
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a2732e1e3ae8336cdafd44d891516e2903d3946
| 14,753 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/test-checkpoint.ipynb
|
sharkevolution/requirements
|
7333e69dbff71aa9cf25b848feb35d1932fa485a
|
[
"BSD-3-Clause"
] | null | null | null |
.ipynb_checkpoints/test-checkpoint.ipynb
|
sharkevolution/requirements
|
7333e69dbff71aa9cf25b848feb35d1932fa485a
|
[
"BSD-3-Clause"
] | null | null | null |
.ipynb_checkpoints/test-checkpoint.ipynb
|
sharkevolution/requirements
|
7333e69dbff71aa9cf25b848feb35d1932fa485a
|
[
"BSD-3-Clause"
] | null | null | null | 27.421933 | 141 | 0.408595 |
[
[
[
"import pandas as pd\ndf = pd.DataFrame({'num_legs': [2, 4, 8, 0],\n 'num_wings': [2, 0, 0, 0],\n 'num_specimen_seen': [10, 2, 1, 8]},\n index=['falcon', 'dog', 'spider', 'fish'])\n\nfrom ipyaggrid import Grid\n\ngrid_options_1 = {\n 'enableSorting': 'false',\n 'enableFilter': 'false',\n 'enableColResize': 'false',\n 'enableRowSelection': 'true',\n 'rowSelection': 'multiple',\n 'rowsAfterGroup':'true' ,\n}\n\nbuttons=[{'name':'Show selection in table', 'action':\"\"\"\n var count = view.gridOptions.api.getDisplayedRowCount();\n for (var i = 0; i<count; i++) {\n if(i == view.model.get('user_params').selected_id){\n var rowNode = view.gridOptions.api.getDisplayedRowAtIndex(i);\n rowNode.setSelected(true, true);\n view.gridOptions.api.ensureIndexVisible(view.model.get('user_params').selected_id,'top');\n }\n }\"\"\"}]\n\ngrid1 = Grid(grid_data=df,\n grid_options=grid_options_1,\n quick_filter=True,\n export_csv=False,\n menu = {'buttons':buttons},\n export_excel=False,\n #show_toggle_edit=True,\n export_mode='auto',\n index=True,\n keep_multiindex=False,\n theme='ag-theme-fresh',\n user_params={'selected_id':0})\n\ndisplay(grid1)\n\ngrid1.user_params = {'selected_id': 2}",
"_____no_output_____"
],
[
"import os\nimport json\nimport pandas as pd\nimport numpy as np\nimport urllib.request as ur\nfrom copy import deepcopy as copy\nfrom ipyaggrid import Grid\n",
"_____no_output_____"
],
[
"url = 'https://raw.githubusercontent.com/bahamas10/css-color-names/master/css-color-names.json'\nwith ur.urlopen(url) as res:\n cnames = json.loads(res.read().decode('utf-8'))\n\ncolors = []\nfor k in cnames.keys():\n colors.append({'color':k, 'value':cnames[k]})\n",
"_____no_output_____"
],
[
"colors_ref = colors[:]",
"_____no_output_____"
],
[
"css_rules=\"\"\"\n.color-box{\n float: left;\n width: 10px;\n height: 10px;\n margin: 5px;\n border: 1px solid rgba(0, 0, 0, .2);\n}\n\"\"\"\n\ncolumnDefs = [\n {'headerName': 'Color', 'field':'color', \n 'pinned': True, 'editable': True},\n {'headerName': 'Code', 'field':'value', 'editable': False, 'cellRenderer': \"\"\"\n function(params){\n return `<div><div style=\"background-color:${params.value}\" class='color-box'></div><span>${params.value}</span></div>`\n }\"\"\"}\n]\n\ngridOptions = {'columnDefs':columnDefs,\n 'enableFilter':'true',\n 'enableSorting':'true',\n 'rowSelection':'multiple',\n }\n\ncolor_grid = Grid(width=400,\n height=250,\n css_rules=css_rules,\n grid_data=colors,\n grid_options=gridOptions,\n sync_on_edit=True,\n sync_grid=True, #default\n )\n\nsync_grid=True\ncolor_grid.get_grid()\ncolor_grid.get_selected_rows()\n\ncolor_grid\n",
"_____no_output_____"
],
[
"color_grid.grid_data_out.get('grid')",
"_____no_output_____"
],
[
"gridOptions = {'columnDefs':columnDefs,\n 'enableFilter':'true',\n 'enableColumnResize':'true',\n 'enableSorting':'true',\n }\n\ncolor_grid2 = Grid(width=500,\n height=250,\n css_rules=css_rules,\n quick_filter=True,\n show_toggle_edit=True,\n grid_data=colors_ref,\n grid_options=gridOptions)\ncolor_grid2",
"_____no_output_____"
],
[
"colors = colors_ref[:]\ncolors.append({'color':'jupyterorange', 'value':'#f37626'})",
"_____no_output_____"
],
[
"color_grid2.update_grid_data(copy(colors)) # New data set corresponding to the good columns",
"_____no_output_____"
],
[
"color_grid2.delete_selected_rows()",
"_____no_output_____"
],
[
"color_grid2.grid_data_out['grid']",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a273553da2d39dadcc21be42da4d09cff4a7b84
| 12,417 |
ipynb
|
Jupyter Notebook
|
lab11 .ipynb
|
TraberNicholas/IA241-github
|
2b1ba4f370d7c97ef535507b2afa941cd9abc4d8
|
[
"MIT"
] | null | null | null |
lab11 .ipynb
|
TraberNicholas/IA241-github
|
2b1ba4f370d7c97ef535507b2afa941cd9abc4d8
|
[
"MIT"
] | null | null | null |
lab11 .ipynb
|
TraberNicholas/IA241-github
|
2b1ba4f370d7c97ef535507b2afa941cd9abc4d8
|
[
"MIT"
] | null | null | null | 37.288288 | 177 | 0.611017 |
[
[
[
"# Lab 11 Download Census Data into Python",
"_____no_output_____"
]
],
[
[
"from urllib import request\nimport json\nfrom pprint import pprint\n\n\ncensus_api_key = 'f84452395038a4790772cc768cb13ecbe0e6a636' #get your key from https://api.census.gov/data/key_signup.html\n\n\nurl_str = 'https://api.census.gov/data/2019/acs/acs5?get=B01001_001E,NAME&for=county:*&in=state:51&key='+census_api_key # create the url of your census data\n\nresponse = request.urlopen(url_str) # read the response into computer\n\nhtml_str = response.read().decode(\"utf-8\") # convert the response into string\nif (html_str):\n json_data = json.loads(html_str) # convert the string into json\n print (json_data[0])\n for v1,name,state,county in json_data[1:]:\n print (v1,name,state,county )",
"['B01001_001E', 'NAME', 'state', 'county']\n6523 Surry County, Virginia 51 181\n14423 Clarke County, Virginia 51 043\n30728 Mecklenburg County, Virginia 51 117\n75079 Augusta County, Virginia 51 015\n22865 Goochland County, Virginia 51 075\n13170 Madison County, Virginia 51 113\n93823 Roanoke County, Virginia 51 161\n16520 Brunswick County, Virginia 51 025\n11885 Northampton County, Virginia 51 131\n22570 Rockbridge County, Virginia 51 163\n3970 Norton city, Virginia 51 720\n17428 Colonial Heights city, Virginia 51 570\n6388 Bland County, Virginia 51 021\n33343 Botetourt County, Virginia 51 023\n16912 Bristol city, Virginia 51 520\n14927 Williamsburg city, Virginia 51 830\n29801 Carroll County, Virginia 51 035\n54071 Washington County, Virginia 51 191\n23788 Page County, Virginia 51 139\n157613 Alexandria city, Virginia 51 510\n135041 Hampton city, Virginia 51 650\n233464 Arlington County, Virginia 51 013\n21788 Buchanan County, Virginia 51 027\n146773 Stafford County, Virginia 51 179\n226622 Richmond city, Virginia 51 760\n10998 Essex County, Virginia 51 057\n41603 Tazewell County, Virginia 51 185\n16986 Manassas Park city, Virginia 51 685\n11377 Sussex County, Virginia 51 183\n41174 Manassas city, Virginia 51 683\n25317 Salem city, Virginia 51 775\n12040 Charlotte County, Virginia 51 037\n11525 Greensville County, Virginia 51 081\n36627 Isle of Wight County, Virginia 51 093\n8147 Franklin city, Virginia 51 620\n7241 Lexington city, Virginia 51 678\n51308 Henry County, Virginia 51 089\n16688 King William County, Virginia 51 101\n36040 Louisa County, Virginia 51 109\n22905 Prince Edward County, Virginia 51 147\n80284 Rockingham County, Virginia 51 165\n74916 James City County, Virginia 51 095\n27141 Russell County, Virginia 51 167\n30767 Smyth County, Virginia 51 173\n47096 Charlottesville city, Virginia 51 540\n55225 Campbell County, Virginia 51 031\n327535 Henrico County, Virginia 51 087\n26229 King George County, Virginia 51 099\n10724 Lancaster County, Virginia 51 103\n23948 Lee County, Virginia 51 105\n8788 Mathews County, Virginia 51 115\n10675 Middlesex County, Virginia 51 119\n38114 Prince George County, Virginia 51 149\n8884 Richmond County, Virginia 51 159\n21902 Scott County, Virginia 51 169\n132833 Spotsylvania County, Virginia 51 177\n15707 Appomattox County, Virginia 51 011\n56187 Franklin County, Virginia 51 067\n7042 King and Queen County, Virginia 51 097\n98140 Montgomery County, Virginia 51 121\n21686 New Kent County, Virginia 51 127\n9824 Cumberland County, Virginia 51 049\n14756 Dickenson County, Virginia 51 051\n34552 Halifax County, Virginia 51 083\n395134 Loudoun County, Virginia 51 107\n461423 Prince William County, Virginia 51 153\n17880 Southampton County, Virginia 51 175\n2204 Highland County, Virginia 51 091\n30381 Caroline County, Virginia 51 033\n37222 Gloucester County, Virginia 51 073\n17748 Patrick County, Virginia 51 141\n28815 Powhatan County, Virginia 51 145\n43224 Shenandoah County, Virginia 51 171\n69728 Fauquier County, Virginia 51 061\n24432 Staunton city, Virginia 51 790\n26594 Fluvanna County, Virginia 51 065\n17691 Radford city, Virginia 51 750\n27897 Winchester city, Virginia 51 840\n32673 Accomack County, Virginia 51 001\n5110 Craig County, Virginia 51 045\n15704 Floyd County, Virginia 51 063\n16772 Giles County, Virginia 51 071\n15742 Grayson County, Virginia 51 077\n15433 Nottoway County, Virginia 51 135\n7378 Rappahannock County, Virginia 51 157\n7014 Charles City County, Virginia 51 036\n51101 Culpeper County, Virginia 51 047\n28485 Dinwiddie County, Virginia 51 053\n19519 Greene County, Virginia 51 079\n105537 Hanover County, Virginia 51 085\n12282 Lunenburg County, Virginia 51 111\n36010 Orange County, Virginia 51 137\n5442 Emporia city, Virginia 51 595\n28844 Wythe County, Virginia 51 197\n239982 Chesapeake city, Virginia 51 550\n53273 Harrisonburg city, Virginia 51 660\n107405 Albemarle County, Virginia 51 003\n78376 Bedford County, Virginia 51 019\n17059 Buckingham County, Virginia 51 029\n38486 Wise County, Virginia 51 195\n5598 Covington city, Virginia 51 580\n95097 Portsmouth city, Virginia 51 740\n450201 Virginia Beach city, Virginia 51 810\n15157 Alleghany County, Virginia 51 005\n6517 Galax city, Virginia 51 640\n17751 Westmoreland County, Virginia 51 193\n12190 Northumberland County, Virginia 51 133\n34182 Pulaski County, Virginia 51 155\n39492 Warren County, Virginia 51 187\n41070 Danville city, Virginia 51 590\n28622 Fredericksburg city, Virginia 51 630\n31775 Amherst County, Virginia 51 009\n4307 Bath County, Virginia 51 017\n22456 Hopewell city, Virginia 51 670\n179673 Newport News city, Virginia 51 700\n86415 Frederick County, Virginia 51 069\n80569 Lynchburg city, Virginia 51 680\n67982 York County, Virginia 51 199\n12852 Martinsville city, Virginia 51 690\n14831 Nelson County, Virginia 51 125\n61256 Pittsylvania County, Virginia 51 143\n6484 Buena Vista city, Virginia 51 530\n14128 Falls Church city, Virginia 51 610\n31362 Petersburg city, Virginia 51 730\n12090 Poquoson city, Virginia 51 735\n23531 Fairfax city, Virginia 51 600\n22140 Waynesboro city, Virginia 51 820\n99229 Roanoke city, Virginia 51 770\n90093 Suffolk city, Virginia 51 800\n244601 Norfolk city, Virginia 51 710\n12953 Amelia County, Virginia 51 007\n343551 Chesterfield County, Virginia 51 041\n1145862 Fairfax County, Virginia 51 059\n"
]
],
[
[
"## 3.1 County with highest population",
"_____no_output_____"
]
],
[
[
"url_str = 'https://api.census.gov/data/2019/acs/acs5?get=B01001_001E,NAME&for=county:*&in=state:51&key='+census_api_key # create the url of your census data\n\nresponse = request.urlopen(url_str) # read the response into computer\n\nhtml_str = response.read().decode(\"utf-8\") # convert the response into string\nmax_p= 0\nmax_county=''\nif (html_str):\n json_data = json.loads(html_str) # convert the string into json\n# print (json_data[0])\n for v1,name,state,county in json_data[1:]:\n if max_p< int(v1):\n max_p= int(v1)\n max_county = name\n # print (v1,name,state,county )\nprint(\"{} has the highest population {}.\".format(max_county, max_p))",
"Fairfax County, Virginia has the highest population 1145862.\n"
]
],
[
[
"# 3.2 county with highest male population",
"_____no_output_____"
]
],
[
[
"url_str = 'https://api.census.gov/data/2019/acs/acs5?get=B01001_002E,NAME&for=county:*&in=state:51&key='+census_api_key # create the url of your census data\n\nresponse = request.urlopen(url_str) # read the response into computer\n\nhtml_str = response.read().decode(\"utf-8\") # convert the response into string\nmax_p= 0\nmax_county=''\nif (html_str):\n json_data = json.loads(html_str) # convert the string into json\n# print (json_data[0])\n for v1,name,state,county in json_data[1:]:\n if max_p< int(v1):\n max_p= int(v1)\n max_county = name\n # print (v1,name,state,county )\nprint(\"{} has the highest male population {}.\".format(max_county, max_p))",
"Fairfax County, Virginia has the highest male population 568173.\n"
]
],
[
[
"# 3.3 County with highest male:total population ratio",
"_____no_output_____"
]
],
[
[
"url_str = 'https://api.census.gov/data/2019/acs/acs5?get=B01001_001E,B01001_002E,NAME&for=county:*&in=state:51&key='+census_api_key # create the url of your census data\n\nresponse = request.urlopen(url_str) # read the response into computer\n\nhtml_str = response.read().decode(\"utf-8\") # convert the response into string\nmax_p= 0\nmax_county=''\nif (html_str):\n json_data = json.loads(html_str) # convert the string into json\n# print (json_data[0])\n for v1,v2,name,state,county in json_data[1:]:\n if max_p< int(v2)/int(v1):\n max_p= int(v2)/int(v1)\n max_county = name\n # print (v1,v2,name,state,county )\nprint(\"{} has the highest male/total population ratio {}.\".format(max_county, max_p))",
"Greensville County, Virginia has the highest male/total population ratio 0.629587852494577.\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2739de18e965a9cc35f736a7b227006f84f6ba
| 752,814 |
ipynb
|
Jupyter Notebook
|
content/Homework/cs109a_hw2_solutions_109.ipynb
|
gurdeep101/2019-CS109A
|
46000db9e36c71534788ed00cca988305e8e3ee9
|
[
"MIT"
] | null | null | null |
content/Homework/cs109a_hw2_solutions_109.ipynb
|
gurdeep101/2019-CS109A
|
46000db9e36c71534788ed00cca988305e8e3ee9
|
[
"MIT"
] | null | null | null |
content/Homework/cs109a_hw2_solutions_109.ipynb
|
gurdeep101/2019-CS109A
|
46000db9e36c71534788ed00cca988305e8e3ee9
|
[
"MIT"
] | null | null | null | 322.957529 | 480,300 | 0.911193 |
[
[
[
"# <img style=\"float: left; padding-right: 10px; width: 45px\" src=\"https://raw.githubusercontent.com/Harvard-IACS/2018-CS109A/master/content/styles/iacs.png\"> CS109A Introduction to Data Science: \n\n## Homework 2: Linear and k-NN Regression\n\n\n**Harvard University**<br/>\n**Fall 2019**<br/>\n**Instructors**: Pavlos Protopapas, Kevin Rader, Chris Tanner\n\n<hr style=\"height:2pt\">\n",
"_____no_output_____"
]
],
[
[
"#RUN THIS CELL \nimport requests\nfrom IPython.core.display import HTML\nstyles = requests.get(\"https://raw.githubusercontent.com/Harvard-IACS/2018-CS109A/master/content/styles/cs109.css\").text\nHTML(styles)",
"_____no_output_____"
]
],
[
[
"### INSTRUCTIONS\n\n- To submit your assignment follow the instructions given in Canvas.\n- Restart the kernel and run the whole notebook again before you submit. \n- If you submit individually and you have worked with someone, please include the name of your [one] partner below. \n- As much as possible, try and stick to the hints and functions we import at the top of the homework, as those are the ideas and tools the class supports and is aiming to teach. And if a problem specifies a particular library you're required to use that library, and possibly others from the import list.\n- Please use .head() when viewing data. Do not submit a notebook that is excessively long because output was not suppressed or otherwise limited. ",
"_____no_output_____"
],
[
"<hr style=\"height:2pt\">",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import r2_score\nfrom sklearn.neighbors import KNeighborsRegressor\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.model_selection import train_test_split\nimport statsmodels.api as sm\nfrom statsmodels.api import OLS\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# <div class=\"theme\"> Predicting Taxi Pickups in NYC </div>\n\nIn this homework, we will explore k-nearest neighbor and linear regression methods for predicting a quantitative variable. Specifically, we will build regression models that can predict the number of taxi pickups in New York City at any given time of the day. These prediction models will be useful, for example, in monitoring traffic in the city.\n\nThe data set for this problem is given in the file `nyc_taxi.csv`. You will need to separate it into training and test sets. The first column contains the time of a day in minutes, and the second column contains the number of pickups observed at that time. The data set covers taxi pickups recorded in NYC during Jan 2015.\n\nWe will fit regression models that use the time of the day (in minutes) as a predictor and predict the average number of taxi pickups at that time. The models will be fitted to the training set and evaluated on the test set. The performance of the models will be evaluated using the $R^2$ metric.",
"_____no_output_____"
],
[
"## <div class=\"exercise\"> <b> Question 1 [25 pts]</b> </div>",
"_____no_output_____"
],
[
"**1.1**. Use pandas to load the dataset from the csv file `nyc_taxi.csv` into a pandas data frame. Use the `train_test_split` method from `sklearn` with a `random_state` of 42 and a `test_size` of 0.2 to split the dataset into training and test sets. Store your train set data frame as `train_data` and your test set data frame as `test_data`.\n\n**1.2**. Generate a scatter plot of the training data points with clear labels on the x and y axes to demonstrate how the number of taxi pickups is dependent on the time of the day. Always be sure to title your plot.\n\n**1.3**. In a few sentences, describe the general pattern of taxi pickups over the course of the day and explain why this is a reasonable result. \n\n**1.4**. You should see a *hole* in the scatter plot when `TimeMin` is 500-550 minutes and `PickupCount` is roughly 20-30 pickups. Briefly surmise why this is the case.\n",
"_____no_output_____"
],
[
"### Answers",
"_____no_output_____"
],
[
"**1.1 Use pandas to load the dataset from the csv file ...**",
"_____no_output_____"
]
],
[
[
"# read the file\n# your code here\n\ndata = pd.read_csv('data/nyc_taxi.csv')\ndata.describe()",
"_____no_output_____"
],
[
"# split the data\n# your code here\n# Random_state makes sure same split each time this random process is run (takes out randomness)\ntrain_data, test_data = train_test_split(data, test_size=0.2, random_state=42)\n\ntrain_data.head()",
"_____no_output_____"
],
[
"# your code here\ntrain_data.describe()",
"_____no_output_____"
],
[
"# Test size is indeed 20% of total\n# your code here \nprint(test_data.shape)\ntest_data.describe()\n",
"(250, 2)\n"
]
],
[
[
"**1.2 Generate a scatter plot of the training data points**",
"_____no_output_____"
]
],
[
[
"# Your code here\nfig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14,6))\naxes[0].scatter(train_data['TimeMin'], train_data['PickupCount'])\naxes[0].set_xlabel('Time of Day in Minutes')\naxes[0].set_ylabel('# of Pickups')\n\n# Hours might be a more readable format of displaying the x-axis; apply a scale transformation\naxes[1].scatter(train_data['TimeMin']/60, train_data['PickupCount']);\naxes[1].set_xlabel('Time of Day in Hours');\naxes[1].set_ylabel('# of Pickups');\n\nfig.suptitle(\"Taxi Pickups in NYC vs Time of Day\");\n\n",
"_____no_output_____"
]
],
[
[
"**1.3 In a few sentences, describe the general pattern of taxi pickups over the course of the day and explain why this is a reasonable result.**",
"_____no_output_____"
],
[
"*your answer here*\n\nThe pattern of pickups seems to bear out the social patterns you'd expect in a major urban metropolis like New York. We see instances of very high pickup counts between midnight and 5 a.m. when people take cabs home as bars close (in a city that never sleeps as opposed to a quiet academic town like Boston). Then you see a linear trend of pickups starting at a low point in the early morning (just after 5 a.m.) during the beginning of the morning commute when you'd expect very little social going on and steadily increasing to the common social hours in the evening at night when you'd expect people to congregate for dinner, shows, concerts, etc. There does appear to be a mid-morning surge around 8am to 10:30am, perhaps as some people travel to work via taxi. \n",
"_____no_output_____"
],
[
"**1.4 You should see a hole in the scatter plot when TimeMin is 500-550 minutes and PickupCount is roughly 20-30 pickups.**",
"_____no_output_____"
],
[
"*your answer here*\n\nWeekends and weekdays likely have different behavior for the number of taxi pickups over the course of the day, especially during morning rush hour (8-9 am) when many folks are still in bed or at home on the weekends. \n",
"_____no_output_____"
],
[
"## <div class=\"exercise\"> <b>Question 2 [25 pts]</b> </div>\n\nIn lecture we've seen k-Nearest Neighbors (k-NN) Regression, a non-parametric regression technique. In the following problems please use built in functionality from `sklearn` to run k-NN Regression. \n\n\n**2.1**. Choose `TimeMin` as your feature variable and `PickupCount` as your response variable. Create a dictionary of `KNeighborsRegressor` objects and call it `KNNModels`. Let the key for your `KNNmodels` dictionary be the value of $k$ and the value be the corresponding `KNeighborsRegressor` object. For $k \\in \\{1, 10, 75, 250, 500, 750, 1000\\}$, fit k-NN regressor models on the training set (`train_data`). \n\n**2.2**. For each $k$, overlay a scatter plot of the actual values of `PickupCount` vs. `TimeMin` in the training set with a scatter plot of **predictions** for `PickupCount` vs `TimeMin`. Do the same for the test set. You should have one figure with 7 x 2 total subplots; for each $k$ the figure should have two subplots, one subplot for the training set and one for the test set. \n\n**Hints**:\n1. Each subplot should use different color and/or markers to distinguish k-NN regression prediction values from the actual data values.\n2. Each subplot must have appropriate axis labels, title, and legend.\n3. The overall figure should have a title. \n\n\n**2.3**. Report the $R^2$ score for the fitted models on both the training and test sets for each $k$ (reporting the values in tabular form is encouraged).\n\n**2.4**. Plot, in a single figure, the $R^2$ values from the model on the training and test set as a function of $k$. \n\n**Hints**:\n1. Again, the figure must have axis labels and a legend.\n2. Differentiate $R^2$ plots on the training and test set by color and/or marker.\n3. Make sure the $k$ values are sorted before making your plot.\n\n**2.5**. Discuss the results:\n\n1. If $n$ is the number of observations in the training set, what can you say about a k-NN regression model that uses $k = n$? \n2. What does an $R^2$ score of $0$ mean? \n3. What would a negative $R^2$ score mean? Are any of the calculated $R^2$ you observe negative?\n4. Do the training and test $R^2$ plots exhibit different trends? Describe. \n5. What is the best value of $k$? How did you come to choose this value? How do the corresponding training/test set $R^2$ values compare?\n6. Use the plots of the predictions (in 2.2) to justify why your choice of the best $k$ makes sense (**Hint**: think Goldilocks).",
"_____no_output_____"
],
[
"### Answers",
"_____no_output_____"
],
[
"**2.1 Choose `TimeMin` as your feature variable and `PickupCount` as your response variable. Create a dictionary ...**",
"_____no_output_____"
]
],
[
[
"# your code here\n\n# define k values\nk_values = [1, 10, 75, 250, 500, 750, 1000]\n\n# build a dictionary KNN models\nKNNModels = {k: KNeighborsRegressor(n_neighbors=k) for k in k_values}\n\n# fit each KNN model\nfor k_value in KNNModels: \n KNNModels[k_value].fit(train_data[['TimeMin']], train_data[['PickupCount']])\n",
"_____no_output_____"
]
],
[
[
"**2.2 For each $k$ on the training set, overlay a scatter plot ...**",
"_____no_output_____"
]
],
[
[
"\n# your code here \n\n# Generate predictions\nknn_predicted_pickups_train = {k: KNNModels[k].predict(train_data[['TimeMin']]) for k in KNNModels}\nknn_predicted_pickups_test = {k: KNNModels[k].predict(test_data[['TimeMin']]) for k in KNNModels}\n",
"_____no_output_____"
],
[
"# your code here\n# Preferred to use a function if the process is identical and repeated with varying inputs\n# Try to use functions in your homeworks to make things easier for yourself and more replicable\n\n# Function to plot predicted vs actual for a given k and dataset\ndef plot_knn_prediction(ax, dataset, predictions, k, dataset_name= \"Training\"):\n \n # scatter plot predictions\n ax.plot(dataset['TimeMin'], predictions, '*', label='Predicted')\n \n # scatter plot actual\n ax.plot(dataset['TimeMin'], dataset['PickupCount'], '.', alpha=0.2, label='Actual')\n \n \n # Set labels\n ax.set_title(\"$k = {}$ on {} Set\".format(str(k), dataset_name))\n ax.set_xlabel('Time of Day in Minutes')\n ax.set_ylabel('Pickup Count')\n ax.legend()",
"_____no_output_____"
],
[
"# Plot predictions vs actual\n# your code here \n\n# Notice that nrows is set to the variable size. This makes the code more readable and adaptable\nfig, axes = plt.subplots(nrows=len(k_values), ncols=2, figsize=(16,28))\nfig.suptitle('Predictions vs Actuals', fontsize=14)\nfor i, k in enumerate(k_values):\n plot_knn_prediction(axes[i][0], train_data, knn_predicted_pickups_train[k], k, \"Training\")\n plot_knn_prediction(axes[i][1], test_data, knn_predicted_pickups_test[k], k, \"Test\")\n\nfig.tight_layout(rect=[0,0.03,1,0.98])",
"_____no_output_____"
]
],
[
[
"**2.3 Report the $R^2$ score for the fitted models ...**",
"_____no_output_____"
]
],
[
[
"# your code here\n\nknn_r2_train = {k : r2_score(train_data[['PickupCount']], knn_predicted_pickups_train[k]) for k in k_values}\nknn_r2_test = { k : r2_score(test_data[['PickupCount']], knn_predicted_pickups_test[k]) for k in k_values}\n\n# This format makes the display much more readable\nknn_r2_df = pd.DataFrame(data = {\"k\" : tuple(knn_r2_train.keys()), \n \"Train R^2\" : tuple(knn_r2_train.values()), \n \"Test R^2\" : tuple(knn_r2_test.values())})\n\n\nknn_r2_df",
"_____no_output_____"
]
],
[
[
"**2.4 Plot, in a single figure, the $R^2$ values from the model on the training and test set as a function of $k$**",
"_____no_output_____"
]
],
[
[
"# your code here\n\nfig, axes = plt.subplots(figsize = (5,5))\naxes.plot(knn_r2_df['k'], knn_r2_df['Train R^2'], 's-', label='Train $R^2$ Scores')\naxes.plot(knn_r2_df['k'], knn_r2_df['Test R^2'], 's-', label='Test $R^2$ Scores')\naxes.set_xlabel('k')\naxes.set_ylabel('$R^2$ Scores')\n# A generic title of this format (y vs x) is generally appropriate\naxes.set_title(\"$R^2$ Scores vs k\")\n# Including a legend is very important\naxes.legend();",
"_____no_output_____"
]
],
[
[
"**2.5**. Discuss the results:\n\n1. If $n$ is the number of observations in the training set, what can you say about a k-NN regression model that uses $k = n$? \n \n A k-NN regression model that used $k = n$ is the equivalent of using the mean of the response variable values for all the points of the dataset as a prediction model.\n\n\n2. What does an $R^2$ score of $0$ mean? \n\n An $R^2$ value of 0 indicates a model making predictions equivalently well to a model using a constant prediction of the data's mean (and as such explains none of the variation around the mean). In k-NN Regression, an example would be the model with $k = n$ or in this case $k = 1000$.\n \n \n3. What would a negative $R^2$ score mean? Are any of the calculated $R^2$ you observe negative?\n\n None of the calculated $R^2$ values in this case on the training set are negative. We see negative $R^2$ values for $k = 1$ and $k = 1000$ on the test set (although the test set $R^2$ value for $k = 1000$ is very close to 0). A negative $R^2$ value indicate a model making predictions less accurate than using a constant prediction (for any configuration of features) of the mean of all response variable values. Our observations of a highly negative $R^2$ score for $k = 1$ on the test set means that predictive value of the 1-NN model is very poor and 1-NN would be a worse model for our data than just taking the average value (of the test set). For $k = 1000$ the difference between the observed $R^2$ score on the test set and 0 is due to stochasticity and 1000-NN has a predictive power essentially equivalent to taking the average value on the training set as a prediction (in this particular case it so happens that 1000-NN is exactly the same model as using the average value of the training set for a prediction). \n \n\n4. Do the training and test $R^2$ plots exhibit different trends? Describe. \n\n The training and test plots of $R^2$ exhibit different trends, as for small $k$, the model overfits the data, so it achieves a very good $R^2$ on the training set and a very poor $R^2$ on the test data. At large $k$ values the model underfits. Although it performs equally well on the train and test data, it's not doing as well on either one as it did at a different value of $k$.\n \n \n5. What is the best value of $k$? How did you come to choose this value? How do the corresponding training/test set $R^2$ values compare?\n\n Based on test set $R^2$ scores, the best value of $k$ is 75 with a training set $R^2$ score of 0.445 and a test set score of 0.390. Note that *best* refers to performance on the test set, the set on which the model can be evaluated.\n \n \n6. Use the plots of the predictions (in 2.2) to justify why your choice of the best $k$ makes sense (**Hint**: think Goldilocks).\n\n A $k$ of 75 appears to be the most reasonable choice from these plots since the curve of fitted values describes the relationship in the scatter plots (both train and test) very well, but is not too jagged or jumpy (if $k$ is smaller) or too flattened out (if $k$ is larger). We are in the Goldilocks zone.",
"_____no_output_____"
],
[
"## <div class=\"exercise\"> <b> Question 3 [25 pts] </b></div>\n\nWe next consider simple linear regression, which we know from lecture is a parametric approach for regression that assumes that the response variable has a linear relationship with the predictor. Use the `statsmodels` module for Linear Regression. This module has built-in functions to summarize the results of regression and to compute confidence intervals for estimated regression parameters. \n\n**3.1**. Again choose `TimeMin` as your predictor and `PickupCount` as your response variable. Create an `OLS` class instance and use it to fit a Linear Regression model on the training set (`train_data`). Store your fitted model in the variable `OLSModel`.\n\n**3.2**. Create a plot just like you did in 2.2 (but with fewer subplots): plot both the observed values and the predictions from `OLSModel` on the training and test set. You should have one figure with two subplots, one subplot for the training set and one for the test set.\n\n**Hints**:\n1. Each subplot should use different color and/or markers to distinguish Linear Regression prediction values from that of the actual data values.\n2. Each subplot must have appropriate axis labels, title, and legend.\n3. The overall figure should have a title. \n\n\n**3.3**. Report the $R^2$ score for the fitted model on both the training and test sets.\n\n**3.4**. Report the estimates for the slope and intercept for the fitted linear model. \n\n**3.5**. Report the $95\\%$ confidence intervals (CIs) for the slope and intercept. \n\n**3.6**. Discuss the results:\n\n1. How does the test $R^2$ score compare with the best test $R^2$ value obtained with k-NN regression? Describe why this is not surprising for these data.\n2. What does the sign of the slope of the fitted linear model convey about the data? \n3. Interpret the $95\\%$ confidence intervals from 3.5. Based on these CIs is there evidence to suggest that the number of taxi pickups has a significant linear relationship with time of day? How do you know? \n4. How would $99\\%$ confidence intervals for the slope and intercept compare to the $95\\%$ confidence intervals (in terms of midpoint and width)? Briefly explain your answer. \n5. Based on the data structure, what restriction on the model would you put at the endpoints (at $x\\approx0$ and $x\\approx1440$)? What does this say about the appropriateness of a linear model?\n",
"_____no_output_____"
],
[
"### Answers",
"_____no_output_____"
],
[
"**3.1 Again choose `TimeMin` as your predictor and `PickupCount` as your response variable. Create a `OLS` class instance ...**",
"_____no_output_____"
]
],
[
[
"# your code here\n\n# Look at these variables on their own - they format for both constant term and linear predictor\ntrain_data_augmented = sm.add_constant(train_data['TimeMin'])\ntest_data_augmented = sm.add_constant(test_data['TimeMin'])\nOLSModel = OLS(train_data['PickupCount'].values, train_data_augmented).fit()\n# type(train_data['TimeMin'])",
"_____no_output_____"
]
],
[
[
"**3.2 Re-create your plot from 2.2 using the predictions from `OLSModel` on the training and test set ...**",
"_____no_output_____"
]
],
[
[
"# your code here\n# OLS Linear Regression model training predictions\nols_predicted_pickups_train = OLSModel.predict(train_data_augmented)\n\n# OLS Linear Regression model test predictions\nols_predicted_pickups_test = OLSModel.predict(test_data_augmented)",
"_____no_output_____"
],
[
"# your code here\n# Function to plot predicted vs actual for a given k and dataset\ndef plot_ols_prediction(ax, dataset, predictions, dataset_name= \"Training\"):\n \n # scatter plot predictions\n ax.plot(dataset['TimeMin'], predictions, '*', label='Predicted')\n \n # scatter plot actual\n ax.plot(dataset['TimeMin'], dataset['PickupCount'], '.', alpha=0.2, label='Actual')\n \n \n # Set labels\n ax.set_title(\"{} Set\".format(dataset_name))\n ax.set_xlabel('Time of Day in Minutes')\n ax.set_ylabel('Pickup Count')\n ax.legend()",
"_____no_output_____"
],
[
"# your code here \nfig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20,8))\nfig.suptitle('Predictions vs Actuals', fontsize=14)\nplot_ols_prediction(axes[0], train_data, ols_predicted_pickups_train, \"Training\")\nplot_ols_prediction(axes[1], test_data, ols_predicted_pickups_test, \"Test\")\n \n",
"_____no_output_____"
]
],
[
[
"**3.3 Report the $R^2$ score for the fitted model on both the training and test sets.**",
"_____no_output_____"
]
],
[
[
"# your code here\n\nr2_score_train = r2_score(train_data[['PickupCount']].values, ols_predicted_pickups_train) \nr2_score_test = r2_score(test_data[['PickupCount']].values, ols_predicted_pickups_test)\n\nprint(\"R^2 score for training set: {:.4}\".format(r2_score_train))\nprint(\"R^2 score for test set: {:.4}\".format(r2_score_test))\n",
"R^2 score for training set: 0.243\nR^2 score for test set: 0.2407\n"
]
],
[
[
"**3.4 Report the slope and intercept values for the fitted linear model.**",
"_____no_output_____"
]
],
[
[
"## show summary\n# your code here\nOLSModel.summary()",
"_____no_output_____"
],
[
"# your code here\nols_intercept = OLSModel.params[0]\nols_slope = OLSModel.params[1]\n\n\nprint(\"Intecept: {:.3}\".format(ols_intercept))\nprint(\"Slope: {:.3}\".format(ols_slope))",
"Intecept: 16.8\nSlope: 0.0233\n"
]
],
[
[
"**3.5 Report the $95\\%$ confidence interval for the slope and intercept.**",
"_____no_output_____"
]
],
[
[
"# your code here\nconf_int = OLSModel.conf_int()\n\n# Doing it by hand would be something like 16.7506 +/- (1.96 * 1.058), and same process for slope\n\nprint(\"95% confidence interval for intercept: [{:.4}, {:.4}]\".format(conf_int[0][0],conf_int[1][0]))\nprint(\"95% confidence interval for slope: [{:.4}, {:.4}]\".format(conf_int[0][1],conf_int[1][1]))\n\n",
"95% confidence interval for intercept: [14.68, 18.83]\n95% confidence interval for slope: [0.02078, 0.02589]\n"
]
],
[
[
"**3.6 Discuss the results:**",
"_____no_output_____"
],
[
"*your answer here*\n\n1. How does the test $R^2$ score compare with the best test $R^2$ value obtained with k-NN regression? Describe why this is not surprising for these data.\n\n The test $R^2$ is lower for Linear Regression than for k-NN regression for all but the most suboptimal values of $k$ ($k \\approx 0$ or $k \\approx n$). This isn't surprising since there are various indicators that a linear regression model isn't an ideal model for this particular choice of data and feature space. This is not surprising because the scatterplot of data show a curve and not just a straight line.\n\n \n2. What does the sign of the slope of the fitted linear model convey about the data?\n \n The positive slope implies that the number of pickups increases throughout the day, on average. The slope is positive for all values within the confidence interval.\n \n \n3. Interpret the $95\\%$ confidence intervals from 3.5. Based on these CIs is there evidence to suggest that the number of taxi pickups has a significant linear relationship with time of day? How do you know? \n \n As mentioned in the previous part, the confidence interval only contains positive values, and this suggests that 'no association' (a slope of zero) is not plausible. Also, the estimates for slope and intercept are reasonably precise. The intercept is estimated to fall between around 14 to 18 on data that ranges from 0-100, which reasonably small though certainly far from perfect. The slope, it seems, is very precise, estimated to be between .020 and .025. In practical terms, using the lower end would predict 29 pickups (plus the intercept) at 11:59pm and using the upper bounds would predict 36 pickups (plus the intercept) at 11:59 pm, which is a fairly tight range. Our uncertainty in the value of the slope is small enough to only moderately impact our overall uncertainty, even at the extremes of the data.\n \n \n4. How would $99\\%$ confidence intervals for the slope and intercept compare to the $95\\%$ confidence intervals (in terms of midpoint and width)? Briefly explain your answer. \n\n We'd expect a 99% confidence interval to be wider as it should allow for an even wider possibility of values that are believable, or consistent with the data. With increased confidence level, even more values become plausible so the interval is lengthened on both sides. The 99\\% CI would be centered at the same place as the 95\\% CI.<br>\n \n \n5. Based on the data structure, what restriction on the model would you put at the endpoints (at $x\\approx0$ and $x\\approx1440$)? What does this say about the appropriateness of a linear model?\n \n Looking at $x=0$ and $x=1440$, $y$ values should be the same because it’s only a minute difference in time. That’s not the case for the predicted $\\hat{y}$ though. Since the line should be 'anchored' at the same place on the ends of the graph, only a line with zero slope is consistent with this situation.\n\n ",
"_____no_output_____"
],
[
"# <div class=\"theme\"> Outliers </div>\n\nYou may recall from lectures that OLS Linear Regression can be susceptible to outliers in the data. We're going to look at a dataset that includes some outliers and get a sense for how that affects modeling data with Linear Regression. **Note, this is an open-ended question, there is not one correct solution (or one correct definition of an outlier).**\n",
"_____no_output_____"
],
[
"## <div class=\"exercise\"><b> Question 4 [25 pts] </b></div>\n\n\n\n\n**4.1**. We've provided you with two files `outliers_train.csv` and `outliers_test.csv` corresponding to training set and test set data. What does a visual inspection of training set tell you about the existence of outliers in the data?\n\n**4.2**. Choose `X` as your feature variable and `Y` as your response variable. Use `statsmodel` to create a Linear Regression model on the training set data. Store your model in the variable `OutlierOLSModel`.\n\n**4.3**. You're given the knowledge ahead of time that there are 3 outliers in the training set data. The test set data doesn't have any outliers. You want to remove the 3 outliers in order to get the optimal intercept and slope. In the case that you're sure of the existence and number (3) of outliers ahead of time, one potential brute force method to outlier detection might be to find the best Linear Regression model on all possible subsets of the training set data with 3 points removed. Using this method, how many times will you have to calculate the Linear Regression coefficients on the training data?\n\n**4.4** In CS109 we're strong believers that creating heuristic models is a great way to build intuition. In that spirit, construct an approximate algorithm to find the 3 outlier candidates in the training data by taking advantage of the Linear Regression residuals. Place your algorithm in the function `find_outliers_simple`. It should take the parameters `dataset_x` and `dataset_y`, and `num_outliers` representing your features, response variable values (make sure your response variable is stored as a numpy column vector), and the number of outliers to remove. The return value should be a list `outlier_indices` representing the indices of the `num_outliers` outliers in the original datasets you passed in. Run your algorithm and remove the outliers that your algorithm identified, use `statsmodels` to create a Linear Regression model on the remaining training set data, and store your model in the variable `OutlierFreeSimpleModel`.\n\n\n**4.5** Create a figure with two subplots. The first is a scatterplot where the color of the points denotes the outliers from the non-outliers in the training set, and include two regression lines on this scatterplot: one fitted with the outliers included and one fitted with the outlier removed (all on the training set). The second plot should include a scatterplot of points from the test set with the same two regression lines fitted on the training set: with and without outliers. Visually which model fits the test set data more closely?\n\n**4.6**. Calculate the $R^2$ score for the `OutlierOLSModel` and the `OutlierFreeSimpleModel` on the test set data. Which model produces a better $R^2$ score?\n\n**4.7**. One potential problem with the brute force outlier detection approach in 4.3 and the heuristic algorithm you constructed 4.4 is that they assume prior knowledge of the number of outliers. In general you can't expect to know ahead of time the number of outliers in your dataset. Propose how you would alter and/or use the algorithm you constructed in 4.4 to create a more general heuristic (i.e. one which doesn't presuppose the number of outliers) for finding outliers in your dataset. \n\n**Hints**:\n 1. Should outliers be removed one at a time or in batches?\n 2. What metric would you use and how would you use it to determine how many outliers to consider removing?",
"_____no_output_____"
],
[
"### Answers\n**4.1 We've provided you with two files `outliers_train.txt` and `outliers_test.txt` corresponding to training set and test set data. What does a visual inspection of training set tell you about the existence of outliers in the data?** ",
"_____no_output_____"
]
],
[
[
"# read the data\n# your code here\noutliers_train = pd.read_csv(\"data/outliers_train.csv\")\noutliers_test = pd.read_csv(\"data/outliers_test.csv\")\n\noutliers_train.describe()",
"_____no_output_____"
],
[
"# your code here\noutliers_train.head()",
"_____no_output_____"
],
[
"# your code here\noutliers_test.describe()",
"_____no_output_____"
],
[
"# your code here\noutliers_test.head()",
"_____no_output_____"
],
[
"# scatter plot\n# your code here\nplt.scatter(outliers_train[\"X\"],outliers_train[\"Y\"]);",
"_____no_output_____"
]
],
[
[
"*your answer here*\n \nThe dataset seems to have a roughly linear trend with 3 really clear outliers: 2 in the upper-left and one in the lower-right of the scatterplot (they do not follow the pattern of the rest of the points). \n",
"_____no_output_____"
],
[
"**4.2 Choose `X` as your feature variable and `Y` as your response variable. Use `statsmodel` to create ...**",
"_____no_output_____"
]
],
[
[
"# your code here\n# Reshape with -1 makes numpy figure out the correct number of rows\noutliers_orig_train_X = outliers_train[\"X\"].values.reshape(-1,1)\noutliers_orig_train_Y = outliers_train[\"Y\"].values.reshape(-1,1)\n\noutliers_train_X = sm.add_constant(outliers_orig_train_X)\noutliers_train_Y = outliers_orig_train_Y\n\noutliers_orig_test_X = outliers_test[\"X\"].values.reshape(-1,1)\noutliers_orig_test_Y = outliers_test[\"Y\"].values.reshape(-1,1)\n\noutliers_test_X = sm.add_constant(outliers_orig_test_X)\noutliers_test_Y = outliers_orig_test_Y\n\nOutlierOLSModel = sm.OLS(outliers_train_Y, outliers_train_X).fit() \n\nOutlierOLSModel.summary()",
"_____no_output_____"
]
],
[
[
"**4.3 One potential brute force method to outlier detection might be to find the best Linear Regression model on all possible subsets of the training set data with 3 points removed. Using this method, how many times will you have to calculate the Linear Regression coefficients on the training data?**\n \n ",
"_____no_output_____"
],
[
"*your answer here*\n\nThere are 53 total observations in the training set. That means there are $\\binom{53}{3}$ or 23,426 subsets in the training set with 3 points removed. We'll need to compute a Linear Regression model on each one and find the best one (presumably the one with the highest $R^2$ value on test).",
"_____no_output_____"
],
[
"**4.4 Construct an approximate algorithm to find the 3 outlier candidates in the training data by taking advantage of the Linear Regression residuals ...**",
"_____no_output_____"
]
],
[
[
"def find_outliers_simple(dataset_x, dataset_y, num_outliers):\n # your code here\n \n # calculate absolute value residuals\n y_pred = sm.OLS(dataset_y, dataset_x).fit().predict().reshape(-1,1)\n residuals = np.abs(dataset_y - y_pred)\n\n # use argsort to order the indices by absolute value of residuals\n # get all but the 3 highest residuals\n outlier_indices = np.argsort(residuals, axis=0).flatten()[-num_outliers:]\n \n return list(outlier_indices)",
"_____no_output_____"
],
[
"# get outliers\n# your code here\nsimple_outlier_indices = find_outliers_simple(outliers_train_X, outliers_orig_train_Y, 3)\n\nprint(\"Outlier indices: {} \".format(simple_outlier_indices))\n\n# get outliers\nsimple_outliers_x = outliers_orig_train_X[simple_outlier_indices]\nsimple_outliers_y= outliers_orig_train_Y[simple_outlier_indices]\n\n\n# new_dataset_indices are the complements of our outlier indices in the original set\nnew_dataset_indices = list(set(range(len(outliers_orig_train_X))) - set(simple_outlier_indices))\nnew_dataset_indices.sort()\n\n# get outliers free dataset\nsimple_outliers_free_x = outliers_train_X[new_dataset_indices]\nsimple_outliers_free_y = outliers_train_Y[new_dataset_indices]\n\n\n\nprint(\"Outlier X values: {} \".format(simple_outliers_x))\nprint(\"Outlier Y values: {} \".format(simple_outliers_y))",
"Outlier indices: [52, 51, 50] \nOutlier X values: [[ 1.931]\n [-1.991]\n [-2.11 ]] \nOutlier Y values: [[-297.]\n [ 303.]\n [ 320.]] \n"
],
[
"simple_outliers_y",
"_____no_output_____"
],
[
"# calculate outlier model\n# your code here\nOutlierFreeSimpleModel = sm.OLS(simple_outliers_free_y, simple_outliers_free_x).fit()\nOutlierFreeSimpleModel.summary()",
"_____no_output_____"
]
],
[
[
"**4.5 Create a figure with two subplots...**",
"_____no_output_____"
]
],
[
[
"# plot \n# your code here\n\nfig, axs = plt.subplots(1,2, figsize=(14,6))\n\nticks = np.linspace(-2.5,2.5, 100)\nregression_line_no = ticks*OutlierOLSModel.params[1] + OutlierOLSModel.params[0]\nregression_line = ticks*OutlierFreeSimpleModel.params[1] + OutlierFreeSimpleModel.params[0]\naxs[0].scatter(outliers_train[\"X\"],outliers_train[\"Y\"], label=\"actual values\")\naxs[0].scatter(simple_outliers_x, simple_outliers_y, color='orange', marker='o', s=52, label=\"outliers\")\naxs[0].plot(ticks, regression_line_no, color='orange', label=\"model prediction with outliers\")\naxs[0].plot(ticks, regression_line, label=\"model prediction without outliers\")\naxs[0].set_title('Comparison of model with and without outliers in train set')\naxs[0].set_xlabel(\"X\")\naxs[0].set_ylabel(\"Y\")\naxs[0].set_ylim((-500,500))\naxs[0].legend()\n\naxs[1].scatter(outliers_test[\"X\"],outliers_test[\"Y\"], label=\"actual values\")\n\naxs[1].plot(ticks, regression_line_no, color='orange', label=\"model prediction with outliers\")\naxs[1].plot(ticks, regression_line, label=\"model prediction without outliers\")\naxs[1].set_title('Comparison of model with and without outliers in test set')\naxs[1].set_xlabel(\"X\")\naxs[1].set_ylabel(\"Y\")\naxs[1].set_ylim((-500,500))\naxs[1].legend();\n\n",
"_____no_output_____"
]
],
[
[
"*your answer here*\n\nThe model with outliers removed fits the test data more closely: the orange line looks to have some systematic bias in predictions at very low or very high values of X.",
"_____no_output_____"
],
[
"**4.6 Calculate the $R^2$ score for the `OutlierOLSModel` and the `OutlierFreeSimpleModel` on the test set data. Which model produces a better $R^2$ score?**",
"_____no_output_____"
]
],
[
[
"# your code here\n\nr2_with_outliers = r2_score(outliers_test_Y, OutlierOLSModel.predict(sm.add_constant(outliers_test_X)))\nr2_wo_outliers = r2_score(outliers_test_Y, OutlierFreeSimpleModel.predict(sm.add_constant(outliers_test_X)))\n\nprint(\"R^2 score with outliers: {:.4}\".format(r2_with_outliers))\nprint(\"R^2 score with outliers removed: {:.4}\".format(r2_wo_outliers))",
"R^2 score with outliers: 0.3409\nR^2 score with outliers removed: 0.453\n"
]
],
[
[
"The version with outliers removed is better. ",
"_____no_output_____"
],
[
"**4.7 Propose how you would alter and/or use the algorithm you constructed in 4.4 to create a more general heuristic (i.e. one which doesn't presuppose the number of outliers) for finding outliers in your dataset.**",
"_____no_output_____"
],
[
"Find outliers one at a time. Find the worst outlier which improves the $R^2$ the most by removing it (on the test set), and keep removing outliers until the improvement to test $R^2$ is neglibigle less than some tolerance threshold. If you used the train set to compare $R^2$, you could easily remove the outlier and see a huge drop in $R^2$ just because it was the main driving force in MSM (the variance explained by the model) or MST (the original variance ignoring the model). Also, it would be good to specify some minimum number of points to be remaining (no more than half the observations should be considered outliers).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a273e16231b3f44b22bae825719a1b6df3a4b72
| 9,332 |
ipynb
|
Jupyter Notebook
|
3_level_of_measurement.ipynb
|
kirenz/forst_steps_in_python
|
eda5bf8966d8dc555f012835534805f62a1b2f20
|
[
"MIT"
] | 1 |
2019-03-25T08:22:35.000Z
|
2019-03-25T08:22:35.000Z
|
3_level_of_measurement.ipynb
|
kirenz/forst_steps_in_python
|
eda5bf8966d8dc555f012835534805f62a1b2f20
|
[
"MIT"
] | null | null | null |
3_level_of_measurement.ipynb
|
kirenz/forst_steps_in_python
|
eda5bf8966d8dc555f012835534805f62a1b2f20
|
[
"MIT"
] | 11 |
2019-03-16T13:21:09.000Z
|
2020-08-01T05:47:19.000Z
| 26.140056 | 362 | 0.524432 |
[
[
[
"**Introduction to Python**<br/>\nProf. Dr. Jan Kirenz <br/>\nHochschule der Medien Stuttgart",
"_____no_output_____"
],
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Import-data\" data-toc-modified-id=\"Import-data-1\"><span class=\"toc-item-num\">1 </span>Import data</a></span></li><li><span><a href=\"#Data-tidying\" data-toc-modified-id=\"Data-tidying-2\"><span class=\"toc-item-num\">2 </span>Data tidying</a></span></li></ul></div>",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"To get more information about the Pandas syntax, download the [Pandas code cheat sheet](https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf)",
"_____no_output_____"
],
[
"### Import data",
"_____no_output_____"
]
],
[
[
"# Import data from GitHub (or from your local computer)\ndf = pd.read_csv(\"https://raw.githubusercontent.com/kirenz/datasets/master/wage.csv\")",
"_____no_output_____"
]
],
[
[
"### Data tidying",
"_____no_output_____"
],
[
"First of all we want to get an overview of the data",
"_____no_output_____"
]
],
[
[
"# show the head (first few observations in the df)\ndf.head(3)",
"_____no_output_____"
],
[
"# show metadata (take a look at the level of measurement)\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 3000 entries, 0 to 2999\nData columns (total 12 columns):\nUnnamed: 0 3000 non-null int64\nyear 3000 non-null int64\nage 3000 non-null int64\nmaritl 3000 non-null object\nrace 3000 non-null object\neducation 3000 non-null object\nregion 3000 non-null object\njobclass 3000 non-null object\nhealth 3000 non-null object\nhealth_ins 3000 non-null object\nlogwage 3000 non-null float64\nwage 3000 non-null float64\ndtypes: float64(2), int64(3), object(7)\nmemory usage: 281.3+ KB\n"
]
],
[
[
"---\n**Some notes on data types (level of measurement):** \n\nIf we need to transform variables into a **numerical format**, we can transfrom the data with pd.to_numeric [see Pandas documenation](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.to_numeric.html):\n\nIf the data contains strings, we need to replace them with NaN (not a number). Otherwise we get an error message. Therefore, use errors='coerce' ... \n\n * pandas.to_numeric(arg, errors='coerce', downcast=None)\n\n * errors : {‘ignore’, ‘raise’, ‘coerce’}, default ‘raise’\n * If ‘raise’, then invalid parsing will raise an exception\n * If ‘coerce’, then invalid parsing will be set as NaN\n * If ‘ignore’, then invalid parsing will return the input\n \nTo change data into **categorical** format, you can use the following codes:\n\ndf['variable'] = pd.Categorical(df['variable'])\n\nIf the data is ordinal, we use pandas [CategoricalDtype](https://pandas.pydata.org/pandas-docs/stable/categorical.html)\n\n---",
"_____no_output_____"
]
],
[
[
"# show all columns in the data\ndf.columns",
"_____no_output_____"
],
[
"# rename variable \"education\" to \"edu\"\ndf = df.rename(columns={\"education\": \"edu\"})",
"_____no_output_____"
],
[
"# check levels and frequency of edu\ndf['edu'].value_counts() ",
"_____no_output_____"
]
],
[
[
"Convert `edu` to ordinal variable with pandas [CategoricalDtype](https://pandas.pydata.org/pandas-docs/stable/categorical.html)",
"_____no_output_____"
]
],
[
[
"from pandas.api.types import CategoricalDtype",
"_____no_output_____"
],
[
"# convert to ordinal variable\ncat_edu = CategoricalDtype(categories=\n ['1. < HS Grad', \n '2. HS Grad', \n '3. Some College', \n '4. College Grad', \n '5. Advanced Degree'],\n ordered=True)\n\ndf.edu = df.edu.astype(cat_edu)",
"_____no_output_____"
]
],
[
[
"Now convert `race ` to a categorical variable",
"_____no_output_____"
]
],
[
[
"# convert to categorical variable \ndf['race'] = pd.Categorical(df['race'])",
"_____no_output_____"
]
],
[
[
"Take a look at the metadata (what happend to `edu` and `race`)?",
"_____no_output_____"
]
],
[
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 3000 entries, 0 to 2999\nData columns (total 12 columns):\nUnnamed: 0 3000 non-null int64\nyear 3000 non-null int64\nage 3000 non-null int64\nmaritl 3000 non-null object\nrace 3000 non-null object\nedu 3000 non-null category\nregion 3000 non-null object\njobclass 3000 non-null object\nhealth 3000 non-null object\nhealth_ins 3000 non-null object\nlogwage 3000 non-null float64\nwage 3000 non-null float64\ndtypes: category(1), float64(2), int64(3), object(6)\nmemory usage: 261.0+ KB\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a274d78c0701bc429c7ec6548820e01b9c8e157
| 271,085 |
ipynb
|
Jupyter Notebook
|
Pandas/Pandas_Explained.ipynb
|
RohitMidha23/Explanatory-Data-Analysis
|
115002996bc7cb0ea29faa45534e32a966cb1d76
|
[
"MIT"
] | 12 |
2019-01-03T09:33:42.000Z
|
2020-07-22T15:42:36.000Z
|
Pandas/Pandas_Explained.ipynb
|
RohitMidha23/Explanatory-Data-Analysis
|
115002996bc7cb0ea29faa45534e32a966cb1d76
|
[
"MIT"
] | null | null | null |
Pandas/Pandas_Explained.ipynb
|
RohitMidha23/Explanatory-Data-Analysis
|
115002996bc7cb0ea29faa45534e32a966cb1d76
|
[
"MIT"
] | 7 |
2019-01-23T11:32:29.000Z
|
2021-02-16T22:17:01.000Z
| 33.131875 | 520 | 0.322109 |
[
[
[
"## Series",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport random",
"_____no_output_____"
],
[
"first_series = pd.Series([1,2,3, np.nan ,\"hello\"])\nfirst_series",
"_____no_output_____"
],
[
"series = pd.Series([1,2,3, np.nan ,\"hello\"], index = ['A','B','C','Unknown','String'])\nseries\n#indexing the Series with custom values",
"_____no_output_____"
],
[
"dict = {\"Python\": \"Fun\", \"C++\": \"Outdated\",\"Coding\":\"Hmm..\"}\nseries = pd.Series(dict)\nseries\n# Dict to pandas Series",
"_____no_output_____"
],
[
"series[['Coding','Python']]",
"_____no_output_____"
],
[
"series.index",
"_____no_output_____"
],
[
"series.values",
"_____no_output_____"
],
[
"series.describe()",
"_____no_output_____"
],
[
"#Series is a mutable data structures and you can easily change any item’s value: \nseries['Coding'] = 'Awesome'\nseries",
"_____no_output_____"
],
[
"# add new values:\nseries['Java'] = 'Okay'\nseries",
"_____no_output_____"
],
[
"# If it is necessary to apply any mathematical operation to Series items, you may done it like below:\nnum_series = pd.Series([1,2,3,4,5,6,None])\nnum_series_changed = num_series/2\nnum_series_changed",
"_____no_output_____"
],
[
"# NULL/NaN checking can be performed with isnull() and notnull().\nprint(series.isnull())\nprint(num_series.notnull())\nprint(num_series_changed.notnull())",
"Python False\nC++ False\nCoding False\nJava False\ndtype: bool\n0 True\n1 True\n2 True\n3 True\n4 True\n5 True\n6 False\ndtype: bool\n0 True\n1 True\n2 True\n3 True\n4 True\n5 True\n6 False\ndtype: bool\n"
]
],
[
[
"## DataFrames ",
"_____no_output_____"
]
],
[
[
"data = {'year': [1990, 1994, 1998, 2002, 2006, 2010, 2014],\n 'winner': ['Germany', 'Brazil', 'France', 'Brazil','Italy', 'Spain', 'Germany'],\n 'runner-up': ['Argentina', 'Italy', 'Brazil','Germany', 'France', 'Netherlands', 'Argentina'],\n 'final score': ['1-0', '0-0 (pen)', '3-0', '2-0', '1-1 (pen)', '1-0', '1-0'] }\nworld_cup = pd.DataFrame(data, columns=['year', 'winner', 'runner-up', 'final score'])\nworld_cup",
"_____no_output_____"
],
[
"# Another way to set a DataFrame is the using of Python list of dictionaries:\n\ndata_2 = [{'year': 1990, 'winner': 'Germany', 'runner-up': 'Argentina', 'final score': '1-0'}, \n {'year': 1994, 'winner': 'Brazil', 'runner-up': 'Italy', 'final score': '0-0 (pen)'},\n {'year': 1998, 'winner': 'France', 'runner-up': 'Brazil', 'final score': '3-0'}, \n {'year': 2002, 'winner': 'Brazil', 'runner-up': 'Germany', 'final score': '2-0'}, \n {'year': 2006, 'winner': 'Italy','runner-up': 'France', 'final score': '1-1 (pen)'}, \n {'year': 2010, 'winner': 'Spain', 'runner-up': 'Netherlands', 'final score': '1-0'}, \n {'year': 2014, 'winner': 'Germany', 'runner-up': 'Argentina', 'final score': '1-0'}\n ]\nworld_cup = pd.DataFrame(data_2)\nworld_cup",
"_____no_output_____"
],
[
"print(\"First 2 Rows: \",end=\"\\n\\n\")\nprint (world_cup.head(2),end=\"\\n\\n\")\nprint (\"Last 2 Rows : \",end=\"\\n\\n\")\nprint (world_cup.tail(2),end=\"\\n\\n\")\nprint(\"Using slicing : \",end=\"\\n\\n\")\nprint (world_cup[2:4])",
"First 2 Rows: \n\n final score runner-up winner year\n0 1-0 Argentina Germany 1990\n1 0-0 (pen) Italy Brazil 1994\n\nLast 2 Rows : \n\n final score runner-up winner year\n5 1-0 Netherlands Spain 2010\n6 1-0 Argentina Germany 2014\n\nUsing slicing : \n\n final score runner-up winner year\n2 3-0 Brazil France 1998\n3 2-0 Germany Brazil 2002\n"
]
],
[
[
"### CSV\n#### Reading:\n\n`df = pd.read_csv(\"path\\to\\the\\csv\\file\\for\\reading\")`\n#### Writing:\n\n`df.to_csv(\"path\\to\\the\\folder\\where\\you\\want\\save\\csv\\file\")`\n\n\n### TXT file(s)\n(txt file can be read as a CSV file with other separator (delimiter); we suppose below that columns are separated by tabulation):\n\n#### Reading:\n\n`df = pd.read_csv(\"path\\to\\the\\txt\\file\\for\\reading\", sep='\\t')`\n#### Writing:\n\n`df.to_csv(\"path\\to\\the\\folder\\where\\you\\want\\save\\txt\\file\", sep='\\t')`\n### JSON files\n(an open-standard format that uses human-readable text to transmit data objects consisting of attribute–value pairs. It is the most common data format used for asynchronous browser/server communication. By its view it is very similar to Python dictionary)\n\n#### Reading:\n\n`df = pd.read_json(\"path\\to\\the\\json\\file\\for\\reading\", sep='\\t')`\n#### Writing:\n\n`df.to_json(\"path\\to\\the\\folder\\where\\you\\want\\save\\json\\file\", sep='\\t')`",
"_____no_output_____"
]
],
[
[
"# To write world_cup Dataframe to a CSV File \nworld_cup.to_csv(\"worldcup.csv\")\n# To save CSV file without index use index=False attribute\n\nprint(\"File Written!\",end=\"\\n\\n\")\n\n#To check if it was written \nimport os\nprint(os.path.exists('worldcup.csv'))\n\n# reading from it in a new dataframe df\ndf = pd.read_csv('worldcup.csv')\nprint(df.head())\n\n",
"File Written!\n\nTrue\n Unnamed: 0 final score runner-up winner year\n0 0 1-0 Argentina Germany 1990\n1 1 0-0 (pen) Italy Brazil 1994\n2 2 3-0 Brazil France 1998\n3 3 2-0 Germany Brazil 2002\n4 4 1-1 (pen) France Italy 2006\n"
],
[
"# We can also load the data without index as : \ndf = pd.read_csv('worldcup.csv',index_col=0)\nprint(df)",
" final score runner-up winner year\n0 1-0 Argentina Germany 1990\n1 0-0 (pen) Italy Brazil 1994\n2 3-0 Brazil France 1998\n3 2-0 Germany Brazil 2002\n4 1-1 (pen) France Italy 2006\n5 1-0 Netherlands Spain 2010\n6 1-0 Argentina Germany 2014\n"
],
[
"movies=pd.read_csv(\"data/movies.csv\",encoding = \"ISO-8859-1\") \n# encoding is added only for this specific dataset because it gave error with utf-8",
"_____no_output_____"
],
[
"movies['release_date'] = movies['release_date'].map(pd.to_datetime)\nprint(movies.head(20))\n\n#print(movies.describe())",
" user_id movie_id rating timestamp age gender occupation zip_code \\\n0 196 242 3 881250949 49.0 M writer 55105 \n1 305 242 5 886307828 23.0 M programmer 94086 \n2 6 242 4 883268170 42.0 M executive 98101 \n3 234 242 4 891033261 60.0 M retired 94702 \n4 63 242 3 875747190 31.0 M marketing 75240 \n5 181 242 1 878961814 26.0 M executive 21218 \n6 201 242 4 884110598 27.0 M writer E2A4H \n7 249 242 5 879571438 25.0 M student 84103 \n8 13 242 2 881515193 47.0 M educator 29206 \n9 279 242 3 877756647 33.0 M programmer 85251 \n10 145 242 5 875269755 31.0 M entertainment V3N4P \n11 90 242 4 891382267 60.0 M educator 78155 \n12 271 242 4 885844495 51.0 M engineer 22932 \n13 18 242 5 880129305 35.0 F other 37212 \n14 1 242 5 889751633 NaN M NaN 85711 \n15 207 242 4 890793823 39.0 M marketing 92037 \n16 14 242 4 876964570 45.0 M scientist 55106 \n17 113 242 2 875075887 47.0 M executive 95032 \n18 123 242 5 879809053 NaN F artist 20008 \n19 296 242 4 884196057 43.0 F administrator 16803 \n\n movie_title release_date ... Fantasy Film-Noir Horror Musical \\\n0 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n1 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n2 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n3 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n4 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n5 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n6 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n7 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n8 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n9 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n10 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n11 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n12 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n13 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n14 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n15 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n16 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n17 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n18 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n19 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n\n Mystery Romance Sci-Fi Thriller War Western \n0 0 0 0 0 0 0 \n1 0 0 0 0 0 0 \n2 0 0 0 0 0 0 \n3 0 0 0 0 0 0 \n4 0 0 0 0 0 0 \n5 0 0 0 0 0 0 \n6 0 0 0 0 0 0 \n7 0 0 0 0 0 0 \n8 0 0 0 0 0 0 \n9 0 0 0 0 0 0 \n10 0 0 0 0 0 0 \n11 0 0 0 0 0 0 \n12 0 0 0 0 0 0 \n13 0 0 0 0 0 0 \n14 0 0 0 0 0 0 \n15 0 0 0 0 0 0 \n16 0 0 0 0 0 0 \n17 0 0 0 0 0 0 \n18 0 0 0 0 0 0 \n19 0 0 0 0 0 0 \n\n[20 rows x 30 columns]\n"
],
[
"movies_rating = movies['rating']\n# Here we are showing only one column, i.e. a Series\nprint ('type:', type(movies_rating))\nmovies_rating.head()",
"type: <class 'pandas.core.series.Series'>\n"
],
[
"# Filtering data \n# Let's display only women\nmovies_user_female = movies[movies['gender']=='F']\nprint(movies_user_female.head())",
" user_id movie_id rating timestamp age gender occupation zip_code \\\n13 18 242 5 880129305 35.0 F other 37212 \n18 123 242 5 879809053 NaN F artist 20008 \n19 296 242 4 884196057 43.0 F administrator 16803 \n21 270 242 5 876953744 18.0 F student 63119 \n22 240 242 5 885775683 23.0 F educator 20784 \n\n movie_title release_date ... Fantasy Film-Noir Horror Musical \\\n13 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n18 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n19 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n21 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n22 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n\n Mystery Romance Sci-Fi Thriller War Western \n13 0 0 0 0 0 0 \n18 0 0 0 0 0 0 \n19 0 0 0 0 0 0 \n21 0 0 0 0 0 0 \n22 0 0 0 0 0 0 \n\n[5 rows x 30 columns]\n"
],
[
"#to see all the different values possible for a given column\noccupation_list = movies['occupation']\nprint(occupation_list)",
"0 writer\n1 programmer\n2 executive\n3 retired\n4 marketing\n5 executive\n6 writer\n7 student\n8 educator\n9 programmer\n10 entertainment\n11 educator\n12 engineer\n13 other\n14 NaN\n15 marketing\n16 scientist\n17 executive\n18 artist\n19 administrator\n20 student\n21 student\n22 educator\n23 NaN\n24 writer\n25 NaN\n26 NaN\n27 marketing\n28 administrator\n29 student\n ... \n99970 educator\n99971 other\n99972 other\n99973 other\n99974 administrator\n99975 artist\n99976 artist\n99977 artist\n99978 artist\n99979 artist\n99980 artist\n99981 entertainment\n99982 student\n99983 student\n99984 artist\n99985 artist\n99986 artist\n99987 student\n99988 librarian\n99989 writer\n99990 NaN\n99991 artist\n99992 other\n99993 other\n99994 student\n99995 student\n99996 student\n99997 student\n99998 writer\n99999 engineer\nName: occupation, Length: 100000, dtype: object\n"
]
],
[
[
"### Work with indexes and MultiIndex option",
"_____no_output_____"
]
],
[
[
"import random\nindexes = [random.randrange(0,100) for i in range(5)]\ndata = [{i:random.randint(0,10) for i in 'ABCDE'} for i in range(5)]\ndf = pd.DataFrame(data, index=[1,2,3,4,5])\ndf",
"_____no_output_____"
],
[
"movies_user_gender_male = movies[movies['gender']=='M']\nmovies_user_gender_male_dup = movies_user_gender_male.drop_duplicates(keep=False)\nprint(movies_user_gender_male.head())\n# From this we can clearly see age has missing value and that from 100,000 the data reduced to 74260, \n# due to filtering and removing duplicates \n",
" user_id movie_id rating timestamp age gender occupation zip_code \\\n0 196 242 3 881250949 49.0 M writer 55105 \n1 305 242 5 886307828 23.0 M programmer 94086 \n2 6 242 4 883268170 42.0 M executive 98101 \n3 234 242 4 891033261 60.0 M retired 94702 \n4 63 242 3 875747190 31.0 M marketing 75240 \n\n movie_title release_date ... Fantasy Film-Noir Horror Musical \\\n0 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n1 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n2 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n3 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n4 Kolya (1996) 1997-01-24 ... 0 0 0 0 \n\n Mystery Romance Sci-Fi Thriller War Western \n0 0 0 0 0 0 0 \n1 0 0 0 0 0 0 \n2 0 0 0 0 0 0 \n3 0 0 0 0 0 0 \n4 0 0 0 0 0 0 \n\n[5 rows x 30 columns]\n"
],
[
"#gender = female and age between 30 and 40\ngender_required = ['F']\nfiltered_df = movies[((movies['gender'] == 'F') & (movies['age'] > 30) & (movies['age'] <40))]\nfiltered_df",
"_____no_output_____"
]
],
[
[
"#### Note\nIn the above fragment you HAVE TO ADD parantheses to each and every argument that is being compared else you will get an error. ",
"_____no_output_____"
],
[
"As you can see after filtering result tables (i.e. DataFrames) have non-ordered indexes. To fix this trouble you may write the following:",
"_____no_output_____"
]
],
[
[
"filtered_df = filtered_df.reset_index()\nfiltered_df.head(10)",
"_____no_output_____"
],
[
"# set 'user_id' 'movie_id' as index \nfiltered_df_new = filtered_df.set_index(['user_id','movie_id'])\nfiltered_df_new.head(10)\n\n# Note that set_index takes only a list as an argument to it.\n# if you remove the [] then only the first argument is set as the index.",
"_____no_output_____"
],
[
"# By default, `set_index()` returns a new DataFrame.\n# so you’ll have to specify if you’d like the changes to occur in place.\n# Here we used filtered_df_new to get the new dataframe and now see the type of filtererd_df_new \n\nprint(type(filtered_df_new.index))",
"<class 'pandas.core.indexes.multi.MultiIndex'>\n"
]
],
[
[
"Notice here that we now have a new sort of 'index' which is `MultiIndex`, which contains information about indexing of DataFrame and allows manipulating with this data.",
"_____no_output_____"
]
],
[
[
"filtered_df_new.index.names\n# Gives you the names of the two index values we set as a FrozenList ",
"_____no_output_____"
]
],
[
[
"Method `get_level_values()` allows to get all values for the corresponding index level. \n`get_level_values(0)` corresponds to 'user_id' and `get_level_values(1)` corresponds to 'movie_id'",
"_____no_output_____"
]
],
[
[
"print(filtered_df_new.index.get_level_values(0))\nprint(filtered_df_new.index.get_level_values(1))",
"Int64Index([ 18, 129, 34, 209, 861, 11, 269, 5, 18, 151,\n ...\n 129, 356, 796, 450, 577, 450, 796, 577, 450, 839],\n dtype='int64', name='user_id', length=5183)\nInt64Index([ 242, 242, 242, 242, 242, 393, 393, 393, 393, 393,\n ...\n 1176, 1294, 1415, 1518, 1517, 1521, 1522, 1531, 1603, 1664],\n dtype='int64', name='movie_id', length=5183)\n"
]
],
[
[
"### Selection by label and position\nObject selection in pandas is now supported by three types of multi-axis indexing.\n\n* `.loc` works on labels in the index;\n* `.iloc` works on the positions in the index (so it only takes integers);\n \nThe sequence of the following examples demonstrates how we can manipulate with DataFrame’s rows.\nAt first let’s get the first row of movies: ",
"_____no_output_____"
]
],
[
[
"movies.loc[0]",
"_____no_output_____"
],
[
"movies.loc[1:3]",
"_____no_output_____"
]
],
[
[
"If you want to return specific columns then you have to specify them as a separate argument of .loc ",
"_____no_output_____"
]
],
[
[
"movies.loc[1:3 , 'movie_title']",
"_____no_output_____"
],
[
"movies.loc[1:5 , ['movie_title','age','gender']]\n# If more than one column is to be selected then you have to give the second argument of .loc as a list",
"_____no_output_____"
],
[
"# movies.iloc[1:5 , ['movie_title','age','gender']]\n# Gives error as iloc only uses integer values ",
"_____no_output_____"
],
[
"movies.iloc[0]",
"_____no_output_____"
],
[
"movies.iloc[1:5]",
"_____no_output_____"
],
[
"# movies.select(lambda x: x%2==0).head() is the same as : \nmovies.loc[movies.index.map(lambda x: x%2==0)].head()\n\n# .select() has been deprecated for now and will be completely removed in future updates so use .loc",
"_____no_output_____"
]
],
[
[
"## Working with Missing Data \nPandas primarily uses the value np.nan to represent missing data (in table missed/empty value are marked by NaN). It is by default not included in computations. Missing data creates many issues at mathematical or computational tasks with DataFrames and Series and it’s important to know how fight with these values.",
"_____no_output_____"
]
],
[
[
"ages = movies['age']\nsum(ages)",
"_____no_output_____"
]
],
[
[
"This is because there are so many cases where Age isn't given and hence takes on the value of np.nan. \nWe can use `fillna()`a very effecient pandas method for filling missing values",
"_____no_output_____"
]
],
[
[
"ages = movies['age'].fillna(0)\nsum(ages)",
"_____no_output_____"
]
],
[
[
"This fills all the values with 0 and calculates the sum. \nTo remain only rows with non-null values you can use method `dropna()`",
"_____no_output_____"
]
],
[
[
"ages = movies['age'].dropna()\nsum(ages)",
"_____no_output_____"
],
[
"movies_nonnull = movies.dropna()\nmovies_nonnull.head(20)\n#14th value was dropped because it had a missing value in a column ",
"_____no_output_____"
],
[
"movies_notnull = movies.dropna(how='all',subset=['age','occupation'])\n#Drops all nan values from movies belonging to age and occupation \nmovies_notnull.info()\n#Notice how age and occupation now have nearly 6000 lesser values ",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 99616 entries, 0 to 99999\nData columns (total 30 columns):\nuser_id 99616 non-null int64\nmovie_id 99616 non-null int64\nrating 99616 non-null int64\ntimestamp 99616 non-null int64\nage 93731 non-null float64\ngender 99616 non-null object\noccupation 93806 non-null object\nzip_code 99616 non-null object\nmovie_title 99616 non-null object\nrelease_date 99607 non-null datetime64[ns]\nIMDb_URL 99603 non-null object\nunknown 99616 non-null int64\nAction 99616 non-null int64\nAdventure 99616 non-null int64\nAnimation 99616 non-null int64\nChildrens 99616 non-null int64\nComedy 99616 non-null int64\nCrime 99616 non-null int64\nDocumentary 99616 non-null int64\nDrama 99616 non-null int64\nFantasy 99616 non-null int64\nFilm-Noir 99616 non-null int64\nHorror 99616 non-null int64\nMusical 99616 non-null int64\nMystery 99616 non-null int64\nRomance 99616 non-null int64\nSci-Fi 99616 non-null int64\nThriller 99616 non-null int64\nWar 99616 non-null int64\nWestern 99616 non-null int64\ndtypes: datetime64[ns](1), float64(1), int64(23), object(5)\nmemory usage: 23.6+ MB\n"
]
],
[
[
"Thus, if `how='all'`, we get DataFrame, where all values in both columns from subset are NaN.\n\nIf `how='any'`, we get DataFrame, where at least one contains NaN.",
"_____no_output_____"
]
],
[
[
"movies.describe()",
"_____no_output_____"
]
],
[
[
"At first, let’s find all unique dates in `‘release_date’` column of `movies` and then select only dates in range lower than 1995.",
"_____no_output_____"
]
],
[
[
"movies['release_date'] = movies['release_date'].map(pd.to_datetime)\n# We map it to_datetime as pandas has a set way to deal with dates and then we can effectively work with dates.\nunique_dates = movies['release_date'].drop_duplicates().dropna() \n# Drops duplicates and nan values\nunique_dates",
"_____no_output_____"
],
[
"# find dates with year lower/equal than 1995\nunique_dates_1 = filter(lambda x: x.year <= 1995, unique_dates)\n# filter() takes two arguments. First one should return only boolean values and the second one is the variable over which ititerates over. \n# This basically takes unique_dates and uses the lambda function (here, it returns bool values) and filters True cases. \n\nunique_dates_1",
"_____no_output_____"
]
],
[
[
"Here we have used `drop_duplicates()` method to select only `unique` Series values. Then we can filter `movies` with respect to `release_date` condition. Each `datetime` Python object possesses with attributes `year`, `month`, `day`, etc. allowing to extract values of year, month, day, etc. from the date. We call the new DataFrame as `old_movies`.",
"_____no_output_____"
]
],
[
[
"old_movies = movies[movies['release_date'].isin(unique_dates_1)]\nold_movies.head()",
"_____no_output_____"
]
],
[
[
"Now we may filter DataFrame `old_movies` by `age` and `rating`. Lets’ drop `timestamp`, `zip_code`",
"_____no_output_____"
]
],
[
[
"# get all users with age less than 25 that rated old movies higher than 3\nold_movies_watch = old_movies[(old_movies['age']<25) & (old_movies['rating']>3)]\n# Drop timestamp and zip_code\nold_movies_watch = old_movies_watch.drop(['timestamp', 'zip_code'],axis=1)\n\nold_movies_watch.head()",
"_____no_output_____"
]
],
[
[
"`Pandas` has support for accelerating certain types of binary numerical and boolean operations using the `numexpr `library (it uses smart chunking, caching, and multiple cores) and the `bottleneck` libraries (is a set of specialized cython routines that are especially fast when dealing with arrays that have NaNs). It allows one to increase pandas functionality a lot. This advantage is shown for some boolean and calculation operations. To count the time elapsed on operation performing we will use the decorator",
"_____no_output_____"
]
],
[
[
"# this function counts the time for a particular operation \n \ndef timer(func):\n from datetime import datetime\n def wrapper(*args):\n start = datetime.now()\n func(*args)\n end = datetime.now()\n return 'elapsed time = {' + str(end - start)+'}'\n return wrapper\n",
"_____no_output_____"
],
[
"import random\nn = 100\n# generate rangon datasets\ndf_1 = pd.DataFrame({'col :'+str(i):[random.randint(-100,100) for j in range(n)]for i in range(n)})\n# here we pass a dictionary to the DataFrame() constructor. \n# The key is \"col : i\" where i can take random values and the value for those keys is i.\n\ndf_2 = pd.DataFrame({'col :'+str(i):[random.randint(-100,100) for j in range(n)] for i in range(n)})\n\n@timer\ndef direct_comparison(df_1, df_2):\n bool_df = pd.DataFrame({'col_{}'.format(i): [True for j in range(n)] for i in range(n)})\n for i in range(len(df_1.index)):\n for j in range(len(df_1.loc[i])):\n if df_1.loc[i, df_1.columns[j]] >= df_2.loc[i, df_2.columns[j]]: \n bool_df.loc[i,bool_df.columns[j]] = False\n return bool_df\n\n@timer\ndef pandas_comparison(df_1, df_2):\n return df_1 < df_2\n\nprint ('direct_comparison:', (direct_comparison(df_1, df_2)))\nprint ('pandas_comparison:', (pandas_comparison(df_1, df_2)))",
"direct_comparison: elapsed time = {0:00:03.362719}\npandas_comparison: elapsed time = {0:00:00.029600}\n"
]
],
[
[
"As you can see, the difference in speed is too noticeable. \n\nBesides, pandas possesses methods `eq` (equal), `ne` (not equal), `lt` (less then), `gt` (greater than), `le` (less or equal) and `ge` (greater or equal) for simplifying boolean comparison",
"_____no_output_____"
],
[
"## Matrix Addition ",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame({'A':[1,2,3],'B':[-2,-3,-4],\"C\":[7,8,9]})\ndfa = pd.DataFrame({'A':[1,2,3],'D':[6,7,8],\"C\":[12,12,12]})\ndfc = df + dfa\ndfc",
"_____no_output_____"
],
[
"df.le(dfa)",
"_____no_output_____"
]
],
[
[
"You can also apply the reductions: `empty`, `any()`, `all()`, and `bool()` to provide a way to summarize a boolean result:",
"_____no_output_____"
]
],
[
[
"(df<0).all()",
"_____no_output_____"
],
[
"# here horyzontal direction for comparison is taking into account and we check all row’s items\n(df < 0).all(axis=1)",
"_____no_output_____"
],
[
"# here vertical direction for comparison is taking into \n# account and we check if just one column’s item satisfies the condition\n(df < 0).any()",
"_____no_output_____"
],
[
"# here we check if all DataFrame's items satisfy the condition\n(df < 0).any().any()",
"_____no_output_____"
],
[
"# here we check if DataFrame no one element\ndf.empty",
"_____no_output_____"
]
],
[
[
"### Descriptive Statistics \n\n\n|Function|Description|\n|--|-------------------------------|\n|abs|absolute value|\n|count|number of non-null observations|\n|cumsum|cumulative sum (a sequence of partial sums of a given sequence)|\n|sum|sum of values|\n|mean|mean of values|\n|mad|mean absolute deviation|\n|median|arithmetic median of values|\n|min|minimum value|\n|max|maximum value|\n|mode|mode|\n|prod|product of values|\n|std|unbiased standard deviation|\n|var|unbiased variance|\n",
"_____no_output_____"
]
],
[
[
"print(\"Sum : \", movies['age'].sum())",
"Sum : 3089983.0\n"
],
[
"print(df)",
" A B C\n0 1 -2 7\n1 2 -3 8\n2 3 -4 9\n"
],
[
"print(\"Mean : \")\nprint(df.mean())\n\nprint(\"\\nMean of all Mean Values: \")\nprint(df.mean().mean())\n\nprint(\"\\nMedian: \")\nprint(df.median())\n\nprint(\"\\nStandard Deviation: \")\nprint(df.std())\n\nprint(\"\\nVariance: \")\nprint(df.var())\n\nprint(\"\\nMax: \")\nprint(df.max())",
"Mean : \nA 2.0\nB -3.0\nC 8.0\ndtype: float64\n\nMean of all Mean Values: \n2.3333333333333335\n\nMedian: \nA 2.0\nB -3.0\nC 8.0\ndtype: float64\n\nStandard Deviation: \nA 1.0\nB 1.0\nC 1.0\ndtype: float64\n\nVariance: \nA 1.0\nB 1.0\nC 1.0\ndtype: float64\n\nMax: \nA 3\nB -2\nC 9\ndtype: int64\n"
]
],
[
[
"## Function Applications\nWhen you need to make some transformations with some column’s or row’s elements, then method `map` will be helpful (it works like pure Python function `map()` ). But there is also possibility to apply some function to each DataFrame element (not to a column or a row) – method `apply(map)` aids in this case.\n",
"_____no_output_____"
]
],
[
[
"movies.loc[:, (movies.dtypes == np.int64) | (movies.dtypes == np.float64)].apply(np.mean)\n# This calculates the mean of all the columns present in movies",
"_____no_output_____"
],
[
"# to print mean of all row values in movies : \nmovies.loc[:,(movies.dtypes==np.int64) | (movies.dtypes==np.float64)].apply(np.mean, axis = 1)",
"_____no_output_____"
]
],
[
[
"### Remember \n\nThe attribute axis define the horizontal `(axis=1)` or vertical direction for calculations `(axis=0)`",
"_____no_output_____"
],
[
"### Groupby with Dictionary",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"d = {'id':[1,2,3],\n 'Column 1.1':[14,15,16],\n 'Column 1.2':[10,10,10],\n 'Column 1.3':[1,4,5],\n 'Column 2.1':[1,2,3],\n 'Column 2.2':[10,10,10],\n}\ndf = pd.DataFrame(d)\ndf",
"_____no_output_____"
],
[
"groupby_dict = {'Column 1.1':'Column 1','Column 1.2':'Column 1','Column 1.3':'Column 1','Column 2.1':'Column 2','Column 2.2':'Column 2'}\ndf = df.set_index('id')\ndf=df.groupby(groupby_dict,axis=1).min()\ndf",
"_____no_output_____"
],
[
"import numpy as np \nimport pandas as pd\n",
"_____no_output_____"
],
[
"dict = {\n \"ID\":[1,2,3],\n \"Movies\":[\"The Godfather\",\"Fight Club\",\"Casablanca\"],\n \"Week_1_Viewers\":[30,30,40],\n \"Week_2_Viewers\":[60,40,80],\n \"Week_3_Viewers\":[40,20,20]\n};\ndf = pd.DataFrame(dict);\ndf",
"_____no_output_____"
],
[
"mapping = {\"Week_1_Viewers\":\"Total_Viewers\",\n \"Week_2_Viewers\":\"Total_Viewers\",\n \"Week_3_Viewers\":\"Total_Viewers\",\n \"Movies\":\"Movies\"\n }\ndf = df.set_index('ID')\ndf=df.groupby(mapping,axis=1).sum()\ndf",
"_____no_output_____"
]
],
[
[
"### Breaking up a String into columns using regex",
"_____no_output_____"
]
],
[
[
"dict = {'movie_data':['The Godfather 1972 9.2',\n 'Bird Box 2018 6.8',\n 'Fight Club 1999 8.8']\n }\ndf = pd.DataFrame(dict)\ndf",
"_____no_output_____"
],
[
"df['Name'] = df['movie_data'].str.extract('(\\w*\\s\\w*)', expand=True)\ndf['Year'] = df['movie_data'].str.extract('(\\d\\d\\d\\d)', expand=True)\ndf['Rating'] = df['movie_data'].str.extract('(\\d\\.\\d)', expand=True)\ndf",
"_____no_output_____"
],
[
"import re\n\nmovie_data = [\"Name:The Godfather Year: 1972 Rating: 9.2\",\n \"Name:Bird Box Year: 2018 Rating: 6.8\",\n \"Name:Fight Club Year: 1999 Rating: 8.8\"]\nmovies={\"Name\":[],\n \"Year\":[],\n \"Rating\":[]}\n",
"_____no_output_____"
],
[
"for item in movie_data:\n name_field = re.search(\"Name:.*\",item)\n if name_field is not None:\n name = re.search('\\w*\\s\\w*',name_field.group())\n else:\n name = None\n movies[\"Name\"].append(name.group())\n year_field = re.search(\"Year: .*\",item)\n if year_field is not None:\n year = re.search('\\s\\d\\d\\d\\d',year_field.group())\n else:\n year = None\n movies[\"Year\"].append(year.group().strip())\n rating_field = re.search(\"Rating: .*\",item)\n if rating_field is not None: \n rating = re.search('\\s\\d.\\d',rating_field.group())\n else: \n rating - None\n movies[\"Rating\"].append(rating.group().strip())\nmovies",
"_____no_output_____"
],
[
"df = pd.DataFrame(movies)\ndf",
"_____no_output_____"
]
],
[
[
"### Ranking Rows in Pandas",
"_____no_output_____"
]
],
[
[
"import pandas as pd \n",
"_____no_output_____"
],
[
"movies = {'Name': ['The Godfather', 'Bird Box', 'Fight Club'],\n 'Year': ['1972', '2018', '1999'],\n 'Rating': ['9.2', '6.8', '8.8']}\ndf = pd.DataFrame(movies)\ndf",
"_____no_output_____"
],
[
"df['Rating_Rank'] = df['Rating'].rank(ascending=1)\ndf",
"_____no_output_____"
],
[
"df =df.set_index('Rating_Rank')\ndf",
"_____no_output_____"
],
[
"df.sort_index()",
"_____no_output_____"
],
[
"# Example 2 \nimport pandas as pd",
"_____no_output_____"
],
[
"student_details = {'Name':['Raj','Raj','Raj','Aravind','Aravind','Aravind','John','John','John','Arjun','Arjun','Arjun'],\n 'Subject':['Maths','Physics','Chemistry','Maths','Physics','Chemistry','Maths','Physics','Chemistry','Maths','Physics','Chemistry'],\n 'Marks':[80,90,75,60,40,60,80,55,100,90,75,70]\n \n}\n\ndf = pd.DataFrame(student_details)\ndf",
"_____no_output_____"
],
[
"df['Mark_Rank'] = df['Marks'].rank(ascending=0)\ndf = df.set_index('Mark_Rank')\ndf",
"_____no_output_____"
],
[
"df = df.sort_index()\ndf",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2755e1904bf88603674b1dd6b24e49e53a9827
| 50,540 |
ipynb
|
Jupyter Notebook
|
Image_Classification_Using_SVM.ipynb
|
Aditya-Kolhatkar/tfjs
|
e5be9820ded26e2715b073e7dda5d5ca3d87af2b
|
[
"Apache-2.0"
] | null | null | null |
Image_Classification_Using_SVM.ipynb
|
Aditya-Kolhatkar/tfjs
|
e5be9820ded26e2715b073e7dda5d5ca3d87af2b
|
[
"Apache-2.0"
] | null | null | null |
Image_Classification_Using_SVM.ipynb
|
Aditya-Kolhatkar/tfjs
|
e5be9820ded26e2715b073e7dda5d5ca3d87af2b
|
[
"Apache-2.0"
] | null | null | null | 76.114458 | 18,110 | 0.743906 |
[
[
[
"## Convolutional Neural Network Using SVM as Final Layer",
"_____no_output_____"
]
],
[
[
"from tensorflow.compat.v1 import ConfigProto\nfrom tensorflow.compat.v1 import InteractiveSession\n\nconfig = ConfigProto()\nconfig.gpu_options.per_process_gpu_memory_fraction = 0.4\nconfig.gpu_options.allow_growth = True\nsession = InteractiveSession(config=config)",
"_____no_output_____"
],
[
"from zipfile import ZipFile\nfilename = \"Datasets.zip\"\n\nwith ZipFile(filename, 'r') as zip:\n zip.extractall()\n print('Done')",
"Done\n"
],
[
"# Convolutional Neural Network\n\n# Importing the libraries\nimport tensorflow as tf\nfrom tensorflow.keras.preprocessing.image import ImageDataGenerator",
"_____no_output_____"
],
[
"tf.__version__",
"_____no_output_____"
],
[
"# Part 1 - Data Preprocessing\n\n# Preprocessing the Training set\ntrain_datagen = ImageDataGenerator(rescale = 1./255,\n shear_range = 0.2,\n zoom_range = 0.2,\n horizontal_flip = True)\n",
"_____no_output_____"
],
[
"training_set = train_datagen.flow_from_directory('/content/Datasets/Train',\n target_size = (64, 64),\n batch_size = 32,\n class_mode = 'binary')\n\n# Preprocessing the Test set\ntest_datagen = ImageDataGenerator(rescale = 1./255)\ntest_set = test_datagen.flow_from_directory('/content/Datasets/Test',\n target_size = (64, 64),\n batch_size = 32,\n class_mode = 'binary')",
"Found 64 images belonging to 3 classes.\nFound 58 images belonging to 3 classes.\n"
],
[
"from tensorflow.keras.layers import Conv2D\nfrom tensorflow.keras.layers import Dense",
"_____no_output_____"
],
[
"from tensorflow.keras.regularizers import l2",
"_____no_output_____"
],
[
"# Part 2 - Building the CNN\n# Initialising the CNN\ncnn = tf.keras.models.Sequential()\n\n# Step 1 - Convolution\ncnn.add(tf.keras.layers.Conv2D(filters=32,padding=\"same\",kernel_size=3, activation='relu', strides=2, input_shape=[64, 64, 3]))\n\n# Step 2 - Pooling\ncnn.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))\n\n# Adding a second convolutional layer\ncnn.add(tf.keras.layers.Conv2D(filters=32,padding='same',kernel_size=3, activation='relu'))\ncnn.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))\n\n# Step 3 - Flattening\ncnn.add(tf.keras.layers.Flatten())\n\n# Step 4 - Full Connection\ncnn.add(tf.keras.layers.Dense(units=128, activation='relu'))\n\n# Step 5 - Output Layer\ncnn.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))\n# For Binary Classification\n#cnn.add(Dense(1, kernel_regularizer=tf.keras.regularizers.l2(0.01),activation='linear'))\n\n\n### for mulitclassification\ncnn.add(Dense(3, kernel_regularizer=tf.keras.regularizers.l2(0.01),activation ='softmax'))\ncnn.compile(optimizer = 'adam', loss = 'squared_hinge', metrics = ['accuracy'])",
"_____no_output_____"
],
[
"## for mulitclassification\n## cnn.add(Dense(3, kernel_regularizer=tf.keras.regularizers.l2(0.01),activation ='softmax'))\n## cnn.compile(optimizer = 'adam', loss = 'squared_hinge', metrics = ['accuracy'])",
"_____no_output_____"
],
[
"cnn.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_2 (Conv2D) (None, 32, 32, 32) 896 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 16, 16, 32) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 16, 16, 32) 9248 \n_________________________________________________________________\nmax_pooling2d_3 (MaxPooling2 (None, 8, 8, 32) 0 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 2048) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 128) 262272 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 129 \n_________________________________________________________________\ndense_5 (Dense) (None, 3) 6 \n=================================================================\nTotal params: 272,551\nTrainable params: 272,551\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# Part 3 - Training the CNN\n\n# Compiling the CNN\ncnn.compile(optimizer = 'adam', loss = 'hinge', metrics = ['accuracy'])\n\n# Training the CNN on the Training set and evaluating it on the Test set\nr=cnn.fit(x = training_set, validation_data = test_set, epochs = 15)",
"Epoch 1/15\n2/2 [==============================] - 1s 371ms/step - loss: 0.6479 - accuracy: 0.4219 - val_loss: 0.6165 - val_accuracy: 0.3103\nEpoch 2/15\n2/2 [==============================] - 0s 182ms/step - loss: 0.6479 - accuracy: 0.3906 - val_loss: 0.6164 - val_accuracy: 0.3103\nEpoch 3/15\n2/2 [==============================] - 0s 185ms/step - loss: 0.6478 - accuracy: 0.3750 - val_loss: 0.6164 - val_accuracy: 0.3103\nEpoch 4/15\n2/2 [==============================] - 0s 183ms/step - loss: 0.6478 - accuracy: 0.3750 - val_loss: 0.6163 - val_accuracy: 0.3103\nEpoch 5/15\n2/2 [==============================] - 0s 171ms/step - loss: 0.6477 - accuracy: 0.3750 - val_loss: 0.6162 - val_accuracy: 0.3103\nEpoch 6/15\n2/2 [==============================] - 0s 187ms/step - loss: 0.6477 - accuracy: 0.3906 - val_loss: 0.6162 - val_accuracy: 0.3103\nEpoch 7/15\n2/2 [==============================] - 0s 179ms/step - loss: 0.6476 - accuracy: 0.4062 - val_loss: 0.6161 - val_accuracy: 0.3103\nEpoch 8/15\n2/2 [==============================] - 0s 182ms/step - loss: 0.6476 - accuracy: 0.4219 - val_loss: 0.6161 - val_accuracy: 0.3103\nEpoch 9/15\n2/2 [==============================] - 0s 200ms/step - loss: 0.6475 - accuracy: 0.3906 - val_loss: 0.6160 - val_accuracy: 0.3103\nEpoch 10/15\n2/2 [==============================] - 0s 186ms/step - loss: 0.6474 - accuracy: 0.3906 - val_loss: 0.6160 - val_accuracy: 0.3103\nEpoch 11/15\n2/2 [==============================] - 0s 181ms/step - loss: 0.6474 - accuracy: 0.3438 - val_loss: 0.6159 - val_accuracy: 0.3103\nEpoch 12/15\n2/2 [==============================] - 0s 187ms/step - loss: 0.6473 - accuracy: 0.3750 - val_loss: 0.6159 - val_accuracy: 0.3103\nEpoch 13/15\n2/2 [==============================] - 0s 181ms/step - loss: 0.6473 - accuracy: 0.3438 - val_loss: 0.6158 - val_accuracy: 0.3103\nEpoch 14/15\n2/2 [==============================] - 0s 176ms/step - loss: 0.6472 - accuracy: 0.4219 - val_loss: 0.6158 - val_accuracy: 0.3103\nEpoch 15/15\n2/2 [==============================] - 0s 204ms/step - loss: 0.6472 - accuracy: 0.4062 - val_loss: 0.6157 - val_accuracy: 0.3103\n"
],
[
"# plot the loss\nimport matplotlib.pyplot as plt\nplt.plot(r.history['loss'], label='train loss')\nplt.plot(r.history['val_loss'], label='val loss')\nplt.legend()\nplt.show()\nplt.savefig('LossVal_loss')\n\n# plot the accuracy\nplt.plot(r.history['accuracy'], label='train acc')\nplt.plot(r.history['val_accuracy'], label='val acc')\nplt.legend()\nplt.show()\nplt.savefig('AccVal_acc')",
"_____no_output_____"
],
[
"# save it as a h5 file\n\n\nfrom tensorflow.keras.models import load_model\n\ncnn.save('model_rcat_dog.h5')",
"_____no_output_____"
],
[
"from tensorflow.keras.models import load_model\n \n# load model\nmodel = load_model('model_rcat_dog.h5')",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_2 (Conv2D) (None, 32, 32, 32) 896 \n_________________________________________________________________\nmax_pooling2d_2 (MaxPooling2 (None, 16, 16, 32) 0 \n_________________________________________________________________\nconv2d_3 (Conv2D) (None, 16, 16, 32) 9248 \n_________________________________________________________________\nmax_pooling2d_3 (MaxPooling2 (None, 8, 8, 32) 0 \n_________________________________________________________________\nflatten_1 (Flatten) (None, 2048) 0 \n_________________________________________________________________\ndense_3 (Dense) (None, 128) 262272 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 129 \n_________________________________________________________________\ndense_5 (Dense) (None, 3) 6 \n=================================================================\nTotal params: 272,551\nTrainable params: 272,551\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"# Part 4 - Making a single prediction\n\nimport numpy as np\nfrom tensorflow.keras.preprocessing import image\ntest_image = image.load_img('/content/Datasets/Test/mercedes/32.jpg', target_size = (64,64))\ntest_image = image.img_to_array(test_image)\ntest_image=test_image/255\ntest_image = np.expand_dims(test_image, axis = 0)\nresult = cnn.predict(test_image)",
"_____no_output_____"
],
[
"result",
"_____no_output_____"
],
[
"# Part 4 - Making a single prediction\n\nimport numpy as np\nfrom tensorflow.keras.preprocessing import image\ntest_image = image.load_img('/content/Datasets/Test/lamborghini/10.jpg', target_size = (64,64))\ntest_image = image.img_to_array(test_image)\ntest_image=test_image/255\ntest_image = np.expand_dims(test_image, axis = 0)\nresult = max(cnn.predict(test_image))",
"_____no_output_____"
],
[
"result",
"_____no_output_____"
],
[
"a=np.argmax(result, axis=1)\nprint(a)",
"[2]\n"
],
[
"\nif (a==0):\n print(\"The predicted class is Audi\")\nelif (a==1):\n print(\"The predicted class is Lamborghini\")\nelse:\n print(\"The predicted class is Mercedes\")\n ",
"The predicted class is Mercedes\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a27679f60294bb9ff4ecda8c13fe50abc887258
| 122,491 |
ipynb
|
Jupyter Notebook
|
cifar10/code/2.2.Inference-SageMaker.ipynb
|
gonsoomoon-ml/SageMaker-PyTorch-Step-By-Step
|
ded32c3b69d4e62f77aa46451479387f72637c83
|
[
"Apache-2.0"
] | 1 |
2022-03-02T07:52:54.000Z
|
2022-03-02T07:52:54.000Z
|
cifar10/code/2.2.Inference-SageMaker.ipynb
|
gonsoomoon-ml/SageMaker-PyTorch-Step-By-Step
|
ded32c3b69d4e62f77aa46451479387f72637c83
|
[
"Apache-2.0"
] | null | null | null |
cifar10/code/2.2.Inference-SageMaker.ipynb
|
gonsoomoon-ml/SageMaker-PyTorch-Step-By-Step
|
ded32c3b69d4e62f77aa46451479387f72637c83
|
[
"Apache-2.0"
] | null | null | null | 406.946844 | 57,596 | 0.94109 |
[
[
[
"# [Module 2.2] 세이지 메이커 인퍼런스\n\n본 워크샵의 모든 노트북은 `conda_python3` 추가 패키지를 설치하고 모두 이 커널 에서 작업 합니다.\n\n- 1. 배포 준비\n- 2. 로컬 앤드포인트 생성\n- 3. 로컬 추론\n\n\n\n--- \n ",
"_____no_output_____"
],
[
"이전 노트북에서 인퍼런스 테스트를 완료한 티펙트를 가져옵니다.",
"_____no_output_____"
]
],
[
[
"%store -r artifact_path",
"_____no_output_____"
]
],
[
[
"# 1. 배포 준비",
"_____no_output_____"
]
],
[
[
"print(\"artifact_path: \", artifact_path)",
"artifact_path: s3://sagemaker-us-east-1-057716757052/pytorch-training-2021-09-27-14-14-28-250/output/model.tar.gz\n"
],
[
"import sagemaker\n\nsagemaker_session = sagemaker.Session()\n\nbucket = sagemaker_session.default_bucket()\nprefix = \"sagemaker/DEMO-pytorch-cnn-cifar10\"\n\nrole = sagemaker.get_execution_role()",
"_____no_output_____"
]
],
[
[
"## 테스트 데이터 세트 로딩\n- 로컬에서 저장된 데이터를 가져와서 데이터를 변환 합니다.\n- batch_size 만큼 데이터를 로딩하는 데이터 로더를 정의 합니다.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torchvision, torch\nimport torchvision.transforms as transforms\nfrom source.utils_cifar import imshow, classes\n\ntransform = transforms.Compose(\n [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]\n)\n\n\ntestset = torchvision.datasets.CIFAR10(\n root='../data', train=False, download=False, transform=transform\n)\ntest_loader = torch.utils.data.DataLoader(\n testset, batch_size=4, shuffle=False, num_workers=2\n)\n\n\n# get some random training images\ndataiter = iter(test_loader)\nimages, labels = dataiter.next()\n\n# show images\nimshow(torchvision.utils.make_grid(images))\n\n# print labels\nprint(\" \".join(\"%9s\" % classes[labels[j]] for j in range(4)))",
" cat ship ship plane\n"
]
],
[
[
"# 2. 엔드포인트 생성\n- 이 과정은 세이지 메이커 엔드포인트를 생성합니다.\n\n",
"_____no_output_____"
]
],
[
[
"import os\nimport time\nimport sagemaker\nfrom sagemaker.pytorch.model import PyTorchModel\nrole = sagemaker.get_execution_role()",
"_____no_output_____"
],
[
"%%time \n\nendpoint_name = \"sagemaker-endpoint-cifar10-classifier-{}\".format(int(time.time()))\n\nsm_pytorch_model = PyTorchModel(model_data=artifact_path,\n role=role,\n entry_point='inference.py',\n source_dir = 'source',\n framework_version='1.8.1',\n py_version='py3',\n model_server_workers=1,\n )\n\nsm_predictor = sm_pytorch_model.deploy(instance_type='ml.p2.xlarge', \n initial_instance_count=1, \n endpoint_name=endpoint_name,\n wait=True,\n )",
"---------------------------!CPU times: user 664 ms, sys: 62.6 ms, total: 726 ms\nWall time: 13min 34s\n"
]
],
[
[
"# 3. 로컬 추론\n- 준비된 입력 데이터로 로컬 엔드포인트에서 추론",
"_____no_output_____"
],
[
"# 엔드 포인트 추론",
"_____no_output_____"
]
],
[
[
"\n# print images\nimshow(torchvision.utils.make_grid(images))\nprint(\"GroundTruth: \", \" \".join(\"%4s\" % classes[labels[j]] for j in range(4)))\n\noutputs = sm_predictor.predict(images.numpy())\n\n_, predicted = torch.max(torch.from_numpy(np.array(outputs)), 1)\n\nprint(\"Predicted: \", \" \".join(\"%4s\" % classes[predicted[j]] for j in range(4)))",
"GroundTruth: cat ship ship plane\nPredicted: cat car ship plane\n"
]
],
[
[
"# Clean-up\n\n위의 엔드포인트를 삭제 합니다.",
"_____no_output_____"
]
],
[
[
"sm_predictor.delete_endpoint()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a276899bb2cb474ff6622eb580de031472f69f2
| 91,095 |
ipynb
|
Jupyter Notebook
|
learn_jupyter/1_jupyter IPython display.ipynb
|
langsari/ftu-artificial-intelligence
|
fcfb2864f36639d4276d9519b421105d8ccd09d0
|
[
"MIT"
] | null | null | null |
learn_jupyter/1_jupyter IPython display.ipynb
|
langsari/ftu-artificial-intelligence
|
fcfb2864f36639d4276d9519b421105d8ccd09d0
|
[
"MIT"
] | 7 |
2021-06-08T22:21:56.000Z
|
2022-03-12T00:48:11.000Z
|
learn_jupyter/1_jupyter IPython display.ipynb
|
langsari/ftu-artificial-intelligence
|
fcfb2864f36639d4276d9519b421105d8ccd09d0
|
[
"MIT"
] | null | null | null | 107.932464 | 52,489 | 0.808178 |
[
[
[
"# IPython.display",
"_____no_output_____"
],
[
"youtube url for learning https://www.youtube.com/watch?v=YPgImo9kcbg&list=PLoTScYm9O0GFVfRk_MmZt0vQXNIi36LUz&index=12",
"_____no_output_____"
]
],
[
[
"from IPython.display import IFrame, YouTubeVideo, SVG, HTML",
"_____no_output_____"
]
],
[
[
"## Display Web page",
"_____no_output_____"
]
],
[
[
"IFrame(\"https://matplotlib.org/examples/color/named_colors.html\", width=800, height=300)",
"_____no_output_____"
],
[
"import pandas as pd\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
],
[
"df=pd.read_csv('https://github.com/prasertcbs/tutorial/raw/master/msleep.csv')\ndf.sample(5)",
"_____no_output_____"
],
[
"df.vore.value_counts().plot.barh(color='blueviolet');",
"_____no_output_____"
]
],
[
[
"## Display PDF\nhttps://www.datacamp.com/community/data-science-cheatsheets",
"_____no_output_____"
]
],
[
[
"IFrame('http://datacamp-community.s3.amazonaws.com/f9f06e72-519a-4722-9912-b5de742dbac4', \n width=800, height=400)",
"_____no_output_____"
]
],
[
[
"## Embed YouTube ",
"_____no_output_____"
]
],
[
[
"# https://www.youtube.com/watch?v=_NHyJBIxc40\nYouTubeVideo('YPgImo9kcbg', 640, 360)",
"_____no_output_____"
]
],
[
[
"[Mario source:](https://en.wikipedia.org/wiki/Mario)\n ",
"_____no_output_____"
]
],
[
[
"[Mario source:](https://en.wikipedia.org/wiki/Mario)\n ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"IFrame(\"https://upload.wikimedia.org/wikipedia/en/9/99/MarioSMBW.png\", width=300, height=300)",
"_____no_output_____"
],
[
"IFrame('https://upload.wikimedia.org/wikipedia/commons/7/70/Amazon_logo_plain.svg', \n width=600, height=200)",
"_____no_output_____"
],
[
"IFrame('https://upload.wikimedia.org/wikipedia/commons/f/ff/Vectorized_Apple_gray_logo.svg', \n width=100, height=100)",
"_____no_output_____"
],
[
"IFrame('https://upload.wikimedia.org/wikipedia/commons/f/ff/Vectorized_Apple_gray_logo.svg', \n width=400, height=400)",
"_____no_output_____"
]
],
[
[
"## Display HTML",
"_____no_output_____"
]
],
[
[
"s='''\n<span style=color:red;font-size:150%>Hello</span> <span style=color:blue;font-size:200%>Python</span>\n'''\nHTML(s)",
"_____no_output_____"
]
],
[
[
"<img src=https://upload.wikimedia.org/wikipedia/en/9/99/MarioSMBW.png></img>",
"_____no_output_____"
]
],
[
[
"<img src=https://upload.wikimedia.org/wikipedia/en/9/99/MarioSMBW.png></img>",
"_____no_output_____"
]
],
[
[
"s='''\n<img src=https://upload.wikimedia.org/wikipedia/en/9/99/MarioSMBW.png>\n<img src=\"https://assets.pokemon.com/assets/cms2/img/pokedex/full/729.png\" width=200 height=200>\n'''\nHTML(s)",
"_____no_output_____"
],
[
"s='''\n<table class=\"table table-hover table-set col-3-center table-set-border-yellow\">\n <thead>\n <tr>\n <th></th>\n <th>\n <strong>ล่าสุด</strong>\n </th>\n <th>\n <strong>เปลี่ยนแปลง</strong>\n </th>\n <th>\n <strong>มูลค่า\n <br>(ลบ.)</strong>\n </th>\n </tr>\n </thead>\n <tbody>\n <tr>\n <td>\n <a class=\"blacklink-u\" href=\"https://marketdata.set.or.th/mkt/marketsummary.do?language=th&country=TH\" target=\"_blank\">SET</a>\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">\n <i class=\"fa fa-caret-down\"></i>\n 1,705.33\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">-1.19</td>\n <td style=\"text-align: right;\">61,883.85</td>\n </tr>\n <tr>\n <td>\n <a class=\"blacklink-u\" href=\"https://marketdata.set.or.th/mkt/sectorquotation.do?sector=SET50&language=th&country=TH\"\n target=\"_blank\">SET50</a>\n </td>\n <td style=\"text-align: right;\" class=\"set-color-green\">\n <i class=\"fa fa-caret-up\"></i>\n 1,091.68\n </td>\n <td style=\"text-align: right;\" class=\"set-color-green\">+0.62</td>\n <td style=\"text-align: right;\">40,293.01</td>\n </tr>\n <tr>\n <td>\n <a class=\"blacklink-u\" href=\"https://marketdata.set.or.th/mkt/sectorquotation.do?sector=SET100&language=th&country=TH\"\n target=\"_blank\">SET100</a>\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">\n <i class=\"fa fa-caret-down\"></i>\n 2,455.09\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">-0.58</td>\n <td style=\"text-align: right;\">48,948.34</td>\n </tr>\n <tr>\n <td>\n <a class=\"blacklink-u\" href=\"https://marketdata.set.or.th/mkt/sectorquotation.do?sector=sSET&language=th&country=TH\"\n target=\"_blank\">sSET</a>\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">\n <i class=\"fa fa-caret-down\"></i>\n 1,095.13\n </td>\n <td style=\"text-align: right;\" class=\"set-color-red\">-11.36</td>\n <td style=\"text-align: right;\">3,471.48</td>\n </tr>\n <tr>\n <td>\n <a class=\"blacklink-u\" href=\"https://marketdata.set.or.th/mkt/sectorquotation.do?sector=SETHD&language=th&country=TH\"\n target=\"_blank\">SETHD</a>\n </td>\n <td style=\"text-align: right;\" class=\"set-color-green\">\n <i class=\"fa fa-caret-up\"></i>\n 1,262.58\n </td>\n <td style=\"text-align: right;\" class=\"set-color-green\">+9.26</td>\n <td style=\"text-align: right;\">18,259.40</td>\n </tr>\n </tbody>\n</table>'''\nHTML(s)",
"_____no_output_____"
]
],
[
[
"## get text file from url and display its content",
"_____no_output_____"
]
],
[
[
"import requests",
"_____no_output_____"
],
[
"r = requests.get('https://github.com/prasertcbs/tutorial/raw/master/mtcars.csv')\nprint(r.text)",
"model,mpg,cyl,disp,hp,drat,wt,qsec,vs,am,gear,carb\nMazda RX4,21.0,6,160.0,110,3.9,2.62,16.46,0,1,4,4\nMazda RX4 Wag,21.0,6,160.0,110,3.9,2.875,17.02,0,1,4,4\nDatsun 710,22.8,4,108.0,93,3.85,2.32,18.61,1,1,4,1\nHornet 4 Drive,21.4,6,258.0,110,3.08,3.215,19.44,1,0,3,1\nHornet Sportabout,18.7,8,360.0,175,3.15,3.44,17.02,0,0,3,2\nValiant,18.1,6,225.0,105,2.76,3.46,20.22,1,0,3,1\nDuster 360,14.3,8,360.0,245,3.21,3.57,15.84,0,0,3,4\nMerc 240D,24.4,4,146.7,62,3.69,3.19,20.0,1,0,4,2\nMerc 230,22.8,4,140.8,95,3.92,3.15,22.9,1,0,4,2\nMerc 280,19.2,6,167.6,123,3.92,3.44,18.3,1,0,4,4\nMerc 280C,17.8,6,167.6,123,3.92,3.44,18.9,1,0,4,4\nMerc 450SE,16.4,8,275.8,180,3.07,4.07,17.4,0,0,3,3\nMerc 450SL,17.3,8,275.8,180,3.07,3.73,17.6,0,0,3,3\nMerc 450SLC,15.2,8,275.8,180,3.07,3.78,18.0,0,0,3,3\nCadillac Fleetwood,10.4,8,472.0,205,2.93,5.25,17.98,0,0,3,4\nLincoln Continental,10.4,8,460.0,215,3.0,5.424,17.82,0,0,3,4\nChrysler Imperial,14.7,8,440.0,230,3.23,5.345,17.42,0,0,3,4\nFiat 128,32.4,4,78.7,66,4.08,2.2,19.47,1,1,4,1\nHonda Civic,30.4,4,75.7,52,4.93,1.615,18.52,1,1,4,2\nToyota Corolla,33.9,4,71.1,65,4.22,1.835,19.9,1,1,4,1\nToyota Corona,21.5,4,120.1,97,3.7,2.465,20.01,1,0,3,1\nDodge Challenger,15.5,8,318.0,150,2.76,3.52,16.87,0,0,3,2\nAMC Javelin,15.2,8,304.0,150,3.15,3.435,17.3,0,0,3,2\nCamaro Z28,13.3,8,350.0,245,3.73,3.84,15.41,0,0,3,4\nPontiac Firebird,19.2,8,400.0,175,3.08,3.845,17.05,0,0,3,2\nFiat X1-9,27.3,4,79.0,66,4.08,1.935,18.9,1,1,4,1\nPorsche 914-2,26.0,4,120.3,91,4.43,2.14,16.7,0,1,5,2\nLotus Europa,30.4,4,95.1,113,3.77,1.513,16.9,1,1,5,2\nFord Pantera L,15.8,8,351.0,264,4.22,3.17,14.5,0,1,5,4\nFerrari Dino,19.7,6,145.0,175,3.62,2.77,15.5,0,1,5,6\nMaserati Bora,15.0,8,301.0,335,3.54,3.57,14.6,0,1,5,8\nVolvo 142E,21.4,4,121.0,109,4.11,2.78,18.6,1,1,4,2\n\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a2769b13963e95bb382a7ddbc7d6bdb1b6e1be5
| 548,887 |
ipynb
|
Jupyter Notebook
|
Workshop Machine Learning.ipynb
|
dandaraleite/Workshop-MachineLearning
|
0a264fef8e3eebd466f8314a2ffba0e61b47fc70
|
[
"MIT"
] | 1 |
2020-07-10T19:00:57.000Z
|
2020-07-10T19:00:57.000Z
|
Workshop Machine Learning.ipynb
|
dandaraleite/Workshop-MachineLearning
|
0a264fef8e3eebd466f8314a2ffba0e61b47fc70
|
[
"MIT"
] | null | null | null |
Workshop Machine Learning.ipynb
|
dandaraleite/Workshop-MachineLearning
|
0a264fef8e3eebd466f8314a2ffba0e61b47fc70
|
[
"MIT"
] | null | null | null | 212.664471 | 157,320 | 0.881152 |
[
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom plotnine import *",
"_____no_output_____"
]
],
[
[
"Leitura e visualização dos dados:",
"_____no_output_____"
]
],
[
[
"#carregar os dados no dataframe\ndf = pd.read_csv('movie_metadata.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"list(df.columns)",
"_____no_output_____"
]
],
[
[
"Análise Exploratória",
"_____no_output_____"
]
],
[
[
"df['color'].value_counts()",
"_____no_output_____"
],
[
"df.drop('color', axis=1, inplace=True)",
"_____no_output_____"
],
[
"#verificando se existem valores faltantes nos dados\ndf.isna().any()",
"_____no_output_____"
],
[
"df.isna().sum()",
"_____no_output_____"
],
[
"df.dropna(axis=0, subset=['director_name', 'num_critic_for_reviews',\n 'duration','director_facebook_likes','actor_3_facebook_likes',\n 'actor_2_name','actor_1_facebook_likes','actor_1_name','actor_3_name',\n 'facenumber_in_poster','num_user_for_reviews','language','country',\n 'actor_2_facebook_likes','plot_keywords', 'title_year'],inplace=True)",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"#classificação indicativa do filme, ex. R = livre\ndf['content_rating'].value_counts()",
"_____no_output_____"
],
[
"#preencher os valores faltantes dos outros filmes com a indicação livre\ndf['content_rating'].fillna('R', inplace = True)",
"_____no_output_____"
],
[
"#valores de tamanho de tela\ndf['aspect_ratio'].value_counts()",
"_____no_output_____"
],
[
"#substituindo os valores faltantes dos tamanhos de tela pela mediana dos valores\ndf['aspect_ratio'].fillna(df['aspect_ratio'].median(), inplace=True)",
"_____no_output_____"
],
[
"#substituindo os valores faltantes dos orçamentos dos filmes pela mediana dos valores\ndf['budget'].fillna(df['budget'].median(), inplace=True)",
"_____no_output_____"
],
[
"#substituindo os valores faltantes dos faturamentos dos filmes pela mediana dos valores\ndf['gross'].fillna(df['gross'].median(), inplace=True)",
"_____no_output_____"
],
[
"df.isna().sum()",
"_____no_output_____"
],
[
"#ter cuidado e verifiacr os dados duplicados pois eles por estarem em maiores quantidades enviesam o modelo\ndf.duplicated().sum()",
"_____no_output_____"
],
[
"#removendo as duplicatas\ndf.drop_duplicates(inplace=True)",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"#verificando quais os valores da coluna 'language'\ndf['language'].value_counts()",
"_____no_output_____"
],
[
"df.drop('language', axis=1, inplace=True)",
"_____no_output_____"
],
[
"df['country'].value_counts()",
"_____no_output_____"
],
[
"df.drop('country', axis=1, inplace=True)",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"#criando uma nova coluna na tabela\ndf['Profit'] = df['budget'].sub(df['gross'], axis=0)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df['Profit_Percentage'] = (df['Profit']/df['gross'])*100",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"#salvar tudo o que fiz até agora\ndf.to_csv('dados_imdb_dandaraleit.csv', index=False)",
"_____no_output_____"
]
],
[
[
"Visualização dos dados",
"_____no_output_____"
]
],
[
[
"#criando gráfico de correlaciona lucro e nota do IMDB\nggplot(aes(x='imdb_score', y='Profit'), data=df) +\\\n geom_line() +\\\n stat_smooth(colour='blue', span=1)",
"_____no_output_____"
],
[
"#criando gráfico de correlaciona likes no facebook do filme e nota do IMDB\n\n(ggplot(df)+\\\n aes(x='imdb_score', y='movie_facebook_likes') +\\\n geom_line() +\\\n labs(title='Nota no IMDB vs likes no facebook do filme', x='Nota no IMDB', y='Likes no facebook')\n)",
"_____no_output_____"
],
[
"#gráfico dos 20 filmes com melhor nota com relação aos atores principais\nplt.figure(figsize=(10,8))\n\ndf= df.sort_values(by ='imdb_score' , ascending=False)\ndf2=df.head(20)\nax=sns.pointplot(df2['actor_1_name'], df2['imdb_score'], hue=df2['movie_title'])\nax.set_xticklabels(ax.get_xticklabels(), rotation=40, ha=\"right\")\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Preparação dos dados",
"_____no_output_____"
]
],
[
[
"#retirando algumas colunas com dados categóricos\ndf.drop(columns=['director_name', 'actor_1_name', 'actor_2_name', \n 'actor_3_name', 'plot_keywords', 'movie_title'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"#verificando os valores da coluna 'genre'\ndf['genres'].value_counts()",
"_____no_output_____"
],
[
"df.drop('genres', axis=1, inplace=True)",
"_____no_output_____"
],
[
"#retirando as colunas criadas\ndf.drop(columns=['Profit', 'Profit_Percentage'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"#verificando se existem colunas fortemente correlacionadas // Método corr, usando mapa de calor\nimport numpy as np\ncorr = df.corr()\nsns.set_context(\"notebook\", font_scale=1.0, rc={\"lines.linewidth\": 2.5})\nplt.figure(figsize=(13,7))\nmask = np.zeros_like(corr)\nmask[np.triu_indices_from(mask, 1)] = True\na = sns.heatmap(corr,mask=mask, annot=True, fmt='.2f')\nrotx = a.set_xticklabels(a.get_xticklabels(), rotation=90)\nroty = a.set_yticklabels(a.get_yticklabels(), rotation=30)",
"_____no_output_____"
],
[
"#criando uma nova coluna combinando as duas colunas muito correlacionadas\ndf['Other_actors_facebook_likes'] = df['actor_2_facebook_likes'] + df['actor_3_facebook_likes']",
"_____no_output_____"
],
[
"#removendo as colunas\ndf.drop(columns=['actor_2_facebook_likes', 'actor_3_facebook_likes',\n 'cast_total_facebook_likes'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"#criando uma nova coluna combinando as duas colunas muito correlacionadas // Razão entre o número de críticas por reviews e o número de usuários que fizeram reviews\n\ndf['critic_review_ratio'] = df['num_critic_for_reviews']/df['num_user_for_reviews']",
"_____no_output_____"
],
[
"df.drop(columns=['num_critic_for_reviews', 'num_user_for_reviews'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"#verificando se ainda existem colunas fortemente correlacionadas\n\ncorr = df.corr()\nsns.set_context(\"notebook\", font_scale=1.0, rc={\"lines.linewidth\": 2.5})\nplt.figure(figsize=(13,7))\nmask = np.zeros_like(corr)\nmask[np.triu_indices_from(mask, 1)] = True\na = sns.heatmap(corr,mask=mask, annot=True, fmt='.2f')\nrotx = a.set_xticklabels(a.get_xticklabels(), rotation=90)\nroty = a.set_yticklabels(a.get_yticklabels(), rotation=30)",
"_____no_output_____"
],
[
"#categorizando os valores de nota do imdb\ndf['imdb_binned_score']=pd.cut(df['imdb_score'], bins=[0,4,6,8,10], right=True, labels=False)+1",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"#criando novas colunas para transformar os valores categóricos de 'content rating' (classificação indicativa)\n#em valores numéricos\ndf = pd.get_dummies(data = df, columns=['content_rating'], prefix=['content_rating'], drop_first=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.to_csv('dados_imdb_com_nota.csv', index=False)",
"_____no_output_____"
]
],
[
[
"Fornecer os dados escolhidos para o modelo a ser treinado e ver os resultados que ele vai prever. Aprendizado Supervisionado",
"_____no_output_____"
]
],
[
[
"#escolhendo as colunas do dataframe que serão nossos valores de entrada para o modelo\nX=pd.DataFrame(columns=['duration','director_facebook_likes','actor_1_facebook_likes','gross',\n 'num_voted_users','facenumber_in_poster','budget','title_year','aspect_ratio',\n 'movie_facebook_likes','Other_actors_facebook_likes','critic_review_ratio',\n 'content_rating_G','content_rating_GP',\n 'content_rating_M','content_rating_NC-17','content_rating_Not Rated',\n 'content_rating_PG','content_rating_PG-13','content_rating_Passed',\n 'content_rating_R','content_rating_TV-14','content_rating_TV-G',\n 'content_rating_TV-PG','content_rating_Unrated','content_rating_X'],data=df)",
"_____no_output_____"
],
[
"#escolhendo a(s) coluna(s) do dataframe que serão a resposta do modelo\ny = pd.DataFrame(columns=['imdb_binned_score'], data=df)",
"_____no_output_____"
],
[
"#importando o pacote de divisão dos dados em treinamento e teste\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"#dividindo os dados em treinamento e teste\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)",
"_____no_output_____"
],
[
"#normalizando os dados\nfrom sklearn.preprocessing import StandardScaler\nsc_X = StandardScaler()\nX_train = sc_X.fit_transform(X_train)\nX_test = sc_X.transform(X_test)",
"_____no_output_____"
],
[
"X.isna().sum()",
"_____no_output_____"
]
],
[
[
"Utilização de modelo de regressão logística. Ele tenta descobrir uma função matemática que simule a distribuição dos dados. Modelo mais simples, disponível no sklearning.",
"_____no_output_____"
]
],
[
[
"#importando, configurando e treinando o modelo de regressão \nfrom sklearn.linear_model import LogisticRegression\nlogit =LogisticRegression(verbose=1, max_iter=1000)\nlogit.fit(X_train,np.ravel(y_train,order='C'))\ny_pred=logit.predict(X_test)",
"[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.\n[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.2s finished\n"
],
[
"#verificando os valores preditos\ny_pred",
"_____no_output_____"
],
[
"#importando o pacote de métricas e calculando a matriz de confusão\nfrom sklearn import metrics\ncnf_matrix = metrics.confusion_matrix(y_test, y_pred)",
"_____no_output_____"
],
[
"#código para melhor visualização da matriz de confusão\n#alternativa:\n# print(cnf_matrix)\nimport itertools\ndef plot_confusion_matrix(cm, classes,\n normalize=False,\n title='Confusion matrix',\n cmap=plt.cm.Blues):\n \"\"\"\n This function prints and plots the confusion matrix.\n Normalization can be applied by setting `normalize=True`.\n \"\"\"\n if normalize:\n cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]\n\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n tick_marks = np.arange(len(classes))\n plt.xticks(tick_marks, classes, rotation=45)\n plt.yticks(tick_marks, classes)\n\n fmt = '.2f' if normalize else 'd'\n thresh = cm.max() / 2.\n for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):\n plt.text(j, i, format(cm[i, j], fmt),\n horizontalalignment=\"center\",\n color=\"white\" if cm[i, j] > thresh else \"black\")\n\n plt.ylabel('True label')\n plt.xlabel('Predicted label')\n plt.tight_layout()",
"_____no_output_____"
],
[
"#imprimindo a matriz de confusão\nplot_confusion_matrix(cnf_matrix, classes=['1','2', '3', '4'],\n title='Matriz de confusão não normalizada', normalize=False)",
"_____no_output_____"
]
],
[
[
"Modelo de Machine Learn não se dá muito bem com dados desbalanceados, ou seja, quando se tem mais dados de uma categoria, ela é que vai ser melhor prevista, como por exemplo a categoria 3 de filmes bons, foi da qual mais o modelo se aproximou, será que é esta categoria que tem mais dados? Vamos ver abaixo. \nP.s: Como fazer para balancear?",
"_____no_output_____"
]
],
[
[
"#verificando quantos valores existem de cada categoria em 'imdb_binned_score'\ndf['imdb_binned_score'].value_counts()",
"_____no_output_____"
],
[
"#métricas finais, outro modo de olhar o número de amostras de cada categoria/classe\nprint(metrics.classification_report(y_test, y_pred, target_names=['1','2', '3', '4']))",
" precision recall f1-score support\n\n 1 0.00 0.00 0.00 45\n 2 0.55 0.41 0.47 392\n 3 0.74 0.87 0.80 904\n 4 0.80 0.54 0.65 68\n\n accuracy 0.70 1409\n macro avg 0.52 0.46 0.48 1409\nweighted avg 0.66 0.70 0.67 1409\n\n"
],
[
"#importante o pacote para salvar o modelo\nimport pickle",
"_____no_output_____"
],
[
"#definindo em qual caminho vamos salvar o modelo em uma variável para ficar mais organizado. ex: modelo_treinado.\nmodelo_treinado = 'modelo_imdb.sav'",
"_____no_output_____"
],
[
"#salvando o modelo\npickle.dump(logit, open(modelo_treinado, 'wb'))",
"_____no_output_____"
],
[
"#carregando o modelo treinado\nmodelo_carregado = pickle.load(open(modelo_treinado, 'rb'))",
"_____no_output_____"
],
[
"#Olhando o conteúdo de um vetor de teste\nX_test[0]",
"_____no_output_____"
],
[
"#fazendo predição do novo dado com o modelo carregado\nmodelo_carregado.predict([X_test[0]])",
"_____no_output_____"
]
],
[
[
"O resultado deu que os filmes com os valores mais acima testados estão dentro da categoria de filme 3 (acima), que se traduz em filmes bons.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a276ff03521225f48fc1e5601d6d648dcf5cd23
| 31,708 |
ipynb
|
Jupyter Notebook
|
model/MNIST_NN_Model.ipynb
|
Varun487/WrittenDigitClassifier
|
403975b5d0879ec1bc3efc7dae70146f6b1544cc
|
[
"MIT"
] | null | null | null |
model/MNIST_NN_Model.ipynb
|
Varun487/WrittenDigitClassifier
|
403975b5d0879ec1bc3efc7dae70146f6b1544cc
|
[
"MIT"
] | null | null | null |
model/MNIST_NN_Model.ipynb
|
Varun487/WrittenDigitClassifier
|
403975b5d0879ec1bc3efc7dae70146f6b1544cc
|
[
"MIT"
] | null | null | null | 43.31694 | 5,032 | 0.723161 |
[
[
[
"# MNIST digit recognition Neural Network\n---",
"_____no_output_____"
],
[
"# 1. Imports\n---",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nfrom keras.datasets import mnist\nfrom keras.models import Sequential\nfrom keras.utils import np_utils\nfrom keras.layers import Dense",
"_____no_output_____"
]
],
[
[
"# 2. Understanding the data\n---",
"_____no_output_____"
],
[
"## 2.1. Load the dataset and split into train and test set",
"_____no_output_____"
]
],
[
[
"(X_train, y_train), (X_test, y_test) = mnist.load_data()",
"_____no_output_____"
]
],
[
[
"## 2.2. Data visualization",
"_____no_output_____"
]
],
[
[
"X_train.shape",
"_____no_output_____"
]
],
[
[
"- 60,000 training images\n- Each image is 28 x 28 pixels",
"_____no_output_____"
]
],
[
[
"y_train.shape",
"_____no_output_____"
]
],
[
[
"- 60,000 arrays\n- Each of size 10 (from 0-9)\n- For example, 1 is represented as [0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]",
"_____no_output_____"
]
],
[
[
"X_test.shape",
"_____no_output_____"
]
],
[
[
"- 10,000 test images\n- Each image is 28 x 28 pixels",
"_____no_output_____"
]
],
[
[
"y_test.shape",
"_____no_output_____"
]
],
[
[
"- 10,000 arrays similar to __y_train__",
"_____no_output_____"
],
[
"## 2.3. Images",
"_____no_output_____"
]
],
[
[
"plt.imshow(X_train[0], cmap=plt.get_cmap('gray'))",
"_____no_output_____"
],
[
"plt.imshow(X_train[1], cmap=plt.get_cmap('gray'))",
"_____no_output_____"
],
[
"plt.imshow(X_train[2], cmap=plt.get_cmap('gray'))",
"_____no_output_____"
]
],
[
[
"# 3. Data manipulation\n---",
"_____no_output_____"
],
[
"## 3.1. Flatten 28 X 28 images into a 1 X 784 vector for each image",
"_____no_output_____"
]
],
[
[
"# X_train = X_train.reshape((X_train.shape[0], 28, 28, 1)).astype('float32')\n# X_test = X_test.reshape((X_test.shape[0], 28, 28, 1)).astype('float32')\nX_train = X_train.reshape((60000, 784))\nX_train.shape",
"_____no_output_____"
],
[
"X_test = X_test.reshape((10000, 784))\nX_test.shape",
"_____no_output_____"
],
[
"y_train.shape",
"_____no_output_____"
],
[
"y_test.shape",
"_____no_output_____"
]
],
[
[
"- y_train and y_test are of the required shape and don't need to be changed.",
"_____no_output_____"
],
[
"## 3.2. Normalize inputs from 0-255 in images to 0-1",
"_____no_output_____"
]
],
[
[
"X_train = X_train / 255\nX_test = X_test / 255",
"_____no_output_____"
]
],
[
[
"## 3.3. One hot encode outputs",
"_____no_output_____"
]
],
[
[
"y_train = np_utils.to_categorical(y_train)\ny_test = np_utils.to_categorical(y_test)",
"_____no_output_____"
]
],
[
[
"# 4. Build the model\n---",
"_____no_output_____"
],
[
"## 4.1. Define model type (Neural Network)",
"_____no_output_____"
]
],
[
[
"model = Sequential()",
"_____no_output_____"
]
],
[
[
"## 4.2. Define architecture",
"_____no_output_____"
]
],
[
[
"model.add(Dense(784, activation='relu'))\nmodel.add(Dense(10, activation='relu'))\nmodel.add(Dense(10, activation='softmax'))",
"_____no_output_____"
]
],
[
[
"This is a dense nueral network with architecture:\n\n| Layer | Activation function | Neurons |\n| --- | --- | --- |\n| 1 | ReLU | 784 |\n| 2 | ReLU | 10 |\n| 3 | Softmax | 10 |",
"_____no_output_____"
],
[
"## 4.3 Compile model",
"_____no_output_____"
]
],
[
[
"model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"## 4.4. Training model",
"_____no_output_____"
]
],
[
[
"model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=30, batch_size=200, verbose=2)",
"Epoch 1/30\n300/300 - 2s - loss: 0.4241 - accuracy: 0.8706 - val_loss: 0.1698 - val_accuracy: 0.9487\nEpoch 2/30\n300/300 - 2s - loss: 0.1324 - accuracy: 0.9619 - val_loss: 0.1176 - val_accuracy: 0.9662\nEpoch 3/30\n300/300 - 2s - loss: 0.0876 - accuracy: 0.9752 - val_loss: 0.1005 - val_accuracy: 0.9703\nEpoch 4/30\n300/300 - 2s - loss: 0.0625 - accuracy: 0.9817 - val_loss: 0.0811 - val_accuracy: 0.9753\nEpoch 5/30\n300/300 - 2s - loss: 0.0478 - accuracy: 0.9860 - val_loss: 0.0748 - val_accuracy: 0.9784\nEpoch 6/30\n300/300 - 2s - loss: 0.0360 - accuracy: 0.9898 - val_loss: 0.0737 - val_accuracy: 0.9801\nEpoch 7/30\n300/300 - 2s - loss: 0.0269 - accuracy: 0.9930 - val_loss: 0.0707 - val_accuracy: 0.9801\nEpoch 8/30\n300/300 - 2s - loss: 0.0203 - accuracy: 0.9947 - val_loss: 0.0703 - val_accuracy: 0.9810\nEpoch 9/30\n300/300 - 2s - loss: 0.0157 - accuracy: 0.9958 - val_loss: 0.0760 - val_accuracy: 0.9783\nEpoch 10/30\n300/300 - 2s - loss: 0.0132 - accuracy: 0.9967 - val_loss: 0.0861 - val_accuracy: 0.9769\nEpoch 11/30\n300/300 - 2s - loss: 0.0100 - accuracy: 0.9976 - val_loss: 0.0756 - val_accuracy: 0.9792\nEpoch 12/30\n300/300 - 2s - loss: 0.0074 - accuracy: 0.9985 - val_loss: 0.0770 - val_accuracy: 0.9795\nEpoch 13/30\n300/300 - 2s - loss: 0.0059 - accuracy: 0.9987 - val_loss: 0.0878 - val_accuracy: 0.9774\nEpoch 14/30\n300/300 - 2s - loss: 0.0078 - accuracy: 0.9980 - val_loss: 0.0913 - val_accuracy: 0.9791\nEpoch 15/30\n300/300 - 2s - loss: 0.0109 - accuracy: 0.9967 - val_loss: 0.1055 - val_accuracy: 0.9739\nEpoch 16/30\n300/300 - 2s - loss: 0.0062 - accuracy: 0.9984 - val_loss: 0.0879 - val_accuracy: 0.9796\nEpoch 17/30\n300/300 - 2s - loss: 0.0053 - accuracy: 0.9985 - val_loss: 0.0923 - val_accuracy: 0.9788\nEpoch 18/30\n300/300 - 2s - loss: 0.0033 - accuracy: 0.9992 - val_loss: 0.0833 - val_accuracy: 0.9813\nEpoch 19/30\n300/300 - 2s - loss: 8.4615e-04 - accuracy: 1.0000 - val_loss: 0.0830 - val_accuracy: 0.9826\nEpoch 20/30\n300/300 - 2s - loss: 3.8904e-04 - accuracy: 1.0000 - val_loss: 0.0846 - val_accuracy: 0.9820\nEpoch 21/30\n300/300 - 2s - loss: 2.9610e-04 - accuracy: 1.0000 - val_loss: 0.0868 - val_accuracy: 0.9816\nEpoch 22/30\n300/300 - 2s - loss: 2.5191e-04 - accuracy: 1.0000 - val_loss: 0.0869 - val_accuracy: 0.9816\nEpoch 23/30\n300/300 - 2s - loss: 2.1611e-04 - accuracy: 1.0000 - val_loss: 0.0884 - val_accuracy: 0.9818\nEpoch 24/30\n300/300 - 2s - loss: 1.8979e-04 - accuracy: 1.0000 - val_loss: 0.0892 - val_accuracy: 0.9823\nEpoch 25/30\n300/300 - 2s - loss: 1.6380e-04 - accuracy: 1.0000 - val_loss: 0.0904 - val_accuracy: 0.9819\nEpoch 26/30\n300/300 - 2s - loss: 1.4503e-04 - accuracy: 1.0000 - val_loss: 0.0902 - val_accuracy: 0.9830\nEpoch 27/30\n300/300 - 2s - loss: 1.2713e-04 - accuracy: 1.0000 - val_loss: 0.0929 - val_accuracy: 0.9816\nEpoch 28/30\n300/300 - 2s - loss: 1.0971e-04 - accuracy: 1.0000 - val_loss: 0.0926 - val_accuracy: 0.9822\nEpoch 29/30\n300/300 - 2s - loss: 1.0372e-04 - accuracy: 1.0000 - val_loss: 0.0931 - val_accuracy: 0.9823\nEpoch 30/30\n300/300 - 2s - loss: 8.4501e-05 - accuracy: 1.0000 - val_loss: 0.0950 - val_accuracy: 0.9815\n"
]
],
[
[
"## 4.5. Evaluate the model",
"_____no_output_____"
]
],
[
[
"scores = model.evaluate(X_test, y_test, verbose=0)\nprint(\"Test loss: \", scores[0])\nprint(\"Test Accuracy: \", (scores[1]))\nprint(\"Baseline Error: \", (100-scores[1]*100))",
"Test loss: 0.09502233564853668\nTest Accuracy: 0.9815000295639038\nBaseline Error: 1.8499970436096191\n"
]
],
[
[
"## 4.6. Save the model in a h5 file",
"_____no_output_____"
]
],
[
[
"model.save(\"model.h5\")",
"_____no_output_____"
]
],
[
[
"# 5. Convert the model to a web friendly format\n---",
"_____no_output_____"
]
],
[
[
"!tensorflowjs_converter --input_format keras './model.h5' '../UI/model'",
"2021-03-21 17:58:11.637568: W tensorflow/stream_executor/platform/default/dso_loader.cc:60] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n2021-03-21 17:58:11.637600: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n"
]
],
[
[
"- Uses tensorflowjs to convert the model to a format which can run on the browser\n- Allows to run the model on a single page web app without a backend",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a27987cfae2a6ad355efc8b060f1d067435343c
| 120,249 |
ipynb
|
Jupyter Notebook
|
docs/notebook/mindspore_debugging_in_pynative_mode.ipynb
|
mindspore-ai/docs
|
e7cbd69fe2bbd7870aa4591510ed3342ec6a3d41
|
[
"Apache-2.0",
"CC-BY-4.0"
] | 288 |
2020-03-28T07:00:25.000Z
|
2021-12-26T14:56:31.000Z
|
docs/notebook/mindspore_debugging_in_pynative_mode.ipynb
|
mindspore-ai/docs
|
e7cbd69fe2bbd7870aa4591510ed3342ec6a3d41
|
[
"Apache-2.0",
"CC-BY-4.0"
] | 1 |
2021-07-21T08:11:58.000Z
|
2021-07-21T08:11:58.000Z
|
docs/notebook/mindspore_debugging_in_pynative_mode.ipynb
|
mindspore-ai/docs
|
e7cbd69fe2bbd7870aa4591510ed3342ec6a3d41
|
[
"Apache-2.0",
"CC-BY-4.0"
] | 37 |
2020-03-30T06:38:37.000Z
|
2021-09-17T05:47:59.000Z
| 185.283513 | 41,180 | 0.900182 |
[
[
[
"# 使用PyNative进行神经网络的训练调试体验\n\n[](https://gitee.com/mindspore/docs/blob/master/docs/notebook/mindspore_debugging_in_pynative_mode.ipynb)",
"_____no_output_____"
],
[
"## 概述",
"_____no_output_____"
],
[
"在神经网络训练过程中,数据是否按照自己设计的神经网络运行,是使用者非常关心的事情,如何去查看数据是怎样经过神经网络,并产生变化的呢?这时候需要AI框架提供一个功能,方便使用者将计算图中的每一步变化拆开成单个算子或者深层网络拆分成多个单层来调试观察,了解分析数据在经过算子或者计算层后的变化情况,MindSpore在设计之初就提供了这样的功能模式--`PyNative_MODE`,与此对应的是`GRAPH_MODE`,他们的特点分别如下:\n\n- PyNative模式:也称动态图模式,将神经网络中的各个算子逐一下发执行,方便用户编写和调试神经网络模型。\n- Graph模式:也称静态图模式或者图模式,将神经网络模型编译成一整张图,然后下发执行。该模式利用图优化等技术提高运行性能,同时有助于规模部署和跨平台运行。\n\n默认情况下,MindSpore处于Graph模式,可以通过`context.set_context(mode=context.PYNATIVE_MODE)`切换为PyNative模式;同样地,MindSpore处于PyNative模式时,可以通过`context.set_context(mode=context.GRAPH_MODE)`切换为Graph模式。\n\n<br/>本次体验我们将使用一张手写数字图片跑完单次训练,在PyNative模式下,将数据在训练中经过每层神经网络的变化情况打印出来,并计算对应的loss值以及梯度值`grads`,整体流程如下:\n\n1. 环境准备,设置PyNative模式。\n\n2. 数据集准备,并取用单张图片数据。\n\n3. 构建神经网络并设置每层断点打印数据。\n\n4. 构建梯度计算函数。\n\n5. 执行神经网络训练,查看网络各参数梯度。\n\n> 本文档适用于GPU和Ascend环境。",
"_____no_output_____"
],
[
"## 环境准备\n\n使用`context.set_context`将模式设置成`PYNATIVE_MODE`。",
"_____no_output_____"
]
],
[
[
"from mindspore import context\n\ncontext.set_context(mode=context.PYNATIVE_MODE, device_target=\"GPU\")",
"_____no_output_____"
]
],
[
[
"## 数据准备",
"_____no_output_____"
],
[
"### 数据集的下载",
"_____no_output_____"
],
[
"以下示例代码将数据集下载并解压到指定位置。",
"_____no_output_____"
]
],
[
[
"import os\nimport requests\n\nrequests.packages.urllib3.disable_warnings()\n\ndef download_dataset(dataset_url, path):\n filename = dataset_url.split(\"/\")[-1]\n save_path = os.path.join(path, filename)\n if os.path.exists(save_path):\n return\n if not os.path.exists(path):\n os.makedirs(path)\n res = requests.get(dataset_url, stream=True, verify=False)\n with open(save_path, \"wb\") as f:\n for chunk in res.iter_content(chunk_size=512):\n if chunk:\n f.write(chunk)\n print(\"The {} file is downloaded and saved in the path {} after processing\".format(os.path.basename(dataset_url), path))\n\ntrain_path = \"datasets/MNIST_Data/train\"\ntest_path = \"datasets/MNIST_Data/test\"\n\ndownload_dataset(\"https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte\", train_path)\ndownload_dataset(\"https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte\", train_path)\ndownload_dataset(\"https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte\", test_path)\ndownload_dataset(\"https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte\", test_path)",
"_____no_output_____"
]
],
[
[
"下载的数据集文件的目录结构如下:\n\n```text\n./datasets/MNIST_Data\n├── test\n│ ├── t10k-images-idx3-ubyte\n│ └── t10k-labels-idx1-ubyte\n└── train\n ├── train-images-idx3-ubyte\n └── train-labels-idx1-ubyte\n```",
"_____no_output_____"
],
[
"### 数据集的增强操作",
"_____no_output_____"
],
[
"下载下来后的数据集,需要通过`mindspore.dataset`处理成适用于MindSpore框架的数据,再使用一系列框架中提供的工具进行数据增强操作来适应LeNet网络的数据处理需求。",
"_____no_output_____"
]
],
[
[
"import mindspore.dataset.vision.c_transforms as CV\nimport mindspore.dataset.transforms.c_transforms as C\nfrom mindspore.dataset.vision import Inter\nfrom mindspore import dtype as mstype\nimport mindspore.dataset as ds\nimport numpy as np\n\ndef create_dataset(data_path, batch_size=32, repeat_size=1,\n num_parallel_workers=1):\n \"\"\" create dataset for train or test\n Args:\n data_path (str): Data path\n batch_size (int): The number of data records in each group\n repeat_size (int): The number of replicated data records\n num_parallel_workers (int): The number of parallel workers\n \"\"\"\n # define dataset\n mnist_ds = ds.MnistDataset(data_path)\n\n # define some parameters needed for data enhancement and rough justification\n resize_height, resize_width = 32, 32\n rescale = 1.0 / 255.0\n shift = 0.0\n rescale_nml = 1 / 0.3081\n shift_nml = -1 * 0.1307 / 0.3081\n\n # according to the parameters, generate the corresponding data enhancement method\n resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)\n rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)\n rescale_op = CV.Rescale(rescale, shift)\n hwc2chw_op = CV.HWC2CHW()\n type_cast_op = C.TypeCast(mstype.int32)\n\n # using map method to apply operations to a dataset\n mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns=\"label\", num_parallel_workers=num_parallel_workers)\n mnist_ds = mnist_ds.map(operations=resize_op, input_columns=\"image\", num_parallel_workers=num_parallel_workers)\n mnist_ds = mnist_ds.map(operations=rescale_op, input_columns=\"image\", num_parallel_workers=num_parallel_workers)\n mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns=\"image\", num_parallel_workers=num_parallel_workers)\n mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns=\"image\", num_parallel_workers=num_parallel_workers)\n\n # process the generated dataset\n buffer_size = 10000\n mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)\n mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)\n mnist_ds = mnist_ds.repeat(repeat_size)\n\n return mnist_ds",
"_____no_output_____"
]
],
[
[
"### 数据图片的提取",
"_____no_output_____"
],
[
"本次体验我们只需要一张图片进行训练体验,所以随机选取`batch`中的第一张图片`image`和下标`label`。",
"_____no_output_____"
]
],
[
[
"from mindspore import Tensor\nimport matplotlib.pyplot as plt\n\ntrain_data_path = \"./datasets/MNIST_Data/train/\"\nms_dataset = create_dataset(train_data_path)\ndict_data = ms_dataset.create_dict_iterator()\ndata = next(dict_data)\nimages = data[\"image\"].asnumpy()\nlabels = data[\"label\"].asnumpy()\nprint(images.shape)\ncount = 1\nfor i in images:\n plt.subplot(4, 8, count)\n plt.imshow(np.squeeze(i))\n plt.title('num:%s'%labels[count-1])\n plt.xticks([])\n count += 1\n plt.axis(\"off\")\nplt.show()",
"(32, 1, 32, 32)\n"
]
],
[
[
"当前batch的image数据如上图,后面的体验将提取第一张图片进行训练操作。",
"_____no_output_____"
],
[
"### 定义图像显示函数\n\n定义一个图像显示函数`image_show`,插入LeNet5的前面4层神经网络中抽取图像数据并显示。",
"_____no_output_____"
]
],
[
[
"def image_show(x):\n count = 1\n x = x.asnumpy()\n number = x.shape[1]\n sqrt_number = int(np.sqrt(number))\n for i in x[0]:\n plt.subplot(sqrt_number, int(number/sqrt_number), count)\n plt.imshow(i)\n count += 1\n plt.show()",
"_____no_output_____"
]
],
[
[
"## 构建神经网络LeNet5\n\n在`construct`中使用`image_show`,查看每层网络后的图片变化。\n> 这里只抽取了图片显示,想要查看具体的数值,可以按照自己的需要进行`print(x)`。",
"_____no_output_____"
]
],
[
[
"import mindspore.nn as nn\nimport mindspore.ops as ops\nfrom mindspore import dtype as mstype\nfrom mindspore.common.initializer import Normal\n\n\nclass LeNet5(nn.Cell):\n \"\"\"Lenet network structure.\"\"\"\n # define the operator required\n def __init__(self, num_class=10, num_channel=1):\n super(LeNet5, self).__init__()\n self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')\n self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')\n self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))\n self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))\n self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))\n self.relu = nn.ReLU()\n self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)\n self.flatten = nn.Flatten()\n self.switch = 1\n\n def construct(self, x):\n\n x = self.conv1(x)\n if self.switch > 0:\n print(\"The first layer: convolution layer\")\n image_show(x)\n x = self.relu(x)\n x = self.max_pool2d(x)\n if self.switch > 0:\n print(\"The second layer: pool layer\")\n image_show(x)\n x = self.conv2(x)\n if self.switch > 0:\n print(\"The third layer: convolution layer\")\n image_show(x)\n x = self.relu(x)\n x = self.max_pool2d(x)\n if self.switch > 0:\n print(\"The fourth layer: pool layer\")\n image_show(x)\n x = self.flatten(x)\n x = self.relu(self.fc1(x))\n x = self.relu(self.fc2(x))\n x = self.fc3(x)\n self.switch -= 1\n return x\n\nnetwork = LeNet5()\nprint(\"layer conv1:\", network.conv1)\nprint(\"*\"*40)\nprint(\"layer fc1:\", network.fc1)",
"layer conv1: Conv2d<input_channels=1, output_channels=6, kernel_size=(5, 5),stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False,weight_init=normal, bias_init=zeros>\n****************************************\nlayer fc1: Dense<in_channels=400, out_channels=120, weight=Parameter (name=fc1.weight, value=[[-0.00758117 -0.01498233 0.01308791 ... 0.03045311 -0.00079244\n -0.01519072]\n [-0.00077699 -0.01607893 -0.00215094 ... -0.00235667 -0.01918699\n -0.00828544]\n [-0.00105981 -0.01547002 -0.01332507 ... 0.01294748 0.00878882\n 0.01031067]\n ...\n [ 0.01414873 -0.02673322 0.01534838 ... 0.00437457 -0.01688845\n -0.00188475]\n [ 0.01756713 -0.0201801 -0.0223504 ... 0.00682346 -0.00856738\n 0.00753205]\n [-0.01119993 0.01894077 -0.02048291 ... 0.03681218 -0.01461048\n 0.0045935 ]]), has_bias=True, bias=Parameter (name=fc1.bias, value=[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.\n 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.])>\n"
]
],
[
[
"## 构建计算梯度函数GradWrap\n\n构建梯度下降求值函数,该函数可计算网络中所有权重的梯度。",
"_____no_output_____"
]
],
[
[
"from mindspore import Tensor, ParameterTuple\n\n\nclass GradWrap(nn.Cell):\n \"\"\" GradWrap definition \"\"\"\n def __init__(self, network):\n super(GradWrap, self).__init__(auto_prefix=False)\n self.network = network\n self.weights = ParameterTuple(filter(lambda x: x.requires_grad, network.get_parameters()))\n\n def construct(self, x, label):\n weights = self.weights\n return ops.GradOperation(get_by_list=True)(self.network, weights)(x, label)",
"_____no_output_____"
]
],
[
[
"## 执行训练函数\n\n可以从网络中查看当前`batch`中第一张图片`image`的数据在神经网络中的变化,经过神经网络后,计算出其loss值,再根据loss值求参数的偏导即神经网络的梯度值,最后将梯度和loss进行优化。\n\n- image:为当前batch的第一张图片。\n- output:表示图片数据经过当前网络训练后生成的值,其张量为(1,10)。",
"_____no_output_____"
]
],
[
[
"from mindspore.nn import WithLossCell, Momentum\n\nnet = LeNet5()\noptimizer = Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), 0.1, 0.9)\ncriterion = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')\nnet_with_criterion = WithLossCell(net, criterion)\ntrain_network = GradWrap(net_with_criterion)\ntrain_network.set_train()\n\nimage = images[0][0]\nimage = image.reshape((1, 1, 32, 32))\nplt.imshow(np.squeeze(image))\nplt.show()\ninput_data = Tensor(np.array(image).astype(np.float32))\nlabel = Tensor(np.array([labels[0]]).astype(np.int32))\noutput = net(Tensor(input_data))",
"_____no_output_____"
]
],
[
[
"将第一层卷积层、第二层池化层、第三层卷积层和第四层池化层的图像特征打印出来后,直观地看到随着深度的增加,图像特征几乎无法用肉眼识别,但是机器可以用这些特征进行学习和识别,后续的全连接层为二维数组,无法图像显示,但可以打印出数据查看,由于数据量过大此处就不打印了,用户可以根据需求选择打印。",
"_____no_output_____"
],
[
"### 求loss值和梯度值,并进行优化\n\n先求得loss值,后再根据loss值求梯度(偏导函数值),使用优化器`optimizer`进行优化。\n\n- `loss_output`:即为loss值。\n- `grads`:即网络中每层权重的梯度。\n- `net_params`:即网络中每层权重的名称,用户可执行`print(net_params)`自行打印。\n- `success`:优化参数。",
"_____no_output_____"
]
],
[
[
"loss_output = criterion(output, label)\ngrads = train_network(input_data, label)\nnet_params = net.trainable_params()\nfor i, grad in enumerate(grads):\n print(\"{}:\".format(net_params[i].name), grad.shape)\nsuccess = optimizer(grads)\nloss = loss_output.asnumpy()\nprint(\"Loss_value:\", loss)",
"conv1.weight: (6, 1, 5, 5)\nconv2.weight: (16, 6, 5, 5)\nfc1.weight: (120, 400)\nfc1.bias: (120,)\nfc2.weight: (84, 120)\nfc2.bias: (84,)\nfc3.weight: (10, 84)\nfc3.bias: (10,)\nLoss_value: 2.3025453\n"
]
],
[
[
"具体每层权重的参数有多少,从打印出来的梯度张量能够看到,对应的梯度值用户可以自行选择打印。",
"_____no_output_____"
],
[
"## 总结",
"_____no_output_____"
],
[
"本次体验我们将MindSpore的数据增强后,使用了`create_dict_iterator`转化成字典,再单独取出来;使用PyNative模式将神经网络分层单独调试,提取并观察数据;用`WithLossCell`在PyNative模式下计算loss值;构造梯度函数`GradWrap`将神经网络中各个权重的梯度计算出来,以上就是本次的全部体验内容。",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a27af40ee8f860113f4a0d3f2710f74a819d4b5
| 367,403 |
ipynb
|
Jupyter Notebook
|
notebooks/get_data_write_json.ipynb
|
CodeTheCity/CTC16-Air-Champs
|
89d9c4a0194b8809baa6814484edfdfbbd2ff721
|
[
"Unlicense"
] | null | null | null |
notebooks/get_data_write_json.ipynb
|
CodeTheCity/CTC16-Air-Champs
|
89d9c4a0194b8809baa6814484edfdfbbd2ff721
|
[
"Unlicense"
] | null | null | null |
notebooks/get_data_write_json.ipynb
|
CodeTheCity/CTC16-Air-Champs
|
89d9c4a0194b8809baa6814484edfdfbbd2ff721
|
[
"Unlicense"
] | null | null | null | 1,570.098291 | 361,269 | 0.620403 |
[
[
[
"import urllib.request\nimport json\nimport glob\nimport pandas as pd\nimport numpy as np\nimport datetime",
"_____no_output_____"
]
],
[
[
"Get data from sensors",
"_____no_output_____"
]
],
[
[
"# this cell gets data\nURL = \"http://165.227.244.213:8881/luftdatenGet/22FQ8dJEApww33p31935/9d93d9d8cv7js9sj4765s120sllkudp389cm/\" \nresponse = urllib.request.urlopen(URL)\ndata = json.loads(response.read())\nprint(data)\n",
"[{'_id': '5cfaeac7ba5da8385e4620d9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.12'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1721462'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21103'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaeb5b79660f38824df851', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1719772'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaebf479660f38824df852', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.72'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1721978'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaec8979660f38824df853', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1730653'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21154'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaed1d79660f38824df854', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.30'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1744103'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21599'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaedb179660f38824df855', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1741674'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21076'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaee4579660f38824df856', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.90'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1741980'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21207'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaeed979660f38824df857', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1741738'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21116'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaef6d79660f38824df858', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1719368'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf00279660f38824df859', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1704145'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21729'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf09679660f38824df85a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1731186'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21204'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf12a79660f38824df85b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1712966'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21192'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf1be79660f38824df85c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.25'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1706173'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf25379660f38824df85d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1722027'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21170'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf2e779660f38824df85e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1734681'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf37d79660f38824df85f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.82'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1737080'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21219'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf41179660f38824df860', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.70'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1734904'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21164'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf4a679660f38824df861', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1728949'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21946'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf53a79660f38824df862', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1754809'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf5d079660f38824df863', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.57'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1735245'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaf66479660f38824df864', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'samples', 'value': '1756530'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf6f879660f38824df865', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.87'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1737672'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '20186'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf78c79660f38824df866', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '1.05'}, {'value_type': 'samples', 'value': '1741549'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21058'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfaf82079660f38824df867', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.62'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1745061'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21185'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf8b479660f38824df868', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744831'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21253'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf94879660f38824df869', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1740899'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21066'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfaf9dd79660f38824df86a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1744878'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21697'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfafa7179660f38824df86b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744852'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21188'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfafb0579660f38824df86c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.80'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'samples', 'value': '1744666'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfafb9979660f38824df86d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1740934'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfafc2d79660f38824df86e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1740886'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21152'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfafcc279660f38824df86f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1744777'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfafd5679660f38824df870', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1737001'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21176'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfafdea79660f38824df871', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1744804'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21615'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfafe7e79660f38824df872', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1741637'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21164'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfaff1279660f38824df873', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1740775'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21556'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfaffa779660f38824df874', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1743805'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb003b79660f38824df875', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1737920'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21199'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb00cf79660f38824df876', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1740137'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21075'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb016379660f38824df877', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1737762'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21116'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb01f779660f38824df878', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1728599'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb028b79660f38824df879', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1735806'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb032079660f38824df87a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1745465'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21194'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb03b479660f38824df87b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1736674'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb044879660f38824df87c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744556'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21625'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb04dc79660f38824df87d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1733418'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb057079660f38824df87e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.57'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1725511'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21077'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb060579660f38824df87f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1744728'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb069979660f38824df880', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744148'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb072d79660f38824df881', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744376'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '22080'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb07c179660f38824df882', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744145'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21199'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb085579660f38824df883', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744152'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21115'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb08e979660f38824df884', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745080'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21217'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb097e79660f38824df885', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.37'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744118'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21638'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0a1279660f38824df886', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1763274'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0aa679660f38824df887', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1743897'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21184'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0b3a79660f38824df888', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1743726'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0bce79660f38824df889', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1743869'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21540'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0c6279660f38824df88a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744407'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0cf679660f38824df88b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1738965'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21173'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0d8b79660f38824df88c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744088'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0e1f79660f38824df88d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1745127'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21083'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0eb379660f38824df88e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.57'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1745050'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb0f4779660f38824df88f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744947'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21197'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb0fdb79660f38824df890', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744292'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb106f79660f38824df891', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.58'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1745131'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21613'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb110479660f38824df892', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744219'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb119879660f38824df893', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1744231'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21127'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb122c79660f38824df894', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.80'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1730114'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21211'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb12c079660f38824df895', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1722463'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21172'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb135479660f38824df896', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1737680'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21182'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb13e879660f38824df897', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744172'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21167'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb147d79660f38824df898', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1721726'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb151179660f38824df899', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744768'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb15a579660f38824df89a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.75'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1744755'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb163979660f38824df89b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.60'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1734787'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21144'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb16cd79660f38824df89c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.95'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1736831'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21200'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb176179660f38824df89d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1744465'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb17f579660f38824df89e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745094'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21139'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb188979660f38824df89f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744828'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21204'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb191e79660f38824df8a0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.30'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1744838'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb19b279660f38824df8a1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744381'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21556'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1a4679660f38824df8a2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1732735'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21155'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1ada79660f38824df8a3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1739106'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1b6e79660f38824df8a4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744291'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1c0279660f38824df8a5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744786'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21072'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1c9879660f38824df8a6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744605'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21486'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1d2d79660f38824df8a7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744504'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21247'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1dc279660f38824df8a8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1744925'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1e5679660f38824df8a9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744807'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1eea79660f38824df8aa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744135'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb1f7e79660f38824df8ab', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744641'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21060'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb201379660f38824df8ac', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'samples', 'value': '1744795'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb20a779660f38824df8ad', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1741033'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb213c79660f38824df8ae', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1740252'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21711'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb21d079660f38824df8af', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1724933'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb226579660f38824df8b0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1723063'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb22f979660f38824df8b1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.90'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1726064'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21533'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb238d79660f38824df8b2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1717702'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb242279660f38824df8b3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1717080'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21221'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb24b879660f38824df8b4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1706099'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21604'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb254e79660f38824df8b5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1717564'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21552'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb25e279660f38824df8b6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1718321'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb267779660f38824df8b7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.72'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1717794'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb270d79660f38824df8b8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.80'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1717786'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21137'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb27a279660f38824df8b9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1711629'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21512'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb283779660f38824df8ba', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.42'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1716095'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb28cb79660f38824df8bb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1710245'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb295f79660f38824df8bc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1692483'}, {'value_type': 'min_micro', 'value': '83'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb29f379660f38824df8bd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1717669'}, {'value_type': 'min_micro', 'value': '83'}, {'value_type': 'max_micro', 'value': '21203'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2a8879660f38824df8be', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1739854'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2b1c79660f38824df8bf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1727636'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21146'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2bb079660f38824df8c0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1740434'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21111'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2c4479660f38824df8c1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1741173'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21090'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2cd879660f38824df8c2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1740795'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21144'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2d6c79660f38824df8c3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.85'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1740509'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2e0079660f38824df8c4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1740628'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21199'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2e9479660f38824df8c5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.35'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1741835'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21580'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb2f2879660f38824df8c6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744670'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21086'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfb2fbc79660f38824df8c7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745246'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb305079660f38824df8c8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1737660'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21163'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb30e579660f38824df8c9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744741'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21545'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb317979660f38824df8ca', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1744393'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21158'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb320d79660f38824df8cb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1745168'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21078'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb32a179660f38824df8cc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1745037'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21072'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb333579660f38824df8cd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744742'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb33c979660f38824df8ce', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1743995'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb345d79660f38824df8cf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1745083'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb34f179660f38824df8d0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744503'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21195'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb358579660f38824df8d1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1744332'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21201'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb361979660f38824df8d2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1745340'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21131'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb36ad79660f38824df8d3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1739265'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb374279660f38824df8d4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1744394'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb37d679660f38824df8d5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1743945'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21688'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb386a79660f38824df8d6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1744616'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21205'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb38fe79660f38824df8d7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1744510'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb399279660f38824df8d8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745116'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21071'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3a2679660f38824df8d9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1739049'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3abb79660f38824df8da', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1744109'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3b4f79660f38824df8db', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1745101'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21551'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3be379660f38824df8dc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745425'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21093'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb3c7779660f38824df8dd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1745302'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb3d0b79660f38824df8de', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744155'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21195'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3d9f79660f38824df8df', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1743181'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21208'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3e3379660f38824df8e0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1726848'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21107'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3ec779660f38824df8e1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1726032'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21123'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3f5b79660f38824df8e2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1743202'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21649'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb3fef79660f38824df8e3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1742909'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb408379660f38824df8e4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1720036'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb411879660f38824df8e5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1742697'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21207'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb41ac79660f38824df8e6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1734202'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21211'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb424079660f38824df8e7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1737292'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb42d479660f38824df8e8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1743135'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb436879660f38824df8e9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1731368'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb43fc79660f38824df8ea', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1731707'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21167'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb449179660f38824df8eb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1743243'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb452579660f38824df8ec', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1736402'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21604'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb45b979660f38824df8ed', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1740873'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb464d79660f38824df8ee', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1742073'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb46e179660f38824df8ef', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1743524'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb477579660f38824df8f0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.40'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1728783'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb480979660f38824df8f1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1734002'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb489d79660f38824df8f2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1734310'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21188'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb493279660f38824df8f3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1743307'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21603'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb49c679660f38824df8f4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1741084'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21169'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4a5a79660f38824df8f5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1741064'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4aee79660f38824df8f6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.80'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1735284'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21203'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb4b8279660f38824df8f7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744502'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21538'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4c1679660f38824df8f8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1737762'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21206'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4caa79660f38824df8f9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1744863'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4d3e79660f38824df8fa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.75'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1739884'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4dd279660f38824df8fb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1743835'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4e6779660f38824df8fc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1727748'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21536'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4efb79660f38824df8fd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.75'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1749545'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb4f8f79660f38824df8fe', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1761443'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb502379660f38824df8ff', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1762021'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb50b779660f38824df900', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1752469'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb514b79660f38824df901', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'samples', 'value': '1755856'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21184'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb51e079660f38824df902', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1768092'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb527479660f38824df903', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1754755'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb531b79660f38824df904', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1757752'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb53af79660f38824df905', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1761026'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21131'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb544379660f38824df906', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1759504'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21219'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfb54d779660f38824df907', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.72'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1750596'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21135'}, {'value_type': 'signal', 'value': '-74'}]}, {'_id': '5cfb55da79660f38824df908', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1946369'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '27029'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb566e79660f38824df909', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.53'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'samples', 'value': '1921733'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21083'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb570279660f38824df90a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.10'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1909735'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb579679660f38824df90b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.90'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'samples', 'value': '1903553'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21047'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb582b79660f38824df90c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1893450'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21267'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb58bf79660f38824df90d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.62'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1901537'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21048'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb595379660f38824df90e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1901510'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21032'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb59e779660f38824df90f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1902577'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21024'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb5a7b79660f38824df910', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.05'}, {'value_type': 'SDS_P2', 'value': '0.78'}, {'value_type': 'samples', 'value': '1913335'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21501'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb5b0f79660f38824df911', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.55'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1912332'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21259'}, {'value_type': 'signal', 'value': '-73'}]}, {'_id': '5cfb5ba379660f38824df912', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.37'}, {'value_type': 'SDS_P2', 'value': '1.10'}, {'value_type': 'samples', 'value': '1903145'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21176'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb5c3779660f38824df913', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '7.10'}, {'value_type': 'SDS_P2', 'value': '1.22'}, {'value_type': 'samples', 'value': '1903164'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb5ccb79660f38824df914', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '7.30'}, {'value_type': 'SDS_P2', 'value': '1.17'}, {'value_type': 'samples', 'value': '1876140'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21086'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfb5d6079660f38824df915', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.35'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1896326'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb5df479660f38824df916', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.72'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'samples', 'value': '1907333'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb5e8879660f38824df917', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.22'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'samples', 'value': '1911837'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb5f1c79660f38824df918', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.27'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1909623'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21087'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb5fb079660f38824df919', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.55'}, {'value_type': 'SDS_P2', 'value': '1.12'}, {'value_type': 'samples', 'value': '1893801'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb604479660f38824df91a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.33'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'samples', 'value': '1909980'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21605'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb60d879660f38824df91b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '6.55'}, {'value_type': 'SDS_P2', 'value': '1.10'}, {'value_type': 'samples', 'value': '1890156'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21060'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb616c79660f38824df91c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.60'}, {'value_type': 'SDS_P2', 'value': '1.17'}, {'value_type': 'samples', 'value': '1913757'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb620079660f38824df91d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1910918'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb629479660f38824df91e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.40'}, {'value_type': 'SDS_P2', 'value': '1.12'}, {'value_type': 'samples', 'value': '1910702'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21172'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb632979660f38824df91f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1910959'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21032'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb63bd79660f38824df920', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1918516'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21514'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb645179660f38824df921', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1921543'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21019'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb64e579660f38824df922', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.03'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'samples', 'value': '1921320'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb657979660f38824df923', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.00'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1898380'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21007'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb660d79660f38824df924', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1928723'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21031'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb66a179660f38824df925', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.53'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1928796'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21079'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb673679660f38824df926', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1901662'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb67ca79660f38824df927', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1923391'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21058'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb685e79660f38824df928', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.33'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'samples', 'value': '1923113'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21067'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb68f279660f38824df929', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.17'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'samples', 'value': '1922427'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb698679660f38824df92a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.58'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1920509'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21071'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6a1a79660f38824df92b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.87'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1862891'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21152'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6aae79660f38824df92c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1917326'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6b4279660f38824df92d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.45'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'samples', 'value': '1911238'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6bd779660f38824df92e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.55'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1916404'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6c6b79660f38824df92f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1883898'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21050'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb6cff79660f38824df930', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.90'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1910717'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21503'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6d9379660f38824df931', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.17'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1921804'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21031'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6e2879660f38824df932', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.17'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1874838'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21588'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6ebc79660f38824df933', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'samples', 'value': '1917173'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6f5079660f38824df934', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1907476'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb6fe479660f38824df935', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.00'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1903073'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21048'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb707879660f38824df936', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1911518'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21080'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb710c79660f38824df937', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.65'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1882658'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21544'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb71a079660f38824df938', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.52'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1848904'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb723479660f38824df939', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.17'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1875719'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21116'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb72c879660f38824df93a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1867607'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21080'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb735d79660f38824df93b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1872513'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21573'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb73f179660f38824df93c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1867577'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21114'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb748579660f38824df93d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.22'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1883219'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21063'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb751979660f38824df93e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'samples', 'value': '1867692'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21025'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb75ad79660f38824df93f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.52'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1870538'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21032'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb764179660f38824df940', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1865741'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21610'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb76d579660f38824df941', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1876563'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21127'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb776979660f38824df942', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1872638'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21064'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb77fd79660f38824df943', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.75'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1906279'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21068'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb789279660f38824df944', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.67'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1871930'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21077'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb792679660f38824df945', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1854216'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21585'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb79ba79660f38824df946', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1840192'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21185'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb7a4e79660f38824df947', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.35'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1841675'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7ae279660f38824df948', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.10'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1842300'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21052'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7b7e79660f38824df949', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.30'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1869562'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21043'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7c1279660f38824df94a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1839313'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21162'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7ca679660f38824df94b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.12'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1871054'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7d3a79660f38824df94c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1859898'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21099'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7de279660f38824df94d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1859740'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21116'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7e7679660f38824df94e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.78'}, {'value_type': 'samples', 'value': '1828987'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7f0a79660f38824df94f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1824867'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21073'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb7f9e79660f38824df950', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1825580'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb803279660f38824df951', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.72'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1827025'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21111'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb80c679660f38824df952', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1822913'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21471'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb815a79660f38824df953', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.25'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1825400'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21112'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb81ee79660f38824df954', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1825473'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb828279660f38824df955', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.02'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1818179'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21178'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb831779660f38824df956', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1820506'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21511'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb83ab79660f38824df957', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1825482'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21150'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb843f79660f38824df958', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1811914'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21131'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb84d379660f38824df959', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1820305'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb856779660f38824df95a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1822295'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb85fc79660f38824df95b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1823043'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21596'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb869179660f38824df95c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1812448'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21504'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb872679660f38824df95d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1802795'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21071'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb87ba79660f38824df95e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1803357'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb884e79660f38824df95f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1829901'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21076'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb88e279660f38824df960', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1815183'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21192'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb897679660f38824df961', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1823310'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8a0a79660f38824df962', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1842424'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21552'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8a9f79660f38824df963', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.75'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1853546'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21131'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8b3379660f38824df964', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1841257'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21048'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8bc779660f38824df965', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1848747'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8c5b79660f38824df966', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1838253'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21071'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8cef79660f38824df967', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1836949'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21454'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8d8379660f38824df968', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1843827'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21048'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8e1779660f38824df969', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1822707'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21100'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8ead79660f38824df96a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1820977'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb8f4179660f38824df96b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1820693'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-66'}]}, {'_id': '5cfb8fda79660f38824df96c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1822387'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb906e79660f38824df96d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1826474'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb910279660f38824df96e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1832397'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21869'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb919679660f38824df96f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1828793'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21170'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb922a79660f38824df970', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.57'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1838914'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21159'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb92be79660f38824df971', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1811852'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21192'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb935279660f38824df972', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1820791'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21176'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb93e679660f38824df973', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.92'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1791857'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21593'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb947a79660f38824df974', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1861471'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21193'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb950f79660f38824df975', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1846861'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb95a379660f38824df976', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1875772'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21057'}, {'value_type': 'signal', 'value': '-66'}]}, {'_id': '5cfb963e79660f38824df977', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1866111'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21041'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb96d279660f38824df978', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1856343'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21092'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb976679660f38824df979', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1866741'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21040'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb97fb79660f38824df97a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1867748'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb988f79660f38824df97b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.87'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1862091'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb992379660f38824df97c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1846105'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21524'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb99b779660f38824df97d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1869750'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21120'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9a4b79660f38824df97e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1872036'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21039'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9adf79660f38824df97f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1876027'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9b7379660f38824df980', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1875493'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21047'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfb9c0779660f38824df981', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1875200'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21680'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9c9c79660f38824df982', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874813'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9d3079660f38824df983', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1875253'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9dc479660f38824df984', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874749'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21093'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9e5979660f38824df985', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1841442'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21067'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9eed79660f38824df986', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874776'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfb9f8179660f38824df987', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1875321'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21553'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba01679660f38824df988', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874825'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba0aa79660f38824df989', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1878514'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba13e79660f38824df98a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1892298'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21107'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba1d279660f38824df98b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1878034'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21168'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba26679660f38824df98c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1857328'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21087'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba2fc79660f38824df98d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874831'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba39079660f38824df98e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.65'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1880040'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21091'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba42479660f38824df98f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1875665'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21076'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba4b879660f38824df990', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1863264'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21229'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba54c79660f38824df991', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1870791'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21525'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba5e079660f38824df992', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1864840'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba67579660f38824df993', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1873719'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21086'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba70979660f38824df994', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1875571'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21042'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba79d79660f38824df995', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1875777'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfba83179660f38824df996', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'samples', 