. For any query, please feel free to contact Ms Chan at 2957 8079. For more job opportunity, please visit our website: www.bondwest.com (Data collected is only for recruitment purpose)\n\n\n\n### Has matches\nRequirements: : : HKCEE/ DSE or above with LCC Intermediate or equivalent At least 2 years' experience in accounting Good interpersonal & presentation skills Self-motivated, responsible, detail-minded and work under pressure Proficient in MS Office, Excel, PowerPoint and Chinese Word Processing Good command in written & spoken English and Mandarin. Experience in SAP in preferable Fresh Graduate also welcome We offer attractive salary and fringe benefits including free shuttle bus from Kwai Fong/Mei Foo to Kwai Chung Container Terminal to the right candidates. Please email your full resume with date available, present and expected salary to cv.hkg @panalpina.com. We are an equal opportunity employer and welcome applications from all qualified candidates. Information provided will be treated in strict confidence and only be used for consideration of your application for the relevant or similar post(s) within Panalpina China Limited. Applicants not having heard from us within 6 weeks from the date of this advertisement may consider their application unsuccessful. All Personal data of unsuccessful applications will be destroyed within 6 months.\n\n\n\n=== No matches, Show Original\nResponsible for handling raw material, electronic components sourcing, supplier partnership development and material expediting, etc. Diploma or above in Purchasing, Engineering or related disciplines At least 3 years proven track record of electronic components, raw material sourcing and procurement in manufacturing industry, preferably gain in electrical household appliance sector Excellent negotiation, communication and sourcing skills Good command of English and Chinese We offer attractive remuneration package including 5-day work, bank holidays, group medical insurance etc to the right candidates. Interested parties please send your full resume including expected salary and date available to Human Resources Department by clicking \"Apply Now\" button. For more details, please visit our web-site at www.simatelex.com.hk\n\n\n\n### Has matches\nRequirements: : Bachelor's degree or above in relevant fieldA minimum of 8 years' experience in working in fabric sourcing, merchandising positionsStrong technical knowledge in fabrics and fabric production processStrong business acumen for the strategic positionProficient in Microsoft OfficeGood command of spoken and written English, Cantonese and Mandarin Interested candidate pls send your CV to Vincent Chow for more details. For other available opportunities, please visit www.connectedgroup.com\n\n\n\n=== No matches, Show Original\nYour new company This Bank is renown for its significance in Chinese market and strong product coverage. It has active participation in significant deals in the market and strong referrals from its counterparts in China. Owing to the steady expansion, a Senior Relationship Manager is needed to join their Corporate Banking division and mange a portfolio of Large China Corporate portfolio and drive the business forward. Your new role You will manage and develop a portfolio of First Tier Conglomerates in China. You will be responsible for growing revenue from the portfolio and maximise revenue return for the bank. You will be responsible for preparing credit analysis and customising proposals to solve clients' enquiries. You will assist in the entire deal process and build a strong relationship with the customers. What you'll need to succeed Your previous experience as a Relationship Manager within Corporate Banking will help you succeed in this role. You will have 5+ years of experience in Global / Corporate Banking. You will also be familiar with loans, trade finance and cash products. You will be a team player in achieving team targets and also detail minded in conducting in-depth financial and credit assessment within credit policy and parameters of the bank. Due to the targeted client segment, you will be required to speak Mandarin, Cantonese and English on a daily basis. Candidates with less experience would also be considered. What you'll get in return You will be offered an opportunity to explore China market under professional guidance. You'll be offered a competitive salary package along with Annual Discretionary bonus and generous employee benefits. You'll receive fast-tracked career progression opportunities and work with a team of proactive, ambitious and like-minded individuals. What you need to do now If you're interested in this role, click 'apply now' or for more information and a confidential discussion on this role or to find out more opportunities in Corporate Banking contact Yetta Chan at +852 2230 7427 or email [email protected]\n\n\n\n### Has matches\nRequirements: : Bachelor or Master degree holder in Finance major or other related disciplines Ability to work effectively in a team, and be a good team player Ability to analyze situations, prioritize, implement processes and solve problem effectively Excellent interpersonal and communications skills Fluent in English and Cantonese language, a communicative level of Mandarin is preferred Willing to learn and interested in Finance, Equity and Investment industries Excellent career prospects will be offered to the right candidates. Salary will be commensurate with qualifications and experience. Attractive remuneration package includes: Medical benefits, Study and Continuous Learning Sponsorship 15 working days' annual leave 5-day work week Salary: 15K per month (Depends on education level & working experience) ***Only candidates authorized to work in Hong Kong will be considered*** Please note: Only shortlisted candidates will be notified for interview within 4 weeks of the date of this advertisement. All personal data collected will be kept confidential and used for recruitment purposes only.\n\n\n\n=== No matches, Show Original\nLeading foreign bank looking for Financial Planning Manager to join them. Your new company Our client is a leading foreign bank with a well-established client base. Currently looking to strengthen its Bancassurance business further, they are investing heavily in order to increase market share. Your new role You'll work closely with Relationship Managers at branch level to deliver wealth management solutions to high-net-worth customers. You'll provide coaching and training for Relationship Managers and other branch staffs on their insurance selling skills and product knowledge. You'll support the Branch Manager to drive marketing campaigns in order to achieve insurance business targets. What you'll need to succeedDegree holder with IIQE 1,2,3,5 and HKSI 1,7,8 qualificationsSolid experience in life insuranceProactive and self-motivating mindset and attitudeFluent in English and Cantonese, Mandarin a definite advantage What you'll get in return With your commitment and expert knowledge in the insurance business, you will be rewarded with a competitive package together with high commissions. You will be provided a promising career development within the banking or insurance industry. What you need to do now If you're interested in this role, click 'apply now' or for more information and a confidential discussion on this role, or to find out about more opportunities in Insurance, please contact Connie Ng at Hays on +852 2230 7429 or email [email protected]\n\n\n\n### Has matches\nRequirements: : Certificate holder in Engineering field of Technical Institute or equivalent Proficiency in operating of CADD software such as MicroStation and AutoCAD Knowledge of MS Office software such as Work and Excel Self-initiative and able to work independently At least a year experience in engineering field but fresh graduate may be considered To apply for this position, please send your full résumé in word format indicating the reference number and title. If you are not contacted by our consultants within 2 weeks, please consider your application unsuccessful. All applications will be treated in strict confidence, and used for recruitment purposes only in accordance with Kelly Services Hong Kong Limited’s Privacy Notice.\n\n\n\n=== No matches, Show Original\nResponsibilities: Identify potential clients and the decision makers and successfully develop these business relationships into new clients; Reach out within your geographic area through e-mail or cold calling to create a robust pipeline of opportunities; Arrange and attend meetings and calls with potential clients by growing, maintaining and leveraging your network; Plan approaches and pitches with the Regional Head of Business Development; Planning and executing a cohesive business development campaign to grow an international network of client relationships; Organize and host events, attend conferences and seminars and provide feedback and information on market; Submit weekly progress reports; Ensure that data is accurately entered and managed within CRM. Qualifications: A marketing and or law degree; At least 3 years experience in a commercial function at a company in the (legal) service industry that provides services to Multinationals; Have an established network in the industry; Excellent communication and presentation skills; Targets and results driven; Creative, resourceful, able to think outside the box and a hands on individual; Be proactive and innovative with strong commercial instincts; Eager to be part of a dynamic, rapidly growing business; Have a willingness to travel; Fluency in verbal and written English is essential, other languages will be an advantage.\n\n\n\n=== No matches, Show Original\nJob Objectives: Several business trip to China main city (e.g. Shenzhen, Shanghai, Beijing, Chengdu,Guangzhou etc.) to hold seminars and meet with high net worth clients To explore Oversea Property, Asset Management and Risk Management solution to individual and corporate clients Assistant Regional Manager develop financial services in Mainland Global finance consultant Establish and maintain good relationship of our large chinese customers and prospects base To assist in business development, marketing and client seminar, recruitment activities People we are looking for: Bachelor degree holder or above in all disciplines, preferably with major in Business Administration, Finance, Accounting, Economics or relevant discipline. Excellent Interpersonal and communication skills as well as good command of both written and spoken English and Chinese (Mandarin & Cantonese) Candidates with IANG visa is welcomed Strong communication skills and trouble-shooting skills Offer and Benefit: One year salary package $15,000 plus 100% commission Intensive Quality Training Programme CFA, CFP or AFP examinations resources and support with individual sponsorship provided Fast track promotion to management level The information provided by applicants will be treated in strict confidence and used solely for recruitment purpose.\n\n\n\n### Has matches\nRequirements: : : Degree Holder in Information Technologies, or any equivalent disciplines 3+ years' experience in IT&Telecommunications industry Solid knowledge in Network Solution: TCP/IP, WAN / LAN, Firewall, Wireless/ Wifi, switch and routing Certificate holder of CCIE / CCNA / CCNA would be advantageous Experience in product development, consultant and project management area Proficiency in Chinese (Cantonese and Mandarin) and English How to apply: If you are interested it, please kindly send your CV to Carmen Ching at carmen.ching @springasia.com.\n\n\n\n### Has matches\nrequirement: Min. 10-15+ years of engineering and pre-sales/account management experience Possess in-depth knowledge in sales cycle with strong sales track record and hand on experience Possess strong analytical and problem solving skills Good understanding of typical customers networks Ability to create an end-to-end security solution for a customer’s environment Excellent communication and presentation skills Relevant certifications highly preferred, e.g. CCNP / CISSP/ CCSA / CCSE Travel occasionally is required Less experience will be considered as Senior solutions engineer consultant If you are the person who look for ambitious career advancement and love to working with a team of great and brilliant people, NOW this is the opportunity! Please apply and send your updated resume to carmen.ching @springasia.com.\n\n\n\n=== No matches, Show Original\nAbout our client Our client is a global IT distributor serving more than 100 countries around the world by providing very comprehensive cross broad IT products and services. Due to the new business expansion, they are looking for a young technical sales person as cloud consultant to join their young and energetic cloud team. About the role: Identify sales leads with peers, present Cloud portfolio to new clients and maintain a good working relationship with different stakeholders Driving subscription and services revenue on Hybrid/Multi-Cloud products through prospects for potential new partners Step up and work with other internal colleagues to enable Partners in up-selling Cloud product Build, manage and maintain a substantial pipeline of qualified opportunities to underpin target achievement with internal sales team and channel partners Present new products and services and enhance existing relationships Using knowledge of the market and competitors, identify and develop the company unique selling propositions and differentiators Experience to architect the framework and may need to deliver project(s) with stakeholders What you will need: Degree in Information Technology or related discipline 4 - 5 years’ sales + hands on technical experience of the latest cloud offerings: (IaaS, PaaS, SaaS) from market-leading cloud platform (e.g Azure, Amazon Web Services, Google Cloud, etc) Knowledge and experience in Microsoft Azure and cloud synergy solution (storage / backup / DR / workspace / big data) Professional Certificate in Azure and/or AWS Cloud Certification Good communication and past project-handling skills is recommended High Proficiency in spoken and written English and Cantonese If you are the person who look for ambitious career advancement and love to working with a team of great and brilliant people, NOW this is the opportunity! Please apply and send your updated resume to carmen.ching @springasia.com.\n\n\n\n### Has matches\nrequirement: Min. 10-15+ years of engineering and sales/ account management experience in IT/ networking/infrastructure industry with FSI client exposure is a PLUS Possess in-depth knowledge in sales cycle with strong sales track record and hand on experience Possess strong analytical and problem solving skills Good understanding of typical customers networks Ability to create an end-to-end security solution for a customer’s environment Excellent communication and presentation skills Travel occasionally is required If you are the person who look for ambitious career advancement and love to working with a team of great and brilliant people, NOW this is the opportunity! Please apply and send your updated resume to carmen.ching @springasia.com.\n\n\n\n### Has matches\nrequirement: 6-8 years of engineering and pre-sales experience Possess strong analytical and problem solving skills Good understanding of typical customers networks Ability to create an end-to-end security solution for a customer’s environment Excellent communication and presentation skills Relevant certifications highly preferred, e.g. CCNP / CISSP/ CCSA / CCSE If you are the person who look for ambitious career advancement and love to working with a team of great and brilliant people, NOW this is the opportunity! Please apply and send your updated resume to carmen.ching @springasia.com.\n\n\n\n=== No matches, Show Original\nThe client is an international law firm, they are looking for a company secretary to work with the partner and a legal consultant to provide company secretarial supports for the corporate team. handle around 70+ private companies, no offshore jurisdiction, some listed co experience would be an advantage. 5+ years Company Secretary experience. (preferable experience gained from law firm) Fluent Chinese and English. Proficiency in Viewpoint (software / system) would be an advantage.\n\n\n\n### Has matches\nRequirements: : 本科以上學歷,行銷,管理,金融等專業; 3-5年以上固定收益銷售工作經驗;有銀行外匯客戶資源,海外資產銷售,海外留學或者海外工作經驗;服務高淨值客戶經驗或有海外投資高端客戶資源;有一定的客戶管道及團隊資源; 熟悉多元金融產品,有良好的銷售技巧,客戶服務及管理能力; 誠實守信,勤奮努力,具有高度的團隊合作和執行力 Please send in your full resume with last drawn, expected salary and availability to Bond West Application Email Address \"Click Here\" or via \"APPLY\" button. For any query, please feel free to contact Ms. Tsui at 2957 8932. For more job opportunity, please visit our website: www.bondwest.com.hk (Data collected is only for recruitment purpose)\n\n\n\n=== No matches, Show Original\n(Ref Number: jobs@0516_at) Our client, a multinational trading firm in TST (5 days) is now looking for a high caliber candidate for the following position: Personal Assistant to GM 25-30K Diploma/ Degree or above Min. 5 - 8 years’ secretary experience in MNC/ Sizable company Experience in supporting to expatriate/ top management Detail & organized mind and good presentation skills Able to work hard & independently with good self motivation & timeline management Excellent command of written & spoken English, Cantonese & Mandarin Computer knowledge in MS Office 2-3 days daily travel to Shenzhen office per week Please send in your full resume with last drawn, expected salary and availability to Bond West Application Email Address \"Click Here\" or via \"APPLY\" button. For any query, please feel free to contact Ms. Tam at 2957 8130. For more job opportunity, please visit our website: www.bondwest.com.hk (Data collected is only for recruitment purpose)\n\n\n\n### Has matches\nRequirements: : : University graduate in Human Resources Management or related disciplines Minimum of 5 to 8 years HR experience in fast moving or service industry of which 3 years in managerial position Well-versed with Employment Ordinance and other related regulations is a must Incumbent must be a \"hands-on\" type of person in management style and be able to inspire and build confidence in the existing management team or make the organizational changes where necessary to ensure the company's continued growth Proactive, result-oriented, highly self-motivated with positive attitude Strong communication and leadership skills We offer a competitive remuneration package including excellent career prospects to the right candidate. To apply online, please click \"Apply Now\" Please visit our website at www.phillip-wain.com to know more about us. (Personal data collected will be kept confidential and used for recruitment purpose only)\n\n\n\n### Has matches\nRequirements: : Degree or Diploma holder in HRM or related disciplines Minimum 3 years’ experience in HR with solid experience in payroll administration, mass recruitment and fast pace environment Well-versed in Employment Ordinance and other HR related regulations Proficient in MS Office especially in MS Excel and Chinese Word processing Mature, attentive to details, organized and independent Immediate available is highly preferred Candidate with more experience may be considered as Senior Human Resources Officer We offer a competitive remuneration package including excellent career prospects to the right candidate. To apply online, please click \"Apply Now\" Please visit our website at www.phillip-wain.com to know more about us. (Personal data collected will be kept confidential and used for recruitment purpose only)\n\n\n\n### Has matches\nRequirements: Qualified accountant or a degree holder in Accounting, Finance or related discipline1 to 2 years experience of FP&AHighly organized, self-motivated and responsibleAbility to act as business partner and to work with all levels across different functions effectively and efficientlyAbility to adapt to a changing environmentAbility to work independently, strong result-orientated and hands-onHigh proficiency in both spoken and written EnglishStrong analytical and problem solving skillsInterested individuals can apply now and send CV to Vivian Wong, or call +852 3972 5831 for more information. Only relevant candidates will be contacted For a more comprehensive list of our vacancies, please visit: www.connectedgroup.com\n\n\n\n### Has matches\nRequirements: : University graduate in Computer Science / Information Technology or a related discipline, at least High Diploma Proficiency in various programming languages and development frameworks / tools: (SQL, C#, .NET, JAVA, ASP.NET, HTML, HTML5) Energetic, proactive, creative and capable of working under pressure Knowledge in Moblie App system is an advantage Open-minded, Well organized, attention to detail, excellent communication skills Good command of English and Chinese Able to work independently Fresh graduates will also be considered Please send in your full resume with last drawn, expected salary and availability to Bond West Application Email Address \"Click Here\" or via \"APPLY\" button. For any query, please feel free to contact Mr. Lo at 2957 8071. For more job opportunity, please visit our website: www.bondwest.com.hk (Data collected is only for recruitment purpose)\n\n\n\n### Has matches\nRequirements: Bachelor degree in Finance/ Accounting or related disciplines10+ years of experience with a multinational Corporation of Retail or FMCG is a MUSTProficient with Excel, PowerPoint and experience with SAPGood command of both verbal and written English is a MUSTDemonstrated analytical skills, comfort with Finance and/or Accounting principles and good understanding and experience with financial KPI's: (retail math and retail financial drivers preferred).Ability to think cross functionally, join data from various sources and develop solutions in a fast-paced environment.Ability to be detail oriented and manage multiple priorities to accomplish assignments simultaneously under tight timelines.Thinking beyond the obvious and do not stop at the first answers.Ability to effectively present information and respond to questions from managers, stakeholders, cross functional business leaders, sales representatives, peers, and customersExperience in leading, coaching, driving and inspiring team membersInterested individuals can apply now and send CV to Vivian Wong, or call +852 3972 5831 for more information. Only relevant candidates will be contacted For a more comprehensive list of our vacancies, please visit: www.connectedgroup.com\n\n\n\n=== No matches, Show Original\nF5 or above with LCCI Intermediate 1-2 years working experience for accounting entry and A/P payment Good knowledge in PC Spoken in basic mandarin is preferred Willing to learn, hard working, responsible & self-motivated\n\n\n\n### Has matches\nRequirements: : F5 or above, 2 years of related operational experience is highly preferred but not a must Knowledge and experience in cross border truck/ logistics business is preferred; while on-the-job training will be provided to inexperienced candidate Customer-oriented, good telephone manner, willing to work under pressure Good command of written & spoken English, Chinese including Putonghua Proficient in PC applications: (MS Word, Excel, Chinese typing) Good Team Player immediate availability is preferred Work Location: #4 Container Terminal, Kwai Chung (Traffic allowance provided) We offer 5 days work and attractive salary to the right candidates. Interested parties please send full resume and expected salary to us via email. All information collected will be used for recruitment purpose only. Applications will be kept for 3 months before proper documentation or disposal as appropriate.\n\n\n\n=== No matches, Show Original\nThe Role Serve the passenger services operations by providing professional customer services to passengers at check-in counter, flight information desk, arrival / transit / baggage hall and boarding gate Facilitate the departure and arrival processes to maintain a secured, punctual and safe operations on behalf of customer airlines The Person HKCEE / HKDSE or equivalent Fluent in Japanese (JLPT N2 is a must), good English and Putonghua Positive attitude with a commitment to work in the aviation industry Experience in customer service is an asset Detail-minded, patient and able to work under pressure Willing to perform shift duty and overtime work in the airport Fresh graduate with no relevant work experience will also be considered A competitive package and promising career prospect will be offered to the right candidate. For more company information, please visit our company website at www.jasg.com or recruitment website at www.itsmorethanjustajob.com Interested candidate please click APPLY NOW If you have any enquiries please contact us by either Whatsapp at 6799 3608 or our recruitment hotline at 2216 2222 Your application and personal information will be treated as strictly confidential and used only for purposes of recruitment and selection. Failure to supply such information may affect your application result. Applicants who are not invited for interview within 8 weeks may consider their applications unsuccessful. All personal data of unsuccessful candidates will be destroyed after 6 months.\n\n\n\n### Has matches\nRequirements: : 1 years working experience in IT technical support and troubleshooting Self-motivated and independent Able to work shift duties Immediate availability is highly preferred. Please send in your full resume with last drawn, expected salary and availability to Bond West Application Email Address \"Click Here\" or via \"APPLY\" button. For any query, please feel free to contact Mr. Yeung at 2957 8966. For more job opportunity, please visit our website: www.bondwest.com (Data collected is only for recruitment purpose)\n\n\n\n### Has matches\nRequirements: : Diploma/ Degree holder At least 3 years solid sales experience in freight forwarding / logistics industry preferred Knowledge on dangerous goods is highly preferred Candidates with less related work experience but with good sales skills are welcome Excellent communication skill and presentation skill Aggressive, self-driven & results-oriented with excellent interpersonal skills Good command of written and spoken English, Cantonese and Mandarin Work location: Lai Chi Kok We have attractive commission scheme to reward good performance. We offer 5-day work and attractive salary to the right candidates. Interested parties please send full resume with expected salary to us. All information collected will be used for recruitment purpose only. Applications will be kept for 3 months before proper documentation or disposal as appropriate.\n\n\n\n### Has matches\nRequirements: : Diploma or Higher Certificate in Building Studies / Civil / Structural Engineering or equivalent Minimum 10 years relevant experience in architectural works or construction field Proficiency in PC application including word-processing and excel Good command of spoken and written in Chinese and English Familiar with Building Ordinance, building contract and construction planning and programming We offer competitive remuneration package and good career prospects to the right candidate. Interested parties, please send your resume stating current & expected salary and available date to Human Resources Department by mail to Goldin Real Estate Financial Holdings Limited, 25-27/F, Goldin Financial Global Centre, 17 Kai Cheung Road, Kowloon Bay or by email, or by fax to 2805 0626. A copy of our personal data (privacy) policy is available on request. Personal data provided by applicants are collected for recruitment purposes only. It is our policy to retain the personal data of unsuccessful applicants for future recruitment purposes for a period of six (6) months. When there are vacancies in our Affiliate during that period, we may transfer your application to them for consideration of employment.\n\n\n\n### Has matches\nRequirements: Degree Holder or above in Civil Engineering/Construction Management/Building or related disciplines. Member of MICE, MIStructE, MHKIE or other related professional qualification is preferred. More than 15 years of relevant working experience, with at least 8 years’ work experience in a similar managerial capacity in the construction field, preferably in large organizations/main contractors. Expertise in project planning and scheduling would be an advantage. Expertise in the use of Planning software (Primavera P6) or Microsoft Project. Conversant with the latest local government regulations & statutory requirements. Excellent presentation&communication skills. Immediately available is preferred. Attractive salary and fringe benefits will be offered to the successful candidates. Please apply with full resume, available date, present and expected salary and quoting the reference code on the letter & envelope to THE HUMAN RESOURCES & TRAINING DEPARTMENT, HIP HING CONSTRUCTION CO., LTD., 11/F., Chevalier Commercial Centre, No. 8 Wang Hoi Road, Kowloon Bay, Hong Kong OR click \"Apply Now\" OR fax to 2530 4360. Company Website: www.hiphing.com.hk All personal data collected will be used for recruitment purposes only. Applicants who are not invited for an interview within 8 weeks may consider their applications unsuccessful.\n\n\n\n### Has matches\nRequirements: Degree in Computer Science, Information Systems or related discipline Relevant experience in Java or ETL Java 2-5 years of hands-on experience in Java, .NET, and Web application programming and familiar with Oracle/MS SQL database Knowledge and hands on capability on BPM, WebSphere, MQ would be a plus Exposure on IBM BPM or other workflow system, Filenet and ECM is highly preferable ETL Minimum 3 years of working experience in banking or finance industry, preferably with exposure to regulatory and management reporting Possess knowledgeable skills in Data Warehouse (DWH) and Business Intelligence (BI) solution is an advantage Solid hands on development experience in Oracle, ETL, BI tools: (OBIEE/Cognos), UNIX script, SQL, PL/SQL and Java. Good command of spoken and written English and Chinese, including Putonghua\n\n\n\n### Has matches\nrequirements Good command of Cantonese and English Good computer knowledge (Word, excel, Windows & Email, etc. ) Good communication skill Independent and willing to learn\n\n\n\n=== No matches, Show Original\nA great opportunity for Data Scientist to make a step up.Client DetailsOur client is a leading Entertainment and Gambling corporation, and currently, because of their expansion within their Customer Experience team, they are looking for a Data Scientist who is specialized in Artificial Intelligence for their Chatbot projects. This position will work closely with the Frontend Developers and UI/UX Designers, and analyse the data generated by their CRM systems. Thus, this will allow the management to set up further strategies. DescriptionWork on the development and mathematical modelling through Big Data related technologiesUse statistical and analytical modelling for the management to predict market trendProvide advices for other data analysts to complete the data related projects ProfileMPhil or MSc or above in Data Science, Mathematics, Management Science, Operation Research, Computer Science etc.Minimum 2 years working experience in Data Science and Big Data related projectsStrong knowledge in SQL, Python, R and Hadoop Job OfferOur client can offer the right candidate a 3 year contract with a competitive package.To apply online please click the 'Apply' button below. For a confidential discussion about this role please contact Jacky Chan on +852 2848 9562.\n\n\n\n### Has matches\nRequirements: Diploma or above in Architectural Studies/Structural Engineering/Building Services Engineering or equivalent Minimum 4 years BIM modeling experience Good knowledge of Revit, Navisworks, Sketchup and Fuzor Member of HKIBIM, MHKIBIM preferable Candidates with less experience will consider as Assistant BIM Engineer / BIM Modeller Attractive salary and fringe benefits will be offered to the successful candidates. Please apply with full resume, available date, present and expected salary and quoting the reference code on the letter & envelope to THE HUMAN RESOURCES & TRAINING DEPARTMENT, HIP HING CONSTRUCTION CO., LTD., 11/F., Chevalier Commercial Centre, No. 8 Wang Hoi Road, Kowloon Bay, Hong Kong OR click \"Apply Now\" OR fax to 2530 4360. Company Website: www.hiphing.com.hk All personal data collected will be used for recruitment purposes only. Applicants who are not invited for an interview within 8 weeks may consider their applications unsuccessful.\n\n\n\n=== No matches, Show Original\nForm 7 or above Minimum 3 years solid experience in merchandising in related field, preferably in buying office Attentive to detail, strong problem-solving and negotiation skill Work independently, under pressure and meeting deadlines Fluent in spoken and written English and Mandarin, knowledge in Spanish is definitely an advantage Proficient in MS Office Immediate availability is preferred Candidate with less experience may be considered as Junior Merchandiser Attractive remuneration, 5-day work, health insurance and secure career prospect will be provided to successful candidates. Please send your resume with expected salary. *****Personal data only for the purpose of recruitment.\n\n\n\n=== No matches, Show Original\nA world leading sourcing office is currently looking for a Senior Merchandiser (Outdoor furniture) to join their dynamic team.Client DetailsOur client is one of the European leading FMCG company. Due to their steady growth, they are now looking for a potential calibre to join the expanding regional team as a Senior Merchandiser.Description Keep track with the orders delivery schedulesSource and develop new product range according to buying briefWork with suppliers to resolve quality concerns and production schedule concernsMonitor daily operation, including sourcing, sampling, price negotiation and project set upWork closely with other departments including Quality Control and Shipping for updating the quality standard and shipment statusCoordinate with factories to ensure timely deliveries ProfileF.5 or above qualificationProactive and well organisedGood communication and negotiation skills to work with clients and suppliersBusiness English and MandarinRelevant merchandising experience in Outdoor furniture/ home itemsJob OfferExcellent career promotion is greatly promised to the right candidate. Our Client offers an attractive remuneration package of monthly salary + attractive year-end bonus, depending on performance. Please call at +852 3602 2493 for more details.International career prospectsCompetitive salaryMedical CoverageMPF5-day Work WeekTo apply online please click the 'Apply' button below. For a confidential discussion about this role please contact [Kenneth] [Leung] on [+852 3602 2493].\n\n\n\n=== No matches, Show Original\nAccounting ManagerOur client is an innovative F&B company. To cope with their expansion in Hong Kong, they are now inviting high caliber candidates to join their team as Accounting Manager.Salary: HK$ 30,000 to 40,000 x 12 month + bonusOffice Location: New TerritoriesJob Responsibilities: Handling full set of accounts and oversee accounting department daily operations and monitor entire month end closing processOversee all activities related to cash flow, taxes, budget, forecast and strategic planningPerformaning monthly and annually management reports including budgeting, forecasting, and variance analysisVerifies that the P&L is accurate and statements are delivered to appropriate individuals in a timely mannerPerform business control to support the business growth and provide constructive advice and analysis for decision makingEnsure financial control is maintained and achieve efficiencies under existing financial processes & procedures, including internal control, risk management, corporate governance requirement...etc.Maintain good banking relationship and working capitalJob Requirement:Degree holder in Accounting, professional qualification of CPA is preferredMinimum 5 years relevant experience in which 2 years in supervisory levelIndustry experince in retail/F&B is highly preferred Able to work under pressure and meet the tight deadlineGood team player with strong analytical mind and supervisory skillStrong communication, interpersonal and problem solving skillsImmediate available is preferredThis is an excellent opportunity to join a fast growing organization who is able to offer the right individual to the chance to impact a fast moving business. Interested individuals can apply now and send CV to Kelvin KO, or call +852 3972 6554 for more information. Only relevant candidates will be contactedFor a more comprehensive list of our vacancies, please visit: www.connectedgroup.com\n\n\n\n### Has matches\nRequirements: : Higher Diploma or Degree holder in Computer Science or IT related disciplines At least 3 years solid working experience in Desktop, Server and Network administration Hands on networking, MS Windows Server, Linux and VMware, firewall, AWS experience. Experience in designing, building and maintaining system and network infrastructure Certified in MCP, MCSE, MCITP, CISSP will be an advantage Self-motivated, hardworking, flexible, customer-focus and able to work independently Excellent interpersonal skills and can work well with stakeholders across multiple countries Candidates with less experience will be considered as Technical Engineer We offer attractive remuneration to the right person with fast track career development opportunities and fringe benefits. Interested parties please apply with detailed resume, including both current and expected salary. Personal data collected will be used for recruitment purpose only. Applicants who are not contacted within 4 weeks should consider their application unsuccessful and will be filed for opportunities in future.\n\n\n\n### Has matches\nRequirements: : Higher Diploma/Degree in fashion, business management or related disciplines Minimum 3 years of relevant experience in retail buying, preferably footwear Strong numeric sense and analytical skills Proficiency in MS Excel Good interpersonal and communication skills Strong command of spoken and written English & Chinese Less experience will be considered as Buyer We offer a 5-day work week, health Insurance and an attractive remuneration package with career development opportunities. Interested parties please send your CV and portfolio with salary history and expected salary through APPLY NOW. Any applications without a portfolio will not be considered. (All personal data collected will be used for recruitment purpose only)\n\n\n\n### Has matches\nRequirements: : We support local hire with solid relevant working experience in HK. Bachelor Degree in Information Technology, Engineering, Computer Science or related disciplines 5-8 years’ relevant experience in IT, Computer Science and related disciplines, preferably in financial industry Strong understanding of internetworking protocols, products and services including Multicast, Unicast, OSPF and BGP Good technical knowledge on Cisco products like routers, switches and wireless Hands on experience in enterprise LAN/WAN/WiFi, network management tools Hands on experience in VoIP and Cisco IPUC Holder of CCNA/CCNP/CCIE will be an advantage Strong sense of responsibility with good analytical skill, self-motivated and detail-minded Positive attitude, fast learning and able to perform in a challenging environment Good command of spoken and written English and Chinese, including Putonghua Application Method: We are committed to build a team of competence individuals who have acquired relevant local solid working experience and with diversified exposure to work together with us. Applicants who do not hear from us within 6 weeks may consider their applications unsuccessful. We provide attractive remuneration package and fringe benefits for the right candidate. Interested parties please send detailed resume with current and expected salaries to Human Resources Department i) by mail: 22/F, Li Po Chun Chambers, 189 Des Voeux Road Central, HK; ii) by fax: 2537 5431; or iii) by using “Apply Now”. Please quote the reference in the application.If application is submitted in hard copy format, it should be placed in a sealed envelope marked “Confidential”. All applications will be treated in strict confidence and personal data provided by job applications will be used for recruitment purposes only. A copy of our Personal Information Collection Statement will be available upon request.\n\n\n\n### Has matches\nRequirements: : University graduate in Computer Science or related disciplines. ECF-C certification is required: CISSP, CISA, CISM, CRISC, CEH, ITIL v3 Minimum 4 years' experience in Information Technology in Financial Institution and preferably information security related experience Sound knowledge of regulatory requirements and strong understanding of financial industry Knowledge on Network Infrastructure and Design is preferred Knowledge on IT security tools such as Privileges ID Management, Network Security Monitoring, End Point Protection, Security Incident Event Management System and Data Loss Prevention System are desirable Able to work independently with good time management Strong organizational skills and ability to manage multiple demands and changing priorities Good command of spoken and written English and Chinese, including Putonghua Candidates with more experience will be considered for Senior Position Interested party, please click \"Apply Now\". Personal data collected will be used for recruitment purposes only.\n\n\n\n=== No matches, Show Original\n我們現為各大公司招聘能操日語或韓語的客戶服務主任。 工作職責: 於熱線中心提供優質專業客戶服務 處理客戶查詢及投訴 一般文職工作 職位要求: 中五或以上程度 一年或以上工作經驗,具客戶服務經驗優先 性格開朗、有耐性、良好溝通能力 良好中文及英文讀寫能力 具日語N1/N2級程度;或韓語4/5級程度\n\n\n\n### Has matches\nRequirements: : University graduate in related disciplines Minimum 5 years' (APM) / 7 years’ (PM) of buying / category management / business development experience gained from fashion / footwear / accessories Strong business sense with analytical mind Pro-active, result-oriented, good communication skill and able to work under pressure Proficient in Excel We offer competitive remuneration package with a wide range of fringe benefits including 5-day work week CNY Bonus Discretionary Bonus Comprehensive Medical Coverage Staff Shopping Discount Non-contributory Retirement Benefits Scheme Birthday Leave & Gift 14-week Maternity Leave Paternity Leave Interested parties please send resume with present and expected salary to Human Resources Department, Swire Resources Limited, 12/F Kingston International Centre, 19 Wang Chiu Road Kowloon Bay, Hong Kong or by fax to 2307 2357 or by clicking the below \"Apply Now\" button.\n\n\n\n### Has matches\nRequirements: : High Diploma in Computer Science, Information Technology or related disciplines Hands-on experience in all-rounded technical skills on desktop support and, ideally on server administration and software and back-end administration Knowledge of Networking and Firewall, Storage, SAN Switch, Load balance Knowledge of AIX, Linux, IBM Tivoli, IBM MQ, IBM TSM, Symantec Netbackup/Backup Exec is preferred Candidates with less experience will also be considered Interested parties please click \"APPLY NOW\" or send your resume with your current and expected salaries to Francis @bgc-group.com *Personal data collected will be used for recruitment purpose only.\n\n\n\n### Has matches\nRequirements: : Degree holder in Computer Science or related disciplines Hands-on experience in Java / C# / ASP.Net / VB.Net / JavaScript Minimum 2 years’ experience in software development Knowledge in IT project in Banking or Finance Industry is a plus Effective spoken and written communication in English Interested parties please click \"APPLY NOW\" and send your updated CV with current and expected salary to jackie @bgc-group.com *Personal data collected will be used for recruitment purpose only\n\n\n\n### Has matches\nRequirements: Graduate work or degree in computer science or engineering a plus Hands on experience in Apache Spark / Scala / Presto / Elasticsearch / HDFS is a definitely plus Knowledge in Java, Spring, php, VueJS, JQuery, Linux shell, Git, Maven will be a plus Be smart to handle trouble shooting, demonstrated experience with debugging code, handling open source library and performance analysis Demonstrated superior performance in prior roles with increasing levels of responsibility and independence Detail oriented, demonstrated ability to handle multiple projects and solve complex problems Interested parties please click \"APPLY NOW\" and send your updated CV with current and expect salary to jackie @bgc-group.com. * Personal data collected will be used for recruitment purposes only.\n\n\n\n### Has matches\nRequirements: : Degree in computer science or related disciplines 3 years of working experience in IT security Ability to understand business impact of information security risks Proficient written and verbal communication skills in English and Chinese Able to work under pressure, meet tight deadlines and work independently Self-motivated to work independently and strong passion for learning and growth If you are ready for new challenges, please click \"APPLY NOW\" or send your resume in WORD formate with the current and expected salaries to Blair @bgc-group.com *Personal data collected will be used for recruitment purpose only\n\n\n\n### Has matches\nRequirements: : : 1. Degree holder or above 2. 1-2 years relevant working experience in marketing sales is preferred 3. Good communication & organization skills 4. Excellent interpersonal and communications skills 5. Proficient in MS office, Word, Excel & Chinese Word Processing 6. Good spoke Putonghua Chinese and English 7. Need to travel to China 8. Immediate available is highly preferred\n\n\n\n=== No matches, Show Original\n我們現為各商場招聘客戶服務主任及賓客服務專員 工作職責: 負責商場的客戶服務、保安及物業管理工作 職位要求: 中五或以上程度 一年或以上顧客服務經驗 良好中文及英文讀寫能力\n\n\n\n### Has matches\nRequirements: Degree in Building / Civil / Structural Engineering or equivalent Chartered membership of professional institution is preferable At least 15 years relevant experience in construction industry, preferably in large scale project of civil / building works Participated in design and build project is an advantage Conversant with management system development, implementation and internal audit (e.g. ISO 9001 or other management systems) Excellent interpersonal skill and proficiency in spoken and written English & Chinese Conversant with Microsoft Word, PowerPoint and Excel Candidate with less experience will be considered as Project Quality Manager Attractive salary and fringe benefits will be offered to the successful candidates. Please apply with full resume, available date, present and expected salary and quoting the reference code on the letter & envelope to THE HUMAN RESOURCES & TRAINING DEPARTMENT, HIP HING CONSTRUCTION CO., LTD., 11/F., Chevalier Commercial Centre, No. 8 Wang Hoi Road, Kowloon Bay, Hong Kong OR click \"Apply Now\" OR fax to 2530 4360. Company Website: www.hiphing.com.hk All personal data collected will be used for recruitment purposes only. Applicants who are not invited for an interview within 8 weeks may consider their applications unsuccessful.\n\n\n\n### Has matches\nRequirements: : Degree holder in Textile / Clothing related discipline Experience in doing research Experience in training is an advantage Excellent command of writing and spoken English and Chinese Plan to develop a career in training Terms of Appointment: Starting salary and level of appointment will be commensurate with qualifications and experience. Remuneration package will be highly competitive. The Authority provides excellent staff development opportunities. Applications: Full resume including current and expected salary, earliest date available and contact telephone number should be mailed to the Human Resources and Administration Department, Clothing Industry Training Authority, 63 Tai Yip Street, Kowloon Bay, Kowloon or simply click “Apply Now” below to submit your application. For information about our organization, please visit our website: www.cita.org.hk. The information provided will only be used for consideration of your application. Applicants not invited for interview within one month may consider their applications unsuccessful and the applications will be retained by the Authority for a maximum period of six months.\n\n\n\n### Has matches\nRequirements: : Diploma or above in Accountancy Knowledge & experience in accounting software of SUN & AS400 is preferred Fluent in English & Chinese (Cantonese & Mandarin) Mature and self-motivated with strong sense of responsibility Organized, independent & able to work under pressure to meet deadline Immediate available is preferred We offer 5-day work and competitive remuneration package to right candidate. Interested parties please send your full resume and expected salary to Ms. Hui by e-mail via \"Apply Now\"\n\n\n\n### Has matches\nRequirements: : Education: F.5 graduates or equivalent Good computer skill Good command of written and spoken English and Chinese Able to work under a pressure Good interpersonal, problem-solving, communication and presentation skills Benefits: 5 days work double pay birthday leave medical allowance bank holiday promotional opportunities\n\n\n\n### Has matches\nRequirements: : : 1-3 years relevant working experience; Strong sense of buying for optimal potential profit; Experience in dealing with overseas customers is an advantage; Good command of both spoken and written English and Chinese; Highly motivated, detail minded and strong sense of responsibility; Immediate available is preferred. Remuneration: Year End Bonus: (optional) Bank Holiday Payable Annual Leave Medical Insurance Staff Discount How to Apply: Interested parties please send your full resume to apply with your current and expected salary to Head of Human Resources. (Personal data collected will be used for recruitment purposes only)\n\n\n\n### Has matches\nRequirements: : University graduate with major in Business Administration, Finance, Accounting or related disciplines Minimum 5+ years banking experience in Treasury settlement role, focus on FX/MM, Fixed Income, Debts new issue, Derivatives, Structure products, OTC Clear and Corporate clients business Knowledge in RTGS (i.e. eMBT and eCMT) and SwiftAlliance system Operate Clearstream and Euroclear clearing platform respectively Good experience in and capability of handling the banking projects such as treasury products and systems. The role mainly support the project team on prepare user requirement, attend project meeting, gap analysis, UAT participation and set-up procedure manual) Strong leadership and communication skills to lead the team to support fast growing business and achieve the tasks within the timeline Conversant with MS Word, Excel & Chinese word processing Good command of written & spoken English and Chinese, including Putonghua Candidates with less experience will be considered as Assistant Manager Interested parties, please click “Apply Now” for application. Personal data collected will be used for recruitment purpose only.\n\n\n\n### Has matches\nRequirements: : University graduate in banking or related disciplines, with professional qualification in banking is preferred Minimum 3 years of experience in banking operations with exposure in various areas, especially for Branch Operations, IT, Treasury & Settlement, Remittance, Securities, Investment products, Private Banking Strong knowledge on banking products and operations. Experience in IT project management would be an advantage Good presentation, negotiation and analytical skills Strong communication and interpersonal skills Good PC knowledge and skills Good command of written & spoken English and Chinese, including Putonghua\n\n\n\n### Has matches\nRequirements: : Bachelor degree holder in Business Administration or related disciplines Minimum 5 years of relevant experience in retail banking Good communication skills, independent and detail-oriented Proficient in MS Office such as Word and Excel Good command of spoken and written English and Chinese, including Putonghua Candidates with less experience will be considered as Officer Interested parties, please click “Apply Now” for application. Personal data collected will be used for recruitment purpose only.\n\n\n\n=== No matches, Show Original\n工作及職責: 一般執貨、收貨、回貨、貨品存放及包裝等工作 確保倉務運作流順和存貨量準確 定期盤點貨物 需輪班工作 (7:00 a.m. - 4:00 p.m./ 8:30 a.m. - 5:30 p.m./ 11:00 a.m. - 8:00 p.m.) 基本要求: 中三或以上程度 工作勤奮及良好品格 能獨立處理工作 能即時上班者為佳 良好粵語,懂讀寫中文和懂閱讀一般英文 半年或以上倉務經驗優先 擁有合資格鏟車牌優先 申請方法: 如有興趣者,可帶同履歷表(需註明居住地區)及過往工作學歷證明 親臨以下招聘日: 日期: 逢星期二至星期五 (公眾假期除外) 時間: 下午2時30分至4時30分 地點: 新界火炭禾穗街15-29號百適二倉12樓(由港鐵火炭站D出口出發,只需步行約5分鐘即可到達) 如未能親臨以上招聘日可Whatsapp 6394-0094或致電2310-6629聯絡預約面試 或按\"Apply Now\"申請 *所有求職者的資料只用作招聘用途*\n\n\n\n### Has matches\nRequirements: : Bachelor or associate degree (or above) in marketing, communication, business administration or other related fields; 1-2 years of solid experience in marketing. Experience in IT-related businesses is an advantage; Rich experience in event management; Knowledge or experience in website management, SEO, SEM, eDM and Google Analytics; Knowledge in Photoshop/ Illustrator/ HTML is a plus; Proficient in Microsoft Office MS Word, Excel and PowerPoint; Strong command of written and spoken English and Chinese; Self-motivated, creative, detail-minded, independent and team player; Able to multi-task and work under pressure; Candidate with more experience will be considered as Senior Marketing Executive. Free Shuttle Bus will be provided: Route 1. Tai Wai > Nam Cheong > Kennedy Town > Cyberport 2 Route 2. Lam Tin > Quarry Bay > Cyberport 2 Route 3. Cyberport 2 > Kennedy Town > Nam Cheong > Tai Wai As a caring company, staff development is one of our top priorities. We offer attractive remuneration packages with a wide range of fringe benefits include medical & dental insurance, education allowance, performance bonus and excellent career prospect to the right candidate. We also offer on-the-job training and specialized training programme to uplift the potential of our staff. Interested parties please send your detailed resume with current and expected salary by email to: hr_manager @ctil.com or by mail to \"Human Resources Department, Computer And Technologies International Limited, Level 10, Cyberport 2, 100 Cyberport Road, Hong Kong\". Please quote the employer reference number in the application. In order to explore more about our growth initiatives and other job opportunities, please visit our website http://www.ctil.com/. All personal data collected will be kept in strict confidence and would only be used for recruitment purpose.\n\n\n\n=== No matches, Show Original\nDue to the business expansion, we are now looking for potential candidate who is independent, experienced and interested to work in Telecommunication Industry. To join our big family, you will be able to widen your job exposure and gain professional development opportunities. About the jobs: Perform 24/7 round-the-clock Tier 1 supports in the PCCW Global Network / Service Operations Center. Identify and resolve private network problem in coordinate with internal and external parties for smooth execution of jobs in order to ensure an integrated and uninterrupted service is maintained. Carry out Network / Service Operation Center routine jobs as per laid down procedures and work instructions. Co-work with other teams to perform incident/problem management on different connectivity service. Working locations: Kwai Chung / Wan Chai / Stanley. The Person: Degree or High Diploma in Engineering / Electronic / Information Technology or other related disciplines. Hard working, well organized and can work with minimum supervision. Willingness to work on shifts. Good written and verbal communication skills in both English and Cantonese. Fresh graduate with good positive attitude will be considered. Job Offer: International business environment with great exposure. Competitive remuneration package with discretionary bonus: (shift allowance will be provided). Professional and personal development opportunities. Medical Insurance will be provided. Attractive salary and fringe benefits will be offered to the successful candidates. Please send your full resume, available date, present and expected salary to \"recruitment.global @ pccwglobal.com\" or click \"Apply Now\". Resumes without current and expected salary will NOT be considered. * Applicants not invited for interview within one month from the posting date may consider their applications unsuccessful. For more information on other job opportunities of PCCW Global, please visit our website. HKT is an equal opportunity employer and welcomes applications from all qualified candidates. Information provided will be treated in strict confidence and will only be used for recruitment-related purposes. Personal data provided by job applicants will be used strictly in accordance with the employer's personal data policies, a copy of which will be provided immediately upon request. Privacy Policy Statement\n\n\n\n### Has matches\nRequirements: : University graduate in Electronic Engineering, Electrical Engineering, or Biomedical / Medical Engineering 1 year technical service engineering experience preferred. Customer oriented with good interpersonal skill and work independently. Good command of English and Chinese. Self-motivated and hard-working. How to Apply Interest parties, please submit your resume by clicking “APPLY NOW”. Personal data provided by job applicants will be used for recruitment purpose only. Candidates who are not being invited for interviews within four weeks may consider their applications unsuccessful. All applications will be kept for maximum of six months as future reference for similar openings. We provide attractive salary, medical insurance, travel allowance and discretionary bonus.\n\n\n\n### Has matches\nRequirements: : Bachelor Degree in Computer Science, Information Systems or related disciplines A minimum of 10 years’ relevant large-scale, complex and mission-critical IT infrastructure support or implementation experiences. Multi-experience in the following disciplines: Client / End-user Hardware and Software: Windows 8 and 10 Collaboration Systems and Tools: Microsoft 365, AD & Exchange, SharePoint, File and Print, AV Facilities Enterprise Mobility Management: VMware Airwatch Privileged ID Management: CyberArk Job Scheduling Tool: Control-M Output and Archiving Management: InfoPrint, OpenText StreamServe, Archiving Server Call Centre System: Avaya, Genesys, and RightFax SAP ERP BASIS ITIL and PMP certifications an advantage Good command of English and Chinese languages, both spoken and written Depending on candidate’s experience, the position of IT Specialist may be considered. In addition, employment may be on permanent or 2-year contract term and renewal of contract will be subject to the Company’s business needs and performance of the individual. Working Location: Admiralty Application: If you are interested in this position, please send your resume (in PDF format) with details of qualification, experience, present and expected salaries, and contact number to the Senior Manager (Human Resources Services), The Hongkong Electric Co., Ltd. on or before 24 June 2019 and quote the reference number in your application. Please also visit our website to know more about our Company http://www.hkelectric.com. Applicants not invited for interview within one month from the closing date may consider their applications unsuccessful. All unsuccessful applications will be kept for six months after the date of this advertisement. We are an equal opportunity employer. Personal data provided by job applicants will be treated in strictest confidence and used only for recruitment-related purposes in accordance with the laws and ordinance of the HKSAR.\n\n\n\n=== No matches, Show Original\nThe Role: Enhance and promote gas applications in Hospital & Government trade Perform account management for Hospital & Government trade include tailor-made proposal and offer to customers Handle town gas design including town gas supply, steam and hot water boiler system and desiccant air-conditioning; Conduct technical / market research Assist in preparing sales and management report Prepare and price tenders Negotiate with client for project price, summarize and submit variation claims, interim payment applications and final account The Person: Degree in Building Services, Mechanical Engineering or relevant engineering disciplines 3-5 years of work experience in related field; candidate with more experience will be considered as Engineer Holder of a valid driving license of Class 1 is an added advantage Able to manage projects independently and work under pressure Multi-tasking, creative, self-motivated and enthusiastic Good command in both written and spoken English and Chinese Immediate available is highly preferred Application with full details stating current and expected salary to: APPLY NOW Deadline for application: 16 Jun 2019 Please quote the reference number (CIMSD/AE/JDB07/19) in your application. (All personal data provided will be treated in strict confidence and used for recruitment purposes only.)\n\n\n\n### Has matches\nRequirements: : Diploma or above in Computer Studies / Computer Science / Information Technology (I.T.) related disciplines Good experience in MS SQL Server, SQL Server Stored Procedure, C#.NET Able to demonstrate systematic and logical reasoning With interest to learn new technologies, including AI, big data, DLT technology, mobile, cloud, etc. Energetic, self-motivated, teamwork, dynamic and with passion for FinTech innovation Experiencing on POS system will be an advantage but not a must We offer: Discretionary bonus Medical insurance Dental insurance Hardship allowance Competitive annual leave days Birthday leave Anniversary leave Family care days Study leave Marriage leave Extra maternity leave with full paid Extra paternity leave with full paid Compassionate leave Home-made soup and dessert How to apply: Please send your resume with expected salary either by the function \"APPLY NOW\" or post Postage address: Human Capital Department Konew Financial Express Limited 4/F Wheelock House 20 Pedder Street Central Hong Kong (We are an equal opportunity employer. Personal data collected will be used for recruitment purpose only. The unsuccessful applications will be destroyed after 6 months.)\n\n\n\n### Has matches\nRequirements: University graduate Minimum 8 years of experience in IT related projects and business requirement analysis Proven experience in leading IT projects and teams with strong project management and influencing skills to drive for consensus with different stakeholders, make reasonable and firm judgements, and achieve planned objectives and results Good English and Chinese communication skills: (both written and verbal) to articulate ideas and issues in laymen terms Good ability in analysis, design and able to manage projects independently from ideas formulation to implementation Strong technical know-how in management and workflow related system implementation, web based solutions, document management systems and data analytics platforms etc. Relevant experience/Certified qualifications in standards and methodologies e.g. PMP and Agile (b) Responsibilities Lead various IT projects: (e.g. web portal, case management, workflow automation, document management, data intelligence and new technology initiatives etc.) as both a project manager and business analyst for projects in different sizing Coordinate and lead projects with different stakeholders, including business users and vendors, from feasibility study to implementation Initiate, liaise and negotiate with users to reach consensus on the requirements, delivery schedule and resource commitment Conduct business impact analysis, technical solution design and assist in change management Provide technical consultancy and IT solution support to different IT teams and business users (Senior) System Analyst / Analyst Programmer / Programmer x 10 Participated in the whole software development life cycle including gather user requirement, requirement analysis and define project scope Responsible for system development / design and analysis Perform system development by using Java or .net or mobile (ios/android/VR) or web technologies: (PHP/Html/css/JavaScript) or Oracle or ETL/Business Intelligence or SAP Prepare system documentations including system specification and system testing Assistant Project Manager need to lead the development team for system implementation Strong sense of responsibility and able to meet project deadlines Higher Diploma or Degree / one year of above in IT development with relevant experience / Good communication 8 year experience or above will consider as Senior position (IT Fresh Graduate consider as Programmer Trainee) (Senior) Project Specialist / Business Analyst / QA officer / Project Trainee Responsibilities Handle user requirement collection, business analysis of various application, Project Management Liaise with business users on scope, testing plans Perform Quality Assurance and provide User Acceptance Testing (UAT) and production support of the application Prepare System Specification and user documentation writing up Project coordination and management (application and / or infrastructure projects) Proper training will be provided to the junior / fresh Requirements: Diploma /Degree in Business, Finance, Computer Science or related disciplines Min 2 years relevant experience in project management /business analysis Strong communication skills Proficiency in both English and Chinese Fresh graduate or less experience also considered and proper training will be provided as Project trainee More experience will consider as Senior Business Analyst / Project Specialist Focus on UAT / Quality Assurance will be consider as QA specialist 7 year or above experience will be considered as Project Manager / Business Analyst Lead\n\n\n\n=== No matches, Show Original\nThis role is exceptionally challenging because it requires both technical knowledge of electronics manufacturing and the ability to communicate empathetically with internal and external parties. Below here are the detailed responsibilities: To work with various departments of product development of various technical aspects; To be responsible for product definition, development and coordination of electronics hardware design and software logic; To be responsible for product testing and verification with quality requirements; To be responsible for products quality requirement meet industry standards, such as Electromagnetic Compatibility (EMC/EMI), safety and/or other specific requirements; and To be responsible for product successful until sustainable production level. Participating in the pilot-production run and/or mass production run in mainland plant is required. To be the right calibre, you should be/have: University Degree in Electrical/Electronic Engineering or related disciplines; 0-6 years’ experience in OEM/ODM manufacturing company; Experience in embedded software or MCU system is preferred. Knowledge in electronic component applications, testing skills and hardware circuitry design is must; Knowledge of industrial quality requirements and safety standards is preferable; We place much emphasis on the career development of our employees, respect the worthiness of individual contributions and expect strong commitment to performance excellence. We offer 5 days work per week, competitive remuneration package and fringe benefits including year-end and mid-year bonuses, medical scheme, life & accident insurance etc to the right candidate. Interested parties please send full resume stating current salary, expected salary and availability by clicking \"Apply Now\" All information received will strictly be kept confidential and be used for employment-related purposes only.\n\n\n\n### Has matches\nRequirements: : : • Degree in Computer Science/Data Communication or related disciplines • Experience in implementation and support of large-scale IP data network and Internet facing infrastructure • Experience in security, networking and general backend application management such as Firewall, Routers, Switches, VPN, VoIP, VC, etc… • Hand-on experience in building and trouble-shooting complex IP networks • Experience in programming with Macro, Perl, Python, C for network automation is a plus • Strong communication and interpersonal skills, independent, proactive • Frequent work on weekend and/or irregular working hours is required Applicants who do not hear from us within 6 weeks may consider their applications unsuccessful. Personal data provided will only be used for the purpose of employment application to HKEX.\n\n\n\n### Has matches\nRequirements: : Bachelor Degree in Finance, Accounting or related disciplines Membership of HKICPA or equivalent A minimum of 5 years’ experience in accounting / auditing Excellent knowledge of Hong Kong / International Reporting Standards and tax operations Excellent PC skills especially in spreadsheet and financial modeling Good knowledge of SAP Financial Management Systems an advantage Good command of English and Chinese languages, both spoken and written Candidates with less relevant experience and/or lower qualification may be considered for the position of Assistant Accountant (Infrastructure Investment). We are an authorised employer of the Hong Kong Institute of CPAs. Working Location: Admiralty Application: If you are interested in this position, please send your resume (in PDF format) with details of qualification, experience, present and expected salaries, and contact number to the Senior Manager (Human Resources Services), The Hongkong Electric Co., Ltd. on or before 24 June 2019 and quote the reference number in your application. Please also visit our website to know more about our Company http://www.hkelectric.com. Applicants not invited for interview within one month from the closing date may consider their applications unsuccessful. All unsuccessful applications will be kept for six months after the date of this advertisement. We are an equal opportunity employer. Personal data provided by job applicants will be treated in strictest confidence and used only for recruitment-related purposes in accordance with the laws and ordinance of the HKSAR.\n\n\n\n### Has matches\nRequirements: : Degree holder is preferred Experience in Ship supply industry is highly preferable (fresh graduate will also be considered) Good command of written and spoken English & Chinese Good knowledge in MS Office and email applications Good interpersonal and communication skills, able to work with people at all levels We offer competitive remuneration package, 5 days work, medical and dental benefits, life insurance, performance bonus, education and training sponsorship, birthday leave, and 10% employer MPF contribution. Interested parties please apply in strict confidence with your full resume, expected salary and contact details. (Personal data collected will be kept under strict confidence and will be used for recruitment purpose only.)\n\n\n\n### Has matches\nRequirements: : Excellent writing, organising, presentation and communication skills; Proficiency with MS Office applications and Chinese word processing especially MS Access; Knowledge in Web design, Photoshop, Illustrator or related software will be an advantage; Responsible, energetic and with excellent communication and interpersonal skills; Detail-minded, independent, well-organized, a good team player If you are looking for a practical work preview and a supervised learning experience, please send your full resume to Human Resources by: - e-mail or , - 13/F, Island Place Tower, No. 510 King’s Road, North Point, Hong Kong Please quote employer’s reference number on your application. Please visit our website at www.atalengineeringgroup.com for more information about us. Personal data collected will be treated in strictest confidence and used for recruitment related purposes only.\n\n\n\n=== No matches, Show Original\nThis role is exceptionally challenging because it requires both technical knowledge of electronics manufacturing and the ability to communicate empathetically with internal and external parties. Below here are the detailed responsibilities: To work with various departments of product development of various technical aspects; To be responsible for product definition, development and coordination of electronics hardware design and software logic; To be responsible for product testing and verification with quality requirements; To be responsible for products quality requirement meet industry standards, such as Electromagnetic Compatibility (EMC/EMI), safety and/or other specific requirements; and To be responsible for product successful until sustainable production level. Participating in the pilot-production run and/or mass production run in mainland plant is required. To be the right calibre, you should be/have: University Degree in Electrical/Electronic Engineering or related disciplines; 0-6 years’ experience in OEM/ODM manufacturing company; Experience in embedded software or MCU system is preferred. Knowledge in electronic component applications, testing skills and hardware circuitry design is must; Knowledge of industrial quality requirements and safety standards is preferable; We place much emphasis on the career development of our employees, respect the worthiness of individual contributions and expect strong commitment to performance excellence. We offer 5 days work per week, competitive remuneration package and fringe benefits including year-end and mid-year bonuses, medical scheme, life & accident insurance etc to the right candidate. Interested parties please send full resume stating current salary, expected salary and availability by clicking 'Apply Now' All information received will strictly be kept confidential and be used for employment-related purposes only.\n"
],
[
"# Count successfully extracted requirement entries\nentry_count = len(df_req)\ndf_req_good = df_req[df_req[\"hasReq\"] == True]\ndf_req_bad = df_req[df_req[\"hasReq\"] == False]\nprint(\"Successful extract Requirement: {} of {}\".format(len(df_req_good), entry_count))\nprint(\"Failed extract Requirement: {} of {}\".format(len(df_req_bad), entry_count))",
"Successful extract Requirement: 70 of 100\nFailed extract Requirement: 30 of 100\n"
],
[
"df_req_good",
"_____no_output_____"
],
[
"idx = 51\ntext_requirement = df_req_good.iloc[idx][\"Req\"]\nje = JobExtractor2(text_requirement, df_token)\nje.assign_text_pre([text_requirement])\nextacted_json = je.run()\nje.output_df(extacted_json)",
"_____no_output_____"
],
[
"# Original job requirement\ntext_requirement",
"_____no_output_____"
],
[
"# End",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1cdda9e2673fda28e9330e114dcd47084af211
| 18,816 |
ipynb
|
Jupyter Notebook
|
code/chap04.ipynb
|
aditya-sudhakar/ModSimPy
|
0804e6166a4dcec8b531e0fbd693cae5a4a49e70
|
[
"MIT"
] | null | null | null |
code/chap04.ipynb
|
aditya-sudhakar/ModSimPy
|
0804e6166a4dcec8b531e0fbd693cae5a4a49e70
|
[
"MIT"
] | null | null | null |
code/chap04.ipynb
|
aditya-sudhakar/ModSimPy
|
0804e6166a4dcec8b531e0fbd693cae5a4a49e70
|
[
"MIT"
] | null | null | null | 25.256376 | 1,092 | 0.543155 |
[
[
[
"# Modeling and Simulation in Python\n\nChapter 4\n\nCopyright 2017 Allen Downey\n\nLicense: [Creative Commons Attribution 4.0 International](https://creativecommons.org/licenses/by/4.0)\n",
"_____no_output_____"
]
],
[
[
"# Configure Jupyter so figures appear in the notebook\n%matplotlib inline\n\n# Configure Jupyter to display the assigned value after an assignment\n%config InteractiveShell.ast_node_interactivity='last_expr_or_assign'\n\n# import functions from the modsim library\nfrom modsim import *",
"_____no_output_____"
]
],
[
[
"## Returning values",
"_____no_output_____"
],
[
"Here's a simple function that returns a value:",
"_____no_output_____"
]
],
[
[
"def add_five(x):\n return x + 5",
"_____no_output_____"
]
],
[
[
"And here's how we call it.",
"_____no_output_____"
]
],
[
[
"y = add_five(3)",
"_____no_output_____"
]
],
[
[
"If you run a function on the last line of a cell, Jupyter displays the result:",
"_____no_output_____"
]
],
[
[
"add_five(5)",
"_____no_output_____"
]
],
[
[
"But that can be a bad habit, because usually if you call a function and don't assign the result in a variable, the result gets discarded.\n\nIn the following example, Jupyter shows the second result, but the first result just disappears.",
"_____no_output_____"
]
],
[
[
"add_five(3)\nadd_five(5)",
"_____no_output_____"
]
],
[
[
"When you call a function that returns a variable, it is generally a good idea to assign the result to a variable.",
"_____no_output_____"
]
],
[
[
"y1 = add_five(3)\ny2 = add_five(5)\n\nprint(y1, y2)",
"8 10\n"
]
],
[
[
"**Exercise:** Write a function called `make_state` that creates a `State` object with the state variables `olin=10` and `wellesley=2`, and then returns the new `State` object.\n\nWrite a line of code that calls `make_state` and assigns the result to a variable named `init`.",
"_____no_output_____"
]
],
[
[
"def make_state(init):\n init = State(olin=10, wellesley=2)\n return init",
"_____no_output_____"
],
[
"make_state(init)",
"_____no_output_____"
]
],
[
[
"## Running simulations",
"_____no_output_____"
],
[
"Here's the code from the previous notebook.",
"_____no_output_____"
]
],
[
[
"def step(state, p1, p2):\n \"\"\"Simulate one minute of time.\n \n state: bikeshare State object\n p1: probability of an Olin->Wellesley customer arrival\n p2: probability of a Wellesley->Olin customer arrival\n \"\"\"\n if flip(p1):\n bike_to_wellesley(state)\n \n if flip(p2):\n bike_to_olin(state)\n \ndef bike_to_wellesley(state):\n \"\"\"Move one bike from Olin to Wellesley.\n \n state: bikeshare State object\n \"\"\"\n if state.olin == 0:\n state.olin_empty += 1\n return\n state.olin -= 1\n state.wellesley += 1\n \ndef bike_to_olin(state):\n \"\"\"Move one bike from Wellesley to Olin.\n \n state: bikeshare State object\n \"\"\"\n if state.wellesley == 0:\n state.wellesley_empty += 1\n return\n state.wellesley -= 1\n state.olin += 1\n \ndef decorate_bikeshare():\n \"\"\"Add a title and label the axes.\"\"\"\n decorate(title='Olin-Wellesley Bikeshare',\n xlabel='Time step (min)', \n ylabel='Number of bikes')",
"_____no_output_____"
]
],
[
[
"Here's a modified version of `run_simulation` that creates a `State` object, runs the simulation, and returns the `State` object.",
"_____no_output_____"
]
],
[
[
"def run_simulation(p1, p2, num_steps):\n \"\"\"Simulate the given number of time steps.\n \n p1: probability of an Olin->Wellesley customer arrival\n p2: probability of a Wellesley->Olin customer arrival\n num_steps: number of time steps\n \"\"\"\n state = State(olin=10, wellesley=2, \n olin_empty=0, wellesley_empty=0)\n \n for i in range(num_steps):\n step(state, p1, p2)\n \n return state",
"_____no_output_____"
]
],
[
[
"Now `run_simulation` doesn't plot anything:",
"_____no_output_____"
]
],
[
[
"state = run_simulation(0.4, 0.2, 60)",
"_____no_output_____"
]
],
[
[
"But after the simulation, we can read the metrics from the `State` object.",
"_____no_output_____"
]
],
[
[
"state.olin_empty",
"_____no_output_____"
]
],
[
[
"Now we can run simulations with different values for the parameters. When `p1` is small, we probably don't run out of bikes at Olin.",
"_____no_output_____"
]
],
[
[
"state = run_simulation(0.2, 0.2, 60)\nstate.olin_empty",
"_____no_output_____"
]
],
[
[
"When `p1` is large, we probably do.",
"_____no_output_____"
]
],
[
[
"state = run_simulation(0.6, 0.2, 60)\nstate.olin_empty",
"_____no_output_____"
]
],
[
[
"## More for loops",
"_____no_output_____"
],
[
"`linspace` creates a NumPy array of equally spaced numbers.",
"_____no_output_____"
]
],
[
[
"p1_array = linspace(0, 1, 5)",
"_____no_output_____"
]
],
[
[
"We can use an array in a `for` loop, like this:",
"_____no_output_____"
]
],
[
[
"for p1 in p1_array:\n print(p1)",
"_____no_output_____"
]
],
[
[
"This will come in handy in the next section.\n\n`linspace` is defined in `modsim.py`. You can get the documentation using `help`.",
"_____no_output_____"
]
],
[
[
"help(linspace)",
"_____no_output_____"
]
],
[
[
"`linspace` is based on a NumPy function with the same name. [Click here](https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html) to read more about how to use it.",
"_____no_output_____"
],
[
"**Exercise:** \nUse `linspace` to make an array of 10 equally spaced numbers from 1 to 10 (including both).",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
]
],
[
[
"**Exercise:** The `modsim` library provides a related function called `linrange`. You can view the documentation by running the following cell:",
"_____no_output_____"
]
],
[
[
"help(linrange)",
"_____no_output_____"
]
],
[
[
"Use `linrange` to make an array of numbers from 1 to 11 with a step size of 2.",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
]
],
[
[
"## Sweeping parameters",
"_____no_output_____"
],
[
"`p1_array` contains a range of values for `p1`.",
"_____no_output_____"
]
],
[
[
"p2 = 0.2\nnum_steps = 60\np1_array = linspace(0, 1, 11)",
"_____no_output_____"
]
],
[
[
"The following loop runs a simulation for each value of `p1` in `p1_array`; after each simulation, it prints the number of unhappy customers at the Olin station:",
"_____no_output_____"
]
],
[
[
"for p1 in p1_array:\n state = run_simulation(p1, p2, num_steps)\n print(p1, state.olin_empty)",
"_____no_output_____"
]
],
[
[
"Now we can do the same thing, but storing the results in a `SweepSeries` instead of printing them.\n\n",
"_____no_output_____"
]
],
[
[
"sweep = SweepSeries()\n\nfor p1 in p1_array:\n state = run_simulation(p1, p2, num_steps)\n sweep[p1] = state.olin_empty",
"_____no_output_____"
]
],
[
[
"And then we can plot the results.",
"_____no_output_____"
]
],
[
[
"plot(sweep, label='Olin')\n\ndecorate(title='Olin-Wellesley Bikeshare',\n xlabel='Arrival rate at Olin (p1 in customers/min)', \n ylabel='Number of unhappy customers')\n\nsavefig('figs/chap02-fig02.pdf')",
"_____no_output_____"
]
],
[
[
"## Exercises\n\n**Exercise:** Wrap this code in a function named `sweep_p1` that takes an array called `p1_array` as a parameter. It should create a new `SweepSeries`, run a simulation for each value of `p1` in `p1_array`, store the results in the `SweepSeries`, and return the `SweepSeries`.\n\nUse your function to plot the number of unhappy customers at Olin as a function of `p1`. Label the axes.",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
],
[
"# Solution goes here",
"_____no_output_____"
]
],
[
[
"**Exercise:** Write a function called `sweep_p2` that runs simulations with `p1=0.5` and a range of values for `p2`. It should store the results in a `SweepSeries` and return the `SweepSeries`.\n",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
],
[
"# Solution goes here",
"_____no_output_____"
]
],
[
[
"## Optional exercises\n\nThe following two exercises are a little more challenging. If you are comfortable with what you have learned so far, you should give them a try. If you feel like you have your hands full, you might want to skip them for now.\n\n**Exercise:** Because our simulations are random, the results vary from one run to another, and the results of a parameter sweep tend to be noisy. We can get a clearer picture of the relationship between a parameter and a metric by running multiple simulations with the same parameter and taking the average of the results.\n\nWrite a function called `run_multiple_simulations` that takes as parameters `p1`, `p2`, `num_steps`, and `num_runs`.\n\n`num_runs` specifies how many times it should call `run_simulation`.\n\nAfter each run, it should store the total number of unhappy customers (at Olin or Wellesley) in a `TimeSeries`. At the end, it should return the `TimeSeries`.\n\nTest your function with parameters\n\n```\np1 = 0.3\np2 = 0.3\nnum_steps = 60\nnum_runs = 10\n```\n\nDisplay the resulting `TimeSeries` and use the `mean` function provided by the `TimeSeries` object to compute the average number of unhappy customers.",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
],
[
"# Solution goes here",
"_____no_output_____"
]
],
[
[
"**Exercise:** Continuting the previous exercise, use `run_multiple_simulations` to run simulations with a range of values for `p1` and\n\n```\np2 = 0.3\nnum_steps = 60\nnum_runs = 20\n```\n\nStore the results in a `SweepSeries`, then plot the average number of unhappy customers as a function of `p1`. Label the axes.\n\nWhat value of `p1` minimizes the average number of unhappy customers?",
"_____no_output_____"
]
],
[
[
"# Solution goes here",
"_____no_output_____"
],
[
"# Solution goes here",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1cdea44f1f7508dd28976c11a0f1116715e8cd
| 96,332 |
ipynb
|
Jupyter Notebook
|
TDBConversion.ipynb
|
richardotis/pycalphad-sandbox
|
43d8786eee8f279266497e9c5f4630d19c893092
|
[
"MIT"
] | 1 |
2017-03-08T18:21:30.000Z
|
2017-03-08T18:21:30.000Z
|
TDBConversion.ipynb
|
richardotis/pycalphad-sandbox
|
43d8786eee8f279266497e9c5f4630d19c893092
|
[
"MIT"
] | null | null | null |
TDBConversion.ipynb
|
richardotis/pycalphad-sandbox
|
43d8786eee8f279266497e9c5f4630d19c893092
|
[
"MIT"
] | 1 |
2018-11-03T01:31:57.000Z
|
2018-11-03T01:31:57.000Z
| 55.426928 | 91 | 0.523948 |
[
[
[
"from pycalphad import Database\nfrom pycalphad.io.tdb import TCPrinter\nfrom pycalphad.io.tdb import write_tdb, read_tdb",
"_____no_output_____"
],
[
"import pycalphad.tests.datasets\ndbf = Database(pycalphad.tests.datasets.ALNIPT_TDB)\nprint(pycalphad.tests.datasets.ALNIPT_TDB)",
"\n$\n ELEMENT /- ELECTRON_GAS 0.0000E+00 0.0000E+00 0.0000E+00!\n ELEMENT VA VACUUM 0.0000E+00 0.0000E+00 0.0000E+00!\n ELEMENT AL FCC_A1 2.6982E+01 4.5773E+03 2.8322E+01!\n ELEMENT NI FCC_A1 5.8690E+01 4.7870E+03 2.9796E+01!\n ELEMENT PT FCC_A1 1.9508E+02 5.7237E+03 4.1631E+01!\n\n$$$$$$$$$$$$$$$$$XUAN\n\n FUNCTION VX1 298.15 -2.2745400E+04; 6000.0 N !\n FUNCTION VX2 298.15 7.5000000E-01; 6000.0 N !\n FUNCTION VX3 298.15 2.2500000E+04; 6000.0 N !\n FUNCTION VX10 298.15 4.1176252E+04; 6000.0 N !\n FUNCTION VX11 298.15 -3.3084025E+01; 6000.0 N !\n FUNCTION VX20 298.15 2.9968958E+03; 6000.0 N !\n FUNCTION VX40 298.15 -2.7046916E+05; 6000.0 N !\n FUNCTION VX41 298.15 -8.3384917E+00; 6000.0 N !\n FUNCTION VX42 298.15 -1.9293253E+04; 6000.0 N !\n FUNCTION VX43 298.15 2.4643347E+01; 6000.0 N !\n FUNCTION VX44 298.15 4.5967650E+04; 6000.0 N !\n FUNCTION VX50 298.15 -2.0570000E+05; 6000.0 N !\n FUNCTION VX51 298.15 1.2175000E+01; 6000.0 N !\n FUNCTION VX53 298.15 -5.0000000E+01; 6000.0 N !\n FUNCTION VX54 298.15 4.5000000E+04; 6000.0 N !\n FUNCTION VX85 298.15 -1.0118662E+05; 6000.0 N !\n FUNCTION VX90 298.15 6.0995004E+00; 6000.0 N !\n FUNCTION VX91 298.15 9.4351782E+00; 6000.0 N !\n FUNCTION VX92 298.15 5.2341182E+00; 6000.0 N !\n FUNCTION VX93 298.15 6.4125253E+00; 6000.0 N !\n FUNCTION VX94 298.15 6.9806493E+00; 6000.0 N !\n FUNCTION VX95 298.15 8.6920000E+00; 6000.0 N !\n FUNCTION VX96 298.15 9.3985666E+00; 6000.0 N !\n\n FUNCTION B2ALPT 298.15 -205700+12.18*T; 6000.0 N !\n FUNCTION LB2ALPT 298.15 -50*T; 6000.0 N !\n\n FUNCTION L1A2ALPT 298.15 45000; 6000.0 N !\n\n FUNCTION B2PTVA 298.15 B2ALVA-B2ALPT; 6000.0 N !\n FUNCTION LB2PTVA 298.15 -15000+5*T; 6000.00 N !\n\n$$$$$$$$$$$$$$$$$$\n\n FUNCTION GHSERAL 2.98150E+02 -7976.15+137.093038*T-24.3671976*T*LN(T)\n -.001884662*T**2-8.77664E-07*T**3+74092*T**(-1); 7.00000E+02 Y\n -11276.24+223.048446*T-38.5844296*T*LN(T)+.018531982*T**2\n -5.764227E-06*T**3+74092*T**(-1); 9.33600E+02 Y\n -11278.378+188.684153*T-31.748192*T*LN(T)-1.231E+28*T**(-9);\n 6.00000E+03 N !\n FUNCTION GBCCAL 2.98150E+02 +10083-4.813*T+GHSERAL#; 6.00000E+03 N !\n FUNCTION GALBCC 298.15 +10083-4.813*T+GHSERAL#; 6000.0 N\n !\n FUNCTION GLIQAL 2.98140E+02 +11005.029-11.841867*T+7.934E-20*T**7\n +GHSERAL#; 9.33590E+02 Y\n +10482.282-11.253974*T+1.231E+28*T**(-9)+GHSERAL#; 6.00000E+03 N !\n\n FUNCTION GHSERNI 2.98150E+02 -5179.159+117.854*T-22.096*T*LN(T)\n -.0048407*T**2; 1.72800E+03 Y\n -27840.655+279.135*T-43.1*T*LN(T)+1.12754E+31*T**(-9); 6.00000E+03 N !\n FUNCTION GBCCNI 2.98150E+02 +8715.084-3.556*T+GHSERNI#; 6.00000E+03 N !\n\n FUNCTION GHSERPT 2.98150E+02 -7595.631+124.388276*T-24.5526*T*LN(T)\n -.00248297*T**2-2.0138E-08*T**3+7974*T**(-1); 1.30000E+03 Y\n -9253.174+161.529616*T-30.2527*T*LN(T)+.002321665*T**2\n -6.56947E-07*T**3-272106*T**(-1); 2.04210E+03 Y\n -222518.973+1021.21087*T-136.422689*T*LN(T)+.020501692*T**2\n -7.60985E-07*T**3+71709819*T**(-1); 4.00000E+03 N !\n FUNCTION GBCCPT 2.98150E+02 +15000-2.4*T+GHSERPT#; 6.00000E+03 N!\n FUNCTION GPTBCC 298.15 +15000-2.4*T+GHSERPT#; 4.00000E+03 N !\n\n FUNCTION VA1 298.15 2.00000000E+05;,, N 05LU !\n$$FUNCTION VA31 298.15 3.00000000E+04;,, N 05LU !\n\n$$FUNCTION VA31 298.15 30000;,, N 05LU !\n$$FUNCTION VA33 298.15 30000;,, N 05LU !\n$$FUNCTION VA35 298.15 30000;,, N 05LU !\n\n$$$$$$GAL2NIPT\n FUNCTION VA40 298.15 0;,, N 05LU !\n$$$$$$GNI2ALPT\n FUNCTION VA42 298.15 0;,, N 05LU !\n$$$$$$GPT2ALNI\n FUNCTION VA44 298.15 0;,, N 05LU !\n\n$$$$$$LALNIALPT\n FUNCTION VA46 298.15 0;,, N 05LU !\n$$$$$$LALNINIPT\n FUNCTION VA48 298.15 0;,, N 05LU !\n$$$$$$LALPTNIPT\n FUNCTION VA50 298.15 0;,, N 05LU !\n\n\n\n\n$$$THIS SET IS LIKE CALPHAD PAPER\n$$FUNCTION VA42 298.15 +3000;,, N 05LU !\n$$FUNCTION VA44 298.15 -3000;,, N 05LU !\n\n\n\n$$FUNCTION VA70 298.15 -5.00000000E+04;,, N 05LU !\n$$FUNCTION VA71 298.15 1.0e1;,, N 05LU !\n\nFUNCTION VA70 298.15 -55000;,, N 05LU !\nFUNCTION VA71 298.15 1.0;,, N 05LU !\n\nFUNCTION VA76 298.15 7.00000000E+03;,, N 05LU !\nFUNCTION VA77 298.15 2.00000000E+03;,, N 05LU !\nFUNCTION VA78 298.15 -9.50000000E+04;,, N 05LU !\nFUNCTION VA79 298.15 6.00000000E+00;,, N 05LU !\nFUNCTION VA85 298.15 -4.50000000E+04;,, N 05LU !\nFUNCTION VA86 298.15 0.0;,, N 05LU !\nFUNCTION VA87 298.15 -5.00000000E+03;,, N 05LU !\nFUNCTION VA88 298.15 0.0;,, N 05LU !\nFUNCTION VA89 298.15 0.0;,, N 05LU !\nFUNCTION VA90 298.15 0.0;,, N 05LU !\nFUNCTION VA91 298.15 -9.80000000E+04;,, N 05LU !\nFUNCTION VA92 298.15 6.00000000E+00;,, N 05LU !\nFUNCTION VA93 298.15 -2.00000000E+04;,, N 05LU !\nFUNCTION VA95 298.15 1.00000000E+05;,, N 05LU !\nFUNCTION VA97 298.15 0.0;,, N 05LU !\nFUNCTION VA98 298.15 0.0;,, N 05LU !\nFUNCTION VA99 298.15 0.0;,, N 05LU !\n\nFUNCTION VA2 298.15 0.0;,, N 05LU !\nFUNCTION VA3 298.15 0.0;,, N 05LU !\nFUNCTION VA4 298.15 0.0;,, N 05LU !\nFUNCTION VA5 298.15 0.0;,, N 05LU !\nFUNCTION VA6 298.15 0.0;,, N 05LU !\nFUNCTION VA32 298.15 0.0;,, N 05LU !\nFUNCTION VA33 298.15 0.0;,, N 05LU !\nFUNCTION VA34 298.15 0.0;,, N 05LU !\nFUNCTION VA35 298.15 0.0;,, N 05LU !\nFUNCTION VA36 298.15 0.0;,, N 05LU !\nFUNCTION VA74 298.15 0.0;,, N 05LU !\nFUNCTION VA75 298.15 0.0;,, N 05LU !\nFUNCTION VA80 298.15 0.0;,, N 05LU !\nFUNCTION VA81 298.15 0.0;,, N 05LU !\nFUNCTION VA60 298.15 0.0;,, N 05LU !\nFUNCTION VA61 298.15 0.0;,, N 05LU !\nFUNCTION VA62 298.15 0.0;,, N 05LU !\nFUNCTION VA63 298.15 0.0;,, N 05LU !\nFUNCTION VA64 298.15 0.0;,, N 05LU !\nFUNCTION VA65 298.15 0.0;,, N 05LU !\nFUNCTION VA66 298.15 0.0;,, N 05LU !\nFUNCTION VA67 298.15 0.0;,, N 05LU !\nFUNCTION VA72 298.15 0.0;,, N 05LU !\nFUNCTION VA73 298.15 0.0;,, N 05LU !\nFUNCTION VA94 298.15 0.0;,, N 05LU !\nFUNCTION VA96 298.15 0.0;,, N 05LU !\n\n FUNCTION LLIQ2 298.15 +81204.81-31.95713*T;,, N 95DUP3 !\n FUNCTION LLIQ3 298.15 +4365.35-2.51632*T;,, N 95DUP3 !\n FUNCTION LLIQ4 298.15 -22101.64+13.16341*T;,, N 95DUP3 !\n FUNCTION LLIQ0 298.15 -5*LLIQ2-9*LLIQ4;,, N 95DUP3 !\n FUNCTION LLIQ1 298.15 -7*UNTIER*LLIQ3;,, N 95DUP3 !\n FUNCTION DEUX 298.15 2;,, N 95DUP3 !\n FUNCTION UNSURDEU 298.15 +DEUX**(-1);,, N 95DUP3 !\n FUNCTION GB2NINI 298.15 +GBCCNI;,, N 95DUP3 !\n FUNCTION GB2ALVA 298.15 +5000-.5*T+UNSURDEU*GBCCAL;,, N 95DUP3 !\n FUNCTION GB2ALNI 298.15 -76198.65+13.202875*T\n +UNSURDEU*GBCCAL+UNSURDEU*GBCCNI;,, N 95DUP3 !\n FUNCTION GB2NIVA 298.15 -GB2ALNI+GB2NINI+GB2ALVA;,, N 95DUP3 !\n FUNCTION SIX 298.15 6;,, N 95DUP3 !\n FUNCTION UNSURSIX 298.15 +SIX**(-1);,, N 95DUP3 !\n FUNCTION GALALVA 298.15 +5000-.5*T+5*UNSURSIX*GBCCAL;,, N 95DUP3 !\n FUNCTION GALNINI 298.15 +5000+GB2ALNI;,, N 95DUP3 !\n FUNCTION GALNIVA 298.15 -59620.987+11.387*T\n +3*UNSURSIX*GBCCAL+2*UNSURSIX*GBCCNI;,, N 95DUP3 !\n FUNCTION GALALNI 298.15 -GALNIVA+GALALVA+GALNINI;,, N 95DUP3 !\n FUNCTION L32ALNI 298.15 -32247.363+21.965*T;,, N 95DUP3 !\n FUNCTION L32NIVA 298.15 -3666.95+1.1722*T;,, N 95DUP3 !\n FUNCTION U1ALNI 298.15 -13415.515+2.0819247*T;,, N 95DUP3 !\n\n FUNCTION UALNI 298.15 -43590+6.22*T;,, N 03SUN !\n FUNCTION ALPHA 298.15 -29600;,, N 03SUN !\n FUNCTION BETA 298.15 -66718+11.64*T;,, N 03SUN !\n FUNCTION AL3NI 298.15 ALPHA;,, N 03SUN !\n FUNCTION AL2NI2 298.15 BETA;,, N 03SUN !\n FUNCTION ALNI3 298.15 UALNI;,, N 03SUN !\n\n FUNCTION URALNI 298.15 -34575+13.22*T;,, N 03SUN !\n\n FUNCTION LFCC0 298.15 +AL3NI+1.5*AL2NI2+ALNI3+1.5*URALNI;,, N 03SUN !\n FUNCTION LFCC1 298.15 +2*AL3NI-2*ALNI3;,, N 03SUN !\n FUNCTION LFCC2 298.15 +AL3NI-1.5*AL2NI2+ALNI3-1.5*URALNI;,, N 03SUN !\n FUNCTION LFCC3 298.15 0.0; 6000.00 N 03SUN !\n FUNCTION U3ALNI 298.15 0.0; 6000.00 N 03SUN !\n\n FUNCTION L0ALNI 298.15 5310-1.46*T;,, N !\n FUNCTION UN_ASS 298.15 0; 300 N !\n\n$****AL-PT\n$ FUNCTION UAB 298.15 -13595+8.3*T; 6000 N !\n$ FUNCTION UPT3AL 298.15 +3*UAB#-3913; 6000 N !\n$ FUNCTION UALPT 298.15 +4*UAB#; 6000 N !\n$ FUNCTION UALPT3 298.15 +3*UAB#; 6000 N !\n$ FUNCTION UL0 298.15 +1412.8+5.7*T; 6000 N !\n$ FUNCTION USRO 298.15 +UAB#; 6000 N !\n$ FUNCTION ULD0 298.15 -110531-22.9*T; 6000 N !\n$ FUNCTION ULD1 298.15 -25094; 6000 N !\n$ FUNCTION ULD2 298.15 +21475; 6000 N !\n$ FUNCTION DG0 298.15 +UALPT3#+1.5*UALPT#+UPT3AL#; 6000\n$ N !\n$ FUNCTION DG1 298.15 +2*UALPT3#-2*UPT3AL#; 6000 N !\n$ FUNCTION DG2 298.15 +UALPT3#-1.5*UALPT#+UPT3AL#; 6000\n$ N !\n\n FUNCTION APL0FCC 2.98150E+02 +41176.252-33.084025*T; 6.00000E+03 N !\n FUNCTION APL1FCC 298.15 0; 6000 N !\n FUNCTION APL2FCC 298.15 0; 6000 N !\n FUNCTION APL3FCC 298.15 0; 6000 N !\n\n FUNCTION RAL3PT1 2.98150E+02 +3*UALPT#+APALP#; 6.00000E+03 N !\n FUNCTION RAL2PT2 2.98150E+02 +4*UALPT#; 6.00000E+03 N !\n FUNCTION RAL1PT3 2.98150E+02 +3*UALPT#+APBET#; 6.00000E+03 N !\n FUNCTION UALPT 2.98150E+02 -22745.4+0.75*T; 6.00000E+03 N !\n FUNCTION RECALPT 2.98150E+02 0; 6.00000E+03 N !\n\n FUNCTION APALP 2.98150E+02 +22500; 6.00000E+03 N !\n FUNCTION APBET 2.98150E+02 0; 6.00000E+03 N !\n\n FUNCTION GAL3PT1 298.15 RAL3PT1-0.1875*APL0FCC-0.09375*APL1FCC\n -0.046875*APL2FCC-0.0234375*APL3FCC; 6000 N !\n FUNCTION GAL2PT2 298.15 RAL2PT2-0.25*APL0FCC; 6000 N !\n FUNCTION GAL1PT3 298.15 RAL1PT3-0.1875*APL0FCC+0.09375*APL1FCC\n -0.046875*APL2FCC+0.0234375*APL3FCC; 6000 N !\n\n FUNCTION ALPTG0 2.98150E+02 +GAL3PT1#+1.5*GAL2PT2#+GAL1PT3#;\n 6.00000E+03 N !\n FUNCTION ALPTG1 2.98150E+02 +2*GAL3PT1#-2*GAL1PT3#; 6.00000E+03 N !\n FUNCTION ALPTG2 2.98150E+02 +GAL3PT1#-1.5*GAL2PT2#+GAL1PT3#;\n 6.00000E+03 N !\n\n FUNCTION UL0 298.15 0; 6000 N !\n FUNCTION UL1 2.98150E+02 2996.8958; 6.00000E+03 N !\n\n$ UAP only used in ternary\n FUNCTION UAP 298.15 +UALPT; 6000 N !\n FUNCTION REC 2.98150E+02 +UALPT#+RECALPT#; 6.00000E+03 N !\n\n$*****NI-PT\n FUNCTION L0FCC 298.15 27500+10.977*T; 6000 N !\n FUNCTION L1FCC 298.15 -6500; 6000 N !\n FUNCTION L2FCC 298.15 0; 6000 N !\n FUNCTION L3FCC 298.15 0; 6000 N !\n\n FUNCTION RNI3PT1 298.15 -1.09000000E+04; 6000 N !\n FUNCTION RNI2PT2 298.15 -1.35000000E+04-0.5*T; 6000 N !\n FUNCTION RNI1PT3 298.15 -8.30000000E+03-0.5*T; 6000 N !\n\n FUNCTION GNI3PT1 298.15 RNI3PT1-0.1875*L0FCC-0.09375*L1FCC\n -0.046875*L2FCC-0.0234375*L3FCC; 6000 N !\n FUNCTION GNI2PT2 298.15 RNI2PT2-0.25*L0FCC; 6000 N !\n FUNCTION GNI1PT3 298.15 RNI1PT3-0.1875*L0FCC+0.09375*L1FCC\n -0.046875*L2FCC+0.0234375*L3FCC; 6000 N !\n\n FUNCTION NIPTG0 2.98150E+02 +GNI3PT1#+1.5*GNI2PT2#+GNI1PT3#;\n 6.00000E+03 N !\n FUNCTION NIPTG1 2.98150E+02 +2*GNI3PT1#-2*GNI1PT3#; 6.00000E+03 N !\n FUNCTION NIPTG2 2.98150E+02 +GNI3PT1#-1.5*GNI2PT2#+GNI1PT3#;\n 6.00000E+03 N !\n\n FUNCTION RECNINI 298.15 -3.67000000E+03; 6000 N !\n FUNCTION RECNIPT 298.15 -3.25000000E+03; 6000 N !\n FUNCTION RECPTPT 298.15 -2.73000000E+03; 6000 N !\n\n$*****NI-AL-PT\n FUNCTION TROIS 2.98150E+02 3; 6.00000E+03 N !\n FUNCTION UNTIER 2.98150E+02 +TROIS#**(-1); 6.00000E+03 N !\n FUNCTION GNIPT 298.15 GNI3PT1#*UNTIER#; 6000 N !\n FUNCTION GAL2NIPT 298.15 2*UAP#+2*U1ALNI#+GNIPT#+VA40+VA41*T; 6000 N !\n FUNCTION GNI2ALPT 298.15 2*U1ALNI#+2*GNIPT#+UAP#+VA42+VA43*T; 6000 N !\n FUNCTION GPT2ALNI 298.15 2*GNIPT#+2*UAP#+U1ALNI#+VA44+VA45*T; 6000 N !\n FUNCTION LALNIALPT 298.15 0.5*U1ALNI+0.5*UAP-0.5*GNIPT+VA46+VA47*T; 6000 N !\n FUNCTION LALNINIPT 298.15 0.5*U1ALNI-0.5*UAP+0.5*GNIPT+VA48+VA49*T; 6000 N !\n FUNCTION LALPTNIPT 298.15 -0.5*U1ALNI+0.5*UAP+0.5*GNIPT+VA50+VA51*T; 6000 N !\n$***************\n\n TYPE_DEFINITION % SEQ *!\n$ DEFINE_SYSTEM_DEFAULT ELEMENT 4 !\n DEFAULT_COMMAND DEF_SYS_ELEMENT VA !\n\n\n$******************************** Liquid\n\n PHASE LIQUID:L % 1 1.0 !\n CONSTITUENT LIQUID:L :AL,NI,PT : !\n\n PARAMETER G(LIQUID,AL;0) 2.98150E+02 +11005.029-11.841867*T\n +7.934E-20*T**7+GHSERAL#; 9.33600E+02 Y\n +10482.282-11.253974*T+1.231E+28*T**(-9)+GHSERAL#; 6.00000E+03 N\n 91DIN !\n PARAMETER G(LIQUID,NI;0) 2.98130E+02 +16414.686-9.397*T\n -3.82318E-21*T**7+GHSERNI#; 1.72800E+03 Y\n +18290.88-10.537*T-1.12754E+31*T**(-9)+GHSERNI#; 6.00E+03 N 91DIN !\n PARAMETER G(LIQUID,PT;0) 2.98150E+02 +12520.614+115.114727*T\n -24.5526*T*LN(T)-.00248297*T**2-2.0138E-08*T**3+7974*T**(-1); 6.0E+02\n Y\n +19019.913+33.017485*T-12.351404*T*LN(T)-.011543133*T**2+9.30579E-07*T**3\n -600885*T**(-1); 2.04210E+03 Y\n +1404.968+205.861909*T-36.5*T*LN(T); 4.00000E+03 N REF283 !\n\n PARAMETER L(LIQUID,AL,NI;0) 298.15 +LLIQ0;,, N 95DUP3 !\n PARAMETER L(LIQUID,AL,NI;1) 298.15 +LLIQ1;,, N 95DUP3 !\n PARAMETER L(LIQUID,AL,NI;2) 298.15 +LLIQ2;,, N 95DUP3 !\n PARAMETER L(LIQUID,AL,NI;3) 298.15 +LLIQ3;,, N 95DUP3 !\n PARAMETER L(LIQUID,AL,NI;4) 298.15 +LLIQ4;,, N 95DUP3 !\n\n PARAMETER L(liquid,ni,pt;0) 2.98150E+02 -4.07756E+04;\n 6.00000E+03 N 05LU !\n PARAMETER L(liquid,ni,pt;1) 2.98150E+02 -5.5E+03; 6.00000E+03 N 05LU !\n PARAMETER L(liquid,ni,pt;2) 2.98150E+02 3.50E+03; 6.00000E+03 N 05LU !\n\n PARAMETER L(liquid,al,ni,pt;0) 2.98150E+02 +VA1+VA2*T;\n 6.00000E+03 N 05LU !\n PARAMETER L(liquid,al,ni,pt;1) 2.98150E+02 +VA3+VA4*T;\n 6.00000E+03 N 05LU !\n PARAMETER L(liquid,al,ni,pt;2) 2.98150E+02 +VA5+VA6*T;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(LIQUID,AL,PT;0) 298.15 +VX40#+VX41#*T; 6000.0 N\n REF0 !\n PARAMETER G(LIQUID,AL,PT;1) 298.15 +VX42#+VX43#*T; 6000.0 N\n REF0 !\n PARAMETER G(LIQUID,AL,PT;2) 298.15 +VX44#+VX45#*T; 6000.0 N\n REF0 !\n PARAMETER G(LIQUID,AL,PT;3) 298.15 +VX46#+VX47#*T; 6000.0 N\n REF0 !\n\n$********************* FCC_A1\n\n TYPE_DEFINITION ( GES A_P_D FCC_A1 MAGNETIC -3.0 2.80000E-01 !\n PHASE FCC_A1 %( 2 1 1 !\n CONSTITUENT FCC_A1 :AL,NI%,PT : VA% : !\n\n PARAMETER G(FCC_A1,AL:VA;0) 2.98150E+02 +GHSERAL#; 6.00000E+03 N\n 91DIN !\n PARAMETER G(FCC_A1,NI:VA;0) 2.98150E+02 +GHSERNI#; 6.00000E+03 N\n 91DIN !\n PARAMETER G(FCC_A1,PT:VA;0) 2.98150E+02 +GHSERPT#; 4.00000E+03 N\n REF283 !\n$ PARAMETER TC(FCC_A1,PT:VA;0) 2.98150E+02 -307.85; 6.00000E+03\n$ N REF: 0 !\n PARAMETER TC(FCC_A1,NI:VA;0) 2.98150E+02 633; 6.00000E+03 N 89DIN !\n PARAMETER BMAGN(FCC_A1,NI:VA;0) 2.98150E+02 .52; 6.00000E+03 N 89DIN !\n$ PARAMETER L(fcc_a1,al,pt:va;0) 2.98150E+02 -262446.89; 2.90000E+03 N !\n$ PARAMETER L(fcc_a1,al,pt:va;1) 2.9815E+02 102728.95-8.57*T; 2.90000E+03 N\n$ REF01!\n PARAMETER TC(FCC_A1,AL,NI:VA;0) 2.98150E+02 -1112; 6.00000E+03 N\n 95DUP3 !\n PARAMETER TC(FCC_A1,AL,NI:VA;1) 2.98150E+02 1745; 6.00000E+03 N\n 95DUP3 !\n\n PARAMETER L(FCC_A1,AL,NI:VA;0) 298.15 +LFCC0+4*L0ALNI;,, N 03SUN !\n PARAMETER L(FCC_A1,AL,NI:VA;1) 298.15 +LFCC1;,, N 03SUN !\n PARAMETER L(FCC_A1,AL,NI:VA;2) 298.15 +LFCC2;,, N 03SUN !\n PARAMETER L(FCC_A1,AL,NI:VA;3) 298.15 +LFCC3;,, N 03SUN !\n\n PARAMETER L(fcc_a1,ni,pt:va;0) 2.98150E+02 +L0FCC+NIPTG0+0.375*RECNINI\n +0.75*RECNIPT#+0.375*RECPTPT#; 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,ni,pt:va;1) 2.98150E+02 +L1FCC+NIPTG1+0.75*RECNINI#\n -0.75*RECPTPT#; 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,ni,pt:va;2) 2.98150E+02 +L2FCC+NIPTG2-1.5*RECNIPT#;\n 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,ni,pt:va;3) 2.98150E+02 +L3FCC-0.75*RECNINI#\n +0.75*RECPTPT#; 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,ni,pt:va;4) 2.98150E+02 -0.375*RECNINI#+0.75*RECNIPT#\n -0.375*RECPTPT#; 6.0E+03 N 05LU !\n\n PARAMETER L(fcc_a1,al,ni,pt:va;0) 2.98150E+02 +VA31+VA32*T;\n 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,al,ni,pt:va;1) 2.98150E+02 +VA33+VA34*T;\n 6.00000E+03 N 05LU !\n PARAMETER L(fcc_a1,al,ni,pt:va;2) 2.98150E+02 +VA35+VA36*T;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_A1,AL,PT:VA;0) 298.15 +APL0FCC#+ALPTG0#+1.5*REC#;\n 6000 N REF0 !\n PARAMETER G(FCC_A1,AL,PT:VA;1) 298.15 +APL1FCC#+ALPTG1#; 6000 N\n REF0 !\n PARAMETER G(FCC_A1,AL,PT:VA;2) 298.15 +APL2FCC#+ALPTG2#-1.5*REC#;\n 6000 N REF0 !\n PARAMETER G(FCC_A1,AL,PT:VA;3) 298.15 +APL3FCC#;\n 6000 N REF0 !\n\n\n$************FCC_L12\n TYPE_DEFINITION * GES AMEND_PHASE_DESCRIPTION FCC_L12 DIS_PART FCC_A1,,,!\n$ TYPE_DEFINITION M GES A_P_D FCC_L12 C_S 2 NI:NI:NI:PT:VA !\n$ TYPE_DEFINITION P GES A_P_D FCC_L12 C_S 3 NI:NI:PT:PT:VA !\n$ TYPE_DEFINITION Q GES A_P_D FCC_L12 C_S 4 NI:PT:PT:PT:VA !\n PHASE FCC_L12 %* 5 .25 .25 .25 .25 1 !\n CONSTITUENT FCC_L12 :AL,NI,PT:AL,NI,PT:AL,NI,PT:AL,NI,PT:VA%: !\n\n PARA G(FCC_L12,AL:AL:AL:AL:VA;0) 298.15 0; 6000 N!\n PARA G(FCC_L12,NI:NI:NI:NI:VA;0) 298.15 0; 6000 N!\n PARA G(FCC_L12,PT:PT:PT:PT:VA;0) 298.15 0; 6000 N!\n\n PARAMETER G(FCC_L12,NI:AL:AL:AL:VA;0) 298.15 +AL3NI; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:NI:AL:AL:VA;0) 298.15 +AL3NI; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:NI:AL:AL:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:AL:NI:AL:VA;0) 298.15 +AL3NI; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:AL:NI:AL:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:NI:NI:AL:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:NI:NI:AL:VA;0) 298.15 +ALNI3; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:AL:AL:NI:VA;0) 298.15 +AL3NI; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:AL:AL:NI:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:NI:AL:NI:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:NI:AL:NI:VA;0) 298.15 +ALNI3; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:AL:NI:NI:VA;0) 298.15 +AL2NI2; ,, N 03SUN !\n PARAMETER G(FCC_L12,NI:AL:NI:NI:VA;0) 298.15 +ALNI3; ,, N 03SUN !\n PARAMETER G(FCC_L12,AL:NI:NI:NI:VA;0) 298.15 +ALNI3; ,, N 03SUN !\n\n PARAMETER G(FCC_L12,PT:AL:AL:AL:VA;0) 298.15 +GAL3PT1#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:PT:AL:AL:VA;0) 298.15 +GAL3PT1#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:PT:AL:AL:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:AL:PT:AL:VA;0) 298.15 +GAL3PT1#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:AL:PT:AL:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:PT:PT:AL:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:PT:PT:AL:VA;0) 298.15 +GAL1PT3#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:AL:AL:PT:VA;0) 298.15 +GAL3PT1#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:AL:AL:PT:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:PT:AL:PT:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:PT:AL:PT:VA;0) 298.15 +GAL1PT3#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:AL:PT:PT:VA;0) 298.15 +GAL2PT2#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,PT:AL:PT:PT:VA;0) 298.15 +GAL1PT3#;\n\t3000 N REF0 !\n PARAMETER G(FCC_L12,AL:PT:PT:PT:VA;0) 298.15 +GAL1PT3#;\n\t3000 N REF0 !\n\n PARAMETER G(FCC_L12,PT:NI:NI:NI:VA;0) 2.98150E+02 +GNI3PT1#;\n6.0E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:NI:NI:VA;0) 2.98150E+02 +GNI3PT1#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:PT:NI:NI:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI:PT:NI:VA;0) 2.98150E+02 +GNI3PT1#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:PT:NI:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:PT:NI:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:PT:PT:NI:VA;0) 2.98150E+02 +GNI1PT3#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI:NI:PT:VA;0) 2.98150E+02 +GNI3PT1#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:NI:PT:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:NI:PT:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:PT:NI:PT:VA;0) 2.98150E+02 +GNI1PT3#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI:PT:PT:VA;0) 2.98150E+02 +GNI2PT2#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:PT:PT:VA;0) 2.98150E+02 +GNI1PT3#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:PT:PT:VA;0) 2.98150E+02 +GNI1PT3#;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,NI:NI:AL:PT:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI:PT:AL:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:NI:PT:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:NI:AL:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:PT:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:AL:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:NI:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:NI:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:PT:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:AL:NI:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:NI:PT:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:NI:AL:VA;0) 2.98150E+02 +GNI2ALPT#;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL:AL:NI:PT:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:AL:PT:NI:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:AL:PT:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:AL:NI:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:PT:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:NI:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:AL:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:AL:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:PT:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:NI:AL:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:AL:PT:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:AL:NI:VA;0) 2.98150E+02 +GAL2NIPT#;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,PT:PT:NI:AL:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:PT:AL:NI:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:PT:AL:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:PT:NI:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:AL:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:NI:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:PT:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:PT:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:AL:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:NI:PT:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:PT:PT:AL:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:PT:NI:VA;0) 2.98150E+02 +GPT2ALNI#;\n6E+03 N 05LU !\n\n PARAMETER L(FCC_L12,AL,NI:*:*:*:VA;0) 298.15 +L0ALNI; ,, N 03SUN !\n PARAMETER L(FCC_L12,*:AL,NI:*:*:VA;0) 298.15 +L0ALNI; ,, N 03SUN !\n PARAMETER L(FCC_L12,*:*:AL,NI:*:VA;0) 298.15 +L0ALNI; ,, N 03SUN !\n PARAMETER L(FCC_L12,*:*:*:AL,NI:VA;0) 298.15 +L0ALNI; ,, N 03SUN !\n\n PARAMETER G(FCC_L12,AL,PT:*:*:*:VA;0) 298.15 +UL0#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:AL,PT:*:*:VA;0) 298.15 +UL0#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:*:AL,PT:*:VA;0) 298.15 +UL0#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:*:*:AL,PT:VA;0) 298.15 +UL0#; 3000 N REF0 !\n\n PARAMETER G(FCC_L12,AL,PT:*:*:*:VA;1) 298.15 +UL1#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:AL,PT:*:*:VA;1) 298.15 +UL1#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:*:AL,PT:*:VA;1) 298.15 +UL1#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:*:*:AL,PT:VA;1) 298.15 +UL1#; 3000 N REF0 !\n\n\n PARAMETER G(FCC_L12,AL,PT:AL,PT:*:*:VA;0) 298.15 +REC#; 3000 N REF0 !\n PARAMETER G(FCC_L12,AL,PT:*:AL,PT:*:VA;0) 298.15 +REC#; 3000 N REF0 !\n PARAMETER G(FCC_L12,AL,PT:*:*:AL,PT:VA;0) 298.15 +REC#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:AL,PT:AL,PT:*:VA;0) 298.15 +REC#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:AL,PT:*:AL,PT:VA;0) 298.15 +REC#; 3000 N REF0 !\n PARAMETER G(FCC_L12,*:*:AL,PT:AL,PT:VA;0) 298.15 +REC#; 3000 N REF0 !\n\n PARAMETER L(FCC_L12,*:*:AL,NI:AL,NI:VA;0) 298.15 +URALNI;,, N 03SUN !\n PARAMETER L(FCC_L12,*:AL,NI:*:AL,NI:VA;0) 298.15 +URALNI;,, N 03SUN !\n PARAMETER L(FCC_L12,AL,NI:*:*:AL,NI:VA;0) 298.15 +URALNI;,, N 03SUN !\n PARAMETER L(FCC_L12,*:AL,NI:AL,NI:*:VA;0) 298.15 +URALNI;,, N 03SUN !\n PARAMETER L(FCC_L12,AL,NI:*:AL,NI:*:VA;0) 298.15 +URALNI;,, N 03SUN !\n PARAMETER L(FCC_L12,AL,NI:AL,NI:*:*:VA;0) 298.15 +URALNI;,, N 03SUN !\n\n PARAMETER G(FCC_L12,NI:NI:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:NI:NI,PT:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:NI,PT:NI:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:NI:NI,PT:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:NI,PT:NI:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:NI:NI:VA;0) 2.98150E+02 RECNINI;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,PT:PT:NI,PT:NI,PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:PT:NI,PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:NI,PT:PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:PT:NI,PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:NI,PT:PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:PT:PT:VA;0) 2.98150E+02 RECPTPT;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL:AL:NI,PT:NI,PT:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:AL:NI,PT:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:NI,PT:AL:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:AL:NI,PT:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:NI,PT:AL:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:AL:AL:VA;0) 2.98150E+02 RECPTPT+VA74+VA75*T;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,NI:PT:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:PT:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:NI:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:NI,PT:PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:NI,PT:NI:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:PT:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:NI:NI,PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:NI,PT:PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:NI,PT:NI:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:NI:PT:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:PT:NI:VA;0) 2.98150E+02 RECNIPT;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,NI,PT:NI,PT:AL:NI:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:NI:AL:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:NI:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:AL:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:NI,PT:NI:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI:NI,PT:AL:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:AL:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:NI,PT:NI:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:NI,PT:AL:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:NI:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI:NI,PT:AL:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA76;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,NI,PT:NI,PT:AL:PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:NI,PT:PT:AL:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:AL:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL:NI,PT:PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:PT:NI,PT:AL:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:PT:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:AL:NI,PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:NI,PT:PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:NI,PT:AL:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,AL:NI,PT:PT:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n PARAMETER G(FCC_L12,PT:NI,PT:AL:NI,PT:VA;0) 2.98150E+02 RECNIPT+VA77;\n 6.00000E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL,NI:AL,PT:*:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,PT:AL,NI:*:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI:*:AL,PT:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,PT:*:AL,NI:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI:*:*:AL,PT:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,PT:*:*:AL,NI:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI:AL,PT:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,PT:AL,NI:*:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:AL,NI:AL,PT:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:AL,PT:AL,NI:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI:*:AL,PT:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,PT:*:AL,NI:VA;0) 2.9815E+02 LALNIALPT;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL,NI:NI,PT:*:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL,NI:*:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI:*:NI,PT:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:*:AL,NI:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI:*:*:NI,PT:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:*:*:AL,NI:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:AL,NI:NI,PT:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:NI,PT:AL,NI:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI:*:NI,PT:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:NI,PT:*:AL,NI:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI:NI,PT:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:NI,PT:AL,NI:*:VA;0) 2.9815E+02 LALNINIPT;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL,PT:NI,PT:*:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:AL,PT:*:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,PT:*:NI,PT:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:*:AL,PT:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,PT:*:*:NI,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,NI,PT:*:*:AL,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:AL,PT:NI,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:NI,PT:AL,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,PT:*:NI,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:NI,PT:*:AL,PT:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,PT:NI,PT:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:NI,PT:AL,PT:*:VA;0) 2.9815E+02 LALPTNIPT;\n6E+03 N 05LU !\n\n PARAMETER G(FCC_L12,AL,NI,PT:AL,NI,PT:*:*:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI,PT:*:AL,NI,PT:*:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n PARAMETER G(FCC_L12,AL,NI,PT:*:*:AL,NI,PT:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI,PT:AL,NI,PT:*:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:AL,NI,PT:*:AL,NI,PT:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n PARAMETER G(FCC_L12,*:*:AL,NI,PT:AL,NI,PT:VA;0) 2.9815E+02\n VA80+VA81*T; 6E+03 N 05LU !\n$***********AL3NI1\n PHASE AL3NI1 % 2 .75 .25 !\n CONSTITUENT AL3NI1 :AL : NI : !\n\n PARAMETER G(AL3NI1,AL:NI;0) 2.98150E+02 -48483.73+12.29913*T\n +.75*GHSERAL#+.25*GHSERNI#; 6.00000E+03 N 95DUP3 !\n\n$******************** AL3NI2\n\n PHASE AL3NI2 % 3 3 2 1 !\n CONSTITUENT AL3NI2 :AL : AL,NI%,PT : NI,VA% : !\n\n PARAMETER G(AL3NI2,AL:AL:NI;0) 298.15 +6*GALALNI;,, N 95DUP3 !\n PARAMETER G(AL3NI2,AL:NI:NI;0) 298.15 +6*GALNINI;,, N 95DUP3 !\n PARAMETER G(AL3NI2,AL:AL:VA;0) 298.15 +6*GALALVA;,, N 95DUP3 !\n PARAMETER G(AL3NI2,AL:NI:VA;0) 298.15 +6*GALNIVA;,, N 95DUP3 !\n\n PARAMETER G(AL3NI2,AL:PT:NI;0) 2.98150E+02 +3*GBCCAL#+GBCCNI#+2*GBCCPT#\n +VA60+VA61*T; 6.00000E+03 N 05LU !\n PARAMETER G(AL3NI2,AL:PT:VA;0) 2.98150E+02 VA62+VA63*T\n +3*GBCCAL#+2*GBCCPT#; 6.00000E+03 N 05LU !\n\n PARAMETER L(AL3NI2,AL:AL,NI:*;0) 298.15 +6*L32ALNI;,, N 95DUP3 !\n PARAMETER L(AL3NI2,AL:*:NI,VA;0) 298.15 +6*L32NIVA;,, N 95DUP3 !\n\n PARAMETER G(AL3NI2,AL:NI,PT:*;0) 2.98150E+02 VA64+VA65*T;\n 6.00000E+03 N 05LU !\n PARAMETER G(AL3NI2,AL:AL,PT:*;0) 2.98150E+02 VA66+VA67*T;\n 6.00000E+03 N 05LU !\n\n$******************** AL3NI5\n\n PHASE AL3NI5 % 2 .375 .625 !\n CONSTITUENT AL3NI5 :AL : NI : !\n\n PARAMETER G(AL3NI5,AL:NI;0) 298.15 -66520+18.9*T\n +.375*GHSERAL+.625*GHSERNI;,, N 03SUN !\n\n$ PARAMETER G(AL3NI5,AL:NI;0) 2.98150E+02 +.375*GHSERAL#+.625*GHSERNI#\n$ -55507.7594+7.2648103*T; 6.00000E+03 N 95DUP3 !\n\n$***************************** BCC_A2\n\n FUNCTION B2ORDER 298.15 0.5*B2ALPT-0.5*LB2ALPT; 6000.0 N !\n FUNCTION L0A2ALPT 298.15 B2ALPT+LB2ALPT; 6000.0 N !\n\n\n$****************** BCC_B2\n PHASE BCC_B2 % 3 .5 .5 3 !\n CONSTITUENT BCC_B2 :AL,NI%,PT,VA : AL%,NI,PT,VA : VA : !\n\n PARA G(BCC_B2,AL:AL:VA;0) 298.15 +GBCCAL; 6000 N 91DIN !\n PARA G(BCC_B2,NI:NI:VA;0) 298.15 +GBCCNI; 6000 N 91DIN !\n PARA G(BCC_B2,PT:PT:VA;0) 298.15 +GBCCPT; 6000 N 91DIN !\n PARA G(BCC_B2,VA:VA:VA;0) 298.15 0; 6000 N !\n PARAMETER TC(BCC_B2,NI:VA:VA;0) 298.15 575;,, N 89DIN !\n PARAMETER BMAGN(BCC_B2,NI:VA:VA;0) 298.15 .85;,, N 89DIN !\n\n FUNCTION B2ALNI 295.15 -152397.3+26.40575*T;,, N 95DUP3 !\nPARA G(BCC_B2,NI:AL:VA;0) 2.9815E+02 +.5*GBCCAL+.5*GBCCNI+.5*B2ALNI;\n6000 N 95DUP3 !\nPARA G(BCC_B2,AL:NI:VA;0) 2.9815E+02 +.5*GBCCAL+.5*GBCCNI+.5*B2ALNI;\n6000 N 95DUP3 !\n\n FUNCTION B2ALVA 295.15 10000-T;,,N 95DUP3 !\nPARA G(BCC_B2,VA:AL:VA;0) 2.9815E+02 +0.5*GBCCAL+.5*B2ALVA; 6000 N 95DUP3 !\nPARA G(BCC_B2,AL:VA:VA;0) 2.9815E+02 +0.5*GBCCAL+.5*B2ALVA; 6000 N 95DUP3 !\n\n PARAMETER G(BCC_B2,AL:PT:VA;0) 2.98150E+02 +.5*GALBCC#+.5*GPTBCC#\n +.5*B2ALPT#; 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,PT:AL:VA;0) 2.98150E+02 +.5*GALBCC#+.5*GPTBCC#\n +.5*B2ALPT#; 6.00000E+03 N REF11 !\n\n FUNCTION B2NIVA 295.15 +162397.3-27.40575*T;,, N 95DUP3 !\nPARA G(BCC_B2,VA:NI:VA;0) 2.9815E+02 +.5*GBCCNI+.5*B2NIVA; 6000 N 95DUP3 !\nPARA G(BCC_B2,NI:VA:VA;0) 2.9815E+02 +.5*GBCCNI+.5*B2NIVA; 6000 N 95DUP3 !\n\nPARA G(BCC_B2,PT:NI:VA;0) 2.9815E+02 +.5*GBCCNI+.5*GBCCPT+VA93+VA94*T;\n 6000 N 05LU !\nPARA G(BCC_B2,NI:PT:VA;0) 2.9815E+02 +.5*GBCCNI+.5*GBCCPT+VA93+VA94*T;\n 6000 N 05LU !\n\n PARAMETER G(BCC_B2,PT:VA:VA;0) 2.98150E+02 +.5*GPTBCC#+.5*B2PTVA#;\n 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,VA:PT:VA;0) 2.98150E+02 +.5*GPTBCC#+.5*B2PTVA#;\n 6.00000E+03 N REF11 !\n\n FUNCTION LB2ALNI 298.15 -62104+19.28*T;,, N 03SUN !\nPARA G(BCC_B2,*:AL,NI:VA;0) 2.9815E+02 +.5*LB2ALNI; 6000 N 95DUP3 !\nPARA G(BCC_B2,AL,NI:*:VA;0) 2.9815E+02 +.5*LB2ALNI; 6000 N 95DUP3 !\n\n FUNCTION LB2ALVA 298.15 200000;,,N !\nPARA G(BCC_B2,*:AL,VA:VA;0) 2.9815E+02 +.5*LB2ALVA; 6000 N 95DUP3 !\nPARA G(BCC_B2,AL,VA:*:VA;0) 2.9815E+02 +.5*LB2ALVA; 6000 N 95DUP3 !\n\n FUNCTION LB2NIVA 298.15 -64024.38+26.49419*T;,, N !\nPARA G(BCC_B2,*:NI,VA:VA;0) 2.9815E+02 +.5*LB2NIVA; 6000 N 95DUP3 !\nPARA G(BCC_B2,NI,VA:*:VA;0) 2.9815E+02 +.5*LB2NIVA; 6000 N 95DUP3 !\n\n\nPARA G(BCC_B2,*:NI,PT:VA;0) 2.9815E+02 +VA87+VA88*T; 6000 N 05LU !\nPARA G(BCC_B2,NI,PT:*:VA;0) 2.9815E+02 +VA87+VA88*T; 6000 N 05LU !\n\n\n PARAMETER G(BCC_B2,*:PT,VA:VA;0) 2.98150E+02 +.5*LB2PTVA#;\n 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,PT,VA:*:VA;0) 2.98150E+02 +.5*LB2PTVA#;\n 6.00000E+03 N REF11 !\n\n PARAMETER G(BCC_B2,AL,PT:AL:VA;0) 2.98150E+02\n -0.5*B2ORDER+0.25*L0A2ALPT+0.375*L1A2ALPT;\n 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,AL:AL,PT:VA;0) 2.98150E+02\n -0.5*B2ORDER+0.25*L0A2ALPT+0.375*L1A2ALPT;\n 6.00000E+03 N REF11 !\n\n PARAMETER G(BCC_B2,AL,PT:PT:VA;0) 2.98150E+02\n -0.5*B2ORDER+0.25*L0A2ALPT-0.375*L1A2ALPT;\n 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,PT:AL,PT:VA;0) 2.98150E+02\n -0.5*B2ORDER+0.25*L0A2ALPT-0.375*L1A2ALPT;\n 6.00000E+03 N REF11 !\n\n PARAMETER G(BCC_B2,AL,PT:*:VA;1) 2.98150E+02 +0.125*L1A2ALPT;\n 6.00000E+03 N REF11 !\n PARAMETER G(BCC_B2,*:AL,PT:VA;1) 2.98150E+02 +0.125*L1A2ALPT;\n 6.00000E+03 N REF11 !\n\n$******************************** Compounds in AL-Pt\n\n$ PHASE AL21PT8 % 2 .724138 .275862 !\n$ CONS AL21PT8 :AL:PT NI:!\n$ PARAMETER G(AL21PT8,AL:NI;0) 2.98150E+02 -35000+.724138*GHSERAL#\n$ +.275862*GHSERNI#; 6.00000E+03 N REF: 0 !\n\n$ PARAMETER G(AL21PT8,AL:PT;0) 298.15 -82342+23.7*T+.7242*GHSERAL#\n$ +.2759*GHSERPT#; 6000 N REF0 !\n\n PHASE ALPT % 2 .5 .5 !\n CONS ALPT :AL:PT NI:!\n PARAMETER G(ALPT,AL:NI;0) 2.98150E+02 VA70+VA71*T+.5*GHSERAL#+.5*GHSERNI#;\n 6.00000E+03 N REF: 0 !\n PARAMETER G(ALPT,AL:NI,PT;0) 2.98150E+02 VA72+VA73*T; 6.00000E+03\n N REF: 0 !\n PARAMETER G(ALPT,AL:PT;0) 298.15 +.5*GHSERAL#+.5*GHSERPT#+VX85#\n +VX95#*T; 6000.0 N REF0 !\n$*******************\n\n PHASE PT2AL % 2 .3333 .6667 !\n CONSTITUENT PT2AL :AL : PT : !\n\n PARAMETER G(PT2AL,AL:PT;0) 298.15 +.3333*GHSERAL#+.6667*GHSERPT#\n -84137+VX90#*T; 6000.0 N REF0 !\n\n\n PHASE PT2AL3 % 2 .6 .4 !\n CONSTITUENT PT2AL3 :AL : PT : !\n\n PARAMETER G(PT2AL3,AL:PT;0) 298.15 +.6*GHSERAL#+.4*GHSERPT#-98234\n +VX91#*T; 6000.0 N REF0 !\n\n\n PHASE PT5AL21 % 2 .8077 .1923 !\n CONSTITUENT PT5AL21 :AL : PT : !\n\n PARAMETER G(PT5AL21,AL:PT;0) 298.15 +.8077*GHSERAL#+.1923*GHSERPT#\n -53148+VX92#*T; 6000.0 N REF0 !\n\n\n PHASE PT5AL3 % 2 .375 .625 !\n CONSTITUENT PT5AL3 :AL : PT : !\n\n PARAMETER G(PT5AL3,AL:PT;0) 298.15 +.375*GHSERAL#+.625*GHSERPT#\n -88904+VX93#*T; 6000.0 N REF0 !\n\n\n PHASE PT8AL21 % 2 .7241 .2759 !\n CONSTITUENT PT8AL21 :AL : PT : !\n\n PARAMETER G(PT8AL21,AL:PT;0) 298.15 +.7241*GHSERAL#+.2759*GHSERPT#\n -74851+VX94#*T; 6000.0 N REF0 !\n\n\n PHASE ALPT2 % 2 .6667 .3333 !\n CONSTITUENT ALPT2 :AL : PT : !\n\n PARAMETER G(ALPT2,AL:PT;0) 298.15 +.6667*GHSERAL#+.3333*GHSERPT#\n -89614+VX96#*T; 6000.0 N REF0 !\n$*************************************\n$ASSESSED_SYSTEM AL-NI(;P3 STP:.8/1200/1) !\n\n\n LIST_OF_REFERENCES\n NUMBER SOURCE\n REF01 'Kaisheng WU and Zhanpeng JIN, J. Phase Equil., Vol.21(3), 2000'\n REF02 'P.Nash and M.F.Singleton, Bulletin of Alloy Phase Diagrams,\n Vol.10(3),1989'\n REF283 'Alan Dinsdale, SGTE Data for Pure Elements,\n Calphad Vol 15(1991) p 317-425,\n also in NPL Report DMA(A)195 Rev. August 1990'\n 91DIN 'Alan Dinsdale, SGTE Data for Pure Elements, Calphad Vol 15(1991)\n p 317-425, also in NPL Report DMA(A)195 Rev. August 1990'\n REF95 'I Ansara, P Willemin B Sundman (1988); Al-Ni'\n REF295 'N. Saunders, unpublished research, COST-507, (1991); Al-Cu'\n REF281 'Alan Dinsdale, SGTE Data for Pure Elements, NPL Report\n DMA(A)195\n September 1989'\n 89DIN 'Alan Dinsdale, SGTE Data for Pure Elements, NPL Report DMA(A)195\n September 1989'\n REF26 'A. Fernandez Guillermet, Z. Metallkde. Vol 79(1988) p.524-536,\n TRITA-MAC 362 (1988); C-CO-NI AND C-CO-FE-NI'\n REF293 'N. Saunders, private communication (1991); Al-Ti-V'\n 95DUP3 'N. Dupin, Thesis, LTPCM, France, 1995; Al-Ni, also in I. Ansara,\n N. Dupin, H.L. Lukas, B. Sundman J. Alloys Compds, 247 (1-2), 20-30\n (1997)'\n 99DUP 'N. Dupin, I. Ansara, Z. metallkd., Vol 90 (1999) p 76-85; Al-Ni'\n 99DUP3 'N. Dupin, July 1999, unpublished revision ; Al-Ni'\n 03SUN 'B. Sundman, N. Dupin, JEEP 2003 Lyon'\n REF0 'S Prins and B Sundman, provisional Al-Pt (2003)'\n 05LU 'X.-G Lu, PhD thesis work, unpublished'\n !\n\n"
],
[
"%time reimported_dbf = Database.from_string(dbf.to_string(fmt='tdb'), fmt='tdb')\nprint(reimported_dbf.to_string(fmt='tdb', groupby='subsystem'))\nassert dbf == reimported_dbf",
"CPU times: user 2.74 s, sys: 2 ms, total: 2.74 s\nWall time: 2.74 s\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ Date: 2015-12-25 11:21\n$ Components: /-, AL, NI, PT, VA\n$ Phases: AL3NI1, AL3NI2, AL3NI5, ALPT, ALPT2, BCC_B2, FCC_A1, FCC_L12, LIQUID,\n$ PT2AL, PT2AL3, PT5AL21, PT5AL3, PT8AL21\n$ Generated by rotis (pycalphad 0.2.5+8.g3309b8c.dirty)\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nELEMENT /- BLANK 0 0 0 !\nELEMENT AL BLANK 0 0 0 !\nELEMENT NI BLANK 0 0 0 !\nELEMENT PT BLANK 0 0 0 !\nELEMENT VA BLANK 0 0 0 !\n\nFUNCTION AL2NI2 298.15 BETA; , N !\nFUNCTION AL3NI 298.15 ALPHA; , N !\nFUNCTION ALNI3 298.15 UALNI; , N !\nFUNCTION ALPHA 298.15 -29600; , N !\nFUNCTION ALPTG0 298.15 GAL1PT3 + 1.5*GAL2PT2 + GAL3PT1; 6000.0 N !\nFUNCTION ALPTG1 298.15 -2*GAL1PT3 + 2*GAL3PT1; 6000.0 N !\nFUNCTION ALPTG2 298.15 GAL1PT3 - 1.5*GAL2PT2 + GAL3PT1; 6000.0 N !\nFUNCTION APALP 298.15 22500; 6000.0 N !\nFUNCTION APBET 298.15 0; 6000.0 N !\nFUNCTION APL0FCC 298.15 -33.084025*T + 41176.252; 6000.0 N !\nFUNCTION APL1FCC 298.15 0; 6000.0 N !\nFUNCTION APL2FCC 298.15 0; 6000.0 N !\nFUNCTION APL3FCC 298.15 0; 6000.0 N !\nFUNCTION B2ALNI 295.15 26.40575*T - 152397.3; , N !\nFUNCTION B2ALPT 298.15 12.18*T - 205700; 6000.0 N !\nFUNCTION B2ALVA 295.15 -T + 10000; , N !\nFUNCTION B2NIVA 295.15 -27.40575*T + 162397.3; , N !\nFUNCTION B2ORDER 298.15 0.5*B2ALPT - 0.5*LB2ALPT; 6000.0 N !\nFUNCTION B2PTVA 298.15 -B2ALPT + B2ALVA; 6000.0 N !\nFUNCTION BETA 298.15 11.64*T - 66718; , N !\nFUNCTION DEUX 298.15 2; , N !\nFUNCTION GAL1PT3 298.15 -0.1875*APL0FCC + 0.09375*APL1FCC - 0.046875*APL2FCC +\n 0.0234375*APL3FCC + RAL1PT3; 6000.0 N !\nFUNCTION GAL2NIPT 298.15 T*VA41 + GNIPT + 2*U1ALNI + 2*UAP + VA40; 6000.0 N !\nFUNCTION GAL2PT2 298.15 -0.25*APL0FCC + RAL2PT2; 6000.0 N !\nFUNCTION GAL3PT1 298.15 -0.1875*APL0FCC - 0.09375*APL1FCC - 0.046875*APL2FCC -\n 0.0234375*APL3FCC + RAL3PT1; 6000.0 N !\nFUNCTION GALALNI 298.15 GALALVA + GALNINI - GALNIVA; , N !\nFUNCTION GALALVA 298.15 -0.5*T + 5*GBCCAL*UNSURSIX + 5000; , N !\nFUNCTION GALBCC 298.15 -4.813*T + GHSERAL + 10083; 6000.0 N !\nFUNCTION GALNINI 298.15 GB2ALNI + 5000; , N !\nFUNCTION GALNIVA 298.15 11.387*T + 3*GBCCAL*UNSURSIX + 2*GBCCNI*UNSURSIX -\n 59620.987; , N !\nFUNCTION GB2ALNI 298.15 13.202875*T + GBCCAL*UNSURDEU + GBCCNI*UNSURDEU -\n 76198.65; , N !\nFUNCTION GB2ALVA 298.15 -0.5*T + GBCCAL*UNSURDEU + 5000; , N !\nFUNCTION GB2NINI 298.15 GBCCNI; , N !\nFUNCTION GB2NIVA 298.15 -GB2ALNI + GB2ALVA + GB2NINI; , N !\nFUNCTION GBCCAL 298.15 -4.813*T + GHSERAL + 10083; 6000.0 N !\nFUNCTION GBCCNI 298.15 -3.556*T + GHSERNI + 8715.084; 6000.0 N !\nFUNCTION GBCCPT 298.15 -2.4*T + GHSERPT + 15000; 6000.0 N !\nFUNCTION GHSERAL 298.15 -8.77664E-7*T**3 - 0.001884662*T**2 -\n 24.3671976*T*LN(T) + 137.093038*T - 7976.15 + 74092/T; 700.0 Y\n -5.764227E-6*T**3 + 0.018531982*T**2 - 38.5844296*T*LN(T) + 223.048446*T -\n 11276.24 + 74092/T; 933.6 Y -31.748192*T*LN(T) + 188.684153*T - 11278.378 -\n 1.231E+28/T**9; 6000.0 N !\nFUNCTION GHSERNI 298.15 -0.0048407*T**2 - 22.096*T*LN(T) + 117.854*T -\n 5179.159; 1728.0 Y -43.1*T*LN(T) + 279.135*T - 27840.655 + 1.12754E+31/T**9;\n 6000.0 N !\nFUNCTION GHSERPT 298.15 -2.0138E-8*T**3 - 0.00248297*T**2 - 24.5526*T*LN(T) +\n 124.388276*T - 7595.631 + 7974/T; 1300.0 Y -6.56947E-7*T**3 +\n 0.002321665*T**2 - 30.2527*T*LN(T) + 161.529616*T - 9253.174 - 272106/T;\n 2042.1 Y -7.60985E-7*T**3 + 0.020501692*T**2 - 136.422689*T*LN(T) +\n 1021.21087*T - 222518.973 + 71709819/T; 4000.0 N !\nFUNCTION GLIQAL 298.14 7.934E-20*T**7 - 11.841867*T + GHSERAL + 11005.029;\n 933.59 Y -11.253974*T + GHSERAL + 10482.282 + 1.231E+28/T**9; 6000.0 N !\nFUNCTION GNI1PT3 298.15 -0.1875*L0FCC + 0.09375*L1FCC - 0.046875*L2FCC +\n 0.0234375*L3FCC + RNI1PT3; 6000.0 N !\nFUNCTION GNI2ALPT 298.15 T*VA43 + 2*GNIPT + 2*U1ALNI + UAP + VA42; 6000.0 N !\nFUNCTION GNI2PT2 298.15 -0.25*L0FCC + RNI2PT2; 6000.0 N !\nFUNCTION GNI3PT1 298.15 -0.1875*L0FCC - 0.09375*L1FCC - 0.046875*L2FCC -\n 0.0234375*L3FCC + RNI3PT1; 6000.0 N !\nFUNCTION GNIPT 298.15 GNI3PT1*UNTIER; 6000.0 N !\nFUNCTION GPT2ALNI 298.15 T*VA45 + 2*GNIPT + U1ALNI + 2*UAP + VA44; 6000.0 N !\nFUNCTION GPTBCC 298.15 -2.4*T + GHSERPT + 15000; 4000.0 N !\nFUNCTION L0A2ALPT 298.15 B2ALPT + LB2ALPT; 6000.0 N !\nFUNCTION L0ALNI 298.15 -1.46*T + 5310; , N !\nFUNCTION L0FCC 298.15 10.977*T + 27500; 6000.0 N !\nFUNCTION L1A2ALPT 298.15 45000; 6000.0 N !\nFUNCTION L1FCC 298.15 -6500; 6000.0 N !\nFUNCTION L2FCC 298.15 0; 6000.0 N !\nFUNCTION L32ALNI 298.15 21.965*T - 32247.363; , N !\nFUNCTION L32NIVA 298.15 1.1722*T - 3666.95; , N !\nFUNCTION L3FCC 298.15 0; 6000.0 N !\nFUNCTION LALNIALPT 298.15 T*VA47 - 0.5*GNIPT + 0.5*U1ALNI + 0.5*UAP + VA46;\n 6000.0 N !\nFUNCTION LALNINIPT 298.15 T*VA49 + 0.5*GNIPT + 0.5*U1ALNI - 0.5*UAP + VA48;\n 6000.0 N !\nFUNCTION LALPTNIPT 298.15 T*VA51 + 0.5*GNIPT - 0.5*U1ALNI + 0.5*UAP + VA50;\n 6000.0 N !\nFUNCTION LB2ALNI 298.15 19.28*T - 62104; , N !\nFUNCTION LB2ALPT 298.15 -50*T; 6000.0 N !\nFUNCTION LB2ALVA 298.15 200000; , N !\nFUNCTION LB2NIVA 298.15 26.49419*T - 64024.38; , N !\nFUNCTION LB2PTVA 298.15 5*T - 15000; 6000.0 N !\nFUNCTION LFCC0 298.15 1.5*AL2NI2 + AL3NI + ALNI3 + 1.5*URALNI; , N !\nFUNCTION LFCC1 298.15 2*AL3NI - 2*ALNI3; , N !\nFUNCTION LFCC2 298.15 -1.5*AL2NI2 + AL3NI + ALNI3 - 1.5*URALNI; , N !\nFUNCTION LFCC3 298.15 0.0; 6000.0 N !\nFUNCTION LLIQ0 298.15 -5*LLIQ2 - 9*LLIQ4; , N !\nFUNCTION LLIQ1 298.15 -7*LLIQ3*UNTIER; , N !\nFUNCTION LLIQ2 298.15 -31.95713*T + 81204.81; , N !\nFUNCTION LLIQ3 298.15 -2.51632*T + 4365.35; , N !\nFUNCTION LLIQ4 298.15 13.16341*T - 22101.64; , N !\nFUNCTION NIPTG0 298.15 GNI1PT3 + 1.5*GNI2PT2 + GNI3PT1; 6000.0 N !\nFUNCTION NIPTG1 298.15 -2*GNI1PT3 + 2*GNI3PT1; 6000.0 N !\nFUNCTION NIPTG2 298.15 GNI1PT3 - 1.5*GNI2PT2 + GNI3PT1; 6000.0 N !\nFUNCTION RAL1PT3 298.15 APBET + 3*UALPT; 6000.0 N !\nFUNCTION RAL2PT2 298.15 4*UALPT; 6000.0 N !\nFUNCTION RAL3PT1 298.15 APALP + 3*UALPT; 6000.0 N !\nFUNCTION REC 298.15 RECALPT + UALPT; 6000.0 N !\nFUNCTION RECALPT 298.15 0; 6000.0 N !\nFUNCTION RECNINI 298.15 -3670.0; 6000.0 N !\nFUNCTION RECNIPT 298.15 -3250.0; 6000.0 N !\nFUNCTION RECPTPT 298.15 -2730.0; 6000.0 N !\nFUNCTION RNI1PT3 298.15 -0.5*T - 8300.0; 6000.0 N !\nFUNCTION RNI2PT2 298.15 -0.5*T - 13500.0; 6000.0 N !\nFUNCTION RNI3PT1 298.15 -10900.0; 6000.0 N !\nFUNCTION SIX 298.15 6; , N !\nFUNCTION TROIS 298.15 3; 6000.0 N !\nFUNCTION U1ALNI 298.15 2.0819247*T - 13415.515; , N !\nFUNCTION U3ALNI 298.15 0.0; 6000.0 N !\nFUNCTION UALNI 298.15 6.22*T - 43590; , N !\nFUNCTION UALPT 298.15 0.75*T - 22745.4; 6000.0 N !\nFUNCTION UAP 298.15 UALPT; 6000.0 N !\nFUNCTION UL0 298.15 0; 6000.0 N !\nFUNCTION UL1 298.15 2996.8958; 6000.0 N !\nFUNCTION UNSURDEU 298.15 1/DEUX; , N !\nFUNCTION UNSURSIX 298.15 1/SIX; , N !\nFUNCTION UNTIER 298.15 1/TROIS; 6000.0 N !\nFUNCTION UN_ASS 298.15 0; 300.0 N !\nFUNCTION URALNI 298.15 13.22*T - 34575; , N !\nFUNCTION VA1 298.15 200000.0; , N !\nFUNCTION VA2 298.15 0.0; , N !\nFUNCTION VA3 298.15 0.0; , N !\nFUNCTION VA32 298.15 0.0; , N !\nFUNCTION VA33 298.15 0.0; , N !\nFUNCTION VA34 298.15 0.0; , N !\nFUNCTION VA35 298.15 0.0; , N !\nFUNCTION VA36 298.15 0.0; , N !\nFUNCTION VA4 298.15 0.0; , N !\nFUNCTION VA40 298.15 0; , N !\nFUNCTION VA42 298.15 0; , N !\nFUNCTION VA44 298.15 0; , N !\nFUNCTION VA46 298.15 0; , N !\nFUNCTION VA48 298.15 0; , N !\nFUNCTION VA5 298.15 0.0; , N !\nFUNCTION VA50 298.15 0; , N !\nFUNCTION VA6 298.15 0.0; , N !\nFUNCTION VA60 298.15 0.0; , N !\nFUNCTION VA61 298.15 0.0; , N !\nFUNCTION VA62 298.15 0.0; , N !\nFUNCTION VA63 298.15 0.0; , N !\nFUNCTION VA64 298.15 0.0; , N !\nFUNCTION VA65 298.15 0.0; , N !\nFUNCTION VA66 298.15 0.0; , N !\nFUNCTION VA67 298.15 0.0; , N !\nFUNCTION VA70 298.15 -55000; , N !\nFUNCTION VA71 298.15 1.0; , N !\nFUNCTION VA72 298.15 0.0; , N !\nFUNCTION VA73 298.15 0.0; , N !\nFUNCTION VA74 298.15 0.0; , N !\nFUNCTION VA75 298.15 0.0; , N !\nFUNCTION VA76 298.15 7000.0; , N !\nFUNCTION VA77 298.15 2000.0; , N !\nFUNCTION VA78 298.15 -95000.0; , N !\nFUNCTION VA79 298.15 6.0; , N !\nFUNCTION VA80 298.15 0.0; , N !\nFUNCTION VA81 298.15 0.0; , N !\nFUNCTION VA85 298.15 -45000.0; , N !\nFUNCTION VA86 298.15 0.0; , N !\nFUNCTION VA87 298.15 -5000.0; , N !\nFUNCTION VA88 298.15 0.0; , N !\nFUNCTION VA89 298.15 0.0; , N !\nFUNCTION VA90 298.15 0.0; , N !\nFUNCTION VA91 298.15 -98000.0; , N !\nFUNCTION VA92 298.15 6.0; , N !\nFUNCTION VA93 298.15 -20000.0; , N !\nFUNCTION VA94 298.15 0.0; , N !\nFUNCTION VA95 298.15 100000.0; , N !\nFUNCTION VA96 298.15 0.0; , N !\nFUNCTION VA97 298.15 0.0; , N !\nFUNCTION VA98 298.15 0.0; , N !\nFUNCTION VA99 298.15 0.0; , N !\nFUNCTION VX1 298.15 -22745.4; 6000.0 N !\nFUNCTION VX10 298.15 41176.252; 6000.0 N !\nFUNCTION VX11 298.15 -33.084025; 6000.0 N !\nFUNCTION VX2 298.15 0.75; 6000.0 N !\nFUNCTION VX20 298.15 2996.8958; 6000.0 N !\nFUNCTION VX3 298.15 22500.0; 6000.0 N !\nFUNCTION VX40 298.15 -270469.16; 6000.0 N !\nFUNCTION VX41 298.15 -8.3384917; 6000.0 N !\nFUNCTION VX42 298.15 -19293.253; 6000.0 N !\nFUNCTION VX43 298.15 24.643347; 6000.0 N !\nFUNCTION VX44 298.15 45967.65; 6000.0 N !\nFUNCTION VX50 298.15 -205700.0; 6000.0 N !\nFUNCTION VX51 298.15 12.175; 6000.0 N !\nFUNCTION VX53 298.15 -50.0; 6000.0 N !\nFUNCTION VX54 298.15 45000.0; 6000.0 N !\nFUNCTION VX85 298.15 -101186.62; 6000.0 N !\nFUNCTION VX90 298.15 6.0995004; 6000.0 N !\nFUNCTION VX91 298.15 9.4351782; 6000.0 N !\nFUNCTION VX92 298.15 5.2341182; 6000.0 N !\nFUNCTION VX93 298.15 6.4125253; 6000.0 N !\nFUNCTION VX94 298.15 6.9806493; 6000.0 N !\nFUNCTION VX95 298.15 8.692; 6000.0 N !\nFUNCTION VX96 298.15 9.3985666; 6000.0 N !\n\nTYPE_DEFINITION % SEQ * !\nDEFINE_SYSTEM_DEFAULT ELEMENT 2 !\nDEFAULT_COMMAND DEFINE_SYSTEM_ELEMENT /- VA !\n\nPHASE AL3NI1 % 2 0.75 0.25 !\nCONSTITUENT AL3NI1 :AL:NI: !\n\nPHASE AL3NI2 % 3 3.0 2.0 1.0 !\nCONSTITUENT AL3NI2 :AL:AL,NI,PT:NI,VA: !\n\nPHASE AL3NI5 % 2 0.375 0.625 !\nCONSTITUENT AL3NI5 :AL:NI: !\n\nPHASE ALPT % 2 0.5 0.5 !\nCONSTITUENT ALPT :AL:NI,PT: !\n\nPHASE ALPT2 % 2 0.6667 0.3333 !\nCONSTITUENT ALPT2 :AL:PT: !\n\nPHASE BCC_B2 % 3 0.5 0.5 3.0 !\nCONSTITUENT BCC_B2 :AL,NI,PT,VA:AL,NI,PT,VA:VA: !\n\nTYPE_DEFINITION ^ GES AMEND_PHASE_DESCRIPTION FCC_A1 MAGNETIC -3.0 0.28 !\nPHASE FCC_A1 %^ 2 1.0 1.0 !\nCONSTITUENT FCC_A1 :AL,NI,PT:VA: !\n\nTYPE_DEFINITION & GES AMEND_PHASE_DESCRIPTION FCC_L12 DISORDERED_PART FCC_A1 !\nPHASE FCC_L12 %& 5 0.25 0.25 0.25 0.25 1.0 !\nCONSTITUENT FCC_L12 :AL,NI,PT:AL,NI,PT:AL,NI,PT:AL,NI,PT:VA: !\n\nPHASE LIQUID % 1 1.0 !\nCONSTITUENT LIQUID :AL,NI,PT: !\n\nPHASE PT2AL % 2 0.3333 0.6667 !\nCONSTITUENT PT2AL :AL:PT: !\n\nPHASE PT2AL3 % 2 0.6 0.4 !\nCONSTITUENT PT2AL3 :AL:PT: !\n\nPHASE PT5AL21 % 2 0.8077 0.1923 !\nCONSTITUENT PT5AL21 :AL:PT: !\n\nPHASE PT5AL3 % 2 0.375 0.625 !\nCONSTITUENT PT5AL3 :AL:PT: !\n\nPHASE PT8AL21 % 2 0.7241 0.2759 !\nCONSTITUENT PT8AL21 :AL:PT: !\n\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ AL $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(AL3NI2,AL:AL:VA;0) 298.15 6*GALALVA; , N !\nPARAMETER G(BCC_B2,AL:AL:VA;0) 298.15 GBCCAL; 6000.0 N !\nPARAMETER G(BCC_B2,AL:VA:VA;0) 298.15 0.5*B2ALVA + 0.5*GBCCAL; 6000.0 N !\nPARAMETER G(BCC_B2,VA:AL:VA;0) 298.15 0.5*B2ALVA + 0.5*GBCCAL; 6000.0 N !\nPARAMETER G(BCC_B2,*:AL,VA:VA;0) 298.15 0.5*LB2ALVA; 6000.0 N !\nPARAMETER G(BCC_B2,AL,VA:*:VA;0) 298.15 0.5*LB2ALVA; 6000.0 N !\nPARAMETER G(FCC_A1,AL:VA;0) 298.15 GHSERAL; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:AL:AL:VA;0) 298.15 0; 6000.0 N !\nPARAMETER G(LIQUID,AL;0) 298.15 7.934E-20*T**7 - 11.841867*T + GHSERAL +\n 11005.029; 933.6 Y -11.253974*T + GHSERAL + 10482.282 + 1.231E+28/T**9;\n 6000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ NI $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER BMAGN(BCC_B2,NI:VA:VA;0) 298.15 0.85; , N !\nPARAMETER G(BCC_B2,NI:NI:VA;0) 298.15 GBCCNI; 6000.0 N !\nPARAMETER G(BCC_B2,NI:VA:VA;0) 298.15 0.5*B2NIVA + 0.5*GBCCNI; 6000.0 N !\nPARAMETER G(BCC_B2,VA:NI:VA;0) 298.15 0.5*B2NIVA + 0.5*GBCCNI; 6000.0 N !\nPARAMETER G(BCC_B2,*:NI,VA:VA;0) 298.15 0.5*LB2NIVA; 6000.0 N !\nPARAMETER G(BCC_B2,NI,VA:*:VA;0) 298.15 0.5*LB2NIVA; 6000.0 N !\nPARAMETER TC(BCC_B2,NI:VA:VA;0) 298.15 575; , N !\nPARAMETER BMAGN(FCC_A1,NI:VA;0) 298.15 0.52; 6000.0 N !\nPARAMETER G(FCC_A1,NI:VA;0) 298.15 GHSERNI; 6000.0 N !\nPARAMETER TC(FCC_A1,NI:VA;0) 298.15 633; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:NI:NI:VA;0) 298.15 0; 6000.0 N !\nPARAMETER G(LIQUID,NI;0) 298.13 -3.82318E-21*T**7 - 9.397*T + GHSERNI +\n 16414.686; 1728.0 Y -10.537*T + GHSERNI + 18290.88 - 1.12754E+31/T**9;\n 6000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ PT $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(BCC_B2,PT:PT:VA;0) 298.15 GBCCPT; 6000.0 N !\nPARAMETER G(BCC_B2,PT:VA:VA;0) 298.15 0.5*B2PTVA + 0.5*GPTBCC; 6000.0 N !\nPARAMETER G(BCC_B2,VA:PT:VA;0) 298.15 0.5*B2PTVA + 0.5*GPTBCC; 6000.0 N !\nPARAMETER G(BCC_B2,*:PT,VA:VA;0) 298.15 0.5*LB2PTVA; 6000.0 N !\nPARAMETER G(BCC_B2,PT,VA:*:VA;0) 298.15 0.5*LB2PTVA; 6000.0 N !\nPARAMETER G(FCC_A1,PT:VA;0) 298.15 GHSERPT; 4000.0 N !\nPARAMETER G(FCC_L12,PT:PT:PT:PT:VA;0) 298.15 0; 6000.0 N !\nPARAMETER G(LIQUID,PT;0) 298.15 -2.0138E-8*T**3 - 0.00248297*T**2 -\n 24.5526*T*LN(T) + 115.114727*T + 12520.614 + 7974/T; 600.0 Y 9.30579E-7*T**3\n - 0.011543133*T**2 - 12.351404*T*LN(T) + 33.017485*T + 19019.913 - 600885/T;\n 2042.1 Y -36.5*T*LN(T) + 205.861909*T + 1404.968; 4000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ VA $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(BCC_B2,VA:VA:VA;0) 298.15 0; 6000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ AL-NI $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(AL3NI1,AL:NI;0) 298.15 12.29913*T + 0.75*GHSERAL + 0.25*GHSERNI -\n 48483.73; 6000.0 N !\nPARAMETER G(AL3NI2,AL:AL:NI;0) 298.15 6*GALALNI; , N !\nPARAMETER G(AL3NI2,AL:NI:NI;0) 298.15 6*GALNINI; , N !\nPARAMETER G(AL3NI2,AL:NI:VA;0) 298.15 6*GALNIVA; , N !\nPARAMETER L(AL3NI2,AL:*:NI,VA;0) 298.15 6*L32NIVA; , N !\nPARAMETER L(AL3NI2,AL:AL,NI:*;0) 298.15 6*L32ALNI; , N !\nPARAMETER G(AL3NI5,AL:NI;0) 298.15 18.9*T + 0.375*GHSERAL + 0.625*GHSERNI -\n 66520; , N !\nPARAMETER G(ALPT,AL:NI;0) 298.15 T*VA71 + 0.5*GHSERAL + 0.5*GHSERNI + VA70;\n 6000.0 N !\nPARAMETER G(BCC_B2,AL:NI:VA;0) 298.15 0.5*B2ALNI + 0.5*GBCCAL + 0.5*GBCCNI;\n 6000.0 N !\nPARAMETER G(BCC_B2,NI:AL:VA;0) 298.15 0.5*B2ALNI + 0.5*GBCCAL + 0.5*GBCCNI;\n 6000.0 N !\nPARAMETER G(BCC_B2,*:AL,NI:VA;0) 298.15 0.5*LB2ALNI; 6000.0 N !\nPARAMETER G(BCC_B2,AL,NI:*:VA;0) 298.15 0.5*LB2ALNI; 6000.0 N !\nPARAMETER L(FCC_A1,AL,NI:VA;0) 298.15 4*L0ALNI + LFCC0; , N !\nPARAMETER L(FCC_A1,AL,NI:VA;1) 298.15 LFCC1; , N !\nPARAMETER L(FCC_A1,AL,NI:VA;2) 298.15 LFCC2; , N !\nPARAMETER L(FCC_A1,AL,NI:VA;3) 298.15 LFCC3; , N !\nPARAMETER TC(FCC_A1,AL,NI:VA;0) 298.15 -1112; 6000.0 N !\nPARAMETER TC(FCC_A1,AL,NI:VA;1) 298.15 1745; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:AL:NI:VA;0) 298.15 AL3NI; , N !\nPARAMETER G(FCC_L12,AL:AL:NI:AL:VA;0) 298.15 AL3NI; , N !\nPARAMETER G(FCC_L12,AL:AL:NI:NI:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,AL:NI:AL:AL:VA;0) 298.15 AL3NI; , N !\nPARAMETER G(FCC_L12,AL:NI:AL:NI:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,AL:NI:NI:AL:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,AL:NI:NI:NI:VA;0) 298.15 ALNI3; , N !\nPARAMETER G(FCC_L12,NI:AL:AL:AL:VA;0) 298.15 AL3NI; , N !\nPARAMETER G(FCC_L12,NI:AL:AL:NI:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,NI:AL:NI:AL:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,NI:AL:NI:NI:VA;0) 298.15 ALNI3; , N !\nPARAMETER G(FCC_L12,NI:NI:AL:AL:VA;0) 298.15 AL2NI2; , N !\nPARAMETER G(FCC_L12,NI:NI:AL:NI:VA;0) 298.15 ALNI3; , N !\nPARAMETER G(FCC_L12,NI:NI:NI:AL:VA;0) 298.15 ALNI3; , N !\nPARAMETER L(FCC_L12,*:*:*:AL,NI:VA;0) 298.15 L0ALNI; , N !\nPARAMETER L(FCC_L12,*:*:AL,NI:*:VA;0) 298.15 L0ALNI; , N !\nPARAMETER L(FCC_L12,*:AL,NI:*:*:VA;0) 298.15 L0ALNI; , N !\nPARAMETER L(FCC_L12,AL,NI:*:*:*:VA;0) 298.15 L0ALNI; , N !\nPARAMETER L(FCC_L12,*:*:AL,NI:AL,NI:VA;0) 298.15 URALNI; , N !\nPARAMETER L(FCC_L12,*:AL,NI:*:AL,NI:VA;0) 298.15 URALNI; , N !\nPARAMETER L(FCC_L12,*:AL,NI:AL,NI:*:VA;0) 298.15 URALNI; , N !\nPARAMETER L(FCC_L12,AL,NI:*:*:AL,NI:VA;0) 298.15 URALNI; , N !\nPARAMETER L(FCC_L12,AL,NI:*:AL,NI:*:VA;0) 298.15 URALNI; , N !\nPARAMETER L(FCC_L12,AL,NI:AL,NI:*:*:VA;0) 298.15 URALNI; , N !\nPARAMETER L(LIQUID,AL,NI;0) 298.15 LLIQ0; , N !\nPARAMETER L(LIQUID,AL,NI;1) 298.15 LLIQ1; , N !\nPARAMETER L(LIQUID,AL,NI;2) 298.15 LLIQ2; , N !\nPARAMETER L(LIQUID,AL,NI;3) 298.15 LLIQ3; , N !\nPARAMETER L(LIQUID,AL,NI;4) 298.15 LLIQ4; , N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ AL-PT $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(AL3NI2,AL:PT:VA;0) 298.15 T*VA63 + 3*GBCCAL + 2*GBCCPT + VA62;\n 6000.0 N !\nPARAMETER G(AL3NI2,AL:AL,PT:*;0) 298.15 T*VA67 + VA66; 6000.0 N !\nPARAMETER G(ALPT,AL:PT;0) 298.15 T*VX95 + 0.5*GHSERAL + 0.5*GHSERPT + VX85;\n 6000.0 N !\nPARAMETER G(ALPT2,AL:PT;0) 298.15 T*VX96 + 0.6667*GHSERAL + 0.3333*GHSERPT -\n 89614; 6000.0 N !\nPARAMETER G(BCC_B2,AL:PT:VA;0) 298.15 0.5*B2ALPT + 0.5*GALBCC + 0.5*GPTBCC;\n 6000.0 N !\nPARAMETER G(BCC_B2,PT:AL:VA;0) 298.15 0.5*B2ALPT + 0.5*GALBCC + 0.5*GPTBCC;\n 6000.0 N !\nPARAMETER G(BCC_B2,*:AL,PT:VA;1) 298.15 0.125*L1A2ALPT; 6000.0 N !\nPARAMETER G(BCC_B2,AL:AL,PT:VA;0) 298.15 -0.5*B2ORDER + 0.25*L0A2ALPT +\n 0.375*L1A2ALPT; 6000.0 N !\nPARAMETER G(BCC_B2,AL,PT:*:VA;1) 298.15 0.125*L1A2ALPT; 6000.0 N !\nPARAMETER G(BCC_B2,AL,PT:AL:VA;0) 298.15 -0.5*B2ORDER + 0.25*L0A2ALPT +\n 0.375*L1A2ALPT; 6000.0 N !\nPARAMETER G(BCC_B2,AL,PT:PT:VA;0) 298.15 -0.5*B2ORDER + 0.25*L0A2ALPT -\n 0.375*L1A2ALPT; 6000.0 N !\nPARAMETER G(BCC_B2,PT:AL,PT:VA;0) 298.15 -0.5*B2ORDER + 0.25*L0A2ALPT -\n 0.375*L1A2ALPT; 6000.0 N !\nPARAMETER G(FCC_A1,AL,PT:VA;0) 298.15 ALPTG0 + APL0FCC + 1.5*REC; 6000.0 N !\nPARAMETER G(FCC_A1,AL,PT:VA;1) 298.15 ALPTG1 + APL1FCC; 6000.0 N !\nPARAMETER G(FCC_A1,AL,PT:VA;2) 298.15 ALPTG2 + APL2FCC - 1.5*REC; 6000.0 N !\nPARAMETER G(FCC_A1,AL,PT:VA;3) 298.15 APL3FCC; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:AL:PT:VA;0) 298.15 GAL3PT1; 3000.0 N !\nPARAMETER G(FCC_L12,AL:AL:PT:AL:VA;0) 298.15 GAL3PT1; 3000.0 N !\nPARAMETER G(FCC_L12,AL:AL:PT:PT:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,AL:PT:AL:AL:VA;0) 298.15 GAL3PT1; 3000.0 N !\nPARAMETER G(FCC_L12,AL:PT:AL:PT:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,AL:PT:PT:AL:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,AL:PT:PT:PT:VA;0) 298.15 GAL1PT3; 3000.0 N !\nPARAMETER G(FCC_L12,PT:AL:AL:AL:VA;0) 298.15 GAL3PT1; 3000.0 N !\nPARAMETER G(FCC_L12,PT:AL:AL:PT:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,PT:AL:PT:AL:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,PT:AL:PT:PT:VA;0) 298.15 GAL1PT3; 3000.0 N !\nPARAMETER G(FCC_L12,PT:PT:AL:AL:VA;0) 298.15 GAL2PT2; 3000.0 N !\nPARAMETER G(FCC_L12,PT:PT:AL:PT:VA;0) 298.15 GAL1PT3; 3000.0 N !\nPARAMETER G(FCC_L12,PT:PT:PT:AL:VA;0) 298.15 GAL1PT3; 3000.0 N !\nPARAMETER G(FCC_L12,*:*:*:AL,PT:VA;0) 298.15 UL0; 3000.0 N !\nPARAMETER G(FCC_L12,*:*:*:AL,PT:VA;1) 298.15 UL1; 3000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,PT:*:VA;0) 298.15 UL0; 3000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,PT:*:VA;1) 298.15 UL1; 3000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:*:*:VA;0) 298.15 UL0; 3000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:*:*:VA;1) 298.15 UL1; 3000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:*:*:VA;0) 298.15 UL0; 3000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:*:*:VA;1) 298.15 UL1; 3000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,PT:AL,PT:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:*:AL,PT:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:AL,PT:*:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:*:AL,PT:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:AL,PT:*:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(FCC_L12,AL,PT:AL,PT:*:*:VA;0) 298.15 REC; 3000.0 N !\nPARAMETER G(LIQUID,AL,PT;0) 298.15 T*VX41 + VX40; 6000.0 N !\nPARAMETER G(LIQUID,AL,PT;1) 298.15 T*VX43 + VX42; 6000.0 N !\nPARAMETER G(LIQUID,AL,PT;2) 298.15 T*VX45 + VX44; 6000.0 N !\nPARAMETER G(LIQUID,AL,PT;3) 298.15 T*VX47 + VX46; 6000.0 N !\nPARAMETER G(PT2AL,AL:PT;0) 298.15 T*VX90 + 0.3333*GHSERAL + 0.6667*GHSERPT -\n 84137; 6000.0 N !\nPARAMETER G(PT2AL3,AL:PT;0) 298.15 T*VX91 + 0.6*GHSERAL + 0.4*GHSERPT - 98234;\n 6000.0 N !\nPARAMETER G(PT5AL21,AL:PT;0) 298.15 T*VX92 + 0.8077*GHSERAL + 0.1923*GHSERPT -\n 53148; 6000.0 N !\nPARAMETER G(PT5AL3,AL:PT;0) 298.15 T*VX93 + 0.375*GHSERAL + 0.625*GHSERPT -\n 88904; 6000.0 N !\nPARAMETER G(PT8AL21,AL:PT;0) 298.15 T*VX94 + 0.7241*GHSERAL + 0.2759*GHSERPT -\n 74851; 6000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ NI-PT $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(BCC_B2,NI:PT:VA;0) 298.15 T*VA94 + 0.5*GBCCNI + 0.5*GBCCPT + VA93;\n 6000.0 N !\nPARAMETER G(BCC_B2,PT:NI:VA;0) 298.15 T*VA94 + 0.5*GBCCNI + 0.5*GBCCPT + VA93;\n 6000.0 N !\nPARAMETER G(BCC_B2,*:NI,PT:VA;0) 298.15 T*VA88 + VA87; 6000.0 N !\nPARAMETER G(BCC_B2,NI,PT:*:VA;0) 298.15 T*VA88 + VA87; 6000.0 N !\nPARAMETER L(FCC_A1,NI,PT:VA;0) 298.15 L0FCC + NIPTG0 + 0.375*RECNINI +\n 0.75*RECNIPT + 0.375*RECPTPT; 6000.0 N !\nPARAMETER L(FCC_A1,NI,PT:VA;1) 298.15 L1FCC + NIPTG1 + 0.75*RECNINI -\n 0.75*RECPTPT; 6000.0 N !\nPARAMETER L(FCC_A1,NI,PT:VA;2) 298.15 L2FCC + NIPTG2 - 1.5*RECNIPT; 6000.0 N !\nPARAMETER L(FCC_A1,NI,PT:VA;3) 298.15 L3FCC - 0.75*RECNINI + 0.75*RECPTPT;\n 6000.0 N !\nPARAMETER L(FCC_A1,NI,PT:VA;4) 298.15 -0.375*RECNINI + 0.75*RECNIPT -\n 0.375*RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:NI:PT:VA;0) 298.15 GNI3PT1; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:PT:NI:VA;0) 298.15 GNI3PT1; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:PT:PT:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:NI:NI:VA;0) 298.15 GNI3PT1; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:NI:PT:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:PT:NI:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:PT:PT:VA;0) 298.15 GNI1PT3; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:NI:NI:VA;0) 298.15 GNI3PT1; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:NI:PT:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:PT:NI:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:PT:PT:VA;0) 298.15 GNI1PT3; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:NI:NI:VA;0) 298.15 GNI2PT2; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:NI:PT:VA;0) 298.15 GNI1PT3; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:PT:NI:VA;0) 298.15 GNI1PT3; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:NI,PT:NI,PT:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:NI:NI,PT:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:NI,PT:NI:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:NI,PT:PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:PT:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:NI,PT:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:NI:NI,PT:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:NI,PT:NI:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:NI,PT:PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:PT:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:NI:NI:VA;0) 298.15 RECNINI; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:NI:PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:PT:NI:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:PT:PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:NI:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:NI,PT:NI:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:NI,PT:PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:PT:NI,PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:NI,PT:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:NI:NI,PT:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:NI,PT:NI:VA;0) 298.15 RECNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:NI,PT:PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:PT:NI,PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:NI,PT:NI,PT:VA;0) 298.15 RECPTPT; 6000.0 N !\nPARAMETER L(LIQUID,NI,PT;0) 298.15 -40775.6; 6000.0 N !\nPARAMETER L(LIQUID,NI,PT;1) 298.15 -5500.0; 6000.0 N !\nPARAMETER L(LIQUID,NI,PT;2) 298.15 3500.0; 6000.0 N !\n\n\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n$ AL-NI-PT $\n$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$\n\nPARAMETER G(AL3NI2,AL:PT:NI;0) 298.15 T*VA61 + 3*GBCCAL + GBCCNI + 2*GBCCPT +\n VA60; 6000.0 N !\nPARAMETER G(AL3NI2,AL:NI,PT:*;0) 298.15 T*VA65 + VA64; 6000.0 N !\nPARAMETER G(ALPT,AL:NI,PT;0) 298.15 T*VA73 + VA72; 6000.0 N !\nPARAMETER L(FCC_A1,AL,NI,PT:VA;0) 298.15 T*VA32 + VA31; 6000.0 N !\nPARAMETER L(FCC_A1,AL,NI,PT:VA;1) 298.15 T*VA34 + VA33; 6000.0 N !\nPARAMETER L(FCC_A1,AL,NI,PT:VA;2) 298.15 T*VA36 + VA35; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:NI:PT:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:PT:NI:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:AL:PT:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:NI:PT:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:PT:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:PT:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:PT:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:AL:NI:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:NI:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:NI:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:NI:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:PT:NI:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:AL:PT:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:NI:PT:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:PT:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:PT:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:PT:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:AL:PT:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI:PT:AL:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:AL:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:AL:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:AL:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:NI:AL:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:PT:PT:AL:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:AL:NI:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:NI:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:NI:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:NI:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:PT:NI:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:AL:AL:VA;0) 298.15 GAL2NIPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:AL:NI:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:AL:PT:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:NI:AL:VA;0) 298.15 GNI2ALPT; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI:PT:AL:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:AL:NI:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,PT:PT:NI:AL:VA;0) 298.15 GPT2ALNI; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,NI:AL,PT:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,NI:NI,PT:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,PT:AL,NI:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,PT:NI,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:NI,PT:AL,NI:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:NI,PT:AL,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI:*:AL,PT:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI:*:NI,PT:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI:AL,PT:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI:NI,PT:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:*:AL,NI:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:*:NI,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:AL,NI:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,PT:NI,PT:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:NI,PT:*:AL,NI:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:NI,PT:*:AL,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:NI,PT:AL,NI:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,*:NI,PT:AL,PT:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL:AL:NI,PT:NI,PT:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI:NI,PT:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:AL:NI,PT:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:NI:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:NI,PT:AL:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:NI,PT:NI:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:NI,PT:PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,AL:NI,PT:PT:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,AL:PT:NI,PT:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:*:*:AL,PT:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:*:*:NI,PT:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:*:AL,PT:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:*:NI,PT:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:AL,PT:*:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI:NI,PT:*:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:*:AL,NI:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:*:NI,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:AL,NI:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:*:NI,PT:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:AL,NI:*:*:VA;0) 298.15 LALNIALPT; 6000.0 N !\nPARAMETER G(FCC_L12,AL,PT:NI,PT:*:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI:AL:NI,PT:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:AL:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI:NI,PT:NI,PT:AL:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:*:*:AL,NI:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:*:*:AL,PT:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:*:AL,NI:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:*:AL,PT:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:AL:NI,PT:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:NI:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:NI,PT:AL:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:NI,PT:NI:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:NI,PT:PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL:PT:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL,NI:*:*:VA;0) 298.15 LALNINIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:AL,PT:*:*:VA;0) 298.15 LALPTNIPT; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:AL:NI,PT:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI:NI,PT:AL:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:AL:AL:VA;0) 298.15 T*VA75 + RECPTPT + VA74;\n 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:AL:NI:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:AL:PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:NI:AL:VA;0) 298.15 RECNIPT + VA76; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:NI,PT:PT:AL:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:AL:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,NI,PT:PT:NI,PT:AL:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,PT:AL:NI,PT:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:AL:NI,PT:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,PT:NI,PT:NI,PT:AL:VA;0) 298.15 RECNIPT + VA77; 6000.0 N !\nPARAMETER G(FCC_L12,*:*:AL,NI,PT:AL,NI,PT:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI,PT:*:AL,NI,PT:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER G(FCC_L12,*:AL,NI,PT:AL,NI,PT:*:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI,PT:*:*:AL,NI,PT:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI,PT:*:AL,NI,PT:*:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER G(FCC_L12,AL,NI,PT:AL,NI,PT:*:*:VA;0) 298.15 T*VA81 + VA80; 6000.0 N !\nPARAMETER L(LIQUID,AL,NI,PT;0) 298.15 T*VA2 + VA1; 6000.0 N !\nPARAMETER L(LIQUID,AL,NI,PT;1) 298.15 T*VA4 + VA3; 6000.0 N !\nPARAMETER L(LIQUID,AL,NI,PT;2) 298.15 T*VA6 + VA5; 6000.0 N !\n\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a1ce2f61a8fb3d288ba7b93e527ffc0fce8c312
| 206,154 |
ipynb
|
Jupyter Notebook
|
notebooks/baseline_model.ipynb
|
SudoHead/movie-classifier
|
274bb69db9e8861ac35ce5ff246f4c3a787f8c44
|
[
"MIT"
] | null | null | null |
notebooks/baseline_model.ipynb
|
SudoHead/movie-classifier
|
274bb69db9e8861ac35ce5ff246f4c3a787f8c44
|
[
"MIT"
] | null | null | null |
notebooks/baseline_model.ipynb
|
SudoHead/movie-classifier
|
274bb69db9e8861ac35ce5ff246f4c3a787f8c44
|
[
"MIT"
] | null | null | null | 348.822335 | 172,556 | 0.929582 |
[
[
[
"# Training baseline model\n\nThis notebook shows the implementation of a baseline model for our movie genre classification problem.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport re\nimport json\nimport nltk\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import MultiLabelBinarizer\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.datasets import make_multilabel_classification\nfrom sklearn.multiclass import OneVsRestClassifier\nfrom sklearn.svm import LinearSVC\nfrom sklearn.metrics import f1_score\nfrom sklearn.metrics import precision_recall_fscore_support",
"_____no_output_____"
]
],
[
[
"Load the data and keep the title information: we will add the title to the overview, and delete the title column. ",
"_____no_output_____"
]
],
[
[
"path = '../data/movies_data_ready.csv'\ndf = pd.read_csv(path)\ndf['genres'] = df['genres'].apply(lambda x: x.split(','))\ndf['overview'] = df['title'].apply(lambda x: x.lower()).astype(str) + ' ' + df['overview']\ndel df['title']\ndf.head()",
"_____no_output_____"
]
],
[
[
"### One-hot vector representation and TF-IDF:",
"_____no_output_____"
]
],
[
[
"multilabel_binarizer = MultiLabelBinarizer()\nmultilabel_binarizer.fit(df['genres'])\n\n# transform target variable\ny = multilabel_binarizer.transform(df['genres'])\nprint(multilabel_binarizer.classes_)\nprint('size = ', len(multilabel_binarizer.classes_))",
"['Action' 'Adventure' 'Animation' 'Comedy' 'Crime' 'Documentary' 'Drama'\n 'Family' 'Fantasy' 'Foreign' 'History' 'Horror' 'Music' 'Mystery'\n 'Romance' 'Science Fiction' 'TV Movie' 'Thriller' 'War' 'Western']\nsize = 20\n"
],
[
"# Split the data in train, validate, test\ntesting_size = 0.15\nx_train, x_test, y_train, y_test = train_test_split(df['overview'], y, test_size=testing_size, random_state=42)\nvalidation_size_relative = testing_size/(1-testing_size)",
"_____no_output_____"
],
[
"tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=100000)\n# create TF-IDF features\nx_train_tfidf = tfidf_vectorizer.fit_transform(x_train.values.astype('U'))\nx_test_tfidf = tfidf_vectorizer.transform(x_test.values.astype('U'))",
"_____no_output_____"
]
],
[
[
"### ML model : Logistic regression",
"_____no_output_____"
]
],
[
[
"lr = LogisticRegression(solver='saga', n_jobs=-1, max_iter=1000)\nclf = OneVsRestClassifier(lr)\n\n# fit model on train data\nclf.fit(x_train_tfidf, y_train)",
"_____no_output_____"
],
[
"# predict probabilities\ny_pred_prob = clf.predict_proba(x_test_tfidf)\n\nt = 0.5 # threshold value\ny_pred_new = np.where(y_pred_prob >= t, 1, 0)\n\nprecision_recall_fscore_support(y_test, y_pred_new, average='micro')",
"_____no_output_____"
]
],
[
[
"### ML model: SVC",
"_____no_output_____"
]
],
[
[
"svc = LinearSVC()\nclf_svm = OneVsRestClassifier(svc)\n\n# fit model on train data\nclf_svm.fit(x_train_tfidf, y_train)",
"_____no_output_____"
],
[
"# make predictions for validation set\ny_pred = clf_svm.predict(x_test_tfidf)\n\nprecision_recall_fscore_support(y_test, y_pred, average='micro')",
"_____no_output_____"
]
],
[
[
"## ROC curves",
"_____no_output_____"
]
],
[
[
"from itertools import cycle\n\nfrom sklearn.metrics import roc_curve, auc\nfrom sklearn.metrics import roc_auc_score\nfrom scipy import interp\nfrom matplotlib import colors as mcolors\nimport seaborn as sns",
"_____no_output_____"
],
[
"def plot_multilabel_ROC(classes_lab, y_score, title, hide_classes=False):\n # Compute ROC curve and ROC area for each class\n fpr = dict()\n tpr = dict()\n thresholds = dict()\n roc_auc = dict()\n n_classes = len(classes_lab)\n for i in range(n_classes):\n fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])\n roc_auc[i] = auc(fpr[i], tpr[i])\n\n # Compute micro-average ROC curve and ROC area\n fpr[\"micro\"], tpr[\"micro\"], thresholds['micro'] = roc_curve(y_test.ravel(), y_score.ravel())\n roc_auc[\"micro\"] = auc(fpr[\"micro\"], tpr[\"micro\"])\n \n # First aggregate all false positive rates\n all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))\n\n # Then interpolate all ROC curves at this points\n mean_tpr = np.zeros_like(all_fpr)\n for i in range(n_classes):\n mean_tpr += interp(all_fpr, fpr[i], tpr[i])\n\n # Finally average it and compute AUC\n mean_tpr /= n_classes\n\n fpr[\"macro\"] = all_fpr\n tpr[\"macro\"] = mean_tpr\n roc_auc[\"macro\"] = auc(fpr[\"macro\"], tpr[\"macro\"])\n\n lw = 3\n \n # Plot all ROC curves\n plt.figure(figsize=(12,12))\n if not hide_classes:\n colors = cycle(sns.color_palette('bright', 8))\n for i, color in zip(range(n_classes), colors):\n lab = classes_lab[i] + '(auc = '+ str(round(roc_auc[i],2)) + ')'\n plt.plot(fpr[i], tpr[i], color=color, label=lab, linewidth=1)\n\n plt.plot(fpr[\"micro\"], tpr[\"micro\"],\n label='micro-average ROC curve (area = {0:0.2f})'''.format(roc_auc[\"micro\"]),\n color='deeppink', linestyle=':', linewidth=8)\n\n plt.plot(fpr[\"macro\"], tpr[\"macro\"],\n label='macro-average ROC curve (area = {0:0.2f})'''.format(roc_auc[\"macro\"]),\n color='navy', linestyle=':', linewidth=8) \n\n plt.plot([0, 1], [0, 1], 'k--', lw=lw)\n plt.xlim([0.0, 1.0])\n plt.ylim([0.0, 1.05])\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title(title)\n plt.legend(loc=\"lower right\")\n plt.show()\n \n return thresholds['micro'], fpr['macro'], tpr['macro']",
"_____no_output_____"
],
[
"multilabel_binarizer.classes_",
"_____no_output_____"
],
[
"title = 'ROC curve for logistic regression'\nthresh, fpr, tpr = plot_multilabel_ROC(multilabel_binarizer.classes_, y_pred_prob, title, hide_classes=False)",
"_____no_output_____"
]
],
[
[
"### Find the best threshold for logistic regression",
"_____no_output_____"
]
],
[
[
"optimal_idx = np.argmax(tpr - fpr)\noptimal_threshold = thresh[optimal_idx]\noptimal_threshold",
"_____no_output_____"
],
[
"y_pred_new = np.where(y_pred_prob > optimal_threshold, 1, 0)\n\nprecision_recall_fscore_support(y_test, y_pred_new, average='micro')",
"_____no_output_____"
]
],
[
[
"### Precision recall curve",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import precision_recall_curve\n\n# precision, recall, thresholds = precision_recall_curve(y_test, y_pred_prob)\nstep = 0.01\nprec = {'micro':{}}\nrecall = {'micro':{}}\nf1 = {'micro':{}}\nthresholds = np.arange(0.0, 1.0, step)\nfor t in thresholds:\n pred_t = np.where(y_pred_prob >= t, 1, 0)\n prec['micro'][t], recall['micro'][t], f1['micro'][t], _ = precision_recall_fscore_support(y_test, pred_t, average='micro')",
"_____no_output_____"
],
[
"plt.plot(list(recall['micro'].values()), list(prec['micro'].values()), lw=2, label='micro avg')\n\nplt.xlabel(\"recall\")\nplt.ylabel(\"precision\")\nplt.legend(loc=\"best\")\nplt.title(\"precision vs. recall curve\")\nplt.show()",
"_____no_output_____"
],
[
"optimal_idx_micro = np.argmax(list(f1['micro'].values()))\nprint('micro optimal threshold:', thresholds[optimal_idx_micro])\ny_pred_new = np.where(y_pred_prob > thresholds[optimal_idx_micro], 1, 0)\nprint(precision_recall_fscore_support(y_test, y_pred_new, average='micro'))",
"micro optimal threshold: 0.24\n(0.5533123028391167, 0.6499666493737494, 0.5977575571686604, None)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a1cec96c4fcf31536191ecdc8e2971259a9df20
| 8,469 |
ipynb
|
Jupyter Notebook
|
tutorials/source_zh_cn/tensor.ipynb
|
bwcsswcx/docs
|
e54b179bb8ca020a9bf0c83926822048057e9536
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
tutorials/source_zh_cn/tensor.ipynb
|
bwcsswcx/docs
|
e54b179bb8ca020a9bf0c83926822048057e9536
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
tutorials/source_zh_cn/tensor.ipynb
|
bwcsswcx/docs
|
e54b179bb8ca020a9bf0c83926822048057e9536
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null | 21.771208 | 772 | 0.500649 |
[
[
[
"# 张量\n\n[](https://gitee.com/mindspore/docs/blob/master/tutorials/source_zh_cn/tensor.ipynb) [](https://obs.dualstack.cn-north-4.myhuaweicloud.com/mindspore-website/notebook/master/tutorials/zh_cn/mindspore_tensor.ipynb) [](https://authoring-modelarts-cnnorth4.huaweicloud.com/console/lab?share-url-b64=aHR0cHM6Ly9vYnMuZHVhbHN0YWNrLmNuLW5vcnRoLTQubXlodWF3ZWljbG91ZC5jb20vbWluZHNwb3JlLXdlYnNpdGUvbm90ZWJvb2svbW9kZWxhcnRzL3F1aWNrX3N0YXJ0L21pbmRzcG9yZV90ZW5zb3IuaXB5bmI=&imageid=65f636a0-56cf-49df-b941-7d2a07ba8c8c)\n\n张量(Tensor)是MindSpore网络运算中的基本数据结构。\n\n首先导入本文档需要的模块和接口,如下所示:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom mindspore import Tensor, context\nfrom mindspore import dtype as mstype\ncontext.set_context(mode=context.GRAPH_MODE, device_target=\"CPU\")",
"_____no_output_____"
]
],
[
[
"## 初始化张量\n\n张量的初始化方式有多种,构造张量时,支持传入`Tensor`、`float`、`int`、`bool`、`tuple`、`list`和`NumPy.array`类型。\n\n- **根据数据直接生成**\n\n可以根据数据创建张量,数据类型可以设置或者自动推断。",
"_____no_output_____"
]
],
[
[
"x = Tensor(0.1)",
"_____no_output_____"
]
],
[
[
"\n- **从NumPy数组生成**\n\n可以从NumPy数组创建张量。",
"_____no_output_____"
]
],
[
[
"arr = np.array([1, 0, 1, 0])\nx_np = Tensor(arr)",
"_____no_output_____"
]
],
[
[
"\n初始值是`NumPy.array`,则生成的`Tensor`数据类型与之对应。\n\n- **继承另一个张量的属性,形成新的张量**\n",
"_____no_output_____"
]
],
[
[
"from mindspore import ops\noneslike = ops.OnesLike()\nx = Tensor(np.array([[0, 1], [2, 1]]).astype(np.int32))\noutput = oneslike(x)\nprint(output)",
"[[1 1]\n [1 1]]\n"
]
],
[
[
"\n- **输出指定大小的恒定值张量**\n\n`shape`是张量的尺寸元组,确定输出的张量的维度。\n",
"_____no_output_____"
]
],
[
[
"from mindspore.ops import operations as ops\n\nshape = (2, 2)\nones = ops.Ones()\noutput = ones(shape, mstype.float32)\nprint(output)\n\nzeros = ops.Zeros()\noutput = zeros(shape, mstype.float32)\nprint(output)",
"[[1. 1.]\n [1. 1.]]\n[[0. 0.]\n [0. 0.]]\n"
]
],
[
[
"\n`Tensor`初始化时,可指定dtype,如`mstype.int32`、`mstype.float32`、`mstype.bool_`等。\n\n## 张量的属性\n\n张量的属性包括形状(shape)和数据类型(dtype)。\n\n- 形状:`Tensor`的shape,是一个tuple。\n- 数据类型:`Tensor`的dtype,是MindSpore的一个数据类型。",
"_____no_output_____"
]
],
[
[
"t1 = Tensor(np.zeros([1,2,3]), mstype.float32)\nprint(\"Datatype of tensor: {}\".format(t1.dtype))\nprint(\"Shape of tensor: {}\".format(t1.shape))",
"Datatype of tensor: Float32\nShape of tensor: (1, 2, 3)\n"
]
],
[
[
"\n## 张量运算\n\n张量之间有很多运算,包括算术、线性代数、矩阵处理(转置、标引、切片)、采样等,下面介绍其中几种操作,张量运算和NumPy的使用方式类似。\n\n类似NumPy的索引和切片操作:\n",
"_____no_output_____"
]
],
[
[
"tensor = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))\nprint(\"First row: {}\".format(tensor[0]))\nprint(\"First column: {}\".format(tensor[:, 0]))\nprint(\"Last column: {}\".format(tensor[..., -1]))",
"First row: [0. 1.]\nFirst column: [0. 2.]\nLast column: [1. 3.]\n"
]
],
[
[
"\n`Concat`将给定维度上的一系列张量连接起来。",
"_____no_output_____"
]
],
[
[
"data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))\ndata2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))\nop = ops.Concat()\noutput = op((data1, data2))\nprint(output)",
"[[0. 1.]\n [2. 3.]\n [4. 5.]\n [6. 7.]]\n"
]
],
[
[
"\n`Stack`则是从另一个维度上将两个张量合并起来。",
"_____no_output_____"
]
],
[
[
"data1 = Tensor(np.array([[0, 1], [2, 3]]).astype(np.float32))\ndata2 = Tensor(np.array([[4, 5], [6, 7]]).astype(np.float32))\nop = ops.Stack()\noutput = op([data1, data2])\nprint(output)",
"[[[0. 1.]\n [2. 3.]]\n\n [[4. 5.]\n [6. 7.]]]\n"
]
],
[
[
"普通运算:",
"_____no_output_____"
]
],
[
[
"input_x = Tensor(np.array([1.0, 2.0, 3.0]), mstype.float32)\ninput_y = Tensor(np.array([4.0, 5.0, 6.0]), mstype.float32)\nmul = ops.Mul()\noutput = mul(input_x, input_y)\nprint(output)",
"[ 4. 10. 18.]\n"
]
],
[
[
"\n## 与NumPy转换\n\n张量可以和NumPy进行互相转换。\n\n### 张量转换为NumPy",
"_____no_output_____"
]
],
[
[
"zeros = ops.Zeros()\noutput = zeros((2,2), mstype.float32)\nprint(\"output: {}\".format(type(output)))\nn_output = output.asnumpy()\nprint(\"n_output: {}\".format(type(n_output)))",
"output: <class 'mindspore.common.tensor.Tensor'>\nn_output: <class 'numpy.ndarray'>\n"
]
],
[
[
"\n### NumPy转换为张量",
"_____no_output_____"
]
],
[
[
"output = np.array([1, 0, 1, 0])\nprint(\"output: {}\".format(type(output)))\nt_output = Tensor(output)\nprint(\"t_output: {}\".format(type(t_output)))",
"output: <class 'numpy.ndarray'>\nt_output: <class 'mindspore.common.tensor.Tensor'>\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1cef2b73017a92fa396f96f552f09bd5c43e82
| 1,349 |
ipynb
|
Jupyter Notebook
|
Module2/Python_Data_Analysis_code/Chapter 8/net_density.ipynb
|
vijaysharmapc/Python-End-to-end-Data-Analysis
|
a00f2d5d1547993e000b2551ec6a1360240885ba
|
[
"MIT"
] | 119 |
2016-08-24T20:12:01.000Z
|
2022-03-23T03:59:30.000Z
|
Chapter 8/net_density.ipynb
|
woaitianfa/PythonDataAnalysisCookbook
|
e41b5c1d097239d876ab64a4ce7ec2fb3f6a5c7b
|
[
"MIT"
] | 3 |
2016-10-18T03:49:11.000Z
|
2020-11-03T12:41:29.000Z
|
Chapter 8/net_density.ipynb
|
woaitianfa/PythonDataAnalysisCookbook
|
e41b5c1d097239d876ab64a4ce7ec2fb3f6a5c7b
|
[
"MIT"
] | 110 |
2016-08-19T01:57:35.000Z
|
2022-02-18T17:02:17.000Z
| 20.134328 | 61 | 0.508525 |
[
[
[
"import networkx as nx\nimport dautil as dl",
"_____no_output_____"
],
[
"context = dl.nb.Context('net_density')\nlr = dl.nb.LatexRenderer(chapter=8, context=context)\nlr.render(r'd = \\frac{2m}{n(n-1)}')\nlr.render(r'd = \\frac{m}{n(n-1)}')",
"_____no_output_____"
],
[
"fb_file = dl.data.SPANFB().load()\nG = nx.read_edgelist(fb_file,\n create_using=nx.Graph(),\n nodetype=int)\nprint('Density', nx.density(G))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a1d065b5cb344a8cb884c851f1b740182b1b7be
| 31,689 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Covid-checkpoint.ipynb
|
alexisvillagra9/covid-barchartrace
|
b80e2a87d84c64ab4bebd2f96da3d75e1fdef14d
|
[
"ImageMagick",
"Zlib"
] | null | null | null |
.ipynb_checkpoints/Covid-checkpoint.ipynb
|
alexisvillagra9/covid-barchartrace
|
b80e2a87d84c64ab4bebd2f96da3d75e1fdef14d
|
[
"ImageMagick",
"Zlib"
] | null | null | null |
.ipynb_checkpoints/Covid-checkpoint.ipynb
|
alexisvillagra9/covid-barchartrace
|
b80e2a87d84c64ab4bebd2f96da3d75e1fdef14d
|
[
"ImageMagick",
"Zlib"
] | null | null | null | 35.249166 | 1,637 | 0.337467 |
[
[
[
"### Import Section\nimport pandas as pd",
"_____no_output_____"
],
[
"### Local Variables\ndatasetPath = './dataset/owid-covid-data.csv'",
"_____no_output_____"
],
[
"### Load dataset\ndf=pd.read_csv(datasetPath)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"print(df['date'].max(),df['date'].min())",
"2020-10-06 2019-12-31\n"
],
[
"df['total_cases'] = df['total_cases'].fillna(0)",
"_____no_output_____"
],
[
"dfToPivot = df[['location','date','total_cases']]",
"_____no_output_____"
],
[
"dfToPivot",
"_____no_output_____"
],
[
"dfPivot = dfToPivot.pivot(index='date', columns='location', values='total_cases')",
"_____no_output_____"
],
[
"dfPivot",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nfig, ax = plt.subplots(figsize=(4, 2.5), dpi=144)\ncolors = plt.cm.Dark2(range(6))\ny = s.index\nwidth = s.values\nax.barh(y=y, width=width, color=colors);",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1d0fa353ee666c3bea12df79e4324a582130fb
| 3,429 |
ipynb
|
Jupyter Notebook
|
08 practice/DecisionTrees.ipynb
|
barjacks/algorithms_mine
|
bc248ed9ebb88aed73c6e8da3d3b9553d9173cdd
|
[
"MIT"
] | null | null | null |
08 practice/DecisionTrees.ipynb
|
barjacks/algorithms_mine
|
bc248ed9ebb88aed73c6e8da3d3b9553d9173cdd
|
[
"MIT"
] | null | null | null |
08 practice/DecisionTrees.ipynb
|
barjacks/algorithms_mine
|
bc248ed9ebb88aed73c6e8da3d3b9553d9173cdd
|
[
"MIT"
] | null | null | null | 18.239362 | 75 | 0.523185 |
[
[
[
"import pandas as pd\n%matplotlib inline",
"_____no_output_____"
],
[
"from sklearn import datasets\nfrom pandas.tools.plotting import scatter_matrix",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"iris = datasets.load_iris() # load iris data set",
"_____no_output_____"
],
[
"x = iris.data[:,2:] # the attributes\ny = iris.target # the target variable",
"_____no_output_____"
],
[
"from sklearn import tree",
"_____no_output_____"
],
[
"dt = tree.DecisionTreeClassifier()",
"_____no_output_____"
],
[
"dt = dt.fit(x,y)",
"_____no_output_____"
],
[
"from sklearn.externals.six import StringIO\nimport pydotplus #pip install pydotplus",
"_____no_output_____"
],
[
"with open(\"iris.dot\", 'w') as f:\n f = tree.export_graphviz(dt, out_file=f)",
"_____no_output_____"
],
[
"import os\nos.unlink('iris.dot')",
"_____no_output_____"
],
[
"dot_data = StringIO() \ntree.export_graphviz(dt, out_file=dot_data) #brew install graphviz\ngraph = pydotplus.graph_from_dot_data(dot_data.getvalue()) \ngraph.write_pdf(\"iris.pdf\") ",
"_____no_output_____"
],
[
"from IPython.display import IFrame\nIFrame(\"iris.pdf\", width=800, height=800)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1d1140a04f5410c79aeafff144027fb23f4604
| 386,039 |
ipynb
|
Jupyter Notebook
|
notebooks/2017-03-31(Speed benchmarks).ipynb
|
h-mayorquin/attractor_sequences
|
885271f30d73a58a7aad83b55949e4e32ba0b45a
|
[
"MIT"
] | 1 |
2016-08-19T18:58:51.000Z
|
2016-08-19T18:58:51.000Z
|
notebooks/2017-03-31(Speed benchmarks).ipynb
|
h-mayorquin/attractor_sequences
|
885271f30d73a58a7aad83b55949e4e32ba0b45a
|
[
"MIT"
] | null | null | null |
notebooks/2017-03-31(Speed benchmarks).ipynb
|
h-mayorquin/attractor_sequences
|
885271f30d73a58a7aad83b55949e4e32ba0b45a
|
[
"MIT"
] | null | null | null | 773.625251 | 79,698 | 0.943148 |
[
[
[
"# Speed benchmarks\nThis is just for having a quick reference of how the speed of running the program scales",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function\nimport pprint\nimport subprocess\nimport sys \nsys.path.append('../')\n# sys.path.append('/home/heberto/learning/attractor_sequences/benchmarking/')\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib\nimport matplotlib.gridspec as gridspec\nfrom mpl_toolkits.axes_grid1 import make_axes_locatable\nimport seaborn as sns\n\n%matplotlib inline\n\nnp.set_printoptions(suppress=True, precision=2)\n\nsns.set(font_scale=2.0)",
"_____no_output_____"
]
],
[
[
"#### Git machine",
"_____no_output_____"
]
],
[
[
"run_old_version = False\nif run_old_version:\n hash_when_file_was_written = '321620ef1b753fe42375bbf535c9ab941b72ae26'\n hash_at_the_moment = subprocess.check_output([\"git\", 'rev-parse', 'HEAD']).strip()\n print('Actual hash', hash_at_the_moment)\n \n print('Hash of the commit used to run the simulation', hash_when_file_was_written)\n subprocess.call(['git', 'checkout', hash_when_file_was_written])",
"_____no_output_____"
]
],
[
[
"#### Load the libraries",
"_____no_output_____"
]
],
[
[
"from benchmarking.standard_program import run_standard_program, calculate_succes_program, training_program\nimport timeit",
"_____no_output_____"
],
[
"def wrapper(func, *args, **kwargs):\n def wrapped():\n return func(*args, **kwargs)\n return wrapped\n",
"_____no_output_____"
]
],
[
[
"## Standard program\n#### Minicolumns",
"_____no_output_____"
]
],
[
[
"hypercolumns = 4\nminicolumns_range = np.arange(10, 100, 5)\nepochs = 1\ntimes_minicolumns = []\n\nfor minicolumns in minicolumns_range:\n function = wrapper(run_standard_program, hypercolumns=hypercolumns, minicolumns=minicolumns, epochs=epochs)\n time = timeit.timeit(function, number=1)\n times_minicolumns.append(time)",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(16, 12))\nax = fig.add_subplot(111)\nax.plot(minicolumns_range, times_minicolumns, '*-', markersize=14)\nax.set_xlabel('Minicolumns')\nax.set_ylabel('Seconds that the program runed');",
"_____no_output_____"
]
],
[
[
"#### Hypercolumns",
"_____no_output_____"
]
],
[
[
"hypercolumns_range = np.arange(4, 20, 2)\nminicolumns = 20\nepochs = 1\n\ntimes_hypercolumns = []\nfor hypercolumns in hypercolumns_range:\n function = wrapper(run_standard_program, hypercolumns, minicolumns, epochs)\n time = timeit.timeit(function, number=1)\n times_hypercolumns.append(time)",
"_____no_output_____"
],
[
"sns.set(font_scale=2.0)\nfig = plt.figure(figsize=(16, 12))\nax = fig.add_subplot(111)\nax.plot(hypercolumns_range, times_hypercolumns, '*-', markersize=14)\nax.set_xlabel('Hypercolumns')\nax.set_ylabel('Seconds that the program runed');",
"_____no_output_____"
]
],
[
[
"#### Epochs",
"_____no_output_____"
]
],
[
[
"hypercolumns = 4\nminicolumns = 20\nepochs_range = np.arange(1, 10, 1)\n\ntimes_epochs = []\nfor epochs in epochs_range:\n function = wrapper(run_standard_program, hypercolumns, minicolumns, epochs)\n time = timeit.timeit(function, number=1)\n times_epochs.append(time)",
"_____no_output_____"
],
[
"sns.set(font_scale=2.0)\nfig = plt.figure(figsize=(16, 12))\nax = fig.add_subplot(111)\nax.plot(epochs_range, times_epochs, '*-', markersize=14)\nax.set_xlabel('Epochs')\nax.set_ylabel('Seconds that the program runed')",
"_____no_output_____"
]
],
[
[
"#### Everything to compare",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(16, 12))\nax1 = fig.add_subplot(131)\nax2 = fig.add_subplot(132)\nax3 = fig.add_subplot(133)\n\nax1.plot(minicolumns_range, times_minicolumns, '*-', markersize=14)\nax2.plot(hypercolumns_range, times_hypercolumns, '*-', markersize=14)\nax3.plot(epochs_range, times_epochs, '*-', markersize=14)\n\nax1.set_title('Minicolumn scaling')\nax2.set_title('Hypercolumn scaling')\nax3.set_title('Epoch scaling')\n\nax1.set_ylabel('Time (s)');\n",
"_____no_output_____"
]
],
[
[
"## Training and recalling times\nHer we run the standard program before and then we test how long it takes for it to run recalls and test recall success",
"_____no_output_____"
]
],
[
[
"hypercolumns = 4\nminicolumns = 10\nepochs = 3\nmanager = run_standard_program(hypercolumns, minicolumns, epochs)",
"_____no_output_____"
]
],
[
[
"#### Recall only",
"_____no_output_____"
]
],
[
[
"T_recall_range = np.arange(3, 20, 1)\ntime_recall = []\n\nfor T_recall in T_recall_range:\n function = wrapper(training_program, manager=manager, T_recall=T_recall)\n time = timeit.timeit(function, number=1)\n time_recall.append(time)",
"3\n4\n5\n6\n7\n8\n9\n10\n11\n12\n13\n14\n15\n16\n17\n18\n19\n"
],
[
"# Plot4\nfig = plt.figure(figsize=(16, 12))\nax = fig.add_subplot(111)\nax.plot(T_recall_range, time_recall, '*-', markersize=14)\n\nax.set_xlabel('T_recall')\nax.set_ylabel('Seconds that the program took to run')\nax.set_title('Normal recall profile')\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Success recall",
"_____no_output_____"
]
],
[
[
"T_recall_range = np.arange(3, 20, 1)\ntime_success = []\n\nfor T_recall in T_recall_range:\n function = wrapper(calculate_succes_program, manager=manager, T_recall=T_recall)\n time = timeit.timeit(function, number=1)\n time_success.append(time)\n\n ",
"_____no_output_____"
],
[
"# Plot\nfig = plt.figure(figsize=(16, 12))\nax = fig.add_subplot(111)\nax.plot(T_recall_range, time_success, '*-', markersize=14)\nax.plot(T_recall_range, time_recall, '*-', markersize=14)\n\nax.set_xlabel('T_recall')\nax.set_ylabel('Seconds that the program took to run')\nax.set_title('Recall Success profiling')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1d17452ee091093759237660eba501b4e16d1c
| 551,563 |
ipynb
|
Jupyter Notebook
|
Lectures/Lecture1/3dasm_Lecture1.ipynb
|
shushu-qin/3dasm_course
|
a53ce9f8d7c692a9b1356946ec11e60b35b7bbcd
|
[
"BSD-3-Clause"
] | 3 |
2022-02-07T18:45:48.000Z
|
2022-02-23T21:45:27.000Z
|
Lectures/Lecture1/3dasm_Lecture1.ipynb
|
shushu-qin/3dasm_course
|
a53ce9f8d7c692a9b1356946ec11e60b35b7bbcd
|
[
"BSD-3-Clause"
] | null | null | null |
Lectures/Lecture1/3dasm_Lecture1.ipynb
|
shushu-qin/3dasm_course
|
a53ce9f8d7c692a9b1356946ec11e60b35b7bbcd
|
[
"BSD-3-Clause"
] | 6 |
2022-02-07T18:45:49.000Z
|
2022-02-25T19:30:17.000Z
| 369.432686 | 159,916 | 0.929455 |
[
[
[
"<!--- <div style=\"text-align: center;\">\n\n<font size=\"5\">\n <b>Data-driven Design and Analyses of Structures and Materials (3dasm)</b>\n</font>\n</div> \n\n<br>\n</br>\n\n<div style=\"text-align: center;\">\n\n<font size=\"5\">\n <b>Lecture 1</b>\n</font>\n</div>\n\n<center>\n\n<img src=docs/tudelft_logo.jpg width=550px>\n</center>\n \n\n \n<div style=\"text-align: center;\">\n <font size=\"4\">\n <b>Miguel A. Bessa | <a href = \"mailto: [email protected]\">[email protected]</a> | Associate Professor</b>\n</font>\n\n\n</div> -->\n\n<img src=docs/tudelft_logo.jpg width=50%>\n\n## Data-driven Design and Analyses of Structures and Materials (3dasm)\n\n## Lecture 1\n\n### Miguel A. Bessa | <a href = \"mailto: [email protected]\">[email protected]</a> | Associate Professor",
"_____no_output_____"
],
[
"## Introduction\n\n**What:** A lecture of the \"3dasm\" course\n\n**Where:** This notebook comes from this [repository](https://github.com/bessagroup/3dasm_course)\n\n**Reference for entire course:** Murphy, Kevin P. *Probabilistic machine learning: an introduction*. MIT press, 2022. Available online [here](https://probml.github.io/pml-book/book1.html)\n\n**How:** We try to follow Murphy's book closely, but the sequence of Chapters and Sections is different. The intention is to use notebooks as an introduction to the topic and Murphy's book as a resource.\n* If working offline: Go through this notebook and read the book.\n* If attending class in person: listen to me (!) but also go through the notebook in your laptop at the same time. Read the book.\n* If attending lectures remotely: listen to me (!) via Zoom and (ideally) use two screens where you have the notebook open in 1 screen and you see the lectures on the other. Read the book.",
"_____no_output_____"
],
[
"**Optional reference (the \"bible\" by the \"bishop\"... pun intended 😆) :** Bishop, Christopher M. *Pattern recognition and machine learning*. Springer Verlag, 2006.\n\n**References/resources to create this notebook:**\n* [Figure (Car stopping distance)](https://korkortonline.se/en/theory/reaction-braking-stopping/)\n* Snippets of code from this awesome [repo](https://github.com/gerdm/prml) by Gerardo Duran-Martin that replicates many figures in Bishop's book\n\nApologies in advance if I missed some reference used in this notebook. Please contact me if that is the case, and I will gladly include it here.",
"_____no_output_____"
],
[
"## **OPTION 1**. Run this notebook **locally in your computer**:\n1. Install miniconda3 [here](https://docs.conda.io/en/latest/miniconda.html)\n2. Open a command window and create a virtual environment called \"3dasm\":\n```\nconda create -n 3dasm python=3 numpy scipy jupyter nb_conda matplotlib pandas scikit-learn rise tensorflow -c conda-forge\n```\n3. Install [git](https://github.com/git-guides/install-git), open command window & clone the repository to your computer:\n```\ngit clone https://github.com/bessagroup/3dasm_course\n```\n4. Load jupyter notebook by typing in (anaconda) command window (it will open in your internet browser):\n```\nconda activate 3dasm\njupyter notebook\n```\n5. Open notebook (3dasm_course/Lectures/Lecture1/3dasm_Lecture1.ipynb)",
"_____no_output_____"
],
[
"**Short note:** My personal environment also has other packages that help me while teaching.\n\n> conda install -n 3dasm -c conda-forge jupyter_contrib_nbextensions hide_code\n\nThen in the 3dasm conda environment:\n\n> jupyter nbextension install --py hide_code --sys-prefix\n>\n> jupyter nbextension enable --py hide_code\n>\n> jupyter serverextension enable --py hide_code\n>\n> jupyter nbextension enable splitcell/splitcell",
"_____no_output_____"
],
[
"## **OPTION 2**. Use **Google's Colab** (no installation required, but times out if idle):\n\n1. go to https://colab.research.google.com\n2. login\n3. File > Open notebook\n4. click on Github (no need to login or authorize anything)\n5. paste the git link: https://github.com/bessagroup/3dasm_course\n6. click search and then click on the notebook (*3dasm_course/Lectures/Lecture1/3dasm_Lecture1.ipynb*)",
"_____no_output_____"
]
],
[
[
"# Basic plotting tools needed in Python.\n\nimport matplotlib.pyplot as plt # import plotting tools to create figures\nimport numpy as np # import numpy to handle a lot of things!\n\n%config InlineBackend.figure_format = \"retina\" # render higher resolution images in the notebook\nplt.style.use(\"seaborn\") # style for plotting that comes from seaborn\nplt.rcParams[\"figure.figsize\"] = (8,4) # rescale figure size appropriately for slides",
"_____no_output_____"
]
],
[
[
"## Outline for today\n\n* Introduction\n - Taking a probabilistic perspective on machine learning\n* Basics of univariate statistics\n - Continuous random variables\n - Probabilities vs probability densities\n - Moments of a probability distribution\n* The mindblowing Bayes' rule\n - The rule that spawns almost every ML model (even when we don't realize it)\n\n**Reading material**: This notebook + Chapter 2 until Section 2.3",
"_____no_output_____"
],
[
"## Get hyped about Artificial Intelligence...",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, YouTubeVideo, HTML\nYouTubeVideo('RNnZwvklwa8', width=512, height=288) # show that slides are interactive:\n # rescale video to 768x432 and back to 512x288",
"_____no_output_____"
]
],
[
[
"**Well...** This class *might* not make you break the world (yet!). Let's focus on the fundamentals:\n\n* Probabilistic perspective on machine learning\n* Supervised learning (especially regression)",
"_____no_output_____"
],
[
"## Machine learning (ML)\n\n* **ML definition**: A computer program that learns from experience $E$ wrt tasks $T$ such that the performance $P$ at those tasks improves with experience $E$.\n\n* We'll treat ML from a **probabilistic perspective**:\n - Treat all unknown quantities as **random variables**\n \n* What are random variables?\n - Variables endowed with probability distributions!",
"_____no_output_____"
],
[
"## The car stopping distance problem\n\n<img src=\"docs/reaction-braking-stopping.svg\" title=\"Car stopping distance\" width=\"50%\" align=\"right\">\n\n<br></br>\nCar stopping distance ${\\color{red}y}$ as a function of its velocity ${\\color{green}x}$ before it starts braking:\n\n${\\color{red}y} = {\\color{blue}z} x + \\frac{1}{2\\mu g} {\\color{green}x}^2 = {\\color{blue}z} x + 0.1 {\\color{green}x}^2$\n\n- ${\\color{blue}z}$ is the driver's reaction time (in seconds)\n- $\\mu$ is the road/tires coefficient of friction (assume $\\mu=0.5$)\n- $g$ is the acceleration of gravity (assume $g=10$ m/s$^2$).",
"_____no_output_____"
],
[
"## The car stopping distance problem\n\n### How to obtain this formula?\n\n$y = d_r + d_{b}$\n\nwhere $d_r$ is the reaction distance, and $d_b$ is the braking distance.\n\n### Reaction distance $d_r$\n\n$d_r = z x$\n\nwith $z$ being the driver's reaction time, and $x$ being the velocity of the car at the start of braking.",
"_____no_output_____"
],
[
"## The car stopping distance problem\n\n### Braking distance $d_b$\n\nKinetic energy of moving car:\n\n$E = \\frac{1}{2}m x^2$ where $m$ is the car mass.\n\nWork done by braking:\n\n$W = \\mu m g d_b$ where $\\mu$ is the coefficient of friction between the road and the tire, $g$ is the acceleration of gravity, and $d_b$ is the car braking distance.\n\nThe braking distance follows from $E=W$:\n\n$d_b = \\frac{1}{2\\mu g}x^2$\n\nTherefore, if we add the reacting distance $d_r$ to the braking distance $d_b$ we get the stopping distance $y$:\n\n$$y = d_r + d_b = z x + \\frac{1}{2\\mu g} x^2$$",
"_____no_output_____"
],
[
"## The car stopping distance problem\n\n<img src=\"docs/reaction-braking-stopping.svg\" title=\"Car stopping distance\" width=\"25%\" align=\"right\">\n\n$y = {\\color{blue}z} x + 0.1 x^2$\n\nThe driver's reaction time ${\\color{blue}z}$ is a **random variable (rv)**\n\n* Every driver has its own reaction time $z$\n\n* Assume the distribution associated to $z$ is Gaussian with **mean** $\\mu_z=1.5$ seconds and **variance** $\\sigma_z^2=0.5$ seconds$^2$\n\n$$\nz \\sim \\mathcal{N}(\\mu_z=1.5,\\sigma_z^2=0.5^2)\n$$\n\nwhere $\\sim$ means \"sampled from\", and $\\mathcal{N}$ indicates a Gaussian **probability density function (pdf)**",
"_____no_output_____"
],
[
"## Univariate Gaussian <a title=\"probability density function\">pdf</a> \n\nThe gaussian <a title=\"probability density function\">pdf</a> is defined as:\n\n$$\n \\mathcal{N}(z | \\mu_z, \\sigma_z^2) = \\frac{1}{\\sqrt{2\\pi\\sigma_z^2}}e^{-\\frac{1}{2\\sigma_z^2}(z - \\mu_z)^2}\n$$\n\nAlternatively, we can write it using the **precision** term $\\lambda_z := 1 / \\sigma_z^2$ instead of using $\\sigma_z^2$:\n\n$$\n \\mathcal{N}(z | \\mu_z, \\lambda_z^{-1}) = \\frac{\\lambda_z^{1/2}}{\\sqrt{2\\pi}}e^{-\\frac{\\lambda_z}{2}(z - \\mu_z)^2}\n$$\n\nAnyway, recall how this <a title=\"probability density function\">pdf</a> looks like...",
"_____no_output_____"
]
],
[
[
"def norm_pdf(z, mu_z, sigma_z2): return 1 / np.sqrt(2 * np.pi * sigma_z2) * np.exp(-(z - mu_z)**2 / (2 * sigma_z2))\nzrange = np.linspace(-8, 4, 200) # create a list of 200 z points between z=-8 and z=4\nfig, ax = plt.subplots() # create a plot\nax.plot(zrange, norm_pdf(zrange, 0, 1), label=r\"$\\mu_z=0; \\ \\sigma_z^2=1$\") # plot norm_pdf(z|0,1)\nax.plot(zrange, norm_pdf(zrange, 1.5, 0.5**2), label=r\"$\\mu_z=1.5; \\ \\sigma_z^2=0.5^2$\") # plot norm_pdf(z|1.5,0.5^2)\nax.plot(zrange, norm_pdf(zrange, -1, 2**2), label=r\"$\\mu_z=-1; \\ \\sigma_z^2=2^2$\") # plot norm_pdf(z|-1,2^2)\nax.set_xlabel(\"z\", fontsize=20) # create x-axis label with font size 20\nax.set_ylabel(\"probability density\", fontsize=20) # create y-axis label with font size 20\nax.legend(fontsize=15) # create legend with font size 15\nax.set_title(\"Three different Gaussian pdfs\", fontsize=20); # create title with font size 20",
"_____no_output_____"
]
],
[
[
"The <span style=\"color:green\">green</span> curve shows the Gaussian <a title=\"probability density function\">pdf</a> of the <a title=\"random variable\">rv</a> $z$ **conditioned** on the mean $\\mu_z=1.5$ and variance $\\sigma_z^2=0.5^2$ for the car stopping distance problem.",
"_____no_output_____"
],
[
"## Univariate Gaussian <a title=\"probability density function\">pdf</a> \n\n$$\n p(z) = \\mathcal{N}(z | \\mu_z, \\sigma_z^2) = \\frac{1}{\\sqrt{2\\pi\\sigma_z^2}}e^{-\\frac{1}{2\\sigma_z^2}(z - \\mu_z)^2}\n$$\n\nThe output of this expression is the **PROBABILITY DENSITY** of $z$ **given** (or conditioned to) a particular $\\mu_z$ and $\\sigma_z^2$.\n\n* **Important**: Probability Density $\\neq$ Probability",
"_____no_output_____"
],
[
"So, what is a probability?",
"_____no_output_____"
],
[
"## Probability\n\nThe probability of an event $A$ is denoted by $\\text{Pr}(A)$.\n\n* $\\text{Pr}(A)$ means the probability with which we believe event A is true\n\n* An event $A$ is a binary variable saying whether or not some state of the world holds.\n\nProbability is defined such that: $0 \\leq \\text{Pr}(A) \\leq 1$\n\nwhere $\\text{Pr}(A)=1$ if the event will definitely happen and $\\text{Pr}(A)=0$ if it definitely will not happen.",
"_____no_output_____"
],
[
"## Joint probability\n\n**Joint probability** of two events: $\\text{Pr}(A \\wedge B)= \\text{Pr}(A, B)$\n\nIf $A$ and $B$ are **independent**: $\\text{Pr}(A, B)= \\text{Pr}(A) \\text{Pr}(B)$\n\nFor example, suppose $z_1$ and $z_2$ are chosen uniformly at random from the set $\\mathcal{Z} = \\{1, 2, 3, 4\\}$.\n\nLet $A$ be the event that $z_1 \\in \\{1, 2\\}$ and $B$ be the event that **another** <a title=\"random variable\">rv</a> denoted as $z_2 \\in \\{3\\}$.\n\nThen we have: $\\text{Pr}(A, B) = \\text{Pr}(A) \\text{Pr}(B) = \\frac{1}{2} \\cdot \\frac{1}{4}$.",
"_____no_output_____"
],
[
"## Probability of a union of two events\n\nProbability of event $A$ or $B$ happening is: $\\text{Pr}(A \\vee B)= \\text{Pr}(A) + \\text{Pr}(B) - \\text{Pr}(A \\wedge B)$\n\nIf these events are mutually exclusive (they can't happen at the same time):\n\n$$\n\\text{Pr}(A \\vee B)= \\text{Pr}(A) + \\text{Pr}(B)\n$$\n\nFor example, suppose an <a title=\"random variable\">rv</a> denoted as $z_1$ is chosen uniformly at random from the set $\\mathcal{Z} = \\{1, 2, 3, 4\\}$.\n\nLet $A$ be the event that $z_1 \\in \\{1, 2\\}$ and $B$ be the event that the **same** <a title=\"random variable\">rv</a> $z_1 \\in \\{3\\}$.\n\nThen we have $\\text{Pr}(A \\vee B) = \\frac{2}{4} + \\frac{1}{4}$.",
"_____no_output_____"
],
[
"## Conditional probability of one event given another\n\nWe define the **conditional probability** of event $B$ happening given that $A$ has occurred as follows:\n\n$$\n\\text{Pr}(B | A)= \\frac{\\text{Pr}(A,B)}{\\text{Pr}(A)}\n$$\n\nThis is not defined if $\\text{Pr}(A) = 0$, since we cannot condition on an impossible event.",
"_____no_output_____"
],
[
"## Conditional independence of one event given another\n\nWe say that event $A$ is conditionally independent of event $B$ if we have $\\text{Pr}(A | B)= \\text{Pr}(A)$\n\nThis implies $\\text{Pr}(B|A) = \\text{Pr}(B)$. Hence, the joint probability becomes $\\text{Pr}(A, B) = \\text{Pr}(A) \\text{Pr}(B)$\n\nThe book uses the notation $A \\perp B$ to denote this property.",
"_____no_output_____"
],
[
"## Coming back to our car stopping distance problem\n\n<img src=\"docs/reaction-braking-stopping.svg\" title=\"Car stopping distance\" width=\"25%\" align=\"right\">\n\n$y = {\\color{blue}z} x + 0.1 x^2$\n\nwhere $z$ is a **continuous** <a title=\"random variable\">rv</a> such that $z \\sim \\mathcal{N}(\\mu_z=1.5,\\sigma_z^2=0.5^2)$.\n\n* What is the probability of an event $Z$ defined by a reaction time $z \\leq 0.52$ seconds?\n\n$$\n\\text{Pr}(Z)=\\text{Pr}(z \\leq 0.52)= P(z=0.52)\n$$\n\nwhere $P(z)$ denotes the **cumulative distribution function (cdf)**. Note that <a title=\"cumulative distribution function\">cdf</a> is denoted with a capital $P$.",
"_____no_output_____"
],
[
"Likewise, we can compute the probability of being in any interval as follows:\n\n$\\text{Pr}(a \\leq z \\leq b)= P(z=b)-P(z=a)$\n\n* But how do we compute the cdf at a particular value $b$, e.g. $P(z=b)$?",
"_____no_output_____"
],
[
"## <a title=\"Cumulative distribution functions\">Cdf's</a> result from <a title=\"probability density functions\">pdf's</a>\n\nA <a title=\"probability density functions\">pdf</a> $p(z)$ is defined as the derivative of the <a title=\"cumulative distribution functions\">cdf</a> $P(z)$:\n\n$$\np(z)=\\frac{d}{d z}P(z)\n$$\n\nSo, given a <a title=\"probability density function\">pdf</a> $p(z)$, we can compute the following probabilities:\n\n$$\\text{Pr}(z \\leq b)=\\int_{-\\infty}^b p(z) dz = P(b)$$\n$$\\text{Pr}(z \\geq a)=\\int_a^{\\infty} p(z) dz = 1 - P(a)$$\n$$\\text{Pr}(a \\leq z \\leq b)=\\int_a^b p(z) dz = P(b) - P(a)$$\n\n**IMPORTANT**: $\\int_{-\\infty}^{\\infty} p(z) dz = 1$",
"_____no_output_____"
],
[
"### Some notes about <a title=\"probability density functions\">pdf's</a>\n\nThe integration to unity is important!\n\n$$\\int_{-\\infty}^{\\infty} p(z) dz = 1$$\n\n**Remember:** the integral of a <a title=\"probability density function\">pdf</a> leads to a probability, and probabilities cannot be larger than 1.\n\nFor example, from this property we can derive the following:\n\n$$\n\\int_{-\\infty}^{\\infty} p(z) dz = \\int_{-\\infty}^{a} p(z) dz + \\int_{a}^{\\infty} p(z) dz\n$$\n\n$$\n\\Rightarrow \\text{Pr}(z \\geq a)= 1 - \\text{Pr}(z \\leq a) = 1 - \\text{P}(a) = 1 - \\int_{-\\infty}^a p(z) dz\n$$",
"_____no_output_____"
],
[
"In some cases we will work with probability distributions that are **unnormalized**, so this comment is important!\n\n* Being unnormalized means that the probability density of the distribution does not integrate to 1.\n* In this case, we cannot call such function a <a title=\"probability density function\">pdf</a>, even though its output is a probability density.",
"_____no_output_____"
],
[
"## <a title=\"Cumulative distribution functions\">Cdf's</a> result from <a title=\"probability density functions\">pdf's</a>\n\nKey point?\n\n* Given a <a title=\"probability density function\">pdf</a> $p(z)$, we can compute the probability of a continuous <a title=\"random variable\">rv</a> $z$ being in a finite interval as follows:\n\n$$\n\\text{Pr}(a \\leq z \\leq b)=\\int_a^b p(z) dz = P(b) - P(a)\n$$\n\nAs the size of the interval gets smaller, we can write\n\n$$\n\\text{Pr}\\left(z - \\frac{dz}{2} \\leq z \\leq z + \\frac{dz}{2}\\right) \\approx p(z) dz\n$$\n\nIntuitively, this says the probability of $z$ being in a small interval around $z$ is the density at $z$ times\nthe width of the interval.",
"_____no_output_____"
]
],
[
[
"from scipy.stats import norm # import from scipy.stats the normal distribution\n\nzrange = np.linspace(-3, 3, 100) # 100 values for plot\nfig_std_norm, (ax1, ax2) = plt.subplots(1, 2) # create a plot with 2 subplots side-by-side\nax1.plot(zrange, norm.cdf(zrange, 0, 1), label=r\"$\\mu_z=0; \\ \\sigma_z=1$\") # plot cdf of standard normal\nax1.set_xlabel(\"z\", fontsize=20)\nax1.set_ylabel(\"probability\", fontsize=20)\nax1.legend(fontsize=15)\nax1.set_title(\"Standard Gaussian cdf\", fontsize=20)\n\nax2.plot(zrange, norm.pdf(zrange, 0, 1), label=r\"$\\mu_z=0; \\ \\sigma_z=1$\") # plot pdf of standard normal\nax2.set_xlabel(\"z\", fontsize=20)\nax2.set_ylabel(\"probability density\", fontsize=20)\nax2.legend(fontsize=15)\nax2.set_title(\"Standard Gaussian pdf\", fontsize=20)\nfig_std_norm.set_size_inches(25, 5) # scale figure to be wider (since there are 2 subplots)",
"_____no_output_____"
]
],
[
[
"## Note about scipy.stats\n\n[scipy](https://docs.scipy.org/doc/scipy/index.html) is an open-source software for mathematics, science, and engineering. It's brilliant and widely used for many things!\n\n**In particular**, [scipy.stats](https://docs.scipy.org/doc/scipy/reference/stats.html) is a simple module within scipy that has statistical functions and operations that are very useful. This way, we don't need to code all the functions ourselves. That's why we are using it to plot the cdf and pdf of the Gaussian distribution from now on, and we will use it for other things later.\n\n* In case you are interested, scipy.stats has a nice [tutorial](https://docs.scipy.org/doc/scipy/tutorial/stats.html)",
"_____no_output_____"
],
[
"## Coming back to our car stopping distance problem\n\n<img src=\"docs/reaction-braking-stopping.svg\" title=\"Car stopping distance\" width=\"25%\" align=\"right\">\n\n$y = {\\color{blue}z} x + 0.1 x^2$\n\nwhere $z$ is a continuous <a title=\"random variable\">rv</a> such that $p(z)= \\mathcal{N}(z | \\mu_z=1.5,\\sigma_z^2=0.5^2)$.\n\n* What is the probability of an event $Z$ defined by a reaction time $z \\leq 0.52$ seconds?\n\n$$\n\\text{Pr}(Z) = \\text{Pr}(z \\leq 0.52) = P(z=0.52) = \\int_{-\\infty}^{0.52} p(z) dz\n$$",
"_____no_output_____"
]
],
[
[
"Pr_Z = norm.cdf(0.52, 1.5, 0.5) # using scipy norm.cdf(z=0.52 | mu_z=1.5, sigma_z=0.5)\n\nprint(\"The probability of event Z is: Pr(Z) = \",round(Pr_Z,3))",
"The probability of event Z is: Pr(Z) = 0.025\n"
],
[
"z_value = 0.52 # z = 0.52 seconds\nzrange = np.linspace(0, 3, 200) # 200 values for plot\nfig_car_norm, (ax1, ax2) = plt.subplots(1, 2) # create subplot (two figures in 1)\nax1.plot(zrange, norm.cdf(zrange, 1.5, 0.5), label=r\"$\\mu_z=1.5; \\ \\sigma_z=0.5$\") # Figure 1 is cdf\nax1.plot(z_value, norm.cdf(z_value, 1.5, 0.5), 'r*',markersize=15, linewidth=2,\n label=u'$P(z=0.52~|~\\mu_z=1.5, \\sigma_z^2=0.5^2)$')\nax1.set_xlabel(\"z\", fontsize=20)\nax1.set_ylabel(\"probability\", fontsize=20)\nax1.legend(fontsize=15)\nax1.set_title(\"Gaussian cdf of $z$ for car problem\", fontsize=20)\nax2.plot(zrange, norm.pdf(zrange, 1.5, 0.5), label=r\"$\\mu_z=1.5; \\ \\sigma_z=0.5$\") # figure 2 is pdf\nax2.plot(z_value, norm.pdf(z_value, 1.5, 0.5), 'r*', markersize=15, linewidth=2,\n label=u'$p(z=0.52~|~\\mu_z=1.5, \\sigma_z^2=0.5^2)$')\nax2.set_xlabel(\"z\", fontsize=20)\nax2.set_ylabel(\"probability density\", fontsize=20)\nax2.legend(fontsize=15)\nax2.set_title(\"Gaussian pdf of $z$ for car problem\", fontsize=20)\nfig_car_norm.set_size_inches(25, 5) # scale figure to be wider (since there are 2 subplots)",
"_____no_output_____"
]
],
[
[
"### Why is the Gaussian distribution so widely used?\n\nSeveral reasons:\n\n1. It has two parameters which are easy to interpret, and which capture some of the most basic properties of a distribution, namely its mean and variance.\n2. The central limit theorem (Sec. 2.8.6 of the book) tells us that sums of independent random variables have an approximately Gaussian distribution, making it a good choice for modeling residual errors or “noise”.\n3. The Gaussian distribution makes the least number of assumptions (has maximum entropy), subject to the constraint of having a specified mean and variance (Sec. 3.4.4 of the book); this makes it a good default choice in many cases.\n4. It has a simple mathematical form, which results in easy to implement, but often highly effective, methods.",
"_____no_output_____"
],
[
"## Car stopping distance problem\n\n<img src=\"docs/reaction-braking-stopping.svg\" title=\"Car stopping distance\" width=\"25%\" align=\"right\">\n\n$y = {\\color{blue}z} x + 0.1 x^2$\n\nwhere $z$ is a continuous <a title=\"random variable\">rv</a> such that $z \\sim \\mathcal{N}(\\mu_z=1.5,\\sigma_z^2=0.5^2)$.\n\n* What is the **expected** value for the reaction time $z$?",
"_____no_output_____"
],
[
"This is not a trick question! It's the mean $\\mu_z$, of course!",
"_____no_output_____"
],
[
"* But how do we compute the expected value for any distribution?",
"_____no_output_____"
],
[
"## Moments of a distribution\n\n### First moment: Expected value or mean\n\nThe expected value (mean) of a distribution is the **first moment** of the distribution:\n\n$$\n\\mathbb{E}[z]= \\int_{\\mathcal{Z}}z p(z) dz\n$$\n\nwhere $\\mathcal{Z}$ indicates the support of the distribution (the $z$ domain). \n\n* Often, $\\mathcal{Z}$ is omitted as it is usually between $-\\infty$ to $\\infty$\n* The expected value $\\mathbb{E}[z]$ is often denoted by $\\mu_z$",
"_____no_output_____"
],
[
"As you might expect (pun intended 😆), the expected value is a linear operator:\n\n$$\n\\mathbb{E}[az+b]= a\\mathbb{E}[z] + b\n$$\n\nwhere $a$ and $b$ are fixed variables (NOT rv's).\n\nAdditionally, for a set of $n$ rv's, one can show that the expectation of their sum is as follows:\n\n$\\mathbb{E}\\left[\\sum_{i=1}^n z_i\\right]= \\sum_{i=1}^n \\mathbb{E}[z_i]$\n\nIf they are **independent**, the expectation of their product is given by\n\n$\\mathbb{E}\\left[\\prod_{i=1}^n z_i\\right]= \\prod_{i=1}^n \\mathbb{E}[z_i]$",
"_____no_output_____"
],
[
"## Moments of a distribution\n\n### Second moment (and relation to Variance)\n\nThe 2nd moment of a distribution $p(z)$ is:\n\n$$\n\\mathbb{E}[z^2]= \\int_{\\mathcal{Z}}z^2 p(z) dz\n$$\n\n#### Variance can be obtained from the 1st and 2nd moments\n\nThe variance is a measure of the “spread” of the distribution:\n\n$$\n\\mathbb{V}[z] = \\mathbb{E}[(z-\\mu_z)^2] = \\int (z-\\mu_z)^2 p(z) dz = \\mathbb{E}[z^2] - \\mu_z^2\n$$\n\n* It is often denoted by the square of the standard deviation, i.e. $\\sigma_z^2 = \\mathbb{V}[z] = \\mathbb{E}[(z-\\mu_z)^2]$",
"_____no_output_____"
],
[
"#### Elaboration of the variance as a result of the first two moments of a distribution\n\n$$\n\\begin{align}\n\\mathbb{V}[z] & = \\mathbb{E}[(z-\\mu_z)^2] \\\\\n& = \\int (z-\\mu_z)^2 p(z) dz \\\\\n& = \\int z^2 p(z) dz + \\mu_z^2 \\int p(z) dz - 2\\mu_z \\int zp(z) dz \\\\\n& = \\mathbb{E}[z^2] - \\mu_z^2\n\\end{align}\n$$\n\nwhere $\\mu_z = \\mathbb{E}[z]$ is the first moment, and $\\mathbb{E}[z^2]$ is the second moment.\n\nTherefore, we can also write the second moment of a distribution as\n\n$$\\mathbb{E}[z^2] = \\sigma_z^2 + \\mu_z^2$$",
"_____no_output_____"
],
[
"#### Variance and standard deviation properties\n\nThe standard deviation is defined as\n\n$ \\sigma_z = \\text{std}[z] = \\sqrt{\\mathbb{V}[z]}$\n\nThe variance of a shifted and scaled version of a random variable is given by\n\n$\\mathbb{V}[a z + b] = a^2\\mathbb{V}[z]$\n\nwhere $a$ and $b$ are fixed variables (NOT rv's).",
"_____no_output_____"
],
[
"If we have a set of $n$ independent rv's, the variance of their sum is given by the sum of their variances\n\n$$\n\\mathbb{V}\\left[\\sum_{i=1}^n z_i\\right] = \\sum_{i=1}^n \\mathbb{V}[z_i]\n$$\n\nThe variance of their product can also be derived, as follows:\n\n$$\n\\begin{align}\n\\mathbb{V}\\left[\\prod_{i=1}^n z_i\\right] & = \\mathbb{E}\\left[ \\left(\\prod_i z_i\\right)^2 \\right] - \\left( \\mathbb{E}\\left[\\prod_i z_i \\right]\\right)^2\\\\\n & = \\mathbb{E}\\left[ \\prod_i z_i^2 \\right] - \\left( \\prod_i\\mathbb{E}\\left[ z_i \\right]\\right)^2\\\\\n & = \\prod_i \\mathbb{E}\\left[ z_i^2 \\right] - \\prod_i\\left( \\mathbb{E}\\left[ z_i \\right]\\right)^2\\\\\n & = \\prod_i \\left( \\mathbb{V}\\left[ z_i \\right] +\\left( \\mathbb{E}\\left[ z_i \\right]\\right)^2 \\right)- \\prod_i\\left( \\mathbb{E}\\left[ z_i \\right]\\right)^2\\\\\n & = \\prod_i \\left( \\sigma_{z,\\,i}^2 + \\mu_{z,\\,i}^2 \\right)- \\prod_i\\mu_{z,\\,i}^2 \\\\\n\\end{align}\n$$",
"_____no_output_____"
],
[
"## Note about higher-order moments\n\n* The $k$-th moment of a distribution $p(z)$ is defined as the expected value of the $k$-th power of $z$, i.e. $z^k$:\n\n$$\n\\mathbb{E}[z^k]= \\int_{\\mathcal{Z}}z^k p(z) dz\n$$",
"_____no_output_____"
],
[
"## Mode of a distribution\n\nThe mode of an <a title=\"random variable\">rv</a> $z$ is the value of $z$ for which $p(z)$ is maximum.\n\nFormally, this is written as,\n\n$$ \\mathbf{z}^* = \\underset{z}{\\mathrm{argmax}}~p(z)$$\n\nIf the distribution is multimodal, this may not be unique:\n* That's why $\\mathbf{z}^*$ is in **bold**, to denote that in general it is a vector that is retrieved!\n* However, if the distribution is unimodal (one maximum), like the univariate Gaussian distribution, then it retrieves a scalar $z^*$\n\nNote that even if there is a unique mode, this point may not be a good summary of the distribution.",
"_____no_output_____"
],
[
"## Mean vs mode for a non-symmetric distribution",
"_____no_output_____"
]
],
[
[
"# 1. Create a gamma pdf with parameter a = 2.0\n\nfrom scipy.stats import gamma # import from scipy.stats the Gamma distribution\n\na = 2.0 # this is the only input parameter needed for this distribution\n\n# Define the support of the distribution (its domain) by using the\n# inverse of the cdf (called ppf) to get the lowest z of the plot that\n# corresponds to Pr = 0.01 and the highest z of the plot that corresponds\n# to Pr = 0.99:\nzrange = np.linspace(gamma.ppf(0.01, a), gamma.ppf(0.99, a), 200) \n\nmu_z, var_z = gamma.stats(2.0, moments='mv') # This computes the mean and variance of the pdf\n\nfig_gamma_pdf, ax = plt.subplots() # a trick to save the figure for later use\nax.plot(zrange, gamma.pdf(zrange, a), label=r\"$\\Gamma(z|a=2.0)$\")\nax.set_xlabel(\"z\", fontsize=20)\nax.set_ylabel(\"probability density\", fontsize=20)\nax.legend(fontsize=15)\nax.set_title(\"Gamma pdf for $a=2.0$\", fontsize=20)\nplt.close(fig_gamma_pdf) # do not plot the figure now. We will show it in a later cell",
"_____no_output_____"
],
[
"# 2. Plot the expected value (mean) for this pdf\nax.plot(mu_z, gamma.pdf(mu_z, a), 'r*', markersize=15, linewidth=2, label=u'$\\mu_z = \\mathbb{E}[z]$')",
"_____no_output_____"
],
[
"# 3. Calculate the mode and plot it\nfrom scipy.optimize import minimize # import minimizer\n\n# Finding the maximum of the gamma pdf can be done by minimizing\n# the negative gamma pdf. So, we create a function that outputs\n# the negative of the gamma pdf given the parameter a=2.0:\ndef neg_gamma_given_a(z): return -gamma.pdf(z,a)\n\n# Use the default optimizer of scipy (L-BFGS) to find the\n# maximum (by minimizing the negative gamma pdf). Note\n# that we need to give an initial guess for the value of z,\n# so we can use, for example, z=mu_z:\nmode_z = minimize(neg_gamma_given_a,mu_z).x\n\nax.plot(mode_z, np.max(gamma.pdf(mode_z, a)),'g^', markersize=15,\n linewidth=2,label=u'mode $\\mathbf{z}^*=\\mathrm{argmax}~p(z)$')\nax.legend() # show legend",
"_____no_output_____"
],
[
"# Code to generate this Gamma distribution hidden during presentation (it's shown as notes)\n\nprint('The mean is ',mu_z) # print the mean calculated for this gamma pdf\nprint('The mode is approximately ',mode_z) # print the mode\nfig_gamma_pdf # show figure of this gamma pdf",
"The mean is 2.0\nThe mode is approximately [1.00001618]\n"
]
],
[
[
"## The amazing Bayes' rule\n<font color='red'>Bayesian</font> <font color='blue'>inference</font> definition:\n* <font color='blue'>Inference</font> means “the act of passing from sample data to generalizations, usually with calculated degrees of certainty”.\n* <font color='red'>Bayesian</font> is used to refer to inference methods that represent “degrees of certainty” using probability theory, and which leverage Bayes’ rule to update the degree of certainty given data.",
"_____no_output_____"
],
[
"**Bayes’ rule** is a formula for computing the probability distribution over possible values of an unknown (or hidden) quantity $z$ given some observed data $y$:\n\n$$\np(z|y) = \\frac{p(y|z) p(z)}{p(y)}\n$$\n\nBayes' rule follows automatically from the identity: $p(z|y) p(y) = p(y|z) p(z) = p(y,z) = p(z,y)$",
"_____no_output_____"
],
[
"## The amazing Bayes' rule\n\n* I know... You don't find it very amazing (yet!).\n* Wait until you realize that almost all ML methods can be derived from this simple formula\n\n$$\np(z|y) = \\frac{p(y|z) p(z)}{p(y)}\n$$",
"_____no_output_____"
],
[
"### See you next class\n\nHave fun!\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a1d3040433f7fae896ca1e33609c199ef95b2af
| 237,797 |
ipynb
|
Jupyter Notebook
|
convnet_cifar10.ipynb
|
CrucifierBladex/cifar10_convnet
|
6df4eb72bf188d1f066e7367939beb4ac5fda77f
|
[
"MIT"
] | null | null | null |
convnet_cifar10.ipynb
|
CrucifierBladex/cifar10_convnet
|
6df4eb72bf188d1f066e7367939beb4ac5fda77f
|
[
"MIT"
] | null | null | null |
convnet_cifar10.ipynb
|
CrucifierBladex/cifar10_convnet
|
6df4eb72bf188d1f066e7367939beb4ac5fda77f
|
[
"MIT"
] | null | null | null | 278.777257 | 126,866 | 0.889856 |
[
[
[
"<a href=\"https://colab.research.google.com/github/CrucifierBladex/cifar10_convnet/blob/main/convnet_cifar10.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from keras import layers,models",
"_____no_output_____"
],
[
"from tensorflow.python.client import device_lib\ndevice_lib.list_local_devices()",
"_____no_output_____"
],
[
"\nmodel=models.Sequential()\nmodel.add(layers.Conv2D(32,(3,3),activation='relu',padding='same',input_shape=(32,32,3)))\nmodel.add(layers.MaxPooling2D((2,2),padding='same'))\n\nmodel.add(layers.Conv2D(64,(3,3),activation='relu',padding='same'))\nmodel.add(layers.MaxPooling2D((2,2),padding='same'))\n\nmodel.add(layers.Conv2D(128,(3,3),activation='relu',padding='same'))\nmodel.add(layers.MaxPooling2D((2,2),padding='same'))\n\nmodel.add(layers.Conv2D(128,(3,3),activation='relu',padding='same'))\nmodel.add(layers.MaxPooling2D((2,2),padding='same'))\n\nmodel.add(layers.GlobalAveragePooling2D())\n\n\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(64,activation='relu'))\nmodel.add(layers.BatchNormalization())\nmodel.add(layers.Dense(10,activation='softmax'))\n\n",
"_____no_output_____"
],
[
"import keras\ndot_img_file = '/content/sample_data/model/model_1.png'\n\nkeras.utils.plot_model(model, to_file=dot_img_file, show_shapes=True)\n\n",
"_____no_output_____"
],
[
"from keras.datasets import cifar10\nfrom keras.utils import to_categorical\n(train_images,train_labels),(test_images,test_labels)=cifar10.load_data()",
"Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz\n170500096/170498071 [==============================] - 4s 0us/step\n"
],
[
"",
"_____no_output_____"
],
[
"train_images=train_images.reshape((50000,32,32,3))\ntrain_images=train_images.astype('float32')/255\ntest_images=test_images.reshape((10000,32,32,3))\ntest_images=test_images.astype('float32')/255\n\n",
"_____no_output_____"
],
[
"train_labels=to_categorical(train_labels)\ntest_labels=to_categorical(test_labels)\n",
"_____no_output_____"
],
[
"model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])\n",
"_____no_output_____"
],
[
"history=model.fit(train_images,train_labels,epochs=30,batch_size=32,validation_data=(test_images,test_labels))",
"Epoch 1/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 1.3163 - accuracy: 0.5332 - val_loss: 1.7575 - val_accuracy: 0.4922\nEpoch 2/30\n1563/1563 [==============================] - 8s 5ms/step - loss: 0.9177 - accuracy: 0.6795 - val_loss: 0.9004 - val_accuracy: 0.6824\nEpoch 3/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.7800 - accuracy: 0.7310 - val_loss: 0.9221 - val_accuracy: 0.6910\nEpoch 4/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.6874 - accuracy: 0.7626 - val_loss: 1.0760 - val_accuracy: 0.6419\nEpoch 5/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.6146 - accuracy: 0.7860 - val_loss: 1.1463 - val_accuracy: 0.6217\nEpoch 6/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.5560 - accuracy: 0.8081 - val_loss: 0.8385 - val_accuracy: 0.7290\nEpoch 7/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.5040 - accuracy: 0.8273 - val_loss: 1.0864 - val_accuracy: 0.6842\nEpoch 8/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.4520 - accuracy: 0.8428 - val_loss: 0.9786 - val_accuracy: 0.6967\nEpoch 9/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.4067 - accuracy: 0.8571 - val_loss: 0.7926 - val_accuracy: 0.7473\nEpoch 10/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.3690 - accuracy: 0.8698 - val_loss: 0.8880 - val_accuracy: 0.7431\nEpoch 11/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.3291 - accuracy: 0.8837 - val_loss: 0.9745 - val_accuracy: 0.7281\nEpoch 12/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.2972 - accuracy: 0.8959 - val_loss: 1.2607 - val_accuracy: 0.6936\nEpoch 13/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.2610 - accuracy: 0.9063 - val_loss: 1.1293 - val_accuracy: 0.7206\nEpoch 14/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.2423 - accuracy: 0.9139 - val_loss: 1.0520 - val_accuracy: 0.7373\nEpoch 15/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.2138 - accuracy: 0.9246 - val_loss: 1.1686 - val_accuracy: 0.7204\nEpoch 16/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.2043 - accuracy: 0.9276 - val_loss: 1.0101 - val_accuracy: 0.7566\nEpoch 17/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1840 - accuracy: 0.9349 - val_loss: 1.0624 - val_accuracy: 0.7465\nEpoch 18/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1709 - accuracy: 0.9395 - val_loss: 1.1517 - val_accuracy: 0.7419\nEpoch 19/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.1581 - accuracy: 0.9433 - val_loss: 1.2897 - val_accuracy: 0.7283\nEpoch 20/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.1450 - accuracy: 0.9489 - val_loss: 1.2003 - val_accuracy: 0.7467\nEpoch 21/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.1457 - accuracy: 0.9488 - val_loss: 1.1294 - val_accuracy: 0.7525\nEpoch 22/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.1317 - accuracy: 0.9528 - val_loss: 1.3046 - val_accuracy: 0.7280\nEpoch 23/30\n1563/1563 [==============================] - 7s 5ms/step - loss: 0.1230 - accuracy: 0.9564 - val_loss: 1.2156 - val_accuracy: 0.7509\nEpoch 24/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1198 - accuracy: 0.9575 - val_loss: 1.3211 - val_accuracy: 0.7434\nEpoch 25/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1168 - accuracy: 0.9589 - val_loss: 1.4556 - val_accuracy: 0.7220\nEpoch 26/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1102 - accuracy: 0.9613 - val_loss: 1.3098 - val_accuracy: 0.7420\nEpoch 27/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1034 - accuracy: 0.9624 - val_loss: 1.2733 - val_accuracy: 0.7458\nEpoch 28/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.1005 - accuracy: 0.9645 - val_loss: 1.2715 - val_accuracy: 0.7567\nEpoch 29/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.0970 - accuracy: 0.9654 - val_loss: 1.3076 - val_accuracy: 0.7385\nEpoch 30/30\n1563/1563 [==============================] - 7s 4ms/step - loss: 0.0949 - accuracy: 0.9664 - val_loss: 1.4074 - val_accuracy: 0.7368\n"
],
[
"history.history.keys()",
"_____no_output_____"
],
[
"import pandas as pd\nhis=pd.DataFrame(history.history)\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set(style='darkgrid')\nhis.plot(y='loss')\nhis",
"_____no_output_____"
],
[
"# summarize history for accuracy\nplt.plot(history.history['accuracy'])\nplt.plot(history.history['val_accuracy'])\nplt.title('model accuracy')\nplt.ylabel('accuracy')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"# summarize history for loss\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"import imageio,cv2\nimport matplotlib.pyplot as plt\nimg=imageio.imread('/content/horse.jpeg')\nimg=cv2.resize(img,(32,32))\nplt.imshow(img)\nimg=img.reshape(1,32,32,3)\nimg=img/255\nmodel.predict(img)",
"_____no_output_____"
],
[
"import numpy as np\n\nnp.argmax(model.predict(img))",
"_____no_output_____"
],
[
"model.save('cifar10class.h5')",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1d3b80931837cdfce350075f772477d940c3ac
| 638,193 |
ipynb
|
Jupyter Notebook
|
Movie Recommendation Engine/MainNotebook.ipynb
|
henry-worrall/Data_Science_Projects
|
20186e4ffbcb42b5a87bf9a104c2c8a028f1cad4
|
[
"MIT"
] | null | null | null |
Movie Recommendation Engine/MainNotebook.ipynb
|
henry-worrall/Data_Science_Projects
|
20186e4ffbcb42b5a87bf9a104c2c8a028f1cad4
|
[
"MIT"
] | null | null | null |
Movie Recommendation Engine/MainNotebook.ipynb
|
henry-worrall/Data_Science_Projects
|
20186e4ffbcb42b5a87bf9a104c2c8a028f1cad4
|
[
"MIT"
] | null | null | null | 457.158309 | 302,851 | 0.636062 |
[
[
[
"#### Information About the Data\n\nu.data -- The full u data set, 100000 ratings by 943 users on 1682 items.\nEach user has rated at least 20 movies. Users and items are\nnumbered consecutively from 1. The data is randomly\nordered. This is a tab separated list of\nuser id | item id | rating | timestamp.\nThe time stamps are unix seconds since 1/1/1970 UTC\n\nu.info -- The number of users, items, and ratings in the u data set.\n\nu.item -- Information about the items (movies); this is a tab separated\nlist of\nmovie id | movie title | release date | video release date |\nIMDb URL | unknown | Action | Adventure | Animation |\nChildren's | Comedy | Crime | Documentary | Drama | Fantasy |\nFilm-Noir | Horror | Musical | Mystery | Romance | Sci-Fi |\nThriller | War | Western |\nThe last 19 fields are the genres, a 1 indicates the movie\nis of that genre, a 0 indicates it is not; movies can be in\nseveral genres at once.\nThe movie ids are the ones used in the u.data data set.\n\nu.genre -- A list of the genres.\n\nu.user -- Demographic information about the users; this is a tab\nseparated list of\nuser id | age | gender | occupation | zip code\nThe user ids are the ones used in the u.data data set.\n\nu.occupation -- A list of the occupations.\n\nu1.base -- The data sets u1.base and u1.test through u5.base and u5.test\nu1.test are 80%/20% splits of the u data into training and test data.\nu2.base Each of u1, …, u5 have disjoint test sets; this if for\nu2.test 5 fold cross validation (where you repeat your experiment\nu3.base with each training and test set and average the results).\nu3.test These data sets can be generated from u.data by mku.sh.\nu4.base\nu4.test\nu5.base\nu5.test\n\nua.base -- The data sets ua.base, ua.test, ub.base, and ub.test\nua.test split the u data into a training set and a test set with\nub.base exactly 10 ratings per user in the test set. The sets\nub.test ua.test and ub.test are disjoint. These data sets can\nbe generated from u.data by mku.sh.\n\nallbut.pl -- The script that generates training and test sets where\nall but n of a users ratings are in the training data.\n\nmku.sh -- A shell script to generate all the u data sets from u.data.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport sklearn as sk\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns",
"_____no_output_____"
],
[
"# info about the dataset\ninfo_path = \"data/u.info\"\npd.read_csv(info_path, sep=' ', names=['Number','Info'])",
"_____no_output_____"
],
[
"# load ratings data\ndata_path = \"data/u.data\" # This is a tab separated list of user id | item id | rating | timestamp. The time stamps are unix seconds since 1/1/1970 UTC.\ncolumns_name=['user_id','item_id','rating','timestamp']\n\ndata=pd.read_csv(data_path,sep=\"\\t\",names=columns_name)\n\nprint(data.head())\nprint(data.shape)",
" user_id item_id rating timestamp\n0 196 242 3 881250949\n1 186 302 3 891717742\n2 22 377 1 878887116\n3 244 51 2 880606923\n4 166 346 1 886397596\n(100000, 4)\n"
],
[
"# load the movies\nmovie_path = \"data/u.item\"\n\ncolumns = \"item_id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western\"\nlist_cols = columns.split(\" | \")\n\nmovies = pd.read_csv(movie_path, sep=\"\\|\", names=list_cols)\nmovies",
"_____no_output_____"
],
[
"# load the users\nusers_path = \"data/u.user\"\n\ncolumns = \"user_id | age | gender | occupation | zip code\"\nlist_cols = columns.split(\" | \")\n\nusers = pd.read_csv(users_path, sep=\"\\|\", names=list_cols)\nusers",
"_____no_output_____"
],
[
"data = pd.merge(data,movies,on=\"item_id\")",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"data = pd.merge(data,users, on=\"user_id\")\ndata",
"_____no_output_____"
],
[
"np.sort(data[\"rating\"].unique())",
"_____no_output_____"
],
[
"data = data.drop([\"video release date\",\"IMDb URL\"], axis=1)\ndata",
"_____no_output_____"
],
[
"data.isna().sum()",
"_____no_output_____"
],
[
"data[data.isnull().any(axis=1)]",
"_____no_output_____"
],
[
"data = data.dropna()\ndata",
"_____no_output_____"
],
[
"data.groupby(\"movie title\").count()['rating'].sort_values(ascending=False)",
"_____no_output_____"
],
[
"ratings = pd.DataFrame(data.groupby(\"movie title\").mean()['rating'])\nratings['number of ratings'] = pd.DataFrame(data.groupby(\"movie title\").count()['rating'])\nratings",
"_____no_output_____"
],
[
"plt.figure(figsize=(12,8))\nplt.axes(xlabel = \"Number of Ratings\", ylabel= \"Number of Movies\")\nplt.hist(ratings['number of ratings'], bins=70)\n\nplt.show",
"_____no_output_____"
],
[
"plt.figure(figsize=(12,8))\nplt.axes(xlabel = \"Average Rating\", ylabel= \"Number of Movies\")\nplt.hist(ratings['rating'], bins=70)\n\nplt.show",
"_____no_output_____"
],
[
"sns.distplot(ratings['rating'], hist=True, kde=True, \n bins=70)\n",
"_____no_output_____"
],
[
"sns.jointplot(x='rating',y='number of ratings',data=ratings,alpha=0.5)",
"_____no_output_____"
],
[
"moviematrix = data.pivot_table(index=\"user_id\", columns=\"movie title\", values=\"rating\")\nmoviematrix",
"_____no_output_____"
],
[
"starwars_user_ratings = moviematrix[\"Star Wars (1977)\"]\nstarwars_user_ratings",
"_____no_output_____"
],
[
"sim_to_starwars = moviematrix.corrwith(starwars_user_ratings)\nsim_to_starwars.sort_values(ascending=False)",
"_____no_output_____"
],
[
"corr_to_starwars = pd.DataFrame(sim_to_starwars, columns=['Correlation'])\ncorr_to_starwars.sort_values(by=['Correlation'])",
"_____no_output_____"
],
[
"#drop NaN values\ncorr_to_starwars.dropna(inplace=True)\ncorr_to_starwars.sort_values(by='Correlation',ascending=False)",
"_____no_output_____"
],
[
"corr_to_starwars = corr_to_starwars.join(ratings['number of ratings'])\ncorr_to_starwars",
"_____no_output_____"
],
[
"corr_to_starwars[corr_to_starwars['number of ratings']>100].sort_values(by='Correlation', ascending=False)",
"_____no_output_____"
],
[
"def MovieRecommendations(movie):\n user_ratings = moviematrix[movie]\n sim_to_movie = moviematrix.corrwith(user_ratings)\n corr_to_movie = pd.DataFrame(sim_to_movie, columns=['Correlation'])\n corr_to_movie.dropna(inplace=True)\n corr_to_movie = corr_to_movie.join(ratings['number of ratings'])\n return corr_to_movie[corr_to_movie['number of ratings']>100].sort_values(by='Correlation', ascending=False)[1:11]",
"_____no_output_____"
],
[
"MovieRecommendations(\"Monty Python's Life of Brian (1979)\")",
"_____no_output_____"
],
[
"data['release date'] = pd.to_datetime(data['release date'])\ndata[data['release date'] == data['release date'].min()][\"movie title\"].unique()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1d3c7c8affbe72cb4828e0699fd50035759959
| 139,302 |
ipynb
|
Jupyter Notebook
|
inst/model_development/notebooks/entity_extraction_model_export.ipynb
|
canfielder/CausalityExtraction
|
f8f0d06dde893f98270c3395ff2ab81d1c5f1108
|
[
"MIT"
] | null | null | null |
inst/model_development/notebooks/entity_extraction_model_export.ipynb
|
canfielder/CausalityExtraction
|
f8f0d06dde893f98270c3395ff2ab81d1c5f1108
|
[
"MIT"
] | 1 |
2021-07-04T15:45:27.000Z
|
2021-07-09T17:28:04.000Z
|
inst/model_development/notebooks/entity_extraction_model_export.ipynb
|
canfielder/CausalityExtraction
|
f8f0d06dde893f98270c3395ff2ab81d1c5f1108
|
[
"MIT"
] | null | null | null | 71.620566 | 26,208 | 0.765517 |
[
[
[
"# Purpose\nThe purpose of this notebook is to train and export the model configuration selected from previous hyperparameter analysis.\n\nThe following are the optimal parameters. Other parameter alignments are also stored in order to be able to compare different iterations of the model\n\n**Parameters Selected**:\n\n* **Embedding**: Glove\n* **Stopwords**: False\n* **Lemmatization**: False\n* **LSTM Stack**: True\n* **Hidden Dimension - Layer 1**: 32\n* **Hidden Dimension - Layer 2**: 128\n* **Dropout** : True\n* **Dropout Rate**: 0.5\n* **Sample Weights**: False\n* **Trainable**: True \n* **Time Distributed Output Layer**: True\n* **Optimizer**: rmsprop",
"_____no_output_____"
],
[
"## Import",
"_____no_output_____"
],
[
"### Packages",
"_____no_output_____"
]
],
[
[
"# General\nimport codecs, io, os, re, sys, time\nfrom collections import OrderedDict \nfrom scipy.stats import uniform\nfrom tqdm import tqdm\n\n# Analysis\nimport numpy as np\nimport pandas as pd\nfrom sklearn.metrics import \\\n accuracy_score, classification_report, confusion_matrix, \\\n precision_recall_fscore_support\nfrom sklearn.model_selection import \\\n ParameterGrid, RandomizedSearchCV, RepeatedStratifiedKFold\nfrom sklearn.utils.class_weight import compute_class_weight\n\n# Visual\nimport matplotlib.pyplot as plt\nimport seaborn as sn\n\n# Deep Learning\nimport tensorflow as tf\nfrom keras.wrappers.scikit_learn import KerasClassifier\nfrom keras.callbacks import EarlyStopping\nfrom keras.layers.experimental.preprocessing import TextVectorization",
"_____no_output_____"
]
],
[
[
"### Custom Functions",
"_____no_output_____"
]
],
[
[
"sys.path.append('*')\nfrom source_entity_extraction import *",
"[nltk_data] Downloading package wordnet to\n[nltk_data] C:\\Users\\canfi\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package wordnet is already up-to-date!\n[nltk_data] Downloading package stopwords to\n[nltk_data] C:\\Users\\canfi\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n"
]
],
[
[
"### Data\nThe training data is imported and the necessary columns are converted to lists.",
"_____no_output_____"
]
],
[
[
"#import data\npath_dir_data =\"./../data/input/\"\nfile_training_data = 'training_data_dir_multiclass.xlsx'\npath_training_data = os.path.join(path_dir_data, file_training_data)\ndataset = pd.read_excel(path_training_data, engine='openpyxl')\n\n#convert into lists\ndf = pd.DataFrame({\n 'text': dataset.sentence, \n 'node1': dataset.node_1, \n 'node2': dataset.node_2\n })\n\ndf.dropna(inplace = True)",
"_____no_output_____"
]
],
[
[
"## Randomness\nTo better control and compare results of the Entity Extraction model between the environments where the model is trainined (Python) and where it will be implemented (R/Shiny), we will attempt to control any random actions by the process to maintain consistent results.",
"_____no_output_____"
]
],
[
[
"random_state = 5590\nnp.random.seed(random_state)\ntf.random.set_seed(random_state)",
"_____no_output_____"
]
],
[
[
"# Model Settings\n## Define All Configurations",
"_____no_output_____"
]
],
[
[
"dct_alignments = {\n \"initial\": {\n \"EMBEDDING\": \"text_vectorization\",\n \"MAX_LENGTH\": 70,\n \"LEMMATIZE\": False,\n \"STOP_WORDS\": False,\n \"LSTM_STACK\": False,\n \"HIDDEN_DIM_1\": \"\",\n \"HIDDEN_DIM_2\": 3,\n \"DROPOUT\": True,\n \"DROPOUT_RATE\": 0.1,\n \"SAMPLE_WEIGHTS\": False,\n \"TRAINABLE\": \"\",\n \"TIME_DISTRIBUTED\": True,\n \"OPTIMIZER\": \"rmsprop\",\n \"EPOCHS\": 60,\n }, \n \"optimal\": {\n \"EMBEDDING\": \"glove\",\n \"MAX_LENGTH\": 50,\n \"LEMMATIZE\": False,\n \"STOP_WORDS\": False,\n \"LSTM_STACK\": True,\n \"HIDDEN_DIM_1\": 32,\n \"HIDDEN_DIM_2\": 128,\n \"DROPOUT\": True,\n \"DROPOUT_RATE\": 0.5,\n \"SAMPLE_WEIGHTS\": False,\n \"TRAINABLE\": True,\n \"TIME_DISTRIBUTED\": True,\n \"OPTIMIZER\": \"rmsprop\",\n \"EPOCHS\": 250,\n }\n}",
"_____no_output_____"
]
],
[
[
"## Select Configuration",
"_____no_output_____"
]
],
[
[
"# Label\nCONFIGURATION_LABEL = \"optimal\"\n\n# Extract Values\nEMBEDDING = dct_alignments[CONFIGURATION_LABEL][\"EMBEDDING\"]\nMAX_LENGTH = dct_alignments[CONFIGURATION_LABEL][\"MAX_LENGTH\"]\nLEMMATIZE = dct_alignments[CONFIGURATION_LABEL][\"LEMMATIZE\"]\nSTOP_WORDS = dct_alignments[CONFIGURATION_LABEL][\"STOP_WORDS\"]\nLSTM_STACK = dct_alignments[CONFIGURATION_LABEL][\"LSTM_STACK\"]\nHIDDEN_DIM_1 = dct_alignments[CONFIGURATION_LABEL][\"HIDDEN_DIM_1\"]\nHIDDEN_DIM_2 = dct_alignments[CONFIGURATION_LABEL][\"HIDDEN_DIM_2\"]\nDROPOUT = dct_alignments[CONFIGURATION_LABEL][\"DROPOUT\"]\nDROPOUT_RATE = dct_alignments[CONFIGURATION_LABEL][\"DROPOUT_RATE\"]\nSAMPLE_WEIGHTS = dct_alignments[CONFIGURATION_LABEL][\"SAMPLE_WEIGHTS\"]\nTRAINABLE = dct_alignments[CONFIGURATION_LABEL][\"TRAINABLE\"]\nTIME_DISTRIBUTED = dct_alignments[CONFIGURATION_LABEL][\"TIME_DISTRIBUTED\"]\nOPTIMIZER = dct_alignments[CONFIGURATION_LABEL][\"OPTIMIZER\"]\nEPOCHS = dct_alignments[CONFIGURATION_LABEL][\"EPOCHS\"]",
"_____no_output_____"
]
],
[
[
"# Global Actions\nThe following section defines global settings or performs actions that are consistent across the entirety of this notebook.",
"_____no_output_____"
],
[
"## Variables\nVaraibles that are used across multiple calls should be defined here.",
"_____no_output_____"
]
],
[
[
"# Global Settings\nMAX_FEATURES = 1000\nBATCH_SIZE = 32\nTIME_STAMP = time.strftime(\"%Y%m%d-%H%M%S\")",
"_____no_output_____"
]
],
[
[
"## Pre-Processing\n",
"_____no_output_____"
],
[
"### Text Processing",
"_____no_output_____"
]
],
[
[
"df = process_text(\n df, \n stopwords = LEMMATIZE,\n lemmatize = STOP_WORDS\n )",
"_____no_output_____"
]
],
[
[
"### Target Generation\nWith the text processing complete we will now create two versions of the target set. The first will have the feature tokens converted into numerical representations for each class: 0, 1, 2. Then we will also create a target set that is a one-hot-encoded representation of the numerical classes.",
"_____no_output_____"
]
],
[
[
"df = target_gen_wrapper(\n df, \n max_length=MAX_LENGTH\n )",
"_____no_output_____"
]
],
[
[
"## Split Data into Training / Test Sets",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\ndf_train, df_test = train_test_split(\n df,\n test_size=0.25, \n random_state = random_state\n )",
"_____no_output_____"
]
],
[
[
"Due to the different nature of random actions between R and Python, it is easier to export the test set than to duplciate the train/test split.",
"_____no_output_____"
]
],
[
[
"subfolder_a = \"outputs\"\nsubfolder_entity = \"entity_extraction\"\nfile_name = 'entity_extraction_test_set.csv'\npath = os.path.join(path_dir_data, subfolder_a, \n subfolder_entity, file_name)\ndf_test.to_csv(path, index_label=False)",
"_____no_output_____"
]
],
[
[
"# Feature/Target Definition\nWe need to define a target variable and perform preprocessing steps on the features before inputting into the model",
"_____no_output_____"
]
],
[
[
"# Features\nX_train = df_train['text'].tolist()\nX_test = df_test['text'].tolist()\n\n# Targets\ny_train_val = df_train['target_labels'].tolist()\ny_test_val = df_test['target_labels'].tolist()",
"_____no_output_____"
]
],
[
[
"### Export Target Classes\nTo simplify eventual work in R, we will generate the our target classes the test dataset and export it.",
"_____no_output_____"
]
],
[
[
"# Export Test Target Values\n# Set File Location\nfile_name = 'entity_extraction_test_target_classes_cause_effect.csv'\npath = os.path.join(path_dir_data, subfolder_a, subfolder_entity, file_name)\n\n# Convert Lists to Dataframe\ndf_targets_test = pd.DataFrame(y_test_val)\n\n# Export Target Values\ndf_targets_test.to_csv(path, index=False, header=False)",
"_____no_output_____"
]
],
[
[
"# Build Model",
"_____no_output_____"
],
[
"## Vectorization Layer",
"_____no_output_____"
]
],
[
[
"vectorization_layer = TextVectorization(\n max_tokens=MAX_FEATURES,\n output_mode='int',\n output_sequence_length=MAX_LENGTH\n )\n\nvectorization_layer.adapt(X_train)\n\nvocab = vectorization_layer.get_vocabulary()\nvocab_len = len(vocab)\nprint(f\"Vocabulary Size: {vocab_len}\")",
"Vocabulary Size: 1000\n"
],
[
"# Inspect vocabulary\nword_index = dict(zip(vocab, range(len(vocab))))\n# word_index",
"_____no_output_____"
],
[
"# # Inspect vectorization output\n# m = 5\n# test_string = X_train[m]\n# print(f\"Test String - Raw:\\n{test_string}\")\n# print()\n# test_string_vec = vectorization_layer([test_string])\n# print(f\"Test String - Vectorized:\\n{test_string_vec[0]}\")",
"_____no_output_____"
]
],
[
[
"## Embedding Layer",
"_____no_output_____"
],
[
"### Initialize",
"_____no_output_____"
]
],
[
[
"dct_embedding_index = {}\n\n# Initialize None for text vectorizaiton\ndct_embedding_index[\"text_vectorization\"] = {\n \"index\": None,\n \"dimension\": None\n}\n\ndct_embedding_matrix = {\n \"text_vectorization\": None\n}",
"_____no_output_____"
]
],
[
[
"### Embedding Matrix",
"_____no_output_____"
],
[
"### Glove",
"_____no_output_____"
],
[
"##### Import/Load Embeddings",
"_____no_output_____"
]
],
[
[
"embed_label = \"glove\"\nembedding_dim = 100\n\n# Define file path\nsubfolder_embed = \"pre_trained\"\nsubfolder_embed_glove = \"glove.6B\"\nfile_name = \"glove.6B.100d.txt\"\npath = os.path.join(path_dir_data, subfolder_embed, subfolder_embed_glove, file_name)\n\nprint(\"Preparing embedding index...\")\nembeddings_index = {}\nwith open(path, encoding=\"utf8\") as f:\n for line in tqdm(f):\n word, coefs = line.split(maxsplit=1)\n coefs = np.fromstring(coefs, \"f\", sep=\" \")\n embeddings_index[word] = coefs\n\ndct_embedding_index[embed_label] = {\n \"index\": embeddings_index,\n \"dimension\": embedding_dim\n}\nprint(f\"Found {len(embeddings_index)} word vectors.\")",
"1588it [00:00, 15879.49it/s]"
]
],
[
[
"##### Create Matrix",
"_____no_output_____"
]
],
[
[
"embedding_matrix = gen_embedding_matrix(\n dct_embedding_index = dct_embedding_index,\n embed_label = embed_label, \n vocabulary_length = vocab_len, \n word_index = word_index\n)\n\ndct_embedding_matrix[embed_label] = embedding_matrix",
"_____no_output_____"
]
],
[
[
"#### FastText",
"_____no_output_____"
],
[
"##### Import/Load Embeddings",
"_____no_output_____"
]
],
[
[
"embed_label = \"fasttext\"\nembedding_dim = 300\n\n# Define file path\nsubfolder_embed = \"pre_trained\"\nsubfolder_embed_fasttext = \"wiki-news-300d-1M.vec\"\nfile_name = \"wiki-news-300d-1M.vec\"\npath = os.path.join(path_dir_data, subfolder_embed, subfolder_embed_fasttext, file_name)\nf = codecs.open(path, encoding='utf-8')\n\nprint(\"Preparing embedding index...\")\nembeddings_index = {}\nfor line in tqdm(f):\n values = line.rstrip().rsplit(' ')\n # print(values)\n word = values[0]\n # print(word)\n coefs = np.asarray(values[1:], dtype='float32')\n # print(coefs)\n embeddings_index[word] = coefs\nf.close()\n\ndct_embedding_index[embed_label] = {\n \"index\": embeddings_index,\n \"dimension\": embedding_dim,\n}\nprint(f'Found {len(embeddings_index)} word vectors.')",
"639it [00:00, 6389.72it/s]"
]
],
[
[
"##### Create Matrix",
"_____no_output_____"
]
],
[
[
"embedding_matrix = gen_embedding_matrix(\n dct_embedding_index = dct_embedding_index,\n embed_label = embed_label, \n vocabulary_length = vocab_len, \n word_index = word_index\n)\n\ndct_embedding_matrix[embed_label] = embedding_matrix",
"_____no_output_____"
]
],
[
[
"## Imbalance Class Management\nThere is an imbalance in the classes predicted by the model. Roughly 90% of tokens are class 0 (not Cause or Entity node, filler words). The remaining classes (1: Cause, 2: Entity) account for about 5% of the remaining tokens, each.\n\nIn order to better predict all classes in the dataset, and not create a model which simply predicts the default class, we need to weight each of these classes differently. Unfortunately, we cannot simply use the **class weights** input for training a Keras model. that is because we are predicting a 3D array as an output, and Keras will not allow the use of **class weights** in such a case. \n\nThere is a workaround, as discussed in Keras Github issue 3653. We can use **sample weights**, with the sample weights mode set to *temporal*. \n\nhttps://github.com/keras-team/keras/issues/3653\n\nTo apply sample weights to our model, we needa matrix of sample weights to account for all input values. This matrix will be the same size as the y_train output array (n samples X sample length). ",
"_____no_output_____"
],
[
"### Sample Weights",
"_____no_output_____"
]
],
[
[
"# Initialize Sample weight matrix\nsample_weight_matrix = np.array(y_train_val).copy()\n\n# Flatten matrix\nsample_weight_matrix_fl = flatten_list(sample_weight_matrix)\n\n# Determine number of classes\nn_classes = np.unique(sample_weight_matrix_fl).shape[0]\n\n# Determine class weights\nclass_weights = compute_class_weight(\n \"balanced\", \n np.unique(sample_weight_matrix_fl), \n np.array(sample_weight_matrix_fl)\n )\n\n# Replace class label with class weight\nfor i in range(0, len(class_weights)):\n sample_weight_matrix = np.where(\n sample_weight_matrix==i, \n class_weights[i], \n sample_weight_matrix\n ) ",
"D:\\anaconda3\\envs\\py-CausalityExtraction_36\\lib\\site-packages\\sklearn\\utils\\validation.py:70: FutureWarning: Pass classes=[0 1 2], y=[0 0 0 ... 0 0 0] as keyword args. From version 0.25 passing these as positional arguments will result in an error\n FutureWarning)\n"
]
],
[
[
"# Train Model",
"_____no_output_____"
],
[
"## Define Embedding Layer",
"_____no_output_____"
]
],
[
[
"embedding_matrix = gen_embedding_matrix(\n dct_embedding_index = dct_embedding_index,\n embed_label = EMBEDDING, \n vocabulary_length = vocab_len, \n word_index = word_index\n )\n\n# Embedding Layer\nembedding_layer = gen_embedding_layer(\n label = EMBEDDING,\n input_dimension = vocab_len,\n output_dimension_wo_init = 64,\n max_length = MAX_LENGTH,\n embedding_matrix = embedding_matrix,\n trainable = TRAINABLE\n )",
"_____no_output_____"
]
],
[
[
"## Compile Model",
"_____no_output_____"
]
],
[
[
"model = compile_model(\n vectorization_layer = vectorization_layer,\n embedding_layer = embedding_layer,\n dropout = DROPOUT,\n dropout_rate = DROPOUT_RATE,\n lstm_stack = LSTM_STACK,\n hidden_dimension_1 = HIDDEN_DIM_1,\n hidden_dimension_2 = HIDDEN_DIM_2,\n sample_weights = SAMPLE_WEIGHTS,\n time_distributed = TIME_DISTRIBUTED,\n optimizer = OPTIMIZER\n)\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ntext_vectorization (TextVect (None, 50) 0 \n_________________________________________________________________\nembeddings_glove (Embedding) (None, 50, 100) 100200 \n_________________________________________________________________\nspatial_dropout1d (SpatialDr (None, 50, 100) 0 \n_________________________________________________________________\nbidirectional (Bidirectional (None, 50, 64) 34048 \n_________________________________________________________________\nbidirectional_1 (Bidirection (None, 50, 256) 197632 \n_________________________________________________________________\ntime_distributed (TimeDistri (None, 50, 3) 771 \n=================================================================\nTotal params: 332,651\nTrainable params: 332,651\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Define Inputs",
"_____no_output_____"
]
],
[
[
"X_train = np.array(X_train)\n\n# Encode targets\ny_train = encode_target(y_train_val)\n\n# Convert target to numpy array for model input\ny_train = np.array(y_train)",
"_____no_output_____"
]
],
[
[
"## Train Model",
"_____no_output_____"
]
],
[
[
"if SAMPLE_WEIGHTS: \n history = model.fit(\n X_train, y_train, \n batch_size=BATCH_SIZE, \n epochs=EPOCHS, \n validation_split=0.2, \n sample_weight=sample_weight_matrix,\n verbose=2\n )\nelse: \n history = model.fit(\n X_train, y_train, \n batch_size=BATCH_SIZE, \n epochs=EPOCHS, \n validation_split=0.2, \n verbose=2\n )",
"Epoch 1/250\n12/12 - 15s - loss: 0.3200 - accuracy: 0.5567 - val_loss: 0.2667 - val_accuracy: 0.6178\nEpoch 2/250\n12/12 - 2s - loss: 0.2844 - accuracy: 0.6267 - val_loss: 0.2377 - val_accuracy: 0.6658\nEpoch 3/250\n12/12 - 2s - loss: 0.2635 - accuracy: 0.6561 - val_loss: 0.2095 - val_accuracy: 0.7294\nEpoch 4/250\n12/12 - 2s - loss: 0.2353 - accuracy: 0.7065 - val_loss: 0.1890 - val_accuracy: 0.7547\nEpoch 5/250\n12/12 - 2s - loss: 0.2087 - accuracy: 0.7508 - val_loss: 0.1876 - val_accuracy: 0.7709\nEpoch 6/250\n12/12 - 2s - loss: 0.2008 - accuracy: 0.7603 - val_loss: 0.1712 - val_accuracy: 0.7807\nEpoch 7/250\n12/12 - 2s - loss: 0.1848 - accuracy: 0.7831 - val_loss: 0.1523 - val_accuracy: 0.8079\nEpoch 8/250\n12/12 - 2s - loss: 0.1789 - accuracy: 0.7915 - val_loss: 0.1546 - val_accuracy: 0.7982\nEpoch 9/250\n12/12 - 2s - loss: 0.1678 - accuracy: 0.8068 - val_loss: 0.1508 - val_accuracy: 0.8144\nEpoch 10/250\n12/12 - 2s - loss: 0.1587 - accuracy: 0.8169 - val_loss: 0.1407 - val_accuracy: 0.8209\nEpoch 11/250\n12/12 - 2s - loss: 0.1562 - accuracy: 0.8213 - val_loss: 0.1478 - val_accuracy: 0.8293\nEpoch 12/250\n12/12 - 2s - loss: 0.1544 - accuracy: 0.8238 - val_loss: 0.1357 - val_accuracy: 0.8306\nEpoch 13/250\n12/12 - 2s - loss: 0.1423 - accuracy: 0.8400 - val_loss: 0.1434 - val_accuracy: 0.8352\nEpoch 14/250\n12/12 - 2s - loss: 0.1431 - accuracy: 0.8412 - val_loss: 0.1362 - val_accuracy: 0.8469\nEpoch 15/250\n12/12 - 2s - loss: 0.1392 - accuracy: 0.8435 - val_loss: 0.1313 - val_accuracy: 0.8404\nEpoch 16/250\n12/12 - 2s - loss: 0.1369 - accuracy: 0.8493 - val_loss: 0.1525 - val_accuracy: 0.8021\nEpoch 17/250\n12/12 - 2s - loss: 0.1309 - accuracy: 0.8580 - val_loss: 0.1302 - val_accuracy: 0.8397\nEpoch 18/250\n12/12 - 2s - loss: 0.1262 - accuracy: 0.8575 - val_loss: 0.1326 - val_accuracy: 0.8507\nEpoch 19/250\n12/12 - 2s - loss: 0.1158 - accuracy: 0.8753 - val_loss: 0.1331 - val_accuracy: 0.8482\nEpoch 20/250\n12/12 - 2s - loss: 0.1120 - accuracy: 0.8840 - val_loss: 0.1283 - val_accuracy: 0.8579\nEpoch 21/250\n12/12 - 2s - loss: 0.1070 - accuracy: 0.8829 - val_loss: 0.1450 - val_accuracy: 0.8391\nEpoch 22/250\n12/12 - 2s - loss: 0.1056 - accuracy: 0.8843 - val_loss: 0.1230 - val_accuracy: 0.8592\nEpoch 23/250\n12/12 - 2s - loss: 0.1043 - accuracy: 0.8852 - val_loss: 0.1247 - val_accuracy: 0.8618\nEpoch 24/250\n12/12 - 2s - loss: 0.0992 - accuracy: 0.8872 - val_loss: 0.1363 - val_accuracy: 0.8449\nEpoch 25/250\n12/12 - 2s - loss: 0.0990 - accuracy: 0.8915 - val_loss: 0.1362 - val_accuracy: 0.8436\nEpoch 26/250\n12/12 - 2s - loss: 0.0933 - accuracy: 0.8959 - val_loss: 0.1358 - val_accuracy: 0.8488\nEpoch 27/250\n12/12 - 2s - loss: 0.0926 - accuracy: 0.8982 - val_loss: 0.1234 - val_accuracy: 0.8631\nEpoch 28/250\n12/12 - 2s - loss: 0.0901 - accuracy: 0.9026 - val_loss: 0.1256 - val_accuracy: 0.8559\nEpoch 29/250\n12/12 - 2s - loss: 0.0892 - accuracy: 0.9031 - val_loss: 0.1184 - val_accuracy: 0.8559\nEpoch 30/250\n12/12 - 2s - loss: 0.0795 - accuracy: 0.9138 - val_loss: 0.1217 - val_accuracy: 0.8657\nEpoch 31/250\n12/12 - 2s - loss: 0.0780 - accuracy: 0.9132 - val_loss: 0.1223 - val_accuracy: 0.8715\nEpoch 32/250\n12/12 - 2s - loss: 0.0830 - accuracy: 0.9116 - val_loss: 0.1183 - val_accuracy: 0.8689\nEpoch 33/250\n12/12 - 2s - loss: 0.0745 - accuracy: 0.9202 - val_loss: 0.1254 - val_accuracy: 0.8618\nEpoch 34/250\n12/12 - 2s - loss: 0.0776 - accuracy: 0.9126 - val_loss: 0.1293 - val_accuracy: 0.8637\nEpoch 35/250\n12/12 - 2s - loss: 0.0693 - accuracy: 0.9271 - val_loss: 0.1217 - val_accuracy: 0.8637\nEpoch 36/250\n12/12 - 2s - loss: 0.0646 - accuracy: 0.9315 - val_loss: 0.1205 - val_accuracy: 0.8741\nEpoch 37/250\n12/12 - 2s - loss: 0.0684 - accuracy: 0.9265 - val_loss: 0.1262 - val_accuracy: 0.8689\nEpoch 38/250\n12/12 - 2s - loss: 0.0644 - accuracy: 0.9317 - val_loss: 0.1302 - val_accuracy: 0.8702\nEpoch 39/250\n12/12 - 2s - loss: 0.0637 - accuracy: 0.9288 - val_loss: 0.1248 - val_accuracy: 0.8702\nEpoch 40/250\n12/12 - 2s - loss: 0.0632 - accuracy: 0.9309 - val_loss: 0.1177 - val_accuracy: 0.8787\nEpoch 41/250\n12/12 - 2s - loss: 0.0644 - accuracy: 0.9314 - val_loss: 0.1183 - val_accuracy: 0.8728\nEpoch 42/250\n12/12 - 2s - loss: 0.0587 - accuracy: 0.9355 - val_loss: 0.1228 - val_accuracy: 0.8741\nEpoch 43/250\n12/12 - 2s - loss: 0.0517 - accuracy: 0.9436 - val_loss: 0.1377 - val_accuracy: 0.8644\nEpoch 44/250\n12/12 - 2s - loss: 0.0566 - accuracy: 0.9355 - val_loss: 0.1181 - val_accuracy: 0.8709\nEpoch 45/250\n12/12 - 2s - loss: 0.0535 - accuracy: 0.9421 - val_loss: 0.1355 - val_accuracy: 0.8735\nEpoch 46/250\n12/12 - 2s - loss: 0.0523 - accuracy: 0.9396 - val_loss: 0.1245 - val_accuracy: 0.8702\nEpoch 47/250\n12/12 - 2s - loss: 0.0534 - accuracy: 0.9425 - val_loss: 0.1136 - val_accuracy: 0.8819\nEpoch 48/250\n12/12 - 2s - loss: 0.0477 - accuracy: 0.9500 - val_loss: 0.1272 - val_accuracy: 0.8696\nEpoch 49/250\n12/12 - 2s - loss: 0.0485 - accuracy: 0.9477 - val_loss: 0.1287 - val_accuracy: 0.8735\nEpoch 50/250\n12/12 - 2s - loss: 0.0504 - accuracy: 0.9450 - val_loss: 0.1162 - val_accuracy: 0.8793\nEpoch 51/250\n12/12 - 2s - loss: 0.0462 - accuracy: 0.9479 - val_loss: 0.1432 - val_accuracy: 0.8683\nEpoch 52/250\n12/12 - 2s - loss: 0.0436 - accuracy: 0.9543 - val_loss: 0.1350 - val_accuracy: 0.8780\nEpoch 53/250\n12/12 - 2s - loss: 0.0479 - accuracy: 0.9467 - val_loss: 0.1559 - val_accuracy: 0.8689\nEpoch 54/250\n12/12 - 2s - loss: 0.0424 - accuracy: 0.9551 - val_loss: 0.1390 - val_accuracy: 0.8722\nEpoch 55/250\n12/12 - 2s - loss: 0.0403 - accuracy: 0.9566 - val_loss: 0.1380 - val_accuracy: 0.8715\nEpoch 56/250\n12/12 - 2s - loss: 0.0426 - accuracy: 0.9531 - val_loss: 0.1445 - val_accuracy: 0.8715\nEpoch 57/250\n12/12 - 2s - loss: 0.0395 - accuracy: 0.9558 - val_loss: 0.1426 - val_accuracy: 0.8774\nEpoch 58/250\n12/12 - 2s - loss: 0.0437 - accuracy: 0.9499 - val_loss: 0.1415 - val_accuracy: 0.8825\nEpoch 59/250\n12/12 - 2s - loss: 0.0406 - accuracy: 0.9558 - val_loss: 0.1334 - val_accuracy: 0.8696\nEpoch 60/250\n12/12 - 2s - loss: 0.0403 - accuracy: 0.9567 - val_loss: 0.1468 - val_accuracy: 0.8624\nEpoch 61/250\n12/12 - 2s - loss: 0.0354 - accuracy: 0.9633 - val_loss: 0.1410 - val_accuracy: 0.8715\nEpoch 62/250\n12/12 - 2s - loss: 0.0355 - accuracy: 0.9610 - val_loss: 0.1349 - val_accuracy: 0.8851\nEpoch 63/250\n12/12 - 2s - loss: 0.0343 - accuracy: 0.9612 - val_loss: 0.1322 - val_accuracy: 0.8845\nEpoch 64/250\n12/12 - 2s - loss: 0.0341 - accuracy: 0.9610 - val_loss: 0.1721 - val_accuracy: 0.8637\nEpoch 65/250\n12/12 - 2s - loss: 0.0325 - accuracy: 0.9635 - val_loss: 0.1411 - val_accuracy: 0.8754\nEpoch 66/250\n12/12 - 2s - loss: 0.0396 - accuracy: 0.9590 - val_loss: 0.1276 - val_accuracy: 0.8793\nEpoch 67/250\n12/12 - 2s - loss: 0.0351 - accuracy: 0.9600 - val_loss: 0.1208 - val_accuracy: 0.8774\nEpoch 68/250\n12/12 - 2s - loss: 0.0283 - accuracy: 0.9693 - val_loss: 0.1374 - val_accuracy: 0.8774\nEpoch 69/250\n12/12 - 2s - loss: 0.0335 - accuracy: 0.9632 - val_loss: 0.1459 - val_accuracy: 0.8728\nEpoch 70/250\n12/12 - 2s - loss: 0.0308 - accuracy: 0.9671 - val_loss: 0.1412 - val_accuracy: 0.8754\nEpoch 71/250\n12/12 - 2s - loss: 0.0290 - accuracy: 0.9670 - val_loss: 0.1330 - val_accuracy: 0.8799\nEpoch 72/250\n12/12 - 2s - loss: 0.0292 - accuracy: 0.9662 - val_loss: 0.1391 - val_accuracy: 0.8754\nEpoch 73/250\n12/12 - 2s - loss: 0.0289 - accuracy: 0.9690 - val_loss: 0.1415 - val_accuracy: 0.8624\nEpoch 74/250\n12/12 - 2s - loss: 0.0315 - accuracy: 0.9642 - val_loss: 0.1390 - val_accuracy: 0.8819\nEpoch 75/250\n12/12 - 2s - loss: 0.0253 - accuracy: 0.9711 - val_loss: 0.1379 - val_accuracy: 0.8897\nEpoch 76/250\n12/12 - 2s - loss: 0.0252 - accuracy: 0.9725 - val_loss: 0.1523 - val_accuracy: 0.8780\nEpoch 77/250\n12/12 - 2s - loss: 0.0277 - accuracy: 0.9679 - val_loss: 0.1518 - val_accuracy: 0.8741\nEpoch 78/250\n12/12 - 2s - loss: 0.0239 - accuracy: 0.9729 - val_loss: 0.1668 - val_accuracy: 0.8657\nEpoch 79/250\n12/12 - 2s - loss: 0.0256 - accuracy: 0.9710 - val_loss: 0.1515 - val_accuracy: 0.8754\nEpoch 80/250\n12/12 - 2s - loss: 0.0231 - accuracy: 0.9755 - val_loss: 0.1514 - val_accuracy: 0.8754\nEpoch 81/250\n12/12 - 2s - loss: 0.0266 - accuracy: 0.9714 - val_loss: 0.1570 - val_accuracy: 0.8735\nEpoch 82/250\n12/12 - 2s - loss: 0.0235 - accuracy: 0.9740 - val_loss: 0.1575 - val_accuracy: 0.8709\nEpoch 83/250\n12/12 - 2s - loss: 0.0216 - accuracy: 0.9763 - val_loss: 0.1887 - val_accuracy: 0.8663\nEpoch 84/250\n12/12 - 2s - loss: 0.0213 - accuracy: 0.9768 - val_loss: 0.1628 - val_accuracy: 0.8741\nEpoch 85/250\n12/12 - 2s - loss: 0.0232 - accuracy: 0.9703 - val_loss: 0.1687 - val_accuracy: 0.8748\nEpoch 86/250\n12/12 - 2s - loss: 0.0237 - accuracy: 0.9758 - val_loss: 0.1712 - val_accuracy: 0.8728\nEpoch 87/250\n12/12 - 2s - loss: 0.0202 - accuracy: 0.9774 - val_loss: 0.1816 - val_accuracy: 0.8689\nEpoch 88/250\n12/12 - 2s - loss: 0.0203 - accuracy: 0.9780 - val_loss: 0.1760 - val_accuracy: 0.8644\nEpoch 89/250\n12/12 - 2s - loss: 0.0190 - accuracy: 0.9797 - val_loss: 0.1659 - val_accuracy: 0.8709\nEpoch 90/250\n12/12 - 2s - loss: 0.0202 - accuracy: 0.9760 - val_loss: 0.1613 - val_accuracy: 0.8728\nEpoch 91/250\n12/12 - 2s - loss: 0.0198 - accuracy: 0.9768 - val_loss: 0.1670 - val_accuracy: 0.8812\nEpoch 92/250\n12/12 - 2s - loss: 0.0189 - accuracy: 0.9789 - val_loss: 0.1727 - val_accuracy: 0.8728\nEpoch 93/250\n12/12 - 2s - loss: 0.0186 - accuracy: 0.9777 - val_loss: 0.1688 - val_accuracy: 0.8838\nEpoch 94/250\n12/12 - 2s - loss: 0.0187 - accuracy: 0.9797 - val_loss: 0.1894 - val_accuracy: 0.8689\nEpoch 95/250\n12/12 - 2s - loss: 0.0187 - accuracy: 0.9777 - val_loss: 0.1580 - val_accuracy: 0.8832\nEpoch 96/250\n12/12 - 2s - loss: 0.0167 - accuracy: 0.9818 - val_loss: 0.1512 - val_accuracy: 0.8923\nEpoch 97/250\n12/12 - 2s - loss: 0.0153 - accuracy: 0.9823 - val_loss: 0.1611 - val_accuracy: 0.8761\nEpoch 98/250\n12/12 - 2s - loss: 0.0205 - accuracy: 0.9800 - val_loss: 0.1466 - val_accuracy: 0.8838\nEpoch 99/250\n12/12 - 2s - loss: 0.0174 - accuracy: 0.9792 - val_loss: 0.1705 - val_accuracy: 0.8819\nEpoch 100/250\n12/12 - 2s - loss: 0.0182 - accuracy: 0.9788 - val_loss: 0.1577 - val_accuracy: 0.8910\nEpoch 101/250\n12/12 - 2s - loss: 0.0171 - accuracy: 0.9814 - val_loss: 0.1720 - val_accuracy: 0.8819\nEpoch 102/250\n12/12 - 2s - loss: 0.0142 - accuracy: 0.9843 - val_loss: 0.1665 - val_accuracy: 0.8864\nEpoch 103/250\n12/12 - 2s - loss: 0.0159 - accuracy: 0.9821 - val_loss: 0.1718 - val_accuracy: 0.8832\nEpoch 104/250\n12/12 - 2s - loss: 0.0159 - accuracy: 0.9807 - val_loss: 0.1725 - val_accuracy: 0.8793\nEpoch 105/250\n12/12 - 2s - loss: 0.0177 - accuracy: 0.9795 - val_loss: 0.1697 - val_accuracy: 0.8819\nEpoch 106/250\n12/12 - 2s - loss: 0.0135 - accuracy: 0.9862 - val_loss: 0.1667 - val_accuracy: 0.8845\nEpoch 107/250\n12/12 - 2s - loss: 0.0136 - accuracy: 0.9843 - val_loss: 0.1677 - val_accuracy: 0.8793\nEpoch 108/250\n12/12 - 2s - loss: 0.0152 - accuracy: 0.9820 - val_loss: 0.1617 - val_accuracy: 0.8845\nEpoch 109/250\n12/12 - 2s - loss: 0.0165 - accuracy: 0.9780 - val_loss: 0.1561 - val_accuracy: 0.8812\nEpoch 110/250\n12/12 - 2s - loss: 0.0131 - accuracy: 0.9847 - val_loss: 0.1730 - val_accuracy: 0.8793\nEpoch 111/250\n12/12 - 2s - loss: 0.0123 - accuracy: 0.9856 - val_loss: 0.1693 - val_accuracy: 0.8871\nEpoch 112/250\n12/12 - 2s - loss: 0.0141 - accuracy: 0.9817 - val_loss: 0.1595 - val_accuracy: 0.8877\nEpoch 113/250\n12/12 - 2s - loss: 0.0150 - accuracy: 0.9833 - val_loss: 0.1700 - val_accuracy: 0.8832\nEpoch 114/250\n12/12 - 2s - loss: 0.0141 - accuracy: 0.9821 - val_loss: 0.1700 - val_accuracy: 0.8832\nEpoch 115/250\n12/12 - 2s - loss: 0.0138 - accuracy: 0.9841 - val_loss: 0.1722 - val_accuracy: 0.8780\nEpoch 116/250\n12/12 - 2s - loss: 0.0117 - accuracy: 0.9865 - val_loss: 0.1768 - val_accuracy: 0.8787\nEpoch 117/250\n12/12 - 2s - loss: 0.0124 - accuracy: 0.9869 - val_loss: 0.1799 - val_accuracy: 0.8767\nEpoch 118/250\n12/12 - 2s - loss: 0.0108 - accuracy: 0.9881 - val_loss: 0.1925 - val_accuracy: 0.8812\nEpoch 119/250\n12/12 - 2s - loss: 0.0116 - accuracy: 0.9856 - val_loss: 0.1940 - val_accuracy: 0.8774\nEpoch 120/250\n12/12 - 2s - loss: 0.0115 - accuracy: 0.9852 - val_loss: 0.1903 - val_accuracy: 0.8754\nEpoch 121/250\n12/12 - 2s - loss: 0.0135 - accuracy: 0.9846 - val_loss: 0.1710 - val_accuracy: 0.8832\nEpoch 122/250\n12/12 - 2s - loss: 0.0100 - accuracy: 0.9885 - val_loss: 0.1801 - val_accuracy: 0.8832\nEpoch 123/250\n12/12 - 2s - loss: 0.0136 - accuracy: 0.9838 - val_loss: 0.1891 - val_accuracy: 0.8728\nEpoch 124/250\n12/12 - 2s - loss: 0.0121 - accuracy: 0.9847 - val_loss: 0.1886 - val_accuracy: 0.8761\nEpoch 125/250\n12/12 - 2s - loss: 0.0122 - accuracy: 0.9850 - val_loss: 0.1938 - val_accuracy: 0.8793\nEpoch 126/250\n12/12 - 2s - loss: 0.0145 - accuracy: 0.9855 - val_loss: 0.1733 - val_accuracy: 0.8832\nEpoch 127/250\n12/12 - 2s - loss: 0.0129 - accuracy: 0.9838 - val_loss: 0.1781 - val_accuracy: 0.8819\nEpoch 128/250\n12/12 - 2s - loss: 0.0091 - accuracy: 0.9887 - val_loss: 0.1832 - val_accuracy: 0.8832\nEpoch 129/250\n12/12 - 2s - loss: 0.0112 - accuracy: 0.9850 - val_loss: 0.1772 - val_accuracy: 0.8819\nEpoch 130/250\n12/12 - 2s - loss: 0.0099 - accuracy: 0.9876 - val_loss: 0.1849 - val_accuracy: 0.8825\nEpoch 131/250\n12/12 - 2s - loss: 0.0116 - accuracy: 0.9887 - val_loss: 0.1969 - val_accuracy: 0.8761\nEpoch 132/250\n12/12 - 2s - loss: 0.0153 - accuracy: 0.9861 - val_loss: 0.1903 - val_accuracy: 0.8838\nEpoch 133/250\n12/12 - 2s - loss: 0.0107 - accuracy: 0.9865 - val_loss: 0.1877 - val_accuracy: 0.8825\nEpoch 134/250\n12/12 - 2s - loss: 0.0101 - accuracy: 0.9872 - val_loss: 0.1852 - val_accuracy: 0.8799\nEpoch 135/250\n12/12 - 2s - loss: 0.0097 - accuracy: 0.9893 - val_loss: 0.1899 - val_accuracy: 0.8722\nEpoch 136/250\n12/12 - 2s - loss: 0.0081 - accuracy: 0.9907 - val_loss: 0.1880 - val_accuracy: 0.8748\nEpoch 137/250\n12/12 - 2s - loss: 0.0109 - accuracy: 0.9891 - val_loss: 0.1883 - val_accuracy: 0.8767\nEpoch 138/250\n12/12 - 2s - loss: 0.0091 - accuracy: 0.9872 - val_loss: 0.1921 - val_accuracy: 0.8812\nEpoch 139/250\n12/12 - 2s - loss: 0.0085 - accuracy: 0.9882 - val_loss: 0.1930 - val_accuracy: 0.8864\nEpoch 140/250\n12/12 - 2s - loss: 0.0123 - accuracy: 0.9867 - val_loss: 0.1797 - val_accuracy: 0.8793\nEpoch 141/250\n12/12 - 2s - loss: 0.0089 - accuracy: 0.9888 - val_loss: 0.1852 - val_accuracy: 0.8838\nEpoch 142/250\n12/12 - 2s - loss: 0.0069 - accuracy: 0.9922 - val_loss: 0.1821 - val_accuracy: 0.8923\nEpoch 143/250\n12/12 - 2s - loss: 0.0098 - accuracy: 0.9873 - val_loss: 0.1849 - val_accuracy: 0.8838\nEpoch 144/250\n12/12 - 2s - loss: 0.0090 - accuracy: 0.9885 - val_loss: 0.1869 - val_accuracy: 0.8825\nEpoch 145/250\n12/12 - 2s - loss: 0.0092 - accuracy: 0.9881 - val_loss: 0.1915 - val_accuracy: 0.8812\nEpoch 146/250\n12/12 - 2s - loss: 0.0085 - accuracy: 0.9888 - val_loss: 0.2103 - val_accuracy: 0.8735\nEpoch 147/250\n12/12 - 2s - loss: 0.0078 - accuracy: 0.9911 - val_loss: 0.1814 - val_accuracy: 0.8942\nEpoch 148/250\n12/12 - 2s - loss: 0.0082 - accuracy: 0.9908 - val_loss: 0.1960 - val_accuracy: 0.8910\nEpoch 149/250\n12/12 - 2s - loss: 0.0091 - accuracy: 0.9895 - val_loss: 0.1979 - val_accuracy: 0.8858\nEpoch 150/250\n12/12 - 2s - loss: 0.0084 - accuracy: 0.9884 - val_loss: 0.1979 - val_accuracy: 0.8825\nEpoch 151/250\n12/12 - 2s - loss: 0.0086 - accuracy: 0.9884 - val_loss: 0.2046 - val_accuracy: 0.8767\nEpoch 152/250\n12/12 - 2s - loss: 0.0077 - accuracy: 0.9904 - val_loss: 0.1960 - val_accuracy: 0.8825\nEpoch 153/250\n12/12 - 2s - loss: 0.0083 - accuracy: 0.9901 - val_loss: 0.1903 - val_accuracy: 0.8838\nEpoch 154/250\n12/12 - 2s - loss: 0.0079 - accuracy: 0.9896 - val_loss: 0.1975 - val_accuracy: 0.8825\nEpoch 155/250\n12/12 - 2s - loss: 0.0082 - accuracy: 0.9890 - val_loss: 0.1916 - val_accuracy: 0.8877\nEpoch 156/250\n12/12 - 2s - loss: 0.0079 - accuracy: 0.9902 - val_loss: 0.1839 - val_accuracy: 0.8910\nEpoch 157/250\n12/12 - 2s - loss: 0.0086 - accuracy: 0.9893 - val_loss: 0.2005 - val_accuracy: 0.8799\nEpoch 158/250\n12/12 - 2s - loss: 0.0077 - accuracy: 0.9902 - val_loss: 0.1937 - val_accuracy: 0.8871\nEpoch 159/250\n12/12 - 2s - loss: 0.0086 - accuracy: 0.9888 - val_loss: 0.2037 - val_accuracy: 0.8825\nEpoch 160/250\n12/12 - 2s - loss: 0.0093 - accuracy: 0.9876 - val_loss: 0.1977 - val_accuracy: 0.8832\nEpoch 161/250\n12/12 - 2s - loss: 0.0080 - accuracy: 0.9911 - val_loss: 0.1979 - val_accuracy: 0.8858\nEpoch 162/250\n12/12 - 2s - loss: 0.0080 - accuracy: 0.9902 - val_loss: 0.1857 - val_accuracy: 0.8923\nEpoch 163/250\n12/12 - 2s - loss: 0.0068 - accuracy: 0.9910 - val_loss: 0.1959 - val_accuracy: 0.8845\nEpoch 164/250\n12/12 - 2s - loss: 0.0065 - accuracy: 0.9907 - val_loss: 0.2048 - val_accuracy: 0.8819\nEpoch 165/250\n12/12 - 2s - loss: 0.0082 - accuracy: 0.9908 - val_loss: 0.1921 - val_accuracy: 0.8884\nEpoch 166/250\n12/12 - 2s - loss: 0.0076 - accuracy: 0.9893 - val_loss: 0.2123 - val_accuracy: 0.8799\nEpoch 167/250\n12/12 - 2s - loss: 0.0085 - accuracy: 0.9901 - val_loss: 0.2113 - val_accuracy: 0.8832\nEpoch 168/250\n12/12 - 2s - loss: 0.0078 - accuracy: 0.9895 - val_loss: 0.2083 - val_accuracy: 0.8793\nEpoch 169/250\n12/12 - 2s - loss: 0.0080 - accuracy: 0.9901 - val_loss: 0.2072 - val_accuracy: 0.8864\nEpoch 170/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9924 - val_loss: 0.2059 - val_accuracy: 0.8877\nEpoch 171/250\n12/12 - 2s - loss: 0.0088 - accuracy: 0.9895 - val_loss: 0.2184 - val_accuracy: 0.8787\nEpoch 172/250\n12/12 - 2s - loss: 0.0066 - accuracy: 0.9911 - val_loss: 0.2109 - val_accuracy: 0.8819\nEpoch 173/250\n12/12 - 2s - loss: 0.0072 - accuracy: 0.9908 - val_loss: 0.1909 - val_accuracy: 0.8968\nEpoch 174/250\n12/12 - 2s - loss: 0.0062 - accuracy: 0.9922 - val_loss: 0.2009 - val_accuracy: 0.8858\nEpoch 175/250\n12/12 - 2s - loss: 0.0065 - accuracy: 0.9921 - val_loss: 0.2142 - val_accuracy: 0.8787\nEpoch 176/250\n12/12 - 2s - loss: 0.0063 - accuracy: 0.9927 - val_loss: 0.2165 - val_accuracy: 0.8825\nEpoch 177/250\n12/12 - 2s - loss: 0.0062 - accuracy: 0.9905 - val_loss: 0.2038 - val_accuracy: 0.8838\nEpoch 178/250\n12/12 - 2s - loss: 0.0064 - accuracy: 0.9914 - val_loss: 0.2134 - val_accuracy: 0.8832\nEpoch 179/250\n12/12 - 2s - loss: 0.0059 - accuracy: 0.9931 - val_loss: 0.2210 - val_accuracy: 0.8819\nEpoch 180/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9917 - val_loss: 0.2077 - val_accuracy: 0.8845\nEpoch 181/250\n12/12 - 2s - loss: 0.0062 - accuracy: 0.9928 - val_loss: 0.2030 - val_accuracy: 0.8929\nEpoch 182/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9928 - val_loss: 0.2128 - val_accuracy: 0.8877\nEpoch 183/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9911 - val_loss: 0.2274 - val_accuracy: 0.8884\nEpoch 184/250\n12/12 - 2s - loss: 0.0063 - accuracy: 0.9917 - val_loss: 0.2189 - val_accuracy: 0.8787\nEpoch 185/250\n12/12 - 2s - loss: 0.0059 - accuracy: 0.9916 - val_loss: 0.2080 - val_accuracy: 0.8845\nEpoch 186/250\n12/12 - 2s - loss: 0.0069 - accuracy: 0.9921 - val_loss: 0.2097 - val_accuracy: 0.8787\nEpoch 187/250\n12/12 - 2s - loss: 0.0052 - accuracy: 0.9910 - val_loss: 0.2119 - val_accuracy: 0.8884\nEpoch 188/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9919 - val_loss: 0.2111 - val_accuracy: 0.8851\nEpoch 189/250\n12/12 - 2s - loss: 0.0054 - accuracy: 0.9922 - val_loss: 0.2277 - val_accuracy: 0.8851\nEpoch 190/250\n12/12 - 2s - loss: 0.0073 - accuracy: 0.9916 - val_loss: 0.2163 - val_accuracy: 0.8864\nEpoch 191/250\n12/12 - 2s - loss: 0.0059 - accuracy: 0.9921 - val_loss: 0.2122 - val_accuracy: 0.8819\nEpoch 192/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9928 - val_loss: 0.2385 - val_accuracy: 0.8702\nEpoch 193/250\n12/12 - 2s - loss: 0.0067 - accuracy: 0.9910 - val_loss: 0.2264 - val_accuracy: 0.8812\nEpoch 194/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9919 - val_loss: 0.2406 - val_accuracy: 0.8761\nEpoch 195/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9904 - val_loss: 0.2243 - val_accuracy: 0.8806\nEpoch 196/250\n12/12 - 2s - loss: 0.0065 - accuracy: 0.9896 - val_loss: 0.2211 - val_accuracy: 0.8832\nEpoch 197/250\n12/12 - 2s - loss: 0.0070 - accuracy: 0.9908 - val_loss: 0.2190 - val_accuracy: 0.8858\nEpoch 198/250\n12/12 - 2s - loss: 0.0064 - accuracy: 0.9916 - val_loss: 0.2241 - val_accuracy: 0.8825\nEpoch 199/250\n12/12 - 2s - loss: 0.0059 - accuracy: 0.9919 - val_loss: 0.2269 - val_accuracy: 0.8812\nEpoch 200/250\n12/12 - 2s - loss: 0.0056 - accuracy: 0.9925 - val_loss: 0.2453 - val_accuracy: 0.8806\nEpoch 201/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9921 - val_loss: 0.2302 - val_accuracy: 0.8825\nEpoch 202/250\n12/12 - 2s - loss: 0.0067 - accuracy: 0.9904 - val_loss: 0.2273 - val_accuracy: 0.8838\nEpoch 203/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9921 - val_loss: 0.2381 - val_accuracy: 0.8799\nEpoch 204/250\n12/12 - 2s - loss: 0.0057 - accuracy: 0.9917 - val_loss: 0.2266 - val_accuracy: 0.8787\nEpoch 205/250\n12/12 - 2s - loss: 0.0055 - accuracy: 0.9913 - val_loss: 0.2208 - val_accuracy: 0.8799\nEpoch 206/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9928 - val_loss: 0.2233 - val_accuracy: 0.8825\nEpoch 207/250\n12/12 - 2s - loss: 0.0053 - accuracy: 0.9924 - val_loss: 0.2195 - val_accuracy: 0.8864\nEpoch 208/250\n12/12 - 2s - loss: 0.0060 - accuracy: 0.9899 - val_loss: 0.2308 - val_accuracy: 0.8806\nEpoch 209/250\n12/12 - 2s - loss: 0.0061 - accuracy: 0.9907 - val_loss: 0.2201 - val_accuracy: 0.8871\nEpoch 210/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9937 - val_loss: 0.2303 - val_accuracy: 0.8858\nEpoch 211/250\n12/12 - 2s - loss: 0.0056 - accuracy: 0.9917 - val_loss: 0.2322 - val_accuracy: 0.8838\nEpoch 212/250\n12/12 - 2s - loss: 0.0053 - accuracy: 0.9924 - val_loss: 0.2368 - val_accuracy: 0.8812\nEpoch 213/250\n12/12 - 2s - loss: 0.0054 - accuracy: 0.9914 - val_loss: 0.2348 - val_accuracy: 0.8812\nEpoch 214/250\n12/12 - 2s - loss: 0.0053 - accuracy: 0.9925 - val_loss: 0.2237 - val_accuracy: 0.8858\nEpoch 215/250\n12/12 - 2s - loss: 0.0054 - accuracy: 0.9908 - val_loss: 0.2365 - val_accuracy: 0.8767\nEpoch 216/250\n12/12 - 2s - loss: 0.0057 - accuracy: 0.9922 - val_loss: 0.2244 - val_accuracy: 0.8890\nEpoch 217/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9927 - val_loss: 0.2207 - val_accuracy: 0.8916\nEpoch 218/250\n12/12 - 2s - loss: 0.0052 - accuracy: 0.9902 - val_loss: 0.2144 - val_accuracy: 0.8864\nEpoch 219/250\n12/12 - 2s - loss: 0.0053 - accuracy: 0.9907 - val_loss: 0.2281 - val_accuracy: 0.8832\nEpoch 220/250\n12/12 - 2s - loss: 0.0049 - accuracy: 0.9930 - val_loss: 0.2325 - val_accuracy: 0.8774\nEpoch 221/250\n12/12 - 2s - loss: 0.0052 - accuracy: 0.9925 - val_loss: 0.2239 - val_accuracy: 0.8806\nEpoch 222/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9936 - val_loss: 0.2107 - val_accuracy: 0.8962\nEpoch 223/250\n12/12 - 2s - loss: 0.0057 - accuracy: 0.9924 - val_loss: 0.2097 - val_accuracy: 0.8955\nEpoch 224/250\n12/12 - 2s - loss: 0.0048 - accuracy: 0.9930 - val_loss: 0.2059 - val_accuracy: 0.8975\nEpoch 225/250\n12/12 - 2s - loss: 0.0062 - accuracy: 0.9910 - val_loss: 0.2152 - val_accuracy: 0.8903\nEpoch 226/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9930 - val_loss: 0.2179 - val_accuracy: 0.8871\nEpoch 227/250\n12/12 - 2s - loss: 0.0045 - accuracy: 0.9930 - val_loss: 0.2294 - val_accuracy: 0.8851\nEpoch 228/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9914 - val_loss: 0.2291 - val_accuracy: 0.8871\nEpoch 229/250\n12/12 - 2s - loss: 0.0042 - accuracy: 0.9950 - val_loss: 0.2202 - val_accuracy: 0.8864\nEpoch 230/250\n12/12 - 2s - loss: 0.0066 - accuracy: 0.9911 - val_loss: 0.2187 - val_accuracy: 0.8903\nEpoch 231/250\n12/12 - 2s - loss: 0.0053 - accuracy: 0.9925 - val_loss: 0.2257 - val_accuracy: 0.8851\nEpoch 232/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9928 - val_loss: 0.2232 - val_accuracy: 0.8884\nEpoch 233/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9921 - val_loss: 0.2200 - val_accuracy: 0.8942\nEpoch 234/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9927 - val_loss: 0.2146 - val_accuracy: 0.8910\nEpoch 235/250\n12/12 - 2s - loss: 0.0051 - accuracy: 0.9925 - val_loss: 0.2198 - val_accuracy: 0.8871\nEpoch 236/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9933 - val_loss: 0.1996 - val_accuracy: 0.8955\nEpoch 237/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9917 - val_loss: 0.2157 - val_accuracy: 0.8864\nEpoch 238/250\n12/12 - 2s - loss: 0.0058 - accuracy: 0.9919 - val_loss: 0.2088 - val_accuracy: 0.8923\nEpoch 239/250\n12/12 - 2s - loss: 0.0046 - accuracy: 0.9934 - val_loss: 0.2121 - val_accuracy: 0.8949\nEpoch 240/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9934 - val_loss: 0.2183 - val_accuracy: 0.8858\nEpoch 241/250\n12/12 - 2s - loss: 0.0056 - accuracy: 0.9921 - val_loss: 0.2149 - val_accuracy: 0.8929\nEpoch 242/250\n12/12 - 2s - loss: 0.0048 - accuracy: 0.9934 - val_loss: 0.2159 - val_accuracy: 0.8910\nEpoch 243/250\n12/12 - 2s - loss: 0.0041 - accuracy: 0.9937 - val_loss: 0.2204 - val_accuracy: 0.8884\nEpoch 244/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9933 - val_loss: 0.2166 - val_accuracy: 0.8897\nEpoch 245/250\n12/12 - 2s - loss: 0.0044 - accuracy: 0.9916 - val_loss: 0.2207 - val_accuracy: 0.8871\nEpoch 246/250\n12/12 - 2s - loss: 0.0041 - accuracy: 0.9931 - val_loss: 0.2312 - val_accuracy: 0.8832\nEpoch 247/250\n12/12 - 2s - loss: 0.0052 - accuracy: 0.9919 - val_loss: 0.2090 - val_accuracy: 0.8916\nEpoch 248/250\n12/12 - 2s - loss: 0.0050 - accuracy: 0.9924 - val_loss: 0.2061 - val_accuracy: 0.8916\nEpoch 249/250\n12/12 - 2s - loss: 0.0046 - accuracy: 0.9908 - val_loss: 0.2160 - val_accuracy: 0.8851\nEpoch 250/250\n12/12 - 2s - loss: 0.0047 - accuracy: 0.9936 - val_loss: 0.2107 - val_accuracy: 0.8871\n"
]
],
[
[
"# Evaluation",
"_____no_output_____"
],
[
"## Generate Predictions",
"_____no_output_____"
]
],
[
[
"# Generate Predictions\ny_pred = []\nfor i in range(len(X_test)):\n y_pred_prob = model.predict(np.array([X_test[i]]))\n y_pred_class = np.argmax(y_pred_prob, axis=-1)[0].tolist()\n y_pred.append(y_pred_class)\n\n# Flatten lists\ny_pred = flatten_list(y_pred)\ny_test = flatten_list(y_test_val)",
"_____no_output_____"
]
],
[
[
"## Classification Report",
"_____no_output_____"
]
],
[
[
"print(classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.98 0.99 0.99 6877\n 1 0.93 0.88 0.90 626\n 2 0.89 0.88 0.89 547\n\n accuracy 0.97 8050\n macro avg 0.94 0.92 0.93 8050\nweighted avg 0.97 0.97 0.97 8050\n\n"
],
[
"df_classification_report = get_classification_report(y_test, y_pred)\n\nfile_name = f\"entity_extraction_configuration_report_{CONFIGURATION_LABEL}_epochs_{EPOCHS}_{TIME_STAMP}.csv\"\npath_classification_report = os.path.join(\n path_dir_data, subfolder_a, subfolder_entity, file_name\n)\n\ndf_classification_report.to_csv(path_classification_report, index_label=False)",
"_____no_output_____"
]
],
[
[
"## Charts",
"_____no_output_____"
],
[
"### Accuracy",
"_____no_output_____"
]
],
[
[
"hist = pd.DataFrame(history.history)\n\n#plot training and validation accuracy\nf = plt.figure(figsize=(5,5))\nplt.plot(hist[\"accuracy\"], label =' Training Accuracy')\nplt.plot(hist[\"val_accuracy\"], label = 'Validation Accuracy')\nplt.legend(loc=\"lower right\")\nplt.show()\n\n# Save and output\nfile_name = f\"enitity_extraction_training_validation_accuracy_{CONFIGURATION_LABEL}_epochs_{EPOCHS}_{TIME_STAMP}.png\"\npath = os.path.join(path_dir_data, subfolder_a, subfolder_entity, file_name)\nf.savefig(path)\n# f.download(path)",
"_____no_output_____"
]
],
[
[
"### Loss",
"_____no_output_____"