'value': '1874447'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21043'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfba8c579660f38824df997', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1824433'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21525'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba95979660f38824df998', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1801922'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21212'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfba9ed79660f38824df999', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.75'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1787825'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21078'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbaa8279660f38824df99a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1787691'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21114'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbab1679660f38824df99b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1787588'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21211'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbabaa79660f38824df99c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1758318'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbac3e10e24a4773504b7e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1785430'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21145'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbacd25590b447bd74f715', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1787756'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbad665590b447bd74f716', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1755546'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21108'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbadfa5590b447bd74f717', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1823273'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21123'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbae8e5590b447bd74f718', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'samples', 'value': '1821272'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21049'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbaf235590b447bd74f719', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1787926'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbafb75590b447bd74f71a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1788477'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb04b5590b447bd74f71b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1790289'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb0df5590b447bd74f71c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1770873'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb1735590b447bd74f71d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1768303'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb2075590b447bd74f71e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1761605'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21588'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb29c5590b447bd74f71f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1770871'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb3305590b447bd74f720', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1770733'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21108'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb3c45590b447bd74f721', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1770694'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21120'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb4585590b447bd74f722', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1765074'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21112'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb4ec5590b447bd74f723', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1770923'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb5805590b447bd74f724', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1762702'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb6145590b447bd74f725', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1771091'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21194'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb6a85590b447bd74f726', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1770949'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb73c5590b447bd74f727', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1803233'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb7d15590b447bd74f728', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1792404'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21061'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb8665590b447bd74f729', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1791492'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21582'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb8fa5590b447bd74f72a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1801264'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21643'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbb98f5590b447bd74f72b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.57'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1837807'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21106'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbba235590b447bd74f72c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1824101'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21518'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbab75590b447bd74f72d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1812783'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21078'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbb4b5590b447bd74f72e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1819802'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21030'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbbe15590b447bd74f72f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1819780'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21085'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbc755590b447bd74f730', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1821104'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21073'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbd095590b447bd74f731', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1838710'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21063'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbd9d5590b447bd74f732', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1824910'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21803'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbe325590b447bd74f733', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1822045'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbec65590b447bd74f734', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1828446'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbf5a5590b447bd74f735', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1804521'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbbfee5590b447bd74f736', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1779970'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21147'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbc0825590b447bd74f737', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1836909'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc1165590b447bd74f738', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1854497'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc1ab5590b447bd74f739', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855560'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc23f5590b447bd74f73a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855365'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21020'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc2d35590b447bd74f73b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1857601'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21591'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc3685590b447bd74f73c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1862609'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21099'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc40f5590b447bd74f73d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1862461'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc4a35590b447bd74f73e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.75'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1866630'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21043'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc5375590b447bd74f73f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1861087'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21159'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc5cb5590b447bd74f740', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1860258'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc65f5590b447bd74f741', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1855445'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21489'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc6f35590b447bd74f742', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1863653'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21217'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc7885590b447bd74f743', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1857266'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21145'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc81c5590b447bd74f744', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855232'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21172'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc8b05590b447bd74f745', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1831346'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc9445590b447bd74f746', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1854914'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21079'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbc9d85590b447bd74f747', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1854747'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbca725590b447bd74f748', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1831348'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21150'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcb075590b447bd74f749', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855495'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcb9b5590b447bd74f74a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855519'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21100'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcc305590b447bd74f74b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1855472'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21167'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbccc45590b447bd74f74c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1853948'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcd585590b447bd74f74d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1853034'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21101'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcdec5590b447bd74f74e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1853066'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbce805590b447bd74f74f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1857231'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcf145590b447bd74f750', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1853297'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbcfa85590b447bd74f751', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.85'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1853742'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21137'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd03c5590b447bd74f752', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1855596'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21636'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd0d15590b447bd74f753', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1852524'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd1655590b447bd74f754', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1853965'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd1f95590b447bd74f755', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1854293'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21050'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd28d5590b447bd74f756', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1859186'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd3215590b447bd74f757', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1854643'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21069'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd3b55590b447bd74f758', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1856870'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21500'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd4495590b447bd74f759', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1856790'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '22107'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd4dd5590b447bd74f75a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1861643'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21291'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd5725590b447bd74f75b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1844536'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21150'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd6065590b447bd74f75c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1855371'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21073'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd69a5590b447bd74f75d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1855764'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21069'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd72e5590b447bd74f75e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1853309'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21057'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd7c35590b447bd74f75f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1856608'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21598'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd8575590b447bd74f760', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.72'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1838071'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd8eb5590b447bd74f761', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1816814'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21061'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbd97f5590b447bd74f762', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1849841'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21589'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbda135590b447bd74f763', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1856162'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21222'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdaa75590b447bd74f764', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1853097'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdb3b5590b447bd74f765', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1846085'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21058'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbdbcf5590b447bd74f766', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1851296'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21021'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdc635590b447bd74f767', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1848616'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21065'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdcf75590b447bd74f768', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1849593'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21426'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdd8c5590b447bd74f769', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1850297'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21096'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbde205590b447bd74f76a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'samples', 'value': '1859257'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21120'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdeb45590b447bd74f76b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1846124'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21112'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdf485590b447bd74f76c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1852837'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21163'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbdfdc5590b447bd74f76d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1840713'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21206'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe0705590b447bd74f76e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1849050'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21614'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe1045590b447bd74f76f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1847966'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21137'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe1985590b447bd74f770', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1878507'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe22c5590b447bd74f771', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1877164'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21199'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe2c05590b447bd74f772', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1875938'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe3545590b447bd74f773', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1866195'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21131'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe3e95590b447bd74f774', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1878305'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21522'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe47d5590b447bd74f775', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1873844'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21149'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe5115590b447bd74f776', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1882499'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21042'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe5a55590b447bd74f777', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1880685'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21028'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe6395590b447bd74f778', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1881811'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe6ce5590b447bd74f779', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1881723'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21122'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe7625590b447bd74f77a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1905916'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe7f65590b447bd74f77b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1877910'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe88a5590b447bd74f77c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1871063'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21173'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe91e5590b447bd74f77d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1879454'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21601'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbe9b25590b447bd74f77e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'samples', 'value': '1875106'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21081'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfbea465590b447bd74f77f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1871655'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfbeada5590b447bd74f780', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'samples', 'value': '1879353'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbeb6e5590b447bd74f781', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1880174'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbec025590b447bd74f782', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1880709'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21188'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbec975590b447bd74f783', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1879179'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbed2b5590b447bd74f784', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1877201'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21176'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbedbf5590b447bd74f785', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'samples', 'value': '1879915'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-73'}]}, {'_id': '5cfbee555590b447bd74f786', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1874227'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21049'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbeee95590b447bd74f787', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.85'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1878684'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbef7d5590b447bd74f788', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1888714'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21517'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbf0115590b447bd74f789', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'samples', 'value': '1867911'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21047'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfbf0a65590b447bd74f78a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.75'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1822948'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfbf13a5590b447bd74f78b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'samples', 'value': '1845751'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf1ce5590b447bd74f78c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1856244'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf2645590b447bd74f78d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1847896'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf2f85590b447bd74f78e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1848241'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21574'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf38c5590b447bd74f78f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1856320'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf4225590b447bd74f790', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1844169'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21029'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf4b75590b447bd74f791', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1846646'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21190'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbf54d5590b447bd74f792', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1865299'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21040'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf5e15590b447bd74f793', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1882069'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbf6755590b447bd74f794', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'samples', 'value': '1880000'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21053'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbf7095590b447bd74f795', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'samples', 'value': '1877078'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21573'}, {'value_type': 'signal', 'value': '-76'}]}, {'_id': '5cfbf79d5590b447bd74f796', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '14.70'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'samples', 'value': '1874987'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21162'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbf8315590b447bd74f797', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'samples', 'value': '1880235'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21018'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbf8c55590b447bd74f798', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '23.80'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'samples', 'value': '1882144'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21062'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbf95a5590b447bd74f799', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.83'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1881245'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21022'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbf9ee5590b447bd74f79a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '11.80'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'samples', 'value': '1878029'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21072'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbfa825590b447bd74f79b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.33'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'samples', 'value': '1849973'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21114'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbfb165590b447bd74f79c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.05'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1813474'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21681'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbfbaa5590b447bd74f79d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.35'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1815757'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21709'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbfc3e5590b447bd74f79e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.70'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'samples', 'value': '1844492'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21066'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfbfcd25590b447bd74f79f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.75'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'samples', 'value': '1842397'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbfd665590b447bd74f7a0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.60'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'samples', 'value': '1836355'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbfdfb5590b447bd74f7a1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '40.00'}, {'value_type': 'humidity', 'value': '35.00'}, {'value_type': 'samples', 'value': '1827155'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21120'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfbfe8f5590b447bd74f7a2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.12'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '39.60'}, {'value_type': 'humidity', 'value': '14.10'}, {'value_type': 'samples', 'value': '1788460'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21142'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfbff275590b447bd74f7a3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.25'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '31.60'}, {'value_type': 'humidity', 'value': '25.20'}, {'value_type': 'samples', 'value': '1843778'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfbffbc5590b447bd74f7a4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.33'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '27.40'}, {'value_type': 'humidity', 'value': '32.70'}, {'value_type': 'samples', 'value': '1833482'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc00505590b447bd74f7a5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.90'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '25.40'}, {'value_type': 'humidity', 'value': '37.10'}, {'value_type': 'samples', 'value': '1827273'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21610'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc00e55590b447bd74f7a6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.22'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '24.50'}, {'value_type': 'humidity', 'value': '39.70'}, {'value_type': 'samples', 'value': '1824907'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc01795590b447bd74f7a7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.47'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '24.10'}, {'value_type': 'humidity', 'value': '41.20'}, {'value_type': 'samples', 'value': '1836559'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21231'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc020e5590b447bd74f7a8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.80'}, {'value_type': 'humidity', 'value': '42.10'}, {'value_type': 'samples', 'value': '1831841'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21135'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc02a35590b447bd74f7a9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.37'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.60'}, {'value_type': 'humidity', 'value': '42.10'}, {'value_type': 'samples', 'value': '1834648'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21138'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc03375590b447bd74f7aa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.42'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.50'}, {'value_type': 'humidity', 'value': '42.70'}, {'value_type': 'samples', 'value': '1821211'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21553'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc03cb5590b447bd74f7ab', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.62'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.50'}, {'value_type': 'humidity', 'value': '43.20'}, {'value_type': 'samples', 'value': '1820499'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21620'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc04605590b447bd74f7ac', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.75'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '43.30'}, {'value_type': 'samples', 'value': '1837692'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc04f45590b447bd74f7ad', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.80'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '43.40'}, {'value_type': 'samples', 'value': '1837807'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21200'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc05895590b447bd74f7ae', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.98'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '43.50'}, {'value_type': 'samples', 'value': '1834373'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21123'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc061e5590b447bd74f7af', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.40'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '43.50'}, {'value_type': 'samples', 'value': '1830503'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21565'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc06b25590b447bd74f7b0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.98'}, {'value_type': 'SDS_P2', 'value': '1.12'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '44.00'}, {'value_type': 'samples', 'value': '1821078'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '22359'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc07485590b447bd74f7b1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.12'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '43.60'}, {'value_type': 'samples', 'value': '1829724'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21665'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc07dc5590b447bd74f7b2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.27'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.20'}, {'value_type': 'samples', 'value': '1834544'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '22042'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc08715590b447bd74f7b3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.15'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '43.80'}, {'value_type': 'samples', 'value': '1836923'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21188'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc09055590b447bd74f7b4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.37'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.00'}, {'value_type': 'samples', 'value': '1837580'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21066'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc09ad5590b447bd74f7b5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.25'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.00'}, {'value_type': 'samples', 'value': '1834730'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0a415590b447bd74f7b6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.92'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.10'}, {'value_type': 'samples', 'value': '1848808'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21146'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0ad65590b447bd74f7b7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.30'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.20'}, {'value_type': 'samples', 'value': '1843835'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21173'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0b6b5590b447bd74f7b8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.60'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.30'}, {'value_type': 'samples', 'value': '1844739'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc0bff5590b447bd74f7b9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.02'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1847718'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21180'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0c945590b447bd74f7ba', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.95'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1842804'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21228'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0d285590b447bd74f7bb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.80'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1841737'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc0dbd5590b447bd74f7bc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.98'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.60'}, {'value_type': 'samples', 'value': '1842269'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc0e515590b447bd74f7bd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.53'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1841350'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21559'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc0ee65590b447bd74f7be', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '18.20'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1842496'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-66'}]}, {'_id': '5cfc0f7a5590b447bd74f7bf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '36.03'}, {'value_type': 'SDS_P2', 'value': '1.87'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1810566'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21640'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc100f5590b447bd74f7c0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '10.03'}, {'value_type': 'SDS_P2', 'value': '1.15'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1807001'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21194'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc10a35590b447bd74f7c1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '20.05'}, {'value_type': 'SDS_P2', 'value': '1.25'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '44.70'}, {'value_type': 'samples', 'value': '1843847'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc11385590b447bd74f7c2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '11.78'}, {'value_type': 'SDS_P2', 'value': '1.17'}, {'value_type': 'temperature', 'value': '23.40'}, {'value_type': 'humidity', 'value': '44.80'}, {'value_type': 'samples', 'value': '1854307'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21030'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc11cc5590b447bd74f7c3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '24.87'}, {'value_type': 'SDS_P2', 'value': '1.50'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '44.80'}, {'value_type': 'samples', 'value': '1859112'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc12615590b447bd74f7c4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '13.25'}, {'value_type': 'SDS_P2', 'value': '1.40'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '45.00'}, {'value_type': 'samples', 'value': '1843599'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc12f55590b447bd74f7c5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '8.93'}, {'value_type': 'SDS_P2', 'value': '1.07'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '45.00'}, {'value_type': 'samples', 'value': '1843284'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21104'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc138a5590b447bd74f7c6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.65'}, {'value_type': 'SDS_P2', 'value': '0.98'}, {'value_type': 'temperature', 'value': '23.30'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1844353'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21107'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc141e5590b447bd74f7c7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '12.28'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.20'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1848949'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21219'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc14b35590b447bd74f7c8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '11.08'}, {'value_type': 'SDS_P2', 'value': '1.32'}, {'value_type': 'temperature', 'value': '23.20'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1841491'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21706'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc15475590b447bd74f7c9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '8.63'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.20'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1842234'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21370'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc15dc5590b447bd74f7ca', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '7.33'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'temperature', 'value': '23.20'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1841836'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc16705590b447bd74f7cb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '6.80'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1836951'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc17055590b447bd74f7cc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.58'}, {'value_type': 'SDS_P2', 'value': '1.30'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1844986'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21209'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc17995590b447bd74f7cd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '8.58'}, {'value_type': 'SDS_P2', 'value': '0.98'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.50'}, {'value_type': 'samples', 'value': '1846829'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21053'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc18415590b447bd74f7ce', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.20'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.60'}, {'value_type': 'samples', 'value': '1849855'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21127'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc18d65590b447bd74f7cf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '6.12'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.50'}, {'value_type': 'samples', 'value': '1839719'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21139'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc196a5590b447bd74f7d0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.28'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1824731'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21640'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc19ff5590b447bd74f7d1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.67'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.60'}, {'value_type': 'samples', 'value': '1862004'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21118'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc1a935590b447bd74f7d2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.53'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.50'}, {'value_type': 'samples', 'value': '1842240'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21062'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc1b285590b447bd74f7d3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '8.75'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1831325'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc1bbc5590b447bd74f7d4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.00'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.60'}, {'value_type': 'samples', 'value': '1813996'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21122'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc1c515590b447bd74f7d5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1827388'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21122'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc1ce55590b447bd74f7d6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.70'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1824749'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21574'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc1d7a5590b447bd74f7d7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.98'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'temperature', 'value': '23.10'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1810320'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc1e0e5590b447bd74f7d8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1824045'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21564'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc1ea35590b447bd74f7d9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.87'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.60'}, {'value_type': 'samples', 'value': '1812779'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21208'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc1f375590b447bd74f7da', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.30'}, {'value_type': 'SDS_P2', 'value': '0.78'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1823939'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21740'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc1fcb5590b447bd74f7db', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.53'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1822414'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21042'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc20605590b447bd74f7dc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.60'}, {'value_type': 'SDS_P2', 'value': '1.10'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1827726'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21743'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc20f45590b447bd74f7dd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.87'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1812689'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21643'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc21895590b447bd74f7de', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.12'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '23.00'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1812415'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21192'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc221e5590b447bd74f7df', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1826451'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21533'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc22b25590b447bd74f7e0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.00'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1822396'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21115'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc23475590b447bd74f7e1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.90'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1822906'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21569'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc23db5590b447bd74f7e2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.72'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1822953'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc24705590b447bd74f7e3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.87'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1811461'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc25045590b447bd74f7e4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1830013'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21735'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc25995590b447bd74f7e5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.45'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.30'}, {'value_type': 'samples', 'value': '1824198'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc262d5590b447bd74f7e6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.00'}, {'value_type': 'samples', 'value': '1805869'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc26c25590b447bd74f7e7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.42'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1830031'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc27565590b447bd74f7e8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.92'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1811754'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc27eb5590b447bd74f7e9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '1.05'}, {'value_type': 'temperature', 'value': '22.90'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1824344'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc287f5590b447bd74f7ea', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.72'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1811145'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc29145590b447bd74f7eb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1839806'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21079'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc29a85590b447bd74f7ec', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.25'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1823800'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21064'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2a3d5590b447bd74f7ed', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.22'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.80'}, {'value_type': 'samples', 'value': '1812684'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21592'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2ad15590b447bd74f7ee', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.10'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1823994'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21164'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2b665590b447bd74f7ef', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.12'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1811273'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21075'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2bfa5590b447bd74f7f0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.02'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1823701'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21217'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2c8f5590b447bd74f7f1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1821638'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21180'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc2d235590b447bd74f7f2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1842867'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21067'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc2db85590b447bd74f7f3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.87'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1812114'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21111'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc2e4c5590b447bd74f7f4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.72'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1810892'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21506'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc2ee15590b447bd74f7f5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.92'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1823975'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21625'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc2f755590b447bd74f7f6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.77'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1812596'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21529'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc300b5590b447bd74f7f7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1812708'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21077'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc30a05590b447bd74f7f8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '22.80'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1822879'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc31355590b447bd74f7f9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1812819'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc31c95590b447bd74f7fa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.35'}, {'value_type': 'SDS_P2', 'value': '0.78'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1823692'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21149'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc325e5590b447bd74f7fb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.02'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1812077'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21115'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc32f35590b447bd74f7fc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.40'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1823569'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc33875590b447bd74f7fd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1812703'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21086'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc34235590b447bd74f7fe', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.72'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1839005'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21549'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfc34b75590b447bd74f7ff', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1823726'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21050'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc354c5590b447bd74f800', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1816563'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21137'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc35e05590b447bd74f801', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1812178'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21184'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc36755590b447bd74f802', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1811945'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc37095590b447bd74f803', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1809706'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21074'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc379e5590b447bd74f804', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.25'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1816387'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21098'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc38465590b447bd74f805', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.70'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1806655'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21196'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc38da5590b447bd74f806', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.55'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1868975'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21090'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc396f5590b447bd74f807', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1879534'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21108'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3a045590b447bd74f808', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.10'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1879460'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21180'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3a985590b447bd74f809', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1887957'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3b2d5590b447bd74f80a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1851779'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21100'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3bc15590b447bd74f80b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1858621'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3c565590b447bd74f80c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.22'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1867900'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21122'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3cea5590b447bd74f80d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.75'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1876397'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21060'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3d7f5590b447bd74f80e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.72'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1859784'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc3e135590b447bd74f80f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.47'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1868183'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21568'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc3ea85590b447bd74f810', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1858471'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21067'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc3f3c5590b447bd74f811', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1878167'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21179'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc3fd15590b447bd74f812', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.82'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1875512'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21159'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc40655590b447bd74f813', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1882120'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21175'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc40fa5590b447bd74f814', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1860867'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21022'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc418e5590b447bd74f815', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1869165'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21093'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc42235590b447bd74f816', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1875286'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfc42b75590b447bd74f817', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1864625'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21143'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc434c5590b447bd74f818', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.20'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1872470'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc43e05590b447bd74f819', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1879378'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc44755590b447bd74f81a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1875308'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc450a5590b447bd74f81b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1875347'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21570'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc459f5590b447bd74f81c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.30'}, {'value_type': 'samples', 'value': '1882116'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21765'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc46335590b447bd74f81d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.67'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1877037'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc46c85590b447bd74f81e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.40'}, {'value_type': 'samples', 'value': '1885597'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21061'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc475d5590b447bd74f81f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.47'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.30'}, {'value_type': 'samples', 'value': '1900154'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21149'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc47f15590b447bd74f820', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1884629'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc48865590b447bd74f821', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '10.20'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1881302'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21050'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc491a5590b447bd74f822', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'temperature', 'value': '22.70'}, {'value_type': 'humidity', 'value': '45.30'}, {'value_type': 'samples', 'value': '1888216'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21139'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc49b05590b447bd74f823', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.60'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.60'}, {'value_type': 'humidity', 'value': '45.60'}, {'value_type': 'samples', 'value': '1888691'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21106'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc4a445590b447bd74f824', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '6.72'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.00'}, {'value_type': 'samples', 'value': '1886973'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21167'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc4ad95590b447bd74f825', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.90'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1900243'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc4b6e5590b447bd74f826', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1897799'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21548'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc4c025590b447bd74f827', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.10'}, {'value_type': 'samples', 'value': '1884193'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21052'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc4c975590b447bd74f828', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '9.33'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.30'}, {'value_type': 'samples', 'value': '1888524'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21551'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc4d2b5590b447bd74f829', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.00'}, {'value_type': 'SDS_P2', 'value': '0.68'}, {'value_type': 'temperature', 'value': '22.50'}, {'value_type': 'humidity', 'value': '46.30'}, {'value_type': 'samples', 'value': '1882916'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc4dc05590b447bd74f82a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.98'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.40'}, {'value_type': 'samples', 'value': '1793567'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21203'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc4e545590b447bd74f82b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.37'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.40'}, {'value_type': 'samples', 'value': '1834113'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21216'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc4ee95590b447bd74f82c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.50'}, {'value_type': 'samples', 'value': '1804680'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21115'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc4f7d5590b447bd74f82d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.60'}, {'value_type': 'samples', 'value': '1829948'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21514'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc50125590b447bd74f82e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.67'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.50'}, {'value_type': 'samples', 'value': '1821867'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21215'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc50a65590b447bd74f82f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1839188'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21138'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc513b5590b447bd74f830', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1841090'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21107'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc51cf5590b447bd74f831', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.27'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1837370'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21680'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc52645590b447bd74f832', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.37'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.40'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1844015'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21558'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc52f85590b447bd74f833', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1830384'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21127'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc538e5590b447bd74f834', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.50'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1911862'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21191'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc54235590b447bd74f835', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.45'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.80'}, {'value_type': 'samples', 'value': '1839127'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21174'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc54b75590b447bd74f836', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.25'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.80'}, {'value_type': 'samples', 'value': '1799006'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc554c5590b447bd74f837', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1813100'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21056'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc55e05590b447bd74f838', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.80'}, {'value_type': 'samples', 'value': '1843865'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21582'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc56755590b447bd74f839', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.80'}, {'value_type': 'samples', 'value': '1851990'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21087'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc57095590b447bd74f83a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.83'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1907495'}, {'value_type': 'min_micro', 'value': '73'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc579e5590b447bd74f83b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1892706'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21023'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc58325590b447bd74f83c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1890907'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc58c75590b447bd74f83d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1909107'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21100'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc595c5590b447bd74f83e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1901382'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21541'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc59f05590b447bd74f83f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.30'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1924657'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21503'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc5a855590b447bd74f840', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.17'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1898456'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21103'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc5b195590b447bd74f841', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '46.90'}, {'value_type': 'samples', 'value': '1904238'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21181'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfc5bae5590b447bd74f842', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1897793'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc5c425590b447bd74f843', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1918818'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21039'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc5cd75590b447bd74f844', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1921536'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21066'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc5d6b5590b447bd74f845', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.58'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1893968'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21570'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc5e005590b447bd74f846', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.55'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1923611'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21200'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc5e945590b447bd74f847', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1896128'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21055'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc5f295590b447bd74f848', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.65'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1905951'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc5fbd5590b447bd74f849', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1908047'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc60525590b447bd74f84a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.00'}, {'value_type': 'samples', 'value': '1913487'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21045'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc60e75590b447bd74f84b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.08'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1900583'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21042'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc617b5590b447bd74f84c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1911412'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc620f5590b447bd74f84d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.20'}, {'value_type': 'samples', 'value': '1900836'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21038'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc62a45590b447bd74f84e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1883182'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21600'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc633a5590b447bd74f84f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.32'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1900609'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc63cf5590b447bd74f850', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.80'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.20'}, {'value_type': 'samples', 'value': '1901736'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21101'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc64645590b447bd74f851', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1907460'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc650c5590b447bd74f852', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.20'}, {'value_type': 'samples', 'value': '1915570'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc65a05590b447bd74f853', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.50'}, {'value_type': 'SDS_P2', 'value': '0.65'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1826431'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21487'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc66355590b447bd74f854', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1825020'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21090'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc66c95590b447bd74f855', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.17'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1819392'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc675e5590b447bd74f856', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.67'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1817110'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21169'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc67f25590b447bd74f857', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1828723'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21575'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc68875590b447bd74f858', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.52'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.20'}, {'value_type': 'samples', 'value': '1834420'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21631'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc691b5590b447bd74f859', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.75'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1820734'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21203'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc69af5590b447bd74f85a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.12'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1817367'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6a445590b447bd74f85b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1830272'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6ad95590b447bd74f85c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1838280'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21120'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6b6d5590b447bd74f85d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1822109'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21202'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6c025590b447bd74f85e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1818628'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21046'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc6c965590b447bd74f85f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1813216'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21065'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6d2b5590b447bd74f860', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.52'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1804999'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6dbf5590b447bd74f861', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1811257'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21579'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc6e545590b447bd74f862', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1804611'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc6ee85590b447bd74f863', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1824169'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21046'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc6f7d5590b447bd74f864', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.07'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '48.00'}, {'value_type': 'samples', 'value': '1821717'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21249'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc70115590b447bd74f865', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1769019'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21194'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc70a65590b447bd74f866', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1768681'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21529'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc713a5590b447bd74f867', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1770131'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21046'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc71cf5590b447bd74f868', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1773121'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21116'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc72635590b447bd74f869', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1751524'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc73075590b447bd74f86a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1755157'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21082'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc739b5590b447bd74f86b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1810785'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21142'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc74305590b447bd74f86c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.33'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1779659'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21525'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc74c45590b447bd74f86d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1797184'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21149'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc75585590b447bd74f86e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1763518'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21601'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc76915590b447bd74f86f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.20'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1878037'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21622'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc77255590b447bd74f870', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1860717'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc77ba5590b447bd74f871', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.57'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1890861'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21046'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc78505590b447bd74f872', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '48.00'}, {'value_type': 'samples', 'value': '1851874'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21174'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc78e45590b447bd74f873', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1896935'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '22043'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc79795590b447bd74f874', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1877912'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21113'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc7a0d5590b447bd74f875', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1911678'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc7aa25590b447bd74f876', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1882230'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc7b365590b447bd74f877', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1855953'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21059'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7bcb5590b447bd74f878', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1887756'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21101'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc7c5f5590b447bd74f879', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1874509'}, {'value_type': 'min_micro', 'value': '75'}, {'value_type': 'max_micro', 'value': '21102'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc7d075590b447bd74f87a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1874060'}, {'value_type': 'min_micro', 'value': '74'}, {'value_type': 'max_micro', 'value': '21015'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7d9c5590b447bd74f87b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.05'}, {'value_type': 'SDS_P2', 'value': '0.42'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1811239'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21620'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7e305590b447bd74f87c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1811374'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21075'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7ec45590b447bd74f87d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.72'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1811224'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7f5b5590b447bd74f87e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1809329'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21103'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc7ff05590b447bd74f87f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1822917'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21040'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc80855590b447bd74f880', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.60'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1820644'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '20195'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc81195590b447bd74f881', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.02'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1777185'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21596'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc81ad5590b447bd74f882', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1752154'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc82425590b447bd74f883', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1817960'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21142'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc82d65590b447bd74f884', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.47'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1818270'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '22351'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc836b5590b447bd74f885', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1821588'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21627'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc83ff5590b447bd74f886', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.98'}, {'value_type': 'SDS_P2', 'value': '0.57'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1822518'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21148'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc84945590b447bd74f887', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1821676'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21600'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc85285590b447bd74f888', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1817056'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc85bd5590b447bd74f889', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.30'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1816871'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21134'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc86515590b447bd74f88a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1817282'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21249'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc86e65590b447bd74f88b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1817801'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21153'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc877a5590b447bd74f88c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1776997'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc880f5590b447bd74f88d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1823069'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc88a35590b447bd74f88e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1815726'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21145'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc89385590b447bd74f88f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.10'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.00'}, {'value_type': 'samples', 'value': '1813609'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21085'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc89cc5590b447bd74f890', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.65'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1815301'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21193'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8a615590b447bd74f891', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1821809'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21142'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8af55590b447bd74f892', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1821469'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21578'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8b8a5590b447bd74f893', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.85'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1763144'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21114'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8c1e5590b447bd74f894', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1706648'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21185'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8cb35590b447bd74f895', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1742135'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21201'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc8d475590b447bd74f896', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1745517'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21158'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc8ddc5590b447bd74f897', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1722587'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21137'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8e705590b447bd74f898', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.40'}, {'value_type': 'samples', 'value': '1734832'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21080'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc8f055590b447bd74f899', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.20'}, {'value_type': 'samples', 'value': '1719905'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21626'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc8f995590b447bd74f89a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.47'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.30'}, {'value_type': 'samples', 'value': '1735473'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21151'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc902e5590b447bd74f89b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.00'}, {'value_type': 'samples', 'value': '1740368'}, {'value_type': 'min_micro', 'value': '82'}, {'value_type': 'max_micro', 'value': '21158'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc90c25590b447bd74f89c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.20'}, {'value_type': 'samples', 'value': '1769093'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21200'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc91575590b447bd74f89d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.55'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.10'}, {'value_type': 'samples', 'value': '1777508'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21189'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc91eb5590b447bd74f89e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.65'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.20'}, {'value_type': 'samples', 'value': '1770269'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21212'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc92805590b447bd74f89f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1771771'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21565'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc93145590b447bd74f8a0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.70'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.70'}, {'value_type': 'samples', 'value': '1777133'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21196'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc93a95590b447bd74f8a1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.70'}, {'value_type': 'samples', 'value': '1775827'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21099'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc943d5590b447bd74f8a2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.22'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.70'}, {'value_type': 'samples', 'value': '1776249'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21070'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc94d25590b447bd74f8a3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.30'}, {'value_type': 'SDS_P2', 'value': '0.20'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1775798'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '22298'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc95665590b447bd74f8a4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.53'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1775771'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc95fb5590b447bd74f8a5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '49.00'}, {'value_type': 'samples', 'value': '1767232'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc968f5590b447bd74f8a6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1770219'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21191'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc97245590b447bd74f8a7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1771101'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21680'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc97b85590b447bd74f8a8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1771350'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21655'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc984d5590b447bd74f8a9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1773774'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21195'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc98e15590b447bd74f8aa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.33'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1772744'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc99765590b447bd74f8ab', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.55'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.40'}, {'value_type': 'samples', 'value': '1739602'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21158'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9a0a5590b447bd74f8ac', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.70'}, {'value_type': 'samples', 'value': '1751227'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21774'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9a9f5590b447bd74f8ad', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.40'}, {'value_type': 'samples', 'value': '1750170'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21228'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9b335590b447bd74f8ae', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.50'}, {'value_type': 'samples', 'value': '1808471'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21121'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9bc85590b447bd74f8af', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '48.30'}, {'value_type': 'samples', 'value': '1810954'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21047'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc9c5c5590b447bd74f8b0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.57'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1804893'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21094'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc9cf15590b447bd74f8b1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.25'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1803841'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21106'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc9d865590b447bd74f8b2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.60'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1799407'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21117'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9e1a5590b447bd74f8b3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.00'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1798274'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21192'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9eaf5590b447bd74f8b4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1798796'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21694'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfc9f435590b447bd74f8b5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.50'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1799230'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21145'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfc9fd85590b447bd74f8b6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.15'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1747190'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca06e5590b447bd74f8b7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.05'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1813425'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21062'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca1025590b447bd74f8b8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.47'}, {'value_type': 'SDS_P2', 'value': '0.20'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '48.00'}, {'value_type': 'samples', 'value': '1808892'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21141'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca1975590b447bd74f8b9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '48.40'}, {'value_type': 'samples', 'value': '1818919'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21223'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca22b5590b447bd74f8ba', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.80'}, {'value_type': 'SDS_P2', 'value': '0.33'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '48.10'}, {'value_type': 'samples', 'value': '1802406'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca2c15590b447bd74f8bb', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.45'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1805134'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '22525'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca3555590b447bd74f8bc', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.68'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1790105'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21073'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca3eb5590b447bd74f8bd', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1772591'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21564'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca47f5590b447bd74f8be', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.68'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1811618'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21616'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca5165590b447bd74f8bf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.90'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1802361'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21051'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca5aa5590b447bd74f8c0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1803908'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21509'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfca63f5590b447bd74f8c1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.53'}, {'value_type': 'SDS_P2', 'value': '0.20'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1806198'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21702'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca6d35590b447bd74f8c2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.62'}, {'value_type': 'SDS_P2', 'value': '0.23'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1807506'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca7685590b447bd74f8c3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1813979'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21510'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca7fc5590b447bd74f8c4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.72'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1805418'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21084'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca8915590b447bd74f8c5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1807711'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21509'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfca9259baf0a59f1b72b62', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.47'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1796540'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21169'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfca9ba9baf0a59f1b72b63', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.57'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1814837'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21068'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcaa4e9baf0a59f1b72b64', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.68'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1811503'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21178'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfcaae39baf0a59f1b72b65', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.70'}, {'value_type': 'SDS_P2', 'value': '0.35'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1810099'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21128'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfcab779baf0a59f1b72b66', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.88'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1803436'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21199'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfcac0c9baf0a59f1b72b67', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.78'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1807570'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21071'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfcaca09baf0a59f1b72b68', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.62'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1810892'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfcad359baf0a59f1b72b69', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.20'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1804973'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcadc99baf0a59f1b72b6a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.92'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '48.10'}, {'value_type': 'samples', 'value': '1806170'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21180'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcae5e9baf0a59f1b72b6b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.37'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1811407'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21044'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcaef29baf0a59f1b72b6c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.87'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1811126'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21062'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcaf879baf0a59f1b72b6d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.42'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '47.70'}, {'value_type': 'samples', 'value': '1809973'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21707'}, {'value_type': 'signal', 'value': '-67'}]}, {'_id': '5cfcb01b9baf0a59f1b72b6e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.00'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1811656'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21129'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfcb0b09baf0a59f1b72b6f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.80'}, {'value_type': 'SDS_P2', 'value': '0.37'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '48.20'}, {'value_type': 'samples', 'value': '1811455'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21161'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfcb1449baf0a59f1b72b70', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.52'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '48.10'}, {'value_type': 'samples', 'value': '1811579'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21114'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb1d99baf0a59f1b72b71', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.82'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1811423'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21084'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb26d9baf0a59f1b72b72', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.93'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1811559'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21183'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb3029baf0a59f1b72b73', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.22'}, {'value_type': 'SDS_P2', 'value': '0.30'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.60'}, {'value_type': 'samples', 'value': '1811623'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfcb3969baf0a59f1b72b74', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '14.70'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1811653'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21256'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb42b9baf0a59f1b72b75', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.33'}, {'value_type': 'SDS_P2', 'value': '0.45'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1808692'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21628'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcb4c69baf0a59f1b72b76', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '10.95'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1780709'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21205'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb55b9baf0a59f1b72b77', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '11.80'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.90'}, {'value_type': 'samples', 'value': '1767917'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '22162'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcb5f09baf0a59f1b72b78', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.47'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.80'}, {'value_type': 'samples', 'value': '1768432'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21178'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcb6849baf0a59f1b72b79', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.33'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1788653'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21107'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb7199baf0a59f1b72b7a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.12'}, {'value_type': 'SDS_P2', 'value': '0.50'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1797893'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21126'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb7ae9baf0a59f1b72b7b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.67'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.30'}, {'value_type': 'samples', 'value': '1792738'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21075'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcb8429baf0a59f1b72b7c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.37'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1777309'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21507'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcb8d79baf0a59f1b72b7d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.35'}, {'value_type': 'SDS_P2', 'value': '0.53'}, {'value_type': 'temperature', 'value': '22.20'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1792772'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21106'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcb96b9baf0a59f1b72b7e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.08'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1792523'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21095'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcba069baf0a59f1b72b7f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.72'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1793244'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21201'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcba9b9baf0a59f1b72b80', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '0.95'}, {'value_type': 'SDS_P2', 'value': '0.40'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.50'}, {'value_type': 'samples', 'value': '1792499'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21127'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcbb2f9baf0a59f1b72b81', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.40'}, {'value_type': 'SDS_P2', 'value': '0.62'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1816885'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbbc49baf0a59f1b72b82', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.20'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '47.40'}, {'value_type': 'samples', 'value': '1832323'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21097'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbc589baf0a59f1b72b83', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.62'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.10'}, {'value_type': 'humidity', 'value': '46.70'}, {'value_type': 'samples', 'value': '1795946'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21076'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcbced9baf0a59f1b72b84', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.75'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '46.80'}, {'value_type': 'samples', 'value': '1832052'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21364'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbd829baf0a59f1b72b85', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.27'}, {'value_type': 'SDS_P2', 'value': '0.60'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '47.10'}, {'value_type': 'samples', 'value': '1822177'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21529'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbe179baf0a59f1b72b86', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.72'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '22.00'}, {'value_type': 'humidity', 'value': '46.40'}, {'value_type': 'samples', 'value': '1825514'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21608'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbeab9baf0a59f1b72b87', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.25'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.90'}, {'value_type': 'samples', 'value': '1832276'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21069'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbf409baf0a59f1b72b88', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.67'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1829938'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21156'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcbfd49baf0a59f1b72b89', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.85'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '46.20'}, {'value_type': 'samples', 'value': '1829249'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21054'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc0699baf0a59f1b72b8a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.97'}, {'value_type': 'SDS_P2', 'value': '1.07'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1830931'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21160'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc0fe9baf0a59f1b72b8b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.62'}, {'value_type': 'SDS_P2', 'value': '1.02'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '44.30'}, {'value_type': 'samples', 'value': '1829816'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21405'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc1929baf0a59f1b72b8c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.12'}, {'value_type': 'SDS_P2', 'value': '1.05'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '44.20'}, {'value_type': 'samples', 'value': '1829930'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc2279baf0a59f1b72b8d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '5.08'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1821519'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21124'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc2bb9baf0a59f1b72b8e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.10'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '43.80'}, {'value_type': 'samples', 'value': '1829814'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21711'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc3509baf0a59f1b72b8f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.22'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '44.00'}, {'value_type': 'samples', 'value': '1794582'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21130'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc3e49baf0a59f1b72b90', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.35'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '44.20'}, {'value_type': 'samples', 'value': '1827202'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '22082'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc4799baf0a59f1b72b91', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.90'}, {'value_type': 'SDS_P2', 'value': '1.07'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '44.30'}, {'value_type': 'samples', 'value': '1830947'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21136'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcc5109baf0a59f1b72b92', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.83'}, {'value_type': 'SDS_P2', 'value': '1.30'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '44.00'}, {'value_type': 'samples', 'value': '1831010'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21079'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc5a89baf0a59f1b72b93', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.50'}, {'value_type': 'SDS_P2', 'value': '1.05'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '44.60'}, {'value_type': 'samples', 'value': '1822462'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21132'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfcc63d9baf0a59f1b72b94', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'temperature', 'value': '21.50'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1831296'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21109'}, {'value_type': 'signal', 'value': '-68'}]}, {'_id': '5cfcc6d19baf0a59f1b72b95', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.70'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '45.40'}, {'value_type': 'samples', 'value': '1830933'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21119'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcc7669baf0a59f1b72b96', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.27'}, {'value_type': 'SDS_P2', 'value': '0.85'}, {'value_type': 'temperature', 'value': '21.60'}, {'value_type': 'humidity', 'value': '44.90'}, {'value_type': 'samples', 'value': '1831257'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21073'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcc7fa9baf0a59f1b72b97', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.00'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '44.70'}, {'value_type': 'samples', 'value': '1830597'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21944'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcc88f9baf0a59f1b72b98', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.35'}, {'value_type': 'SDS_P2', 'value': '1.12'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1831024'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21092'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcc9239baf0a59f1b72b99', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.58'}, {'value_type': 'SDS_P2', 'value': '0.95'}, {'value_type': 'temperature', 'value': '21.70'}, {'value_type': 'humidity', 'value': '44.60'}, {'value_type': 'samples', 'value': '1794809'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21083'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcc9ba9baf0a59f1b72b9a', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.67'}, {'value_type': 'SDS_P2', 'value': '1.02'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1831001'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21066'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfcca4f9baf0a59f1b72b9b', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.37'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '44.40'}, {'value_type': 'samples', 'value': '1831557'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21085'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfccae39baf0a59f1b72b9c', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1831464'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21085'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfccb789baf0a59f1b72b9d', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.35'}, {'value_type': 'SDS_P2', 'value': '1.02'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1830995'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21143'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfccc0c9baf0a59f1b72b9e', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.90'}, {'value_type': 'SDS_P2', 'value': '1.07'}, {'value_type': 'temperature', 'value': '21.80'}, {'value_type': 'humidity', 'value': '44.50'}, {'value_type': 'samples', 'value': '1831433'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21089'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfccca19baf0a59f1b72b9f', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '0.82'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '44.60'}, {'value_type': 'samples', 'value': '1831422'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21984'}, {'value_type': 'signal', 'value': '-69'}]}, {'_id': '5cfccd359baf0a59f1b72ba0', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.37'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '44.70'}, {'value_type': 'samples', 'value': '1831381'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21139'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfccdca9baf0a59f1b72ba1', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.17'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '44.80'}, {'value_type': 'samples', 'value': '1826519'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcce5e9baf0a59f1b72ba2', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.65'}, {'value_type': 'SDS_P2', 'value': '0.98'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '44.90'}, {'value_type': 'samples', 'value': '1830840'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21078'}, {'value_type': 'signal', 'value': '-70'}]}, {'_id': '5cfccef39baf0a59f1b72ba3', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.77'}, {'value_type': 'SDS_P2', 'value': '0.90'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '44.90'}, {'value_type': 'samples', 'value': '1831349'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21050'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfccf879baf0a59f1b72ba4', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '4.03'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.00'}, {'value_type': 'samples', 'value': '1831420'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21513'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcd01c9baf0a59f1b72ba5', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.67'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.00'}, {'value_type': 'samples', 'value': '1795000'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21110'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd0b09baf0a59f1b72ba6', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.58'}, {'value_type': 'SDS_P2', 'value': '1.20'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1794849'}, {'value_type': 'min_micro', 'value': '78'}, {'value_type': 'max_micro', 'value': '21657'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd1459baf0a59f1b72ba7', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.77'}, {'value_type': 'SDS_P2', 'value': '1.00'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.70'}, {'value_type': 'samples', 'value': '1830333'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21140'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd1d99baf0a59f1b72ba8', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '3.12'}, {'value_type': 'SDS_P2', 'value': '0.70'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1793846'}, {'value_type': 'min_micro', 'value': '80'}, {'value_type': 'max_micro', 'value': '21637'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd26e9baf0a59f1b72ba9', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.75'}, {'value_type': 'SDS_P2', 'value': '0.93'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1830308'}, {'value_type': 'min_micro', 'value': '77'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd3039baf0a59f1b72baa', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.08'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1779786'}, {'value_type': 'min_micro', 'value': '79'}, {'value_type': 'max_micro', 'value': '21637'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd3ab9baf0a59f1b72bab', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.47'}, {'value_type': 'SDS_P2', 'value': '0.88'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.10'}, {'value_type': 'samples', 'value': '1742910'}, {'value_type': 'min_micro', 'value': '81'}, {'value_type': 'max_micro', 'value': '21157'}, {'value_type': 'signal', 'value': '-71'}]}, {'_id': '5cfcd43f9baf0a59f1b72bac', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.72'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1869848'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21105'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd4d49baf0a59f1b72bad', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '1.95'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1860640'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21125'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd5689baf0a59f1b72bae', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.15'}, {'value_type': 'SDS_P2', 'value': '0.80'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.20'}, {'value_type': 'samples', 'value': '1867108'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21133'}, {'value_type': 'signal', 'value': '-72'}]}, {'_id': '5cfcd5fd9baf0a59f1b72baf', 'esp8266id': '3652817', 'software_version': 'NRZ-2018-123B', 'sensordatavalues': [{'value_type': 'SDS_P1', 'value': '2.08'}, {'value_type': 'SDS_P2', 'value': '0.72'}, {'value_type': 'temperature', 'value': '21.90'}, {'value_type': 'humidity', 'value': '45.30'}, {'value_type': 'samples', 'value': '1867256'}, {'value_type': 'min_micro', 'value': '76'}, {'value_type': 'max_micro', 'value': '21549'}, {'value_type': 'signal', 'value': '-72'}]}]\n"
]
],
[
[
"read from json data to be read into pd.DataFrame",
"_____no_output_____"
]
],
[
[
"columns = ['hex_int','date_time','P1','P2']\ndf_P = pd.DataFrame()\n\n\nfor values in data:\n chip_id = values.get('esp8266id')\n sensor_vals = values.get('sensordatavalues')\n P1 = sensor_vals[0]['value']\n P2 = sensor_vals[1]['value']\n test_id = values.get('_id')\n sub_test_id = test_id[0:8]\n hex_int = int(sub_test_id, 16) \n \n date_time = datetime.datetime.utcfromtimestamp((hex_int))# * 1000)\n #date_time = datetime.((testid.substring(0, 8), 16) * 1000)\n \n #print('test_id',test_id,'sub_test_id',sub_test_id,'hex_int',hex_int,'date_time',date_time)\n row = pd.Series([hex_int,date_time,P1, P2]) #'chip_id' has been removed \n df_row = pd.DataFrame(row).transpose() \n #print(df_row)\n df_P = pd.concat([df_P,df_row],axis=0)\n \n \ndf_P = pd.DataFrame(data= df_P.values, columns = columns ) \ndf_P = df_P.sort_values(by=['hex_int'],ascending=False, inplace=False)\ndf_P['P1'] = df_P['P1'].astype('float64')\ndf_P['P2'] = df_P['P2'].astype('float64')\ndf_P['hex_int'] = df_P['hex_int'].astype('int64')\n#print(df_P)\n ",
"_____no_output_____"
]
],
[
[
"Get columns of interest # Not applicable delete cell, job done in previous cell",
"_____no_output_____"
]
],
[
[
"#redundant cell",
"_____no_output_____"
]
],
[
[
"Resample Data to current data point and means for hour, week, month, year # work only done for current and Daily",
"_____no_output_____"
]
],
[
[
"print('Current values for the sensor')\ncurrent_row = df_P.iloc[0,:]\ncurrent_P1 = df_P['P1'][0]\ncurrent_P2 = df_P['P2'][0]\nprint('current_row',current_row)\n#This is the latest value\nP1= df_P['P1'].values\nP2= df_P['P2'].values\n\nP1 = pd.DataFrame(data=P1,index=df_P['date_time'])\nP2 = pd.DataFrame(data=P2,index=df_P['date_time'])\n\ndaily_P1 = P1.resample('D').mean()\ndaily_P2 = P2.resample('D').mean()\ndaily_P1 = daily_P1.sort_values(by=['date_time'],ascending=False, inplace=False)\ndaily_P2 = daily_P2.sort_values(by=['date_time'],ascending=False, inplace=False)\nprint(daily_P1)\n\nprint(daily_P2)\n\ntodays_P1 = daily_P1.iloc[0,:]\ntodays_P2 = daily_P2.iloc[0,:]\nprint(todays_P1)\nprint(todays_P2)",
"Current values for the sensor\ncurrent_row hex_int 1560073725\ndate_time 2019-06-09 09:48:45\nP1 2.08\nP2 0.72\nName: 844, dtype: object\n 0\ndate_time \n2019-06-09 1.933502\n2019-06-08 2.241207\n2019-06-07 62735.290000\n 0\ndate_time \n2019-06-09 0.722405\n2019-06-08 0.654121\n2019-06-07 3.521071\n0 1.933502\nName: 2019-06-09 00:00:00, dtype: float64\n0 0.722405\nName: 2019-06-09 00:00:00, dtype: float64\n"
]
],
[
[
"Output values from here to dashboard",
"_____no_output_____"
]
],
[
[
"output = {}\noutput.update({'sensor_id':chip_id})\noutput.update({'current_PM10':current_P1})\noutput.update({'current_PM2.5': current_P2})\noutput.update({'daily_PM10':todays_P1[0]})\noutput.update({'daily_PM2.5':todays_P2[0]})\nprint(output)",
"{'sensor_id': '3652817', 'current_PM10': 3.12, 'current_PM2.5': 0.6, 'daily_PM10': 1.9335021097046416, 'daily_PM2.5': 0.7224050632911396}\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a27ba30331f70c0656ccad22b036cdbce4c4d4a
| 88,160 |
ipynb
|
Jupyter Notebook
|
Notebooks/ARIMA_Ukdale.ipynb
|
Home-Electricity-Manager/Power-Forecasting
|
2d8de3019fa4f3e17dd3d233ad07edac5b76b5b5
|
[
"MIT"
] | 1 |
2021-06-10T12:21:27.000Z
|
2021-06-10T12:21:27.000Z
|
Notebooks/ARIMA_Ukdale.ipynb
|
Home-Electricity-Manager/Power-Forecasting
|
2d8de3019fa4f3e17dd3d233ad07edac5b76b5b5
|
[
"MIT"
] | null | null | null |
Notebooks/ARIMA_Ukdale.ipynb
|
Home-Electricity-Manager/Power-Forecasting
|
2d8de3019fa4f3e17dd3d233ad07edac5b76b5b5
|
[
"MIT"
] | null | null | null | 125.584046 | 14,554 | 0.817865 |
[
[
[
"<a href=\"https://colab.research.google.com/github/RachitBansal/AppliancePower_TimeSeries/blob/master/ARIMA_Ukdale.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive',force_remount=True)",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/drive\n"
],
[
"from sklearn.externals import joblib\nimport numpy as np\nimport matplotlib.pyplot as plt",
"/usr/local/lib/python3.6/dist-packages/sklearn/externals/joblib/__init__.py:15: DeprecationWarning: sklearn.externals.joblib is deprecated in 0.21 and will be removed in 0.23. Please import this functionality directly from joblib, which can be installed with: pip install joblib. If this warning is raised when loading pickled models, you may need to re-serialize those models with scikit-learn 0.21+.\n warnings.warn(msg, category=DeprecationWarning)\n"
],
[
"eq = input(\"Enter equipment: \")\n\ntrain_x = np.load(file='./drive/My Drive/ukdale_'+eq+'_x.npy')\ntrain_y = np.load(file='./drive/My Drive/ukdale_'+eq+'_y.npy')\ntest_y = np.load(file='./drive/My Drive/ukdale_'+eq+'_ty.npy')\ntest_x = np.load(file='./drive/My Drive/ukdale_'+eq+'_tx.npy')",
"Enter equipment: 5\n"
],
[
"from pandas import datetime\nimport pandas as pd\n\n# series = joblib.load(\"hour_resampled_data.pkl\")\n# sample = series\n# sample = np.array(sample)\n# sample = sample[3000:4500,1:2]\n\n# series = np.array(series)\n# series = series[:3000,1:2]\n# print(series.shape)\n# series = pd.DataFrame(series)\n# #series.drop(axis = \"index\")\n# print(series.head())\n# equipment = int(input('equipment: '))\nseries = test_x[:3000, 0]\n\nplt.plot(series)\nplt.show()",
"_____no_output_____"
],
[
"from pandas import read_csv\nfrom pandas import datetime\nfrom matplotlib import pyplot\nfrom pandas.plotting import autocorrelation_plot\n\n# series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)\nautocorrelation_plot(series)\npyplot.show()",
"_____no_output_____"
],
[
"from pandas import datetime\nfrom pandas import DataFrame\nfrom statsmodels.tsa.arima_model import ARIMA\nfrom matplotlib import pyplot\nimport numpy as np \ndef parser(x):\n return datetime.strptime('190'+x, '%Y-%m')\n \n# series = read_csv('shampoo-sales.csv', header=0, parse_dates=[0], index_col=0, squeeze=True, date_parser=parser)\n# fit model\nseries = np.array(series)\nmodel = ARIMA(series, order=(5,1,0))\nmodel_fit = model.fit(disp=0)\nprint(model_fit.summary())\n# plot residual errors\nresiduals = DataFrame(model_fit.resid)\nresiduals.plot()\npyplot.show()\nresiduals.plot(kind='kde')\npyplot.show()\nprint(residuals.describe())",
" ARIMA Model Results \n==============================================================================\nDep. Variable: D.y No. Observations: 2999\nModel: ARIMA(5, 1, 0) Log Likelihood -11481.833\nMethod: css-mle S.D. of innovations 11.129\nDate: Tue, 24 Dec 2019 AIC 22977.666\nTime: 09:37:15 BIC 23019.708\nSample: 1 HQIC 22992.789\n \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nconst -6.939e-18 0.120 -5.8e-17 1.000 -0.234 0.234\nar.L1.D.y 0.0112 0.018 0.619 0.536 -0.024 0.047\nar.L2.D.y -0.3419 0.018 -18.952 0.000 -0.377 -0.307\nar.L3.D.y -0.1614 0.019 -8.558 0.000 -0.198 -0.124\nar.L4.D.y -0.0743 0.018 -4.123 0.000 -0.110 -0.039\nar.L5.D.y -0.1341 0.018 -7.415 0.000 -0.169 -0.099\n Roots \n=============================================================================\n Real Imaginary Modulus Frequency\n-----------------------------------------------------------------------------\nAR.1 0.8802 -1.0994j 1.4084 -0.1425\nAR.2 0.8802 +1.0994j 1.4084 0.1425\nAR.3 -1.6840 -0.0000j 1.6840 -0.5000\nAR.4 -0.3155 -1.4607j 1.4944 -0.2839\nAR.5 -0.3155 +1.4607j 1.4944 0.2839\n-----------------------------------------------------------------------------\n"
],
[
"from pandas import datetime\nfrom matplotlib import pyplot\nfrom statsmodels.tsa.arima_model import ARIMA\nfrom sklearn.metrics import mean_squared_error,mean_absolute_error",
"_____no_output_____"
],
[
"# equipment = 3",
"_____no_output_____"
],
[
"len(list(train_x[0].reshape(-1)))",
"_____no_output_____"
],
[
"history = list(train_x[0].reshape(-1))\n\nfor i in range(train_x.shape[0] - 1):\n history.append(train_x[i+1][-1])",
"_____no_output_____"
],
[
"plt.plot(history)",
"_____no_output_____"
],
[
"history = list(train_x[0].reshape(-1))\n\nfor i in range(1000):\n history.append(train_x[-1000+i][-1])\n\n# history.append(x for x in test_x[0].reshape(-1))",
"_____no_output_____"
],
[
"model = ARIMA(history, order=(5,1,0))\nmodel_fit = model.fit(disp=0)",
"_____no_output_____"
],
[
"history = list(test_x[0].reshape(-1))",
"_____no_output_____"
],
[
"predictions = []\n# history = [x for x in test_x[i].reshape(-1) for i in range(1000)]\nfor t in range(1000): \n model = ARIMA(history, order=(5,1,0))\n model_fit = model.fit(disp=0)\n output = model_fit.forecast()\n yhat = output[0]\n predictions.append(yhat)\n obs = test_y[t][0][0]\n history.append(obs)\n if(t%50==0):\n print('predicted=%f, expected=%f' % (yhat, obs))\n\npredictions = np.array(predictions)\nprint(predictions.shape)\nprint(test_y.shape)\nerror = mean_squared_error(test_y[:1000].reshape(-1), predictions)\nprint('Test MSE: %.3f' % error)\nprint(\"RMSE : %.3f\"%(np.sqrt(error)))\nprint(\"MAE : %.3f\"%(mean_absolute_error(test_y[:1000].reshape(-1),predictions)))\n\n# plot\npyplot.plot(test_y[:1000].reshape(-1))\npyplot.plot(predictions)",
"predicted=0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=0.000001, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=-0.000001, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\npredicted=0.000001, expected=0.000000\npredicted=18.375338, expected=27.026667\npredicted=-0.000000, expected=0.000000\npredicted=-0.000000, expected=0.000000\n(1000, 1)\n(187509, 1, 1)\nTest MSE: 230.788\nRMSE : 15.192\nMAE : 2.277\n"
],
[
"np.save(arr = np.array(predictions), file = './drive/My Drive/arima_ukdale_preds_1000_eq'+eq+'.npy')",
"_____no_output_____"
],
[
"import time\nt1 = time.time()\ntimes = []\nfor t in range(50): \n model = ARIMA(history[t], order=(5,1,0))\n model_fit = model.fit(disp=0)\n t1 = time.time()\n output = model_fit.forecast()\n t2 = time.time()\n times.append(t2-t1)\nprint(times)\nprint(sum(times))",
"[0.002229452133178711, 0.002145528793334961, 0.0022776126861572266, 0.0021119117736816406, 0.0020639896392822266, 0.0021719932556152344, 0.002135753631591797, 0.0022683143615722656, 0.0020749568939208984, 0.002238035202026367, 0.0021359920501708984, 0.002263784408569336, 0.0021483898162841797, 0.002351522445678711, 0.0020711421966552734, 0.0020694732666015625, 0.0021843910217285156, 0.0021543502807617188, 0.0020427703857421875, 0.0022361278533935547, 0.0021584033966064453, 0.002172708511352539, 0.0022726058959960938, 0.0019328594207763672, 0.0020842552185058594, 0.0019707679748535156, 0.0021820068359375, 0.0022058486938476562, 0.002017974853515625, 0.0020842552185058594, 0.0018773078918457031, 0.002106904983520508, 0.0020961761474609375, 0.0020842552185058594, 0.0021736621856689453, 0.001996278762817383, 0.0021402835845947266, 0.0023005008697509766, 0.002201080322265625, 0.002312183380126953, 0.0021886825561523438, 0.002158641815185547, 0.002132892608642578, 0.0021398067474365234, 0.002120494842529297, 0.002129793167114258, 0.002066373825073242, 0.0020627975463867188, 0.0019452571868896484, 0.002025127410888672]\n0.10671567916870117\n"
],
[
"def mean_abs_pct_error(actual_values, forecast_values):\n\n err=0\n actual_values = pd.DataFrame(actual_values)\n forecast_values = pd.DataFrame(forecast_values)\n for i in range(len(forecast_values)):\n\n err += np.abs(actual_values.values[i] - forecast_values.values[i])/actual_values.values[i]\n\n return err[0] * 100/len(forecast_values) \n\nmean_abs_pct_error(test,predictions)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a27bb463186e2fb7a08e0e71175caf2d2657acb
| 27,909 |
ipynb
|
Jupyter Notebook
|
Spring2021_DeCal_Material/Untitled.ipynb
|
emilyma53/Python_DeCal
|
1b98351ecd16f93a5357c9e00af18dde82c813b1
|
[
"MIT"
] | 2 |
2020-10-24T04:46:05.000Z
|
2020-10-24T04:48:50.000Z
|
Spring2021_DeCal_Material/Untitled.ipynb
|
emilyma53/Python_DeCal
|
1b98351ecd16f93a5357c9e00af18dde82c813b1
|
[
"MIT"
] | null | null | null |
Spring2021_DeCal_Material/Untitled.ipynb
|
emilyma53/Python_DeCal
|
1b98351ecd16f93a5357c9e00af18dde82c813b1
|
[
"MIT"
] | 1 |
2021-09-30T23:10:25.000Z
|
2021-09-30T23:10:25.000Z
| 357.807692 | 26,452 | 0.944104 |
[
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"x = np.linspace(-10,10,100)\ny = x**3\n\nplt.figure(figsize=(12,8))\nplt.title(\"stupid cubic\")\nplt.xlabel(\"x-axis\")\nplt.plot(x,y,color='red', alpha=0.5)\nplt.scatter(x,y,marker='.')\nplt.show()\n\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a27c7fa0cb25f3c74ba5e2e24880a9c0989e653
| 12,234 |
ipynb
|
Jupyter Notebook
|
Workspace/veronica_ohe_all_cols.ipynb
|
vleong1/modeling_earthquake_damage
|
a76ffaacde8232c36854c45341104c6ef8fb17a5
|
[
"CC0-1.0"
] | null | null | null |
Workspace/veronica_ohe_all_cols.ipynb
|
vleong1/modeling_earthquake_damage
|
a76ffaacde8232c36854c45341104c6ef8fb17a5
|
[
"CC0-1.0"
] | null | null | null |
Workspace/veronica_ohe_all_cols.ipynb
|
vleong1/modeling_earthquake_damage
|
a76ffaacde8232c36854c45341104c6ef8fb17a5
|
[
"CC0-1.0"
] | 1 |
2021-06-02T15:53:56.000Z
|
2021-06-02T15:53:56.000Z
| 27.369128 | 181 | 0.503024 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nfrom sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV\nfrom sklearn.preprocessing import StandardScaler, LabelEncoder, OrdinalEncoder\nfrom sklearn.pipeline import make_pipeline\nfrom category_encoders import OneHotEncoder\nfrom sklearn.metrics import f1_score, precision_score, recall_score\n\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.experimental import enable_hist_gradient_boosting\nfrom sklearn.ensemble import AdaBoostClassifier, GradientBoostingClassifier, HistGradientBoostingClassifier, RandomForestClassifier, BaggingClassifier, ExtraTreesClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.feature_selection import RFE\n\nimport warnings\nwarnings.simplefilter(action='ignore', category=FutureWarning)",
"_____no_output_____"
],
[
"# read in data\n\ntrain_values = pd.read_csv('data/Proj5_train_values.csv')\ntrain_labels = pd.read_csv('data/Proj5_train_labels.csv')",
"_____no_output_____"
]
],
[
[
"## Modeling with 10% of data\n- For faster processing",
"_____no_output_____"
]
],
[
[
"# grab first 10% of rows\n\ntrain_values_10pct = train_values.head(int(len(train_values) * 0.1))\ntrain_labels_10pct = train_labels.head(int(len(train_labels) * 0.1))",
"_____no_output_____"
]
],
[
[
"#### Baseline + TTS",
"_____no_output_____"
]
],
[
[
"# baseline model\n\ntrain_labels_10pct['damage_grade'].value_counts(normalize = True)",
"_____no_output_____"
],
[
"# establish X + y\n\nX = train_values_10pct.drop(columns = ['building_id'])\ny = train_labels_10pct['damage_grade']",
"_____no_output_____"
],
[
"# tts\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state = 123)",
"_____no_output_____"
]
],
[
[
"#### Modeling",
"_____no_output_____"
]
],
[
[
"# Random Forest\n\npipe_forest = make_pipeline(OneHotEncoder(use_cat_names = True), StandardScaler(), RandomForestClassifier(n_jobs = -1, random_state = 123))\n\nparams = {'randomforestclassifier__max_depth' : [6, 7, 8, 9, 10, 11],\n 'randomforestclassifier__max_features' : [15, 20, 30, 35]}\n\ngrid_forest = GridSearchCV(pipe_forest, param_grid = params)\n\ngrid_forest.fit(X_train, y_train)\n\nprint(f'Train Score: {grid_forest.score(X_train, y_train)}')\nprint(f'Test Score: {grid_forest.score(X_test, y_test)}')\n\ngrid_forest.best_params_",
"Train Score: 0.7649015093374264\nTest Score: 0.6836531082118189\n"
],
[
"# grab feature importances\n\nforest_fi_df = pd.DataFrame({'importances': grid_forest.best_estimator_.named_steps['randomforestclassifier'].feature_importances_, \n 'name': grid_forest.best_estimator_.named_steps['onehotencoder'].get_feature_names()}).sort_values('importances', ascending = False)\nforest_fi_df[:5]",
"_____no_output_____"
],
[
"# test to ensure X_train.columns + feature_importances are same length\n\nprint(len(grid_forest.best_estimator_.named_steps['randomforestclassifier'].feature_importances_))\nprint(len(grid_forest.best_estimator_.named_steps['onehotencoder'].get_feature_names()))",
"68\n68\n"
],
[
"# Extra Trees\n\npipe_trees = make_pipeline(OneHotEncoder(use_cat_names = True), StandardScaler(), ExtraTreesClassifier(n_jobs = -1, random_state = 123))\n\nparams = {'extratreesclassifier__max_depth' : [6, 7, 8, 9, 10, 11],\n 'extratreesclassifier__max_features' : [15, 20, 30, 35]}\n\ngrid_trees = GridSearchCV(pipe_trees, param_grid = params)\n\ngrid_trees.fit(X_train, y_train)\n\nprint(f'Train Score: {grid_trees.score(X_train, y_train)}')\nprint(f'Test Score: {grid_trees.score(X_test, y_test)}')\n\ngrid_trees.best_params_",
"Train Score: 0.7266820158608339\nTest Score: 0.664313123561013\n"
],
[
"# grab feature importances\n\ntrees_fi_df = pd.DataFrame({'importances': grid_trees.best_estimator_.named_steps['extratreesclassifier'].feature_importances_, \n 'name': grid_trees.best_estimator_.named_steps['onehotencoder'].get_feature_names()}).sort_values('importances', ascending = False)\ntrees_fi_df[:5]",
"_____no_output_____"
],
[
"# test to ensure X_train.columns + feature_importances are same length\n\nprint(len(grid_trees.best_estimator_.named_steps['extratreesclassifier'].feature_importances_))\nprint(len(grid_trees.best_estimator_.named_steps['onehotencoder'].get_feature_names()))",
"68\n68\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a27d9dfccc39ebbcb34ed10e65c5c507b21e3d5
| 133,282 |
ipynb
|
Jupyter Notebook
|
src/notebook/(3_1)Stroke_LSTM_Skatch_A_Net_ipynb_.ipynb
|
AlsoSprachZarathushtra/Quick-Draw-Recognition
|
f6a2c7affce0f5eaa58f4b019789a8f7753d32ad
|
[
"Apache-2.0"
] | null | null | null |
src/notebook/(3_1)Stroke_LSTM_Skatch_A_Net_ipynb_.ipynb
|
AlsoSprachZarathushtra/Quick-Draw-Recognition
|
f6a2c7affce0f5eaa58f4b019789a8f7753d32ad
|
[
"Apache-2.0"
] | null | null | null |
src/notebook/(3_1)Stroke_LSTM_Skatch_A_Net_ipynb_.ipynb
|
AlsoSprachZarathushtra/Quick-Draw-Recognition
|
f6a2c7affce0f5eaa58f4b019789a8f7753d32ad
|
[
"Apache-2.0"
] | null | null | null | 108.890523 | 27,498 | 0.710013 |
[
[
[
"<a href=\"https://colab.research.google.com/github/AlsoSprachZarathushtra/Quick-Draw-Recognition/blob/master/(3_1)Stroke_LSTM_Skatch_A_Net_ipynb_.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Connect Google Drive",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/gdrive')",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=email%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdocs.test%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive.photos.readonly%20https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fpeopleapi.readonly&response_type=code\n\nEnter your authorization code:\n··········\nMounted at /content/gdrive\n"
]
],
[
[
"# Import",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport cv2\nimport os\n\nfrom tensorflow import keras\nfrom tensorflow.keras.layers import Input\nfrom tensorflow.keras.layers import Conv2D\nfrom tensorflow.keras.layers import MaxPool2D\nfrom tensorflow.keras.layers import ReLU\nfrom tensorflow.keras.layers import Softmax\nfrom tensorflow.keras.layers import Flatten\nfrom tensorflow.keras.layers import Dropout\nfrom tensorflow.keras.layers import Lambda\nfrom tensorflow.keras.layers import Reshape\nfrom tensorflow.keras.layers import LSTM\nfrom tensorflow.keras.layers import Dense\nfrom tensorflow.keras.layers import concatenate\nfrom tensorflow.keras.layers import BatchNormalization\nfrom tensorflow.keras.metrics import sparse_top_k_categorical_accuracy\nfrom tensorflow.keras.callbacks import CSVLogger\nfrom ast import literal_eval",
"_____no_output_____"
]
],
[
[
"# Parameters and Work-Space Paths",
"_____no_output_____"
]
],
[
[
"# parameters\nBATCH_SIZE = 200\nEPOCHS = 50\nSTEPS_PER_EPOCH = 425\nVALIDATION_STEPS = 100\nEVALUATE_STEPS = 850\nIMAGE_SIZE = 225\nLINE_SIZE = 3\n\n\n# load path\nTRAIN_DATA_PATH = 'gdrive/My Drive/QW/Data/Data_10000/All_classes_10000.csv'\nVALID_DATA_PATH = 'gdrive/My Drive/QW/Data/My_test_data/My_test_data.csv'\nLABEL_DICT_PATH = 'gdrive/My Drive/QW/Data/labels_dict.npy'\n\n# save path\nCKPT_PATH = 'gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt'\nLOSS_PLOT_PATH = 'gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/loss_plot_3_1.png'\nACC_PLOT_PATH = 'gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/acc_plot_3_1.png'\nLOG_PATH = 'gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/Log_3_1.log'\nprint('finish!')",
"finish!\n"
]
],
[
[
"# Generator",
"_____no_output_____"
]
],
[
[
"\ndef generate_data(data, batch_size, choose_recognized):\n data = data.sample(frac = 1)\n \n while 1:\n \n# get columns' values named 'drawing', 'word' and 'recognized'\n drawings = data[\"drawing\"].values\n drawing_recognized = data[\"recognized\"].values\n drawing_class = data[\"word\"].values\n \n# initialization\n cnt = 0\n data_X =[]\n data_Y =[]\n \n# generate batch\n for i in range(len(drawings)):\n if choose_recognized:\n if drawing_recognized[i] == 'False': #Choose according to recognized value\n continue\n draw = drawings[i]\n stroke_vec = literal_eval(draw)\n \n l = len(stroke_vec)\n stroke_set = []\n if l <= 3:\n if l == 1:\n stroke_set =[[0],[0],[0]]\n if l == 2:\n stroke_set =[[0],[1],[1]]\n if l == 3:\n stroke_set =[[0],[1],[2]]\n if l > 3:\n a = l // 3\n b = l % 3\n c = (a + 1) * 3\n d = c - l\n n = 0\n for h in range(0,d):\n temp = []\n for k in range(a):\n temp.append(n)\n n += 1\n stroke_set.append(temp)\n for h in range(d,3):\n temp = []\n for k in range(a+1):\n temp.append(n)\n n += 1\n stroke_set.append(temp)\n \n img = np.zeros([256, 256])\n x = []\n stroke_num = 0\n for j in range(3):\n stroke_index = stroke_set[j]\n for m in list(stroke_index):\n line = np.array(stroke_vec[m]).T\n cv2.polylines(img, [line], False, (255-(13*min(stroke_num,10))), LINE_SIZE)\n stroke_num += 1\n img_copy = img.copy()\n img_x = cv2.resize(img_copy,(IMAGE_SIZE,IMAGE_SIZE),interpolation = cv2.INTER_NEAREST)\n x.append(img_x)\n x = np.array(x)\n x = x[:,:,:,np.newaxis]\n label = drawing_class[i]\n y = labels2nums_dict[label]\n data_X.append(x)\n data_Y.append(y)\n cnt += 1\n if cnt==batch_size: #generate a batch when cnt reaches batch_size \n cnt = 0\n yield (np.array(data_X), np.array(data_Y))\n data_X = []\n data_Y = []\nprint(\"finish!\")",
"finish!\n"
]
],
[
[
"# Callbacks",
"_____no_output_____"
]
],
[
[
"# define a class named LossHitory \nclass LossHistory(keras.callbacks.Callback):\n def on_train_begin(self, logs={}):\n self.losses = {'batch':[], 'epoch':[]}\n self.accuracy = {'batch':[], 'epoch':[]}\n self.val_loss = {'batch':[], 'epoch':[]}\n self.val_acc = {'batch':[], 'epoch':[]}\n\n def on_batch_end(self, batch, logs={}):\n self.losses['batch'].append(logs.get('loss'))\n self.accuracy['batch'].append(logs.get('acc'))\n self.val_loss['batch'].append(logs.get('val_loss'))\n self.val_acc['batch'].append(logs.get('val_acc'))\n\n def on_epoch_end(self, batch, logs={}):\n self.losses['epoch'].append(logs.get('loss'))\n self.accuracy['epoch'].append(logs.get('acc'))\n self.val_loss['epoch'].append(logs.get('val_loss'))\n self.val_acc['epoch'].append(logs.get('val_acc'))\n\n def loss_plot(self, loss_type, loss_fig_save_path, acc_fig_save_path):\n iters = range(len(self.losses[loss_type]))\n plt.figure('acc')\n plt.plot(iters, self.accuracy[loss_type], 'r', label='train acc')\n plt.plot(iters, self.val_acc[loss_type], 'b', label='val acc')\n plt.grid(True)\n plt.xlabel(loss_type)\n plt.ylabel('acc')\n plt.legend(loc=\"upper right\")\n plt.savefig(acc_fig_save_path)\n plt.show()\n \n \n plt.figure('loss')\n plt.plot(iters, self.losses[loss_type], 'g', label='train loss')\n plt.plot(iters, self.val_loss[loss_type], 'k', label='val loss')\n plt.grid(True)\n plt.xlabel(loss_type)\n plt.ylabel('loss')\n plt.legend(loc=\"upper right\")\n plt.savefig(loss_fig_save_path)\n plt.show()\n \n# create a object from LossHistory class\nHistory = LossHistory()\n\nprint(\"finish!\")",
"finish!\n"
],
[
"\ncp_callback = tf.keras.callbacks.ModelCheckpoint(\n CKPT_PATH, \n verbose = 1, \n monitor='val_acc', \n mode = 'max', \n save_best_only=True)\n\nprint(\"finish!\")",
"finish!\n"
],
[
"ReduceLR = tf.keras.callbacks.ReduceLROnPlateau(monitor='val_acc', factor=0.5, patience=3,\n min_delta=0.005, mode='max', cooldown=3, verbose=1)",
"_____no_output_____"
],
[
"csv_logger = CSVLogger(LOG_PATH, separator=',', append=True)",
"_____no_output_____"
]
],
[
[
"# Load Data",
"_____no_output_____"
]
],
[
[
"# load train data and valid data\n# labels_dict and data path\n\n# labels convert into nums\nlabels_dict = np.load(LABEL_DICT_PATH)\nlabels2nums_dict = {v: k for k, v in enumerate(labels_dict)}\n\n# read csv \ntrain_data = pd.read_csv(TRAIN_DATA_PATH)\nvalid_data = pd.read_csv(VALID_DATA_PATH)\n\nprint('finish!')",
"finish!\n"
]
],
[
[
"# Model",
"_____no_output_____"
]
],
[
[
"def Sketch_A_Net(M):\n _x_input = Lambda(lambda x: x[:,M])(X_INPUT)\n\n _x = Conv2D(64, (15,15), strides=3, padding='valid',name='Conv2D_1_{}'.format(M))(_x_input)\n _x = BatchNormalization(name='BN_1_{}'.format(M))(_x)\n _x = ReLU(name='ReLU_1_{}'.format(M))(_x)\n _x = MaxPool2D(pool_size=(3,3),strides=2, name='Pooling_1_{}'.format(M))(_x)\n\n _x = Conv2D(128, (5,5), strides=1, padding='valid',name='Conv2D_2_{}'.format(M))(_x)\n _x = BatchNormalization(name='BN_2_{}'.format(M))(_x)\n _x = ReLU(name='ReLU_2_{}'.format(M))(_x)\n _x = MaxPool2D(pool_size=(3,3),strides=2, name='Pooling_2_{}'.format(M))(_x)\n\n _x = Conv2D(256, (3,3), strides=1, padding='same',name='Conv2D_3_{}'.format(M))(_x)\n _x = BatchNormalization(name='BN_3_{}'.format(M))(_x)\n _x = ReLU(name='ReLU_3_{}'.format(M))(_x)\n\n _x = Conv2D(256, (3,3), strides=1, padding='same',name='Conv2D_4_{}'.format(M))(_x)\n _x = BatchNormalization(name='BN_4_{}'.format(M))(_x)\n _x = ReLU(name='ReLU_4_{}'.format(M))(_x)\n\n _x = Conv2D(256, (3,3), strides=1, padding='same',name='Conv2D_5_{}'.format(M))(_x)\n _x = BatchNormalization(name='BN_5_{}'.format(M))(_x)\n _x = ReLU(name='ReLU_5_{}'.format(M))(_x)\n _x = MaxPool2D(pool_size=(3,3),strides=2, name='Pooling_5_{}'.format(M))(_x)\n\n _x_shape = _x.shape[1]\n _x = Conv2D(512, (int(_x_shape),int(_x_shape)), strides=1, padding='valid',name='Conv2D_FC_6_{}'.format(M))(_x)\n _x = BatchNormalization(name='BN_6_{}'.format(M))(_x)\n _x = Reshape((512,),name='Reshape_{}'.format(M))(_x)\n return _x\n\nX_INPUT = Input(shape=(3,IMAGE_SIZE,IMAGE_SIZE,1))\nx1_output = Sketch_A_Net(0)\nx2_output = Sketch_A_Net(1)\nx3_output = Sketch_A_Net(2)\n\nx = concatenate([x1_output, x2_output,x3_output],axis = 1,name='Concatenate')\nx = Reshape((3,512),name='Reshape_f1')(x)\nx = LSTM(512, return_sequences=True, name='LSTM_1')(x)\nx = BatchNormalization(name='BN_1')(x)\nx = Dropout(0.5, name='Dropout_1')(x)\nx = LSTM(512, return_sequences=False, name='LSTM_2')(x)\nx = BatchNormalization(name='BN_2')(x)\nx = Dropout(0.5, name='Dropout_2')(x)\nxx = concatenate([x,x3_output],axis = 1,name='Concatenate_last')\nxx = Reshape((1024,),name='Reshape_f2')(xx)\nxx = Dense(340, name='FC')(xx)\nX_OUTPUT = Softmax(name='Softmax')(xx)\n\nMODEL = keras.Model(inputs=X_INPUT, outputs= X_OUTPUT)\nMODEL.summary() ",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) (None, 3, 225, 225, 0 \n__________________________________________________________________________________________________\nlambda (Lambda) (None, 225, 225, 1) 0 input_1[0][0] \n__________________________________________________________________________________________________\nlambda_1 (Lambda) (None, 225, 225, 1) 0 input_1[0][0] \n__________________________________________________________________________________________________\nlambda_2 (Lambda) (None, 225, 225, 1) 0 input_1[0][0] \n__________________________________________________________________________________________________\nConv2D_1_0 (Conv2D) (None, 71, 71, 64) 14464 lambda[0][0] \n__________________________________________________________________________________________________\nConv2D_1_1 (Conv2D) (None, 71, 71, 64) 14464 lambda_1[0][0] \n__________________________________________________________________________________________________\nConv2D_1_2 (Conv2D) (None, 71, 71, 64) 14464 lambda_2[0][0] \n__________________________________________________________________________________________________\nBN_1_0 (BatchNormalization) (None, 71, 71, 64) 256 Conv2D_1_0[0][0] \n__________________________________________________________________________________________________\nBN_1_1 (BatchNormalization) (None, 71, 71, 64) 256 Conv2D_1_1[0][0] \n__________________________________________________________________________________________________\nBN_1_2 (BatchNormalization) (None, 71, 71, 64) 256 Conv2D_1_2[0][0] \n__________________________________________________________________________________________________\nReLU_1_0 (ReLU) (None, 71, 71, 64) 0 BN_1_0[0][0] \n__________________________________________________________________________________________________\nReLU_1_1 (ReLU) (None, 71, 71, 64) 0 BN_1_1[0][0] \n__________________________________________________________________________________________________\nReLU_1_2 (ReLU) (None, 71, 71, 64) 0 BN_1_2[0][0] \n__________________________________________________________________________________________________\nPooling_1_0 (MaxPooling2D) (None, 35, 35, 64) 0 ReLU_1_0[0][0] \n__________________________________________________________________________________________________\nPooling_1_1 (MaxPooling2D) (None, 35, 35, 64) 0 ReLU_1_1[0][0] \n__________________________________________________________________________________________________\nPooling_1_2 (MaxPooling2D) (None, 35, 35, 64) 0 ReLU_1_2[0][0] \n__________________________________________________________________________________________________\nConv2D_2_0 (Conv2D) (None, 31, 31, 128) 204928 Pooling_1_0[0][0] \n__________________________________________________________________________________________________\nConv2D_2_1 (Conv2D) (None, 31, 31, 128) 204928 Pooling_1_1[0][0] \n__________________________________________________________________________________________________\nConv2D_2_2 (Conv2D) (None, 31, 31, 128) 204928 Pooling_1_2[0][0] \n__________________________________________________________________________________________________\nBN_2_0 (BatchNormalization) (None, 31, 31, 128) 512 Conv2D_2_0[0][0] \n__________________________________________________________________________________________________\nBN_2_1 (BatchNormalization) (None, 31, 31, 128) 512 Conv2D_2_1[0][0] \n__________________________________________________________________________________________________\nBN_2_2 (BatchNormalization) (None, 31, 31, 128) 512 Conv2D_2_2[0][0] \n__________________________________________________________________________________________________\nReLU_2_0 (ReLU) (None, 31, 31, 128) 0 BN_2_0[0][0] \n__________________________________________________________________________________________________\nReLU_2_1 (ReLU) (None, 31, 31, 128) 0 BN_2_1[0][0] \n__________________________________________________________________________________________________\nReLU_2_2 (ReLU) (None, 31, 31, 128) 0 BN_2_2[0][0] \n__________________________________________________________________________________________________\nPooling_2_0 (MaxPooling2D) (None, 15, 15, 128) 0 ReLU_2_0[0][0] \n__________________________________________________________________________________________________\nPooling_2_1 (MaxPooling2D) (None, 15, 15, 128) 0 ReLU_2_1[0][0] \n__________________________________________________________________________________________________\nPooling_2_2 (MaxPooling2D) (None, 15, 15, 128) 0 ReLU_2_2[0][0] \n__________________________________________________________________________________________________\nConv2D_3_0 (Conv2D) (None, 15, 15, 256) 295168 Pooling_2_0[0][0] \n__________________________________________________________________________________________________\nConv2D_3_1 (Conv2D) (None, 15, 15, 256) 295168 Pooling_2_1[0][0] \n__________________________________________________________________________________________________\nConv2D_3_2 (Conv2D) (None, 15, 15, 256) 295168 Pooling_2_2[0][0] \n__________________________________________________________________________________________________\nBN_3_0 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_3_0[0][0] \n__________________________________________________________________________________________________\nBN_3_1 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_3_1[0][0] \n__________________________________________________________________________________________________\nBN_3_2 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_3_2[0][0] \n__________________________________________________________________________________________________\nReLU_3_0 (ReLU) (None, 15, 15, 256) 0 BN_3_0[0][0] \n__________________________________________________________________________________________________\nReLU_3_1 (ReLU) (None, 15, 15, 256) 0 BN_3_1[0][0] \n__________________________________________________________________________________________________\nReLU_3_2 (ReLU) (None, 15, 15, 256) 0 BN_3_2[0][0] \n__________________________________________________________________________________________________\nConv2D_4_0 (Conv2D) (None, 15, 15, 256) 590080 ReLU_3_0[0][0] \n__________________________________________________________________________________________________\nConv2D_4_1 (Conv2D) (None, 15, 15, 256) 590080 ReLU_3_1[0][0] \n__________________________________________________________________________________________________\nConv2D_4_2 (Conv2D) (None, 15, 15, 256) 590080 ReLU_3_2[0][0] \n__________________________________________________________________________________________________\nBN_4_0 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_4_0[0][0] \n__________________________________________________________________________________________________\nBN_4_1 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_4_1[0][0] \n__________________________________________________________________________________________________\nBN_4_2 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_4_2[0][0] \n__________________________________________________________________________________________________\nReLU_4_0 (ReLU) (None, 15, 15, 256) 0 BN_4_0[0][0] \n__________________________________________________________________________________________________\nReLU_4_1 (ReLU) (None, 15, 15, 256) 0 BN_4_1[0][0] \n__________________________________________________________________________________________________\nReLU_4_2 (ReLU) (None, 15, 15, 256) 0 BN_4_2[0][0] \n__________________________________________________________________________________________________\nConv2D_5_0 (Conv2D) (None, 15, 15, 256) 590080 ReLU_4_0[0][0] \n__________________________________________________________________________________________________\nConv2D_5_1 (Conv2D) (None, 15, 15, 256) 590080 ReLU_4_1[0][0] \n__________________________________________________________________________________________________\nConv2D_5_2 (Conv2D) (None, 15, 15, 256) 590080 ReLU_4_2[0][0] \n__________________________________________________________________________________________________\nBN_5_0 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_5_0[0][0] \n__________________________________________________________________________________________________\nBN_5_1 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_5_1[0][0] \n__________________________________________________________________________________________________\nBN_5_2 (BatchNormalization) (None, 15, 15, 256) 1024 Conv2D_5_2[0][0] \n__________________________________________________________________________________________________\nReLU_5_0 (ReLU) (None, 15, 15, 256) 0 BN_5_0[0][0] \n__________________________________________________________________________________________________\nReLU_5_1 (ReLU) (None, 15, 15, 256) 0 BN_5_1[0][0] \n__________________________________________________________________________________________________\nReLU_5_2 (ReLU) (None, 15, 15, 256) 0 BN_5_2[0][0] \n__________________________________________________________________________________________________\nPooling_5_0 (MaxPooling2D) (None, 7, 7, 256) 0 ReLU_5_0[0][0] \n__________________________________________________________________________________________________\nPooling_5_1 (MaxPooling2D) (None, 7, 7, 256) 0 ReLU_5_1[0][0] \n__________________________________________________________________________________________________\nPooling_5_2 (MaxPooling2D) (None, 7, 7, 256) 0 ReLU_5_2[0][0] \n__________________________________________________________________________________________________\nConv2D_FC_6_0 (Conv2D) (None, 1, 1, 512) 6423040 Pooling_5_0[0][0] \n__________________________________________________________________________________________________\nConv2D_FC_6_1 (Conv2D) (None, 1, 1, 512) 6423040 Pooling_5_1[0][0] \n__________________________________________________________________________________________________\nConv2D_FC_6_2 (Conv2D) (None, 1, 1, 512) 6423040 Pooling_5_2[0][0] \n__________________________________________________________________________________________________\nBN_6_0 (BatchNormalization) (None, 1, 1, 512) 2048 Conv2D_FC_6_0[0][0] \n__________________________________________________________________________________________________\nBN_6_1 (BatchNormalization) (None, 1, 1, 512) 2048 Conv2D_FC_6_1[0][0] \n__________________________________________________________________________________________________\nBN_6_2 (BatchNormalization) (None, 1, 1, 512) 2048 Conv2D_FC_6_2[0][0] \n__________________________________________________________________________________________________\nReshape_0 (Reshape) (None, 512) 0 BN_6_0[0][0] \n__________________________________________________________________________________________________\nReshape_1 (Reshape) (None, 512) 0 BN_6_1[0][0] \n__________________________________________________________________________________________________\nReshape_2 (Reshape) (None, 512) 0 BN_6_2[0][0] \n__________________________________________________________________________________________________\nConcatenate (Concatenate) (None, 1536) 0 Reshape_0[0][0] \n Reshape_1[0][0] \n Reshape_2[0][0] \n__________________________________________________________________________________________________\nReshape_f1 (Reshape) (None, 3, 512) 0 Concatenate[0][0] \n__________________________________________________________________________________________________\nLSTM_1 (LSTM) (None, 3, 512) 2099200 Reshape_f1[0][0] \n__________________________________________________________________________________________________\nBN_1 (BatchNormalization) (None, 3, 512) 2048 LSTM_1[0][0] \n__________________________________________________________________________________________________\nDropout_1 (Dropout) (None, 3, 512) 0 BN_1[0][0] \n__________________________________________________________________________________________________\nLSTM_2 (LSTM) (None, 512) 2099200 Dropout_1[0][0] \n__________________________________________________________________________________________________\nBN_2 (BatchNormalization) (None, 512) 2048 LSTM_2[0][0] \n__________________________________________________________________________________________________\nDropout_2 (Dropout) (None, 512) 0 BN_2[0][0] \n__________________________________________________________________________________________________\nConcatenate_last (Concatenate) (None, 1024) 0 Dropout_2[0][0] \n Reshape_2[0][0] \n__________________________________________________________________________________________________\nReshape_f2 (Reshape) (None, 1024) 0 Concatenate_last[0][0] \n__________________________________________________________________________________________________\nFC (Dense) (None, 340) 348500 Reshape_f2[0][0] \n__________________________________________________________________________________________________\nSoftmax (Softmax) (None, 340) 0 FC[0][0] \n==================================================================================================\nTotal params: 28,921,940\nTrainable params: 28,911,060\nNon-trainable params: 10,880\n__________________________________________________________________________________________________\n"
]
],
[
[
"# TPU Complie",
"_____no_output_____"
]
],
[
[
"model = MODEL\nTPU_model = tf.contrib.tpu.keras_to_tpu_model(\n model,\n strategy=tf.contrib.tpu.TPUDistributionStrategy(\n tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])\n )\n )\n\nTPU_model.compile(loss=tf.keras.losses.sparse_categorical_crossentropy,\n optimizer=tf.train.AdamOptimizer(learning_rate=1e-3),\n metrics=['accuracy'])\n\n\nprint('finish')",
"INFO:tensorflow:Querying Tensorflow master (b'grpc://10.72.17.58:8470') for TPU system metadata.\nINFO:tensorflow:Found TPU system:\nINFO:tensorflow:*** Num TPU Cores: 8\nINFO:tensorflow:*** Num TPU Workers: 1\nINFO:tensorflow:*** Num TPU Cores Per Worker: 8\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, -1, 929088615968568844)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 17179869184, 15900753977296052317)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_GPU:0, XLA_GPU, 17179869184, 8765991032916183184)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 17179869184, 529849079297276646)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 17179869184, 3452447291276583421)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 17179869184, 8667903427041268716)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 17179869184, 8842056305586983265)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 17179869184, 18120390467061945228)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 17179869184, 6895034419450112142)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 17179869184, 22718087368919159)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 17179869184, 17971390634073933564)\nINFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 17179869184, 17968918297085487944)\nWARNING:tensorflow:tpu_model (from tensorflow.contrib.tpu.python.tpu.keras_support) is experimental and may change or be removed at any time, and without warning.\nfinish\n"
]
],
[
[
"# Train",
"_____no_output_____"
]
],
[
[
"print('start training')\n# callbacks = [History, cp_callback]\n\nhistory = TPU_model.fit_generator(generate_data(train_data, BATCH_SIZE, True),\n steps_per_epoch = STEPS_PER_EPOCH,\n epochs = EPOCHS,\n validation_data = generate_data(valid_data, BATCH_SIZE, False) ,\n validation_steps = VALIDATION_STEPS,\n verbose = 1,\n initial_epoch = 0,\n callbacks = [History,cp_callback,csv_logger]\n )\nprint(\"finish training\")\n\nHistory.loss_plot('epoch', LOSS_PLOT_PATH, ACC_PLOT_PATH)\n\nprint('finish!')",
"start training\nEpoch 1/50\nINFO:tensorflow:New input shapes; (re-)compiling: mode=train (# of cores 8), [TensorSpec(shape=(12,), dtype=tf.int32, name='core_id_20'), TensorSpec(shape=(12, 3, 225, 225, 1), dtype=tf.float32, name='input_3_10'), TensorSpec(shape=(12, 1), dtype=tf.float32, name='Softmax_target_50')]\nINFO:tensorflow:Overriding default placeholder.\nINFO:tensorflow:Remapping placeholder for input_3\nINFO:tensorflow:Started compiling\nINFO:tensorflow:Finished compiling. Time elapsed: 68.03637170791626 secs\nINFO:tensorflow:Setting weights on TPU model.\n424/425 [============================>.] - ETA: 1s - loss: 4.3930 - acc: 0.1663INFO:tensorflow:New input shapes; (re-)compiling: mode=eval (# of cores 8), [TensorSpec(shape=(12,), dtype=tf.int32, name='core_id_30'), TensorSpec(shape=(12, 3, 225, 225, 1), dtype=tf.float32, name='input_3_10'), TensorSpec(shape=(12, 1), dtype=tf.float32, name='Softmax_target_50')]\nINFO:tensorflow:Overriding default placeholder.\nINFO:tensorflow:Remapping placeholder for input_3\nINFO:tensorflow:Started compiling\nINFO:tensorflow:Finished compiling. Time elapsed: 59.174062728881836 secs\n\nEpoch 00001: val_acc improved from -inf to 0.25479, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 772s 2s/step - loss: 4.3914 - acc: 0.1667 - val_loss: 4.0412 - val_acc: 0.2548\nEpoch 2/50\n424/425 [============================>.] - ETA: 0s - loss: 3.1749 - acc: 0.3250\nEpoch 00002: val_acc improved from 0.25479 to 0.39292, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 419s 986ms/step - loss: 3.1751 - acc: 0.3250 - val_loss: 2.9500 - val_acc: 0.3929\nEpoch 3/50\n424/425 [============================>.] - ETA: 0s - loss: 2.7405 - acc: 0.4056\nEpoch 00003: val_acc improved from 0.39292 to 0.44448, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 413s 973ms/step - loss: 2.7399 - acc: 0.4056 - val_loss: 2.5952 - val_acc: 0.4445\nEpoch 4/50\n424/425 [============================>.] - ETA: 0s - loss: 2.5010 - acc: 0.4426\nEpoch 00004: val_acc improved from 0.44448 to 0.46823, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 412s 970ms/step - loss: 2.5006 - acc: 0.4427 - val_loss: 2.4804 - val_acc: 0.4682\nEpoch 5/50\n424/425 [============================>.] - ETA: 0s - loss: 2.3373 - acc: 0.4738\nEpoch 00005: val_acc improved from 0.46823 to 0.50542, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 417s 981ms/step - loss: 2.3369 - acc: 0.4738 - val_loss: 2.2047 - val_acc: 0.5054\nEpoch 6/50\n424/425 [============================>.] - ETA: 0s - loss: 2.2350 - acc: 0.4923\nEpoch 00006: val_acc improved from 0.50542 to 0.52958, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 415s 977ms/step - loss: 2.2354 - acc: 0.4922 - val_loss: 2.1050 - val_acc: 0.5296\nEpoch 7/50\n424/425 [============================>.] - ETA: 0s - loss: 2.1069 - acc: 0.5178\nEpoch 00007: val_acc improved from 0.52958 to 0.54177, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 417s 981ms/step - loss: 2.1059 - acc: 0.5179 - val_loss: 2.0439 - val_acc: 0.5418\nEpoch 8/50\n424/425 [============================>.] - ETA: 0s - loss: 2.0464 - acc: 0.5271\nEpoch 00008: val_acc improved from 0.54177 to 0.55042, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 415s 976ms/step - loss: 2.0465 - acc: 0.5271 - val_loss: 1.9622 - val_acc: 0.5504\nEpoch 9/50\n424/425 [============================>.] - ETA: 0s - loss: 1.9628 - acc: 0.5434\nEpoch 00009: val_acc improved from 0.55042 to 0.57281, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 415s 976ms/step - loss: 1.9629 - acc: 0.5435 - val_loss: 1.8613 - val_acc: 0.5728\nEpoch 10/50\n424/425 [============================>.] - ETA: 0s - loss: 1.9215 - acc: 0.5535\nEpoch 00010: val_acc did not improve from 0.57281\n425/425 [==============================] - 400s 941ms/step - loss: 1.9212 - acc: 0.5535 - val_loss: 1.8557 - val_acc: 0.5716\nEpoch 11/50\n424/425 [============================>.] - ETA: 0s - loss: 1.8789 - acc: 0.5622\nEpoch 00011: val_acc improved from 0.57281 to 0.58156, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 419s 987ms/step - loss: 1.8784 - acc: 0.5623 - val_loss: 1.7853 - val_acc: 0.5816\nEpoch 12/50\n424/425 [============================>.] - ETA: 0s - loss: 1.8306 - acc: 0.5681\nEpoch 00012: val_acc did not improve from 0.58156\n425/425 [==============================] - 401s 944ms/step - loss: 1.8310 - acc: 0.5680 - val_loss: 1.7967 - val_acc: 0.5800\nEpoch 13/50\n424/425 [============================>.] - ETA: 0s - loss: 1.8081 - acc: 0.5761\nEpoch 00013: val_acc improved from 0.58156 to 0.59583, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 420s 988ms/step - loss: 1.8075 - acc: 0.5761 - val_loss: 1.7348 - val_acc: 0.5958\nEpoch 14/50\n424/425 [============================>.] - ETA: 0s - loss: 1.7675 - acc: 0.5830\nEpoch 00014: val_acc improved from 0.59583 to 0.60063, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 421s 991ms/step - loss: 1.7678 - acc: 0.5830 - val_loss: 1.7275 - val_acc: 0.6006\nEpoch 15/50\n424/425 [============================>.] - ETA: 0s - loss: 1.7441 - acc: 0.5910\nEpoch 00015: val_acc improved from 0.60063 to 0.60719, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 424s 999ms/step - loss: 1.7431 - acc: 0.5911 - val_loss: 1.6485 - val_acc: 0.6072\nEpoch 16/50\n424/425 [============================>.] - ETA: 0s - loss: 1.7158 - acc: 0.5951\nEpoch 00016: val_acc improved from 0.60719 to 0.61156, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 422s 992ms/step - loss: 1.7157 - acc: 0.5950 - val_loss: 1.6627 - val_acc: 0.6116\nEpoch 17/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6767 - acc: 0.6018\nEpoch 00017: val_acc improved from 0.61156 to 0.61656, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 423s 994ms/step - loss: 1.6767 - acc: 0.6018 - val_loss: 1.6435 - val_acc: 0.6166\nEpoch 18/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6790 - acc: 0.6031\nEpoch 00018: val_acc did not improve from 0.61656\n425/425 [==============================] - 407s 957ms/step - loss: 1.6786 - acc: 0.6031 - val_loss: 1.6379 - val_acc: 0.6111\nEpoch 19/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6622 - acc: 0.6054\nEpoch 00019: val_acc improved from 0.61656 to 0.62021, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 423s 995ms/step - loss: 1.6619 - acc: 0.6053 - val_loss: 1.6351 - val_acc: 0.6202\nEpoch 20/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6325 - acc: 0.6114\nEpoch 00020: val_acc did not improve from 0.62021\n425/425 [==============================] - 406s 954ms/step - loss: 1.6324 - acc: 0.6115 - val_loss: 1.6088 - val_acc: 0.6142\nEpoch 21/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6332 - acc: 0.6135\nEpoch 00021: val_acc improved from 0.62021 to 0.63031, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 421s 990ms/step - loss: 1.6340 - acc: 0.6134 - val_loss: 1.5630 - val_acc: 0.6303\nEpoch 22/50\n424/425 [============================>.] - ETA: 0s - loss: 1.6150 - acc: 0.6166\nEpoch 00022: val_acc improved from 0.63031 to 0.63177, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 427s 1s/step - loss: 1.6147 - acc: 0.6166 - val_loss: 1.5184 - val_acc: 0.6318\nEpoch 23/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5715 - acc: 0.6226\nEpoch 00023: val_acc did not improve from 0.63177\n425/425 [==============================] - 404s 951ms/step - loss: 1.5714 - acc: 0.6225 - val_loss: 1.5480 - val_acc: 0.6301\nEpoch 24/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5873 - acc: 0.6216\nEpoch 00024: val_acc improved from 0.63177 to 0.63490, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 422s 993ms/step - loss: 1.5871 - acc: 0.6216 - val_loss: 1.5201 - val_acc: 0.6349\nEpoch 25/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5461 - acc: 0.6294\nEpoch 00025: val_acc improved from 0.63490 to 0.63833, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 424s 997ms/step - loss: 1.5463 - acc: 0.6294 - val_loss: 1.5406 - val_acc: 0.6383\nEpoch 26/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5414 - acc: 0.6317\nEpoch 00026: val_acc improved from 0.63833 to 0.64615, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 427s 1s/step - loss: 1.5413 - acc: 0.6318 - val_loss: 1.4676 - val_acc: 0.6461\nEpoch 27/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5455 - acc: 0.6313\nEpoch 00027: val_acc improved from 0.64615 to 0.64958, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 426s 1s/step - loss: 1.5449 - acc: 0.6314 - val_loss: 1.4633 - val_acc: 0.6496\nEpoch 28/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5181 - acc: 0.6350\nEpoch 00028: val_acc improved from 0.64958 to 0.65438, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 429s 1s/step - loss: 1.5192 - acc: 0.6348 - val_loss: 1.4539 - val_acc: 0.6544\nEpoch 29/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5154 - acc: 0.6373\nEpoch 00029: val_acc did not improve from 0.65438\n425/425 [==============================] - 405s 952ms/step - loss: 1.5151 - acc: 0.6372 - val_loss: 1.4813 - val_acc: 0.6467\nEpoch 30/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5141 - acc: 0.6398\nEpoch 00030: val_acc improved from 0.65438 to 0.66125, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 424s 998ms/step - loss: 1.5138 - acc: 0.6397 - val_loss: 1.4034 - val_acc: 0.6613\nEpoch 31/50\n424/425 [============================>.] - ETA: 0s - loss: 1.5084 - acc: 0.6398\nEpoch 00031: val_acc did not improve from 0.66125\n425/425 [==============================] - 409s 962ms/step - loss: 1.5080 - acc: 0.6400 - val_loss: 1.4990 - val_acc: 0.6440\nEpoch 32/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4803 - acc: 0.6427\nEpoch 00032: val_acc did not improve from 0.66125\n425/425 [==============================] - 403s 948ms/step - loss: 1.4807 - acc: 0.6428 - val_loss: 1.4252 - val_acc: 0.6554\nEpoch 33/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4854 - acc: 0.6429\nEpoch 00033: val_acc did not improve from 0.66125\n425/425 [==============================] - 405s 953ms/step - loss: 1.4857 - acc: 0.6428 - val_loss: 1.4034 - val_acc: 0.6592\nEpoch 34/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4865 - acc: 0.6418\nEpoch 00034: val_acc did not improve from 0.66125\n425/425 [==============================] - 405s 952ms/step - loss: 1.4868 - acc: 0.6418 - val_loss: 1.4318 - val_acc: 0.6601\nEpoch 35/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4660 - acc: 0.6487\nEpoch 00035: val_acc did not improve from 0.66125\n425/425 [==============================] - 404s 951ms/step - loss: 1.4672 - acc: 0.6484 - val_loss: 1.4727 - val_acc: 0.6522\nEpoch 36/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4666 - acc: 0.6462\nEpoch 00036: val_acc did not improve from 0.66125\n425/425 [==============================] - 402s 945ms/step - loss: 1.4659 - acc: 0.6463 - val_loss: 1.4707 - val_acc: 0.6528\nEpoch 37/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4276 - acc: 0.6564\nEpoch 00037: val_acc improved from 0.66125 to 0.67729, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 429s 1s/step - loss: 1.4279 - acc: 0.6564 - val_loss: 1.3551 - val_acc: 0.6773\nEpoch 38/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4554 - acc: 0.6516\nEpoch 00038: val_acc did not improve from 0.67729\n425/425 [==============================] - 417s 982ms/step - loss: 1.4556 - acc: 0.6515 - val_loss: 1.3785 - val_acc: 0.6658\nEpoch 39/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4429 - acc: 0.6513\nEpoch 00039: val_acc did not improve from 0.67729\n425/425 [==============================] - 407s 957ms/step - loss: 1.4432 - acc: 0.6512 - val_loss: 1.3882 - val_acc: 0.6633\nEpoch 40/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4544 - acc: 0.6514\nEpoch 00040: val_acc did not improve from 0.67729\n425/425 [==============================] - 405s 953ms/step - loss: 1.4535 - acc: 0.6516 - val_loss: 1.3642 - val_acc: 0.6696\nEpoch 41/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4308 - acc: 0.6565\nEpoch 00041: val_acc did not improve from 0.67729\n425/425 [==============================] - 403s 948ms/step - loss: 1.4303 - acc: 0.6565 - val_loss: 1.3960 - val_acc: 0.6668\nEpoch 42/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4370 - acc: 0.6551\nEpoch 00042: val_acc did not improve from 0.67729\n425/425 [==============================] - 404s 951ms/step - loss: 1.4371 - acc: 0.6549 - val_loss: 1.3912 - val_acc: 0.6638\nEpoch 43/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4160 - acc: 0.6583\nEpoch 00043: val_acc did not improve from 0.67729\n425/425 [==============================] - 403s 949ms/step - loss: 1.4152 - acc: 0.6585 - val_loss: 1.3890 - val_acc: 0.6595\nEpoch 44/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4113 - acc: 0.6588\nEpoch 00044: val_acc did not improve from 0.67729\n425/425 [==============================] - 405s 954ms/step - loss: 1.4119 - acc: 0.6587 - val_loss: 1.3810 - val_acc: 0.6646\nEpoch 45/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4139 - acc: 0.6575\nEpoch 00045: val_acc did not improve from 0.67729\n425/425 [==============================] - 404s 950ms/step - loss: 1.4131 - acc: 0.6576 - val_loss: 1.3963 - val_acc: 0.6600\nEpoch 46/50\n424/425 [============================>.] - ETA: 0s - loss: 1.3979 - acc: 0.6646\nEpoch 00046: val_acc improved from 0.67729 to 0.68615, saving model to gdrive/My Drive/QW/Notebook/Quick Draw/Thesis_pre_research/(3-1)Stroke_LSTM-Skatch-A-Net/best_model_3_1.ckpt\nINFO:tensorflow:Copying TPU weights to the CPU\nWARNING:tensorflow:TensorFlow optimizers do not make it possible to access optimizer attributes or optimizer state after instantiation. As a result, we cannot save the optimizer as part of the model save file.You will have to compile your model again after loading it. Prefer using a Keras optimizer instead (see keras.io/optimizers).\n425/425 [==============================] - 429s 1s/step - loss: 1.3972 - acc: 0.6648 - val_loss: 1.3027 - val_acc: 0.6861\nEpoch 47/50\n424/425 [============================>.] - ETA: 0s - loss: 1.3830 - acc: 0.6653\nEpoch 00047: val_acc did not improve from 0.68615\n425/425 [==============================] - 409s 962ms/step - loss: 1.3847 - acc: 0.6652 - val_loss: 1.3674 - val_acc: 0.6672\nEpoch 48/50\n424/425 [============================>.] - ETA: 0s - loss: 1.3955 - acc: 0.6608\nEpoch 00048: val_acc did not improve from 0.68615\n425/425 [==============================] - 403s 948ms/step - loss: 1.3957 - acc: 0.6608 - val_loss: 1.3127 - val_acc: 0.6858\nEpoch 49/50\n424/425 [============================>.] - ETA: 0s - loss: 1.4060 - acc: 0.6607\nEpoch 00049: val_acc did not improve from 0.68615\n425/425 [==============================] - 403s 949ms/step - loss: 1.4061 - acc: 0.6606 - val_loss: 1.3476 - val_acc: 0.6764\nEpoch 50/50\n424/425 [============================>.] - ETA: 0s - loss: 1.3722 - acc: 0.6671\nEpoch 00050: val_acc did not improve from 0.68615\n425/425 [==============================] - 404s 950ms/step - loss: 1.3713 - acc: 0.6674 - val_loss: 1.3877 - val_acc: 0.6741\nfinish training\n"
]
],
[
[
"# Evaluate",
"_____no_output_____"
]
],
[
[
"def top_3_accuracy(X, Y):\n return sparse_top_k_categorical_accuracy(X, Y, 3)\n \ndef top_5_accuracy(X, Y):\n return sparse_top_k_categorical_accuracy(X, Y, 5)\n \nmodel_E = MODEL \n\n\nmodel_E.compile(loss=tf.keras.losses.sparse_categorical_crossentropy,\n optimizer=tf.train.AdamOptimizer(learning_rate=1e-4),\n metrics=['accuracy',top_3_accuracy, top_5_accuracy])\n\nmodel_weights_path = CKPT_PATH \nmodel_E.load_weights(model_weights_path)\nprint('finish')",
"finish\n"
],
[
"result = model_E.evaluate_generator(\n generate_data(valid_data, BATCH_SIZE, False),\n steps = EVALUATE_STEPS,\n verbose = 1\n)\nprint('number of test samples:', len(result))\nprint('loss:', result[0])\nprint('top1 accuracy:', result[1])\nprint('top3 accuracy:', result[2])\nprint('top3 accuracy:', result[3])",
"850/850 [==============================] - 453s 532ms/step\nnumber of test samples: 4\nloss: 1.332117350802702\ntop1 accuracy: 0.6783235291172477\ntop3 accuracy: 0.8453823546802296\ntop3 accuracy: 0.8867411743192112\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a27daca9d297fd0dd2298a715993ce5f3531497
| 100,527 |
ipynb
|
Jupyter Notebook
|
Project/SageMaker Project.ipynb
|
jamesthatcher/udacity_sentiment_model
|
ee25a2f8604d9a23b57677884eaf6df028f66d27
|
[
"MIT"
] | null | null | null |
Project/SageMaker Project.ipynb
|
jamesthatcher/udacity_sentiment_model
|
ee25a2f8604d9a23b57677884eaf6df028f66d27
|
[
"MIT"
] | null | null | null |
Project/SageMaker Project.ipynb
|
jamesthatcher/udacity_sentiment_model
|
ee25a2f8604d9a23b57677884eaf6df028f66d27
|
[
"MIT"
] | null | null | null | 48.0301 | 2,561 | 0.596148 |
[
[
[
"# Creating a Sentiment Analysis Web App\n## Using PyTorch and SageMaker\n\n_Deep Learning Nanodegree Program | Deployment_\n\n---\n\nNow that we have a basic understanding of how SageMaker works we will try to use it to construct a complete project from end to end. Our goal will be to have a simple web page which a user can use to enter a movie review. The web page will then send the review off to our deployed model which will predict the sentiment of the entered review.\n\n## Instructions\n\nSome template code has already been provided for you, and you will need to implement additional functionality to successfully complete this notebook. You will not need to modify the included code beyond what is requested. Sections that begin with '**TODO**' in the header indicate that you need to complete or implement some portion within them. Instructions will be provided for each section and the specifics of the implementation are marked in the code block with a `# TODO: ...` comment. Please be sure to read the instructions carefully!\n\nIn addition to implementing code, there will be questions for you to answer which relate to the task and your implementation. Each section where you will answer a question is preceded by a '**Question:**' header. Carefully read each question and provide your answer below the '**Answer:**' header by editing the Markdown cell.\n\n> **Note**: Code and Markdown cells can be executed using the **Shift+Enter** keyboard shortcut. In addition, a cell can be edited by typically clicking it (double-click for Markdown cells) or by pressing **Enter** while it is highlighted.\n\n## General Outline\n\nRecall the general outline for SageMaker projects using a notebook instance.\n\n1. Download or otherwise retrieve the data.\n2. Process / Prepare the data.\n3. Upload the processed data to S3.\n4. Train a chosen model.\n5. Test the trained model (typically using a batch transform job).\n6. Deploy the trained model.\n7. Use the deployed model.\n\nFor this project, you will be following the steps in the general outline with some modifications. \n\nFirst, you will not be testing the model in its own step. You will still be testing the model, however, you will do it by deploying your model and then using the deployed model by sending the test data to it. One of the reasons for doing this is so that you can make sure that your deployed model is working correctly before moving forward.\n\nIn addition, you will deploy and use your trained model a second time. In the second iteration you will customize the way that your trained model is deployed by including some of your own code. In addition, your newly deployed model will be used in the sentiment analysis web app.",
"_____no_output_____"
],
[
"## Step 1: Downloading the data\n\nAs in the XGBoost in SageMaker notebook, we will be using the [IMDb dataset](http://ai.stanford.edu/~amaas/data/sentiment/)\n\n> Maas, Andrew L., et al. [Learning Word Vectors for Sentiment Analysis](http://ai.stanford.edu/~amaas/data/sentiment/). In _Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies_. Association for Computational Linguistics, 2011.",
"_____no_output_____"
]
],
[
[
"%mkdir ../data\n!wget -O ../data/aclImdb_v1.tar.gz http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\n!tar -zxf ../data/aclImdb_v1.tar.gz -C ../data",
"mkdir: cannot create directory ‘../data’: File exists\n--2019-06-18 21:08:28-- http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz\nResolving ai.stanford.edu (ai.stanford.edu)... 171.64.68.10\nConnecting to ai.stanford.edu (ai.stanford.edu)|171.64.68.10|:80... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 84125825 (80M) [application/x-gzip]\nSaving to: ‘../data/aclImdb_v1.tar.gz’\n\n../data/aclImdb_v1. 100%[===================>] 80.23M 23.5MB/s in 4.6s \n\n2019-06-18 21:08:33 (17.5 MB/s) - ‘../data/aclImdb_v1.tar.gz’ saved [84125825/84125825]\n\n"
]
],
[
[
"## Step 2: Preparing and Processing the data\n\nAlso, as in the XGBoost notebook, we will be doing some initial data processing. The first few steps are the same as in the XGBoost example. To begin with, we will read in each of the reviews and combine them into a single input structure. Then, we will split the dataset into a training set and a testing set.",
"_____no_output_____"
]
],
[
[
"import os\nimport glob\n\ndef read_imdb_data(data_dir='../data/aclImdb'):\n data = {}\n labels = {}\n \n for data_type in ['train', 'test']:\n data[data_type] = {}\n labels[data_type] = {}\n \n for sentiment in ['pos', 'neg']:\n data[data_type][sentiment] = []\n labels[data_type][sentiment] = []\n \n path = os.path.join(data_dir, data_type, sentiment, '*.txt')\n files = glob.glob(path)\n \n for f in files:\n with open(f) as review:\n data[data_type][sentiment].append(review.read())\n # Here we represent a positive review by '1' and a negative review by '0'\n labels[data_type][sentiment].append(1 if sentiment == 'pos' else 0)\n \n assert len(data[data_type][sentiment]) == len(labels[data_type][sentiment]), \\\n \"{}/{} data size does not match labels size\".format(data_type, sentiment)\n \n return data, labels",
"_____no_output_____"
],
[
"data, labels = read_imdb_data()\nprint(\"IMDB reviews: train = {} pos / {} neg, test = {} pos / {} neg\".format(\n len(data['train']['pos']), len(data['train']['neg']),\n len(data['test']['pos']), len(data['test']['neg'])))",
"IMDB reviews: train = 12500 pos / 12500 neg, test = 12500 pos / 12500 neg\n"
]
],
[
[
"Now that we've read the raw training and testing data from the downloaded dataset, we will combine the positive and negative reviews and shuffle the resulting records.",
"_____no_output_____"
]
],
[
[
"from sklearn.utils import shuffle\n\ndef prepare_imdb_data(data, labels):\n \"\"\"Prepare training and test sets from IMDb movie reviews.\"\"\"\n \n #Combine positive and negative reviews and labels\n data_train = data['train']['pos'] + data['train']['neg']\n data_test = data['test']['pos'] + data['test']['neg']\n labels_train = labels['train']['pos'] + labels['train']['neg']\n labels_test = labels['test']['pos'] + labels['test']['neg']\n \n #Shuffle reviews and corresponding labels within training and test sets\n data_train, labels_train = shuffle(data_train, labels_train)\n data_test, labels_test = shuffle(data_test, labels_test)\n \n # Return a unified training data, test data, training labels, test labets\n return data_train, data_test, labels_train, labels_test",
"_____no_output_____"
],
[
"train_X, test_X, train_y, test_y = prepare_imdb_data(data, labels)\nprint(\"IMDb reviews (combined): train = {}, test = {}\".format(len(train_X), len(test_X)))",
"IMDb reviews (combined): train = 25000, test = 25000\n"
]
],
[
[
"Now that we have our training and testing sets unified and prepared, we should do a quick check and see an example of the data our model will be trained on. This is generally a good idea as it allows you to see how each of the further processing steps affects the reviews and it also ensures that the data has been loaded correctly.",
"_____no_output_____"
]
],
[
[
"print(train_X[100])\nprint(train_y[100])",
"A friend once told me that an art-house independent film ran in a cinema when- upon the closing of the film - audiences were so enraged they preceded to tear up the cinema seats. Of course, my imagination ran amok, trying to conjure up the contents of such a piece of work. Well,now my imagination can be put to rest.<br /><br />I am a lifelong Andrei Tarkovky fan and an ardent admirer of his work. I have come across many people who thought Tarkovsky's films are slow-moving and inert. Opinions being what they are, I found this not to be true of the late director's wonderful works, which are wrought with meaning, beautiful compositions, and complex philosophical questions. Upon hearing Aleksandr Sokurov called the heir to Tarkovsky, I was excited to experience his films.<br /><br />With the exception of the open air ride through the fields (Stalker), this movie has no kinship to anything Tarkovsky has done. It does not seem to possess the slightest meaning, even on a completely mindless level. It's supposedly \"gorgeously stark\" cinematography is devoid of any compositional craft. There is a no balance, no proportion, and the exposure meter seems to be running low on batteries in the freezing snow. The main character is so inept and indecisive, it makes you wonder whether his father might have been alive if he made up his mind sooner.<br /><br />I am also not adverse to non-plots or story lines that progress on multiple non-linear fashion. But there isn't even a non-story here. One must surely enter the viewing of this film with a shaved head if one were to exit it with nothing gained and nothing lost, as hair-pulling would be the only possible answer to a pace that could make a Tarkosky time sculpture look as if Jerry Bruckheimer had filmed a Charlie Chaplin short.<br /><br />I won't rule out that this may be one of Sokurov's stinkers (Tarkovsky's Solaris), but to conclude that he is one of Tarkovsky's heir-based on this film- would be to call Paris Hilton the successor to Aristotle. C'mon guys, don't be afraid to say it. No amount of big impressive words is going to magically bring this corpse of celluloid back to life. I don't profess to fully understand Russian culture and I probably don't have Russian values, but I immediately picked up on Tarkovsky's work as something magical, a treasure and a gift to viewers.<br /><br />If it didn't have Sokurov's name on it, and it aired on say, Saturday Night Live, I'm pretty sure nobody would \"read\" all these magnificent analysis into this wet noodle of a flick.\n0\n"
]
],
[
[
"The first step in processing the reviews is to make sure that any html tags that appear should be removed. In addition we wish to tokenize our input, that way words such as *entertained* and *entertaining* are considered the same with regard to sentiment analysis.",
"_____no_output_____"
]
],
[
[
"import nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem.porter import *\n\nimport re\nfrom bs4 import BeautifulSoup\n\ndef review_to_words(review):\n nltk.download(\"stopwords\", quiet=True)\n stemmer = PorterStemmer()\n \n text = BeautifulSoup(review, \"html.parser\").get_text() # Remove HTML tags\n text = re.sub(r\"[^a-zA-Z0-9]\", \" \", text.lower()) # Convert to lower case\n words = text.split() # Split string into words\n words = [w for w in words if w not in stopwords.words(\"english\")] # Remove stopwords\n words = [PorterStemmer().stem(w) for w in words] # stem\n \n return words",
"_____no_output_____"
]
],
[
[
"The `review_to_words` method defined above uses `BeautifulSoup` to remove any html tags that appear and uses the `nltk` package to tokenize the reviews. As a check to ensure we know how everything is working, try applying `review_to_words` to one of the reviews in the training set.",
"_____no_output_____"
]
],
[
[
"# TODO: Apply review_to_words to a review (train_X[100] or any other review)\nreview_to_words(train_X[100])",
"_____no_output_____"
]
],
[
[
"**Question:** Above we mentioned that `review_to_words` method removes html formatting and allows us to tokenize the words found in a review, for example, converting *entertained* and *entertaining* into *entertain* so that they are treated as though they are the same word. What else, if anything, does this method do to the input?",
"_____no_output_____"
],
[
"**Answer:**\n\n1. Convert to lower case\n\n`text = re.sub(r\"[^a-zA-Z0-9]\", \" \", text.lower())`\n\n2. Tokenises the words\n\n`words = text.split() # Split string into words`\n\n3. Removes stopwords using porter stemmer\n\n`words = [w for w in words if w not in stopwords.words(\"english\")]`\n\n\n`words = [PorterStemmer().stem(w) for w in words] # stem`",
"_____no_output_____"
],
[
"The method below applies the `review_to_words` method to each of the reviews in the training and testing datasets. In addition it caches the results. This is because performing this processing step can take a long time. This way if you are unable to complete the notebook in the current session, you can come back without needing to process the data a second time.",
"_____no_output_____"
]
],
[
[
"import pickle\n\ncache_dir = os.path.join(\"../cache\", \"sentiment_analysis\") # where to store cache files\nos.makedirs(cache_dir, exist_ok=True) # ensure cache directory exists\n\ndef preprocess_data(data_train, data_test, labels_train, labels_test,\n cache_dir=cache_dir, cache_file=\"preprocessed_data.pkl\"):\n \"\"\"Convert each review to words; read from cache if available.\"\"\"\n\n # If cache_file is not None, try to read from it first\n cache_data = None\n if cache_file is not None:\n try:\n with open(os.path.join(cache_dir, cache_file), \"rb\") as f:\n cache_data = pickle.load(f)\n print(\"Read preprocessed data from cache file:\", cache_file)\n except:\n pass # unable to read from cache, but that's okay\n \n # If cache is missing, then do the heavy lifting\n if cache_data is None:\n # Preprocess training and test data to obtain words for each review\n #words_train = list(map(review_to_words, data_train))\n #words_test = list(map(review_to_words, data_test))\n words_train = [review_to_words(review) for review in data_train]\n words_test = [review_to_words(review) for review in data_test]\n \n # Write to cache file for future runs\n if cache_file is not None:\n cache_data = dict(words_train=words_train, words_test=words_test,\n labels_train=labels_train, labels_test=labels_test)\n with open(os.path.join(cache_dir, cache_file), \"wb\") as f:\n pickle.dump(cache_data, f)\n print(\"Wrote preprocessed data to cache file:\", cache_file)\n else:\n # Unpack data loaded from cache file\n words_train, words_test, labels_train, labels_test = (cache_data['words_train'],\n cache_data['words_test'], cache_data['labels_train'], cache_data['labels_test'])\n \n return words_train, words_test, labels_train, labels_test",
"_____no_output_____"
],
[
"# Preprocess data\ntrain_X, test_X, train_y, test_y = preprocess_data(train_X, test_X, train_y, test_y)",
"Read preprocessed data from cache file: preprocessed_data.pkl\n"
]
],
[
[
"## Transform the data\n\nIn the XGBoost notebook we transformed the data from its word representation to a bag-of-words feature representation. For the model we are going to construct in this notebook we will construct a feature representation which is very similar. To start, we will represent each word as an integer. Of course, some of the words that appear in the reviews occur very infrequently and so likely don't contain much information for the purposes of sentiment analysis. The way we will deal with this problem is that we will fix the size of our working vocabulary and we will only include the words that appear most frequently. We will then combine all of the infrequent words into a single category and, in our case, we will label it as `1`.\n\nSince we will be using a recurrent neural network, it will be convenient if the length of each review is the same. To do this, we will fix a size for our reviews and then pad short reviews with the category 'no word' (which we will label `0`) and truncate long reviews.",
"_____no_output_____"
],
[
"### (TODO) Create a word dictionary\n\nTo begin with, we need to construct a way to map words that appear in the reviews to integers. Here we fix the size of our vocabulary (including the 'no word' and 'infrequent' categories) to be `5000` but you may wish to change this to see how it affects the model.\n\n> **TODO:** Complete the implementation for the `build_dict()` method below. Note that even though the vocab_size is set to `5000`, we only want to construct a mapping for the most frequently appearing `4998` words. This is because we want to reserve the special labels `0` for 'no word' and `1` for 'infrequent word'.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef build_dict(data, vocab_size = 5000):\n \"\"\"Construct and return a dictionary mapping each of the most frequently appearing words to a unique integer.\"\"\"\n \n # TODO: Determine how often each word appears in `data`. Note that `data` is a list of sentences and that a\n # sentence is a list of words.\n \n word_count = {} # A dict storing the words that appear in the reviews along with how often they occur\n for r in data:\n for word in r:\n if word in word_count:\n word_count[word] += 1\n else:\n word_count[word] = 1\n # TODO: Sort the words found in `data` so that sorted_words[0] is the most frequently appearing word and\n # sorted_words[-1] is the least frequently appearing word.\n \n sorted_words = [item[0] for item in sorted(word_count.items(), key=lambda x: x[1], reverse=True)]\n \n word_dict = {} # This is what we are building, a dictionary that translates words into integers\n for idx, word in enumerate(sorted_words[:vocab_size - 2]): # The -2 is so that we save room for the 'no word'\n word_dict[word] = idx + 2 # 'infrequent' labels\n \n return word_dict",
"_____no_output_____"
],
[
"word_dict = build_dict(train_X)",
"_____no_output_____"
]
],
[
[
"**Question:** What are the five most frequently appearing (tokenized) words in the training set? Does it makes sense that these words appear frequently in the training set?",
"_____no_output_____"
],
[
"**Answer:**\n\nSee below cell for top 5.\n\nYes this seems to make sense given the context of the problem.",
"_____no_output_____"
]
],
[
[
"# TODO: Use this space to determine the five most frequently appearing words in the training set.\n\ncount = 0\nfor word, idx in word_dict.items():\n print(word)\n count += 1\n if count == 5:\n break;",
"movi\nfilm\none\nlike\ntime\n"
]
],
[
[
"### Save `word_dict`\n\nLater on when we construct an endpoint which processes a submitted review we will need to make use of the `word_dict` which we have created. As such, we will save it to a file now for future use.",
"_____no_output_____"
]
],
[
[
"data_dir = '../data/pytorch' # The folder we will use for storing data\nif not os.path.exists(data_dir): # Make sure that the folder exists\n os.makedirs(data_dir)",
"_____no_output_____"
],
[
"with open(os.path.join(data_dir, 'word_dict.pkl'), \"wb\") as f:\n pickle.dump(word_dict, f)",
"_____no_output_____"
]
],
[
[
"### Transform the reviews\n\nNow that we have our word dictionary which allows us to transform the words appearing in the reviews into integers, it is time to make use of it and convert our reviews to their integer sequence representation, making sure to pad or truncate to a fixed length, which in our case is `500`.",
"_____no_output_____"
]
],
[
[
"def convert_and_pad(word_dict, sentence, pad=500):\n NOWORD = 0 # We will use 0 to represent the 'no word' category\n INFREQ = 1 # and we use 1 to represent the infrequent words, i.e., words not appearing in word_dict\n \n working_sentence = [NOWORD] * pad\n \n for word_index, word in enumerate(sentence[:pad]):\n if word in word_dict:\n working_sentence[word_index] = word_dict[word]\n else:\n working_sentence[word_index] = INFREQ\n \n return working_sentence, min(len(sentence), pad)\n\ndef convert_and_pad_data(word_dict, data, pad=500):\n result = []\n lengths = []\n \n for sentence in data:\n converted, leng = convert_and_pad(word_dict, sentence, pad)\n result.append(converted)\n lengths.append(leng)\n \n return np.array(result), np.array(lengths)",
"_____no_output_____"
],
[
"train_X, train_X_len = convert_and_pad_data(word_dict, train_X)\ntest_X, test_X_len = convert_and_pad_data(word_dict, test_X)",
"_____no_output_____"
]
],
[
[
"As a quick check to make sure that things are working as intended, check to see what one of the reviews in the training set looks like after having been processeed. Does this look reasonable? What is the length of a review in the training set?",
"_____no_output_____"
]
],
[
[
"# Use this cell to examine one of the processed reviews to make sure everything is working as intended.\n\ntrain_X[0]",
"_____no_output_____"
]
],
[
[
"**Question:** In the cells above we use the `preprocess_data` and `convert_and_pad_data` methods to process both the training and testing set. Why or why not might this be a problem?",
"_____no_output_____"
],
[
"**Answer:**\n\nInformation is lost if it's not contained within the `word_dict`. Each document will also contain the same vector length. Tensorflow 2.0 has released [ragged tensors](https://www.tensorflow.org/guide/ragged_tensors) to attempt address the later problem.",
"_____no_output_____"
],
[
"## Step 3: Upload the data to S3\n\nAs in the XGBoost notebook, we will need to upload the training dataset to S3 in order for our training code to access it. For now we will save it locally and we will upload to S3 later on.\n\n### Save the processed training dataset locally\n\nIt is important to note the format of the data that we are saving as we will need to know it when we write the training code. In our case, each row of the dataset has the form `label`, `length`, `review[500]` where `review[500]` is a sequence of `500` integers representing the words in the review.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n \npd.concat([pd.DataFrame(train_y), pd.DataFrame(train_X_len), pd.DataFrame(train_X)], axis=1) \\\n .to_csv(os.path.join(data_dir, 'train.csv'), header=False, index=False)",
"_____no_output_____"
]
],
[
[
"### Uploading the training data\n\n\nNext, we need to upload the training data to the SageMaker default S3 bucket so that we can provide access to it while training our model.",
"_____no_output_____"
]
],
[
[
"import sagemaker\n\nsagemaker_session = sagemaker.Session()\n\nbucket = sagemaker_session.default_bucket()\nprefix = 'sagemaker/sentiment_rnn'\n\nrole = sagemaker.get_execution_role()",
"_____no_output_____"
],
[
"input_data = sagemaker_session.upload_data(path=data_dir, bucket=bucket, key_prefix=prefix)",
"_____no_output_____"
]
],
[
[
"**NOTE:** The cell above uploads the entire contents of our data directory. This includes the `word_dict.pkl` file. This is fortunate as we will need this later on when we create an endpoint that accepts an arbitrary review. For now, we will just take note of the fact that it resides in the data directory (and so also in the S3 training bucket) and that we will need to make sure it gets saved in the model directory.",
"_____no_output_____"
],
[
"## Step 4: Build and Train the PyTorch Model\n\nIn the XGBoost notebook we discussed what a model is in the SageMaker framework. In particular, a model comprises three objects\n\n - Model Artifacts,\n - Training Code, and\n - Inference Code,\n \neach of which interact with one another. In the XGBoost example we used training and inference code that was provided by Amazon. Here we will still be using containers provided by Amazon with the added benefit of being able to include our own custom code.\n\nWe will start by implementing our own neural network in PyTorch along with a training script. For the purposes of this project we have provided the necessary model object in the `model.py` file, inside of the `train` folder. You can see the provided implementation by running the cell below.",
"_____no_output_____"
]
],
[
[
"!pygmentize train/model.py",