]
],
[
[
"# plot training and validation accuracy\nf = plt.figure(figsize=(5,5))\nplt.plot(hist[\"loss\"], label = 'Training Loss')\nplt.plot(hist[\"val_loss\"], label = 'Validation Loss')\nplt.legend(loc=\"upper right\")\nplt.show()\n\n# Save and output\nfile_name = f\"enitity_extraction_training_validation_loss_{CONFIGURATION_LABEL}_epochs_{EPOCHS}_{TIME_STAMP}.png\"\npath = os.path.join(path_dir_data, subfolder_a, subfolder_entity, file_name)\nf.savefig(path)\n# f.download(path)",
"_____no_output_____"
]
],
[
[
"## Confusion Matrix",
"_____no_output_____"
]
],
[
[
"# Create confusion matrix\ncm = confusion_matrix(y_test, y_pred)\ndf_cm = pd.DataFrame(cm, columns=np.unique(y_test), index = np.unique(y_pred))\ndf_cm.index.name = 'Actual'\ndf_cm.columns.name = 'Predicted'\n\n# Visualize\nplt.figure(figsize = (10,7))\nsn.set(font_scale=1.4)#for label size\nsn.heatmap(df_cm, cmap=\"Blues\", annot=True , fmt='d', annot_kws={\"size\": 16}) ;# font size",
"_____no_output_____"
]
],
[
[
"# Save and Restore Model\nThe following section tests saving and restoring the model.",
"_____no_output_____"
],
[
"## Save",
"_____no_output_____"
]
],
[
[
"# Export Model\nfolder_keras_model = f\"entity_extraction_epoch_{CONFIGURATION_LABEL}_epochs_{EPOCHS}_{TIME_STAMP}\"\npath_keras_model = os.path.join(\n path_dir_data, subfolder_a, subfolder_entity, folder_keras_model\n)\n\n# SavedModel\nmodel.save(path_keras_model)",
"INFO:tensorflow:Assets written to: ./../data\\outputs\\entity_extraction\\entity_extraction_epoch_optimal_epochs_250_20210310-101431\\assets\n"
]
],
[
[
"# Restore",
"_____no_output_____"
]
],
[
[
"from tensorflow import keras\nmodel = keras.models.load_model(path_keras_model)\n\nmodel.summary()",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ntext_vectorization (TextVect (None, 50) 0 \n_________________________________________________________________\nembeddings_glove (Embedding) (None, 50, 100) 100200 \n_________________________________________________________________\nspatial_dropout1d (SpatialDr (None, 50, 100) 0 \n_________________________________________________________________\nbidirectional (Bidirectional (None, 50, 64) 34048 \n_________________________________________________________________\nbidirectional_1 (Bidirection (None, 50, 256) 197632 \n_________________________________________________________________\ntime_distributed (TimeDistri (None, 50, 3) 771 \n=================================================================\nTotal params: 332,651\nTrainable params: 332,651\nNon-trainable params: 0\n_________________________________________________________________\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1d3dd420ee9ab0daa58264132a2c1c69ea871d
| 197,473 |
ipynb
|
Jupyter Notebook
|
Python intro part 2 and snake/homework/coints.ipynb
|
YuriiKoteyka/Machine-Learning
|
5f929d5e3597c41eb2c9a20c242f6734f094584d
|
[
"MIT"
] | null | null | null |
Python intro part 2 and snake/homework/coints.ipynb
|
YuriiKoteyka/Machine-Learning
|
5f929d5e3597c41eb2c9a20c242f6734f094584d
|
[
"MIT"
] | null | null | null |
Python intro part 2 and snake/homework/coints.ipynb
|
YuriiKoteyka/Machine-Learning
|
5f929d5e3597c41eb2c9a20c242f6734f094584d
|
[
"MIT"
] | null | null | null | 1,462.762963 | 194,932 | 0.962851 |
[
[
[
"## [Dead Man's Chest](https://en.wikipedia.org/wiki/Dead_Man%27s_Chest)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"found_coins = 20 # знайдені монети\nmagic_coins = 10 # магічні монети\nstolen_coins = 3 # вкрадені монети",
"_____no_output_____"
]
],
[
[
"Створи list монеток coints",
"_____no_output_____"
]
],
[
[
"coins = [20,10,3]",
"_____no_output_____"
]
],
[
[
"Підрахуй суму монеток в coints за допомогою функції sum",
"_____no_output_____"
]
],
[
[
"coins = [20,10,3]\nsum_coins = sum(coins)\nprint(sum_coins)",
"33\n"
]
],
[
[
"Підрахуй суму монеток в coints за допомогою циклу",
"_____no_output_____"
]
],
[
[
"def sum_coins(numList):\n theSum = 0\n for i in numList:\n theSum = theSum + i\n return theSum\n\nprint(sum_coins([20,10,3]))\n",
"33\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1d4f94e05991241b02dfdc770b6d680c90e08b
| 178,704 |
ipynb
|
Jupyter Notebook
|
bag_of_words_meets_bags_of_popcorn/01.ipynb
|
yunshuipiao/sw_kaggle
|
2bd32670a74fcb407486bd382b414937c109160f
|
[
"Apache-2.0"
] | 6 |
2018-05-19T06:35:58.000Z
|
2021-02-16T07:28:24.000Z
|
bag_of_words_meets_bags_of_popcorn/01.ipynb
|
yunshuipiao/sw_kaggle
|
2bd32670a74fcb407486bd382b414937c109160f
|
[
"Apache-2.0"
] | null | null | null |
bag_of_words_meets_bags_of_popcorn/01.ipynb
|
yunshuipiao/sw_kaggle
|
2bd32670a74fcb407486bd382b414937c109160f
|
[
"Apache-2.0"
] | 5 |
2019-02-19T03:06:45.000Z
|
2021-02-16T07:29:29.000Z
| 24.847608 | 2,333 | 0.420125 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"train = pd.read_csv(\"./datasets/labeledTrainData.tsv\", header=0, delimiter='\\t', quoting=3)\ntrain.head()",
"_____no_output_____"
],
[
"train.shape",
"_____no_output_____"
],
[
"train.columns.values",
"_____no_output_____"
],
[
"train[\"review\"][0]",
"_____no_output_____"
],
[
"from bs4 import BeautifulSoup",
"_____no_output_____"
],
[
"example1 = BeautifulSoup(train[\"review\"][0])",
"/anaconda3/lib/python3.6/site-packages/bs4/__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system (\"lxml\"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.\n\nThe code that caused this warning is on line 193 of the file /anaconda3/lib/python3.6/runpy.py. To get rid of this warning, change code that looks like this:\n\n BeautifulSoup(YOUR_MARKUP})\n\nto this:\n\n BeautifulSoup(YOUR_MARKUP, \"lxml\")\n\n markup_type=markup_type))\n"
],
[
"example1.get_text()",
"_____no_output_____"
],
[
"import re",
"_____no_output_____"
],
[
"letters_only = re.sub(\"[^a-zA-Z]\", \" \", example1.get_text()) #替换非字母为空格\nletters_only",
"_____no_output_____"
],
[
"lower_case = letters_only.lower()\nwords = lower_case.split()",
"_____no_output_____"
],
[
"# import nltk\n# nltk.download()",
"_____no_output_____"
],
[
"from nltk.corpus import stopwords",
"_____no_output_____"
],
[
"stopwords.words(\"english\")",
"_____no_output_____"
],
[
"words = [w for w in words if not w in stopwords.words(\"english\")]",
"_____no_output_____"
],
[
"words",
"_____no_output_____"
],
[
"def review_to_words(raw_review):\n review_text = BeautifulSoup(raw_review).get_text()\n letters_only = re.sub(\"[^a-zA-Z]\", \" \", review_text)\n \n words = letters_only.lower().split()\n \n stops = set(stopwords.words('english'))\n meaningful_words = [w for w in words if not w in stops]\n return(\" \".join(meaningful_words))\n ",
"_____no_output_____"
],
[
"clean_review = review_to_words(train[\"review\"][0])",
"/anaconda3/lib/python3.6/site-packages/bs4/__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system (\"lxml\"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.\n\nThe code that caused this warning is on line 193 of the file /anaconda3/lib/python3.6/runpy.py. To get rid of this warning, change code that looks like this:\n\n BeautifulSoup(YOUR_MARKUP})\n\nto this:\n\n BeautifulSoup(YOUR_MARKUP, \"lxml\")\n\n markup_type=markup_type))\n"
],
[
"clean_review",
"_____no_output_____"
],
[
"print(\"Cleaning and parsing the training set movie reviews...\\n\")\nnumber = 10000\nnum_reviews = train[\"review\"][:number].size\nclean_train_reviews = []\nfor i in range(0, num_reviews):\n if (i + 1) % 1000 == 0:\n print(\"Review {} of {}\".format(i + 1, num_reviews))\n clean_train_reviews.append(review_to_words(train[\"review\"][i]))",
"Cleaning and parsing the training set movie reviews...\n\n"
],
[
"\nprint(\"creating the bag of words...\")\nfrom sklearn.feature_extraction.text import CountVectorizer\nvertorizer = CountVectorizer(analyzer='word', tokenizer=None, \n preprocessor=None, stop_words=None, \n max_features=5000)\ntrain_data_features = vertorizer.fit_transform(clean_train_reviews)\ntrain_data_features = train_data_features.toarray()",
"creating the bag of words...\n"
],
[
"train_data_features.shape #每一个词由5000维的向量表示",
"_____no_output_____"
],
[
"vocab = vertorizer.get_feature_names()",
"_____no_output_____"
],
[
"vocab #5000",
"_____no_output_____"
],
[
"import numpy as np\ndist = np.sum(train_data_features, axis=0) # axis=0 对每一列进行操作\nfor tag, count in zip(vocab, dist):\n print(str(count) + \" : \" + tag) #每个单词出现的次数",
"88 : abandoned\n61 : abc\n46 : abilities\n185 : ability\n557 : able\n36 : abraham\n43 : absence\n122 : absolute\n584 : absolutely\n109 : absurd\n84 : abuse\n38 : abusive\n107 : academy\n198 : accent\n84 : accents\n141 : accept\n58 : acceptable\n56 : accepted\n39 : access\n127 : accident\n76 : accidentally\n51 : accomplished\n131 : according\n75 : account\n129 : accurate\n53 : accused\n32 : ace\n68 : achieve\n60 : achieved\n48 : achievement\n424 : across\n530 : act\n267 : acted\n2554 : acting\n1395 : action\n129 : actions\n34 : active\n948 : actor\n1842 : actors\n513 : actress\n148 : actresses\n166 : acts\n303 : actual\n1669 : actually\n58 : ad\n113 : adam\n37 : adams\n175 : adaptation\n63 : adapted\n313 : add\n180 : added\n72 : adding\n130 : addition\n130 : adds\n47 : adequate\n53 : admire\n232 : admit\n44 : admittedly\n38 : adolescent\n39 : adorable\n207 : adult\n128 : adults\n38 : advance\n46 : advanced\n60 : advantage\n213 : adventure\n81 : adventures\n40 : advertising\n96 : advice\n39 : advise\n128 : affair\n35 : affairs\n36 : affect\n56 : affected\n49 : afford\n37 : aforementioned\n129 : afraid\n88 : africa\n113 : african\n72 : afternoon\n61 : afterwards\n486 : age\n107 : aged\n35 : agency\n39 : agenda\n145 : agent\n35 : agents\n86 : ages\n43 : aging\n424 : ago\n215 : agree\n36 : agreed\n35 : agrees\n54 : ah\n175 : ahead\n42 : aid\n50 : aids\n40 : aim\n55 : aimed\n251 : air\n59 : aired\n37 : airplane\n52 : airport\n75 : aka\n36 : akshay\n162 : al\n148 : alan\n70 : alas\n69 : albeit\n101 : albert\n37 : album\n44 : alcohol\n37 : alcoholic\n40 : alert\n112 : alex\n51 : alexander\n95 : alice\n41 : alicia\n129 : alien\n77 : aliens\n60 : alike\n52 : alison\n183 : alive\n164 : allen\n128 : allow\n119 : allowed\n61 : allowing\n102 : allows\n35 : ally\n1234 : almost\n438 : alone\n727 : along\n39 : alongside\n539 : already\n80 : alright\n3708 : also\n35 : altered\n32 : alternative\n1015 : although\n48 : altogether\n39 : alvin\n1309 : always\n37 : amanda\n72 : amateur\n80 : amateurish\n77 : amazed\n552 : amazing\n70 : amazingly\n33 : ambiguous\n53 : ambitious\n339 : america\n969 : american\n162 : americans\n36 : amitabh\n290 : among\n63 : amongst\n219 : amount\n36 : amused\n198 : amusing\n42 : amy\n37 : analysis\n90 : ancient\n87 : anderson\n60 : andrew\n82 : andrews\n129 : andy\n76 : angel\n36 : angela\n43 : angeles\n61 : angels\n76 : anger\n99 : angle\n72 : angles\n135 : angry\n125 : animal\n166 : animals\n192 : animated\n301 : animation\n104 : anime\n111 : ann\n119 : anna\n105 : anne\n42 : annie\n63 : annoyed\n416 : annoying\n1760 : another\n155 : answer\n85 : answers\n105 : anthony\n193 : anti\n47 : antics\n37 : anton\n32 : antonio\n46 : antonioni\n130 : anybody\n119 : anymore\n1071 : anyone\n1167 : anything\n442 : anyway\n44 : anyways\n131 : anywhere\n247 : apart\n152 : apartment\n54 : appalling\n116 : apparent\n394 : apparently\n181 : appeal\n100 : appealing\n237 : appear\n212 : appearance\n41 : appearances\n134 : appeared\n65 : appearing\n314 : appears\n190 : appreciate\n99 : appreciated\n39 : appreciation\n135 : approach\n94 : appropriate\n33 : appropriately\n32 : april\n144 : area\n57 : areas\n39 : arguably\n50 : argue\n48 : argument\n66 : arm\n41 : armed\n77 : arms\n157 : army\n69 : arnold\n1478 : around\n44 : arrested\n35 : arrival\n48 : arrive\n42 : arrived\n71 : arrives\n37 : arrogant\n513 : art\n155 : arthur\n129 : artist\n145 : artistic\n67 : artists\n118 : arts\n33 : artsy\n68 : ashamed\n32 : ashley\n89 : asian\n194 : aside\n261 : ask\n109 : asked\n100 : asking\n126 : asks\n79 : asleep\n214 : aspect\n159 : aspects\n111 : ass\n32 : assassin\n45 : assault\n36 : assigned\n71 : assistant\n52 : associated\n91 : assume\n51 : astaire\n38 : asylum\n45 : atlantis\n285 : atmosphere\n65 : atmospheric\n80 : atrocious\n54 : attached\n169 : attack\n59 : attacked\n74 : attacks\n416 : attempt\n44 : attempted\n53 : attempting\n257 : attempts\n32 : attend\n342 : attention\n108 : attitude\n43 : attitudes\n33 : attorney\n47 : attracted\n58 : attraction\n139 : attractive\n875 : audience\n189 : audiences\n46 : audio\n33 : audrey\n85 : aunt\n44 : austin\n54 : australia\n92 : australian\n62 : authentic\n99 : author\n47 : authority\n36 : automatically\n155 : available\n314 : average\n328 : avoid\n43 : avoided\n38 : awake\n164 : award\n101 : awards\n113 : aware\n1100 : away\n48 : awe\n179 : awesome\n691 : awful\n108 : awkward\n48 : babe\n33 : babies\n304 : baby\n42 : bacall\n1962 : back\n51 : backdrop\n247 : background\n41 : backgrounds\n3719 : bad\n277 : badly\n61 : bag\n57 : baker\n60 : bakshi\n62 : balance\n105 : ball\n40 : ballet\n40 : balls\n209 : band\n38 : bands\n49 : bang\n113 : bank\n38 : banned\n172 : bar\n97 : barbara\n49 : bare\n177 : barely\n36 : bargain\n33 : barrel\n63 : barry\n38 : barrymore\n71 : base\n73 : baseball\n554 : based\n64 : basement\n193 : basic\n312 : basically\n84 : basis\n41 : basketball\n78 : bat\n37 : bathroom\n153 : batman\n249 : battle\n59 : battles\n36 : bay\n74 : bbc\n81 : beach\n87 : bear\n63 : bears\n66 : beast\n137 : beat\n54 : beaten\n63 : beating\n45 : beatles\n42 : beats\n43 : beatty\n936 : beautiful\n188 : beautifully\n262 : beauty\n282 : became\n649 : become\n549 : becomes\n151 : becoming\n149 : bed\n51 : bedroom\n48 : beer\n132 : began\n296 : begin\n580 : beginning\n318 : begins\n34 : behave\n106 : behavior\n36 : behaviour\n485 : behind\n54 : beings\n44 : bela\n69 : belief\n41 : beliefs\n291 : believable\n993 : believe\n89 : believed\n86 : believes\n67 : believing\n42 : bell\n34 : belong\n62 : belongs\n70 : beloved\n37 : belushi\n258 : ben\n32 : bend\n40 : beneath\n37 : benefit\n47 : bergman\n34 : bernard\n169 : besides\n2604 : best\n89 : bet\n33 : betrayal\n60 : bette\n2271 : better\n70 : bettie\n42 : beverly\n334 : beyond\n43 : bible\n1387 : big\n111 : bigger\n213 : biggest\n32 : biko\n257 : bill\n34 : billed\n144 : billy\n45 : bin\n35 : biography\n47 : bird\n43 : birds\n79 : birth\n53 : birthday\n1216 : bit\n48 : bite\n138 : bits\n69 : bitter\n202 : bizarre\n839 : black\n32 : blacks\n41 : blade\n70 : blah\n63 : blair\n35 : blaise\n36 : blake\n110 : blame\n128 : bland\n55 : blank\n36 : blast\n47 : blatant\n49 : bleak\n41 : blend\n40 : blew\n119 : blind\n48 : block\n73 : blockbuster\n44 : blond\n105 : blonde\n500 : blood\n123 : bloody\n85 : blow\n45 : blowing\n77 : blown\n48 : blows\n176 : blue\n46 : blues\n33 : blunt\n53 : bo\n109 : board\n94 : boat\n103 : bob\n50 : bobby\n84 : bodies\n405 : body\n47 : bold\n57 : boll\n72 : bollywood\n90 : bomb\n150 : bond\n41 : bone\n33 : bonnie\n40 : bonus\n935 : book\n188 : books\n35 : boom\n40 : boot\n47 : border\n77 : bore\n202 : bored\n58 : boredom\n696 : boring\n34 : boris\n160 : born\n37 : borrowed\n148 : boss\n149 : bother\n72 : bothered\n38 : bottle\n173 : bottom\n167 : bought\n57 : bound\n98 : bourne\n246 : box\n34 : boxer\n57 : boxing\n644 : boy\n139 : boyfriend\n248 : boys\n66 : brad\n48 : brady\n189 : brain\n40 : brains\n88 : branagh\n52 : brand\n63 : brando\n76 : brave\n49 : brazil\n235 : break\n96 : breaking\n104 : breaks\n56 : breasts\n73 : breath\n71 : breathtaking\n33 : breed\n148 : brian\n54 : bride\n60 : bridge\n44 : bridget\n181 : brief\n48 : briefly\n98 : bright\n54 : brilliance\n477 : brilliant\n94 : brilliantly\n370 : bring\n83 : bringing\n234 : brings\n69 : britain\n352 : british\n57 : broad\n44 : broadcast\n81 : broadway\n60 : broke\n97 : broken\n46 : brooklyn\n74 : brooks\n60 : brosnan\n442 : brother\n238 : brothers\n286 : brought\n112 : brown\n166 : bruce\n123 : brutal\n41 : brutality\n38 : bsg\n88 : buck\n52 : bucks\n55 : bud\n55 : buddies\n111 : buddy\n704 : budget\n37 : buff\n35 : buffalo\n39 : buffs\n47 : bug\n57 : bugs\n140 : build\n173 : building\n46 : buildings\n45 : builds\n88 : built\n38 : bull\n46 : bullet\n56 : bullets\n34 : bully\n338 : bunch\n58 : buried\n51 : burn\n40 : burned\n62 : burning\n85 : burns\n62 : burt\n44 : burton\n80 : bus\n66 : bush\n253 : business\n34 : buster\n70 : busy\n35 : butler\n56 : butt\n47 : button\n308 : buy\n69 : buying\n34 : bye\n66 : cabin\n114 : cable\n105 : cage\n89 : caine\n32 : cake\n38 : caliber\n74 : california\n358 : call\n611 : called\n68 : calling\n105 : calls\n34 : calm\n690 : came\n112 : cameo\n61 : cameos\n714 : camera\n39 : cameras\n42 : cameron\n178 : camp\n40 : campbell\n68 : campy\n56 : canada\n95 : canadian\n42 : cancer\n131 : candy\n460 : cannot\n77 : cant\n88 : capable\n37 : capital\n41 : capote\n134 : captain\n40 : captivating\n117 : capture\n109 : captured\n87 : captures\n37 : capturing\n515 : car\n60 : card\n53 : cardboard\n37 : cards\n593 : care\n48 : cared\n429 : career\n42 : careers\n34 : careful\n54 : carefully\n34 : carell\n93 : cares\n37 : caricatures\n71 : caring\n40 : carl\n43 : carla\n33 : carmen\n47 : carol\n81 : carpenter\n43 : carrey\n47 : carrie\n60 : carried\n67 : carries\n133 : carry\n68 : carrying\n106 : cars\n69 : carter\n199 : cartoon\n57 : cartoons\n38 : cary\n613 : case\n59 : cases\n95 : cash\n34 : cassavetes\n1476 : cast\n244 : casting\n145 : castle\n201 : cat\n186 : catch\n35 : catchy\n84 : category\n57 : catherine\n58 : catholic\n48 : cats\n234 : caught\n217 : cause\n85 : caused\n76 : causes\n43 : causing\n37 : cave\n55 : cd\n42 : celebrity\n61 : cell\n41 : celluloid\n41 : cena\n104 : center\n40 : centered\n43 : centers\n167 : central\n225 : century\n33 : cerebral\n327 : certain\n583 : certainly\n46 : cg\n143 : cgi\n45 : chain\n61 : chair\n70 : challenge\n34 : challenged\n35 : challenges\n33 : challenging\n39 : champion\n55 : championship\n71 : chan\n443 : chance\n41 : chances\n413 : change\n185 : changed\n146 : changes\n73 : changing\n189 : channel\n38 : channels\n37 : chaos\n53 : chaplin\n43 : chapter\n2810 : character\n50 : characterization\n2886 : characters\n65 : charge\n54 : charisma\n63 : charismatic\n165 : charles\n206 : charlie\n50 : charlotte\n165 : charm\n180 : charming\n181 : chase\n37 : chased\n56 : chases\n63 : chasing\n42 : chavez\n107 : che\n373 : cheap\n42 : cheated\n34 : cheating\n343 : check\n32 : checked\n50 : checking\n40 : cheek\n63 : cheese\n251 : cheesy\n186 : chemistry\n38 : cher\n48 : chess\n39 : chest\n80 : chick\n103 : chief\n530 : child\n141 : childhood\n41 : childish\n598 : children\n78 : chilling\n35 : chills\n78 : china\n138 : chinese\n212 : choice\n68 : choices\n86 : choose\n35 : chooses\n37 : choppy\n41 : choreographed\n55 : choreography\n35 : chorus\n72 : chose\n88 : chosen\n185 : chris\n77 : christ\n161 : christian\n45 : christians\n227 : christmas\n152 : christopher\n60 : christy\n35 : chuck\n152 : church\n40 : cia\n62 : cinderella\n584 : cinema\n154 : cinematic\n47 : cinematographer\n431 : cinematography\n35 : circle\n83 : circumstances\n37 : cities\n41 : citizen\n33 : citizens\n471 : city\n60 : civil\n52 : civilization\n107 : claim\n51 : claimed\n77 : claims\n68 : claire\n36 : clan\n88 : clark\n34 : clash\n368 : class\n44 : classes\n739 : classic\n39 : classical\n83 : classics\n32 : claus\n35 : clay\n87 : clean\n322 : clear\n342 : clearly\n200 : clever\n49 : cleverly\n326 : clich\n40 : cliche\n50 : cliff\n38 : climactic\n174 : climax\n42 : clint\n71 : clips\n32 : clive\n516 : close\n34 : closed\n58 : closely\n65 : closer\n38 : closest\n41 : closet\n75 : closing\n149 : clothes\n41 : clothing\n40 : clown\n179 : club\n82 : clue\n52 : clues\n35 : clumsy\n255 : co\n39 : coach\n37 : coast\n35 : coaster\n82 : code\n32 : coffee\n36 : coherent\n216 : cold\n71 : cole\n136 : collection\n196 : college\n34 : colonel\n130 : color\n49 : colorful\n86 : colors\n47 : colour\n69 : columbo\n100 : com\n42 : combat\n94 : combination\n34 : combine\n84 : combined\n1298 : come\n65 : comedian\n126 : comedic\n186 : comedies\n1252 : comedy\n988 : comes\n39 : comfortable\n397 : comic\n67 : comical\n53 : comics\n419 : coming\n33 : command\n269 : comment\n126 : commentary\n39 : commented\n312 : comments\n103 : commercial\n52 : commercials\n45 : commit\n70 : committed\n195 : common\n38 : communist\n127 : community\n46 : companion\n222 : company\n133 : compare\n202 : compared\n33 : comparing\n91 : comparison\n32 : compassion\n34 : compelled\n145 : compelling\n55 : competent\n52 : competition\n44 : complain\n33 : complaining\n55 : complaint\n441 : complete\n751 : completely\n172 : complex\n38 : complexity\n74 : complicated\n49 : composed\n36 : composer\n175 : computer\n79 : con\n50 : conceived\n208 : concept\n35 : concern\n103 : concerned\n51 : concerning\n57 : concerns\n60 : concert\n193 : conclusion\n63 : condition\n32 : conditions\n40 : confidence\n36 : confident\n123 : conflict\n32 : conflicts\n147 : confused\n159 : confusing\n60 : confusion\n46 : connect\n54 : connected\n96 : connection\n38 : connery\n34 : connor\n36 : conscious\n49 : consequences\n36 : conservative\n195 : consider\n48 : considerable\n183 : considered\n227 : considering\n33 : consistent\n41 : consistently\n58 : consists\n50 : conspiracy\n125 : constant\n157 : constantly\n36 : constructed\n39 : construction\n58 : contact\n65 : contain\n41 : contained\n159 : contains\n100 : contemporary\n139 : content\n100 : context\n137 : continue\n54 : continued\n102 : continues\n85 : continuity\n56 : contract\n43 : contrary\n87 : contrast\n91 : contrived\n202 : control\n34 : controlled\n59 : controversial\n48 : conventional\n84 : conversation\n47 : conversations\n69 : convey\n34 : conviction\n80 : convince\n96 : convinced\n195 : convincing\n41 : convincingly\n48 : convoluted\n58 : cook\n398 : cool\n74 : cooper\n260 : cop\n33 : copies\n143 : cops\n240 : copy\n106 : core\n65 : corner\n104 : corny\n43 : corporate\n"
],
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(train_data_features, train[\"sentiment\"][:10000], test_size=0.1)",
"_____no_output_____"
],
[
"print(\"Training the random forest...\")\nfrom sklearn.ensemble import RandomForestClassifier\nrf_clf = RandomForestClassifier(n_estimators=50) # 100的效果最好\nforest = rf_clf.fit(X_train, y_train)",
"Training the random forest...\n"
],
[
"# evaluate\nfrom sklearn.metrics import accuracy_score\ny_pred = forest.predict(X_test)\naccuracy_score(y_pred, y_test)",
"_____no_output_____"
],
[
"test = pd.read_csv(\"./datasets/testData.tsv\", header=0, delimiter=\"\\t\", quoting=3)",
"_____no_output_____"
],
[
"test.shape",
"_____no_output_____"
],
[
"num_reviews = len(test[\"review\"])",
"_____no_output_____"
],
[
"clean_test_reviews = []\nprint(\"Cleaning and parsing the test set movie reviews...\")\nfor i in range(num_reviews):\n if (i + 1) % 1000 == 0:\n print(\"Review {} of {}\".format(i + 1, num_reviews))\n clean_test_reviews.append(review_to_words(test[\"review\"][i]))",
"Cleaning and parsing the test set movie reviews...\n"
],
[
"test_data_features = vertorizer.transform(clean_test_reviews)\ntest_data_features = test_data_features.toarray()",
"_____no_output_____"
],
[
"result = rf_clf.predict(test_data_features)",
"_____no_output_____"
],
[
"output = pd.DataFrame({\n \"id\":test[\"id\"],\n \"sentiment\":result\n})\noutput.to_csv(\"result.csv\", index=False, quoting=3)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1d5a1c25a1ef532f95fec7f68ede9158924b9e
| 549,148 |
ipynb
|
Jupyter Notebook
|
notebooks/datasets/data/schools/schools.ipynb
|
jiobu1/labspt15-cityspire-g-ds
|
5e94db65008c51c8ca1448d236cb46bd74c022fc
|
[
"MIT"
] | null | null | null |
notebooks/datasets/data/schools/schools.ipynb
|
jiobu1/labspt15-cityspire-g-ds
|
5e94db65008c51c8ca1448d236cb46bd74c022fc
|
[
"MIT"
] | null | null | null |
notebooks/datasets/data/schools/schools.ipynb
|
jiobu1/labspt15-cityspire-g-ds
|
5e94db65008c51c8ca1448d236cb46bd74c022fc
|
[
"MIT"
] | null | null | null | 87.014419 | 2,457 | 0.708206 |
[
[
[
"## Creating schools.csv\n\n1. Install packages\n2. Create cities.csv with full state name/ city column to use in getting school information\n3. For persisitance creating a schools csv using selenium to get school information from greatschools.org\n4. Clean csv for use in schools endpoint",
"_____no_output_____"
],
[
"### 1. Import necessary libraries",
"_____no_output_____"
]
],
[
[
"from bs4 import BeautifulSoup\nimport json\nimport pandas as pd\nfrom state_abbr import us_state_abbrev as abbr\nfrom selenium import webdriver\nimport urllib.parse\nimport re",
"/Users/jisha/.pyenv/versions/3.8.6/lib/python3.8/site-packages/pandas/compat/__init__.py:120: UserWarning: Could not import the lzma module. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.\n warnings.warn(msg)\n"
]
],
[
[
"### 2. Create cities.csv with full state name/ city column to use in getting school information",
"_____no_output_____"
]
],
[
[
"# create city state list\ncities = pd.read_excel('notebooks/datasets/data/schools/csv/List of Cities.xlsx')\n\n# just get the second and third colun\ncities = cities[['Unnamed: 1','Unnamed: 2']]\n\n# create new dictionary with reversed key, value pairs\nfull = dict(map(reversed, abbr.items()))\n\n# map state abbreviations to full name\ncities['states'] = cities['Unnamed: 2'].map(full)\n\n# making sure state/city combo conform to url format of \"-\" for \" \"\ncities['states'] = cities['states'].str.strip()\ncities['states'] = cities['states'].str.replace(\" \", \"-\")\ncities['Unnamed: 1'] = cities['Unnamed: 1'].str.replace(\" \", \"-\")\n\n# remove extraneous header rows\ncities = cities.iloc[2:]\ncities['city'] = (cities['states'] + '/'+ cities['Unnamed: 1']).str.lower()\nprint(cities.head())\n\n# persist by creating new csv\ncities.to_csv('notebooks/datasets/data/schools/csv/cities.csv')",
"_____no_output_____"
]
],
[
[
"### 3. For persisitance creating a schools csv using selenium and Beautiful Soup to get school information from greatschools.org",
"_____no_output_____"
]
],
[
[
"# Looping through each city in the file\ncities = pd.read_csv('csv/cities.csv')\n\nrecords = []\ntotal_schools = []\n\n# selenium driver\ndriver = webdriver.Chrome()\n\n# url for greatschools pre_url and post_url (with state/city inbetween)\nurl_pre = 'http://www.greatschools.org/'\n\nfor i in cities['city']:\n fetching = True\n\n page = 0\n\n while fetching: \n page += 1\n url = url_pre + urllib.parse.quote(i) + '/schools/?page={}&tableView=Overview&view=table'.format(page) \n print(\"Fetching \", url)\n\n driver.get(url)\n html = driver.page_source\n soup = BeautifulSoup(html, 'html.parser')\n\n # check if last page\n page_status = soup.find('div', {'class': 'pagination-summary'})\n page_status_text = page_status.text.strip()\n print(page_status_text)\n page_status_regex = re.search(r\".* (\\d+) to (\\d+) of (\\d+)\", page_status_text)\n beginning, ending, total = page_status_regex.groups()\n total_schools.append(total)\n if int(ending) >= int(total):\n fetching = False\n \n table = soup.find(\"table\", { \"class\" : \"\" })\n for row in table.find_all(\"tr\"):\n cell = row.find_all(\"td\")\n if len(cell) == 7:\n school = row.find('a', {'class':'name'}).text.strip()\n try:\n score = row.find('div', {'class': 'circle-rating--small'}).text.strip()\n except AttributeError:\n score = '0/10'\n rating = row.find('div', {'class': 'scale'}).text.strip()\n try:\n address = row.find('div', {'class': 'address'}).text.strip()\n except AttributeError:\n address = \"Unavailable\"\n school_type = cell[1].find(text=True)\n grade = cell[2].find(text=True)\n students = cell[3].find(text=True)\n student_teacher_ratio = cell[4].find(text=True)\n try: \n district = cell[6].find(text=True)\n except AttributeError:\n district = 'Unavailable'\n\n records.append({ \n 'School': school, \n 'Score': score, \n 'Rating': rating, \n 'Address': address, \n 'Type': school_type,\n 'Grades' : grade,\n 'Total Students Enrolled': students,\n 'Students per teacher' : student_teacher_ratio, \n 'District': district\n })\n\ndriver.close()",
"Fetching http://www.greatschools.org/ohio/akron/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/ohio/akron/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 208 of 208 schools found in Akron, OH\nFetching http://www.greatschools.org/georgia/albany/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 109 schools found in Albany, GA\nFetching http://www.greatschools.org/georgia/albany/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 109 schools found in Albany, GA\nFetching http://www.greatschools.org/georgia/albany/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 109 schools found in Albany, GA\nFetching http://www.greatschools.org/georgia/albany/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 109 schools found in Albany, GA\nFetching http://www.greatschools.org/georgia/albany/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 109 of 109 schools found in Albany, GA\nFetching http://www.greatschools.org/new-york/albany/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/new-york/albany/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 151 of 151 schools found in Albany, NY\nFetching http://www.greatschools.org/oregon/albany/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 43 schools found in Albany, OR\nFetching http://www.greatschools.org/oregon/albany/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 43 of 43 schools found in Albany, OR\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/new-mexico/albuquerque/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 543 of 543 schools found in Albuquerque, NM\nFetching http://www.greatschools.org/louisiana/alexandria/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Alexandria, LA\nFetching http://www.greatschools.org/louisiana/alexandria/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Alexandria, LA\nFetching http://www.greatschools.org/louisiana/alexandria/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Alexandria, LA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/allentown/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 157 of 157 schools found in Allentown, PA\nFetching http://www.greatschools.org/pennsylvania/altoona/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 53 schools found in Altoona, PA\nFetching http://www.greatschools.org/pennsylvania/altoona/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 53 schools found in Altoona, PA\nFetching http://www.greatschools.org/pennsylvania/altoona/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 53 of 53 schools found in Altoona, PA\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/texas/amarillo/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 145 of 145 schools found in Amarillo, TX\nFetching http://www.greatschools.org/washington/anacortes/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 23 of 23 schools found in Anacortes, WA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/california/anaheim/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 192 of 192 schools found in Anaheim, CA\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/alaska/anchorage/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 327 of 327 schools found in Anchorage, AK\nFetching http://www.greatschools.org/indiana/anderson/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Anderson, IN\nFetching http://www.greatschools.org/indiana/anderson/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Anderson, IN\nFetching http://www.greatschools.org/indiana/anderson/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Anderson, IN\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/michigan/ann-arbor/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 144 of 144 schools found in Ann Arbor, MI\nFetching http://www.greatschools.org/wisconsin/appleton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 109 schools found in Appleton, WI\nFetching http://www.greatschools.org/wisconsin/appleton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 109 schools found in Appleton, WI\nFetching http://www.greatschools.org/wisconsin/appleton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 109 schools found in Appleton, WI\nFetching http://www.greatschools.org/wisconsin/appleton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 109 schools found in Appleton, WI\nFetching http://www.greatschools.org/wisconsin/appleton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 109 of 109 schools found in Appleton, WI\nFetching http://www.greatschools.org/texas/arlington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/texas/arlington/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 238 of 238 schools found in Arlington, TX\nFetching http://www.greatschools.org/california/arroyo-grande/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 27 schools found in Arroyo Grande, CA\nFetching http://www.greatschools.org/california/arroyo-grande/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 27 of 27 schools found in Arroyo Grande, CA\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/north-carolina/asheville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 143 of 143 schools found in Asheville, NC\nFetching http://www.greatschools.org/kentucky/ashland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 45 schools found in Ashland, KY\nFetching http://www.greatschools.org/kentucky/ashland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 45 of 45 schools found in Ashland, KY\nFetching http://www.greatschools.org/ohio/ashland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 28 schools found in Ashland, OH\nFetching http://www.greatschools.org/ohio/ashland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 28 of 28 schools found in Ashland, OH\nFetching http://www.greatschools.org/ohio/athens/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 12 of 12 schools found in Athens, OH\nFetching http://www.greatschools.org/new-jersey/atlantic-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in Atlantic City, NJ\nFetching http://www.greatschools.org/new-jersey/atlantic-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in Atlantic City, NJ\nFetching http://www.greatschools.org/maine/auburn/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 46 schools found in Auburn, ME\nFetching http://www.greatschools.org/maine/auburn/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 46 of 46 schools found in Auburn, ME\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/colorado/aurora/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 230 of 230 schools found in Aurora, CO\nFetching http://www.greatschools.org/texas/austin/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/texas/austin/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 715 of 715 schools found in Austin, TX\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/california/bakersfield/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 301 of 301 schools found in Bakersfield, CA\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maryland/baltimore/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 680 of 680 schools found in Baltimore, MD\nFetching http://www.greatschools.org/maine/bangor/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 66 schools found in Bangor, ME\nFetching http://www.greatschools.org/maine/bangor/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 66 schools found in Bangor, ME\nFetching http://www.greatschools.org/maine/bangor/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 66 of 66 schools found in Bangor, ME\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/louisiana/baton-rouge/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 397 of 397 schools found in Baton Rouge, LA\nFetching http://www.greatschools.org/michigan/bay-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 56 schools found in Bay City, MI\nFetching http://www.greatschools.org/michigan/bay-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 56 schools found in Bay City, MI\nFetching http://www.greatschools.org/michigan/bay-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 56 of 56 schools found in Bay City, MI\nFetching http://www.greatschools.org/texas/beaumont/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 97 schools found in Beaumont, TX\nFetching http://www.greatschools.org/texas/beaumont/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 97 schools found in Beaumont, TX\nFetching http://www.greatschools.org/texas/beaumont/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 97 schools found in Beaumont, TX\nFetching http://www.greatschools.org/texas/beaumont/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 97 of 97 schools found in Beaumont, TX\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellevue/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 139 of 139 schools found in Bellevue, WA\nFetching http://www.greatschools.org/washington/bellingham/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 110 schools found in Bellingham, WA\nFetching http://www.greatschools.org/washington/bellingham/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 110 schools found in Bellingham, WA\nFetching http://www.greatschools.org/washington/bellingham/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 110 schools found in Bellingham, WA\nFetching http://www.greatschools.org/washington/bellingham/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 110 schools found in Bellingham, WA\nFetching http://www.greatschools.org/washington/bellingham/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 110 of 110 schools found in Bellingham, WA\nFetching http://www.greatschools.org/wisconsin/beloit/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 45 schools found in Beloit, WI\nFetching http://www.greatschools.org/wisconsin/beloit/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 45 of 45 schools found in Beloit, WI\nFetching http://www.greatschools.org/oregon/bend/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 114 schools found in Bend, OR\nFetching http://www.greatschools.org/oregon/bend/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 114 schools found in Bend, OR\nFetching http://www.greatschools.org/oregon/bend/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 114 schools found in Bend, OR\nFetching http://www.greatschools.org/oregon/bend/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 114 schools found in Bend, OR\nFetching http://www.greatschools.org/oregon/bend/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 114 of 114 schools found in Bend, OR\nFetching http://www.greatschools.org/michigan/benton-harbor/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 27 schools found in Benton Harbor, MI\nFetching http://www.greatschools.org/michigan/benton-harbor/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 27 of 27 schools found in Benton Harbor, MI\nFetching http://www.greatschools.org/montana/billings/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 94 schools found in Billings, MT\nFetching http://www.greatschools.org/montana/billings/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 94 schools found in Billings, MT\nFetching http://www.greatschools.org/montana/billings/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 94 schools found in Billings, MT\nFetching http://www.greatschools.org/montana/billings/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 94 of 94 schools found in Billings, MT\nFetching http://www.greatschools.org/mississippi/biloxi/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Biloxi, MS\nFetching http://www.greatschools.org/mississippi/biloxi/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Biloxi, MS\nFetching http://www.greatschools.org/north-dakota/bismarck/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 96 schools found in Bismarck, ND\nFetching http://www.greatschools.org/north-dakota/bismarck/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 96 schools found in Bismarck, ND\nFetching http://www.greatschools.org/north-dakota/bismarck/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 96 schools found in Bismarck, ND\nFetching http://www.greatschools.org/north-dakota/bismarck/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 96 of 96 schools found in Bismarck, ND\nFetching http://www.greatschools.org/virginia/blacksburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in Blacksburg, VA\nFetching http://www.greatschools.org/virginia/blacksburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in Blacksburg, VA\nFetching http://www.greatschools.org/illinois/bloomington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 58 schools found in Bloomington, IL\nFetching http://www.greatschools.org/illinois/bloomington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 58 schools found in Bloomington, IL\nFetching http://www.greatschools.org/illinois/bloomington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 58 of 58 schools found in Bloomington, IL\nFetching http://www.greatschools.org/louisiana/bossier-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 65 schools found in Bossier City, LA\nFetching http://www.greatschools.org/louisiana/bossier-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 65 schools found in Bossier City, LA\nFetching http://www.greatschools.org/louisiana/bossier-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 65 of 65 schools found in Bossier City, LA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/massachusetts/boston/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 321 of 321 schools found in Boston, MA\nFetching http://www.greatschools.org/colorado/boulder/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 124 schools found in Boulder, CO\nFetching http://www.greatschools.org/colorado/boulder/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 124 schools found in Boulder, CO\nFetching http://www.greatschools.org/colorado/boulder/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 124 schools found in Boulder, CO\nFetching http://www.greatschools.org/colorado/boulder/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 124 schools found in Boulder, CO\nFetching http://www.greatschools.org/colorado/boulder/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 124 of 124 schools found in Boulder, CO\nFetching http://www.greatschools.org/kentucky/bowling-green/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 118 schools found in Bowling Green, KY\nFetching http://www.greatschools.org/kentucky/bowling-green/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 118 schools found in Bowling Green, KY\nFetching http://www.greatschools.org/kentucky/bowling-green/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 118 schools found in Bowling Green, KY\nFetching http://www.greatschools.org/kentucky/bowling-green/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 118 schools found in Bowling Green, KY\nFetching http://www.greatschools.org/kentucky/bowling-green/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 118 of 118 schools found in Bowling Green, KY\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/florida/bradenton/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 168 of 168 schools found in Bradenton, FL\nFetching http://www.greatschools.org/washington/bremerton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 72 schools found in Bremerton, WA\nFetching http://www.greatschools.org/washington/bremerton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 72 schools found in Bremerton, WA\nFetching http://www.greatschools.org/washington/bremerton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 72 of 72 schools found in Bremerton, WA\nFetching http://www.greatschools.org/connecticut/bridgeport/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 106 schools found in Bridgeport, CT\nFetching http://www.greatschools.org/connecticut/bridgeport/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 106 schools found in Bridgeport, CT\nFetching http://www.greatschools.org/connecticut/bridgeport/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 106 schools found in Bridgeport, CT\nFetching http://www.greatschools.org/connecticut/bridgeport/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 106 schools found in Bridgeport, CT\nFetching http://www.greatschools.org/connecticut/bridgeport/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 106 of 106 schools found in Bridgeport, CT\nFetching http://www.greatschools.org/new-jersey/bridgeton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 40 schools found in Bridgeton, NJ\nFetching http://www.greatschools.org/new-jersey/bridgeton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 40 of 40 schools found in Bridgeton, NJ\nFetching http://www.greatschools.org/tennessee/bristol/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 30 schools found in Bristol, TN\nFetching http://www.greatschools.org/tennessee/bristol/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 30 of 30 schools found in Bristol, TN\nFetching http://www.greatschools.org/south-dakota/brookings/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Brookings, SD\nFetching http://www.greatschools.org/south-dakota/brookings/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Brookings, SD\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/brownsville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 187 of 187 schools found in Brownsville, TX\nFetching http://www.greatschools.org/texas/bryan/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 79 schools found in Bryan, TX\nFetching http://www.greatschools.org/texas/bryan/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 79 schools found in Bryan, TX\nFetching http://www.greatschools.org/texas/bryan/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 79 schools found in Bryan, TX\nFetching http://www.greatschools.org/texas/bryan/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 79 of 79 schools found in Bryan, TX\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/new-york/buffalo/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 427 of 427 schools found in Buffalo, NY\nFetching http://www.greatschools.org/vermont/burlington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 52 schools found in Burlington, VT\nFetching http://www.greatschools.org/vermont/burlington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 52 schools found in Burlington, VT\nFetching http://www.greatschools.org/vermont/burlington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 52 of 52 schools found in Burlington, VT\nFetching http://www.greatschools.org/massachusetts/cambridge/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 96 schools found in Cambridge, MA\nFetching http://www.greatschools.org/massachusetts/cambridge/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 96 schools found in Cambridge, MA\nFetching http://www.greatschools.org/massachusetts/cambridge/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 96 schools found in Cambridge, MA\nFetching http://www.greatschools.org/massachusetts/cambridge/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 96 of 96 schools found in Cambridge, MA\nFetching http://www.greatschools.org/ohio/canton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 122 schools found in Canton, OH\nFetching http://www.greatschools.org/ohio/canton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 122 schools found in Canton, OH\nFetching http://www.greatschools.org/ohio/canton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 122 schools found in Canton, OH\nFetching http://www.greatschools.org/ohio/canton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 122 schools found in Canton, OH\nFetching http://www.greatschools.org/ohio/canton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 122 of 122 schools found in Canton, OH\nFetching http://www.greatschools.org/florida/cape-coral/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 83 schools found in Cape Coral, FL\nFetching http://www.greatschools.org/florida/cape-coral/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 83 schools found in Cape Coral, FL\nFetching http://www.greatschools.org/florida/cape-coral/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 83 schools found in Cape Coral, FL\nFetching http://www.greatschools.org/florida/cape-coral/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 83 of 83 schools found in Cape Coral, FL\nFetching http://www.greatschools.org/california/carlsbad/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 65 schools found in Carlsbad, CA\nFetching http://www.greatschools.org/california/carlsbad/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 65 schools found in Carlsbad, CA\nFetching http://www.greatschools.org/california/carlsbad/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 65 of 65 schools found in Carlsbad, CA\nFetching http://www.greatschools.org/indiana/carmel/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 49 schools found in Carmel, IN\nFetching http://www.greatschools.org/indiana/carmel/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 49 of 49 schools found in Carmel, IN\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/wyoming/casper/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 146 of 146 schools found in Casper, WY\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/iowa/cedar-rapids/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 136 of 136 schools found in Cedar Rapids, IA\nFetching http://www.greatschools.org/pennsylvania/chambersburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 53 schools found in Chambersburg, PA\nFetching http://www.greatschools.org/pennsylvania/chambersburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 53 schools found in Chambersburg, PA\nFetching http://www.greatschools.org/pennsylvania/chambersburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 53 of 53 schools found in Chambersburg, PA\nFetching http://www.greatschools.org/illinois/champaign/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 64 schools found in Champaign, IL\nFetching http://www.greatschools.org/illinois/champaign/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 64 schools found in Champaign, IL\nFetching http://www.greatschools.org/illinois/champaign/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 64 of 64 schools found in Champaign, IL\nFetching http://www.greatschools.org/north-carolina/chapel-hill/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 90 schools found in Chapel Hill, NC\nFetching http://www.greatschools.org/north-carolina/chapel-hill/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 90 schools found in Chapel Hill, NC\nFetching http://www.greatschools.org/north-carolina/chapel-hill/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 90 schools found in Chapel Hill, NC\nFetching http://www.greatschools.org/north-carolina/chapel-hill/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 90 of 90 schools found in Chapel Hill, NC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/south-carolina/charleston/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 147 of 147 schools found in Charleston, SC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/north-carolina/charlotte/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 827 of 827 schools found in Charlotte, NC\nFetching http://www.greatschools.org/virginia/charlottesville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 83 schools found in Charlottesville, VA\nFetching http://www.greatschools.org/virginia/charlottesville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 83 schools found in Charlottesville, VA\nFetching http://www.greatschools.org/virginia/charlottesville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 83 schools found in Charlottesville, VA\nFetching http://www.greatschools.org/virginia/charlottesville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 83 of 83 schools found in Charlottesville, VA\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/wyoming/cheyenne/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 190 of 190 schools found in Cheyenne, WY\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/california/chico/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 83 schools found in Chico, CA\nFetching http://www.greatschools.org/california/chico/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 83 schools found in Chico, CA\nFetching http://www.greatschools.org/california/chico/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 83 schools found in Chico, CA\nFetching http://www.greatschools.org/california/chico/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 83 of 83 schools found in Chico, CA\nFetching http://www.greatschools.org/virginia/christiansburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 25 schools found in Christiansburg, VA\nFetching http://www.greatschools.org/utah/clearfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 20 of 20 schools found in Clearfield, UT\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/florida/clearwater/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 146 of 146 schools found in Clearwater, FL\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/ohio/cleveland/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 525 schools found in Cleveland, OH\nFetching http://www.greatschools.org/iowa/clinton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 19 of 19 schools found in Clinton, IA\nFetching http://www.greatschools.org/texas/college-station/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 53 schools found in College Station, TX\nFetching http://www.greatschools.org/texas/college-station/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 53 schools found in College Station, TX\nFetching http://www.greatschools.org/texas/college-station/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 53 of 53 schools found in College Station, TX\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/colorado/colorado-springs/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 393 of 393 schools found in Colorado Springs, CO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/missouri/columbia/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 152 of 152 schools found in Columbia, MO\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/south-carolina/columbia/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 258 of 258 schools found in Columbia, SC\nFetching http://www.greatschools.org/indiana/columbus/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 68 schools found in Columbus, IN\nFetching http://www.greatschools.org/indiana/columbus/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 68 schools found in Columbus, IN\nFetching http://www.greatschools.org/indiana/columbus/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 68 of 68 schools found in Columbus, IN\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/ohio/columbus/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 617 of 617 schools found in Columbus, OH\nFetching http://www.greatschools.org/north-carolina/concord/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 112 schools found in Concord, NC\nFetching http://www.greatschools.org/north-carolina/concord/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 112 schools found in Concord, NC\nFetching http://www.greatschools.org/north-carolina/concord/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 112 schools found in Concord, NC\nFetching http://www.greatschools.org/north-carolina/concord/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 112 schools found in Concord, NC\nFetching http://www.greatschools.org/north-carolina/concord/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 112 of 112 schools found in Concord, NC\nFetching http://www.greatschools.org/arkansas/conway/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 75 schools found in Conway, AR\nFetching http://www.greatschools.org/arkansas/conway/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 75 schools found in Conway, AR\nFetching http://www.greatschools.org/arkansas/conway/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 75 schools found in Conway, AR\nFetching http://www.greatschools.org/south-carolina/conway/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Conway, SC\nFetching http://www.greatschools.org/south-carolina/conway/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Conway, SC\nFetching http://www.greatschools.org/california/corcoran/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 13 of 13 schools found in Corcoran, CA\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/texas/corpus-christi/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 248 of 248 schools found in Corpus Christi, TX\nFetching http://www.greatschools.org/iowa/council-bluffs/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 68 schools found in Council Bluffs, IA\nFetching http://www.greatschools.org/iowa/council-bluffs/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 68 schools found in Council Bluffs, IA\nFetching http://www.greatschools.org/iowa/council-bluffs/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 68 of 68 schools found in Council Bluffs, IA\nFetching http://www.greatschools.org/florida/crestview/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 42 schools found in Crestview, FL\nFetching http://www.greatschools.org/florida/crestview/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 42 of 42 schools found in Crestview, FL\nFetching http://www.greatschools.org/maryland/cumberland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in Cumberland, MD\nFetching http://www.greatschools.org/maryland/cumberland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in Cumberland, MD\nFetching http://www.greatschools.org/texas/dallas/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/texas/dallas/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 883 of 883 schools found in Dallas, TX\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/ohio/dayton/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 337 of 337 schools found in Dayton, OH\nFetching http://www.greatschools.org/florida/daytona-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 95 schools found in Daytona Beach, FL\nFetching http://www.greatschools.org/florida/daytona-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 95 schools found in Daytona Beach, FL\nFetching http://www.greatschools.org/florida/daytona-beach/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 95 schools found in Daytona Beach, FL\nFetching http://www.greatschools.org/florida/daytona-beach/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 95 of 95 schools found in Daytona Beach, FL\nFetching http://www.greatschools.org/illinois/decatur/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 60 schools found in Decatur, IL\nFetching http://www.greatschools.org/illinois/decatur/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 60 schools found in Decatur, IL\nFetching http://www.greatschools.org/illinois/decatur/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 60 of 60 schools found in Decatur, IL\nFetching http://www.greatschools.org/colorado/denver/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/colorado/denver/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 632 of 632 schools found in Denver, CO\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/iowa/des-moines/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 193 of 193 schools found in Des Moines, IA\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/michigan/detroit/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 510 of 510 schools found in Detroit, MI\nFetching http://www.greatschools.org/arizona/douglas/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in Douglas, AZ\nFetching http://www.greatschools.org/arizona/douglas/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in Douglas, AZ\nFetching http://www.greatschools.org/delaware/dover/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 89 schools found in Dover, DE\nFetching http://www.greatschools.org/delaware/dover/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 89 schools found in Dover, DE\nFetching http://www.greatschools.org/delaware/dover/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 89 schools found in Dover, DE\nFetching http://www.greatschools.org/delaware/dover/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 89 of 89 schools found in Dover, DE\nFetching http://www.greatschools.org/minnesota/duluth/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 83 schools found in Duluth, MN\nFetching http://www.greatschools.org/minnesota/duluth/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 83 schools found in Duluth, MN\nFetching http://www.greatschools.org/minnesota/duluth/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 83 schools found in Duluth, MN\nFetching http://www.greatschools.org/minnesota/duluth/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 83 of 83 schools found in Duluth, MN\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/north-carolina/durham/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 410 of 410 schools found in Durham, NC\nFetching http://www.greatschools.org/michigan/east-lansing/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 33 schools found in East Lansing, MI\nFetching http://www.greatschools.org/michigan/east-lansing/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 33 of 33 schools found in East Lansing, MI\nFetching http://www.greatschools.org/wisconsin/eau-claire/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 81 schools found in Eau Claire, WI\nFetching http://www.greatschools.org/wisconsin/eau-claire/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 81 schools found in Eau Claire, WI\nFetching http://www.greatschools.org/wisconsin/eau-claire/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 81 schools found in Eau Claire, WI\nFetching http://www.greatschools.org/wisconsin/eau-claire/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 81 of 81 schools found in Eau Claire, WI\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/texas/edinburg/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 135 of 135 schools found in Edinburg, TX\nFetching http://www.greatschools.org/illinois/effingham/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 21 of 21 schools found in Effingham, IL\nFetching http://www.greatschools.org/california/el-centro/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 54 schools found in El Centro, CA\nFetching http://www.greatschools.org/california/el-centro/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 54 schools found in El Centro, CA\nFetching http://www.greatschools.org/california/el-centro/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 54 of 54 schools found in El Centro, CA\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/texas/el-paso/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 591 of 591 schools found in El Paso, TX\nFetching http://www.greatschools.org/kentucky/elizabethtown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 59 schools found in Elizabethtown, KY\nFetching http://www.greatschools.org/kentucky/elizabethtown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 59 schools found in Elizabethtown, KY\nFetching http://www.greatschools.org/kentucky/elizabethtown/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 59 of 59 schools found in Elizabethtown, KY\nFetching http://www.greatschools.org/nevada/elko/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 22 of 22 schools found in Elko, NV\nFetching http://www.greatschools.org/ohio/elyria/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 52 schools found in Elyria, OH\nFetching http://www.greatschools.org/ohio/elyria/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 52 schools found in Elyria, OH\nFetching http://www.greatschools.org/ohio/elyria/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 52 of 52 schools found in Elyria, OH\nFetching http://www.greatschools.org/oklahoma/enid/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 46 schools found in Enid, OK\nFetching http://www.greatschools.org/oklahoma/enid/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 46 of 46 schools found in Enid, OK\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/pennsylvania/erie/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 158 of 158 schools found in Erie, PA\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/oregon/eugene/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 205 of 205 schools found in Eugene, OR\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/indiana/evansville/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 252 of 252 schools found in Evansville, IN\nFetching http://www.greatschools.org/alaska/fairbanks/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 99 schools found in Fairbanks, AK\nFetching http://www.greatschools.org/alaska/fairbanks/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 99 schools found in Fairbanks, AK\nFetching http://www.greatschools.org/alaska/fairbanks/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 99 schools found in Fairbanks, AK\nFetching http://www.greatschools.org/alaska/fairbanks/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 99 of 99 schools found in Fairbanks, AK\nFetching http://www.greatschools.org/california/fairfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 70 schools found in Fairfield, CA\nFetching http://www.greatschools.org/california/fairfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 70 schools found in Fairfield, CA\nFetching http://www.greatschools.org/california/fairfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 70 of 70 schools found in Fairfield, CA\nFetching http://www.greatschools.org/arkansas/fayetteville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 88 schools found in Fayetteville, AR\nFetching http://www.greatschools.org/arkansas/fayetteville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 88 schools found in Fayetteville, AR\nFetching http://www.greatschools.org/arkansas/fayetteville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 88 schools found in Fayetteville, AR\nFetching http://www.greatschools.org/arkansas/fayetteville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 88 of 88 schools found in Fayetteville, AR\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/north-carolina/fayetteville/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 431 of 431 schools found in Fayetteville, NC\nFetching http://www.greatschools.org/arizona/flagstaff/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 72 schools found in Flagstaff, AZ\nFetching http://www.greatschools.org/arizona/flagstaff/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 72 schools found in Flagstaff, AZ\nFetching http://www.greatschools.org/arizona/flagstaff/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 72 of 72 schools found in Flagstaff, AZ\nFetching http://www.greatschools.org/michigan/flint/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/michigan/flint/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/michigan/flint/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/michigan/flint/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/michigan/flint/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/michigan/flint/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 130 of 130 schools found in Flint, MI\nFetching http://www.greatschools.org/south-carolina/florence/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 93 schools found in Florence, SC\nFetching http://www.greatschools.org/south-carolina/florence/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 93 schools found in Florence, SC\nFetching http://www.greatschools.org/south-carolina/florence/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 93 schools found in Florence, SC\nFetching http://www.greatschools.org/south-carolina/florence/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 93 of 93 schools found in Florence, SC\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/colorado/fort-collins/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 150 schools found in Fort Collins, CO\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-lauderdale/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 219 of 219 schools found in Fort Lauderdale, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/florida/fort-myers/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 169 of 169 schools found in Fort Myers, FL\nFetching http://www.greatschools.org/arkansas/fort-smith/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 102 schools found in Fort Smith, AR\nFetching http://www.greatschools.org/arkansas/fort-smith/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 102 schools found in Fort Smith, AR\nFetching http://www.greatschools.org/arkansas/fort-smith/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 102 schools found in Fort Smith, AR\nFetching http://www.greatschools.org/arkansas/fort-smith/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 102 schools found in Fort Smith, AR\nFetching http://www.greatschools.org/arkansas/fort-smith/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 102 of 102 schools found in Fort Smith, AR\nFetching http://www.greatschools.org/florida/fort-walton-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Fort Walton Beach, FL\nFetching http://www.greatschools.org/florida/fort-walton-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Fort Walton Beach, FL\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/indiana/fort-wayne/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 313 of 313 schools found in Fort Wayne, IN\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/texas/fort-worth/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 578 of 578 schools found in Fort Worth, TX\nFetching http://www.greatschools.org/tennessee/franklin/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 81 schools found in Franklin, TN\nFetching http://www.greatschools.org/tennessee/franklin/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 81 schools found in Franklin, TN\nFetching http://www.greatschools.org/tennessee/franklin/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 81 schools found in Franklin, TN\nFetching http://www.greatschools.org/tennessee/franklin/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 81 of 81 schools found in Franklin, TN\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/florida/gainesville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 160 of 160 schools found in Gainesville, FL\nFetching http://www.greatschools.org/colorado/grand-junction/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 88 schools found in Grand Junction, CO\nFetching http://www.greatschools.org/colorado/grand-junction/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 88 schools found in Grand Junction, CO\nFetching http://www.greatschools.org/colorado/grand-junction/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 88 schools found in Grand Junction, CO\nFetching http://www.greatschools.org/colorado/grand-junction/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 88 of 88 schools found in Grand Junction, CO\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/michigan/grand-rapids/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 274 of 274 schools found in Grand Rapids, MI\nFetching http://www.greatschools.org/oregon/grants-pass/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Grants Pass, OR\nFetching http://www.greatschools.org/oregon/grants-pass/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Grants Pass, OR\nFetching http://www.greatschools.org/oregon/grants-pass/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Grants Pass, OR\nFetching http://www.greatschools.org/montana/great-falls/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 52 schools found in Great Falls, MT\nFetching http://www.greatschools.org/montana/great-falls/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 52 schools found in Great Falls, MT\nFetching http://www.greatschools.org/montana/great-falls/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 52 of 52 schools found in Great Falls, MT\nFetching http://www.greatschools.org/colorado/greeley/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 66 schools found in Greeley, CO\nFetching http://www.greatschools.org/colorado/greeley/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 66 schools found in Greeley, CO\nFetching http://www.greatschools.org/colorado/greeley/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 66 of 66 schools found in Greeley, CO\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/wisconsin/green-bay/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 166 of 166 schools found in Green Bay, WI\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greensboro/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 368 of 368 schools found in Greensboro, NC\nFetching http://www.greatschools.org/north-carolina/greenville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 107 schools found in Greenville, NC\nFetching http://www.greatschools.org/north-carolina/greenville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 107 schools found in Greenville, NC\nFetching http://www.greatschools.org/north-carolina/greenville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 107 schools found in Greenville, NC\nFetching http://www.greatschools.org/north-carolina/greenville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 107 schools found in Greenville, NC\nFetching http://www.greatschools.org/north-carolina/greenville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 107 of 107 schools found in Greenville, NC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/south-carolina/greenville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 181 of 181 schools found in Greenville, SC\nFetching http://www.greatschools.org/mississippi/gulfport/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 71 schools found in Gulfport, MS\nFetching http://www.greatschools.org/mississippi/gulfport/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 71 schools found in Gulfport, MS\nFetching http://www.greatschools.org/mississippi/gulfport/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 71 of 71 schools found in Gulfport, MS\nFetching http://www.greatschools.org/maryland/hagerstown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Hagerstown, MD\nFetching http://www.greatschools.org/maryland/hagerstown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Hagerstown, MD\nFetching http://www.greatschools.org/maryland/hagerstown/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Hagerstown, MD\nFetching http://www.greatschools.org/new-jersey/hammonton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 17 of 17 schools found in Hammonton, NJ\nFetching http://www.greatschools.org/california/hanford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Hanford, CA\nFetching http://www.greatschools.org/california/hanford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Hanford, CA\nFetching http://www.greatschools.org/california/hanford/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Hanford, CA\nFetching http://www.greatschools.org/pennsylvania/hanover/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 42 schools found in Hanover, PA\nFetching http://www.greatschools.org/pennsylvania/hanover/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 42 of 42 schools found in Hanover, PA\nFetching http://www.greatschools.org/texas/harlingen/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 101 schools found in Harlingen, TX\nFetching http://www.greatschools.org/texas/harlingen/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 101 schools found in Harlingen, TX\nFetching http://www.greatschools.org/texas/harlingen/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 101 schools found in Harlingen, TX\nFetching http://www.greatschools.org/texas/harlingen/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 101 schools found in Harlingen, TX\nFetching http://www.greatschools.org/texas/harlingen/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 101 of 101 schools found in Harlingen, TX\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/pennsylvania/harrisburg/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 182 of 182 schools found in Harrisburg, PA\nFetching http://www.greatschools.org/virginia/harrisonburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 54 schools found in Harrisonburg, VA\nFetching http://www.greatschools.org/virginia/harrisonburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 54 schools found in Harrisonburg, VA\nFetching http://www.greatschools.org/virginia/harrisonburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 54 of 54 schools found in Harrisonburg, VA\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/connecticut/hartford/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 160 of 160 schools found in Hartford, CT\nFetching http://www.greatschools.org/mississippi/hattiesburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 98 schools found in Hattiesburg, MS\nFetching http://www.greatschools.org/mississippi/hattiesburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 98 schools found in Hattiesburg, MS\nFetching http://www.greatschools.org/mississippi/hattiesburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 98 schools found in Hattiesburg, MS\nFetching http://www.greatschools.org/mississippi/hattiesburg/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 98 of 98 schools found in Hattiesburg, MS\nFetching http://www.greatschools.org/nevada/henderson/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 106 schools found in Henderson, NV\nFetching http://www.greatschools.org/nevada/henderson/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 106 schools found in Henderson, NV\nFetching http://www.greatschools.org/nevada/henderson/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 106 schools found in Henderson, NV\nFetching http://www.greatschools.org/nevada/henderson/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 106 schools found in Henderson, NV\nFetching http://www.greatschools.org/nevada/henderson/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 106 of 106 schools found in Henderson, NV\nFetching http://www.greatschools.org/north-carolina/hickory/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 59 schools found in Hickory, NC\nFetching http://www.greatschools.org/north-carolina/hickory/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 59 schools found in Hickory, NC\nFetching http://www.greatschools.org/north-carolina/hickory/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 59 of 59 schools found in Hickory, NC\nFetching http://www.greatschools.org/north-carolina/high-point/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 115 schools found in High Point, NC\nFetching http://www.greatschools.org/north-carolina/high-point/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 115 schools found in High Point, NC\nFetching http://www.greatschools.org/north-carolina/high-point/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 115 schools found in High Point, NC\nFetching http://www.greatschools.org/north-carolina/high-point/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 115 schools found in High Point, NC\nFetching http://www.greatschools.org/north-carolina/high-point/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 115 of 115 schools found in High Point, NC\nFetching http://www.greatschools.org/oregon/hillsboro/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 90 schools found in Hillsboro, OR\nFetching http://www.greatschools.org/oregon/hillsboro/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 90 schools found in Hillsboro, OR\nFetching http://www.greatschools.org/oregon/hillsboro/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 90 schools found in Hillsboro, OR\nFetching http://www.greatschools.org/oregon/hillsboro/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 90 of 90 schools found in Hillsboro, OR\nFetching http://www.greatschools.org/michigan/holland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 63 schools found in Holland, MI\nFetching http://www.greatschools.org/michigan/holland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 63 schools found in Holland, MI\nFetching http://www.greatschools.org/michigan/holland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 63 of 63 schools found in Holland, MI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/hawaii/honolulu/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 246 of 246 schools found in Honolulu, HI\nFetching http://www.greatschools.org/michigan/houghton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 8 of 8 schools found in Houghton, MI\nFetching http://www.greatschools.org/louisiana/houma/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Houma, LA\nFetching http://www.greatschools.org/louisiana/houma/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Houma, LA\nFetching http://www.greatschools.org/louisiana/houma/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Houma, LA\nFetching http://www.greatschools.org/texas/houston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/idaho/idaho-falls/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 85 schools found in Idaho Falls, ID\nFetching http://www.greatschools.org/idaho/idaho-falls/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 85 schools found in Idaho Falls, ID\nFetching http://www.greatschools.org/idaho/idaho-falls/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 85 schools found in Idaho Falls, ID\nFetching http://www.greatschools.org/idaho/idaho-falls/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 85 of 85 schools found in Idaho Falls, ID\nFetching http://www.greatschools.org/pennsylvania/indiana/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 32 schools found in Indiana, PA\nFetching http://www.greatschools.org/pennsylvania/indiana/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 32 of 32 schools found in Indiana, PA\nFetching http://www.greatschools.org/iowa/iowa-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 64 schools found in Iowa City, IA\nFetching http://www.greatschools.org/iowa/iowa-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 64 schools found in Iowa City, IA\nFetching http://www.greatschools.org/iowa/iowa-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 64 of 64 schools found in Iowa City, IA\nFetching http://www.greatschools.org/new-york/ithaca/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 47 schools found in Ithaca, NY\nFetching http://www.greatschools.org/new-york/ithaca/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 47 of 47 schools found in Ithaca, NY\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/mississippi/jackson/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 300 schools found in Jackson, MS\nFetching http://www.greatschools.org/tennessee/jackson/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 101 schools found in Jackson, TN\nFetching http://www.greatschools.org/tennessee/jackson/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 101 schools found in Jackson, TN\nFetching http://www.greatschools.org/tennessee/jackson/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 101 schools found in Jackson, TN\nFetching http://www.greatschools.org/tennessee/jackson/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 101 schools found in Jackson, TN\nFetching http://www.greatschools.org/tennessee/jackson/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 101 of 101 schools found in Jackson, TN\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/florida/jacksonville/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 833 of 833 schools found in Jacksonville, FL\nFetching http://www.greatschools.org/wisconsin/janesville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 71 schools found in Janesville, WI\nFetching http://www.greatschools.org/wisconsin/janesville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 71 schools found in Janesville, WI\nFetching http://www.greatschools.org/wisconsin/janesville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 71 of 71 schools found in Janesville, WI\nFetching http://www.greatschools.org/indiana/jasper/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 21 of 21 schools found in Jasper, IN\nFetching http://www.greatschools.org/missouri/jefferson-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Jefferson City, MO\nFetching http://www.greatschools.org/missouri/jefferson-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Jefferson City, MO\nFetching http://www.greatschools.org/missouri/jefferson-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Jefferson City, MO\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/new-jersey/jersey-city/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 197 of 197 schools found in Jersey City, NJ\nFetching http://www.greatschools.org/missouri/joplin/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 65 schools found in Joplin, MO\nFetching http://www.greatschools.org/missouri/joplin/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 65 schools found in Joplin, MO\nFetching http://www.greatschools.org/missouri/joplin/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 65 of 65 schools found in Joplin, MO\nFetching http://www.greatschools.org/alaska/juneau/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 54 schools found in Juneau, AK\nFetching http://www.greatschools.org/alaska/juneau/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 54 schools found in Juneau, AK\nFetching http://www.greatschools.org/alaska/juneau/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 54 of 54 schools found in Juneau, AK\nFetching http://www.greatschools.org/michigan/kalamazoo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 125 schools found in Kalamazoo, MI\nFetching http://www.greatschools.org/michigan/kalamazoo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 125 schools found in Kalamazoo, MI\nFetching http://www.greatschools.org/michigan/kalamazoo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 125 schools found in Kalamazoo, MI\nFetching http://www.greatschools.org/michigan/kalamazoo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 125 schools found in Kalamazoo, MI\nFetching http://www.greatschools.org/michigan/kalamazoo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 125 schools found in Kalamazoo, MI\nFetching http://www.greatschools.org/washington/kennewick/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 49 schools found in Kennewick, WA\nFetching http://www.greatschools.org/washington/kennewick/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 49 of 49 schools found in Kennewick, WA\nFetching http://www.greatschools.org/texas/killeen/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/texas/killeen/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/texas/killeen/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/texas/killeen/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/texas/killeen/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/texas/killeen/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 134 of 134 schools found in Killeen, TX\nFetching http://www.greatschools.org/arizona/kingman/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 44 schools found in Kingman, AZ\nFetching http://www.greatschools.org/arizona/kingman/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 44 of 44 schools found in Kingman, AZ\nFetching http://www.greatschools.org/tennessee/kingsport/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 79 schools found in Kingsport, TN\nFetching http://www.greatschools.org/tennessee/kingsport/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 79 schools found in Kingsport, TN\nFetching http://www.greatschools.org/tennessee/kingsport/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 79 schools found in Kingsport, TN\nFetching http://www.greatschools.org/tennessee/kingsport/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 79 of 79 schools found in Kingsport, TN\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/florida/kissimmee/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 132 of 132 schools found in Kissimmee, FL\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/tennessee/knoxville/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 295 of 295 schools found in Knoxville, TN\nFetching http://www.greatschools.org/indiana/kokomo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 85 schools found in Kokomo, IN\nFetching http://www.greatschools.org/indiana/kokomo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 85 schools found in Kokomo, IN\nFetching http://www.greatschools.org/indiana/kokomo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 85 schools found in Kokomo, IN\nFetching http://www.greatschools.org/indiana/kokomo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 85 of 85 schools found in Kokomo, IN\nFetching http://www.greatschools.org/indiana/la-porte/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 30 schools found in La Porte, IN\nFetching http://www.greatschools.org/indiana/la-porte/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 30 of 30 schools found in La Porte, IN\nFetching http://www.greatschools.org/indiana/lafayette/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 124 schools found in Lafayette, IN\nFetching http://www.greatschools.org/indiana/lafayette/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 124 schools found in Lafayette, IN\nFetching http://www.greatschools.org/indiana/lafayette/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 124 schools found in Lafayette, IN\nFetching http://www.greatschools.org/indiana/lafayette/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 124 schools found in Lafayette, IN\nFetching http://www.greatschools.org/indiana/lafayette/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 124 of 124 schools found in Lafayette, IN\nFetching http://www.greatschools.org/louisiana/lafayette/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 120 schools found in Lafayette, LA\nFetching http://www.greatschools.org/louisiana/lafayette/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 120 schools found in Lafayette, LA\nFetching http://www.greatschools.org/louisiana/lafayette/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 120 schools found in Lafayette, LA\nFetching http://www.greatschools.org/louisiana/lafayette/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 120 schools found in Lafayette, LA\nFetching http://www.greatschools.org/louisiana/lafayette/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 120 of 120 schools found in Lafayette, LA\nFetching http://www.greatschools.org/louisiana/lake-charles/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 94 schools found in Lake Charles, LA\nFetching http://www.greatschools.org/louisiana/lake-charles/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 94 schools found in Lake Charles, LA\nFetching http://www.greatschools.org/louisiana/lake-charles/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 94 schools found in Lake Charles, LA\nFetching http://www.greatschools.org/louisiana/lake-charles/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 94 of 94 schools found in Lake Charles, LA\nFetching http://www.greatschools.org/arizona/lake-havasu-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Lake Havasu City, AZ\nFetching http://www.greatschools.org/arizona/lake-havasu-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Lake Havasu City, AZ\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/florida/lakeland/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 211 of 211 schools found in Lakeland, FL\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/pennsylvania/lancaster/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 158 of 158 schools found in Lancaster, PA\nFetching http://www.greatschools.org/michigan/lansing/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 123 schools found in Lansing, MI\nFetching http://www.greatschools.org/michigan/lansing/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 123 schools found in Lansing, MI\nFetching http://www.greatschools.org/michigan/lansing/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 123 schools found in Lansing, MI\nFetching http://www.greatschools.org/michigan/lansing/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 123 schools found in Lansing, MI\nFetching http://www.greatschools.org/michigan/lansing/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 123 of 123 schools found in Lansing, MI\nFetching http://www.greatschools.org/texas/laredo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/texas/laredo/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 216 of 216 schools found in Laredo, TX\nFetching http://www.greatschools.org/new-mexico/las-cruces/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 124 schools found in Las Cruces, NM\nFetching http://www.greatschools.org/new-mexico/las-cruces/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 124 schools found in Las Cruces, NM\nFetching http://www.greatschools.org/new-mexico/las-cruces/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 124 schools found in Las Cruces, NM\nFetching http://www.greatschools.org/new-mexico/las-cruces/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 124 schools found in Las Cruces, NM\nFetching http://www.greatschools.org/new-mexico/las-cruces/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 124 of 124 schools found in Las Cruces, NM\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/nevada/las-vegas/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 514 of 514 schools found in Las Vegas, NV\nFetching http://www.greatschools.org/oklahoma/lawton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 81 schools found in Lawton, OK\nFetching http://www.greatschools.org/oklahoma/lawton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 81 schools found in Lawton, OK\nFetching http://www.greatschools.org/oklahoma/lawton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 81 schools found in Lawton, OK\nFetching http://www.greatschools.org/oklahoma/lawton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 81 of 81 schools found in Lawton, OK\nFetching http://www.greatschools.org/pennsylvania/lebanon/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Lebanon, PA\nFetching http://www.greatschools.org/pennsylvania/lebanon/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Lebanon, PA\nFetching http://www.greatschools.org/north-carolina/lenoir/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 43 schools found in Lenoir, NC\nFetching http://www.greatschools.org/north-carolina/lenoir/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 43 of 43 schools found in Lenoir, NC\nFetching http://www.greatschools.org/idaho/lewiston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 26 schools found in Lewiston, ID\nFetching http://www.greatschools.org/idaho/lewiston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 26 of 26 schools found in Lewiston, ID\nFetching http://www.greatschools.org/maine/lewiston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 69 schools found in Lewiston, ME\nFetching http://www.greatschools.org/maine/lewiston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 69 schools found in Lewiston, ME\nFetching http://www.greatschools.org/maine/lewiston/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 69 of 69 schools found in Lewiston, ME\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/kentucky/lexington/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 301 of 301 schools found in Lexington, KY\nFetching http://www.greatschools.org/ohio/lima/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 77 schools found in Lima, OH\nFetching http://www.greatschools.org/ohio/lima/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 77 schools found in Lima, OH\nFetching http://www.greatschools.org/ohio/lima/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 77 schools found in Lima, OH\nFetching http://www.greatschools.org/ohio/lima/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 77 of 77 schools found in Lima, OH\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/nebraska/lincoln/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 450 schools found in Lincoln, NE\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/arkansas/little-rock/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 330 of 330 schools found in Little Rock, AR\nFetching http://www.greatschools.org/california/lodi/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 56 schools found in Lodi, CA\nFetching http://www.greatschools.org/california/lodi/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 56 schools found in Lodi, CA\nFetching http://www.greatschools.org/california/lodi/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 56 of 56 schools found in Lodi, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/california/long-beach/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 236 of 236 schools found in Long Beach, CA\nFetching http://www.greatschools.org/texas/longview/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 81 schools found in Longview, TX\nFetching http://www.greatschools.org/texas/longview/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 81 schools found in Longview, TX\nFetching http://www.greatschools.org/texas/longview/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 81 schools found in Longview, TX\nFetching http://www.greatschools.org/texas/longview/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 81 of 81 schools found in Longview, TX\nFetching http://www.greatschools.org/washington/longview/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 37 schools found in Longview, WA\nFetching http://www.greatschools.org/washington/longview/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 37 of 37 schools found in Longview, WA\nFetching http://www.greatschools.org/new-mexico/los-alamos/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 19 of 19 schools found in Los Alamos, NM\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,693 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/texas/lubbock/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 203 of 203 schools found in Lubbock, TX\nFetching http://www.greatschools.org/virginia/lynchburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 91 schools found in Lynchburg, VA\nFetching http://www.greatschools.org/virginia/lynchburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 91 schools found in Lynchburg, VA\nFetching http://www.greatschools.org/virginia/lynchburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 91 schools found in Lynchburg, VA\nFetching http://www.greatschools.org/virginia/lynchburg/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 91 of 91 schools found in Lynchburg, VA\nFetching http://www.greatschools.org/california/madera/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 96 schools found in Madera, CA\nFetching http://www.greatschools.org/california/madera/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 96 schools found in Madera, CA\nFetching http://www.greatschools.org/california/madera/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 96 schools found in Madera, CA\nFetching http://www.greatschools.org/california/madera/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 96 of 96 schools found in Madera, CA\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/wisconsin/madison/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 227 of 227 schools found in Madison, WI\nFetching http://www.greatschools.org/new-hampshire/manchester/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 100 schools found in Manchester, NH\nFetching http://www.greatschools.org/new-hampshire/manchester/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 100 schools found in Manchester, NH\nFetching http://www.greatschools.org/new-hampshire/manchester/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 100 schools found in Manchester, NH\nFetching http://www.greatschools.org/new-hampshire/manchester/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 100 schools found in Manchester, NH\nFetching http://www.greatschools.org/wisconsin/manitowoc/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Manitowoc, WI\nFetching http://www.greatschools.org/wisconsin/manitowoc/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Manitowoc, WI\nFetching http://www.greatschools.org/florida/marco-island/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 13 of 13 schools found in Marco Island, FL\nFetching http://www.greatschools.org/minnesota/marshall/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 17 of 17 schools found in Marshall, MN\nFetching http://www.greatschools.org/ohio/massillon/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 50 schools found in Massillon, OH\nFetching http://www.greatschools.org/ohio/massillon/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 50 schools found in Massillon, OH\nFetching http://www.greatschools.org/south-carolina/mauldin/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 16 of 16 schools found in Mauldin, SC\nFetching http://www.greatschools.org/florida/melbourne/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 99 schools found in Melbourne, FL\nFetching http://www.greatschools.org/florida/melbourne/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 99 schools found in Melbourne, FL\nFetching http://www.greatschools.org/florida/melbourne/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 99 schools found in Melbourne, FL\nFetching http://www.greatschools.org/florida/melbourne/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 99 of 99 schools found in Melbourne, FL\nFetching http://www.greatschools.org/california/merced/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 85 schools found in Merced, CA\nFetching http://www.greatschools.org/california/merced/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 85 schools found in Merced, CA\nFetching http://www.greatschools.org/california/merced/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 85 schools found in Merced, CA\nFetching http://www.greatschools.org/california/merced/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 85 of 85 schools found in Merced, CA\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/arizona/mesa/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 333 of 333 schools found in Mesa, AZ\nFetching http://www.greatschools.org/florida/miami/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/connecticut/milford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 48 schools found in Milford, CT\nFetching http://www.greatschools.org/connecticut/milford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 48 of 48 schools found in Milford, CT\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/wisconsin/milwaukee/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 718 of 718 schools found in Milwaukee, WI\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/minnesota/minneapolis/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 540 of 540 schools found in Minneapolis, MN\nFetching http://www.greatschools.org/texas/mission/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/texas/mission/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 159 of 159 schools found in Mission, TX\nFetching http://www.greatschools.org/montana/missoula/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 68 schools found in Missoula, MT\nFetching http://www.greatschools.org/montana/missoula/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 68 schools found in Missoula, MT\nFetching http://www.greatschools.org/montana/missoula/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 68 of 68 schools found in Missoula, MT\nFetching http://www.greatschools.org/california/modesto/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/california/modesto/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 177 of 177 schools found in Modesto, CA\nFetching http://www.greatschools.org/illinois/moline/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 34 schools found in Moline, IL\nFetching http://www.greatschools.org/illinois/moline/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 34 of 34 schools found in Moline, IL\nFetching http://www.greatschools.org/louisiana/monroe/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 105 schools found in Monroe, LA\nFetching http://www.greatschools.org/louisiana/monroe/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 105 schools found in Monroe, LA\nFetching http://www.greatschools.org/louisiana/monroe/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 105 schools found in Monroe, LA\nFetching http://www.greatschools.org/louisiana/monroe/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 105 schools found in Monroe, LA\nFetching http://www.greatschools.org/louisiana/monroe/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 105 of 105 schools found in Monroe, LA\nFetching http://www.greatschools.org/north-carolina/morganton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 63 schools found in Morganton, NC\nFetching http://www.greatschools.org/north-carolina/morganton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 63 schools found in Morganton, NC\nFetching http://www.greatschools.org/north-carolina/morganton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 63 of 63 schools found in Morganton, NC\nFetching http://www.greatschools.org/west-virginia/morgantown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 66 schools found in Morgantown, WV\nFetching http://www.greatschools.org/west-virginia/morgantown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 66 schools found in Morgantown, WV\nFetching http://www.greatschools.org/west-virginia/morgantown/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 66 of 66 schools found in Morgantown, WV\nFetching http://www.greatschools.org/tennessee/morristown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 51 schools found in Morristown, TN\nFetching http://www.greatschools.org/tennessee/morristown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 51 schools found in Morristown, TN\nFetching http://www.greatschools.org/tennessee/morristown/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 51 of 51 schools found in Morristown, TN\nFetching http://www.greatschools.org/washington/mount-vernon/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 69 schools found in Mount Vernon, WA\nFetching http://www.greatschools.org/washington/mount-vernon/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 69 schools found in Mount Vernon, WA\nFetching http://www.greatschools.org/washington/mount-vernon/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 69 of 69 schools found in Mount Vernon, WA\nFetching http://www.greatschools.org/tennessee/murfreesboro/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 125 schools found in Murfreesboro, TN\nFetching http://www.greatschools.org/tennessee/murfreesboro/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 125 schools found in Murfreesboro, TN\nFetching http://www.greatschools.org/tennessee/murfreesboro/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 125 schools found in Murfreesboro, TN\nFetching http://www.greatschools.org/tennessee/murfreesboro/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 125 schools found in Murfreesboro, TN\nFetching http://www.greatschools.org/tennessee/murfreesboro/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 125 schools found in Murfreesboro, TN\nFetching http://www.greatschools.org/iowa/muscatine/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 24 of 24 schools found in Muscatine, IA\nFetching http://www.greatschools.org/michigan/muskegon/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 69 schools found in Muskegon, MI\nFetching http://www.greatschools.org/michigan/muskegon/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 69 schools found in Muskegon, MI\nFetching http://www.greatschools.org/michigan/muskegon/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 69 of 69 schools found in Muskegon, MI\nFetching http://www.greatschools.org/oklahoma/muskogee/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 46 schools found in Muskogee, OK\nFetching http://www.greatschools.org/oklahoma/muskogee/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 46 of 46 schools found in Muskogee, OK\nFetching http://www.greatschools.org/south-carolina/myrtle-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 69 schools found in Myrtle Beach, SC\nFetching http://www.greatschools.org/south-carolina/myrtle-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 69 schools found in Myrtle Beach, SC\nFetching http://www.greatschools.org/south-carolina/myrtle-beach/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 69 of 69 schools found in Myrtle Beach, SC\nFetching http://www.greatschools.org/california/napa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 96 schools found in Napa, CA\nFetching http://www.greatschools.org/california/napa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 96 schools found in Napa, CA\nFetching http://www.greatschools.org/california/napa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 96 schools found in Napa, CA\nFetching http://www.greatschools.org/california/napa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 96 of 96 schools found in Napa, CA\nFetching http://www.greatschools.org/florida/naples/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/florida/naples/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 167 of 167 schools found in Naples, FL\nFetching http://www.greatschools.org/new-hampshire/nashua/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 83 schools found in Nashua, NH\nFetching http://www.greatschools.org/new-hampshire/nashua/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 83 schools found in Nashua, NH\nFetching http://www.greatschools.org/new-hampshire/nashua/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 83 schools found in Nashua, NH\nFetching http://www.greatschools.org/new-hampshire/nashua/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 83 of 83 schools found in Nashua, NH\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/tennessee/nashville/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 511 of 511 schools found in Nashville, TN\nFetching http://www.greatschools.org/texas/new-braunfels/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in New Braunfels, TX\nFetching http://www.greatschools.org/texas/new-braunfels/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in New Braunfels, TX\nFetching http://www.greatschools.org/texas/new-braunfels/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in New Braunfels, TX\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-haven/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 127 of 127 schools found in New Haven, CT\nFetching http://www.greatschools.org/connecticut/new-london/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 29 schools found in New London, CT\nFetching http://www.greatschools.org/connecticut/new-london/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 29 of 29 schools found in New London, CT\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/louisiana/new-orleans/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 314 of 314 schools found in New Orleans, LA\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-jersey/newark/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 294 of 294 schools found in Newark, NJ\nFetching http://www.greatschools.org/new-york/niagara-falls/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Niagara Falls, NY\nFetching http://www.greatschools.org/new-york/niagara-falls/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Niagara Falls, NY\nFetching http://www.greatschools.org/michigan/niles/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 28 schools found in Niles, MI\nFetching http://www.greatschools.org/michigan/niles/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 28 of 28 schools found in Niles, MI\nFetching http://www.greatschools.org/south-carolina/north-charleston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 80 schools found in North Charleston, SC\nFetching http://www.greatschools.org/south-carolina/north-charleston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 80 schools found in North Charleston, SC\nFetching http://www.greatschools.org/south-carolina/north-charleston/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 80 schools found in North Charleston, SC\nFetching http://www.greatschools.org/south-carolina/north-charleston/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 80 of 80 schools found in North Charleston, SC\nFetching http://www.greatschools.org/arkansas/north-little-rock/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 73 schools found in North Little Rock, AR\nFetching http://www.greatschools.org/arkansas/north-little-rock/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 73 schools found in North Little Rock, AR\nFetching http://www.greatschools.org/arkansas/north-little-rock/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 73 of 73 schools found in North Little Rock, AR\nFetching http://www.greatschools.org/south-carolina/north-myrtle-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 6 of 6 schools found in North Myrtle Beach, SC\nFetching http://www.greatschools.org/florida/north-port/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 23 of 23 schools found in North Port, FL\nFetching http://www.greatschools.org/connecticut/norwalk/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 61 schools found in Norwalk, CT\nFetching http://www.greatschools.org/connecticut/norwalk/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 61 schools found in Norwalk, CT\nFetching http://www.greatschools.org/connecticut/norwalk/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 61 of 61 schools found in Norwalk, CT\nFetching http://www.greatschools.org/connecticut/norwich/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Norwich, CT\nFetching http://www.greatschools.org/connecticut/norwich/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Norwich, CT\nFetching http://www.greatschools.org/california/oakland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/california/oakland/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 335 of 335 schools found in Oakland, CA\nFetching http://www.greatschools.org/florida/ocala/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/florida/ocala/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 189 of 189 schools found in Ocala, FL\nFetching http://www.greatschools.org/texas/odessa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 102 schools found in Odessa, TX\nFetching http://www.greatschools.org/texas/odessa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 102 schools found in Odessa, TX\nFetching http://www.greatschools.org/texas/odessa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 102 schools found in Odessa, TX\nFetching http://www.greatschools.org/texas/odessa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 102 schools found in Odessa, TX\nFetching http://www.greatschools.org/texas/odessa/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 102 of 102 schools found in Odessa, TX\nFetching http://www.greatschools.org/utah/ogden/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 107 schools found in Ogden, UT\nFetching http://www.greatschools.org/utah/ogden/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 107 schools found in Ogden, UT\nFetching http://www.greatschools.org/utah/ogden/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 107 schools found in Ogden, UT\nFetching http://www.greatschools.org/utah/ogden/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 107 schools found in Ogden, UT\nFetching http://www.greatschools.org/utah/ogden/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 107 of 107 schools found in Ogden, UT\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/oklahoma/oklahoma-city/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 452 of 452 schools found in Oklahoma City, OK\nFetching http://www.greatschools.org/washington/olympia/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 117 schools found in Olympia, WA\nFetching http://www.greatschools.org/washington/olympia/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 117 schools found in Olympia, WA\nFetching http://www.greatschools.org/washington/olympia/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 117 schools found in Olympia, WA\nFetching http://www.greatschools.org/washington/olympia/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 117 schools found in Olympia, WA\nFetching http://www.greatschools.org/washington/olympia/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 117 of 117 schools found in Olympia, WA\nFetching http://www.greatschools.org/california/ontario/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 84 schools found in Ontario, CA\nFetching http://www.greatschools.org/california/ontario/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 84 schools found in Ontario, CA\nFetching http://www.greatschools.org/california/ontario/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 84 schools found in Ontario, CA\nFetching http://www.greatschools.org/california/ontario/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 84 of 84 schools found in Ontario, CA\nFetching http://www.greatschools.org/utah/orem/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 68 schools found in Orem, UT\nFetching http://www.greatschools.org/utah/orem/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 68 schools found in Orem, UT\nFetching http://www.greatschools.org/utah/orem/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 68 of 68 schools found in Orem, UT\nFetching http://www.greatschools.org/florida/orlando/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/orlando/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 657 of 657 schools found in Orlando, FL\nFetching http://www.greatschools.org/florida/ormond-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Ormond Beach, FL\nFetching http://www.greatschools.org/florida/ormond-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Ormond Beach, FL\nFetching http://www.greatschools.org/kentucky/owensboro/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 109 schools found in Owensboro, KY\nFetching http://www.greatschools.org/kentucky/owensboro/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 109 schools found in Owensboro, KY\nFetching http://www.greatschools.org/kentucky/owensboro/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 109 schools found in Owensboro, KY\nFetching http://www.greatschools.org/kentucky/owensboro/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 109 schools found in Owensboro, KY\nFetching http://www.greatschools.org/kentucky/owensboro/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 109 of 109 schools found in Owensboro, KY\nFetching http://www.greatschools.org/california/oxnard/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 113 schools found in Oxnard, CA\nFetching http://www.greatschools.org/california/oxnard/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 113 schools found in Oxnard, CA\nFetching http://www.greatschools.org/california/oxnard/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 113 schools found in Oxnard, CA\nFetching http://www.greatschools.org/california/oxnard/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 113 schools found in Oxnard, CA\nFetching http://www.greatschools.org/california/oxnard/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 113 of 113 schools found in Oxnard, CA\nFetching http://www.greatschools.org/florida/palm-bay/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Palm Bay, FL\nFetching http://www.greatschools.org/florida/palm-bay/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Palm Bay, FL\nFetching http://www.greatschools.org/florida/palm-bay/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Palm Bay, FL\nFetching http://www.greatschools.org/florida/panama-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 120 schools found in Panama City, FL\nFetching http://www.greatschools.org/florida/panama-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 120 schools found in Panama City, FL\nFetching http://www.greatschools.org/florida/panama-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 120 schools found in Panama City, FL\nFetching http://www.greatschools.org/florida/panama-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 120 schools found in Panama City, FL\nFetching http://www.greatschools.org/florida/panama-city/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 120 of 120 schools found in Panama City, FL\nFetching http://www.greatschools.org/mississippi/pascagoula/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in Pascagoula, MS\nFetching http://www.greatschools.org/mississippi/pascagoula/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in Pascagoula, MS\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/florida/pensacola/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 218 of 218 schools found in Pensacola, FL\nFetching http://www.greatschools.org/illinois/peoria/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 124 schools found in Peoria, IL\nFetching http://www.greatschools.org/illinois/peoria/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 124 schools found in Peoria, IL\nFetching http://www.greatschools.org/illinois/peoria/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 124 schools found in Peoria, IL\nFetching http://www.greatschools.org/illinois/peoria/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 124 schools found in Peoria, IL\nFetching http://www.greatschools.org/illinois/peoria/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 124 of 124 schools found in Peoria, IL\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/arizona/phoenix/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 989 of 989 schools found in Phoenix, AZ\nFetching http://www.greatschools.org/massachusetts/pittsfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 50 schools found in Pittsfield, MA\nFetching http://www.greatschools.org/massachusetts/pittsfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 50 schools found in Pittsfield, MA\nFetching http://www.greatschools.org/idaho/pocatello/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 55 schools found in Pocatello, ID\nFetching http://www.greatschools.org/idaho/pocatello/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 55 schools found in Pocatello, ID\nFetching http://www.greatschools.org/idaho/pocatello/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 55 of 55 schools found in Pocatello, ID\nFetching http://www.greatschools.org/texas/port-arthur/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 43 schools found in Port Arthur, TX\nFetching http://www.greatschools.org/texas/port-arthur/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 43 of 43 schools found in Port Arthur, TX\nFetching http://www.greatschools.org/michigan/portage/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 42 schools found in Portage, MI\nFetching http://www.greatschools.org/michigan/portage/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 42 of 42 schools found in Portage, MI\nFetching http://www.greatschools.org/california/porterville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 58 schools found in Porterville, CA\nFetching http://www.greatschools.org/california/porterville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 58 schools found in Porterville, CA\nFetching http://www.greatschools.org/california/porterville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 58 of 58 schools found in Porterville, CA\nFetching http://www.greatschools.org/maine/portland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 88 schools found in Portland, ME\nFetching http://www.greatschools.org/maine/portland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 88 schools found in Portland, ME\nFetching http://www.greatschools.org/maine/portland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 88 schools found in Portland, ME\nFetching http://www.greatschools.org/maine/portland/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 88 of 88 schools found in Portland, ME\nFetching http://www.greatschools.org/oregon/portland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/oregon/portland/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 681 of 681 schools found in Portland, OR\nFetching http://www.greatschools.org/arizona/prescott/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 44 schools found in Prescott, AZ\nFetching http://www.greatschools.org/arizona/prescott/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 44 of 44 schools found in Prescott, AZ\nFetching http://www.greatschools.org/utah/provo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 59 schools found in Provo, UT\nFetching http://www.greatschools.org/utah/provo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 59 schools found in Provo, UT\nFetching http://www.greatschools.org/utah/provo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 59 of 59 schools found in Provo, UT\nFetching http://www.greatschools.org/colorado/pueblo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 103 schools found in Pueblo, CO\nFetching http://www.greatschools.org/colorado/pueblo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 103 schools found in Pueblo, CO\nFetching http://www.greatschools.org/colorado/pueblo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 103 schools found in Pueblo, CO\nFetching http://www.greatschools.org/colorado/pueblo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 103 schools found in Pueblo, CO\nFetching http://www.greatschools.org/colorado/pueblo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 103 of 103 schools found in Pueblo, CO\nFetching http://www.greatschools.org/wisconsin/racine/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 107 schools found in Racine, WI\nFetching http://www.greatschools.org/wisconsin/racine/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 107 schools found in Racine, WI\nFetching http://www.greatschools.org/wisconsin/racine/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 107 schools found in Racine, WI\nFetching http://www.greatschools.org/wisconsin/racine/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 107 schools found in Racine, WI\nFetching http://www.greatschools.org/wisconsin/racine/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 107 of 107 schools found in Racine, WI\nFetching http://www.greatschools.org/virginia/radford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 11 of 11 schools found in Radford, VA\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/north-carolina/raleigh/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 464 of 464 schools found in Raleigh, NC\nFetching http://www.greatschools.org/south-dakota/rapid-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 121 schools found in Rapid City, SD\nFetching http://www.greatschools.org/south-dakota/rapid-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 121 schools found in Rapid City, SD\nFetching http://www.greatschools.org/south-dakota/rapid-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 121 schools found in Rapid City, SD\nFetching http://www.greatschools.org/south-dakota/rapid-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 121 schools found in Rapid City, SD\nFetching http://www.greatschools.org/south-dakota/rapid-city/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 121 of 121 schools found in Rapid City, SD\nFetching http://www.greatschools.org/oregon/redmond/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 37 schools found in Redmond, OR\nFetching http://www.greatschools.org/oregon/redmond/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 37 of 37 schools found in Redmond, OR\nFetching http://www.greatschools.org/nevada/reno/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/nevada/reno/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 163 of 163 schools found in Reno, NV\nFetching http://www.greatschools.org/washington/richland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 47 schools found in Richland, WA\nFetching http://www.greatschools.org/washington/richland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 47 of 47 schools found in Richland, WA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/virginia/richmond/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 433 of 433 schools found in Richmond, VA\nFetching http://www.greatschools.org/california/riverside/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/california/riverside/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 203 of 203 schools found in Riverside, CA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/virginia/roanoke/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 145 of 145 schools found in Roanoke, VA\nFetching http://www.greatschools.org/minnesota/rochester/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 105 schools found in Rochester, MN\nFetching http://www.greatschools.org/minnesota/rochester/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 105 schools found in Rochester, MN\nFetching http://www.greatschools.org/minnesota/rochester/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 105 schools found in Rochester, MN\nFetching http://www.greatschools.org/minnesota/rochester/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 105 schools found in Rochester, MN\nFetching http://www.greatschools.org/minnesota/rochester/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 105 of 105 schools found in Rochester, MN\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/new-york/rochester/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 403 of 403 schools found in Rochester, NY\nFetching http://www.greatschools.org/illinois/rock-island/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 28 schools found in Rock Island, IL\nFetching http://www.greatschools.org/illinois/rock-island/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 28 of 28 schools found in Rock Island, IL\nFetching http://www.greatschools.org/illinois/rockford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 121 schools found in Rockford, IL\nFetching http://www.greatschools.org/illinois/rockford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 121 schools found in Rockford, IL\nFetching http://www.greatschools.org/illinois/rockford/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 121 schools found in Rockford, IL\nFetching http://www.greatschools.org/illinois/rockford/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 121 schools found in Rockford, IL\nFetching http://www.greatschools.org/illinois/rockford/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 121 of 121 schools found in Rockford, IL\nFetching http://www.greatschools.org/north-carolina/rocky-mount/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 118 schools found in Rocky Mount, NC\nFetching http://www.greatschools.org/north-carolina/rocky-mount/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 118 schools found in Rocky Mount, NC\nFetching http://www.greatschools.org/north-carolina/rocky-mount/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 118 schools found in Rocky Mount, NC\nFetching http://www.greatschools.org/north-carolina/rocky-mount/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 118 schools found in Rocky Mount, NC\nFetching http://www.greatschools.org/north-carolina/rocky-mount/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 118 of 118 schools found in Rocky Mount, NC\nFetching http://www.greatschools.org/arkansas/rogers/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 74 schools found in Rogers, AR\nFetching http://www.greatschools.org/arkansas/rogers/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 74 schools found in Rogers, AR\nFetching http://www.greatschools.org/arkansas/rogers/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 74 of 74 schools found in Rogers, AR\nFetching http://www.greatschools.org/new-york/rome/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 25 schools found in Rome, NY\nFetching http://www.greatschools.org/california/roseville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 91 schools found in Roseville, CA\nFetching http://www.greatschools.org/california/roseville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 91 schools found in Roseville, CA\nFetching http://www.greatschools.org/california/roseville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 91 schools found in Roseville, CA\nFetching http://www.greatschools.org/california/roseville/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 91 of 91 schools found in Roseville, CA\nFetching http://www.greatschools.org/texas/round-rock/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 115 schools found in Round Rock, TX\nFetching http://www.greatschools.org/texas/round-rock/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 115 schools found in Round Rock, TX\nFetching http://www.greatschools.org/texas/round-rock/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 115 schools found in Round Rock, TX\nFetching http://www.greatschools.org/texas/round-rock/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 115 schools found in Round Rock, TX\nFetching http://www.greatschools.org/texas/round-rock/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 115 of 115 schools found in Round Rock, TX\nFetching http://www.greatschools.org/vermont/rutland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 35 schools found in Rutland, VT\nFetching http://www.greatschools.org/vermont/rutland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 35 of 35 schools found in Rutland, VT\nFetching http://www.greatschools.org/california/sacramento/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/california/sacramento/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 527 of 527 schools found in Sacramento, CA\nFetching http://www.greatschools.org/oregon/salem/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/oregon/salem/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 197 of 197 schools found in Salem, OR\nFetching http://www.greatschools.org/california/salinas/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 122 schools found in Salinas, CA\nFetching http://www.greatschools.org/california/salinas/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 122 schools found in Salinas, CA\nFetching http://www.greatschools.org/california/salinas/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 122 schools found in Salinas, CA\nFetching http://www.greatschools.org/california/salinas/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 122 schools found in Salinas, CA\nFetching http://www.greatschools.org/california/salinas/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 122 of 122 schools found in Salinas, CA\nFetching http://www.greatschools.org/maryland/salisbury/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 57 schools found in Salisbury, MD\nFetching http://www.greatschools.org/maryland/salisbury/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 57 schools found in Salisbury, MD\nFetching http://www.greatschools.org/maryland/salisbury/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 57 of 57 schools found in Salisbury, MD\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/utah/salt-lake-city/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 264 of 264 schools found in Salt Lake City, UT\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-bernardino/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 157 of 157 schools found in San Bernardino, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-diego/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 798 of 798 schools found in San Diego, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-francisco/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 527 of 527 schools found in San Francisco, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-jose/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 650 schools found in San Jose, CA\nFetching http://www.greatschools.org/california/san-luis-obispo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 68 schools found in San Luis Obispo, CA\nFetching http://www.greatschools.org/california/san-luis-obispo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 68 schools found in San Luis Obispo, CA\nFetching http://www.greatschools.org/california/san-luis-obispo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 68 of 68 schools found in San Luis Obispo, CA\nFetching http://www.greatschools.org/florida/sanford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 72 schools found in Sanford, FL\nFetching http://www.greatschools.org/florida/sanford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 72 schools found in Sanford, FL\nFetching http://www.greatschools.org/florida/sanford/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 72 of 72 schools found in Sanford, FL\nFetching http://www.greatschools.org/california/santa-barbara/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 118 schools found in Santa Barbara, CA\nFetching http://www.greatschools.org/california/santa-barbara/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 118 schools found in Santa Barbara, CA\nFetching http://www.greatschools.org/california/santa-barbara/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 118 schools found in Santa Barbara, CA\nFetching http://www.greatschools.org/california/santa-barbara/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 118 schools found in Santa Barbara, CA\nFetching http://www.greatschools.org/california/santa-barbara/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 118 of 118 schools found in Santa Barbara, CA\nFetching http://www.greatschools.org/california/santa-clara/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 86 schools found in Santa Clara, CA\nFetching http://www.greatschools.org/california/santa-clara/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 86 schools found in Santa Clara, CA\nFetching http://www.greatschools.org/california/santa-clara/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 86 schools found in Santa Clara, CA\nFetching http://www.greatschools.org/california/santa-clara/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 86 of 86 schools found in Santa Clara, CA\nFetching http://www.greatschools.org/california/santa-cruz/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 80 schools found in Santa Cruz, CA\nFetching http://www.greatschools.org/california/santa-cruz/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 80 schools found in Santa Cruz, CA\nFetching http://www.greatschools.org/california/santa-cruz/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 80 schools found in Santa Cruz, CA\nFetching http://www.greatschools.org/california/santa-cruz/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 80 of 80 schools found in Santa Cruz, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/california/santa-rosa/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 182 of 182 schools found in Santa Rosa, CA\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/florida/sarasota/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 179 of 179 schools found in Sarasota, FL\nFetching http://www.greatschools.org/new-york/schenectady/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 122 schools found in Schenectady, NY\nFetching http://www.greatschools.org/new-york/schenectady/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 122 schools found in Schenectady, NY\nFetching http://www.greatschools.org/new-york/schenectady/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 122 schools found in Schenectady, NY\nFetching http://www.greatschools.org/new-york/schenectady/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 122 schools found in Schenectady, NY\nFetching http://www.greatschools.org/new-york/schenectady/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 122 of 122 schools found in Schenectady, NY\nFetching http://www.greatschools.org/nebraska/scottsbluff/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Scottsbluff, NE\nFetching http://www.greatschools.org/nebraska/scottsbluff/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Scottsbluff, NE\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/arizona/scottsdale/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 172 of 172 schools found in Scottsdale, AZ\nFetching http://www.greatschools.org/pennsylvania/scranton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 86 schools found in Scranton, PA\nFetching http://www.greatschools.org/pennsylvania/scranton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 86 schools found in Scranton, PA\nFetching http://www.greatschools.org/pennsylvania/scranton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 86 schools found in Scranton, PA\nFetching http://www.greatschools.org/pennsylvania/scranton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 86 of 86 schools found in Scranton, PA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/washington/seattle/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 552 of 552 schools found in Seattle, WA\nFetching http://www.greatschools.org/florida/sebastian/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 12 of 12 schools found in Sebastian, FL\nFetching http://www.greatschools.org/florida/sebring/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 44 schools found in Sebring, FL\nFetching http://www.greatschools.org/florida/sebring/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 44 of 44 schools found in Sebring, FL\nFetching http://www.greatschools.org/wisconsin/sheboygan/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 69 schools found in Sheboygan, WI\nFetching http://www.greatschools.org/wisconsin/sheboygan/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 69 schools found in Sheboygan, WI\nFetching http://www.greatschools.org/wisconsin/sheboygan/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 69 of 69 schools found in Sheboygan, WI\nFetching http://www.greatschools.org/wyoming/sheridan/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 56 schools found in Sheridan, WY\nFetching http://www.greatschools.org/wyoming/sheridan/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 56 schools found in Sheridan, WY\nFetching http://www.greatschools.org/wyoming/sheridan/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 56 of 56 schools found in Sheridan, WY\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/louisiana/shreveport/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 188 of 188 schools found in Shreveport, LA\nFetching http://www.greatschools.org/arizona/sierra-vista/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 37 schools found in Sierra Vista, AZ\nFetching http://www.greatschools.org/arizona/sierra-vista/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 37 of 37 schools found in Sierra Vista, AZ\nFetching http://www.greatschools.org/iowa/sioux-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 97 schools found in Sioux City, IA\nFetching http://www.greatschools.org/iowa/sioux-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 97 schools found in Sioux City, IA\nFetching http://www.greatschools.org/iowa/sioux-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 97 schools found in Sioux City, IA\nFetching http://www.greatschools.org/iowa/sioux-city/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 97 of 97 schools found in Sioux City, IA\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/south-dakota/sioux-falls/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 247 of 247 schools found in Sioux Falls, SD\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/indiana/south-bend/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 206 of 206 schools found in South Bend, IN\nFetching http://www.greatschools.org/vermont/south-burlington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 20 of 20 schools found in South Burlington, VT\nFetching http://www.greatschools.org/south-carolina/spartanburg/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 91 schools found in Spartanburg, SC\nFetching http://www.greatschools.org/south-carolina/spartanburg/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 91 schools found in Spartanburg, SC\nFetching http://www.greatschools.org/south-carolina/spartanburg/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 91 schools found in Spartanburg, SC\nFetching http://www.greatschools.org/south-carolina/spartanburg/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 91 of 91 schools found in Spartanburg, SC\nFetching http://www.greatschools.org/washington/spokane/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/washington/spokane/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 279 of 279 schools found in Spokane, WA\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/illinois/springfield/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 129 of 129 schools found in Springfield, IL\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/massachusetts/springfield/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 148 of 148 schools found in Springfield, MA\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/missouri/springfield/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 165 of 165 schools found in Springfield, MO\nFetching http://www.greatschools.org/ohio/springfield/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 72 schools found in Springfield, OH\nFetching http://www.greatschools.org/ohio/springfield/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 72 schools found in Springfield, OH\nFetching http://www.greatschools.org/ohio/springfield/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 72 of 72 schools found in Springfield, OH\nFetching http://www.greatschools.org/connecticut/stamford/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 96 schools found in Stamford, CT\nFetching http://www.greatschools.org/connecticut/stamford/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 96 schools found in Stamford, CT\nFetching http://www.greatschools.org/connecticut/stamford/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 96 schools found in Stamford, CT\nFetching http://www.greatschools.org/connecticut/stamford/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 96 of 96 schools found in Stamford, CT\nFetching http://www.greatschools.org/pennsylvania/state-college/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 60 schools found in State College, PA\nFetching http://www.greatschools.org/pennsylvania/state-college/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 60 schools found in State College, PA\nFetching http://www.greatschools.org/pennsylvania/state-college/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 60 of 60 schools found in State College, PA\nFetching http://www.greatschools.org/ohio/steubenville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 17 of 17 schools found in Steubenville, OH\nFetching http://www.greatschools.org/california/stockton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/stockton/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 252 of 252 schools found in Stockton, CA\nFetching http://www.greatschools.org/california/sunnyvale/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 80 schools found in Sunnyvale, CA\nFetching http://www.greatschools.org/california/sunnyvale/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 80 schools found in Sunnyvale, CA\nFetching http://www.greatschools.org/california/sunnyvale/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 80 schools found in Sunnyvale, CA\nFetching http://www.greatschools.org/california/sunnyvale/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 80 of 80 schools found in Sunnyvale, CA\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/new-york/syracuse/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 156 of 156 schools found in Syracuse, NY\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/washington/tacoma/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 256 of 256 schools found in Tacoma, WA\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tallahassee/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 241 of 241 schools found in Tallahassee, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/florida/tampa/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 613 of 613 schools found in Tampa, FL\nFetching http://www.greatschools.org/new-mexico/taos/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 23 of 23 schools found in Taos, NM\nFetching http://www.greatschools.org/texas/temple/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 76 schools found in Temple, TX\nFetching http://www.greatschools.org/texas/temple/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 76 schools found in Temple, TX\nFetching http://www.greatschools.org/texas/temple/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 76 schools found in Temple, TX\nFetching http://www.greatschools.org/texas/temple/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 76 of 76 schools found in Temple, TX\nFetching http://www.greatschools.org/arkansas/texarkana/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Texarkana, AR\nFetching http://www.greatschools.org/arkansas/texarkana/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Texarkana, AR\nFetching http://www.greatschools.org/louisiana/thibodaux/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 39 schools found in Thibodaux, LA\nFetching http://www.greatschools.org/louisiana/thibodaux/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 39 of 39 schools found in Thibodaux, LA\nFetching http://www.greatschools.org/california/thousand-oaks/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 71 schools found in Thousand Oaks, CA\nFetching http://www.greatschools.org/california/thousand-oaks/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 71 schools found in Thousand Oaks, CA\nFetching http://www.greatschools.org/california/thousand-oaks/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 71 of 71 schools found in Thousand Oaks, CA\nFetching http://www.greatschools.org/florida/titusville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 46 schools found in Titusville, FL\nFetching http://www.greatschools.org/florida/titusville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 46 of 46 schools found in Titusville, FL\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/ohio/toledo/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 339 of 339 schools found in Toledo, OH\nFetching http://www.greatschools.org/kansas/topeka/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 92 schools found in Topeka, KS\nFetching http://www.greatschools.org/kansas/topeka/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 92 schools found in Topeka, KS\nFetching http://www.greatschools.org/kansas/topeka/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 92 schools found in Topeka, KS\nFetching http://www.greatschools.org/kansas/topeka/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 92 of 92 schools found in Topeka, KS\nFetching http://www.greatschools.org/new-jersey/trenton/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 113 schools found in Trenton, NJ\nFetching http://www.greatschools.org/new-jersey/trenton/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 113 schools found in Trenton, NJ\nFetching http://www.greatschools.org/new-jersey/trenton/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 113 schools found in Trenton, NJ\nFetching http://www.greatschools.org/new-jersey/trenton/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 113 schools found in Trenton, NJ\nFetching http://www.greatschools.org/new-jersey/trenton/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 113 of 113 schools found in Trenton, NJ\nFetching http://www.greatschools.org/new-york/troy/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 56 schools found in Troy, NY\nFetching http://www.greatschools.org/new-york/troy/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 56 schools found in Troy, NY\nFetching http://www.greatschools.org/new-york/troy/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 56 of 56 schools found in Troy, NY\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/arizona/tucson/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 741 of 741 schools found in Tucson, AZ\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/oklahoma/tulsa/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 292 of 292 schools found in Tulsa, OK\nFetching http://www.greatschools.org/idaho/twin-falls/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 42 schools found in Twin Falls, ID\nFetching http://www.greatschools.org/idaho/twin-falls/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 42 of 42 schools found in Twin Falls, ID\nFetching http://www.greatschools.org/texas/tyler/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 116 schools found in Tyler, TX\nFetching http://www.greatschools.org/texas/tyler/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 116 schools found in Tyler, TX\nFetching http://www.greatschools.org/texas/tyler/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 116 schools found in Tyler, TX\nFetching http://www.greatschools.org/texas/tyler/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 116 schools found in Tyler, TX\nFetching http://www.greatschools.org/texas/tyler/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 116 of 116 schools found in Tyler, TX\nFetching http://www.greatschools.org/illinois/urbana/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 37 schools found in Urbana, IL\nFetching http://www.greatschools.org/illinois/urbana/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 37 of 37 schools found in Urbana, IL\nFetching http://www.greatschools.org/new-york/utica/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 50 schools found in Utica, NY\nFetching http://www.greatschools.org/new-york/utica/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 50 schools found in Utica, NY\nFetching http://www.greatschools.org/california/vallejo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 71 schools found in Vallejo, CA\nFetching http://www.greatschools.org/california/vallejo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 71 schools found in Vallejo, CA\nFetching http://www.greatschools.org/california/vallejo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 71 of 71 schools found in Vallejo, CA\nFetching http://www.greatschools.org/florida/vero-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 80 schools found in Vero Beach, FL\nFetching http://www.greatschools.org/florida/vero-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 80 schools found in Vero Beach, FL\nFetching http://www.greatschools.org/florida/vero-beach/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 80 schools found in Vero Beach, FL\nFetching http://www.greatschools.org/florida/vero-beach/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 80 of 80 schools found in Vero Beach, FL\nFetching http://www.greatschools.org/texas/victoria/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 86 schools found in Victoria, TX\nFetching http://www.greatschools.org/texas/victoria/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 86 schools found in Victoria, TX\nFetching http://www.greatschools.org/texas/victoria/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 86 schools found in Victoria, TX\nFetching http://www.greatschools.org/texas/victoria/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 86 of 86 schools found in Victoria, TX\nFetching http://www.greatschools.org/new-jersey/vineland/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 54 schools found in Vineland, NJ\nFetching http://www.greatschools.org/new-jersey/vineland/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 54 schools found in Vineland, NJ\nFetching http://www.greatschools.org/new-jersey/vineland/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 54 of 54 schools found in Vineland, NJ\nFetching http://www.greatschools.org/california/visalia/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 121 schools found in Visalia, CA\nFetching http://www.greatschools.org/california/visalia/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 121 schools found in Visalia, CA\nFetching http://www.greatschools.org/california/visalia/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 121 schools found in Visalia, CA\nFetching http://www.greatschools.org/california/visalia/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 121 schools found in Visalia, CA\nFetching http://www.greatschools.org/california/visalia/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 121 of 121 schools found in Visalia, CA\nFetching http://www.greatschools.org/texas/waco/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/texas/waco/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/texas/waco/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/texas/waco/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/texas/waco/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/texas/waco/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 139 of 139 schools found in Waco, TX\nFetching http://www.greatschools.org/washington/walla-walla/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 34 schools found in Walla Walla, WA\nFetching http://www.greatschools.org/washington/walla-walla/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 34 of 34 schools found in Walla Walla, WA\nFetching http://www.greatschools.org/georgia/warner-robins/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Warner Robins, GA\nFetching http://www.greatschools.org/georgia/warner-robins/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Warner Robins, GA\nFetching http://www.greatschools.org/georgia/warner-robins/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Warner Robins, GA\nFetching http://www.greatschools.org/michigan/warren/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 79 schools found in Warren, MI\nFetching http://www.greatschools.org/michigan/warren/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 79 schools found in Warren, MI\nFetching http://www.greatschools.org/michigan/warren/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 79 schools found in Warren, MI\nFetching http://www.greatschools.org/michigan/warren/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 79 of 79 schools found in Warren, MI\nFetching http://www.greatschools.org/ohio/warren/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 59 schools found in Warren, OH\nFetching http://www.greatschools.org/ohio/warren/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 59 schools found in Warren, OH\nFetching http://www.greatschools.org/ohio/warren/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 59 of 59 schools found in Warren, OH\nFetching http://www.greatschools.org/pennsylvania/warren/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 15 of 15 schools found in Warren, PA\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/district-of-columbia/washington/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 761 of 761 schools found in Washington, DC\nFetching http://www.greatschools.org/north-carolina/washington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 38 schools found in Washington, NC\nFetching http://www.greatschools.org/north-carolina/washington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 38 of 38 schools found in Washington, NC\nFetching http://www.greatschools.org/iowa/waterloo/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 52 schools found in Waterloo, IA\nFetching http://www.greatschools.org/iowa/waterloo/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 52 schools found in Waterloo, IA\nFetching http://www.greatschools.org/iowa/waterloo/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 52 of 52 schools found in Waterloo, IA\nFetching http://www.greatschools.org/new-york/watertown/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 35 schools found in Watertown, NY\nFetching http://www.greatschools.org/new-york/watertown/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 35 of 35 schools found in Watertown, NY\nFetching http://www.greatschools.org/california/watsonville/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Watsonville, CA\nFetching http://www.greatschools.org/california/watsonville/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Watsonville, CA\nFetching http://www.greatschools.org/california/watsonville/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Watsonville, CA\nFetching http://www.greatschools.org/wisconsin/waukesha/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 82 schools found in Waukesha, WI\nFetching http://www.greatschools.org/wisconsin/waukesha/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 82 schools found in Waukesha, WI\nFetching http://www.greatschools.org/wisconsin/waukesha/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 82 schools found in Waukesha, WI\nFetching http://www.greatschools.org/wisconsin/waukesha/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 82 of 82 schools found in Waukesha, WI\nFetching http://www.greatschools.org/wisconsin/wausau/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 57 schools found in Wausau, WI\nFetching http://www.greatschools.org/wisconsin/wausau/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 57 schools found in Wausau, WI\nFetching http://www.greatschools.org/wisconsin/wausau/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 57 of 57 schools found in Wausau, WI\nFetching http://www.greatschools.org/washington/wenatchee/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 41 schools found in Wenatchee, WA\nFetching http://www.greatschools.org/washington/wenatchee/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 41 of 41 schools found in Wenatchee, WA\nFetching http://www.greatschools.org/indiana/west-lafayette/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 31 schools found in West Lafayette, IN\nFetching http://www.greatschools.org/indiana/west-lafayette/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 31 of 31 schools found in West Lafayette, IN\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/florida/west-palm-beach/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 199 of 199 schools found in West Palm Beach, FL\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/kansas/wichita/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 201 of 201 schools found in Wichita, KS\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/delaware/wilmington/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 298 of 298 schools found in Wilmington, DE\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/north-carolina/wilmington/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 163 of 163 schools found in Wilmington, NC\nFetching http://www.greatschools.org/virginia/winchester/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Winchester, VA\nFetching http://www.greatschools.org/virginia/winchester/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Winchester, VA\nFetching http://www.greatschools.org/virginia/winchester/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Winchester, VA\nFetching http://www.greatschools.org/minnesota/winona/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 24 of 24 schools found in Winona, MN\nFetching http://www.greatschools.org/florida/winter-haven/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 87 schools found in Winter Haven, FL\nFetching http://www.greatschools.org/florida/winter-haven/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 87 schools found in Winter Haven, FL\nFetching http://www.greatschools.org/florida/winter-haven/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 87 schools found in Winter Haven, FL\nFetching http://www.greatschools.org/florida/winter-haven/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 87 of 87 schools found in Winter Haven, FL\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/massachusetts/worcester/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 133 of 133 schools found in Worcester, MA\nFetching http://www.greatschools.org/michigan/wyoming/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 50 schools found in Wyoming, MI\nFetching http://www.greatschools.org/michigan/wyoming/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 50 schools found in Wyoming, MI\nFetching http://www.greatschools.org/washington/yakima/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 106 schools found in Yakima, WA\nFetching http://www.greatschools.org/washington/yakima/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 106 schools found in Yakima, WA\nFetching http://www.greatschools.org/washington/yakima/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 106 schools found in Yakima, WA\nFetching http://www.greatschools.org/washington/yakima/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 106 schools found in Yakima, WA\nFetching http://www.greatschools.org/washington/yakima/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 106 of 106 schools found in Yakima, WA\nFetching http://www.greatschools.org/california/yuba-city/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 62 schools found in Yuba City, CA\nFetching http://www.greatschools.org/california/yuba-city/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 62 schools found in Yuba City, CA\nFetching http://www.greatschools.org/california/yuba-city/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 62 of 62 schools found in Yuba City, CA\nFetching http://www.greatschools.org/arizona/yuma/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 109 schools found in Yuma, AZ\nFetching http://www.greatschools.org/arizona/yuma/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 109 schools found in Yuma, AZ\nFetching http://www.greatschools.org/arizona/yuma/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 109 schools found in Yuma, AZ\nFetching http://www.greatschools.org/arizona/yuma/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 109 schools found in Yuma, AZ\nFetching http://www.greatschools.org/arizona/yuma/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 109 of 109 schools found in Yuma, AZ\n"
],
[
"df = pd.DataFrame.from_dict(records)",
"_____no_output_____"
],
[
"print(df.shape)\ndf.head()",
"(58782, 9)\n"
],
[
"df.to_csv('files/schools.csv')",
"_____no_output_____"
],
[
"df = pd.read_csv('files/schools.csv')\nprint(df.shape)\ndf.head()",
"(58782, 10)\n"
]
],
[
[
"### Creating new csv\n- for cities that were truncated during scraping\n- retrieved first 25 rather than all the records",
"_____no_output_____"
]
],
[
[
"from selenium import webdriver\nfrom bs4 import BeautifulSoup\nimport urllib.parse\nimport json\nimport pandas as pd\nimport re",
"/Users/jisha/.pyenv/versions/3.8.6/lib/python3.8/site-packages/pandas/compat/__init__.py:120: UserWarning: Could not import the lzma module. Your installed Python is incomplete. Attempting to use lzma compression will result in a RuntimeError.\n warnings.warn(msg)\n"
],
[
"# Looping through each city in the file\n\n# These cities were not fully scraped, returned a truncated list\ncities = ['illinois/chicago', 'texas/houston', 'california/los-angeles', 'florida/miami', 'new-york/new-york', 'texas/san-antonio']\n\nrecords = []\ntotal_schools = []\n\n# selenium driver\ndriver = webdriver.Chrome()\n\n# url for greatschools pre_url and post_url (with state/city inbetween)\nurl_pre = 'http://www.greatschools.org/'\n\nfor i in cities:\n fetching = True\n\n page = 0\n\n while fetching: \n page += 1\n url = url_pre + urllib.parse.quote(i) + '/schools/?page={}&tableView=Overview&view=table'.format(page) \n print(\"Fetching \", url)\n\n driver.get(url)\n html = driver.page_source\n soup = BeautifulSoup(html, 'html.parser')\n\n # check if last page\n page_status = soup.find('div', {'class': 'pagination-summary'})\n print(page_status.text.strip())\n page_status_list = page_status.text.strip().split()\n ending = (page_status_list[3]).replace(',', '')\n total = (page_status_list[5]).replace(',' , '') \n\n total_schools.append(total)\n if int(ending) >= int(total):\n\n fetching = False\n \n table = soup.find(\"table\", { \"class\" : \"\" })\n for row in table.find_all(\"tr\"):\n cell = row.find_all(\"td\")\n if len(cell) == 7:\n school = row.find('a', {'class':'name'}).text.strip()\n try:\n score = row.find('div', {'class': 'circle-rating--small'}).text.strip()\n except AttributeError:\n score = '0/10'\n rating = row.find('div', {'class': 'scale'}).text.strip()\n try:\n address = row.find('div', {'class': 'address'}).text.strip()\n except AttributeError:\n address = \"Unavailable\"\n school_type = cell[1].find(text=True)\n grade = cell[2].find(text=True)\n students = cell[3].find(text=True)\n student_teacher_ratio = cell[4].find(text=True)\n try: \n district = cell[6].find(text=True)\n except AttributeError:\n district = 'Unavailable'\n\n records.append({ \n 'School': school, \n 'Score': score, \n 'Rating': rating, \n 'Address': address, \n 'Type': school_type,\n 'Grades' : grade,\n 'Total Students Enrolled': students,\n 'Students per teacher' : student_teacher_ratio, \n 'District': district\n })\n\ndriver.close()",
"Fetching http://www.greatschools.org/illinois/chicago/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1100 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=45&tableView=Overview&view=table\nShowing 1101 to 1125 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=46&tableView=Overview&view=table\nShowing 1126 to 1150 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=47&tableView=Overview&view=table\nShowing 1151 to 1175 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=48&tableView=Overview&view=table\nShowing 1176 to 1200 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=49&tableView=Overview&view=table\nShowing 1201 to 1225 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=50&tableView=Overview&view=table\nShowing 1226 to 1250 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=51&tableView=Overview&view=table\nShowing 1251 to 1275 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=52&tableView=Overview&view=table\nShowing 1276 to 1300 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=53&tableView=Overview&view=table\nShowing 1301 to 1325 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=54&tableView=Overview&view=table\nShowing 1326 to 1350 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=55&tableView=Overview&view=table\nShowing 1351 to 1375 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=56&tableView=Overview&view=table\nShowing 1376 to 1400 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=57&tableView=Overview&view=table\nShowing 1401 to 1425 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=58&tableView=Overview&view=table\nShowing 1426 to 1450 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=59&tableView=Overview&view=table\nShowing 1451 to 1475 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=60&tableView=Overview&view=table\nShowing 1476 to 1500 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=61&tableView=Overview&view=table\nShowing 1501 to 1525 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=62&tableView=Overview&view=table\nShowing 1526 to 1550 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=63&tableView=Overview&view=table\nShowing 1551 to 1575 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=64&tableView=Overview&view=table\nShowing 1576 to 1600 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=65&tableView=Overview&view=table\nShowing 1601 to 1625 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=66&tableView=Overview&view=table\nShowing 1626 to 1650 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=67&tableView=Overview&view=table\nShowing 1651 to 1675 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=68&tableView=Overview&view=table\nShowing 1676 to 1700 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=69&tableView=Overview&view=table\nShowing 1701 to 1725 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=70&tableView=Overview&view=table\nShowing 1726 to 1750 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=71&tableView=Overview&view=table\nShowing 1751 to 1775 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=72&tableView=Overview&view=table\nShowing 1776 to 1800 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=73&tableView=Overview&view=table\nShowing 1801 to 1825 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/illinois/chicago/schools/?page=74&tableView=Overview&view=table\nShowing 1826 to 1850 of 1,850 schools found in Chicago, IL\nFetching http://www.greatschools.org/texas/houston/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1100 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=45&tableView=Overview&view=table\nShowing 1101 to 1125 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=46&tableView=Overview&view=table\nShowing 1126 to 1150 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=47&tableView=Overview&view=table\nShowing 1151 to 1175 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=48&tableView=Overview&view=table\nShowing 1176 to 1200 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=49&tableView=Overview&view=table\nShowing 1201 to 1225 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=50&tableView=Overview&view=table\nShowing 1226 to 1250 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=51&tableView=Overview&view=table\nShowing 1251 to 1275 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=52&tableView=Overview&view=table\nShowing 1276 to 1300 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=53&tableView=Overview&view=table\nShowing 1301 to 1325 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=54&tableView=Overview&view=table\nShowing 1326 to 1350 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=55&tableView=Overview&view=table\nShowing 1351 to 1375 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=56&tableView=Overview&view=table\nShowing 1376 to 1400 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=57&tableView=Overview&view=table\nShowing 1401 to 1425 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=58&tableView=Overview&view=table\nShowing 1426 to 1450 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=59&tableView=Overview&view=table\nShowing 1451 to 1475 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=60&tableView=Overview&view=table\nShowing 1476 to 1500 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=61&tableView=Overview&view=table\nShowing 1501 to 1525 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=62&tableView=Overview&view=table\nShowing 1526 to 1550 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=63&tableView=Overview&view=table\nShowing 1551 to 1575 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=64&tableView=Overview&view=table\nShowing 1576 to 1600 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=65&tableView=Overview&view=table\nShowing 1601 to 1625 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=66&tableView=Overview&view=table\nShowing 1626 to 1650 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=67&tableView=Overview&view=table\nShowing 1651 to 1675 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=68&tableView=Overview&view=table\nShowing 1676 to 1700 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=69&tableView=Overview&view=table\nShowing 1701 to 1725 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=70&tableView=Overview&view=table\nShowing 1726 to 1750 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=71&tableView=Overview&view=table\nShowing 1751 to 1775 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=72&tableView=Overview&view=table\nShowing 1776 to 1800 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=73&tableView=Overview&view=table\nShowing 1801 to 1825 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=74&tableView=Overview&view=table\nShowing 1826 to 1850 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=75&tableView=Overview&view=table\nShowing 1851 to 1875 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=76&tableView=Overview&view=table\nShowing 1876 to 1900 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=77&tableView=Overview&view=table\nShowing 1901 to 1925 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/texas/houston/schools/?page=78&tableView=Overview&view=table\nShowing 1926 to 1950 of 1,950 schools found in Houston, TX\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1100 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=45&tableView=Overview&view=table\nShowing 1101 to 1125 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=46&tableView=Overview&view=table\nShowing 1126 to 1150 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=47&tableView=Overview&view=table\nShowing 1151 to 1175 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=48&tableView=Overview&view=table\nShowing 1176 to 1200 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=49&tableView=Overview&view=table\nShowing 1201 to 1225 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=50&tableView=Overview&view=table\nShowing 1226 to 1250 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=51&tableView=Overview&view=table\nShowing 1251 to 1275 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=52&tableView=Overview&view=table\nShowing 1276 to 1300 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=53&tableView=Overview&view=table\nShowing 1301 to 1325 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=54&tableView=Overview&view=table\nShowing 1326 to 1350 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=55&tableView=Overview&view=table\nShowing 1351 to 1375 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=56&tableView=Overview&view=table\nShowing 1376 to 1400 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=57&tableView=Overview&view=table\nShowing 1401 to 1425 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=58&tableView=Overview&view=table\nShowing 1426 to 1450 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=59&tableView=Overview&view=table\nShowing 1451 to 1475 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=60&tableView=Overview&view=table\nShowing 1476 to 1500 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=61&tableView=Overview&view=table\nShowing 1501 to 1525 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=62&tableView=Overview&view=table\nShowing 1526 to 1550 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=63&tableView=Overview&view=table\nShowing 1551 to 1575 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=64&tableView=Overview&view=table\nShowing 1576 to 1600 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=65&tableView=Overview&view=table\nShowing 1601 to 1625 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=66&tableView=Overview&view=table\nShowing 1626 to 1650 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=67&tableView=Overview&view=table\nShowing 1651 to 1675 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/california/los-angeles/schools/?page=68&tableView=Overview&view=table\nShowing 1676 to 1694 of 1,694 schools found in Los Angeles, CA\nFetching http://www.greatschools.org/florida/miami/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1100 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=45&tableView=Overview&view=table\nShowing 1101 to 1125 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=46&tableView=Overview&view=table\nShowing 1126 to 1150 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=47&tableView=Overview&view=table\nShowing 1151 to 1175 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=48&tableView=Overview&view=table\nShowing 1176 to 1200 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=49&tableView=Overview&view=table\nShowing 1201 to 1225 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/florida/miami/schools/?page=50&tableView=Overview&view=table\nShowing 1226 to 1243 of 1,243 schools found in Miami, FL\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1100 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/new-york/new-york/schools/?page=45&tableView=Overview&view=table\nShowing 1101 to 1109 of 1,109 schools found in New York, NY\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=1&tableView=Overview&view=table\nShowing 1 to 25 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=2&tableView=Overview&view=table\nShowing 26 to 50 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=3&tableView=Overview&view=table\nShowing 51 to 75 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=4&tableView=Overview&view=table\nShowing 76 to 100 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=5&tableView=Overview&view=table\nShowing 101 to 125 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=6&tableView=Overview&view=table\nShowing 126 to 150 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=7&tableView=Overview&view=table\nShowing 151 to 175 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=8&tableView=Overview&view=table\nShowing 176 to 200 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=9&tableView=Overview&view=table\nShowing 201 to 225 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=10&tableView=Overview&view=table\nShowing 226 to 250 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=11&tableView=Overview&view=table\nShowing 251 to 275 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=12&tableView=Overview&view=table\nShowing 276 to 300 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=13&tableView=Overview&view=table\nShowing 301 to 325 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=14&tableView=Overview&view=table\nShowing 326 to 350 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=15&tableView=Overview&view=table\nShowing 351 to 375 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=16&tableView=Overview&view=table\nShowing 376 to 400 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=17&tableView=Overview&view=table\nShowing 401 to 425 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=18&tableView=Overview&view=table\nShowing 426 to 450 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=19&tableView=Overview&view=table\nShowing 451 to 475 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=20&tableView=Overview&view=table\nShowing 476 to 500 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=21&tableView=Overview&view=table\nShowing 501 to 525 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=22&tableView=Overview&view=table\nShowing 526 to 550 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=23&tableView=Overview&view=table\nShowing 551 to 575 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=24&tableView=Overview&view=table\nShowing 576 to 600 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=25&tableView=Overview&view=table\nShowing 601 to 625 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=26&tableView=Overview&view=table\nShowing 626 to 650 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=27&tableView=Overview&view=table\nShowing 651 to 675 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=28&tableView=Overview&view=table\nShowing 676 to 700 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=29&tableView=Overview&view=table\nShowing 701 to 725 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=30&tableView=Overview&view=table\nShowing 726 to 750 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=31&tableView=Overview&view=table\nShowing 751 to 775 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=32&tableView=Overview&view=table\nShowing 776 to 800 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=33&tableView=Overview&view=table\nShowing 801 to 825 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=34&tableView=Overview&view=table\nShowing 826 to 850 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=35&tableView=Overview&view=table\nShowing 851 to 875 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=36&tableView=Overview&view=table\nShowing 876 to 900 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=37&tableView=Overview&view=table\nShowing 901 to 925 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=38&tableView=Overview&view=table\nShowing 926 to 950 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=39&tableView=Overview&view=table\nShowing 951 to 975 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=40&tableView=Overview&view=table\nShowing 976 to 1000 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=41&tableView=Overview&view=table\nShowing 1001 to 1025 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=42&tableView=Overview&view=table\nShowing 1026 to 1050 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=43&tableView=Overview&view=table\nShowing 1051 to 1075 of 1,095 schools found in San Antonio, TX\nFetching http://www.greatschools.org/texas/san-antonio/schools/?page=44&tableView=Overview&view=table\nShowing 1076 to 1095 of 1,095 schools found in San Antonio, TX\n"
],
[
"df_missing = pd.DataFrame.from_dict(records)",
"_____no_output_____"
],
[
"df_missing.to_csv('files/missing_schools.csv')\nprint(df_missing.shape)\ndf_missing.head()",
"(8941, 9)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a1d80690b0f592ad469ed5004482cf20c638569
| 216,730 |
ipynb
|
Jupyter Notebook
|
Demos/Ch4_integration.ipynb
|
skhadem/numerical-analysis-class
|
a022fc2e73254800a1e193f94280446223ef01ae
|
[
"BSD-3-Clause"
] | 10 |
2020-08-25T19:11:46.000Z
|
2021-11-12T21:49:44.000Z
|
Demos/Ch4_integration.ipynb
|
skhadem/numerical-analysis-class
|
a022fc2e73254800a1e193f94280446223ef01ae
|
[
"BSD-3-Clause"
] | 1 |
2020-09-01T21:44:12.000Z
|
2020-09-01T21:44:12.000Z
|
Demos/Ch4_integration.ipynb
|
skhadem/numerical-analysis-class
|
a022fc2e73254800a1e193f94280446223ef01ae
|
[
"BSD-3-Clause"
] | 13 |
2020-08-25T21:25:17.000Z
|
2021-03-03T04:14:26.000Z
| 285.923483 | 48,138 | 0.907452 |
[
[
[
"<a href=\"https://colab.research.google.com/github/stephenbeckr/numerical-analysis-class/blob/master/Demos/Ch4_integration.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Numerical Integration (quadrature)\n\n- See also Prof. Brown's [integration notebook](https://github.com/cu-numcomp/numcomp-class/blob/master/Integration.ipynb) for CSCI-3656 [](https://colab.research.google.com/github/cu-numcomp/numcomp-class/blob/master/Integration.ipynb)\n- Bengt Fornberg's talk [Gregory formulas and improving on the Trapezoidal rule](https://www.colorado.edu/amath/sites/default/files/attached-files/2019_unm_0.pdf)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.interpolate import BarycentricInterpolator as interp\n\n# From Table 9.2 in Quarteroni, Sacco and Saleri \"Numerical Mathematics\" (Springer, 2000)\nClosedNewtonCotesWeights = { 1:[1/2,1/2], 2:[1/3,4/3,1/3], 3:[3/8,9/8,9/8,3/8], 4:[14/45, 64/45, 24/45, 64/45, 14/45], \n 5:[95/288, 375/288,250/288, 250/288, 375/288, 95/288], 6:[41/140,216/140,27/140,272/140,27/140,216/140,41/140]}\nClosedNewtonCotesNames = {1:\"n=1, Trapezoid\", 2:\"n=2, Simpson's\", 3:\"n=3, Simpson's 3/8\", 4:\"n=4, Boole's\", 5:\"n=5\", 6:\"n=6\"}",
"_____no_output_____"
],
[
"f = lambda x : np.cos(x)\nF = lambda x : np.sin(x) # dF/dx = f\na,b = -1,2\n\n\n# Other examples to try\n# f = lambda x : x**(3/2)\n# F = lambda x : 2/5*x**(5/2)\n# a,b = 0,1\n\n# f = lambda x : 1/(1+x**2) # aka Runge's function\n# F = lambda x : np.arctan(x)\n# a,b = -5,5\n\n\n\nI = F(b) - F(a)\nprint(\"Integral I is {:.3f}\".format(I))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');",
"Integral I is 1.751\n"
]
],
[
[
"### Try the Trapezoidal rule, n = 1",
"_____no_output_____"
]
],
[
[
"n = 1\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=1, Trapezoid\nTrue integral: 1.751, Estimate: 0.186, Abs. Error: 1.56454\n"
]
],
[
[
"### And Simpson's rule, n=2",
"_____no_output_____"
]
],
[
[
"n = 2\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=2, Simpson's\nTrue integral: 1.751, Estimate: 1.817, Abs. Error: 0.06647\n"
]
],
[
[
"### n=3",
"_____no_output_____"
]
],
[
[
"n = 3\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=3, Simpson's 3/8\nTrue integral: 1.751, Estimate: 1.779, Abs. Error: 0.02863\n"
]
],
[
[
"### n=4",
"_____no_output_____"
]
],
[
[
"n = 4\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=4, Boole's\nTrue integral: 1.751, Estimate: 1.750, Abs. Error: 0.00092\n"
]
],
[
[
"### n=5",
"_____no_output_____"
]
],
[
[
"n = 5\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=5\nTrue integral: 2.747, Estimate: 2.308, Abs. Error: 0.43911\n"
]
],
[
[
"### n=6",
"_____no_output_____"
]
],
[
[
"n = 6\nprint(\"Using the rule: \", ClosedNewtonCotesNames[n] )\nweights = ClosedNewtonCotesWeights[n]\n(nodes,h) = np.linspace(a,b,n+1,retstep=True) # retstep tells it to return the spacing h\n\nI_estimate = h*np.dot( weights, f(nodes) )\np = interp(nodes,f(nodes))\n\nx = np.linspace(a,b)\nplt.fill_between( x, f(x), alpha=0.5);\nplt.axvline(color='k');\nplt.axhline(color='k');\nplt.plot( x, p(x), 'r-', label=\"Interpolating polynomial\" )\nplt.legend()\n\nprint(\"True integral: {:.3f}, Estimate: {:.3f}, Abs. Error: {:.5f}\".format(I,I_estimate,abs(I-I_estimate)))\nnodes.tolist(),h,weights",
"Using the rule: n=6\nTrue integral: 2.747, Estimate: 3.870, Abs. Error: 1.12365\n"
]
],
[
[
"## Let's try different kinds of functions",
"_____no_output_____"
]
],
[
[
"def tryAllRules( f, F, a, b):\n err = []\n for n in range(1,6+1):\n weights = ClosedNewtonCotesWeights[n]\n (nodes,h) = np.linspace(a,b,n+1,retstep=True)\n I_estimate = h*np.dot( weights, f(nodes) )\n I = F(b) - F(a) # True answer\n err.append( abs(I_estimate - I))\n return np.array( err )\n\n\nf = lambda x : np.cos(x)\nF = lambda x : np.sin(x) # dF/dx = f\na,b = -1,2\nerr1 = tryAllRules( f, F, a, b)\n\n# Other examples to try\nf = lambda x : x**(3/2)\nF = lambda x : 2/5*x**(5/2)\na,b = 0,1\nerr2 = tryAllRules( f, F, a, b)\n\nf = lambda x : x**(11/2)\nF = lambda x : 2/13*x**(5/13)\na,b = 0,1\nerr3 = tryAllRules( f, F, a, b)\n\n# Runge's function\nf = lambda x : 1/(1+x**2)\nF = lambda x : np.arctan(x)\na,b = -5,5\nerr4 = tryAllRules( f, F, a, b)\n\nprint(\"Rows are different n, columns are different functions\")\nprint(np.array2string( np.array([err1,err2,err3,err4]).T, precision=2))",
"Rows are different n, columns are different functions\n[[1.56e+00 1.00e-01 3.46e-01 2.36e+00]\n [6.65e-02 2.37e-03 2.76e-02 4.05e+00]\n [2.86e-02 1.29e-03 1.24e-02 6.65e-01]\n [9.15e-04 3.03e-04 1.22e-04 3.73e-01]\n [5.11e-04 2.11e-04 6.92e-05 4.39e-01]\n [1.04e-05 8.73e-05 5.90e-07 1.12e+00]]\n"
]
],
[
[
"### Let's examine Runge's function more closely\n$$f(x) = \\frac{1}{1+x^2}$$\n\nOur error wasn't going down, but the function is $C^\\infty(\\mathbb{R})$. Did we make a mistake?\n\nNo, our formula was correct, the issue is that the $f'(\\xi)$ term (and $f''(\\xi)$, etc.) are very large. One way to think of this issue is that the function has a **singularity** (though it is on the imaginary axis, at $\\pm i$).\n\n(Btw, how do you prounce Runge? It's German, and you can listen to native speakers say it [at Forvo](https://forvo.com/search/Runge/))",
"_____no_output_____"
]
],
[
[
"import sympy\nfrom sympy.abc import x\nfrom sympy import init_printing\nfrom sympy.utilities.lambdify import lambdify\ninit_printing()\nimport matplotlib as mpl\nmpl.rcParams['mathtext.fontset'] = 'cm'\nmpl.rcParams.update({'font.size': 20})\n\n\nf = lambda x : 1/(1+x**2)\nF = lambda x : np.arctan(x)\na,b = -5,5\n\ng = 1/(1+x**2) # symbolic version\n\ngNumerical = lambdify(x,g) # avoid sympy plotting\nxGrid = np.linspace(a,b,150)\nplt.figure(figsize=(10,8)) \nplt.plot( xGrid, gNumerical(xGrid),label='$f(x)$' )\n\n\n#k = 3 # order of derivative\nfor k in range(1,6):\n dg = lambdify(x,sympy.diff(g,x,k))\n plt.plot( xGrid, dg(xGrid), label=\"$f^{(\"+str(k)+\")}(x)$\");\nplt.axvline(color='k');\nplt.axhline(color='k');\n#plt.legend(prop={'size': 20});\nplt.legend()\nplt.title(\"Runge's function\");\n\n#sympy.plot(g); # sympy plots are not so nice\n\n# sympy.plot(sympy.diff(g,x,k));",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1d8a4250607d6038a0afd30197083966d9f66c
| 366,183 |
ipynb
|
Jupyter Notebook
|
MuZero_tf.ipynb
|
tfrizza/MuZero
|
8783d2819f465df066071379d0bf4fa7ccd1a0df
|
[
"MIT"
] | 2 |
2020-04-30T02:38:44.000Z
|
2020-05-18T06:34:27.000Z
|
MuZero_tf.ipynb
|
0xtristan/MuZero
|
8783d2819f465df066071379d0bf4fa7ccd1a0df
|
[
"MIT"
] | 1 |
2020-05-25T09:42:09.000Z
|
2020-05-25T09:42:09.000Z
|
MuZero_tf.ipynb
|
0xtristan/MuZero
|
8783d2819f465df066071379d0bf4fa7ccd1a0df
|
[
"MIT"
] | 1 |
2020-12-25T00:38:06.000Z
|
2020-12-25T00:38:06.000Z
| 88.535542 | 28,047 | 0.587548 |
[
[
[
"import argparse\nimport gym\nfrom gym import wrappers\nimport numpy as np\nimport pdb\nimport os\nimport random\nimport time\nimport gc\nimport cv2\nimport pdb\nfrom tqdm import tqdm\n\nimport collections\nimport math\nimport typing\nfrom typing import Dict, List, Optional\n\nimport tensorflow as tf\nprint(tf.__version__)\nprint(\"Num GPUs Available: \", len(tf.config.experimental.list_physical_devices('GPU')))\nprint(tf.config.experimental.list_physical_devices())\n\nimport ray\nray.init()\n\nimport matplotlib.pyplot as plt\nfrom IPython import display\n%matplotlib inline",
"2.1.0\nNum GPUs Available: 0\n[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:XLA_CPU:0', device_type='XLA_CPU')]\n"
]
],
[
[
"## TPU Setup",
"_____no_output_____"
]
],
[
[
"# resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])\n# tf.config.experimental_connect_to_cluster(resolver)\n# # This is the TPU initialization code that has to be at the beginning.\n# tf.tpu.experimental.initialize_tpu_system(resolver)\n# strategy = tf.distribute.experimental.TPUStrategy(resolver)",
"_____no_output_____"
]
],
[
[
"## Gym Env",
"_____no_output_____"
]
],
[
[
"ENVS = {\n 'breakout': 'Breakout-v0',\n 'pong': 'Pong-v0',\n 'cartpole': 'CartPole-v0',\n}\nSTATE_PREPFN = {\n 'breakout': lambda s: s[50:, :, :],\n 'pong': lambda s: s[50:, :, :],\n}",
"_____no_output_____"
]
],
[
[
"Env has:\n* observation\n* reward\n* done\n* info\n\nActions are:\n['NOOP', 'FIRE', 'RIGHT', 'LEFT']",
"_____no_output_____"
]
],
[
[
"# env = gym.make(ENVS['breakout'])\n\n# # set seed\n# # env.seed(args.seed)\n# # np.random.seed(args.seed)\n# # torch.manual_seed(args.seed)\n\n# # episode loop\n# for i in range(1):\n# o = env.reset()\n# render = plt.imshow(env.render(mode='rgb_array'))\n# # rollout inner loop\n# for t in range(100):\n# # render code\n# render.set_data(env.render(mode='rgb_array')) # just update the data\n# display.display(plt.gcf())\n# display.clear_output(wait=True)\n \n# # print(o.shape)\n# a = env.action_space.sample()\n# # print(a)\n# o, r, done, _ = env.step(a)\n# # print(r)\n# if done:\n# print(\"Episode finished after {} timesteps\".format(t+1))\n# break\n# env.close()",
"_____no_output_____"
]
],
[
[
"## Helpers ",
"_____no_output_____"
]
],
[
[
"MAXIMUM_FLOAT_VALUE = float('inf')\n\nKnownBounds = collections.namedtuple('KnownBounds', ['min', 'max'])\n\n\nclass MinMaxStats(object):\n \"\"\"A class that holds the min-max values of the tree.\"\"\"\n\n def __init__(self, known_bounds: Optional[KnownBounds]):\n self.maximum = known_bounds.max if known_bounds else -MAXIMUM_FLOAT_VALUE\n self.minimum = known_bounds.min if known_bounds else MAXIMUM_FLOAT_VALUE\n\n def update(self, value: float):\n self.maximum = max(self.maximum, value)\n self.minimum = min(self.minimum, value)\n\n def normalize(self, value: float) -> float:\n if self.maximum > self.minimum:\n # We normalize only when we have set the maximum and minimum values.\n return (value - self.minimum) / (self.maximum - self.minimum)\n return value",
"_____no_output_____"
]
],
[
[
"### MuZero Config Params",
"_____no_output_____"
]
],
[
[
"class MuZeroConfig(object):\n\n def __init__(self,\n action_space_size: int,\n max_moves: int,\n discount: float,\n dirichlet_alpha: float,\n num_simulations: int,\n batch_size: int,\n td_steps: int,\n num_actors: int,\n lr_init: float,\n lr_decay_steps: float,\n visit_softmax_temperature_fn,\n known_bounds: Optional[KnownBounds] = None):\n ### Self-Play\n self.action_space_size = action_space_size\n self.num_actors = num_actors\n\n self.visit_softmax_temperature_fn = visit_softmax_temperature_fn\n self.max_moves = max_moves\n self.num_simulations = num_simulations\n self.discount = discount\n\n # Root prior exploration noise.\n self.root_dirichlet_alpha = dirichlet_alpha\n self.root_exploration_fraction = 0.25\n\n # UCB formula\n self.pb_c_base = 19652\n self.pb_c_init = 1.25\n\n # If we already have some information about which values occur in the\n # environment, we can use them to initialize the rescaling.\n # This is not strictly necessary, but establishes identical behaviour to\n # AlphaZero in board games.\n self.known_bounds = known_bounds\n\n ### Training\n self.selfplay_iterations = int(1) ##\n self.training_steps = int(1000e3)\n self.checkpoint_interval = int(1e3)\n self.window_size = int(1e6)\n self.batch_size = batch_size\n self.num_unroll_steps = 5\n self.td_steps = td_steps\n\n self.weight_decay = 1e-4\n self.momentum = 0.9\n\n # Exponential learning rate schedule\n self.lr_init = lr_init\n self.lr_decay_rate = 0.1\n self.lr_decay_steps = lr_decay_steps\n\n def new_game(self):\n return Game(self.action_space_size, self.discount)\n \ndef make_atari_config() -> MuZeroConfig:\n\n def visit_softmax_temperature(num_moves, training_steps):\n if training_steps < 500e3:\n return 1.0\n elif training_steps < 750e3:\n return 0.5\n else:\n return 0.25\n\n return MuZeroConfig(\n action_space_size=4,\n max_moves=27000, # Half an hour at action repeat 4.\n discount=0.997,\n dirichlet_alpha=0.25,\n num_simulations=50,\n batch_size=16,#1024,\n td_steps=10,\n num_actors=4,#350,\n lr_init=0.05,\n lr_decay_steps=350e3,\n visit_softmax_temperature_fn=visit_softmax_temperature)",
"_____no_output_____"
],
[
"# class Action(object):\n\n# def __init__(self, index: int):\n# self.index = index\n\n# def __hash__(self):\n# return self.index\n\n# def __eq__(self, other):\n# return self.index == other.index\n\n# def __gt__(self, other):\n# return self.index > other.index\n \n# def __str__(self):\n# return f\"Action({self.index})\"\n \n# def __repr__(self):\n# return \"<%s(%s) at %s>\" % (self.__class__.__name__, self.index, id(self))",
"_____no_output_____"
],
[
"class Node(object):\n\n def __init__(self, prior: float):\n self.visit_count = 0\n self.to_play = -1\n self.prior = prior\n self.value_sum = 0.0\n self.children = {}\n self.hidden_state = None\n self.reward = 0.0\n\n def expanded(self) -> bool:\n return len(self.children) > 0\n\n def value(self) -> float:\n if self.visit_count == 0:\n return 0.0\n return self.value_sum / self.visit_count",
"_____no_output_____"
],
[
"class ActionHistory(object):\n \"\"\"Simple history container used inside the search.\n\n Only used to keep track of the actions executed.\n \"\"\"\n\n def __init__(self, history: List[int], action_space_size: int):\n self.history = list(history)\n self.action_space_size = action_space_size\n\n def clone(self):\n return ActionHistory(self.history, self.action_space_size)\n\n def add_action(self, action: int):\n self.history.append(action)\n\n def last_action(self) -> int:\n return self.history[-1]\n\n def action_space(self) -> List[int]:\n return [i for i in range(self.action_space_size)]",
"_____no_output_____"
],
[
"class Environment(object):\n \"\"\"The environment MuZero is interacting with.\"\"\"\n def __init__(self):\n self.env = gym.make(ENVS['breakout'])\n self.obs_history = [self.prepro(self.env.reset())]\n self.done = False\n \n def step(self, action: int):\n obs, reward, self.done, info = self.env.step(action)\n self.obs_history.append(self.prepro(obs))\n return float(reward)\n \n def terminal(self):\n return self.done\n \n # @tf.function\n def legal_actions(self):\n \"\"\"Env specific rules for legality of moves\n TODO: if at wall don't allow movement into the wall\"\"\"\n return [a for a in range(self.env.action_space.n)]\n\n def prepro(self, obs, size=(80,80)):\n \"\"\"Crop, resize, B&W\"\"\"\n p_obs = obs[25:195,:,0] / 255 # crop and normalise to [0,1]\n return cv2.resize(p_obs, size, interpolation=cv2.INTER_NEAREST) # resize\n\n # def prepro(self, obs, size=(80,80)):\n # return obs\n def get_obs(self, start:int, end:int=None):\n return self.obs_history[max(start,0):end]",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"Refresher on TD Learning, which is what is used to estimate the value targets.\n\nIf we were to calculate value function without estimation we would have to wait until the final reward updates could be propagated:\n$$V(s_t) = V(s_t) + \\alpha[R_t-V(s_t)]$$\nwhere $s_t$ is state visited at time $t$, $R_t$ is total reward after time $t$ and $\\alpha$ is the LR.\n\nHowever for TD methods, an estimate of the final reward is calculated at each state and (s,a) value updated for every step of the way. We are essentially doing a finite step lookahead and updating based on that estimate. TD method is called a \"bootstrapping\" method, becuase the value is updated partly using an existing estimate and not a final reward.\n$$V(s_t) = V(s_t) + \\alpha[r_{t+1}+\\gamma V(s_{t+1})-V(s_t)]$$\nand in our case we formulate this as an N step bootstrap:\n$$z_t=u_{t+1} + \\gamma u_{t+2} + ... + \\gamma^{n-1} u_{t+n} + \\gamma^n \\nu_{t+n}$$",
"_____no_output_____"
]
],
[
[
"class Game(object):\n \"\"\"A single episode of interaction with the environment. (One trajectory)\"\"\"\n def __init__(self, action_space_size: int, discount: float):\n self.env = Environment()\n self.history = [] # actual actions a\n self.rewards = [] # observed rewards u\n self.child_visits = [] # search tree action distributions pi\n self.root_values = [] # values ν\n self.action_space_size = action_space_size\n self.gamma = discount\n \n def terminal(self) -> bool:\n return self.env.terminal()\n \n def legal_actions(self) -> List[int]:\n return self.env.legal_actions()\n \n def apply(self, action: int):\n reward = self.env.step(action)\n self.rewards.append(reward)\n self.history.append(action)\n \n def store_search_statistics(self, root: Node):\n \"\"\"Stores the MCTS search value of node and search policy (visits ratio of children)\"\"\"\n sum_visits = sum(child.visit_count for child in root.children.values())\n action_space = (index for index in range(self.action_space_size))\n # search policy π = [0.1,0.5,0.4] probability over children\n self.child_visits.append([\n root.children[a].visit_count / sum_visits if a in root.children else 0\n for a in action_space\n ])\n # search value ν\n self.root_values.append(root.value())\n \n def make_image(self, t: int, feat_history_len:int = 32):\n \"\"\"Observation at chosen position w/ history\"\"\"\n # Game specific feature planes\n # For Atari we have the 32 most recent RGB frames at resolution 96x96\n # Instead I use 80x80x1 B&W\n frames = self.env.get_obs(t-feat_history_len+1, t+2) # We want 32 frames up to and including t\n # Cast to tensor and add dummy batch dim\n # Todo: figure out how to stack RGB images - i.e. colour & time dimensions\n frame_tensor = tf.convert_to_tensor(np.stack(frames,axis=-1))\n # If we're missing a channel dim add one\n # if len(frame_tensor.shape)==3:\n # frame_tensor = frame_tensor.expand_dims(-1) # this is wrong\n # Pad out sequences with insufficient history\n padding_size = feat_history_len-frame_tensor.shape[-1]\n padded_frames = tf.pad(frame_tensor, paddings=[[0, 0], [0, 0], [padding_size, 0]], constant_values=0)\n padded_frames = tf.expand_dims(padded_frames, 0) # dummy batch dim for 4D\n return padded_frames\n \n def make_target(self, t: int, K: int, td: int):\n \"\"\"\n (value,reward,policy) target for each unroll step t to t+K\n This is taken from actuals results of the game (to be stored in replay buffer)\n Uses TD learning to calculate value target via n step bootstrap, see above\n \"\"\"\n # The value target is the discounted root value of the search tree N steps\n # into the future, plus the discounted sum of all rewards until then.\n # Returns target tuple (value, reward, policy) i.e. (z,u,pi)\n # K=5\n targets = []\n for current_index in range(t, t + K + 1):\n ## Value Target z_{t+K} ##\n \n bootstrap_index = current_index + td \n # If our TD lookahead is still before the end of the game, the update with that \n # future game state value estimate ν_{t+N}\n if bootstrap_index < len(self.root_values):\n # γ^N*ν_{t+N}\n value = self.root_values[bootstrap_index] * self.gamma**td\n else:\n value = 0\n \n # Rest of the TD value estimate from observed rewards: u_{t+1} + ... + γ^{N-1} u_{t+n}\n for i, reward in enumerate(self.rewards[current_index:bootstrap_index]):\n value += reward * self.gamma**i\n \n ## Reward u_{t+K} and Action π_{t+K} Targets ##\n \n # For simplicity the network always predicts the most recently received\n # reward, even for the initial representation network where we already\n # know this reward.\n if current_index > 0 and current_index <= len(self.rewards):\n last_reward = self.rewards[current_index - 1]\n else:\n last_reward = 0\n \n if current_index < len(self.root_values):\n targets.append((value, last_reward, self.child_visits[current_index]))\n else:\n # States past the end are treated as absorbing states\n targets.append((0, last_reward, []))\n return targets \n \n # @tf.function\n def action_history(self) -> ActionHistory:\n return ActionHistory(self.history, self.action_space_size)",
"_____no_output_____"
],
[
"class ReplayBuffer(object):\n \"\"\"Stores the target tuples to sample from later during training\"\"\"\n def __init__(self, config: MuZeroConfig):\n self.window_size = config.window_size\n self.batch_size = config.batch_size\n self.buffer = []\n\n def save_game(self, game):\n # Pop off oldest replays to make space for new ones\n if len(self.buffer) > self.window_size:\n self.buffer.pop(0)\n self.buffer.append(game)\n\n def sample_batch(self, K: int, td: int):\n \"\"\"\n Inputs\n K: num unroll steps\n td: num TD steps\n Outputs\n (observation, next K actions, target tuple)\n \"\"\"\n games = [self.sample_game() for _ in range(self.batch_size)]\n game_pos = [(g, self.sample_position(g)) for g in games]\n return [(g.make_image(i), g.history[i:i + K],\n g.make_target(i, K, td))\n for (g, i) in game_pos]\n\n def sample_game(self) -> Game:\n # TODO: figure out sampling regime\n # Sample game from buffer either uniformly or according to some priority e.g. importance sampling.\n game_ix = random.randint(0,len(self.buffer)-1) # random uniform\n return self.buffer[game_ix]\n\n def sample_position(self, game) -> int:\n # Sample position from game either uniformly or according to some priority.\n pos_ix = random.randint(0,len(game.root_values)-1) # random uniform\n return pos_ix",
"_____no_output_____"
]
],
[
[
"## NN Networks",
"_____no_output_____"
],
[
"#### 1. Prediction Network (F)\nThe prediction function pk, vk = fθ(sk) uses the same architecture as AlphaZero: one or two convolutional layers that preserve the resolution but reduce the number of planes, followed by a fully connected layer to the size of the output.\n\n#### 2. Dynamics Network (G)\nBoth the representation and dynamics function use the same architecture as AlphaZero, but with 16 instead of 20 residual blocks. We use 3x3 kernels and 256 hidden planes for each convolution. \n\nFor the dynamics function (which always operates at the downsampled resolution of 6x6), the action is first encoded as an image, then stacked with the hidden state of the previous step along the plane dimension\n\n#### 3. Representation Network (H)\nFor Atari, where observations have large spatial resolution, the representation function starts with a sequence\nof convolutions with stride 2 to reduce the spatial resolution. Specifically, starting with an input observation of resolution 96x96 and 128 planes (32 history frames of 3 color channels each, concatenated with the corresponding 32 actions broadcast to planes), we downsample as follows:\n* 1 convolution with stride 2 and 128 output planes, output resolution 48x48. \n* 2 residual blocks with 128 planes \n* 1 convolution with stride 2 and 256 output planes, output resolution 24x24. \n* 3 residual blocks with 256 planes. \n* Average pooling with stride 2, output resolution 12x12. \n* 3 residual blocks with 256 planes. \n* Average pooling with stride 2, output resolution 6x6.\nThe kernel size is 3x3 for all operations.",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras.layers import Conv2D, BatchNormalization, Dense, Add, ReLU, Input, Flatten\nfrom tensorflow.keras.models import Model\n\ndef ResBlock(x_in, nf=128):\n x = Conv2D(nf, 3, padding='same', use_bias=False)(x_in)\n x = BatchNormalization()(x)\n x = ReLU()(x)\n x = Conv2D(nf, 3, padding='same', use_bias=False)(x)\n x = BatchNormalization()(x)\n x = Add()([x, input_data])\n x = ReLU()(x)\n return x\n\ndef ConvBlock(x_in, nf, s=1, bn=True):\n x = Conv2D(nf, 3, padding='same', strides=s, use_bias=not bn)(x_in)\n if bn: x = BatchNormalization()(x)\n x = ReLU()(x)\n return x\n\ndef ReprNet(input_shape=(80,80,32), nf=128):\n o = Input(shape=input_shape)\n x = ConvBlock(o, nf, 2)\n x = ConvBlock(x, nf, 2)\n x = ConvBlock(x, nf, 2)\n s = ConvBlock(x, nf, 2)\n return Model(o, s)\n\ndef DynaNet(input_shape=(5,5,129), nf=128):\n s = Input(shape=input_shape)\n x = ConvBlock(s, nf)\n x = ConvBlock(x, nf)\n x = ConvBlock(x, nf)\n s_new = ConvBlock(x, nf)\n \n r = Flatten()(s_new)\n r = Dense(1)(r)\n return Model(s, [s_new, r])\n\ndef PredNet(input_shape=(5,5,128), nf=64, num_actions=4):\n s = Input(shape=input_shape)\n x = ConvBlock(s, nf)\n x = ConvBlock(x, nf//2) \n x = Flatten()(x)\n\n a = Dense(num_actions)(x)\n v = Dense(1)(x)\n return Model(s, [a, v])",
"_____no_output_____"
],
[
"# Input: (32,80,80) - 80x80 game in B&W with 32 length obs history\n# Output: (128,5,5) - s0\nReprNet().summary()",
"Model: \"model_9\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_10 (InputLayer) [(None, 80, 80, 32)] 0 \n_________________________________________________________________\nconv2d_30 (Conv2D) (None, 40, 40, 128) 36864 \n_________________________________________________________________\nbatch_normalization_30 (Batc (None, 40, 40, 128) 512 \n_________________________________________________________________\nre_lu_30 (ReLU) (None, 40, 40, 128) 0 \n_________________________________________________________________\nconv2d_31 (Conv2D) (None, 20, 20, 128) 147456 \n_________________________________________________________________\nbatch_normalization_31 (Batc (None, 20, 20, 128) 512 \n_________________________________________________________________\nre_lu_31 (ReLU) (None, 20, 20, 128) 0 \n_________________________________________________________________\nconv2d_32 (Conv2D) (None, 10, 10, 128) 147456 \n_________________________________________________________________\nbatch_normalization_32 (Batc (None, 10, 10, 128) 512 \n_________________________________________________________________\nre_lu_32 (ReLU) (None, 10, 10, 128) 0 \n_________________________________________________________________\nconv2d_33 (Conv2D) (None, 5, 5, 128) 147456 \n_________________________________________________________________\nbatch_normalization_33 (Batc (None, 5, 5, 128) 512 \n_________________________________________________________________\nre_lu_33 (ReLU) (None, 5, 5, 128) 0 \n=================================================================\nTotal params: 481,280\nTrainable params: 480,256\nNon-trainable params: 1,024\n_________________________________________________________________\n"
],
[
"# Input: (129,5,5) - 5x5 internal state with nf channels +1 action dim\n# Output: (128,5,5), (1,) - s', r\nDynaNet().summary()",
"Model: \"model_10\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_11 (InputLayer) [(None, 5, 5, 129)] 0 \n_________________________________________________________________\nconv2d_34 (Conv2D) (None, 5, 5, 128) 148608 \n_________________________________________________________________\nbatch_normalization_34 (Batc (None, 5, 5, 128) 512 \n_________________________________________________________________\nre_lu_34 (ReLU) (None, 5, 5, 128) 0 \n_________________________________________________________________\nconv2d_35 (Conv2D) (None, 5, 5, 128) 147456 \n_________________________________________________________________\nbatch_normalization_35 (Batc (None, 5, 5, 128) 512 \n_________________________________________________________________\nre_lu_35 (ReLU) (None, 5, 5, 128) 0 \n_________________________________________________________________\nconv2d_36 (Conv2D) (None, 5, 5, 128) 147456 \n_________________________________________________________________\nbatch_normalization_36 (Batc (None, 5, 5, 128) 512 \n_________________________________________________________________\nre_lu_36 (ReLU) (None, 5, 5, 128) 0 \n_________________________________________________________________\nconv2d_37 (Conv2D) (None, 5, 5, 128) 147456 \n_________________________________________________________________\nbatch_normalization_37 (Batc (None, 5, 5, 128) 512 \n_________________________________________________________________\nre_lu_37 (ReLU) (None, 5, 5, 128) 0 \n_________________________________________________________________\nflatten_6 (Flatten) (None, 3200) 0 \n_________________________________________________________________\ndense_9 (Dense) (None, 1) 3201 \n=================================================================\nTotal params: 596,225\nTrainable params: 595,201\nNon-trainable params: 1,024\n_________________________________________________________________\n"
],
[
"# Input: (128,5,5) - 5x5 internal state with nf channels\n# Output: (4,), (1,) - p, v\nPredNet().summary()",
"Model: \"model_11\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_12 (InputLayer) [(None, 5, 5, 128)] 0 \n__________________________________________________________________________________________________\nconv2d_38 (Conv2D) (None, 5, 5, 64) 73728 input_12[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_38 (BatchNo (None, 5, 5, 64) 256 conv2d_38[0][0] \n__________________________________________________________________________________________________\nre_lu_38 (ReLU) (None, 5, 5, 64) 0 batch_normalization_38[0][0] \n__________________________________________________________________________________________________\nconv2d_39 (Conv2D) (None, 5, 5, 32) 18432 re_lu_38[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_39 (BatchNo (None, 5, 5, 32) 128 conv2d_39[0][0] \n__________________________________________________________________________________________________\nre_lu_39 (ReLU) (None, 5, 5, 32) 0 batch_normalization_39[0][0] \n__________________________________________________________________________________________________\nflatten_7 (Flatten) (None, 800) 0 re_lu_39[0][0] \n__________________________________________________________________________________________________\ndense_10 (Dense) (None, 4) 3204 flatten_7[0][0] \n__________________________________________________________________________________________________\ndense_11 (Dense) (None, 1) 801 flatten_7[0][0] \n==================================================================================================\nTotal params: 96,549\nTrainable params: 96,357\nNon-trainable params: 192\n__________________________________________________________________________________________________\n"
],
[
"class NetworkOutput(typing.NamedTuple):\n value: float\n reward: float\n policy_logits: tf.Tensor # Dict[Action, float]\n hidden_state: List[float] # not sure about this one lol",
"_____no_output_____"
],
[
"class Network(object):\n \"\"\"TODO: Implement in Pytorch/TF\"\"\"\n def __init__(self, h_in=5, w_in=5, c_in=32, nf=128, n_acts=4):\n # Initialise a uniform network - should I init these networks explicitly?\n self.f = PredNet((5,5,nf), nf, n_acts)\n self.g = DynaNet((5,5,nf+1), nf)\n self.h = ReprNet((80,80,32), nf)\n self.steps = 0\n\n# @tf.function\n def initial_inference(self, obs) -> NetworkOutput:\n # representation + prediction function\n # input: 32x80x80 observation\n state = self.h(obs)\n policy_logits, value = self.f(state)\n # state, policy_logits, value = self.initial_inference_compiled(obs)\n # policy = {Action(i):p for i,p in enumerate(policy_logits[0])}\n policy = policy_logits[0]\n return NetworkOutput(value[0], 0.0, policy, state) # keep state 4D\n \n# @tf.function\n def recurrent_inference(self, state, action) -> NetworkOutput:\n # dynamics + prediction function\n # Input: hidden state nfx5x5\n # Concat/pad action to channel dim of states\n state_action = tf.pad(state, paddings=[[0, 0], [0, 0], [0, 0], [0, 1]], constant_values=action)\n next_state, reward = self.g(state_action)\n policy_logits, value = self.f(next_state)\n # next_state, reward, policy_logits, value = self.recurrent_inference_compiled(state, action)\n # policy = {Action(i):p for i,p in enumerate(policy_logits[0])}\n policy = policy_logits[0]\n return NetworkOutput(value[0], reward[0], policy, next_state)\n\n def get_weights(self):\n # Returns the weights of this network.\n self.steps += 1 # probably not ideal\n return [self.f.parameters(), self.g.parameters(), self.h.parameters()]\n\n def training_steps(self) -> int:\n # How many steps / batches the network has been trained for.\n return self.steps",
"_____no_output_____"
],
[
"class SharedStorage(object):\n\n def __init__(self):\n self._networks = {}\n\n def latest_network(self) -> Network:\n if self._networks:\n return self._networks[max(self._networks.keys())]\n else:\n # policy -> uniform, value -> 0, reward -> 0\n return make_uniform_network()\n\n def save_network(self, step: int, network: Network):\n self._networks[step] = network\n\ndef make_uniform_network():\n return Network()",
"_____no_output_____"
]
],
[
[
"# 1. Self-play",
"_____no_output_____"
]
],
[
[
"# Each self-play job is independent of all others; it takes the latest network\n# snapshot, produces a game and makes it available to the training job by\n# writing it to a shared replay buffer.\[email protected]\ndef run_selfplay(config: MuZeroConfig, storage: SharedStorage,\n replay_buffer: ReplayBuffer):\n \"\"\"TODO: Multithread this\"\"\"\n # tf.summary.trace_on()\n for i in tqdm(range(config.selfplay_iterations), desc='Self-play iter'):\n network = storage.latest_network()\n game = play_game(config, network)\n print(game.root_values)\n replay_buffer.save_game(game)\n # tf.summary.trace_export(\"Selfplay\", step=i, profiler_outdir='logs')\n # tf.summary.trace_off()",
"_____no_output_____"
]
],
[
[
"### Run 1 Game/Trajectory",
"_____no_output_____"
]
],
[
[
"# Each game is produced by starting at the initial board position, then\n# repeatedly executing a Monte Carlo Tree Search to generate moves until the end\n# of the game is reached.\ndef play_game(config: MuZeroConfig, network: Network) -> Game:\n game = config.new_game()\n\n while not game.terminal() and len(game.history) < config.max_moves:\n # At the root of the search tree we use the representation function h to\n # obtain a hidden state given the current observation.\n root = Node(0)\n current_observation = game.make_image(-1) # 80x80x32\n expand_node(root, game.legal_actions(),\n network.initial_inference(current_observation))\n add_exploration_noise(config, root)\n\n # We then run a Monte Carlo Tree Search using only action sequences and the\n # model learned by the network.\n run_mcts(config, root, game.action_history(), network)\n action = select_action(config, len(game.history), root, network)\n game.apply(action)\n game.store_search_statistics(root)\n return game",
"_____no_output_____"
]
],
[
[
"#### Exploration Noise",
"_____no_output_____"
]
],
[
[
"# At the start of each search, we add dirichlet noise to the prior of the root\n# to encourage the search to explore new actions.\n# @tf.function\ndef add_exploration_noise(config: MuZeroConfig, node: Node):\n actions = list(node.children.keys())\n noise = np.random.dirichlet([config.root_dirichlet_alpha] * len(actions))\n frac = config.root_exploration_fraction\n for a, n in zip(actions, noise):\n node.children[a].prior = node.children[a].prior * (1 - frac) + n * frac",
"_____no_output_____"
]
],
[
[
"### Softmax search policy $\\pi$",
"_____no_output_____"
]
],
[
[
"# @tf.function\ndef select_action(config: MuZeroConfig, num_moves: int, node: Node,\n network: Network) -> int:\n \"\"\"Search policy: softmax probability over actions dictated by visited counts\"\"\"\n # Visit counts of chilren nodes - policy proportional to counts\n visit_counts = [\n (child.visit_count, action) for action, child in node.children.items()\n ]\n # Get softmax temp\n t = config.visit_softmax_temperature_fn(\n num_moves=num_moves, training_steps=network.training_steps())\n _, action = softmax_sample(visit_counts, t)\n return action\n\n# @tf.function\ndef softmax_sample(distribution, T: float):\n counts = np.array([d[0] for d in distribution])\n actions = [d[1] for d in distribution]\n softmax_probs = softmax(counts/T)\n sampled_action = np.random.choice(actions, size=1, p=softmax_probs)[0]\n return _, sampled_action\n# return nn.Softmax(dim=0)(distribution/T)\n\n# @tf.function\ndef softmax(x, axis=-1):\n e_x = np.exp(x - np.max(x))\n return e_x / e_x.sum(axis=axis, keepdims=True)",
"_____no_output_____"
]
],
[
[
"### MCTS",
"_____no_output_____"
]
],
[
[
"# Core Monte Carlo Tree Search algorithm.\n# To decide on an action, we run N simulations, always starting at the root of\n# the search tree and traversing the tree according to the UCB formula until we\n# reach a leaf node.\ndef run_mcts(config: MuZeroConfig, root: Node, action_history: ActionHistory,\n network: Network):\n \"\"\"TODO: Multithread\"\"\"\n min_max_stats = MinMaxStats(config.known_bounds)\n\n for _ in range(config.num_simulations):\n history = action_history.clone()\n node = root\n search_path = [node]\n\n # Traverse tree, expanding by highest UCB until leaf reached\n while node.expanded():\n action, node = select_child(config, node, min_max_stats) # UCB selection\n history.add_action(action)\n search_path.append(node)\n\n # Inside the search tree we use the dynamics function to obtain the next\n # hidden state given an action and the previous hidden state.\n parent = search_path[-2] # parent of leaf\n # Dynamics: g(s_{k-1},a_k) = r_k, s_k\n # Predictions: f(s_k) = v_k, p_k\n # -> (v,r,p,s)\n network_output = network.recurrent_inference(parent.hidden_state,\n history.last_action())\n # expand node using v,r,p predictions from NN\n expand_node(node, history.action_space(), network_output)\n\n # back up values to the root node\n backpropagate(search_path, network_output.value, config.discount, \n min_max_stats)",
"_____no_output_____"
]
],
[
[
"#### i. Selection: UCB Child Selection\nWe select the child node/state based on the action that maximises over an upper confidence bound (UCB):\n$$a^{k}=\\arg \\max _{a}\\left[Q(s, a)+P(s, a) \\cdot \\frac{\\sqrt{\\sum_{b} N(s, b)}}{1+N(s, a)}\\left(c_{1}+\\log \\left(\\frac{\\sum_{b} N(s, b)+c_{2}+1}{c_{2}}\\right)\\right)\\right]$$\nTo clarify: $\\sum_{b} N(s, b)$ is just the sum of counts over all child nodes, i.e. the count of the parent node.\n\n\"The constants c1 and c2 are used to control the influence of the prior P(s, a) relative to the value Q(s, a) as\nnodes are visited more often. In our experiments, $c_1$ = 1.25 and $c_2$ = 19652\" - (pg. 12)",
"_____no_output_____"
]
],
[
[
"# Select the child with the highest UCB score.\ndef select_child(config: MuZeroConfig, node: Node,\n min_max_stats: MinMaxStats):\n _, action, child = max(\n (ucb_score(config, node, child, min_max_stats), action,\n child) for action, child in node.children.items())\n return action, child\n\n# The score for a node is based on its value, plus an exploration bonus based on\n# the prior.\n# @tf.function\ndef ucb_score(config: MuZeroConfig, parent: Node, child: Node,\n min_max_stats: MinMaxStats) -> float:\n pb_c = math.log((parent.visit_count + config.pb_c_base + 1) /\n config.pb_c_base) + config.pb_c_init\n pb_c *= math.sqrt(parent.visit_count) / (child.visit_count + 1)\n\n # P(s,a)*pb_c\n prior_score = pb_c * child.prior\n # Q(s,a)\n if child.visit_count > 0:\n value_score = child.reward + config.discount * min_max_stats.normalize(\n child.value())\n else:\n value_score = 0\n return prior_score + value_score",
"_____no_output_____"
]
],
[
[
"#### ii. Expansion: Leaf Node Expansion + Prediction",
"_____no_output_____"
]
],
[
[
"# We expand a node using the value, reward and policy prediction obtained from\n# the neural network.\n# @tf.function\ndef expand_node(node: Node, actions: List[int], network_output: NetworkOutput):\n \"\"\"Updates predictions for state s, reward r and policy p for node based on NN outputs\"\"\"\n # Update leaf with predictions from parent\n node.hidden_state = network_output.hidden_state # s\n node.reward = network_output.reward # r\n # policy = {a: tf.math.exp(network_output.policy_logits[a]) for a in actions} # unnormalised probabilities\n policy = [tf.math.exp(network_output.policy_logits[a]) for a in actions] # unnormalised probabilities\n policy_sum = tf.reduce_sum(policy) \n for action in range(len(policy)):\n p = policy[action]\n node.children[action] = Node(p / policy_sum) # p",
"_____no_output_____"
]
],
[
[
"#### iii. Backup: Search Tree Update/Backprop\n$$G^{k}=\\sum_{\\tau=0}^{l-1-k} \\gamma^{\\tau} r_{k+1+\\tau}+\\gamma^{l-k} v^{l}$$\nFor $k = l...1$, we update the statistics for each edge $\\left(s^{k-1}, a^{k}\\right)$ in the simulation\n$$Q\\left(s^{k-1}, a^{k}\\right):=\\frac{N\\left(s^{k-1}, a^{k}\\right) \\cdot Q\\left(s^{k-1}, a^{k}\\right)+G^{k}}{N\\left(s^{k-1}, a^{k}\\right)+1}$$\n$$N\\left(s^{k-1}, a^{k}\\right):=N\\left(s^{k-1}, a^{k}\\right)+1$$\nQ value estimates are normalised so that we can combine value estimates with probabilities via pUCT rule (above)\n$$\\bar{Q}\\left(s^{k-1}, a^{k}\\right)=\\frac{Q\\left(s^{k-1}, a^{k}\\right)-\\min _{s, a \\in \\operatorname{Tree}} Q(s, a)}{\\max _{s, a \\in \\operatorname{Tree}} Q(s, a)-\\min _{s, a \\in \\operatorname{Tree}} Q(s, a)}$$",
"_____no_output_____"
]
],
[
[
"# At the end of a simulation, we propagate the evaluation all the way up the\n# tree to the root.\n# @tf.function\ndef backpropagate(search_path: List[Node], value: float,\n discount: float, min_max_stats: MinMaxStats):\n # Traverse back up UCB search path\n for node in reversed(search_path):\n node.value_sum += value # if node.to_play == to_play else -value\n node.visit_count += 1\n min_max_stats.update(node.value())\n\n value = discount * value + node.reward",
"_____no_output_____"
],
[
"##################################\n####### Part 2: Training #########\nfrom tensorflow.keras.optimizers import Adam, Optimizer\nfrom tensorflow.compat.v1.train import get_global_step\n\n\ndef train_network(config: MuZeroConfig, storage: SharedStorage,\n replay_buffer: ReplayBuffer):\n# while len(replay_buffer.buffer)==0: pass\n network = Network()\n learning_rate = config.lr_init * config.lr_decay_rate**(\n# get_global_step() / config.lr_decay_steps)\n 1)\n optimizer = Adam(learning_rate, config.momentum)\n\n for i in range(config.training_steps):\n if i % config.checkpoint_interval == 0:\n storage.save_network(i, network)\n batch = replay_buffer.sample_batch(config.num_unroll_steps, config.td_steps)\n update_weights(optimizer, network, batch, config.weight_decay)\n storage.save_network(config.training_steps, network)\n\n\ndef scale_gradient(tensor, scale):\n \"\"\"Scales the gradient for the backward pass.\"\"\"\n return tensor * scale + tf.stop_gradient(tensor) * (1 - scale)\n\n\ndef update_weights(optimizer: Optimizer, network: Network, batch,\n weight_decay: float):\n loss = 0\n for image, actions, targets in batch:\n # Initial step, from the real observation.\n value, reward, policy_logits, hidden_state = network.initial_inference(\n image)\n predictions = [(1.0, value, reward, policy_logits)]\n\n # Recurrent steps, from action and previous hidden state.\n for action in actions:\n value, reward, policy_logits, hidden_state = network.recurrent_inference(\n hidden_state, action)\n predictions.append((1.0 / len(actions), value, reward, policy_logits))\n\n hidden_state = scale_gradient(hidden_state, 0.5)\n\n for prediction, target in zip(predictions, targets):\n gradient_scale, value, reward, policy_logits = prediction\n target_value, target_reward, target_policy = target\n\n l = (\n scalar_loss(value, target_value) +\n scalar_loss(reward, target_reward) +\n tf.nn.softmax_cross_entropy_with_logits(\n logits=policy_logits, labels=target_policy))\n\n loss += scale_gradient(l, gradient_scale)\n\n for weights in network.get_weights():\n loss += weight_decay * tf.nn.l2_loss(weights)\n\n optimizer.minimize(loss)\n\n\ndef scalar_loss(prediction, target) -> float:\n # MSE in board games, cross entropy between categorical values in Atari.\n return -1",
"_____no_output_____"
]
],
[
[
"### Testing",
"_____no_output_____"
]
],
[
[
"# MuZero training is split into two independent parts: Network training and\n# self-play data generation.\n# These two parts only communicate by transferring the latest network checkpoint\n# from the training to the self-play, and the finished games from the self-play\n# to the training.\nclass Muzero(object):\n def __init__(self, config: MuZeroConfig):\n self.config = config\n self.storage = SharedStorage()\n self.replay_buffer = ReplayBuffer(config)\n \n def launch_job(self, f, *args):\n # f(*args)\n f.remote(*args)\n \n def run(self):\n for _ in range(self.config.num_actors):\n self.launch_job(run_selfplay, self.config, self.storage, self.replay_buffer)\n train_network(self.config, self.storage, self.replay_buffer)\n return self.storage.latest_network()\n\n \n# def muzero(config: MuZeroConfig):\n# storage = SharedStorage()\n# replay_buffer = ReplayBuffer(config)\n\n# for _ in range(config.num_actors):\n# launch_job(run_selfplay, config, storage, replay_buffer)\n\n# # train_network(config, storage, replay_buffer)\n\n# return storage.latest_network()",
"_____no_output_____"
],
[
"config = make_atari_config()\nmz = Muzero(config)",
"_____no_output_____"
],
[
"ray.init()",
"2020-04-30 23:39:17,352\tINFO resource_spec.py:212 -- Starting Ray with 9.08 GiB memory available for workers and up to 4.56 GiB for objects. You can adjust these settings with ray.init(memory=<bytes>, object_store_memory=<bytes>).\n2020-04-30 23:39:17,639\tINFO services.py:1148 -- View the Ray dashboard at \u001b[1m\u001b[32mlocalhost:8265\u001b[39m\u001b[22m\n"
],
[
"mz.run()",
"Self-play iter: 0%| | 0/1 [00:00<?, ?it/s]2020-04-30 23:39:28.721783: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m 2020-04-30 23:39:28.756070: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f93385bfdc0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m 2020-04-30 23:39:28.756118: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\nSelf-play iter: 0%| | 0/1 [00:00<?, ?it/s]\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m 2020-04-30 23:39:28.776501: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m 2020-04-30 23:39:28.797378: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fa2f3fe3c30 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m 2020-04-30 23:39:28.797421: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\nSelf-play iter: 0%| | 0/1 [00:00<?, ?it/s]2020-04-30 23:39:28.950556: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n\u001b[2m\u001b[36m(pid=11801)\u001b[0m 2020-04-30 23:39:28.980927: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fcc9adc03a0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n\u001b[2m\u001b[36m(pid=11801)\u001b[0m 2020-04-30 23:39:28.980978: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\nSelf-play iter: 0%| | 0/1 [00:00<?, ?it/s]2020-04-30 23:39:29.299706: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\n\u001b[2m\u001b[36m(pid=11808)\u001b[0m 2020-04-30 23:39:29.322882: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7fb1f3d20de0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n\u001b[2m\u001b[36m(pid=11808)\u001b[0m 2020-04-30 23:39:29.322927: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m WARNING:tensorflow:Layer conv2d_6 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m \n\u001b[2m\u001b[36m(pid=11810)\u001b[0m If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m \n\u001b[2m\u001b[36m(pid=11810)\u001b[0m To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.\n\u001b[2m\u001b[36m(pid=11810)\u001b[0m \n\u001b[2m\u001b[36m(pid=11812)\u001b[0m WARNING:tensorflow:Layer conv2d_6 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m \n\u001b[2m\u001b[36m(pid=11812)\u001b[0m If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m \n\u001b[2m\u001b[36m(pid=11812)\u001b[0m To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.\n\u001b[2m\u001b[36m(pid=11812)\u001b[0m \n\u001b[2m\u001b[36m(pid=11801)\u001b[0m WARNING:tensorflow:Layer conv2d_6 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\n\u001b[2m\u001b[36m(pid=11801)\u001b[0m \n\u001b[2m\u001b[36m(pid=11801)\u001b[0m If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.\n\u001b[2m\u001b[36m(pid=11801)\u001b[0m \n\u001b[2m\u001b[36m(pid=11801)\u001b[0m To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.\n\u001b[2m\u001b[36m(pid=11801)\u001b[0m \n\u001b[2m\u001b[36m(pid=11808)\u001b[0m WARNING:tensorflow:Layer conv2d_6 is casting an input tensor from dtype float64 to the layer's dtype of float32, which is new behavior in TensorFlow 2. The layer has dtype float32 because it's dtype defaults to floatx.\n\u001b[2m\u001b[36m(pid=11808)\u001b[0m \n\u001b[2m\u001b[36m(pid=11808)\u001b[0m If you intended to run this layer in float32, you can safely ignore this warning. If in doubt, this warning is likely only an issue if you are porting a TensorFlow 1.X model to TensorFlow 2.\n\u001b[2m\u001b[36m(pid=11808)\u001b[0m \n\u001b[2m\u001b[36m(pid=11808)\u001b[0m To change all layers to have dtype float64 by default, call `tf.keras.backend.set_floatx('float64')`. To change just this layer, pass dtype='float64' to the layer constructor. If you are the author of this layer, you can disable autocasting by passing autocast=False to the base Layer constructor.\n\u001b[2m\u001b[36m(pid=11808)\u001b[0m \n\u001b[2m\u001b[36m(pid=11808)\u001b[0m [<tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01625987], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01730009], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01532874], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01461578], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01609246], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0164874], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01778697], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01684255], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688369], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01701035], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01600514], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01716549], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01731716], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01730009], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01707115], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01483417], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01722653], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0165587], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01571291], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01687381], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0166847], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01803908], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01453499], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01679387], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01730007], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01647183], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01754177], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01746436], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01628561], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01690666], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0162466], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01634086], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01690666], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01677313], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0157327], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01750897], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01625987], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01625987], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01701791], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01645399], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01754914], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01765563], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01640906], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01661474], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01687381], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01625987], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01681672], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0150422], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01453499], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01453499], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01677313], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688369], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01659638], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01669119], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01663902], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01754914], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01681672], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01756596], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01634086], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01597648], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01646278], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01706664], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01532874], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01641805], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01658651], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01784716], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01730009], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01571291], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01643873], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01754177], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01677313], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01658651], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01733362], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01641805], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01609246], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01749952], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0180457], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01728865], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01707115], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0180457], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01681672], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01646278], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01552402], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0177231], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0162466], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01752926], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0178431], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01681672], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0165587], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01634561], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01634086], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01634086], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01749952], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0150422], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01688579], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01679387], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01679387], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01643873], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01716549], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.0154237], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01681672], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01744934], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01559991], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01754914], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01805795], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01765412], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01703234], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01716549], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01679387], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01687382], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01677313], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01617614], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01716765], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01743229], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01735247], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01847727], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01803908], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01461578], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01564568], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01680139], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01613126], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01716549], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01641805], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01618196], dtype=float32)>, <tf.Tensor: shape=(1,), dtype=float32, numpy=array([0.01617614], dtype=float32)>]\n"
],
[
"len(mz.replay_buffer.buffer)",
"_____no_output_____"
],
[
"mz.replay_buffer.buffer",
"_____no_output_____"
],
[
"ray.shutdown()",
"_____no_output_____"
],
[
"# !pip install memory-profiler",
"_____no_output_____"
],
[
"# with strategy.scope():\nconfig = make_atari_config()\nss = SharedStorage()\nrbuf = ReplayBuffer(config)\n\nrun_selfplay(config, ss, rbuf)",
"Self-play iter: 100%|██████████| 1/1 [02:23<00:00, 143.04s/it]\n"
]
],
[
[
"**ncalls**\nfor the number of calls,\n\n**tottime**\nfor the total time spent in the given function (and excluding time made in calls to sub-functions)\n\n**percall**\nis the quotient of tottime divided by ncalls\n\n**cumtime**\nis the cumulative time spent in this and all subfunctions (from invocation till exit). This figure is accurate even for recursive functions.\n\n**percall**\nis the quotient of cumtime divided by primitive calls\n\n**filename:lineno(function)**\nprovides the respective data of each function",
"_____no_output_____"
]
],
[
[
"import cProfile\ncProfile.run('run_selfplay(config, ss, rbuf)', filename='trace.prof')",
"Self-play iter: 100%|██████████| 1/1 [02:28<00:00, 148.28s/it]\n"
],
[
"import pstats\np = pstats.Stats('trace.prof')\np.sort_stats('tottime').print_stats(10)",
"Wed Apr 29 14:37:33 2020 trace.prof\n\n 55230475 function calls (55072481 primitive calls) in 157.398 seconds\n\n Ordered by: internal time\n List reduced from 2058 to 10 due to restriction <10>\n\n ncalls tottime percall cumtime percall filename:lineno(function)\n 456966 52.023 0.000 52.023 0.000 {method '_numpy_internal' of 'tensorflow.python.framework.ops.EagerTensor' objects}\n 1678974 39.434 0.000 39.434 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_FastPathExecute}\n 24617 8.728 0.000 8.728 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_Execute}\n1261332/1261058 4.339 0.000 18.527 0.000 /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py:1290(convert_to_tensor)\n 746908 4.268 0.000 5.069 0.000 /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/constant_op.py:68(convert_to_eager_tensor)\n 752389 2.797 0.000 32.070 0.000 /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:981(binary_op_wrapper)\n 116131 2.625 0.000 106.026 0.001 {built-in method builtins.max}\n 1399943 2.493 0.000 3.712 0.000 /usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py:6189(name_scope)\n 181460 2.111 0.000 54.528 0.000 <ipython-input-24-9602d5b20ed6>:11(ucb_score)\n 323012 1.819 0.000 22.952 0.000 /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_ops.py:1007(r_binary_op_wrapper)\n\n\n"
],
[
"#@title Default title text\ntrace=\"\"\"ncalls tottime percall cumtime percall filename:lineno(function)\n 47 0.000 0.000 0.001 0.000 <__array_function__ internals>:2(all)\n 294 0.001 0.000 0.011 0.000 <__array_function__ internals>:2(amax)\n 338 0.001 0.000 0.008 0.000 <__array_function__ internals>:2(any)\n 297 0.001 0.000 0.017 0.000 <__array_function__ internals>:2(concatenate)\n 2 0.000 0.000 0.001 0.000 <__array_function__ internals>:2(copyto)\n 370 0.001 0.000 0.009 0.000 <__array_function__ internals>:2(prod)\n 294 0.001 0.000 0.027 0.000 <__array_function__ internals>:2(stack)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:151(__exit__)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:157(_get_module_lock)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:176(cb)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:194(_lock_unlock_module)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:211(_call_with_frames_removed)\n 6 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:222(_verbose_message)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:35(_new_module)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:369(__init__)\n 190 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:391(__eq__)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:403(cached)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:416(parent)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:424(has_location)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:504(_init_module_attrs)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:564(module_from_spec)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:58(__init__)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:78(acquire)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:917(_sanity_check)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:966(_find_and_load)\n 1 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:982(_gcd_import)\n 129 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:997(_handle_fromlist)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:106(_write_atomic)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:1359(_get_supported_file_loaders)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:263(cache_from_source)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:361(_get_cached)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:373(_calc_mode)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:393(_check_name_wrapper)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:47(_w_long)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:497(_code_to_bytecode)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:524(spec_from_file_location)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:57(_path_join)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:59(<listcomp>)\n 8 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:63(_path_split)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:661(is_package)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:669(create_module)\n 2 0.000 0.000 0.001 0.000 <frozen importlib._bootstrap_external>:672(exec_module)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:735(source_to_code)\n 2 0.000 0.000 0.001 0.000 <frozen importlib._bootstrap_external>:743(get_code)\n 6 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:75(_path_stat)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:800(__init__)\n 190 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:806(__eq__)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:825(get_filename)\n 4 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:830(get_data)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:840(path_stats)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:845(_cache_bytecode)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:85(_path_is_mode_type)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:850(set_data)\n 2 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap_external>:99(_path_isdir)\n 71628 0.252 0.000 24.637 0.000 <ipython-input-40-ef54d4819491>:13(update)\n 102386 1.625 0.000 30.763 0.000 <ipython-input-40-ef54d4819491>:17(normalize)\n 294 0.000 0.000 0.000 0.000 <ipython-input-40-ef54d4819491>:9(__init__)\n 1 0.000 0.000 0.201 0.201 <ipython-input-41-b6219d23a42f>:56(new_game)\n 294 0.000 0.000 0.000 0.000 <ipython-input-41-b6219d23a42f>:61(visit_softmax_temperature)\n 882 0.000 0.000 0.000 0.000 <ipython-input-42-30c928fcc991>:12(__gt__)\n 121128 0.042 0.000 0.042 0.000 <ipython-input-42-30c928fcc991>:3(__init__)\n 259602 0.044 0.000 0.044 0.000 <ipython-input-42-30c928fcc991>:6(__hash__)\n 77893 0.024 0.000 0.024 0.000 <ipython-input-42-30c928fcc991>:9(__eq__)\n 71628 0.088 0.000 0.109 0.000 <ipython-input-43-28c03be0c141>:12(expanded)\n 174308 0.529 0.000 18.052 0.000 <ipython-input-43-28c03be0c141>:15(value)\n 60270 0.050 0.000 0.050 0.000 <ipython-input-43-28c03be0c141>:3(__init__)\n 14700 0.027 0.000 0.070 0.000 <ipython-input-44-ef803af33755>:11(clone)\n 56928 0.079 0.000 0.096 0.000 <ipython-input-44-ef803af33755>:14(add_action)\n 14700 0.006 0.000 0.006 0.000 <ipython-input-44-ef803af33755>:17(last_action)\n 14700 0.036 0.000 0.083 0.000 <ipython-input-44-ef803af33755>:20(action_space)\n 14700 0.034 0.000 0.047 0.000 <ipython-input-44-ef803af33755>:21(<listcomp>)\n 14994 0.043 0.000 0.043 0.000 <ipython-input-44-ef803af33755>:7(__init__)\n 295 0.000 0.000 0.000 0.000 <ipython-input-45-8c7d8a00adce>:13(terminal)\n 294 0.002 0.000 0.003 0.000 <ipython-input-45-8c7d8a00adce>:16(legal_actions)\n 294 0.001 0.000 0.002 0.000 <ipython-input-45-8c7d8a00adce>:19(<listcomp>)\n 295 0.025 0.000 0.035 0.000 <ipython-input-45-8c7d8a00adce>:21(prepro)\n 294 0.001 0.000 0.001 0.000 <ipython-input-45-8c7d8a00adce>:29(get_obs)\n 1 0.000 0.000 0.201 0.201 <ipython-input-45-8c7d8a00adce>:3(__init__)\n 294 0.003 0.000 0.254 0.001 <ipython-input-45-8c7d8a00adce>:8(step)\n 295 0.001 0.000 0.001 0.000 <ipython-input-46-1362272aa653>:12(terminal)\n 294 0.001 0.000 0.004 0.000 <ipython-input-46-1362272aa653>:15(legal_actions)\n 294 0.002 0.000 0.256 0.001 <ipython-input-46-1362272aa653>:18(apply)\n 294 0.003 0.000 0.049 0.000 <ipython-input-46-1362272aa653>:23(store_search_statistics)\n 1470 0.000 0.000 0.000 0.000 <ipython-input-46-1362272aa653>:25(<genexpr>)\n 1470 0.001 0.000 0.001 0.000 <ipython-input-46-1362272aa653>:26(<genexpr>)\n 294 0.002 0.000 0.005 0.000 <ipython-input-46-1362272aa653>:29(<listcomp>)\n 1 0.000 0.000 0.201 0.201 <ipython-input-46-1362272aa653>:3(__init__)\n 294 0.006 0.000 0.200 0.001 <ipython-input-46-1362272aa653>:35(make_image)\n 294 0.001 0.000 0.001 0.000 <ipython-input-46-1362272aa653>:97(action_history)\n 1 0.000 0.000 0.000 0.000 <ipython-input-47-5f58c4392d1b>:8(save_game)\n 10 0.000 0.000 2.271 0.227 <ipython-input-48-a3aee8082806>:14(ConvBlock)\n 1 0.000 0.000 0.221 0.221 <ipython-input-48-a3aee8082806>:20(ReprNet)\n 1 0.000 0.000 1.955 1.955 <ipython-input-48-a3aee8082806>:28(DynaNet)\n 1 0.000 0.000 0.149 0.149 <ipython-input-48-a3aee8082806>:39(PredNet)\n 294 0.008 0.000 0.754 0.003 <ipython-input-53-ed847ba989f4>:16(initial_inference)\n 294 0.004 0.000 0.005 0.000 <ipython-input-53-ed847ba989f4>:22(<dictcomp>)\n 1 0.000 0.000 2.325 2.325 <ipython-input-53-ed847ba989f4>:3(__init__)\n 14700 0.421 0.000 27.850 0.002 <ipython-input-53-ed847ba989f4>:32(recurrent_inference)\n 14700 0.188 0.000 0.230 0.000 <ipython-input-53-ed847ba989f4>:40(<dictcomp>)\n 294 0.000 0.000 0.000 0.000 <ipython-input-53-ed847ba989f4>:48(training_steps)\n 1 0.000 0.000 2.325 2.325 <ipython-input-54-0886533d695a>:16(make_uniform_network)\n 1 0.000 0.000 2.325 2.325 <ipython-input-54-0886533d695a>:6(latest_network)\n 1 0.427 0.427 190.490 190.490 <ipython-input-55-37c85f058a24>:1(run_selfplay)\n 1 0.086 0.086 181.856 181.856 <ipython-input-56-aaae3305ad34>:1(play_game)\n 294 0.004 0.000 0.021 0.000 <ipython-input-57-fd1ed6f6ed97>:1(add_exploration_noise)\n 294 0.003 0.000 0.074 0.000 <ipython-input-58-4ec0544e5e1c>:1(select_action)\n 294 0.008 0.000 0.070 0.000 <ipython-input-58-4ec0544e5e1c>:14(softmax_sample)\n 294 0.000 0.000 0.000 0.000 <ipython-input-58-4ec0544e5e1c>:15(<listcomp>)\n 294 0.000 0.000 0.000 0.000 <ipython-input-58-4ec0544e5e1c>:16(<listcomp>)\n 294 0.006 0.000 0.020 0.000 <ipython-input-58-4ec0544e5e1c>:22(softmax)\n 294 0.001 0.000 0.001 0.000 <ipython-input-58-4ec0544e5e1c>:6(<listcomp>)\n 294 0.561 0.002 180.199 0.613 <ipython-input-59-6a2401fc79df>:1(run_mcts)\n 56928 0.192 0.000 107.099 0.002 <ipython-input-60-c9d2d71ff63b>:1(select_child)\n 227712 2.436 0.000 67.272 0.000 <ipython-input-60-c9d2d71ff63b>:10(ucb_score)\n 284640 0.616 0.000 67.888 0.000 <ipython-input-60-c9d2d71ff63b>:4(<genexpr>)\n 14994 0.118 0.000 0.358 0.000 <ipython-input-61-5f8fc43a9ebe>:1(expand_node)\n 14994 0.089 0.000 0.158 0.000 <ipython-input-61-5f8fc43a9ebe>:6(<dictcomp>)\n 14700 1.077 0.000 43.962 0.003 <ipython-input-62-24dec825edc5>:1(backpropagate)\n 1 0.000 0.000 190.543 190.543 <string>:1(<module>)\n 1049 0.000 0.000 0.001 0.000 <string>:12(__new__)\n 128 0.000 0.000 0.000 0.000 <string>:16(_make)\n 18 0.000 0.000 0.000 0.000 <string>:24(_replace)\n 1 0.000 0.000 0.000 0.000 __init__.py:108(import_module)\n 2 0.000 0.000 0.001 0.001 __init__.py:11(unparse)\n 1 0.000 0.000 0.000 0.000 __init__.py:120(getLevelName)\n 1 0.000 0.000 0.004 0.004 __init__.py:1310(warning)\n 36 0.000 0.000 0.000 0.000 __init__.py:1359(log)\n 1 0.000 0.000 0.000 0.000 __init__.py:1406(makeRecord)\n 1 0.000 0.000 0.004 0.004 __init__.py:1421(_log)\n 1 0.000 0.000 0.004 0.004 __init__.py:1446(handle)\n 1 0.000 0.000 0.004 0.004 __init__.py:1500(callHandlers)\n 37 0.000 0.000 0.000 0.000 __init__.py:1530(getEffectiveLevel)\n 37 0.000 0.000 0.000 0.000 __init__.py:1544(isEnabledFor)\n 1 0.000 0.000 0.000 0.000 __init__.py:251(__init__)\n 1 0.000 0.000 0.000 0.000 __init__.py:329(getMessage)\n 1 0.000 0.000 0.000 0.000 __init__.py:387(usesTime)\n 1 0.000 0.000 0.000 0.000 __init__.py:390(format)\n 1 0.000 0.000 0.000 0.000 __init__.py:4(_game_dir)\n 1 0.000 0.000 0.000 0.000 __init__.py:458(close)\n 3 0.000 0.000 0.000 0.000 __init__.py:517(__init__)\n 38 0.000 0.000 0.000 0.000 __init__.py:537(__missing__)\n 1 0.000 0.000 0.000 0.000 __init__.py:542(usesTime)\n 1 0.000 0.000 0.000 0.000 __init__.py:548(formatMessage)\n 1 0.000 0.000 0.000 0.000 __init__.py:564(format)\n 3 0.000 0.000 0.000 0.000 __init__.py:586(update)\n 1 0.000 0.000 0.000 0.000 __init__.py:639(__del__)\n 1 0.000 0.000 0.000 0.000 __init__.py:7(get_game_path)\n 2 0.000 0.000 0.000 0.000 __init__.py:705(filter)\n 2 0.000 0.000 0.000 0.000 __init__.py:809(acquire)\n 2 0.000 0.000 0.000 0.000 __init__.py:816(release)\n 1 0.000 0.000 0.000 0.000 __init__.py:829(format)\n 1 0.000 0.000 0.004 0.004 __init__.py:852(handle)\n 1 0.000 0.000 0.004 0.004 __init__.py:971(flush)\n 1 0.000 0.000 0.004 0.004 __init__.py:982(emit)\n 23 0.000 0.000 0.000 0.000 _asarray.py:16(asarray)\n 294 0.000 0.000 0.001 0.000 _asarray.py:88(asanyarray)\n 926 0.001 0.000 0.004 0.000 _collections_abc.py:657(get)\n 656 0.001 0.000 0.002 0.000 _collections_abc.py:664(__contains__)\n 2484 0.003 0.000 0.004 0.000 _collections_abc.py:676(items)\n 2484 0.001 0.000 0.001 0.000 _collections_abc.py:698(__init__)\n 7585 0.016 0.000 0.016 0.000 _collections_abc.py:742(__iter__)\n 336 0.000 0.000 0.001 0.000 _collections_abc.py:879(__iter__)\n 20 0.000 0.000 0.000 0.000 _internal.py:830(npy_ctypes_check)\n 294 0.000 0.000 0.002 0.000 _methods.py:36(_sum)\n 3 0.000 0.000 0.000 0.000 _methods.py:44(_any)\n 1 0.000 0.000 0.000 0.000 _monitor.py:98(report)\n 6 0.000 0.000 0.000 0.000 _ufunc_config.py:139(geterr)\n 6 0.000 0.000 0.000 0.000 _ufunc_config.py:39(seterr)\n 3 0.000 0.000 0.000 0.000 _ufunc_config.py:441(__enter__)\n 3 0.000 0.000 0.000 0.000 _ufunc_config.py:446(__exit__)\n 1 0.000 0.000 0.000 0.000 _weakrefset.py:106(remove)\n 173 0.000 0.000 0.001 0.000 _weakrefset.py:116(update)\n 909 0.000 0.000 0.000 0.000 _weakrefset.py:16(__init__)\n 909 0.000 0.000 0.001 0.000 _weakrefset.py:20(__enter__)\n 909 0.001 0.000 0.001 0.000 _weakrefset.py:26(__exit__)\n 397 0.000 0.000 0.001 0.000 _weakrefset.py:36(__init__)\n 227 0.000 0.000 0.000 0.000 _weakrefset.py:38(_remove)\n 698 0.000 0.000 0.000 0.000 _weakrefset.py:52(_commit_removals)\n 1231 0.001 0.000 0.003 0.000 _weakrefset.py:58(__iter__)\n 1 0.000 0.000 0.000 0.000 _weakrefset.py:67(__len__)\n 432634 0.450 0.000 0.450 0.000 _weakrefset.py:70(__contains__)\n 351 0.389 0.001 1.716 0.005 _weakrefset.py:81(add)\n 239505 0.548 0.000 0.998 0.000 abc.py:180(__instancecheck__)\n 174 0.000 0.000 0.000 0.000 activations.py:338(linear)\n 23 0.000 0.000 0.000 0.000 activations.py:425(get)\n 18/6 0.000 0.000 0.000 0.000 activity.py:126(referenced)\n 404 0.001 0.000 0.002 0.000 activity.py:172(finalize)\n 55 0.000 0.000 0.000 0.000 activity.py:191(mark_param)\n 44 0.000 0.000 0.000 0.000 activity.py:210(__init__)\n 22 0.000 0.000 0.000 0.000 activity.py:224(__init__)\n 170 0.000 0.000 0.000 0.000 activity.py:232(_in_constructor)\n 710 0.002 0.000 0.006 0.000 activity.py:251(_track_symbol)\n 404 0.000 0.000 0.003 0.000 activity.py:303(_enter_scope)\n 404 0.000 0.000 0.002 0.000 activity.py:306(_exit_scope)\n 374 0.000 0.000 0.003 0.000 activity.py:312(_exit_and_record_scope)\n 173 0.000 0.000 0.035 0.000 activity.py:317(_process_statement)\n 8 0.000 0.000 0.000 0.000 activity.py:334(visit_Expr)\n 8 0.000 0.000 0.000 0.000 activity.py:337(visit_Raise)\n 22 0.000 0.000 0.004 0.000 activity.py:340(visit_Return)\n 95 0.000 0.000 0.022 0.000 activity.py:343(visit_Assign)\n 540 0.000 0.000 0.012 0.000 activity.py:366(visit_Name)\n 170 0.000 0.000 0.009 0.000 activity.py:384(visit_Attribute)\n 139/107 0.000 0.000 0.021 0.000 activity.py:409(visit_Call)\n 22 0.000 0.000 0.003 0.000 activity.py:477(visit_arguments)\n 22 0.000 0.000 0.041 0.002 activity.py:499(visit_FunctionDef)\n 18 0.000 0.000 0.027 0.002 activity.py:533(visit_With)\n 18 0.000 0.000 0.006 0.000 activity.py:539(visit_withitem)\n 8 0.000 0.000 0.001 0.000 activity.py:581(visit_ExceptHandler)\n 22 0.000 0.000 0.042 0.002 activity.py:592(resolve)\n 426 0.001 0.000 0.003 0.000 activity.py:92(__init__)\n 10 0.000 0.000 0.004 0.000 advanced_activations.py:344(__init__)\n 118 0.000 0.000 0.063 0.001 advanced_activations.py:360(call)\n 146 0.000 0.000 0.000 0.000 ag_ctx.py:29(_control_ctx)\n 38 0.000 0.000 0.000 0.000 ag_ctx.py:35(control_status_ctx)\n 36 0.000 0.000 0.000 0.000 ag_ctx.py:49(__init__)\n 36 0.000 0.000 0.000 0.000 ag_ctx.py:53(__enter__)\n 36 0.000 0.000 0.000 0.000 ag_ctx.py:61(__exit__)\n 270 0.000 0.000 0.002 0.000 ag_logging.py:114(get_verbosity)\n 270 0.000 0.000 0.002 0.000 ag_logging.py:121(has_verbosity)\n 231 0.000 0.000 0.002 0.000 ag_logging.py:138(log)\n 3 0.000 0.000 0.000 0.000 ale_python_interface.py:115(_as_bytes)\n 1 0.000 0.000 0.000 0.000 ale_python_interface.py:127(__init__)\n 1 0.000 0.000 0.000 0.000 ale_python_interface.py:141(setInt)\n 1 0.000 0.000 0.000 0.000 ale_python_interface.py:145(setFloat)\n 1 0.188 0.188 0.188 0.188 ale_python_interface.py:148(loadROM)\n 880 0.152 0.000 0.152 0.000 ale_python_interface.py:151(act)\n 294 0.001 0.000 0.001 0.000 ale_python_interface.py:154(game_over)\n 1 0.010 0.010 0.010 0.010 ale_python_interface.py:157(reset_game)\n 1 0.000 0.000 0.000 0.000 ale_python_interface.py:196(getMinimalActionSet)\n 294 0.000 0.000 0.000 0.000 ale_python_interface.py:205(lives)\n 1 0.000 0.000 0.000 0.000 ale_python_interface.py:211(getScreenDims)\n 295 0.023 0.000 0.050 0.000 ale_python_interface.py:251(getScreenRGB2)\n 3 0.000 0.000 0.000 0.000 ale_python_interface.py:353(__del__)\n 7010 0.004 0.000 0.008 0.000 anno.py:111(getanno)\n 28849 0.014 0.000 0.029 0.000 anno.py:119(hasanno)\n 3155 0.004 0.000 0.006 0.000 anno.py:123(setanno)\n 5010 0.002 0.000 0.007 0.000 anno.py:141(copyanno)\n 2 0.000 0.000 0.001 0.000 anno.py:150(dup)\n 35 0.000 0.000 0.000 0.000 api.py:126(__init__)\n 1835 0.001 0.000 0.001 0.000 api.py:129(get_effective_source_map)\n 35 0.000 0.000 0.000 0.000 api.py:155(autograph_artifact)\n 38 0.000 0.000 0.000 0.000 api.py:160(is_autograph_artifact)\n 53 0.000 0.000 1.279 0.024 api.py:337(_call_unconverted)\n 114 0.000 0.000 0.000 0.000 api.py:351(_is_known_loaded_type)\n 88/18 0.002 0.000 1.561 0.087 api.py:378(converted_call)\n 228 0.001 0.000 0.002 0.000 api.py:480(<genexpr>)\n 2 0.000 0.000 0.000 0.000 arg_defaults.py:72(visit_FunctionDef)\n 2 0.000 0.000 0.000 0.000 arg_defaults.py:79(visit_arguments)\n 2 0.000 0.000 0.000 0.000 arg_defaults.py:94(transform)\n 44688 0.095 0.000 1.588 0.000 array_ops.py:1041(strided_slice)\n 134064 0.106 0.000 2.791 0.000 array_ops.py:1281(stack)\n 134388 0.158 0.000 0.583 0.000 array_ops.py:1432(_should_not_autopack)\n 270398 0.085 0.000 0.085 0.000 array_ops.py:1438(<genexpr>)\n 134388 0.067 0.000 0.650 0.000 array_ops.py:1442(_autopacking_conversion_function)\n 43 0.000 0.000 0.003 0.000 array_ops.py:198(fill)\n 226 0.001 0.000 0.107 0.000 array_ops.py:239(identity)\n 23 0.000 0.000 0.003 0.000 array_ops.py:2676(wrapped)\n 23 0.000 0.000 0.003 0.000 array_ops.py:2684(zeros)\n 20 0.000 0.000 0.003 0.000 array_ops.py:2934(ones)\n 3 0.000 0.000 0.003 0.001 array_ops.py:2984(placeholder)\n 10 0.000 0.000 0.010 0.001 array_ops.py:3029(placeholder_with_default)\n 311 0.001 0.000 0.164 0.001 array_ops.py:3144(pad_v2)\n 311 0.003 0.000 0.163 0.001 array_ops.py:3202(pad)\n 221/17 0.000 0.000 0.000 0.000 array_ops.py:3297(_get_paddings_constant)\n 85/17 0.000 0.000 0.000 0.000 array_ops.py:3314(<listcomp>)\n 294 0.001 0.000 0.011 0.000 array_ops.py:347(expand_dims_v2)\n 20 0.000 0.000 0.011 0.001 array_ops.py:4093(squeeze)\n 20 0.000 0.000 0.013 0.001 array_ops.py:4148(squeeze_v2)\n 37 0.000 0.000 0.023 0.001 array_ops.py:58(reshape)\n 44688 0.073 0.000 0.227 0.000 array_ops.py:823(_check_index)\n 44688 0.787 0.000 6.693 0.000 array_ops.py:843(_slice_helper)\n 385 0.000 0.000 0.001 0.000 ast.py:118(copy_location)\n 57878 0.015 0.000 0.020 0.000 ast.py:166(iter_fields)\n 256 0.000 0.000 0.000 0.000 ast.py:178(iter_child_nodes)\n 131 0.000 0.000 0.001 0.000 ast.py:215(walk)\n18632/170 0.013 0.000 0.231 0.001 ast.py:249(visit)\n 2676/149 0.005 0.000 0.014 0.000 ast.py:255(generic_visit)\n 35 0.000 0.000 0.002 0.000 ast.py:30(parse)\n14149/335 0.033 0.000 0.177 0.001 ast.py:302(generic_visit)\n 35 0.000 0.000 0.011 0.000 ast3.py:10(visit_Module)\n 43/38 0.000 0.000 0.004 0.000 ast3.py:114(visit_Call)\n 34 0.000 0.000 0.000 0.000 ast3.py:139(visit_NameConstant)\n 12 0.000 0.000 0.001 0.000 ast3.py:149(visit_arguments)\n 213 0.000 0.000 0.003 0.000 ast3.py:162(visit_Name)\n 16 0.000 0.000 0.000 0.000 ast3.py:17(visit_Num)\n 22 0.000 0.000 0.000 0.000 ast3.py:172(visit_arg)\n 4 0.000 0.000 0.000 0.000 ast3.py:187(visit_ExceptHandler)\n 29 0.000 0.000 0.000 0.000 ast3.py:218(visit_Constant)\n 23 0.000 0.000 0.000 0.000 ast3.py:234(_make_arg)\n 83 0.000 0.000 0.001 0.000 ast3.py:250(visit_Name)\n 2 0.000 0.000 0.000 0.000 ast3.py:258(visit_ExceptHandler)\n 6/2 0.000 0.000 0.002 0.001 ast3.py:310(visit_FunctionDef)\n 4 0.000 0.000 0.000 0.000 ast3.py:34(visit_Str)\n 2 0.000 0.000 0.001 0.001 ast3.py:353(visit_With)\n 19/15 0.000 0.000 0.001 0.000 ast3.py:369(visit_Call)\n 6 0.000 0.000 0.000 0.000 ast3.py:378(visit_arguments)\n 6 0.000 0.000 0.000 0.000 ast3.py:380(<listcomp>)\n 6 0.000 0.000 0.000 0.000 ast3.py:392(<listcomp>)\n 35 0.000 0.000 0.011 0.000 ast3.py:398(ast_to_gast)\n 2 0.000 0.000 0.002 0.001 ast3.py:402(gast_to_ast)\n 12/6 0.000 0.000 0.006 0.001 ast3.py:50(visit_FunctionDef)\n 4 0.000 0.000 0.003 0.001 ast3.py:96(visit_With)\n 395 0.002 0.000 0.003 0.000 ast_util.py:278(parallel_walk)\n 82 0.000 0.000 0.000 0.000 ast_util.py:34(__init__)\n 2017/82 0.006 0.000 0.017 0.000 ast_util.py:38(copy)\n 228/41 0.000 0.000 0.014 0.000 ast_util.py:42(<listcomp>)\n 5 0.000 0.000 0.006 0.001 ast_util.py:44(<genexpr>)\n 82 0.000 0.000 0.017 0.000 ast_util.py:64(copy_clean)\n 476/43 0.000 0.000 0.013 0.000 astn.py:11(<listcomp>)\n 876/180 0.002 0.000 0.011 0.000 astn.py:17(generic_visit)\n 2710/45 0.002 0.000 0.013 0.000 astn.py:9(_visit)\n 294 0.004 0.000 0.214 0.001 atari_env.py:111(step)\n 295 0.001 0.000 0.051 0.000 atari_env.py:125(_get_image)\n 295 0.001 0.000 0.052 0.000 atari_env.py:135(_get_obs)\n 1 0.000 0.000 0.010 0.010 atari_env.py:143(reset)\n 1 0.000 0.000 0.191 0.191 atari_env.py:26(__init__)\n 1 0.000 0.000 0.188 0.188 atari_env.py:83(seed)\n 4962 0.003 0.000 0.008 0.000 auto_control_deps.py:121(op_is_stateful)\n 93 0.000 0.000 0.000 0.000 auto_control_deps.py:148(__init__)\n 186 0.001 0.000 0.091 0.000 auto_control_deps.py:152(mark_as_return)\n 93 0.000 0.000 0.002 0.000 auto_control_deps.py:195(__enter__)\n 93 0.018 0.000 0.284 0.003 auto_control_deps.py:270(__exit__)\n 2481 0.000 0.000 0.000 0.000 auto_control_deps.py:391(<listcomp>)\n 10 0.000 0.000 0.000 0.000 auto_control_deps.py:401(<listcomp>)\n 2481 0.012 0.000 0.241 0.000 auto_control_deps.py:452(_get_resource_inputs)\n 2481 0.002 0.000 0.003 0.000 auto_control_deps.py:471(<listcomp>)\n 2481 0.001 0.000 0.002 0.000 auto_control_deps.py:472(<listcomp>)\n 1484 0.001 0.000 0.003 0.000 auto_control_deps_utils.py:102(<genexpr>)\n 1719 0.002 0.000 0.004 0.000 auto_control_deps_utils.py:109(<genexpr>)\n 20 0.000 0.000 0.002 0.000 auto_control_deps_utils.py:33(get_read_only_resource_input_indices_graph)\n 80 0.000 0.000 0.000 0.000 auto_control_deps_utils.py:51(<listcomp>)\n 80 0.000 0.000 0.000 0.000 auto_control_deps_utils.py:60(_get_read_only_resource_input_indices_op)\n 80 0.000 0.000 0.000 0.000 auto_control_deps_utils.py:63(<listcomp>)\n 2481 0.011 0.000 0.186 0.000 auto_control_deps_utils.py:86(get_read_write_resource_inputs)\n 3 0.000 0.000 0.004 0.001 backend.py:1024(placeholder)\n 36 0.000 0.000 0.000 0.000 backend.py:1091(is_placeholder)\n 10 0.000 0.000 0.011 0.001 backend.py:1110(freezable_variable)\n 84 0.000 0.000 0.001 0.000 backend.py:1181(int_shape)\n 20 0.000 0.000 0.000 0.000 backend.py:169(cast_to_floatx)\n 3 0.000 0.000 0.000 0.000 