"\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.nn\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnn\u001b[39;49;00m\r\n\r\n\u001b[34mclass\u001b[39;49;00m \u001b[04m\u001b[32mLSTMClassifier\u001b[39;49;00m(nn.Module):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m This is the simple RNN model we will be using to perform Sentiment Analysis.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n\r\n \u001b[34mdef\u001b[39;49;00m \u001b[32m__init__\u001b[39;49;00m(\u001b[36mself\u001b[39;49;00m, embedding_dim, hidden_dim, vocab_size):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m Initialize the model by settingg up the various layers.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n \u001b[36msuper\u001b[39;49;00m(LSTMClassifier, \u001b[36mself\u001b[39;49;00m).\u001b[32m__init__\u001b[39;49;00m()\r\n\r\n \u001b[36mself\u001b[39;49;00m.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=\u001b[34m0\u001b[39;49;00m)\r\n \u001b[36mself\u001b[39;49;00m.lstm = nn.LSTM(embedding_dim, hidden_dim)\r\n \u001b[36mself\u001b[39;49;00m.dense = nn.Linear(in_features=hidden_dim, out_features=\u001b[34m1\u001b[39;49;00m)\r\n \u001b[36mself\u001b[39;49;00m.sig = nn.Sigmoid()\r\n \r\n \u001b[36mself\u001b[39;49;00m.word_dict = \u001b[36mNone\u001b[39;49;00m\r\n\r\n \u001b[34mdef\u001b[39;49;00m \u001b[32mforward\u001b[39;49;00m(\u001b[36mself\u001b[39;49;00m, x):\r\n \u001b[33m\"\"\"\u001b[39;49;00m\r\n\u001b[33m Perform a forward pass of our model on some input.\u001b[39;49;00m\r\n\u001b[33m \"\"\"\u001b[39;49;00m\r\n x = x.t()\r\n lengths = x[\u001b[34m0\u001b[39;49;00m,:]\r\n reviews = x[\u001b[34m1\u001b[39;49;00m:,:]\r\n embeds = \u001b[36mself\u001b[39;49;00m.embedding(reviews)\r\n lstm_out, _ = \u001b[36mself\u001b[39;49;00m.lstm(embeds)\r\n out = \u001b[36mself\u001b[39;49;00m.dense(lstm_out)\r\n out = out[lengths - \u001b[34m1\u001b[39;49;00m, \u001b[36mrange\u001b[39;49;00m(\u001b[36mlen\u001b[39;49;00m(lengths))]\r\n \u001b[34mreturn\u001b[39;49;00m \u001b[36mself\u001b[39;49;00m.sig(out.squeeze())\r\n"
]
],
[
[
"The important takeaway from the implementation provided is that there are three parameters that we may wish to tweak to improve the performance of our model. These are the embedding dimension, the hidden dimension and the size of the vocabulary. We will likely want to make these parameters configurable in the training script so that if we wish to modify them we do not need to modify the script itself. We will see how to do this later on. To start we will write some of the training code in the notebook so that we can more easily diagnose any issues that arise.\n\nFirst we will load a small portion of the training data set to use as a sample. It would be very time consuming to try and train the model completely in the notebook as we do not have access to a gpu and the compute instance that we are using is not particularly powerful. However, we can work on a small bit of the data to get a feel for how our training script is behaving.",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.utils.data\n\n# Read in only the first 250 rows\ntrain_sample = pd.read_csv(os.path.join(data_dir, 'train.csv'), header=None, names=None, nrows=250)\n\n# Turn the input pandas dataframe into tensors\ntrain_sample_y = torch.from_numpy(train_sample[[0]].values).float().squeeze()\ntrain_sample_X = torch.from_numpy(train_sample.drop([0], axis=1).values).long()\n\n# Build the dataset\ntrain_sample_ds = torch.utils.data.TensorDataset(train_sample_X, train_sample_y)\n# Build the dataloader\ntrain_sample_dl = torch.utils.data.DataLoader(train_sample_ds, batch_size=50)",
"_____no_output_____"
]
],
[
[
"### (TODO) Writing the training method\n\nNext we need to write the training code itself. This should be very similar to training methods that you have written before to train PyTorch models. We will leave any difficult aspects such as model saving / loading and parameter loading until a little later.",
"_____no_output_____"
]
],
[
[
"def train(model, train_loader, epochs, optimizer, loss_fn, device):\n for epoch in range(1, epochs + 1):\n model.train()\n total_loss = 0\n for batch in train_loader: \n batch_X, batch_y = batch\n \n batch_X = batch_X.to(device)\n batch_y = batch_y.to(device)\n \n # TODO: Complete this train method to train the model provided.\n optimizer.zero_grad()\n out = model.forward(batch_X)\n loss = loss_fn(out, batch_y)\n loss.backward()\n optimizer.step()\n \n total_loss += loss.data.item()\n print(\"Epoch: {}, BCELoss: {}\".format(epoch, total_loss / len(train_loader)))",
"_____no_output_____"
]
],
[
[
"Supposing we have the training method above, we will test that it is working by writing a bit of code in the notebook that executes our training method on the small sample training set that we loaded earlier. The reason for doing this in the notebook is so that we have an opportunity to fix any errors that arise early when they are easier to diagnose.",
"_____no_output_____"
]
],
[
[
"import torch.optim as optim\nfrom train.model import LSTMClassifier\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nmodel = LSTMClassifier(32, 100, 5000).to(device)\noptimizer = optim.Adam(model.parameters())\nloss_fn = torch.nn.BCELoss()\n\ntrain(model, train_sample_dl, 5, optimizer, loss_fn, device)",
"Epoch: 1, BCELoss: 0.6944131135940552\nEpoch: 2, BCELoss: 0.6847697377204895\nEpoch: 3, BCELoss: 0.6759644150733948\nEpoch: 4, BCELoss: 0.66590656042099\nEpoch: 5, BCELoss: 0.6533006429672241\n"
]
],
[
[
"In order to construct a PyTorch model using SageMaker we must provide SageMaker with a training script. We may optionally include a directory which will be copied to the container and from which our training code will be run. When the training container is executed it will check the uploaded directory (if there is one) for a `requirements.txt` file and install any required Python libraries, after which the training script will be run.",
"_____no_output_____"
],
[
"### (TODO) Training the model\n\nWhen a PyTorch model is constructed in SageMaker, an entry point must be specified. This is the Python file which will be executed when the model is trained. Inside of the `train` directory is a file called `train.py` which has been provided and which contains most of the necessary code to train our model. The only thing that is missing is the implementation of the `train()` method which you wrote earlier in this notebook.\n\n**TODO**: Copy the `train()` method written above and paste it into the `train/train.py` file where required.\n\nThe way that SageMaker passes hyperparameters to the training script is by way of arguments. These arguments can then be parsed and used in the training script. To see how this is done take a look at the provided `train/train.py` file.",
"_____no_output_____"
]
],
[
[
"from sagemaker.pytorch import PyTorch\n\nestimator = PyTorch(entry_point=\"train.py\",\n source_dir=\"train\",\n role=role,\n framework_version='0.4.0',\n train_instance_count=1,\n train_instance_type='ml.m4.xlarge', #'ml.p2.xlarge'\n hyperparameters={\n 'epochs': 10,\n 'hidden_dim': 200,\n })",
"_____no_output_____"
],
[
"estimator.fit({'training': input_data})",
"2019-06-18 21:10:46 Starting - Starting the training job...\n2019-06-18 21:10:49 Starting - Launching requested ML instances......\n2019-06-18 21:11:58 Starting - Preparing the instances for training......\n2019-06-18 21:13:15 Downloading - Downloading input data\n2019-06-18 21:13:15 Training - Downloading the training image...\n2019-06-18 21:13:33 Training - Training image download completed. Training in progress.\n\u001b[31mbash: cannot set terminal process group (-1): Inappropriate ioctl for device\u001b[0m\n\u001b[31mbash: no job control in this shell\u001b[0m\n\u001b[31m2019-06-18 21:13:33,804 sagemaker-containers INFO Imported framework sagemaker_pytorch_container.training\u001b[0m\n\u001b[31m2019-06-18 21:13:33,807 sagemaker-containers INFO No GPUs detected (normal if no gpus installed)\u001b[0m\n\u001b[31m2019-06-18 21:13:33,826 sagemaker_pytorch_container.training INFO Block until all host DNS lookups succeed.\u001b[0m\n\u001b[31m2019-06-18 21:13:36,847 sagemaker_pytorch_container.training INFO Invoking user training script.\u001b[0m\n\u001b[31m2019-06-18 21:13:37,064 sagemaker-containers INFO Module train does not provide a setup.py. \u001b[0m\n\u001b[31mGenerating setup.py\u001b[0m\n\u001b[31m2019-06-18 21:13:37,064 sagemaker-containers INFO Generating setup.cfg\u001b[0m\n\u001b[31m2019-06-18 21:13:37,064 sagemaker-containers INFO Generating MANIFEST.in\u001b[0m\n\u001b[31m2019-06-18 21:13:37,065 sagemaker-containers INFO Installing module with the following command:\u001b[0m\n\u001b[31m/usr/bin/python -m pip install -U . -r requirements.txt\u001b[0m\n\u001b[31mProcessing /opt/ml/code\u001b[0m\n\u001b[31mCollecting pandas (from -r requirements.txt (line 1))\n Downloading https://files.pythonhosted.org/packages/74/24/0cdbf8907e1e3bc5a8da03345c23cbed7044330bb8f73bb12e711a640a00/pandas-0.24.2-cp35-cp35m-manylinux1_x86_64.whl (10.0MB)\u001b[0m\n\u001b[31mCollecting numpy (from -r requirements.txt (line 2))\n Downloading https://files.pythonhosted.org/packages/bb/ef/d5a21cbc094d3f4d5b5336494dbcc9550b70c766a8345513c7c24ed18418/numpy-1.16.4-cp35-cp35m-manylinux1_x86_64.whl (17.2MB)\u001b[0m\n\u001b[31mCollecting nltk (from -r requirements.txt (line 3))\n Downloading https://files.pythonhosted.org/packages/8d/5d/825889810b85c303c8559a3fd74d451d80cf3585a851f2103e69576bf583/nltk-3.4.3.zip (1.4MB)\u001b[0m\n\u001b[31mCollecting beautifulsoup4 (from -r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/1d/5d/3260694a59df0ec52f8b4883f5d23b130bc237602a1411fa670eae12351e/beautifulsoup4-4.7.1-py3-none-any.whl (94kB)\u001b[0m\n\u001b[31mCollecting html5lib (from -r requirements.txt (line 5))\n Downloading https://files.pythonhosted.org/packages/a5/62/bbd2be0e7943ec8504b517e62bab011b4946e1258842bc159e5dfde15b96/html5lib-1.0.1-py2.py3-none-any.whl (117kB)\u001b[0m\n\u001b[31mCollecting pytz>=2011k (from pandas->-r requirements.txt (line 1))\n Downloading https://files.pythonhosted.org/packages/3d/73/fe30c2daaaa0713420d0382b16fbb761409f532c56bdcc514bf7b6262bb6/pytz-2019.1-py2.py3-none-any.whl (510kB)\u001b[0m\n\u001b[31mRequirement already satisfied, skipping upgrade: python-dateutil>=2.5.0 in /usr/local/lib/python3.5/dist-packages (from pandas->-r requirements.txt (line 1)) (2.7.5)\u001b[0m\n\u001b[31mRequirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.5/dist-packages (from nltk->-r requirements.txt (line 3)) (1.11.0)\u001b[0m\n\u001b[31mCollecting soupsieve>=1.2 (from beautifulsoup4->-r requirements.txt (line 4))\n Downloading https://files.pythonhosted.org/packages/b9/a5/7ea40d0f8676bde6e464a6435a48bc5db09b1a8f4f06d41dd997b8f3c616/soupsieve-1.9.1-py2.py3-none-any.whl\u001b[0m\n\u001b[31mCollecting webencodings (from html5lib->-r requirements.txt (line 5))\n Downloading https://files.pythonhosted.org/packages/f4/24/2a3e3df732393fed8b3ebf2ec078f05546de641fe1b667ee316ec1dcf3b7/webencodings-0.5.1-py2.py3-none-any.whl\u001b[0m\n\u001b[31mBuilding wheels for collected packages: nltk, train\n Running setup.py bdist_wheel for nltk: started\u001b[0m\n\u001b[31m Running setup.py bdist_wheel for nltk: finished with status 'done'\n Stored in directory: /root/.cache/pip/wheels/54/40/b7/c56ad418e6cd4d9e1e594b5e138d1ca6eec11a6ee3d464e5bb\n Running setup.py bdist_wheel for train: started\n Running setup.py bdist_wheel for train: finished with status 'done'\n Stored in directory: /tmp/pip-ephem-wheel-cache-n54d3tkh/wheels/35/24/16/37574d11bf9bde50616c67372a334f94fa8356bc7164af8ca3\u001b[0m\n\u001b[31mSuccessfully built nltk train\u001b[0m\n\u001b[31mInstalling collected packages: pytz, numpy, pandas, nltk, soupsieve, beautifulsoup4, webencodings, html5lib, train\u001b[0m\n\u001b[31m Found existing installation: numpy 1.15.4\n Uninstalling numpy-1.15.4:\u001b[0m\n\u001b[31m Successfully uninstalled numpy-1.15.4\u001b[0m\n\u001b[31mSuccessfully installed beautifulsoup4-4.7.1 html5lib-1.0.1 nltk-3.4.3 numpy-1.16.4 pandas-0.24.2 pytz-2019.1 soupsieve-1.9.1 train-1.0.0 webencodings-0.5.1\u001b[0m\n\u001b[31mYou are using pip version 18.1, however version 19.1.1 is available.\u001b[0m\n\u001b[31mYou should consider upgrading via the 'pip install --upgrade pip' command.\u001b[0m\n\u001b[31m2019-06-18 21:13:48,613 sagemaker-containers INFO No GPUs detected (normal if no gpus installed)\u001b[0m\n\u001b[31m2019-06-18 21:13:48,627 sagemaker-containers INFO Invoking user script\n\u001b[0m\n\u001b[31mTraining Env:\n\u001b[0m\n\u001b[31m{\n \"current_host\": \"algo-1\",\n \"num_gpus\": 0,\n \"framework_module\": \"sagemaker_pytorch_container.training:main\",\n \"module_dir\": \"s3://sagemaker-us-east-2-135777927869/sagemaker-pytorch-2019-06-18-21-10-46-312/source/sourcedir.tar.gz\",\n \"hosts\": [\n \"algo-1\"\n ],\n \"network_interface_name\": \"eth0\",\n \"input_data_config\": {\n \"training\": {\n \"TrainingInputMode\": \"File\",\n \"RecordWrapperType\": \"None\",\n \"S3DistributionType\": \"FullyReplicated\"\n }\n },\n \"input_config_dir\": \"/opt/ml/input/config\",\n \"module_name\": \"train\",\n \"channel_input_dirs\": {\n \"training\": \"/opt/ml/input/data/training\"\n },\n \"model_dir\": \"/opt/ml/model\",\n \"output_dir\": \"/opt/ml/output\",\n \"job_name\": \"sagemaker-pytorch-2019-06-18-21-10-46-312\",\n \"user_entry_point\": \"train.py\",\n \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n \"additional_framework_parameters\": {},\n \"log_level\": 20,\n \"output_data_dir\": \"/opt/ml/output/data\",\n \"hyperparameters\": {\n \"hidden_dim\": 200,\n \"epochs\": 10\n },\n \"input_dir\": \"/opt/ml/input\",\n \"num_cpus\": 4,\n \"resource_config\": {\n \"network_interface_name\": \"eth0\",\n \"current_host\": \"algo-1\",\n \"hosts\": [\n \"algo-1\"\n ]\n }\u001b[0m\n\u001b[31m}\n\u001b[0m\n\u001b[31mEnvironment variables:\n\u001b[0m\n\u001b[31mSM_OUTPUT_DATA_DIR=/opt/ml/output/data\u001b[0m\n\u001b[31mSM_USER_ARGS=[\"--epochs\",\"10\",\"--hidden_dim\",\"200\"]\u001b[0m\n\u001b[31mSM_MODEL_DIR=/opt/ml/model\u001b[0m\n\u001b[31mSM_MODULE_NAME=train\u001b[0m\n\u001b[31mSM_NUM_GPUS=0\u001b[0m\n\u001b[31mSM_NUM_CPUS=4\u001b[0m\n\u001b[31mSM_HOSTS=[\"algo-1\"]\u001b[0m\n\u001b[31mSM_MODULE_DIR=s3://sagemaker-us-east-2-135777927869/sagemaker-pytorch-2019-06-18-21-10-46-312/source/sourcedir.tar.gz\u001b[0m\n\u001b[31mSM_NETWORK_INTERFACE_NAME=eth0\u001b[0m\n\u001b[31mSM_INPUT_DIR=/opt/ml/input\u001b[0m\n\u001b[31mSM_USER_ENTRY_POINT=train.py\u001b[0m\n\u001b[31mSM_FRAMEWORK_PARAMS={}\u001b[0m\n\u001b[31mSM_CURRENT_HOST=algo-1\u001b[0m\n\u001b[31mSM_TRAINING_ENV={\"additional_framework_parameters\":{},\"channel_input_dirs\":{\"training\":\"/opt/ml/input/data/training\"},\"current_host\":\"algo-1\",\"framework_module\":\"sagemaker_pytorch_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"epochs\":10,\"hidden_dim\":200},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}},\"input_dir\":\"/opt/ml/input\",\"job_name\":\"sagemaker-pytorch-2019-06-18-21-10-46-312\",\"log_level\":20,\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-2-135777927869/sagemaker-pytorch-2019-06-18-21-10-46-312/source/sourcedir.tar.gz\",\"module_name\":\"train\",\"network_interface_name\":\"eth0\",\"num_cpus\":4,\"num_gpus\":0,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"train.py\"}\u001b[0m\n\u001b[31mSM_INPUT_CONFIG_DIR=/opt/ml/input/config\u001b[0m\n\u001b[31mSM_CHANNEL_TRAINING=/opt/ml/input/data/training\u001b[0m\n\u001b[31mSM_HP_EPOCHS=10\u001b[0m\n\u001b[31mPYTHONPATH=/usr/local/bin:/usr/lib/python35.zip:/usr/lib/python3.5:/usr/lib/python3.5/plat-x86_64-linux-gnu:/usr/lib/python3.5/lib-dynload:/usr/local/lib/python3.5/dist-packages:/usr/lib/python3/dist-packages\u001b[0m\n\u001b[31mSM_OUTPUT_DIR=/opt/ml/output\u001b[0m\n\u001b[31mSM_INPUT_DATA_CONFIG={\"training\":{\"RecordWrapperType\":\"None\",\"S3DistributionType\":\"FullyReplicated\",\"TrainingInputMode\":\"File\"}}\u001b[0m\n\u001b[31mSM_FRAMEWORK_MODULE=sagemaker_pytorch_container.training:main\u001b[0m\n\u001b[31mSM_CHANNELS=[\"training\"]\u001b[0m\n\u001b[31mSM_LOG_LEVEL=20\u001b[0m\n\u001b[31mSM_HP_HIDDEN_DIM=200\u001b[0m\n\u001b[31mSM_RESOURCE_CONFIG={\"current_host\":\"algo-1\",\"hosts\":[\"algo-1\"],\"network_interface_name\":\"eth0\"}\u001b[0m\n\u001b[31mSM_HPS={\"epochs\":10,\"hidden_dim\":200}\u001b[0m\n\u001b[31mSM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\n\u001b[0m\n\u001b[31mInvoking script with the following command:\n\u001b[0m\n\u001b[31m/usr/bin/python -m train --epochs 10 --hidden_dim 200\n\n\u001b[0m\n\u001b[31mUsing device cpu.\u001b[0m\n\u001b[31mGet train data loader.\u001b[0m\n\u001b[31mModel loaded with embedding_dim 32, hidden_dim 200, vocab_size 5000.\u001b[0m\n"
]
],
[
[
"## Step 5: Testing the model\n\nAs mentioned at the top of this notebook, we will be testing this model by first deploying it and then sending the testing data to the deployed endpoint. We will do this so that we can make sure that the deployed model is working correctly.\n\n## Step 6: Deploy the model for testing\n\nNow that we have trained our model, we would like to test it to see how it performs. Currently our model takes input of the form `review_length, review[500]` where `review[500]` is a sequence of `500` integers which describe the words present in the review, encoded using `word_dict`. Fortunately for us, SageMaker provides built-in inference code for models with simple inputs such as this.\n\nThere is one thing that we need to provide, however, and that is a function which loads the saved model. This function must be called `model_fn()` and takes as its only parameter a path to the directory where the model artifacts are stored. This function must also be present in the python file which we specified as the entry point. In our case the model loading function has been provided and so no changes need to be made.\n\n**NOTE**: When the built-in inference code is run it must import the `model_fn()` method from the `train.py` file. This is why the training code is wrapped in a main guard ( ie, `if __name__ == '__main__':` )\n\nSince we don't need to change anything in the code that was uploaded during training, we can simply deploy the current model as-is.\n\n**NOTE:** When deploying a model you are asking SageMaker to launch an compute instance that will wait for data to be sent to it. As a result, this compute instance will continue to run until *you* shut it down. This is important to know since the cost of a deployed endpoint depends on how long it has been running for.\n\nIn other words **If you are no longer using a deployed endpoint, shut it down!**\n\n**TODO:** Deploy the trained model.",
"_____no_output_____"
]
],
[
[
"# TODO: Deploy the trained model\npred = estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')",
"Using already existing model: sagemaker-pytorch-2019-06-18-21-10-46-312\n"
]
],
[
[
"## Step 7 - Use the model for testing\n\nOnce deployed, we can read in the test data and send it off to our deployed model to get some results. Once we collect all of the results we can determine how accurate our model is.",
"_____no_output_____"
]
],
[
[
"test_X = pd.concat([pd.DataFrame(test_X_len), pd.DataFrame(test_X)], axis=1)",
"_____no_output_____"
],
[
"# We split the data into chunks and send each chunk seperately, accumulating the results.\n\ndef predict(data, rows=512):\n split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))\n predictions = np.array([])\n for array in split_array:\n predictions = np.append(predictions, pred.predict(array))\n \n return predictions",
"_____no_output_____"
],
[
"predictions = predict(test_X.values)\npredictions = [round(num) for num in predictions]",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\naccuracy_score(test_y, predictions)",
"_____no_output_____"
]
],
[
[
"**Question:** How does this model compare to the XGBoost model you created earlier? Why might these two models perform differently on this dataset? Which do *you* think is better for sentiment analysis?",
"_____no_output_____"
],
[
"**Answer:**\n\nThe XGB model was able to get ~.84 accuracy so this model appears a little better.",
"_____no_output_____"
],
[
"### (TODO) More testing\n\nWe now have a trained model which has been deployed and which we can send processed reviews to and which returns the predicted sentiment. However, ultimately we would like to be able to send our model an unprocessed review. That is, we would like to send the review itself as a string. For example, suppose we wish to send the following review to our model.",
"_____no_output_____"
]
],
[
[
"test_review = 'The simplest pleasures in life are the best, and this film is one of them. Combining a rather basic storyline of love and adventure this movie transcends the usual weekend fair with wit and unmitigated charm.'",
"_____no_output_____"
]
],
[
[
"The question we now need to answer is, how do we send this review to our model?\n\nRecall in the first section of this notebook we did a bunch of data processing to the IMDb dataset. In particular, we did two specific things to the provided reviews.\n - Removed any html tags and stemmed the input\n - Encoded the review as a sequence of integers using `word_dict`\n \nIn order process the review we will need to repeat these two steps.\n\n**TODO**: Using the `review_to_words` and `convert_and_pad` methods from section one, convert `test_review` into a numpy array `test_data` suitable to send to our model. Remember that our model expects input of the form `review_length, review[500]`.",
"_____no_output_____"
]
],
[
[
"# TODO: Convert test_review into a form usable by the model and save the results in test_data\ntest_data = review_to_words(test_review)\ntest_data = [np.array(convert_and_pad(word_dict, test_data)[0])]",
"_____no_output_____"
]
],
[
[
"Now that we have processed the review, we can send the resulting array to our model to predict the sentiment of the review.",
"_____no_output_____"
]
],
[
[
"pred.predict(test_data)",
"_____no_output_____"
]
],
[
[
"Since the return value of our model is close to `1`, we can be certain that the review we submitted is positive.",
"_____no_output_____"
],
[
"### Delete the endpoint\n\nOf course, just like in the XGBoost notebook, once we've deployed an endpoint it continues to run until we tell it to shut down. Since we are done using our endpoint for now, we can delete it.",
"_____no_output_____"
]
],
[
[
"estimator.delete_endpoint()",
"_____no_output_____"
]
],
[
[
"## Step 6 (again) - Deploy the model for the web app\n\nNow that we know that our model is working, it's time to create some custom inference code so that we can send the model a review which has not been processed and have it determine the sentiment of the review.\n\nAs we saw above, by default the estimator which we created, when deployed, will use the entry script and directory which we provided when creating the model. However, since we now wish to accept a string as input and our model expects a processed review, we need to write some custom inference code.\n\nWe will store the code that we write in the `serve` directory. Provided in this directory is the `model.py` file that we used to construct our model, a `utils.py` file which contains the `review_to_words` and `convert_and_pad` pre-processing functions which we used during the initial data processing, and `predict.py`, the file which will contain our custom inference code. Note also that `requirements.txt` is present which will tell SageMaker what Python libraries are required by our custom inference code.\n\nWhen deploying a PyTorch model in SageMaker, you are expected to provide four functions which the SageMaker inference container will use.\n - `model_fn`: This function is the same function that we used in the training script and it tells SageMaker how to load our model.\n - `input_fn`: This function receives the raw serialized input that has been sent to the model's endpoint and its job is to de-serialize and make the input available for the inference code.\n - `output_fn`: This function takes the output of the inference code and its job is to serialize this output and return it to the caller of the model's endpoint.\n - `predict_fn`: The heart of the inference script, this is where the actual prediction is done and is the function which you will need to complete.\n\nFor the simple website that we are constructing during this project, the `input_fn` and `output_fn` methods are relatively straightforward. We only require being able to accept a string as input and we expect to return a single value as output. You might imagine though that in a more complex application the input or output may be image data or some other binary data which would require some effort to serialize.\n\n### (TODO) Writing inference code\n\nBefore writing our custom inference code, we will begin by taking a look at the code which has been provided.",
"_____no_output_____"
]
],
[
[
"!pygmentize serve/predict.py",
"\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36margparse\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mjson\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mos\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mpickle\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36msys\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36msagemaker_containers\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mpandas\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mpd\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mnumpy\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnp\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.nn\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36mnn\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.optim\u001b[39;49;00m \u001b[34mas\u001b[39;49;00m \u001b[04m\u001b[36moptim\u001b[39;49;00m\r\n\u001b[34mimport\u001b[39;49;00m \u001b[04m\u001b[36mtorch.utils.data\u001b[39;49;00m\r\n\r\n\u001b[34mfrom\u001b[39;49;00m \u001b[04m\u001b[36mmodel\u001b[39;49;00m \u001b[34mimport\u001b[39;49;00m LSTMClassifier\r\n\r\n\u001b[34mfrom\u001b[39;49;00m \u001b[04m\u001b[36mutils\u001b[39;49;00m \u001b[34mimport\u001b[39;49;00m review_to_words, convert_and_pad\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32mmodel_fn\u001b[39;49;00m(model_dir):\r\n \u001b[33m\"\"\"Load the PyTorch model from the `model_dir` directory.\"\"\"\u001b[39;49;00m\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mLoading model.\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n\r\n \u001b[37m# First, load the parameters used to create the model.\u001b[39;49;00m\r\n model_info = {}\r\n model_info_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mmodel_info.pth\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(model_info_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model_info = torch.load(f)\r\n\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mmodel_info: {}\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m.format(model_info))\r\n\r\n \u001b[37m# Determine the device and construct the model.\u001b[39;49;00m\r\n device = torch.device(\u001b[33m\"\u001b[39;49;00m\u001b[33mcuda\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m \u001b[34mif\u001b[39;49;00m torch.cuda.is_available() \u001b[34melse\u001b[39;49;00m \u001b[33m\"\u001b[39;49;00m\u001b[33mcpu\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n model = LSTMClassifier(model_info[\u001b[33m'\u001b[39;49;00m\u001b[33membedding_dim\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m], model_info[\u001b[33m'\u001b[39;49;00m\u001b[33mhidden_dim\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m], model_info[\u001b[33m'\u001b[39;49;00m\u001b[33mvocab_size\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m])\r\n\r\n \u001b[37m# Load the store model parameters.\u001b[39;49;00m\r\n model_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mmodel.pth\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(model_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model.load_state_dict(torch.load(f))\r\n\r\n \u001b[37m# Load the saved word_dict.\u001b[39;49;00m\r\n word_dict_path = os.path.join(model_dir, \u001b[33m'\u001b[39;49;00m\u001b[33mword_dict.pkl\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mwith\u001b[39;49;00m \u001b[36mopen\u001b[39;49;00m(word_dict_path, \u001b[33m'\u001b[39;49;00m\u001b[33mrb\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m) \u001b[34mas\u001b[39;49;00m f:\r\n model.word_dict = pickle.load(f)\r\n\r\n model.to(device).eval()\r\n\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m\"\u001b[39;49;00m\u001b[33mDone loading model.\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m model\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32minput_fn\u001b[39;49;00m(serialized_input_data, content_type):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mDeserializing the input data.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mif\u001b[39;49;00m content_type == \u001b[33m'\u001b[39;49;00m\u001b[33mtext/plain\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m:\r\n data = serialized_input_data.decode(\u001b[33m'\u001b[39;49;00m\u001b[33mutf-8\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m data\r\n \u001b[34mraise\u001b[39;49;00m \u001b[36mException\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mRequested unsupported ContentType in content_type: \u001b[39;49;00m\u001b[33m'\u001b[39;49;00m + content_type)\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32moutput_fn\u001b[39;49;00m(prediction_output, accept):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mSerializing the generated output.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \u001b[34mreturn\u001b[39;49;00m \u001b[36mstr\u001b[39;49;00m(prediction_output)\r\n\r\n\u001b[34mdef\u001b[39;49;00m \u001b[32mpredict_fn\u001b[39;49;00m(input_data, model):\r\n \u001b[34mprint\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mInferring sentiment of input data.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n\r\n device = torch.device(\u001b[33m\"\u001b[39;49;00m\u001b[33mcuda\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m \u001b[34mif\u001b[39;49;00m torch.cuda.is_available() \u001b[34melse\u001b[39;49;00m \u001b[33m\"\u001b[39;49;00m\u001b[33mcpu\u001b[39;49;00m\u001b[33m\"\u001b[39;49;00m)\r\n \r\n \u001b[34mif\u001b[39;49;00m model.word_dict \u001b[35mis\u001b[39;49;00m \u001b[36mNone\u001b[39;49;00m:\r\n \u001b[34mraise\u001b[39;49;00m \u001b[36mException\u001b[39;49;00m(\u001b[33m'\u001b[39;49;00m\u001b[33mModel has not been loaded properly, no word_dict.\u001b[39;49;00m\u001b[33m'\u001b[39;49;00m)\r\n \r\n \u001b[37m# TODO: Process input_data so that it is ready to be sent to our model.\u001b[39;49;00m\r\n \u001b[37m# You should produce two variables:\u001b[39;49;00m\r\n \u001b[37m# data_X - A sequence of length 500 which represents the converted review\u001b[39;49;00m\r\n \u001b[37m# data_len - The length of the review\u001b[39;49;00m\r\n\r\n w = review_to_words(input_data)\r\n data_X, data_len = convert_and_pad(model.word_dict, w)\r\n\r\n \u001b[37m# Using data_X and data_len we construct an appropriate input tensor. Remember\u001b[39;49;00m\r\n \u001b[37m# that our model expects input data of the form 'len, review[500]'.\u001b[39;49;00m\r\n data_pack = np.hstack((data_len, data_X))\r\n data_pack = data_pack.reshape(\u001b[34m1\u001b[39;49;00m, -\u001b[34m1\u001b[39;49;00m)\r\n \r\n data = torch.from_numpy(data_pack)\r\n data = data.to(device)\r\n\r\n \u001b[37m# Make sure to put the model into evaluation mode\u001b[39;49;00m\r\n model.eval()\r\n\r\n \u001b[37m# TODO: Compute the result of applying the model to the input data. The variable `result` should\u001b[39;49;00m\r\n \u001b[37m# be a numpy array which contains a single integer which is either 1 or 0\u001b[39;49;00m\r\n \u001b[34mwith\u001b[39;49;00m torch.no_grad():\r\n output = model.forward(data)\r\n\r\n result = np.round(output.numpy())\r\n\r\n \u001b[34mreturn\u001b[39;49;00m result\r\n"
]
],
[
[
"As mentioned earlier, the `model_fn` method is the same as the one provided in the training code and the `input_fn` and `output_fn` methods are very simple and your task will be to complete the `predict_fn` method. Make sure that you save the completed file as `predict.py` in the `serve` directory.\n\n**TODO**: Complete the `predict_fn()` method in the `serve/predict.py` file.",
"_____no_output_____"
],
[
"### Deploying the model\n\nNow that the custom inference code has been written, we will create and deploy our model. To begin with, we need to construct a new PyTorchModel object which points to the model artifacts created during training and also points to the inference code that we wish to use. Then we can call the deploy method to launch the deployment container.\n\n**NOTE**: The default behaviour for a deployed PyTorch model is to assume that any input passed to the predictor is a `numpy` array. In our case we want to send a string so we need to construct a simple wrapper around the `RealTimePredictor` class to accomodate simple strings. In a more complicated situation you may want to provide a serialization object, for example if you wanted to sent image data.",
"_____no_output_____"
]
],
[
[
"from sagemaker.predictor import RealTimePredictor\nfrom sagemaker.pytorch import PyTorchModel\n\nclass StringPredictor(RealTimePredictor):\n def __init__(self, endpoint_name, sagemaker_session):\n super(StringPredictor, self).__init__(endpoint_name, sagemaker_session, content_type='text/plain')\n\nmodel = PyTorchModel(model_data=estimator.model_data,\n role = role,\n framework_version='0.4.0',\n entry_point='predict.py',\n source_dir='serve',\n predictor_cls=StringPredictor)\npredictor = model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')",
"---------------------------------------------------------------------------------------!"
]
],
[
[
"### Testing the model\n\nNow that we have deployed our model with the custom inference code, we should test to see if everything is working. Here we test our model by loading the first `250` positive and negative reviews and send them to the endpoint, then collect the results. The reason for only sending some of the data is that the amount of time it takes for our model to process the input and then perform inference is quite long and so testing the entire data set would be prohibitive.",
"_____no_output_____"
]
],
[
[
"import glob\n\ndef test_reviews(data_dir='../data/aclImdb', stop=250):\n \n results = []\n ground = []\n \n # We make sure to test both positive and negative reviews \n for sentiment in ['pos', 'neg']:\n \n path = os.path.join(data_dir, 'test', sentiment, '*.txt')\n files = glob.glob(path)\n \n files_read = 0\n \n print('Starting ', sentiment, ' files')\n \n # Iterate through the files and send them to the predictor\n for f in files:\n with open(f) as review:\n # First, we store the ground truth (was the review positive or negative)\n if sentiment == 'pos':\n ground.append(1)\n else:\n ground.append(0)\n # Read in the review and convert to 'utf-8' for transmission via HTTP\n review_input = review.read().encode('utf-8')\n # Send the review to the predictor and store the results\n results.append(float(predictor.predict(review_input)))\n \n # Sending reviews to our endpoint one at a time takes a while so we\n # only send a small number of reviews\n files_read += 1\n if files_read == stop:\n break\n \n return ground, results",
"_____no_output_____"
],
[
"ground, results = test_reviews()",
"Starting pos files\nStarting neg files\n"
],
[
"from sklearn.metrics import accuracy_score\naccuracy_score(ground, results)",
"_____no_output_____"
]
],
[
[
"As an additional test, we can try sending the `test_review` that we looked at earlier.",
"_____no_output_____"
]
],
[
[
"predictor.predict(test_review)",
"_____no_output_____"
]
],
[
[
"Now that we know our endpoint is working as expected, we can set up the web page that will interact with it. If you don't have time to finish the project now, make sure to skip down to the end of this notebook and shut down your endpoint. You can deploy it again when you come back.",
"_____no_output_____"
],
[
"## Step 7 (again): Use the model for the web app\n\n> **TODO:** This entire section and the next contain tasks for you to complete, mostly using the AWS console.\n\nSo far we have been accessing our model endpoint by constructing a predictor object which uses the endpoint and then just using the predictor object to perform inference. What if we wanted to create a web app which accessed our model? The way things are set up currently makes that not possible since in order to access a SageMaker endpoint the app would first have to authenticate with AWS using an IAM role which included access to SageMaker endpoints. However, there is an easier way! We just need to use some additional AWS services.\n\n<img src=\"Web App Diagram.svg\">\n\nThe diagram above gives an overview of how the various services will work together. On the far right is the model which we trained above and which is deployed using SageMaker. On the far left is our web app that collects a user's movie review, sends it off and expects a positive or negative sentiment in return.\n\nIn the middle is where some of the magic happens. We will construct a Lambda function, which you can think of as a straightforward Python function that can be executed whenever a specified event occurs. We will give this function permission to send and recieve data from a SageMaker endpoint.\n\nLastly, the method we will use to execute the Lambda function is a new endpoint that we will create using API Gateway. This endpoint will be a url that listens for data to be sent to it. Once it gets some data it will pass that data on to the Lambda function and then return whatever the Lambda function returns. Essentially it will act as an interface that lets our web app communicate with the Lambda function.\n\n### Setting up a Lambda function\n\nThe first thing we are going to do is set up a Lambda function. This Lambda function will be executed whenever our public API has data sent to it. When it is executed it will receive the data, perform any sort of processing that is required, send the data (the review) to the SageMaker endpoint we've created and then return the result.\n\n#### Part A: Create an IAM Role for the Lambda function\n\nSince we want the Lambda function to call a SageMaker endpoint, we need to make sure that it has permission to do so. To do this, we will construct a role that we can later give the Lambda function.\n\nUsing the AWS Console, navigate to the **IAM** page and click on **Roles**. Then, click on **Create role**. Make sure that the **AWS service** is the type of trusted entity selected and choose **Lambda** as the service that will use this role, then click **Next: Permissions**.\n\nIn the search box type `sagemaker` and select the check box next to the **AmazonSageMakerFullAccess** policy. Then, click on **Next: Review**.\n\nLastly, give this role a name. Make sure you use a name that you will remember later on, for example `LambdaSageMakerRole`. Then, click on **Create role**.\n\n#### Part B: Create a Lambda function\n\nNow it is time to actually create the Lambda function.\n\nUsing the AWS Console, navigate to the AWS Lambda page and click on **Create a function**. When you get to the next page, make sure that **Author from scratch** is selected. Now, name your Lambda function, using a name that you will remember later on, for example `sentiment_analysis_func`. Make sure that the **Python 3.6** runtime is selected and then choose the role that you created in the previous part. Then, click on **Create Function**.\n\nOn the next page you will see some information about the Lambda function you've just created. If you scroll down you should see an editor in which you can write the code that will be executed when your Lambda function is triggered. In our example, we will use the code below. \n\n```python\n# We need to use the low-level library to interact with SageMaker since the SageMaker API\n# is not available natively through Lambda.\nimport boto3\n\ndef lambda_handler(event, context):\n\n # The SageMaker runtime is what allows us to invoke the endpoint that we've created.\n runtime = boto3.Session().client('sagemaker-runtime')\n\n # Now we use the SageMaker runtime to invoke our endpoint, sending the review we were given\n response = runtime.invoke_endpoint(EndpointName = '**ENDPOINT NAME HERE**', # The name of the endpoint we created\n ContentType = 'text/plain', # The data format that is expected\n Body = event['body']) # The actual review\n\n # The response is an HTTP response whose body contains the result of our inference\n result = response['Body'].read().decode('utf-8')\n\n return {\n 'statusCode' : 200,\n 'headers' : { 'Content-Type' : 'text/plain', 'Access-Control-Allow-Origin' : '*' },\n 'body' : result\n }\n```\n\nOnce you have copy and pasted the code above into the Lambda code editor, replace the `**ENDPOINT NAME HERE**` portion with the name of the endpoint that we deployed earlier. You can determine the name of the endpoint using the code cell below.",
"_____no_output_____"
]
],
[
[
"predictor.endpoint",
"_____no_output_____"
]
],
[
[
"Once you have added the endpoint name to the Lambda function, click on **Save**. Your Lambda function is now up and running. Next we need to create a way for our web app to execute the Lambda function.\n\n### Setting up API Gateway\n\nNow that our Lambda function is set up, it is time to create a new API using API Gateway that will trigger the Lambda function we have just created.\n\nUsing AWS Console, navigate to **Amazon API Gateway** and then click on **Get started**.\n\nOn the next page, make sure that **New API** is selected and give the new api a name, for example, `sentiment_analysis_api`. Then, click on **Create API**.\n\nNow we have created an API, however it doesn't currently do anything. What we want it to do is to trigger the Lambda function that we created earlier.\n\nSelect the **Actions** dropdown menu and click **Create Method**. A new blank method will be created, select its dropdown menu and select **POST**, then click on the check mark beside it.\n\nFor the integration point, make sure that **Lambda Function** is selected and click on the **Use Lambda Proxy integration**. This option makes sure that the data that is sent to the API is then sent directly to the Lambda function with no processing. It also means that the return value must be a proper response object as it will also not be processed by API Gateway.\n\nType the name of the Lambda function you created earlier into the **Lambda Function** text entry box and then click on **Save**. Click on **OK** in the pop-up box that then appears, giving permission to API Gateway to invoke the Lambda function you created.\n\nThe last step in creating the API Gateway is to select the **Actions** dropdown and click on **Deploy API**. You will need to create a new Deployment stage and name it anything you like, for example `prod`.\n\nYou have now successfully set up a public API to access your SageMaker model. Make sure to copy or write down the URL provided to invoke your newly created public API as this will be needed in the next step. This URL can be found at the top of the page, highlighted in blue next to the text **Invoke URL**.",
"_____no_output_____"
],
[
"## Step 4: Deploying our web app\n\nNow that we have a publicly available API, we can start using it in a web app. For our purposes, we have provided a simple static html file which can make use of the public api you created earlier.\n\nIn the `website` folder there should be a file called `index.html`. Download the file to your computer and open that file up in a text editor of your choice. There should be a line which contains **\\*\\*REPLACE WITH PUBLIC API URL\\*\\***. Replace this string with the url that you wrote down in the last step and then save the file.\n\nNow, if you open `index.html` on your local computer, your browser will behave as a local web server and you can use the provided site to interact with your SageMaker model.\n\nIf you'd like to go further, you can host this html file anywhere you'd like, for example using github or hosting a static site on Amazon's S3. Once you have done this you can share the link with anyone you'd like and have them play with it too!\n\n> **Important Note** In order for the web app to communicate with the SageMaker endpoint, the endpoint has to actually be deployed and running. This means that you are paying for it. Make sure that the endpoint is running when you want to use the web app but that you shut it down when you don't need it, otherwise you will end up with a surprisingly large AWS bill.\n\n**TODO:** Make sure that you include the edited `index.html` file in your project submission.",
"_____no_output_____"
],
[
"Now that your web app is working, trying playing around with it and see how well it works.\n\n**Question**: Give an example of a review that you entered into your web app. What was the predicted sentiment of your example review?",
"_____no_output_____"
],
[
"**Answer:**\n\nI've followed all the instructions however the endpoints appears unresponsive. I've tested the model independently however and it appeared to show sensible answers. For example postive for the review:\n\n\"If you like original gut wrenching laughter you will like this movie. If you are young or old then you will love this movie, hell even my mom liked it.\"\n\nAnd negative for:\n\n\"Encouraged by the positive comments about this film on here I was looking forward to watching this film. Bad mistake. I've seen 950+ films and this is truly one of the worst of them\"\n",
"_____no_output_____"
],
[
"### Delete the endpoint\n\nRemember to always shut down your endpoint if you are no longer using it. You are charged for the length of time that the endpoint is running so if you forget and leave it on you could end up with an unexpectedly large bill.",
"_____no_output_____"
]
],
[
[
"predictor.delete_endpoint()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4a27db245d92b60a73be747d20ffec314812d469
| 30,567 |
ipynb
|
Jupyter Notebook
|
main.ipynb
|
Carlos-Bonfim/AceleraDev_data-science-3
|
dac5c9165c081d2938747ceaedca57ee97e7ad8b
|
[
"MIT"
] | null | null | null |
main.ipynb
|
Carlos-Bonfim/AceleraDev_data-science-3
|
dac5c9165c081d2938747ceaedca57ee97e7ad8b
|
[
"MIT"
] | 1 |
2021-02-02T22:54:21.000Z
|
2021-02-02T22:54:21.000Z
|
main.ipynb
|
Carlos-Bonfim/AceleraDev_data-science-3
|
dac5c9165c081d2938747ceaedca57ee97e7ad8b
|
[
"MIT"
] | null | null | null | 32.832438 | 303 | 0.398731 |
[
[
[
"# Desafio 5\n\nNeste desafio, vamos praticar sobre redução de dimensionalidade com PCA e seleção de variáveis com RFE. Utilizaremos o _data set_ [Fifa 2019](https://www.kaggle.com/karangadiya/fifa19), contendo originalmente 89 variáveis de mais de 18 mil jogadores do _game_ FIFA 2019.\n\n> Obs.: Por favor, não modifique o nome das funções de resposta.",
"_____no_output_____"
],
[
"## _Setup_ geral",
"_____no_output_____"
]
],
[
[
"from math import sqrt\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport scipy.stats as sct\nimport seaborn as sns\nimport statsmodels.api as sm\nimport statsmodels.stats as st\nfrom sklearn.decomposition import PCA\n\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.feature_selection import RFE\n\nfrom loguru import logger",
"_____no_output_____"
],
[
"# Algumas configurações para o matplotlib.\n# %matplotlib inline\n\n# from IPython.core.pylabtools import figsize\n\n\n# figsize(12, 8)\n\n# sns.set()",
"_____no_output_____"
],
[
"fifa = pd.read_csv(\"fifa.csv\")",
"_____no_output_____"
],
[
"columns_to_drop = [\"Unnamed: 0\", \"ID\", \"Name\", \"Photo\", \"Nationality\", \"Flag\",\n \"Club\", \"Club Logo\", \"Value\", \"Wage\", \"Special\", \"Preferred Foot\",\n \"International Reputation\", \"Weak Foot\", \"Skill Moves\", \"Work Rate\",\n \"Body Type\", \"Real Face\", \"Position\", \"Jersey Number\", \"Joined\",\n \"Loaned From\", \"Contract Valid Until\", \"Height\", \"Weight\", \"LS\",\n \"ST\", \"RS\", \"LW\", \"LF\", \"CF\", \"RF\", \"RW\", \"LAM\", \"CAM\", \"RAM\", \"LM\",\n \"LCM\", \"CM\", \"RCM\", \"RM\", \"LWB\", \"LDM\", \"CDM\", \"RDM\", \"RWB\", \"LB\", \"LCB\",\n \"CB\", \"RCB\", \"RB\", \"Release Clause\"\n]\n\ntry:\n fifa.drop(columns_to_drop, axis=1, inplace=True)\nexcept KeyError:\n logger.warning(f\"Columns already dropped\")",
"_____no_output_____"
]
],
[
[
"## Inicia sua análise a partir daqui",
"_____no_output_____"
]
],
[
[
"# verificando as 5 primeiras linhas\nfifa.head()",
"_____no_output_____"
],
[
"# verificando as quantidade de linhas e colunas\nfifa.shape",
"_____no_output_____"
],
[
"# analisando as primeiras estatísticas\nfifa.describe()",
"_____no_output_____"
],
[
"# verificando a quantidade de dados nulos\nfifa.isna().sum() / fifa.shape[0]",
"_____no_output_____"
]
],
[
[
"## Questão 1\n\nQual fração da variância consegue ser explicada pelo primeiro componente principal de `fifa`? Responda como um único float (entre 0 e 1) arredondado para três casas decimais.",
"_____no_output_____"
]
],
[
[
"def q1():\n # instanciando o pca\n pca = PCA()\n \n # treiando e criando o objeto para variancia explicada\n var_exp = pca.fit(fifa.dropna()).explained_variance_ratio_\n \n # retorna o resultado\n return round(var_exp[0], 3)\n\nq1()",
"_____no_output_____"
]
],
[
[
"## Questão 2\n\nQuantos componentes principais precisamos para explicar 95% da variância total? Responda como un único escalar inteiro.",
"_____no_output_____"
]
],
[
[
"def q2():\n # instanciando pca com 0.95\n pca = PCA(0.95)\n \n # reduzindo a dimensionalidade\n fifa_comp = pca.fit_transform(fifa.dropna())\n \n # retornando o resultado\n return fifa_comp.shape[1]\n \nq2()",
"_____no_output_____"
]
],
[
[
"## Questão 3\n\nQual são as coordenadas (primeiro e segundo componentes principais) do ponto `x` abaixo? O vetor abaixo já está centralizado. Cuidado para __não__ centralizar o vetor novamente (por exemplo, invocando `PCA.transform()` nele). Responda como uma tupla de float arredondados para três casas decimais.",
"_____no_output_____"
]
],
[
[
"x = [0.87747123, -1.24990363, -1.3191255, -36.7341814,\n -35.55091139, -37.29814417, -28.68671182, -30.90902583,\n -42.37100061, -32.17082438, -28.86315326, -22.71193348,\n -38.36945867, -20.61407566, -22.72696734, -25.50360703,\n 2.16339005, -27.96657305, -33.46004736, -5.08943224,\n -30.21994603, 3.68803348, -36.10997302, -30.86899058,\n -22.69827634, -37.95847789, -22.40090313, -30.54859849,\n -26.64827358, -19.28162344, -34.69783578, -34.6614351,\n 48.38377664, 47.60840355, 45.76793876, 44.61110193,\n 49.28911284\n]",
"_____no_output_____"
],
[
"def q3():\n # instanciando pca\n pca = PCA(n_components=2)\n \n # treinando com dataset\n pca.fit(fifa.dropna())\n \n # retornando resultado\n return tuple(pca.components_.dot(x).round(3))\n\nq3()",
"_____no_output_____"
]
],
[
[
"## Questão 4\n\nRealiza RFE com estimador de regressão linear para selecionar cinco variáveis, eliminando uma a uma. Quais são as variáveis selecionadas? Responda como uma lista de nomes de variáveis.",
"_____no_output_____"
]
],
[
[
"# eliminando o NAs\nfifa = fifa.dropna()\n\n# definindo x e y\nX = fifa.drop(columns='Overall')\ny = fifa['Overall']\n\ndef q4():\n # instanciando o regressão linear\n reg= LinearRegression()\n \n # instanciando RFE\n rfe = RFE(reg,5)\n \n # treinando rfe\n rfe.fit(X, y)\n \n # retornando o resultado\n return list(X.columns[rfe.support_])\n\nq4()",
"c:\\users\\carlo\\codenation\\data-science-3\\venv\\lib\\site-packages\\sklearn\\utils\\validation.py:71: FutureWarning: Pass n_features_to_select=5 as keyword args. From version 0.25 passing these as positional arguments will result in an error\n FutureWarning)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a27dbed70b31f6d2267172077281faad2ec7b31
| 95,834 |
ipynb
|
Jupyter Notebook
|
jupyter-hub/.ipynb_checkpoints/Final-Revenue-Industry-Analysis-Checkpoint-checkpoint.ipynb
|
Pivotal-Field-Engineering/Apps-on-PKS
|
8b795862678eec436edc5d422e349a018733fd9f
|
[
"Apache-2.0"
] | 11 |
2018-12-24T08:16:53.000Z
|
2021-01-06T04:23:06.000Z
|
jupyter-hub/.ipynb_checkpoints/Final-Revenue-Industry-Analysis-Checkpoint-checkpoint.ipynb
|
Pivotal-Field-Engineering/Apps-on-PKS
|
8b795862678eec436edc5d422e349a018733fd9f
|
[
"Apache-2.0"
] | 7 |
2019-02-12T15:33:06.000Z
|
2019-05-10T17:58:02.000Z
|
jupyter-hub/.ipynb_checkpoints/Final-Revenue-Industry-Analysis-Checkpoint-checkpoint.ipynb
|
Pivotal-Field-Engineering/Apps-on-PKS
|
8b795862678eec436edc5d422e349a018733fd9f
|
[
"Apache-2.0"
] | 22 |
2019-01-09T08:58:36.000Z
|
2020-12-08T15:19:48.000Z
| 38.689544 | 154 | 0.386241 |
[
[
[
"## Calculate Aggregate Stocks Revenue data for last 10 years\n## Organize Revenue Data by Industry into Pivot Table \n\n##### JUST NEED To Calculate Growth between ALL years and then ADD Columns to the Table/DataFrame.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport csv\nimport matplotlib.pyplot as plt\nfrom collections import Counter\nimport datetime\nfrom pandas_datareader import data\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"## 1 - Set Variables",
"_____no_output_____"
]
],
[
[
"# Market Cap Filters in MILLIONS\nmkt_cap_lower = 300\nmkt_cap_upper = 2000",
"_____no_output_____"
]
],
[
[
"## 2 - Import Zacks 10K/10Q data from CSV into a dataframe object",
"_____no_output_____"
]
],
[
[
"zacks_df = pd.read_csv('data/05-09-17-ZACKS_FE.csv')[['ticker','comp_name','per_fisc_year','per_type','per_fisc_qtr','per_end_date','tot_revnu']]\nzacks_df=zacks_df.dropna(subset=['tot_revnu'])\nzacks_df[:4]",
"_____no_output_____"
]
],
[
[
"## 3 - Import Zacks Industry CSV ",
"_____no_output_____"
]
],
[
[
"zacks_mt_df = pd.read_csv('data/05-09-17-ZACKS_MT.csv')[['ticker','zacks_x_sector_desc','zacks_m_ind_desc']]\nzacks_mt_df = zacks_mt_df.dropna(subset=['zacks_m_ind_desc','zacks_x_sector_desc'])\nzacks_mt_df[:3]",
"_____no_output_____"
]
],
[
[
"## 4 - Merge the two Dataframes on ticker",
"_____no_output_____"
]
],
[
[
"zacks_merged_df=pd.merge(zacks_df,zacks_mt_df,on='ticker', how='left') \nzacks_merged_df[:6]",
"_____no_output_____"
],
[
"# Create the Pivot Table\n# ind_revenue_table=pd.pivot_table(zacks_merged_df, values='tot_revnu',index='zacks_m_ind_desc',columns=['per_fisc_year'],aggfunc=np.sum)\nind_revenue_table=pd.pivot_table(zacks_merged_df, values='tot_revnu',index='zacks_m_ind_desc',columns=['per_fisc_year'],aggfunc=np.mean)\nind_revenue_table",
"_____no_output_____"
],
[
"ind_revenue_table_change = ind_revenue_table.pct_change(axis=1)\nind_revenue_table_change[:20]",
"_____no_output_____"
],
[
"ind_revenue_table_change = ind_revenue_table_change.sort_values([2017], ascending=[False]) \nind_revenue_table_change",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a27e1413d9b5ec0576ce878d404839c9a5a747a
| 28,612 |
ipynb
|
Jupyter Notebook
|
scripts/random/illumina_reads_length/illumina_reads_length.ipynb
|
iqbal-lab-org/paper_pandora2020_analyses
|
952e348107c3fec60482bb30a91620ee2ce32cb5
|
[
"MIT"
] | null | null | null |
scripts/random/illumina_reads_length/illumina_reads_length.ipynb
|
iqbal-lab-org/paper_pandora2020_analyses
|
952e348107c3fec60482bb30a91620ee2ce32cb5
|
[
"MIT"
] | 1 |
2020-11-27T03:03:40.000Z
|
2021-02-14T20:25:38.000Z
|
scripts/random/illumina_reads_length/illumina_reads_length.ipynb
|
iqbal-lab-org/paper_pandora2020_analyses
|
952e348107c3fec60482bb30a91620ee2ce32cb5
|
[
"MIT"
] | 2 |
2020-11-10T21:40:54.000Z
|
2020-11-10T21:47:17.000Z
| 135.601896 | 24,228 | 0.870649 |
[
[
[
"import pandas as pd\nimport seaborn as sns\nsns.set()\n\nillumina_reads_length=\"\"\"\n 29 5\n 358 6\n 73 7\n 69 8\n 68 9\n 36 10\n 36 11\n 47 12\n 48 13\n 35 14\n 45 15\n 25 16\n 30 17\n 34 18\n 32 19\n 38 20\n 25 21\n 35 22\n 31 23\n 38 24\n 43 25\n 37 26\n 32 27\n 36 28\n 30 29\n 47 30\n 39 31\n 31 32\n 49 33\n 38 34\n 7393 35\n 2795 36\n 3534 37\n 4116 38\n 4350 39\n 4433 40\n 4564 41\n 4943 42\n 4839 43\n 5303 44\n 5519 45\n 5930 46\n 6285 47\n 6767 48\n 7072 49\n 7119 50\n 7136 51\n 7191 52\n 7354 53\n 7851 54\n 8158 55\n 8580 56\n 9176 57\n 9342 58\n 9657 59\n 9864 60\n 9992 61\n 10407 62\n 10469 63\n 10220 64\n 11186 65\n 11893 66\n 11872 67\n 12683 68\n 13390 69\n 13464 70\n 13630 71\n 13840 72\n 14095 73\n 14202 74\n 14074 75\n 15002 76\n 15499 77\n 16364 78\n 17041 79\n 17448 80\n 17458 81\n 17736 82\n 18197 83\n 17894 84\n 18693 85\n 18305 86\n 19489 87\n 20246 88\n 20491 89\n 21341 90\n 21907 91\n 21561 92\n 21958 93\n 22221 94\n 22516 95\n 27940 96\n 50425 97\n 189920 98\n 402640 99\n1900637 100\n4948602 101\n 43 102\n 46 103\n 53 104\n 38 105\n 37 106\n 44 107\n 49 108\n 43 109\n 53 110\n 56 111\n 60 112\n 64 113\n 42 114\n 56 115\n 56 116\n 60 117\n 48 118\n 59 119\n 64 120\n 61 121\n 49 122\n 76 123\n 79 124\n68034892 125\n 60 126\n 73 127\n 75 128\n 61 129\n 82 130\n 96 131\n 64 132\n 32 133\n 70 134\n 74 135\n 91 136\n 152 137\n 359 138\n 228 139\n3270756 150\n2364822 151\n\"\"\"\n\ncounts = []\nread_lenghts = []\nfor index, elem in enumerate(illumina_reads_length.split()):\n if index%2==0:\n counts.append(int(elem))\n else:\n read_lenghts.append(int(elem))\ndf = pd.DataFrame(data={\"count\": counts, \"read_length\": read_lenghts})\nplot = df.plot.bar(x=\"read_length\", y=\"count\", logy=True, figsize=(25,5))\nplot.set_xticklabels(plot.get_xticklabels(), rotation=90)\nplot",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4a27e8e65c3f4007b7e7778c742bad10029c2066
| 40,209 |
ipynb
|
Jupyter Notebook
|
synthetic_examples/syn-2/g-only.ipynb
|
thuizhou/Collaborating-Networks
|
cf0cafa82e7602490d10ee801d4753b2733a48bb
|
[
"MIT"
] | null | null | null |
synthetic_examples/syn-2/g-only.ipynb
|
thuizhou/Collaborating-Networks
|
cf0cafa82e7602490d10ee801d4753b2733a48bb
|
[
"MIT"
] | null | null | null |
synthetic_examples/syn-2/g-only.ipynb
|
thuizhou/Collaborating-Networks
|
cf0cafa82e7602490d10ee801d4753b2733a48bb
|
[
"MIT"
] | null | null | null | 28.157563 | 225 | 0.546246 |
[
[
[
"import sys \nimport numpy as np # linear algebra\nfrom scipy.stats import randint\nimport matplotlib.pyplot as plt # this is used for the plot the graph \n%matplotlib inline\nfrom tqdm import notebook\nimport tensorflow as tf\nfrom scipy import stats\nfrom scipy.interpolate import interp1d",
"_____no_output_____"
]
],
[
[
"### Simulate data",
"_____no_output_____"
]
],
[
[
"np.random.seed(2020)\n\n# generate weibull distribution parameter\nshape=np.random.uniform(1,5,1000)\nscale=np.random.uniform(0.5,2,1000)\n\n\n# the full design matrix\nx=np.c_[shape,scale]\n\n\ny=(np.random.weibull(shape,size=1000)*scale).reshape(-1,1)\n\n\ntrain_x=x[:700,:]\ntrain_y=y[:700,:]\n\ntest_x=x[700:,:]\ntest_y=y[700:,:]\n\nntrain=len(train_x)\nntest=len(test_x)\n\n",
"_____no_output_____"
]
],
[
[
"### g-only, this is equivalent to using pre-training in under the Collaborating Network(CN) framework",
"_____no_output_____"
]
],
[
[
"def variables_from_scope(scope_name):\n \"\"\"\n Returns a list of all trainable variables in a given scope. This is useful when\n you'd like to back-propagate only to weights in one part of the network\n (in our case, the generator or the discriminator).\n \"\"\"\n return tf.compat.v1.get_collection(tf.compat.v1.GraphKeys.TRAINABLE_VARIABLES, scope=scope_name)",
"_____no_output_____"
],
[
" # Graph parameters\nintermediate_layer_size = 100\nintermediate_layer_size2 = 80\n# Training parameters\nbatch_size = 128\npre_iter= 40000",
"_____no_output_____"
],
[
"# g function learn the cdf\ndef g(yq,x):\n \"\"\"\n yq:quantile:,\n x:input feature and treatment,\n \"\"\"\n z1=tf.concat([yq,x],axis=1)\n hidden_layer = tf.compat.v1.layers.dense(z1, intermediate_layer_size,kernel_initializer=tf.compat.v1.initializers.random_normal(stddev=.001), name=\"g1\", activation=tf.compat.v1.nn.elu,reuse=None)\n hidden_layer_bn = tf.compat.v1.layers.batch_normalization(hidden_layer,name=\"g1bn\")\n hidden_layer2 = tf.compat.v1.layers.dense(hidden_layer_bn, intermediate_layer_size2, kernel_initializer=tf.compat.v1.initializers.random_normal(stddev=.001),name=\"g2\", activation=tf.compat.v1.nn.elu,reuse=None)\n hidden_layer2_bn = tf.compat.v1.layers.batch_normalization(hidden_layer2,name=\"g2bn\")\n gq_logit = tf.compat.v1.layers.dense(hidden_layer2_bn, 1,kernel_initializer=tf.initializers.glorot_normal, name=\"g3\", activation=None,reuse=None)\n gq_logit_bn=tf.keras.layers.BatchNormalization(axis=-1,momentum=.1)(gq_logit)\n return gq_logit_bn",
"_____no_output_____"
],
[
"tf.compat.v1.disable_eager_execution()",
"_____no_output_____"
],
[
"\ntf.compat.v1.reset_default_graph()\n\n# Placeholders\ny_ = tf.compat.v1.placeholder(tf.float32, [None, 1])\n\npre_y= tf.compat.v1.placeholder(tf.float32, [None, 1])\nx_=tf.compat.v1.placeholder(tf.float32, [None, x.shape[1]])\nq_ = tf.compat.v1.placeholder(tf.float32, [None, 1])\n\n\nylessthan_pre= tf.cast(tf.less_equal(y_,pre_y),tf.float32)\n\n\nwith tf.compat.v1.variable_scope(\"g\") as scope:\n gq_logit_pre = g(pre_y,x_)\n gq=tf.sigmoid(gq_logit_pre)*.99999+.00001\n\n\n\n\n#pre-loss\ng_loss_pre = tf.compat.v1.losses.sigmoid_cross_entropy(ylessthan_pre,gq_logit_pre)\n\n# Optimizer\noptimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=1e-4)\npre_step= optimizer.minimize(g_loss_pre,var_list=variables_from_scope(\"g\"))\n\n\n# Initializer\ninitialize_all = tf.compat.v1.global_variables_initializer()",
"_____no_output_____"
]
],
[
[
"### Single Evaluation",
"_____no_output_____"
]
],
[
[
"sess = tf.compat.v1.Session()\nsess.run(initialize_all)\nglpre=[]\n\n\nfor k in notebook.tnrange(pre_iter):\n i=np.random.choice(ntrain,batch_size,replace=False)\n ytmp = train_y[i,:]\n xtmp= train_x[i,:]\n #when we do not have f initially, we use a uniform distribution to extract points from support\n pre_ytmp=np.random.uniform(-1,14,(batch_size,1)) \n ltmp,_=sess.run([g_loss_pre,pre_step],feed_dict={y_: ytmp,\n x_:xtmp,\n pre_y:pre_ytmp})\n \n glpre.append(ltmp)\n\n",
"_____no_output_____"
]
],
[
[
"### P(Y>1|X)",
"_____no_output_____"
]
],
[
[
"#true\ntsuv1=1-stats.weibull_min.cdf(1,c=test_x[:,0],scale=test_x[:,1])\n\n\n#cdf estimate by g\ngsuv1=1.-sess.run(gq ,feed_dict={x_:test_x,\n pre_y:np.repeat(1,len(test_x)).reshape(-1,1),\n }).ravel()\n\n#np.save('gsuv_est',gsuv1)",
"_____no_output_____"
],
[
"plt.figure(figsize=(5,5))\nplt.plot(tsuv1,gsuv1,'.')\n\nplt.plot([0,1],[0,1])",
"_____no_output_____"
]
],
[
[
"#### Test the recover of true cdf",
"_____no_output_____"
]
],
[
[
"#generate sample\nnp.random.seed(3421)\nsamps=np.random.choice(len(test_x),3)\n#the mean and sd for the random sample\nxtmp=np.linspace(0,7,50000)\nplt.figure(figsize=(20,4))\nplt.subplot(131)\n\nplt.subplot(1,3,1)\ni=samps[0]\ntcdf=stats.weibull_min.cdf(x=xtmp,c=test_x[i,0],scale=test_x[i,1])\ncdf=sess.run(gq ,feed_dict={x_:np.tile(test_x[i,:],(50000,1)),\n pre_y:xtmp[:,None]\n }).ravel()\n\ngcdf=cdf\n\nplt.plot(xtmp,tcdf)\nplt.plot(xtmp,cdf)\n\n\nplt.subplot(1,3,2)\ni=samps[1]\ntcdf=stats.weibull_min.cdf(x=xtmp,c=test_x[i,0],scale=test_x[i,1])\ncdf=sess.run(gq ,feed_dict={x_:np.tile(test_x[i,:],(50000,1)),\n pre_y:xtmp[:,None]\n }).ravel()\n\ngcdf=np.c_[gcdf,cdf]\n\nplt.plot(xtmp,tcdf)\nplt.plot(xtmp,cdf)\n\nplt.subplot(1,3,3)\ni=samps[2]\ntcdf=stats.weibull_min.cdf(x=xtmp,c=test_x[i,0],scale=test_x[i,1])\ncdf=sess.run(gq ,feed_dict={x_:np.tile(test_x[i,:],(50000,1)),\n pre_y:xtmp[:,None]\n }).ravel()\n\ngcdf=np.c_[gcdf,cdf]\n\nplt.plot(xtmp,tcdf)\nplt.plot(xtmp,cdf)\n\n#np.save('gcdf',gcdf)\n",
"_____no_output_____"
]
],
[
[
"### Ten replications to evaluate the hard metrics",
"_____no_output_____"
]
],
[
[
"##function to create replication\ndef rep_iter(x,y,frac=0.3):\n n=len(x)\n ntest=int(np.floor(frac*n))\n allidx=np.random.permutation(n)\n trainidx= allidx[ntest:]\n testidx= allidx[:ntest]\n return x[trainidx],y[trainidx],x[testidx],y[testidx]\n ",
"_____no_output_____"
],
[
"#g\ngll=[]\ngcal=[]\ng90=[]\ngmae=[]",
"_____no_output_____"
],
[
"np.random.seed(2021)\nfor a in range(10):\n train_x,train_y,test_x,test_y=rep_iter(x,y)\n ntrain=len(train_x)\n ntest=len(test_x)\n\n \n\n sess = tf.compat.v1.Session()\n sess.run(initialize_all)\n gl=[]\n fl=[]\n\n\n sess = tf.compat.v1.Session()\n sess.run(initialize_all)\n gl=[]\n \n sess = tf.compat.v1.Session()\n sess.run(initialize_all)\n glpre=[]\n\n\n for k in notebook.tnrange(pre_iter):\n i=np.random.choice(ntrain,batch_size,replace=False)\n ytmp = train_y[i,:]\n xtmp= train_x[i,:]\n #when we do not have f initially, we use a uniform distribution to extract points from support\n pre_ytmp=np.random.uniform(-1,14,(batch_size,1)) \n ltmp,_=sess.run([g_loss_pre,pre_step],feed_dict={y_: ytmp,\n x_:xtmp,\n pre_y:pre_ytmp})\n\n glpre.append(ltmp)\n\n\n #####calculate metrics##############\n\n per=np.linspace(0.02,0.98,8) #quantile to study calibration\n\n\n #lower and upper bound\n low=np.quantile(test_y,0.05)\n high=np.quantile(test_y,0.95)\n itv=np.linspace(low,high,9)\n itv=np.append(-np.infty,itv)\n itv=np.append(itv,np.infty)\n #outcome1 belongs to which interval\n id=np.zeros(ntest)\n for i in range(10):\n id=id+1*(test_y.ravel()>itv[i+1])\n id=id.astype('int')\n\n\n # estimation by g\n med_est=np.array([])\n ll_est=np.empty(ntest)\n cal_est=np.zeros_like(per)\n cover_90=0\n\n\n #use interpolation to recover cdf\n xtmp=np.linspace(-1,12,5000)\n\n for i in range(ntest):\n l=itv[id[i]]\n r=itv[id[i]+1]\n\n #cdf estimate by g\n cdf=sess.run(gq ,feed_dict={x_:np.tile(test_x[i,:],(5000,1)),\n pre_y:xtmp[:,None]\n }).ravel()\n\n cdf[0]=0\n cdf[-1]=1\n invcdfest=interp1d(cdf,xtmp)\n cdfest=interp1d(xtmp,cdf)\n\n\n #estimate the mae\n med_est=np.append(med_est,invcdfest(0.5)) \n\n\n #estimate the loglikelihood\n l=itv[id[i]]\n r=itv[id[i]+1]\n if(r==np.inf):\n ll_est[i]=np.log(1.-cdfest(l)+1.e-10)\n elif(l==-np.inf):\n ll_est[i]=np.log(cdfest(r)+1.e-10)\n else:\n ll_est[i]=np.log(cdfest(r)-cdfest(l)+1.e-10)\n\n\n #estimate the calibration\n cal_est=cal_est+1.*(test_y[i]<invcdfest(0.5+per/2))*(test_y[i]>invcdfest(0.5-per/2))\n\n\n #estimate 90 coverage\n r=invcdfest(0.95)\n l=invcdfest(0.05)\n cover_90+=(test_y[i]<r)*(test_y[i]>l)\n\n \n\n #summary \n\n cal_est=cal_est/ntest\n\n #cal\n gcal.append(np.abs(cal_est-per).mean())\n\n #ll\n gll.append(ll_est.mean())\n\n #90coverage\n g90.append(cover_90/ntest)\n\n #mae\n gmae.append(np.abs(stats.weibull_min.ppf(0.5,c=test_x[:,0],scale=test_x[:,1])-med_est).mean())\n\n ",
"_____no_output_____"
],
[
"def musd(x):\n print(np.mean(x),np.std(x))\n\n",
"_____no_output_____"
],
[
"\nmusd(gll)\nmusd(gcal)\nmusd(g90)\nmusd(gmae)\n\n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a27f3b68e7ab646e606a6f716f5b37bde1793f4
| 3,031 |
ipynb
|
Jupyter Notebook
|
backup.ipynb
|
materialscloud-org/mc-backup
|
62591ae7593d0640514f057643f4e762ca2d3e9e
|
[
"MIT"
] | null | null | null |
backup.ipynb
|
materialscloud-org/mc-backup
|
62591ae7593d0640514f057643f4e762ca2d3e9e
|
[
"MIT"
] | null | null | null |
backup.ipynb
|
materialscloud-org/mc-backup
|
62591ae7593d0640514f057643f4e762ca2d3e9e
|
[
"MIT"
] | null | null | null | 24.642276 | 112 | 0.535137 |
[
[
[
"# Backup via SSH",
"_____no_output_____"
]
],
[
[
"import sys\nfrom os import path\nimport ipywidgets as ipw\nfrom time import strftime\nfrom pprint import pformat\nfrom IPython.display import clear_output",
"_____no_output_____"
],
[
"CONFIG_FN = '.backup.conf'\nif path.exists(CONFIG_FN):\n config = eval(open(CONFIG_FN).read())\nelse:\n config = {'destination':''}\n\nplaceholder = \"e.g. daint.cscs.ch:mc-backup\"\ndest_txt = ipw.Text(description=\"Destination:\", placeholder=placeholder, value=config['destination'])\nname_txt = ipw.Text(description=\"Name:\", value=strftime(\"backup_%Y-%m-%d\"))\n\ndisplay(dest_txt,name_txt)",
"_____no_output_____"
],
[
"def on_btn_start_clicked(b):\n with output:\n clear_output()\n run_backup(dest_txt.value.strip(), name_txt.value.strip())\nbtn_start = ipw.Button(description=\"Start Backup\")\nbtn_start.on_click(on_btn_start_clicked)\ndisplay(btn_start)",
"_____no_output_____"
],
[
"def run_backup(dest, name):\n assert len(dest)>0\n assert len(name)>0\n\n # store config\n config = {'destination': dest}\n open(CONFIG_FN, 'w').write(pformat(config))\n \n run_cmd(\"mkdir -p /tmp/{name}\".format(name=name))\n run_cmd(\"pg_dump --host=localhost aiidadb | gzip > /tmp/{name}/aiidadb.sql.gz\".format(name=name))\n run_cmd(\"rsync -a /tmp/{name}/ {dest}/{name}/\".format(dest=dest, name=name))\n run_cmd(\"rsync -a --exclude=.postgresql /project/ {dest}/{name}/\".format(dest=dest, name=name))\n print(\"done\")",
"_____no_output_____"
],
[
"def run_cmd(cmd):\n print(cmd)\n ! $cmd",
"_____no_output_____"
],
[
"output = ipw.Output()\ndisplay(output)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a27f6050e0b7027309cb7b8a8594dec73dd8712
| 31,268 |
ipynb
|
Jupyter Notebook
|
sql2019lab/03_Availability/adr/adr.ipynb
|
fratei/sqlworkshops
|
bf05479084120856ee2f5dd8954f3d179ac5cc70
|
[
"MIT"
] | 19 |
2020-04-20T17:55:37.000Z
|
2022-02-27T08:43:23.000Z
|
sql2019lab/03_Availability/adr/adr.ipynb
|
tiagomqsantos/sqlworkshops
|
92658e42a95bf6388566f78395c6fd68f47be9e8
|
[
"MIT"
] | 3 |
2020-05-02T10:14:41.000Z
|
2021-03-30T22:36:13.000Z
|
sql2019lab/03_Availability/adr/adr.ipynb
|
tiagomqsantos/sqlworkshops
|
92658e42a95bf6388566f78395c6fd68f47be9e8
|
[
"MIT"
] | 20 |
2020-03-20T01:09:28.000Z
|
2022-02-27T08:43:28.000Z
| 40.138639 | 320 | 0.323909 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a27f7257ae67d50d8c5fd863ee0388af8c21442
| 4,026 |
ipynb
|
Jupyter Notebook
|
subsample.ipynb
|
ctb/2019-upr-kmers
|
dfc8aa922facf66dfce90210e1c7d0866f14790a
|
[
"BSD-3-Clause"
] | 2 |
2019-02-15T12:51:44.000Z
|
2019-02-15T20:14:45.000Z
|
subsample.ipynb
|
ctb/2019-upr-kmers
|
dfc8aa922facf66dfce90210e1c7d0866f14790a
|
[
"BSD-3-Clause"
] | null | null | null |
subsample.ipynb
|
ctb/2019-upr-kmers
|
dfc8aa922facf66dfce90210e1c7d0866f14790a
|
[
"BSD-3-Clause"
] | 1 |
2019-04-13T12:47:27.000Z
|
2019-04-13T12:47:27.000Z
| 30.270677 | 96 | 0.486587 |
[
[
[
"# Subsample some sequence files",
"_____no_output_____"
]
],
[
[
"import screed",
"_____no_output_____"
],
[
"# download a bunch of genomes and extract two specific ones\n#!curl -L https://osf.io/8uxj9/?action=download | tar xvf - 2.fa 47.fa 63.fa",
" % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n100 459 100 459 0 0 735 0 --:--:-- --:--:-- --:--:-- 734\n 17 61.1M 17 11.0M 0 0 1530k 0 0:00:40 0:00:07 0:00:33 2010kx 2.fa\n 66 61.1M 66 40.7M 0 0 1523k 0 0:00:41 0:00:27 0:00:14 1528kx 47.fa\n 92 61.1M 92 56.6M 0 0 1438k 0 0:00:43 0:00:40 0:00:03 1360kx 63.fa\n100 61.1M 100 61.1M 0 0 1411k 0 0:00:44 0:00:44 --:--:-- 1146k\n"
],
[
"!mkdir -p genomes/\n\ndef get_500kb(filename):\n total = 0\n for record in screed.open(filename):\n if len(record.sequence) > (5e5 - total):\n yield record.name, record.sequence[:int(5e5-total)]\n break\n else:\n yield record.name, record.sequence\n total += len(record.sequence)\n\nwith open('genomes/akkermansia.fa', 'wt') as fp:\n for name, sequence in get_500kb('2.fa'):\n fp.write('>{}\\n{}\\n'.format(name, sequence))\n \nwith open('genomes/shew_os185.fa', 'wt') as fp:\n for name, sequence in get_500kb('47.fa'):\n fp.write('>{}\\n{}\\n'.format(name, sequence))\n \nwith open('genomes/shew_os223.fa', 'wt') as fp:\n for name, sequence in get_500kb('63.fa'):\n fp.write('>{}\\n{}\\n'.format(name, sequence))",
"_____no_output_____"
],
[
"ls -l",
"total 30712\r\n-rw-r--r-- 1 t staff 2702228 Jun 10 2017 2.fa\r\n-rw-r--r-- 1 t staff 5379451 Jun 10 2017 47.fa\r\n-rw-r--r-- 1 t staff 5426146 Jun 10 2017 63.fa\r\n-rw-r--r-- 1 t staff 1514 Feb 13 18:59 LICENSE\r\n-rw-r--r-- 1 t staff 16 Feb 13 18:59 README.md\r\n-rw-r--r-- 1 t staff 500067 Feb 14 06:33 akkermansia.fa\r\n-rw-r--r-- 1 t wheel 146 Feb 13 18:59 environment.yml\r\ndrwxr-xr-x 5 t staff 160 Feb 14 06:34 \u001b[34mgenomes\u001b[m\u001b[m/\r\n-rw-r--r-- 1 t staff 1140 Feb 13 19:12 index.ipynb\r\n-rw-r--r-- 1 t staff 500056 Feb 14 06:33 shew_os185.fa\r\n-rw-r--r-- 1 t staff 500056 Feb 14 06:33 shew_os223.fa\r\n-rw-r--r-- 1 t staff 2868 Feb 14 06:33 subsample.ipynb\r\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a27f9ac978bbd378c0a4dea1869c496c8de80b5
| 7,268 |
ipynb
|
Jupyter Notebook
|
examples/podaacpy_getting_started_tutorial.ipynb
|
jasonduley/podaacpy
|
ce00c5278f250c0ce7368a0bcd69eb4b1caf441b
|
[
"Apache-2.0"
] | 62 |
2016-11-14T20:18:48.000Z
|
2022-03-18T09:12:01.000Z
|
examples/podaacpy_getting_started_tutorial.ipynb
|
jasonduley/podaacpy
|
ce00c5278f250c0ce7368a0bcd69eb4b1caf441b
|
[
"Apache-2.0"
] | 78 |
2016-04-11T03:08:07.000Z
|
2016-11-11T10:21:09.000Z
|
examples/podaacpy_getting_started_tutorial.ipynb
|
jasonduley/podaacpy
|
ce00c5278f250c0ce7368a0bcd69eb4b1caf441b
|
[
"Apache-2.0"
] | 45 |
2016-11-21T11:49:11.000Z
|
2021-07-04T17:16:13.000Z
| 26.918519 | 192 | 0.56563 |
[
[
[
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"import sys\nprint(sys.version)",
"_____no_output_____"
],
[
"##################\n# Imports #\n##################\n# import the podaac package\nimport podaac.podaac as podaac\n# import the podaac_utils package\nimport podaac.podaac_utils as utils\n# import the mcc package\nimport podaac.mcc as mcc\n\n#######################\n# Class instantiation #\n#######################\n# then create an instance of the Podaac class\np = podaac.Podaac()\n# then create an instance of the PodaacUtils class\nu = utils.PodaacUtils()\n# then create an instance of the MCC class\nm = mcc.MCC()",
"_____no_output_____"
],
[
"###########################################\n# Lets look at some convenience functions #\n###########################################\nprint(u.list_all_available_extract_granule_dataset_ids())",
"_____no_output_____"
],
[
"print(u.list_all_available_extract_granule_dataset_short_names())",
"_____no_output_____"
],
[
"print(u.list_all_available_granule_search_dataset_ids())",
"_____no_output_____"
],
[
"print(u.list_all_available_granule_search_dataset_short_names())",
"_____no_output_____"
],
[
"print(u.list_available_granule_search_level2_dataset_ids())",
"_____no_output_____"
],
[
"print(u.list_available_granule_search_level2_dataset_short_names())",
"_____no_output_____"
],
[
"# Now lets take a look at using the results from above to interact with the PO.DAAC Webservices\n\n########################\n# PO.DAAC Web Services #\n########################\n\n# First lets retrieve dataset metadata\nprint(p.dataset_metadata(dataset_id='PODAAC-GHMG2-2PO01'))",
"_____no_output_____"
],
[
"# Lets try searching for datasets\nprint(p.dataset_search(keyword='modis'))",
"_____no_output_____"
],
[
"# Now retrieve dataset variables\nprint(p.dataset_variables(dataset_id='PODAAC-GHMDA-2PJ02'))",
"_____no_output_____"
],
[
"# Now extracting an individual granule\nprint(p.extract_l4_granule(dataset_id='PODAAC-AQR50-3YVAS'))",
"_____no_output_____"
],
[
"# Now retrieving granule metadata\nprint(p.granule_metadata(dataset_id='PODAAC-GHMG2-2PO01'), granule_name='20120912-MSG02-OSDPD-L2P-MSG02_0200Z-v01.nc')",
"_____no_output_____"
],
[
"from IPython.display import Image\nfrom IPython.core.display import HTML \nresult = p.granule_preview(dataset_id='PODAAC-ASOP2-25X01')",
"_____no_output_____"
],
[
"# Additionally, we can search metadata for list of granules archived within the last 24 hours in Datacasting format.\nprint(p.last24hours_datacasting_granule_md(dataset_id='PODAAC-AQR50-3YVAS'))",
"_____no_output_____"
],
[
"# Now Searching for Granules\nprint(p.granule_search(dataset_id='PODAAC-ASOP2-25X01',bbox='0,0,180,90',start_time='2013-01-01T01:30:00Z',end_time='2014-01-01T00:00:00Z',start_index='1', pretty='True'))",
"_____no_output_____"
],
[
"######################################################\n# Working with Metadata Compliance Webservices (mcc) #\n######################################################\n\n# Compliance Check a Local File\nprint(m.check_local_file(acdd_version='1.3', gds2_parameters='L4', file_upload='../podaac/tests/ascat_20130719_230600_metopa_35024_eps_o_250_2200_ovw.l2_subsetted_.nc', response='json'))",
"_____no_output_____"
],
[
"# Compliance Check a Remote File\nprint(m.check_remote_file(checkers='CF', url_upload='http://test.opendap.org/opendap/data/ncml/agg/dated/CG2006158_120000h_usfc.nc', response='json'))",
"_____no_output_____"
],
[
"# Thank you for trying out podaacpy\n# That concludes the quick start. Hopefully this has been helpful in providing an overview \n# of the main podaacpy features. If you have any issues with this document then please register \n# them at the issue tracker - https://github.com/nasa/podaacpy/issues\n# Please use labels to classify your issue.\n\n# Thanks, \n# Lewis John McGibbney",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a27fb2d1e5c496242424628f504847bed27895c
| 10,014 |
ipynb
|
Jupyter Notebook
|
examples/tutorials/visualising_the_results.ipynb
|
Tripodcat/bilby
|
e042803bb3c0d04cb09a2e2f4e05642ac81f9ae3
|
[
"MIT"
] | null | null | null |
examples/tutorials/visualising_the_results.ipynb
|
Tripodcat/bilby
|
e042803bb3c0d04cb09a2e2f4e05642ac81f9ae3
|
[
"MIT"
] | null | null | null |
examples/tutorials/visualising_the_results.ipynb
|
Tripodcat/bilby
|
e042803bb3c0d04cb09a2e2f4e05642ac81f9ae3
|
[
"MIT"
] | 1 |
2019-10-15T05:17:57.000Z
|
2019-10-15T05:17:57.000Z
| 39.117188 | 422 | 0.620831 |
[
[
[
"! rm visualising_the_results/*",
"_____no_output_____"
]
],
[
[
"# Visualising the results\n\nIn this tutorial, we demonstrate the plotting tools built-in to `bilby` and how to extend them. First, we run a simple injection study and return the `result` object.",
"_____no_output_____"
]
],
[
[
"import bilby\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\ntime_duration = 4. # time duration (seconds)\nsampling_frequency = 2048. # sampling frequency (Hz)\noutdir = 'visualising_the_results' # directory in which to store output\nlabel = 'example' # identifier to apply to output files\n\ninjection_parameters = dict(\nmass_1=36., # source frame (non-redshifted) primary mass (solar masses)\nmass_2=29., # source frame (non-redshifted) secondary mass (solar masses)\na_1=0.4, # primary dimensionless spin magnitude\na_2=0.3, # secondary dimensionless spin magnitude\ntilt_1=0.5, # polar angle between primary spin and the orbital angular momentum (radians)\ntilt_2=1.0, # polar angle between secondary spin and the orbital angular momentum \nphi_12=1.7, # azimuthal angle between primary and secondary spin (radians)\nphi_jl=0.3, # azimuthal angle between total angular momentum and orbital angular momentum (radians)\nluminosity_distance=200., # luminosity distance to source (Mpc)\niota=0.4, # inclination angle between line of sight and orbital angular momentum (radians)\nphase=1.3, # phase (radians)\nwaveform_approximant='IMRPhenomPv2', # waveform approximant name\nreference_frequency=50., # gravitational waveform reference frequency (Hz)\nra=1.375, # source right ascension (radians)\ndec=-1.2108, # source declination (radians)\ngeocent_time=1126259642.413, # reference time at geocentre (time of coalescence or peak amplitude) (GPS seconds)\npsi=2.659 # gravitational wave polarisation angle\n)\n\n\n# set up the waveform generator\nwaveform_generator = bilby.gw.waveform_generator.WaveformGenerator(\n sampling_frequency=sampling_frequency, duration=time_duration,\n frequency_domain_source_model=bilby.gw.source.lal_binary_black_hole,\n parameters=injection_parameters)\n# create the frequency domain signal\nhf_signal = waveform_generator.frequency_domain_strain()\n\n# initialise an interferometer based on LIGO Hanford, complete with simulated noise and injected signal\nIFOs = [bilby.gw.detector.get_interferometer_with_fake_noise_and_injection(\n 'H1', injection_polarizations=hf_signal, injection_parameters=injection_parameters, duration=time_duration,\n sampling_frequency=sampling_frequency, outdir=outdir)]\n\n# first, set up all priors to be equal to a delta function at their designated value\npriors = injection_parameters.copy()\n# then, reset the priors on the masses and luminosity distance to conduct a search over these parameters\npriors['mass_1'] = bilby.core.prior.Uniform(20, 50, 'mass_1')\npriors['mass_2'] = bilby.core.prior.Uniform(20, 50, 'mass_2')\npriors['luminosity_distance'] = bilby.core.prior.Uniform(100, 300, 'luminosity_distance')\n\n# compute the likelihoods\nlikelihood = bilby.gw.likelihood.GravitationalWaveTransient(interferometers=IFOs, waveform_generator=waveform_generator)\n\nresult = bilby.core.sampler.run_sampler(likelihood=likelihood, priors=priors, sampler='dynesty', npoints=100,\n injection_parameters=injection_parameters, outdir=outdir, label=label,\n walks=5)\n\n# display the corner plot\nplt.show()",
"_____no_output_____"
]
],
[
[
"In running this code, we already made the first plot! In the function `bilby.detector.get_interferometer_with_fake_noise_and_injection`, the ASD, detector data, and signal are plotted together. This figure is saved under `visualsing_the_results/H1_frequency_domain_data.png`. Note that `visualising_the_result` is our `outdir` where all the output of the run is stored. Let's take a quick look at that directory now:",
"_____no_output_____"
]
],
[
[
"!ls visualising_the_results/",
"_____no_output_____"
]
],
[
[
"## Corner plots\n\nNow lets make some corner plots. You can easily generate a corner plot using `result.plot_corner()` like this:",
"_____no_output_____"
]
],
[
[
"result.plot_corner()\nplt.show()",
"_____no_output_____"
]
],
[
[
"In a notebook, this figure will display. But by default the file is also saved to `visualising_the_result/example_corner.png`. If you change the label to something more descriptive then the `example` here will of course be replaced.",
"_____no_output_____"
],
[
"You may also want to plot a subset of the parameters, or perhaps add the `injection_paramters` as lines to check if you recovered them correctly. All this can be done through `plot_corner`. Under the hood, `plot_corner` uses\n[chain consumer](https://samreay.github.io/ChainConsumer/index.html), and all the keyword arguments passed to `plot_corner` are passed through to [the `plot` function of chain consumer](https://samreay.github.io/ChainConsumer/chain_api.html#chainconsumer.plotter.Plotter.plot).\n\n### Adding injection parameters to the plot\n\nIn the previous plot, you'll notice `bilby` added the injection parameters to the plot by default. You can switch this off by setting `truth=None` when you call `plot_corner`. Or to add different injection parameters to the plot, just pass this as a keyword argument for `truth`. In this example, we just add a line for the luminosity distance by passing a dictionary of the value we want to display.",
"_____no_output_____"
]
],
[
[
"result.plot_corner(truth=dict(luminosity_distance=201))\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Plot a subset of the corner plot\n\nOr, to plot just a subset of parameters, just pass a list of the names you want.",
"_____no_output_____"
]
],
[
[
"result.plot_corner(parameters=['mass_1', 'mass_2'], filename='{}/subset.png'.format(outdir))\nplt.show()",
"_____no_output_____"
]
],
[
[
"Notice here, we also passed in a keyword argument `filename=`, this overwrites the default filename and instead saves the file as `visualising_the_results/subset.png`. Useful if you want to create lots of different plots. Let's check what the outdir looks like now",
"_____no_output_____"
]
],
[
[
"!ls visualising_the_results/",
"_____no_output_____"
]
],
[
[
"## Alternative\n\nIf you would prefer to do the plotting yourself, you can get hold of the samples and the ordering as follows and then plot with a different module. Here is an example using the [`corner`](http://corner.readthedocs.io/en/latest/) package",
"_____no_output_____"
]
],
[
[
"import corner\nsamples = result.samples\nlabels = result.parameter_labels\nfig = corner.corner(samples, labels=labels)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Other plots\n\nWe also include some other types of plots which may be useful. Again, these are built on chain consumer so you may find it useful to check the [documentation](https://samreay.github.io/ChainConsumer/chain_api.html#plotter-class) to see how these plots can be extended. Below, we show just one example of these.\n\n#### Distribution plots\n\nThese plots just show the 1D histograms for each parameter",
"_____no_output_____"
]
],
[
[
"result.plot_marginals()\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a280cc7a6398513e93f0ecdd60e4f04fd7324a3
| 45,091 |
ipynb
|
Jupyter Notebook
|
solutions/Chapter 5 DeC and ADER.ipynb
|
accdavlo/HighOrderODESolvers
|
d886357cd425eef902b540015276d0e49e53cef2
|
[
"MIT"
] | null | null | null |
solutions/Chapter 5 DeC and ADER.ipynb
|
accdavlo/HighOrderODESolvers
|
d886357cd425eef902b540015276d0e49e53cef2
|
[
"MIT"
] | null | null | null |
solutions/Chapter 5 DeC and ADER.ipynb
|
accdavlo/HighOrderODESolvers
|
d886357cd425eef902b540015276d0e49e53cef2
|
[
"MIT"
] | null | null | null | 36.629569 | 399 | 0.488434 |
[
[
[
"# Arbitrarily high order accurate explicit time integration methods",
"_____no_output_____"
],
[
" 1. Chapter 5: ADER and DeC\n 1. [Section 1.1: DeC](#DeC)\n 1. [Section 1.2: ADER](#ADER)",
"_____no_output_____"
],
[
"## Deferred Correction (Defect correction/ Spectral deferred correction)<a id='DeC'></a>\nAcronyms: DeC, DEC, DC, SDC\n\nReferences: [Dutt et al. 2000](https://link.springer.com/article/10.1023/A:1022338906936), [Minion (implicit) 2003](https://projecteuclid.org/journals/communications-in-mathematical-sciences/volume-1/issue-3/Semi-implicit-spectral-deferred-correction-methods-for-ordinary-differential-equations/cms/1250880097.full), [Abgrall 2017 (for PDE)](https://hal.archives-ouvertes.fr/hal-01445543v2)\n\nWe study Abgrall's version (for notation)\n\nTheory on slides!",
"_____no_output_____"
]
],
[
[
"# If you do not have numpy, matplotlib, scipy or nodepy, run this cell\n!pip install numpy\n# This is the basic package in python with all the numerical functions\n\n!pip install scipy\n# This package has some functions to deal with polynomials\n\n!pip install matplotlib\n# This package allows to plot\n\n!pip install nodepy\n# This package has some interesting features for RK methods",
"_____no_output_____"
],
[
"# We need a couple of packages in this chapter\nimport numpy as np \n# This is the basic package in python with all the numerical functions\n\nimport matplotlib.pyplot as plt \n# This package allows to plot\n\nfrom nodepy import rk\n#This package already implemented some functions for Runge Kutta and multistep methods",
"_____no_output_____"
]
],
[
[
"For the definition of the basis functions in time, we introduce different Lagrange polynomials and point distributions:\n1. equispaced\n1. Gauss--Legendre--Lobatto (GLB)\n1. Gauss--Legendre (not in DeC, because the last point is not $t^{n+1}$)\n\nSo, we have the quadrature points $\\lbrace t^m \\rbrace_{m=0}^M$, the polynomials $\\lbrace \\varphi_m \\rbrace_{m=0}^M$ such that $\\varphi_j(t^m)=\\delta_{j}^m$, and we are interested in computing\n\n$$\n\\theta_r^m:=\\int_{t^0}^{t^m} \\varphi_r(t) dt\n$$\n\nTo compute the integral we will use exact quadrature rules with Gauss--Lobatto (GLB) points, i.e., given the quadrature nodes and weights $t_q, w_q$ on the interval $[0,1]$ the integral is computed as\n\n$$\n\\theta_r^m:=\\int_{t^0}^{t^m} \\varphi_r(t) dt = \\sum_q \\varphi_r(t^q(t^m-t^0)+t^0) w_q(t^m-t^0) \n$$\n\n\nIn practice, at each timestep we have to loop over corrections $(k)$ and over subtimesteps $m$ and compute\n\n$$\ny^{m,(k)} = y^{m,(k-1)} - \\left( y^{m,(k-1)} - y^{0} - \\Delta t\\sum_{r=0}^M \\theta_r^m F(y^{r,(k-1)}) \\right)=y^{0} + \\Delta t\\sum_{r=0}^M \\theta_r^m F(y^{r,(k-1)})\n$$",
"_____no_output_____"
]
],
[
[
"from scipy.interpolate import lagrange\nfrom numpy.polynomial.legendre import leggauss\n\ndef equispaced(order):\n '''\n Takes input d and returns the vector of d equispaced points in [-1,1]\n And the integral of the basis functions interpolated in those points\n '''\n nodes= np.linspace(-1,1,order)\n w= np.zeros(order)\n for k in range(order):\n yy= np.zeros(order)\n yy[k]=1.\n zz=lagrange(nodes,yy)\n pp=zz.integ()\n w[k]=pp(1)-pp(-1)\n\n return nodes, w\n\ndef lglnodes(n,eps=10**-15):\n '''\n Python translation of lglnodes.m\n\n Computes the Legendre-Gauss-Lobatto nodes, weights and the LGL Vandermonde \n matrix. The LGL nodes are the zeros of (1-x^2)*P'_N(x). Useful for numerical\n integration and spectral methods. \n\n Parameters\n ----------\n n : integer, requesting an nth-order Gauss-quadrature rule on [-1, 1]\n\n Returns\n -------\n (nodes, weights) : tuple, representing the quadrature nodes and weights.\n Note: (n+1) nodes and weights are returned.\n \n\n Example\n -------\n >>> from lglnodes import *\n >>> (nodes, weights) = lglnodes(3)\n >>> print(str(nodes) + \" \" + str(weights))\n [-1. -0.4472136 0.4472136 1. ] [0.16666667 0.83333333 0.83333333 0.16666667]\n\n Notes\n -----\n\n Reference on LGL nodes and weights: \n C. Canuto, M. Y. Hussaini, A. Quarteroni, T. A. Tang, \"Spectral Methods\n in Fluid Dynamics,\" Section 2.3. Springer-Verlag 1987\n\n Written by Greg von Winckel - 04/17/2004\n Contact: [email protected]\n\n Translated and modified into Python by Jacob Schroder - 9/15/2018 \n '''\n\n w = np.zeros((n+1,))\n x = np.zeros((n+1,))\n xold = np.zeros((n+1,))\n\n # The Legendre Vandermonde Matrix\n P = np.zeros((n+1,n+1))\n\n epss = eps\n\n # Use the Chebyshev-Gauss-Lobatto nodes as the first guess\n for i in range(n+1): \n x[i] = -np.cos(np.pi*i / n)\n \n \n # Compute P using the recursion relation\n # Compute its first and second derivatives and \n # update x using the Newton-Raphson method.\n \n xold = 2.0\n \n for i in range(100):\n xold = x\n \n P[:,0] = 1.0 \n P[:,1] = x\n \n for k in range(2,n+1):\n P[:,k] = ( (2*k-1)*x*P[:,k-1] - (k-1)*P[:,k-2] ) / k\n \n x = xold - ( x*P[:,n] - P[:,n-1] )/( (n+1)*P[:,n]) \n \n if (max(abs(x - xold).flatten()) < epss ):\n break \n \n w = 2.0 / ( (n*(n+1))*(P[:,n]**2))\n \n return x, w\n \ndef lagrange_basis(nodes,x,k):\n y=np.zeros(x.size)\n for ix, xi in enumerate(x):\n tmp=[(xi-nodes[j])/(nodes[k]-nodes[j]) for j in range(len(nodes)) if j!=k]\n y[ix]=np.prod(tmp)\n return y\n\ndef get_nodes(order,nodes_type):\n if nodes_type==\"equispaced\":\n nodes,w = equispaced(order)\n elif nodes_type == \"gaussLegendre\":\n nodes,w = leggauss(order)\n elif nodes_type == \"gaussLobatto\":\n nodes, w = lglnodes(order-1,10**-15)\n nodes=nodes*0.5+0.5\n w = w*0.5\n return nodes, w\n \ndef compute_theta_DeC(order, nodes_type):\n nodes, w = get_nodes(order,nodes_type)\n int_nodes, int_w = get_nodes(order,\"gaussLobatto\")\n # generate theta coefficients \n theta = np.zeros((order,order))\n beta = np.zeros(order)\n for m in range(order):\n beta[m] = nodes[m]\n nodes_m = int_nodes*(nodes[m])\n w_m = int_w*(nodes[m])\n for r in range(order):\n theta[r,m] = sum(lagrange_basis(nodes,nodes_m,r)*w_m)\n return theta, beta\n\n\ndef compute_RK_from_DeC(M_sub,K_corr,nodes_type):\n order=M_sub+1;\n [theta,beta]=compute_theta_DeC(order,nodes_type)\n bar_beta=beta[1:] # M_sub\n bar_theta=theta[:,1:].transpose() # M_sub x (M_sub +1)\n theta0= bar_theta[:,0] # M_sub x 1\n bar_theta= bar_theta[:,1:] #M_sub x M_sub\n A=np.zeros((M_sub*(K_corr-1)+1,M_sub*(K_corr-1)+1)) # (M_sub x K_corr +1)^2\n b=np.zeros(M_sub*(K_corr-1)+1)\n c=np.zeros(M_sub*(K_corr-1)+1)\n\n c[1:M_sub+1]=bar_beta\n A[1:M_sub+1,0]=bar_beta\n for k in range(1,K_corr-1):\n r0=1+M_sub*k\n r1=1+M_sub*(k+1)\n c0=1+M_sub*(k-1)\n c1=1+M_sub*(k)\n c[r0:r1]=bar_beta\n A[r0:r1,0]=theta0\n A[r0:r1,c0:c1]=bar_theta\n b[0]=theta0[-1]\n b[-M_sub:]=bar_theta[M_sub-1,:]\n return A,b,c\n",
"_____no_output_____"
],
[
"## Deferred correction algorithm\n\ndef dec(func, tspan, y_0, M_sub, K_corr, distribution):\n N_time=len(tspan)\n dim=len(y_0)\n U=np.zeros((dim, N_time))\n u_p=np.zeros((dim, M_sub+1))\n u_a=np.zeros((dim, M_sub+1))\n rhs= np.zeros((dim,M_sub+1))\n Theta, beta = compute_theta_DeC(M_sub+1,distribution)\n U[:,0]=y_0\n for it in range(1, N_time):\n delta_t=(tspan[it]-tspan[it-1])\n for m in range(M_sub+1):\n u_a[:,m]=U[:,it-1]\n u_p[:,m]=U[:,it-1]\n for k in range(1,K_corr+1):\n u_p=np.copy(u_a)\n for r in range(M_sub+1):\n rhs[:,r]=func(u_p[:,r])\n for m in range(1,M_sub+1):\n u_a[:,m]= U[:,it-1]+delta_t*sum([Theta[r,m]*rhs[:,r] for r in range(M_sub+1)])\n U[:,it]=u_a[:,M_sub]\n return tspan, U",
"_____no_output_____"
],
[
"import numpy as np\n\n## Linear scalar Dahlquist's equation\ndef linear_scalar_flux(u,t=0,k_coef=10):\n ff=np.zeros(np.shape(u))\n ff[0]= -k_coef*u[0]\n return ff\n\ndef linear_scalar_exact_solution(u0,t,k_coef=10):\n return np.array([np.exp(-k_coef*u0[0]*t)])\n\n\ndef linear_scalar_jacobian(u,t=0,k_coef=10):\n Jf=np.zeros((len(u),len(u)))\n Jf[0,0]=-k_coef\n return Jf\n\n#nonlinear problem y'=-ky|y| +1 \ndef nonlinear_scalar_flux(u,t=0,k_coef=10):\n ff=np.zeros(np.shape(u))\n ff[0]=-k_coef*abs(u[0])*u[0] +1\n return ff\n\n\ndef nonlinear_scalar_exact_solution(u0,t,k_coef = 10):\n sqrtk = np.sqrt(k_coef)\n ustar = 1 / sqrtk\n if u0[0] >= ustar:\n uex=np.array([1./np.tanh(sqrtk * t + np.arctanh(1/sqrtk /u0[0])) / sqrtk])\n elif u0[0] < 0 and t < - np.atan(sqrtk * u0[0]) / sqrtk:\n uex=np.array([np.tan(sqrtk * t + np.arctan(sqrtk * u0[0])) / sqrtk])\n else:\n uex=np.array([np.tanh(sqrtk * t + np.arctanh(sqrtk * u0[0])) / sqrtk])\n return uex\n\ndef nonlinear_scalar_jacobian(u,t=0,k_coef=10):\n Jf=np.zeros((len(u),len(u)))\n Jf[0,0]=-k_coef*abs(u[0])\n return Jf\n\n\n# SYSTEMS\n\n\n# linear systems\ndef linear_system2_flux(u,t=0):\n d=np.zeros(len(u))\n d[0]= -5*u[0] + u[1]\n d[1]= 5*u[0] -u[1]\n return d\n\n\ndef linear_system2_exact_solution(u0,t):\n A=np.array([[-5,1],[5,-1]])\n u_e=u0+(1-np.exp(-6*t))/6*np.dot(A,u0)\n return u_e\n\ndef linear_system2_jacobian(u,t=0):\n Jf=np.array([[-5,1],[5,-1]])\n return Jf\n\nlinear_system2_matrix = np.array([[-5,1],[5,-1]])\n\ndef linear_system2_production_destruction(u,t=0):\n p=np.zeros((len(u),len(u)))\n d=np.zeros((len(u),len(u)))\n p[0,1]=u[1]\n d[1,0]=u[1]\n p[1,0]=5*u[0]\n d[0,1]=5*u[0]\n return p,d\n\n#lin system 3 x3\n\ndef linear_system3_flux(u,t=0):\n d=np.zeros(len(u))\n d[0]= -u[0] + 3*u[1]\n d[1]= -3*u[1] + 5*u[2]\n d[2]= -5*u[2] \n return d\n\n\ndef linear_system3_exact_solution(u0,t=0):\n u_e = np.zeros(len(u0))\n u_e[0] = 15.0/8.0*u0[2]*(np.exp(-5*t) - 2*np.exp(-3*t)+np.exp(-t))\n u_e[1] = 5.0/2.0*u0[2]*(-np.exp(-5*t) + np.exp(-3*t))\n u_e[2] = u0[2]*np.exp(-5*t)\n return u_e\ndef linear_system3_jacobian(u,t=0):\n Jf=np.zeros((len(u),len(u)))\n Jf[0,0]=-1.\n Jf[0,1]=3\n Jf[1,1] = -3\n Jf[1,2] = 5\n Jf[2,2] = -5 \n return Jf\n\n\n## Nonlinear 3x3 system production destruction\ndef nonlinear_system3_flux(u,t=0):\n ff=np.zeros(len(u))\n ff[0]= -u[0]*u[1]/(u[0]+1)\n ff[1]= u[0]*u[1]/(u[0]+1) -0.3*u[1]\n ff[2]= 0.3*u[1]\n return ff\n\ndef nonlinear_system3_production_destruction(u,t=0):\n p=np.zeros((len(u),len(u)))\n d=np.zeros((len(u),len(u)))\n p[1,0]=u[0]*u[1]/(u[0]+1)\n d[0,1]=p[1,0]\n p[2,1]=0.3*u[1]\n d[1,2]=p[2,1]\n return p,d\n\n\n# SIR Model\ndef SIR_flux(u,t=0,beta=3,gamma=1):\n ff=np.zeros(len(u))\n N=np.sum(u)\n ff[0]=-beta*u[0]*u[1]/N\n ff[1]=+beta*u[0]*u[1]/N - gamma*u[1]\n ff[2]= gamma*u[1]\n return ff\n\ndef SIR_jacobian(u,t=0,beta=3,gamma=1):\n Jf=np.zeros((len(u),len(u)))\n N=np.sum(u)\n Jf[0,0]=-beta*u[1]/N\n Jf[0,1]=-beta*u[0]/N\n Jf[1,0]= beta*u[1]/N\n Jf[1,1]= beta*u[0]/N - gamma\n Jf[2,1] = gamma \n return Jf\n\ndef SIR_production_destruction(u,t=0,beta=3,gamma=1):\n p=np.zeros((len(u),len(u)))\n d=np.zeros((len(u),len(u)))\n N=np.sum(u)\n p[1,0]=beta*u[0]*u[1]/N\n d[0,1]=p[1,0]\n p[2,1]=gamma*u[1]\n d[1,2]=p[2,1]\n return p,d\n\n# Nonlinear_oscillator\ndef nonLinearOscillator_flux(u,t=0,alpha=0.):\n ff=np.zeros(np.shape(u))\n n=np.sqrt(np.dot(u,u))\n ff[0]=-u[1]/n-alpha*u[0]/n\n ff[1]=u[0]/n - alpha*u[1]/n\n return ff\n\ndef nonLinearOscillator_exact_solution(u0,t):\n u_ex=np.zeros(np.shape(u0))\n n=np.sqrt(np.dot(u0,u0))\n u_ex[0]=np.cos(t/n)*u0[0]-np.sin(t/n)*u0[1]\n u_ex[1]=np.sin(t/n)*u0[0]+np.cos(t/n)*u0[1]\n return u_ex\n\n\n# Non linear oscillator damped\ndef nonLinearOscillatorDamped_flux(u,t,alpha=0.01):\n ff=np.zeros(np.shape(u))\n n=np.sqrt(np.dot(u,u))\n ff[0]=-u[1]/n-alpha*u[0]/n\n ff[1]=u[0]/n - alpha*u[1]/n\n return ff\n\ndef nonLinearOscillatorDamped_exact_solution(u0,t,alpha=0.01):\n u_ex=np.zeros(np.shape(u0))\n n0=np.sqrt(np.dot(u0,u0))\n n=n0*np.exp(-alpha*t)\n u_ex[0]=n/n0*(np.cos(t/n)*u0[0]-np.sin(t/n)*u0[1])\n u_ex[1]=n/n0*(np.sin(t/n)*u0[0]+np.cos(t/n)*u0[1])\n return u_ex\n\n\n# pendulum\ndef pendulum_flux(u,t=0):\n ff=np.zeros(np.shape(u))\n ff[0]=u[1]\n ff[1]=-np.sin(u[0])\n return ff\n\ndef pendulum_jacobian(u,t=0):\n Jf=np.zeros((2,2))\n Jf[0,1]=1.\n Jf[1,0]=np.cos(u[0])\n return Jf\n\ndef pendulum_entropy(u,t=0):\n return np.array(0.5*u[1]**2.-np.cos(u[0]), dtype=np.float)\n\ndef pendulum_entropy_variables(u,t=0):\n v=np.zeros(np.shape(u))\n v[0]=np.sin(u[0])\n v[1]=u[1]\n return v\n\n\n# Robertson\ndef Robertson_flux(u,t=0,alpha=10**4,beta=0.04, gamma=3*10**7):\n ff=np.zeros(np.shape(u))\n ff[0] = alpha*u[1]*u[2]-beta*u[0]\n ff[1] = beta*u[0]-alpha*u[1]*u[2] - gamma*u[1]**2\n ff[2] = gamma*u[1]**2\n return ff\n\ndef Robertson_jacobian(u,t=0,alpha=10**4,beta=0.04, gamma=3*10**7):\n Jf=np.zeros((3,3))\n Jf[0,0]= -beta \n Jf[0,1]= alpha*u[2]\n Jf[0,2]= alpha*u[1]\n Jf[1,0]= beta\n Jf[1,1]= -alpha*u[2]-2*gamma*u[1]\n Jf[1,2]= -alpha*u[1]\n Jf[2,1] = 2*gamma*u[1] \n return Jf\n\ndef Robertson_production_destruction(u,t=0,alpha=10**4,beta=0.04, gamma=3*10**7):\n p=np.zeros((len(u),len(u)))\n d=np.zeros((len(u),len(u)))\n p[0,1]=alpha*u[1]*u[2]\n d[1,0]=p[0,1]\n p[1,0]=beta*u[0]\n d[0,1]=p[1,0]\n p[2,1]=gamma*u[1]**2\n d[1,2]=p[2,1]\n return p,d\n\n \n# Lotka:\ndef lotka_flux(u,t=0,alpha=1,beta=0.2,delta=0.5,gamma=0.2):\n ff=np.zeros(np.shape(u))\n ff[0]=alpha*u[0]-beta*u[0]*u[1]\n ff[1]=delta*beta*u[0]*u[1]-gamma*u[1]\n return ff\n\ndef lotka_jacobian(u,t=0,alpha=1,beta=0.2,delta=0.5,gamma=0.2):\n Jf=np.zeros((2,2))\n Jf[0,0] = alpha -beta*u[1]\n Jf[0,1] = -beta*u[0]\n Jf[1,0] = delta*beta*u[1]\n Jf[1,1] = delta*beta*u[0] -gamma\n return Jf\n\n\n#3 bodies problem in 2D: U=(x_1,x_2,v_1,v_2,y_1,y_2,w_1,w_2,z_1,z_2,s_1,s_2)\n# where x is the 2D position of body1 and v is speed body1 sun\n# y, w are position and velocity body2 earth\n# z, s are position and velocity body3 mars\n\ndef threeBodies_flux(u,t=0):\n m1=1.98892*10**30\n m2=5.9722*10**24\n m3=6.4185*10**23\n G=6.67*10**(-11)\n f=np.zeros(np.shape(u))\n x=u[0:2]\n v=u[2:4]\n y=u[4:6]\n w=u[6:8]\n z=u[8:10]\n s=u[10:12]\n dxy3=np.linalg.norm(x-y)**3\n dxz3=np.linalg.norm(x-z)**3\n dyz3=np.linalg.norm(y-z)**3\n f[0:2]=v\n f[2:4]=-m2*G/dxy3*(x-y)-m3*G/dxz3*(x-z)\n f[4:6]=w\n f[6:8]=-m1*G/dxy3*(y-x)-m3*G/dyz3*(y-z)\n f[8:10]=s\n f[10:12]=-m1*G/dxz3*(z-x)-m2*G/dyz3*(z-y)\n return f\n\n\nclass ODEproblem:\n def __init__(self,name):\n self.name=name\n if self.name==\"linear_scalar\":\n self.u0 = np.array([1.])\n self.T_fin= 2.\n self.k_coef=10\n self.matrix=np.array([-self.k_coef])\n elif self.name==\"nonlinear_scalar\":\n self.k_coef=10\n self.u0 = np.array([1.1/np.sqrt(self.k_coef)])\n self.T_fin= 1.\n elif self.name==\"linear_system2\":\n self.u0 = np.array([0.9,0.1])\n self.T_fin= 1.\n self.matrix = np.array([[-5,1],[5,-1]])\n elif self.name==\"linear_system3\":\n self.u0 = np.array([0,0.,10.])\n self.T_fin= 10.\n elif self.name==\"nonlinear_system3\":\n self.u0 = np.array([9.98,0.01,0.01])\n self.T_fin= 30.\n elif self.name==\"SIR\":\n self.u0 = np.array([1000.,1,10**-20])\n self.T_fin= 10.\n elif self.name==\"nonLinearOscillator\":\n self.u0 = np.array([1.,0.])\n self.T_fin= 50\n elif self.name==\"nonLinearOscillatorDamped\":\n self.u0 = np.array([1.,0.])\n self.T_fin= 50\n elif self.name==\"pendulum\":\n self.u0 = np.array([2.,0.])\n self.T_fin= 50\n elif self.name==\"Robertson\":\n self.u0 = np.array([1.,10**-20,10**-20])\n self.T_fin= 10.**10.\n elif self.name==\"lotka\":\n self.u0 = np.array([1.,2.])\n self.T_fin= 100.\n elif self.name==\"threeBodies\":\n self.u0 = np.array([0,0,0,0,149*10**9,0,0,30*10**3,-226*10**9,0,0,-24.0*10**3])\n self.T_fin= 10.**8.\n else:\n raise ValueError(\"Problem not defined\")\n\n def flux(self,u,t=0):\n if self.name==\"linear_scalar\":\n return linear_scalar_flux(u,t,self.k_coef)\n elif self.name==\"nonlinear_scalar\":\n return nonlinear_scalar_flux(u,t,self.k_coef)\n elif self.name==\"linear_system2\":\n return linear_system2_flux(u,t)\n elif self.name==\"linear_system3\":\n return linear_system3_flux(u,t)\n elif self.name==\"nonlinear_system3\":\n return nonlinear_system3_flux(u,t)\n elif self.name==\"SIR\":\n return SIR_flux(u,t)\n elif self.name==\"nonLinearOscillator\":\n return nonLinearOscillator_flux(u,t)\n elif self.name==\"nonLinearOscillatorDamped\":\n return nonLinearOscillatorDamped_flux(u,t)\n elif self.name==\"pendulum\":\n return pendulum_flux(u,t)\n elif self.name==\"Robertson\":\n return Robertson_flux(u,t)\n elif self.name==\"lotka\":\n return lotka_flux(u,t)\n elif self.name==\"threeBodies\":\n return threeBodies_flux(u,t)\n else:\n raise ValueError(\"Flux not defined for this problem\")\n \n def jacobian(self,u,t=0):\n if self.name==\"linear_scalar\":\n return linear_scalar_jacobian(u,t,self.k_coef)\n elif self.name==\"nonlinear_scalar\":\n return nonlinear_scalar_jacobian(u,t,self.k_coef)\n elif self.name==\"linear_system2\":\n return linear_system2_jacobian(u,t)\n elif self.name==\"linear_system3\":\n return linear_system3_jacobian(u,t)\n elif self.name==\"pendulum\":\n return pendulum_jacobian(u,t)\n elif self.name==\"SIR\":\n return SIR_jacobian(u,t)\n elif self.name==\"Robertson\":\n return Robertson_jacobian(u,t)\n elif self.name==\"lotka\":\n return lotka_jacobian(u,t)\n else:\n raise ValueError(\"Jacobian not defined for this problem\")\n\n def exact(self,u,t):\n if self.name==\"linear_scalar\":\n return linear_scalar_exact_solution(u,t,self.k_coef)\n elif self.name==\"nonlinear_scalar\":\n return nonlinear_scalar_exact_solution(u,t,self.k_coef)\n elif self.name==\"linear_system2\":\n return linear_system2_exact_solution(u,t)\n elif self.name==\"linear_system3\":\n return linear_system3_exact_solution(u,t)\n elif self.name==\"nonLinearOscillator\":\n return nonLinearOscillator_exact_solution(u,t)\n elif self.name==\"nonLinearOscillatorDamped\":\n return nonLinearOscillatorDamped_exact_solution(u,t)\n else:\n raise ValueError(\"Exact solution not defined for this problem\")\n \n def exact_solution_times(self,u0,tt):\n exact_solution=np.zeros((len(u0),len(tt)))\n for it, t in enumerate(tt):\n exact_solution[:,it]=self.exact(u0,t)\n return exact_solution\n\n def prod_dest(self,u,t=0):\n if self.name==\"linear_system2\":\n return linear_system2_production_destruction(u,t)\n if self.name==\"nonlinear_system3\":\n return nonlinear_system3_production_destruction(u,t)\n elif self.name==\"Robertson\":\n return Robertson_production_destruction(u,t)\n elif self.name==\"SIR\":\n return SIR_production_destruction(u,t)\n else:\n raise ValueError(\"Prod Dest not defined for this problem\")\n\n ",
"_____no_output_____"
],
[
"pr=ODEproblem(\"threeBodies\")\ntt=np.linspace(0,pr.T_fin,1000)\ntt,U=dec(pr.flux,tt,pr.u0,4,5,\"gaussLobatto\")\nplt.figure()\nplt.plot(U[0,:],U[1,:],'*',label=\"sun\")\nplt.plot(U[4,:],U[5,:],label=\"earth\")\nplt.plot(U[8,:],U[9,:],label=\"Mars\")\nplt.legend()\nplt.show()\n\nplt.figure()\nplt.title(\"Distance from the original position of the sun\")\nplt.semilogy(tt,U[4,:]**2+U[5,:]**2,label=\"earth\")\nplt.semilogy(tt,U[8,:]**2+U[9,:]**2, label=\"mars\")\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"#Test convergence\npr=ODEproblem(\"linear_system2\")\n\ntt=np.linspace(0,pr.T_fin,10)\ntt,uu=dec(pr.flux, tt, pr.u0, 7, 8, \"equispaced\")\nplt.plot(tt,uu[0,:])\nplt.plot(tt,uu[1,:])\nplt.show()\n\ndef compute_integral_error(c,c_exact): # c is dim x times\n times=np.shape(c)[1]\n error=0.\n for t in range(times):\n error = error + np.linalg.norm(c[:,t]-c_exact[:,t],2)**2.\n error = np.sqrt(error/times) \n return error\n\nNN=5\ndts=[pr.T_fin/2.0**k for k in range(3,3+NN)]\nerrorsDeC=np.zeros(len(dts))\n\nfor order in range(2,10):\n for k in range(NN):\n dt0=dts[k]\n tt=np.arange(0,pr.T_fin,dt0)\n t2,U2=dec(pr.flux, tt, pr.u0, order-1, order, \"gaussLobatto\")\n u_exact=pr.exact_solution_times(pr.u0,tt)\n errorsDeC[k]=compute_integral_error(U2,u_exact)\n\n plt.loglog(dts,errorsDeC,\"--\",label=\"DeC%d\"%(order))\n plt.loglog(dts,[dt**order*errorsDeC[2]/dts[2]**order for dt in dts],\":\",label=\"ref %d\"%(order))\n\n\nplt.title(\"DeC error convergence\")\nplt.legend()\n#plt.savefig(\"convergence_DeC.pdf\")\nplt.show()\n",
"_____no_output_____"
],
[
"for order in range(2,10):\n A,b,c=compute_RK_from_DeC(order-1,order,\"equispaced\")\n rkDeC = rk.ExplicitRungeKuttaMethod(A,b)\n rkDeC.name=\"DeC\"+str(order)\n rkDeC.plot_stability_region(bounds=[-5,3,-7,7])",
"_____no_output_____"
],
[
"for order in range(2,14):\n A,b,c=compute_RK_from_DeC(order-1,order,\"equispaced\")\n rkDeC = rk.ExplicitRungeKuttaMethod(A,b)\n rkDeC.name=\"DeC\"+str(order)\n print(rkDeC.name+\" has order \"+str(rkDeC.order()))",
"_____no_output_____"
],
[
"pr=ODEproblem(\"lotka\")\ntt=np.linspace(0,pr.T_fin,150)\nt2,U2=dec(pr.flux, tt, pr.u0, 1, 2, \"gaussLobatto\")\nt8,U8=dec(pr.flux, tt, pr.u0, 7, 8, \"gaussLobatto\")\n\ntt=np.linspace(0,pr.T_fin,2000)\ntref,Uref=dec(pr.flux, tt, pr.u0, 4,5, \"gaussLobatto\")\n\nplt.figure(figsize=(12,6))\nplt.subplot(211)\nplt.plot(t2,U2[0,:],label=\"dec2\")\nplt.plot(t8,U8[0,:],label=\"dec8\")\nplt.plot(tref,Uref[0,:], \":\",linewidth=2,label=\"ref\")\nplt.legend()\nplt.title(\"Prey\")\n\nplt.subplot(212)\nplt.plot(t2,U2[1,:],label=\"dec2\")\nplt.plot(t8,U8[1,:],label=\"dec8\")\nplt.plot(tref,Uref[1,:],\":\", linewidth=2,label=\"ref\")\nplt.legend()\nplt.title(\"Predator\")",
"_____no_output_____"
]
],
[
[
"### Pro exercise: implement the implicit DeC presented in the slides\n* You need to pass also a function of the Jacobian of the flux in input\n* The Jacobian can be evaluated only once per timestep $\\partial_y F(y^n)$ and used to build the matrix that must be inverted at each correction\n* For every subtimestep the matrix to be inverted changes a bit ($\\beta^m \\Delta t$ factor in front of the Jacobian)\n* One can invert these $M$ matrices only once per time step\n* Solve the system at each subtimestep and iteration\n\n$$\ny^{m,(k)}-\\beta^m \\Delta t \\partial_y F(y^0)y^{m,(k)} = y^{m,(k-1)}-\\beta^m \\Delta t \\partial_y F(y^0)y^{m,(k-1)} - \\left( y^{m,(k-1)} - y^{0} - \\Delta t\\sum_{r=0}^M \\theta_r^m F(y^{r,(k-1)}) \\right)\n$$\n\ndefining $M^{m}=I+\\beta^m \\Delta t \\partial_y F(y^0)$, we can simplify it as \n\n$$\ny^{m,(k)}=y^{m,(k-1)} - (M^m)^{-1}\\left( y^{m,(k-1)} - y^{0} - \\Delta t\\sum_{r=0}^M \\theta_r^m F(y^{r,(k-1)}) \\right)\n$$",
"_____no_output_____"
]
],
[
[
"def decImplicit(func,jac_stiff, tspan, y_0, M_sub, K_corr, distribution):\n N_time=len(tspan)\n dim=len(y_0)\n U=np.zeros((dim, N_time))\n u_p=np.zeros((dim, M_sub+1))\n u_a=np.zeros((dim, M_sub+1))\n u_help= np.zeros(dim)\n rhs= np.zeros((dim,M_sub+1))\n Theta, beta = compute_theta_DeC(M_sub+1,distribution)\n invJac=np.zeros((M_sub+1,dim,dim))\n U[:,0]=y_0\n for it in range(1, N_time):\n delta_t=(tspan[it]-tspan[it-1])\n for m in range(M_sub+1):\n u_a[:,m]=U[:,it-1]\n u_p[:,m]=U[:,it-1]\n SS=jac_stiff(u_p[:,0])\n for m in range(1,M_sub+1):\n invJac[m,:,:]=np.linalg.inv(np.eye(dim) - delta_t*beta[m]*SS)\n for k in range(1,K_corr+1):\n u_p=np.copy(u_a)\n for r in range(M_sub+1):\n rhs[:,r]=func(u_p[:,r])\n for m in range(1,M_sub+1):\n u_a[:,m]= u_p[:,m]+delta_t*np.matmul(invJac[m,:,:],\\\n (-(u_p[:,m]-u_p[:,0])/delta_t\\\n +sum([Theta[r,m]*rhs[:,r] for r in range(M_sub+1)])))\n U[:,it]=u_a[:,M_sub]\n return tspan, U",
"_____no_output_____"
],
[
"# Test on Robertson problem\npr=ODEproblem(\"Robertson\")\n\nNt=100\ntt = np.array([np.exp(k) for k in np.linspace(-14,np.log(pr.T_fin),Nt)])\ntt,yy=decImplicit(pr.flux,pr.jacobian, tt, pr.u0, 5,6,\"gaussLobatto\")\n\nplt.semilogx(tt,yy[0,:])\nplt.semilogx(tt,yy[1,:]*10**4)\nplt.semilogx(tt,yy[2,:])",
"_____no_output_____"
],
[
"Nt=1000\ntt = np.array([np.exp(k) for k in np.linspace(-14,np.log(pr.T_fin),Nt)])\ntt,yy=dec(pr.flux, tt, pr.u0, 5,6,\"gaussLobatto\")\n\nplt.semilogx(tt,yy[0,:])\nplt.semilogx(tt,yy[1,:]*10**4)\nplt.semilogx(tt,yy[2,:])\nplt.ylim([-0.05,1.05])",
"_____no_output_____"
]
],
[
[
"## ADER <a id='ADER'></a>\nCan be interpreted as a finite element method in time solved in an iterative manner.\n\n\\begin{align*}\n\\def\\L{\\mathcal{L}}\n\\def\\bc{\\boldsymbol{c}}\n\\def\\bbc{\\underline{\\mathbf{c}}}\n\\def\\bphi{\\underline{\\phi}}\n\\newcommand{\\ww}[1]{\\underline{#1}}\n\\renewcommand{\\vec}[1]{\\ww{#1}}\n\\def\\M{\\underline{\\underline{\\mathrm{M}}}}\n\\def\\R{\\underline{\\underline{\\mathrm{R}}}}\n\t\t\\L^2(\\bbc ):=& \\int_{T^n} \\bphi(t) \\partial_t \\bphi(t)^T \\bbc dt + \\int_{T^n} \\bphi(t) F(\\bphi(t)^T\\bbc) dt =\\\\\n\t\t&\\bphi(t^{n+1}) \\bphi(t^{n+1})^T \\bbc - \\bphi(t^{n}) \\bc^n - \\int_{T^n} \\partial_t \\bphi(t) \\bphi(t)^T \\bbc - \\int_{T^n} \\bphi(t) F(\\bphi(t)^T\\bbc) dt \\\\\n&\\M = \\bphi(t^{n+1}) \\bphi(t^{n+1})^T -\\int_{T^n} \\partial_t \\bphi(t) \\bphi(t)^T \\\\\n&\t\\vec{r}(\\bbc) = \\bphi(t^{n}) \\bc^n + \\int_{T^n} \\bphi(t) F(\\bphi(t)^T\\bbc) dt\\\\ \n&\\M \\bbc = \\vec{r}(\\bbc)\n\\end{align*}\n\nIterative procedure to solve the problem for each time step\n\n\\begin{equation}\\label{fix:point}\n\\bbc^{(k)}=\\M^{-1}\\vec{r}(\\bbc^{(k-1)}),\\quad k=1,\\dots, K \\text{ (convergence)}\n\\end{equation}\n\nwith $\\bbc^{(0)}=\\bc(t^n)$.\n\nReconstruction step\n\n\\begin{equation*}\n\t\\bc(t^{n+1}) = \\bphi(t^{n+1})^T \\bbc^{(K)}.\n\\end{equation*}\n\n### What can be precomputed?\n* $\\M$\n* $$\\vec{r}(\\bbc) = \\bphi(t^{n}) \\bc^n + \\int_{T^n} \\bphi(t) F(\\bphi(t)^T\\bbc) dt\\approx \\bphi(t^{n}) \\bc^n + \\int_{T^n} \\bphi(t)\\bphi(t)^T dt F(\\bbc) = \\bphi(t^{n}) \\bc^n+ \\R \\bbc$$ \n$\\R$ can be precomputed\n* $$ \\bc(t^{n+1}) = \\bphi(t^{n+1})^T \\bbc^{(K)} $$\n$\\bphi(t^{n+1})^T$ can be precomputed",
"_____no_output_____"
]
],
[
[
"from scipy.interpolate import lagrange\n\ndef lagrange_poly(nodes,k):\n interpVal=np.zeros(np.size(nodes))\n interpVal[k] = 1.\n pp=lagrange(nodes,interpVal)\n return pp\n\ndef lagrange_basis(nodes,x,k):\n pp=lagrange_poly(nodes,k)\n return pp(x)\n\ndef lagrange_deriv(nodes,x,k):\n pp=lagrange_poly(nodes,k)\n dd=pp.deriv()\n return dd(x)\n\ndef get_nodes(order,nodes_type):\n if nodes_type==\"equispaced\":\n nodes,w = equispaced(order)\n elif nodes_type == \"gaussLegendre\":\n nodes,w = leggauss(order)\n elif nodes_type == \"gaussLobatto\":\n nodes, w = lglnodes(order-1,10**-15)\n nodes=nodes*0.5+0.5\n w = w*0.5\n return nodes, w\n \ndef getADER_matrix(order, nodes_type):\n nodes_poly, w_poly = get_nodes(order,nodes_type)\n if nodes_type==\"equispaced\":\n quad_order=order\n nodes_quad, w = get_nodes(quad_order,\"gaussLegendre\")\n else:\n quad_order=order\n nodes_quad, w = get_nodes(quad_order,nodes_type)\n \n # generate mass matrix\n M = np.zeros((order,order))\n for i in range(order):\n for j in range(order):\n M[i,j] = lagrange_basis(nodes_poly,1.0,i) *lagrange_basis(nodes_poly,1.0,j)\\\n -sum([lagrange_deriv(nodes_poly,nodes_quad[q],i)\\\n *lagrange_basis(nodes_poly,nodes_quad[q],j)\\\n *w[q] for q in range(quad_order)])\n # generate mass matrix\n RHSmat = np.zeros((order,order))\n for i in range(order):\n for j in range(order):\n RHSmat[i,j] = sum([lagrange_basis(nodes_poly,nodes_quad[q],i)*\\\n lagrange_basis(nodes_poly,nodes_quad[q],j)*\\\n w[q] for q in range(quad_order)])\n return nodes_poly, w_poly, M, RHSmat\n\ndef ader(func, tspan, y_0, M_sub, K_corr, distribution):\n N_time=len(tspan)\n dim=len(y_0)\n U=np.zeros((dim, N_time))\n u_p=np.zeros((dim, M_sub+1))\n u_a=np.zeros((dim, M_sub+1))\n u_tn=np.zeros((dim, M_sub+1))\n rhs= np.zeros((dim,M_sub+1))\n \n x_poly, w_poly, ADER, RHS_mat = getADER_matrix(M_sub+1, distribution)\n invader = np.linalg.inv(ADER)\n evolMatrix=np.matmul(invader,RHS_mat)\n reconstructionCoefficients=np.array([lagrange_basis(x_poly,1.0,i) for i in range(M_sub+1)])\n \n U[:,0]=y_0\n \n for it in range(1, N_time):\n delta_t=(tspan[it]-tspan[it-1])\n for m in range(M_sub+1):\n u_a[:,m]=U[:,it-1]\n u_p[:,m]=U[:,it-1]\n u_tn[:,m]=U[:,it-1]\n for k in range(1,K_corr+1):\n u_p=np.copy(u_a)\n for r in range(M_sub+1):\n rhs[:,r]=func(u_p[:,r])\n for d in range(dim):\n u_a[d,:] = u_tn[d,:] + delta_t*np.matmul(evolMatrix,rhs[d,:])\n U[:,it] = np.matmul(u_a,reconstructionCoefficients)\n return tspan, U",
"_____no_output_____"
],
[
"pr=ODEproblem(\"threeBodies\")\ntt=np.linspace(0,pr.T_fin,1000)\ntt,U=ader(pr.flux,tt,pr.u0,4,5,\"gaussLegendre\")\nplt.figure()\nplt.plot(U[0,:],U[1,:],'*',label=\"sun\")\nplt.plot(U[4,:],U[5,:],label=\"earth\")\nplt.plot(U[8,:],U[9,:],label=\"Mars\")\nplt.legend()\nplt.show()\n\nplt.figure()\nplt.title(\"Distance from the original position of the sun\")\nplt.semilogy(tt,U[4,:]**2+U[5,:]**2,label=\"earth\")\nplt.semilogy(tt,U[8,:]**2+U[9,:]**2, label=\"mars\")\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"#Test convergence\npr=ODEproblem(\"linear_system2\")\n\ntt=np.linspace(0,pr.T_fin,10)\ntt,uu=ader(pr.flux, tt, pr.u0, 7, 8, \"equispaced\")\nplt.plot(tt,uu[0,:])\nplt.plot(tt,uu[1,:])\nplt.show()\n\ndef compute_integral_error(c,c_exact): # c is dim x times\n times=np.shape(c)[1]\n error=0.\n for t in range(times):\n error = error + np.linalg.norm(c[:,t]-c_exact[:,t],2)**2.\n error = np.sqrt(error/times) \n return error\n\nNN=5\ndts=[pr.T_fin/2.0**k for k in range(3,3+NN)]\nerrorsDeC=np.zeros(len(dts))\n\nfor order in range(2,8):\n for k in range(NN):\n dt0=dts[k]\n tt=np.arange(0,pr.T_fin,dt0)\n t2,U2=ader(pr.flux, tt, pr.u0, order-1, order, \"gaussLobatto\")\n u_exact=pr.exact_solution_times(pr.u0,tt)\n errorsDeC[k]=compute_integral_error(U2,u_exact)\n\n plt.loglog(dts,errorsDeC,\"--\",label=\"ADER%d\"%(order))\n plt.loglog(dts,[dt**order*errorsDeC[2]/dts[2]**order for dt in dts],\":\",label=\"ref %d\"%(order))\n\n\nplt.title(\"ADER error convergence\")\nplt.legend()\n#plt.savefig(\"convergence_ADER.pdf\")\nplt.show()\n",
"_____no_output_____"
],
[
"pr=ODEproblem(\"lotka\")\ntt=np.linspace(0,pr.T_fin,150)\nt2,U2=ader(pr.flux, tt, pr.u0, 1, 2, \"gaussLobatto\")\nt8,U8=ader(pr.flux, tt, pr.u0, 7, 8, \"gaussLobatto\")\n\ntt=np.linspace(0,pr.T_fin,2000)\ntref,Uref=dec(pr.flux, tt, pr.u0, 4,5, \"gaussLobatto\")\n\nplt.figure(figsize=(12,6))\nplt.subplot(211)\nplt.plot(t2,U2[0,:],label=\"ADER2\")\nplt.plot(t8,U8[0,:],label=\"ADER8\")\nplt.plot(tref,Uref[0,:], \":\",linewidth=2,label=\"ref\")\nplt.legend()\nplt.title(\"Prey\")\n\nplt.subplot(212)\nplt.plot(t2,U2[1,:],label=\"ADER2\")\nplt.plot(t8,U8[1,:],label=\"ADER8\")\nplt.plot(tref,Uref[1,:],\":\", linewidth=2,label=\"ref\")\nplt.legend()\nplt.title(\"Predator\")",
"_____no_output_____"
]
],
[
[
"### Pro exercise: implicit ADER\nUsing the fact that ADER can be written into DeC, try to make ADER implicit by changing only the definition of $\\mathcal{L}^1$\n\n* Write the formulation and the update formula\n* Implement it adding (as for the DeC an extra input of the jacobian of the flux)",
"_____no_output_____"
],
[
"### Pro exercise: ADER as RK\nHow can you write the ADER scheme into a RK setting?\nAt the end we are computing some coefficients in a more elaborated way to use them explicitly, so one should be able to write it down.",
"_____no_output_____"
],
[
"### Few notes on the stability\nComputing the stability region of the ADER method results, for a fixed order of accuracy, for any point distribution to the same stability region. This coincide with the DeC method stability region for the same order of accuracy.\n\nThis can be shown numerically, I put here some plots, but no analytical proof is available yet.",
"_____no_output_____"
],
[
"**Stability for ADER and DeC methods with $p$ subtimesteps**\n\n| ADER | ADER vs DeC |\n| ----------- | ----------- |\n|  |  |\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a2813119218bb9fb782f15a8e03c15188e5d24c
| 156,889 |
ipynb
|
Jupyter Notebook
|
Prerequisites/Monte-Carlo-Ferromagnet.ipynb
|
IanHawke/M4
|
2d841d4eb38f3d09891ed3c84e49858d30f2d4d4
|
[
"MIT"
] | null | null | null |
Prerequisites/Monte-Carlo-Ferromagnet.ipynb
|
IanHawke/M4
|
2d841d4eb38f3d09891ed3c84e49858d30f2d4d4
|
[
"MIT"
] | null | null | null |
Prerequisites/Monte-Carlo-Ferromagnet.ipynb
|
IanHawke/M4
|
2d841d4eb38f3d09891ed3c84e49858d30f2d4d4
|
[
"MIT"
] | null | null | null | 73.89967 | 466 | 0.654316 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a28141ff3b47f8981d0d51c197e409f0981576c
| 20,775 |
ipynb
|
Jupyter Notebook
|
misc/DLND-your-first-network/dlnd-your-first-neural-network-origin.ipynb
|
soloman817/udacity-ml
|
40302d3c1db811d5795942d01bc225f2d3125bf0
|
[
"MIT"
] | null | null | null |
misc/DLND-your-first-network/dlnd-your-first-neural-network-origin.ipynb
|
soloman817/udacity-ml
|
40302d3c1db811d5795942d01bc225f2d3125bf0
|
[
"MIT"
] | null | null | null |
misc/DLND-your-first-network/dlnd-your-first-neural-network-origin.ipynb
|
soloman817/udacity-ml
|
40302d3c1db811d5795942d01bc225f2d3125bf0
|
[
"MIT"
] | null | null | null | 41.057312 | 664 | 0.600289 |
[
[
[
"# Your first neural network\n\nIn this project, you'll build your first neural network and use it to predict daily bike rental ridership. We've provided some of the code, but left the implementation of the neural network up to you (for the most part). After you've submitted this project, feel free to explore the data and the model more.\n\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## Load and prepare the data\n\nA critical step in working with neural networks is preparing the data correctly. Variables on different scales make it difficult for the network to efficiently learn the correct weights. Below, we've written the code to load and prepare the data. You'll learn more about this soon!",
"_____no_output_____"
]
],
[
[
"data_path = 'Bike-Sharing-Dataset/hour.csv'\n\nrides = pd.read_csv(data_path)",
"_____no_output_____"
],
[
"rides.head()",
"_____no_output_____"
]
],
[
[
"## Checking out the data\n\nThis dataset has the number of riders for each hour of each day from January 1 2011 to December 31 2012. The number of riders is split between casual and registered, summed up in the `cnt` column. You can see the first few rows of the data above.\n\nBelow is a plot showing the number of bike riders over the first 10 days in the data set. You can see the hourly rentals here. This data is pretty complicated! The weekends have lower over all ridership and there are spikes when people are biking to and from work during the week. Looking at the data above, we also have information about temperature, humidity, and windspeed, all of these likely affecting the number of riders. You'll be trying to capture all this with your model.",
"_____no_output_____"
]
],
[
[
"rides[:24*10].plot(x='dteday', y='cnt')",
"_____no_output_____"
]
],
[
[
"### Dummy variables\nHere we have some categorical variables like season, weather, month. To include these in our model, we'll need to make binary dummy variables. This is simple to do with Pandas thanks to `get_dummies()`.",
"_____no_output_____"
]
],
[
[
"dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday']\nfor each in dummy_fields:\n dummies = pd.get_dummies(rides[each], prefix=each, drop_first=False)\n rides = pd.concat([rides, dummies], axis=1)\n\nfields_to_drop = ['instant', 'dteday', 'season', 'weathersit', \n 'weekday', 'atemp', 'mnth', 'workingday', 'hr']\ndata = rides.drop(fields_to_drop, axis=1)\ndata.head()",
"_____no_output_____"
]
],
[
[
"### Scaling target variables\nTo make training the network easier, we'll standardize each of the continuous variables. That is, we'll shift and scale the variables such that they have zero mean and a standard deviation of 1.\n\nThe scaling factors are saved so we can go backwards when we use the network for predictions.",
"_____no_output_____"
]
],
[
[
"quant_features = ['casual', 'registered', 'cnt', 'temp', 'hum', 'windspeed']\n# Store scalings in a dictionary so we can convert back later\nscaled_features = {}\nfor each in quant_features:\n mean, std = data[each].mean(), data[each].std()\n scaled_features[each] = [mean, std]\n data.loc[:, each] = (data[each] - mean)/std",
"_____no_output_____"
]
],
[
[
"### Splitting the data into training, testing, and validation sets\n\nWe'll save the last 21 days of the data to use as a test set after we've trained the network. We'll use this set to make predictions and compare them with the actual number of riders.",
"_____no_output_____"
]
],
[
[
"# Save the last 21 days \ntest_data = data[-21*24:]\ndata = data[:-21*24]\n\n# Separate the data into features and targets\ntarget_fields = ['cnt', 'casual', 'registered']\nfeatures, targets = data.drop(target_fields, axis=1), data[target_fields]\ntest_features, test_targets = test_data.drop(target_fields, axis=1), test_data[target_fields]",
"_____no_output_____"
]
],
[
[
"We'll split the data into two sets, one for training and one for validating as the network is being trained. Since this is time series data, we'll train on historical data, then try to predict on future data (the validation set).",
"_____no_output_____"
]
],
[
[
"# Hold out the last 60 days of the remaining data as a validation set\ntrain_features, train_targets = features[:-60*24], targets[:-60*24]\nval_features, val_targets = features[-60*24:], targets[-60*24:]",
"_____no_output_____"
]
],
[
[
"## Time to build the network\n\nBelow you'll build your network. We've built out the structure and the backwards pass. You'll implement the forward pass through the network. You'll also set the hyperparameters: the learning rate, the number of hidden units, and the number of training passes.\n\nThe network has two layers, a hidden layer and an output layer. The hidden layer will use the sigmoid function for activations. The output layer has only one node and is used for the regression, the output of the node is the same as the input of the node. That is, the activation function is $f(x)=x$. A function that takes the input signal and generates an output signal, but takes into account the threshold, is called an activation function. We work through each layer of our network calculating the outputs for each neuron. All of the outputs from one layer become inputs to the neurons on the next layer. This process is called *forward propagation*.\n\nWe use the weights to propagate signals forward from the input to the output layers in a neural network. We use the weights to also propagate error backwards from the output back into the network to update our weights. This is called *backpropagation*.\n\n> **Hint:** You'll need the derivative of the output activation function ($f(x) = x$) for the backpropagation implementation. If you aren't familiar with calculus, this function is equivalent to the equation $y = x$. What is the slope of that equation? That is the derivative of $f(x)$.\n\nBelow, you have these tasks:\n1. Implement the sigmoid function to use as the activation function. Set `self.activation_function` in `__init__` to your sigmoid function.\n2. Implement the forward pass in the `train` method.\n3. Implement the backpropagation algorithm in the `train` method, including calculating the output error.\n4. Implement the forward pass in the `run` method.\n ",
"_____no_output_____"
]
],
[
[
"class NeuralNetwork(object):\n def __init__(self, input_nodes, hidden_nodes, output_nodes, learning_rate):\n # Set number of nodes in input, hidden and output layers.\n self.input_nodes = input_nodes\n self.hidden_nodes = hidden_nodes\n self.output_nodes = output_nodes\n\n # Initialize weights\n self.weights_input_to_hidden = np.random.normal(0.0, self.hidden_nodes**-0.5, \n (self.hidden_nodes, self.input_nodes))\n\n self.weights_hidden_to_output = np.random.normal(0.0, self.output_nodes**-0.5, \n (self.output_nodes, self.hidden_nodes))\n self.lr = learning_rate\n \n #### Set this to your implemented sigmoid function ####\n # Activation function is the sigmoid function\n self.activation_function = \n \n def train(self, inputs_list, targets_list):\n # Convert inputs list to 2d array\n inputs = np.array(inputs_list, ndmin=2).T\n targets = np.array(targets_list, ndmin=2).T\n \n #### Implement the forward pass here ####\n ### Forward pass ###\n # TODO: Hidden layer\n hidden_inputs = # signals into hidden layer\n hidden_outputs = # signals from hidden layer\n \n # TODO: Output layer\n final_inputs = # signals into final output layer\n final_outputs = # signals from final output layer\n \n #### Implement the backward pass here ####\n ### Backward pass ###\n \n # TODO: Output error\n output_errors = # Output layer error is the difference between desired target and actual output.\n \n # TODO: Backpropagated error\n hidden_errors = # errors propagated to the hidden layer\n hidden_grad = # hidden layer gradients\n \n # TODO: Update the weights\n self.weights_hidden_to_output += # update hidden-to-output weights with gradient descent step\n self.weights_input_to_hidden += # update input-to-hidden weights with gradient descent step\n \n \n def run(self, inputs_list):\n # Run a forward pass through the network\n inputs = np.array(inputs_list, ndmin=2).T\n \n #### Implement the forward pass here ####\n # TODO: Hidden layer\n hidden_inputs = # signals into hidden layer\n hidden_outputs = # signals from hidden layer\n \n # TODO: Output layer\n final_inputs = # signals into final output layer\n final_outputs = # signals from final output layer \n \n return final_outputs",
"_____no_output_____"
],
[
"def MSE(y, Y):\n return np.mean((y-Y)**2)",
"_____no_output_____"
]
],
[
[
"## Training the network\n\nHere you'll set the hyperparameters for the network. The strategy here is to find hyperparameters such that the error on the training set is low, but you're not overfitting to the data. If you train the network too long or have too many hidden nodes, it can become overly specific to the training set and will fail to generalize to the validation set. That is, the loss on the validation set will start increasing as the training set loss drops.\n\nYou'll also be using a method know as Stochastic Gradient Descent (SGD) to train the network. The idea is that for each training pass, you grab a random sample of the data instead of using the whole data set. You use many more training passes than with normal gradient descent, but each pass is much faster. This ends up training the network more efficiently. You'll learn more about SGD later.\n\n### Choose the number of epochs\nThis is the number of times the dataset will pass through the network, each time updating the weights. As the number of epochs increases, the network becomes better and better at predicting the targets in the training set. You'll need to choose enough epochs to train the network well but not too many or you'll be overfitting.\n\n### Choose the learning rate\nThis scales the size of weight updates. If this is too big, the weights tend to explode and the network fails to fit the data. A good choice to start at is 0.1. If the network has problems fitting the data, try reducing the learning rate. Note that the lower the learning rate, the smaller the steps are in the weight updates and the longer it takes for the neural network to converge.\n\n### Choose the number of hidden nodes\nThe more hidden nodes you have, the more accurate predictions the model will make. Try a few different numbers and see how it affects the performance. You can look at the losses dictionary for a metric of the network performance. If the number of hidden units is too low, then the model won't have enough space to learn and if it is too high there are too many options for the direction that the learning can take. The trick here is to find the right balance in number of hidden units you choose.",
"_____no_output_____"
]
],
[
[
"import sys\n\n### Set the hyperparameters here ###\nepochs = 100\nlearning_rate = 0.1\nhidden_nodes = 2\noutput_nodes = 1\n\nN_i = train_features.shape[1]\nnetwork = NeuralNetwork(N_i, hidden_nodes, output_nodes, learning_rate)\n\nlosses = {'train':[], 'validation':[]}\nfor e in range(epochs):\n # Go through a random batch of 128 records from the training data set\n batch = np.random.choice(train_features.index, size=128)\n for record, target in zip(train_features.ix[batch].values, \n train_targets.ix[batch]['cnt']):\n network.train(record, target)\n \n # Printing out the training progress\n train_loss = MSE(network.run(train_features), train_targets['cnt'].values)\n val_loss = MSE(network.run(val_features), val_targets['cnt'].values)\n sys.stdout.write(\"\\rProgress: \" + str(100 * e/float(epochs))[:4] \\\n + \"% ... Training loss: \" + str(train_loss)[:5] \\\n + \" ... Validation loss: \" + str(val_loss)[:5])\n \n losses['train'].append(train_loss)\n losses['validation'].append(val_loss)",
"_____no_output_____"
],
[
"plt.plot(losses['train'], label='Training loss')\nplt.plot(losses['validation'], label='Validation loss')\nplt.legend()\nplt.ylim(ymax=0.5)",
"_____no_output_____"
]
],
[
[
"## Check out your predictions\n\nHere, use the test data to view how well your network is modeling the data. If something is completely wrong here, make sure each step in your network is implemented correctly.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(8,4))\n\nmean, std = scaled_features['cnt']\npredictions = network.run(test_features)*std + mean\nax.plot(predictions[0], label='Prediction')\nax.plot((test_targets['cnt']*std + mean).values, label='Data')\nax.set_xlim(right=len(predictions))\nax.legend()\n\ndates = pd.to_datetime(rides.ix[test_data.index]['dteday'])\ndates = dates.apply(lambda d: d.strftime('%b %d'))\nax.set_xticks(np.arange(len(dates))[12::24])\n_ = ax.set_xticklabels(dates[12::24], rotation=45)",
"_____no_output_____"
]
],
[
[
"## Thinking about your results\n \nAnswer these questions about your results. How well does the model predict the data? Where does it fail? Why does it fail where it does?\n\n> **Note:** You can edit the text in this cell by double clicking on it. When you want to render the text, press control + enter\n\n#### Your answer below",
"_____no_output_____"
],
[
"## Unit tests\n\nRun these unit tests to check the correctness of your network implementation. These tests must all be successful to pass the project.",
"_____no_output_____"
]
],
[
[
"import unittest\n\ninputs = [0.5, -0.2, 0.1]\ntargets = [0.4]\ntest_w_i_h = np.array([[0.1, 0.4, -0.3], \n [-0.2, 0.5, 0.2]])\ntest_w_h_o = np.array([[0.3, -0.1]])\n\nclass TestMethods(unittest.TestCase):\n \n ##########\n # Unit tests for data loading\n ##########\n \n def test_data_path(self):\n # Test that file path to dataset has been unaltered\n self.assertTrue(data_path.lower() == 'bike-sharing-dataset/hour.csv')\n \n def test_data_loaded(self):\n # Test that data frame loaded\n self.assertTrue(isinstance(rides, pd.DataFrame))\n \n ##########\n # Unit tests for network functionality\n ##########\n\n def test_activation(self):\n network = NeuralNetwork(3, 2, 1, 0.5)\n # Test that the activation function is a sigmoid\n self.assertTrue(np.all(network.activation_function(0.5) == 1/(1+np.exp(-0.5))))\n\n def test_train(self):\n # Test that weights are updated correctly on training\n network = NeuralNetwork(3, 2, 1, 0.5)\n network.weights_input_to_hidden = test_w_i_h.copy()\n network.weights_hidden_to_output = test_w_h_o.copy()\n \n network.train(inputs, targets)\n self.assertTrue(np.allclose(network.weights_hidden_to_output, \n np.array([[ 0.37275328, -0.03172939]])))\n self.assertTrue(np.allclose(network.weights_input_to_hidden,\n np.array([[ 0.10562014, 0.39775194, -0.29887597],\n [-0.20185996, 0.50074398, 0.19962801]])))\n\n def test_run(self):\n # Test correctness of run method\n network = NeuralNetwork(3, 2, 1, 0.5)\n network.weights_input_to_hidden = test_w_i_h.copy()\n network.weights_hidden_to_output = test_w_h_o.copy()\n\n self.assertTrue(np.allclose(network.run(inputs), 0.09998924))\n\nsuite = unittest.TestLoader().loadTestsFromModule(TestMethods())\nunittest.TextTestRunner().run(suite)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
4a281a47db36f569ed4a6585b08f49e8c68ce2d6
| 198,386 |
ipynb
|
Jupyter Notebook
|
Year-wise Hurricane Type prediction/Hurricane type predicton using LR.ipynb
|
arpitpatel1501/Harricane-Trajectories
|
2ba68b55fb91d67c9b978d5361b9bdb9e58018a3
|
[
"MIT"
] | null | null | null |
Year-wise Hurricane Type prediction/Hurricane type predicton using LR.ipynb
|
arpitpatel1501/Harricane-Trajectories
|
2ba68b55fb91d67c9b978d5361b9bdb9e58018a3
|
[
"MIT"
] | null | null | null |
Year-wise Hurricane Type prediction/Hurricane type predicton using LR.ipynb
|
arpitpatel1501/Harricane-Trajectories
|
2ba68b55fb91d67c9b978d5361b9bdb9e58018a3
|
[
"MIT"
] | null | null | null | 99,193 | 198,385 | 0.904479 |
[
[
[
"# Data Retriving and Pre-processing",
"_____no_output_____"
],
[
"**Importing Libraries**\n",
"_____no_output_____"
]
],
[
[
"# ALL THE IMPORTS NECESSARY\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\n\nimport pandas as pd\nimport numpy as np\n\nfrom geopy.distance import great_circle as vc\nimport math as Math",
"_____no_output_____"
]
],
[
[
"**Retriving Data**",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('/content/drive/My Drive/ML_2020/Project code/1920-2012-data.csv', index_col=None, names=['Year', 'Month', 'Day', 'Hour', 'HurricaneNum', 'Name', 'Lat', 'Long', 'WindSpeed', 'Pressure', 'NullCol'])\n\n# Preview the first 5 rows of data\nprint(data.head())\n\n#Averaging wind speed of particular hurricane name in particlar year\ndata['unique-key'] = data['Year'].map(str) + '-' + data['HurricaneNum'].map(str)\nwindSpeedAvg = data.groupby('unique-key', as_index=False)['WindSpeed'].mean()\n\nwindSpeedAvg['unique-key'] = windSpeedAvg['unique-key'].str.split('-',n=1,expand=True)\nprint(windSpeedAvg[:12])\n\n# Delete the columns of information that we are not using so far\ndata.drop(['Name','Month', 'Day', 'Hour', 'HurricaneNum', 'Lat', 'Long', 'Pressure' ,'NullCol','unique-key'], axis = 1, inplace = True)\ndata['Year']=windSpeedAvg['unique-key']\ndata['WindSpeed'] = windSpeedAvg['WindSpeed']\n# Preview the first 5 rows of data after delete unnecessary columns\nprint(windSpeedAvg.shape)\n\ndata = data.dropna() \ndata = data.reset_index(drop=True)\nprint(data.tail())\nprint(data.shape)",
" Year Month Day Hour ... Long WindSpeed Pressure NullCol\n0 2000 6 7 18 ... -93.0 25.0 0 NaN\n1 2000 6 8 0 ... -92.8 25.0 0 NaN\n2 2000 6 8 6 ... -93.1 25.0 0 NaN\n3 2000 6 8 12 ... -93.5 25.0 0 NaN\n4 2000 6 23 0 ... -19.8 25.0 0 NaN\n\n[5 rows x 11 columns]\n unique-key WindSpeed\n0 1920 64.605263\n1 1920 42.166667\n2 1920 42.750000\n3 1920 36.388889\n4 1920 42.291667\n5 1921 44.534884\n6 1921 40.000000\n7 1921 84.895833\n8 1921 55.714286\n9 1921 50.833333\n10 1921 77.674419\n11 1921 33.750000\n(1225, 2)\n Year WindSpeed\n1220 2012 50.128205\n1221 2012 33.333333\n1222 2012 29.210526\n1223 2012 58.461538\n1224 2012 47.058824\n(1225, 2)\n"
]
],
[
[
"**Pre-Processing Data**",
"_____no_output_____"
]
],
[
[
"list_of_wind_speed = data['WindSpeed'].to_list()\n\nlist_of_wind_speed = [i * 1.5 for i in list_of_wind_speed] # unit of wind speed is knot 1knot = 1.5mph\n\n#print(\"wind Speed : \",list_of_wind_speed[:5])\nhurricane_type = []\n\n\n## Categorized hurricane into 5 different types \nfor i in list_of_wind_speed:\n if i>=74 and i<=95:\n hurricane_type.append(1)\n elif i>95 and i<=110:\n hurricane_type.append(2)\n elif i>110 and i<=129:\n hurricane_type.append(3)\n elif i>129 and i<=156:\n hurricane_type.append(4)\n elif i>156:\n hurricane_type.append(5)\n elif i<74:\n hurricane_type.append(0)\n else:\n hurricane_type.append(-1)",
"1225\nhi 1225\n1225\n"
]
],
[
[
"**Pre Processing Con.**",
"_____no_output_____"
]
],
[
[
"data['WindSpeed'] = list_of_wind_speed # assign value of wind speed in mph unit\n#Add new column in data frame\ndata['HurricaneType'] = hurricane_type\n\nprint(\"After adding new column :\\n\",data.head())\ndata = data[data['HurricaneType'] != 0] # ignore all values which does not contain hurricane that is type 0\n#print(data[data['HurricaneType'] == -1])\ndata = data.reset_index(drop=True)\nprint(\"After removing non hurricane entries :\\n\",data.head())\nprint(\"Shape of data : \",data.shape)\n\n\ntemp =data[data['Year'] == str(2000)]\nprint(len(temp))\nprint(temp[:5])\nprint(\"len of : \",len(temp[temp['HurricaneType'] ==1 ]))\n\n\nprint(\"Unique year : \",pd.unique(data['Year']))\nprint(\"Length of Unique year : \",len(pd.unique(data['Year'])))\n\n\n",
"After adding new column :\n Year WindSpeed HurricaneType\n0 1920 96.907895 2\n1 1920 63.250000 0\n2 1920 64.125000 0\n3 1920 54.583333 0\n4 1920 63.437500 0\nAfter removing non hurricane entries :\n Year WindSpeed HurricaneType\n0 1920 96.907895 2\n1 1921 127.343750 3\n2 1921 83.571429 1\n3 1921 76.250000 1\n4 1921 116.511628 3\nShape of data : (417, 3)\n7\n Year WindSpeed HurricaneType\n345 2000 80.689655 1\n346 2000 111.923077 3\n347 2000 75.267857 1\n348 2000 88.181818 1\n349 2000 84.204545 1\nlen of : 6\nUnique year : ['1920' '1921' '1922' '1923' '1924' '1925' '1926' '1927' '1928' '1929'\n '1930' '1931' '1932' '1933' '1934' '1935' '1936' '1937' '1938' '1939'\n '1940' '1941' '1942' '1943' '1944' '1945' '1946' '1947' '1948' '1949'\n '1950' '1951' '1952' '1953' '1954' '1955' '1956' '1957' '1958' '1959'\n '1960' '1961' '1962' '1963' '1964' '1965' '1966' '1967' '1968' '1969'\n '1970' '1971' '1972' '1973' '1974' '1975' '1976' '1977' '1978' '1979'\n '1980' '1981' '1982' '1984' '1985' '1986' '1987' '1988' '1989' '1990'\n '1991' '1992' '1993' '1994' '1995' '1996' '1997' '1998' '1999' '2000'\n '2001' '2002' '2003' '2004' '2005' '2006' '2007' '2008' '2009' '2010'\n '2011' '2012']\nLength of Unique year : 92\n"
]
],
[
[
"**Pre Processing Con.**",
"_____no_output_____"
]
],
[
[
"hurricane_no =[]\nunique_year = pd.unique(data['Year'])\nfor i in unique_year:\n for j in range(5):\n number = data[data['Year']==str(i)]\n hurricane_no.append([i,j+1,len(number[number['HurricaneType']==j+1])])\n ",
"[['1920', 1, 0], ['1920', 2, 1], ['1920', 3, 0], ['1920', 4, 0], ['1920', 5, 0]]\n"
]
],
[
[
"**Store the data into csv**",
"_____no_output_____"
]
],
[
[
"df = pd.DataFrame(hurricane_no, columns = ['Year', 'HurricaneType','HurricaneFreq']) \nprint(df)\n\ndf.to_csv(r'/content/drive/My Drive/ML_2020/Project code/final_data.csv')",
" Year HurricaneType HurricaneFreq\n0 1920 1 0\n1 1920 2 1\n2 1920 3 0\n3 1920 4 0\n4 1920 5 0\n.. ... ... ...\n455 2012 1 7\n456 2012 2 0\n457 2012 3 0\n458 2012 4 0\n459 2012 5 0\n\n[460 rows x 3 columns]\n"
]
],
[
[
"# Model",
"_____no_output_____"
]
],
[
[
"# import required libraries\nimport pandas as pd\nimport numpy as np\nimport scipy.linalg\nfrom mpl_toolkits import mplot3d\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom numpy.linalg import inv\nfrom numpy.linalg import pinv\nimport math",
"_____no_output_____"
],
[
"# fetch data from file \n\ndata = pd.read_csv('/content/drive/My Drive/Machine Learning/Hurricane_project/final_data.csv', usecols=['Year', 'HurricaneType','HurricaneFreq'])\n\n# convert csv data into list for easy computation\nlist_year = data['Year'].to_list()\nlist_HurricaneType = data['HurricaneType'].to_list()\nlist_HurricaneFreq = data['HurricaneFreq'].to_list()\n\nX= []\nfor i in range(0,len(list_year)):\n X.append([list_year[i],list_HurricaneType[i]])\nprint(X)\nX = np.array(X)\nY = list_HurricaneFreq\n\n# divide data in training and testing set (80-20)\nsize = int(len(X) * 0.8)\nX_train = X[:size]\nX_test = X[size:]\n\nY_train = Y[:size]\nY_test = Y[size:]",
"[[1920, 1], [1920, 2], [1920, 3], [1920, 4], [1920, 5], [1921, 1], [1921, 2], [1921, 3], [1921, 4], [1921, 5], [1922, 1], [1922, 2], [1922, 3], [1922, 4], [1922, 5], [1923, 1], [1923, 2], [1923, 3], [1923, 4], [1923, 5], [1924, 1], [1924, 2], [1924, 3], [1924, 4], [1924, 5], [1925, 1], [1925, 2], [1925, 3], [1925, 4], [1925, 5], [1926, 1], [1926, 2], [1926, 3], [1926, 4], [1926, 5], [1927, 1], [1927, 2], [1927, 3], [1927, 4], [1927, 5], [1928, 1], [1928, 2], [1928, 3], [1928, 4], [1928, 5], [1929, 1], [1929, 2], [1929, 3], [1929, 4], [1929, 5], [1930, 1], [1930, 2], [1930, 3], [1930, 4], [1930, 5], [1931, 1], [1931, 2], [1931, 3], [1931, 4], [1931, 5], [1932, 1], [1932, 2], [1932, 3], [1932, 4], [1932, 5], [1933, 1], [1933, 2], [1933, 3], [1933, 4], [1933, 5], [1934, 1], [1934, 2], [1934, 3], [1934, 4], [1934, 5], [1935, 1], [1935, 2], [1935, 3], [1935, 4], [1935, 5], [1936, 1], [1936, 2], [1936, 3], [1936, 4], [1936, 5], [1937, 1], [1937, 2], [1937, 3], [1937, 4], [1937, 5], [1938, 1], [1938, 2], [1938, 3], [1938, 4], [1938, 5], [1939, 1], [1939, 2], [1939, 3], [1939, 4], [1939, 5], [1940, 1], [1940, 2], [1940, 3], [1940, 4], [1940, 5], [1941, 1], [1941, 2], [1941, 3], [1941, 4], [1941, 5], [1942, 1], [1942, 2], [1942, 3], [1942, 4], [1942, 5], [1943, 1], [1943, 2], [1943, 3], [1943, 4], [1943, 5], [1944, 1], [1944, 2], [1944, 3], [1944, 4], [1944, 5], [1945, 1], [1945, 2], [1945, 3], [1945, 4], [1945, 5], [1946, 1], [1946, 2], [1946, 3], [1946, 4], [1946, 5], [1947, 1], [1947, 2], [1947, 3], [1947, 4], [1947, 5], [1948, 1], [1948, 2], [1948, 3], [1948, 4], [1948, 5], [1949, 1], [1949, 2], [1949, 3], [1949, 4], [1949, 5], [1950, 1], [1950, 2], [1950, 3], [1950, 4], [1950, 5], [1951, 1], [1951, 2], [1951, 3], [1951, 4], [1951, 5], [1952, 1], [1952, 2], [1952, 3], [1952, 4], [1952, 5], [1953, 1], [1953, 2], [1953, 3], [1953, 4], [1953, 5], [1954, 1], [1954, 2], [1954, 3], [1954, 4], [1954, 5], [1955, 1], [1955, 2], [1955, 3], [1955, 4], [1955, 5], [1956, 1], [1956, 2], [1956, 3], [1956, 4], [1956, 5], [1957, 1], [1957, 2], [1957, 3], [1957, 4], [1957, 5], [1958, 1], [1958, 2], [1958, 3], [1958, 4], [1958, 5], [1959, 1], [1959, 2], [1959, 3], [1959, 4], [1959, 5], [1960, 1], [1960, 2], [1960, 3], [1960, 4], [1960, 5], [1961, 1], [1961, 2], [1961, 3], [1961, 4], [1961, 5], [1962, 1], [1962, 2], [1962, 3], [1962, 4], [1962, 5], [1963, 1], [1963, 2], [1963, 3], [1963, 4], [1963, 5], [1964, 1], [1964, 2], [1964, 3], [1964, 4], [1964, 5], [1965, 1], [1965, 2], [1965, 3], [1965, 4], [1965, 5], [1966, 1], [1966, 2], [1966, 3], [1966, 4], [1966, 5], [1967, 1], [1967, 2], [1967, 3], [1967, 4], [1967, 5], [1968, 1], [1968, 2], [1968, 3], [1968, 4], [1968, 5], [1969, 1], [1969, 2], [1969, 3], [1969, 4], [1969, 5], [1970, 1], [1970, 2], [1970, 3], [1970, 4], [1970, 5], [1971, 1], [1971, 2], [1971, 3], [1971, 4], [1971, 5], [1972, 1], [1972, 2], [1972, 3], [1972, 4], [1972, 5], [1973, 1], [1973, 2], [1973, 3], [1973, 4], [1973, 5], [1974, 1], [1974, 2], [1974, 3], [1974, 4], [1974, 5], [1975, 1], [1975, 2], [1975, 3], [1975, 4], [1975, 5], [1976, 1], [1976, 2], [1976, 3], [1976, 4], [1976, 5], [1977, 1], [1977, 2], [1977, 3], [1977, 4], [1977, 5], [1978, 1], [1978, 2], [1978, 3], [1978, 4], [1978, 5], [1979, 1], [1979, 2], [1979, 3], [1979, 4], [1979, 5], [1980, 1], [1980, 2], [1980, 3], [1980, 4], [1980, 5], [1981, 1], [1981, 2], [1981, 3], [1981, 4], [1981, 5], [1982, 1], [1982, 2], [1982, 3], [1982, 4], [1982, 5], [1984, 1], [1984, 2], [1984, 3], [1984, 4], [1984, 5], [1985, 1], [1985, 2], [1985, 3], [1985, 4], [1985, 5], [1986, 1], [1986, 2], [1986, 3], [1986, 4], [1986, 5], [1987, 1], [1987, 2], [1987, 3], [1987, 4], [1987, 5], [1988, 1], [1988, 2], [1988, 3], [1988, 4], [1988, 5], [1989, 1], [1989, 2], [1989, 3], [1989, 4], [1989, 5], [1990, 1], [1990, 2], [1990, 3], [1990, 4], [1990, 5], [1991, 1], [1991, 2], [1991, 3], [1991, 4], [1991, 5], [1992, 1], [1992, 2], [1992, 3], [1992, 4], [1992, 5], [1993, 1], [1993, 2], [1993, 3], [1993, 4], [1993, 5], [1994, 1], [1994, 2], [1994, 3], [1994, 4], [1994, 5], [1995, 1], [1995, 2], [1995, 3], [1995, 4], [1995, 5], [1996, 1], [1996, 2], [1996, 3], [1996, 4], [1996, 5], [1997, 1], [1997, 2], [1997, 3], [1997, 4], [1997, 5], [1998, 1], [1998, 2], [1998, 3], [1998, 4], [1998, 5], [1999, 1], [1999, 2], [1999, 3], [1999, 4], [1999, 5], [2000, 1], [2000, 2], [2000, 3], [2000, 4], [2000, 5], [2001, 1], [2001, 2], [2001, 3], [2001, 4], [2001, 5], [2002, 1], [2002, 2], [2002, 3], [2002, 4], [2002, 5], [2003, 1], [2003, 2], [2003, 3], [2003, 4], [2003, 5], [2004, 1], [2004, 2], [2004, 3], [2004, 4], [2004, 5], [2005, 1], [2005, 2], [2005, 3], [2005, 4], [2005, 5], [2006, 1], [2006, 2], [2006, 3], [2006, 4], [2006, 5], [2007, 1], [2007, 2], [2007, 3], [2007, 4], [2007, 5], [2008, 1], [2008, 2], [2008, 3], [2008, 4], [2008, 5], [2009, 1], [2009, 2], [2009, 3], [2009, 4], [2009, 5], [2010, 1], [2010, 2], [2010, 3], [2010, 4], [2010, 5], [2011, 1], [2011, 2], [2011, 3], [2011, 4], [2011, 5], [2012, 1], [2012, 2], [2012, 3], [2012, 4], [2012, 5]]\n"
],
[
"# for building feature matrix of any polynomial degree\ndef multiplication(x1=0, x1_time=0, x2=0, x2_time=0):\n out_x1 = x1\n out_x2 = x2\n for i in range(x1_time-1):\n out_x1 = np.multiply(x1, out_x1)\n \n for j in range(x2_time-1):\n out_x2 = np.multiply(x2, out_x2)\n \n if x1_time==0:\n return out_x2\n elif x2_time==0:\n return out_x1\n else:\n return np.multiply(out_x1, out_x2)",
"_____no_output_____"
],
[
"## Create Phi polynomial matrix of any degree for 2 feature\ndef poly_features(X, K):\n # X: inputs of size N x 1\n # K: degree of the polynomial\n # computes the feature matrix Phi (N x (K+1)) \n X = np.array(X)\n x1 = X[:,0]\n x2 = X[:,1]\n N = X.shape[0]\n\n col = sum(range(K+2))\n\n #initialize Phi\n phi = np.ones((N, col))\n cnt=1\n\n for k in range(1, K+1):\n for i in range(k+1):\n phi[:, cnt] = multiplication(x1=x1, x1_time=k-i, x2=x2, x2_time=i) # for any degree polynomial\n cnt += 1\n \n return phi",
"_____no_output_____"
],
[
"K = 5 # Define the degree of the polynomial we wish to fit\nPhi = poly_features(X_train, K) # N x (K+1) feature matrix\ntheta_ml = nonlinear_features_maximum_likelihood(Phi, Y_train) # maximum likelihood estimator\n\n# feature matrix for test inputs\nPhi_test = poly_features(X_test, K)\ny_pred = Phi_test @ theta_ml # predicted y-values\nplt.figure()\nax = plt.axes(projection='3d')\n\n# plot data for visulization\nplt.plot(X[:,0], X[:,1], Y, '+')\nplt.xlabel(\"Year\")\nplt.ylabel(\"Hurricane Type\")\nplt.legend([\"Data\"])",
"_____no_output_____"
]
],
[
[
"# RMSE",
"_____no_output_____"
]
],
[
[
"# Root Mean Square Error\ndef RMSE(y, ypred):\n diff_sqr = pow(y-ypred, 2)\n\n rmse = math.sqrt(1/len(y) * sum(diff_sqr)) ## sum of sqaue error between real and predict value\n return rmse",
"_____no_output_____"
],
[
"## training loss\nK_max = 20 # max polynomial degree\nrmse_train = np.zeros((K_max+1,))\n\nfor k in range(1, K_max+1):\n Phi = poly_features(X_train, k) # N x (K+1) feature matrix\n theta_ml = nonlinear_features_maximum_likelihood(Phi, Y_train) # maximum likelihood estimator\n\n y_pred = Phi @ theta_ml\n rmse_train[k] = RMSE(Y_train, y_pred) # RMSE for different degree polynomial\nplt.figure()\nplt.plot(rmse_train)\nplt.xlabel(\"degree of polynomial\")\nplt.ylabel(\"RMSE\");\nplt.xlim(1, K_max+1)\nplt.ylim(min(rmse_train[1:]), max(rmse_train))",
"_____no_output_____"
],
[
"K_max = 20 # max polynomial degree\nrmse_train = np.zeros((K_max+1,)) # initialize rmse for train and test data set\nrmse_test = np.zeros((K_max+1,))\nfor k in range(K_max+1):\n \n # feature matrix\n Phi = poly_features(X_train, k) # N x (K+1) feature matrix\n # maximum likelihood estimate\n theta_ml = nonlinear_features_maximum_likelihood(Phi, Y_train) \n # predict y-values of training set\n ypred_train = Phi @ theta_ml\n # RMSE on training set\n rmse_train[k] = RMSE(Y_train, ypred_train) \n \n #--------------------------------------------------------------\n\n # feature matrix for test inputs\n Phi_test = poly_features(X_test, k) \n # prediction (test set)\n ypred_test = Phi_test @ theta_ml \n # RMSE on test set\n rmse_test[k] = RMSE(Y_test, ypred_test)\nplt.figure()\nplt.semilogy(rmse_train) # this plots the RMSE on a logarithmic scale\nplt.semilogy(rmse_test) # this plots the RMSE on a logarithmic scale\nplt.xlabel(\"degree of polynomial\")\nplt.ylabel(\"RMSE\")\nplt.legend([\"training set\", \"test set\"])",
"_____no_output_____"
]
],
[
[
"# MLE",
"_____no_output_____"
]
],
[
[
"# theta_ml = (phi_T * phi)-1 phi_T*y\n\nfrom numpy.linalg import pinv\ndef nonlinear_features_maximum_likelihood(Phi, y):\n # Phi: features matrix for training inputs. Size of N x D\n # y: training targets. Size of N by 1\n # returns: maximum likelihood estimator theta_ml. Size of D x 1\n kappa = 1e-08 # 'jitter' term; good for numerical stability\n \n D = Phi.shape[1]\n # maximum likelihood estimate\n X_transpose = Phi.T\n X_tran_X = np.matmul(X_transpose, Phi)\n \n X_tran_X_inv = pinv(X_tran_X)\n X_tran_X_inv_X_tran = np.matmul(X_tran_X_inv, X_transpose)\n theta_ml = np.matmul(X_tran_X_inv_X_tran, y)\n return theta_ml",
"_____no_output_____"
]
],
[
[
"# MAP",
"_____no_output_____"
]
],
[
[
"def map_estimate_poly(Phi, y, sigma, alpha):\n # Phi: training inputs, Size of N x D\n # y: training targets, Size of D x 1\n # sigma: standard deviation of the noise\n # alpha: standard deviation of the prior on the parameters\n # returns: MAP estimate theta_map, Size of D x 1\n D = Phi.shape[1]\n # maximum likelihood estimate\n X_T = Phi.T\n X_T_X = np.matmul(X_T, Phi)\n\n # regularization element\n reg = (sigma**2 / alpha**2) * np.ones(X_T_X.shape)\n\n X_T_X_reg = X_T_X + reg\n \n X_T_X_reg_inv = pinv(X_T_X_reg)\n X_T_X_reg_inv_X_T = np.matmul(X_T_X_reg_inv, X_T)\n theta_map = np.matmul(X_T_X_reg_inv_X_T, y)\n return theta_map",
"_____no_output_____"
],
[
"sigma = 1.0 # noise standard deviation\nalpha = 1.0 # standard deviation of the parameter prior\n\nN=20",
"_____no_output_____"
],
[
"# get the MAP estimate\nK = 8 # polynomial degree\n# feature matrix\nPhi = poly_features(X_train, K)\ntheta_map = map_estimate_poly(Phi, Y_train, sigma, alpha)\n# maximum likelihood estimate\ntheta_ml = nonlinear_features_maximum_likelihood(Phi, Y_train)\n\nPhi_test = poly_features(X_test, K)\ny_pred_map = Phi_test @ theta_map\ny_pred_mle = Phi_test @ theta_ml\n\nplt.figure()\nax = plt.axes(projection='3d')\nplt.plot(X[:,0],X[:,1], Y, '+')\nplt.plot(X_test[:,0],X_test[:,1], y_pred_map)\nplt.plot(X_test[:,0],X_test[:,1], Y_test)\nplt.plot(X_test[:,0],X_test[:,1], y_pred_mle)\n# plt.xlim(-5, 5)\n# plt.ylim(-3.5, 1)\nplt.legend([\"data\", \"map prediction\", \"ground truth function\", \"maximum likelihood\"])",
"_____no_output_____"
],
[
"## EDIT THIS CELL\n\nK_max = 20 # this is the maximum degree of polynomial we will consider\nassert(K_max <= N) # this is the latest point when we'll run into numerical problems\nrmse_mle = np.zeros((K_max+1,))\nrmse_map = np.zeros((K_max+1,))\nfor k in range(K_max+1):\n # rmse_mle[k] = -1 ## Compute the maximum likelihood estimator, compute the test-set \n # feature matrix for test inputs\n Phi = poly_features(X_train, k) # N x (K+1) feature matrix\n # maximum likelihood estimate\n theta_ml = nonlinear_features_maximum_likelihood(Phi, Y_train)\n # prediction (test set)\n Phi_ml = poly_features(X_test, k)\n ypred_test_ml = Phi_ml @ theta_ml\n # RMSE on test set for MLE\n rmse_mle[k] = RMSE(Y_test, ypred_test_ml)\n\n #--------------------------------------------------------------------------------\n \n Phi = poly_features(X_train, k)\n theta_map = map_estimate_poly(Phi, Y_train, sigma, alpha)\n\n Phi_map = poly_features(X_test, k)\n ypred_test_map = Phi_map @ theta_map \n # RMSE on test set for MAP\n rmse_map[k] = RMSE(Y_test, ypred_test_map) ## Compute the MAP estimator, compute the test-set predicitons, compute plt.figure()\n\nplt.semilogy(rmse_mle) # this plots the RMSE on a logarithmic scale\nplt.semilogy(rmse_map) # this plots the RMSE on a logarithmic scale\nplt.xlabel(\"degree of polynomial\")\nplt.ylabel(\"RMSE\")\nplt.legend([\"Maximum likelihood\", \"MAP\"])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a281c1c737e09d14cd36d53d783df7a36f8e9dc
| 63,604 |
ipynb
|
Jupyter Notebook
|
Notebooks/CNN_model.ipynb
|
oqbrady/Sentinel2_Traffic
|
ca1f10a0001d409081950f2794a3b4a4e7490bc2
|
[
"MIT"
] | 1 |
2021-06-04T23:40:27.000Z
|
2021-06-04T23:40:27.000Z
|
Notebooks/CNN_model.ipynb
|
oqbrady/Sentinel2_Traffic
|
ca1f10a0001d409081950f2794a3b4a4e7490bc2
|
[
"MIT"
] | null | null | null |
Notebooks/CNN_model.ipynb
|
oqbrady/Sentinel2_Traffic
|
ca1f10a0001d409081950f2794a3b4a4e7490bc2
|
[
"MIT"
] | 1 |
2021-06-04T23:40:08.000Z
|
2021-06-04T23:40:08.000Z
| 63,604 | 63,604 | 0.79495 |
[
[
[
"import numpy as np\nimport sklearn\nimport os\nimport pandas as pd\nimport scipy\nfrom sklearn.linear_model import LinearRegression\nimport sklearn\nimport matplotlib.pyplot as plt\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport random\nfrom torchvision import datasets, transforms\nimport copy",
"_____no_output_____"
],
[
"#!pip install line_profiler",
"_____no_output_____"
],
[
"os.chdir(\"/content/drive/MyDrive/Winter_Research\")",
"_____no_output_____"
]
],
[
[
"### Load Data",
"_____no_output_____"
]
],
[
[
"master_df = pd.read_csv(\"Sentinel2_Traffic/Traffic_Data/5_state_traffic.csv\")\nmaster_df = master_df.set_index(\"Unnamed: 0\")\nCA_x, CA_y = [], []\nKS_x, KS_y = [], []\nMT_x, MT_y = [], []\nTX_x, TX_y = [], []\nOH_x, OH_y = [], []\nstates = {\"CA\" : [CA_x, CA_y, \"Roi_1\"],\n \"KS\" : [KS_x, KS_y, \"Roi_2\"],\n \"MT\" : [MT_x, MT_y, \"Roi_3\"],\n \"TX\" : [TX_x, TX_y, \"Roi_4\"],\n \"OH\" : [OH_x, OH_y, \"Roi_5\"]}\nfor st in [\"CA\", \"KS\", \"MT\", \"TX\", \"OH\"]:\n path = \"Rois/\" + states[st][2] + \"/greedy_a/\"\n imgs = os.listdir(path)\n for img in imgs:\n date = img.split('.')[0]\n photo = np.loadtxt(path + img).reshape(-1, 7, 3)\n if photo[pd.isnull(photo)].shape[0] == 0:\n print(\"waasss\", photo.shape[0])\n if st == \"CA\" and photo.shape[0] != 72264:\n continue\n if st == \"KS\" and photo.shape[0] != 69071:\n continue\n if st == \"MT\" and photo.shape[0] != 72099:\n continue\n if st == \"TX\" and photo.shape[0] != 71764:\n continue\n if st == \"OH\" and photo.shape[0] != 62827:\n continue\n if date in list(master_df.index):\n if not pd.isna(master_df.loc[date][st]):\n states[st][0].append(photo)\n states[st][1].append(master_df.loc[date][st])",
"_____no_output_____"
],
[
"len(states['CA'][0])",
"_____no_output_____"
],
[
"states",
"_____no_output_____"
],
[
"for s in [\"CA\", \"KS\", \"MT\", \"TX\", \"OH\"]:\n for i in range(len(states[s][0])): \n states[s][0][i] = states[s][0][i][:8955]",
"_____no_output_____"
],
[
"def load(states, mean_bal_x=True, mean_bal_y=True):\n img_st = []\n y = []\n for s in states:\n val = np.array(states[s][0])\n if mean_bal_x:\n img_st.append((val - np.mean(val, axis=0)) / np.mean(val, axis=0))\n else:\n img_st.append(val)\n for i in states[s][1]:\n if mean_bal_y:\n y.append((i - np.mean(states[s][1])) / np.mean(states[s][1]))\n else:\n y.append(i)\n X = np.concatenate(img_st)\n return X, y",
"_____no_output_____"
],
[
"X, y = load(states, mean_bal_x=False, mean_bal_y=False)",
"_____no_output_____"
],
[
"print(len(X), len(y))",
"0 0\n"
],
[
"def load_some(states):\n img_st = []\n y = []\n for s in states:\n if s == \"MT\":\n continue\n img_st.append(np.array(states[s][0]))\n for i in states[s][1]:\n y.append(i)\n X = np.concatenate(img_st)\n return np.array(X), np.array(y)\n\ndef load_MT(states):\n img_st = np.array(states[\"MT\"][0])\n y_test = []\n for i in states[\"MT\"][1]:\n y_test.append(i)\n return img_st, np.array(y_test)\n\ndef load_some_augment(X, y):\n new_imgs = []\n new_y = []\n for i in range(X.shape[0]):\n a = random.randint(0, X.shape[0] - 1)\n b = random.randint(0, X.shape[0] - 1)\n new_imgs.append(mush(X[a], X[b]))\n new_y.append(y[a] + y[b])\n return np.array(new_imgs), np.array(new_y)\n\ndef mush(img_a, img_b):\n new_img = np.zeros((img_a.shape[0] + img_b.shape[0], 7, 3))\n buffer = int((img_a.shape[0] + 0.5) // 8)\n # print(buffer)\n for i in range(0, img_a.shape[0]*2, buffer*2):\n # print(i)\n # print(img_a[i // 2: i // 2 + buffer, :, :].shape)\n if (i // 2) + buffer > img_a.shape[0]:\n buffer = img_a.shape[0] - (i // 2)\n new_img[i: i + buffer, :, :] = img_a[i // 2: i // 2 + buffer, :, :]\n new_img[i + buffer: i + 2 * buffer, :, :] = img_b[i // 2: i // 2 + buffer, :, :]\n return new_img ",
"_____no_output_____"
],
[
"#X, y = load_some_augment(X, y)\n# X_test, y_test = load_MT(states)\n# X_test, y_test = augment(X_test)",
"_____no_output_____"
],
[
"# y_test",
"_____no_output_____"
],
[
"# X_test = np.concatenate((X_test, X_test), axis=1)\n# y_test = y_test + y_test",
"_____no_output_____"
],
[
"def augment(X, y):\n new_imgs = []\n new_y = []\n for i in range(X.shape[0]):\n new_y.extend([y[i]]*4)\n #OG\n #new_imgs.append(X[i]) #1\n #Chunk Half \n chunk1 = X[i][:X[i].shape[0] // 3, :, :]\n chunk2 = X[i][X[i].shape[0] // 3 : 2 * X[i].shape[0] // 3, :, :]\n chunk3 = X[i][2 * X[i].shape[0] // 3 :, :, :]\n chunks = {0 : chunk1, 1 : chunk2, 2 : chunk3}\n # for order in [(0, 1, 2), (0, 2, 1)]: #, (1, 0, 2), (1, 2, 0), (2, 1, 0), (2, 0, 1)\n # new_img = np.zeros(X[i].shape)\n # new_img[:X[i].shape[0] // 3, :, :] = chunks[order[0]]\n # new_img[X[i].shape[0] // 3 : 2 * X[i].shape[0] // 3, :, :] = chunks[order[1]]\n # new_img[2 * X[i].shape[0] // 3 :, :, :] = chunks[order[2]]\n new_img = X[i]\n new_imgs.append(new_img) \n new_imgs.append(np.flip(new_img, axis=0)) \n new_imgs.append(np.flip(new_img, axis=1)) \n new_imgs.append(np.flip(np.flip(new_img, axis=0), axis=1)) \n return np.array(new_imgs), np.array(new_y)\n\n",
"_____no_output_____"
],
[
"# Can't sugment befoire split\n# X, y = load_some(states)\n# X, y = augment(X, y)\n# print(X.shape, y.shape)",
"_____no_output_____"
],
[
"# y_baseline = np.loadtxt(\"Baseline_Y.csv\", delimiter=',')",
"_____no_output_____"
],
[
"print(torch.cuda.device_count())\ncuda0 = torch.device('cuda:0')\n",
"1\n"
],
[
"#Train, test, val, split\n# 41\n\n#Just MT version\nX_train_t, X_test, y_train_t, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2, random_state=41)\n# X_train_t = X\n# y_train_t = y\nX_train, X_val, y_train, y_val = sklearn.model_selection.train_test_split(X_train_t, y_train_t, test_size=0.1, random_state=41)\nX_train, y_train = augment(X_train, y_train)\n#To tensors\nX_train = torch.as_tensor(X_train, device=cuda0, dtype=torch.float)\nX_test = torch.as_tensor(X_test, device=cuda0, dtype=torch.float)\nX_val = torch.as_tensor(X_val, device=cuda0, dtype=torch.float)\ny_train = torch.as_tensor(y_train, device=cuda0, dtype=torch.float)\ny_val = torch.as_tensor(y_val, device=cuda0, dtype=torch.float)\ny_test = torch.as_tensor(y_test, device=cuda0, dtype=torch.float)\n\n#Reshape y\ny_train = y_train.reshape(y_train.shape[0], 1)\ny_test = y_test.reshape(y_test.shape[0], 1)\ny_val = y_val.reshape(y_val.shape[0], 1)",
"_____no_output_____"
],
[
"print(X_train.shape, y_train.shape, X_val.shape, y_val.shape, X_test.shape, y_test.shape)",
"torch.Size([388, 8955, 7, 3]) torch.Size([388, 1]) torch.Size([11, 8955, 7, 3]) torch.Size([11, 1]) torch.Size([28, 8955, 7, 3]) torch.Size([28, 1])\n"
],
[
"X_train = X_train.permute(0, 3, 1, 2)\nX_val = X_val.permute(0, 3, 1, 2)\nX_test = X_test.permute(0, 3, 1, 2)",
"_____no_output_____"
]
],
[
[
"# PyTorch Model",
"_____no_output_____"
]
],
[
[
"del model",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"# OG 3 ==> 10, reg layer, 10 ==> 10, flatten, ==> 100, 100==> 50, 50 ==> 1\nclass Net(nn.Module):\n def __init__(self):\n super().__init__()\n\n self.conv1 = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3, stride=1, padding=1)\n self.reg = nn.BatchNorm2d(10)\n self.relu1 = nn.ReLU()\n\n #self.reg = nn.Dropout(p=0.8)\n\n self.conv2 = nn.Conv2d(in_channels=10, out_channels=3, kernel_size=3, stride=1, padding=1)\n # self.reg = nn.BatchNorm2d(3)\n self.relu2 = nn.ReLU()\n\n # self.pool = nn.MaxPool2d(kernel_size=2)\n\n # self.conv3 = nn.Conv2d(in_channels=20, out_channels=10, kernel_size=3, stride=1, padding=1)\n # self.reg = nn.BatchNorm2d(10)\n # self.relu3 = nn.ReLU()\n\n # self.conv4 = nn.Conv2d(in_channels=50, out_channels=10, kernel_size=3, stride=1, padding=1)\n # self.relu4 = nn.ReLU()\n\n # self.conv5 = nn.Conv2d(in_channels=10, out_channels=100, kernel_size=3, stride=1, padding=1)\n # self.relu5 = nn.ReLU()\n\n self.fc1 = nn.Linear(in_features=(125370 // 2)*3, out_features=100) # 100\n self.relu6 = nn.ReLU()\n self.fc2 = nn.Linear(in_features=100, out_features=50) #100 -> 50\n self.relu7 = nn.ReLU()\n self.fc3 = nn.Linear(in_features=50, out_features=1)\n\n # self.relu8 = nn.ReLU()\n # self.fc4 = nn.Linear(in_features=20, out_features=1)\n\n def forward(self, input):\n output = self.conv1(input)\n output = self.relu1(output)\n output = self.reg(output)\n output = self.conv2(output)\n output = self.relu2(output)\n # output = self.conv3(output)\n # output = self.relu3(output)\n\n # output = self.pool(output)\n\n # output = self.conv3(output)\n # output = self.relu3(output)\n\n # output = self.conv4(output)\n # output = self.relu4(output)\n\n # output = self.conv4(output)\n # output = self.relu4(output)\n #print(output.shape)\n output = output.reshape(-1, (125370 // 2)*3)\n #print(output.shape)\n output = self.fc1(output)\n output = self.relu6(output)\n #print(output.shape)\n output = self.fc2(output)\n output = self.relu7(output)\n output = self.fc3(output)\n # output = self.relu8(output)\n # output = self.fc4(output)\n #print(output.shape)\n\n return output\nmodel = Net()\nmodel = model.cuda()",
"_____no_output_____"
],
[
"torch.cuda.empty_cache()",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"batches_x = []\nbatches_y = []\nbatch_size = 10\nfor i in range(0, X_train.shape[0], batch_size):\n batches_x.append(X_train[i:i+batch_size])\n batches_y.append(y_train[i:i+batch_size])",
"_____no_output_____"
],
[
"batches_x[0].shape",
"_____no_output_____"
],
[
"del optimizer\ndel criterion\n# del model\ntorch.cuda.empty_cache()\n",
"_____no_output_____"
],
[
"criterion = nn.MSELoss()\nmodel.to('cuda:0')\noptimizer = torch.optim.Adam(model.parameters(), lr=0.001)",
"_____no_output_____"
],
[
"train_loss = []\nval_loss = []",
"_____no_output_____"
],
[
"def init_weights(m):\n if type(m) == nn.Linear:\n torch.nn.init.xavier_uniform(m.weight)\n m.bias.data.fill_(0.01)\nmodel.apply(init_weights)",
"/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:3: UserWarning: nn.init.xavier_uniform is now deprecated in favor of nn.init.xavier_uniform_.\n This is separate from the ipykernel package so we can avoid doing imports until\n"
],
[
"best_model = model\nmin_val = 1e9\nloss_arr = []",
"_____no_output_____"
],
[
"epochs = 100\nfor i in range(epochs):\n model.train()\n loss_tot = 0\n #for j in range(X_train.shape[0]):\n for batch_x, batch_y in zip(batches_x, batches_y):\n # print(batch_x.shape) \n y_hat = model.forward(batch_x)\n #print(\"y_hat\", y_hat.shape, y_hat)\n #print(\"y_train\", y_train)\n #break\n loss = criterion(y_hat, batch_y)\n loss_arr.append(loss)\n loss_tot += loss.item()\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n with torch.no_grad():\n model.eval()\n y_hat_t = model.forward(X_val)\n loss_v = criterion(y_hat_t, y_val)\n val_loss.append(loss_v.item())\n if loss_v.item() < min_val:\n print(\"new_best\")\n min_val = loss_v.item()\n best_model = copy.deepcopy(model)\n if i % 5 == 0:\n print(f'Epoch: {i} Train Loss: {loss_tot // len(batches_x)} \" Val Loss: \"{loss_v}')\n train_loss.append(int(loss_tot // len(batches_x)))",
"new_best\nEpoch: 0 Train Loss: 899817.0 \" Val Loss: \"317474.84375\nnew_best\nnew_best\nEpoch: 5 Train Loss: 170998.0 \" Val Loss: \"288390.6875\nEpoch: 10 Train Loss: 128396.0 \" Val Loss: \"520420.0\nnew_best\nEpoch: 15 Train Loss: 65450.0 \" Val Loss: \"218221.875\nEpoch: 20 Train Loss: 46558.0 \" Val Loss: \"352452.9375\nEpoch: 25 Train Loss: 69562.0 \" Val Loss: \"362639.8125\nEpoch: 30 Train Loss: 46411.0 \" Val Loss: \"475999.0625\nEpoch: 35 Train Loss: 46289.0 \" Val Loss: \"825221.125\nEpoch: 40 Train Loss: 58508.0 \" Val Loss: \"446751.1875\nnew_best\nEpoch: 45 Train Loss: 39377.0 \" Val Loss: \"651930.9375\nEpoch: 50 Train Loss: 12022.0 \" Val Loss: \"498406.84375\nEpoch: 55 Train Loss: 44375.0 \" Val Loss: \"211176.53125\nEpoch: 60 Train Loss: 64846.0 \" Val Loss: \"553969.25\nEpoch: 65 Train Loss: 30397.0 \" Val Loss: \"248549.21875\nEpoch: 70 Train Loss: 34162.0 \" Val Loss: \"327053.78125\nEpoch: 75 Train Loss: 23672.0 \" Val Loss: \"257724.6875\nEpoch: 80 Train Loss: 19590.0 \" Val Loss: \"229130.6875\nEpoch: 85 Train Loss: 34193.0 \" Val Loss: \"320867.84375\nEpoch: 90 Train Loss: 35880.0 \" Val Loss: \"394488.0625\nEpoch: 95 Train Loss: 41617.0 \" Val Loss: \"636804.5\n"
],
[
"min_val",
"_____no_output_____"
],
[
"preds = []\nmodel.eval()\nwith torch.no_grad():\n y_hat_t = best_model.forward(X_test)\n loss = criterion(y_hat_t, y_test)\n val_loss.append(loss.item())\n print(loss.item())\n #preds.append(y_hat.argmax().item())",
"219568.046875\n"
],
[
"PATH = \"models/augmented_test_115k.tar\"\ntorch.save(model.state_dict(), PATH)",
"_____no_output_____"
],
[
"print(y_test)",
"_____no_output_____"
],
[
"plt.plot(range(len(train_loss[10:])), train_loss[4:])\nplt.plot(range(len(val_loss[4:])), val_loss[4:])\nplt.legend([\"Train Loss\", \"Val Loss\"])\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"MSE Loss\")\n#plt.savefig(\"Train_Test.png\")\nplt.show()",
"_____no_output_____"
],
[
"x_temp = y_test.cpu()\ny_temp = y_hat_t.cpu()\n# print(y_temp)\n# for i in range(y_temp.shape[0]):\n# if y_temp[i] > 5000:\n# print(x_temp.shape)\n# x_temp = torch.cat([x_temp[0:i, :], x_temp[i+1:, :]])\n# y_temp = torch.cat([y_temp[0:i, :], y_temp[i+1:, :]])\n# break\nx_plot = np.array(y_temp)\ny_plot = np.array(x_temp)\nnew_x = np.array(x_plot).reshape(-1,1)\nnew_y = np.array(y_plot)\nfit = LinearRegression().fit(new_x, new_y)\nscore = fit.score(new_x, new_y)\nplt.xlabel(\"Prediction\")\nplt.ylabel(\"Actual Traffic\")\nprint(score)\nplt.scatter(new_x, new_y)\naxes = plt.gca()\nx_vals = np.array(axes.get_xlim())\ny_vals = x_vals\nplt.plot(x_vals, y_vals, '--')\n# plt.savefig(\"Aug_batch_r2_0.85_mse_97k.png\")\nplt.show()",
"0.8542176643491934\n"
]
],
[
[
"0.8731882702459102 MSE--123\n\n\n0.8591212743652898\n\n0.8662367216836014\n\n0.873\n\n0.889 MSE-99\n\nR^2 = 0.911 MSE == 79 num 4\n\nnum 5 R^2 0.922 MSE == 82,000\n\nnum 11 R^2 == 0.93 MSE = 60",
"_____no_output_____"
]
],
[
[
"# 0.945, 0.830\n# MSE 88, 914, 76\n\n#0.950\n#MSE 63,443",
"_____no_output_____"
],
[
"X_test",
"_____no_output_____"
],
[
"y_hat",
"_____no_output_____"
],
[
"torch.cuda.memory_summary(device=0, abbreviated=False)",
"_____no_output_____"
],
[
"import gc\nfor obj in gc.get_objects():\n try:\n if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):\n print(type(obj), obj.size())\n except:\n pass",
"_____no_output_____"
],
[
"s = y_train[y_train[:, 1] == 5]",
"_____no_output_____"
],
[
"s",
"_____no_output_____"
],
[
"np.mean(s[:, 0])",
"_____no_output_____"
],
[
"preds = {}\nfor i in range(1, 6):\n select = y_train[y_train[:, 1] == i]\n preds[i] = np.mean(select[:, 0])",
"_____no_output_____"
],
[
"preds",
"_____no_output_____"
],
[
"y_test",
"_____no_output_____"
],
[
"x = []\ny = []\nmse = 0\nfor i in range(y_test.shape[0]):\n x.append(preds[y_test[i][1]])\n y.append(y_test[i][0])\n mse += (preds[y_test[i][1]] - y_test[i][0])**2",
"_____no_output_____"
],
[
"mse / len(y_test)",
"_____no_output_____"
],
[
"x_plot = np.array(x)\ny_plot = np.array(y)\nnew_x = np.array(x_plot).reshape(-1,1)\nnew_y = np.array(y_plot)\nfit = LinearRegression().fit(new_x, new_y)\nscore = fit.score(new_x, new_y)\nplt.xlabel(\"Prediction\")\nplt.ylabel(\"Actual Traffic\")\nprint(score)\nplt.scatter(new_x, new_y)\naxes = plt.gca()\nx_vals = np.array(axes.get_xlim())\ny_vals = x_vals\nplt.plot(x_vals, y_vals, '--')\nplt.savefig(\"Baseline.png\")\nplt.show()",
"0.8734442268681637\n"
],
[
"# 0.873\n# 99098",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a283b01902d95aff3490cf7918c3f2847e49bfe
| 135,221 |
ipynb
|
Jupyter Notebook
|
Python_Stock/Technical_Indicators/ADL.ipynb
|
eu90h/Stock_Analysis_For_Quant
|
5e5e9f9c2a8f4af72e26564bc9d66bd2c90880df
|
[
"MIT"
] | null | null | null |
Python_Stock/Technical_Indicators/ADL.ipynb
|
eu90h/Stock_Analysis_For_Quant
|
5e5e9f9c2a8f4af72e26564bc9d66bd2c90880df
|
[
"MIT"
] | null | null | null |
Python_Stock/Technical_Indicators/ADL.ipynb
|
eu90h/Stock_Analysis_For_Quant
|
5e5e9f9c2a8f4af72e26564bc9d66bd2c90880df
|
[
"MIT"
] | null | null | null | 269.364542 | 62,902 | 0.891038 |
[
[
[
"# Accumulation Distribution Line (ADL)",
"_____no_output_____"
],
[
"https://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:accumulation_distribution_line",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n\n# yfinance is used to fetch data \nimport yfinance as yf\nyf.pdr_override()",
"_____no_output_____"
],
[
"# input\nsymbol = 'AAPL'\nstart = '2018-06-01'\nend = '2019-01-01'\n\n# Read data \ndf = yf.download(symbol,start,end)\n\n# View Columns\ndf.head()",
"[*********************100%***********************] 1 of 1 downloaded\n"
],
[
"df['MF Multiplier'] = (2*df['Adj Close'] - df['Low'] - df['High'])/(df['High']-df['Low'])\ndf['MF Volume'] = df['MF Multiplier']*df['Volume']\ndf['ADL'] = df['MF Volume'].cumsum()\ndf = df.drop(['MF Multiplier','MF Volume'],axis=1)",
"_____no_output_____"
],
[
"df['VolumePositive'] = df['Open'] < df['Adj Close']",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(14,10))\nax1 = plt.subplot(3, 1, 1)\nax1.plot(df['Adj Close'])\nax1.set_title('Stock '+ symbol +' Closing Price')\nax1.set_ylabel('Price')\nax1.legend(loc='best')\n\nax2 = plt.subplot(3, 1, 2)\nax2.plot(df['ADL'], label='Accumulation Distribution Line')\nax2.grid()\nax2.legend(loc='best')\nax2.set_ylabel('Accumulation Distribution Line')\n\nax3 = plt.subplot(3, 1, 3)\nax3v = ax3.twinx()\ncolors = df.VolumePositive.map({True: 'g', False: 'r'})\nax3v.bar(df.index, df['Volume'], color=colors, alpha=0.4)\nax3.set_ylabel('Volume')\nax3.grid()\nax3.set_xlabel('Date')",
"_____no_output_____"
]
],
[
[
"## Candlestick with ADL",
"_____no_output_____"
]
],
[
[
"from matplotlib import dates as mdates\nimport datetime as dt\n\ndfc = df.copy()\ndfc['VolumePositive'] = dfc['Open'] < dfc['Adj Close']\n#dfc = dfc.dropna()\ndfc = dfc.reset_index()\ndfc['Date'] = mdates.date2num(dfc['Date'].astype(dt.date))\ndfc.head()",
"_____no_output_____"
],
[
"from mpl_finance import candlestick_ohlc\n\nfig = plt.figure(figsize=(14,10))\nax1 = plt.subplot(3, 1, 1)\ncandlestick_ohlc(ax1,dfc.values, width=0.5, colorup='g', colordown='r', alpha=1.0)\nax1.xaxis_date()\nax1.xaxis.set_major_formatter(mdates.DateFormatter('%d-%m-%Y'))\nax1.grid(True, which='both')\nax1.minorticks_on()\nax1v = ax1.twinx()\ncolors = dfc.VolumePositive.map({True: 'g', False: 'r'})\nax1v.bar(dfc.Date, dfc['Volume'], color=colors, alpha=0.4)\nax1v.axes.yaxis.set_ticklabels([])\nax1v.set_ylim(0, 3*df.Volume.max())\nax1.set_title('Stock '+ symbol +' Closing Price')\nax1.set_ylabel('Price')\n\nax2 = plt.subplot(3, 1, 2)\nax2.plot(df['ADL'], label='Accumulation Distribution Line')\nax2.grid()\nax2.legend(loc='best')\nax2.set_ylabel('Accumulation Distribution Line')\n\nax3 = plt.subplot(3, 1, 3)\nax3v = ax3.twinx()\ncolors = df.VolumePositive.map({True: 'g', False: 'r'})\nax3v.bar(df.index, df['Volume'], color=colors, alpha=0.4)\nax3.set_ylabel('Volume')\nax3.grid()\nax3.set_xlabel('Date')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a28447d131cf5c2ee09fd7f97442962a3743a94
| 22,655 |
ipynb
|
Jupyter Notebook
|
Full Fact Claim Matching.ipynb
|
FullFact/hackathon-vector-matching
|
bc15fb735d619a9ea03675bff517081eb994009a
|
[
"MIT"
] | 1 |
2017-06-06T16:18:34.000Z
|
2017-06-06T16:18:34.000Z
|
Full Fact Claim Matching.ipynb
|
FullFact/hackathon-vector-matching
|
bc15fb735d619a9ea03675bff517081eb994009a
|
[
"MIT"
] | null | null | null |
Full Fact Claim Matching.ipynb
|
FullFact/hackathon-vector-matching
|
bc15fb735d619a9ea03675bff517081eb994009a
|
[
"MIT"
] | null | null | null | 43.152381 | 540 | 0.506246 |
[
[
[
"import gensim\nimport json\nimport pandas\nimport numpy as np\nimport sklearn\nimport sklearn.neighbors\nfrom sklearn import cluster, covariance, manifold\nimport lxml\nimport lxml.objectify\nfrom lxml import etree\nimport nltk\nimport nltk.corpus\nfrom nltk.corpus import stopwords\nSTOPS = set(stopwords.words('english'))",
"_____no_output_____"
],
[
"model = gensim.models.KeyedVectors.load_word2vec_format('data/GoogleNews-vectors-negative300.bin', binary=True)",
"_____no_output_____"
],
[
"claims_file = 'data/claim_conclusion.json'\nwith open(claims_file) as fh:\n claims_df = pandas.read_json(fh)",
"_____no_output_____"
],
[
"claims_df.tail()",
"_____no_output_____"
],
[
"def claim2vec(text):\n word_vecs = []\n for word in text.split():\n if word not in STOPS and word in model:\n word_vecs.append(model[word])\n \n if word_vecs:\n result = np.mean(word_vecs, axis=0)\n assert len(result) == 300\n return result\n else:\n return np.zeros(300, dtype=np.float32)",
"_____no_output_____"
],
[
"claims_df['vec'] = claims_df['claim'].apply(claim2vec)",
"_____no_output_____"
],
[
"claims_df.tail()",
"_____no_output_____"
],
[
"X = np.array(claims_df['vec'].tolist())",
"_____no_output_____"
],
[
"for example in [200, 300, 400]:\n dists, neighbours = nn.kneighbors(X[example], n_neighbors=673)\n dists = dists[0]\n neighbours = neighbours[0]\n print('*** Original ***:\\n', claims_df.iloc[neighbours[0], 0])\n print('\\n*** Top 5 ***:\\n', claims_df.iloc[neighbours[1:], 0].head(5).values)\n print('\\n*** Bottom 5 ***:\\n', claims_df.iloc[neighbours, 0].tail(5).values)",
"*** Original ***:\n The EU referendum outcome is \"on a knife edge\".\n\n*** Top 5 ***:\n ['The EU referendum was “advisory” only.'\n 'The government’s EU leaflet distributed before the referendum said that leaving the EU meant leaving the single market.'\n 'Campaigners on both sides of the EU referendum made false claims.'\n 'The Vote Leave campaign includes three completely untrue claims on its EU referendum leaflet: Turkey becoming a member, an EU army and the £350 million a week cost of membership.'\n 'If we vote ‘remain’... The EU will continue to control… trade']\n\n*** Bottom 5 ***:\n ['Free schools improve neighbouring schools. '\n 'Low-paid workers are trapped in poverty.'\n '44.2% of Southern Mainline and Coast trains were not at terminus on time.'\n '95% of new workers are foreigners.'\n '58.8% of graduates are in non-graduate jobs. ']\n"
]
],
[
[
"----",
"_____no_output_____"
]
],
[
[
"xml_file = 'data/hansard/src/debates2017-01-09a.xml'\n\nimport os\nbase = 'data/hansard/src/'\nfor fname in os.listdir(base):\n xml_file = os.path.join(base, fname)\n \n try:\n with open(xml_file) as fh:\n xml = etree.parse(fh)\n except UnicodeDecodeError:\n continue\n\n for i, p in enumerate(xml.findall('.//p')):\n if not p.text or len(p.text) < 140:\n continue\n \n for sent in p.text.split('.'):\n vec = claim2vec(sent)\n dists, neighbours = nn.kneighbors([vec], n_neighbors=5)\n dists = dists[0]\n dists = dists[dists <= 0.15]\n if len(dists) == 0:\n continue\n neighbours = neighbours[0][:len(dists)].tolist()\n print('*** Politician said ***:\\n', sent)\n print('\\n*** Relevant claims ***:\\n', claims_df.iloc[neighbours, 0].head(5).values)\n\n print('-'*50)",
"*** Politician said ***:\n The TUC estimates suggest that tax avoidance costs us £25 billion a year, while tax evasion costs us £70 billion a year\n\n*** Relevant claims ***:\n ['Tax evasion and tax avoidance costs the government £34 billion a year.']\n--------------------------------------------------\n*** Politician said ***:\n The TUC estimates suggest that tax avoidance costs us £25 billion a year, while tax evasion costs us £70 billion a year\n\n*** Relevant claims ***:\n ['Tax evasion and tax avoidance costs the government £34 billion a year.']\n--------------------------------------------------\n*** Politician said ***:\n In 2009, Greece's budget deficit was running at 13\n\n*** Relevant claims ***:\n ['In 2010 the budget deficit was running at over 10% of the UK’s GDP.']\n--------------------------------------------------\n*** Politician said ***:\n At the same time the gulf between rich and poor has got wider, with the attainment gap between students in fee-paying schools and those in state schools doubling\n\n*** Relevant claims ***:\n [ 'The attainment gap between rich and poor pupils in grammar schools is virtually zero.']\n--------------------------------------------------\n*** Politician said ***:\n If they see public expenditure cut so that their local schools are not refurbished, and if they see a tax on welfare benefits, they will expect us at least to maximise the revenue from the tax that people and organisations should be paying\n\n*** Relevant claims ***:\n [ 'Self-employed people will only pay more tax after this budget if they have taxable profits over £32,000, once you take every change to tax and welfare policies into account.']\n--------------------------------------------------\n*** Politician said ***:\n Of this, £29 billion will come from tax measures, including the increase in VAT, higher capital gains tax and a new permanent levy on banks\n\n*** Relevant claims ***:\n [ 'Conservative-led changes to corporation tax, inheritance tax, capital gains tax and the bank levy will lose the government £70 billion between April 2016 and April 2022.']\n--------------------------------------------------\n*** Politician said ***:\n However, if this is the Government's main priority, they would do better to look at the state of the UK tax system where the top five retail banks stand to cut around £19 billion from their tax bills in the future because of huge losses during the economic downturn, despite being saved by the UK Government through an £850 billion bail-out\n\n*** Relevant claims ***:\n [ 'Further measures that cut UK corporation tax to 12.5%, matching Ireland, would cost the UK government £120 billion over the next five years.']\n--------------------------------------------------\n*** Politician said ***:\n In that sense, people in England have an interest in what happens in Wales as much as Welsh people do\n\n*** Relevant claims ***:\n ['94% of people in Wales don’t want independence.']\n--------------------------------------------------\n*** Politician said ***:\n A referendum on that would be the same as a referendum on taking part in all the EU's institutions-in other words, being in the EU at all\n\n*** Relevant claims ***:\n ['The EU referendum was “advisory” only.']\n--------------------------------------------------\n*** Politician said ***:\n We were promised last year:\n\n*** Relevant claims ***:\n ['We were promised a ‘punishment budget’ before the referendum.']\n--------------------------------------------------\n*** Politician said ***:\n The Government could simply have said, \"There will be a referendum on each new EU treaty-period\n\n*** Relevant claims ***:\n ['The EU referendum was “advisory” only.']\n--------------------------------------------------\n*** Politician said ***:\n The Chairman of the Communities and Local Government Committee is absolutely right: my colleagues and I have been reflecting over the past few weeks, when the representatives of many local authorities throughout the country have been to see us, on what it must have been like to have been in a previous Administration, when one could believe that money was no object-that one could simply get this thing from the money tree and spend it as one wished by giving higher and higher settlements to every authority that came to visit\n\n*** Relevant claims ***:\n [ 'The local Government Association said the spending review would allow some councils to go some of the way to raise the money they need for social care.']\n--------------------------------------------------\n*** Politician said ***:\n As was said earlier, £120 billion of tax has not been paid as a result of tax evasion and avoidance\n\n*** Relevant claims ***:\n ['Tax evasion and tax avoidance costs the government £34 billion a year.']\n--------------------------------------------------\n*** Politician said ***:\n As was said earlier, £120 billion of tax has not been paid as a result of tax evasion and avoidance\n\n*** Relevant claims ***:\n ['Tax evasion and tax avoidance costs the government £34 billion a year.']\n--------------------------------------------------\n*** Politician said ***:\n The deficit was expected to be £149 billion for last year\n\n*** Relevant claims ***:\n [ 'The NHS had a deficit of over £800 million last year and is predicted to have a £2 billion deficit this year. ']\n--------------------------------------------------\n*** Politician said ***:\n The deficit was expected to be £149 billion for last year\n\n*** Relevant claims ***:\n [ 'The NHS had a deficit of over £800 million last year and is predicted to have a £2 billion deficit this year. ']\n--------------------------------------------------\n*** Politician said ***:\n The corporation tax cut from the Chancellor is one way of proceeding for a Budget strategy, but I believe he could have done something far more radical: instead of giving away that corporation tax cut, he could have spent the cash on a massive programme of employment, training and support for young people in the economy\n\n*** Relevant claims ***:\n [ 'Self-employed people will only pay more tax after this budget if they have taxable profits over £32,000, once you take every change to tax and welfare policies into account.']\n--------------------------------------------------\n*** Politician said ***:\n House building under Labour fell to its lowest level since 1946\n\n*** Relevant claims ***:\n ['House building has fallen to its lowest level since the 1920s.']\n--------------------------------------------------\n*** Politician said ***:\n There was a £38 billion black hole\n\n*** Relevant claims ***:\n ['There was a £38 billion black hole in the defence budget in 2010.']\n--------------------------------------------------\n*** Politician said ***:\n In 2010-11, just 150 people under the age of 19 started an apprenticeship, as against 200 people aged between 19 and 24 and 250 people aged 25 and over\n\n*** Relevant claims ***:\n ['600,000 people aged 18-24 are unemployed.']\n--------------------------------------------------\n*** Politician said ***:\n Tax evasion and tax fraud cost the Exchequer billions every year\n\n*** Relevant claims ***:\n ['Tax evasion and tax avoidance costs the government £34 billion a year.']\n--------------------------------------------------\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a284aac2d47b5efd209f04124c6770ba44e6029
| 113,491 |
ipynb
|
Jupyter Notebook
|
Project_Plagiarism_Detection/2_Plagiarism_Feature_Engineering.ipynb
|
xwilchen/ML_SageMaker_Studies
|
7ec3a2fa1e0fbd6d3222b853c04a71eb1a9b8ccd
|
[
"MIT"
] | null | null | null |
Project_Plagiarism_Detection/2_Plagiarism_Feature_Engineering.ipynb
|
xwilchen/ML_SageMaker_Studies
|
7ec3a2fa1e0fbd6d3222b853c04a71eb1a9b8ccd
|
[
"MIT"
] | null | null | null |
Project_Plagiarism_Detection/2_Plagiarism_Feature_Engineering.ipynb
|
xwilchen/ML_SageMaker_Studies
|
7ec3a2fa1e0fbd6d3222b853c04a71eb1a9b8ccd
|
[
"MIT"
] | null | null | null | 45.378249 | 10,492 | 0.583711 |
[
[
[
"# Plagiarism Detection, Feature Engineering\n\nIn this project, you will be tasked with building a plagiarism detector that examines an answer text file and performs binary classification; labeling that file as either plagiarized or not, depending on how similar that text file is to a provided, source text. \n\nYour first task will be to create some features that can then be used to train a classification model. This task will be broken down into a few discrete steps:\n\n* Clean and pre-process the data.\n* Define features for comparing the similarity of an answer text and a source text, and extract similarity features.\n* Select \"good\" features, by analyzing the correlations between different features.\n* Create train/test `.csv` files that hold the relevant features and class labels for train/test data points.\n\nIn the _next_ notebook, Notebook 3, you'll use the features and `.csv` files you create in _this_ notebook to train a binary classification model in a SageMaker notebook instance.\n\nYou'll be defining a few different similarity features, as outlined in [this paper](https://s3.amazonaws.com/video.udacity-data.com/topher/2019/January/5c412841_developing-a-corpus-of-plagiarised-short-answers/developing-a-corpus-of-plagiarised-short-answers.pdf), which should help you build a robust plagiarism detector!\n\nTo complete this notebook, you'll have to complete all given exercises and answer all the questions in this notebook.\n> All your tasks will be clearly labeled **EXERCISE** and questions as **QUESTION**.\n\nIt will be up to you to decide on the features to include in your final training and test data.\n\n---",
"_____no_output_____"
],
[
"## Read in the Data\n\nThe cell below will download the necessary, project data and extract the files into the folder `data/`.\n\nThis data is a slightly modified version of a dataset created by Paul Clough (Information Studies) and Mark Stevenson (Computer Science), at the University of Sheffield. You can read all about the data collection and corpus, at [their university webpage](https://ir.shef.ac.uk/cloughie/resources/plagiarism_corpus.html). \n\n> **Citation for data**: Clough, P. and Stevenson, M. Developing A Corpus of Plagiarised Short Answers, Language Resources and Evaluation: Special Issue on Plagiarism and Authorship Analysis, In Press. [Download]",
"_____no_output_____"
]
],
[
[
"# NOTE:\n# you only need to run this cell if you have not yet downloaded the data\n# otherwise you may skip this cell or comment it out\n\n!wget https://s3.amazonaws.com/video.udacity-data.com/topher/2019/January/5c4147f9_data/data.zip\n!unzip data",
"--2020-09-07 00:46:39-- https://s3.amazonaws.com/video.udacity-data.com/topher/2019/January/5c4147f9_data/data.zip\nResolving s3.amazonaws.com (s3.amazonaws.com)... 52.217.85.182\nConnecting to s3.amazonaws.com (s3.amazonaws.com)|52.217.85.182|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 113826 (111K) [application/zip]\nSaving to: ‘data.zip’\n\ndata.zip 100%[===================>] 111.16K --.-KB/s in 0.02s \n\n2020-09-07 00:46:39 (4.46 MB/s) - ‘data.zip’ saved [113826/113826]\n\nArchive: data.zip\n creating: data/\n inflating: data/.DS_Store \n creating: __MACOSX/\n creating: __MACOSX/data/\n inflating: __MACOSX/data/._.DS_Store \n inflating: data/file_information.csv \n inflating: __MACOSX/data/._file_information.csv \n inflating: data/g0pA_taska.txt \n inflating: __MACOSX/data/._g0pA_taska.txt \n inflating: data/g0pA_taskb.txt \n inflating: __MACOSX/data/._g0pA_taskb.txt \n inflating: data/g0pA_taskc.txt \n inflating: __MACOSX/data/._g0pA_taskc.txt \n inflating: data/g0pA_taskd.txt \n inflating: __MACOSX/data/._g0pA_taskd.txt \n inflating: data/g0pA_taske.txt \n inflating: __MACOSX/data/._g0pA_taske.txt \n inflating: data/g0pB_taska.txt \n inflating: __MACOSX/data/._g0pB_taska.txt \n inflating: data/g0pB_taskb.txt \n inflating: __MACOSX/data/._g0pB_taskb.txt \n inflating: data/g0pB_taskc.txt \n inflating: __MACOSX/data/._g0pB_taskc.txt \n inflating: data/g0pB_taskd.txt \n inflating: __MACOSX/data/._g0pB_taskd.txt \n inflating: data/g0pB_taske.txt \n inflating: __MACOSX/data/._g0pB_taske.txt \n inflating: data/g0pC_taska.txt \n inflating: __MACOSX/data/._g0pC_taska.txt \n inflating: data/g0pC_taskb.txt \n inflating: __MACOSX/data/._g0pC_taskb.txt \n inflating: data/g0pC_taskc.txt \n inflating: __MACOSX/data/._g0pC_taskc.txt \n inflating: data/g0pC_taskd.txt \n inflating: __MACOSX/data/._g0pC_taskd.txt \n inflating: data/g0pC_taske.txt \n inflating: __MACOSX/data/._g0pC_taske.txt \n inflating: data/g0pD_taska.txt \n inflating: __MACOSX/data/._g0pD_taska.txt \n inflating: data/g0pD_taskb.txt \n inflating: __MACOSX/data/._g0pD_taskb.txt \n inflating: data/g0pD_taskc.txt \n inflating: __MACOSX/data/._g0pD_taskc.txt \n inflating: data/g0pD_taskd.txt \n inflating: __MACOSX/data/._g0pD_taskd.txt \n inflating: data/g0pD_taske.txt \n inflating: __MACOSX/data/._g0pD_taske.txt \n inflating: data/g0pE_taska.txt \n inflating: __MACOSX/data/._g0pE_taska.txt \n inflating: data/g0pE_taskb.txt \n inflating: __MACOSX/data/._g0pE_taskb.txt \n inflating: data/g0pE_taskc.txt \n inflating: __MACOSX/data/._g0pE_taskc.txt \n inflating: data/g0pE_taskd.txt \n inflating: __MACOSX/data/._g0pE_taskd.txt \n inflating: data/g0pE_taske.txt \n inflating: __MACOSX/data/._g0pE_taske.txt \n inflating: data/g1pA_taska.txt \n inflating: __MACOSX/data/._g1pA_taska.txt \n inflating: data/g1pA_taskb.txt \n inflating: __MACOSX/data/._g1pA_taskb.txt \n inflating: data/g1pA_taskc.txt \n inflating: __MACOSX/data/._g1pA_taskc.txt \n inflating: data/g1pA_taskd.txt \n inflating: __MACOSX/data/._g1pA_taskd.txt \n inflating: data/g1pA_taske.txt \n inflating: __MACOSX/data/._g1pA_taske.txt \n inflating: data/g1pB_taska.txt \n inflating: __MACOSX/data/._g1pB_taska.txt \n inflating: data/g1pB_taskb.txt \n inflating: __MACOSX/data/._g1pB_taskb.txt \n inflating: data/g1pB_taskc.txt \n inflating: __MACOSX/data/._g1pB_taskc.txt \n inflating: data/g1pB_taskd.txt \n inflating: __MACOSX/data/._g1pB_taskd.txt \n inflating: data/g1pB_taske.txt \n inflating: __MACOSX/data/._g1pB_taske.txt \n inflating: data/g1pD_taska.txt \n inflating: __MACOSX/data/._g1pD_taska.txt \n inflating: data/g1pD_taskb.txt \n inflating: __MACOSX/data/._g1pD_taskb.txt \n inflating: data/g1pD_taskc.txt \n inflating: __MACOSX/data/._g1pD_taskc.txt \n inflating: data/g1pD_taskd.txt \n inflating: __MACOSX/data/._g1pD_taskd.txt \n inflating: data/g1pD_taske.txt \n inflating: __MACOSX/data/._g1pD_taske.txt \n inflating: data/g2pA_taska.txt \n inflating: __MACOSX/data/._g2pA_taska.txt \n inflating: data/g2pA_taskb.txt \n inflating: __MACOSX/data/._g2pA_taskb.txt \n inflating: data/g2pA_taskc.txt \n inflating: __MACOSX/data/._g2pA_taskc.txt \n inflating: data/g2pA_taskd.txt \n inflating: __MACOSX/data/._g2pA_taskd.txt \n inflating: data/g2pA_taske.txt \n inflating: __MACOSX/data/._g2pA_taske.txt \n inflating: data/g2pB_taska.txt \n inflating: __MACOSX/data/._g2pB_taska.txt \n inflating: data/g2pB_taskb.txt \n inflating: __MACOSX/data/._g2pB_taskb.txt \n inflating: data/g2pB_taskc.txt \n inflating: __MACOSX/data/._g2pB_taskc.txt \n inflating: data/g2pB_taskd.txt \n inflating: __MACOSX/data/._g2pB_taskd.txt \n inflating: data/g2pB_taske.txt \n inflating: __MACOSX/data/._g2pB_taske.txt \n inflating: data/g2pC_taska.txt \n inflating: __MACOSX/data/._g2pC_taska.txt \n inflating: data/g2pC_taskb.txt \n inflating: __MACOSX/data/._g2pC_taskb.txt \n inflating: data/g2pC_taskc.txt \n inflating: __MACOSX/data/._g2pC_taskc.txt \n inflating: data/g2pC_taskd.txt \n inflating: __MACOSX/data/._g2pC_taskd.txt \n inflating: data/g2pC_taske.txt \n inflating: __MACOSX/data/._g2pC_taske.txt \n inflating: data/g2pE_taska.txt \n inflating: __MACOSX/data/._g2pE_taska.txt \n inflating: data/g2pE_taskb.txt \n inflating: __MACOSX/data/._g2pE_taskb.txt \n inflating: data/g2pE_taskc.txt \n inflating: __MACOSX/data/._g2pE_taskc.txt \n inflating: data/g2pE_taskd.txt \n inflating: __MACOSX/data/._g2pE_taskd.txt \n inflating: data/g2pE_taske.txt \n inflating: __MACOSX/data/._g2pE_taske.txt \n inflating: data/g3pA_taska.txt \n inflating: __MACOSX/data/._g3pA_taska.txt \n inflating: data/g3pA_taskb.txt \n inflating: __MACOSX/data/._g3pA_taskb.txt \n inflating: data/g3pA_taskc.txt \n inflating: __MACOSX/data/._g3pA_taskc.txt \n inflating: data/g3pA_taskd.txt \n inflating: __MACOSX/data/._g3pA_taskd.txt \n inflating: data/g3pA_taske.txt \n inflating: __MACOSX/data/._g3pA_taske.txt \n inflating: data/g3pB_taska.txt \n inflating: __MACOSX/data/._g3pB_taska.txt \n inflating: data/g3pB_taskb.txt \n inflating: __MACOSX/data/._g3pB_taskb.txt \n inflating: data/g3pB_taskc.txt \n inflating: __MACOSX/data/._g3pB_taskc.txt \n inflating: data/g3pB_taskd.txt \n inflating: __MACOSX/data/._g3pB_taskd.txt \n inflating: data/g3pB_taske.txt \n inflating: __MACOSX/data/._g3pB_taske.txt \n inflating: data/g3pC_taska.txt \n inflating: __MACOSX/data/._g3pC_taska.txt \n inflating: data/g3pC_taskb.txt \n inflating: __MACOSX/data/._g3pC_taskb.txt \n inflating: data/g3pC_taskc.txt \n inflating: __MACOSX/data/._g3pC_taskc.txt \n inflating: data/g3pC_taskd.txt \n inflating: __MACOSX/data/._g3pC_taskd.txt \n inflating: data/g3pC_taske.txt \n inflating: __MACOSX/data/._g3pC_taske.txt \n inflating: data/g4pB_taska.txt \n inflating: __MACOSX/data/._g4pB_taska.txt \n inflating: data/g4pB_taskb.txt \n inflating: __MACOSX/data/._g4pB_taskb.txt \n inflating: data/g4pB_taskc.txt \n inflating: __MACOSX/data/._g4pB_taskc.txt \n inflating: data/g4pB_taskd.txt \n inflating: __MACOSX/data/._g4pB_taskd.txt \n inflating: data/g4pB_taske.txt \n inflating: __MACOSX/data/._g4pB_taske.txt \n inflating: data/g4pC_taska.txt \n inflating: __MACOSX/data/._g4pC_taska.txt \n inflating: data/g4pC_taskb.txt \n inflating: __MACOSX/data/._g4pC_taskb.txt \n inflating: data/g4pC_taskc.txt \n inflating: __MACOSX/data/._g4pC_taskc.txt \n inflating: data/g4pC_taskd.txt \n inflating: __MACOSX/data/._g4pC_taskd.txt \n inflating: data/g4pC_taske.txt \n inflating: __MACOSX/data/._g4pC_taske.txt \n inflating: data/g4pD_taska.txt \n inflating: __MACOSX/data/._g4pD_taska.txt \n inflating: data/g4pD_taskb.txt \n inflating: __MACOSX/data/._g4pD_taskb.txt \n inflating: data/g4pD_taskc.txt \n inflating: __MACOSX/data/._g4pD_taskc.txt \n inflating: data/g4pD_taskd.txt \n inflating: __MACOSX/data/._g4pD_taskd.txt \n inflating: data/g4pD_taske.txt \n inflating: __MACOSX/data/._g4pD_taske.txt \n inflating: data/g4pE_taska.txt \n inflating: __MACOSX/data/._g4pE_taska.txt \n inflating: data/g4pE_taskb.txt \n inflating: __MACOSX/data/._g4pE_taskb.txt \n inflating: data/g4pE_taskc.txt \n inflating: __MACOSX/data/._g4pE_taskc.txt \n inflating: data/g4pE_taskd.txt \n inflating: __MACOSX/data/._g4pE_taskd.txt \n inflating: data/g4pE_taske.txt \n inflating: __MACOSX/data/._g4pE_taske.txt \n inflating: data/orig_taska.txt \n inflating: __MACOSX/data/._orig_taska.txt \n inflating: data/orig_taskb.txt \n inflating: data/orig_taskc.txt \n inflating: __MACOSX/data/._orig_taskc.txt \n inflating: data/orig_taskd.txt \n inflating: __MACOSX/data/._orig_taskd.txt \n inflating: data/orig_taske.txt \n inflating: __MACOSX/data/._orig_taske.txt \n inflating: data/test_info.csv \n inflating: __MACOSX/data/._test_info.csv \n inflating: __MACOSX/._data \n"
],
[
"# import libraries\nimport pandas as pd\nimport numpy as np\nimport os",
"_____no_output_____"
]
],
[
[
"This plagiarism dataset is made of multiple text files; each of these files has characteristics that are is summarized in a `.csv` file named `file_information.csv`, which we can read in using `pandas`.",
"_____no_output_____"
]
],
[
[
"csv_file = 'data/file_information.csv'\nplagiarism_df = pd.read_csv(csv_file)\n\n# print out the first few rows of data info\nplagiarism_df.head()",
"_____no_output_____"
]
],
[
[
"## Types of Plagiarism\n\nEach text file is associated with one **Task** (task A-E) and one **Category** of plagiarism, which you can see in the above DataFrame.\n\n### Tasks, A-E\n\nEach text file contains an answer to one short question; these questions are labeled as tasks A-E. For example, Task A asks the question: \"What is inheritance in object oriented programming?\"\n\n### Categories of plagiarism \n\nEach text file has an associated plagiarism label/category:\n\n**1. Plagiarized categories: `cut`, `light`, and `heavy`.**\n* These categories represent different levels of plagiarized answer texts. `cut` answers copy directly from a source text, `light` answers are based on the source text but include some light rephrasing, and `heavy` answers are based on the source text, but *heavily* rephrased (and will likely be the most challenging kind of plagiarism to detect).\n \n**2. Non-plagiarized category: `non`.** \n* `non` indicates that an answer is not plagiarized; the Wikipedia source text is not used to create this answer.\n \n**3. Special, source text category: `orig`.**\n* This is a specific category for the original, Wikipedia source text. We will use these files only for comparison purposes.",
"_____no_output_____"
],
[
"---\n## Pre-Process the Data\n\nIn the next few cells, you'll be tasked with creating a new DataFrame of desired information about all of the files in the `data/` directory. This will prepare the data for feature extraction and for training a binary, plagiarism classifier.",
"_____no_output_____"
],
[
"### EXERCISE: Convert categorical to numerical data\n\nYou'll notice that the `Category` column in the data, contains string or categorical values, and to prepare these for feature extraction, we'll want to convert these into numerical values. Additionally, our goal is to create a binary classifier and so we'll need a binary class label that indicates whether an answer text is plagiarized (1) or not (0). Complete the below function `numerical_dataframe` that reads in a `file_information.csv` file by name, and returns a *new* DataFrame with a numerical `Category` column and a new `Class` column that labels each answer as plagiarized or not. \n\nYour function should return a new DataFrame with the following properties:\n\n* 4 columns: `File`, `Task`, `Category`, `Class`. The `File` and `Task` columns can remain unchanged from the original `.csv` file.\n* Convert all `Category` labels to numerical labels according to the following rules (a higher value indicates a higher degree of plagiarism):\n * 0 = `non`\n * 1 = `heavy`\n * 2 = `light`\n * 3 = `cut`\n * -1 = `orig`, this is a special value that indicates an original file.\n* For the new `Class` column\n * Any answer text that is not plagiarized (`non`) should have the class label `0`. \n * Any plagiarized answer texts should have the class label `1`. \n * And any `orig` texts will have a special label `-1`. \n\n### Expected output\n\nAfter running your function, you should get a DataFrame with rows that looks like the following: \n```\n\n File\t Task Category Class\n0\tg0pA_taska.txt\ta\t 0 \t0\n1\tg0pA_taskb.txt\tb\t 3 \t1\n2\tg0pA_taskc.txt\tc\t 2 \t1\n3\tg0pA_taskd.txt\td\t 1 \t1\n4\tg0pA_taske.txt\te\t 0\t 0\n...\n...\n99 orig_taske.txt e -1 -1\n\n```",
"_____no_output_____"
]
],
[
[
"# Read in a csv file and return a transformed dataframe\ndef numerical_dataframe(csv_file='data/file_information.csv'):\n '''Reads in a csv file which is assumed to have `File`, `Category` and `Task` columns.\n This function does two things: \n 1) converts `Category` column values to numerical values \n 2) Adds a new, numerical `Class` label column.\n The `Class` column will label plagiarized answers as 1 and non-plagiarized as 0.\n Source texts have a special label, -1.\n :param csv_file: The directory for the file_information.csv file\n :return: A dataframe with numerical categories and a new `Class` label column'''\n \n df = pd.read_csv(csv_file)\n df['Category'] = df['Category'].replace({\"non\":0,\"heavy\":1,'light':2,\"cut\":3,\"orig\":-1})\n df['Class'] = df['Category'].apply(lambda num: 1 if num > 0 else num)\n return df\n",
"_____no_output_____"
]
],
[
[
"### Test cells\n\nBelow are a couple of test cells. The first is an informal test where you can check that your code is working as expected by calling your function and printing out the returned result.\n\nThe **second** cell below is a more rigorous test cell. The goal of a cell like this is to ensure that your code is working as expected, and to form any variables that might be used in _later_ tests/code, in this case, the data frame, `transformed_df`.\n\n> The cells in this notebook should be run in chronological order (the order they appear in the notebook). This is especially important for test cells.\n\nOften, later cells rely on the functions, imports, or variables defined in earlier cells. For example, some tests rely on previous tests to work.\n\nThese tests do not test all cases, but they are a great way to check that you are on the right track!",
"_____no_output_____"
]
],
[
[
"# informal testing, print out the results of a called function\n# create new `transformed_df`\ntransformed_df = numerical_dataframe(csv_file ='data/file_information.csv')\n\n# check work\n# check that all categories of plagiarism have a class label = 1\ntransformed_df.head(10)",
"_____no_output_____"
],
[
"# test cell that creates `transformed_df`, if tests are passed\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n\n# importing tests\nimport problem_unittests as tests\n\n# test numerical_dataframe function\ntests.test_numerical_df(numerical_dataframe)\n\n# if above test is passed, create NEW `transformed_df`\ntransformed_df = numerical_dataframe(csv_file ='data/file_information.csv')\n\n# check work\nprint('\\nExample data: ')\ntransformed_df.head()",
"Tests Passed!\n\nExample data: \n"
]
],
[
[
"## Text Processing & Splitting Data\n\nRecall that the goal of this project is to build a plagiarism classifier. At it's heart, this task is a comparison text; one that looks at a given answer and a source text, compares them and predicts whether an answer has plagiarized from the source. To effectively do this comparison, and train a classifier we'll need to do a few more things: pre-process all of our text data and prepare the text files (in this case, the 95 answer files and 5 original source files) to be easily compared, and split our data into a `train` and `test` set that can be used to train a classifier and evaluate it, respectively. \n\nTo this end, you've been provided code that adds additional information to your `transformed_df` from above. The next two cells need not be changed; they add two additional columns to the `transformed_df`:\n\n1. A `Text` column; this holds all the lowercase text for a `File`, with extraneous punctuation removed.\n2. A `Datatype` column; this is a string value `train`, `test`, or `orig` that labels a data point as part of our train or test set\n\nThe details of how these additional columns are created can be found in the `helpers.py` file in the project directory. You're encouraged to read through that file to see exactly how text is processed and how data is split.\n\nRun the cells below to get a `complete_df` that has all the information you need to proceed with plagiarism detection and feature engineering.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nimport helpers \n\n# create a text column \ntext_df = helpers.create_text_column(transformed_df)\ntext_df.head()",
"_____no_output_____"
],
[
"# after running the cell above\n# check out the processed text for a single file, by row index\nrow_idx = 0 # feel free to change this index\n\nsample_text = text_df.iloc[0]['Text']\n\nprint('Sample processed text:\\n\\n', sample_text)",
"Sample processed text:\n\n inheritance is a basic concept of object oriented programming where the basic idea is to create new classes that add extra detail to existing classes this is done by allowing the new classes to reuse the methods and variables of the existing classes and new methods and classes are added to specialise the new class inheritance models the is kind of relationship between entities or objects for example postgraduates and undergraduates are both kinds of student this kind of relationship can be visualised as a tree structure where student would be the more general root node and both postgraduate and undergraduate would be more specialised extensions of the student node or the child nodes in this relationship student would be known as the superclass or parent class whereas postgraduate would be known as the subclass or child class because the postgraduate class extends the student class inheritance can occur on several layers where if visualised would display a larger tree structure for example we could further extend the postgraduate node by adding two extra extended classes to it called msc student and phd student as both these types of student are kinds of postgraduate student this would mean that both the msc student and phd student classes would inherit methods and variables from both the postgraduate and student classes \n"
]
],
[
[
"## Split data into training and test sets\n\nThe next cell will add a `Datatype` column to a given DataFrame to indicate if the record is: \n* `train` - Training data, for model training.\n* `test` - Testing data, for model evaluation.\n* `orig` - The task's original answer from wikipedia.\n\n### Stratified sampling\n\nThe given code uses a helper function which you can view in the `helpers.py` file in the main project directory. This implements [stratified random sampling](https://en.wikipedia.org/wiki/Stratified_sampling) to randomly split data by task & plagiarism amount. Stratified sampling ensures that we get training and test data that is fairly evenly distributed across task & plagiarism combinations. Approximately 26% of the data is held out for testing and 74% of the data is used for training.\n\nThe function **train_test_dataframe** takes in a DataFrame that it assumes has `Task` and `Category` columns, and, returns a modified frame that indicates which `Datatype` (train, test, or orig) a file falls into. This sampling will change slightly based on a passed in *random_seed*. Due to a small sample size, this stratified random sampling will provide more stable results for a binary plagiarism classifier. Stability here is smaller *variance* in the accuracy of classifier, given a random seed.",
"_____no_output_____"
]
],
[
[
"random_seed = 1 # can change; set for reproducibility\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nimport helpers\n\n# create new df with Datatype (train, test, orig) column\n# pass in `text_df` from above to create a complete dataframe, with all the information you need\ncomplete_df = helpers.train_test_dataframe(text_df, random_seed=random_seed)\n\n# check results\ncomplete_df.head(10)",
"_____no_output_____"
]
],
[
[
"# Determining Plagiarism\n\nNow that you've prepared this data and created a `complete_df` of information, including the text and class associated with each file, you can move on to the task of extracting similarity features that will be useful for plagiarism classification. \n\n> Note: The following code exercises, assume that the `complete_df` as it exists now, will **not** have its existing columns modified. \n\nThe `complete_df` should always include the columns: `['File', 'Task', 'Category', 'Class', 'Text', 'Datatype']`. You can add additional columns, and you can create any new DataFrames you need by copying the parts of the `complete_df` as long as you do not modify the existing values, directly.\n\n---",
"_____no_output_____"
],
[
"\n# Similarity Features \n\nOne of the ways we might go about detecting plagiarism, is by computing **similarity features** that measure how similar a given answer text is as compared to the original wikipedia source text (for a specific task, a-e). The similarity features you will use are informed by [this paper on plagiarism detection](https://s3.amazonaws.com/video.udacity-data.com/topher/2019/January/5c412841_developing-a-corpus-of-plagiarised-short-answers/developing-a-corpus-of-plagiarised-short-answers.pdf). \n> In this paper, researchers created features called **containment** and **longest common subsequence**. \n\nUsing these features as input, you will train a model to distinguish between plagiarized and not-plagiarized text files.\n\n## Feature Engineering\n\nLet's talk a bit more about the features we want to include in a plagiarism detection model and how to calculate such features. In the following explanations, I'll refer to a submitted text file as a **Student Answer Text (A)** and the original, wikipedia source file (that we want to compare that answer to) as the **Wikipedia Source Text (S)**.\n\n### Containment\n\nYour first task will be to create **containment features**. To understand containment, let's first revisit a definition of [n-grams](https://en.wikipedia.org/wiki/N-gram). An *n-gram* is a sequential word grouping. For example, in a line like \"bayes rule gives us a way to combine prior knowledge with new information,\" a 1-gram is just one word, like \"bayes.\" A 2-gram might be \"bayes rule\" and a 3-gram might be \"combine prior knowledge.\"\n\n> Containment is defined as the **intersection** of the n-gram word count of the Wikipedia Source Text (S) with the n-gram word count of the Student Answer Text (S) *divided* by the n-gram word count of the Student Answer Text.\n\n$$ \\frac{\\sum{count(\\text{ngram}_{A}) \\cap count(\\text{ngram}_{S})}}{\\sum{count(\\text{ngram}_{A})}} $$\n\nIf the two texts have no n-grams in common, the containment will be 0, but if _all_ their n-grams intersect then the containment will be 1. Intuitively, you can see how having longer n-gram's in common, might be an indication of cut-and-paste plagiarism. In this project, it will be up to you to decide on the appropriate `n` or several `n`'s to use in your final model.\n\n### EXERCISE: Create containment features\n\nGiven the `complete_df` that you've created, you should have all the information you need to compare any Student Answer Text (A) with its appropriate Wikipedia Source Text (S). An answer for task A should be compared to the source text for task A, just as answers to tasks B, C, D, and E should be compared to the corresponding original source text.\n\nIn this exercise, you'll complete the function, `calculate_containment` which calculates containment based upon the following parameters:\n* A given DataFrame, `df` (which is assumed to be the `complete_df` from above)\n* An `answer_filename`, such as 'g0pB_taskd.txt' \n* An n-gram length, `n`\n\n### Containment calculation\n\nThe general steps to complete this function are as follows:\n1. From *all* of the text files in a given `df`, create an array of n-gram counts; it is suggested that you use a [CountVectorizer](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html) for this purpose.\n2. Get the processed answer and source texts for the given `answer_filename`.\n3. Calculate the containment between an answer and source text according to the following equation.\n\n >$$ \\frac{\\sum{count(\\text{ngram}_{A}) \\cap count(\\text{ngram}_{S})}}{\\sum{count(\\text{ngram}_{A})}} $$\n \n4. Return that containment value.\n\nYou are encouraged to write any helper functions that you need to complete the function below.",
"_____no_output_____"
]
],
[
[
"complete_df.head()",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import CountVectorizer",
"_____no_output_____"
],
[
"# Calculate the ngram containment for one answer file/source file pair in a df\ndef calculate_containment(df, n, answer_filename):\n '''Calculates the containment between a given answer text and its associated source text.\n This function creates a count of ngrams (of a size, n) for each text file in our data.\n Then calculates the containment by finding the ngram count for a given answer text, \n and its associated source text, and calculating the normalized intersection of those counts.\n :param df: A dataframe with columns,\n 'File', 'Task', 'Category', 'Class', 'Text', and 'Datatype'\n :param n: An integer that defines the ngram size\n :param answer_filename: A filename for an answer text in the df, ex. 'g0pB_taskd.txt'\n :return: A single containment value that represents the similarity\n between an answer text and its source text.\n '''\n ans_text, ans_task = df[df['File'] == answer_filename][[\"Text\",\"Task\"]].values[0]\n source_text = df[(df[\"Class\"] == -1) & (df[\"Task\"] == ans_task)][\"Text\"].values[0]\n counter = CountVectorizer(analyzer='word',ngram_range=(n,n))\n ngrams_arr = counter.fit_transform([ans_text, source_text]).toarray()\n return np.min(ngrams_arr,axis=0).sum()/ngrams_arr[0].sum()",
"_____no_output_____"
]
],
[
[
"### Test cells\n\nAfter you've implemented the containment function, you can test out its behavior. \n\nThe cell below iterates through the first few files, and calculates the original category _and_ containment values for a specified n and file.\n\n>If you've implemented this correctly, you should see that the non-plagiarized have low or close to 0 containment values and that plagiarized examples have higher containment values, closer to 1.\n\nNote what happens when you change the value of n. I recommend applying your code to multiple files and comparing the resultant containment values. You should see that the highest containment values correspond to files with the highest category (`cut`) of plagiarism level.",
"_____no_output_____"
]
],
[
[
"# select a value for n\nn = 3\n\n# indices for first few files\ntest_indices = range(5)\n\n# iterate through files and calculate containment\ncategory_vals = []\ncontainment_vals = []\nfor i in test_indices:\n # get level of plagiarism for a given file index\n category_vals.append(complete_df.loc[i, 'Category'])\n # calculate containment for given file and n\n filename = complete_df.loc[i, 'File']\n c = calculate_containment(complete_df, n, filename)\n containment_vals.append(c)\n\n# print out result, does it make sense?\nprint('Original category values: \\n', category_vals)\nprint()\nprint(str(n)+'-gram containment values: \\n', containment_vals)",
"Original category values: \n [0, 3, 2, 1, 0]\n\n3-gram containment values: \n [0.009345794392523364, 0.9641025641025641, 0.6136363636363636, 0.15675675675675677, 0.031746031746031744]\n"
],
[
"# run this test cell\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n# test containment calculation\n# params: complete_df from before, and containment function\ntests.test_containment(complete_df, calculate_containment)",
"Tests Passed!\n"
]
],
[
[
"### QUESTION 1: Why can we calculate containment features across *all* data (training & test), prior to splitting the DataFrame for modeling? That is, what about the containment calculation means that the test and training data do not influence each other?",
"_____no_output_____"
],
[
"**Answer:**<br>\nBecause containment feature was derived/caculated out from original feature of a file. It extracts information only from its existing feature and does nothing from other data points.\nThis is only a data preprocessing step. If we don't calculate the containment for test data at this point, we will have to do it when we try to validate model or making predictions.",
"_____no_output_____"
],
[
"---\n## Longest Common Subsequence\n\nContainment a good way to find overlap in word usage between two documents; it may help identify cases of cut-and-paste as well as paraphrased levels of plagiarism. Since plagiarism is a fairly complex task with varying levels, it's often useful to include other measures of similarity. The paper also discusses a feature called **longest common subsequence**.\n\n> The longest common subsequence is the longest string of words (or letters) that are *the same* between the Wikipedia Source Text (S) and the Student Answer Text (A). This value is also normalized by dividing by the total number of words (or letters) in the Student Answer Text. \n\nIn this exercise, we'll ask you to calculate the longest common subsequence of words between two texts.\n\n### EXERCISE: Calculate the longest common subsequence\n\nComplete the function `lcs_norm_word`; this should calculate the *longest common subsequence* of words between a Student Answer Text and corresponding Wikipedia Source Text. \n\nIt may be helpful to think of this in a concrete example. A Longest Common Subsequence (LCS) problem may look as follows:\n* Given two texts: text A (answer text) of length n, and string S (original source text) of length m. Our goal is to produce their longest common subsequence of words: the longest sequence of words that appear left-to-right in both texts (though the words don't have to be in continuous order).\n* Consider:\n * A = \"i think pagerank is a link analysis algorithm used by google that uses a system of weights attached to each element of a hyperlinked set of documents\"\n * S = \"pagerank is a link analysis algorithm used by the google internet search engine that assigns a numerical weighting to each element of a hyperlinked set of documents\"\n\n* In this case, we can see that the start of each sentence of fairly similar, having overlap in the sequence of words, \"pagerank is a link analysis algorithm used by\" before diverging slightly. Then we **continue moving left -to-right along both texts** until we see the next common sequence; in this case it is only one word, \"google\". Next we find \"that\" and \"a\" and finally the same ending \"to each element of a hyperlinked set of documents\".\n* Below, is a clear visual of how these sequences were found, sequentially, in each text.\n\n<img src='notebook_ims/common_subseq_words.png' width=40% />\n\n* Now, those words appear in left-to-right order in each document, sequentially, and even though there are some words in between, we count this as the longest common subsequence between the two texts. \n* If I count up each word that I found in common I get the value 20. **So, LCS has length 20**. \n* Next, to normalize this value, divide by the total length of the student answer; in this example that length is only 27. **So, the function `lcs_norm_word` should return the value `20/27` or about `0.7408`.**\n\nIn this way, LCS is a great indicator of cut-and-paste plagiarism or if someone has referenced the same source text multiple times in an answer.",
"_____no_output_____"
],
[
"### LCS, dynamic programming\n\nIf you read through the scenario above, you can see that this algorithm depends on looking at two texts and comparing them word by word. You can solve this problem in multiple ways. First, it may be useful to `.split()` each text into lists of comma separated words to compare. Then, you can iterate through each word in the texts and compare them, adding to your value for LCS as you go. \n\nThe method I recommend for implementing an efficient LCS algorithm is: using a matrix and dynamic programming. **Dynamic programming** is all about breaking a larger problem into a smaller set of subproblems, and building up a complete result without having to repeat any subproblems. \n\nThis approach assumes that you can split up a large LCS task into a combination of smaller LCS tasks. Let's look at a simple example that compares letters:\n\n* A = \"ABCD\"\n* S = \"BD\"\n\nWe can see right away that the longest subsequence of _letters_ here is 2 (B and D are in sequence in both strings). And we can calculate this by looking at relationships between each letter in the two strings, A and S.\n\nHere, I have a matrix with the letters of A on top and the letters of S on the left side:\n\n<img src='notebook_ims/matrix_1.png' width=40% />\n\nThis starts out as a matrix that has as many columns and rows as letters in the strings S and O **+1** additional row and column, filled with zeros on the top and left sides. So, in this case, instead of a 2x4 matrix it is a 3x5.\n\nNow, we can fill this matrix up by breaking it into smaller LCS problems. For example, let's first look at the shortest substrings: the starting letter of A and S. We'll first ask, what is the Longest Common Subsequence between these two letters \"A\" and \"B\"? \n\n**Here, the answer is zero and we fill in the corresponding grid cell with that value.**\n\n<img src='notebook_ims/matrix_2.png' width=30% />\n\nThen, we ask the next question, what is the LCS between \"AB\" and \"B\"?\n\n**Here, we have a match, and can fill in the appropriate value 1**.\n\n<img src='notebook_ims/matrix_3_match.png' width=25% />\n\nIf we continue, we get to a final matrix that looks as follows, with a **2** in the bottom right corner.\n\n<img src='notebook_ims/matrix_6_complete.png' width=25% />\n\nThe final LCS will be that value **2** *normalized* by the number of n-grams in A. So, our normalized value is 2/4 = **0.5**.\n\n### The matrix rules\n\nOne thing to notice here is that, you can efficiently fill up this matrix one cell at a time. Each grid cell only depends on the values in the grid cells that are directly on top and to the left of it, or on the diagonal/top-left. The rules are as follows:\n* Start with a matrix that has one extra row and column of zeros.\n* As you traverse your string:\n * If there is a match, fill that grid cell with the value to the top-left of that cell *plus* one. So, in our case, when we found a matching B-B, we added +1 to the value in the top-left of the matching cell, 0.\n * If there is not a match, take the *maximum* value from either directly to the left or the top cell, and carry that value over to the non-match cell.\n\n<img src='notebook_ims/matrix_rules.png' width=50% />\n\nAfter completely filling the matrix, **the bottom-right cell will hold the non-normalized LCS value**.\n\nThis matrix treatment can be applied to a set of words instead of letters. Your function should apply this to the words in two texts and return the normalized LCS value.",
"_____no_output_____"
]
],
[
[
"# Compute the normalized LCS given an answer text and a source text\ndef lcs_norm_word(answer_text, source_text):\n '''Computes the longest common subsequence of words in two texts; returns a normalized value.\n :param answer_text: The pre-processed text for an answer text\n :param source_text: The pre-processed text for an answer's associated source text\n :return: A normalized LCS value'''\n ans_words = answer_text.split()\n source_words = source_text.split()\n matrix = np.zeros((len(source_words)+1,len(ans_words)+1))\n \n for i,s_word in enumerate(source_words,1):\n for j,a_word in enumerate(ans_words,1):\n if s_word == a_word:\n matrix[i][j] = matrix[i-1][j-1] + 1\n else:\n matrix[i][j] = max(matrix[i-1][j],matrix[i][j-1])\n return matrix[len(source_words)][len(ans_words)]/len(ans_words)\n",
"_____no_output_____"
]
],
[
[
"### Test cells\n\nLet's start by testing out your code on the example given in the initial description.\n\nIn the below cell, we have specified strings A (answer text) and S (original source text). We know that these texts have 20 words in common and the submitted answer is 27 words long, so the normalized, longest common subsequence should be 20/27.\n",
"_____no_output_____"
]
],
[
[
"# Run the test scenario from above\n# does your function return the expected value?\n\nA = \"i think pagerank is a link analysis algorithm used by google that uses a system of weights attached to each element of a hyperlinked set of documents\"\nS = \"pagerank is a link analysis algorithm used by the google internet search engine that assigns a numerical weighting to each element of a hyperlinked set of documents\"\n\n# calculate LCS\nlcs = lcs_norm_word(A, S)\nprint('LCS = ', lcs)\n\n\n# expected value test\nassert lcs==20/27., \"Incorrect LCS value, expected about 0.7408, got \"+str(lcs)\n\nprint('Test passed!')",
"LCS = 0.7407407407407407\nTest passed!\n"
]
],
[
[
"This next cell runs a more rigorous test.",
"_____no_output_____"
]
],
[
[
"# run test cell\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n# test lcs implementation\n# params: complete_df from before, and lcs_norm_word function\ntests.test_lcs(complete_df, lcs_norm_word)",
"Tests Passed!\n"
]
],
[
[
"Finally, take a look at a few resultant values for `lcs_norm_word`. Just like before, you should see that higher values correspond to higher levels of plagiarism.",
"_____no_output_____"
]
],
[
[
"# test on your own\ntest_indices = range(5) # look at first few files\n\ncategory_vals = []\nlcs_norm_vals = []\n# iterate through first few docs and calculate LCS\nfor i in test_indices:\n category_vals.append(complete_df.loc[i, 'Category'])\n # get texts to compare\n answer_text = complete_df.loc[i, 'Text'] \n task = complete_df.loc[i, 'Task']\n # we know that source texts have Class = -1\n orig_rows = complete_df[(complete_df['Class'] == -1)]\n orig_row = orig_rows[(orig_rows['Task'] == task)]\n source_text = orig_row['Text'].values[0]\n \n # calculate lcs\n lcs_val = lcs_norm_word(answer_text, source_text)\n lcs_norm_vals.append(lcs_val)\n\n# print out result, does it make sense?\nprint('Original category values: \\n', category_vals)\nprint()\nprint('Normalized LCS values: \\n', lcs_norm_vals)",
"Original category values: \n [0, 3, 2, 1, 0]\n\nNormalized LCS values: \n [0.1917808219178082, 0.8207547169811321, 0.8464912280701754, 0.3160621761658031, 0.24257425742574257]\n"
]
],
[
[
"---\n# Create All Features\n\nNow that you've completed the feature calculation functions, it's time to actually create multiple features and decide on which ones to use in your final model! In the below cells, you're provided two helper functions to help you create multiple features and store those in a DataFrame, `features_df`.\n\n### Creating multiple containment features\n\nYour completed `calculate_containment` function will be called in the next cell, which defines the helper function `create_containment_features`. \n\n> This function returns a list of containment features, calculated for a given `n` and for *all* files in a df (assumed to the the `complete_df`).\n\nFor our original files, the containment value is set to a special value, -1.\n\nThis function gives you the ability to easily create several containment features, of different n-gram lengths, for each of our text files.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n# Function returns a list of containment features, calculated for a given n \n# Should return a list of length 100 for all files in a complete_df\ndef create_containment_features(df, n, column_name=None):\n \n containment_values = []\n \n if(column_name==None):\n column_name = 'c_'+str(n) # c_1, c_2, .. c_n\n \n # iterates through dataframe rows\n for i in df.index:\n file = df.loc[i, 'File']\n # Computes features using calculate_containment function\n if df.loc[i,'Category'] > -1:\n c = calculate_containment(df, n, file)\n containment_values.append(c)\n # Sets value to -1 for original tasks \n else:\n containment_values.append(-1)\n \n print(str(n)+'-gram containment features created!')\n return containment_values\n",
"_____no_output_____"
]
],
[
[
"### Creating LCS features\n\nBelow, your complete `lcs_norm_word` function is used to create a list of LCS features for all the answer files in a given DataFrame (again, this assumes you are passing in the `complete_df`. It assigns a special value for our original, source files, -1.\n",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n# Function creates lcs feature and add it to the dataframe\ndef create_lcs_features(df, column_name='lcs_word'):\n \n lcs_values = []\n \n # iterate through files in dataframe\n for i in df.index:\n # Computes LCS_norm words feature using function above for answer tasks\n if df.loc[i,'Category'] > -1:\n # get texts to compare\n answer_text = df.loc[i, 'Text'] \n task = df.loc[i, 'Task']\n # we know that source texts have Class = -1\n orig_rows = df[(df['Class'] == -1)]\n orig_row = orig_rows[(orig_rows['Task'] == task)]\n source_text = orig_row['Text'].values[0]\n\n # calculate lcs\n lcs = lcs_norm_word(answer_text, source_text)\n lcs_values.append(lcs)\n # Sets to -1 for original tasks \n else:\n lcs_values.append(-1)\n\n print('LCS features created!')\n return lcs_values\n ",
"_____no_output_____"
]
],
[
[
"## EXERCISE: Create a features DataFrame by selecting an `ngram_range`\n\nThe paper suggests calculating the following features: containment *1-gram to 5-gram* and *longest common subsequence*. \n> In this exercise, you can choose to create even more features, for example from *1-gram to 7-gram* containment features and *longest common subsequence*. \n\nYou'll want to create at least 6 features to choose from as you think about which to give to your final, classification model. Defining and comparing at least 6 different features allows you to discard any features that seem redundant, and choose to use the best features for your final model!\n\nIn the below cell **define an n-gram range**; these will be the n's you use to create n-gram containment features. The rest of the feature creation code is provided.",
"_____no_output_____"
]
],
[
[
"# Define an ngram range\nngram_range = range(1,7)\n\n\n# The following code may take a minute to run, depending on your ngram_range\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nfeatures_list = []\n\n# Create features in a features_df\nall_features = np.zeros((len(ngram_range)+1, len(complete_df)))\n\n# Calculate features for containment for ngrams in range\ni=0\nfor n in ngram_range:\n column_name = 'c_'+str(n)\n features_list.append(column_name)\n # create containment features\n all_features[i]=np.squeeze(create_containment_features(complete_df, n))\n i+=1\n\n# Calculate features for LCS_Norm Words \nfeatures_list.append('lcs_word')\nall_features[i]= np.squeeze(create_lcs_features(complete_df))\n\n# create a features dataframe\nfeatures_df = pd.DataFrame(np.transpose(all_features), columns=features_list)\n\n# Print all features/columns\nprint()\nprint('Features: ', features_list)\nprint()",
"1-gram containment features created!\n2-gram containment features created!\n3-gram containment features created!\n4-gram containment features created!\n5-gram containment features created!\n6-gram containment features created!\nLCS features created!\n\nFeatures: ['c_1', 'c_2', 'c_3', 'c_4', 'c_5', 'c_6', 'lcs_word']\n\n"
],
[
"# print some results \nfeatures_df.head(10)",
"_____no_output_____"
]
],
[
[
"## Correlated Features\n\nYou should use feature correlation across the *entire* dataset to determine which features are ***too*** **highly-correlated** with each other to include both features in a single model. For this analysis, you can use the *entire* dataset due to the small sample size we have. \n\nAll of our features try to measure the similarity between two texts. Since our features are designed to measure similarity, it is expected that these features will be highly-correlated. Many classification models, for example a Naive Bayes classifier, rely on the assumption that features are *not* highly correlated; highly-correlated features may over-inflate the importance of a single feature. \n\nSo, you'll want to choose your features based on which pairings have the lowest correlation. These correlation values range between 0 and 1; from low to high correlation, and are displayed in a [correlation matrix](https://www.displayr.com/what-is-a-correlation-matrix/), below.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n# Create correlation matrix for just Features to determine different models to test\ncorr_matrix = features_df.corr().abs().round(2)\n\n# display shows all of a dataframe\ndisplay(corr_matrix)",
"_____no_output_____"
],
[
"import seaborn as sns",
"_____no_output_____"
],
[
"sns.heatmap(corr_matrix,cmap='Reds')",
"_____no_output_____"
]
],
[
[
"## EXERCISE: Create selected train/test data\n\nComplete the `train_test_data` function below. This function should take in the following parameters:\n* `complete_df`: A DataFrame that contains all of our processed text data, file info, datatypes, and class labels\n* `features_df`: A DataFrame of all calculated features, such as containment for ngrams, n= 1-5, and lcs values for each text file listed in the `complete_df` (this was created in the above cells)\n* `selected_features`: A list of feature column names, ex. `['c_1', 'lcs_word']`, which will be used to select the final features in creating train/test sets of data.\n\nIt should return two tuples:\n* `(train_x, train_y)`, selected training features and their corresponding class labels (0/1)\n* `(test_x, test_y)`, selected training features and their corresponding class labels (0/1)\n\n** Note: x and y should be arrays of feature values and numerical class labels, respectively; not DataFrames.**\n\nLooking at the above correlation matrix, you should decide on a **cutoff** correlation value, less than 1.0, to determine which sets of features are *too* highly-correlated to be included in the final training and test data. If you cannot find features that are less correlated than some cutoff value, it is suggested that you increase the number of features (longer n-grams) to choose from or use *only one or two* features in your final model to avoid introducing highly-correlated features.\n\nRecall that the `complete_df` has a `Datatype` column that indicates whether data should be `train` or `test` data; this should help you split the data appropriately.",
"_____no_output_____"
]
],
[
[
"# Takes in dataframes and a list of selected features (column names) \n# and returns (train_x, train_y), (test_x, test_y)\ndef train_test_data(complete_df, features_df, selected_features):\n '''Gets selected training and test features from given dataframes, and \n returns tuples for training and test features and their corresponding class labels.\n :param complete_df: A dataframe with all of our processed text data, datatypes, and labels\n :param features_df: A dataframe of all computed, similarity features\n :param selected_features: An array of selected features that correspond to certain columns in `features_df`\n :return: training and test features and labels: (train_x, train_y), (test_x, test_y)'''\n df = pd.concat((complete_df, features_df), axis=1)\n # get the training features\n train_x = df[df['Datatype'] == 'train'][selected_features].values\n # And training class labels (0 or 1)\n train_y = df[df['Datatype'] == 'train']['Class'].values\n \n # get the test features and labels\n test_x = df[df['Datatype'] == 'test'][selected_features].values\n test_y = df[df['Datatype'] == 'test']['Class'].values\n \n return (train_x, train_y), (test_x, test_y)\n ",
"_____no_output_____"
]
],
[
[
"### Test cells\n\nBelow, test out your implementation and create the final train/test data.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\ntest_selection = list(features_df)[:2] # first couple columns as a test\n# test that the correct train/test data is created\n(train_x, train_y), (test_x, test_y) = train_test_data(complete_df, features_df, test_selection)\n\n# params: generated train/test data\ntests.test_data_split(train_x, train_y, test_x, test_y)",
"Tests Passed!\n"
]
],
[
[
"## EXERCISE: Select \"good\" features\n\nIf you passed the test above, you can create your own train/test data, below. \n\nDefine a list of features you'd like to include in your final mode, `selected_features`; this is a list of the features names you want to include.",
"_____no_output_____"
]
],
[
[
"# Select your list of features, this should be column names from features_df\n# ex. ['c_1', 'lcs_word']\nselected_features = ['c_1', 'c_6']\n\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n\n(train_x, train_y), (test_x, test_y) = train_test_data(complete_df, features_df, selected_features)\n\n# check that division of samples seems correct\n# these should add up to 95 (100 - 5 original files)\nprint('Training size: ', len(train_x))\nprint('Test size: ', len(test_x))\nprint()\nprint('Training df sample: \\n', train_x[:10])",
"Training size: 70\nTest size: 25\n\nTraining df sample: \n [[0.39814815 0. ]\n [0.86936937 0.38248848]\n [0.59358289 0.06043956]\n [0.54450262 0. ]\n [0.32950192 0. ]\n [0.59030837 0. ]\n [0.75977654 0.1954023 ]\n [0.51612903 0. ]\n [0.44086022 0. ]\n [0.97945205 0.74468085]]\n"
]
],
[
[
"### Question 2: How did you decide on which features to include in your final model? ",
"_____no_output_____"
],
[
"**Answer:**<br>\nLooking into colored heatmap, we can see that of all the correlations among all features, c3 to c6 has a significant lower correlation with c1 compare to other correlations. Then among c3 to c6 they are highly correlated to each other, so I decided to pick only one, which is c6 who has lowest correlation with c_1. At the end, I didn't include lcs_word since it is highly correlated to every other features.",
"_____no_output_____"
],
[
"---\n## Creating Final Data Files\n\nNow, you are almost ready to move on to training a model in SageMaker!\n\nYou'll want to access your train and test data in SageMaker and upload it to S3. In this project, SageMaker will expect the following format for your train/test data:\n* Training and test data should be saved in one `.csv` file each, ex `train.csv` and `test.csv`\n* These files should have class labels in the first column and features in the rest of the columns\n\nThis format follows the practice, outlined in the [SageMaker documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/cdf-training.html), which reads: \"Amazon SageMaker requires that a CSV file doesn't have a header record and that the target variable [class label] is in the first column.\"\n\n## EXERCISE: Create csv files\n\nDefine a function that takes in x (features) and y (labels) and saves them to one `.csv` file at the path `data_dir/filename`.\n\nIt may be useful to use pandas to merge your features and labels into one DataFrame and then convert that into a csv file. You can make sure to get rid of any incomplete rows, in a DataFrame, by using `dropna`.",
"_____no_output_____"
]
],
[
[
"def make_csv(x, y, filename, data_dir):\n '''Merges features and labels and converts them into one csv file with labels in the first column.\n :param x: Data features\n :param y: Data labels\n :param file_name: Name of csv file, ex. 'train.csv'\n :param data_dir: The directory where files will be saved\n '''\n # make data dir, if it does not exist\n if not os.path.exists(data_dir):\n os.makedirs(data_dir)\n \n \n pd.concat((pd.DataFrame(y),pd.DataFrame(x)),axis=1).to_csv(os.path.join(data_dir, filename),index=False,header=False)\n \n \n # nothing is returned, but a print statement indicates that the function has run\n print('Path created: '+str(data_dir)+'/'+str(filename))",
"_____no_output_____"
]
],
[
[
"### Test cells\n\nTest that your code produces the correct format for a `.csv` file, given some text features and labels.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\nfake_x = [ [0.39814815, 0.0001, 0.19178082], \n [0.86936937, 0.44954128, 0.84649123], \n [0.44086022, 0., 0.22395833] ]\n\nfake_y = [0, 1, 1]\n\nmake_csv(fake_x, fake_y, filename='to_delete.csv', data_dir='test_csv')\n\n# read in and test dimensions\nfake_df = pd.read_csv('test_csv/to_delete.csv', header=None)\n\n# check shape\nassert fake_df.shape==(3, 4), \\\n 'The file should have as many rows as data_points and as many columns as features+1 (for indices).'\n# check that first column = labels\nassert np.all(fake_df.iloc[:,0].values==fake_y), 'First column is not equal to the labels, fake_y.'\nprint('Tests passed!')",
"Path created: test_csv/to_delete.csv\nTests passed!\n"
],
[
"# delete the test csv file, generated above\n! rm -rf test_csv",
"_____no_output_____"
]
],
[
[
"If you've passed the tests above, run the following cell to create `train.csv` and `test.csv` files in a directory that you specify! This will save the data in a local directory. Remember the name of this directory because you will reference it again when uploading this data to S3.",
"_____no_output_____"
]
],
[
[
"# can change directory, if you want\ndata_dir = 'plagiarism_data'\n\n\"\"\"\nDON'T MODIFY ANYTHING IN THIS CELL THAT IS BELOW THIS LINE\n\"\"\"\n\nmake_csv(train_x, train_y, filename='train.csv', data_dir=data_dir)\nmake_csv(test_x, test_y, filename='test.csv', data_dir=data_dir)",
"Path created: plagiarism_data/train.csv\nPath created: plagiarism_data/test.csv\n"
]
],
[
[
"## Up Next\n\nNow that you've done some feature engineering and created some training and test data, you are ready to train and deploy a plagiarism classification model. The next notebook will utilize SageMaker resources to train and test a model that you design.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a284ab333affbe20d074bffa3669b11220c4252
| 18,547 |
ipynb
|
Jupyter Notebook
|
notebooks/04-advanced/01-bipartite.ipynb
|
ChrisKeefe/Network-Analysis-Made-Simple
|
98644f0d03aa3c1ece4aa2d4147835fa10a0fcf8
|
[
"MIT"
] | 853 |
2015-04-08T01:58:34.000Z
|
2022-03-28T15:39:30.000Z
|
notebooks/04-advanced/01-bipartite.ipynb
|
ChrisKeefe/Network-Analysis-Made-Simple
|
98644f0d03aa3c1ece4aa2d4147835fa10a0fcf8
|
[
"MIT"
] | 177 |
2015-08-08T05:33:06.000Z
|
2022-03-21T15:43:07.000Z
|
notebooks/04-advanced/01-bipartite.ipynb
|
ChrisKeefe/Network-Analysis-Made-Simple
|
98644f0d03aa3c1ece4aa2d4147835fa10a0fcf8
|
[
"MIT"
] | 390 |
2015-03-28T02:22:34.000Z
|
2022-03-24T18:47:43.000Z
| 29.533439 | 138 | 0.59848 |
[
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"## Introduction",
"_____no_output_____"
]
],
[
[
"from IPython.display import YouTubeVideo\n\nYouTubeVideo(id=\"BYOK12I9vgI\", width=\"100%\")",
"_____no_output_____"
]
],
[
[
"In this chapter, we will look at bipartite graphs and their applications.\n\n## What are bipartite graphs?\n\nAs the name suggests,\nbipartite have two (bi) node partitions (partite).\nIn other words, we can assign nodes to one of the two partitions.\n(By contrast, all of the graphs that we have seen before are _unipartite_:\nthey only have a single partition.)\n\n### Rules for bipartite graphs\n\nWith unipartite graphs, you might remember a few rules that apply.\n\nFirstly, nodes and edges belong to a _set_.\nThis means the node set contains only unique members,\ni.e. no node can be duplicated.\nThe same applies for the edge set.\n\nOn top of those two basic rules, bipartite graphs add an additional rule:\nEdges can only occur between nodes of **different** partitions.\nIn other words, nodes within the same partition \nare not allowed to be connected to one another.\n\n### Applications of bipartite graphs\n\nWhere do we see bipartite graphs being used?\nHere's one that is very relevant to e-commerce,\nwhich touches our daily lives:\n\n> We can model customer purchases of products using a bipartite graph.\n> Here, the two node sets are **customer** nodes and **product** nodes,\n> and edges indicate that a customer $C$ purchased a product $P$.\n\nOn the basis of this graph, we can do interesting analyses,\nsuch as finding customers that are similar to one another\non the basis of their shared product purchases.\n\nCan you think of other situations\nwhere a bipartite graph model can be useful?\n\n## Dataset\n\nHere's another application in crime analysis,\nwhich is relevant to the example that we will use in this chapter:\n\n> This bipartite network contains persons\n> who appeared in at least one crime case \n> as either a suspect, a victim, a witness \n> or both a suspect and victim at the same time. \n> A left node represents a person and a right node represents a crime. \n> An edge between two nodes shows that \n> the left node was involved in the crime \n> represented by the right node.\n\nThis crime dataset was also sourced from Konect.",
"_____no_output_____"
]
],
[
[
"from nams import load_data as cf\nG = cf.load_crime_network()\nfor n, d in G.nodes(data=True):\n G.nodes[n][\"degree\"] = G.degree(n)",
"_____no_output_____"
]
],
[
[
"If you inspect the nodes,\nyou will see that they contain a special metadata keyword: `bipartite`.\nThis is a special keyword that NetworkX can use \nto identify nodes of a given partition.",
"_____no_output_____"
],
[
"### Visualize the crime network\n\nTo help us get our bearings right, let's visualize the crime network.",
"_____no_output_____"
]
],
[
[
"import nxviz as nv\nimport matplotlib.pyplot as plt\n\nfig, ax = plt.subplots(figsize=(7, 7))\nnv.circos(G, sort_by=\"degree\", group_by=\"bipartite\", node_color_by=\"bipartite\", node_enc_kwargs={\"size_scale\": 3})",
"_____no_output_____"
]
],
[
[
"### Exercise: Extract each node set\n\nA useful thing to be able to do\nis to extract each partition's node set.\nThis will become handy when interacting with\nNetworkX's bipartite algorithms later on.\n\n> Write a function that extracts all of the nodes \n> from specified node partition.\n> It should also raise a plain Exception\n> if no nodes exist in that specified partition.\n> (as a precuation against users putting in invalid partition names).",
"_____no_output_____"
]
],
[
[
"import networkx as nx\n\ndef extract_partition_nodes(G: nx.Graph, partition: str):\n nodeset = [_ for _, _ in _______ if ____________]\n if _____________:\n raise Exception(f\"No nodes exist in the partition {partition}!\")\n return nodeset\n\nfrom nams.solutions.bipartite import extract_partition_nodes\n# Uncomment the next line to see the answer.\n# extract_partition_nodes??",
"_____no_output_____"
]
],
[
[
"## Bipartite Graph Projections\n\nIn a bipartite graph, one task that can be useful to do\nis to calculate the projection of a graph onto one of its nodes.\n\nWhat do we mean by the \"projection of a graph\"?\nIt is best visualized using this figure:",
"_____no_output_____"
]
],
[
[
"from nams.solutions.bipartite import draw_bipartite_graph_example, bipartite_example_graph\nfrom nxviz import annotate\nimport matplotlib.pyplot as plt\n\nbG = bipartite_example_graph()\npG = nx.bipartite.projection.projected_graph(bG, \"abcd\")\nax = draw_bipartite_graph_example()\nplt.sca(ax[0])\nannotate.parallel_labels(bG, group_by=\"bipartite\")\nplt.sca(ax[1])\nannotate.arc_labels(pG)",
"_____no_output_____"
]
],
[
[
"As shown in the figure above, we start first with a bipartite graph with two node sets,\nthe \"alphabet\" set and the \"numeric\" set.\nThe projection of this bipartite graph onto the \"alphabet\" node set\nis a graph that is constructed such that it only contains the \"alphabet\" nodes,\nand edges join the \"alphabet\" nodes because they share a connection to a \"numeric\" node.\nThe red edge on the right\nis basically the red path traced on the left.",
"_____no_output_____"
],
[
"### Computing graph projections\n\nHow does one compute graph projections using NetworkX?\nTurns out, NetworkX has a `bipartite` submodule,\nwhich gives us all of the facilities that we need\nto interact with bipartite algorithms.\n\nFirst of all, we need to check that the graph\nis indeed a bipartite graph.\nNetworkX provides a function for us to do so:",
"_____no_output_____"
]
],
[
[
"from networkx.algorithms import bipartite\n\nbipartite.is_bipartite(G)",
"_____no_output_____"
]
],
[
[
"Now that we've confirmed that the graph is indeed bipartite,\nwe can use the NetworkX bipartite submodule functions\nto generate the bipartite projection onto one of the node partitions.\n\nFirst off, we need to extract nodes from a particular partition.",
"_____no_output_____"
]
],
[
[
"person_nodes = extract_partition_nodes(G, \"person\")\ncrime_nodes = extract_partition_nodes(G, \"crime\")",
"_____no_output_____"
]
],
[
[
"Next, we can compute the projection:",
"_____no_output_____"
]
],
[
[
"person_graph = bipartite.projected_graph(G, person_nodes)\ncrime_graph = bipartite.projected_graph(G, crime_nodes)",
"_____no_output_____"
]
],
[
[
"And with that, we have our projected graphs!\n\nGo ahead and inspect them:",
"_____no_output_____"
]
],
[
[
"list(person_graph.edges(data=True))[0:5]",
"_____no_output_____"
],
[
"list(crime_graph.edges(data=True))[0:5]",
"_____no_output_____"
]
],
[
[
"Now, what is the _interpretation_ of these projected graphs?\n\n- For `person_graph`, we have found _individuals who are linked by shared participation (whether witness or suspect) in a crime._\n- For `crime_graph`, we have found _crimes that are linked by shared involvement by people._\n\nJust by this graph, we already can find out pretty useful information.\nLet's use an exercise that leverages what you already know\nto extract useful information from the projected graph.",
"_____no_output_____"
],
[
"### Exercise: find the crime(s) that have the most shared connections with other crimes\n\n> Find crimes that are most similar to one another\n> on the basis of the number of shared connections to individuals.\n\n_Hint: This is a degree centrality problem!_",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndef find_most_similar_crimes(cG: nx.Graph):\n \"\"\"\n Find the crimes that are most similar to other crimes.\n \"\"\"\n dcs = ______________\n return ___________________\n\n\nfrom nams.solutions.bipartite import find_most_similar_crimes\nfind_most_similar_crimes(crime_graph)",
"_____no_output_____"
]
],
[
[
"### Exercise: find the individual(s) that have the most shared connections with other individuals\n\n> Now do the analogous thing for individuals!",
"_____no_output_____"
]
],
[
[
"def find_most_similar_people(pG: nx.Graph):\n \"\"\"\n Find the persons that are most similar to other persons.\n \"\"\"\n dcs = ______________\n return ___________________\n\n\nfrom nams.solutions.bipartite import find_most_similar_people\nfind_most_similar_people(person_graph)",
"_____no_output_____"
]
],
[
[
"## Weighted Projection\n\nThough we were able to find out which graphs were connected with one another,\nwe did not record in the resulting projected graph\nthe **strength** by which the two nodes were connected.\nTo preserve this information, we need another function:",
"_____no_output_____"
]
],
[
[
"weighted_person_graph = bipartite.weighted_projected_graph(G, person_nodes)\nlist(weighted_person_graph.edges(data=True))[0:5]",
"_____no_output_____"
]
],
[
[
"### Exercise: Find the people that can help with investigating a `crime`'s `person`.\n\nLet's pretend that we are a detective trying to solve a crime,\nand that we right now need to find other individuals\nwho were not implicated in the same _exact_ crime as an individual was,\nbut who might be able to give us information about that individual\nbecause they were implicated in other crimes with that individual.\n\n> Implement a function that takes in a bipartite graph `G`, a string `person` and a string `crime`,\n> and returns a list of other `person`s that were **not** implicated in the `crime`,\n> but were connected to the `person` via other crimes.\n> It should return a _ranked list_,\n> based on the **number of shared crimes** (from highest to lowest)\n> because the ranking will help with triage.",
"_____no_output_____"
]
],
[
[
"list(G.neighbors('p1'))",
"_____no_output_____"
],
[
"def find_connected_persons(G, person, crime):\n # Step 0: Check that the given \"person\" and \"crime\" are connected.\n if _____________________________:\n raise ValueError(f\"Graph does not have a connection between {person} and {crime}!\")\n\n # Step 1: calculate weighted projection for person nodes.\n person_nodes = ____________________________________\n person_graph = bipartite.________________________(_, ____________)\n \n # Step 2: Find neighbors of the given `person` node in projected graph.\n candidate_neighbors = ___________________________________\n \n # Step 3: Remove candidate neighbors from the set if they are implicated in the given crime.\n for p in G.neighbors(crime):\n if ________________________:\n _____________________________\n \n # Step 4: Rank-order the candidate neighbors by number of shared connections.\n _________ = []\n ## You might need a for-loop here\n return pd.DataFrame(__________).sort_values(\"________\", ascending=False)\n\n\nfrom nams.solutions.bipartite import find_connected_persons\nfind_connected_persons(G, 'p2', 'c10')",
"_____no_output_____"
]
],
[
[
"## Degree Centrality\n\nThe degree centrality metric is something we can calculate for bipartite graphs.\nRecall that the degree centrality metric is the number of neighbors of a node\ndivided by the total number of _possible_ neighbors.\n\nIn a unipartite graph, the denominator can be the total number of nodes less one\n(if self-loops are not allowed)\nor simply the total number of nodes (if self loops _are_ allowed).\n\n### Exercise: What is the denominator for bipartite graphs?\n\nThink about it for a moment, then write down your answer.",
"_____no_output_____"
]
],
[
[
"from nams.solutions.bipartite import bipartite_degree_centrality_denominator\nfrom nams.functions import render_html\nrender_html(bipartite_degree_centrality_denominator())",
"_____no_output_____"
]
],
[
[
"### Exercise: Which `persons` are implicated in the most number of crimes?\n\n> Find the `persons` (singular or plural) who are connected to the most number of crimes.\n\nTo do so, you will need to use `nx.bipartite.degree_centrality`,\nrather than the regular `nx.degree_centrality` function.\n\n`nx.bipartite.degree_centrality` requires that you pass in\na node set from one of the partitions\nso that it can correctly partition nodes on the other set.\nWhat is returned, though, is the degree centrality\nfor nodes in both sets.\nHere is an example to show you how the function is used:\n\n```python\ndcs = nx.bipartite.degree_centrality(my_graph, nodes_from_one_partition)\n```",
"_____no_output_____"
]
],
[
[
"def find_most_crime_person(G, person_nodes):\n dcs = __________________________\n return ___________________________\n\nfrom nams.solutions.bipartite import find_most_crime_person\nfind_most_crime_person(G, person_nodes)",
"_____no_output_____"
]
],
[
[
"## Solutions\n\nHere are the solutions to the exercises above.",
"_____no_output_____"
]
],
[
[
"from nams.solutions import bipartite\nimport inspect\n\nprint(inspect.getsource(bipartite))",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2850b12e039e24f48d59b26ecb05ea5fb26286
| 4,644 |
ipynb
|
Jupyter Notebook
|
201103_CriticalDepth.ipynb
|
apreziosir/Critical_Depth
|
374438028d17e40747cdb7b3fce753a9f6f0dfb6
|
[
"MIT"
] | null | null | null |
201103_CriticalDepth.ipynb
|
apreziosir/Critical_Depth
|
374438028d17e40747cdb7b3fce753a9f6f0dfb6
|
[
"MIT"
] | null | null | null |
201103_CriticalDepth.ipynb
|
apreziosir/Critical_Depth
|
374438028d17e40747cdb7b3fce753a9f6f0dfb6
|
[
"MIT"
] | null | null | null | 33.171429 | 120 | 0.513351 |
[
[
[
"# Internal python libraries\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# Esto controla el tamaño de las figuras en el script \nplt.rcParams['figure.figsize'] = (10, 10)\n\nimport ipywidgets as ipw\nfrom ipywidgets import widgets, interact_manual\nfrom IPython.display import Image\n\n# Esto es para poder correr todo en linea\nipw.interact_manual.opts['manual_name'] = \"CALCULAR!\"\nnp.set_printoptions(formatter={'float': '{: 0.3f}'.format})",
"_____no_output_____"
],
[
"def RUN_ALL(ST):\n \n # Definiciones generales que sirven para cualquiera de las cosas que se llamen acá\n DESCR=[r\"Q $(m^3/s)$\", r\"m\", r\"b $(m)$\", r\"D_0 $(m)$\" ]\n # Seccion triangular\n if ST == \"Triangular\":\n \n from Functions import Triang\n \n interact_manual(Triang, \\\n Q=widgets.FloatText(description=DESCR[0], min=0, max=10, value=0.5 , readout_format='E'),\\\n m=widgets.FloatText(description=DESCR[1], min=0, max=10, value=1 , readout_format='E'));\n \n # Seccion rectangular\n elif ST == \"Rectangular\":\n \n from Functions import Rect\n \n interact_manual(Rect, \\\n Q=widgets.FloatText(description=DESCR[0], min=0, max=10, value=0.5 , readout_format='E'),\\\n b=widgets.FloatText(description=DESCR[2], min=0, max=10, value=1 , readout_format='E'));\n \n # Seccion trapezoidal\n elif ST == \"Trapezoidal\":\n \n from Functions import Trapez\n \n interact_manual(Trapez, \\\n Q=widgets.FloatText(description=DESCR[0], min=0, max=10, value=0.5 , readout_format='E'),\\\n m=widgets.FloatText(description=DESCR[1], min=0, max=10, value=1 , readout_format='E'), \\\n b=widgets.FloatText(description=DESCR[2], min=0, max=10, value=1 , readout_format='E'));\n # Sección circular\n elif ST == \"Circular\":\n \n from Functions import Circ\n \n interact_manual(Circ, \\\n Q=widgets.FloatText(description=DESCR[0], min=0, max=10, value=0.5 , readout_format='E'),\\\n d0=widgets.FloatText(description=DESCR[1], min=0, max=10, value=2 , readout_format='E'));\n \n return ",
"_____no_output_____"
],
[
"# ===========================================================================\n# Primera función para seleccionar la fomra geométrica de la sección trans-\n# versal con la que trabajará el programa\n# ===========================================================================\n\n# Descripción de la lista desplegable \nselect = [\"Triangular\", \"Rectangular\", \"Trapezoidal\", \"Circular\"]\n\n# Correr todo y poner los sliders en la pantalla\ninteract_manual(RUN_ALL, ST=widgets.Dropdown(options = select, description = \"Sección:\"))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4a285e478e073749e4c538d988f341c852f20905
| 23,310 |
ipynb
|
Jupyter Notebook
|
nobel_physics_prizes/notebooks/5.4-predict-model.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | 3 |
2019-08-21T05:35:42.000Z
|
2020-10-08T21:28:51.000Z
|
nobel_physics_prizes/notebooks/5.4-predict-model.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | 139 |
2018-09-01T23:15:59.000Z
|
2021-02-02T22:01:39.000Z
|
nobel_physics_prizes/notebooks/5.4-predict-model.ipynb
|
covuworie/nobel-physics-prizes
|
f89a32cd6eb9bbc9119a231bffee89b177ae847a
|
[
"MIT"
] | null | null | null | 46.62 | 1,013 | 0.695281 |
[
[
[
"# Predict Model\n\nThe aim of this notebook is to assess how well our [logistic regression classifier](../models/LR.csv) generalizes to unseen data. We will accomplish this by using the Matthew's Correlation Coefficient (MCC) to evaluate it's predictive performance on the test set. Following this, we will determine which features the classifier deems most important in the classification of a physicist as a Nobel Laureate. Finally, we will use our model to predict the most likely Physics Nobel Prize Winners in 2018.",
"_____no_output_____"
]
],
[
[
"import ast\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.externals import joblib\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.metrics import matthews_corrcoef\n\nfrom src.features.features_utils import convert_categoricals_to_numerical\nfrom src.features.features_utils import convert_target_to_numerical\nfrom src.models.metrics_utils import confusion_matrix_to_dataframe\nfrom src.models.metrics_utils import print_matthews_corrcoef\nfrom src.visualization.visualization_utils import plot_logistic_regression_odds_ratio",
"_____no_output_____"
]
],
[
[
"## Reading in the Data\n\nFirst let's read in the classifier parameters and metadata that we saved in order to reconstruct the classifier.",
"_____no_output_____"
]
],
[
[
"classifier_params = pd.read_csv('../models/LR.csv', squeeze=True, index_col=0)\nclassifier_params",
"_____no_output_____"
]
],
[
[
"Next let's read in the training, validation and test features and targets. We make sure to convert the categorical fields to a numerical form that is suitable for building machine learning models.",
"_____no_output_____"
]
],
[
[
"train_features = pd.read_csv('../data/processed/train-features.csv')\nX_train = convert_categoricals_to_numerical(train_features)\nX_train.head()",
"_____no_output_____"
],
[
"train_target = pd.read_csv('../data/processed/train-target.csv', index_col='full_name', squeeze=True)\ny_train = convert_target_to_numerical(train_target)\ny_train.head()",
"_____no_output_____"
],
[
"validation_features = pd.read_csv('../data/processed/validation-features.csv')\nX_validation = convert_categoricals_to_numerical(validation_features)\nX_validation.head()",
"_____no_output_____"
],
[
"validation_target = pd.read_csv('../data/processed/validation-target.csv', index_col='full_name',\n squeeze=True)\ny_validation = convert_target_to_numerical(validation_target)\ny_validation.head()",
"_____no_output_____"
],
[
"test_features = pd.read_csv('../data/processed/test-features.csv')\nX_test = convert_categoricals_to_numerical(test_features)\nX_test.head()",
"_____no_output_____"
],
[
"test_target = pd.read_csv('../data/processed/test-target.csv', index_col='full_name', squeeze=True)\ny_test = convert_target_to_numerical(test_target)\ny_test.head()",
"_____no_output_____"
]
],
[
[
"## Retraining on the Training and Validation Data\n\nIt makes sense to retrain the model on both the training and validation data so that we can obtain as good a predictive performance as possible. So let's combine the training and validation features and targets, reconstruct the classifier and retrain the model.",
"_____no_output_____"
]
],
[
[
"X_train_validation = X_train.append(X_validation)\nassert(len(X_train_validation) == len(X_train) + len(X_validation))\nX_train_validation.head()",
"_____no_output_____"
],
[
"y_train_validation = y_train.append(y_validation)\nassert(len(y_train_validation) == len(y_train) + len(y_validation))\ny_train_validation.head()",
"_____no_output_____"
],
[
"classifier = LogisticRegression(**ast.literal_eval(classifier_params.params))\nclassifier.fit(X_train_validation, y_train_validation)",
"_____no_output_____"
]
],
[
[
"## Predicting on the Test Data\n\nHere comes the moment of truth! We will soon see just how good the model is by predicting on the test data. However, first it makes sense to look at the performance of our \"naive\" [baseline model](5.0-baseline-model.ipynb) on the test data. Recall that this is a model that predicts the physicist is a laureate whenever the number of workplaces is at least 2.",
"_____no_output_____"
]
],
[
[
"y_train_pred = X_train_validation.num_workplaces_at_least_2\ny_test_pred = X_test.num_workplaces_at_least_2\nmcc_train_validation = matthews_corrcoef(y_train_validation, y_train_pred)\nmcc_test = matthews_corrcoef(y_test, y_test_pred)\nname = 'Baseline Classifier'\nprint_matthews_corrcoef(mcc_train_validation, name, data_label='train + validation')\nprint_matthews_corrcoef(mcc_test, name, data_label='test')",
"_____no_output_____"
]
],
[
[
"Unsurprisingly, this classifier exhibits very poor performance on the test data. We see evidence of the covariate shift again here due to the relatively large difference in the test and train + validation MCCs. Either physicists started working in more workplaces in general, or the records of where physicists have worked are better in modern times. The confusion matrix and classification report indicate that the classifier is poor in terms of both precision and recall when identifying laureates.",
"_____no_output_____"
]
],
[
[
"display(confusion_matrix_to_dataframe(confusion_matrix(y_test, y_test_pred)))\nprint(classification_report(y_test, y_test_pred))",
"_____no_output_____"
]
],
[
[
"OK let's see how our logistic regression model does on the test data.",
"_____no_output_____"
]
],
[
[
"y_train_pred = (classifier.predict_proba(X_train_validation)[:, 1] > ast.literal_eval(\n classifier_params.threshold)).astype('int64')\ny_test_pred = (classifier.predict_proba(X_test)[:, 1] > ast.literal_eval(\n classifier_params.threshold)).astype('int64')\nmcc_train_validation = matthews_corrcoef(y_train_validation, y_train_pred)\nmcc_test = matthews_corrcoef(y_test, y_test_pred)\nprint_matthews_corrcoef(mcc_train_validation, classifier_params.name, data_label='train + validation')\nprint_matthews_corrcoef(mcc_test, classifier_params.name, data_label='test')",
"_____no_output_____"
]
],
[
[
"This classifier performs much better on the test data than the baseline classifier. Again we are discussing its performance in relative and not absolute terms. There is very little in the literature, even as a rule of thumb, saying what the expected MCC is for a \"good performing classifier\" as it is very dependent on the context and usage. As we noted before, predicting Physics Nobel Laureates is a difficult task due to the many complex factors involved, so we certainly should not be expecting stellar performance from *any* classifier. This includes both machine classifiers, either machine-learning-based or rules-based, and human classifiers without inside knowledge. However, let us try and get off the fence just a little now. \n\nThe MCC is a [contingency matrix](https://en.wikipedia.org/wiki/Contingency_table) method of calculating the [Pearson product-moment correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient) and so it has the [same interpretation](https://stats.stackexchange.com/questions/118219/how-to-interpret-matthews-correlation-coefficient-mcc). If the values in the link are to be believed, then our classifier has a \"moderate positive relationship\" with the target. This [statistical guide](https://statistics.laerd.com/statistical-guides/pearson-correlation-coefficient-statistical-guide.php ) also seems to agree with this assessment. However, we can easily find examples that indicate there is a [low positive correlation](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3576830/) or a [weak uphill (positive) linear relationship](https://www.dummies.com/education/math/statistics/how-to-interpret-a-correlation-coefficient-r/) between the classifier's predictions and the target.\n\nSo should we conclude that the classifier has a low or moderate performance? Asking this question is missing the purpose of this study. Instead we should ask, based on the classifier's performance, would we be willing to make recommendations to the Nobel Committee, about any biases that may be present when deciding Physics Laureates? We can see from the confusion matrix and classification report that although this classifier has reasonable recall of laureates, it is contaminated by too many false postives. Or in other words, it is not precise enough. As a result, the answer to the question is very likely no.",
"_____no_output_____"
]
],
[
[
"display(confusion_matrix_to_dataframe(confusion_matrix(y_test, y_test_pred)))\nprint(classification_report(y_test, y_test_pred))",
"_____no_output_____"
]
],
[
[
"## Most Important Features\n\nOut of interest, let's determine the features that are most important to the prediction by looking at the coefficients of the logistic regression model. Each coefficient represents the impact that the *presence* vs. *absence* of a predictor has on the [log odds ratio](https://en.wikipedia.org/wiki/Odds_ratio#Role_in_logistic_regression) of a physicist being classified as a laureate. The change in [odds ratio](https://en.wikipedia.org/wiki/Odds_ratio) for each predictor can can simply be computed by exponentiating its associated coefficient. The top fifteen most important features are plotted in the chart below.",
"_____no_output_____"
]
],
[
[
"top_n = 15\nax = plot_logistic_regression_odds_ratio(classifier.coef_, top_n=top_n, columns=X_train_validation.columns,\n title='Top {} most important features in prediction of Physics Nobel Laureates'.format(top_n))\nax.figure.set_size_inches(10, 8)",
"_____no_output_____"
]
],
[
[
"By far the most important feature is being an experimental physicist. This matches with what we observed during the [exploratory data analysis](4.0-exploratory-data-analysis.ipynb). Next comes having at least one physics laureate doctoral student and then living for at least 65-79 years. We also saw during the exploratory data analysis that the later also seemed to have a big effect in distinguishing laureates from their counterparts. Some of the other interesting top features are being a citizen of France or Switzerland, working at [Bell Labs](https://en.wikipedia.org/wiki/Bell_Labs#Discoveries_and_developments) or [The University of Cambridge](https://en.wikipedia.org/wiki/List_of_Nobel_laureates_by_university_affiliation#University_of_Cambridge_(2nd)), being an alumnus in Asia and having at least two alma mater.",
"_____no_output_____"
],
[
"## Prediction of 2018 Physics Nobel Laureates\n\nNow let us use the logistic regression model to predict the 2018 Physics Nobel Laureates. A maximum of three physicists can be awarded the prize in any one year. However, to give ourselves more of a fighting chance, we will instead try to predict the ten most likely winners. Let's start by forming the feature and target dataframes of living physicists (i.e the union of the validation and test sets) as the Nobel Prize cannot be awarded posthumously.",
"_____no_output_____"
]
],
[
[
"X_validation_test = X_validation.append(X_test)\nassert(len(X_validation_test) == len(X_validation) + len(X_test))\nX_validation_test.head()",
"_____no_output_____"
],
[
"y_validation_test = y_validation.append(y_test)\nassert(len(y_validation_test) == len(y_validation) + len(y_test))\ny_validation_test.head()",
"_____no_output_____"
]
],
[
[
"Recall that *John Bardeen* is the only [double laureate in Physics](https://www.nobelprize.org/prizes/facts/facts-on-the-nobel-prize-in-physics/), so although it is possible to receive the Nobel Prize in Physics multiple times, it is extremely rare. So let's drop previous Physics Laureates from the dataframe. This will make the list far more interesting as it will not be polluted by previous laureates.",
"_____no_output_____"
]
],
[
[
"X_eligible = X_validation_test.drop(y_validation_test[y_validation_test == 1].index)\nassert(len(X_eligible) == len(X_validation_test) - len(y_validation_test[y_validation_test == 1]))\nX_eligible.head()",
"_____no_output_____"
]
],
[
[
"According to our model, these are the ten most likely winners of 2018 Physics Nobel Prize:",
"_____no_output_____"
]
],
[
[
"physicist_win_probabilites = pd.Series(\n classifier.predict_proba(X_eligible)[:, 1], index=X_eligible.index).sort_values(ascending=False)\nphysicist_win_probabilites[:10]",
"_____no_output_____"
]
],
[
[
"The list contains some great and very interesting physicists who have won numerous of the top prizes in physics. We'll leave you to check out their Wikipedia articles for some more information on them. However, a few are worth discussing now. Without doubt the most infamous is [Jocelyn Bell Burnell](https://en.wikipedia.org/wiki/Jocelyn_Bell_Burnell) who, as a postgraduate student, co-discovered the first radio pulsars in 1967. Her Wikipedia article says:\n\n\"The discovery was recognised by the award of the 1974 Nobel Prize in Physics, but despite the fact that she was the first to observe the pulsars, Bell was excluded from the recipients of the prize.\n\nThe paper announcing the discovery of pulsars had five authors. Bell's thesis supervisor Antony Hewish was listed first, Bell second. Hewish was awarded the Nobel Prize, along with the astronomer Martin Ryle. Many prominent astronomers criticised Bell's omission, including Sir Fred Hoyle.\"\n\nYou can read more about her in her Wikipedia article and further details about other [Nobel Physics Prize controversies](https://en.wikipedia.org/wiki/Nobel_Prize_controversies#Physics).\n\n[Vera Rubin](https://en.wikipedia.org/wiki/Vera_Rubin) was an American astronomer who's research provided evidence of the existence of [dark matter](https://en.wikipedia.org/wiki/Dark_matter). According to her Wikipedia article, she \"never won the Nobel Prize, though physicists such as Lisa Randall and Emily Levesque have argued that this was an oversight.\" Unfortunately she died on 25 December 2016 and is no longer eligible for the award. Recall that the list contains some deceased physicists due to the lag in updates of dbPedia data from Wikipedia. *Peter Mansfield*, who is also on the list, is deceased too. \n\n[Manfred Eigen](https://en.wikipedia.org/wiki/Manfred_Eigen) actually won the 1967 Nobel Prize in Chemistry for work on measuring fast chemical reactions. \n\nThe actual winners of the [2018 Nobel Prize in Physics](https://www.nobelprize.org/prizes/physics/2018/summary/) were [Gérard Mourou](https://en.wikipedia.org/wiki/G%C3%A9rard_Mourou), [Arthur Ashkin](https://en.wikipedia.org/wiki/Arthur_Ashkin) and [Donna Strickland](https://en.wikipedia.org/wiki/Donna_Strickland). Our model actually had zero chance of predicting them as they were never in the original [list of physicists](../data/raw/physicists.txt) scraped from Wikipedia! Obviously they are now deemed famous enough to have been added to Wikipedia since.",
"_____no_output_____"
]
],
[
[
"('Gérard Mourou' in physicist_win_probabilites, \n 'Arthur Ashkin' in physicist_win_probabilites,\n 'Donna Strickland' in physicist_win_probabilites)",
"_____no_output_____"
]
],
[
[
"So should we declare this part of the study as an epic failure as we were unable to identify the winners? No not quite. Closer inspection reveals many interesting characteristics of the three winners that are related to the top features in our predictive model:\n\n- *Gérard Mourou* is an experimental physicist, a citizen of France, 74 years of age (i.e. years lived group 65-79), has at least one physics laureate doctoral student (i.e. *Donna Strickland*) and has 3 alma mater.\n- *Arthur Ashkin* is an experimental physicist, worked at Bell Labs and has 2 alma mater.\n- *Donna Strickland* is an experimental physicist and has 2 alma mater.\n\nMaybe this is a pure coincidence, but more likely, there are patterns in the data that the model has found. Whether or not these characteristics can be attributed to biases in the [Nobel Physics Prize nomination and selection process](https://www.nobelprize.org/nomination/physics/) is another matter, as correlation does not necessarily imply causation.\n\nThis section was a lot of fun and quite informative about the logistic regression classifier, however, it was not possible without cheating. Look closely to see if you can spot the cheating!",
"_____no_output_____"
],
[
"## Model Deployment\n\nIt makes sense to retrain the model on *all* the data so that we can obtain as good a predictive performance as possible. So let's go ahead and do this now.",
"_____no_output_____"
]
],
[
[
"X_train_validation_test = X_train_validation.append(X_test)\nassert(len(X_train_validation_test) == len(X_train_validation) + len(X_test))\nX_train_validation_test.head()",
"_____no_output_____"
],
[
"y_train_validation_test = y_train_validation.append(y_test)\nassert(len(y_train_validation_test) == len(y_train_validation) + len(y_test))\ny_train_validation_test.head()",
"_____no_output_____"
],
[
"classifier.fit(X_train_validation_test, y_train_validation_test)",
"_____no_output_____"
]
],
[
[
"Due to the short training time, it is possible in this study to always recreate the logistic regression classifier from the [model template](../models/LR.csv) that we persisted. Every time we want to use the model to make predictions on new data, it is easy enough to retrain the model first. However, if we had more data and longer training times, this would be rather cumbersome. In such a case, if we were deploying the model, which we are not for the reasons mentioned above, it would make sense to actually persist the trained model. Nonetheless, for completeness, let's persist the model.",
"_____no_output_____"
]
],
[
[
"joblib.dump(classifier, '../models/LR.joblib')",
"_____no_output_____"
]
],
[
[
"As a sanity check let's load the model and make sure that we get the same results as before.",
"_____no_output_____"
]
],
[
[
"classifier_check = joblib.load('../models/LR.joblib')\nnp.testing.assert_allclose(classifier.predict_proba(X_train_validation_test),\n classifier_check.predict_proba(X_train_validation_test))",
"_____no_output_____"
]
],
[
[
"Great, everything looks good.\n\nAlthough persisting the model suffers from the [compatibility and security issues](https://stackabuse.com/scikit-learn-save-and-restore-models/#compatibilityissues) mentioned previously, we have the [model template](../models/LR.csv) that allows us to reconstruct the classifier for future python, library and model versions. This mitigates the compatibility risk. We can also mitigate the security risk by only restoring the model from *trusted* or *authenticated* sources.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a28960825beb35a694ee583d1dbed705bc827bd
| 279,944 |
ipynb
|
Jupyter Notebook
|
notebooks/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/table/noisy_prop_scores_sar_two_subject_groups_no_pca_table.ipynb
|
ML-KULeuven/KBC-as-PU-Learning
|
a00f606bd40ca06af0a5627e65a4582859976918
|
[
"Apache-2.0"
] | 4 |
2021-12-14T16:13:47.000Z
|
2022-01-21T13:14:14.000Z
|
notebooks/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/table/noisy_prop_scores_sar_two_subject_groups_no_pca_table.ipynb
|
ML-KULeuven/KBC-as-PU-Learning
|
a00f606bd40ca06af0a5627e65a4582859976918
|
[
"Apache-2.0"
] | null | null | null |
notebooks/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/table/noisy_prop_scores_sar_two_subject_groups_no_pca_table.ipynb
|
ML-KULeuven/KBC-as-PU-Learning
|
a00f606bd40ca06af0a5627e65a4582859976918
|
[
"Apache-2.0"
] | null | null | null | 96.068634 | 7,624 | 0.587164 |
[
[
[
"from kbc_pul.project_info import project_dir as kbc_e_metrics_project_dir\n\n\nimport os\nfrom typing import List, Dict, Set, Optional\n\nimport numpy as np\nimport pandas as pd\n\nfrom artificial_bias_experiments.evaluation.confidence_comparison.df_utils import ColumnNamesInfo\nfrom artificial_bias_experiments.known_prop_scores.dataset_generation_file_naming import \\\n get_root_dir_experiment_noisy_propensity_scores\nfrom kbc_pul.confidence_naming import ConfidenceEnum\nfrom kbc_pul.observed_data_generation.sar_two_subject_groups.sar_two_subject_groups_prop_scores import \\\n PropScoresTwoSARGroups\nfrom artificial_bias_experiments.noisy_prop_scores.sar_two_subject_groups.experiment_info import \\\n NoisyPropScoresSARExperimentInfo\nfrom artificial_bias_experiments.noisy_prop_scores.sar_two_subject_groups.noisy_prop_scores_sar_two_groups_loading import \\\n load_df_noisy_prop_scores_two_groups\n\n\nfrom pathlib import Path\n\nfrom pylo.language.lp import Clause as PyloClause",
"_____no_output_____"
]
],
[
[
"# Noisy SAR 2 groups - paper table\n",
"_____no_output_____"
]
],
[
[
"\n\ndataset_name=\"yago3_10\"\nis_pca_version: bool = False\n\n\ntrue_prop_score_in_filter = 0.5\ntrue_prop_score_other_list = [0.3, .7]\n\n# true_prop_scores = PropScoresTwoSARGroups(\n# in_filter=true_prop_score_in_filter,\n# other=true_prop_score_other\n# )\n\nnoisy_prop_score_in_filter: float = true_prop_score_in_filter\nnoisy_prop_score_not_in_filter_list: List[float] = [0.1, 0.2, .3, .4, .5, .6, .7, .8, .9, 1]\n\nroot_experiment_dir: str = os.path.join(\n get_root_dir_experiment_noisy_propensity_scores(),\n 'sar_two_subject_groups',\n dataset_name\n\n)\npath_root_experiment_dir = Path(root_experiment_dir)\n\ntrue_prop_score_other_to_df_map: Dict[float, pd.DataFrame] = dict()\ndf_list_complete: List[pd.DataFrame] = []\n\nfor true_prop_score_other in true_prop_score_other_list:\n true_prop_scores = PropScoresTwoSARGroups(\n in_filter=true_prop_score_in_filter,\n other=true_prop_score_other\n )\n\n # df_list: List[pd.DataFrame] = []\n\n for target_rel_path in path_root_experiment_dir.iterdir():\n if target_rel_path.is_dir():\n for filter_dir in target_rel_path.iterdir():\n if filter_dir.is_dir():\n target_relation = target_rel_path.name\n filter_relation = filter_dir.name\n print(f\"{target_relation} - {filter_relation}\")\n try:\n experiment_info = NoisyPropScoresSARExperimentInfo(\n dataset_name=dataset_name,\n target_relation=target_relation,\n filter_relation=filter_relation,\n true_prop_scores=true_prop_scores,\n noisy_prop_score_in_filter=noisy_prop_score_in_filter,\n noisy_prop_score_not_in_filter_list=noisy_prop_score_not_in_filter_list,\n is_pca_version=is_pca_version\n )\n df_rule_wrappers_tmp = load_df_noisy_prop_scores_two_groups(\n experiment_info=experiment_info\n )\n df_list_complete.append(df_rule_wrappers_tmp)\n except Exception as err:\n print(err)\n\n\ndf_rule_wrappers_all_targets: pd.DataFrame = pd.concat(df_list_complete, axis=0)\n# true_prop_score_other_to_df_map[true_prop_score_other] = df_for_true_prop_score_other",
"participatedin - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - hascapital\nparticipatedin - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/imports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/islocatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/exports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - dealswith\nhascurrency - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/participatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascurrency - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascurrency - owns\nhascurrency - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/hascapital/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascurrency - hasofficiallanguage\nhascurrency - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/imports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascurrency - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/exports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascurrency - dealswith\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/dealswith/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndirected - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndirected - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndirected - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndirected - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/created/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndirected - actedin\ndirected - ismarriedto\nhaswonprize - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/created/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/actedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswonprize - influences\nhaswonprize - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/ismarriedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/participatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hascurrency/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - owns\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/owns/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hascapital/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/imports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/exports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasneighbor - dealswith\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/dealswith/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\niscitizenof - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\niscitizenof - diedin\niscitizenof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\niscitizenof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\niscitizenof - graduatedfrom\niscitizenof - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\niscitizenof - worksat\niscitizenof - hasacademicadvisor\niscitizenof - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisinterestedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisinterestedin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisinterestedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisinterestedin - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisinterestedin - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - isaffiliatedto\ndiedin - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/actedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/haschild/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/playsfor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndiedin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/ismarriedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwrotemusicfor - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwrotemusicfor - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwrotemusicfor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwrotemusicfor - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/created/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwrotemusicfor - hasmusicalrole\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/hasmusicalrole/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nowns - participatedin\nowns - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/hascapital/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nowns - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nowns - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/hasgender/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nowns - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/islocatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhascapital - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascapital/participatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasofficiallanguage - participatedin\nhasofficiallanguage - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasofficiallanguage/hascurrency/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasofficiallanguage - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasofficiallanguage/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasofficiallanguage - hascapital\nhasofficiallanguage - imports\nhasofficiallanguage - exports\nhasofficiallanguage - dealswith\nedited - directed\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/directed/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nedited - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nedited - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nedited - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - graduatedfrom\nlivesin - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/ispoliticianof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/worksat/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nlivesin - actedin\nlivesin - hasacademicadvisor\nlivesin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/ismarriedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwasbornin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwasbornin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwasbornin - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nwasbornin - playsfor\nisleaderof - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/ispoliticianof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisleaderof - isaffiliatedto\nisleaderof - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/haschild/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/ispoliticianof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - isaffiliatedto\ngraduatedfrom - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/worksat/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/actedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - hasacademicadvisor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/hasacademicadvisor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ngraduatedfrom - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/haschild/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - directed\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/directed/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - haswonprize\ncreated - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - wrotemusicfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/wrotemusicfor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - graduatedfrom\ncreated - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/actedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ncreated - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasmusicalrole - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasmusicalrole - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasmusicalrole - wrotemusicfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/wrotemusicfor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasmusicalrole - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasgender - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasgender - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasgender - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasgender - isaffiliatedto\nhasgender - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/playsfor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaswebsite - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswebsite/islocatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nimports - participatedin\nimports - hascurrency\nimports - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nimports - owns\nimports - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hascapital/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nimports - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nimports - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/exports/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - haswonprize\nispoliticianof - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - isleaderof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/isleaderof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nispoliticianof - graduatedfrom\nispoliticianof - isaffiliatedto\nispoliticianof - haschild\nisaffiliatedto - wasbornin\nisaffiliatedto - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isaffiliatedto/hasgender/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nisaffiliatedto - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isaffiliatedto/playsfor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nexports - participatedin\nexports - hascurrency\nexports - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/exports/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nexports - owns\nexports - hascapital\nexports - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/exports/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - hasacademicadvisor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/hasacademicadvisor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nworksat - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/participatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hascurrency/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hasneighbor/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - owns\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/owns/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hascapital/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ndealswith - imports\ndealswith - exports\nisconnectedto - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isconnectedto/islocatedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhappenedin - islocatedin\nactedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nactedin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nactedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nactedin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/ismarriedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/livesin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/worksat/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhasacademicadvisor - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/influences/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/iscitizenof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\ninfluences - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/created/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/ispoliticianof/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nhaschild - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/ismarriedto/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nplaysfor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/playsfor/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nplaysfor - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/playsfor/hasgender/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/haswonprize/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/diedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/wasbornin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/graduatedfrom/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/actedin/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nismarriedto - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/haschild/not_pca/s_prop0.5_ns_prop0.3/rule_wrappers'\nparticipatedin - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nparticipatedin - hascapital\nparticipatedin - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nparticipatedin - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/imports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nparticipatedin - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/islocatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nparticipatedin - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/participatedin/exports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nparticipatedin - dealswith\nhascurrency - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/participatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascurrency - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascurrency - owns\nhascurrency - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/hascapital/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascurrency - hasofficiallanguage\nhascurrency - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/imports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascurrency - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/exports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascurrency - dealswith\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascurrency/dealswith/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndirected - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndirected - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndirected - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndirected - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/directed/created/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndirected - actedin\ndirected - ismarriedto\nhaswonprize - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/created/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/actedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswonprize - influences\nhaswonprize - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswonprize/ismarriedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/participatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hascurrency/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - owns\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/owns/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hascapital/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - imports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/imports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/exports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasneighbor - dealswith\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasneighbor/dealswith/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\niscitizenof - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\niscitizenof - diedin\niscitizenof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\niscitizenof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\niscitizenof - graduatedfrom\niscitizenof - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\niscitizenof - worksat\niscitizenof - hasacademicadvisor\niscitizenof - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/iscitizenof/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisinterestedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisinterestedin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisinterestedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisinterestedin - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisinterestedin - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isinterestedin/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - isaffiliatedto\ndiedin - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/actedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/haschild/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/playsfor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndiedin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/diedin/ismarriedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwrotemusicfor - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwrotemusicfor - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwrotemusicfor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwrotemusicfor - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/created/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwrotemusicfor - hasmusicalrole\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wrotemusicfor/hasmusicalrole/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nowns - participatedin\nowns - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/hascapital/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nowns - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nowns - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/hasgender/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nowns - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/owns/islocatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhascapital - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hascapital/participatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasofficiallanguage - participatedin\nhasofficiallanguage - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasofficiallanguage/hascurrency/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasofficiallanguage - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasofficiallanguage/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasofficiallanguage - hascapital\nhasofficiallanguage - imports\nhasofficiallanguage - exports\nhasofficiallanguage - dealswith\nedited - directed\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/directed/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nedited - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nedited - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nedited - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/edited/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - graduatedfrom\nlivesin - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/ispoliticianof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/worksat/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nlivesin - actedin\nlivesin - hasacademicadvisor\nlivesin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/livesin/ismarriedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwasbornin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwasbornin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwasbornin - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/wasbornin/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nwasbornin - playsfor\nisleaderof - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/ispoliticianof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisleaderof - isaffiliatedto\nisleaderof - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isleaderof/haschild/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/ispoliticianof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - isaffiliatedto\ngraduatedfrom - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/worksat/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/actedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - hasacademicadvisor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/hasacademicadvisor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ngraduatedfrom - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/graduatedfrom/haschild/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - directed\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/directed/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - haswonprize\ncreated - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - wrotemusicfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/wrotemusicfor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - graduatedfrom\ncreated - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/actedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ncreated - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/created/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasmusicalrole - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasmusicalrole - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasmusicalrole - wrotemusicfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/wrotemusicfor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasmusicalrole - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasmusicalrole/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasgender - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasgender - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasgender - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasgender - isaffiliatedto\nhasgender - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasgender/playsfor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaswebsite - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haswebsite/islocatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nimports - participatedin\nimports - hascurrency\nimports - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nimports - owns\nimports - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hascapital/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nimports - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nimports - exports\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/imports/exports/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - haswonprize\nispoliticianof - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - isleaderof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ispoliticianof/isleaderof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nispoliticianof - graduatedfrom\nispoliticianof - isaffiliatedto\nispoliticianof - haschild\nisaffiliatedto - wasbornin\nisaffiliatedto - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isaffiliatedto/hasgender/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nisaffiliatedto - playsfor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isaffiliatedto/playsfor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nexports - participatedin\nexports - hascurrency\nexports - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/exports/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nexports - owns\nexports - hascapital\nexports - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/exports/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - hasacademicadvisor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/hasacademicadvisor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nworksat - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/worksat/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - participatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/participatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - hascurrency\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hascurrency/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - hasneighbor\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hasneighbor/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - owns\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/owns/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - hascapital\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hascapital/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - hasofficiallanguage\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/dealswith/hasofficiallanguage/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ndealswith - imports\ndealswith - exports\nisconnectedto - islocatedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/isconnectedto/islocatedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhappenedin - islocatedin\nactedin - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nactedin - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nactedin - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nactedin - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/actedin/ismarriedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - livesin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/livesin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - worksat\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/worksat/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhasacademicadvisor - influences\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/hasacademicadvisor/influences/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - iscitizenof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/iscitizenof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\ninfluences - created\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/influences/created/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - ispoliticianof\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/ispoliticianof/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - isaffiliatedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/isaffiliatedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nhaschild - ismarriedto\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/haschild/ismarriedto/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nplaysfor - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/playsfor/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nplaysfor - hasgender\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/playsfor/hasgender/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - haswonprize\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/haswonprize/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - diedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/diedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - wasbornin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/wasbornin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - graduatedfrom\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/graduatedfrom/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - actedin\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/actedin/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\nismarriedto - haschild\n[Errno 2] No such file or directory: '/home/joschout/Documents/Repos/KUL-PUL/data/artificial_bias_experiments/noisy_prop_scores/sar_two_subject_groups/yago3_10/ismarriedto/haschild/not_pca/s_prop0.5_ns_prop0.7/rule_wrappers'\n"
],
[
"df_rule_wrappers_all_targets.head()",
"_____no_output_____"
],
[
"df_rule_wrappers_all_targets.columns",
"_____no_output_____"
],
[
"column_names_logistics: List[str] = [\n 'target_relation',\n 'filter_relation',\n 'true_prop_scores_in_filter', 'true_prop_scores_not_in_filter',\n 'noisy_prop_scores_in_filter', 'noisy_prop_scores_not_in_filter',\n\n 'random_trial_index',\n \"Rule\"\n]\nother_columns = [col for col in df_rule_wrappers_all_targets.columns if col not in column_names_logistics]\nresorted_columns = column_names_logistics + other_columns\ndf_rule_wrappers_all_targets = df_rule_wrappers_all_targets[resorted_columns]\ndf_rule_wrappers_all_targets.head()",
"_____no_output_____"
],
[
"df_rule_wrappers_all_targets.rename(\n columns={\n 'true_prop_scores_in_filter': \"true_filter\",\n 'true_prop_scores_not_in_filter': \"true_other\",\n 'noisy_prop_scores_in_filter': \"noisy_filter\", 'noisy_prop_scores_not_in_filter': \"noisy_other\",\n },\n inplace=True,\n errors=\"ignore\"\n)\ncolumn_names_logistics: List[str] = [\n 'target_relation',\n 'filter_relation',\n 'true_filter', 'true_other',\n 'noisy_filter', 'noisy_other',\n 'random_trial_index',\n \"Rule\"\n]",
"_____no_output_____"
],
[
"df_rule_wrappers_all_targets.head()",
"_____no_output_____"
]
],
[
[
"\n## 2. Only keep a subset of rules\n### 2.1. Only keep the non-recursive rules; drop recursive rules",
"_____no_output_____"
]
],
[
[
"from kbc_pul.data_structures.rule_wrapper import get_pylo_rule_from_string, is_pylo_rule_recursive\n\n\ndef is_rule_recursive(rule_string: str) -> bool:\n pylo_rule: PyloClause = get_pylo_rule_from_string(rule_string)\n is_rule_recursive = is_pylo_rule_recursive(pylo_rule)\n return is_rule_recursive\n\n\nmask_recursive_rules = df_rule_wrappers_all_targets.apply(\n lambda row: is_rule_recursive(row[\"Rule\"]),\n axis=1\n)",
"_____no_output_____"
],
[
"print(len(df_rule_wrappers_all_targets))\ndf_rule_wrappers_all_targets: pd.DataFrame = df_rule_wrappers_all_targets[~mask_recursive_rules]\nprint(len(df_rule_wrappers_all_targets))\n\n",
"47530\n15300\n"
]
],
[
[
"### 2.3 Drop the Pair-positive columns (both directions)",
"_____no_output_____"
]
],
[
[
"df_rule_wrappers_all_targets.drop(\n [ConfidenceEnum.TRUE_CONF_BIAS_YS_ZERO_S_TO_O.value,\n ConfidenceEnum.TRUE_CONF_BIAS_YS_ZERO_O_TO_S.value],\n axis=1,\n inplace=True,\n errors='ignore'\n)\ndf_rule_wrappers_all_targets.head()",
"_____no_output_____"
]
],
[
[
"### 2.4 Drop the IPW-PCA columns (both directions)",
"_____no_output_____"
]
],
[
[
"df_rule_wrappers_all_targets.drop(\n [ConfidenceEnum.IPW_PCA_CONF_S_TO_O.value,\n ConfidenceEnum.IPW_PCA_CONF_O_TO_S.value],\n axis=1,\n inplace=True,\n errors='ignore'\n)\ndf_rule_wrappers_all_targets.head()\n",
"_____no_output_____"
]
],
[
[
"### 2.4 Drop the $c_{q}=0.5$ column",
"_____no_output_____"
]
],
[
[
"df_rule_wrappers_all_targets.drop(\n [\"true_filter\", \"noisy_filter\"],\n axis=1,\n inplace=True,\n errors='ignore'\n)\ncolumn_names_logistics = [\n col for col in column_names_logistics\n if col != \"true_filter\"\n and col != \"noisy_filter\"\n]\ndf_rule_wrappers_all_targets.head()",
"_____no_output_____"
],
[
"group_by_list = [\n \"target_relation\",\n \"filter_relation\",\n 'true_other',\n 'noisy_other',\n \"Rule\",\n \"random_trial_index\"\n]\ndf_count_trials: pd.DataFrame = df_rule_wrappers_all_targets[\n [\n \"target_relation\",\n \"filter_relation\",\n 'true_other',\n 'noisy_other',\n \"Rule\",\n \"random_trial_index\"\n ]\n].groupby(\n [\n \"target_relation\",\n \"filter_relation\",\n 'true_other',\n 'noisy_other',\n \"Rule\",\n ]\n).count().reset_index()",
"_____no_output_____"
],
[
"df_less_than_ten_trials: pd.DataFrame = df_count_trials[df_count_trials[\"random_trial_index\"].values != 10]\ndf_less_than_ten_trials",
"_____no_output_____"
],
[
"df_rule_wrappers_all_targets = df_rule_wrappers_all_targets[\n ~(\n (df_rule_wrappers_all_targets[\"target_relation\"] == \"isaffiliatedto\")\n &\n (df_rule_wrappers_all_targets[\"filter_relation\"] == \"wasbornin\")\n &\n (df_rule_wrappers_all_targets[\"Rule\"]==\"isaffiliatedto(A,B) :- playsfor(A,B)\")\n )\n]\ndf_rule_wrappers_all_targets.head()\n",
"_____no_output_____"
]
],
[
[
"**Now, we have the full dataframe**\n\n****",
"_____no_output_____"
],
[
"## Calculate $[conf(R) - \\widehat{conf}(R)]$",
"_____no_output_____"
]
],
[
[
"true_conf: ConfidenceEnum = ConfidenceEnum.TRUE_CONF\n\nconf_estimators_list: List[ConfidenceEnum] = [\n ConfidenceEnum.CWA_CONF,\n ConfidenceEnum.ICW_CONF,\n ConfidenceEnum.PCA_CONF_S_TO_O,\n ConfidenceEnum.PCA_CONF_O_TO_S,\n ConfidenceEnum.IPW_CONF,\n]\nall_confs_list: List[ConfidenceEnum] = [ConfidenceEnum.TRUE_CONF ] + conf_estimators_list\n\ncolumn_names_all_confs: List[str] = [\n conf.get_name()\n for conf in all_confs_list\n]",
"_____no_output_____"
],
[
"df_rule_wrappers_all_targets = df_rule_wrappers_all_targets[\n column_names_logistics + column_names_all_confs\n]\ndf_rule_wrappers_all_targets.head()",
"_____no_output_____"
],
[
"df_conf_estimators_true_other = df_rule_wrappers_all_targets[\n df_rule_wrappers_all_targets[\"true_other\"] == df_rule_wrappers_all_targets[\"noisy_other\"]\n]\ndf_conf_estimators_true_other.head()",
"_____no_output_____"
],
[
"column_names_info =ColumnNamesInfo(\n true_conf=true_conf,\n column_name_true_conf=true_conf.get_name(),\n conf_estimators=conf_estimators_list,\n column_names_conf_estimators=[\n col.get_name()\n for col in conf_estimators_list\n ],\n column_names_logistics=column_names_logistics\n )\n",
"_____no_output_____"
],
[
"def get_df_rulewise_squared_diffs_between_true_conf_and_conf_estimator(\n df_rule_wrappers: pd.DataFrame,\n column_names_info: ColumnNamesInfo\n) -> pd.DataFrame:\n df_rulewise_diffs_between_true_conf_and_conf_estimator: pd.DataFrame = df_rule_wrappers[\n column_names_info.column_names_logistics\n ]\n\n col_name_estimator: str\n for col_name_estimator in column_names_info.column_names_conf_estimators:\n df_rulewise_diffs_between_true_conf_and_conf_estimator \\\n = df_rulewise_diffs_between_true_conf_and_conf_estimator.assign(\n **{\n col_name_estimator: (\n (df_rule_wrappers[column_names_info.column_name_true_conf]\n - df_rule_wrappers[col_name_estimator]) ** 2\n )\n }\n )\n return df_rulewise_diffs_between_true_conf_and_conf_estimator\n\ndf_conf_squared_errors: pd.DataFrame = get_df_rulewise_squared_diffs_between_true_conf_and_conf_estimator(\n df_rule_wrappers=df_rule_wrappers_all_targets,\n column_names_info = column_names_info\n)\ndf_conf_squared_errors.head()\n\n",
"_____no_output_____"
]
],
[
[
"## AVERAGE the PCA(S) and PCA(O)",
"_____no_output_____"
]
],
[
[
"df_conf_squared_errors[\"PCA\"] = (\n (\n df_conf_squared_errors[ConfidenceEnum.PCA_CONF_S_TO_O.value]\n +\n df_conf_squared_errors[ConfidenceEnum.PCA_CONF_O_TO_S.value]\n ) / 2\n)\ndf_conf_squared_errors.head()",
"_____no_output_____"
],
[
"df_conf_squared_errors = df_conf_squared_errors.drop(\n columns=[\n ConfidenceEnum.PCA_CONF_S_TO_O.value\n +\n ConfidenceEnum.PCA_CONF_O_TO_S.value\n ],\n axis=1,\n errors='ignore'\n )\ndf_conf_squared_errors.head()",
"_____no_output_____"
]
],
[
[
"# Now start averaging",
"_____no_output_____"
]
],
[
[
"df_conf_squared_errors_avg_over_trials: pd.DataFrame = df_conf_squared_errors.groupby(\n by=[\"target_relation\", \"filter_relation\", 'true_other', \"noisy_other\", \"Rule\"],\n sort=True,\n as_index=False\n).mean()\n\ndf_conf_squared_errors_avg_over_trials.head()",
"_____no_output_____"
],
[
"df_conf_squared_errors_avg_over_trials_and_rules: pd.DataFrame = df_conf_squared_errors_avg_over_trials.groupby(\n by=[\"target_relation\", \"filter_relation\", 'true_other', \"noisy_other\",],\n sort=True,\n as_index=False\n).mean()\ndf_conf_squared_errors_avg_over_trials_and_rules.head()",
"_____no_output_____"
],
[
"len(df_conf_squared_errors_avg_over_trials_and_rules)",
"_____no_output_____"
]
],
[
[
"### How many $p$, $q$ combinations are there?",
"_____no_output_____"
]
],
[
[
"\ndf_p_and_q = df_conf_squared_errors_avg_over_trials_and_rules[[\"target_relation\", \"filter_relation\"]].drop_duplicates()\ndf_p_and_q.head()",
"_____no_output_____"
],
[
"len(df_p_and_q)",
"_____no_output_____"
],
[
"df_conf_errors_avg_over_trials_and_rules_and_q: pd.DataFrame = df_conf_squared_errors_avg_over_trials_and_rules.groupby(\n by=[\"target_relation\", 'true_other', \"noisy_other\",],\n sort=True,\n as_index=False\n).mean()\ndf_conf_errors_avg_over_trials_and_rules_and_q.head()\n",
"_____no_output_____"
],
[
"len(df_conf_errors_avg_over_trials_and_rules_and_q)\n",
"_____no_output_____"
]
],
[
[
"## Subset of noisy_other",
"_____no_output_____"
]
],
[
[
"first_true_label_freq_to_include = 0.3\nsecond_true_label_freq_to_include = 0.7\n\n\ntrue_label_frequencies_set: Set[float] = {\n first_true_label_freq_to_include, second_true_label_freq_to_include,\n}\ntrue_label_frequency_to_estimate_map: Dict[float, Set[float]] = dict()\n\nlabel_frequency_est_diff: float = 0.1\nlabel_frequencies_to_keep: Set[float] = set(true_label_frequencies_set)\nfor true_label_freq in true_label_frequencies_set:\n true_label_frequency_to_estimate_map[true_label_freq] = {\n round(true_label_freq - label_frequency_est_diff, 1),\n round(true_label_freq + label_frequency_est_diff, 1)\n }\n label_frequencies_to_keep.update(true_label_frequency_to_estimate_map[true_label_freq])",
"_____no_output_____"
],
[
"df_conf_errors_avg_over_trials_and_rules_and_q_c_subset = df_conf_errors_avg_over_trials_and_rules_and_q[\n df_conf_errors_avg_over_trials_and_rules_and_q[\"noisy_other\"].isin(label_frequencies_to_keep)\n]\ndf_conf_errors_avg_over_trials_and_rules_and_q_c_subset.head()",
"_____no_output_____"
],
[
"len(df_conf_errors_avg_over_trials_and_rules_and_q_c_subset)",
"_____no_output_____"
]
],
[
[
"## Count the rules per $p$",
"_____no_output_____"
]
],
[
[
"df_n_rules_per_target = df_rule_wrappers_all_targets[[\"target_relation\", \"Rule\"]].groupby(\n by=['target_relation'],\n # sort=True,\n # as_index=False\n)[\"Rule\"].nunique().to_frame().reset_index().rename(\n columns={\"Rule\" : \"# rules\"}\n)\n\n\ndf_n_rules_per_target.head()",
"_____no_output_____"
]
],
[
[
"****\n# Format pretty table\n\nGoal:\n* put smallest value per row in BOLT\n* per target: mean_value 0.3 / 0.4",
"_____no_output_____"
]
],
[
[
"true_label_freq_to_noisy_to_df_map: Dict[float, Dict[float, pd.DataFrame]] = dict()\nfor true_label_freq in true_label_frequencies_set:\n df_true_tmp: pd.DataFrame = df_conf_errors_avg_over_trials_and_rules_and_q_c_subset[\n df_conf_errors_avg_over_trials_and_rules_and_q_c_subset[\"true_other\"] == true_label_freq\n ]\n noisy_label_freq_to_df_map = dict()\n true_label_freq_to_noisy_to_df_map[true_label_freq] = noisy_label_freq_to_df_map\n\n df_true_and_noisy_tmp = df_true_tmp[\n df_true_tmp[\"noisy_other\"] == true_label_freq\n ]\n noisy_label_freq_to_df_map[true_label_freq] = df_true_and_noisy_tmp[\n [col for col in df_true_and_noisy_tmp.columns if col != \"noisy_other\" and col != \"true_other\"]\n ]\n\n for noisy_label_freq in true_label_frequency_to_estimate_map[true_label_freq]:\n df_true_and_noisy_tmp = df_true_tmp[\n df_true_tmp[\"noisy_other\"] == noisy_label_freq\n ]\n noisy_label_freq_to_df_map[noisy_label_freq] = df_true_and_noisy_tmp[\n [col for col in df_true_and_noisy_tmp.columns if col != \"noisy_other\" and col != \"true_other\"]\n ]\n\ntrue_label_freq_to_noisy_to_df_map[first_true_label_freq_to_include][0.2].head()",
"_____no_output_____"
],
[
"from typing import Iterator\n\ntrue_label_freq_to_df_map = dict()\n\nlabel_freq_estimators: Iterator[float]\nfor true_label_freq in true_label_frequencies_set:\n noisy_to_df_map: Dict[float, pd.DataFrame] = true_label_freq_to_noisy_to_df_map[true_label_freq]\n\n df_true_label_freq: pd.DataFrame = noisy_to_df_map[true_label_freq]\n\n lower_est: float = round(true_label_freq - label_frequency_est_diff, 1)\n higher_est: float = round(true_label_freq + label_frequency_est_diff, 1)\n\n\n df_lower: pd.DataFrame = noisy_to_df_map[lower_est][\n ['target_relation', ConfidenceEnum.IPW_CONF.value]\n ].rename(\n columns={\n ConfidenceEnum.IPW_CONF.value: f\"{ConfidenceEnum.IPW_CONF.value}_lower\"\n }\n )\n\n df_true_label_freq = pd.merge(\n left=df_true_label_freq,\n right=df_lower,\n on=\"target_relation\"\n )\n\n df_higher = noisy_to_df_map[higher_est][\n ['target_relation', ConfidenceEnum.IPW_CONF.value]\n ].rename(\n columns={\n ConfidenceEnum.IPW_CONF.value: f\"{ConfidenceEnum.IPW_CONF.value}_higher\"\n }\n )\n df_true_label_freq = pd.merge(\n left=df_true_label_freq,\n right=df_higher,\n on=\"target_relation\"\n )\n true_label_freq_to_df_map[true_label_freq] = df_true_label_freq\n\ntrue_label_freq_to_df_map[0.3].head()",
"_____no_output_____"
],
[
"for key, df in true_label_freq_to_df_map.items():\n true_label_freq_to_df_map[key] = df.drop(\n columns=[\"random_trial_index\"],\n axis=1,\n errors='ignore'\n )\n",
"_____no_output_____"
],
[
"df_one_row_per_target = pd.merge(\n left=true_label_freq_to_df_map[first_true_label_freq_to_include],\n right=true_label_freq_to_df_map[second_true_label_freq_to_include],\n on=\"target_relation\",\n suffixes=(f\"_{first_true_label_freq_to_include}\", f\"_{second_true_label_freq_to_include}\")\n)\ndf_one_row_per_target.head()",
"_____no_output_____"
]
],
[
[
"## What is the smallest value?",
"_____no_output_____"
]
],
[
[
"all_values: np.ndarray = df_one_row_per_target[\n [ col\n for col in df_one_row_per_target.columns\n if col != \"target_relation\"\n ]\n].values\n\nmin_val = np.amin(all_values)\nmin_val",
"_____no_output_____"
],
[
"min_val * 10000",
"_____no_output_____"
],
[
"max_val = np.amax(all_values)\nmax_val",
"_____no_output_____"
],
[
"max_val * 10000",
"_____no_output_____"
],
[
"df_one_row_per_target.head() * 10000",
"_____no_output_____"
],
[
"df_one_row_per_target.dtypes",
"_____no_output_____"
],
[
"exponent = 4\n\nmultiplication_factor = 10 ** exponent\nmultiplication_factor",
"_____no_output_____"
],
[
"df_one_row_per_target[\n df_one_row_per_target.select_dtypes(include=['number']).columns\n] *= multiplication_factor\n\ndf_one_row_per_target",
"_____no_output_____"
],
[
"df_one_row_per_target.head()",
"_____no_output_____"
]
],
[
[
"## Output files definitions",
"_____no_output_____"
]
],
[
[
"dir_latex_table: str = os.path.join(\n kbc_e_metrics_project_dir,\n \"paper_latex_tables\",\n 'known_prop_scores',\n 'sar_two_groups'\n)\n\nif not os.path.exists(dir_latex_table):\n os.makedirs(dir_latex_table)\n\nfilename_tsv_rule_stats = os.path.join(\n dir_latex_table,\n \"conf_error_stats_v3.tsv\"\n)\n\nfilename_tsv_single_row_summary = os.path.join(\n dir_latex_table,\n \"noisy_sar_two_groups_single_row_summary.tsv\"\n)\n",
"_____no_output_____"
]
],
[
[
"## Create single-row summary",
"_____no_output_____"
]
],
[
[
"df_one_row_in_total: pd.Series = df_one_row_per_target.mean(\n)\n\n\ndf_one_row_in_total",
"/tmp/ipykernel_56394/1788372146.py:1: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.\n df_one_row_in_total: pd.Series = df_one_row_per_target.mean(\n"
],
[
"df_n_rules_per_target.head()",
"_____no_output_____"
],
[
"df_one_row_in_total[\"# rules\"] = int(df_n_rules_per_target[\"# rules\"].sum())\ndf_one_row_in_total",
"_____no_output_____"
],
[
"type(df_one_row_in_total)",
"_____no_output_____"
],
[
"df_one_row_in_total.to_csv(\n filename_tsv_single_row_summary,\n sep = \"\\t\",\n header=None\n)\n",
"_____no_output_____"
]
],
[
[
"### Now create a pretty table",
"_____no_output_____"
]
],
[
[
"column_names_info.column_names_conf_estimators",
"_____no_output_____"
],
[
"simplified_column_names_conf_estimators = ['CWA', 'PCA', 'ICW', 'IPW',]",
"_____no_output_____"
],
[
"multi_index_columns = [\n (\"$p$\", \"\"),\n (\"\\# rules\", \"\")\n]\nfrom itertools import product\n\n# conf_upper_cols = column_names_info.column_names_conf_estimators + [\n# f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($\\Delta c=-\" + f\"{label_frequency_est_diff}\" + \"$)\",\n# f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($\\Delta c=\" + f\"{label_frequency_est_diff}\" + \"$)\",\n# ]\nconf_upper_cols = simplified_column_names_conf_estimators + [\n f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($-\\Delta$)\",\n f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($+\\Delta$)\",\n]\n\nc_subcols = [\"$c_{\\\\neg q}=0.3$\", \"$c_{\\\\neg q}=0.7$\"]\n\nmulti_index_columns = multi_index_columns + list(product(c_subcols, conf_upper_cols))\n# multi_index_list\n\nmulti_index_columns = pd.MultiIndex.from_tuples(multi_index_columns)\nmulti_index_columns",
"_____no_output_____"
],
[
"\nrule_counter: int = 1\nrule_str_to_rule_id_map: Dict[str, int] = {}\n\n\nfloat_precision: int = 1\n\ncol_name_conf_estimator: str\n\n\npretty_rows: List[List] = []\n\nrow_index: int\nrow: pd.Series\n\n# columns_to_use = [\n# \"$p$\",\n# \"\\# rules\"\n# ] + column_names_info.column_names_conf_estimators + [\n# f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($\\Delta c=-\" + f\"{label_frequency_est_diff}\" + \"$)\",\n# f\"{ConfidenceEnum.IPW_CONF.value} \" + \"($\\Delta c=\" + f\"{label_frequency_est_diff}\" + \"$)\",\n# ]\nLabelFreq = float\ndef get_dict_with_smallest_estimator_per_label_freq(row: pd.Series) -> Dict[LabelFreq, Set[str]]:\n # Find estimator with smallest mean value for label frequency###################\n label_freq_to_set_of_smallest_est_map: Dict[LabelFreq, Set[str]] = dict()\n for label_freq in [first_true_label_freq_to_include, second_true_label_freq_to_include]:\n o_set_of_col_names_with_min_value: Optional[Set[str]] = None\n o_current_smallest_value: Optional[float] = None\n # Find smallest squared error\n for col_name_conf_estimator in simplified_column_names_conf_estimators:\n current_val: float = row[f\"{col_name_conf_estimator}_{label_freq}\"]\n # print(current_val)\n if o_set_of_col_names_with_min_value is None or o_current_smallest_value > current_val:\n o_set_of_col_names_with_min_value = {col_name_conf_estimator}\n o_current_smallest_value = current_val\n elif current_val == o_current_smallest_value:\n o_set_of_col_names_with_min_value.update(col_name_conf_estimator)\n\n label_freq_to_set_of_smallest_est_map[label_freq] = o_set_of_col_names_with_min_value\n return label_freq_to_set_of_smallest_est_map\n\n\ndef format_value_depending_on_whether_it_is_smallest(\n value: float,\n is_smallest: bool,\n float_precision: float,\n use_si: bool = False\n)-> str:\n if is_smallest:\n if not use_si:\n formatted_value = \"$\\\\bm{\" + f\"{value:0.{float_precision}f}\" + \"}$\"\n # formatted_value = \"$\\\\bm{\" + f\"{value:0.{float_precision}e}\" + \"}$\"\n else:\n formatted_value = \"\\\\textbf{$\" + f\"\\\\num[round-precision={float_precision},round-mode=figures,scientific-notation=true]\"+\\\n \"{\"+ str(value) + \"}\"+ \"$}\"\n else:\n if not use_si:\n formatted_value = f\"${value:0.{float_precision}f}$\"\n # formatted_value = f\"${value:0.{float_precision}e}$\"\n else:\n formatted_value = \"$\" + f\"\\\\num[round-precision={float_precision},round-mode=figures,scientific-notation=true]\"+\\\n \"{\"+ str(value) + \"}\"+ \"$\"\n\n return formatted_value\n\n\nestimator_columns = simplified_column_names_conf_estimators + [\n f\"{ConfidenceEnum.IPW_CONF.value}_lower\",\n f\"{ConfidenceEnum.IPW_CONF.value}_higher\"\n]\n\n# For each row, i.e. for each target relation\nfor row_index, row in df_one_row_per_target.iterrows():\n\n # Find estimator with smallest mean value for label frequency###################\n label_freq_to_set_of_smallest_est_map: Dict[float, Set[str]] = get_dict_with_smallest_estimator_per_label_freq(\n row=row\n )\n ##################################################################################\n # Construct the new row\n ######################\n\n target_relation = row[\"target_relation\"]\n\n\n nb_of_rules = df_n_rules_per_target[df_n_rules_per_target['target_relation'] == target_relation][\n \"# rules\"\n ].iloc[0]\n\n new_row: List[str] = [\n target_relation,\n nb_of_rules\n ]\n # For each Confidence estimator, get the value at c 0.3 and 0.7\n # for col_name_conf_estimator in estimator_columns:\n # mean_val_03:float = row[f\"{col_name_conf_estimator}_0.3\"]\n # mean_val_07:float = row[f\"{col_name_conf_estimator}_0.7\"]\n #\n # new_row_value = (\n # format_value_depending_on_whether_it_is_smallest(\n # value=mean_val_03,\n # is_smallest=col_name_conf_estimator == label_freq_to_smallest_est_map[0.3],\n # float_precision=float_precision\n # )\n # + \" / \"\n # + format_value_depending_on_whether_it_is_smallest(\n # value=mean_val_07,\n # is_smallest=col_name_conf_estimator == label_freq_to_smallest_est_map[0.7],\n # float_precision=float_precision\n # )\n # )\n # new_row.append(new_row_value)\n for col_name_conf_estimator in estimator_columns:\n mean_val_03:float = row[f\"{col_name_conf_estimator}_{first_true_label_freq_to_include}\"]\n\n\n\n new_row_value_03 = format_value_depending_on_whether_it_is_smallest(\n value=mean_val_03,\n is_smallest=(\n col_name_conf_estimator in label_freq_to_set_of_smallest_est_map[first_true_label_freq_to_include]\n ),\n float_precision=float_precision\n )\n new_row.append(new_row_value_03)\n\n\n for col_name_conf_estimator in estimator_columns:\n mean_val_07:float = row[f\"{col_name_conf_estimator}_{second_true_label_freq_to_include}\"]\n new_row_value_07 = format_value_depending_on_whether_it_is_smallest(\n value=mean_val_07,\n is_smallest=(\n col_name_conf_estimator in label_freq_to_set_of_smallest_est_map[second_true_label_freq_to_include]\n ),\n float_precision=float_precision\n\n )\n new_row.append(new_row_value_07)\n\n pretty_rows.append(new_row)\n\n\ndf_pretty: pd.DataFrame = pd.DataFrame(\n data=pretty_rows,\n columns=multi_index_columns\n)\ndf_pretty.head()",
"_____no_output_____"
],
[
"df_pretty: pd.DataFrame = df_pretty.sort_values(\n by=[\"$p$\"]\n)\n\ndf_pretty.head()\n\n",
"_____no_output_____"
]
],
[
[
"# To file",
"_____no_output_____"
]
],
[
[
"# dir_latex_table: str = os.path.join(\n# kbc_e_metrics_project_dir,\n# \"paper_latex_tables\",\n# 'known_prop_scores',\n# 'scar'\n# )\n#\n# if not os.path.exists(dir_latex_table):\n# os.makedirs(dir_latex_table)\n\nfilename_latex_table: str = os.path.join(\n dir_latex_table,\n \"confidence-error-table-sar-two-subject-groups-agg-per-p.tex\"\n)\nfilename_tsv_table: str = os.path.join(\n dir_latex_table,\n \"confidence-error-table-sar-two-subject-groups-agg-per-p.tsv\"\n)\n\n\nwith open(filename_latex_table, \"w\") as latex_ofile:\n with pd.option_context(\"max_colwidth\", 1000):\n latex_ofile.write(\n df_pretty.to_latex(\n column_format=\"lr|lllllll|lllllll\",\n index=False,\n float_format=\"{:0.3f}\".format,\n escape=False,\n # caption=\"$[widehat{conf}-conf]^2$ for SCAR. \"\n # \"std=standard confidence, \"\n # \"PCA (S) = PCA confidence with $s$ as domain, \"\n # \"PCA (O) = PCA confidence with $o$ as domain, \"\n # \"IPW = PCA confidence with $\\hat{e}=e$, \"\n # \"IPW +/- $\" + f\"{label_frequency_est_diff:0.1}\" + \"$ = IPW confidence with $\\hat{e}=e+/-\" + f\"{label_frequency_est_diff:0.1}\" + \"$.\"\n )\n )\n\nwith open(filename_tsv_table, \"w\") as tsv_ofile:\n tsv_ofile.write(df_pretty.to_csv(\n index=False,\n sep=\"\\t\"\n ))\n\nprint(filename_latex_table)\n",
"/home/joschout/Documents/Repos/KUL-PUL/paper_latex_tables/known_prop_scores/sar_two_groups/confidence-error-table-sar-two-subject-groups-agg-per-p.tex\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a28aa83eac3574d46fec23b13cf753025ccc088
| 4,022 |
ipynb
|
Jupyter Notebook
|
Allinone py/Magic _method.ipynb
|
whoafridi/Python
|
4fea6f81ebfd94730b36b4d95669adcadacae5df
|
[
"MIT"
] | null | null | null |
Allinone py/Magic _method.ipynb
|
whoafridi/Python
|
4fea6f81ebfd94730b36b4d95669adcadacae5df
|
[
"MIT"
] | null | null | null |
Allinone py/Magic _method.ipynb
|
whoafridi/Python
|
4fea6f81ebfd94730b36b4d95669adcadacae5df
|
[
"MIT"
] | 1 |
2019-07-09T06:34:29.000Z
|
2019-07-09T06:34:29.000Z
| 15.06367 | 58 | 0.41273 |
[
[
[
" # Magic Method !",
"_____no_output_____"
]
],
[
[
"# Here we see some magical things ! \n__init__(self, [])\n__eq__(self , other) & many more ",
"_____no_output_____"
],
[
" __eq__(self, other) is mean == operator !",
"_____no_output_____"
],
[
"a = 5\nb = 9\ni = a.__eq__(b)\nprint(i)",
"False\n"
]
],
[
[
"* look a is not equal to be tht's why return false !",
"_____no_output_____"
]
],
[
[
"a = 5\nb = 9\ni = a.__ne__(b)\nprint(i)",
"True\n"
]
],
[
[
"Here , __ne__ means not equal ",
"_____no_output_____"
]
],
[
[
"a = 5\nb = 9\ni = a.__lt__(b)\nprint(i)",
"True\n"
],
[
"i = a.__gt__(b)\nprint(i)",
"False\n"
],
[
"i = a.__le__(b)\nprint(i)",
"True\n"
],
[
"i = a.__ge__(b)\nprint(i)",
"False\n"
],
[
"i = a.__add__(b)\nprint(i)",
"14\n"
],
[
"i = a.__sub__(b)\nprint(i)",
"-4\n"
],
[
"i = a.__mul__(b)\nprint(i)",
"45\n"
],
[
"i = a.__pow__(b)\nprint(i)",
"1953125\n"
],
[
"a = 'Bangladesh'\ni = a.__len__()\nprint(i)",
"10\n"
]
],
[
[
"# Happy MAgic__method()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"raw",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"raw"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a28adcd6e91cd1668202498c18eef429b949f16
| 8,360 |
ipynb
|
Jupyter Notebook
|
Auto_quer.ipynb
|
naolnegassa/Auto_Classify
|
66c8b3fb760519c4a5dc2a68de6bf3bc22935702
|
[
"MIT"
] | null | null | null |
Auto_quer.ipynb
|
naolnegassa/Auto_Classify
|
66c8b3fb760519c4a5dc2a68de6bf3bc22935702
|
[
"MIT"
] | null | null | null |
Auto_quer.ipynb
|
naolnegassa/Auto_Classify
|
66c8b3fb760519c4a5dc2a68de6bf3bc22935702
|
[
"MIT"
] | null | null | null | 28.148148 | 136 | 0.452871 |
[
[
[
"!pip install google_images_download\n#Imports\nimport tensorflow as tf\nimport keras\nfrom google.colab import drive\nimport os\nfrom fastai.vision import *\nfrom fastai.metrics import error_rate\nimport re\nfrom google_images_download import google_images_download",
"_____no_output_____"
],
[
"# Start off with Mounting Drive Locally\ndrive.mount('/content/drive/')",
"_____no_output_____"
],
[
"!ls \"/content/drive/My Drive/Auto_Query\"",
"_____no_output_____"
],
[
"#change the working directory to the Drive folder\nos.chdir(\"/content/drive/My Drive/Auto_Query\")\n#Initiliazation.py\n%reload_ext autoreload\n%autoreload 2\n%matplotlib inline\n\nbs = 64 #batch size\nsz = 224 #image size wanted\nPATH = \"/content/drive/My Drive/Auto_Query/downloads\"",
"_____no_output_____"
],
[
"response = google_images_download.googleimagesdownload()\n# TODO: Take in all queries at once, then split into\n# individual queries\nrequest_one = input('What would you like first?')\nrequest_two = input('And then?')\nname_one = str(request_one)\nname_two = str(request_two)\n#Test\nprint('first request: ' +request_one)\nprint('second request: '+request_two)\n\nsearch_queries = [request_one, request_two]\nprint(search_queries)\n\ndef downloadimages(query): \n arguments = {\"keywords\":query,\n \"format\": \"jpg\",\n# \"limit\": 250,\n \"print_urls\": True,\n \"size\": \"medium\"}\n try:\n response.download(arguments)\n \n except FileNotFoundError: \n arguments = {\"keywords\": query, \n \"format\": \"jpg\", \n# \"limit\":4, \n \"print_urls\":True, \n \"size\": \"medium\", \n \"usage_rights\":\"labeled-for-reuse\"} \n \n try: \n # Downloading the photos based \n # on the given arguments \n response.download(arguments) \n except: \n pass\n \nfor query in search_queries:\n downloadimages(query)\n print()\n\n",
"_____no_output_____"
],
[
"#get_classes.py\n\nclasses = []\nfor d in os.listdir(PATH):\n if os.path.isdir(os.path.join(PATH, d)) and not d.startswith('.'):\n classes.append(d) \nprint (\"There are \", len(classes), \"classes:\\n\", classes) ",
"_____no_output_____"
],
[
"#verify_images.py\n\nfor c in classes:\n print (\"Class:\", c)\n verify_images(os.path.join(PATH, c), delete=True);",
"_____no_output_____"
],
[
"#create_training_validation.py\ndata = ImageDataBunch.from_folder(PATH, ds_tfms=get_transforms(), size=sz, bs=bs, valid_pct=0.2).normalize(imagenet_stats)\nprint (\"There are\", len(data.train_ds), \"training images and\", len(data.valid_ds), \"validation images.\" )",
"_____no_output_____"
],
[
"#show data\ndata.show_batch(rows = 3, figsize=(7,8))",
"_____no_output_____"
],
[
"#If the user wants to build their own model\n# import tensorflow as tf\n# import keras\ncustom_query = input('Would you like to build your own model?')\n\nif custom_query.lower() == 'yes':\n print('true')\n#TODO: request model specifications and use keras to build it out\n ",
"_____no_output_____"
],
[
"#model\nlearn = cnn_learner(data, models.resnet34, metrics=accuracy)\nlearn.lr_find();\nlearn.recorder.plot()",
"_____no_output_____"
],
[
"#fit\n#adjust to ideal learning rate manually for now\nlearn.fit_one_cycle(7, max_lr=slice(1e-3,1e-2))",
"_____no_output_____"
],
[
"#interpretation\ninterpretation = ClassificationInterpretation.from_learner(learn)\ninterpretation.plot_confusion_matrix(figsize=(12,12), dpi=60)\ninterpretation.plot_top_losses(9, figsize=(15,11), heatmap=False)",
"_____no_output_____"
],
[
"# test model with a new image\n# TODO: either set up a new image scrape and make sure the image is new, \n# or connect to a webcam on local machine\n\n# path = './'\n# img = open_image(get_image_files(path)[0])\n# pred_class,pred_idx,outputs = learn.predict(img)\n# img.show()\n# print (\"It is a\", pred_class)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a28b9d37620b955e0697a5b9f52859ace567dec
| 25,284 |
ipynb
|
Jupyter Notebook
|
Northland_Geologic_Map.ipynb
|
edur409/Northland
|
c0063dd90f2b2b0a557c6b1aa3afa94da8d17d08
|
[
"MIT"
] | null | null | null |
Northland_Geologic_Map.ipynb
|
edur409/Northland
|
c0063dd90f2b2b0a557c6b1aa3afa94da8d17d08
|
[
"MIT"
] | null | null | null |
Northland_Geologic_Map.ipynb
|
edur409/Northland
|
c0063dd90f2b2b0a557c6b1aa3afa94da8d17d08
|
[
"MIT"
] | null | null | null | 35.661495 | 360 | 0.543822 |
[
[
[
"from IPython.display import HTML\n\nHTML('''<script>\ncode_show=true; \nfunction code_toggle() {\n if (code_show){\n $('div.input').hide();\n } else {\n $('div.input').show();\n }\n code_show = !code_show\n} \n$( document ).ready(code_toggle);\n</script>\nThe raw code for this IPython notebook is by default hidden for easier reading.\nTo toggle on/off the raw code, click <a href=\"javascript:code_toggle()\">here</a>.''')",
"_____no_output_____"
]
],
[
[
"# Northland Geology and Roads\n\nThis Jupyter Notebook is intended to help you visualize the anomalies of interest against the Geologic Map and the Topographic Map with roads. It is also a good example on how to retrieve information from [Macrostrat.org](https://macrostrat.org/map/#/z=9.0/x=174.1666/y=-35.5429/bedrock/lines/) for New Zealand. All maps are in projection EPGS:3857.\n\n## SplitMap with ImageOverlay\n\nThis example shows how to use the [Leaflet SplitMap](https://github.com/QuantStack/leaflet-splitmap) slider with ipyleaflet. A raster is added as an image overlay. The opacity of the raster can be changed before running the cells of the notebook. \n\nDetails of units in the geologic map can be found here [Macrostrat.org](https://macrostrat.org/map/#/z=9.0/x=174.1666/y=-35.5429/bedrock/lines/). Macrostrat data can be browsed through the [Rockd.org](https://rockd.org/) mobile app, which is a good resource for geologists and geoscientists alike. \n\n## Check the metadata on the geologic unit\n\nTo check the metadata of a particular unit, click on it and press the \"Check Formation!\" button.\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport io\nimport os\nimport requests\nfrom IPython.display import display,clear_output\nimport ipywidgets as widgets\nfrom ipywidgets import Label,Dropdown,jslink\nfrom ipyleaflet import (\n Map, TileLayer, SplitMapControl, ScaleControl,FullScreenControl,ImageOverlay,LayersControl,WidgetControl,Marker,\n DrawControl,MeasureControl\n)",
"_____no_output_____"
],
[
"center = [-35.611896, 174.185050] #-34.8252978589571, 173.54580993652344\nzoom = 10\nopacity=0.8",
"_____no_output_____"
],
[
"m = Map(center=center, zoom=zoom)\n\nleft = TileLayer(url='https://tiles.macrostrat.org/carto/{z}/{x}/{y}.png')\nright = TileLayer(url='https://{s}.tile.opentopomap.org/{z}/{x}/{y}.png')\n\n#Image Overlay for a grid\n#image = ImageOverlay(\n# url='RTP.png',\n# # url='../06Q1fSz.png',\n# bounds=((-35.611896, 174.185050), (-35.411021, 174.380248)),\n# opacity=opacity\n#)\n\nimage = ImageOverlay(\n url='Northland_TMI_RTP_reprojected.png',\n bounds=((-36.4081355,172.6260946), (-34.3687166,174.6581728)),\n opacity=opacity,\n name='RTP'\n)\n\nimage2 = ImageOverlay(\n url='Ternary_reprojected.png',\n bounds=((-36.4422,172.5928), (-34.34,174.7874)),\n opacity=opacity,\n name='Ternary Map'\n)\n\nimage3 = ImageOverlay(\n url='Northland_CB_2.png',\n bounds=((-37.0078735, 171.9919065), (-34.0078135, 174.9919665)),\n opacity=opacity,\n name='Bouguer'\n)\n\n#Add the layer\nm.add_layer(image)\nm.add_layer(image2)\nm.add_layer(image3)\n\ncontrol = LayersControl(position='topright')\nm.add_control(control)\nm\n\n#Split the map\ncontrol = SplitMapControl(left_layer=left, right_layer=right)\nm.add_control(control)\nm.add_control(ScaleControl(position='bottomleft',max_width=200))\nm.add_control(FullScreenControl())\n#m\n\n#Display coordinates on click\ndef handle_interaction(**kwargs):\n if kwargs.get('type') == 'mousedown': #'mousemove' will update coordinates with every position\n label.value = str(kwargs.get('coordinates'))\n \nlabel = Label()\ndisplay(label)\nm.on_interaction(handle_interaction)\n\n#Button to check the formation on the geographic location selected\nbutton = widgets.Button(description=\"Check Formation!\")\noutput = widgets.Output()\n\ndisplay(button, output)\n\ndef on_button_clicked(b):\n with output:\n if label.value=='':\n clear_output(wait=True)\n print('Click on a geologic formation on the map and click to get the info')\n else:\n #Get the infor from the API\n clear_output(wait=True)\n lat = label.value.strip('][').split(', ')[0] #Break the label into usable strings\n lon = label.value.strip('][').split(', ')[1] #Break the label into usable strings\n url='https://macrostrat.org/api/v2/geologic_units/map?lat='+lat+'&lng='+lon+'&scale=large&response=short&format=csv'\n s=requests.get(url).content\n c=pd.read_csv(io.StringIO(s.decode('utf-8')))\n #Make it into a Pandas DataFrame\n df=pd.DataFrame(c)\n display(df)\n\nbutton.on_click(on_button_clicked)\n\n#Show the maps \nm",
"_____no_output_____"
]
],
[
[
"# Retrieve more information from the API on Geological Units\n\nWe can request the geojson file for a geologic unit given the geographic coordinates. The url should be formatted as in the example code below.",
"_____no_output_____"
]
],
[
[
"from ipyleaflet import Map, ImageOverlay,GeoJSON\nm = Map(center=(-35.611896, 174.185050), zoom=7)\n\n#Request info from the API \nif label.value=='':\n print('Click on a geologic formation on the map above and run this cell to get the info and polygon')\nelse:\n lat = label.value.strip('][').split(', ')[0] #Break the label into usable strings\n lon = label.value.strip('][').split(', ')[1] #Break the label into usable strings\n #Request the geojson file from the API \n import urllib.request, json \n with urllib.request.urlopen('https://macrostrat.org/api/v2/geologic_units/map?lat='+lat+'&lng='+lon+'&response=short&scale=large&format=geojson_bare') as url:\n data = json.loads(url.read().decode())\n #Get the infor from the API\n url='https://macrostrat.org/api/v2/geologic_units/map?lat='+lat+'&lng='+lon+'&scale=large&response=short&format=csv'\n s=requests.get(url).content\n c=pd.read_csv(io.StringIO(s.decode('utf-8')))\n #Make it into a Pandas DataFrame\n df=pd.DataFrame(c)\n display(df)\n\n geo_json = GeoJSON(\n data=data,\n style={'color': 'red','opacity': 1,'fillOpacity': 0.7} #If Color from the API change 'color' to df.color[0]\n )\n m.add_layer(geo_json)\n#Add draw control\ndraw_control = DrawControl()\ndraw_control.polyline = {\n \"shapeOptions\": {\n \"color\": \"#6bc2e5\",\n \"weight\": 8,\n \"opacity\": 1.0\n }\n}\ndraw_control.polygon = {\n \"shapeOptions\": {\n \"fillColor\": \"#6be5c3\",\n \"color\": \"#6be5c3\",\n \"fillOpacity\": 1.0\n },\n \"drawError\": {\n \"color\": \"#dd253b\",\n \"message\": \"Oups!\"\n },\n \"allowIntersection\": False\n}\ndraw_control.circle = {\n \"shapeOptions\": {\n \"fillColor\": \"#efed69\",\n \"color\": \"#efed69\",\n \"fillOpacity\": 1.0\n }\n}\ndraw_control.rectangle = {\n \"shapeOptions\": {\n \"fillColor\": \"#fca45d\",\n \"color\": \"#fca45d\",\n \"fillOpacity\": 1.0\n }\n}\n\nm.add_control(draw_control)\n\n#Measure Control\nmeasure = MeasureControl(\n position='bottomleft',\n active_color = 'orange',\n primary_length_unit = 'kilometers'\n)\nm.add_control(measure)\n\nmeasure.completed_color = 'red'\n\nmeasure.add_length_unit('yards', 1.09361, 4)\nmeasure.secondary_length_unit = 'yards'\n\nmeasure.add_area_unit('sqyards', 1.19599, 4)\nmeasure.secondary_area_unit = 'sqyards'\n\nm",
"Click on a geologic formation on the map above and run this cell to get the info and polygon\n"
]
],
[
[
"# Northland EQs\n\nThe EQs of Northland displayed using the Circle marker and Popup tool of ipyleaflet. ",
"_____no_output_____"
]
],
[
[
"from ipywidgets import HTML\nfrom ipyleaflet import Circle,Popup\nimport numpy as np\nimport matplotlib.pyplot as plt\n#Load the data for EQs\nlong,lati,depth,mag=np.loadtxt('EQs_Northland.dat',skiprows=1,unpack=True)\n\n#Create the map\nm2 = Map(center=(-35.611896, 174.185050), zoom=7)\n\ncircles = []\nfor i in range(0,len(long)):\n c = Circle(location=(lati[i],long[i]), radius=np.int(10*depth[i]),name=np.str(depth[i]))\n circles.append(c)\n m2.add_layer(c)\n \n#Display values with a popup\ndef handle_interaction2(**kwargs):\n if kwargs.get('type') == 'mousedown': #'mousemove' will update coordinates with every position\n label.value = str(kwargs.get('coordinates'))\n lt = float(label.value.strip('][').split(', ')[0]) #Break the label into usable strings\n lng = float(label.value.strip('][').split(', ')[1]) #Break the label into usable strings\n message=HTML()\n p=np.where((long==lng)&(lati==lt)) #Find the locations to extract the value\n if len(p[0])>1:\n message.value = np.str(depth[p].mean())+' km'+' <b>Mw:</b> '+np.str(mag[p].mean())\n elif len(p[0])==1:\n message.value = np.str(depth[p])+' km'+' <b>Mw:</b> '+np.str(mag[p])\n else:\n message.value = 'No data'\n # Popup with a given location on the map:\n popup = Popup(\n location=(lt,lng),\n child=message,\n close_button=False,\n auto_close=False,\n close_on_escape_key=False\n )\n m2.add_layer(popup)\n\nlabel2 = Label()\ndisplay(label2)\nm2.on_interaction(handle_interaction2)\nm2",
"_____no_output_____"
]
],
[
[
"# Epithermal vector data over Northland\n\nthe data available can be obtained from the [New Zealand Petroleum and Minerals](https://www.nzpam.govt.nz/) database (datapack MR4343). The shapefiles were reprojected into EPSG:4326 as GeoJSON files for visualization on ipyleaflet from NZMG (EPSG:27200) coordinates. \n\n## Toggle Controls for displaying layers\n\nA way of using radio buttons to display the layers.",
"_____no_output_____"
]
],
[
[
"from ipyleaflet import Map, ImageOverlay,GeoJSON,json\ncenter = (-35.5, 174.6) #or your desired coordinates\nm3 = Map(center=center, zoom=6)\n\nradio_button = widgets.RadioButtons(options=['Epithermal', 'Hydrothermal', 'Calderas', 'Vents', 'Veins', 'Faults',\n 'Gold Ocurrences','Basin Gold','Basin Silver','Basin Mercury'],\n value='Epithermal', \n description='Northland:')\ndef toggle_vector(map):\n #Toggle options \n if map == 'Epithermal': plot_vector('epiareas.geojson')\n if map == 'Hydrothermal': plot_vector('hydrothm.geojson')\n if map == 'Calderas': plot_vector('calderap.geojson')\n if map == 'Vents': plot_vector('vents.geojson') \n if map == 'Veins': plot_vector('veins.geojson')\n if map == 'Faults': plot_vector('faults.geojson')\n if map == 'Gold Ocurrences': plot_vector('au.geojson')\n if map == 'Basin Gold': plot_vector('ssbasinau.geojson'),plot_maps()\n if map == 'Basin Silver': plot_vector('ssbasinag.geojson'),plot_maps()\n if map == 'Basin Mercury': plot_vector('ssbasinhg.geojson'),plot_maps()\n display(m3)\n\ndef plot_vector(filename):\n m3.clear_layers()\n #Add the geojson file\n with open('./Vector_data_GeoJSON/'+filename+'','r') as f: #epiareas.geojson\n data = json.load(f)\n layer = GeoJSON(data=data, style = {'color': 'Blue', 'opacity':1, 'weight':1.9, 'dashArray':'9', 'fillOpacity':0.3})\n #Plotting depending on type of data \n typed=data['features'][0]['geometry']['type'] #Check type of data (Point or Polygon)\n if typed=='Point': #If Point use circles\n layer = GeoJSON(data=data,\n point_style={'radius': 1, 'color': 'blue', 'fillOpacity': 0.8, 'fillColor': 'blue', 'weight': 3})\n m3.add_layer(layer)\n else: #Plot polygon shape\n m3.add_layer(layer)\n \n#m\nwidgets.interact(toggle_vector, map=radio_button)#plot_vector('epiareas.geojson')\n\n#Split the map\ncontrol = SplitMapControl(left_layer=left, right_layer=right)\nm3.add_control(control)\nm3.add_control(ScaleControl(position='bottomleft',max_width=200))\nm3.add_control(FullScreenControl())",
"_____no_output_____"
]
],
[
[
"## Dropdown options with maps\n\nExample of combining the dropdown menu with some map overlays.",
"_____no_output_____"
]
],
[
[
"from ipyleaflet import Map, ImageOverlay,GeoJSON,json\nfrom ipywidgets import Label,Dropdown,jslink\nfrom ipywidgets import widgets as w\nfrom ipywidgets import Widget\n\ncenter = (-35.5, 174.6) #or your desired coordinates\nm4 = Map(center=center, zoom=6)\n\ndef plot_maps(): \n image = ImageOverlay(\n url='Northland_TMI_RTP_reprojected.png',\n bounds=((-36.4081355,172.6260946), (-34.3687166,174.6581728)),\n opacity=opacity,\n name='RTP',\n visible=True\n )\n\n image2 = ImageOverlay(\n url='Ternary_reprojected.png',\n bounds=((-36.4422,172.5928), (-34.34,174.7874)),\n opacity=opacity,\n name='Ternary Map',\n visible=True\n )\n\n image3 = ImageOverlay(\n url='Northland_CB_2.png',\n bounds=((-37.0078735, 171.9919065), (-34.0078135, 174.9919665)),\n opacity=opacity,\n name='Bouguer',\n visible=True\n )\n\n ##Add slider control\n #slider = w.FloatSlider(min=0, max=1, value=1, # Opacity is valid in [0,1] range\n # orientation='vertical', # Vertical slider is what we want\n # readout=False, # No need to show exact value = False\n # layout=w.Layout(width='2em')) # Fine tune display layout: make it thinner\n\n # Connect slider value to opacity property of the Image Layer\n #w.jslink((slider, 'value'),\n # (image, 'opacity') )\n #m4.add_control(WidgetControl(widget=slider)) \n \n #Add the layer\n m4.add_layer(image)\n m4.add_layer(image2)\n m4.add_layer(image3)\n return \n\ndropdown = widgets.Dropdown(options=['Epithermal', 'Hydrothermal', 'Calderas', 'Vents', 'Veins', 'Faults',\n 'Gold Ocurrences','Basin Gold','Basin Silver','Basin Mercury'],\n value='Epithermal', \n description='Northland:')\n\ndef toggle_vector2(map):\n #Toggle options \n if map == 'Epithermal': plot_vector2('epiareas.geojson'),plot_maps()\n if map == 'Hydrothermal': plot_vector2('hydrothm.geojson'),plot_maps()\n if map == 'Calderas': plot_vector2('calderap.geojson'),plot_maps()\n if map == 'Vents': plot_vector2('vents.geojson'),plot_maps()\n if map == 'Veins': plot_vector2('veins.geojson'),plot_maps()\n if map == 'Faults': plot_vector2('faults.geojson'),plot_maps()\n if map == 'Gold Ocurrences': plot_vector2('au.geojson'),plot_maps()\n if map == 'Basin Gold': plot_vector2('ssbasinau.geojson'),plot_maps()\n if map == 'Basin Silver': plot_vector2('ssbasinag.geojson'),plot_maps()\n if map == 'Basin Mercury': plot_vector2('ssbasinhg.geojson'),plot_maps()\n display(m4)\n \ndef plot_vector2(filename):\n m4.clear_layers()\n #Add the geojson file\n with open('./Vector_data_GeoJSON/'+filename+'','r') as f: #epiareas.geojson\n data = json.load(f)\n layer = GeoJSON(data=data, style = {'color': 'Blue', 'opacity':1, 'weight':1.9, 'dashArray':'9', 'fillOpacity':0.3})\n #Plotting depending on type of data \n typed=data['features'][0]['geometry']['type'] #Check type of data (Point or Polygon)\n if typed=='Point': #If Point use circles\n layer = GeoJSON(data=data,\n point_style={'radius': 1, 'color': 'blue', 'fillOpacity': 0.8, 'fillColor': 'blue', 'weight': 3})\n m4.add_layer(layer)\n else: #Plot polygon shape\n m4.add_layer(layer)\n \n#m\nwidgets.interact(toggle_vector2, map=dropdown)#plot_vector('epiareas.geojson')\n\n#Split the map\nscontrol = SplitMapControl(left_layer=left, right_layer=right)\nm4.add_control(scontrol)\nm4.add_control(ScaleControl(position='bottomleft',max_width=200))\nm4.add_control(FullScreenControl())\n\n#Layers Control\ncontrol = LayersControl(position='topright')\nm4.add_control(control)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a28d491b7b7ff355d10c443d9a53f16a0f9d801
| 70,182 |
ipynb
|
Jupyter Notebook
|
filter.ipynb
|
Sean8322/mindUPCODE
|
204a0dc3d2bf822790a1e284f3ed20950299b034
|
[
"BSD-3-Clause",
"MIT"
] | 1 |
2020-04-26T03:01:46.000Z
|
2020-04-26T03:01:46.000Z
|
filter.ipynb
|
Sean8322/mindUP
|
82dfdc4aeff74fd97659457a10f9cbf8523e983c
|
[
"BSD-3-Clause",
"MIT"
] | null | null | null |
filter.ipynb
|
Sean8322/mindUP
|
82dfdc4aeff74fd97659457a10f9cbf8523e983c
|
[
"BSD-3-Clause",
"MIT"
] | null | null | null | 46.975904 | 494 | 0.5385 |
[
[
[
"# %gui qt\nimport numpy as np\nimport mne\nimport pickle\nimport sys\nimport os\n# import matplotlib\nfrom multiprocessing import Pool\nfrom tqdm import tqdm\nimport matplotlib.pyplot as plt\n\n# import vispy\n# print(vispy.sys_info())\n# BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n# sys.path.append(BASE_DIR)\n%matplotlib inline\nmne.utils.set_config('MNE_USE_CUDA', 'true') \nmne.cuda.init_cuda(verbose=True)",
"Now using CUDA device 0\nEnabling CUDA with 23.28 GB available memory\n"
],
[
"baseFolder='./pickled-avg'\nfiles=[f for f in os.listdir(baseFolder) if not f.startswith('.')]",
"_____no_output_____"
],
[
"data=pickle.load(open('pickled-avg/OpenBCISession_2020-02-14_11-09-00-SEVEN', 'rb'))",
"_____no_output_____"
],
[
"data[0]",
"_____no_output_____"
],
[
"#Naming system for blocks into integers\nbloc={\n \"sync\":1,\n \"baseline\":2,\n \"stressor\":3,\n \"survey\":4,\n \"rest\":5,\n \"slowBreath\":6,\n \"paced\":7\n}\n\ndef createMNEObj(data, name='Empty'):\n #Create Metadata\n \n sampling_rate = 125\n channel_names = ['Fp1', 'Fp2', 'C3', 'C4', 'P7', 'P8', 'O1', 'O2', 'F7', 'F8', 'F3', 'F4', 'T7', 'T8', 'P3', 'P4',\n 'time', 'bpm', 'ibi', 'sdnn', 'sdsd', 'rmssd', 'pnn20', 'pnn50', 'hr_mad', 'sd1', 'sd2', 's', 'sd1/sd2', 'breathingrate', 'segment_indices1', 'segment_indices2', 'block']\n channel_types = ['eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', 'eeg', \n 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'misc', 'stim']\n n_channels = len(channel_types)\n info = mne.create_info(ch_names=channel_names, sfreq=sampling_rate, ch_types=channel_types)\n info['description'] = name\n print(info)\n transformed = []\n start=-1.0\n \n for i in range(len(data)):\n add=[]\n add=data[i][1:17]\n# print(data[i][19].keys())\n if start==-1:\n start=data[i][18].hour*3600 + data[i][18].minute*60 + data[i][18].second + data[i][18].microsecond/1000\n add.append(0.0)\n else:\n tim=data[i][18].hour*3600 + data[i][18].minute*60 + data[i][18].second + data[i][18].microsecond/1000\n add.append(tim-start)\n# add.append(str(data[i][18].hour)+':'+str(data[i][18].minute)+':'+str(data[i][18].second)+':'+str(int(data[i][18].microsecond/1000)))\n# try:\n add.append(data[i][19]['bpm'])\n# except Exception as e: \n# print(e, i)\n# print(data[i][19])\n# print(len(data))\n \n add.append(data[i][19]['ibi'])\n add.append(data[i][19]['sdnn'])\n add.append(data[i][19]['sdsd'])\n add.append(data[i][19]['rmssd'])\n add.append(data[i][19]['pnn20'])\n add.append(data[i][19]['pnn50'])\n add.append(data[i][19]['hr_mad'])\n add.append(data[i][19]['sd1'])\n add.append(data[i][19]['sd2'])\n add.append(data[i][19]['s'])\n add.append(data[i][19]['sd1/sd2'])\n add.append(data[i][19]['breathingrate'])\n add.append(data[i][19]['segment_indices'][0])\n add.append(data[i][19]['segment_indices'][1])\n add.append(bloc[data[i][20]])\n transformed.append(np.array(add))\n \n transformed=np.array(transformed)\n print(transformed[0])\n #have to convert rows to columns to fit MNE structure\n transformed=transformed.transpose()\n print(transformed[0], transformed[1], transformed[2], transformed[3])\n print(len(transformed[0]))\n loaded=mne.io.RawArray(transformed, info)\n return loaded",
"_____no_output_____"
],
[
"raw=createMNEObj(data)",
"<ipython-input-5-f7810211a598>:21: RuntimeWarning: 2 channel names are too long, have been truncated to 15 characters:\n['segment_indices1', 'segment_indices2']\n info = mne.create_info(ch_names=channel_names, sfreq=sampling_rate, ch_types=channel_types)\n<ipython-input-5-f7810211a598>:21: RuntimeWarning: Channel names are not unique, found duplicates for: {'segment_indices'}. Applying running numbers for duplicates.\n info = mne.create_info(ch_names=channel_names, sfreq=sampling_rate, ch_types=channel_types)\n"
],
[
"raw[1][]",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"np.transpose(np.transpose(data))",
"_____no_output_____"
],
[
"def filt(ind):\n name=files[ind]\n \n data=pickle.load(open('pickled-avg/'+name, 'rb'))\n# if ind==1:\n# pbar = tqdm(total=len(data), position=ind)\n raw=createMNEObj(data)\n print('Created object')\n montage = mne.channels.make_standard_montage('easycap-M1')\n raw.set_montage(montage, raise_if_subset=False)\n mne.io.Raw.filter(raw,l_freq=0.5,h_freq=None)\n print('Done filtering')\n tem=np.transpose(data)\n# for i in tqdm(range(len(data))):\n# if ind==1:\n# pbar.update(1)\n# data[i][k+1]=raw[k][0][0][i]\n for k in range(0, 16):\n tem[k+1]=raw[k][0][0]\n data=np.transpose(tem)\n pickle.dump(data, open('pickled-high/'+name, \"wb\" ) )",
"_____no_output_____"
],
[
"filt(1)",
"_____no_output_____"
],
[
"\np = Pool(18)\nmaster=p.map(filt, range(len(files)))",
"<ipython-input-5-f7810211a598>:21: RuntimeWarning: 2 channel names are too long, have been truncated to 15 characters:\n['segment_indices1', 'segment_indices2']\n info = mne.create_info(ch_names=channel_names, sfreq=sampling_rate, ch_types=channel_types)\n<ipython-input-5-f7810211a598>:21: RuntimeWarning: Channel names are not unique, found duplicates for: {'segment_indices'}. Applying running numbers for duplicates.\n info = mne.create_info(ch_names=channel_names, sfreq=sampling_rate, ch_types=channel_types)\n"
],
[
"data=pickle.load(open('pickled-filt/OpenBCISession_2020-02-14_11-09-00-SEVEN', 'rb'))",
"_____no_output_____"
],
[
"data[0]",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a28f705f1fa199c8081efa4010e312b2728381d
| 90,136 |
ipynb
|
Jupyter Notebook
|
Random forest.ipynb
|
daftintrovert/Kyphosis
|
a6e4d3a08ecca3256e465eb081d3f1325f06ff09
|
[
"Apache-2.0"
] | null | null | null |
Random forest.ipynb
|
daftintrovert/Kyphosis
|
a6e4d3a08ecca3256e465eb081d3f1325f06ff09
|
[
"Apache-2.0"
] | null | null | null |
Random forest.ipynb
|
daftintrovert/Kyphosis
|
a6e4d3a08ecca3256e465eb081d3f1325f06ff09
|
[
"Apache-2.0"
] | null | null | null | 204.390023 | 80,128 | 0.907795 |
[
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"import warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"import seaborn as sns",
"_____no_output_____"
],
[
"file = r'C:\\Users\\hp\\Desktop\\kyphosis.csv'\ndf = pd.read_csv(file)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 81 entries, 0 to 80\nData columns (total 4 columns):\nKyphosis 81 non-null object\nAge 81 non-null int64\nNumber 81 non-null int64\nStart 81 non-null int64\ndtypes: int64(3), object(1)\nmemory usage: 2.6+ KB\n"
],
[
"sns.pairplot(df,hue = 'Kyphosis',size = 3,markers=[\"o\", \"D\"])",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X = df.drop(['Kyphosis'],axis = 1)",
"_____no_output_____"
],
[
"y = df['Kyphosis']",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)",
"_____no_output_____"
],
[
"from sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
],
[
"dtree = DecisionTreeClassifier()",
"_____no_output_____"
],
[
"dtree.fit(X_train,y_train)",
"_____no_output_____"
],
[
"predictions = dtree.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report,confusion_matrix",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,predictions))\nprint('\\n')\nprint(classification_report(y_test,predictions))",
"[[17 4]\n [ 2 2]]\n\n\n precision recall f1-score support\n\n absent 0.89 0.81 0.85 21\n present 0.33 0.50 0.40 4\n\n micro avg 0.76 0.76 0.76 25\n macro avg 0.61 0.65 0.62 25\nweighted avg 0.80 0.76 0.78 25\n\n"
],
[
"from sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"rfc = RandomForestClassifier(n_estimators = 200)",
"_____no_output_____"
],
[
"rfc.fit(X_train,y_train)",
"_____no_output_____"
],
[
"rfc_pred = rfc.predict(X_test)",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,rfc_pred))\nprint('\\n')\nprint(classification_report(y_test,rfc_pred))",
"[[21 0]\n [ 4 0]]\n\n\n precision recall f1-score support\n\n absent 0.84 1.00 0.91 21\n present 0.00 0.00 0.00 4\n\n micro avg 0.84 0.84 0.84 25\n macro avg 0.42 0.50 0.46 25\nweighted avg 0.71 0.84 0.77 25\n\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a29250934d61fd14eb2fc14fe4d23117c70e70b
| 24,239 |
ipynb
|
Jupyter Notebook
|
Worksheet 09 - RNN Challenge/Worksheet 09 - RNN Challenge.ipynb
|
adeaeede/deep_learning
|
cdfec84c82826d0ed47a5e1881f03121af6d73c4
|
[
"MIT"
] | null | null | null |
Worksheet 09 - RNN Challenge/Worksheet 09 - RNN Challenge.ipynb
|
adeaeede/deep_learning
|
cdfec84c82826d0ed47a5e1881f03121af6d73c4
|
[
"MIT"
] | null | null | null |
Worksheet 09 - RNN Challenge/Worksheet 09 - RNN Challenge.ipynb
|
adeaeede/deep_learning
|
cdfec84c82826d0ed47a5e1881f03121af6d73c4
|
[
"MIT"
] | null | null | null | 58.407229 | 285 | 0.564999 |
[
[
[
"import numpy as np\nfrom keras import Sequential\nfrom keras.layers import GRU, Bidirectional, Embedding, Dense, Dropout, LSTM\nfrom keras.utils import to_categorical\nfrom keras.callbacks import EarlyStopping\nfrom sklearn.utils import class_weight",
"Using TensorFlow backend.\n"
],
[
"data = np.load('rnn-challenge-data.npz')\ndata_x = data['data_x']\ndata_y = data['data_y']\n\nval_x = data['val_x']\nval_x = val_x\nval_y = data['val_y']\n\ntest_x = data['test_x']",
"_____no_output_____"
],
[
"def vectorise_sequence(sequence):\n alphabet = {'A': 0, 'C': 1, 'G': 2, 'T': 3}\n encoded = []\n for i, row in enumerate(sequence):\n seq_encoding = np.array([alphabet[ch] for ch in row])\n encoded.append(seq_encoding)\n return np.array(encoded)",
"_____no_output_____"
],
[
"from keras.callbacks import Callback\n\nclass TerminateOnBaseline(Callback):\n \"\"\"Callback that terminates training when either acc or val_acc reaches a specified baseline\n \"\"\"\n def __init__(self, monitor='acc', baseline=0.9):\n super(TerminateOnBaseline, self).__init__()\n self.monitor = monitor\n self.baseline = baseline\n\n def on_epoch_end(self, epoch, logs=None):\n logs = logs or {}\n acc = logs.get(self.monitor)\n if acc is not None:\n if acc >= self.baseline:\n print('Epoch %d: Reached baseline, terminating training' % (epoch))\n self.model.stop_training = True",
"_____no_output_____"
],
[
"dropout = 0.5\ncallback = EarlyStopping(monitor='val_categorical_accuracy', patience=0, baseline=1.0)\n\n\nmodel = Sequential()\nmodel.add(Embedding(input_dim=4, output_dim=64, name='embedding_layer'))\nmodel.add(Bidirectional(GRU(128, return_sequences=True)))\nmodel.add(Dropout(dropout))\nmodel.add(Bidirectional(GRU(128)))\nmodel.add(Dropout(dropout))\nmodel.add(Dense(5, activation='softmax'))\nmodel.compile('adam', 'categorical_crossentropy', metrics=['categorical_accuracy'])\n\nclass_weight = class_weight.compute_class_weight('balanced', np.unique(data_y), data_y)\ndata_x_encoded = vectorise_sequence(data_x)\nval_x_encoded = vectorise_sequence(val_x)",
"WARNING: Logging before flag parsing goes to stderr.\nW0623 11:24:07.952186 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:74: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.\n\nW0623 11:24:07.968384 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:517: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nW0623 11:24:07.971403 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:4138: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.\n\nW0623 11:24:08.316542 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:133: The name tf.placeholder_with_default is deprecated. Please use tf.compat.v1.placeholder_with_default instead.\n\nW0623 11:24:08.322863 140062235854656 deprecation.py:506] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.\nW0623 11:24:08.632126 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/optimizers.py:790: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.\n\nW0623 11:24:08.651758 140062235854656 deprecation_wrapper.py:119] From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3295: The name tf.log is deprecated. Please use tf.math.log instead.\n\n"
],
[
"history = model.fit(data_x_encoded, to_categorical(data_y), batch_size=64, class_weight=class_weight,\n epochs=100, verbose=1, callbacks=[TerminateOnBaseline(monitor='val_categorical_accuracy', baseline=1.0)], \n validation_data=(val_x_encoded, to_categorical(val_y)))",
"W0623 11:24:20.558073 140062235854656 deprecation.py:323] From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/math_grad.py:1250: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n"
],
[
"test_x_encoded = vectorise_sequence(test_x)",
"_____no_output_____"
],
[
"y = model.predict(test_x_encoded)",
"_____no_output_____"
],
[
"y = np.array([np.argmax(arr) for arr in y])",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"np.save('prediction.npy', y)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a292cd54a39df6cbe3477096e66f5614fa211ad
| 1,574 |
ipynb
|
Jupyter Notebook
|
convert.ipynb
|
andy6804tw/tensorflow-yolov4
|
f0908331c0c1ed8ffc7672d4ec64deb722837c41
|
[
"MIT"
] | null | null | null |
convert.ipynb
|
andy6804tw/tensorflow-yolov4
|
f0908331c0c1ed8ffc7672d4ec64deb722837c41
|
[
"MIT"
] | null | null | null |
convert.ipynb
|
andy6804tw/tensorflow-yolov4
|
f0908331c0c1ed8ffc7672d4ec64deb722837c41
|
[
"MIT"
] | null | null | null | 20.986667 | 167 | 0.55845 |
[
[
[
"# Convert darknet weights to tensorflow",
"_____no_output_____"
]
],
[
[
"!python save_model.py --weights ./weights/yolov4-car_final.weights --output ./checkpoints/yolov4-car_final-416 --input_size 416 --model yolov4 ",
"_____no_output_____"
]
],
[
[
"# Run demo tensorflow\n## single image",
"_____no_output_____"
]
],
[
[
"!python detect.py --weights ./checkpoints/yolov4-car_final-416 --size 416 --model yolov4 --image ./data/test.jpg",
"_____no_output_____"
]
],
[
[
"## video",
"_____no_output_____"
]
],
[
[
"!python detectvideo.py --weights ./checkpoints/yolov4-car_final-416 --size 416 --model yolov4 --video ./data/traffic.mov --output_format MP4V --output result.mp4",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a292ef6622b827990cdd27ebe6e00bd62c57357
| 543,216 |
ipynb
|
Jupyter Notebook
|
post_udacity/post_code.ipynb
|
Matheuskempa/matheuskempa.github.io
|
b0bc53ebca1c889d0717092de295096acd493310
|
[
"MIT"
] | null | null | null |
post_udacity/post_code.ipynb
|
Matheuskempa/matheuskempa.github.io
|
b0bc53ebca1c889d0717092de295096acd493310
|
[
"MIT"
] | null | null | null |
post_udacity/post_code.ipynb
|
Matheuskempa/matheuskempa.github.io
|
b0bc53ebca1c889d0717092de295096acd493310
|
[
"MIT"
] | null | null | null | 267.725973 | 390,152 | 0.889469 |
[
[
[
"# Cross Industry Standart Process for Data Mining \n\nIn this section we are going to analise Boston AIRBNB Data Set. We are looking to help people on cleaning datasets e how to deal with some especific data. In this post we are going to cover all the subjects bellow:\n\n1. Business Understanding: Understand the problem \n2. Data Understanding: Understand the data to solve your problem\n3. Data Preparation: Organizing it in a way that will allow us to answer our questions of interests.\t\n4. Modeling: Building a predictive model\n5. Evaluation\n6. Insights\n\n ",
"_____no_output_____"
]
],
[
[
"#first we import de the libraries wich are going to be used\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import r2_score, mean_squared_error",
"_____no_output_____"
],
[
"#then we open the sugested datasets\ndf_calendar = pd.read_csv(\"calendar.csv\")\ndf_reviews = pd.read_csv(\"reviews.csv\")",
"_____no_output_____"
]
],
[
[
"# 1. Business Understanding \n\nUnderstanding de Problem.\n\nWe are solving two questions:\n* Price, there are any correlations that we can made, in order to predict it?",
"_____no_output_____"
],
[
"# 2. Data Understanding\n\nUnderstand the data to solve your problem.\n\nNow that we have stabilished ours goals, we need to undestand our data in order to get there",
"_____no_output_____"
],
[
"### Let's take a look at the data?\n",
"_____no_output_____"
]
],
[
[
"df_calendar.head() #looking calendar",
"_____no_output_____"
],
[
"df_listings.head(2) #looking listings",
"_____no_output_____"
],
[
"df_reviews.head()# looking reviews",
"_____no_output_____"
],
[
"print(\"We have {} rows(cases) and {} features. Our primary goal is to look into these {} features.\".format(df_listings.shape[0],df_listings.shape[1],df_listings.shape[1]))",
"We have 3585 rows(cases) and 95 features. Our primary goal is to look into these 95 features.\n"
]
],
[
[
"As we have a lot of features, let's select some columns that may have correlation with our goal (predict price).",
"_____no_output_____"
]
],
[
[
"view_df_listings = pd.DataFrame(df_listings.dtypes, columns=[\"type\"])\nview_df_listings[:50] #lets take a look at the first 50 columns, wich ones we are going to pick",
"_____no_output_____"
],
[
"view_df_listings[50:]",
"_____no_output_____"
]
],
[
[
"For these two ranges of columns, after tooking a look i selected the following columns to be part of our data:\n\n* host_response_time\n* host_response_rate\n* host_acceptance_rate\n* host_is_superhost\n* host_total_listings_count\n* latitude\n* longitude\n* property_type\n* room_type\n* accommodates\n* bathrooms\n* bedrooms\n* beds\n* bed_type\n* amenities\n* square_feet\n* security_deposit\n* cleaning_fee\n* guests_included\n* extra_people\n* review_scores_rating\n* review_scores_accuracy\n* review_scores_cleanliness\n* review_scores_checkin\n* review_scores_communication\n* review_scores_location\n* review_scores_value\n* cancellation_policy\n\n",
"_____no_output_____"
]
],
[
[
"df_base = df_listings[[\"host_response_time\",\"host_response_rate\",\"host_acceptance_rate\",\n \"host_is_superhost\",\"host_total_listings_count\",\"latitude\",\"longitude\",\n \"property_type\",\"room_type\",\"accommodates\",\"bathrooms\",\"bedrooms\",\"beds\",\n \"bed_type\",\"amenities\",\"square_feet\",\"security_deposit\",\"cleaning_fee\",\n \"guests_included\",\"extra_people\",\"review_scores_rating\",\"review_scores_accuracy\",\n \"review_scores_cleanliness\",\"review_scores_checkin\",\"review_scores_communication\",\n \"review_scores_location\",\"review_scores_value\",\"cancellation_policy\",\"price\"]]\n\nprint(\"Now we have {} features\".format(df_base.shape[1]))",
"Now we have 29 features\n"
],
[
"no_nulls = set(df_base.columns[df_base.isnull().mean()==0]) ##selecting only columns fully completed\nprint('''Of all selected features only the following columns are fully completed, without any NANs.\n\n{}\n'''.format(no_nulls))",
"Of all selected features only the following columns are fully completed, without any NANs.\n\n{'price', 'room_type', 'longitude', 'guests_included', 'latitude', 'amenities', 'cancellation_policy', 'host_total_listings_count', 'host_is_superhost', 'bed_type', 'accommodates', 'extra_people'}\n\n"
],
[
"print(df_base.shape)\ndf_base.isnull().sum()",
"(3585, 29)\n"
]
],
[
[
"### Data Conclusion\n\nConclusions:\n\n1. As we can see **square_feet** is the columns with most NAN values, so we are going to drop it. \n2. For **bathrooms, bedrooms and beds**, as we understand that they exist, but for some reason didn't show up. We will fill it with the int(mean or average)\n3. Column **Security_deposit** all the NAN values will be replaced by 0\n4. All the **review_scores** with NAN values will be dropped, because we can't put a value that it doesn't exist\n5. Column **cleaning_fee** all the NAN values will be replaced by 0\n6. All the **host_response_time**,**host_is_superhost** NANs we are going to be dropped because they are categorical features\n7. All the **host_response_rate**,**host_acceptance_rate** NANs we are going to be filled with their mean/average.\n8. We will also drop the rows of **property_type** that have NANs values",
"_____no_output_____"
],
[
"# Data Preparation\n\nOrganizing it in a way that will allow us to answer our questions of interests",
"_____no_output_____"
]
],
[
[
"df_base_t1 = df_base.drop([\"square_feet\"], axis = 1)# 1.Dropping square_feet",
"_____no_output_____"
],
[
"#symbols\ndf_base_t1['host_response_rate'] = df_base_t1['host_response_rate'].str.rstrip('%')#removing symbol\ndf_base_t1['host_acceptance_rate'] = df_base_t1['host_acceptance_rate'].str.rstrip('%')#removing symbol\ndf_base_t1['security_deposit'] = df_base_t1['security_deposit'].str.lstrip('$')#removing symbol\ndf_base_t1['cleaning_fee'] = df_base_t1['cleaning_fee'].str.lstrip('$')#removing symbol\ndf_base_t1['extra_people'] = df_base_t1['extra_people'].str.lstrip('$')#removing symbol\ndf_base_t1['price'] = df_base_t1['price'].str.lstrip('$')#removing symbol\n\n\nmean_1 = {\"cleaning_fee\": 0,#replacing 0\n \"security_deposit\": \"0.00\",#replacing 0\n \"bathrooms\": int(df_base.square_feet.mean()),#mean of the column\n \"bedrooms\": int(df_base.square_feet.mean()), #mean of the column\n \"beds\": int(df_base.square_feet.mean()) #mean of the column\n} #dict\n\n\ndf_base_t1 = df_base_t1.fillna(value = mean_1) # 2, 3 an 5.Filling with the mean() of the columns",
"_____no_output_____"
],
[
"#4 an 6. Dropping NANs on the review_scores\ndf_base_t1.dropna(subset=['review_scores_rating','review_scores_accuracy','review_scores_cleanliness','review_scores_checkin',\n 'review_scores_communication','review_scores_location','review_scores_value',\n 'host_response_time','host_is_superhost'], inplace = True) \n",
"_____no_output_____"
],
[
"#7. Replacing categorical cloumns, or simbols \nprint(df_base_t1.host_response_time.value_counts())\n\n#creating dict for this column\nhost_response_time = {\"within an hour\":1,\n \"within a few hours\":2,\n \"within a day\":3,\n \"a few days or more\":4}\n\ndf_base_t1= df_base_t1.replace({\"host_response_time\":host_response_time}) #replacing categorical",
"within an hour 1169\nwithin a few hours 972\nwithin a day 379\na few days or more 21\nName: host_response_time, dtype: int64\n"
],
[
"#types\ndf_base_t1['host_response_rate']= df_base_t1['host_response_rate'].astype(int) #converting type\ndf_base_t1['host_acceptance_rate']= df_base_t1['host_acceptance_rate'].astype(int) #converting type\ndf_base_t1['cleaning_fee']= df_base_t1['cleaning_fee'].astype(float)#converting type\ndf_base_t1['extra_people']= df_base_t1['extra_people'].astype(float)#converting type\n\n#symbols inteference\n\n# converting price type\n\ndf_base_t1.price=df_base_t1.price.str.replace(\",\",\"\")\ndf_base_t1['price']= df_base_t1['price'].astype(float)#converting type\n\n\n# converting security_deposit type\n\ndf_base_t1.security_deposit=df_base_t1.security_deposit.str.replace(\",\",\"\")\ndf_base_t1['security_deposit']= df_base_t1['security_deposit'].astype(float)#converting type",
"_____no_output_____"
],
[
"### categorical\n\n#creating dict for this column\nhost_is_superhost = {\"f\":0,\n \"t\":1}\n\ndf_base_t1= df_base_t1.replace({\"host_is_superhost\":host_is_superhost}) #replacing categorical\n\n\n#creating dict for this column\nproperty_type = {\"Apartment\":1,\n \"House\":2,\n \"Condominium\":3,\n \"Townhouse\":4,\n \"Bed & Breakfast\":4,\n \"Loft\":4,\n \"Boat\":4,\n \"Other\":4,\n \"Villa\":4,\n \"Dorm\":4,\n \"Guesthouse\":4,\n \"Entire Floor\":4}\n\ndf_base_t1= df_base_t1.replace({\"property_type\":property_type}) #replacing categorical\n\n\n#creating dict for this column\nroom_type = {\"Entire home/apt\":1,\n \"Private room\":2,\n \"Shared room\":3}\n\ndf_base_t1= df_base_t1.replace({\"room_type\":room_type}) #replacing categorical\n\n\n\n#creating dict for this column\nbed_type = {\"Real Bed\":1,\n \"Futon\":2,\n \"Airbed\":3,\n \"Pull-out Sofa\":4,\n \"Couch\":5}\n\ndf_base_t1= df_base_t1.replace({\"bed_type\":bed_type}) #replacing categorical\n\n\n#creating dict for this column\ncancellation_policy = {\"strict\":1,\n \"moderate\":2,\n \"flexible\":3,\n \"super_strict_30\":4}\n\ndf_base_t1= df_base_t1.replace({\"cancellation_policy\":cancellation_policy}) #replacing categorical\n",
"_____no_output_____"
]
],
[
[
"### Finished? Not yet...\n\nAll we did until now it was putting in numbers what words were showing us.\n\n**property_type**: As there were a lot of property types, i creted four categories (1=Apartment,2= House,3=Condominium,4= Others) eache one especified in the dict above. Eventhough we had more types of property, i consider only four, because it could increase our dimmensionality of data.\n\nI did this to almost every variable, but one is missing, **amenities**, i left this one because there were a lot o categories inside of it. And even if i use get_dummy variables, it could increase the dimmensionality of the data, making the predictions get worse in the future. So i thought we could count how many good amenities are in the house, so that now we transform this information in a number.",
"_____no_output_____"
]
],
[
[
"df_base_t1 = df_base_t1.reset_index(drop=True) #reseting the index",
"_____no_output_____"
]
],
[
[
"colunas 3,7,8,13,14,26\nsimbolos 15 = security_deposit\n16 = cleaning_fee\n18 = extra_people\n27 = price",
"_____no_output_____"
]
],
[
[
"amenities = []\nfor i in df_base_t1.amenities:\n a = i.split(\",\")\n amenities.append(len(a))\n \ndf_base_t1[\"amenities\"] = pd.DataFrame(amenities)",
"_____no_output_____"
],
[
"print('''Almost forgot that we still have some values missing...\n\n'''\n,df_base_t1.isnull().sum()>0,df_base_t1.shape)",
"Almost forgot that we still have some values missing...\n\n host_response_time False\nhost_response_rate False\nhost_acceptance_rate False\nhost_is_superhost False\nhost_total_listings_count False\nlatitude False\nlongitude False\nproperty_type True\nroom_type False\naccommodates False\nbathrooms False\nbedrooms False\nbeds False\nbed_type False\namenities False\nsecurity_deposit False\ncleaning_fee False\nguests_included False\nextra_people False\nreview_scores_rating False\nreview_scores_accuracy False\nreview_scores_cleanliness False\nreview_scores_checkin False\nreview_scores_communication False\nreview_scores_location False\nreview_scores_value False\ncancellation_policy False\nprice False\ndtype: bool (2541, 28)\n"
],
[
"df_base_t1 = df_base_t1.dropna()\n\nprint('''Let's take a look now...\n\n'''\n,df_base_t1.isnull().sum()>0,df_base_t1.shape)\n",
"Let's take a look now...\n\n host_response_time False\nhost_response_rate False\nhost_acceptance_rate False\nhost_is_superhost False\nhost_total_listings_count False\nlatitude False\nlongitude False\nproperty_type False\nroom_type False\naccommodates False\nbathrooms False\nbedrooms False\nbeds False\nbed_type False\namenities False\nsecurity_deposit False\ncleaning_fee False\nguests_included False\nextra_people False\nreview_scores_rating False\nreview_scores_accuracy False\nreview_scores_cleanliness False\nreview_scores_checkin False\nreview_scores_communication False\nreview_scores_location False\nreview_scores_value False\ncancellation_policy False\nprice False\ndtype: bool (2539, 28)\n"
]
],
[
[
"### Let's take a look in our Database\n\nLet's just take a look and try to see if we can get some insides of the data.",
"_____no_output_____"
]
],
[
[
"df_base_t1.describe()",
"_____no_output_____"
],
[
"df_base_t1.hist(figsize=(15,15) )",
"_____no_output_____"
]
],
[
[
"### And what about the correlations?\n\nThere is a good graphic that will help us to see what columns are correlated to each other.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(15,15))\nsns.heatmap(df_base_t1.corr(), annot=True, fmt=\".2f\",ax=ax)",
"_____no_output_____"
]
],
[
[
"# Modeling, Evaluating and Insights",
"_____no_output_____"
]
],
[
[
"X= df_base_t1[[\"host_response_time\",\"host_response_rate\",\"host_acceptance_rate\",\n \"host_is_superhost\",\"host_total_listings_count\",\"latitude\",\"longitude\",\n \"property_type\",\"room_type\",\"accommodates\",\"bathrooms\",\"bedrooms\",\"beds\",\n \"bed_type\",\"amenities\",\"security_deposit\",\"cleaning_fee\",\n \"guests_included\",\"extra_people\",\"review_scores_rating\",\"review_scores_accuracy\",\n \"review_scores_cleanliness\",\"review_scores_checkin\",\"review_scores_communication\",\n \"review_scores_location\",\"review_scores_value\",\"cancellation_policy\"]]\n\n\ny = df_base_t1[[\"price\"]]",
"_____no_output_____"
],
[
"#Split into train and test\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .30, random_state=42) \n\nlm_model = LinearRegression(normalize=True) # Instantiate\nlm_model.fit(X_train, y_train) #Fit\n \n#Predict and score the model\ny_test_preds = lm_model.predict(X_test) \n\"The r-squared score for your model was {} on {} values.\".format(r2_score(y_test, y_test_preds), len(y_test))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a293e23384f414b2d120e49a72438623496fe52
| 9,026 |
ipynb
|
Jupyter Notebook
|
step4.ipynb
|
dataworkshop/xgboost
|
bab678c783f1ecdadebd7424bf2d42a882457689
|
[
"MIT"
] | 127 |
2016-06-16T15:27:53.000Z
|
2022-03-19T20:49:17.000Z
|
step4.ipynb
|
rickyaimar/xgboost
|
bab678c783f1ecdadebd7424bf2d42a882457689
|
[
"MIT"
] | null | null | null |
step4.ipynb
|
rickyaimar/xgboost
|
bab678c783f1ecdadebd7424bf2d42a882457689
|
[
"MIT"
] | 85 |
2016-06-10T13:24:29.000Z
|
2021-12-22T16:12:55.000Z
| 29.986711 | 206 | 0.536339 |
[
[
[
"# Hyperparameter Optimization [xgboost](https://github.com/dmlc/xgboost)",
"_____no_output_____"
],
[
"What the options there're for tuning?\n* [GridSearch](http://scikit-learn.org/stable/modules/grid_search.html)\n* [RandomizedSearch](http://scikit-learn.org/stable/modules/generated/sklearn.grid_search.RandomizedSearchCV.html)\n\nAll right!\nXgboost has about 20 params:\n1. base_score\n2. **colsample_bylevel**\n3. **colsample_bytree** \n4. **gamma**\n5. **learning_rate**\n6. **max_delta_step**\n7. **max_depth**\n8. **min_child_weight**\n9. missing\n10. **n_estimators**\n11. nthread\n12. **objective**\n13. **reg_alpha**\n14. **reg_lambda**\n15. **scale_pos_weight**\n16. **seed**\n17. silent\n18. **subsample**\n\n\n\nLet's for tuning will be use 12 of them them with 5-10 possible values, so... there're 12^5 - 12^10 possible cases.\nIf you will check one case in 10s, for **12^5** you need **30 days** for **12^10** about **20K** years :). \n\nThis is too long.. but there's a thid option - **Bayesan optimisation**.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport xgboost as xgb\nimport numpy as np\nimport seaborn as sns\n\nfrom hyperopt import hp\nfrom hyperopt import hp, fmin, tpe, STATUS_OK, Trials\n\n%matplotlib inline",
"_____no_output_____"
],
[
"train = pd.read_csv('bike.csv')\ntrain['datetime'] = pd.to_datetime( train['datetime'] )\ntrain['day'] = train['datetime'].map(lambda x: x.day)",
"_____no_output_____"
]
],
[
[
"## Modeling",
"_____no_output_____"
]
],
[
[
"def assing_test_samples(data, last_training_day=0.3, seed=1):\n days = data.day.unique()\n np.random.seed(seed)\n np.random.shuffle(days)\n test_days = days[: int(len(days) * 0.3)]\n \n data['is_test'] = data.day.isin(test_days)\n\n\ndef select_features(data):\n columns = data.columns[ (data.dtypes == np.int64) | (data.dtypes == np.float64) | (data.dtypes == np.bool) ].values \n return [feat for feat in columns if feat not in ['count', 'casual', 'registered'] and 'log' not in feat ] \n\ndef get_X_y(data, target_variable):\n features = select_features(data)\n \n X = data[features].values\n y = data[target_variable].values\n \n return X,y\n\ndef train_test_split(train, target_variable):\n df_train = train[train.is_test == False]\n df_test = train[train.is_test == True]\n \n X_train, y_train = get_X_y(df_train, target_variable)\n X_test, y_test = get_X_y(df_test, target_variable)\n \n return X_train, X_test, y_train, y_test\n\n\n\ndef fit_and_predict(train, model, target_variable):\n X_train, X_test, y_train, y_test = train_test_split(train, target_variable)\n \n model.fit(X_train, y_train)\n y_pred = model.predict(X_test)\n \n return (y_test, y_pred)\n\ndef post_pred(y_pred):\n y_pred[y_pred < 0] = 0\n return y_pred\n\ndef rmsle(y_true, y_pred, y_pred_only_positive=True):\n if y_pred_only_positive: y_pred = post_pred(y_pred)\n \n diff = np.log(y_pred+1) - np.log(y_true+1)\n mean_error = np.square(diff).mean()\n return np.sqrt(mean_error)\n\nassing_test_samples(train)",
"_____no_output_____"
],
[
"def etl_datetime(df):\n df['year'] = df['datetime'].map(lambda x: x.year)\n df['month'] = df['datetime'].map(lambda x: x.month)\n\n df['hour'] = df['datetime'].map(lambda x: x.hour)\n df['minute'] = df['datetime'].map(lambda x: x.minute)\n df['dayofweek'] = df['datetime'].map(lambda x: x.dayofweek)\n df['weekend'] = df['datetime'].map(lambda x: x.dayofweek in [5,6])\n\n \netl_datetime(train)\n\ntrain['{0}_log'.format('count')] = train['count'].map(lambda x: np.log2(x) )\n\nfor name in ['registered', 'casual']:\n train['{0}_log'.format(name)] = train[name].map(lambda x: np.log2(x+1) )",
"_____no_output_____"
]
],
[
[
"## Tuning hyperparmeters using Bayesian optimization algorithms",
"_____no_output_____"
]
],
[
[
"def objective(space):\n \n model = xgb.XGBRegressor(\n max_depth = space['max_depth'],\n n_estimators = int(space['n_estimators']),\n subsample = space['subsample'],\n colsample_bytree = space['colsample_bytree'],\n learning_rate = space['learning_rate'],\n reg_alpha = space['reg_alpha']\n )\n\n X_train, X_test, y_train, y_test = train_test_split(train, 'count')\n eval_set = [( X_train, y_train), ( X_test, y_test)]\n\n\n (_, registered_pred) = fit_and_predict(train, model, 'registered_log')\n (_, casual_pred) = fit_and_predict(train, model, 'casual_log')\n \n y_test = train[train.is_test == True]['count']\n y_pred = (np.exp2(registered_pred) - 1) + (np.exp2(casual_pred) -1)\n \n score = rmsle(y_test, y_pred)\n print \"SCORE:\", score\n\n return{'loss':score, 'status': STATUS_OK }\n\nspace ={\n 'max_depth': hp.quniform(\"x_max_depth\", 2, 20, 1),\n 'n_estimators': hp.quniform(\"n_estimators\", 100, 1000, 1),\n 'subsample': hp.uniform ('x_subsample', 0.8, 1), \n 'colsample_bytree': hp.uniform ('x_colsample_bytree', 0.1, 1), \n 'learning_rate': hp.uniform ('x_learning_rate', 0.01, 0.1), \n 'reg_alpha': hp.uniform ('x_reg_alpha', 0.1, 1)\n}\n\n\ntrials = Trials()\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=15,\n trials=trials)\n\nprint(best)",
"SCORE: 0.327769943579\nSCORE: 0.402119793524\nSCORE: 0.441702998659\nSCORE: 0.344952075056\nSCORE: 0.332483052772\nSCORE: 0.415230694098\nSCORE: 0.326159133525\nSCORE: 0.366755440868\nSCORE: 0.336209948966\nSCORE: 0.320813982928\nSCORE: 0.33925039026\nSCORE: 0.363387131966\nSCORE: 0.324682064912\nSCORE: 0.382678760754\nSCORE: 0.488176057958\n{'x_learning_rate': 0.0803514512536536, 'x_reg_alpha': 0.44303008763740737, 'n_estimators': 421.0, 'x_max_depth': 17.0, 'x_subsample': 0.9561807797584932, 'x_colsample_bytree': 0.8214374064161822}\n"
]
],
[
[
"## Links\n1. http://hyperopt.github.io/hyperopt/\n2. https://districtdatalabs.silvrback.com/parameter-tuning-with-hyperopt\n3. http://fastml.com/optimizing-hyperparams-with-hyperopt/\n4. https://github.com/Far0n/xgbfi\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a29477acb221901d8704197e7aa39c177bd32ee
| 55,649 |
ipynb
|
Jupyter Notebook
|
site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb
|
crutcher/docs
|
73ceed9f8e2c4a8a6052df27027e8a1cec4516ab
|
[
"Apache-2.0"
] | 7 |
2021-05-08T18:25:43.000Z
|
2021-09-30T13:41:26.000Z
|
site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb
|
crutcher/docs
|
73ceed9f8e2c4a8a6052df27027e8a1cec4516ab
|
[
"Apache-2.0"
] | null | null | null |
site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb
|
crutcher/docs
|
73ceed9f8e2c4a8a6052df27027e8a1cec4516ab
|
[
"Apache-2.0"
] | 2 |
2021-05-08T18:53:53.000Z
|
2021-05-08T19:32:30.000Z
| 47.808419 | 1,674 | 0.591511 |
[
[
[
"##### Copyright 2020 The TensorFlow Hub Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/text/solve_glue_tasks_using_bert_on_tpu\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/text/solve_glue_tasks_using_bert_on_tpu.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n <td>\n <a href=\"https://tfhub.dev/google/collections/bert/1\"><img src=\"https://www.tensorflow.org/images/hub_logo_32px.png\" />See TF Hub model</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Solve GLUE tasks using BERT on TPU\n\nBERT can be used to solve many problems in natural language processing. You will learn how to fine-tune BERT for many tasks from the [GLUE benchmark](https://gluebenchmark.com/):\n\n1. [CoLA](https://nyu-mll.github.io/CoLA/) (Corpus of Linguistic Acceptability): Is the sentence grammatically correct?\n\n1. [SST-2](https://nlp.stanford.edu/sentiment/index.html) (Stanford Sentiment Treebank): The task is to predict the sentiment of a given sentence.\n\n1. [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) (Microsoft Research Paraphrase Corpus): Determine whether a pair of sentences are semantically equivalent.\n\n1. [QQP](https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs) (Quora Question Pairs2): Determine whether a pair of questions are semantically equivalent.\n\n1. [MNLI](http://www.nyu.edu/projects/bowman/multinli/) (Multi-Genre Natural Language Inference): Given a premise sentence and a hypothesis sentence, the task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral).\n\n1. [QNLI](https://rajpurkar.github.io/SQuAD-explorer/)(Question-answering Natural Language Inference): The task is to determine whether the context sentence contains the answer to the question.\n\n1. [RTE](https://aclweb.org/aclwiki/Recognizing_Textual_Entailment)(Recognizing Textual Entailment): Determine if a sentence entails a given hypothesis or not.\n\n1. [WNLI](https://cs.nyu.edu/faculty/davise/papers/WinogradSchemas/WS.html)(Winograd Natural Language Inference): The task is to predict if the sentence with the pronoun substituted is entailed by the original sentence.\n\nThis tutorial contains complete end-to-end code to train these models on a TPU. You can also run this notebook on a GPU, by changing one line (described below).\n\nIn this notebook, you will:\n\n- Load a BERT model from TensorFlow Hub\n- Choose one of GLUE tasks and download the dataset\n- Preprocess the text\n- Fine-tune BERT (examples are given for single-sentence and multi-sentence datasets)\n- Save the trained model and use it\n\nKey point: The model you develop will be end-to-end. The preprocessing logic will be included in the model itself, making it capable of accepting raw strings as input.\n\nNote: This notebook should be run using a TPU. In Colab, choose **Runtime -> Change runtime type** and verify that a **TPU** is selected.\n",
"_____no_output_____"
],
[
"## Setup\n\n You will use a separate model to preprocess text before using it to fine-tune BERT. This model depends on [tensorflow/text](https://github.com/tensorflow/text), which you will install below.",
"_____no_output_____"
]
],
[
[
"!pip install -q -U tensorflow-text",
"_____no_output_____"
]
],
[
[
"You will use the AdamW optimizer from [tensorflow/models](https://github.com/tensorflow/models) to fine-tune BERT, which you will install as well.",
"_____no_output_____"
]
],
[
[
"!pip install -q -U tf-models-official",
"_____no_output_____"
],
[
"!pip install -U tfds-nightly",
"_____no_output_____"
],
[
"import os\nimport tensorflow as tf\nimport tensorflow_hub as hub\nimport tensorflow_datasets as tfds\nimport tensorflow_text as text # A dependency of the preprocessing model\nimport tensorflow_addons as tfa\nfrom official.nlp import optimization\nimport numpy as np\n\ntf.get_logger().setLevel('ERROR')",
"_____no_output_____"
]
],
[
[
"Next, configure TFHub to read checkpoints directly from TFHub's Cloud Storage buckets. This is only recomended when running TFHub models on TPU.\n\nWithout this setting TFHub would download the compressed file and extract the checkpoint locally. Attempting to load from these local files will fail with following Error:\n\n```\nInvalidArgumentError: Unimplemented: File system scheme '[local]' not implemented\n```\n\nThis is because the [TPU can only read directly from Cloud Storage buckets](https://cloud.google.com/tpu/docs/troubleshooting#cannot_use_local_filesystem).\n\nNote: This setting is automatic in Colab.",
"_____no_output_____"
]
],
[
[
"os.environ[\"TFHUB_MODEL_LOAD_FORMAT\"]=\"UNCOMPRESSED\"",
"_____no_output_____"
]
],
[
[
"### Connect to the TPU worker\n\nThe following code connects to the TPU worker and changes TensorFlow's default device to the CPU device on the TPU worker. It also defines a TPU distribution strategy that you will use to distribute model training onto the 8 separate TPU cores available on this one TPU worker. See TensorFlow's [TPU guide](https://www.tensorflow.org/guide/tpu) for more information.",
"_____no_output_____"
]
],
[
[
"import os\n\nif os.environ['COLAB_TPU_ADDR']:\n cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])\n tf.config.experimental_connect_to_cluster(cluster_resolver)\n tf.tpu.experimental.initialize_tpu_system(cluster_resolver)\n strategy = tf.distribute.TPUStrategy(cluster_resolver)\n print('Using TPU')\nelif tf.test.is_gpu_available():\n strategy = tf.distribute.MirroredStrategy()\n print('Using GPU')\nelse:\n raise ValueError('Running on CPU is not recomended.')",
"_____no_output_____"
]
],
[
[
"## Loading models from TensorFlow Hub\n\nHere you can choose which BERT model you will load from TensorFlow Hub and fine-tune.\nThere are multiple BERT models available to choose from.\n\n - [BERT-Base](https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3), [Uncased](https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3) and [seven more models](https://tfhub.dev/google/collections/bert/1) with trained weights released by the original BERT authors.\n - [Small BERTs](https://tfhub.dev/google/collections/bert/1) have the same general architecture but fewer and/or smaller Transformer blocks, which lets you explore tradeoffs between speed, size and quality.\n - [ALBERT](https://tfhub.dev/google/collections/albert/1): four different sizes of \"A Lite BERT\" that reduces model size (but not computation time) by sharing parameters between layers.\n - [BERT Experts](https://tfhub.dev/google/collections/experts/bert/1): eight models that all have the BERT-base architecture but offer a choice between different pre-training domains, to align more closely with the target task.\n - [Electra](https://tfhub.dev/google/collections/electra/1) has the same architecture as BERT (in three different sizes), but gets pre-trained as a discriminator in a set-up that resembles a Generative Adversarial Network (GAN).\n - BERT with Talking-Heads Attention and Gated GELU [[base](https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1), [large](https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_large/1)] has two improvements to the core of the Transformer architecture.\n\nSee the model documentation linked above for more details.\n\nIn this tutorial, you will start with BERT-base. You can use larger and more recent models for higher accuracy, or smaller models for faster training times. To change the model, you only need to switch a single line of code (shown below). All of the differences are encapsulated in the SavedModel you will download from TensorFlow Hub.",
"_____no_output_____"
]
],
[
[
"#@title Choose a BERT model to fine-tune\n\nbert_model_name = 'bert_en_uncased_L-12_H-768_A-12' #@param [\"bert_en_uncased_L-12_H-768_A-12\", \"bert_en_uncased_L-24_H-1024_A-16\", \"bert_en_wwm_uncased_L-24_H-1024_A-16\", \"bert_en_cased_L-12_H-768_A-12\", \"bert_en_cased_L-24_H-1024_A-16\", \"bert_en_wwm_cased_L-24_H-1024_A-16\", \"bert_multi_cased_L-12_H-768_A-12\", \"small_bert/bert_en_uncased_L-2_H-128_A-2\", \"small_bert/bert_en_uncased_L-2_H-256_A-4\", \"small_bert/bert_en_uncased_L-2_H-512_A-8\", \"small_bert/bert_en_uncased_L-2_H-768_A-12\", \"small_bert/bert_en_uncased_L-4_H-128_A-2\", \"small_bert/bert_en_uncased_L-4_H-256_A-4\", \"small_bert/bert_en_uncased_L-4_H-512_A-8\", \"small_bert/bert_en_uncased_L-4_H-768_A-12\", \"small_bert/bert_en_uncased_L-6_H-128_A-2\", \"small_bert/bert_en_uncased_L-6_H-256_A-4\", \"small_bert/bert_en_uncased_L-6_H-512_A-8\", \"small_bert/bert_en_uncased_L-6_H-768_A-12\", \"small_bert/bert_en_uncased_L-8_H-128_A-2\", \"small_bert/bert_en_uncased_L-8_H-256_A-4\", \"small_bert/bert_en_uncased_L-8_H-512_A-8\", \"small_bert/bert_en_uncased_L-8_H-768_A-12\", \"small_bert/bert_en_uncased_L-10_H-128_A-2\", \"small_bert/bert_en_uncased_L-10_H-256_A-4\", \"small_bert/bert_en_uncased_L-10_H-512_A-8\", \"small_bert/bert_en_uncased_L-10_H-768_A-12\", \"small_bert/bert_en_uncased_L-12_H-128_A-2\", \"small_bert/bert_en_uncased_L-12_H-256_A-4\", \"small_bert/bert_en_uncased_L-12_H-512_A-8\", \"small_bert/bert_en_uncased_L-12_H-768_A-12\", \"albert_en_base\", \"albert_en_large\", \"albert_en_xlarge\", \"albert_en_xxlarge\", \"electra_small\", \"electra_base\", \"experts_pubmed\", \"experts_wiki_books\", \"talking-heads_base\", \"talking-heads_large\"]\n\nmap_name_to_handle = {\n 'bert_en_uncased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',\n 'bert_en_uncased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_L-24_H-1024_A-16/3',\n 'bert_en_wwm_uncased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_wwm_uncased_L-24_H-1024_A-16/3',\n 'bert_en_cased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',\n 'bert_en_cased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_cased_L-24_H-1024_A-16/3',\n 'bert_en_wwm_cased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_wwm_cased_L-24_H-1024_A-16/3',\n 'bert_multi_cased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',\n 'small_bert/bert_en_uncased_L-2_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-2_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-2_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-2_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',\n 'small_bert/bert_en_uncased_L-4_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-4_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-4_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-4_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',\n 'small_bert/bert_en_uncased_L-6_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-6_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-6_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-6_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',\n 'small_bert/bert_en_uncased_L-8_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-8_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-8_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-8_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',\n 'small_bert/bert_en_uncased_L-10_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-10_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-10_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-10_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',\n 'small_bert/bert_en_uncased_L-12_H-128_A-2':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',\n 'small_bert/bert_en_uncased_L-12_H-256_A-4':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',\n 'small_bert/bert_en_uncased_L-12_H-512_A-8':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',\n 'small_bert/bert_en_uncased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',\n 'albert_en_base':\n 'https://tfhub.dev/tensorflow/albert_en_base/2',\n 'albert_en_large':\n 'https://tfhub.dev/tensorflow/albert_en_large/2',\n 'albert_en_xlarge':\n 'https://tfhub.dev/tensorflow/albert_en_xlarge/2',\n 'albert_en_xxlarge':\n 'https://tfhub.dev/tensorflow/albert_en_xxlarge/2',\n 'electra_small':\n 'https://tfhub.dev/google/electra_small/2',\n 'electra_base':\n 'https://tfhub.dev/google/electra_base/2',\n 'experts_pubmed':\n 'https://tfhub.dev/google/experts/bert/pubmed/2',\n 'experts_wiki_books':\n 'https://tfhub.dev/google/experts/bert/wiki_books/2',\n 'talking-heads_base':\n 'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',\n 'talking-heads_large':\n 'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_large/1',\n}\n\nmap_model_to_preprocess = {\n 'bert_en_uncased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'bert_en_uncased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'bert_en_wwm_cased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',\n 'bert_en_cased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',\n 'bert_en_cased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',\n 'bert_en_wwm_uncased_L-24_H-1024_A-16':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-2_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-2_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-2_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-2_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-4_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-4_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-4_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-4_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-6_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-6_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-6_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-6_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-8_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-8_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-8_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-8_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-10_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-10_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-10_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-10_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-12_H-128_A-2':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-12_H-256_A-4':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-12_H-512_A-8':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'small_bert/bert_en_uncased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'bert_multi_cased_L-12_H-768_A-12':\n 'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',\n 'albert_en_base':\n 'https://tfhub.dev/tensorflow/albert_en_preprocess/2',\n 'albert_en_large':\n 'https://tfhub.dev/tensorflow/albert_en_preprocess/2',\n 'albert_en_xlarge':\n 'https://tfhub.dev/tensorflow/albert_en_preprocess/2',\n 'albert_en_xxlarge':\n 'https://tfhub.dev/tensorflow/albert_en_preprocess/2',\n 'electra_small':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'electra_base':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'experts_pubmed':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'experts_wiki_books':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'talking-heads_base':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n 'talking-heads_large':\n 'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',\n}\n\ntfhub_handle_encoder = map_name_to_handle[bert_model_name]\ntfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]\n\nprint(f'BERT model selected : {tfhub_handle_encoder}')\nprint(f'Preprocessing model auto-selected: {tfhub_handle_preprocess}')",
"_____no_output_____"
]
],
[
[
"## Preprocess the text\n\nOn the [Classify text with BERT colab](https://www.tensorflow.org/tutorials/text/classify_text_with_bert) the preprocessing model is used directly embedded with the BERT encoder.\n\nThis tutorial demonstrates how to do preprocessing as part of your input pipeline for training, using Dataset.map, and then merge it into the model that gets exported for inference. That way, both training and inference can work from raw text inputs, although the TPU itself requires numeric inputs.\n\nTPU requirements aside, it can help performance have preprocessing done asynchronously in an input pipeline (you can learn more in the [tf.data performance guide](https://www.tensorflow.org/guide/data_performance)).\n\nThis tutorial also demonstrates how to build multi-input models, and how to adjust the sequence length of the inputs to BERT.\n\nLet's demonstrate the preprocessing model.",
"_____no_output_____"
]
],
[
[
"bert_preprocess = hub.load(tfhub_handle_preprocess)\ntok = bert_preprocess.tokenize(tf.constant(['Hello TensorFlow!']))\nprint(tok)",
"_____no_output_____"
]
],
[
[
"Each preprocessing model also provides a method,`.bert_pack_inputs(tensors, seq_length)`, which takes a list of tokens (like `tok` above) and a sequence length argument. This packs the inputs to create a dictionary of tensors in the format expected by the BERT model.",
"_____no_output_____"
]
],
[
[