backend.py:207(get_uid)\n 71 0.000 0.000 0.005 0.000 backend.py:304(learning_phase)\n 71 0.000 0.000 0.000 0.000 backend.py:334(global_learning_phase_is_set)\n 71 0.000 0.000 0.000 0.000 backend.py:338(_mark_func_graph_as_unsaveable)\n 118 0.004 0.000 0.062 0.001 backend.py:4400(relu)\n 1989 0.002 0.000 0.007 0.000 backend.py:531(get_graph)\n 38 0.000 0.000 0.000 0.000 backend.py:598(get_default_graph_uid_map)\n 71 0.000 0.000 0.000 0.000 backend.py:6123(_key)\n 81 0.000 0.000 0.000 0.000 backend.py:6142(_get_recursive)\n 81 0.000 0.000 0.000 0.000 backend.py:6155(__getitem__)\n 56 0.000 0.000 0.000 0.000 backend.py:725(is_sparse)\n 483 0.001 0.000 0.001 0.000 backend.py:776(name_scope)\n 56 0.000 0.000 0.000 0.000 backend.py:862(track_variable)\n 38 0.000 0.000 0.000 0.000 backend.py:870(unique_object_name)\n 12 0.000 0.000 0.000 0.000 backend_config.py:112(image_data_format)\n 61 0.000 0.000 0.000 0.000 backend_config.py:65(floatx)\n 1856 0.002 0.000 0.004 0.000 backprop.py:165(_must_record_gradient)\n2512/1932 0.005 0.000 0.040 0.000 base.py:452(_method_wrapper)\n 310 0.000 0.000 0.001 0.000 base.py:576(_maybe_initialize_trackable)\n 122 0.000 0.000 0.000 0.000 base.py:655(_deferred_dependencies)\n 122 0.000 0.000 0.000 0.000 base.py:670(_lookup_dependency)\n 56 0.001 0.000 0.061 0.001 base.py:684(_add_variable_with_custom_getter)\n 56 0.000 0.000 0.000 0.000 base.py:756(_preload_simple_restoration)\n 122 0.001 0.000 0.003 0.000 base.py:793(_track_trackable)\n 66 0.000 0.000 0.001 0.000 base.py:847(_handle_deferred_dependencies)\n 396 0.000 0.000 0.000 0.000 base_layer.py:1005(trainable)\n 482 0.000 0.000 0.000 0.000 base_layer.py:1025(input_spec)\n 38 0.000 0.000 0.000 0.000 base_layer.py:1060(input_spec)\n 519/71 0.001 0.000 0.012 0.000 base_layer.py:1291(_clear_losses)\n 20 0.000 0.000 0.006 0.000 base_layer.py:1380(add_update)\n 20 0.000 0.000 0.004 0.000 base_layer.py:1433(process_update)\n 20 0.000 0.000 0.004 0.000 base_layer.py:1459(<listcomp>)\n 20 0.000 0.000 0.000 0.000 base_layer.py:1463(<listcomp>)\n 3 0.000 0.000 0.000 0.000 base_layer.py:1792(input)\n 41 0.000 0.000 0.000 0.000 base_layer.py:1916(inbound_nodes)\n 35 0.000 0.000 0.000 0.000 base_layer.py:1922(outbound_nodes)\n 41 0.000 0.000 0.002 0.000 base_layer.py:1983(_set_dtype_policy)\n 1022 0.001 0.000 0.001 0.000 base_layer.py:2012(_compute_dtype)\n 483 0.002 0.000 0.014 0.000 base_layer.py:2025(_maybe_cast_inputs)\n 447 0.003 0.000 0.005 0.000 base_layer.py:2040(f)\n 483 0.000 0.000 0.000 0.000 base_layer.py:2099(_name_scope)\n 41 0.000 0.000 0.002 0.000 base_layer.py:2102(_init_set_name)\n 483 0.000 0.000 0.000 0.000 base_layer.py:2201(_handle_activity_regularization)\n 483 0.003 0.000 0.013 0.000 base_layer.py:2218(_set_mask_metadata)\n 894 0.000 0.000 0.001 0.000 base_layer.py:2223(<genexpr>)\n 36 0.000 0.000 0.000 0.000 base_layer.py:2233(<listcomp>)\n 273 0.000 0.000 0.000 0.000 base_layer.py:2235(<listcomp>)\n 174 0.000 0.000 0.000 0.000 base_layer.py:2241(<listcomp>)\n 483 0.002 0.000 0.012 0.000 base_layer.py:2258(_collect_input_masks)\n 483 0.000 0.000 0.000 0.000 base_layer.py:2266(<lambda>)\n 966 0.002 0.000 0.004 0.000 base_layer.py:2272(_call_arg_was_passed)\n 108 0.000 0.000 0.000 0.000 base_layer.py:2283(_get_call_arg_value)\n 35 0.000 0.000 0.005 0.000 base_layer.py:2293(_set_connectivity_metadata_)\n 35 0.000 0.000 0.004 0.000 base_layer.py:2317(_add_inbound_node)\n 35 0.000 0.000 0.000 0.000 base_layer.py:2329(<lambda>)\n 35 0.000 0.000 0.000 0.000 base_layer.py:2331(<lambda>)\n 35 0.000 0.000 0.000 0.000 base_layer.py:2333(<lambda>)\n 3 0.000 0.000 0.000 0.000 base_layer.py:2358(_get_node_attribute_at_index)\n 483 0.001 0.000 1.800 0.004 base_layer.py:2394(_maybe_build)\n 70 0.000 0.000 0.000 0.000 base_layer.py:2408(<genexpr>)\n 35 0.000 0.000 0.000 0.000 base_layer.py:2409(<lambda>)\n 41/3 0.000 0.000 0.001 0.000 base_layer.py:2446(_get_trainable_state)\n 1312 0.002 0.000 0.008 0.000 base_layer.py:2469(_obj_reference_counts)\n 1557 0.001 0.000 0.002 0.000 base_layer.py:2476(_maybe_create_attribute)\n 656 0.002 0.000 0.009 0.000 base_layer.py:2493(__delattr__)\n7486/4292 0.011 0.000 1.751 0.000 base_layer.py:2543(__setattr__)\n 10 0.000 0.000 0.000 0.000 base_layer.py:2579(<genexpr>)\n 85 0.000 0.000 0.000 0.000 base_layer.py:2604(<genexpr>)\n 50 0.000 0.000 0.000 0.000 base_layer.py:2608(<genexpr>)\n 41 0.000 0.000 0.000 0.000 base_layer.py:2654(_attribute_sentinel)\n 41 0.000 0.000 0.004 0.000 base_layer.py:2665(_init_call_fn_args)\n 41 0.000 0.000 0.003 0.000 base_layer.py:2677(_call_full_argspec)\n 41 0.000 0.000 0.003 0.000 base_layer.py:2684(_call_fn_args)\n 38 0.000 0.000 0.000 0.000 base_layer.py:2693(_call_accepts_kwargs)\n 38 0.000 0.000 0.000 0.000 base_layer.py:2698(_should_compute_mask)\n 519 0.001 0.000 0.001 0.000 base_layer.py:2716(_eager_losses)\n 41 0.001 0.000 0.010 0.000 base_layer.py:278(__init__)\n 35 0.000 0.000 0.000 0.000 base_layer.py:386(build)\n 56 0.001 0.000 0.063 0.001 base_layer.py:440(add_weight)\n 174 0.000 0.000 0.000 0.000 base_layer.py:741(compute_mask)\n 483/71 0.018 0.000 3.512 0.049 base_layer.py:763(__call__)\n 966 0.001 0.000 0.001 0.000 base_layer.py:812(<genexpr>)\n 966 0.001 0.000 0.003 0.000 base_layer.py:887(<genexpr>)\n 142 0.000 0.000 0.000 0.000 base_layer.py:976(dtype)\n 1154 0.000 0.000 0.000 0.000 base_layer.py:981(name)\n 38 0.000 0.000 0.000 0.000 base_layer.py:986(dynamic)\n 56 0.000 0.000 0.011 0.000 base_layer_utils.py:121(<lambda>)\n 483 0.001 0.000 0.005 0.000 base_layer_utils.py:160(have_all_keras_metadata)\n 966 0.000 0.000 0.001 0.000 base_layer_utils.py:161(<genexpr>)\n 483 0.001 0.000 0.013 0.000 base_layer_utils.py:272(needs_keras_history)\n 142 0.000 0.000 0.000 0.000 base_layer_utils.py:294(<genexpr>)\n 1069 0.001 0.000 0.008 0.000 base_layer_utils.py:301(is_in_keras_graph)\n 986 0.001 0.000 0.043 0.000 base_layer_utils.py:306(is_in_eager_or_tf_function)\n 951 0.003 0.000 0.040 0.000 base_layer_utils.py:311(is_in_tf_function)\n 36 0.002 0.000 0.011 0.000 base_layer_utils.py:329(uses_keras_history)\n 36 0.000 0.000 0.001 0.000 base_layer_utils.py:374(mark_checked)\n 36 0.000 0.000 0.000 0.000 base_layer_utils.py:384(_mark_checked)\n 2091 0.001 0.000 0.002 0.000 base_layer_utils.py:390(call_context)\n 966 0.002 0.000 0.005 0.000 base_layer_utils.py:420(enter)\n 1069 0.002 0.000 0.007 0.000 base_layer_utils.py:453(in_keras_graph)\n 483 0.001 0.000 0.004 0.000 base_layer_utils.py:471(autocast_context_manager)\n 483 0.001 0.000 0.001 0.000 base_layer_utils.py:488(is_subclassed)\n 56 0.001 0.000 0.057 0.001 base_layer_utils.py:51(make_variable)\n 35 0.000 0.000 0.019 0.001 base_layer_utils.py:627(mark_as_return)\n 35 0.000 0.000 0.018 0.001 base_layer_utils.py:630(_mark_as_return)\n 117 0.000 0.000 0.000 0.000 base_layer_utils.py:703(v2_dtype_behavior_enabled)\n 1 0.000 0.000 0.002 0.002 box.py:24(__init__)\n 3 0.000 0.000 0.000 0.000 box.py:39(_get_precision)\n 2 0.000 0.000 0.002 0.001 break_statements.py:152(transform)\n 3788 0.003 0.000 0.008 0.000 c_api_util.py:157(tf_buffer)\n 3144 0.012 0.000 0.012 0.000 c_api_util.py:190(tf_output)\n 60 0.000 0.000 0.002 0.000 c_api_util.py:45(__init__)\n 544 0.001 0.000 0.229 0.000 c_api_util.py:53(__del__)\n 58 0.000 0.000 0.000 0.000 c_api_util.py:86(__init__)\n 538 0.002 0.000 0.090 0.000 c_api_util.py:94(__del__)\n 2 0.000 0.000 0.009 0.004 call_trees.py:111(visit_FunctionDef)\n 2 0.000 0.000 0.008 0.004 call_trees.py:141(visit_With)\n 6 0.000 0.000 0.000 0.000 call_trees.py:146(_args_to_tuple)\n 6 0.000 0.000 0.001 0.000 call_trees.py:164(_kwargs_to_dict)\n 12/11 0.000 0.000 0.007 0.001 call_trees.py:175(visit_Call)\n 2 0.000 0.000 0.009 0.004 call_trees.py:226(transform)\n 2 0.000 0.000 0.000 0.000 call_trees.py:43(__init__)\n 6 0.000 0.000 0.000 0.000 call_trees.py:58(__init__)\n 6 0.000 0.000 0.000 0.000 call_trees.py:63(_consume_args)\n 5 0.000 0.000 0.000 0.000 call_trees.py:69(add_arg)\n 6 0.000 0.000 0.000 0.000 call_trees.py:81(finalize)\n 6 0.000 0.000 0.000 0.000 call_trees.py:85(to_ast)\n 44 0.000 0.000 0.001 0.000 cfg.py:175(__init__)\n 44 0.000 0.000 0.001 0.000 cfg.py:202(reset)\n 44 0.000 0.000 0.000 0.000 cfg.py:203(<dictcomp>)\n 44 0.000 0.000 0.000 0.000 cfg.py:206(<dictcomp>)\n 44 0.001 0.000 0.016 0.000 cfg.py:210(_visit_internal)\n 22 0.000 0.000 0.012 0.001 cfg.py:234(visit_forward)\n 22 0.000 0.000 0.004 0.000 cfg.py:237(visit_reverse)\n 22 0.000 0.000 0.000 0.000 cfg.py:277(__init__)\n 44 0.000 0.000 0.000 0.000 cfg.py:281(reset)\n 151 0.000 0.000 0.000 0.000 cfg.py:322(_connect_nodes)\n 173 0.001 0.000 0.001 0.000 cfg.py:337(_add_new_node)\n 16 0.000 0.000 0.000 0.000 cfg.py:361(begin_statement)\n 16 0.000 0.000 0.000 0.000 cfg.py:370(end_statement)\n 143 0.000 0.000 0.001 0.000 cfg.py:380(add_ordinary_node)\n 30 0.000 0.000 0.000 0.000 cfg.py:395(_add_jump_node)\n 30 0.000 0.000 0.000 0.000 cfg.py:414(_connect_jump_to_finally_sections)\n 30 0.000 0.000 0.000 0.000 cfg.py:427(add_exit_node)\n 8 0.000 0.000 0.000 0.000 cfg.py:458(connect_raise_node)\n 22 0.000 0.000 0.000 0.000 cfg.py:473(enter_section)\n 22 0.000 0.000 0.000 0.000 cfg.py:485(exit_section)\n 8 0.000 0.000 0.000 0.000 cfg.py:528(enter_cond_section)\n 16 0.000 0.000 0.000 0.000 cfg.py:542(new_cond_branch)\n 8 0.000 0.000 0.000 0.000 cfg.py:556(exit_cond_section)\n 8 0.000 0.000 0.000 0.000 cfg.py:563(enter_except_section)\n 22 0.000 0.000 0.002 0.000 cfg.py:588(build)\n 22 0.000 0.000 0.000 0.000 cfg.py:642(__init__)\n 30 0.000 0.000 0.000 0.000 cfg.py:651(_enter_lexical_scope)\n 30 0.000 0.000 0.000 0.000 cfg.py:654(_exit_lexical_scope)\n 30 0.000 0.000 0.000 0.000 cfg.py:658(_get_enclosing_finally_scopes)\n 8 0.000 0.000 0.000 0.000 cfg.py:667(_get_enclosing_except_scopes)\n 143 0.000 0.000 0.010 0.000 cfg.py:676(_process_basic_statement)\n 30 0.000 0.000 0.000 0.000 cfg.py:680(_process_exit_statement)\n 173 0.000 0.000 0.000 0.000 cfg.py:73(__init__)\n 22 0.000 0.000 0.013 0.001 cfg.py:730(visit_FunctionDef)\n 22 0.000 0.000 0.000 0.000 cfg.py:754(visit_Return)\n 8 0.000 0.000 0.000 0.000 cfg.py:763(visit_Expr)\n 95 0.000 0.000 0.006 0.000 cfg.py:766(visit_Assign)\n 173 0.000 0.000 0.001 0.000 cfg.py:78(freeze)\n 8 0.000 0.000 0.000 0.000 cfg.py:787(visit_Raise)\n 8 0.000 0.000 0.000 0.000 cfg.py:879(visit_ExceptHandler)\n 8 0.000 0.000 0.001 0.000 cfg.py:893(visit_Try)\n 18 0.000 0.000 0.008 0.000 cfg.py:935(visit_With)\n 22 0.000 0.000 0.013 0.001 cfg.py:943(build)\n 2 0.000 0.000 0.000 0.000 codecs.py:185(__init__)\n 19851 0.010 0.000 0.021 0.000 compat.py:114(as_str)\n 246 0.000 0.000 0.000 0.000 compat.py:39(_date_to_date_number)\n 246 0.000 0.000 0.000 0.000 compat.py:63(forward_compatible)\n 6209 0.007 0.000 0.012 0.000 compat.py:64(as_bytes)\n 19851 0.008 0.000 0.011 0.000 compat.py:90(as_text)\n 4 0.000 0.000 0.000 0.000 compilerop.py:137(check_linecache_ipython)\n 20 0.000 0.000 0.004 0.000 cond_v2.py:1127(_set_read_only_resource_inputs_attr)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:1147(<listcomp>)\n 20 0.001 0.000 0.076 0.004 cond_v2.py:191(_build_cond)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:257(<listcomp>)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:260(<listcomp>)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:269(<listcomp>)\n 20 0.000 0.000 0.019 0.001 cond_v2.py:295(<listcomp>)\n 20 0.000 0.000 0.001 0.000 cond_v2.py:496(_make_inputs_match)\n 40 0.000 0.000 0.000 0.000 cond_v2.py:524(<listcomp>)\n 20 0.001 0.000 0.310 0.015 cond_v2.py:58(cond_v2)\n 20 0.000 0.000 0.001 0.000 cond_v2.py:619(_make_indexed_slices_indices_types_match)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:629(<listcomp>)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:632(<listcomp>)\n 120 0.000 0.000 0.000 0.000 cond_v2.py:637(<genexpr>)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:683(_get_op_and_outputs)\n 20 0.000 0.000 0.001 0.000 cond_v2.py:692(_pack_sequence_as)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:760(_check_same_outputs)\n 20 0.000 0.000 0.001 0.000 cond_v2.py:804(_get_output_shapes)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:814(verify_captures)\n 20 0.000 0.000 0.000 0.000 cond_v2.py:820(<dictcomp>)\n 2 0.000 0.000 0.003 0.002 conditional_expressions.py:44(transform)\n 805 0.000 0.000 0.001 0.000 config_lib.py:33(matches)\n 768 0.000 0.000 0.001 0.000 config_lib.py:50(get_action)\n 37 0.000 0.000 0.000 0.000 config_lib.py:62(get_action)\n 615293 0.545 0.000 7.645 0.000 constant_op.py:164(constant)\n 615293 0.953 0.000 7.101 0.000 constant_op.py:265(_constant_impl)\n 134388 0.070 0.000 1.363 0.000 constant_op.py:318(_constant_tensor_conversion_function)\n 43 0.000 0.000 0.001 0.000 constant_op.py:330(_tensor_shape_tensor_conversion_function)\n 615191 4.950 0.000 5.772 0.000 constant_op.py:68(convert_to_eager_tensor)\n 122 0.000 0.000 0.000 0.000 constraints.py:280(get)\n 15014 0.010 0.000 0.010 0.000 context.py:1021(function_call_options)\n 58 0.000 0.000 0.005 0.000 context.py:1050(add_function)\n 538 0.002 0.000 0.543 0.001 context.py:1096(remove_function)\n 2382 0.002 0.000 0.002 0.000 context.py:1146(op_callbacks)\n 15014 0.004 0.000 0.004 0.000 context.py:127(executor_type)\n 29988 0.008 0.000 0.008 0.000 context.py:135(config_proto_serialized)\n 2 0.000 0.000 0.000 0.000 context.py:1562(disable_run_metadata)\n 1 0.000 0.000 2.249 2.249 context.py:1583(export_run_metadata)\n 9026 0.002 0.000 0.002 0.000 context.py:1601(context_switches)\n 1 0.000 0.000 0.000 0.000 context.py:1616(__init__)\n 1 0.000 0.000 0.000 0.000 context.py:1621(__enter__)\n 1 0.000 0.000 0.000 0.000 context.py:1655(__exit__)\n 2599334 0.638 0.000 0.638 0.000 context.py:1702(context)\n 123774 0.034 0.000 0.034 0.000 context.py:1709(context_safe)\n 15053 0.026 0.000 0.043 0.000 context.py:1714(ensure_initialized)\n 33 0.000 0.000 0.000 0.000 context.py:1724(global_seed)\n 123658 0.196 0.000 0.334 0.000 context.py:1734(executing_eagerly)\n 56 0.000 0.000 0.000 0.000 context.py:1864(shared_name)\n 2119 0.002 0.000 0.006 0.000 context.py:1885(graph_mode)\n 1596 0.002 0.000 0.005 0.000 context.py:1890(eager_mode)\n 1 0.000 0.000 0.000 0.000 context.py:1900(device)\n 3715 0.005 0.000 0.010 0.000 context.py:218(push)\n 58 0.000 0.000 0.005 0.000 context.py:2230(add_function)\n 538 0.001 0.000 0.545 0.001 context.py:2235(remove_function)\n 116 0.000 0.000 0.000 0.000 context.py:2248(_tmp_in_graph_mode)\n 3715 0.003 0.000 0.004 0.000 context.py:238(pop)\n 646128 0.286 0.000 0.286 0.000 context.py:492(ensure_initialized)\n 631075 0.213 0.000 0.213 0.000 context.py:723(_handle)\n 7430 0.008 0.000 0.013 0.000 context.py:747(_mode)\n 2710312 1.143 0.000 1.143 0.000 context.py:765(executing_eagerly)\n 44845 0.014 0.000 0.014 0.000 context.py:777(scope_name)\n 89688 0.047 0.000 0.047 0.000 context.py:782(scope_name)\n 630480 0.216 0.000 0.216 0.000 context.py:787(device_name)\n 2 0.000 0.000 0.000 0.000 context.py:792(device_spec)\n 2 0.000 0.000 0.000 0.000 context.py:797(_set_device)\n 1 0.000 0.000 0.000 0.000 context.py:801(device)\n 2119 0.005 0.000 0.022 0.000 contextlib.py:129(contextmanager)\n 18838 0.012 0.000 0.043 0.000 contextlib.py:157(helper)\n 3 0.000 0.000 0.000 0.000 contextlib.py:36(_recreate_cm)\n 3 0.000 0.000 0.000 0.000 contextlib.py:49(inner)\n 18838 0.026 0.000 0.031 0.000 contextlib.py:59(__init__)\n18838/11274 0.008 0.000 0.159 0.000 contextlib.py:79(__enter__)\n18838/11297 0.017 0.000 0.075 0.000 contextlib.py:85(__exit__)\n 2 0.000 0.000 0.001 0.001 continue_statements.py:117(_visit_non_loop_body)\n 2 0.000 0.000 0.002 0.001 continue_statements.py:143(visit_With)\n 2 0.000 0.000 0.002 0.001 continue_statements.py:161(transform)\n 2 0.000 0.000 0.000 0.000 continue_statements.py:29(__init__)\n 4 0.000 0.000 0.000 0.000 continue_statements.py:52(__init__)\n 7 0.000 0.000 0.000 0.000 continue_statements.py:77(_postprocess_statement)\n 2 0.000 0.000 0.003 0.002 control_flow.py:49(visit_FunctionDef)\n 2 0.000 0.000 0.003 0.002 control_flow.py:528(transform)\n 20 0.000 0.000 0.310 0.015 control_flow_ops.py:1098(cond)\n 2423 0.001 0.000 0.002 0.000 control_flow_util.py:180(GetOutputContext)\n 2481 0.001 0.000 0.001 0.000 control_flow_util.py:191(GetContainingWhileContext)\n 80 0.000 0.000 0.000 0.000 control_flow_util.py:213(GetContainingXLAContext)\n 2423 0.003 0.000 0.005 0.000 control_flow_util.py:266(CheckInputFromValidContext)\n 20 0.000 0.000 0.000 0.000 control_flow_util.py:50(EnableControlFlowV2)\n 80 0.000 0.000 0.000 0.000 control_flow_util.py:68(InXlaContext)\n 40 0.000 0.000 0.000 0.000 control_flow_util.py:73(GraphOrParentsInXlaContext)\n 2481 0.002 0.000 0.004 0.000 control_flow_util.py:82(IsInWhileLoop)\n 20 0.000 0.000 0.000 0.000 control_flow_util_v2.py:113(maybe_propagate_compile_time_consts_in_xla)\n 20 0.000 0.000 0.000 0.000 control_flow_util_v2.py:231(output_all_intermediates)\n 20 0.000 0.000 0.000 0.000 control_flow_util_v2.py:42(in_defun)\n 40 0.000 0.000 0.017 0.000 control_flow_util_v2.py:53(create_new_tf_function)\n 40 0.000 0.000 0.000 0.000 control_flow_util_v2.py:68(unique_fn_name)\n 20 0.000 0.000 0.001 0.000 control_flow_util_v2.py:85(maybe_set_lowering_attr)\n 12 0.000 0.000 0.000 0.000 conv_utils.py:189(normalize_data_format)\n 10 0.000 0.000 0.000 0.000 conv_utils.py:200(normalize_padding)\n 10 0.000 0.000 0.000 0.000 conv_utils.py:28(convert_data_format)\n 30 0.000 0.000 0.000 0.000 conv_utils.py:51(normalize_tuple)\n 123 0.001 0.000 0.002 0.000 conversion.py:119(has)\n 38 0.000 0.000 0.000 0.000 conversion.py:125(__getitem__)\n 70 0.000 0.000 0.000 0.000 conversion.py:147(_get_key)\n 91 0.000 0.000 0.000 0.000 conversion.py:163(_get_key)\n 2 0.000 0.000 0.012 0.006 conversion.py:182(_wrap_into_dynamic_factory)\n 35 0.000 0.000 0.264 0.008 conversion.py:254(_convert_with_cache)\n 35 0.001 0.000 0.001 0.000 conversion.py:298(_instantiate)\n 35 0.000 0.000 0.000 0.000 conversion.py:316(<genexpr>)\n 35 0.000 0.000 0.266 0.008 conversion.py:340(convert)\n 54/20 0.001 0.000 0.004 0.000 conversion.py:366(is_whitelisted)\n 88 0.000 0.000 0.001 0.000 conversion.py:471(is_in_whitelist_cache)\n 3 0.000 0.000 0.000 0.000 conversion.py:479(cache_whitelisted)\n 2 0.000 0.000 0.231 0.115 conversion.py:488(convert_entity_to_ast)\n 2 0.000 0.000 0.000 0.000 conversion.py:635(_add_reserved_symbol)\n 2 0.000 0.000 0.000 0.000 conversion.py:646(_add_self_references)\n 2 0.000 0.000 0.231 0.115 conversion.py:669(convert_func_to_ast)\n 2 0.000 0.000 0.216 0.108 conversion.py:729(node_to_graph)\n 35 0.000 0.000 0.000 0.000 conversion.py:90(get_module)\n 35 0.000 0.000 0.000 0.000 conversion.py:93(get_factory)\n 71 0.000 0.000 0.000 0.000 converter.py:158(__init__)\n 357 0.000 0.000 0.000 0.000 converter.py:175(as_tuple)\n 121 0.000 0.000 0.000 0.000 converter.py:179(__hash__)\n 118 0.000 0.000 0.000 0.000 converter.py:182(__eq__)\n 74 0.000 0.000 0.000 0.000 converter.py:189(uses)\n 35 0.000 0.000 0.000 0.000 converter.py:193(call_options)\n 2 0.000 0.000 0.002 0.001 converter.py:201(to_ast)\n 2 0.000 0.000 0.000 0.000 converter.py:221(list_of_features)\n 2 0.000 0.000 0.000 0.000 converter.py:223(<genexpr>)\n 2 0.000 0.000 0.000 0.000 converter.py:268(__init__)\n 22 0.000 0.000 0.000 0.000 converter.py:282(__init__)\n 2124/22 0.002 0.000 0.049 0.002 converter.py:337(visit)\n 201 0.000 0.000 0.000 0.000 converter.py:352(__init__)\n 22 0.000 0.000 0.166 0.008 converter.py:357(standard_analysis)\n 20 0.000 0.000 0.205 0.010 converter.py:387(apply_)\n 10 0.000 0.000 0.009 0.001 convolutional.py:102(__init__)\n 10 0.000 0.000 0.025 0.003 convolutional.py:151(build)\n 118 0.001 0.000 0.213 0.002 convolutional.py:193(call)\n 20 0.000 0.000 0.000 0.000 convolutional.py:284(_get_channel_axis)\n 10 0.000 0.000 0.000 0.000 convolutional.py:290(_get_input_channel)\n 10 0.000 0.000 0.000 0.000 convolutional.py:297(_get_padding_op)\n 118 0.001 0.000 0.003 0.000 convolutional.py:306(_recreate_conv_op)\n 10 0.000 0.000 0.010 0.001 convolutional.py:565(__init__)\n 3 0.000 0.000 0.002 0.001 core.py:1116(__init__)\n 3 0.000 0.000 0.007 0.002 core.py:1147(build)\n 56 0.001 0.000 0.178 0.003 core.py:1179(call)\n 1 0.000 0.000 0.000 0.000 core.py:132(unwrapped)\n 1 0.000 0.000 0.000 0.000 core.py:208(__init__)\n 2 0.000 0.000 0.001 0.000 core.py:629(__init__)\n 37 0.001 0.000 0.046 0.001 core.py:634(call)\n 37 0.000 0.000 0.002 0.000 core.py:669(compute_output_shape)\n 296 0.016 0.000 0.016 0.000 ctypeslib.py:350(_ctype_ndarray)\n 296 0.002 0.000 0.003 0.000 ctypeslib.py:376(_ctype_from_dtype_scalar)\n 296 0.001 0.000 0.004 0.000 ctypeslib.py:455(_ctype_from_dtype)\n 296 0.001 0.000 0.005 0.000 ctypeslib.py:464(as_ctypes_type)\n 296 0.005 0.000 0.026 0.000 ctypeslib.py:526(as_ctypes)\n 802 0.011 0.000 0.039 0.000 custom_gradient.py:44(copy_handle_data)\n 782 0.003 0.000 0.003 0.000 custom_gradient.py:74(<listcomp>)\n 782 0.001 0.000 0.001 0.000 custom_gradient.py:76(<listcomp>)\n 782 0.001 0.000 0.002 0.000 custom_gradient.py:77(<listcomp>)\n 696/676 0.001 0.000 0.004 0.000 data_structures.py:103(sticky_attribute_assignment)\n 20 0.000 0.000 0.000 0.000 data_structures.py:140(__init__)\n 10 0.000 0.000 0.000 0.000 data_structures.py:152(__init__)\n 30 0.000 0.000 0.000 0.000 data_structures.py:161(_attribute_sentinel)\n 20 0.000 0.000 0.000 0.000 data_structures.py:173(_track_value)\n 118 0.000 0.000 0.001 0.000 data_structures.py:195(_layers)\n 118 0.000 0.000 0.002 0.000 data_structures.py:208(layers)\n 10 0.000 0.000 0.000 0.000 data_structures.py:309(__init__)\n 20 0.000 0.000 0.000 0.000 data_structures.py:330(_name_element)\n 118 0.000 0.000 0.000 0.000 data_structures.py:333(_values)\n 336 0.000 0.000 0.000 0.000 data_structures.py:377(__getitem__)\n 10 0.000 0.000 0.000 0.000 data_structures.py:383(__len__)\n 10 0.000 0.000 0.000 0.000 data_structures.py:414(__init__)\n 20 0.000 0.000 0.000 0.000 data_structures.py:431(_non_append_mutation)\n 20 0.000 0.000 0.000 0.000 data_structures.py:447(_external_modification)\n 10 0.000 0.000 0.000 0.000 data_structures.py:475(_make_storage)\n 10 0.000 0.000 0.000 0.000 data_structures.py:479(_check_external_modification)\n 10 0.000 0.000 0.000 0.000 data_structures.py:487(_update_snapshot)\n 10 0.000 0.000 0.000 0.000 data_structures.py:525(__setitem__)\n 20 0.000 0.000 0.000 0.000 data_structures.py:576(__eq__)\n 20 0.000 0.000 0.000 0.000 data_structures.py:614(_track_value)\n 33 0.000 0.000 0.000 0.000 data_structures.py:66(_should_wrap_tuple)\n 768/676 0.001 0.000 0.002 0.000 data_structures.py:80(wrap_or_unwrap)\n 2481 0.002 0.000 0.007 0.000 dataset_ops.py:4530(_resource_resolver)\n 2 0.000 0.000 0.000 0.000 def_function.py:318(__init__)\n 6 0.000 0.000 0.000 0.000 def_function.py:321(__del__)\n 2 0.000 0.000 0.000 0.000 def_function.py:338(__init__)\n 4 0.000 0.000 0.001 0.000 def_function.py:420(_defun_with_scope)\n 18 0.000 0.000 1.562 0.087 def_function.py:424(wrapped_fn)\n 4 0.000 0.000 0.001 0.000 def_function.py:448(_defun)\n 2 0.000 0.000 0.437 0.218 def_function.py:472(_initialize)\n 2 0.000 0.000 0.000 0.000 def_function.py:53(__init__)\n 29988 0.045 0.000 0.045 0.000 def_function.py:555(_get_tracing_count)\n 14994 0.099 0.000 17.339 0.001 def_function.py:560(__call__)\n 18 0.000 0.000 0.000 0.000 def_function.py:58(called_with_tracing)\n 14994 0.075 0.000 17.126 0.001 def_function.py:602(_call)\n 14976 0.026 0.000 0.026 0.000 def_function.py:68(called_without_tracing)\n 8 0.000 0.000 0.000 0.000 def_function.py:710(python_function)\n 6 0.000 0.000 0.000 0.000 def_function.py:715(input_signature)\n 18 0.000 0.000 0.000 0.000 def_function.py:76(get_tracing_count)\n 14994 0.058 0.000 0.121 0.000 def_function.py:963(__get__)\n 116/96 0.001 0.000 0.323 0.003 deprecation.py:473(new_func)\n 138 0.000 0.000 0.000 0.000 deprecation.py:583(deprecated_argument_lookup)\n 1 0.000 0.000 0.000 0.000 device.py:45(is_device_spec)\n 118 0.000 0.000 0.000 0.000 device_context.py:21(enclosing_tpu_context)\n 41 0.000 0.000 0.001 0.000 directives.py:117(visit_Name)\n 14 0.000 0.000 0.001 0.000 directives.py:126(visit_Attribute)\n 5 0.000 0.000 0.001 0.000 directives.py:134(visit_Assign)\n 2 0.000 0.000 0.002 0.001 directives.py:177(transform)\n 2 0.000 0.000 0.000 0.000 directives.py:50(__init__)\n 1 0.000 0.000 0.000 0.000 discrete.py:13(__init__)\n134726/134706 0.081 0.000 3.013 0.000 dispatch.py:177(wrapper)\n 486 0.000 0.000 0.000 0.000 distribute_lib.py:2677(value_container)\n 486 0.000 0.000 0.000 0.000 distribute_lib.py:627(extended)\n 144 0.000 0.000 0.001 0.000 distribution_strategy_context.py:179(get_strategy)\n 141 0.000 0.000 0.001 0.000 distribution_strategy_context.py:199(has_strategy)\n 486 0.001 0.000 0.003 0.000 distribution_strategy_context.py:215(get_strategy_and_replica_context)\n 141 0.000 0.000 0.000 0.000 distribution_strategy_context.py:312(_get_default_strategy)\n 630 0.000 0.000 0.000 0.000 distribution_strategy_context.py:337(_get_default_replica_mode)\n 630 0.002 0.000 0.004 0.000 distribution_strategy_context.py:79(_get_per_thread_mode)\n 74 0.000 0.000 0.000 0.000 dtypes.py:103(as_numpy_dtype)\n 309793 0.664 0.000 1.100 0.000 dtypes.py:172(is_compatible_with)\n 941272 1.326 0.000 1.329 0.000 dtypes.py:192(__eq__)\n 452980 0.282 0.000 0.842 0.000 dtypes.py:205(__ne__)\n 805476 0.365 0.000 0.482 0.000 dtypes.py:606(as_dtype)\n 1699685 1.610 0.000 1.610 0.000 dtypes.py:71(_is_ref_dtype)\n 1699685 0.844 0.000 2.454 0.000 dtypes.py:84(base_dtype)\n 597 0.001 0.000 0.001 0.000 enum.py:267(__call__)\n 2 0.000 0.000 0.000 0.000 enum.py:297(__contains__)\n 597 0.000 0.000 0.000 0.000 enum.py:517(__new__)\n 25780 0.007 0.000 0.010 0.000 enum.py:581(__hash__)\n 1719 0.001 0.000 0.002 0.000 errors_impl.py:117(__str__)\n 1719 0.002 0.000 0.005 0.000 errors_impl.py:264(__init__)\n 1719 0.003 0.000 0.003 0.000 errors_impl.py:64(__init__)\n 1719 0.000 0.000 0.000 0.000 errors_impl.py:86(message)\n 256 0.000 0.000 0.001 0.000 execute.py:159(make_float)\n 944 0.001 0.000 0.001 0.000 execute.py:166(make_int)\n 420 0.000 0.000 0.001 0.000 execute.py:177(make_str)\n 359 0.000 0.000 0.000 0.000 execute.py:184(make_bool)\n 786 0.001 0.000 0.003 0.000 execute.py:191(make_type)\n 53 0.000 0.000 0.000 0.000 execute.py:201(make_shape)\n 588 0.002 0.000 0.019 0.000 execute.py:236(args_to_matching_eager)\n 294 0.000 0.000 0.001 0.000 execute.py:271(<listcomp>)\n 15288 0.055 0.000 12.284 0.001 execute.py:33(quick_execute)\n 1 0.000 0.000 0.000 0.000 ezpickle.py:20(__init__)\n 338 0.000 0.000 0.000 0.000 fromnumeric.py:2232(_any_dispatcher)\n 338 0.001 0.000 0.006 0.000 fromnumeric.py:2236(any)\n 47 0.000 0.000 0.000 0.000 fromnumeric.py:2320(_all_dispatcher)\n 47 0.000 0.000 0.001 0.000 fromnumeric.py:2324(all)\n 294 0.000 0.000 0.000 0.000 fromnumeric.py:2546(_amax_dispatcher)\n 294 0.002 0.000 0.008 0.000 fromnumeric.py:2551(amax)\n 370 0.000 0.000 0.000 0.000 fromnumeric.py:2838(_prod_dispatcher)\n 370 0.001 0.000 0.007 0.000 fromnumeric.py:2843(prod)\n 1049 0.005 0.000 0.019 0.000 fromnumeric.py:73(_wrapreduction)\n 1049 0.001 0.000 0.001 0.000 fromnumeric.py:74(<dictcomp>)\n 58 0.000 0.000 0.001 0.000 func_graph.py:1011(<listcomp>)\n 209 0.000 0.000 0.000 0.000 func_graph.py:1018(<genexpr>)\n 2063 0.003 0.000 0.008 0.000 func_graph.py:1048(device_stack_has_callable)\n 2063 0.001 0.000 0.002 0.000 func_graph.py:1050(<genexpr>)\n 116 0.000 0.000 0.001 0.000 func_graph.py:1054(check_mutation)\n 58 0.000 0.000 0.000 0.000 func_graph.py:1074(flatten)\n 58 0.000 0.000 0.000 0.000 func_graph.py:1086(<listcomp>)\n 20 0.000 0.000 0.001 0.000 func_graph.py:1091(pack_sequence_as)\n 802 0.005 0.000 0.310 0.000 func_graph.py:1116(_create_substitute_placeholder)\n 58 0.000 0.000 0.014 0.000 func_graph.py:1129(_get_defun_inputs_from_args)\n 35 0.000 0.000 0.000 0.000 func_graph.py:1135(_get_composite_tensor_spec)\n 116 0.001 0.000 0.016 0.000 func_graph.py:1141(_get_defun_inputs)\n 35 0.000 0.000 0.000 0.000 func_graph.py:1192(<listcomp>)\n 35 0.000 0.000 0.000 0.000 func_graph.py:1194(<listcomp>)\n 58 0.000 0.000 0.001 0.000 func_graph.py:1258(_get_defun_inputs_from_kwargs)\n 544 0.006 0.000 0.560 0.001 func_graph.py:1269(dismantle_func_graph)\n 18 0.000 0.000 0.000 0.000 func_graph.py:127(<listcomp>)\n 116 0.000 0.000 0.002 0.000 func_graph.py:130(<listcomp>)\n 60 0.001 0.000 0.008 0.000 func_graph.py:165(__init__)\n 742 0.002 0.000 0.009 0.000 func_graph.py:265(watch_variable)\n 822 0.001 0.000 0.003 0.000 func_graph.py:321(control_dependencies)\n 2119 0.006 0.000 0.060 0.000 func_graph.py:362(as_default)\n 4238 0.025 0.000 0.123 0.000 func_graph.py:365(inner_cm)\n 1368 0.001 0.000 0.001 0.000 func_graph.py:429(outer_graph)\n 58 0.000 0.000 0.000 0.000 func_graph.py:493(variables)\n 58 0.000 0.000 0.000 0.000 func_graph.py:495(<listcomp>)\n2484/2464 0.019 0.000 0.717 0.000 func_graph.py:530(_create_op_internal)\n 3356 0.006 0.000 0.330 0.000 func_graph.py:597(capture)\n 802 0.004 0.000 0.319 0.000 func_graph.py:646(_capture_helper)\n 802 0.002 0.000 0.002 0.000 func_graph.py:664(add_capture)\n 40 0.000 0.000 0.000 0.000 func_graph.py:678(reset_captures)\n 116 0.000 0.000 0.007 0.000 func_graph.py:69(convert_structure_to_signature)\n 544 0.007 0.000 0.016 0.000 func_graph.py:692(clear_captures)\n 98 0.000 0.000 0.000 0.000 func_graph.py:730(external_captures)\n 98 0.000 0.000 0.000 0.000 func_graph.py:733(<listcomp>)\n 58 0.000 0.000 0.000 0.000 func_graph.py:735(internal_captures)\n 58 0.000 0.000 0.000 0.000 func_graph.py:738(<listcomp>)\n 18 0.000 0.000 0.000 0.000 func_graph.py:740(deferred_external_captures)\n 18 0.000 0.000 0.000 0.000 func_graph.py:743(<listcomp>)\n 58 0.000 0.000 0.000 0.000 func_graph.py:745(deferred_internal_captures)\n 58 0.000 0.000 0.000 0.000 func_graph.py:748(<listcomp>)\n 58 0.003 0.000 2.048 0.035 func_graph.py:796(func_graph_from_py_func)\n 35 0.000 0.000 0.002 0.000 func_graph.py:82(encode_arg)\n 58 0.000 0.000 0.000 0.000 func_graph.py:914(<listcomp>)\n 151 0.001 0.000 0.084 0.001 func_graph.py:925(convert)\n 18 0.000 0.000 1.561 0.087 func_graph.py:953(wrapper)\n 36 0.000 0.000 0.000 0.000 func_graph.py:97(<genexpr>)\n44688/29988 0.027 0.000 0.123 0.000 function.py:105(<lambda>)\n 18 0.000 0.000 0.029 0.002 function.py:1498(__init__)\n 89 0.000 0.000 0.002 0.000 function.py:1551(<genexpr>)\n 14994 0.073 0.000 14.068 0.001 function.py:1647(_filtered_call)\n 29988 0.033 0.000 0.047 0.000 function.py:1662(<genexpr>)\n 14994 0.195 0.000 13.851 0.001 function.py:1667(_call_flat)\n 14994 0.049 0.000 0.073 0.000 function.py:1811(captured_inputs)\n 14994 0.004 0.000 0.004 0.000 function.py:1817(<listcomp>)\n 14994 0.132 0.000 0.879 0.000 function.py:1954(_build_call_outputs)\n 6 0.000 0.000 0.001 0.000 function.py:1998(from_function_and_signature)\n 6 0.000 0.000 0.000 0.000 function.py:2081(__init__)\n 6 0.000 0.000 0.000 0.000 function.py:2100(<dictcomp>)\n 6 0.000 0.000 0.000 0.000 function.py:2106(<dictcomp>)\n 30032 0.011 0.000 0.011 0.000 function.py:2142(input_signature)\n 14996 0.054 0.000 0.257 0.000 function.py:2155(canonicalize_function_inputs)\n 14996 0.069 0.000 0.169 0.000 function.py:2242(_convert_numpy_inputs)\n 4 0.000 0.000 0.000 0.000 function.py:2320(__init__)\n 4 0.000 0.000 0.001 0.000 function.py:2358(__init__)\n 14992 0.062 0.000 16.544 0.001 function.py:2416(__call__)\n 30026 0.022 0.000 0.033 0.000 function.py:2431(input_signature)\n 2 0.000 0.000 0.436 0.218 function.py:2441(_get_concrete_function_internal_garbage_collected)\n 14994 0.143 0.000 0.621 0.000 function.py:2570(_cache_key)\n 18 0.000 0.000 1.862 0.103 function.py:2639(_create_graph_function)\n 18 0.000 0.000 0.000 0.000 function.py:2653(<listcomp>)\n 14994 0.081 0.000 2.904 0.000 function.py:2711(_maybe_define_function)\n 18 0.000 0.000 0.000 0.000 function.py:277(_parse_func_attrs)\n 14994 0.009 0.000 0.009 0.000 function.py:313(__init__)\n 4 0.000 0.000 0.001 0.000 function.py:3159(defun_with_attributes)\n 14994 0.003 0.000 0.003 0.000 function.py:316(__enter__)\n 14994 0.011 0.000 0.011 0.000 function.py:319(__exit__)\n 4 0.000 0.000 0.001 0.000 function.py:3196(decorated)\n 2 0.000 0.000 0.000 0.000 function.py:3240(__init__)\n 18 0.000 0.000 0.000 0.000 function.py:3244(target)\n 2 0.000 0.000 0.000 0.000 function.py:3264(class_method_to_instance_method)\n 18 0.000 0.000 1.561 0.087 function.py:3282(bound_method_wrapper)\n 12 0.000 0.000 0.000 0.000 function.py:3324(__init__)\n 36 0.145 0.004 1.365 0.038 function.py:3327(__del__)\n 18 0.000 0.000 0.000 0.000 function.py:3341(__init__)\n 538 0.002 0.000 0.562 0.001 function.py:3348(__del__)\n 18 0.000 0.000 0.000 0.000 function.py:404(_inference_name)\n 58 0.000 0.000 0.000 0.000 function.py:429(__init__)\n 538 0.001 0.000 0.546 0.001 function.py:432(__del__)\n 58 0.003 0.000 0.040 0.001 function.py:460(__init__)\n 822 0.000 0.000 0.000 0.000 function.py:470(<genexpr>)\n 58 0.000 0.000 0.000 0.000 function.py:471(<listcomp>)\n 58 0.000 0.000 0.000 0.000 function.py:489(<listcomp>)\n 58 0.000 0.000 0.000 0.000 function.py:490(<listcomp>)\n 58 0.000 0.000 0.000 0.000 function.py:491(<listcomp>)\n 58 0.000 0.000 0.000 0.000 function.py:493(<listcomp>)\n 58 0.000 0.000 0.000 0.000 function.py:522(<listcomp>)\n 58 0.000 0.000 0.001 0.000 function.py:523(<listcomp>)\n 784 0.000 0.000 0.000 0.000 function.py:532(<genexpr>)\n 40 0.000 0.000 0.002 0.000 function.py:537(add_to_graph)\n 138 0.000 0.000 0.000 0.000 function.py:549(name)\n 14994 0.260 0.000 12.551 0.001 function.py:557(call)\n 18 0.000 0.000 0.026 0.001 function.py:645(__init__)\n 18 0.000 0.000 0.000 0.000 function.py:807(forward)\n59682/14994 0.109 0.000 0.184 0.000 function.py:87(_make_input_signature_hashable)\n 2 0.000 0.000 0.011 0.005 function_scopes.py:131(transform)\n 4 0.000 0.000 0.000 0.000 function_scopes.py:31(__init__)\n 2 0.000 0.000 0.002 0.001 function_scopes.py:38(visit_Return)\n 2 0.000 0.000 0.000 0.000 function_scopes.py:46(_function_scope_options)\n 2 0.000 0.000 0.011 0.005 function_scopes.py:90(visit_FunctionDef)\n 35 0.000 0.000 0.001 0.000 function_wrappers.py:43(__init__)\n 35 0.000 0.000 0.000 0.000 function_wrappers.py:70(__enter__)\n 35 0.000 0.000 0.000 0.000 function_wrappers.py:79(__exit__)\n 35 0.000 0.000 0.000 0.000 function_wrappers.py:87(mark_return_value)\n 2121 0.008 0.000 0.015 0.000 functools.py:44(update_wrapper)\n 2121 0.002 0.000 0.002 0.000 functools.py:74(wraps)\n 2015 0.004 0.000 0.005 0.000 gast.py:15(create_node)\n 35 0.000 0.000 0.012 0.000 gast.py:297(parse)\n 125 0.000 0.000 0.000 0.000 gast.py:321(copy_location)\n 294 0.001 0.000 0.010 0.000 gen_array_ops.py:2211(expand_dims)\n 43 0.000 0.000 0.002 0.000 gen_array_ops.py:3265(fill)\n 226 0.001 0.000 0.105 0.000 gen_array_ops.py:3873(identity)\n 303 0.003 0.000 0.142 0.000 gen_array_ops.py:6383(pad)\n 294 0.003 0.000 0.082 0.000 gen_array_ops.py:6449(pad_eager_fallback)\n 8 0.000 0.000 0.013 0.002 gen_array_ops.py:6463(pad_v2)\n 3 0.000 0.000 0.003 0.001 gen_array_ops.py:6637(placeholder)\n 10 0.000 0.000 0.010 0.001 gen_array_ops.py:6771(placeholder_with_default)\n 37 0.000 0.000 0.021 0.001 gen_array_ops.py:7997(reshape)\n 20 0.000 0.000 0.011 0.001 gen_array_ops.py:9817(squeeze)\n 20 0.000 0.000 0.000 0.000 gen_array_ops.py:9873(<listcomp>)\n 44688 0.086 0.000 1.483 0.000 gen_array_ops.py:9998(strided_slice)\n 10 0.000 0.000 0.024 0.002 gen_functional_ops.py:272(_if)\n 10 0.000 0.000 0.000 0.000 gen_functional_ops.py:321(<listcomp>)\n 10 0.000 0.000 0.000 0.000 gen_functional_ops.py:328(<listcomp>)\n 10 0.000 0.000 0.007 0.001 gen_functional_ops.py:646(stateless_if)\n 10 0.000 0.000 0.000 0.000 gen_functional_ops.py:699(<listcomp>)\n 10 0.000 0.000 0.000 0.000 gen_functional_ops.py:706(<listcomp>)\n 56 0.000 0.000 0.009 0.000 gen_logging_ops.py:23(_assert)\n 204785 0.370 0.000 6.447 0.000 gen_math_ops.py:10071(sub)\n 1 0.000 0.000 0.001 0.001 gen_math_ops.py:1944(cast)\n 13 0.000 0.000 0.000 0.000 gen_math_ops.py:306(add)\n 109860 0.208 0.000 4.469 0.000 gen_math_ops.py:3175(equal)\n 255856 0.551 0.000 7.082 0.000 gen_math_ops.py:3911(greater)\n 348028 0.436 0.000 13.686 0.000 gen_math_ops.py:451(add_v2)\n 99646 0.355 0.000 4.657 0.000 gen_math_ops.py:4830(less)\n 10 0.000 0.000 0.009 0.001 gen_math_ops.py:5330(logical_and)\n 56 0.000 0.000 0.011 0.000 gen_math_ops.py:5389(logical_not)\n 56 0.001 0.000 0.088 0.002 gen_math_ops.py:5537(mat_mul)\n 174027 0.259 0.000 5.247 0.000 gen_math_ops.py:6060(mul)\n 276694 0.401 0.000 7.796 0.000 gen_math_ops.py:7225(real_div)\n 118 0.001 0.000 0.059 0.000 gen_nn_ops.py:10328(relu)\n 128 0.002 0.000 0.361 0.003 gen_nn_ops.py:4200(fused_batch_norm_v3)\n 56 0.000 0.000 0.031 0.001 gen_nn_ops.py:642(bias_add)\n 118 0.002 0.000 0.207 0.002 gen_nn_ops.py:856(conv2d)\n 118 0.000 0.000 0.001 0.000 gen_nn_ops.py:943(<listcomp>)\n 118 0.000 0.000 0.000 0.000 gen_nn_ops.py:954(<listcomp>)\n 118 0.000 0.000 0.000 0.000 gen_nn_ops.py:964(<listcomp>)\n 13 0.000 0.000 0.001 0.000 gen_random_ops.py:687(random_uniform)\n 56 0.000 0.000 0.002 0.000 gen_resource_variable_ops.py:1147(var_handle_op)\n 56 0.000 0.000 0.002 0.000 gen_resource_variable_ops.py:121(assign_variable_op)\n 56 0.000 0.000 0.001 0.000 gen_resource_variable_ops.py:1229(var_is_initialized_op)\n 742 0.006 0.000 0.665 0.001 gen_resource_variable_ops.py:445(read_variable_op)\n 66 0.000 0.000 0.001 0.000 generic_utils.py:350(deserialize_keras_object)\n 20 0.000 0.000 0.000 0.000 generic_utils.py:742(to_list)\n 38 0.000 0.000 0.001 0.000 generic_utils.py:759(to_snake_case)\n 483 0.000 0.000 0.001 0.000 generic_utils.py:769(is_all_none)\n 47 0.000 0.000 0.000 0.000 generic_utils.py:786(validate_kwargs)\n 1 0.000 0.000 0.000 0.000 genericpath.py:117(_splitext)\n 42 0.000 0.000 0.001 0.000 genericpath.py:16(exists)\n 588 0.001 0.000 0.002 0.000 getlimits.py:365(__new__)\n 37 0.000 0.000 0.000 0.000 getlimits.py:497(__init__)\n 37 0.000 0.000 0.000 0.000 getlimits.py:521(max)\n 820 0.013 0.000 0.257 0.000 graph_only_ops.py:29(graph_placeholder)\n 3 0.000 0.000 0.000 0.000 graph_view.py:143(__init__)\n 13 0.000 0.000 0.000 0.000 init_ops_v2.py:1021(_assert_float_dtype)\n 13 0.000 0.000 0.000 0.000 init_ops_v2.py:1044(__init__)\n 13 0.000 0.000 0.004 0.000 init_ops_v2.py:1061(random_uniform)\n 23 0.000 0.000 0.003 0.000 init_ops_v2.py:117(__call__)\n 20 0.000 0.000 0.003 0.000 init_ops_v2.py:157(__call__)\n 13 0.000 0.000 0.000 0.000 init_ops_v2.py:503(__init__)\n 13 0.000 0.000 0.004 0.000 init_ops_v2.py:525(__call__)\n 13 0.000 0.000 0.000 0.000 init_ops_v2.py:749(__init__)\n 13 0.000 0.000 0.000 0.000 init_ops_v2.py:994(_compute_fans)\n 66 0.000 0.000 0.003 0.000 initializers.py:169(deserialize)\n 66 0.001 0.000 0.001 0.000 initializers.py:176(<dictcomp>)\n 142 0.000 0.000 0.004 0.000 initializers.py:189(get)\n 3 0.000 0.000 0.007 0.002 input_layer.py:194(Input)\n 3 0.000 0.000 0.007 0.002 input_layer.py:88(__init__)\n 518 0.004 0.000 0.013 0.000 input_spec.py:132(assert_input_compatibility)\n 38 0.000 0.000 0.000 0.000 input_spec.py:57(__init__)\n 38 0.000 0.000 0.000 0.000 input_spec.py:75(<dictcomp>)\n 145 0.002 0.000 0.008 0.000 inspect.py:1089(getfullargspec)\n 35 0.000 0.000 0.000 0.000 inspect.py:1495(currentframe)\n 482 0.000 0.000 0.000 0.000 inspect.py:159(isfunction)\n 17 0.000 0.000 0.000 0.000 inspect.py:172(isgeneratorfunction)\n 145 0.002 0.000 0.005 0.000 inspect.py:2102(_signature_from_function)\n 230/145 0.001 0.000 0.005 0.000 inspect.py:2183(_signature_from_callable)\n 66 0.000 0.000 0.000 0.000 inspect.py:229(istraceback)\n 66 0.000 0.000 0.000 0.000 inspect.py:239(isframe)\n 485 0.001 0.000 0.002 0.000 inspect.py:2452(__init__)\n 970 0.000 0.000 0.000 0.000 inspect.py:2502(name)\n 705 0.000 0.000 0.000 0.000 inspect.py:2506(default)\n 485 0.000 0.000 0.000 0.000 inspect.py:2510(annotation)\n 485 0.000 0.000 0.000 0.000 inspect.py:2514(kind)\n 64 0.000 0.000 0.000 0.000 inspect.py:253(iscode)\n 145 0.001 0.000 0.001 0.000 inspect.py:2732(__init__)\n 38 0.000 0.000 0.000 0.000 inspect.py:277(isbuiltin)\n 630 0.000 0.000 0.000 0.000 inspect.py:2781(<genexpr>)\n 145 0.000 0.000 0.000 0.000 inspect.py:2817(parameters)\n 145 0.000 0.000 0.000 0.000 inspect.py:2821(return_annotation)\n 17 0.000 0.000 0.000 0.000 inspect.py:479(getmro)\n 2 0.000 0.000 0.000 0.000 inspect.py:485(unwrap)\n 2 0.000 0.000 0.000 0.000 inspect.py:502(_is_wrapper)\n 172 0.000 0.000 0.000 0.000 inspect.py:64(ismodule)\n 60 0.000 0.000 0.001 0.000 inspect.py:643(getfile)\n 58 0.000 0.000 0.002 0.000 inspect.py:680(getsourcefile)\n 123 0.000 0.000 0.000 0.000 inspect.py:687(<genexpr>)\n 164 0.000 0.000 0.000 0.000 inspect.py:690(<genexpr>)\n 17 0.000 0.000 0.000 0.000 inspect.py:702(getabsfile)\n 99 0.000 0.000 0.001 0.000 inspect.py:714(getmodule)\n 307 0.000 0.000 0.000 0.000 inspect.py:73(isclass)\n 4 0.000 0.000 0.000 0.000 inspect.py:760(findsource)\n 618 0.000 0.000 0.000 0.000 inspect.py:81(ismethod)\n 4 0.000 0.000 0.000 0.000 inspect.py:882(__init__)\n 282 0.000 0.000 0.000 0.000 inspect.py:891(tokeneater)\n 4 0.000 0.000 0.002 0.000 inspect.py:935(getblock)\n 2 0.000 0.000 0.001 0.001 inspect.py:946(getsourcelines)\n 2 0.002 0.001 0.006 0.003 inspect_utils.py:116(_fix_linecache_record)\n 2 0.000 0.000 0.008 0.004 inspect_utils.py:143(getimmediatesource)\n 2 0.000 0.000 0.000 0.000 inspect_utils.py:151(getnamespace)\n 51 0.000 0.000 0.000 0.000 inspect_utils.py:240(_get_unbound_function)\n 17 0.000 0.000 0.000 0.000 inspect_utils.py:250(getdefiningclass)\n 17 0.000 0.000 0.000 0.000 inspect_utils.py:265(getmethodclass)\n 2 0.000 0.000 0.000 0.000 inspect_utils.py:339(getfutureimports)\n 2 0.000 0.000 0.000 0.000 inspect_utils.py:350(<genexpr>)\n 2 0.000 0.000 0.000 0.000 inspect_utils.py:60(islambda)\n 51 0.000 0.000 0.000 0.000 inspect_utils.py:68(isnamedtuple)\n 38 0.000 0.000 0.002 0.000 inspect_utils.py:82(isbuiltin)\n 5928 0.001 0.000 0.001 0.000 inspect_utils.py:84(<genexpr>)\n 38 0.000 0.000 0.000 0.000 inspect_utils.py:96(isconstructor)\n 36 0.000 0.000 0.003 0.000 iostream.py:195(schedule)\n 11 0.000 0.000 0.000 0.000 iostream.py:307(_is_master_process)\n 11 0.000 0.000 0.001 0.000 iostream.py:320(_schedule_flush)\n 8 0.000 0.000 0.009 0.001 iostream.py:334(flush)\n 11 0.000 0.000 0.002 0.000 iostream.py:382(write)\n 36 0.000 0.000 0.000 0.000 iostream.py:93(_event_pipe)\n 521/483 0.002 0.000 0.006 0.000 layer_utils.py:126(wrapped)\n 44 0.000 0.000 0.000 0.000 layer_utils.py:161(mark_as)\n 521 0.000 0.000 0.000 0.000 layer_utils.py:166(in_cached_state)\n 51 0.000 0.000 0.000 0.000 layer_utils.py:179(__init__)\n 48 0.000 0.000 1.716 0.036 layer_utils.py:194(add_parent)\n 521 0.001 0.000 0.001 0.000 layer_utils.py:205(get)\n 44/41 0.000 0.000 0.000 0.000 layer_utils.py:209(_set)\n 41 0.000 0.000 0.000 0.000 layer_utils.py:216(mark_cached)\n 3 0.000 0.000 0.000 0.000 layer_utils.py:220(invalidate)\n 68/58 0.000 0.000 0.001 0.000 layer_utils.py:224(invalidate_all)\n1246/1128 0.002 0.000 0.008 0.000 layer_utils.py:234(filter_empty_layer_containers)\n 798 0.000 0.000 0.001 0.000 layer_utils.py:37(is_layer)\n 912 0.001 0.000 0.001 0.000 layer_utils.py:43(has_weights)\n 4 0.000 0.000 0.000 0.000 linecache.py:37(getlines)\n 4 0.000 0.000 0.000 0.000 linecache.py:53(checkcache)\n 22 0.000 0.000 0.000 0.000 liveness.py:106(__init__)\n 22 0.000 0.000 0.029 0.001 liveness.py:112(visit_FunctionDef)\n 22 0.000 0.000 0.000 0.000 liveness.py:155(__init__)\n 2407/22 0.002 0.000 0.029 0.001 liveness.py:160(visit)\n 22 0.000 0.000 0.028 0.001 liveness.py:170(visit_FunctionDef)\n 16 0.000 0.000 0.000 0.000 liveness.py:178(_block_statement_live_out)\n 34 0.000 0.000 0.000 0.000 liveness.py:186(_block_statement_live_in)\n 8 0.000 0.000 0.003 0.000 liveness.py:213(visit_Try)\n 8 0.000 0.000 0.001 0.000 liveness.py:218(visit_ExceptHandler)\n 18 0.000 0.000 0.020 0.001 liveness.py:223(visit_With)\n 8 0.000 0.000 0.000 0.000 liveness.py:227(visit_Expr)\n 22 0.000 0.000 0.058 0.003 liveness.py:235(resolve)\n 22 0.000 0.000 0.000 0.000 liveness.py:43(__init__)\n 346 0.000 0.000 0.000 0.000 liveness.py:49(init_state)\n 241 0.001 0.000 0.002 0.000 liveness.py:52(visit_node)\n 2 0.000 0.000 0.002 0.001 loader.py:36(load_source)\n 2 0.000 0.000 0.020 0.010 loader.py:56(load_ast)\n 2484 0.004 0.000 0.008 0.000 lock_util.py:106(_another_group_active)\n 4968 0.002 0.000 0.002 0.000 lock_util.py:108(<genexpr>)\n 7452 0.003 0.000 0.003 0.000 lock_util.py:110(_validate_group_id)\n 2484 0.001 0.000 0.001 0.000 lock_util.py:119(__init__)\n 2484 0.002 0.000 0.018 0.000 lock_util.py:123(__enter__)\n 2484 0.002 0.000 0.026 0.000 lock_util.py:126(__exit__)\n 60 0.000 0.000 0.001 0.000 lock_util.py:54(__init__)\n 2484 0.004 0.000 0.006 0.000 lock_util.py:74(group)\n 2484 0.007 0.000 0.016 0.000 lock_util.py:86(acquire)\n 2484 0.008 0.000 0.023 0.000 lock_util.py:96(release)\n 1 0.000 0.000 0.000 0.000 logger.py:24(info)\n 2 0.000 0.000 0.003 0.002 logical_expressions.py:135(transform)\n 41 0.000 0.000 0.000 0.000 loss_scale.py:421(get)\n 41 0.000 0.000 0.000 0.000 loss_scale.py:46(get)\n 306094 1.668 0.000 27.875 0.000 math_ops.py:1007(r_binary_op_wrapper)\n 276694 2.108 0.000 13.183 0.000 math_ops.py:1074(_truediv_python3)\n 348028 0.706 0.000 15.197 0.000 math_ops.py:1271(_add_dispatch)\n 174027 0.293 0.000 5.572 0.000 math_ops.py:1279(_mul_dispatch)\n 10 0.000 0.000 0.009 0.001 math_ops.py:1360(logical_and)\n 109860 0.435 0.000 5.735 0.000 math_ops.py:1484(tensor_equals)\n 92 0.000 0.000 0.002 0.000 math_ops.py:732(cast)\n 697440 3.196 0.000 37.093 0.000 math_ops.py:981(binary_op_wrapper)\n 1668 0.001 0.000 0.002 0.000 memory.py:24(dismantle_ordered_dict)\n 392 0.000 0.000 0.000 0.000 module_wrapper.py:154(__getattribute__)\n 3 0.000 0.000 0.000 0.000 monitoring.py:134(get_cell)\n 3 0.000 0.000 0.000 0.000 monitoring.py:293(__init__)\n 3 0.000 0.000 0.000 0.000 monitoring.py:301(set)\n 3 0.000 0.000 0.000 0.000 monitoring.py:333(get_cell)\n 2 0.000 0.000 0.000 0.000 multiarray.py:1043(copyto)\n 297 0.000 0.000 0.000 0.000 multiarray.py:145(concatenate)\n 10 0.000 0.000 0.000 0.000 naming.py:103(new_symbol)\n 4 0.000 0.000 0.000 0.000 naming.py:35(__init__)\n 2 0.000 0.000 0.000 0.000 naming.py:39(_as_symbol_name)\n 2 0.000 0.000 0.000 0.000 naming.py:90(function_name)\n 30816 0.015 0.000 0.081 0.000 nest.py:104(_is_namedtuple)\n 151 0.000 0.000 0.002 0.000 nest.py:1288(yield_flat_paths)\n 15954 0.082 0.000 0.141 0.000 nest.py:129(_sequence_like)\n 116 0.000 0.000 0.003 0.000 nest.py:1355(flatten_with_tuple_paths)\n 76124 0.038 0.000 0.302 0.000 nest.py:191(_yield_value)\n 76426 0.073 0.000 0.265 0.000 nest.py:196(_yield_sorted_items)\n 203612 0.109 0.000 0.580 0.000 nest.py:259(flatten)\n 136 0.000 0.000 0.001 0.000 nest.py:341(assert_same_structure)\n 15918 0.075 0.000 0.409 0.000 nest.py:444(_packed_nest_with_indices)\n 17653 0.056 0.000 0.636 0.000 nest.py:479(_pack_sequence_as)\n 17653 0.016 0.000 0.652 0.000 nest.py:519(pack_sequence_as)\n 2181 0.008 0.000 0.142 0.000 nest.py:555(map_structure)\n 2181 0.001 0.000 0.005 0.000 nest.py:613(<listcomp>)\n 2181 0.002 0.000 0.113 0.000 nest.py:617(<listcomp>)\n 221/151 0.000 0.000 0.002 0.000 nest.py:702(_yield_flat_up_to)\n 1288 0.001 0.000 0.002 0.000 nest.py:96(_sorted)\n 3 0.000 0.000 0.000 0.000 network.py:1356(_validate_graph_inputs_and_outputs)\n 3 0.000 0.000 0.000 0.000 network.py:1359(<setcomp>)\n 3 0.000 0.000 0.000 0.000 network.py:1394(<listcomp>)\n 3 0.000 0.000 0.000 0.000 network.py:1499(_compute_tensor_usage_count)\n 6 0.000 0.000 0.000 0.000 network.py:1507(<genexpr>)\n 35 0.000 0.000 0.000 0.000 network.py:1515(<setcomp>)\n 3 0.000 0.000 0.000 0.000 network.py:1584(_set_save_spec)\n 38 0.000 0.000 0.000 0.000 network.py:1620(_make_node_key)\n 3 0.000 0.000 0.002 0.001 network.py:1624(_map_graph_network)\n 40/5 0.000 0.000 0.001 0.000 network.py:1649(build_map)\n 3 0.000 0.000 0.007 0.002 network.py:167(__init__)\n 38 0.000 0.000 0.000 0.000 network.py:1766(<lambda>)\n 3 0.000 0.000 0.000 0.000 network.py:1799(<listcomp>)\n 3 0.000 0.000 0.001 0.000 network.py:193(_base_init)\n 3 0.000 0.000 0.006 0.002 network.py:229(_init_graph_network)\n 8 0.000 0.000 0.000 0.000 network.py:253(<genexpr>)\n 3 0.000 0.000 0.000 0.000 network.py:262(<lambda>)\n 3 0.000 0.000 0.000 0.000 network.py:346(_set_output_names)\n 3 0.000 0.000 0.001 0.000 network.py:378(dynamic)\n 41 0.000 0.000 0.000 0.000 network.py:382(<genexpr>)\n 471/387 0.001 0.000 0.004 0.000 network.py:438(__setattr__)\n 210 0.000 0.000 0.000 0.000 network.py:444(<genexpr>)\n 3 0.000 0.000 0.000 0.000 network.py:512(_should_compute_mask)\n 6 0.000 0.000 0.001 0.000 network.py:527(layers)\n 36 0.000 0.000 0.000 0.000 network.py:584(input_spec)\n 36 0.000 0.000 1.206 0.033 network.py:695(call)\n 36 0.008 0.000 1.206 0.033 network.py:800(_run_internal_graph)\n 36 0.000 0.000 0.000 0.000 network.py:828(<listcomp>)\n 824 0.001 0.000 0.001 0.000 network.py:853(<genexpr>)\n 412 0.001 0.000 0.001 0.000 network.py:858(<lambda>)\n 108 0.000 0.000 0.000 0.000 network.py:877(_map_tensor_if_from_keras_layer)\n 36 0.000 0.000 0.000 0.000 network.py:905(<listcomp>)\n 36 0.000 0.000 0.000 0.000 network.py:918(_flatten_to_reference_inputs)\n 36 0.000 0.000 0.005 0.000 network.py:931(_conform_to_reference_input)\n 128 0.001 0.000 0.618 0.005 nn_impl.py:1425(fused_batch_norm)\n 10 0.000 0.000 0.004 0.000 nn_ops.py:1021(__init__)\n 10 0.000 0.000 0.001 0.000 nn_ops.py:1084(_build_op)\n 118 0.000 0.000 0.209 0.002 nn_ops.py:1093(__call__)\n 118 0.000 0.000 0.000 0.000 nn_ops.py:1531(_convert_padding)\n 10 0.000 0.000 0.001 0.000 nn_ops.py:161(__init__)\n 118 0.001 0.000 0.208 0.002 nn_ops.py:1920(conv2d)\n 118 0.000 0.000 0.209 0.002 nn_ops.py:230(__call__)\n 56 0.000 0.000 0.000 0.000 nn_ops.py:2725(_tf_deterministic_ops)\n 56 0.001 0.000 0.088 0.002 nn_ops.py:2738(bias_add)\n 10 0.000 0.000 0.002 0.000 nn_ops.py:503(__init__)\n 30 0.000 0.000 0.000 0.000 nn_ops.py:533(<genexpr>)\n 30 0.000 0.000 0.000 0.000 nn_ops.py:534(<genexpr>)\n 236 0.000 0.000 0.001 0.000 nn_ops.py:60(_get_sequence)\n 118 0.000 0.000 0.209 0.002 nn_ops.py:637(__call__)\n 10 0.000 0.000 0.001 0.000 nn_ops.py:720(_get_strides_and_dilation_rate)\n 41 0.000 0.000 0.000 0.000 node.py:117(<listcomp>)\n 76 0.000 0.000 0.001 0.000 node.py:134(iterate_inbound)\n 38 0.000 0.000 0.000 0.000 node.py:153(<listcomp>)\n 38 0.000 0.000 0.000 0.000 node.py:168(_get_all_node_dependencies)\n 41 0.000 0.000 0.003 0.000 node.py:66(__init__)\n 10 0.000 0.000 0.012 0.001 normalization.py:176(__init__)\n 10 0.000 0.000 0.000 0.000 normalization.py:249(_raise_if_fused_cannot_be_used)\n 10 0.000 0.000 0.000 0.000 normalization.py:274(_fused_can_be_used)\n 236 0.000 0.000 0.000 0.000 normalization.py:281(trainable)\n 10 0.000 0.000 0.000 0.000 normalization.py:285(trainable)\n 10 0.000 0.000 0.012 0.001 normalization.py:291(_get_trainable_var)\n 40 0.000 0.000 0.001 0.000 normalization.py:297(_param_dtype)\n 118 0.000 0.000 0.001 0.000 normalization.py:305(_support_zero_size_input)\n 10 0.001 0.000 1.764 0.176 normalization.py:310(build)\n 10 0.000 0.000 0.000 0.000 normalization.py:372(<dictcomp>)\n 118 0.001 0.000 0.837 0.007 normalization.py:523(_fused_batch_norm)\n 128 0.000 0.000 0.000 0.000 normalization.py:550(_maybe_add_or_remove_bessels_correction)\n 10 0.000 0.000 0.053 0.005 normalization.py:568(_fused_batch_norm_training)\n 118 0.000 0.000 0.565 0.005 normalization.py:584(_fused_batch_norm_inference)\n 10 0.000 0.000 0.000 0.000 normalization.py:611(<lambda>)\n 10 0.000 0.000 0.000 0.000 normalization.py:612(<lambda>)\n 118 0.000 0.000 0.022 0.000 normalization.py:710(_get_training_value)\n 118 0.001 0.000 0.860 0.007 normalization.py:724(call)\n 22 0.000 0.000 0.000 0.000 numeric.py:1786(isscalar)\n 2 0.000 0.000 0.001 0.000 numeric.py:283(full)\n 594 0.001 0.000 0.002 0.000 numerictypes.py:293(issubclass_)\n 297 0.001 0.000 0.003 0.000 numerictypes.py:365(issubdtype)\n 1312 0.000 0.000 0.000 0.000 object_identity.py:125(__init__)\n 2406 0.001 0.000 0.002 0.000 object_identity.py:128(_wrap_key)\n 1531 0.002 0.000 0.004 0.000 object_identity.py:131(__getitem__)\n 669 0.001 0.000 0.001 0.000 object_identity.py:134(__setitem__)\n 206 0.000 0.000 0.001 0.000 object_identity.py:137(__delitem__)\n 6072 0.007 0.000 0.008 0.000 object_identity.py:174(__init__)\n 6227 0.001 0.000 0.001 0.000 object_identity.py:175(<genexpr>)\n 3946 0.002 0.000 0.003 0.000 object_identity.py:183(_wrap_key)\n 1741 0.001 0.000 0.003 0.000 object_identity.py:186(__contains__)\n 200 0.000 0.000 0.000 0.000 object_identity.py:189(discard)\n 1940 0.002 0.000 0.008 0.000 object_identity.py:192(add)\n 7423 0.006 0.000 0.020 0.000 object_identity.py:195(update)\n 7423 0.003 0.000 0.011 0.000 object_identity.py:196(<listcomp>)\n 313 0.000 0.000 0.000 0.000 object_identity.py:208(__len__)\n 11767 0.006 0.000 0.006 0.000 object_identity.py:211(__iter__)\n 832 0.001 0.000 0.003 0.000 object_identity.py:220(_wrap_key)\n 58 0.000 0.000 0.001 0.000 object_identity.py:223(__len__)\n 58 0.000 0.000 0.001 0.000 object_identity.py:225(<listcomp>)\n 1568 0.001 0.000 0.001 0.000 object_identity.py:227(__iter__)\n 7184 0.002 0.000 0.002 0.000 object_identity.py:35(__init__)\n 1750 0.000 0.000 0.000 0.000 object_identity.py:38(unwrapped)\n 947 0.000 0.000 0.000 0.000 object_identity.py:42(_assert_type)\n 947 0.000 0.000 0.001 0.000 object_identity.py:54(__eq__)\n 7184 0.002 0.000 0.003 0.000 object_identity.py:63(__hash__)\n 832 0.001 0.000 0.002 0.000 object_identity.py:75(__init__)\n 1452 0.000 0.000 0.000 0.000 object_identity.py:78(unwrapped)\n 2382 0.004 0.000 0.008 0.000 op_callbacks.py:118(should_invoke_op_callbacks)\n 256 0.000 0.000 0.001 0.000 op_def_library.py:141(_MakeFloat)\n 944 0.000 0.000 0.001 0.000 op_def_library.py:148(_MakeInt)\n 420 0.000 0.000 0.001 0.000 op_def_library.py:159(_MakeStr)\n 359 0.000 0.000 0.000 0.000 op_def_library.py:166(_MakeBool)\n 1825 0.005 0.000 0.012 0.000 op_def_library.py:173(_MakeType)\n 53 0.000 0.000 0.001 0.000 op_def_library.py:184(_MakeShape)\n 40 0.000 0.000 0.000 0.000 op_def_library.py:216(_MakeFunc)\n 3124 0.001 0.000 0.001 0.000 op_def_library.py:235(_MaybeColocateWith)\n1562/1132 0.106 0.000 1.223 0.001 op_def_library.py:299(_apply_op_helper)\n 1039 0.002 0.000 0.002 0.000 op_def_library.py:38(_Attr)\n 20 0.000 0.000 0.000 0.000 op_def_library.py:447(<listcomp>)\n 2192 0.001 0.000 0.001 0.000 op_def_library.py:46(_AttrValue)\n 2393 0.002 0.000 0.006 0.000 op_def_library.py:510(<listcomp>)\n 2864 0.006 0.000 0.011 0.000 op_def_library.py:53(_SatisfiesTypeConstraint)\n 2393 0.002 0.000 0.002 0.000 op_def_library.py:64(_IsListParameter)\n 374 0.000 0.000 0.001 0.000 op_def_library.py:682(<listcomp>)\n 40 0.000 0.000 0.000 0.000 op_def_library.py:695(<listcomp>)\n 20 0.000 0.000 0.001 0.000 op_def_library.py:700(<listcomp>)\n 1562 0.002 0.000 0.002 0.000 op_def_library.py:737(<listcomp>)\n 5095 0.002 0.000 0.004 0.000 op_def_library.py:80(_IsListValue)\n 1562 0.002 0.000 0.009 0.000 op_def_library.py:84(_Flatten)\n 1562 0.002 0.000 0.006 0.000 op_def_library.py:87(<listcomp>)\n 1562 0.001 0.000 0.001 0.000 op_def_library.py:89(<listcomp>)\n 4043 0.002 0.000 0.002 0.000 op_def_registry.py:34(get)\n 1082 0.000 0.000 0.000 0.000 ops.py:102(tensor_id)\n 1170 0.002 0.000 0.010 0.000 ops.py:1058(shape)\n 20 0.000 0.000 0.000 0.000 ops.py:1071(get_shape)\n 110154 0.181 0.000 0.181 0.000 ops.py:1115(graph)\n 174602 0.205 0.000 4.781 0.000 ops.py:1220(convert_to_tensor_v2)\n1171640/1170898 4.081 0.000 17.454 0.000 ops.py:1290(convert_to_tensor)\n 20 0.000 0.000 0.015 0.001 ops.py:1365(internal_convert_n_to_tensor)\n 151 0.000 0.000 0.010 0.000 ops.py:1444(convert_to_tensor_or_composite)\n 151 0.000 0.000 0.010 0.000 ops.py:1467(internal_convert_to_tensor_or_composite)\n 1280595 0.200 0.000 0.200 0.000 ops.py:156(__init__)\n 2484 0.036 0.000 0.058 0.000 ops.py:1579(_NodeDef)\n 1280595 0.159 0.000 0.159 0.000 ops.py:159(__enter__)\n 2484 0.035 0.000 0.201 0.000 ops.py:1606(_create_c_op)\n 1280595 0.221 0.000 0.221 0.000 ops.py:162(__exit__)\n 20 0.000 0.000 0.000 0.000 ops.py:1636(<listcomp>)\n 2484 0.050 0.000 0.455 0.000 ops.py:1681(__init__)\n 102 0.000 0.000 0.000 0.000 ops.py:1764(<listcomp>)\n 4805 0.003 0.000 0.012 0.000 ops.py:1767(<genexpr>)\n 2484 0.004 0.000 0.010 0.000 ops.py:1837(_control_flow_post_processing)\n 7327 0.001 0.000 0.001 0.000 ops.py:1878(_get_control_flow_context)\n 20 0.000 0.000 0.000 0.000 ops.py:1894(name)\n 2491 0.001 0.000 0.001 0.000 ops.py:2087(_add_control_inputs)\n 357 0.000 0.000 0.001 0.000 ops.py:209(is_dense_tensor_like)\n 4987 0.001 0.000 0.001 0.000 ops.py:2149(outputs)\n 3798 0.007 0.000 0.023 0.000 ops.py:2154(inputs)\n 80 0.000 0.000 0.000 0.000 ops.py:2198(_control_outputs)\n 80 0.000 0.000 0.000 0.000 ops.py:2213(<listcomp>)\n 32643 0.011 0.000 0.032 0.000 ops.py:2218(type)\n 10406 0.002 0.000 0.002 0.000 ops.py:2223(graph)\n 58 0.000 0.000 0.002 0.000 ops.py:2264(_set_attr)\n 58 0.000 0.000 0.001 0.000 ops.py:2273(_set_attr_with_buf)\n 1759 0.009 0.000 0.137 0.000 ops.py:2313(get_attr)\n 3318 0.003 0.000 0.007 0.000 ops.py:255(uid)\n 1695 0.001 0.000 0.001 0.000 ops.py:2643(name_from_scope_name)\n 60 0.002 0.000 0.005 0.000 ops.py:2704(__init__)\n 36 0.000 0.000 0.000 0.000 ops.py:2821(_variable_creator_scope)\n 18 0.000 0.000 0.000 0.000 ops.py:2845(<lambda>)\n 4312 0.002 0.000 0.003 0.000 ops.py:2857(_variable_creator_stack)\n 4238 0.001 0.000 0.001 0.000 ops.py:2881(_variable_creator_stack)\n 5008 0.001 0.000 0.001 0.000 ops.py:2885(_check_not_finalized)\n 2484 0.010 0.000 0.012 0.000 ops.py:2894(_add_op)\n 5016 0.002 0.000 0.002 0.000 ops.py:2913(_c_graph)\n 40 0.000 0.000 0.000 0.000 ops.py:2954(seed)\n 60 0.000 0.000 0.000 0.000 ops.py:2959(seed)\n 3366 0.001 0.000 0.001 0.000 ops.py:2990(_get_control_flow_context)\n 1604 0.000 0.000 0.000 0.000 ops.py:2998(_set_control_flow_context)\n 40 0.000 0.000 0.000 0.000 ops.py:3139(_is_function)\n 40 0.000 0.000 0.002 0.000 ops.py:3161(_add_function)\n 21467 0.006 0.000 0.006 0.000 ops.py:3196(building_function)\n 2484 0.029 0.000 0.682 0.000 ops.py:3260(_create_op_internal)\n 4907 0.002 0.000 0.002 0.000 ops.py:3314(<genexpr>)\n 2484 0.022 0.000 0.070 0.000 ops.py:3363(_create_op_helper)\n 828 0.007 0.000 0.007 0.000 ops.py:3603(get_operations)\n 2583 0.003 0.000 0.003 0.000 ops.py:3642(_get_operation_by_name_unsafe)\n 2423 0.002 0.000 0.007 0.000 ops.py:3665(_get_operation_by_tf_operation)\n 2423 0.005 0.000 0.012 0.000 ops.py:3690(_get_tensor_by_tf_output)\n 922 0.002 0.000 0.005 0.000 ops.py:3710(_get_op_def)\n 2119 0.002 0.000 0.008 0.000 ops.py:3728(as_default)\n 100 0.000 0.000 0.000 0.000 ops.py:3814(get_collection_ref)\n 58 0.000 0.000 0.000 0.000 ops.py:3839(get_collection)\n 20 0.000 0.000 0.000 0.000 ops.py:3879(get_all_collection_keys)\n 20 0.000 0.000 0.000 0.000 ops.py:3882(<listcomp>)\n 3144 0.011 0.000 0.032 0.000 ops.py:389(__init__)\n 9937 0.004 0.000 0.006 0.000 ops.py:3921(_name_stack)\n 4244 0.002 0.000 0.002 0.000 ops.py:3928(_name_stack)\n 4244 0.012 0.000 0.033 0.000 ops.py:3933(name_scope)\n 2967 0.008 0.000 0.014 0.000 ops.py:4048(unique_name)\n 99 0.000 0.000 0.000 0.000 ops.py:4100(get_name_scope)\n 1484 0.002 0.000 0.012 0.000 ops.py:4117(_colocate_with_for_gradient)\n 1484 0.004 0.000 0.008 0.000 ops.py:4130(colocate_with)\n 3144 0.004 0.000 0.036 0.000 ops.py:416(_create_with_tf_output)\n 8725 0.002 0.000 0.002 0.000 ops.py:422(op)\n 10230 0.002 0.000 0.002 0.000 ops.py:427(dtype)\n 2484 0.007 0.000 0.020 0.000 ops.py:4281(_apply_device_functions)\n 4599 0.003 0.000 0.004 0.000 ops.py:432(graph)\n 822 0.001 0.000 0.001 0.000 ops.py:4364(__init__)\n 822 0.003 0.000 0.006 0.000 ops.py:4399(__enter__)\n 822 0.002 0.000 0.005 0.000 ops.py:4409(__exit__)\n 822 0.000 0.000 0.000 0.000 ops.py:4417(control_inputs)\n 822 0.001 0.000 0.001 0.000 ops.py:4421(add_op)\n 70 0.000 0.000 0.000 0.000 ops.py:4426(op_in_group)\n 822 0.001 0.000 0.001 0.000 ops.py:4431(_push_control_dependencies_controller)\n 822 0.001 0.000 0.003 0.000 ops.py:4434(_pop_control_dependencies_controller)\n 20 0.000 0.000 0.000 0.000 ops.py:4438(_current_control_dependencies)\n 2484 0.003 0.000 0.007 0.000 ops.py:4445(_control_dependencies_for_inputs)\n 822 0.000 0.000 0.000 0.000 ops.py:4476(<genexpr>)\n 2484 0.002 0.000 0.007 0.000 ops.py:4479(_record_op_seen_by_control_dependencies)\n 822 0.001 0.000 0.002 0.000 ops.py:4488(control_dependencies)\n 2178 0.001 0.000 0.013 0.000 ops.py:451(shape)\n 112 0.001 0.000 0.001 0.000 ops.py:4602(_attr_scope)\n 2 0.000 0.000 0.000 0.000 ops.py:4804(prevent_feeding)\n 20 0.000 0.000 0.000 0.000 ops.py:4812(prevent_fetching)\n 60 0.000 0.000 0.000 0.000 ops.py:4823(switch_to_thread_local)\n 13607 0.007 0.000 0.010 0.000 ops.py:4840(_device_function_stack)\n 2484 0.002 0.000 0.005 0.000 ops.py:4861(_snapshot_device_function_stack_metadata)\n 3603 0.002 0.000 0.002 0.000 ops.py:4877(_device_function_stack)\n 5750 0.003 0.000 0.004 0.000 ops.py:4886(_colocation_stack)\n 2484 0.004 0.000 0.007 0.000 ops.py:4901(_snapshot_colocation_stack_metadata)\n 2484 0.001 0.000 0.001 0.000 ops.py:4903(<dictcomp>)\n 1524 0.001 0.000 0.001 0.000 ops.py:4908(_colocation_stack)\n 8256 0.005 0.000 0.009 0.000 ops.py:4917(_control_dependencies_stack)\n 1604 0.001 0.000 0.001 0.000 ops.py:4929(_control_dependencies_stack)\n 21981 0.021 0.000 0.033 0.000 ops.py:4936(_distribution_strategy_stack)\n 4238 0.002 0.000 0.002 0.000 ops.py:4943(_distribution_strategy_stack)\n 4721 0.002 0.000 0.003 0.000 ops.py:4959(_auto_cast_variable_read_dtype)\n 5204 0.004 0.000 0.007 0.000 ops.py:4974(_auto_cast_variable_read_dtype)\n 966 0.001 0.000 0.003 0.000 ops.py:4980(_enable_auto_casting_variables)\n 2484 0.003 0.000 0.009 0.000 ops.py:5002(_mutation_lock)\n 561 0.002 0.000 0.012 0.000 ops.py:502(_c_api_shape)\n 1 0.000 0.000 0.000 0.000 ops.py:5021(device)\n 551 0.000 0.000 0.000 0.000 ops.py:510(<listcomp>)\n 742 0.002 0.000 0.007 0.000 ops.py:5110(_colocate_with_for_gradient)\n 742 0.000 0.000 0.007 0.000 ops.py:5133(colocate_with)\n 921 0.002 0.000 0.007 0.000 ops.py:5144(control_dependencies)\n 65499 0.040 0.000 0.050 0.000 ops.py:5184(get_default)\n 4238 0.004 0.000 0.006 0.000 ops.py:5201(get_controller)\n 65499 0.096 0.000 0.161 0.000 ops.py:5371(get_default)\n 45139 0.015 0.000 0.015 0.000 ops.py:5378(_GetGlobalDefaultGraph)\n 4238 0.018 0.000 0.058 0.000 ops.py:5391(get_controller)\n 1596 0.008 0.000 0.015 0.000 ops.py:5412(_get_outer_context_and_inner_device_stack)\n 640 0.002 0.000 0.010 0.000 ops.py:5450(init_scope)\n 111401 0.128 0.000 0.479 0.000 ops.py:5555(executing_eagerly_outside_functions)\n 953 0.001 0.000 0.003 0.000 ops.py:5588(inside_function)\n 65499 0.053 0.000 0.214 0.000 ops.py:5800(get_default_graph)\n 1 0.000 0.000 0.000 0.000 ops.py:5824(get_name_scope)\n 1562 0.002 0.000 0.006 0.000 ops.py:5859(_get_graph_from_inputs)\n 122 0.000 0.000 0.000 0.000 ops.py:593(get_shape)\n 75 0.001 0.000 0.001 0.000 ops.py:597(set_shape)\n 544 0.306 0.001 0.539 0.001 ops.py:6075(dismantle_graph)\n 58 0.000 0.000 0.000 0.000 ops.py:6155(get_collection)\n 1326824 2.710 0.000 4.137 0.000 ops.py:6189(name_scope)\n 44689 0.045 0.000 0.045 0.000 ops.py:6227(<genexpr>)\n 1639 0.002 0.000 0.002 0.000 ops.py:6243(__init__)\n 1639 0.003 0.000 0.034 0.000 ops.py:6262(__enter__)\n 1639 0.002 0.000 0.007 0.000 ops.py:6302(__exit__)\n 44844 0.095 0.000 0.155 0.000 ops.py:6360(enter_eager_name_scope)\n 45327 0.060 0.000 0.067 0.000 ops.py:6405(__init__)\n 45327 0.102 0.000 0.294 0.000 ops.py:6423(__enter__)\n 44844 0.027 0.000 0.083 0.000 ops.py:6437(<lambda>)\n 45327 0.062 0.000 0.173 0.000 ops.py:6444(__exit__)\n 742 0.000 0.000 0.000 0.000 ops.py:6579(_op_to_colocate_with)\n 294 0.000 0.000 0.001 0.000 ops.py:6604(_is_keras_symbolic_tensor)\n 220 0.000 0.000 0.001 0.000 ops.py:665(consumers)\n 2484 0.010 0.000 0.011 0.000 ops.py:6690(_reconstruct_sequence_inputs)\n 20 0.000 0.000 0.001 0.000 ops.py:6747(set_int_list_attr)\n 220 0.000 0.000 0.000 0.000 ops.py:675(<listcomp>)\n 5788 0.002 0.000 0.002 0.000 ops.py:699(_as_tf_output)\n 465362 1.969 0.000 58.337 0.000 ops.py:883(__bool__)\n 480366 0.521 0.000 60.015 0.000 ops.py:924(_numpy)\n 1998757 1.248 0.000 1.677 0.000 ops.py:931(dtype)\n 15004 0.053 0.000 3.760 0.000 ops.py:937(numpy)\n 8 0.000 0.000 0.000 0.000 origin_info.py:162(__init__)\n 4 0.000 0.000 0.000 0.000 origin_info.py:169(__init__)\n 307 0.000 0.000 0.000 0.000 origin_info.py:191(_absolute_lineno)\n 307 0.000 0.000 0.000 0.000 origin_info.py:194(_absolute_col_offset)\n 307 0.001 0.000 0.002 0.000 origin_info.py:197(_attach_origin_info)\n 522/4 0.001 0.000 0.005 0.001 origin_info.py:212(visit)\n 4 0.000 0.000 0.009 0.002 origin_info.py:226(resolve)\n 2 0.000 0.000 0.003 0.002 origin_info.py:263(resolve_entity)\n 118 0.000 0.000 0.000 0.000 origin_info.py:57(line_loc)\n 2 0.001 0.000 0.015 0.008 origin_info.py:89(create_source_map)\n 271 0.001 0.000 0.001 0.000 os.py:664(__getitem__)\n 271 0.000 0.000 0.000 0.000 os.py:742(encode)\n 270 0.000 0.000 0.002 0.000 os.py:760(getenv)\n 2 0.000 0.000 0.002 0.001 parser.py:119(_attempt_to_parse_normal_source)\n 2 0.000 0.000 0.010 0.005 parser.py:182(parse_entity)\n 2 0.000 0.000 0.000 0.000 parser.py:209(<genexpr>)\n 35 0.000 0.000 0.012 0.000 parser.py:220(parse)\n 13 0.000 0.000 0.001 0.000 parser.py:244(parse_expression)\n 2 0.000 0.000 0.003 0.002 parser.py:263(unparse)\n 2 0.000 0.000 0.000 0.000 parser.py:46(_unfold_continuations)\n 2 0.000 0.000 0.001 0.001 parser.py:51(dedent_block)\n 41 0.000 0.000 0.001 0.000 policy.py:302(__init__)\n 41 0.000 0.000 0.000 0.000 policy.py:351(_parse_name)\n 214 0.000 0.000 0.000 0.000 policy.py:391(variable_dtype)\n 1073 0.000 0.000 0.000 0.000 policy.py:406(compute_dtype)\n 16 0.000 0.000 0.000 0.000 policy.py:434(should_cast_variables)\n 41 0.000 0.000 0.000 0.000 policy.py:454(name)\n 38 0.000 0.000 0.001 0.000 policy.py:489(global_policy)\n 38 0.000 0.000 0.000 0.000 policy.py:512(policy_defaults_to_floatx)\n 1 0.000 0.000 0.000 0.000 posixpath.py:121(splitext)\n 3 0.000 0.000 0.000 0.000 posixpath.py:144(basename)\n 1 0.000 0.000 0.000 0.000 posixpath.py:154(dirname)\n 3 0.000 0.000 0.000 0.000 posixpath.py:338(normpath)\n 3 0.000 0.000 0.000 0.000 posixpath.py:376(abspath)\n 11 0.000 0.000 0.000 0.000 posixpath.py:41(_get_sep)\n 3 0.000 0.000 0.000 0.000 posixpath.py:64(isabs)\n 4 0.000 0.000 0.000 0.000 posixpath.py:75(join)\n 1 0.000 0.000 0.000 0.000 process.py:146(name)\n 1 0.000 0.000 0.000 0.000 process.py:35(current_process)\n 2 0.000 0.000 0.000 0.000 profiler.py:87(stop)\n 2056 0.000 0.000 0.000 0.000 qual_names.py:112(has_subscript)\n 2056 0.000 0.000 0.000 0.000 qual_names.py:115(has_attr)\n8615/8445 0.003 0.000 0.004 0.000 qual_names.py:163(__hash__)\n 1016/986 0.001 0.000 0.002 0.000 qual_names.py:166(__eq__)\n 24/12 0.000 0.000 0.000 0.000 qual_names.py:171(__str__)\n 773 0.001 0.000 0.010 0.000 qual_names.py:225(visit_Name)\n 246 0.001 0.000 0.007 0.000 qual_names.py:230(visit_Attribute)\n 48 0.000 0.000 0.023 0.000 qual_names.py:260(resolve)\n 1041 0.001 0.000 0.001 0.000 qual_names.py:68(__init__)\n 16 0.000 0.000 0.000 0.000 random.py:223(_randbelow)\n 16 0.000 0.000 0.000 0.000 random.py:255(choice)\n 3 0.000 0.000 0.000 0.000 random.py:680(getrandbits)\n 13 0.000 0.000 0.004 0.000 random_ops.py:204(random_uniform)\n 13 0.000 0.000 0.000 0.000 random_seed.py:41(get_seed)\n 26 0.000 0.000 0.000 0.000 re.py:169(match)\n 92 0.000 0.000 0.001 0.000 re.py:184(sub)\n 985 0.000 0.000 0.001 0.000 re.py:231(compile)\n 1103 0.000 0.000 0.000 0.000 re.py:286(_compile)\n 76 0.000 0.000 0.000 0.000 re.py:324(_subx)\n 20 0.000 0.000 0.000 0.000 re.py:330(filter)\n 173 0.000 0.000 0.002 0.000 reaching_definitions.py:101(__sub__)\n 22 0.000 0.000 0.001 0.000 reaching_definitions.py:115(__init__)\n 346 0.000 0.000 0.000 0.000 reaching_definitions.py:124(init_state)\n 173 0.002 0.000 0.012 0.000 reaching_definitions.py:127(visit_node)\n 22 0.000 0.000 0.000 0.000 reaching_definitions.py:206(__init__)\n 22 0.000 0.000 0.037 0.002 reaching_definitions.py:213(visit_FunctionDef)\n 524 0.001 0.000 0.004 0.000 reaching_definitions.py:245(visit_Name)\n 16 0.000 0.000 0.000 0.000 reaching_definitions.py:267(_aggregate_predecessors_defined_in)\n 8 0.000 0.000 0.002 0.000 reaching_definitions.py:298(visit_Try)\n 8 0.000 0.000 0.001 0.000 reaching_definitions.py:302(visit_ExceptHandler)\n 1819/22 0.002 0.000 0.038 0.002 reaching_definitions.py:308(visit)\n 22 0.000 0.000 0.038 0.002 reaching_definitions.py:320(resolve)\n 201 0.000 0.000 0.000 0.000 reaching_definitions.py:52(__init__)\n 1189 0.001 0.000 0.003 0.000 reaching_definitions.py:69(__init__)\n 497 0.001 0.000 0.001 0.000 reaching_definitions.py:72(<dictcomp>)\n 135 0.000 0.000 0.001 0.000 reaching_definitions.py:76(<dictcomp>)\n 173 0.001 0.000 0.001 0.000 reaching_definitions.py:82(__eq__)\n 173 0.000 0.000 0.001 0.000 reaching_definitions.py:88(__ne__)\n 324 0.002 0.000 0.004 0.000 reaching_definitions.py:91(__or__)\n 1 0.000 0.000 0.000 0.000 registration.py:102(spec)\n 1 0.000 0.000 0.191 0.191 registration.py:141(make)\n 1 0.000 0.000 0.000 0.000 registration.py:15(load)\n 1 0.000 0.000 0.191 0.191 registration.py:49(make)\n 1 0.000 0.000 0.191 0.191 registration.py:81(make)\n 2481 0.001 0.000 0.002 0.000 registry.py:74(list)\n 4962 0.004 0.000 0.009 0.000 registry.py:82(lookup)\n 145 0.000 0.000 0.000 0.000 regularizers.py:297(get)\n 742 0.001 0.000 0.725 0.001 resource_variable_ops.py:1233(_dense_var_to_tensor)\n 56 0.000 0.000 0.054 0.001 resource_variable_ops.py:1335(__init__)\n 56 0.003 0.000 0.054 0.001 resource_variable_ops.py:1436(_init_from_args)\n 56 0.003 0.000 0.027 0.000 resource_variable_ops.py:146(_variable_handle_from_shape_and_dtype)\n 742 0.001 0.000 0.726 0.001 resource_variable_ops.py:1824(_dense_var_to_tensor)\n 56 0.000 0.000 0.028 0.000 resource_variable_ops.py:198(eager_safe_variable_handle)\n 56 0.000 0.000 0.000 0.000 resource_variable_ops.py:268(__init__)\n 742 0.001 0.000 0.003 0.000 resource_variable_ops.py:314(_maybe_set_handle_data)\n 742 0.002 0.000 0.021 0.000 resource_variable_ops.py:326(variable_accessed)\n 56 0.001 0.000 0.003 0.000 resource_variable_ops.py:337(__init__)\n 486 0.000 0.000 0.000 0.000 resource_variable_ops.py:493(dtype)\n 10 0.000 0.000 0.000 0.000 resource_variable_ops.py:513(shape)\n 742 0.003 0.000 0.722 0.001 resource_variable_ops.py:545(value)\n 798 0.000 0.000 0.000 0.000 resource_variable_ops.py:583(trainable)\n 742 0.003 0.000 0.698 0.001 resource_variable_ops.py:631(_read_variable_op)\n 742 0.003 0.000 0.671 0.001 resource_variable_ops.py:634(read_and_set_handle)\n 56 0.000 0.000 0.000 0.000 resource_variable_ops.py:84(_set_handle_shapes_and_types)\n 2 0.000 0.000 0.002 0.001 return_statements.py:111(visit_With)\n 2 0.000 0.000 0.002 0.001 return_statements.py:151(visit_FunctionDef)\n 8 0.000 0.000 0.000 0.000 return_statements.py:159(__init__)\n 4 0.000 0.000 0.000 0.000 return_statements.py:172(__init__)\n 2 0.000 0.000 0.000 0.000 return_statements.py:221(__init__)\n 2 0.000 0.000 0.002 0.001 return_statements.py:225(visit_Return)\n 9 0.000 0.000 0.000 0.000 return_statements.py:252(_postprocess_statement)\n 4/2 0.000 0.000 0.004 0.002 return_statements.py:275(_visit_statement_block)\n 2 0.000 0.000 0.004 0.002 return_statements.py:317(visit_With)\n 2 0.000 0.000 0.011 0.005 return_statements.py:339(visit_FunctionDef)\n 6 0.000 0.000 0.000 0.000 return_statements.py:37(__init__)\n 2 0.000 0.000 0.013 0.006 return_statements.py:394(transform)\n 2 0.000 0.000 0.000 0.000 return_statements.py:68(visit_Return)\n 9 0.000 0.000 0.000 0.000 return_statements.py:72(_postprocess_statement)\n 4/2 0.000 0.000 0.002 0.001 return_statements.py:91(_visit_statement_block)\n 3 0.000 0.000 0.001 0.000 seeding.py:11(np_random)\n 4 0.000 0.000 0.000 0.000 seeding.py:21(hash_seed)\n 3 0.000 0.000 0.000 0.000 seeding.py:45(create_seed)\n 7 0.000 0.000 0.000 0.000 seeding.py:69(_bigint_from_bytes)\n 3 0.000 0.000 0.000 0.000 seeding.py:80(_int_list_from_bigint)\n 294 0.000 0.000 0.001 0.000 shape_base.py:209(_arrays_for_stack_dispatcher)\n 294 0.001 0.000 0.001 0.000 shape_base.py:348(_stack_dispatcher)\n 294 0.003 0.000 0.024 0.000 shape_base.py:357(stack)\n 294 0.001 0.000 0.002 0.000 shape_base.py:420(<listcomp>)\n 294 0.001 0.000 0.001 0.000 shape_base.py:424(<setcomp>)\n 294 0.001 0.000 0.001 0.000 shape_base.py:432(<listcomp>)\n 2522 0.003 0.000 0.004 0.000 six.py:586(iteritems)\n 128 0.000 0.000 0.825 0.006 smart_cond.py:27(smart_cond)\n 246 0.000 0.000 0.002 0.000 smart_cond.py:62(smart_constant_value)\n 36 0.003 0.000 0.003 0.000 socket.py:342(send)\n 2 0.000 0.000 0.001 0.000 space.py:21(seed)\n 2 0.000 0.000 0.001 0.000 space.py:9(__init__)\n 35 0.000 0.000 0.000 0.000 special_values.py:90(retval)\n 20 0.000 0.000 0.000 0.000 sre_parse.py:963(expand_template)\n 3 0.000 0.000 0.000 0.000 std.py:1051(__repr__)\n 2 0.000 0.000 0.000 0.000 std.py:1054(_comparable)\n 2 0.000 0.000 0.000 0.000 std.py:1058(__hash__)\n 2 0.000 0.000 0.004 0.002 std.py:1061(__iter__)\n 1 0.000 0.000 0.001 0.001 std.py:1221(close)\n 2 0.000 0.000 0.000 0.000 std.py:1238(fp_write)\n 2 0.000 0.000 0.006 0.003 std.py:1275(refresh)\n 4 0.000 0.000 0.004 0.001 std.py:1383(moveto)\n 3 0.000 0.000 0.000 0.000 std.py:1388(format_dict)\n 3 0.000 0.000 0.007 0.002 std.py:1403(display)\n 3 0.000 0.000 0.000 0.000 std.py:146(__init__)\n 3 0.000 0.000 0.000 0.000 std.py:153(__format__)\n 5 0.000 0.000 0.000 0.000 std.py:226(format_interval)\n 1 0.000 0.000 0.000 0.000 std.py:267(ema)\n 1 0.000 0.000 0.000 0.000 std.py:286(status_printer)\n 3 0.000 0.000 0.002 0.001 std.py:296(fp_write)\n 3 0.000 0.000 0.002 0.001 std.py:302(print_status)\n 3 0.000 0.000 0.000 0.000 std.py:309(format_meter)\n 1 0.000 0.000 0.000 0.000 std.py:504(__new__)\n 1 0.000 0.000 0.000 0.000 std.py:526(_get_free_pos)\n 4 0.000 0.000 0.000 0.000 std.py:529(<genexpr>)\n 1 0.000 0.000 0.000 0.000 std.py:533(_decr_instances)\n 1 0.000 0.000 0.000 0.000 std.py:606(get_lock)\n 1 0.000 0.000 0.003 0.003 std.py:772(__init__)\n 6 0.000 0.000 0.000 0.000 std.py:88(acquire)\n 6 0.000 0.000 0.000 0.000 std.py:92(release)\n 4 0.000 0.000 0.000 0.000 std.py:96(__enter__)\n 4 0.000 0.000 0.000 0.000 std.py:99(__exit__)\n 1 1.256 1.256 3.151 3.151 summary_ops_v2.py:1062(run_metadata_graphs)\n 1 0.000 0.000 0.004 0.004 summary_ops_v2.py:1157(trace_on)\n 1 0.470 0.470 5.869 5.869 summary_ops_v2.py:1202(trace_export)\n 2 0.000 0.000 0.000 0.000 summary_ops_v2.py:1258(trace_off)\n 2 0.000 0.000 0.000 0.000 summary_ops_v2.py:573(summary_scope)\n 1 0.000 0.000 0.000 0.000 summary_ops_v2.py:614(write)\n 640 0.001 0.000 0.001 0.000 tape.py:117(stop_recording)\n 1544 0.001 0.000 0.003 0.000 tape.py:144(record_operation)\n 14994 0.011 0.000 0.028 0.000 tape.py:187(could_possibly_record)\n 486 0.002 0.000 0.007 0.000 tape.py:73(variable_accessed)\n 2 0.000 0.000 0.000 0.000 tempfile.py:236(_infer_return_type)\n 2 0.000 0.000 0.000 0.000 tempfile.py:257(_sanitize_params)\n 2 0.000 0.000 0.000 0.000 tempfile.py:285(rng)\n 2 0.000 0.000 0.000 0.000 tempfile.py:296(__next__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:299(<listcomp>)\n 2 0.000 0.000 0.000 0.000 tempfile.py:376(_get_candidate_names)\n 2 0.000 0.000 0.000 0.000 tempfile.py:390(_mkstemp_inner)\n 2 0.000 0.000 0.000 0.000 tempfile.py:430(gettempdir)\n 2 0.000 0.000 0.000 0.000 tempfile.py:565(__init__)\n 4 0.000 0.000 0.000 0.000 tempfile.py:580(close)\n 2 0.000 0.000 0.000 0.000 tempfile.py:590(__del__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:608(__init__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:614(__getattr__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:622(func_wrapper)\n 2 0.000 0.000 0.000 0.000 tempfile.py:635(__enter__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:641(__exit__)\n 2 0.000 0.000 0.000 0.000 tempfile.py:646(close)\n 2 0.000 0.000 0.000 0.000 tempfile.py:663(NamedTemporaryFile)\n 28 0.000 0.000 0.000 0.000 templates.py:111(__init__)\n 82 0.000 0.000 0.017 0.000 templates.py:129(_prepare_replacement)\n 20 0.000 0.000 0.016 0.001 templates.py:146(visit_Expr)\n 8 0.000 0.000 0.000 0.000 templates.py:154(visit_keyword)\n 4/2 0.000 0.000 0.007 0.003 templates.py:172(visit_FunctionDef)\n 22 0.000 0.000 0.001 0.000 templates.py:185(visit_Attribute)\n 108 0.000 0.000 0.019 0.000 templates.py:197(visit_Name)\n 81/70 0.000 0.000 0.000 0.000 templates.py:218(_convert_to_ast)\n 8 0.000 0.000 0.000 0.000 templates.py:228(<listcomp>)\n 4 0.000 0.000 0.000 0.000 templates.py:230(<genexpr>)\n 18 0.000 0.000 0.034 0.002 templates.py:234(replace)\n 18 0.000 0.000 0.008 0.000 templates.py:275(<listcomp>)\n 6 0.000 0.000 0.005 0.001 templates.py:279(replace_as_expression)\n 78 0.000 0.000 0.000 0.000 templates.py:43(__init__)\n 140/52 0.000 0.000 0.001 0.000 templates.py:46(visit)\n 70 0.000 0.000 0.000 0.000 templates.py:54(_apply_override)\n 6 0.000 0.000 0.000 0.000 templates.py:58(visit_Attribute)\n 10 0.000 0.000 0.000 0.000 templates.py:64(visit_Tuple)\n 54 0.000 0.000 0.001 0.000 templates.py:72(visit_Name)\n 615910 0.472 0.000 0.669 0.000 tensor_conversion_registry.py:114(get)\n 480780 0.481 0.000 6.743 0.000 tensor_conversion_registry.py:50(_default_conversion_function)\n 10 0.000 0.000 0.000 0.000 tensor_shape.py:1019(with_rank_at_least)\n 56 0.000 0.000 0.000 0.000 tensor_shape.py:1057(is_compatible_with)\n 40 0.000 0.000 0.001 0.000 tensor_shape.py:1119(most_specific_compatible_shape)\n 144 0.000 0.000 0.001 0.000 tensor_shape.py:1149(is_fully_defined)\n 448 0.000 0.000 0.000 0.000 tensor_shape.py:1152(<genexpr>)\n 533 0.000 0.000 0.001 0.000 tensor_shape.py:1163(as_list)\n 533 0.001 0.000 0.001 0.000 tensor_shape.py:1174(<listcomp>)\n 1031 0.005 0.000 0.007 0.000 tensor_shape.py:1176(as_proto)\n 1021 0.001 0.000 0.001 0.000 tensor_shape.py:1182(<listcomp>)\n 2 0.000 0.000 0.000 0.000 tensor_shape.py:1186(__eq__)\n 635 0.000 0.000 0.001 0.000 tensor_shape.py:1213(as_shape)\n 64 0.000 0.000 0.000 0.000 tensor_shape.py:1221(unknown_shape)\n 10 0.000 0.000 0.000 0.000 tensor_shape.py:130(dimension_at_index)\n 3893 0.005 0.000 0.006 0.000 tensor_shape.py:185(__init__)\n 62 0.000 0.000 0.000 0.000 tensor_shape.py:211(__eq__)\n 6497 0.001 0.000 0.001 0.000 tensor_shape.py:243(value)\n 419 0.000 0.000 0.001 0.000 tensor_shape.py:248(is_compatible_with)\n 320 0.000 0.000 0.001 0.000 tensor_shape.py:264(assert_is_compatible_with)\n 320 0.000 0.000 0.002 0.000 tensor_shape.py:278(merge_with)\n 4728 0.003 0.000 0.010 0.000 tensor_shape.py:700(as_dimension)\n 1655 0.004 0.000 0.017 0.000 tensor_shape.py:742(__init__)\n 1528 0.002 0.000 0.011 0.000 tensor_shape.py:771(<listcomp>)\n 2256 0.001 0.000 0.001 0.000 tensor_shape.py:773(_v2_behavior)\n 1714 0.001 0.000 0.001 0.000 tensor_shape.py:802(rank)\n 503 0.000 0.000 0.000 0.000 tensor_shape.py:809(dims)\n 820 0.000 0.000 0.001 0.000 tensor_shape.py:821(ndims)\n 295 0.000 0.000 0.000 0.000 tensor_shape.py:826(__len__)\n 56 0.000 0.000 0.000 0.000 tensor_shape.py:832(__bool__)\n 111 0.000 0.000 0.000 0.000 tensor_shape.py:839(__iter__)\n 444 0.000 0.000 0.000 0.000 tensor_shape.py:845(<genexpr>)\n 2219 0.003 0.000 0.004 0.000 tensor_shape.py:849(__getitem__)\n 90 0.001 0.000 0.004 0.000 tensor_shape.py:909(merge_with)\n 89 0.000 0.000 0.000 0.000 tensor_shape.py:97(dimension_value)\n 90 0.000 0.000 0.000 0.000 tensor_shape.py:971(assert_same_rank)\n 52 0.000 0.000 0.002 0.000 tensor_shape.py:999(with_rank)\n 21 0.000 0.000 0.000 0.000 tensor_spec.py:39(__init__)\n 21 0.000 0.000 0.000 0.000 tensor_spec.py:63(shape)\n 15 0.000 0.000 0.001 0.000 tensor_util.py:1003(shape_tensor)\n 93 0.000 0.000 0.002 0.000 tensor_util.py:1022(maybe_set_static_shape)\n 48 0.000 0.000 0.000 0.000 tensor_util.py:185(GetFromNumpyDTypeDict)\n 48 0.000 0.000 0.000 0.000 tensor_util.py:193(GetNumpyAppendFn)\n 173/102 0.000 0.000 0.000 0.000 tensor_util.py:218(_GetDenseDimensions)\n 72 0.000 0.000 0.001 0.000 tensor_util.py:262(inner)\n 72 0.000 0.000 0.001 0.000 tensor_util.py:263(<listcomp>)\n 30 0.000 0.000 0.000 0.000 tensor_util.py:275(_check_not_tensor)\n 30 0.000 0.000 0.000 0.000 tensor_util.py:276(<listcomp>)\n 102 0.000 0.000 0.001 0.000 tensor_util.py:304(_AssertCompatible)\n 102 0.000 0.000 0.001 0.000 tensor_util.py:334(_is_array_like)\n 102 0.003 0.000 0.010 0.000 tensor_util.py:355(make_tensor_proto)\n 2 0.000 0.000 0.000 0.000 tensor_util.py:564(MakeNdarray)\n 2 0.000 0.000 0.000 0.000 tensor_util.py:591(<listcomp>)\n 32 0.000 0.000 0.001 0.000 tensor_util.py:669(_ConstantValue)\n 42 0.000 0.000 0.001 0.000 tensor_util.py:797(constant_value)\n 2 0.000 0.000 0.001 0.000 tensor_util.py:835(constant_value_as_shape)\n 2 0.000 0.000 0.000 0.000 tensor_util.py:974(<listcomp>)\n 586 0.001 0.000 0.003 0.000 tensor_util.py:978(is_tensor)\n 18 0.000 0.000 0.000 0.000 textwrap.py:414(dedent)\n 243 0.000 0.000 0.000 0.000 tf2.py:43(enabled)\n 2119 0.004 0.000 0.042 0.000 tf_contextlib.py:25(contextmanager)\n 1100 0.001 0.000 0.001 0.000 tf_decorator.py:114(_has_tf_decorator_attr)\n 18 0.000 0.000 0.000 0.000 tf_decorator.py:128(rewrap)\n 720 0.001 0.000 0.003 0.000 tf_decorator.py:200(unwrap)\n 2149 0.005 0.000 0.006 0.000 tf_decorator.py:236(__init__)\n 742 0.000 0.000 0.000 0.000 tf_decorator.py:262(decorated_target)\n 18 0.000 0.000 0.000 0.000 tf_decorator.py:266(decorated_target)\n 12 0.000 0.000 0.000 0.000 tf_decorator.py:278(decorator_argspec)\n 2149 0.007 0.000 0.016 0.000 tf_decorator.py:67(make_decorator)\n 145 0.000 0.000 0.008 0.000 tf_inspect.py:238(getfullargspec)\n 60 0.001 0.000 0.005 0.000 tf_inspect.py:260(getcallargs)\n 60 0.000 0.000 0.000 0.000 tf_inspect.py:283(<listcomp>)\n 89 0.000 0.000 0.001 0.000 tf_inspect.py:335(getmodule)\n 2 0.000 0.000 0.000 0.000 tf_inspect.py:350(getsourcefile)\n 2 0.000 0.000 0.001 0.001 tf_inspect.py:355(getsourcelines)\n 153 0.000 0.000 0.001 0.000 tf_inspect.py:365(isclass)\n 111 0.000 0.000 0.000 0.000 tf_inspect.py:370(isfunction)\n 17 0.000 0.000 0.000 0.000 tf_inspect.py:385(isgeneratorfunction)\n 226 0.000 0.000 0.001 0.000 tf_inspect.py:390(ismethod)\n 1 0.000 0.000 0.004 0.004 tf_logging.py:171(warn)\n 36 0.000 0.000 0.000 0.000 tf_logging.py:210(vlog)\n 1 0.000 0.000 0.000 0.000 tf_logging.py:45(_get_caller)\n 1 0.000 0.000 0.000 0.000 tf_logging.py:75(_logger_find_caller)\n 37 0.000 0.000 0.000 0.000 tf_logging.py:93(get_logger)\n 35 0.000 0.000 0.002 0.000 tf_stack.py:105(__init__)\n 1835 0.001 0.000 0.001 0.000 tf_stack.py:123(get_filtered_filenames)\n 2514 0.004 0.000 0.079 0.000 tf_stack.py:131(extract_stack)\n 70 0.000 0.000 0.000 0.000 tf_stack.py:53(__enter__)\n 70 0.000 0.000 0.000 0.000 tf_stack.py:71(__exit__)\n 35 0.000 0.000 0.000 0.000 tf_stack.py:83(reset)\n 35 0.000 0.000 0.000 0.000 tf_stack.py:95(reset)\n 20 0.001 0.000 0.003 0.000 tf_utils.py:102(get_reachable_from_inputs)\n 72/36 0.000 0.000 0.001 0.000 tf_utils.py:157(map_structure_with_atomic)\n 36 0.000 0.000 0.000 0.000 tf_utils.py:185(<listcomp>)\n 36 0.000 0.000 0.001 0.000 tf_utils.py:193(convert_shapes)\n 108 0.000 0.000 0.000 0.000 tf_utils.py:220(_is_shape_component)\n 72 0.000 0.000 0.000 0.000 tf_utils.py:223(_is_atomic_shape)\n 72 0.000 0.000 0.000 0.000 tf_utils.py:230(<genexpr>)\n 36 0.000 0.000 0.000 0.000 tf_utils.py:234(_convert_shape)\n 966 0.001 0.000 0.011 0.000 tf_utils.py:325(are_all_symbolic_tensors)\n 1967 0.001 0.000 0.010 0.000 tf_utils.py:326(<genexpr>)\n 1001 0.003 0.000 0.009 0.000 tf_utils.py:332(is_symbolic_tensor)\n 3 0.000 0.000 0.000 0.000 tf_utils.py:411(assert_no_legacy_layers)\n 128 0.000 0.000 0.826 0.006 tf_utils.py:42(smart_cond)\n 3 0.000 0.000 0.000 0.000 tf_utils.py:425(<listcomp>)\n 46 0.000 0.000 0.002 0.000 tf_utils.py:436(maybe_init_scope)\n 3 0.000 0.000 0.000 0.000 tf_utils.py:475(get_tensor_spec)\n 118 0.000 0.000 0.001 0.000 tf_utils.py:68(constant_value)\n 44 0.000 0.000 0.000 0.000 threading.py:1062(_wait_for_tstate_lock)\n 1 0.000 0.000 0.000 0.000 threading.py:1076(name)\n 44 0.000 0.000 0.000 0.000 threading.py:1104(is_alive)\n 1 0.000 0.000 0.000 0.000 threading.py:1230(current_thread)\n 68 0.001 0.000 0.001 0.000 threading.py:215(__init__)\n 8 0.000 0.000 0.000 0.000 threading.py:239(__enter__)\n 8 0.000 0.000 0.000 0.000 threading.py:242(__exit__)\n 6 0.000 0.000 0.000 0.000 threading.py:248(_release_save)\n 6 0.000 0.000 0.000 0.000 threading.py:251(_acquire_restore)\n 2490 0.002 0.000 0.003 0.000 threading.py:254(_is_owned)\n 6 0.000 0.000 0.007 0.001 threading.py:263(wait)\n 2484 0.006 0.000 0.009 0.000 threading.py:334(notify)\n 2484 0.004 0.000 0.013 0.000 threading.py:357(notify_all)\n 8 0.000 0.000 0.000 0.000 threading.py:498(__init__)\n 45 0.000 0.000 0.000 0.000 threading.py:506(is_set)\n 8 0.000 0.000 0.007 0.001 threading.py:533(wait)\n 60 0.000 0.000 0.000 0.000 threading.py:74(RLock)\n 294 0.002 0.000 0.216 0.001 time_limit.py:14(step)\n 1 0.000 0.000 0.010 0.010 time_limit.py:23(reset)\n 1 0.000 0.000 0.000 0.000 time_limit.py:5(__init__)\n 1 0.000 0.000 0.000 0.000 tmp555ck6zk.py:2(<module>)\n 1 0.000 0.000 0.000 0.000 tmp555ck6zk.py:2(create_converted_entity_factory)\n 1 0.000 0.000 0.000 0.000 tmp555ck6zk.py:4(create_converted_entity)\n 1 0.000 0.000 0.067 0.067 tmp555ck6zk.py:6(tf__initial_inference_compiled)\n 17 0.000 0.000 0.000 0.000 tmpqiwkscxv.py:2(create_converted_entity_factory)\n 17 0.000 0.000 0.000 0.000 tmpqiwkscxv.py:4(create_converted_entity)\n 17 0.000 0.000 0.000 0.000 tmpqiwkscxv.py:6(tf____hash__)\n 1 0.000 0.000 0.000 0.000 tmpwx_3xg_e.py:2(<module>)\n 17 0.000 0.000 0.000 0.000 tmpwx_3xg_e.py:2(create_converted_entity_factory)\n 17 0.000 0.000 0.000 0.000 tmpwx_3xg_e.py:4(create_converted_entity)\n 17 0.001 0.000 1.224 0.072 tmpwx_3xg_e.py:6(tf__recurrent_inference_compiled)\n 981 0.000 0.000 0.001 0.000 tokenize.py:152(_compile)\n 2 0.000 0.000 0.000 0.000 tokenize.py:224(__init__)\n 2 0.000 0.000 0.000 0.000 tokenize.py:243(untokenize)\n 2 0.000 0.000 0.000 0.000 tokenize.py:280(compat)\n 2 0.000 0.000 0.000 0.000 tokenize.py:317(untokenize)\n 1059 0.003 0.000 0.006 0.000 tokenize.py:492(_tokenize)\n 10 0.000 0.000 0.000 0.000 tokenize.py:739(generate_tokens)\n 2481 0.003 0.000 0.021 0.000 tpu.py:210(tpu_replicated_input_resolver)\n 4962 0.007 0.000 0.016 0.000 tpu.py:226(replace_with_unreplicated_resources)\n 4547 0.007 0.000 0.007 0.000 traceable_stack.py:119(peek_objs)\n 4547 0.001 0.000 0.001 0.000 traceable_stack.py:121(<genexpr>)\n 4968 0.002 0.000 0.002 0.000 traceable_stack.py:123(peek_traceable_objs)\n 7808 0.003 0.000 0.004 0.000 traceable_stack.py:127(__len__)\n 116 0.000 0.000 0.000 0.000 traceable_stack.py:131(copy)\n 1720 0.001 0.000 0.001 0.000 traceable_stack.py:83(__init__)\n2210/2090 0.002 0.000 0.008 0.000 tracking.py:417(wrapped)\n 164 0.000 0.000 0.000 0.000 tracking.py:77(__setattr__)\n 3 0.000 0.000 0.010 0.003 training.py:166(__init__)\n 3 0.000 0.000 0.001 0.000 training.py:352(_reset_compile_cache)\n 3 0.000 0.000 0.000 0.000 training_utils.py:1901(get_input_shape_and_dtype)\n 3 0.000 0.000 0.000 0.000 training_utils.py:1915(_is_graph_model)\n 3 0.000 0.000 0.000 0.000 training_utils.py:1935(get_static_batch_size)\n 64 0.000 0.000 0.000 0.000 transformer.py:100(__init__)\n 24 0.000 0.000 0.000 0.000 transformer.py:108(__enter__)\n 24 0.000 0.000 0.000 0.000 transformer.py:112(__exit__)\n 84 0.000 0.000 0.000 0.000 transformer.py:115(enter)\n 44 0.000 0.000 0.000 0.000 transformer.py:118(exit)\n 2 0.000 0.000 0.000 0.000 transformer.py:121(stack)\n 322 0.000 0.000 0.000 0.000 transformer.py:125(level)\n 710 0.000 0.000 0.000 0.000 transformer.py:133(__iter__)\n 108 0.000 0.000 0.000 0.000 transformer.py:136(__getattr__)\n 51 0.000 0.000 0.000 0.000 transformer.py:139(__setattr__)\n 110 0.000 0.000 0.000 0.000 transformer.py:175(__init__)\n 1216 0.000 0.000 0.001 0.000 transformer.py:178(__getitem__)\n 110 0.000 0.000 0.000 0.000 transformer.py:236(__init__)\n 372/76 0.001 0.000 0.074 0.001 transformer.py:273(visit_block)\n11164/110 0.025 0.000 0.185 0.002 transformer.py:408(visit)\n 2 0.000 0.000 0.000 0.000 transformer.py:43(__init__)\n 21 0.000 0.000 0.001 0.000 unparser.py:115(_Assign)\n 15/9 0.000 0.000 0.000 0.000 unparser.py:14(interleave)\n 6 0.000 0.000 0.000 0.000 unparser.py:141(_Return)\n 2 0.000 0.000 0.000 0.000 unparser.py:223(_Raise)\n 2 0.000 0.000 0.000 0.000 unparser.py:245(_Try)\n 2 0.000 0.000 0.000 0.000 unparser.py:292(_ExceptHandler)\n 2 0.000 0.000 0.001 0.001 unparser.py:32(__init__)\n 6/2 0.000 0.000 0.001 0.000 unparser.py:346(_FunctionDef)\n 6/2 0.000 0.000 0.001 0.000 unparser.py:352(__FunctionDef_helper)\n 43 0.000 0.000 0.000 0.000 unparser.py:42(fill)\n 2 0.000 0.000 0.001 0.000 unparser.py:422(_generic_With)\n 2 0.000 0.000 0.001 0.000 unparser.py:435(_With)\n 4 0.000 0.000 0.000 0.000 unparser.py:445(_Str)\n 388 0.000 0.000 0.000 0.000 unparser.py:46(write)\n 12 0.000 0.000 0.000 0.000 unparser.py:50(enter)\n 83 0.000 0.000 0.000 0.000 unparser.py:520(_Name)\n 17 0.000 0.000 0.000 0.000 unparser.py:523(_NameConstant)\n 12 0.000 0.000 0.000 0.000 unparser.py:55(leave)\n 8 0.000 0.000 0.000 0.000 unparser.py:555(_Num)\n 5/1 0.000 0.000 0.000 0.000 unparser.py:570(_List)\n 7 0.000 0.000 0.000 0.000 unparser.py:572(<lambda>)\n 263/2 0.000 0.000 0.001 0.000 unparser.py:59(dispatch)\n 15 0.000 0.000 0.000 0.000 unparser.py:651(_Tuple)\n 8 0.000 0.000 0.000 0.000 unparser.py:658(<lambda>)\n 28 0.000 0.000 0.000 0.000 unparser.py:706(_Attribute)\n 19/15 0.000 0.000 0.000 0.000 unparser.py:716(_Call)\n 11 0.000 0.000 0.000 0.000 unparser.py:772(_arg)\n 6 0.000 0.000 0.000 0.000 unparser.py:779(_arguments)\n 10 0.000 0.000 0.000 0.000 unparser.py:837(_keyword)\n 2 0.000 0.000 0.000 0.000 unparser.py:859(_withitem)\n 2 0.000 0.000 0.000 0.000 unparser.py:88(_Expr)\n 8 0.000 0.000 0.000 0.000 unsupported_features_checker.py:32(visit_Attribute)\n 2 0.000 0.000 0.001 0.000 unsupported_features_checker.py:60(verify)\n 3 0.000 0.000 0.000 0.000 util.py:1070(__init__)\n 3 0.000 0.000 0.000 0.000 util.py:1338(saver_with_op_caching)\n 3 0.000 0.000 0.000 0.000 utils.py:134(__init__)\n 3 0.000 0.000 0.000 0.000 utils.py:138(__format__)\n 1 0.000 0.000 0.000 0.000 utils.py:151(__eq__)\n 1 0.000 0.000 0.000 0.000 utils.py:188(_is_utf)\n 1 0.000 0.000 0.000 0.000 utils.py:202(_supports_unicode)\n 6 0.000 0.000 0.000 0.000 utils.py:209(_is_ascii)\n 1 0.000 0.000 0.000 0.000 utils.py:218(_environ_cols_wrapper)\n 1 0.000 0.000 0.000 0.000 utils.py:270(_environ_cols_linux)\n 4 0.000 0.000 0.000 0.000 utils.py:288(_term_move_up)\n 58 0.000 0.000 0.000 0.000 variable_scope.py:1167(use_resource)\n 116 0.000 0.000 0.000 0.000 variable_scope.py:1203(set_use_resource)\n 58 0.000 0.000 0.000 0.000 variable_scope.py:1421(get_variable_scope_store)\n 58 0.000 0.000 0.001 0.000 variable_scope.py:1434(get_variable_scope)\n 56 0.000 0.000 0.055 0.001 variable_scope.py:2558(default_variable_creator)\n 112 0.000 0.000 0.000 0.000 variables.py:150(validate_synchronization_aggregation_trainable)\n 56 0.000 0.000 0.055 0.001 variables.py:181(_variable_v1_call)\n 56 0.000 0.000 0.055 0.001 variables.py:198(<lambda>)\n 112/56 0.000 0.000 0.056 0.001 variables.py:257(__call__)\n 3 0.000 0.000 0.000 0.000 version_utils.py:46(__new__)\n 41 0.000 0.000 0.019 0.000 version_utils.py:55(__new__)\n 114/44 0.018 0.000 0.018 0.000 version_utils.py:61(swap_class)\n 137/85 0.000 0.000 0.014 0.000 version_utils.py:73(<genexpr>)\n 426 0.001 0.000 0.002 0.000 weakref.py:102(__init__)\n 11 0.000 0.000 0.000 0.000 weakref.py:109(remove)\n 173 0.000 0.000 0.000 0.000 weakref.py:125(_commit_removals)\n 55 0.000 0.000 0.000 0.000 weakref.py:165(__setitem__)\n 228 0.000 0.000 0.001 0.000 weakref.py:208(items)\n 426 0.000 0.000 0.000 0.000 weakref.py:288(update)\n 55 0.000 0.000 0.000 0.000 weakref.py:334(__new__)\n 55 0.000 0.000 0.000 0.000 weakref.py:339(__init__)\n 47 0.000 0.000 0.000 0.000 weakref.py:354(__init__)\n 46/40 0.001 0.000 0.053 0.001 weakref.py:356(remove)\n 38 0.000 0.000 0.000 0.000 weakref.py:371(_commit_removals)\n 15639 0.013 0.000 0.013 0.000 weakref.py:393(__getitem__)\n 291 0.000 0.000 0.000 0.000 weakref.py:406(__setitem__)\n 2329 0.002 0.000 0.003 0.000 weakref.py:428(get)\n 15709 0.051 0.000 0.051 0.000 weakref.py:431(__contains__)\n 76 0.000 0.000 0.000 0.000 weakref.py:438(items)\n 123 0.000 0.000 0.000 0.000 weakref.py:480(pop)\n 38 0.000 0.000 0.000 0.000 weakref.py:487(update)\n 36163 0.026 0.000 0.026 0.000 {built-in method __new__ of type object at 0x9d12c0}\n 4 0.000 0.000 0.000 0.000 {built-in method _hashlib.openssl_sha512}\n 4 0.000 0.000 0.000 0.000 {built-in method _imp.acquire_lock}\n 2 0.000 0.000 0.000 0.000 {built-in method _imp.extension_suffixes}\n 8 0.000 0.000 0.000 0.000 {built-in method _imp.lock_held}\n 4 0.000 0.000 0.000 0.000 {built-in method _imp.release_lock}\n 7 0.000 0.000 0.000 0.000 {built-in method _struct.unpack}\n 125 0.000 0.000 0.000 0.000 {built-in method _thread.allocate_lock}\n 2590 0.001 0.000 0.001 0.000 {built-in method _thread.get_ident}\n 5 0.000 0.000 0.000 0.000 {built-in method _weakref._remove_dead_weakref}\n 2 0.000 0.000 0.000 0.000 {built-in method atexit.register}\n 11 0.000 0.000 0.000 0.000 {built-in method builtins.abs}\n 139469 0.087 0.000 0.197 0.000 {built-in method builtins.all}\n 5753 0.005 0.000 0.015 0.000 {built-in method builtins.any}\n 3009 0.000 0.000 0.000 0.000 {built-in method builtins.callable}\n 37 0.002 0.000 0.002 0.000 {built-in method builtins.compile}\n 66 0.001 0.000 0.001 0.000 {built-in method builtins.dir}\n 19 0.000 0.000 0.000 0.000 {built-in method builtins.divmod}\n 3/1 0.000 0.000 190.543 190.543 {built-in method builtins.exec}\n 262157 0.248 0.000 0.432 0.000 {built-in method builtins.getattr}\n 155572 0.074 0.000 0.076 0.000 {built-in method builtins.hasattr}\n79498/79328 0.039 0.000 0.045 0.000 {built-in method builtins.hash}\n 12533 0.002 0.000 0.002 0.000 {built-in method builtins.id}\n 6914761 1.723 0.000 2.721 0.000 {built-in method builtins.isinstance}\n 616835 0.172 0.000 0.172 0.000 {built-in method builtins.issubclass}\n 4952 0.001 0.000 0.001 0.000 {built-in method builtins.iter}\n213609/213471 0.057 0.000 0.057 0.000 {built-in method builtins.len}\n 131443 2.668 0.000 119.248 0.001 {built-in method builtins.max}\n 71630 0.625 0.000 12.027 0.000 {built-in method builtins.min}\n80698/65569 0.052 0.000 0.292 0.000 {built-in method builtins.next}\n 63 0.000 0.000 0.000 0.000 {built-in method builtins.ord}\n 2 0.000 0.000 0.000 0.000 {built-in method builtins.print}\n 29 0.000 0.000 0.000 0.000 {built-in method builtins.repr}\n 74904 0.039 0.000 0.063 0.000 {built-in method builtins.setattr}\n 16448 0.030 0.000 0.031 0.000 {built-in method builtins.sorted}\n 15288 0.019 0.000 0.020 0.000 {built-in method builtins.sum}\n 1 0.000 0.000 0.000 0.000 {built-in method fcntl.ioctl}\n 3 0.000 0.000 0.000 0.000 {built-in method from_bytes}\n 2 0.000 0.000 0.000 0.000 {built-in method io.open}\n 2 0.000 0.000 0.000 0.000 {built-in method marshal.dumps}\n 59976 0.037 0.000 0.037 0.000 {built-in method math.exp}\n 227712 0.208 0.000 0.208 0.000 {built-in method math.log}\n 227725 0.078 0.000 0.078 0.000 {built-in method math.sqrt}\n 735 0.004 0.000 0.004 0.000 {built-in method numpy.array}\n1642/1348 0.020 0.000 0.050 0.000 {built-in method numpy.core._multiarray_umath.implement_array_function}\n 294 0.000 0.000 0.000 0.000 {built-in method numpy.core._multiarray_umath.normalize_axis_index}\n 297 0.001 0.000 0.001 0.000 {built-in method numpy.empty}\n 2 0.000 0.000 0.000 0.000 {built-in method numpy.frombuffer}\n 12 0.000 0.000 0.000 0.000 {built-in method numpy.geterrobj}\n 6 0.000 0.000 0.000 0.000 {built-in method numpy.seterrobj}\n 1 0.000 0.000 0.000 0.000 {built-in method numpy.zeros}\n 24 0.000 0.000 0.000 0.000 {built-in method posix.fspath}\n 14 0.000 0.000 0.000 0.000 {built-in method posix.getpid}\n 4 0.000 0.000 0.000 0.000 {built-in method posix.open}\n 2 0.000 0.000 0.000 0.000 {built-in method posix.replace}\n 52 0.001 0.000 0.001 0.000 {built-in method posix.stat}\n 6 0.000 0.000 0.000 0.000 {built-in method posix.urandom}\n 36 0.000 0.000 0.000 0.000 {built-in method sys._getframe}\n 1719 0.001 0.000 0.001 0.000 {built-in method sys.exc_info}\n 2 0.000 0.000 0.000 0.000 {built-in method sys.getrecursionlimit}\n 10 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.AddControlInput}\n 2481 0.004 0.000 0.004 0.000 {built-in method tensorflow.python._pywrap_tf_session.GetOperationInputs}\n 58 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_tf_session.SetAttr}\n 782 0.007 0.000 0.007 0.000 {built-in method tensorflow.python._pywrap_tf_session.SetHandleShapeAndType}\n 60 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.SetRequireShapeInferenceFns}\n 20 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_AddInputList}\n 2373 0.009 0.000 0.009 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_AddInput}\n 1952 0.003 0.000 0.003 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_DeleteBuffer}\n 538 0.088 0.000 0.088 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_DeleteFunction}\n 544 0.228 0.000 0.228 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_DeleteGraph}\n 2484 0.056 0.000 0.056 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_FinishOperation}\n 58 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_FunctionToFunctionDef}\n 175 0.038 0.000 0.038 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GetBuffer}\n 40 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphCopyFunction}\n 76 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphGetOpDef}\n 561 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphGetTensorShapeHelper}\n 782 0.003 0.000 0.003 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphSetOutputHandleShapesAndTypes_wrapper}\n 75 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphSetTensorShape_wrapper}\n 58 0.011 0.000 0.011 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_GraphToFunction_wrapper}\n 58 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_NewBufferFromString}\n 1894 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_NewBuffer}\n 60 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_NewGraph}\n 2484 0.025 0.000 0.025 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_NewOperation}\n 1759 0.104 0.000 0.109 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationGetAttrValueProto}\n 80 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationGetControlOutputs_wrapper}\n 2443 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationName}\n 2484 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationNumOutputs}\n 32643 0.021 0.000 0.021 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationOpType}\n 220 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationOutputConsumers_wrapper}\n 3144 0.005 0.000 0.005 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_OperationOutputType}\n 5101 0.021 0.000 0.021 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_SetAttrValueProto}\n 30 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_tf_session.TF_TryEvaluateConstant_wrapper}\n 58 0.005 0.000 0.005 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_ContextAddFunction}\n 2 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_ContextDisableRunMetadata}\n 1 1.149 1.149 1.149 1.149 {built-in method tensorflow.python._pywrap_tfe.TFE_ContextExportRunMetadata}\n 538 0.541 0.001 0.541 0.001 {built-in method tensorflow.python._pywrap_tfe.TFE_ContextRemoveFunction}\n 3 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_MonitoringBoolGaugeCellSet}\n 3 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_MonitoringGetCellBoolGauge1}\n 14994 0.125 0.000 0.125 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_EncodeArg}\n 15288 12.214 0.001 12.214 0.001 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_Execute}\n 1514521 48.281 0.000 48.281 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_FastPathExecute}\n 16850 0.020 0.000 0.020 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetIsEmpty}\n 320 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetIsStopped}\n 14994 0.015 0.000 0.015 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetPossibleGradientTypes}\n 1544 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetRecordOperation}\n 152 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetRestartOnThread}\n 152 0.000 0.000 0.000 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeSetStopOnThread}\n 486 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_TapeVariableAccessed}\n 3318 0.004 0.000 0.004 0.000 {built-in method tensorflow.python._pywrap_tfe.TFE_Py_UID}\n 136 0.001 0.000 0.001 0.000 {built-in method tensorflow.python._pywrap_utils.AssertSameStructure}\n 203612 0.470 0.000 0.471 0.000 {built-in method tensorflow.python._pywrap_utils.Flatten}\n 30816 0.013 0.000 0.013 0.000 {built-in method tensorflow.python._pywrap_utils.IsAttrs}\n 30816 0.010 0.000 0.010 0.000 {built-in method tensorflow.python._pywrap_utils.IsCompositeTensor}\n 15368 0.005 0.000 0.005 0.000 {built-in method tensorflow.python._pywrap_utils.IsMappingView}\n 15404 0.005 0.000 0.005 0.000 {built-in method tensorflow.python._pywrap_utils.IsMapping}\n 15954 0.009 0.000 0.009 0.000 {built-in method tensorflow.python._pywrap_utils.IsMutableMapping}\n 30816 0.066 0.000 0.066 0.000 {built-in method tensorflow.python._pywrap_utils.IsNamedtuple}\n 90561 0.049 0.000 0.049 0.000 {built-in method tensorflow.python._pywrap_utils.IsSequenceOrComposite}\n 5181 0.002 0.000 0.002 0.000 {built-in method tensorflow.python._pywrap_utils.IsSequence}\n 30816 0.009 0.000 0.009 0.000 {built-in method tensorflow.python._pywrap_utils.IsTypeSpec}\n 2514 0.072 0.000 0.074 0.000 {built-in method tensorflow.python._tf_stack.extract_stack}\n 6 0.000 0.000 0.000 0.000 {built-in method time.time}\n 4968 0.017 0.000 0.017 0.000 {method 'ByteSize' of 'google.protobuf.pyext._message.CMessage' objects}\n 5256 0.009 0.000 0.009 0.000 {method 'CopyFrom' of 'google.protobuf.pyext._message.CMessage' objects}\n 8276 0.006 0.000 0.006 0.000 {method 'HasField' of 'google.protobuf.pyext._message.CMessage' objects}\n 175 1.070 0.006 1.070 0.006 {method 'ParseFromString' of 'google.protobuf.pyext._message.CMessage' objects}\n 5942 1.839 0.000 1.839 0.000 {method 'SerializeToString' of 'google.protobuf.pyext._message.CMessage' objects}\n 434 0.000 0.000 0.000 0.000 {method 'SetInParent' of 'google.protobuf.pyext._message.CMessage' objects}\n 40 0.000 0.000 0.000 0.000 {method 'WhichOneof' of 'google.protobuf.pyext._message.CMessage' objects}\n 2 0.000 0.000 0.000 0.000 {method '__enter__' of '_io._IOBase' objects}\n 8 0.000 0.000 0.000 0.000 {method '__enter__' of '_thread.lock' objects}\n 2 0.000 0.000 0.000 0.000 {method '__exit__' of '_io._IOBase' objects}\n 8 0.000 0.000 0.000 0.000 {method '__exit__' of '_thread.lock' objects}\n 1999051 0.430 0.000 0.430 0.000 {method '_datatype_enum' of 'tensorflow.python.framework.ops.EagerTensor' objects}\n 480366 59.494 0.000 59.494 0.000 {method '_numpy_internal' of 'tensorflow.python.framework.ops.EagerTensor' objects}\n 474 0.001 0.000 0.001 0.000 {method '_shape_tuple' of 'tensorflow.python.framework.ops.EagerTensor' objects}\n 6 0.000 0.000 0.000 0.000 {method 'acquire' of '_multiprocessing.SemLock' objects}\n 8 0.000 0.000 0.000 0.000 {method 'acquire' of '_thread.RLock' objects}\n 22514 0.022 0.000 0.022 0.000 {method 'acquire' of '_thread.lock' objects}\n 7818 0.003 0.000 0.005 0.000 {method 'add' of 'set' objects}\n 42 0.000 0.000 0.000 0.000 {method 'append' of 'collections.deque' objects}\n 56 0.000 0.000 0.000 0.000 {method 'append' of 'google.protobuf.pyext._message.RepeatedCompositeContainer' objects}\n 398801 0.068 0.000 0.068 0.000 {method 'append' of 'list' objects}\n 22 0.000 0.000 0.000 0.000 {method 'astype' of 'numpy.ndarray' objects}\n 16 0.000 0.000 0.000 0.000 {method 'bit_length' of 'int' objects}\n 294 0.028 0.000 0.039 0.000 {method 'choice' of 'numpy.random.mtrand.RandomState' objects}\n 2 0.000 0.000 0.000 0.000 {method 'close' of '_io.TextIOWrapper' objects}\n 61 0.000 0.000 0.000 0.000 {method 'copy' of 'dict' objects}\n 15006 0.052 0.000 0.052 0.000 {method 'copy' of 'numpy.ndarray' objects}\n 38 0.000 0.000 0.000 0.000 {method 'count' of 'list' objects}\n 98 0.000 0.000 0.000 0.000 {method 'decode' of 'bytes' objects}\n 1 0.000 0.000 0.000 0.000 {method 'difference' of 'set' objects}\n 4 0.000 0.000 0.000 0.000 {method 'digest' of '_hashlib.HASH' objects}\n 294 0.009 0.000 0.016 0.000 {method 'dirichlet' of 'numpy.random.mtrand.RandomState' objects}\n 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}\n 427 0.000 0.000 0.000 0.000 {method 'discard' of 'set' objects}\n 5874 0.003 0.000 0.003 0.000 {method 'encode' of 'str' objects}\n 45065 0.024 0.000 0.024 0.000 {method 'endswith' of 'str' objects}\n 6 0.000 0.000 0.000 0.000 {method 'extend' of 'bytearray' objects}\n 129 0.000 0.000 0.000 0.000 {method 'extend' of 'collections.deque' objects}\n 20 0.000 0.000 0.000 0.000 {method 'extend' of 'google.protobuf.pyext._message.RepeatedCompositeContainer' objects}\n 414 0.000 0.000 0.000 0.000 {method 'extend' of 'google.protobuf.pyext._message.RepeatedScalarContainer' objects}\n 4803 0.002 0.000 0.002 0.000 {method 'extend' of 'list' objects}\n 931 0.000 0.000 0.000 0.000 {method 'find' of 'str' objects}\n 18 0.000 0.000 0.000 0.000 {method 'findall' of '_sre.SRE_Pattern' objects}\n 2 0.000 0.000 0.000 0.000 {method 'flush' of '_io._IOBase' objects}\n 165 0.000 0.000 0.000 0.000 {method 'format' of 'str' objects}\n 296 0.000 0.000 0.000 0.000 {method 'from_address' of '_ctypes.PyCArrayType' objects}\n 164547 0.074 0.000 0.083 0.000 {method 'get' of 'dict' objects}\n 23 0.000 0.000 0.000 0.000 {method 'getrandbits' of '_random.Random' objects}\n 2 0.000 0.000 0.000 0.000 {method 'getvalue' of '_io.StringIO' objects}\n 66 0.000 0.000 0.000 0.000 {method 'group' of '_sre.SRE_Match' objects}\n 200 0.000 0.000 0.000 0.000 {method 'insert' of 'list' objects}\n 20 0.000 0.000 0.000 0.000 {method 'intersection' of 'set' objects}\n 10 0.000 0.000 0.000 0.000 {method 'isdigit' of 'str' objects}\n 1337 0.000 0.000 0.000 0.000 {method 'isidentifier' of 'str' objects}\n 35 0.000 0.000 0.000 0.000 {method 'issubset' of 'set' objects}\n 81879 0.023 0.000 0.023 0.000 {method 'items' of 'dict' objects}\n 77 0.000 0.000 0.000 0.000 {method 'join' of 'str' objects}\n 19534 0.006 0.000 0.006 0.000 {method 'keys' of 'dict' objects}\n 3040 0.001 0.000 0.001 0.000 {method 'lower' of 'str' objects}\n 2 0.000 0.000 0.000 0.000 {method 'lstrip' of 'str' objects}\n 5617 0.009 0.000 0.009 0.000 {method 'match' of '_sre.SRE_Pattern' objects}\n 888 0.001 0.000 0.001 0.000 {method 'newbyteorder' of 'numpy.dtype' objects}\n 9619 0.002 0.000 0.002 0.000 {method 'pop' of 'dict' objects}\n 54795 0.029 0.000 0.029 0.000 {method 'pop' of 'list' objects}\n 19900 0.042 0.000 0.042 0.000 {method 'popitem' of 'collections.OrderedDict' objects}\n 129 0.000 0.000 0.000 0.000 {method 'popleft' of 'collections.deque' objects}\n 294 0.005 0.000 0.005 0.000 {method 'randint' of 'numpy.random.mtrand.RandomState' objects}\n 48 0.000 0.000 0.000 0.000 {method 'ravel' of 'numpy.ndarray' objects}\n 2 0.000 0.000 0.000 0.000 {method 'read' of '_io.FileIO' objects}\n 77 0.000 0.000 0.000 0.000 {method 'readline' of '_io.StringIO' objects}\n 1346 0.014 0.000 0.015 0.000 {method 'reduce' of 'numpy.ufunc' objects}\n 6 0.000 0.000 0.000 0.000 {method 'release' of '_multiprocessing.SemLock' objects}\n 8 0.000 0.000 0.000 0.000 {method 'release' of '_thread.RLock' objects}\n 19968 0.006 0.000 0.006 0.000 {method 'release' of '_thread.lock' objects}\n 964 0.000 0.000 0.000 0.000 {method 'remove' of 'set' objects}\n 50 0.000 0.000 0.000 0.000 {method 'replace' of 'str' objects}\n 2 0.000 0.000 0.000 0.000 {method 'reshape' of 'numpy.ndarray' objects}\n 6 0.000 0.000 0.000 0.000 {method 'rfind' of 'str' objects}\n 16 0.000 0.000 0.000 0.000 {method 'rpartition' of 'str' objects}\n 2 0.000 0.000 0.000 0.000 {method 'rsplit' of 'str' objects}\n 16 0.000 0.000 0.000 0.000 {method 'rstrip' of 'str' objects}\n 1 0.000 0.000 0.000 0.000 {method 'search' of '_sre.SRE_Pattern' objects}\n 3 0.000 0.000 0.000 0.000 {method 'seed' of 'numpy.random.mtrand.RandomState' objects}\n 38 0.000 0.000 0.000 0.000 {method 'setdefault' of 'dict' objects}\n 100 0.000 0.000 0.000 0.000 {method 'sort' of 'list' objects}\n 981 0.000 0.000 0.000 0.000 {method 'span' of '_sre.SRE_Match' objects}\n 24 0.000 0.000 0.000 0.000 {method 'split' of 'str' objects}\n 8159 0.002 0.000 0.002 0.000 {method 'startswith' of 'str' objects}\n 19 0.000 0.000 0.000 0.000 {method 'strip' of 'str' objects}\n 111 0.001 0.000 0.001 0.000 {method 'sub' of '_sre.SRE_Pattern' objects}\n 294 0.001 0.000 0.003 0.000 {method 'sum' of 'numpy.ndarray' objects}\n 1719 0.001 0.000 0.003 0.000 {method 'throw' of 'generator' objects}\n 4 0.000 0.000 0.000 0.000 {method 'to_bytes' of 'int' objects}\n 54 0.000 0.000 0.000 0.000 {method 'tostring' of 'numpy.ndarray' objects}\n 2227 0.001 0.000 0.001 0.000 {method 'update' of 'dict' objects}\n 9163 0.002 0.000 0.003 0.000 {method 'update' of 'set' objects}\n 321 0.000 0.000 0.000 0.000 {method 'upper' of 'str' objects}\n 272 0.000 0.000 0.000 0.000 {method 'values' of 'collections.OrderedDict' objects}\n 18050 0.006 0.000 0.006 0.000 {method 'values' of 'dict' objects}\n 145 0.000 0.000 0.000 0.000 {method 'values' of 'mappingproxy' objects}\n 2 0.000 0.000 0.000 0.000 {method 'write' of '_io.FileIO' objects}\n 431 0.000 0.000 0.000 0.000 {method 'write' of '_io.StringIO' objects}\n 2 0.000 0.000 0.000 0.000 {method 'write' of '_io.TextIOWrapper' objects}\n 295 0.010 0.000 0.010 0.000 {resize}\n 20 0.000 0.000 0.000 0.000 {tensorflow.python.framework.fast_tensor_util.AppendBoolArrayToTensorProto}\n 28 0.000 0.000 0.000 0.000 {tensorflow.python.framework.fast_tensor_util.AppendFloat32ArrayToTensorProto}\"\"\"",
"_____no_output_____"
],
[
"import pandas as pd\n\n# df_trace = pd.DataFrame([x.split()[:5]+[''.join(x.split()[5:])] for x in trace.split('\\n')[1:]], columns=['ncalls','tottime','percall','cumtime','percall_cum','filename'])\ndf_trace = pd.read_csv('trace.txt')\ndf_trace = df_trace.astype({'tottime':'float','percall':'float','cumtime':'float','percall_cum':'float'})",
"_____no_output_____"
],
[
"pd.set_option('max_colwidth', 800)",
"_____no_output_____"
],
[
"df_trace.sort_values(by=['tottime'],ascending=False).head(25)",
"_____no_output_____"
],
[
"pdb.pm()",
"> <ipython-input-51-8cf5eb3da8e0>(1)<module>()\n-> df_trace.sort_values(by=['tottime'],ascending=False).head(25)\n"
]
],
[
[
"#### Status\nSelf play runs! Now to check if it's actually doing what we want it to...",
"_____no_output_____"
]
],
[
[
"# Load the TensorBoard notebook extension.\n%load_ext tensorboard",
"_____no_output_____"
],
[
"# Launch TensorBoard and navigate to the Profile tab to view performance profile\n%tensorboard --logdir=logs",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1d9d3a710ddc0e4d3ed90629eef0de39064723
| 167,621 |
ipynb
|
Jupyter Notebook
|
day7/3. Assignment/.ipynb_checkpoints/assignment_7_conflict_mapping-checkpoint.ipynb
|
terratenney/csda1000_FT
|
47125741cf3137df350e209446afac284ce1dc40
|
[
"MIT"
] | null | null | null |
day7/3. Assignment/.ipynb_checkpoints/assignment_7_conflict_mapping-checkpoint.ipynb
|
terratenney/csda1000_FT
|
47125741cf3137df350e209446afac284ce1dc40
|
[
"MIT"
] | null | null | null |
day7/3. Assignment/.ipynb_checkpoints/assignment_7_conflict_mapping-checkpoint.ipynb
|
terratenney/csda1000_FT
|
47125741cf3137df350e209446afac284ce1dc40
|
[
"MIT"
] | 4 |
2018-06-06T16:09:16.000Z
|
2018-06-28T09:28:21.000Z
| 50.995132 | 21,876 | 0.487421 |
[
[
[
"%matplotlib inline\n\nimport pandas as pd\nimport geopandas\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"# Case study - Conflict mapping: mining sites in eastern DR Congo\n\nIn this case study, we will explore a dataset on artisanal mining sites located in eastern DR Congo.\n\n**Note**: this tutorial is meant as a hands-on session, and most code examples are provided as exercises to be filled in. I highly recommend actually trying to do this yourself, but if you want to follow the solved tutorial, you can find this in the `_solved` directory.\n\n---\n\n#### Background\n\n[IPIS](http://ipisresearch.be/), the International Peace Information Service, manages a database on mining site visits in eastern DR Congo: http://ipisresearch.be/home/conflict-mapping/maps/open-data/\n\nSince 2009, IPIS has visited artisanal mining sites in the region during various data collection campaigns. As part of these campaigns, surveyor teams visit mining sites in the field, meet with miners and complete predefined questionnaires. These contain questions about the mining site, the minerals mined at the site and the armed groups possibly present at the site.\n\nSome additional links:\n\n* Tutorial on the same data using R from IPIS (but without geospatial aspect): http://ipisresearch.be/home/conflict-mapping/maps/open-data/open-data-tutorial/\n* Interactive web app using the same data: http://www.ipisresearch.be/mapping/webmapping/drcongo/v5/",
"_____no_output_____"
],
[
"## 1. Importing and exploring the data",
"_____no_output_____"
],
[
"### The mining site visit data\n\nIPIS provides a WFS server to access the data. We can send a query to this server to download the data, and load the result into a geopandas GeoDataFrame:",
"_____no_output_____"
]
],
[
[
"import requests\nimport json\n\nwfs_url = \"http://geo.ipisresearch.be/geoserver/public/ows\"\nparams = dict(service='WFS', version='1.0.0', request='GetFeature',\n typeName='public:cod_mines_curated_all_opendata_p_ipis', outputFormat='json')\n\nr = requests.get(wfs_url, params=params)\ndata_features = json.loads(r.content.decode('UTF-8'))\ndata_visits = geopandas.GeoDataFrame.from_features(data_features)\ndata_visits",
"_____no_output_____"
]
],
[
[
"However, the data is also provided in the class folder as a GeoJSON file, so it is certainly available during the tutorial.",
"_____no_output_____"
],
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Read the GeoJSON file `data/cod_mines_curated_all_opendata_p_ipis.geojson` using geopandas, and call the result `data_visits`.</li>\n <li>Inspect the first 5 rows, and check the number of observations</li>\n </ul> \n\n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping3.py\ndata_visits = geopandas.read_file(\"./cod_mines_curated_all_opendata_p_ipis.geojson\")",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping4.py\ndata_visits.head()",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping5.py\nlen(data_visits)",
"_____no_output_____"
]
],
[
[
"The provided dataset contains a lot of information, much more than we are going to use in this tutorial. Therefore, we will select a subset of the column:",
"_____no_output_____"
]
],
[
[
"data_visits = data_visits[['vid', 'project', 'visit_date', 'name', 'pcode', 'workers_numb', 'interference', 'armed_group1', 'mineral1', 'geometry']]",
"_____no_output_____"
],
[
"data_visits.head()",
"_____no_output_____"
]
],
[
[
"Before starting the actual geospatial tutorial, we will use some more advanced pandas queries to construct a subset of the data that we will use further on: ",
"_____no_output_____"
]
],
[
[
"# Take only the data of visits by IPIS\ndata_ipis = data_visits[data_visits['project'].str.contains('IPIS') & (data_visits['workers_numb'] > 0)]",
"_____no_output_____"
],
[
"# For those mining sites that were visited multiple times, take only the last visit\ndata_ipis_lastvisit = data_ipis.sort_values('visit_date').groupby('pcode', as_index=False).last()\ndata = geopandas.GeoDataFrame(data_ipis_lastvisit, crs=data_visits.crs)",
"_____no_output_____"
]
],
[
[
"### Data on protected areas in the same region\n\nNext to the mining site data, we are also going to use a dataset on protected areas (national parks) in Congo. This dataset was downloaded from http://www.wri.org/our-work/project/congo-basin-forests/democratic-republic-congo#project-tabs and included in the tutorial repository: `data/cod_conservation.zip`.",
"_____no_output_____"
],
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Extract the `data/cod_conservation.zip` archive, and read the shapefile contained in it. Assign the resulting GeoDataFrame to a variable named `protected_areas`.</li>\n <li>Quickly plot the GeoDataFrame.</li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping10.py\n# or to read it directly from the zip file:\n# protected_areas = geopandas.read_file(\"/Conservation\", vfs=\"zip://./data/cod_conservation.zip\")",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping11.py\n",
"_____no_output_____"
]
],
[
[
"### Conversion to a common Coordinate Reference System\n\nWe will see that both datasets use a different Coordinate Reference System (CRS). For many operations, however, it is important that we use a consistent CRS, and therefore we will convert both to a commong CRS.\n\nBut first, we explore problems we can encounter related to CRSs.\n\n---",
"_____no_output_____"
],
[
"[Goma](https://en.wikipedia.org/wiki/Goma) is the capital city of North Kivu province of Congo, close to the border with Rwanda. It's coordinates are 1.66°S 29.22°E.\n\n<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Create a single Point object representing the location of Goma. Call this `goma`.</li>\n <li>Calculate the distances of all mines to Goma, and show the 5 smallest distances (mines closest to Goma).</li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping12.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping13.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping14.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping15.py",
"_____no_output_____"
]
],
[
[
"The distances we see here in degrees, which is not helpful for interpreting those distances. That is a reason we will convert the data to another coordinate reference system (CRS) for the remainder of this tutorial.",
"_____no_output_____"
],
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Make a visualization of the national parks and the mining sites on a single plot.</li>\n </ul> \n \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping16.py\nax = protected_areas.plot()\ndata.plot(ax=ax, color='C1')",
"_____no_output_____"
]
],
[
[
"You will notice that the protected areas and mining sites do not map to the same area on the plot. This is because the Coordinate Reference Systems (CRS) differ for both datasets. Another reason we will need to convert the CRS!\n\nLet's check the Coordinate Reference System (CRS) for both datasets.\n\nThe mining sites data uses the [WGS 84 lat/lon (EPSG 4326)](http://spatialreference.org/ref/epsg/4326/) CRS:",
"_____no_output_____"
]
],
[
[
"data.crs",
"_____no_output_____"
]
],
[
[
"The protected areas dataset, on the other hand, uses a [WGS 84 / World Mercator (EPSG 3395)](http://spatialreference.org/ref/epsg/wgs-84-world-mercator/) projection (with meters as unit):",
"_____no_output_____"
]
],
[
[
"protected_areas.crs",
"_____no_output_____"
]
],
[
[
"We will convert both datasets to a local UTM zone, so we can plot them together and that distance-based calculations give sensible results.\n\nTo find the appropriate UTM zone, you can check http://www.dmap.co.uk/utmworld.htm or https://www.latlong.net/lat-long-utm.html, and in this case we will use UTM zone 35, which gives use EPSG 32735: https://epsg.io/32735\n\n<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Convert both datasets (`data` and `protected_areas`) to EPSG 32735. Name the results `data_utm` and `protected_areas_utm`.</li>\n <li>Try again to visualize both datasets on a single map.</li>\n </ul> \n\n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping19.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping20.py",
"_____no_output_____"
]
],
[
[
"### More advanced visualizations\n\n<p>For the following exercises, check the first section of the [04-more-on-visualization.ipynb](04-more-on-visualization.ipynb) notebook for tips and tricks to plot with GeoPandas.</p>",
"_____no_output_____"
],
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Make a visualization of the national parks and the mining sites on a single plot.</li>\n <li>Pay attention to the following details:\n <ul>\n <li>Make the figure a bit bigger.</li>\n <li>The protected areas should be plotted in green</li>\n <li>For plotting the mining sites, adjust the markersize and use an `alpha=0.5`.</li>\n <li>Remove the figure border and x and y labels (coordinates)</li>\n </ul> \n </li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping21.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping22.py",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n \n In addition to the previous figure:\n <ul>\n <li>Give the mining sites a distinct color based on the `'interference'` column, indicating whether an armed group is present at the mining site or not.</li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping23.py",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n \n In addition to the previous figure:\n <ul>\n <li>Give the mining sites a distinct color based on the `'mineral1'` column, indicating which mineral is the primary mined mineral.</li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping24.py",
"_____no_output_____"
]
],
[
[
"## 2. Spatial operations",
"_____no_output_____"
],
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n \n <ul>\n <li>Access the geometry of the \"Kahuzi-Biega National park\".</li>\n <li>Filter the mining sites to select those that are located in this national park.</li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping25.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping26.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping27.py",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-success\">\n <b>EXERCISE</b>: Determine for each mining site the \"closest\" protected area:\n \n <ul>\n <li> PART 1 - do this for a single mining site:\n <ul>\n <li>Get a single mining site, e.g. the first of the dataset.</li>\n <li>Calculate the distance (in km's) to all protected areas for this mining site</li>\n <li>Get the index of the minimum distance (tip: `idxmin()`) and get the name of the protected are corresponding to this index.</li>\n </ul> \n </li>\n <li> PART 2 - apply this procedure on each geometry:\n <ul>\n <li>Write the above procedure as a function that gets a single site and the protected areas dataframe as input and returns the name of the closest protected area as output.</li>\n <li>Apply this function to all sites using the `.apply()` method on `data_utm.geometry`.</li>\n </ul> \n </li>\n </ul> \n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping28.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping29.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping30.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping31.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping32.py",
"_____no_output_____"
]
],
[
[
"## 3. Using spatial join to determine mining sites in the protected areas\n\nBased on the analysis and visualizations above, we can already see that there are mining sites inside the protected areas. Let's now do an actual spatial join to determine which sites are within the protected areas.",
"_____no_output_____"
],
[
"### Mining sites in protected areas\n\n<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Add information about the protected areas to the mining sites dataset, using a spatial join:\n <ul>\n <li>Call the result `data_within_protected`</li>\n <li>If the result is empty, this is an indication that the coordinate reference system is not matching. Make sure to re-project the data (see above).</li>\n \n </ul>\n </li>\n <li>How many mining sites are located within a national park?</li>\n <li>Count the number of mining sites per national park (pandas tip: check `value_counts()`)</li>\n\n </ul> \n\n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping33.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping34.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping35.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping36.py",
"_____no_output_____"
]
],
[
[
"### Mining sites in the borders of protected areas\n\nAnd what about the borders of the protected areas? (just outside the park)\n\n<div class=\"alert alert-success\">\n <b>EXERCISE</b>:\n <ul>\n <li>Create a new dataset, `protected_areas_borders`, that contains the border area (10 km wide) of each protected area:\n <ul>\n <li>Tip: one way of doing this is with the `buffer` and `difference` function.</li>\n <li>Plot the resulting borders as a visual check of correctness.</li>\n </ul>\n </li>\n <li>Count the number of mining sites per national park that are located within its borders</li>\n\n </ul> \n\n</div>",
"_____no_output_____"
]
],
[
[
"# %load _solved/solutions/case-conflict-mapping37.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping38.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping39.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping40.py",
"_____no_output_____"
],
[
"# %load _solved/solutions/case-conflict-mapping41.py",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a1daaba60e393f13580468d89de4aab1167b01f
| 646,881 |
ipynb
|
Jupyter Notebook
|
notebooks/3_Preprocessing_geometry.ipynb
|
covid-frame/covid-frame
|
32d50cafa3ba3388cd44cdb49136727b870def62
|
[
"Apache-2.0"
] | null | null | null |
notebooks/3_Preprocessing_geometry.ipynb
|
covid-frame/covid-frame
|
32d50cafa3ba3388cd44cdb49136727b870def62
|
[
"Apache-2.0"
] | null | null | null |
notebooks/3_Preprocessing_geometry.ipynb
|
covid-frame/covid-frame
|
32d50cafa3ba3388cd44cdb49136727b870def62
|
[
"Apache-2.0"
] | null | null | null | 630.488304 | 228,272 | 0.948776 |
[
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"BASE_PATH=\"/mnt/Archivos/dataset-xray\"",
"_____no_output_____"
],
[
"from pathlib import Path\nfrom covidframe.tools.load import load_database",
"_____no_output_____"
],
[
"base_dir = Path(BASE_PATH)\nDEFAULT_DATABASE_NAME_TRAIN = \"database_clean_balanced_train.metadata.csv\"\nDEFAULT_DATABASE_NAME_TEST = \"database_clean_balanced_test.metadata.csv\"",
"_____no_output_____"
],
[
"df_train = load_database(filename= base_dir / DEFAULT_DATABASE_NAME_TRAIN)\ndf_test = load_database(filename= base_dir / DEFAULT_DATABASE_NAME_TEST)",
"_____no_output_____"
],
[
"from covidframe.tools.image import load_image",
"_____no_output_____"
],
[
"df_train[\"vector\"]= df_train[\"image_path\"].apply(lambda x: load_image(x))",
"_____no_output_____"
],
[
"df_train[\"vector\"]",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"df_train[\"size\"] = df_train[\"vector\"].apply(lambda x: x.shape)",
"_____no_output_____"
],
[
"df_train[\"size\"]",
"_____no_output_____"
],
[
"df_train[\"size\"].mode",
"_____no_output_____"
],
[
"df_train[\"is_squared\"] = df_train[\"size\"].apply(lambda x: x[0]==x[1])",
"_____no_output_____"
],
[
"df_train['is_squared'] = df_train['is_squared'].astype('category')",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"plt.imshow(df_train[\"vector\"].iloc[0],cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"fig = plt.figure()\nax = fig.add_subplot(1,1,1)\nsns.histplot(data=df_train, ax=ax,y=\"is_squared\", hue=\"category\",multiple=\"stack\")",
"_____no_output_____"
],
[
"df_train['aspect_ratio'] = df_train[\"size\"].apply(lambda x: x[1]/x[0])",
"_____no_output_____"
],
[
"fig = plt.figure()\nax = fig.add_subplot(1,1,1)\nsns.histplot(data=df_train[df_train[\"aspect_ratio\"]!=1], ax=ax,x=\"aspect_ratio\", hue=\"category\",multiple=\"stack\")",
"_____no_output_____"
],
[
"test_image = df_train[\"vector\"].iloc[0]",
"_____no_output_____"
],
[
"test_image.shape[0]",
"_____no_output_____"
],
[
"from covidframe.tools.image import crop_image",
"_____no_output_____"
],
[
"n_image = crop_image(test_image, (200,200))",
"_____no_output_____"
],
[
"n_image.shape",
"_____no_output_____"
],
[
"plt.imshow(n_image,cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"from covidframe.tools.image import to_equal_aspect_ratio",
"_____no_output_____"
],
[
"eq_aspect = to_equal_aspect_ratio(test_image)",
"_____no_output_____"
],
[
"eq_aspect.shape",
"_____no_output_____"
],
[
"plt.imshow(eq_aspect,cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"element = df_train[df_train[\"aspect_ratio\"]>1.2].iloc[0]",
"_____no_output_____"
],
[
"nq_image = element[\"vector\"]",
"_____no_output_____"
],
[
"plt.imshow(nq_image,cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"nq_image.shape",
"_____no_output_____"
],
[
"n_image = to_equal_aspect_ratio(nq_image)",
"_____no_output_____"
],
[
"n_image.shape",
"_____no_output_____"
],
[
"plt.imshow(n_image,cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"from covidframe.tools.image import resize_image",
"_____no_output_____"
],
[
"r_image = resize_image(n_image,(299,299))",
"_____no_output_____"
],
[
"plt.imshow(r_image,cmap=\"Greys_r\")",
"_____no_output_____"
],
[
"r_image.shape",
"_____no_output_____"
],
[
"interpolations = [\"linear\", \"area\", \"nearest\", \"cubic\"]",
"_____no_output_____"
],
[
"images = [resize_image(n_image,(299,299), interpolation) for interpolation in interpolations]",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(12,12))\naxes = fig.subplots(ncols=2,nrows=2)\n\nfor ax, image, interpolation in zip(axes.ravel(), images, interpolations):\n ax.imshow(image,cmap=\"Greys_r\")\n ax.set_title(f\"{interpolation} interpolation\")",
"_____no_output_____"
],
[
"from covidframe.plot.image import plot_histogram",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(12,12))\naxes = fig.subplots(ncols=2,nrows=2)\n\nfor ax, image, interpolation in zip(axes.ravel(), images, interpolations):\n plot_histogram(image, ax=ax)\n ax.set_title(f\"{interpolation} interpolation\")",
"_____no_output_____"
],
[
"NEW_SIZE = (299,299)",
"_____no_output_____"
],
[
"df_train[\"resized\"] = df_train[\"vector\"].apply(lambda x: resize_image(to_equal_aspect_ratio(x), NEW_SIZE))",
"_____no_output_____"
],
[
"df_train[\"new_size\"] = df_train[\"resized\"].apply(lambda x: x.shape)",
"_____no_output_____"
],
[
"df_train[\"new_size\"].unique()",
"_____no_output_____"
],
[
"np.stack(df_train[\"resized\"]).shape",
"_____no_output_____"
],
[
"from covidframe.integrate import process_images_in_df, load_images_in_df, describe_images_in_df",
"_____no_output_____"
],
[
"n_df_test = process_images_in_df(df_test, NEW_SIZE)",
"Loading images into dataframe\nDescribing images\nResizing images in dataframe\n"
],
[
"df_train[\"is_squared\"] = df_train[\"is_squared\"].astype(\"bool\")",
"_____no_output_____"
],
[
"n_df_test[\"is_squared\"] = n_df_test[\"is_squared\"].astype(\"bool\")",
"_____no_output_____"
],
[
"IMAGE_DF_TRAIN_NAME = \"database_balanced_train.h5\"\nIMAGE_DF_TEST_NAME = \"database_balanced_test.h5\"",
"_____no_output_____"
],
[
"from covidframe.tools.save import save_database_to_hdf",
"_____no_output_____"
],
[
"save_database_to_hdf(df_train.drop(columns=\"vector\"), base_dir / IMAGE_DF_TRAIN_NAME)",
"/home/luighi/.local/lib/python3.9/site-packages/pandas/core/generic.py:2703: PerformanceWarning: \nyour performance may suffer as PyTables will pickle object types that it cannot\nmap directly to c-types [inferred_type->mixed,key->block0_values] [items->Index(['image_path', 'image_name', 'original_category', 'id', 'type', 'source',\n 'folder_name', 'im_hash', 'original_image_path', 'original_image_name',\n 'category', 'size', 'resized', 'new_size'],\n dtype='object')]\n\n pytables.to_hdf(\n"
],
[
"save_database_to_hdf(n_df_test.drop(columns=\"vector\"), base_dir / IMAGE_DF_TEST_NAME)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1dc0116444ab2829cad05a4fd18aa7f9d74f7e
| 68,614 |
ipynb
|
Jupyter Notebook
|
Notebooks/Notebook.ipynb
|
cdiazbas/LMpyMilne
|
dde4251d57eceb48c4726fc329781060f281391f
|
[
"MIT"
] | null | null | null |
Notebooks/Notebook.ipynb
|
cdiazbas/LMpyMilne
|
dde4251d57eceb48c4726fc329781060f281391f
|
[
"MIT"
] | null | null | null |
Notebooks/Notebook.ipynb
|
cdiazbas/LMpyMilne
|
dde4251d57eceb48c4726fc329781060f281391f
|
[
"MIT"
] | null | null | null | 241.598592 | 36,664 | 0.896217 |
[
[
[
"# Milne",
"_____no_output_____"
]
],
[
[
"#All libraries necesary:\n%matplotlib inline\nimport matplotlib\nmatplotlib.rcParams['figure.figsize'] = (10, 6)\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom math import pi, sin, cos\nfrom copy import deepcopy\nfrom mutils2 import *\nimport time\n# import seaborn\nfrom milne import *",
"_____no_output_____"
],
[
"# PARAMETROS:\nnlinea = 3 # Numero linea en fichero\nx = np.arange(-2.8,2.8,20e-3) # Array Longitud de onda\nB = 992. # Campo magnetico\ngamma = np.deg2rad(134.) # Inclinacion\nxi = np.deg2rad(145.) # Angulo azimutal\nvlos = 0.0 # velocidad km/s\neta0 = 73. # Cociente de abs linea-continuo\na = 0.2 # Parametro de amortiguamiento\nddop = 0.02 # Anchura Doppler\n# Sc = 4.0 # Cociente Gradiente y Ordenada de la funcion fuente\nS_0=0.5 # Ordenada de la funcion fuente\nS_1=0.5 # Gradiente de la funcion fuente\n\nparam = paramLine(nlinea)\nstokes = stokesSyn(param,x,B,gamma,xi,vlos,eta0,a,ddop,S_0,S_1)\nfor i in range(4):\n plt.subplot(2,2,i+1)\n if i == 0: plt.ylim(0,1.1)\n plt.plot(x,stokes[i])\n plt.plot([0,0],[min(stokes[i]),max(stokes[i])],'k--')",
"----------------------------------------------------\nElement = SI1\nlambda0 = 10827.089\nju=2.0, lu=1, su=1.0\njl=2.0, ll=1, sl=1.0\ng_u = 1.50\ng_l = 1.50\ngeff = 1.50\n"
]
],
[
[
"# LM- Milne",
"_____no_output_____"
]
],
[
[
"from lmfit import minimize, Parameters, fit_report\nfrom LMmilne import *",
"_____no_output_____"
],
[