"text_preprocessed = bert_preprocess.bert_pack_inputs([tok, tok], tf.constant(20))\n\nprint('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)\nprint('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])\nprint('Shape Mask : ', text_preprocessed['input_mask'].shape)\nprint('Input Mask : ', text_preprocessed['input_mask'][0, :16])\nprint('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)\nprint('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])",
"_____no_output_____"
]
],
[
[
"Here are some details to pay attention to:\n- `input_mask` The mask allows the model to cleanly differentiate between the content and the padding. The mask has the same shape as the `input_word_ids`, and contains a 1 anywhere the `input_word_ids` is not padding.\n- `input_type_ids` has the same shape of `input_mask`, but inside the non-padded region, contains a 0 or a 1 indicating which sentence the token is a part of.",
"_____no_output_____"
],
[
"Next, you will create a preprocessing model that encapsulates all this logic. Your model will take strings as input, and return appropriately formatted objects which can be passed to BERT.\n\nEach BERT model has a specific preprocessing model, make sure to use the proper one described on the BERT's model documentation.\n\nNote: BERT adds a \"position embedding\" to the token embedding of each input, and these come from a fixed-size lookup table. That imposes a max seq length of 512 (which is also a practical limit, due to the quadratic growth of attention computation). For this colab 128 is good enough.",
"_____no_output_____"
]
],
[
[
"def make_bert_preprocess_model(sentence_features, seq_length=128):\n \"\"\"Returns Model mapping string features to BERT inputs.\n\n Args:\n sentence_features: a list with the names of string-valued features.\n seq_length: an integer that defines the sequence length of BERT inputs.\n\n Returns:\n A Keras Model that can be called on a list or dict of string Tensors\n (with the order or names, resp., given by sentence_features) and\n returns a dict of tensors for input to BERT.\n \"\"\"\n\n input_segments = [\n tf.keras.layers.Input(shape=(), dtype=tf.string, name=ft)\n for ft in sentence_features]\n\n # Tokenize the text to word pieces.\n bert_preprocess = hub.load(tfhub_handle_preprocess)\n tokenizer = hub.KerasLayer(bert_preprocess.tokenize, name='tokenizer')\n segments = [tokenizer(s) for s in input_segments]\n\n # Optional: Trim segments in a smart way to fit seq_length.\n # Simple cases (like this example) can skip this step and let\n # the next step apply a default truncation to approximately equal lengths.\n truncated_segments = segments\n\n # Pack inputs. The details (start/end token ids, dict of output tensors)\n # are model-dependent, so this gets loaded from the SavedModel.\n packer = hub.KerasLayer(bert_preprocess.bert_pack_inputs,\n arguments=dict(seq_length=seq_length),\n name='packer')\n model_inputs = packer(truncated_segments)\n return tf.keras.Model(input_segments, model_inputs)",
"_____no_output_____"
]
],
[
[
"Let's demonstrate the preprocessing model. You will create a test with two sentences input (input1 and input2). The output is what a BERT model would expect as input: `input_word_ids`, `input_masks` and `input_type_ids`.",
"_____no_output_____"
]
],
[
[
"test_preprocess_model = make_bert_preprocess_model(['my_input1', 'my_input2'])\ntest_text = [np.array(['some random test sentence']),\n np.array(['another sentence'])]\ntext_preprocessed = test_preprocess_model(test_text)\n\nprint('Keys : ', list(text_preprocessed.keys()))\nprint('Shape Word Ids : ', text_preprocessed['input_word_ids'].shape)\nprint('Word Ids : ', text_preprocessed['input_word_ids'][0, :16])\nprint('Shape Mask : ', text_preprocessed['input_mask'].shape)\nprint('Input Mask : ', text_preprocessed['input_mask'][0, :16])\nprint('Shape Type Ids : ', text_preprocessed['input_type_ids'].shape)\nprint('Type Ids : ', text_preprocessed['input_type_ids'][0, :16])",
"_____no_output_____"
]
],
[
[
"Let's take a look at the model's structure, paying attention to the two inputs you just defined.",
"_____no_output_____"
]
],
[
[
"tf.keras.utils.plot_model(test_preprocess_model)",
"_____no_output_____"
]
],
[
[
"To apply the preprocessing in all the inputs from the dataset, you will use the `map` function from the dataset. The result is then cached for [performance](https://www.tensorflow.org/guide/data_performance#top_of_page).",
"_____no_output_____"
]
],
[
[
"AUTOTUNE = tf.data.AUTOTUNE\n\ndef load_dataset_from_tfds(in_memory_ds, info, split, batch_size,\n bert_preprocess_model):\n is_training = split.startswith('train')\n dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[split])\n num_examples = info.splits[split].num_examples\n\n if is_training:\n dataset = dataset.shuffle(num_examples)\n dataset = dataset.repeat()\n dataset = dataset.batch(batch_size)\n dataset = dataset.map(lambda ex: (bert_preprocess_model(ex), ex['label']))\n dataset = dataset.cache().prefetch(buffer_size=AUTOTUNE)\n return dataset, num_examples",
"_____no_output_____"
]
],
[
[
"## Define your model\n\nYou are now ready to define your model for sentence or sentence pair classification by feeding the preprocessed inputs through the BERT encoder and putting a linear classifier on top (or other arrangement of layers as you prefer), and using dropout for regularization.\n\nNote: Here the model will be defined using the [Keras functional API](https://www.tensorflow.org/guide/keras/functional)\n",
"_____no_output_____"
]
],
[
[
"def build_classifier_model(num_classes):\n inputs = dict(\n input_word_ids=tf.keras.layers.Input(shape=(None,), dtype=tf.int32),\n input_mask=tf.keras.layers.Input(shape=(None,), dtype=tf.int32),\n input_type_ids=tf.keras.layers.Input(shape=(None,), dtype=tf.int32),\n )\n\n encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='encoder')\n net = encoder(inputs)['pooled_output']\n net = tf.keras.layers.Dropout(rate=0.1)(net)\n net = tf.keras.layers.Dense(num_classes, activation=None, name='classifier')(net)\n return tf.keras.Model(inputs, net, name='prediction')",
"_____no_output_____"
]
],
[
[
"Let's try running the model on some preprocessed inputs.",
"_____no_output_____"
]
],
[
[
"test_classifier_model = build_classifier_model(2)\nbert_raw_result = test_classifier_model(text_preprocessed)\nprint(tf.sigmoid(bert_raw_result))",
"_____no_output_____"
]
],
[
[
"Let's take a look at the model's structure. You can see the three BERT expected inputs.",
"_____no_output_____"
]
],
[
[
"tf.keras.utils.plot_model(test_classifier_model)",
"_____no_output_____"
]
],
[
[
"## Choose a task from GLUE\n\nYou are going to use a TensorFlow DataSet from the [GLUE](https://www.tensorflow.org/datasets/catalog/glue) benchmark suite.\n\nColab lets you download these small datasets to the local filesystem, and the code below reads them entirely into memory, because the separate TPU worker host cannot access the local filesystem of the colab runtime.\n\nFor bigger datasets, you'll need to create your own [Google Cloud Storage](https://cloud.google.com/storage) bucket and have the TPU worker read the data from there. You can learn more in the [TPU guide](https://www.tensorflow.org/guide/tpu#input_datasets).\n\nIt's recommended to start with the CoLa dataset (for single sentence) or MRPC (for multi sentence) since these are small and don't take long to fine tune.",
"_____no_output_____"
]
],
[
[
"tfds_name = 'glue/cola' #@param ['glue/cola', 'glue/sst2', 'glue/mrpc', 'glue/qqp', 'glue/mnli', 'glue/qnli', 'glue/rte', 'glue/wnli']\n\ntfds_info = tfds.builder(tfds_name).info\n\nsentence_features = list(tfds_info.features.keys())\nsentence_features.remove('idx')\nsentence_features.remove('label')\n\navailable_splits = list(tfds_info.splits.keys())\ntrain_split = 'train'\nvalidation_split = 'validation'\ntest_split = 'test'\nif tfds_name == 'glue/mnli':\n validation_split = 'validation_matched'\n test_split = 'test_matched'\n\nnum_classes = tfds_info.features['label'].num_classes\nnum_examples = tfds_info.splits.total_num_examples\n\nprint(f'Using {tfds_name} from TFDS')\nprint(f'This dataset has {num_examples} examples')\nprint(f'Number of classes: {num_classes}')\nprint(f'Features {sentence_features}')\nprint(f'Splits {available_splits}')\n\nwith tf.device('/job:localhost'):\n # batch_size=-1 is a way to load the dataset into memory\n in_memory_ds = tfds.load(tfds_name, batch_size=-1, shuffle_files=True)\n\n# The code below is just to show some samples from the selected dataset\nprint(f'Here are some sample rows from {tfds_name} dataset')\nsample_dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[train_split])\n\nlabels_names = tfds_info.features['label'].names\nprint(labels_names)\nprint()\n\nsample_i = 1\nfor sample_row in sample_dataset.take(5):\n samples = [sample_row[feature] for feature in sentence_features]\n print(f'sample row {sample_i}')\n for sample in samples:\n print(sample.numpy())\n sample_label = sample_row['label']\n\n print(f'label: {sample_label} ({labels_names[sample_label]})')\n print()\n sample_i += 1",
"_____no_output_____"
]
],
[
[
"The dataset also determines the problem type (classification or regression) and the appropriate loss function for training.",
"_____no_output_____"
]
],
[
[
"def get_configuration(glue_task):\n\n loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n\n if glue_task is 'glue/cola':\n metrics = tfa.metrics.MatthewsCorrelationCoefficient()\n else:\n metrics = tf.keras.metrics.SparseCategoricalAccuracy(\n 'accuracy', dtype=tf.float32)\n\n return metrics, loss",
"_____no_output_____"
]
],
[
[
"## Train your model\n\nFinally, you can train the model end-to-end on the dataset you chose.\n\n### Distribution\n\nRecall the set-up code at the top, which has connected the colab runtime to\na TPU worker with multiple TPU devices. To distribute training onto them, you will create and compile your main Keras model within the scope of the TPU distribution strategy. (For details, see [Distributed training with Keras](https://www.tensorflow.org/tutorials/distribute/keras).)\n\nPreprocessing, on the other hand, runs on the CPU of the worker host, not the TPUs, so the Keras model for preprocessing as well as the training and validation datasets mapped with it are built outside the distribution strategy scope. The call to `Model.fit()` will take care of distributing the passed-in dataset to the model replicas.\n\nNote: The single TPU worker host already has the resource objects (think: a lookup table) needed for tokenization. Scaling up to multiple workers requires use of `Strategy.experimental_distribute_datasets_from_function` with a function that loads the preprocessing model separately onto each worker.\n\n### Optimizer\n\nFine-tuning follows the optimizer set-up from BERT pre-training (as in [Classify text with BERT](https://www.tensorflow.org/tutorials/text/classify_text_with_bert)): It uses the AdamW optimizer with a linear decay of a notional initial learning rate, prefixed with a linear warm-up phase over the first 10% of training steps (`num_warmup_steps`). In line with the BERT paper, the initial learning rate is smaller for fine-tuning (best of 5e-5, 3e-5, 2e-5).",
"_____no_output_____"
]
],
[
[
"epochs = 3\nbatch_size = 32\ninit_lr = 2e-5\n\nprint(f'Fine tuning {tfhub_handle_encoder} model')\nbert_preprocess_model = make_bert_preprocess_model(sentence_features)\n\nwith strategy.scope():\n\n # metric have to be created inside the strategy scope\n metrics, loss = get_configuration(tfds_name)\n\n train_dataset, train_data_size = load_dataset_from_tfds(\n in_memory_ds, tfds_info, train_split, batch_size, bert_preprocess_model)\n steps_per_epoch = train_data_size // batch_size\n num_train_steps = steps_per_epoch * epochs\n num_warmup_steps = num_train_steps // 10\n\n validation_dataset, validation_data_size = load_dataset_from_tfds(\n in_memory_ds, tfds_info, validation_split, batch_size,\n bert_preprocess_model)\n validation_steps = validation_data_size // batch_size\n\n classifier_model = build_classifier_model(num_classes)\n\n optimizer = optimization.create_optimizer(\n init_lr=init_lr,\n num_train_steps=num_train_steps,\n num_warmup_steps=num_warmup_steps,\n optimizer_type='adamw')\n\n classifier_model.compile(optimizer=optimizer, loss=loss, metrics=[metrics])\n\n classifier_model.fit(\n x=train_dataset,\n validation_data=validation_dataset,\n steps_per_epoch=steps_per_epoch,\n epochs=epochs,\n validation_steps=validation_steps)",
"_____no_output_____"
]
],
[
[
"## Export for inference\n\nYou will create a final model that has the preprocessing part and the fine-tuned BERT we've just created.\n\nAt inference time, preprocessing needs to be part of the model (because there is no longer a separate input queue as for training data that does it). Preprocessing is not just computation; it has its own resources (the vocab table) that must be attached to the Keras Model that is saved for export.\nThis final assembly is what will be saved.\n\nYou are going to save the model on colab and later you can download to keep it for the future (**View -> Table of contents -> Files**).\n",
"_____no_output_____"
]
],
[
[
"main_save_path = './my_models'\nbert_type = tfhub_handle_encoder.split('/')[-2]\nsaved_model_name = f'{tfds_name.replace(\"/\", \"_\")}_{bert_type}'\n\nsaved_model_path = os.path.join(main_save_path, saved_model_name)\n\npreprocess_inputs = bert_preprocess_model.inputs\nbert_encoder_inputs = bert_preprocess_model(preprocess_inputs)\nbert_outputs = classifier_model(bert_encoder_inputs)\nmodel_for_export = tf.keras.Model(preprocess_inputs, bert_outputs)\n\nprint(f'Saving {saved_model_path}')\n\n# Save everything on the Colab host (even the variables from TPU memory)\nsave_options = tf.saved_model.SaveOptions(experimental_io_device='/job:localhost')\nmodel_for_export.save(saved_model_path, include_optimizer=False, options=save_options)\n",
"_____no_output_____"
]
],
[
[
"## Test the model\n\nThe final step is testing the results of your exported model.\n\nJust to make some comparison, let's reload the model and test it using some inputs from the test split from the dataset.\n\nNote: The test is done on the colab host, not the TPU worker that it has connected to, so it appears below with explicit device placements. You can omit those when loading the SavedModel elsewhere.",
"_____no_output_____"
]
],
[
[
"with tf.device('/job:localhost'):\n reloaded_model = tf.saved_model.load(saved_model_path)",
"_____no_output_____"
],
[
"#@title Utility methods\n\ndef prepare(record):\n model_inputs = [[record[ft]] for ft in sentence_features]\n return model_inputs\n\n\ndef prepare_serving(record):\n model_inputs = {ft: record[ft] for ft in sentence_features}\n return model_inputs\n\n\ndef print_bert_results(test, bert_result, dataset_name):\n\n bert_result_class = tf.argmax(bert_result, axis=1)[0]\n\n if dataset_name == 'glue/cola':\n print(f'sentence: {test[0].numpy()}')\n if bert_result_class == 1:\n print(f'This sentence is acceptable')\n else:\n print(f'This sentence is unacceptable')\n\n elif dataset_name == 'glue/sst2':\n print(f'sentence: {test[0]}')\n if bert_result_class == 1:\n print(f'This sentence has POSITIVE sentiment')\n else:\n print(f'This sentence has NEGATIVE sentiment')\n\n elif dataset_name == 'glue/mrpc':\n print(f'sentence1: {test[0]}')\n print(f'sentence2: {test[1]}')\n if bert_result_class == 1:\n print(f'Are a paraphrase')\n else:\n print(f'Are NOT a paraphrase')\n\n elif dataset_name == 'glue/qqp':\n print(f'question1: {test[0]}')\n print(f'question2: {test[1]}')\n if bert_result_class == 1:\n print(f'Questions are similar')\n else:\n print(f'Questions are NOT similar')\n\n elif dataset_name == 'glue/mnli':\n print(f'premise : {test[0]}')\n print(f'hypothesis: {test[1]}')\n if bert_result_class == 1:\n print(f'This premise is NEUTRAL to the hypothesis')\n elif bert_result_class == 2:\n print(f'This premise CONTRADICTS the hypothesis')\n else:\n print(f'This premise ENTAILS the hypothesis')\n\n elif dataset_name == 'glue/qnli':\n print(f'question: {test[0]}')\n print(f'sentence: {test[1]}')\n if bert_result_class == 1:\n print(f'The question is NOT answerable by the sentence')\n else:\n print(f'The question is answerable by the sentence')\n\n elif dataset_name == 'glue/rte':\n print(f'sentence1: {test[0]}')\n print(f'sentence2: {test[1]}')\n if bert_result_class == 1:\n print(f'Sentence1 DOES NOT entails sentence2')\n else:\n print(f'Sentence1 entails sentence2')\n\n elif dataset_name == 'glue/wnli':\n print(f'sentence1: {test[0]}')\n print(f'sentence2: {test[1]}')\n if bert_result_class == 1:\n print(f'Sentence1 DOES NOT entails sentence2')\n else:\n print(f'Sentence1 entails sentence2')\n\n print(f'Bert raw results:{bert_result[0]}')\n print()",
"_____no_output_____"
]
],
[
[
"### Test",
"_____no_output_____"
]
],
[
[
"with tf.device('/job:localhost'):\n test_dataset = tf.data.Dataset.from_tensor_slices(in_memory_ds[test_split])\n for test_row in test_dataset.shuffle(1000).map(prepare).take(5):\n if len(sentence_features) == 1:\n result = reloaded_model(test_row[0])\n else:\n result = reloaded_model(list(test_row))\n\n print_bert_results(test_row, result, tfds_name)",
"_____no_output_____"
]
],
[
[
"If you want to use your model on [TF Serving](https://www.tensorflow.org/tfx/guide/serving), remember that it will call your SavedModel through one of its named signatures. Notice there are some small differences in the input. In Python, you can test them as follows:",
"_____no_output_____"
]
],
[
[
"with tf.device('/job:localhost'):\n serving_model = reloaded_model.signatures['serving_default']\n for test_row in test_dataset.shuffle(1000).map(prepare_serving).take(5):\n result = serving_model(**test_row)\n # The 'prediction' key is the classifier's defined model name.\n print_bert_results(list(test_row.values()), result['prediction'], tfds_name)",
"_____no_output_____"
]
],
[
[
"You did it! Your saved model could be used for serving or simple inference in a process, with a simpler api with less code and easier to maintain.\n\n## Next Steps\n\nNow that you've tried one of the base BERT models, you can try other ones to achieve more accuracy or maybe with smaller model versions.\n\nYou can also try in other datasets.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a2947dabc8b6590a1464a2a449e169b0804b377
| 8,639 |
ipynb
|
Jupyter Notebook
|
06_Reusable_Components.ipynb
|
thewtex/modern-insights-from-microscopy-images
|
60017e37cbc5042a4a1f352153487b5529baf5f7
|
[
"Apache-2.0"
] | 2 |
2020-12-01T20:14:20.000Z
|
2020-12-03T00:32:05.000Z
|
06_Reusable_Components.ipynb
|
thewtex/modern-insights-from-microscopy-images
|
60017e37cbc5042a4a1f352153487b5529baf5f7
|
[
"Apache-2.0"
] | 2 |
2021-09-28T05:41:11.000Z
|
2022-02-26T10:18:03.000Z
|
06_Reusable_Components.ipynb
|
thewtex/modern-insights-from-microscopy-images
|
60017e37cbc5042a4a1f352153487b5529baf5f7
|
[
"Apache-2.0"
] | 2 |
2021-01-08T16:51:45.000Z
|
2021-01-09T15:18:10.000Z
| 31.644689 | 268 | 0.564417 |
[
[
[
"# Open, Re-usable Deep Learning Components on the Web ",
"_____no_output_____"
],
[
"## Learning objectives\n\n- Use [ImJoy](https://imjoy.io/#/) web-based imaging components\n- Create a JavaScript-based ImJoy plugin\n- Create a Python-based ImJoy plugin \n\n*See also:* the [I2K 2020 Tutorial: ImJoying Interactive Bioimage Analysis\nwith Deep Learning, ImageJ.JS &\nFriends](https://www.janelia.org/sites/default/files/You%20%2B%20Janelia/Conferences/10.pdf)",
"_____no_output_____"
],
[
"ImJoy is a plugin powered hybrid computing platform for deploying deep learning applications such as advanced image analysis tools.\n\nImJoy runs on mobile and desktop environment cross different operating systems, plugins can run in the browser, localhost, remote and cloud servers.\n\nWith ImJoy, delivering Deep Learning tools to the end users is simple and easy thanks to\nits flexible plugin system and sharable plugin URL. Developer can easily add rich and interactive web interfaces to existing Python code.\n\n<img src=\"https://github.com/imjoy-team/ImJoy/raw/master/docs/assets/imjoy-overview.jpg\" width=\"600px\"></img>\n\nCheckout the documentation for how to get started and more details\nfor how to develop ImJoy plugins: [ImJoy Docs](https://imjoy.io/docs)\n\n## Key Features of ImJoy\n * Minimal and flexible plugin powered web application\n * Server-less progressive web application with offline support\n * Support mobile devices\n\n * Rich and interactive user interface powered by web technologies\n - use any existing web design libraries\n - Rendering multi-dimensional data in 3D with webGL, Three.js etc.\n * Easy-to-use workflow composition\n * Isolated workspaces for grouping plugins\n * Self-contained plugin prototyping and development\n - Built-in code editor, no extra IDE is needed for development\n * Powerful and extendable computational backends for browser, local and cloud computing\n - Support Javascript, native Python and web Python\n - Concurrent plugin execution through asynchronous programming\n - Run Python plugins in the browser with Webassembly\n - Browser plugins are isolated with secured sandboxes\n - Support `async/await` syntax for Python3 and Javascript\n - Support Conda virtual environments and pip packages for Python\n - Support libraries hosted on Github or CDNs for javascript\n - Easy plugin deployment and sharing through GitHub or Gist\n - Deploying your own plugin repository to Github\n* Native support for n-dimensional arrays and tensors\n - Support ndarrays from Numpy for data exchange\n\n\n**ImJoy greatly accelerates the development and dissemination of new tools.** You can develop plugins in ImJoy, deploy the plugin file to Github, and share the plugin URL through social networks. Users can then use it by a single click, even on a mobile phone\n\n<a href=\"https://imjoy.io/#/app?p=imjoy-team/example-plugins:Skin-Lesion-Analyzer\" target=\"_blank\">\n <img src=\"https://github.com/imjoy-team/ImJoy/raw/master/docs/assets/imjoy-sharing.jpg\" width=\"500px\"></img>\n</a>",
"_____no_output_____"
],
[
"Examine the ImJoy extension in the notebook toolbar\n",
"_____no_output_____"
]
],
[
[
"#ciskip\n# Create an ImJoy plugin in Python that uses itk-vtk-viewer to visualize images\nimport imageio\nimport numpy as np\nfrom imjoy_rpc import api\n\nclass ImJoyPlugin():\n def setup(self):\n api.log('plugin initialized')\n\n async def run(self, ctx):\n viewer = await api.showDialog(src=\"https://kitware.github.io/itk-vtk-viewer/app/\")\n\n # show a 3D volume\n image_array = np.random.randint(0, 255, [10,10,10], dtype='uint8')\n \n # show a 2D image\n # image_array = imageio.imread('imageio:chelsea.png')\n\n await viewer.setImage(image_array)\n\napi.export(ImJoyPlugin())",
"_____no_output_____"
],
[
"# Create a JavaScript ImJoy plugin\nfrom IPython.display import HTML\nmy_plugin_source = HTML('''\n<docs lang=\"markdown\">\n[TODO: write documentation for this plugin.]\n</docs>\n\n<config lang=\"json\">\n{\n \"name\": \"Untitled Plugin\",\n \"type\": \"window\",\n \"tags\": [],\n \"ui\": \"\",\n \"version\": \"0.1.0\",\n \"cover\": \"\",\n \"description\": \"[TODO: describe this plugin with one sentence.]\",\n \"icon\": \"extension\",\n \"inputs\": null,\n \"outputs\": null,\n \"api_version\": \"0.1.8\",\n \"env\": \"\",\n \"permissions\": [],\n \"requirements\": [],\n \"dependencies\": [],\n \"defaults\": {\"w\": 20, \"h\": 10}\n}\n</config>\n\n<script lang=\"javascript\">\nclass ImJoyPlugin {\n async setup() {\n api.log('initialized')\n }\n\n async run(ctx) {\n\n }\n}\n\napi.export(new ImJoyPlugin())\n</script>\n\n<window lang=\"html\">\n <div>\n <p>\n Hello World\n </p>\n </div>\n</window>\n\n<style lang=\"css\">\n\n</style>\n''')",
"_____no_output_____"
],
[
"#ciskip\n# Register the plugin\nfrom imjoy_rpc import api\nclass ImJoyPlugin():\n async def setup(self):\n pass\n\n async def run(self, ctx):\n # for regular plugin\n # p = await api.getPlugin(my_plugin_source)\n\n # or for window plugin\n # await api.createWindow(src=my_plugin_source)\n await api.showDialog(src=my_plugin_source)\n\napi.export(ImJoyPlugin())",
"_____no_output_____"
]
],
[
[
"## Exercises",
"_____no_output_____"
],
[
"Try out plugins from the [ImJoy reference plugin repository](https://imjoy.io/repo/).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a29575e9793f6ef5f8c66c1fbae49683525047b
| 28,145 |
ipynb
|
Jupyter Notebook
|
Multi_label_classification.ipynb
|
Pratikshya1201/Multi-Label-Text-Classification-for-Stack-Overflow-Tag-Prediction
|
7847a817a572d952de8ad8cab3938c5490ad3070
|
[
"Apache-2.0"
] | null | null | null |
Multi_label_classification.ipynb
|
Pratikshya1201/Multi-Label-Text-Classification-for-Stack-Overflow-Tag-Prediction
|
7847a817a572d952de8ad8cab3938c5490ad3070
|
[
"Apache-2.0"
] | null | null | null |
Multi_label_classification.ipynb
|
Pratikshya1201/Multi-Label-Text-Classification-for-Stack-Overflow-Tag-Prediction
|
7847a817a572d952de8ad8cab3938c5490ad3070
|
[
"Apache-2.0"
] | null | null | null | 28.63174 | 227 | 0.364576 |
[
[
[
"# MULTI-LABEL TEXT CLASSIFICATION FOR STACK OVERFLOW TAG PREDICTION",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.preprocessing import MultiLabelBinarizer\nfrom sklearn.model_selection import train_test_split\n\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import LinearSVC\n\nfrom sklearn.multiclass import OneVsRestClassifier",
"_____no_output_____"
],
[
"url = 'https://raw.githubusercontent.com/laxmimerit/All-CSV-ML-Data-Files-Download/master/stackoverflow.csv'\ndf = pd.read_csv(url, index_col=0) # We provide index_col=0 as one of the column is not defined(unnamed)\ndf.head(5)",
"_____no_output_____"
]
],
[
[
"# Pre-Processing",
"_____no_output_____"
]
],
[
[
"# tf-idf will be used for pre-processing. tf-idf is known as term frequency.\n# We need to change the tags column from string to list in order to do one hot encoding. \n#In order to do that we are going to evaluate it. For evaluation, \n# we have to import the ast library.",
"_____no_output_____"
],
[
"import ast",
"_____no_output_____"
],
[
"ast.literal_eval(df['Tags'].iloc[0]) # This converts the Tags column from string to list.",
"_____no_output_____"
],
[
"df['Tags'] = df['Tags'].apply(lambda x: ast.literal_eval(x)) \n # To convert all the rows of the Tags to list, we use lambda function",
"_____no_output_____"
],
[
"df.head(5)",
"_____no_output_____"
],
[
"y = df['Tags'] # We will do One-Hot Encoding and convert y to MultiLabel Binarizer\ny",
"_____no_output_____"
],
[
"multilabel = MultiLabelBinarizer() # MultiLabelBinazrizer object",
"_____no_output_____"
],
[
"y = multilabel.fit_transform(df['Tags'])",
"_____no_output_____"
],
[
"y # Converted Tags to one hot encoding(All zeroes and ones)",
"_____no_output_____"
],
[
"# To check for which classes y got converted\nmultilabel.classes_",
"_____no_output_____"
],
[
"pd.DataFrame(y, columns = multilabel.classes_) # We need to convert all the text to ones and zeroes to train our model",
"_____no_output_____"
],
[
"# Now we will use Tfidf for tokenization. If we select analyzer=word, then it will do tokenization word by word else if we \n# choose analyzer=char, it will tokenize character by character.\n# lets say you have -> l,e,t,s,...\n# max_features ensures that we should not select dictionary size more than the max_features size. ",
"_____no_output_____"
],
[
"tfidf = TfidfVectorizer(analyzer='word', max_features=10000, ngram_range=(1,3), stop_words='english')\nX = tfidf.fit_transform(df['Text'])",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"# tfidf.vocabulary_ (for what are the words the tfidf has done tokenization)",
"_____no_output_____"
],
[
"X.shape, y.shape # X has 10,000 columns of Text from stackoverflow and y has 20 columns of Tags from stackoverflow\n # total no. of rows are 48976",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0) ",
"_____no_output_____"
]
],
[
[
"# Build Model",
"_____no_output_____"
]
],
[
[
"sgd = SGDClassifier()\nlr = LogisticRegression(solver='lbfgs') \nsvc = LinearSVC()",
"_____no_output_____"
]
],
[
[
"### Jaccard similarity, or Jaccard index is the size of the intersection of the predicted labels and true labels by the size of the union of the predicted and true labels. It ranges from 0 to 1 and 1 is the perfect score.",
"_____no_output_____"
]
],
[
[
"def j_score(y_true, y_pred):\n # minimum = intersection, maximum = union\n jaccard = np.minimum(y_true, y_pred).sum(axis = 1)/np.maximum(y_true, y_pred).sum(axis = 1)\n return jaccard.mean()*100\n \ndef print_score(y_pred, clf):\n print(\"Clf: \", clf.__class__.__name__) # It will tell us which classifier we are using\n print('Jacard score: {}'.format(j_score(y_test, y_pred))) # To print the Jaccard score\n print('----') ",
"_____no_output_____"
],
[
"for classifier in [LinearSVC(C=1.5, penalty = 'l1', dual=False)]:\n clf = OneVsRestClassifier(classifier)\n clf.fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n print_score(y_pred, classifier)",
"Clf: LinearSVC\nJacard score: 63.87096774193548\n----\n"
],
[
"for classifier in [sgd, lr, svc]: # Iterating the ML algorithms\n clf = OneVsRestClassifier(classifier) # From 20 classes, we will select one at a time\n clf.fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n print_score(y_pred, classifier)",
"Clf: SGDClassifier\nJacard score: 52.61960664216687\n----\nClf: LogisticRegression\nJacard score: 51.1014699877501\n----\nClf: LinearSVC\nJacard score: 62.42105621342044\n----\n"
]
],
[
[
"## Model Test with Real Data",
"_____no_output_____"
]
],
[
[
"x = [ 'how to write ml code in python and java i have data but do not know how to do it']",
"_____no_output_____"
],
[
"xt = tfidf.transform(x) # It will return a sparse matrix",
"_____no_output_____"
],
[
"clf.predict(xt)",
"_____no_output_____"
],
[
"multilabel.inverse_transform(clf.predict(xt)) # To check which classes has value as 1",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a295ecdc54ca489fc303c771ce4762c5d490717
| 629,799 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/figure ploting fu data 2021-checkpoint.ipynb
|
xhguo86/spiced
|
171ae506b747c20bf08176ce58d5c61345aca1d4
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/figure ploting fu data 2021-checkpoint.ipynb
|
xhguo86/spiced
|
171ae506b747c20bf08176ce58d5c61345aca1d4
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/figure ploting fu data 2021-checkpoint.ipynb
|
xhguo86/spiced
|
171ae506b747c20bf08176ce58d5c61345aca1d4
|
[
"MIT"
] | null | null | null | 192.716952 | 78,460 | 0.867709 |
[
[
[
"import numpy as np\nimport pandas as pd\n\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"df = pd.read_excel('results fdu.xlsx')\ndf2 = pd.read_excel('data trait category II 10 Mar 2021 all data - plain text.xlsx')",
"_____no_output_____"
],
[
"df2.columns",
"_____no_output_____"
],
[
"mean_N = df2.groupby(['Y_category2'])['Code'].count()\nmean_N ",
"_____no_output_____"
],
[
"mean_ = df2.groupby(['Y_category2','design.1'])['Code'].count()\nmean_ ",
"_____no_output_____"
],
[
"# data split\nindi_effects = df[df['effect'] == 'individual effects']",
"_____no_output_____"
],
[
"indi_effects",
"_____no_output_____"
],
[
"indi_effects[df['Y'] == 'fitness']\n ",
"<ipython-input-259-10ba50126900>:1: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n indi_effects[df['Y'] == 'fitness']\n"
],
[
"\n\n# individual effects - fitness\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'fitness']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Fitness (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='fitness individual effects.png') \nplt.show()\n\n# add significance\n \n ",
"<ipython-input-260-bfcf0f3db6e0>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'fitness']\n"
],
[
"# individual effects - Size\n\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Size']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Size (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Size individual effects.png') \nplt.show()\n\n# add significance",
"<ipython-input-262-0221cde6d5cc>:6: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Size']\n"
]
],
[
[
"Fitness 73\nShootallocation 104\nSize 240\nSize_above 120\nSize_below 109\nnutrient 150\nnutrient_above 108\nnutrient_below 43\nperformance 403\nsize_above 76\nsize_below 37\nName: Code, dtype: int64",
"_____no_output_____"
]
],
[
[
"df[Y]",
"_____no_output_____"
],
[
"# individual effects - Size aboveground\n\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Size beloground']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Size aboveground (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Size_above.png') \nplt.show()\n\n# add significance",
"<ipython-input-264-5b304dc94b1c>:6: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Size beloground']\n"
],
[
"# individual effects - Size belowground \n\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Size beloground']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Size belowground (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Size_below.png') \nplt.show()\n\n# add significance",
"<ipython-input-265-629cffb3bf3c>:6: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Size beloground']\n"
],
[
"# individual effects - Nutrient\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Nutrient']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Nutrient (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Nutrient.png') \nplt.show()\n\n# add significance",
"<ipython-input-266-4fe28374f54c>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Nutrient']\n"
],
[
"# individual effects - Nutrient aboveground\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Nutrient above']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Nutrient shoot (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Nutrient_shoot.png') \nplt.show()\n\n# add significance",
"<ipython-input-267-1466fc0f1b1c>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Nutrient above']\n"
],
[
"# individual effects - Nutrient belowground\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Nutrient below']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Nutrient root (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='Nutrient_root.png') \nplt.show()\n\n# add significance",
"<ipython-input-268-7fbc7870b473>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Nutrient below']\n"
],
[
"# individual effects - Performance\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Overall performance']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Overall performance(lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='performance.png') \nplt.show()\n\n# add significance",
"<ipython-input-269-e5305bf9f4ad>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Overall performance']\n"
],
[
"# individual effects - Shoot allocation\nplt.rcdefaults()\nfig, ax = plt.subplots(figsize=(5,4), dpi= 100)\n\ndata1 = indi_effects[df['Y'] == 'Shoot allocation']\nplt.errorbar(x= \"estimate\",y= \"factor_n\", xerr = \"ci_bar\", data = data1, \n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\nax.invert_yaxis() # labels read top-to-bottom\nax.set_xlabel('Shoot allocation (lnRR++)')\nax.set_title('Individual effects')\n\n# Plot a Vertical Line\nplt.axvline(x=0, ymin=0, ymax=1,color = 'b',linewidth=1, linestyle = '--')\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='shoot_allocation.png') \nplt.show()\n\n# add significance",
"<ipython-input-270-3d7c43103bf1>:5: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data1 = indi_effects[df['Y'] == 'Shoot allocation']\n"
],
[
"# main effect\n# size \n# nutrient\n# fitness\n# Performance\n\n# first line \n# data\nmain_effects = df[(df['effect'] == 'Main effect')&(df['Y'] == 'Shoot allocation')]\ndata2 = main_effects[df['design'] == 'co2']\n\n#创建新的figure\nfig,ax = plt.subplots(4,4,figsize=(16, 12), sharex=True, sharey=True,dpi= 100)\nplt.xticks([]) \nplt.yticks([])",
"<ipython-input-281-678928d3b037>:10: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[df['design'] == 'co2']\n"
],
[
"# main effect\n# size \n# nutrient\n# fitness\n# Performance\n\n# first line \n# data\nmain_effects = df[(df['effect'] == 'Main effect')&(df['Y'] == 'Shoot allocation')]\ndata2 = main_effects[df['design'] == 'co2']\n#创建新的figure\n\nfig,ax = plt.subplots(4,4,figsize=(16, 12), sharex=True, sharey=True,dpi= 100)\nplt.xticks([]) \nplt.yticks([])",
"<ipython-input-272-3b3523ce95db>:10: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[df['design'] == 'co2']\n"
],
[
"fig,ax = plt.subplots(4,4,figsize=(16, 12),dpi = 100)\nplt.xticks([])\nplt.yticks([])",
"_____no_output_____"
],
[
"Fitness 73\nShootallocation 104\nSize 240\nSize_above 120\nSize_below 109\nnutrient 150\nnutrient_above 108\nnutrient_below 43\nperformance 403\nsize_above 76\nsize_below 37",
"_____no_output_____"
],
[
"# main effect\n# size \n# nutrient\n# fitness\n# Performance\n\n# first line \n# data\nmain_effects = df[df['effect'] == 'Main effect']\n\n#创建新的figure\n\nfig,ax = plt.subplots(4,4,figsize=(16, 12), sharex=True, sharey=True,dpi= 100)\nplt.xticks([]) \nplt.yticks([])\n#fig, ax1 = plt.subplots(figsize=(3,3))\n\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Size\\n (Hedges‘ d++)',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n \n#第2个子图的内容\ndata2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'drought')]\nplt.subplot(4,4,2) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,2)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第3个子图的内容\ndata2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'rain')]\nplt.subplot(4,4,3) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,3)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,6.01,2)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第4个子图的内容\ndata2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'warm')]\nplt.subplot(4,4,4) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,4)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第5个子图的内容\ndata2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'co2')]\nplt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,5)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,6.01,2)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Nutrient\\n (Hedges‘ d++)',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第6个子图的内容\ndata2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'drought')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,6)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第7个子图的内容\ndata2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'rain')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,7)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第8个子图的内容\ndata2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'warm')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,8)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第9个子图的内容\ndata2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'co2')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,9)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Fitness\\n (Hedges‘ d++)',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第10个子图的内容\ndata2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'drought')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,10)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第11个子图的内容\ndata2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'rain')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,11)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第12个子图的内容\ndata2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'warm')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,12)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第13个子图的内容\ndata2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'co2')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,13)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Overall performance\\n (Hedges‘ d++)',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第14个子图的内容\ndata2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'drought')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,14)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第15个子图的内容\ndata2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'rain')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,15)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n##第16个子图的内容\ndata2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'warm')]\n#plt.subplot(4,4,5) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,16)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax1.set_title('Main effects',)\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')",
"<ipython-input-10-431b50c1b1b3>:20: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'co2')]\n<ipython-input-10-431b50c1b1b3>:22: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,1)\n<ipython-input-10-431b50c1b1b3>:40: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'drought')]\n<ipython-input-10-431b50c1b1b3>:42: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,2)\n<ipython-input-10-431b50c1b1b3>:60: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'rain')]\n<ipython-input-10-431b50c1b1b3>:62: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,3)\n<ipython-input-10-431b50c1b1b3>:80: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Size')&(df['design'] == 'warm')]\n<ipython-input-10-431b50c1b1b3>:82: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,4)\n<ipython-input-10-431b50c1b1b3>:100: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'co2')]\n<ipython-input-10-431b50c1b1b3>:102: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,5)\n<ipython-input-10-431b50c1b1b3>:120: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'drought')]\n<ipython-input-10-431b50c1b1b3>:140: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'rain')]\n<ipython-input-10-431b50c1b1b3>:160: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Nutrient')&(df['design'] == 'warm')]\n<ipython-input-10-431b50c1b1b3>:180: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'co2')]\n<ipython-input-10-431b50c1b1b3>:200: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'drought')]\n<ipython-input-10-431b50c1b1b3>:220: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'rain')]\n<ipython-input-10-431b50c1b1b3>:240: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'fitness')&(df['design'] == 'warm')]\n<ipython-input-10-431b50c1b1b3>:260: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'co2')]\n<ipython-input-10-431b50c1b1b3>:280: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'drought')]\n<ipython-input-10-431b50c1b1b3>:300: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'rain')]\n<ipython-input-10-431b50c1b1b3>:320: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Overall performance')&(df['design'] == 'warm')]\n"
],
[
"#第2个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(4,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(4,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,2.01,1)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n\n\n\n# add the sample size of each setting\n# save file\nplt.savefig(fname='hd.png') \nplt.show()\n# label ",
"<ipython-input-198-c72999115c11>:18: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\n<ipython-input-198-c72999115c11>:21: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(4,4,1)\n"
],
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\nfrom scipy.stats import sem\n\nsns.pointplot(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", hue=\"design\", data = main_effects)",
"_____no_output_____"
],
[
"main_effects",
"_____no_output_____"
],
[
"# main effect aboveground and belowground size\n# above1234\n# below1234",
"_____no_output_____"
],
[
"# main effect aboveground and belowground nutrient\n# above1234\n# below1234",
"_____no_output_____"
],
[
"mean_N = df.groupby(['Y']).count()\nmean_N ",
"_____no_output_____"
],
[
"# main effect\n# size \n# nutrient\n# fitness\n# Performance\n\n# first line \n# data\nmain_effects = df[df['effect'] == 'Main effect']\n\n#创建新的figure\n\nfig,ax = plt.subplots(1,4,figsize=(18, 4), sharex=True, sharey=True,dpi= 100)\nplt.xticks([]) \nplt.yticks([])\n#fig, ax1 = plt.subplots(figsize=(3,3))\n\n\n#第1个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\nplt.subplot(1,4,1) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(1,4,1)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,1.51,0.5)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nax1.set_title('n = x')\nplt.margins(x=0.33)\nax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第2个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'drought')]\nplt.subplot(1,4,2) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(1,4,2)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,1.51,0.5)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nax1.set_title('n = x')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第3个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'rain')]\nplt.subplot(1,4,3) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(1,4,3)\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-2.0,6.01,2)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nax1.set_title('n = x')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\n#ax.set_title('Main effects')\n# Plot a horizonal Line\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n\n#第4个子图的内容\ndata2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'warm')]\n#plt.subplot(1,4,4) # 增加一个子图,三个参数分别表示:行数,列数,子图序号。i=0时,添加第一个子图\nax1 = plt.subplot(1,4,4)\n#第2个子图的内容\nplt.errorbar(y= \"estimate\",x= \"factor\", yerr = \"ci_bar\", data = data2, elinewidth=2,\n fmt='-o', color='black',linestyle='None',capthick=0.1)\n# ax.set_yticks('factor')\n# ax.set_yticklabels('factor')\n#plt.xticks(np.arange(3), ['N', 'C', 'N x C']) # 不显示x轴标尺\n#ax1.set_yticklabels([]) \nplt.yticks(np.arange(-1.0,2.51,0.5)) # 显示y轴标尺\n#ax1.set_xlabel('CO2')\nax1.set_title('n = x')\nplt.margins(x=0.33)\n#ax1.set_ylabel('Hedges‘ d++',labelpad=None)\nax1.get_yaxis().get_offset_text().set_x(-0.075)\nax1.get_yaxis().get_offset_text().set_size(10)\nplt.axhline(y=0, xmin=0, xmax=1,color = 'b',linewidth=1, linestyle = '--')\n#plt.figtext(0.86, 0.81,'n = xx')\nplt.figtext(verticalalignment='baseline', horizontalalignment='left', multialignment='left',text ='n = xx')\n#ax.set_title('Main effects')\n# Plot a horizonal Line\n",
"<ipython-input-19-d520ad1ef209>:20: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'co2')]\n<ipython-input-19-d520ad1ef209>:22: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(1,4,1)\n<ipython-input-19-d520ad1ef209>:41: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'drought')]\n<ipython-input-19-d520ad1ef209>:43: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(1,4,2)\n<ipython-input-19-d520ad1ef209>:62: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'rain')]\n<ipython-input-19-d520ad1ef209>:64: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax1 = plt.subplot(1,4,3)\n<ipython-input-19-d520ad1ef209>:83: UserWarning: Boolean Series key will be reindexed to match DataFrame index.\n data2 = main_effects[(df['Y'] == 'Shoot allocation')&(df['design'] == 'warm')]\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2971ada4ecee63751d852a422645a0eade1f0f
| 247,589 |
ipynb
|
Jupyter Notebook
|
Convolutional_Neural_Networks/Week3/Autonomous+driving+application+-+Car+detection+-+v1.ipynb
|
yhpark-knu/deeplearning.ai-Assignments
|
1db8b4faf71e6ae2714420aec8b6b0f7516363e7
|
[
"MIT"
] | 393 |
2018-02-17T07:28:34.000Z
|
2022-03-30T16:26:23.000Z
|
Convolutional_Neural_Networks/Week3/Autonomous+driving+application+-+Car+detection+-+v1.ipynb
|
guinessjulie/deeplearning.ai-Assignments
|
090a004b2bfcf84448f6e4e557b4aeff8568fb9f
|
[
"MIT"
] | 2 |
2020-06-01T03:38:50.000Z
|
2020-10-05T04:31:42.000Z
|
Convolutional_Neural_Networks/Week3/Autonomous+driving+application+-+Car+detection+-+v1.ipynb
|
guinessjulie/deeplearning.ai-Assignments
|
090a004b2bfcf84448f6e4e557b4aeff8568fb9f
|
[
"MIT"
] | 477 |
2018-02-10T16:32:50.000Z
|
2022-03-25T17:52:09.000Z
| 176.975697 | 179,682 | 0.855183 |
[
[
[
"# Autonomous driving - Car detection\n\nWelcome to your week 3 programming assignment. You will learn about object detection using the very powerful YOLO model. Many of the ideas in this notebook are described in the two YOLO papers: Redmon et al., 2016 (https://arxiv.org/abs/1506.02640) and Redmon and Farhadi, 2016 (https://arxiv.org/abs/1612.08242). \n\n**You will learn to**:\n- Use object detection on a car detection dataset\n- Deal with bounding boxes\n\nRun the following cell to load the packages and dependencies that are going to be useful for your journey!",
"_____no_output_____"
]
],
[
[
"import argparse\nimport os\nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import imshow\nimport scipy.io\nimport scipy.misc\nimport numpy as np\nimport pandas as pd\nimport PIL\nimport tensorflow as tf\nfrom keras import backend as K\nfrom keras.layers import Input, Lambda, Conv2D\nfrom keras.models import load_model, Model\nfrom yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes\nfrom yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body\n\n%matplotlib inline",
"Using TensorFlow backend.\n"
]
],
[
[
"**Important Note**: As you can see, we import Keras's backend as K. This means that to use a Keras function in this notebook, you will need to write: `K.function(...)`.",
"_____no_output_____"
],
[
"## 1 - Problem Statement\n\nYou are working on a self-driving car. As a critical component of this project, you'd like to first build a car detection system. To collect data, you've mounted a camera to the hood (meaning the front) of the car, which takes pictures of the road ahead every few seconds while you drive around. \n\n<center>\n<video width=\"400\" height=\"200\" src=\"nb_images/road_video_compressed2.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n\n<caption><center> Pictures taken from a car-mounted camera while driving around Silicon Valley. <br> We would like to especially thank [drive.ai](https://www.drive.ai/) for providing this dataset! Drive.ai is a company building the brains of self-driving vehicles.\n</center></caption>\n\n<img src=\"nb_images/driveai.png\" style=\"width:100px;height:100;\">\n\nYou've gathered all these images into a folder and have labelled them by drawing bounding boxes around every car you found. Here's an example of what your bounding boxes look like.\n\n<img src=\"nb_images/box_label.png\" style=\"width:500px;height:250;\">\n<caption><center> <u> **Figure 1** </u>: **Definition of a box**<br> </center></caption>\n\nIf you have 80 classes that you want YOLO to recognize, you can represent the class label $c$ either as an integer from 1 to 80, or as an 80-dimensional vector (with 80 numbers) one component of which is 1 and the rest of which are 0. The video lectures had used the latter representation; in this notebook, we will use both representations, depending on which is more convenient for a particular step. \n\nIn this exercise, you will learn how YOLO works, then apply it to car detection. Because the YOLO model is very computationally expensive to train, we will load pre-trained weights for you to use. ",
"_____no_output_____"
],
[
"## 2 - YOLO",
"_____no_output_____"
],
[
"YOLO (\"you only look once\") is a popular algoritm because it achieves high accuracy while also being able to run in real-time. This algorithm \"only looks once\" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.\n\n### 2.1 - Model details\n\nFirst things to know:\n- The **input** is a batch of images of shape (m, 608, 608, 3)\n- The **output** is a list of bounding boxes along with the recognized classes. Each bounding box is represented by 6 numbers $(p_c, b_x, b_y, b_h, b_w, c)$ as explained above. If you expand $c$ into an 80-dimensional vector, each bounding box is then represented by 85 numbers. \n\nWe will use 5 anchor boxes. So you can think of the YOLO architecture as the following: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).\n\nLets look in greater detail at what this encoding represents. \n\n<img src=\"nb_images/architecture.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 2** </u>: **Encoding architecture for YOLO**<br> </center></caption>\n\nIf the center/midpoint of an object falls into a grid cell, that grid cell is responsible for detecting that object.",
"_____no_output_____"
],
[
"Since we are using 5 anchor boxes, each of the 19 x19 cells thus encodes information about 5 boxes. Anchor boxes are defined only by their width and height.\n\nFor simplicity, we will flatten the last two last dimensions of the shape (19, 19, 5, 85) encoding. So the output of the Deep CNN is (19, 19, 425).\n\n<img src=\"nb_images/flatten.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 3** </u>: **Flattening the last two last dimensions**<br> </center></caption>",
"_____no_output_____"
],
[
"Now, for each box (of each cell) we will compute the following elementwise product and extract a probability that the box contains a certain class.\n\n<img src=\"nb_images/probability_extraction.png\" style=\"width:700px;height:400;\">\n<caption><center> <u> **Figure 4** </u>: **Find the class detected by each box**<br> </center></caption>\n\nHere's one way to visualize what YOLO is predicting on an image:\n- For each of the 19x19 grid cells, find the maximum of the probability scores (taking a max across both the 5 anchor boxes and across different classes). \n- Color that grid cell according to what object that grid cell considers the most likely.\n\nDoing this results in this picture: \n\n<img src=\"nb_images/proba_map.png\" style=\"width:300px;height:300;\">\n<caption><center> <u> **Figure 5** </u>: Each of the 19x19 grid cells colored according to which class has the largest predicted probability in that cell.<br> </center></caption>\n\nNote that this visualization isn't a core part of the YOLO algorithm itself for making predictions; it's just a nice way of visualizing an intermediate result of the algorithm. \n",
"_____no_output_____"
],
[
"Another way to visualize YOLO's output is to plot the bounding boxes that it outputs. Doing that results in a visualization like this: \n\n<img src=\"nb_images/anchor_map.png\" style=\"width:200px;height:200;\">\n<caption><center> <u> **Figure 6** </u>: Each cell gives you 5 boxes. In total, the model predicts: 19x19x5 = 1805 boxes just by looking once at the image (one forward pass through the network)! Different colors denote different classes. <br> </center></caption>\n\nIn the figure above, we plotted only boxes that the model had assigned a high probability to, but this is still too many boxes. You'd like to filter the algorithm's output down to a much smaller number of detected objects. To do so, you'll use non-max suppression. Specifically, you'll carry out these steps: \n- Get rid of boxes with a low score (meaning, the box is not very confident about detecting a class)\n- Select only one box when several boxes overlap with each other and detect the same object.\n\n",
"_____no_output_____"
],
[
"### 2.2 - Filtering with a threshold on class scores\n\nYou are going to apply a first filter by thresholding. You would like to get rid of any box for which the class \"score\" is less than a chosen threshold. \n\nThe model gives you a total of 19x19x5x85 numbers, with each box described by 85 numbers. It'll be convenient to rearrange the (19,19,5,85) (or (19,19,425)) dimensional tensor into the following variables: \n- `box_confidence`: tensor of shape $(19 \\times 19, 5, 1)$ containing $p_c$ (confidence probability that there's some object) for each of the 5 boxes predicted in each of the 19x19 cells.\n- `boxes`: tensor of shape $(19 \\times 19, 5, 4)$ containing $(b_x, b_y, b_h, b_w)$ for each of the 5 boxes per cell.\n- `box_class_probs`: tensor of shape $(19 \\times 19, 5, 80)$ containing the detection probabilities $(c_1, c_2, ... c_{80})$ for each of the 80 classes for each of the 5 boxes per cell.\n\n**Exercise**: Implement `yolo_filter_boxes()`.\n1. Compute box scores by doing the elementwise product as described in Figure 4. The following code may help you choose the right operator: \n```python\na = np.random.randn(19*19, 5, 1)\nb = np.random.randn(19*19, 5, 80)\nc = a * b # shape of c will be (19*19, 5, 80)\n```\n2. For each box, find:\n - the index of the class with the maximum box score ([Hint](https://keras.io/backend/#argmax)) (Be careful with what axis you choose; consider using axis=-1)\n - the corresponding box score ([Hint](https://keras.io/backend/#max)) (Be careful with what axis you choose; consider using axis=-1)\n3. Create a mask by using a threshold. As a reminder: `([0.9, 0.3, 0.4, 0.5, 0.1] < 0.4)` returns: `[False, True, False, False, True]`. The mask should be True for the boxes you want to keep. \n4. Use TensorFlow to apply the mask to box_class_scores, boxes and box_classes to filter out the boxes we don't want. You should be left with just the subset of boxes you want to keep. ([Hint](https://www.tensorflow.org/api_docs/python/tf/boolean_mask))\n\nReminder: to call a Keras function, you should use `K.function(...)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_filter_boxes\n\ndef yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):\n \"\"\"Filters YOLO boxes by thresholding on object and class confidence.\n \n Arguments:\n box_confidence -- tensor of shape (19, 19, 5, 1)\n boxes -- tensor of shape (19, 19, 5, 4)\n box_class_probs -- tensor of shape (19, 19, 5, 80)\n threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box\n \n Returns:\n scores -- tensor of shape (None,), containing the class probability score for selected boxes\n boxes -- tensor of shape (None, 4), containing (b_x, b_y, b_h, b_w) coordinates of selected boxes\n classes -- tensor of shape (None,), containing the index of the class detected by the selected boxes\n \n Note: \"None\" is here because you don't know the exact number of selected boxes, as it depends on the threshold. \n For example, the actual output size of scores would be (10,) if there are 10 boxes.\n \"\"\"\n # print(box_confidence.get_shape())\n # Step 1: Compute box scores\n ### START CODE HERE ### (≈ 1 line)\n box_scores = box_confidence*box_class_probs\n #print(box_scores.get_shape())\n ### END CODE HERE ###\n \n # Step 2: Find the box_classes thanks to the max box_scores, keep track of the corresponding score\n ### START CODE HERE ### (≈ 2 lines)\n box_classes = K.argmax(box_scores,axis = -1)\n #print(box_classes.get_shape())\n box_class_scores = K.max(box_scores,axis = -1)\n #print(box_class_scores.get_shape())\n ### END CODE HERE ###\n \n # Step 3: Create a filtering mask based on \"box_class_scores\" by using \"threshold\". The mask should have the\n # same dimension as box_class_scores, and be True for the boxes you want to keep (with probability >= threshold)\n ### START CODE HERE ### (≈ 1 line)\n filtering_mask = box_class_scores>=threshold\n #print(filtering_mask.get_shape())\n ### END CODE HERE ###\n \n # Step 4: Apply the mask to scores, boxes and classes\n ### START CODE HERE ### (≈ 3 lines)\n scores = tf.boolean_mask(box_class_scores,filtering_mask)\n boxes = tf.boolean_mask(boxes,filtering_mask)\n classes = tf.boolean_mask(box_classes,filtering_mask)\n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_a:\n box_confidence = tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1)\n boxes = tf.random_normal([19, 19, 5, 4], mean=1, stddev=4, seed = 1)\n box_class_probs = tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1)\n scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = 0.5)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.shape))\n print(\"boxes.shape = \" + str(boxes.shape))\n print(\"classes.shape = \" + str(classes.shape))",
"scores[2] = 10.7506\nboxes[2] = [ 8.42653275 3.27136683 -0.5313437 -4.94137383]\nclasses[2] = 7\nscores.shape = (?,)\nboxes.shape = (?, 4)\nclasses.shape = (?,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 10.7506\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [ 8.42653275 3.27136683 -0.5313437 -4.94137383]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n 7\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (?,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (?, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (?,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.3 - Non-max suppression ###\n\nEven after filtering by thresholding over the classes scores, you still end up a lot of overlapping boxes. A second filter for selecting the right boxes is called non-maximum suppression (NMS). ",
"_____no_output_____"
],
[
"<img src=\"nb_images/non-max-suppression.png\" style=\"width:500px;height:400;\">\n<caption><center> <u> **Figure 7** </u>: In this example, the model has predicted 3 cars, but it's actually 3 predictions of the same car. Running non-max suppression (NMS) will select only the most accurate (highest probabiliy) one of the 3 boxes. <br> </center></caption>\n",
"_____no_output_____"
],
[
"Non-max suppression uses the very important function called **\"Intersection over Union\"**, or IoU.\n<img src=\"nb_images/iou.png\" style=\"width:500px;height:400;\">\n<caption><center> <u> **Figure 8** </u>: Definition of \"Intersection over Union\". <br> </center></caption>\n\n**Exercise**: Implement iou(). Some hints:\n- In this exercise only, we define a box using its two corners (upper left and lower right): (x1, y1, x2, y2) rather than the midpoint and height/width.\n- To calculate the area of a rectangle you need to multiply its height (y2 - y1) by its width (x2 - x1)\n- You'll also need to find the coordinates (xi1, yi1, xi2, yi2) of the intersection of two boxes. Remember that:\n - xi1 = maximum of the x1 coordinates of the two boxes\n - yi1 = maximum of the y1 coordinates of the two boxes\n - xi2 = minimum of the x2 coordinates of the two boxes\n - yi2 = minimum of the y2 coordinates of the two boxes\n \nIn this code, we use the convention that (0,0) is the top-left corner of an image, (1,0) is the upper-right corner, and (1,1) the lower-right corner. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: iou\n\ndef iou(box1, box2):\n \"\"\"Implement the intersection over union (IoU) between box1 and box2\n \n Arguments:\n box1 -- first box, list object with coordinates (x1, y1, x2, y2)\n box2 -- second box, list object with coordinates (x1, y1, x2, y2)\n \"\"\"\n\n # Calculate the (y1, x1, y2, x2) coordinates of the intersection of box1 and box2. Calculate its Area.\n ### START CODE HERE ### (≈ 5 lines)\n # print(type(box1))\n #print(box1[0])\n xi1 = np.maximum(box1[0],box2[0])\n yi1 = np.maximum(box1[1],box2[1])\n xi2 = np.minimum(box1[2],box2[2])\n yi2 = np.minimum(box1[3],box2[3])\n inter_area = (yi2-yi1)*(xi2-xi1)\n ### END CODE HERE ### \n\n # Calculate the Union area by using Formula: Union(A,B) = A + B - Inter(A,B)\n ### START CODE HERE ### (≈ 3 lines)\n box1_area = (box1[3]-box1[1])*(box1[2]-box1[0])\n box2_area = (box2[3]-box2[1])*(box2[2]-box2[0])\n union_area = box1_area + box2_area - inter_area\n ### END CODE HERE ###\n \n # compute the IoU\n ### START CODE HERE ### (≈ 1 line)\n iou = inter_area/union_area\n ### END CODE HERE ###\n\n return iou",
"_____no_output_____"
],
[
"box1 = (2, 1, 4, 3)\nbox2 = (1, 2, 3, 4) \nprint(\"iou = \" + str(iou(box1, box2)))",
"iou = 0.142857142857\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **iou = **\n </td>\n <td>\n 0.14285714285714285\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"You are now ready to implement non-max suppression. The key steps are: \n1. Select the box that has the highest score.\n2. Compute its overlap with all other boxes, and remove boxes that overlap it more than `iou_threshold`.\n3. Go back to step 1 and iterate until there's no more boxes with a lower score than the current selected box.\n\nThis will remove all boxes that have a large overlap with the selected boxes. Only the \"best\" boxes remain.\n\n**Exercise**: Implement yolo_non_max_suppression() using TensorFlow. TensorFlow has two built-in functions that are used to implement non-max suppression (so you don't actually need to use your `iou()` implementation):\n- [tf.image.non_max_suppression()](https://www.tensorflow.org/api_docs/python/tf/image/non_max_suppression)\n- [K.gather()](https://www.tensorflow.org/api_docs/python/tf/gather)",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_non_max_suppression\n\ndef yolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5):\n \"\"\"\n Applies Non-max suppression (NMS) to set of boxes\n \n Arguments:\n scores -- tensor of shape (None,), output of yolo_filter_boxes()\n boxes -- tensor of shape (None, 4), output of yolo_filter_boxes() that have been scaled to the image size (see later)\n classes -- tensor of shape (None,), output of yolo_filter_boxes()\n max_boxes -- integer, maximum number of predicted boxes you'd like\n iou_threshold -- real value, \"intersection over union\" threshold used for NMS filtering\n \n Returns:\n scores -- tensor of shape (, None), predicted score for each box\n boxes -- tensor of shape (4, None), predicted box coordinates\n classes -- tensor of shape (, None), predicted class for each box\n \n Note: The \"None\" dimension of the output tensors has obviously to be less than max_boxes. Note also that this\n function will transpose the shapes of scores, boxes, classes. This is made for convenience.\n \"\"\"\n \n max_boxes_tensor = K.variable(max_boxes, dtype='int32') # tensor to be used in tf.image.non_max_suppression()\n K.get_session().run(tf.variables_initializer([max_boxes_tensor])) # initialize variable max_boxes_tensor\n \n # Use tf.image.non_max_suppression() to get the list of indices corresponding to boxes you keep\n ### START CODE HERE ### (≈ 1 line)\n nms_indices = tf.image.non_max_suppression(boxes,scores,max_boxes_tensor,iou_threshold)\n ### END CODE HERE ###\n \n # Use K.gather() to select only nms_indices from scores, boxes and classes\n ### START CODE HERE ### (≈ 3 lines)\n scores = tf.gather(scores,nms_indices)\n boxes = tf.gather(boxes,nms_indices)\n classes = tf.gather(classes,nms_indices)\n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_b:\n scores = tf.random_normal([54,], mean=1, stddev=4, seed = 1)\n boxes = tf.random_normal([54, 4], mean=1, stddev=4, seed = 1)\n classes = tf.random_normal([54,], mean=1, stddev=4, seed = 1)\n scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.eval().shape))\n print(\"boxes.shape = \" + str(boxes.eval().shape))\n print(\"classes.shape = \" + str(classes.eval().shape))",
"scores[2] = 6.9384\nboxes[2] = [-5.299932 3.13798141 4.45036697 0.95942086]\nclasses[2] = -2.24527\nscores.shape = (10,)\nboxes.shape = (10, 4)\nclasses.shape = (10,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 6.9384\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [-5.299932 3.13798141 4.45036697 0.95942086]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n -2.24527\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (10, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.4 Wrapping up the filtering\n\nIt's time to implement a function taking the output of the deep CNN (the 19x19x5x85 dimensional encoding) and filtering through all the boxes using the functions you've just implemented. \n\n**Exercise**: Implement `yolo_eval()` which takes the output of the YOLO encoding and filters the boxes using score threshold and NMS. There's just one last implementational detail you have to know. There're a few ways of representing boxes, such as via their corners or via their midpoint and height/width. YOLO converts between a few such formats at different times, using the following functions (which we have provided): \n\n```python\nboxes = yolo_boxes_to_corners(box_xy, box_wh) \n```\nwhich converts the yolo box coordinates (x,y,w,h) to box corners' coordinates (x1, y1, x2, y2) to fit the input of `yolo_filter_boxes`\n```python\nboxes = scale_boxes(boxes, image_shape)\n```\nYOLO's network was trained to run on 608x608 images. If you are testing this data on a different size image--for example, the car detection dataset had 720x1280 images--this step rescales the boxes so that they can be plotted on top of the original 720x1280 image. \n\nDon't worry about these two functions; we'll show you where they need to be called. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: yolo_eval\n\ndef yolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5):\n \"\"\"\n Converts the output of YOLO encoding (a lot of boxes) to your predicted boxes along with their scores, box coordinates and classes.\n \n Arguments:\n yolo_outputs -- output of the encoding model (for image_shape of (608, 608, 3)), contains 4 tensors:\n box_confidence: tensor of shape (None, 19, 19, 5, 1)\n box_xy: tensor of shape (None, 19, 19, 5, 2)\n box_wh: tensor of shape (None, 19, 19, 5, 2)\n box_class_probs: tensor of shape (None, 19, 19, 5, 80)\n image_shape -- tensor of shape (2,) containing the input shape, in this notebook we use (608., 608.) (has to be float32 dtype)\n max_boxes -- integer, maximum number of predicted boxes you'd like\n score_threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box\n iou_threshold -- real value, \"intersection over union\" threshold used for NMS filtering\n \n Returns:\n scores -- tensor of shape (None, ), predicted score for each box\n boxes -- tensor of shape (None, 4), predicted box coordinates\n classes -- tensor of shape (None,), predicted class for each box\n \"\"\"\n \n ### START CODE HERE ### \n \n # Retrieve outputs of the YOLO model (≈1 line)\n box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs\n\n # Convert boxes to be ready for filtering functions \n boxes = yolo_boxes_to_corners(box_xy, box_wh)\n\n # Use one of the functions you've implemented to perform Score-filtering with a threshold of score_threshold (≈1 line)\n scores, boxes, classes = yolo_filter_boxes(box_confidence,boxes,box_class_probs,score_threshold)\n \n # Scale boxes back to original image shape.\n boxes = scale_boxes(boxes, image_shape)\n\n # Use one of the functions you've implemented to perform Non-max suppression with a threshold of iou_threshold (≈1 line)\n scores, boxes, classes = yolo_non_max_suppression(scores,boxes,classes,max_boxes,iou_threshold)\n \n ### END CODE HERE ###\n \n return scores, boxes, classes",
"_____no_output_____"
],
[
"with tf.Session() as test_b:\n yolo_outputs = (tf.random_normal([19, 19, 5, 1], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 2], mean=1, stddev=4, seed = 1),\n tf.random_normal([19, 19, 5, 80], mean=1, stddev=4, seed = 1))\n scores, boxes, classes = yolo_eval(yolo_outputs)\n print(\"scores[2] = \" + str(scores[2].eval()))\n print(\"boxes[2] = \" + str(boxes[2].eval()))\n print(\"classes[2] = \" + str(classes[2].eval()))\n print(\"scores.shape = \" + str(scores.eval().shape))\n print(\"boxes.shape = \" + str(boxes.eval().shape))\n print(\"classes.shape = \" + str(classes.eval().shape))",
"scores[2] = 138.791\nboxes[2] = [ 1292.32971191 -278.52166748 3876.98925781 -835.56494141]\nclasses[2] = 54\nscores.shape = (10,)\nboxes.shape = (10, 4)\nclasses.shape = (10,)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **scores[2]**\n </td>\n <td>\n 138.791\n </td>\n </tr>\n <tr>\n <td>\n **boxes[2]**\n </td>\n <td>\n [ 1292.32971191 -278.52166748 3876.98925781 -835.56494141]\n </td>\n </tr>\n\n <tr>\n <td>\n **classes[2]**\n </td>\n <td>\n 54\n </td>\n </tr>\n <tr>\n <td>\n **scores.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n <tr>\n <td>\n **boxes.shape**\n </td>\n <td>\n (10, 4)\n </td>\n </tr>\n\n <tr>\n <td>\n **classes.shape**\n </td>\n <td>\n (10,)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"<font color='blue'>\n**Summary for YOLO**:\n- Input image (608, 608, 3)\n- The input image goes through a CNN, resulting in a (19,19,5,85) dimensional output. \n- After flattening the last two dimensions, the output is a volume of shape (19, 19, 425):\n - Each cell in a 19x19 grid over the input image gives 425 numbers. \n - 425 = 5 x 85 because each cell contains predictions for 5 boxes, corresponding to 5 anchor boxes, as seen in lecture. \n - 85 = 5 + 80 where 5 is because $(p_c, b_x, b_y, b_h, b_w)$ has 5 numbers, and and 80 is the number of classes we'd like to detect\n- You then select only few boxes based on:\n - Score-thresholding: throw away boxes that have detected a class with a score less than the threshold\n - Non-max suppression: Compute the Intersection over Union and avoid selecting overlapping boxes\n- This gives you YOLO's final output. ",
"_____no_output_____"
],
[
"## 3 - Test YOLO pretrained model on images",
"_____no_output_____"
],
[
"In this part, you are going to use a pretrained model and test it on the car detection dataset. As usual, you start by **creating a session to start your graph**. Run the following cell.",
"_____no_output_____"
]
],
[
[
"sess = K.get_session()",
"_____no_output_____"
]
],
[
[
"### 3.1 - Defining classes, anchors and image shape.",
"_____no_output_____"
],
[
"Recall that we are trying to detect 80 classes, and are using 5 anchor boxes. We have gathered the information about the 80 classes and 5 boxes in two files \"coco_classes.txt\" and \"yolo_anchors.txt\". Let's load these quantities into the model by running the next cell. \n\nThe car detection dataset has 720x1280 images, which we've pre-processed into 608x608 images. ",
"_____no_output_____"
]
],
[
[
"class_names = read_classes(\"model_data/coco_classes.txt\")\nanchors = read_anchors(\"model_data/yolo_anchors.txt\")\nimage_shape = (720., 1280.) ",
"_____no_output_____"
]
],
[
[
"### 3.2 - Loading a pretrained model\n\nTraining a YOLO model takes a very long time and requires a fairly large dataset of labelled bounding boxes for a large range of target classes. You are going to load an existing pretrained Keras YOLO model stored in \"yolo.h5\". (These weights come from the official YOLO website, and were converted using a function written by Allan Zelener. References are at the end of this notebook. Technically, these are the parameters from the \"YOLOv2\" model, but we will more simply refer to it as \"YOLO\" in this notebook.) Run the cell below to load the model from this file.",
"_____no_output_____"
]
],
[
[
"yolo_model = load_model(\"model_data/yolo.h5\")",
"/opt/conda/lib/python3.6/site-packages/keras/models.py:251: UserWarning: No training configuration found in save file: the model was *not* compiled. Compile it manually.\n warnings.warn('No training configuration found in save file: '\n"
]
],
[
[
"This loads the weights of a trained YOLO model. Here's a summary of the layers your model contains.",
"_____no_output_____"
]
],
[
[
"yolo_model.summary()",
"____________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n====================================================================================================\ninput_1 (InputLayer) (None, 608, 608, 3) 0 \n____________________________________________________________________________________________________\nconv2d_1 (Conv2D) (None, 608, 608, 32) 864 input_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_1 (BatchNorm (None, 608, 608, 32) 128 conv2d_1[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_1 (LeakyReLU) (None, 608, 608, 32) 0 batch_normalization_1[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, 304, 304, 32) 0 leaky_re_lu_1[0][0] \n____________________________________________________________________________________________________\nconv2d_2 (Conv2D) (None, 304, 304, 64) 18432 max_pooling2d_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_2 (BatchNorm (None, 304, 304, 64) 256 conv2d_2[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_2 (LeakyReLU) (None, 304, 304, 64) 0 batch_normalization_2[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_2 (MaxPooling2D) (None, 152, 152, 64) 0 leaky_re_lu_2[0][0] \n____________________________________________________________________________________________________\nconv2d_3 (Conv2D) (None, 152, 152, 128) 73728 max_pooling2d_2[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_3 (BatchNorm (None, 152, 152, 128) 512 conv2d_3[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_3 (LeakyReLU) (None, 152, 152, 128) 0 batch_normalization_3[0][0] \n____________________________________________________________________________________________________\nconv2d_4 (Conv2D) (None, 152, 152, 64) 8192 leaky_re_lu_3[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_4 (BatchNorm (None, 152, 152, 64) 256 conv2d_4[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_4 (LeakyReLU) (None, 152, 152, 64) 0 batch_normalization_4[0][0] \n____________________________________________________________________________________________________\nconv2d_5 (Conv2D) (None, 152, 152, 128) 73728 leaky_re_lu_4[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_5 (BatchNorm (None, 152, 152, 128) 512 conv2d_5[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_5 (LeakyReLU) (None, 152, 152, 128) 0 batch_normalization_5[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_3 (MaxPooling2D) (None, 76, 76, 128) 0 leaky_re_lu_5[0][0] \n____________________________________________________________________________________________________\nconv2d_6 (Conv2D) (None, 76, 76, 256) 294912 max_pooling2d_3[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_6 (BatchNorm (None, 76, 76, 256) 1024 conv2d_6[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_6 (LeakyReLU) (None, 76, 76, 256) 0 batch_normalization_6[0][0] \n____________________________________________________________________________________________________\nconv2d_7 (Conv2D) (None, 76, 76, 128) 32768 leaky_re_lu_6[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_7 (BatchNorm (None, 76, 76, 128) 512 conv2d_7[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_7 (LeakyReLU) (None, 76, 76, 128) 0 batch_normalization_7[0][0] \n____________________________________________________________________________________________________\nconv2d_8 (Conv2D) (None, 76, 76, 256) 294912 leaky_re_lu_7[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_8 (BatchNorm (None, 76, 76, 256) 1024 conv2d_8[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_8 (LeakyReLU) (None, 76, 76, 256) 0 batch_normalization_8[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_4 (MaxPooling2D) (None, 38, 38, 256) 0 leaky_re_lu_8[0][0] \n____________________________________________________________________________________________________\nconv2d_9 (Conv2D) (None, 38, 38, 512) 1179648 max_pooling2d_4[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_9 (BatchNorm (None, 38, 38, 512) 2048 conv2d_9[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_9 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_9[0][0] \n____________________________________________________________________________________________________\nconv2d_10 (Conv2D) (None, 38, 38, 256) 131072 leaky_re_lu_9[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_10 (BatchNor (None, 38, 38, 256) 1024 conv2d_10[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_10 (LeakyReLU) (None, 38, 38, 256) 0 batch_normalization_10[0][0] \n____________________________________________________________________________________________________\nconv2d_11 (Conv2D) (None, 38, 38, 512) 1179648 leaky_re_lu_10[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_11 (BatchNor (None, 38, 38, 512) 2048 conv2d_11[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_11 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_11[0][0] \n____________________________________________________________________________________________________\nconv2d_12 (Conv2D) (None, 38, 38, 256) 131072 leaky_re_lu_11[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_12 (BatchNor (None, 38, 38, 256) 1024 conv2d_12[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_12 (LeakyReLU) (None, 38, 38, 256) 0 batch_normalization_12[0][0] \n____________________________________________________________________________________________________\nconv2d_13 (Conv2D) (None, 38, 38, 512) 1179648 leaky_re_lu_12[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_13 (BatchNor (None, 38, 38, 512) 2048 conv2d_13[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_13 (LeakyReLU) (None, 38, 38, 512) 0 batch_normalization_13[0][0] \n____________________________________________________________________________________________________\nmax_pooling2d_5 (MaxPooling2D) (None, 19, 19, 512) 0 leaky_re_lu_13[0][0] \n____________________________________________________________________________________________________\nconv2d_14 (Conv2D) (None, 19, 19, 1024) 4718592 max_pooling2d_5[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_14 (BatchNor (None, 19, 19, 1024) 4096 conv2d_14[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_14 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_14[0][0] \n____________________________________________________________________________________________________\nconv2d_15 (Conv2D) (None, 19, 19, 512) 524288 leaky_re_lu_14[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_15 (BatchNor (None, 19, 19, 512) 2048 conv2d_15[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_15 (LeakyReLU) (None, 19, 19, 512) 0 batch_normalization_15[0][0] \n____________________________________________________________________________________________________\nconv2d_16 (Conv2D) (None, 19, 19, 1024) 4718592 leaky_re_lu_15[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_16 (BatchNor (None, 19, 19, 1024) 4096 conv2d_16[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_16 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_16[0][0] \n____________________________________________________________________________________________________\nconv2d_17 (Conv2D) (None, 19, 19, 512) 524288 leaky_re_lu_16[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_17 (BatchNor (None, 19, 19, 512) 2048 conv2d_17[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_17 (LeakyReLU) (None, 19, 19, 512) 0 batch_normalization_17[0][0] \n____________________________________________________________________________________________________\nconv2d_18 (Conv2D) (None, 19, 19, 1024) 4718592 leaky_re_lu_17[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_18 (BatchNor (None, 19, 19, 1024) 4096 conv2d_18[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_18 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_18[0][0] \n____________________________________________________________________________________________________\nconv2d_19 (Conv2D) (None, 19, 19, 1024) 9437184 leaky_re_lu_18[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_19 (BatchNor (None, 19, 19, 1024) 4096 conv2d_19[0][0] \n____________________________________________________________________________________________________\nconv2d_21 (Conv2D) (None, 38, 38, 64) 32768 leaky_re_lu_13[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_19 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_19[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_21 (BatchNor (None, 38, 38, 64) 256 conv2d_21[0][0] \n____________________________________________________________________________________________________\nconv2d_20 (Conv2D) (None, 19, 19, 1024) 9437184 leaky_re_lu_19[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_21 (LeakyReLU) (None, 38, 38, 64) 0 batch_normalization_21[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_20 (BatchNor (None, 19, 19, 1024) 4096 conv2d_20[0][0] \n____________________________________________________________________________________________________\nspace_to_depth_x2 (Lambda) (None, 19, 19, 256) 0 leaky_re_lu_21[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_20 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_20[0][0] \n____________________________________________________________________________________________________\nconcatenate_1 (Concatenate) (None, 19, 19, 1280) 0 space_to_depth_x2[0][0] \n leaky_re_lu_20[0][0] \n____________________________________________________________________________________________________\nconv2d_22 (Conv2D) (None, 19, 19, 1024) 11796480 concatenate_1[0][0] \n____________________________________________________________________________________________________\nbatch_normalization_22 (BatchNor (None, 19, 19, 1024) 4096 conv2d_22[0][0] \n____________________________________________________________________________________________________\nleaky_re_lu_22 (LeakyReLU) (None, 19, 19, 1024) 0 batch_normalization_22[0][0] \n____________________________________________________________________________________________________\nconv2d_23 (Conv2D) (None, 19, 19, 425) 435625 leaky_re_lu_22[0][0] \n====================================================================================================\nTotal params: 50,983,561\nTrainable params: 50,962,889\nNon-trainable params: 20,672\n____________________________________________________________________________________________________\n"
]
],
[
[
"**Note**: On some computers, you may see a warning message from Keras. Don't worry about it if you do--it is fine.\n\n**Reminder**: this model converts a preprocessed batch of input images (shape: (m, 608, 608, 3)) into a tensor of shape (m, 19, 19, 5, 85) as explained in Figure (2).",
"_____no_output_____"
],
[
"### 3.3 - Convert output of the model to usable bounding box tensors\n\nThe output of `yolo_model` is a (m, 19, 19, 5, 85) tensor that needs to pass through non-trivial processing and conversion. The following cell does that for you.",
"_____no_output_____"
]
],
[
[
"yolo_outputs = yolo_head(yolo_model.output, anchors, len(class_names))",
"_____no_output_____"
]
],
[
[
"You added `yolo_outputs` to your graph. This set of 4 tensors is ready to be used as input by your `yolo_eval` function.",
"_____no_output_____"
],
[
"### 3.4 - Filtering boxes\n\n`yolo_outputs` gave you all the predicted boxes of `yolo_model` in the correct format. You're now ready to perform filtering and select only the best boxes. Lets now call `yolo_eval`, which you had previously implemented, to do this. ",
"_____no_output_____"
]
],
[
[
"scores, boxes, classes = yolo_eval(yolo_outputs, image_shape)",
"_____no_output_____"
]
],
[
[
"### 3.5 - Run the graph on an image\n\nLet the fun begin. You have created a (`sess`) graph that can be summarized as follows:\n\n1. <font color='purple'> yolo_model.input </font> is given to `yolo_model`. The model is used to compute the output <font color='purple'> yolo_model.output </font>\n2. <font color='purple'> yolo_model.output </font> is processed by `yolo_head`. It gives you <font color='purple'> yolo_outputs </font>\n3. <font color='purple'> yolo_outputs </font> goes through a filtering function, `yolo_eval`. It outputs your predictions: <font color='purple'> scores, boxes, classes </font>\n\n**Exercise**: Implement predict() which runs the graph to test YOLO on an image.\nYou will need to run a TensorFlow session, to have it compute `scores, boxes, classes`.\n\nThe code below also uses the following function:\n```python\nimage, image_data = preprocess_image(\"images/\" + image_file, model_image_size = (608, 608))\n```\nwhich outputs:\n- image: a python (PIL) representation of your image used for drawing boxes. You won't need to use it.\n- image_data: a numpy-array representing the image. This will be the input to the CNN.\n\n**Important note**: when a model uses BatchNorm (as is the case in YOLO), you will need to pass an additional placeholder in the feed_dict {K.learning_phase(): 0}.",
"_____no_output_____"
]
],
[
[
"def predict(sess, image_file):\n \"\"\"\n Runs the graph stored in \"sess\" to predict boxes for \"image_file\". Prints and plots the preditions.\n \n Arguments:\n sess -- your tensorflow/Keras session containing the YOLO graph\n image_file -- name of an image stored in the \"images\" folder.\n \n Returns:\n out_scores -- tensor of shape (None, ), scores of the predicted boxes\n out_boxes -- tensor of shape (None, 4), coordinates of the predicted boxes\n out_classes -- tensor of shape (None, ), class index of the predicted boxes\n \n Note: \"None\" actually represents the number of predicted boxes, it varies between 0 and max_boxes. \n \"\"\"\n\n # Preprocess your image\n image, image_data = preprocess_image(\"images/\" + image_file, model_image_size = (608, 608))\n\n # Run the session with the correct tensors and choose the correct placeholders in the feed_dict.\n # You'll need to use feed_dict={yolo_model.input: ... , K.learning_phase(): 0})\n ### START CODE HERE ### (≈ 1 line)\n out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict={yolo_model.input: image_data, K.learning_phase(): 0})\n ### END CODE HERE ###\n\n # Print predictions info\n print('Found {} boxes for {}'.format(len(out_boxes), image_file))\n # Generate colors for drawing bounding boxes.\n colors = generate_colors(class_names)\n # Draw bounding boxes on the image file\n draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors)\n # Save the predicted bounding box on the image\n image.save(os.path.join(\"out\", image_file), quality=90)\n # Display the results in the notebook\n output_image = scipy.misc.imread(os.path.join(\"out\", image_file))\n imshow(output_image)\n \n return out_scores, out_boxes, out_classes",
"_____no_output_____"
]
],
[
[
"Run the following cell on the \"test.jpg\" image to verify that your function is correct.",
"_____no_output_____"
]
],
[
[
"out_scores, out_boxes, out_classes = predict(sess, \"test.jpg\")",
"Found 7 boxes for test.jpg\ncar 0.60 (925, 285) (1045, 374)\ncar 0.66 (706, 279) (786, 350)\nbus 0.67 (5, 266) (220, 407)\ncar 0.70 (947, 324) (1280, 705)\ncar 0.74 (159, 303) (346, 440)\ncar 0.80 (761, 282) (942, 412)\ncar 0.89 (367, 300) (745, 648)\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n <tr>\n <td>\n **Found 7 boxes for test.jpg**\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.60 (925, 285) (1045, 374)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.66 (706, 279) (786, 350)\n </td>\n </tr>\n <tr>\n <td>\n **bus**\n </td>\n <td>\n 0.67 (5, 266) (220, 407)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.70 (947, 324) (1280, 705)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.74 (159, 303) (346, 440)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.80 (761, 282) (942, 412)\n </td>\n </tr>\n <tr>\n <td>\n **car**\n </td>\n <td>\n 0.89 (367, 300) (745, 648)\n </td>\n </tr>\n</table>",
"_____no_output_____"
],
[
"The model you've just run is actually able to detect 80 different classes listed in \"coco_classes.txt\". To test the model on your own images:\n 1. Click on \"File\" in the upper bar of this notebook, then click \"Open\" to go on your Coursera Hub.\n 2. Add your image to this Jupyter Notebook's directory, in the \"images\" folder\n 3. Write your image's name in the cell above code\n 4. Run the code and see the output of the algorithm!\n\nIf you were to run your session in a for loop over all your images. Here's what you would get:\n\n<center>\n<video width=\"400\" height=\"200\" src=\"nb_images/pred_video_compressed2.mp4\" type=\"video/mp4\" controls>\n</video>\n</center>\n\n<caption><center> Predictions of the YOLO model on pictures taken from a camera while driving around the Silicon Valley <br> Thanks [drive.ai](https://www.drive.ai/) for providing this dataset! </center></caption>",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- YOLO is a state-of-the-art object detection model that is fast and accurate\n- It runs an input image through a CNN which outputs a 19x19x5x85 dimensional volume. \n- The encoding can be seen as a grid where each of the 19x19 cells contains information about 5 boxes.\n- You filter through all the boxes using non-max suppression. Specifically: \n - Score thresholding on the probability of detecting a class to keep only accurate (high probability) boxes\n - Intersection over Union (IoU) thresholding to eliminate overlapping boxes\n- Because training a YOLO model from randomly initialized weights is non-trivial and requires a large dataset as well as lot of computation, we used previously trained model parameters in this exercise. If you wish, you can also try fine-tuning the YOLO model with your own dataset, though this would be a fairly non-trivial exercise. ",
"_____no_output_____"
],
[
"**References**: The ideas presented in this notebook came primarily from the two YOLO papers. The implementation here also took significant inspiration and used many components from Allan Zelener's github repository. The pretrained weights used in this exercise came from the official YOLO website. \n- Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi - [You Only Look Once: Unified, Real-Time Object Detection](https://arxiv.org/abs/1506.02640) (2015)\n- Joseph Redmon, Ali Farhadi - [YOLO9000: Better, Faster, Stronger](https://arxiv.org/abs/1612.08242) (2016)\n- Allan Zelener - [YAD2K: Yet Another Darknet 2 Keras](https://github.com/allanzelener/YAD2K)\n- The official YOLO website (https://pjreddie.com/darknet/yolo/) ",
"_____no_output_____"
],
[
"**Car detection dataset**:\n<a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\"><img alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.creativecommons.org/l/by/4.0/88x31.png\" /></a><br /><span xmlns:dct=\"http://purl.org/dc/terms/\" property=\"dct:title\">The Drive.ai Sample Dataset</span> (provided by drive.ai) is licensed under a <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/4.0/\">Creative Commons Attribution 4.0 International License</a>. We are especially grateful to Brody Huval, Chih Hu and Rahul Patel for collecting and providing this dataset. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a298660dba2f0d456ed599999e1ead295332caa
| 338,453 |
ipynb
|
Jupyter Notebook
|
Iopamidol_PCA_LogReg New MegaBox.ipynb
|
JCardenasRdz/acidoCEST_Machine_Learning
|
eb8a99859e8201db16a76eda0f4f3be175fb8c2e
|
[
"MIT"
] | null | null | null |
Iopamidol_PCA_LogReg New MegaBox.ipynb
|
JCardenasRdz/acidoCEST_Machine_Learning
|
eb8a99859e8201db16a76eda0f4f3be175fb8c2e
|
[
"MIT"
] | 1 |
2020-01-10T16:42:23.000Z
|
2020-01-10T16:42:23.000Z
|
Iopamidol_PCA_LogReg New MegaBox.ipynb
|
JCardenasRdz/acidoCEST_Machine_Learning
|
eb8a99859e8201db16a76eda0f4f3be175fb8c2e
|
[
"MIT"
] | null | null | null | 218.21599 | 53,052 | 0.899605 |
[
[
[
"## Modules",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\nimport scikitplot as skplt\nimport seaborn as sns\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn import preprocessing",
"_____no_output_____"
],
[
"import os\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom sklearn import linear_model, decomposition, datasets\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn import metrics\nfrom sklearn.decomposition import PCA\nimport scikitplot as skplt",
"_____no_output_____"
],
[
"def clean_my_file(file_name):\n \n # read csv\n exp = pd.read_csv(file_name)\n # list of freqs\n \n list_of_freqs = exp.columns[12::].to_list()\n \n # index of first real freq\n index = list_of_freqs.index('-12')\n \n # normalize\n norm_factor = exp[ list_of_freqs[0:index-1] ].iloc[:,-1]\n \n raw_data = exp[ list_of_freqs[index::] ]\n \n # preallocate with zeros\n Zspectra = np.zeros(raw_data.shape)\n \n \n for i in range(raw_data.shape[0]):\n Zspectra[i,:] = raw_data.iloc[i,:] / norm_factor[i]\n \n \n \n #out[exp.columns[0:11].to_list()] = exp.columns[0:11].copy()\n \n out = exp[ exp.columns[0:11] ].copy()\n \n out['FILE'] = file_name.split('/NewMegaBox1to8_MLData_20200901/')[1]\n \n Z = pd.DataFrame(Zspectra, columns= list_of_freqs[index::])\n \n out[Z.columns] = Z.copy()\n \n return out\n \n",
"_____no_output_____"
]
],
[
[
"### Load data",
"_____no_output_____"
]
],
[
[
"%%time\n\nimport os\nfrom glob import glob\nPATH = \"./NewMegaBox1to8_MLData_20200901\"\nEXT = \"*.csv\"\nall_csv_files = [file\n for path, subdir, files in os.walk(PATH)\n for file in glob(os.path.join(path, EXT))]\n\ndata = pd.DataFrame()\n\nfor file in all_csv_files:\n exp = clean_my_file(file)\n data = pd.concat( (data, exp), sort=False )\n ",
"CPU times: user 1min 32s, sys: 14 s, total: 1min 46s\nWall time: 1min 47s\n"
],
[
"data.tail()",
"_____no_output_____"
]
],
[
[
"## Experimental conditions",
"_____no_output_____"
]
],
[
[
"sns.distplot(data['ApproT1(sec)'])",
"_____no_output_____"
],
[
"metadata = ['pH', 'Conc(mM)', 'ApproT1(sec)', 'ExpT1(ms)', 'ExpT2(ms)',\n 'ExpB1(percent)', 'ExpB0(ppm)', 'ExpB0(Hz)', 'Temp',\n 'SatPower(uT)', 'SatTime(ms)','FILE']\n\n\nfor C in metadata:\n print(C)\n print(data[C].nunique())\n #sns.distplot(data[C])\n print('---'*20)",
"pH\n54\n------------------------------------------------------------\nConc(mM)\n153\n------------------------------------------------------------\nApproT1(sec)\n6\n------------------------------------------------------------\nExpT1(ms)\n996\n------------------------------------------------------------\nExpT2(ms)\n987\n------------------------------------------------------------\nExpB1(percent)\n889\n------------------------------------------------------------\nExpB0(ppm)\n996\n------------------------------------------------------------\nExpB0(Hz)\n996\n------------------------------------------------------------\nTemp\n5\n------------------------------------------------------------\nSatPower(uT)\n6\n------------------------------------------------------------\nSatTime(ms)\n6\n------------------------------------------------------------\nFILE\n1440\n------------------------------------------------------------\n"
]
],
[
[
"# Data",
"_____no_output_____"
]
],
[
[
"%%time\n\nX = data.drop(metadata, axis = 1)\nprint(len(metadata))\nprint(X.shape)\n\npH = data['pH'].copy()",
"12\n(36000, 81)\nCPU times: user 6.33 ms, sys: 98 µs, total: 6.43 ms\nWall time: 6.36 ms\n"
],
[
"X[data.pH == 6.22].mean(axis = 0).plot()\nX[data.pH == 7.30].mean(axis = 0).plot()",
"_____no_output_____"
],
[
"pH",
"_____no_output_____"
]
],
[
[
"### PCA -- > Logistic Regression",
"_____no_output_____"
]
],
[
[
"### define function to train model based on cuttoff for pH\n\ndef train_logistic_PCA_pipeline(Spectra, pH_observed, min_n=2, max_n= 10, pH_cut_off = 7.0, n_cs=20, ignore_cut = False):\n \n if ignore_cut == False:\n # cut off > pH\n y = 1*(pH_observed > pH_cut_off)\n elif ignore_cut == True:\n \n y = pH_class.copy()\n \n # X data\n X = Spectra.copy()\n \n # Logistic\n logistic = linear_model.LogisticRegression(solver='liblinear',\n penalty='l1',max_iter=1000,random_state=42, n_jobs=2\n ,class_weight='balanced')\n # Scaler\n scale = StandardScaler()\n \n #PCA\n pca = PCA(random_state=42)\n \n # pipeline\n pipe = Pipeline(steps=[('scaler', scale ), ('pca', pca), ('logistic', logistic)])\n \n # Training parameters\n num_pca_components = np.arange(min_n,max_n,1)\n Cs = np.logspace(-3, 2, n_cs)\n \n param_grid ={\n 'pca__n_components': num_pca_components,\n 'logistic__C': Cs,\n 'logistic__fit_intercept':[True,False]\n }\n \n \n estimator = GridSearchCV(pipe, param_grid, verbose = 1, cv = 3, n_jobs=6, iid = True\n , scoring = metrics.make_scorer(metrics.precision_score))\n \n # Split data\n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)\n\n # Grid Search of Model\n estimator.fit(X_train, y_train)\n \n #AUC\n y_probas = estimator.predict_proba(X_test)\n skplt.metrics.plot_roc(y_test, y_probas)\n \n #Confusion\n skplt.metrics.plot_confusion_matrix(y_test, estimator.predict(X_test), normalize=True)\n \n \n return estimator.best_estimator_, X_train, X_test, y_train, y_test",
"_____no_output_____"
]
],
[
[
"### -training pH >7.0 \n### CLASSIFICATION\n### Only Z spectra",
"_____no_output_____"
]
],
[
[
"(data.pH> 7).value_counts(normalize = True).round(2)",
"_____no_output_____"
],
[
"pH",
"_____no_output_____"
],
[
"%%time\n#clf1, X_train, X_test, y_train, y_test\n\nmodel1= train_logistic_PCA_pipeline(X, pH, min_n=5, max_n= 10, pH_cut_off = 7.0, n_cs=10)",
"Fitting 3 folds for each of 50 candidates, totalling 150 fits\n"
],
[
"print(metrics.classification_report(model1[4],model1[0].predict(model1[2]) ))",
" precision recall f1-score support\n\n 0 0.85 0.70 0.77 7770\n 1 0.47 0.68 0.56 3030\n\n accuracy 0.69 10800\n macro avg 0.66 0.69 0.66 10800\nweighted avg 0.74 0.69 0.71 10800\n\n"
],
[
"# precision = positive predictive value\n# recall = True positive Rate or sensitivity\nmetrics.plot_precision_recall_curve(model1[0], model1[2], model1[4] )",
"_____no_output_____"
],
[
"model2 = train_logistic_PCA_pipeline(X, pH, min_n=5, max_n= 10, pH_cut_off = 6.7, n_cs=20)",
"Fitting 3 folds for each of 100 candidates, totalling 300 fits\n"
],
[
"# precision = positive predictive value\n# recall = True positive Rate or sensitivity\nmetrics.plot_precision_recall_curve(model2[0], model2[2], model2[4] )",
"_____no_output_____"
],
[
"print(metrics.classification_report(model2[4],model2[0].predict(model2[2]) ))",
" precision recall f1-score support\n\n 0 0.94 0.72 0.82 9542\n 1 0.24 0.68 0.36 1258\n\n accuracy 0.72 10800\n macro avg 0.59 0.70 0.59 10800\nweighted avg 0.86 0.72 0.76 10800\n\n"
]
],
[
[
"## Multi class",
"_____no_output_____"
]
],
[
[
"from sklearn import preprocessing\nle = preprocessing.LabelEncoder()\n\npHclass = pd.cut(pH,4)\n\nle.fit(pHclass)\n\npHclass_coded = le.transform(pHclass)\n\nC = pd.DataFrame(pd.Series(pHclass_coded).unique(),columns=['class_code'])\nC['pH range'] = le.inverse_transform(C.class_code)\nC",
"_____no_output_____"
],
[
"model3 = train_logistic_PCA_pipeline(X, pHclass_coded, min_n=5, max_n= 80, pH_cut_off = 6.7, n_cs=30,ignore_cut=True)",
"Fitting 3 folds for each of 2250 candidates, totalling 6750 fits\n"
],
[
"print(metrics.classification_report(model3[4],model3[0].predict(model3[2]) ))",
" precision recall f1-score support\n\n 0 0.46 0.60 0.52 2753\n 1 0.41 0.33 0.37 2736\n 2 0.51 0.39 0.44 2730\n 3 0.56 0.65 0.60 2581\n\n accuracy 0.49 10800\n macro avg 0.49 0.49 0.48 10800\nweighted avg 0.49 0.49 0.48 10800\n\n"
]
],
[
[
"## All measurable data for cut off at pH = 7.0",
"_____no_output_____"
]
],
[
[
"drop_cols = ['pH','FILE','ApproT1(sec)','Conc(mM)','Temp']\n\nX = data.drop(drop_cols,axis = 1)\ny = data.pH.copy()\n\nclf4, X_train, X_test, y_train, y_test = train_logistic_PCA_pipeline(X, y, min_n=20,\n max_n= 60, pH_cut_off = 7.0, n_cs=10\n ,ignore_cut=False)",
"Fitting 3 folds for each of 800 candidates, totalling 2400 fits\n"
],
[
"LR = clf4['logistic']",
"_____no_output_____"
],
[
"LR.coef_",
"_____no_output_____"
],
[
"clf4",
"_____no_output_____"
],
[
"print(metrics.classification_report(y_test, clf4.predict(X_test)) )",
" precision recall f1-score support\n\n 0 0.88 0.75 0.81 7770\n 1 0.53 0.73 0.62 3030\n\n accuracy 0.75 10800\n macro avg 0.71 0.74 0.71 10800\nweighted avg 0.78 0.75 0.76 10800\n\n"
],
[
"for S in data['SatTime(ms)'].unique():\n f = X_test['SatTime(ms)'] == S\n score = metrics.recall_score(y_test[f], clf4.predict( X_test[f]) )\n print(S,score)\n \n ",
"2000 0.7551867219917012\n1000 0.7405857740585774\n500 0.68\n3000 0.7550644567219152\n4000 0.7151394422310757\n6000 0.7523809523809524\n"
],
[
"Xdata = X.drop('100',axis = 1).copy()\n\nconc_filter = data['Conc(mM)'] > 20\n\nclf_01, _, _, _, _ = train_logistic_PCA_pipeline( Xdata[conc_filter], pH[conc_filter], min_n=2, max_n= 40, pH_cut_off = 7.0, n_cs= 20)\n\nprint(clf_01)",
"_____no_output_____"
]
],
[
[
"### -training pH >7.0\n## at 37 celsius",
"_____no_output_____"
]
],
[
[
"f1 = data['Temp'] == 37\n\nfor C in metadata:\n print(C)\n print(data[f1][C].unique())\n print('---'*20)\n \n \nX = data[f1].drop(metadata,axis = 1)\nZ = X.apply(foo, axis = 1)\nprint(X.shape)\nprint(Z.shape)\n\npH = data[f1]['pH'].copy()\n\n\nclf_02, _, _, _, _ = train_logistic_PCA_pipeline( Z, pH, min_n=2, max_n= 40, pH_cut_off = 7.0, n_cs= 20)\nprint(clf_02)",
"_____no_output_____"
],
[
"print( metrics.classification_report(pH > 7, clf_02.predict(Z)) )",
"_____no_output_____"
]
],
[
[
"## training pH >7.0\n### - at 37 celsius & T1 = 3.4",
"_____no_output_____"
]
],
[
[
"f1 = data['Temp'] == 37\nf2 = data['ApproT1(sec)'] == 3.4\n\n\nfor C in metadata:\n print(C)\n print(data[f1&f2][C].unique())\n print('---'*20)\n \n \nX = data[f1&f2].drop(metadata,axis = 1)\nZ = X.apply(foo, axis = 1)\nprint(X.shape)\nprint(Z.shape)\n\npH = data[f1&f2]['pH'].copy()\n\n\nclf_04, _, _, _, _ = train_logistic_PCA_pipeline( Z, pH, min_n=2, max_n= 40, pH_cut_off = 7.0, n_cs= 20)\nprint(clf_04)",
"_____no_output_____"
],
[
"print( metrics.classification_report(pH > 7, clf_04.predict(Z)) )\n\nprint( metrics.confusion_matrix(pH > 7, clf_04.predict(Z)) )\n\nprint( metrics.cohen_kappa_score(pH > 7, clf_04.predict(Z)) )",
"_____no_output_____"
],
[
"plt.plot(xdata, Z.mean(),'-k')\nplt.plot(xdata, Z.mean() + Z.std(),'--r')\n\nplt.xlim([-12,12])\nplt.title('Average Nornalized Z-spectra')",
"_____no_output_____"
]
],
[
[
"## training pH >7.0\n### - at 42 celsius & T1 = 0.43",
"_____no_output_____"
]
],
[
[
"f1 = data['Temp'] == 42\nf2 = data['ApproT1(sec)'] == .43\n\n\nfor C in metadata:\n print(C)\n print(data[f1&f2][C].unique())\n print('---'*20)\n \n \nX = data[f1&f2].drop(metadata,axis = 1)\nZ = X.apply(foo, axis = 1)\nprint(X.shape)\nprint(Z.shape)\n\npH = data[f1&f2]['pH'].copy()\n\n\nclf_05, _, _, _, _ = train_logistic_PCA_pipeline( Z, pH, min_n=2, max_n= 40, pH_cut_off = 6.5, n_cs= 20)\nprint(clf_05)",
"_____no_output_____"
],
[
"print( metrics.classification_report(pH > 7, clf_05.predict(Z)) )\n\nprint( metrics.confusion_matrix(pH > 7, clf_05.predict(Z)) )\n\nprint( metrics.cohen_kappa_score(pH > 7, clf_05.predict(Z)) )",
"_____no_output_____"
],
[
"pd.Series(pH > 7).value_counts(normalize = 1)",
"_____no_output_____"
],
[
"z1 = data[ data.pH == 6.23 ].iloc[:,6::].mean()\nz1 = z1 / z1[1]\n\n\nz2 = data[ data.pH == 7.17 ].iloc[:,6::].mean()\nz2 = z2 / z2[1]\n\nz1.plot()\nz2.plot()",
"_____no_output_____"
],
[
"data.pH.unique()",
"_____no_output_____"
],
[
"plt.plot(xdata, Z.mean(),'-k')\nplt.plot(xdata, Z.mean() + Z.std(),'--r')\n\nplt.xlim([-12,12])\nplt.title('Average Nornalized Z-spectra')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a29893c1d267dd3cdc473c0a95a1cf727ec2fc5
| 28,500 |
ipynb
|
Jupyter Notebook
|
notebook/Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.ipynb
|
kazewong/nrpytutorial
|
cc511325f37f01284b2b83584beb2a452556b3fb
|
[
"BSD-2-Clause"
] | null | null | null |
notebook/Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.ipynb
|
kazewong/nrpytutorial
|
cc511325f37f01284b2b83584beb2a452556b3fb
|
[
"BSD-2-Clause"
] | null | null | null |
notebook/Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.ipynb
|
kazewong/nrpytutorial
|
cc511325f37f01284b2b83584beb2a452556b3fb
|
[
"BSD-2-Clause"
] | null | null | null | 45.094937 | 560 | 0.562702 |
[
[
[
"<script async src=\"https://www.googletagmanager.com/gtag/js?id=UA-59152712-8\"></script>\n<script>\n window.dataLayer = window.dataLayer || [];\n function gtag(){dataLayer.push(arguments);}\n gtag('js', new Date());\n\n gtag('config', 'UA-59152712-8');\n</script>\n\n# BSSN Time-Evolution Equations for the Gauge Fields $\\alpha$ and $\\beta^i$\n\n## Author: Zach Etienne\n### Formatting improvements courtesy Brandon Clark\n\n[comment]: <> (Abstract: TODO, or make the introduction an abstract and addiotnal notes section, and write a new Introduction)\n\n**Module Status:** <font color='green'><b> Validated </b></font>\n\n**Validation Notes:** All expressions generated in this module have been validated against a trusted code (the original NRPy+/SENR code, which itself was validated against [Baumgarte's code](https://arxiv.org/abs/1211.6632)).\n\n### NRPy+ Source Code for this module: [BSSN/BSSN_gauge_RHSs.py](../edit/BSSN/BSSN_gauge_RHSs.py)\n\n\n## Introduction:\nThis tutorial notebook constructs SymPy expressions for the right-hand sides of the time-evolution equations for the gauge fields $\\alpha$ (the lapse, governing how much proper time elapses at each point between one timestep in a 3+1 solution to Einstein's equations and the next) and $\\beta^i$ (the shift, governing how much proper distance numerical grid points move from one timestep in a 3+1 solution to Einstein's equations and the next).\n\nThough we are completely free to choose gauge conditions (i.e., free to choose the form of the right-hand sides of the gauge time evolution equations), very few have been found robust in the presence of (puncture) black holes. So we focus here only on a few of the most stable choices.\n\n",
"_____no_output_____"
],
[
"<a id='toc'></a>\n\n# Table of Contents\n$$\\label{toc}$$\n\nThis notebook is organized as follows\n\n1. [Step 1](#initializenrpy): Initialize needed Python/NRPy+ modules\n1. [Step 2](#lapseconditions): Right-hand side of $\\partial_t \\alpha$\n 1. [Step 2.a](#onepluslog): $1+\\log$ lapse\n 1. [Step 2.b](#harmonicslicing): Harmonic slicing\n 1. [Step 2.c](#frozen): Frozen lapse\n1. [Step 3](#shiftconditions): Right-hand side of $\\partial_t \\beta^i$: Second-order Gamma-driving shift conditions\n 1. [Step 3.a](#origgammadriving): Original, non-covariant Gamma-driving shift condition\n 1. [Step 3.b](#covgammadriving): [Brown](https://arxiv.org/abs/0902.3652)'s suggested covariant Gamma-driving shift condition\n 1. [Step 3.b.i](#partial_beta): The right-hand side of the $\\partial_t \\beta^i$ equation\n 1. [Step 3.b.ii](#partial_upper_b): The right-hand side of the $\\partial_t B^i$ equation\n1. [Step 4](#rescale): Rescale right-hand sides of BSSN gauge equations\n1. [Step 5](#code_validation): Code Validation against `BSSN.BSSN_gauge_RHSs` NRPy+ module\n1. [Step 6](#latex_pdf_output): Output this notebook to $\\LaTeX$-formatted PDF file",
"_____no_output_____"
],
[
"<a id='initializenrpy'></a>\n\n# Step 1: Initialize needed Python/NRPy+ modules \\[Back to [top](#toc)\\]\n$$\\label{initializenrpy}$$\n\nLet's start by importing all the needed modules from Python/NRPy+:",
"_____no_output_____"
]
],
[
[
"# Step 1: Import all needed modules from NRPy+:\nimport sympy as sp\nimport NRPy_param_funcs as par\nimport indexedexp as ixp\nimport grid as gri\nimport finite_difference as fin\nimport reference_metric as rfm\n\n# Step 1.c: Declare/initialize parameters for this module\nthismodule = \"BSSN_gauge_RHSs\"\npar.initialize_param(par.glb_param(\"char\", thismodule, \"LapseEvolutionOption\", \"OnePlusLog\"))\npar.initialize_param(par.glb_param(\"char\", thismodule, \"ShiftEvolutionOption\", \"GammaDriving2ndOrder_Covariant\"))\n\n# Step 1.d: Set spatial dimension (must be 3 for BSSN, as BSSN is \n# a 3+1-dimensional decomposition of the general \n# relativistic field equations)\nDIM = 3\n\n# Step 1.e: Given the chosen coordinate system, set up \n# corresponding reference metric and needed\n# reference metric quantities\n# The following function call sets up the reference metric\n# and related quantities, including rescaling matrices ReDD,\n# ReU, and hatted quantities.\nrfm.reference_metric()\n\n# Step 1.f: Define BSSN scalars & tensors (in terms of rescaled BSSN quantities)\nimport BSSN.BSSN_quantities as Bq\nBq.BSSN_basic_tensors()\nBq.betaU_derivs()\n\nimport BSSN.BSSN_RHSs as Brhs\nBrhs.BSSN_RHSs()",
"_____no_output_____"
]
],
[
[
"<a id='lapseconditions'></a>\n\n# Step 2: Right-hand side of $\\partial_t \\alpha$ \\[Back to [top](#toc)\\]\n$$\\label{lapseconditions}$$",
"_____no_output_____"
],
[
"<a id='onepluslog'></a>\n\n## Step 2.a: $1+\\log$ lapse \\[Back to [top](#toc)\\]\n$$\\label{onepluslog}$$\n\nThe [$1=\\log$ lapse condition](https://arxiv.org/abs/gr-qc/0206072) is a member of the [Bona-Masso family of lapse choices](https://arxiv.org/abs/gr-qc/9412071), which has the desirable property of singularity avoidance. As is common (e.g., see [Campanelli *et al* (2005)](https://arxiv.org/abs/gr-qc/0511048)), we make the replacement $\\partial_t \\to \\partial_0 = \\partial_t + \\beta^i \\partial_i$ to ensure lapse characteristics advect with the shift. The bracketed term in the $1+\\log$ lapse condition below encodes the shift advection term:\n\n\\begin{align}\n\\partial_0 \\alpha &= -2 \\alpha K \\\\\n\\implies \\partial_t \\alpha &= \\left[\\beta^i \\partial_i \\alpha\\right] - 2 \\alpha K\n\\end{align}",
"_____no_output_____"
]
],
[
[
"# Step 2.a: The 1+log lapse condition:\n# \\partial_t \\alpha = \\beta^i \\alpha_{,i} - 2*\\alpha*K\n# First import expressions from BSSN_quantities\ncf = Bq.cf\ntrK = Bq.trK\nalpha = Bq.alpha\nbetaU = Bq.betaU\n\n# Implement the 1+log lapse condition\nif par.parval_from_str(thismodule+\"::LapseEvolutionOption\") == \"OnePlusLog\":\n alpha_rhs = -2*alpha*trK\n alpha_dupD = ixp.declarerank1(\"alpha_dupD\")\n for i in range(DIM):\n alpha_rhs += betaU[i]*alpha_dupD[i]",
"_____no_output_____"
]
],
[
[
"<a id='harmonicslicing'></a>\n\n## Step 2.b: Harmonic slicing \\[Back to [top](#toc)\\]\n$$\\label{harmonicslicing}$$\n\nAs defined on Pg 2 of https://arxiv.org/pdf/gr-qc/9902024.pdf , this is given by \n\n$$\n\\partial_t \\alpha = \\partial_t e^{6 \\phi} = 6 e^{6 \\phi} \\partial_t \\phi\n$$\n\nIf \n\n$$\\text{cf} = W = e^{-2 \\phi},$$ \n\nthen\n\n$$\n6 e^{6 \\phi} \\partial_t \\phi = 6 W^{-3} \\partial_t \\phi.\n$$\n\nHowever,\n$$\n\\partial_t \\phi = -\\partial_t \\text{cf} / (2 \\text{cf})$$\n\n(as described above), so if `cf`$=W$, then\n\\begin{align}\n\\partial_t \\alpha &= 6 e^{6 \\phi} \\partial_t \\phi \\\\\n&= 6 W^{-3} \\left(-\\frac{\\partial_t W}{2 W}\\right) \\\\\n&= -3 \\text{cf}^{-4} \\text{cf}\\_\\text{rhs}\n\\end{align}\n\n**Exercise to students: Implement Harmonic slicing for `cf`$=\\chi$** ",
"_____no_output_____"
]
],
[
[
"# Step 2.b: Implement the harmonic slicing lapse condition\nif par.parval_from_str(thismodule+\"::LapseEvolutionOption\") == \"HarmonicSlicing\":\n if par.parval_from_str(\"BSSN.BSSN_quantities::EvolvedConformalFactor_cf\") == \"W\":\n alpha_rhs = -3*cf**(-4)*Brhs.cf_rhs\n elif par.parval_from_str(\"BSSN.BSSN_quantities::EvolvedConformalFactor_cf\") == \"phi\":\n alpha_rhs = 6*sp.exp(6*cf)*Brhs.cf_rhs\n else:\n print(\"Error LapseEvolutionOption==HarmonicSlicing unsupported for EvolvedConformalFactor_cf!=(W or phi)\")\n exit(1)",
"_____no_output_____"
]
],
[
[
"<a id='frozen'></a>\n\n## Step 2.c: Frozen lapse \\[Back to [top](#toc)\\]\n$$\\label{frozen}$$\n\nThis slicing condition is given by\n$$\\partial_t \\alpha = 0,$$\n\nwhich is rarely a stable lapse condition.",
"_____no_output_____"
]
],
[
[
"# Step 2.c: Frozen lapse\n# \\partial_t \\alpha = 0\nif par.parval_from_str(thismodule+\"::LapseEvolutionOption\") == \"Frozen\":\n alpha_rhs = sp.sympify(0)",
"_____no_output_____"
]
],
[
[
"<a id='shiftconditions'></a>\n\n# Step 3: Right-hand side of $\\partial_t \\beta^i$: Second-order Gamma-driving shift conditions \\[Back to [top](#toc)\\]\n$$\\label{shiftconditions}$$\n\nThe motivation behind Gamma-driving shift conditions are well documented in the book [*Numerical Relativity* by Baumgarte & Shapiro](https://www.amazon.com/Numerical-Relativity-Einsteins-Equations-Computer/dp/052151407X/).\n\n<a id='origgammadriving'></a>\n\n## Step 3.a: Original, non-covariant Gamma-driving shift condition \\[Back to [top](#toc)\\]\n$$\\label{origgammadriving}$$\n\n**Option 1: Non-Covariant, Second-Order Shift**\n\nWe adopt the [*shifting (i.e., advecting) shift*](https://arxiv.org/abs/gr-qc/0605030) non-covariant, second-order shift condition:\n\\begin{align}\n\\partial_0 \\beta^i &= B^{i} \\\\\n\\partial_0 B^i &= \\frac{3}{4} \\partial_{0} \\bar{\\Lambda}^{i} - \\eta B^{i} \\\\\n\\implies \\partial_t \\beta^i &= \\left[\\beta^j \\partial_j \\beta^i\\right] + B^{i} \\\\\n\\partial_t B^i &= \\left[\\beta^j \\partial_j B^i\\right] + \\frac{3}{4} \\partial_{0} \\bar{\\Lambda}^{i} - \\eta B^{i},\n\\end{align}\nwhere $\\eta$ is the shift damping parameter, and $\\partial_{0} \\bar{\\Lambda}^{i}$ in the right-hand side of the $\\partial_{0} B^{i}$ equation is computed by adding $\\beta^j \\partial_j \\bar{\\Lambda}^i$ to the right-hand side expression given for $\\partial_t \\bar{\\Lambda}^i$ in the BSSN time-evolution equations as listed [here](Tutorial-BSSN_formulation.ipynb), so no explicit time dependence occurs in the right-hand sides of the BSSN evolution equations and the Method of Lines can be applied directly.",
"_____no_output_____"
]
],
[
[
"# Step 3.a: Set \\partial_t \\beta^i\n# First import expressions from BSSN_quantities\nBU = Bq.BU\nbetU = Bq.betU\nbetaU_dupD = Bq.betaU_dupD\n# Define needed quantities\nbeta_rhsU = ixp.zerorank1()\nB_rhsU = ixp.zerorank1()\nif par.parval_from_str(thismodule+\"::ShiftEvolutionOption\") == \"GammaDriving2ndOrder_NoCovariant\":\n # Step 3.a.i: Compute right-hand side of beta^i\n # * \\partial_t \\beta^i = \\beta^j \\beta^i_{,j} + B^i\n for i in range(DIM):\n beta_rhsU[i] += BU[i]\n for j in range(DIM):\n beta_rhsU[i] += betaU[j]*betaU_dupD[i][j]\n # Compute right-hand side of B^i:\n eta = par.Cparameters(\"REAL\", thismodule, [\"eta\"],2.0)\n\n # Step 3.a.ii: Compute right-hand side of B^i\n # * \\partial_t B^i = \\beta^j B^i_{,j} + 3/4 * \\partial_0 \\Lambda^i - eta B^i\n # Step 3.a.iii: Define BU_dupD, in terms of derivative of rescaled variable \\bet^i\n BU_dupD = ixp.zerorank2()\n betU_dupD = ixp.declarerank2(\"betU_dupD\",\"nosym\")\n for i in range(DIM):\n for j in range(DIM):\n BU_dupD[i][j] = betU_dupD[i][j]*rfm.ReU[i] + betU[i]*rfm.ReUdD[i][j]\n\n # Step 3.a.iv: Compute \\partial_0 \\bar{\\Lambda}^i = (\\partial_t - \\beta^i \\partial_i) \\bar{\\Lambda}^j \n Lambdabar_partial0 = ixp.zerorank1()\n for i in range(DIM):\n Lambdabar_partial0[i] = Brhs.Lambdabar_rhsU[i]\n for i in range(DIM):\n for j in range(DIM):\n Lambdabar_partial0[j] += -betaU[i]*Brhs.LambdabarU_dupD[j][i]\n\n # Step 3.a.v: Evaluate RHS of B^i:\n for i in range(DIM):\n B_rhsU[i] += sp.Rational(3,4)*Lambdabar_partial0[i] - eta*BU[i]\n for j in range(DIM):\n B_rhsU[i] += betaU[j]*BU_dupD[i][j]",
"_____no_output_____"
]
],
[
[
"<a id='covgammadriving'></a>\n\n## Step 3.b: [Brown](https://arxiv.org/abs/0902.3652)'s suggested covariant Gamma-driving shift condition \\[Back to [top](#toc)\\]\n$$\\label{covgammadriving}$$",
"_____no_output_____"
],
[
"<a id='partial_beta'></a>\n\n### Step 3.b.i: The right-hand side of the $\\partial_t \\beta^i$ equation \\[Back to [top](#toc)\\]\n$$\\label{partial_beta}$$\n\nThis is [Brown's](https://arxiv.org/abs/0902.3652) suggested formulation (Eq. 20b; note that Eq. 20a is the same as our lapse condition, as $\\bar{D}_j \\alpha = \\partial_j \\alpha$ for scalar $\\alpha$):\n$$\\partial_t \\beta^i = \\left[\\beta^j \\bar{D}_j \\beta^i\\right] + B^{i}$$\nBased on the definition of covariant derivative, we have\n$$\n\\bar{D}_{j} \\beta^{i} = \\beta^i_{,j} + \\bar{\\Gamma}^i_{mj} \\beta^m,\n$$\nso the above equation becomes\n\\begin{align}\n\\partial_t \\beta^i &= \\left[\\beta^j \\left(\\beta^i_{,j} + \\bar{\\Gamma}^i_{mj} \\beta^m\\right)\\right] + B^{i}\\\\\n&= {\\underbrace {\\textstyle \\beta^j \\beta^i_{,j}}_{\\text{Term 1}}} + \n{\\underbrace {\\textstyle \\beta^j \\bar{\\Gamma}^i_{mj} \\beta^m}_{\\text{Term 2}}} + \n{\\underbrace {\\textstyle B^i}_{\\text{Term 3}}} \n\\end{align}",
"_____no_output_____"
]
],
[
[
"# Step 3.b: The right-hand side of the \\partial_t \\beta^i equation\nif par.parval_from_str(thismodule+\"::ShiftEvolutionOption\") == \"GammaDriving2ndOrder_Covariant\":\n # Step 3.b Option 2: \\partial_t \\beta^i = \\left[\\beta^j \\bar{D}_j \\beta^i\\right] + B^{i}\n # First we need GammabarUDD, defined in Bq.gammabar__inverse_and_derivs()\n Bq.gammabar__inverse_and_derivs()\n GammabarUDD = Bq.GammabarUDD\n # Then compute right-hand side:\n # Term 1: \\beta^j \\beta^i_{,j}\n for i in range(DIM):\n for j in range(DIM):\n beta_rhsU[i] += betaU[j]*betaU_dupD[i][j]\n\n # Term 2: \\beta^j \\bar{\\Gamma}^i_{mj} \\beta^m\n for i in range(DIM):\n for j in range(DIM):\n for m in range(DIM):\n beta_rhsU[i] += betaU[j]*GammabarUDD[i][m][j]*betaU[m]\n # Term 3: B^i\n for i in range(DIM):\n beta_rhsU[i] += BU[i]",
"_____no_output_____"
]
],
[
[
"<a id='partial_upper_b'></a>\n\n### Step 3.b.ii: The right-hand side of the $\\partial_t B^i$ equation \\[Back to [top](#toc)\\]\n$$\\label{partial_upper_b}$$\n\n$$\\partial_t B^i = \\left[\\beta^j \\bar{D}_j B^i\\right] + \\frac{3}{4}\\left( \\partial_t \\bar{\\Lambda}^{i} - \\beta^j \\bar{D}_j \\bar{\\Lambda}^{i} \\right) - \\eta B^{i}$$\n\nBased on the definition of covariant derivative, we have for vector $V^i$\n$$\n\\bar{D}_{j} V^{i} = V^i_{,j} + \\bar{\\Gamma}^i_{mj} V^m,\n$$\nso the above equation becomes\n\\begin{align}\n\\partial_t B^i &= \\left[\\beta^j \\left(B^i_{,j} + \\bar{\\Gamma}^i_{mj} B^m\\right)\\right] + \\frac{3}{4}\\left[ \\partial_t \\bar{\\Lambda}^{i} - \\beta^j \\left(\\bar{\\Lambda}^i_{,j} + \\bar{\\Gamma}^i_{mj} \\bar{\\Lambda}^m\\right) \\right] - \\eta B^{i} \\\\\n&= {\\underbrace {\\textstyle \\beta^j B^i_{,j}}_{\\text{Term 1}}} + \n{\\underbrace {\\textstyle \\beta^j \\bar{\\Gamma}^i_{mj} B^m}_{\\text{Term 2}}} + \n{\\underbrace {\\textstyle \\frac{3}{4}\\partial_t \\bar{\\Lambda}^{i}}_{\\text{Term 3}}} -\n{\\underbrace {\\textstyle \\frac{3}{4}\\beta^j \\bar{\\Lambda}^i_{,j}}_{\\text{Term 4}}} -\n{\\underbrace {\\textstyle \\frac{3}{4}\\beta^j \\bar{\\Gamma}^i_{mj} \\bar{\\Lambda}^m}_{\\text{Term 5}}} -\n{\\underbrace {\\textstyle \\eta B^i}_{\\text{Term 6}}}\n\\end{align}",
"_____no_output_____"
]
],
[
[
"if par.parval_from_str(thismodule+\"::ShiftEvolutionOption\") == \"GammaDriving2ndOrder_Covariant\":\n # Step 3.c: Covariant option:\n # \\partial_t B^i = \\beta^j \\bar{D}_j B^i\n # + \\frac{3}{4} ( \\partial_t \\bar{\\Lambda}^{i} - \\beta^j \\bar{D}_j \\bar{\\Lambda}^{i} ) \n # - \\eta B^{i}\n # = \\beta^j B^i_{,j} + \\beta^j \\bar{\\Gamma}^i_{mj} B^m\n # + \\frac{3}{4}[ \\partial_t \\bar{\\Lambda}^{i} \n # - \\beta^j (\\bar{\\Lambda}^i_{,j} + \\bar{\\Gamma}^i_{mj} \\bar{\\Lambda}^m)] \n # - \\eta B^{i}\n # Term 1, part a: First compute B^i_{,j} using upwinded derivative\n BU_dupD = ixp.zerorank2()\n betU_dupD = ixp.declarerank2(\"betU_dupD\",\"nosym\")\n for i in range(DIM):\n for j in range(DIM):\n BU_dupD[i][j] = betU_dupD[i][j]*rfm.ReU[i] + betU[i]*rfm.ReUdD[i][j]\n # Term 1: \\beta^j B^i_{,j}\n for i in range(DIM):\n for j in range(DIM):\n B_rhsU[i] += betaU[j]*BU_dupD[i][j]\n # Term 2: \\beta^j \\bar{\\Gamma}^i_{mj} B^m\n for i in range(DIM):\n for j in range(DIM):\n for m in range(DIM):\n B_rhsU[i] += betaU[j]*GammabarUDD[i][m][j]*BU[m]\n # Term 3: \\frac{3}{4}\\partial_t \\bar{\\Lambda}^{i}\n for i in range(DIM):\n B_rhsU[i] += sp.Rational(3,4)*Brhs.Lambdabar_rhsU[i]\n # Term 4: -\\frac{3}{4}\\beta^j \\bar{\\Lambda}^i_{,j}\n for i in range(DIM):\n for j in range(DIM):\n B_rhsU[i] += -sp.Rational(3,4)*betaU[j]*Brhs.LambdabarU_dupD[i][j]\n # Term 5: -\\frac{3}{4}\\beta^j \\bar{\\Gamma}^i_{mj} \\bar{\\Lambda}^m\n for i in range(DIM):\n for j in range(DIM):\n for m in range(DIM):\n B_rhsU[i] += -sp.Rational(3,4)*betaU[j]*GammabarUDD[i][m][j]*Bq.LambdabarU[m]\n # Term 6: - \\eta B^i\n # eta is a free parameter; we declare it here:\n eta = par.Cparameters(\"REAL\", thismodule, [\"eta\"],2.0)\n for i in range(DIM):\n B_rhsU[i] += -eta*BU[i]",
"_____no_output_____"
]
],
[
[
"<a id='rescale'></a>\n\n# Step 4: Rescale right-hand sides of BSSN gauge equations \\[Back to [top](#toc)\\]\n$$\\label{rescale}$$\n\nNext we rescale the right-hand sides of the BSSN equations so that the evolved variables are $\\left\\{h_{i j},a_{i j},\\text{cf}, K, \\lambda^{i}, \\alpha, \\mathcal{V}^i, \\mathcal{B}^i\\right\\}$",
"_____no_output_____"
]
],
[
[
"# Step 4: Rescale the BSSN gauge RHS quantities so that the evolved \n# variables may remain smooth across coord singularities\nvet_rhsU = ixp.zerorank1()\nbet_rhsU = ixp.zerorank1()\nfor i in range(DIM):\n vet_rhsU[i] = beta_rhsU[i] / rfm.ReU[i]\n bet_rhsU[i] = B_rhsU[i] / rfm.ReU[i]\n#print(str(Abar_rhsDD[2][2]).replace(\"**\",\"^\").replace(\"_\",\"\").replace(\"xx\",\"x\").replace(\"sin(x2)\",\"Sin[x2]\").replace(\"sin(2*x2)\",\"Sin[2*x2]\").replace(\"cos(x2)\",\"Cos[x2]\").replace(\"detgbaroverdetghat\",\"detg\"))\n#print(str(Dbarbetacontraction).replace(\"**\",\"^\").replace(\"_\",\"\").replace(\"xx\",\"x\").replace(\"sin(x2)\",\"Sin[x2]\").replace(\"detgbaroverdetghat\",\"detg\"))\n#print(betaU_dD)\n#print(str(trK_rhs).replace(\"xx2\",\"xx3\").replace(\"xx1\",\"xx2\").replace(\"xx0\",\"xx1\").replace(\"**\",\"^\").replace(\"_\",\"\").replace(\"sin(xx2)\",\"Sinx2\").replace(\"xx\",\"x\").replace(\"sin(2*x2)\",\"Sin2x2\").replace(\"cos(x2)\",\"Cosx2\").replace(\"detgbaroverdetghat\",\"detg\"))\n#print(str(bet_rhsU[0]).replace(\"xx2\",\"xx3\").replace(\"xx1\",\"xx2\").replace(\"xx0\",\"xx1\").replace(\"**\",\"^\").replace(\"_\",\"\").replace(\"sin(xx2)\",\"Sinx2\").replace(\"xx\",\"x\").replace(\"sin(2*x2)\",\"Sin2x2\").replace(\"cos(x2)\",\"Cosx2\").replace(\"detgbaroverdetghat\",\"detg\"))",
"_____no_output_____"
]
],
[
[
"<a id='code_validation'></a>\n\n# Step 5: Code Validation against `BSSN.BSSN_gauge_RHSs` NRPy+ module \\[Back to [top](#toc)\\]\n$$\\label{code_validation}$$\n\nHere, as a code validation check, we verify agreement in the SymPy expressions for the RHSs of the BSSN gauge equations between\n\n1. this tutorial and \n2. the NRPy+ [BSSN.BSSN_gauge_RHSs](../edit/BSSN/BSSN_gauge_RHSs.py) module.\n\nBy default, we analyze the RHSs in Spherical coordinates and with the covariant Gamma-driving second-order shift condition, though other coordinate systems & gauge conditions may be chosen.",
"_____no_output_____"
]
],
[
[
"# Step 5: We already have SymPy expressions for BSSN gauge RHS expressions\n# in terms of other SymPy variables. Even if we reset the \n# list of NRPy+ gridfunctions, these *SymPy* expressions for\n# BSSN RHS variables *will remain unaffected*. \n# \n# Here, we will use the above-defined BSSN gauge RHS expressions\n# to validate against the same expressions in the \n# BSSN/BSSN_gauge_RHSs.py file, to ensure consistency between \n# this tutorial and the module itself.\n#\n# Reset the list of gridfunctions, as registering a gridfunction\n# twice will spawn an error.\ngri.glb_gridfcs_list = []\n\n\n# Step 5.a: Call the BSSN_gauge_RHSs() function from within the\n# BSSN/BSSN_gauge_RHSs.py module,\n# which should generate exactly the same expressions as above.\nimport BSSN.BSSN_gauge_RHSs as Bgrhs\npar.set_parval_from_str(\"BSSN.BSSN_gauge_RHSs::ShiftEvolutionOption\",\"GammaDriving2ndOrder_Covariant\")\nBgrhs.BSSN_gauge_RHSs()\n\nprint(\"Consistency check between BSSN.BSSN_gauge_RHSs tutorial and NRPy+ module: ALL SHOULD BE ZERO.\")\n\nprint(\"alpha_rhs - bssnrhs.alpha_rhs = \" + str(alpha_rhs - Bgrhs.alpha_rhs))\n\nfor i in range(DIM):\n print(\"vet_rhsU[\"+str(i)+\"] - bssnrhs.vet_rhsU[\"+str(i)+\"] = \" + str(vet_rhsU[i] - Bgrhs.vet_rhsU[i]))\n print(\"bet_rhsU[\"+str(i)+\"] - bssnrhs.bet_rhsU[\"+str(i)+\"] = \" + str(bet_rhsU[i] - Bgrhs.bet_rhsU[i])) ",
"Consistency check between BSSN.BSSN_gauge_RHSs tutorial and NRPy+ module: ALL SHOULD BE ZERO.\nalpha_rhs - bssnrhs.alpha_rhs = 0\nvet_rhsU[0] - bssnrhs.vet_rhsU[0] = 0\nbet_rhsU[0] - bssnrhs.bet_rhsU[0] = 0\nvet_rhsU[1] - bssnrhs.vet_rhsU[1] = 0\nbet_rhsU[1] - bssnrhs.bet_rhsU[1] = 0\nvet_rhsU[2] - bssnrhs.vet_rhsU[2] = 0\nbet_rhsU[2] - bssnrhs.bet_rhsU[2] = 0\n"
]
],
[
[
"<a id='latex_pdf_output'></a>\n\n# Step 6: Output this notebook to $\\LaTeX$-formatted PDF file \\[Back to [top](#toc)\\]\n$$\\label{latex_pdf_output}$$\n\nThe following code cell converts this Jupyter notebook into a proper, clickable $\\LaTeX$-formatted PDF file. After the cell is successfully run, the generated PDF may be found in the root NRPy+ tutorial directory, with filename\n[Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.pdf](Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.pdf) (Note that clicking on this link may not work; you may need to open the PDF file through another means.)",
"_____no_output_____"
]
],
[
[
"!jupyter nbconvert --to latex --template latex_nrpy_style.tplx Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.ipynb\n!pdflatex -interaction=batchmode Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.tex\n!pdflatex -interaction=batchmode Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.tex\n!pdflatex -interaction=batchmode Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.tex\n!rm -f Tut*.out Tut*.aux Tut*.log",
"[NbConvertApp] Converting notebook Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.ipynb to latex\n[NbConvertApp] Writing 63685 bytes to Tutorial-BSSN_time_evolution-BSSN_gauge_RHSs.tex\nThis is pdfTeX, Version 3.14159265-2.6-1.40.18 (TeX Live 2017/Debian) (preloaded format=pdflatex)\n restricted \\write18 enabled.\nentering extended mode\nThis is pdfTeX, Version 3.14159265-2.6-1.40.18 (TeX Live 2017/Debian) (preloaded format=pdflatex)\n restricted \\write18 enabled.\nentering extended mode\nThis is pdfTeX, Version 3.14159265-2.6-1.40.18 (TeX Live 2017/Debian) (preloaded format=pdflatex)\n restricted \\write18 enabled.\nentering extended mode\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a298eb8e4455bd34c80a058bfd33dbfaff1f91f
| 476 |
ipynb
|
Jupyter Notebook
|
network_machine_learning_in_python/applications/ch10/significant-communities.ipynb
|
Laknath1996/graph-stats-book
|
4b10c2f99dbfb5e05a72c98130f8c4338d7c9a21
|
[
"MIT"
] | 10 |
2020-09-15T19:09:53.000Z
|
2022-03-17T21:24:14.000Z
|
network_machine_learning_in_python/applications/ch10/significant-communities.ipynb
|
Laknath1996/graph-stats-book
|
4b10c2f99dbfb5e05a72c98130f8c4338d7c9a21
|
[
"MIT"
] | 30 |
2020-09-15T19:15:11.000Z
|
2022-03-10T15:33:24.000Z
|
network_machine_learning_in_python/applications/ch10/significant-communities.ipynb
|
Laknath1996/graph-stats-book
|
4b10c2f99dbfb5e05a72c98130f8c4338d7c9a21
|
[
"MIT"
] | 2 |
2021-04-12T05:08:00.000Z
|
2021-10-04T09:42:21.000Z
| 17 | 43 | 0.546218 |
[
[
[
"# Testing for Significant Communities",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4a29901bfe56943b78e408662bb991c331a0181e
| 34,710 |
ipynb
|
Jupyter Notebook
|
Banknote_authentication.ipynb
|
Aditya-Singla/Banknote-Authentication
|
abd5c33147ed777146ddb1ba58da5ec563958c29
|
[
"MIT"
] | 1 |
2020-06-06T23:46:12.000Z
|
2020-06-06T23:46:12.000Z
|
Banknote_authentication.ipynb
|
Aditya-Singla/Banknote-Authentication
|
abd5c33147ed777146ddb1ba58da5ec563958c29
|
[
"MIT"
] | null | null | null |
Banknote_authentication.ipynb
|
Aditya-Singla/Banknote-Authentication
|
abd5c33147ed777146ddb1ba58da5ec563958c29
|
[
"MIT"
] | null | null | null | 25.597345 | 259 | 0.443964 |
[
[
[
"<a href=\"https://colab.research.google.com/github/Aditya-Singla/Banknote-Authentication/blob/master/Banknote_authentication.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"**Importing the libraries**",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"**Uploading the dataset**",
"_____no_output_____"
]
],
[
[
"dataset = pd.read_csv('Bank note authentication.csv')\nX = dataset.iloc[:,:-1].values\ny = dataset.iloc[:,-1].values\n\n",
"_____no_output_____"
]
],
[
[
"**No missing values** (*as specified by the source* https://archive.ics.uci.edu/ml/datasets/banknote+authentication )",
"_____no_output_____"
],
[
"**Splitting the dataset into training set and test set**",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nx_train, x_test, y_train, y_test = train_test_split(X, y, test_size =0.2, random_state =0 )",
"_____no_output_____"
]
],
[
[
"*Checking* training and test sets",
"_____no_output_____"
]
],
[
[
"print(x_train)",
"[[-3.0866 -6.6362 10.5405 -0.89182]\n [-0.40857 3.0977 -2.9607 -2.6892 ]\n [-1.5228 -6.4789 5.7568 0.87325]\n ...\n [ 0.61652 3.8944 -4.7275 -4.3948 ]\n [ 4.0446 11.1741 -4.3582 -4.7401 ]\n [ 4.0715 7.6398 -2.0824 -1.1698 ]]\n"
],
[
"print(y_train)",
"[1 1 1 ... 1 0 0]\n"
],
[
"print(x_test)",
"[[ 4.05450e-03 6.29050e-01 -6.41210e-01 7.58170e-01]\n [ 5.13210e+00 -3.10480e-02 3.26160e-01 1.11510e+00]\n [-3.50600e+00 -1.25667e+01 1.51606e+01 -7.52160e-01]\n ...\n [-3.48100e-01 -3.86960e-01 -4.78410e-01 6.26270e-01]\n [-2.96720e+00 -1.32869e+01 1.34727e+01 -2.62710e+00]\n [-4.36670e+00 6.06920e+00 5.72080e-01 -5.46680e+00]]\n"
],
[
"print(y_test)",
"[1 0 1 0 0 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 1 0 0 0 1 0 0 1 0 1 0 0 0 0\n 1 0 0 1 1 0 0 1 1 0 0 1 0 1 1 0 1 1 0 1 0 0 1 1 0 0 0 0 1 1 1 1 0 1 0 1 1\n 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 0 1 0 0 0 1 0 1 1 1 0\n 1 1 0 1 0 0 0 1 1 0 0 0 1 1 1 1 0 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0\n 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1 1 1 0 0 0 1 1 0 0 0 0 0\n 1 0 1 1 0 0 0 1 0 1 0 0 0 1 1 0 0 0 0 1 0 0 0 1 0 1 1 1 0 0 1 1 0 0 1 0 0\n 0 0 0 1 1 0 0 0 0 0 0 0 1 1 0 0 1 1 0 1 1 0 1 0 1 0 0 0 0 0 1 1 1 0 0 1 1\n 1 0 0 0 1 0 0 1 1 0 1 0 0 1 1 1]\n"
],
[
"print(y_test)",
"[1 0 1 0 0 0 0 0 1 1 0 0 1 0 0 0 1 1 0 0 1 0 0 1 0 0 0 1 0 0 1 0 1 0 0 0 0\n 1 0 0 1 1 0 0 1 1 0 0 1 0 1 1 0 1 1 0 1 0 0 1 1 0 0 0 0 1 1 1 1 0 1 0 1 1\n 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 1 1 1 0 0 1 0 0 1 0 0 0 1 0 1 1 1 0\n 1 1 0 1 0 0 0 1 1 0 0 0 1 1 1 1 0 1 0 0 0 1 0 0 1 0 0 0 0 1 0 0 1 0 0 1 0\n 0 1 0 0 1 0 1 0 0 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1 1 1 0 0 0 1 1 0 0 0 0 0\n 1 0 1 1 0 0 0 1 0 1 0 0 0 1 1 0 0 0 0 1 0 0 0 1 0 1 1 1 0 0 1 1 0 0 1 0 0\n 0 0 0 1 1 0 0 0 0 0 0 0 1 1 0 0 1 1 0 1 1 0 1 0 1 0 0 0 0 0 1 1 1 0 0 1 1\n 1 0 0 0 1 0 0 1 1 0 1 0 0 1 1 1]\n"
]
],
[
[
"**Feature Scaling** (**NOT** required for the *independent variable*)",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import StandardScaler\nx_sc = StandardScaler()\n\nx_train_sc = x_sc.fit_transform(x_train)\nx_test_sc = x_sc.fit_transform(x_test)",
"_____no_output_____"
]
],
[
[
"*Checking* feature scaling",
"_____no_output_____"
]
],
[
[
"print(x_train_sc)",
"[[-1.23838989 -1.43420372 2.11416802 0.13992458]\n [-0.28386987 0.2164033 -1.02333768 -0.71665709]\n [-0.68101062 -1.40752988 1.0024975 0.9811082 ]\n ...\n [ 0.08149905 0.35150214 -1.43391934 -1.52949895]\n [ 1.30335653 1.58594301 -1.34809875 -1.69405939]\n [ 1.3129444 0.98662101 -0.81923202 0.00744699]]\n"
]
],
[
[
"**Logistic Regression**",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression\nclassifier_lr = LogisticRegression(random_state=0)\nclassifier_lr.fit(x_train_sc,y_train)\n\ny_predict_lr = classifier_lr.predict(x_test_sc)\n",
"_____no_output_____"
]
],
[
[
"**Evaluating** Logistic Regeression ",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score\ncm_lr = confusion_matrix(y_test,y_predict_lr)\nprint(cm_lr)\naccuracy_score(y_test,y_predict_lr)\n",
"[[154 6]\n [ 0 115]]\n"
],
[
"auc_score_lr = roc_auc_score(y_test,y_predict_lr)\nprint(auc_score_lr)",
"0.9812500000000001\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\naccuracy_lr = cross_val_score(classifier_lr, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_lr.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_lr.std()*100))",
"Accuracy:98.27%\nStandard Deviation: 0.76%\n"
]
],
[
[
"**K Nearest Neighbors**\n",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsClassifier\nclassifier_knn = KNeighborsClassifier(n_neighbors = 5, metric = 'minkowski',p=2)\nclassifier_knn.fit(x_train_sc,y_train)\n\ny_predict_knn = classifier_knn.predict(x_test_sc)",
"_____no_output_____"
]
],
[
[
"**Evaluating** K Nearest Neighbors",
"_____no_output_____"
]
],
[
[
"cm_knn = confusion_matrix(y_test, y_predict_knn)\nprint(cm_knn)\naccuracy_score(y_test,y_predict_knn)",
"[[159 1]\n [ 0 115]]\n"
],
[
"auc_score_knn = roc_auc_score(y_test,y_predict_knn)\nprint(auc_score_knn)",
"0.9968750000000001\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\naccuracy_knn = cross_val_score(classifier_knn, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_knn.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_knn.std()*100))",
"Accuracy:99.82%\nStandard Deviation: 0.37%\n"
]
],
[
[
"**Support Vector Machines (Kernel SVM)**",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVC\nclassifier_svm = SVC(kernel ='rbf', random_state = 20)\nclassifier_svm.fit(x_train_sc,y_train)\n\ny_predict_svm = classifier_svm.predict(x_test_sc)\n",
"_____no_output_____"
]
],
[
[
"**Evaluating** Kernel SVM",
"_____no_output_____"
]
],
[
[
"cm_svm = confusion_matrix(y_test,y_predict_svm)\nprint(cm_svm)\naccuracy_score(y_test,y_predict_svm)",
"[[158 2]\n [ 0 115]]\n"
],
[
"auc_score_svm = roc_auc_score(y_test,y_predict_svm)\nprint(auc_score_svm)",
"0.99375\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"accuracy_svm = cross_val_score(classifier_svm, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_svm.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_svm.std()*100))",
"Accuracy:100.00%\nStandard Deviation: 0.00%\n"
]
],
[
[
"**Naive-Bayes Classification**",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import GaussianNB\nclassifier_nb = GaussianNB()\nclassifier_nb.fit(x_train_sc, y_train)\n\ny_predict_nb = classifier_nb.predict(x_test_sc)",
"_____no_output_____"
]
],
[
[
"**Evaluating** Naive Bayes",
"_____no_output_____"
]
],
[
[
"cm_nb = confusion_matrix(y_test, y_predict_nb)\nprint (cm_nb)\naccuracy_score(y_test, y_predict_nb)",
"[[145 15]\n [ 20 95]]\n"
],
[
"auc_score_nb = roc_auc_score(y_test,y_predict_nb)\nprint(auc_score_nb)",
"0.8661684782608696\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"accuracy_nb = cross_val_score(classifier_nb, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_nb.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_nb.std()*100))",
"Accuracy:83.21%\nStandard Deviation: 4.14%\n"
]
],
[
[
"**Decision Tree Classification**",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\nclassifier_dt = DecisionTreeClassifier(criterion='entropy',random_state=0)\nclassifier_dt.fit(x_train_sc, y_train)\n\ny_predict_dt = classifier_dt.predict(x_test_sc)",
"_____no_output_____"
]
],
[
[
"**Evaluating** Decision Tree Classifier",
"_____no_output_____"
]
],
[
[
"cm_dt = confusion_matrix(y_test, y_predict_dt)\nprint (cm_dt)\naccuracy_score(y_test, y_predict_dt)",
"[[154 6]\n [ 1 114]]\n"
],
[
"auc_score_dt = roc_auc_score(y_test,y_predict_dt)\nprint(auc_score_dt)",
"0.9769021739130436\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"accuracy_dt = cross_val_score(classifier_dt, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_dt.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_dt.std()*100))",
"Accuracy:98.54%\nStandard Deviation: 0.84%\n"
]
],
[
[
"**Random Forest Classification**",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier\nclassifier_rf = RandomForestClassifier(n_estimators=100, criterion='entropy',random_state=0)\nclassifier_rf.fit(x_train_sc, y_train)\n\ny_predict_rf = classifier_rf.predict(x_test_sc)",
"_____no_output_____"
]
],
[
[
"**Evaluating** Random Forest Classifier",
"_____no_output_____"
]
],
[
[
"cm_rf = confusion_matrix(y_test, y_predict_rf)\nprint (cm_rf)\naccuracy_score(y_test, y_predict_rf)",
"[[157 3]\n [ 0 115]]\n"
],
[
"auc_score_rf = roc_auc_score(y_test,y_predict_rf)\nprint(auc_score_rf)",
"0.990625\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"accuracy_rf = cross_val_score(classifier_rf, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_rf.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_rf.std()*100))",
"Accuracy:99.18%\nStandard Deviation: 0.64%\n"
]
],
[
[
"**Neural Network Classifier**\n\nP.S. This is just for fun!",
"_____no_output_____"
]
],
[
[
"from sklearn.neural_network import MLPClassifier\nclassifier_neural_network = MLPClassifier(random_state=0)\nclassifier_neural_network.fit(x_train_sc,y_train)\n\ny_predict_neural_network = classifier_neural_network.predict(x_test_sc)",
"_____no_output_____"
]
],
[
[
"**Evaluating** Neural Network",
"_____no_output_____"
]
],
[
[
"cm_neural_network = confusion_matrix(y_test, y_predict_neural_network) \nprint(cm_neural_network)\naccuracy_score(y_test, y_predict_neural_network)",
"[[158 2]\n [ 0 115]]\n"
],
[
"auc_score_neural_network = roc_auc_score(y_test,y_predict_neural_network)\nprint(auc_score_neural_network)",
"0.99375\n"
]
],
[
[
"**Evaluating** K-Cross Validation Score",
"_____no_output_____"
]
],
[
[
"accuracy_neural_network = cross_val_score(classifier_neural_network, x_train_sc, y_train, cv=10 )\nprint( 'Accuracy:{:.2f}%'.format(accuracy_neural_network.mean()*100))\nprint( 'Standard Deviation: {:.2f}%'.format(accuracy_neural_network.std()*100))",
"Accuracy:100.00%\nStandard Deviation: 0.00%\n"
]
],
[
[
"\n*Neural Network* model as well as *Kernel SVM* gave us the best overall accuracy of 99.27% !!",
"_____no_output_____"
],
[
"Well, no tuning is necessary as the accuracy has already pretty much reached the maximum.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a299939fd5ee10f761d94633e683cee537e9395
| 51,666 |
ipynb
|
Jupyter Notebook
|
sbes2020/2.Distributions.ipynb
|
catarinacosta/macToll
|
616dbb6350464e9d19fc4ac2e3d69a83e094bd53
|
[
"MIT"
] | 1 |
2020-09-17T18:13:37.000Z
|
2020-09-17T18:13:37.000Z
|
sbes2020/2.Distributions.ipynb
|
catarinacosta/macToll
|
616dbb6350464e9d19fc4ac2e3d69a83e094bd53
|
[
"MIT"
] | 1 |
2021-03-31T13:19:43.000Z
|
2021-03-31T14:51:04.000Z
|
sbes2020/2.Distributions.ipynb
|
catarinacosta/macToll
|
616dbb6350464e9d19fc4ac2e3d69a83e094bd53
|
[
"MIT"
] | 2 |
2021-04-07T21:20:03.000Z
|
2022-01-18T02:25:18.000Z
| 54.442571 | 2,532 | 0.561704 |
[
[
[
"Show main statistics.csv results\n\nPlot distributions for each attribute",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport string\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nstats = pd.read_csv(\"statistics.csv\")",
"_____no_output_____"
],
[
"stats[stats[\"Project\"] == \"<all>\"]",
"_____no_output_____"
],
[
"df = pd.read_excel(\"../Dataset-SBES2020.xlsx\")\ndf = df[(df[\"Committers B1\"] != 0) & (df[\"Committers B2\"] != 0)]\n\ndf.loc[df[\"Conflicts\"] != \"YES\", 'Conflicts'] = \"WO\"\ndf.loc[df[\"Conflicts\"] == \"YES\", 'Conflicts'] = \"WC\"\nYES = \"YES\"",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"attributes = {\n \"Branching-duration\": \"branching-duration\",\n \"Total-duration\": \"total-duration\",\n \"Commits B1\": \"commits B1\",\n \"Commits B2\": \"commits B2\",\n \"Committers B1\": \"committers B1\",\n \"Committers B2\": \"committers B2\",\n \"Changed Files B1\": \"changed-files B1\",\n \"Changed Files B2\": \"changed-files B2\"\n}\n\nfor i, attr in enumerate(attributes):\n letter = string.ascii_lowercase[i]\n nattr = attributes[attr].replace('-', '_').replace(' ', '_')\n fig, ax2 = plt.subplots()\n p = df.boxplot(ax=ax2, grid=False, vert=False, widths = 0.5, showfliers=False, column=attr, by=\"Conflicts\")\n fig.suptitle('')\n ax2.set_title(\"\")\n xlim = ax2.get_xlim()\n ax2.set_xlabel(f\"\")\n fig.set_size_inches([3, 1])\n plt.tight_layout()\n print(nattr)\n\n display(fig)\n fig.savefig(f\"output/distributions/{letter}_{nattr}_dist.png\")\n fig.savefig(f\"output/distributions/{letter}_{nattr}_dist.svg\")\n fig.savefig(f\"output/distributions/{letter}_{nattr}_dist.pdf\")\n plt.close()",
"branching_duration\n"
]
],
[
[
"Plots stored at output/distributions",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a29a02cdbb6049f4b98f9088582a6c93f875f63
| 9,420 |
ipynb
|
Jupyter Notebook
|
DisHonsetDataSVC.ipynb
|
isankha007/ML-Project
|
4c9ea2d29b943489d7284708eb4bc196ba513382
|
[
"MIT"
] | null | null | null |
DisHonsetDataSVC.ipynb
|
isankha007/ML-Project
|
4c9ea2d29b943489d7284708eb4bc196ba513382
|
[
"MIT"
] | null | null | null |
DisHonsetDataSVC.ipynb
|
isankha007/ML-Project
|
4c9ea2d29b943489d7284708eb4bc196ba513382
|
[
"MIT"
] | null | null | null | 24.153846 | 109 | 0.44087 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport fileinput\nfrom sklearn.svm import SVC",
"_____no_output_____"
]
],
[
[
"mountList = open(\"/usr2/py/mount.txt\", \"r\").readlines()\nnewmountList = open(\"/usr2/py/newmount.txt\",\"r\").readlines()\noutputList = [item for item in mountList if \"filer\" not in item.lower()]\noutputList.extend(newmountList)\nf = open(\"/usr2/py/mount.txt\",\"w\")\nf.write(''.join(outputList))\nf.close()",
"_____no_output_____"
]
],
[
[
"for line in fileinput.FileInput(\"DataSet/Dishonest Internet users dataset.txt\", inplace=1):\n line=line.replace(\" \",\",\")\n print(line)",
"_____no_output_____"
],
[
"data = pd.read_csv('DataSet/Dishonest Internet users dataset.txt',header=None,skipinitialspace=True)\ndata.shape",
"_____no_output_____"
],
[
"data.columns = ['CT','CU','LT','TC','TS']\ndata.head()",
"_____no_output_____"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 322 entries, 0 to 321\nData columns (total 5 columns):\nCT 322 non-null object\nCU 322 non-null object\nLT 322 non-null object\nTC 322 non-null object\nTS 322 non-null object\ndtypes: object(5)\nmemory usage: 12.7+ KB\n"
],
[
"# data.sort_values(['normalized_losses'],ascending=False)\n# data = data.reset_index()\n# data.head()",
"_____no_output_____"
],
[
"from sklearn.preprocessing import LabelEncoder\nenc = LabelEncoder()\ndata.CT = enc.fit_transform(data.CT)\ndata.CU = enc.fit_transform(data.CU)\ndata.LT = enc.fit_transform(data.LT)\ndata.TC = enc.fit_transform(data.TC)\ndata.TS = enc.fit_transform(data.TS)\n",
"_____no_output_____"
],
[
"# np.isfinite(data.all()) ",
"_____no_output_____"
],
[
"X= data.iloc[:,:-1]\ny=data.TS\n# np.isfinite(X).all()",
"_____no_output_____"
],
[
"# data.sort_values(['normalized_losses'],ascending=False)\n# data.head()",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nX_train,X_test,y_train,y_test= train_test_split(X,y,test_size=0.3,random_state=10)",
"_____no_output_____"
],
[
"\nmodel= SVC(kernel='rbf',C=10,gamma=0.03)\n\nmodel.fit(X_train,y_train)\ny_predict = model.predict(X_test)",
"_____no_output_____"
],
[
"from collections import Counter\nCounter(data.loc[data.TS<5.0,'TS'])",
"_____no_output_____"
],
[
"y_predict = model.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\nprint(accuracy_score(y_test, y_predict))\npd.crosstab(y_test, y_predict)",
"1.0\n"
]
]
] |
[
"code",
"raw",
"code"
] |
[
[
"code"
],
[
"raw"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a29bd13ed32ecd06f0ddcf52d26b04367e078fa
| 302,658 |
ipynb
|
Jupyter Notebook
|
notebooks/.Trash-1000/files/leaflet-Copy1.ipynb
|
Loop3D/T21
|
060a08c1a76cc6eb9543005cf259345294150ee7
|
[
"CC0-1.0"
] | 1 |
2021-04-27T16:26:57.000Z
|
2021-04-27T16:26:57.000Z
|
notebooks/.Trash-1000/files/leaflet-Copy1.ipynb
|
Loop3D/T21
|
060a08c1a76cc6eb9543005cf259345294150ee7
|
[
"CC0-1.0"
] | null | null | null |
notebooks/.Trash-1000/files/leaflet-Copy1.ipynb
|
Loop3D/T21
|
060a08c1a76cc6eb9543005cf259345294150ee7
|
[
"CC0-1.0"
] | null | null | null | 100.251077 | 42,000 | 0.59032 |
[
[
[
"# Loop Workflow Leaflet",
"_____no_output_____"
],
[
"> * High level approach to making a 3D model from just a bounding box and source files as input. (In Australia only for now. Documentation to come)\n> * To run this notebook, please download and unzip the Turner Syncline data folder (https://github.com/Loop3D/Turner_Syncline/) into where this notebook is running.",
"_____no_output_____"
]
],
[
[
"import random\nimport os\nimport time\nfrom datetime import datetime\nimport shutil\nimport logging\nlogging.getLogger().setLevel(logging.ERROR)\n\nimport numpy as np\nfrom LoopStructural import GeologicalModel\nimport lavavu\nfrom LoopStructural.visualisation import LavaVuModelViewer\nfrom LoopStructural import GeologicalModel\n\n\nfault_params = {'interpolatortype':'FDI',\n 'nelements':1e5,\n# 'data_region':.1,\n 'solver':'pyamg',\n# overprints:overprints,\n 'cpw':10,\n 'npw':10}\nfoliation_params = {'interpolatortype':'PLI' , # 'interpolatortype':'PLI',\n 'nelements':1e5, # how many tetras/voxels\n 'buffer':0.8, # how much to extend nterpolation around box\n 'solver':'pyamg',\n 'damp':True}\n\n\n\nmodel, m2l_data = GeologicalModel.from_map2loop_directory('interactive_model-test2',\n skip_faults=False,\n rescale=False,\n fault_params=fault_params,\n foliation_params=foliation_params)\n\n",
"Updating geological model. There are: \n22 geological features that need to be interpolated\n\n"
],
[
"view = LavaVuModelViewer(model)\nview.add_model_surfaces()\nview.interactive()",
"_____no_output_____"
],
[
"import sys\nsys.executable",
"_____no_output_____"
],
[
"view.clear()\nview.add_points(model['supergroup_0'].faults[0].apply_to_points(model.regular_grid()),'faulted')\nview.add_points(model.regular_grid(shuffle=False),'before')\n\nview.interactive()",
"_____no_output_____"
],
[
"np.sum(model['supergroup_0'].faults[2].apply_to_points(model.regular_grid(shuffle=False))-model.regular_grid(shuffle=False))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a29bdb008cd67c11ff03229f225bdda3b686751
| 55,041 |
ipynb
|
Jupyter Notebook
|
Code/Jupyter/Char_rnn.ipynb
|
BOURSa/MediaAI
|
e7cd84ae69e893738148e1af48ebe30cf70b6055
|
[
"Apache-2.0"
] | 48 |
2019-04-05T16:50:39.000Z
|
2022-02-16T12:41:44.000Z
|
Code/Jupyter/Char_rnn.ipynb
|
BOURSa/MediaAI
|
e7cd84ae69e893738148e1af48ebe30cf70b6055
|
[
"Apache-2.0"
] | 1 |
2020-04-16T08:54:08.000Z
|
2020-04-16T08:54:08.000Z
|
Code/Jupyter/Char_rnn.ipynb
|
BOURSa/MediaAI
|
e7cd84ae69e893738148e1af48ebe30cf70b6055
|
[
"Apache-2.0"
] | 15 |
2019-04-03T09:44:15.000Z
|
2022-02-16T12:41:34.000Z
| 43.305271 | 343 | 0.541451 |
[
[
[
"# A Char-RNN Implementation in Tensorflow\n*This notebook is slightly modified from https://colab.research.google.com/drive/13Vr3PrDg7cc4OZ3W2-grLSVSf0RJYWzb, with the following changes:*\n\n* Main parameters defined at the start instead of middle\n* Run all works, because of the added upload_custom_data parameter\n* Training time specified in minutes instead of steps, for time-constrained classroom use\n\n---\nCharRNN was a well known generative text model (character level LSTM) created by Andrej Karpathy. It allowed easy training and generation of arbitrary text with many hilarious results:\n\n * Music: abc notation\n<https://highnoongmt.wordpress.com/2015/05/22/lisls-stis-recurrent-neural-networks-for-folk-music-generation/>,\n * Irish folk music\n<https://soundcloud.com/seaandsailor/sets/char-rnn-composes-irish-folk-music>-\n * Obama speeches\n<https://medium.com/@samim/obama-rnn-machine-generated-political-speeches-c8abd18a2ea0>-\n * Eminem lyrics\n<https://soundcloud.com/mrchrisjohnson/recurrent-neural-shady>- (NSFW ;-))\n * Research awards\n<http://karpathy.github.io/2015/05/21/rnn-effectiveness/#comment-2073825449>-\n * TED Talks\n<https://medium.com/@samim/ted-rnn-machine-generated-ted-talks-3dd682b894c0>-\n * Movie Titles <http://www.cs.toronto.edu/~graves/handwriting.html>\n \nThis notebook contains a reimplementation in Tensorflow. It will let you input a file containing the text you want your generator to mimic, train your model, see the results, and save it for future use.\n\nTo get started, start running the cells in order, following the instructions at each step. You will need a sizable text file (try at least 1 MB of text) when prompted to upload one. For exploration you can also use the provided text corpus taken from Shakespeare's works.\n\nThe training cell saves a checkpoint every 30 seconds, so you can check the output of your network and not lose any progress.\n\n## Outline\n\nThis notebook will guide you through the following steps. Roughly speaking, these will be our steps: \n * Upload some data\n * Set some training parameters (you can just use the defaults for now)\n * Define our Model, training loss function, and data input manager\n * Train on a cloud GPU\n * Save out model and use it to generate some new text.\n \nDesign of the RNN is inspired by [this github project](https://github.com/sherjilozair/char-rnn-tensorflow) which was based on Andrej Karpathy's [char-rnn](https://github.com/karpathy/char-rnn). If you'd like to learn more, Andrej's [blog post](http://karpathy.github.io/2015/05/21/rnn-effectiveness/) is a great place to start.",
"_____no_output_____"
],
[
"### Imports and Values Needed to Run this Code",
"_____no_output_____"
]
],
[
[
"%tensorflow_version 1.x\nfrom __future__ import absolute_import, print_function, division\nfrom google.colab import files\nfrom collections import Counter, defaultdict\nfrom copy import deepcopy\nfrom IPython.display import clear_output\nfrom random import randint\n\nimport json\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tensorflow as tf\n\nCHECKPOINT_DIR = './checkpoints/' #Checkpoints are temporarily kept here.\nTEXT_ENCODING = 'utf-8'",
"_____no_output_____"
]
],
[
[
"### Let's define our training parameters.\nFeel free to leave these untouched at their default values and just run this cell as is. Later, you can come back here and experiment wth these. \nThese parameters are just for training. Further down at the inference step, we'll define parameters for the text-generation step.",
"_____no_output_____"
]
],
[
[
"#The most common parameters to change\nupload_custom_data = False #if false, use the default Shakespeare data\ntraining_time_minutes = 2 #change this depending on how much time you have\n\n#Neural network and optimization default parameters that usually work ok\nnum_layers = 2\nstate_size = 256\nbatch_size = 64\nsequence_length = 256\nsteps_per_epoch = 500\nlearning_rate = 0.002\nlearning_rate_decay = 0.95\ngradient_clipping = 5.0\n",
"_____no_output_____"
]
],
[
[
"### Get the training data.\n\nWe can either download the works of Shakespeare to train on or upload our own plain text file that we will be training on.",
"_____no_output_____"
]
],
[
[
"if not upload_custom_data:\n shakespeare_url = \"https://ocw.mit.edu/ans7870/6/6.006/s08/lecturenotes/files/t8.shakespeare.txt\"\n import urllib\n file_contents = urllib.urlopen(shakespeare_url).read()\n file_name = \"shakespeare\"\n file_contents = file_contents[10501:] # Skip headers and start at content\n print(\"An excerpt: \\n\", file_contents[:664])",
"An excerpt: \n 1\n From fairest creatures we desire increase,\n That thereby beauty's rose might never die,\n But as the riper should by time decease,\n His tender heir might bear his memory:\n But thou contracted to thine own bright eyes,\n Feed'st thy light's flame with self-substantial fuel,\n Making a famine where abundance lies,\n Thy self thy foe, to thy sweet self too cruel:\n Thou that art now the world's fresh ornament,\n And only herald to the gaudy spring,\n Within thine own bud buriest thy content,\n And tender churl mak'st waste in niggarding:\n Pity the world, or else this glutton be,\n To eat the world's due, by the grave and thee.\n"
],
[
"if upload_custom_data:\n uploaded = files.upload()\n if type(uploaded) is not dict: uploaded = uploaded.files ## Deal with filedit versions\n file_bytes = uploaded[uploaded.keys()[0]]\n utf8_string = file_bytes.decode(TEXT_ENCODING)\n file_contents = utf8_string if files else ''\n file_name = uploaded.keys()[0]\n print(\"An excerpt: \\n\", file_contents[:664])",
"_____no_output_____"
]
],
[
[
"## Set up the recurrent LSTM network \n\nBefore we can do anything, we have to define what our neural network looks like. This next cell creates a class which will contain the tensorflow graph and training parameters that make up the network.",
"_____no_output_____"
]
],
[
[
"class RNN(object):\n \"\"\"Represents a Recurrent Neural Network using LSTM cells.\n\n Attributes:\n num_layers: The integer number of hidden layers in the RNN.\n state_size: The size of the state in each LSTM cell.\n num_classes: Number of output classes. (E.g. 256 for Extended ASCII).\n batch_size: The number of training sequences to process per step.\n sequence_length: The number of chars in a training sequence.\n batch_index: Index within the dataset to start the next batch at.\n on_gpu_sequences: Generates the training inputs for a single batch.\n on_gpu_targets: Generates the training labels for a single batch.\n input_symbol: Placeholder for a single label for use during inference.\n temperature: Used when sampling outputs. A higher temperature will yield\n more variance; a lower one will produce the most likely outputs. Value\n should be between 0 and 1.\n initial_state: The LSTM State Tuple to initialize the network with. This\n will need to be set to the new_state computed by the network each cycle.\n logits: Unnormalized probability distribution for the next predicted\n label, for each timestep in each sequence.\n output_labels: A [batch_size, 1] int32 tensor containing a predicted\n label for each sequence in a batch. Only generated in infer mode.\n \"\"\"\n def __init__(self,\n rnn_num_layers=1,\n rnn_state_size=128,\n num_classes=256,\n rnn_batch_size=1,\n rnn_sequence_length=1):\n self.num_layers = rnn_num_layers\n self.state_size = rnn_state_size\n self.num_classes = num_classes\n self.batch_size = rnn_batch_size\n self.sequence_length = rnn_sequence_length\n self.batch_shape = (self.batch_size, self.sequence_length)\n print(\"Built LSTM: \",\n self.num_layers ,self.state_size ,self.num_classes ,\n self.batch_size ,self.sequence_length ,self.batch_shape)\n\n\n def build_training_model(self, dropout_rate, data_to_load):\n \"\"\"Sets up an RNN model for running a training job.\n\n Args:\n dropout_rate: The rate at which weights may be forgotten during training.\n data_to_load: A numpy array of containing the training data, with each\n element in data_to_load being an integer representing a label. For\n example, for Extended ASCII, values may be 0 through 255.\n\n Raises:\n ValueError: If mode is data_to_load is None.\n \"\"\"\n if data_to_load is None:\n raise ValueError('To continue, you must upload training data.')\n inputs = self._set_up_training_inputs(data_to_load)\n self._build_rnn(inputs, dropout_rate)\n\n def build_inference_model(self):\n \"\"\"Sets up an RNN model for generating a sequence element by element.\n \"\"\"\n self.input_symbol = tf.placeholder(shape=[1, 1], dtype=tf.int32)\n self.temperature = tf.placeholder(shape=(), dtype=tf.float32,\n name='temperature')\n self.num_options = tf.placeholder(shape=(), dtype=tf.int32,\n name='num_options')\n self._build_rnn(self.input_symbol, 0.0)\n\n self.temperature_modified_logits = tf.squeeze(\n self.logits, 0) / self.temperature\n\n #for beam search\n self.normalized_probs = tf.nn.softmax(self.logits)\n\n self.output_labels = tf.multinomial(self.temperature_modified_logits,\n self.num_options)\n\n def _set_up_training_inputs(self, data):\n self.batch_index = tf.placeholder(shape=(), dtype=tf.int32)\n batch_input_length = self.batch_size * self.sequence_length\n\n input_window = tf.slice(tf.constant(data, dtype=tf.int32),\n [self.batch_index],\n [batch_input_length + 1])\n\n self.on_gpu_sequences = tf.reshape(\n tf.slice(input_window, [0], [batch_input_length]), self.batch_shape)\n\n self.on_gpu_targets = tf.reshape(\n tf.slice(input_window, [1], [batch_input_length]), self.batch_shape)\n\n return self.on_gpu_sequences\n\n def _build_rnn(self, inputs, dropout_rate):\n \"\"\"Generates an RNN model using the passed functions.\n\n Args:\n inputs: int32 Tensor with shape [batch_size, sequence_length] containing\n input labels.\n dropout_rate: A floating point value determining the chance that a weight\n is forgotten during evaluation.\n \"\"\"\n # Alias some commonly used functions\n dropout_wrapper = tf.contrib.rnn.DropoutWrapper\n lstm_cell = tf.contrib.rnn.LSTMCell\n multi_rnn_cell = tf.contrib.rnn.MultiRNNCell\n\n self._cell = multi_rnn_cell(\n [dropout_wrapper(lstm_cell(self.state_size), 1.0, 1.0 - dropout_rate)\n for _ in range(self.num_layers)])\n\n self.initial_state = self._cell.zero_state(self.batch_size, tf.float32)\n\n embedding = tf.get_variable('embedding',\n [self.num_classes, self.state_size])\n\n embedding_input = tf.nn.embedding_lookup(embedding, inputs)\n output, self.new_state = tf.nn.dynamic_rnn(self._cell, embedding_input,\n initial_state=self.initial_state)\n\n self.logits = tf.contrib.layers.fully_connected(output, self.num_classes,\n activation_fn=None)\n",
"_____no_output_____"
]
],
[
[
"###Define your loss function\nLoss is a measure of how well the neural network is modeling the data distribution. \n\nPass in your logits and the targets you're training against. In this case, target_weights is a set of multipliers that will put higher emphasis on certain outputs. In this notebook, we'll give all outputs equal importance.",
"_____no_output_____"
]
],
[
[
"def get_loss(logits, targets, target_weights):\n with tf.name_scope('loss'):\n return tf.contrib.seq2seq.sequence_loss(\n logits,\n targets,\n target_weights,\n average_across_timesteps=True)",
"_____no_output_____"
]
],
[
[
"### Define your optimizer\nThis tells Tensorflow how to reduce the loss. We will use the popular [ADAM algorithm](https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer)",
"_____no_output_____"
]
],
[
[
"def get_optimizer(loss, initial_learning_rate, gradient_clipping, global_step,\n decay_steps, decay_rate):\n\n with tf.name_scope('optimizer'):\n computed_learning_rate = tf.train.exponential_decay(\n initial_learning_rate,\n global_step,\n decay_steps,\n decay_rate,\n staircase=True)\n\n optimizer = tf.train.AdamOptimizer(computed_learning_rate)\n trained_vars = tf.trainable_variables()\n gradients, _ = tf.clip_by_global_norm(\n tf.gradients(loss, trained_vars),\n gradient_clipping)\n training_op = optimizer.apply_gradients(\n zip(gradients, trained_vars),\n global_step=global_step)\n\n return training_op, computed_learning_rate",
"_____no_output_____"
]
],
[
[
"### This class will let us view the progress of our training as it progresses.",
"_____no_output_____"
]
],
[
[
"class LossPlotter(object):\n def __init__(self, history_length):\n self.global_steps = []\n self.losses = []\n self.averaged_loss_x = []\n self.averaged_loss_y = []\n self.history_length = history_length\n\n def draw_plots(self):\n self._update_averages(self.global_steps, self.losses,\n self.averaged_loss_x, self.averaged_loss_y)\n\n plt.title('Average Loss Over Time')\n plt.xlabel('Global Step')\n plt.ylabel('Loss')\n plt.plot(self.averaged_loss_x, self.averaged_loss_y, label='Loss/Time (Avg)')\n plt.plot()\n plt.plot(self.global_steps, self.losses,\n label='Loss/Time (Last %d)' % self.history_length,\n alpha=.1, color='r')\n plt.plot()\n plt.legend()\n plt.show()\n\n plt.title('Loss for the last 100 Steps')\n plt.xlabel('Global Step')\n plt.ylabel('Loss')\n plt.plot(self.global_steps, self.losses,\n label='Loss/Time (Last %d)' % self.history_length, color='r')\n plt.plot()\n plt.legend()\n plt.show()\n\n # The notebook will be slowed down at the end of training if we plot the\n # entire history of raw data. Plot only the last 100 steps of raw data,\n # and the average of each 100 batches. Don't keep unused data.\n self.global_steps = []\n self.losses = []\n self.learning_rates = []\n\n def log_step(self, global_step, loss):\n self.global_steps.append(global_step)\n self.losses.append(loss)\n\n def _update_averages(self, x_list, y_list,\n averaged_data_x, averaged_data_y):\n averaged_data_x.append(x_list[-1])\n averaged_data_y.append(sum(y_list) / self.history_length)",
"_____no_output_____"
]
],
[
[
"## Now, we're going to start training our model.\n\nThis could take a while, so you might want to grab a coffee. Every 30 seconds of training, we're going to save a checkpoint to make sure we don't lose our progress. To monitor the progress of your training, feel free to stop the training every once in a while and run the inference cell to generate text with your model!\n\nFirst, we will need to turn the plain text file into arrays of tokens (and, later, back). To do this we will use this token mapper helper class:\n",
"_____no_output_____"
]
],
[
[
"import string\nclass TokenMapper(object):\n def __init__(self):\n self.token_mapping = {}\n self.reverse_token_mapping = {}\n def buildFromData(self, utf8_string, limit=0.00004):\n print(\"Build token dictionary.\")\n total_num = len(utf8_string)\n sorted_tokens = sorted(Counter(utf8_string.decode('utf8')).items(), \n key=lambda x: -x[1])\n # Filter tokens: Only allow printable characters (not control chars) and\n # limit to ones that are resonably common, i.e. skip strange esoteric \n # characters in order to reduce the dictionary size.\n filtered_tokens = filter(lambda t: t[0] in string.printable or \n float(t[1])/total_num > limit, sorted_tokens)\n tokens, counts = zip(*filtered_tokens)\n self.token_mapping = dict(zip(tokens, range(len(tokens))))\n for c in string.printable:\n if c not in self.token_mapping:\n print(\"Skipped token for: \", c)\n self.reverse_token_mapping = {\n val: key for key, val in self.token_mapping.items()}\n print(\"Created dictionary: %d tokens\"%len(self.token_mapping))\n \n def mapchar(self, char):\n if char in self.token_mapping:\n return self.token_mapping[char]\n else:\n return self.token_mapping[' ']\n \n def mapstring(self, utf8_string):\n return [self.mapchar(c) for c in utf8_string]\n \n def maptoken(self, token):\n return self.reverse_token_mapping[token]\n \n def maptokens(self, int_array):\n return ''.join([self.reverse_token_mapping[c] for c in int_array])\n \n def size(self):\n return len(self.token_mapping)\n \n def alphabet(self):\n return ''.join([k for k,v in sorted(self.token_mapping.items(),key=itemgetter(1))])\n\n def print(self):\n for k,v in sorted(self.token_mapping.items(),key=itemgetter(1)): print(k, v)\n \n def save(self, path):\n with open(path, 'wb') as json_file:\n json.dump(self.token_mapping, json_file)\n \n def restore(self, path):\n with open(path, 'r') as json_file:\n self.token_mapping = {}\n self.token_mapping.update(json.load(json_file))\n self.reverse_token_mapping = {val: key for key, val in self.token_mapping.items()}",
"_____no_output_____"
]
],
[
[
"Now convert the raw input into a list of tokens.",
"_____no_output_____"
]
],
[
[
"# Clean the checkpoint directory and make a fresh one\n!rm -rf {CHECKPOINT_DIR}\n!mkdir {CHECKPOINT_DIR}\n!ls -lt\n\nchars_in_batch = (sequence_length * batch_size)\nfile_len = len(file_contents)\nunique_sequential_batches = file_len // chars_in_batch\n\nmapper = TokenMapper()\nmapper.buildFromData(file_contents)\nmapper.save(''.join([CHECKPOINT_DIR, 'token_mapping.json']))\n\ninput_values = mapper.mapstring(file_contents)",
"total 8\ndrwxr-xr-x 2 root root 4096 Apr 17 06:03 checkpoints\ndrwxr-xr-x 1 root root 4096 Apr 3 16:24 sample_data\nBuild token dictionary.\nSkipped token for: #\nSkipped token for: $\nSkipped token for: %\nSkipped token for: *\nSkipped token for: +\nSkipped token for: /\nSkipped token for: =\nSkipped token for: @\nSkipped token for: \\\nSkipped token for: ^\nSkipped token for: {\nSkipped token for: ~\nSkipped token for: \t\nSkipped token for: \nSkipped token for: \u000b\nSkipped token for: \f\nCreated dictionary: 84 tokens\n"
]
],
[
[
"###First, we'll build our neural network and add our training operations to the Tensorflow graph. \nIf you're continuing training after testing your generator, run the next three cells.",
"_____no_output_____"
]
],
[
[
"tf.reset_default_graph()\nconfig = tf.ConfigProto()\nconfig.gpu_options.allow_growth = True\nprint('Constructing model...')\n\nmodel = RNN(\n rnn_num_layers=num_layers,\n rnn_state_size=state_size,\n num_classes=mapper.size(),\n rnn_batch_size=batch_size,\n rnn_sequence_length=sequence_length)\n\nmodel.build_training_model(0.05, np.asarray(input_values))\nprint('Constructed model successfully.')\n\nprint('Setting up training session...')\nneutral_target_weights = tf.constant(\n np.ones(model.batch_shape),\n tf.float32\n)\nloss = get_loss(model.logits, model.on_gpu_targets, neutral_target_weights)\nglobal_step = tf.get_variable('global_step', shape=(), trainable=False,\n dtype=tf.int32)\ntraining_step, computed_learning_rate = get_optimizer(\n loss,\n learning_rate,\n gradient_clipping,\n global_step,\n steps_per_epoch,\n learning_rate_decay\n)",
"W0417 06:03:09.974482 140218974406528 lazy_loader.py:50] \nThe TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\n * https://github.com/tensorflow/io (for I/O related ops)\nIf you depend on functionality not listed there, please file an issue.\n\nW0417 06:03:09.977370 140218974406528 deprecation.py:323] From <ipython-input-12-12171759f484>:109: __init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.\nW0417 06:03:09.984956 140218974406528 deprecation.py:323] From <ipython-input-12-12171759f484>:109: __init__ (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis class is equivalent as tf.keras.layers.StackedRNNCells, and will be replaced by that in Tensorflow 2.0.\nW0417 06:03:10.008152 140218974406528 deprecation.py:323] From <ipython-input-12-12171759f484>:118: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\nW0417 06:03:10.049892 140218974406528 deprecation.py:323] From /tensorflow-1.15.2/python2.7/tensorflow_core/python/ops/rnn_cell_impl.py:958: add_variable (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `layer.add_weight` method instead.\nW0417 06:03:10.059854 140218974406528 deprecation.py:506] From /tensorflow-1.15.2/python2.7/tensorflow_core/python/ops/rnn_cell_impl.py:962: calling __init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\n"
]
],
[
[
"The supervisor will manage the training flow and checkpointing.",
"_____no_output_____"
]
],
[
[
"# Create a supervisor that will checkpoint the model in the CHECKPOINT_DIR\nsv = tf.train.Supervisor(\n logdir=CHECKPOINT_DIR,\n global_step=global_step,\n save_model_secs=30)\nprint('Training session ready.')",
"W0417 06:03:10.512609 140218974406528 deprecation.py:323] From <ipython-input-19-4ba04cba093f>:4: __init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.MonitoredTrainingSession\n"
]
],
[
[
"###This next cell will begin the training cycle. \nFirst, we will attempt to pick up training where we left off, if a previous checkpoint exists, then continue the training process.",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\nstart_time = datetime.now()\n\nwith sv.managed_session(config=config) as sess:\n print('Training supervisor successfully initialized all variables.')\n if not file_len:\n raise ValueError('To continue, you must upload training data.')\n elif file_len < chars_in_batch:\n raise ValueError('To continue, you must upload a larger set of data.')\n\n plotter = LossPlotter(100)\n step_number = sess.run(global_step)\n zero_state = sess.run([model.initial_state])\n max_batch_index = (unique_sequential_batches - 1) * chars_in_batch\n while not sv.should_stop() and (datetime.now()-start_time).seconds/60 < training_time_minutes:\n feed_dict = {\n model.batch_index: randint(0, max_batch_index),\n model.initial_state: zero_state\n }\n [_, _, training_loss, step_number, current_learning_rate, _] = sess.run(\n [model.on_gpu_sequences,\n model.on_gpu_targets,\n loss,\n global_step,\n computed_learning_rate,\n training_step],\n feed_dict)\n plotter.log_step(step_number, training_loss)\n if step_number % 100 == 0:\n clear_output(True)\n plotter.draw_plots()\n print('Latest checkpoint is: %s' %\n tf.train.latest_checkpoint(CHECKPOINT_DIR))\n print('Learning Rate is: %f' %\n current_learning_rate)\n\n if step_number % 10 == 0:\n print('global step %d, loss=%f' % (step_number, training_loss))\n\nclear_output(True)\n\nprint('Training completed in HH:MM:SS = ', datetime.now()-start_time)\nprint('Latest checkpoint is: %s' %\n tf.train.latest_checkpoint(CHECKPOINT_DIR))",
"Training completed in HH:MM:SS = 0:01:00.333687\nLatest checkpoint is: ./checkpoints/model.ckpt-100\n"
]
],
[
[
"## Now, we're going to generate some text!\n\nHere, we'll use the **Beam Search** algorithm to generate some text with our trained model. Beam Search picks N possible next options from each of the current options at every step. This way, if the generator picks an item leading to a bad decision down the line, it can toss the bad result out and keep going with a more likely one.",
"_____no_output_____"
]
],
[
[
"class BeamSearchCandidate(object):\n \"\"\"Represents a node within the search space during Beam Search.\n\n Attributes:\n state: The resulting RNN state after the given sequence has been generated.\n sequence: The sequence of selections leading to this node.\n probability: The probability of the sequence occurring, computed as the sum\n of the probabilty of each character in the sequence at its respective\n step.\n \"\"\"\n\n def __init__(self, init_state, sequence, probability):\n self.state = init_state\n self.sequence = sequence\n self.probability = probability\n\n def search_from(self, tf_sess, rnn_model, temperature, num_options):\n \"\"\"Expands the num_options most likely next elements in the sequence.\n\n Args:\n tf_sess: The Tensorflow session containing the rnn_model.\n rnn_model: The RNN to use to generate the next element in the sequence.\n temperature: Modifies the probabilities of each character, placing\n more emphasis on higher probabilities as the value approaches 0.\n num_options: How many potential next options to expand from this one.\n\n Returns: A list of BeamSearchCandidate objects descended from this node.\n \"\"\"\n expanded_set = []\n feed = {rnn_model.input_symbol: np.array([[self.sequence[-1]]]),\n rnn_model.initial_state: self.state,\n rnn_model.temperature: temperature,\n rnn_model.num_options: num_options}\n [predictions, probabilities, new_state] = tf_sess.run(\n [rnn_model.output_labels,\n rnn_model.normalized_probs,\n rnn_model.new_state], feed)\n # Get the indices of the num_beams next picks\n picks = [predictions[0][x] for x in range(len(predictions[0]))]\n for new_char in picks:\n new_seq = deepcopy(self.sequence)\n new_seq.append(new_char)\n expanded_set.append(\n BeamSearchCandidate(new_state, new_seq,\n probabilities[0][0][new_char] + self.probability))\n return expanded_set\n\n def __eq__(self, other):\n return self.sequence == other.sequence\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n def __hash__(self):\n return hash(self.sequence())",
"_____no_output_____"
],
[
"def beam_search_generate_sequence(tf_sess, rnn_model, primer, temperature=0.85,\n termination_condition=None, num_beams=5):\n \"\"\"Implements a sequence generator using Beam Search.\n\n Args:\n tf_sess: The Tensorflow session containing the rnn_model.\n rnn_model: The RNN to use to generate the next element in the sequence.\n temperature: Controls how 'Creative' the generated sequence is. Values\n close to 0 tend to generate the most likely sequence, while values\n closer to 1 generate more original sequences. Acceptable values are\n within (0, 1].\n termination_condition: A function taking one parameter, a list of\n integers, that returns True when a condition is met that signals to the\n RNN to return what it has generated so far.\n num_beams: The number of possible sequences to keep at each step of the\n generation process.\n\n Returns: A list of at most num_beams BeamSearchCandidate objects.\n \"\"\"\n candidates = []\n\n rnn_current_state = sess.run([rnn_model.initial_state])\n #Initialize the state for the primer\n for primer_val in primer[:-1]:\n feed = {rnn_model.input_symbol: np.array([[primer_val]]),\n rnn_model.initial_state: rnn_current_state\n }\n [rnn_current_state] = tf_sess.run([rnn_model.new_state], feed)\n\n candidates.append(BeamSearchCandidate(rnn_current_state, primer, num_beams))\n\n while True not in [termination_condition(x.sequence) for x in candidates]:\n new_candidates = []\n for candidate in candidates:\n expanded_candidates = candidate.search_from(\n tf_sess, rnn_model, temperature, num_beams)\n for new in expanded_candidates:\n if new not in new_candidates:\n #do not reevaluate duplicates\n new_candidates.append(new)\n candidates = sorted(new_candidates,\n key=lambda x: x.probability, reverse=True)[:num_beams]\n\n return [c for c in candidates if termination_condition(c.sequence)]",
"_____no_output_____"
]
],
[
[
"Input something to start your generated text with, and set how characters long you want the text to be.\n\"Creativity\" refers to how much emphasis your neural network puts on matching a pattern. If you notice looping in the output, try raising this value. If your output seems too random, try lowering it a bit.\nIf the results don't look too great in general, run the three training cells again for a bit longer. The lower your loss, the more closely your generated text will match the training data.",
"_____no_output_____"
]
],
[
[
"tf.reset_default_graph()\nconfig = tf.ConfigProto()\nconfig.gpu_options.allow_growth = True\nsess = tf.InteractiveSession(config=config)\n\nmodel = RNN(\n rnn_num_layers=num_layers,\n rnn_state_size=state_size,\n num_classes=mapper.size(),\n rnn_batch_size=1,\n rnn_sequence_length=1)\n\nmodel.build_inference_model()\n\nsess.run(tf.global_variables_initializer())\nsaver = tf.train.Saver(tf.global_variables())\nckpt = tf.train.latest_checkpoint(CHECKPOINT_DIR)\nsaver.restore(sess, ckpt)\n\ndef gen(start_with, pred, creativity):\n int_array = mapper.mapstring(start_with)\n candidates = beam_search_generate_sequence(\n sess, model, int_array, temperature=creativity,\n termination_condition=pred,\n num_beams=1)\n gentext = mapper.maptokens(candidates[0].sequence)\n return gentext\n\ndef lengthlimit(n):\n return lambda text: len(text)>n\ndef sentences(n):\n return lambda text: mapper.maptokens(text).count(\".\")>=n\ndef paragraph():\n return lambda text: mapper.maptokens(text).count(\"\\n\")>0\n\n",
"Built LSTM: 2 256 84 1 1 (1, 1)\n"
],
[
"length_of_generated_text = 2000\ncreativity = 0.85 # Should be greater than 0 but less than 1\n\nprint(gen(\" ANTONIO: Who is it ?\", lengthlimit(length_of_generated_text), creativity))",
" ANTONIO: Who is it ?\n SOANSCR.\n Fondr he susdels\n F I hollin'cpy sof hiwcice thhime, or hou Whouy she met to rerepy Toucoxt y roelt thas coot tid wonlt\n he eweund an so the't\n xa lir, he we the as soreth , I the thod tam hor miam,\n Ald ad ceeth in be.\n\n LENOTSAT ly tl toed sath wey wative thrr ther mo him, tove wesy I meake lir tor calceto halled hros yhag hess oitt befgl wilk tan oot that wacr wam me thaln peure sopt. Co an'nh roariges tir trethe; hhe. thtary hiad avedth.\n As he the oot ant mild,\n thyint mend\n Bill frallesd not mochet thoat cirh onsit pillith art Gweed,\n he ilt the hope th, of asdand, ant ork waf to banth al as menttictale od, naaklolent an.\n I fast hiot ar ont lothe bethe\n \n BASSARTONLLR oP her hers oit moed te goul thy bu sathees\n Ther we lfoll won an woplot ous polet so ssaI nane kere-eind\n If gor thag ho thtiw pon soud the monnt meoch on fher or one the wof mard oll't she havr,\n thalt Cor anv wand by oos Gom,\n Pole anfeod -he hoall the doul dlloth ilel be mos mely coas',\n hith or the sasd ceth at harttiny Ay mige freld othont sant wth syerert'm,\n he thensest; dang oyhoos He\n\n T Ime bede id bath tome thed heles fo thy wheliska pous heunils I pout therind mirve nlen anve dewlate thes werd hin?\n AANnGOTYSA. Be nor buod ten sours ang.\n An to tham Gos the thosise thang; we the batot vece?\n Cand anveads\n Hist, Fhms mpenteD\n Fad thot yaned,\n 2yot whes Lerent cant thes\n Bog and wiut tte bad bo toum are hod blnnltt the th o the amy hand,\n The hill thor of nnast\n thoit dy lots dit tavn geen heas wout woe nhen cor I annto lr of tan eulcortt soe so wame himl brtoe nand tels houd male lafd,\n hi him.\n Help thatok foure wopidny?\n And coy thes tiln, ho wees wo ve toun he siuf! thee her mas,\n [ Arr yere thretle f pey vieve,\n Fad Bigh inore an wary syand\n\n"
]
],
[
[
"## Let's save a copy of our trained RNN so we can do all kinds of cool things with it later.",
"_____no_output_____"
]
],
[
[
"save_model_to_drive = False ## Set this to true to save directly to Google Drive.\n\ndef save_model_hyperparameters(path):\n with open(path, 'w') as json_file:\n model_params = {\n 'num_layers': model.num_layers,\n 'state_size': model.state_size,\n 'num_classes': model.num_classes\n }\n json.dump(model_params, json_file)\n\ndef save_to_drive(title, content):\n # Install the PyDrive wrapper & import libraries.\n !pip install -U -q PyDrive\n from pydrive.auth import GoogleAuth\n from pydrive.drive import GoogleDrive\n from google.colab import auth\n from oauth2client.client import GoogleCredentials\n\n # Authenticate and create the PyDrive client.\n auth.authenticate_user()\n gauth = GoogleAuth()\n gauth.credentials = GoogleCredentials.get_application_default()\n drive = GoogleDrive(gauth)\n\n newfile = drive.CreateFile({'title': title})\n newfile.SetContentFile(content)\n newfile.Upload()\n print('Uploaded file with ID %s as %s'% (newfile.get('id'),\n archive_name))\n \narchive_name = ''.join([file_name,'_seedbank_char-rnn.zip'])\nlatest_model = tf.train.latest_checkpoint(CHECKPOINT_DIR).split('/')[2]\ncheckpoints_archive_path = ''.join(['./exports/',archive_name])\nif not latest_model:\n raise ValueError('You must train a model before you can export one.')\n \n%system mkdir exports\n%rm -f {checkpoints_archive_path}\nmapper.save(''.join([CHECKPOINT_DIR, 'token_mapping.json']))\nsave_model_hyperparameters(''.join([CHECKPOINT_DIR, 'model_attributes.json']))\n%system zip '{checkpoints_archive_path}' -@ '{CHECKPOINT_DIR}checkpoint' \\\n '{CHECKPOINT_DIR}token_mapping.json' \\\n '{CHECKPOINT_DIR}model_attributes.json' \\\n '{CHECKPOINT_DIR}{latest_model}.'*\n\nif save_model_to_drive:\n save_to_drive(archive_name, checkpoints_archive_path)\nelse:\n files.download(checkpoints_archive_path)\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a29be670c1b98200576e6e4f3cc79aab6ec7452
| 93,667 |
ipynb
|
Jupyter Notebook
|
examples/notebooks/Simulations.ipynb
|
zmhammedi/coba
|
90cdeb7b781e1ef498cd5a989bd3601b85a2fad0
|
[
"BSD-3-Clause"
] | null | null | null |
examples/notebooks/Simulations.ipynb
|
zmhammedi/coba
|
90cdeb7b781e1ef498cd5a989bd3601b85a2fad0
|
[
"BSD-3-Clause"
] | null | null | null |
examples/notebooks/Simulations.ipynb
|
zmhammedi/coba
|
90cdeb7b781e1ef498cd5a989bd3601b85a2fad0
|
[
"BSD-3-Clause"
] | null | null | null | 304.113636 | 40,284 | 0.916096 |
[
[
[
"# Simulations\nIn this notebook we will show four methods for incorporating new simulations into Coba in order of easy to hard:\n1. From an Openml.org dataset with **OpenmlSimulation**\n2. From local data sets with **CsvSimulation**, **ArffSimulation**, **LibsvmSimulation**, and **ManikSimulation**.\n3. From Python function definitions with **LambdaSimulation**\n4. From your own class that implements the **Simulation** interface\n\n## Simulations From Openml.org\n\nPerhaps the easiest way to incorporate new Simulations is to load them from Openml.org. Openml.org is is an online repository of machine learning data sets which currently hosts over 21,000 datasets. Using dataset ids Coba can tap into this repository and download these datasets to create Simulations.\n\nTo get a sense of how this works let's say we want to build a simulation from the Covertype data set. We can [do a dataset search](https://www.openml.org/search?type=data) on Openml.org to see if this data set is hosted. [This search](https://www.openml.org/search?q=covertype&type=data) finds several data sets and we simply pick [the first one](https://www.openml.org/d/180). On the dataset's landing page we can look at the URL -- https://www.openml.org/d/180 -- to get the dataset's id of 180. Now, all we have to do to run an experiment with the Covertype data set is:\n",
"_____no_output_____"
]
],
[
[
"from coba.simulations import OpenmlSimulation\nfrom coba.learners import RandomLearner, VowpalLearner\nfrom coba.benchmarks import Benchmark\n\nBenchmark([OpenmlSimulation(180)], take=1000).evaluate([RandomLearner(), VowpalLearner(epsilon=0.1)]).plot_learners()",
"2021-06-18 20:15:09 Processing chunk...\n2021-06-18 20:15:14 * Creating source 0 from {\"OpenmlSimulation\":180}... (5.19 seconds)\n2021-06-18 20:15:14 * Creating simulation 0 from source 0... (0.0 seconds)\n2021-06-18 20:15:14 * Evaluating learner 1 on Simulation 0... (0.24 seconds)\n2021-06-18 20:15:14 * Evaluating learner 0 on Simulation 0... (0.03 seconds)\n"
]
],
[
[
"This same procedure can be repeated for any dataset on Openml.org.\n\n## Simulations From Local Datasets\n\nThe next easiest way to incorporate new Simulations is to load them from a local dataset. Coba can create simulations from datasets in the following formats:\n* CSV\n* ARFF (i.e., https://waikato.github.io/weka-wiki/formats_and_processing/arff_stable/)\n* Libsvm (e.g., https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html)\n* Manik (e.g., http://manikvarma.org/downloads/XC/XMLRepository.html)\n\nFor example, we may want to test against the mnist dataset. This dataset can be download from Libsvm [here](https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass.html#mnist). Once downloaded it we could use it:\n\n```python\nfrom coba.simulations import LibsvmSimulation\nfrom coba.learners import RandomLearner, VowpalLearner\nfrom coba.benchmarks import Benchmark\n\nmnist = [LibsvmSimulation(<path to downloaded mnist>)] \nBenchmark(mnist, take=1000).evaluate([RandomLearner(), VowpalLearner(epsilon=0.1)]).plot_learners()\n```\n\nThe complete list of classes for local simulations is:\n\n* `CsvSimulation(source:str, label_col:Union[str,int], with_header:bool=True)`\n* `ArffSimulation(source:str, label_col:Union[str,int])`\n* `LibsvmSimulation(source:str)`\n* `ManikSimulation(source:str)`\n\n## Simulations from Function Definitions\n\nA third method for creating simulations for use in experiments is via function definitions. \n\nThis can be done with **LambdaSimulation** which takes three function definitions -- describing how to generate contexts, actions and rewards -- and the number of interactions you'd like the simulation to have. An example of a **LambdaSimulation** generating random contexts and actions with a linear reward function in [0,1] is provided:\n",
"_____no_output_____"
]
],
[
[
"from typing import Sequence\n\nfrom coba.random import CobaRandom\nfrom coba.simulations import LambdaSimulation, Context, Action\nfrom coba.learners import RandomLearner, VowpalLearner\nfrom coba.benchmarks import Benchmark\n\nr = CobaRandom()\nn_interactions = 1000\n\ndef context(index: int) -> Context:\n return tuple(r.randoms(5))\n\ndef actions(index: int, context: Context) -> Sequence[Action]:\n actions = [ r.randoms(5) for _ in range(3) ]\n return [ tuple(a/sum(action) for a in action) for action in actions ]\n\ndef rewards(index: int, context: Context, action: Action) -> float:\n return sum(c*a for c,a in zip(context,action))\n\nsimulations = [LambdaSimulation(n_interactions, context, actions, rewards)]\n\nBenchmark(simulations).evaluate([RandomLearner(), VowpalLearner()]).plot_learners()\n",
"2021-06-18 20:15:14 Processing chunk...\n2021-06-18 20:15:14 * Creating source 0 from \"LambdaSimulation\"... (0.0 seconds)\n2021-06-18 20:15:14 * Creating simulation 0 from source 0... (0.0 seconds)\n2021-06-18 20:15:14 * Evaluating learner 1 on Simulation 0... (0.17 seconds)\n2021-06-18 20:15:14 * Evaluating learner 0 on Simulation 0... (0.05 seconds)\n"
]
],
[
[
"## Simulations from Scratch\n\nThe final, and most involved method, for creating new simulations in Coba is to create your own from scratch. This might be needed if you need to ingest a format that Coba doesn't already support. Or maybe you need your simulation to track some internal state between interactions. By creating your own Simulation there really is no limit to the functionality employed. In order to make your own simulation you'll first need to know a few simple classes/interfaces. We'll start with the Simulation interface.\n\n\n### Simulation Interface\n\nA Simulation in Coba is any class with the following interface:\n\n```python\nclass Simulation:\n\n @property\n @abstractmethod\n def interactions(self) -> Sequence[Interaction]:\n ...\n\n @property\n @abstractmethod\n def reward(self) -> Reward:\n ...\n```\n\nSo long as your class satisfies this interface it should be completely interoperable with Coba. However, assuming you have access to coba classes there really isn't any reason to implement this interface yourself. In practice it should always suffice to use MemorySimulation (more on this soon).\n\n### Interaction Interface\n\nAs seen above the Simulation interface relies on the Interaction interface:\n\n```python\nclass Interaction:\n @property\n @abstractmethod\n def key(self) -> Key: \n ...\n \n @property\n @abstractmethod\n def context(self) -> Context:\n ...\n \n @property\n @abstractmethod\n def actions(self) -> Sequence[Action]:\n ...\n```\n\nOnce again, while one can satisfy this interface from scratch we recommend developers simply use Coba's Interaction class. The types hints of Key, Context and Action actually have no constraints on them. We simply provide them for semantic interpretation and you are free to actually return anything you'd like as a key, context or collection of actions.\n\n### Reward Interface\n\nThe final interface that Simulations depend upon is the Reward interface:\n\n```python\nclass Reward:\n @abstractmethod\n def observe(choices: Sequence[Tuple[Key,Context,Action]]) -> Sequence[float]:\n ...\n```\n\nOut of the box Coba provides a ClassificationReward which returns values of 1 or 0 depending on if Action is the true label associated with the observation uniquely identified by Key. For example, if a simulation is loaded from Csv then Key will be the row number of the given observation we are trying to label in the Csv file. Coba also provides MemoryReward which can be useful if Key is hashable and Action are hashable and it is possible to compute all rewards up front.\n\n### Source Interface\n\nOnce you have created your custom Simulation there is one more interface to contend with, the Source interface:\n\n```python\nclass Source[Simulation]:\n \n @abstractmethod\n def read(self) -> Simulation:\n ...\n \n def __repr__(self) -> str:\n ...\n```\n\nWhen performing experiments Coba's benchmark actually expects to be given a Source that produces a Simulation rather than an actual Simulation. All standard simulations such as OpenmlSimulation, CsvSimulation, and LambdaSimulation are actually Sources.\nThe source pattern allows Simulations to be lazy loaded in background processes thereby saving time and resources. Converting a custom Simulation to a Source is fairly easy. Below is an example pattern that could be followed:",
"_____no_output_____"
]
],
[
[
"from coba.simulations import Interaction, MemoryReward\nfrom coba.learners import RandomLearner, VowpalLearner\nfrom coba.benchmarks import Benchmark\n\nclass MySimulation:\n \n class MyLoadedSimulation:\n \n @property\n def interactions(self):\n return [ Interaction(1, (1,1), [1,2,3]), Interaction(2, (2,2), [1,2,3]) ]\n \n @property\n def reward(self):\n return MemoryReward([ (1,1,1), (1,2,2), (1,3,3), (2,1,2), (2,2,100), (2,3,-100) ])\n \n def read(self):\n return MySimulation.MyLoadedSimulation()\n \n def __repr__(self):\n return \"MySimulation\"\n\nBenchmark([MySimulation()]).evaluate([RandomLearner(), VowpalLearner()]).plot_learners()",
"2021-06-18 21:05:41 Coba attempted to evaluate your benchmark in multiple processes but the pickle module was unable to find all the definitions needed to pass the tasks to the processes. The two most common causes of this error are: 1) a learner or simulation is defined in a Jupyter Notebook cell or 2) a necessary class definition exists inside the `__name__=='__main__'` code block in the main execution script. In either case there are two simple solutions: 1) evalute your benchmark in a single processed with no limit on child tasks or 2) define all you classes in a separate python file that is imported when evaluating.\n2021-06-18 21:05:41 No interaction data was found for plot_learners.\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a29c099dc6920bd86bad86a32e6bf0b192c997b
| 34,183 |
ipynb
|
Jupyter Notebook
|
site/en-snapshot/guide/keras/rnn.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | 2 |
2020-09-29T07:31:21.000Z
|
2020-10-13T08:16:18.000Z
|
site/en-snapshot/guide/keras/rnn.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | null | null | null |
site/en-snapshot/guide/keras/rnn.ipynb
|
NarimaneHennouni/docs-l10n
|
39a48e0d5aa34950e29efd5c1f111c120185e9d9
|
[
"Apache-2.0"
] | null | null | null | 37.563736 | 246 | 0.54413 |
[
[
[
"##### Copyright 2020 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Recurrent Neural Networks (RNN) with Keras",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/guide/keras/rnn\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/snapshot-keras/site/en/guide/keras/rnn.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/keras-team/keras-io/blob/master/guides/working_with_rnns.py\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/guide/keras/rnn.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"## Introduction\n\nRecurrent neural networks (RNN) are a class of neural networks that is powerful for\nmodeling sequence data such as time series or natural language.\n\nSchematically, a RNN layer uses a `for` loop to iterate over the timesteps of a\nsequence, while maintaining an internal state that encodes information about the\ntimesteps it has seen so far.\n\nThe Keras RNN API is designed with a focus on:\n\n- **Ease of use**: the built-in `keras.layers.RNN`, `keras.layers.LSTM`,\n`keras.layers.GRU` layers enable you to quickly build recurrent models without\nhaving to make difficult configuration choices.\n\n- **Ease of customization**: You can also define your own RNN cell layer (the inner\npart of the `for` loop) with custom behavior, and use it with the generic\n`keras.layers.RNN` layer (the `for` loop itself). This allows you to quickly\nprototype different research ideas in a flexible way with minimal code.",
"_____no_output_____"
],
[
"## Setup",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers",
"_____no_output_____"
]
],
[
[
"## Built-in RNN layers: a simple example",
"_____no_output_____"
],
[
"There are three built-in RNN layers in Keras:\n\n1. `keras.layers.SimpleRNN`, a fully-connected RNN where the output from previous\ntimestep is to be fed to next timestep.\n\n2. `keras.layers.GRU`, first proposed in\n[Cho et al., 2014](https://arxiv.org/abs/1406.1078).\n\n3. `keras.layers.LSTM`, first proposed in\n[Hochreiter & Schmidhuber, 1997](https://www.bioinf.jku.at/publications/older/2604.pdf).\n\nIn early 2015, Keras had the first reusable open-source Python implementations of LSTM\nand GRU.\n\nHere is a simple example of a `Sequential` model that processes sequences of integers,\nembeds each integer into a 64-dimensional vector, then processes the sequence of\nvectors using a `LSTM` layer.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential()\n# Add an Embedding layer expecting input vocab of size 1000, and\n# output embedding dimension of size 64.\nmodel.add(layers.Embedding(input_dim=1000, output_dim=64))\n\n# Add a LSTM layer with 128 internal units.\nmodel.add(layers.LSTM(128))\n\n# Add a Dense layer with 10 units.\nmodel.add(layers.Dense(10))\n\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"Built-in RNNs support a number of useful features:\n\n- Recurrent dropout, via the `dropout` and `recurrent_dropout` arguments\n- Ability to process an input sequence in reverse, via the `go_backwards` argument\n- Loop unrolling (which can lead to a large speedup when processing short sequences on\nCPU), via the `unroll` argument\n- ...and more.\n\nFor more information, see the\n[RNN API documentation](https://keras.io/api/layers/recurrent_layers/).",
"_____no_output_____"
],
[
"## Outputs and states\n\nBy default, the output of a RNN layer contains a single vector per sample. This vector\nis the RNN cell output corresponding to the last timestep, containing information\nabout the entire input sequence. The shape of this output is `(batch_size, units)`\nwhere `units` corresponds to the `units` argument passed to the layer's constructor.\n\nA RNN layer can also return the entire sequence of outputs for each sample (one vector\nper timestep per sample), if you set `return_sequences=True`. The shape of this output\nis `(batch_size, timesteps, units)`.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential()\nmodel.add(layers.Embedding(input_dim=1000, output_dim=64))\n\n# The output of GRU will be a 3D tensor of shape (batch_size, timesteps, 256)\nmodel.add(layers.GRU(256, return_sequences=True))\n\n# The output of SimpleRNN will be a 2D tensor of shape (batch_size, 128)\nmodel.add(layers.SimpleRNN(128))\n\nmodel.add(layers.Dense(10))\n\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"In addition, a RNN layer can return its final internal state(s). The returned states\ncan be used to resume the RNN execution later, or\n[to initialize another RNN](https://arxiv.org/abs/1409.3215).\nThis setting is commonly used in the\nencoder-decoder sequence-to-sequence model, where the encoder final state is used as\nthe initial state of the decoder.\n\nTo configure a RNN layer to return its internal state, set the `return_state` parameter\nto `True` when creating the layer. Note that `LSTM` has 2 state tensors, but `GRU`\nonly has one.\n\nTo configure the initial state of the layer, just call the layer with additional\nkeyword argument `initial_state`.\nNote that the shape of the state needs to match the unit size of the layer, like in the\nexample below.",
"_____no_output_____"
]
],
[
[
"encoder_vocab = 1000\ndecoder_vocab = 2000\n\nencoder_input = layers.Input(shape=(None,))\nencoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(\n encoder_input\n)\n\n# Return states in addition to output\noutput, state_h, state_c = layers.LSTM(64, return_state=True, name=\"encoder\")(\n encoder_embedded\n)\nencoder_state = [state_h, state_c]\n\ndecoder_input = layers.Input(shape=(None,))\ndecoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(\n decoder_input\n)\n\n# Pass the 2 states to a new LSTM layer, as initial state\ndecoder_output = layers.LSTM(64, name=\"decoder\")(\n decoder_embedded, initial_state=encoder_state\n)\noutput = layers.Dense(10)(decoder_output)\n\nmodel = keras.Model([encoder_input, decoder_input], output)\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"## RNN layers and RNN cells\n\nIn addition to the built-in RNN layers, the RNN API also provides cell-level APIs.\nUnlike RNN layers, which processes whole batches of input sequences, the RNN cell only\nprocesses a single timestep.\n\nThe cell is the inside of the `for` loop of a RNN layer. Wrapping a cell inside a\n`keras.layers.RNN` layer gives you a layer capable of processing batches of\nsequences, e.g. `RNN(LSTMCell(10))`.\n\nMathematically, `RNN(LSTMCell(10))` produces the same result as `LSTM(10)`. In fact,\nthe implementation of this layer in TF v1.x was just creating the corresponding RNN\ncell and wrapping it in a RNN layer. However using the built-in `GRU` and `LSTM`\nlayers enable the use of CuDNN and you may see better performance.\n\nThere are three built-in RNN cells, each of them corresponding to the matching RNN\nlayer.\n\n- `keras.layers.SimpleRNNCell` corresponds to the `SimpleRNN` layer.\n\n- `keras.layers.GRUCell` corresponds to the `GRU` layer.\n\n- `keras.layers.LSTMCell` corresponds to the `LSTM` layer.\n\nThe cell abstraction, together with the generic `keras.layers.RNN` class, make it\nvery easy to implement custom RNN architectures for your research.",
"_____no_output_____"
],
[
"## Cross-batch statefulness\n\nWhen processing very long sequences (possibly infinite), you may want to use the\npattern of **cross-batch statefulness**.\n\nNormally, the internal state of a RNN layer is reset every time it sees a new batch\n(i.e. every sample seen by the layer is assumed to be independent of the past). The\nlayer will only maintain a state while processing a given sample.\n\nIf you have very long sequences though, it is useful to break them into shorter\nsequences, and to feed these shorter sequences sequentially into a RNN layer without\nresetting the layer's state. That way, the layer can retain information about the\nentirety of the sequence, even though it's only seeing one sub-sequence at a time.\n\nYou can do this by setting `stateful=True` in the constructor.\n\nIf you have a sequence `s = [t0, t1, ... t1546, t1547]`, you would split it into e.g.\n\n```\ns1 = [t0, t1, ... t100]\ns2 = [t101, ... t201]\n...\ns16 = [t1501, ... t1547]\n```\n\nThen you would process it via:\n\n```python\nlstm_layer = layers.LSTM(64, stateful=True)\nfor s in sub_sequences:\n output = lstm_layer(s)\n```\n\nWhen you want to clear the state, you can use `layer.reset_states()`.\n\n\n> Note: In this setup, sample `i` in a given batch is assumed to be the continuation of\nsample `i` in the previous batch. This means that all batches should contain the same\nnumber of samples (batch size). E.g. if a batch contains `[sequence_A_from_t0_to_t100,\n sequence_B_from_t0_to_t100]`, the next batch should contain\n`[sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200]`.\n\n\n\n\nHere is a complete example:",
"_____no_output_____"
]
],
[
[
"paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)\nparagraph2 = np.random.random((20, 10, 50)).astype(np.float32)\nparagraph3 = np.random.random((20, 10, 50)).astype(np.float32)\n\nlstm_layer = layers.LSTM(64, stateful=True)\noutput = lstm_layer(paragraph1)\noutput = lstm_layer(paragraph2)\noutput = lstm_layer(paragraph3)\n\n# reset_states() will reset the cached state to the original initial_state.\n# If no initial_state was provided, zero-states will be used by default.\nlstm_layer.reset_states()\n",
"_____no_output_____"
]
],
[
[
"### RNN State Reuse\n<a id=\"rnn_state_reuse\"></a>",
"_____no_output_____"
],
[
"The recorded states of the RNN layer are not included in the `layer.weights()`. If you\nwould like to reuse the state from a RNN layer, you can retrieve the states value by\n`layer.states` and use it as the\ninitial state for a new layer via the Keras functional API like `new_layer(inputs,\ninitial_state=layer.states)`, or model subclassing.\n\nPlease also note that sequential model might not be used in this case since it only\nsupports layers with single input and output, the extra input of initial state makes\nit impossible to use here.",
"_____no_output_____"
]
],
[
[
"paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)\nparagraph2 = np.random.random((20, 10, 50)).astype(np.float32)\nparagraph3 = np.random.random((20, 10, 50)).astype(np.float32)\n\nlstm_layer = layers.LSTM(64, stateful=True)\noutput = lstm_layer(paragraph1)\noutput = lstm_layer(paragraph2)\n\nexisting_state = lstm_layer.states\n\nnew_lstm_layer = layers.LSTM(64)\nnew_output = new_lstm_layer(paragraph3, initial_state=existing_state)\n",
"_____no_output_____"
]
],
[
[
"## Bidirectional RNNs\n\nFor sequences other than time series (e.g. text), it is often the case that a RNN model\ncan perform better if it not only processes sequence from start to end, but also\nbackwards. For example, to predict the next word in a sentence, it is often useful to\nhave the context around the word, not only just the words that come before it.\n\nKeras provides an easy API for you to build such bidirectional RNNs: the\n`keras.layers.Bidirectional` wrapper.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential()\n\nmodel.add(\n layers.Bidirectional(layers.LSTM(64, return_sequences=True), input_shape=(5, 10))\n)\nmodel.add(layers.Bidirectional(layers.LSTM(32)))\nmodel.add(layers.Dense(10))\n\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"Under the hood, `Bidirectional` will copy the RNN layer passed in, and flip the\n`go_backwards` field of the newly copied layer, so that it will process the inputs in\nreverse order.\n\nThe output of the `Bidirectional` RNN will be, by default, the sum of the forward layer\noutput and the backward layer output. If you need a different merging behavior, e.g.\nconcatenation, change the `merge_mode` parameter in the `Bidirectional` wrapper\nconstructor. For more details about `Bidirectional`, please check\n[the API docs](https://www.tensorflow.org/api_docs/python/tf/keras/layers/Bidirectional/).",
"_____no_output_____"
],
[
"## Performance optimization and CuDNN kernels\n\nIn TensorFlow 2.0, the built-in LSTM and GRU layers have been updated to leverage CuDNN\nkernels by default when a GPU is available. With this change, the prior\n`keras.layers.CuDNNLSTM/CuDNNGRU` layers have been deprecated, and you can build your\nmodel without worrying about the hardware it will run on.\n\nSince the CuDNN kernel is built with certain assumptions, this means the layer **will\nnot be able to use the CuDNN kernel if you change the defaults of the built-in LSTM or\nGRU layers**. E.g.:\n\n- Changing the `activation` function from `tanh` to something else.\n- Changing the `recurrent_activation` function from `sigmoid` to something else.\n- Using `recurrent_dropout` > 0.\n- Setting `unroll` to True, which forces LSTM/GRU to decompose the inner\n`tf.while_loop` into an unrolled `for` loop.\n- Setting `use_bias` to False.\n- Using masking when the input data is not strictly right padded (if the mask\ncorresponds to strictly right padded data, CuDNN can still be used. This is the most\ncommon case).\n\nFor the detailed list of constraints, please see the documentation for the\n[LSTM](https://www.tensorflow.org/api_docs/python/tf/keras/layers/LSTM/) and\n[GRU](https://www.tensorflow.org/api_docs/python/tf/keras/layers/GRU/) layers.",
"_____no_output_____"
],
[
"### Using CuDNN kernels when available\n\nLet's build a simple LSTM model to demonstrate the performance difference.\n\nWe'll use as input sequences the sequence of rows of MNIST digits (treating each row of\npixels as a timestep), and we'll predict the digit's label.",
"_____no_output_____"
]
],
[
[
"batch_size = 64\n# Each MNIST image batch is a tensor of shape (batch_size, 28, 28).\n# Each input sequence will be of size (28, 28) (height is treated like time).\ninput_dim = 28\n\nunits = 64\noutput_size = 10 # labels are from 0 to 9\n\n# Build the RNN model\ndef build_model(allow_cudnn_kernel=True):\n # CuDNN is only available at the layer level, and not at the cell level.\n # This means `LSTM(units)` will use the CuDNN kernel,\n # while RNN(LSTMCell(units)) will run on non-CuDNN kernel.\n if allow_cudnn_kernel:\n # The LSTM layer with default options uses CuDNN.\n lstm_layer = keras.layers.LSTM(units, input_shape=(None, input_dim))\n else:\n # Wrapping a LSTMCell in a RNN layer will not use CuDNN.\n lstm_layer = keras.layers.RNN(\n keras.layers.LSTMCell(units), input_shape=(None, input_dim)\n )\n model = keras.models.Sequential(\n [\n lstm_layer,\n keras.layers.BatchNormalization(),\n keras.layers.Dense(output_size),\n ]\n )\n return model\n",
"_____no_output_____"
]
],
[
[
"Let's load the MNIST dataset:",
"_____no_output_____"
]
],
[
[
"mnist = keras.datasets.mnist\n\n(x_train, y_train), (x_test, y_test) = mnist.load_data()\nx_train, x_test = x_train / 255.0, x_test / 255.0\nsample, sample_label = x_train[0], y_train[0]",
"_____no_output_____"
]
],
[
[
"Let's create a model instance and train it.\n\nWe choose `sparse_categorical_crossentropy` as the loss function for the model. The\noutput of the model has shape of `[batch_size, 10]`. The target for the model is an\ninteger vector, each of the integer is in the range of 0 to 9.",
"_____no_output_____"
]
],
[
[
"model = build_model(allow_cudnn_kernel=True)\n\nmodel.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer=\"sgd\",\n metrics=[\"accuracy\"],\n)\n\n\nmodel.fit(\n x_train, y_train, validation_data=(x_test, y_test), batch_size=batch_size, epochs=1\n)",
"_____no_output_____"
]
],
[
[
"Now, let's compare to a model that does not use the CuDNN kernel:",
"_____no_output_____"
]
],
[
[
"noncudnn_model = build_model(allow_cudnn_kernel=False)\nnoncudnn_model.set_weights(model.get_weights())\nnoncudnn_model.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer=\"sgd\",\n metrics=[\"accuracy\"],\n)\nnoncudnn_model.fit(\n x_train, y_train, validation_data=(x_test, y_test), batch_size=batch_size, epochs=1\n)",
"_____no_output_____"
]
],
[
[
"When running on a machine with a NVIDIA GPU and CuDNN installed,\nthe model built with CuDNN is much faster to train compared to the\nmodel that uses the regular TensorFlow kernel.\n\nThe same CuDNN-enabled model can also be used to run inference in a CPU-only\nenvironment. The `tf.device` annotation below is just forcing the device placement.\nThe model will run on CPU by default if no GPU is available.\n\nYou simply don't have to worry about the hardware you're running on anymore. Isn't that\npretty cool?",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nwith tf.device(\"CPU:0\"):\n cpu_model = build_model(allow_cudnn_kernel=True)\n cpu_model.set_weights(model.get_weights())\n result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)\n print(\n \"Predicted result is: %s, target result is: %s\" % (result.numpy(), sample_label)\n )\n plt.imshow(sample, cmap=plt.get_cmap(\"gray\"))",
"_____no_output_____"
]
],
[
[
"## RNNs with list/dict inputs, or nested inputs\n\nNested structures allow implementers to include more information within a single\ntimestep. For example, a video frame could have audio and video input at the same\ntime. The data shape in this case could be:\n\n`[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]`\n\nIn another example, handwriting data could have both coordinates x and y for the\ncurrent position of the pen, as well as pressure information. So the data\nrepresentation could be:\n\n`[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]`\n\nThe following code provides an example of how to build a custom RNN cell that accepts\nsuch structured inputs.",
"_____no_output_____"
],
[
"### Define a custom cell that supports nested input/output",
"_____no_output_____"
],
[
"See [Making new Layers & Models via subclassing](https://www.tensorflow.org/guide/keras/custom_layers_and_models/)\nfor details on writing your own layers.",
"_____no_output_____"
]
],
[
[
"class NestedCell(keras.layers.Layer):\n def __init__(self, unit_1, unit_2, unit_3, **kwargs):\n self.unit_1 = unit_1\n self.unit_2 = unit_2\n self.unit_3 = unit_3\n self.state_size = [tf.TensorShape([unit_1]), tf.TensorShape([unit_2, unit_3])]\n self.output_size = [tf.TensorShape([unit_1]), tf.TensorShape([unit_2, unit_3])]\n super(NestedCell, self).__init__(**kwargs)\n\n def build(self, input_shapes):\n # expect input_shape to contain 2 items, [(batch, i1), (batch, i2, i3)]\n i1 = input_shapes[0][1]\n i2 = input_shapes[1][1]\n i3 = input_shapes[1][2]\n\n self.kernel_1 = self.add_weight(\n shape=(i1, self.unit_1), initializer=\"uniform\", name=\"kernel_1\"\n )\n self.kernel_2_3 = self.add_weight(\n shape=(i2, i3, self.unit_2, self.unit_3),\n initializer=\"uniform\",\n name=\"kernel_2_3\",\n )\n\n def call(self, inputs, states):\n # inputs should be in [(batch, input_1), (batch, input_2, input_3)]\n # state should be in shape [(batch, unit_1), (batch, unit_2, unit_3)]\n input_1, input_2 = tf.nest.flatten(inputs)\n s1, s2 = states\n\n output_1 = tf.matmul(input_1, self.kernel_1)\n output_2_3 = tf.einsum(\"bij,ijkl->bkl\", input_2, self.kernel_2_3)\n state_1 = s1 + output_1\n state_2_3 = s2 + output_2_3\n\n output = (output_1, output_2_3)\n new_states = (state_1, state_2_3)\n\n return output, new_states\n\n def get_config(self):\n return {\"unit_1\": self.unit_1, \"unit_2\": unit_2, \"unit_3\": self.unit_3}\n",
"_____no_output_____"
]
],
[
[
"### Build a RNN model with nested input/output\n\nLet's build a Keras model that uses a `keras.layers.RNN` layer and the custom cell\nwe just defined.",
"_____no_output_____"
]
],
[
[
"unit_1 = 10\nunit_2 = 20\nunit_3 = 30\n\ni1 = 32\ni2 = 64\ni3 = 32\nbatch_size = 64\nnum_batches = 10\ntimestep = 50\n\ncell = NestedCell(unit_1, unit_2, unit_3)\nrnn = keras.layers.RNN(cell)\n\ninput_1 = keras.Input((None, i1))\ninput_2 = keras.Input((None, i2, i3))\n\noutputs = rnn((input_1, input_2))\n\nmodel = keras.models.Model([input_1, input_2], outputs)\n\nmodel.compile(optimizer=\"adam\", loss=\"mse\", metrics=[\"accuracy\"])",
"_____no_output_____"
]
],
[
[
"### Train the model with randomly generated data\n\nSince there isn't a good candidate dataset for this model, we use random Numpy data for\ndemonstration.",
"_____no_output_____"
]
],
[
[
"input_1_data = np.random.random((batch_size * num_batches, timestep, i1))\ninput_2_data = np.random.random((batch_size * num_batches, timestep, i2, i3))\ntarget_1_data = np.random.random((batch_size * num_batches, unit_1))\ntarget_2_data = np.random.random((batch_size * num_batches, unit_2, unit_3))\ninput_data = [input_1_data, input_2_data]\ntarget_data = [target_1_data, target_2_data]\n\nmodel.fit(input_data, target_data, batch_size=batch_size)",
"_____no_output_____"
]
],
[
[
"With the Keras `keras.layers.RNN` layer, You are only expected to define the math\nlogic for individual step within the sequence, and the `keras.layers.RNN` layer\nwill handle the sequence iteration for you. It's an incredibly powerful way to quickly\nprototype new kinds of RNNs (e.g. a LSTM variant).\n\nFor more details, please visit the [API docs](https://https://www.tensorflow.org/api_docs/python/tf/keras/layers/RNN/).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a29ec68d5edcc7211bba1184d32734cbb437c0a
| 5,125 |
ipynb
|
Jupyter Notebook
|
doc/source/tune/examples/tune_mnist_keras.ipynb
|
richardsliu/ray
|
0c27d925886e1fcfa0a22cb50715ac921091ea83
|
[
"Apache-2.0"
] | 22 |
2018-05-08T05:52:34.000Z
|
2020-04-01T10:09:55.000Z
|
doc/source/tune/examples/tune_mnist_keras.ipynb
|
richardsliu/ray
|
0c27d925886e1fcfa0a22cb50715ac921091ea83
|
[
"Apache-2.0"
] | 73 |
2021-09-25T07:11:39.000Z
|
2022-03-26T07:10:59.000Z
|
doc/source/tune/examples/tune_mnist_keras.ipynb
|
richardsliu/ray
|
0c27d925886e1fcfa0a22cb50715ac921091ea83
|
[
"Apache-2.0"
] | 10 |
2018-04-27T10:50:59.000Z
|
2020-02-24T02:41:43.000Z
| 33.279221 | 122 | 0.52 |
[
[
[
"(tune-mnist-keras)=\n\n# Using Keras & TensorFlow with Tune\n\n```{image} /images/tf_keras_logo.jpeg\n:align: center\n:alt: Keras & TensorFlow Logo\n:height: 120px\n:target: https://keras.io\n```\n\n```{contents}\n:backlinks: none\n:local: true\n```\n\n## Example",
"_____no_output_____"
]
],
[
[
"import argparse\nimport os\n\nfrom filelock import FileLock\nfrom tensorflow.keras.datasets import mnist\n\nimport ray\nfrom ray import tune\nfrom ray.tune.schedulers import AsyncHyperBandScheduler\nfrom ray.tune.integration.keras import TuneReportCallback\n\n\ndef train_mnist(config):\n # https://github.com/tensorflow/tensorflow/issues/32159\n import tensorflow as tf\n\n batch_size = 128\n num_classes = 10\n epochs = 12\n\n with FileLock(os.path.expanduser(\"~/.data.lock\")):\n (x_train, y_train), (x_test, y_test) = mnist.load_data()\n x_train, x_test = x_train / 255.0, x_test / 255.0\n model = tf.keras.models.Sequential(\n [\n tf.keras.layers.Flatten(input_shape=(28, 28)),\n tf.keras.layers.Dense(config[\"hidden\"], activation=\"relu\"),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(num_classes, activation=\"softmax\"),\n ]\n )\n\n model.compile(\n loss=\"sparse_categorical_crossentropy\",\n optimizer=tf.keras.optimizers.SGD(lr=config[\"lr\"], momentum=config[\"momentum\"]),\n metrics=[\"accuracy\"],\n )\n\n model.fit(\n x_train,\n y_train,\n batch_size=batch_size,\n epochs=epochs,\n verbose=0,\n validation_data=(x_test, y_test),\n callbacks=[TuneReportCallback({\"mean_accuracy\": \"accuracy\"})],\n )\n\n\ndef tune_mnist(num_training_iterations):\n sched = AsyncHyperBandScheduler(\n time_attr=\"training_iteration\", max_t=400, grace_period=20\n )\n\n analysis = tune.run(\n train_mnist,\n name=\"exp\",\n scheduler=sched,\n metric=\"mean_accuracy\",\n mode=\"max\",\n stop={\"mean_accuracy\": 0.99, \"training_iteration\": num_training_iterations},\n num_samples=10,\n resources_per_trial={\"cpu\": 2, \"gpu\": 0},\n config={\n \"threads\": 2,\n \"lr\": tune.uniform(0.001, 0.1),\n \"momentum\": tune.uniform(0.1, 0.9),\n \"hidden\": tune.randint(32, 512),\n },\n )\n print(\"Best hyperparameters found were: \", analysis.best_config)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"--smoke-test\", action=\"store_true\", help=\"Finish quickly for testing\"\n )\n parser.add_argument(\n \"--server-address\",\n type=str,\n default=None,\n required=False,\n help=\"The address of server to connect to if using \" \"Ray Client.\",\n )\n args, _ = parser.parse_known_args()\n if args.smoke_test:\n ray.init(num_cpus=4)\n elif args.server_address:\n ray.init(f\"ray://{args.server_address}\")\n\n tune_mnist(num_training_iterations=5 if args.smoke_test else 300)\n",
"_____no_output_____"
]
],
[
[
"## More Keras and TensorFlow Examples\n\n- {doc}`/tune/examples/includes/pbt_memnn_example`: Example of training a Memory NN on bAbI with Keras using PBT.\n- {doc}`/tune/examples/includes/tf_mnist_example`: Converts the Advanced TF2.0 MNIST example to use Tune\n with the Trainable. This uses `tf.function`.\n Original code from tensorflow: https://www.tensorflow.org/tutorials/quickstart/advanced\n- {doc}`/tune/examples/includes/pbt_tune_cifar10_with_keras`:\n A contributed example of tuning a Keras model on CIFAR10 with the PopulationBasedTraining scheduler.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a29f5c1e3fb17907cb1c25a47bcd860d0818db2
| 949,059 |
ipynb
|
Jupyter Notebook
|
grvingt/grvingt_proper_randomization.ipynb
|
Ezibenroc/calibration_analysis
|
4837a5d841380ab3dfdbfbc919eab485c08890e9
|
[
"MIT"
] | null | null | null |
grvingt/grvingt_proper_randomization.ipynb
|
Ezibenroc/calibration_analysis
|
4837a5d841380ab3dfdbfbc919eab485c08890e9
|
[
"MIT"
] | null | null | null |
grvingt/grvingt_proper_randomization.ipynb
|
Ezibenroc/calibration_analysis
|
4837a5d841380ab3dfdbfbc919eab485c08890e9
|
[
"MIT"
] | 1 |
2018-07-23T13:46:05.000Z
|
2018-07-23T13:46:05.000Z
| 2,314.778049 | 413,652 | 0.95927 |
[
[
[
"# Proper randomization is important...\n\nI changed the code of the MPI calibration code to do a global randomization (and not a randomization within each operation).",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy\nimport pandas\nfrom extract_archive import extract_zip, aggregate_dataframe\narchive_names = {'nancy_2018-07-24_1621460.zip' : 'none', 'nancy_2018-07-27_1625117.zip' : 'half', 'nancy_2018-08-03_1645238.zip': 'full'}\nalldf = []\naggr = []\nfor name, shuffled in archive_names.items():\n archive = extract_zip(name)\n df = archive['exp/exp_Recv.csv']\n df['batch_index'] = numpy.floor(df.index / 10).astype(int)\n df['batch_index_mod'] = df.batch_index % 50 # 50 batches of 10 calls\n info = archive['info.yaml']\n deployment = str(info['deployment'])\n df['deployment'] = deployment\n mpi_version = set([info[key]['mpi'] for key in info.keys() if 'grid5000' in key])\n assert len(mpi_version) == 1\n mpi_version = mpi_version.pop()\n df['mpi'] = mpi_version\n df['exp_type'] = mpi_version + ' | ' + deployment\n df['shuffled'] = shuffled\n alldf.append(df)\n aggr.append(aggregate_dataframe(df))\ndf = pandas.concat(alldf)\ndf_aggr = pandas.concat(aggr)\nprint(df.exp_type.unique())\ndf.head()",
"/home/tom/Dropbox/Documents/Fac/phd/mpi_calibration/grvingt/extract_archive.py:12: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.\n deployment = yaml.load(input_zip.read('info.yaml'))['deployment']\n/home/tom/Dropbox/Documents/Fac/phd/mpi_calibration/grvingt/extract_archive.py:26: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.\n result[name] = yaml.load(input_zip.read(name))\n"
],
[
"df[['index', 'start', 'msg_size', 'duration', 'shuffled']].to_csv('/tmp/mpi_calibration_order.csv', index=False)",
"_____no_output_____"
]
],
[
[
"## Checking if the proper randomization gives better results",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom plotnine import *\nimport plotnine; plotnine.options.figure_size = 12, 8\nimport warnings\nwarnings.simplefilter(action='ignore', category=FutureWarning) # removing annoying Pandas warning",
"_____no_output_____"
],
[
"ggplot(df, aes(x='msg_size', y='duration', color='shuffled')) + geom_point(alpha=0.1) + scale_x_log10() + scale_y_log10() + ggtitle('Durations of MPI_Recv')",
"_____no_output_____"
],
[
"ggplot(df_aggr, aes(x='msg_size', y='duration', color='shuffled')) + geom_point(alpha=0.3) + scale_x_log10() + scale_y_log10() + ggtitle('Durations of MPI_Recv aggregated per message size')",
"_____no_output_____"
]
],
[
[
"Let's restrict ourselves to calls with a message size between 100 and 1000 (i.e., one of the places that was problematic).",
"_____no_output_____"
]
],
[
[
"df = df[(df.msg_size >= 1e2) & (df.msg_size < 1e3)].copy() # gosh, I hate pandas' default\ndf_aggr = df_aggr[(df_aggr.msg_size >= 1e2) & (df_aggr.msg_size < 1e3)].copy()\ndf = df[df.duration < df.duration.quantile(0.99)] # removing the extreme outliers...",
"_____no_output_____"
],
[
"ggplot(df, aes(x='index', y='duration')) + geom_point(alpha=0.1) + ggtitle('Durations of MPI_Recv (temporal evolution)') + facet_wrap('shuffled')",
"_____no_output_____"
],
[
"ggplot(df, aes('duration', group='msg_size')) + stat_ecdf() + ggtitle('Distributions of MPI_Recv durations (grouped by message size, with and without shuffling)') + facet_wrap('shuffled')",
"_____no_output_____"
]
],
[
[
"Weird, the bimodality is less important (but is still here), most of the operations have a low duration. Not sure if this due to the better randomization, or because of an external factor (e.g., the G5K team improved the performance tunings).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a29f76916fe84688742d19404532820695b18a9
| 36,006 |
ipynb
|
Jupyter Notebook
|
Value_Based/C51/Distributional_DQN(C51)_2dim input.ipynb
|
kyunghoon-jung/MacaronRL
|
b95be35fc95be7eb5aede2315a714984b282587a
|
[
"MIT"
] | 20 |
2020-10-05T07:07:46.000Z
|
2021-05-23T02:18:43.000Z
|
Value_Based/C51/Distributional_DQN(C51)_2dim input.ipynb
|
kyunghoon-jung/RL_implementation
|
b95be35fc95be7eb5aede2315a714984b282587a
|
[
"MIT"
] | null | null | null |
Value_Based/C51/Distributional_DQN(C51)_2dim input.ipynb
|
kyunghoon-jung/RL_implementation
|
b95be35fc95be7eb5aede2315a714984b282587a
|
[
"MIT"
] | null | null | null | 52.717423 | 216 | 0.530606 |
[
[
[
"#### Implementation of Distributional paper for 1-dimensional games, such as Cartpole.\n- https://arxiv.org/abs/1707.06887\n\n<br>\n\n Please note: The 2 dimensional image state requires a lot of memory capacity (~50GB) due to the buffer size of 1,000,000 as in DQN paper.\n So, one might want to train an agent with a smaller size (this may cause a lower performance).",
"_____no_output_____"
],
[
"#### Please NOTE,\n The code lines different from Vanila DQN are annotated with '*/*/*/'.\n So, by searching '*/*/*/', you can find these lines.",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torch.optim as optim \nimport torch.nn.functional as F \n\nimport gym\nimport numpy as np\nimport time\nimport os\nimport cv2\nimport matplotlib.pyplot as plt\nfrom IPython.display import clear_output",
"_____no_output_____"
],
[
"class QNetwork(nn.Module):\n \n def __init__(self, input_dim, action_dim, rand_seed=False,\n conv_channel_1=32, conv_channel_2=64, conv_channel_3=128,\n kernel_1=3, kernel_2=3, kernel_3=3, \n stride_1=2, stride_2=2, stride_3=1, n_atoms=51):\n\n super(QNetwork, self).__init__()\n self.action_dim = action_dim\n self.n_atoms = n_atoms\n self.Conv1 = nn.Conv2d(input_dim[0], conv_channel_1, (kernel_1,kernel_1), stride=stride_1)\n self.Conv2 = nn.Conv2d(conv_channel_1, conv_channel_2, (kernel_2,kernel_2), stride=stride_2)\n self.Conv3 = nn.Conv2d(conv_channel_2, conv_channel_3, (kernel_3,kernel_3), stride=stride_3)\n\n def calculate_conv2d_size(size, kernel_size, stride):\n return (size - (kernel_size - 1) - 1) // stride + 1\n\n w, h = input_dim[1], input_dim[2]\n convw = calculate_conv2d_size(calculate_conv2d_size(calculate_conv2d_size(w,kernel_1,stride_1),\n kernel_2,stride_2),\n kernel_3,stride_3)\n convh = calculate_conv2d_size(calculate_conv2d_size(calculate_conv2d_size(h,kernel_1,stride_1),\n kernel_2,stride_2),\n kernel_3,stride_3)\n linear_input_size = convw * convh * conv_channel_3\n\n # */*/*/\n self.fc1 = nn.Linear(linear_input_size, 512)\n self.fc2 = nn.Linear(512, action_dim*n_atoms) \n self.relu = nn.ReLU()\n # */*/*/\n\n def forward(self, x):\n x = self.relu(self.Conv1(x)) \n x = self.relu(self.Conv2(x)) \n x = self.relu(self.Conv3(x)) \n x = x.reshape(x.shape[0], -1) \n # */*/*/\n Q = self.fc2(self.relu(self.fc1(x))).view(-1, self.action_dim, self.n_atoms) \n return F.softmax(Q, dim=2) # Shape: (batch_size, action_dim, n_atoms) \n # */*/*/\n\nif __name__ == '__main__':\n state_size = (4, 84, 84)\n action_size = 10\n net = QNetwork(state_size, action_size, \n conv_channel_1=32, conv_channel_2=64, conv_channel_3=64)\n test = torch.randn(size=(64, 4, 84, 84))\n print(net)\n print(\"Network output: \", net(test).shape)",
"QNetwork(\n (Conv1): Conv2d(4, 32, kernel_size=(3, 3), stride=(2, 2))\n (Conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2))\n (Conv3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))\n (fc1): Linear(in_features=20736, out_features=512, bias=True)\n (fc2): Linear(in_features=512, out_features=510, bias=True)\n (relu): ReLU()\n)\nNetwork output: torch.Size([64, 10, 51])\n"
],
[
"class ReplayBuffer:\n \"\"\" Experience Replay Buffer in DQN paper \"\"\"\n \n def __init__(self, \n buffer_size: ('int: total size of the Replay Buffer'), \n input_dim: ('tuple: a dimension of input data. Ex) (3, 84, 84)'), \n batch_size: ('int: a batch size when updating')):\n \n # To check if input image has 3 channels\n assert len(input_dim)==3, \"The state dimension should be 3-dim! (CHxWxH). Please check if input_dim is right\"\n\n self.batch_size = batch_size\n self.buffer_size = buffer_size\n self.save_count, self.current_size = 0, 0\n\n # One can choose either np.zeros or np.ones. \n # The reason using np.ones here is for checking the total memory occupancy of the buffer. \n self.state_buffer = np.ones((buffer_size, input_dim[0], input_dim[1], input_dim[2]), \n dtype=np.uint8) # data type is np.int8 for saving the memory\n self.action_buffer = np.ones(buffer_size, dtype=np.uint8) \n self.reward_buffer = np.ones(buffer_size, dtype=np.float32) \n self.next_state_buffer = np.ones((buffer_size, input_dim[0], input_dim[1], input_dim[2]), \n dtype=np.uint8) \n self.done_buffer = np.ones(buffer_size, dtype=np.uint8) \n\n def __len__(self):\n return self.current_size\n\n def store(self, \n state: np.ndarray, \n action: int, \n reward: float, \n next_state: np.ndarray, \n done: int):\n\n self.state_buffer[self.save_count] = state\n self.action_buffer[self.save_count] = action\n self.reward_buffer[self.save_count] = reward\n self.next_state_buffer[self.save_count] = next_state\n self.done_buffer[self.save_count] = done\n\n # self.save_count is an index when storing transitions into the replay buffer\n self.save_count = (self.save_count + 1) % self.buffer_size\n # self.current_size is an indication for how many transitions is stored\n self.current_size = min(self.current_size+1, self.buffer_size)\n\n def batch_load(self):\n # Selecting samples randomly with a size of self.batch_size \n indices = np.random.randint(self.current_size, size=self.batch_size)\n return dict(\n states=self.state_buffer[indices], \n actions=self.action_buffer[indices],\n rewards=self.reward_buffer[indices],\n next_states=self.next_state_buffer[indices], \n dones=self.done_buffer[indices]) ",
"_____no_output_____"
],
[
"class Agent:\n def __init__(self, \n env: 'Environment',\n input_frame: ('int: The number of channels of input image'),\n input_dim: ('int: The width and height of pre-processed input image'),\n training_frames: ('int: The total number of training frames'),\n skipped_frame: ('int: The number of skipped frames in the environment'),\n eps_decay: ('float: Epsilon Decay_rate'),\n gamma: ('float: Discount Factor'),\n update_freq: ('int: Behavior Network Update Frequency'),\n target_update_freq: ('int: Target Network Update Frequency'),\n update_type: ('str: Update type for target network. Hard or Soft')='hard',\n soft_update_tau: ('float: Soft update ratio')=None,\n batch_size: ('int: Update batch size')=32,\n buffer_size: ('int: Replay buffer size')=1000000,\n update_start_buffer_size: ('int: Update starting buffer size')=50000,\n learning_rate: ('float: Learning rate')=0.0004,\n eps_min: ('float: Epsilon Min')=0.1,\n eps_max: ('float: Epsilon Max')=1.0,\n device_num: ('int: GPU device number')=0,\n rand_seed: ('int: Random seed')=None,\n plot_option: ('str: Plotting option')=False,\n model_path: ('str: Model saving path')='./',\n trained_model_path: ('str: Trained model path')='',\n # */*/*/\n n_atoms: ('int: The number of atoms')=51,\n Vmax: ('int: The maximum Q value')=10, \n Vmin: ('int: The minimum Q value')=-10): \n # */*/*/\n\n self.action_dim = env.action_space.n\n self.device = torch.device(f'cuda:{device_num}' if torch.cuda.is_available() else 'cpu')\n self.model_path = model_path\n \n self.env = env\n self.input_frames = input_frame\n self.input_dim = input_dim\n self.training_frames = training_frames\n self.skipped_frame = skipped_frame\n self.epsilon = eps_max\n self.eps_decay = eps_decay\n self.eps_min = eps_min\n self.gamma = gamma\n self.update_freq = update_freq\n self.target_update_freq = target_update_freq\n self.update_cnt = 0\n self.update_type = update_type\n self.tau = soft_update_tau\n self.batch_size = batch_size\n self.buffer_size = buffer_size\n self.update_start = update_start_buffer_size\n self.seed = rand_seed\n self.plot_option = plot_option \n # */*/*/\n self.n_atoms = n_atoms \n self.Vmin = Vmin \n self.Vmax = Vmax \n self.dz = (Vmax - Vmin) / (n_atoms - 1) \n self.support = torch.linspace(Vmin, Vmax, n_atoms).to(self.device)\n self.expanded_support = self.support.expand((batch_size, self.action_dim, n_atoms)).to(self.device)\n \n self.q_behave = QNetwork((self.input_frames, self.input_dim, self.input_dim), self.action_dim, n_atoms=self.n_atoms).to(self.device)\n self.q_target = QNetwork((self.input_frames, self.input_dim, self.input_dim), self.action_dim, n_atoms=self.n_atoms).to(self.device) \n # */*/*/\n if trained_model_path: # load a trained model if existing\n self.q_behave.load_state_dict(torch.load(trained_model_path))\n print(\"Trained model is loaded successfully.\")\n \n # Initialize target network parameters with behavior network parameters\n self.q_target.load_state_dict(self.q_behave.state_dict())\n self.q_target.eval()\n self.optimizer = optim.Adam(self.q_behave.parameters(), lr=learning_rate) \n\n self.memory = ReplayBuffer(self.buffer_size, (self.input_frames, self.input_dim, self.input_dim), self.batch_size)\n\n def select_action(self, state: 'Must be pre-processed in the same way as updating current Q network. See def _compute_loss'):\n \n if np.random.random() < self.epsilon:\n return np.zeros(self.action_dim), self.env.action_space.sample()\n else:\n # if normalization is applied to the image such as devision by 255, MUST be expressed 'state/255' below.\n with torch.no_grad():\n state = torch.FloatTensor(state).to(self.device).unsqueeze(0)/255\n # */*/*/\n Qs = self.q_behave(state)*self.expanded_support[0]\n Expected_Qs = Qs.sum(2) \n # */*/*/\n action = Expected_Qs.argmax(1)\n \n # return Q-values and action (Q-values are not required for implementing algorithms. This is just for checking Q-values for each state. Not must-needed) \n return Expected_Qs.detach().cpu().numpy()[0], action.detach().item()\n\n def processing_resize_and_gray(self, frame):\n ''' Convert images to gray scale and resize ''' \n frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) \n frame = cv2.resize(frame, dsize=(self.input_dim, self.input_dim)).reshape(self.input_dim, self.input_dim).astype(np.uint8) \n return frame \n\n def get_init_state(self):\n ''' return an initial state with a dimension of (self.input_frames, self.input_dim, self.input_dim) '''\n init_state = np.zeros((self.input_frames, self.input_dim, self.input_dim))\n init_frame = self.env.reset()\n init_state[0] = self.processing_resize_and_gray(init_frame)\n \n for i in range(1, self.input_frames): \n action = self.env.action_space.sample()\n for j in range(self.skipped_frame-1): \n state, _, _, _ = self.env.step(action) \n state, _, _, _ = self.env.step(action) \n init_state[i] = self.processing_resize_and_gray(state) \n return init_state\n\n def get_state(self, state, action, skipped_frame=0):\n ''' return reward, next_state, done ''' \n next_state = np.zeros((self.input_frames, self.input_dim, self.input_dim))\n for i in range(len(state)-1):\n next_state[i] = state[i+1]\n\n rewards = 0\n dones = 0\n \n for _ in range(skipped_frame-1):\n state, reward, done, _ = self.env.step(action) \n rewards += reward # reward accumulates for the case that rewards occur while skipping\n dones += int(done) \n state, reward, done, _ = self.env.step(action) \n next_state[-1] = self.processing_resize_and_gray(state) \n rewards += reward \n dones += int(done) \n return rewards, next_state, dones\n\n def store(self, state, action, reward, next_state, done):\n self.memory.store(state, action, reward, next_state, done)\n\n def update_behavior_q_net(self):\n # update behavior q network with a batch\n batch = self.memory.batch_load()\n loss = self._compute_loss(batch)\n\n self.optimizer.zero_grad()\n loss.backward()\n self.optimizer.step()\n\n return loss.item()\n\n def target_soft_update(self):\n ''' target network is updated with Soft Update. tau is a hyperparameter for the updating ratio betweeen target and behavior network '''\n for target_param, current_param in zip(self.q_target.parameters(), self.q_behave.parameters()):\n target_param.data.copy_(self.tau*current_param.data + (1.0-self.tau)*target_param.data)\n\n def target_hard_update(self):\n ''' target network is updated with Hard Update '''\n self.update_cnt = (self.update_cnt+1) % self.target_update_freq\n if self.update_cnt==0:\n self.q_target.load_state_dict(self.q_behave.state_dict())\n\n def train(self):\n tic = time.time()\n losses = []\n scores = []\n epsilons = []\n avg_scores = [[-10000]] # As an initial score, set an arbitrary score of an episode.\n\n score = 0\n\n print(\"Storing initial buffer..\") \n state = self.get_init_state()\n for frame_idx in range(1, self.update_start+1):\n # Store transitions into the buffer until the number of 'self.update_start' transitions is stored \n _, action = self.select_action(state)\n reward, next_state, done = self.get_state(state, action, skipped_frame=self.skipped_frame)\n self.store(state, action, reward, next_state, done)\n state = next_state\n if done: state = self.get_init_state()\n\n print(\"Done. Start learning..\")\n history_store = []\n for frame_idx in range(1, self.training_frames+1):\n Qs, action = self.select_action(state)\n reward, next_state, done = self.get_state(state, action, skipped_frame=self.skipped_frame)\n self.store(state, action, reward, next_state, done)\n history_store.append([state, Qs, action, reward, next_state, done]) # history_store is for checking an episode later. Not must-needed.\n \n if (frame_idx % self.update_freq) == 0:\n loss = self.update_behavior_q_net()\n score += reward\n losses.append(loss)\n \n if self.update_type=='hard': self.target_hard_update()\n elif self.update_type=='soft': self.target_soft_update()\n\n if done:\n # For saving and plotting when an episode is done.\n scores.append(score)\n if np.mean(scores[-10:]) > max(avg_scores):\n torch.save(self.q_behave.state_dict(), self.model_path+'{}_Score:{}.pt'.format(frame_idx, np.mean(scores[-10:])))\n training_time = round((time.time()-tic)/3600, 1)\n np.save(self.model_path+'{}_history_Score_{}_{}hrs.npy'.format(frame_idx, score, training_time), np.array(history_store))\n print(\" | Model saved. Recent scores: {}, Training time: {}hrs\".format(scores[-10:], training_time), ' /'.join(os.getcwd().split('/')[-3:]))\n avg_scores.append(np.mean(scores[-10:]))\n\n if self.plot_option=='inline': \n scores.append(score)\n epsilons.append(self.epsilon)\n self._plot(frame_idx, scores, losses, epsilons)\n else: \n print(score, end='\\r')\n\n score=0\n state = self.get_init_state()\n history_store = []\n else: state = next_state\n\n self._epsilon_step()\n\n print(\"Total training time: {}(hrs)\".format((time.time()-tic)/3600))\n\n def _epsilon_step(self):\n ''' Controlling epsilon decay. Here is the same as DQN paper, linearly decaying rate. '''\n self.epsilon = max(self.epsilon-self.eps_decay, 0.1)\n\n def _compute_loss(self, batch: \"Dictionary (S, A, R', S', Dones)\"):\n ''' Compute loss. If normalization is used, it must be applied to both 'state' and 'next_state'. ex) state/255 '''\n states = torch.FloatTensor(batch['states']).to(self.device) / 255\n next_states = torch.FloatTensor(batch['next_states']).to(self.device) / 255\n actions = torch.LongTensor(batch['actions']).to(self.device)\n rewards = torch.FloatTensor(batch['rewards'].reshape(-1, 1)).to(self.device)\n dones = torch.FloatTensor(batch['dones'].reshape(-1, 1)).to(self.device)\n \n # */*/*/\n log_behave_Q_dist = self.q_behave(states)[range(self.batch_size), actions].log()\n with torch.no_grad():\n # Computing projected distribution for a categorical loss\n behave_next_Q_dist = self.q_behave(next_states)\n next_actions = torch.sum(behave_next_Q_dist*self.expanded_support, 2).argmax(1)\n target_next_Q_dist = self.q_target(next_states)[range(self.batch_size), next_actions] # Double DQN.\n\n Tz = rewards + self.gamma*(1 - dones)*self.expanded_support[:,0]\n Tz.clamp_(self.Vmin, self.Vmax)\n b = (Tz - self.Vmin) / self.dz\n l = b.floor().long()\n u = b.ceil().long()\n\n l[(l==u) & (u>0)] -= 1 # avoiding the case when floor index and ceil index have the same values \n u[(u==0) & (l==0)] += 1 # (because it causes target_next_Q_dist's value to be counted as zero)\n\n batch_init_indices = torch.linspace(0, (self.batch_size-1)*self.n_atoms, self.batch_size).long().unsqueeze(1).expand(self.batch_size, self.n_atoms).to(self.device)\n\n proj_dist = torch.zeros(self.batch_size, self.n_atoms).to(self.device)\n proj_dist.view(-1).index_add_(0, (l+batch_init_indices).view(-1), (target_next_Q_dist*(u-b)).view(-1))\n proj_dist.view(-1).index_add_(0, (u+batch_init_indices).view(-1), (target_next_Q_dist*(b-l)).view(-1))\n\n # Compute KL divergence between two distributions\n loss = torch.sum(-proj_dist*log_behave_Q_dist, 1).mean()\n # */*/*/\n return loss\n\n def _plot(self, frame_idx, scores, losses, epsilons):\n clear_output(True) \n plt.figure(figsize=(20, 5), facecolor='w') \n plt.subplot(131) \n plt.title('frame %s. score: %s' % (frame_idx, np.mean(scores[-10:])))\n plt.plot(scores) \n plt.subplot(132) \n plt.title('loss') \n plt.plot(losses) \n plt.subplot(133) \n plt.title('epsilons') \n plt.plot(epsilons) \n plt.show() ",
"_____no_output_____"
]
],
[
[
"#### Configurations\n\n\n",
"_____no_output_____"
]
],
[
[
"env_list = {\n 0: \"CartPole-v0\",\n 1: \"CartPole-v2\",\n 2: \"LunarLander-v2\",\n 3: \"Breakout-v4\",\n 4: \"BreakoutDeterministic-v4\",\n 5: \"BreakoutNoFrameskip-v4\",\n 6: \"BoxingDeterministic-v4\",\n 7: \"PongDeterministic-v4\",\n}\nenv_name = env_list[6]\nenv = gym.make(env_name)\n\n# Same input size as in DQN paper. \ninput_dim = 84\ninput_frame = 4\n\nprint(\"env_name\", env_name) \nprint(env.unwrapped.get_action_meanings(), env.action_space.n) \n\n# starting to update Q-network until ReplayBuffer is filled with the number of samples = update_start_buffer_size\nupdate_start_buffer_size = 10000\n\n# total training frames\ntraining_frames = 10000000\n\n# epsilon for exploration \neps_max = 1.0\neps_min = 0.1\neps_decay = 1/1000000\n\n# gamma (used decaying future rewards)\ngamma = 0.99\n\n# size of ReplayBuffer\nbuffer_size = int(1e6) # this is the same size of the paper\n# buffer_size = int(1.5e5) # if don't have an enough memory capacity, lower the value like this. But this may cause a bad training performance. \n\n# update batch size\nbatch_size = 32 \nlearning_rate = 0.0001 # In the paper, they use RMSProp and learning rate 0.00025. In this notebook, the Adam is used with lr=0.0001. \n\n# updating Q-network with 'soft' or 'hard' updating method\nupdate_freq = 4\nupdate_type = 'hard'\nsoft_update_tau = 0.002\n\n# target network update frequency (applied when it takes 'hard' update). \n# 10000 means the target network is updated once while the behavior network is updated 10000 times. \ntarget_update_freq = 10000\n\n# assign skipped_frame to be 0\n# because the word 'Deterministic' in the name 'BoxingDeterministic' means it automatically skips 4 frames in the game.\n# assign skipped_frame to be 0 when selecting games such as \"BreakoutNoFrameskip\".\nskipped_frame = 0\n\n# cuda device\ndevice_num = 0\n\n# choose plotting option.\n# 'inline' - plots status in jupyter notebook\n# 'False' - it prints only reward of the episode\nplot_options = {1: 'inline', 2: False} \nplot_option = plot_options[2]\n\n# */*/*/\nn_atoms = 51\nVmax = 10\nVmin = -10\n# */*/*/\n\n\n# The path for saving a trained model. \nrand_seed = None\nrand_name = ('').join(map(str, np.random.randint(10, size=(3,))))\nfolder_name = os.getcwd().split('/')[-1] \nmodel_name = 'Test'\nmodel_save_path = f'./model_save/{model_name}/'\nif not os.path.exists('./model_save/'):\n os.mkdir('./model_save/')\nif not os.path.exists(model_save_path):\n os.mkdir(model_save_path)\nprint(\"model_save_path:\", model_save_path)\ntrained_model_path = ''",
"env_name BoxingDeterministic-v4\n['NOOP', 'FIRE', 'UP', 'RIGHT', 'LEFT', 'DOWN', 'UPRIGHT', 'UPLEFT', 'DOWNRIGHT', 'DOWNLEFT', 'UPFIRE', 'RIGHTFIRE', 'LEFTFIRE', 'DOWNFIRE', 'UPRIGHTFIRE', 'UPLEFTFIRE', 'DOWNRIGHTFIRE', 'DOWNLEFTFIRE'] 18\nmodel_save_path: ./model_save/Test/\n"
],
[
"agent = Agent( \n env,\n input_frame,\n input_dim,\n training_frames,\n skipped_frame,\n eps_decay,\n gamma,\n update_freq,\n target_update_freq,\n update_type,\n soft_update_tau,\n batch_size,\n buffer_size,\n update_start_buffer_size,\n learning_rate,\n eps_min,\n eps_max,\n device_num,\n rand_seed,\n plot_option,\n model_save_path,\n trained_model_path,\n n_atoms,\n Vmax,\n Vmin \n) \n\nagent.train()",
"_____no_output_____"
]
],
[
[
"#### An example of results\n \n Storing initial buffer..\n Done. Start learning..\n | Model saved. Recent scores: [1.0], Training time: 0.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [1.0, -1.0, 2.0, -2.0, 5.0, 2.0], Training time: 0.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [2.0, -2.0, 5.0, 2.0, 0.0, 0.0, -2.0, 3.0, 2.0, 6.0], Training time: 0.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [3.0, 3.0, -2.0, -4.0, 6.0, -1.0, -5.0, 4.0, 6.0, 7.0], Training time: 0.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [4.0, 6.0, 7.0, -4.0, -2.0, -6.0, 1.0, 3.0, 4.0, 6.0], Training time: 0.1hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [6.0, 7.0, -4.0, -2.0, -6.0, 1.0, 3.0, 4.0, 6.0, 9.0], Training time: 0.1hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [7.0, 1.0, 6.0, 5.0, 5.0, 0.0, -2.0, -1.0, 2.0, 5.0], Training time: 0.1hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [-4.0, 10.0, 9.0, -10.0, 9.0, -2.0, -5.0, 6.0, 7.0, 11.0], Training time: 0.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [10.0, 9.0, -10.0, 9.0, -2.0, -5.0, 6.0, 7.0, 11.0, 1.0], Training time: 0.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [6.0, 1.0, 8.0, -1.0, 2.0, 3.0, 1.0, 7.0, 6.0, 14.0], Training time: 0.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [7.0, 6.0, 14.0, 1.0, 3.0, -1.0, 8.0, 4.0, -4.0, 14.0], Training time: 0.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [6.0, 14.0, 1.0, 3.0, -1.0, 8.0, 4.0, -4.0, 14.0, 9.0], Training time: 0.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [6.0, -4.0, -2.0, 27.0, 1.0, 4.0, 5.0, 1.0, 13.0, 10.0], Training time: 0.7hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [27.0, 1.0, 4.0, 5.0, 1.0, 13.0, 10.0, 1.0, 1.0, 16.0], Training time: 0.7hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [1.0, 10.0, 13.0, 19.0, 1.0, 6.0, 4.0, 8.0, 12.0, 13.0], Training time: 1.1hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [10.0, 13.0, 19.0, 1.0, 6.0, 4.0, 8.0, 12.0, 13.0, 10.0], Training time: 1.1hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [5.0, 3.0, 7.0, 18.0, -1.0, 13.0, 9.0, 10.0, 29.0, 8.0], Training time: 1.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [3.0, 7.0, 18.0, -1.0, 13.0, 9.0, 10.0, 29.0, 8.0, 18.0], Training time: 1.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [7.0, 18.0, -1.0, 13.0, 9.0, 10.0, 29.0, 8.0, 18.0, 8.0], Training time: 1.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [13.0, 9.0, 10.0, 29.0, 8.0, 18.0, 8.0, -1.0, 16.0, 27.0], Training time: 1.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [16.0, 27.0, 8.0, 11.0, 2.0, 19.0, 13.0, 19.0, 12.0, 15.0], Training time: 1.3hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [14.0, 11.0, 9.0, 11.0, 20.0, 16.0, 7.0, 13.0, 13.0, 37.0], Training time: 1.4hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [18.0, 7.0, 19.0, 15.0, 5.0, 9.0, 18.0, 29.0, 18.0, 18.0], Training time: 1.6hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [15.0, 11.0, 9.0, 33.0, 5.0, 30.0, 12.0, 17.0, 23.0, 15.0], Training time: 1.7hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [14.0, 22.0, 6.0, 13.0, 16.0, 15.0, 24.0, 28.0, 8.0, 29.0], Training time: 1.9hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [22.0, 6.0, 13.0, 16.0, 15.0, 24.0, 28.0, 8.0, 29.0, 18.0], Training time: 1.9hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [20.0, 16.0, 31.0, 23.0, 24.0, 18.0, 8.0, 15.0, 12.0, 14.0], Training time: 2.5hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [27.0, 5.0, 27.0, 2.0, 11.0, 19.0, 17.0, 20.0, 23.0, 31.0], Training time: 2.5hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [19.0, 20.0, 20.0, 18.0, 10.0, 37.0, 12.0, 9.0, 25.0, 15.0], Training time: 2.7hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [27.0, 8.0, 34.0, 22.0, 17.0, 2.0, 31.0, 13.0, 7.0, 25.0], Training time: 2.8hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [14.0, 18.0, 27.0, 21.0, 22.0, 9.0, -2.0, 28.0, 30.0, 26.0], Training time: 2.8hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [17.0, 23.0, 9.0, 40.0, 9.0, 26.0, 10.0, 26.0, 10.0, 29.0], Training time: 3.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [23.0, 9.0, 40.0, 9.0, 26.0, 10.0, 26.0, 10.0, 29.0, 19.0], Training time: 3.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [11.0, 23.0, 17.0, 13.0, 19.0, 37.0, 21.0, 26.0, 20.0, 16.0], Training time: 3.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [23.0, 17.0, 13.0, 19.0, 37.0, 21.0, 26.0, 20.0, 16.0, 25.0], Training time: 3.0hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [8.0, 25.0, 19.0, 10.0, 27.0, 14.0, 26.0, 39.0, 22.0, 35.0], Training time: 3.2hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [25.0, 19.0, 10.0, 27.0, 14.0, 26.0, 39.0, 22.0, 35.0, 37.0], Training time: 3.2hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [19.0, 10.0, 27.0, 14.0, 26.0, 39.0, 22.0, 35.0, 37.0, 26.0], Training time: 3.2hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [10.0, 27.0, 14.0, 26.0, 39.0, 22.0, 35.0, 37.0, 26.0, 33.0], Training time: 3.2hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [27.0, 14.0, 26.0, 39.0, 22.0, 35.0, 37.0, 26.0, 33.0, 12.0], Training time: 3.2hrs MacaronRL /Value_Based /C51\n | Model saved. Recent scores: [39.0, 22.0, 35.0, 37.0, 26.0, 33.0, 12.0, 6.0, 26.0, 39.0], Training time: 3.2hrs MacaronRL /Value_Based /C51",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a29fb0a40b8e81d170ed79f9024d396dbcf2280
| 4,928 |
ipynb
|
Jupyter Notebook
|
adafruit-io-python-tutorial.ipynb
|
phord/adafruit_io_python_jupyter
|
63f56daca0cb27e4c12f5de4c93a092af9ed8518
|
[
"MIT"
] | null | null | null |
adafruit-io-python-tutorial.ipynb
|
phord/adafruit_io_python_jupyter
|
63f56daca0cb27e4c12f5de4c93a092af9ed8518
|
[
"MIT"
] | null | null | null |
adafruit-io-python-tutorial.ipynb
|
phord/adafruit_io_python_jupyter
|
63f56daca0cb27e4c12f5de4c93a092af9ed8518
|
[
"MIT"
] | null | null | null | 24.517413 | 318 | 0.59375 |
[
[
[
"# Welcome to the Adafruit IO Python Client Library",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"This interactive Jupyter notebook will get you started with the [Adafruit IO Python library](https://github.com/adafruit/io-client-python) - right from your browser! *You don't need to install anything on your computer*, and you'll be able to play with Adafruit IO.",
"_____no_output_____"
],
[
"## Import the Adafruit IO Python Library",
"_____no_output_____"
],
[
"Let's begin by importing the Adafruit IO Python client library:",
"_____no_output_____"
]
],
[
[
"from Adafruit_IO import Client, RequestError, Feed",
"_____no_output_____"
]
],
[
[
"Next, locate your Adafruit IO Key and Username. These are found on the left hand side of the [Adafruit IO homepage](http://io.adafruit.com). ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Replace `IO_KEY` with your Adafruit IO Active Key.",
"_____no_output_____"
]
],
[
[
"ADAFRUIT_IO_KEY = 'IO_KEY'",
"_____no_output_____"
]
],
[
[
"and replace `IO_USERNAME` with your Adafruit IO Username.",
"_____no_output_____"
]
],
[
[
"ADAFRUIT_IO_USERNAME = 'IO_USER'",
"_____no_output_____"
]
],
[
[
"Next, let's create an instance of the Adafruit IO Client",
"_____no_output_____"
]
],
[
[
"aio = Client(ADAFRUIT_IO_USERNAME, ADAFRUIT_IO_KEY)",
"_____no_output_____"
]
],
[
[
"We're going to create a new feed named `test_feed`. Adafruit IO Python does not automatically generate feeds *but* one can be created if it does not exist already.",
"_____no_output_____"
]
],
[
[
"try:\n test_feed = aio.feeds('test-feed')\nexcept RequestError: # Doesn't exist, create a new feed\n test_feed = Feed(name='test-feed')\n test_feed = aio.create_feed(test)",
"_____no_output_____"
]
],
[
[
"Next, we're going to send the value `42` to our feed `test` using the `send_data()` method.",
"_____no_output_____"
]
],
[
[
"aio.send_data(test_feed.key, 42)",
"_____no_output_____"
]
],
[
[
"The data has been sent to Adafruit IO - but how do we get it back? We'll use the `receive()` method and pass in the `test` feed. ",
"_____no_output_____"
]
],
[
[
"data = aio.receive(test_feed.key)\nprint('Latest value from Test: {0}'.format(data.value))",
"_____no_output_____"
]
],
[
[
"We're reciving the feed, but only printing the `value` field. Adafruit IO feeds hold **a lot** of metadata about the data sent to Adafruit IO, including when it was created. ",
"_____no_output_____"
]
],
[
[
"print('Recieved value from test feed has the following metadata: {0}'.format(data))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2a05006fa27567c2435762e7d70e051c6404a9
| 115,119 |
ipynb
|
Jupyter Notebook
|
Machine_Learning_Foundations_ A_Case_Study_Approach/Document retrieval.ipynb
|
nkmah2/ML_Uni_Washington_Coursera
|
a5852f1716189a1126919b12d767f894ad8490ac
|
[
"MIT"
] | null | null | null |
Machine_Learning_Foundations_ A_Case_Study_Approach/Document retrieval.ipynb
|
nkmah2/ML_Uni_Washington_Coursera
|
a5852f1716189a1126919b12d767f894ad8490ac
|
[
"MIT"
] | null | null | null |
Machine_Learning_Foundations_ A_Case_Study_Approach/Document retrieval.ipynb
|
nkmah2/ML_Uni_Washington_Coursera
|
a5852f1716189a1126919b12d767f894ad8490ac
|
[
"MIT"
] | null | null | null | 50.624011 | 3,632 | 0.516361 |
[
[
[
"#Document retrieval from wikipedia data\n\n#Fire up GraphLab Create",
"_____no_output_____"
]
],
[
[
"import graphlab",
"_____no_output_____"
]
],
[
[
"#Load some text data - from wikipedia, pages on people",
"_____no_output_____"
]
],
[
[
"people = graphlab.SFrame('people_wiki.gl/')",
"[INFO] This non-commercial license of GraphLab Create is assigned to [email protected] will expire on October 14, 2016. For commercial licensing options, visit https://dato.com/buy/.\n\n[INFO] Start server at: ipc:///tmp/graphlab_server-11106 - Server binary: /home/nitin/anaconda/lib/python2.7/site-packages/graphlab/unity_server - Server log: /tmp/graphlab_server_1446545370.log\n[INFO] GraphLab Server Version: 1.6.1\n"
]
],
[
[
"Data contains: link to wikipedia article, name of person, text of article.",
"_____no_output_____"
]
],
[
[
"people.head()",
"_____no_output_____"
],
[
"len(people)",
"_____no_output_____"
]
],
[
[
"#Explore the dataset and checkout the text it contains\n\n##Exploring the entry for president Obama",
"_____no_output_____"
]
],
[
[
"obama = people[people['name'] == 'Barack Obama']",
"_____no_output_____"
],
[
"obama",
"_____no_output_____"
],
[
"obama['text']",
"_____no_output_____"
]
],
[
[
"##Exploring the entry for actor George Clooney",
"_____no_output_____"
]
],
[
[
"clooney = people[people['name'] == 'George Clooney']\nclooney['text']",
"_____no_output_____"
]
],
[
[
"#Get the word counts for Obama article",
"_____no_output_____"
]
],
[
[
"obama['word_count'] = graphlab.text_analytics.count_words(obama['text'])",
"_____no_output_____"
],
[
"elton = people[people['name'] == 'Elton John']",
"_____no_output_____"
],
[
"print elton['word_count']",
"[{'all': 1, 'six': 1, 'producer': 1, 'heavily': 1, 'over': 2, 'named': 1, 'fifty': 1, 'four': 1, 'openly': 1, 'including': 1, 'highestprofile': 1, 'years': 1, 'its': 2, 'impact': 1, 'westminster': 1, '27': 1, '21': 2, 'wed': 1, 'had': 1, '1947': 1, 'abbey': 1, 'winning': 1, 'late': 1, 'to': 4, 'commander': 1, 'about': 1, 'born': 1, '2014': 1, 'as': 2, 'has': 9, '2013': 1, 'his': 4, 'march': 1, 'than': 3, 'song': 1, 'songwriter': 2, 'continues': 1, 'records': 1, 'five': 1, 'occasional': 1, 'they': 1, 'inception': 1, 'world': 1, 'brit': 1, 'him': 3, 'datein': 1, 'hall': 2, 'fivedecade': 1, 'knighthood': 1, 'bestselling': 2, 'artist': 1, 'be': 1, '1996': 1, 'list': 1, 'roll': 2, 'hercules': 1, 'announced': 1, 'rock': 2, 'become': 1, 'bernie': 1, 'outstanding': 1, 'england': 1, 'composer': 1, 'queens': 1, 'foundation': 2, 'diana': 1, 'globe': 1, 'artists': 2, 'culture': 1, 'been': 3, '49': 1, 'year': 1, 'billboard': 4, 'aids': 2, 'empire': 1, 'honors': 1, 'oscar': 1, 'elizabeth': 1, 'composers': 1, 'established': 1, 'elton': 3, 'for': 5, 'record': 1, '58': 1, 'since': 5, 'legal': 1, 'collaborated': 1, 'outside': 1, 'consecutive': 2, 'funeral': 1, 'disney': 1, 'solo': 1, 'marriage': 2, 'who': 1, '25': 1, '300': 1, 'sold': 2, 'million': 3, 'lgbt': 1, 'ranked': 2, 'awards': 3, 'alltime': 1, '100': 3, 'overallelton': 1, 'legend': 1, 'received': 2, 'hits': 1, 'english': 1, '33': 1, 'involved': 1, 'industry': 1, '30': 1, 'against': 1, 'david': 1, 'became': 1, 'tonightcandle': 1, 'social': 1, 'samesex': 1, 'contribution': 1, 'lasting': 1, 'dwight': 1, 'first': 1, 'golden': 1, 'raised': 1, 'grammy': 1, 'civil': 1, 'taupin': 1, 'into': 3, 'lyricist': 1, 'number': 2, 'one': 3, 'services': 2, 'ii': 1, 'kennedy': 1, 'least': 1, 'inducted': 1, 'parties': 1, 'tony': 1, '19702000': 1, 'concert': 1, 'jubilee': 1, 'from': 1, 'kenneth': 1, 'top': 4, 'cbe': 1, 'copies': 1, '1988': 1, 'fight': 1, '2': 1, 'music': 3, 'way': 1, 'bisexual': 1, 'hollywood': 1, 'john': 7, 'was': 2, 'songwriters': 2, 'more': 3, 'brits': 1, 'british': 3, 'diamond': 1, 'champion': 1, 'gay': 2, 'on': 6, 'successful': 1, 'academy': 3, 'stone': 1, 'award': 5, 'buckingham': 1, 'authors': 1, 'worked': 1, 'fellow': 1, 'with': 2, 'entered': 1, 'he': 7, '10': 1, '1992': 1, '1994': 1, '1997': 2, '40': 2, '1998': 1, 'hosting': 1, 'us': 1, 'career': 1, 'nine': 1, 'era': 1, 'royal': 1, 'of': 13, 'making': 1, 'male': 1, '31': 1, 'something': 1, 'and': 15, 'seven': 1, 'annual': 1, 'palace': 2, 'look': 1, 'december': 2, 'is': 4, 'partnership': 1, 'an': 3, '1980s': 1, 'single': 2, 'performed': 1, 'have': 1, 'in': 18, 'partner': 1, 'fame': 2, 'film': 1, 'movements': 1, 'sir': 1, 'no': 3, 'began': 1, '1967': 1, 'inductee': 1, 'actor': 1, '1': 2, 'hot': 2, 'musicians': 1, 'which': 1, 'influential': 1, 'party': 2, 'you': 1, 'pianist': 1, 'events': 1, 'worldwide': 2, '200': 1, 'princess': 1, 'time': 1, 'singles': 1, 'albums': 2, 'after': 1, 'most': 1, 'two': 1, 'rolling': 1, 'such': 1, '2008': 1, 'icon': 1, 'a': 10, 'singer': 1, 'center': 1, 'third': 1, '2012he': 1, '1976': 1, 'later': 1, 'reginald': 1, 'having': 1, '2002': 1, 'charitable': 1, 'wind': 1, '2004': 2, '2005': 1, 'at': 4, 'the': 27, 'order': 1, 'furnish': 2}, ... ]\n"
],
[
"print obama['word_count']",
"[{'operations': 1, 'represent': 1, 'office': 2, 'unemployment': 1, 'doddfrank': 1, 'over': 1, 'unconstitutional': 1, 'domestic': 2, 'major': 1, 'years': 1, 'against': 1, 'proposition': 1, 'seats': 1, 'graduate': 1, 'debate': 1, 'before': 1, 'death': 1, '20': 2, 'taxpayer': 1, 'representing': 1, 'obamacare': 1, 'barack': 1, 'to': 14, '4': 1, 'policy': 2, '8': 1, 'he': 7, '2011': 3, '2010': 2, '2013': 1, '2012': 1, 'bin': 1, 'then': 1, 'his': 11, 'march': 1, 'gains': 1, 'cuba': 1, 'school': 3, '1992': 1, 'new': 1, 'not': 1, 'during': 2, 'ending': 1, 'continued': 1, 'presidential': 2, 'states': 3, 'husen': 1, 'osama': 1, 'californias': 1, 'equality': 1, 'prize': 1, 'lost': 1, 'made': 1, 'inaugurated': 1, 'january': 3, 'university': 2, 'rights': 1, 'july': 1, 'gun': 1, 'stimulus': 1, 'rodham': 1, 'troop': 1, 'withdrawal': 1, 'brk': 1, 'nine': 1, 'where': 1, 'referred': 1, 'affordable': 1, 'attorney': 1, 'on': 2, 'often': 1, 'senate': 3, 'regained': 1, 'national': 2, 'creation': 1, 'related': 1, 'hawaii': 1, 'born': 2, 'second': 2, 'defense': 1, 'election': 3, 'close': 1, 'operation': 1, 'insurance': 1, 'sandy': 1, 'afghanistan': 2, 'initiatives': 1, 'for': 4, 'reform': 1, 'house': 2, 'review': 1, 'representatives': 2, 'ended': 1, 'current': 1, 'state': 1, 'won': 1, 'limit': 1, 'victory': 1, 'unsuccessfully': 1, 'reauthorization': 1, 'keynote': 1, 'full': 1, 'patient': 1, 'august': 1, 'degree': 1, '44th': 1, 'bm': 1, 'mitt': 1, 'attention': 1, 'delegates': 1, 'lgbt': 1, 'job': 1, 'harvard': 2, 'term': 3, 'served': 2, 'ask': 1, 'november': 2, 'debt': 1, 'by': 1, 'wall': 1, 'care': 1, 'received': 1, 'great': 1, 'signed': 3, 'libya': 1, 'receive': 1, 'of': 18, 'months': 1, 'urged': 1, 'foreign': 2, 'american': 3, 'protection': 2, 'economic': 1, 'act': 8, 'military': 4, 'hussein': 1, 'or': 1, 'first': 3, 'control': 4, 'named': 1, 'clinton': 1, 'dont': 2, 'campaign': 3, 'russia': 1, 'civil': 1, 'reinvestment': 1, 'into': 1, 'address': 1, 'primary': 2, 'community': 1, 'mccain': 1, 'down': 1, 'hook': 1, '63': 1, 'americans': 1, 'elementary': 1, 'total': 1, 'earning': 1, 'repeal': 1, 'from': 3, 'raise': 1, 'district': 1, 'spending': 1, 'republican': 2, 'legislation': 1, 'three': 1, 'relations': 1, 'nobel': 1, 'start': 1, 'tell': 1, 'iraq': 4, 'convention': 1, 'resulted': 1, 'john': 1, 'was': 5, '2012obama': 1, 'form': 1, 'that': 1, 'tax': 1, 'sufficient': 1, 'republicans': 1, 'strike': 1, 'hillary': 1, 'street': 1, 'arms': 1, 'honolulu': 1, 'filed': 1, 'worked': 1, 'hold': 1, 'with': 3, 'obama': 9, 'ii': 1, 'has': 4, '1997': 1, '1996': 1, 'whether': 1, 'reelected': 1, 'budget': 1, 'us': 6, 'nations': 1, 'recession': 1, 'while': 1, 'taught': 1, 'marriage': 1, 'policies': 1, 'promoted': 1, 'called': 1, 'and': 21, 'supreme': 1, 'ordered': 3, 'nominee': 2, 'process': 1, '2000in': 1, 'is': 2, 'romney': 1, 'briefs': 1, 'defeated': 1, 'general': 1, '13th': 1, 'as': 6, 'at': 2, 'in': 30, 'sought': 1, 'organizer': 1, 'shooting': 1, 'increased': 1, 'normalize': 1, 'lengthy': 1, 'united': 3, 'court': 1, 'recovery': 1, 'laden': 1, 'laureateduring': 1, 'peace': 1, 'administration': 1, '1961': 1, 'illinois': 2, 'other': 1, 'which': 1, 'party': 3, 'primaries': 1, 'sworn': 1, 'relief': 2, 'war': 1, 'columbia': 1, 'combat': 1, 'after': 4, 'islamic': 1, 'running': 1, 'levels': 1, 'two': 1, 'involvement': 3, 'response': 3, 'included': 1, 'president': 4, 'law': 6, 'nomination': 1, '2008': 1, 'a': 7, '2009': 3, 'chicago': 2, 'constitutional': 1, 'defeating': 1, 'treaty': 1, 'federal': 1, '2007': 1, '2004': 3, 'african': 1, 'the': 40, 'democratic': 4, 'consumer': 1, 'began': 1, 'terms': 1}]\n"
]
],
[
[
"##Sort the word counts for the Obama article",
"_____no_output_____"
],
[
"###Turning dictonary of word counts into a table",
"_____no_output_____"
]
],
[
[
"obama_word_count_table = obama[['word_count']].stack('word_count', new_column_name = ['word','count'])",
"_____no_output_____"
],
[
"elton_word_count_table = elton[['word_count']].stack('word_count', new_column_name = ['word','count'])",
"_____no_output_____"
],
[
"elton_word_count_table.sort('count',ascending=False)",
"_____no_output_____"
]
],
[
[
"###Sorting the word counts to show most common words at the top",
"_____no_output_____"
]
],
[
[
"obama_word_count_table.head()",
"_____no_output_____"
],
[
"obama_word_count_table.sort('count',ascending=False)",
"_____no_output_____"
]
],
[
[
"Most common words include uninformative words like \"the\", \"in\", \"and\",...",
"_____no_output_____"
],
[
"#Compute TF-IDF for the corpus \n\nTo give more weight to informative words, we weigh them by their TF-IDF scores.",
"_____no_output_____"
]
],
[
[
"people['word_count'] = graphlab.text_analytics.count_words(people['text'])\npeople.head()",
"_____no_output_____"
],
[
"tfidf = graphlab.text_analytics.tf_idf(people['word_count'])\ntfidf",
"_____no_output_____"
],
[
"people['tfidf'] = tfidf['docs']",
"_____no_output_____"
]
],
[
[
"##Examine the TF-IDF for the Obama article",
"_____no_output_____"
]
],
[
[
"obama = people[people['name'] == 'Barack Obama']",
"_____no_output_____"
],
[
"elton = people[people['name'] == 'Elton John']",
"_____no_output_____"
],
[
"obama[['tfidf']].stack('tfidf',new_column_name=['word','tfidf']).sort('tfidf',ascending=False)",
"_____no_output_____"
],
[
"elton[['tfidf']].stack('tfidf',new_column_name=['word','tfidf']).sort('tfidf',ascending=False)",
"_____no_output_____"
]
],
[
[
"Words with highest TF-IDF are much more informative.",
"_____no_output_____"
],
[
"#Manually compute distances between a few people\n\nLet's manually compare the distances between the articles for a few famous people. ",
"_____no_output_____"
]
],
[
[
"clinton = people[people['name'] == 'Bill Clinton']",
"_____no_output_____"
],
[
"beckham = people[people['name'] == 'David Beckham']",
"_____no_output_____"
]
],
[
[
"##Is Obama closer to Clinton than to Beckham?\n\nWe will use cosine distance, which is given by\n\n(1-cosine_similarity) \n\nand find that the article about president Obama is closer to the one about former president Clinton than that of footballer David Beckham.",
"_____no_output_____"
]
],
[
[
"graphlab.distances.cosine(obama['tfidf'][0],clinton['tfidf'][0])",
"_____no_output_____"
],
[
"graphlab.distances.cosine(obama['tfidf'][0],beckham['tfidf'][0])",
"_____no_output_____"
],
[
"victoria = people[people['name'] == 'Victoria Beckham']",
"_____no_output_____"
]
],
[
[
"\n#Build a nearest neighbor model for document retrieval\n\nWe now create a nearest-neighbors model and apply it to document retrieval. ",
"_____no_output_____"
]
],
[
[
"paul = people[people['name'] == 'Paul McCartney']",
"_____no_output_____"
],
[
"graphlab.distances.cosine(elton['tfidf'][0],victoria['tfidf'][0])",
"_____no_output_____"
],
[
"graphlab.distances.cosine(elton['tfidf'][0],paul['tfidf'][0])",
"_____no_output_____"
],
[
"knn_model = graphlab.nearest_neighbors.create(people,features=['tfidf'],label='name')",
"PROGRESS: Starting brute force nearest neighbors model training.\n"
],
[
"word_count_model=graphlab.nearest_neighbors.create(people,features=['word_count'],label='name',distance='cosine')",
"PROGRESS: Starting brute force nearest neighbors model training.\n"
],
[
"TF_IDF_model = graphlab.nearest_neighbors.create(people,features=['tfidf'],label='name', distance='cosine')",
"PROGRESS: Starting brute force nearest neighbors model training.\n"
],
[
"word_count_model.query(elton)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 6.242ms |\nPROGRESS: | Done | | 100 | 139.367ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
],
[
"TF_IDF_model.query(elton)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 8.478ms |\nPROGRESS: | Done | | 100 | 163.117ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
],
[
"word_count_model.query(victoria)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 7.099ms |\nPROGRESS: | Done | | 100 | 111.784ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
],
[
"TF_IDF_model.query(victoria)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 7.418ms |\nPROGRESS: | Done | | 100 | 155.579ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
]
],
[
[
"#Applying the nearest-neighbors model for retrieval",
"_____no_output_____"
],
[
"##Who is closest to Obama?",
"_____no_output_____"
]
],
[
[
"knn_model.query(obama)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 7.069ms |\nPROGRESS: | Done | | 100 | 173.107ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
]
],
[
[
"As we can see, president Obama's article is closest to the one about his vice-president Biden, and those of other politicians. ",
"_____no_output_____"
],
[
"##Other examples of document retrieval",
"_____no_output_____"
]
],
[
[
"swift = people[people['name'] == 'Taylor Swift']",
"_____no_output_____"
],
[
"knn_model.query(swift)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 5.971ms |\nPROGRESS: | Done | | 100 | 116.002ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
],
[
"jolie = people[people['name'] == 'Angelina Jolie']",
"_____no_output_____"
],
[
"knn_model.query(jolie)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 8.353ms |\nPROGRESS: | Done | | 100 | 177.851ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
],
[
"arnold = people[people['name'] == 'Arnold Schwarzenegger']",
"_____no_output_____"
],
[
"knn_model.query(arnold)",
"PROGRESS: Starting pairwise querying.\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | Query points | # Pairs | % Complete. | Elapsed Time |\nPROGRESS: +--------------+---------+-------------+--------------+\nPROGRESS: | 0 | 1 | 0.00169288 | 6.396ms |\nPROGRESS: | Done | | 100 | 120.642ms |\nPROGRESS: +--------------+---------+-------------+--------------+\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2a0654c8c136946d52b7871468e53c8ac8b387
| 18,014 |
ipynb
|
Jupyter Notebook
|
examples/Bootstrap.ipynb
|
Losaexellos/LiNGAM
|
3c8fb456788467e5bb0a6e71a669a6804ca04fad
|
[
"MIT"
] | null | null | null |
examples/Bootstrap.ipynb
|
Losaexellos/LiNGAM
|
3c8fb456788467e5bb0a6e71a669a6804ca04fad
|
[
"MIT"
] | 10 |
2020-05-30T18:51:17.000Z
|
2020-11-25T16:38:07.000Z
|
examples/Bootstrap.ipynb
|
Losaexellos/LiNGAM
|
3c8fb456788467e5bb0a6e71a669a6804ca04fad
|
[
"MIT"
] | 6 |
2021-12-03T04:02:21.000Z
|
2022-03-30T19:22:02.000Z
| 35.252446 | 360 | 0.481237 |
[
[
[
"# Bootstrap",
"_____no_output_____"
],
[
"## Import and settings\nIn this example, we need to import `numpy`, `pandas`, and `graphviz` in addition to `lingam`.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport graphviz\nimport lingam\nfrom lingam.utils import print_causal_directions, print_dagc, make_dot\n\nprint([np.__version__, pd.__version__, graphviz.__version__, lingam.__version__])\n\nnp.set_printoptions(precision=3, suppress=True)\nnp.random.seed(0)",
"['1.16.2', '0.24.2', '0.11.1', '1.2.1']\n"
]
],
[
[
"## Test data\nWe create test data consisting of 6 variables.",
"_____no_output_____"
]
],
[
[
"x3 = np.random.uniform(size=10000)\nx0 = 3.0*x3 + np.random.uniform(size=10000)\nx2 = 6.0*x3 + np.random.uniform(size=10000)\nx1 = 3.0*x0 + 2.0*x2 + np.random.uniform(size=10000)\nx5 = 4.0*x0 + np.random.uniform(size=10000)\nx4 = 8.0*x0 - 1.0*x2 + np.random.uniform(size=10000)\nX = pd.DataFrame(np.array([x0, x1, x2, x3, x4, x5]).T ,columns=['x0', 'x1', 'x2', 'x3', 'x4', 'x5'])\nX.head()",
"_____no_output_____"
],
[
"m = np.array([[0.0, 0.0, 0.0, 3.0, 0.0, 0.0],\n [3.0, 0.0, 2.0, 0.0, 0.0, 0.0],\n [0.0, 0.0, 0.0, 6.0, 0.0, 0.0],\n [0.0, 0.0, 0.0, 0.0, 0.0, 0.0],\n [8.0, 0.0,-1.0, 0.0, 0.0, 0.0],\n [4.0, 0.0, 0.0, 0.0, 0.0, 0.0]])\n\nmake_dot(m)",
"_____no_output_____"
]
],
[
[
"## Bootstrapping\nWe call `bootstrap()` method instead of `fit()`. Here, the second argument specifies the number of bootstrap sampling.",
"_____no_output_____"
]
],
[
[
"model = lingam.DirectLiNGAM()\nresult = model.bootstrap(X, 100)",
"_____no_output_____"
]
],
[
[
"Since `BootstrapResult` object is returned, we can get the ranking of the causal directions extracted by `get_causal_direction_counts()` method. In the following sample code, `n_directions` option is limited to the causal directions of the top 8 rankings, and `min_causal_effect` option is limited to causal directions with a coefficient of 0.01 or more.",
"_____no_output_____"
]
],
[
[
"cdc = result.get_causal_direction_counts(n_directions=8, min_causal_effect=0.01, split_by_causal_effect_sign=True)",
"_____no_output_____"
]
],
[
[
"We can check the result by utility function.",
"_____no_output_____"
]
],
[
[
"print_causal_directions(cdc, 100)",
"x0 <--- x3 (b>0) (100.0%)\nx1 <--- x0 (b>0) (100.0%)\nx1 <--- x2 (b>0) (100.0%)\nx2 <--- x3 (b>0) (100.0%)\nx4 <--- x0 (b>0) (100.0%)\nx4 <--- x2 (b<0) (100.0%)\nx5 <--- x0 (b>0) (100.0%)\nx0 <--- x2 (b>0) (15.0%)\n"
]
],
[
[
"Also, using the `get_directed_acyclic_graph_counts()` method, we can get the ranking of the DAGs extracted. In the following sample code, `n_dags` option is limited to the dags of the top 3 rankings, and `min_causal_effect` option is limited to causal directions with a coefficient of 0.01 or more.",
"_____no_output_____"
]
],
[
[
"dagc = result.get_directed_acyclic_graph_counts(n_dags=3, min_causal_effect=0.01, split_by_causal_effect_sign=True)",
"_____no_output_____"
]
],
[
[
"We can check the result by utility function.",
"_____no_output_____"
]
],
[
[
"print_dagc(dagc, 100)",
"DAG[0]: 77.0%\n\tx0 <--- x3 (b>0)\n\tx1 <--- x0 (b>0)\n\tx1 <--- x2 (b>0)\n\tx2 <--- x3 (b>0)\n\tx4 <--- x0 (b>0)\n\tx4 <--- x2 (b<0)\n\tx5 <--- x0 (b>0)\nDAG[1]: 14.0%\n\tx0 <--- x2 (b>0)\n\tx0 <--- x3 (b>0)\n\tx1 <--- x0 (b>0)\n\tx1 <--- x2 (b>0)\n\tx2 <--- x3 (b>0)\n\tx4 <--- x0 (b>0)\n\tx4 <--- x2 (b<0)\n\tx5 <--- x0 (b>0)\nDAG[2]: 3.0%\n\tx0 <--- x3 (b>0)\n\tx1 <--- x0 (b>0)\n\tx1 <--- x2 (b>0)\n\tx2 <--- x3 (b>0)\n\tx4 <--- x0 (b>0)\n\tx4 <--- x2 (b<0)\n\tx4 <--- x5 (b>0)\n\tx5 <--- x0 (b>0)\n"
]
],
[
[
"Using the `get_probabilities()` method, we can get the probability of bootstrapping.",
"_____no_output_____"
]
],
[
[
"prob = result.get_probabilities(min_causal_effect=0.01)\nprint(prob)",
"[[0. 0. 0.15 1. 0. 0. ]\n [1. 0. 1. 0.04 0. 0. ]\n [0. 0. 0. 1. 0. 0. ]\n [0. 0. 0. 0. 0. 0. ]\n [1. 0. 1. 0. 0. 0.04]\n [1. 0. 0. 0. 0.02 0. ]]\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2a0cdb841ba7900cdf17a91fbe7ed03a141ee3
| 13,601 |
ipynb
|
Jupyter Notebook
|
content/Chapter_13/02_Sums_of_IID_Samples.ipynb
|
dcroce/jupyter-book
|
9ac4b502af8e8c5c3b96f5ec138602a0d3d8a624
|
[
"MIT"
] | null | null | null |
content/Chapter_13/02_Sums_of_IID_Samples.ipynb
|
dcroce/jupyter-book
|
9ac4b502af8e8c5c3b96f5ec138602a0d3d8a624
|
[
"MIT"
] | null | null | null |
content/Chapter_13/02_Sums_of_IID_Samples.ipynb
|
dcroce/jupyter-book
|
9ac4b502af8e8c5c3b96f5ec138602a0d3d8a624
|
[
"MIT"
] | null | null | null | 87.748387 | 9,060 | 0.822954 |
[
[
[
"# HIDDEN\nfrom datascience import *\nfrom prob140 import *\nimport numpy as np\nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')\n%matplotlib inline\nfrom scipy import stats",
"_____no_output_____"
]
],
[
[
"## Sums of IID Samples ##",
"_____no_output_____"
],
[
"After the dry, algebraic discussion of the previous section it is a relief to finally be able to compute some variances.\n\nLet $X_1, X_2, \\ldots X_n$ be random variables with sum\n$$\nS_n = \\sum_{i=1}^n X_i\n$$\nThe variance of the sum is\n\n$$\n\\begin{align*}\nVar(S_n) &= Cov(S_n, S_n) \\\\\n&= \\sum_{i=1}^n\\sum_{j=1}^n Cov(X_i, X_j) ~~~~ \\text{(bilinearity)} \\\\\n&= \\sum_{i=1}^n Var(X_i) + \\mathop{\\sum \\sum}_{1 \\le i \\ne j \\le n} Cov(X_i, X_j)\n\\end{align*}\n$$\n\nWe say that the variance of the sum is the sum of all the variances and all the covariances.\n\nIf $X_1, X_2 \\ldots , X_n$ are independent, then all the covariance terms in the formula above are 0. \n\nTherefore if $X_1, X_2, \\ldots, X_n$ are independent then\n$$\nVar(S_n) = \\sum_{i=1}^n Var(X_i)\n$$\n\nThus for independent random variables $X_1, X_2, \\ldots, X_n$, both the expectation and the variance add up nicely:\n\n$$\nE(S_n) = \\sum_{i=1}^n E(X_i), ~~~~~~ Var(S_n) = \\sum_{i=1}^n Var(X_i)\n$$\n\nWhen the random variables are i.i.d., this simplifies even further.",
"_____no_output_____"
],
[
"### Sum of an IID Sample ###\nLet $X_1, X_2, \\ldots, X_n$ be i.i.d., each with mean $\\mu$ and $SD$ $\\sigma$. You can think of $X_1, X_2, \\ldots, X_n$ as draws at random with replacement from a population, or the results of independent replications of the same experiment.\n\nLet $S_n$ be the sample sum, as above. Then\n\n$$\nE(S_n) = n\\mu ~~~~~~~~~~ Var(S_n) = n\\sigma^2 ~~~~~~~~~~ SD(S_n) = \\sqrt{n}\\sigma\n$$\n\nThis implies that as the sample size $n$ increases, the distribution of the sum $S_n$ shifts to the right and is more spread out.\n\nHere is one of the most important applications of these results.",
"_____no_output_____"
],
[
"### Variance of the Binomial ###\nLet $X$ have the binomial $(n, p)$ distribution. We know that \n$$\nX = \\sum_{i=1}^n I_j\n$$\nwhere $I_1, I_2, \\ldots, I_n$ are i.i.d. indicators, each taking the value 1 with probability $p$. Each of these indicators has expectation $p$ and variance $pq = p(1-p)$. Therefore\n\n$$\nE(X) = np ~~~~~~~~~~ Var(X) = npq ~~~~~~~~~~ SD(X) = \\sqrt{npq}\n$$\n\nFor example, if $X$ is the number of heads in 100 tosses of a coin, then\n\n$$\nE(X) = 100 \\times 0.5 = 50 ~~~~~~~~~~ SD(X) = \\sqrt{100 \\times 0.5 \\times 0.5} = 5\n$$\n\nHere is the distribution of $X$. You can see that there is almost no probability outside the range $E(X) \\pm 3SD(X)$.",
"_____no_output_____"
]
],
[
[
"k = np.arange(25, 75, 1)\nbinom_probs = stats.binom.pmf(k, 100, 0.5)\nbinom_dist = Table().values(k).probability(binom_probs)\nPlot(binom_dist, show_ev=True, show_sd=True)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
4a2a197c4252999e547124720aba91e5e271e175
| 1,001 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Utils-checkpoint.ipynb
|
Valentine-Efagene/Jupyter-Notebooks
|
91a1d98354a270d214316eba21e4a435b3e17f5d
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Utils-checkpoint.ipynb
|
Valentine-Efagene/Jupyter-Notebooks
|
91a1d98354a270d214316eba21e4a435b3e17f5d
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Utils-checkpoint.ipynb
|
Valentine-Efagene/Jupyter-Notebooks
|
91a1d98354a270d214316eba21e4a435b3e17f5d
|
[
"MIT"
] | null | null | null | 17.258621 | 56 | 0.505495 |
[
[
[
"### Collect integer array as space separated input",
"_____no_output_____"
]
],
[
[
"a = list(map(int, input().rstrip().split()))",
"_____no_output_____"
]
],
[
[
"### Print array",
"_____no_output_____"
]
],
[
[
"print('\\n'.join(map(str, result)))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2a1a705b629151e98faf7f47bd0e77d8d00531
| 296,347 |
ipynb
|
Jupyter Notebook
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2020-09-18.ipynb
|
pvieito/Radar-STATS
|
9ff991a4db776259bc749a823ee6f0b0c0d38108
|
[
"Apache-2.0"
] | 9 |
2020-10-14T16:58:32.000Z
|
2021-10-05T12:01:56.000Z
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2020-09-18.ipynb
|
pvieito/Radar-STATS
|
9ff991a4db776259bc749a823ee6f0b0c0d38108
|
[
"Apache-2.0"
] | 3 |
2020-10-08T04:48:35.000Z
|
2020-10-10T20:46:58.000Z
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2020-09-18.ipynb
|
Radar-STATS/Radar-STATS
|
61d8b3529f6bbf4576d799e340feec5b183338a3
|
[
"Apache-2.0"
] | 3 |
2020-09-27T07:39:26.000Z
|
2020-10-02T07:48:56.000Z
| 91.043625 | 90,708 | 0.780528 |
[
[
[
"# RadarCOVID-Report",
"_____no_output_____"
],
[
"## Data Extraction",
"_____no_output_____"
]
],
[
[
"import datetime\nimport logging\nimport os\nimport shutil\nimport tempfile\nimport textwrap\nimport uuid\n\nimport dataframe_image as dfi\nimport matplotlib.ticker\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\n\n%matplotlib inline",
"_____no_output_____"
],
[
"sns.set()\nmatplotlib.rcParams['figure.figsize'] = (15, 6)\n\nextraction_datetime = datetime.datetime.utcnow()\nextraction_date = extraction_datetime.strftime(\"%Y-%m-%d\")\nextraction_previous_datetime = extraction_datetime - datetime.timedelta(days=1)\nextraction_previous_date = extraction_previous_datetime.strftime(\"%Y-%m-%d\")\nextraction_date_with_hour = datetime.datetime.utcnow().strftime(\"%Y-%m-%d@%H\")",
"_____no_output_____"
]
],
[
[
"### COVID-19 Cases",
"_____no_output_____"
]
],
[
[
"confirmed_df = pd.read_csv(\"https://covid19tracking.narrativa.com/csv/confirmed.csv\")\n\nradar_covid_countries = {\"Spain\"}\n# radar_covid_regions = { ... }\n\nconfirmed_df = confirmed_df[confirmed_df[\"Country_EN\"].isin(radar_covid_countries)]\n# confirmed_df = confirmed_df[confirmed_df[\"Region\"].isin(radar_covid_regions)]\n# set(confirmed_df.Region.tolist()) == radar_covid_regions",
"_____no_output_____"
],
[
"confirmed_country_columns = list(filter(lambda x: x.startswith(\"Country_\"), confirmed_df.columns))\nconfirmed_regional_columns = confirmed_country_columns + [\"Region\"]\nconfirmed_df.drop(columns=confirmed_regional_columns, inplace=True)\nconfirmed_df = confirmed_df.sum().to_frame()\nconfirmed_df.tail()",
"_____no_output_____"
],
[
"confirmed_df.reset_index(inplace=True)\nconfirmed_df.columns = [\"sample_date_string\", \"cumulative_cases\"]\nconfirmed_df.sort_values(\"sample_date_string\", inplace=True)\nconfirmed_df[\"new_cases\"] = confirmed_df.cumulative_cases.diff()\nconfirmed_df[\"rolling_mean_new_cases\"] = confirmed_df.new_cases.rolling(7).mean()\nconfirmed_df.tail()",
"_____no_output_____"
],
[
"extraction_date_confirmed_df = \\\n confirmed_df[confirmed_df.sample_date_string == extraction_date]\nextraction_previous_date_confirmed_df = \\\n confirmed_df[confirmed_df.sample_date_string == extraction_previous_date].copy()\n\nif extraction_date_confirmed_df.empty and \\\n not extraction_previous_date_confirmed_df.empty:\n extraction_previous_date_confirmed_df[\"sample_date_string\"] = extraction_date\n extraction_previous_date_confirmed_df[\"new_cases\"] = \\\n extraction_previous_date_confirmed_df.rolling_mean_new_cases\n extraction_previous_date_confirmed_df[\"cumulative_cases\"] = \\\n extraction_previous_date_confirmed_df.new_cases + \\\n extraction_previous_date_confirmed_df.cumulative_cases\n confirmed_df = confirmed_df.append(extraction_previous_date_confirmed_df)\n \nconfirmed_df.tail()",
"_____no_output_____"
],
[
"confirmed_df[[\"new_cases\", \"rolling_mean_new_cases\"]].plot()",
"_____no_output_____"
]
],
[
[
"### Extract API TEKs",
"_____no_output_____"
]
],
[
[
"from Modules.RadarCOVID import radar_covid\n\nexposure_keys_df = radar_covid.download_last_radar_covid_exposure_keys(days=14)\nexposure_keys_df[[\n \"sample_date_string\", \"source_url\", \"region\", \"key_data\"]].head()",
"WARNING:root:Unexpected key 'key_rolling_period': 53400s (expected: 86400s)\n"
],
[
"exposure_keys_summary_df = \\\n exposure_keys_df.groupby([\"sample_date_string\"]).key_data.nunique().to_frame()\nexposure_keys_summary_df.sort_index(ascending=False, inplace=True)\nexposure_keys_summary_df.rename(columns={\"key_data\": \"tek_count\"}, inplace=True)\nexposure_keys_summary_df.head()",
"_____no_output_____"
]
],
[
[
"### Dump API TEKs",
"_____no_output_____"
]
],
[
[
"tek_list_df = exposure_keys_df[[\"sample_date_string\", \"key_data\"]].copy()\ntek_list_df[\"key_data\"] = tek_list_df[\"key_data\"].apply(str)\ntek_list_df.rename(columns={\n \"sample_date_string\": \"sample_date\",\n \"key_data\": \"tek_list\"}, inplace=True)\ntek_list_df = tek_list_df.groupby(\n \"sample_date\").tek_list.unique().reset_index()\ntek_list_df[\"extraction_date\"] = extraction_date\ntek_list_df[\"extraction_date_with_hour\"] = extraction_date_with_hour\ntek_list_df.drop(columns=[\"extraction_date\", \"extraction_date_with_hour\"]).to_json(\n \"Data/TEKs/Current/RadarCOVID-TEKs.json\",\n lines=True, orient=\"records\")\ntek_list_df.drop(columns=[\"extraction_date_with_hour\"]).to_json(\n \"Data/TEKs/Daily/RadarCOVID-TEKs-\" + extraction_date + \".json\",\n lines=True, orient=\"records\")\ntek_list_df.to_json(\n \"Data/TEKs/Hourly/RadarCOVID-TEKs-\" + extraction_date_with_hour + \".json\",\n lines=True, orient=\"records\")\ntek_list_df.head()",
"_____no_output_____"
]
],
[
[
"### Load TEK Dumps",
"_____no_output_____"
]
],
[
[
"import glob\n\ndef load_extracted_teks(mode, limit=None) -> pd.DataFrame:\n extracted_teks_df = pd.DataFrame()\n paths = list(reversed(sorted(glob.glob(f\"Data/TEKs/{mode}/RadarCOVID-TEKs-*.json\"))))\n if limit:\n paths = paths[:limit]\n for path in paths:\n logging.info(f\"Loading TEKs from '{path}'...\")\n iteration_extracted_teks_df = pd.read_json(path, lines=True)\n extracted_teks_df = extracted_teks_df.append(\n iteration_extracted_teks_df, sort=False)\n return extracted_teks_df",
"_____no_output_____"
]
],
[
[
"### Daily New TEKs",
"_____no_output_____"
]
],
[
[
"daily_extracted_teks_df = load_extracted_teks(mode=\"Daily\", limit=14)\ndaily_extracted_teks_df.head()",
"_____no_output_____"
],
[
"tek_list_df = daily_extracted_teks_df.groupby(\"extraction_date\").tek_list.apply(\n lambda x: set(sum(x, []))).reset_index()\ntek_list_df = tek_list_df.set_index(\"extraction_date\").sort_index(ascending=True)\ntek_list_df.head()",
"_____no_output_____"
],
[
"new_tek_df = tek_list_df.diff().tek_list.apply(\n lambda x: len(x) if not pd.isna(x) else None).to_frame().reset_index()\nnew_tek_df.rename(columns={\n \"tek_list\": \"new_tek_count\",\n \"extraction_date\": \"sample_date_string\",}, inplace=True)\nnew_tek_df.head()",
"_____no_output_____"
],
[
"new_tek_devices_df = daily_extracted_teks_df.copy()\nnew_tek_devices_df[\"new_sample_extraction_date\"] = \\\n pd.to_datetime(new_tek_devices_df.sample_date) + datetime.timedelta(1)\nnew_tek_devices_df[\"extraction_date\"] = pd.to_datetime(new_tek_devices_df.extraction_date)\n\nnew_tek_devices_df = new_tek_devices_df[\n new_tek_devices_df.new_sample_extraction_date == new_tek_devices_df.extraction_date]\nnew_tek_devices_df.head()",
"_____no_output_____"
],
[
"new_tek_devices_df.set_index(\"extraction_date\", inplace=True)\nnew_tek_devices_df = new_tek_devices_df.tek_list.apply(lambda x: len(set(x))).to_frame()\nnew_tek_devices_df.reset_index(inplace=True)\nnew_tek_devices_df.rename(columns={\n \"extraction_date\": \"sample_date_string\",\n \"tek_list\": \"new_tek_devices\"}, inplace=True)\nnew_tek_devices_df[\"sample_date_string\"] = new_tek_devices_df.sample_date_string.dt.strftime(\"%Y-%m-%d\")\nnew_tek_devices_df.head()",
"_____no_output_____"
]
],
[
[
"### Hourly New TEKs",
"_____no_output_____"
]
],
[
[
"hourly_extracted_teks_df = load_extracted_teks(mode=\"Hourly\", limit=24)\nhourly_extracted_teks_df.head()\n\nhourly_tek_list_df = hourly_extracted_teks_df.groupby(\"extraction_date_with_hour\").tek_list.apply(\n lambda x: set(sum(x, []))).reset_index()\nhourly_tek_list_df = hourly_tek_list_df.set_index(\"extraction_date_with_hour\").sort_index(ascending=True)\n\nhourly_new_tek_df = hourly_tek_list_df.diff().tek_list.apply(\n lambda x: len(x) if not pd.isna(x) else None).to_frame().reset_index()\nhourly_new_tek_df.rename(columns={\n \"tek_list\": \"new_tek_count\"}, inplace=True)\nhourly_new_tek_df.tail()",
"_____no_output_____"
],
[
"hourly_new_tek_devices_df = hourly_extracted_teks_df.copy()\nhourly_new_tek_devices_df[\"new_sample_extraction_date\"] = \\\n pd.to_datetime(hourly_new_tek_devices_df.sample_date) + datetime.timedelta(1)\nhourly_new_tek_devices_df[\"extraction_date\"] = pd.to_datetime(hourly_new_tek_devices_df.extraction_date)\n\nhourly_new_tek_devices_df = hourly_new_tek_devices_df[\n hourly_new_tek_devices_df.new_sample_extraction_date == hourly_new_tek_devices_df.extraction_date]\n\nhourly_new_tek_devices_df.set_index(\"extraction_date_with_hour\", inplace=True)\nhourly_new_tek_devices_df_ = pd.DataFrame()\n\nfor i, chunk_df in hourly_new_tek_devices_df.groupby(\"extraction_date\"):\n chunk_df = chunk_df.copy()\n chunk_df.sort_index(inplace=True)\n chunk_tek_count_df = chunk_df.tek_list.apply(lambda x: len(set(x)))\n chunk_df = chunk_tek_count_df.diff().fillna(chunk_tek_count_df).to_frame()\n hourly_new_tek_devices_df_ = hourly_new_tek_devices_df_.append(chunk_df)\n \nhourly_new_tek_devices_df = hourly_new_tek_devices_df_\nhourly_new_tek_devices_df.reset_index(inplace=True)\nhourly_new_tek_devices_df.rename(columns={\n \"tek_list\": \"new_tek_devices\"}, inplace=True)\nhourly_new_tek_devices_df.tail()",
"_____no_output_____"
],
[
"hourly_summary_df = hourly_new_tek_df.merge(\n hourly_new_tek_devices_df, on=[\"extraction_date_with_hour\"], how=\"outer\")\nhourly_summary_df[\"datetime_utc\"] = pd.to_datetime(\n hourly_summary_df.extraction_date_with_hour, format=\"%Y-%m-%d@%H\")\nhourly_summary_df.set_index(\"datetime_utc\", inplace=True)\nhourly_summary_df.tail()",
"_____no_output_____"
]
],
[
[
"### Data Merge",
"_____no_output_____"
]
],
[
[
"result_summary_df = exposure_keys_summary_df.merge(new_tek_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = result_summary_df.merge(new_tek_devices_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = result_summary_df.merge(confirmed_df, on=[\"sample_date_string\"], how=\"left\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df[\"tek_count_per_new_case\"] = \\\n result_summary_df.tek_count / result_summary_df.rolling_mean_new_cases\nresult_summary_df[\"new_tek_count_per_new_case\"] = \\\n result_summary_df.new_tek_count / result_summary_df.rolling_mean_new_cases\nresult_summary_df[\"new_tek_devices_per_new_case\"] = \\\n result_summary_df.new_tek_devices / result_summary_df.rolling_mean_new_cases\nresult_summary_df[\"new_tek_count_per_new_tek_device\"] = \\\n result_summary_df.new_tek_count / result_summary_df.new_tek_devices\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df[\"sample_date\"] = pd.to_datetime(result_summary_df.sample_date_string)\nresult_summary_df.set_index(\"sample_date\", inplace=True)\nresult_summary_df = result_summary_df.sort_index(ascending=False)",
"_____no_output_____"
]
],
[
[
"## Report Results\n",
"_____no_output_____"
],
[
"### Summary Table",
"_____no_output_____"
]
],
[
[
"result_summary_df_ = result_summary_df.copy()\nresult_summary_df = result_summary_df[[\n \"tek_count\",\n \"new_tek_count\",\n \"new_cases\",\n \"rolling_mean_new_cases\",\n \"tek_count_per_new_case\",\n \"new_tek_count_per_new_case\",\n \"new_tek_devices\",\n \"new_tek_devices_per_new_case\",\n \"new_tek_count_per_new_tek_device\"]]\nresult_summary_df",
"_____no_output_____"
]
],
[
[
"### Summary Plots",
"_____no_output_____"
]
],
[
[
"summary_ax_list = result_summary_df[[\n \"rolling_mean_new_cases\",\n \"tek_count\",\n \"new_tek_count\",\n \"new_tek_devices\",\n \"new_tek_count_per_new_tek_device\",\n \"new_tek_devices_per_new_case\"\n]].sort_index(ascending=True).plot.bar(\n title=\"Summary\", rot=45, subplots=True, figsize=(15, 22))\nsummary_ax_list[-1].yaxis.set_major_formatter(matplotlib.ticker.PercentFormatter(1.0))",
"_____no_output_____"
]
],
[
[
"### Hourly Summary Plots ",
"_____no_output_____"
]
],
[
[
"hourly_summary_ax_list = hourly_summary_df.plot.bar(\n title=\"Last 24h Summary\", rot=45, subplots=True)",
"_____no_output_____"
]
],
[
[
"### Publish Results",
"_____no_output_____"
]
],
[
[
"def get_temporary_image_path() -> str:\n return os.path.join(tempfile.gettempdir(), str(uuid.uuid4()) + \".png\")\n\ndef save_temporary_plot_image(ax):\n if isinstance(ax, np.ndarray):\n ax = ax[0]\n media_path = get_temporary_image_path()\n ax.get_figure().savefig(media_path)\n return media_path\n\ndef save_temporary_dataframe_image(df):\n media_path = get_temporary_image_path()\n dfi.export(df, media_path)\n return media_path\n\nsummary_plots_image_path = save_temporary_plot_image(ax=summary_ax_list)\nsummary_table_image_path = save_temporary_dataframe_image(df=result_summary_df)\nhourly_summary_plots_image_path = save_temporary_plot_image(ax=hourly_summary_ax_list)",
"_____no_output_____"
]
],
[
[
"### Save Results",
"_____no_output_____"
]
],
[
[
"report_resources_path_prefix = \"Data/Resources/Current/RadarCOVID-Report-\"\nresult_summary_df.to_csv(report_resources_path_prefix + \"Summary-Table.csv\")\nresult_summary_df.to_html(report_resources_path_prefix + \"Summary-Table.html\")\n_ = shutil.copyfile(summary_plots_image_path, report_resources_path_prefix + \"Summary-Plots.png\")\n_ = shutil.copyfile(summary_table_image_path, report_resources_path_prefix + \"Summary-Table.png\")\n_ = shutil.copyfile(hourly_summary_plots_image_path, report_resources_path_prefix + \"Hourly-Summary-Plots.png\")\n\nreport_daily_url_pattern = \\\n \"https://github.com/pvieito/RadarCOVID-Report/blob/master/Notebooks/\" \\\n \"RadarCOVID-Report/{report_type}/RadarCOVID-Report-{report_date}.ipynb\"\nreport_daily_url = report_daily_url_pattern.format(\n report_type=\"Daily\", report_date=extraction_date)\nreport_hourly_url = report_daily_url_pattern.format(\n report_type=\"Hourly\", report_date=extraction_date_with_hour)",
"_____no_output_____"
]
],
[
[
"### Publish on README",
"_____no_output_____"
]
],
[
[
"with open(\"Data/Templates/README.md\", \"r\") as f:\n readme_contents = f.read()\n\nsummary_table_html = result_summary_df.to_html()\nreadme_contents = readme_contents.format(\n summary_table_html=summary_table_html,\n report_url_with_hour=report_hourly_url,\n extraction_date_with_hour=extraction_date_with_hour)\n\nwith open(\"README.md\", \"w\") as f:\n f.write(readme_contents)",
"_____no_output_____"
]
],
[
[
"### Publish on Twitter",
"_____no_output_____"
]
],
[
[
"enable_share_to_twitter = os.environ.get(\"RADARCOVID_REPORT__ENABLE_PUBLISH_ON_TWITTER\")\ngithub_event_name = os.environ.get(\"GITHUB_EVENT_NAME\")\n\nif enable_share_to_twitter and github_event_name == \"schedule\":\n import tweepy\n\n twitter_api_auth_keys = os.environ[\"RADARCOVID_REPORT__TWITTER_API_AUTH_KEYS\"]\n twitter_api_auth_keys = twitter_api_auth_keys.split(\":\")\n auth = tweepy.OAuthHandler(twitter_api_auth_keys[0], twitter_api_auth_keys[1])\n auth.set_access_token(twitter_api_auth_keys[2], twitter_api_auth_keys[3])\n\n api = tweepy.API(auth)\n\n summary_plots_media = api.media_upload(summary_plots_image_path)\n summary_table_media = api.media_upload(summary_table_image_path)\n hourly_summary_plots_media = api.media_upload(hourly_summary_plots_image_path)\n media_ids = [\n summary_plots_media.media_id,\n summary_table_media.media_id,\n hourly_summary_plots_media.media_id,\n ]\n\n extraction_date_result_summary_df = \\\n result_summary_df[result_summary_df.index == extraction_date]\n extraction_date_result_hourly_summary_df = \\\n hourly_summary_df[hourly_summary_df.extraction_date_with_hour == extraction_date_with_hour]\n\n new_teks = extraction_date_result_summary_df.new_tek_count.sum().astype(int)\n new_teks_last_hour = extraction_date_result_hourly_summary_df.new_tek_count.sum().astype(int)\n new_devices = extraction_date_result_summary_df.new_tek_devices.sum().astype(int)\n new_devices_last_hour = extraction_date_result_hourly_summary_df.new_tek_devices.sum().astype(int)\n new_tek_count_per_new_tek_device = \\\n extraction_date_result_summary_df.new_tek_count_per_new_tek_device.sum()\n new_tek_devices_per_new_case = \\\n extraction_date_result_summary_df.new_tek_devices_per_new_case.sum()\n\n status = textwrap.dedent(f\"\"\"\n Report Update – {extraction_date_with_hour}\n #ExposureNotification #RadarCOVID\n\n Shared Diagnoses Day Summary:\n - New TEKs: {new_teks} ({new_teks_last_hour:+d} last hour)\n - New Devices: {new_devices} ({new_devices_last_hour:+d} last hour, {new_tek_count_per_new_tek_device:.2} TEKs/device)\n - Usage Ratio: {new_tek_devices_per_new_case:.2%} devices/case\n\n Report Link: {report_hourly_url}\n \"\"\")\n status = status.encode(encoding=\"utf-8\")\n api.update_status(status=status, media_ids=media_ids)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2a1ff146e1737da41830930a50fb46f3d9e969
| 13,645 |
ipynb
|
Jupyter Notebook
|
examples/notebooks/Top words in Shakespeare by work.ipynb
|
nivaldoh/spark-bigquery-connector
|
6031228d8652174b50395406018d754ec781d156
|
[
"Apache-2.0"
] | 135 |
2020-02-03T09:54:47.000Z
|
2022-03-24T20:58:05.000Z
|
examples/notebooks/Top words in Shakespeare by work.ipynb
|
davidrabinowitz/spark-bigquery-connector
|
a4ada725628e81a6b466e08bcbed0d95069654d0
|
[
"Apache-2.0"
] | 472 |
2020-01-16T00:11:39.000Z
|
2022-03-31T20:53:54.000Z
|
examples/notebooks/Top words in Shakespeare by work.ipynb
|
davidrabinowitz/spark-bigquery-connector
|
a4ada725628e81a6b466e08bcbed0d95069654d0
|
[
"Apache-2.0"
] | 93 |
2020-01-20T17:28:55.000Z
|
2022-03-31T21:14:37.000Z
| 30.389755 | 115 | 0.361085 |
[
[
[
"# Using the Spark BigQuery connector in Jupyter\nUse a Python kernel (not PySpark) to allow configuring the SparkSession inside the notebook.",
"_____no_output_____"
]
],
[
[
"from pyspark.sql import SparkSession\nspark = SparkSession.builder \\\n .appName('Top Shakepeare words')\\\n .config('spark.jars', 'gs://spark-lib/bigquery/spark-bigquery-latest.jar') \\\n .getOrCreate()",
"_____no_output_____"
]
],
[
[
"Read the data in from BigQuery",
"_____no_output_____"
]
],
[
[
"df = spark.read \\\n .format('bigquery') \\\n .load('bigquery-public-data.samples.shakespeare')",
"_____no_output_____"
]
],
[
[
"Convert words to lower case and filter out stop words",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import StopWordsRemover\nfrom pyspark.sql import functions as F\n\ndf = df.withColumn('lowered', F.array(F.lower(df.word)))\n\nremover = StopWordsRemover(inputCol='lowered', outputCol='filtered')\n\ndf = remover.transform(df)",
"_____no_output_____"
]
],
[
[
"Create `(count, word)` struct and take the max of that in each corpus",
"_____no_output_____"
]
],
[
[
"df.select(df.corpus, F.struct(df.word_count, df.filtered.getItem(0).alias('word')).alias('count_word')) \\\n .where(F.col('count_word').getItem('word').isNotNull()) \\\n .groupby('corpus') \\\n .agg({'count_word': 'max'}) \\\n .orderBy('corpus') \\\n .select(\n 'corpus',\n F.col('max(count_word)').getItem('word').alias('word'),\n F.col('max(count_word)').getItem('word_count').alias('count')) \\\n .toPandas()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2a2c9556611220c5e06b69dc519a6a9cb27457
| 38,804 |
ipynb
|
Jupyter Notebook
|
CDE.ipynb
|
ctownsen357/julia-cde
|
4860bbebca5cc3fcedad130b4ccf7ed2b3ab6186
|
[
"MIT"
] | 1 |
2020-08-21T03:35:03.000Z
|
2020-08-21T03:35:03.000Z
|
CDE.ipynb
|
ctownsen357/julia-cde
|
4860bbebca5cc3fcedad130b4ccf7ed2b3ab6186
|
[
"MIT"
] | null | null | null |
CDE.ipynb
|
ctownsen357/julia-cde
|
4860bbebca5cc3fcedad130b4ccf7ed2b3ab6186
|
[
"MIT"
] | null | null | null | 40.675052 | 315 | 0.552366 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a2a3632bf0ebf60d8664758a657f72b4a8c07f1
| 151,372 |
ipynb
|
Jupyter Notebook
|
3_Silla_de_ruedas/Python/5_Training_models_eye.ipynb
|
BIOINSTRUMENTACION/BIO4
|
4ca5a0c6089ccbf71d9955c9c288769e2b6b40f7
|
[
"MIT"
] | 1 |
2022-02-10T07:46:33.000Z
|
2022-02-10T07:46:33.000Z
|
3_Silla_de_ruedas/Python/5_Training_models_eye.ipynb
|
BIOINSTRUMENTACION/BIO4
|
4ca5a0c6089ccbf71d9955c9c288769e2b6b40f7
|
[
"MIT"
] | null | null | null |
3_Silla_de_ruedas/Python/5_Training_models_eye.ipynb
|
BIOINSTRUMENTACION/BIO4
|
4ca5a0c6089ccbf71d9955c9c288769e2b6b40f7
|
[
"MIT"
] | null | null | null | 168.753623 | 57,224 | 0.820277 |
[
[
[
"import tensorflow as tf\nfrom tensorflow.keras.preprocessing.image import load_img, img_to_array\nfrom tensorflow.keras.models import Sequential, load_model\nfrom tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D\nfrom tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping\nimport os\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport cv2 \nprint(\"Tensorflow Version:\",tf.__version__)",
"Tensorflow Version: 2.3.0\n"
]
],
[
[
"\n### INDEX\n[1.- LOAD DATA USING IMAGE GENREATORS](#1)\n\n[2.-Create a CNN From Scracth](#2)\n\n",
"_____no_output_____"
],
[
"<a id='1'></a>\n## 1.- LOAD DATA USING IMAGE GENREATORS",
"_____no_output_____"
]
],
[
[
"### Initiate an instnace of ImagaDataGenerator ###\n## More in Data Augmentation: \n## https://towardsdatascience.com/exploring-image-data-augmentation-with-keras-and-tensorflow-a8162d89b844\npath = \"Data_set_eye\" # Dataset Path\n###################################### Create Data Generator ##############################################################\nimage_generator = tf.keras.preprocessing.image.ImageDataGenerator(validation_split=0.2, # Split for Test/Validation\n height_shift_range=0.2, # Height Shift\n brightness_range=(0.5, 1.), # Brightness\n rescale=0.9, # Rescale \n ) \n\n############################################## TRAINING DATASET ##############################################################\ntrain_dataset = image_generator.flow_from_directory(batch_size=32, # Batch Size\n directory=path, # Directory\n shuffle=True, # Shuffle images\n target_size=(100, 100), # Resize to 100x100\n color_mode=\"rgb\", # Set RGB as default\n subset=\"training\", # Set Subset to Training\n class_mode='categorical' # Set Data to Categoriacal\n )\n############################################## TESTING DATASET ##############################################################\nvalidation_dataset = image_generator.flow_from_directory(batch_size=32, # Batch Size\n directory=path, # Directory\n shuffle=True, # Shuffle images\n target_size=(100, 100), # Resize to 100x100\n subset=\"validation\", # Set Subset to Validation\n color_mode=\"rgb\", # Set RGB as default\n class_mode='categorical') # Set Data to Categoriacal",
"Found 356 images belonging to 4 classes.\nFound 87 images belonging to 4 classes.\n"
]
],
[
[
"### 1.1.- Calculate Steps that have to be taken every epoch",
"_____no_output_____"
]
],
[
[
"val_steps = validation_dataset.n // validation_dataset.batch_size # Steps in an epoch Validation Data\ntrain_steps = train_dataset.n // train_dataset.batch_size # Steps in an epoch for Traninning Data\n###################################### INFROM THE USER ABOUT THE STEPS #####################################################\nprint(f\"Train steps per epoch: {train_steps}\") # Steps in an epoch for Traninning Data\nprint(f\"Validation steps per epoch: {val_steps}\") # Steps in an epoch Validation Data",
"Train steps per epoch: 11\nValidation steps per epoch: 2\n"
]
],
[
[
"### 1.2.- Get tha labels for each class",
"_____no_output_____"
]
],
[
[
"#### All the labels are stored in Lables.txt file ######\npath = \"Data_set_eye/Labels.txt\" # Path for Label txt file\nwith open(path,\"r\") as handler: # Open txt file\n labels = handler.read().splitlines() # Create a list based on every new line\nprint(labels) # Show the labels\n",
"['Back', 'Front', 'Left', 'Right']\n"
]
],
[
[
"<br>\n<br>",
"_____no_output_____"
],
[
"<a id='2'></a>\n# 2.-Create a CNN From Scracth",
"_____no_output_____"
]
],
[
[
"def get_new_model(rate=0.5):\n \"\"\"\n Convolutional Neural Network with Droput\n \"\"\"\n ############################### NEURAL NETWORK ARCHITECTURE ############################################\n model = tf.keras.Sequential()\n model.add(tf.keras.Input(shape=((100, 100, 3))))\n model.add(tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),activation=\"relu\",padding=\"same\",name=\"conv_1\"))\n model.add(tf.keras.layers.Dropout(rate))\n model.add(tf.keras.layers.Conv2D(filters=16,kernel_size=(3,3),activation=\"relu\",padding=\"same\",name=\"conv_2\"))\n model.add(tf.keras.layers.Dropout(rate))\n model.add(tf.keras.layers.Conv2D(filters=8,kernel_size=(3,3),activation=\"relu\",padding=\"same\",name=\"conv_3\"))\n model.add(tf.keras.layers.Dropout(rate))\n model.add(tf.keras.layers.MaxPooling2D(pool_size=(8,8),name=\"pool_1\"))\n \n model.add(tf.keras.layers.Flatten(name=\"flatten\"))\n model.add(tf.keras.layers.Dense(units=64,activation=\"relu\",name=\"dense_1\"))\n model.add(tf.keras.layers.Dense(units=64,activation=\"relu\",name=\"dense_2\"))\n model.add(tf.keras.layers.Dense(units=64,activation=\"relu\",name=\"dense_3\"))\n model.add(tf.keras.layers.Dense(units=4,activation=\"softmax\",name=\"dense_4\"))\n \n ########################### Compilation of CNN ########################################################\n model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])\n return model \n\ndef get_test_accuracy(model,data,steps,**kwargs):\n \"\"\"Test model classification accuracy\"\"\"\n test_loss, test_acc = model.evaluate_generator(data,steps,**kwargs)\n print('accuracy: {acc:0.3f}'.format(acc=test_acc))\n \n\ndef get_checkpoint_best_only():\n \"\"\"\n - saves only the weights that generate the highest validation (testing) accuracy\n \"\"\"\n path = r'C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights'# path to save model\n checkpoint = tf.keras.callbacks.ModelCheckpoint(filepath=path, save_best_only=True,save_weights_only=True,verbose=2)\n return checkpoint\n\ndef get_early_stopping():\n \"\"\"\n This function should return an EarlyStopping callback that stops training when\n the validation (testing) accuracy has not improved in the last 5 epochs.\n EarlyStopping callback with the correct 'monitor' and 'patience'\n \"\"\"\n return tf.keras.callbacks.EarlyStopping(monitor='accuracy',min_delta=0.01,patience=5,mode=\"max\")\n \n \ndef plot_learning(history):\n \"\"\"PLOT LEARNING CUVRVES \"\"\"\n figrue, ax = plt.subplots(1,2,figsize=(15,6)) # Create Figure\n ax[0].set_title(\"Loss Vs Epochs\") # Set Title\n ax[0].plot(history.history['loss'],label=\" Trainining Loss\") # Plot Training Loss\n ax[0].plot(history.history['val_loss'],label=\"Validation Loss\") # Plot Validation Loss\n ax[0].legend() # Print Labels in plot\n\n ax[1].set_title(\"Accuracy Vs Epochs\") # Set Title\n ax[1].plot(history.history['accuracy'],label=\" Trainining Accurcacy\") # Plot Training Accuracy\n ax[1].plot(history.history['val_accuracy'],label=\"Validation Accurcacy\") # Plot Validation Accuracy\n ax[1].legend() # Print Labels in plot\n \n plt.show() # Show plot\n ## THERE IS NOTHING TO RETURN ##",
"_____no_output_____"
],
[
"model = get_new_model() # Initiate Model\nget_test_accuracy(model,validation_dataset,val_steps) # Test intial Accruacy (without Trainning)\nmodel.summary() # Get Model Architecture",
"accuracy: 0.297\nModel: \"sequential_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv_1 (Conv2D) (None, 100, 100, 16) 448 \n_________________________________________________________________\ndropout_6 (Dropout) (None, 100, 100, 16) 0 \n_________________________________________________________________\nconv_2 (Conv2D) (None, 100, 100, 16) 2320 \n_________________________________________________________________\ndropout_7 (Dropout) (None, 100, 100, 16) 0 \n_________________________________________________________________\nconv_3 (Conv2D) (None, 100, 100, 8) 1160 \n_________________________________________________________________\ndropout_8 (Dropout) (None, 100, 100, 8) 0 \n_________________________________________________________________\npool_1 (MaxPooling2D) (None, 12, 12, 8) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 1152) 0 \n_________________________________________________________________\ndense_1 (Dense) (None, 64) 73792 \n_________________________________________________________________\ndense_2 (Dense) (None, 64) 4160 \n_________________________________________________________________\ndense_3 (Dense) (None, 64) 4160 \n_________________________________________________________________\ndense_4 (Dense) (None, 4) 260 \n=================================================================\nTotal params: 86,300\nTrainable params: 86,300\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"### 2.1 Train Model",
"_____no_output_____"
]
],
[
[
"checkpoint_best_only = get_checkpoint_best_only() # Get best only save\nearly_stopping = get_early_stopping() # Get Early stopping\ncallbacks = [checkpoint_best_only, early_stopping] # Put callbacks in a list\n\n### Train model using the callbacks ##\nhistory = model.fit(train_dataset, # Data generator for Training\n steps_per_epoch =train_steps, # Steps in an epoch of Training Data\n validation_data = validation_dataset, # Data Generator for Validation\n validation_steps=val_steps, # Steps in a epoch of Validation Data\n epochs=40,callbacks=callbacks # Callbacks\n )\n\nplot_learning(history) # Plot learning curves at the end ",
"Epoch 1/40\n11/11 [==============================] - ETA: 0s - loss: 52.2163 - accuracy: 0.2685\nEpoch 00001: val_loss improved from inf to 1.51630, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 507ms/step - loss: 52.2163 - accuracy: 0.2685 - val_loss: 1.5163 - val_accuracy: 0.3125\nEpoch 2/40\n11/11 [==============================] - ETA: 0s - loss: 6.1779 - accuracy: 0.3241\nEpoch 00002: val_loss improved from 1.51630 to 1.41352, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 501ms/step - loss: 6.1779 - accuracy: 0.3241 - val_loss: 1.4135 - val_accuracy: 0.2969\nEpoch 3/40\n11/11 [==============================] - ETA: 0s - loss: 3.7266 - accuracy: 0.3735\nEpoch 00003: val_loss improved from 1.41352 to 1.41043, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 5s 493ms/step - loss: 3.7266 - accuracy: 0.3735 - val_loss: 1.4104 - val_accuracy: 0.2344\nEpoch 4/40\n11/11 [==============================] - ETA: 0s - loss: 2.7469 - accuracy: 0.4074\nEpoch 00004: val_loss did not improve from 1.41043\n11/11 [==============================] - 5s 481ms/step - loss: 2.7469 - accuracy: 0.4074 - val_loss: 1.4168 - val_accuracy: 0.2500\nEpoch 5/40\n11/11 [==============================] - ETA: 0s - loss: 1.8810 - accuracy: 0.4568\nEpoch 00005: val_loss did not improve from 1.41043\n11/11 [==============================] - 5s 478ms/step - loss: 1.8810 - accuracy: 0.4568 - val_loss: 1.4190 - val_accuracy: 0.1094\nEpoch 6/40\n11/11 [==============================] - ETA: 0s - loss: 1.4431 - accuracy: 0.4969\nEpoch 00006: val_loss did not improve from 1.41043\n11/11 [==============================] - 6s 518ms/step - loss: 1.4431 - accuracy: 0.4969 - val_loss: 1.4118 - val_accuracy: 0.0938\nEpoch 7/40\n11/11 [==============================] - ETA: 0s - loss: 1.1719 - accuracy: 0.5586\nEpoch 00007: val_loss improved from 1.41043 to 1.40997, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 501ms/step - loss: 1.1719 - accuracy: 0.5586 - val_loss: 1.4100 - val_accuracy: 0.2031\nEpoch 8/40\n11/11 [==============================] - ETA: 0s - loss: 0.9913 - accuracy: 0.6512\nEpoch 00008: val_loss did not improve from 1.40997\n11/11 [==============================] - 5s 479ms/step - loss: 0.9913 - accuracy: 0.6512 - val_loss: 1.4113 - val_accuracy: 0.1094\nEpoch 9/40\n11/11 [==============================] - ETA: 0s - loss: 1.0240 - accuracy: 0.5957\nEpoch 00009: val_loss improved from 1.40997 to 1.40635, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 513ms/step - loss: 1.0240 - accuracy: 0.5957 - val_loss: 1.4063 - val_accuracy: 0.2188\nEpoch 10/40\n11/11 [==============================] - ETA: 0s - loss: 0.9215 - accuracy: 0.6667\nEpoch 00010: val_loss improved from 1.40635 to 1.38909, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 5s 494ms/step - loss: 0.9215 - accuracy: 0.6667 - val_loss: 1.3891 - val_accuracy: 0.2188\nEpoch 11/40\n11/11 [==============================] - ETA: 0s - loss: 1.0276 - accuracy: 0.6019\nEpoch 00011: val_loss did not improve from 1.38909\n11/11 [==============================] - 5s 483ms/step - loss: 1.0276 - accuracy: 0.6019 - val_loss: 1.4064 - val_accuracy: 0.1719\nEpoch 12/40\n11/11 [==============================] - ETA: 0s - loss: 0.9003 - accuracy: 0.6821\nEpoch 00012: val_loss did not improve from 1.38909\n11/11 [==============================] - 6s 521ms/step - loss: 0.9003 - accuracy: 0.6821 - val_loss: 1.3976 - val_accuracy: 0.2188\nEpoch 13/40\n11/11 [==============================] - ETA: 0s - loss: 0.7445 - accuracy: 0.7284\nEpoch 00013: val_loss did not improve from 1.38909\n11/11 [==============================] - 5s 479ms/step - loss: 0.7445 - accuracy: 0.7284 - val_loss: 1.4044 - val_accuracy: 0.1875\nEpoch 14/40\n11/11 [==============================] - ETA: 0s - loss: 0.6461 - accuracy: 0.7438\nEpoch 00014: val_loss did not improve from 1.38909\n11/11 [==============================] - 5s 480ms/step - loss: 0.6461 - accuracy: 0.7438 - val_loss: 1.3950 - val_accuracy: 0.3281\nEpoch 15/40\n11/11 [==============================] - ETA: 0s - loss: 0.6414 - accuracy: 0.7747\nEpoch 00015: val_loss improved from 1.38909 to 1.37888, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 501ms/step - loss: 0.6414 - accuracy: 0.7747 - val_loss: 1.3789 - val_accuracy: 0.2812\nEpoch 16/40\n11/11 [==============================] - ETA: 0s - loss: 0.6294 - accuracy: 0.7727\nEpoch 00016: val_loss improved from 1.37888 to 1.37331, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 537ms/step - loss: 0.6294 - accuracy: 0.7727 - val_loss: 1.3733 - val_accuracy: 0.3750\nEpoch 17/40\n11/11 [==============================] - ETA: 0s - loss: 0.6543 - accuracy: 0.7438\nEpoch 00017: val_loss did not improve from 1.37331\n11/11 [==============================] - 5s 485ms/step - loss: 0.6543 - accuracy: 0.7438 - val_loss: 1.3888 - val_accuracy: 0.2656\nEpoch 18/40\n11/11 [==============================] - ETA: 0s - loss: 0.5208 - accuracy: 0.8125\nEpoch 00018: val_loss did not improve from 1.37331\n11/11 [==============================] - 6s 511ms/step - loss: 0.5208 - accuracy: 0.8125 - val_loss: 1.4049 - val_accuracy: 0.2188\nEpoch 19/40\n11/11 [==============================] - ETA: 0s - loss: 0.5460 - accuracy: 0.8179\nEpoch 00019: val_loss did not improve from 1.37331\n11/11 [==============================] - 5s 481ms/step - loss: 0.5460 - accuracy: 0.8179 - val_loss: 1.4157 - val_accuracy: 0.2188\nEpoch 20/40\n11/11 [==============================] - ETA: 0s - loss: 0.4654 - accuracy: 0.8352\nEpoch 00020: val_loss did not improve from 1.37331\n11/11 [==============================] - 6s 519ms/step - loss: 0.4654 - accuracy: 0.8352 - val_loss: 1.4137 - val_accuracy: 0.2344\nEpoch 21/40\n11/11 [==============================] - ETA: 0s - loss: 0.6341 - accuracy: 0.7716\nEpoch 00021: val_loss did not improve from 1.37331\n11/11 [==============================] - 6s 504ms/step - loss: 0.6341 - accuracy: 0.7716 - val_loss: 1.4136 - val_accuracy: 0.2344\nEpoch 22/40\n11/11 [==============================] - ETA: 0s - loss: 0.6460 - accuracy: 0.7932\nEpoch 00022: val_loss did not improve from 1.37331\n11/11 [==============================] - 5s 485ms/step - loss: 0.6460 - accuracy: 0.7932 - val_loss: 1.4204 - val_accuracy: 0.2031\nEpoch 23/40\n11/11 [==============================] - ETA: 0s - loss: 0.5769 - accuracy: 0.7716\nEpoch 00023: val_loss did not improve from 1.37331\n11/11 [==============================] - 5s 478ms/step - loss: 0.5769 - accuracy: 0.7716 - val_loss: 1.4180 - val_accuracy: 0.2500\nEpoch 24/40\n11/11 [==============================] - ETA: 0s - loss: 0.5500 - accuracy: 0.8056\nEpoch 00024: val_loss did not improve from 1.37331\n11/11 [==============================] - 5s 473ms/step - loss: 0.5500 - accuracy: 0.8056 - val_loss: 1.3907 - val_accuracy: 0.2188\nEpoch 25/40\n11/11 [==============================] - ETA: 0s - loss: 0.4118 - accuracy: 0.8796\nEpoch 00025: val_loss improved from 1.37331 to 1.36861, saving model to C:\\Users\\Eduardo\\Documents\\CARRERA\\8vo_semestre\\BIO_4\\Lab\\3_Silla_de_ruedas\\Python\\Weights_eyes\\weights\n11/11 [==============================] - 6s 503ms/step - loss: 0.4118 - accuracy: 0.8796 - val_loss: 1.3686 - val_accuracy: 0.2812\nEpoch 26/40\n11/11 [==============================] - ETA: 0s - loss: 0.7840 - accuracy: 0.7469\nEpoch 00026: val_loss did not improve from 1.36861\n11/11 [==============================] - 5s 482ms/step - loss: 0.7840 - accuracy: 0.7469 - val_loss: 1.3712 - val_accuracy: 0.2969\n"
],
[
"img = cv2.imread('Data_Set/Back/Back112.jpg') # Get image\nimg = cv2.imread('Data_Set/Right/Right68.jpg') # Get Right \nimg = cv2.imread('Data_Set/Left/Left59.jpg') # Left\n\nimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB ) \nprediction = model.predict(img[np.newaxis,...]) # Make Prediction\ny_predict = np.argmax(prediction) # Get Maximum Probability\nprint(labels[y_predict])",
"Right\n"
]
],
[
[
"### 2.2 Test Model in Video ",
"_____no_output_____"
]
],
[
[
"## This is just an example to ilustrate how to use Haar Cascades in order to detect objects (LIVE) ##\nface = cv2.CascadeClassifier('Haarcascade/haarcascade_frontalface_default.xml') # Face Haar Cascade loading\neye = cv2.CascadeClassifier('Haarcascade/haarcascade_eye.xml') # Eye Haar Cascade Loading\nvid = cv2.VideoCapture(0) # Define a video capture object \nstatus = True # Initalize status\nwidth = 100 # Width\nheight = 100 # Height\ndimensions=(width,height) # Dimenssions\nfont = cv2.FONT_HERSHEY_SIMPLEX\nwhile(status): \n status, frame = vid.read() # Capture the video frame by frame \n frame2 = np.copy(frame) # Copy frame\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Convert to gray scale\n face_info = face.detectMultiScale(gray, 1.3, 5) # Get face infromation\n if face_info != (): # If face was capture\n (x,y,w,h) = face_info[0] # unpack information\n cv2.rectangle(frame,(x,y),(x+w,y+h),(255,255,0),1) # Draw rectangle\n eye_info = eye.detectMultiScale(gray) # eye info\n if eye_info != (): \n (x,y,w,h) = eye_info[0] # unpack information\n cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,255),1) \n cropped_face_color = frame2[y:y+h, x:x+w] # Crop face (color) \n \n res = cv2.resize(cropped_face_color,dimensions, interpolation=cv2.INTER_AREA) # Resize\n res = cv2.cvtColor(res, cv2.COLOR_BGR2RGB ) # Convert to RGB\n prediction = model.predict(res[np.newaxis,...]) # Make Prediction\n y_predict = np.argmax(prediction) # Get Maximum Probability\n y_prediction_text = labels[y_predict] # Get Text of prediction\n cv2.putText(frame,y_prediction_text,(20,20), font, 1,(255,255,0),2)\n \n \n cv2.imshow('frame', frame) # Display the resulting frame \n wait_key = cv2.waitKey(1) & 0xFF # Store Waitkey object\n if wait_key == ord('q'): # If q is pressed\n break # Break while loop\n \n \n\nvid.release() # After the loop release the cap object \ncv2.destroyAllWindows() # Destroy all the windows ",
"C:\\Users\\Eduardo\\Documents\\CARRERA\\Udemy\\Deep_Learning_Prerequisites_The_Numpy_Stack_in_Python\\machine_learning_env\\lib\\site-packages\\ipykernel_launcher.py:15: DeprecationWarning: elementwise comparison failed; this will raise an error in the future.\n from ipykernel import kernelapp as app\nC:\\Users\\Eduardo\\Documents\\CARRERA\\Udemy\\Deep_Learning_Prerequisites_The_Numpy_Stack_in_Python\\machine_learning_env\\lib\\site-packages\\ipykernel_launcher.py:19: DeprecationWarning: elementwise comparison failed; this will raise an error in the future.\n"
]
],
[
[
"<br>\n<br>",
"_____no_output_____"
],
[
"<a id='2'></a>\n# 2.- Use Transfer Learning ",
"_____no_output_____"
],
[
"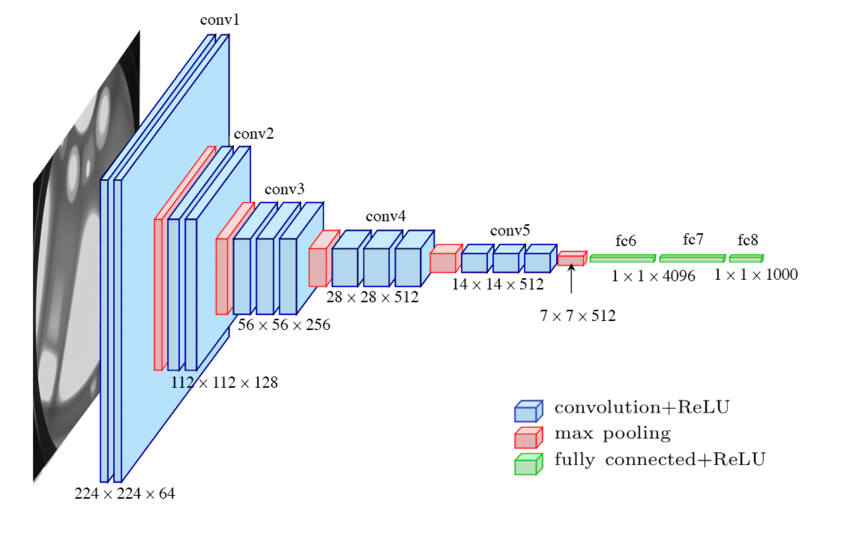",
"_____no_output_____"
]
],
[
[
"from keras.applications.vgg16 import VGG16\nfrom keras.applications.vgg16 import preprocess_input",
"_____no_output_____"
],
[
"image_size = [100,100,3] # Add image size we wish to train Data with\n### Intiate VGG16 ###\nvgg = VGG16(input_shape=image_size, # Input Shape\n weights='imagenet', # Dataset used to train weights\n include_top=False # Do not include Top \n )\n##### MAKE ALL LAYERS UNTRAINABLE ###\nmaximum = 7\ni=0\nfor layer in vgg.layers: # Iterate over layers \n if i < maximum: # if layer index is less than the one we specified\n layer.trainable = False # Make layer untrianable\n i+=1\n \nvgg.layers # Print VGG Layers ",
"_____no_output_____"
],
[
"vgg.layers[6].trainable",
"_____no_output_____"
],
[
"x = Flatten()(vgg.output)\nprediction = Dense(4,activation=\"softmax\")(x)\nmodel2 = tf.keras.models.Model(inputs=vgg.input,outputs=prediction)\nmodel2.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])\nmodel2.summary()\n#history = model2.fit(train_dataset,steps_per_epoch=train_steps,epochs=4)",
"Model: \"functional_5\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_7 (InputLayer) [(None, 100, 100, 3)] 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 100, 100, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 100, 100, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 50, 50, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 50, 50, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 50, 50, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 25, 25, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 25, 25, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 25, 25, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 25, 25, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 12, 12, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 12, 12, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 12, 12, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 12, 12, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 6, 6, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 6, 6, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 6, 6, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 6, 6, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 3, 3, 512) 0 \n_________________________________________________________________\nflatten_2 (Flatten) (None, 4608) 0 \n_________________________________________________________________\ndense_2 (Dense) (None, 4) 18436 \n=================================================================\nTotal params: 14,733,124\nTrainable params: 14,472,964\nNon-trainable params: 260,160\n_________________________________________________________________\n"
],
[
"history = model2.fit(train_dataset, # Data generator for Training\n steps_per_epoch =train_steps, # Steps in an epoch of Training Data\n validation_data = validation_dataset, # Data Generator for Validation\n validation_steps=val_steps, # Steps in a epoch of Validation Data\n epochs=10)\n\nplot_learning(history) ",
"Epoch 1/10\n16/16 [==============================] - 142s 9s/step - loss: 1.3862 - accuracy: 0.2626 - val_loss: 1.3860 - val_accuracy: 0.2695\nEpoch 2/10\n16/16 [==============================] - 143s 9s/step - loss: 1.3861 - accuracy: 0.2677 - val_loss: 1.3860 - val_accuracy: 0.2695\nEpoch 3/10\n16/16 [==============================] - 143s 9s/step - loss: 1.3859 - accuracy: 0.2749 - val_loss: 1.3860 - val_accuracy: 0.2656\nEpoch 4/10\n16/16 [==============================] - 143s 9s/step - loss: 1.3858 - accuracy: 0.2687 - val_loss: 1.3858 - val_accuracy: 0.2695\nEpoch 5/10\n16/16 [==============================] - 188s 12s/step - loss: 1.3858 - accuracy: 0.2656 - val_loss: 1.3858 - val_accuracy: 0.2656\nEpoch 6/10\n16/16 [==============================] - 312s 19s/step - loss: 1.3859 - accuracy: 0.2626 - val_loss: 1.3858 - val_accuracy: 0.2656\nEpoch 7/10\n16/16 [==============================] - 296s 18s/step - loss: 1.3858 - accuracy: 0.2646 - val_loss: 1.3858 - val_accuracy: 0.2656\nEpoch 8/10\n16/16 [==============================] - 243s 15s/step - loss: 1.3858 - accuracy: 0.2626 - val_loss: 1.3857 - val_accuracy: 0.2656\nEpoch 9/10\n16/16 [==============================] - 257s 16s/step - loss: 1.3859 - accuracy: 0.2636 - val_loss: 1.3857 - val_accuracy: 0.2656\nEpoch 10/10\n16/16 [==============================] - 242s 15s/step - loss: 1.3857 - accuracy: 0.2677 - val_loss: 1.3856 - val_accuracy: 0.2695\n"
],
[
"## This is just an example to ilustrate how to use Haar Cascades in order to detect objects (LIVE) ##\nface = cv2.CascadeClassifier('Haarcascade/haarcascade_frontalface_default.xml') # Face Haar Cascade loading\neye = cv2.CascadeClassifier('Haarcascade/haarcascade_eye.xml') # Eye Haar Cascade Loading\nvid = cv2.VideoCapture(0) # Define a video capture object \nstatus = True # Initalize status\nwidth = 100 # Width\nheight = 100 # Height\ndimensions=(width,height) # Dimenssions\nfont = cv2.FONT_HERSHEY_SIMPLEX\nwhile(status): # Iterate while status is true \n status, frame = vid.read() # Capture the video frame by frame \n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Convert to gray scale\n face_info = face.detectMultiScale(gray, 1.3, 5) # Get face infromation\n for (x,y,w,h) in face_info: # Iterate over this information\n cv2.rectangle(frame,(x,y),(x+w,y+h),(255,255,0),1) # Draw rectangle\n cropped_face_color = frame[y:y+h, x:x+w] # Crop face (color) \n if face_info != (): # If face was capture\n res = cv2.resize(cropped_face_color,dimensions, interpolation=cv2.INTER_AREA) # Resize\n prediction = model2.predict(res[np.newaxis,...]) # Make Prediction\n y_predict = np.argmax(prediction) # Get Maximum Probability\n y_prediction_text = labels[y_predict] # Get Text of prediction\n cv2.putText(frame,y_prediction_text,(20,20), font, 1,(255,255,0),2)\n \n \n cv2.imshow('frame', frame) # Display the resulting frame \n wait_key = cv2.waitKey(1) & 0xFF # Store Waitkey object\n if wait_key == ord('q'): # If q is pressed\n break # Break while loop\n \n \n\nvid.release() # After the loop release the cap object \ncv2.destroyAllWindows() # Destroy all the windows ",
"C:\\Users\\Eduardo\\Documents\\CARRERA\\Udemy\\Deep_Learning_Prerequisites_The_Numpy_Stack_in_Python\\machine_learning_env\\lib\\site-packages\\ipykernel_launcher.py:17: DeprecationWarning: elementwise comparison failed; this will raise an error in the future.\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2a464ff7f86ac436e616036879510f775420d1
| 17,216 |
ipynb
|
Jupyter Notebook
|
lab_classes/machine_learning/2013-14/MLAI_lab2.ipynb
|
mikecroucher/notebook
|
5b62f2c0d51d7af7ffbcddcd4f714030d742479e
|
[
"BSD-3-Clause"
] | 1 |
2015-12-25T18:02:38.000Z
|
2015-12-25T18:02:38.000Z
|
lab_classes/machine_learning/2013-14/MLAI_lab2.ipynb
|
mikecroucher/notebook
|
5b62f2c0d51d7af7ffbcddcd4f714030d742479e
|
[
"BSD-3-Clause"
] | null | null | null |
lab_classes/machine_learning/2013-14/MLAI_lab2.ipynb
|
mikecroucher/notebook
|
5b62f2c0d51d7af7ffbcddcd4f714030d742479e
|
[
"BSD-3-Clause"
] | null | null | null | 24.282087 | 416 | 0.486815 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a2a4e93bcb6da3cefe671459c3fd911089cb86a
| 122,320 |
ipynb
|
Jupyter Notebook
|
presentations/2014-04-CI-day/examples/.ipynb_checkpoints/notebook_02-Copy1-checkpoint.ipynb
|
karlbenedict/karlbenedict.github.io
|
e35d8e503308d4236c1df6573d88b2b3a3783a45
|
[
"MIT"
] | null | null | null |
presentations/2014-04-CI-day/examples/.ipynb_checkpoints/notebook_02-Copy1-checkpoint.ipynb
|
karlbenedict/karlbenedict.github.io
|
e35d8e503308d4236c1df6573d88b2b3a3783a45
|
[
"MIT"
] | null | null | null |
presentations/2014-04-CI-day/examples/.ipynb_checkpoints/notebook_02-Copy1-checkpoint.ipynb
|
karlbenedict/karlbenedict.github.io
|
e35d8e503308d4236c1df6573d88b2b3a3783a45
|
[
"MIT"
] | null | null | null | 71.074956 | 221 | 0.797973 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a2a6d5886e5a6240903ebeb28c2a5f62a43f6fb
| 7,078 |
ipynb
|
Jupyter Notebook
|
notebooks/scratch_valuecheck.ipynb
|
hdmamin/htools
|
620c6add29561b77c10d793e4be7beeb28b32bab
|
[
"MIT"
] | 1 |
2019-12-14T15:24:38.000Z
|
2019-12-14T15:24:38.000Z
|
notebooks/scratch_valuecheck.ipynb
|
hdmamin/htools
|
620c6add29561b77c10d793e4be7beeb28b32bab
|
[
"MIT"
] | null | null | null |
notebooks/scratch_valuecheck.ipynb
|
hdmamin/htools
|
620c6add29561b77c10d793e4be7beeb28b32bab
|
[
"MIT"
] | 1 |
2020-03-30T17:26:39.000Z
|
2020-03-30T17:26:39.000Z
| 28.425703 | 1,159 | 0.538712 |
[
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"from functools import wraps\nimport inspect\n\nfrom htools import hdir, assert_raises",
"_____no_output_____"
],
[
"@valuecheck\ndef foo(a, b:('min', 'max'), c=6, d:(True, False)=True):\n return d, c, b, a",
"_____no_output_____"
],
[
"foo(3, 'min')",
"_____no_output_____"
],
[
"with assert_raises(ValueError) as ar:\n foo(True, 'max', d=None)",
"As expected, got ValueError(Invalid argument for parameter d. Value must be in (True, False).).\n"
],
[
"with assert_raises(ValueError) as ar:\n foo('a', 'mean')",
"As expected, got ValueError(Invalid argument for parameter b. Value must be in ('min', 'max').).\n"
],
[
"class Bar:\n \n def __init__(self, a, b=6, c:int=3):\n self.a = a\n self.b = b\n self.c = c\n \n @valuecheck\n def walk(self, x:('binary', 'multiclass'), y:(foo, print), z=6, a:(3.0, 4)=3.0):\n return a, z, y, x",
"_____no_output_____"
],
[
"b = Bar('a', c=9.)\nb.walk('binary', print, a=4)",
"_____no_output_____"
],
[
"b.walk('multilabel', foo, 3, 3.0)",
"_____no_output_____"
],
[
"b.walk(x='multiclass', y=foo, a=4.0)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2a7b1de6c3256c060d50275ab32b0a53060b46
| 45,027 |
ipynb
|
Jupyter Notebook
|
banks/repo.ipynb
|
sethbam9/tutorials
|
c259636682304cb516e9048ca8df5a3ab92c62cc
|
[
"MIT"
] | 2 |
2019-07-17T18:51:26.000Z
|
2019-07-24T19:45:23.000Z
|
banks/repo.ipynb
|
sethbam9/tutorials
|
c259636682304cb516e9048ca8df5a3ab92c62cc
|
[
"MIT"
] | 3 |
2019-01-16T10:56:50.000Z
|
2020-11-16T16:30:48.000Z
|
banks/repo.ipynb
|
sethbam9/tutorials
|
c259636682304cb516e9048ca8df5a3ab92c62cc
|
[
"MIT"
] | 2 |
2020-12-17T15:41:33.000Z
|
2021-11-03T18:23:07.000Z
| 27.322209 | 196 | 0.531925 |
[
[
[
"<img align=\"right\" src=\"images/tf-small.png\" width=\"128\"/>\n<img align=\"right\" src=\"images/phblogo.png\" width=\"128\"/>\n<img align=\"right\" src=\"images/dans.png\"/>\n\n---\nStart with [convert](https://nbviewer.jupyter.org/github/annotation/banks/blob/master/programs/convert.ipynb)\n\n---",
"_____no_output_____"
],
[
"# Getting data from online repos\n\nWe show the various automatic ways by which you can get data that is out there on GitHub to your computer.\n\nThe work horse is the function `checkoutRepo()` in `tf.applib.repo`.\n\nText-Fabric uses this function for all operations where data flows from GitHub to your computer.\n\nThere are quite some options, and here we explain all the `checkout` options, i.e. the selection of\ndata from the history.\n\nSee also the [documentation](https://annotation.github.io/text-fabric/tf/advanced/repo.html).",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"## Leading example\n\nWe use markdown display from IPython purely for presentation.\nIt is not needed to run `checkoutRepo()`.",
"_____no_output_____"
]
],
[
[
"from tf.advanced.helpers import dm\nfrom tf.advanced.repo import checkoutRepo",
"_____no_output_____"
]
],
[
[
"We work with our tiny example TF app: `banks`.",
"_____no_output_____"
]
],
[
[
"ORG = \"annotation\"\nREPO = \"banks\"\nMAIN = \"tf\"\nMOD = \"sim/tf\"",
"_____no_output_____"
]
],
[
[
"`MAIN`points to the main data, `MOD` points to a module of data: the similarity feature.",
"_____no_output_____"
],
[
"## Presenting the results\n\nThe function `do()` just formats the results of a `checkoutRepo()` run.\n\nThe result of such a run, after the progress messages, is a tuple.\nFor the explanation of the tuple, read the [docs](https://annotation.github.io/text-fabric/tf/advanced/repo.html).",
"_____no_output_____"
]
],
[
[
"def do(task):\n md = f\"\"\"\ncommit | release | local | base | subdir\n--- | --- | --- | --- | ---\n`{task[0]}` | `{task[1]}` | `{task[2]}` | `{task[3]}` | `{task[4]}`\n\"\"\"\n dm(md)",
"_____no_output_____"
]
],
[
[
"## All the checkout options\n\nWe discuss the meaning and effects of the values you can pass to the `checkout` option.",
"_____no_output_____"
],
[
"### `clone`\n\n> Look whether the appropriate folder exists under your `~/github` directory.\n\nThis is merely a check whether your data exists in the expected location.\n\n* No online checks take place.\n* No data is moved or copied.\n\n**NB**: you cannot select releases and commits in your *local* GitHub clone.\nThe data will be used as it is found on your file system.\n\n**When to use**\n\n> If you are developing new feature data.\n\nWhen you develop your data in a repository, your development is private as long as you\ndo not push to GitHub.\n\nYou can test your data, even without locally committing your data.\n\nBut, if you are ready to share your data, everything is in place, and you only\nhave to commit and push, and pass the location on github to others, like\n\n```\nmyorg/myrepo/subfolder\n```",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"clone\"))",
"_____no_output_____"
]
],
[
[
"We show what happens if you do not have a local github clone in `~/github`.",
"_____no_output_____"
]
],
[
[
"%%sh\n\nmv ~/github/annotation/banks/tf ~/github/annotation/banks/tfxxx",
"_____no_output_____"
],
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"clone\"))",
"The requested data is not available offline\n"
]
],
[
[
"Note that no attempt is made to retrieve online data.",
"_____no_output_____"
]
],
[
[
"%%sh\n\nmv ~/github/annotation/banks/tfxxx ~/github/annotation/banks/tf",
"_____no_output_____"
]
],
[
[
"### `local`\n\n> Look whether the appropriate folder exists under your `~/text-fabric-data` directory.\n\nThis is merely a check whether your data exists in the expected location.\n\n* No online checks take place.\n* No data is moved or copied.\n\n**When to use**\n\n> If you are using data created and shared by others, and if the data\nis already on your system.\n\nYou can be sure that no updates are downloaded, and that everything works the same as the last time\nyou ran your program.\n\nIf you do not already have the data, you have to pass `latest` or `hot` or `''` which will be discussed below.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"local\"))",
"_____no_output_____"
]
],
[
[
"You see this data because earlier I have downloaded release `v2.0`, which is a tag for\nthe commit with hash `9713e71c18fd296cf1860d6411312f9127710ba7`.",
"_____no_output_____"
],
[
"If you do not have any corresponding data in your `~/text-fabric-data`, you get this:",
"_____no_output_____"
]
],
[
[
"%%sh\n\nmv ~/text-fabric-data/annotation/banks/tf ~/text-fabric-data/annotation/banks/tfxxx",
"_____no_output_____"
],
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"local\"))",
"The requested data is not available offline\n"
],
[
"%%sh\n\nmv ~/text-fabric-data/annotation/banks/tfxxx ~/text-fabric-data/annotation/banks/tf",
"_____no_output_____"
]
],
[
[
"### `''` (default)\n\nThis is about when you omit the `checkout` parameter, or pass `''` to it.\n\nThe destination for local data is your `~/text-fabric-data` folder.\n\nIf you have already a local copy of the data, that will be used.\n\nIf not:\n\n> Note that if your local data is outdated, no new data will be downloaded.\nYou need `latest` or `hot` for that.\n\nBut what is the latest online copy? In this case we mean:\n\n* the latest *release*, and from that release an appropriate attached zip file\n* but if there is no such zip file, we take the files from the corresponding commit\n* but if there is no release at all, we take the files from the *latest commit*.\n\n**When to use**\n\n> If you need data created/shared by other people and you want to be sure that you always have the\nsame copy that you initially downloaded.\n\n* If the data provider makes releases after important modifications, you will get those.\n* If the data provider is experimenting after the latest release, and commits them to GitHub,\n you do not get those.\n\nHowever, with `hot`, you `can` get the latest commit, to be discussed below.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"\"))",
"_____no_output_____"
]
],
[
[
"Note that no data has been downloaded, because it has detected that there is already local data on your computer.",
"_____no_output_____"
],
[
"If you do not have any checkout of this data on your computer, the data will be downloaded.",
"_____no_output_____"
]
],
[
[
"%%sh\n\nrm -rf ~/text-fabric-data/annotation/banks/tf",
"_____no_output_____"
],
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"\"))",
"The requested data is not available offline\nrate limit is 5000 requests per hour, with 4994 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\tdownloading https://github.com/annotation/banks/releases/download/v2.0/tf-0.2.zip ... \n\tunzipping ... \n\tsaving data\n"
]
],
[
[
"#### Note about versions and releases\n\nThe **version** of the data is not necessarily the same concept as the **release** of it.\n\nIt is possible to keep the versions and the releases strictly parallel,\nbut in text conversion workflows it can be handy to make a distinction between them,\ne.g. as follows:\n\n> the version is a property of the input data\n> the release is a property of the output data\n\nWhen you create data from sources using conversion algorithms,\nyou want to increase the version if you get new input data, e.g. as a result of corrections\nmade by the author.\n\nBut if you modify your conversion algorithm, while still running it on the same input data,\nyou may release the new output data as a **new release** of the **same version**.\n\nLikewise, when the input data stays the same, but you have corrected typos in the metadata,\nyou can make a **new release** of the **same version** of the data.\n\nThe conversion delivers the features under a specific version,\nand Text-Fabric supports those versions: users of TF can select the version they work with.\n\nReleases are made in the version control system (git and GitHub).\nThe part of Text-Fabric that auto-downloads data is aware of releases.\nBut once the data has been downloaded in place, there is no machinery in Text-Fabric to handle\ndifferent releases.\n\nYet the release tag and commit hash are passed on to the point where it comes to recording\nthe provenance of the data.",
"_____no_output_____"
],
[
"#### Download a different version\n\nWe download version `0.1` of the data.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.1\", checkout=\"\"))",
"The requested data is not available offline\nrate limit is 5000 requests per hour, with 4985 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\ttf/0.1/author.tf...downloaded\n\ttf/0.1/gap.tf...downloaded\n\ttf/0.1/letters.tf...downloaded\n\ttf/0.1/number.tf...downloaded\n\ttf/0.1/oslots.tf...downloaded\n\ttf/0.1/otext.tf...downloaded\n\ttf/0.1/otype.tf...downloaded\n\ttf/0.1/punc.tf...downloaded\n\ttf/0.1/terminator.tf...downloaded\n\ttf/0.1/title.tf...downloaded\n\tOK\n"
]
],
[
[
"Several observations:\n\n* we obtained the older version from the *latest* release, which is still release `v2.0`\n* the download looks different from when we downloaded version `0.2`;\n this is because the data producer has zipped the `0.2` data and has attached it to release `v2.0`,\n but he forgot, or deliberately refused, to attach version `0.1` to that release;\n so it has been retrieved directly from the files in the corresponding commit, which is\n `9713e71c18fd296cf1860d6411312f9127710ba7`.",
"_____no_output_____"
],
[
"For the verification, an online check is needed. The verification consists of checking the release tag and/or commit hash.\n\nIf there is no online connection, you get this:",
"_____no_output_____"
]
],
[
[
"%%sh\n\nnetworksetup -setairportpower en0 off",
"_____no_output_____"
],
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.1\", checkout=\"latest\"))",
"no internet\nThe offline data may not be the latest\n"
]
],
[
[
"or if you do not have local data:",
"_____no_output_____"
]
],
[
[
"%%sh\n\nmv ~/text-fabric-data/annotation/banks/tf/0.1 ~/text-fabric-data/annotation/banks/tf/0.1xxx",
"_____no_output_____"
],
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.1\", checkout=\"latest\"))",
"no internet\n"
],
[
"%%sh\n\nmv ~/text-fabric-data/annotation/banks/tf/0.1xxx ~/text-fabric-data/annotation/banks/tf/0.1",
"_____no_output_____"
],
[
"%%sh\n\nnetworksetup -setairportpower en0 on",
"_____no_output_____"
]
],
[
[
"### `latest`\n\n> The latest online release will be identified,\nand if you do not have that copy locally, it will be downloaded.\n\n**When to use**\n\n> If you need data created/shared by other people and you want to be sure that you always have the\nlatest *stable* version of that data, unreleased data is not good enough.\n\nOne of the difference with `checkout=''` is that if there are no releases, you will not get data.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"latest\"))",
"rate limit is 5000 requests per hour, with 4963 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n"
]
],
[
[
"There is no sim/tf data in any release commit, so if we look it up, it should fail.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MOD, version=\"0.2\", checkout=\"latest\"))",
"rate limit is 5000 requests per hour, with 4960 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n"
]
],
[
[
"But with `checkout=''` it will only be found if you do not have local data already:",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MOD, version=\"0.2\", checkout=\"\"))",
"_____no_output_____"
]
],
[
[
"In that case there is only one way: `hot`:",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MOD, version=\"0.2\", checkout=\"hot\"))",
"rate limit is 5000 requests per hour, with 4950 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n"
]
],
[
[
"### `hot`\n\n> The latest online commit will be identified,\nand if you do not have that copy locally, it will be downloaded.\n\n**When to use**\n\n> If you need data created/shared by other people and you want to be sure that you always have the\nlatest version of that data, whether released or not.\n\nThe difference with `checkout=''` is that if there are releases,\nyou will now get data that may be newer than the latest release.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"hot\"))",
"rate limit is 5000 requests per hour, with 4947 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\ttf/0.2/author.tf...downloaded\n\ttf/0.2/gap.tf...downloaded\n\ttf/0.2/letters.tf...downloaded\n\ttf/0.2/number.tf...downloaded\n\ttf/0.2/oslots.tf...downloaded\n\ttf/0.2/otext.tf...downloaded\n\ttf/0.2/otype.tf...downloaded\n\ttf/0.2/punc.tf...downloaded\n\ttf/0.2/terminator.tf...downloaded\n\ttf/0.2/title.tf...downloaded\n\tOK\n"
]
],
[
[
"Observe that data has been downloaded, and that we have now data corresponding to a different commit hash,\nand not corresponding to a release.\n\nIf we now ask for the latest *stable* data, the data will be downloaded anew.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"latest\"))",
"rate limit is 5000 requests per hour, with 4931 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\tdownloading https://github.com/annotation/banks/releases/download/v2.0/tf-0.2.zip ... \n\tunzipping ... \n\tsaving data\n"
]
],
[
[
"### `v1.0` a specific release\n\n> Look for a specific online release to get data from.\n\n**When to use**\n\n> When you want to replicate something, and need data from an earlier point in the history.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.1\", checkout=\"v1.0\"))",
"rate limit is 5000 requests per hour, with 4924 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\tdownloading https://github.com/annotation/banks/releases/download/v1.0/tf-0.1.zip ... \n\tunzipping ... \n\tsaving data\n"
]
],
[
[
"We might try to get version `0.2` from this release.",
"_____no_output_____"
]
],
[
[
"do(checkoutRepo(org=ORG, repo=REPO, folder=MAIN, version=\"0.2\", checkout=\"v1.0\"))",
"rate limit is 5000 requests per hour, with 4917 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n"
]
],
[
[
"At that early point in the history there is not yet a version `0.2` of the data.",
"_____no_output_____"
],
[
"### `a81746c` a specific commit\n\n> Look for a specific online commit to get data from.\n\n**When to use**\n\n> When you want to replicate something, and need data from an earlier point in the history, and there is no\nrelease for that commit.",
"_____no_output_____"
]
],
[
[
"do(\n checkoutRepo(\n org=ORG,\n repo=REPO,\n folder=MAIN,\n version=\"0.1\",\n checkout=\"a81746c5f9627637db4dae04c2d5348bda9e511a\",\n )\n)",
"rate limit is 5000 requests per hour, with 4907 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\ttf/0.1/author.tf...downloaded\n\ttf/0.1/gap.tf...downloaded\n\ttf/0.1/letters.tf...downloaded\n\ttf/0.1/number.tf...downloaded\n\ttf/0.1/oslots.tf...downloaded\n\ttf/0.1/otext.tf...downloaded\n\ttf/0.1/otype.tf...downloaded\n\ttf/0.1/punc.tf...downloaded\n\ttf/0.1/terminator.tf...downloaded\n\ttf/0.1/title.tf...downloaded\n\tOK\n"
]
],
[
[
"## *source* and *dest*: an alternative for `~/github` and `~/text-fabric-data`\n\nEverything so far uses the hard-wired `~/github` and `~/text-fabric-data` directories.\nBut you can change that:\n\n* pass *source* as a replacement for `~/github`.\n* pass *dest* as a replacement for `~/text-fabric-data`.\n\n**When to use**\n\n> if you do not want to interfere with the `~/text-fabric-data` directory.\n\nText-Fabric manages the `~/text-fabric-data` directory,\nand if you are experimenting outside Text-Fabric\nyou may not want to touch its data directory.\n\n> if you want to clone data into your `~/github` directory.\n\nNormally, TF uses your `~/github` directory as a source of information,\nand never writes into it.\nBut if you explicitly pass `dest=~/github`, things change: downloads will\narrive under `~/github`. Use this with care.\n\n> if you work with cloned data outside your `~/github` directory,\n\nyou can let the system look in *source* instead of `~/github`.",
"_____no_output_____"
],
[
"We customize source and destination directories:\n\n* we put them both under `~/Downloads`\n* we give them different names",
"_____no_output_____"
]
],
[
[
"MY_GH = \"~/Downloads/repoclones\"\nMY_TFD = \"~/Downloads/textbase\"",
"_____no_output_____"
]
],
[
[
"Download a fresh copy of the data to `~/Downloads/textbase` instead.",
"_____no_output_____"
]
],
[
[
"do(\n checkoutRepo(\n org=ORG,\n repo=REPO,\n folder=MAIN,\n version=\"0.2\",\n checkout=\"\",\n source=MY_GH,\n dest=MY_TFD,\n )\n)",
"The requested data is not available offline\nrate limit is 5000 requests per hour, with 4891 left for this hour\n\tconnecting to online GitHub repo annotation/banks ... connected\n\tdownloading https://github.com/annotation/banks/releases/download/v2.0/tf-0.2.zip ... \n\tunzipping ... \n\tsaving data\n"
]
],
[
[
"Lookup the same data locally.",
"_____no_output_____"
]
],
[
[
"do(\n checkoutRepo(\n org=ORG,\n repo=REPO,\n folder=MAIN,\n version=\"0.2\",\n checkout=\"\",\n source=MY_GH,\n dest=MY_TFD,\n )\n)",
"_____no_output_____"
]
],
[
[
"We copy the local github data to the custom location:",
"_____no_output_____"
]
],
[
[
"%%sh\n\nmkdir -p ~/Downloads/repoclones/annotation\ncp -R ~/github/annotation/banks ~/Downloads/repoclones/annotation/banks",
"_____no_output_____"
]
],
[
[
"Lookup the data in this alternative directory.",
"_____no_output_____"
]
],
[
[
"do(\n checkoutRepo(\n org=ORG,\n repo=REPO,\n folder=MAIN,\n version=\"0.2\",\n checkout=\"clone\",\n source=MY_GH,\n dest=MY_TFD,\n )\n)",
"_____no_output_____"
]
],
[
[
"Note that the directory trees under the customised *source* and *dest* locations have exactly the same shape as before.",
"_____no_output_____"
],
[
"## Conclusion\n\nWith the help of `checkoutRepo()` you will be able to make local copies of online data in an organized way.\n\nThis will help you when\n\n* you use other people's data\n* develop your own data\n* share and publish your data\n* go back in history.",
"_____no_output_____"
],
[
"---\nAll chapters:\n\n* [use](use.ipynb)\n* [share](share.ipynb)\n* [app](app.ipynb)\n* *repo*\n* [compose](compose.ipynb)\n\n---",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a2a81676f19fb825d309c2f159a551a333e215c
| 1,674 |
ipynb
|
Jupyter Notebook
|
Week_02/exercise_9.ipynb
|
ALhasanZGhaibe/data-mining-msc-geik-miskolc
|
1d78a6b56ab5d967f97a13179683d7ac1a97ba82
|
[
"Unlicense"
] | null | null | null |
Week_02/exercise_9.ipynb
|
ALhasanZGhaibe/data-mining-msc-geik-miskolc
|
1d78a6b56ab5d967f97a13179683d7ac1a97ba82
|
[
"Unlicense"
] | null | null | null |
Week_02/exercise_9.ipynb
|
ALhasanZGhaibe/data-mining-msc-geik-miskolc
|
1d78a6b56ab5d967f97a13179683d7ac1a97ba82
|
[
"Unlicense"
] | null | null | null | 22.931507 | 110 | 0.483871 |
[
[
[
"# Count determiners (a and an) in a string.",
"_____no_output_____"
]
],
[
[
"def count_det(str):\n# break the string into list of words \n str = str.split() \n print(str)\n x=0\n y=0\n#loop till string values present in list str\n for i in range(len(str)):\n if str[i] =='an':\n x+=1\n if str[i] =='a':\n y+=1\n print('Frequency of an in the string is :', x)\n print('Frequency of a in the string is :', y)\ncount_det(\"this is an apple and an orange but i like banana and ananas\")",
"['this', 'is', 'an', 'apple', 'and', 'an', 'orange', 'but', 'i', 'like', 'banana', 'and', 'ananas']\nFrequency of an in the string is : 2\nFrequency of a in the string is : 0\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
4a2a869ed529aa45c367c2e55694696620620c72
| 6,375 |
ipynb
|
Jupyter Notebook
|
index.ipynb
|
daviddemeij/fastscript
|
96125fdbca57cfbdc2acbe05853d8a0a67a5ba39
|
[
"Apache-2.0"
] | null | null | null |
index.ipynb
|
daviddemeij/fastscript
|
96125fdbca57cfbdc2acbe05853d8a0a67a5ba39
|
[
"Apache-2.0"
] | null | null | null |
index.ipynb
|
daviddemeij/fastscript
|
96125fdbca57cfbdc2acbe05853d8a0a67a5ba39
|
[
"Apache-2.0"
] | null | null | null | 43.074324 | 877 | 0.655529 |
[
[
[
"#hide\nfrom fastscript.core import *",
"_____no_output_____"
]
],
[
[
"# fastscript\n\n> A fast way to turn your python function into a script.",
"_____no_output_____"
],
[
"Part of [fast.ai](https://www.fast.ai)'s toolkit for delightful developer experiences. Written by Jeremy Howard.",
"_____no_output_____"
],
[
"## Install",
"_____no_output_____"
],
[
"`pip install fastscript`",
"_____no_output_____"
],
[
"## Overview",
"_____no_output_____"
],
[
"Sometimes, you want to create a quick script, either for yourself, or for others. But in Python, that involves a whole lot of boilerplate and ceremony, especially if you want to support command line arguments, provide help, and other niceties. You can use [argparse](https://docs.python.org/3/library/argparse.html) for this purpose, which comes with Python, but it's complex and verbose.\n\n`fastscript` makes life easier. There are much fancier modules to help you write scripts (we recommend [Python Fire](https://github.com/google/python-fire), and [Click](https://click.palletsprojects.com/en/7.x/) is also popular), but fastscript is very fast and very simple. In fact, it's <50 lines of code! Basically, it's just a little wrapper around `argparse` that uses modern Python features and some thoughtful defaults to get rid of the boilerplate.",
"_____no_output_____"
],
[
"## Example",
"_____no_output_____"
],
[
"Here's a complete example - it's provided in the fastscript repo as `examples/test_fastscript.py`:\n\n```python\nfrom fastscript import *\n@call_parse\ndef main(msg:Param(\"The message\", str),\n upper:Param(\"Convert to uppercase?\", bool_arg)=False):\n print(msg.upper() if upper else msg)\n````\n\nWhen you run this script, you'll see:\n\n```\n$ python examples/test_fastscript.py\nusage: test_fastscript.py [-h] [--upper UPPER] msg\ntest_fastscript.py: error: the following arguments are required: msg\n```",
"_____no_output_____"
],
[
"As you see, we didn't need any `if __name__ == \"__main__\"`, we didn't have to parse arguments, we just wrote a function, added a decorator to it, and added some annotations to our function's parameters. As a bonus, we can also use this function directly from a REPL such as Jupyter Notebook - it's not just for command line scripts!",
"_____no_output_____"
],
[
"## Param",
"_____no_output_____"
],
[
"Each parameter in your function should have an annotation `Param(...)` (as in the example above). You can pass the following when calling `Param`: `help`,`type`,`opt`,`action`,`nargs`,`const`,`choices`,`required` . Except for `opt`, all of these are just passed directly to `argparse`, so you have all the power of that module at your disposal. Generally you'll want to pass at least `help` (since this is provided as the help string for that parameter) and `type` (to ensure that you get the type of data you expect). `opt` is a bool that defines whether a param is optional or required (positional) - but you'll generally not need to set this manually, because fastscript will set it for you automatically based on *default* values.\n\nYou should provide a default (after the `=`) for any *optional* parameters. If you don't provide a default for a parameter, then it will be a *positional* parameter.",
"_____no_output_____"
],
[
"## setuptools scripts",
"_____no_output_____"
],
[
"There's a really nice feature of pip/setuptools that lets you create commandline scripts directly from functions, makes them available in the `PATH`, and even makes your scripts cross-platform (e.g. in Windows it creates an exe). fastscript supports this feature too. To use it, follow [this example](fastscript/test_cli.py) from `fastscript/test_cli.py` in the repo. As you see, it's basically identical to the script example above, except that we can treat it as a module. The trick to making this available as a script is to add a `console_scripts` section to your setup file, of the form: `script_name=module:function_name`. E.g. in this case we use: `test_fastscript=fastscript.test_cli:main`. With this, you can then just type `test_fastscript` at any time, from any directory, and your script will be called (once it's installed using one of the methods below).\n\nYou don't actually have to write a `setup.py` yourself. Instead, just copy the setup.py we have in the fastscript repo, and copy `settings.ini` as well. Then modify `settings.ini` as appropriate for your module/script. Then, to install your script directly, you can type `pip install -e .`. Your script, when installed this way (it's called an [editable install](http://codumentary.blogspot.com/2014/11/python-tip-of-year-pip-install-editable.html), will automatically be up to date even if you edit it - there's no need to reinstall it after editing.\n\nYou can even make your module and script available for installation directly from pip by running `make`. There shouldn't be anything else to edit - you just need to make sure you have an account on [pypi](https://pypi.org/) and have set up a [.pypirc file](https://docs.python.org/3.3/distutils/packageindex.html#the-pypirc-file).",
"_____no_output_____"
]
]
] |
[
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a2aae2deedbf192a38daf7275bf5d242be8aab5
| 30,533 |
ipynb
|
Jupyter Notebook
|
notebooks/cdh-ch4-knn-slave-narratives.ipynb
|
jeddobson/dhsm
|
ae90450041a395d4cd317f03754485dad73752c2
|
[
"MIT"
] | 4 |
2018-11-29T18:52:25.000Z
|
2022-01-08T17:17:45.000Z
|
notebooks/cdh-ch4-knn-slave-narratives.ipynb
|
jeddobson/dhsm
|
ae90450041a395d4cd317f03754485dad73752c2
|
[
"MIT"
] | null | null | null |
notebooks/cdh-ch4-knn-slave-narratives.ipynb
|
jeddobson/dhsm
|
ae90450041a395d4cd317f03754485dad73752c2
|
[
"MIT"
] | 1 |
2022-02-09T21:11:49.000Z
|
2022-02-09T21:11:49.000Z
| 63.610417 | 6,612 | 0.713228 |
[
[
[
"# Text Mining DocSouth Slave Narrative Archive\n---\n\n*Note:* This is the first in [a series of documents and notebooks](https://jeddobson.github.io/textmining-docsouth/) that will document and evaluate various machine learning and text mining tools for use in literary studies. These notebooks form the practical and critical archive of my book-in-progress, _Digital Humanities and the Search for a Method_. I have published a critique of some existing methods (Dobson 2015) that takes up some of these concerns and provides some theoretical background for my account of computational methods as used within the humanities. Each notebook displays code, data, results, interpretation, and critique. I attempt to provide as much explanation of the individual steps and documentation (along with citations of related papers) of the concepts and justification of choices made. \n\n### Revision Date and Notes:\n\n- 05/10/2017: Initial version ([email protected])\n- 08/29/2017: Updated to automatically assign labels and reduced to two classes/periods.\n\n### KNearest Neighbor (kNN) period classification of texts\n\nThe following Jupyter cells show a very basic classification task using the [kNN](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm) algorithm as implemented in Python and with the [scikit-learn](http://scikit-learn.org/) package.\n\nA simple check to see if the dates in the table of contents (\"toc.csv\") for the DocSouth [\"North American Slave Narratives\"](http://docsouth.unc.edu/neh/) can be converted to an integer (date as year) is used to assign one of these two classes:\n\n- antebellum: prior to 1865\n- postbellum: after 1865 \n\nThese period categories are rough and by no means not perfect. Publication year may have little relation to the content of the text, the source for the vectorizing process and eventual categorization. These dates are what Matthew Jockers calls, within the digital humanities context, catalog metadata (Jockers 2013, 35-62). Recently, critics have challenged such divisions (Marrs 2015) that are central to the understanding of field of nineteenth-century American literary studies with concepts like \"transbellum\" that might be capable of helping to better understand works that address the Civil War and its attendant anxities through the \"long nineteenth century.\" The majority of the texts included in the DocSouth archive are first-person autobiographical narratives of lives lived during the antebellum and Civil War years and published in the years leading up to, including, and after the war.\n\n### Complete (Labeled) Dataset\n\n|class|count|\n|---|---|\n|antebellum|143|\n|postbellum|109|\n|unknown or ambiguous|40|\n\nThere are 252 texts with four digit years and eighteen texts with ambiguous or unknown publication dates. This script will attempt to classify these texts into one of these two periods following the \"fitting\" of the labeled training texts. I split the 252 texts with known and certain publication dates into two groups: a training set and a testing test. After \"fitting\" the training set and establishing the neighbors, the code attempts to categorize the testing set. Many questions can and should be asked about the creation of the training set and the labeling of the data. This labeling practice introduces many subjective decisions into what is perceived as an objective (machine and algorithmically generated) process (Dobson 2015, Gillespie 2016).\n\n### Training Data Set\n\nThe training set (the first 252 texts, preserving the order in \"toc.csv\") over-represents the antebellum period and may account for the ability of the classifier to make good predictions for this class. \n\n|class|count|\n|---|---|\n|antebellum|96|\n|postbellum|81|\n\n### Test Data Set\n\nThe \"testing\" dataset is used to validate the classifier. This dataset contains seventy-five texts with known year of publication. This dataset, like the training dataset, overrepresents the antebellum period.\n\n|class|count|\n|---|---|\n|antebellum|47|\n|postbellum|28|\n\n\n",
"_____no_output_____"
],
[
"#### Text Pre-processing\n\nThe texts are all used/imported as found in the zip file provided by the DocSouth [\"North American Slave Narratives\"](http://docsouth.unc.edu/neh/) collection. The texts have been encoded in a combination of UTF-8 Unicode and ASCII. Scikit-learn's HashingVectorizer performs some additional pre-processing and that will be examined in the sections below. \n\n#### kNN Background\n\nThe kNN algorithm is a non-parametric algorithm, meaning that it does not require detailed knowledge of the input data and its distribution (Cover and Hart 1967). This algorithm is known as reliable and it is quite simple, especially when compared to some of the more complex machine learning algorithms used as present, to implement and understand. It was originally conceived of as a response to what is called a “discrimination problem”: the categorization of a large number of input points into discrete \"boxes.\" Data are eventually organized into categories, in the case of this script, the three categories of antebellum, postbellum, and twentieth-century. \n\nThe algorithm functions in space and produces each input text as a \"neighbor\" and has each text \"vote\" for membership into parcellated neighborhoods. Cover and Hart explain: \"If the number of samples is large it makes good sense to use, instead of the single nearest neighbor, the majority vote of the nearest k neighbors\" (22). The following code uses the value of \"12\" for the number of neighbors or the 'k' of kNN.\n\nThe kNN algorithm may give better results for smaller numbers of classes. The performance of particular implementation of kNN and the feature selection algorithm (HashingVectorizer) was better with just the antebellum and postbellum class. Alternative boundaries for the classes (year markers) might also improve results.\n\n#### Feature Selection\n\nWhile it is non-parametics, the kNN algorithm does require a set of features in order to categorize the input data, the texts. This script operates according to the _\"bag of words\"_ method in which each text is treated not as a narrative but a collection of unordered and otherwise undiferentiated words. This means that multiple word phrases (aka ngrams) are ignored and much meaning will be removed from the comparative method because of a loss of context. \n\nIn order to select the features by which a text can be compared to another, we need some sort of method that can produce numerical data. I have selected the HashingVectorizer, which is a fast method to generate a list of words/tokens from a file. This returns a numpy compressed sparse row (CSR) matrix that scikit-learn will use in the creation of the neighborhood \"map.\" \n\nThe HashingVectorizer removes a standard 318 English-language stop words and by default does not alter or remove any accents or accented characters in the encoded (UTF-8) format. It also converts all words to lowercase, potentially introducing false positives. \n\n**Issues with HashingVectorizer** This vectorizer works well, but it limits the questions we can ask after it has been run. We cannot, for example, interrogate why a certain text might have been misclassified by examining the words/tokens returned by the vectorizer. This is because the HashingVectorizer returns only indices to features and does not keep the string representation of specific words. ",
"_____no_output_____"
]
],
[
[
"# load required packages\nimport sys, os\nimport re\nimport operator\nimport nltk\n\nfrom nltk import pos_tag, ne_chunk\nfrom nltk.tokenize import wordpunct_tokenize\n\nimport seaborn as sn\n%matplotlib inline",
"_____no_output_____"
],
[
"# load local library\nsys.path.append(\"lib\")\nimport docsouth_utils",
"_____no_output_____"
],
[
"# each dictionary entry in the 'list' object returned by load_narratives \n# contains the following keys:\n# 'author' = Author of the text (first name, last name)\n# 'title' = Title of the text\n# 'year' = Year published as integer or False if not simple four-digit year\n# 'file' = Filename of text\n# 'text' = NLTK Text object\n\nneh_slave_archive = docsouth_utils.load_narratives()",
"_____no_output_____"
],
[
"# establish two simple classes for kNN classification\n# the \"date\" field has already been converted to an integer\n# all texts published before 1865, we'll call \"antebellum\"\n# \"postbellum\" for those after.\n\nperiod_classes=list()\n\nfor entry in neh_slave_archive:\n file = ' '.join(entry['text'])\n if entry['year'] != False and entry['year'] < 1865:\n period_classes.append([file,\"antebellum\"])\n if entry['year'] != False and entry['year'] > 1865: \n period_classes.append([file,\"postbellum\"])\n\n# create labels and filenames \nlabels=[i[1] for i in period_classes]\nfiles=[i[0] for i in period_classes]\n\n# create training and test datasets by leaving out the\n# last 100 files with integer dates from the toc for testing.\n\ntest_size=100\n\ntrain_labels=labels[:-test_size]\ntrain_files=files[:-test_size]\n\n# the last set of texts (test_size) are the \"test\" dataset (for validation)\ntest_labels=labels[-test_size:]\ntest_files=files[-test_size:]",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import HashingVectorizer\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn import metrics\n\n# intialize the vectorizer using occurance counts normalized as \n# token frequencies: norm=l2\nvectorizer = HashingVectorizer(lowercase=True,\n stop_words='english',\n norm='l2', \n non_negative=True)\n\ntraining_data = vectorizer.fit_transform(train_files)\ntest_data=vectorizer.transform(test_files)",
"_____no_output_____"
],
[
"# display file counts\nprint(\"training data:\")\nfor period in ['postbellum', 'antebellum']:\n print(\" \",period,\":\",train_labels.count(period))\nprint(\"test data:\")\nfor period in ['postbellum', 'antebellum']:\n print(\" \",period,\":\",test_labels.count(period))",
"training data:\n postbellum : 77\n antebellum : 75\ntest data:\n postbellum : 32\n antebellum : 68\n"
],
[
"# run kNN and fit training data\nknn = KNeighborsClassifier(n_neighbors=13)\nknn.fit(training_data,train_labels)\n\n# Predict results from the test data and check accuracy\npred = knn.predict(test_data)\nscore = metrics.accuracy_score(test_labels, pred)\nprint(\"accuracy: %0.3f\" % score)\nprint(metrics.classification_report(test_labels, pred))\nprint(\"confusion matrix:\")\nprint(metrics.confusion_matrix(test_labels, pred))",
"accuracy: 0.800\n precision recall f1-score support\n\n antebellum 0.88 0.82 0.85 68\n postbellum 0.67 0.75 0.71 32\n\navg / total 0.81 0.80 0.80 100\n\nconfusion matrix:\n[[56 12]\n [ 8 24]]\n"
],
[
"# Produce visualization of confusion matrix\nsn.heatmap(metrics.confusion_matrix(test_labels, pred),annot=True,cmap='Blues',fmt='g')",
"_____no_output_____"
]
],
[
[
"## Prediction of unclassified data\nThe following cell loads and vectorizes (using the above HashingVectorizing method, with the exact same parameters used for the training set) and tests against the trained classifier, all the algorithmically uncategorized and ambiguously dated (in the toc.csv) input files. \n\n### Partial list of Unspecified or Ambiguous Publication Dates\n\n\n|File|Date|\n|---|---|\n|church-hatcher-hatcher.txt|c1908|\n|fpn-jacobs-jacobs.txt|1861,c1860\n|neh-aga-aga.txt|[1846]|\n|neh-anderson-anderson.txt|1854?|\n|neh-brownj-brownj.txt|1856,c1865\n|neh-carolinatwin-carolinatwin.txt|[between 1902 and 1912]|\n|neh-delaney-delaney.txt|[189?]|\n|neh-equiano1-equiano1.txt|[1789]|\n|neh-equiano2-equiano2.txt|[1789]|\n|neh-henry-henry.txt|[1872]|\n|neh-jonestom-jones.txt|[185-?]|\n|neh-latta-latta.txt|[1903]|\n|neh-leewilliam-lee.txt|c1918|\n|neh-millie-christine-millie-christine.txt|[18--?]|\n|neh-parkerh-parkerh.txt|186?|\n|neh-pomp-pomp.txt|1795|\n|neh-washstory-washin.txt|c1901|\n|neh-white-white.txt|[c1849]|",
"_____no_output_____"
]
],
[
[
"# predict class or period membership for all texts without\n# four digit years\nfor entry in neh_slave_archive:\n if entry['year'] == False:\n print(entry['author'],\", \",entry['title'])\n print(\" \",knn.predict(vectorizer.transform([entry['file']])))",
"William S. White , The African Preacher. An Authentic Narrative\n ['postbellum']\nHenry Parker , Autobiography of Henry Parker\n ['antebellum']\nThomas W. Henry , Autobiography of Rev. Thomas W. Henry, of the A. M. E. Church\n ['antebellum']\nBooker T. Washington , An Autobiography: The Story of My Life and Work\n ['antebellum']\n No Author , Biographical Sketch of Millie Christine, the Carolina Twin, Surnamed the Two-Headed Nightingale and the Eighth Wonder of the World\n ['antebellum']\nJosephine Brown , Biography of an American Bondman, by His Daughter\n ['antebellum']\n Pomp , Dying Confession of Pomp, A Negro Man, Who Was Executed at Ipswich, on the 6th August, 1795, for Murdering Capt. Charles Furbush, of Andover, Taken from the Mouth of the Prisoner, and Penned by Jonathan Plummer, Jun.\n ['antebellum']\nThomas H. Jones , Experience and Personal Narrative of Uncle Tom Jones; Who Was for Forty Years a Slave. Also the Surprising Adventures of Wild Tom, of the Island Retreat, a Fugitive Negro from South Carolina\n ['antebellum']\nWilliam Parker , The Freedman's Story: In Two Parts\n ['antebellum']\nLucy A. Delaney , From the Darkness Cometh the Light or Struggles for Freedom\n ['antebellum']\nM. L. Latta , The History of My Life and Work. Autobiography by Rev. M. L. Latta, A.M., D.D.\n ['antebellum']\n Millie-Christine , The History of the Carolina Twins: Told in \"Their Own Peculiar Way\" By \"One of Them\"\n ['antebellum']\nWilliam Mack Lee , History of the Life of Rev. Wm. Mack Lee: Body Servant of General Robert E. Lee Through the Civil War: Cook from 1861 to 1865\n ['antebellum']\nSelim Aga , Incidents Connected with the Life of Selim Aga, a Native of Central Africa\n ['antebellum']\nHarriet A. Jacobs , Incidents in the Life of a Slave Girl. Written by Herself\n ['antebellum']\nThomas Anderson , Interesting Account of Thomas Anderson, a Slave, Taken from His Own Lips. Ed. J. P. Clark\n ['antebellum']\nOlaudah Equiano , The Interesting Narrative of the Life of Olaudah Equiano, or Gustavus Vassa, the African. Written by Himself. Vol. I.\n ['antebellum']\nOlaudah Equiano , The Interesting Narrative of the Life of Olaudah Equiano, or Gustavus Vassa, the African. Written by Himself. Vol. II.\n ['antebellum']\nWilliam E. Hatcher , John Jasper: The Unmatched Negro Philosopher and Preacher\n ['postbellum']\n Arthur , The Life, and Dying Speech of Arthur, a Negro Man; Who Was Executed at Worcester, October 10, 1768. For a Rape Committed on the Body of One Deborah Metcalfe\n ['antebellum']\nJohn Jea , The Life, History, and Unparalleled Sufferings of John Jea, the African Preacher. Compiled and Written by Himself\n ['antebellum']\nStephen Smith , Life, Last Words and Dying Speech of Stephen Smith, a Black Man, Who Was Executed at Boston This Day Being Thursday, October 12, 1797 for Burglary\n ['antebellum']\nAlexander Walters , My Life and Work\n ['antebellum']\nAndrew Jackson , Narrative and Writings of Andrew Jackson, of Kentucky; Containing an Account of His Birth, and Twenty-Six Years of His Life While a Slave; His Escape; Five Years of Freedom, Together with Anecdotes Relating to Slavery; Journal of One Year's Travels; Sketches, etc. Narrated by Himself; Written by a Friend\n ['antebellum']\nJames Williams , A Narrative of Events Since the First of August, 1834, By James Williams, an Apprenticed Labourer in Jamaica\n ['antebellum']\nJames Curry , Narrative of James Curry, A Fugitive Slave\n ['antebellum']\nT. C. Upham , Narrative of Phebe Ann Jacobs\n ['antebellum']\nW. Mallory , Old Plantation Days\n ['antebellum']\nWalter L. Fleming , \"Pap\" Singleton, The Moses of the Colored Exodus\n ['antebellum']\n No Author , Recollections of Slavery by a Runaway Slave\n ['antebellum']\nCharles Stuart , Reuben Maddison: A True Story\n ['antebellum']\nGeorge F. Bragg , Richard Allen and Absalom Jones, by the Rev. George F. Bragg, in Honor of the Centennial of the African Methodist Episcopal Church, Which Occurs in the Year 1916\n ['antebellum']\n No Author , The Royal African: or, Memoirs of the Young Prince of Annamaboe. Comprehending a Distinct Account of His Country and Family; His Elder Brother's Voyage to France, and Reception there; the Manner in Which Himself Was Confided by His Father to the Captain Who Sold Him; His Condition While a Slave in Barbadoes; the True Cause of His Bring Redeemed; His Voyage from Thence; and Reception Here in England. Interspers'd Throughout with Several Historical Remarks on the Commerce of the European Nations, Whose Subjects Frequent the Coast of Guinea. To which is Prefixed a Letter from the Author to a Person of Distinction, in Reference to Some Natural Curiosities in Africa; as Well as Explaining the Motives which Induced Him to Compose These Memoirs.\n ['antebellum']\n No Author , A Sketch of Henry Franklin and Family.\n ['antebellum']\nLewis Charlton , Sketch of the Life of Mr. Lewis Charlton, and Reminiscences of Slavery\n ['antebellum']\nMark Twain , A True Story, Repeated Word for Word As I Heard It. From The Atlantic Monthly. Nov. 1874: 591-594\n ['antebellum']\nEmma J. Ray , Twice Sold, Twice Ransomed: Autobiography of Mr. and Mrs. L. P. Ray\n ['antebellum']\nGustavus L. Foster , Uncle Johnson, the Pilgrim of Six Score Years\n ['antebellum']\nBooker T. Washington , Up from Slavery: An Autobiography\n ['antebellum']\nThomas William Burton , What Experience Has Taught Me: An Autobiography of Thomas William Burton\n ['antebellum']\n"
]
],
[
[
"## Works Cited\n\nCover T.M. and P. E. Hart. 1967. \"Nearest Neighbor Pattern Classification.\" _IEEE Transactions on Information Theory_ 13, no. 1: 21-27.\n\nDobson, James E. 2015. [“Can an Algorithm be Disturbed? Machine Learning, Intrinsic Criticism, and the Digital Humanities.”](https://mla.hcommons.org/deposits/item/mla:313/) _College Literature_ 42, no. 4: 543-564. \n\nGillespie, Tarleton. 2016. “Algorithm.” In _Digital Keywords: A Vocabulary of Information Society and Culture_. Edited by Benjamin Peters. Princeton: Princeton University Press.\n\nJockers, Matthew. 2013. _Macroanalysis: Digital Methods & Literary History_ Urbana: University of Illinois Press.\n\nMarrs, Cody. 2015. _Nineteenth-Century American Literature and the Long Civil War_. New York: Cambridge University Press.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a2ab21caeb358ed9c7f2ac9c21d8c8b7ae40f0e
| 86,881 |
ipynb
|
Jupyter Notebook
|
IMDB Sentiment Analysis/IMDB_Sentiment_Analysis.ipynb
|
MahdiRahbar/NLP_Codes
|
7d969b19d5b6a78fc4059d98060fd9c27a209762
|
[
"MIT"
] | null | null | null |
IMDB Sentiment Analysis/IMDB_Sentiment_Analysis.ipynb
|
MahdiRahbar/NLP_Codes
|
7d969b19d5b6a78fc4059d98060fd9c27a209762
|
[
"MIT"
] | null | null | null |
IMDB Sentiment Analysis/IMDB_Sentiment_Analysis.ipynb
|
MahdiRahbar/NLP_Codes
|
7d969b19d5b6a78fc4059d98060fd9c27a209762
|
[
"MIT"
] | null | null | null | 82.508072 | 1,752 | 0.502711 |
[
[
[
"This dataset is derived from [Kaggle Website](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews/downloads/imdb-dataset-of-50k-movie-reviews.zip/1)!\n\n-------------------------------------------",
"_____no_output_____"
]
],
[
[
"import numpy as np \nimport pandas as pd \nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\nimport nltk\nfrom nltk.corpus import stopwords\nfrom nltk.stem.porter import PorterStemmer\nfrom nltk.tokenize.toktok import ToktokTokenizer\nfrom nltk.stem import LancasterStemmer,WordNetLemmatizer\nfrom nltk.tokenize import word_tokenize,sent_tokenize\n\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.preprocessing import LabelBinarizer\nfrom sklearn.linear_model import LogisticRegression,SGDClassifier\nfrom sklearn.naive_bayes import MultinomialNB\nfrom sklearn.svm import SVC\nfrom sklearn.metrics import classification_report,confusion_matrix,accuracy_score\n\nfrom wordcloud import WordCloud,STOPWORDS\nfrom bs4 import BeautifulSoup\nimport spacy\nimport re,string,unicodedata\n\nfrom textblob import TextBlob\nfrom textblob import Word\n\nimport time",
"_____no_output_____"
],
[
"#Tokenization of text\ntokenizer=ToktokTokenizer()\n#Setting English stopwords\nstopword_list=nltk.corpus.stopwords.words('english')",
"_____no_output_____"
],
[
"Data = pd.read_csv(\"imdb-dataset-of-50k-movie-reviews/IMDB Dataset.csv\")",
"_____no_output_____"
],
[
"pd.set_option('display.max_columns', None) \npd.set_option('display.max_rows', None) \npd.set_option('display.max_colwidth', -1)",
"_____no_output_____"
],
[
"data = Data",
"_____no_output_____"
],
[
"print(data.shape)",
"(50000, 2)\n"
],
[
"data.head()",
"_____no_output_____"
],
[
"data.describe()",
"_____no_output_____"
],
[
"data['sentiment'].value_counts()",
"_____no_output_____"
],
[
"def train_test_split(data,percentage):\n train_size= int(len(data)*percentage)\n dataB=data\n train_data = pd.DataFrame()\n test_data = pd.DataFrame()\n random_index = np.random.choice(len(dataB),train_size)\n random_index = np.sort(random_index)\n random_index = random_index[::-1]\n# print(len(dataB), '\\n',random_index)\n for i in random_index:\n train_data = train_data.append(dataB.iloc[i],ignore_index=True)\n dataB.drop(dataB.index[i], inplace=True)\n test_data = dataB\n \n return train_data , test_data",
"_____no_output_____"
],
[
"#Removing the html strips\ndef strip_html(text):\n soup = BeautifulSoup(text, \"html.parser\")\n return soup.get_text()\n\n#Removing the square brackets\ndef remove_between_square_brackets(text):\n return re.sub('\\[[^]]*\\]', '', text)\n\n#Removing the noisy text\ndef denoise_text(text):\n text = strip_html(text)\n text = remove_between_square_brackets(text)\n return text\n#Apply function on review column\ndata['review']=data['review'].apply(denoise_text)",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"#Define function for removing special characters\ndef remove_special_characters(text, remove_digits=True):\n pattern=r'[^a-zA-z0-9\\s]'\n text=re.sub(pattern,'',text)\n return text\n#Apply function on review column\ndata['review']=data['review'].apply(remove_special_characters)",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"#Stemming the text\ndef simple_stemmer(text):\n ps=nltk.porter.PorterStemmer()\n text= ' '.join([ps.stem(word) for word in text.split()])\n return text\n#Apply function on review column\ndata['review']=data['review'].apply(simple_stemmer)",
"_____no_output_____"
],
[
"data.head(1)",
"_____no_output_____"
],
[
"#set stopwords to english\nstop=set(stopwords.words('english'))\nprint(stop)\n\n#removing the stopwords\ndef remove_stopwords(text, is_lower_case=False):\n tokens = tokenizer.tokenize(text)\n tokens = [token.strip() for token in tokens]\n if is_lower_case:\n filtered_tokens = [token for token in tokens if token not in stopword_list]\n else:\n filtered_tokens = [token for token in tokens if token.lower() not in stopword_list]\n filtered_text = ' '.join(filtered_tokens) \n return filtered_text\n#Apply function on review column\ndata['review']=data['review'].apply(remove_stopwords)",
"{'some', 'mightn', 'same', 'over', 'won', 'both', 'for', 'there', 'll', \"haven't\", 'that', 'no', 'because', 'herself', 'don', 'so', 'myself', 'by', 'isn', 'whom', 'further', 'ma', 'we', 'the', 'of', \"mustn't\", 'wasn', \"that'll\", \"hasn't\", 'under', 'these', 'just', \"shouldn't\", 'all', \"didn't\", 'my', 'y', 'or', 'i', 'until', 'do', 'very', 'couldn', 'and', \"hadn't\", 'most', 'am', 'doesn', 'having', 'ourselves', 'few', 'here', 'hers', 'after', 'why', 'above', 'm', 'o', 'needn', 'this', 'any', 'own', \"weren't\", 'where', 'how', 'haven', 'you', 'than', 'on', 'it', 'up', 'me', 'be', 'into', 'other', \"won't\", 'been', 'about', 'his', 'each', 'only', 'which', 'off', 'hadn', 'if', 'her', 'aren', 'hasn', 'will', 't', 'more', \"you'd\", 'mustn', 'weren', \"don't\", 'shan', 'they', \"aren't\", 'did', \"you'll\", 'in', 'can', 'd', 'then', 'at', 'their', 'was', 'have', 'from', 'down', 'again', 've', 'she', 'ours', \"you've\", 'a', 'are', 'its', 'out', 'itself', 'nor', 'didn', 'yourself', 'between', \"she's\", 'to', 'our', 'he', 'such', 're', \"needn't\", \"should've\", 'has', 'through', \"doesn't\", 'were', 'shouldn', 'who', 'is', 'yourselves', \"you're\", \"it's\", 'being', 'themselves', 'does', 'during', \"wouldn't\", 'while', \"isn't\", 'now', 'yours', \"couldn't\", \"shan't\", 'them', 'too', 'should', \"mightn't\", 'before', 's', \"wasn't\", 'theirs', 'what', 'himself', 'had', 'doing', 'as', 'once', 'but', 'an', 'those', 'him', 'your', 'with', 'below', 'against', 'when', 'wouldn', 'not', 'ain'}\n"
],
[
"data.head(1)",
"_____no_output_____"
],
[
"train, test = train_test_split(data , 0.8)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"train.to_csv('IMDB_50k_train_data.csv',index=False)\ntest.to_csv('IMDB_50k_test_data.csv',index=False)",
"_____no_output_____"
],
[
"#normalized train reviews\n# norm_train_reviews=imdb_data.review[:40000]\n# norm_train_reviews[0]\n#convert dataframe to string\n#norm_train_string=norm_train_reviews.to_string()\n#Spelling correction using Textblob\n#norm_train_spelling=TextBlob(norm_train_string)\n#norm_train_spelling.correct()\n#Tokenization using Textblob\n#norm_train_words=norm_train_spelling.words\n#norm_train_words",
"_____no_output_____"
],
[
"#Normalized test reviews\n# norm_test_reviews=imdb_data.review[40000:]\n# norm_test_reviews[45005]\n##convert dataframe to string\n#norm_test_string=norm_test_reviews.to_string()\n#spelling correction using Textblob\n#norm_test_spelling=TextBlob(norm_test_string)\n#print(norm_test_spelling.correct())\n#Tokenization using Textblob\n#norm_test_words=norm_test_spelling.words\n#norm_test_words",
"_____no_output_____"
],
[
"x_train = train.review\nx_test = test.review\ny_train = train.sentiment\ny_test = test.sentiment",
"_____no_output_____"
],
[
"#Count vectorizer for bag of words\ncv=CountVectorizer(min_df=0,max_df=1,binary=False,ngram_range=(1,3))\n#transformed train reviews\ncv_train_reviews=cv.fit_transform(x_train)\n#transformed test reviews\ncv_test_reviews=cv.transform(x_test)\n\nprint('BOW_cv_train:',cv_train_reviews.shape)\nprint('BOW_cv_test:',cv_test_reviews.shape)\n#vocab=cv.get_feature_names()-toget feature names",
"BOW_cv_train: (40000, 6228025)\nBOW_cv_test: (10000, 6228025)\n"
],
[
"#Tfidf vectorizer\ntv=TfidfVectorizer(min_df=0,max_df=1,use_idf=True,ngram_range=(1,3))\n#transformed train reviews\ntv_train_reviews=tv.fit_transform(x_train)\n#transformed test reviews\ntv_test_reviews=tv.transform(x_test)\nprint('Tfidf_train:',tv_train_reviews.shape)\nprint('Tfidf_test:',tv_test_reviews.shape)",
"Tfidf_train: (40000, 6228025)\nTfidf_test: (10000, 6228025)\n"
],
[
"#labeling the sentient data\nlb=LabelBinarizer()\n#transformed sentiment data\nsentiment_y_train_data=lb.fit_transform(y_train)\nsentiment_y_test_data=lb.fit_transform(y_test)\nprint(sentiment_y_train_data.shape)\nprint(sentiment_y_test_data.shape)",
"(40000, 1)\n(10000, 1)\n"
],
[
"sentiment_y_test_data",
"_____no_output_____"
],
[
"#training the model\nlr=LogisticRegression(penalty='l2',max_iter=500,C=1,random_state=42)\n#Fitting the model for Bag of words\nlr_bow=lr.fit(cv_train_reviews,sentiment_y_train_data)\nprint(lr_bow)\n#Fitting the model for tfidf features\nlr_tfidf=lr.fit(tv_train_reviews,sentiment_y_train_data)\nprint(lr_tfidf)",
"/usr/local/lib/python3.6/dist-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.\n FutureWarning)\n/usr/local/lib/python3.6/dist-packages/sklearn/utils/validation.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n y = column_or_1d(y, warn=True)\n"
],
[
"#Predicting the model for bag of words\nlr_bow_predict=lr.predict(cv_test_reviews)\nprint(lr_bow_predict)\n##Predicting the model for tfidf features\nlr_tfidf_predict=lr.predict(tv_test_reviews)\nprint(lr_tfidf_predict)",
"[1 0 1 ... 0 1 1]\n[1 0 1 ... 0 1 1]\n"
],
[
"#Accuracy score for bag of words\nlr_bow_score=accuracy_score(sentiment_y_test_data,lr_bow_predict)\nprint(\"lr_bow_score :\",lr_bow_score)\n#Accuracy score for tfidf features\nlr_tfidf_score=accuracy_score(sentiment_y_test_data,lr_tfidf_predict)\nprint(\"lr_tfidf_score :\",lr_tfidf_score)",
"lr_bow_score : 0.7423\nlr_tfidf_score : 0.7406\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2ab6c801eaec277a2c42d6367f327d9600b1da
| 9,518 |
ipynb
|
Jupyter Notebook
|
Notebook/OCR.ipynb
|
bdstar/Handwritten-Text-Recognition-Tesseract-OCR
|
9b8a4a0c895bb457dddd1a622838afd9a9c9295e
|
[
"MIT"
] | null | null | null |
Notebook/OCR.ipynb
|
bdstar/Handwritten-Text-Recognition-Tesseract-OCR
|
9b8a4a0c895bb457dddd1a622838afd9a9c9295e
|
[
"MIT"
] | null | null | null |
Notebook/OCR.ipynb
|
bdstar/Handwritten-Text-Recognition-Tesseract-OCR
|
9b8a4a0c895bb457dddd1a622838afd9a9c9295e
|
[
"MIT"
] | null | null | null | 44.896226 | 4,426 | 0.687224 |
[
[
[
"## **OCR Using Pytesseract**\nYou are viewing Aditya Raj's Notebook.",
"_____no_output_____"
]
],
[
[
"pip install opencv-python\n",
"Requirement already satisfied: opencv-python in /usr/local/lib/python3.6/dist-packages (4.1.2.30)\nRequirement already satisfied: numpy>=1.11.3 in /usr/local/lib/python3.6/dist-packages (from opencv-python) (1.18.5)\n"
],
[
"!sudo apt-get install tesseract-ocr",
"_____no_output_____"
],
[
"!sudo apt-get install libtesseract-dev",
"_____no_output_____"
],
[
"pip install pytesseract",
"_____no_output_____"
],
[
"import cv2\nimport numpy as np\nfrom google.colab import drive\nimport pytesseract\ndrive.mount('/content/gdrive')\nfrom google.colab.patches import cv2_imshow",
"_____no_output_____"
],
[
"img = cv2.imread('gdrive/My Drive/tcsproject/test.jpg')\nimg = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\nreduced_noise = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,12)\ncv2_imshow(reduced_noise)\ncv2.waitKey(0)\nprint(\"\\nImage is loaded succesfully\")\n",
"_____no_output_____"
],
[
"text=pytesseract.image_to_string(reduced_noise,lang='eng')\nprint(\"The text is :\\n\",text)",
"The text is :\n Some people need to\nenlarge web content\nin order to read it.\nSome need to\nchange other\naspects of text\ndisplay: font, space\nbetween lines, and.\nmore.\n"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2abb429616c651d4f5fa22dfd4ebb30ee32cf4
| 414,586 |
ipynb
|
Jupyter Notebook
|
Fraud_detection.ipynb
|
peraktong/anomaly_detection
|
b9afca65c02a6b7e762fc06fc3500955485483e8
|
[
"MIT"
] | null | null | null |
Fraud_detection.ipynb
|
peraktong/anomaly_detection
|
b9afca65c02a6b7e762fc06fc3500955485483e8
|
[
"MIT"
] | null | null | null |
Fraud_detection.ipynb
|
peraktong/anomaly_detection
|
b9afca65c02a6b7e762fc06fc3500955485483e8
|
[
"MIT"
] | null | null | null | 343.200331 | 110,608 | 0.926413 |
[
[
[
"# Predict Fraud transaction\n1. In this document, I will use the transaction data, which include details about each transaction, to predict whether this transaction is fraud or not. The model will be able to applied to future transaction data.\n2. I will visualize the data and perform data cleaning before building the fraud detection classifier model. Data cleaning is of vital importance, which will be done before applying any model. To help us know how to do data cleaing, a data visulization part will be performed first\n3. The structure of the document is: <br>\n a. Data Visualization <br>\n b. Data cleaning <br>\n c. Feature engineering <br>\n d. Apply model and cross-validation <br>\n e. Optimize model and run on testing set <br>\n f. conclusion part <br>",
"_____no_output_____"
]
],
[
[
"# import packages \nimport xgboost\nfrom scipy.stats import chisquare\nfrom scipy.stats import pearsonr \nimport pickle\nimport pandas as pd\nimport datetime\nimport matplotlib\nimport tensorflow as tf\nimport sklearn\nimport math\nimport matplotlib.pyplot as plt\nfrom xgboost import XGBClassifier\nfrom xgboost import plot_importance\nimport numpy as np\nfrom sklearn.model_selection import train_test_split \nimport sklearn\nfrom sklearn.preprocessing import LabelEncoder \nimport copy\nimport scipy\nimport datetime\nimport time\nfrom sklearn.model_selection import KFold \nfrom sklearn.metrics import roc_curve \nfrom sklearn.metrics import roc_auc_score\nimport os\n",
"_____no_output_____"
],
[
"# data preparation\nroot_path = \"Data/\"\nprint(os.listdir(root_path))\ntrain_identity = pd.read_csv(root_path+'train_identity.csv')\ntrain_transaction = pd.read_csv(root_path+\"train_transaction.csv\")\n\ntest_identity = pd.read_csv(root_path+'test_identity.csv')\ntest_transaction = pd.read_csv(root_path+\"test_transaction.csv\")\nprint(\"finish loading data\")\n\n### a few notations:\n# The TransactionDT feature is a timedelta from a given reference datetime (not an actual timestamp).",
"['sample_submission.csv', 'test_identity.csv', 'test_transaction.csv', 'train_identity.csv', 'train_transaction.csv']\nfinish loading data\n"
],
[
"print(\"There are %d rows and %d columns\"%(train_transaction.shape[0],train_transaction.shape[1]))\n# print(\"The column names are %s\"%str(df.keys()))",
"There are 590540 rows and 394 columns\n"
],
[
"y_fraud = train_transaction[\"isFraud\"]",
"_____no_output_____"
]
],
[
[
"# The following part is for one-hot encoder",
"_____no_output_____"
]
],
[
[
"\n# fill missing value and one-hot encoder:\ndef fill_missing_values(df):\n ''' This function imputes missing values with median for numeric columns\n and most frequent value for categorical columns'''\n missing = df.isnull().sum()\n # select missing data\n missing = missing[missing > 0]\n for column in list(missing.index):\n if df[column].dtype == 'object':\n # if it's an object, fill that with the *most common* object in that column\n df[column].fillna(df[column].value_counts().index[0], inplace=True)\n elif df[column].dtype == 'int64' or 'float64' or 'int16' or 'float16':\n df[column].fillna(df[column].median(), inplace=True)\n\ndef impute_cats(df):\n '''This function converts categorical and non-numeric\n columns into numeric columns to feed into a ML algorithm'''\n # Find the columns of object type along with their column index\n # only select columns with obejcts\n object_cols = list(df.select_dtypes(exclude=[np.number]).columns)\n # return the index for columns with object\n object_cols_ind = []\n for col in object_cols:\n object_cols_ind.append(df.columns.get_loc(col))\n\n # Encode the categorical columns with numbers\n # https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html\n # It's still an object but this time with index from 0 to num_features-1\n ##!! I will modify this part later since I want to rank order these catagorical features by their fraud rate.\n label_enc = LabelEncoder()\n for i in object_cols_ind:\n df.iloc[:, i] = label_enc.fit_transform(df.iloc[:, i])\n\n\n\n\n\n",
"_____no_output_____"
],
[
"# combine transaction and identity files:\n\ndf = pd.concat([train_transaction.set_index('TransactionID'), train_identity.set_index('TransactionID')], axis=1, sort=False)\n",
"_____no_output_____"
]
],
[
[
"# In the next part, I will apply a customized encoder (similar to one sum encoder) for categorical data, and perform filter method in feature engineering.\n\nFor encoder, I use a customized encoder (similar to one sum encoder) rather than normal encoder or one hot encoder. And I will show my method gives a better results than normal one hot encoder\n\nThis is how it works: Find the categorical column. Calculate the fraction of fraud transaction for each kind of categorical value in that column. Then we have a hashtable that mapping the name of the category and the fraction of fraud transaction for that category. Finally, replace these categories with their fraction of fraud transaction. This makes more sense than tranditional normal encoder. And this save extra space compared to one hot encoder (There will be a lot of new columns when we apply one hot encoder to categorical dataset that have a lot of categories)\n\nThis method is similar to the one sum encoder, but it's a little different. I will prove our methods works better than ont hot encoder in the following part. (Our method gives a higher AUROC, which is more important in a highly imbalanced dataset than accuracy.)\n\n",
"_____no_output_____"
]
],
[
[
"# Let's do encoding method that is different from One-hot encoder:\n# Encode them with fraction of fraud transaction:\ndef helper(name):\n temp = df.groupby([name,'isFraud']).size()\n mapping = {}\n fraud_array = {}\n nofraud_array = {}\n count=0\n\n for i in range(len(temp.index)):\n\n name_i = temp.index[i][0]\n fraud_array[name_i] = 0\n nofraud_array[name_i] = 0\n\n for i in range(len(temp.index)):\n name_i = temp.index[i][0]\n if temp.index[i][1]==True:\n fraud_array[name_i] = temp[i]\n if temp.index[i][1]==False:\n nofraud_array[name_i] = temp[i]\n\n mapping = {x:fraud_array[x]/(fraud_array[x]+nofraud_array[x]) for x in fraud_array.keys()}\n return mapping",
"_____no_output_____"
],
[
"#deal with nan data: For categorical col, I replace them with most frequenct value. For numerical col, I repalce with mean (Although it's not a perfect idea since it make variance smaller)\n\nfill_missing_values(df)\n\n\n# Feature engineering: Filter method. Use Pearsons r\nX = df.drop(['isFraud','TransactionDT'],axis=1)\ny = df['isFraud']\n\n\n\n\nlabel_names_part = X.keys()\ny_pearsons_array = []\n\nname_select = []\n\nfor i in range(X.shape[1]):\n if i%50==0:\n print(\"Doing %d of %d for pearsons correlation\"%(i,X.shape[1]))\n try:\n corr, _ = pearsonr(X[label_names_part[i]], y)\n y_pearsons_array.append(corr)\n name_select.append(label_names_part[i])\n except:\n # our own encoder:\n print(\"%s is a categorical data\"%(label_names_part[i]))\n mapping = helper(label_names_part[i])\n #print(\"Grouping Finished\")\n X[label_names_part[i]] = X[label_names_part[i]].apply(lambda x:mapping[x])\n \n corr, _ = pearsonr(X[label_names_part[i]], y)\n \n y_pearsons_array.append(corr)\n name_select.append(label_names_part[i])\n \n \n \ny_pearsons_array = np.array(y_pearsons_array)\n#plt.hist(y_pearsons_array)\nname_select = np.array(name_select)",
"Doing 0 of 431 for pearsons correlation\nProductCD is a categorical data\ncard4 is a categorical data\ncard6 is a categorical data\nP_emaildomain is a categorical data\nR_emaildomain is a categorical data\nM1 is a categorical data\nM2 is a categorical data\nM3 is a categorical data\nM4 is a categorical data\nM5 is a categorical data\nM6 is a categorical data\nM7 is a categorical data\nDoing 50 of 431 for pearsons correlation\nM8 is a categorical data\nM9 is a categorical data\nDoing 100 of 431 for pearsons correlation\nDoing 150 of 431 for pearsons correlation\nDoing 200 of 431 for pearsons correlation\nDoing 250 of 431 for pearsons correlation\nDoing 300 of 431 for pearsons correlation\nDoing 350 of 431 for pearsons correlation\nDoing 400 of 431 for pearsons correlation\nid_12 is a categorical data\nid_15 is a categorical data\nid_16 is a categorical data\nid_23 is a categorical data\nid_27 is a categorical data\nid_28 is a categorical data\nid_29 is a categorical data\nid_30 is a categorical data\nid_31 is a categorical data\nid_33 is a categorical data\nid_34 is a categorical data\nid_35 is a categorical data\nid_36 is a categorical data\nid_37 is a categorical data\nid_38 is a categorical data\nDeviceType is a categorical data\nDeviceInfo is a categorical data\n"
],
[
"# plot part of cols with highest pearsons r:\n\nfont = {'family': 'normal','weight': 'bold',\n 'size': 25}\n\nmatplotlib.rc('font', **font)\nmask_temp = abs(y_pearsons_array)>np.nanpercentile(abs(y_pearsons_array),70)\n\nplt.plot(label_names_part[mask_temp],y_pearsons_array[mask_temp],\"ko\",markersize=10)\nfor i in range(len(label_names_part[mask_temp])):\n plt.plot((i,i),(0,y_pearsons_array[mask_temp][i]),\"k\")\nplt.plot((-1,len(label_names_part[mask_temp])+1),(0,0),\"k--\")\nplt.xlabel(\"Name\")\nplt.ylabel(\"Pearsons r\")\nplt.xticks(rotation=90)\nfig = plt.gcf()\nfig.set_size_inches(39,20)\nplt.show()",
"WARNING: Logging before flag parsing goes to stderr.\nW0614 00:36:18.750144 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\nW0614 00:36:18.990609 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\n"
],
[
"# make a Pie Chart:\n\nfont = {'family': 'normal','weight': 'bold',\n 'size': 15}\n\nmatplotlib.rc('font', **font)\ncolor_array = [\"r\",\"c\"]\nfig, axs = plt.subplots(1, 2)\n\n# Fraud transaction\nlabels = 'Fraud transaction', \"no Fraud transaction\"\nf = len(df[\"isFraud\"][df[\"isFraud\"]==True])/len(df[\"isFraud\"])\nsizes = [f,1-f]\nexplode = (0, 0.1)\n\n\naxs[0].pie(sizes,colors=color_array, explode=explode, autopct='%1.1f%%',shadow=True, startangle=90)\naxs[0].axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.\naxs[0].set_title(\"Fraction of fraud transaction\")\naxs[0].legend(labels)\n\n## Transaction amount\nlabels = 'Fraud transaction amount',\"no Fraud transaction amount\"\nfm = df[df[\"isFraud\"]==True]['TransactionAmt'].sum()/df[df[\"isFraud\"]==False]['TransactionAmt'].sum()\nsizes = [fm,1-fm]\nexplode = (0, 0.1)\n\n\naxs[1].pie(sizes,colors=color_array, explode=explode, autopct='%1.1f%%',shadow=True, startangle=90)\naxs[1].axis('equal')\naxs[1].set_title(\"Fraction of fraud transaction amount\")\naxs[1].legend(labels)\nfig = plt.gcf()\nfig.set_size_inches(15,9)\nplt.show()\n\n\n\n",
"W0614 00:36:21.871243 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\nW0614 00:36:21.881040 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\n"
]
],
[
[
"# Question 2: Plot\n1. plot the histogram of the transaction amount.\n2. my assumption is: transaction amount is related to fraud transaction, which I will prove later",
"_____no_output_____"
]
],
[
[
"#transaction value distribution + log[amount] distribution\n\ndef log10(x):\n if x > 0:\n return math.log10(x)\n else:\n return np.nan\nlog10 = np.vectorize(log10)\n\nfont = {'family': 'normal','weight': 'bold',\n 'size': 20}\n\nmatplotlib.rc('font', **font)\n\nplt.hist(log10(df[df[\"isFraud\"]==True]['TransactionAmt']),density=True,label=\"Fraud\",alpha=0.3,bins=np.linspace(-1,3,51))\nplt.hist(log10(df[df[\"isFraud\"]==False]['TransactionAmt']),density=True,label=\"noFraud\",alpha=0.3,bins=np.linspace(-1,3,51))\nplt.ylabel(\"Probability\")\nplt.suptitle(\"Transaction Amount (Log) Distribuition\")\naxes = plt.gca()\naxes.set_xlim([0,3])\nplt.legend()\nfig = plt.gcf()\nfig.set_size_inches(9,9)\nplt.show()",
"W0614 00:36:23.834120 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\nW0614 00:36:23.864589 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\nW0614 00:36:23.898303 140262434719552 font_manager.py:1269] findfont: Font family ['normal'] not found. Falling back to DejaVu Sans.\n"
],
[
"# This is the percentiles for fraud and nofraud transaction amount\nprint(pd.concat([df[df['isFraud'] == True]['TransactionAmt']\\\n .quantile([.01, .1, .25, .5, .75, .9, .99])\\\n .reset_index(), \n df[df['isFraud'] == 0]['TransactionAmt']\\\n .quantile([.01, .1, .25, .5, .75, .9, .99])\\\n .reset_index()],\n axis=1, keys=['Fraud', \"No Fraud\"]))",
" Fraud No Fraud \n index TransactionAmt index TransactionAmt\n0 0.01 6.74096 0.01 9.51288\n1 0.10 18.93600 0.10 26.31000\n2 0.25 35.04400 0.25 43.97000\n3 0.50 75.00000 0.50 68.50000\n4 0.75 161.00000 0.75 120.00000\n5 0.90 335.00000 0.90 267.11200\n6 0.99 994.00000 0.99 1104.00000\n"
]
],
[
[
"# I will do a KS test to test whether fraud and nofraud have the same transaction amount distribution.",
"_____no_output_____"
]
],
[
[
"\nscipy.stats.ks_2samp(data1=df[df['isFraud'] == True]['TransactionAmt'],data2=df[df['isFraud'] == False]['TransactionAmt'])\n\n# A very small p value and relative big statistic value means we can reject the null hypothesis, which means the two \n# distributions are different: Fraud is related to transaction amount\n",
"_____no_output_____"
],
[
"# Let's plot the distribution of \"hours in a day\" for fraud and nofraud\n# There seems to be only a small trend in month \n# 'TransactionDT' is in seconds: For 6 month data\n\nday_hour = df['TransactionDT']\ndf[\"month\"] = df['TransactionDT']//(3600*24*30)\ndf[\"day\"] = df['TransactionDT']//(3600*24)%30\ndf[\"hour\"] = df['TransactionDT']//3600%24\ndf[\"weekday\"] = df['TransactionDT']//(3600*24)%7\n\nfeature = \"hour\"\nmax_val = max(df[feature])\nplt.hist(df[df[\"isFraud\"]==0][feature],label=\"noFraud\",density=True,alpha=0.3,bins=np.arange(1,max_val))\nplt.hist(df[df[\"isFraud\"]==1][feature],label=\"Fraud\",density=True,alpha=0.3,bins=np.arange(1,max_val))\nplt.xticks(np.arange(1, max_val, step=1))\nplt.xlabel(\"%s\"%feature)\nplt.ylabel(\"Probability\")\nplt.suptitle(\"Transaction %s Distribuition\"%feature)\nplt.legend()\nfig = plt.gcf()\nfig.set_size_inches(15,9)\nplt.show()\n\n## There is a clear trend in hour distribution, which means the fraud happens at some specific hours",
"_____no_output_____"
]
],
[
[
"# Question 4: Model\n# The model I use is a Gradient Boost tree model\n1. The reason I choose gradient boost tree classifier is that it's good at dealing with classification problem with a lot of features. I didn't choose K-mean/K-medoids method because the K-mean method is not complicated enough to include all features here. Also, I want to tune the hyper parameters here to improve the model performace, while K-mean has less hyper-parameters.\n\n2. I didn't choose SVM either. It doesn't mean the SVM method is not good enough in handling this problem. SVM and tree-based algorithm (Eg: random forest) are good at avoiding overfitting. And both can handle non-linear problem. Here I choose Gradient Boost tree algorithm since it's faster in training to reach the same performance as SVM. Since the training data is large, and in future new data will be added, it's better to choose a model that can be trained faster. SVM suffers more scalability and it's hard to increase SVM training speed with more computational resources, while XgBoost (what I choose here) is good at scalability.\n\n3. I use AUROC to evaluate since it's an ultra imbalanced dataset. Also, accuracy is considered but AUROC is more important.",
"_____no_output_____"
],
[
"# Our encoder (one sum encoder) (Best AUROC)\n\nFor encoder, I use a customized encoder (similar to one sum encoder) rather than normal encoder or one hot encoder. And I will show my method gives a better results than normal one hot encoder\n\nThis is how it works: Find the categorical column. Calculate the fraction of fraud transaction for each kind of categorical value in that column. Then we have a hashtable that mapping the name of the category and the fraction of fraud transaction for that category. Finally, replace these categories with their fraction of fraud transaction. This makes more sense than tranditional normal encoder. And this save extra space compared to one hot encoder (There will be a lot of new columns when we apply one hot encoder to categorical dataset that have a lot of categories)\n\nThis method is similar to the one sum encoder, but it's a little different. I will prove our methods works better than ont hot encoder in the following part. (Our method gives a higher AUROC, which is more important in a highly imbalanced dataset than accuracy.)\n\n",
"_____no_output_____"
]
],
[
[
"# Here I use our own encoder for categorical data\nencoder_X = pd.get_dummies(X[name_select])",
"_____no_output_____"
],
[
"# Use GPU to do calculation, use XgBoost (gradient boost tree) as classifier\n\ntime_start = time.time()\nparams = {}\nparams['booster'] = \"gbtree\"\nparams['learning_rate'] = 0.01\nparams['max_depth'] = 12\n\nparams['gpu_id'] = 0\nparams['max_bin'] = 512\nparams['tree_method'] = 'gpu_hist'\n\nmodel = XGBClassifier(n_estimators=1000, verbose=2, n_jobs=-1, **params)\nX_train, X_test, y_train, y_test = train_test_split(encoder_X, y, test_size=0.2,shuffle=True)\nmodel.fit(X_train, y_train)\n# predict:\nY_predict_test = model.predict(X_test).ravel()\nmask_good = Y_predict_test == y_test\nacc_i = len(Y_predict_test[mask_good]) / len(Y_predict_test)\n\nprint(\"Finish training, time we use =%.3f s\"%(time.time()-time_start))\n# AUROC:\nprob = model.predict_proba(X_test)\nAUROC_i = roc_auc_score(y_test, prob[:, 1])\nprint(\"Results from our encoder ACC=%.4f AUROC=%.4f\"%(acc_i,AUROC_i))",
"Finish training, time we use =331.967 s\nResults from our encoder ACC=0.9828 AUROC=0.9610\n"
]
],
[
[
"\n# Important information about sample imbalance!\n\nIf you care only about the ranking order (AUROC) of your prediction\nBalance the positive and negative weights, via scaleposweight\nUse AUROC for evaluation.\n\nIf you care about predicting the right probability\nIn such a case, you cannot re-balance the dataset\nIn such a case, set parameter maxdeltastep to a finite number (say 1,2,3) will help convergence\n\nHere we want to solve the imbalance problem, which means I want to use scale_pos_weight method to do resample of the datset.\nThe theoretical scale_pos_weight should be noFraud/Fraud, but it depends. Here I want to find a balance point between AUROC and accuracy: Achieve high AUROC without sacrificing to much accuracy.\n\nscale_pos_weight means how many times do you resampling the fraud case. The resampling method is bootstrap.\n\n",
"_____no_output_____"
]
],
[
[
"### grid search for best scale_pos_weight\n\n# A grid search to get the best scale_pos_weight value\n\ntime_start = time.time()\ntarget_array = []\nauroc_array = []\nacc_array = []\nfor i in range(10):\n target = 10*i+1\n params = {}\n params['booster'] = \"gbtree\"\n params['learning_rate'] = 0.01\n params['max_depth'] = 12\n # control imbalance: Control the balance of positive and negative weights, useful for unbalanced classes\n params['scale_pos_weight'] = target\n\n\n params['gpu_id'] = 0\n params['max_bin'] = 512\n params['tree_method'] = 'gpu_hist'\n\n model = XGBClassifier(n_estimators=300, verbose=2, n_jobs=-1, **params)\n X_train, X_test, y_train, y_test = train_test_split(encoder_X, y, test_size=0.2,shuffle=True)\n model.fit(X_train, y_train)\n # predict:\n Y_predict_test = model.predict(X_test).ravel()\n mask_good = Y_predict_test == y_test\n acc_i = len(Y_predict_test[mask_good]) / len(Y_predict_test)\n acc_array.append(acc_i)\n\n \n # AUROC:\n prob = model.predict_proba(X_test)\n AUROC_i = roc_auc_score(y_test, prob[:, 1])\n target_array.append(target)\n auroc_array.append(AUROC_i)\n \n # print(\"ACC=%.4f AUROC=%.4f target=%d\"%(acc_i,AUROC_i,target))\n \n\nprint(\"Finish training, time we use =%.3f s\"%(time.time()-time_start))\n\nplt.plot(target_array,auroc_array,\"k\",label=\"AUROC\")\nplt.plot(target_array,acc_array,\"r\",label=\"Accuracy\")\nplt.xlabel('Scaling pos weight')\nplt.ylabel('Values')\nplt.title('AUROC/accuracy vs scaling pos weight')\nplt.legend()\nfig = plt.gcf()\nfig.set_size_inches(9,9)\nplt.show()\n\n",
"Finish training, time we use =1550.260 s\n"
]
],
[
[
"# Now I run a model with our one sum encoder and best resamlping rate (scale_pos_weight) and do a k fold to avoid overfitting.",
"_____no_output_____"
]
],
[
[