" # PARAMETROS:\n nlinea = 3 # Numero linea en fichero\n x = arange(-0.3, 0.3, 1e-2) # Array Longitud de onda\n B = 600. # Campo magnetico\n gamma = rad(30.) # Inclinacion\n xi = rad(160.) # Angulo azimutal\n vlos = 1.1\n eta0 = 3. # Cociente de abs linea-continuo\n a = 0.2 # Parametro de amortiguamiento\n ddop = 0.05 # Anchura Doppler\n S_0 = 0.3 # Ordenada de la funcion fuente\n S_1 = 0.6 # Gradiente de la funcion fuente\n Chitol = 1e-6\n Maxifev = 280\n pesoI = 1.\n pesoQ = 4.\n pesoU = 4.\n pesoV = 2.\n param = paramLine(nlinea)\n\n # Array de valores iniciales\n p=[B,gamma,xi,vlos,eta0,a,ddop,S_0,S_1]\n\n # Cargamos los datos:\n y2 = np.load('Profiles/stoke2.npy')\n x = np.arange(-2.8,2.8,20e-3)\n yc = list(y2[0])+list(y2[1])+list(y2[2])+list(y2[3])\n time0 = time.time()\n \n # Modulo Initial conditions:\n iB, igamma, ixi = initialConditions(y2,nlinea,x,param)\n ixi = rad(( grad(ixi) + 180. ) % 180.)\n igamma = rad(( grad(igamma) + 180. ) % 180.)\n\n # Array de valores iniciales\n p=[iB,igamma,ixi,vlos,eta0,a,ddop,S_0,S_1]\n \n \n ps = max(y2[0])/max(list(y2[1])+list(y2[2]))\n #print('Peso Q,U sugerido:',ps)\n pesoV = 1./max(y2[3])\n pesoQ = 1./max(y2[1])\n pesoU = 1./max(y2[2])\n \n print('----------------------------------------------------')\n print('pesos V: {0:2.3f}'.format(pesoV))\n print('pesos Q,U: {0:2.3f}, {1:2.3f}'.format(pesoQ, pesoU))\n\n # Establecemos los pesos\n peso = ones(len(yc))\n peso[0:int(len(yc)/4)] = pesoI\n peso[int(len(yc)/4):int(3*len(yc)/4)] = pesoQ\n peso[int(2*len(yc)/4):int(3*len(yc)/4)] = pesoU\n peso[int(3*len(yc)/4):] = pesoV\n\n\n print('--------------------------------------------------------------------')\n\n from math import pi\n p0 = Parameters()\n p0.add('B', value=p[0], min=50.0, max= 2000.)\n p0.add('gamma', value=p[1], min=0., max = pi)\n p0.add('xi', value=p[2], min=0., max = pi)\n p0.add('vlos', value=p[3], min=-20., max =+20.)\n p0.add('eta0', value=p[4], min=0., max = 6.)\n p0.add('a', value=p[5], min=0., max = 0.5)\n p0.add('ddop', value=p[6], min=0.0, max = 0.5)\n p0.add('S_0', value=p[7], min=0.0, max = 1.5)\n p0.add('S_1', value=p[8], min=0.0, max = 1.5)\n \n stokes0 = stokesSyn(param,x,B,gamma,xi,vlos,eta0,a,ddop,S_0,S_1)\n \n [ysync, out] = inversionStokes(p0,x,yc,param,Chitol,Maxifev,peso)\n print('Time: {0:2.4f} s'.format(time.time()-time0)) \n print(fit_report(out, show_correl=False))\n\n\n # plot section:\n import matplotlib.pyplot as plt\n\n stokes = list(split(yc, 4))\n synthetic = list(split(ysync, 4))\n for i in range(4):\n plt.subplot(2,2,i+1)\n if i == 0: plt.ylim(0,1.1)\n plt.plot(x,stokes0[i],'g-', alpha=0.5)\n plt.plot(x,stokes[i],'k-',alpha =0.8)\n plt.plot(x,synthetic[i],'r-')",
"----------------------------------------------------\nElement = SI1\nlambda0 = 10827.089\nju=2.0, lu=1, su=1.0\njl=2.0, ll=1, sl=1.0\ng_u = 1.50\ng_l = 1.50\ngeff = 1.50\n----------------------------------------------------\npesos V: 16.679\npesos Q,U: 222.988, 160.273\n--------------------------------------------------------------------\nTime: 0.4116 s\n[[Fit Statistics]]\n # fitting method = leastsq\n # function evals = 189\n # data points = 1120\n # variables = 9\n chi-square = 0.00139241\n reduced chi-square = 1.2533e-06\n Akaike info crit = -15211.5414\n Bayesian info crit = -15166.3516\n[[Variables]]\n B: 605.985184 +/- 10.8665473 (1.79%) (init = 639.9538)\n gamma: 2.50077659 +/- 0.01514764 (0.61%) (init = 2.348586)\n xi: 1.53647617 +/- 0.03602136 (2.34%) (init = 1.952555)\n vlos: -0.24451874 +/- 0.03604944 (14.74%) (init = 1.1)\n eta0: 5.99999996 +/- 0.14417288 (2.40%) (init = 3)\n a: 0.50000000 +/- 0.01040380 (2.08%) (init = 0.2)\n ddop: 0.05978797 +/- 0.00224040 (3.75%) (init = 0.05)\n S_0: 0.42127235 +/- 0.00532242 (1.26%) (init = 0.3)\n S_1: 0.53512280 +/- 0.00555264 (1.04%) (init = 0.6)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1dc942e1daeeec35b5b924772684fafb040e09
| 460,944 |
ipynb
|
Jupyter Notebook
|
notebooks/IMDB/IMDB Fastext.ipynb
|
apmoore1/calibration
|
96b77432ac0aa582165d2012fb738377ec17d1f5
|
[
"MIT"
] | null | null | null |
notebooks/IMDB/IMDB Fastext.ipynb
|
apmoore1/calibration
|
96b77432ac0aa582165d2012fb738377ec17d1f5
|
[
"MIT"
] | null | null | null |
notebooks/IMDB/IMDB Fastext.ipynb
|
apmoore1/calibration
|
96b77432ac0aa582165d2012fb738377ec17d1f5
|
[
"MIT"
] | null | null | null | 275.354839 | 42,120 | 0.826272 |
[
[
[
"import math\n\nfrom tensorflow.python.keras.datasets import imdb\nfrom tensorflow.python.keras.preprocessing import sequence\nfrom tensorflow.python.keras import layers\nfrom tensorflow.python.keras.models import Sequential\n\nimport numpy as np\n\nfrom sklearn.calibration import calibration_curve\nfrom sklearn import metrics",
"/home/andrew/Envs/calibration/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
],
[
"def ece(predictions, confidences, labels, n_bins=10, max_ece=False):\n # Get the different bins\n bins = np.linspace(0, 1, n_bins + 1)\n low_bins = bins[:-1]\n up_bins = bins[1:]\n all_bins = zip(low_bins, up_bins)\n \n num_samples = predictions.shape[0]\n ece_bin_values = []\n # For each bin work out the weighted difference between \n # confidence and accuracy\n for low_bin, up_bin in all_bins:\n bin_conf_indcies = np.nonzero((confidences > low_bin) &\n (confidences <= up_bin))\n bin_confs = confidences[bin_conf_indcies]\n bin_preds = predictions[bin_conf_indcies]\n bin_labels = labels[bin_conf_indcies]\n \n num_samples_in_bin = bin_confs.shape[0]\n if num_samples_in_bin == 0:\n ece_bin_values.append(0)\n continue\n bin_weight = num_samples_in_bin / num_samples\n \n bin_acc = (bin_labels == bin_preds).mean()\n bin_mean_conf = bin_confs.mean()\n \n bin_acc_conf_diff = abs(bin_acc - bin_mean_conf)\n weighted_diff = bin_weight * bin_acc_conf_diff\n ece_bin_values.append(weighted_diff)\n # Return the max ece or the weighted average\n print(' '.join([f'{ece_value:.2f}'for ece_value in ece_bin_values]))\n if max_ece:\n return max(ece_bin_values)\n else:\n total_weighted_ece = sum(ece_bin_values)\n return total_weighted_ece",
"_____no_output_____"
],
[
"def adapt_ece(confidences, labels, samples_per_bin=250, root_error=False):\n label_conf = list(zip(labels, confidences))\n sorted_label_conf = sorted(label_conf, key=lambda x: x[1])\n num_samples = confidences.shape[0]\n bin_indexs = list(range(0, num_samples, samples_per_bin))\n # Merge the last bin with the second to last bin\n bin_indexs.append((num_samples + 1))\n low_bins = bin_indexs[:-1]\n up_bins = bin_indexs[1:]\n all_bins = list(zip(low_bins, up_bins))\n number_bins = len(all_bins)\n ece_bin_values = []\n for low_bin, up_bin in all_bins:\n bin_label_conf = sorted_label_conf[low_bin : up_bin]\n bin_label = np.array([label for label, conf in bin_label_conf])\n bin_conf = np.array([conf for label, conf in bin_label_conf])\n bin_size = bin_conf.shape[0]\n bin_mean_conf = bin_conf.mean()\n bin_mean_label = bin_label.mean()\n bin_mse = math.pow((bin_mean_conf - bin_mean_label), 2)\n bin_mse = bin_mse * bin_size\n ece_bin_values.append(bin_mse)\n print(' '.join([f'{ece_value:.2f}'for ece_value in ece_bin_values]))\n ece_error = sum(ece_bin_values) / num_samples\n if root_error:\n return math.sqrt(ece_error)\n else:\n return ece_error\n ",
"_____no_output_____"
],
[
"ngram_range = 1\nmax_features = 20000\nmaxlen = 400\nbatch_size = 32\nembedding_dims = 50\nepochs = 5\nprint('Loading data...')\n(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features,\n seed=113)\nprint(len(x_train), 'train sequences')\nprint(len(x_test), 'test sequences')\nprint(f'Average train sequence length: {np.mean(list(map(len, x_train)))}')\nprint(f'Average test sequence length: {np.mean(list(map(len, x_test)))}')",
"Loading data...\n25000 train sequences\n25000 test sequences\nAverage train sequence length: 238.71364\nAverage test sequence length: 230.8042\n"
],
[
"# This makes all of the sequences the same size\nprint('Pad sequences (samples x time)')\nx_train = sequence.pad_sequences(x_train, maxlen=maxlen)\nx_test = sequence.pad_sequences(x_test, maxlen=maxlen)\nprint('x_train shape:', x_train.shape)\nprint('x_test shape:', x_test.shape)",
"Pad sequences (samples x time)\nx_train shape: (25000, 400)\nx_test shape: (25000, 400)\n"
],
[
"model = Sequential()\n\n# we start off with an efficient embedding layer which maps\n# our vocab indices into embedding_dims dimensions\nmodel.add(layers.Embedding(max_features,\n embedding_dims,\n input_length=maxlen))\n\n# we add a GlobalAveragePooling1D, which will average the embeddings\n# of all words in the document\nmodel.add(layers.GlobalAveragePooling1D())\n\n# We project onto a single unit output layer, and squash it with a sigmoid:\nmodel.add(layers.Dense(1, activation='sigmoid'))\n\nmodel.compile(loss='binary_crossentropy',\n optimizer='adam',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"train_eces = []\ntrain_max_eces = []\ntrain_accs = []\ntrain_briers = []\ntrain_cross_entropys = []\ntrain_abs_calibration = []\ntrain_mse_calibration = []\ntrain_adapt_eces = []\ntrain_adapt_rmse_eces = []\n\n\n\nval_eces = []\nval_max_eces = []\nval_accs = []\nvalid_briers = []\nval_cross_entropys = []\nvalid_abs_calibration = []\nvalid_mse_calibration = []\nval_adapt_eces = []\nval_adapt_rmse_eces = []\n\n\nfor j in range(1, 50):\n print(f'epoch {j}')\n model.fit(x_train, y_train,\n batch_size=batch_size,\n epochs=1,\n validation_data=(x_test, y_test))\n \n preds_train = model.predict(x_train)\n preds_val = model.predict(x_test)\n \n conf_train = preds_train.max(axis=1)\n conf_val = preds_val.max(axis=1)\n \n preds_train_labels = np.round(preds_train).reshape(preds_train.shape[0],)\n preds_val_labels = np.round(preds_val).reshape(preds_val.shape[0],)\n\n \n train_ece = ece(preds_train_labels, conf_train, y_train, n_bins=15)\n train_eces.append(train_ece)\n train_max_ece = ece(preds_train_labels, conf_train, y_train, max_ece=True, n_bins=15)\n train_max_eces.append(train_max_ece)\n train_adapt_ece = adapt_ece(conf_train, y_train)\n train_adapt_eces.append(train_adapt_ece)\n train_adapt_rmse_ece = adapt_ece(conf_train, y_train, root_error=True)\n train_adapt_rmse_eces.append(train_adapt_rmse_ece)\n train_cat_acc = metrics.accuracy_score(y_train, preds_train_labels)\n train_accs.append(train_cat_acc)\n train_cross_entropy = metrics.log_loss(y_train, preds_train)\n train_cross_entropys.append(train_cross_entropy)\n train_brier = metrics.brier_score_loss(y_train, preds_train)\n train_briers.append(train_brier)\n \n train_empirical_probs, train_predicted_probs= calibration_curve(y_train , conf_train,n_bins=15)\n train_abs_cal = abs(train_empirical_probs - train_predicted_probs).mean()\n train_mse_cal = ((train_empirical_probs - train_predicted_probs)**2).mean()\n train_abs_calibration.append(train_abs_cal)\n train_mse_calibration.append(train_mse_cal)\n print(f'Train: ece {train_ece:.2f} max ece {train_max_ece:.2f} acc '\n f'{train_cat_acc:.2f} entropy {train_cross_entropy:.2f} '\n f'brier {train_brier:.2f} adapt {train_adapt_ece:.2f} '\n f'cal abs {train_abs_cal:.2f} cal mse {train_mse_cal:.2f}')\n \n val_ece = ece(preds_val_labels, conf_val, y_test, n_bins=15)\n val_eces.append(val_ece)\n val_max_ece = ece(preds_val_labels, conf_val, y_test, max_ece=True, n_bins=15)\n val_max_eces.append(val_max_ece)\n val_adapt_ece = adapt_ece(conf_val, y_test)\n val_adapt_eces.append(val_adapt_ece)\n val_adapt_rmse_ece = adapt_ece(conf_val, y_test, root_error=True)\n val_adapt_rmse_eces.append(val_adapt_rmse_ece)\n val_cat_acc = metrics.accuracy_score(y_test, preds_val_labels)\n val_accs.append(val_cat_acc)\n val_cross_entropy = metrics.log_loss(y_test, preds_val)\n val_cross_entropys.append(val_cross_entropy)\n valid_brier = metrics.brier_score_loss(y_test, preds_val)\n valid_briers.append(valid_brier)\n \n valid_empirical_probs, valid_predicted_probs= calibration_curve(y_test , conf_val,n_bins=15)\n val_abs_cal = abs(valid_empirical_probs - valid_predicted_probs).mean()\n val_mse_cal = ((valid_empirical_probs-valid_predicted_probs)**2).mean()\n valid_abs_calibration.append(val_abs_cal)\n valid_mse_calibration.append(val_mse_cal)\n print(f'Val: ece {val_ece:.2f} max ece {val_max_ece:.2f} '\n f'acc {val_cat_acc:.2f} entropy {val_cross_entropy:.2f} '\n f'brier {valid_brier:.2f} adapt {val_adapt_ece:.2f} '\n f'cal abs {val_abs_cal:.2f} cal mse {val_mse_cal:.2f}')",
"epoch 1\nTrain on 25000 samples, validate on 25000 samples\nEpoch 1/1\n25000/25000 [==============================] - 36s 1ms/step - loss: 0.6689 - acc: 0.6694 - val_loss: 0.6395 - val_acc: 0.7770\n0.00 0.00 0.00 0.00 0.00 0.02 0.11 0.09 0.07 0.01 0.00 0.00 0.00 0.00 0.00\n0.00 0.00 0.00 0.00 0.00 0.02 0.11 0.09 0.07 0.01 0.00 0.00 0.00 0.00 0.00\n22.54 28.19 28.86 30.72 26.09 29.16 30.11 33.04 32.32 34.42 26.69 30.66 30.43 32.31 27.23 25.64 27.29 29.00 27.98 20.26 24.73 21.99 18.84 18.01 19.34 17.94 13.17 15.28 20.27 13.73 19.03 15.05 15.72 7.07 5.30 7.66 9.25 9.00 8.01 6.10 9.36 5.69 4.90 3.44 0.09 3.36 0.71 0.17 0.57 0.04 0.02 0.00 0.06 0.12 0.11 0.32 4.26 3.68 0.58 3.53 3.00 5.81 6.33 6.88 7.11 10.35 15.66 19.19 12.08 18.30 21.51 17.95 27.34 25.17 28.21 35.06 22.64 27.45 23.40 36.95 31.48 28.44 30.89 29.18 31.63 31.27 35.22 37.08 38.14 36.87 32.62 32.76 36.58 39.67 35.60 42.17 39.17 35.79 38.00 33.83\n22.54 28.19 28.86 30.72 26.09 29.16 30.11 33.04 32.32 34.42 26.69 30.66 30.43 32.31 27.23 25.64 27.29 29.00 27.98 20.26 24.73 21.99 18.84 18.01 19.34 17.94 13.17 15.28 20.27 13.73 19.03 15.05 15.72 7.07 5.30 7.66 9.25 9.00 8.01 6.10 9.36 5.69 4.90 3.44 0.09 3.36 0.71 0.17 0.57 0.04 0.02 0.00 0.06 0.12 0.11 0.32 4.26 3.68 0.58 3.53 3.00 5.81 6.33 6.88 7.11 10.35 15.66 19.19 12.08 18.30 21.51 17.95 27.34 25.17 28.21 35.06 22.64 27.45 23.40 36.95 31.48 28.44 30.89 29.18 31.63 31.27 35.22 37.08 38.14 36.87 32.62 32.76 36.58 39.67 35.60 42.17 39.17 35.79 38.00 33.83\nTrain: ece 0.30 max ece 0.11 acc 0.79 entropy 0.63 brier 0.22 adapt 0.08 cal abs 0.30 cal mse 0.10\n0.00 0.00 0.00 0.00 0.00 0.02 0.10 0.09 0.06 0.00 0.00 0.00 0.00 0.00 0.00\n0.00 0.00 0.00 0.00 0.00 0.02 0.10 0.09 0.06 0.00 0.00 0.00 0.00 0.00 0.00\n24.95 24.69 23.93 27.43 23.55 27.80 30.07 30.20 26.18 28.10 32.18 29.25 25.13 26.86 30.69 26.41 27.47 26.53 20.15 21.00 20.69 15.58 21.21 17.56 24.13 14.43 13.20 16.33 8.21 10.27 16.40 8.60 5.11 8.86 7.88 6.32 9.25 5.60 6.64 6.10 6.20 1.71 1.60 1.82 0.98 2.30 0.27 0.29 1.27 0.02 0.05 0.60 0.14 2.06 0.12 0.41 1.13 1.38 2.36 8.84 3.78 6.23 7.81 6.69 9.45 9.73 11.25 13.32 14.59 16.95 15.28 14.65 21.43 11.62 18.80 25.12 23.03 24.69 22.63 23.00 28.52 26.29 32.17 25.11 28.78 31.92 30.86 29.78 36.63 24.37 30.51 32.86 39.09 38.35 35.87 33.34 33.61 37.19 37.18 31.97\n24.95 24.69 23.93 27.43 23.55 27.80 30.07 30.20 26.18 28.10 32.18 29.25 25.13 26.86 30.69 26.41 27.47 26.53 20.15 21.00 20.69 15.58 21.21 17.56 24.13 14.43 13.20 16.33 8.21 10.27 16.40 8.60 5.11 8.86 7.88 6.32 9.25 5.60 6.64 6.10 6.20 1.71 1.60 1.82 0.98 2.30 0.27 0.29 1.27 0.02 0.05 0.60 0.14 2.06 0.12 0.41 1.13 1.38 2.36 8.84 3.78 6.23 7.81 6.69 9.45 9.73 11.25 13.32 14.59 16.95 15.28 14.65 21.43 11.62 18.80 25.12 23.03 24.69 22.63 23.00 28.52 26.29 32.17 25.11 28.78 31.92 30.86 29.78 36.63 24.37 30.51 32.86 39.09 38.35 35.87 33.34 33.61 37.19 37.18 31.97\nVal: ece 0.29 max ece 0.10 acc 0.78 entropy 0.64 brier 0.22 adapt 0.07 cal abs 0.29 cal mse 0.09\nepoch 2\nTrain on 25000 samples, validate on 25000 samples\nEpoch 1/1\n25000/25000 [==============================] - 36s 1ms/step - loss: 0.5936 - acc: 0.7888 - val_loss: 0.5585 - val_acc: 0.7956\n0.00 0.00 0.01 0.03 0.06 0.07 0.05 0.02 0.04 0.03 0.01 0.01 0.00 0.00 0.00\n0.00 0.00 0.01 0.03 0.06 0.07 0.05 0.02 0.04 0.03 0.01 0.01 0.00 0.00 0.00\n3.90 6.85 9.27 11.70 12.61 14.56 13.01 14.61 15.60 16.04 18.07 17.87 21.52 23.63 22.71 17.83 17.50 17.63 17.24 20.69 15.96 15.54 17.63 17.67 17.19 16.71 10.24 12.41 11.16 12.91 15.27 8.72 16.69 17.11 8.57 4.40 5.49 7.38 2.88 4.83 5.37 6.26 1.36 0.71 0.21 3.88 0.50 0.90 2.14 0.02 0.02 0.17 0.54 4.56 2.68 4.89 9.67 6.53 5.35 8.70 11.13 11.62 8.48 16.51 16.59 15.17 16.77 14.31 19.55 24.94 18.47 17.40 20.11 17.89 24.85 24.88 22.93 24.73 21.07 17.67 20.33 23.71 24.07 26.95 19.97 23.29 22.32 24.33 21.41 22.06 19.63 18.87 19.12 18.03 18.83 17.79 15.00 13.74 10.30 7.05\n3.90 6.85 9.27 11.70 12.61 14.56 13.01 14.61 15.60 16.04 18.07 17.87 21.52 23.63 22.71 17.83 17.50 17.63 17.24 20.69 15.96 15.54 17.63 17.67 17.19 16.71 10.24 12.41 11.16 12.91 15.27 8.72 16.69 17.11 8.57 4.40 5.49 7.38 2.88 4.83 5.37 6.26 1.36 0.71 0.21 3.88 0.50 0.90 2.14 0.02 0.02 0.17 0.54 4.56 2.68 4.89 9.67 6.53 5.35 8.70 11.13 11.62 8.48 16.51 16.59 15.17 16.77 14.31 19.55 24.94 18.47 17.40 20.11 17.89 24.85 24.88 22.93 24.73 21.07 17.67 20.33 23.71 24.07 26.95 19.97 23.29 22.32 24.33 21.41 22.06 19.63 18.87 19.12 18.03 18.83 17.79 15.00 13.74 10.30 7.05\nTrain: ece 0.34 max ece 0.07 acc 0.82 entropy 0.54 brier 0.18 adapt 0.05 cal abs 0.20 cal mse 0.05\n0.00 0.00 0.01 0.03 0.05 0.07 0.05 0.02 0.04 0.02 0.01 0.00 0.00 0.00 0.00\n0.00 0.00 0.01 0.03 0.05 0.07 0.05 0.02 0.04 0.02 0.01 0.00 0.00 0.00 0.00\n4.79 7.03 9.65 9.17 9.34 11.80 16.38 14.14 13.30 17.33 14.80 18.79 15.01 18.86 21.41 16.14 15.25 15.38 20.32 16.14 18.32 17.31 14.81 13.91 19.08 13.00 12.54 10.43 10.85 7.39 11.60 11.09 7.24 5.34 3.45 8.21 5.55 4.14 3.62 3.35 5.72 2.25 1.24 0.52 0.94 0.20 0.00 0.00 0.01 0.87 0.48 0.07 0.83 2.23 5.73 2.32 3.43 6.56 11.53 15.32 7.41 10.08 13.19 9.45 18.38 14.41 16.00 21.56 16.67 19.43 20.07 11.24 20.27 20.29 22.64 20.29 18.07 21.40 19.68 15.92 26.79 20.47 21.43 19.54 16.66 22.56 14.19 24.22 23.12 17.52 20.25 16.90 16.29 17.01 14.93 17.72 14.29 13.64 11.86 6.87\n4.79 7.03 9.65 9.17 9.34 11.80 16.38 14.14 13.30 17.33 14.80 18.79 15.01 18.86 21.41 16.14 15.25 15.38 20.32 16.14 18.32 17.31 14.81 13.91 19.08 13.00 12.54 10.43 10.85 7.39 11.60 11.09 7.24 5.34 3.45 8.21 5.55 4.14 3.62 3.35 5.72 2.25 1.24 0.52 0.94 0.20 0.00 0.00 0.01 0.87 0.48 0.07 0.83 2.23 5.73 2.32 3.43 6.56 11.53 15.32 7.41 10.08 13.19 9.45 18.38 14.41 16.00 21.56 16.67 19.43 20.07 11.24 20.27 20.29 22.64 20.29 18.07 21.40 19.68 15.92 26.79 20.47 21.43 19.54 16.66 22.56 14.19 24.22 23.12 17.52 20.25 16.90 16.29 17.01 14.93 17.72 14.29 13.64 11.86 6.87\nVal: ece 0.32 max ece 0.07 acc 0.80 entropy 0.56 brier 0.19 adapt 0.05 cal abs 0.19 cal mse 0.04\nepoch 3\nTrain on 25000 samples, validate on 25000 samples\nEpoch 1/1\n25000/25000 [==============================] - 36s 1ms/step - loss: 0.4995 - acc: 0.8367 - val_loss: 0.4753 - val_acc: 0.8285\n0.01 0.02 0.03 0.04 0.05 0.05 0.04 0.00 0.00 0.02 0.02 0.02 0.01 0.00 0.00\n0.01 0.02 0.03 0.04 0.05 0.05 0.04 0.00 0.00 0.02 0.02 0.02 0.01 0.00 0.00\n0.42 1.58 2.29 3.77 4.76 4.89 5.40 8.08 8.51 9.69 12.53 14.24 14.55 12.88 15.37 14.02 17.09 15.64 16.26 15.85 17.99 17.02 18.07 19.79 15.45 20.76 17.95 18.46 18.97 18.38 16.15 18.67 20.76 21.10 22.01 16.21 12.21 13.47 13.35 12.85 10.23 8.93 11.65 6.60 4.44 5.77 5.07 1.33 1.58 2.27 1.38 0.93 0.07 0.21 2.21 0.25 1.48 1.38 4.91 3.96 9.62 4.53 6.15 5.40 9.33 9.17 10.59 12.15 9.10 10.09 11.60 10.52 9.10 12.62 13.29 10.45 10.63 10.85 12.79 13.40 8.49 9.75 10.73 10.46 8.20 9.76 8.62 8.63 7.88 6.07 7.24 6.13 5.64 5.06 4.69 3.81 2.91 2.03 1.32 0.56\n0.42 1.58 2.29 3.77 4.76 4.89 5.40 8.08 8.51 9.69 12.53 14.24 14.55 12.88 15.37 14.02 17.09 15.64 16.26 15.85 17.99 17.02 18.07 19.79 15.45 20.76 17.95 18.46 18.97 18.38 16.15 18.67 20.76 21.10 22.01 16.21 12.21 13.47 13.35 12.85 10.23 8.93 11.65 6.60 4.44 5.77 5.07 1.33 1.58 2.27 1.38 0.93 0.07 0.21 2.21 0.25 1.48 1.38 4.91 3.96 9.62 4.53 6.15 5.40 9.33 9.17 10.59 12.15 9.10 10.09 11.60 10.52 9.10 12.62 13.29 10.45 10.63 10.85 12.79 13.40 8.49 9.75 10.73 10.46 8.20 9.76 8.62 8.63 7.88 6.07 7.24 6.13 5.64 5.06 4.69 3.81 2.91 2.03 1.32 0.56\nTrain: ece 0.32 max ece 0.05 acc 0.85 entropy 0.45 brier 0.14 adapt 0.04 cal abs 0.15 cal mse 0.03\n0.01 0.02 0.03 0.04 0.05 0.05 0.04 0.01 0.00 0.02 0.02 0.01 0.01 0.00 0.00\n0.01 0.02 0.03 0.04 0.05 0.05 0.04 0.01 0.00 0.02 0.02 0.01 0.01 0.00 0.00\n0.57 1.54 2.86 2.65 5.59 6.03 4.73 7.12 5.92 7.55 12.62 10.93 13.48 14.64 16.84 13.06 15.12 15.23 20.03 18.43 13.39 18.98 17.92 13.83 12.51 21.26 16.29 14.66 16.52 12.15 21.22 16.18 18.11 19.02 13.69 9.28 6.68 10.63 8.87 10.26 10.55 8.50 4.82 6.18 1.57 3.69 2.27 3.69 0.57 1.84 0.57 0.96 0.10 0.96 0.59 0.75 0.60 5.11 2.16 5.37 3.42 6.35 5.90 4.66 9.15 2.59 7.42 6.62 12.24 9.57 10.25 8.55 12.01 10.17 12.56 9.10 11.79 10.34 13.15 9.90 9.25 8.25 6.93 9.14 6.36 8.45 8.46 6.75 8.08 6.01 5.33 4.97 5.07 5.41 4.07 3.41 4.17 2.60 1.37 0.52\n0.57 1.54 2.86 2.65 5.59 6.03 4.73 7.12 5.92 7.55 12.62 10.93 13.48 14.64 16.84 13.06 15.12 15.23 20.03 18.43 13.39 18.98 17.92 13.83 12.51 21.26 16.29 14.66 16.52 12.15 21.22 16.18 18.11 19.02 13.69 9.28 6.68 10.63 8.87 10.26 10.55 8.50 4.82 6.18 1.57 3.69 2.27 3.69 0.57 1.84 0.57 0.96 0.10 0.96 0.59 0.75 0.60 5.11 2.16 5.37 3.42 6.35 5.90 4.66 9.15 2.59 7.42 6.62 12.24 9.57 10.25 8.55 12.01 10.17 12.56 9.10 11.79 10.34 13.15 9.90 9.25 8.25 6.93 9.14 6.36 8.45 8.46 6.75 8.08 6.01 5.33 4.97 5.07 5.41 4.07 3.41 4.17 2.60 1.37 0.52\nVal: ece 0.30 max ece 0.05 acc 0.83 entropy 0.48 brier 0.15 adapt 0.03 cal abs 0.15 cal mse 0.03\nepoch 4\nTrain on 25000 samples, validate on 25000 samples\nEpoch 1/1\n"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn-whitegrid')",
"_____no_output_____"
]
],
[
[
"# Accuracy",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_accs, 'b')\nplt.plot(val_accs, 'r')\nplt.savefig('accuracy.png', dpi = 300)",
"_____no_output_____"
],
[
"np.array(val_accs).argmax()",
"_____no_output_____"
],
[
"val_accs[18]",
"_____no_output_____"
],
[
"val_accs[47]",
"_____no_output_____"
],
[
"val_accs[21]",
"_____no_output_____"
]
],
[
[
"# Brier score",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_briers, 'b')\nplt.plot(valid_briers, 'r')\nplt.savefig('Briers.png', dpi = 300)",
"_____no_output_____"
],
[
"np.argmin(train_briers)",
"_____no_output_____"
],
[
"np.argmin(valid_briers)",
"_____no_output_____"
]
],
[
[
"# Cross Entropy\n\nGot NAN values after 10 epochs",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_cross_entropys, 'b')\nplt.plot(val_cross_entropys, 'r')\nplt.savefig('cross entropy.png', dpi = 300)",
"_____no_output_____"
]
],
[
[
"# Adapted ECE",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_adapt_eces, 'b')\nplt.plot(val_adapt_eces, 'r')\nplt.savefig('Adapted ECE.png', dpi = 300)",
"_____no_output_____"
],
[
"np.argmin(train_adapt_eces)",
"_____no_output_____"
],
[
"np.argmin(val_adapt_eces)",
"_____no_output_____"
]
],
[
[
"# RMSE adapted ECE",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_adapt_rmse_eces, 'b')\nplt.plot(val_adapt_rmse_eces, 'r')\nplt.savefig('RMSE Adapted ECE.png', dpi = 300)",
"_____no_output_____"
],
[
"np.argmin(train_adapt_rmse_eces)",
"_____no_output_____"
],
[
"np.argmin(val_adapt_rmse_eces)",
"_____no_output_____"
]
],
[
[
"# ECE",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_eces, 'b')\nplt.plot(val_eces, 'r')\nplt.savefig('ece.png', dpi = 300)",
"_____no_output_____"
]
],
[
[
"# Absolute Calibration",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_abs_calibration, 'b')\nplt.plot(valid_abs_calibration, 'r')\nplt.savefig('Absolute Calibration.png', dpi = 300)",
"_____no_output_____"
],
[
"np.array(valid_abs_calibration).argmin()",
"_____no_output_____"
],
[
"np.array(train_abs_calibration).argmin()",
"_____no_output_____"
]
],
[
[
"# MCE",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_max_eces, 'b')\nplt.plot(val_max_eces, 'r')\nplt.savefig('mce.png', dpi = 300)",
"_____no_output_____"
]
],
[
[
"# MSE Calibration",
"_____no_output_____"
]
],
[
[
"fig=plt.figure(figsize=(10,10))\nplt.plot(train_mse_calibration, 'b')\nplt.plot(valid_mse_calibration, 'r')\nplt.savefig('MSE Calibration.png', dpi = 300)",
"_____no_output_____"
],
[
"np.array(valid_abs_calibration).argmin()",
"_____no_output_____"
],
[
"np.array(train_abs_calibration).argmin()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a1dd631d38e6cf545bc5e8d50eb1f5d83145e6d
| 8,402 |
ipynb
|
Jupyter Notebook
|
code/SFM_gtsam.ipynb
|
ayushbaid/opencv_sfm
|
bc94cfcd8e7c16a033020a93e1c297683c32baa3
|
[
"MIT"
] | 1 |
2020-10-11T10:02:41.000Z
|
2020-10-11T10:02:41.000Z
|
code/SFM_gtsam.ipynb
|
ayushbaid/opencv_sfm
|
bc94cfcd8e7c16a033020a93e1c297683c32baa3
|
[
"MIT"
] | null | null | null |
code/SFM_gtsam.ipynb
|
ayushbaid/opencv_sfm
|
bc94cfcd8e7c16a033020a93e1c297683c32baa3
|
[
"MIT"
] | null | null | null | 26.25625 | 111 | 0.544275 |
[
[
[
"import gtsam\nimport numpy as np\nfrom gtsam.gtsam import (Cal3_S2, DoglegOptimizer,\n GenericProjectionFactorCal3_S2, NonlinearFactorGraph,\n Point3, Pose3, Point2, PriorFactorPoint3, PriorFactorPose3,\n Rot3, SimpleCamera, Values)\n\nfrom utils import get_matches_and_e, load_image",
"_____no_output_____"
],
[
"def symbol(name: str, index: int) -> int:\n \"\"\" helper for creating a symbol without explicitly casting 'name' from str to int \"\"\"\n return gtsam.symbol(ord(name), index)",
"_____no_output_____"
],
[
"def get_camera_calibration(fx, fy, s, cx, cy):\n return Cal3_S2(fx, fy, s, cx, cy)",
"_____no_output_____"
],
[
"# Define the camera observation noise model\nmeasurement_noise = gtsam.noiseModel_Isotropic.Sigma(2, 1.0) # one pixel in u and v",
"_____no_output_____"
],
[
"img1 = load_image('img56.jpg', path='../data/lettuce_home/set6/')\nimg2 = load_image('img58.jpg', path='../data/lettuce_home/set6/')\npoints_1, points_2, e_estimate, r, t = get_matches_and_e(img1, img2)",
"selected points with ratio: 68\n"
],
[
"print(e_estimate)\nprint(r)\nt = +(t/t[0])*0.05\nprint(t)",
"[[ 0.02161564 -0.1086115 -0.1994536 ]\n [ 0.2627051 -0.05079752 -0.62249989]\n [ 0.36620042 0.59124258 0.07199701]]\n[array([[ 0.93237012, -0.26533176, 0.24553006],\n [ 0.26541593, 0.96355595, 0.03338131],\n [-0.24543907, 0.03404385, 0.96881406]]), array([[ 0.52519455, -0.72216304, 0.45016799],\n [-0.70583895, -0.66517095, -0.24359595],\n [ 0.47535466, -0.18981084, -0.85907496]])]\n[[ 0.05 ]\n [-0.01510818]\n [ 0.00788698]]\n"
],
[
"# Create a factor graph\ngraph = NonlinearFactorGraph()\nK = get_camera_calibration(644, 644, 0, 213, 387)",
"_____no_output_____"
],
[
"# add all the image points to the factor graph\nfor (i, point) in enumerate(points_1):\n # wrap the point in a measurement\n #print('adding point for camera1')\n factor = GenericProjectionFactorCal3_S2(\n Point2(point), measurement_noise, symbol('x', 0), symbol('l', i), K)\n graph.push_back(factor)\n \nfor (i, point) in enumerate(points_2):\n #print('adding point for camera2')\n factor = GenericProjectionFactorCal3_S2(\n Point2(point), measurement_noise, symbol('x', 1), symbol('l', i), K)\n graph.push_back(factor)",
"_____no_output_____"
],
[
"# Add a prior on pose of camera 1.\n# 0.3 rad std on roll,pitch,yaw and 0.1m on x,y,z\npose_noise = gtsam.noiseModel_Diagonal.Sigmas(np.array([0.3, 0.3, 0.3, 0.1, 0.1, 0.1]))\nfactor = PriorFactorPose3(symbol('x', 0), Pose3(Rot3.Rodrigues(0, 0, 0), Point3(0, 0, 0)), pose_noise)\ngraph.push_back(factor)",
"_____no_output_____"
],
[
"# Add a prior on pose of camera 2\n# 0.3 rad std on roll,pitch,yaw and 0.1m on x,y,z\npose_noise = gtsam.noiseModel_Diagonal.Sigmas(np.array([0.3, 0.3, 0.3, 0.1, 0.1, 0.1]))\nfactor = PriorFactorPose3(symbol('x', 1), Pose3(Rot3(r), Point3(t[0], t[1], t[2])), pose_noise)\ngraph.push_back(factor)",
"_____no_output_____"
],
[
"# point_noise = gtsam.noiseModel_Isotropic.Sigma(3, 0.1)\n# factor = PriorFactorPoint3(symbol('l', 0), Point3(1,0,0), point_noise)\n# graph.push_back(factor)",
"_____no_output_____"
],
[
"graph.print_('Factor Graph:\\n')",
"_____no_output_____"
],
[
"# Create the data structure to hold the initial estimate to the solution\ninitial_estimate = Values()\n\nr_init = Rot3.Rodrigues(0, 0, 0)\nt_init = Point3(0, 0, 0)\ntransformed_pose = Pose3(r_init, t_init)\ninitial_estimate.insert(symbol('x', 0), transformed_pose)\n\nr_init = Rot3(r)\nt_init = Point3(t[0], t[1], t[2])\ntransformed_pose = Pose3(r_init, t_init)\ninitial_estimate.insert(symbol('x', 1), transformed_pose)\n\nfor j, point in enumerate(points_1):\n initial_estimate.insert(symbol('l', j), Point3(0.05*point[0]/640, 0.05*point[1]/640,0.05))\n \n\ninitial_estimate.print_('Initial Estimates:\\n')",
"_____no_output_____"
],
[
"# Optimize the graph and print results\nparams = gtsam.DoglegParams()\nparams.setVerbosity('VALUES')\noptimizer = DoglegOptimizer(graph, initial_estimate, params)\nprint('Optimizing:')",
"Optimizing:\n"
],
[
"result = optimizer.optimize()\nresult.print_('Final results:\\n')\nprint('initial error = {}'.format(graph.error(initial_estimate)))\nprint('final error = {}'.format(graph.error(result)))",
"initial error = 48836395.56021277\nfinal error = 5.3863958532626866\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1de7ac21dd3283bfeae799072ccf3ec1a5ccd3
| 15,337 |
ipynb
|
Jupyter Notebook
|
nbs/resimulation.ipynb
|
Torvaney/wingback
|
c3112371841042199d59ec01c7867e5fff5d25e2
|
[
"MIT"
] | 12 |
2021-06-10T11:11:33.000Z
|
2022-03-10T19:17:00.000Z
|
nbs/resimulation.ipynb
|
Torvaney/wingback
|
c3112371841042199d59ec01c7867e5fff5d25e2
|
[
"MIT"
] | null | null | null |
nbs/resimulation.ipynb
|
Torvaney/wingback
|
c3112371841042199d59ec01c7867e5fff5d25e2
|
[
"MIT"
] | null | null | null | 41.904372 | 202 | 0.495012 |
[
[
[
"# default_exp resimulation",
"_____no_output_____"
]
],
[
[
"# Match resimulation\n\n> Simulating match outcomes based on the xG of individual shots",
"_____no_output_____"
]
],
[
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"#export\nimport collections\nimport itertools\n\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"Use Poisson-Binomial distribution calculation from https://github.com/tsakim/poibin\n\nIt looks like [there are plans to package the code](https://github.com/tsakim/poibin/pull/8), but for now, just copy+paste the requisite class in here (original code is provided with MIT License).",
"_____no_output_____"
]
],
[
[
"#export\n\n\nclass PoiBin(object):\n \"\"\"Poisson Binomial distribution for random variables.\n This class implements the Poisson Binomial distribution for Bernoulli\n trials with different success probabilities. The distribution describes\n thus a random variable that is the sum of independent and not identically\n distributed single Bernoulli random variables.\n The class offers methods for calculating the probability mass function, the\n cumulative distribution function, and p-values for right-sided testing.\n \"\"\"\n\n def __init__(self, probabilities):\n \"\"\"Initialize the class and calculate the ``pmf`` and ``cdf``.\n :param probabilities: sequence of success probabilities :math:`p_i \\\\in\n [0, 1] \\\\forall i \\\\in [0, N]` for :math:`N` independent but not\n identically distributed Bernoulli random variables\n :type probabilities: numpy.array\n \"\"\"\n self.success_probabilities = np.array(probabilities)\n self.number_trials = self.success_probabilities.size\n self.check_input_prob()\n self.omega = 2 * np.pi / (self.number_trials + 1)\n self.pmf_list = self.get_pmf_xi()\n self.cdf_list = self.get_cdf(self.pmf_list)\n\n# ------------------------------------------------------------------------------\n# Methods for the Poisson Binomial Distribution\n# ------------------------------------------------------------------------------\n\n def pmf(self, number_successes):\n \"\"\"Calculate the probability mass function ``pmf`` for the input values.\n The ``pmf`` is defined as\n .. math::\n pmf(k) = Pr(X = k), k = 0, 1, ..., n.\n :param number_successes: number of successful trials for which the\n probability mass function is calculated\n :type number_successes: int or list of integers\n \"\"\"\n self.check_rv_input(number_successes)\n return self.pmf_list[number_successes]\n\n def cdf(self, number_successes):\n \"\"\"Calculate the cumulative distribution function for the input values.\n The cumulative distribution function ``cdf`` for a number ``k`` of\n successes is defined as\n .. math::\n cdf(k) = Pr(X \\\\leq k), k = 0, 1, ..., n.\n :param number_successes: number of successful trials for which the\n cumulative distribution function is calculated\n :type number_successes: int or list of integers\n \"\"\"\n self.check_rv_input(number_successes)\n return self.cdf_list[number_successes]\n\n def pval(self, number_successes):\n \"\"\"Return the p-values corresponding to the input numbers of successes.\n The p-values for right-sided testing are defined as\n .. math::\n pval(k) = Pr(X \\\\geq k ), k = 0, 1, ..., n.\n .. note::\n Since :math:`cdf(k) = Pr(X <= k)`, the function returns\n .. math::\n 1 - cdf(X < k) & = 1 - cdf(X <= k - 1)\n & = 1 - cdf(X <= k) + pmf(X = k),\n k = 0, 1, .., n.\n :param number_successes: number of successful trials for which the\n p-value is calculated\n :type number_successes: int, numpy.array, or list of integers\n \"\"\"\n self.check_rv_input(number_successes)\n i = 0\n try:\n isinstance(number_successes, collections.Iterable)\n pvalues = np.array(number_successes, dtype='float')\n # if input is iterable (list, numpy.array):\n for k in number_successes:\n pvalues[i] = 1. - self.cdf(k) + self.pmf(k)\n i += 1\n return pvalues\n except TypeError:\n # if input is an integer:\n if number_successes == 0:\n return 1\n else:\n return 1 - self.cdf(number_successes - 1)\n\n# ------------------------------------------------------------------------------\n# Methods to obtain pmf and cdf\n# ------------------------------------------------------------------------------\n\n def get_cdf(self, event_probabilities):\n \"\"\"Return the values of the cumulative density function.\n Return a list which contains all the values of the cumulative\n density function for :math:`i = 0, 1, ..., n`.\n :param event_probabilities: array of single event probabilities\n :type event_probabilities: numpy.array\n \"\"\"\n cdf = np.empty(self.number_trials + 1)\n cdf[0] = event_probabilities[0]\n for i in range(1, self.number_trials + 1):\n cdf[i] = cdf[i - 1] + event_probabilities[i]\n return cdf\n\n def get_pmf_xi(self):\n \"\"\"Return the values of the variable ``xi``.\n The components ``xi`` make up the probability mass function, i.e.\n :math:`\\\\xi(k) = pmf(k) = Pr(X = k)`.\n \"\"\"\n chi = np.empty(self.number_trials + 1, dtype=complex)\n chi[0] = 1\n half_number_trials = int(\n self.number_trials / 2 + self.number_trials % 2)\n # set first half of chis:\n chi[1:half_number_trials + 1] = self.get_chi(\n np.arange(1, half_number_trials + 1))\n # set second half of chis:\n chi[half_number_trials + 1:self.number_trials + 1] = np.conjugate(\n chi[1:self.number_trials - half_number_trials + 1] [::-1])\n chi /= self.number_trials + 1\n xi = np.fft.fft(chi)\n if self.check_xi_are_real(xi):\n xi = xi.real\n else:\n raise TypeError(\"pmf / xi values have to be real.\")\n xi += np.finfo(type(xi[0])).eps\n return xi\n\n def get_chi(self, idx_array):\n \"\"\"Return the values of ``chi`` for the specified indices.\n :param idx_array: array of indices for which the ``chi`` values should\n be calculated\n :type idx_array: numpy.array\n \"\"\"\n # get_z:\n exp_value = np.exp(self.omega * idx_array * 1j)\n xy = 1 - self.success_probabilities + \\\n self.success_probabilities * exp_value[:, np.newaxis]\n # sum over the principal values of the arguments of z:\n argz_sum = np.arctan2(xy.imag, xy.real).sum(axis=1)\n # get d value:\n exparg = np.log(np.abs(xy)).sum(axis=1)\n d_value = np.exp(exparg)\n # get chi values:\n chi = d_value * np.exp(argz_sum * 1j)\n return chi\n\n# ------------------------------------------------------------------------------\n# Auxiliary functions\n# ------------------------------------------------------------------------------\n\n def check_rv_input(self, number_successes):\n \"\"\"Assert that the input values ``number_successes`` are OK.\n The input values ``number_successes`` for the random variable have to be\n integers, greater or equal to 0, and smaller or equal to the total\n number of trials ``self.number_trials``.\n :param number_successes: number of successful trials\n :type number_successes: int or list of integers \"\"\"\n try:\n for k in number_successes:\n assert (type(k) == int or type(k) == np.int64), \\\n \"Values in input list must be integers\"\n assert k >= 0, 'Values in input list cannot be negative.'\n assert k <= self.number_trials, \\\n 'Values in input list must be smaller or equal to the ' \\\n 'number of input probabilities \"n\"'\n except TypeError:\n assert (type(number_successes) == int or \\\n type(number_successes) == np.int64), \\\n 'Input value must be an integer.'\n assert number_successes >= 0, \"Input value cannot be negative.\"\n assert number_successes <= self.number_trials, \\\n 'Input value cannot be greater than ' + str(self.number_trials)\n return True\n\n @staticmethod\n def check_xi_are_real(xi_values):\n \"\"\"Check whether all the ``xi``s have imaginary part equal to 0.\n The probabilities :math:`\\\\xi(k) = pmf(k) = Pr(X = k)` have to be\n positive and must have imaginary part equal to zero.\n :param xi_values: single event probabilities\n :type xi_values: complex\n \"\"\"\n return np.all(xi_values.imag <= np.finfo(float).eps)\n\n def check_input_prob(self):\n \"\"\"Check that all the input probabilities are in the interval [0, 1].\"\"\"\n if self.success_probabilities.shape != (self.number_trials,):\n raise ValueError(\n \"Input must be an one-dimensional array or a list.\")\n if not np.all(self.success_probabilities >= 0):\n raise ValueError(\"Input probabilities have to be non negative.\")\n if not np.all(self.success_probabilities <= 1):\n raise ValueError(\"Input probabilities have to be smaller than 1.\")",
"_____no_output_____"
],
[
"#export\n\n\ndef poisson_binomial_pmf(probs, xs):\n return PoiBin(probs).pmf(xs)\n\n\ndef resimulate_match(shots, up_to=26, min_xg=0.0001, **kwargs):\n \"\"\"\n 'Resimulate' a match based on xG. Takes a list of maps, where each map\n represents a shot has and has 'is_home' (bool) and 'xg' (float) keys.\n \"\"\"\n\n # Prevent potential underflow\n home_xgs = [max(s['xg'], min_xg) for s in shots if s['is_home']]\n away_xgs = [max(s['xg'], min_xg) for s in shots if not s['is_home']]\n\n home_scores = list(range(min(len(home_xgs) + 1, up_to)))\n away_scores = list(range(min(len(away_xgs) + 1, up_to)))\n\n home_probs = dict(zip(home_scores, poisson_binomial_pmf(home_xgs, home_scores)))\n away_probs = dict(zip(away_scores, poisson_binomial_pmf(away_xgs, away_scores)))\n\n scores = []\n for h, a in itertools.product(range(up_to), repeat=2):\n home_prob = home_probs.get(h, 0)\n away_prob = away_probs.get(a, 0)\n scores.append({\n 'home_goals': h,\n 'away_goals': a,\n 'home_probability': home_prob,\n 'away_probability': away_prob,\n 'probability': home_prob*away_prob,\n **kwargs\n })\n\n # Keep everything up to 4-4; filter out P == 0 results above that\n return [\n s for s in scores \n if s['probability'] > 0 \n or (s['home_goals'] < 5 and s['away_goals'] < 5)\n ]\n",
"_____no_output_____"
],
[
"def extract_prob(probs, home_goals, away_goals):\n filtered = [p for p in probs if p['home_goals'] == home_goals and p['away_goals'] == away_goals]\n if len(filtered) == 0:\n return 0\n return filtered[0]['probability']\n\n\nprobs = resimulate_match([\n {'is_home': True, 'xg': 0.1}\n])\n\nassert np.isclose(extract_prob(probs, 1, 0), 0.1)",
"_____no_output_____"
],
[
"shots = [\n {\"is_home\": False, \"xg\": 0.030929630622267723},\n {\"is_home\": False, \"xg\": 0.021505167707800865},\n {\"is_home\": False, \"xg\": 0.013733051717281342},\n {\"is_home\": False, \"xg\": 0.06314441561698914},\n]\nprobs = resimulate_match(shots)\n\nassert np.isclose(\n extract_prob(probs, 0, 4),\n np.product([s['xg'] for s in shots])\n)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a1df446da4ef877f59a5feda83ca45f413961a7
| 777,069 |
ipynb
|
Jupyter Notebook
|
src/what-s-this-chai-and-datascience.ipynb
|
RsTaK/CTDS.SHOW
|
6efccbaaf98a65a2089db62250af01b2d1a4f292
|
[
"MIT"
] | null | null | null |
src/what-s-this-chai-and-datascience.ipynb
|
RsTaK/CTDS.SHOW
|
6efccbaaf98a65a2089db62250af01b2d1a4f292
|
[
"MIT"
] | null | null | null |
src/what-s-this-chai-and-datascience.ipynb
|
RsTaK/CTDS.SHOW
|
6efccbaaf98a65a2089db62250af01b2d1a4f292
|
[
"MIT"
] | null | null | null | 143.370664 | 104,648 | 0.6824 |
[
[
[
"<div align=\"center\">\n <font size=\"6\">Solving the Mystery of Chai Time Data Science</font>\n</div>\n<br>\n<div align=\"center\">\n <font size=\"4\">A Data Science podcast series by Sanyam Bhutani</font>\n</div>\n\n---\n\n<img src=\"https://miro.medium.com/max/1400/0*ovcHbNV5470zvsH5.jpeg\" alt=\"drawing\"/>\n\n---\n<div>\n <font size=\"5\">Mr. RsTaK, Where are we?</font>\n</div>\n<br>\n\n\n \nHello my dear Kagglers. As you all know I love Kaggle and its community. I spend most of my time surfing my Kaggle feed, scrolling over discussion forms, appreciating the efforts put on by various Kagglers via their unique / interesting way of Storytelling. <br><br>\nSo, this morning when i was following my usual routine in Kaggle, I came across this Dataset named [Chai Time Data Science | CTDS.Show](https://www.kaggle.com/rohanrao/chai-time-data-science) provided by Mr. [Vopani](https://www.kaggle.com/rohanrao) and Mr. [Sanyam Bhutani](https://www.kaggle.com/init27). \nAt first glance, I was like what's this? How they know I'm having a tea break? \nOh no buddy! I was wrong. It's [CTDS.Show](https://chaitimedatascience.com) :)\n\n\n\n---\n\n<div>\n <font size=\"5\">Chai Time Data Science (CTDS.Show)</font>\n</div>\n<img align=\"right\" src=\"https://api.breaker.audio/shows/681460/episodes/55282147/image?v=0987aece49022c8863600c4cf5b67eb8&width=400&height=400\" height=600 width=400>\n<br>\n\n\n \nChai Time Data Science show is a [Podcast](https://anchor.fm/chaitimedatascience) + [Video](https://www.youtube.com/playlist?list=PLLvvXm0q8zUbiNdoIazGzlENMXvZ9bd3x) + [Blog](https://sanyambhutani.com/tag/chaitimedatascience/) based show for interviews with Practitioners, Kagglers & Researchers and all things Data Science.\n\n[CTDS.Show](https://chaitimedatascience.com), driven by the community under the supervision of Mr. [Sanyam Bhutani](https://www.kaggle.com/init27) gonna complete its 1 year anniversary on **21st June, 2020** and to celebrate this achievement they decided to run a **Kaggle contest** around the dataset with all of the **75+ ML Hero interviews** on the series.\n\nAccording to our Host, The competition is aimed at articulating insights from the Interviews with ML Heroes. Provided a dataset consists of detailed Stats, Transcripts of CTDS.Show, the goal is to use these and come up with interesting insights or stories based on the 100+ interviews with ML Heroes.\n\nWe have our Dataset containing :\n* **Description.csv** : This file consists of the **descriptions texts** from YouTube and Audio\n\n* **Episodes.csv** : This file contains the **statistics of all the Episodes** of the Chai Time Data Science show.\n\n* **YouTube Thumbnail Types.csv** : This file consists of the **description of Anchor/Audio thumbnail of the episodes**\n\n* **Anchor Thumbnail Types.csv** : This file contains the **statistics of the Anchor/Audio thumbnail**\n\n* **Raw Subtitles** : Directory containing **74 text files** having raw subtitles of all the episodes\n\n* **Cleaned Subtitles** : Directory containing cleaned subtitles (in CSV format) \n \nHmm.. Seems we have some stories to talk about..\n\nCongratulating [CTDS.Show](https://chaitimedatascience.com) for their **1 year anniversary**, Let's get it started :)\n\n---\n\n**<font id=\"toc\">Btw This gonna be a long kernel. So, Hey! Looking for a guide :) ?</font>**\n<br><br>\n  <b><a href=\"#0\">0. Importing Necessary Libraries</a><br></b>\n\n  <b><a href=\"#1\">1. A Closer look to our Dataset</a><br></b>\n\n    <b><a href=\"#1.1\">1.1. Exploring YouTube Thumbnail Types.csv</a><br></b>\n    <b><a href=\"#1.2\">1.2. Exploring Anchor Thumbnail Types.csv</a><br></b>\n    <b><a href=\"#1.3\">1.3. Exploring Description.csv</a><br></b>\n    <b><a href=\"#1.4\">1.4. Exploring Episodes.csv</a><br></b>\n\n      <b><a href=\"#1.4.1\">1.4.1. Missing Values ?</a><br></b>\n      <b><a href=\"#1.4.2\">1.4.2. M0-M8 Episodes</a><br></b>\n      <b><a href=\"#1.4.3\">1.4.3. Solving the Mystery of Missing Values</a><br></b>\n      <b><a href=\"#1.4.9\">1.4.4. Is it a Gender Biased Show?</a><br></b>\n      <b><a href=\"#1.4.4\">1.4.5. Time for a Chai Break</a><br></b>\n      <b><a href=\"#1.4.5\">1.4.6. How to get More Audience?</a><br></b>\n      <b><a href=\"#1.4.6\">1.4.7. Youtube Favors CTDS?</a><br></b>\n      <b><a href=\"#1.4.7\">1.4.8. Do Thumbnails really matter?</a><br></b>\n      <b><a href=\"#1.4.11\">1.4.9. How much Viewers wanna watch?</a><br></b>\n      <b><a href=\"#1.4.8\">1.4.10. Performance on Other Platforms</a><br></b>\n      <b><a href=\"#1.4.10\">1.4.11. Distribution of Heores by Country and Nationality</a><br></b>\n      <b><a href=\"#1.4.12\">1.4.12. Any Relation between Release Date of Epiosdes?</a><br></b>\n      <b><a href=\"#1.4.13\">1.4.13. Do I know about Release of anniversary interview episode?</a><br></b>\n\n\n    <b><a href=\"#1.5\">1.5. Exploring Raw / Cleaned Substitles</a><br></b>\n      <b><a href=\"#1.5.1\">1.5.1. A Small Shoutout to Ramshankar Yadhunath</a><br></b>\n      <b><a href=\"#1.5.2\">1.5.2. Intro is Bad for CTDS ?</a><br></b>\n      <b><a href=\"#1.5.3\">1.5.3. Who Speaks More ?</a><br></b>\n      <b><a href=\"#1.5.4\">1.5.4. Frequency of Questions Per Episode </a><br></b>\n      <b><a href=\"#1.5.5\">1.5.5. Favourite Text ? </a><br></b>\n\n  <b><a href=\"#2\">2. End Notes</a><br></b>\n\n  <b><a href=\"#3\">3. Credits</a><br></b>\n",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-danger\"> \n<b>Note :</b> Sometimes, Plotly Graphs fails to render with the Kernel. Please restart the page in that case\n</div>\n\n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"0\" size=\"5\">Importing Necessary Libraries</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n",
"_____no_output_____"
]
],
[
[
"import os\n\nimport warnings\nwarnings.simplefilter(\"ignore\")\nwarnings.filterwarnings(\"ignore\", category=DeprecationWarning) \n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nimport missingno as msno\n\nimport plotly.express as px\n\nimport plotly.graph_objects as go\nfrom plotly.subplots import make_subplots\n\n!pip install pywaffle\nfrom pywaffle import Waffle\n\nfrom bokeh.layouts import column, row\nfrom bokeh.models.tools import HoverTool\nfrom bokeh.models import ColumnDataSource, Whisker\nfrom bokeh.plotting import figure, output_notebook, show\n\noutput_notebook()\n\nfrom IPython.display import IFrame\n\npd.set_option('display.max_columns', None)",
"Collecting pywaffle\r\n Downloading pywaffle-0.5.1-py2.py3-none-any.whl (525 kB)\r\n\u001b[K |████████████████████████████████| 525 kB 5.1 MB/s \r\n\u001b[?25hRequirement already satisfied: matplotlib in /opt/conda/lib/python3.7/site-packages (from pywaffle) (3.2.1)\r\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/lib/python3.7/site-packages (from matplotlib->pywaffle) (2.4.7)\r\nRequirement already satisfied: numpy>=1.11 in /opt/conda/lib/python3.7/site-packages (from matplotlib->pywaffle) (1.18.1)\r\nRequirement already satisfied: cycler>=0.10 in /opt/conda/lib/python3.7/site-packages (from matplotlib->pywaffle) (0.10.0)\r\nRequirement already satisfied: python-dateutil>=2.1 in /opt/conda/lib/python3.7/site-packages (from matplotlib->pywaffle) (2.8.1)\r\nRequirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/lib/python3.7/site-packages (from matplotlib->pywaffle) (1.2.0)\r\nRequirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from cycler>=0.10->matplotlib->pywaffle) (1.14.0)\r\nInstalling collected packages: pywaffle\r\nSuccessfully installed pywaffle-0.5.1\r\n"
]
],
[
[
"<div>\n<b><font id=\"1\" size=\"5\">A Closer look to our Directories</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\nLet's dive into each and every aspect of our Dataset step by step in order to get every inches out of it...\n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.1\" size=\"4\">Exploring YouTube Thumbnail Types.csv</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\nAs per our knowledge, This file consists of the description of Anchor/Audio thumbnail of the episodes. Let's explore more about it...\n",
"_____no_output_____"
]
],
[
[
"YouTube_df=pd.read_csv(\"../input/chai-time-data-science/YouTube Thumbnail Types.csv\")\nprint(\"No of Datapoints : {}\\nNo of Features : {}\".format(YouTube_df.shape[0], YouTube_df.shape[1]))\nYouTube_df.head()",
"No of Datapoints : 4\nNo of Features : 6\n"
]
],
[
[
"So, Basically [CTDS](https://chaitimedatascience.com) uses **4 types of Thumbnails** in their Youtube videos. Its 2020 and people still uses YouTube default image as thumbnail ! \n\nHmm... a Smart decision or just a blind arrow, We'll figure it out in our futher analysis ...",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.2\" size=\"4\">Exploring Anchor Thumbnail Types.csv</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\nSo, This file contains the statistics of the Anchor/Audio thumbnail",
"_____no_output_____"
]
],
[
[
"Anchor_df=pd.read_csv(\"../input/chai-time-data-science/Anchor Thumbnail Types.csv\")\nprint(\"No of Datapoints : {}\\nNo of Features : {}\".format(Anchor_df.shape[0], Anchor_df.shape[1]))\nAnchor_df.head()",
"No of Datapoints : 4\nNo of Features : 6\n"
]
],
[
[
"It's just similar to Youtube Thumbnail Types. \n\nIf you are wondering What's anchor then it's a free platform for podcast creation",
"_____no_output_____"
]
],
[
[
"IFrame('https://anchor.fm/chaitimedatascience', width=800, height=450)",
"_____no_output_____"
]
],
[
[
"<div>\n<b><font id=\"1.3\" size=\"4\">Exploring Description.csv</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\nThis file consists of the descriptions texts from YouTube and Audio\n",
"_____no_output_____"
]
],
[
[
"Des_df=pd.read_csv(\"../input/chai-time-data-science/Description.csv\")\nprint(\"No of Datapoints : {}\\nNo of Features : {}\".format(Des_df.shape[0], Des_df.shape[1]))\nDes_df.head()",
"No of Datapoints : 85\nNo of Features : 2\n"
]
],
[
[
"\nSo, We have description for every episode. Let's have a close look what we have here",
"_____no_output_____"
]
],
[
[
"def show_description(specific_id=None, top_des=None):\n \n if specific_id is not None:\n print(Des_df[Des_df.episode_id==specific_id].description.tolist()[0])\n \n if top_des is not None:\n for each_des in range(top_des): \n print(Des_df.description.tolist()[each_des])\n print(\"-\"*100)\n",
"_____no_output_____"
]
],
[
[
"<b>⚒️ About the Function :</b> \n\nIn order to explore our Descriptions, I just wrote a small script. It has two options:\n* Either You provide specific episode id(specific_id) to have a look at that particular description\n* Or you can provide a number(top_des) and this script will display description for top \"x\" numbers that you provided in top_des\n\n",
"_____no_output_____"
]
],
[
[
"show_description(\"E1\")",
"In the first Episode, Sanyam Bhutani interviews Kaggle Triple Grandmaster: Abhishek Thakur. They talk about Abhishek's journey into Data Science and Kaggle; his Kaggle Experience and current projects. \n\nInterview with Machine Learning Hero Series: https://medium.com/dsnet/interviews-with-machine-learning-heroes-ad9358385278 \n\nFollow:\nAbhishek Thakur: https://www.kaggle.com/abhishek\nhttps://www.linkedin.com/in/abhisvnit/\nhttps://twitter.com/abhi1thakur\n\nSanyam Bhutani: https://twitter.com/bhutanisanyam1\n\nAbout:\nhttp://chaitimedatascience.com/\nA show for Interviews with Practitioners, Kagglers & Researchers and all things Data Science hosted by Sanyam Bhutani. \n\nYou can expect weekly episodes every Sunday, Thursday available as Video, Podcast, and blogposts.\n\nIf you'd like to support the podcast: https://www.patreon.com/chaitimedatascience\nIntro track: \nFlow by LiQWYD https://soundcloud.com/liqwyd\n"
],
[
"show_description(top_des=3)",
"Interview with ML Hero Series: https://medium.com/p/bfaaf38df219\n\nhttp://chaitimedatascience.com/\nA show for Interviews with Practitioners, Kagglers & Researchers and all things Data Science hosted by Sanyam Bhutani. \n\nYou can expect weekly episodes every Sunday, Thursday available as Video, Podcast, and blogpost.\n\nIntro track: \nFlow by LiQWYD https://soundcloud.com/liqwyd\n----------------------------------------------------------------------------------------------------\nIn the first Episode, Sanyam Bhutani interviews Kaggle Triple Grandmaster: Abhishek Thakur. They talk about Abhishek's journey into Data Science and Kaggle; his Kaggle Experience and current projects. \n\nInterview with Machine Learning Hero Series: https://medium.com/dsnet/interviews-with-machine-learning-heroes-ad9358385278 \n\nFollow:\nAbhishek Thakur: https://www.kaggle.com/abhishek\nhttps://www.linkedin.com/in/abhisvnit/\nhttps://twitter.com/abhi1thakur\n\nSanyam Bhutani: https://twitter.com/bhutanisanyam1\n\nAbout:\nhttp://chaitimedatascience.com/\nA show for Interviews with Practitioners, Kagglers & Researchers and all things Data Science hosted by Sanyam Bhutani. \n\nYou can expect weekly episodes every Sunday, Thursday available as Video, Podcast, and blogposts.\n\nIf you'd like to support the podcast: https://www.patreon.com/chaitimedatascience\nIntro track: \nFlow by LiQWYD https://soundcloud.com/liqwyd\n----------------------------------------------------------------------------------------------------\nAudio Version Available here: https://anchor.fm/chaitimedatascience\n\nIn this Episode, Sanyam Bhutani interviews Kaggle Competition Master: Ryan Chesler. They talk about Ryan's journey into Data Science and Kaggle; his Kaggle Experience and current projects as well as his solution to the Jigsaw Unintended Bias in Toxicity Classification Kaggle Competition\n\nInterview with Machine Learning Hero Series: https://medium.com/dsnet/interviews-with-machine-learning-heroes-ad9358385278 \n\nFollow:\nRyan Chesler: https://www.kaggle.com/ryches\nhttps://www.linkedin.com/in/ryan-chesler/\nhttps://twitter.com/ryan_chesler\n\nSanyam Bhutani: https://twitter.com/bhutanisanyam1\n\nAbout:\nhttp://chaitimedatascience.com/\nA show for Interviews with Practitioners, Kagglers & Researchers and all things Data Science hosted by Sanyam Bhutani. \n\nYou can expect weekly episodes every Sunday, Thursday available as Video, Podcast, and blogposts.\n\nIf you'd like to support the podcast: https://www.patreon.com/chaitimedatascience\nIntro track: \nFlow by LiQWYD https://soundcloud.com/liqwyd\n----------------------------------------------------------------------------------------------------\n"
]
],
[
[
"<div class=\"alert alert-block alert-warning\"> \n<b>Advice :</b> Feel free to play with the function \"show_description()\" to have a look over various descriptions provided in a go\n</div>\n\n<br>\n\n<b>🧠 My Cessation: </b> \n* Although I went through some description and realized it just contains **URL**, **Necessary links** for social media sites with a **little description** of the current show and some **announcements regarding future releases**\n* I'm **not gonna put stress** in this area because **I don't think there's much to scrap in them**. Right now, let's move ahead. \n \n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4\" size=\"4\">Exploring Episodes.csv</font></b>\n</div>\n\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\nThis file contains the statistics of all the Episodes of the Chai Time Data Science show.\n\nOkay ! So, it's the big boy itself .. \n",
"_____no_output_____"
]
],
[
[
"Episode_df=pd.read_csv(\"../input/chai-time-data-science/Episodes.csv\")\nprint(\"No of Datapoints : {}\\nNo of Features : {}\".format(Episode_df.shape[0], Episode_df.shape[1]))\nEpisode_df.head()",
"No of Datapoints : 85\nNo of Features : 36\n"
]
],
[
[
"Wew ! That's a lot of features. \n\nI'm sure We'll gonna explore some interesting insights from this Metadata \nIf you reached till here, then please bare me for couple of minutes more.. <br><br>\nNow, We'll gonna have a big sip of our \"Chai\" :) \n\n<img align=\"center\" src=\"https://external-preview.redd.it/VVHgy7UiRHOUfs6v91tRSDgvvUIXlJvyiD822RG4Fhg.png?auto=webp&s=d6fb054c1f57ec09b5b45bcd7ee0e821b53449c9\" height=400 width=600>",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.1\" size=\"3\">Missing Values</font></b>\n</div>\n<br>\n\nBefore diving into our analysis, Let's have check for Missing Values in our CSV..\n\nFor this purpose, I'm gonna use this library named [missingno](https://github.com/ResidentMario/missingno).\n\nJust use this line :\n>import missingno as msno\n\n[missingno](https://github.com/ResidentMario/missingno) helps us to deal with missing values in a dataset with the help of visualisations. With over 2k stars on github, this library is already very popular.",
"_____no_output_____"
]
],
[
[
"msno.matrix(Episode_df)",
"_____no_output_____"
]
],
[
[
"Aah shit ! Here We go again..\n<img src=\"https://memegenerator.net/img/instances/64277502.jpg\" height=224 width=224>\n\n<b>📌 Observations :</b>\n* We can clearly see that **heroes_kaggle_username**, **heroes_twitter_handle** have **lots of missing values**\n* We can observe **bunch of data missing** from column name **heroes to heroes_twitter_handle** in a **continous way(that big block region)** which shows a **specific reason** of data missing at those points\n* **Few datapoints** are too **missing** in **anchor**, **spotify** and **apple** section i.e. missing data in **podcasts**\n\nThere is also a chart on the right side of plot.It summarizes the general shape of the data completeness and points out the rows with the maximum and minimum nullity in the dataset.\n\nWell, Before giving any False Proclaim Let's explore more about it..",
"_____no_output_____"
]
],
[
[
"\n\ntemp=Episode_df.isnull().sum().reset_index().rename(columns={\"index\": \"Name\", 0: \"Count\"})\ntemp=temp[temp.Count!=0]\n\nSource=ColumnDataSource(temp)\n\ntooltips = [\n \n (\"Feature Name\", \"@Name\"),\n (\"No of Missing entites\", \"@Count\")\n]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400,tooltips=tooltips, x_range = temp[\"Name\"].values, title = \"Count of Missing Values\")\nfig1.vbar(\"Name\", top = \"Count\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8)\n\nfig1.xaxis.major_label_orientation = np.pi / 8\nfig1.xaxis.axis_label = \"Features\"\nfig1.yaxis.axis_label = \"Count\"\n\nfig1.grid.grid_line_color=\"#feffff\"\n\n\nshow(fig1)",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n* Columns from **heroes** to **heroes_nationality** has same about of missing data. Seems We can find a **reasonable relation** between them\n* About **45.88% (85-39)** and **22.35% (85-19)** of Data missing in column name **heroes_kaggle_username** and **heroes_twitter_handle** respectively\n* We have just **1 missing value** in **anchor** and **spotify**, **2 missing values** in **apple section** that is quite easy to handle\n\n<br>\n\n<b>🧠 My Cessation: </b>\n* Come-on. I don't understand. Chai Time Data Science show is about interviews with our Heroes. \nSo, How do we have **11 missing values in Feature \"heroes\"**\n\n<img src=\"https://eatrealamerica.com/wp-content/uploads/2018/05/Fishy-Smell.png\">\n<br>\nLet's find out..",
"_____no_output_____"
]
],
[
[
"Episode_df[Episode_df.heroes.isnull()]",
"_____no_output_____"
]
],
[
[
"<b>💭 Interesting..</b>\n* episode_id \"E0\" was all about Chai Time Data Science Launch Announcement\n* episode_id \"E69\" was Birthday Special\nIt make sense why there's no hero for the following episodes\n\nBut What are these M0-M8 episodes .. ?\n\n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.2\" size=\"3\">M0-M8 Episodes</font></b>\n</div>\n<br>\n\n* Looking around for a while, I realized M0-M8 was a small mini-series based on fast.ai summaries and the Things Jeremy says to do that were released on same date.\n\n<b>🧠 My Cessation: </b>\n\n* Well for the sake of our analysis, I'll treat them as outlier for the current CSV and will analyise them seperately. So, I'm gonna remove them from this CSV, storing seperately for later analysis\n \n",
"_____no_output_____"
]
],
[
[
"temp=[id for id in Episode_df.episode_id if id.startswith('M')]\nfastai_df=Episode_df[Episode_df.episode_id.isin(temp)]\nEpisode_df=Episode_df[~Episode_df.episode_id.isin(temp)]",
"_____no_output_____"
]
],
[
[
"Also, ignoring \"E0\" and \"E69\" for right now ...",
"_____no_output_____"
]
],
[
[
"dummy_df=Episode_df[(Episode_df.episode_id!=\"E0\") & (Episode_df.episode_id!=\"E69\")]",
"_____no_output_____"
],
[
"msno.matrix(dummy_df)",
"_____no_output_____"
],
[
"temp=dummy_df.isnull().sum().reset_index().rename(columns={\"index\": \"Name\", 0: \"Count\"})\ntemp=temp[temp.Count!=0]\n\nSource=ColumnDataSource(temp)\n\ntooltips = [\n (\"Feature Name\", \"@Name\"),\n (\"No of Missing entites\", \"@Count\")\n]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400,tooltips=tooltips, x_range = temp[\"Name\"].values, title = \"Count of Missing Values\")\nfig1.vbar(\"Name\", top = \"Count\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8)\n\nfig1.xaxis.major_label_orientation = np.pi / 4\nfig1.xaxis.axis_label = \"Features\"\nfig1.yaxis.axis_label = \"Count\"\n\nfig1.grid.grid_line_color=\"#feffff\"\n\nshow(fig1)",
"_____no_output_____"
]
],
[
[
"Now, That's much better.. \n\nBut We still have a lots of Missing Values",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.3\" size=\"3\">Solving the Mystery of Missing Values</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"parent=[]\nnames =[]\nvalues=[]\ntemp=dummy_df.groupby([\"category\"]).heroes_gender.value_counts()\nfor k in temp.index:\n parent.append(k[0])\n names.append(k[1])\n values.append(temp.loc[k])\n\ndf1 = pd.DataFrame(\n dict(names=names, parents=parent,values=values))\n\n\nparent=[]\nnames =[]\nvalues=[]\ntemp=dummy_df.groupby([\"category\",\"heroes_gender\"]).heroes_kaggle_username.count()\nfor k in temp.index:\n parent.append(k[0])\n names.append(k[1])\n values.append(temp.loc[k])\n\ndf2 = pd.DataFrame(\n dict(names=names, parents=parent,values=values))\n\n\nfig = px.sunburst(df1, path=['names', 'parents'], values='values', color='parents',hover_data=[\"names\"], title=\"Heroes associated with Categories\")\nfig.update_traces( \n textinfo='percent entry+label',\n hovertemplate = \"Industry:%{label}: <br>Count: %{value}\"\n )\nfig.show()\n\n\nfig = px.sunburst(df2, path=['names', 'parents'], values='values', color='parents', title=\"Heroes associated with Categories having Kaggle Account\")\nfig.update_traces( \n textinfo='percent entry+label',\n hovertemplate = \"Industry:%{label}: <br>Count: %{value}\"\n )\nfig.show()",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n \n* Heores associated with \"Category\" **Kaggle** are expected to have a **Kaggle account**\n* Ignoring the counts from \"Category\" Kaggle (74-31=43), **Out of 43 only 15 Heroes have Kaggle account**.\n* This **explains all Missing 28 Values** from our CSV\n* Similarly We have **8 Heroes who don't have twitter handle**. It's okay. Even I don't have a twitter handle :D\n\n<div>\n<b><font size=\"3\">Wanna know a fun fact ?</font></b>\n</div>\n<br>\n\n> Because of this Kaggle platform, Now I've aprox **42%** chance of becoming a CTDS Hero :) ...\n<img src=\"https://i.imgflip.com/2so1le.jpg\" width=224 height=224> \n<br>\n \nAhem Ahem... Focus [RsTaK](https://www.kaggle.com/rahulgulia) Focus.. Let's get back to our work.\n \nWait? Guess I missed something.. \nWhat's that gender ratio?",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.9\" size=\"3\">Is it a Gender Biased Show?</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"gender = Episode_df.heroes_gender.value_counts()\n\nfig = plt.figure(\n FigureClass=Waffle, \n rows=5,\n columns=12,\n values=gender,\n colors = ('#20639B', '#ED553B'),\n title={'label': 'Gender Distribution', 'loc': 'left'},\n labels=[\"{}({})\".format(a, b) for a, b in zip(gender.index, gender) ],\n legend={'loc': 'lower left', 'bbox_to_anchor': (0, -0.4), 'ncol': len(Episode_df), 'framealpha': 0},\n font_size=30, \n icons = 'child',\n figsize=(12, 5), \n icon_legend=True\n)",
"_____no_output_____"
]
],
[
[
"Jokes apart, We can't give any strong statement over this. \n\nBut yea, I'm hoping for more Female Heroes :D\n\n<b>🧠 My Cessation: </b>\n\nI won't talk much about relation of gender with other features because :\n* Gender feature is highly biased towards one category\n\nSo, We can not conclude any relation with other features. \n* If we had a good gender ratio, then we could have talked about impact of gender \n\nEven if we somehow observe any positive conclusion for Female gender then I would say it will be just a coincidence. There are other factors apart from gender that may have resulted in positive conclusion for Female gender.\n\nWith such a biased and small sample size for Female, We can not comment any strong statement on that",
"_____no_output_____"
]
],
[
[
"dummy_df[dummy_df.apple_listeners.isnull()]",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n \nFollowing our analysis, We realized :\n* CTDS had an episode with **Tuatini Godard, episode_id : \"E12\" exclusively for Youtube**. Although it was an **Audio Only video**(if it makes sense :D ) released on Youtube\n* If it was an Audio Only Version, then **Why it wasn't released on other platforms** ? Hmmm... interesting. Well, I think Mr. [Sanyam Bhutani](https://www.kaggle.com/init27) can answer this well. \n* Similarly, CTDS had an **episode with Rachel Thomas released at every platform expect for Apple**\n \nWith this, We have solved all the mysteries related to the Missing Data. Now we can finally explore other aspects of this CSV \n\nBut before that..",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.4\" size=\"3\">Time for a Chai Break</font></b>\n</div>\n<img src=\"https://encrypted-tbn0.gstatic.com/images?q=tbn%3AANd9GcQf6ziN-7WH50MIZZQtJbO0Czsll5wTud7E3Q&usqp=CAU\" width=400 height=400>\n<br> \n\nWhile having a sip of my Chai (Tea), I'm just curious **Why this show is named \"Chai Time Data Science\"?** <br><br>\nWell, I **don't have a solid answer** for this but maybe its just **because our Host loves Chai?** Hmmm.. So You wanna say our Host is more Hardcore Chai Lover than me?\n\nHey ! Hold my Chai..\n \n",
"_____no_output_____"
]
],
[
[
"fig = go.Figure([go.Pie(labels=Episode_df.flavour_of_tea.value_counts().index.to_list(),values=Episode_df.flavour_of_tea.value_counts().values,hovertemplate = '<br>Type: %{label}</br>Count: %{value}<br>Popularity: %{percent}</br>', name = '')])\nfig.update_layout(title_text=\"What Host drinks everytime ?\", template=\"plotly_white\", title_x=0.45, title_y = 1)\nfig.data[0].marker.line.color = 'rgb(255, 255, 255)'\nfig.data[0].marker.line.width = 2\nfig.update_traces(hole=.4,)\nfig.show()",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n\n* **Masala Chai (count=16)** and **Ginger Chai (count=16)** seems to be **favourite Chai** of our Host **followed by Herbal Tea (count=11) and Sulemani Chai (count=11)**\n\n* Also, Our Host seems to be **quite experimental with Chai**. He has varities of flavour in his belly\n\nOh Man ! This time you win. You're a real Chai lover\n\n\n<b>Now, One Question arises..❓</b>\n\n<b>So, Host drinking any specific Chai at specific time have any relation with other factors or success of CTDS?</b>\n\n<b>🧠 My Cessation: </b>\n\n* Thinking practically, **I don't think** drinking Chai at any specific time can have **any real impact** for the show.\n* Believing on such things is an **example of superstition**. \n* No doubt, as per the data it **may have some relation** with other factors. But to support any statement here, I would like to quote a **famous sentence used in statistics** i.e. \n\n<img src=\"https://miro.medium.com/max/420/1*lYw_nshU1qg3dqbqgpWoDA.png\" width=400 height=400>\n<br>\n\n<div class=\"alert-block alert-info\"> \n <b>Correlation</b> does not imply <b>Causation</b> \n</div>",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.5\" size=\"3\">How to get More Audience?</font></b>\n</div>\n<br>\n \nWell, rewarding for your victory in that Chai Lover Challenge, I'll try to assist CTDS on how to get more Audience 😄 \n* Ofcourse CTDS.Shows are a kind of gem, fully informative, covering interviews with some successfull people\n* But talking Statistically here, We'll gonna define Success of an Episode by amount of Audience it gathered\n",
"_____no_output_____"
]
],
[
[
"temp=dummy_df.isnull().sum().reset_index().rename(columns={\"index\": \"Name\", 0: \"Count\"})\ntemp=temp[temp.Count!=0]\n\nSource=ColumnDataSource(temp)\n\ntooltips = [\n (\"Feature Name\", \"@Name\"),\n (\"No of Missing entites\", \"@Count\")\n]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400,tooltips=tooltips, x_range = temp[\"Name\"].values, title = \"Count of Missing Values\")\nfig1.vbar(\"Name\", top = \"Count\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8)\n\nfig1.xaxis.major_label_orientation = np.pi / 4\nfig1.xaxis.axis_label = \"Features\"\nfig1.yaxis.axis_label = \"Count\"\n\nfig1.grid.grid_line_color=\"#feffff\"\n\nshow(fig1)",
"_____no_output_____"
],
[
"Episode_df.release_date = pd.to_datetime(Episode_df.release_date)\nSource = ColumnDataSource(Episode_df)\nfastai_df.release_date = pd.to_datetime(fastai_df.release_date)\nSource2 = ColumnDataSource(fastai_df)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Episode Title\", \"@episode_name\"),\n (\"Hero Present\", \"@heroes\"),\n (\"CTR\", \"@youtube_ctr\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\ntooltips2 = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Episode Title\", \"@episode_name\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Subscriber Gain\", \"@youtube_subscribers\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\n\nfig1 = figure(background_fill_color=\"#ebf4f6\",plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"CTR Per Episode\")\nfig1.line(\"release_date\", \"youtube_ctr\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"youtube_ctr\")\nfig1.varea(source=Source, x=\"release_date\", y1=0, y2=\"youtube_ctr\", alpha=0.2, fill_color='#55FF88', legend_label=\"youtube_ctr\")\nfig1.line(\"release_date\", Episode_df.youtube_ctr.mean(), source = Source, color = \"#f2a652\", alpha = 0.8,line_dash=\"dashed\", legend_label=\"Youtube CTR Mean : {:.3f}\".format(Episode_df.youtube_ctr.mean()))\nfig1.circle(x=\"release_date\", y=\"youtube_ctr\", source = Source2, color = \"#5bab37\", alpha = 0.8, legend_label=\"M0-M8 Series\")\n\nfig1.add_tools(HoverTool(tooltips=tooltips,formatters={\"@release_date\": \"datetime\"}))\nfig1.xaxis.axis_label = \"Release Date\"\nfig1.yaxis.axis_label = \"Click Per Impression\"\n\nfig1.grid.grid_line_color=\"#feffff\"\n\nfig2 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"Subscriber Gain Per Episode\")\nfig2.line(\"release_date\", \"youtube_subscribers\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Subscribers\")\nfig2.varea(source=Source, x=\"release_date\", y1=0, y2=\"youtube_subscribers\", alpha=0.2, fill_color='#55FF88', legend_label=\"Subscribers\")\nfig2.circle(x=\"release_date\", y=\"youtube_subscribers\", source = Source2, color = \"#5bab37\", alpha = 0.8, legend_label=\"M0-M8 Series\")\n\n\nfig2.add_tools(HoverTool(tooltips=tooltips2,formatters={\"@release_date\": \"datetime\"}))\nfig2.xaxis.axis_label = \"Release Date\"\nfig2.yaxis.axis_label = \"Subscriber Count\"\n\nfig2.grid.grid_line_color=\"#feffff\"\n\nshow(column(fig1, fig2))",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n\nFrom the Graphs, We can see :\n* On an average, CTDS episodes had **2.702 CTR**\n* **38 out of 76 (50% exact)** have CTRs above the average\n* Episode **E1, E27 and E49 seems to be lucky** for CTDS in terms of **Subscriber Count**\n* Episode E19 had the **best CTR (8.460)** which is self explanatory from the Episode Title. Everyone loves to know about MOOC(s) and ML Interviews in Industries\n \n<b>🤖 M0-M8 Series :</b>\n* Despite related to Fast.ai, M0-M7 **doesn't perform** that well as compared to other vides related to fast.ai\n* **M0 and M1 though received a good amount of CTR** but other M Series quite below the average CTR\n* **M0 and M1 has better impact on subscriber gain** as compared to other M series but overall series doesn't perform well on Subscriber gain\n* All M0-M8 series were released on the **same day**, which can be the reason for this incident. M0-M1 despite having good CTR **fails to hold the viewers interest on M series** \n \n<b>💭 Interestingly..</b>, \n* Episode **E19 despite of having best CTR** till now (8.460), **didn't contributed much** in Subscriber Count (only 7 Subscriber Gained) \n\nBut Why ❓\n* CTR **doen't mean that person likes the content**, or **he/she will be watching that video** for long or will be **subscribing to the channel**\n* Maybe that video was **recommended on his newsfeed and he/she clicked on it** just to check the video\n* Maybe he/she **doesn't liked the content** \n* Maybe he/she **accidently clicked** on the video\n\nThere's an huge possibility of such cases. But in conclusion, We can say high CTR reflect cases like :\n* People clicked on the video maybe because of the **Thumbnail, or Title was soothing**. Maybe he/she clicked because of the **hero mentioned in Title/Thumbnail**\n\n📃 I don't know how Youtube algorithm works. But for the sake of answering exceptional case of E19, My hypothetical answer will be:\n* Title contains the word **\"MOOC\"**. Since now a days everyone wanna **break into DataScience**, Youtube algorithm may have **suggested **that video to people looking for MOOCs\n* Most of other episodes have similar kind of Titles stating **\"Interview with\"** or have some terms that **are't that begineer friendly**. Resulting in **low CTR** \n* Supporting my hypothesis, observe **E27** (having fast.ai in Title that is a famous MOOC), **E38**(Title with Youngest Grandmaster may have attracted people to click),**E49** (Getting started in Datascience), **E60**(Terms like NLP and Open Source Projects) and **E75**(again fast.ai)\n* You can **argue for E12** which has the word \"Freelancing\" in the Title. Well **exceptions** will be there\n\nOkay What's about organic reach of channel or reach via Heroes?",
"_____no_output_____"
]
],
[
[
"Source = ColumnDataSource(Episode_df)\nSource2 = ColumnDataSource(fastai_df)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Impression Views\", \"@youtube_impression_views\"),\n (\"Non Impression Views\", \"@youtube_nonimpression_views\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\ntooltips2 = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Subscriber Gain\", \"@youtube_subscribers\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"Impression-Non Impression Views Per Episode\")\nfig1.line(\"release_date\", \"youtube_impression_views\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Impression Views\")\nfig1.line(\"release_date\", \"youtube_nonimpression_views\", source = Source, color = \"#f2a652\", alpha = 0.8, legend_label=\"Non Impression Views\")\nfig1.varea(source=Source, x=\"release_date\", y1=0, y2=\"youtube_impression_views\", alpha=0.2, fill_color='#55FF88', legend_label=\"Impression Views\")\nfig1.varea(source=Source, x=\"release_date\", y1=0, y2=\"youtube_nonimpression_views\", alpha=0.2, fill_color='#e09d53', legend_label=\"Non Impression Views\")\nfig1.circle(x=\"release_date\", y=\"youtube_impression_views\", source = Source2, color = \"#5bab37\", alpha = 0.8, legend_label=\"M0-M8 Series Impression Views\")\nfig1.circle(x=\"release_date\", y=\"youtube_nonimpression_views\", source = Source2, color = \"#2d3328\", alpha = 0.8, legend_label=\"M0-M8 Series Non Impression Views\")\n\n\n\nfig1.add_tools(HoverTool(tooltips=tooltips,formatters={\"@release_date\": \"datetime\"}))\nfig1.xaxis.axis_label = \"Release Date\"\nfig1.yaxis.axis_label = \"Total Views\"\n\nfig2 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"Subscriber Gain Per Episode\")\nfig2.line(\"release_date\", \"youtube_subscribers\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Subscribers\")\nfig2.varea(source=Source, x=\"release_date\", y1=0, y2=\"youtube_subscribers\", alpha=0.2, fill_color='#55FF88', legend_label=\"Subscribers\")\nfig2.circle(x=\"release_date\", y=\"youtube_subscribers\", source = Source2, color = \"#5bab37\", alpha = 0.8, legend_label=\"M0-M8 Series\")\n\n\nfig2.add_tools(HoverTool(tooltips=tooltips2,formatters={\"@release_date\": \"datetime\"}))\nfig2.xaxis.axis_label = \"Release Date\"\nfig2.yaxis.axis_label = \"Subscriber Count\"\n\n\nshow(column(fig1, fig2))",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n* Mostly Non Impression Views are **greater than Impression views**. CTDS seems to have a **loyal fan base** that's sharing his videos, producing more Non Impression Views\n* In some cases, there's sharp increase in views and **big difference** between Impression and Non Impression Views. \n* People **love to see specific Heroes**. Hero choice do matter\n* Total Views(especially Non Impression Views) definately plays role in Subscriber Gain\n* Though M series doesn't have good performance, but if you watch carefully, you'll realise **M series has better Impression Views than Non Impression Views**",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.6\" size=\"3\">Youtube Favors CTDS?</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"data1={\n \"Youtube Impressions\":Episode_df.youtube_impressions.sum(), \n \"Youtube Impression Views\": Episode_df.youtube_impression_views.sum(), \n \"Youtube NonImpression Views\" : Episode_df.youtube_nonimpression_views.sum()\n }\n\ntext=(\"Youtube Impressions\",\"Youtube Impression Views\",\"Youtube NonImpression Views\")\n\nfig = go.Figure(go.Funnelarea(\n textinfo= \"text+value\",\n text =list(data1.keys()),\n values = list(data1.values()),\n title = {\"position\": \"top center\", \"text\": \"Youtube and Views\"},\n name = '', showlegend=False,customdata=['Video Thumbnail shown to Someone', 'Views From Youtube Impressions', 'Views without Youtube Impressions'], hovertemplate = '%{customdata} <br>Count: %{value}</br>'\n ))\nfig.show()",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n\nFew things to note here :\n \n* Well, I havn't cracked Youtube Algorithm, but it seems Youtube has its blessing over CTDS\n* CTDS Episodes is only able to convert **2.84%** of **Youtube Impressions into Viewers**\n* **65.12%** of CTDS views are **Non Impression views**\n \nSeems It's clear Youtube Thumbnail, Video Title are the important factor for deciding whether a person will click on the video or not. \n\nWait, You want some figures?",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.7\" size=\"3\">Do Thumbnails really matter ?</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"colors = [\"red\", \"olive\", \"darkred\", \"goldenrod\"]\n\nindex={\n 0:\"YouTube default image\",\n 1:\"YouTube default image with custom annotation\",\n 2:\"Mini Series: Custom Image with annotations\",\n 3:\"Custom image with CTDS branding, Title and Tags\"\n}\n\np = figure(background_fill_color=\"#ebf4f6\", plot_width=600, plot_height=300, title=\"Thumbnail Type VS CTR\")\n\nbase, lower, upper = [], [], []\n\nfor each_thumbnail_ref in index:\n if each_thumbnail_ref==2:\n temp = fastai_df[fastai_df.youtube_thumbnail_type==each_thumbnail_ref].youtube_ctr \n else:\n temp = Episode_df[Episode_df.youtube_thumbnail_type==each_thumbnail_ref].youtube_ctr\n mpgs_mean = temp.mean()\n mpgs_std = temp.std()\n lower.append(mpgs_mean - mpgs_std)\n upper.append(mpgs_mean + mpgs_std)\n base.append(each_thumbnail_ref)\n\n source_error = ColumnDataSource(data=dict(base=base, lower=lower, upper=upper))\n p.add_layout(\n Whisker(source=source_error, base=\"base\", lower=\"lower\", upper=\"upper\")\n )\n\n tooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Hero Present\", \"@heroes\"),\n ]\n\n color = colors[each_thumbnail_ref % len(colors)]\n p.circle(y=temp, x=each_thumbnail_ref, color=color, legend_label=index[each_thumbnail_ref])\n print(\"Mean CTR for Thumbnail Type {} : {:.3f} \".format(index[each_thumbnail_ref], temp.mean()))\nshow(p)",
"Mean CTR for Thumbnail Type YouTube default image : 2.565 \nMean CTR for Thumbnail Type YouTube default image with custom annotation : 2.725 \nMean CTR for Thumbnail Type Mini Series: Custom Image with annotations : 1.969 \nMean CTR for Thumbnail Type Custom image with CTDS branding, Title and Tags : 3.115 \n"
]
],
[
[
"<b>📌 Observations :</b>\n\nFrom above Box-Plot : \n* It seems Type of Thumbnail do have **some impact on CTR**\n* Despite of using **YouTube default image for maximum of time**, it's average CTR is **lowest** as compared to CTR from other Youtube Thumbnail\n* Since **Count of other YouTube thumbnails are less**, We can't say What's the best Thumbnail\n* CTR depends on other factors too like Title, Hero featured in the Episode etc. Still we can **confidently** say that **Thumbnails other than YouTube default image attracts** more Users to click on the Video \n* As We talked about M series, M0-M1 failed to keep interest of people in the series. \n* Although their Mean CTR is lowest yet we can observe M0-M1 has a **better CTR as compared to majority of Episodes with Youtube default thumbnails**. \n\nIn short, Don't use **Default Youtube Image for Thumbnail**\n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.11\" size=\"3\">How much Viewers wanna watch?</font></b>\n</div>\n<br>\nEpisodes have different duration.\n\nIn order to get a significant insight, I'll calculate the **percentage of each Episode watched**..",
"_____no_output_____"
]
],
[
[
"a=Episode_df[[\"episode_id\", \"episode_duration\", \"youtube_avg_watch_duration\"]]\na[\"percentage\"]=(a.youtube_avg_watch_duration/a.episode_duration)*100\n\nb=fastai_df[[\"episode_id\", \"episode_duration\", \"youtube_avg_watch_duration\"]]\nb[\"percentage\"]=(b.youtube_avg_watch_duration/b.episode_duration)*100\n\ntemp=a.append(b).reset_index().drop([\"index\"], axis=1)\n\nSource = ColumnDataSource(temp)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Episode Duration\", \"@episode_duration\"),\n (\"Youtube Avg Watch_duration Views\", \"@youtube_avg_watch_duration\"),\n (\"Percentage of video watched\", \"@percentage\"),\n ]\n\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 1000, plot_height = 400, x_range = temp[\"episode_id\"].values, title = \"Percentage of Episode Watched\")\nfig1.line(\"episode_id\", \"percentage\", source = Source, color = \"#03c2fc\", alpha = 0.8)\nfig1.line(\"episode_id\", temp.percentage.mean(), source = Source, color = \"#f2a652\", alpha = 0.8,line_dash=\"dashed\", legend_label=\"Mean : {:.3f}\".format(temp.percentage.mean()))\n\nfig1.add_tools(HoverTool(tooltips=tooltips))\nfig1.xaxis.axis_label = \"Episode Id\"\nfig1.yaxis.axis_label = \"Percentage\"\n\nfig1.xaxis.major_label_orientation = np.pi / 3\nshow(column(fig1))",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n\n* On an average, **13.065%** of Episode is watched by Viewers\n* But **most Episode** haave watched percentage **less** than this threshold. \n\n<b> How does it make sense ❓</b>\n* That's because we have **some outliers** like E0 and M series that has watched percentage over **20%**. \n\n<b> But Why such outliers occured ❓</b>\n* That's because they have **low Episode Duration**\n\nIn this fast moving world, Humans get **bored** of things very **easily**. E0 and M Series having **low Episode Duration** made viewers to **watch more**.\n\nIf they'll subscribe to the channel or not that's a different thing. That depends on the content.\n\n<b>In order to give more to Viewers and Community, Short lengthed Episodes can be a big step </b>",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.8\" size=\"3\">Performance on Other Platforms</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"colors = [\"red\", \"olive\", \"darkred\", \"goldenrod\"]\n\nindex={\n 0:\"YouTube default playlist image\",\n 1:\"CTDS Branding\",\n 2:\"Mini Series: Custom Image with annotations\",\n 3:\"Custom image with CTDS branding, Title and Tags\"\n}\n\np = figure(background_fill_color=\"#ebf4f6\", plot_width=600, plot_height=300, title=\"Thumbnail Type VS Anchor Plays\")\n\nbase, lower, upper = [], [], []\n\nfor each_thumbnail_ref in index:\n if each_thumbnail_ref==2:\n temp = fastai_df[fastai_df.youtube_thumbnail_type==each_thumbnail_ref].anchor_plays \n else:\n temp = Episode_df[Episode_df.youtube_thumbnail_type==each_thumbnail_ref].anchor_plays\n mpgs_mean = temp.mean()\n mpgs_std = temp.std()\n lower.append(mpgs_mean - mpgs_std)\n upper.append(mpgs_mean + mpgs_std)\n base.append(each_thumbnail_ref)\n\n source_error = ColumnDataSource(data=dict(base=base, lower=lower, upper=upper))\n p.add_layout(\n Whisker(source=source_error, base=\"base\", lower=\"lower\", upper=\"upper\")\n )\n\n tooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Hero Present\", \"@heroes\"),\n ]\n\n color = colors[each_thumbnail_ref % len(colors)]\n p.circle(y=temp, x=each_thumbnail_ref, color=color, legend_label=index[each_thumbnail_ref])\n print(\"Mean Anchor Plays for Thumbnail Type {} : {:.3f} \".format(index[each_thumbnail_ref], temp.mean()))\nshow(p)",
"Mean Anchor Plays for Thumbnail Type YouTube default playlist image : 620.939 \nMean Anchor Plays for Thumbnail Type CTDS Branding : 534.500 \nMean Anchor Plays for Thumbnail Type Mini Series: Custom Image with annotations : 309.000 \nMean Anchor Plays for Thumbnail Type Custom image with CTDS branding, Title and Tags : 387.375 \n"
]
],
[
[
"<b>📌 Observations :</b>\n \n* **55.40%** of the Anchor Thumbnail have **CTDS Branding**\n* But on an Average, **Podcasts with YouTube default playlist** image performs **better** in terms of Anchor Plays",
"_____no_output_____"
]
],
[
[
"Episode_df.release_date = pd.to_datetime(Episode_df.release_date)\nSource = ColumnDataSource(Episode_df)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Episode Title\", \"@episode_name\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Anchor Plays\", \"@anchor_plays\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\ntooltips2 = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Episode Title\", \"@episode_name\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Spotify Starts Plays\", \"@spotify_starts\"),\n (\"Spotify Streams\", \"@spotify_streams\"),\n (\"Spotify Listeners\", \"@spotify_listeners\"),\n (\"Category\", \"@category\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"Anchor Plays Per Episode\")\nfig1.line(\"release_date\", \"anchor_plays\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Anchor Plays\")\nfig1.line(\"release_date\", Episode_df.anchor_plays.mean(), source = Source, color = \"#f2a652\", alpha = 0.8, line_dash=\"dashed\", legend_label=\"Anchor Plays Mean : {:.3f}\".format(Episode_df.youtube_ctr.mean()))\n\n\nfig1.add_tools(HoverTool(tooltips=tooltips,formatters={\"@release_date\": \"datetime\"}))\nfig1.xaxis.axis_label = \"Release Date\"\nfig1.yaxis.axis_label = \"Anchor Plays\"\n\nfig2 = figure(background_fill_color=\"#ebf4f6\", plot_width = 600, plot_height = 400, x_axis_type = \"datetime\", title = \"Performance on Spotify Per Episode\")\nfig2.line(\"release_date\", \"spotify_starts\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Spotify Starts Plays\")\nfig2.line(\"release_date\", \"spotify_streams\", source = Source, color = \"#f2a652\", alpha = 0.8, legend_label=\"Spotify Streams\")\nfig2.line(\"release_date\", \"spotify_listeners\", source = Source, color = \"#03fc5a\", alpha = 0.8, legend_label=\"Spotify Listeners\")\n\n\nfig2.add_tools(HoverTool(tooltips=tooltips2,formatters={\"@release_date\": \"datetime\"}))\nfig2.xaxis.axis_label = \"Release Date\"\nfig2.yaxis.axis_label = \"Total Plays\"\n\n\nshow(column(fig1,fig2))",
"_____no_output_____"
]
],
[
[
" \n* It's 2020 and Seems now-a-days people aren't not much into podcasts and Audios",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.10\" size=\"3\">Distribution of Heores by Country and Nationality</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"temp=Episode_df.groupby([\"heroes_location\", \"heroes\"])[\"heroes_nationality\"].value_counts()\n\nparent=[]\nnames =[]\nvalues=[]\nheroes=[]\nfor k in temp.index:\n parent.append(k[0])\n heroes.append(k[1])\n names.append(k[2])\n values.append(temp.loc[k])\n\ndf = pd.DataFrame(\n dict(names=names, parents=parent,values=values, heroes=heroes))\ndf[\"World\"] = \"World\"\n\nfig = px.treemap(\n df,\n path=['World', 'parents','names','heroes'], values='values',color='parents')\n\nfig.update_layout( \n width=1000,\n height=700,\n title_text=\"Distribution of Heores by Country and Nationality\")\nfig.show()",
"_____no_output_____"
]
],
[
[
"\n* Most of our Heroes lives in USA but There's quite range of Diversity in Heroes Nationality within a country which is good to know ",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.12\" size=\"3\">Any Relation between Release Date of Epiosdes?</font></b>\n</div>",
"_____no_output_____"
]
],
[
[
"a=Episode_df.release_date\nb=(a-a.shift(periods=1, fill_value='2019-07-21')).astype('timedelta64[D]')\nd = {'episode_id':Episode_df.episode_id, 'heroes':Episode_df.heroes, 'release_date': Episode_df.release_date, 'day_difference': b}\ntemp = pd.DataFrame(d)\n\nSource = ColumnDataSource(temp)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Hero Present\", \"@heroes\"),\n (\"Day Difference\", \"@day_difference\"),\n (\"Date\", \"@release_date{%F}\"),\n ]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 1000, plot_height = 400, x_axis_type = \"datetime\", title = \"Day difference between Each Release Date\")\nfig1.line(\"release_date\", \"day_difference\", source = Source, color = \"#03c2fc\", alpha = 0.8)\n\nfig1.add_tools(HoverTool(tooltips=tooltips,formatters={\"@release_date\": \"datetime\"}))\nfig1.xaxis.axis_label = \"Date\"\nfig1.yaxis.axis_label = \"No of Days\"\n\nfig1.xaxis.major_label_orientation = np.pi / 3\nshow(column(fig1))",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n* Seems 2020 made Sanyam a bit consistant on his Release Date having a difference of 3 or 4 days between each release till 18th July",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.4.13\" size=\"3\">Do I know about Release of anniversary interview episode?</font></b>\n</div>\n<br>\nBecause of time shortage, I didn't scraped new data myself.\n\nThough I visited his Youtube Channel and manually examined his Release Patterns\n\n\n| Episode Id | Release | Day Difference |\n|----------|:-------------:|:-------------:|\n| E75 | 2020-06-18 | 4 |\n| E76 | 2020-06-21 | 3 |\n| E77 | 2020-06-28 | 7 |\n| E78 | 2020-07-02 | 4 |\n| E79 | 2020-07-09 | 7 |\n| E80 | 2020-07-12 | 3 |\n\nMaybe He's experimenting with a new pattern\n\n<b> Can We pin-point when 1 year anniversary interview episode❓</b>\n**Actually No!**\n\nThough a small pattern can be observed in Release dates, He has bit **odd recording pattern** :\n* Who knows He may have 3-4 videos already recorded and ready to be released. \n* Even if He records anniversary interview episode today, We can not say when He'll gonna release that Episode\n\nAs per his Release pattern, He's been releasing his Episodes **after 3 or 4 days**. \n\n* Considering **E77 and E79 as exception**, He'll more probably release **E81** on **2020-07-16** or **2020-07-15**\n* If He's experimenting with a new pattern (**7 day difference after one video**), then E81 will be released on **2020-07-19** followed by **E82** on **2020-07-22** or **2020-07-23**\n\nIf I'm correct then Mr. [Sanyam Bhutani](https://www.kaggle.com/init27), Please don't forget to give a small shoutout to me 😄",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.5\" size=\"4\"> Exploring Raw / Cleaned Substitles</font></b>\n</div>\n<a href=\"#toc\"><span class=\"label label-info\">Go back to our Guide</span></a>\n\n<br>\n\nSo, We have 2 directories here :\n* Raw Subtitles : Tanscript in Text format\n* Cleaned Subtitles : Tanscript in CSV format with Timestamp\n",
"_____no_output_____"
]
],
[
[
"def show_script(id):\n return pd.read_csv(\"../input/chai-time-data-science/Cleaned Subtitles/{}.csv\".format(id))",
"_____no_output_____"
],
[
"df = show_script(\"E1\")\ndf",
"_____no_output_____"
]
],
[
[
"<div>\n<b><font id=\"1.5.1\" size=\"3\">A Small Shoutout to Ramshankar Yadhunath</font></b>\n</div>\n<br>\n\nI would like to give a small shoutout to [Ramshankar Yadhunath](https://www.kaggle.com/thedatabeast) for providing a feature engineering script in his [Kernel](https://www.kaggle.com/thedatabeast/making-perfect-chai-and-other-tales). \n\nHey Guys, If you followed me till here, then dont forget to check out his [Kernel](https://www.kaggle.com/thedatabeast/making-perfect-chai-and-other-tales) too.",
"_____no_output_____"
]
],
[
[
"# feature engineer the transcript features\ndef conv_to_sec(x):\n \"\"\" Time to seconds \"\"\"\n\n t_list = x.split(\":\")\n if len(t_list) == 2:\n m = t_list[0]\n s = t_list[1]\n time = int(m) * 60 + int(s)\n else:\n h = t_list[0]\n m = t_list[1]\n s = t_list[2]\n time = int(h) * 60 * 60 + int(m) * 60 + int(s)\n return time\n\n\ndef get_durations(nums, size):\n \"\"\" Get durations i.e the time for which each speaker spoke continuously \"\"\"\n\n diffs = []\n for i in range(size - 1):\n diffs.append(nums[i + 1] - nums[i])\n diffs.append(30) # standard value for all end of the episode CFA by Sanyam\n return diffs\n\n\ndef transform_transcript(sub, episode_id):\n \"\"\" Transform the transcript of the given episode \"\"\"\n\n # create the time second feature that converts the time into the unified qty. of seconds\n sub[\"Time_sec\"] = sub[\"Time\"].apply(conv_to_sec)\n\n # get durations\n sub[\"Duration\"] = get_durations(sub[\"Time_sec\"], sub.shape[0])\n\n # providing an identity to each transcript\n sub[\"Episode_ID\"] = episode_id\n sub = sub[[\"Episode_ID\", \"Time\", \"Time_sec\", \"Duration\", \"Speaker\", \"Text\"]]\n\n return sub\n\n\ndef combine_transcripts(sub_dir):\n \"\"\" Combine all the 75 transcripts of the ML Heroes Interviews together as one dataframe \"\"\"\n\n episodes = []\n for i in range(1, 76):\n file = \"E\" + str(i) + \".csv\"\n try:\n sub_epi = pd.read_csv(os.path.join(sub_dir, file))\n sub_epi = transform_transcript(sub_epi, (\"E\" + str(i)))\n episodes.append(sub_epi)\n except:\n continue\n return pd.concat(episodes, ignore_index=True)\n\n\n# create the combined transcript dataset\nsub_dir = \"../input/chai-time-data-science/Cleaned Subtitles\"\ntranscripts = combine_transcripts(sub_dir)\ntranscripts.head()",
"_____no_output_____"
]
],
[
[
"Now, We have some Data to work with. \n\nThanking [Ramshankar Yadhunath](https://www.kaggle.com/thedatabeast) once again, Let's get it started ..\n\n<div class=\"alert alert-block alert-warning\"> \n<b>Note :</b> Transcript for E0 and E4 is missing\n</div>\n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.5.2\" size=\"3\">Intro is Bad for CTDS ?</font></b>\n</div>\n<br>\nFrom our previous analysis, We realised Majority of the Episodes have quite less watch time i.e. less than 13.065% of the total Duration. \n\nIn such case, How much CTDS intro hurts itself in terms of intro duration.\n\nLet's find out...",
"_____no_output_____"
]
],
[
[
"temp = Episode_df[[\"episode_id\",\"youtube_avg_watch_duration\"]]\ntemp=temp[(temp.episode_id!=\"E0\") & (temp.episode_id!=\"E4\")]\n\nintro=[]\n\nfor i in transcripts.Episode_ID.unique():\n intro.append(transcripts[transcripts.Episode_ID==i].iloc[0].Duration)\ntemp[\"Intro_Duration\"]=intro\ntemp[\"diff\"]=temp.youtube_avg_watch_duration-temp.Intro_Duration\n\nSource = ColumnDataSource(temp)\n\ntooltips = [\n (\"Episode Id\", \"@episode_id\"),\n (\"Youtube Avg Watch_duration Views\", \"@youtube_avg_watch_duration\"),\n (\"Intro Duration\", \"@Intro_Duration\"),\n (\"Avg Duration of Content Watched\", \"@diff\"),\n ]\n\n\nfig1 = figure(background_fill_color=\"#ebf4f6\", plot_width = 1000, plot_height = 600, x_range = temp[\"episode_id\"].values, title = \"Impact of Intro Durations\")\nfig1.line(\"episode_id\", \"youtube_avg_watch_duration\", source = Source, color = \"#03c2fc\", alpha = 0.8, legend_label=\"Youtube Avg Watch_duration Views\")\nfig1.line(\"episode_id\", \"Intro_Duration\", source = Source, color = \"#f2a652\", alpha = 0.8, legend_label=\"Intro Duration\")\nfig1.line(\"episode_id\", \"diff\", source = Source, color = \"#03fc5a\", alpha = 0.8, legend_label=\"Avg Duration of Content Watched\")\n\n\nfig1.add_tools(HoverTool(tooltips=tooltips))\nfig1.xaxis.axis_label = \"Episode Id\"\nfig1.yaxis.axis_label = \"Percentage\"\n\nfig1.xaxis.major_label_orientation = np.pi / 3\nshow(column(fig1))",
"_____no_output_____"
],
[
"print(\"{:.2f} % of Episodes have Avg Duration of Content Watched less than 5 minutes\".format(len(temp[temp[\"diff\"]<300])/len(temp)*100))\nprint(\"{:.2f} % of Episodes have Avg Duration of Content Watched less than 4 minutes\".format(len(temp[temp[\"diff\"]<240])/len(temp)*100))\nprint(\"{:.2f} % of Episodes have Avg Duration of Content Watched less than 3 minutes\".format(len(temp[temp[\"diff\"]<180])/len(temp)*100))\nprint(\"{:.2f} % of Episodes have Avg Duration of Content Watched less than 2 minutes\".format(len(temp[temp[\"diff\"]<120])/len(temp)*100))\nprint(\"In {} case, Viewer left in the Intro Duration\".format(len(temp[temp[\"diff\"]<0])))",
"81.08 % of Episodes have Avg Duration of Content Watched less than 5 minutes\n72.97 % of Episodes have Avg Duration of Content Watched less than 4 minutes\n45.95 % of Episodes have Avg Duration of Content Watched less than 3 minutes\n22.97 % of Episodes have Avg Duration of Content Watched less than 2 minutes\nIn 1 case, Viewer left in the Intro Duration\n"
]
],
[
[
"<b>🧠 My Cessation: </b>\n* Observing the graph and stats, it's clear it's a high time\n* We don't have Transcript of M Series where the Percentage of Episode Watched i.e. Episode had small Duration.\n* Concluding from analysis We can now strongly comment, Episode with shorter length will definitely help\n\nThere's lots of things to improve.\n\n* Shorter Duration Videos can be delivered highlighting the important aspects of the Shows\n* Short Summaries can be provided in the description. Maybe after reading them, Viewers could devote for a longer Show (depending on the interest on the topic reflected in summery)\n* Full length Show can be provided as Podcast in Apple, Spotify, Anchor. If Viewer after shorter duration videos and summeries wishes to have a full show, they can have it from there\n\nWith 45.95% of Episodes having Avg Duration of Content Watched less than 3 minutes, We can hardly gain any useful insight or can comment on quality of Content delivered.\n\nBut Okay! We can have some fun though 😄",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.5.3\" size=\"3\">Who Speaks More ?</font></b>\n</div>\n<br>",
"_____no_output_____"
]
],
[
[
"host_text = []\nhero_text = []\nfor i in transcripts.Episode_ID.unique():\n host_text.append([i, transcripts[(transcripts.Episode_ID==i) & (transcripts.Speaker==\"Sanyam Bhutani\")].Text])\n hero_text.append([i, transcripts[(transcripts.Episode_ID==i) & (transcripts.Speaker!=\"Sanyam Bhutani\")].Text])\n\ntemp_host={}\ntemp_hero={}\nfor i in range(len(transcripts.Episode_ID.unique())):\n host_text_count = len(host_text[i][1])\n hero_text_count = len(hero_text[i][1])\n temp_host[hero_text[i][0]]=host_text_count\n temp_hero[hero_text[i][0]]=hero_text_count\n \ndef getkey(dict): \n list = [] \n for key in dict.keys(): \n list.append(key) \n return list\n\ndef getvalue(dict): \n list = [] \n for key in dict.values(): \n list.append(key) \n return list",
"_____no_output_____"
],
[
"Source = ColumnDataSource(data=dict(\n x=getkey(temp_host),\n y=getvalue(temp_host),\n a=getkey(temp_hero),\n b=getvalue(temp_hero),\n))\n\ntooltips = [\n (\"Episode Id\", \"@x\"),\n (\"No of Times Host Speaks\", \"@y\"),\n (\"No of Times Hero Speaks\", \"@b\"),\n]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\",plot_width = 1000, tooltips=tooltips,plot_height = 400, x_range = getkey(temp_host), title = \"Who Speaks More ?\")\nfig1.vbar(\"x\", top = \"y\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8, legend_label=\"No of Times Host Speaks\")\nfig1.vbar(\"a\", top = \"b\", source = Source, width = 0.4, color = \"#e7f207\", alpha=.8, legend_label=\"No of Times Hero Speaks\")\n\nfig1.xaxis.axis_label = \"Episode\"\nfig1.yaxis.axis_label = \"Count\"\n\nfig1.grid.grid_line_color=\"#feffff\"\nfig1.xaxis.major_label_orientation = np.pi / 4\n\nshow(fig1)",
"_____no_output_____"
]
],
[
[
"* Excluding Few Episodes, Ratio between No of Times One Speaks is quite mantained\n* E69 was AMA episode. That's why there is no Hero",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.5.4\" size=\"3\">Frequency of Questions Per Episode </font></b>\n</div>\n<br>",
"_____no_output_____"
]
],
[
[
"ques=0\ntotal_ques={}\nfor episode in range(len(transcripts.Episode_ID.unique())):\n for each_text in range(len(host_text[episode][1])):\n ques += host_text[episode][1].reset_index().iloc[each_text].Text.count(\"?\")\n total_ques[hero_text[episode][0]]= ques\n ques=0",
"_____no_output_____"
],
[
"from statistics import mean \nSource = ColumnDataSource(data=dict(\n x=getkey(total_ques),\n y=getvalue(total_ques),\n))\n\ntooltips = [\n (\"Episode Id\", \"@x\"),\n (\"No of Questions\", \"@y\"),\n]\n\nfig1 = figure(background_fill_color=\"#ebf4f6\",plot_width = 1000, plot_height = 400,tooltips=tooltips, x_range = getkey(temp_host), title = \"Questions asked Per Episode\")\nfig1.vbar(\"x\", top = \"y\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8, legend_label=\"No of Questions asked Per Episode\")\nfig1.line(\"x\", mean(getvalue(total_ques)), source = Source, color = \"#f2a652\", alpha = 0.8,line_dash=\"dashed\", legend_label=\"Average Questions : {:.3f}\".format(mean(getvalue(total_ques))))\n\nfig1.xaxis.axis_label = \"Episode\"\nfig1.yaxis.axis_label = \"No of Questions\"\n\nfig1.legend.location = \"top_left\"\n\nfig1.grid.grid_line_color=\"#feffff\"\nfig1.xaxis.major_label_orientation = np.pi / 4\n\nshow(fig1)",
"_____no_output_____"
]
],
[
[
"* On an Average, around 30 Questions are asked by Host\n* E69 being AMA Episode justifies the reason of having such high no of Questions",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"1.5.5\" size=\"3\">Favourite Text ?</font></b>\n</div>\n<br>\n\n<b>⚒️ About the Function :</b> \n\nWell, I'm gonna write a small function. You can pass a Hero Name and it will create a graph about 7 most common words spoken by that person \n\n\nBut before that I would like to give a small Shoutout to [Parul Pandey](https://www.kaggle.com/parulpandey) for providing a text cleaning script in her [Kernel](https://www.kaggle.com/parulpandey/how-to-explore-the-ctds-show-data).",
"_____no_output_____"
]
],
[
[
"import re\nimport nltk\nfrom statistics import mean \nfrom collections import Counter\nimport string\n\ndef clean_text(text):\n '''Make text lowercase, remove text in square brackets,remove links,remove punctuation\n and remove words containing numbers.'''\n text = text.lower()\n text = re.sub('\\[.*?\\]', '', text)\n text = re.sub('https?://\\S+|www\\.\\S+', '', text)\n text = re.sub('<.*?>+', '', text)\n text = re.sub('[%s]' % re.escape(string.punctuation), '', text)\n text = re.sub('\\n', '', text)\n text = re.sub('\\w*\\d\\w*', '', text)\n return text\n\n\ndef text_preprocessing(text):\n \"\"\"\n Cleaning and parsing the text.\n\n \"\"\"\n tokenizer = nltk.tokenize.RegexpTokenizer(r'\\w+')\n nopunc = clean_text(text)\n tokenized_text = tokenizer.tokenize(nopunc)\n #remove_stopwords = [w for w in tokenized_text if w not in stopwords.words('english')]\n combined_text = ' '.join(tokenized_text)\n return combined_text",
"_____no_output_____"
],
[
"transcripts['Text'] = transcripts['Text'].apply(str).apply(lambda x: text_preprocessing(x))",
"_____no_output_____"
],
[
"def get_data(speakername=None):\n label=[]\n value=[]\n\n text_data=transcripts[(transcripts.Speaker==speakername)].Text.tolist()\n temp=list(filter(lambda x: x.count(\" \")<10 , text_data)) \n\n freq=nltk.FreqDist(temp).most_common(7)\n for each in freq:\n label.append(each[0])\n value.append(each[1])\n \n \n Source = ColumnDataSource(data=dict(\n x=label,\n y=value,\n ))\n\n tooltips = [\n (\"Favourite Text\", \"@x\"),\n (\"Frequency\", \"@y\"),\n ]\n\n fig1 = figure(background_fill_color=\"#ebf4f6\",plot_width = 600, tooltips=tooltips, plot_height = 400, x_range = label, title = \"Favourite Text\")\n fig1.vbar(\"x\", top = \"y\", source = Source, width = 0.4, color = \"#76b4bd\", alpha=.8)\n\n fig1.xaxis.axis_label = \"Text\"\n fig1.yaxis.axis_label = \"Frequency\"\n\n\n fig1.grid.grid_line_color=\"#feffff\"\n fig1.xaxis.major_label_orientation = np.pi / 4\n\n show(fig1)\n",
"_____no_output_____"
],
[
"get_data(speakername=\"Sanyam Bhutani\")",
"_____no_output_____"
]
],
[
[
"<b>📌 Observations :</b>\n* Okay, Yeah seems to be favourite words of [Sanyam Bhutani](https://www.kaggle.com/init27)\n* Well He has some different laughs for different scenario I guess 😄\n* We have all the Transcript where [Sanyam Bhutani](https://www.kaggle.com/init27) speaks. So, It's common that you'll find words with good frequency for [Sanyam Bhutani](https://www.kaggle.com/init27) only.\n* But you can still try. Who knows I might be missing something interesting 😄\n\n<div class=\"alert-block alert-info\"> \n <b>Tip:</b> Pass your favourite hero name in function get_data() and you're good to go\n</div>",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"2\" size=\"5\">End Notes</font></b>\n</div>\n<br>\n\n \nWith this, I end my analysis on this Dataset named [Chai Time Data Science | CTDS.Show](https://www.kaggle.com/rohanrao/chai-time-data-science) provided by Mr. [Vopani](https://www.kaggle.com/rohanrao) and Mr. [Sanyam Bhutani](https://www.kaggle.com/init27).<br><br>\nIt was a wonderfull experience for me<br><br>\nSomehow if my Analysis/Way of StoryTelling hurted any sentiments then I apologize for that <br><br>\nAnd yea Congraulations to [Chai Time Data Science | CTDS.Show](https://www.kaggle.com/rohanrao/chai-time-data-science) for completing a successfull 1 Year journey.<br><br>\n \nNow I can finally enjoy my Chai break in a peace\n\n<img src=\"https://imgmediagumlet.lbb.in/media/2018/07/5b5712e41d12b6235f1385a4_1532433124061.jpeg?w=750&h=500&dpr=1\" width=400 height=400>\n \n",
"_____no_output_____"
],
[
"<div>\n<b><font id=\"3\" size=\"5\">Credits</font></b>\n</div>\n<br>\nThanks everyone for these amazing photos. A Small shoutout to all of you\n\n* https://miro.medium.com/max/1400/0*ovcHbNV5470zvsH5.jpeg\n<br>\n* https://api.breaker.audio/shows/681460/episodes/55282147/image?v=0987aece49022c8863600c4cf5b67eb8&width=400&height=400\n<br>\n* https://external-preview.redd.it/VVHgy7UiRHOUfs6v91tRSDgvvUIXlJvyiD822RG4Fhg.png?auto=webp&s=d6fb054c1f57ec09b5b45bcd7ee0e821b53449c9\n<br>\n* https://memegenerator.net/img/instances/64277502.jpg\n<br>\n* https://miro.medium.com/max/420/1*lYw_nshU1qg3dqbqgpWoDA.png\n<br>\n* https://eatrealamerica.com/wp-content/uploads/2018/05/Fishy-Smell.png\n<br>\n* https://i.imgflip.com/2so1le.jpg\n<br>\n* https://encrypted-tbn0.gstatic.com/images?q=tbn%3AANd9GcQf6ziN-7WH50MIZZQtJbO0Czsll5wTud7E3Q&usqp=CAU\n<br>\n* https://imgmediagumlet.lbb.in/media/2018/07/5b5712e41d12b6235f1385a4_1532433124061.jpeg?w=750&h=500&dpr=1\n<br>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a1df5f9e2172dd0ca7b89b8644bb9a65f70cd15
| 821 |
ipynb
|
Jupyter Notebook
|
Untitled.ipynb
|
kurotachimi/gcf_cm_cut_and_match
|
5106c85ed9e71a65cff7bc327eda22d6bc2d9be7
|
[
"MIT"
] | null | null | null |
Untitled.ipynb
|
kurotachimi/gcf_cm_cut_and_match
|
5106c85ed9e71a65cff7bc327eda22d6bc2d9be7
|
[
"MIT"
] | null | null | null |
Untitled.ipynb
|
kurotachimi/gcf_cm_cut_and_match
|
5106c85ed9e71a65cff7bc327eda22d6bc2d9be7
|
[
"MIT"
] | null | null | null | 16.098039 | 34 | 0.485993 |
[
[
[
"ls ../test_data/tmp.mp3\n\n",
"tmp.mp3\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a1e02a6787469272e1323f10f135b7d99d77856
| 71,097 |
ipynb
|
Jupyter Notebook
|
Support_Vector_Machines.ipynb
|
secakalfaoglu/ML-Algorithms
|
8aa857016ecfa5a13d75a3da68acf661710c4ccc
|
[
"MIT"
] | null | null | null |
Support_Vector_Machines.ipynb
|
secakalfaoglu/ML-Algorithms
|
8aa857016ecfa5a13d75a3da68acf661710c4ccc
|
[
"MIT"
] | null | null | null |
Support_Vector_Machines.ipynb
|
secakalfaoglu/ML-Algorithms
|
8aa857016ecfa5a13d75a3da68acf661710c4ccc
|
[
"MIT"
] | null | null | null | 71,097 | 71,097 | 0.725066 |
[
[
[
"from google.colab import drive\ndrive.mount('/content/drive/', force_remount=True)",
"Mounted at /content/drive/\n"
],
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn import metrics\nfrom sklearn.metrics import classification_report, confusion_matrix,precision_recall_curve, auc, roc_curve\n%matplotlib inline",
"_____no_output_____"
],
[
"covid_data = pd.read_csv('/content/drive/MyDrive/ML/Cleaned-Data.csv', nrows=50000)",
"_____no_output_____"
],
[
"covid_data.head(5)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"feature_columns = ['Fever', 'Tiredness', 'Pains','Dry-Cough']\nX = covid_data[feature_columns]\ny = covid_data['Age_60+']\nfrom sklearn.preprocessing import LabelEncoder\nle = LabelEncoder()\ny = le.fit_transform(y)\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)",
"_____no_output_____"
],
[
"from sklearn.svm import SVC",
"_____no_output_____"
],
[
"model = SVC()",
"_____no_output_____"
],
[
"model.fit(X_train,y_train)",
"_____no_output_____"
],
[
"predictions = model.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report,confusion_matrix",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,predictions))",
"[[13041 0]\n [ 1959 0]]\n"
],
[
"print(classification_report(y_test,predictions))",
" precision recall f1-score support\n\n 0 0.87 1.00 0.93 13041\n 1 0.00 0.00 0.00 1959\n\n accuracy 0.87 15000\n macro avg 0.43 0.50 0.47 15000\nweighted avg 0.76 0.87 0.81 15000\n\n"
],
[
"param_grid = {'C': [0.1,1, 10, 100, 1000], 'gamma': [1,0.1,0.01,0.001,0.0001], 'kernel': ['rbf']} ",
"_____no_output_____"
],
[
"from sklearn.model_selection import GridSearchCV",
"_____no_output_____"
],
[
"grid = GridSearchCV(SVC(),param_grid,refit=True,verbose=3)",
"_____no_output_____"
],
[
"# May take awhile!\ngrid.fit(X_train,y_train)",
"Fitting 5 folds for each of 25 candidates, totalling 125 fits\n[CV] C=0.1, gamma=1, kernel=rbf ......................................\n"
],
[
"grid.best_params_",
"_____no_output_____"
],
[
"grid.best_estimator_",
"_____no_output_____"
],
[
"grid_predictions = grid.predict(X_test)",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,grid_predictions))",
"[[13041 0]\n [ 1959 0]]\n"
],
[
"print(classification_report(y_test,grid_predictions))",
" precision recall f1-score support\n\n 0 0.87 1.00 0.93 13041\n 1 0.00 0.00 0.00 1959\n\n accuracy 0.87 15000\n macro avg 0.43 0.50 0.47 15000\nweighted avg 0.76 0.87 0.81 15000\n\n"
],
[
"fpr, tpr, threshold= metrics.roc_curve(y_test, predictions)\nroc_auc=metrics.auc(fpr,tpr)\nplt.title('Roc')\nplt.plot(fpr,tpr,'b',label='Auc=%0.2f'%roc_auc)\nplt.legend(loc='lower right')\nplt.plot([0,1],[0,1],'r--')\nplt.xlim([0,1])\nplt.ylim([0,1])\nplt.ylabel('True Positive Rate')\nplt.xlabel('False Positive Rate')\nplt.show()",
"_____no_output_____"
],
[
"cm = confusion_matrix(y_test, predictions)\nx_axis_labels = [\"60- Yaş\", \"60+ Yaş\"]\ny_axis_labels = [\"60- Yaş\", \"60+ Yaş\"]\nf, ax = plt.subplots(figsize =(7,7))\nsns.heatmap(cm, annot = True, linewidths=0.2, linecolor=\"black\", fmt = \".0f\", ax=ax, cmap=\"Purples\", xticklabels=x_axis_labels, yticklabels=y_axis_labels)\nplt.xlabel(\"Tahmin\")\nplt.ylabel(\"Doğru\")\nplt.title('SVM için Confusion Matrixi')\n#plt.savefig(\"lrcm.png\", format='png', dpi=500, bbox_inches='tight')\nplt.show()\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1e1057a70589da1da4ea9524fe2d9e4a7efa7c
| 91,668 |
ipynb
|
Jupyter Notebook
|
examples/Popups.ipynb
|
beaswift/folium
|
b44e95be4ec2bdcf4898e48a749a64edfb8a2ea8
|
[
"MIT"
] | null | null | null |
examples/Popups.ipynb
|
beaswift/folium
|
b44e95be4ec2bdcf4898e48a749a64edfb8a2ea8
|
[
"MIT"
] | null | null | null |
examples/Popups.ipynb
|
beaswift/folium
|
b44e95be4ec2bdcf4898e48a749a64edfb8a2ea8
|
[
"MIT"
] | null | null | null | 222.495146 | 39,748 | 0.938485 |
[
[
[
"import os\nimport folium\n\nprint(folium.__version__)",
"0.5.0\n"
]
],
[
[
"# How to create Popups\n\n## Simple popups\n\nYou can define your popup at the feature creation, but you can also overwrite them afterwards:",
"_____no_output_____"
]
],
[
[
"m = folium.Map([45, 0], zoom_start=4)\n\nfolium.Marker([45, -30], popup='inline implicit popup').add_to(m)\n\nfolium.CircleMarker(\n location=[45, -10],\n radius=25,\n fill=True,\n popup=folium.Popup('inline explicit Popup')\n).add_to(m)\n\nls = folium.PolyLine(\n locations=[[43, 7], [43, 13], [47, 13], [47, 7], [43, 7]],\n color='red'\n)\n\nls.add_child(folium.Popup('outline Popup on Polyline'))\nls.add_to(m)\n\ngj = folium.GeoJson(\n data={\n 'type': 'Polygon',\n 'coordinates': [[[27, 43], [33, 43], [33, 47], [27, 47]]]\n }\n)\n\ngj.add_child(folium.Popup('outline Popup on GeoJSON'))\ngj.add_to(m)\n\nm.save(os.path.join('results', 'simple_popups.html'))\n\nm",
"_____no_output_____"
],
[
"m = folium.Map([45, 0], zoom_start=2)\n\nfolium.Marker(\n location=[45, -10],\n popup=folium.Popup(\"Let's try quotes\", parse_html=True)\n).add_to(m)\n\nfolium.Marker(\n location=[45, -30],\n popup=folium.Popup(u\"Ça c'est chouette\", parse_html=True)\n).add_to(m)\n\nm",
"_____no_output_____"
]
],
[
[
"## Vega Popup\n\nYou may know that it's possible to create awesome Vega charts with (or without) `vincent`. If you're willing to put one inside a popup, it's possible thanks to `folium.Vega`.",
"_____no_output_____"
]
],
[
[
"import json\nimport numpy as np\nimport vincent\n\nscatter_points = {\n 'x': np.random.uniform(size=(100,)),\n 'y': np.random.uniform(size=(100,)),\n}\n\n# Let's create the vincent chart.\nscatter_chart = vincent.Scatter(scatter_points,\n iter_idx='x',\n width=600,\n height=300)\n\n# Let's convert it to JSON.\nscatter_json = scatter_chart.to_json()\n\n# Let's convert it to dict.\nscatter_dict = json.loads(scatter_json)",
"_____no_output_____"
],
[
"m = folium.Map([43, -100], zoom_start=4)\n\npopup = folium.Popup()\nfolium.Vega(scatter_chart, height=350, width=650).add_to(popup)\nfolium.Marker([30, -120], popup=popup).add_to(m)\n\n# Let's create a Vega popup based on scatter_json.\npopup = folium.Popup(max_width=0)\nfolium.Vega(scatter_json, height=350, width=650).add_to(popup)\nfolium.Marker([30, -100], popup=popup).add_to(m)\n\n# Let's create a Vega popup based on scatter_dict.\npopup = folium.Popup(max_width=650)\nfolium.Vega(scatter_dict, height=350, width=650).add_to(popup)\nfolium.Marker([30, -80], popup=popup).add_to(m)\n\nm.save(os.path.join('results', 'vega_popups.html'))\n\nm",
"_____no_output_____"
]
],
[
[
"## Fancy HTML popup",
"_____no_output_____"
]
],
[
[
"import branca\n\n\nm = folium.Map([43, -100], zoom_start=4)\n\nhtml = \"\"\"\n <h1> This is a big popup</h1><br>\n With a few lines of code...\n <p>\n <code>\n from numpy import *<br>\n exp(-2*pi)\n </code>\n </p>\n \"\"\"\n\n\nfolium.Marker([30, -100], popup=html).add_to(m)\n\nm.save(os.path.join('results', 'html_popups.html'))\n\nm",
"_____no_output_____"
]
],
[
[
"You can also put any HTML code inside of a Popup, thaks to the `IFrame` object.",
"_____no_output_____"
]
],
[
[
"m = folium.Map([43, -100], zoom_start=4)\n\nhtml = \"\"\"\n <h1> This popup is an Iframe</h1><br>\n With a few lines of code...\n <p>\n <code>\n from numpy import *<br>\n exp(-2*pi)\n </code>\n </p>\n \"\"\"\n\niframe = branca.element.IFrame(html=html, width=500, height=300)\npopup = folium.Popup(iframe, max_width=500)\n\nfolium.Marker([30, -100], popup=popup).add_to(m)\n\nm.save(os.path.join('results', 'html_popups.html'))\n\nm",
"_____no_output_____"
],
[
"import pandas as pd\n\ndf = pd.DataFrame(data=[['apple', 'oranges'], ['other', 'stuff']], columns=['cats', 'dogs'])\n\nm = folium.Map([43, -100], zoom_start=4)\n\nhtml = df.to_html(classes='table table-striped table-hover table-condensed table-responsive')\n\npopup = folium.Popup(html)\n\nfolium.Marker([30, -100], popup=popup).add_to(m)\n\nm.save(os.path.join('results', 'html_popups.html'))\n\nm",
"_____no_output_____"
]
],
[
[
"Note that you can put another `Figure` into an `IFrame` ; this should let you do stange things...",
"_____no_output_____"
]
],
[
[
"# Let's create a Figure, with a map inside.\nf = branca.element.Figure()\nfolium.Map([-25, 150], zoom_start=3).add_to(f)\n\n# Let's put the figure into an IFrame.\niframe = branca.element.IFrame(width=500, height=300)\nf.add_to(iframe)\n\n# Let's put the IFrame in a Popup\npopup = folium.Popup(iframe, max_width=2650)\n\n# Let's create another map.\nm = folium.Map([43, -100], zoom_start=4)\n\n# Let's put the Popup on a marker, in the second map.\nfolium.Marker([30, -100], popup=popup).add_to(m)\n\n# We get a map in a Popup. Not really useful, but powerful.\nm.save(os.path.join('results', 'map_popups.html'))\n\nm",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1e33cdeef0266d4be4d128d40679fee062e709
| 962 |
ipynb
|
Jupyter Notebook
|
20201111_NC_MNIST_CA.ipynb
|
nunocalaim/self-organising-systems
|
4ac570c2f46e96b4c64c7080a2445662cdde2088
|
[
"Apache-2.0"
] | null | null | null |
20201111_NC_MNIST_CA.ipynb
|
nunocalaim/self-organising-systems
|
4ac570c2f46e96b4c64c7080a2445662cdde2088
|
[
"Apache-2.0"
] | null | null | null |
20201111_NC_MNIST_CA.ipynb
|
nunocalaim/self-organising-systems
|
4ac570c2f46e96b4c64c7080a2445662cdde2088
|
[
"Apache-2.0"
] | null | null | null | 24.666667 | 253 | 0.527027 |
[
[
[
"<a href=\"https://colab.research.google.com/github/nunocalaim/self-organising-systems/blob/master/20201111_NC_MNIST_CA.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
4a1e34f5688eabea27952d918a46b72df87ed51a
| 23,072 |
ipynb
|
Jupyter Notebook
|
notebooks/Policies for Replicas and Thresholding for SVMs.ipynb
|
uwescience/expression_state
|
2b268ffe957cbbc825c67be02f03672061022b4f
|
[
"MIT"
] | null | null | null |
notebooks/Policies for Replicas and Thresholding for SVMs.ipynb
|
uwescience/expression_state
|
2b268ffe957cbbc825c67be02f03672061022b4f
|
[
"MIT"
] | null | null | null |
notebooks/Policies for Replicas and Thresholding for SVMs.ipynb
|
uwescience/expression_state
|
2b268ffe957cbbc825c67be02f03672061022b4f
|
[
"MIT"
] | null | null | null | 63.911357 | 9,780 | 0.658851 |
[
[
[
"# Policies for Replicas and Thresholding for SVMs\n\nSuppose we are given features $x$ such that $x_{ijk}$ is the $i$-th instance, $j$-th feature, and $k$-th replication of that instance and the corresponding class labels $y_i$. This notebook explores the following questions:\n\n- How should the replicas be used? Averaged? As additional instances?\n- Does thresholding (of feature values) increase classification accuracy?\n- How should thresholding be used in combination with replicas?",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## Experiment\n\n- Ground truth feature values are taken from a hypergrid of density $D$ in each feature over the range $[-1, 1]$ such that there are $D$ evenly spaced points for each feature. As a result, there are $D^J$ feature values in the ground truth.\n- Class values are assigned using the separating hyperplane $\\sum_j x_j = 0$ applied to ground truth feature values. A class value of 1 is assigned if $\\sum_j x_j > 0$ and -1 otherwise. The importance of a feature can be weighted by changing the separating hyperplane.\n- The replications are obtained by adding noise from $N(0, \\sigma^2)$ to each ground truth feature value.\n- Accuracy is evaluated for feature vectors $\\alpha (1, \\cdots, 1)$ by computing average accuracy for a set $alpha$ and at different $\\sigma^2$. The result of an experiment displays a plot of $\\alpha \\in [-\\epsilon, \\epsilon]$ versus accuracy at a value of $\\sigma^2$.",
"_____no_output_____"
],
[
"## Creating the Grid",
"_____no_output_____"
]
],
[
[
"def makeGrid(density, dim, min_val=-1, max_val=1):\n \"\"\"\n Creates a uniform grid on a space of arbitrary dimension.\n :param float density: points per unit\n \"\"\"\n coords = [np.linspace(min_val, max_val, density*(max_val - min_val)) for _ in range(dim)]\n return np.meshgrid(*coords)\n\ngrid = makeGrid(5, 2)\n\n",
"_____no_output_____"
],
[
"np.reshape(grid[0], 100, 1)",
"_____no_output_____"
],
[
"np.reshape(grid[1], 100, 1)",
"_____no_output_____"
],
[
"# Reshape grid into a list of vectors\nnp.array()",
"_____no_output_____"
],
[
"plt.scatter(grid[0], grid[1])",
"_____no_output_____"
],
[
"arr = np.array(range(12))\narr",
"_____no_output_____"
],
[
"mat = np.reshape(arr, (2,3,2))\nmat",
"_____no_output_____"
],
[
"np.reshape(mat, (6, 2))",
"_____no_output_____"
],
[
"min_val = -1; max_val = 1; density = 2; num_dim = 3\ncoords = [np.linspace(min_val, max_val,\n density*(max_val - min_val))\n for _ in range(num_dim)]\ngrid = np.meshgrid(*coords)\ngrid",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1e443b321848532bc4285d63cef7a80291aff0
| 92,168 |
ipynb
|
Jupyter Notebook
|
laba09.ipynb
|
kollieartwolf/rudn-bop-1st-gr-2020-py
|
a679af82a3d00aef306ae7eba66347ddcbc6c06d
|
[
"MIT"
] | 3 |
2021-06-14T11:14:04.000Z
|
2022-01-15T15:47:44.000Z
|
laba09.ipynb
|
kollieartwolf/rudn-bop-1st-gr-2020-py
|
a679af82a3d00aef306ae7eba66347ddcbc6c06d
|
[
"MIT"
] | null | null | null |
laba09.ipynb
|
kollieartwolf/rudn-bop-1st-gr-2020-py
|
a679af82a3d00aef306ae7eba66347ddcbc6c06d
|
[
"MIT"
] | 3 |
2021-12-28T15:23:02.000Z
|
2022-03-11T11:45:46.000Z
| 34.161601 | 823 | 0.51915 |
[
[
[
"# Лабораторная работа 9. ООП.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"# 1. Создание классов и объектов\nВ языке программирования Python классы создаются с помощью инструкции `class`, за которой следует произвольное имя класса, после которого ставится двоеточие; далее с новой строки и с отступом реализуется тело класса:",
"_____no_output_____"
]
],
[
[
"class A: # class <имя класса>:\n pass # <тело класса>",
"_____no_output_____"
]
],
[
[
"Создание экземпляра класса:",
"_____no_output_____"
]
],
[
[
"a = A() # имя_переменной = ИмяКласса()",
"_____no_output_____"
],
[
"print(a, 'объект класса', type(a))",
"<__main__.A object at 0x7f294c4ec2b0> объект класса <class '__main__.A'>\n"
]
],
[
[
"# 2. Класс как модуль (библиотека)\nКласс можно представить подобно модулю (библиотеки):\n\n- в нем могут быть свои переменные со значениями и функции\n- у класса есть собственное пространство имен, доступ к которым возможен через имя класса:",
"_____no_output_____"
]
],
[
[
"class CLASS:\n const = 5 # атрибут класса\n def adder(v): # функция-метод\n return v + CLASS.const",
"_____no_output_____"
],
[
"CLASS.const",
"_____no_output_____"
],
[
"CLASS.adder(4)",
"_____no_output_____"
]
],
[
[
"# 3. Класс как создатель объектов\n",
"_____no_output_____"
]
],
[
[
"Object = CLASS()",
"_____no_output_____"
],
[
"Object.const",
"_____no_output_____"
],
[
"Object.adder(100)",
"_____no_output_____"
]
],
[
[
"Дело в том, что классы и объекты не просто модули. Класс создает объекты, которые в определенном смысле являются его наследниками (копиями). \n\nЭто значит, что если у объекта нет собственного поля `const`, то интерпретатор ищет его уровнем выше, то есть в классе. Таким образом, если мы присваиваем объекту поле с таким же именем как в классе, то оно перекрывает, т. е. переопределяет, поле класса:",
"_____no_output_____"
]
],
[
[
"Object.const",
"_____no_output_____"
],
[
"Object.const = 10\nObject.const",
"_____no_output_____"
],
[
"CLASS.const",
"_____no_output_____"
]
],
[
[
"Видно, что `Object.const` и `CLASS.const` – это разные переменные. \n\n`Object.const` находится в пространстве имен объекта `Object`. \n\n`CLASS.const` – в пространстве класса `CLASS`. \n\nЕсли не задавать поле `const` объекту `Object`, то интерпретатор поднимется выше по дереву наследования и придет в класс, где и найдет это поле.\n\nМетоды также наследуются объектами класса. В данном случае у объекта `Object` нет своего собственного метода `adder`, поэтому он ищется в классе `CLASS`. Однако от класса может быть порождено множество объектов. И методы предназначаются для обработки объектов. Таким образом, когда вызывается метод, в него надо передать конкретный объект, который он будет обрабатывать.\n\n\nВыражение Object.adder(100) выполняется интерпретатором следующим образом:\n\n- Ищу атрибут `adder()` у объекта `Object`. Не нахожу.\n- Тогда иду искать в класс `CLASS`, так как он создал объект `Object`.\n- Здесь нахожу искомый метод. Передаю ему объект, к которому этот метод надо применить, и аргумент, указанный в скобках.\n\nДругими словами, выражение `Object.adder(100)` преобразуется в выражение `CLASS.adder(Object, 100)`.\n\nТаким образом, интерпретатор попытался передать в метод `adder()` класса `CLASS` два параметра – объект `Object` и число `100`. Но мы запрограммировали метод `adder()` так, что он принимает только один параметр. ",
"_____no_output_____"
],
[
"Однако:",
"_____no_output_____"
]
],
[
[
"Object.adder()",
"_____no_output_____"
]
],
[
[
"Получается странная ситуация. Ведь `adder()` вызывается не только через класс, но и через порожденные от него объекты. Однако в последнем случае всегда будет возникать ошибка.\n\nМожет понадобиться метод с параметрами, но которому не надо передавать экземпляр данного класса. Для таких ситуаций предназначены статические методы. Такие методы могут вызываться через объекты данного класса, но сам объект в качестве аргумента в них не передается.\n\nВ Python острой необходимости в статических методах нет, так как код может находиться за пределами класса, и программа не начинает выполняться из класса. Если нам нужна просто какая-нибудь функция, мы можем определить ее в основной ветке. Однако в Python тоже можно реализовать статические методы с помощью декоратора `@staticmethod`:",
"_____no_output_____"
]
],
[
[
"class CLASS:\n const = 5 # атрибут класса\n @staticmethod \n def adder(v): # функция-метод\n return v + CLASS.const",
"_____no_output_____"
],
[
"Object = CLASS()",
"_____no_output_____"
],
[
"Object.adder(5)",
"_____no_output_____"
]
],
[
[
"Статические методы в Python – это, по сути, обычные функции, помещенные в класс для удобства и находящиеся в пространстве имен этого класса. Это может быть какой-то вспомогательный код.\n\nВообще, если в теле метода не используется ссылка на конкретный объект (чаще всего обозначаемый как `self`), имеет смысл сделать метод статическим.",
"_____no_output_____"
],
[
"# 4. Изменение полей объекта\n\nВ Python объекту можно не только переопределять поля и методы, унаследованные от класса, также можно добавить новые, которых нет в классе:",
"_____no_output_____"
]
],
[
[
"Object1 = CLASS()\nObject2 = CLASS()",
"_____no_output_____"
],
[
"Object2.str = 'abcd'\nObject2.str",
"_____no_output_____"
],
[
"Object1.str",
"_____no_output_____"
],
[
"CLASS.str",
"_____no_output_____"
]
],
[
[
"Однако в программировании так делать не принято, потому что тогда объекты одного класса будут отличаться между собой по набору атрибутов. Это затруднит автоматизацию их обработки, внесет в программу хаос.\n\nПоэтому принято присваивать полям, а также получать их значения, путем вызова методов (сеттеров (`set` – установить) и геттеров (`get` – получить)):",
"_____no_output_____"
]
],
[
[
"class CLASS:\n def setName(self, n):\n self.name = n \n def getName(self):\n try:\n return self.name\n except:\n return \"No name\"",
"_____no_output_____"
],
[
"first = CLASS()\nsecond = CLASS()",
"_____no_output_____"
],
[
"first.setName(\"Bob\")\nfirst.getName()",
"_____no_output_____"
],
[
"print(second.getName())",
"No name\n"
]
],
[
[
"# 5. Специальные методы\n\n# 5.1. Конструктор класса (метод `__init__()`)\n\nВ объектно-ориентированном программировании конструктором класса называют метод, который автоматически вызывается при создании объектов. Его также можно назвать конструктором объектов класса. Имя такого метода обычно регламентируется синтаксисом конкретного языка программирования. \n\nВ Python роль конструктора играет метод `__init__()`.\n\nВ Python наличие пар знаков подчеркивания спереди и сзади в имени метода говорит о том, что он принадлежит к группе методов перегрузки операторов. Если подобные методы определены в классе, то объекты могут участвовать в таких операциях, как сложение, вычитание, вызываться в качестве функций и др.\n\nПри этом методы перегрузки операторов не надо вызывать по имени. Вызовом для них является сам факт участия объекта в определенной операции. В случае конструктора класса – это операция создания объекта. Так как объект создается в момент вызова класса по имени, то в этот момент вызывается метод `__init__()`, если он определен в классе.\n\nНеобходимость конструкторов связана с тем, что нередко объекты должны иметь собственные свойства сразу. \n\nПусть имеется класс `Person`, объекты которого обязательно должны иметь имя и фамилию:",
"_____no_output_____"
]
],
[
[
"class Person:\n def setName(self, n, s):\n self.name = n\n self.surname = s",
"_____no_output_____"
],
[
"p1 = Person()\np1.setName(\"Bill\", \"Ross\")",
"_____no_output_____"
]
],
[
[
"Или:",
"_____no_output_____"
]
],
[
[
"class Person:\n def __init__(self, n, s):\n self.name = n\n self.surname = s",
"_____no_output_____"
]
],
[
[
"В свою очередь, конструктор класса не позволит создать объект без обязательных полей:",
"_____no_output_____"
]
],
[
[
"p2 = Person()",
"_____no_output_____"
],
[
"p2 = Person(\"Sam\", \"Baker\")\nprint(p2.name, p2.surname)",
"Sam Baker\n"
]
],
[
[
"Однако бывает, что надо допустить создание объекта, даже если никакие данные в конструктор не передаются. В таком случае параметрам конструктора класса задаются значения по умолчанию:",
"_____no_output_____"
]
],
[
[
"class Rectangle:\n def __init__(self, w = 0.5, h = 1):\n self.width = w\n self.height = h\n def square(self):\n return self.width * self.height",
"_____no_output_____"
],
[
"rec1 = Rectangle(5, 2)\nrec2 = Rectangle()\nrec3 = Rectangle(3)\nrec4 = Rectangle(h = 4)\n\nprint(rec1.square())\nprint(rec2.square())\nprint(rec3.square())\nprint(rec4.square())",
"10\n0.5\n3\n2.0\n"
]
],
[
[
"# 5.2. Конструктор и деструктор\n\nПомимо конструктора объектов, в языках программирования есть обратный ему метод – деструктор. Он вызывается для уничтожения объекта.\n\nВ языке программирования Python объект уничтожается, когда исчезают все связанные с ним переменные или им присваивается другое значение, в результате чего связь со старым объектом теряется. Удалить переменную можно с помощью команды языка `del`.\n\nВ классах Python функцию деструктора выполняет метод `__del__()`.",
"_____no_output_____"
]
],
[
[
"class Student:\n \n def __init__(self, name, surname, position=1):\n self.name = name\n self.surname = surname\n self.position = position\n \n def display(self):\n return self.name, self.surname, self.position\n \n def __del__(self):\n print (\"Goodbye %s %s\" %(self.name, self.surname))",
"_____no_output_____"
],
[
"p1 = Student('big', 'dude', 3) \np2 = Student('small', 'croon', 4)\np3 = Student('neutral', 'guy', 5)",
"_____no_output_____"
],
[
"print (p1.display())\nprint (p2.display())\nprint (p3.display())",
"('big', 'dude', 3)\n('small', 'croon', 4)\n('neutral', 'guy', 5)\n"
],
[
"del p2",
"Goodbye small croon\n"
],
[
"print(p2.display())",
"_____no_output_____"
]
],
[
[
"# 5.3. Специальные методы",
"_____no_output_____"
],
[
"В Python есть ряд зарезервированных имен методов создаваемого класса – специальные (или стандартные) методы.\n\nБолее подробную информацию о них вы можете найти в соответствующей [документации по Python](https://docs.python.org/3/reference/datamodel.html).\n\nНапример:\n\n`__bool__()`\n\nВозвращает True или False.\n\n`__call__()`\n\nПозволяет использовать объект как функцию, т.е. его можно вызвать.\n\n`__len__()`\n\nЧаще всего реализуется в коллекциях и сходными с ними по логике работы типами, которые позволяют хранить наборы данных. Для списка (`list`) `__len__()` возвращает количество элементов в списке, для строки – количество символов в строке. Вызывается функцией `len()`, встроенной в язык Python.",
"_____no_output_____"
],
[
"# Метод `__setattr__()`\n\nВ Python атрибуты объекту можно назначать за пределами класса:",
"_____no_output_____"
]
],
[
[
"class A:\n def __init__(self, v):\n self.field1 = v",
"_____no_output_____"
],
[
"a = A(10)\na.field2 = 20\nprint(a.field1, a.field2)",
"10 20\n"
]
],
[
[
"Если такое поведение нежелательно, его можно запретить с помощью метода перегрузки оператора присваивания атрибуту `__setattr__()`:",
"_____no_output_____"
]
],
[
[
"class A:\n def __init__(self, v):\n self.field1 = v\n def __setattr__(self, attr, value):\n if attr == 'field1':\n self.__dict__[attr] = value\n else:\n raise AttributeError('Произошло обращение к несуществующему атрибуту!')",
"_____no_output_____"
],
[
"a = A(15)\na.field1",
"_____no_output_____"
],
[
"a.field2 = 30",
"_____no_output_____"
],
[
"a.field2",
"_____no_output_____"
],
[
"a.__dict__",
"_____no_output_____"
]
],
[
[
"Метод `__setattr__()`, если он присутствует в классе, вызывается всегда, когда какому-либо атрибуту выполняется присваивание. Обратите внимание, что присвоение несуществующему атрибуту также обозначает его добавление к объекту.\n\nКогда создается объект `a`, в конструктор передается число `15`. Здесь для объекта заводится атрибут `field1`. Факт попытки присвоения ему значения тут же отправляет интерпретатор в метод `__setattr__()`, где проверяется, соответствует ли имя атрибута строке `'field1'`. Если так, то атрибут и соответствующее ему значение добавляются в словарь атрибутов объекта.\n\nНельзя в `__setattr__()` написать просто `self.field1 = value`, так как это приведет к новому рекурсивному вызову метода `__setattr__()`. Поэтому поле назначается через словарь `__dict__`, который есть у всех объектов, и в котором хранятся их атрибуты со значениями.\n\nЕсли параметр `attr` не соответствует допустимым полям, то искусственно возбуждается исключение `AttributeError`. Мы это видим, когда в основной ветке пытаемся обзавестись полем `field2`.",
"_____no_output_____"
],
[
"# Пример 1. Числа Фибоначчи\n\nПоследовательность чисел Фибоначчи задаётся рекуррентным выражением:\n\n$$ F_n = \\begin{cases}\n 0, n = 0, \\\\\n 1, n = 1, \\\\\n F_{n-1}+F_{n-2}, n > 1.\n \\end{cases} $$\n\nЧто даёт следующую последовательность: {0, 1, 1, 2, 3, 5, 8, 13, 21, 34, …}.",
"_____no_output_____"
],
[
"Один из способов решения, который может показаться логичным и эффективным, — решение с помощью рекурсии:",
"_____no_output_____"
]
],
[
[
"def Fibonacci_Recursion(n):\n if n == 0:\n return 0\n if n == 1:\n return 1\n return Fibonacci_Recursion (n-1) + Fibonacci_Recursion (n-2)",