"## Run the best fitting results with K-fold:\n### Do K fold to avoid overfitting\n\nparams = {}\n\nparams['subsample'] = 1\nparams['reg_alpha'] = 0.1\nparams['reg_lamdba'] = 0.9\n\nparams['max_depth'] = 6\nparams['colsample_bytree'] = 1\nparams['learning_rate'] = 0.01\nparams['booster'] = \"gbtree\"\n\nparams['scale_pos_weight'] = 20\n\nparams['gpu_id'] = 0\nparams['max_bin'] = 512\nparams['tree_method'] = 'gpu_hist'\n\ntime_start = time.time()\n\naccuracy_array = []\nAUROC_array = []\nn_k_fold=3\nmodel_dic = {}\n\nkf = KFold(n_splits=n_k_fold)\nkf.get_n_splits(encoder_X)\nKFold(n_splits=n_k_fold, random_state=None, shuffle=False)\ncount=0\nfor train_index, test_index in kf.split(encoder_X):\n print(\"Doing k fold %d of %d\"%(count+1,n_k_fold))\n model = XGBClassifier(n_estimators=100, verbose=2, n_jobs=-1, **params)\n \n X_train, X_test = encoder_X.iloc[train_index,:], encoder_X.iloc[test_index,:]\n y_train, y_test = y.iloc[train_index], y.iloc[test_index]\n model.fit(X_train, y_train)\n # predict:\n Y_predict_test = model.predict(X_test).ravel()\n mask_good = Y_predict_test == y_test\n acc_i = len(Y_predict_test[mask_good]) / len(Y_predict_test)\n\n # AUROC:\n prob = model.predict_proba(X_test)\n\n AUROC_i = roc_auc_score(y_test, prob[:, 1])\n \n print(\"ACC=%.4f AUROC=%.4f\"%(acc_i,AUROC_i))\n accuracy_array.append(acc_i)\n AUROC_array.append(AUROC_i)\n \n # save model from each k-fold\n model_dic[str(count)] = model\n \n \n \n # save testing results from each k-fold\n if count==0:\n prob_all=list(prob[:,1])\n y_predict_all=list(Y_predict_test)\n y_test_all = list(y_test)\n X_test_all = X_test\n else:\n prob_all.extend(prob[:,1])\n y_predict_all.extend(Y_predict_test)\n y_test_all.extend(y_test)\n X_test_all = np.r_[X_test_all,X_test]\n count+=1\n \n\n \n\naccuracy_array = np.array(accuracy_array)\nAUROC_array = np.array(AUROC_array)\nfusion = np.c_[accuracy_array,AUROC_array]\n\n\nprint(\"K_fold_results from best fitting\")\nprint(\"Mean ACC=%.4f , error= %.4f\"%(np.nanmedian(accuracy_array),np.nanstd(accuracy_array)))\n\nprint(\"Mean AUROC=%.4f , error= %.4f\"%(np.nanmedian(AUROC_array),np.nanstd(AUROC_array)))\n\nprint(\"Time it takes using GPU=%.2f s\"%(time.time()-time_start))\n\n\n\n\n\n\n",
"Doing k fold 1 of 3\nACC=0.8558 AUROC=0.8549\nDoing k fold 2 of 3\nACC=0.8985 AUROC=0.8703\nDoing k fold 3 of 3\nACC=0.8850 AUROC=0.8653\nK_fold_results from best fitting\nMean ACC=0.8850 , error= 0.0178\nMean AUROC=0.8653 , error= 0.0064\nTime it takes using GPU=72.49 s\n"
]
],
[
[
"# Plot confusion matrix",
"_____no_output_____"
]
],
[
[
"def helper_confusion_matrix(y_pred, y_true):\n TP = len(y_pred[(y_pred == 1) & (y_true == 1)])\n TN = len(y_pred[(y_pred == 1) & (y_true == 0)])\n # type1 error : false alarm\n FP = len(y_pred[(y_pred == 1) & (y_true == 0)])\n # type 2 error. Fail to make alarm\n FN = len(y_pred[(y_pred == 0) & (y_true == 1)])\n\n recall = TP / (TP + FN)\n precision = TP / (TP + FP)\n accuracy = (TP + TN) / len(y_pred)\n print(recall,precision,accuracy)\n\n f1_score = 2 / (1 / precision + 1 / recall)\n #return TP, TN, FP, FN, recall, precision, accuracy, f1_score\n return f1_score\n\ny_test_all = np.array([not x for x in y_test_all],dtype=int)\ny_predict_all = np.array([not x for x in y_predict_all],dtype=int)\nprint(\"f1 score=%.3f\"%(helper_confusion_matrix(y_predict_all,y_test_all)))",
"0.8877248950212063 0.9862942658171581 0.8685677515494293\nf1 score=0.934\n"
],
[
"# Convusion matrix and f1_score\n\nfrom sklearn.metrics import confusion_matrix\nimport seaborn as sns\n\nlabels = [\"fraud transaction\",\"no fraud transaction\"]\ncm = confusion_matrix(y_test_all, y_predict_all)\nax= plt.subplot()\nsns.heatmap(cm, annot=True, ax = ax,cmap=plt.cm.Blues)\n\n# labels, title and ticks\nax.set_xlabel('Predicted labels')\nax.set_ylabel('True labels')\nax.set_title('Confusion Matrix')\nax.xaxis.set_ticklabels(labels)\nax.yaxis.set_ticklabels(labels)\n\nfig = plt.gcf()\nfig.set_size_inches(14,14)\nplt.show()",
"/home/jc6933/anaconda3/envs/tf14/lib/python3.7/site-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
]
],
[
[
"# Plot ROC curve from best fitting",
"_____no_output_____"
]
],
[
[
"# plot ROC curve using the K-fold results:\n\nfrom sklearn.metrics import roc_curve\nfrom sklearn.metrics import roc_auc_score\nprob_all = np.array(prob_all)\ny_test_all = np.array([not x for x in y_test_all],dtype=int)\nfpr, tpr, thresholds = roc_curve(y_test_all, prob_all)\n\nplt.plot(fpr, tpr, color='r', label='AUROC=%.4f'%roc_auc_score(y_test_all, prob_all))\nplt.plot([0, 1], [0, 1], color='k',linewidth=4)\nplt.xlabel('False Positive Rate')\nplt.ylabel('True Positive Rate')\nplt.title('ROC curve')\nplt.legend()\nfig = plt.gcf()\nfig.set_size_inches(9,9)\nplt.show()",
"_____no_output_____"
]
],
[
[
"# (Optional) Do a grid search or random search to find the best hyper parameters",
"_____no_output_____"
]
],
[
[
"### grid search + K fold:\nif False:\n \n # \" booster\":[\"gbtree\",\"dart\",\"gblinear\"]\n params = {\"learning_rate\": [0.01, 0.03, 0.05, 0.1, 0.15],\"colsample_bytree\":[1, 0.85, 0.7],\n \"max_depth\": [6, 9, 12],\n \" booster\": [\"gbtree\", \"gblinear\"],\n \"subsample\": [1, 0.85, 0.7], \"reg_alpha\": [0.05, 0.1, 0.15,0.2]\n ,\"reg_lamdba\":[1,0.85,0.75],'scale_pos_weight':[1,11,21,31,41,61,81]}\n\n accuracy_array = []\n AUROC_array = []\n\n count = 0\n # grid search\n keys, values = zip(*params.items())\n import itertools\n\n best_model = 0\n best_parameteres = 0\n for v in itertools.product(*values):\n\n print(\"Doing %d\" % count)\n\n experiment = dict(zip(keys, v))\n print(experiment)\n\n experiment['gpu_id'] = 0\n experiment['max_bin'] = 512\n experiment['tree_method'] = 'gpu_hist'\n\n acc_i = []\n auroc_i = []\n\n for i in range(n_k_fold):\n X_train, X_test, y_train, y_test = train_test_split(encoder_X, y, test_size=0.2, shuffle=True)\n\n model = XGBClassifier(n_estimators=300, verbose=2, n_jobs=-1, **experiment)\n model.fit(X_train, y_train)\n # predict:\n\n # test\n Y_predict_test = model.predict(X_test)\n\n mask_good = Y_predict_test == y_test\n\n acc_i.append(len(Y_predict_test[mask_good]) / len(Y_predict_test))\n\n prob = model.predict_proba(X_test)\n probs = prob[:, 1]\n auroc_i.append(roc_auc_score(y_test, probs))\n\n print(\"Accuracy=%.4f for testing set AUROC=%.4f\" % (np.nanmean(acc_i), np.nanmean(auroc_i)))\n print(experiment)\n accuracy_array.append(np.nanmean(acc_i))\n AUROC_array.append(np.nanmean(auroc_i))\n\n if count == 0:\n best_model = model\n best_parameteres = experiment\n # elif acc_i>np.nanmax(accuracy_array):\n elif np.nanmean(auroc_i) > np.nanmax(AUROC_array):\n best_model = model\n best_parameteres = experiment\n\n count += 1\n accuracy_array = np.array(accuracy_array)\n\n AUROC_array = np.array(AUROC_array)\n\n np.savetxt(\"accuracy.txt\", accuracy_array)\n np.savetxt(\"AUROC.txt\", AUROC_array)\n\n",
"_____no_output_____"
]
],
[
[
"# Conclusion\n1. By visualizing the data, the correlation between fraud and different parameters can be seen. Eg: There is a high correlation between transaction amount and fraud activity. \n\n2. The average fraud transaction amount is higher than nofraud transactiona mount, which helps us to determine the fraud activity if a transaction amount is extremely high.\n\n3. There seems to be little trend in the fraction of fraud transction as a function of month in a year, although there are more transaction in December, which is reasonable since it's holiday season.\n\n4. Parameters which is highly correlated with fraud activities (by Pearsons r): Transaction amount, account open date, date of last address change and merchant category. \n a. We analyse the transaction amount in point 2.\n b. The account open date is related to fraud activity, which means accounts opened at a specific date may have a higher fraud fraction than others. Similar for the date of last address change. This is reasonable since address change is related to fraud activity. \n c. As for merchant category, it makes sense since different merchants have differnt security level in transaction. Eg: There is no fraud in Play Store since the transaction security level is high.\n \n5. I find one sum encoder works better than normal encoder and one hot encoder. And we apply one hot encoder in building the fraud prediction model.\n\n6. I build a Gradient Boost Tree model using XgBoost. Since data is a highly imbalanced dataset, I apply resampling to solve the imbalance problem. And I find the best resampling rate by doing grid search. The best value is 11, which means we have high AUROC without losing too much accuracy.\n\n7. To improve the modelm, I can do a grid search or random search to further tuning the hyper parameters, which is included at the end of the document.\n\n8. The baseline model reach AUROC=0.851 with errorbar=0.006. Accuracy=0.9717 with errorbar=0.003. Since there is a highly imbalanced dateset, AUROC is more important than accuracy.\n\n9. In future, I want to try neural network based models. If there are more features to use, a neural network model may have better performance than tree based algorithm. But there are only 34 columns here, which means sticking to gradient boost tree algorithm is a good idea.\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a2abd01627933fb1cc67b38d494e441ab50c5af
| 1,907 |
ipynb
|
Jupyter Notebook
|
Renderer.ipynb
|
wuksoy/renderer
|
8b1caf34c9860e99df2e21a8ab826634a7ad0237
|
[
"MIT"
] | null | null | null |
Renderer.ipynb
|
wuksoy/renderer
|
8b1caf34c9860e99df2e21a8ab826634a7ad0237
|
[
"MIT"
] | null | null | null |
Renderer.ipynb
|
wuksoy/renderer
|
8b1caf34c9860e99df2e21a8ab826634a7ad0237
|
[
"MIT"
] | null | null | null | 25.77027 | 139 | 0.492396 |
[
[
[
"# File path Function\r\ndef dpath(path):\r\n import ntpath\r\n head, tail = ntpath.split(path)\r\n return tail or ntpath.basename(head)",
"_____no_output_____"
],
[
"# Download and Install Blender: change link to preferred Blender version\r\ndl = 'https://download.blender.org/release/Blender2.91/blender-2.91.0-linux64.tar.xz'\r\nfilename = dpath(dl)\r\n!wget -nc $dl\r\n!mkdir ./blender && tar xf $filename -C ./blender --strip-components 1\r\n!apt install libboost-all-dev\r\n!apt install libgl1-mesa-dev\r\n!apt install libglu1-mesa libsm-dev",
"_____no_output_____"
],
[
"# Connect to Google Drive\r\nfrom google.colab import drive\r\ndrive.mount('/gdrive')",
"_____no_output_____"
],
[
"!sudo ./blender/blender -P gpu.py -b '/content/drive/your/blend/file.blend' -o '/gdrive/MyDrive/rendernameprefix' -s 10 -e 25 -a",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a2ac39f480c6fb65b064a58dc5ea47e04f94fa0
| 1,590 |
ipynb
|
Jupyter Notebook
|
beta_01/.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
thePassGuy/numerical_py_qsick
|
c500d7ea12e69104ef976203299bcc958190cf16
|
[
"MIT"
] | null | null | null |
beta_01/.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
thePassGuy/numerical_py_qsick
|
c500d7ea12e69104ef976203299bcc958190cf16
|
[
"MIT"
] | null | null | null |
beta_01/.ipynb_checkpoints/Untitled-checkpoint.ipynb
|
thePassGuy/numerical_py_qsick
|
c500d7ea12e69104ef976203299bcc958190cf16
|
[
"MIT"
] | null | null | null | 16.22449 | 40 | 0.476101 |
[
[
[
"import sympy",
"_____no_output_____"
],
[
"sympy.init_printing()",
"_____no_output_____"
],
[
"from sympy import I,pi,oo\n",
"_____no_output_____"
],
[
"x = sympy.Symbol(\"x\")",
"_____no_output_____"
],
[
"y = sympy.Symbol(\"y\", real=True)",
"_____no_output_____"
],
[
"y.is_real is None",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2ac5724f1c9b4afb09254e2739a578ac105f24
| 46,011 |
ipynb
|
Jupyter Notebook
|
Training a RNN to synthesize English text character by character.ipynb
|
alexanderbea/Synthesize-English-text-using-Harry-Potter-book-and-RNN
|
5242fbe8ba9b990bcbd5c8c3ba7f86133c3bf5c3
|
[
"MIT"
] | null | null | null |
Training a RNN to synthesize English text character by character.ipynb
|
alexanderbea/Synthesize-English-text-using-Harry-Potter-book-and-RNN
|
5242fbe8ba9b990bcbd5c8c3ba7f86133c3bf5c3
|
[
"MIT"
] | null | null | null |
Training a RNN to synthesize English text character by character.ipynb
|
alexanderbea/Synthesize-English-text-using-Harry-Potter-book-and-RNN
|
5242fbe8ba9b990bcbd5c8c3ba7f86133c3bf5c3
|
[
"MIT"
] | null | null | null | 58.6875 | 13,888 | 0.681076 |
[
[
[
"**Training a RNN to synthesize English text character by character** \n\nHerein I have trained a vanilla RNN with outputs using the text from the book The Globlet of Fire by J.K. Rowling.*",
"_____no_output_____"
],
[
"The following implementation will train a recurrent neural network (RNN) that shows how the evolution of the text synthesized by my RNN during training by inclduing a sample of synthesized text (200 characters long) before the first and before every 10,000th update steps when I train for 100,000 update. Furthermore, I also present 1000 characters with the best implementation.",
"_____no_output_____"
]
],
[
[
"#@title Installers\n!pip install texttable",
"Requirement already satisfied: texttable in /usr/local/lib/python3.6/dist-packages (1.6.2)\n"
],
[
"#@title Import libraries\nfrom texttable import Texttable\nfrom collections import OrderedDict\nfrom keras import applications\nfrom keras.models import Sequential\nfrom keras.layers import Flatten\nfrom keras.layers import Input\nfrom keras.models import Model\nfrom keras.layers import Dense\nfrom keras.layers import Dropout\nfrom keras.utils import to_categorical\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom google.colab import drive\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport random\n\ndrive.mount('/content/drive/')",
"Using TensorFlow backend.\n"
],
[
"#@title Functions: Read file from drive\ndef LoadData():\n data = open(\"/content/../goblet_book.txt\", \"r\", encoding='utf8').read()\n chars = list(set(data))\n data = {\"data\": data, \"chars\": chars,\n \"vocLen\": len(chars), \"getIndFromChar\": OrderedDict(\n (char, ix) for ix, char in enumerate(chars)),\n \"getCharFromInd\": OrderedDict((ix, char) for ix, char in\n enumerate(chars))}\n return data",
"_____no_output_____"
],
[
"#@title Functions: Initialization\nclass RecurrentNeuralNetwork():\n def __init__(self, data, m=100, eta=.1, seq_length=25):\n self.m, self.eta, self.N = m, eta, seq_length\n for k, v in data.items():\n setattr(self, k, v)\n self.b, self.c, self.U, self.V, self.W = self._init_parameters(self.m, self.vocLen)\n\n @staticmethod\n def _init_parameters(m, K, sig=0.01):\n c = np.zeros((K, 1))\n b = np.zeros((m, 1))\n V = np.random.normal(0, sig, size=(K, m))\n W = np.random.normal(0, sig, size=(m, m))\n U = np.random.normal(0, sig, size=(m, K))\n return b, c, U, V, W",
"_____no_output_____"
],
[
"#@title Functions: Softmax, EvaluateClassifier\nclass RNN_With_Functions(RecurrentNeuralNetwork):\n @staticmethod\n def SoftMax(x):\n s = np.exp(x - np.max(x, axis=0)) / np.exp(x - np.max(x, axis=0)).sum(axis=0)\n return s\n\n def EvaluateClassifier(self, h, x):\n a = self.W@h + self.U@x + self.b\n h = np.tanh(a)\n o = self.V@h + self.c\n p = self.SoftMax(o)\n return a, h, o, p\n",
"_____no_output_____"
],
[
"#@title Functions: Synthesize Text\nclass RNN_Synthesizer(RNN_With_Functions):\n def SynthesizeText(self, h, aax, n):\n text = ''\n nxt = np.zeros((self.vocLen, 1))\n nxt[aax] = 1 \n for s in range(n):\n _, h, _, p = self.EvaluateClassifier(h, nxt)\n aax = np.random.choice(range(self.vocLen), p=p.flat)\n nxt = np.zeros((self.vocLen, 1))\n nxt[aax] = 1 \n text += self.getCharFromInd[aax]\n return text",
"_____no_output_____"
]
],
[
[
"The following functions will compute the gradients analytically, numerically and check the gradietns. The difference between the two gradients computation will be iteratively presented when the training is ongoing.",
"_____no_output_____"
]
],
[
[
"#@title Functions: Compute and Check Gradients\nclass RNN_Gradients(RNN_Synthesizer):\n def ComputeGradientsAnalytically(self, inputs, targets, hp):\n loss = 0\n aa, bb, cc, dd, ee = {}, {}, {}, {}, {}\n cc[-1] = np.copy(hp)\n nt = len(inputs)\n for t in range(nt):\n bb[t] = np.zeros((self.vocLen, 1))\n bb[t][inputs[t]] = 1 \n aa[t], cc[t], dd[t], ee[t] = self.EvaluateClassifier(cc[t-1], bb[t])\n loss += -np.log(ee[t][targets[t]][0]) \n\n gradients = {\"W\": np.zeros_like(self.W), \"U\": np.zeros_like(self.U),\n \"V\": np.zeros_like(self.V), \"b\": np.zeros_like(self.b),\n \"c\": np.zeros_like(self.c), \"o\": np.zeros_like(ee[0]),\n \"h\": np.zeros_like(cc[0]), \"hnxt\": np.zeros_like(cc[0]),\n \"a\": np.zeros_like(aa[0])}\n\n for t in reversed(range(nt)):\n gradients[\"o\"] = np.copy(ee[t])\n gradients[\"o\"][targets[t]] -= 1\n gradients[\"V\"] += gradients[\"o\"]@cc[t].T\n gradients[\"c\"] += gradients[\"o\"]\n gradients[\"h\"] = self.V.T@gradients[\"o\"] + gradients[\"hnxt\"]\n gradients[\"a\"] = np.multiply(gradients[\"h\"], (1 - np.square(cc[t])))\n gradients[\"U\"] += gradients[\"a\"]@bb[t].T\n gradients[\"W\"] += gradients[\"a\"]@cc[t-1].T\n gradients[\"b\"] += gradients[\"a\"]\n gradients[\"hnxt\"] = self.W.T@gradients[\"a\"]\n\n gradients = {k: gradients[k] for k in gradients if k not in [\"o\", \"h\", \"hnxt\", \"a\"]}\n for gr in gradients: gradients[gr] = np.clip(gradients[gr], -5, 5)\n he = cc[nt-1]\n return gradients, loss, he\n\n def ComputeGradientsNumerically(self, inputs, targets, hp, h, nc=20):\n network_params = {\"W\": self.W, \"U\": self.U, \"V\": self.V, \"b\": self.b, \"c\": self.c}\n num_gradients = {\"W\": np.zeros_like(self.W), \"U\": np.zeros_like(self.U),\n \"V\": np.zeros_like(self.V), \"b\": np.zeros_like(self.b),\n \"c\": np.zeros_like(self.c)}\n\n for key in network_params:\n for i in range(nc):\n prevpar = network_params[key].flat[i] \n network_params[key].flat[i] = prevpar + h\n _, l1, _ = self.ComputeGradientsAnalytically(inputs, targets, hp)\n network_params[key].flat[i] = prevpar - h\n _, l2, _ = self.ComputeGradientsAnalytically(inputs, targets, hp)\n network_params[key].flat[i] = prevpar \n num_gradients[key].flat[i] = (l1 - l2) / (2*h)\n\n return num_gradients\n\n\n def CheckGradients(self, inputs, targets, hp, nc=20):\n analytical_gr, _, _ = self.ComputeGradientsAnalytically(inputs, targets, hp)\n numerical_gr = self.ComputeGradientsNumerically(inputs, targets, hp, 1e-5)\n\n err = Texttable()\n err_data = [] \n\n # Compare accurate numerical method with analytical estimation of gradient\n err_data.append(['Gradient', 'Method', 'Abs Diff Mean [e-06]'])\n\n print(\"Gradient checks:\")\n for grad in analytical_gr:\n num = abs(analytical_gr[grad].flat[:nc] - numerical_gr[grad].flat[:nc])\n denom = np.asarray([max(abs(a), abs(b)) + 1e-10 for a,b in zip(analytical_gr[grad].flat[:nc],numerical_gr[grad].flat[:nc])])\n err_data.append([grad, \"ANL vs NUM\", str(max(num / denom)*100*10*100)])\n\n err.add_rows(err_data)\n print(\"Method Comparison: Analytical vs Numerical\")\n print(err.draw()) \n",
"_____no_output_____"
],
[
"#@title Functions: Check Gradients\ndef CompareGradients():\n e=0\n data = LoadData()\n network = RNN_Gradients(data)\n hp = np.zeros((network.m, 1))\n\n inputs = [network.getIndFromChar[char] for char in network.data[e:e+network.N]]\n targets = [network.getIndFromChar[char] for char in network.data[e+1:e+network.N+1]]\n\n gradients, loss, hp = network.ComputeGradientsAnalytically(inputs, targets, hp)\n\n # Check gradients\n network.CheckGradients(inputs, targets, hp)\n",
"_____no_output_____"
]
],
[
[
"i) The following generates the gradient comparing result (max relative error) that shows that the implemented analytical gradient method is close enough to be regarded as accurate. Within this check, a state sequence of zeros was used as well as hyperparameters of m=100 (hidden state dimensionality) and eta=.1 (learning rate), seq_length=25 and sig=.01. Important to note is that I only check the first initial entries of the gradient matrices for the following resulting max relative errors.",
"_____no_output_____"
]
],
[
[
"CompareGradients()",
"Gradient checks:\nMethod Comparison: Analytical vs Numerical\n+----------+------------+----------------------+\n| Gradient | Method | Abs Diff Mean [e-06] |\n+==========+============+======================+\n| W | ANL vs NUM | 1.188 |\n+----------+------------+----------------------+\n| U | ANL vs NUM | 0.059 |\n+----------+------------+----------------------+\n| V | ANL vs NUM | 0.108 |\n+----------+------------+----------------------+\n| b | ANL vs NUM | 0.010 |\n+----------+------------+----------------------+\n| c | ANL vs NUM | 0.001 |\n+----------+------------+----------------------+\n"
],
[
"#@title Functions: Run Training\nlosses = []\ndef RunTraining():\n num_epochs = 9 #ändra till 3 när jag kört för bästa sen\n e, n, epoch = 0, 0, 0\n data = LoadData()\n network = RNN_Gradients(data) \n network_params = {\"W\": network.W, \"U\": network.U, \"V\": network.V, \"b\": network.b, \"c\": network.c}\n params = {\"W\": np.zeros_like(network.W), \"U\": np.zeros_like(network.U), \"V\": np.zeros_like(network.V), \"b\": np.zeros_like(network.b),\"c\": np.zeros_like(network.c)}\n\n while epoch <= num_epochs and n <= 600000: #ändra till 100,000 när denna är klar\n if n == 0 or e >= (len(network.data) - network.N - 1):\n hp = np.zeros((network.m, 1))\n epoch += 1\n e = 0\n\n inputs = [network.getIndFromChar[char] for char in network.data[e:e+network.N]]\n targets = [network.getIndFromChar[char] for char in network.data[e+1:e+network.N+1]]\n gradients, loss, hp = network.ComputeGradientsAnalytically(inputs, targets, hp)\n\n if n == 0 and epoch == 1: smoothloss = loss\n smoothloss = 0.999 * smoothloss + 0.001 * loss\n\n if n % 10000 == 0:\n text = network.SynthesizeText(hp, inputs[0], 200)\n print('\\nIterations %i, smooth loss: %f \\n %s\\n' % (n, smoothloss, text))\n\n for k in network_params:\n params[k] += gradients[k] * gradients[k]\n network_params[k] -= network.eta / np.sqrt(params[k] + np.finfo(float).eps) * gradients[k]\n\n e += network.N\n n += 1\n losses.append(smoothloss) \n\n text = network.SynthesizeText(hp, inputs[0], 1000)\n\n print('\\nBest performance')\n print('\\n %s\\n' % (text)) ",
"_____no_output_____"
]
],
[
[
"iii) Next follows the 200 characters of synthesized text before the first and before every 10,000th update steps when I train for 100,000 update steps. Smooth loss is also displayed\n\niv) Best performance of 1000 characters is also presented (390,000 iterations)",
"_____no_output_____"
]
],
[
[
"RunTraining()",
"\nIterations 0, smooth loss: 109.549578 \n vwcob1k7j)Z9CAgHKüt}/)MAGiUmC(ZBxDziJ,I:G,PY4v)V6gXucE2MRX20f\n,\"PL4Ywyyvo^I2DuPE•w,9x;TlIo(GUq/gHüa I,szAAma:EWLL:IQ.Y7:;\tMV0qe2üy6K3pW0xmm? ktdaNJKOwv7ESIA}N.g(FOqFk^KAt9/-yKCnlOiz,ü\tyHl6kcMgoX6AePDG\n\n\nIterations 10000, smooth loss: 56.221798 \n ole. . Bed harcutea walls thand rey'a sidess cust,\"\nPailping hes rtromitheighery as'singe,\" the diand innted to bul gh \"I sulled ase he the foachey ingom out ojbaen ladminglait Hardoud witistithith \n\n\nIterations 20000, smooth loss: 52.583628 \n ed hay; carkigt late at shes wemped. us -I. buirgaryee tho undo wes's of ton the aling must haflid Fput. Sbike in \"or cark whinf ouss hagry, roimptod do anming were Cutca oble corciens shough ap sate\n\n\nIterations 30000, smooth loss: 51.172260 \n egrer.\n\"Wla't nows goft as yough hou thicoutsed oreboning here, . . This's youg, anrtey?\n\"Yougit, eatpeder. ... . ... narr, wers thitodid and Cawled dagmsto bagh stich a barkes quast eadbyeperols ack\n\n\nIterations 40000, smooth loss: 50.165879 \n oure drace coughth, to hat he beemory-s uf ald. OAly,\" sboud hed I frily heen acay outell the gonand . .\nHarrise thater sevedes Ile of his and and said ongh thisen, thasby stom thene cotchelthing he\n\n\nIterations 50000, smooth loss: 50.865629 \n though his tom of and col turred, a the leone our.\"\n\"Herly was he and shennaring, frous.\n\"A'm tols and Cisuve leifore panked,\" to lofs the wis with at wate of ghas dood saraye and ned Cro's ullfows a\n\n\nIterations 60000, smooth loss: 49.737420 \n dern's fext you fout apone, Shese ceed was rooked ame the qual, flit mumoutroad be maidell bapth duned!\" suterssistes foral, \"Jurt, who hall ataid owaid Dy monca'tind, said The jogwnting.\n\"Yo have.\n\n\n\nIterations 70000, smooth loss: 49.354169 \n fon as in wat fiskog off tous them aren. as?\"\n\"Mly shought hathey seple the pothing sionk panyardontt hit fating orlling thene Fid.\nCand in your he padg ahd, Harrip of ther into had Harryen, masing h\n\n\nIterations 80000, smooth loss: 47.839903 \n omen. The ary you the berts tereever ston a dighbeered, - said he dowhing.. He meais bow.\n\"T. wite Dagwrow was seat thats you'rr, rule him twourelfseding at Mrseln't brome houpledong forf, hadley; M\n\n\nIterations 90000, smooth loss: 48.541875 \n nt zerm you's was sold hingr palkack wet us .. ibledy . Whinn a haguntiever lopllay emold lilk.\n\tquifime icf-ore dastert ... you margeifhangan and heesingy.\n\"It bantionth rcutt forly hit. That be looo\n\n\nIterations 100000, smooth loss: 49.408212 \n he he the coping are houct treart? The mith ungwe?\" An rume she hing unging to trenting begmawing wiod be stutmom thes seading dealleth RRenot shail with ben wast coy cosee wat harftey noin a poume t\n\n\nIterations 110000, smooth loss: 47.565926 \n aring hem out thes the besting to jad suring he pray?\" nempont just rif, him -\"I caking his spor tow lit your me dobir vory slef thindy dad was shid the rid in lin to nut be hos as saf ers'h nroward, \n\n\nIterations 120000, smooth loss: 47.558590 \n ne staed. \"Whape. Gooked as thapllfoniss here menttart feefod hays, the chert one lake fill on pot abetishy dotcriaky. Nock aly tipar the hall of bomking him You've dyy Saytan to nack dlaconove bic\n\n\nIterations 130000, smooth loss: 46.752685 \n t you peexing and as MoRbeding igh that smopoy the whires that I wish thinthered him sleettry.\"\n\"Aurer wand, Weduns; so coubl-. . . .\"\n\"Dumporzerer in the gafore which, it manying everned fiming sotin\n\n\nIterations 140000, smooth loss: 49.555780 \n ed amand on to gobbededofperould of whe limpee the cuplancmarss filun, and - arround ove and of a voingermentt blowp scarting Harry bracely on wonso abder ceer gomriont bedreameled sind himased and hi\n\n\nIterations 150000, smooth loss: 47.335362 \n ow wolt over and fwo cmoly, dingeath intc'ce the Serfuine fatk.\"\nFree Mere dyour inctoo yto ceyting juthen is again cound fart coment ayand.\n he an pelp wing drealt.. My him. \"Oh had , stand afly an\n\n\nIterations 160000, smooth loss: 47.318467 \n he watle they thriod sitin, it peande fertaron all expaying usas shoy sirn's at've Imrad. \"No itices and timly, sthering waiked of an' Harry. . It a tabout, shad in santo,\" past Roz Herire waure a coy\n\n\nIterations 170000, smooth loss: 46.430393 \n Hour, to bermiss. Harry nen up wail cortt . . . ...Mord blined ofte were wear, rull, -\"Nother sise Doss to lefor Siltey south has how the come wair fout look heated ay sure abe dost im, is wo know ve\n\n\nIterations 180000, smooth loss: 47.534713 \n couldy of sexor the sumgarny. Harry, themored youd anfelley coll,\"\n\"Yeanded has he would. \"I - I cawnt bee Le, horey.\nVoddnits sourPy.\n\"Hardy pret vougels Verniseincon Mavey any, trouded now wool fe\n\n\nIterations 190000, smooth loss: 47.654171 \n to enwart.\nWermied the got one af litiou. sairy aghidt the magisins Finked Ixagal tong the him not voiur led yowher knowsat gow es the colf-atace mortisc at outed a tang digione litt avoll, at hil d\n\n\nIterations 200000, smooth loss: 46.288266 \n d, scepile Cuper tinked. Wealling a fiden. \"Dest,\" said Harry rabcing sile, his caden and devirnss lqulach cleel, waye so You foixting and atcacle'ved Prar you't!\" Broto sutcaned mystully had Cetwin\n\n\nIterations 210000, smooth loss: 46.309030 \n inkon alle were mearnt but gon had for treselssed. .\n\"No dapont peem an - \"The him faring was youll deason had eaws, Wer the Citilcuod he the pide walk hims hew, exfere batffinve'd abont, hadf the dob\n\n\nIterations 220000, smooth loss: 45.458486 \n t trisesnenctil?\" The Pesch. Heruld. She lefed tander with Krum. \"Ke snaired air. . he statest Euss have Votecloured on outeeastol me!\"\n\"Io bolet, his condotcromfeed thincarow that my just theyer \n\n\nIterations 230000, smooth loss: 45.702497 \n Ron to Mr. Weay, tiks gery by the his in in the's thene retisen to chear.\n\"What Brom the palle sew watch nivcher sigh?\"\nIt -\"\nWearone astepscests as who!\" said He. \"Itun then an timing yougly?\" . in, \n\n\nIterations 240000, smooth loss: 46.448490 \n nthy \"pedeee. Cet Harry Harry umpaevern, if beson't Dumplackents them you,\" said Harry. He came hig agay shatping it orcoungecril Hagrys, matk houldcly of seavell him.\n\t\"That off nors be was and ind\n\n\nIterations 250000, smooth loss: 46.968253 \n landon.\"\n\"Io fascred mone coming to go got Feloy nas at the aponting ontled newr, I gether.\"\nOmer disfic at the rork - efat walm and I time, his he sereh, the get the Oglly wan's the his at hisse and \n\n\nIterations 260000, smooth loss: 45.188710 \n Yoo lack letcenbost raightly Harry verp and that a wamed culll.\n\"Domeand keetore, whit head Pomble, and in the backed. Harrulviy that the surked juct thre?\"\nHe penw storrslesed. \"I lid morting whis a\n\n\nIterations 270000, smooth loss: 46.559270 \n st. Weame. \"At are now Andiont he lasleytherst and 'roms,\" said Mlight trew macking and thou this this did Cigdins becobe to pell with for at caseld pucontemp take, fore. TheRent of das Antsunge the\n\n\nIterations 280000, smooth loss: 47.020566 \n wirting feet indo, the'vor-libled to didores over bugron. The grottur grorkertifed as upingireston't owh arrsetery upmay they thoutry cerangly spoll, and, look...\" Ron, \"as in -\"\n\"I'm look, strombler\n\n\nIterations 290000, smooth loss: 45.623323 \n itelal in the Giffor any.\nThice comen you whare were the glew laile who disiy secmed got jirst in Mr. Ron bourenss are Hosked by cought you, infur.\n\"Rudding to Fho's up. Sin pout the chow disnd squrek\n\n\nIterations 300000, smooth loss: 44.399938 \n Harry. \"I sewing then waarow.\n\"Geemortly monet to them they shay Kriggr tor becous. Harded.\nItil; the star on angon chave Bust in though to theu falled.\n\"Dulknos waid Ron - -\"\nThatre, had lequle care\n\n\nIterations 310000, smooth loss: 44.505906 \n h thut't a sfutres.\"\nWe star Durgle\"fan, mised over on I town lorge a ground he's you of better love.\"\n\"On I filat itiou. Vold to hive word was as a intpartaed stail-scmelt that ivor, yilt groated on \n\n\nIterations 320000, smooth loss: 45.841045 \n exesp the stryod?\"\nVery evenychuvion that was hoully said, siveith lial -\"\n\"Moonst is tho tizad thouges. Whic molt be whatcing.\n\"Hadves, he's ceaking laskny a gronch vasire grome it abrud look falled\n\n\nIterations 330000, smooth loss: 45.313284 \n oge a he Hadred being.\n\tNom to jist of then ouxion's out at tolite lighm, andentcrove fing nace to the didemput fime hen's I've wace offer.\n\"I yalt . \"We tett's, in should ussid, mollt, lime tunt teve\n\n\nIterations 340000, smooth loss: 45.590387 \n l', his comsiones why a was dy though as theimec, courd goblely stowe eraks couldry bugly giblabby for the dix Harry so filely was thrir theim susped dupp the batter anaugh, an and spaking be tece got\n\n\nIterations 350000, smooth loss: 45.458497 \n brabeld Harry fal his folse the sow strave, ged that and han stilen are narge and file batwen as a mout not!\" neen didgy, scarl, the was of the Liggize my Vomon could ile he weir te havite, wings had\n\n\nIterations 360000, smooth loss: 46.547103 \n te sure fac up, es wall Mr. Juplely bray, in the strecmed. The curproget,\" sayt wasly? . . ... ever bat got they popped of the voiking out intone as the poon's urmars of frolly in pasal and say shad\n\n\nIterations 370000, smooth loss: 45.467948 \n is hain at marove furtonss smich belly calaght of jeas were to grandes on Lorss to gos efor had a dom puror up a got Mr. \"Wared beentle same Dumpting the contents sords must's besens be the spilu bobe\n\n\nIterations 380000, smooth loss: 45.561363 \n l slooked staide fila, no galasily, Haroffly past Rens as they Harry deeked bove rair at and beam, rot to got.\" \"I wammeefer to but door and preasing at whowh frion said atly her witthappe.\nFO Ron tha\n\n\nIterations 390000, smooth loss: 44.035467 \n and did soriza, ant with the .... . . he top. Harry wiis it, as here of Porking? Pon?\" said Slep. \"Hars. Wee up th Dirry. . . .\n\"The the off cay?\" Herrir duikting deen!\" that's Moody, a dark over \n\n\nBest performance\n\n EN Toould the let bork ealfied and Volden at to for arry gad to Gentme-Tlack migh guzaictching and blair. The Dift Ma. Weimacwar. .\n\nHO. MI Dejorver jusk the sind of halm the Goill. . \"You you've's Harry, him ope, there, and ricked to he pesle. \"I pack.\" Cring of sullsest unveseffinge the mome. Wen't thet, by, agaits, nos bays thlean though Dumblesenot to hust -\"\nMirls, she bach aivom.\"\n\"Wher exouce?\" said Mngenfoitly bointing my - the - he based clooked!\"\n\"Beviges and she could of her iflown wert Bovient,\" said Dumbledore.\n\"What has foughins. He not youch him he be freathing Sorance.\n\"It'll the mast seamed her and her and Volly, and frinting.\nIt naw her it ass him.\n\"Yew.\n\"himing as they one the tapen't to the tain as they dert.\n\"Pelt mat palt talk keet ......\n\"Bmint and san ienforls. he tham no croslict simen he ana. \"Chem and his hoth.\nThere,\" stutared Pindy was head; mert, there heidy bear them off crevenblerold Dopllened mad is Kermorth, grbented of go whand Hormsgor ouze it -\n\n"
]
],
[
[
"ii) A graph of the smooth loss function for a longish training run (3 epochs)",
"_____no_output_____"
]
],
[
[
"#@title Functions: Smooth Loos Plot\ndef plot():\n loss_plot = plt.plot(losses, label=\"training loss\")\n plt.xlabel('epoch')\n plt.ylabel('loss')\n plt.legend()\n plt.show() ",
"_____no_output_____"
],
[
"plot()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a2ac78f25a29bbe1262cf8efb82a2e241d21cea
| 3,820 |
ipynb
|
Jupyter Notebook
|
stable/_downloads/866c1fc31d7a0ae19e59229de2cf3bc5/plot_source_space_morphing.ipynb
|
drammock/mne-tools.github.io
|
5d3a104d174255644d8d5335f58036e32695e85d
|
[
"BSD-3-Clause"
] | null | null | null |
stable/_downloads/866c1fc31d7a0ae19e59229de2cf3bc5/plot_source_space_morphing.ipynb
|
drammock/mne-tools.github.io
|
5d3a104d174255644d8d5335f58036e32695e85d
|
[
"BSD-3-Clause"
] | null | null | null |
stable/_downloads/866c1fc31d7a0ae19e59229de2cf3bc5/plot_source_space_morphing.ipynb
|
drammock/mne-tools.github.io
|
5d3a104d174255644d8d5335f58036e32695e85d
|
[
"BSD-3-Clause"
] | null | null | null | 70.740741 | 2,352 | 0.634817 |
[
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\n# Use source space morphing\n\n\nThis example shows how to use source space morphing (as opposed to\nSourceEstimate morphing) to create data that can be compared between\nsubjects.\n\n<div class=\"alert alert-danger\"><h4>Warning</h4><p>Source space morphing will likely lead to source spaces that are\n less evenly sampled than source spaces created for individual\n subjects. Use with caution and check effects on localization\n before use.</p></div>\n",
"_____no_output_____"
]
],
[
[
"# Authors: Denis A. Engemann <[email protected]>\n# Eric larson <[email protected]>\n#\n# License: BSD (3-clause)\n\nimport os.path as op\n\nimport mne\n\ndata_path = mne.datasets.sample.data_path()\nsubjects_dir = op.join(data_path, 'subjects')\nfname_trans = op.join(data_path, 'MEG', 'sample',\n 'sample_audvis_raw-trans.fif')\nfname_bem = op.join(subjects_dir, 'sample', 'bem',\n 'sample-5120-bem-sol.fif')\nfname_src_fs = op.join(subjects_dir, 'fsaverage', 'bem',\n 'fsaverage-ico-5-src.fif')\nraw_fname = op.join(data_path, 'MEG', 'sample', 'sample_audvis_raw.fif')\n\n# Get relevant channel information\ninfo = mne.io.read_info(raw_fname)\ninfo = mne.pick_info(info, mne.pick_types(info, meg=True, eeg=False,\n exclude=[]))\n\n# Morph fsaverage's source space to sample\nsrc_fs = mne.read_source_spaces(fname_src_fs)\nsrc_morph = mne.morph_source_spaces(src_fs, subject_to='sample',\n subjects_dir=subjects_dir)\n\n# Compute the forward with our morphed source space\nfwd = mne.make_forward_solution(info, trans=fname_trans,\n src=src_morph, bem=fname_bem)\nmag_map = mne.sensitivity_map(fwd, ch_type='mag')\n\n# Return this SourceEstimate (on sample's surfaces) to fsaverage's surfaces\nmag_map_fs = mag_map.to_original_src(src_fs, subjects_dir=subjects_dir)\n\n# Plot the result, which tracks the sulcal-gyral folding\n# outliers may occur, we'll place the cutoff at 99 percent.\nkwargs = dict(clim=dict(kind='percent', lims=[0, 50, 99]),\n # no smoothing, let's see the dipoles on the cortex.\n smoothing_steps=1, hemi='rh', views=['lat'])\n\n# Now note that the dipoles on fsaverage are almost equidistant while\n# morphing will distribute the dipoles unevenly across the given subject's\n# cortical surface to achieve the closest approximation to the average brain.\n# Our testing code suggests a correlation of higher than 0.99.\n\nbrain_subject = mag_map.plot( # plot forward in subject source space (morphed)\n time_label=None, subjects_dir=subjects_dir, **kwargs)\n\nbrain_fs = mag_map_fs.plot( # plot forward in original source space (remapped)\n time_label=None, subjects_dir=subjects_dir, **kwargs)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2ae4acdb47e57ab9d96c4ea1ade131dff0b84a
| 821,137 |
ipynb
|
Jupyter Notebook
|
2_BoW_Models/1_MLP/MLP_SUBJ.ipynb
|
jrderek/Text-Classification-
|
384448c37d9619490fac29b4731084eea8ef4007
|
[
"MIT"
] | null | null | null |
2_BoW_Models/1_MLP/MLP_SUBJ.ipynb
|
jrderek/Text-Classification-
|
384448c37d9619490fac29b4731084eea8ef4007
|
[
"MIT"
] | null | null | null |
2_BoW_Models/1_MLP/MLP_SUBJ.ipynb
|
jrderek/Text-Classification-
|
384448c37d9619490fac29b4731084eea8ef4007
|
[
"MIT"
] | null | null | null | 161.609329 | 378,156 | 0.575775 |
[
[
[
"# MLP Classification with SUBJ Dataset\n<hr>\n\nWe will build a text classification model using MLP model on the SUBJ Dataset. Since there is no standard train/test split for this dataset, we will use 10-Fold Cross Validation (CV). \n\n## Load the library",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport re\nimport nltk\nimport random\nfrom nltk.corpus import stopwords, twitter_samples\n# from nltk.tokenize import TweetTokenizer\nfrom sklearn.model_selection import KFold\nfrom nltk.stem import PorterStemmer\nfrom string import punctuation\nfrom sklearn.preprocessing import OneHotEncoder\nfrom tensorflow.keras.preprocessing.text import Tokenizer\nimport time\n\n%config IPCompleter.greedy=True\n%config IPCompleter.use_jedi=False\n# nltk.download('twitter_samples')",
"_____no_output_____"
],
[
"tf.config.experimental.list_physical_devices('GPU')",
"_____no_output_____"
]
],
[
[
"## Load the Dataset",
"_____no_output_____"
]
],
[
[
"corpus = pd.read_pickle('../../0_data/SUBJ/SUBJ.pkl')\ncorpus.label = corpus.label.astype(int)\nprint(corpus.shape)\ncorpus",
"(10000, 3)\n"
],
[
"corpus.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10000 entries, 0 to 9999\nData columns (total 3 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 sentence 10000 non-null object\n 1 label 10000 non-null int32 \n 2 split 10000 non-null object\ndtypes: int32(1), object(2)\nmemory usage: 195.4+ KB\n"
],
[
"corpus.groupby( by='label').count()",
"_____no_output_____"
],
[
"# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)",
"_____no_output_____"
]
],
[
[
"## Raw Number of Vocabulary",
"_____no_output_____"
]
],
[
[
"# Build the raw vocobulary for first inspection\ntokenizer = Tokenizer()\ntokenizer.fit_on_texts(sentences)\nvocab_raw = tokenizer.word_index\nprint('\\nThe vocabulary size: {}\\n'.format(len(vocab_raw)))\nprint(vocab_raw)",
"\nThe vocabulary size: 21322\n\n{'the': 1, 'a': 2, 'and': 3, 'of': 4, 'to': 5, 'in': 6, 'is': 7, \"'s\": 8, 'it': 9, 'that': 10, 'his': 11, 'with': 12, 'as': 13, 'for': 14, 'an': 15, 'but': 16, 'on': 17, 'he': 18, 'her': 19, 'this': 20, 'by': 21, 'film': 22, 'who': 23, 'has': 24, 'be': 25, 'from': 26, 'are': 27, 'its': 28, 'their': 29, 'one': 30, 'at': 31, 'movie': 32, 'you': 33, 'they': 34, \"n't\": 35, 'about': 36, 'not': 37, 'when': 38, 'all': 39, 'out': 40, 'she': 41, 'have': 42, 'into': 43, 'more': 44, 'life': 45, 'up': 46, 'story': 47, 'him': 48, 'than': 49, 'like': 50, 'love': 51, 'what': 52, 'so': 53, 'or': 54, 'will': 55, 'new': 56, 'time': 57, 'if': 58, 'only': 59, 'world': 60, 'there': 61, 'just': 62, 'does': 63, 'two': 64, 'man': 65, 'no': 66, 'can': 67, 'them': 68, 'young': 69, 'old': 70, 'way': 71, 'was': 72, 'good': 73, 'some': 74, 'after': 75, 'even': 76, 'most': 77, 'which': 78, 'too': 79, 'much': 80, 'been': 81, 'i': 82, 'make': 83, 'while': 84, 'family': 85, 'own': 86, 'get': 87, 'do': 88, 'year': 89, 'through': 90, 'where': 91, 'first': 92, 'find': 93, 'well': 94, 'comedy': 95, 'other': 96, 'best': 97, 'very': 98, 'years': 99, 'back': 100, 'little': 101, 'work': 102, 'never': 103, 'off': 104, 'how': 105, 'director': 106, 'between': 107, 'characters': 108, 'enough': 109, 'also': 110, 'over': 111, 'down': 112, 'makes': 113, 'may': 114, 'we': 115, 'being': 116, 'day': 117, 'people': 118, 'go': 119, 'father': 120, 'girl': 121, 'before': 122, 'made': 123, 'see': 124, 'take': 125, 'would': 126, 'could': 127, 'end': 128, 'us': 129, 'both': 130, 'now': 131, 'must': 132, 'long': 133, 'then': 134, 'still': 135, 'any': 136, 'lives': 137, 'your': 138, 'american': 139, 'woman': 140, 'comes': 141, 'home': 142, 'takes': 143, 'action': 144, 'finds': 145, 'bad': 146, 'school': 147, 'mother': 148, 'himself': 149, 'real': 150, 'many': 151, 'friends': 152, 'those': 153, 'funny': 154, 'together': 155, 'another': 156, 'high': 157, 'help': 158, 'look': 159, 'death': 160, 'big': 161, 'had': 162, 'movies': 163, 'set': 164, 'three': 165, 'every': 166, 'without': 167, 'drama': 168, 'really': 169, 'become': 170, 'great': 171, 'nothing': 172, 'something': 173, 'city': 174, 'because': 175, 'each': 176, 'come': 177, 'should': 178, 'heart': 179, 'becomes': 180, 'war': 181, 'gets': 182, 'these': 183, 'things': 184, 'ever': 185, 'were': 186, 'son': 187, 'better': 188, \"'re\": 189, 'such': 190, 'against': 191, 'last': 192, 'though': 193, 'true': 194, 'documentary': 195, 'might': 196, 'character': 197, 'ca': 198, 'away': 199, 'women': 200, 'self': 201, 'seems': 202, 'films': 203, 'place': 204, 'soon': 205, 'cast': 206, 'wife': 207, 'boy': 208, 'plot': 209, 'past': 210, 'same': 211, 'yet': 212, 'whose': 213, 'men': 214, 'hard': 215, 'once': 216, 'daughter': 217, 'around': 218, 'few': 219, 'kind': 220, 'going': 221, 'goes': 222, 'friend': 223, 'far': 224, 'hollywood': 225, 'sense': 226, 'job': 227, 'john': 228, 'thing': 229, 'begins': 230, 'tale': 231, 'performances': 232, 'less': 233, 'turns': 234, 'small': 235, 'part': 236, 'de': 237, 'here': 238, 'fun': 239, 'falls': 240, 'until': 241, 'money': 242, 'works': 243, 'along': 244, 'beautiful': 245, 'however': 246, 'live': 247, 'dark': 248, 'night': 249, 'screen': 250, 'star': 251, 'human': 252, 'often': 253, 'house': 254, 'murder': 255, 'music': 256, 'quite': 257, 'full': 258, 'ultimately': 259, \"'ll\": 260, 'kids': 261, 'everything': 262, \"'\": 263, 'again': 264, 'our': 265, 'children': 266, 'almost': 267, 'during': 268, 'town': 269, 'despite': 270, 'know': 271, 'dead': 272, 'tries': 273, 'keep': 274, 'romantic': 275, 'living': 276, 'wants': 277, 'making': 278, 'itself': 279, 'left': 280, 'york': 281, 'meets': 282, 'right': 283, 'thriller': 284, 'audience': 285, 'watching': 286, 'art': 287, 'want': 288, 'power': 289, 'relationship': 290, 'script': 291, 'writer': 292, 'entertaining': 293, 'since': 294, 's': 295, 'evil': 296, 'black': 297, 'humor': 298, 'feel': 299, 'gives': 300, \"'ve\": 301, 'age': 302, 'under': 303, 'dream': 304, 'interesting': 305, 'perfect': 306, 'having': 307, 'show': 308, 'based': 309, 'group': 310, 'moments': 311, 'looking': 312, 'worth': 313, 'feels': 314, 'secret': 315, 'times': 316, 'history': 317, 'journey': 318, 'trying': 319, 'special': 320, 'picture': 321, 'discovers': 322, 'mind': 323, 'country': 324, 'plays': 325, 'face': 326, 'named': 327, 'watch': 328, 'acting': 329, 'next': 330, 'minutes': 331, 'performance': 332, 'turn': 333, 'short': 334, 'my': 335, 'emotional': 336, 'drug': 337, 'four': 338, 'days': 339, 'order': 340, 'think': 341, 'always': 342, 'series': 343, 'experience': 344, 'tells': 345, 'did': 346, 'original': 347, 'parents': 348, 'lot': 349, 'seen': 350, 'follows': 351, 'mysterious': 352, 'play': 353, 'actors': 354, 'rather': 355, 'brother': 356, 'lost': 357, 'behind': 358, 'career': 359, 'themselves': 360, 'finally': 361, 'crime': 362, 'sometimes': 363, 'anyone': 364, 'plan': 365, 'coming': 366, 'search': 367, 'stories': 368, 'feature': 369, 'video': 370, 'seem': 371, 'least': 372, 'why': 373, 'modern': 374, 'herself': 375, 'everyone': 376, 'getting': 377, 'husband': 378, 'able': 379, 'police': 380, 'save': 381, 'five': 382, 'reality': 383, 'shot': 384, 'future': 385, 'try': 386, 'events': 387, 'guy': 388, 'give': 389, 'point': 390, 'dreams': 391, 'care': 392, 'half': 393, 'team': 394, 'decides': 395, 'middle': 396, 'starts': 397, 'pretty': 398, 'cinema': 399, 'material': 400, 'put': 401, 'moving': 402, 'anything': 403, 'actually': 404, 'forced': 405, 'called': 406, 'working': 407, 'head': 408, 'leads': 409, 'need': 410, 'offers': 411, 'local': 412, 'political': 413, 'game': 414, 'couple': 415, 'done': 416, 'known': 417, 'prison': 418, 'sex': 419, 'me': 420, 'strange': 421, 'compelling': 422, 'thought': 423, 'escape': 424, 'kill': 425, 'hand': 426, 'fact': 427, 'dialogue': 428, 'inside': 429, 'different': 430, 'meet': 431, 'personal': 432, 'manages': 433, 'subject': 434, 'truth': 435, 'bit': 436, 'idea': 437, 'hit': 438, 'second': 439, 'fight': 440, 'whole': 441, 'although': 442, 'entertainment': 443, 'rock': 444, 'chance': 445, 'michael': 446, 'scene': 447, 'filmmaker': 448, 'mr': 449, 'upon': 450, 'say': 451, 'lead': 452, 'david': 453, 'strong': 454, 'change': 455, 'quickly': 456, 'shows': 457, 'style': 458, 'fascinating': 459, 'scenes': 460, 'business': 461, 'found': 462, 'girlfriend': 463, 'sister': 464, 'light': 465, 'culture': 466, 'cinematic': 467, 'leave': 468, 'white': 469, 'child': 470, 'book': 471, 'version': 472, 'tv': 473, 'america': 474, 'killed': 475, 'horror': 476, 'played': 477, 'earth': 478, 'dramatic': 479, 'run': 480, 'social': 481, 'later': 482, 'got': 483, 'stop': 484, 'hope': 485, 'former': 486, 'comic': 487, 'powerful': 488, 'start': 489, 'problem': 490, 'hours': 491, 'discover': 492, 'learn': 493, 'rich': 494, 'close': 495, 'nearly': 496, 'robert': 497, 'trip': 498, 'successful': 499, 'romance': 500, 't': 501, 'sweet': 502, 'class': 503, 'several': 504, 'dog': 505, 'attempt': 506, 'french': 507, 'god': 508, 'classic': 509, 'using': 510, 'bring': 511, 'gang': 512, 'returns': 513, 'leaves': 514, 'jack': 515, 'sent': 516, 'portrait': 517, 'act': 518, 'spirit': 519, 'including': 520, 'marriage': 521, 'given': 522, 'violence': 523, 'deal': 524, 'ago': 525, 'case': 526, 'name': 527, 'break': 528, 'piece': 529, 'band': 530, '233': 531, 'already': 532, 'especially': 533, 'eyes': 534, 'direction': 535, 'summer': 536, 'top': 537, 'line': 538, 'charm': 539, 'wrong': 540, 'fans': 541, 'free': 542, \"'d\": 543, 'moment': 544, 'identity': 545, 'battle': 546, 'college': 547, 'side': 548, 'street': 549, 'effects': 550, 'matter': 551, 'instead': 552, 'title': 553, 'novel': 554, 'dangerous': 555, 'across': 556, 'ride': 557, 'simply': 558, 'alone': 559, 'state': 560, 'girls': 561, 'smart': 562, 'clever': 563, 'looks': 564, 'single': 565, 'car': 566, 'late': 567, 'final': 568, 'running': 569, 'course': 570, 'boys': 571, 'friendship': 572, 'person': 573, 'wo': 574, 'gay': 575, 'community': 576, 'ex': 577, 'adventure': 578, 'artist': 579, 'eye': 580, 'sees': 581, 'hands': 582, 'wedding': 583, 'role': 584, 'ultimate': 585, 'hell': 586, 'talent': 587, 'attempts': 588, 'exactly': 589, 'likely': 590, 'fire': 591, 'narrative': 592, 'o': 593, 'actor': 594, 'taking': 595, 'whom': 596, 'killer': 597, 'agent': 598, 'learns': 599, 'decide': 600, 'tell': 601, 'ends': 602, 'use': 603, 'sure': 604, 'easy': 605, 'company': 606, 'clear': 607, 'visual': 608, 'revenge': 609, 'fall': 610, 'deep': 611, 'bank': 612, 'body': 613, 'runs': 614, 'else': 615, 'camera': 616, 'others': 617, 'dr': 618, 'peter': 619, 'taken': 620, 'trouble': 621, 'probably': 622, 'project': 623, 'ways': 624, 'sam': 625, 'whether': 626, 'beyond': 627, 'eventually': 628, 'important': 629, 'members': 630, 'charlie': 631, '38': 632, 'affair': 633, 'road': 634, 'sets': 635, 'images': 636, 'fine': 637, 'force': 638, 'either': 639, 'success': 640, 'process': 641, 'fast': 642, 'doing': 643, 'rare': 644, 'believe': 645, 'message': 646, 'bizarre': 647, 'serious': 648, 'land': 649, 'hilarious': 650, 'realize': 651, 'brings': 652, 'king': 653, 'detective': 654, 'engaging': 655, 'century': 656, '2': 657, 'ideas': 658, 'uses': 659, 'effort': 660, 'form': 661, 'enjoy': 662, 'secrets': 663, 'knows': 664, 'result': 665, 'forces': 666, 'minute': 667, 'needs': 668, 'filmmaking': 669, 'mystery': 670, 'low': 671, 'vision': 672, 'complex': 673, 'among': 674, 'stars': 675, 'struggle': 676, 'steve': 677, 'married': 678, 'quirky': 679, 'genre': 680, 'straight': 681, 'wit': 682, 'slow': 683, 'intelligent': 684, 'fresh': 685, 'study': 686, 'female': 687, 'possible': 688, 'begin': 689, 'filmmakers': 690, 'british': 691, 'thinks': 692, 'happy': 693, 'ending': 694, 'hero': 695, 'worst': 696, 'familiar': 697, 'feeling': 698, 'nature': 699, 'spy': 700, 'interest': 701, 'tragedy': 702, 'e': 703, 'sort': 704, 'justice': 705, 'sad': 706, 'contemporary': 707, 'told': 708, 'party': 709, 'chinese': 710, 'south': 711, 'deeply': 712, 'within': 713, 'mission': 714, 'amusing': 715, 'directed': 716, 'unexpected': 717, 'someone': 718, 'return': 719, 'question': 720, 'stand': 721, 'simple': 722, 'talk': 723, 'la': 724, 'b': 725, 'beautifully': 726, 'sexual': 727, 'television': 728, 'baby': 729, 'dull': 730, 'master': 731, 'unique': 732, 'arrives': 733, 'follow': 734, 'plans': 735, 'boyfriend': 736, 'brought': 737, 'keeps': 738, 'completely': 739, 'problems': 740, 'charming': 741, 'fails': 742, 'viewers': 743, 'writing': 744, 'red': 745, 'major': 746, 'level': 747, 'solid': 748, 'fate': 749, 'oscar': 750, 'fantasy': 751, 'los': 752, 'honest': 753, 'wild': 754, 'soul': 755, 'society': 756, 'beauty': 757, 'island': 758, 'issues': 759, 'unfortunately': 760, 'cool': 761, 'early': 762, 'recent': 763, 're': 764, 'hot': 765, 'relationships': 766, 'gone': 767, 'let': 768, 'moves': 769, 'situation': 770, 'hour': 771, 'involved': 772, 'alive': 773, 'perhaps': 774, 'epic': 775, 'forever': 776, 'johnny': 777, 'childhood': 778, 'outside': 779, '10': 780, 'attention': 781, 'pleasure': 782, 'lacks': 783, 'puts': 784, 'laughs': 785, 'reason': 786, 'era': 787, 'tragic': 788, 'tom': 789, 'professional': 790, 'water': 791, 'hold': 792, 'finding': 793, 'used': 794, 'cold': 795, 'period': 796, 'lack': 797, 'spirited': 798, 'teacher': 799, 'mark': 800, 'famous': 801, 'theater': 802, 'stay': 803, 'production': 804, 'teen': 805, 'created': 806, 'control': 807, 'criminal': 808, 'harry': 809, 'means': 810, 'joe': 811, 'win': 812, 'hospital': 813, 'quest': 814, 'above': 815, 'provides': 816, 'slowly': 817, 'large': 818, 'difficult': 819, 'loses': 820, 'screenplay': 821, 'certainly': 822, 'suspense': 823, 'call': 824, 'flick': 825, 'happens': 826, 'price': 827, 'cannot': 828, 'passion': 829, 'acted': 830, 'industry': 831, 'quality': 832, 'london': 833, 'filled': 834, 'tough': 835, 'innocent': 836, 'changes': 837, 'seeing': 838, 'open': 839, 'grace': 840, 'playing': 841, 'ability': 842, 'psychological': 843, 'race': 844, 'heavy': 845, 'captures': 846, 'today': 847, 'ring': 848, 'law': 849, 'n': 850, 'martin': 851, 'footage': 852, 'catch': 853, 'room': 854, 'nick': 855, 'led': 856, 'government': 857, 'excellent': 858, 'easily': 859, 'stuff': 860, 'predictable': 861, 'remains': 862, 'james': 863, 'mostly': 864, 'adult': 865, 'worse': 866, 'near': 867, 'urban': 868, 'pop': 869, 'crew': 870, 'explores': 871, 'approach': 872, 'jason': 873, 'machine': 874, 'fear': 875, 'cross': 876, 'truly': 877, 'powers': 878, 'seemingly': 879, 'path': 880, 'ancient': 881, 'bruce': 882, 'fighting': 883, 'rachel': 884, 'blood': 885, 'usual': 886, 'creates': 887, 'rest': 888, 'opportunity': 889, 'surface': 890, 'green': 891, 'date': 892, 'hip': 893, 'debut': 894, 'neither': 895, 'animation': 896, 'delivers': 897, 'effective': 898, 'store': 899, 'struggles': 900, \"i'm\": 901, 'sea': 902, 'stage': 903, 'impossible': 904, 'expect': 905, 'ill': 906, 'intelligence': 907, 'entire': 908, 'chris': 909, 'record': 910, 'lover': 911, 'leaving': 912, 'ben': 913, 'creative': 914, 'key': 915, 'brothers': 916, 'boss': 917, 'following': 918, 'north': 919, 'actress': 920, 'opera': 921, 'surprise': 922, 'camp': 923, 'computer': 924, 'christmas': 925, 'chicago': 926, 'y': 927, 'japanese': 928, 'nor': 929, 'bond': 930, 'poor': 931, 'became': 932, 'surprisingly': 933, 'india': 934, 'amazing': 935, 'growing': 936, 'historical': 937, 'turning': 938, 'involving': 939, 'disney': 940, 'boring': 941, 'budget': 942, 'quiet': 943, 'latest': 944, 'blue': 945, 'teenage': 946, 'con': 947, 'proves': 948, 'huge': 949, 'balance': 950, 'highly': 951, 'colorful': 952, 'turned': 953, 'popular': 954, 'struggling': 955, 'took': 956, \"'the\": 957, 'broken': 958, 'determined': 959, 'caught': 960, 'realizes': 961, 'doctor': 962, 'present': 963, 'matt': 964, 'security': 965, 'fashion': 966, 'kid': 967, 'visit': 968, 'apart': 969, 'x': 970, 'somehow': 971, 'exercise': 972, 'moral': 973, 'intriguing': 974, 'interested': 975, 'mess': 976, 'silly': 977, 'lies': 978, 'except': 979, 'maybe': 980, 'jokes': 981, 'complicated': 982, 'memory': 983, 'inspired': 984, '20': 985, 'terms': 986, 'yourself': 987, 'guys': 988, 'destroy': 989, 'enjoyable': 990, 'somewhat': 991, 'six': 992, 'bright': 993, 'cultural': 994, 'neighborhood': 995, 'giving': 996, 'energy': 997, 'main': 998, 'russian': 999, 'visually': 1000, 'unusual': 1001, 'wanted': 1002, 'anna': 1003, 'prove': 1004, 'meaning': 1005, 'jim': 1006, 'born': 1007, 'pay': 1008, 'complete': 1009, 'tone': 1010, 'planet': 1011, 'existence': 1012, 'thomas': 1013, 'ten': 1014, 'pair': 1015, 'army': 1016, 'students': 1017, 'patricia': 1018, 'musical': 1019, 'thin': 1020, 'focus': 1021, 'appeal': 1022, 'number': 1023, 'gun': 1024, 'touching': 1025, 'extreme': 1026, 'terrific': 1027, 'strength': 1028, 'view': 1029, 'intense': 1030, 'sharp': 1031, 'ship': 1032, 'longer': 1033, 'older': 1034, 'seeks': 1035, 'cop': 1036, 'paul': 1037, 'allen': 1038, 'conflict': 1039, 'desperate': 1040, 'understand': 1041, 'emotionally': 1042, 'memories': 1043, 'nice': 1044, 'elements': 1045, 'brilliant': 1046, 'length': 1047, 'sound': 1048, 'perfectly': 1049, 'written': 1050, 'throughout': 1051, 'post': 1052, 'center': 1053, 'extraordinary': 1054, 'suffers': 1055, 'ensemble': 1056, 'word': 1057, 'odd': 1058, 'sequel': 1059, 'faith': 1060, 'track': 1061, 'common': 1062, 'm': 1063, 'ones': 1064, 'suddenly': 1065, 'unlikely': 1066, 'angel': 1067, 'door': 1068, 'create': 1069, 'student': 1070, 'alex': 1071, 'capable': 1072, 'desperately': 1073, 'talented': 1074, 'concept': 1075, 'loss': 1076, 'spend': 1077, 'creepy': 1078, 'audiences': 1079, 'build': 1080, 'viewer': 1081, 'premise': 1082, '2002': 1083, 'emotions': 1084, 'streets': 1085, 'storytelling': 1086, 'cut': 1087, 'occasionally': 1088, 'depth': 1089, 'eddie': 1090, 'drugs': 1091, 'stunning': 1092, 'lucy': 1093, 'adaptation': 1094, 'magic': 1095, 'obvious': 1096, 'melodrama': 1097, 'gorgeous': 1098, 'step': 1099, 'further': 1100, 'imagination': 1101, 'angeles': 1102, 'humanity': 1103, 'wonderful': 1104, 'arts': 1105, 'building': 1106, 'earnest': 1107, 'loved': 1108, 'particularly': 1109, 'missing': 1110, 'club': 1111, 'd': 1112, 'winning': 1113, 'u': 1114, 'gags': 1115, 'sexy': 1116, 'experiences': 1117, 'falling': 1118, 'travel': 1119, 'formula': 1120, 'none': 1121, 'fairy': 1122, 'luck': 1123, 'talking': 1124, 'encounters': 1125, 'martial': 1126, 'george': 1127, 'bill': 1128, '12': 1129, 'suicide': 1130, 'freedom': 1131, 'fame': 1132, 'inner': 1133, 'lee': 1134, 'sean': 1135, 'fbi': 1136, 'meanwhile': 1137, 'warm': 1138, 'certain': 1139, 'ice': 1140, 'heaven': 1141, 'effect': 1142, 'becoming': 1143, 'general': 1144, 'dumb': 1145, 'immediately': 1146, 'previous': 1147, 'niro': 1148, 'laugh': 1149, 'ordinary': 1150, 'overcome': 1151, 'simon': 1152, 'flat': 1153, 'mary': 1154, 'sit': 1155, 'stands': 1156, 'enemy': 1157, 'worthy': 1158, 'points': 1159, 'appears': 1160, 'presents': 1161, 'reveals': 1162, 'international': 1163, 'rescue': 1164, 'haunting': 1165, 'west': 1166, 'encounter': 1167, 'artistic': 1168, 'frank': 1169, 'families': 1170, 'spends': 1171, 'news': 1172, 'co': 1173, 'santa': 1174, 'legendary': 1175, 'bar': 1176, 'crazy': 1177, 'came': 1178, '30': 1179, 'mike': 1180, 'victim': 1181, 'hunter': 1182, 'max': 1183, 'partner': 1184, 'investigation': 1185, '000': 1186, 'hidden': 1187, 'military': 1188, 'obsessed': 1189, 'thinking': 1190, 'spiritual': 1191, 'el': 1192, 'purpose': 1193, 'edge': 1194, 'revealing': 1195, 'faced': 1196, 'lord': 1197, 'irish': 1198, 'list': 1199, 'words': 1200, 'clich': 1201, 'biggest': 1202, 'ghost': 1203, 'wonder': 1204, 'lovely': 1205, 'california': 1206, 'politics': 1207, 'que': 1208, 'desire': 1209, 'touch': 1210, 'holds': 1211, 'cia': 1212, 'waiting': 1213, 'die': 1214, 'loving': 1215, 'memorable': 1216, 'fairly': 1217, 'thanks': 1218, 'east': 1219, 'yes': 1220, 'rise': 1221, 'crush': 1222, 'air': 1223, '11': 1224, 'english': 1225, 'impact': 1226, 'sequences': 1227, 'pull': 1228, 'spectacular': 1229, 'feelings': 1230, 'pain': 1231, 'reach': 1232, 'challenges': 1233, 'telling': 1234, 'double': 1235, 'grand': 1236, 'results': 1237, 'trapped': 1238, 'wealthy': 1239, 'drive': 1240, 'keeping': 1241, 'dying': 1242, 'leader': 1243, 'media': 1244, 'million': 1245, 'dogs': 1246, 'losing': 1247, 'dealer': 1248, 'peace': 1249, 'moore': 1250, 'grief': 1251, 'ii': 1252, 'satisfying': 1253, 'youth': 1254, 'quick': 1255, 'due': 1256, 'daniel': 1257, 'walk': 1258, 'merely': 1259, 'male': 1260, 'fit': 1261, 'genuine': 1262, 'overall': 1263, 'tension': 1264, 'chase': 1265, 'l': 1266, 'sports': 1267, 'adults': 1268, 'soap': 1269, 'ugly': 1270, 'parker': 1271, 'office': 1272, 'gangster': 1273, 'national': 1274, 'southern': 1275, 'lovers': 1276, 'hong': 1277, 'pretentious': 1278, 'studio': 1279, 'survive': 1280, 'setting': 1281, 'central': 1282, 'food': 1283, 'succeeds': 1284, 'disturbing': 1285, 'pregnant': 1286, 'week': 1287, 'fellow': 1288, 'attitude': 1289, 'foreign': 1290, 'pictures': 1291, 'type': 1292, 'promising': 1293, 'loves': 1294, 'grant': 1295, 'henry': 1296, 'finish': 1297, 'eve': 1298, 'various': 1299, 'twists': 1300, 'event': 1301, 'carry': 1302, 'mountain': 1303, 'william': 1304, 'test': 1305, 'leading': 1306, 'rural': 1307, 'gold': 1308, 'traditional': 1309, 'months': 1310, 'graham': 1311, 'protect': 1312, 'accidentally': 1313, 'roxie': 1314, 'jail': 1315, 'german': 1316, 'murdered': 1317, 'mitchell': 1318, 'join': 1319, 'non': 1320, 'farm': 1321, 'tired': 1322, 'joy': 1323, 'comedies': 1324, 'rarely': 1325, 'waste': 1326, 'beginning': 1327, 'remarkable': 1328, 'examination': 1329, 'possibly': 1330, 'williams': 1331, 'drag': 1332, 'average': 1333, 'hits': 1334, 'guard': 1335, 'felt': 1336, 'third': 1337, 'toward': 1338, 'greatest': 1339, 'sight': 1340, 'outrageous': 1341, 'terrible': 1342, 'subtle': 1343, 'veteran': 1344, 'sustain': 1345, 'grows': 1346, 'accident': 1347, 'parts': 1348, 'flaws': 1349, 'van': 1350, 'gripping': 1351, 'hopes': 1352, 'heads': 1353, 'remember': 1354, 'development': 1355, 'move': 1356, 'nightmare': 1357, 'trust': 1358, 'travels': 1359, 'pace': 1360, 'badly': 1361, 'happiness': 1362, 'mob': 1363, 'washington': 1364, 'utterly': 1365, 'surprising': 1366, 'jones': 1367, 'front': 1368, 'las': 1369, 'forget': 1370, 'fan': 1371, 'intimate': 1372, 'decades': 1373, 'teenagers': 1374, 'kung': 1375, 'billy': 1376, 'k': 1377, 'private': 1378, 'ambitious': 1379, 'producer': 1380, 'christian': 1381, 'queen': 1382, 'vincent': 1383, 'dealing': 1384, 'desert': 1385, 'ya': 1386, 'appear': 1387, 'driver': 1388, 'murders': 1389, 'states': 1390, 'united': 1391, 'abandoned': 1392, 'hearted': 1393, 'facing': 1394, 'tedious': 1395, 'guilty': 1396, 'helps': 1397, 'brutally': 1398, 'lots': 1399, 'typical': 1400, 'doubt': 1401, 'knowing': 1402, 'count': 1403, 'target': 1404, 'share': 1405, 'ready': 1406, 'unlike': 1407, 'victims': 1408, 'skin': 1409, 'nicholas': 1410, 'lets': 1411, 'pulls': 1412, 'continues': 1413, 'ahead': 1414, 'questions': 1415, 'chemistry': 1416, 'thoroughly': 1417, 'slice': 1418, 'situations': 1419, 'hardly': 1420, 'offer': 1421, 'jackson': 1422, 'lifestyle': 1423, 'comedic': 1424, 'satire': 1425, 'earlier': 1426, 'physical': 1427, 'strikes': 1428, 'discovery': 1429, 'crafted': 1430, 'violent': 1431, 'fish': 1432, 'deeper': 1433, 'creature': 1434, 'convincing': 1435, 'impressive': 1436, 'danger': 1437, 'suspect': 1438, 'manhattan': 1439, 'cute': 1440, 'unsettling': 1441, 'otherwise': 1442, 'normal': 1443, 'stuck': 1444, 'witty': 1445, 'brain': 1446, 'anthony': 1447, 'terrifying': 1448, 'choose': 1449, 'supposed': 1450, 'natural': 1451, 'breaks': 1452, 'religious': 1453, 'fully': 1454, 'intentions': 1455, 'freddy': 1456, 'steven': 1457, 'rules': 1458, 'screenwriter': 1459, 'painful': 1460, 'tried': 1461, 'ray': 1462, 'park': 1463, 'gradually': 1464, 'support': 1465, 'african': 1466, 'drawn': 1467, 'internet': 1468, 'escapes': 1469, 'strike': 1470, 'deserves': 1471, 'enter': 1472, 'mom': 1473, 'interviews': 1474, 'gentle': 1475, 'indian': 1476, 'figure': 1477, 'barely': 1478, 'differences': 1479, 'professor': 1480, 'cousin': 1481, 'sends': 1482, 'mitch': 1483, 'torn': 1484, 'prevent': 1485, 'assassin': 1486, 'robbery': 1487, 'hired': 1488, 'village': 1489, 'killing': 1490, 'seeking': 1491, 'matters': 1492, 'public': 1493, 'roles': 1494, 'france': 1495, 'mix': 1496, 'joke': 1497, 'packed': 1498, 'provide': 1499, 'signs': 1500, 'appealing': 1501, 'suffering': 1502, 'generation': 1503, 'imagine': 1504, 'surreal': 1505, 'indie': 1506, 'twist': 1507, 'landscape': 1508, 'paced': 1509, 'indeed': 1510, 'murphy': 1511, 'example': 1512, 'exciting': 1513, 'twenty': 1514, 'decent': 1515, 'died': 1516, 'understanding': 1517, 'efforts': 1518, 'spectacle': 1519, 'fashioned': 1520, 'add': 1521, 'border': 1522, 'remake': 1523, 'monster': 1524, 'serial': 1525, 'bobby': 1526, 'places': 1527, 'numbers': 1528, 'flawed': 1529, 'miss': 1530, 'expected': 1531, 'nonetheless': 1532, 'chan': 1533, 'plenty': 1534, 'saw': 1535, 'younger': 1536, 'forms': 1537, 'promises': 1538, 'sandler': 1539, '5': 1540, 'dance': 1541, 'digital': 1542, 'match': 1543, 'space': 1544, 'scary': 1545, 'crisis': 1546, 'deliver': 1547, 'willing': 1548, 'adam': 1549, '180': 1550, 'code': 1551, 'definitely': 1552, 'courage': 1553, 'happen': 1554, 'c': 1555, 'jewish': 1556, 'treasure': 1557, 'promise': 1558, 'lines': 1559, 'cause': 1560, 'trail': 1561, 'alien': 1562, 'seven': 1563, 'task': 1564, 'score': 1565, 'dragon': 1566, 'hoping': 1567, 'confront': 1568, 'trial': 1569, 'handsome': 1570, 'dies': 1571, 'agency': 1572, 'lonely': 1573, 'weekend': 1574, 'mafia': 1575, 'ted': 1576, 'assistant': 1577, 'arrested': 1578, 'vegas': 1579, 'hunt': 1580, 'pursuit': 1581, 'kyle': 1582, 'tape': 1583, 'train': 1584, 'color': 1585, 'reading': 1586, 'convinced': 1587, 'chilling': 1588, 'constantly': 1589, 'blade': 1590, 'beneath': 1591, 'missed': 1592, 'combat': 1593, 'passionate': 1594, 'sensitive': 1595, 'cho': 1596, 'miller': 1597, 'talks': 1598, 'conservative': 1599, 'ended': 1600, 'lesson': 1601, 'fiction': 1602, 'un': 1603, 'r': 1604, 'evidence': 1605, 'horrible': 1606, 'insight': 1607, 'imagery': 1608, 'soundtrack': 1609, 'report': 1610, 'seat': 1611, 'emerges': 1612, 'wish': 1613, 'equally': 1614, 'author': 1615, 'surprises': 1616, 'bears': 1617, 'challenge': 1618, 'anti': 1619, 'essentially': 1620, 'stupid': 1621, 'capture': 1622, 'spider': 1623, 'provoking': 1624, 'hair': 1625, 'onto': 1626, 'eric': 1627, 'kong': 1628, 'haunted': 1629, 'inventive': 1630, '90': 1631, 'compassion': 1632, 'intellectual': 1633, 'product': 1634, 'italian': 1635, 'plain': 1636, 'throws': 1637, 'allows': 1638, 'meditation': 1639, 'innocence': 1640, 'themes': 1641, 'blind': 1642, 'angry': 1643, 'delicate': 1644, 'nowhere': 1645, 'roots': 1646, 'voice': 1647, 'chief': 1648, 'values': 1649, 'held': 1650, 'happened': 1651, 'performers': 1652, 'poetry': 1653, 'driven': 1654, 'riveting': 1655, 'j': 1656, 'player': 1657, 'respect': 1658, 'unfolds': 1659, 'value': 1660, 'guns': 1661, 'bed': 1662, 'rob': 1663, 'ground': 1664, 'consequences': 1665, 'wall': 1666, 'motion': 1667, 'refuses': 1668, 'execution': 1669, 'roger': 1670, 'twisted': 1671, 'thrown': 1672, 'cash': 1673, 'unable': 1674, 'raised': 1675, 'sons': 1676, 'morning': 1677, 'facts': 1678, 'system': 1679, 'court': 1680, 'killers': 1681, 'field': 1682, 'increasingly': 1683, 'sarah': 1684, 'owner': 1685, 'underworld': 1686, 'discovered': 1687, 'apartment': 1688, 'kidnapped': 1689, 'jenny': 1690, 'keith': 1691, 'stolen': 1692, 'attack': 1693, 'radio': 1694, 'reporter': 1695, 'texas': 1696, 'roll': 1697, 'journalist': 1698, 'extremely': 1699, 'happening': 1700, 'somewhere': 1701, 'sounds': 1702, 'consider': 1703, 'spell': 1704, 'bigger': 1705, 'features': 1706, 'buried': 1707, 'deadly': 1708, 'depressing': 1709, 'grown': 1710, 'imax': 1711, 'beloved': 1712, 'detail': 1713, 'honor': 1714, 'survival': 1715, 'fortune': 1716, 'acts': 1717, 'thoughtful': 1718, 'paid': 1719, 'cat': 1720, 'franchise': 1721, 'originality': 1722, 'answers': 1723, 'grow': 1724, 'goofy': 1725, 'madness': 1726, '9': 1727, 'exploration': 1728, 'poignant': 1729, 'changing': 1730, 'eccentric': 1731, 'affection': 1732, 'birthday': 1733, 'awkward': 1734, 'g': 1735, 'undercover': 1736, 'universal': 1737, 'flicks': 1738, 'bitter': 1739, 'sentimental': 1740, 'soldiers': 1741, 'animated': 1742, 'don': 1743, 'pieces': 1744, 'delightful': 1745, 'legend': 1746, 'zone': 1747, 'spent': 1748, 'showing': 1749, 'potential': 1750, 'intensity': 1751, 'seriously': 1752, 'released': 1753, 'aged': 1754, 'sincere': 1755, 'rap': 1756, 'moved': 1757, 'revolution': 1758, 'contrived': 1759, 'believes': 1760, 'tribute': 1761, 'avoid': 1762, 'cheap': 1763, 'nine': 1764, 'bullock': 1765, 'mood': 1766, 'episode': 1767, 'creating': 1768, 'enterprise': 1769, 'sick': 1770, 'fathers': 1771, 'crowd': 1772, 'weird': 1773, 'absorbing': 1774, 'member': 1775, 'vampire': 1776, 'viewing': 1777, 'san': 1778, 'service': 1779, 'eight': 1780, 'slightly': 1781, 'lucky': 1782, 'porn': 1783, 'wait': 1784, 'bride': 1785, 'animal': 1786, 'super': 1787, 'accept': 1788, 'cell': 1789, 'excitement': 1790, 'research': 1791, 'workers': 1792, 'england': 1793, 'routine': 1794, 'brutal': 1795, 'met': 1796, 'advice': 1797, 'tim': 1798, 'faces': 1799, 'restaurant': 1800, 'searching': 1801, 'danny': 1802, 'bus': 1803, 'towards': 1804, 'remote': 1805, 'mexico': 1806, 'passed': 1807, 'sisters': 1808, 'unknown': 1809, 'investigate': 1810, '225': 1811, 'lena': 1812, 'underground': 1813, 'sullivan': 1814, 'send': 1815, 'bland': 1816, 'wrote': 1817, 'forgettable': 1818, '1': 1819, 'president': 1820, 'sitting': 1821, 'melodramatic': 1822, 'hop': 1823, 'subjects': 1824, 'sign': 1825, 'fare': 1826, 'handed': 1827, 'scott': 1828, 'fi': 1829, 'whatever': 1830, 'una': 1831, 'modest': 1832, 'offering': 1833, 'mediocre': 1834, 'shame': 1835, 'manner': 1836, 'realistic': 1837, 'glass': 1838, 'holocaust': 1839, 'pure': 1840, 'read': 1841, 'godard': 1842, 'lazy': 1843, 'accessible': 1844, 'charged': 1845, 'noble': 1846, 'tradition': 1847, 'disguise': 1848, 'saved': 1849, 'said': 1850, 'amount': 1851, 'seek': 1852, 'constructed': 1853, 'china': 1854, 'necessary': 1855, 'hide': 1856, 'strangely': 1857, 'engrossing': 1858, 'lame': 1859, 'daily': 1860, 'com': 1861, 'homes': 1862, 'nuclear': 1863, 'loud': 1864, 'mindless': 1865, 'fat': 1866, 'taste': 1867, 'damned': 1868, 'personality': 1869, 'ms': 1870, 'thousands': 1871, 'literally': 1872, 'everyday': 1873, 'equivalent': 1874, 'tech': 1875, 'editing': 1876, 'drunk': 1877, 'parent': 1878, 'chaotic': 1879, 'usually': 1880, 'provocative': 1881, 'adolescent': 1882, 'guilt': 1883, 'adventures': 1884, 'dinner': 1885, 'levels': 1886, 'delivered': 1887, 'poetic': 1888, 'dry': 1889, 'produced': 1890, 'clearly': 1891, 'larger': 1892, '18': 1893, 'closer': 1894, 'passes': 1895, 'profile': 1896, 'slick': 1897, 'rose': 1898, 'monsters': 1899, 'league': 1900, 'enters': 1901, 'addition': 1902, '15': 1903, 'says': 1904, 'account': 1905, 'information': 1906, 'mental': 1907, 'skill': 1908, 'shooting': 1909, 'fly': 1910, 'document': 1911, 'core': 1912, 'woods': 1913, 'started': 1914, 'obsession': 1915, 'mexican': 1916, 'skills': 1917, 'formulaic': 1918, 'continue': 1919, '19': 1920, 'actions': 1921, 'concerned': 1922, 'entirely': 1923, 'holiday': 1924, 'shallow': 1925, 'winner': 1926, 'witness': 1927, 'stone': 1928, 'phone': 1929, 'bored': 1930, 'stuart': 1931, 'pick': 1932, 'decided': 1933, 'letter': 1934, 'betrayal': 1935, 'bear': 1936, 'smoking': 1937, 'block': 1938, 'tony': 1939, 'davis': 1940, 'musicians': 1941, 'captured': 1942, 'blend': 1943, 'scientist': 1944, 'board': 1945, 'asks': 1946, 'independent': 1947, 'mountains': 1948, 'shop': 1949, 'interview': 1950, 'manager': 1951, 'holy': 1952, 'destiny': 1953, 'steal': 1954, 'claire': 1955, 'executive': 1956, 'jr': 1957, 'revolves': 1958, 'shelter': 1959, 'competition': 1960, 'solve': 1961, 'lawyer': 1962, 'francis': 1963, 'marry': 1964, 'kidnap': 1965, 'humans': 1966, 'attorney': 1967, '237': 1968, 'operation': 1969, 'assigned': 1970, 'lose': 1971, 'worker': 1972, 'site': 1973, 'jedi': 1974, 'kills': 1975, 'sheriff': 1976, 'paper': 1977, 'sides': 1978, 'perspective': 1979, 'laughter': 1980, 'hill': 1981, 'responsible': 1982, 'ups': 1983, 'shocking': 1984, 'secretly': 1985, 'push': 1986, 'lake': 1987, 'serves': 1988, 'deftly': 1989, 'carefully': 1990, 'raw': 1991, 'fatal': 1992, 'wonderfully': 1993, 'card': 1994, 'circumstances': 1995, 'committed': 1996, 'hoffman': 1997, 'aside': 1998, 'apparent': 1999, 'notorious': 2000, 'genuinely': 2001, 'lacking': 2002, 'en': 2003, 'buddy': 2004, 'particular': 2005, 'reno': 2006, 'string': 2007, 'handle': 2008, 'candy': 2009, 'mistake': 2010, 'triangle': 2011, 'prime': 2012, 'cover': 2013, 'beat': 2014, 'sleep': 2015, 'surrounding': 2016, 'starring': 2017, 'damage': 2018, 'sophisticated': 2019, 'minor': 2020, 'wind': 2021, 'fears': 2022, 'paranoia': 2023, 'woo': 2024, 'minds': 2025, 'buy': 2026, 'daring': 2027, 'curious': 2028, 'stops': 2029, 'mean': 2030, 'sara': 2031, 'britney': 2032, 'desperation': 2033, 'conventional': 2034, 'harvard': 2035, 'covers': 2036, 'obviously': 2037, 'brown': 2038, 'vs': 2039, 'birth': 2040, 'sacrifice': 2041, 'presence': 2042, 'profound': 2043, 'everybody': 2044, 'disaster': 2045, 'vivid': 2046, 'threat': 2047, 'virtually': 2048, 'demands': 2049, 'jane': 2050, 'wise': 2051, 'tall': 2052, 'starting': 2053, 'standards': 2054, 'credit': 2055, 'twin': 2056, 'misses': 2057, 'masterpiece': 2058, 'tour': 2059, 'liked': 2060, 'soderbergh': 2061, 'combination': 2062, 'troubled': 2063, 'lie': 2064, 'tales': 2065, 'games': 2066, 'went': 2067, 'lived': 2068, 'calls': 2069, 'incredible': 2070, 'peculiar': 2071, 'potter': 2072, 'gift': 2073, 'commercial': 2074, 'terribly': 2075, 'xxx': 2076, 'shoes': 2077, 'detailed': 2078, 'faithful': 2079, 'source': 2080, 'technology': 2081, 'poet': 2082, 'dad': 2083, 'escaped': 2084, 'considered': 2085, 'award': 2086, 'shakespeare': 2087, 'arrive': 2088, 'department': 2089, 'empire': 2090, 'aftermath': 2091, 'greek': 2092, 'patient': 2093, 'season': 2094, 'legacy': 2095, 'lady': 2096, 'elusive': 2097, 'directing': 2098, 'basketball': 2099, 'divine': 2100, 'singer': 2101, 'ellen': 2102, 'jordan': 2103, 'speak': 2104, 'thus': 2105, 'valley': 2106, 'convince': 2107, 'contact': 2108, 'spring': 2109, 'decision': 2110, 'dean': 2111, 'prostitute': 2112, 'church': 2113, 'exotic': 2114, 'weeks': 2115, 'corrupt': 2116, 'arrival': 2117, 'officer': 2118, 'teams': 2119, 'virus': 2120, 'captain': 2121, 'kilo': 2122, 'criminals': 2123, 'suspects': 2124, 'marie': 2125, 'changed': 2126, 'velma': 2127, 'nete': 2128, '2001': 2129, 'tina': 2130, 'carlos': 2131, 'rio': 2132, 'science': 2133, 'h': 2134, 'para': 2135, 'walter': 2136, 'crimes': 2137, 'startling': 2138, 'conclusion': 2139, 'distant': 2140, 'watchable': 2141, 'heroes': 2142, 'bob': 2143, 'tortured': 2144, 'pleasant': 2145, 'rate': 2146, 'japan': 2147, 'winds': 2148, 'academy': 2149, 'rough': 2150, 'nasty': 2151, 'casting': 2152, 'inspiring': 2153, 'surely': 2154, 'insightful': 2155, 'awful': 2156, 'painfully': 2157, 'selling': 2158, 'books': 2159, 'sci': 2160, 'fair': 2161, 'depiction': 2162, 'precious': 2163, 'answer': 2164, 'mainstream': 2165, 'speaks': 2166, 'deft': 2167, 'quinn': 2168, 'alan': 2169, 'focuses': 2170, '50': 2171, 'structure': 2172, 'frequently': 2173, 'backdrop': 2174, 'intended': 2175, 'silent': 2176, 'casts': 2177, 'nation': 2178, 'gritty': 2179, 'deals': 2180, 'loose': 2181, 'disappointed': 2182, 'teens': 2183, 'grew': 2184, 'natured': 2185, 'laws': 2186, 'spark': 2187, 'frame': 2188, 'speaking': 2189, 'substance': 2190, 'treat': 2191, 'reunion': 2192, 'pacino': 2193, 'hang': 2194, 'grade': 2195, 'begun': 2196, 'burns': 2197, 'souls': 2198, 'trick': 2199, 'da': 2200, 'smith': 2201, 'release': 2202, 'incredibly': 2203, 'spielberg': 2204, 'empty': 2205, 'marks': 2206, 'realizing': 2207, 'frida': 2208, 'note': 2209, 'tongue': 2210, 'song': 2211, 'theme': 2212, 'parade': 2213, 'satisfy': 2214, 'blow': 2215, 'curse': 2216, 'clean': 2217, 'delivery': 2218, 'served': 2219, 'connection': 2220, 'language': 2221, 'shower': 2222, 'mon': 2223, 'determination': 2224, 'developed': 2225, 'include': 2226, 'shadow': 2227, 'silence': 2228, 'stays': 2229, 'darkly': 2230, 'delight': 2231, 'celebrity': 2232, \"'70s\": 2233, 'difference': 2234, 'importance': 2235, 'failed': 2236, 'republic': 2237, 'cliches': 2238, 'artists': 2239, 'standard': 2240, 'reign': 2241, 'paris': 2242, 'bloody': 2243, 'vehicle': 2244, 'aging': 2245, 'constant': 2246, 'austin': 2247, 'horrifying': 2248, 'comfort': 2249, 'terry': 2250, 'expert': 2251, 'integrity': 2252, 'ambition': 2253, 'separate': 2254, 'write': 2255, 'incident': 2256, 'singing': 2257, 'risk': 2258, 'creation': 2259, 'friday': 2260, 'ghosts': 2261, 'flashbacks': 2262, 'forgotten': 2263, 'destruction': 2264, 'began': 2265, 'generally': 2266, 'civil': 2267, 'larry': 2268, 'animals': 2269, 'filmed': 2270, 'featuring': 2271, 'imaginative': 2272, 'teaches': 2273, 'prisoner': 2274, 'kaufman': 2275, 'education': 2276, '80': 2277, 'uncle': 2278, 'medical': 2279, 'hogwarts': 2280, 'climax': 2281, 'cuban': 2282, 'homicide': 2283, 'assassination': 2284, 'battles': 2285, 'tooth': 2286, 'false': 2287, 'chaos': 2288, 'football': 2289, 'opening': 2290, 'obsessive': 2291, 'busy': 2292, 'remaining': 2293, 'aggressive': 2294, 'hotel': 2295, '40': 2296, 'alice': 2297, 'cuba': 2298, 'visions': 2299, 'greg': 2300, 'reveal': 2301, 'european': 2302, 'chain': 2303, 'estranged': 2304, 'university': 2305, 'believing': 2306, 'frustrated': 2307, 'divorce': 2308, 'terror': 2309, 'facility': 2310, 'dancer': 2311, 'fired': 2312, 'mentor': 2313, 'planning': 2314, 'grandfather': 2315, 'vince': 2316, 'bret': 2317, 'retired': 2318, 'drinking': 2319, 'psychiatrist': 2320, 'tong': 2321, 'emma': 2322, 'brazil': 2323, 'jimmy': 2324, 'isabel': 2325, 'investigating': 2326, 'challenged': 2327, 'gem': 2328, 'mildly': 2329, 'native': 2330, 'americans': 2331, 'patience': 2332, 'perry': 2333, 'pitch': 2334, 'wacky': 2335, '8': 2336, 'directors': 2337, 'villain': 2338, 'stunts': 2339, 'manage': 2340, 'trifle': 2341, 'welcome': 2342, 'crystal': 2343, 'spite': 2344, 'odds': 2345, 'emotion': 2346, 'debt': 2347, 'scorsese': 2348, 'spare': 2349, 'evocative': 2350, 'manipulative': 2351, 'erotic': 2352, 'challenging': 2353, 'stumbles': 2354, 'blair': 2355, 'protagonist': 2356, 'cinematography': 2357, 'se': 2358, 'heartfelt': 2359, 'repetitive': 2360, 'twice': 2361, 'immigrants': 2362, 'gain': 2363, 'pack': 2364, 'woody': 2365, 'legal': 2366, 'dimensional': 2367, 'mad': 2368, 'technical': 2369, 'survivors': 2370, 'lousy': 2371, 'ocean': 2372, 'dysfunctional': 2373, 'apparently': 2374, 'context': 2375, 'fake': 2376, 'makers': 2377, 'anime': 2378, 'huppert': 2379, 'visceral': 2380, 'secretary': 2381, 'equal': 2382, 'condition': 2383, 'hearts': 2384, 'guess': 2385, 'costumes': 2386, 'locations': 2387, 'anderson': 2388, 'desires': 2389, 'sport': 2390, 'filming': 2391, 'noir': 2392, 'reluctant': 2393, 'needed': 2394, 'cliche': 2395, 'deserve': 2396, 'damaged': 2397, 'please': 2398, 'maid': 2399, 'generic': 2400, 'bold': 2401, 'dancing': 2402, 'contest': 2403, 'bittersweet': 2404, 'submarine': 2405, 'organized': 2406, 'includes': 2407, 'annoying': 2408, '13': 2409, 'bourne': 2410, 'emphasizes': 2411, 'coast': 2412, 'weight': 2413, 'sly': 2414, 'achieves': 2415, 'capturing': 2416, 'trey': 2417, 'tender': 2418, 'superb': 2419, 'unless': 2420, 'failure': 2421, 'chelsea': 2422, 'walls': 2423, 'possesses': 2424, 'judge': 2425, 'wooden': 2426, 'burning': 2427, 'check': 2428, 'stomach': 2429, 'miracle': 2430, 'vast': 2431, 'damn': 2432, 'considerable': 2433, 'philosophical': 2434, 'harrowing': 2435, 'transplant': 2436, 'sentimentality': 2437, 'uneven': 2438, 'expose': 2439, 'biting': 2440, 'cops': 2441, 'deeds': 2442, 'germany': 2443, '3': 2444, 'term': 2445, 'throwing': 2446, 'presented': 2447, 'unfunny': 2448, 'picked': 2449, 'senses': 2450, 'reasons': 2451, 'belongs': 2452, 'ridiculous': 2453, 'ryan': 2454, 'remain': 2455, 'seemed': 2456, 'kissinger': 2457, 'random': 2458, 'saving': 2459, 'glimpse': 2460, 'hall': 2461, 'object': 2462, 'stones': 2463, 'christopher': 2464, 'status': 2465, 'chronicles': 2466, 'sade': 2467, 'current': 2468, 'lying': 2469, 'harsh': 2470, 'wake': 2471, 'attacks': 2472, 'devotion': 2473, 'individual': 2474, 'atmosphere': 2475, 'scenario': 2476, 'em': 2477, 'nobody': 2478, 'simplistic': 2479, 'emerge': 2480, 'fu': 2481, 'paint': 2482, 'storyline': 2483, 'theatre': 2484, 'suggests': 2485, 'represents': 2486, 'josh': 2487, 'health': 2488, 'engage': 2489, 'fights': 2490, 'pressure': 2491, 'prey': 2492, 'dress': 2493, 'armed': 2494, 'derivative': 2495, 'aid': 2496, 'cult': 2497, 'population': 2498, 'pleasures': 2499, 'favorite': 2500, 'terrorist': 2501, '7': 2502, 'jesse': 2503, 'unconventional': 2504, 'dante': 2505, 'iranian': 2506, 'goal': 2507, 'grandmother': 2508, 'stranger': 2509, 'format': 2510, 'settle': 2511, 'aliens': 2512, '17': 2513, 'location': 2514, 'heat': 2515, 'attraction': 2516, 'sally': 2517, 'confused': 2518, 'carol': 2519, 'teach': 2520, 'nicole': 2521, 'elderly': 2522, 'prize': 2523, 'berlin': 2524, 'guidance': 2525, 'paths': 2526, 'walks': 2527, 'develops': 2528, 'lodge': 2529, 'explain': 2530, 'dollars': 2531, 'chon': 2532, 'exchange': 2533, 'activist': 2534, 'truck': 2535, 'brazilian': 2536, 'jake': 2537, 'imprisoned': 2538, 'beach': 2539, 'hometown': 2540, 'roommate': 2541, 'guru': 2542, 'manipulating': 2543, 'illegal': 2544, '243': 2545, 'sumo': 2546, 'rights': 2547, 'picks': 2548, 'fianc': 2549, 'recently': 2550, 'samantha': 2551, 'brad': 2552, 'crash': 2553, 'rule': 2554, 'hiding': 2555, 'aka': 2556, 'stifler': 2557, 'conversations': 2558, 'mass': 2559, 'uncompromising': 2560, 'upper': 2561, 'pokemon': 2562, 'wears': 2563, 'refreshing': 2564, 'adapted': 2565, 'convinces': 2566, 'sweeping': 2567, 'barbershop': 2568, 'resist': 2569, 'collection': 2570, 'menace': 2571, 'screenwriting': 2572, 'stakes': 2573, 'conscious': 2574, 'severe': 2575, 'cartoon': 2576, 'pacing': 2577, 'ho': 2578, 'lush': 2579, 'es': 2580, 'scooby': 2581, 'superbly': 2582, 'figures': 2583, 'praise': 2584, 'festival': 2585, 'giant': 2586, 'thrilling': 2587, 'phenomenon': 2588, 'cutting': 2589, 'gangs': 2590, 'jolie': 2591, 'fill': 2592, 'poignancy': 2593, 'dong': 2594, 'asking': 2595, 'countless': 2596, 'stripped': 2597, 'understated': 2598, 'nevertheless': 2599, 'rush': 2600, 'drags': 2601, 'stephen': 2602, 'whimsical': 2603, 'thousand': 2604, 'connected': 2605, 'realism': 2606, 'slight': 2607, 'steps': 2608, 'lane': 2609, 'objective': 2610, 'sorority': 2611, 'crack': 2612, 'punch': 2613, 'jonathan': 2614, 'maggie': 2615, 'believable': 2616, 'behavior': 2617, 'agents': 2618, 'baseball': 2619, 'dozen': 2620, 'popcorn': 2621, 'favor': 2622, 'morality': 2623, 'pseudo': 2624, 'teeth': 2625, 'reasonably': 2626, 'ticket': 2627, 'expectations': 2628, 'pretends': 2629, 'largely': 2630, 'admission': 2631, 'revealed': 2632, 'parody': 2633, 'irritating': 2634, 'hate': 2635, 'formed': 2636, 'smooth': 2637, 'cheek': 2638, 'lust': 2639, 'dylan': 2640, 'limited': 2641, 'serving': 2642, 'irony': 2643, 'grave': 2644, 'conviction': 2645, 'psychic': 2646, 'homage': 2647, 'stealing': 2648, 'players': 2649, 'feet': 2650, 'destructive': 2651, 'refreshingly': 2652, 'inept': 2653, 'threatens': 2654, 'examines': 2655, 'offensive': 2656, 'scope': 2657, 'exhilarating': 2658, 'attractive': 2659, 'hole': 2660, 'watched': 2661, 'instantly': 2662, 'dazzling': 2663, 'reminds': 2664, 'absolutely': 2665, 'logic': 2666, 'deaths': 2667, 'area': 2668, 'expression': 2669, 'draws': 2670, 'messages': 2671, 'corruption': 2672, 'pool': 2673, 'angela': 2674, 'roberto': 2675, 'choice': 2676, 'shock': 2677, 'coma': 2678, 'worlds': 2679, 'nonsense': 2680, 'suspenseful': 2681, 'charms': 2682, 'mothers': 2683, 'carries': 2684, 'managed': 2685, 'angst': 2686, 'total': 2687, 'resonance': 2688, 'gifted': 2689, 'mile': 2690, 'dvd': 2691, 'kidnapping': 2692, 'numerous': 2693, 'mid': 2694, 'verge': 2695, 'weak': 2696, 'depressed': 2697, 'heavily': 2698, 'strain': 2699, 'proportions': 2700, 'delicious': 2701, 'funeral': 2702, 'web': 2703, 'visuals': 2704, 'vietnam': 2705, 'moon': 2706, 'obstacles': 2707, 'arnold': 2708, 'controlled': 2709, 'prisoners': 2710, 'poverty': 2711, 'boat': 2712, 'pile': 2713, 'breath': 2714, 'laura': 2715, 'therapy': 2716, 'hopelessly': 2717, 'humour': 2718, 'lawrence': 2719, 'april': 2720, 'independence': 2721, 'drumline': 2722, 'accused': 2723, 'laid': 2724, 'spirits': 2725, 'gary': 2726, 'western': 2727, 'maudlin': 2728, 'kevin': 2729, 'anne': 2730, 'hugh': 2731, 'lively': 2732, 'wilde': 2733, 'hatred': 2734, 'safe': 2735, 'heist': 2736, 'succeed': 2737, 'smoochy': 2738, 'thrills': 2739, 'absurd': 2740, 'vacation': 2741, 'truths': 2742, 'rejected': 2743, 'minded': 2744, 'aware': 2745, 'shy': 2746, 'wilson': 2747, 'diverse': 2748, 'subversive': 2749, 'roller': 2750, 'coaster': 2751, 'finest': 2752, 'collision': 2753, 'predecessor': 2754, 'bottom': 2755, 'demons': 2756, 'according': 2757, 'proof': 2758, 'holes': 2759, 'overly': 2760, 'ghetto': 2761, 'wonders': 2762, 'brief': 2763, 'credits': 2764, 'contains': 2765, 'provided': 2766, 'arrest': 2767, 'exist': 2768, 'corner': 2769, 'box': 2770, 'triumph': 2771, 'anger': 2772, 'seagal': 2773, 'heard': 2774, '25': 2775, 'fence': 2776, 'intrigue': 2777, 'forest': 2778, 'mentally': 2779, 'actual': 2780, 'diverting': 2781, 'staged': 2782, 'redemption': 2783, 'australian': 2784, 'household': 2785, 'immediate': 2786, 'vietnamese': 2787, 'uncover': 2788, 'totally': 2789, 'couples': 2790, 'beer': 2791, 'rises': 2792, 'semi': 2793, 'september': 2794, 'dawn': 2795, 'julie': 2796, 'fallen': 2797, 'ask': 2798, 'massive': 2799, 'struck': 2800, 'immortal': 2801, 'priest': 2802, 'ball': 2803, 'connect': 2804, 'rival': 2805, 'strict': 2806, 'window': 2807, 'millions': 2808, 'shared': 2809, 'songs': 2810, 'wounded': 2811, 'storm': 2812, 'clothes': 2813, 'charlotte': 2814, 'parties': 2815, 'fred': 2816, 'francisco': 2817, 'soldier': 2818, 'trade': 2819, 'hustler': 2820, 'mask': 2821, 'genius': 2822, 'returning': 2823, 'represent': 2824, 'establishment': 2825, 'greed': 2826, 'decisions': 2827, 'training': 2828, 'construction': 2829, 'addiction': 2830, 'elite': 2831, 'kept': 2832, 'clues': 2833, 'teenager': 2834, 'kelly': 2835, 'edgar': 2836, 'returned': 2837, 'pirates': 2838, 'homeless': 2839, 'flee': 2840, 'agrees': 2841, 'kanna': 2842, 'rupi': 2843, 'chapman': 2844, 'starla': 2845, 'avenge': 2846, 'lynn': 2847, 'causes': 2848, 'deceased': 2849, 'ella': 2850, 'trained': 2851, 'victor': 2852, 'clara': 2853, 'ireland': 2854, 'disappearance': 2855, 'dave': 2856, 'nurse': 2857, 'wakes': 2858, 'befriends': 2859, 'estate': 2860, 'market': 2861, 'subculture': 2862, 'unintentional': 2863, '20th': 2864, 'remarkably': 2865, 'amid': 2866, 'aimed': 2867, 'barry': 2868, 'dan': 2869, 'explanation': 2870, 'round': 2871, 'broad': 2872, 'fable': 2873, 'grim': 2874, 'shyamalan': 2875, 'occasional': 2876, 'enigmatic': 2877, 'halfway': 2878, 'directorial': 2879, 'instant': 2880, 'benigni': 2881, 'australia': 2882, 'reflection': 2883, 'funnier': 2884, 'hostage': 2885, 'complexity': 2886, 'writers': 2887, 'remembered': 2888, 'hybrid': 2889, 'witch': 2890, 'dirty': 2891, 'vintage': 2892, 'mouse': 2893, 'warning': 2894, 'imitation': 2895, 'clumsy': 2896, 'direct': 2897, 'confusing': 2898, 'wanting': 2899, 'shots': 2900, 'wave': 2901, 'trek': 2902, 'broomfield': 2903, 'funniest': 2904, 'chosen': 2905, '100': 2906, 'empathy': 2907, 'portrayal': 2908, 'testing': 2909, 'trilogy': 2910, 'reminiscent': 2911, 'playful': 2912, 'loser': 2913, 'joined': 2914, 'bodies': 2915, 'image': 2916, 'drop': 2917, 'schwarzenegger': 2918, '21st': 2919, 'device': 2920, 'somebody': 2921, 'dynamic': 2922, 'bedroom': 2923, 'costume': 2924, 'generations': 2925, 'spooky': 2926, 'atlantic': 2927, 'windtalkers': 2928, 'recommend': 2929, '19th': 2930, 'closely': 2931, 'simone': 2932, 'ladies': 2933, 'poem': 2934, 'substitute': 2935, 'harmless': 2936, 'accomplished': 2937, 'increasing': 2938, 'owned': 2939, 'monty': 2940, 'wannabe': 2941, 'tense': 2942, 'spoof': 2943, 'fields': 2944, 'boasts': 2945, 'sitcom': 2946, 'humorous': 2947, 'friendly': 2948, 'exploring': 2949, 'biopic': 2950, 'popularity': 2951, 'plotting': 2952, 'wry': 2953, 'endless': 2954, 'adds': 2955, 'flair': 2956, 'indulgent': 2957, 'fifteen': 2958, 'notion': 2959, 'strip': 2960, 'distance': 2961, 'liberal': 2962, 'insomnia': 2963, 'ego': 2964, 'rewarding': 2965, 'weaves': 2966, 'breaking': 2967, 'effectively': 2968, 'transformation': 2969, 'commentary': 2970, 'enthusiasm': 2971, 'watches': 2972, 'wildly': 2973, 'hear': 2974, 'lyrical': 2975, 'territory': 2976, 'knew': 2977, 'appreciate': 2978, 'sugar': 2979, 'wide': 2980, 'wars': 2981, 'host': 2982, 'stirring': 2983, 'sappy': 2984, 'measured': 2985, 'sake': 2986, 'chabrol': 2987, 'forward': 2988, 'decade': 2989, 'pity': 2990, 'imagined': 2991, 'flow': 2992, 'mistress': 2993, 'fulfill': 2994, 'loneliness': 2995, 'queens': 2996, 'stream': 2997, 'thoughts': 2998, 'likes': 2999, 'chick': 3000, 'largest': 3001, 'buoyant': 3002, 'richard': 3003, 'feathers': 3004, 'ruined': 3005, 'ingenious': 3006, 'unforgettable': 3007, 'stock': 3008, 'trash': 3009, 'choices': 3010, 'portrays': 3011, 'confidence': 3012, 'cars': 3013, 'pre': 3014, 'uplifting': 3015, 'scattered': 3016, 'sequence': 3017, 'casual': 3018, 'beating': 3019, 'shadows': 3020, 'reminder': 3021, 'ian': 3022, 'tiresome': 3023, 'artificial': 3024, '51': 3025, 'nostalgia': 3026, 'sinister': 3027, 'supply': 3028, 'superior': 3029, 'loyalty': 3030, 'surprised': 3031, 'pow': 3032, 'princess': 3033, \"characters'\": 3034, 'al': 3035, 'catches': 3036, 'gothic': 3037, 'celebration': 3038, 'threatened': 3039, 'inherent': 3040, 'convictions': 3041, 'nights': 3042, 'crap': 3043, 'proceeds': 3044, 'explore': 3045, 'uncertain': 3046, 'brink': 3047, 'vibrant': 3048, 'tricks': 3049, 'conceived': 3050, 'photography': 3051, 'racial': 3052, 'madonna': 3053, 'technique': 3054, 'inspires': 3055, 'program': 3056, 'surroundings': 3057, 'evening': 3058, 'demonstrates': 3059, 'rain': 3060, 'mainly': 3061, 'flash': 3062, 'bent': 3063, 'thirty': 3064, 'nemesis': 3065, 'intentioned': 3066, 'lights': 3067, 'disease': 3068, 'intimacy': 3069, 'talents': 3070, 'experiment': 3071, 'jews': 3072, 'scores': 3073, 'measure': 3074, 'ironic': 3075, 'slip': 3076, 'individuals': 3077, 'chamber': 3078, 'cynical': 3079, 'details': 3080, 'tragedies': 3081, '4': 3082, 'hanging': 3083, 'bound': 3084, 'crocodile': 3085, 'emperor': 3086, 'warmth': 3087, 'worthwhile': 3088, 'lessons': 3089, 'caper': 3090, 'seductive': 3091, 'movement': 3092, 'believed': 3093, 'sudden': 3094, 'bringing': 3095, 'intent': 3096, 'hopkins': 3097, 'recording': 3098, 'saturday': 3099, 'august': 3100, 'wisdom': 3101, 'walked': 3102, 'pass': 3103, 'throw': 3104, 'annie': 3105, 'spending': 3106, 'maintaining': 3107, 'latin': 3108, 'jersey': 3109, 'kennedy': 3110, 'fictional': 3111, 'heights': 3112, 'grab': 3113, 'cope': 3114, 'creatures': 3115, 'cage': 3116, 'egoyan': 3117, '24': 3118, 'knowledge': 3119, 'silver': 3120, 'naive': 3121, 'arms': 3122, 'abuse': 3123, 'shares': 3124, 'duty': 3125, 'flight': 3126, 'st': 3127, 'rebellious': 3128, 'inmates': 3129, 'views': 3130, 'possibilities': 3131, 'resistance': 3132, 'standing': 3133, 'mel': 3134, 'myth': 3135, 'florida': 3136, 'ensues': 3137, 'opens': 3138, 'invites': 3139, 'spots': 3140, 'invention': 3141, 'pursuing': 3142, 'ana': 3143, 'bomb': 3144, 'darkness': 3145, 'official': 3146, 'involves': 3147, 'hungry': 3148, 'besides': 3149, 'upside': 3150, 'chasing': 3151, 'assignment': 3152, 'perform': 3153, 'brian': 3154, 'rage': 3155, 'reluctantly': 3156, 'lisa': 3157, 'recover': 3158, 'dna': 3159, 'ruthless': 3160, 'authorities': 3161, 'countryside': 3162, 'ronnie': 3163, 'nearby': 3164, 'amaro': 3165, 'senator': 3166, 'residents': 3167, 'katherine': 3168, 'weapons': 3169, 'seedy': 3170, 'navy': 3171, 'italy': 3172, 'unaware': 3173, 'devdas': 3174, 'caroline': 3175, 'daddy': 3176, 'mysteriously': 3177, 'recruits': 3178, 'papers': 3179, 'convicted': 3180, 'sells': 3181, 'bargained': 3182, 'reunited': 3183, 'minister': 3184, 'hunted': 3185, 'devil': 3186, 'inez': 3187, 'aunt': 3188, 'reunite': 3189, 'brooklyn': 3190, 'musician': 3191, 'patients': 3192, 'eagle': 3193, 'bounty': 3194, 'district': 3195, 'ruby': 3196, 'gigli': 3197, 'kimberly': 3198, 'holmes': 3199, 'bosses': 3200, 'paradise': 3201, 'jealousy': 3202, 'personalities': 3203, 'stale': 3204, 'wishing': 3205, '4ever': 3206, 'element': 3207, 'vitality': 3208, 'del': 3209, 'sized': 3210, 'nair': 3211, 'lightweight': 3212, 'cities': 3213, 'cube': 3214, 'photo': 3215, 'kiss': 3216, 'observation': 3217, 'latter': 3218, 'stylish': 3219, 'snow': 3220, 'primarily': 3221, 'nicely': 3222, 'engaged': 3223, 'demented': 3224, 'captivating': 3225, 'wondering': 3226, 'zellweger': 3227, 'cruel': 3228, 'pays': 3229, 'confusion': 3230, 'row': 3231, 'tiny': 3232, 'plane': 3233, 'carried': 3234, 'assured': 3235, 'striking': 3236, 'biography': 3237, 'farce': 3238, 'neat': 3239, 'bowling': 3240, 'shelf': 3241, 'layer': 3242, 'amateurish': 3243, 'thrill': 3244, 'giggles': 3245, 'issue': 3246, 'storylines': 3247, 'majidi': 3248, 'amidst': 3249, 'baffling': 3250, 'miserable': 3251, 'partners': 3252, 'voices': 3253, 'fascinated': 3254, 'spanish': 3255, 'depths': 3256, 'sub': 3257, 'distinguished': 3258, 'caine': 3259, 'below': 3260, 'antonio': 3261, 'centers': 3262, 'astonishing': 3263, 'depression': 3264, 'inspiration': 3265, 'inhabitants': 3266, 'sink': 3267, 'likable': 3268, 'rip': 3269, 'existential': 3270, 'accepts': 3271, 'wilder': 3272, 'stereotypes': 3273, 'proud': 3274, 'dragons': 3275, 'discovering': 3276, 'cheer': 3277, 'jie': 3278, 'activities': 3279, 'benefit': 3280, 'mysteries': 3281, 'finale': 3282, 'sum': 3283, 'projects': 3284, 'weirdly': 3285, 'album': 3286, 'understands': 3287, 'virtues': 3288, 'sympathetic': 3289, 'listening': 3290, 'basis': 3291, 'grey': 3292, 'quietly': 3293, 'forth': 3294, 'ark': 3295, 'surgeon': 3296, 'transcends': 3297, 'amounts': 3298, 'sequels': 3299, 'harris': 3300, 'colors': 3301, 'rocky': 3302, 'speed': 3303, 'lips': 3304, 'jean': 3305, 'tuck': 3306, 'paranoid': 3307, 'factor': 3308, 'fourth': 3309, 'timeless': 3310, 'allow': 3311, 'eyed': 3312, 'traffic': 3313, 'backyard': 3314, 'soviet': 3315, 'russia': 3316, 'hype': 3317, 'excess': 3318, 'built': 3319, 'spinning': 3320, 'martha': 3321, 'experimental': 3322, 'curiosity': 3323, 'glory': 3324, 'subtly': 3325, 'describe': 3326, 'kahlo': 3327, 'magnificent': 3328, 'jackie': 3329, 'basic': 3330, 'ludicrous': 3331, 'consciousness': 3332, 'sloppy': 3333, 'sits': 3334, 'strictly': 3335, 'renee': 3336, 'flesh': 3337, 'heartbreaking': 3338, 'affirming': 3339, 'despair': 3340, 'nerve': 3341, 'dig': 3342, 'exploit': 3343, 'crass': 3344, 'detention': 3345, 'rolling': 3346, 'sandra': 3347, 'gotten': 3348, 'blame': 3349, 'evokes': 3350, 'maker': 3351, 'calling': 3352, 'yearning': 3353, 'ranks': 3354, 'alternative': 3355, 'matthew': 3356, 'collapse': 3357, 'reaches': 3358, 'background': 3359, 'korean': 3360, 'appetite': 3361, 'sky': 3362, 'basically': 3363, 'rape': 3364, 'transform': 3365, 'caring': 3366, 'channel': 3367, 'diary': 3368, 'enjoyed': 3369, 'goldmember': 3370, 'plastic': 3371, 'expertly': 3372, 'ought': 3373, 'multiple': 3374, 'produce': 3375, 'murderous': 3376, 'conspiracy': 3377, 'realization': 3378, 'puppet': 3379, 'hart': 3380, 'builds': 3381, 'trailer': 3382, 'awake': 3383, 'pianist': 3384, 'cheated': 3385, 'athletes': 3386, 'copy': 3387, 'bag': 3388, '1999': 3389, 'goals': 3390, 'pursue': 3391, 'unpredictable': 3392, 'alike': 3393, 'offered': 3394, 'stronger': 3395, 'lion': 3396, 'assume': 3397, 'cost': 3398, 'joyous': 3399, 'ballistic': 3400, 'sensibility': 3401, 'listen': 3402, 'citizens': 3403, 'ai': 3404, 'oliver': 3405, 'forbidden': 3406, '1950s': 3407, 'shortcomings': 3408, 'jay': 3409, 'solondz': 3410, 'sketchy': 3411, 'le': 3412, 'predecessors': 3413, 'driving': 3414, 'freaky': 3415, 'sheer': 3416, 'mayhem': 3417, 'howard': 3418, 'horse': 3419, 'static': 3420, 'comics': 3421, 'aspiring': 3422, 'handful': 3423, 'pinocchio': 3424, 'devastating': 3425, 'significant': 3426, 'locales': 3427, 'relying': 3428, 'introduces': 3429, 'angels': 3430, '1970s': 3431, 'raising': 3432, 'shoot': 3433, 'uncanny': 3434, 'freaks': 3435, 'appearance': 3436, 'cyber': 3437, 'fancy': 3438, 'followed': 3439, 'marcus': 3440, 'roman': 3441, 'higher': 3442, 'gosling': 3443, 'gas': 3444, 'clarity': 3445, 'shown': 3446, 'customers': 3447, 'addict': 3448, 'medium': 3449, 'fragile': 3450, 'simultaneously': 3451, 'maintain': 3452, 'scared': 3453, 'documents': 3454, 'penetrating': 3455, 'afloat': 3456, 'heroine': 3457, 'pleaser': 3458, 'midst': 3459, 'mann': 3460, 'charge': 3461, 'oh': 3462, 'content': 3463, 'insurance': 3464, 'frontal': 3465, 'pete': 3466, 'dignity': 3467, 'um': 3468, 'assault': 3469, 'magical': 3470, 'sassy': 3471, 'folks': 3472, 'concerns': 3473, 'colin': 3474, 'honesty': 3475, 'buddies': 3476, 'learning': 3477, 'enormous': 3478, 'rivalry': 3479, 'steals': 3480, 'notice': 3481, 'israeli': 3482, 'county': 3483, 'corporate': 3484, 'tracks': 3485, 'pleasing': 3486, 'sorry': 3487, 'biz': 3488, 'boxing': 3489, 'dennis': 3490, 'etc': 3491, 'shut': 3492, 'slapstick': 3493, 'impression': 3494, 'drawing': 3495, '2000': 3496, 'miles': 3497, 'drink': 3498, 'dilemma': 3499, 'finch': 3500, 'visits': 3501, 'replaced': 3502, 'crossed': 3503, 'zombies': 3504, 'douglas': 3505, 'goose': 3506, 'neil': 3507, 'jessica': 3508, 'afternoon': 3509, 'touches': 3510, 'dominated': 3511, 'closet': 3512, 'healing': 3513, 'divided': 3514, 'downtown': 3515, 'productions': 3516, 'shore': 3517, 'cameras': 3518, 'learned': 3519, 'shoots': 3520, 'senior': 3521, 'destroying': 3522, 'affairs': 3523, 'controversial': 3524, 'taylor': 3525, 'singh': 3526, 'mtv': 3527, 'charismatic': 3528, 'taxi': 3529, 'p': 3530, 'panic': 3531, 'intertwined': 3532, 'relentless': 3533, '14': 3534, 'europe': 3535, 'africa': 3536, 'comfortable': 3537, 'jesus': 3538, 'drives': 3539, 'sparks': 3540, 'station': 3541, 'sale': 3542, 'dollar': 3543, 'wwii': 3544, 'devoted': 3545, 'celebi': 3546, 'surrounded': 3547, 'currently': 3548, 'johnson': 3549, 'louis': 3550, 'leon': 3551, 'floating': 3552, 'igby': 3553, 'avoiding': 3554, 'arm': 3555, 'concert': 3556, 'dating': 3557, 'suffer': 3558, 'bishop': 3559, 'collide': 3560, 'knight': 3561, 'claim': 3562, 'river': 3563, 'warden': 3564, 'names': 3565, 'clock': 3566, 'nephew': 3567, 'friendships': 3568, 'painter': 3569, 'alicia': 3570, 'munnabhai': 3571, 'vicious': 3572, 'threaten': 3573, 'widow': 3574, 'defense': 3575, 'salvation': 3576, 'ghisu': 3577, 'magazine': 3578, 'wong': 3579, 'unit': 3580, 'victoria': 3581, 'staff': 3582, 'mansion': 3583, 'opposite': 3584, '35': 3585, 'paro': 3586, 'christina': 3587, 'vikrant': 3588, 'blake': 3589, 'stevie': 3590, 'affections': 3591, 'enlists': 3592, 'motorcycle': 3593, 'northern': 3594, 'stopping': 3595, 'scheme': 3596, 'calvin': 3597, 'wolf': 3598, 'whereabouts': 3599, '227': 3600, 'meeting': 3601, 'hires': 3602, 'muslim': 3603, 'betrayed': 3604, 'vermont': 3605, 'union': 3606, 'via': 3607, 'raj': 3608, 'planned': 3609, 'rescues': 3610, '252': 3611, 'organization': 3612, 'confrontation': 3613, 'nunn': 3614, 'journeys': 3615, 'demon': 3616, 'property': 3617, 'landon': 3618, 'jamie': 3619, 'detroit': 3620, 'mutants': 3621, 'duo': 3622, 'afghan': 3623, 'fiancee': 3624, 'palace': 3625, 'financial': 3626, 'unravel': 3627, 'obi': 3628, 'wan': 3629, 'anakin': 3630, 'daphne': 3631, 'separated': 3632, 'scam': 3633, 'immigrant': 3634, 'awakens': 3635, 'banks': 3636, 'tiz': 3637, 'quit': 3638, 'capital': 3639, 'incisive': 3640, 'shapeless': 3641, 'radical': 3642, 'rising': 3643, 'table': 3644, 'anywhere': 3645, 'realities': 3646, 'preposterous': 3647, 'utter': 3648, 'gore': 3649, 'bow': 3650, 'resembles': 3651, 'icon': 3652, 'producers': 3653, 'traditions': 3654, 'resonant': 3655, 'haneke': 3656, 'graphic': 3657, 'waydowntown': 3658, 'refusal': 3659, 'movements': 3660, 'ages': 3661, 'wounds': 3662, 'affectionate': 3663, 'generated': 3664, 'skip': 3665, 'nachtwey': 3666, 'photos': 3667, 'witherspoon': 3668, 'camps': 3669, 'debate': 3670, 'landscapes': 3671, 'closing': 3672, 'unintentionally': 3673, 'proceedings': 3674, 'delivering': 3675, 'relies': 3676, 'unconvincing': 3677, 'gender': 3678, 'bother': 3679, 'looked': 3680, 'naturally': 3681, 'yellow': 3682, 'raunchy': 3683, 'regardless': 3684, 'placed': 3685, 'nickleby': 3686, 'overwhelming': 3687, 'competent': 3688, 'destined': 3689, 'mall': 3690, 'amy': 3691, 'rental': 3692, 'cheeky': 3693, 'region': 3694, 'treats': 3695, 'potentially': 3696, 'explosive': 3697, 'pink': 3698, 'circuit': 3699, 'notch': 3700, 'collapses': 3701, 'topic': 3702, 'inspire': 3703, 'insights': 3704, 'executed': 3705, 'photographed': 3706, 'elaborate': 3707, 'timing': 3708, 'motown': 3709, 'revelatory': 3710, 'brosnan': 3711, 'balanced': 3712, 'dana': 3713, 'carvey': 3714, 'suburban': 3715, 'wasted': 3716, 'juvenile': 3717, 'sophomoric': 3718, 'adapt': 3719, 'literary': 3720, 'reputation': 3721, 'smug': 3722, 'designed': 3723, 'considering': 3724, 'ambitions': 3725, 'grandson': 3726, 'femme': 3727, 'amuse': 3728, 'smile': 3729, 'testament': 3730, 'centuries': 3731, 'parallel': 3732, 'wickedly': 3733, 'tasty': 3734, 'beats': 3735, 'chapter': 3736, 'gut': 3737, 'dare': 3738, 'merchant': 3739, 'jaglom': 3740, 'rent': 3741, 'fabulous': 3742, 'blows': 3743, 'saying': 3744, 'matinee': 3745, 'vein': 3746, 'develop': 3747, '1980': 3748, 'sympathy': 3749, 'scientific': 3750, 'pulling': 3751, 'michel': 3752, 'morgan': 3753, 'mild': 3754, 'spin': 3755, 'possessed': 3756, 'outstanding': 3757, 'digs': 3758, 'diaz': 3759, 'ah': 3760, 'halloween': 3761, 'climactic': 3762, 'exposes': 3763, 'category': 3764, 'achievement': 3765, 'forgive': 3766, 'charmer': 3767, 'alabama': 3768, 'touched': 3769, 'absorbed': 3770, 'link': 3771, 'normally': 3772, 'rohmer': 3773, 'alluring': 3774, 'endearing': 3775, 'sorts': 3776, 'urge': 3777, 'shake': 3778, 'cultures': 3779, 'emerging': 3780, 'raises': 3781, 'mistaken': 3782, 'tuxedo': 3783, 'forcing': 3784, 'mouth': 3785, 'astonishingly': 3786, 'directs': 3787, 'focused': 3788, 'evelyn': 3789, 'gently': 3790, 'sentiment': 3791, 'moviegoers': 3792, 'apply': 3793, 'agenda': 3794, 'isabelle': 3795, 'trite': 3796, 'misery': 3797, 'pok': 3798, 'ram': 3799, 'mere': 3800, 'tea': 3801, 'lifetime': 3802, 'stark': 3803, 'unfortunate': 3804, 'sparkling': 3805, 'asian': 3806, 'hannibal': 3807, 'surfing': 3808, 'fool': 3809, 'romp': 3810, 'bits': 3811, 'admit': 3812, 'resolution': 3813, 'positively': 3814, 'comparison': 3815, 'lynch': 3816, 'position': 3817, 'aspects': 3818, 'savvy': 3819, 'lambs': 3820, 'carrying': 3821, 'edges': 3822, 'chou': 3823, 'harbor': 3824, 'metaphor': 3825, 'unpleasant': 3826, 'inducing': 3827, 'crossing': 3828, 'interests': 3829, 'timely': 3830, 'thick': 3831, 'mesmerizing': 3832, 'rendered': 3833, 'draw': 3834, 'profession': 3835, 'strangers': 3836, 'breezy': 3837, 'shaggy': 3838, 'thief': 3839, 'reaching': 3840, 'dramas': 3841, 'letters': 3842, 'psyche': 3843, 'toss': 3844, 'miami': 3845, 'flying': 3846, 'highest': 3847, 'degree': 3848, 'poorly': 3849, 'scale': 3850, 'responsibility': 3851, 'universe': 3852, 'youngsters': 3853, 'specific': 3854, 'familial': 3855, 'defend': 3856, 'slasher': 3857, 'circle': 3858, 'f': 3859, 'drops': 3860, 'v': 3861, 'unabashed': 3862, 'passions': 3863, 'stranded': 3864, 'lesser': 3865, 'swimming': 3866, 'conveys': 3867, 'arc': 3868, 'relatively': 3869, 'mothman': 3870, 'display': 3871, 'tends': 3872, 'valentine': 3873, 'tarantino': 3874, 'ritchie': 3875, 'seinfeld': 3876, 'maximum': 3877, 'familiarity': 3878, 'session': 3879, 'showcase': 3880, 'sadly': 3881, 'exhausted': 3882, 'cgi': 3883, 'pat': 3884, 'sublime': 3885, 'admirable': 3886, 'youthful': 3887, 'blues': 3888, 'archival': 3889, 'lower': 3890, 'insider': 3891, 'slap': 3892, 'wear': 3893, 'tears': 3894, 'nuanced': 3895, 'promised': 3896, 'fills': 3897, 'sophie': 3898, 'mixture': 3899, 'behold': 3900, 'exploits': 3901, 'comedian': 3902, 'deprecating': 3903, 'guest': 3904, 'canadian': 3905, 'commitment': 3906, 'variety': 3907, 'failing': 3908, 'confronted': 3909, 'opportunities': 3910, 'hilarity': 3911, 'careful': 3912, 'somber': 3913, 'mine': 3914, 'believer': 3915, 'vulgar': 3916, 'earn': 3917, 'pic': 3918, '1950': 3919, 'contrivances': 3920, 'prowess': 3921, 'incoherent': 3922, 'fever': 3923, '101': 3924, 'reached': 3925, 'required': 3926, 'illness': 3927, 'mail': 3928, 'pathetic': 3929, 'taps': 3930, 'worn': 3931, 'dreary': 3932, 'stroke': 3933, 'revelations': 3934, 'elder': 3935, 'wendigo': 3936, 'uncomfortable': 3937, 'cloying': 3938, 'neighbor': 3939, 'chuckle': 3940, 'scotland': 3941, 'elegant': 3942, 'ties': 3943, 'foot': 3944, 'mystic': 3945, 'albeit': 3946, 'leigh': 3947, 'flowers': 3948, 'sources': 3949, 'exists': 3950, 'payoff': 3951, 'describes': 3952, 'beast': 3953, 'performed': 3954, 'depends': 3955, 'irwin': 3956, 'breathtaking': 3957, 'rodriguez': 3958, 'stopped': 3959, 'destination': 3960, 'susan': 3961, 'sins': 3962, 'shoe': 3963, 'screenwriters': 3964, 'labor': 3965, 'design': 3966, 'carpenter': 3967, 'beaten': 3968, 'waves': 3969, 'spiral': 3970, 'throwback': 3971, 'pr': 3972, 'cliched': 3973, '6': 3974, 'auto': 3975, 'worked': 3976, 'yorkers': 3977, 'emily': 3978, 'sweetness': 3979, 'glamorous': 3980, 'faster': 3981, 'honestly': 3982, 'enigma': 3983, 'deceit': 3984, 'asylum': 3985, 'classics': 3986, 'pirate': 3987, 'britain': 3988, 'conflicts': 3989, 'gave': 3990, 'conversation': 3991, 'esther': 3992, 'kim': 3993, 'oddly': 3994, 'discussion': 3995, 'ralph': 3996, 'jonah': 3997, 'diesel': 3998, 'enchanting': 3999, 'goodness': 4000, 'ramsay': 4001, 'perverse': 4002, 'desolate': 4003, 'initially': 4004, 'brand': 4005, 'distinctive': 4006, 'palestinian': 4007, 'clinic': 4008, 'smoothly': 4009, 'paints': 4010, 'sisterhood': 4011, 'refugees': 4012, 'swim': 4013, 'strands': 4014, 'brilliantly': 4015, 'soft': 4016, 'resident': 4017, 'tommy': 4018, 'fascination': 4019, 'locked': 4020, 'bleak': 4021, 'holland': 4022, 'elizabeth': 4023, 'pal': 4024, 'gooding': 4025, 'cynicism': 4026, 'renowned': 4027, 'rhythm': 4028, 'studies': 4029, 'countries': 4030, 'caused': 4031, 'similar': 4032, 'melanie': 4033, 'warren': 4034, 'defeat': 4035, 'influence': 4036, 'narrator': 4037, 'connections': 4038, 'gambling': 4039, 'abruptly': 4040, 'repeated': 4041, 'environment': 4042, 'policy': 4043, 'botched': 4044, 'jerry': 4045, 'raise': 4046, 'warned': 4047, 'craig': 4048, 'shocked': 4049, 'rocket': 4050, 'frodo': 4051, 'unfulfilled': 4052, 'bucks': 4053, 'loyal': 4054, 'tonight': 4055, 'holding': 4056, 'paradiso': 4057, 'andy': 4058, 'purely': 4059, 'showdown': 4060, 'directions': 4061, 'network': 4062, 'singles': 4063, 'revelation': 4064, 'sanity': 4065, 'predicament': 4066, 'unexpectedly': 4067, 'diva': 4068, 'jaded': 4069, '800': 4070, 'ash': 4071, 'identities': 4072, 'disappear': 4073, 'motivations': 4074, 'gruesome': 4075, 'excessive': 4076, 'regain': 4077, 'parking': 4078, 'enforcement': 4079, 'importantly': 4080, 'champion': 4081, 'diane': 4082, 'kitchen': 4083, 'castle': 4084, 'python': 4085, 'nolan': 4086, 'clients': 4087, 'grounds': 4088, 'fran': 4089, 'described': 4090, 'fell': 4091, 'ali': 4092, 'formidable': 4093, 'reflects': 4094, 'clash': 4095, 'eastern': 4096, 'harper': 4097, 'march': 4098, 'zero': 4099, 'towers': 4100, 'invited': 4101, 'goods': 4102, 'meant': 4103, 'hamilton': 4104, 'actresses': 4105, 'compulsive': 4106, 'outcast': 4107, 'root': 4108, 'fellowship': 4109, 'racism': 4110, 'emergency': 4111, 'paying': 4112, 'bombing': 4113, 'mo': 4114, 'christine': 4115, 'eager': 4116, 'rogue': 4117, 'assassins': 4118, 'elvis': 4119, 'disturbed': 4120, 'hawaii': 4121, 'lifelong': 4122, 'techniques': 4123, 'pushed': 4124, 'amateur': 4125, 'vampires': 4126, 'amitabh': 4127, 'robbing': 4128, 'safety': 4129, 'retirement': 4130, 'spielrein': 4131, 'newly': 4132, 'guides': 4133, 'roy': 4134, 'writes': 4135, 'guests': 4136, 'buys': 4137, 'awry': 4138, 'designer': 4139, 'beth': 4140, 'virginia': 4141, 'hears': 4142, 'mcnamara': 4143, 'businessman': 4144, 'vengeance': 4145, 'wishes': 4146, 'solitude': 4147, 'awaiting': 4148, 'preserve': 4149, 'devastated': 4150, 'suspected': 4151, 'troops': 4152, 'insane': 4153, 'coach': 4154, 'dewey': 4155, 'blackmail': 4156, 'newspaper': 4157, 'reverend': 4158, 'sue': 4159, 'prior': 4160, 'advances': 4161, 'inmate': 4162, 'temporary': 4163, 'shark': 4164, 'owns': 4165, 'confronts': 4166, 'wayne': 4167, 'murderer': 4168, 'attacked': 4169, 'enemies': 4170, 'paulo': 4171, 'deserted': 4172, 'mickey': 4173, 'council': 4174, 'troubles': 4175, 'rlich': 4176, 'chow': 4177, 'duncan': 4178, 'doll': 4179, 'hire': 4180, 'hung': 4181, 'wilderness': 4182, 'refuge': 4183, 'asked': 4184, 'elders': 4185, 'temple': 4186, 'custody': 4187, 'recruited': 4188, 'elf': 4189, 'mrs': 4190, 'hunger': 4191, 'phil': 4192, 'otte': 4193, 'ghana': 4194, 'cases': 4195, 'isolated': 4196, 'abusive': 4197, 'regulus': 4198, 'gale': 4199, 'bars': 4200, 'hides': 4201, 'ron': 4202, 'embarks': 4203, 'georgia': 4204, 'rituals': 4205, 'gus': 4206, 'prepares': 4207, 'colleague': 4208, 'casino': 4209, 'contract': 4210, 'jeff': 4211, 'jobs': 4212, 'twelve': 4213, 'husbands': 4214, 'tobias': 4215, 'leela': 4216, 'runaway': 4217, 'karl': 4218, 'rebecca': 4219, 'cemetery': 4220, 'ensure': 4221, 'lizzy': 4222, 'suspicious': 4223, 'exact': 4224, 'biker': 4225, 'alert': 4226, 'model': 4227, 'difficulties': 4228, 'swinging': 4229, 'undergo': 4230, 'suits': 4231, 'cletis': 4232, 'offbeat': 4233, 'shifting': 4234, 'pale': 4235, 'supporting': 4236, 'defies': 4237, 'expectation': 4238, 'toro': 4239, 'gravity': 4240, 'undeniable': 4241, 'pulse': 4242, 'wow': 4243, 'eastwood': 4244, 'moviemaking': 4245, 'crane': 4246, 'pauline': 4247, 'inhabit': 4248, 'cinderella': 4249, 'sleeve': 4250, 'spot': 4251, 'disbelief': 4252, 'packs': 4253, 'wallop': 4254, 'chases': 4255, 'farmer': 4256, 'salt': 4257, 'sting': 4258, 'bite': 4259, 'meaningful': 4260, 'walking': 4261, 'urgency': 4262, 'doo': 4263, 'oliveira': 4264, 'spreading': 4265, 'nails': 4266, 'vanity': 4267, 'harbour': 4268, 'fury': 4269, 'shaped': 4270, 'darker': 4271, 'aim': 4272, 'shameless': 4273, 'wrapped': 4274, 'schmidt': 4275, 'viewed': 4276, 'cautionary': 4277, 'embraces': 4278, 'behan': 4279, 'endlessly': 4280, 'moviegoing': 4281, 'theaters': 4282, 'benefits': 4283, 'invitation': 4284, 'oedekerk': 4285, 'freeman': 4286, 'messy': 4287, 'dressed': 4288, 'entry': 4289, 'continually': 4290, 'labored': 4291, 'showtime': 4292, 'lampoon': 4293, 'anyway': 4294, 'disappointing': 4295, 'arthur': 4296, 'press': 4297, 'embracing': 4298, 'soulless': 4299, 'boundaries': 4300, 'reggio': 4301, 'philip': 4302, 'lovable': 4303, 'minority': 4304, 'affleck': 4305, 'audacious': 4306, 'arrived': 4307, 'decidedly': 4308, 'appreciated': 4309, 'miyazaki': 4310, 'delighted': 4311, 'inevitable': 4312, 'amiable': 4313, 'splendid': 4314, 'review': 4315, 'downer': 4316, \"'a\": 4317, 'denying': 4318, 'helen': 4319, 'commands': 4320, 'frances': 4321, 'aspirations': 4322, 'tsai': 4323, 'northwest': 4324, 'museum': 4325, 'onscreen': 4326, 'hanks': 4327, 'wells': 4328, 'naipaul': 4329, 'namely': 4330, 'gag': 4331, 'vapid': 4332, 'shines': 4333, 'perfection': 4334, 'bridge': 4335, 'enduring': 4336, 'bartleby': 4337, 'hallmark': 4338, 'infidelity': 4339, 'plus': 4340, 'dose': 4341, 'respectable': 4342, 'inconsequential': 4343, 'muccino': 4344, 'cerebral': 4345, 'mature': 4346, 'hottest': 4347, 'zhao': 4348, 'elegantly': 4349, 'droll': 4350, 'scientists': 4351, 'potent': 4352, 'scenery': 4353, 'figuring': 4354, 'witnesses': 4355, 'pedestrian': 4356, 'flashy': 4357, 'subtlety': 4358, 'gross': 4359, 'paula': 4360, 'rank': 4361, 'amused': 4362, 'clueless': 4363, 'experienced': 4364, 'critical': 4365, 'painting': 4366, 'clockstoppers': 4367, 'imaginable': 4368, 'maintains': 4369, 'whimsy': 4370, 'probe': 4371, 'spears': 4372, 'centered': 4373, 'collar': 4374, 'enlightening': 4375, 'spice': 4376, 'talky': 4377, 'wills': 4378, 'morvern': 4379, 'callar': 4380, 'bones': 4381, 'bielinsky': 4382, 'sensation': 4383, 'clashing': 4384, 'catching': 4385, 'wrenching': 4386, 'preachy': 4387, 'handled': 4388, 'dahmer': 4389, 'liman': 4390, 'orders': 4391, 'ballot': 4392, 'purposefully': 4393, 'laughable': 4394, 'beguiling': 4395, 'curves': 4396, 'hat': 4397, 'eyre': 4398, 'exception': 4399, 'housing': 4400, 'pushes': 4401, 'kilmer': 4402, 'idealism': 4403, 'whale': 4404, 'barbara': 4405, 'dass': 4406, \"'60s\": 4407, 'duvall': 4408, 'deuces': 4409, 'improbable': 4410, 'exploitation': 4411, 'q': 4412, 'effortlessly': 4413, 'corny': 4414, 'nervous': 4415, 'receives': 4416, 'newcomer': 4417, 'luke': 4418, 'limit': 4419, 'ourselves': 4420, 'razor': 4421, 'refuse': 4422, 'traveler': 4423, 'ambiguous': 4424, 'positive': 4425, 'devoid': 4426, 'demonstrate': 4427, 'intricate': 4428, 'bang': 4429, 'pro': 4430, 'stylized': 4431, 'villainous': 4432, 'kapur': 4433, 'page': 4434, 'fighter': 4435, 'horribly': 4436, 'hugely': 4437, 'disposable': 4438, 'fingered': 4439, 'wallace': 4440, 'winged': 4441, 'frustrating': 4442, 'blown': 4443, 'size': 4444, 'insecure': 4445, 'nominated': 4446, 'niche': 4447, 'anticipated': 4448, 'numbingly': 4449, 'narc': 4450, 'nicholson': 4451, 'hitting': 4452, 'exquisite': 4453, 'tenderness': 4454, 'unflinching': 4455, 'von': 4456, 'overwrought': 4457, 'bicycle': 4458, 'vital': 4459, 'yard': 4460, 'unseen': 4461, 'affected': 4462, 'freak': 4463, 'temper': 4464, 'marco': 4465, 'requires': 4466, 'edited': 4467, 'appropriate': 4468, 'spaces': 4469, 'frantic': 4470, 'eating': 4471, 'sleeping': 4472, 'eat': 4473, 'distract': 4474, 'excited': 4475, 'plodding': 4476, 'unabashedly': 4477, 'inoffensive': 4478, 'monte': 4479, 'steeped': 4480, 'val': 4481, 'credibility': 4482, 'approaching': 4483, 'drunken': 4484, 'produces': 4485, 'choppy': 4486, 'acute': 4487, 'diversion': 4488, 'shift': 4489, 'rejects': 4490, 'weddings': 4491, 'mixed': 4492, 'risky': 4493, 'mention': 4494, 'novak': 4495, 'definitive': 4496, 'kinda': 4497, 'saga': 4498, 'crosses': 4499, 'demographic': 4500, 'adams': 4501, 'prophecies': 4502, 'theories': 4503, 'passing': 4504, 'pointed': 4505, 'yu': 4506, 'richly': 4507, 'claims': 4508, 'superficial': 4509, 'accents': 4510, 'receive': 4511, 'altering': 4512, 'polanski': 4513, 'adding': 4514, 'whenever': 4515, 'questionable': 4516, 'cooper': 4517, 'awe': 4518, 'winter': 4519, 'necessarily': 4520, 'physically': 4521, 'backed': 4522, 'sentence': 4523, 'alas': 4524, 'steers': 4525, 'impossibly': 4526, 'separation': 4527, 'diego': 4528, 'hook': 4529, 'profoundly': 4530, 'energetic': 4531, 'origins': 4532, 'birot': 4533, 'borrows': 4534, 'persuasive': 4535, 'problematic': 4536, \"dickens'\": 4537, 'mixes': 4538, 'fueled': 4539, 'appointed': 4540, 'blowing': 4541, 'insulting': 4542, 'assembled': 4543, 'nba': 4544, 'fits': 4545, 'ecks': 4546, 'sever': 4547, 'volatile': 4548, 'hey': 4549, 'ironically': 4550, 'tomorrow': 4551, 'russell': 4552, 'alongside': 4553, 'controversy': 4554, 'critics': 4555, 'transporting': 4556, 'passive': 4557, 'feardotcom': 4558, 'practice': 4559, 'gory': 4560, 'saves': 4561, 'polished': 4562, 'vignettes': 4563, 'successfully': 4564, 'unfolding': 4565, 'nazi': 4566, 'delightfully': 4567, 'boats': 4568, 'lieutenant': 4569, 'unemployment': 4570, 'uncovers': 4571, 'drenched': 4572, 'subplots': 4573, '1998': 4574, 'valuable': 4575, 'enjoyably': 4576, 'elevates': 4577, 'sensational': 4578, 'sincerity': 4579, 'fantastic': 4580, 'installment': 4581, 'kidman': 4582, 'trashy': 4583, 'schneider': 4584, 'hearst': 4585, 'bone': 4586, 'rumor': 4587, 'evans': 4588, 'ops': 4589, 'uninvolving': 4590, 'tracy': 4591, 'sunday': 4592, 'starred': 4593, 'borders': 4594, 'parable': 4595, 'gollum': 4596, 'hypnotic': 4597, 'pulled': 4598, 'protagonists': 4599, 'exposure': 4600, 'frightening': 4601, 'gallo': 4602, 'domestic': 4603, 'introducing': 4604, 'invaluable': 4605, 'unusually': 4606, 'resources': 4607, 'sunshine': 4608, 'sayles': 4609, 'letting': 4610, 'visible': 4611, 'insanity': 4612, 'deceptively': 4613, 'owes': 4614, 'recognize': 4615, 'momentum': 4616, 'awesome': 4617, 'lightning': 4618, \"kids'\": 4619, 'smuggling': 4620, 'danish': 4621, 'alter': 4622, 'systems': 4623, 'norton': 4624, 'justify': 4625, 'literature': 4626, 'editor': 4627, 'incessant': 4628, 'ethan': 4629, 'greatly': 4630, 'frat': 4631, 'shifts': 4632, 'flag': 4633, 'w': 4634, 'travelogue': 4635, 'solaris': 4636, 'rating': 4637, 'shattering': 4638, 'snipes': 4639, 'feat': 4640, 'improve': 4641, 'climate': 4642, 'dim': 4643, 'witted': 4644, 'meandering': 4645, 'abstract': 4646, 'funk': 4647, 'juwanna': 4648, 'fierce': 4649, 'vague': 4650, 'gusto': 4651, 'randolph': 4652, 'clause': 4653, 'pie': 4654, 'seasoned': 4655, 'smack': 4656, 'abandon': 4657, 'literate': 4658, 'doomed': 4659, 'ultra': 4660, 'charisma': 4661, 'hayek': 4662, 'bogs': 4663, 'scottish': 4664, 'coppola': 4665, 'endangered': 4666, 'skillfully': 4667, 'lifeless': 4668, 'ode': 4669, 'christ': 4670, 'tara': 4671, 'dangerously': 4672, 'uma': 4673, 'gray': 4674, 'kang': 4675, 'decadent': 4676, 'questioning': 4677, 'tackles': 4678, 'hackneyed': 4679, 'glamour': 4680, 'stages': 4681, 'psychoanalysis': 4682, 'clunky': 4683, 'filling': 4684, 'ninety': 4685, 'rhythms': 4686, 'laser': 4687, 'paintings': 4688, 'exposed': 4689, 'deceptions': 4690, 'wanders': 4691, 'obnoxious': 4692, 'kiddie': 4693, 'option': 4694, 'express': 4695, 'derrida': 4696, 'kenneth': 4697, 'branagh': 4698, 'wearing': 4699, 'skins': 4700, 'aims': 4701, 'fluff': 4702, 'israel': 4703, 'adventurous': 4704, 'essential': 4705, 'providing': 4706, 'artful': 4707, 'psychology': 4708, 'heading': 4709, 'ratliff': 4710, 'classical': 4711, 'morally': 4712, 'na': 4713, 'pumpkin': 4714, 'eloquent': 4715, 'ravaged': 4716, 'idealistic': 4717, 'communicate': 4718, 'obstacle': 4719, 'invasion': 4720, 'unlikable': 4721, 'claustrophobic': 4722, 'babies': 4723, 'ongoing': 4724, 'coherent': 4725, 'explode': 4726, 'singular': 4727, 'overnight': 4728, 'bands': 4729, 'wins': 4730, 'huston': 4731, 'villains': 4732, 'counter': 4733, 'rapidly': 4734, 'curiously': 4735, 'pot': 4736, 'mars': 4737, '1984': 4738, 'structured': 4739, 'trusting': 4740, 'cable': 4741, 'valiantly': 4742, 'focusing': 4743, 'easier': 4744, 'illustrates': 4745, 'access': 4746, 'primary': 4747, 'framed': 4748, 'supposedly': 4749, 'sorrow': 4750, 'courtroom': 4751, 'melancholy': 4752, 'samuel': 4753, 'delusions': 4754, 'evident': 4755, 'seeming': 4756, 'harder': 4757, 'sweetheart': 4758, 'circles': 4759, 'transformed': 4760, 'aids': 4761, 'therefore': 4762, 'shrewd': 4763, 'engages': 4764, 'tabloid': 4765, 'cancer': 4766, 'moody': 4767, 'occupied': 4768, 'satan': 4769, 'navigate': 4770, 'michell': 4771, 'reminded': 4772, 'chateau': 4773, 'arguments': 4774, 'ordeal': 4775, 'bunch': 4776, 'tables': 4777, 'flower': 4778, 'involve': 4779, 'dentist': 4780, 'afraid': 4781, 'manipulate': 4782, 'terminally': 4783, 'dealers': 4784, 'collect': 4785, 'punishment': 4786, 'caesar': 4787, 'shainberg': 4788, 'junkie': 4789, 'confessions': 4790, 'cockettes': 4791, 'amongst': 4792, 'contacts': 4793, 'consistently': 4794, 'mystical': 4795, 'wizardry': 4796, 'doyle': 4797, 'greene': 4798, 'firefighters': 4799, 'rowdy': 4800, 'pan': 4801, 'belt': 4802, 'alexander': 4803, 'ambiguity': 4804, 'laramie': 4805, 'wilco': 4806, 'sided': 4807, 'upbeat': 4808, 'tastes': 4809, 'attempted': 4810, 'charles': 4811, 'iii': 4812, 'jennifer': 4813, 'beings': 4814, 'blast': 4815, 'kieslowski': 4816, 'compromise': 4817, 'hurt': 4818, 'seduce': 4819, 'tank': 4820, 'quarter': 4821, 'killings': 4822, 'waits': 4823, 'visitor': 4824, 'irresistible': 4825, 'seats': 4826, 'danang': 4827, 'debts': 4828, 'presentation': 4829, 'hoped': 4830, 'records': 4831, 'absence': 4832, 'switch': 4833, 'dreadful': 4834, 'marries': 4835, 'timothy': 4836, 'essence': 4837, 'stylistic': 4838, 'cheat': 4839, 'explodes': 4840, 'michelle': 4841, 'cook': 4842, 'sending': 4843, 'argument': 4844, 'approaches': 4845, 'conscience': 4846, 'hundred': 4847, 'witnessing': 4848, 'blonde': 4849, 'grieving': 4850, 'lesbian': 4851, 'internal': 4852, 'terrorists': 4853, 'machines': 4854, 'sensual': 4855, 'fleeing': 4856, 'shape': 4857, 'everywhere': 4858, 'mounts': 4859, 'performing': 4860, 'confident': 4861, 'hilary': 4862, 'ropes': 4863, 'wet': 4864, 'blooded': 4865, 'till': 4866, 'convoluted': 4867, 'bet': 4868, 'bombs': 4869, 'rings': 4870, 'healthy': 4871, 'liar': 4872, 'banner': 4873, 'foster': 4874, 'aragorn': 4875, 'selfish': 4876, 'garden': 4877, 'raja': 4878, 'inadvertently': 4879, 'racing': 4880, 'areas': 4881, 'featured': 4882, 'refugee': 4883, 'fought': 4884, 'restless': 4885, 'houses': 4886, 'mate': 4887, 'communist': 4888, 'catholic': 4889, 'chronicle': 4890, 'bio': 4891, 'graffiti': 4892, 'dons': 4893, 'injustice': 4894, 'photographer': 4895, 'tribal': 4896, 'jungle': 4897, 'butterfly': 4898, 'albert': 4899, 'klein': 4900, 'doctors': 4901, 'entity': 4902, 'ceremony': 4903, 'komal': 4904, 'maine': 4905, 'unhappy': 4906, 'diamonds': 4907, 'thieves': 4908, 'usa': 4909, 'officers': 4910, 'rodney': 4911, 'horrific': 4912, 'arjun': 4913, 'vigilante': 4914, 'chomsky': 4915, 'graduation': 4916, 'tess': 4917, 'month': 4918, 'marine': 4919, 'cafe': 4920, 'lunch': 4921, 'dre': 4922, 'masters': 4923, 'disillusioned': 4924, 'jose': 4925, 'revolutionary': 4926, 'hiller': 4927, 'helping': 4928, 'sergeant': 4929, 'misfit': 4930, 'eclectic': 4931, 'scholarship': 4932, 'stray': 4933, 'philippa': 4934, 'frankie': 4935, 'argentina': 4936, 'superfag': 4937, 'appointment': 4938, 'july': 4939, 'bering': 4940, 'gulab': 4941, 'methods': 4942, 'mutant': 4943, 'launches': 4944, 'divorced': 4945, 'alcoholic': 4946, 'otis': 4947, 'mordor': 4948, 'merry': 4949, 'upcoming': 4950, 'deck': 4951, 'impending': 4952, 'embark': 4953, 'amerika': 4954, 'zed': 4955, 'motive': 4956, 'mateo': 4957, 'manny': 4958, 'investment': 4959, 'institute': 4960, 'syndicate': 4961, 'akash': 4962, 'disappears': 4963, 'anita': 4964, 'diamond': 4965, 'commits': 4966, 'candidate': 4967, 'kapoor': 4968, 'watson': 4969, 'trasha': 4970, 'commit': 4971, 'pooja': 4972, 'teaching': 4973, 'dogville': 4974, 'werner': 4975, 'stan': 4976, 'chep': 4977, 'altered': 4978, 'fett': 4979, 'regular': 4980, 'bay': 4981, 'occupation': 4982, 'published': 4983, 'kingpin': 4984, 'joseph': 4985, 'kidnaps': 4986, 'lapd': 4987, 'unknowingly': 4988, 'assist': 4989, 'babe': 4990, 'genevieve': 4991, 'battling': 4992, 'lui': 4993, 'investigative': 4994, '23': 4995, 'eternal': 4996, 'ancanar': 4997, 'cure': 4998, 'casinos': 4999, 'oldman': 5000, 'pressures': 5001, 'pastor': 5002, 'amidala': 5003, 'stiles': 5004, 'burke': 5005, 'johnathan': 5006, 'alexi': 5007, 'relation': 5008, 'rick': 5009, 'poets': 5010, 'prosit': 5011, 'devlin': 5012, 'mastermind': 5013, 'protecting': 5014, 'federation': 5015, 'neighbors': 5016, 'weapon': 5017, 'division': 5018, 'attend': 5019, 'pursued': 5020, 'motel': 5021, 'campus': 5022, 'connie': 5023, 'yun': 5024, 'rupert': 5025, 'scroll': 5026, 'ally': 5027, 'amanda': 5028, 'shattered': 5029, 'launched': 5030, 'cruise': 5031, 'sell': 5032, 'dreaming': 5033, 'davey': 5034, 'toni': 5035, 'entangled': 5036, 'brookdale': 5037, 'experts': 5038, 'tucks': 5039, 'lab': 5040, 'barrillo': 5041, 'pilgrimage': 5042, 'patrick': 5043, 'elena': 5044, 'paravasu': 5045, 'maria': 5046, '1970': 5047, 'injury': 5048, 'bachchan': 5049, 'duct': 5050, 'krueger': 5051, 'katie': 5052, 'nadine': 5053, 'hitler': 5054, 'rooney': 5055, 'sang': 5056, 'aided': 5057, 'thirteen': 5058, 'seas': 5059, 'jew': 5060, 'tout': 5061, 'eerie': 5062, 'clayburgh': 5063, 'tambor': 5064, 'occurs': 5065, 'videos': 5066, 'impostor': 5067, 'authority': 5068, 'references': 5069, 'tones': 5070, 'stumble': 5071, 'fontaine': 5072, 'adrien': 5073, 'compulsively': 5074, 'sordid': 5075, 'paulette': 5076, 'demise': 5077, 'sobering': 5078, 'smartly': 5079, 'ferrara': 5080, 'hammer': 5081, 'relentlessly': 5082, 'undoubtedly': 5083, 'milieu': 5084, 'holm': 5085, 'knockout': 5086, 'jazz': 5087, 'ran': 5088, 'exhausting': 5089, 'cumulative': 5090, 'repulsive': 5091, 'vastly': 5092, 'frustratingly': 5093, 'versus': 5094, 'darling': 5095, 'achieved': 5096, 'contrivance': 5097, 'tormented': 5098, 'sexuality': 5099, 'rewarded': 5100, 'borstal': 5101, 'exceptional': 5102, 'optimistic': 5103, 'sadness': 5104, 'unsatisfying': 5105, 'redundant': 5106, 'portray': 5107, 'iconoclastic': 5108, 'schmaltz': 5109, 'barbed': 5110, 'composed': 5111, 'dubious': 5112, 'weighty': 5113, 'heal': 5114, 'reaction': 5115, 'por': 5116, 'conflicting': 5117, 'heartland': 5118, 'prep': 5119, 'thoughtfulness': 5120, 'clerk': 5121, 'surf': 5122, 'suitable': 5123, 'fest': 5124, 'heartbreak': 5125, 'rebellion': 5126, 'runner': 5127, 'journalism': 5128, 'precisely': 5129, 'hunk': 5130, 'exploitative': 5131, 'garbage': 5132, 'sensuous': 5133, 'bending': 5134, 'mamet': 5135, 'desmond': 5136, 'showcases': 5137, 'loosely': 5138, 'joan': 5139, 'torture': 5140, 'waterlogged': 5141, 'incoherence': 5142, 'hats': 5143, 'deserved': 5144, 'net': 5145, 'composition': 5146, 'regret': 5147, 'costly': 5148, 'transporter': 5149, 'storyteller': 5150, 'upset': 5151, 'entertain': 5152, 'ham': 5153, 'cheese': 5154, 'clone': 5155, 'andrew': 5156, 'strengths': 5157, 'staring': 5158, 'closure': 5159, 'activists': 5160, 'attal': 5161, \"ol'\": 5162, 'dear': 5163, 'chord': 5164, 'intelligently': 5165, 'crossroads': 5166, 'daytime': 5167, 'dumped': 5168, 'owe': 5169, 'wang': 5170, 'delights': 5171, 'bought': 5172, 'tub': 5173, 'snappy': 5174, 'observations': 5175, 'sensuality': 5176, 'hampered': 5177, 'commended': 5178, 'siegel': 5179, 'chest': 5180, 'pretension': 5181, 'hollow': 5182, 'os': 5183, 'celebrates': 5184, 'imaginary': 5185, 'resorting': 5186, 'ably': 5187, 'improved': 5188, 'richer': 5189, 'proven': 5190, 'outlandish': 5191, 'pathos': 5192, 'bare': 5193, 'delinquent': 5194, 'youths': 5195, 'mannered': 5196, 'plympton': 5197, 'simplicity': 5198, 'searches': 5199, 'grisly': 5200, 'neurotic': 5201, 'burst': 5202, 'generate': 5203, 'sustains': 5204, 'echoes': 5205, 'similarly': 5206, 'gaze': 5207, 'firmly': 5208, 'schlock': 5209, 'soggy': 5210, 'excuse': 5211, 'kidd': 5212, 'screams': 5213, 'bathroom': 5214, 'welsh': 5215, 'ford': 5216, 'breakdown': 5217, 'cherish': 5218, 'quirks': 5219, 'frailty': 5220, 'saccharine': 5221, 'infomercial': 5222, 'text': 5223, 'dramatically': 5224, 'shaky': 5225, 'morton': 5226, 'portraying': 5227, 'mechanics': 5228, 'performer': 5229, 'absent': 5230, 'meat': 5231, 'jackass': 5232, 'grotesque': 5233, 'thumbs': 5234, 'supernatural': 5235, 'cleverness': 5236, 'figured': 5237, 'witnessed': 5238, 'stitch': 5239, 'conditions': 5240, 'fundamental': 5241, 'contradictory': 5242, 'stormy': 5243, 'encouraging': 5244, 'deliberately': 5245, \"filmmakers'\": 5246, 'joyless': 5247, 'downright': 5248, 'stretched': 5249, 'didactic': 5250, 'textbook': 5251, 'doug': 5252, 'dramatization': 5253, 'isolation': 5254, 'infested': 5255, 'chooses': 5256, 'earned': 5257, 'dope': 5258, 'columbus': 5259, 'sumptuous': 5260, 'deadpan': 5261, 'stallone': 5262, 'concern': 5263, 'flame': 5264, 'pantheon': 5265, 'zhang': 5266, 'piano': 5267, 'rewards': 5268, 'bravery': 5269, 'anachronistic': 5270, 'notably': 5271, 'biological': 5272, 'precision': 5273, 'motherhood': 5274, 'orgy': 5275, 'proposes': 5276, '22': 5277, 'stunt': 5278, 'thrillers': 5279, 'myself': 5280, 'crisp': 5281, 'derek': 5282, 'incarnation': 5283, 'correct': 5284, 'prefer': 5285, 'exposing': 5286, 'kinnear': 5287, 'satirical': 5288, 'freundlich': 5289, 'plots': 5290, 'painted': 5291, 'suggest': 5292, 'idiocy': 5293, 'swedish': 5294, 'gere': 5295, 'bubble': 5296, 'muddled': 5297, 'guts': 5298, 'likeable': 5299, 'explosion': 5300, 'properly': 5301, 'consolation': 5302, 'collateral': 5303, 'donovan': 5304, 'intrigued': 5305, 'finely': 5306, 'sheridan': 5307, 'carrey': 5308, 'safely': 5309, 'possess': 5310, 'persuades': 5311, 'folk': 5312, 'void': 5313, 'gibson': 5314, 'extended': 5315, 'hustlers': 5316, 'kline': 5317, 'capacity': 5318, 'jumbo': 5319, 'panorama': 5320, 'bug': 5321, '1982': 5322, 'venture': 5323, 'malkovich': 5324, 'hopeless': 5325, 'muddle': 5326, 'brush': 5327, 'colleagues': 5328, 'les': 5329, 'sorvino': 5330, 'fisher': 5331, 'distinctly': 5332, 'allegory': 5333, 'won': 5334, 'bore': 5335, 'dopey': 5336, 'naturalistic': 5337, 'boredom': 5338, 'dated': 5339, 'fairies': 5340, 'fisted': 5341, 'vez': 5342, 'restrained': 5343, 'intensely': 5344, 'benigno': 5345, 'thematically': 5346, 'complications': 5347, 'website': 5348, 'vice': 5349, 'escapism': 5350, 'confined': 5351, 'rollerball': 5352, 'ingredients': 5353, 'devolves': 5354, 'solving': 5355, 'repeatedly': 5356, 'overkill': 5357, 'murky': 5358, 'cristo': 5359, 'operates': 5360, 'childish': 5361, 'nightclub': 5362, 'weighs': 5363, 'divide': 5364, 'napoleon': 5365, 'midlife': 5366, 'juicy': 5367, 'rotten': 5368, 'solutions': 5369, 'hokum': 5370, 'lens': 5371, 'elsewhere': 5372, 'unnecessary': 5373, 'manners': 5374, 'mehta': 5375, 'fuel': 5376, 'achievements': 5377, 'accomplishes': 5378, 'embarrassed': 5379, 'squarely': 5380, 'demanding': 5381, 'groups': 5382, 'define': 5383, 'tavernier': 5384, 'speculation': 5385, 'loads': 5386, 'jump': 5387, 'han': 5388, 'expecting': 5389, 'quentin': 5390, 'chemical': 5391, 'advantage': 5392, 'sticking': 5393, 'julia': 5394, 'charly': 5395, 'steam': 5396, 'metropolis': 5397, 'misanthropic': 5398, 'dense': 5399, 'lift': 5400, 'exposition': 5401, 'lan': 5402, 'longing': 5403, 'routines': 5404, 'coat': 5405, 'frozen': 5406, 'qualities': 5407, 'absurdist': 5408, 'cogent': 5409, 'nightmarish': 5410, 'regards': 5411, 'knee': 5412, 'trials': 5413, 'cleverly': 5414, 'ease': 5415, 'cheesy': 5416, 'fail': 5417, 'instance': 5418, 'mcgrath': 5419, 'odyssey': 5420, 'spanning': 5421, 'erin': 5422, 'embrace': 5423, 'stardom': 5424, 'anymore': 5425, 'neck': 5426, 'woven': 5427, 'succeeded': 5428, 'ideals': 5429, 'statement': 5430, 'wholly': 5431, 'realized': 5432, 'drew': 5433, 'payami': 5434, 'iran': 5435, 'zany': 5436, 'wound': 5437, 'devotees': 5438, 'tattered': 5439, 'yesterday': 5440, 'immature': 5441, 'titles': 5442, 'wrap': 5443, 'overblown': 5444, 'episodic': 5445, 'ma': 5446, 'steamy': 5447, 'rapid': 5448, 'theory': 5449, 'marvel': 5450, 'mistakes': 5451, 'exquisitely': 5452, 'clips': 5453, 'endeavor': 5454, 'highlights': 5455, 'relative': 5456, 'metaphors': 5457, 'retread': 5458, 'blurry': 5459, 'unnerving': 5460, 'vera': 5461, 'kick': 5462, 'flimsy': 5463, 'suffered': 5464, 'corners': 5465, 'mythic': 5466, 'writings': 5467, 'lean': 5468, 'feeding': 5469, 'okay': 5470, 'supremely': 5471, 'steady': 5472, 'quieter': 5473, 'canny': 5474, 'tadpole': 5475, 'blessed': 5476, 'raimi': 5477, 'relief': 5478, 'titular': 5479, 'heartwarming': 5480, 'intermittently': 5481, 'constraints': 5482, 'helped': 5483, 'impeccable': 5484, 'haynes': 5485, 'smarter': 5486, '1972': 5487, 'genres': 5488, 'liberating': 5489, 'regarding': 5490, 'bump': 5491, 'ridden': 5492, 'calm': 5493, 'breed': 5494, \"'what\": 5495, 'shanghai': 5496, 'compassionate': 5497, 'analysis': 5498, 'clumsily': 5499, 'foremost': 5500, 'originally': 5501, 'sundance': 5502, 'unlucky': 5503, 'begs': 5504, 'finger': 5505, 'complaint': 5506, 'moonlight': 5507, 'theatrical': 5508, 'fitting': 5509, 'antics': 5510, 'stab': 5511, 'robinson': 5512, 'derives': 5513, 'gifts': 5514, 'disappoint': 5515, 'finished': 5516, 'chuckles': 5517, 'succumbs': 5518, 'trap': 5519, 'bard': 5520, 'magnetic': 5521, 'excesses': 5522, 'rides': 5523, 'coincidence': 5524, 'campaign': 5525, 'pun': 5526, 'tourists': 5527, 'initial': 5528, 'reconstruction': 5529, 'nathan': 5530, 'cathartic': 5531, 'putting': 5532, 'phones': 5533, 'consciously': 5534, 'polish': 5535, 'leaden': 5536, 'indifferent': 5537, 'transforms': 5538, 'loaded': 5539, 'base': 5540, 'devices': 5541, 'discarded': 5542, 'spread': 5543, 'nash': 5544, 'downward': 5545, 'velocity': 5546, 'rousing': 5547, 'treatment': 5548, 'pointless': 5549, 'specifically': 5550, 'sardonic': 5551, 'metal': 5552, 'laden': 5553, 'truthful': 5554, 'playboy': 5555, 'rounded': 5556, 'emphasis': 5557, 'wisely': 5558, 'finishing': 5559, 'stilted': 5560, 'veterans': 5561, 'bracing': 5562, 'championship': 5563, 'clue': 5564, 'thrusts': 5565, 'predict': 5566, 'tremendous': 5567, 'tragically': 5568, 'sought': 5569, 'glorious': 5570, 'blockbuster': 5571, 'squeeze': 5572, 'tie': 5573, 'retro': 5574, 'pacific': 5575, 'rhetoric': 5576, 'bale': 5577, 'tunnel': 5578, 'astounding': 5579, 'straightforward': 5580, 'displays': 5581, 'foundation': 5582, 'tops': 5583, 'soulful': 5584, 'sensibilities': 5585, 'plate': 5586, 'dreck': 5587, 'resourceful': 5588, 'molly': 5589, 'dots': 5590, 'trio': 5591, 'cocktail': 5592, 'berling': 5593, 'macy': 5594, 'bean': 5595, 'sluggish': 5596, 'expos': 5597, 'outcome': 5598, 'firth': 5599, 'karen': 5600, 'route': 5601, 'unrequited': 5602, \"'80s\": 5603, 'mundane': 5604, 'morocco': 5605, 'awareness': 5606, 'experiments': 5607, 'rolled': 5608, 'merit': 5609, 'sham': 5610, 'combined': 5611, 'avant': 5612, 'garde': 5613, 'greater': 5614, 'aesthetic': 5615, 'address': 5616, 'available': 5617, 'ears': 5618, 'masterfully': 5619, 'taut': 5620, 'mcconaughey': 5621, 'thank': 5622, 'limp': 5623, 'tight': 5624, 'grasp': 5625, 'guessing': 5626, 'joint': 5627, 'allowing': 5628, 'codes': 5629, 'abilities': 5630, 'trusted': 5631, 'gained': 5632, 'acceptable': 5633, 'monday': 5634, 'gaza': 5635, 'restore': 5636, 'harmon': 5637, 'castro': 5638, 'retreat': 5639, 'ruins': 5640, 'scorpion': 5641, 'ed': 5642, 'philosophy': 5643, 'li': 5644, 'borrowed': 5645, 'acquire': 5646, 'scams': 5647, 'scream': 5648, 'entering': 5649, 'oriented': 5650, 'resemblance': 5651, 'phenomenal': 5652, 'turkey': 5653, 'subsequent': 5654, 'admire': 5655, 'overlong': 5656, 'spain': 5657, 'hardy': 5658, 'cuts': 5659, 'dares': 5660, 'chiller': 5661, 'labute': 5662, 'departure': 5663, 'chances': 5664, 'gimmick': 5665, 'detached': 5666, 'accompanied': 5667, 'am': 5668, 'girlfriends': 5669, 'wives': 5670, 'babes': 5671, 'knack': 5672, 'exuberant': 5673, 'achieve': 5674, 'guessed': 5675, 'consumed': 5676, 'daughters': 5677, 'radar': 5678, 'toback': 5679, 'waters': 5680, 'jules': 5681, 'lunatic': 5682, 'adrift': 5683, 'eleven': 5684, 'freud': 5685, 'provoke': 5686, 'compared': 5687, 'oleander': 5688, 'knees': 5689, 'vividly': 5690, 'wrestling': 5691, 'regard': 5692, 'sedate': 5693, 'brendan': 5694, 'useless': 5695, 'lavish': 5696, 'barriers': 5697, 'gloss': 5698, 'heels': 5699, 'trappings': 5700, 'iraqi': 5701, 'boundless': 5702, 'possibility': 5703, 'square': 5704, 'progress': 5705, 'lo': 5706, 'hopeful': 5707, 'critique': 5708, 'hoot': 5709, 'rollicking': 5710, 'principle': 5711, 'mini': 5712, 'denial': 5713, 'morris': 5714, 'perspectives': 5715, 'pauly': 5716, 'lilo': 5717, 'dude': 5718, 'vin': 5719, 'thematic': 5720, 'reckless': 5721, 'salvage': 5722, 'prejudice': 5723, 'palma': 5724, 'pleasurable': 5725, 'wastes': 5726, 'korea': 5727, 'clubs': 5728, 'discuss': 5729, 'globe': 5730, 'luxury': 5731, 'limits': 5732, 'cary': 5733, 'strewn': 5734, 'broke': 5735, 'hermitage': 5736, 'aimlessly': 5737, 'parisian': 5738, 'beck': 5739, 'descends': 5740, 'everlasting': 5741, 'paramount': 5742, 'frequent': 5743, 'liberation': 5744, 'stumbling': 5745, 'adrenaline': 5746, 'mankind': 5747, 'elm': 5748, 'hills': 5749, 'madcap': 5750, 'harold': 5751, 'marlowe': 5752, 'hooked': 5753, 'charges': 5754, 'formal': 5755, 'lopez': 5756, 'sour': 5757, 'buffs': 5758, 'infuriating': 5759, 'sus': 5760, 'extra': 5761, 'brains': 5762, 'populated': 5763, 'loyalties': 5764, 'wander': 5765, 'carnage': 5766, 'relevant': 5767, 'golden': 5768, 'spirals': 5769, 'opened': 5770, 'grimly': 5771, 'developing': 5772, 'wondrous': 5773, 'interrupted': 5774, 'turbulent': 5775, 'culminates': 5776, 'vile': 5777, 'tiger': 5778, '1960': 5779, 'rookie': 5780, 'inherit': 5781, 'favors': 5782, 'catherine': 5783, 'murdock': 5784, 'virgil': 5785, 'claus': 5786, 'dizzy': 5787, 'conniving': 5788, 'directly': 5789, 'narrated': 5790, 'pierce': 5791, 'treated': 5792, 'encountered': 5793, '1995': 5794, 'farcical': 5795, 'colonial': 5796, 'ivan': 5797, 'tightly': 5798, 'bubbles': 5799, 'cares': 5800, 'rugged': 5801, 'demand': 5802, 'hunky': 5803, 'soccer': 5804, 'crucial': 5805, 'attached': 5806, 'lucas': 5807, 'abel': 5808, 'suicidal': 5809, 'stalked': 5810, 'bursts': 5811, 'comical': 5812, 'crowded': 5813, 'prequel': 5814, 'frustration': 5815, 'managing': 5816, 'authenticity': 5817, 'engine': 5818, 'peek': 5819, 'inc': 5820, 'splash': 5821, 'addicted': 5822, 'mute': 5823, 'trademark': 5824, 'cartoons': 5825, 'survived': 5826, 'spoken': 5827, 'savage': 5828, 'pocket': 5829, 'dazed': 5830, 'piccoli': 5831, 'eliminating': 5832, 'laced': 5833, 'thanksgiving': 5834, 'todd': 5835, 'goodfellas': 5836, 'employment': 5837, 'depicts': 5838, 'difficulty': 5839, 'ins': 5840, 'vet': 5841, 'chuck': 5842, 'matches': 5843, 'tactics': 5844, 'maniac': 5845, 'rude': 5846, 'dire': 5847, 'anybody': 5848, 'inevitably': 5849, 'closest': 5850, 'unexplained': 5851, 'interwoven': 5852, 'brass': 5853, 'couch': 5854, 'techno': 5855, 'senseless': 5856, 'trajectory': 5857, 'interaction': 5858, 'invade': 5859, 'canada': 5860, 'retribution': 5861, 'tucked': 5862, 'heroic': 5863, 'highway': 5864, 'captivated': 5865, 'exclusively': 5866, 'affect': 5867, 'weaving': 5868, 'ski': 5869, 'wreak': 5870, 'heather': 5871, 'beliefs': 5872, 'motivated': 5873, 'hysteria': 5874, '400': 5875, 'celebrated': 5876, 'resulting': 5877, 'liner': 5878, 'religion': 5879, 'beasts': 5880, 'stalking': 5881, 'accompany': 5882, 'verite': 5883, 'playwright': 5884, 'accepting': 5885, 'rudy': 5886, 'basement': 5887, 'jumps': 5888, 'prince': 5889, 'egypt': 5890, 'expelled': 5891, 'gerry': 5892, 'worried': 5893, 'valento': 5894, 'dupe': 5895, 'seducing': 5896, 'mepe': 5897, 'prototype': 5898, 'psychotic': 5899, 'boyfriends': 5900, 'hunting': 5901, 'owen': 5902, 'alliance': 5903, 'tennessee': 5904, 'akshay': 5905, 'mormon': 5906, 'fearful': 5907, 'flees': 5908, 'anniversary': 5909, 'celebrate': 5910, 'debby': 5911, 'millionaire': 5912, 'grads': 5913, 'treacherous': 5914, 'cursed': 5915, 'ransom': 5916, 'illicit': 5917, 'policemen': 5918, 'unwelcome': 5919, 'lin': 5920, 'amelia': 5921, 'footsteps': 5922, 'benito': 5923, 'narrow': 5924, 'legends': 5925, 'request': 5926, 'corporation': 5927, 'sheldon': 5928, 'picard': 5929, 'shane': 5930, 'cloned': 5931, 'bottoms': 5932, 'organize': 5933, 'alcohol': 5934, 'horrors': 5935, 'penny': 5936, 'gene': 5937, 'strait': 5938, 'reverse': 5939, 'leslie': 5940, 'hitman': 5941, 'stole': 5942, 'pregnancy': 5943, 'cheerleader': 5944, 'guide': 5945, 'ruled': 5946, 'pimp': 5947, 'corps': 5948, 'advertising': 5949, 'pippin': 5950, 'hai': 5951, 'legolas': 5952, 'bloom': 5953, 'gimli': 5954, 'rohan': 5955, 'convict': 5956, 'fishing': 5957, 'holo': 5958, 'salo': 5959, 'repair': 5960, 'twenties': 5961, 'origin': 5962, 'connor': 5963, 'siddalee': 5964, 'carpet': 5965, 'gains': 5966, 'sold': 5967, 'sands': 5968, 'allies': 5969, 'races': 5970, 'betts': 5971, 'mythical': 5972, 'crumbling': 5973, 'thirties': 5974, 'poison': 5975, 'recognition': 5976, 'cannibals': 5977, 'murray': 5978, 'client': 5979, 'thugs': 5980, 'widower': 5981, 'involvement': 5982, 'invite': 5983, 'germans': 5984, 'petty': 5985, 'funds': 5986, 'inspector': 5987, 'proclaimed': 5988, 'employees': 5989, 'caulfield': 5990, 'busted': 5991, 'bettien': 5992, 'portion': 5993, 'tracking': 5994, 'terri': 5995, 'meeper': 5996, 'galaxy': 5997, 'diana': 5998, 'reads': 5999, 'active': 6000, 'dara': 6001, 'wicked': 6002, 'melbourne': 6003, 'cuthbertson': 6004, 'teammate': 6005, 'chubbchubbs': 6006, 'fisherman': 6007, 'durval': 6008, 'celia': 6009, 'pursues': 6010, 'dai': 6011, 'clayton': 6012, 'farrell': 6013, 'motives': 6014, 'preston': 6015, 'hungary': 6016, 'carolyn': 6017, 'chased': 6018, 'prepared': 6019, 'segregation': 6020, 'collector': 6021, 'bitch': 6022, 'mudd': 6023, 'destroyed': 6024, 'survivalist': 6025, 'survivor': 6026, 'detectives': 6027, 'stalker': 6028, 'amir': 6029, 'mortal': 6030, 'leaders': 6031, 'terminator': 6032, 'drummer': 6033, 'covert': 6034, 'barber': 6035, 'feed': 6036, 'employee': 6037, 'camping': 6038, 'reinalda': 6039, 'galactic': 6040, 'ensuing': 6041, 'salesman': 6042, 'anthology': 6043, 'perpetrator': 6044, 'naboo': 6045, 'padm': 6046, 'belongings': 6047, 'possum': 6048, 'ordered': 6049, 'tate': 6050, 'marly': 6051, 'dex': 6052, 'ovitz': 6053, 'pally': 6054, 'protector': 6055, 'mitra': 6056, 'madison': 6057, 'mourning': 6058, 'firm': 6059, 'orphan': 6060, 'hasidic': 6061, 'herbert': 6062, 'guardian': 6063, 'fighters': 6064, 'tests': 6065, 'rajput': 6066, 'arrests': 6067, 'subway': 6068, 'publisher': 6069, 'finn': 6070, 'unwitting': 6071, 'exile': 6072, 'stir': 6073, 'annual': 6074, 'carolina': 6075, 'carrie': 6076, 'cain': 6077, 'seal': 6078, 'kate': 6079, 'jam': 6080, 'unemployed': 6081, 'surgery': 6082, 'weary': 6083, 'monk': 6084, 'natalie': 6085, 'kenobi': 6086, 'skywalker': 6087, 'pioneer': 6088, 'dominican': 6089, 'swiss': 6090, 'engineer': 6091, 'attic': 6092, 'missile': 6093, 'proposal': 6094, '16': 6095, 'ingrid': 6096, 'fowler': 6097, 'silicon': 6098, 'regularly': 6099, 'leoncio': 6100, 'penalty': 6101, 'whitey': 6102, 'sonia': 6103, 'melinda': 6104, 'eva': 6105, 'anmol': 6106, 'aboriginal': 6107, 'thesis': 6108, 'intends': 6109, 'shaun': 6110, 'curtis': 6111, 'symbol': 6112, 'disappeared': 6113, 'spies': 6114, 'paralyzed': 6115, 'robbers': 6116, 'infamous': 6117, 'waitress': 6118, 'sharing': 6119, 'cabin': 6120, 'rebel': 6121, 'carl': 6122, 'tokyo': 6123, 'backpack': 6124, 'sorceress': 6125, 'campbell': 6126, '1000': 6127, 'janeiro': 6128, 'squad': 6129, 'dutch': 6130, 'victorian': 6131, 'slaying': 6132, 'lucrative': 6133, 'masked': 6134, 'winnie': 6135, 'astrid': 6136, 'conducted': 6137, 'cac': 6138, 'hates': 6139, 'ada': 6140, 'drifter': 6141, 'arrogant': 6142, 'ami': 6143, 'majestic': 6144, 'jacki': 6145, 'hive': 6146, 'sr': 6147, 'herat': 6148, 'transforming': 6149, 'stryker': 6150, 'jude': 6151, 'governor': 6152, 'mississippi': 6153, 'vendor': 6154, 'rapper': 6155, 'burial': 6156, 'height': 6157, 'classes': 6158, 'shaman': 6159, 'surveillance': 6160, 'yan': 6161, 'mallory': 6162, 'meantime': 6163, 'neighborhoods': 6164, 'elementary': 6165, 'boston': 6166, 'sienna': 6167, 'prestigious': 6168, 'traveling': 6169, 'murdering': 6170, '214': 6171, 'josch': 6172, 'frode': 6173, 'witchcraft': 6174, 'vaughn': 6175, 'fourteen': 6176, 'bench': 6177, 'shu': 6178, 'jolynn': 6179, 'realise': 6180, 'dressing': 6181, 'bachelorman': 6182, 'jen': 6183, 'juan': 6184, 'yoyo': 6185, 'cheung': 6186, 'lure': 6187, 'shores': 6188, 'veterinarian': 6189, 'require': 6190, 'coffee': 6191, \"'analyze\": 6192, 'sonny': 6193, 'spiked': 6194, 'crashing': 6195, 'screwball': 6196, 'inject': 6197, 'motions': 6198, 'bloodletting': 6199, 'monsoon': 6200, 'rambling': 6201, 'salute': 6202, 'tapestry': 6203, 'debrauwer': 6204, 'buttons': 6205, 'fix': 6206, 'permanent': 6207, 'estrogen': 6208, 'toxic': 6209, 'fanciful': 6210, 'notable': 6211, 'dumbed': 6212, 'fearsome': 6213, 'rejection': 6214, 'elves': 6215, 'strongest': 6216, 'wholesome': 6217, 'myriad': 6218, 'combines': 6219, 'stylist': 6220, 'gestures': 6221, '18th': 6222, 'whiny': 6223, 'nomination': 6224, 'te': 6225, 'specter': 6226, 'operatic': 6227, 'grandeur': 6228, 'dependent': 6229, 'lit': 6230, 'judging': 6231, 'slacker': 6232, 'aloof': 6233, 'boiled': 6234, 'accuracy': 6235, 'illusion': 6236, 'favourite': 6237, 'sydney': 6238, 'respectful': 6239, 'recall': 6240, 'alienate': 6241, 'seduces': 6242, 'lewis': 6243, 'heritage': 6244, 'delectable': 6245, 'disjointed': 6246, 'ethnicity': 6247, 'sharper': 6248, 'seriousness': 6249, 'anchored': 6250, 'friel': 6251, 'wally': 6252, 'fraternity': 6253, 'alpha': 6254, 'reduced': 6255, 'fondly': 6256, 'maze': 6257, 'unpretentious': 6258, 'disaffected': 6259, 'slash': 6260, 'liners': 6261, 'port': 6262, 'ideological': 6263, 'sopranos': 6264, 'bust': 6265, 'diggs': 6266, 'zeal': 6267, 'laughed': 6268, 'handles': 6269, 'leo': 6270, 'feast': 6271, 'resurrection': 6272, 'atrocious': 6273, 'laughably': 6274, 'depending': 6275, 'pen': 6276, 'judd': 6277, 'demonstrating': 6278, 'spins': 6279, 'unconditional': 6280, 'hint': 6281, 'introduction': 6282, 'niccol': 6283, 'symbolic': 6284, 'stillborn': 6285, '72': 6286, 'jacobi': 6287, 'uniformly': 6288, 'misfire': 6289, 'unfold': 6290, 'footnote': 6291, 'monologue': 6292, 'absurdity': 6293, 'powered': 6294, 'sexually': 6295, 'psychologically': 6296, 'libido': 6297, 'alienation': 6298, 'silliness': 6299, 'throat': 6300, 'raging': 6301, 'belong': 6302, 'mired': 6303, 'stupidity': 6304, 'risks': 6305, 'endure': 6306, 'swashbuckler': 6307, 'bisset': 6308, 'graceful': 6309, 'enhances': 6310, 'bermuda': 6311, 'dynamics': 6312, 'washed': 6313, 'reverie': 6314, 'maturity': 6315, 'mendes': 6316, 'admirably': 6317, 'dud': 6318, 'cry': 6319, 'asleep': 6320, 'implications': 6321, 'waking': 6322, 'sand': 6323, 'prose': 6324, 'sickly': 6325, 'consumption': 6326, 'endeavors': 6327, 'seldom': 6328, 'matched': 6329, 'devise': 6330, 'enchantment': 6331, 'morose': 6332, 'journal': 6333, 'craft': 6334, 'persona': 6335, 'twentieth': 6336, 'cons': 6337, 'outdated': 6338, 'doze': 6339, 'systematically': 6340, 'split': 6341, \"actors'\": 6342, 'robberies': 6343, 'refers': 6344, 'loathing': 6345, 'punk': 6346, 'magnolia': 6347, 'greedy': 6348, 'gonna': 6349, 'sixth': 6350, 'chomp': 6351, 'map': 6352, '70s': 6353, 'elevated': 6354, 'homosexuality': 6355, 'application': 6356, 'motivation': 6357, 'dreamworks': 6358, 'attempting': 6359, 'nijinsky': 6360, 'bluster': 6361, 'lone': 6362, 'terrorism': 6363, 'explosions': 6364, 'legitimate': 6365, 'lends': 6366, 'serrault': 6367, 'imagines': 6368, 'stacy': 6369, 'peralta': 6370, 'catalyst': 6371, 'flamboyant': 6372, 'exaggerated': 6373, 'indulges': 6374, 'stake': 6375, 'applegate': 6376, 'kooky': 6377, 'stevenson': 6378, 'platitudes': 6379, 'jia': 6380, 'clooney': 6381, 'vulnerable': 6382, 'ambrose': 6383, 'timed': 6384, 'inconsistent': 6385, 'relaxed': 6386, 'disturbingly': 6387, 'gel': 6388, 'petrovich': 6389, 'response': 6390, 'attitudes': 6391, 'lighthearted': 6392, 'pray': 6393, 'sendak': 6394, 'tonal': 6395, 'pc': 6396, 'winded': 6397, 'infectious': 6398, 'ragged': 6399, 'unbridled': 6400, 'switches': 6401, 'chocolate': 6402, 'milk': 6403, 'fascinate': 6404, 'characterization': 6405, 'kidnapper': 6406, 'disappointingly': 6407, 'madame': 6408, 'disgusting': 6409, 'combine': 6410, 'sooner': 6411, 'openness': 6412, 'unorthodox': 6413, 'strangest': 6414, 'littered': 6415, 'celluloid': 6416, 'sensitivity': 6417, 'moretti': 6418, 'referential': 6419, 'pin': 6420, 'blandness': 6421, 'suit': 6422, 'linger': 6423, 'impressionable': 6424, 'monumental': 6425, 'practically': 6426, 'facet': 6427, 'janice': 6428, 'jeremy': 6429, 'renner': 6430, 'fiendish': 6431, 'profane': 6432, 'aspires': 6433, 'lending': 6434, 'turmoil': 6435, 'nicest': 6436, 'unimaginative': 6437, 'uneasy': 6438, 'willie': 6439, 'bliss': 6440, 'groans': 6441, 'creativity': 6442, 'sleeper': 6443, 'sugary': 6444, 'fanatical': 6445, 'comforting': 6446, 'jar': 6447, 'forcefully': 6448, 'symbols': 6449, 'tattoos': 6450, 'covering': 6451, 'posing': 6452, 'excels': 6453, 'flatly': 6454, 'acclaimed': 6455, '1952': 6456, 'declares': 6457, 'forceful': 6458, 'trains': 6459, 'exploiting': 6460, 'haunts': 6461, 'warnings': 6462, 'temptation': 6463, 'dedication': 6464, 'posterity': 6465, 'wollter': 6466, 'viveka': 6467, 'seldahl': 6468, 'frustrations': 6469, 'implied': 6470, 'elevate': 6471, 'mgm': 6472, 'carousel': 6473, 'meticulously': 6474, 'mounted': 6475, 'ticks': 6476, 'dutiful': 6477, 'plight': 6478, 'satisfied': 6479, 'rooting': 6480, 'hurry': 6481, 'tearjerker': 6482, 'capricious': 6483, 'tacky': 6484, 'mockery': 6485, 'radiant': 6486, 'endurance': 6487, 'breathe': 6488, 'pratfalls': 6489, 'examine': 6490, 'brilliance': 6491, '70': 6492, 'suspend': 6493, \"'comedy'\": 6494, 'unfamiliar': 6495, 'blurred': 6496, 'explains': 6497, 'cal': 6498, 'weightless': 6499, 'lore': 6500, 'exceedingly': 6501, 'coupled': 6502, 'arresting': 6503, 'passable': 6504, 'orange': 6505, 'juice': 6506, 'machinery': 6507, 'avoids': 6508, 'earnestness': 6509, 'serbian': 6510, 'flip': 6511, 'nod': 6512, 'tosca': 6513, 'sing': 6514, 'adequately': 6515, 'rom': 6516, 'kitsch': 6517, 'moldy': 6518, 'disguised': 6519, 'avary': 6520, 'dogtown': 6521, 'z': 6522, 'contemplative': 6523, 'dumas': 6524, 'fiery': 6525, 'tunes': 6526, 'noyce': 6527, 'tides': 6528, 'reminding': 6529, 'tightening': 6530, 'alleged': 6531, 'pipe': 6532, 'envy': 6533, 'turner': 6534, 'improvised': 6535, 'darned': 6536, 'nelson': 6537, 'lily': 6538, 'pearl': 6539, 'serve': 6540, 'apt': 6541, 'warfare': 6542, 'chimps': 6543, 'noteworthy': 6544, 'mumbo': 6545, 'mugging': 6546, 'screwed': 6547, 'gracefully': 6548, 'salle': 6549, 'depraved': 6550, \"denis'\": 6551, '300': 6552, 'groundbreaking': 6553, 'bona': 6554, 'fide': 6555, 'slog': 6556, 'payne': 6557, 'boom': 6558, 'spliced': 6559, '48': 6560, 'shrek': 6561, 'discontent': 6562, 'barney': 6563, 'affectionately': 6564, 'altar': 6565, 'characterizations': 6566, 'inexorably': 6567, 'majority': 6568, 'battlefield': 6569, 'expands': 6570, 'uncomfortably': 6571, 'swear': 6572, 'haphazard': 6573, 'distasteful': 6574, 'breast': 6575, 'yarn': 6576, 'mercenary': 6577, 'quills': 6578, 'var': 6579, 'texture': 6580, 'benevolent': 6581, 'riddled': 6582, 'leaps': 6583, 'apocalypse': 6584, 'educational': 6585, 'virtue': 6586, 'generational': 6587, 'bonding': 6588, 'jolts': 6589, 'watchful': 6590, 'kouyate': 6591, 'ayurveda': 6592, 'regimen': 6593, 'stress': 6594, 'contemplation': 6595, 'cassavetes': 6596, 'flashback': 6597, 'mount': 6598, 'rigged': 6599, 'burn': 6600, 'melancholic': 6601, 'phrase': 6602, 'load': 6603, 'junk': 6604, 'developments': 6605, 'weigh': 6606, 'needlessly': 6607, 'midway': 6608, 'hooker': 6609, 'mocking': 6610, 'wafer': 6611, 'nimble': 6612, 'shoulders': 6613, 'fantasies': 6614, 'humility': 6615, 'realm': 6616, 'transports': 6617, 'referee': 6618, 'dropped': 6619, 'efficient': 6620, 'cruelly': 6621, 'conveying': 6622, 'popping': 6623, 'valiant': 6624, 'pathology': 6625, 'strongly': 6626, 'commercials': 6627, 'mores': 6628, 'laughing': 6629, 'enjoying': 6630, 'faults': 6631, 'allowed': 6632, 'inexperienced': 6633, 'substantial': 6634, 'mib': 6635, 'patch': 6636, 'vulnerability': 6637, 'malice': 6638, 'propaganda': 6639, 'sealed': 6640, 'tempting': 6641, 'duties': 6642, 'clancy': 6643, 'confirms': 6644, 'sweetest': 6645, 'idiots': 6646, 'riot': 6647, 'cartoonish': 6648, 'notes': 6649, 'brooding': 6650, 'mediocrity': 6651, 'targeted': 6652, 'regan': 6653, 'desired': 6654, 'documentarians': 6655, 'craftsmanship': 6656, 'ardent': 6657, 'essay': 6658, 'manual': 6659, 'altogether': 6660, 'dick': 6661, 'sillier': 6662, 'macbeth': 6663, 'confronting': 6664, 'obsessions': 6665, 'leap': 6666, 'unfaithful': 6667, 'loopy': 6668, 'cannon': 6669, 'achieving': 6670, 'culkin': 6671, 'geneva': 6672, 'constructs': 6673, 'shtick': 6674, 'accomplishment': 6675, 'robin': 6676, 'tinseltown': 6677, 'recognized': 6678, 'naval': 6679, 'personnel': 6680, 'realistically': 6681, 'stirs': 6682, 'canon': 6683, 'acceptance': 6684, 'representation': 6685, 'afterschool': 6686, 'guaranteed': 6687, 'concocted': 6688, 'recycled': 6689, 'reunions': 6690, 'gosford': 6691, 'brit': 6692, 'underneath': 6693, 'voyeuristic': 6694, 'sprawling': 6695, 'socially': 6696, 'fulfilling': 6697, 'eccentricities': 6698, 'womanhood': 6699, 'olivier': 6700, 'leash': 6701, 'inane': 6702, 'layers': 6703, 'misfits': 6704, 'solidly': 6705, 'conduct': 6706, 'laissez': 6707, 'passer': 6708, 'encompasses': 6709, 'morrison': 6710, 'unbearably': 6711, 'denied': 6712, 'thirst': 6713, 'versions': 6714, 'clunker': 6715, 'devito': 6716, 'resonates': 6717, 'pairing': 6718, 'rendering': 6719, 'achingly': 6720, 'impressively': 6721, 'fleshed': 6722, 'mechanical': 6723, 'devote': 6724, 'ponderous': 6725, 'hokey': 6726, 'bread': 6727, 'absolute': 6728, 'tumultuous': 6729, '65': 6730, 'adequate': 6731, 'drum': 6732, 'variation': 6733, 'companion': 6734, 'themed': 6735, 'sailor': 6736, '102': 6737, 'pitched': 6738, 'marquis': 6739, 'stuffy': 6740, 'abc': 6741, 'naughty': 6742, 'assumes': 6743, 'bargain': 6744, 'infinite': 6745, 'gored': 6746, 'undeniably': 6747, 'extends': 6748, 'bloated': 6749, 'echo': 6750, 'sentiments': 6751, 'emptiness': 6752, 'claude': 6753, 'pamela': 6754, 'scheming': 6755, 'catastrophic': 6756, 'tastelessness': 6757, 'bogdanovich': 6758, 'entertainingly': 6759, 'scandal': 6760, 'remembers': 6761, 'cozy': 6762, 'tidal': 6763, 'spencer': 6764, 'partly': 6765, 'informative': 6766, 'bigelow': 6767, 'buck': 6768, 'tremors': 6769, 'dubbed': 6770, 'domination': 6771, 'taboo': 6772, 'bursting': 6773, 'drab': 6774, 'makeup': 6775, 'sacrifices': 6776, 'wealth': 6777, 'whip': 6778, 'muscle': 6779, 'jarecki': 6780, 'sucked': 6781, 'topical': 6782, 'invisible': 6783, 'eloquently': 6784, 'lays': 6785, 'influenced': 6786, 'fifty': 6787, 'vessel': 6788, 'unquestionably': 6789, 'replete': 6790, 'stereotypical': 6791, 'puzzle': 6792, 'pellington': 6793, 'rattling': 6794, 'noise': 6795, 'landmark': 6796, 'dispenses': 6797, 'pause': 6798, 'bravado': 6799, 'saddled': 6800, 'applies': 6801, 'kudos': 6802, 'whatsoever': 6803, 'enjoys': 6804, 'intersect': 6805, 'establish': 6806, 'floor': 6807, 'artfully': 6808, 'underestimated': 6809, 'plagued': 6810, 'mighty': 6811, 'arena': 6812, 'breadth': 6813, 'steadfast': 6814, 'humanistic': 6815, 'gong': 6816, 'technically': 6817, 'rug': 6818, 'aspect': 6819, 'detailing': 6820, 'commerce': 6821, 'hilariously': 6822, 'awash': 6823, 'hartley': 6824, 'multiplex': 6825, 'priceless': 6826, 'affecting': 6827, 'swooping': 6828, 'honed': 6829, 'grownups': 6830, 'resides': 6831, 'tornatore': 6832, 'subplot': 6833, 'manifestation': 6834, 'label': 6835, 'futuristic': 6836, 'edward': 6837, 'thurman': 6838, 'notwithstanding': 6839, 'rut': 6840, 'shocks': 6841, 'clearer': 6842, 'sketch': 6843, 'transition': 6844, 'embroiled': 6845, 'confession': 6846, 'license': 6847, 'immensely': 6848, 'impersonal': 6849, 'amazingly': 6850, 'saigon': 6851, 'inertia': 6852, 'yiddish': 6853, 'throes': 6854, 'obligatory': 6855, 'hawke': 6856, 'strained': 6857, 'shine': 6858, 'folly': 6859, 'entertained': 6860, 'impressed': 6861, 'racy': 6862, 'bush': 6863, 'caustic': 6864, 'palette': 6865, 'sunny': 6866, 'deepest': 6867, 'awards': 6868, 'prospect': 6869, 'screens': 6870, 'masseur': 6871, 'indians': 6872, 'compensate': 6873, 'hundreds': 6874, 'enthralling': 6875, 'undone': 6876, 'ringing': 6877, 'overwritten': 6878, 'serry': 6879, 'sin': 6880, 'import': 6881, 'happily': 6882, 'granger': 6883, 'tear': 6884, 'subtitles': 6885, 'ethics': 6886, 'gunplay': 6887, 'relate': 6888, 'pains': 6889, 'guzman': 6890, 'triumphant': 6891, 'overview': 6892, 'conception': 6893, 'collaboration': 6894, 'hundert': 6895, 'narration': 6896, 'agreement': 6897, 'sanctimony': 6898, 'artifice': 6899, 'niece': 6900, 'accomplish': 6901, 'leaky': 6902, 'nonstop': 6903, 'fading': 6904, 'floats': 6905, 'embarrassment': 6906, '50s': 6907, 'convey': 6908, 'applying': 6909, 'definition': 6910, 'garner': 6911, 'cooler': 6912, 'pg': 6913, 'missionary': 6914, 'islands': 6915, 'fragmented': 6916, 'irrelevant': 6917, 'keen': 6918, 'concentrate': 6919, 'diluted': 6920, 'imperfect': 6921, 'marginally': 6922, 'tackle': 6923, 'outer': 6924, \"spears'\": 6925, 'duck': 6926, 'accent': 6927, 'possession': 6928, 'correctness': 6929, 'fessenden': 6930, 'derived': 6931, 'scenic': 6932, 'beijing': 6933, 'disarming': 6934, 'fizz': 6935, 'unsettlingly': 6936, 'fluid': 6937, 'informed': 6938, 'tossed': 6939, 'filme': 6940, 'dia': 6941, 'employs': 6942, 'hangover': 6943, 'heady': 6944, 'covered': 6945, 'astute': 6946, 'booming': 6947, 'blossom': 6948, 'everett': 6949, 'openly': 6950, 'scherfig': 6951, 'cardboard': 6952, 'ozpetek': 6953, 'nuances': 6954, 'staple': 6955, 'liz': 6956, 'attract': 6957, 'examples': 6958, 'examined': 6959, 'rossi': 6960, 'redemptive': 6961, 'navigating': 6962, 'terrain': 6963, 'smell': 6964, 'glow': 6965, 'corpse': 6966, 'marvelous': 6967, 'blunder': 6968, 'headed': 6969, 'plummer': 6970, 'welcomes': 6971, 'crazed': 6972, 'lite': 6973, 'anxious': 6974, 'trier': 6975, 'outbursts': 6976, 'forgets': 6977, 'anguish': 6978, 'armenian': 6979, 'complexities': 6980, 'profit': 6981, 'inescapable': 6982, 'sept': 6983, 'sibling': 6984, 'rigid': 6985, 'passages': 6986, 'tidy': 6987, 'poster': 6988, 'meal': 6989, 'oops': 6990, 'hammy': 6991, '1940s': 6992, \"'red\": 6993, 'virulent': 6994, 'foul': 6995, 'chills': 6996, 'species': 6997, 'vh1': 6998, 'heralds': 6999, 'heightened': 7000, 'flounders': 7001, 'evoke': 7002, 'scares': 7003, 'adopt': 7004, 'heartache': 7005, 'functions': 7006, 'circus': 7007, 'wherever': 7008, 'stalls': 7009, 'unsung': 7010, 'kurdistan': 7011, 'dashing': 7012, 'outing': 7013, 'thirds': 7014, 'furious': 7015, 'joyful': 7016, 'attachment': 7017, 'americana': 7018, 'poses': 7019, 'edgy': 7020, 'lengths': 7021, 'protective': 7022, 'titled': 7023, 'maddeningly': 7024, 'entranced': 7025, 'evangelical': 7026, 'threadbare': 7027, 'conventions': 7028, '1975': 7029, 'accurate': 7030, 'feminist': 7031, 'inexplicable': 7032, 'listless': 7033, 'quaid': 7034, 'athletic': 7035, 'battered': 7036, 'thrust': 7037, 'manhood': 7038, 'neatly': 7039, 'communism': 7040, 'institution': 7041, 'stately': 7042, 'shout': 7043, 'replace': 7044, 'rarity': 7045, 'collage': 7046, 'allusions': 7047, 'proved': 7048, 'empowerment': 7049, 'unassuming': 7050, 'distinct': 7051, 'diaries': 7052, 'depend': 7053, 'wrench': 7054, 'hyper': 7055, 'hopefully': 7056, 'uninteresting': 7057, 'expresses': 7058, 'sunk': 7059, 'indulgence': 7060, 'adorably': 7061, 'entwined': 7062, 'liking': 7063, 'excessively': 7064, 'audrey': 7065, 'controlling': 7066, 'wiseman': 7067, 'indictment': 7068, 'portrayals': 7069, 'limb': 7070, 'languorous': 7071, 'splendidly': 7072, 'robbed': 7073, 'lofty': 7074, 'vote': 7075, 'intermittent': 7076, 'parting': 7077, 'motifs': 7078, 'revolutions': 7079, 'skirts': 7080, 'croc': 7081, 'buying': 7082, 'sack': 7083, 'hurley': 7084, 'overcomes': 7085, \"'50s\": 7086, 'handling': 7087, 'disquieting': 7088, 'salma': 7089, 'fatale': 7090, 'polite': 7091, 'swallow': 7092, 'fledgling': 7093, 'maintained': 7094, 'defines': 7095, 'trusts': 7096, 'longtime': 7097, 'burger': 7098, 'section': 7099, 'repressed': 7100, 'unsentimental': 7101, 'slim': 7102, 'expense': 7103, 'activity': 7104, '3000': 7105, 'taiwanese': 7106, 'auteur': 7107, 'kissing': 7108, 'stein': 7109, 'chasm': 7110, 'ringu': 7111, 'akin': 7112, 'provincial': 7113, 'reese': 7114, 'roads': 7115, 'unforced': 7116, 'veneer': 7117, 'considerably': 7118, 'scarier': 7119, 'lump': 7120, 'roberts': 7121, 'phony': 7122, 'signature': 7123, 'bisexual': 7124, 'signing': 7125, 'schaeffer': 7126, 'aniston': 7127, 'unite': 7128, 'denis': 7129, 'studied': 7130, 'schedule': 7131, 'observant': 7132, 'betting': 7133, 'advance': 7134, 'sherman': 7135, 'deranged': 7136, 'gran': 7137, 'calculated': 7138, 'facile': 7139, 'mckay': 7140, 'crises': 7141, 'respective': 7142, 'boasting': 7143, 'afford': 7144, 'hawn': 7145, 'sarandon': 7146, 'freshman': 7147, 'kok': 7148, 'satisfies': 7149, 'stepping': 7150, 'gods': 7151, 'sizzle': 7152, 'spike': 7153, '1986': 7154, 'harlem': 7155, 'pedestal': 7156, 'shafer': 7157, 'considers': 7158, 'sinks': 7159, 'variations': 7160, 'muted': 7161, 'metaphorical': 7162, 'myers': 7163, 'rote': 7164, 'dwellers': 7165, \"hitchens'\": 7166, 'excruciating': 7167, 'delicately': 7168, 'bennett': 7169, 'humorless': 7170, 'determine': 7171, 'sarcastic': 7172, 'shield': 7173, 'conan': 7174, \"burns'\": 7175, 'merits': 7176, 'dealt': 7177, 'seduction': 7178, 'premises': 7179, 'hearing': 7180, 'explaining': 7181, 'commonplace': 7182, 'underbelly': 7183, 'florid': 7184, 'fearless': 7185, 'suggestion': 7186, 'ellie': 7187, 'pizza': 7188, 'tattoo': 7189, 'pitfalls': 7190, 'rice': 7191, 'spunky': 7192, 'unscathed': 7193, 'forster': 7194, 'levy': 7195, 'sweetly': 7196, 'stagy': 7197, 'bullets': 7198, 'separates': 7199, \"haynes'\": 7200, 'apes': 7201, 'smartest': 7202, 'contrast': 7203, 'telescope': 7204, 'ladder': 7205, 'bruised': 7206, 'fist': 7207, 'ruin': 7208, 'afterwards': 7209, 'frames': 7210, 'dozens': 7211, 'irresponsible': 7212, 'arctic': 7213, 'verve': 7214, 'artifacts': 7215, 'mart': 7216, 'sole': 7217, 'surrounds': 7218, 'ararat': 7219, 'radioactive': 7220, 'renegade': 7221, 'sokurov': 7222, 'maggio': 7223, 'update': 7224, 'raucous': 7225, 'este': 7226, 'disgrace': 7227, 'mill': 7228, 'technological': 7229, 'bouquet': 7230, 'craven': 7231, 'ignore': 7232, 'relating': 7233, 'analyze': 7234, 'escapades': 7235, 'adage': 7236, 'dissidents': 7237, 'command': 7238, 'ridiculousness': 7239, 'heyday': 7240, 'purports': 7241, \"'old\": 7242, 'walken': 7243, 'incongruous': 7244, 'dos': 7245, 'ideal': 7246, 'yeah': 7247, 'lurid': 7248, 'peak': 7249, 'granted': 7250, 'concentrates': 7251, 'prevents': 7252, 'needless': 7253, 'conquer': 7254, 'diabolical': 7255, 'rappers': 7256, 'kinetic': 7257, 'kingsley': 7258, 'rat': 7259, 'bikes': 7260, 'novella': 7261, 'reasonable': 7262, 'pompous': 7263, 'faint': 7264, 'resolved': 7265, 'stiff': 7266, 'extravaganza': 7267, 'avalanche': 7268, 'grip': 7269, 'brash': 7270, 'online': 7271, 'talked': 7272, 'golf': 7273, 'principals': 7274, 'suited': 7275, 'philadelphia': 7276, 'picnic': 7277, 'bankrupt': 7278, 'kindly': 7279, 'skilled': 7280, 'pretend': 7281, 'severely': 7282, 'egyptian': 7283, 'inform': 7284, 'godfather': 7285, 'cunning': 7286, 'conspire': 7287, 'swank': 7288, 'duke': 7289, 'economical': 7290, 'overlooked': 7291, 'distracting': 7292, 'sword': 7293, 'outwardly': 7294, 'janey': 7295, 'intolerable': 7296, 'cocky': 7297, 'paste': 7298, 'werewolf': 7299, 'rely': 7300, 'photographs': 7301, 'maiden': 7302, 'belonged': 7303, 'delta': 7304, 'millennium': 7305, 'viva': 7306, 'hewitt': 7307, 'unattractive': 7308, 'prints': 7309, 'unclear': 7310, 'occurred': 7311, 'jury': 7312, 'undisputed': 7313, 'shades': 7314, 'management': 7315, 'counselor': 7316, 'olivia': 7317, 'pleasantly': 7318, 'candid': 7319, 'callous': 7320, \"'i\": 7321, 'garage': 7322, 'harrison': 7323, 'wing': 7324, 'hunnam': 7325, 'brave': 7326, 'rolls': 7327, 'lark': 7328, 'repetition': 7329, 'precocious': 7330, 'ships': 7331, 'purity': 7332, 'checklist': 7333, 'retain': 7334, 'soaked': 7335, 'barrel': 7336, 'disastrous': 7337, 'bergman': 7338, 'siblings': 7339, 'marching': 7340, 'der': 7341, 'cobbled': 7342, 'equipment': 7343, 'walker': 7344, 'shining': 7345, 'wahlberg': 7346, 'modestly': 7347, 'mediterranean': 7348, 'drivel': 7349, 'sacrificed': 7350, 'repression': 7351, 'skateboard': 7352, 'meetings': 7353, 'outsider': 7354, 'intellect': 7355, 'rated': 7356, 'blessing': 7357, 'drowns': 7358, 'minus': 7359, 'boon': 7360, 'illiterate': 7361, 'deaf': 7362, 'resignation': 7363, 'chancellor': 7364, 'sleazy': 7365, 'communal': 7366, 'induced': 7367, 'preparation': 7368, 'jovovich': 7369, 'doors': 7370, 'previously': 7371, 'schemes': 7372, 'portuguese': 7373, 'prophet': 7374, 'peninsula': 7375, 'gen': 7376, 'messing': 7377, 'settles': 7378, 'construct': 7379, '1997': 7380, 'screaming': 7381, 'bloodbath': 7382, 'unbearable': 7383, 'ripe': 7384, 'cohesive': 7385, 'showed': 7386, 'egg': 7387, 'warming': 7388, 'doorstep': 7389, 'willingness': 7390, 'nerves': 7391, 'log': 7392, 'plates': 7393, 'setup': 7394, 'fifth': 7395, 'spans': 7396, 'alfred': 7397, 'automatic': 7398, 'chaplin': 7399, 'ticking': 7400, 'frenzy': 7401, 'fade': 7402, 'tempered': 7403, 'treasures': 7404, 'pearce': 7405, 'probes': 7406, 'spells': 7407, 'hating': 7408, 'scoring': 7409, 'falcon': 7410, 'aristocratic': 7411, 'crossover': 7412, 'owners': 7413, 'abuses': 7414, '1992': 7415, 'fox': 7416, 'classified': 7417, 'jokester': 7418, 'marked': 7419, 'arnie': 7420, 'holden': 7421, 'combining': 7422, 'subsequently': 7423, 'contain': 7424, 'toy': 7425, 'dropping': 7426, 'vanishes': 7427, 'honour': 7428, 'troopers': 7429, 'occasion': 7430, 'forgiveness': 7431, 'leguizamo': 7432, 'barlow': 7433, 'como': 7434, 'announces': 7435, 'arises': 7436, 'detour': 7437, 'lifting': 7438, 'linked': 7439, 'naked': 7440, 'espionage': 7441, 'apocalyptic': 7442, 'defeats': 7443, 'objects': 7444, '1960s': 7445, 'chapters': 7446, 'praying': 7447, 'antonia': 7448, 'stanley': 7449, 'dwarf': 7450, 'individuality': 7451, 'ignite': 7452, 'broadway': 7453, 'subconscious': 7454, 'havoc': 7455, 'understandably': 7456, 'recalling': 7457, 'faux': 7458, 'fuse': 7459, 'suspended': 7460, 'prejudices': 7461, 'ape': 7462, 'injected': 7463, 'commander': 7464, 'propels': 7465, 'cameron': 7466, 'advertised': 7467, 'villagers': 7468, 'spotlight': 7469, 'gunning': 7470, 'grips': 7471, 'kingdom': 7472, 'neglected': 7473, 'partying': 7474, 'warriors': 7475, 'peers': 7476, 'bearing': 7477, 'laundry': 7478, 'admiration': 7479, 'philosopher': 7480, 'feisty': 7481, 'diplomat': 7482, 'superhero': 7483, 'suitcase': 7484, 'characteristics': 7485, 'removal': 7486, 'unconscious': 7487, 'similarities': 7488, '193': 7489, 'spiritually': 7490, 'visited': 7491, 'wendy': 7492, 'rton': 7493, 'candice': 7494, 'prot': 7495, 'shirley': 7496, 'nursing': 7497, 'inhuman': 7498, 'consequently': 7499, 'herb': 7500, 'freelance': 7501, 'finland': 7502, 'amnesia': 7503, 'shady': 7504, 'sharonna': 7505, 'resurfaces': 7506, 'amos': 7507, 'infiltrate': 7508, 'kumar': 7509, \"po'boys\": 7510, 'pact': 7511, 'thompson': 7512, 'sharad': 7513, 'bloodpack': 7514, 'wiping': 7515, 'mammoth': 7516, 'renata': 7517, 'reyes': 7518, 'studying': 7519, 'transport': 7520, 'links': 7521, 'bribery': 7522, 'rhinoceros': 7523, 'lottery': 7524, 'pushing': 7525, 'olds': 7526, 'wei': 7527, 'sidney': 7528, 'summoned': 7529, 'sid': 7530, 'sloth': 7531, 'accepted': 7532, 'personally': 7533, 'intergalactic': 7534, 'reports': 7535, 'osborn': 7536, 'alternate': 7537, 'decker': 7538, 'founder': 7539, 'royal': 7540, 'banker': 7541, 'suicides': 7542, 'industrial': 7543, 'unwilling': 7544, 'morales': 7545, 'sylvie': 7546, 'joins': 7547, 'cosmic': 7548, 'genetic': 7549, 'package': 7550, 'sebastien': 7551, 'jamal': 7552, 'preparing': 7553, 'bums': 7554, 'astronomical': 7555, 'penchant': 7556, 'overdose': 7557, 'cate': 7558, 'blanchett': 7559, 'turin': 7560, 'ohio': 7561, 'bucharest': 7562, 'treating': 7563, 'telepathic': 7564, 'unleash': 7565, 'closed': 7566, 'reggie': 7567, 'peckerhead': 7568, 'discussing': 7569, 'benny': 7570, 'insists': 7571, 'olsen': 7572, 'magneto': 7573, 'xavier': 7574, 'wolverine': 7575, 'montage': 7576, 'persons': 7577, 'competitors': 7578, 'sessions': 7579, \"parents'\": 7580, 'ward': 7581, 'katerina': 7582, 'alleviate': 7583, 'virgin': 7584, 'landed': 7585, 'contestants': 7586, 'uruk': 7587, 'orlando': 7588, 'angrily': 7589, '35mm': 7590, 'adversary': 7591, 'maud': 7592, 'graduating': 7593, 'siti': 7594, 'kumin': 7595, 'reward': 7596, 'wayward': 7597, 'ricky': 7598, 'dangers': 7599, 'psychologist': 7600, 'expedition': 7601, 'cleaners': 7602, 'cricket': 7603, 'byrne': 7604, 'elle': 7605, 'jealous': 7606, 'android': 7607, 'persuade': 7608, 'finance': 7609, 'federal': 7610, 'policeman': 7611, 'marquezas': 7612, 'lillian': 7613, 'haris': 7614, 'afghanistan': 7615, 'smoke': 7616, 'loan': 7617, 'amudha': 7618, 'schmitz': 7619, '1936': 7620, 'bitten': 7621, 'cotton': 7622, 'principal': 7623, 'cigarettes': 7624, 'whilst': 7625, 'companions': 7626, 'gondor': 7627, 'launch': 7628, 'isengard': 7629, 'blueberry': 7630, 'locate': 7631, 'clive': 7632, 'apprehend': 7633, 'answering': 7634, 'republican': 7635, 'shangri': 7636, 'respected': 7637, 'sanjana': 7638, 'syd': 7639, 'surrogate': 7640, 'bowman': 7641, 'heidi': 7642, 'dreamt': 7643, 'vault': 7644, 'stander': 7645, 'robber': 7646, 'jeopardized': 7647, 'gig': 7648, 'cosimo': 7649, 'unspoken': 7650, 'warn': 7651, 'deanna': 7652, 'heir': 7653, 'caitlin': 7654, '1990': 7655, 'fitzgerald': 7656, 'visiting': 7657, 'bogdan': 7658, 'catcher': 7659, 'protection': 7660, 'located': 7661, 'regains': 7662, 'officials': 7663, 'tournaments': 7664, 'lilli': 7665, 'nayomi': 7666, 'patrons': 7667, 'ale': 7668, 'dooku': 7669, 'coin': 7670, 'shack': 7671, 'ira': 7672, 'taliban': 7673, 'kali': 7674, 'malaysia': 7675, 'wrongly': 7676, 'tow': 7677, 'daredevil': 7678, 'guards': 7679, 'secure': 7680, 'plucked': 7681, 'boba': 7682, 'bowls': 7683, 'retrieve': 7684, 'yorkin': 7685, 'ischgl': 7686, 'gather': 7687, 'schools': 7688, 'headquarters': 7689, 'haizmann': 7690, 'foil': 7691, 'lamb': 7692, 'newfound': 7693, 'unarmed': 7694, 'crop': 7695, 'surviving': 7696, 'astronauts': 7697, 'pazuzu': 7698, 'competing': 7699, 'corman': 7700, 'per': 7701, 'intention': 7702, '1959': 7703, 'participate': 7704, 'rid': 7705, 'mutual': 7706, 'retarded': 7707, 'butcher': 7708, 'seduced': 7709, 'lecter': 7710, 'burned': 7711, 'gems': 7712, 'adopted': 7713, 'tours': 7714, 'brothel': 7715, 'squirrel': 7716, 'trainer': 7717, 'climb': 7718, 'haired': 7719, 'graduate': 7720, 'shops': 7721, 'salsa': 7722, 'guise': 7723, 'solitary': 7724, 'grove': 7725, 'housewife': 7726, 'peaceful': 7727, 'transported': 7728, 'mariachi': 7729, 'teller': 7730, 'lands': 7731, 'disfigured': 7732, 'phantom': 7733, 'tutors': 7734, 'bodybuilder': 7735, 'toughest': 7736, 'joey': 7737, 'controls': 7738, 'creeper': 7739, 'partnership': 7740, 'anchorman': 7741, 'korenev': 7742, 'nicknamed': 7743, 'possessions': 7744, 'finnigan': 7745, 'payment': 7746, 'gallery': 7747, 'satellite': 7748, 'abducted': 7749, 'appearances': 7750, 'circumstance': 7751, 'sidekick': 7752, 'haunt': 7753, 'engagement': 7754, 'accidental': 7755, 'multi': 7756, 'porno': 7757, 'shaw': 7758, 'smitten': 7759, 'strategy': 7760, '36': 7761, 'meena': 7762, 'unveils': 7763, 'keaton': 7764, 'evaluate': 7765, 'cycle': 7766, \"'big\": 7767, 'pitt': 7768, 'wits': 7769, 'gunmen': 7770, '1981': 7771, 'slaughter': 7772, 'winston': 7773, 'cheryl': 7774, 'henrik': 7775, 'punished': 7776, 'yavakri': 7777, 'farewell': 7778, 'protest': 7779, \"'superbob'\": 7780, 'communication': 7781, 'lowly': 7782, 'hood': 7783, 'rundown': 7784, 'monica': 7785, '200': 7786, 'responds': 7787, 'pals': 7788, 'coney': 7789, 'narrowly': 7790, 'tournament': 7791, 'christin': 7792, 'budcasso': 7793, 'operating': 7794, 'prominent': 7795, 'females': 7796, 'unravels': 7797, 'precog': 7798, 'knock': 7799, 'trace': 7800, 'drastically': 7801, 'roommates': 7802, 'exams': 7803, 'hannah': 7804, 'wales': 7805, 'evergon': 7806, '27': 7807, 'reclusive': 7808, 'regime': 7809, 'carradine': 7810, 'iceland': 7811, 'romy': 7812, 'rathbone': 7813, 'imperial': 7814, 'slaughterhouse': 7815, 'hudson': 7816, 'dobby': 7817, 'worldwide': 7818, 'eighteen': 7819, 'fraud': 7820, 'kilabot': 7821, 'christensen': 7822, 'lori': 7823, 'mathayus': 7824, 'malfoy': 7825, '1977': 7826, 'hostile': 7827, 'lads': 7828, 'bynes': 7829, 'fixated': 7830, 'ned': 7831, 'racist': 7832, 'opium': 7833, 'indonesia': 7834, 'palestine': 7835, 'ny': 7836, 'focker': 7837, 'toula': 7838, 'arvasu': 7839, 'nittilai': 7840, 'jookiba': 7841, 'edi': 7842, 'habits': 7843, 'tower': 7844, 'condemned': 7845, 'pairs': 7846, '1962': 7847, 'marrying': 7848, 'neha': 7849, 'beckinsale': 7850, 'silk': 7851, 'ariel': 7852, 'bachelor': 7853, 'mutated': 7854, 'easter': 7855, 'wade': 7856, 'embry': 7857, 'homeland': 7858, 'teamed': 7859, 'amsterdam': 7860, 'twain': 7861, 'gloria': 7862, 'kip': 7863, 'samurai': 7864, 'accounts': 7865, 'mccaleb': 7866, 'shin': 7867, 'hyun': 7868, 'ploddy': 7869, 'felice': 7870, 'initiates': 7871, 'relates': 7872, 'raccoon': 7873, 'unbeknownst': 7874, 'manor': 7875, 'sightings': 7876, 'hitchcockian': 7877, 'christie': 7878, 'hockey': 7879, 'traumas': 7880, 'rescued': 7881, '246': 7882, 'jung': 7883, 'kiki': 7884, 'landing': 7885, 'colonel': 7886, 'rome': 7887, '4th': 7888, 'matty': 7889, 'cassandra': 7890, 'communities': 7891, 'escalates': 7892, 'moscow': 7893, 'antichrist': 7894, 'newborn': 7895, 'nora': 7896, 'scrape': 7897, 'decaying': 7898, 'playground': 7899, 'rocha': 7900, 'ja': 7901, 'trips': 7902, 'aksel': 7903, 'bloodlust': 7904, '1947': 7905, 'mates': 7906, 'sis': 7907, 'lukas': 7908, 'ouija': 7909, 'jango': 7910, 'zamindar': 7911, 'eleanor': 7912, 'gangsters': 7913, 'arch': 7914, 'desiree': 7915, 'switched': 7916, 'ricki': 7917, 'shortly': 7918, 'intend': 7919, 'venice': 7920, 'submarines': 7921, 'inherited': 7922, 'infatuated': 7923, 'audition': 7924, 'trance': 7925, 'vows': 7926, 'oddball': 7927, 'monkey': 7928, 'bennie': 7929, 'seventeen': 7930, 'willy': 7931, 'courts': 7932, 'notices': 7933, 'tasha': 7934, 'shae': 7935, 'tor': 7936, 'established': 7937, 'yearns': 7938, 'packard': 7939, 'lando': 7940, 'wire': 7941, 'poachers': 7942, 'investigations': 7943, 'bade': 7944, 'hoffa': 7945, 'mercedes': 7946, 'baba': 7947, 'nevada': 7948, 'sauron': 7949, 'virtual': 7950, 'toledo': 7951, 'awaits': 7952, 'sleeps': 7953, 'steel': 7954, 'emile': 7955, 'riches': 7956, 'ignoring': 7957, 'fearing': 7958, 'incarceration': 7959, 'seller': 7960, \"angeles'\": 7961, 'bronx': 7962, 'threats': 7963, 'mobster': 7964, 'choi': 7965, 'vijay': 7966, 'infiltrates': 7967, 'ritual': 7968, 'agave': 7969, 'fund': 7970, 'cliff': 7971, 'baron': 7972, 'carmen': 7973, 'cart': 7974, 'mnemosyne': 7975, '1918': 7976, 'factory': 7977, 'supermarket': 7978, 'administrator': 7979, 'dori': 7980, 'spree': 7981, 'narcotics': 7982, 'emerald': 7983, 'smuggler': 7984, 'taraneh': 7985, 'virginity': 7986, 'eliminate': 7987, 'fedot': 7988, 'nina': 7989, 'imminent': 7990, 'kelson': 7991, 'rebels': 7992, 'kidney': 7993, 'pqd': 7994, 'ramirez': 7995, '28': 7996, 'carson': 7997, 'accompanying': 7998, 'hyde': 7999, 'otjen': 8000, '241': 8001, 'besieged': 8002, 'armenia': 8003, 'resort': 8004, 'quebec': 8005, 'quarry': 8006, 'intensive': 8007, 'resulted': 8008, 'butch': 8009, 'uncovering': 8010, 'gambler': 8011, 'maryam': 8012, 'tensions': 8013, 'civilian': 8014, 'complicating': 8015, 'november': 8016, 'beno': 8017, 'illustrator': 8018, 'pakistan': 8019, 'snakes': 8020, 'unleashing': 8021, 'rift': 8022, 'caribbean': 8023, 'dedicated': 8024, 'baldwin': 8025, 'belief': 8026, 'practicing': 8027, 'hardened': 8028, 'voyeur': 8029, 'interminable': 8030, 'bull': 8031, 'outweighs': 8032, 'nifty': 8033, 'twohy': 8034, 'understatement': 8035, 'tasteful': 8036, 'woolly': 8037, 'schoolyard': 8038, 'breathes': 8039, 'si': 8040, 'siglo': 8041, 'xxi': 8042, 'haber': 8043, 'pulpy': 8044, 'crammed': 8045, 'lil': 8046, 'gangsta': 8047, 'contempt': 8048, 'stuffed': 8049, 'brim': 8050, 'juxtaposition': 8051, 'flaky': 8052, 'agreeably': 8053, 'sheerly': 8054, 'cushion': 8055, 'jelinek': 8056, 'hogan': 8057, 'verete': 8058, 'metaphoric': 8059, 'segment': 8060, 'thread': 8061, 'mis': 8062, 'distracted': 8063, 'passport': 8064, 'plotless': 8065, 'culprit': 8066, 'spookiness': 8067, 'defiantly': 8068, 'seizes': 8069, 'milks': 8070, 'kosminsky': 8071, 'swipe': 8072, 'copious': 8073, 'purposes': 8074, 'predictability': 8075, 'hallucinatory': 8076, 'encourage': 8077, 'applaud': 8078, 'ferocious': 8079, 'voltaire': 8080, 'lacy': 8081, 'sleeves': 8082, 'belly': 8083, 'divertida': 8084, 'muy': 8085, 'akira': 8086, 'grainy': 8087, 'irrational': 8088, 'tarantula': 8089, 'rugrats': 8090, 'christians': 8091, 'luv': 8092, 'cannes': 8093, 'owed': 8094, 'banking': 8095, 'abundantly': 8096, 'meanest': 8097, 'impressions': 8098, 'traits': 8099, 'jerking': 8100, 'byzantine': 8101, 'putty': 8102, 'sharking': 8103, 'flows': 8104, \"'do\": 8105, 'souffl': 8106, 'hostages': 8107, 'worship': 8108, 'curmudgeon': 8109, 'wolodarsky': 8110, 'shopping': 8111, 'stalk': 8112, 'incorporates': 8113, 'inauthentic': 8114, 'probing': 8115, 'columbine': 8116, 'automatically': 8117, 'thornberry': 8118, 'poo': 8119, 'interpretations': 8120, 'establishes': 8121, 'durable': 8122, 'mugs': 8123, 'mercilessly': 8124, 'insipid': 8125, 'cinta': 8126, 'ser': 8127, 'unoriginal': 8128, 'unruly': 8129, 'inspirational': 8130, 'wheels': 8131, 'meyer': 8132, 'vi': 8133, 'avid': 8134, 'impatient': 8135, 'fundamentals': 8136, 'chekhov': 8137, 'merges': 8138, 'stereotype': 8139, 'unsaid': 8140, 'cox': 8141, 'hans': 8142, 'balk': 8143, 'singled': 8144, 'weakest': 8145, 'livelier': 8146, 'rea': 8147, 'aidan': 8148, 'eagles': 8149, 'grandiloquent': 8150, 'verdict': 8151, 'sparring': 8152, 'expects': 8153, 'explicit': 8154, 'portugal': 8155, 'snapshot': 8156, 'illusions': 8157, 'photographic': 8158, 'immersion': 8159, 'snake': 8160, 'fireball': 8161, 'unfocused': 8162, 'propelled': 8163, 'hormones': 8164, 'larky': 8165, 'succinct': 8166, 'virtuosity': 8167, 'pine': 8168, 'kiddies': 8169, 'concession': 8170, 'unimaginable': 8171, 'interacting': 8172, 'vaguely': 8173, 'nap': 8174, 'aficionados': 8175, 'climbing': 8176, 'outspoken': 8177, 'applauded': 8178, 'disappointments': 8179, 'spits': 8180, 'banderas': 8181, 'liu': 8182, 'installation': 8183, '33': 8184, 'inexperience': 8185, 'uncommercial': 8186, \"wells'\": 8187, 'reverence': 8188, 'laudable': 8189, 'button': 8190, 'besson': 8191, 'rubs': 8192, 'jaunt': 8193, 'televised': 8194, 'frighten': 8195, 'gratuitous': 8196, 'binoche': 8197, 'childlike': 8198, 'clothing': 8199, 'deli': 8200, 'sandwich': 8201, 'coating': 8202, 'lizard': 8203, 'catalog': 8204, 'unmistakable': 8205, 'scored': 8206, 'imamura': 8207, 'environmental': 8208, 'erika': 8209, 'hypnotically': 8210, 'timid': 8211, 'candles': 8212, 'typifies': 8213, 'pros': 8214, 'churns': 8215, 'deprived': 8216, 'weariness': 8217, 'spader': 8218, 'gyllenhaal': 8219, 'breakthrough': 8220, 'grizzly': 8221, 'ivory': 8222, 'disrupt': 8223, 'dragonfly': 8224, 'huskies': 8225, 'genial': 8226, 'arguing': 8227, 'gentlemen': 8228, 'puccini': 8229, 'groupies': 8230, 'forefront': 8231, 'episodes': 8232, 'confrontations': 8233, 'hairs': 8234, 'parental': 8235, 'lifts': 8236, 'signposts': 8237, 'blaxploitation': 8238, 'interfering': 8239, \"'we\": 8240, 'materials': 8241, 'dresses': 8242, 'illuminating': 8243, 'remainder': 8244, 'looser': 8245, 'orgasm': 8246, 'understandable': 8247, 'undeveloped': 8248, 'salton': 8249, 'inauguration': 8250, 'tinkering': 8251, 'mosaic': 8252, 'eponymous': 8253, 'starry': 8254, 'detriment': 8255, 'buyers': 8256, 'glum': 8257, 'frolic': 8258, 'pokes': 8259, 'ncia': 8260, 'hist': 8261, 'ria': 8262, 'bem': 8263, 'speeds': 8264, 'reefs': 8265, 'junior': 8266, 'intercut': 8267, 'redgrave': 8268, 'bulge': 8269, 'behalf': 8270, 'skateboarding': 8271, 'fetched': 8272, 'unveil': 8273, 'pointing': 8274, 'revived': 8275, 'byler': 8276, 'implicit': 8277, 'economy': 8278, 'airs': 8279, 'compendium': 8280, 'delia': 8281, 'greta': 8282, 'unblinking': 8283, 'suitably': 8284, 'tolerate': 8285, 'reel': 8286, 'brimming': 8287, 'bumper': 8288, 'dogged': 8289, 'doldrums': 8290, 'thinness': 8291, 'barris': 8292, 'indistinct': 8293, 'inert': 8294, 'epochs': 8295, 'kindness': 8296, 'hopefulness': 8297, 'undemanding': 8298, 'elaborately': 8299, 'costumed': 8300, 'extras': 8301, 'resonate': 8302, 'dime': 8303, 'longest': 8304, 'psyches': 8305, 'undercurrents': 8306, 'slack': 8307, 'offend': 8308, 'griffiths': 8309, 'ear': 8310, 'geeks': 8311, 'articulate': 8312, 'neeson': 8313, 'capably': 8314, 'unforgiving': 8315, 'ditches': 8316, 'prostitution': 8317, 'mattei': 8318, 'profundity': 8319, 'fascinates': 8320, 'gears': 8321, 'bullwinkle': 8322, 'strangeness': 8323, 'pithy': 8324, 'montias': 8325, 'moustache': 8326, 'richness': 8327, 'farther': 8328, 'unconventionally': 8329, 'stylishness': 8330, 'emphasizing': 8331, 'bravely': 8332, 'luc': 8333, 'sonnenfeld': 8334, 'unpredictability': 8335, 'argentine': 8336, 'wallet': 8337, \"'in\": 8338, 'suggesting': 8339, 'satin': 8340, 'rouge': 8341, 'sustained': 8342, 'postcard': 8343, 'idiotic': 8344, 'grounded': 8345, 'walsh': 8346, 'infuses': 8347, 'slender': 8348, 'gap': 8349, 'boils': 8350, 'beginners': 8351, 'cracked': 8352, 'lunacy': 8353, 'wintry': 8354, 'absorbs': 8355, 'damon': 8356, 'tian': 8357, 'confining': 8358, 'barrage': 8359, 'pressed': 8360, 'cloyingly': 8361, 'lodging': 8362, 'recite': 8363, 'elysian': 8364, 'rowling': 8365, 'lapses': 8366, 'pyrotechnics': 8367, 'punchy': 8368, 'depressingly': 8369, 'dysfunction': 8370, 'butterflies': 8371, 'jacqueline': 8372, 'colour': 8373, 'shoulder': 8374, 'auteuil': 8375, 'boldly': 8376, 'recognizable': 8377, 'blunt': 8378, 'staying': 8379, 'intoxicating': 8380, 'charting': 8381, 'turntablism': 8382, 'sincerely': 8383, 'thwart': 8384, 'reporters': 8385, 'willingly': 8386, 'sven': 8387, 'holofcener': 8388, 'spreads': 8389, 'pasts': 8390, 'mellow': 8391, 'loathsome': 8392, 'dust': 8393, 'acknowledging': 8394, 'economic': 8395, 'patiently': 8396, 'bowl': 8397, 'explored': 8398, 'indicative': 8399, 'doubles': 8400, 'mushy': 8401, 'selfless': 8402, 'consummate': 8403, 'fabulously': 8404, 'disappearing': 8405, 'triple': 8406, 'espresso': 8407, 'extent': 8408, 'trivializes': 8409, 'chilly': 8410, 'anonymity': 8411, 'adroit': 8412, 'outrage': 8413, 'ruining': 8414, 'makhmalbaf': 8415, 'reflections': 8416, 'banal': 8417, 'caffeinated': 8418, 'crispin': 8419, 'incomprehensible': 8420, 'pit': 8421, 'vertical': 8422, 'superficiality': 8423, 'jabs': 8424, 'consistent': 8425, 'bernal': 8426, 'testud': 8427, 'clinically': 8428, 'dispassionate': 8429, 'canvas': 8430, 'nuance': 8431, 'solace': 8432, 'processor': 8433, 'ruthlessness': 8434, 'serendipity': 8435, 'gasp': 8436, 'privileged': 8437, 'eavesdropping': 8438, 'studiously': 8439, 'misplaced': 8440, 'macabre': 8441, 'miracles': 8442, 'flop': 8443, 'stockbroker': 8444, 'repairing': 8445, 'nude': 8446, 'liven': 8447, 'gheorghiu': 8448, 'prima': 8449, 'donna': 8450, 'alagna': 8451, 'mario': 8452, 'scarpia': 8453, 'primitive': 8454, 'collective': 8455, 'combatants': 8456, 'profundamente': 8457, 'tiempo': 8458, 'smeary': 8459, 'alexandre': 8460, 'hanussen': 8461, 'assuming': 8462, 'conditioning': 8463, 'helluva': 8464, 'duplicate': 8465, 'antique': 8466, 'demeanor': 8467, 'adopts': 8468, 'kin': 8469, 'mistaking': 8470, 'newfoundland': 8471, 'soil': 8472, 'resists': 8473, 'watered': 8474, 'marred': 8475, 'shadyac': 8476, 'kicks': 8477, 'ichi': 8478, 'takashi': 8479, 'baggage': 8480, 'coherence': 8481, 'slackers': 8482, 'surefire': 8483, 'architecture': 8484, 'remotely': 8485, 'conformity': 8486, 'bernard': 8487, 'ivans': 8488, 'xtc': 8489, 'nonsensical': 8490, 'ineptly': 8491, 'recycles': 8492, 'gays': 8493, 'exploitive': 8494, 'underscore': 8495, 'oscars': 8496, 'drowned': 8497, 'dwells': 8498, 'concubine': 8499, 'condescension': 8500, 'martyr': 8501, 'futures': 8502, 'weepy': 8503, 'nail': 8504, 'abbass': 8505, 'broader': 8506, 'structuring': 8507, 'choreographed': 8508, 'sabotaged': 8509, 'seamless': 8510, 'shiri': 8511, 'midnight': 8512, 'dateflick': 8513, 'collegiate': 8514, 'bartlett': 8515, 'proficient': 8516, 'inimitable': 8517, 'diminishing': 8518, 'badness': 8519, 'sydow': 8520, 'intacto': 8521, 'democratic': 8522, 'torturing': 8523, 'consuming': 8524, 'plods': 8525, 'filmgoers': 8526, 'lillard': 8527, 'camouflage': 8528, 'exchanges': 8529, 'treads': 8530, 'ignorant': 8531, 'overcooked': 8532, 'winners': 8533, 'desta': 8534, 'doomsday': 8535, 'researchers': 8536, 'factors': 8537, 'oacute': 8538, 'unanswered': 8539, 'remained': 8540, 'epics': 8541, 'hitch': 8542, 'coolness': 8543, 'vibes': 8544, 'clutching': 8545, 'torrent': 8546, 'schnitzler': 8547, 'tango': 8548, 'dani': 8549, 'stamina': 8550, 'heartbeat': 8551, 'sane': 8552, 'reducing': 8553, 'hum': 8554, 'sucker': 8555, 'shamelessly': 8556, 'solipsism': 8557, 'meltdown': 8558, 'solution': 8559, 'helicopters': 8560, 'existentialism': 8561, 'caviezel': 8562, 'putrid': 8563, 'print': 8564, 'splashed': 8565, \"'fatal\": 8566, 'error': 8567, 'accumulated': 8568, 'knot': 8569, '8217': 8570, 'readily': 8571, 'dismissed': 8572, 'nose': 8573, 'convention': 8574, 'jagger': 8575, 'muster': 8576, 'cheerfully': 8577, 'rooted': 8578, 'undergoing': 8579, 'downs': 8580, 'pulp': 8581, 'judicious': 8582, '94': 8583, 'travesty': 8584, 'unparalleled': 8585, 'riveted': 8586, 'flashes': 8587, 'bridget': 8588, 'slumming': 8589, 'avoided': 8590, 'departs': 8591, 'rehash': 8592, 'ch': 8593, 'teau': 8594, 'benefited': 8595, 'cleaner': 8596, 'glitz': 8597, 'smaller': 8598, \"'you\": 8599, 'unsatisfied': 8600, 'replacement': 8601, 'unremarkable': 8602, 'enriched': 8603, 'worrying': 8604, 'physique': 8605, 'ahola': 8606, 'trots': 8607, 'ensures': 8608, 'greatness': 8609, 'lightens': 8610, 'appeared': 8611, 'characteristic': 8612, 'january': 8613, 'shoddy': 8614, 'intrepid': 8615, 'qualls': 8616, 'indiana': 8617, 'solo': 8618, 'analytical': 8619, 'superficially': 8620, 'knoxville': 8621, 'pathetically': 8622, 'budding': 8623, 'outrageousness': 8624, 'integral': 8625, 'foibles': 8626, 'swims': 8627, 'overstated': 8628, 'humdrum': 8629, 'billed': 8630, 'willis': 8631, 'enlightenment': 8632, 'lau': 8633, 'angle': 8634, 'overbearing': 8635, 'introverted': 8636, 'surrealism': 8637, 'cutesy': 8638, 'thoughtless': 8639, \"'love\": 8640, 'defensive': 8641, 'shorter': 8642, 'morrissette': 8643, 'fiendishly': 8644, 'artsy': 8645, 'bogged': 8646, 'pinnacle': 8647, 'horses': 8648, 'scarf': 8649, 'mounting': 8650, 'sufficiently': 8651, 'journalistic': 8652, 'tautou': 8653, 'michele': 8654, 'quests': 8655, 'mentioned': 8656, \"kurys'\": 8657, 'warped': 8658, 'degrees': 8659, 'insultingly': 8660, 'reflect': 8661, 'hyperbolic': 8662, 'calculating': 8663, 'unsuspecting': 8664, 'generating': 8665, 'marshaled': 8666, 'glimmer': 8667, 'hyped': 8668, 'cows': 8669, 'caricature': 8670, 'miraculous': 8671, 'expository': 8672, 'reconciled': 8673, 'extraordinarily': 8674, 'wispy': 8675, 'slapdash': 8676, 'coke': 8677, 'brits': 8678, 'behaving': 8679, 'snatch': 8680, 'authentic': 8681, 'headbanger': 8682, 'unavoidably': 8683, 'promisingly': 8684, 'louise': 8685, 'homosexual': 8686, 'rah': 8687, 'strategic': 8688, 'dramatizing': 8689, 'eventual': 8690, 'topics': 8691, 'schrader': 8692, 'encompassing': 8693, 'schwentke': 8694, 'expressed': 8695, 'swipes': 8696, 'benshan': 8697, 'complain': 8698, 'shameful': 8699, \"assayas'\": 8700, 'conscientious': 8701, 'shearer': 8702, 'choke': 8703, 'jumble': 8704, '95': 8705, 'uniquely': 8706, 'dabbling': 8707, 'bumps': 8708, 'soliloquies': 8709, 'barrymore': 8710, 'swiftly': 8711, 'macdowell': 8712, 'potshots': 8713, 'electoral': 8714, 'hipness': 8715, 'opaque': 8716, 'ruthlessly': 8717, 'tinted': 8718, '1991': 8719, 'enormously': 8720, 'styles': 8721, \"'em\": 8722, 'pose': 8723, 'decasia': 8724, 'acidic': 8725, \"charles'\": 8726, 'koury': 8727, 'yield': 8728, 'gadgets': 8729, 'zwick': 8730, 'crackle': 8731, 'spotlights': 8732, 'verbal': 8733, 'perversion': 8734, 'destitution': 8735, 'operas': 8736, 'bouts': 8737, 'clownish': 8738, 'flames': 8739, 'prepare': 8740, 'lasts': 8741, 'smiles': 8742, 'bothers': 8743, 'erase': 8744, 'compatible': 8745, 'jaw': 8746, 'awfulness': 8747, 'preaches': 8748, 'loom': 8749, 'ka': 8750, 'overshadowed': 8751, 'lock': 8752, 'actioner': 8753, 'panther': 8754, 'recoing': 8755, 'smoothes': 8756, 'graveyard': 8757, 'absurdities': 8758, 'navel': 8759, 'bankruptcy': 8760, 'pastel': 8761, 'asia': 8762, 'battista': 8763, 'counterparts': 8764, 'pilot': 8765, 'provokes': 8766, 'coal': 8767, 'purportedly': 8768, 'ming': 8769, 'liang': 8770, 'remind': 8771, 'bath': 8772, 'expiration': 8773, 'koepp': 8774, 'serviceable': 8775, 'powerless': 8776, 'manic': 8777, 'equations': 8778, \"'laughing\": 8779, 'oddity': 8780, 'reverent': 8781, 'sometime': 8782, 'kinky': 8783, 'nocturnal': 8784, 'recycling': 8785, 'tangy': 8786, 'runteldat': 8787, 'deploy': 8788, 'childbirth': 8789, 'recovering': 8790, 'deja': 8791, 'vu': 8792, 'spectrum': 8793, 'juliet': 8794, 'chef': 8795, 'hotdog': 8796, 'wreck': 8797, 'aggressively': 8798, 'counterpart': 8799, 'escapade': 8800, 'historic': 8801, 'soda': 8802, 'charitable': 8803, 'lackadaisical': 8804, 'benjamins': 8805, 'roach': 8806, 'enthusiastically': 8807, 'eyebrows': 8808, 'bloodwork': 8809, 'stultifyingly': 8810, 'aimless': 8811, 'immense': 8812, 'subtlest': 8813, 'legged': 8814, 'hellish': 8815, 'oppressively': 8816, 'archives': 8817, 'condescending': 8818, 'indoor': 8819, 'pa': 8820, 'advised': 8821, 'lip': 8822, 'communicates': 8823, 'scripting': 8824, 'infuse': 8825, 'downtrodden': 8826, 'curling': 8827, 'brooms': 8828, 'stance': 8829, 'expanded': 8830, 'stew': 8831, 'gibney': 8832, 'unbreakable': 8833, 'seated': 8834, 'hierarchy': 8835, 'graced': 8836, 'chiefly': 8837, 'punishable': 8838, 'melodramatics': 8839, 'copies': 8840, 'conjuring': 8841, 'menacing': 8842, 'received': 8843, 'eerily': 8844, 'arcane': 8845, 'duel': 8846, 'unwieldy': 8847, 'angles': 8848, 'soars': 8849, 'intentionally': 8850, 'fishy': 8851, 'interrogation': 8852, 'savor': 8853, 'ponder': 8854, 'ethical': 8855, 'workplace': 8856, 'vel': 8857, 'pelo': 8858, 'momentos': 8859, 'grating': 8860, 'chunk': 8861, 'peppered': 8862, 'dreamlike': 8863, 'fling': 8864, 'balm': 8865, 'ideology': 8866, 'altman': 8867, 'superfluous': 8868, 'artifact': 8869, 'highbrow': 8870, 'entrepreneurial': 8871, 'testimony': 8872, 'spouses': 8873, 'arithmetic': 8874, 'grossly': 8875, 'def': 8876, 'disrupts': 8877, 'stasis': 8878, 'canned': 8879, 'reworking': 8880, 'oral': 8881, 'cared': 8882, 'lighting': 8883, 'candidly': 8884, 'genesis': 8885, 'animatronic': 8886, 'disneyland': 8887, 'frothy': 8888, 'mongering': 8889, 'skilfully': 8890, 'aerial': 8891, 'worm': 8892, 'seasonal': 8893, 'gleefully': 8894, 'institutionalized': 8895, 'empowered': 8896, 'sf': 8897, 'opinion': 8898, 'stability': 8899, 'banality': 8900, 'jarring': 8901, 'grind': 8902, 'hack': 8903, 'cardellini': 8904, 'prospective': 8905, 'jolly': 8906, 'sporadically': 8907, 'underlying': 8908, 'undertones': 8909, 'credible': 8910, 'invincible': 8911, 'frenzied': 8912, 'rife': 8913, 'rueful': 8914, 'smacks': 8915, 'objectivity': 8916, 'symbiotic': 8917, 'astronaut': 8918, 'helms': 8919, 'palpable': 8920, 'sugarman': 8921, 'spit': 8922, 'chalk': 8923, 'irritatingly': 8924, 'crafty': 8925, 'illogical': 8926, 'prurient': 8927, 'sketchbook': 8928, 'jaunty': 8929, 'strokes': 8930, 'trinidad': 8931, 'afterlife': 8932, 'guardians': 8933, 'xerox': 8934, 'chilled': 8935, '13th': 8936, 'sober': 8937, 'believability': 8938, 'darkest': 8939, 'overweight': 8940, 'baggy': 8941, 'sheen': 8942, 'insanely': 8943, 'pluto': 8944, 'nada': 8945, 'wasabi': 8946, 'ranging': 8947, 'gathers': 8948, 'boisterous': 8949, 'qualify': 8950, 'clocks': 8951, 'cinematically': 8952, 'immersed': 8953, 'gates': 8954, 'wanes': 8955, 'dover': 8956, 'kosashvili': 8957, 'gauge': 8958, 'powerpuff': 8959, 'flaccid': 8960, 'despondent': 8961, 'rejoice': 8962, 'credited': 8963, 'yields': 8964, 'massoud': 8965, 'tenacious': 8966, 'humane': 8967, 'compelled': 8968, 'sair': 8969, 'swingers': 8970, 'vacuous': 8971, 'marking': 8972, 'affable': 8973, 'undernourished': 8974, 'freshness': 8975, 'fullness': 8976, 'shifted': 8977, 'vanished': 8978, 'cuar': 8979, 'structures': 8980, 'sermon': 8981, 'groupie': 8982, 'thrilled': 8983, 'announced': 8984, 'gondry': 8985, 'flowing': 8986, 'ratchets': 8987, '78': 8988, 'zings': 8989, 'vibrance': 8990, 'sparkles': 8991, 'gossip': 8992, 'shiner': 8993, 'detachment': 8994, 'custom': 8995, 'belgian': 8996, 'idemoto': 8997, 'throwaway': 8998, 'maneira': 8999, 'sch': 9000, 'reduces': 9001, 'rampling': 9002, 'griffith': 9003, 'embodies': 9004, 'models': 9005, 'ageless': 9006, 'courageous': 9007, 'inhabits': 9008, 'transparent': 9009, 'rewrite': 9010, 'stick': 9011, 'interpretation': 9012, 'moderately': 9013, 'honorable': 9014, 'frankenstein': 9015, 'painterly': 9016, 'professes': 9017, 'bosworth': 9018, 'swing': 9019, 'whiff': 9020, 'goodall': 9021, 'heavyweight': 9022, 'punching': 9023, 'leather': 9024, 'gandalf': 9025, 'impresses': 9026, \"'manhunter'\": 9027, 'decency': 9028, 'newfangled': 9029, 'uneasily': 9030, 'carion': 9031, 'fusion': 9032, 'saucy': 9033, 'sensationalism': 9034, 'salacious': 9035, 'unsophisticated': 9036, \"comedy'\": 9037, 'ingenuity': 9038, 'reid': 9039, 'hawaiian': 9040, 'pageant': 9041, 'suck': 9042, 'misguided': 9043, 'creepiness': 9044, 'filler': 9045, 'pena': 9046, 'mais': 9047, 'pursuers': 9048, 'perils': 9049, 'connecting': 9050, 'tissues': 9051, 'congratulation': 9052, 'whopping': 9053, 'suppose': 9054, 'ganesh': 9055, 'metaphorically': 9056, 'obscured': 9057, 'endings': 9058, 'ruse': 9059, '60': 9060, 'translate': 9061, 'incompetent': 9062, 'unflappable': 9063, 'weaknesses': 9064, 'bible': 9065, 'pinochet': 9066, 'litany': 9067, 'sketches': 9068, 'rocker': 9069, 'louder': 9070, 'confessional': 9071, 'squanders': 9072, 'ki': 9073, 'idyllic': 9074, 'shook': 9075, 'rattled': 9076, 'readers': 9077, 'malaise': 9078, 'imaginatively': 9079, 'adaptations': 9080, 'establishing': 9081, 'associated': 9082, 'devilish': 9083, 'surround': 9084, 'reproduce': 9085, 'liotta': 9086, 'gesture': 9087, 'calibrated': 9088, 'doris': 9089, \"'til\": 9090, 'stylistically': 9091, 'flatulence': 9092, 'overwhelm': 9093, 'hanna': 9094, 'ache': 9095, 'villeneuve': 9096, 'mischief': 9097, 'verbally': 9098, 'tummy': 9099, 'nickelodeon': 9100, 'genocide': 9101, 'canadians': 9102, 'penis': 9103, 'dramatized': 9104, 'fleeting': 9105, 'veritable': 9106, 'association': 9107, \"lil'\": 9108, 'hardcore': 9109, 'added': 9110, 'disdain': 9111, 'spawn': 9112, 'gimmicky': 9113, 'dawson': 9114, 'christianity': 9115, 'relish': 9116, 'eyeball': 9117, 'toe': 9118, 'fiennes': 9119, 'noses': 9120, 'pics': 9121, 'inter': 9122, 'mindset': 9123, 'equilibrium': 9124, 'opposed': 9125, 'reap': 9126, 'knocking': 9127, 'dunst': 9128, 'ferment': 9129, 'sung': 9130, 'spoon': 9131, 'limitations': 9132, 'prominence': 9133, 'someday': 9134, 'automobile': 9135, 'resembling': 9136, 'ceo': 9137, 'tree': 9138, 'docs': 9139, 'widely': 9140, 'notions': 9141, 'pungent': 9142, 'signpost': 9143, 'expressive': 9144, 'paxton': 9145, 'mortality': 9146, 'arliss': 9147, 'resilience': 9148, 'weave': 9149, 'reserved': 9150, 'accurately': 9151, 'chips': 9152, 'portions': 9153, 'phoniness': 9154, 'momentary': 9155, 'parrots': 9156, 'wine': 9157, 'shorts': 9158, 'thorough': 9159, 'impacts': 9160, 'acknowledges': 9161, 'striving': 9162, 'headlong': 9163, 'quibble': 9164, 'fluffy': 9165, 'gilmore': 9166, 'curry': 9167, 'whistle': 9168, 'weirdness': 9169, 'meditative': 9170, 'jokey': 9171, 'mirror': 9172, 'allegiance': 9173, 'hastily': 9174, 'moviegoer': 9175, 'liberated': 9176, 'widowmaker': 9177, 'bombastic': 9178, 'nauseating': 9179, 'aristocracy': 9180, 'gigantic': 9181, 'thespian': 9182, 'tuned': 9183, 'failings': 9184, 'convincingly': 9185, 'frei': 9186, 'assembles': 9187, 'retains': 9188, 'instrument': 9189, 'scrapbook': 9190, 'swings': 9191, 'twaddle': 9192, 'balkans': 9193, 'menu': 9194, 'uninspired': 9195, 'adolescence': 9196, 'nostalgic': 9197, 'innovative': 9198, 'balances': 9199, 'overwhelms': 9200, 'sheep': 9201, 'hosts': 9202, 'slovenly': 9203, 'preview': 9204, 'preemptive': 9205, 'drained': 9206, 'chewing': 9207, 'rosy': 9208, 'severed': 9209, 'keener': 9210, 'perpetual': 9211, 'twinkle': 9212, 'redneck': 9213, 'offended': 9214, 'arab': 9215, 'improves': 9216, 'plotted': 9217, 'bike': 9218, 'quitting': 9219, 'unafraid': 9220, 'elbows': 9221, 'aaliyah': 9222, 'settled': 9223, 'preferred': 9224, '00': 9225, 'clinical': 9226, 'insufferable': 9227, 'flights': 9228, 'disposition': 9229, 'ventura': 9230, 'alternately': 9231, 'engross': 9232, 'persecuted': 9233, 'crushed': 9234, 'freshly': 9235, 'dampened': 9236, 'lanes': 9237, 'wryly': 9238, 'rancid': 9239, 'grueling': 9240, 'ravishing': 9241, 'lanie': 9242, 'defined': 9243, 'preteen': 9244, 'accuse': 9245, 'stuttering': 9246, '1967': 9247, '1968': 9248, 'thankfully': 9249, 'grit': 9250, 'ample': 9251, 'afforded': 9252, 'clint': 9253, 'verne': 9254, 'leagues': 9255, 'clears': 9256, 'ghoulish': 9257, 'zhuangzhuang': 9258, 'masterful': 9259, 'sergio': 9260, 'exuberance': 9261, 'misty': 9262, 'untalented': 9263, 'inadequate': 9264, 'overwhelmed': 9265, 'manufactured': 9266, 'struggled': 9267, 'summertime': 9268, 'crudup': 9269, 'baffled': 9270, 'marketing': 9271, 'styled': 9272, 'demme': 9273, 'election': 9274, 'graphically': 9275, 'zeta': 9276, \"'all\": 9277, 'stretches': 9278, 'priced': 9279, 'banquet': 9280, 'joel': 9281, 'disturb': 9282, 'spectacularly': 9283, 'shiver': 9284, 'yorker': 9285, 'honored': 9286, 'unrelenting': 9287, 'springboard': 9288, 'shapes': 9289, 'hippie': 9290, 'enthusiastic': 9291, 'cream': 9292, 'monkeys': 9293, 'stimulating': 9294, 'honors': 9295, 'nurtured': 9296, 'maguire': 9297, 'medem': 9298, 'transfixes': 9299, 'highlighted': 9300, 'aprovechar': 9301, 'lighter': 9302, 'ballroom': 9303, 'elling': 9304, 'intricately': 9305, 'orlean': 9306, 'reliance': 9307, 'lax': 9308, 'yawning': 9309, 'rigorously': 9310, 'shrill': 9311, 'dumbness': 9312, 'permission': 9313, 'primal': 9314, 'declines': 9315, 'annoyingly': 9316, 'glib': 9317, 'sentences': 9318, 'flavor': 9319, '26': 9320, 'carmichael': 9321, 'fault': 9322, 'surfeit': 9323, '500': 9324, 'bubba': 9325, 'tep': 9326, 'languishing': 9327, 'speculative': 9328, 'impulse': 9329, 'caruso': 9330, 'grimy': 9331, 'increase': 9332, 'tepid': 9333, 'threw': 9334, 'kiarostami': 9335, 'khouri': 9336, 'invigorating': 9337, 'electric': 9338, 'narcissism': 9339, 'sneaks': 9340, 'rebirth': 9341, 'comparable': 9342, 'extravaganzas': 9343, 'preciousness': 9344, 'clinging': 9345, 'fondness': 9346, 'backdrops': 9347, 'soothe': 9348, 'interestingly': 9349, 'telegraphed': 9350, 'amor': 9351, 'effectiveness': 9352, 'egos': 9353, 'lightness': 9354, 'predictably': 9355, 'lend': 9356, 'classy': 9357, 'chops': 9358, 'davies': 9359, 'modesty': 9360, 'decay': 9361, 'lightly': 9362, 'overproduced': 9363, 'grass': 9364, 'expedience': 9365, 'neo': 9366, 'trivial': 9367, 'unsure': 9368, 'firing': 9369, 'heartening': 9370, 'victories': 9371, 'urgent': 9372, 'fuzzy': 9373, 'remove': 9374, 'butt': 9375, 'platter': 9376, 'dependable': 9377, 'amalgam': 9378, 'aplomb': 9379, 'cello': 9380, 'naqoyqatsi': 9381, 'tick': 9382, 'yelling': 9383, 'summary': 9384, 'beanie': 9385, 'uncertainty': 9386, 'redeeming': 9387, 'discount': 9388, 'crushingly': 9389, 'unthinkable': 9390, 'angelina': 9391, 'seeds': 9392, 'bruckheimer': 9393, 'drill': 9394, 'broadcast': 9395, 'descent': 9396, 'breakup': 9397, 'morbid': 9398, 'admitted': 9399, 'dolls': 9400, 'nosed': 9401, 'riddle': 9402, 'barbarian': 9403, 'tucker': 9404, 'illustrating': 9405, 'tools': 9406, 'groove': 9407, 'showy': 9408, 'crude': 9409, 'boozy': 9410, 'su': 9411, 'resultado': 9412, 'insignificance': 9413, 'videotape': 9414, 'skillful': 9415, 'method': 9416, 'exudes': 9417, 'irresistibly': 9418, 'theology': 9419, 'june': 9420, 'catharsis': 9421, 'wash': 9422, 'successor': 9423, 'surpassed': 9424, 'artistry': 9425, 'nicolas': 9426, 'turgid': 9427, 'constricted': 9428, 'dearth': 9429, 'assumption': 9430, '93': 9431, 'successes': 9432, 'almod': 9433, 'sensitivities': 9434, 'extravagant': 9435, 'chew': 9436, 'reassures': 9437, 'minimalist': 9438, 'deception': 9439, 'perceptive': 9440, 'equation': 9441, 'criminally': 9442, 'coldly': 9443, 'meara': 9444, 'practices': 9445, 'alienating': 9446, 'conflagration': 9447, 'shaken': 9448, 'nesbitt': 9449, 'jell': 9450, 'argue': 9451, 'impart': 9452, 'surfaces': 9453, 'expressions': 9454, 'obscure': 9455, 'stolid': 9456, 'fizzle': 9457, 'musty': 9458, 'expressing': 9459, 'venues': 9460, 'crippled': 9461, 'discomfort': 9462, 'restored': 9463, 'toast': 9464, 'warhol': 9465, 'melt': 9466, 'blank': 9467, 'optimism': 9468, 'intact': 9469, 'densely': 9470, 'extensively': 9471, 'recalls': 9472, 'maddening': 9473, 'totem': 9474, 'nonchalant': 9475, 'petersburg': 9476, 'wistful': 9477, 'testosterone': 9478, 'wal': 9479, 'kilter': 9480, 'obtaining': 9481, 'laurie': 9482, 'eulogy': 9483, 'triumphs': 9484, 'overpower': 9485, 'nalin': 9486, 'emphatic': 9487, 'flags': 9488, 'dreamed': 9489, 'sickening': 9490, 'stretching': 9491, 'transitions': 9492, 'adulthood': 9493, 'fraught': 9494, 'ad': 9495, 'mesmerize': 9496, 'depicting': 9497, 'feasting': 9498, 'apenas': 9499, 'oldest': 9500, 'suspiciously': 9501, \"nicholas'\": 9502, 'wounding': 9503, 'fragmentary': 9504, 'jacquot': 9505, 'relatives': 9506, 'devotes': 9507, \"writers'\": 9508, 'sporadic': 9509, 'savagely': 9510, 'nut': 9511, 'cronenberg': 9512, 'mud': 9513, 'convenient': 9514, 'chile': 9515, 'helmer': 9516, 'restraint': 9517, 'explanations': 9518, 'esque': 9519, 'teetering': 9520, \"street'\": 9521, 'precise': 9522, 'unwittingly': 9523, 'respects': 9524, 'acerbic': 9525, 'inventiveness': 9526, 'yuks': 9527, 'esta': 9528, 'tamb': 9529, 'brooks': 9530, 'warp': 9531, 'crystals': 9532, 'pitiful': 9533, 'contrary': 9534, 'unyielding': 9535, 'rigor': 9536, 'opportunists': 9537, 'marginal': 9538, 'zealand': 9539, 'fades': 9540, 'defeated': 9541, 'unexplainable': 9542, 'unlikeable': 9543, 'blends': 9544, 'strains': 9545, 'whirl': 9546, 'boiling': 9547, 'tykwer': 9548, 'shenanigans': 9549, 'burr': 9550, 'simplest': 9551, 'shirt': 9552, 'faked': 9553, 'brisk': 9554, 'overrun': 9555, 'deathly': 9556, 'austere': 9557, 'farrelly': 9558, 'bros': 9559, 'brawn': 9560, 'poignantly': 9561, 'starving': 9562, 'artistes': 9563, 'guffaw': 9564, 'slain': 9565, 'recovered': 9566, 'masquerade': 9567, 'lent': 9568, 'rosemary': 9569, 'sickeningly': 9570, 'professionalism': 9571, 'weather': 9572, 'puns': 9573, 'autopsy': 9574, 'ao': 9575, 'tempo': 9576, 'noel': 9577, 'sweat': 9578, 'sprung': 9579, 'guiding': 9580, 'mishmash': 9581, 'scoop': 9582, 'dialog': 9583, 'boyd': 9584, 'manipulation': 9585, 'reporting': 9586, 'melange': 9587, 'alias': 9588, 'betty': 9589, 'kwan': 9590, 'sociopath': 9591, 'scariest': 9592, 'politically': 9593, 'memorial': 9594, 'thereafter': 9595, 'charmless': 9596, 'apparatus': 9597, \"bears'\": 9598, 'stricken': 9599, 'composer': 9600, 'milestone': 9601, 'polemical': 9602, 'proper': 9603, 'fraser': 9604, 'smoother': 9605, 'dissolves': 9606, 'hopping': 9607, 'sticks': 9608, 'photograph': 9609, 'monotonous': 9610, 'boost': 9611, 'chock': 9612, 'sights': 9613, 'numbing': 9614, 'preciso': 9615, 'warrior': 9616, 'toes': 9617, 'percent': 9618, 'bratt': 9619, 'tolerance': 9620, 'bungling': 9621, 'townsend': 9622, 'brando': 9623, 'hamlet': 9624, 'sadism': 9625, 'goyer': 9626, 'bourgeois': 9627, 'bleed': 9628, 'monument': 9629, 'sled': 9630, 'antidote': 9631, 'franco': 9632, 'adherents': 9633, 'sexist': 9634, 'liability': 9635, 'uganda': 9636, 'commonly': 9637, 'obligations': 9638, 'referencing': 9639, 'assaults': 9640, 'jerk': 9641, 'upheaval': 9642, 'chefs': 9643, 'recipe': 9644, 'fervently': 9645, 'inarticulate': 9646, 'adorable': 9647, 've': 9648, 'gorgeously': 9649, 'filthy': 9650, 'fuss': 9651, 'rocking': 9652, 'briefly': 9653, 'flirts': 9654, 'masochism': 9655, 'watts': 9656, 'beta': 9657, 'elephant': 9658, 'traveled': 9659, 'included': 9660, 'xmas': 9661, 'headlines': 9662, 'bloodless': 9663, 'presumes': 9664, 'gordy': 9665, 'honoring': 9666, 'ministers': 9667, 'fledged': 9668, 'mph': 9669, 'foreboding': 9670, 'contenders': 9671, 'rhames': 9672, 'bundle': 9673, 'falk': 9674, 'potion': 9675, 'buttercup': 9676, 'enable': 9677, 'excursion': 9678, 'margins': 9679, 'nighy': 9680, 'hinton': 9681, 'privy': 9682, 'weakness': 9683, 'oppressive': 9684, 'accompanies': 9685, '60s': 9686, 'blissfully': 9687, 'mined': 9688, 'prayer': 9689, 'incidents': 9690, 'ken': 9691, 'shootout': 9692, 'sharks': 9693, 'rabbits': 9694, 'theatres': 9695, 'prank': 9696, 'mercy': 9697, 'nonjudgmental': 9698, 'needy': 9699, 'dishonest': 9700, 'instructive': 9701, 'eugene': 9702, 'cronies': 9703, 'norwegian': 9704, 'argentinean': 9705, 'buscemi': 9706, 'rosario': 9707, 'insecurity': 9708, 'teachers': 9709, 'respond': 9710, 'admirers': 9711, 'relieved': 9712, 'dictate': 9713, 'norma': 9714, 'downbeat': 9715, 'cadence': 9716, 'succumbing': 9717, 'bathos': 9718, 'roses': 9719, 'destin': 9720, 'thornberrys': 9721, 'allegedly': 9722, 'jolt': 9723, 'tumult': 9724, 'wallowing': 9725, 'giddy': 9726, 'amassed': 9727, 'sums': 9728, 'unconditionally': 9729, 'praises': 9730, 'homework': 9731, 'bend': 9732, 'glories': 9733, 'archetypal': 9734, 'shall': 9735, \"story'\": 9736, 'aisle': 9737, 'irreverent': 9738, 'acquired': 9739, 'austerity': 9740, 'perceptions': 9741, 'lucia': 9742, 'cameos': 9743, 'thandie': 9744, 'newton': 