"_____no_output_____"
]
],
[
[
"Используя такую функцию, мы будем решать задачу «с конца» — будем шаг за шагом уменьшать n, пока не дойдем до известных значений.\n\nНо, как мы видели ранее эта реализация многократно повторяет решение одних и тех же задач. Это связано с тем, что одни и те же промежуточные данные вычисляются по несколько раз, а число операций нарастает с той же скоростью, с какой растут числа Фибоначчи — экспоненциально.\n\nОдин из выходов из данной ситуации — сохранение уже найденных промежуточных результатов с целью их повторного использования (кеширование). Причём кеш должен храниться во внешней области памяти.",
"_____no_output_____"
]
],
[
[
"def Fibonacci_Recursion_cache(n, cache):\n if n == 0:\n return 0\n if n == 1:\n return 1\n if cache[n] > 0:\n return cache[n]\n cache[n] = Fibonacci_Recursion_cache (n-1, cache) + Fibonacci_Recursion_cache (n-2, cache)\n return cache[n]",
"_____no_output_____"
]
],
[
[
"Приведенное решение достаточно эффективно (за исключением накладных расходов на вызов функций). Но можно поступить ещё проще:",
"_____no_output_____"
]
],
[
[
"def Fibonacci(n):\n fib = [0]*max(2,n)\n fib[0] = 1\n fib[1] = 1\n for i in range(2, n):\n fib[i] = fib[i - 1] + fib[i - 2]\n\n return fib[n-1]",
"_____no_output_____"
]
],
[
[
"Такое решение можно назвать решением «с начала» — мы первым делом заполняем известные значения, затем находим первое неизвестное значение, потом следующее и т.д., пока не дойдем до нужного.\n\nТак и работает динамическое программирование: сначала решили все подзадачи (нашли все `F[i]` для `i < n`), затем, зная решения подзадач, нашли решение исходной задачи.",
"_____no_output_____"
],
[
"# Упражнение 1\n\nСоздайте класс для вычисления чисел Фибоначчи. Каждое число Фибоначчи является объектом этого класса, которое имеет атрибуты: значение и номер. Используйте функции для инициализации (вычисления) чисел Фибоначчи как сторонние по отношению к этому классу.",
"_____no_output_____"
]
],
[
[
"class Fiber:\n n = 1\n def __init__(self, n):\n self.n = n\n def calculate(self):\n return Fibonacci(self.n)",
"_____no_output_____"
],
[
"k = Fiber(int(input('Введите необходимое число: ')))\nprint(k.calculate())",
"Введите необходимое число: 12\n144\n"
]
],
[
[
"# Упражнение 2\n\nПоместите функции для вычисления чисел Фибоначчи внутрь созданного класса как статические функции.",
"_____no_output_____"
]
],
[
[
"class Fiber2:\n # метод без @staticmethod, но принимает только число и не требует объекта\n def calculate(n):\n fib = [0]*max(2,n)\n fib[0] = 1\n fib[1] = 1\n for i in range(2, n):\n fib[i] = fib[i - 1] + fib[i - 2]\n return fib[n-1]",
"_____no_output_____"
],
[
"# пример использования:\nprint(Fiber2.calculate(int(input('Введите необходимое число: '))))",
"Введите необходимое число: 12\n144\n"
]
],
[
[
"# Упражнение 3\n\nПерегрузите операции сложения, вычитания, умножения и деления для созданного класса как операции с номерами чисел Фибоначи.",
"_____no_output_____"
]
],
[
[
"class FiberSuper:\n def __init__(self, n):\n self.setNumber(n)\n \n def setNumber(self, n):\n self.n = n\n self.fib = Fiber2.calculate(n)\n \n def getNumber(self):\n return self.n\n \n def getFibonacci(self):\n return self.fib\n \n def __add__(self1, self2):\n return FiberSuper(self1.n + self2.n)\n \n def __mul__(self1, self2):\n return FiberSuper(self1.n * self2.n)\n \n def __sub__(self1, self2):\n return FiberSuper(abs(self1.n - self2.n))\n \n def __truediv__(self1, self2):\n return FiberSuper(self1.n // self2.n)",
"_____no_output_____"
],
[
"k1 = FiberSuper(16)\nk2 = FiberSuper(8)\n\nprint('k1: ', k1.getNumber(), ' - ', k1.getFibonacci())\nprint('k2: ', k2.getNumber(), ' - ', k2.getFibonacci())\n\nprint('k1 + k2: ', (k1 + k2).getNumber(), ' - ', (k1 + k2).getFibonacci())\nprint('k1 * k2: ', (k1 * k2).getNumber(), ' - ', (k1 * k2).getFibonacci())\nprint('k1 - k2: ', (k1 - k2).getNumber(), ' - ', (k1 - k2).getFibonacci())\nprint('k1 / k2: ', (k1 / k2).getNumber(), ' - ', (k1 / k2).getFibonacci())",
"k1: 16 - 987\nk2: 8 - 21\nk1 + k2: 24 - 46368\nk1 * k2: 128 - 251728825683549488150424261\nk1 - k2: 8 - 21\nk1 / k2: 2 - 1\n"
]
],
[
[
"# Домашнее задание (базовое):",
"_____no_output_____"
],
[
"# Задание 1. \n\nСоздать класс с двумя переменными. Добавить функцию вывода на экран и функцию изменения этих переменных. Добавить функцию, которая находит сумму значений этих переменных, и функцию, которая находит наибольшее значение из этих двух переменных.",
"_____no_output_____"
]
],
[
[
"class Couple:\n def __init__(self, x, y):\n self.x = x\n self.y = y\n \n def setFirst(self, x):\n self.x = x\n \n def getFirst(self):\n return self.x\n \n def setSecond(self, y):\n self.y = y\n \n def getSecond(self):\n return self.y\n \n def out(self):\n print('First: ', self.x)\n print('Second: ', self.y)\n \n def getSum(self):\n return self.x + self.y\n \n def getMax(self):\n return max(self.x, self.y)",
"_____no_output_____"
],
[
"Beta = Couple(12, 8)\n\nBeta.out()\nprint()\nprint('Sum: ', Beta.getSum())\nprint('Max: ', Beta.getMax())",
"First: 12\nSecond: 8\n\nSum: 20\nMax: 12\n"
]
],
[
[
"# Задание 2. ",
"_____no_output_____"
],
[
"Составить описание класса многочленов от одной переменной, задаваемых степенью многочлена и массивом коэффициентов. Предусмотреть методы для вычисления значения многочлена для заданного аргумента, операции сложения, вычитания и умножения многочленов с получением нового объекта-многочлена, вывод на экран описания многочлена.",
"_____no_output_____"
]
],
[
[
"class Polynom:\n '''\n Полином исключительно положительных степеней (это нужно для интерактивного задания)\n Можно было сделать и лучше, как всегда)\n '''\n def __init__(self, polynom = None):\n if polynom is not None:\n self.__dict__.update(polynom)\n return\n power = int(input('Введите степень многочлена: '))\n for each in range(power, -1, -1):\n try:\n self.__dict__.update({str('power' + str(each)): \n float(input(f'Введите коэффициент при одночлене со степенью {each}: '))})\n except:\n self.__dict__.update({str('power' + str(each)): \n 0})\n \n def count(self, x):\n value = 0\n for each in self.__dict__.keys():\n value += self.__dict__[each] * (x ** int(each[5:]))\n return value\n \n def form(self):\n form = ''\n keys = list(self.__dict__.keys())\n keys.sort()\n keys.reverse()\n for each in keys:\n if self.__dict__[each] == 0:\n continue\n if form != '':\n form += ' + '\n form += '(' + str(self.__dict__[each]) + ')' + ('*x**(' + each[5:] + ')') * int(bool(int(each[5:])))\n return form\n \n def __add__(self1, self2):\n coefficients = {}\n for obj in [self1, self2]:\n for key in obj.__dict__.keys():\n if key not in coefficients.keys():\n coefficients[key] = obj.__dict__[key]\n else:\n coefficients[key] += obj.__dict__[key]\n return Polynom(coefficients)\n \n def __sub__(self1, self2):\n coefficients = self1.__dict__.copy()\n for key in self2.__dict__.keys():\n if key not in coefficients.keys():\n coefficients[key] = 0 - (self2.__dict__[key])\n else:\n coefficients[key] -= self2.__dict__[key]\n return Polynom(coefficients)\n \n def __mul__(self1, self2):\n coefficients = {}\n for key1 in self1.__dict__.keys():\n for key2 in self2.__dict__.keys():\n new_key = 'power' + str(int(key1[5:]) * int(key2[5]))\n if new_key not in coefficients.keys():\n coefficients[new_key] = self1.__dict__[key1] * self2.__dict__[key2]\n else:\n coefficients[new_key] += self1.__dict__[key1] * self2.__dict__[key2]\n return Polynom(coefficients)",
"_____no_output_____"
],
[
"parabole = Polynom()\nprint('Значение функции:', parabole.count(float(input('Введите значение аргумента: '))))",
"Введите степень многочлена: 2\nВведите коэффициент при одночлене со степенью 2: 1\nВведите коэффициент при одночлене со степенью 1: 0\nВведите коэффициент при одночлене со степенью 0: 0\nВведите значение аргумента: 4\nЗначение функции: 16.0\n"
],
[
"polynom1 = Polynom()\nprint(polynom1.form())",
"Введите степень многочлена: 2\nВведите коэффициент при одночлене со степенью 2: 1\nВведите коэффициент при одночлене со степенью 1: 3\nВведите коэффициент при одночлене со степенью 0: 8\n(1.0)*x**(2) + (3.0)*x**(1) + (8.0)\n"
],
[
"polynom2 = Polynom()\nprint(polynom2.form())",
"Введите степень многочлена: 3\nВведите коэффициент при одночлене со степенью 3: 1\nВведите коэффициент при одночлене со степенью 2: 1\nВведите коэффициент при одночлене со степенью 1: 3\nВведите коэффициент при одночлене со степенью 0: 17\n(1.0)*x**(3) + (1.0)*x**(2) + (3.0)*x**(1) + (17.0)\n"
],
[
"print((polynom1 + polynom2).form())",
"(1.0)*x**(3) + (2.0)*x**(2) + (6.0)*x**(1) + (25.0)\n"
],
[
"print('Значение суммы функций в точке равно:', (polynom1 + polynom2).count(float(input('Введите значение аргумента: '))))",
"Введите значение аргумента: 456\nЗначение суммы функций в точке равно: 95237449.0\n"
],
[
"print('Значение разности функций в точке равно:', (polynom2 - polynom1).count(float(input('Введите значение аргумента: '))))",
"Введите значение аргумента: 7\nЗначение разности функций в точке равно: 352.0\n"
],
[
"print('Форма произведения функций представляется в виде y =', (polynom1 * polynom2).form())",
"Форма произведения функций представляется в виде y = (1.0)*x**(6) + (1.0)*x**(4) + (3.0)*x**(3) + (6.0)*x**(2) + (9.0)*x**(1) + (244.0)\n"
],
[
"print((polynom1 * polynom2).count(12))",
"3013120.0\n"
]
],
[
[
"# Задание 3.\n\nСоставить описание класса для вектора, заданного координатами его концов в трехмерном пространстве. Обеспечить операции сложения и вычитания векторов с получением нового вектора (суммы или разности), вычисления скалярного произведения двух векторов, длины вектора, косинуса угла между векторами.",
"_____no_output_____"
]
],
[
[
"class Vector:\n def __init__(self, dot1, dot2):\n self.begin = dot1\n self.end = dot2\n self.entity = [ self.end[0] - self.begin[0], self.end[1] - self.begin[1], self.end[2] - self.begin[2] ]\n self.length = ( (self.entity[0]) ** 2 + (self.entity[1]) ** 2 + (self.entity[2]) ** 2 ) ** 0.5\n \n def __add__(self1, self2):\n return Vector([self1.begin[0], \n self1.begin[1], \n self1.begin[2]], \n [(self1.end[0] + self2.entity[0]), \n (self1.end[1] + self2.entity[1]),\n (self1.end[2] + self2.entity[2])])\n \n def __sub__(self1, self2):\n return Vector([self1.begin[0], \n self1.begin[1], \n self1.begin[2]], \n [(self1.end[0] - self2.entity[0]), \n (self1.end[1] - self2.entity[1]),\n (self1.end[2] - self2.entity[2])])\n \n def __mul__(self1, self2):\n return self1.entity[0] * self2.entity[0] + self1.entity[1] * self2.entity[1] + self1.entity[2] * self2.entity[2]\n \n def getLength(self):\n return self.length\n \n def getCos(self1, self2):\n return self1 * self2 / (self1.getLength() * self2.getLength())\n \n def about(self):\n print('Вектор №%i:' % id(self))\n print('\\tКоординаты вектора:', self.entity)\n print('\\tКоординаты начальной точки:', self.begin)\n print('\\tКоординаты конечной точки:', self.end)\n print('\\tДлина вектора:', self.length)",
"_____no_output_____"
],
[
"vectors = []\n\nfor i in range(2):\n print('Задаём %i-й вектор.' % i)\n x1, y1, z1 = map(float, input('Введите координаты первой точки через пробел: ').split())\n x2, y2, z2 = map(float, input('Введите координаты второй точки через пробел: ').split())\n vectors.append(Vector([x1, y1, z1],\n [x2, y2, z2]))",
"Задаём 0-й вектор.\nВведите координаты первой точки через пробел: 0 1 2\nВведите координаты второй точки через пробел: 0 2 4\nЗадаём 1-й вектор.\nВведите координаты первой точки через пробел: 0 0 0\nВведите координаты второй точки через пробел: 1 1 1\n"
],
[
"v1 = vectors[0]\nv1.about()\nv2 = vectors[1]\nv2.about()",
"Вектор №140380543485072:\n\tКоординаты вектора: [0.0, 1.0, 2.0]\n\tКоординаты начальной точки: [0.0, 1.0, 2.0]\n\tКоординаты конечной точки: [0.0, 2.0, 4.0]\n\tДлина вектора: 2.23606797749979\nВектор №140380543485216:\n\tКоординаты вектора: [1.0, 1.0, 1.0]\n\tКоординаты начальной точки: [0.0, 0.0, 0.0]\n\tКоординаты конечной точки: [1.0, 1.0, 1.0]\n\tДлина вектора: 1.7320508075688772\n"
],
[
"print('Сложим векторы.')\n(v1 + v2).about()",
"Сложим векторы.\nВектор №140380543485024:\n\tКоординаты вектора: [1.0, 2.0, 3.0]\n\tКоординаты начальной точки: [0.0, 1.0, 2.0]\n\tКоординаты конечной точки: [1.0, 3.0, 5.0]\n\tДлина вектора: 3.7416573867739413\n"
],
[
"print('Вычтем векторы друг из друга.')\n(v1 - v2).about()\n(v2 - v1).about()\nprint('Длины векторов совпадают.' * int((v1 - v2).getLength() == (v2 - v1).getLength()))",
"Вычтем векторы друг из друга.\nВектор №140380543484160:\n\tКоординаты вектора: [-1.0, 0.0, 1.0]\n\tКоординаты начальной точки: [0.0, 1.0, 2.0]\n\tКоординаты конечной точки: [-1.0, 1.0, 3.0]\n\tДлина вектора: 1.4142135623730951\nВектор №140380124865152:\n\tКоординаты вектора: [1.0, 0.0, -1.0]\n\tКоординаты начальной точки: [0.0, 0.0, 0.0]\n\tКоординаты конечной точки: [1.0, 0.0, -1.0]\n\tДлина вектора: 1.4142135623730951\nДлины векторов совпадают.\n"
],
[
"print('Найдём скалярное произведение векторов.')\nprint('v1 * v2 =', v1 * v2)",
"Найдём скалярное произведение векторов.\nv1 * v2 = 3.0\n"
],
[
"print('Найдём косинус угла (в радианах) между векторами.')\nprint('cos(v1, v2) =', Vector.getCos(v1, v2))",
"Найдём косинус угла (в радианах) между векторами.\ncos(v1, v2) = 0.7745966692414834\n"
]
],
[
[
"# Задание 4. Поезда.\n\nСоздайте структуру с именем `train`, содержащую поля: \n\n- название пунктов отправления и назначения;\n- время отправления и прибытия. \n\nПерегрузить операцию сложения: два поезда можно сложить, если пункт назначения первого совпадает с пунктом отправления второго, и время прибытия первого раньше, чем отправление второго.",
"_____no_output_____"
]
],
[
[
"from time import mktime, gmtime, strptime, strftime\nmktime(gmtime())",
"_____no_output_____"
],
[
"class Train:\n def __init__(self, times = None, stations = None, united = False):\n if times is None and stations is None:\n self.buyTicket()\n return\n self.departure_time = times[0]\n self.arrival_time = times[1]\n self.departure_station = stations[0]\n self.arrival_station = stations[1]\n self.road_time = self.arrival_time - self.departure_time\n self.united = united\n \n def buyTicket(self):\n self.departure_station = input('Вы покупаете билет на поезд.\\n\\tУкажите станцию отправления: ')\n self.departure_time = mktime(strptime(input('\\tКогда отправляется поезд?\\n\\t\\tВведите дату (число.месяц.год): '), '%d.%m.%Y'))\n self.departure_time += mktime(strptime(input('\\t\\tВведите время (часы:минуты): '), '%H:%M'))\n self.arrival_station = input('\\tУкажите станцию прибытия: ')\n self.arrival_time = mktime(strptime(input('\\tКогда прибывает поезд?\\n\\t\\tВведите дату (ЧЧ.ММ.ГГГГ): '), '%d.%m.%Y'))\n self.arrival_time += mktime(strptime(input('\\t\\tВведите время (ЧЧ:ММ): '), '%H:%M'))\n self.united = False\n print('Спасибо за покупку! Ваш билет - под номером %i.' % id(self))\n \n def about(self):\n print('Поезд %s - %s%s' % (self.departure_station, self.arrival_station, ' (ОБЪЕДИНЁННЫЙ)' * int(self.united)))\n print('\\tВремя отправления: %s' % strftime('%a, %d %b %Y %H:%M', gmtime(self.departure_time)))\n print('\\tВремя прибытия: %s' % strftime('%a, %d %b %Y %H:%M', gmtime(self.arrival_time)))\n print('\\tБилет на поезд: %i' % id(self))\n print('\\tВремени в пути: %i часов %i минут' % ((self.arrival_time - self.departure_time) // 3600, \n (self.arrival_time - self.departure_time) % 3600 // 60))\n \n def __add__(self1, self2):\n if self1.arrival_station == self2.departure_station and self1.arrival_time < self2.departure_time:\n return Train(times = [self1.departure_time, self2.arrival_time], \n stations = [self1.departure_station, self2.arrival_station],\n united = True)",
"_____no_output_____"
],
[
"MSK_SPB = Train([mktime(strptime('26.12.2019 18:30', '%d.%m.%Y %H:%M')), \n mktime(strptime('27.12.2019 5:39', '%d.%m.%Y %H:%M'))], \n ['Москва', 'Санкт-Петербург'], False)",
"_____no_output_____"
],
[
"SPB_HSK = Train([mktime(strptime('27.12.2019 12:00', '%d.%m.%Y %H:%M')), \n mktime(strptime('01.01.2020 15:26', '%d.%m.%Y %H:%M'))], \n ['Санкт-Петербург', 'Хельсинки'], False)",
"_____no_output_____"
],
[
"MSK_SPB = Train()",
"Вы покупаете билет на поезд.\n\tУкажите станцию отправления: Пушкино\n\tКогда отправляется поезд?\n\t\tВведите дату (число.месяц.год): 26.12.2019\n\t\tВведите время (часы:минуты): 18:30\n\tУкажите станцию прибытия: Санкт-Петербург\n\tКогда прибывает поезд?\n\t\tВведите дату (ЧЧ.ММ.ГГГГ): 27.12.2019\n\t\tВведите время (ЧЧ:ММ): 5:39\nСпасибо за покупку! Ваш билет - под номером 140592874663648.\n"
],
[
"SPB_HSK = Train()",
"Вы покупаете билет на поезд.\n\tУкажите станцию отправления: Санкт-Петербург\n\tКогда отправляется поезд?\n\t\tВведите дату (число.месяц.год): 27.12.2019\n\t\tВведите время (часы:минуты): 12:00\n\tУкажите станцию прибытия: Хельсинки\n\tКогда прибывает поезд?\n\t\tВведите дату (ЧЧ.ММ.ГГГГ): 01.01.2020\n\t\tВведите время (ЧЧ:ММ): 15:26\nСпасибо за покупку! Ваш билет - под номером 140592874230736.\n"
],
[
"MSK_SPB.about()\nSPB_HSK.about()",
"Поезд Москва - Санкт-Петербург\n\tВремя отправления: Thu, 26 Dec 2019 15:30\n\tВремя прибытия: Fri, 27 Dec 2019 02:39\n\tБилет на поезд: 140356461967344\n\tВремени в пути: 11 часов 9 минут\nПоезд Санкт-Петербург - Хельсинки\n\tВремя отправления: Fri, 27 Dec 2019 09:00\n\tВремя прибытия: Wed, 01 Jan 2020 12:26\n\tБилет на поезд: 140356470555840\n\tВремени в пути: 123 часов 26 минут\n"
],
[
"(MSK_SPB + SPB_HSK).about()",
"Поезд Москва - Хельсинки (ОБЪЕДИНЁННЫЙ)\n\tВремя отправления: Thu, 26 Dec 2019 15:30\n\tВремя прибытия: Wed, 01 Jan 2020 12:26\n\tБилет на поезд: 140356470555984\n\tВремени в пути: 140 часов 56 минут\n"
]
],
[
[
"# Домашнее задание (дополнительное):",
"_____no_output_____"
],
[
"# Библиотека.\n\nОписать класс «библиотека». Предусмотреть возможность работы с произвольным числом книг, поиска книги по какому-либо признаку (например, по автору или по году издания), добавления книг в библиотеку, удаления книг из нее, сортировки книг по разным полям.",
"_____no_output_____"
]
],
[
[
"class Book:\n def __init__(self,\n title = None,\n authors = None,\n link = None,\n description = None,\n language = None,\n yearOfPublishing = None,\n publishingHouse = None,\n ISBN = None,\n volume = None,\n cost = None,\n ageLimit = None):\n self.title = title\n self.authors = authors\n self.link = link # здесь располагается ссылка на книгу в интернете\n try:\n self.mainAuthor = self.authors.pop(0)\n except:\n self.mainAuthor = None\n self.description = description\n self.language = language\n self.yearOfPublishing = yearOfPublishing\n self.publishingHouse = publishingHouse\n self.ISBN = ISBN\n self.volume = volume\n self.cost = cost\n self.ageLimit = ageLimit\n \n def split_str(string, length):\n for i in range(0, len(string), length):\n yield string[i : i + length].strip()\n \n def new():\n print('Вы написали книгу? Поздравляем! Давайте заполним информацию о ней и опубликуем!')\n try:\n self = Book()\n self.title = input('\\tУкажите название книги: ')\n self.mainAuthor = input('\\tУкажите ваше ФИО - или инициалы: ')\n self.authors = list(map(str, input('\\tБыли ли у вашей книги соавторы? ' + \n 'Укажите их через запятую - или оставьте поле ввода пустым: ').split(', ')))\n self.description = input('\\tВведите описание своей книги: ')\n self.language = input('\\tВведите язык, на котором вы написали книгу: ')\n self.ageLimit = int(input('\\tВведите возраст, с которого вашу книгу можно читать: '))\n self.volume = int(input('\\tВведите объём печатного текста в страницах формата А5: '))\n\n self.link = input('\\tНаконец, если ваша книга опубликована, укажите на неё ссылку - или оставьте поле ввода пустым: ')\n if self.link == '':\n self.link = None\n if input('\\tКстати, не хотите её опубликовать?) Введите \"Да\", чтобы перейти к публикации: ') == 'Да':\n self.publish()\n print('\\tИнформация о книге успешно заполнена.')\n except:\n print('Оу... К сожалению, информация о книге была введена неправильно, и создание электронной версии ' +\n 'не может быть продолжено.')\n self = None\n finally:\n return self\n \n def publish(self):\n print()\n print('### Статья \"Публикация книг\", автор - Титов Климентий.')\n print('\"\"\"')\n print('Опубликовать свою книгу позволяет платформа Самиздата от Литрес: https://selfpub.ru/. ' + \n 'Выполняйте следующую последовательность действий:')\n print('1. Зарегистрируйтесь на сайте')\n print('2. Сохраните текст работы в документе DOCX или книге FB2')\n print('3. Укажите всю необходимую информацию о книге')\n print('4. Выберите способ распространения книги. Например, чтобы иметь возможность распространять печатную версию, ' + \n 'выберите Базовый или Безлимитный способ')\n print('5. Создайте эстетичную обложку')\n print('6. И, наконец, отправьте книгу на модерацию.')\n print('После успешной модерации ваша книга будет автоматически опубликована. Не забудьте заполнить данные о книге ' + \n 'здесь: вам нужно будет задать необходимые значения при помощи методов setISBN(ISBN), setYearOfPublishing' + \n '(yearOfPublishing), setPublishingHouse(publishingHouse), setCost(cost) и setLink(link). ' + \n 'И, конечно же, наслаждайтесь результатом!')\n print('\"\"\"')\n print()\n \n def setISBN(self, ISBN):\n self.ISBN = ISBN\n \n def setYearOfPublishing(self, yearOfPublishing):\n self.yearOfPublishing = yearOfPublishing\n \n def setPublishingHouse(self, publishingHouse):\n self.publishingHouse = publishingHouse\n \n def setCost(self, cost):\n self.cost = cost\n \n def setLink(self, link):\n self.link = link\n \n def about(self):\n print(f'Книга \"{self.title}\"')\n print(f'\\tАвтор - {self.mainAuthor}')\n if self.authors != []:\n print('\\tСоавторы:')\n for author in self.authors:\n print(f'\\t\\t{author}')\n if self.description:\n print('\\tОписание:')\n print('\\t\\t\"\"\"\\n\\t\\t' + '\\n\\t\\t'.join(Book.split_str(self.description, 80)) + '\\n\\t\\t\"\"\"')\n if self.language:\n print(f'\\tЯзык: {self.language}')\n if self.yearOfPublishing:\n print(f'\\tГод публикации - {self.yearOfPublishing}')\n if self.publishingHouse:\n print(f'\\tИздательство: {self.publishingHouse}')\n if self.ISBN:\n print(f'\\tISBN: {self.ISBN}')\n if self.volume:\n print(f'\\tОбъём книги: {self.volume} стр.')\n if self.cost:\n print(f'\\tСтоимость книги: {self.cost} руб.')\n if self.ageLimit:\n print(f'\\tВозрастное ограничение: {self.ageLimit}+')\n if self.link:\n print(f'\\tСсылка на книгу: {self.link}')\n \n def properties():\n return ['mainAuthor', 'authors', 'description', 'language', 'yearOfPublushing', \n 'publishingHouse', 'ISBN', 'volume', 'cost', 'ageLimit', 'link']",
"_____no_output_____"
],
[
"_1984 = Book(title = '1984',\n authors = ['Джордж Оруэлл'],\n link = 'https://www.litres.ru/dzhordzh-oruell/1984/',\n description = 'Своеобразный антипод второй великой антиутопии XX века – «О дивный новый мир» ' + \n 'Олдоса Хаксли. Что, в сущности, страшнее: доведенное до абсурда «общество потребления» ' + \n '– или доведенное до абсолюта «общество идеи»? По Оруэллу, нет и не может быть ничего ужаснее ' + \n 'тотальной несвободы…',\n language = 'Русский',\n yearOfPublishing = 2014,\n publishingHouse = 'Издательство АСТ',\n ISBN = '978-5-17-080115-2',\n volume = 320,\n cost = 119,\n ageLimit = 16)\n_1984.about()",
"Книга \"1984\"\n\tАвтор - Джордж Оруэлл\n\tОписание:\n\t\t\"\"\"\n\t\tСвоеобразный антипод второй великой антиутопии XX века – «О дивный новый мир» Ол\n\t\tдоса Хаксли. Что, в сущности, страшнее: доведенное до абсурда «общество потребле\n\t\tния» – или доведенное до абсолюта «общество идеи»? По Оруэллу, нет и не может бы\n\t\tть ничего ужаснее тотальной несвободы…\n\t\t\"\"\"\n\tЯзык: Русский\n\tГод публикации - 2014\n\tИздательство: Издательство АСТ\n\tISBN: 978-5-17-080115-2\n\tОбъём книги: 320 стр.\n\tСтоимость книги: 119 руб.\n\tВозрастное ограничение: 16+\n\tСсылка на книгу: https://www.litres.ru/dzhordzh-oruell/1984/\n"
],
[
"Satan = Book.new()",
"Вы написали книгу? Поздравляем! Давайте заполним информацию о ней и опубликуем!\n\tУкажите название книги: Satan\n\tУкажите ваше ФИО - или инициалы: Влад\n\tБыли ли у вашей книги соавторы? Укажите их через запятую - или оставьте поле ввода пустым: \n\tВведите описание своей книги: Книга про сатану\n\tВведите язык, на котором вы написали книгу: русский\n\tВведите возраст, с которого вашу книгу можно читать: 219\n\tВведите объём печатного текста в страницах формата А5: 300\n\tНаконец, если ваша книга опубликована, укажите на неё ссылку - или оставьте поле ввода пустым: \n\tКстати, не хотите её опубликовать?) Введите \"Да\", чтобы перейти к публикации: Да\n\n### Статья \"Публикация книг\", автор - Титов Климентий.\n\"\"\"\nОпубликовать свою книгу позволяет платформа Самиздата от Литрес: https://selfpub.ru/. Выполняйте следующую последовательность действий:\n1. Зарегистрируйтесь на сайте\n2. Сохраните текст работы в документе DOCX или книге FB2\n3. Укажите всю необходимую информацию о книге\n4. Выберите способ распространения книги. Например, чтобы иметь возможность распространять печатную версию, выберите Базовый или Безлимитный способ\n5. Создайте эстетичную обложку\n6. И, наконец, отправьте книгу на модерацию.\nПосле успешной модерации ваша книга будет автоматически опубликована. Не забудьте заполнить данные о книге здесь: вам нужно будет задать необходимые значения при помощи методов setISBN(ISBN), setYearOfPublishing(yearOfPublishing), setPublishingHouse(publishingHouse), setCost(cost) и setLink(link). И, конечно же, наслаждайтесь результатом!\n\"\"\"\n\n\tИнформация о книге успешно заполнена.\n"
],
[
"Property = Book.new()",
"Вы написали книгу? Поздравляем! Давайте заполним информацию о ней и опубликуем!\n\tУкажите название книги: Проперти\n\tУкажите ваше ФИО - или инициалы: Снежская Виктория\n\tБыли ли у вашей книги соавторы? Укажите их через запятую - или оставьте поле ввода пустым: \n\tВведите описание своей книги: О Е\n\tВведите язык, на котором вы написали книгу: русский\n\tВведите возраст, с которого вашу книгу можно читать: 12\n\tВведите объём печатного текста в страницах формата А5: 320\n\tНаконец, если ваша книга опубликована, укажите на неё ссылку - или оставьте поле ввода пустым: \n\tКстати, не хотите её опубликовать?) Введите \"Да\", чтобы перейти к публикации: \n\tИнформация о книге успешно заполнена.\n"
],
[
"Seveina = Book(title = 'Севейна', authors = ['Титов Климентий', 'Снежская Виктория'], yearOfPublishing = 2019)\nTheOldManandtheSea = Book(title = 'The Old Man and the Sea', authors = ['Эрнест Хемингуэй'])\nTheGreatGatsby = Book(title = 'The Great Gatsby', authors = ['Фрэнсис Фиджеральд Скотт'])",
"_____no_output_____"
],
[
"class Library:\n storage = {} # формат данных {ID: Book}\n readers = {} # формат данных {ФИО: взятые книги [ID1, ID2,..]}\n \n def __init__(self,\n name = None,\n address = None,\n owner = None,\n workers = None,\n contacts = None):\n self.name = name\n self.address = address\n self.owner = owner\n self.workers = workers\n self.contacts = contacts\n \n def printWorkers(self):\n print('Сотрудники:')\n for workerIndex in range(len(self.workers)):\n name = self.workers[workerIndex]\n print(f'\\tID {workerIndex}\\tФИО {name}')\n\n def printBooks(self, sortingKey = 'order'):\n print('Книги:')\n if sortingKey == 'order':Именно\n for bookIndex in self.storage.keys():\n title = self.storage[bookIndex].title\n print(f'\\tID {bookIndex}\\tНазвание \"{title}\"')\n else:\n try:\n books = list(self.storage.items())\n books.sort(key=lambda i: i[1][eval(sortingKey)])\n for book in books:\n prop = eval(f'book[1].{sortingKey}')\n ID = book[0]\n print(f'\\tID {ID}\\tСвойство \"{sortingKey}\": {prop}')\n except:\n print('Не удалось вывести отсортированный список книг.')\n \n def printReaders(self):\n print('Читатели:')\n for reader in self.readers.keys():\n books = self.readers[reader]\n print(f'\\tФИО {reader}\\tКниги: {books}')\n \n def isInProcess(self, ID):\n for reader in self.readers.keys():\n if ID in self.readers[reader]:\n return True\n return False\n \n def shell(self):\n print(f'Оболочка библиотеки \"{self.name}\":')\n print(f'\\tРабота с организацией')\n print(f'\\t000. Добавить сотрудника')\n print(f'\\t001. Удалить сотрудника')\n print(f'\\tРабота с книгами')\n print(f'\\t100. Добавить книгу')\n print(f'\\t101. Удалить книгу')\n print(f'\\t102. Вывести список книг')\n print(f'\\t103. Принудительно вернуть книгу')\n print(f'\\t104. Отредактировать свойства книги')\n print(f'\\t105. Поиск по библиотеке')\n print(f'\\t106. Просмотр свойств книги')\n print(f'\\tРабота с читателями')\n print(f'\\t200. Добавить нового читателя')\n print(f'\\t201. Удалить читателя (если список задолженностей пуст)')\n print(f'\\t202. Взять книгу')\n print(f'\\t203. Вернуть книгу')\n print(f'\\tВнештатные ситуации')\n print(f'\\t300. Книга утеряна')\n print(f'\\t301. Написана новая книга')\n print(f'\\t302. Ликвидировать предприятие')\n print(f'\\t-1. Выйти из оболочки')\n while True:\n action = input('Введите номер действия: ')\n \n if action == '000':\n # добавить сотрудника\n self.workers.append(input('Введите ФИО нового сотрудника: '))\n print('Сотрудник успешно добавлен.')\n\n elif action == '001':\n # удалить сотрудника\n self.printWorkers()\n ID = input('Введите ID работника, которого хотите уволить - или оставьте поле ввода пустым: ')\n if ID == '':\n continue\n try:\n ID = int(ID)\n del self.workers[ID]\n except:\n print('Попытка увольнения не удалась. Может, ваш сотрудник восстал против вас?..')\n\n elif action == '100':\n # добавить книгу\n corners = list(map(str, input('Перечислите названия объектов Book через точку с запятой, если они заданы - ' + \n 'или оставьте поле ввода пустым: ').split('; ')))\n self.append(corners)\n\n elif action == '101':\n # удалить книгу\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n self.remove(ID)\n except:\n print('Удаление книги не удалось.')\n \n elif action == '102':\n # вывести список книг\n self.printBooks()\n \n elif action == '103':\n # принудительный возврат книги\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n self.back(ID)\n except:\n print('Возврат книги не удался.')\n \n elif action == '104':\n # отредактировать свойства книги\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n print('Достуные свойства редактирования:', Book.properties())\n key = input('Введите свойство книги, которое вы хотите отредактировать (будьте внимательны при написании свойства): ')\n value = input('Введите значение (строки - в кавычках, числа - без, списки поддерживаются): ')\n book = self.storage[ID]\n exec(f'book.{key} = {value}')\n except:\n print('Возврат книги не удался.')\n \n elif action == '105':\n # поиск по библиотеке\n print('Достуные свойства поиска:', Book.properties())\n key = input('Введите свойство книги, по которому вы хотите найти книги (будьте внимательны при написании свойства): ')\n value = input('Введите значение (строки - в кавычках, числа - без, списки поддерживаются): ')\n try:\n for bookIndex in self.storage.keys():\n if eval(f'self.storage[bookIndex].{key}') == eval(value):\n title = self.storage[bookIndex].title\n print(f'\\tID {bookIndex}\\tНазвание {title}')\n except:\n print('Поиск не удался.')\n \n elif action == '106':\n # просмотр свойств книги\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n self.storage[ID].about()\n except:\n print('Просмотр свойств не удался.')\n \n elif action == '200':\n # добавить читателя\n name = input('Введите ФИО: ')\n if name not in self.readers.keys():\n self.readers[name] = []\n print('Читатель успешно добавлен.')\n else:\n print('Такой читатель уже существует.')\n \n elif action == '201':\n # удалить читателя\n self.printReaders()\n name = input('Введите ФИО: ')\n if name not in self.readers.keys():\n print('Такого читателя не существует.')\n continue\n elif self.readers[name] != []:\n print('Читатель не вернул все книги.')\n continue\n else:\n del self.readers[name]\n print('Удаление прошло успешно.')\n \n elif action == '202':\n # взять книгу\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n if not self.isInProcess(ID):\n self.printReaders()\n name = input('Введите ФИО: ')\n self.readers[name].append(ID)\n print('Книга взята.')\n else:\n print('Книга сейчас у читателя, её нельзя взять.')\n except:\n print('Взять такую книгу нельзя.')\n \n elif action == '203':\n # вернуть книгу\n self.printReaders()\n try:\n name = input('Введите ФИО: ')\n books = self.readers[name]\n for book in books:\n title = self.storage[book].title\n print(f'\\tID {book}\\tНазвание \"{title}\"')\n ID = int(input('Введите id книги: '))\n self.readers[name].remove(ID)\n except:\n print('Книгу вернуть не удалось.') \n \n elif action == '300':\n # книга утеряна\n self.printBooks()\n try:\n ID = int(input('Введите id книги: '))\n self.bookWasLost(ID)\n except:\n print('Пропажа не была зарегистрирована.')\n \n elif action == '301':\n # написана новая книга\n book = Book.new()\n if book is not None:\n self.append([book])\n print('Книга добавлена в библиотеку.')\n \n elif action == '302':\n # ликвидировать предприятие\n really = (input('Вы уверены? Введите \"Да\" - или оставьте поле ввода пустым: ') == 'Да')\n if really:\n self.__del__()\n \n elif action == '-1':\n return\n \n def new():\n print('Вы решили создать свою собственную библиотеку?! Да здравствует либертарианский рынок!')\n self = Library()\n self.owner = input('\\tПрежде всего, укажите ФИО человека, который будет владельцем библиотеки: ')\n self.workers = list(map(str, input('\\tВы уже наняли работников? Если да, перечислите их через запятую ' + \n '- или оставьте поле ввода пустым: ').split(', ')))\n self.name = input('\\tКак вы назовёте своё предприятие? ')\n self.address = input('\\tУкажите юридический адрес: ')\n self.contacts = list(map(str, input('\\tУкажите контакты организации (номер телефона, эл. почту, ссылки) через пробел: ').split()))\n print('Поздравляем, вы не иначе как создали свою библиотеку! Можете подавать документы на регистрацию предприятия в ФНС России!')\n return self\n \n def append(self, books):\n if books == []:\n self.setupCard()\n for book in books:\n try:\n ID = self.getNewID()\n exec(f'self.storage[ID] = {book}')\n except:\n print(f'Объекта {book} не существует.')\n \n \n def setupCard(self):\n print('Заполнение информации о новой книге библиотеки.')\n try:\n book = Book()\n book.title = input('\\tНазвание книги: ')\n book.mainAuthor = input('\\tАвтор: ')\n book.authors = list(map(str, input('\\tСоавторы (через запятую): ').split(', ')))\n book.description = input('\\tАннотация: ')\n book.language = input('\\tЯзык текста: ')\n book.ageLimit = int(input('\\tМинимальный возраст читателя: '))\n book.volume = int(input('\\tОбъём печатного текста в страницах формата А5: '))\n book.ISBN = input('\\tISBN: ')\n book.yearOfPublishing = int(input('\\tГод публикации: '))\n book.publishingHouse = input('\\tИздательство: ')\n book.cost = int(input('\\tСтоимость: '))\n book.link = input('\\tСсылка на книгу в Интернете: ')\n ID = self.getNewID()\n self.storage[ID] = book\n print('Книга была успешно добавлена в библиотеку.')\n except:\n print('Заполнение было прервано из-за некорректных данных. Будьте внимательны - попробуйте ещё раз.')\n \n def getNewID(self):\n if len(list(self.storage.keys())) != 0:\n return max(list(storage.keys())) + 1\n else:\n return 1\n \n def bookWasLost(self, ID):\n print('Стоимость книги должны возместить.')\n \n def remove(self, ID):\n if input('Введите \"Да\", чтобы подтвердить удаление книги: ') == 'Да':\n if ID in self.storage.keys():\n del self.storage[ID]\n for readerIndex in self.readers.keys():\n if ID in self.readers[readerIndex]:\n self.readers[readerIndex].remove(ID)\n print('Удаление совершено успешно.')\n \n def back(self, ID):\n for readerIndex in self.readers.keys():\n if ID in self.readers[readerIndex]:\n self.readers[readerIndex].remove(ID)\n print('Возврат совершён успешно.')\n break",
"_____no_output_____"
],
[
"AGATA = Library.new()",
"Вы решили создать свою собственную библиотеку?! Да здравствует либертарианский рынок!\n\tПрежде всего, укажите ФИО человека, который будет владельцем библиотеки: Влад\n\tВы уже наняли работников? Если да, перечислите их через запятую - или оставьте поле ввода пустым: Клим, Шамиль\n\tКак вы назовёте своё предприятие? PXTextBlock\n\tУкажите юридический адрес: Чашка\n\tУкажите контакты организации (номер телефона, эл. почту, ссылки) через пробел: https://vk.com/loldturuyh\nПоздравляем, вы не иначе как создали свою библиотеку! Можете подавать документы на регистрацию предприятия в ФНС России!\n"
],
[
"Beta = Library(name = 'Beta', address = '', owner = 'Mark CDA', workers = [], contacts = [])",
"_____no_output_____"
],
[
"AGATA.shell()",
"Оболочка библиотеки \"PXTextBlock\":\n\tРабота с организацией\n\t000. Добавить сотрудника\n\t001. Удалить сотрудника\n\tРабота с книгами\n\t100. Добавить книгу\n\t101. Удалить книгу\n\t102. Вывести список книг\n\t103. Принудительно вернуть книгу\n\t104. Отредактировать свойства книги\n\t105. Поиск по библиотеке\n\t106. Просмотр свойств книги\n\tРабота с читателями\n\t200. Добавить нового читателя\n\t201. Удалить читателя (если список задолженностей пуст)\n\t202. Взять книгу\n\t203. Вернуть книгу\n\tВнештатные ситуации\n\t300. Книга утеряна\n\t301. Написана новая книга\n\t302. Ликвидировать предприятие\n\t-1. Выйти из оболочки\n"
],
[
"Seveina = Book('Севейна')",
"_____no_output_____"
]
],
[
[
"# Обобщённое число.\n\nСоздайте класс, обобщающий понятие комплексных, двойных и дуальных чисел.\n\nТакие числа объединены одной формой записи:\n\n$$ c = a + ib,$$\n\nгде `c` – обобщённое число (комплексное, двойное или дуальное), `a` и `b` – вещественные числа, i – некоммутирующий символ.\n\nИменно из-за наличия символа `i` число `c` не просто сумма `a` и `b`. Такие числа можно представлять как вектор на плоскости `(a,b)`.\n\nА символ `i` обладает следующим свойством:\n\n- для комплексных чисел\n\n$$ i^2 = -1 $$\n\n- для двойных чисел\n\n$$ i^2 = 1 $$\n\n- для дуальных чисел\n\n$$ i^2 = 0 $$\n\nПерегрузить для них базовые операции: сложения, вычитания, умножения и деления.\n\nНапример, операция умножения для таких чисел имеет вид:\n\n$$ (a_1+b_1i)\\cdot (a_2+b_2i)=a_1a_2+b_1a_2i+a_1b_2i+b_1b_2i^{2}=(a_1a_2+b_1b_2i^{2})+(b_1a_2+a_1b_2)i. $$",
"_____no_output_____"
],
[
"Статус: `задание не решено`.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a1e5097daee5514d9987d6d3b8e058f0b4352bd
| 9,242 |
ipynb
|
Jupyter Notebook
|
templates/old_ClusterAgglomerative.ipynb
|
DevashishX/AbstractClustering
|
68ffc657b517c81adbdbd5b19d37a9ef18651e3c
|
[
"MIT"
] | null | null | null |
templates/old_ClusterAgglomerative.ipynb
|
DevashishX/AbstractClustering
|
68ffc657b517c81adbdbd5b19d37a9ef18651e3c
|
[
"MIT"
] | null | null | null |
templates/old_ClusterAgglomerative.ipynb
|
DevashishX/AbstractClustering
|
68ffc657b517c81adbdbd5b19d37a9ef18651e3c
|
[
"MIT"
] | null | null | null | 27.670659 | 764 | 0.538844 |
[
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nfrom sklearn import cluster, datasets\nimport seaborn as sns\nimport json\nimport sys\nimport codecs\nimport os\nfrom collections import defaultdict, Counter",
"_____no_output_____"
],
[
"def show_histogram(d):\n plt.figure(figsize=(16,8))\n c = {k: len(d[k]) for k in d.keys()}\n bars, heights = zip(*c.items())\n y_pos = range(len(bars))\n plt.bar(y_pos, heights)\n plt.xticks(y_pos, bars, rotation=90)\n plt.show()",
"_____no_output_____"
],
[
"embedDir = \"../MegaSentEmbs/\"\ndumpdir = \"../dump/\"\noldlist = os.listdir(embedDir)\nfilelist = sorted([embedDir+f for f in oldlist if f[-3:]==\"pkl\"])\n# filenum = len(filelist)\nfilenum = 5\n# print(filelist)\nsmalllist = filelist[:filenum]\nprint(\"smalllist: \", smalllist)",
"smalllist: ['../MegaSentEmbs/repository_embedding_100_2013-03-18.pkl', '../MegaSentEmbs/repository_embedding_101_2013-03-18.pkl', '../MegaSentEmbs/repository_embedding_102_2013-03-18.pkl', '../MegaSentEmbs/repository_embedding_103_2013-03-18.pkl', '../MegaSentEmbs/repository_embedding_104_2013-03-18.pkl']\n"
]
],
[
[
"#Read all the pandas dataframes",
"_____no_output_____"
]
],
[
[
"megadf = pd.DataFrame()\nfor f in smalllist:\n tempdf = pd.read_pickle(f)\n # print(tempdf.shape)\n megadf = megadf.append(tempdf, ignore_index = True)\n\nprint(megadf.shape)\nprint(megadf.tail())",
"(2433, 4)\n id title \\\n2428 9549863 In Search of the Argonauts \n2429 9549864 When Is A National Team Not A National Team? \n2430 9549866 Football and the Cyprus conflict \n2431 9549873 Optimisation of Mobile Communication Networks ... \n2432 9549874 Free Search of Global Value \n\n abstract \\\n2428 [paper, examines, concerted, attempt, group, s... \n2429 [essay, analyzes, anomaly, recognition, place,... \n2430 [essay, look, football, role, cyprus, conflict... \n2431 [mini, conference, optimisation, mobile, commu... \n2432 [article, present, novel, investigation, two, ... \n\n embedding \n2428 [-0.20942938586860307, 0.40039306438355393, -0... \n2429 [-0.1677260275156407, 0.26426473158190433, -0.... \n2430 [-0.15642487500000005, 0.19240105999999996, -0... \n2431 [0.3354838166666667, 0.06920026666666669, 0.11... \n2432 [0.5210028771929824, -0.03993977192982456, 0.0... \n"
],
[
"predata = megadf[\"embedding\"]\n\ndata = np.matrix(predata.to_list())\nprint(data.shape)\n",
"(2433, 250)\n"
]
],
[
[
"#Number of Clusters",
"_____no_output_____"
]
],
[
[
"k = 50",
"_____no_output_____"
],
[
"print(\"Starting Clustering Process\")\nmodel = cluster.AgglomerativeClustering(n_clusters=k, affinity='euclidean', linkage='ward')\nmodel.fit(data)\nprint(\"Agglomerative.fit(data) Done!\")",
"Starting Clustering Process\nAgglomerative.fit(data) Done!\n"
],
[
"print(\"hello\")",
"hello\n"
],
[
"centroids = model.cluster_centers_\nlabels = model.labels_\nmegadf[\"clusterlabel\"]=labels",
"_____no_output_____"
],
[
"plt.figure(figsize=(16,16))\nsns.countplot(\"clusterlabel\", data=megadf)",
"_____no_output_____"
],
[
"import dtale\ns = megadf[megadf[\"clusterlabel\"] == 48].loc[:, [\"title\", \"abstract\"]]\n# megadf.columns\ndtale.show(s)\n# s",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1e635f8eee4f4e0a87940e28407e44f2818106
| 8,914 |
ipynb
|
Jupyter Notebook
|
docs/examples/driver_examples/QCoDeS example with InstrumentGroup and DelegateInstrument.ipynb
|
jakeogh/Qcodes
|
3042317038e89264d481b212c9640c4d6b356c88
|
[
"MIT"
] | 223 |
2016-10-29T15:00:24.000Z
|
2022-03-20T06:53:34.000Z
|
docs/examples/driver_examples/QCoDeS example with InstrumentGroup and DelegateInstrument.ipynb
|
jakeogh/Qcodes
|
3042317038e89264d481b212c9640c4d6b356c88
|
[
"MIT"
] | 3,406 |
2016-10-25T10:44:50.000Z
|
2022-03-31T09:47:35.000Z
|
docs/examples/driver_examples/QCoDeS example with InstrumentGroup and DelegateInstrument.ipynb
|
jakeogh/Qcodes
|
3042317038e89264d481b212c9640c4d6b356c88
|
[
"MIT"
] | 263 |
2016-10-25T11:35:36.000Z
|
2022-03-31T08:53:20.000Z
| 23.033592 | 461 | 0.506394 |
[
[
[
"# Qcodes example with InstrumentGroup driver\n\nThis notebooks explains how to use the `InstrumentGroup` driver.\n\n## About\nThe goal of the `InstrumentGroup` driver is to combine several instruments as submodules into one instrument. Typically, this is meant to be used with the `DelegateInstrument` driver. An example usage of this is to create an abstraction for devices on a chip.\n\n## Usage\nThe way it's used is mainly by specifying an entry in the station YAML. For instance, to create a Chip that has one or more Devices on it that point to different source parameters. The example below shows three devices, each of which is initialised in one of the supported ways. Device1 has only DelegateParameters, while device2 and device3 have both DelegateParameters and channels added. Device3 adds its channels using a custom channel wrapper class. ",
"_____no_output_____"
]
],
[
[
"%%writefile example.yaml\n\ninstruments:\n dac:\n type: qcodes.tests.instrument_mocks.MockDAC\n init:\n num_channels: 3\n\n lockin1:\n type: qcodes.tests.instrument_mocks.MockLockin\n\n lockin2:\n type: qcodes.tests.instrument_mocks.MockLockin\n\n MockChip_123:\n type: qcodes.instrument.delegate.InstrumentGroup\n init:\n submodules_type: qcodes.instrument.delegate.DelegateInstrument\n submodules:\n device1:\n parameters:\n gate:\n - dac.ch01.voltage\n source:\n - lockin1.frequency\n - lockin1.amplitude\n - lockin1.phase\n - lockin1.time_constant\n drain:\n - lockin1.X\n - lockin1.Y\n device2:\n parameters:\n readout:\n - lockin1.phase\n channels:\n gate_1: dac.ch01\n device3:\n parameters:\n readout:\n - lockin1.phase\n channels:\n type: qcodes.tests.instrument_mocks.MockCustomChannel\n gate_1:\n channel: dac.ch02\n current_valid_range: [-0.5, 0]\n gate_2:\n channel: dac.ch03\n current_valid_range: [-1, 0]\n\n set_initial_values_on_load: true\n initial_values:\n device1:\n gate.step: 5e-4\n gate.inter_delay: 12.5e-4\n device2:\n gate_1.voltage.post_delay: 0.01\n device3:\n gate_2.voltage.post_delay: 0.03",
"Overwriting example.yaml\n"
],
[
"import qcodes as qc",
"Logging hadn't been started.\nActivating auto-logging. Current session state plus future input saved.\nFilename : /Users/jana/.qcodes/logs/command_history.log\nMode : append\nOutput logging : True\nRaw input log : False\nTimestamping : True\nState : active\nQcodes Logfile : /Users/jana/.qcodes/logs/210608-31608-qcodes.log\n"
],
[
"station = qc.Station(config_file=\"example.yaml\")\nlockin1 = station.load_lockin1()\nlockin2 = station.load_lockin2()\ndac = station.load_dac()\nchip = station.load_MockChip_123(station=station)",
"_____no_output_____"
],
[
"chip.device1.gate()",
"_____no_output_____"
],
[
"dac.ch01.voltage()",
"_____no_output_____"
],
[
"chip.device1.gate(1.0)\nchip.device1.gate()",
"_____no_output_____"
],
[
"dac.ch01.voltage()",
"_____no_output_____"
],
[
"chip.device1.source()",
"_____no_output_____"
],
[
"chip.device1.drain()",
"_____no_output_____"
]
],
[
[
"Device with channels/gates:",
"_____no_output_____"
]
],
[
[
"chip.device2.gate_1",
"_____no_output_____"
]
],
[
[
"Setting voltages to a channel/gate of device2:",
"_____no_output_____"
]
],
[
[
"print(chip.device2.gate_1.voltage())\nchip.device2.gate_1.voltage(-0.74)\nprint(chip.device2.gate_1.voltage())",
"1.0\n-0.74\n"
]
],
[
[
"Check initial values of device3, from which only gate_2.voltage.post_delay was set.",
"_____no_output_____"
]
],
[
[
"chip.device3.gate_1.voltage.post_delay",
"_____no_output_____"
],
[
"chip.device3.gate_2.voltage.post_delay",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a1e75e00cbc8cd07af0dc1819d3fc2269856c2e
| 10,872 |
ipynb
|
Jupyter Notebook
|
ts-tbt-sisl-tutorial-master/TB_06/run.ipynb
|
rwiuff/QuantumTransport
|
5367ca2130b7cf82fefd4e2e7c1565e25ba68093
|
[
"MIT"
] | 1 |
2021-09-25T14:05:45.000Z
|
2021-09-25T14:05:45.000Z
|
ts-tbt-sisl-tutorial-master/TB_06/run.ipynb
|
rwiuff/QuantumTransport
|
5367ca2130b7cf82fefd4e2e7c1565e25ba68093
|
[
"MIT"
] | 1 |
2020-03-31T03:17:38.000Z
|
2020-03-31T03:17:38.000Z
|
ts-tbt-sisl-tutorial-master/TB_06/run.ipynb
|
rwiuff/QuantumTransport
|
5367ca2130b7cf82fefd4e2e7c1565e25ba68093
|
[
"MIT"
] | 2 |
2020-01-27T10:27:51.000Z
|
2020-06-17T10:18:18.000Z
| 28.165803 | 387 | 0.562638 |
[
[
[
"from __future__ import print_function\nimport sisl\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom functools import partial\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"TBtrans is capable of calculating transport in $N\\ge 1$ electrode systems. In this example we will explore a 4-terminal graphene GNR cross-bar (one zGNR, the other aGNR) system.",
"_____no_output_____"
]
],
[
[
"graphene = sisl.geom.graphene(orthogonal=True)",
"_____no_output_____"
],
[
"R = [0.1, 1.43]\nhop = [0., -2.7]",
"_____no_output_____"
]
],
[
[
"Create the two electrodes in $x$ and $y$ directions. We will force the systems to be nano-ribbons, i.e. only periodic along the ribbon. In `sisl` there are two ways of accomplishing this.\n\n1. Explicitly set number of auxiliary supercells\n2. Add vacuum beyond the orbital interaction ranges\n\nThe below code uses the first method. \n\nPlease see if you can change the creation of `elec_x` by adding vacuum. \n**HINT**: Look at the documentation for the `sisl.Geometry` and search for vacuum. To know the orbital distance look up `maxR` in the geometry class as well.",
"_____no_output_____"
]
],
[
[
"elec_y = graphene.tile(3, axis=0)\nelec_y.set_nsc([1, 3, 1])\nelec_y.write('elec_y.xyz')\nelec_x = graphene.tile(5, axis=1)\nelec_x.set_nsc([3, 1, 1])\nelec_x.write('elec_x.xyz')",
"_____no_output_____"
]
],
[
[
"Subsequently we create the electronic structure.",
"_____no_output_____"
]
],
[
[
"H_y = sisl.Hamiltonian(elec_y)\nH_y.construct((R, hop))\nH_y.write('ELEC_Y.nc') \nH_x = sisl.Hamiltonian(elec_x)\nH_x.construct((R, hop))\nH_x.write('ELEC_X.nc')",
"_____no_output_____"
]
],
[
[
"Now we have created the electronic structure for the electrodes. All that is needed is the electronic structure of the device region, i.e. the crossing nano-ribbons.",
"_____no_output_____"
]
],
[
[
"dev_y = elec_y.tile(30, axis=1)\ndev_y = dev_y.translate( -dev_y.center(what='xyz') )\ndev_x = elec_x.tile(18, axis=0)\ndev_x = dev_x.translate( -dev_x.center(what='xyz') )",
"_____no_output_____"
]
],
[
[
"Remove any atoms that are *duplicated*, i.e. when we overlay these two geometries some atoms are the same.",
"_____no_output_____"
]
],
[
[
"device = dev_y.add(dev_x)\ndevice.set_nsc([1,1,1])\nduplicates = []\nfor ia in dev_y:\n idx = device.close(ia, 0.1)\n if len(idx) > 1:\n duplicates.append(idx[1])\ndevice = device.remove(duplicates)",
"_____no_output_____"
]
],
[
[
"Can you explain why `set_nsc([1, 1, 1])` is called? And if so, is it necessary to do this step?\n\n---\n\nEnsure the lattice vectors are big enough for plotting.\nTry and convince your-self that the lattice vectors are unimportant for tbtrans in this example. \n*HINT*: what is the periodicity?",
"_____no_output_____"
]
],
[
[
"device = device.add_vacuum(70, 0).add_vacuum(20, 1)\ndevice = device.translate( device.center(what='cell') - device.center(what='xyz') )\ndevice.write('device.xyz')",
"_____no_output_____"
]
],
[
[
"Since this system has 4 electrodes we need to tell tbtrans where the 4 electrodes are in the device. The following lines prints out the fdf-lines that are appropriate for each of the electrodes (`RUN.fdf` is already filled correctly):",
"_____no_output_____"
]
],
[
[
"print('elec-Y-1: semi-inf -A2: {}'.format(1))\nprint('elec-Y-2: semi-inf +A2: end {}'.format(len(dev_y)))\nprint('elec-X-1: semi-inf -A1: {}'.format(len(dev_y) + 1))\nprint('elec-X-2: semi-inf +A1: end {}'.format(-1))",
"_____no_output_____"
],
[
"H = sisl.Hamiltonian(device)\nH.construct([R, hop])\nH.write('DEVICE.nc')",
"_____no_output_____"
]
],
[
[
"# Exercises\n\nIn this example we have more than 1 transmission paths. Before you run the below code which plots all relevant transmissions ($T_{ij}$ for $j>i$), consider if there are any symmetries, and if so, determine how many different transmission spectra you should expect? Please plot the geometry using your favourite geometry viewer (`molden`, `Jmol`, ...). The answer is not so trivial.",
"_____no_output_____"
]
],
[
[
"tbt = sisl.get_sile('siesta.TBT.nc')",
"_____no_output_____"
]
],
[
[
"Make easy function calls for plotting energy resolved quantites:",
"_____no_output_____"
]
],
[
[
"E = tbt.E\nEplot = partial(plt.plot, E)",
"_____no_output_____"
],
[
"# Make a shorthand version for the function (simplifies the below line)\nT = tbt.transmission\nt12, t13, t14, t23, t24, t34 = T(0, 1), T(0, 2), T(0, 3), T(1, 2), T(1, 3), T(2, 3)\nEplot(t12, label=r'$T_{12}$'); Eplot(t13, label=r'$T_{13}$'); Eplot(t14, label=r'$T_{14}$');\nEplot(t23, label=r'$T_{23}$'); Eplot(t24, label=r'$T_{24}$'); \nEplot(t34, label=r'$T_{34}$');\nplt.ylabel('Transmission'); plt.xlabel('Energy [eV]'); plt.ylim([0, None]); plt.legend();",
"_____no_output_____"
]
],
[
[
"- In `RUN.fdf` we have added the flag `TBT.T.All` which tells tbtrans to calculate *all* transmissions, i.e. between all $i\\to j$ for all $i,j \\in \\{1,2,3,4\\}$. This flag is by default `False`, why?\n- Create 3 plots each with $T_{1j}$ and $T_{j1}$ for all $j\\neq1$.",
"_____no_output_____"
]
],
[
[
"# Insert plot of T12 and T21",
"_____no_output_____"
],
[
"# Insert plot of T13 and T31",
"_____no_output_____"
],
[
"# Insert plot of T14 and T41",
"_____no_output_____"
]
],
[
[
"- Considering symmetries, try to figure out which transmissions ($T_{ij}$) are unique?\n- Plot the bulk DOS for the 2 differing electrodes.\n- Plot the spectral DOS injected by all 4 electrodes.",
"_____no_output_____"
]
],
[
[
"# Helper routines, this makes BDOS(...) == tbt.BDOS(..., norm='atom')\nBDOS = partial(tbt.BDOS, norm='atom')\nADOS = partial(tbt.ADOS, norm='atom')",
"_____no_output_____"
]
],
[
[
"Bulk density of states:",
"_____no_output_____"
]
],
[
[
"Eplot(..., label=r'$BDOS_1$');\nEplot(..., label=r'$BDOS_2$');\nplt.ylabel('DOS [1/eV/N]'); plt.xlabel('Energy [eV]'); plt.ylim([0, None]); plt.legend();",
"_____no_output_____"
]
],
[
[
"Spectral density of states for all electrodes:\n- As a final exercise you can explore the details of the density of states for single atoms. Take for instance atom 205 (204 in Python index) which is in *both* GNR at the crossing. \nFeel free to play around with different atoms, subset of atoms (pass a `list`) etc. ",
"_____no_output_____"
]
],
[
[
"Eplot(..., label=r'$ADOS_1$');\n...\nplt.ylabel('DOS [1/eV/N]'); plt.xlabel('Energy [eV]'); plt.ylim([0, None]); plt.legend();",
"_____no_output_____"
]
],
[
[
"- For 2D structures one can easily plot the DOS per atom via a scatter plot in `matplotlib`, here is the skeleton code for that, you should select an energy point and figure out how to extract the atom resolved DOS (you will need to look-up the documentation for the `ADOS` method to figure out which flag to use.",
"_____no_output_____"
]
],
[
[
"Eidx = tbt.Eindex(...)\nADOS = [tbt.ADOS(i, ....) for i in range(4)]\nf, axs = plt.subplots(2, 2, figsize=(10, 10))\na_xy = tbt.geometry.xyz[tbt.a_dev, :2]\nfor i in range(4):\n A = ADOS[i]\n A *= 100 / A.max() # normalize to maximum 100 (simply for plotting)\n axs[i // 2][i % 2].scatter(a_xy[:, 0], a_xy[:, 1], A, c=\"bgrk\"[i], alpha=.5);\nplt.xlabel('x [Ang]'); plt.ylabel('y [Ang]'); plt.axis('equal');",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1e77f7b8035bdc26ec2b2f0ce6abb75446a17a
| 67,843 |
ipynb
|
Jupyter Notebook
|
Calibration/Calibration_Datasets_Specific_Warnings.ipynb
|
bobmyhill/VESIcal
|
f401226b55bdb6c8e6f1838aba78927664c89706
|
[
"MIT"
] | 16 |
2020-06-22T09:07:32.000Z
|
2022-01-12T13:42:12.000Z
|
Calibration/Calibration_Datasets_Specific_Warnings.ipynb
|
bobmyhill/VESIcal
|
f401226b55bdb6c8e6f1838aba78927664c89706
|
[
"MIT"
] | 136 |
2020-05-22T21:43:23.000Z
|
2022-03-07T22:06:33.000Z
|
Calibration/Calibration_Datasets_Specific_Warnings.ipynb
|
bobmyhill/VESIcal
|
f401226b55bdb6c8e6f1838aba78927664c89706
|
[
"MIT"
] | 3 |
2021-05-18T08:21:02.000Z
|
2022-03-25T01:08:10.000Z
| 77.62357 | 9,688 | 0.71098 |
[
[
[
"#pip install xlwt openpyxl xlsxwriter xlrd ",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport seaborn as sns\n",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
],
[
"# Loading in Calibration datasets",
"_____no_output_____"
]
],
[
[
"#CO2 only\ndf_Eguchi_CO2= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Eguchi_CO2', index_col=0)\ndf_Allison_CO2= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Allison_CO2', index_col=0)\ndf_Dixon_CO2= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Dixon_CO2', index_col=0)\ndf_MagmaSat_CO2= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='MagmaSat_CO2', index_col=0)\ndf_Shishkina_CO2=pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Shishkina_CO2', index_col=0)\n\n#H2O Only\ndf_Iacono_H2O= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Iacono_H2O', index_col=0)\ndf_Shishkina_H2O=pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Shishkina_H2O', index_col=0)\ndf_MagmaSat_H2O= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='MagmSat_H2OExt', index_col=0)\ndf_Dixon_H2O=pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Dixon_H2O', index_col=0)\ndf_Moore_H2O=pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Moore_H2O', index_col=0)\n\n#Mixed CO2-H2O\ndf_Iacono_CO2H2O= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='Iacono_H2O-CO2', index_col=0)\ndf_MagmaSat_CO2H2O= pd.read_excel('Solubility_Datasets_V1.xlsx', sheet_name='MagmaSat_CO2H2O', index_col=0)\n",
"_____no_output_____"
]
],
[
[
"# Subdividing up the Allison dataset by the different systems",
"_____no_output_____"
]
],
[
[
"#San Francisco Volcanic Field\ndf_Allison_CO2_SFVF=df_Allison_CO2.loc[df_Allison_CO2['Location']=='SFVF']\n#Sunset Crater\ndf_Allison_CO2_SunsetCrater=df_Allison_CO2.loc[df_Allison_CO2['Location']=='SunsetCrater']\n#Erebus\ndf_Allison_CO2_Erebus=df_Allison_CO2.loc[df_Allison_CO2['Location']=='Erebus']\n#Vesuvius\ndf_Allison_CO2_Vesuvius=df_Allison_CO2.loc[df_Allison_CO2['Location']=='Vesuvius']\n#Etna\ndf_Allison_CO2_Etna=df_Allison_CO2.loc[df_Allison_CO2['Location']=='Etna']\n#Stromboli\ndf_Allison_CO2_Stromboli=df_Allison_CO2.loc[df_Allison_CO2['Location']=='Stromboli']",
"_____no_output_____"
]
],
[
[
"# Calculating min and max P and T for each model",
"_____no_output_____"
]
],
[
[
"# Calculating limits - Magmasat read off their graph\nminDixonP_H2O=df_Dixon_H2O[\"P (bars)\"].min()\nmaxDixonP_H2O=df_Dixon_H2O[\"P (bars)\"].max()\nminDixonT_H2O=1200\nmaxDixonT_H2O=1200\n\nminDixonP_CO2=df_Dixon_CO2[\"P (bars)\"].min()\nmaxDixonP_CO2=df_Dixon_CO2[\"P (bars)\"].max()\nminDixonT_CO2=1200\nmaxDixonT_CO2=1200\n\nminDixonP_CO2H2O=df_Dixon_CO2[\"P (bars)\"].min()\nmaxDixonP_CO2H2O=df_Dixon_CO2[\"P (bars)\"].max()\nminDixonT_CO2H2O=1200\nmaxDixonT_CO2H2O=1200\n\n\nminMooreP_H2O=df_Moore_H2O[\"P (bars)\"].min()\nmaxMooreP_H2O=df_Moore_H2O[\"P (bars)\"].max()\nmaxMooreP_H2O_Pub=3000\nminMooreT_H2O=df_Moore_H2O[\"T (C)\"].min()\nmaxMooreT_H2O=df_Moore_H2O[\"T (C)\"].max()\n\n \nminIaconoP_H2O=df_Iacono_H2O[\"P (bar)\"].min()\nmaxIaconoP_H2O=df_Iacono_H2O[\"P (bar)\"].max()\nminIaconoT_H2O=df_Iacono_H2O[\"T (K)\"].min()-273.15\nmaxIaconoT_H2O=df_Iacono_H2O[\"T (K)\"].max()-273.15 \n\nminIaconoP_CO2H2O=df_Iacono_CO2H2O[\"P (bar)\"].min()\nmaxIaconoP_CO2H2O=df_Iacono_CO2H2O[\"P (bar)\"].max()\nminIaconoT_CO2H2O=df_Iacono_CO2H2O[\"T (K)\"].min()-273.15\nmaxIaconoT_CO2H2O=df_Iacono_CO2H2O[\"T (K)\"].max()-273.15\n\nminEguchiP_CO2=10000*df_Eguchi_CO2[\"P(GPa)\"].min()\nmaxEguchiP_CO2=10000*df_Eguchi_CO2[\"P(GPa)\"].max()\nminEguchiT_CO2=df_Eguchi_CO2[\"T(°C)\"].min()\nmaxEguchiT_CO2=df_Eguchi_CO2[\"T(°C)\"].max() \n\nminAllisonP_CO2=df_Allison_CO2[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2=df_Allison_CO2[\"Pressure (bars)\"].max()\nminAllisonP_CO2_SFVF=df_Allison_CO2_SFVF[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_SFVF=df_Allison_CO2_SFVF[\"Pressure (bars)\"].max()\nminAllisonP_CO2_SunsetCrater=df_Allison_CO2_SunsetCrater[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_SunsetCrater=df_Allison_CO2_SunsetCrater[\"Pressure (bars)\"].max()\nminAllisonP_CO2_Erebus=df_Allison_CO2_Erebus[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_Erebus=df_Allison_CO2_Erebus[\"Pressure (bars)\"].max()\nminAllisonP_CO2_Vesuvius=df_Allison_CO2_Vesuvius[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_Vesuvius=df_Allison_CO2_Vesuvius[\"Pressure (bars)\"].max()\nminAllisonP_CO2_Etna=df_Allison_CO2_Etna[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_Etna=df_Allison_CO2_Etna[\"Pressure (bars)\"].max()\nminAllisonP_CO2_Stromboli=df_Allison_CO2_Stromboli[\"Pressure (bars)\"].min()\nmaxAllisonP_CO2_Stromboli=df_Allison_CO2_Stromboli[\"Pressure (bars)\"].max()\n\nminAllisonT_CO2=1200\nmaxAllisonT_CO2=1200\n\nminShishkinaP_H2O=10*df_Shishkina_H2O[\"P (MPa)\"].min()\nmaxShishkinaP_H2O=10*df_Shishkina_H2O[\"P (MPa)\"].max()\nminShishkinaT_H2O=df_Shishkina_H2O[\"T (°C)\"].min()\nmaxShishkinaT_H2O=df_Shishkina_H2O[\"T (°C)\"].max() \n\nminShishkinaP_CO2=10*df_Shishkina_CO2[\"P (MPa)\"].min()\nmaxShishkinaP_CO2=10*df_Shishkina_CO2[\"P (MPa)\"].max()\nminShishkinaT_CO2=df_Shishkina_CO2[\"T (°C)\"].min()\nmaxShishkinaT_CO2=df_Shishkina_CO2[\"T (°C)\"].max() \n# Measured off Magmasat graph\nminMagmasatP_CO2=10*0\nmaxMagmasatP_CO2=10*3000\nminMagmasatT_CO2=1139\nmaxMagmasatT_CO2=1730\nminMagmasatP_H2O=10*0\nmaxMagmasatP_H2O=10*2000\nminMagmasatT_H2O=550\nmaxMagmasatT_H2O=1418\n\n",
"_____no_output_____"
]
],
[
[
"# Table of calibration limits",
"_____no_output_____"
]
],
[
[
"columns=['Publication', 'Species', 'Min P (bars)', 'Max P (bars)', 'Min T (C)', 'Max T (C)', 'notes']\ndf_PT2=pd.DataFrame([['Dixon 1997', 'H2O', minDixonP_H2O, maxDixonP_H2O, minDixonT_H2O, maxDixonT_H2O, '-'],\n ['Dixon 1997', 'CO2', minDixonP_CO2, maxDixonP_CO2, minDixonT_CO2, maxDixonT_CO2, '-'],\n ['Moore et al. 1998 (cal datasat)', 'H2O', minMooreP_H2O, maxMooreP_H2O, minMooreT_H2O, maxMooreT_H2O, '2 samples in dataset with >3kbar P'],\n ['Moore et al. 1998 (author range)', 'H2O', 0, 3000, 700, 1200, 'Paper says reliable up to 3kbar'],\n ['Iacono-Marziano et al., 2012', 'H2O', minIaconoP_H2O, maxIaconoP_H2O, minIaconoT_H2O, maxIaconoT_H2O, '-'],\n ['Iacono-Marziano et al., 2012', 'CO2-H2O', minIaconoP_CO2H2O, maxIaconoP_CO2H2O, minIaconoT_CO2H2O, maxIaconoT_CO2H2O, '-'],\n ['Shishkina et al., 2014', 'H2O', minShishkinaP_H2O, maxShishkinaP_H2O, minShishkinaT_H2O, maxShishkinaT_H2O, '-'],\n ['Shishkina et al., 2014', 'CO2', minShishkinaP_CO2, maxShishkinaP_CO2, minShishkinaT_CO2, maxShishkinaT_CO2, '-'],\n ['Ghiorso and Gualda., 2015 (MagmaSat)', 'H2O', minMagmasatP_H2O, maxMagmasatP_H2O, minMagmasatT_H2O, maxMagmasatT_H2O, '-'],\n ['Ghiorso and Gualda., 2015 (MagmaSat)', 'CO2', minMagmasatP_CO2, maxMagmasatP_CO2, minMagmasatT_CO2, maxMagmasatT_CO2, '-'],\n ['Eguchi and Dasgupta, 2018', 'CO2', minEguchiP_CO2, maxEguchiP_CO2, minEguchiT_CO2, maxEguchiT_CO2, '-'], \n ['Allison et al. 2019 (All Data)', 'CO2', minAllisonP_CO2, maxAllisonP_CO2, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (SFVF)', 'CO2', minAllisonP_CO2_SFVF, maxAllisonP_CO2_SFVF, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (Sunset Crater)', 'CO2', minAllisonP_CO2_SunsetCrater, maxAllisonP_CO2_SunsetCrater, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (Erebus)', 'CO2', minAllisonP_CO2_Erebus, maxAllisonP_CO2_Erebus, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (Vesuvius)', 'CO2', minAllisonP_CO2_Vesuvius, maxAllisonP_CO2_Vesuvius, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (Etna)', 'CO2', minAllisonP_CO2_Etna, maxAllisonP_CO2_Etna, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ['Allison et al. 2019 (Etna)', 'CO2', minAllisonP_CO2_Stromboli, maxAllisonP_CO2_Stromboli, minAllisonT_CO2, maxAllisonT_CO2, '-'],\n ],\n \n columns=columns).set_index('Publication')\n \n\n#save to excel file for easy import into manuscript\nwith pd.ExcelWriter(\"Table_of_Calibration_Limits.xlsx\") as writer:\n df_PT2.to_excel(writer, 'Table')\n \ndf_PT2 \n",
"_____no_output_____"
]
],
[
[
"# Things to include for Dixon CO2 model\nCaution: \n1. This CO2 model is only valid where C dissolves as carbonate ions, and is not applicable for intermediate-silicic compositions where C is also present as molecular CO2. \n2. T is assumed to be constant at 1200C in the equations of Dixon. There is some temperature dependence in the implementation of this model through the fugacity and <font color='red'>{insert other terms where this is true}. </font>\n\n3. The compositional dependence of CO2 in the Dixon, 1997 model is incorperated emperically through the parameter Pi. Dixon (1997) provide an equation for Pi in terms of oxide fractions at 1200C, 1kbar. However, they also show that in the North arch Volcanic field, there is a strong correlation between Pi and SiO2, allowing a simplification of the compositional dependence in terms of SiO2. This was implemented in Volatilecalc, and is used in this model. Note:\n\n[Part A](#pA)<br>Equation 1 will only be valid if your samples have similar major element systematics to the calibration dataset of Dixon, 1997. We provide a plot in notebook X to assess this. Crucially, if the full Pi term in your sample suite does not follow the same trajectory with SiO2 as the North Arch dataset, this simplification will lead to innaccurate results. \n[Part B](#pA)<br> Equation 1 is only valid for 40-49 wt% SiO2. In VolatileCalc, you cannot enter a SiO2 value>49 wt%. In the literature, for samples with >49 wt% SiO2, the SiO2 content has been set to 49wt% to allow the Dixon model to be used (e.g., Tucker et al., 2019; Coombs et al. 2005). Newman and Lowenstern suggest that calculating the result with SiO2=49wt% would generally be valid for basalts with ~52 wt% SiO2. In our code, samples with SiO2>49 are calculated assuming SiO2=49.\n\nHere's how this is implemented in our code:\nif sample['SiO2'] > 48.9:\n return 3.817e-7\n else:\n return 8.7e-6 - 1.7e-7*sample['SiO2']\n\n[Part C](#pA)<br> It is unclear whether the Pi dependence, and by extension, equation 1 are valid at pressures >1000 bars. Lesne et al. (2011) suggest it may hold to 2000 bars, in VolatileCalc, the limit is placed at 5000 bars. 2) The correlation between Pi and SiO2 was only parameterized between 40-49 wt% SiO2. In our code, if SiO2 of the sample>49 wt%, Extrapolation beyond this \n\nSpecific errors to spit out if you do exceed our parameters\n\n1. Your SiO2>49 wt%, please see caution statement \n2. This pressure is above the limit of 2000 bars that Lesne et al. 2011 suggest the Dixon compositoinal dependence may be valid too. \n3. This pressure is above the upper limit of 5,000 bars as suggested by Volatile Calc (Newman and Lowenstern, 2001)\"\n4. This pressure is above the maximum experimentally calibrated pressure reported by Dixon (1997). Extrapolation should be stable to 20,000 bars.\"\n5. This pressure is above the maximum extrapolated pressure reported by Dixon et al. (1995)\"\n6. In the Dixon model, T is assumed to be constant at 1200C. <font color='red'>Simon, not sure the best way to explain that although it is out of range, Temp isn't super sensitive for basalts </font> \n\n",
"_____no_output_____"
],
[
"# Things to include for the Moore model\nCaution:\n1. This is an emperical model, so care should be taken extrapolating the results beyond the calibration range of the dataset. \n\nSpecific errors\n\n1. PSat>3000 : Your P is >3000 bars, authors warn against extrapolating beyond this point due to limitations of calibration dataset, as well as the fact high P may be problematic due to critical behavoir\n2. Temp>1200, Temp< 700 - You are outside the calibration range for temperature defined by the authors - caution is need intepreting these results. \n ",
"_____no_output_____"
],
[
"# Things to include for Iacono-Marziano model\nCaution\n1. This semi-empirical model has limited composition range. In particular, the authors warn that the effect of MgO, FeO and Na2O on solubiltiy are poorly constrained due to limited variation in their dataset. In particular, they emphasize that they only have a single pressure for Na-rich melts, so high Na2O melts are not well calibrated at various pressures\n2. The temperature range is limited to 1200-1300 C, with combined H2O-CO2 between 1100-1400. \n3. This model ignores the effect of ferric/ferrous iron, although Papale has showed this has a big effect. \n\n\nSpecific errors - \n1. Your temperature is out of range for X\n2. Your pressures is out of range of X. \n3. Your MgO is out of range of their dataset - the authors specifically warn the effect of MgO on solubility is poorly constrained due to limited variability in the calibration dataset. <font color='red'>Simon, not sure if we want errors like only N samples in database have MgO contents equal to yours, as there are a few at higher ones </font> \n4. Your FeO is out of range - the authors specifically warn the effect of FeO on solubility is poorly constrained due to limited variability in the calibration dataset. <font color='red'>Simon, not sure if we want errors like only N samples in database have FeO contents equal to yours, as there are a few at higher ones </font> \n5. Your Na2O is out of range - the authors specifically warn that high Na2O melts are not handled well, as the database only contains these at 1 pressure. <font color='red'>Simon, not sure if we want errors like only N samples in database have Na2O contents equal to yours, as there are a few at higher ones </font> \n\n",
"_____no_output_____"
]
],
[
[
"# As few outliers, might be better to say only 1 composition in database has high enough FeO or something\n\nplt.hist(df_Iacono_CO2H2O[\"MgO\"], bins = [0,1,2,3,4,5,6,7,8,9,10,11]) \nplt.xlabel(\"MgO, wt%\")\nplt.ylabel(\"Number of samples\")\nplt.title(\"histogram MgO Iacono\") \nplt.show()\n\n\nplt.hist(df_Iacono_CO2H2O[\"FeOT\"], bins = [0,1,2,3,4,5,6,7,8,9,10,11]) \nplt.xlabel(\"FeO*, wt%\")\nplt.ylabel(\"Number of samples\")\nplt.title(\"histogram FeOT Iacono\") \nplt.show()\n\nplt.hist(df_Iacono_CO2H2O[\"Na2O\"], bins = [0,1,2,3,4,5,6,7,8,9,10,11]) \nplt.xlabel(\"Na$_2$O, wt%\")\nplt.ylabel(\"Number of samples\")\nplt.title(\"histogram Na2O Iacono\") \nplt.show()",
"_____no_output_____"
]
],
[
[
"# Things to include for Shishkina model\nCaution: \n1. This is an emperical model, so care should be taken extrapolating the results beyond the calibration range of the dataset. \n2. This CO2 model is only valid where C dissolves as carbonate ions, and is not applicable for intermediate-silicic compositions where C is also present as molecular CO2.\n3. This model only provides H2O and CO2 models separatly. They are combined in this study in <font color='red'>Simon what is best way to explain how its done here </font>\n4. Note than H2O eq can be used for mafic-int melts, at relatively oxidised conditions (NNO+1 to NNO+4). Pure CO2 fluid experiments are more reduced, Fe2+/T>0.8 where reported. Warn against use of CO2 for highly alkali compositions.<font color='red'>Simon, not sure whether we want to implement warnings for this, or just state it in the info/caution section </font> \n\nSpecific errors\n1. Your pressure is out of range\n2. Your temp is out of range\n3. Your SiO2 is > 54 wt%, which is the limit of the calibration range of the CO2 dataset, the authors specifically warn that the model isn't applicable for intermediate-silicic compositions where C is also present as molecular CO2. The H2O model extends up to 69 wt%. \n4. Your K2O+Na2O is outside the range for the CO2 model of X <font color='red'>Simon this is based on caution they say to take for alkali compositions </font>\n",
"_____no_output_____"
]
],
[
[
"# Simon - do we want to code in things like this? \ndf_Shishkina_CO2[\"K2O+Na2O\"]=df_Shishkina_CO2[\"K2O\"]+df_Shishkina_CO2[\"Na2O\"]\ndf_Shishkina_H2O[\"K2O+Na2O\"]=df_Shishkina_H2O[\"K2O\"]+df_Shishkina_H2O[\"Na2O\"]\ncolumns=['Model', 'Oxide', 'Min', 'Max']\nShish_Lim=pd.DataFrame([['Shishkina-H2O', 'SiO2', df_Shishkina_H2O[\"SiO2\"].min(), df_Shishkina_H2O[\"SiO2\"].max()],\n ['Shishkina-CO2', 'SiO2', df_Shishkina_CO2[\"SiO2\"].min(), df_Shishkina_CO2[\"SiO2\"].max()],\n ['Shishkina-CO2', 'K2O+Na2O', df_Shishkina_CO2[\"K2O+Na2O\"].min(), df_Shishkina_CO2[\"K2O+Na2O\"].max()],\n ['Shishkina-H2O', 'K2O+Na2O', df_Shishkina_H2O[\"K2O+Na2O\"].min(), df_Shishkina_H2O[\"K2O+Na2O\"].max()],\n #['Shishkina-H2O', 'SiO2', df_Shishkina_H2O[\"SiO2\"].min(), df_Shishkina_H2O[\"SiO2\"].max()],\n #['Shishkina-CO2', 'SiO2', df_Shishkina_CO2[\"SiO2\"].min()],df_Shishkina_CO2[\"SiO2\"].min()\n ], \n columns=columns)\nShish_Lim",
"_____no_output_____"
]
],
[
[
"# Magmasat",
"_____no_output_____"
],
[
"Specific errors\n1. Your Temp is <800C. Authors warn that below this, the calibration dataset only have H2O experiments, and very few, so concern with extrapolation to lower temp. \n",
"_____no_output_____"
],
[
"# Things to include for Eguchi and Dasgupta, 2018\nCaution\n1. This model is for CO2 only, and was only calibrated on H2O-poor compositions (~0.2-1 wt%). The authors suggest that for hydrous melts, a mixed CO2-H2O fluid saturation model must be used. The authors show comparisons in their paper; the difference between magmasat and this model is <30% for up to 4.5 wt% H2O, concluding that this model does a reasaonble job of predicting CO2 solubility up to 2-4 wt% <font color='red'>This is suprising to me, given the differences I found with Allison... Would it work/not work to combine this model with a different H2O model as allison do?S </font>\n\nSpecific errors\n1. your H2O>1 wt%. The model is only calibrated on water-poor compositions. The authors suggest the model works reasonably well up to H2O contents of 2-3 wt%. \n2. Your P is >50000 bars, the authors warn the model works poorly at higher pressures, possibly due to a structural change in silicate melt at pressures above 5 GPa\n3. Your P is <503 bars, which is the minimum pressure in the calibration dataset. ",
"_____no_output_____"
],
[
"# Things to include for Allison model\n\nCaution:\n\n1. For the Allison model, please select which of their 5 systems, SFVF, Sunset crater, Erebus, Vesuvius, Etna and Stromboli is most suitable for your system using the element diagrams in the \"calibration\" notebook. <font color='red'>Simon should we try clustering in SiO2-Na2O-K2O space </font>\n2. Note that the pressure calibration range for SFVF, Sunset Crater, Erebus and Vesuvius only incorperates pressures from ~4000-6000 bars. For Etna the authors added data from Iacono-Marziano et al. 2012 and Lesne et al. 2011, extending the calibration dataset down to ~485 bars, while for strombili, they include data from Lesne extending it down to ~269 bars. \n3. Temperature is assumed to be fixed at 1200C in the Allison model. \n4. Although this model is technically a CO2-only model, in all their calculations they combine their CO2 model with the H2O model of Lesne et al. 2011. You should implement a water model as well to get reliable answers\n\nSpecific errors-\n1. Your P>7000 bars, the spreadsheet provided by Allison et al. (2019) would not have given an answer.\n2. Your P<50 bars, the spreadsheet provided by Allison et al. (2019) would not have given an answer.\n3. <font color='red'>Include pressure range for each model? and build errors out of that </font> \n4. You have not choosen a water model. Your results may be unrelible. \n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a1e7ad4ed6142e16ed0ceac30801c966112b01a
| 293,996 |
ipynb
|
Jupyter Notebook
|
Lecture Jupyter Notebooks/Lecture 8 Kalman Filter.ipynb
|
DPritykin/Control-Theory-Course
|
f27c13cd0bf9671518c78414f8c3963c7cb870d6
|
[
"MIT"
] | 6 |
2022-02-21T06:42:30.000Z
|
2022-03-14T05:18:00.000Z
|
Lecture Jupyter Notebooks/Lecture 8 Kalman Filter.ipynb
|
DPritykin/Control-Theory-Course
|
f27c13cd0bf9671518c78414f8c3963c7cb870d6
|
[
"MIT"
] | null | null | null |
Lecture Jupyter Notebooks/Lecture 8 Kalman Filter.ipynb
|
DPritykin/Control-Theory-Course
|
f27c13cd0bf9671518c78414f8c3963c7cb870d6
|
[
"MIT"
] | 1 |
2022-03-07T16:25:30.000Z
|
2022-03-07T16:25:30.000Z
| 433.622419 | 74,856 | 0.934054 |
[
[
[
"\n# Обратные связи в контуре управления\n\nДля рассмотренных в предыдущих лекциях регуляторов требуется оценивать состояние объекта управления. Для построения таких оценок необходимо реализовать обратные связи в контуре управления. На практике для этого используются специальные устройства: датчики.",
"_____no_output_____"
],
[
"# Случайные величины\n\nСлучайная величина -- это переменная, значениее которой определяется в результате эксперимента, подверженного влиянию случайных факторов. Случайные величины характеризуются функция плотности вероятности\n\\begin{equation}\np(a \\leq \\xi \\leq b) = \\int_{a}^{b} p(\\xi) \\,d\\xi\n\\end{equation}\nкоторая определяет вероятность попадания значения $\\xi$ в интервал $[a \\quad b]$.\n\nМатематическим ожиданием случайной величины называется \n\\begin{equation}\n\\mathbb{E}[\\xi] = \\int_{-\\infty}^{\\infty} \\xi \\cdot p(\\xi) \\,d\\xi\n\\end{equation}\n\nДисперсия случайной величины\n\\begin{equation}\n\\mathbb{D}[\\xi] = \\mathbb{E}[\\left(\\xi - \\mathbb{E}[\\xi]\\right)^2]\n\\end{equation}\n\nКовариация двух случайных величин\n\\begin{equation}\n \\Sigma[\\xi_1, \\xi_2] = \\mathbb{E}[(\\xi_1 - \\mathbb{E}[\\xi_1]) (\\xi_2 - \\mathbb{E}[\\xi_2])]\n\\end{equation}",
"_____no_output_____"
]
],
[
[
"# [ПРИМЕР 1] Измерения случайной величины\nimport numpy as np\n\nxi = np.random.random()\nprint(xi)",
"0.030119762146224804\n"
],
[
"# [ПРИМЕР 2] Распределение случайной величины\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nnp.random.seed(200)\nN = 999\nxi = np.random.random(N)\n\n# plot xi\nfig1 = plt.figure(figsize=(10,5))\nax1 = fig1.add_subplot(1,1,1)\n\nax1.set_title(\"Random variable xi\")\nax1.plot(range(N), xi, color = 'b')\nax1.set_ylabel(r'xi')\nax1.set_xlabel(r'n')\nax1.grid(True)",
"_____no_output_____"
],
[
"# [ПРИМЕР 3] Нормальное распределение\nimport numpy as np\nimport scipy.stats as st\nimport matplotlib.pyplot as plt\n\nimport numpy as np\nx = np.random.normal(3, 1, 100000)\n\n_, bins, _ = plt.hist(x, 50, density = True, alpha = 0.5)\n\nmu, sigma = st.norm.fit(x)\nbest_fit_line = st.norm.pdf(bins, mu, sigma)\n\nplt.plot(bins, best_fit_line)",
"_____no_output_____"
],
[
"# [ПРИМЕР 4] Математическое ожидание и дисперсия\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n#np.random.seed(200)\nN = 999\nxi = np.random.normal(0, 1, N)\ne = np.mean(xi)\nprint(\"Expected value: \", (e))\nd = np.mean((xi - e)**2)\nprint(\"Variance: \", (d))\n\n# plot xi\nfig1 = plt.figure(figsize=(10,5))\nax1 = fig1.add_subplot(1,1,1)\n\nax1.set_title(\"Random variable xi\")\nax1.plot(range(N), xi, color = 'b')\nax1.set_ylabel(r'xi')\nax1.set_xlabel(r'n')\nax1.set_ylim([-4 * d, 4 * d])\nax1.grid(True)",
"Expected value: 0.04443358006592432\nVariance: 1.0092073745363526\n"
],
[
"mean = [0, 0]\ncovariance_mat = [[1., -0.5], [-0.5, 1.]] \nx, y = np.random.multivariate_normal(mean, covariance_mat, 10000000).T\n\nplt.figure(figsize = (3, 3 ))\nplt.hist2d(x, y, bins=(1000, 1000), cmap = plt.cm.jet)\nplt.subplots_adjust(bottom = 0, top = 1, left = 0, right = 1)\nplt.xlim(-5, 5)\nplt.ylim(-5, 5)\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Фильтр Калмана (Линейные системы)\n\nМодель системы (процесса):\n$$x_k = A_k \\cdot x_{k-1} + B_k \\cdot u_k + w_k,$$\n\nгде $w_k$~$N(0, Q_k)$ - нормально распределённый случайный процесс, характеризующийся нулевым математическим ожиданием и матрицей ковариации $Q_k$.\n\nМодель наблюдений (измерений):\n$$y_k = H_k \\cdot x_k + v_k,$$\n\nгде $v_k$ - нормально распределённый случайный процесс, характеризующийся нулевым математическим ожиданием и матрицей ковариации $R_k$.\n\nТребуется получить оценку вектора состояния системы $\\hat{x}_k$, зная аналогичную оценку на предыдущем шаге ($\\hat{x}_{k-1}$), выход системы (вектор измерений) $y_k$ и вектор управляющих параметров $u_k$.\n\n## Прогноз\n\nПрогноз (экстраполяция) вектора состояния с помощью модели процесса:\n$$\\overline{x}_k = A_k \\cdot \\hat{x}_{k-1} + B_k \\cdot u_k ,$$\n\nПрогноз матрицы ковариации ошибок:\n$$\\overline{P}_k = A_k\\cdot \\hat{P}_{k-1}\\cdot A_k^T + Q_k$$\n\n\n## Коррекция\n\nВычисление коэффициента усиления Калмана:\n$$K_k = \\overline{P}_k \\cdot H_{k}^T \\cdot \\left(H_k\\cdot \\overline{P}_k\\cdot H_k^T + R_k\\right)^{-1}$$\n\nОценка матрицы ковариации ошибки:\n$$\\hat{P}_k = \\left(I - K_k\\cdot H_k\\right)\\cdot \\overline{P}_k$$\n\nОценка вектора состояния:\n$$\\hat{x}_k = \\overline{x}_k + K_k\\cdot\\left(y_k - H_k\\cdot\\overline{x}_k\\right)$$",
"_____no_output_____"
],
[
"# Пример\n\nРассмотрим задачу о движении точки по прямой под действием случайных (постоянных внутри каждого такта управления) ускорений.\n\nВектор состояния системы включает в себя координату $x$ и скорость $v$, то есть $x_k = [x \\quad v]^T$. Уравнения движения:\n\n$$x_k = A_k \\cdot x_{k-1} + G_k \\cdot a_k,$$\nгде\n$$A_k = \n\\begin{pmatrix}\n1 & \\Delta t \\\\\n0 & 1\n\\end{pmatrix}, \\quad\nG_k = \\begin{pmatrix}\n0.5 \\Delta t^2 \\\\\n\\Delta t\n\\end{pmatrix}.\n$$\n\nМатрица ковариации шума процесса:\n$$Q = G\\cdot G^T \\cdot \\sigma_a^2,$$\nгде $\\sigma_a$ характеризует случайное распределение ускорений.\n\nНа каждом такте процесса измеряется координата точки. Таким образом, матрица наблюдения\n$$H = \n\\begin{pmatrix}\n1 & 0 \n\\end{pmatrix},$$\n\nа модель наблюдений\n$$y_k = H \\cdot x_k + v_k,$$\n\nгде $v_k$ - нормально распределённый шум измерений ($\\sigma_m$). Матрица ковариации шума измерений:\n$R = \\left[ \\sigma_m^2 \\right].$",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom random import normalvariate\n\nclass RealWorld:\n def __init__(self, sigma_acc, sigma_meas, dt):\n self.time = 0.0\n self.time_step = dt \n self.position = 0.0\n self.sigma_acc = sigma_acc\n self.velocity = 0.1\n self.measurement = None\n\n # шум измерений\n self.sigma_meas = sigma_meas\n\n def measure(self):\n if self.measurement == None:\n self.measurement = self.position + normalvariate(0, self.sigma_meas)\n \n return self.measurement\n\n def step(self):\n self.time += self.time_step\n acceleration = normalvariate(0, self.sigma_acc)\n self.position += self.velocity * self.time_step + 0.5 * acceleration * self.time_step**2\n self.velocity += acceleration * self.time_step\n\n self.measurement = None ",
"_____no_output_____"
]
],
[
[
"# Пример\n\nРассмотрим задачу о движении точки по прямой под действием случайных (постоянных внутри каждого такта управления) ускорений.\n\nВектор состояния системы включает в себя координату $x$ и скорость $v$, то есть $x_k = [x \\quad v]^T$. Уравнения движения:\n\n$$x_k = A_k \\cdot x_{k-1} + G_k \\cdot a_k,$$\nгде\n$$A_k = \n\\begin{pmatrix}\n1 & \\Delta t \\\\\n0 & 1\n\\end{pmatrix}, \\quad\nG_k = \\begin{pmatrix}\n0.5 \\Delta t^2 \\\\\n\\Delta t\n\\end{pmatrix}.\n$$\n\nМатрица ковариации шума процесса:\n$$Q = G\\cdot G^T \\cdot \\sigma_a^2,$$\nгде $\\sigma_a$ характеризует случайное распределение ускорений.\n\nНа каждом такте процесса измеряется координата точки. Таким образом, матрица наблюдения\n$$H = \n\\begin{pmatrix}\n1 & 0 \n\\end{pmatrix},$$\n\nа модель наблюдений\n$$y_k = H \\cdot x_k + v_k,$$\n\nгде $v_k$ - нормально распределённый шум измерений ($\\sigma_m$). Матрица ковариации шума измерений:\n$R = \\left[ \\sigma_m^2 \\right].$",
"_____no_output_____"
]
],
[
[
"sigma_a = 0.01 # нормально распределённые ускорения\n\n# дисперсия шума измерений\nsigma_measurement = 10.\n\nworld = RealWorld(sigma_a, sigma_measurement, 0.5)\n\n#оператор эволюции\nA = np.array([[1., world.time_step],[0., 1.]])\nG = np.array([0.5 * world.time_step**2, world.time_step])\n\n# шум процесса\nQ = np.outer(G, G) * sigma_a**2\n\n# матрица ковариации ошибки\nposition_uncertainty = 1.\nvelocity_uncertainty = 1. \nP = np.array([[position_uncertainty, 0.],[0., velocity_uncertainty]])\n\n#модель наблюдений, измеряем только положение\nH = np.array([1., 0.]) \n\n# дисперсия шума измерений\nR = np.array([sigma_measurement**2]) ",
"_____no_output_____"
],
[
"episode_len = 1000\ndata = np.zeros((6, episode_len))\n\nfor i in range(episode_len):\n world.step()\n measurement = world.measure()\n\n if i == 0: # первое измерение\n x_est = np.array([measurement, 0.]) \n elif i == 1: # второе измерение\n x_est = np.array([measurement, ( measurement - data[4, i-1] ) / world.time_step])\n else: # если i >=2 начинаем применять модель\n ##################################################################\n # прогноз\n vel_est = data[5, i-1]\n pos_est = data[4, i-1] + vel_est * world.time_step\n x_pred = np.array([pos_est, vel_est])\n\n # прогноз матрицы ковариации ошибки\n P_pred = A.dot(P).dot(A.T) + Q\n \n ################################################################## \n # Коррекция\n K = P_pred.dot(H.T) / (H.dot(P_pred).dot(H.T) + R)\n P = (np.eye(2) - K.dot(H)).dot(P_pred)\n \n x_est = x_pred + K.dot(measurement - H.dot(x_pred))\n \n data[:, i] = np.array([world.time, world.position, world.velocity, measurement, x_est[0], x_est[1]])\n \n\n# plot\nfig1 = plt.figure(figsize=(16,8))\nax1 = fig1.add_subplot(1,2,1)\nax2 = fig1.add_subplot(1,2,2)\n\n# r\nax1.set_title(\"position\")\nax1.plot(data[0, :], data[3, :], 'k', label = 'pos_mes')\nax1.plot(data[0, :], data[1, :], 'r', label = 'pos_world')\n#ax1.plot(data[0, :], data[4, :]-data[1, :], 'g', label = 'pos_est')\n\nax1.set_ylabel(r'r')\nax1.set_xlabel(r't, [s]')\nax1.grid(True)\nax1.legend()\n\n# v\nax2.set_title(\"velocity\")\nax2.plot(data[0, :], data[2, :], 'r', label = 'v')\n#ax2.plot(data[0, :], data[5, :], 'g', label = 'v_est')\n\nax2.set_ylabel(r'v')\nax2.set_xlabel(r't, [s]')\nax2.grid(True)\nax2.legend()\n\nfig2 = plt.figure(figsize=(16,8))\nax3 = fig2.add_subplot(1,2,1)\nax4 = fig2.add_subplot(1,2,2)\n\n# r\nax3.set_title(\"position\")\nax3.plot(data[0, :], data[1, :], 'r', label = 'pos_world')\nax3.plot(data[0, :], data[4, :], 'g', label = 'pos_est')\n\nax3.set_ylabel(r'r')\nax3.set_xlabel(r't, [s]')\nax3.grid(True)\nax3.legend()\n\n# v\nax4.set_title(\"velocity\")\nax4.plot(data[0, :], data[2, :], 'r', label = 'v')\nax4.plot(data[0, :], data[5, :], 'g', label = 'v_est')\n\nax4.set_ylabel(r'v')\nax4.set_xlabel(r't, [s]')\nax4.grid(True)\nax4.legend()",
"_____no_output_____"
]
],
[
[
"# Модель измерений\nРассмотрим движение системы\n\\begin{equation}\n\\dot{x} = f(x).\n\\end{equation}\n\nВектор измерений $z$ зависит от состояния системы, а также содержит случайную компоненту\n\\begin{equation}\nz(x) = h(x) + \\xi.\n\\end{equation}\nФункция $h(x)$ связывает состояние системы с измерением датчика.\n\nНапример,\nесли датчик GNNS-приемника в одномерной задаче движения тележки по рельсам\nсмещен от центра тележки $x$ на расстояние $r$,\nможно записать\n\\begin{equation}\nh(x) = x + r.\n\\end{equation}",
"_____no_output_____"
],
[
"# Расширенный фильтр Калмана (Extended Kalman Filter)\n\nРасширенный фильтр Калмана подразумевает, как правило, нелиинейную модель системы (процесса):\n\n\\begin{equation}\n\\dot{x} = f(x) + w(t).\n\\end{equation}\n\nШум $w$ имеет нормальное распределение, нулевое математическое ожидание и матрицу ковариации $Q$.\n\nМодель наблюдений также может описываться нелинейным уравнением\n\\begin{equation}\ny = h(x) + v(t),\n\\end{equation}\nгде $v$ имеет нормальное распределение, нулевое математическое ожидание и матрицу ковариации $R$. Однако, как правило, считается, что измерения обрабатываются фильтром периодически с частотой такта управления, поэтому модель записывают в видее соотношенийми между вектором состояния на момент получения измерений $x_k = x(t_k)$ и набором измерений $y_k = y(t_k)$:\n\\begin{equation}\ny_k = h(x_k) + v_k.\n\\end{equation}\n\nАлгоритм снова выполняется в два этапа - прогноз и коррекция.\n\n## Прогноз\n\nПрогноз (экстраполяция) вектора состояния с помощью нелинейной модели процесса:\n$$\\overline{x}_k = \\hat{x}_{k-1} + \\int_{t_{k-1}}^{t_k} f(x)dt,$$\n\nПрогноз матрицы ковариации ошибок:\n\\begin{equation}\n\\overline{P}_k = \\Phi_k \\cdot \\hat{P}_{k-1} \\cdot \\Phi_k^T + Q,\n\\end{equation}\nгде\n\\begin{equation}\n\\Phi_k = I + F\\cdot \\Delta t = I +\\frac{\\partial f(x)}{\\partial x}\\cdot(t_k -t_{k-1})\n\\end{equation}\n\n\n## Коррекция\n\nЗдесь отличие от линейного алгоритма в необходимости линеаризовать модель наблюдений, чтобы получить матрицу $H$:\n\\begin{equation}\nH_k = \\frac{\\partial h(x}{\\partial x}.\n\\end{equation}\n\nВычисление коэффициента усиления Калмана:\n$$K_k = \\overline{P}_k \\cdot H_{k}^T \\cdot \\left(H_k\\cdot \\overline{P}_k\\cdot H_k^T + R_k\\right)^{-1}$$\n\nОценка матрицы ковариации ошибки:\n$$\\hat{P}_k = \\left(I - K_k\\cdot H_k\\right)\\cdot \\overline{P}_k$$\n\nОценка вектора состояния:\n$$\\hat{x}_k = \\overline{x}_k + K_k\\cdot\\left(y_k - h(\\overline{x}_k)\\right)$$\n",
"_____no_output_____"
],
[
"# Пример: Вращение твёрдого тела с неподвижным центром масс\n\nОриентация твердого тела описывается кватернионом $q$, задающим положение связанной с телом системы координат относительно некоторой неподвижной системы координат. Говорят, что кватернион $q^{\\mathrm{BI}}$ задает ориентацию некоторого базиса (B) относительно некоторого другого базиса (I), если представление любого вектора $\\mathbf{v}$ в этих системах координат определяется соотношением:\n$$\\mathbf{v}^{\\mathrm{B}} = q^{\\mathrm{BI}}\\circ\\mathbf{v}^{\\mathrm{I}}\\circ \\tilde{q}^{\\mathrm{BI}}$$\n\nКинематические уравнения твердого тела записываются как:\n\n\\begin{equation}\\label{eq:quat}\\tag{1}\n\\dot{q} = \\frac{1}{2}q\\circ \\boldsymbol{\\omega},\n\\end{equation}\n\nгде $q$ - кватернион ориентации тела, $\\boldsymbol{\\omega}$ - угловая скорость тела в рпоекциях на связанные с телом оси.\n\nМодель движения твёрдого тела с неодвижной точкой дополняется динамическими уравнениями Эйлера\n\n\\begin{equation}\\label{eq:euler}\\tag{2}\n\\mathbf{J}\\cdot \\dot{\\boldsymbol{\\omega}} + \\boldsymbol{\\omega} \\times \\mathbf{J}\\cdot \\boldsymbol{\\omega} = \\mathbf{T},\n\\end{equation}\n\nгде $\\mathbf{J}$ - тензор инерции тела, $\\mathbf{T}$ - главный момнет сил, действующих на тело.\n\nТаким образом, вектор состояния состояит из 4х компонент кватерниона ориентации и 3х компонент вектора угловой скорости. А модель процесса состоит из уравнений \\eqref{eq:quat} и \\eqref{eq:euler}.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a1e8bd4a1f4628e5a82dc0c3e779f31ab71be4c
| 110,001 |
ipynb
|
Jupyter Notebook
|
notebooks/audio-features.ipynb
|
idilsulo/change-the-way-you-listen
|
51803f2d30c34c20e3a680199776aa5feb1b3ac3
|
[
"MIT"
] | 2 |
2020-10-19T06:35:49.000Z
|
2021-11-14T16:28:15.000Z
|
notebooks/audio-features.ipynb
|
idilsulo/change-the-way-you-listen
|
51803f2d30c34c20e3a680199776aa5feb1b3ac3
|
[
"MIT"
] | null | null | null |
notebooks/audio-features.ipynb
|
idilsulo/change-the-way-you-listen
|
51803f2d30c34c20e3a680199776aa5feb1b3ac3
|
[
"MIT"
] | 1 |
2020-10-22T13:23:46.000Z
|
2020-10-22T13:23:46.000Z
| 42.969141 | 1,258 | 0.468523 |
[
[
[
"import spotipy\nfrom spotipy.oauth2 import SpotifyOAuth\nimport pandas as pd\nimport time",
"_____no_output_____"
],
[
"scope = 'user-top-read user-library-read'\nsp = spotipy.Spotify(client_credentials_manager=SpotifyOAuth(scope=scope))",
"_____no_output_____"
],
[
"sp.user_playlists(sp.current_user()['id'])",
"_____no_output_____"
],
[
"results = sp.current_user_top_artists(time_range='short_term', limit=50)",
"_____no_output_____"
],
[
"all_genres = [genre for r in results['items'] for genre in r['genres'] ]",
"_____no_output_____"
],
[
"all_genres",
"_____no_output_____"
],
[
"from collections import Counter\ntop_genres = Counter(all_genres)\ntop_genres = {key : value for key, value in sorted(top_genres.items(), key=lambda k: k[1], reverse=True)}\ntop_genres",
"_____no_output_____"
],
[
"results",
"_____no_output_____"
],
[
"top_genres_and_artists = [[r['name'], r['id'], r['genres']] if len(r['genres']) > 0 else [r['name'], r['id'], ['unknown genre']] for r in results['items']]\ntop_genres_and_artists",
"_____no_output_____"
],
[
"artists = []\nfor artist_name, artist_id, genres in top_genres_and_artists:\n if 'indie soul' in genres:\n artists.append([artist_name, artist_id])",
"_____no_output_____"
],
[
"artists",
"_____no_output_____"
],
[
"def get_top_genres():\n results = sp.current_user_top_artists(time_range='short_term', limit=50)\n all_genres = [genre for r in results['items'] for genre in r['genres']]\n top_genres = Counter(all_genres)\n top_genres = {key : value for key, value in sorted(top_genres.items(), key=lambda k: k[1], reverse=True)}\n return top_genres",
"_____no_output_____"
],
[
"def get_top_artists(top_genres):\n # TO-DO: Let user select from top genres\n top_genre = list(top_genres.keys())[0] # Get the only one top genre for now\n print(\"Selected genre: %s\" % (top_genre))\n artists = []\n for artist_name, artist_id, genres in top_genres_and_artists:\n if top_genre in genres:\n artists.append([artist_name, artist_id])\n print(\"Selected artists belonging to this genre: \", artists)\n return artists",
"_____no_output_____"
],
[
"def get_discography(artist_id, min_track_duration=30000):\n tracks = []\n album_ids = [album['id'] for album in sp.artist_albums(artist_id)['items'] if album['album_type'] != 'compilation' ]\n for album_id in album_ids:\n # track_ids = [track['id'] for track in sp.album_tracks(album_id)['items'] if track['duration_ms'] > min_track_duration]\n for track in sp.album_tracks(album_id)['items']:\n # There are unexpected results while retrieving the discography of an artist\n # Only get the albums that the artist owns\n flag = False\n for artist in track['artists']:\n if artist['id'] == artist_id:\n flag = True\n break\n if flag and track['duration_ms'] > min_track_duration:\n tracks.append(track['id'])\n if len(tracks) == 100:\n break\n return tracks",
"_____no_output_____"
],
[
"def get_all_features(artists):\n t = time.time()\n df = pd.DataFrame()\n for artist_name, artist_id in artists:\n try:\n tracks = get_discography(artist_id)\n except:\n time.sleep(2)\n tracks = get_discography(artist_id)\n \n while(len(tracks) > 0):\n if len(df) == 0:\n df = pd.DataFrame(sp.audio_features(tracks=tracks[:100]))\n df['artist_name'] = artist_name\n df['artist_id'] = artist_id\n # Could not add track names in here\n # API does not return audio features of all tracks\n # There might be a restriction on different markets\n # df['track_name'] = track_names[:100]\n else:\n df_feats = pd.DataFrame(sp.audio_features(tracks=tracks[:100]))\n df_feats['artist_name'] = artist_name\n df_feats['artist_id'] = artist_id\n # df_feats['track_name'] = track_names[:100]\n df = df.append(df_feats)\n tracks = tracks[100:]\n print(time.time() - t) \n return df",
"_____no_output_____"
],
[
"top_genres = get_top_genres()\nartists = get_top_artists(top_genres)\ndf = get_all_features(artists)",
"Selected genre: indie soul\nSelected artists belonging to this genre: [[\"L'Impératrice\", '4PwlsrN0t5mLN0C827cbEU'], ['Romare', '6d1HqiWNEKV9zFqQM9WeYo'], ['Four Tet', '7Eu1txygG6nJttLHbZdQOh'], ['Elder Island', '3EnbnmqrrvApHJs6FMvYik'], ['HNNY', '6Yae9Ia1nq6JLLojBzwN1r'], ['Maribou State', '7zrkALJ9ayRjzysp4QYoEg'], ['Weval', '12tZvy2xFpWSkuJ3FsfisZ'], ['Pional', '49mZfy9v5oNXAxp8FadWwI'], ['Kazy Lambist', '41Ue54Vb6iWx2dcdRCM6oH']]\n13.64065408706665\n"
],
[
"df.tempo.median()",
"_____no_output_____"
],
[
"df.tempo.mean()",
"_____no_output_____"
],
[
"(df.tempo.min() + df.tempo.max()) / 2",
"_____no_output_____"
],
[
"df.sample(800)",
"_____no_output_____"
],
[
"def return_playlist(**kwargs):\n \"\"\"\n danceability='default', energy='default', speechiness='default', \n acousticness='default', instrumentalness='default', liveness='default', \n valence='default', tempo='default'\n \"\"\"\n \n # Select tracks based on the provided ranges\n top_genres = get_top_genres()\n artists = get_top_artists(top_genres)\n df = get_all_features(artists)\n print(len(df))\n # Sort dataframe based on provided features\n # Randomly return tracks based on sorted \n # TO-DO: Select tracks based on user market\n for feature, value in kwargs.items():\n avg = (df[feature].min() + df[feature].max()) / 2\n if value == 'high':\n # df.sort_values(feature, ascending=False, inplace=True)\n df = df[df[feature] > avg]\n elif value == 'low':\n # df.sort_values(feature, ascending=True, inplace=True)\n df = df[df[feature] < avg]\n \n print(len(df))\n \n # df = df.head(len(df)//3)\n \n try:\n return df.sample(25)\n except:\n return df",
"_____no_output_____"
],
[
"playlist = return_playlist(danceability='high', instrumentalness='low', valence=\"low\", tempo=\"low\", energy=\"low\")",
"Selected genre: indie soul\nSelected artists belonging to this genre: [[\"L'Impératrice\", '4PwlsrN0t5mLN0C827cbEU'], ['Romare', '6d1HqiWNEKV9zFqQM9WeYo'], ['Four Tet', '7Eu1txygG6nJttLHbZdQOh'], ['Elder Island', '3EnbnmqrrvApHJs6FMvYik'], ['HNNY', '6Yae9Ia1nq6JLLojBzwN1r'], ['Maribou State', '7zrkALJ9ayRjzysp4QYoEg'], ['Weval', '12tZvy2xFpWSkuJ3FsfisZ'], ['Pional', '49mZfy9v5oNXAxp8FadWwI'], ['Kazy Lambist', '41Ue54Vb6iWx2dcdRCM6oH']]\n11.631968975067139\n701\n570\n204\n113\n86\n50\n"
],
[
"playlist",
"_____no_output_____"
],
[
"def get_playlist_tracks(playlist):\n track_uris = playlist['uri'].to_list()\n artist_names = playlist['artist_name'].to_list()\n track_names = [track['name'] for track in sp.tracks(track_uris)['tracks']]\n tracks = [\"{} by {}\".format(track, artist) for track, artist in zip(track_names, artist_names)]\n return tracks, track_uris",
"_____no_output_____"
],
[
"_, ids = get_playlist_tracks(playlist)",
"_____no_output_____"
],
[
"ids",
"_____no_output_____"
],
[
"string = \"\"\nfor i in ids:\n string += i\n string += \" \"\nstring",
"_____no_output_____"
],
[
"string[:-1].split(\" \")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1e92fea7b3c5153f2a878053b102d806ec5733
| 426,972 |
ipynb
|
Jupyter Notebook
|
code/graphics.ipynb
|
jeanHeibig/diffusionFeymanKac
|
d2a74fc6868163cf902a8c01c0df41c0e7e34acb
|
[
"MIT"
] | null | null | null |
code/graphics.ipynb
|
jeanHeibig/diffusionFeymanKac
|
d2a74fc6868163cf902a8c01c0df41c0e7e34acb
|
[
"MIT"
] | null | null | null |
code/graphics.ipynb
|
jeanHeibig/diffusionFeymanKac
|
d2a74fc6868163cf902a8c01c0df41c0e7e34acb
|
[
"MIT"
] | null | null | null | 1,163.411444 | 140,446 | 0.959098 |
[
[
[
"# Graphics",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nfrom PIL import Image",
"_____no_output_____"
]
],
[
[
"## Heat Kernel",
"_____no_output_____"
]
],
[
[
"alpha = 1 / 2\nd = 1\nK = lambda t, x, y: (4 * np.pi * alpha * t) ** (-d / 2) * np.exp(-(np.abs(x - y) ** 2) / (4 * alpha * t))\nt = 1\nx = 0\ny = np.linspace(-5, 5, 100)\nplt.figure(figsize=(10, 2.5))\n#plt.title('Noyau de la chaleur')\nplt.plot(y, K(t, x, y))\nplt.xlabel('$y$')\nplt.ylabel('$K(1, 0, y)$')\nplt.tight_layout()\nplt.savefig('heatKernel.png', transparent=True)",
"_____no_output_____"
]
],
[
[
"## Cover image",
"_____no_output_____"
]
],
[
[
"piCreature = plt.imread('piCreature.png')\nfire = plt.imread('fire.jpg') # http://designbeep.com/2012/09/04/32-free-high-resolution-fire-textures-for-designers/\nice = plt.imread('ice.jpg') # http://www.antarcticglaciers.org/antarctica-2/photographs/ice-textures-and-patterns/\n\npx, py, _ = piCreature.shape\nfx, fy, _ = fire.shape\nix, iy, _ = ice.shape\n\nfxx = np.arange(0, fx - 1, fx // px)\nfyy = np.arange(0, fy - 1, fy // py)\nfireResize = fire[fxx, :, :]\nfireResize = fireResize[:, fyy, :]\nixx = np.arange(0, ix - 1, ix // px)\niyy = np.arange(0, iy - 1, iy // py)\niceResize = ice[ixx, :, :]\niceResize = iceResize[:, iyy, :]\nfireCut = fireResize[:px, :py, :]\niceCut = ice[:px, :py, :]",
"_____no_output_____"
],
[
"plt.imshow(piCreature)",
"_____no_output_____"
],
[
"plt.imshow(fireCut)",
"_____no_output_____"
],
[
"plt.imshow(iceCut)",
"_____no_output_____"
],
[
"newPi = piCreature.copy()[..., :3]\nnewPi2 = piCreature.copy()[..., :3]\nnewPi[piCreature[..., 3] !=0] = (piCreature[..., :3] * fireCut)[piCreature[..., 3] !=0] / 255\nnewPi2[piCreature[..., 3] ==0] = (piCreature[..., :3] * iceCut)[piCreature[..., 3] ==0] / 255\n# end = np.maximum(np.minimum(newPi + newPi2 - 1, 1), 0)\nend = (newPi + newPi2) / 2\nlayer = np.ones((px, py))",
"_____no_output_____"
],
[
"# https://towardsdatascience.com/image-processing-with-python-5b35320a4f3c\n\n# Gaussian formula\ndef gaus(std, mean, x):\n return (1/(std))*np.e**(-(x-mean)**2/(2*std**2))\n \n# function used to normalize values to between 0-1\ndef norm(vals):\n return [(v-min(vals))/(max(vals)-min(vals)) for v in vals]\n \n# function to build x/y Gaussian function from width (x) and height (y)\ndef build_gaus(width, height):\n # get a uniform range of floats in the range 0-1 for the x/y axes\n x_vals = np.arange(0, width, 1)\n y_vals = np.arange(0, height, 1)\n \n # calculate standard deviation/mean - meaningless in this case\n # but required to produce Gaussian\n x_std, y_std = np.std(x_vals), np.std(y_vals)\n x_m, y_m = np.mean(x_vals), np.mean(y_vals)\n\n # create Gaussians for both x/y axes\n x_gaussian = [gaus(x_std, x_m, x) for x in x_vals]\n y_gaussian = [gaus(y_std, y_m, y) for y in y_vals]\n\n # normalize the Gaussian to 0-1\n x_gaussian = np.array(norm(x_gaussian))\n y_gaussian = np.array(norm(y_gaussian))\n \n return x_gaussian, y_gaussian\n\n# first we build our x/y Gaussian functions\nx_gaus, y_gaus = build_gaus(layer.shape[0], layer.shape[1])\n\nfactor = 0.5\n# apply the Gaussian functions to our image array\nlayer = layer * (x_gaus**factor)[:, None]\nlayer = layer * (y_gaus**factor)[None, :] # factor changes vignette strength\n#layer = layer.T # transpose back to original shape",
"_____no_output_____"
],
[
"layer[piCreature[..., 0] < 0.5] = 1\nlayer[layer < 0.2] = 0.2\nlayer = (layer - 0.2) / 0.8\nplt.imshow(layer)",
"_____no_output_____"
],
[
"final = np.concatenate((end, layer[:, :, None]), axis=2)\nplt.imshow(final)\nim = Image.fromarray((final * 255).astype(np.uint8))\nim.save(\"cover.png\")",
"_____no_output_____"
],
[
"orange = np.array([179, 3, 38])\nblue = np.array([58, 76, 192])\npiCreature2 = piCreature.copy()\npiCreature2[piCreature2[..., 3] != 0] = 1\nnewPi3 = piCreature2.copy()[..., :3]\nnewPi4 = piCreature2.copy()[..., :3]\nnewPi3[piCreature2[..., 3] !=0] = (piCreature2[..., :3] * orange)[piCreature2[..., 3] !=0] / 255\nnewPi4[piCreature2[..., 3] ==0] = (piCreature2[..., :3] * blue)[piCreature2[..., 3] ==0] / 255\nend2 = np.maximum(np.minimum(newPi3 + newPi4 - 1, 1), 0)",
"_____no_output_____"
],
[
"im = Image.fromarray((end2 * 255).astype(np.uint8))\nim.save(\"piHeat.png\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1e9d86acebf9901f0277adaf48b4c528165973
| 40,797 |
ipynb
|
Jupyter Notebook
|
Satellite/Lat_Lon_Pixel.ipynb
|
sanchitnis/BTech-Project
|
f1039aacd3882234b8f726456dbc782c96083ff4
|
[
"MIT"
] | 23 |
2019-10-15T17:06:38.000Z
|
2022-01-25T06:50:16.000Z
|
Satellite/Lat_Lon_Pixel.ipynb
|
sanchitnis/BTech-Project
|
f1039aacd3882234b8f726456dbc782c96083ff4
|
[
"MIT"
] | 2 |
2020-01-21T12:32:35.000Z
|
2020-03-03T07:04:46.000Z
|
Satellite/Lat_Lon_Pixel.ipynb
|
sanchitnis/BTech-Project
|
f1039aacd3882234b8f726456dbc782c96083ff4
|
[
"MIT"
] | 21 |
2019-12-08T12:55:58.000Z
|
2022-03-10T17:33:01.000Z
| 38.891325 | 281 | 0.510332 |
[
[
[
"# Latitude, Longitude for any pixel in a GeoTiff File\nHow to generate the latitude and longitude for a pixel at any given position in a GeoTiff file.",
"_____no_output_____"
]
],
[
[
"from osgeo import ogr, osr, gdal",
"_____no_output_____"
],
[
"# opening the geotiff file\nds = gdal.Open('G:\\BTP\\Satellite\\Data\\Test2\\LE07_L1GT_147040_20050506_20170116_01_T2\\LE07_L1GT_147040_20050506_20170116_01_T2_B1.TIF')",
"_____no_output_____"
],
[
"col, row, band = ds.RasterXSize, ds.RasterYSize, ds.RasterCount\nprint(col, row, band)",
"(7801, 7071, 1)\n"
],
[
"xoff, a, b, yoff, d, e = ds.GetGeoTransform()\nprint(xoff, a, b, yoff, d, e)\n\n# details about the params: GDAL affine transform parameters\n# xoff,yoff = left corner \n# a,e = weight,height of pixels\n# b,d = rotation of the image (zero if image is north up)",
"(514485.0, 30.0, 0.0, 3300915.0, 0.0, -30.0)\n"
],
[
"def pixel2coord(x, y):\n \"\"\"Returns global coordinates from coordinates x,y of the pixel\"\"\"\n xp = a * x + b * y + xoff\n yp = d * x + e * y + yoff\n return(xp, yp)",
"_____no_output_____"
],
[
"x,y = pixel2coord(col/2,row/2)\nprint (x, y)",
"(631485.0, 3194865.0)\n"
]
],
[
[
"#### These global coordinates are in a *projected coordinated system*, which is a representation of the spheroidal earth's surface, but flattened and distorted onto a plane.\n#### To convert these into latitude and longitude, we need to convert these coordinates into *geographic coordinate system*.",
"_____no_output_____"
]
],
[
[
"# get the existing coordinate system\nold_cs= osr.SpatialReference()\nold_cs.ImportFromWkt(ds.GetProjectionRef())\n\n# create the new coordinate system\nwgs84_wkt = \"\"\"\nGEOGCS[\"WGS 84\",\n DATUM[\"WGS_1984\",\n SPHEROID[\"WGS 84\",6378137,298.257223563,\n AUTHORITY[\"EPSG\",\"7030\"]],\n AUTHORITY[\"EPSG\",\"6326\"]],\n PRIMEM[\"Greenwich\",0,\n AUTHORITY[\"EPSG\",\"8901\"]],\n UNIT[\"degree\",0.01745329251994328,\n AUTHORITY[\"EPSG\",\"9122\"]],\n AUTHORITY[\"EPSG\",\"4326\"]]\"\"\"\nnew_cs = osr.SpatialReference()\nnew_cs.ImportFromWkt(wgs84_wkt)\n\n# create a transform object to convert between coordinate systems\ntransform = osr.CoordinateTransformation(old_cs,new_cs) ",
"_____no_output_____"
],
[
"# converting into geographic coordinate system\nlonx, latx, z = transform.TransformPoint(x,y)",
"_____no_output_____"
],
[
"print (latx, lonx, z)",
"(28.874828865052745, 76.34826151423796, 0.0)\n"
],
[
"# rb = ds.GetRasterBand(1)\npx,py = col/2,row/2 # the pixel location\npix = ds.ReadAsArray(px,py,1,1) \nprint pix[0][0] # pixel value",
"11647\n"
]
],
[
[
"# Reverse Geocoding\nConverting a lat/long to a physical address or location. ",
"_____no_output_____"
],
[
"We want the name of the DISTRICT.",
"_____no_output_____"
],
[
"## --------------------------------------------------------------------------------\n### API 1: Not so accurate\n## --------------------------------------------------------------------------------",
"_____no_output_____"
]
],
[
[
"coordinates = (latx,lonx)\nresults = rg.search(coordinates)\nprint results\nprint type(results)\nprint type(results[0])\nresults[0]",
"Loading formatted geocoded file...\n[{'name': 'Jaisalmer', 'cc': 'IN', 'lon': '70.90387', 'admin1': 'Rajasthan', 'admin2': 'Jaisalmer', 'lat': '26.91763'}]\n<type 'list'>\n<type 'dict'>\n"
],
[
"k = 4 # If we want k*k pixels in total from the image\n\n\nfor i in range(0,col,col/k):\n for j in range(0,row,row/k):\n \n # fetching the lat and lon coordinates \n x,y = pixel2coord(i,j)\n lonx, latx, z = transform.TransformPoint(x,y)\n \n # fetching the name of district\n coordinates = (latx,lonx)\n results = rg.search(coordinates)\n \n # The pixel value for that location\n px,py = i,j \n pix = ds.ReadAsArray(px,py,1,1) \n pix = pix[0][0]\n \n # printing\n s = \"The pixel value for the location Lat: {0:5.1f}, Long: {1:5.1f} ({2:15}) is {3:7}\".format(latx,lonx,results[0][\"name\"],pix)\n print (s)",
"The pixel value for the location Lat: 28.5, Long: 70.2 (Sadiqabad ) is 0\nThe pixel value for the location Lat: 28.0, Long: 70.2 (Sadiqabad ) is 0\nThe pixel value for the location Lat: 27.4, Long: 70.2 (Khairpur ) is 0\nThe pixel value for the location Lat: 26.9, Long: 70.2 (Jaisalmer ) is 0\nThe pixel value for the location Lat: 26.4, Long: 70.2 (Jaisalmer ) is 0\nThe pixel value for the location Lat: 28.5, Long: 70.8 (Khanpur ) is 0\nThe pixel value for the location Lat: 28.0, Long: 70.8 (Kot Samaba ) is 11992\nThe pixel value for the location Lat: 27.4, Long: 70.8 (Jaisalmer ) is 11661\nThe pixel value for the location Lat: 26.9, Long: 70.8 (Jaisalmer ) is 11701\nThe pixel value for the location Lat: 26.4, Long: 70.8 (Jaisalmer ) is 0\nThe pixel value for the location Lat: 28.5, Long: 71.4 (Ahmadpur East ) is 0\nThe pixel value for the location Lat: 27.9, Long: 71.4 (Khanpur ) is 11247\nThe pixel value for the location Lat: 27.4, Long: 71.4 (Jaisalmer ) is 11653\nThe pixel value for the location Lat: 26.9, Long: 71.3 (Jaisalmer ) is 11307\nThe pixel value for the location Lat: 26.4, Long: 71.3 (Barmer ) is 0\nThe pixel value for the location Lat: 28.5, Long: 72.0 (Yazman ) is 0\nThe pixel value for the location Lat: 27.9, Long: 71.9 (Phalodi ) is 11547\nThe pixel value for the location Lat: 27.4, Long: 71.9 (Pokaran ) is 11637\nThe pixel value for the location Lat: 26.9, Long: 71.9 (Pokaran ) is 11881\nThe pixel value for the location Lat: 26.4, Long: 71.9 (Pokaran ) is 0\nThe pixel value for the location Lat: 28.4, Long: 72.5 (Fort Abbas ) is 0\nThe pixel value for the location Lat: 27.9, Long: 72.5 (Bikaner ) is 0\nThe pixel value for the location Lat: 27.4, Long: 72.5 (Phalodi ) is 0\nThe pixel value for the location Lat: 26.9, Long: 72.5 (Phalodi ) is 0\nThe pixel value for the location Lat: 26.4, Long: 72.5 (Jodhpur ) is 0\n"
]
],
[
[
"## --------------------------------------------------------------------------------\n### API 2\n## --------------------------------------------------------------------------------",
"_____no_output_____"
]
],
[
[
"g = geocoder.google([latx,lonx], method='reverse')\nprint type(g)\nprint g\nprint g.city\nprint g.state\nprint g.state_long\nprint g.country\nprint g.country_long\nprint g.address",
"<class 'geocoder.google_reverse.GoogleReverse'>\n<[OK] Google - Reverse #6 results>\nAmrit Nagar\nRJ\nRajasthan\nIN\nIndia\nUnnamed Road, Amrit Nagar, Rajasthan 342023, India\n"
]
],
[
[
"###### The above wrapper for Google API is not good enough for us. Its not providing us with the district.",
"_____no_output_____"
],
[
"##### Lets try another python library available for the Google Geo API ",
"_____no_output_____"
]
],
[
[
"results = Geocoder.reverse_geocode(latx, lonx)\nprint results.city\nprint results.country\nprint results.street_address\nprint results.administrative_area_level_1\nprint results.administrative_area_level_2 ## THIS GIVES THE DISTRICT !! <----------------\nprint results.administrative_area_level_3",
"Amrit Nagar\nIndia\nNone\nRajasthan\nBarmer\nNone\n"
]
],
[
[
"##### This is what we need, we are getting the district name for given lat,lon coordinates",
"_____no_output_____"
]
],
[
[
"## Converting the unicode string to ascii string\nv = results.country\nprint type(v)\nv = v.encode(\"ascii\")\nprint type(v)\nprint v",
"<type 'unicode'>\n<type 'str'>\nIndia\n"
]
],
[
[
"##### Now lets check for an image from Rajasthan",
"_____no_output_____"
]
],
[
[
"k = 4 # If we want k*k pixels in total from the image\n\n\nfor i in range(0,col,col/k):\n for j in range(0,row,row/k):\n \n # fetching the lat and lon coordinates \n x,y = pixel2coord(i,j)\n lonx, latx, z = transform.TransformPoint(x,y)\n \n # fetching the name of district\n results = Geocoder.reverse_geocode(latx, lonx)\n \n # The pixel value for that location\n px,py = i,j \n pix = ds.ReadAsArray(px,py,1,1) \n pix = pix[0][0]\n \n # printing\n if results.country.encode('ascii') == 'India':\n s = \"Lat: {0:5.1f}, Long: {1:5.1f}, District: {2:12}, Pixel Val: {3:7}\".format(latx,lonx,results.administrative_area_level_2,pix)\n print (s)",
"Lat: 27.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.9, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.4, Long: 70.8, District: Jaisalmer , Pixel Val: 11661\nLat: 26.9, Long: 70.8, District: Jaisalmer , Pixel Val: 11701\nLat: 26.4, Long: 70.8, District: Jaisalmer , Pixel Val: 0\nLat: 27.4, Long: 71.4, District: Jaisalmer , Pixel Val: 11653\nLat: 26.9, Long: 71.3, District: Jaisalmer , Pixel Val: 11307\nLat: 26.4, Long: 71.3, District: Barmer , Pixel Val: 0\nLat: 27.9, Long: 71.9, District: Jaisalmer , Pixel Val: 11547\nLat: 27.4, Long: 71.9, District: Jodhpur , Pixel Val: 11637\nLat: 26.9, Long: 71.9, District: Jaisalmer , Pixel Val: 11881\nLat: 26.4, Long: 71.9, District: Barmer , Pixel Val: 0\nLat: 28.4, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.9, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.4, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.9, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.4, Long: 72.5, District: Barmer , Pixel Val: 0\n"
]
],
[
[
"# Bing Maps REST API",
"_____no_output_____"
]
],
[
[
"import requests # To make the REST API Call\nimport json",
"_____no_output_____"
],
[
"(latx,lonx)",
"_____no_output_____"
],
[
"url = \"http://dev.virtualearth.net/REST/v1/Locations/\"\npoint = str(latx)+\",\"+str(lonx)\nkey = \"Aktjg1X8bLQ_KhLQbVueYMhXDEMo7OaTweIkBvFojInYE4tVxoTp1bGKWbtU_OPJ\"\nresponse = requests.get(url+point+\"?key=\"+key)\nprint(response.status_code)",
"_____no_output_____"
],
[
"data = response.json()\nprint(type(data))",
"<type 'dict'>\n"
],
[
"data",
"_____no_output_____"
],
[
"s = data[\"resourceSets\"][0][\"resources\"][0][\"address\"][\"adminDistrict2\"]\ns = s.encode(\"ascii\")\ns",
"_____no_output_____"
],
[
"url = \"http://dev.virtualearth.net/REST/v1/Locations/\"\nkey = \"Aktjg1X8bLQ_KhLQbVueYMhXDEMo7OaTweIkBvFojInYE4tVxoTp1bGKWbtU_OPJ\"",
"_____no_output_____"
]
],
[
[
"## Bing API Test\n#### For 100 pixel locations",
"_____no_output_____"
]
],
[
[
"k = 10 # If we want k*k pixels in total from the image\n\n\nfor i in range(0,col,col/k):\n for j in range(0,row,row/k):\n \n ############### fetching the lat and lon coordinates #######################################\n x,y = pixel2coord(i,j)\n lonx, latx, z = transform.TransformPoint(x,y)\n \n ############### fetching the name of district ##############################################\n point = str(latx)+\",\"+str(lonx)\n response = requests.get(url+point+\"?key=\"+key)\n data = response.json()\n s = data[\"resourceSets\"][0][\"resources\"][0][\"address\"]\n if s[\"countryRegion\"].encode(\"ascii\") != \"India\":\n print (\"Outside Indian Territory\")\n continue\n district = s[\"adminDistrict2\"].encode(\"ascii\")\n \n ############### The pixel value for that location ##########################################\n px,py = i,j \n pix = ds.ReadAsArray(px,py,1,1) \n pix = pix[0][0]\n \n # printing\n s = \"Lat: {0:5.1f}, Long: {1:5.1f}, District: {2:12}, Pixel Val: {3:7}\".format(latx,lonx,district,pix)\n print (s)",
"Outside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.7, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.2, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.0, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.8, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.6, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nLat: 27.6, Long: 70.4, District: Jaisalmer , Pixel Val: 11591\nLat: 27.4, Long: 70.4, District: Jaisalmer , Pixel Val: 11860\nLat: 27.2, Long: 70.4, District: Jaisalmer , Pixel Val: 12666\nLat: 27.0, Long: 70.4, District: Jaisalmer , Pixel Val: 12044\nLat: 26.8, Long: 70.4, District: Jaisalmer , Pixel Val: 12579\nLat: 26.6, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.7, District: Jaisalmer , Pixel Val: 11610\nLat: 27.6, Long: 70.7, District: Jaisalmer , Pixel Val: 11842\nLat: 27.4, Long: 70.7, District: Jaisalmer , Pixel Val: 11577\nLat: 27.2, Long: 70.7, District: Jaisalmer , Pixel Val: 12740\nLat: 27.0, Long: 70.7, District: Jaisalmer , Pixel Val: 12015\nLat: 26.8, Long: 70.7, District: Jaisalmer , Pixel Val: 11851\nLat: 26.6, Long: 70.7, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.6, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.6, Long: 70.9, District: Jaisalmer , Pixel Val: 11602\nLat: 27.4, Long: 70.9, District: Jaisalmer , Pixel Val: 12231\nLat: 27.2, Long: 70.9, District: Jaisalmer , Pixel Val: 11390\nLat: 27.0, Long: 70.9, District: Jaisalmer , Pixel Val: 11898\nLat: 26.8, Long: 70.9, District: Jaisalmer , Pixel Val: 11736\nLat: 26.6, Long: 70.9, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.9, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.6, Long: 71.1, District: Jaisalmer , Pixel Val: 12236\nLat: 27.4, Long: 71.1, District: Jaisalmer , Pixel Val: 11572\nLat: 27.2, Long: 71.1, District: Jaisalmer , Pixel Val: 12053\nLat: 27.0, Long: 71.1, District: Jaisalmer , Pixel Val: 11647\nLat: 26.8, Long: 71.1, District: Jaisalmer , Pixel Val: 11882\nLat: 26.6, Long: 71.1, District: Jaisalmer , Pixel Val: 11974\nLat: 26.4, Long: 71.1, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.4, District: Jaisalmer , Pixel Val: 11996\nLat: 27.6, Long: 71.4, District: Jaisalmer , Pixel Val: 11815\nLat: 27.4, Long: 71.4, District: Jaisalmer , Pixel Val: 11647\nLat: 27.2, Long: 71.3, District: Jaisalmer , Pixel Val: 12070\nLat: 27.0, Long: 71.3, District: Jaisalmer , Pixel Val: 11955\nLat: 26.8, Long: 71.3, District: Jaisalmer , Pixel Val: 11199\nLat: 26.6, Long: 71.3, District: Jaisalmer , Pixel Val: 11723\nLat: 26.4, Long: 71.3, District: Barmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.6, District: Jaisalmer , Pixel Val: 11977\nLat: 27.6, Long: 71.6, District: Jaisalmer , Pixel Val: 11268\nLat: 27.4, Long: 71.6, District: Jaisalmer , Pixel Val: 10623\nLat: 27.2, Long: 71.6, District: Jaisalmer , Pixel Val: 11803\nLat: 27.0, Long: 71.6, District: Jaisalmer , Pixel Val: 11594\nLat: 26.8, Long: 71.6, District: Jaisalmer , Pixel Val: 11549\nLat: 26.6, Long: 71.6, District: Jaisalmer , Pixel Val: 11265\nLat: 26.4, Long: 71.6, District: Barmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.8, District: Jaisalmer , Pixel Val: 11508\nLat: 27.6, Long: 71.8, District: Jaisalmer , Pixel Val: 11511\nLat: 27.4, Long: 71.8, District: Jaisalmer , Pixel Val: 11616\nLat: 27.2, Long: 71.8, District: Jaisalmer , Pixel Val: 11215\nLat: 27.0, Long: 71.8, District: Jaisalmer , Pixel Val: 11814\nLat: 26.8, Long: 71.8, District: Jaisalmer , Pixel Val: 11511\nLat: 26.6, Long: 71.8, District: Jaisalmer , Pixel Val: 11989\nLat: 26.4, Long: 71.8, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nLat: 28.2, Long: 72.1, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.1, District: Bikaner , Pixel Val: 11208\nLat: 27.8, Long: 72.0, District: Jaisalmer , Pixel Val: 11468\nLat: 27.6, Long: 72.0, District: Jaisalmer , Pixel Val: 9761\nLat: 27.4, Long: 72.0, District: Jodhpur , Pixel Val: 11618\nLat: 27.2, Long: 72.0, District: Jodhpur , Pixel Val: 22059\nLat: 27.0, Long: 72.0, District: Jaisalmer , Pixel Val: 11562\nLat: 26.8, Long: 72.0, District: Jaisalmer , Pixel Val: 11302\nLat: 26.6, Long: 72.0, District: Jaisalmer , Pixel Val: 11163\nLat: 26.4, Long: 72.0, District: Jaisalmer , Pixel Val: 0\nLat: 28.5, Long: 72.3, District: Bikaner , Pixel Val: 0\nLat: 28.2, Long: 72.3, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.3, District: Bikaner , Pixel Val: 10845\nLat: 27.8, Long: 72.3, District: Bikaner , Pixel Val: 10621\nLat: 27.6, Long: 72.3, District: Jaisalmer , Pixel Val: 11299\nLat: 27.4, Long: 72.3, District: Jodhpur , Pixel Val: 11236\nLat: 27.2, Long: 72.3, District: Jodhpur , Pixel Val: 11267\nLat: 27.0, Long: 72.3, District: Jodhpur , Pixel Val: 0\nLat: 26.8, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 26.6, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 26.4, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 28.4, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 28.2, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.8, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.6, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.4, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 27.2, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 27.0, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.8, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.6, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.4, Long: 72.5, District: Jodhpur , Pixel Val: 0\n"
]
],
[
[
"# We have another player in the ground! \nCan Reverse Geocode by using the python libraries `shapely` and `fiona` with a shapefile for all the district boundaries of India ",
"_____no_output_____"
]
],
[
[
"import fiona\nfrom shapely.geometry import Point, shape\n\n# Change this for Win7\nbase = \"/Users/macbook/Documents/BTP/Satellite/Data/Maps/Districts/Census_2011\"\nfc = fiona.open(base+\"/2011_Dist.shp\")",
"_____no_output_____"
],
[
"def reverse_geocode(pt):\n for feature in fc:\n if shape(feature['geometry']).contains(pt):\n return feature['properties']['DISTRICT']\n return \"NRI\"",
"_____no_output_____"
],
[
"k = 10 # If we want k*k pixels in total from the image\n\n\nfor i in range(0,col,col/k):\n for j in range(0,row,row/k):\n \n ############### fetching the lat and lon coordinates #######################################\n x,y = pixel2coord(i,j)\n lonx, latx, z = transform.TransformPoint(x,y)\n \n ############### fetching the name of district ##############################################\n point = Point(lonx,latx)\n district = reverse_geocode(point)\n if district==\"NRI\":\n print (\"Outside Indian Territory\")\n continue\n \n ############### The pixel value for that location ##########################################\n px,py = i,j \n pix = ds.ReadAsArray(px,py,1,1) \n pix = pix[0][0]\n \n # printing\n s = \"Lat: {0:5.1f}, Long: {1:5.1f}, District: {2:12}, Pixel Val: {3:7}\".format(latx,lonx,district,pix)\n print (s)",
"Outside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.7, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.2, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 27.0, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.8, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.6, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.2, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nLat: 27.6, Long: 70.4, District: Jaisalmer , Pixel Val: 11591\nLat: 27.4, Long: 70.4, District: Jaisalmer , Pixel Val: 11860\nLat: 27.2, Long: 70.4, District: Jaisalmer , Pixel Val: 12666\nLat: 27.0, Long: 70.4, District: Jaisalmer , Pixel Val: 12044\nLat: 26.8, Long: 70.4, District: Jaisalmer , Pixel Val: 12579\nLat: 26.6, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.4, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.9, Long: 70.7, District: Jaisalmer , Pixel Val: 11610\nLat: 27.6, Long: 70.7, District: Jaisalmer , Pixel Val: 11842\nLat: 27.4, Long: 70.7, District: Jaisalmer , Pixel Val: 11577\nLat: 27.2, Long: 70.7, District: Jaisalmer , Pixel Val: 12740\nLat: 27.0, Long: 70.7, District: Jaisalmer , Pixel Val: 12015\nLat: 26.8, Long: 70.7, District: Jaisalmer , Pixel Val: 11851\nLat: 26.6, Long: 70.7, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.6, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.6, Long: 70.9, District: Jaisalmer , Pixel Val: 11602\nLat: 27.4, Long: 70.9, District: Jaisalmer , Pixel Val: 12231\nLat: 27.2, Long: 70.9, District: Jaisalmer , Pixel Val: 11390\nLat: 27.0, Long: 70.9, District: Jaisalmer , Pixel Val: 11898\nLat: 26.8, Long: 70.9, District: Jaisalmer , Pixel Val: 11736\nLat: 26.6, Long: 70.9, District: Jaisalmer , Pixel Val: 0\nLat: 26.4, Long: 70.9, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.6, Long: 71.1, District: Jaisalmer , Pixel Val: 12236\nLat: 27.4, Long: 71.1, District: Jaisalmer , Pixel Val: 11572\nLat: 27.2, Long: 71.1, District: Jaisalmer , Pixel Val: 12053\nLat: 27.0, Long: 71.1, District: Jaisalmer , Pixel Val: 11647\nLat: 26.8, Long: 71.1, District: Jaisalmer , Pixel Val: 11882\nLat: 26.6, Long: 71.1, District: Jaisalmer , Pixel Val: 11974\nLat: 26.4, Long: 71.1, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.4, District: Jaisalmer , Pixel Val: 11996\nLat: 27.6, Long: 71.4, District: Jaisalmer , Pixel Val: 11815\nLat: 27.4, Long: 71.4, District: Jaisalmer , Pixel Val: 11647\nLat: 27.2, Long: 71.3, District: Jaisalmer , Pixel Val: 12070\nLat: 27.0, Long: 71.3, District: Jaisalmer , Pixel Val: 11955\nLat: 26.8, Long: 71.3, District: Jaisalmer , Pixel Val: 11199\nLat: 26.6, Long: 71.3, District: Jaisalmer , Pixel Val: 11723\nLat: 26.4, Long: 71.3, District: Barmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.6, District: Jaisalmer , Pixel Val: 11977\nLat: 27.6, Long: 71.6, District: Jaisalmer , Pixel Val: 11268\nLat: 27.4, Long: 71.6, District: Jaisalmer , Pixel Val: 10623\nLat: 27.2, Long: 71.6, District: Jaisalmer , Pixel Val: 11803\nLat: 27.0, Long: 71.6, District: Jaisalmer , Pixel Val: 11594\nLat: 26.8, Long: 71.6, District: Jaisalmer , Pixel Val: 11549\nLat: 26.6, Long: 71.6, District: Jaisalmer , Pixel Val: 11265\nLat: 26.4, Long: 71.6, District: Barmer , Pixel Val: 0\nOutside Indian Territory\nOutside Indian Territory\nOutside Indian Territory\nLat: 27.8, Long: 71.8, District: Jaisalmer , Pixel Val: 11508\nLat: 27.6, Long: 71.8, District: Jaisalmer , Pixel Val: 11511\nLat: 27.4, Long: 71.8, District: Jaisalmer , Pixel Val: 11616\nLat: 27.2, Long: 71.8, District: Jaisalmer , Pixel Val: 11215\nLat: 27.0, Long: 71.8, District: Jaisalmer , Pixel Val: 11814\nLat: 26.8, Long: 71.8, District: Jaisalmer , Pixel Val: 11511\nLat: 26.6, Long: 71.8, District: Jaisalmer , Pixel Val: 11989\nLat: 26.4, Long: 71.8, District: Jaisalmer , Pixel Val: 0\nOutside Indian Territory\nLat: 28.2, Long: 72.1, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.1, District: Bikaner , Pixel Val: 11208\nLat: 27.8, Long: 72.0, District: Jaisalmer , Pixel Val: 11468\nLat: 27.6, Long: 72.0, District: Jaisalmer , Pixel Val: 9761\nLat: 27.4, Long: 72.0, District: Jodhpur , Pixel Val: 11618\nLat: 27.2, Long: 72.0, District: Jodhpur , Pixel Val: 22059\nLat: 27.0, Long: 72.0, District: Jaisalmer , Pixel Val: 11562\nLat: 26.8, Long: 72.0, District: Jaisalmer , Pixel Val: 11302\nLat: 26.6, Long: 72.0, District: Jaisalmer , Pixel Val: 11163\nLat: 26.4, Long: 72.0, District: Jaisalmer , Pixel Val: 0\nLat: 28.5, Long: 72.3, District: Bikaner , Pixel Val: 0\nLat: 28.2, Long: 72.3, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.3, District: Bikaner , Pixel Val: 10845\nLat: 27.8, Long: 72.3, District: Bikaner , Pixel Val: 10621\nLat: 27.6, Long: 72.3, District: Jaisalmer , Pixel Val: 11299\nLat: 27.4, Long: 72.3, District: Jodhpur , Pixel Val: 11236\nLat: 27.2, Long: 72.3, District: Jodhpur , Pixel Val: 11267\nLat: 27.0, Long: 72.3, District: Jodhpur , Pixel Val: 0\nLat: 26.8, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 26.6, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 26.4, Long: 72.2, District: Jodhpur , Pixel Val: 0\nLat: 28.4, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 28.2, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 28.0, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.8, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.6, Long: 72.5, District: Bikaner , Pixel Val: 0\nLat: 27.4, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 27.2, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 27.0, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.8, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.6, Long: 72.5, District: Jodhpur , Pixel Val: 0\nLat: 26.4, Long: 72.5, District: Jodhpur , Pixel Val: 0\n"
]
],
[
[
"# Now we can proceed to GenFeatures Notebook",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a1eb998f1e938dd2a4088e083a621f72409d10d
| 5,276 |
ipynb
|
Jupyter Notebook
|
lts/nts/pkg_docs/notebooks/04-random-baseline.ipynb
|
fsperotto/lts
|
31ad9d0f0daa65d10f31580d37b4b2a184328ddf
|
[
"CC0-1.0"
] | 1 |
2021-01-17T21:39:57.000Z
|
2021-01-17T21:39:57.000Z
|
lts/nts/pkg_docs/notebooks/04-random-baseline.ipynb
|
fsperotto/lts
|
31ad9d0f0daa65d10f31580d37b4b2a184328ddf
|
[
"CC0-1.0"
] | null | null | null |
lts/nts/pkg_docs/notebooks/04-random-baseline.ipynb
|
fsperotto/lts
|
31ad9d0f0daa65d10f31580d37b4b2a184328ddf
|
[
"CC0-1.0"
] | 1 |
2021-01-17T21:41:18.000Z
|
2021-01-17T21:41:18.000Z
| 34.940397 | 103 | 0.5163 |
[
[
[
"import os, sys\nmodule_path = os.path.abspath(os.path.join('..'))\nsys.path.append(module_path)\n\nimport random\nfrom src.loader import *\nfrom src.metrics import Metrics, avg_dicts\nfrom tqdm import tqdm\n\n\nclass Random:\n \"\"\" Random baseline: probability of 1/(Avg seg length) \n that a sentence ends a seg \n \"\"\"\n \n evalu = Metrics()\n \n def __init__(self):\n pass\n \n def __call__(self, *args):\n return self.validate(*args)\n \n def validate(self, dirname):\n \"\"\" Sample N floats in range [0,1]. If a float is less than the inverse\n of the average segment length, then say that is a predicted segmentation \"\"\"\n if 'probability' not in self.__dict__:\n self.probability, self.labels, self.counts = self.parametrize(dirname)\n \n samples = [random.random() for _ in self.labels]\n preds = [1 if s <= self.probability else 0 \n for s in samples]\n batch = PseudoBatch(self.counts, self.labels)\n metrics_dict = self.evalu(batch, preds)\n \n return batch, preds, metrics_dict\n \n def parametrize(self, dirname):\n \"\"\" Return 1 / average segment as random probability pred, test_dir's labels \"\"\"\n counts = flatten([self.parse_files(f) for f in crawl_directory(dirname)])\n labels = counts_to_labels(counts)\n avg_segs = sum(counts) / len(counts)\n probability = 1 / avg_segs\n \n return probability, labels, counts\n \n def parse_files(self, filename, minlen=1):\n \"\"\" Count number of segments in each subsection of a document \"\"\"\n counts, subsection = [], ''\n with open(filename, encoding='utf-8', errors='strict') as f:\n\n # For each line in the file, skipping initial break\n for line in f.readlines()[1:]:\n\n # This '========' indicates a new subsection\n if line.startswith('========'):\n counts.append(len(sent_tokenizer.tokenize(subsection.strip())))\n subsection = ''\n else:\n subsection += ' ' + line\n\n # Edge case of last subsection needs to be appended\n counts.append(len(sent_tokenizer.tokenize(subsection.strip())))\n\n return [c for c in counts if c >= minlen]\n \n def cross_validate(self, *args, trials=100):\n \"\"\" \"\"\"\n dictionaries = []\n for seed in tqdm(range(trials)):\n random.seed(seed)\n batch, preds, metrics_dict = self.validate(*args)\n dictionaries.append(metrics_dict)\n \n merged = avg_dicts(dictionaries)\n return merged\n \nrandom_baseline = Random()\n# _, _, metrics_dict = random_baseline.validate('../data/wiki_50/test')\nmetrics_dict = random_baseline.cross_validate('../data/wiki_50/test', trials=100)\nfor k, v in metrics_dict.items():\n print(k, ':', v)",
"100%|██████████| 100/100 [00:14<00:00, 6.76it/s]"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a1ec49eda0135410f12fe2ff805c4f611472fdb
| 36,668 |
ipynb
|
Jupyter Notebook
|
dlnd_tv_script_generation.ipynb
|
debadyutirc/simpson_tv_script_generation
|
3845a7646a3d19073a0bca6aa4bdcdd2c36e46b2
|
[
"MIT"
] | null | null | null |
dlnd_tv_script_generation.ipynb
|
debadyutirc/simpson_tv_script_generation
|
3845a7646a3d19073a0bca6aa4bdcdd2c36e46b2
|
[
"MIT"
] | null | null | null |
dlnd_tv_script_generation.ipynb
|
debadyutirc/simpson_tv_script_generation
|
3845a7646a3d19073a0bca6aa4bdcdd2c36e46b2
|
[
"MIT"
] | null | null | null | 34.98855 | 556 | 0.56807 |
[
[
[
"# TV Script Generation\nIn this project, you'll generate your own [Simpsons](https://en.wikipedia.org/wiki/The_Simpsons) TV scripts using RNNs. You'll be using part of the [Simpsons dataset](https://www.kaggle.com/wcukierski/the-simpsons-by-the-data) of scripts from 27 seasons. The Neural Network you'll build will generate a new TV script for a scene at [Moe's Tavern](https://simpsonswiki.com/wiki/Moe's_Tavern).\n## Get the Data\nThe data is already provided for you. You'll be using a subset of the original dataset. It consists of only the scenes in Moe's Tavern. This doesn't include other versions of the tavern, like \"Moe's Cavern\", \"Flaming Moe's\", \"Uncle Moe's Family Feed-Bag\", etc..",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport helper\n\ndata_dir = './data/simpsons/moes_tavern_lines.txt'\ntext = helper.load_data(data_dir)\n# Ignore notice, since we don't use it for analysing the data\ntext = text[81:]",
"_____no_output_____"
]
],
[
[
"## Explore the Data\nPlay around with `view_sentence_range` to view different parts of the data.",
"_____no_output_____"
]
],
[
[
"view_sentence_range = (0, 10)\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport numpy as np\n\nprint('Dataset Stats')\nprint('Roughly the number of unique words: {}'.format(len({word: None for word in text.split()})))\nscenes = text.split('\\n\\n')\nprint('Number of scenes: {}'.format(len(scenes)))\nsentence_count_scene = [scene.count('\\n') for scene in scenes]\nprint('Average number of sentences in each scene: {}'.format(np.average(sentence_count_scene)))\n\nsentences = [sentence for scene in scenes for sentence in scene.split('\\n')]\nprint('Number of lines: {}'.format(len(sentences)))\nword_count_sentence = [len(sentence.split()) for sentence in sentences]\nprint('Average number of words in each line: {}'.format(np.average(word_count_sentence)))\n\nprint()\nprint('The sentences {} to {}:'.format(*view_sentence_range))\nprint('\\n'.join(text.split('\\n')[view_sentence_range[0]:view_sentence_range[1]]))",
"Dataset Stats\nRoughly the number of unique words: 11492\nNumber of scenes: 262\nAverage number of sentences in each scene: 15.248091603053435\nNumber of lines: 4257\nAverage number of words in each line: 11.50434578341555\n\nThe sentences 0 to 10:\nMoe_Szyslak: (INTO PHONE) Moe's Tavern. Where the elite meet to drink.\nBart_Simpson: Eh, yeah, hello, is Mike there? Last name, Rotch.\nMoe_Szyslak: (INTO PHONE) Hold on, I'll check. (TO BARFLIES) Mike Rotch. Mike Rotch. Hey, has anybody seen Mike Rotch, lately?\nMoe_Szyslak: (INTO PHONE) Listen you little puke. One of these days I'm gonna catch you, and I'm gonna carve my name on your back with an ice pick.\nMoe_Szyslak: What's the matter Homer? You're not your normal effervescent self.\nHomer_Simpson: I got my problems, Moe. Give me another one.\nMoe_Szyslak: Homer, hey, you should not drink to forget your problems.\nBarney_Gumble: Yeah, you should only drink to enhance your social skills.\n\n\n"
]
],
[
[
"## Implement Preprocessing Functions\nThe first thing to do to any dataset is preprocessing. Implement the following preprocessing functions below:\n- Lookup Table\n- Tokenize Punctuation\n\n### Lookup Table\nTo create a word embedding, you first need to transform the words to ids. In this function, create two dictionaries:\n- Dictionary to go from the words to an id, we'll call `vocab_to_int`\n- Dictionary to go from the id to word, we'll call `int_to_vocab`\n\nReturn these dictionaries in the following tuple `(vocab_to_int, int_to_vocab)`",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport problem_unittests as tests\nfrom collections import Counter\n\ndef create_lookup_tables(text):\n \"\"\"\n Create lookup tables for vocabulary\n :param text: The text of tv scripts split into words\n :return: A tuple of dicts (vocab_to_int, int_to_vocab)\n \"\"\"\n # TODO: Implement Function\n words = ' '.join([ c for c in text])\n count = Counter(words.split())\n vocab = sorted(count, key=count.get, reverse=True)\n vocab_to_int = {word: index for index, word in enumerate(vocab, 1)}\n int_to_vocab = {index: word for index, word in enumerate(vocab, 1)}\n return vocab_to_int, int_to_vocab\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_create_lookup_tables(create_lookup_tables)",
"Tests Passed\n"
]
],
[
[
"### Tokenize Punctuation\nWe'll be splitting the script into a word array using spaces as delimiters. However, punctuations like periods and exclamation marks make it hard for the neural network to distinguish between the word \"bye\" and \"bye!\".\n\nImplement the function `token_lookup` to return a dict that will be used to tokenize symbols like \"!\" into \"||Exclamation_Mark||\". Create a dictionary for the following symbols where the symbol is the key and value is the token:\n- Period ( . )\n- Comma ( , )\n- Quotation Mark ( \" )\n- Semicolon ( ; )\n- Exclamation mark ( ! )\n- Question mark ( ? )\n- Left Parentheses ( ( )\n- Right Parentheses ( ) )\n- Dash ( -- )\n- Return ( \\n )\n\nThis dictionary will be used to token the symbols and add the delimiter (space) around it. This separates the symbols as it's own word, making it easier for the neural network to predict on the next word. Make sure you don't use a token that could be confused as a word. Instead of using the token \"dash\", try using something like \"||dash||\".",
"_____no_output_____"
]
],
[
[
"def token_lookup():\n \"\"\"\n Generate a dict to turn punctuation into a token.\n :return: Tokenize dictionary where the key is the punctuation and the value is the token\n \"\"\"\n # TODO: Implement Function\n punctuations = {\n '.' : '||period||',\n ',' : '||comma||',\n '\"' : '||quotation_mark||',\n ';' : '||semicolon||',\n '!' : '||exclamation_mark||',\n '?' : '||question_mark||',\n '(' : '||left_parentheses',\n ')' : '||right_parentheses',\n '--' : '||dash||',\n '\\n' : '||return||'\n }\n return punctuations\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_tokenize(token_lookup)",
"Tests Passed\n"
]
],
[
[
"## Preprocess all the data and save it\nRunning the code cell below will preprocess all the data and save it to file.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\n# Preprocess Training, Validation, and Testing Data\nhelper.preprocess_and_save_data(data_dir, token_lookup, create_lookup_tables)",
"_____no_output_____"
]
],
[
[
"# Check Point\nThis is your first checkpoint. If you ever decide to come back to this notebook or have to restart the notebook, you can start from here. The preprocessed data has been saved to disk.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport helper\nimport numpy as np\nimport problem_unittests as tests\n\nint_text, vocab_to_int, int_to_vocab, token_dict = helper.load_preprocess()",
"_____no_output_____"
]
],
[
[
"## Build the Neural Network\nYou'll build the components necessary to build a RNN by implementing the following functions below:\n- get_inputs\n- get_init_cell\n- get_embed\n- build_rnn\n- build_nn\n- get_batches\n\n### Check the Version of TensorFlow and Access to GPU",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nfrom distutils.version import LooseVersion\nimport warnings\nimport tensorflow as tf\n\n# Check TensorFlow Version\nassert LooseVersion(tf.__version__) >= LooseVersion('1.0'), 'Please use TensorFlow version 1.0 or newer'\nprint('TensorFlow Version: {}'.format(tf.__version__))\n\n# Check for a GPU\nif not tf.test.gpu_device_name():\n warnings.warn('No GPU found. Please use a GPU to train your neural network.')\nelse:\n print('Default GPU Device: {}'.format(tf.test.gpu_device_name()))",
"TensorFlow Version: 1.2.1\n"
]
],
[
[
"### Input\nImplement the `get_inputs()` function to create TF Placeholders for the Neural Network. It should create the following placeholders:\n- Input text placeholder named \"input\" using the [TF Placeholder](https://www.tensorflow.org/api_docs/python/tf/placeholder) `name` parameter.\n- Targets placeholder\n- Learning Rate placeholder\n\nReturn the placeholders in the following tuple `(Input, Targets, LearningRate)`",
"_____no_output_____"
]
],
[
[
"def get_inputs():\n \"\"\"\n Create TF Placeholders for input, targets, and learning rate.\n :return: Tuple (input, targets, learning rate)\n \"\"\"\n # TODO: Implement Function\n inputs = tf.placeholder(tf.int32, [None, None], name=\"input\")\n targets = tf.placeholder(tf.int32, [None, None], name=\"targets\")\n lr = tf.placeholder(tf.float32, name='learning_rate')\n return inputs, targets, lr\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_inputs(get_inputs)",
"Tests Passed\n"
]
],
[
[
"### Build RNN Cell and Initialize\nStack one or more [`BasicLSTMCells`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/BasicLSTMCell) in a [`MultiRNNCell`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/MultiRNNCell).\n- The Rnn size should be set using `rnn_size`\n- Initalize Cell State using the MultiRNNCell's [`zero_state()`](https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/MultiRNNCell#zero_state) function\n - Apply the name \"initial_state\" to the initial state using [`tf.identity()`](https://www.tensorflow.org/api_docs/python/tf/identity)\n\nReturn the cell and initial state in the following tuple `(Cell, InitialState)`",
"_____no_output_____"
]
],
[
[
"def get_init_cell(batch_size, rnn_size):\n \"\"\"\n Create an RNN Cell and initialize it.\n :param batch_size: Size of batches\n :param rnn_size: Size of RNNs\n :return: Tuple (cell, initialize state)\n \"\"\"\n # TODO: Implement Function\n lstm = tf.contrib.rnn.BasicLSTMCell(rnn_size)\n cell = tf.contrib.rnn.MultiRNNCell([lstm, lstm])\n initialize_state = tf.identity(cell.zero_state(batch_size, tf.float32), name='initial_state')\n return cell, initialize_state\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_init_cell(get_init_cell)",
"Tests Passed\n"
]
],
[
[
"### Word Embedding\nApply embedding to `input_data` using TensorFlow. Return the embedded sequence.",
"_____no_output_____"
]
],
[
[
"def get_embed(input_data, vocab_size, embed_dim):\n \"\"\"\n Create embedding for <input_data>.\n :param input_data: TF placeholder for text input.\n :param vocab_size: Number of words in vocabulary.\n :param embed_dim: Number of embedding dimensions\n :return: Embedded input.\n \"\"\"\n # TODO: Implement Function\n embeddings = tf.Variable(tf.random_normal([vocab_size, embed_dim], stddev=0.1), name='embeddings')\n embed = tf.nn.embedding_lookup(embeddings, input_data, name='embed')\n return embed\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_embed(get_embed)",
"Tests Passed\n"
]
],
[
[
"### Build RNN\nYou created a RNN Cell in the `get_init_cell()` function. Time to use the cell to create a RNN.\n- Build the RNN using the [`tf.nn.dynamic_rnn()`](https://www.tensorflow.org/api_docs/python/tf/nn/dynamic_rnn)\n - Apply the name \"final_state\" to the final state using [`tf.identity()`](https://www.tensorflow.org/api_docs/python/tf/identity)\n\nReturn the outputs and final_state state in the following tuple `(Outputs, FinalState)` ",
"_____no_output_____"
]
],
[
[
"def build_rnn(cell, inputs):\n \"\"\"\n Create a RNN using a RNN Cell\n :param cell: RNN Cell\n :param inputs: Input text data\n :return: Tuple (Outputs, Final State)\n \"\"\"\n # TODO: Implement Function\n outputs, final_state = tf.nn.dynamic_rnn(cell, inputs, dtype=tf.float32)\n final_state = tf.identity(final_state, name='final_state')\n return outputs, final_state\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_build_rnn(build_rnn)",
"Tests Passed\n"
]
],
[
[
"### Build the Neural Network\nApply the functions you implemented above to:\n- Apply embedding to `input_data` using your `get_embed(input_data, vocab_size, embed_dim)` function.\n- Build RNN using `cell` and your `build_rnn(cell, inputs)` function.\n- Apply a fully connected layer with a linear activation and `vocab_size` as the number of outputs.\n\nReturn the logits and final state in the following tuple (Logits, FinalState) ",
"_____no_output_____"
]
],
[
[
"def build_nn(cell, rnn_size, input_data, vocab_size, embed_dim):\n \"\"\"\n Build part of the neural network\n :param cell: RNN cell\n :param rnn_size: Size of rnns\n :param input_data: Input data\n :param vocab_size: Vocabulary size\n :param embed_dim: Number of embedding dimensions\n :return: Tuple (Logits, FinalState)\n \"\"\"\n # TODO: Implement Function\n embedded_inputs = get_embed(input_data, vocab_size, rnn_size)\n outputs, final_state = build_rnn(cell, embedded_inputs)\n logits = tf.contrib.layers.fully_connected(outputs, vocab_size, \n activation_fn=None, \n weights_initializer=tf.truncated_normal_initializer(stddev=0.1), \n biases_initializer=tf.zeros_initializer())\n return logits, final_state\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_build_nn(build_nn)",
"Tests Passed\n"
]
],
[
[
"### Batches\nImplement `get_batches` to create batches of input and targets using `int_text`. The batches should be a Numpy array with the shape `(number of batches, 2, batch size, sequence length)`. Each batch contains two elements:\n- The first element is a single batch of **input** with the shape `[batch size, sequence length]`\n- The second element is a single batch of **targets** with the shape `[batch size, sequence length]`\n\nIf you can't fill the last batch with enough data, drop the last batch.\n\nFor exmple, `get_batches([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20], 3, 2)` would return a Numpy array of the following:\n```\n[\n # First Batch\n [\n # Batch of Input\n [[ 1 2], [ 7 8], [13 14]]\n # Batch of targets\n [[ 2 3], [ 8 9], [14 15]]\n ]\n\n # Second Batch\n [\n # Batch of Input\n [[ 3 4], [ 9 10], [15 16]]\n # Batch of targets\n [[ 4 5], [10 11], [16 17]]\n ]\n\n # Third Batch\n [\n # Batch of Input\n [[ 5 6], [11 12], [17 18]]\n # Batch of targets\n [[ 6 7], [12 13], [18 1]]\n ]\n]\n```\n\nNotice that the last target value in the last batch is the first input value of the first batch. In this case, `1`. This is a common technique used when creating sequence batches, although it is rather unintuitive.",
"_____no_output_____"
]
],
[
[
"def get_batches(int_text, batch_size, seq_length):\n \"\"\"\n Return batches of input and target\n :param int_text: Text with the words replaced by their ids\n :param batch_size: The size of batch\n :param seq_length: The length of sequence\n :return: Batches as a Numpy array\n \"\"\"\n # Calculate the number of batches\n num_batches = len(int_text) // (batch_size * seq_length)\n # Drop long batches. Transform into a numpy array and reshape it for our purposes\n np_text = np.array(int_text[:num_batches * (batch_size * seq_length)])\n # Reshape the data to give us the inputs sequence.\n in_text = np_text.reshape(-1, seq_length)\n # Roll (shift) and reshape to get target sequences (maybe not optimal)\n tar_text = np.roll(np_text, -1).reshape(-1, seq_length)\n output = np.zeros(shape=(num_batches, 2, batch_size, seq_length), dtype=np.int)\n # Prepare the output\n for idx in range(0, in_text.shape[0]):\n jj = idx % num_batches\n ii = idx // num_batches\n output[jj,0,ii,:] = in_text[idx,:]\n output[jj,1,ii,:] = tar_text[idx,:]\n return output\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_batches(get_batches)",
"Tests Passed\n"
]
],
[
[
"## Neural Network Training\n### Hyperparameters\nTune the following parameters:\n\n- Set `num_epochs` to the number of epochs.\n- Set `batch_size` to the batch size.\n- Set `rnn_size` to the size of the RNNs.\n- Set `embed_dim` to the size of the embedding.\n- Set `seq_length` to the length of sequence.\n- Set `learning_rate` to the learning rate.\n- Set `show_every_n_batches` to the number of batches the neural network should print progress.",
"_____no_output_____"
]
],
[
[
"# Number of Epochs\nnum_epochs = 50\n# Batch Size\nbatch_size = 128\n# RNN Size\nrnn_size = 512\n# Embedding Dimension Size\nembed_dim = 256\n# Sequence Length\nseq_length = 16\n# Learning Rate\nlearning_rate = 0.007\n# Show stats for every n number of batches\nshow_every_n_batches = 100\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nsave_dir = './save'",
"_____no_output_____"
]
],
[
[
"### Build the Graph\nBuild the graph using the neural network you implemented.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nfrom tensorflow.contrib import seq2seq\n\ntrain_graph = tf.Graph()\nwith train_graph.as_default():\n vocab_size = len(int_to_vocab)\n input_text, targets, lr = get_inputs()\n input_data_shape = tf.shape(input_text)\n cell, initial_state = get_init_cell(input_data_shape[0], rnn_size)\n logits, final_state = build_nn(cell, rnn_size, input_text, vocab_size, embed_dim)\n\n # Probabilities for generating words\n probs = tf.nn.softmax(logits, name='probs')\n\n # Loss function\n cost = seq2seq.sequence_loss(\n logits,\n targets,\n tf.ones([input_data_shape[0], input_data_shape[1]]))\n\n # Optimizer\n optimizer = tf.train.AdamOptimizer(lr)\n\n # Gradient Clipping\n gradients = optimizer.compute_gradients(cost)\n capped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients if grad is not None]\n train_op = optimizer.apply_gradients(capped_gradients)",
"_____no_output_____"
]
],
[
[
"## Train\nTrain the neural network on the preprocessed data. If you have a hard time getting a good loss, check the [forums](https://discussions.udacity.com/) to see if anyone is having the same problem.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nbatches = get_batches(int_text, batch_size, seq_length)\n\nwith tf.Session(graph=train_graph) as sess:\n sess.run(tf.global_variables_initializer())\n\n for epoch_i in range(num_epochs):\n state = sess.run(initial_state, {input_text: batches[0][0]})\n\n for batch_i, (x, y) in enumerate(batches):\n feed = {\n input_text: x,\n targets: y,\n initial_state: state,\n lr: learning_rate}\n train_loss, state, _ = sess.run([cost, final_state, train_op], feed)\n\n # Show every <show_every_n_batches> batches\n if (epoch_i * len(batches) + batch_i) % show_every_n_batches == 0:\n print('Epoch {:>3} Batch {:>4}/{} train_loss = {:.3f}'.format(\n epoch_i,\n batch_i,\n len(batches),\n train_loss))\n\n # Save Model\n saver = tf.train.Saver()\n saver.save(sess, save_dir)\n print('Model Trained and Saved')",
"Epoch 0 Batch 0/33 train_loss = 8.822\nEpoch 3 Batch 1/33 train_loss = 4.674\nEpoch 6 Batch 2/33 train_loss = 4.154\nEpoch 9 Batch 3/33 train_loss = 3.656\nEpoch 12 Batch 4/33 train_loss = 3.257\nEpoch 15 Batch 5/33 train_loss = 2.757\nEpoch 18 Batch 6/33 train_loss = 2.074\nEpoch 21 Batch 7/33 train_loss = 1.630\nEpoch 24 Batch 8/33 train_loss = 1.216\nEpoch 27 Batch 9/33 train_loss = 0.931\nEpoch 30 Batch 10/33 train_loss = 0.619\nEpoch 33 Batch 11/33 train_loss = 0.521\nEpoch 36 Batch 12/33 train_loss = 0.420\nEpoch 39 Batch 13/33 train_loss = 0.292\nEpoch 42 Batch 14/33 train_loss = 0.238\nEpoch 45 Batch 15/33 train_loss = 0.206\nEpoch 48 Batch 16/33 train_loss = 0.244\nModel Trained and Saved\n"
]
],
[
[
"## Save Parameters\nSave `seq_length` and `save_dir` for generating a new TV script.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\n# Save parameters for checkpoint\nhelper.save_params((seq_length, save_dir))",
"_____no_output_____"
]
],
[
[
"# Checkpoint",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL\n\"\"\"\nimport tensorflow as tf\nimport numpy as np\nimport helper\nimport problem_unittests as tests\n\n_, vocab_to_int, int_to_vocab, token_dict = helper.load_preprocess()\nseq_length, load_dir = helper.load_params()",
"_____no_output_____"
]
],
[
[
"## Implement Generate Functions\n### Get Tensors\nGet tensors from `loaded_graph` using the function [`get_tensor_by_name()`](https://www.tensorflow.org/api_docs/python/tf/Graph#get_tensor_by_name). Get the tensors using the following names:\n- \"input:0\"\n- \"initial_state:0\"\n- \"final_state:0\"\n- \"probs:0\"\n\nReturn the tensors in the following tuple `(InputTensor, InitialStateTensor, FinalStateTensor, ProbsTensor)` ",
"_____no_output_____"
]
],
[
[
"def get_tensors(loaded_graph):\n \"\"\"\n Get input, initial state, final state, and probabilities tensor from <loaded_graph>\n :param loaded_graph: TensorFlow graph loaded from file\n :return: Tuple (InputTensor, InitialStateTensor, FinalStateTensor, ProbsTensor)\n \"\"\"\n # TODO: Implement Function\n input_tensor = loaded_graph.get_tensor_by_name('input:0')\n initial_state_tensor = loaded_graph.get_tensor_by_name('initial_state:0')\n final_state_tensor = loaded_graph.get_tensor_by_name('final_state:0')\n probs_tensor = loaded_graph.get_tensor_by_name('probs:0')\n return (input_tensor, initial_state_tensor, final_state_tensor, probs_tensor)\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_get_tensors(get_tensors)",
"Tests Passed\n"
]
],
[
[
"### Choose Word\nImplement the `pick_word()` function to select the next word using `probabilities`.",
"_____no_output_____"
]
],
[
[
"def pick_word(probabilities, int_to_vocab):\n \"\"\"\n Pick the next word in the generated text\n :param probabilities: Probabilites of the next word\n :param int_to_vocab: Dictionary of word ids as the keys and words as the values\n :return: String of the predicted word\n \"\"\"\n # TODO: Implement Function\n return int_to_vocab[np.argmax(probabilities)]\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntests.test_pick_word(pick_word)",
"Tests Passed\n"
]
],
[
[
"## Generate TV Script\nThis will generate the TV script for you. Set `gen_length` to the length of TV script you want to generate.",
"_____no_output_____"
]
],
[
[
"gen_length = 200\n# homer_simpson, moe_szyslak, or Barney_Gumble\nprime_word = 'moe_szyslak'\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nloaded_graph = tf.Graph()\nwith tf.Session(graph=loaded_graph) as sess:\n # Load saved model\n loader = tf.train.import_meta_graph(load_dir + '.meta')\n loader.restore(sess, load_dir)\n\n # Get Tensors from loaded model\n input_text, initial_state, final_state, probs = get_tensors(loaded_graph)\n\n # Sentences generation setup\n gen_sentences = [prime_word + ':']\n prev_state = sess.run(initial_state, {input_text: np.array([[1]])})\n\n # Generate sentences\n for n in range(gen_length):\n # Dynamic Input\n dyn_input = [[vocab_to_int[word] for word in gen_sentences[-seq_length:]]]\n dyn_seq_length = len(dyn_input[0])\n\n # Get Prediction\n probabilities, prev_state = sess.run(\n [probs, final_state],\n {input_text: dyn_input, initial_state: prev_state})\n \n pred_word = pick_word(probabilities[0][dyn_seq_length-1], int_to_vocab)\n #pred_word = pick_word(probabilities[dyn_seq_length-1], int_to_vocab)\n\n gen_sentences.append(pred_word)\n \n # Remove tokens\n tv_script = ' '.join(gen_sentences)\n for key, token in token_dict.items():\n ending = ' ' if key in ['\\n', '(', '\"'] else ''\n tv_script = tv_script.replace(' ' + token.lower(), key)\n tv_script = tv_script.replace('\\n ', '\\n')\n tv_script = tv_script.replace('( ', '(')\n \n print(tv_script)",
"INFO:tensorflow:Restoring parameters from ./save\nmoe_szyslak:(shocked) that's how it works? i was just drawin' wangs on the numbers of that thing.\nlenny_leonard: you know, ever since obama came in, but i ain't angry.\ncarl_carlson:(competitive) i can jump off the only literature in this bar. sure works for me though.\nmoe_szyslak: this is a crowbar!\nmoe_szyslak: see? they got the back of my cruiser.\nhomer_simpson: yes!!\nmoe_szyslak: i'll take it!\nmoe_szyslak: oh, yeah. and, at least two of you, please.\n\n\nlenny_leonard: you know, moe, that sign is souped up six. if i wanted to give you some peanuts in a new town, and they spend an irishman.(beat) your tab's 14 billion his swimmers.\nlenny_leonard:(sympathetic) aw, that's a girl, moe.\nmoe_szyslak:(looking at homer) next to the first time.\nhomer_simpson:(suspiciously) but that's barney's seat like\" is their sanctuary, you just know, we had a man to hooters\n"
]
],
[
[
"# The TV Script is Nonsensical\nIt's ok if the TV script doesn't make any sense. We trained on less than a megabyte of text. In order to get good results, you'll have to use a smaller vocabulary or get more data. Luckly there's more data! As we mentioned in the begging of this project, this is a subset of [another dataset](https://www.kaggle.com/wcukierski/the-simpsons-by-the-data). We didn't have you train on all the data, because that would take too long. However, you are free to train your neural network on all the data. After you complete the project, of course.\n# Submitting This Project\nWhen submitting this project, make sure to run all the cells before saving the notebook. Save the notebook file as \"dlnd_tv_script_generation.ipynb\" and save it as a HTML file under \"File\" -> \"Download as\". Include the \"helper.py\" and \"problem_unittests.py\" files in your submission.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a1eca4c6e7154948d60adb0166ac74b525b7576
| 7,487 |
ipynb
|
Jupyter Notebook
|
simple.ipynb
|
jadermcs/ZeCarioca
|
56bb0bcf38ae7e85cefa83c583ca779af69f0587
|
[
"MIT"
] | null | null | null |
simple.ipynb
|
jadermcs/ZeCarioca
|
56bb0bcf38ae7e85cefa83c583ca779af69f0587
|
[
"MIT"
] | null | null | null |
simple.ipynb
|
jadermcs/ZeCarioca
|
56bb0bcf38ae7e85cefa83c583ca779af69f0587
|
[
"MIT"
] | null | null | null | 72.68932 | 1,474 | 0.657673 |
[
[
[
"import torch\nfrom transformers import GPT2Tokenizer, GPT2LMHeadModel",
"_____no_output_____"
],
[
"checkpoint = \"models/checkpoint-88-lower\"\ntokenizer = GPT2Tokenizer.from_pretrained(checkpoint)\nmodel = GPT2LMHeadModel.from_pretrained(checkpoint)",
"_____no_output_____"
],
[
"text = \"\"\nwhile True:\n text += \"<sos_u>\" + input().lower() + \"<eos_u>\"\n while not text.endswith(\"<eos_r>\"):\n inputs = tokenizer(text, return_tensors=\"pt\")\n outputs = model(**inputs, labels=inputs[\"input_ids\"])\n loss, logits = outputs[:2]\n predicted_index = torch.argmax(logits[0, -1, :]).item()\n predicted_text = tokenizer.decode([predicted_index])\n text += predicted_text\n print(text)",
"ola, gostaria de consultar meu saldo\n<sos_u>ola, gostaria de consultar meu saldo<eos_u><sos_b>[info_placa]<eos_b><sos_a>[info_placa][req_cpf][req_ajuda]<eos_a><sos_r>Olá, qual seu cpf e qual a placa do carro?<eos_r>\ncpf 04935834512 jgm-3453\n<sos_u>ola, gostaria de consultar meu saldo<eos_u><sos_b>[info_placa]<eos_b><sos_a>[info_placa][req_cpf][req_ajuda]<eos_a><sos_r>Olá, qual seu cpf e qual a placa do carro?<eos_r><sos_u>cpf 04935834512 jgm-3453<eos_u><sos_b>[confirmacao]cpf 04935834512 jgm-3453<eos_b><sos_a>[req_placa][req_placa][req_placa]<eos_a><sos_r>O saldo atual é de [valor]. Posso ajudar em mais alguma coisa?<eos_r>\nnao, valeu, so isso\n<sos_u>ola, gostaria de consultar meu saldo<eos_u><sos_b>[info_placa]<eos_b><sos_a>[info_placa][req_cpf][req_ajuda]<eos_a><sos_r>Olá, qual seu cpf e qual a placa do carro?<eos_r><sos_u>cpf 04935834512 jgm-3453<eos_u><sos_b>[confirmacao]cpf 04935834512 jgm-3453<eos_b><sos_a>[req_placa][req_placa][req_placa]<eos_a><sos_r>O saldo atual é de [valor]. Posso ajudar em mais alguma coisa?<eos_r><sos_u>nao, valeu, so isso<eos_u><sos_b>[info_cpf][negacao]<eos_b><sos_a>[negacao][agradecimento]<eos_a><sos_r>De nada! Nós agradecemos o seu contato e estamos sempre à disposição. Até a próxima!<eos_r>\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a1ed2a0b68ca47b7b867a89e88295afada50ec9
| 73,870 |
ipynb
|
Jupyter Notebook
|
Example.ipynb
|
peytondmurray/bhsim
|
772b9312d9c91700053416f8bee81607ed4731fd
|
[
"MIT"
] | null | null | null |
Example.ipynb
|
peytondmurray/bhsim
|
772b9312d9c91700053416f8bee81607ed4731fd
|
[
"MIT"
] | null | null | null |
Example.ipynb
|
peytondmurray/bhsim
|
772b9312d9c91700053416f8bee81607ed4731fd
|
[
"MIT"
] | null | null | null | 794.301075 | 71,920 | 0.957087 |
[
[
[
"import bh\nimport sympy as sy\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.cm as cm\nimport cmocean.cm as ccm\nimport matplotlib.transforms as mt\nimport scipy.interpolate as si\nimport out\nplt.style.use('dark_background')",
"_____no_output_____"
],
[
"th0 = 80\nalpha = np.linspace(0, 2*np.pi, 1000)\nr_vals = np.arange(6, 60, 0.5)\nn_vals = [0, 1]\nm = 1\n\nfix, ax = plt.subplots(figsize=(40, 40))\nfig = out.generate_image(ax, alpha, r_vals, th0, n_vals, m, None);",
"_____no_output_____"
],
[
"fig.savefig('blackhole.png', dpi=300)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a1ed3eff596f1193e8669637898bc4bbd2cc0c7
| 336,812 |
ipynb
|
Jupyter Notebook
|
_site/codici/ae.ipynb
|
tvml/ml2021
|
d72a6762af9cd12019d87237d061bbb39f560da9
|
[
"MIT"
] | null | null | null |
_site/codici/ae.ipynb
|
tvml/ml2021
|
d72a6762af9cd12019d87237d061bbb39f560da9
|
[
"MIT"
] | null | null | null |
_site/codici/ae.ipynb
|
tvml/ml2021
|
d72a6762af9cd12019d87237d061bbb39f560da9
|
[
"MIT"
] | null | null | null | 181.765785 | 70,608 | 0.860587 |
[
[
[
"<a href=\"https://colab.research.google.com/github/tvml/ml2021/blob/main/codici/ae.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"IS_COLAB = ('google.colab' in str(get_ipython()))\nif IS_COLAB:\n %tensorflow_version 2.x",
"_____no_output_____"
],
[
"import tensorflow as tf\nfrom tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D, Flatten, Reshape\nfrom tensorflow.keras.models import Model, Sequential\nfrom tensorflow.keras import regularizers\nfrom tensorflow.keras.datasets import mnist\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nprint(tf.__version__)",
"2.4.1\n"
],
[
"from platform import python_version\n\nprint(python_version())",
"3.8.0\n"
],
[
"if IS_COLAB:\n from google.colab import drive\n drive.mount('/gdrive')\n filepath = \"/gdrive/My Drive/colab_data/\"\nelse:\n filepath = \"../ml_store\"",
"_____no_output_____"
],
[
"def save_model(m,filename):\n model_json = m.to_json()\n with open(filepath+filename+\".json\", \"w\") as json_file:\n json_file.write(model_json)\n # serialize weights to HDF5\n m.save_weights(filepath+filename+\".h5\")\n print(\"Saved model to disk\")\n\ndef load_model_weights(filename, model):\n model.load_weights(filepath+filename+\".h5\")\n print(\"Loaded weights from disk\")\n return model\n\ndef load_model(filename):\n json_file = open(filepath+filename+'.json', 'r')\n loaded_model_json = json_file.read()\n json_file.close()\n m = model_from_json(loaded_model_json)\n # load weights into new model\n m.load_weights(filepath+filename+\".h5\")\n print(\"Loaded model from disk\")\n return m",
"_____no_output_____"
],
[
"# this is the size of our encoded representations\nencoding_dim = 32\ninput_size = 784",
"_____no_output_____"
],
[
"ae = Sequential()\n\n# Encoder Layers\nae.add(Dense(encoding_dim, input_shape=(input_size,), activation='relu'))\n\n# Decoder Layers\nae.add(Dense(input_size, activation='sigmoid'))\n\nae.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_1 (Dense) (None, 32) 25120 \n_________________________________________________________________\ndense_2 (Dense) (None, 784) 25872 \n=================================================================\nTotal params: 50,992\nTrainable params: 50,992\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"ae.compile(optimizer='adadelta', loss='binary_crossentropy')",
"_____no_output_____"
],
[
"(x_train, _), (x_test, _) = mnist.load_data()",
"_____no_output_____"
],
[
"x_train = x_train.astype('float32') / 255.\nx_test = x_test.astype('float32') / 255.\nx_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))\nx_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))\nprint(x_train.shape)\nprint(x_test.shape)",
"(60000, 784)\n(10000, 784)\n"
],
[
"#ae = load_model_weights('ae', ae)",
"Loaded weights from disk\n"
],
[
"history = ae.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True, validation_data=(x_test, x_test))",
"Train on 60000 samples, validate on 10000 samples\nEpoch 1/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.1026 - val_loss: 0.1008\nEpoch 2/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1022 - val_loss: 0.1005\nEpoch 3/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1019 - val_loss: 0.1001\nEpoch 4/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1016 - val_loss: 0.0998\nEpoch 5/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1013 - val_loss: 0.0995\nEpoch 6/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1010 - val_loss: 0.0993\nEpoch 7/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1007 - val_loss: 0.0990\nEpoch 8/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1005 - val_loss: 0.0988\nEpoch 9/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1002 - val_loss: 0.0985\nEpoch 10/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.1000 - val_loss: 0.0983\nEpoch 11/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0998 - val_loss: 0.0981\nEpoch 12/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0995 - val_loss: 0.0979\nEpoch 13/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.0993 - val_loss: 0.0977\nEpoch 14/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0992 - val_loss: 0.0975\nEpoch 15/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0990 - val_loss: 0.0973\nEpoch 16/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0988 - val_loss: 0.0972\nEpoch 17/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.0986 - val_loss: 0.0970\nEpoch 18/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0985 - val_loss: 0.0969\nEpoch 19/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0983 - val_loss: 0.0967\nEpoch 20/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0982 - val_loss: 0.0966\nEpoch 21/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.0981 - val_loss: 0.0965\nEpoch 22/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0979 - val_loss: 0.0964\nEpoch 23/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0978 - val_loss: 0.0962\nEpoch 24/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0977 - val_loss: 0.0961\nEpoch 25/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0976 - val_loss: 0.0960\nEpoch 26/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0975 - val_loss: 0.0959\nEpoch 27/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.0974 - val_loss: 0.0958\nEpoch 28/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0973 - val_loss: 0.0958\nEpoch 29/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0972 - val_loss: 0.0957\nEpoch 30/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0971 - val_loss: 0.0956\nEpoch 31/50\n60000/60000 [==============================] - 1s 14us/step - loss: 0.0971 - val_loss: 0.0955\nEpoch 32/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0970 - val_loss: 0.0954\nEpoch 33/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0969 - val_loss: 0.0954\nEpoch 34/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0968 - val_loss: 0.0953\nEpoch 35/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0968 - val_loss: 0.0952\nEpoch 36/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0967 - val_loss: 0.0952\nEpoch 37/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0966 - val_loss: 0.0951\nEpoch 38/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0966 - val_loss: 0.0951\nEpoch 39/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0965 - val_loss: 0.0950\nEpoch 40/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0965 - val_loss: 0.0950\nEpoch 41/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0964 - val_loss: 0.0949\nEpoch 42/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0963 - val_loss: 0.0948\nEpoch 43/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0963 - val_loss: 0.0948\nEpoch 44/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0962 - val_loss: 0.0947\nEpoch 45/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0962 - val_loss: 0.0947\nEpoch 46/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0961 - val_loss: 0.0946\nEpoch 47/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0961 - val_loss: 0.0946\nEpoch 48/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0960 - val_loss: 0.0946\nEpoch 49/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0960 - val_loss: 0.0945\nEpoch 50/50\n60000/60000 [==============================] - 1s 13us/step - loss: 0.0959 - val_loss: 0.0945\n"
],
[
"save_model(ae,'ae')",
"Saved model to disk\n"
],
[
"ae.layers[0].get_weights()[0][780,:]",
"_____no_output_____"
],
[
"input_img = Input(shape=(input_size,))\nencoder_layer1 = ae.layers[0]\nencoder = Model(input_img, encoder_layer1(input_img))\n\nencoder.summary()",
"Model: \"model_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 784) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 32) 25120 \n=================================================================\nTotal params: 25,120\nTrainable params: 25,120\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"num_images = 10\nnp.random.seed(42)\nrandom_test_images = np.random.randint(x_test.shape[0], size=num_images)\n\nencoded_imgs = encoder.predict(x_test)\ndecoded_imgs = ae.predict(x_test)\n\nplt.figure(figsize=(18, 4))\n\nfor i, image_idx in enumerate(random_test_images):\n # plot original image\n ax = plt.subplot(3, num_images, i + 1)\n plt.imshow(x_test[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n \n # plot encoded image\n ax = plt.subplot(3, num_images, num_images + i + 1)\n plt.imshow(encoded_imgs[image_idx].reshape(8, 4))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n\n # plot reconstructed image\n ax = plt.subplot(3, num_images, 2*num_images + i + 1)\n plt.imshow(decoded_imgs[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\nplt.show()",
"_____no_output_____"
],
[
"ae1 = Sequential()\n\n# Encoder Layers\nae1.add(Dense(encoding_dim, input_shape=(input_size,), activation='relu',\n activity_regularizer=regularizers.l1(10e-6)))\n\n# Decoder Layers\nae1.add(Dense(input_size, activation='sigmoid'))\n\nae1.summary()",
"Model: \"sequential_3\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_5 (Dense) (None, 32) 25120 \n_________________________________________________________________\ndense_6 (Dense) (None, 784) 25872 \n=================================================================\nTotal params: 50,992\nTrainable params: 50,992\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"ae1.compile(optimizer='adadelta', loss='binary_crossentropy')",
"_____no_output_____"
],
[
"#ae1 = load_model_weights('ae1', ae1)",
"Loaded weights from disk\n"
],
[
"ae1.fit(x_train, x_train,\n epochs=150,\n batch_size=256,\n shuffle=True,\n validation_data=(x_test, x_test))\n",
"Train on 60000 samples, validate on 10000 samples\nEpoch 1/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.4958 - val_loss: 0.3276\nEpoch 2/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.3185 - val_loss: 0.3114\nEpoch 3/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.3078 - val_loss: 0.3043\nEpoch 4/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.3020 - val_loss: 0.2997\nEpoch 5/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2980 - val_loss: 0.2961\nEpoch 6/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2948 - val_loss: 0.2933\nEpoch 7/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2922 - val_loss: 0.2909\nEpoch 8/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2899 - val_loss: 0.2888\nEpoch 9/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2879 - val_loss: 0.2869\nEpoch 10/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2861 - val_loss: 0.2852\nEpoch 11/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2845 - val_loss: 0.2836\nEpoch 12/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2830 - val_loss: 0.2822\nEpoch 13/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2816 - val_loss: 0.2809\nEpoch 14/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2804 - val_loss: 0.2797\nEpoch 15/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2792 - val_loss: 0.2786\nEpoch 16/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2782 - val_loss: 0.2776\nEpoch 17/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2772 - val_loss: 0.2767\nEpoch 18/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2764 - val_loss: 0.2759\nEpoch 19/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2756 - val_loss: 0.2752\nEpoch 20/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2749 - val_loss: 0.2745\nEpoch 21/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2742 - val_loss: 0.2739\nEpoch 22/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2737 - val_loss: 0.2733\nEpoch 23/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2731 - val_loss: 0.2728\nEpoch 24/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2727 - val_loss: 0.2724\nEpoch 25/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2722 - val_loss: 0.2720\nEpoch 26/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2719 - val_loss: 0.2716\nEpoch 27/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2715 - val_loss: 0.2713\nEpoch 28/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2712 - val_loss: 0.2710\nEpoch 29/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2709 - val_loss: 0.2706\nEpoch 30/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2706 - val_loss: 0.2704\nEpoch 31/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2703 - val_loss: 0.2701\nEpoch 32/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2701 - val_loss: 0.2699\nEpoch 33/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2698 - val_loss: 0.2696\nEpoch 34/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2696 - val_loss: 0.2694\nEpoch 35/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2694 - val_loss: 0.2692\nEpoch 36/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2692 - val_loss: 0.2690\nEpoch 37/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2690 - val_loss: 0.2688\nEpoch 38/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2688 - val_loss: 0.2686\nEpoch 39/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2686 - val_loss: 0.2684\nEpoch 40/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2684 - val_loss: 0.2683\nEpoch 41/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2683 - val_loss: 0.2681\nEpoch 42/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2681 - val_loss: 0.2679\nEpoch 43/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2679 - val_loss: 0.2678\nEpoch 44/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2678 - val_loss: 0.2676\nEpoch 45/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2676 - val_loss: 0.2674\nEpoch 46/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2675 - val_loss: 0.2673\nEpoch 47/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2673 - val_loss: 0.2671\nEpoch 48/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2672 - val_loss: 0.2670\nEpoch 49/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2670 - val_loss: 0.2669\nEpoch 50/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2669 - val_loss: 0.2667\nEpoch 51/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2667 - val_loss: 0.2666\nEpoch 52/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2666 - val_loss: 0.2665\nEpoch 53/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2665 - val_loss: 0.2663\nEpoch 54/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2663 - val_loss: 0.2662\nEpoch 55/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2662 - val_loss: 0.2661\nEpoch 56/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2661 - val_loss: 0.2659\nEpoch 57/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2659 - val_loss: 0.2658\nEpoch 58/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2658 - val_loss: 0.2657\nEpoch 59/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2657 - val_loss: 0.2656\nEpoch 60/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2656 - val_loss: 0.2654\nEpoch 61/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2655 - val_loss: 0.2653\nEpoch 62/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2653 - val_loss: 0.2652\nEpoch 63/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2652 - val_loss: 0.2651\nEpoch 64/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2651 - val_loss: 0.2650\nEpoch 65/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2650 - val_loss: 0.2649\nEpoch 66/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2649 - val_loss: 0.2647\nEpoch 67/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2648 - val_loss: 0.2646\nEpoch 68/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2647 - val_loss: 0.2645\nEpoch 69/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2646 - val_loss: 0.2644\nEpoch 70/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2645 - val_loss: 0.2643\nEpoch 71/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2643 - val_loss: 0.2642\nEpoch 72/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2642 - val_loss: 0.2641\nEpoch 73/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2641 - val_loss: 0.2640\nEpoch 74/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2640 - val_loss: 0.2639\nEpoch 75/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2639 - val_loss: 0.2638\nEpoch 76/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2638 - val_loss: 0.2637\nEpoch 77/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2637 - val_loss: 0.2636\nEpoch 78/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2636 - val_loss: 0.2635\nEpoch 79/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2635 - val_loss: 0.2634\nEpoch 80/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2634 - val_loss: 0.2633\nEpoch 81/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2634 - val_loss: 0.2633\nEpoch 82/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2633 - val_loss: 0.2631\nEpoch 83/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2632 - val_loss: 0.2631\nEpoch 84/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2631 - val_loss: 0.2629\nEpoch 85/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2630 - val_loss: 0.2628\nEpoch 86/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2629 - val_loss: 0.2628\nEpoch 87/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2628 - val_loss: 0.2627\nEpoch 88/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2627 - val_loss: 0.2626\nEpoch 89/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2626 - val_loss: 0.2625\nEpoch 90/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2626 - val_loss: 0.2624\nEpoch 91/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2625 - val_loss: 0.2623\nEpoch 92/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2624 - val_loss: 0.2623\nEpoch 93/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2623 - val_loss: 0.2621\nEpoch 94/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2622 - val_loss: 0.2620\nEpoch 95/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2621 - val_loss: 0.2620\nEpoch 96/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2621 - val_loss: 0.2619\nEpoch 97/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2620 - val_loss: 0.2618\nEpoch 98/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2619 - val_loss: 0.2618\nEpoch 99/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2618 - val_loss: 0.2616\nEpoch 100/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2617 - val_loss: 0.2616\nEpoch 101/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2617 - val_loss: 0.2618\nEpoch 102/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2616 - val_loss: 0.2614\nEpoch 103/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2615 - val_loss: 0.2613\nEpoch 104/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2614 - val_loss: 0.2613\nEpoch 105/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2614 - val_loss: 0.2612\nEpoch 106/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2613 - val_loss: 0.2612\nEpoch 107/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2612 - val_loss: 0.2611\nEpoch 108/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2611 - val_loss: 0.2610\nEpoch 109/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2611 - val_loss: 0.2609\nEpoch 110/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2610 - val_loss: 0.2609\nEpoch 111/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2609 - val_loss: 0.2607\nEpoch 112/150\n60000/60000 [==============================] - 1s 14us/step - loss: 0.2609 - val_loss: 0.2607\nEpoch 113/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2608 - val_loss: 0.2606\nEpoch 114/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2607 - val_loss: 0.2605\nEpoch 115/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2607 - val_loss: 0.2605\nEpoch 116/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2606 - val_loss: 0.2604\nEpoch 117/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2605 - val_loss: 0.2603\nEpoch 118/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2605 - val_loss: 0.2603\nEpoch 119/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2604 - val_loss: 0.2602\nEpoch 120/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2603 - val_loss: 0.2601\nEpoch 121/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2603 - val_loss: 0.2601\nEpoch 122/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2602 - val_loss: 0.2601\nEpoch 123/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2601 - val_loss: 0.2601\nEpoch 124/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2601 - val_loss: 0.2599\nEpoch 125/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2600 - val_loss: 0.2599\nEpoch 126/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2600 - val_loss: 0.2599\nEpoch 127/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2599 - val_loss: 0.2598\nEpoch 128/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2598 - val_loss: 0.2596\nEpoch 129/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2598 - val_loss: 0.2596\nEpoch 130/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2597 - val_loss: 0.2597\nEpoch 131/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2597 - val_loss: 0.2596\nEpoch 132/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2596 - val_loss: 0.2594\nEpoch 133/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2596 - val_loss: 0.2596\nEpoch 134/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2595 - val_loss: 0.2593\nEpoch 135/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2594 - val_loss: 0.2593\nEpoch 136/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2594 - val_loss: 0.2592\nEpoch 137/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2593 - val_loss: 0.2592\nEpoch 138/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2593 - val_loss: 0.2591\nEpoch 139/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2592 - val_loss: 0.2591\nEpoch 140/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2592 - val_loss: 0.2590\nEpoch 141/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2591 - val_loss: 0.2589\nEpoch 142/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2591 - val_loss: 0.2589\nEpoch 143/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2590 - val_loss: 0.2588\nEpoch 144/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2589 - val_loss: 0.2588\nEpoch 145/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2589 - val_loss: 0.2587\nEpoch 146/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2588 - val_loss: 0.2587\nEpoch 147/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2588 - val_loss: 0.2587\nEpoch 148/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2587 - val_loss: 0.2585\nEpoch 149/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2587 - val_loss: 0.2585\nEpoch 150/150\n60000/60000 [==============================] - 1s 13us/step - loss: 0.2586 - val_loss: 0.2584\n"
],
[
"save_model(ae1,'ae1')",
"Saved model to disk\n"
],
[
"input_img = Input(shape=(input_size,))\nencoder_layer1 = ae1.layers[0]\nencoder1 = Model(input_img, encoder_layer1(input_img))\n\nencoder1.summary()",
"Model: \"model_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_2 (InputLayer) (None, 784) 0 \n_________________________________________________________________\ndense_5 (Dense) (None, 32) 25120 \n=================================================================\nTotal params: 25,120\nTrainable params: 25,120\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"num_images = 10\nnp.random.seed(42)\nrandom_test_images = np.random.randint(x_test.shape[0], size=num_images)\n\nencoded_imgs = encoder1.predict(x_test)\ndecoded_imgs = ae1.predict(x_test)\n\nplt.figure(figsize=(18, 4))\n\nfor i, image_idx in enumerate(random_test_images):\n # plot original image\n ax = plt.subplot(3, num_images, i + 1)\n plt.imshow(x_test[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n \n # plot encoded image\n ax = plt.subplot(3, num_images, num_images + i + 1)\n plt.imshow(encoded_imgs[image_idx].reshape(8, 4))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n\n # plot reconstructed image\n ax = plt.subplot(3, num_images, 2*num_images + i + 1)\n plt.imshow(decoded_imgs[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\nplt.show()",
"_____no_output_____"
],
[
"ae2 = Sequential()\n\n# Encoder Layers\nae2.add(Dense(4 * encoding_dim, input_shape=(784,), activation='relu'))\nae2.add(Dense(2 * encoding_dim, activation='relu'))\nae2.add(Dense(encoding_dim, activation='relu'))\n\n# Decoder Layers\nae2.add(Dense(2 * encoding_dim, activation='relu'))\nae2.add(Dense(4 * encoding_dim, activation='relu'))\nae2.add(Dense(784, activation='sigmoid'))\n\nae2.summary()",
"Model: \"sequential_4\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_7 (Dense) (None, 128) 100480 \n_________________________________________________________________\ndense_8 (Dense) (None, 64) 8256 \n_________________________________________________________________\ndense_9 (Dense) (None, 32) 2080 \n_________________________________________________________________\ndense_10 (Dense) (None, 64) 2112 \n_________________________________________________________________\ndense_11 (Dense) (None, 128) 8320 \n_________________________________________________________________\ndense_12 (Dense) (None, 784) 101136 \n=================================================================\nTotal params: 222,384\nTrainable params: 222,384\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"ae2.compile(optimizer='adam', loss='binary_crossentropy')",
"_____no_output_____"
],
[
"ae2 = load_model_weights('ae2', ae2)",
"Loaded weights from disk\n"
],
[
"ae2.fit(x_train, x_train,\n epochs=50,\n batch_size=256,\n validation_data=(x_test, x_test))",
"Train on 60000 samples, validate on 10000 samples\nEpoch 1/50\n60000/60000 [==============================] - 1s 20us/step - loss: 0.0895 - val_loss: 0.0883\nEpoch 2/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0886 - val_loss: 0.0880\nEpoch 3/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0886 - val_loss: 0.0879\nEpoch 4/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0886 - val_loss: 0.0878\nEpoch 5/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0885 - val_loss: 0.0878\nEpoch 6/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0884 - val_loss: 0.0878\nEpoch 7/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0883 - val_loss: 0.0879\nEpoch 8/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0883 - val_loss: 0.0877\nEpoch 9/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0882 - val_loss: 0.0877\nEpoch 10/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0881 - val_loss: 0.0879\nEpoch 11/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0881 - val_loss: 0.0880\nEpoch 12/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0880 - val_loss: 0.0876\nEpoch 13/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0879 - val_loss: 0.0876\nEpoch 14/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0878 - val_loss: 0.0873\nEpoch 15/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0878 - val_loss: 0.0874\nEpoch 16/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0877 - val_loss: 0.0874\nEpoch 17/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0876 - val_loss: 0.0875\nEpoch 18/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0876 - val_loss: 0.0873\nEpoch 19/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0876 - val_loss: 0.0871\nEpoch 20/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0875 - val_loss: 0.0870\nEpoch 21/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0875 - val_loss: 0.0873\nEpoch 22/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0874 - val_loss: 0.0870\nEpoch 23/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0874 - val_loss: 0.0869\nEpoch 24/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0873 - val_loss: 0.0869\nEpoch 25/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0872 - val_loss: 0.0868\nEpoch 26/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0872 - val_loss: 0.0869\nEpoch 27/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0872 - val_loss: 0.0866\nEpoch 28/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0871 - val_loss: 0.0866\nEpoch 29/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0870 - val_loss: 0.0870\nEpoch 30/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0870 - val_loss: 0.0866\nEpoch 31/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0870 - val_loss: 0.0866\nEpoch 32/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0870 - val_loss: 0.0867\nEpoch 33/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0869 - val_loss: 0.0867\nEpoch 34/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0868 - val_loss: 0.0864\nEpoch 35/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0868 - val_loss: 0.0867\nEpoch 36/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0868 - val_loss: 0.0864\nEpoch 37/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0867 - val_loss: 0.0865\nEpoch 38/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0867 - val_loss: 0.0864\nEpoch 39/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0866 - val_loss: 0.0865\nEpoch 40/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0866 - val_loss: 0.0861\nEpoch 41/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0866 - val_loss: 0.0868\nEpoch 42/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0866 - val_loss: 0.0862\nEpoch 43/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0865 - val_loss: 0.0862\nEpoch 44/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0865 - val_loss: 0.0864\nEpoch 45/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0865 - val_loss: 0.0862\nEpoch 46/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0864 - val_loss: 0.0861\nEpoch 47/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0864 - val_loss: 0.0862\nEpoch 48/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0863 - val_loss: 0.0861\nEpoch 49/50\n60000/60000 [==============================] - 1s 18us/step - loss: 0.0863 - val_loss: 0.0861\nEpoch 50/50\n60000/60000 [==============================] - 1s 17us/step - loss: 0.0863 - val_loss: 0.0861\n"
],
[
"save_model(ae2,'ae2')",
"Saved model to disk\n"
],
[
"input_img = Input(shape=(input_size,))\nencoder_layer1 = ae2.layers[0]\nencoder_layer2 = ae2.layers[1]\nencoder_layer3 = ae2.layers[2]\nencoder2 = Model(input_img, encoder_layer3(encoder_layer2(encoder_layer1(input_img))))\n\nencoder2.summary()",
"Model: \"model_3\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_3 (InputLayer) (None, 784) 0 \n_________________________________________________________________\ndense_7 (Dense) (None, 128) 100480 \n_________________________________________________________________\ndense_8 (Dense) (None, 64) 8256 \n_________________________________________________________________\ndense_9 (Dense) (None, 32) 2080 \n=================================================================\nTotal params: 110,816\nTrainable params: 110,816\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"num_images = 10\nnp.random.seed(42)\nrandom_test_images = np.random.randint(x_test.shape[0], size=num_images)\n\nencoded_imgs = encoder2.predict(x_test)\ndecoded_imgs = ae2.predict(x_test)\n\nplt.figure(figsize=(18, 4))\n\nfor i, image_idx in enumerate(random_test_images):\n # plot original image\n ax = plt.subplot(3, num_images, i + 1)\n plt.imshow(x_test[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n \n # plot encoded image\n ax = plt.subplot(3, num_images, num_images + i + 1)\n plt.imshow(encoded_imgs[image_idx].reshape(8, 4))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n\n # plot reconstructed image\n ax = plt.subplot(3, num_images, 2*num_images + i + 1)\n plt.imshow(decoded_imgs[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\nplt.show()",
"_____no_output_____"
],
[
"x_train_r = x_train.reshape((len(x_train), 28, 28, 1))\nx_test_r = x_test.reshape((len(x_test), 28, 28, 1))",
"_____no_output_____"
],
[
"autoencoder = Sequential()\n\n# Encoder Layers\nautoencoder.add(Conv2D(16, (3, 3), activation='relu', padding='same', input_shape=x_train_r.shape[1:]))\nautoencoder.add(MaxPooling2D((2, 2), padding='same'))\nautoencoder.add(Conv2D(8, (3, 3), activation='relu', padding='same'))\nautoencoder.add(MaxPooling2D((2, 2), padding='same'))\nautoencoder.add(Conv2D(8, (3, 3), strides=(2,2), activation='relu', padding='same'))\n\n# Flatten encoding for visualization\nautoencoder.add(Flatten())\nautoencoder.add(Reshape((4, 4, 8)))\n\n# Decoder Layers\nautoencoder.add(Conv2D(8, (3, 3), activation='relu', padding='same'))\nautoencoder.add(UpSampling2D((2, 2)))\nautoencoder.add(Conv2D(8, (3, 3), activation='relu', padding='same'))\nautoencoder.add(UpSampling2D((2, 2)))\nautoencoder.add(Conv2D(16, (3, 3), activation='relu'))\nautoencoder.add(UpSampling2D((2, 2)))\nautoencoder.add(Conv2D(1, (3, 3), activation='sigmoid', padding='same'))\n\nautoencoder.summary()",
"Model: \"sequential_5\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_1 (Conv2D) (None, 28, 28, 16) 160 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 14, 14, 8) 1160 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 4, 4, 8) 584 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 128) 0 \n_________________________________________________________________\nreshape_1 (Reshape) (None, 4, 4, 8) 0 \n_________________________________________________________________\nconv2d_4 (Conv2D) (None, 4, 4, 8) 584 \n_________________________________________________________________\nup_sampling2d_1 (UpSampling2 (None, 8, 8, 8) 0 \n_________________________________________________________________\nconv2d_5 (Conv2D) (None, 8, 8, 8) 584 \n_________________________________________________________________\nup_sampling2d_2 (UpSampling2 (None, 16, 16, 8) 0 \n_________________________________________________________________\nconv2d_6 (Conv2D) (None, 14, 14, 16) 1168 \n_________________________________________________________________\nup_sampling2d_3 (UpSampling2 (None, 28, 28, 16) 0 \n_________________________________________________________________\nconv2d_7 (Conv2D) (None, 28, 28, 1) 145 \n=================================================================\nTotal params: 4,385\nTrainable params: 4,385\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"encoder = Model(inputs=autoencoder.input, outputs=autoencoder.get_layer('flatten_1').output)\nencoder.summary()",
"Model: \"model_4\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_1_input (InputLayer) (None, 28, 28, 1) 0 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 28, 28, 16) 160 \n_________________________________________________________________\nmax_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0 \n_________________________________________________________________\nconv2d_2 (Conv2D) (None, 14, 14, 8) 1160 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 4, 4, 8) 584 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 128) 0 \n=================================================================\nTotal params: 1,904\nTrainable params: 1,904\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"autoencoder.compile(optimizer='adam', loss='binary_crossentropy')",
"_____no_output_____"
],
[
"autoencoder = load_model_weights('ae3',autoencoder)",
"Loaded weights from disk\n"
],
[
"autoencoder.fit(x_train_r, x_train_r,\n epochs=10,\n batch_size=128,\n validation_data=(x_test_r, x_test_r))",
"Train on 60000 samples, validate on 10000 samples\nEpoch 1/10\n60000/60000 [==============================] - 3s 48us/step - loss: 0.0917 - val_loss: 0.0901\nEpoch 2/10\n60000/60000 [==============================] - 3s 46us/step - loss: 0.0909 - val_loss: 0.0894\nEpoch 3/10\n60000/60000 [==============================] - 3s 47us/step - loss: 0.0902 - val_loss: 0.0888\nEpoch 4/10\n60000/60000 [==============================] - 3s 47us/step - loss: 0.0897 - val_loss: 0.0887\nEpoch 5/10\n60000/60000 [==============================] - 3s 48us/step - loss: 0.0892 - val_loss: 0.0881\nEpoch 6/10\n60000/60000 [==============================] - 3s 48us/step - loss: 0.0888 - val_loss: 0.0874\nEpoch 7/10\n60000/60000 [==============================] - 3s 47us/step - loss: 0.0884 - val_loss: 0.0870\nEpoch 8/10\n60000/60000 [==============================] - 3s 47us/step - loss: 0.0880 - val_loss: 0.0874\nEpoch 9/10\n60000/60000 [==============================] - 3s 46us/step - loss: 0.0877 - val_loss: 0.0866\nEpoch 10/10\n60000/60000 [==============================] - 3s 46us/step - loss: 0.0874 - val_loss: 0.0861\n"
],
[
"save_model(autoencoder, 'ae3')",
"Saved model to disk\n"
],
[
"num_images = 10\nnp.random.seed(42)\nrandom_test_images = np.random.randint(x_test.shape[0], size=num_images)\n\nencoded_imgs = encoder.predict(x_test_r)\ndecoded_imgs = autoencoder.predict(x_test_r)\n\nplt.figure(figsize=(18, 4))\n\nfor i, image_idx in enumerate(random_test_images):\n # plot original image\n ax = plt.subplot(3, num_images, i + 1)\n plt.imshow(x_test[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n \n # plot encoded image\n ax = plt.subplot(3, num_images, num_images + i + 1)\n plt.imshow(encoded_imgs[image_idx].reshape(16, 8))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\n\n # plot reconstructed image\n ax = plt.subplot(3, num_images, 2*num_images + i + 1)\n plt.imshow(decoded_imgs[image_idx].reshape(28, 28))\n plt.gray()\n ax.get_xaxis().set_visible(False)\n ax.get_yaxis().set_visible(False)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1ed546348d06c40b03c699f15b747c302bb2a9
| 32,567 |
ipynb
|
Jupyter Notebook
|
forecasting/notebooks_exploration_2/data_cleaning.ipynb
|
Duncan-Haywood/finance_ml_analysis
|
ce42917fe69e81cf19f3f4893d3cc0f60cfd961c
|
[
"MIT"
] | 1 |
2021-05-05T18:24:47.000Z
|
2021-05-05T18:24:47.000Z
|
forecasting/notebooks_exploration_2/data_cleaning.ipynb
|
Duncan-Haywood/finance_ml_analysis
|
ce42917fe69e81cf19f3f4893d3cc0f60cfd961c
|
[
"MIT"
] | null | null | null |
forecasting/notebooks_exploration_2/data_cleaning.ipynb
|
Duncan-Haywood/finance_ml_analysis
|
ce42917fe69e81cf19f3f4893d3cc0f60cfd961c
|
[
"MIT"
] | 1 |
2021-05-25T19:09:48.000Z
|
2021-05-25T19:09:48.000Z
| 40.0086 | 171 | 0.376209 |
[
[
[
"# !pip install --upgrade sklearn\nimport pandas as pd\nimport numpy as np\n# !pwd",
"Requirement already up-to-date: sklearn in /Users/admin/miniconda3/lib/python3.8/site-packages (0.0)\nRequirement already satisfied, skipping upgrade: scikit-learn in /Users/admin/miniconda3/lib/python3.8/site-packages (from sklearn) (0.23.2)\nRequirement already satisfied, skipping upgrade: scipy>=0.19.1 in /Users/admin/miniconda3/lib/python3.8/site-packages (from scikit-learn->sklearn) (1.5.4)\nRequirement already satisfied, skipping upgrade: numpy>=1.13.3 in /Users/admin/miniconda3/lib/python3.8/site-packages (from scikit-learn->sklearn) (1.19.5)\nRequirement already satisfied, skipping upgrade: joblib>=0.11 in /Users/admin/miniconda3/lib/python3.8/site-packages (from scikit-learn->sklearn) (1.0.1)\nRequirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /Users/admin/miniconda3/lib/python3.8/site-packages (from scikit-learn->sklearn) (2.1.0)\n"
],
[
"df = pd.read_pickle(\"forecasting/notebooks_exploration_2/['AAPL']_daily.pkl\")\n# df.dropna(axis=0, inplace=True)\n# df = df.reset_index().drop(labels=[i for i in range(10)])\ndf.replace([np.inf, -np.inf], np.nan, inplace=True)\ndf.dropna(axis=1, inplace=True)\ndisplay(df,df.info(), df.describe())\n# display(df.AAPL)",
"<class 'pandas.core.frame.DataFrame'>\nIndex: 5028 entries, 2001-04-02 to 2021-03-26\nColumns: 184 entries, ('AAPL', 'open') to ('AAPL', 'year_sin')\ndtypes: float64(183), int64(1)\nmemory usage: 7.1+ MB\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a1ed94b7cb7f8e4d29eda24958c8a912fe977dc
| 250,387 |
ipynb
|
Jupyter Notebook
|
slgTensorflow/neural_net_training.ipynb
|
slegroux/slgEdu
|
b54db17213e9914b6498a3a7d8552fa06f808260
|
[
"Apache-2.0"
] | null | null | null |
slgTensorflow/neural_net_training.ipynb
|
slegroux/slgEdu
|
b54db17213e9914b6498a3a7d8552fa06f808260
|
[
"Apache-2.0"
] | null | null | null |
slgTensorflow/neural_net_training.ipynb
|
slegroux/slgEdu
|
b54db17213e9914b6498a3a7d8552fa06f808260
|
[
"Apache-2.0"
] | null | null | null | 494.835968 | 77,104 | 0.92139 |
[
[
[
"import tensorflow as tf\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nplt.style.use('ggplot')",
"_____no_output_____"
]
],
[
[
"## Data",
"_____no_output_____"
]
],
[
[
"n_observations = 10000\nxs = np.linspace(-3,3,n_observations)\nys = np.sin(xs) + np.random.uniform(-0.5,0.5,n_observations)\nplt.plot(xs,ys, marker='+',alpha=0.4)",
"_____no_output_____"
]
],
[
[
"## Cost",
"_____no_output_____"
]
],
[
[
"sess = tf.Session()\nX = tf.placeholder(tf.float32, name='X')\nY = tf.placeholder(tf.float32, name='Y')\nn = tf.random_normal([1000],stddev=0.1).eval(session=sess)\nplt.hist(n)",
"_____no_output_____"
],
[
"W = tf.Variable(tf.random_normal([1], dtype=tf.float32, stddev=0.1), name='weight')\nB = tf.Variable(tf.constant([0], dtype=tf.float32), name='bias')\nY_pred = X * W + B",
"_____no_output_____"
],
[
"cost = tf.abs(Y_pred - Y)\n# sum over all samples (similar to np.mean)\ncost = tf.reduce_mean(cost)",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"sess = tf.InteractiveSession()\n\n# Plot the true data distribution\nfig, ax = plt.subplots(1, 1)\nax.scatter(xs, ys, alpha=0.15, marker='+')\n\n# with tf.Session() as sess:\n# we already have an interactive session open\n\n# init all the variables in the graph\n# This will set `W` and `b` to their initial random normal value.\nsess.run(tf.global_variables_initializer())\n\n# We now run a loop over epochs\nprev_training_cost = 0.0\nn_iterations = 500\noptimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost)\n\nfor it_i in range(n_iterations):\n sess.run(optimizer, feed_dict={X: xs, Y: ys})\n training_cost = sess.run(cost, feed_dict={X: xs, Y: ys})\n\n # every 10 iterations\n if it_i % 10 == 0:\n # let's plot the x versus the predicted y\n ys_pred = Y_pred.eval(feed_dict={X: xs}, session=sess)\n\n # We'll draw points as a scatter plot just like before\n # Except we'll also scale the alpha value so that it gets\n # darker as the iterations get closer to the end\n ax.plot(xs, ys_pred, 'k', alpha=float(it_i) / (n_iterations/2.))\n fig.show()\n plt.draw()\n\n # And let's print our training cost: mean of absolute differences\n# print(training_cost)\n\n # Allow the training to quit if we've reached a minimum\n if np.abs(prev_training_cost - training_cost) < 0.000001:\n break\n\n # Keep track of the training cost\n prev_training_cost = training_cost\n",
"_____no_output_____"
]
],
[
[
"## Stochastic/minibatch gradient descent",
"_____no_output_____"
]
],
[
[
"idxs = np.arange(100)\nrand_idxs = np.random.permutation(idxs)\nbatch_size = 10\nn_batches = len(rand_idxs) // batch_size\nprint('# of batches:', n_batches)",
"('# of batches:', 10)\n"
],
[
"def distance(p1, p2):\n return tf.abs(p1 - p2)\n\ndef train(X, Y, Y_pred, n_iterations=100, batch_size=200, learning_rate=0.02):\n cost = tf.reduce_mean(distance(Y_pred, Y))\n optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)\n fig, ax = plt.subplots(1, 1)\n ax.scatter(xs, ys, alpha=0.15, marker='+')\n ax.set_xlim([-4, 4])\n ax.set_ylim([-2, 2])\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n\n # We now run a loop over epochs\n prev_training_cost = 0.0\n for it_i in range(n_iterations):\n idxs = np.random.permutation(range(len(xs)))\n n_batches = len(idxs) // batch_size\n for batch_i in range(n_batches):\n idxs_i = idxs[batch_i * batch_size: (batch_i + 1) * batch_size]\n sess.run(optimizer, feed_dict={X: xs[idxs_i], Y: ys[idxs_i]})\n\n training_cost = sess.run(cost, feed_dict={X: xs, Y: ys})\n\n if it_i % 10 == 0:\n ys_pred = Y_pred.eval(feed_dict={X: xs}, session=sess)\n ax.plot(xs, ys_pred, 'k', alpha=it_i / float(n_iterations))\n print(training_cost)\n fig.show()\n plt.draw()",
"_____no_output_____"
],
[
"Y_pred = tf.Variable(tf.random_normal([1]), name='bias')\nfor pow_i in range(0, 4):\n W = tf.Variable(\n tf.random_normal([1], stddev=0.1), name='weight_%d' % pow_i)\n Y_pred = tf.add(tf.mul(tf.pow(X, pow_i), W), Y_pred)\n\n# And then we'll retrain with our new Y_pred\ntrain(X, Y, Y_pred)\n0.487767",
"0.697558\n0.488421\n0.376293\n0.621024\n0.524434\n0.300169\n0.646549\n0.437128\n0.295415\n0.587943\n"
],
[
"from tensorflow.python.framework import ops\nops.reset_default_graph()\ng = tf.get_default_graph()\nsess = tf.InteractiveSession()\n\nn_observations = 10000\nxs = np.linspace(-3,3,n_observations)\nys = np.sin(xs) + np.random.uniform(-0.5,0.5,n_observations)\n\nX = tf.placeholder(tf.float32, shape=[1, None], name='X')\nY = tf.placeholder(tf.float32, shape=[1, None], name='Y')\n\nW = tf.Variable(tf.random_normal([1], dtype=tf.float32, stddev=0.1), name='weight')\nB = tf.Variable(tf.constant([0], dtype=tf.float32), name='bias')\nY_pred = X * W + B\n\ndef linear(X, n_input, n_output, activation=None, scope=None):\n with tf.variable_scope(scope or \"linear\"):\n W = tf.get_variable(\n name='W',\n shape=[n_input, n_output],\n initializer=tf.random_normal_initializer(mean=0.0, stddev=0.1))\n b = tf.get_variable(\n name='b',\n shape=[n_output],\n initializer=tf.constant_initializer())\n h = tf.matmul(X, W) + b\n if activation is not None:\n h = activation(h)\n return h\n\n\n# h = linear(X, 2, 10, scope='layer1')\n# h2 = linear(h, 10, 10, scope='layer2')\n# h3 = linear(h2, 10, 3, scope='layer3')\n# [op.name for op in tf.get_default_graph().get_operations()]\n\n# train on previous example\nsimple = linear(X,1,1)\n\ndef distance(p1, p2):\n return tf.abs(p1 - p2)\n",
"_____no_output_____"
],
[
"n_iterations = 100\nbatch_size = 10\ncost = tf.reduce_mean(tf.reduce_sum(distance(Y_pred, Y), 1))\noptimizer = tf.train.AdamOptimizer(0.001).minimize(cost)\n# # optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)\nsess.run(tf.global_variables_initializer())\n# # We now run a loop over epochs\nprev_training_cost = 0.0\nfor it_i in range(n_iterations):\n idxs = np.random.permutation(range(len(xs)))\n n_batches = len(idxs) // batch_size\n for batch_i in range(n_batches):\n idxs_i = idxs[batch_i * batch_size: (batch_i + 1) * batch_size]\n sess.run(optimizer, feed_dict={X: xs[idxs_i], Y: ys[idxs_i]})\n\n# training_cost = sess.run(cost, feed_dict={X: xs, Y: ys})\n# print(it_i, training_cost)",
"_____no_output_____"
],
[
"def train2(X, Y, Y_pred, n_iterations=100, batch_size=50, learning_rate=0.02):\n# n_iterations = 500\n# batch_size = 50\n cost = tf.reduce_mean(tf.reduce_sum(distance(Y_pred, Y), 1))\n optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)\n # optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)\n sess.run(tf.global_variables_initializer())\n # We now run a loop over epochs\n prev_training_cost = 0.0\n for it_i in range(n_iterations):\n idxs = np.random.permutation(range(len(xs)))\n n_batches = len(idxs) // batch_size\n for batch_i in range(n_batches):\n idxs_i = idxs[batch_i * batch_size: (batch_i + 1) * batch_size]\n sess.run(optimizer, feed_dict={X: xs[idxs_i], Y: ys[idxs_i]})\n\n training_cost = sess.run(cost, feed_dict={X: xs, Y: ys})\n print(it_i, training_cost)\n\n # if (it_i + 1) % 20 == 0:\n # ys_pred = Y_pred.eval(feed_dict={X: xs}, session=sess)\n # fig, ax = plt.subplots(1, 1)\n # # img = np.clip(ys_pred.reshape(img.shape), 0, 255).astype(np.uint8)\n # plt.imshow(img)\n # plt.show()\n\ntrain2(X, Y, Y_pred)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1edc1dbb38a0a42a3ae3f3a70c897273a796da
| 79,880 |
ipynb
|
Jupyter Notebook
|
model_rnn/breath/lstm.ipynb
|
nikhilkmr300/sop-covid
|
0854aa5ee0d15b7976c79730d2ff76a8e645d1e7
|
[
"BSD-4-Clause-UC"
] | null | null | null |
model_rnn/breath/lstm.ipynb
|
nikhilkmr300/sop-covid
|
0854aa5ee0d15b7976c79730d2ff76a8e645d1e7
|
[
"BSD-4-Clause-UC"
] | null | null | null |
model_rnn/breath/lstm.ipynb
|
nikhilkmr300/sop-covid
|
0854aa5ee0d15b7976c79730d2ff76a8e645d1e7
|
[
"BSD-4-Clause-UC"
] | 1 |
2020-12-07T09:36:31.000Z
|
2020-12-07T09:36:31.000Z
| 120.664653 | 25,882 | 0.777041 |
[
[
[
"from google.colab import drive\ndrive.mount('/content/drive', force_remount=True)",
"Mounted at /content/drive\n"
],
[
"cd /content/drive/MyDrive/sop-covid/voice/model_rnn/breath",
"/content/drive/MyDrive/sop-covid/voice/model_rnn/breath\n"
],
[
"!unzip ../../data_rnn/data_breath.zip",
"Archive: ../../data_rnn/data_breath.zip\nreplace data_breath/valid_y.npy? [y]es, [n]o, [A]ll, [N]one, [r]ename: "
],
[
"import numpy as np\nimport tensorflow as tf\nimport tensorflow.keras as keras\nimport matplotlib.pyplot as plt\nimport pickle\nimport os\n\nimport sys\nsys.path.append('..')\n\nfrom utils import *",
"_____no_output_____"
],
[
"SEED = 1\nnp.random.seed(SEED)\ntf.random.set_seed(SEED)",
"_____no_output_____"
],
[
"train_X = np.load(os.path.join('data_breath', 'train_X.npy'))\ntrain_y = np.load(os.path.join('data_breath', 'train_y.npy'))\n\nvalid_X = np.load(os.path.join('data_breath', 'valid_X.npy'))\nvalid_y = np.load(os.path.join('data_breath', 'valid_y.npy'))\n\ntest_X = np.load(os.path.join('data_breath', 'test_X.npy'))\ntest_y = np.load(os.path.join('data_breath', 'test_y.npy'))",
"_____no_output_____"
],
[
"sc = Scaler()\nsc.fit(train_X, (0, 1))\n\ntrain_X_n = sc.transform(train_X, 'normalize')\ntrain_X_s = sc.transform(train_X, 'standardize')\n\nvalid_X_n = sc.transform(valid_X, 'normalize')\nvalid_X_s = sc.transform(valid_X, 'standardize')\n\ntest_X_n = sc.transform(test_X, 'normalize')\ntest_X_s = sc.transform(test_X, 'standardize')",
"_____no_output_____"
],
[
"# Undersampling the majority class to make the distribution 50:50.\ntrain_X_n_under = train_X[:int(2 * train_y.sum())]\ntrain_y_under = train_y[:int(2 * train_y.sum())]\n\nvalid_X_n_under = valid_X[:int(2 * valid_y.sum())]\nvalid_y_under = valid_y[:int(2 * valid_y.sum())]\n\ntest_X_n_under = test_X[:int(2 * test_y.sum())]\ntest_y_under = test_y[:int(2 * test_y.sum())]",
"_____no_output_____"
],
[
"# Hyperparameters\nlearning_rate = 1e-3\nepochs = 100\nbatch_size = 256",
"_____no_output_____"
],
[
"# Callback for early stopping\nes_callback = keras.callbacks.EarlyStopping(\n monitor='val_loss',\n min_delta=0.0001,\n patience=5,\n restore_best_weights=True\n)\n\n# Callback for reducing learning rate on loss plateauing\nplateau_callback = keras.callbacks.ReduceLROnPlateau(\n monitor='val_loss',\n factor=0.1,\n patience=5,\n min_delta=0.0001\n)",
"_____no_output_____"
],
[
"metrics = [\n keras.metrics.BinaryAccuracy(name='acc'),\n keras.metrics.Precision(name='precision'),\n keras.metrics.Recall(name='recall'),\n keras.metrics.AUC(name='auc'),\n keras.metrics.TruePositives(name='tp'),\n keras.metrics.FalsePositives(name='fp'),\n keras.metrics.TrueNegatives(name='tn'),\n keras.metrics.FalseNegatives(name='fn')\n]",
"_____no_output_____"
],
[
"model = keras.Sequential([\n keras.layers.LSTM(32, activation='tanh', return_sequences=True, input_shape=train_X.shape[1:]),\n keras.layers.LSTM(32, activation='tanh', return_sequences=False),\n keras.layers.Dense(32, activation='relu'),\n keras.layers.Dense(1, activation='sigmoid')\n])",
"_____no_output_____"
],
[
"model.compile(\n optimizer=keras.optimizers.Adam(lr=learning_rate),\n loss='binary_crossentropy',\n metrics=metrics\n)",
"_____no_output_____"
],
[
"# %%script echo \"Comment line with %%script echo to run this cell.\"\n\nhistory = model.fit(\n train_X_n_under,\n train_y_under,\n epochs=epochs,\n batch_size=batch_size,\n validation_data=(valid_X_n_under, valid_y_under),\n callbacks=[es_callback, plateau_callback],\n shuffle=True\n)",
"Epoch 1/100\n2/2 [==============================] - 2s 830ms/step - loss: 0.6952 - acc: 0.5036 - precision: 0.5020 - recall: 0.9343 - auc: 0.5247 - tp: 128.0000 - fp: 127.0000 - tn: 10.0000 - fn: 9.0000 - val_loss: 0.6988 - val_acc: 0.5000 - val_precision: 0.5000 - val_recall: 0.8824 - val_auc: 0.4152 - val_tp: 15.0000 - val_fp: 15.0000 - val_tn: 2.0000 - val_fn: 2.0000\nEpoch 2/100\n2/2 [==============================] - 1s 259ms/step - loss: 0.6898 - acc: 0.5219 - precision: 0.5124 - recall: 0.9051 - auc: 0.5578 - tp: 124.0000 - fp: 118.0000 - tn: 19.0000 - fn: 13.0000 - val_loss: 0.7005 - val_acc: 0.4706 - val_precision: 0.4839 - val_recall: 0.8824 - val_auc: 0.4602 - val_tp: 15.0000 - val_fp: 16.0000 - val_tn: 1.0000 - val_fn: 2.0000\nEpoch 3/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6880 - acc: 0.5219 - precision: 0.5123 - recall: 0.9124 - auc: 0.5862 - tp: 125.0000 - fp: 119.0000 - tn: 18.0000 - fn: 12.0000 - val_loss: 0.6998 - val_acc: 0.4706 - val_precision: 0.4839 - val_recall: 0.8824 - val_auc: 0.4464 - val_tp: 15.0000 - val_fp: 16.0000 - val_tn: 1.0000 - val_fn: 2.0000\nEpoch 4/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6845 - acc: 0.5328 - precision: 0.5187 - recall: 0.9124 - auc: 0.6063 - tp: 125.0000 - fp: 116.0000 - tn: 21.0000 - fn: 12.0000 - val_loss: 0.6982 - val_acc: 0.4706 - val_precision: 0.4828 - val_recall: 0.8235 - val_auc: 0.5225 - val_tp: 14.0000 - val_fp: 15.0000 - val_tn: 2.0000 - val_fn: 3.0000\nEpoch 5/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6810 - acc: 0.5438 - precision: 0.5261 - recall: 0.8832 - auc: 0.6222 - tp: 121.0000 - fp: 109.0000 - tn: 28.0000 - fn: 16.0000 - val_loss: 0.6957 - val_acc: 0.4706 - val_precision: 0.4815 - val_recall: 0.7647 - val_auc: 0.5484 - val_tp: 13.0000 - val_fp: 14.0000 - val_tn: 3.0000 - val_fn: 4.0000\nEpoch 6/100\n2/2 [==============================] - 1s 263ms/step - loss: 0.6767 - acc: 0.5474 - precision: 0.5340 - recall: 0.7445 - auc: 0.6211 - tp: 102.0000 - fp: 89.0000 - tn: 48.0000 - fn: 35.0000 - val_loss: 0.6936 - val_acc: 0.5882 - val_precision: 0.8000 - val_recall: 0.2353 - val_auc: 0.6626 - val_tp: 4.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 13.0000\nEpoch 7/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6729 - acc: 0.5949 - precision: 0.8095 - recall: 0.2482 - auc: 0.6530 - tp: 34.0000 - fp: 8.0000 - tn: 129.0000 - fn: 103.0000 - val_loss: 0.6903 - val_acc: 0.5588 - val_precision: 0.7500 - val_recall: 0.1765 - val_auc: 0.6782 - val_tp: 3.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 14.0000\nEpoch 8/100\n2/2 [==============================] - 1s 258ms/step - loss: 0.6709 - acc: 0.6022 - precision: 0.8333 - recall: 0.2555 - auc: 0.6600 - tp: 35.0000 - fp: 7.0000 - tn: 130.0000 - fn: 102.0000 - val_loss: 0.6891 - val_acc: 0.5882 - val_precision: 0.8000 - val_recall: 0.2353 - val_auc: 0.7024 - val_tp: 4.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 13.0000\nEpoch 9/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6689 - acc: 0.5949 - precision: 0.8095 - recall: 0.2482 - auc: 0.6790 - tp: 34.0000 - fp: 8.0000 - tn: 129.0000 - fn: 103.0000 - val_loss: 0.6864 - val_acc: 0.5882 - val_precision: 0.8000 - val_recall: 0.2353 - val_auc: 0.7007 - val_tp: 4.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 13.0000\nEpoch 10/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6666 - acc: 0.5985 - precision: 0.8000 - recall: 0.2628 - auc: 0.6900 - tp: 36.0000 - fp: 9.0000 - tn: 128.0000 - fn: 101.0000 - val_loss: 0.6859 - val_acc: 0.6176 - val_precision: 0.8333 - val_recall: 0.2941 - val_auc: 0.7232 - val_tp: 5.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 12.0000\nEpoch 11/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6647 - acc: 0.6131 - precision: 0.8163 - recall: 0.2920 - auc: 0.6890 - tp: 40.0000 - fp: 9.0000 - tn: 128.0000 - fn: 97.0000 - val_loss: 0.6847 - val_acc: 0.6471 - val_precision: 0.8571 - val_recall: 0.3529 - val_auc: 0.7128 - val_tp: 6.0000 - val_fp: 1.0000 - val_tn: 16.0000 - val_fn: 11.0000\nEpoch 12/100\n2/2 [==============================] - 1s 256ms/step - loss: 0.6609 - acc: 0.6204 - precision: 0.8000 - recall: 0.3212 - auc: 0.6943 - tp: 44.0000 - fp: 11.0000 - tn: 126.0000 - fn: 93.0000 - val_loss: 0.6850 - val_acc: 0.7353 - val_precision: 0.7222 - val_recall: 0.7647 - val_auc: 0.6886 - val_tp: 13.0000 - val_fp: 5.0000 - val_tn: 12.0000 - val_fn: 4.0000\nEpoch 13/100\n2/2 [==============================] - 1s 261ms/step - loss: 0.6585 - acc: 0.6387 - precision: 0.6319 - recall: 0.6642 - auc: 0.6912 - tp: 91.0000 - fp: 53.0000 - tn: 84.0000 - fn: 46.0000 - val_loss: 0.6799 - val_acc: 0.5882 - val_precision: 0.5652 - val_recall: 0.7647 - val_auc: 0.6713 - val_tp: 13.0000 - val_fp: 10.0000 - val_tn: 7.0000 - val_fn: 4.0000\nEpoch 14/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6564 - acc: 0.6131 - precision: 0.5917 - recall: 0.7299 - auc: 0.7007 - tp: 100.0000 - fp: 69.0000 - tn: 68.0000 - fn: 37.0000 - val_loss: 0.6829 - val_acc: 0.5294 - val_precision: 0.5200 - val_recall: 0.7647 - val_auc: 0.6471 - val_tp: 13.0000 - val_fp: 12.0000 - val_tn: 5.0000 - val_fn: 4.0000\nEpoch 15/100\n2/2 [==============================] - 1s 268ms/step - loss: 0.6523 - acc: 0.6131 - precision: 0.5906 - recall: 0.7372 - auc: 0.7012 - tp: 101.0000 - fp: 70.0000 - tn: 67.0000 - fn: 36.0000 - val_loss: 0.6889 - val_acc: 0.6176 - val_precision: 0.6000 - val_recall: 0.7059 - val_auc: 0.6332 - val_tp: 12.0000 - val_fp: 8.0000 - val_tn: 9.0000 - val_fn: 5.0000\nEpoch 16/100\n2/2 [==============================] - 1s 267ms/step - loss: 0.6508 - acc: 0.6277 - precision: 0.6159 - recall: 0.6788 - auc: 0.6919 - tp: 93.0000 - fp: 58.0000 - tn: 79.0000 - fn: 44.0000 - val_loss: 0.6866 - val_acc: 0.6471 - val_precision: 0.6471 - val_recall: 0.6471 - val_auc: 0.6349 - val_tp: 11.0000 - val_fp: 6.0000 - val_tn: 11.0000 - val_fn: 6.0000\nEpoch 17/100\n2/2 [==============================] - 1s 263ms/step - loss: 0.6482 - acc: 0.6423 - precision: 0.6535 - recall: 0.6058 - auc: 0.6933 - tp: 83.0000 - fp: 44.0000 - tn: 93.0000 - fn: 54.0000 - val_loss: 0.6807 - val_acc: 0.6176 - val_precision: 0.6250 - val_recall: 0.5882 - val_auc: 0.6471 - val_tp: 10.0000 - val_fp: 6.0000 - val_tn: 11.0000 - val_fn: 7.0000\nEpoch 18/100\n2/2 [==============================] - 1s 267ms/step - loss: 0.6436 - acc: 0.6460 - precision: 0.6587 - recall: 0.6058 - auc: 0.7044 - tp: 83.0000 - fp: 43.0000 - tn: 94.0000 - fn: 54.0000 - val_loss: 0.6732 - val_acc: 0.6471 - val_precision: 0.6190 - val_recall: 0.7647 - val_auc: 0.6955 - val_tp: 13.0000 - val_fp: 8.0000 - val_tn: 9.0000 - val_fn: 4.0000\nEpoch 19/100\n2/2 [==============================] - 1s 259ms/step - loss: 0.6360 - acc: 0.6606 - precision: 0.6486 - recall: 0.7007 - auc: 0.7235 - tp: 96.0000 - fp: 52.0000 - tn: 85.0000 - fn: 41.0000 - val_loss: 0.6714 - val_acc: 0.6176 - val_precision: 0.5909 - val_recall: 0.7647 - val_auc: 0.6851 - val_tp: 13.0000 - val_fp: 9.0000 - val_tn: 8.0000 - val_fn: 4.0000\nEpoch 20/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6334 - acc: 0.6241 - precision: 0.5988 - recall: 0.7518 - auc: 0.7259 - tp: 103.0000 - fp: 69.0000 - tn: 68.0000 - fn: 34.0000 - val_loss: 0.6702 - val_acc: 0.5588 - val_precision: 0.5417 - val_recall: 0.7647 - val_auc: 0.6782 - val_tp: 13.0000 - val_fp: 11.0000 - val_tn: 6.0000 - val_fn: 4.0000\nEpoch 21/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.6336 - acc: 0.5949 - precision: 0.5699 - recall: 0.7737 - auc: 0.7237 - tp: 106.0000 - fp: 80.0000 - tn: 57.0000 - fn: 31.0000 - val_loss: 0.6629 - val_acc: 0.6176 - val_precision: 0.5909 - val_recall: 0.7647 - val_auc: 0.6799 - val_tp: 13.0000 - val_fp: 9.0000 - val_tn: 8.0000 - val_fn: 4.0000\nEpoch 22/100\n2/2 [==============================] - 1s 261ms/step - loss: 0.6264 - acc: 0.6241 - precision: 0.6000 - recall: 0.7445 - auc: 0.7265 - tp: 102.0000 - fp: 68.0000 - tn: 69.0000 - fn: 35.0000 - val_loss: 0.6485 - val_acc: 0.6471 - val_precision: 0.6316 - val_recall: 0.7059 - val_auc: 0.6834 - val_tp: 12.0000 - val_fp: 7.0000 - val_tn: 10.0000 - val_fn: 5.0000\nEpoch 23/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6180 - acc: 0.6861 - precision: 0.6783 - recall: 0.7080 - auc: 0.7275 - tp: 97.0000 - fp: 46.0000 - tn: 91.0000 - fn: 40.0000 - val_loss: 0.6368 - val_acc: 0.7353 - val_precision: 0.8333 - val_recall: 0.5882 - val_auc: 0.6972 - val_tp: 10.0000 - val_fp: 2.0000 - val_tn: 15.0000 - val_fn: 7.0000\nEpoch 24/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6133 - acc: 0.6898 - precision: 0.7826 - recall: 0.5255 - auc: 0.7260 - tp: 72.0000 - fp: 20.0000 - tn: 117.0000 - fn: 65.0000 - val_loss: 0.6286 - val_acc: 0.7353 - val_precision: 0.8333 - val_recall: 0.5882 - val_auc: 0.6990 - val_tp: 10.0000 - val_fp: 2.0000 - val_tn: 15.0000 - val_fn: 7.0000\nEpoch 25/100\n2/2 [==============================] - 1s 262ms/step - loss: 0.6104 - acc: 0.6861 - precision: 0.7742 - recall: 0.5255 - auc: 0.7175 - tp: 72.0000 - fp: 21.0000 - tn: 116.0000 - fn: 65.0000 - val_loss: 0.6292 - val_acc: 0.7059 - val_precision: 0.7059 - val_recall: 0.7059 - val_auc: 0.6903 - val_tp: 12.0000 - val_fp: 5.0000 - val_tn: 12.0000 - val_fn: 5.0000\nEpoch 26/100\n2/2 [==============================] - 1s 273ms/step - loss: 0.6048 - acc: 0.6752 - precision: 0.6935 - recall: 0.6277 - auc: 0.7235 - tp: 86.0000 - fp: 38.0000 - tn: 99.0000 - fn: 51.0000 - val_loss: 0.6393 - val_acc: 0.6471 - val_precision: 0.6471 - val_recall: 0.6471 - val_auc: 0.6713 - val_tp: 11.0000 - val_fp: 6.0000 - val_tn: 11.0000 - val_fn: 6.0000\nEpoch 27/100\n2/2 [==============================] - 1s 264ms/step - loss: 0.6037 - acc: 0.6788 - precision: 0.6842 - recall: 0.6642 - auc: 0.7256 - tp: 91.0000 - fp: 42.0000 - tn: 95.0000 - fn: 46.0000 - val_loss: 0.6233 - val_acc: 0.7059 - val_precision: 0.7692 - val_recall: 0.5882 - val_auc: 0.6903 - val_tp: 10.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 7.0000\nEpoch 28/100\n2/2 [==============================] - 1s 267ms/step - loss: 0.6011 - acc: 0.6825 - precision: 0.7358 - recall: 0.5693 - auc: 0.7231 - tp: 78.0000 - fp: 28.0000 - tn: 109.0000 - fn: 59.0000 - val_loss: 0.6315 - val_acc: 0.6176 - val_precision: 0.7000 - val_recall: 0.4118 - val_auc: 0.6972 - val_tp: 7.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 10.0000\nEpoch 29/100\n2/2 [==============================] - 1s 263ms/step - loss: 0.6003 - acc: 0.6825 - precision: 0.7841 - recall: 0.5036 - auc: 0.7305 - tp: 69.0000 - fp: 19.0000 - tn: 118.0000 - fn: 68.0000 - val_loss: 0.6136 - val_acc: 0.7059 - val_precision: 0.7692 - val_recall: 0.5882 - val_auc: 0.7024 - val_tp: 10.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 7.0000\nEpoch 30/100\n2/2 [==============================] - 1s 263ms/step - loss: 0.5883 - acc: 0.7007 - precision: 0.7391 - recall: 0.6204 - auc: 0.7499 - tp: 85.0000 - fp: 30.0000 - tn: 107.0000 - fn: 52.0000 - val_loss: 0.6396 - val_acc: 0.6471 - val_precision: 0.6316 - val_recall: 0.7059 - val_auc: 0.6851 - val_tp: 12.0000 - val_fp: 7.0000 - val_tn: 10.0000 - val_fn: 5.0000\nEpoch 31/100\n2/2 [==============================] - 1s 265ms/step - loss: 0.6045 - acc: 0.6715 - precision: 0.6556 - recall: 0.7226 - auc: 0.7473 - tp: 99.0000 - fp: 52.0000 - tn: 85.0000 - fn: 38.0000 - val_loss: 0.6002 - val_acc: 0.7059 - val_precision: 0.7692 - val_recall: 0.5882 - val_auc: 0.7007 - val_tp: 10.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 7.0000\nEpoch 32/100\n2/2 [==============================] - 1s 265ms/step - loss: 0.5853 - acc: 0.7007 - precision: 0.7099 - recall: 0.6788 - auc: 0.7564 - tp: 93.0000 - fp: 38.0000 - tn: 99.0000 - fn: 44.0000 - val_loss: 0.6104 - val_acc: 0.6471 - val_precision: 0.7273 - val_recall: 0.4706 - val_auc: 0.7284 - val_tp: 8.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 9.0000\nEpoch 33/100\n2/2 [==============================] - 1s 270ms/step - loss: 0.5855 - acc: 0.6934 - precision: 0.7789 - recall: 0.5401 - auc: 0.7667 - tp: 74.0000 - fp: 21.0000 - tn: 116.0000 - fn: 63.0000 - val_loss: 0.5929 - val_acc: 0.7059 - val_precision: 0.7692 - val_recall: 0.5882 - val_auc: 0.7215 - val_tp: 10.0000 - val_fp: 3.0000 - val_tn: 14.0000 - val_fn: 7.0000\nEpoch 34/100\n2/2 [==============================] - 1s 265ms/step - loss: 0.5666 - acc: 0.7226 - precision: 0.7480 - recall: 0.6715 - auc: 0.7756 - tp: 92.0000 - fp: 31.0000 - tn: 106.0000 - fn: 45.0000 - val_loss: 0.6222 - val_acc: 0.6765 - val_precision: 0.6875 - val_recall: 0.6471 - val_auc: 0.6990 - val_tp: 11.0000 - val_fp: 5.0000 - val_tn: 12.0000 - val_fn: 6.0000\nEpoch 35/100\n2/2 [==============================] - 1s 260ms/step - loss: 0.5758 - acc: 0.7007 - precision: 0.6871 - recall: 0.7372 - auc: 0.7703 - tp: 101.0000 - fp: 46.0000 - tn: 91.0000 - fn: 36.0000 - val_loss: 0.6260 - val_acc: 0.6471 - val_precision: 0.6316 - val_recall: 0.7059 - val_auc: 0.7163 - val_tp: 12.0000 - val_fp: 7.0000 - val_tn: 10.0000 - val_fn: 5.0000\nEpoch 36/100\n2/2 [==============================] - 1s 259ms/step - loss: 0.5802 - acc: 0.7007 - precision: 0.6708 - recall: 0.7883 - auc: 0.7684 - tp: 108.0000 - fp: 53.0000 - tn: 84.0000 - fn: 29.0000 - val_loss: 0.6195 - val_acc: 0.6176 - val_precision: 0.6111 - val_recall: 0.6471 - val_auc: 0.7093 - val_tp: 11.0000 - val_fp: 7.0000 - val_tn: 10.0000 - val_fn: 6.0000\nEpoch 37/100\n2/2 [==============================] - 1s 263ms/step - loss: 0.5784 - acc: 0.7007 - precision: 0.6752 - recall: 0.7737 - auc: 0.7667 - tp: 106.0000 - fp: 51.0000 - tn: 86.0000 - fn: 31.0000 - val_loss: 0.6157 - val_acc: 0.7059 - val_precision: 0.8182 - val_recall: 0.5294 - val_auc: 0.7024 - val_tp: 9.0000 - val_fp: 2.0000 - val_tn: 15.0000 - val_fn: 8.0000\nEpoch 38/100\n2/2 [==============================] - 1s 257ms/step - loss: 0.5660 - acc: 0.7190 - precision: 0.7778 - recall: 0.6131 - auc: 0.7709 - tp: 84.0000 - fp: 24.0000 - tn: 113.0000 - fn: 53.0000 - val_loss: 0.6336 - val_acc: 0.6765 - val_precision: 0.8000 - val_recall: 0.4706 - val_auc: 0.7232 - val_tp: 8.0000 - val_fp: 2.0000 - val_tn: 15.0000 - val_fn: 9.0000\n"
],
[
"# %%script echo \"Comment line with %%script echo to run this cell.\"\n\nmodel.save('lstm.h5')",
"_____no_output_____"
],
[
"# %%script echo \"Comment line with %%script echo to run this cell.\"\n\nwith open('lstm_history.pickle', 'wb') as f:\n pickle.dump(history.history, f)",
"_____no_output_____"
],
[
"model = keras.models.load_model('lstm.h5')",
"_____no_output_____"
],
[
"with open('lstm_history.pickle', 'rb') as f:\n history = pickle.load(f)",
"_____no_output_____"
],
[
"model.predict(test_X_n_under)",
"_____no_output_____"
],
[
"model.evaluate(test_X_n_under, test_y_under)",
"2/2 [==============================] - 0s 77ms/step - loss: 0.7634 - acc: 0.6111 - precision: 0.6000 - recall: 0.6667 - auc: 0.5694 - tp: 12.0000 - fp: 8.0000 - tn: 10.0000 - fn: 6.0000\n"
],
[
"plt.plot(\n np.arange(1, len(history['loss']) + 1),\n history['loss'],\n color='b',\n label='Training'\n)\nplt.plot(\n np.arange(1, len(history['val_loss']) + 1),\n history['val_loss'],\n color='r',\n label='Validation'\n)\nplt.xlabel('Epoch')\nplt.ylabel('Loss')\nplt.xticks(np.arange(0, len(history['loss']) + 1, 5))\nplt.legend()",
"_____no_output_____"
],
[
"plt.plot(\n np.arange(1, len(history['acc']) + 1),\n history['acc'],\n color='b',\n label='Training'\n)\nplt.plot(\n np.arange(1, len(history['val_acc']) + 1),\n history['val_acc'],\n color='r',\n label='Validation'\n)\nplt.xlabel('Epoch')\nplt.ylabel('Accuracy')\nplt.xticks(np.arange(0, len(history['loss']) + 1, 5))\nplt.legend()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1ee3c9bb8d9950c5933b056afc38a7bfec8189
| 18,290 |
ipynb
|
Jupyter Notebook
|
coding/hacker rank.ipynb
|
vadim-ivlev/STUDY
|
286675fcdf154ea605f50059c4a60b212b3ba4b9
|
[
"MIT"
] | null | null | null |
coding/hacker rank.ipynb
|
vadim-ivlev/STUDY
|
286675fcdf154ea605f50059c4a60b212b3ba4b9
|
[
"MIT"
] | null | null | null |
coding/hacker rank.ipynb
|
vadim-ivlev/STUDY
|
286675fcdf154ea605f50059c4a60b212b3ba4b9
|
[
"MIT"
] | null | null | null | 24.321809 | 224 | 0.436905 |
[
[
[
"https://www.testdome.com/questions/python/two-sum/14289?questionIds=14288,14289&generatorId=92&type=fromtest&testDifficulty=Easy\n\nWrite a function that, given a list and a target sum, returns zero-based indices of any two distinct elements whose sum is equal to the target sum. If there are no such elements, the function should return (-1, -1).\n\nFor example, `find_two_sum([1, 3, 5, 7, 9], 12)` should return a tuple containing any of the following pairs of indices:\n```\n1 and 4 (3 + 9 = 12)\n2 and 3 (5 + 7 = 12)\n3 and 2 (7 + 5 = 12)\n4 and 1 (9 + 3 = 12)\n```\n",
"_____no_output_____"
]
],
[
[
"# Это единственный комментарий который имеет смысл\n# I s\ndef find_index(m,a):\n try:\n return a.index(m)\n except :\n return -1\n \n \ndef find_two_sum(a, s):\n '''\n >>> (3, 5) == find_two_sum([1, 3, 5, 7, 9], 12)\n True\n '''\n if len(a)<2: \n return (-1,-1)\n\n idx = dict( (v,i) for i,v in enumerate(a) )\n\n for i in a:\n m = s - i\n k = idx.get(m,-1)\n if k != -1 :\n return (i,k)\n\n return (-1, -1)\n\n\nprint(find_two_sum([1, 3, 5, 7, 9], 12))\n\n\nif __name__ == '__main__':\n import doctest; doctest.testmod()\n \n",
"(3, 4)\n**********************************************************************\nFile \"__main__\", line 11, in __main__.find_two_sum\nFailed example:\n (3, 5) == find_two_sum([1, 3, 5, 7, 9], 12)\nExpected:\n True\nGot:\n False\n**********************************************************************\n1 items had failures:\n 1 of 1 in __main__.find_two_sum\n***Test Failed*** 1 failures.\n"
]
],
[
[
"https://stackoverflow.com/questions/28309430/edit-ipython-cell-in-an-external-editor\n\n\nEdit IPython cell in an external editor\n---\n\nThis is what I came up with. I added 2 shortcuts:\n\n- 'g' to launch gvim with the content of the current cell (you can replace gvim with whatever text editor you like).\n- 'u' to update the content of the current cell with what was saved by gvim.\nSo, when you want to edit the cell with your preferred editor, hit 'g', make the changes you want to the cell, save the file in your editor (and quit), then hit 'u'.\n\nJust execute this cell to enable these features:\n",
"_____no_output_____"
]
],
[
[
"%%javascript\n\nIPython.keyboard_manager.command_shortcuts.add_shortcut('g', {\n handler : function (event) {\n \n var input = IPython.notebook.get_selected_cell().get_text();\n \n var cmd = \"f = open('.toto.py', 'w');f.close()\";\n if (input != \"\") {\n cmd = '%%writefile .toto.py\\n' + input;\n }\n IPython.notebook.kernel.execute(cmd);\n //cmd = \"import os;os.system('open -a /Applications/MacVim.app .toto.py')\";\n //cmd = \"!open -a /Applications/MacVim.app .toto.py\";\n cmd = \"!code .toto.py\";\n\n IPython.notebook.kernel.execute(cmd);\n return false;\n }}\n);\n\nIPython.keyboard_manager.command_shortcuts.add_shortcut('u', {\n handler : function (event) {\n function handle_output(msg) {\n var ret = msg.content.text;\n IPython.notebook.get_selected_cell().set_text(ret);\n }\n var callback = {'output': handle_output};\n var cmd = \"f = open('.toto.py', 'r');print(f.read())\";\n IPython.notebook.kernel.execute(cmd, {iopub: callback}, {silent: false});\n return false;\n }}\n);\n",
"_____no_output_____"
],
[
"# v=getattr(a, 'pop')(1)\ns='print 4 7 '\ncommands={\n 'print':print,\n 'len':len\n }\n\n\ndef exec_string(s):\n global commands\n chunks=s.split()\n func_name=chunks[0] if len(chunks) else 'blbl'\n func=commands.get(func_name,None)\n \n params=[int(x) for x in chunks[1:]]\n if func:\n func(*params)\n\nexec_string(s)\n\n",
"4 7\n"
]
],
[
[
"# Symmetric Difference\n\nhttps://www.hackerrank.com/challenges/symmetric-difference/problem\n\n#### Task \nGiven sets of integers, and , print their symmetric difference in ascending order. The term symmetric difference indicates those values that exist in either or but do not exist in both.\n\n#### Input Format\n\nThe first line of input contains an integer, . \nThe second line contains space-separated integers. \nThe third line contains an integer, . \nThe fourth line contains space-separated integers.\n\n##### Output Format\n\nOutput the symmetric difference integers in ascending order, one per line.\n\n#### Sample Input\n````\n4\n2 4 5 9\n4\n2 4 11 12\n````\n##### Sample Output\n````\n5\n9\n11\n12\n````",
"_____no_output_____"
]
],
[
[
"M = int(input())\nm =set((map(int,input().split())))\nN = int(input())\nn =set((map(int,input().split())))",
"Enter size of a set. Press Enter for 4:\n2 4 5 9\n4\n2 4 11 12\n"
],
[
"m ^ n",
"_____no_output_____"
],
[
"S='add 5 6'\nmethod, *args = S.split()\nprint(method)\nprint(*map(int,args))\nmethod,(*map(int,args))\n\n# methods\n# (*map(int,args))\n\n# command='add'.split()\n# method, args = command[0], list(map(int,command[1:]))\n# method, args",
"add\n5 6\n"
],
[
"for _ in range(2):\n met, *args = input().split()\n print(met, args)\n try:\n pass\n\n# methods[met](*list(map(int,args)))\n except:\n pass\n\n",
"add 5 6\nadd ['5', '6']\nadd\nadd []\n"
],
[
"class Stack:\n def __init__(self):\n self.data = []\n\n def is_empty(self):\n return self.data == []\n\n def size(self):\n return len(self.data)\n\n def push(self, val):\n self.data.append(val)\n\n def clear(self):\n self.data.clear()\n \n def pop(self):\n return self.data.pop()\n\n def __repr__(self):\n return \"Stack(\"+str(self.data)+\")\"\n\n",
"_____no_output_____"
],
[
"def sum_list(ls):\n if len(ls)==0:\n return 0\n elif len(ls)==1:\n return ls[0]\n else:\n return ls[0] + sum_list(ls[1:])\n\ndef max_list(ls):\n print(ls)\n if len(ls)==0:\n return None\n elif len(ls)==1:\n return ls[0]\n else:\n\n m = max_list(ls[1:])\n return ls[0] if ls[0]>m else m\n \ndef reverse_list(ls):\n if len(ls)<2:\n return ls\n \n return reverse_list(ls[1:])+ls[0:1]\n\n\ndef is_ana(s=''):\n if len(s)<2:\n return True\n return s[0]==s[-1] and is_ana(s[1:len(s)-1])\n \n \n \nprint(is_ana(\"abc\"))\n",
"False\n"
],
[
"import turtle\n\nmyTurtle = turtle.Turtle()\nmyWin = turtle.Screen()\n\ndef drawSpiral(myTurtle, lineLen):\n if lineLen > 0:\n myTurtle.forward(lineLen)\n myTurtle.right(90)\n drawSpiral(myTurtle,lineLen-5)\n\ndrawSpiral(myTurtle,100)\n# myWin.exitonclick()\n",
"_____no_output_____"
],
[
"t.forward(100)",
"_____no_output_____"
],
[
"from itertools import combinations_with_replacement\nlist(combinations_with_replacement([1,1,3,3,3],2))\n",
"_____no_output_____"
],
[
"hash((1,2))",
"_____no_output_____"
],
[
"# 4 \n# a a c d\n# 2\n\n\nfrom itertools import combinations\n\n# N=int(input())\n# s=input().split()\n# k=int(input())\n\ns='a a c d'.split()\nk=2\n\n\ncombs=list(combinations(s,k))\n\n\nprint('{:.4f}'.format(len([x for x in combs if 'a' in x])/len(combs)))\n\n# ------------------------------------------\n\nimport random\n\nnum_trials=10000\nnum_found=0\n\nfor i in range(num_trials):\n if 'a' in random.sample(s,k):\n num_found+=1\n \n\n\nprint('{:.4f}'.format(num_found/num_trials))",
"0.8333\n0.8356\n"
],
[
"dir(5)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1ef36e49cd22d65a708e69cb3b6f6bcf0793bd
| 208,371 |
ipynb
|
Jupyter Notebook
|
AnaliseTweets.ipynb
|
MayaraMachado/tweet_analysis
|
d5f0f06d96bd2f0920fa314965e7d67f21449f75
|
[
"MIT"
] | 4 |
2021-01-04T01:54:25.000Z
|
2021-05-20T04:06:55.000Z
|
AnaliseTweets.ipynb
|
MayaraMachado/tweet_analysis
|
d5f0f06d96bd2f0920fa314965e7d67f21449f75
|
[
"MIT"
] | null | null | null |
AnaliseTweets.ipynb
|
MayaraMachado/tweet_analysis
|
d5f0f06d96bd2f0920fa314965e7d67f21449f75
|
[
"MIT"
] | 2 |
2020-11-18T05:05:13.000Z
|
2021-05-20T04:07:01.000Z
| 338.26461 | 71,318 | 0.925052 |
[
[
[
"!pip install unidecode googletrans\n!pip install squarify",
"_____no_output_____"
],
[
"import re\nimport time\nimport tweepy\nimport folium\nimport squarify \nimport warnings\nimport collections\nimport numpy as np\nimport pandas as pd\nfrom PIL import Image\nfrom folium import plugins\nfrom datetime import datetime\nfrom textblob import TextBlob\nimport matplotlib.pyplot as plt\nfrom unidecode import unidecode\nfrom googletrans import Translator\nfrom geopy.geocoders import Nominatim\nfrom wordcloud import WordCloud, STOPWORDS",
"_____no_output_____"
],
[
"# Adicione suas credenciais para a API do Twitter\n\nCONSUMER_KEY = YOUR_CONSUMER_KEY\nCONSUMER_SECRET = YOUR_CONSUMER_SECRET\nACCESS_TOKEN = YOUR_ACCESS_TOKEN\nACCESS_TOKEN_SECRET = YOUR_ACCESS_TOKEN_SECRET",
"_____no_output_____"
]
],
[
[
"# Implementação da classe para obter os tweets",
"_____no_output_____"
]
],
[
[
"class TweetAnalyzer():\n\n def __init__(self, consumer_key, consumer_secret, access_token, access_token_secret):\n '''\n Conectar com o tweepy\n '''\n auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\n auth.set_access_token(access_token, access_token_secret)\n\n self.conToken = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True, retry_count=5, retry_delay=10)\n \n def __clean_tweet(self, tweets_text):\n '''\n Tweet cleansing.\n '''\n\n clean_text = re.sub(r'RT+', '', tweets_text) \n clean_text = re.sub(r'@\\S+', '', clean_text) \n clean_text = re.sub(r'http\\S+', '', clean_text) \n clean_text = clean_text.replace(\"\\n\", \" \")\n\n return clean_text\n\n def search_by_keyword(self, keyword, count=10, result_type='mixed', lang='en', tweet_mode='extended'):\n '''\n Search for the twitters thar has commented the keyword subject.\n '''\n tweets_iter = tweepy.Cursor(self.conToken.search,\n q=keyword, tweet_mode=tweet_mode,\n rpp=count, result_type=result_type,\n since=datetime(2020,7,31,0,0,0).date(),\n lang=lang, include_entities=True).items(count)\n\n return tweets_iter\n\n def prepare_tweets_list(self, tweets_iter):\n '''\n Transforming the data to DataFrame.\n '''\n\n tweets_data_list = []\n for tweet in tweets_iter:\n if not 'retweeted_status' in dir(tweet):\n tweet_text = self.__clean_tweet(tweet.full_text)\n tweets_data = {\n 'len' : len(tweet_text),\n 'ID' : tweet.id,\n 'User' : tweet.user.screen_name,\n 'UserName' : tweet.user.name,\n 'UserLocation' : tweet.user.location,\n 'TweetText' : tweet_text,\n 'Language' : tweet.user.lang,\n 'Date' : tweet.created_at,\n 'Source': tweet.source,\n 'Likes' : tweet.favorite_count,\n 'Retweets' : tweet.retweet_count,\n 'Coordinates' : tweet.coordinates,\n 'Place' : tweet.place \n }\n tweets_data_list.append(tweets_data)\n\n return tweets_data_list\n\n def sentiment_polarity(self, tweets_text_list):\n tweets_sentiments_list = []\n\n for tweet in tweets_text_list:\n polarity = TextBlob(tweet).sentiment.polarity\n if polarity > 0:\n tweets_sentiments_list.append('Positive')\n elif polarity < 0:\n tweets_sentiments_list.append('Negative')\n else:\n tweets_sentiments_list.append('Neutral')\n\n return tweets_sentiments_list",
"_____no_output_____"
],
[
"analyzer = TweetAnalyzer(consumer_key = CONSUMER_KEY, consumer_secret = CONSUMER_SECRET, access_token = ACCESS_TOKEN, access_token_secret=ACCESS_TOKEN_SECRET)\nkeyword = (\"'Black is King' OR 'black is king' OR 'Beyonce' OR 'beyonce' OR #blackisking OR '#BlackIsKing' OR 'black is king beyonce'\")\ncount = 5000",
"_____no_output_____"
],
[
"tweets_iter = analyzer.search_by_keyword(keyword, count)\ntweets_list = analyzer.prepare_tweets_list(tweets_iter)",
"Rate limit reached. Sleeping for: 747\n"
],
[
"tweets_df = pd.DataFrame(tweets_list)",
"_____no_output_____"
]
],
[
[
"# Análises",
"_____no_output_____"
],
[
"## Qual o tweet mais curtido e retweetado?\n",
"_____no_output_____"
]
],
[
[
"likes_max = np.max(tweets_df['Likes'])\n\nlikes = tweets_df[tweets_df.Likes == likes_max].index[0]\n\nprint(f\"O tweet com mais curtidas é: {tweets_df['TweetText'][likes]}\")\nprint(f\"Numero de curtidas: {likes_max}\")",
"O tweet com mais curtidas é: Ngl it is kinda wild that Beyoncé ain’t said nun when Black is King had a lot of Nigerian culture in it\nNumero de curtidas: 601\n"
],
[
"retweet_max = np.max(tweets_df['Retweets'])\n\nretweet = tweets_df[tweets_df.Retweets == retweet_max].index[0]\n\nprint(f\"O tweet com mais retweets é: {tweets_df['TweetText'][retweet]}\")\nprint(f\"Numero de curtidas: {retweet_max}\")",
"O tweet com mais retweets é: Beyonce used una make money with Black Is King and Brown Skin Girl, now blacks called her to add her voice, she japa. Henceforth, na celeb wey join #EndSARS we go stream and patronize. Awon ole - extortists. #ReformTheNigerianPolice #ReconstructNigeria\nNumero de curtidas: 346\n"
]
],
[
[
"## Qual a porcentagem dos sentimentos captado?",
"_____no_output_____"
]
],
[
[
"tweets_df['Sentiment'] = analyzer.sentiment_polarity(tweets_df['TweetText'])\nsentiment_percentage = tweets_df.groupby('Sentiment')['ID'].count().apply(lambda x : 100 * x / count)",
"_____no_output_____"
],
[
"sentiment_percentage.plot(kind='bar')\nplt.show()\nplt.savefig('sentiments_tweets.png', bbox_inches='tight', pad_inches=0.5)",
"_____no_output_____"
]
],
[
[
"## Quais as palavras mais atribuídas?",
"_____no_output_____"
]
],
[
[
"words = ' '.join(tweets_df['TweetText'])\n\nwords_clean = \" \".join([word for word in words.split()])\n\nwarnings.simplefilter('ignore')\n\nmask = np.array(Image.open('crown.png'))\nwc = WordCloud(stopwords=STOPWORDS, mask=mask,\n max_words=1000, max_font_size=100,\n min_font_size=10, random_state=42,\n background_color='white', mode=\"RGB\",\n width=mask.shape[1], height=mask.shape[0],\n normalize_plurals=True).generate(words_clean)\n\nplt.imshow(wc, interpolation=\"bilinear\")\nplt.axis(\"off\")\nplt.savefig('black_is_king_cloud.png', dpi=300)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Quais são as fonte de tweets mais utilizados?",
"_____no_output_____"
]
],
[
[
"# Calcular quantidade de source\nsource_list = tweets_df['Source'].tolist()\noccurrences = collections.Counter(source_list)\n\nsource_df = pd.DataFrame({'Total':list(occurrences.values())}, index=occurrences.keys())\nsources_sorted = source_df.sort_values('Total', ascending=True)",
"_____no_output_____"
],
[
"# Plotar gráfico\nplt.style.use('ggplot')\nplt.rcParams['axes.edgecolor']='#333F4B'\nplt.rcParams['axes.linewidth']=0.8\nplt.rcParams['xtick.color']='#333F4B'\nplt.rcParams['ytick.color']='#333F4B'\nmy_range=list(range(1,len(sources_sorted.index)+1))\n\nax = sources_sorted.Total.plot(kind='barh',color='#1f77b4', alpha=0.8, linewidth=5, figsize=(15,15))\nax.get_xaxis().set_major_formatter(plt.FuncFormatter(lambda x, loc: \"{:,}\".format(int(x))))\n\nplt.savefig('source_tweets.png', bbox_inches='tight', pad_inches=0.5)",
"_____no_output_____"
],
[
"# Distribuição das 5 primeiras fontes mais utilizadas\nsquarify.plot(sizes=sources_sorted['Total'][:5], label=sources_sorted.index, alpha=.5)\nplt.axis('off')\nplt.show() ",
"_____no_output_____"
]
],
[
[
"## De quais regiões vieram os tweets",
"_____no_output_____"
]
],
[
[
"geolocator = Nominatim(user_agent=\"TweeterSentiments\")\n\nlatitude = []\nlongitude = []\n\nfor user_location in tweets_df['UserLocation']:\n try:\n location = geolocator.geocode(user_location)\n latitude.append(location.latitude)\n longitude.append(location.longitude)\n except:\n continue\n\ncoordenadas = np.column_stack((latitude, longitude))\n\nmapa = folium.Map(zoom_start=3.)\nmapa.add_child(plugins.HeatMap(coordenadas))\nmapa.save('Mapa_calor_tweets.html')\n\nmapa",
"_____no_output_____"
]
],
[
[
"## Análise temporal dos tweets",
"_____no_output_____"
]
],
[
[
"data = tweets_df\n\ndata['Date'] = pd.to_datetime(data['Date']).apply(lambda x: x.date())\ntlen = pd.Series(data['Date'].value_counts(), index=data['Date'])\n\ntlen.plot(figsize=(16,4), color='b')\nplt.savefig('timeline_tweets.png', bbox_inches='tight', pad_inches=0.5)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a1ef466460da6ec8d1621b151e6482ff48adc64
| 121,358 |
ipynb
|
Jupyter Notebook
|
Machine Learning/From Scratch Implementation/Principal Components Analysis.ipynb
|
zementalist/Professional-Experience
|
04fc2db56ea3dd2389577ae90e479028009724f5
|
[
"Apache-2.0"
] | null | null | null |
Machine Learning/From Scratch Implementation/Principal Components Analysis.ipynb
|
zementalist/Professional-Experience
|
04fc2db56ea3dd2389577ae90e479028009724f5
|
[
"Apache-2.0"
] | null | null | null |
Machine Learning/From Scratch Implementation/Principal Components Analysis.ipynb
|
zementalist/Professional-Experience
|
04fc2db56ea3dd2389577ae90e479028009724f5
|
[
"Apache-2.0"
] | null | null | null | 135.595531 | 14,896 | 0.881417 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport math",
"_____no_output_____"
],
[
"# Define functions\n\n# Scale values\ndef scale(arr):\n return (np.array(arr) - np.mean(arr)) / np.std(arr)\n\n# Find the slope of the best fitting line\ndef fit_slope(x, y):\n return (np.mean(x) * np.mean(y) - np.mean(x * y)) / (np.mean(x)**2 - np.mean(x**2))\n\n# Rotate point counterclockwise\ndef rotate(origin, point, angle):\n \"\"\"\n Rotate a point counterclockwise by a given angle around a given origin.\n\n The angle should be given in radians.\n \"\"\"\n ox, oy = origin\n px, py = point\n\n qx = ox + math.cos(angle) * (px - ox) - math.sin(angle) * (py - oy)\n qy = oy + math.sin(angle) * (px - ox) + math.cos(angle) * (py - oy)\n return qx, qy\n\n# Calculate variation\ndef variation(array, mean=0):\n return np.sum((mean - array) ** 2) / (array.shape[0]-1)\n\n# Find the coordination of the intersection between 2 lines\ndef lines_intersection(coefficients1, coefficients2):\n coefficients1, coefficients2 = np.copy(coefficients1), np.copy(coefficients2)\n if coefficients1.shape[0] < coefficients2.shape[0]:\n coefficients1 = np.pad(coefficients1, (0,coefficients2.shape[0]-coefficients1.shape[0]), \n 'constant', constant_values=0)\n bias1 = 0\n bias2 = coefficients2[-1]\n elif coefficients1.shape[0] > coefficients2.shape[0]:\n coefficients2 = np.pad(coefficients2, (0, coefficients1.shape[0]-coefficients2.shape[0]), \n 'constant', constant_values=0)\n bias2 = 0\n bias1 = coefficients1[-1]\n else:\n bias1 = coefficients1[-1]\n bias2 = coefficients2[-1]\n bias_sum = bias2 - bias1\n coefficients1 = coefficients1[:-1]\n coefficients2 = coefficients2[:-1]\n total = 0\n for i in range(coefficients1.shape[0]):\n total += coefficients1[i] + (-1 * coefficients2[i])\n \n # No intersection\n if total == 0:\n return None\n x = (1/total) * bias_sum\n y = [x * coefficients1 + bias1][0][0]\n return [x,y]\n \n# Find a prependicular line (can be moved from some point (origin))\ndef find_prependicular_line(coefficients, origin=None):\n coefficients = np.copy(coefficients)\n bias = coefficients[-1]\n slopes = coefficients[:-1]\n slopes = -1 * np.reciprocal(slopes, dtype='float')\n coefficients[:-1] = slopes\n if origin is None:\n origin = np.zeros(coefficients.shape[0]-1)\n bias += np.sum(slopes * -1 * origin[:-1]) + origin[-1]\n coefficients[-1] = bias\n return coefficients\n\ndef project_points_onto_line(x, y, coefficients):\n if x.shape[0] != y.shape[0]:\n return None\n projections_x = np.zeros(x.shape[0])\n projections_y = np.zeros(x.shape[0])\n for i in range(x.shape[0]):\n # pr is prependicular line\n pr_slope, pr_b = find_prependicular_line(coefficients, np.array([x[i], y[i]]))\n inter_x, inter_y = lines_intersection(coefficients, np.array([pr_slope, pr_b]))\n projections_x[i] = inter_x\n projections_y[i] = inter_y\n return projections_x, projections_y",
"_____no_output_____"
],
[
"# original data\nx1 = np.array([10, 11, 8, 3, 2, 1], dtype='float')\nx2 = np.array([6, 4, 5, 3, 2.8, 1], dtype='float')\n\n# Visualize\nplt.scatter(x1,x2)\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Original data\")",
"_____no_output_____"
],
[
"# Shifting data to center\nx1_avg_pt = np.average(x1)\nx2_avg_pt = np.average(x2)\nx1 -= x1_avg_pt\nx2 -= x2_avg_pt\n\n# Visualize shifted data\nplt.scatter(x1, x2)\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Original data shifted to 0 as the new origin\")",
"_____no_output_____"
],
[
"# Finding best fitting line which intersects with the origin\npc1_x = np.arange(np.min(x1), np.max(x1)+1)\npc1_slope = fit_slope(x1,x2)\npc1_y = pc1_slope * pc1_x + 0\n\n# Visualize best fitting line (PC1)\nplt.scatter(x1, x2)\nplt.plot(pc1_x, pc1_y)\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"PC1\")",
"_____no_output_____"
],
[
"# Finding PC2 (prependicular on PC1)\npc2_x = np.arange(np.min(x2), np.max(x2)+1)\npc2_slope = -1 * (1/pc1_slope)\npc2_y = pc2_slope * pc2_x\n\n# # Scale values using Pythagorean theoery\n# a = 1/pc1_slope\n# b = 1\n# c = np.sqrt([a**2 + b**2])\n# # x1, x2, pc1_x, pc1_y, pc2_y, pc2_x = x1/c, x2/c, pc1_x/c, pc1_y/c, pc2_y/c, pc2_x/c",
"_____no_output_____"
],
[
"# Visualize PC1 & PC2\nplt.scatter(x1, x2)\nplt.plot(pc1_x, pc1_y)\nplt.plot(pc2_x, pc2_y, color='red')\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"PC1 (blue) & PC2 (red)\")\n",
"_____no_output_____"
],
[
"# Projection of data points onto PC1\nprojections_pc1_x, projections_pc1_y = project_points_onto_line(x1, x2, np.array([pc1_slope, 0]))",
"_____no_output_____"
],
[
"# Visualize projections of data points on PC1\nplt.scatter(x1, x2)\nplt.scatter(projections_pc1_x, projections_pc1_y)\nplt.plot(pc1_x, pc1_y, color='red')\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Projection of data points onto PC1\")",
"_____no_output_____"
],
[
"# Projection of data points onto PC2\nprojections_pc2_x, projections_pc2_y = project_points_onto_line(x1, x2, np.array([pc2_slope, 0]))",
"_____no_output_____"
],
[
"# Visualize of projection of data points onto PC2\nplt.scatter(x1, x2)\nplt.scatter(projections_pc2_x, projections_pc2_y)\nplt.plot(pc2_x, pc2_y, color='red')\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Projection of data points onto PC2\")",
"_____no_output_____"
],
[
"# Visualize original data & projections\nplt.scatter(x1, x2)\nplt.scatter(projections_pc1_x, projections_pc1_y, color='red')\nplt.scatter(projections_pc2_x, projections_pc2_y, color='green')\nplt.plot(pc1_x, pc1_y, color='red')\nplt.plot(pc2_x, pc2_y, color='green')\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Original data & their projections on PC1 and PC2\")",
"_____no_output_____"
],
[
"# Rotating all data points so PC1 & PC2 are identical onto X,Y axes\ndegrees = math.atan(pc1_slope) * -1\norigin = [0,0]\n[x1,x2] = rotate(origin, [x1,x2], degrees)\n[pc1_x, pc1_y] = rotate(origin, [pc1_x, pc1_y], degrees)\n[pc2_x, pc2_y] = rotate(origin, [pc2_x, pc2_y], degrees)\n[projections_pc1_x, projections_pc1_y] = rotate(origin, [projections_pc1_x, projections_pc1_y], degrees)\n[projections_pc2_x, projections_pc2_y] = rotate(origin, [projections_pc2_x, projections_pc2_y], degrees)",
"_____no_output_____"
],
[
"# Visualize projections of data after rotation\nplt.scatter(projections_pc1_x, projections_pc1_y)\nplt.scatter(projections_pc2_x, projections_pc2_y)\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Projections of data after rotation\")",
"_____no_output_____"
],
[
"# Visualize the corresponding projections\nplt.scatter(projections_pc1_x, projections_pc2_y)\nplt.axis('equal')\nplt.axvline(0)\nplt.axhline(0)\nplt.title(\"Corresponding Projections of PC1 & PC2\")",
"_____no_output_____"
],
[
"# Calculate variations for PC1 and PC2 and the sum of them\npc1_variation = variation(projections_pc1_x, mean=0)\npc2_variation = variation(projections_pc2_y, mean=0)\ntotal_variation = pc1_variation + pc2_variation\n\n# Calculate percentages of PC1 and PC2\npc1_percentage = pc1_variation / total_variation * 100\npc2_percentage = pc2_variation / total_variation * 100 # yeah I know it's 100 - pc1_percentage :)",
"_____no_output_____"
],
[
"# Visualize Percentages\nplt.bar([\"PC1\", \"PC2\"], [pc1_percentage, pc2_percentage], width=0.25)\nplt.title(\"PC1 and PC2 Percentages\")\n\nprint(f\"PC1 Variation: {pc1_variation}\\t PC1 Percentage: {pc1_percentage}\")\nprint(f\"PC2 Variation: {pc2_variation}\\t PC2 Percentage: {pc2_percentage}\")",
"PC1 Variation: 21.28023469133954\t PC1 Percentage: 96.31971043153078\nPC2 Variation: 0.8130986419937987\t PC2 Percentage: 3.6802895684692145\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a1efc1fd32c0234b86ab796bb1df6331a19e9a0
| 132,005 |
ipynb
|
Jupyter Notebook
|
14-Natural-Language-Processing/03_Document_Classification.ipynb
|
ashishpatel26/Data-Science-Tutorial-By-Lambda-School
|
c145f5cc0559ee8ba7260b53e011c165e842fde0
|
[
"MIT"
] | 15 |
2019-07-23T20:17:55.000Z
|
2021-12-09T02:32:53.000Z
|
14-Natural-Language-Processing/03_Document_Classification.ipynb
|
abdelrhman2023/Data-Science-Tutorial-By-Lambda-School
|
c145f5cc0559ee8ba7260b53e011c165e842fde0
|
[
"MIT"
] | null | null | null |
14-Natural-Language-Processing/03_Document_Classification.ipynb
|
abdelrhman2023/Data-Science-Tutorial-By-Lambda-School
|
c145f5cc0559ee8ba7260b53e011c165e842fde0
|
[
"MIT"
] | 23 |
2019-10-12T15:32:41.000Z
|
2022-03-13T05:05:13.000Z
| 31.497256 | 627 | 0.37997 |
[
[
[
"# Document Classification & Clustering - Lecture\n\nWhat could we do with the document-term-matrices (dtm[s]) created in the previous notebook? We could visualize them or train an algorithm to do some specific task. We have covered both classification and clustering before, so we won't focus on the particulars of algorithms. Instead we'll focus on the unique problems of dealing with text input for these models.\n\n## Contents\n* [Part 1](#p1): Vectorize a whole Corpus\n* [Part 2](#p2): Tune the vectorizer\n* [Part 3](#p3): Apply Vectorizer to Classification problem\n* [Part 4](#p4): Introduce topic modeling on text data\n\n**Business Case**: Your managers at Smartphone Inc. have asked to develop a system to bucket text messages into two categories: **spam** and **not spam (ham)**. The system will be implemented on your companies products to help users identify suspicious texts.",
"_____no_output_____"
],
[
"# Spam Filter - Count Vectorization Method",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\npd.set_option('display.max_colwidth', 200)",
"_____no_output_____"
]
],
[
[
"**Import the data and take a look at it**",
"_____no_output_____"
]
],
[
[
"def load():\n url = \"https://raw.githubusercontent.com/sokjc/BayesNotBaes/master/sms.tsv\"\n\n df = pd.read_csv(url, sep='\\t', header=None, \n names=['label', 'msg'])\n df = df.rename(columns={\"msg\":\"text\"})\n \n # encode target\n df['label_num'] = df['label'].map({'ham': 0, 'spam': 1})\n \n return df\n\npd.set_option('display.max_colwidth', 200)\ndf = load()\ndf.tail()",
"_____no_output_____"
]
],
[
[
"Notice that this text isn't as coherent as the job listings. We'll proceed like normal though. \n\nWhat is the ratio of Spam to Ham messages?",
"_____no_output_____"
]
],
[
[
"df['label'].value_counts()",
"_____no_output_____"
],
[
"df['label'].value_counts(normalize=True)",
"_____no_output_____"
]
],
[
[
"**Model Validation - Train Test Split** (Cross Validation would be better here) ",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\nX = df['text']\ny = df['label_num']\n\nX_train, X_test, y_train, y_test = \\\n train_test_split(X, y, test_size=0.2, random_state=812)",
"_____no_output_____"
],
[
"print(X_train.shape,\n X_test.shape,\n y_train.shape,\n y_test.shape, sep='\\n')",
"(4457,)\n(1115,)\n(4457,)\n(1115,)\n"
]
],
[
[
"**Count Vectorizer**\n\nToday we're just going to let Scikit-Learn do our text cleaning and preprocessing for us.\n\nLets run our vectorizer on our text messages and take a peek at the tokenization of the vocabulary",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\n\nvectorizer = CountVectorizer(max_features=None, ngram_range=(1,1), \n stop_words='english')\n\nvectorizer.fit(X_train)\n\nprint(vectorizer.get_feature_names()[300:325])",
"['150p16', '150pm', '150ppermesssubscription', '150ppm', '150ppmpobox10183bhamb64xe', '150ppmsg', '150pw', '151', '153', '15541', '16', '165', '1680', '169', '177', '18', '1843', '18p', '18yrs', '195', '1apple', '1b6a5ecef91ff9', '1cup', '1da', '1er']\n"
]
],
[
[
"Now we'll complete the vectorization with `.transform()`",
"_____no_output_____"
]
],
[
[
"train_word_counts = vectorizer.transform(X_train)\n\n# not necessary to save to a dataframe, but helpful for previewing\nX_train_vectorized = pd.DataFrame(train_word_counts.toarray(), \n columns=vectorizer.get_feature_names())\n\nprint(X_train_vectorized.shape)\nX_train_vectorized.head()",
"(4457, 7443)\n"
]
],
[
[
"We also need to vectorize our `X_test` data, but **we need to use the same vocabulary as the training dataset**, so we'll just call `.transform()` on `X_test` to get our `X_test_vectorized`",
"_____no_output_____"
]
],
[
[
"test_word_counts = vectorizer.transform(X_test)\n\nX_test_vectorized = pd.DataFrame(test_word_counts.toarray(), \n columns=vectorizer.get_feature_names())\n\nprint(X_test_vectorized.shape)\nX_test_vectorized.head()",
"(1115, 7443)\n"
]
],
[
[
"Lets run some classification models and see what kind of accuracy we can get!",
"_____no_output_____"
],
[
"# Model Selection",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score\n\ndef assess_model(model, X_train, X_test, \n y_train, y_test, vect_type='Count'):\n model.fit(X_train, y_train)\n\n train_predictions = model.predict(X_train)\n test_predictions = model.predict(X_test)\n\n result = {}\n result['model'] = str(model).split('(')[0]\n result['acc_train'] = accuracy_score(y_train, train_predictions)\n result['acc_test'] = accuracy_score(y_test, test_predictions)\n result['vect_type'] = vect_type\n print(result)\n \n return result",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import MultinomialNB # Multinomial Naive Bayes\nfrom sklearn.ensemble import RandomForestClassifier\n\nmodels = [LogisticRegression(random_state=42, solver='lbfgs'),\n MultinomialNB(),\n RandomForestClassifier()]\n\nresults = []\nfor model in models:\n result = assess_model(\n model,\n X_train_vectorized, X_test_vectorized, y_train, y_test)\n \n results.append(result)\n \npd.DataFrame.from_records(results)",
"{'model': 'LogisticRegression', 'acc_train': 0.9957370428539376, 'acc_test': 0.9766816143497757, 'vect_type': 'Count'}\n{'model': 'MultinomialNB', 'acc_train': 0.9934933811981154, 'acc_test': 0.9856502242152466, 'vect_type': 'Count'}\n"
]
],
[
[
"# Spam Filter - TF-IDF Vectorization Method",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer\n\nvectorizer = TfidfVectorizer(\n max_features=None, ngram_range=(1,1), stop_words='english')\n\n# fit to train\nvectorizer.fit(X_train)\nprint(vectorizer)",
"TfidfVectorizer(analyzer='word', binary=False, decode_error='strict',\n dtype=<class 'numpy.float64'>, encoding='utf-8', input='content',\n lowercase=True, max_df=1.0, max_features=None, min_df=1,\n ngram_range=(1, 1), norm='l2', preprocessor=None, smooth_idf=True,\n stop_words='english', strip_accents=None, sublinear_tf=False,\n token_pattern='(?u)\\\\b\\\\w\\\\w+\\\\b', tokenizer=None, use_idf=True,\n vocabulary=None)\n"
],
[
"# apply to train\ntrain_word_counts = vectorizer.transform(X_train)\n\nX_train_vectorized = pd.DataFrame(train_word_counts.toarray(),\n columns=vectorizer.get_feature_names())\n\nprint(X_train_vectorized.shape)\nX_train_vectorized.head()",
"(4457, 7443)\n"
],
[
"# apply to test\ntest_word_counts = vectorizer.transform(X_test)\n\nX_test_vectorized = pd.DataFrame(test_word_counts.toarray(),\n columns=vectorizer.get_feature_names())\n\nprint(X_test_vectorized.shape)\nX_test_vectorized.head()",
"(1115, 7443)\n"
],
[
"models = [LogisticRegression(random_state=42, solver='lbfgs'),\n MultinomialNB(),\n RandomForestClassifier()]\n\nfor model in models:\n result = assess_model(\n model,\n X_train_vectorized, X_test_vectorized, y_train, y_test,\n vect_type='Tfidf')\n \n results.append(result)\n \npd.DataFrame.from_records(results)",
"{'model': 'LogisticRegression', 'acc_train': 0.9703836661431456, 'acc_test': 0.9551569506726457, 'vect_type': 'Tfidf'}\n{'model': 'MultinomialNB', 'acc_train': 0.982499439084586, 'acc_test': 0.9659192825112107, 'vect_type': 'Tfidf'}\n"
]
],
[
[
"# Sentiment Analysis\n\nThe objective of **sentiment analysis** is to take a text phrase and determine if its sentiment is: Postive, Neutral, or Negative. \n\nSuppose that you wanted to use NLP to classify reviews for your company's products as either positive, neutral, or negative. Maybe you don't trust the star ratings left by the users and you want an additional measure of sentiment from each review - maybe you would use this as a feature generation technique for additional modeling, or to identify disgruntled customers and reach out to them to improve your customer service, etc. Sentiment Analysis has also been used heavily in stock market price estimation by trying to track the sentiment of the tweets of individuals after breaking news comes out about a company.\n\nDoes every word in each review contribute to its overall sentiment? Not really. Stop words for example don't really tell us much about the overall sentiment of the text, so just like we did before, we will discard them. ",
"_____no_output_____"
],
[
"### NLTK Movie Review Sentiment Analysis",
"_____no_output_____"
],
[
"`pip install -U nltk`",
"_____no_output_____"
]
],
[
[
"import random\nimport nltk",
"_____no_output_____"
],
[
"def load_movie_reviews():\n from nltk.corpus import movie_reviews\n nltk.download('movie_reviews')\n nltk.download('stopwords')\n \n print(\"Total reviews:\", len(movie_reviews.fileids()))\n print(\"Positive reviews:\", len(movie_reviews.fileids('pos')))\n print(\"Negative reviews:\", len(movie_reviews.fileids('neg')))\n \n # Get Reviews and randomize\n reviews = [(list(movie_reviews.words(fileid)), category)\n for category in movie_reviews.categories()\n for fileid in movie_reviews.fileids(category)]\n\n random.shuffle(reviews)\n \n documents = []\n sentiments = []\n\n for review in reviews:\n # Add sentiment to list\n if review[1] == \"pos\":\n sentiments.append(1)\n else:\n sentiments.append(0)\n\n # Add text to list\n review_text = \" \".join(review[0])\n documents.append(review_text)\n\n df = pd.DataFrame({\"text\": documents, \n \"sentiment\": sentiments})\n \n return df",
"_____no_output_____"
],
[
"df = load_movie_reviews()\ndf.head()",
"[nltk_data] Downloading package movie_reviews to\n[nltk_data] C:\\Users\\City_Year\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package movie_reviews is already up-to-date!\n[nltk_data] Downloading package stopwords to\n[nltk_data] C:\\Users\\City_Year\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\nTotal reviews: 2000\nPositive reviews: 1000\nNegative reviews: 1000\n"
]
],
[
[
"### Train Test Split",
"_____no_output_____"
]
],
[
[
"X = df['text']\ny = df['sentiment']\n\nX_train, X_test, y_train, y_test = \\\n train_test_split(X, y, test_size=0.2, random_state=42)",
"_____no_output_____"
]
],
[
[
"# Sentiment Analysis - CountVectorizer",
"_____no_output_____"
],
[
"## Generate vocabulary from train dataset",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\n\nvectorizer = CountVectorizer(max_features=None, ngram_range=(1,1), \n stop_words='english')\n\nvectorizer.fit(X_train)",
"_____no_output_____"
],
[
"train_word_counts = vectorizer.transform(X_train)\n\nX_train_vectorized = pd.DataFrame(train_word_counts.toarray(), \n columns=vectorizer.get_feature_names())\n\nprint(X_train_vectorized.shape)\nX_train_vectorized.head()",
"(1600, 35989)\n"
],
[
"test_word_counts = vectorizer.transform(X_test)\n\nX_test_vectorized = pd.DataFrame(test_word_counts.toarray(), columns=vectorizer.get_feature_names())\n\nprint(X_test_vectorized.shape)\nX_test_vectorized.head()",
"(400, 35989)\n"
]
],
[
[
"### Model Selection",
"_____no_output_____"
]
],
[
[
"models = [LogisticRegression(random_state=42, solver='lbfgs'),\n MultinomialNB(),\n RandomForestClassifier()]",
"_____no_output_____"
],
[
"results = []",
"_____no_output_____"
],
[
"for model in models:\n result = assess_model(\n model,\n X_train_vectorized, X_test_vectorized, y_train, y_test,\n vect_type='Count')\n \n results.append(result)\n \npd.DataFrame.from_records(results)",
"{'model': 'LogisticRegression', 'acc_train': 1.0, 'acc_test': 0.8375, 'vect_type': 'Count'}\n{'model': 'MultinomialNB', 'acc_train': 0.975625, 'acc_test': 0.785, 'vect_type': 'Count'}\n"
]
],
[
[
"# Sentiment Analysis - tfidfVectorizer",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer\n\nvectorizer = TfidfVectorizer(max_features=2000, ngram_range=(1,2),\n min_df = 5, max_df = .80,\n stop_words='english')\n\nvectorizer.fit(X_train)",
"_____no_output_____"
],
[
"train_word_counts = vectorizer.transform(X_train)\n\nX_train_vectorized = pd.DataFrame(train_word_counts.toarray(), columns=vectorizer.get_feature_names())\n\nprint(X_train_vectorized.shape)\nX_train_vectorized.head()",
"(1600, 2000)\n"
],
[
"test_word_counts = vectorizer.transform(X_test)\n\nX_test_vectorized = pd.DataFrame(test_word_counts.toarray(), \n columns=vectorizer.get_feature_names())\n\nprint(X_test_vectorized.shape)\nX_test_vectorized.head()",
"(400, 2000)\n"
]
],
[
[
"### Model Selection",
"_____no_output_____"
]
],
[
[
"for model in models:\n result = assess_model(\n model,\n X_train_vectorized, X_test_vectorized, y_train, y_test,\n vect_type='tfidf')\n \n results.append(result)\n \npd.DataFrame.from_records(results)",
"{'model': 'LogisticRegression', 'acc_train': 0.93875, 'acc_test': 0.82, 'vect_type': 'tfidf'}\n{'model': 'MultinomialNB', 'acc_train': 0.883125, 'acc_test': 0.7725, 'vect_type': 'tfidf'}\n{'model': 'RandomForestClassifier', 'acc_train': 0.99375, 'acc_test': 0.69, 'vect_type': 'tfidf'}\n"
]
],
[
[
"# Using NLTK to clean the data",
"_____no_output_____"
],
[
"### Importing the data fresh to avoid variable collisions",
"_____no_output_____"
]
],
[
[
"df = load_movie_reviews()",
"[nltk_data] Downloading package movie_reviews to\n[nltk_data] C:\\Users\\City_Year\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package movie_reviews is already up-to-date!\n[nltk_data] Downloading package stopwords to\n[nltk_data] C:\\Users\\City_Year\\AppData\\Roaming\\nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\nTotal reviews: 2000\nPositive reviews: 1000\nNegative reviews: 1000\n"
]
],
[
[
"### Cleaning function to apply to each document",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import stopwords\nimport string\n\n# turn a doc into clean tokens\ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # remove punctuation from each token\n table = str.maketrans('', '', string.punctuation)\n tokens = [w.translate(table) for w in tokens]\n # remove remaining tokens that are not alphabetic\n tokens = [word for word in tokens if word.isalpha()]\n # filter out stop words\n stop_words = set(stopwords.words('english'))\n tokens = [w for w in tokens if not w in stop_words]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) > 1]\n return tokens\n\ndf_nltk = pd.DataFrame()\ndf_nltk['text'] = df.text.apply(clean_doc)\ndf_nltk['sentiment'] = df.sentiment\ndf_nltk.head()",
"_____no_output_____"
]
],
[
[
"### Reformat reviews for sklearn",
"_____no_output_____"
]
],
[
[
"documents = []\nfor review in df_nltk.text:\n review = \" \".join(review)\n documents.append(review)\n \nsentiment = list(df_nltk.sentiment)\nnew_df = pd.DataFrame({'text': documents, 'sentiment': sentiment})\nnew_df.head()",
"_____no_output_____"
]
],
[
[
"### Train Test Split",
"_____no_output_____"
]
],
[
[
"X = new_df.text\ny = new_df.sentiment\n\nX_train, X_test, y_train, y_test = \\\n train_test_split(X, y, test_size=0.2, random_state=42)",
"_____no_output_____"
]
],
[
[
"### Vectorize the reviews",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer\n\nvectorizer = TfidfVectorizer(max_features=None, ngram_range=(1,1), \n stop_words='english')\n\nvectorizer.fit(X_train)",
"_____no_output_____"
],
[
"train_word_counts = vectorizer.transform(X_train)\n\nX_train_vectorized = pd.DataFrame(train_word_counts.toarray(), \n columns=vectorizer.get_feature_names())\n\nprint(X_train_vectorized.shape)\nX_train_vectorized.head()",
"(1600, 35240)\n"
],
[
"test_word_counts = vectorizer.transform(X_test)\n\nX_test_vectorized = pd.DataFrame(test_word_counts.toarray(), columns=vectorizer.get_feature_names())\n\nprint(X_test_vectorized.shape)\nX_test_vectorized.head()",
"(400, 35240)\n"
]
],
[
[
"### Model Selection",
"_____no_output_____"
]
],
[
[
"models = [LogisticRegression(random_state=42, solver='lbfgs'),\n MultinomialNB(),\n RandomForestClassifier()]",
"_____no_output_____"
],
[
"results = []",
"_____no_output_____"
],
[
"for model in models:\n result = assess_model(\n model,\n X_train_vectorized, X_test_vectorized, y_train, y_test,\n vect_type='Tfidf')\n \n results.append(result)\n \npd.DataFrame.from_records(results)",
"{'model': 'LogisticRegression', 'acc_train': 0.985, 'acc_test': 0.8125, 'vect_type': 'Tfidf'}\n{'model': 'MultinomialNB', 'acc_train': 0.975625, 'acc_test': 0.8025, 'vect_type': 'Tfidf'}\n"
],
[
"# import xgboost as xgb\nfrom xgboost.sklearn import XGBClassifier\n\nclf = XGBClassifier(\n #hyper params\n n_jobs = -1,\n)\n\nclf.fit(X_train_vectorized, y_train, eval_metric = 'auc')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a1f00b3ed1f7db4dfcc9cc7a6df57f08c02c6de
| 38,491 |
ipynb
|
Jupyter Notebook
|
Projects/DNA_double_helix/double-helix.ipynb
|
thmosqueiro/3D-Playing
|
81fbafeaec4687561ab00e4f13bfe5d6480ffa76
|
[
"WTFPL"
] | null | null | null |
Projects/DNA_double_helix/double-helix.ipynb
|
thmosqueiro/3D-Playing
|
81fbafeaec4687561ab00e4f13bfe5d6480ffa76
|
[
"WTFPL"
] | null | null | null |
Projects/DNA_double_helix/double-helix.ipynb
|
thmosqueiro/3D-Playing
|
81fbafeaec4687561ab00e4f13bfe5d6480ffa76
|
[
"WTFPL"
] | null | null | null | 271.06338 | 35,406 | 0.918786 |
[
[
[
"%matplotlib inline\n\nimport matplotlib as mp\nfrom mpl_toolkits.mplot3d import Axes3D\nimport numpy as np\nimport matplotlib.pyplot as pl",
"_____no_output_____"
],
[
"# Parameters\na = 1.0\nb = 0.8\n\nwavelength = 1. # length of each turn\nNturns = 20 # number of helices' turns\nNpoints = 1e2 # number of points in the curves",
"_____no_output_____"
],
[
"def degrad(x):\n return (x / 180. * np.pi)\n\n# Derived parameters\nt = np.linspace(0, wavelength*Nturns, int(Npoints) )\nomega = degrad(32.5)/wavelength\ntheta = wavelength * 1.5\nskip = int(Npoints/Nturns)",
"_____no_output_____"
],
[
"colors = np.random.choice(['red', 'yellow', 'blue', 'black'], Nturns)",
"_____no_output_____"
],
[
"# Curves\nx1 = a*np.sin(omega*t)\ny1 = b*np.cos(omega*t)\n\nx2 = a*np.sin(omega*t + theta)\ny2 = b*np.cos(omega*t + theta)\n\n\n# Interactive plotting\nfig = pl.figure()\nax = fig.gca(projection='3d')\nax.plot(x1, y1, t, '-b', lw=4)\nax.plot(x2, y2, t, '-r', lw=4)\n\nrg = np.arange(Nturns) * skip\ndx = (x1 - x2)[rg]\ndy = (y1 - y2)[rg]\nax.quiver(x1[rg], y1[rg], t[rg], -dx, -dy, 0, length=.5, color=colors, pivot='tail', lw=3)\nax.quiver(x2[rg], y2[rg], t[rg], dx, dy, 0, length=.5, color=colors, pivot='tail', lw=3)\nax.set_xlim([-3,3])\nax.set_ylim([-3,3])\n\n# For some reason, the red curve is always plotted in front of the blue\npl.show()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.