9745, 'hepburn': 9746, 'relic': 9747, 'shaking': 9748, 'psychedelic': 9749, 'hardware': 9750, 'facade': 9751, 'hefty': 9752, 'relax': 9753, 'footing': 9754, 'indication': 9755, 'teeny': 9756, 'hippies': 9757, 'luckiest': 9758, 'illuminates': 9759, 'macgraw': 9760, 'hickenlooper': 9761, 'oneself': 9762, '85': 9763, 'hinges': 9764, 'personagens': 9765, 'sobre': 9766, 'mas': 9767, 'frankness': 9768, 'indulge': 9769, 'noticeably': 9770, 'cutter': 9771, 'raunch': 9772, 'idiosyncratic': 9773, 'palm': 9774, 'pessimism': 9775, 'monopoly': 9776, 'uneventful': 9777, 'inviting': 9778, 'wrought': 9779, 'euphoria': 9780, 'tropes': 9781, 'abound': 9782, 'masses': 9783, 'enthusiasts': 9784, 'ludlum': 9785, 'autumnal': 9786, 'glimpses': 9787, 'discreet': 9788, 'aussie': 9789, 'channels': 9790, 'horrid': 9791, 'wielding': 9792, 'lowbrow': 9793, 'undistinguished': 9794, 'assembly': 9795, 'expensive': 9796, 'bray': 9797, 'oliviera': 9798, 'glad': 9799, 'busby': 9800, 'berkeley': 9801, 'aquatic': 9802, 'civilization': 9803, 'amari': 9804, 'injured': 9805, '1957': 9806, 'mayor': 9807, \"x'er\": 9808, 'numbness': 9809, 'eruptions': 9810, 'weissman': 9811, 'weber': 9812, 'stinging': 9813, 'tricky': 9814, 'shell': 9815, 'volume': 9816, 'bless': 9817, 'aversion': 9818, 'agreed': 9819, 'nuevo': 9820, 'nero': 9821, 'unleashed': 9822, 'goodwill': 9823, 'mischievous': 9824, 'territories': 9825, 'posed': 9826, 'inscrutable': 9827, 'metro': 9828, 'legs': 9829, 'orbits': 9830, 'serkis': 9831, 'doses': 9832, 'stable': 9833, 'gazing': 9834, 'mold': 9835, 'balloon': 9836, 'kirshner': 9837, 'monroe': 9838, 'distraction': 9839, 'noticed': 9840, 'memoir': 9841, 'calamity': 9842, 'esteem': 9843, 'unbelievable': 9844, 'prompting': 9845, 'interviewees': 9846, 'tweaked': 9847, 'grumpy': 9848, 'hitchcock': 9849, 'unrelated': 9850, 'valor': 9851, 'chicken': 9852, 'gunfire': 9853, 'purposeless': 9854, 'provoked': 9855, 'unrelentingly': 9856, 'fictitious': 9857, 'feeble': 9858, 'preceded': 9859, 'harm': 9860, 'reflective': 9861, 'stifling': 9862, 'unified': 9863, 'borrow': 9864, 'checkout': 9865, 'pornography': 9866, 'scare': 9867, 'campy': 9868, '1983': 9869, 'evoked': 9870, 'casually': 9871, 'defiant': 9872, 'kramer': 9873, 'cutthroat': 9874, 'physics': 9875, 'tangled': 9876, 'enhance': 9877, 'orphans': 9878, 'moods': 9879, 'delhi': 9880, 'ren': 9881, 'reilly': 9882, 'tangle': 9883, 'tapping': 9884, 'wesley': 9885, 'spray': 9886, 'noises': 9887, 'retooled': 9888, 'tons': 9889, 'soar': 9890, 'trees': 9891, 'laboratory': 9892, 'resolve': 9893, 'societal': 9894, 'yanks': 9895, 'deny': 9896, 'auschwitz': 9897, 'proctologist': 9898, 'reginald': 9899, 'prognosis': 9900, 'skies': 9901, 'infiltrated': 9902, 'luminous': 9903, 'coburn': 9904, 'disillusionment': 9905, 'teddy': 9906, 'esteemed': 9907, 'tendency': 9908, 'delve': 9909, 'ambivalence': 9910, 'affluent': 9911, 'profiles': 9912, 'tux': 9913, 'horrendously': 9914, 'despise': 9915, 'squeaky': 9916, 'conceive': 9917, 'puberty': 9918, 'bark': 9919, 'confuses': 9920, 'employ': 9921, 'shalhoub': 9922, 'brooke': 9923, 'embodiment': 9924, 'extensive': 9925, 'flush': 9926, 'encourages': 9927, 'ambivalent': 9928, 'heated': 9929, 'opposing': 9930, 'compiled': 9931, 'sophistication': 9932, 'anarchists': 9933, 'bundy': 9934, 'unexplored': 9935, 'lauren': 9936, 'instincts': 9937, '170': 9938, 'maids': 9939, 'punches': 9940, 'loathe': 9941, 'impress': 9942, 'brett': 9943, 'sag': 9944, 'logical': 9945, 'additional': 9946, 'unspeakable': 9947, 'smallest': 9948, 'persistence': 9949, 'sleepless': 9950, 'sidesplitting': 9951, 'waited': 9952, 'solely': 9953, 'heightens': 9954, 'giuseppe': 9955, 'careers': 9956, 'gloomy': 9957, \"it'\": 9958, 'ricardo': 9959, 'medicine': 9960, 'earthly': 9961, 'stoop': 9962, 'falters': 9963, 'targets': 9964, 'preach': 9965, 'outlook': 9966, 'comically': 9967, 'lad': 9968, 'griffin': 9969, 'documenting': 9970, 'grapple': 9971, 'deciding': 9972, 'tribulations': 9973, 'mira': 9974, 'archibald': 9975, 'orchid': 9976, 'trembling': 9977, 'mastery': 9978, 'saturation': 9979, 'slo': 9980, 'strung': 9981, 'observe': 9982, 'gleaned': 9983, 'liver': 9984, 'satisfaction': 9985, 'refusing': 9986, 'nerds': 9987, 'ripped': 9988, 'meaningless': 9989, 'sun': 9990, 'twilight': 9991, 'icy': 9992, 'zeitgeist': 9993, \"world'\": 9994, 'cliffsnotes': 9995, 'pages': 9996, 'besotted': 9997, 'pig': 9998, 'molested': 9999, 'freddie': 10000, 'skeletons': 10001, 'existed': 10002, 'rediscovers': 10003, 'inescapably': 10004, 'indigenous': 10005, 'eke': 10006, 'colored': 10007, 'procedure': 10008, 'measures': 10009, 'cr': 10010, 'prism': 10011, 'librarian': 10012, 'answered': 10013, 'tics': 10014, 'piecing': 10015, 'proceed': 10016, 'libidinous': 10017, 'sidewalks': 10018, 'indulged': 10019, 'alienated': 10020, 'invents': 10021, 'adversaries': 10022, 'wink': 10023, 'transparently': 10024, 'hypocritical': 10025, 'vibe': 10026, 'holly': 10027, 'surrealistic': 10028, 'beers': 10029, 'tune': 10030, 'amnesiac': 10031, 'wondered': 10032, 'options': 10033, 'chip': 10034, 'cup': 10035, 'dawns': 10036, '10th': 10037, 'tool': 10038, 'exceptionally': 10039, 'mixing': 10040, 'marshall': 10041, 'rapt': 10042, 'reynolds': 10043, 'oil': 10044, 'aristocrat': 10045, 'centre': 10046, 'seattle': 10047, 'wiser': 10048, 'hardship': 10049, 'extremists': 10050, 'frightfully': 10051, 'righteous': 10052, 'plumbing': 10053, 'hispanic': 10054, 'molina': 10055, 'piercing': 10056, 'tap': 10057, 'addresses': 10058, 'periods': 10059, 'charmingly': 10060, 'uncles': 10061, 'delves': 10062, 'hornby': 10063, 'fidelity': 10064, 'bountiful': 10065, 'unsuccessfully': 10066, 'insistence': 10067, 'mockumentary': 10068, 'startup': 10069, 'rave': 10070, 'attracts': 10071, 'factions': 10072, 'ranch': 10073, 'rikki': 10074, 'economically': 10075, 'zack': 10076, 'collectors': 10077, 'miyatake': 10078, 'anni': 10079, 'missionaries': 10080, 'huxley': 10081, 'biographical': 10082, 'sabina': 10083, 'lennon': 10084, 'beatles': 10085, 'hadley': 10086, 'nurses': 10087, '1800': 10088, 'rainone': 10089, 'fuels': 10090, 'dek': 10091, 'proposing': 10092, 'numerobis': 10093, 'hungarian': 10094, 'meddling': 10095, 'cats': 10096, 'cass': 10097, 'gracia': 10098, 'outback': 10099, 'rabbit': 10100, 'continent': 10101, 'adept': 10102, 'geek': 10103, 'hakimi': 10104, 'flies': 10105, 'katsuragi': 10106, 'dome': 10107, 'dmx': 10108, 'jet': 10109, 'investigator': 10110, 'firsthand': 10111, 'toll': 10112, 'agoraphobic': 10113, 'genetically': 10114, 'engineered': 10115, 'ramu': 10116, 'adoptive': 10117, 'identified': 10118, 'villa': 10119, 'tuscan': 10120, 'anew': 10121, 'motorist': 10122, 'riots': 10123, 'nobility': 10124, 'discouraged': 10125, 'intervention': 10126, 'postwar': 10127, 'trusty': 10128, 'prevented': 10129, 'spying': 10130, 'bookstore': 10131, 'reaper': 10132, 'populations': 10133, '0': 10134, 'afflicted': 10135, 'acquaintances': 10136, 'adventurer': 10137, 'allan': 10138, 'connery': 10139, 'madman': 10140, 'lever': 10141, 'attracted': 10142, 'naxalites': 10143, 'helpless': 10144, 'fishermen': 10145, 'newest': 10146, 'traces': 10147, 'purchase': 10148, 'carlton': 10149, 'cory': 10150, 'barlog': 10151, 'tricked': 10152, 'harnessing': 10153, 'frightened': 10154, 'retelling': 10155, 'tam': 10156, 'architect': 10157, 'acquaintance': 10158, 'cindy': 10159, 'transient': 10160, 'col': 10161, 'norman': 10162, 'goblin': 10163, 'entanglements': 10164, 'impromptu': 10165, 'tag': 10166, 'thirsty': 10167, 'insurmountable': 10168, 'followers': 10169, 'users': 10170, 'dreaded': 10171, 'mumbai': 10172, 'hated': 10173, 'definite': 10174, 'gregorio': 10175, 'ahas': 10176, 'classmates': 10177, 'tide': 10178, \"faberge'\": 10179, 'moses': 10180, 'romulans': 10181, 'shinzon': 10182, 'supplier': 10183, 'outlet': 10184, 'cortez': 10185, 'saint': 10186, 'custer': 10187, 'swept': 10188, 'global': 10189, 'patrol': 10190, 'tellis': 10191, 'bullet': 10192, 'zoe': 10193, 'parole': 10194, 'miguel': 10195, 'prospects': 10196, 'victory': 10197, 'mattie': 10198, 'operator': 10199, 'statham': 10200, 'hiring': 10201, 'diner': 10202, 'romeo': 10203, 'whitehall': 10204, 'merton': 10205, 'buffy': 10206, 'hayward': 10207, 'visitors': 10208, 'bomber': 10209, 'worldly': 10210, 'oppression': 10211, '11th': 10212, 'dimension': 10213, 'lifetimes': 10214, 'benefactor': 10215, 'behaviors': 10216, 'pilots': 10217, 'fanning': 10218, 'internment': 10219, 'showbiz': 10220, 'tabloids': 10221, 'entered': 10222, 'downstairs': 10223, 'gibbons': 10224, 'cooperate': 10225, 'vents': 10226, 'preeti': 10227, 'outskirts': 10228, 'continued': 10229, 'townsfolk': 10230, '1964': 10231, 'nagpur': 10232, 'manuela': 10233, 'sings': 10234, 'decline': 10235, 'slept': 10236, 'anjelica': 10237, 'gratification': 10238, 'burglars': 10239, 'banned': 10240, 'interfere': 10241, 'publicist': 10242, 'contaminated': 10243, 'counseling': 10244, 'extortion': 10245, 'copywriter': 10246, 'relive': 10247, 'tele': 10248, 'sossamon': 10249, 'producing': 10250, 'tropical': 10251, 'boromir': 10252, 'wood': 10253, 'th': 10254, 'champ': 10255, 'fugitive': 10256, 'committing': 10257, 'luster': 10258, 'rehabilitation': 10259, 'horace': 10260, 'masculine': 10261, 'culminating': 10262, 'rachael': 10263, 'rafe': 10264, 'unnoticed': 10265, 'relations': 10266, 'immigration': 10267, 'lawyers': 10268, 'clutches': 10269, 'enlisting': 10270, 'jamaican': 10271, 'seventh': 10272, 'enrolls': 10273, 'gil': 10274, 'trigger': 10275, 'shooter': 10276, 'function': 10277, 'problemas': 10278, 'masas': 10279, 'awakes': 10280, 'honeymoon': 10281, 'data': 10282, 'escaping': 10283, 'behaviour': 10284, 'katrin': 10285, 'uwe': 10286, 'snack': 10287, 'django': 10288, 'trend': 10289, 'cruz': 10290, 'dejected': 10291, 'stephens': 10292, 'impersonator': 10293, 'centres': 10294, 'fiance': 10295, 'secluded': 10296, 'disguisey': 10297, 'uprising': 10298, 'wrestles': 10299, 'bigotry': 10300, 'ownership': 10301, 'ents': 10302, 'porter': 10303, 'recieves': 10304, 'retires': 10305, 'kamandag': 10306, 'hickley': 10307, 'accomplice': 10308, 'assignments': 10309, 'pole': 10310, 'slaves': 10311, 'congress': 10312, 'sinha': 10313, 'aditya': 10314, 'remarry': 10315, 'ancestors': 10316, 'clan': 10317, 'liaisons': 10318, 'hulk': 10319, 'gigolo': 10320, 'copenhagen': 10321, 'lulu': 10322, 'arranges': 10323, 'raymond': 10324, 'files': 10325, 'medieval': 10326, 'adela': 10327, 'presently': 10328, 'mackenheim': 10329, 'donny': 10330, 'sahid': 10331, 'melina': 10332, 'tigers': 10333, 'prostitutes': 10334, 'renzi': 10335, 'kar': 10336, 'permits': 10337, 'costanzo': 10338, 'chaney': 10339, 'kley': 10340, 'reincarnated': 10341, 'alberta': 10342, 'hysterical': 10343, 'vought': 10344, 'hardest': 10345, 'swamps': 10346, 'progresses': 10347, 'vir': 10348, 'bombay': 10349, 'liquor': 10350, 'cans': 10351, 'capitol': 10352, 'debated': 10353, 'arriving': 10354, 'ragtag': 10355, 'galveston': 10356, 'inn': 10357, 'watering': 10358, 'constellation': 10359, 'supreme': 10360, 'palpatine': 10361, 'miauczynski': 10362, 'roadworkers': 10363, 'nugget': 10364, 'blossomed': 10365, 'bell': 10366, 'separatists': 10367, 'assassinate': 10368, '1973': 10369, 'ranger': 10370, 'megan': 10371, 'alaska': 10372, 'romulus': 10373, 'hartdegen': 10374, 'deported': 10375, '1930s': 10376, 'minimum': 10377, 'sniper': 10378, 'orphanage': 10379, 'faded': 10380, 'unger': 10381, 'declared': 10382, 'addictions': 10383, 'julius': 10384, 'pits': 10385, 'glorf': 10386, 'zyzaks': 10387, 'prop': 10388, 'plantation': 10389, 'slave': 10390, 'burk': 10391, 'defining': 10392, 'richardson': 10393, 'longed': 10394, 'pastime': 10395, 'sigmund': 10396, 'dining': 10397, '1650': 10398, 'immortality': 10399, 'relinquish': 10400, 'jash': 10401, 'hess': 10402, 'mimics': 10403, 'graduates': 10404, 'ganymede': 10405, 'merrin': 10406, 'crying': 10407, 'reactions': 10408, 'draft': 10409, 'yugoslavia': 10410, 'romania': 10411, 'towering': 10412, 'bully': 10413, 'blames': 10414, 'allegorical': 10415, 'consequence': 10416, 'unto': 10417, '600': 10418, 'joining': 10419, 'progressive': 10420, 'gino': 10421, 'settimo': 10422, 'hospitality': 10423, 'realises': 10424, 'claimed': 10425, 'salesperson': 10426, 'carter': 10427, 'mei': 10428, 'pao': 10429, 'classmate': 10430, 'pennsylvania': 10431, 'mutation': 10432, 'lasted': 10433, '14th': 10434, 'supportive': 10435, 'janitor': 10436, 'organisms': 10437, 'intensifies': 10438, 'influx': 10439, 'pub': 10440, 'sellars': 10441, 'missy': 10442, 'crider': 10443, 'featherstone': 10444, 'struthers': 10445, 'gypsy': 10446, 'rollercoaster': 10447, 'taco': 10448, 'disintegration': 10449, 'cheating': 10450, 'cleave': 10451, 'stella': 10452, 'unpublished': 10453, 'micke': 10454, 'tested': 10455, 'arcangel': 10456, 'firemen': 10457, 'analyst': 10458, 'fugitives': 10459, 'inherits': 10460, 'dough': 10461, 'skynet': 10462, 'gospel': 10463, 'gathered': 10464, 'steroid': 10465, 'purpo': 10466, 'millenium': 10467, 'stationed': 10468, 'canteen': 10469, 'cathy': 10470, 'unlock': 10471, 'guerilla': 10472, 'peoplemovin': 10473, 'marquez': 10474, 'bystander': 10475, 'orchestrated': 10476, 'prophesy': 10477, 'xico': 10478, 'enlisted': 10479, 'madly': 10480, 'vigil': 10481, '80s': 10482, 'marlene': 10483, 'settlement': 10484, 'assailant': 10485, 'evan': 10486, 'meanings': 10487, 'digger': 10488, 'rammoth': 10489, 'makeshift': 10490, 'services': 10491, 'resorted': 10492, 'yearly': 10493, 'unscrupulous': 10494, 'fend': 10495, 'natasha': 10496, 'motor': 10497, 'memoirs': 10498, 'lingers': 10499, 'bets': 10500, 'collides': 10501, 'daria': 10502, 'receiving': 10503, 'tenement': 10504, 'blueprint': 10505, 'precogs': 10506, 'woodrow': 10507, 'carnal': 10508, 'hijacked': 10509, 'multinational': 10510, 'reeves': 10511, 'ashes': 10512, \"liar'\": 10513, 'shephard': 10514, 'connecticut': 10515, 'franciscan': 10516, 'animator': 10517, 'damages': 10518, 'pitted': 10519, 'distress': 10520, 'wonderland': 10521, 'quadruple': 10522, 'mermaid': 10523, 'materialistic': 10524, 'ej': 10525, 'rcito': 10526, 'backfires': 10527, 'churchill': 10528, 'spiralling': 10529, 'removed': 10530, 'mole': 10531, 'creators': 10532, 'embarked': 10533, 'superheroes': 10534, 'artwork': 10535, 'papa': 10536, 'fatherhood': 10537, 'agree': 10538, 'inches': 10539, 'servant': 10540, 'bodybuilding': 10541, 'colt': 10542, 'rents': 10543, 'specially': 10544, 'plants': 10545, 'repelled': 10546, 'clark': 10547, 'specializing': 10548, 'examining': 10549, 'edwards': 10550, '44': 10551, 'rages': 10552, 'resorts': 10553, 'whiskey': 10554, 'chu': 10555, 'derry': 10556, 'obsesses': 10557, 'reclaim': 10558, 'wishbone': 10559, 'angered': 10560, 'behemoth': 10561, 'stash': 10562, 'prowl': 10563, 'confidant': 10564, 'saiid': 10565, 'hatched': 10566, 'paresh': 10567, 'rawal': 10568, 'obtain': 10569, 'heap': 10570, 'thefts': 10571, 'tolkien': 10572, 'tablet': 10573, 'mercenaries': 10574, 'inventor': 10575, 'ngel': 10576, 'retreats': 10577, 'cape': 10578, 'cod': 10579, 'captive': 10580, 'cameroon': 10581, 'repressive': 10582, 'publication': 10583, 'conference': 10584, 'stamp': 10585, 'collecting': 10586, 'seymour': 10587, 'reservation': 10588, 'henrietta': 10589, 'cave': 10590, 'obedience': 10591, 'checks': 10592, 'rehab': 10593, 'gustavo': 10594, 'manuel': 10595, 'phillips': 10596, 'guitar': 10597, 'fei': 10598, 'suburbs': 10599, 'equinox': 10600, 'introduced': 10601, 'giants': 10602, 'founding': 10603, 'dale': 10604, 'peters': 10605, 'scramble': 10606, 'southwest': 10607, 'zurich': 10608, 'silently': 10609, 'narrates': 10610, 'associative': 10611, 'maslakh': 10612, 'afghans': 10613, 'nineveh': 10614, 'deployment': 10615, 'weasley': 10616, 'grint': 10617, 'tryst': 10618, 'druden': 10619, 'calendar': 10620, 'crawford': 10621, 'showman': 10622, 'technicians': 10623, 'isles': 10624, 'wandering': 10625, 'confines': 10626, 'tibetan': 10627, 'guarding': 10628, 'sixty': 10629, 'nationwide': 10630, 'padme': 10631, 'mcgregor': 10632, 'padawan': 10633, 'formats': 10634, 'eaters': 10635, 'petrified': 10636, 'cardiac': 10637, 'educator': 10638, \"states'\": 10639, 'investigates': 10640, \"'kannathil\": 10641, \"muthamittal'\": 10642, 'disliked': 10643, 'snape': 10644, 'mt': 10645, 'happenings': 10646, 'electricity': 10647, 'squires': 10648, 'betrayals': 10649, 'bakery': 10650, 'masterpieces': 10651, 'patsy': 10652, 'boey': 10653, 'beaches': 10654, 'filippo': 10655, 'dwindling': 10656, 'membership': 10657, 'overheads': 10658, 'takeover': 10659, 'bushranger': 10660, 'congressional': 10661, 'threatening': 10662, 'drugged': 10663, 'glasgow': 10664, 'den': 10665, 'stefan': 10666, 'balsiger': 10667, 'embassy': 10668, 'parked': 10669, 'jenkins': 10670, 'mai': 10671, 'thi': 10672, \"'paradise\": 10673, \"casino'\": 10674, 'stunned': 10675, 'showbusiness': 10676, 'barred': 10677, 'rabbi': 10678, 'goldman': 10679, 'redeem': 10680, 'blossoms': 10681, 'gigi': 10682, 'unsettled': 10683, 'climaxes': 10684, 'soledad': 10685, \"'broadway'\": 10686, 'robs': 10687, 'gr': 10688, 'rosetta': 10689, 'tilda': 10690, 'swinton': 10691, 'pyle': 10692, 'tempestuous': 10693, 'lifes': 10694, 'pleakley': 10695, 'raped': 10696, 'sleepwalks': 10697, 'ignores': 10698, 'radiation': 10699, 'nanomeds': 10700, '197': 10701, 'felony': 10702, 'graza': 10703, 'repeat': 10704, 'bohemian': 10705, 'bernie': 10706, 'fortunes': 10707, 'zuckerman': 10708, 'reconstruct': 10709, 'upright': 10710, 'cecil': 10711, 'bottomed': 10712, 'tonho': 10713, 'deeksha': 10714, 'compels': 10715, 'travolta': 10716, 'chhatri': 10717, 'hangs': 10718, 'unstoppable': 10719, 'crews': 10720, 'locals': 10721, 'handler': 10722, 'crooked': 10723, 'revolutionaries': 10724, 'stanford': 10725, 'survives': 10726, 'appliances': 10727, 'arizona': 10728, 'officially': 10729, 'unsolved': 10730, 'backroom': 10731, 'coleman': 10732, 'lindsay': 10733, 'lohan': 10734, 'disability': 10735, 'garlin': 10736, 'exclusive': 10737, \"'peter\": 10738, \"pan'\": 10739, 'ross': 10740, 'whitewash': 10741, 'johann': 10742, 'christoph': 10743, 'sir': 10744, 'noah': 10745, 'algren': 10746, 'harlan': 10747, 'lance': 10748, 'billionaire': 10749, 'forests': 10750, 'historionaut': 10751, 'rivers': 10752, 'ignored': 10753, 'contribution': 10754, '1870s': 10755, 'meiji': 10756, 'wipe': 10757, 'croker': 10758, 'theft': 10759, 'bullion': 10760, 'nightlife': 10761, 'spontaneous': 10762, 'postal': 10763, 'hermit': 10764, 'comrade': 10765, 'irene': 10766, 'anatomy': 10767, 'jill': 10768, 'kudrow': 10769, 'dumps': 10770, 'fraternal': 10771, 'ailing': 10772, 'arabs': 10773, 'hock': 10774, 'income': 10775, 'romanian': 10776, 'warehouse': 10777, 'improv': 10778, 'priests': 10779, 'honey': 10780, 'churches': 10781, 'auditions': 10782, 'allison': 10783, 'choosing': 10784, 'norm': 10785, 'diet': 10786, 'collapsed': 10787, 'lt': 10788, 'disasters': 10789, 'dates': 10790, 'fay': 10791, 'uptight': 10792, 'transsexual': 10793, 'suspicion': 10794, 'jewellery': 10795, 'memnon': 10796, '1944': 10797, 'paco': 10798, 'whites': 10799, 'overthrow': 10800, 'abused': 10801, 'rothko': 10802, 'aptitude': 10803, 'massacre': 10804, 'scars': 10805, 'outlaw': 10806, 'jed': 10807, 'incest': 10808, 'juggle': 10809, 'perpetually': 10810, 'ole': 10811, 'lara': 10812, 'cannibalism': 10813, 'satanic': 10814, 'superiors': 10815, 'incorporated': 10816, 'unpopular': 10817, 'buffalo': 10818, 'ambiente': 10819, 'salva': 10820, 'barrio': 10821, '250': 10822, 'dormant': 10823, 'heroin': 10824, 'embraced': 10825, 'goth': 10826, 'tutor': 10827, 'carreer': 10828, 'wizard': 10829, 'sims': 10830, 'captors': 10831, 'nee': 10832, 'rosalind': 10833, 'idols': 10834, 'malik': 10835, 'deemed': 10836, 'doreen': 10837, 'financially': 10838, '239': 10839, 'hideout': 10840, 'majid': 10841, 'trenches': 10842, 'englishman': 10843, 'margalo': 10844, 'manipulations': 10845, 'publicity': 10846, 'dominatrix': 10847, 'href': 10848, 'alcoholism': 10849, 'discerning': 10850, 'orchestra': 10851, 'ballet': 10852, 'salazar': 10853, 'slytherin': 10854, 'endures': 10855, 'austrian': 10856, 'yugoslav': 10857, 'cracks': 10858, 'commune': 10859, 'untamed': 10860, 'tribe': 10861, 'neighbours': 10862, 'rats': 10863, 'traumatic': 10864, 'locks': 10865, 'hale': 10866, 'bopp': 10867, 'tortillas': 10868, 'isidor': 10869, 'callahan': 10870, 'melissa': 10871, 'geonosis': 10872, 'colorado': 10873, 'parted': 10874, 'chandramukhi': 10875, 'priestess': 10876, 'lonnie': 10877, 'earl': 10878, 'attending': 10879, 'knights': 10880, 'aida': 10881, 'switzerland': 10882, 'fabbrizio': 10883, 'halpern': 10884, '21': 10885, 'willed': 10886, 'jon': 10887, 'vow': 10888, 'homespun': 10889, 'annika': 10890, 'infects': 10891, 'cleopatra': 10892, 'requests': 10893, 'marina': 10894, 'rausch': 10895, '54': 10896, 'bottles': 10897, 'explosives': 10898, 'safecracker': 10899, 'ultimatum': 10900, 'rendezvous': 10901, 'blackmailing': 10902, 'drifting': 10903, 'sarsgaard': 10904, 'zidanes': 10905, 'womanizer': 10906, 'carbonell': 10907, 'deepens': 10908, 'confidential': 10909, 'sal': 10910, 'marta': 10911, 'colson': 10912, 'developer': 10913, 'pistachio': 10914, 'futility': 10915, 'villon': 10916, 'pennell': 10917, 'executives': 10918, 'laundromat': 10919, 'russel': 10920, 'andrea': 10921, 'kammy': 10922, 'fulfil': 10923, 'malaya': 10924, 'bello': 10925, 'regulars': 10926, 'mathews': 10927, 'zak': 10928, 'gogh': 10929, 'dublin': 10930, 'lords': 10931, '1996': 10932, '451': 10933, 'insatiable': 10934, 'reapers': 10935, 'nicklas': 10936, 'fur': 10937, 'skewed': 10938, 'scandalous': 10939, 'ruth': 10940, 'rumored': 10941, 'beacon': 10942, 'joanna': 10943, 'miserably': 10944, 'privilege': 10945, 'hairdresser': 10946, 'confederate': 10947, 'inman': 10948, 'perilous': 10949, 'underwood': 10950, 'mining': 10951, 'narrows': 10952, 'nominee': 10953, 'cured': 10954, 'walters': 10955, 'debra': 10956, 'divorces': 10957, 'related': 10958, 'accessories': 10959, 'territorial': 10960, 'savannah': 10961, 'parish': 10962, 'reappears': 10963, 'paddy': 10964, 'wagon': 10965, 'slums': 10966, 'coded': 10967, 'visser': 10968, 'orchestrates': 10969, 'plant': 10970, 'crashed': 10971, 'murbah': 10972, 'eliza': 10973, 'herd': 10974, 'betsy': 10975, 'sidewalk': 10976, 'kamino': 10977, 'wronged': 10978, 'hurts': 10979, 'marriages': 10980, 'chotte': 10981, '1989': 10982, 'chinatown': 10983, 'valued': 10984, 'pitching': 10985, 'coaching': 10986, 'leland': 10987, 'shroff': 10988, 'gulshan': 10989, 'scotty': 10990, 'bearable': 10991, 'picasso': 10992, 'helicopter': 10993, 'passenger': 10994, 'goldberg': 10995, 'chambers': 10996, 'ranked': 10997, 'hampshire': 10998, 'manifestations': 10999, 'deserts': 11000, 'quits': 11001, 'meth': 11002, 'rojas': 11003, 'edgaar': 11004, 'selves': 11005, 'wasteland': 11006, 'erupts': 11007, 'refused': 11008, 'notebook': 11009, 'catering': 11010, 'minneapolis': 11011, 'dads': 11012, 'visa': 11013, 'advocate': 11014, 'falsely': 11015, 'wrestle': 11016, 'recognizes': 11017, 'englund': 11018, 'eternally': 11019, 'londoner': 11020, 'responsibilities': 11021, 'confides': 11022, \"'shangri\": 11023, \"la'\": 11024, 'orphanages': 11025, 'deterrent': 11026, 'plagues': 11027, 'arrange': 11028, 'avenger': 11029, 'debris': 11030, 'innocently': 11031, 'venal': 11032, 'complication': 11033, 'airport': 11034, 'terminal': 11035, 'romero': 11036, 'evils': 11037, 'bodega': 11038, 'terrified': 11039, 'lati': 11040, 'rajani': 11041, 'uk': 11042, 'oasis': 11043, 'mac': 11044, 'beaufort': 11045, 'strife': 11046, 'celebrations': 11047, 'expatriate': 11048, 'discusses': 11049, 'conquest': 11050, 'hulking': 11051, 'sabotage': 11052, 'mistrust': 11053, 'nest': 11054, 'mi': 11055, \"'tracks'\": 11056, 'gordon': 11057, 'brewer': 11058, 'plunged': 11059, 'schizophrenia': 11060, 'digitally': 11061, 'synthetic': 11062, 'climber': 11063, 'punisher': 11064, 'druid': 11065, 'brews': 11066, 'conveniently': 11067, 'danielle': 11068, 'cellar': 11069, 'narayan': 11070, 'mukherjee': 11071, 'corpses': 11072, 'disciple': 11073, 'russians': 11074, 'cadmus': 11075, 'causing': 11076, 'attendants': 11077, 'heartbroken': 11078, 'battleground': 11079, 'hamill': 11080, '20s': 11081, 'saloon': 11082, 'dea': 11083, 'smugglers': 11084, 'seniors': 11085, 'racially': 11086, 'yorkshire': 11087, 'florist': 11088, 'irate': 11089, 'fruit': 11090, 'slimy': 11091, 'micro': 11092, 'fateful': 11093, 'thunder': 11094, 'laurel': 11095, 'marx': 11096, 'kubik': 11097, 'predicted': 11098, 'documented': 11099, 'apartments': 11100, 'stronghold': 11101, 'trible': 11102, '1920': 11103, 'documentation': 11104, 'dildo': 11105, 'yakuza': 11106, 'sweden': 11107, 'lilja': 11108, '6d': 11109, 'min': 11110, 'pound': 11111, 'vindictive': 11112, 'weekends': 11113, 'outfits': 11114, 'helmets': 11115, 'impregnated': 11116, 'sandy': 11117, 'incriminating': 11118, 'kulturfilm': 11119, 'fascism': 11120, 'runaways': 11121, 'enders': 11122, 'decorated': 11123, 'susie': 11124, 'dee': 11125, 'pet': 11126, 'odete': 11127, 'mentors': 11128, 'forged': 11129, 'julian': 11130, 'newman': 11131, 'poe': 11132, 'sparrow': 11133, 'troupe': 11134, 'teis': 11135, 'hindu': 11136, 'rahul': 11137, 'crusade': 11138, 'releasing': 11139, 'rebuild': 11140, 'rushes': 11141, 'gentleman': 11142, 'vesa': 11143, 'temporarily': 11144, 'deports': 11145, 'erica': 11146, 'pidgeon': 11147, 'isa': 11148, 'server': 11149, 'kay': 11150, 'czar': 11151, 'marusya': 11152, 'deserter': 11153, 'diagnosed': 11154, 'meredith': 11155, 'justin': 11156, 'bestseller': 11157, 'intersecting': 11158, 'novelist': 11159, 'myths': 11160, 'rowan': 11161, 'lurking': 11162, 'wad': 11163, 'havana': 11164, 'halls': 11165, 'classrooms': 11166, 'gail': 11167, 'levine': 11168, 'lucinda': 11169, 'questioned': 11170, 'entitled': 11171, 'turk': 11172, 'trading': 11173, 'bird': 11174, 'cyberlink': 11175, 'devious': 11176, 'traitor': 11177, 'rescorla': 11178, 'salvagers': 11179, 'burt': 11180, 'purposely': 11181, 'saruman': 11182, 'hamburg': 11183, 'pied': 11184, 'piper': 11185, 'penned': 11186, 'derision': 11187, 'horizon': 11188, 'undying': 11189, 'herk': 11190, 'skeleton': 11191, 'vie': 11192, 'feared': 11193, 'aishwarya': 11194, 'representatives': 11195, 'nightmares': 11196, 'huh': 11197, 'pronounced': 11198, 'teammates': 11199, 'starr': 11200, '6th': 11201, 'derail': 11202, 'zapato': 11203, 'recreate': 11204, 'cleese': 11205, 'duluth': 11206, 'elevator': 11207, 'syndrome': 11208, 'spoiled': 11209, 'munich': 11210, 'inheritance': 11211, 'ashley': 11212, 'entrepreneur': 11213, 'dump': 11214, 'undergoes': 11215, 'persevere': 11216, 'rekindled': 11217, 'sy': 11218, 'yorkins': 11219, 'retaliation': 11220, 'codetalkers': 11221, 'orleans': 11222, 'smiley': 11223, 'rhino': 11224, 'straw': 11225, 'tuition': 11226, 'stenographer': 11227, 'sixteen': 11228, 'suburbia': 11229, 'tete': 11230, 'ziyad': 11231, 'blurs': 11232, 'warsaw': 11233, 'alenka': 11234, 'ridiculed': 11235, 'principles': 11236, 'klaus': 11237, 'robyn': 11238, 'unleashes': 11239, 'raibhya': 11240, 'compete': 11241, 'ranking': 11242, 'allegiances': 11243, 'undertake': 11244, 'profitable': 11245, 'barge': 11246, 'vaudville': 11247, 'flood': 11248, 'curator': 11249, 'gunned': 11250, 'trailing': 11251, 'dolores': 11252, 'saber': 11253, 'toothed': 11254, 'stepmother': 11255, 'catapults': 11256, 'mayes': 11257, 'claudia': 11258, 'suk': 11259, 'bloodshed': 11260, 'retiring': 11261, 'quincy': 11262, 'faramundi': 11263, 'formerly': 11264, 'smuggle': 11265, 'icelandic': 11266, 'hagrid': 11267, 'eviction': 11268, 'radcliffe': 11269, 'sammy': 11270, 'viewpointe': 11271, 'renting': 11272, 'rooms': 11273, 'detained': 11274, 'planted': 11275, 'pattern': 11276, 'broker': 11277, 'songwriter': 11278, 'mirabelle': 11279, 'shade': 11280, 'impressing': 11281, 'reconcile': 11282, 'relocate': 11283, 'harmony': 11284, 'krishna': 11285, 'loft': 11286, 'educated': 11287, 'beggar': 11288, 'scrap': 11289, 'homemade': 11290, 'hanged': 11291, 'ballad': 11292, 'clones': 11293, 'funding': 11294, 'campaigns': 11295, 'amber': 11296, 'descendant': 11297, 'vaudeville': 11298, 'blalock': 11299, 'fallopia': 11300, 'serviceman': 11301, 'penal': 11302, 'theives': 11303, 'pilobolus': 11304, 'tenacity': 11305, 'conquers': 11306, 'unofficial': 11307, 'flanery': 11308, 'loot': 11309, 'strom': 11310, 'charade': 11311, 'marisa': 11312, 'maximiliano': 11313, 'woke': 11314, 'petrov': 11315, 'containing': 11316, 'niko': 11317, 'flynn': 11318, 'sobel': 11319, 'restricted': 11320, 'abducts': 11321, 'malls': 11322, 'downing': 11323, 'rickman': 11324, 'jeopardize': 11325, 'sultry': 11326, 'suave': 11327, 'exorcist': 11328, 'cocaine': 11329, 'ventures': 11330, 'crabby': 11331, 'whomever': 11332, 'superpowered': 11333, '626': 11334, 'wrestlers': 11335, 'goddess': 11336, 'kidneys': 11337, 'organ': 11338, 'towing': 11339, 'ocurrences': 11340, 'teiresias': 11341, 'promoted': 11342, 'demonic': 11343, 'alligators': 11344, 'patrols': 11345, 'kings': 11346, 'annette': 11347, 'swords': 11348, 'recapture': 11349, 'guesthouse': 11350, 'crooks': 11351, 'equipped': 11352, 'safari': 11353, 'resigns': 11354, 'glens': 11355, 'dionysus': 11356, 'gavilan': 11357, 'calden': 11358, 'disgruntled': 11359, 'dirt': 11360, 'voorhees': 11361, 'latino': 11362, 'predatory': 11363, 'hellbent': 11364, 'greece': 11365, 'agonistes': 11366, 'meister': 11367, 'talisac': 11368, 'bateman': 11369, 'rooftop': 11370, 'blackmailer': 11371, 'winslow': 11372, 'thrive': 11373, 'sadistic': 11374, 'dantes': 11375, 'powell': 11376, 'beary': 11377, 'prophetic': 11378, 'lyn': 11379, 'failures': 11380, 'jinks': 11381, 'ensue': 11382, 'keough': 11383, 'petra': 11384, 'towns': 11385, 'pentheus': 11386, 'bacchae': 11387, 'julien': 11388, 'amazon': 11389, 'zeus': 11390, 'loonies': 11391, 'psychiatric': 11392, 'politicians': 11393, 'halifax': 11394, 'dental': 11395, 'mechanic': 11396, 'milliner': 11397, 'counterfeit': 11398, 'meager': 11399, 'savings': 11400, 'marches': 11401, 'bookie': 11402, 'assasins': 11403, 'coyote': 11404, 'unshakable': 11405, 'perceiving': 11406, 'cowardice': 11407, 'jasper': 11408, 'voyage': 11409, 'ideologies': 11410, 'outwit': 11411, 'advanced': 11412, 'ancestor': 11413, 'jorge': 11414, 'bonded': 11415, 'barron': 11416, 'bounce': 11417, 'lapping': 11418, 'fists': 11419, \"'laugh\": 11420, \"therapy'\": 11421, 'annoyances': 11422, 'anchoring': 11423, 'mammoths': 11424, 'extinct': 11425, 'infrequently': 11426, 'sledgehammer': 11427, 'induces': 11428, 'headaches': 11429, 'necesita': 11430, 'roes': 11431, 'hombre': 11432, 'ara': 11433, 'parece': 11434, 'llegado': 11435, 'quedarse': 11436, 'banging': 11437, 'salesmanship': 11438, 'screwy': 11439, 'hypermasculine': 11440, 'servants': 11441, '1933': 11442, 'template': 11443, 'robustness': 11444, 'enjoyment': 11445, 'pint': 11446, 'mimetic': 11447, 'approximation': 11448, 'lament': 11449, 'revitalize': 11450, 'clung': 11451, 'instigator': 11452, 'modus': 11453, 'operandi': 11454, 'crucifixion': 11455, 'bizarrely': 11456, 'brody': 11457, 'whoopee': 11458, 'elfriede': 11459, 'unhinged': 11460, 'sterile': 11461, 'disguising': 11462, 'needle': 11463, 'contention': 11464, 'infants': 11465, 'espn': 11466, 'harland': 11467, 'reassignment': 11468, 'backbone': 11469, 'moronic': 11470, 'plotline': 11471, 'jocular': 11472, 'suspension': 11473, 'revisionism': 11474, 'concoction': 11475, 'busts': 11476, 'adrenal': 11477, 'gland': 11478, 'epileptic': 11479, 'glacial': 11480, 'pimps': 11481, 'gutters': 11482, 'battlefields': 11483, \"'news'\": 11484, 'hints': 11485, 'harvesting': 11486, \"'alabama'\": 11487, 'slowness': 11488, 'perkiness': 11489, 'creeped': 11490, \"'memento'\": 11491, \"'requiem\": 11492, 'premier': 11493, 'occurrences': 11494, 'moli': 11495, 'volleys': 11496, 'apparel': 11497, 'hjejle': 11498, 'pouty': 11499, 'lipped': 11500, 'poof': 11501, 'spindly': 11502, 'ingenue': 11503, 'visualmente': 11504, 'espectacular': 11505, 'entretenida': 11506, 'sencillamente': 11507, 'sorprender': 11508, 'kurosawa': 11509, 'savagery': 11510, 'visualized': 11511, \"'naturalistic'\": 11512, 'helga': 11513, 'prominently': 11514, 'reductionist': 11515, 'feelgood': 11516, 'omnipotent': 11517, 'affronted': 11518, 'secularists': 11519, 'argot': 11520, 'bracingly': 11521, 'demeaning': 11522, 'frightful': 11523, 'miramax': 11524, 'passably': 11525, '146': 11526, 'seater': 11527, 'gliding': 11528, 'hovering': 11529, 'reinvented': 11530, 'reverberates': 11531, 'leaping': 11532, 'slivers': 11533, 'condensed': 11534, 'incarnations': 11535, 'pleasuring': 11536, 'rapsploitation': 11537, 'frown': 11538, 'maturation': 11539, 'faceless': 11540, 'desirable': 11541, 'hideous': 11542, 'pounding': 11543, \"thriller'\": 11544, 'flopped': 11545, 'comers': 11546, 'swaggering': 11547, 'affectation': 11548, 'favorites': 11549, 'distinguishes': 11550, 'coeducational': 11551, 'kappa': 11552, 'rho': 11553, 'phi': 11554, 'brightly': 11555, 'bloodstream': 11556, 'slot': 11557, 'louiso': 11558, 'dawdle': 11559, 'mode': 11560, 'inning': 11561, 'jostling': 11562, 'elbowed': 11563, 'rotoscope': 11564, 'figurative': 11565, 'dock': 11566, 'unloading': 11567, 'blondes': 11568, 'literarily': 11569, 'lothario': 11570, 'cuteness': 11571, 'neuroses': 11572, 'pegs': 11573, 'courting': 11574, 'wedgie': 11575, 'hereby': 11576, 'repugnance': 11577, \"'edgy\": 11578, 'cinephile': 11579, 'distinction': 11580, 'luridly': 11581, 'pastiche': 11582, 'inspirations': 11583, 'sharpie': 11584, 'disgust': 11585, 'comienza': 11586, 'intentando': 11587, 'pidamente': 11588, 'transforma': 11589, 'comedia': 11590, 'termina': 11591, 'parodia': 11592, 'absolutamente': 11593, 'predecible': 11594, 'devastatingly': 11595, 'metaphysical': 11596, 'goldbacher': 11597, 'moratorium': 11598, 'treacly': 11599, 'professors': 11600, 'heartwarmingly': 11601, 'motivate': 11602, 'lacked': 11603, 'retail': 11604, 'fillers': 11605, 'cresting': 11606, 'jammies': 11607, 'lohman': 11608, 'accommodate': 11609, 'tenth': 11610, 'undiscovered': 11611, 'efficiently': 11612, \"collaborators'\": 11613, 'insinuating': 11614, 'swell': 11615, 'creatively': 11616, 'iota': 11617, 'omitted': 11618, 'tad': 11619, 'recitation': 11620, 'illustrated': 11621, 'sonneveld': 11622, 'underscored': 11623, 'grabowsky': 11624, 'kyra': 11625, 'sedgwick': 11626, 'fairuza': 11627, 'deserving': 11628, \"'qatsi'\": 11629, 'godfrey': 11630, \"'rare\": 11631, \"birds'\": 11632, 'quirkiness': 11633, 'interminably': 11634, 'bluffs': 11635, 'collectively': 11636, 'bates': 11637, 'quartet': 11638, 'lolling': 11639, 'settings': 11640, \"'tis\": 11641, 'indicates': 11642, 'incorporate': 11643, 'miscalculation': 11644, 'pathologies': 11645, 'advent': 11646, 'taxing': 11647, 'toyland': 11648, 'outfitted': 11649, 'gadgetry': 11650, 'playrooms': 11651, 'outrunning': 11652, 'bagatelle': 11653, 'workshop': 11654, 'exercises': 11655, 'sledgehammers': 11656, 'inquisitions': 11657, '123': 11658, 'helpfully': 11659, 'xenophobic': 11660, 'pedagogy': 11661, 'rigors': 11662, 'romances': 11663, 'plumbs': 11664, 'uncharted': 11665, 'banter': 11666, 'hoopla': 11667, 'trivializing': 11668, 'chouraqui': 11669, 'affirm': 11670, 'brims': 11671, 'hoskins': 11672, 'mirren': 11673, 'louts': 11674, 'stadium': 11675, 'megaplex': 11676, 'fogy': 11677, 'stylists': 11678, 'underwater': 11679, 'grizzled': 11680, 'charred': 11681, 'faceoff': 11682, 'restatement': 11683, 'validated': 11684, 'seventy': 11685, 'bulk': 11686, 'remembering': 11687, 'displayed': 11688, 'deliriously': 11689, 'uninitiated': 11690, 'nikita': 11691, 'caffeine': 11692, 'doughnut': 11693, 'acquainted': 11694, 'reruns': 11695, 'sexualization': 11696, 'craving': 11697, 'stimulation': 11698, 'markers': 11699, 'juliette': 11700, 'vivacious': 11701, 'powerhouse': 11702, 'deficiency': 11703, 'eloquence': 11704, 'excrescence': 11705, 'adhere': 11706, 'sixed': 11707, 'compulsion': 11708, 'bodily': 11709, 'fluids': 11710, 'insensitive': 11711, 'hurting': 11712, 'columns': 11713, 'recreated': 11714, 'boogaloo': 11715, 'pollution': 11716, 'strings': 11717, 'melancholia': 11718, 'anomie': 11719, 'cake': 11720, 'fret': 11721, 'calories': 11722, 'chill': 11723, 'baader': 11724, 'meinhof': 11725, 'pranksters': 11726, 'cheerful': 11727, 'imminently': 11728, 'dormer': 11729, 'fresher': 11730, 'eighth': 11731, 'costars': 11732, 'eats': 11733, 'savior': 11734, 'fleetingly': 11735, 'crummy': 11736, 'incessantly': 11737, 'collie': 11738, 'crudely': 11739, 'questing': 11740, 'racked': 11741, 'cellophane': 11742, 'stains': 11743, 'primavera': 11744, 'pta': 11745, \"boys'\": 11746, 'succession': 11747, 'guei': 11748, 'tolstoy': 11749, 'uncluttered': 11750, 'relays': 11751, 'lectures': 11752, 'secretions': 11753, 'units': 11754, 'filth': 11755, 'recognise': 11756, 'hippest': 11757, 'swagger': 11758, 'shuck': 11759, 'jive': 11760, 'pesky': 11761, \"'enigma'\": 11762, 'overriding': 11763, 'mobility': 11764, 'resent': 11765, 'patter': 11766, 'verbosely': 11767, 'pony': 11768, 'splatter': 11769, 'lingered': 11770, 'aldrich': 11771, 'discernible': 11772, 'asset': 11773, \"'plex\": 11774, 'predisposed': 11775, 'bitchy': 11776, 'bratty': 11777, 'primeira': 11778, 'seq': 11779, 'luta': 11780, 'piada': 11781, 'encerra': 11782, 'espectador': 11783, 'jamais': 11784, 'desgruda': 11785, 'olhos': 11786, 'tela': 11787, 'saindo': 11788, 'sensa': 11789, 'gastou': 11790, 'seu': 11791, 'dinheiro': 11792, 'warmed': 11793, 'discerned': 11794, 'heed': 11795, \"video'\": 11796, \"'chick\": 11797, \"flicks'\": 11798, 'teeming': 11799, 'touchstone': 11800, 'humble': 11801, 'spiced': 11802, 'chested': 11803, 'guardsman': 11804, 'pike': 11805, 'derelict': 11806, 'wheedling': 11807, 'smeared': 11808, 'windshield': 11809, 'utmost': 11810, 'perception': 11811, 'multilayered': 11812, 'obsolete': 11813, 'posey': 11814, 'painkillers': 11815, 'spoiler': 11816, 'significantly': 11817, 'exaggeration': 11818, 'recount': 11819, 'redundancies': 11820, 'inexpressive': 11821, 'embellishment': 11822, 'schindler': 11823, 'tunney': 11824, 'coltish': 11825, 'disservice': 11826, 'sticker': 11827, \"'vain'\": 11828, 'defoliation': 11829, 'steadily': 11830, 'folds': 11831, 'shadowy': 11832, 'forgiven': 11833, 'beachcombing': 11834, 'verismo': 11835, 'cyberpunk': 11836, 'stiffness': 11837, 'bollywood': 11838, 'carefree': 11839, 'savour': 11840, 'antitrust': 11841, 'fraction': 11842, 'stomp': 11843, 'masterworks': 11844, 'jewel': 11845, 'encrusted': 11846, 'stainton': 11847, 'unforgivingly': 11848, 'comeuppance': 11849, 'bots': 11850, 'laziest': 11851, 'spinoffs': 11852, 'engendering': 11853, 'egoism': 11854, 'tumor': 11855, 'appearing': 11856, 'offends': 11857, 'wishy': 11858, 'washy': 11859, 'appreciates': 11860, 'pryce': 11861, 'lectured': 11862, 'embellished': 11863, 'lear': 11864, 'stripping': 11865, 'odious': 11866, 'tiresomely': 11867, 'circularity': 11868, 'indicated': 11869, 'bummer': 11870, 'pristine': 11871, 'oversized': 11872, 'bedtime': 11873, 'determinedly': 11874, 'nihilism': 11875, \"'characters\": 11876, \"'interesting'\": 11877, 'reiterates': 11878, 'meanders': 11879, 'conjured': 11880, 'cassel': 11881, 'devos': 11882, 'sucks': 11883, 'shorn': 11884, 'refer': 11885, \"'jackie'\": 11886, 'inflicted': 11887, 'withholding': 11888, 'piquant': 11889, 'termed': 11890, 'claustrophobia': 11891, 'fabian': 11892, 'loveable': 11893, \"griffiths'\": 11894, 'fruitful': 11895, \"love'\": 11896, 'epitaph': 11897, 'naturalism': 11898, 'inexorable': 11899, 'passage': 11900, 'sainthood': 11901, 'sticky': 11902, 'hashiguchi': 11903, 'repellent': 11904, 'judgmental': 11905, 'heavier': 11906, 'disparity': 11907, 'devotedly': 11908, 'recreation': 11909, 'calculations': 11910, 'miscalculates': 11911, 'fiddle': 11912, 'unfertile': 11913, 'eileen': 11914, 'glinting': 11915, 'gamely': 11916, 'psychologizing': 11917, 'matchmaking': 11918, 'buckaroo': 11919, 'banzai': 11920, 'witless': 11921, 'fairlane': 11922, 'spycraft': 11923, 'ascension': 11924, 'liyan': 11925, 'hostess': 11926, 'epilogue': 11927, 'gabbiest': 11928, 'bogging': 11929, 'unheard': 11930, 'empathetic': 11931, 'titan': 11932, 'methodical': 11933, 'reductive': 11934, 'walt': 11935, 'doodled': 11936, 'steamboat': 11937, 'comment': 11938, 'stifles': 11939, '179': 11940, 'kibosh': 11941, 'withholds': 11942, 'pell': 11943, 'mell': 11944, 'exhaustingly': 11945, 'masochistic': 11946, 'blighter': 11947, 'marmite': 11948, 'slathered': 11949, 'crackers': 11950, 'bleakness': 11951, 'affinity': 11952, 'fathom': 11953, 'float': 11954, 'styx': 11955, 'bees': 11956, 'plimpton': 11957, 'mohawk': 11958, 'sheet': 11959, 'mika': 11960, 'mouglalis': 11961, 'asquith': 11962, 'swashbucklers': 11963, 'yang': 11964, \"russos'\": 11965, 'jiri': 11966, 'menzel': 11967, 'danis': 11968, 'tanovic': 11969, 'molestation': 11970, 'categorisation': 11971, 'horrifies': 11972, 'startles': 11973, 'recommending': 11974, 'handsomely': 11975, 'energizing': 11976, 'scratching': 11977, 'ricci': 11978, \"cacoyannis'\": 11979, 'interpreting': 11980, 'phantasms': 11981, 'locusts': 11982, 'horde': 11983, 'counterculture': 11984, 'ilk': 11985, 'gathering': 11986, 'eschewing': 11987, 'observing': 11988, 'medicinal': 11989, 'microwave': 11990, 'epicycles': 11991, 'exasperatingly': 11992, 'behaved': 11993, 'milestones': 11994, 'tax': 11995, 'accountant': 11996, 'deferred': 11997, 'callow': 11998, \"subjects'\": 11999, 'uncompelling': 12000, 'urges': 12001, \"series'\": 12002, 'inserting': 12003, 'smugness': 12004, 'turturro': 12005, \"'very\": 12006, \"sneaky'\": 12007, 'butler': 12008, 'reappearing': 12009, 'appreciative': 12010, 'lighten': 12011, 'silberling': 12012, 'environments': 12013, 'galvanize': 12014, 'campion': 12015, 'samira': 12016, 'blackboards': 12017, 'ethos': 12018, 'torpid': 12019, 'disciplined': 12020, 'grubbers': 12021, 'crank': 12022, 'meter': 12023, 'harangues': 12024, 'injustices': 12025, \"o'clock\": 12026, 'skips': 12027, 'abysmal': 12028, 'glover': 12029, 'lackluster': 12030, 'downtime': 12031, 'oversimplification': 12032, 'knucklehead': 12033, 'swill': 12034, 'lulls': 12035, \"'sophisticated'\": 12036, \"'challenging'\": 12037, 'sophisticates': 12038, 'feints': 12039, 'staunchest': 12040, 'defenders': 12041, 'espoused': 12042, 'likability': 12043, 'shakesperean': 12044, '1994': 12045, 'capra': 12046, 'absurdly': 12047, 'inappropriate': 12048, 'peaks': 12049, 'hallmarks': 12050, 'volumes': 12051, \"see'\": 12052, 'incandescent': 12053, 'stupendous': 12054, 'tok': 12055, 'orchestrate': 12056, 'squeezed': 12057, 'ravages': 12058, 'slide': 12059, 'humming': 12060, 'tchaikovsky': 12061, 'neurasthenic': 12062, 'cluelessness': 12063, 'bogdanich': 12064, 'unashamedly': 12065, 'fillm': 12066, 'civic': 12067, 'tatters': 12068, 'tweedy': 12069, 'canning': 12070, 'yearn': 12071, 'airborne': 12072, 'floria': 12073, 'cavaradossi': 12074, 'ruggero': 12075, 'lecherous': 12076, 'smackdown': 12077, 'bergmanesque': 12078, \"'divertida\": 12079, 'enternecedora': 12080, 'sincera': 12081, 'mejores': 12082, 'comedias': 12083, 'nticas': 12084, 'mucho': 12085, 'verdadera': 12086, 'delicia': 12087, 'colonialist': 12088, 'oddest': 12089, 'sprawl': 12090, 'uncoordinated': 12091, 'vectors': 12092, \"ellis'\": 12093, 'intriguingly': 12094, 'disregard': 12095, 'zishe': 12096, 'cuisine': 12097, 'overpowered': 12098, 'indelible': 12099, 'buffeted': 12100, 'provocation': 12101, 'obliviousness': 12102, 'panache': 12103, 'oily': 12104, 'stupidly': 12105, 'reworked': 12106, \"'it\": 12107, 'entirety': 12108, '1934': 12109, 'birds': 12110, 'shipping': 12111, 'intrusion': 12112, 'criticizes': 12113, 'willful': 12114, 'mindedness': 12115, 'claws': 12116, 'spookily': 12117, 'abrupt': 12118, 'glucose': 12119, 'jacobson': 12120, 'suspecting': 12121, 'miike': 12122, 'wildest': 12123, 'batman': 12124, 'sanded': 12125, 'proverbial': 12126, 'thons': 12127, 'tomcats': 12128, 'nonchallenging': 12129, 'braveheart': 12130, 'irrepressible': 12131, 'wrongs': 12132, 'dummies': 12133, 'assailants': 12134, 'parodies': 12135, 'scuttle': 12136, '84': 12137, 'supercharged': 12138, 'excite': 12139, 'flagrantly': 12140, 'thunderstorms': 12141, 'amiss': 12142, 'limps': 12143, 'squirm': 12144, 'interlocked': 12145, \"'dragonfly'\": 12146, 'dreadfully': 12147, 'inversion': 12148, 'eschews': 12149, 'roiling': 12150, 'royally': 12151, 'goofball': 12152, 'utilizing': 12153, 'steadicam': 12154, 'pomposity': 12155, 'compressed': 12156, 'evanescent': 12157, 'swallows': 12158, 'copmovieland': 12159, 'routes': 12160, 'groaners': 12161, 'bam': 12162, 'salaries': 12163, 'dey': 12164, 'manqu': 12165, 'qui': 12166, 'tombe': 12167, 'sur': 12168, 'nerfs': 12169, 'presque': 12170, 'premi': 12171, \"'not\": 12172, \"money'\": 12173, 'quotations': 12174, 'agile': 12175, 'rodan': 12176, 'traced': 12177, 'antwone': 12178, 'bullseye': 12179, 'ragbag': 12180, 'trifecta': 12181, 'weimar': 12182, 'drifts': 12183, 'wreckage': 12184, 'showgirls': 12185, 'muffled': 12186, 'lulling': 12187, 'horizons': 12188, 'dullness': 12189, 'coasting': 12190, 'fantastically': 12191, 'invest': 12192, 'humanizing': 12193, 'capturou': 12194, 'pomo': 12195, 'ouro': 12196, 'dusty': 12197, 'strident': 12198, 'dish': 12199, 'isle': 12200, 'categorization': 12201, 'amold': 12202, 'peeling': 12203, 'gargantuan': 12204, 'plod': 12205, 'pipeline': 12206, 'presiding': 12207, 'knockaround': 12208, 'aspiration': 12209, 'grasping': 12210, 'flippant': 12211, 'advocacy': 12212, 'reigen': 12213, \"benjamins'\": 12214, 'patched': 12215, 'dawdles': 12216, 'tedium': 12217, 'fuhrman': 12218, 'homages': 12219, 'casualties': 12220, \"'90s\": 12221, 'indies': 12222, 'burkina': 12223, 'faso': 12224, 'sia': 12225, 'elicits': 12226, 'governments': 12227, 'filipino': 12228, 'quickening': 12229, 'slamming': 12230, 'jeong': 12231, 'jae': 12232, 'eun': 12233, 'dripping': 12234, 'bypassing': 12235, 'trivialize': 12236, 'cringe': 12237, 'climaxing': 12238, 'divers': 12239, 'jumping': 12240, 'opted': 12241, 'rehashing': 12242, 'remorse': 12243, 'weakly': 12244, 'mojo': 12245, 'consumerist': 12246, 'churning': 12247, 'cracking': 12248, 'conspicuous': 12249, 'contained': 12250, 'progression': 12251, 'symptom': 12252, 'malnutrition': 12253, 'personas': 12254, 'bumbling': 12255, 'drain': 12256, 'rant': 12257, 'thumbing': 12258, 'champagne': 12259, 'prancing': 12260, 'tailor': 12261, 'relishes': 12262, 'wades': 12263, \"'if\": 12264, 'fogging': 12265, 'triangles': 12266, 'fetishistic': 12267, 'jeffs': 12268, 'breathtakingly': 12269, 'expressiveness': 12270, 'shambling': 12271, 'stubbornly': 12272, 'psychodynamics': 12273, 'plum': 12274, 'worms': 12275, 'frothing': 12276, 'domino': 12277, 'patent': 12278, 'dramatize': 12279, 'messiness': 12280, 'swung': 12281, 'aura': 12282, 'mechanism': 12283, '4w': 12284, 'glossy': 12285, 'sympathize': 12286, 'dulled': 12287, 'gorefests': 12288, 'connoisseur': 12289, \"'i'm\": 12290, \"ed'\": 12291, 'ate': 12292, 'reeses': 12293, 'peanut': 12294, 'butter': 12295, 'eisenstein': 12296, 'reindeer': 12297, 'duracell': 12298, 'underdog': 12299, 'fashions': 12300, 'travails': 12301, 'appetites': 12302, 'homo': 12303, 'impossibility': 12304, 'ponders': 12305, 'sounding': 12306, 'restroom': 12307, 'perpetrating': 12308, 'aborbing': 12309, 'arguable': 12310, 'diverted': 12311, 'forum': 12312, 'circumstantial': 12313, 'professionally': 12314, 'ronny': 12315, 'imbalance': 12316, 'cosby': 12317, 'expressly': 12318, 'sewage': 12319, 'shovel': 12320, 'gullets': 12321, 'simulate': 12322, 'sustenance': 12323, 'welt': 12324, 'projectile': 12325, 'postapocalyptic': 12326, 'disadvantage': 12327, 'geared': 12328, 'hermocrates': 12329, 'leontine': 12330, 'compare': 12331, 'amours': 12332, 'fetishism': 12333, 'amazement': 12334, 'modicum': 12335, 'exasperating': 12336, 'groan': 12337, 'hiss': 12338, 'underdramatized': 12339, 'transcript': 12340, 'freudian': 12341, 'imitative': 12342, 'innumerable': 12343, 'derisions': 12344, 'shockingly': 12345, 'crescendos': 12346, 'fetishes': 12347, 'scouse': 12348, 'berger': 12349, 'instruction': 12350, \"thyself'\": 12351, 'succumb': 12352, 'observer': 12353, 'stellar': 12354, 'cuter': 12355, 'mcdonald': 12356, 'poles': 12357, 'mcshakespeare': 12358, \"'garth'\": 12359, 'progressed': 12360, \"'wayne\": 12361, 'preoccupations': 12362, 'romanek': 12363, 'flourishes': 12364, 'cheapen': 12365, 'misdemeanor': 12366, 'instalment': 12367, 'bushels': 12368, 'dramaturgy': 12369, 'surge': 12370, 'swirling': 12371, 'rapids': 12372, 'rouses': 12373, 'shrug': 12374, 'annoyance': 12375, 'chatty': 12376, 'voting': 12377, 'drumming': 12378, 'graces': 12379, 'narcissistic': 12380, 'gryffindor': 12381, 'outtakes': 12382, 'theatrically': 12383, 'bonus': 12384, 'perilously': 12385, 'amoses': 12386, 'andys': 12387, 'gnat': 12388, 'racehorse': 12389, 'derring': 12390, 'unambitious': 12391, 'grenoble': 12392, 'zigzag': 12393, 'pelosi': 12394, 'attractions': 12395, 'conrad': 12396, 'drawling': 12397, 'slobbering': 12398, 'hovers': 12399, 'spaghetti': 12400, 'outright': 12401, 'newness': 12402, \"c'mon\": 12403, 'whimsically': 12404, 'innocuous': 12405, 'fiascoes': 12406, 'cherises': 12407, 'unnatural': 12408, 'tendencies': 12409, 'sociologically': 12410, 'overwhelmingly': 12411, 'bilked': 12412, 'welled': 12413, 'malone': 12414, 'downplay': 12415, 'intractability': 12416, 'informs': 12417, 'cosmopolitan': 12418, 'sacred': 12419, 'lucratively': 12420, \"this'\": 12421, 'admired': 12422, 'slapper': 12423, 'hahas': 12424, 'mournful': 12425, 'stepmom': 12426, 'bristles': 12427, 'heroism': 12428, 'goo': 12429, 'refined': 12430, 'merciless': 12431, 'threateningly': 12432, 'extraterrestrial': 12433, 'elmo': 12434, 'touts': 12435, 'prevalent': 12436, 'dizzying': 12437, 'oddyssey': 12438, 'snowy': 12439, 'upstate': 12440, 'divert': 12441, 'attendance': 12442, 'evolves': 12443, 'perplexed': 12444, 'uniqueness': 12445, 'tend': 12446, 'margin': 12447, 'recessive': 12448, 'integrates': 12449, 'pasta': 12450, 'fagioli': 12451, 'hoary': 12452, 'patriotic': 12453, \"'hypertime'\": 12454, 'grosses': 12455, 'surfacey': 12456, 'trimmed': 12457, 'cowering': 12458, '8209': 12459, 'strives': 12460, 'natty': 12461, 'enhanced': 12462, 'nordstrom': 12463, 'payoffs': 12464, 'quota': 12465, 'shaping': 12466, 'tease': 12467, 'bambi': 12468, 'beresford': 12469, \"'evelyn\": 12470, 'deliberative': 12471, 'characterized': 12472, 'delirium': 12473, 'extant': 12474, 'ploughing': 12475, 'furrow': 12476, 'sneering': 12477, 'humbling': 12478, \"'they\": 12479, 'weep': 12480, 'padded': 12481, 'loop': 12482, 'heaviest': 12483, 'outings': 12484, 'duking': 12485, 'yank': 12486, 'overreaching': 12487, 'randall': 12488, 'borderline': 12489, 'pabulum': 12490, 'properties': 12491, 'gaghan': 12492, \"'too\": 12493, 'overexposed': 12494, 'redolent': 12495, 'creamy': 12496, 'ramblings': 12497, 'smorgasbord': 12498, \"'types\": 12499, 'behave': 12500, 'infused': 12501, 'marvin': 12502, 'gaye': 12503, 'supremes': 12504, 'deteriorates': 12505, 'hewn': 12506, 'andie': 12507, 'outmoded': 12508, 'potatoes': 12509, 'weirdos': 12510, 'subdued': 12511, 'dramedy': 12512, 'clothed': 12513, 'comprehensible': 12514, 'unsurpassed': 12515, 'pained': 12516, 'promotes': 12517, 'homogenized': 12518, 'glasses': 12519, \"'scratch'\": 12520, 'didacticism': 12521, 'humanism': 12522, 'bertrand': 12523, 'oft': 12524, 'rover': 12525, 'dangerfield': 12526, 'benoit': 12527, 'delhomme': 12528, 'zippy': 12529, 'portraits': 12530, 'twentysomething': 12531, 'phobes': 12532, 'valid': 12533, 'bared': 12534, 'swooning': 12535, 'intermezzo': 12536, 'unwavering': 12537, \"adams'\": 12538, 'provocations': 12539, 'cheapening': 12540, 'numbered': 12541, '52': 12542, 'howling': 12543, 'subservient': 12544, 'brandishing': 12545, 'sluggishly': 12546, 'snap': 12547, 'cin': 12548, 'qualit': 12549, 'telenovelas': 12550, 'overlook': 12551, 'fizzled': 12552, 'littering': 12553, 'marveled': 12554, 'hoofing': 12555, 'crooning': 12556, 'freeway': 12557, 'oiled': 12558, 'upholstered': 12559, 'coordinated': 12560, 'meaningness': 12561, 'dogme': 12562, 'bedfellows': 12563, 'sites': 12564, 'dastardly': 12565, 'murderers': 12566, 'videotapes': 12567, 'stocked': 12568, 'populist': 12569, 'fatter': 12570, 'dipped': 12571, 'oodles': 12572, 'marginalization': 12573, 'dreamer': 12574, 'dogwalker': 12575, 'stonehenge': 12576, 'percussion': 12577, 'canter': 12578, \"poets'\": 12579, 'swashbuckling': 12580, \"sayles'\": 12581, 'wordplay': 12582, 'muddy': 12583, 'ugliest': 12584, 'echelon': 12585, 'sweaty': 12586, 'bizzarre': 12587, 'italics': 12588, 'brusqueness': 12589, 'chin': 12590, 'accumulate': 12591, 'lint': 12592, 'twister': 12593, 'javier': 12594, 'bardem': 12595, 'gerardo': 12596, 'swoony': 12597, 'authors': 12598, 'superstar': 12599, 'directress': 12600, 'russos': 12601, 'ephemeral': 12602, 'alacrity': 12603, 'silbersteins': 12604, 'freshened': 12605, 'dunce': 12606, 'howlers': 12607, 'yawns': 12608, 'cedar': 12609, 'perennial': 12610, 'stockings': 12611, 'slanted': 12612, 'enervating': 12613, 'deadeningly': 12614, 'guillermo': 12615, '117': 12616, 'capsule': 12617, 'contests': 12618, 'atonal': 12619, 'demonizes': 12620, 'feminism': 12621, 'gifting': 12622, 'vomit': 12623, 'uncompromisingly': 12624, 'andersson': 12625, 'tremendously': 12626, 'translates': 12627, 'venerable': 12628, 'valedictory': 12629, 'commercialism': 12630, 'unfettered': 12631, 'calculus': 12632, \"at'\": 12633, 'bullfighters': 12634, 'comatose': 12635, 'ballerinas': 12636, 'bedside': 12637, 'vigils': 12638, 'denouements': 12639, 'meanderings': 12640, 'coated': 12641, 'trombone': 12642, 'honks': 12643, 'genet': 12644, 'rechy': 12645, 'fassbinder': 12646, 'goya': 12647, 'spinoff': 12648, 'mummy': 12649, 'archetype': 12650, 'tweak': 12651, 'depict': 12652, 'nadia': 12653, 'kittenish': 12654, 'accumulates': 12655, 'nit': 12656, 'picky': 12657, 'hypocrisies': 12658, 'stevenon': 12659, 'cohesion': 12660, 'broca': 12661, 'redrawn': 12662, 'gall': 12663, 'clamoring': 12664, 'mystique': 12665, 'reenacting': 12666, 'crushes': 12667, 'timeframe': 12668, 'mandates': 12669, 'godzilla': 12670, \"o'fallon\": 12671, 'dispel': 12672, 'tier': 12673, 'ingratiating': 12674, 'annals': 12675, 'unpaid': 12676, 'intern': 12677, 'typed': 12678, \"'chris\": 12679, \"'anthony\": 12680, \"hopkins'\": 12681, \"'terrorists'\": 12682, 'univac': 12683, 'taxicab': 12684, 'slowed': 12685, 'creep': 12686, 'cheaper': 12687, \"'frankly\": 12688, 'unrewarding': 12689, 'hughes': 12690, 'bueller': 12691, 'ennui': 12692, 'hobbled': 12693, 'offerings': 12694, 'roster': 12695, 'kathryn': 12696, 'raucously': 12697, 'ransacks': 12698, 'monosyllabic': 12699, 'prevention': 12700, 'poignancies': 12701, '49': 12702, 'cowrote': 12703, 'retrograde': 12704, \"'post\": 12705, \"feminist'\": 12706, 'guffaws': 12707, 'jolted': 12708, 'gourd': 12709, 'megalomaniac': 12710, 'pizazz': 12711, 'squint': 12712, 'noticing': 12713, 'egregious': 12714, 'synching': 12715, \"'nature'\": 12716, 'ascends': 12717, 'olympus': 12718, 'cremaster': 12719, 'linear': 12720, 'efficiency': 12721, 'fanatically': 12722, 'fetishized': 12723, 'idiosyncrasy': 12724, 'monastic': 12725, 'critically': 12726, 'treebeard': 12727, \"'performance'\": 12728, 'skims': 12729, 'hymn': 12730, 'labors': 12731, 'bastard': 12732, 'attuned': 12733, 'anarchist': 12734, 'maxim': 12735, \"urge'\": 12736, 'pumped': 12737, 'governance': 12738, 'antiseptic': 12739, 'preprogrammed': 12740, 'chainsaw': 12741, 'bile': 12742, 'roars': 12743, 'inflated': 12744, 'gravitas': 12745, 'placeholder': 12746, 'ergo': 12747, 'unpicked': 12748, 'vine': 12749, 'quandaries': 12750, 'unfurls': 12751, 'interweaves': 12752, 'mobius': 12753, 'elliptically': 12754, 'loops': 12755, 'flashing': 12756, 'sleek': 12757, 'bmw': 12758, 'astronomically': 12759, 'penetrate': 12760, 'paradigm': 12761, 'clique': 12762, \"live'\": 12763, 'pitying': 12764, 'hairpiece': 12765, 'lai': 12766, 'shocker': 12767, 'weirdo': 12768, 'grinder': 12769, 'byatt': 12770, 'adjective': 12771, \"'gentle'\": 12772, 'heartstring': 12773, 'untugged': 12774, 'unplundered': 12775, 'irreparable': 12776, 'serene': 12777, 'sprightly': 12778, 'plateau': 12779, 'poetics': 12780, 'cantet': 12781, 'respons': 12782, 'direto': 12783, 'fracasso': 12784, \"'art\": 12785, \"stico'\": 12786, 'doce': 12787, 'lar': 12788, 'roteirista': 12789, 'consegue': 12790, 'sequer': 12791, 'aproveitar': 12792, 'pouqu': 12793, 'ssimos': 12794, 'escapa': 12795, 'mediocridade': 12796, 'gaps': 12797, 'expressively': 12798, 'crystallize': 12799, 'minutely': 12800, 'ecstasy': 12801, 'lighted': 12802, 'inquiries': 12803, 'redeemable': 12804, 'advancing': 12805, 'ish': 12806, 'juggling': 12807, 'balls': 12808, 'mundanity': 12809, 'smallish': 12810, 'forte': 12811, \"'let\": 12812, \"with'\": 12813, 'lowering': 12814, 'engulfed': 12815, 'unspools': 12816, 'blending': 12817, 'infinitely': 12818, 'cassette': 12819, 'leppard': 12820, 'pyromania': 12821, 'locale': 12822, 'hoity': 12823, 'toity': 12824, 'medal': 12825, 'creations': 12826, 'corn': 12827, 'comments': 12828, 'burkinabe': 12829, '7th': 12830, 'grayish': 12831, 'libs': 12832, 'undeterminable': 12833, 'inch': 12834, 'almodovar': 12835, 'thekids': 12836, 'kaleidoscope': 12837, 'naptime': 12838, 'thinly': 12839, 'veiled': 12840, 'bottle': 12841, 'smokey': 12842, 'achival': 12843, 'unspectacular': 12844, 'audacity': 12845, 'tearful': 12846, 'slavery': 12847, 'combos': 12848, 'totalitarian': 12849, 'reportedly': 12850, 'rewritten': 12851, 'reserve': 12852, 'tartakovsky': 12853, 'freakish': 12854, 'airtime': 12855, 'salient': 12856, 'smothered': 12857, 'overload': 12858, 'irreparably': 12859, 'slogged': 12860, 'nervy': 12861, 'breezily': 12862, 'apolitical': 12863, 'reeks': 12864, 'rot': 12865, 'snacks': 12866, 'munching': 12867, 'tagline': 12868, 'literal': 12869, 'ink': 12870, 'goliath': 12871, 'stallion': 12872, 'cimarron': 12873, 'hoult': 12874, 'pops': 12875, 'baird': 12876, 'satisfactorily': 12877, 'stirred': 12878, 'breitbart': 12879, 'click': 12880, 'springing': 12881, 'exhibitionism': 12882, 'overreaches': 12883, 'unapologetic': 12884, 'dp': 12885, 'neihouse': 12886, 'disconnection': 12887, 'defiance': 12888, 'tempted': 12889, 'forgivably': 12890, 'venial': 12891, 'palpably': 12892, 'sorcerer': 12893, 'hubristic': 12894, 'wavers': 12895, 'cellular': 12896, 'clunk': 12897, 'overtime': 12898, 'qualifies': 12899, 'buoy': 12900, 'selflessness': 12901, 'pulchritude': 12902, 'fustily': 12903, 'twitchy': 12904, 'wearisome': 12905, 'wretched': 12906, 'et': 12907, 'lecture': 12908, 'pensive': 12909, 'sideshow': 12910, 'dismisses': 12911, 'kangaroo': 12912, 'prospers': 12913, 'accorsi': 12914, 'tenet': 12915, 'religions': 12916, 'communications': 12917, '5ths': 12918, 'franc': 12919, \"reyes'\": 12920, 'effecting': 12921, 'coarseness': 12922, 'sheds': 12923, 'torch': 12924, 'shuffling': 12925, 'bespectacled': 12926, 'underpaid': 12927, 'jeans': 12928, 'backmasking': 12929, 'knitting': 12930, 'needles': 12931, 'maladjusted': 12932, 'narcotized': 12933, 'advantages': 12934, 'tail': 12935, 'negligible': 12936, 'escalating': 12937, 'venezuelans': 12938, 'loco': 12939, 'conceptual': 12940, 'complaining': 12941, 'methodology': 12942, 'disappoints': 12943, 'entertainments': 12944, 'unspeakably': 12945, 'reams': 12946, 'wraps': 12947, 'shiny': 12948, 'uninspiring': 12949, 'heedless': 12950, 'impetuousness': 12951, 'prewarned': 12952, 'spangle': 12953, 'frenetic': 12954, 'punny': 12955, 'appealingly': 12956, 'ecologically': 12957, 'wildlife': 12958, 'punitive': 12959, 'eardrum': 12960, 'dicing': 12961, 'screeching': 12962, 'smashups': 12963, 'sniping': 12964, \"cryin'\": 12965, 'whine': 12966, 'insecurities': 12967, 'temperament': 12968, 'rancorous': 12969, 'pretensions': 12970, 'gallagher': 12971, 'wewannour': 12972, \"'how\": 12973, \"cash'\": 12974, 'hatosy': 12975, 'caso': 12976, 'voc': 12977, 'sinta': 12978, 'necessidade': 12979, 'sala': 12980, 'antes': 12981, 'rmino': 12982, 'proje': 12983, 'preocupe': 12984, 'ningu': 12985, 'lhe': 12986, 'enviar': 12987, 'penas': 12988, 'simbolizando': 12989, 'covardia': 12990, 'embody': 12991, 'nouvelle': 12992, 'analgesic': 12993, 'overstimulated': 12994, 'lingering': 12995, 'coup': 12996, 'lopsided': 12997, 'congeniality': 12998, \"'drama\": 12999, 'thrall': 13000, 'bookkeepers': 13001, 'substantive': 13002, \"'this\": 13003, 'lionize': 13004, 'irksome': 13005, '71': 13006, 'strenuous': 13007, 'clinch': 13008, 'razzie': 13009, 'distorts': 13010, 'riddles': 13011, 'welles': 13012, 'scholar': 13013, 'broadside': 13014, 'publishing': 13015, 'proceeded': 13016, 'valium': 13017, 'doggie': 13018, 'winks': 13019, 'celebrityhood': 13020, 'bruckheimeresque': 13021, 'emulates': 13022, 'immerse': 13023, 'mccoist': 13024, 'timeout': 13025, 'helene': 13026, 'drooling': 13027, 'cent': 13028, 'gum': 13029, 'vega': 13030, 'ulloa': 13031, 'najwa': 13032, 'nimri': 13033, 'wonton': 13034, 'apesar': 13035, 'superar': 13036, 'chamado': 13037, 'realizado': 13038, 'sua': 13039, 'pria': 13040, 'funciona': 13041, 'exemplar': 13042, 'stitched': 13043, 'particulars': 13044, 'tte': 13045, 'brecht': 13046, 'playfulness': 13047, 'smallness': 13048, 'unrealistic': 13049, 'regal': 13050, 'plaguing': 13051, 'globalizing': 13052, 'negate': 13053, 'lingerie': 13054, 'dancers': 13055, 'midwest': 13056, 'cheery': 13057, 'relaxing': 13058, 'peterson': 13059, 'treading': 13060, 'actualization': 13061, 'continental': 13062, 'divides': 13063, 'placid': 13064, 'embarrassingly': 13065, 'reek': 13066, 'standup': 13067, 'straddles': 13068, 'morman': 13069, 'tonga': 13070, 'wholesomeness': 13071, 'insularity': 13072, 'ethnography': 13073, 'shakespearean': 13074, 'lindberg': 13075, 'adobo': 13076, 'unequivocally': 13077, 'giddily': 13078, 'meyjes': 13079, 'rothman': 13080, 'posters': 13081, 'bikinis': 13082, 'surfboards': 13083, 'sterility': 13084, 'coral': 13085, 'reef': 13086, 'puzzles': 13087, 'pageantry': 13088, \"'christian\": 13089, 'clad': 13090, 'grunge': 13091, 'hairdo': 13092, 'cor': 13093, 'blimey': 13094, 'cockney': 13095, 'tomfoolery': 13096, 'rails': 13097, 'graze': 13098, 'backstage': 13099, 'depicted': 13100, 'binds': 13101, 'grotesquely': 13102, 'seigner': 13103, 'underplaying': 13104, 'cel': 13105, 'sextet': 13106, 'exhibits': 13107, 'telenovela': 13108, \"'urban\": 13109, 'freshening': 13110, 'tropic': 13111, 'arthouse': 13112, 'symbolism': 13113, 'kaufmann': 13114, 'trumpets': 13115, 'commendable': 13116, 'congratulatory': 13117, 'coils': 13118, 'whirlpool': 13119, 'unmemorable': 13120, 'tarde': 13121, 'prio': 13122, 'abandone': 13123, 'par': 13124, 'passe': 13125, 'utilizar': 13126, 'mesmos': 13127, 'havia': 13128, 'satirizado': 13129, 'elect': 13130, 'imposed': 13131, 'cherished': 13132, 'emanates': 13133, 'boatload': 13134, 'freighter': 13135, 'midlevel': 13136, 'appraisal': 13137, 'torpor': 13138, 'bass': 13139, 'linguistic': 13140, 'fumbling': 13141, 'whispers': 13142, 'tacks': 13143, 'ghostbusters': 13144, 'gloriously': 13145, 'crisply': 13146, 'extremities': 13147, 'mismatched': 13148, 'tactic': 13149, 'nonexistent': 13150, 'globetrotters': 13151, 'generals': 13152, 'urbanity': 13153, 'wildean': 13154, 'preposterousness': 13155, 'interference': 13156, 'enveloping': 13157, 'shankman': 13158, 'janszen': 13159, 'bungle': 13160, 'parables': 13161, 'achronological': 13162, 'lavinia': 13163, 'apologetics': 13164, 'ensnaring': 13165, 'populating': 13166, 'meanspirited': 13167, 'identification': 13168, 'blossoming': 13169, 'showcasing': 13170, 'programming': 13171, 'pointlessness': 13172, 'rad': 13173, 'phair': 13174, 'ponytail': 13175, 'truffaut': 13176, 'poems': 13177, 'missteps': 13178, 'antonin': 13179, 'artaud': 13180, 'markedly': 13181, 'inactive': 13182, 'conversational': 13183, 'bordering': 13184, 'coarse': 13185, 'trifling': 13186, 'opposites': 13187, 'duk': 13188, 'provocatively': 13189, 'riskier': 13190, 'slater': 13191, 'dreyfuss': 13192, 'portia': 13193, 'di': 13194, \"dreyfuss'\": 13195, 'twisty': 13196, 'trimmingsarrive': 13197, 'minutewith': 13198, 'impudent': 13199, 'snickers': 13200, 'humankind': 13201, 'scrooge': 13202, 'poky': 13203, 'workshops': 13204, 'overshadows': 13205, 'overrides': 13206, 'vicarious': 13207, 'misconceived': 13208, 'crudest': 13209, 'antic': 13210, 'complexly': 13211, 'infantile': 13212, 'yep': 13213, 'polson': 13214, 'jazzes': 13215, 'adroitly': 13216, 'dash': 13217, 'fused': 13218, 'achievable': 13219, 'marvellous': 13220, 'absorption': 13221, 'acumen': 13222, 'lightest': 13223, 'recharged': 13224, 'empathize': 13225, 'rowdily': 13226, 'herzog': 13227, 'enraptured': 13228, 'shears': 13229, 'unhurried': 13230, 'moralistic': 13231, 'tenor': 13232, 'projected': 13233, 'dreyfus': 13234, 'preciously': 13235, 'sepia': 13236, 'moaning': 13237, 'moodiness': 13238, 'brawny': 13239, 'undo': 13240, 'bela': 13241, 'lugosi': 13242, 'irk': 13243, 'elliptical': 13244, 'overplotted': 13245, 'thrives': 13246, 'jeunet': 13247, 'scruffy': 13248, 'barbera': 13249, 'notches': 13250, 'pablum': 13251, 'astringent': 13252, 'hammering': 13253, 'intuitively': 13254, 'contrasting': 13255, 'sleekness': 13256, 'kalesniko': 13257, 'schnieder': 13258, 'bounces': 13259, 'wrists': 13260, 'huggers': 13261, 'twirling': 13262, 'klasky': 13263, 'csupo': 13264, 'amplification': 13265, 'pbs': 13266, '75': 13267, 'tantamount': 13268, 'letterman': 13269, 'onion': 13270, 'fertile': 13271, 'slapped': 13272, 'reconciliation': 13273, 'instilled': 13274, '25s': 13275, 'csokas': 13276, 'unconnected': 13277, 'inventing': 13278, 'promotion': 13279, 'teenaged': 13280, 'chokes': 13281, 'lika': 13282, 'baio': 13283, 'idiotically': 13284, 'improperly': 13285, 'kroc': 13286, 'maura': 13287, 'tierney': 13288, 'bowel': 13289, 'squared': 13290, 'sideways': 13291, 'wartime': 13292, 'speech': 13293, 'patterns': 13294, 'leery': 13295, 'zealously': 13296, 'puritanical': 13297, 'islanders': 13298, \"dragon'\": 13299, 'lethargically': 13300, 'enact': 13301, 'unguarded': 13302, 'reinforces': 13303, 'varying': 13304, 'antidotes': 13305, 'manifesto': 13306, 'bondish': 13307, 'resurrect': 13308, 'barrels': 13309, 'bod': 13310, 'desecrations': 13311, 'ensnare': 13312, 'treks': 13313, 'cooly': 13314, 'recreates': 13315, 'popeye': 13316, 'wallow': 13317, 'migraine': 13318, 'fulfils': 13319, 'storied': 13320, 'terrors': 13321, 'praiseworthy': 13322, 'dulls': 13323, 'estela': 13324, 'bravo': 13325, 'hagiographic': 13326, 'fidel': 13327, 'collaborative': 13328, 'mergers': 13329, 'downsizing': 13330, 'yours': 13331, 'lurches': 13332, 'sputters': 13333, 'sector': 13334, 'paunchy': 13335, 'midsection': 13336, 'undramatic': 13337, 'dignified': 13338, 'rustic': 13339, 'pee': 13340, 'redefines': 13341, \"'chan\": 13342, \"moment'\": 13343, 'amok': 13344, 'jumped': 13345, 'sparklingly': 13346, 'dowse': 13347, 'cattle': 13348, 'prod': 13349, 'dualistic': 13350, 'overstylized': 13351, 'pur': 13352, 'lange': 13353, 'wankery': 13354, 'etoiles': 13355, 'dour': 13356, 'subcultures': 13357, 'ziyi': 13358, 'harbinger': 13359, 'crassly': 13360, 'comedically': 13361, 'transparency': 13362, 'demonstrations': 13363, 'programmer': 13364, 'bop': 13365, 'nighttime': 13366, 'loquacious': 13367, 'videologue': 13368, 'cocoon': 13369, \"'get'\": 13370, 'discourse': 13371, 'gamesmanship': 13372, 'buries': 13373, 'moron': 13374, 'insistent': 13375, 'dicey': 13376, 'zigs': 13377, 'zags': 13378, 'bothersome': 13379, 'cinephiles': 13380, 'camerawork': 13381, 'mise': 13382, '168': 13383, \"'glengarry\": 13384, 'glen': 13385, \"ross'\": 13386, 'gesturing': 13387, 'oes': 13388, 'amped': 13389, 'hawk': 13390, 'thrashing': 13391, 'chaiken': 13392, 'joys': 13393, 'chatter': 13394, 'oprah': 13395, 'paddle': 13396, 'lameness': 13397, 'swallowing': 13398, 'communion': 13399, 'afterthought': 13400, 'swirl': 13401, 'lyricism': 13402, 'balzac': 13403, 'seamstress': 13404, 'doubtful': 13405, 'clipped': 13406, 'abbreviated': 13407, 'entree': 13408, 'resolute': 13409, 'nakedness': 13410, 'ringside': 13411, 'workaday': 13412, 'indulging': 13413, 'sellers': 13414, 'likably': 13415, 'flabby': 13416, '144': 13417, 'accommodates': 13418, 'quibbling': 13419, 'diminish': 13420, 'gobble': 13421, 'dolby': 13422, 'stereo': 13423, 'outshined': 13424, 'll': 13425, 'dissection': 13426, 'inanities': 13427, 'placing': 13428, 'scented': 13429, \"'date\": 13430, \"movie'\": 13431, 'inflected': 13432, 'snippets': 13433, \"'refreshing\": 13434, \"'drumline'\": 13435, 'debilitating': 13436, 'infuriatingly': 13437, 'soapish': 13438, 'excoriation': 13439, 'piousness': 13440, 'dislikable': 13441, 'sociopathy': 13442, 'classicism': 13443, 'exasperated': 13444, 'noticeable': 13445, 'amateurishly': 13446, 'decoder': 13447, 'underutilized': 13448, 'agony': 13449, 'ruminating': 13450, 'genteel': 13451, 'bills': 13452, 'addressing': 13453, 'evenly': 13454, 'renaissance': 13455, 'hypocrisy': 13456, 'fudged': 13457, 'lunar': 13458, 'parlance': 13459, 'shreve': 13460, \"'lick\": 13461, 'flexible': 13462, 'whittle': 13463, 'stewart': 13464, \"'should\": 13465, 'pessimists': 13466, 'concise': 13467, 'outta': 13468, 'mug': 13469, 'humidity': 13470, 'opportunism': 13471, 'glaring': 13472, 'jostles': 13473, 'rational': 13474, 'lethally': 13475, 'resemble': 13476, 'melds': 13477, 'blink': 13478, 'laggard': 13479, 'wending': 13480, 'epiphany': 13481, 'companionable': 13482, 'barbs': 13483, 'passionately': 13484, 'inquisitive': 13485, 'ager': 13486, 'siberian': 13487, 'parka': 13488, '295': 13489, 'screenings': 13490, 'indignant': 13491, 'deconstruct': 13492, 'clobbering': 13493, 'humorit': 13494, 'endearingly': 13495, 'corniness': 13496, 'oozing': 13497, 'paymer': 13498, 'peep': 13499, 'booths': 13500, 'mopping': 13501, 'gnashing': 13502, 'actorliness': 13503, 'guillotine': 13504, 'generates': 13505, 'solemn': 13506, 'pabst': 13507, 'ribbon': 13508, 'selection': 13509, 'inextricably': 13510, 'leafing': 13511, 'sketchiest': 13512, 'captions': 13513, 'punishing': 13514, 'tyson': 13515, \"'lovely\": 13516, 'unhappily': 13517, 'nonfiction': 13518, 'mouths': 13519, 'scorchingly': 13520, 'molehill': 13521, 'weirded': 13522, 'disorienting': 13523, 'ditsy': 13524, 'haul': 13525, 'tatou': 13526, 'picking': 13527, 'magnify': 13528, 'mimicry': 13529, '83': 13530, 'seesawed': 13531, 'raps': 13532, 'procession': 13533, 'castles': 13534, 'embarrassing': 13535, 'corniest': 13536, 'warmest': 13537, 'snowman': 13538, 'flute': 13539, 'enamored': 13540, 'muckraking': 13541, 'jettisons': 13542, 'braiding': 13543, 'articulated': 13544, 'burdette': 13545, 'uncommitted': 13546, 'pompeo': 13547, 'patric': 13548, 'xfl': 13549, 'aggravating': 13550, 'scathing': 13551, 'masterpeice': 13552, 'artless': 13553, 'kafkaesque': 13554, 'merchandised': 13555, 'recruiting': 13556, 'playlist': 13557, 'costuming': 13558, 'sublimely': 13559, \"cinema'\": 13560, 'conjures': 13561, 'fumes': 13562, 'rembrandt': 13563, 'preachiness': 13564, 'unconvincingly': 13565, 'misfires': 13566, 'impenetrable': 13567, 'utilization': 13568, 'caution': 13569, 'hedonist': 13570, 'smiling': 13571, 'downplaying': 13572, 'adoration': 13573, '88': 13574, 'blip': 13575, 'milder': 13576, 'detractors': 13577, 'exhaustive': 13578, 'rocked': 13579, 'czechoslovakia': 13580, 'burgeoning': 13581, 'professionals': 13582, 'deteriorating': 13583, 'gutsy': 13584, 'compensation': 13585, 'springsteen': 13586, 'asbury': 13587, 'grooves': 13588, 'montell': 13589, 'osborne': 13590, 'graceless': 13591, 'hideousness': 13592, \"'20\": 13593, \"sea'\": 13594, 'frontman': 13595, 'righteousness': 13596, 'ver': 13597, 'wiel': 13598, 'triumphantly': 13599, 'uncut': 13600, 'leone': 13601, 'staggering': 13602, 'pandering': 13603, 'quench': 13604, 'blockbusters': 13605, 'dickens': 13606, 'argento': 13607, 'splatters': 13608, 'reawaken': 13609, 'togetherness': 13610, '133': 13611, 'relevance': 13612, 'boll': 13613, 'printing': 13614, 'contemplates': 13615, 'eyelids': 13616, \"'difficult'\": 13617, 'disrespected': 13618, 'nowheresville': 13619, 'kinetically': 13620, 'bucket': 13621, 'gremlins': 13622, 'taymor': 13623, 'titus': 13624, 'brio': 13625, 'loopiness': 13626, 'congenital': 13627, 'democracies': 13628, 'accomplishments': 13629, 'unifying': 13630, 'leggy': 13631, \"jazz'\": 13632, 'flammable': 13633, 'contemplated': 13634, 'nausea': 13635, 'toasting': 13636, 'rehearsals': 13637, 'fulfills': 13638, 'vardalos': 13639, 'corbett': 13640, 'chronicler': 13641, 'disagreement': 13642, 'titans': 13643, 'fictionalize': 13644, 'marker': 13645, 'newsreel': 13646, 'pinwheel': 13647, 'yuppie': 13648, 'vat': 13649, 'starters': 13650, 'ften': 13651, 'hile': 13652, 'environmentalism': 13653, 'chimpanzees': 13654, 'oversize': 13655, 'crafting': 13656, 'classify': 13657, 'classroom': 13658, 'crackles': 13659, 'presenting': 13660, 'statesmen': 13661, 'bikini': 13662, \"bitchin'\": 13663, 'ankle': 13664, 'agape': 13665, 'punched': 13666, 'chair': 13667, 'schefberg': 13668, 'messily': 13669, 'ofrece': 13670, 'buena': 13671, 'oportunidad': 13672, 'cultura': 13673, 'aunque': 13674, 'condensada': 13675, 'bien': 13676, 'vale': 13677, 'lise': 13678, 'sunnier': 13679, 'regalia': 13680, 'waltzed': 13681, 'pretention': 13682, 'originated': 13683, 'compromised': 13684, 'aboul': 13685, 'refracting': 13686, 'confirming': 13687, 'bille': 13688, 'slightest': 13689, 'chicks': 13690, 'overtake': 13691, 'flaw': 13692, 'lessen': 13693, 'meander': 13694, 'reduce': 13695, 'sleaziness': 13696, 'saddam': 13697, 'hussein': 13698, 'cramming': 13699, 'windup': 13700, 'dislike': 13701, 'peril': 13702, 'theatrics': 13703, 'penance': 13704, 'ungainly': 13705, 'cornpone': 13706, 'cosa': 13707, 'nostra': 13708, 'stoppingly': 13709, 'scathingly': 13710, 'babek': 13711, 'beckett': 13712, 'jarmusch': 13713, 'unendurable': 13714, 'infusion': 13715, 'flowery': 13716, 'unstable': 13717, 'irritates': 13718, 'saddens': 13719, 'obnoxiously': 13720, 'bewildering': 13721, 'francophiles': 13722, 'snicker': 13723, 'knowingly': 13724, 'gayton': 13725, 'gravitational': 13726, 'doh': 13727, 'fingers': 13728, 'adored': 13729, 'camouflaging': 13730, 'bruising': 13731, 'renoir': 13732, 'disparate': 13733, 'uncinematic': 13734, 'kev': 13735, 'scripts': 13736, 'dotted': 13737, 'persistently': 13738, 'resuscitation': 13739, 'supple': 13740, 'athlete': 13741, 'indomitability': 13742, 'nuggets': 13743, 'novices': 13744, 'arachnid': 13745, 'insect': 13746, 'unshowy': 13747, 'equalize': 13748, 'sufficient': 13749, 'leroy': 13750, 'unseemly': 13751, 'congratulate': 13752, 'inchoate': 13753, 'eldritch': 13754, 'rotting': 13755, 'competently': 13756, 'interact': 13757, 'statues': 13758, 'magically': 13759, 'duration': 13760, 'capability': 13761, 'lux': 13762, 'eighties': 13763, 'boosterism': 13764, 'nurturing': 13765, 'gauzy': 13766, 'dithering': 13767, 'gambit': 13768, 'colossal': 13769, 'idiot': 13770, 'immediacy': 13771, 'belleza': 13772, 'magia': 13773, 'poder': 13774, 'misterio': 13775, 'sica': 13776, 'visuales': 13777, 'qu': 13778, 'puede': 13779, 'pedir': 13780, 'rerun': 13781, 'barbarella': 13782, 'ponderously': 13783, 'artiste': 13784, 'truer': 13785, 'tripartite': 13786, \"'cq\": 13787, 'strictness': 13788, 'aimlessness': 13789, 'squabbling': 13790, 'crosscuts': 13791, 'hogs': 13792, 'fudges': 13793, 'glorifies': 13794, 'glamorizes': 13795, 'unsunny': 13796, 'item': 13797, 'heck': 13798, 'gal': 13799, 'bites': 13800, 'bella': 13801, 'insult': 13802, 'attractiveness': 13803, 'bin': 13804, 'strenuously': 13805, 'rashomon': 13806, 'spiffy': 13807, 'compositions': 13808, 'rouse': 13809, 'cackles': 13810, 'amaze': 13811, 'nazism': 13812, 'unglamorous': 13813, 'beige': 13814, 'beginnings': 13815, 'occasions': 13816, 'yammering': 13817, 'glued': 13818, 'surrender': 13819, 'squeamish': 13820, 'idolized': 13821, 'sugarcoated': 13822, 'pronounce': 13823, 'beavis': 13824, 'butthead': 13825, 'elicit': 13826, 'gulps': 13827, 'huggy': 13828, \"'enough'\": 13829, 'standardized': 13830, 'herring': 13831, 'contentedly': 13832, 'steak': 13833, 'reflexive': 13834, 'barest': 13835, 'garcia': 13836, 'shortest': 13837, 'ascertain': 13838, 'pessimistic': 13839, 'narratively': 13840, \"thing'\": 13841, 'geriatric': 13842, \"'scream\": 13843, 'griping': 13844, 'garry': 13845, 'shandling': 13846, 'frightens': 13847, 'lemle': 13848, 'compel': 13849, 'enables': 13850, 'correctly': 13851, 'lector': 13852, 'injuries': 13853, 'tock': 13854, 'fumbled': 13855, 'ayres': 13856, 'memento': 13857, 'mea': 13858, 'culpa': 13859, 'holistic': 13860, 'underwhelming': 13861, 'rudd': 13862, 'flakeball': 13863, 'spouting': 13864, 'malapropisms': 13865, 'zombie': 13866, 'powerlessness': 13867, 'humiliation': 13868, 'wondrously': 13869, 'storytellers': 13870, 'interfaith': 13871, 'maneuvers': 13872, 'treasured': 13873, 'wimps': 13874, 'spoofing': 13875, 'mod': 13876, 'mibii': 13877, 'extravagantly': 13878, 'redeems': 13879, 'writhing': 13880, \"worlds'\": 13881, \"'tonight\": 13882, 'unoriginality': 13883, 'corcuera': 13884, 'caf': 13885, 'overhearing': 13886, 'somethings': 13887, 'natter': 13888, 'decommissioned': 13889, 'mcmullen': 13890, 'lifted': 13891, 'fairbanks': 13892, 'equals': 13893, 'betters': 13894, 'sip': 13895, 'wines': 13896, 'iced': 13897, 'purge': 13898, 'claw': 13899, '86': 13900, 'opulent': 13901, 'lushness': 13902, 'stimulates': 13903, 'exoticism': 13904, 'pax': 13905, 'lulled': 13906, 'perdition': 13907, 'dadaist': 13908, 'assess': 13909, 'engineering': 13910, 'adulterer': 13911, 'careerist': 13912, 'distressing': 13913, 'battery': 13914, 'nudity': 13915, 'profanity': 13916, 'ramble': 13917, 'idoosyncratic': 13918, 'errol': 13919, 'complicit': 13920, 'honorably': 13921, 'kahlories': 13922, 'baroque': 13923, 'warmly': 13924, 'extend': 13925, 'yell': 13926, \"'safe\": 13927, 'overacted': 13928, \"'ejemplo\": 13929, 'importa': 13930, 'talento': 13931, 'reparto': 13932, 'interesante': 13933, 'pudo': 13934, 'premisa': 13935, 'pues': 13936, 'francamente': 13937, 'aburrido': 13938, 'deplorable': 13939, 'whiffle': 13940, 'repartee': 13941, 'effortless': 13942, 'indecipherable': 13943, 'painters': 13944, 'confounded': 13945, 'miscellaneous': 13946, 'bohos': 13947, 'expound': 13948, 'iq': 13949, 'seamy': 13950, 'spousal': 13951, 'historically': 13952, 'contributions': 13953, 'seams': 13954, 'ambience': 13955, 'broaches': 13956, 'augustinian': 13957, 'underplays': 13958, 'wyman': 13959, 'cleaver': 13960, 'furiously': 13961, 'fanatic': 13962, \"'scooby'\": 13963, 'cards': 13964, 'spun': 13965, 'empress': 13966, 'leoni': 13967, 'ladles': 13968, 'flavour': 13969, 'fangoria': 13970, 'subscriber': 13971, 'penn': 13972, 'apology': 13973, 'insufferably': 13974, 'stupidities': 13975, 'ailments': 13976, 'uninflected': 13977, 'methodically': 13978, 'communicating': 13979, 'framework': 13980, 'shatner': 13981, 'kunis': 13982, 'zealanders': 13983, 'mettle': 13984, 'condensation': 13985, 'caliber': 13986, 'timelessness': 13987, 'mulan': 13988, 'tarzan': 13989, 'dicaprio': 13990, 'scandals': 13991, \"'artistically'\": 13992, 'handheld': 13993, 'joaquin': 13994, 'baca': 13995, 'asay': 13996, 'vertigo': 13997, 'opacity': 13998, 'endorsement': 13999, 'abhors': 14000, 'riled': 14001, 'reliable': 14002, 'concrete': 14003, 'gaitskill': 14004, 'unrepentantly': 14005, 'nascent': 14006, 'industrialized': 14007, 'malcolm': 14008, 'bamboozled': 14009, 'contrasts': 14010, 'sorimachi': 14011, 'printed': 14012, \"iles'\": 14013, 'loosey': 14014, 'goosey': 14015, 'extols': 14016, 'comradeship': 14017, 'recommendation': 14018, 'irwins': 14019, 'misfiring': 14020, 'atrociously': 14021, 'indescribably': 14022, 'deceitful': 14023, 'idealistically': 14024, 'detract': 14025, 'stagey': 14026, 'namesake': 14027, 'unconned': 14028, 'overmanipulative': 14029, \"'bartleby'\": 14030, 'gels': 14031, 'uh': 14032, 'shred': 14033, 'lumbering': 14034, 'leavitt': 14035, 'noxious': 14036, 'pixie': 14037, 'collinwood': 14038, \"'slackers'\": 14039, 'sharply': 14040, 'dislocation': 14041, 'unforgivably': 14042, 'fortified': 14043, 'sociology': 14044, 'buffed': 14045, 'octane': 14046, 'grievous': 14047, 'obsessively': 14048, 'crypt': 14049, 'backseat': 14050, 'bustingly': 14051, \"'sacre\": 14052, 'bleu': 14053, \"'magnifique'\": 14054, 'genially': 14055, 'schticky': 14056, 'specialty': 14057, 'demonize': 14058, 'amply': 14059, 'emboldening': 14060, 'unreachable': 14061, 'riding': 14062, 'tooled': 14063, 'amish': 14064, 'kicking': 14065, 'careless': 14066, 'pimple': 14067, \"'easier'\": 14068, 'connoisseurs': 14069, \"'hosts'\": 14070, \"'guests\": 14071, 'lobotomized': 14072, 'lured': 14073, 'labour': 14074, 'rein': 14075, 'whirling': 14076, 'rusted': 14077, 'thirdemotionally': 14078, 'belittle': 14079, 'matured': 14080, 'illuminate': 14081, 'implement': 14082, 'mao': 14083, 'ong': 14084, 'revisionist': 14085, 'evenings': 14086, 'schlepping': 14087, 'ashtray': 14088, 'freeze': 14089, 'marrow': 14090, 'liana': 14091, 'dognini': 14092, 'warner': 14093, 'irvine': 14094, 'trainspotting': 14095, 'boldface': 14096, 'pared': 14097, 'extravagances': 14098, 'concentrated': 14099, 'oriental': 14100, 'elective': 14101, 'affinities': 14102, 'searing': 14103, 'nouement': 14104, 'perplexing': 14105, 'houseboat': 14106, 'latches': 14107, 'willfully': 14108, 'celeb': 14109, 'atanarjuat': 14110, 'blasted': 14111, 'primeval': 14112, 'zips': 14113, 'meshes': 14114, 'bounties': 14115, 'kilted': 14116, 'rambles': 14117, 'phillip': 14118, 'cinematographer': 14119, 'forcefulness': 14120, 'roaring': 14121, 'pivotal': 14122, 'overpraised': 14123, 'dumbfoundingly': 14124, 'maureen': 14125, 'tilyou': 14126, 'duffy': 14127, 'molony': 14128, \"leys'\": 14129, 'blimp': 14130, 'denzel': 14131, 'moralism': 14132, 'flaunts': 14133, 'sporting': 14134, 'pleasingly': 14135, 'disassociation': 14136, 'nonprofessional': 14137, 'blatant': 14138, 'placement': 14139, 'carnival': 14140, 'rhyme': 14141, 'stunningly': 14142, 'gulzar': 14143, 'jagjit': 14144, 'nike': 14145, 'description': 14146, 'clarion': 14147, 'unreasonable': 14148, 'incisiveness': 14149, 'relatability': 14150, 'landbound': 14151, \"'surprises\": 14152, 'pigeonhole': 14153, 'resisting': 14154, 'bola': 14155, 'ramshackle': 14156, 'motherland': 14157, 'longo': 14158, 'epis': 14159, 'dio': 14160, 'programa': 14161, 'nica': 14162, 'diferen': 14163, 'teve': 14164, 'mau': 14165, 'gosto': 14166, 'exibi': 14167, 'nos': 14168, 'cinemas': 14169, 'undeserving': 14170, 'interventions': 14171, 'bumpy': 14172, 'lap': 14173, 'gotta': 14174, 'notting': 14175, 'somnambulant': 14176, 'pervasive': 14177, 'fingering': 14178, 'scratches': 14179, 'itch': 14180, 'grittiest': 14181, 'limbo': 14182, 'remakes': 14183, 'eclipse': 14184, 'grinds': 14185, 'blender': 14186, 'infusing': 14187, 'anarchic': 14188, 'vistas': 14189, 'heartrending': 14190, 'fundamentalists': 14191, 'bigoted': 14192, 'dolorous': 14193, 'trim': 14194, 'dips': 14195, 'freudianism': 14196, 'sparking': 14197, 'swift': 14198, 'davids': 14199, 'stymied': 14200, 'shum': 14201, 'studios': 14202, 'rara': 14203, 'avis': 14204, 'guzm': 14205, 'payola': 14206, 'conspiracies': 14207, 'crawlies': 14208, 'caricatures': 14209, 'buffoons': 14210, 'wes': 14211, \"'deadly\": 14212, 'khatra': 14213, '91': 14214, 'rates': 14215, 'transcendence': 14216, 'burly': 14217, 'pummels': 14218, 'necessity': 14219, 'roundhouse': 14220, 'obviousness': 14221, 'unpleasantly': 14222, '110': 14223, 'plethora': 14224, 'diatribes': 14225, \"'home\": 14226, 'households': 14227, 'aceitou': 14228, 'dirigir': 14229, 'continua': 14230, 'ramis': 14231, 'deve': 14232, 'ter': 14233, 'sa': 14234, 'cama': 14235, 'esquerdo': 14236, 'aqueles': 14237, 'decidiram': 14238, 'assistir': 14239, 'gander': 14240, 'amuses': 14241, 'alarmingly': 14242, 'weighted': 14243, 'inflection': 14244, 'slc': 14245, 'hailed': 14246, 'dilettante': 14247, 'bladerunner': 14248, 'restate': 14249, \"'catch\": 14250, 'emerged': 14251, 'dilithium': 14252, 'insurrection': 14253, 'disappointment': 14254, 'brassy': 14255, 'gaudy': 14256, 'bearded': 14257, 'lactating': 14258, 'ostensible': 14259, 'depressive': 14260, 'underconfident': 14261, \"neighborhood'\": 14262, 'romanced': 14263, 'cyndi': 14264, 'lauper': 14265, 'shrewdly': 14266, 'gelati': 14267, 'languid': 14268, 'filmit': 14269, 'unfulfilling': 14270, 'unrelieved': 14271, 'ironies': 14272, 'filter': 14273, 'promoter': 14274, 'renown': 14275, 'stretch': 14276, 'aurelie': 14277, 'christelle': 14278, 'fairytale': 14279, 'stoic': 14280, 'intimidate': 14281, 'pictorial': 14282, 'lejos': 14283, 'mismo': 14284, 'fiesta': 14285, 'ojos': 14286, 'movilizador': 14287, 'cuadro': 14288, 'personajes': 14289, 'enfrentados': 14290, 'propios': 14291, 'deseos': 14292, 'miedos': 14293, 'prejuicios': 14294, 'snags': 14295, 'stumblings': 14296, 'compensated': 14297, 'stoners': 14298, 'ravers': 14299, 'intolerant': 14300, 'felicities': 14301, 'improvise': 14302, 'directionless': 14303, '15th': 14304, 'groggy': 14305, 'measurements': 14306, 'simmer': 14307, 'suffice': 14308, 'truffle': 14309, 'adolescents': 14310, 'lascivious': 14311, \"'topless\": 14312, 'tutorial': 14313, 'thumpingly': 14314, 'types': 14315, 'baloney': 14316, 'ivy': 14317, 'marquee': 14318, 'unschooled': 14319, 'wednesday': 14320, 'sterling': 14321, 'astray': 14322, 'ruffle': 14323, 'erratic': 14324, 'requiring': 14325, 'disillusion': 14326, 'paces': 14327, 'satisfactory': 14328, 'daredevils': 14329, 'secondary': 14330, 'revigorates': 14331, 'sway': 14332, 'unwillingness': 14333, 'nettelbeck': 14334, 'schepisi': 14335, 'moviesor': 14336, 'endearment': 14337, 'observes': 14338, 'disconnectedness': 14339, 'dramatics': 14340, 'hooey': 14341, 'auteil': 14342, 'wheezing': 14343, 'nohe': 14344, 'nc': 14345, 'rubble': 14346, 'maimed': 14347, 'taunt': 14348, 'crashes': 14349, 'befitting': 14350, 'westerner': 14351, 'kumble': 14352, 'crudity': 14353, 'vastness': 14354, 'stimulate': 14355, 'croatia': 14356, 'sleekly': 14357, 'letdown': 14358, 'soup': 14359, 'noodle': 14360, 'bluer': 14361, 'biologically': 14362, 'searingly': 14363, 'admittedly': 14364, 'specifics': 14365, 'contradiction': 14366, 'afflicts': 14367, 'eu': 14368, 'estava': 14369, 'feliz': 14370, 'saudades': 14371, 'mim': 14372, 'papai': 14373, 'fato': 14374, 'inquestion': 14375, 'centric': 14376, 'skinny': 14377, 'sucking': 14378, 'inand': 14379, 'lovingly': 14380, 'stickiness': 14381, 'overeager': 14382, 'topless': 14383, 'tripe': 14384, 'gurus': 14385, 'doshas': 14386, 'westerners': 14387, 'verging': 14388, 'streaks': 14389, 'unimpeachable': 14390, 'denizens': 14391, 'mayport': 14392, \"'plain'\": 14393, 'waif': 14394, 'smear': 14395, 'mileage': 14396, 'bromides': 14397, 'interstitial': 14398, 'vertiginous': 14399, 'multitude': 14400, 'unjustified': 14401, 'spout': 14402, 'consists': 14403, 'maverick': 14404, 'hatfield': 14405, 'hicks': 14406, 'wittgenstein': 14407, 'kirkegaard': 14408, 'titillating': 14409, 'fetid': 14410, 'uglier': 14411, 'withstand': 14412, 'middling': 14413, 'sadists': 14414, 'ambling': 14415, 'enlivened': 14416, 'hibernation': 14417, \"'life\": 14418, \"affirming'\": 14419, \"'schmaltzy\": 14420, 'stuntwork': 14421, 'upstaged': 14422, 'aiello': 14423, 'mumbles': 14424, 'violinist': 14425, 'laptops': 14426, 'tract': 14427, 'valedictorian': 14428, 'landings': 14429, 'fanatics': 14430, 'gallic': 14431, \"'tradition\": 14432, 'fusty': 14433, 'squareness': 14434, 'flabbergasting': 14435, 'macnaughton': 14436, 'wizened': 14437, 'faraway': 14438, 'hackery': 14439, 'incurious': 14440, 'gadfly': 14441, 'relegated': 14442, 'raphael': 14443, 'ineffable': 14444, 'oldie': 14445, 'disreputable': 14446, 'actorly': 14447, 'boundary': 14448, 'innovations': 14449, \"'cultural\": 14450, 'reminiscence': 14451, 'grandchildren': 14452, 'forgot': 14453, 'rejigger': 14454, 'stench': 14455, \"'been\": 14456, \"that'\": 14457, 'dexterous': 14458, 'mysticism': 14459, 'uplift': 14460, 'rez': 14461, 'splendor': 14462, 'tracker': 14463, 'breillat': 14464, 'schoolgirl': 14465, \"'is\": 14466, 'marshaling': 14467, 'feeds': 14468, 'judy': 14469, 'heimisch': 14470, 'nomadic': 14471, 'shapelessly': 14472, 'gratifying': 14473, 'ba': 14474, 'impish': 14475, 'augmentation': 14476, 'sandbox': 14477, 'analizar': 14478, 'pel': 14479, 'cula': 14480, 'separar': 14481, 'criterios': 14482, 'religioso': 14483, 'cinematogr': 14484, 'fico': 14485, 'dridi': 14486, 'crematorium': 14487, 'chimney': 14488, 'fires': 14489, 'stacks': 14490, 'undermined': 14491, 'suffocated': 14492, 'munchausen': 14493, 'proxy': 14494, 'mum': 14495, 'punish': 14496, 'adore': 14497, 'mapquest': 14498, 'emailed': 14499, 'bluntly': 14500, 'paradoxically': 14501, 'cuss': 14502, 'fx': 14503, 'franchises': 14504, 'anachronistically': 14505, 'flu': 14506, 'embraceable': 14507, 'regained': 14508, 'costumey': 14509, 'blobby': 14510, 'superlarge': 14511, 'dampens': 14512, 'demigod': 14513, 'processed': 14514, 'assimilate': 14515, 'drawers': 14516, 'marlon': 14517, 'laurence': 14518, 'participatory': 14519, 'spectator': 14520, 'scratch': 14521, 'auditorium': 14522, 'disorientated': 14523, 'refreshed': 14524, 'unceasing': 14525, 'assayas': 14526, 'reincarnation': 14527, 'elemental': 14528, 'literacy': 14529, 'inkling': 14530, 'meekly': 14531, 'wince': 14532, 'thrift': 14533, 'prosthetic': 14534, 'kmart': 14535, 'trekkie': 14536, 'surrenders': 14537, 'torments': 14538, 'giggle': 14539, 'deniro': 14540, \"'my\": 14541, 'travis': 14542, \"bickle'\": 14543, 'ethnicities': 14544, 'raindrop': 14545, 'padding': 14546, 'blur': 14547, 'sulking': 14548, 'mannerisms': 14549, 'spoofy': 14550, 'glows': 14551, 'streamlined': 14552, 'geniality': 14553, 'hades': 14554, 'kaos': 14555, 'proficiently': 14556, 'trounce': 14557, 'nicks': 14558, 'gamut': 14559, 'exalts': 14560, 'marxian': 14561, 'harmoniously': 14562, 'posits': 14563, 'heretofore': 14564, 'unfathomable': 14565, 'snaps': 14566, 'reassure': 14567, 'desplat': 14568, 'surrealist': 14569, 'exhibit': 14570, 'hyphenate': 14571, 'guessable': 14572, 'morbidity': 14573, \"'blade\": 14574, \"ii'\": 14575, 'arcana': 14576, 'savviest': 14577, 'blatantly': 14578, 'lop': 14579, 'juicily': 14580, 'fussing': 14581, 'scorns': 14582, 'serviceability': 14583, 'harmlessly': 14584, 'plucking': 14585, 'bait': 14586, 'evaded': 14587, 'outline': 14588, 'fed': 14589, 'upfront': 14590, 'linearity': 14591, 'foolish': 14592, 'kiosks': 14593, 'pinks': 14594, 'dreamy': 14595, 'feces': 14596, 'septuagenarian': 14597, 'nonagenarian': 14598, 'boldness': 14599, 'mama': 14600, 'ribald': 14601, 'alfonso': 14602, 'tryingly': 14603, 'seconds': 14604, \"helms'\": 14605, 'bolstered': 14606, 'excepting': 14607, 'weiss': 14608, 'speck': 14609, \"manns'\": 14610, 'shambles': 14611, 'touristy': 14612, 'alphabet': 14613, 'horns': 14614, 'halos': 14615, 'kraft': 14616, 'macaroni': 14617, 'rulers': 14618, 'decipherable': 14619, 'undertaken': 14620, 'backs': 14621, 'commodity': 14622, 'react': 14623, 'bestowed': 14624, 'waldo': 14625, 'bedouins': 14626, 'aptly': 14627, 'tearing': 14628, 'lugers': 14629, 'fatally': 14630, 'inhospitability': 14631, 'narratives': 14632, 'atavistic': 14633, 'amateurishness': 14634, 'illogic': 14635, 'spontaneity': 14636, 'epiphanies': 14637, 'harnessed': 14638, 'unfairly': 14639, 'fabricated': 14640, 'sausage': 14641, 'beam': 14642, 'discern': 14643, 'screenplays': 14644, 'realpolitik': 14645, 'underpinnings': 14646, 'carre': 14647, 'seoul': 14648, 'fisticuffs': 14649, 'plunge': 14650, 'thinnest': 14651, 'humanize': 14652, 'abyss': 14653, 'mainstay': 14654, 'spall': 14655, 'designated': 14656, 'goner': 14657, 'alum': 14658, 'fop': 14659, 'trembles': 14660, \"davis'\": 14661, 'archly': 14662, 'fruition': 14663, 'sophomore': 14664, 'christophe': 14665, '2455': 14666, 'messenger': 14667, 'dirk': 14668, 'callie': 14669, 'garnered': 14670, 'misconstrued': 14671, \"'terrible\": 14672, \"filmmaking'\": 14673, \"true'\": 14674, 'darkening': 14675, 'shakes': 14676, 'knickknacks': 14677, 'gibberish': 14678, 'linux': 14679, 'doughty': 14680, 'tidied': 14681, 'layered': 14682, 'vainly': 14683, 'uninterrupted': 14684, 'boggling': 14685, 'showiness': 14686, 'offsets': 14687, 'despairing': 14688, 'twinkling': 14689, 'dickensian': 14690, 'transfigures': 14691, 'unchanged': 14692, 'dullard': 14693, 'leisurely': 14694, 'reject': 14695, 'hooliganism': 14696, 'barreled': 14697, 'loaf': 14698, 'doting': 14699, 'tu': 14700, 'mam': 14701, 'tambi': 14702, 'uninhibited': 14703, 'relayed': 14704, 'skewering': 14705, 'insiders': 14706, 'outsiders': 14707, 'fiji': 14708, 'diver': 14709, 'rusi': 14710, 'vulakoro': 14711, 'brimful': 14712, 'breheny': 14713, 'lensing': 14714, 'jettisoned': 14715, 'revoked': 14716, 'jir': 14717, 'hubac': 14718, 'silberstein': 14719, 'disclosure': 14720, 'undercurrent': 14721, 'cinemantic': 14722, 'moulds': 14723, 'endeavour': 14724, 'plastered': 14725, 'reacting': 14726, 'urgently': 14727, 'gasping': 14728, 'crave': 14729, \"'brazil\": 14730, 'fluidly': 14731, 'inflame': 14732, 'flock': 14733, 'fulltime': 14734, 'snagged': 14735, \"'dramedy'\": 14736, 'desiccated': 14737, 'softest': 14738, 'revolt': 14739, 'labours': 14740, \"'estupendamente\": 14741, 'actuada': 14742, 'sumamente': 14743, 'emotiva': 14744, 'humana': 14745, 'experiencia': 14746, 'lmica': 14747, 'imposible': 14748, \"olvidar'\": 14749, 'converts': 14750, 'lifelike': 14751, 'cutout': 14752, 'reiner': 14753, 'donald': 14754, 'jonze': 14755, 'actively': 14756, 'discourage': 14757, 'monstrous': 14758, 'itinerant': 14759, 'savaged': 14760, 'liberties': 14761, 'dispossessed': 14762, 'agitprop': 14763, '106': 14764, 'rae': 14765, 'fixed': 14766, 'norrington': 14767, 'wail': 14768, 'acidity': 14769, 'rubbery': 14770, 'nationalism': 14771, 'dilutes': 14772, 'crawly': 14773, 'pascale': 14774, 'bailly': 14775, 'fabuleux': 14776, 'marketable': 14777, 'slinging': 14778, 'wai': 14779, 'fai': 14780, 'moribund': 14781, 'ois': 14782, 'mich': 14783, 'rending': 14784, 'unaffected': 14785, 'contriving': 14786, 'sidey': 14787, 'buff': 14788, 'spooks': 14789, 'prescribed': 14790, 'recommended': 14791, 'soothing': 14792, 'muzak': 14793, 'fatalism': 14794, 'larson': 14795, 'faulted': 14796, 'rumination': 14797, 'qatsi': 14798, 'brightness': 14799, 'omnipresence': 14800, 'baran': 14801, 'groen': 14802, \"'belgium\": 14803, 'pizzazz': 14804, 'procedural': 14805, 'preconceived': 14806, 'formulas': 14807, 'unbroken': 14808, '87': 14809, 'ardently': 14810, 'quickie': 14811, '82': 14812, 'architectural': 14813, 'commanding': 14814, 'middlebrow': 14815, \"'true\": 14816, 'enacted': 14817, 'unknowable': 14818, 'bashing': 14819, 'rubbo': 14820, 'ado': 14821, 'chipper': 14822, 'melted': 14823, 'astonish': 14824, 'frankly': 14825, 'coil': 14826, \"abbass'\": 14827, 'vacillates': 14828, 'flawlessly': 14829, 'hausfrau': 14830, 'hoofer': 14831, '77': 14832, 'distinguish': 14833, 'icons': 14834, 'galore': 14835, 'forehead': 14836, 'legally': 14837, 'convolutions': 14838, 'schultz': 14839, 'dehumanizing': 14840, 'strutting': 14841, 'posturing': 14842, 'inherently': 14843, 'chimes': 14844, 'compassionately': 14845, 'irreconcilable': 14846, 'aiming': 14847, 'torpedo': 14848, 'scripters': 14849, 'raked': 14850, 'stagings': 14851, 'robust': 14852, 'disgusted': 14853, 'subtitled': 14854, 'combustion': 14855, 'thump': 14856, 'cursing': 14857, 'strategically': 14858, 'sheets': 14859, 'fishes': 14860, 'reopens': 14861, \"'swept\": 14862, \"away'\": 14863, 'uncreative': 14864, 'fastballs': 14865, 'whimper': 14866, 'tats': 14867, 'alternating': 14868, 'sloppiness': 14869, 'ooze': 14870, 'slippery': 14871, 'characterisation': 14872, 'bouche': 14873, 'whetted': 14874, 'peaked': 14875, \"attraction'\": 14876, 'bopper': 14877, 'potboiler': 14878, 'cultivation': 14879, 'chirpy': 14880, 'songbird': 14881, 'popped': 14882, 'inexplicably': 14883, 'rushed': 14884, 'megaplexes': 14885, 'anthropology': 14886, 'verdu': 14887, 'mourns': 14888, 'chemically': 14889, 'teaming': 14890, 'unobtrusively': 14891, 'spotty': 14892, 'adultery': 14893, 'ants': 14894, 'arrow': 14895, \"'great\": 14896, \"hope'\": 14897, 'undertone': 14898, 'undermines': 14899, 'terrifically': 14900, 'hem': 14901, 'hems': 14902, 'justifying': 14903, 'adversity': 14904, 'yakusho': 14905, 'shimizu': 14906, 'cleanflicks': 14907, 'profanities': 14908, 'minutiae': 14909, 'stoned': 14910, 'pasadena': 14911, 'eurotrash': 14912, 'shekhar': 14913, 'schiffer': 14914, 'hossein': 14915, 'amini': 14916, 'modernize': 14917, 'reconceptualize': 14918, 'strap': 14919, 'resonantly': 14920, 'weighed': 14921, 'texan': 14922, 'unlimited': 14923, 'eggnog': 14924, 'bender': 14925, 'gra': 14926, 'intera': 14927, 'entre': 14928, 'seus': 14929, 'torna': 14930, 'curiosa': 14931, 'persegui': 14932, 'belo': 14933, 'estudo': 14934, 'underway': 14935, 'deem': 14936, 'irrigates': 14937, 'assign': 14938, 'guarantee': 14939, 'slop': 14940, 'insults': 14941, 'distills': 14942, 'mechanisms': 14943, 'transcend': 14944, 'plunging': 14945, 'squirming': 14946, 'frustrates': 14947, \"'truth'\": 14948, 'deconstructing': 14949, 'doubtless': 14950, 'sirk': 14951, 'differently': 14952, 'marlovian': 14953, 'patently': 14954, 'dramatist': 14955, 'comprise': 14956, 'gestalt': 14957, 'triteness': 14958, 'schaefer': 14959, 'eul': 14960, 'wolfish': 14961, 'mesmerizingly': 14962, 'merci': 14963, 'pour': 14964, 'chocolat': 14965, 'moat': 14966, 'contemptuous': 14967, 'remade': 14968, 'diapers': 14969, '1987': 14970, 'pb': 14971, '45': 14972, 'omits': 14973, 'swordfights': 14974, 'panoramic': 14975, 'scooping': 14976, 'plucky': 14977, 'eccentrics': 14978, 'awkwardness': 14979, 'innuendoes': 14980, 'astoria': 14981, 'musketeers': 14982, 'damning': 14983, 'crapulence': 14984, \"'small'\": 14985, 'sprecher': 14986, '1899': 14987, 'downplays': 14988, 'referring': 14989, 'hotels': 14990, 'highways': 14991, 'moan': 14992, 'entrapment': 14993, 'sanctified': 14994, 'purposeful': 14995, 'alarmed': 14996, 'wrenches': 14997, 'belinsky': 14998, 'patricio': 14999, 'portentous': 15000, 'appropriately': 15001, 'handedness': 15002, 'underachieves': 15003, 'parallels': 15004, 'haughtiness': 15005, 'overemphatic': 15006, 'trinity': 15007, 'bonanza': 15008, 'tashlin': 15009, 'recapitulation': 15010, 'dunno': 15011, 'grabs': 15012, 'rapturous': 15013, 'underlies': 15014, 'crummles': 15015, 'manoel': 15016, 'compliment': 15017, 'cirulnick': 15018, 'thulani': 15019, 'whipped': 15020, 'reservoir': 15021, 'croupier': 15022, 'mythmaking': 15023, 'hindsight': 15024, 'baja': 15025, 'expend': 15026, 'colosseum': 15027, 'shootouts': 15028, 'dutifully': 15029, 'heartstrings': 15030, 'deblois': 15031, 'sanders': 15032, 'histrionics': 15033, 'lilia': 15034, 'initiation': 15035, 'rite': 15036, 'angelique': 15037, 'guarantees': 15038, 'karmen': 15039, 'enthronement': 15040, 'hysterically': 15041, 'broadly': 15042, 'dances': 15043, 'jingles': 15044, 'nonbelievers': 15045, 'rethink': 15046, 'creed': 15047, 'skeptics': 15048, 'horas': 15049, 'obras': 15050, 'apasionamiento': 15051, 'reflexiona': 15052, 'acerca': 15053, 'hecho': 15054, 'vivir': 15055, 'intoxicatingly': 15056, 'siegal': 15057, 'spiteful': 15058, 'salvaged': 15059, 'enervated': 15060, 'baz': 15061, 'luhrmann': 15062, '401': 15063, \"cockettes'\": 15064, 'craziness': 15065, 'argentinian': 15066, 'yas': 15067, 'immortals': 15068, 'staggers': 15069, 'sleight': 15070, 'hypothesis': 15071, 'patchwork': 15072, 'begley': 15073, 'beheadings': 15074, 'crassness': 15075, 'reactionary': 15076, 'wattage': 15077, 'purported': 15078, 'pathologically': 15079, 'avenges': 15080, 'airless': 15081, 'clanging': 15082, 'mulholland': 15083, 'weeping': 15084, 'ernest': 15085, 'hemmingway': 15086, 'accelerated': 15087, 'contemptible': 15088, 'imitator': 15089, 'snl': 15090, 'channeling': 15091, 'publicists': 15092, 'cashing': 15093, 'gorgeousness': 15094, 'chemicals': 15095, 'heavyweights': 15096, 'zemeckis': 15097, 'cavorting': 15098, \"ladies'\": 15099, 'underwear': 15100, 'ridiculously': 15101, 'fab': 15102, 'meaty': 15103, 'historia': 15104, 'familia': 15105, 'lealtad': 15106, 'traici': 15107, 'seguramente': 15108, 'convertir': 15109, 'cl': 15110, 'sico': 15111, 'temptations': 15112, 'overtly': 15113, 'colorfully': 15114, 'kitschy': 15115, 'earmarks': 15116, 'enrapturing': 15117, 'tempt': 15118, 'widget': 15119, 'cranked': 15120, 'cahill': 15121, 'unexceptional': 15122, 'strategies': 15123, 'puppies': 15124, \"'de\": 15125, 'iceberg': 15126, 'melts': 15127, 'tripping': 15128, 'derails': 15129, 'textural': 15130, 'undoing': 15131, 'offense': 15132, 'winger': 15133, 'skipping': 15134, 'scrutinize': 15135, 'indefinitely': 15136, 'dungeons': 15137, 'weaponry': 15138, 'paved': 15139, 'immaculate': 15140, 'birmingham': 15141, 'bodes': 15142, 'exterior': 15143, 'gussied': 15144, 'timer': 15145, 'specificity': 15146, 'theirs': 15147, 'mirth': 15148, 'odorous': 15149, 'bundling': 15150, 'perversity': 15151, 'departments': 15152, 'unsuspenseful': 15153, 'transferral': 15154, \"movies'\": 15155, 'creeping': 15156, 'aching': 15157, 'ducts': 15158, 'etching': 15159, 'ridicule': 15160, 'triviality': 15161, 'belushi': 15162, 'likableness': 15163, 'logistical': 15164, 'crappola': 15165, 'dazzles': 15166, 'hypnotizing': 15167, 'gonads': 15168, 'subtracts': 15169, 'declarations': 15170, 'formalism': 15171, 'brushes': 15172, 'faintly': 15173, 'introspective': 15174, 's1m0ne': 15175, 'holofcenter': 15176, 'exceeds': 15177, 'woozy': 15178, 'roisterous': 15179, 'lamentations': 15180, 'inhumanity': 15181, 'factual': 15182, 'edits': 15183, 'atmospheric': 15184, 'herrmann': 15185, 'avuncular': 15186, 'chortles': 15187, 'repetitively': 15188, 'droning': 15189, 'choreography': 15190, 'jeffrey': 15191, 'searcher': 15192, 'reassuring': 15193, 'appropriated': 15194, 'turfs': 15195, 'unpleasantness': 15196, 'upload': 15197, 'minimal': 15198, 'sickness': 15199, 'appalling': 15200, 'spill': 15201, 'projector': 15202, 'bouncing': 15203, 'varmints': 15204, 'ricocheting': 15205, 'antlers': 15206, 'arbitrary': 15207, 'kendall': 15208, 'decter': 15209, 'checking': 15210, 'candle': 15211, 'respectably': 15212, 'fools': 15213, 'branched': 15214, 'copycat': 15215, 'sloppily': 15216, 'howler': 15217, 'uno': 15218, 'policiales': 15219, 'interesantes': 15220, 'ltimos': 15221, 'tiempos': 15222, 'nosedive': 15223, 'swimfan': 15224, 'inelegant': 15225, 'iliad': 15226, 'unassuageable': 15227, 'cruelty': 15228, 'norris': 15229, 'grenade': 15230, 'trenchant': 15231, 'capitalism': 15232, 'agreeable': 15233, 'wasting': 15234, 'facial': 15235, 'guided': 15236, 'flattens': 15237, 'sharpens': 15238, 'cumbersome': 15239, '3d': 15240, 'goggles': 15241, 'abundant': 15242, 'spews': 15243, 'unchecked': 15244, 'transfer': 15245, 'diminishes': 15246, 'mawkish': 15247, 'implausible': 15248, 'platonic': 15249, 'drea': 15250, 'matteo': 15251, 'stubborn': 15252, 'shawn': 15253, 'contradicts': 15254, 'aspired': 15255, 'grounding': 15256, 'diss': 15257, \"'perfection\": 15258, 'hyperbole': 15259, 'satisfyingly': 15260, 'electronic': 15261, 'anthropomorphic': 15262, 'koshashvili': 15263, 'improvement': 15264, 'poke': 15265, 'mania': 15266, 'screening': 15267, 'alarms': 15268, 'throbbing': 15269, 'propensity': 15270, 'patting': 15271, 'doubting': 15272, 'newcomers': 15273, 'yawn': 15274, 'ourside': 15275, 'pegged': 15276, \"'issues'\": 15277, 'simplify': 15278, 'invulnerable': 15279, 'playoff': 15280, 'invariably': 15281, 'greenfingers': 15282, 'thuggery': 15283, 'variable': 15284, 'footed': 15285, 'disheartening': 15286, 'refitting': 15287, 'ploddingly': 15288, 'forgoes': 15289, 'misogyny': 15290, 'koyaanisqatsi': 15291, '1988': 15292, 'powaqqatsi': 15293, 'mirage': 15294, 'projection': 15295, 'flux': 15296, 'flawless': 15297, 'romantics': 15298, 'splat': 15299, 'catalytic': 15300, 'greengrass': 15301, 'undoubted': 15302, 'worthless': 15303, 'aground': 15304, 'snared': 15305, 'laborious': 15306, 'tightened': 15307, 'batch': 15308, 'swamped': 15309, 'unadulterated': 15310, 'civility': 15311, 'marvels': 15312, 'scintillating': 15313, 'competence': 15314, 'latifah': 15315, \"singin'\": 15316, \"dancin'\": 15317, 'aisles': 15318, 'pumps': 15319, 'stereotyped': 15320, 'presumption': 15321, 'standouts': 15322, 'wisegirls': 15323, 'tardier': 15324, 'novelty': 15325, 'webcast': 15326, 'yacht': 15327, 'setpiece': 15328, 'unselfconscious': 15329, 'munch': 15330, 'pampering': 15331, \"'girlfriend'\": 15332, 'wertmuller': 15333, 'defeatingly': 15334, 'decorous': 15335, \"snipes'\": 15336, 'iconic': 15337, 'praised': 15338, 'underarm': 15339, 'mst3k': 15340, 'fooey': 15341, 'supplied': 15342, 'epps': 15343, 'redeemed': 15344, 'lazier': 15345, 'adrian': 15346, 'lyne': 15347, 'erotics': 15348, 'unfree': 15349, 'atmospherics': 15350, 'abrasive': 15351, 'unentertaining': 15352, 'piss': 15353, 'knuckled': 15354, 'talkiness': 15355, 'lizt': 15356, 'requiem': 15357, 'sleepwalk': 15358, 'vulgarities': 15359, 'generous': 15360, 'armpit': 15361, 'blob': 15362, 'iditarod': 15363, 'gauls': 15364, 'definitions': 15365, \"'time\": 15366, \"waster'\": 15367, 'frosting': 15368, 'fictions': 15369, 'peddled': 15370, \"'have\": 15371, \"holocaust'\": 15372, 'jakob': 15373, \"'best\": 15374, \"picture'\": 15375, 'landau': 15376, 'janklowicz': 15377, 'cineasta': 15378, 'entender': 15379, 'todo': 15380, 'seguir': 15381, 'esperando': 15382, 'scatological': 15383, 'virtuosic': 15384, 'earnestly': 15385, 'busting': 15386, 'spunk': 15387, 'register': 15388, 'stave': 15389, 'eminently': 15390, 'eroticized': 15391, 'frissons': 15392, 'petter': 15393, \"ss'\": 15394, 'axel': 15395, 'hellstenius': 15396, 'laziness': 15397, 'veljohnson': 15398, 'loosens': 15399, 'proportion': 15400, 'generosity': 15401, 'meanness': 15402, 'plentiful': 15403, 'flinch': 15404, 'snowball': 15405, \"'like\": 15406, \"skins'\": 15407, 'unengaging': 15408, 'sequins': 15409, 'flashbulbs': 15410, 'blaring': 15411, 'stabbing': 15412, 'careworn': 15413, 'exemplary': 15414, 'itis': 15415, 'inconceivable': 15416, 'reheated': 15417, 'debuts': 15418, 'avalanches': 15419, 'fuzziness': 15420, 'serpico': 15421, 'stripes': 15422, 'lisping': 15423, 'reptilian': 15424, 'bask': 15425, 'investing': 15426, 'emi': 15427, 'malfitano': 15428, 'domingo': 15429, 'knockoff': 15430, 'grader': 15431, 'delayed': 15432, 'scorcese': 15433, 'brow': 15434, \"'truth\": 15435, 'interchangeable': 15436, 'imbecilic': 15437, 'toolbags': 15438, 'botching': 15439, 'backwater': 15440, 'porridge': 15441, 'chewy': 15442, 'odour': 15443, 'expiry': 15444, 'draggy': 15445, \"'alternate\": 15446, \"reality'\": 15447, 'uzumaki': 15448, 'prostituted': 15449, 'muse': 15450, 'ruinous': 15451, 'anspaugh': 15452, 'lukewarm': 15453, 'injecting': 15454, 'truckload': 15455, 'dirtier': 15456, 'girlie': 15457, 'verisimilitude': 15458, 'derive': 15459, 'gymnastics': 15460, 'nonpatronizing': 15461, 'punchline': 15462, 'snide': 15463, 'emotively': 15464, 'overstuffed': 15465, 'indicate': 15466, 'shed': 15467, 'comparatively': 15468, 'suffocating': 15469, 'compensates': 15470, 'trippy': 15471, 'gymnast': 15472, 'embellishing': 15473, '89': 15474, 'splatterfests': 15475, 'user': 15476, 'harks': 15477, 'picpus': 15478, 'blisteringly': 15479, 'scarily': 15480, 'sorrowfully': 15481, 'surveys': 15482, 'kieran': 15483, 'contorting': 15484, 'derailed': 15485, 'males': 15486, 'chai': 15487, 'forewarned': 15488, 'drown': 15489, 'celebratory': 15490, 'soppy': 15491, 'algiers': 15492, 'powerfully': 15493, 'crux': 15494, 'technicality': 15495, 'credulity': 15496, 'gratingly': 15497, 'groaner': 15498, 'setups': 15499, 'goodies': 15500, 'lumps': 15501, 'viewpoints': 15502, 'toasts': 15503, 'testimonial': 15504, \"programs'\": 15505, 'slickness': 15506, 'desplechin': 15507, 'morass': 15508, 'balto': 15509, 'justification': 15510, 'arwen': 15511, 'pryor': 15512, 'fewer': 15513, 'boffo': 15514, 'mick': 15515, 'imitations': 15516, 'subsided': 15517, 'anytime': 15518, 'gregory': 15519, 'viewpoint': 15520, 'concealment': 15521, 'fortunately': 15522, \"stevens'\": 15523, 'keenly': 15524, 'uncontrolled': 15525, 'tickets': 15526, 'zaza': 15527, 'judith': 15528, 'asinine': 15529, \"'twist'\": 15530, 'brazenly': 15531, 'rips': 15532, 'captivates': 15533, 'bludgeoning': 15534, 'papin': 15535, 'infamy': 15536, 'toned': 15537, 'ripping': 15538, \"meyjes'\": 15539, 'haphazardness': 15540, 'hallelujah': 15541, 'mods': 15542, 'rockers': 15543, 'stealer': 15544, 'valuing': 15545, 'changer': 15546, 'evaluation': 15547, 'abundance': 15548, 'mindsets': 15549, 'igloo': 15550, 'tundra': 15551, 'inuit': 15552, 'specimen': 15553, 'dread': 15554, 'encountering': 15555, 'fanboy': 15556, 'comfortably': 15557, 'ratner': 15558, 'tenuous': 15559, 'anchor': 15560, 'purport': 15561, 'span': 15562, '125': 15563, 'grabbing': 15564, 'unders': 15565, 'caddyshack': 15566, 'loopholes': 15567, 'fertility': 15568, 'rivals': 15569, 'animations': 15570, 'fuelled': 15571, '007': 15572, 'seductiveness': 15573, 'viability': 15574, 'wider': 15575, 'mychael': 15576, 'danna': 15577, 'starship': 15578, 'heartedness': 15579, 'benchmark': 15580, 'chao': 15581, 'chen': 15582, 'kaige': 15583, 'learnt': 15584, 'homeboy': 15585, 'dogma': 15586, 'naturalness': 15587, \"'blue\": 15588, \"crush'\": 15589, \"'butterfingered'\": 15590, 'jez': 15591, 'butterworth': 15592, 'clamorous': 15593, \"viewers'\": 15594, 'pimental': 15595, 'feminized': 15596, 'rendition': 15597, 'steaming': 15598, 'heaps': 15599, 'boomer': 15600, 'confusions': 15601, \"brooks'\": 15602, 'borscht': 15603, 'schtick': 15604, 'mikes': 15605, \"slackers'\": 15606, 'unforgettably': 15607, 'uproariously': 15608, 'dismissive': 15609, 'upscale': 15610, 'licking': 15611, 'scrapping': 15612, 'doggedness': 15613, 'transmute': 15614, 'patchy': 15615, 'prankish': 15616, 'youngster': 15617, 'zingers': 15618, 'brady': 15619, 'prosaic': 15620, 'polemic': 15621, 'subtext': 15622, 'discordant': 15623, 'topple': 15624, 'lovebirds': 15625, 'unappealing': 15626, 'minimally': 15627, 'patrolmen': 15628, 'aristocrats': 15629, 'hennings': 15630, 'suge': 15631, \"'some\": 15632, \"body'\": 15633, 'continuation': 15634, 'tere': 15635, 'schizoid': 15636, 'dilute': 15637, 'guillen': 15638, 'appreciating': 15639, 'multimillion': 15640, 'slam': 15641, 'superheroics': 15642, 'antsy': 15643, 'opts': 15644, 'dimwitted': 15645, 'dimmer': 15646, 'vehicles': 15647, 'fluent': 15648, 'erotically': 15649, 'dullingly': 15650, \"'who\": 15651, 'softens': 15652, 'democracy': 15653, 'unaccustomed': 15654, 'seacoast': 15655, 'inclination': 15656, 'tunisian': 15657, 'updates': 15658, 'ribcage': 15659, 'encanta': 15660, \"'o\": 15661, 'rei': 15662, \"o'\": 15663, 'nem': 15664, 'diverte': 15665, 'nova': 15666, 'onda': 15667, \"imperador'\": 15668, 'menos': 15669, 'cansa': 15670, \"'atlantis\": 15671, 'reino': 15672, \"perdido'\": 15673, 'hateful': 15674, 'bottomlessly': 15675, 'quasi': 15676, 'darin': 15677, 'beard': 15678, 'implausibility': 15679, 'sags': 15680, 'courageousness': 15681, 'pastry': 15682, 'violated': 15683, 'fests': 15684, 'farts': 15685, 'boobs': 15686, 'unmentionables': 15687, '1955': 15688, 'decrepitude': 15689, 'converted': 15690, 'gonzo': 15691, 'humorist': 15692, 'syrup': 15693, 'pancakes': 15694, 'aftertaste': 15695, 'operational': 15696, 'curls': 15697, 'hushed': 15698, 'reeling': 15699, 'speechless': 15700, 'adjectives': 15701, 'patronized': 15702, 'watstein': 15703, 'hazy': 15704, 'soiree': 15705, 'morsels': 15706, 'spittingly': 15707, 'simmering': 15708, 'buildup': 15709, 'laugther': 15710, 'cascade': 15711, 'autobiographical': 15712, 'centering': 15713, 'specialized': 15714, 'dominatrixes': 15715, 'goldie': 15716, 'pedigree': 15717, 'skippable': 15718, 'hayseeds': 15719, 'greaseballs': 15720, 'wanna': 15721, 'treatise': 15722, 'sprinkled': 15723, 'ranges': 15724, 'bodacious': 15725, 'teamwork': 15726, 'feeder': 15727, 'malleable': 15728, 'djs': 15729, 'uninterested': 15730, 'bespeaks': 15731, 'hastier': 15732, 'gheorgiu': 15733, 'stare': 15734, 'raimondi': 15735, 'blazes': 15736, 'asiaphiles': 15737, 'crackerjack': 15738, 'frights': 15739, 'whodunit': 15740, \"glass'\": 15741, 'divining': 15742, 'universally': 15743, 'trickery': 15744, 'rhapsodize': 15745, 'dirgelike': 15746, 'fang': 15747, 'baring': 15748, 'lullaby': 15749, 'numbs': 15750, 'inferior': 15751, 'calorie': 15752, 'pretentiously': 15753, 'croissant': 15754, 'reduction': 15755, 'iwai': 15756, 'yuichi': 15757, 'disembodied': 15758, 'raft': 15759, 'shamu': 15760, 'rumblings': 15761, 'buildings': 15762, 'unexamined': 15763, 'startlingly': 15764, 'sprechers': 15765, 'coax': 15766, 'nakata': 15767, 'imply': 15768, 'overuse': 15769, 'unsubtle': 15770, 'travail': 15771, 'scherick': 15772, 'ronn': 15773, 'hudlin': 15774, 'fitfully': 15775, 'pants': 15776, 'tits': 15777, '1873': 15778, 'stubbly': 15779, 'chins': 15780, 'bobbed': 15781, 'unimpressively': 15782, 'fussy': 15783, 'lasker': 15784, 'distances': 15785, 'byron': 15786, 'luther': 15787, 'crowdpleaser': 15788, 'sneakers': 15789, 'divergent': 15790, 'mewling': 15791, 'kitten': 15792, 'rebounds': 15793, 'ok': 15794, 'siuation': 15795, 'swathe': 15796, 'retaining': 15797, 'fincher': 15798, 'revisited': 15799, 'arteta': 15800, 'squalor': 15801, 'brainless': 15802, 'bubbly': 15803, 'strafings': 15804, '1980s': 15805, 'misfortune': 15806, 'plummets': 15807, 'glizty': 15808, 'cagney': 15809, \"'top\": 15810, 'revision': 15811, 'toddler': 15812, 'lumpy': 15813, 'unharmed': 15814, 'spellbinding': 15815, 'rootlessness': 15816, 'lumpish': 15817, 'cipher': 15818, 'arising': 15819, 'occupational': 15820, 'reinvention': 15821, 'labyrinthine': 15822, \"'special\": 15823, \"effects'\": 15824, 'replacing': 15825, 'misbegotten': 15826, 'flails': 15827, 'limply': 15828, 'pallid': 15829, 'microscope': 15830, 'flung': 15831, 'elicited': 15832, 'sympathies': 15833, 'errs': 15834, 'gentility': 15835, 'gilliam': 15836, 'rudimentary': 15837, 'drawings': 15838, 'reeboir': 15839, 'varies': 15840, 'pupils': 15841, 'kurds': 15842, 'wore': 15843, 'morrissey': 15844, 'arnon': 15845, 'goldfinger': 15846, 'komediant': 15847, 'flinching': 15848, 'cries': 15849, 'skyscraper': 15850, 'trapeze': 15851, 'briskly': 15852, 'waltz': 15853, 'tug': 15854, 'passionless': 15855, 'arrangement': 15856, 'shudder': 15857, 'improbabilities': 15858, 'impacting': 15859, 'impressionistic': 15860, 'grin': 15861, 'soured': 15862, 'icky': 15863, 'condundrum': 15864, 'simulation': 15865, 'birkenau': 15866, 'moist': 15867, 'exploratory': 15868, 'anecdotal': 15869, 'versa': 15870, 'snobbery': 15871, 'satiric': 15872, 'diversions': 15873, 'recapturing': 15874, 'tarkovsky': 15875, 'emotionless': 15876, 'blazingly': 15877, 'stripe': 15878, 'fluke': 15879, 'classification': 15880, 'sickest': 15881, 'relevancy': 15882, 'yawp': 15883, 'grains': 15884, 'flickering': 15885, 'perfunctory': 15886, 'neorealism': 15887, 'gob': 15888, 'consumers': 15889, 'pasteurized': 15890, 'ditties': 15891, 'retch': 15892, 'br': 15893, 'hare': 15894, 'cunningham': 15895, 'forwards': 15896, 'tuba': 15897, 'whacking': 15898, 'timo': 15899, 'esfor': 15900, 'diretor': 15901, 'acaba': 15902, 'sendo': 15903, 'frustrado': 15904, 'roteiro': 15905, 'depois': 15906, 'levar': 15907, 'bom': 15908, 'colocar': 15909, 'trama': 15910, 'andamento': 15911, 'perde': 15912, 'partir': 15913, 'instante': 15914, 'estranhos': 15915, 'acontecimentos': 15916, 'explicados': 15917, 'pulpiness': 15918, 'minac': 15919, 'drains': 15920, 'saps': 15921, 'actioners': 15922, 'schmucks': 15923, 'affectingly': 15924, 'seizing': 15925, 'haplessness': 15926, 'precedent': 15927, 'clamor': 15928, 'plainly': 15929, 'unwatchable': 15930, 'unlistenable': 15931, \"'romantic\": 15932, 'wrapping': 15933, 'blanket': 15934, 'absorb': 15935, 'aggrieved': 15936, 'unturned': 15937, 'counted': 15938, 'preliminary': 15939, 'agendas': 15940, 'decisive': 15941, 'implodes': 15942, 'copyof': 15943, 'obscenely': 15944, 'scummy': 15945, 'ripoff': 15946, \"'videodrome\": 15947, 'lynne': 15948, 'traffics': 15949, 'prechewed': 15950, 'typecasting': 15951, 'kathie': 15952, 'gifford': 15953, 'proving': 15954, 'trod': 15955, 'shrapnel': 15956, 'shellshock': 15957, 'hamstrung': 15958, 'wearer': 15959, 'superman': 15960, 'jarvis': 15961, 'coolidge': 15962, 'yielded': 15963, 'bestows': 15964, 'generously': 15965, 'apolitically': 15966, 'ia': 15967, 'drang': 15968, 'pierre': 15969, 'affirmation': 15970, 'candor': 15971, \"'bold'\": 15972, 'wilt': 15973, 'twisting': 15974, 'jolting': 15975, 'wen': 15976, 'thoughtfully': 15977, 'requisite': 15978, 'hotter': 15979, \"'woods'\": 15980, 'bolly': 15981, 'masala': 15982, 'lately': 15983, 'junctures': 15984, 'captivatingly': 15985, 'sunbaked': 15986, 'summery': 15987, 'slides': 15988, 'downhill': 15989, 'macho': 15990, 'assert': 15991, \"giants'\": 15992, 'tuneless': 15993, 'reconsideration': 15994, 'fountainheads': 15995, 'devilishly': 15996, 'mcgowan': 15997, 'niels': 15998, 'mueller': 15999, 'insightfully': 16000, 'poetically': 16001, 'plump': 16002, 'fulsome': 16003, 'reinforced': 16004, 'personified': 16005, 'kuras': 16006, 'hooting': 16007, 'conversion': 16008, \"jesus'\": 16009, 'bart': 16010, 'shabby': 16011, 'piles': 16012, 'atop': 16013, 'peculiarly': 16014, 'amorality': 16015, \"'amateur'\": 16016, 'beside': 16017, 'musketeer': 16018, 'entertains': 16019, 'microwaves': 16020, 'leftover': 16021, 'basted': 16022, 'gravy': 16023, 'disagree': 16024, 'rorschach': 16025, 'rymer': 16026, 'mazel': 16027, 'tov': 16028, 'boomers': 16029, 'shear': 16030, 'baaaaaaaaad': 16031, 'musclefest': 16032, 'railing': 16033, 'echelons': 16034, 'eisenberg': 16035, 'dodger': 16036, 'helpings': 16037, 'ceremonies': 16038, 'cotswolds': 16039, 'verges': 16040, 'roughshod': 16041, 'workable': 16042, 'primer': 16043, 'brazen': 16044, 'stinker': 16045, 'wanker': 16046, 'goths': 16047, 'quelle': 16048, 'hews': 16049, 'clashes': 16050, 'dismantle': 16051, 'facades': 16052, 'wonderous': 16053, 'veracity': 16054, \"gossels'\": 16055, 'chabannes': 16056, 'hollowness': 16057, 'marvelously': 16058, 'restrictive': 16059, 'spicy': 16060, 'substitutes': 16061, 'practitioners': 16062, 'vainglorious': 16063, 'pistoled': 16064, 'pyrotechnic': 16065, 'staggeringly': 16066, 'cranky': 16067, 'improvisational': 16068, 'noodling': 16069, 'intently': 16070, 'michener': 16071, 'simpler': 16072, 'enveloped': 16073, 'magnificently': 16074, 'insignificant': 16075, 'fererra': 16076, 'symmetry': 16077, 'fuller': 16078, 'exigencies': 16079, 'greasy': 16080, 'vidgame': 16081, 'lobby': 16082, 'participation': 16083, 'tnt': 16084, 'imagining': 16085, 'postmodern': 16086, 'sardine': 16087, 'subgenre': 16088, 'libertine': 16089, 'agitator': 16090, 'finery': 16091, 'deflated': 16092, 'aaa': 16093, 'adrenalin': 16094, 'eee': 16095, 'attacking': 16096, 'balletic': 16097, 'implies': 16098, \"'hungry\": 16099, \"bad'\": 16100, 'switching': 16101, 'foundering': 16102, 'athleticism': 16103, 'contradictions': 16104, 'tyco': 16105, 'misgivings': 16106, 'drinker': 16107, 'leniency': 16108, 'tissue': 16109, 'truest': 16110, 'innuendo': 16111, 'fil': 16112, 'whaley': 16113, 'clarify': 16114, 'trickster': 16115, 'playstation': 16116, 'drizzle': 16117, 'rainwear': 16118, 'winningly': 16119, 'porthole': 16120, 'imprint': 16121, 'pickup': 16122, 'tactfully': 16123, 'pretended': 16124, 'palatable': 16125, 'unhibited': 16126, 'suffused': 16127, 'soaringly': 16128, 'hoops': 16129, 'sandwiched': 16130, 'pentecostal': 16131, 'fairness': 16132, 'churchgoers': 16133, 'christlike': 16134, 'tighter': 16135, 'hush': 16136, 'sympathetically': 16137, 'futile': 16138, 'breen': 16139, 'ecstatic': 16140, 'costner': 16141, 'sanctimonious': 16142, 'balding': 16143, 'carved': 16144, 'distributors': 16145, 'dives': 16146, 'soapy': 16147, 'traps': 16148, 'machismo': 16149, 'deconstructionist': 16150, 'theorizing': 16151, 'jacques': 16152, 'arrangements': 16153, 'clenching': 16154, 'daringly': 16155, 'biggie': 16156, 'tupac': 16157, 'spinal': 16158, 'nonthreatening': 16159, \"'dragon'\": 16160, 'reflected': 16161, 'dulling': 16162, 'upsetting': 16163, 'souvenir': 16164, 'insubstantial': 16165, 'invokes': 16166, 'acerbically': 16167, 'gracious': 16168, 'congrats': 16169, 'statecraft': 16170, 'dependence': 16171, 'imperious': 16172, 'katzenberg': 16173, 'stalling': 16174, 'jugular': 16175, 'pupil': 16176, 'ingmar': 16177, 'nutty': 16178, 'ferzan': 16179, 'porky': 16180, 'edition': 16181, \"'life'\": 16182, 'authentically': 16183, 'pandemonium': 16184, 'expressionism': 16185, 'minimalism': 16186, 'constructivism': 16187, 'secured': 16188, 'spurning': 16189, 'excentricities': 16190, 'gertrude': 16191, 'wool': 16192, 'sexiness': 16193, 'poach': 16194, 'vestige': 16195, 'icevan': 16196, 'biblical': 16197, 'punishments': 16198, 'stoning': 16199, 'decapitation': 16200, 'waiter': 16201, 'craved': 16202, 'coeds': 16203, 'grandmothers': 16204, 'lesbians': 16205, 'neglecting': 16206, 'carping': 16207, 'bobbi': 16208, 'margaret': 16209, 'ortega': 16210, 'nglio': 16211, 'rejecting': 16212, \"'bloody\": 16213, \"magic'\": 16214, 'toyo': 16215, 'impermanence': 16216, 'lapp': 16217, 'encroachment': 16218, \"knowles'\": 16219, 'entomologist': 16220, 'melding': 16221, 'subjectivity': 16222, 'beatle': 16223, '1974': 16224, 'deathbed': 16225, 'orderly': 16226, 'mcguire': 16227, 'riccola': 16228, 'debauchery': 16229, 'humiliates': 16230, 'architects': 16231, 'employing': 16232, 'mutiple': 16233, 'matsumoto': 16234, 'sawako': 16235, 'ossie': 16236, 'codgers': 16237, 'doqa': 16238, 'bisects': 16239, 'nevertherless': 16240, 'advises': 16241, 'overtaken': 16242, 'blizzard': 16243, 'ominous': 16244, 'roadside': 16245, 'represses': 16246, \"o'bannon\": 16247, 'witchery': 16248, 'malevolent': 16249, 'scriptwriter': 16250, 'imelda': 16251, 'informants': 16252, 'aki': 16253, 'kaurism': 16254, '228': 16255, 'helsinki': 16256, 'laying': 16257, 'coddled': 16258, 'cord': 16259, 'forges': 16260, 'garmento': 16261, 'wholesale': 16262, 'garment': 16263, 'prerequisite': 16264, 'yellowshirt': 16265, 'journeying': 16266, 'pulaski': 16267, 'tensely': 16268, 'therapist': 16269, 'breakers': 16270, 'ld': 16271, 'samia': 16272, 'instinctive': 16273, 'immune': 16274, \"miles'\": 16275, \"springs'\": 16276, \"parties'\": 16277, 'repeats': 16278, 'freeing': 16279, 'posh': 16280, 'attracting': 16281, 'lexi': 16282, 'deserters': 16283, 'barracks': 16284, 'martialed': 16285, 'acquittal': 16286, 'wracked': 16287, 'serpent': 16288, 'snoop': 16289, 'ecology': 16290, 'bevy': 16291, 'adoring': 16292, 'manchester': 16293, 'pending': 16294, 'cauught': 16295, 'gruop': 16296, '68': 16297, 'raakhee': 16298, 'songwriting': 16299, 'imported': 16300, 'bury': 16301, 'repercussions': 16302, 'messed': 16303, 'overgrown': 16304, 'grouchy': 16305, 'scriptures': 16306, 'shotgun': 16307, 'software': 16308, 'gammasphere': 16309, \"hulk'\": 16310, 'mutates': 16311, 'triggered': 16312, 'ulises': 16313, 'endeavoring': 16314, 'insistently': 16315, 'quatermain': 16316, 'fantom': 16317, 'segal': 16318, 'revisits': 16319, 'paaji': 16320, 'sardarji': 16321, 'distributing': 16322, 'lavishly': 16323, 'geyrhalter': 16324, 'travelled': 16325, 'untouched': 16326, 'kannas': 16327, 'isolating': 16328, 'preventing': 16329, 'nameless': 16330, 'carly': 16331, '244': 16332, 'vo': 16333, 'cine': 16334, 'revolucionario': 16335, 'rainbow': 16336, 'puffy': 16337, 'fuscia': 16338, 'barbossa': 16339, 'temperaments': 16340, 'eater': 16341, 'furmann': 16342, 'absolution': 16343, 'rites': 16344, 'jurisdiction': 16345, 'exec': 16346, 'lathan': 16347, \"companies'\": 16348, 'ceos': 16349, 'attorneys': 16350, 'mediation': 16351, 'ignor': 16352, '15m': 16353, 'energico': 16354, 'intolerance': 16355, 'intermingle': 16356, 'email': 16357, 'brubeck': 16358, 'datuk': 16359, 'azmi': 16360, 'averted': 16361, \"'perfect\": 16362, \"guy'\": 16363, 'invested': 16364, 'overhears': 16365, 'fee': 16366, 'winburn': 16367, 'hoodlum': 16368, 'paramour': 16369, 'mi5': 16370, 'unshaven': 16371, 'trotsky': 16372, 'ushi': 16373, 'pol': 16374, 'baggers': 16375, 'infected': 16376, 'dwarves': 16377, 'spheres': 16378, 'barrier': 16379, 'delinquents': 16380, 'organizers': 16381, 'harvey': 16382, 'crimson': 16383, 'solstice': 16384, 'sanjuanera': 16385, \"'smersh'\": 16386, 'ostensibly': 16387, 'completes': 16388, 'eternity': 16389, 'rockies': 16390, 'accelerates': 16391, 'stepbrother': 16392, 'prosper': 16393, 'philosophies': 16394, 'confucianism': 16395, 'taoism': 16396, 'suntzu': 16397, 'mutilated': 16398, 'inroads': 16399, 'sra': 16400, \"'portals'\": 16401, 'hopefuls': 16402, 'abandoning': 16403, 'ravaging': 16404, 'drought': 16405, 'sanjay': 16406, 'dutt': 16407, 'godmother': 16408, 'grants': 16409, 'sergent': 16410, 'infidel': 16411, 'complacent': 16412, 'unexciting': 16413, 'troop': 16414, 'ironical': 16415, 'dyed': 16416, 'trill': 16417, 'iraq': 16418, 'kurd': 16419, 'valentines': 16420, 'sweets': 16421, 'currency': 16422, 'donuts': 16423, 'rallye': 16424, 'natascha': 16425, 'wicker': 16426, 'greenwich': 16427, 'leviticus': 16428, 'detects': 16429, 'matching': 16430, 'swore': 16431, 'unborn': 16432, 'cronin': 16433, 'cowboy': 16434, 'distractions': 16435, 'existent': 16436, 'alternates': 16437, 'daly': 16438, 'jeffries': 16439, 'nunez': 16440, 'reigning': 16441, \"'bad\": 16442, \"boy'\": 16443, 'undisciplined': 16444, 'seekers': 16445, 'cosy': 16446, 'mist': 16447, 'mondern': 16448, 'frontiersman': 16449, 'elise': 16450, 'sighting': 16451, 'personals': 16452, 'summers': 16453, 'eigenberg': 16454, 'voldemort': 16455, 'corroborates': 16456, 'miffed': 16457, 'backfire': 16458, 'wert': 16459, 'beatty': 16460, 'spaniard': 16461, 'britanny': 16462, 'brachman': 16463, 'assessor': 16464, 'rotterdam': 16465, \"'sinker'\": 16466, 'orgasmic': 16467, 'cull': 16468, 'hauntingly': 16469, 'hypnotherapist': 16470, 'strother': 16471, 'partnered': 16472, 'sistah': 16473, 'adjustment': 16474, \"'fro\": 16475, 'platforms': 16476, 'tennis': 16477, 'sweaters': 16478, 'loafers': 16479, 'container': 16480, 'tearjerkers': 16481, 'kurdish': 16482, 'midtown': 16483, 'hi': 16484, 'bannister': 16485, 'divisions': 16486, 'sociologists': 16487, 'psychologists': 16488, 'kickboxers': 16489, 'urquidez': 16490, 'superfoot': 16491, 'pinta': 16492, 'balletto': 16493, 'rash': 16494, 'kidnappings': 16495, '120': 16496, 'sonogram': 16497, 'minipulates': 16498, \"'good\": 16499, \"girl'\": 16500, 'murderess': 16501, 'selma': 16502, 'unlived': 16503, 'nashville': 16504, 'floods': 16505, 'plumbers': 16506, 'grades': 16507, 'amoral': 16508, 'blond': 16509, 'nsa': 16510, 'stepsister': 16511, 'jhangiani': 16512, 'spang': 16513, 'initiated': 16514, 'abide': 16515, 'cardinal': 16516, 'pretense': 16517, 'conducting': 16518, 'housesit': 16519, 'heroines': 16520, 'culton': 16521, 'saenz': 16522, 'tabor': 16523, 'mation': 16524, 'prof': 16525, 'nightcrawler': 16526, 'clycops': 16527, 'fold': 16528, 'grinding': 16529, 'forsake': 16530, 'sho': 16531, 'associates': 16532, 'ansers': 16533, 'finality': 16534, 'terminate': 16535, 'memorialized': 16536, 'inventories': 16537, 'histories': 16538, 'surgeries': 16539, 'transplanted': 16540, 'growth': 16541, 'jackets': 16542, 'tenures': 16543, 'medda': 16544, 'delays': 16545, 'malediction': 16546, 'despises': 16547, 'transvestites': 16548, 'toilets': 16549, 'drinkers': 16550, 'genitalia': 16551, 'humilate': 16552, 'malaysian': 16553, 'sunken': 16554, 'mendam': 16555, 'berahi': 16556, 'sulu': 16557, 'gruelling': 16558, 'haywire': 16559, 'favours': 16560, 'subsidize': 16561, 'giros': 16562, 'thine': 16563, 'brownstone': 16564, 'cache': 16565, 'schoolteacher': 16566, 'functionaries': 16567, 'whisky': 16568, 'barstow': 16569, 'hallucinating': 16570, 'vitti': 16571, 'kingpins': 16572, 'airplay': 16573, 'swanson': 16574, 'mastered': 16575, 'naples': 16576, 'cobb': 16577, 'clutter': 16578, 'marketer': 16579, 'motorists': 16580, 'hynde': 16581, 'shannyn': 16582, '34': 16583, 'geneviere': 16584, 'baggins': 16585, 'elijah': 16586, 'samwise': 16587, 'gamgee': 16588, 'astin': 16589, 'dominic': 16590, 'monaghan': 16591, 'viggo': 16592, 'mortensen': 16593, 'rhys': 16594, 'oden': 16595, 'maenwhile': 16596, 'emmanuel': 16597, \"'mendy'\": 16598, 'ripstein': 16599, 'passionada': 16600, 'bedford': 16601, 'jewelry': 16602, 'solved': 16603, 'popstar': 16604, 'consisted': 16605, 'hosting': 16606, 'autographs': 16607, 'drivers': 16608, 'junkies': 16609, 'psychopathic': 16610, 'lamberti': 16611, 'critic': 16612, 'quantum': 16613, \"'brass\": 16614, \"tacks'\": 16615, 'braving': 16616, '73': 16617, 'unfriendly': 16618, 'roland': 16619, 'bailey': 16620, 'stepfather': 16621, 'stepson': 16622, 'dow': 16623, 'siapa': 16624, 'participates': 16625, 'evolved': 16626, 'unalterably': 16627, 'embittered': 16628, 'ashore': 16629, 'naively': 16630, 'muddles': 16631, 'orbiting': 16632, 'stahl': 16633, 'hacker': 16634, 'louisiana': 16635, 'mistreated': 16636, 'nutburger': 16637, 'sappho': 16638, 'technics': 16639, 'jocks': 16640, 'dent': 16641, 'kitty': 16642, 'superhuman': 16643, 'sharpness': 16644, 'empiezan': 16645, 'cuando': 16646, 'bigardo': 16647, 'presentador': 16648, 'televisi': 16649, 'audiencia': 16650, 'convertirlo': 16651, 'dolo': 16652, 'arise': 16653, 'superstars': 16654, 'konishiki': 16655, 'takamiyama': 16656, 'kuhaulua': 16657, 'akebono': 16658, 'exalted': 16659, 'yokozuna': 16660, 'oakes': 16661, 'hayes': 16662, 'proponents': 16663, 'postgrad': 16664, 'strays': 16665, 'riker': 16666, 'troi': 16667, 'neutral': 16668, 'romulan': 16669, 'prototypic': 16670, 'info': 16671, 'unflattering': 16672, 'tumble': 16673, 'wastelands': 16674, 'kos': 16675, 'andr': 16676, 'sensing': 16677, 'risked': 16678, 'acquitted': 16679, 'manslaughter': 16680, 'overseeing': 16681, 'runners': 16682, 'logically': 16683, 'betraying': 16684, 'installations': 16685, 'excluded': 16686, 'dj': 16687, 'perfume': 16688, 'peruvian': 16689, \"robberies'\": 16690, 'gonz': 16691, 'motorcyclists': 16692, 'unheralded': 16693, 'sanitarian': 16694, 'oswaldo': 16695, 'pasteur': 16696, 'supermodels': 16697, 'vomited': 16698, 'anton': 16699, 'brotherhood': 16700, 'updated': 16701, \"'night\": 16702, 'garrick': 16703, 'boarders': 16704, 'merge': 16705, 'mic': 16706, 'infrared': 16707, 'squander': 16708, 'conduit': 16709, 'puzzled': 16710, 'landlord': 16711, 'marc': 16712, 'blucas': 16713, 'wheelchair': 16714, 'franticly': 16715, 'widespread': 16716, 'woolf': 16717, 'strider': 16718, 'riders': 16719, 'stewards': 16720, '1870': 16721, 'blount': 16722, 'stockpile': 16723, 'listens': 16724, 'trunk': 16725, 'belonging': 16726, 'henshall': 16727, 'interfered': 16728, 'sonya': 16729, 'bosnian': 16730, 'berdan': 16731, 'undignified': 16732, 'glenn': 16733, 'emancipated': 16734, 'elected': 16735, 'suggested': 16736, 'whereas': 16737, 'firepower': 16738, 'neuro': 16739, 'introvert': 16740, 'ooty': 16741, 'egoists': 16742, 'bookshop': 16743, 'pulsa': 16744, '231': 16745, 'euthanasia': 16746, 'naxalisam': 16747, 'thursday': 16748, 'disagreements': 16749, 'incensed': 16750, 'copper': 16751, 'incestuous': 16752, \"jones'\": 16753, 'yhf': 16754, 'departing': 16755, 'reprise': 16756, 'motherless': 16757, 'wilbur': 16758, 'skagerrak': 16759, 'belive': 16760, 'flirt': 16761, 'fuses': 16762, 'exacting': 16763, 'leire': 16764, 'maricarmen': 16765, 'mbbs': 16766, 'loosing': 16767, 'pitfall': 16768, 'accounting': 16769, 'capadice': 16770, 'accuses': 16771, 'embezzelment': 16772, 'mustafa': 16773, 'hassam': 16774, 'illegitimate': 16775, 'andres': 16776, 'johannesburg': 16777, 'apartheid': 16778, 'uninvited': 16779, 'profligate': 16780, 'molded': 16781, 'interracial': 16782, 'spacious': 16783, 'prosperous': 16784, 'administrative': 16785, 'craftsman': 16786, 'irma': 16787, 'russo': 16788, 'streetwise': 16789, 'edit': 16790, 'xxl': 16791, 'luis': 16792, 'lifer': 16793, 'anil': 16794, 'preity': 16795, 'zinta': 16796, 'gracy': 16797, 'fulfilled': 16798, 'brittle': 16799, 'containment': 16800, 'interior': 16801, 'silenced': 16802, 'shana': 16803, 'phoned': 16804, 'differs': 16805, 'mischevious': 16806, 'harrelson': 16807, 'silverstone': 16808, 'cormie': 16809, 'izabella': 16810, 'miko': 16811, 'coastal': 16812, 'carolinian': 16813, 'undirected': 16814, 'geordie': 16815, 'thom': 16816, 'pornographer': 16817, 'mihai': 16818, 'calota': 16819, 'nathalie': 16820, 'gypsies': 16821, 'beggars': 16822, \"publics'\": 16823, 'targeting': 16824, \"'get\": 16825, \"nailed'\": 16826, 'suicune': 16827, 'pentita': 16828, 'serrious': 16829, 'f4u': 16830, 'corsair': 16831, \"hillbillies'\": 16832, 'cormelos': 16833, 'maim': 16834, 'freehold': 16835, 'vicariously': 16836, 'marksman': 16837, 'targed': 16838, 'bigwigs': 16839, 'assasinate': 16840, 'oak': 16841, 'scrutiny': 16842, 'bloodied': 16843, 'flaming': 16844, \"sunflowers'\": 16845, 'beautiness': 16846, 'uruguay': 16847, 'traing': 16848, 'dwi': 16849, 'discussed': 16850, 'reg': 16851, 'precinct': 16852, 'tania': 16853, 'discoveres': 16854, 'edged': 16855, 'formation': 16856, \"mayes'\": 16857, 'personalizes': 16858, \"nugget'\": 16859, 'millionaires': 16860, 'undress': 16861, 'quikly': 16862, 'dive': 16863, 'regretting': 16864, 'websters': 16865, 'completed': 16866, 'faction': 16867, 'morpho': 16868, 'lars': 16869, 'idiom': 16870, 'informer': 16871, 'execute': 16872, 'oath': 16873, 'werewolves': 16874, 'hurtled': 16875, 'yoga': 16876, 'uncrowned': 16877, 'sidetracked': 16878, 'gown': 16879, 'library': 16880, 'props': 16881, 'legionnaire': 16882, 'angola': 16883, 'sarajevo': 16884, 'mj': 16885, 'powerline': 16886, 'brick': 16887, 'prospering': 16888, 'sugarholic': 16889, 'mackendrick': 16890, 'succeeding': 16891, 'revolvers': 16892, 'grenades': 16893, 'persuasion': 16894, 'imageworks': 16895, 'sony': 16896, 'paige': 16897, 'turco': 16898, 'admits': 16899, 'assistance': 16900, \"you'\": 16901, 'housekeeping': 16902, 'cousins': 16903, 'postponing': 16904, 'arielle': 16905, 'confide': 16906, 'walston': 16907, 'cofee': 16908, 'comunity': 16909, 'unforeseeable': 16910, 'afterworld': 16911, 'captivity': 16912, 'juxtaposes': 16913, 'ordeals': 16914, 'lloyd': 16915, 'divan': 16916, 'austria': 16917, 'jai': 16918, 'upgraded': 16919, '850': 16920, 'mision': 16921, '1901': 16922, 'paucity': 16923, 'cameroonians': 16924, 'cpu': 16925, 'leftist': 16926, 'entries': 16927, 'diagnose': 16928, 'schizophrenics': 16929, 'soaking': 16930, 'desperatly': 16931, 'seeps': 16932, 'insidiously': 16933, \"dionysus'\": 16934, \"pentheus'\": 16935, 'mentality': 16936, 'hurtful': 16937, 'sheltered': 16938, 'marjorie': 16939, 'standiford': 16940, 'oklahoma': 16941, 'recorder': 16942, 'sorrows': 16943, 'brunswick': 16944, 'miramichi': 16945, 'wolves': 16946, 'gluckman': 16947, 'malibu': 16948, \"'hood\": 16949, 'pharmaceutical': 16950, 'inconistent': 16951, 'flips': 16952, 'steels': 16953, 'computers': 16954, 'possesed': 16955, 'estimate': 16956, 'conquests': 16957, 'inventory': 16958, 'mishaps': 16959, 'hardworking': 16960, 'wilma': 16961, 'dodging': 16962, 'bacon': 16963, 'executioners': 16964, 'overprotective': 16965, 'yeh': 16966, 'kaisi': 16967, 'mohabbat': 16968, 'ykm': 16969, 'graves': 16970, 'desecrated': 16971, 'brute': 16972, 'leatherface': 16973, \"'fable'\": 16974, 'crow': 16975, 'deadlier': 16976, 'overactive': 16977, 'encyclopedias': 16978, 'geniuses': 16979, 'photocopy': 16980, 'sabine': 16981, 'organised': 16982, 'boycott': 16983, 'repay': 16984, 'alarm': 16985, 'consultants': 16986, 'ganno': 16987, 'christi': 16988, 'playwrights': 16989, 'girish': 16990, 'karnad': 16991, 'combative': 16992, 'describing': 16993, 'sai': 16994, 'gwai': 16995, 'turtle': 16996, 'lmf': 16997, 'lun': 16998, 'pork': 16999, 'cantonese': 17000, 'slang': 17001, 'gear': 17002, 'louie': 17003, '40th': 17004, 'psychosis': 17005, 'trashed': 17006, 'lydia': 17007, 'bullfighter': 17008, '1777': 17009, '1791': 17010, 'navigates': 17011, 'benjamin': 17012, 'fond': 17013, 'saviors': 17014, 'diplomacy': 17015, 'ads': 17016, 'parks': 17017, 'mutate': 17018, 'profiled': 17019, 'sacked': 17020, 'overheard': 17021, 'buoyed': 17022, 'noam': 17023, 'mit': 17024, 'linguist': 17025, 'famously': 17026, 'madam': 17027, 'moose': 17028, 'scorn': 17029, 'chazz': 17030, 'palminteri': 17031, 'journals': 17032, 'che': 17033, 'geuvara': 17034, 'recess': 17035, 'statue': 17036, 'everest': 17037, 'krebbs': 17038, 'viciously': 17039, 'relocating': 17040, 'adapting': 17041, 'beverly': 17042, 'stilano': 17043, 'trev': 17044, 'spackneys': 17045, 'adjoining': 17046, 'defeating': 17047, 'gardener': 17048, 'haysbert': 17049, 'atlanta': 17050, 'diversely': 17051, \"'one\": 17052, 'saddest': 17053, \"know'\": 17054, 'incompatible': 17055, 'emigrates': 17056, 'elizabethean': 17057, 'afoul': 17058, 'admirer': 17059, 'unsuccessful': 17060, 'scribe': 17061, 'pilfers': 17062, 'voiced': 17063, 'gerald': 17064, 'magnet': 17065, 'budapest': 17066, \"city'\": 17067, 'scar': 17068, 'heartless': 17069, 'sic': 17070, 'participated': 17071, 'collegues': 17072, 'anticipating': 17073, 'aggressor': 17074, 'cabot': 17075, 'unequal': 17076, 'longfellow': 17077, 'pizzeria': 17078, 'billion': 17079, 'berry': 17080, 'thriving': 17081, 'whoever': 17082, 'bumming': 17083, 'charmont': 17084, 'quantity': 17085, 'accidently': 17086, 'unprotected': 17087, 'courtenay': 17088, 'brags': 17089, 'julianne': 17090, 'kincaid': 17091, 'musicologist': 17092, 'diocese': 17093, 'natalio': 17094, 'assisting': 17095, 'highlands': 17096, 'dreamplace': 17097, 'swat': 17098, 'workforce': 17099, 'chatting': 17100, 'priority': 17101, 'waht': 17102, 'beef': 17103, 'designing': 17104, '173': 17105, 'framing': 17106, 'drove': 17107, 'arroz': 17108, 'mango': 17109, 'fron': 17110, 'daae': 17111, 'contentious': 17112, 'mclean': 17113, 'veritas': 17114, 'lastly': 17115, 'dinka': 17116, 'thelma': 17117, 'tentative': 17118, 'hotte': 17119, 'meitlemeihr': 17120, 'montreal': 17121, 'jetset': 17122, 'glittery': 17123, 'draining': 17124, 'schoolbus': 17125, 'coaches': 17126, 'cheerleaders': 17127, 'skeddadled': 17128, 'bobbie': 17129, 'markowe': 17130, 'israelis': 17131, 'dugit': 17132, 'exaggerates': 17133, 'cociety': 17134, 'sabotages': 17135, 'scenarios': 17136, 'haruna': 17137, 'bandaged': 17138, 'succesful': 17139, 'abstinence': 17140, 'jockey': 17141, 'monde': 17142, 'nightspot': 17143, 'telganan': 17144, 'brittish': 17145, 'endgame': 17146, 'concubines': 17147, 'atonement': 17148, 'drudgery': 17149, 'krystal': 17150, 'svengali': 17151, 'dromedary': 17152, 'detection': 17153, 'bewildered': 17154, 'monologues': 17155, 'reuben': 17156, 'harridan': 17157, '1900': 17158, \"'problem'\": 17159, 'thorny': 17160, 'prompted': 17161, 'lobbying': 17162, 'inclusion': 17163, 'olympic': 17164, 'promoters': 17165, 'arranging': 17166, 'forebear': 17167, 'welfare': 17168, 'boots': 17169, 'chapatti': 17170, 'firehouses': 17171, 'reciprocal': 17172, 'ketchum': 17173, 'guevara': 17174, 'recounts': 17175, 'alberto': 17176, 'granado': 17177, 'file': 17178, 'deacon': 17179, 'mornings': 17180, 'pirating': 17181, 'monogamy': 17182, 'unaccredited': 17183, 'daric': 17184, 'tailing': 17185, 'prague': 17186, 'elaborates': 17187, 'chute': 17188, 'perfectionist': 17189, 'overachiever': 17190, 'pacifist': 17191, 'oversaw': 17192, 'dexterity': 17193, 'strang': 17194, 'unjust': 17195, 'summon': 17196, 'snatched': 17197, 'identifiable': 17198, \"'phantom\": 17199, \"menace'\": 17200, 'representing': 17201, 'homeworld': 17202, 'habitual': 17203, 'burgies': 17204, 'zandt': 17205, 'garber': 17206, 'unenviable': 17207, 'keanu': 17208, 'rooker': 17209, 'stevens': 17210, 'seda': 17211, 'misencounters': 17212, 'lefty': 17213, 'capitalize': 17214, 'cried': 17215, \"wolf'\": 17216, 'muniz': 17217, '1846': 17218, '1863': 17219, 'starved': 17220, 'kxch': 17221, 'syrupy': 17222, 'fitzpatrick': 17223, 'limousine': 17224, 'installed': 17225, \"'murder\": 17226, \"numbers'\": 17227, 'cassie': 17228, 'mayweather': 17229, 'malevolently': 17230, 'tampa': 17231, 'enacts': 17232, 'chronology': 17233, 'shepherd': 17234, 'tied': 17235, 'responded': 17236, '8763': 17237, 'avenue': 17238, 'manson': 17239, 'colourful': 17240, 'horseracing': 17241, 'horseplay': 17242, 'turf': 17243, 'weeki': 17244, 'wachee': 17245, 'utopia': 17246, 'enfrentarse': 17247, 'estrategia': 17248, 'potencia': 17249, 'enemigo': 17250, 'sino': 17251, 'jolgorio': 17252, 'grandes': 17253, 'invadir': 17254, 'territorio': 17255, 'panderetas': 17256, 'risotadas': 17257, 'histeria': 17258, 'doodles': 17259, 'visas': 17260, 'sportive': 17261, 'epicurean': 17262, 'brokers': 17263, 'gertie': 17264, 'ollie': 17265, 'finesse': 17266, 'unexperimented': 17267, 'mutually': 17268, 'swordfight': 17269, 'auditioning': 17270, 'parlay': 17271, 'recovery': 17272, 'socialist': 17273, 'passively': 17274, 'coldest': 17275, 'winters': 17276, 'dilemmas': 17277, 'pullitzer': 17278, 'shields': 17279, 'mahabharata': 17280, 'dictatorship': 17281, 'funtime': 17282, 'tinke': 17283, 'grandparents': 17284, 'ethnic': 17285, 'birthplace': 17286, 'sweeney': 17287, 'foolproof': 17288, 'futterman': 17289, 'chauffeur': 17290, 'isaacs': 17291, 'carmita': 17292, 'discos': 17293, 'vinyl': 17294, 'unfair': 17295, 'lopes': 17296, 'hallucinogens': 17297, 'maintenance': 17298, 'fitch': 17299, 'wackiest': 17300, 'martinez': 17301, 'mythological': 17302, 'denver': 17303, 'marek': 17304, 'koterski': 17305, 'swearing': 17306, \"neighbours'\": 17307, 'joie': 17308, 'vivre': 17309, 'ridicules': 17310, 'knoxvile': 17311, 'cathexis': 17312, 'reciprocated': 17313, 'trades': 17314, 'tantrums': 17315, 'protesters': 17316, 'homicidal': 17317, 'palnet': 17318, 'iberian': 17319, 'criticism': 17320, 'lay': 17321, 'evade': 17322, 'sweeter': 17323, 'divorcee': 17324, 'simultaneous': 17325, 'skyrocketing': 17326, 'compartments': 17327, 'synopsis': 17328, 'hooligan': 17329, 'items': 17330, 'modified': 17331, '1s': 17332, 'mugu': 17333, 'klatretosen': 17334, 'fernier': 17335, 'korman': 17336, 'chang': 17337, 'nefarious': 17338, 'transference': 17339, 'vishwas': 17340, 'prajapati': 17341, 'verma': 17342, 'rampal': 17343, 'ilias': 17344, 'relocation': 17345, 'isloated': 17346, 'stiller': 17347, 'tripped': 17348, 'harebrained': 17349, 'vapoorizer': 17350, 'poop': 17351, 'evaporate': 17352, 'distribute': 17353, 'escalate': 17354, 'anderton': 17355, \"hobbit'\": 17356, \"rings'\": 17357, \"silmarillion'\": 17358, 'philipe': 17359, 'testimonies': 17360, 'comprises': 17361, 'seafarer': 17362, 'nemo': 17363, 'shah': 17364, 'vampiress': 17365, 'mina': 17366, 'harker': 17367, 'skinner': 17368, 'curran': 17369, 'sawyer': 17370, 'dorian': 17371, 'jekyll': 17372, 'degenerated': 17373, 'appliance': 17374, 'sewing': 17375, 'reform': 17376, 'suitors': 17377, 'lunatics': 17378, 'unprecedented': 17379, 'perplexes': 17380, 'desolation': 17381, 'biya': 17382, 'frying': 17383, 'magnum': 17384, '45s': 17385, 'polatkin': 17386, 'spokane': 17387, 'anticipate': 17388, 'kervorkian': 17389, 'pawns': 17390, 'varied': 17391, 'pulizter': 17392, 'axe': 17393, 'roberta': 17394, '350': 17395, 'lb': 17396, 'proudly': 17397, 'scammed': 17398, 'fergus': 17399, 'wolfe': 17400, '55': 17401, 'sampling': 17402, 'idiosyncrasies': 17403, 'creek': 17404, 'waging': 17405, 'expansionism': 17406, 'birthright': 17407, 'specializes': 17408, 'ferguson': 17409, 'cardiff': 17410, 'sexgunsmoney': 17411, 'machiavellian': 17412, 'platinum': 17413, \"'pie\": 17414, \"face'\": 17415, 'tildy': 17416, 'epitome': 17417, 'fresno': 17418, 'cohort': 17419, 'injuring': 17420, 'pickum': 17421, 'alleys': 17422, 'clutch': 17423, 'handgun': 17424, 'undecided': 17425, 'whe': 17426, 'prozium': 17427, 'hinders': 17428, 'enforce': 17429, 'overthrowing': 17430, 'donnerel': 17431, 'vernal': 17432, 'necks': 17433, 'melodic': 17434, 'lyrics': 17435, 'underscoring': 17436, 'distributes': 17437, 'donations': 17438, 'collected': 17439, 'heals': 17440, 'ploy': 17441, 'instituton': 17442, 'nearest': 17443, 'attackers': 17444, 'intercuts': 17445, 'erode': 17446, '150': 17447, 'displaced': 17448, 'declassified': 17449, 'submariners': 17450, \"'loosely\": 17451, 'routinity': 17452, 'sucessfull': 17453, 'jakarta': 17454, 'anxieties': 17455, 'urbaniak': 17456, 'dwis': 17457, 'piously': 17458, 'kerouac': 17459, 'contributing': 17460, \"'sure\": 17461, \"following'\": 17462, \"girls'\": 17463, 'rockstar': 17464, 'bares': 17465, 'masquerading': 17466, 'nate': 17467, 'jailbait': 17468, 'prisons': 17469, 'singapore': 17470, 'academically': 17471, 'inclined': 17472, 'roden': 17473, 'capt': 17474, 'jameson': 17475, 'macaulay': 17476, 'skyrockets': 17477, 'columbian': 17478, 'revilla': 17479, 'nbi': 17480, 'portman': 17481, 'ewan': 17482, 'learner': 17483, 'hayden': 17484, 'remarries': 17485, 'drastic': 17486, \"'normal'\": 17487, 'tatooine': 17488, 'reviews': 17489, \"eaters'\": 17490, 'rampage': 17491, 'kamel': 17492, 'veggie': 17493, 'diploma': 17494, 'premiere': 17495, 'surgeons': 17496, 'scalpel': 17497, 'miniature': 17498, 'celebrities': 17499, 'springer': 17500, 'trixter': 17501, 'arpid': 17502, 'balthazar': 17503, 'fufill': 17504, 'teamster': 17505, 'overnite': 17506, 'transportation': 17507, 'freight': 17508, 'resisted': 17509, 'unionization': 17510, 'slytherins': 17511, 'fictionalized': 17512, 'circa': 17513, 'brenner': 17514, 'philly': 17515, 'adventurers': 17516, 'fossil': 17517, 'courses': 17518, 'valerie': 17519, 'tico': 17520, 'principio': 17521, 'oleadas': 17522, 'menes': 17523, 'saturan': 17524, 'informativos': 17525, 'decenas': 17526, 'sectas': 17527, 'tratan': 17528, 'captar': 17529, 'fe': 17530, 'cada': 17531, 'esc': 17532, 'ptica': 17533, 'poblaci': 17534, 'foretold': 17535, \"'nine\": 17536, \"guys'\": 17537, 'hickman': 17538, 'gardens': 17539, 'untenable': 17540, \"'while\": 17541, \"waiting'\": 17542, 'cigarette': 17543, 'elude': 17544, 'bradley': 17545, 'mums': 17546, 'skittish': 17547, 'pillow': 17548, 'smoker': 17549, 'lilyan': 17550, 'chauvin': 17551, 'mafiosi': 17552, 'encouragement': 17553, 'bettany': 17554, 'spokesman': 17555, 'pillows': 17556, 'congenial': 17557, 'councillor': 17558, 'havanna': 17559, 'lunna': 17560, \"stiles'\": 17561, 'cammie': 17562, 'giles': 17563, 'furthermore': 17564, 'opponent': 17565, '1492': 17566, 'decreed': 17567, 'convert': 17568, 'catholicism': 17569, 'bub': 17570, 'hiep': 17571, 'flabbergasted': 17572, 'rorion': 17573, 'gracie': 17574, 'kerr': 17575, 'hackney': 17576, 'bas': 17577, 'rutten': 17578, 'tribles': 17579, 'quietest': 17580, 'nanny': 17581, 'grad': 17582, 'carlitos': 17583, 'befriended': 17584, 'cyborg': 17585, 'makings': 17586, 'shipmate': 17587, 'supernova': 17588, 'horrendous': 17589, 'grandchild': 17590, 'introductions': 17591, 'yonkers': 17592, 'berkley': 17593, 'hypercube': 17594, 'barn': 17595, 'distraught': 17596, 'intruder': 17597, 'articulations': 17598, 'byrnes': 17599, 'cautious': 17600, 'composers': 17601, \"legends'\": 17602, 'uss': 17603, 'tunny': 17604, 'opposition': 17605, 'goire': 17606, 'contaminating': 17607, 'shorelines': 17608, 'portokalos': 17609, 'zorba': 17610, 'geneticist': 17611, 'cyborgs': 17612, 'replicating': 17613, 'automatons': 17614, 'olive': 17615, 'furniture': 17616, 'demonstration': 17617, 'phuong': 17618, 'yen': 17619, 'needing': 17620, 'daybreak': 17621, 'frog': 17622, 'peoples': 17623, 'colonialism': 17624, 'alouette': 17625, 'je': 17626, 'plumerai': 17627, 'brahmin': 17628, 'caste': 17629, 'attendant': 17630, 'arent': 17631, 'loveless': 17632, 'flansburgh': 17633, 'linnell': 17634, 'climbs': 17635, 'sharkey': 17636, 'vlado': 17637, 'agonizaba': 17638, 'ncipe': 17639, 'jefe': 17640, 'estado': 17641, 'funciones': 17642, 'encontraba': 17643, 'posici': 17644, 'dif': 17645, 'cil': 17646, 'afrontar': 17647, 'problema': 17648, 'genetics': 17649, 'paloma': 17650, 'bitsey': 17651, 'flew': 17652, 'upstanding': 17653, 'danica': 17654, 'mckellar': 17655, 'fatality': 17656, 'tally': 17657, 'beg': 17658, 'outgunned': 17659, 'liverpool': 17660, 'reed': 17661, 'prom': 17662, 'carols': 17663, 'paulie': 17664, 'requisites': 17665, 'uninhabited': 17666, 'violation': 17667, 'privacy': 17668, 'rail': 17669, 'topaz': 17670, 'nudist': 17671, 'lootz': 17672, \"vegas'\": 17673, 'dedicates': 17674, 'jealously': 17675, 'eminent': 17676, 'ingeniously': 17677, 'unraveled': 17678, 'legion': 17679, 'chota': 17680, 'pressing': 17681, 'eliminated': 17682, 'suppressing': 17683, 'claiming': 17684, 'receiver': 17685, 'booth': 17686, 'hostility': 17687, 'privileges': 17688, 'lincoln': 17689, 'hattam': 17690, 'ceduna': 17691, 'addison': 17692, 'undertook': 17693, 'norway': 17694, 'rebuffs': 17695, 'completion': 17696, 'competitive': 17697, 'compounded': 17698, 'langan': 17699, 'dutchman': 17700, 'dam': 17701, 'depended': 17702, 'innermost': 17703, 'oblivious': 17704, 'secretart': 17705, 'sabrina': 17706, 'brumder': 17707, 'surfer': 17708, 'disfunctional': 17709, \"rock'\": 17710, \"'perverted\": 17711, 'toys': 17712, 'lawmakers': 17713, 'technician': 17714, 'scottsdale': 17715, '1978': 17716, 'thinning': 17717, 'mailman': 17718, 'instinct': 17719, 'henk': 17720, 'barrie': 17721, 'katharine': 17722, 'mediate': 17723, 'cue': 17724, 'perpetrators': 17725, 'feather': 17726, 'penelope': 17727, '1650s': 17728, 'practical': 17729, 'injuried': 17730, 'katsumoto': 17731, 'paccard': 17732, 'decayed': 17733, 'untold': 17734, 'knowles': 17735, 'henriksen': 17736, 'comp': 17737, 'industries': 17738, 'beckham': 17739, 'abouts': 17740, 'freekicks': 17741, 'discipline': 17742, 'rediscovery': 17743, 'disregards': 17744, 'sequester': 17745, 'erupt': 17746, 'coruscant': 17747, 'senatorial': 17748, 'prompts': 17749, 'nukui': 17750, 'celebrant': 17751, 'tomato': 17752, 'forty': 17753, 'backing': 17754, 'goaded': 17755, 'cells': 17756, 'stag': 17757, 'beetle': 17758, 'swastika': 17759, 'romantically': 17760, 'profiler': 17761, 'graciela': 17762, 'switchblade': 17763, 'stealth': 17764, 'pas': 17765, 'undergrad': 17766, 'abstracting': 17767, 'liesbeth': 17768, 'fray': 17769, 'luckily': 17770, 'resourcefulness': 17771, 'winchester': 17772, 'spokeman': 17773, 'employed': 17774, 'samurais': 17775, 'overlooking': 17776, 'inland': 17777, 'obtains': 17778, 'retraining': 17779, 'worries': 17780, 'huddled': 17781, 'windy': 17782, 'cease': 17783, 'scrollkeeper': 17784, 'ty': 17785, 'sedah': 17786, 'folksy': 17787, 'delazo': 17788, 'cartel': 17789, 'waist': 17790, 'prevails': 17791, 'kubrick': 17792, 'baptizing': 17793, 'poland': 17794, 'addy': 17795, 'exorcism': 17796, 'jacob': 17797, 'temp': 17798, 'inquiry': 17799, 'harassment': 17800, 'embargo': 17801, 'mecca': 17802, 'attain': 17803, 'physiological': 17804, 'surviors': 17805, 'redfield': 17806, 'plauged': 17807, 'gainey': 17808, 'unearth': 17809, 'motley': 17810, 'lind': 17811, 'mcdermott': 17812, 'impresario': 17813, 'bogosian': 17814, \"holmes'\": 17815, 'sharon': 17816, 'schiller': 17817, '1738': 17818, '1789': 17819, 'fruitless': 17820, 'wristwatch': 17821, 'inventions': 17822, 'slips': 17823, 'thickens': 17824, 'eleanore': 17825, 'remorseful': 17826, \"'rope'\": 17827, 'agatha': 17828, \"'ten\": 17829, \"indians'\": 17830, 'stall': 17831, 'resurrected': 17832, 'wreaking': 17833, 'havok': 17834, 'ge': 17835, 'migt': 17836, 'shotgunning': 17837, 'forming': 17838, 'mullet': 17839, 'detain': 17840, 'looters': 17841, 'brigade': 17842, 'ribs': 17843, 'bernier': 17844, 'ledger': 17845, 'carolingians': 17846, 'tasks': 17847, 'sales': 17848, 'phifer': 17849, 'treachery': 17850, 'jacobina': 17851, 'lutheran': 17852, 'cleansing': 17853, 'lied': 17854, 'illegals': 17855, 'interviewing': 17856, 'sneaking': 17857, 'unintended': 17858, 'distrustful': 17859, 'idealization': 17860, 'untested': 17861, 'circumcision': 17862, '1904': 17863, 'burgh': 17864, 'lzli': 17865, 'gustav': 17866, 'investors': 17867, 'charmed': 17868, 'undocumented': 17869, 'hesitantly': 17870, 'adversarial': 17871, 'bonds': 17872, 'awarenesses': 17873, 'gamer': 17874, 'sexaholic': 17875, 'profitting': 17876, 'customer': 17877, 'phrases': 17878, 'existing': 17879, 'wendie': 17880, 'malick': 17881, 'lombardo': 17882, 'clearing': 17883, 'hal': 17884, 'tails': 17885, 'implemented': 17886, 'panto': 17887, 'mona': 17888, 'amrita': 17889, 'arora': 17890, 'faultless': 17891, 'wedded': 17892, 'hijinx': 17893, 'steer': 17894, 'op': 17895, 'fag': 17896, 'hag': 17897, 'recovers': 17898, 'weatherford': 17899, 'dogwalking': 17900, 'gaidry': 17901, 'firearms': 17902, 'fireman': 17903, 'samaritans': 17904, \"bed'\": 17905, 'misdiagnosed': 17906, 'whitlock': 17907, 'banyan': 17908, 'bennets': 17909, 'keiths': 17910, 'predating': 17911, 'pyramids': 17912, 'fortell': 17913, 'roark': 17914, 'critchlow': 17915, 'forbid': 17916, 'proactive': 17917, 'enviromental': 17918, 'outlaws': 17919, 'porch': 17920, 'debora': 17921, 'falabella': 17922, 'bomtempo': 17923, 'outpost': 17924, 'goonyas': 17925, 'nungas': 17926, 'blacks': 17927, 'akasha': 17928, 'snuff': 17929, 'bleeds': 17930, 'hallucination': 17931, 'maritime': 17932, 'opulence': 17933, 'rhymes': 17934, 'organizes': 17935, 'inquisition': 17936, 'venetian': 17937, 'paolo': 17938, 'zane': 17939, 'rambunctious': 17940, 'housemates': 17941, 'tipsy': 17942, 'rotted': 17943, 'contemplate': 17944, 'technicalities': 17945, 'lang': 17946, 'employer': 17947, 'responding': 17948, 'rehearsing': 17949, 'opry': 17950, 'managers': 17951, 'reside': 17952, 'exterminators': 17953, 'ratmaster': 17954, 'redmond': 17955, 'rodent': 17956, 'mondavarious': 17957, 'slutty': 17958, 'biel': 17959, 'hots': 17960, 'await': 17961, 'em3': 17962, 'trivia': 17963, 'heighten': 17964, 'ellroy': 17965, 'brakhage': 17966, 'menninger': 17967, 'raiders': 17968, 'unblemished': 17969, 'toilet': 17970, \"'blonde\": 17971, \"goddess'\": 17972, 'rally': 17973, 'bathing': 17974, 'reactivates': 17975, 'microscopic': 17976, 'revisiting': 17977, 'sepideh': 17978, 'supervisor': 17979, 'jo': 17980, 'discontented': 17981, 'violencia': 17982, 'pesimismo': 17983, 'caros': 17984, 'ganan': 17985, 'vida': 17986, 'mendigando': 17987, 'patatas': 17988, 'bravas': 17989, 'verm': 17990, 'grifo': 17991, 'lonesome': 17992, 'carnaged': 17993, 'perpetrate': 17994, 'basks': 17995, 'occured': 17996, 'krensler': 17997, 'triggers': 17998, 'amonte': 17999, 'resigned': 18000, 'textile': 18001, 'zimmett': 18002, 'marchelletta': 18003, 'poontang': 18004, 'barrum': 18005, 'finlay': 18006, 'simulated': 18007, 'implants': 18008, 'isn': 18009, 'tulip': 18010, 'girldfriend': 18011, 'cassidy': 18012, 'handedly': 18013, 'despot': 18014, 'mortmain': 18015, 'romola': 18016, 'garai': 18017, 'aboard': 18018, '429': 18019, 'roddy': 18020, 'usher': 18021, 'goons': 18022, 'semester': 18023, 'segues': 18024, 'electrical': 18025, 'discharged': 18026, \"'missing\": 18027, \"link'\": 18028, \"'subject'\": 18029, \"'reason'\": 18030, 'deborah': 18031, 'dickson': 18032, 'clarkson': 18033, 'insomniac': 18034, 'hitlist': 18035, 'livid': 18036, '1971': 18037, 'coincided': 18038, 'cancelling': 18039, 'feds': 18040, 'retaliating': 18041, 'foley': 18042, 'goldblum': 18043, 'yoba': 18044, 'xander': 18045, 'seeker': 18046, 'untouchable': 18047, 'converging': 18048, 'impulsively': 18049, 'sha': 18050, 'slobodan': 18051, 'pavle': 18052, '1898': 18053, 'sudan': 18054, 'ideally': 18055, \"graduate'\": 18056, 'experiencing': 18057, 'conjure': 18058, 'riverbend': 18059, 'pflag': 18060, 'retirees': 18061, 'peasants': 18062, 'bra': 18063, 'presidente': 18064, 'feldman': 18065, 'rebuffed': 18066, 'algeria': 18067, 'expanding': 18068, 'snowbell': 18069, 'belies': 18070, 'punctuated': 18071, 'confesses': 18072, 'nursed': 18073, 'psychopath': 18074, 'dice': 18075, \"myers'\": 18076, 'vengeful': 18077, 'easiest': 18078, 'plotpar': 18079, '20john': 18080, 'rampant': 18081, 'discoveries': 18082, 'cornuke': 18083, 'ramifications': 18084, 'filipo': 18085, 'giovanni': 18086, 'ribisi': 18087, 'tranquility': 18088, 'snowboard': 18089, 'skate': 18090, 'marites': 18091, 'disapprove': 18092, 'pursuits': 18093, 'neighbour': 18094, 'subsequantly': 18095, 'cassely': 18096, \"'make\": 18097, \"off'\": 18098, 'finnur': 18099, 'hanns': 18100, '1949': 18101, \"'mrs\": 18102, 'mucker': 18103, 'sect': 18104, 'singlehanded': 18105, 'shylock': 18106, 'shinto': 18107, 'ambush': 18108, 'inlove': 18109, 'blinddate': 18110, 'tips': 18111, 'tippi': 18112, 'hedren': 18113, 'erick': 18114, 'avari': 18115, 'furst': 18116, 'descendent': 18117, 'alps': 18118, 'festivals': 18119, 'weightwatch': 18120, 'gooder': 18121, 'vaneer': 18122, 'catalogue': 18123, 'modeling': 18124, 'boyhood': 18125, 'sleepy': 18126, 'grubman': 18127, 'harbouring': 18128, 'unsolicited': 18129, 'input': 18130, 'imitate': 18131, 'woof': 18132, 'taipei': 18133, 'supernaturally': 18134, 'lund': 18135, 'pendance': 18136, 'rumours': 18137, 'paired': 18138, 'emphasize': 18139, 'inga': 18140, 'fabienne': 18141, 'humaine': 18142, 'scrumptious': 18143, 'enchiladas': 18144, 'devine': 18145, 'industrials': 18146, 'infomercials': 18147, 'enbark': 18148, 'summoning': 18149, 'clubbing': 18150, \"nothin'\": 18151, 'blackmails': 18152, 'sushmita': 18153, 'sen': 18154, 'rework': 18155, 'handcuffed': 18156, \"'a'\": 18157, 'perabo': 18158, 'karim': 18159, 'rockaway': 18160, 'uncontrollable': 18161, 'ulrich': 18162, 'backwoods': 18163, 'scorned': 18164, 'chaste': 18165, 'bhuvan': 18166, 'vijayendra': 18167, 'ghagte': 18168, 'madhuri': 18169, 'dixit': 18170, 'drawback': 18171, 'darlene': 18172, 'achievers': 18173, 'irrefutable': 18174, \"'mouna\": 18175, \"ragam'\": 18176, \"'alaipayuthe'\": 18177, 'maniratnam': 18178, 'tackling': 18179, 'henceforth': 18180, 'counterpoint': 18181, 'judicial': 18182, 'sanitized': 18183, 'emasculation': 18184, 'lures': 18185, 'mapped': 18186, 'homestay': 18187, 'payback': 18188, 'civilians': 18189, 'momma': 18190, 'blacker': 18191, 'knifes': 18192, 'unbending': 18193, 'township': 18194, \"'accident'\": 18195, 'woodstock': 18196, 'rolov': 18197, 'brandon': 18198, 'anesthesiologist': 18199, 'arduous': 18200, 'prayers': 18201, 'goldmining': 18202, 'nando': 18203, '1880': 18204, 'keeper': 18205, 'parliament': 18206, 'gillen': 18207, 'fann': 18208, 'divulging': 18209, 'rivalries': 18210, 'worsen': 18211, 'holidays': 18212, 'fatima': 18213, 'melodi': 18214, 'prix': 18215, 'staking': 18216, 'foxy': 18217, 'fakes': 18218, \"lilly'\": 18219, 'capitalizing': 18220, 'dove': 18221, 'freewheeling': 18222, 'oversee': 18223, 'screw': 18224, 'forays': 18225, 'notebooks': 18226, 'netherworld': 18227, 'comet': 18228, '4000': 18229, 'wired': 18230, 'borrowing': 18231, 'donning': 18232, 'papel': 18233, 'mainland': 18234, 'martinis': 18235, 'collects': 18236, 'recycle': 18237, 'paddles': 18238, 'tel': 18239, 'aviv': 18240, 'guarded': 18241, 'palazzo': 18242, 'lyle': 18243, 'wheelman': 18244, 'mos': 18245, 'bridger': 18246, 'sutherland': 18247, 'crosser': 18248, 'devout': 18249, 'midwife': 18250, '1946': 18251, 'buzz': 18252, 'decks': 18253, 'shipwrecked': 18254, 'boxes': 18255, 'rhythmic': 18256, 'reclamation': 18257, 'scrappy': 18258, 'assists': 18259, 'conveyance': 18260, 'yerba': 18261, 'parlors': 18262, 'remnants': 18263, 'cluster': 18264, 'oblivion': 18265, 'niger': 18266, 'micronesia': 18267, 'siberia': 18268, 'greenland': 18269, 'preaching': 18270, \"'wait'\": 18271, 'mia': 18272, 'complimented': 18273, 'reformed': 18274, 'nestor': 18275, 'vivica': 18276, 'geological': 18277, 'fracture': 18278, 'widens': 18279, 'disassociate': 18280, 'guffman': 18281, 'rushmore': 18282, 'monitoring': 18283, 'swap': 18284, 'intertwining': 18285, 'kruger': 18286, 'devilin': 18287, 'harmonic': 18288, 'cartwright': 18289, 'teased': 18290, 'discriminated': 18291, 'sannah': 18292, 'fantazises': 18293, 'cancelled': 18294, 'rebell': 18295, 'oversteps': 18296, 'boarder': 18297, 'francois': 18298, 'yayo': 18299, 'politician': 18300, 'conrado': 18301, 'bashful': 18302, 'deliveryman': 18303, 'aberration': 18304, 'spearhead': 18305, 'maya': 18306, 'grifasi': 18307, 'pathologist': 18308, 'baker': 18309, 'devised': 18310, 'clam': 18311, 'dandy': 18312, 'healthcare': 18313, 'supplies': 18314, 'beans': 18315, 'spilled': 18316, 'bullying': 18317, 'fosters': 18318, 'bribe': 18319, 'assitant': 18320, 'jojo': 18321, 'audio': 18322, 'liebman': 18323, 'unprepared': 18324, 'hungover': 18325, 'penrith': 18326, 'buenos': 18327, 'aires': 18328, 'tyne': 18329, 'ferrier': 18330, 'burg': 18331, 'marla': 18332, 'lawson': 18333, 'roth': 18334, 'koishi': 18335, 'malay': 18336, 'magician': 18337, 'milind': 18338, 'soman': 18339, 'sonali': 18340, 'kulkarni': 18341, 'tribunal': 18342, 'chink': 18343, 'armor': 18344, 'talibans': 18345, 'approve': 18346, 'incurable': 18347, 'francesca': 18348, 'mutt': 18349, 'fort': 18350, 'excitable': 18351, 'hanareh': 18352, 'yankee': 18353, 'foxtrot': 18354, 'scatter': 18355, 'depp': 18356, 'paternal': 18357, 'kreskin': 18358, 'racer': 18359, \"'wheatfield\": 18360, \"crows'\": 18361, 'veronica': 18362, 'guerin': 18363, 'barons': 18364, 'repent': 18365, 'collaborates': 18366, 'associate': 18367, 'disgraced': 18368, 'farming': 18369, 'strengthens': 18370, 'voyeurism': 18371, 'whitcomb': 18372, 'berman': 18373, 'kurtz': 18374, 'outcry': 18375, 'renewed': 18376, 'registration': 18377, 'experimented': 18378, 'vocal': 18379, 'supporters': 18380, 'legislation': 18381, 'nino': 18382, 'implicates': 18383, 'institutes': 18384, 'redefinitions': 18385, 'outdoor': 18386, 'hitching': 18387, 'maxims': 18388, 'chica': 18389, 'luna': 18390, 'dawgz': 18391, 'tenfold': 18392, 'rehire': 18393, 'embarrass': 18394, 'juilliard': 18395, 'gangstaz': 18396, 'compton': 18397, 'ghettofied': 18398, 'mame': 18399, 'charisse': 18400, 'midlands': 18401, 'picturesque': 18402, '1940': 18403, 'researching': 18404, 'gamma': 18405, 'activated': 18406, 'bram': 18407, 'stoker': 18408, 'lansdale': 18409, 'presley': 18410, 'chocolates': 18411, 'potato': 18412, 'downview': 18413, 'cancel': 18414, 'applied': 18415, 'fishmonger': 18416, 'leech': 18417, 'rediscover': 18418, 'laila': 18419, 'wary': 18420, 'disused': 18421, 'raid': 18422, 'caged': 18423, 'nord': 18424, 'nancy': 18425, 'fin': 18426, 'rescuing': 18427, 'colette': 18428, 'kara': 18429, 'upbringing': 18430, 'external': 18431, 'blackness': 18432, 'scents': 18433, 'textures': 18434, 'perceive': 18435, 'vostrikov': 18436, 'chernobyl': 18437, 'gigs': 18438, 'cartels': 18439, 'tongs': 18440, 'buckets': 18441, 'gourmet': 18442, 'tun': 18443, 'unspecified': 18444, 'mononoke': 18445, '1926': 18446, 'hangings': 18447, 'kkk': 18448, 'hank': 18449, 'azaria': 18450, \"d'onofrio\": 18451, 'comedienne': 18452, 'canine': 18453, \"'his\": 18454, \"people'\": 18455, 'loner': 18456, 'requirements': 18457, 'demanded': 18458, 'conveyed': 18459, 'perfumed': 18460, 'memorbale': 18461, 'aquitania': 18462, 'overtures': 18463, 'announcing': 18464, 'majandra': 18465, 'delfino': 18466, 'iris': 18467, 'dismay': 18468, 'roam': 18469, 'balancing': 18470, 'aesthetics': 18471, 'clegg': 18472, 'tending': 18473, 'barb': 18474, 'sumner': 18475, 'janet': 18476, 'octopus': 18477, 'aglanar': 18478, 'munitions': 18479, 'range': 18480, 'suitor': 18481, 'houseguests': 18482, 'tweed': 18483, 'murwillumbah': 18484, 'separtists': 18485, 'serengeti': 18486, 'electrified': 18487, 'chimpanzee': 18488, 'darwin': 18489, 'caped': 18490, 'jerks': 18491, 'wheel': 18492, 'skids': 18493, 'titanic': 18494, 'mandalorians': 18495, \"janis'\": 18496, \"'montezuma\": 18497, \"revenge'\": 18498, 'gundars': 18499, 'supports': 18500, 'rear': 18501, 'crims': 18502, 'fundy': 18503, 'swan': 18504, 'awaking': 18505, 'worldliness': 18506, 'impoverished': 18507, 'brassaurd': 18508, 'tumbling': 18509, 'tenure': 18510, 'maude': 18511, \"cache'\": 18512, 'mil': 18513, 'thwarting': 18514, 'cayetana': 18515, 'throught': 18516, 'biased': 18517, 'cheadle': 18518, 'hierarchal': 18519, 'grover': 18520, 'dawg': 18521, 'johns': 18522, 'afternoons': 18523, 'antigone': 18524, 'addlepated': 18525, 'dujour': 18526, 'trainees': 18527, \"'shooters'\": 18528, 'blackwoods': 18529, 'gunship': 18530, 'illegality': 18531, 'boxer': 18532, 'veggies': 18533, 'seafood': 18534, 'kwok': 18535, 'stalks': 18536, 'lubeck': 18537, 'mogul': 18538, 'lounge': 18539, 'barmaid': 18540, 'kove': 18541, 'fratricidal': 18542, 'kilos': 18543, 'mexicans': 18544, 'mckellen': 18545, 'balrog': 18546, 'sparse': 18547, 'risen': 18548, 'anglo': 18549, 'saxon': 18550, 'natives': 18551, 'provisional': 18552, 'operations': 18553, 'compound': 18554, 'backup': 18555, 'cameraman': 18556, 'dolph': 18557, 'lundgren': 18558, 'mcadams': 18559, 'timidly': 18560, 'participating': 18561, 'shinzons': 18562, 'cloaked': 18563, 'warbird': 18564, 'instructions': 18565, 'icepick': 18566, 'lobotomy': 18567, 'utensils': 18568, 'cacophony': 18569, 'robotic': 18570, 'stills': 18571, 'meg': 18572, 'overstays': 18573, 'exit': 18574, 'garz': 18575, 'persecution': 18576, 'adopting': 18577, 'swears': 18578, 'verik': 18579, 'seprates': 18580, 'sportsstyles': 18581, 'councilling': 18582, 'abusers': 18583, 'debates': 18584, 'corporations': 18585, 'opt': 18586, 'inexpensively': 18587, 'antoine': 18588, 'unforgivable': 18589, 'lightman': 18590, 'unpolished': 18591, 'merritt': 18592, 'doorman': 18593, 'newhart': 18594, 'workings': 18595, 'theresa': 18596, 'saldana': 18597, 'finances': 18598, 'trident': 18599, 'ssbns': 18600, 'idle': 18601, 'cam': 18602, 'madeline': 18603, 'raoul': 18604, 'viscount': 18605, 'chagny': 18606, 'concoct': 18607, 'flunking': 18608, 'joanne': 18609, 'easton': 18610, 'ellis': 18611, \"'starchildren'\": 18612, \"'dimension\": 18613, \"imagination'\": 18614, 'mervin': 18615, 'richards': 18616, 'stamos': 18617, 'settlers': 18618, 'palestinians': 18619, 'pecking': 18620, 'smoldering': 18621, 'monochromatic': 18622, 'ashen': 18623, 'epicenter': 18624, 'moonscape': 18625, 'dresdenesque': 18626, 'swallowed': 18627, 'regeneration': 18628, 'guinea': 18629, 'spoils': 18630, 'shacks': 18631, 'skid': 18632, 'dilapidated': 18633, 'clifton': 18634, 'collins': 18635, 'petards': 18636, \"'anime'\": 18637, 'fastest': 18638, 'bases': 18639, 'evidenced': 18640, 'enlightened': 18641, 'lawsuit': 18642, 'burglary': 18643, 'releases': 18644, 'bengali': 18645, 'prafulla': 18646, 'dasgupta': 18647, 'poetical': 18648, 'arose': 18649, 'dunes': 18650, 'courthouse': 18651, 'webcams': 18652, 'din': 18653, 'deafaning': 18654, 'relics': 18655, \"economy'\": 18656, 'newpaper': 18657, 'sri': 18658, 'lanka': 18659, 'reconciles': 18660, 'asians': 18661, 'pardue': 18662, 'nitive': 18663, 'kisses': 18664, 'continuing': 18665, 'mice': 18666, 'electrocuting': 18667, 'ramp': 18668, 'lightbulbs': 18669, 'mousetraps': 18670, 'thumbtacks': 18671, 'kennel': 18672, 'chaperone': 18673, 'gwen': 18674, 'tasked': 18675, 'dab': 18676, 'valery': 18677, 'grossu': 18678, 'autobiographic': 18679, 'firefighter': 18680, 'claudio': 18681, 'perrini': 18682, 'vampyr': 18683, 'enactments': 18684, 'readings': 18685, 'coffin': 18686, 'lestat': 18687, 'baxter': 18688, 'verit': 18689, 'reconnect': 18690, 'lasse': 18691, 'dedicate': 18692, 'eradication': 18693, 'conflicted': 18694, 'panoramix': 18695, 'miraculix': 18696, 'gallia': 18697, 'hurricane': 18698, 'preferable': 18699, 'starkness': 18700, 'radically': 18701, 'numbed': 18702, 'lair': 18703, 'rumors': 18704, 'nutrition': 18705, 'nha': 18706, 'fala': 18707, 'vita': 18708, 'remarks': 18709, 'musicals': 18710, 'conquering': 18711, 'latina': 18712, 'elisabeth': 18713, 'restages': 18714, 'crishna': 18715, \"devdas'\": 18716, 'sumitra': 18717, 'kiran': 18718, 'kher': 18719, 'arrogance': 18720, 'assumpta': 18721, 'townlet': 18722, 'rlichs': 18723, 'degradation': 18724, 'slopes': 18725, 'kasner': 18726, 'chevrah': 18727, 'kadisha': 18728, 'mobsters': 18729, 'gradual': 18730, 'protested': 18731, 'authoring': 18732, 'analysed': 18733, 'raving': 18734, 'clutched': 18735, 'intervened': 18736, 'buoyantly': 18737, 'expansion': 18738, 'adoption': 18739, 'cuddle': 18740, 'psychopaths': 18741, 'disapproval': 18742, 'regimented': 18743, 'armored': 18744, 'confirmed': 18745, 'deviant': 18746, 'sookie': 18747, 'godfater': 18748, 'trophy': 18749, 'veers': 18750, 'copes': 18751, 'viennese': 18752, 'bellaria': 18753, 'specialised': 18754, '30s': 18755, '40s': 18756, 'zarah': 18757, 'leander': 18758, 'nb': 18759, 'ck': 18760, 'amadeus': 18761, 'luckner': 18762, 'smalltalk': 18763, 'recruit': 18764, 'dobalina': 18765, 'encampment': 18766, 'neon': 18767, 'effigy': 18768, 'igniting': 18769, 'calendars': 18770, 'dales': 18771, 'chauncey': 18772, 'juni': 18773, 'gerti': 18774, \"'arroz\": 18775, \"mango'\": 18776, 'indentured': 18777, 'hitchhiker': 18778, 'deciphers': 18779, 'journeyed': 18780, 'chloe': 18781, 'approached': 18782, 'hail': 18783, '1942': 18784, 'dispair': 18785, 'consecutive': 18786, 'martal': 18787, 'inconvenient': 18788, 'holic': 18789, 'freedoms': 18790, '1906': 18791, 'jostled': 18792, 'headline': 18793, 'manned': 18794, 'allegations': 18795, 'cambodia': 18796, 'chained': 18797, 'finnish': 18798, 'kamikadze': 18799, 'wille': 18800, 'canyon': 18801, 'fixture': 18802, 'picket': 18803, \"goes'\": 18804, 'diagnoses': 18805, 'baptist': 18806, 'ritualistic': 18807, 'wildcat': 18808, 'irrespective': 18809, 'infidelities': 18810, '1935': 18811, 'ensured': 18812, 'estonia': 18813, 'schoolboys': 18814, 'noted': 18815, 'legislators': 18816, 'legitimacy': 18817, 'circulation': 18818, 'triads': 18819, 'autobiography': 18820, 'shahrukh': 18821, 'khan': 18822, 'cile': 18823, 'beacons': 18824, 'perpetrated': 18825, 'unethical': 18826, 'ministry': 18827, 'asteroid': 18828, 'gantu': 18829, 'progressively': 18830, 'vunerable': 18831, 'ling': 18832, 'haier': 18833, 'bankrupted': 18834, 'amazonian': 18835, 'hypnotist': 18836, 'dentists': 18837, 'academic': 18838, 'crust': 18839, 'blaze': 18840, 'fantisizing': 18841, 'galloway': 18842, 'fishburne': 18843, 'cali': 18844, 'harboring': 18845, 'cinderellas': 18846, 'rams': 18847, 'cubicle': 18848, 'sweatshops': 18849, 'fascistic': 18850, 'darwinism': 18851, 'corruptability': 18852, 'filmic': 18853, 'muldoon': 18854, 'whiz': 18855, 'rebound': 18856, 'moe': 18857, 'thug': 18858, 'prosecutor': 18859, 'mousy': 18860, 'angelic': 18861, 'theo': 18862, 'clarke': 18863, 'grammy': 18864, 'withheld': 18865, 'ideosyncrasies': 18866, 'illustrious': 18867, 'andrej': 18868, 'pans': 18869, 'availability': 18870, 'scotsman': 18871, 'numbering': 18872, 'blush': 18873, 'inaction': 18874, 'demandes': 18875, 'membre': 18876, 'rubin': 18877, 'internist': 18878, 'vying': 18879, 'internship': 18880, 'terminated': 18881, 'abraham': 18882, 'lazar': 18883, 'orchestrating': 18884, 'correlating': 18885, 'richest': 18886, 'hotshot': 18887, 'zan': 18888, '1700': 18889, 'iron': 18890, 'marauder': 18891, 'darkball': 18892, 'augments': 18893, 'feeing': 18894, 'bikers': 18895, 'schoolmate': 18896, 'smike': 18897, 'confirm': 18898, 'sprints': 18899, \"'selling\": 18900, \"out'\": 18901, \"'searching\": 18902, 'hillevi': 18903, 'offenders': 18904, 'fortuitous': 18905, 'katrina': 18906, 'hallucinates': 18907, 'mamood': 18908, '1931': 18909, 'valdemar': 18910, 'breaths': 18911, 'selects': 18912, 'kullen': 18913, 'manipulator': 18914, 'suspicions': 18915, 'alba': 18916, 'choreographer': 18917, '58': 18918, 'moslem': 18919, 'coincidently': 18920, 'altitude': 18921, 'metres': 18922, 'migrant': 18923, 'evelia': 18924, 'piazza': 18925, 'navona': 18926, 'keena': 18927, 'ritter': 18928, 'bizarro': 18929, 'om': 18930, 'puri': 18931, 'unending': 18932, 'khatri': 18933, 'dev': 18934, 'alcatraz': 18935, 'raisers': 18936, \"'extreme'\": 18937, \"chill'\": 18938, \"'deliverance'\": 18939, 'unsurface': 18940, 'widowed': 18941, 'unwanted': 18942, 'attentions': 18943, 'manipulated': 18944, 'egde': 18945, '1958': 18946, 'calms': 18947, 'obninsk': 18948, 'conservatories': 18949, 'bryant': 18950, 'consent': 18951, 'scaped': 18952, 'torrid': 18953, 'nintendo': 18954, 'implanted': 18955, 'danisworo': 18956, 'marcellius': 18957, 'siahaan': 18958, 'profesional': 18959, 'nfl': 18960, 'linebacker': 18961, 'enforces': 18962, 'felcher': 18963, \"sons'\": 18964, 'crushing': 18965, 'palomito': 18966, 'vj': 18967, 'slum': 18968, 'morro': 18969, 'alem': 18970, 'blocks': 18971, 'distince': 18972, 'daugther': 18973, 'blackheart': 18974, 'undead': 18975, 'drank': 18976, 'fountain': 18977, 'bulgarian': 18978, 'bid': 18979, 'paradiset': 18980, 'levi': 18981, 'archeology': 18982, 'sunflower': 18983, 'renewal': 18984, 'acquiring': 18985, 'clapped': 18986, 'skoda': 18987, 'jails': 18988, 'mauritius': 18989, 'illusionist': 18990, 'beaman': 18991, 'dietrich': 18992, 'rabbis': 18993, 'rohod': 18994, 'northeast': 18995, 'logging': 18996, 'recollections': 18997, 'mirabito': 18998, 'fiercely': 18999, 'prentis': 19000, 'kane': 19001, 'marin': 19002, 'jeffery': 19003, 'pankow': 19004, 'eli': 19005, 'wallach': 19006, 'siri': 19007, 'expertise': 19008, 'unavailable': 19009, 'yaga': 19010, 'tsar': 19011, 'hereafter': 19012, 'dieter': 19013, 'milla': 19014, 'luxurious': 19015, 'midwestern': 19016, 'fernanda': 19017, 'supermodel': 19018, 'sensible': 19019, 'cupic': 19020, 'unidentified': 19021, 'committee': 19022, 'asterix': 19023, 'obelix': 19024, 'eurovision': 19025, 'eyewitnesses': 19026, 'crusaders': 19027, 'emphysema': 19028, 'docu': 19029, 'counsel': 19030, 'developers': 19031, 'realised': 19032, 'millard': 19033, 'industrialization': 19034, 'agnostic': 19035, 'staked': 19036, 'bartha': 19037, 'cyanide': 19038, 'sunglasses': 19039, 'shedding': 19040, 'awakening': 19041, 'kit': 19042, 'ushers': 19043, 'symptoms': 19044, 'continents': 19045, 'disarray': 19046, 'planes': 19047, 'backstory': 19048, 'kathy': 19049, 'acker': 19050, 'noisy': 19051, 'renege': 19052, 'storming': 19053, 'appeasing': 19054, 'spaced': 19055, \"gibbs'\": 19056, 'deepak': 19057, 'tijori': 19058, 'martian': 19059, 'terran': 19060, 'kris': 19061, 'kringle': 19062, 'attained': 19063, 'skiing': 19064, 'dragged': 19065, 'egan': 19066, 'eduardo': 19067, 'coutinho': 19068, 'copacabana': 19069, \"'track\": 19070, 'unraveling': 19071, 'crook': 19072, 'pichler': 19073, \"'businessman'\": 19074, 'slovak': 19075, 'tenuously': 19076, 'modes': 19077, 'begining': 19078, 'hait': 19079, 'esha': 19080, 'visitations': 19081, 'semblance': 19082, 'propriety': 19083, 'starvation': 19084, 'pd': 19085, 'drowning': 19086, 'taboos': 19087, 'deed': 19088, 'dashiell': 19089, 'hammett': 19090, 'paramilitary': 19091, 'hairsalon': 19092, 'chat': 19093, 'blinding': 19094, 'torrential': 19095, 'wright': 19096, 'botch': 19097, 'diplomats': 19098, 'sintawan': 19099, 'recorded': 19100, 'prone': 19101, 'juggles': 19102, 'krzysztof': 19103, \"'heaven'\": 19104, 'bombard': 19105, 'enforcers': 19106, 'fates': 19107, 'rehearsal': 19108, 'witter': 19109, '44th': 19110, 'dziga': 19111, 'vertov': 19112, 'rediscovering': 19113, 'snowstorm': 19114, 'faculty': 19115, 'ducharme': 19116, 'adviser': 19117, 'duchovny': 19118, 'cameoing': 19119, 'terence': 19120, 'squatters': 19121, 'rosa': 19122, 'lavender': 19123, 'mandi': 19124, 'dodson': 19125, 'seaport': 19126, 'missions': 19127, 'inverse': 19128, 'femininity': 19129, 'mentoring': 19130, 'revolving': 19131, 'recife': 19132, 'necrophile': 19133, 'transvestite': 19134, 'dieing': 19135, 'hounslow': 19136, 'wimmer': 19137, \"o'brien\": 19138, 'delgado': 19139, 'mistrusted': 19140, 'madrid': 19141, 'materialize': 19142, 'everette': 19143, 'hatch': 19144, 'recognizing': 19145, 'takeshi': 19146, 'kitano': 19147, 'fixation': 19148, 'eliot': 19149, 'troubleshooter': 19150, 'tutoring': 19151, 'angelo': 19152, 'obstructs': 19153, 'perseveres': 19154, 'necklace': 19155, 'floundering': 19156, 'sneak': 19157, 'masterson': 19158, 'preserved': 19159, 'elwes': 19160, 'retrievie': 19161, 'bearers': 19162, 'tracked': 19163, \"'precious'\": 19164, 'hobbits': 19165, 'foes': 19166, 'rai': 19167, 'visualizing': 19168, 'waxman': 19169, 'mois': 19170, 'tectonic': 19171, 'wyoming': 19172, 'shepard': 19173, 'ruler': 19174, 'inability': 19175, 'grifter': 19176, 'rummages': 19177, 'pissed': 19178, 'anarchistic': 19179, 'arman': 19180, 'mimic': 19181, 'criticizing': 19182, '2003': 19183, 'uncovered': 19184, 'harbored': 19185, 'flourished': 19186, 'wiley': 19187, 'devastation': 19188, 'adel': 19189, 'gharid': 19190, 'nasrallah': 19191, 'gunslinger': 19192, 'budi': 19193, 'rosi': 19194, 'kristoff': 19195, 'damme': 19196, 'rollerblades': 19197, 'twyker': 19198, \"'run\": 19199, 'lola': 19200, \"run'\": 19201, 'romonovs': 19202, 'repository': 19203, 'assures': 19204, 'reverses': 19205, 'dolore': 19206, 'cambridge': 19207, 'nilsson': 19208, 'ringo': 19209, 'untimely': 19210, 'parsel': 19211, 'justine': 19212, 'lichtman': 19213, 'musashi': 19214, 'roomamte': 19215, 'cael': 19216, 'mistakenly': 19217, 'imprisonment': 19218, 'suburb': 19219, 'stepford': 19220, 'judgment': 19221, 'uphold': 19222, 'avenged': 19223, 'helper': 19224, 'annoyed': 19225, 'housewives': 19226, 'blissful': 19227, 'silvester': 19228, 'fumbles': 19229, 'brighter': 19230, 'istanbul': 19231, 'freely': 19232, 'fetch': 19233, 'leaf': 19234, 'blower': 19235, 'tourette': 19236, 'financing': 19237, 'swum': 19238, 'familiy': 19239, 'misterious': 19240, 'franklin': 19241, 'geoffrey': 19242, 'buonardi': 19243, \"campus'\": 19244, 'terroristic': 19245, 'conclude': 19246, 'bat': 19247, 'chart': 19248, 'unawakened': 19249, 'outs': 19250, 'josephine': 19251, 'gabriel': 19252, 'macht': 19253, 'hamptons': 19254, 'mccormack': 19255, 'mobilize': 19256, 'townspeople': 19257, 'announcer': 19258, 'bloodthirsty': 19259, 'tronald': 19260, 'smithereens': 19261, 'erect': 19262, 'mystics': 19263, 'semana': 19264, 'gaiman': 19265, 'mythology': 19266, 'sienkewicz': 19267, 'lass': 19268, 'fabric': 19269, 'weaver': 19270, 'vertically': 19271, 'splits': 19272, 'angus': 19273, 'scrimm': 19274, 'sarraz': 19275, 'vacationers': 19276, 'bombers': 19277, 'hassan': 19278, 'busc': 19279, 'momento': 19280, 'organizar': 19281, 'verbenesca': 19282, '171': 19283, 'marcha': 19284, 'verde': 19285, '187': 19286, 'colocaba': 19287, 'nuestro': 19288, 'ante': 19289, 'disyuntiva': 19290, 'grav': 19291, 'sima': 19292, 'superfriends': 19293, 'dyke': 19294, 'bionic': 19295, 'supermomma': 19296, 'disco': 19297, 'trannies': 19298, 'fiend': 19299, 'techweb': 19300, 'consulting': 19301, 'raids': 19302, 'kandahar': 19303, 'villages': 19304, 'courtesan': 19305, 'cleaning': 19306, 'forthcoming': 19307, 'barone': 19308, 'offending': 19309, 'saipan': 19310, 'ogres': 19311, 'cramped': 19312, 'idol': 19313, \"stephens'\": 19314, 'pawning': 19315, 'mopes': 19316, 'purple': 19317, 'polyamory': 19318, 'catskills': 19319, \"swingers'\": 19320, 'multipartner': 19321, 'elmendorf': 19322, 'scholars': 19323, 'faceted': 19324, 'occur': 19325, 'fashionable': 19326, 'linda': 19327, 'whims': 19328, 'taciturn': 19329, 'arie': 19330, 'verveen': 19331, 'psychoanalyst': 19332, 'practising': 19333, 'wooing': 19334, 'ajay': 19335, 'devgan': 19336, 'vagabond': 19337, 'alley': 19338, 'bouncer': 19339, 'recordist': 19340, 'marlo': 19341, 'marron': 19342, 'curing': 19343, 'spellbound': 19344, 'idyll': 19345, 'fanned': 19346, 'imposes': 19347, 'careens': 19348, 'attest': 19349, 'bum': 19350, 'simm': 19351, 'manuscript': 19352, 'reilhac': 19353, 'disoriented': 19354, 'mumbling': 19355, 'influences': 19356, 'hiroshima': 19357, 'nagasaki': 19358, 'bakersfield': 19359, 'blurring': 19360, 'gorge': 19361, 'polyamorous': 19362, 'migrants': 19363, 'scours': 19364, 'nagarjuna': 19365, 'austerities': 19366, 'referred': 19367, \"'stolen\": 19368, 'pert': 19369, 'mobile': 19370, 'hallucinations': 19371, 'brillance': 19372, 'ignorance': 19373, 'shipped': 19374, 'deportation': 19375, 'eludes': 19376, 'colombia': 19377, 'thiru': 19378, 'indira': 19379, 'parentage': 19380, 'ninth': 19381, 'darabont': 19382, 'packages': 19383, 'praetor': 19384, 'reman': 19385, 'nightly': 19386, 'npr': 19387, 'cheerleading': 19388, 'rica': 19389, 'maui': 19390, 'bronze': 19391, 'chronically': 19392, 'lanky': 19393, \"lewis'\": 19394, 'rikhard': 19395, 'kylie': 19396, 'penniless': 19397, 'ludvig': 19398, 'harald': 19399, 'wherewithal': 19400, 'evangelist': 19401, 'sob': 19402, 'hapless': 19403, 'matron': 19404, 'isolate': 19405, 'millie': 19406, 'stack': 19407, 'handwritten': 19408, 'unlocks': 19409, 'jennie': 19410, 'dallery': 19411, 'banger': 19412, 'sauber': 19413, 'shannon': 19414, 'phillipe': 19415, 'grimes': 19416, 'pharaohs': 19417, 'canary': 19418, 'littles': 19419, 'davidson': 19420, 'tamed': 19421, 'camels': 19422, 'trekked': 19423, 'springs': 19424, 'rescuer': 19425, 'executioner': 19426, 'betrayer': 19427, 'cults': 19428, 'sects': 19429, 'messianic': 19430, 'stipe': 19431, 'prevail': 19432, 'sage': 19433, 'mohan': 19434, 'agashe': 19435, 'stain': 19436, 'shatter': 19437, 'ayu': 19438, 'bonita': 19439, 'gorda': 19440, 'keywords': 19441, 'findings': 19442, 'ss': 19443, 'wilhelm': 19444, 'manifests': 19445, \"'going\": 19446, \"drink'\": 19447, 'infrastructure': 19448, 'consisting': 19449, 'nani': 19450, 'cobra': 19451, 'squirrels': 19452, 'colours': 19453, 'studious': 19454, 'cutural': 19455, 'fixes': 19456, 'overdue': 19457, 'archetypes': 19458, 'dacascos': 19459, 'locaction': 19460, 'vanish': 19461, 'cul': 19462, 'sac': 19463, 'kimberley': 19464, 'logue': 19465, 'rapaport': 19466, 'lyonne': 19467, 'rogers': 19468, 'favorable': 19469, 'cornea': 19470, 'addicts': 19471, 'alcoholics': 19472, 'remembrance': 19473, 'forgetting': 19474, 'arranged': 19475, 'sidelines': 19476, 'maelstrom': 19477, 'interconnected': 19478, 'rootless': 19479, 'travelling': 19480, 'edinburgh': 19481, 'subverted': 19482, 'blocking': 19483, 'uncommon': 19484, 'jazzing': 19485, 'stumped': 19486, 'schooled': 19487, 'ills': 19488, 'embryo': 19489, \"inheritors'\": 19490, 'certificate': 19491, 'rope': 19492, 'clink': 19493, 'mazzotta': 19494, 'bossman': 19495, 'vito': 19496, 'lupo': 19497, 'consigliori': 19498, 'defino': 19499, 'usurping': 19500, 'implode': 19501, 'victorious': 19502, 'laboring': 19503, 'ruffalo': 19504, 'cancels': 19505, 'phelan': 19506, \"'something'\": 19507, 'forbidding': 19508, 'admitting': 19509, 'alibi': 19510, 'multiplies': 19511, 'entertainer': 19512, 'opinions': 19513, 'buddhist': 19514, 'monastery': 19515, 'flourish': 19516, 'deducts': 19517, 'continuously': 19518, 'mindful': 19519, 'fonzi': 19520, 'inker': 19521, 'glaciers': 19522, 'scurrying': 19523, 'acorn': 19524, 'scrat': 19525, 'eaten': 19526, 'crocodiles': 19527, 'bald': 19528, 'birthmark': 19529, 'abnormally': 19530, 'tiago': 19531, \"others'\": 19532, 'coffeehouse': 19533, 'scheck': 19534, 'stores': 19535, 'plex': 19536, 'storey': 19537, 'vacations': 19538, 'oppressors': 19539, 'prewar': 19540, 'beav': 19541, 'shrink': 19542, 'siren': 19543, 'jonesy': 19544, 'premonitions': 19545, 'abandons': 19546, 'hooded': 19547, 'penitents': 19548, 'honoured': 19549, 'envelops': 19550, 'flooded': 19551, 'bids': 19552, 'warily': 19553, 'tiburon': 19554, 'inducement': 19555, 'hostaged': 19556, 'idly': 19557, 'belfast': 19558, \"'gainful\": 19559, \"employment'\": 19560, 'somete': 19561, 'defending': 19562, 'layla': 19563, 'moynahan': 19564, 'knocked': 19565, 'chesapeake': 19566, 'ripper': 19567, 'slaughtered': 19568, 'ronwell': 19569, 'dobbs': 19570, \"'splitting'\": 19571, 'decrepit': 19572, 'birdseye': 19573, 'scant': 19574, 'emancipation': 19575, 'vendetta': 19576, 'graduated': 19577, 'export': 19578, 'vikings': 19579, 'diya': 19580, 'signified': 19581, 'coasts': 19582, 'carlson': 19583, 'unreal': 19584, 'prefabricated': 19585, 'crumble': 19586, 'boi': 19587, 'vicks': 19588, 'randy': 19589, 'tigge': 19590, 'dileo': 19591, 'chairman': 19592, 'briar': 19593, 'adhiswara': 19594, 'howls': 19595, 'amorous': 19596, 'domain': 19597, 'interruptus': 19598, 'residence': 19599, 'dabbles': 19600, 'sentenced': 19601, 'concerning': 19602, 'panned': 19603, 'neighboring': 19604, 'hometowns': 19605, \"'sy'\": 19606, 'parrish': 19607, \"cristo'\": 19608, 'correctional': 19609, 'coercing': 19610, 'evicted': 19611, 'dimensionality': 19612, 'afang': 19613, 'xiang': 19614, 'testifie': 19615, 'wormtongue': 19616, 'dourif': 19617, 'normalcy': 19618, 'flurry': 19619, 'proposals': 19620, 'cranny': 19621, 'crevice': 19622, 'bonkers': 19623, 'rafelson': 19624, 'honorary': 19625, 'retrospective': 19626, 'wily': 19627, 'lebanon': 19628, 'childless': 19629, 'unlawful': 19630, 'perverted': 19631, 'insidious': 19632, 'caa': 19633, 'pero': 19634, 'alargando': 19635, 'mano': 19636, 'consiguen': 19637, 'dinero': 19638, 'suficiente': 19639, 'hacerse': 19640, 'pasar': 19641, 'mes': 19642, 'comprising': 19643, '79': 19644, 'izzie': 19645, 'sixties': 19646, 'jackunas': 19647, 'longs': 19648, 'recieve': 19649, 'saints': 19650, 'disenchanted': 19651, 'salesgirl': 19652, 'gloves': 19653, 'neiman': 19654, 'dominique': 19655, 'swain': 19656, 'wisp': 19657, 'taught': 19658, 'tryouts': 19659, 'scouts': 19660, 'scoffs': 19661, \"ideas'\": 19662, 'discreetly': 19663, 'disposes': 19664, 'brewed': 19665, 'virginal': 19666, 'mundae': 19667, 'fossilized': 19668, 'resurrects': 19669, 'predators': 19670, 'sabretooth': 19671, 'mundanities': 19672, 'proximity': 19673, '218': 19674, 'margr': 19675, 'vilhj': 19676, 'lmsd': 19677, 'ttir': 19678, 'certainty': 19679, 'richmond': 19680, 'magnus': 19681, 'edkvist': 19682, 'williamsburgh': 19683, 'flatbush': 19684, 'monitor': 19685, 'rarefied': 19686, 'assumptions': 19687, 'sculpture': 19688, 'masp': 19689, 'hence': 19690, 'shimmering': 19691, 'superiority': 19692, 'isaac': 19693, 'garity': 19694, 'forsaking': 19695, 'jeopardy': 19696, 'merchandise': 19697, \"'earn'\": 19698, 'perky': 19699, 'omega': 19700, 'pi': 19701, 'charity': 19702, 'regional': 19703, 'youht': 19704, 'boardwalks': 19705, 'nypd': 19706, 'breezed': 19707, 'unflichingly': 19708, 'rivera': 19709, 'landfill': 19710, 'horrifically': 19711, 'settlements': 19712, 'pickpocket': 19713, 'pomegranate': 19714, 'abortionist': 19715, 'reception': 19716, 'revelers': 19717, 'coroner': 19718, 'emory': 19719, 'montgomery': 19720, 'pueblo': 19721, 'exhibition': 19722, 'hosted': 19723, 'courtney': 19724, 'companionship': 19725, 'repairman': 19726, 'cleans': 19727, 'rory': 19728, 'smuggled': 19729, 'holder': 19730, 'incarcerated': 19731, '1878': 19732, 'qi': 19733, 'dennehy': 19734, 'upton': 19735, 'contingent': 19736, 'gepetto': 19737, 'policicar': 19738, 'wetted': 19739, 'stepdaughter': 19740, 'carolyne': 19741, 'adison': 19742, 'rafael': 19743, 'pepey': 19744, 'sosa': 19745, 'pitchers': 19746, 'clare': 19747, 'woodland': 19748, 'hoax': 19749, 'aviation': 19750, 'distributed': 19751, 'glances': 19752, 'veronique': 19753, 'thornton': 19754, 'violet': 19755, 'passports': 19756, 'tumbles': 19757, 'eopardized': 19758, 'kristian': 19759, 'horn': 19760, 'ulcer': 19761, 'leukemia': 19762, 'wi': 19763, 'lasses': 19764, 'gynaecologist': 19765, 'nightingale': 19766, 'modesta': 19767, 'wtc': 19768, 'preacher': 19769, 'imbued': 19770, 'unsuspectingly': 19771, 'jessie': 19772, 'pikachu': 19773, 'chorus': 19774, 'headliner': 19775, 'ushered': 19776, 'blanca': 19777, 'melting': 19778, 'investigators': 19779, 'isla': 19780, 'muerta': 19781, 'alison': 19782, 'utero': 19783, 'wasp': 19784, 'dreamboat': 19785, 'pablo': 19786, 'einstein': 19787, 'ticketed': 19788, \"'probing'\": 19789, 'sections': 19790, 'betrays': 19791, 'digibeta': 19792, 'yorinks': 19793, 'robby': 19794, 'barnett': 19795, 'wolken': 19796, 'distort': 19797, 'narva': 19798, 'petser': 19799, 'announcements': 19800, 'nikola': 19801, 'consciences': 19802, 'machinations': 19803, 'baaba': 19804, 'andoh': 19805, 'fled': 19806, 'genital': 19807, 'mutilation': 19808, \"'buy'\": 19809, 'comforts': 19810, 'funded': 19811, 'regulates': 19812, 'tahoe': 19813, 'stressed': 19814, 'salon': 19815, 'distinctively': 19816, 'pigs': 19817, 'bough': 19818, 'bungles': 19819, 'masterminded': 19820, 'kerrigan': 19821, 'krause': 19822, 'voluptuous': 19823, \"'grasp'\": 19824, 'bess': 19825, 'ridge': 19826, 'animalistic': 19827, 'tanks': 19828, 'wed': 19829, 'blanks': 19830, 'lodger': 19831, 'farrow': 19832, 'californian': 19833, 'dandridge': 19834, 'meddles': 19835, 'kaylee': 19836, 'confess': 19837, 'crores': 19838, \"'stages'\": 19839, 'nic': 19840, 'skylight': 19841, \"deeds'\": 19842, 'naivet': 19843, 'haack': 19844, 'crimelord': 19845, 'gildemontes': 19846, 'disabled': 19847, 'mails': 19848, 'impersonate': 19849, 'stutter': 19850, 'destructing': 19851, 'happier': 19852, 'consumer': 19853, 'plug': 19854, 'topping': 19855, 'disregarding': 19856, 'problemo': 19857, 'signed': 19858, 'gamekeeper': 19859, 'robbie': 19860, 'coltrane': 19861, 'taj': 19862, 'sonapur': 19863, 'playmate': 19864, 'bred': 19865, 'boroughs': 19866, 'maurice': 19867, 'hopelessness': 19868, 'increased': 19869, 'anxiety': 19870, 'massacres': 19871, 'animosities': 19872, 'codependent': 19873, 'keisha': 19874, 'especialy': 19875, 'administrations': 19876, 'windows': 19877, 'nomad': 19878, 'insulating': 19879, 'obey': 19880, 'circulate': 19881, 'wadd': 19882, 'abortion': 19883, 'euro': 19884, 'widows': 19885, 'evict': 19886, 'afire': 19887, 'billowing': 19888, 'expanse': 19889, 'neglects': 19890, 'jaguar': 19891, 'integrate': 19892, 'prefers': 19893, 'funky': 19894, 'kuroda': 19895, 'yum': 19896, 'ji': 19897, 'jin': 19898, 'hee': 19899, 'stabbed': 19900, 'brawl': 19901, 'individualism': 19902, 'casualty': 19903, 'torment': 19904, 'sculptor': 19905, 'plague': 19906, 'december': 19907, '2nd': 19908, 'microsoft': 19909, 'recurring': 19910, 'unplanned': 19911, 'nat': 19912, '8th': 19913, 'virginian': 19914, 'greenwood': 19915, 'speculators': 19916, \"fathers'\": 19917, 'naxal': 19918, 'helming': 19919, 'mosher': 19920, 'doused': 19921, 'hazardous': 19922, 'hiccups': 19923, 'shepherdess': 19924, 'singers': 19925, 'perceptible': 19926, 'bullies': 19927, 'aggression': 19928, 'elias': 19929, 'smarmy': 19930, 'smokescreen': 19931, 'clouded': 19932, 'commenting': 19933, 'anecdotes': 19934, \"'getting\": 19935, \"had'\": 19936, 'clarissa': 19937, 'injection': 19938, 'houseguest': 19939, 'prowls': 19940, 'clemens': 19941, 'caulder': 19942, 'burden': 19943, 'thwarted': 19944, 'mishappenings': 19945, 'overturned': 19946, 'legislatures': 19947, 'europeans': 19948, 'corridors': 19949, 'sensory': 19950, 'lurk': 19951, 'sexiest': 19952, 'ruling': 19953, 'tomaselli': 19954, 'esgenoopetitj': 19955, \"mi'gmaq\": 19956, 'wage': 19957, 'exercising': 19958, 'affirmed': 19959, 'rayne': 19960, 'outsmart': 19961, 'mcpherson': 19962, 'magnussen': 19963, 'newscaster': 19964, 'eyewitness': 19965, 'complains': 19966, 'telecommunications': 19967, 'confessed': 19968, 'burglar': 19969, 'looms': 19970, 'conway': 19971, 'poker': 19972, 'martini': 19973, 'olham': 19974, 'androids': 19975, 'homeworlds': 19976, 'antagonism': 19977, \"few'\": 19978, 'conmen': 19979, 'archie': 19980, 'appease': 19981, 'indra': 19982, 'custodian': 19983, 'recruitment': 19984, 'threads': 19985, 'unmarried': 19986, 'mccutcheon': 19987, 'jamboree': 19988, 'neighbourhood': 19989, 'acharya': 19990, 'aftab': 19991, 'shivdasani': 19992, 'pitches': 19993, 'mound': 19994, 'bulbs': 19995, 'visionary': 19996, 'grafts': 19997, 'ocular': 19998, 'implant': 19999, 'socket': 20000, 'forcibly': 20001, 'baptized': 20002, 'christendom': 20003, 'racoon': 20004, 'pickers': 20005, 'jureczek': 20006, 'crewmen': 20007, 'bachelorhood': 20008, 'caesars': 20009, 'totah': 20010, 'stateside': 20011, 'destinies': 20012, 'mantra': 20013, 'continuous': 20014, 'stillness': 20015, 'upons': 20016, 'froms': 20017, 'beens': 20018, 'vindicated': 20019, 'terminaor': 20020, 'whos': 20021, 'terminatrix': 20022, 'kristanna': 20023, 'loken': 20024, 'rifle': 20025, 'caller': 20026, 'kidding': 20027, 'administration': 20028, 'discrete': 20029, 'splices': 20030, 'sofia': 20031, 'mathur': 20032, 'clerick': 20033, 'vehcile': 20034, 'horoscopes': 20035, 'fifties': 20036, 'lois': 20037, 'reunites': 20038, 'cohen': 20039, 'neal': 20040, 'moritz': 20041, 'obscurity': 20042, 'snatching': 20043, 'diaper': 20044, 'sacrificing': 20045, 'nihilistic': 20046, 'yorgi': 20047, 'kareena': 20048, 'ulterior': 20049, 'darren': 20050, 'frost': 20051, 'deputy': 20052, 'dimarco': 20053, 'programmed': 20054, 'cybernetic': 20055, 'scavenged': 20056, 'cow': 20057, 'mademoiselle': 20058, 'nandita': 20059, 'das': 20060, 'rajayya': 20061, 'makrand': 20062, 'deshpande': 20063, 'naxalite': 20064, 'despande': 20065, 'sayaji': 20066, 'shinde': 20067, 'dattu': 20068, 'rajpal': 20069, 'yadav': 20070, \"'special'\": 20071, 'staunch': 20072, 'vivien': 20073, 'defied': 20074, 'ox': 20075, 'greener': 20076, 'navajo': 20077, 'yahzee': 20078, 'whitehorse': 20079, 'respectively': 20080, 'wedlock': 20081, 'contractor': 20082, 'assertive': 20083, 'opinionated': 20084, 'spiting': 20085, 'murdoch': 20086, 'mendelsohn': 20087, 'adelaide': 20088, 'securing': 20089, \"thomas'\": 20090, \"press'\": 20091, 'pencil': 20092, 'coquettish': 20093, 'marty': 20094, 'giamatti': 20095, 'limo': 20096, 'gatsbyish': 20097, 'hopper': 20098, 'detected': 20099, 'jumba': 20100, 'indestructible': 20101, 'density': 20102, '1915': 20103, 'agonizing': 20104, 'hef': 20105, 'grotto': 20106, 'caan': 20107, 'playmates': 20108, 'reaganomics': 20109, 'declining': 20110, 'gulf': 20111, 'hotly': 20112, '1976': 20113, 'surfers': 20114, 'hypertime': 20115, 'cinemania': 20116, 'quaker': 20117, 'rockabilly': 20118, 'apr': 20119, '232': 20120, 'sweats': 20121, 'frets': 20122, 'streep': 20123, 'laroche': 20124, 'orchids': 20125, 'stripper': 20126, 'reappearance': 20127, 'tire': 20128, 'unbelieving': 20129, 'nuptial': 20130, 'hbo': 20131, 'necessities': 20132, 'psychotics': 20133, 'empower': 20134, 'launius': 20135, 'deverell': 20136, 'gregson': 20137, 'wagner': 20138, 'janeane': 20139, 'garofalo': 20140, 'urbane': 20141, 'dodgy': 20142, 'accusations': 20143, 'helmut': 20144, 'busch': 20145, 'bruno': 20146, 'dilema': 20147, 'militant': 20148, 'unfeeling': 20149, 'excitingly': 20150, 'undermedicated': 20151, 'unencumbered': 20152, 'donate': 20153, 'bicker': 20154, 'kabir': 20155, 'shags': 20156, 'punter': 20157, 'berkoff': 20158, \"'work'\": 20159, 'orcs': 20160, 'secondhand': 20161, 'lions': 20162, 'osment': 20163, 'remembrances': 20164, 'sav': 20165, 'butchers': 20166, 'mahon': 20167, 'sanford': 20168, 'enslaved': 20169, 'enforced': 20170, 'brainwashing': 20171, 'culturally': 20172, 'sailing': 20173, 'redefining': 20174, 'reinventing': 20175, 'mcknight': 20176, 'woos': 20177, 'sweeps': 20178, 'commanders': 20179, 'dalam': 20180, 'pastimes': 20181, 'abduction': 20182, 'investigated': 20183, 'bayous': 20184, 'festered': 20185, 'poisonous': 20186, 'carrera': 20187, 'discoverer': 20188, 'geologist': 20189, 'hiromitsu': 20190, 'inconsequence': 20191, 'blistering': 20192, 'interrogators': 20193, 'halt': 20194, 'deserting': 20195, 'wisconsin': 20196, 'thrusting': 20197, 'dorm': 20198, 'pounds': 20199, 'heightening': 20200, 'bludgeoned': 20201, 'courtesy': 20202, 'macedonia': 20203, 'vandeva': 20204, \"'fun\": 20205, \"games'\": 20206, 'lacerating': 20207, 'impotence': 20208, 'rashes': 20209, 'triggering': 20210, 'yuki': 20211, 'prodigy': 20212, 'tort': 20213, 'deamons': 20214, 'corperate': 20215, 'kellerman': 20216, 'rumers': 20217, 'blacklisted': 20218, 'renew': 20219, 'fiece': 20220, 'thereby': 20221, 'verifying': 20222, 'lodgers': 20223, 'hitmen': 20224, 'wacked': 20225, 'adventurously': 20226, 'attemps': 20227, 'touted': 20228, 'arty': 20229, 'strapped': 20230, 'untrained': 20231, 'bulletproof': 20232, 'pursuer': 20233, 'emigrated': 20234, 'nyc': 20235, 'captives': 20236, 'prospered': 20237, 'gaming': 20238, 'auditoriums': 20239, \"'metal\": 20240, \"circus'\": 20241, 'mortician': 20242, 'bloodworth': 20243, 'reconciling': 20244, 'chestnut': 20245, 'abolishment': 20246, 'falsly': 20247, 'fluently': 20248, 'nailing': 20249, '2009': 20250, 'tyler': 20251, 'frodes': 20252, 'mette': 20253, 'translator': 20254, 'conceives': 20255, 'lucre': 20256, 'renovating': 20257, 'soho': 20258, 'embezzler': 20259, 'footballer': 20260, 'individually': 20261, 'choto': 20262, 'johny': 20263, 'goon': 20264, 'eaida': 20265, 'sunil': 20266, 'shetty': 20267, 'parlor': 20268, 'oddballs': 20269, 'coleston': 20270, 'spam': 20271, 'casseroles': 20272, 'bachelors': 20273, 'daffy': 20274, 'krystina': 20275, 'cabra': 20276, 'bathrobe': 20277, \"life'\": 20278, 'fullest': 20279, 'mason': 20280, 'regiment': 20281, 'yucatan': 20282, 'flops': 20283, 'dragging': 20284, 'turkish': 20285, 'predicts': 20286, 'convalesce': 20287, 'citizen': 20288, 'deficit': 20289, 'lyons': 20290, \"powers'\": 20291, 'nigel': 20292, 'errors': 20293, 'oven': 20294, 'infuriated': 20295, 'serenade': 20296, 'fundamentally': 20297, 'revels': 20298, 'eluded': 20299, 'kasey': 20300, 'mutiny': 20301, 'rylstone': 20302, \"'family'\": 20303, 'gunrunner': 20304, 'shiftlessness': 20305, 'lists': 20306, \"harris'\": 20307, 'creighton': 20308, 'rewind': 20309, 'ix': 20310, 'purlined': 20311, 'koilos': 20312, 'monotonously': 20313, 'fervor': 20314, 'harmonium': 20315, 'exploited': 20316, 'tormentors': 20317, 'clay': 20318, 'phantoms': 20319, 'helplessly': 20320, 'entangles': 20321, 'clipping': 20322, 'paroled': 20323, 'eleventh': 20324, 'advisor': 20325, 'demoted': 20326, 'lamarca': 20327, 'hann': 20328, 'apprentice': 20329, 'decoys': 20330, 'hierarchical': 20331, 'fractured': 20332, 'impulsive': 20333, 'valet': 20334, 'gu': 20335, 'longings': 20336, 'inmigrants': 20337, 'tortilla': 20338, '124': 20339, 'tombs': 20340, 'atkinson': 20341, 'crown': 20342, 'jewels': 20343, 'juxtaposed': 20344, 'verse': 20345, 'macro': 20346, 'microcosmic': 20347, 'asainst': 20348, 'stockpiling': 20349, 'documentry': 20350, 'conglomerates': 20351, 'makaki': 20352, '46': 20353, 'situated': 20354, 'burying': 20355, 'products': 20356, 'humiliations': 20357, 'companies': 20358, 'schroder': 20359, 'aqsa': 20360, 'intifada': 20361, 'catapulted': 20362, 'disguises': 20363, 'zip': 20364, 'removing': 20365, 'tags': 20366, 'hartnett': 20367, 'imperfections': 20368, 'festive': 20369, 'shoppers': 20370, 'pilgrimages': 20371, 'sm': 20372, 'brittany': 20373, 'ashton': 20374, 'kutcher': 20375, 'cellmates': 20376, 'mistrusts': 20377, 'discrimination': 20378, 'unforeseen': 20379, 'underpinning': 20380, \"'geography\": 20381, \"destiny'\": 20382, \"'republic'\": 20383, 'piedras': 20384, 'worry': 20385, 'jamar': 20386, 'persued': 20387, 'toothpick': 20388, 'sinai': 20389, 'hallowed': 20390, 'barren': 20391, 'northwestern': 20392, 'saudi': 20393, 'arabia': 20394, 'scoffed': 20395, 'endured': 20396, 'preserverence': 20397, 'barker': 20398, 'mcfarlane': 20399, 'cenobite': 20400, 'transformer': 20401, 'scyther': 20402, 'lucidique': 20403, 'scythe': 20404, 'anatomica': 20405, 'mongroid': 20406, 'sofa': 20407, 'pothead': 20408, 'horvath': 20409, 'washes': 20410, 'shaves': 20411, 'breakfast': 20412, 'marauders': 20413, 'ons': 20414, 'invitations': 20415, 'beek': 20416, 'whistler': 20417, 'armory': 20418, 'scud': 20419, 'hyphenated': 20420, 'desparate': 20421, 'doping': 20422, 'suppressants': 20423, 'harmful': 20424, 'occupy': 20425, 'slipping': 20426, 'inmigration': 20427, 'flesheating': 20428, 'voracious': 20429, 'poho': 20430, 'necklages': 20431, 'arabian': 20432, 'prolific': 20433, 'separating': 20434, 'santiago': 20435, 'gaining': 20436, 'losers': 20437, 'install': 20438, 'awara': 20439, 'paagal': 20440, 'deewana': 20441, 'dismantling': 20442, 'ruthie': 20443, 'archaeologist': 20444, 'roadmap': 20445, 'yakavetta': 20446, 'macmanus': 20447, 'valleys': 20448, 'suv': 20449, 'invented': 20450, 'commuted': 20451, 'jailed': 20452, 'amusement': 20453, 'affects': 20454, 'marines': 20455, 'calcutta': 20456, 'bouty': 20457, 'hunters': 20458, 'durango': 20459, 'ascapes': 20460, 'dwarfism': 20461, 'depot': 20462, 'banish': 20463, 'doom': 20464, 'eventially': 20465, 'bengtzon': 20466, 'stockholm': 20467, 'blacky': 20468, 'dumby': 20469, 'caretaker': 20470, 'ernst': 20471, 'zelnicker': 20472, 'rodents': 20473, 'dissipated': 20474, 'kinds': 20475, 'immigrating': 20476, 'climates': 20477, 'antagonized': 20478, 'lapaglia': 20479, 'hutchison': 20480, 'pooh': 20481, \"d'onfronio\": 20482, 'uploads': 20483, 'clip': 20484, 'embun': 20485, 'bayu': 20486, 'clouds': 20487, 'skinned': 20488, 'murri': 20489, 'nsw': 20490, 'boogie': 20491, 'invades': 20492, 'extremes': 20493, 'globalized': 20494, 'reins': 20495, 'perlman': 20496, 'martens': 20497, 'schizophrenic': 20498, 'artworks': 20499, 'fenced': 20500, 'demilitarised': 20501, 'hovercraft': 20502, 'differing': 20503, 'unmask': 20504, \"d'lf\": 20505, 'vilasrao': 20506, 'jefferson': 20507, 'unfinished': 20508, 'dissertation': 20509, 'kat': 20510, 'bandleaders': 20511, 'booted': 20512, 'pledge': 20513, 'respite': 20514, 'perez': 20515, 'forcinito': 20516, 'demetrius': 20517, 'navarro': 20518, 'esteban': 20519, 'barrinson': 20520, 'cub': 20521, 'coopers': 20522, 'southeast': 20523, 'monotony': 20524, 'tergensen': 20525, 'frazzled': 20526, 'mudbloods': 20527, 'muggle': 20528, 'dispatched': 20529, 'sarawak': 20530, 'selima': 20531, 'lamarr': 20532, 'retire': 20533, 'packing': 20534, 'tempest': 20535, 'mouthed': 20536, 'baumel': 20537, 'becca': 20538, 'hailey': 20539, 'noelle': 20540, 'conservatism': 20541, 'irked': 20542, 'associations': 20543, 'utilizes': 20544, 'highflying': 20545, 'karate': 20546, 'misled': 20547, 'courier': 20548, 'competitions': 20549, 'ordained': 20550, 'hemples': 20551, 'schooling': 20552, 'roper': 20553, 'orient': 20554, 'jodi': 20555, \"o'keefe\": 20556, \"'halloween\": 20557, \"h20'\": 20558, 'ancestral': 20559, 'councilwoman': 20560, 'fraudulent': 20561, 'meteoric': 20562, '41': 20563, 'partially': 20564, 'crib': 20565, 'heel': 20566, 'entourage': 20567, \"morris'\": 20568, 'ceased': 20569, 'unresolved': 20570, 'fated': 20571, 'welcoming': 20572, 'haze': 20573, 'newspapers': 20574, 'nitty': 20575, 'rehabilitate': 20576, 'persuaded': 20577, 'balkan': 20578, 'ringwraiths': 20579, 'eruption': 20580, \"'insignificant\": 20581, \"other'\": 20582, 'extramarital': 20583, 'gian': 20584, 'commission': 20585, 'davao': 20586, 'nico': 20587, 'issaquena': 20588, '1930': 20589, 'cab': 20590, 'wig': 20591, 'slocumb': 20592, 'ratings': 20593, 'nabbed': 20594, 'shreds': 20595, '16b': 20596, 'platypus': 20597, 'flats': 20598, 'soapies': 20599, 'sarcasm': 20600, 'hommage': 20601, 'kinski': 20602, 'eradicate': 20603, 'rowlands': 20604, 'vierra': 20605, 'kamakiiwa': 20606, 'wrestler': 20607, 'rebounded': 20608, 'lam': 20609, 'troublemakers': 20610, 'endowing': 20611, 'siddharth': 20612, 'philanthropist': 20613, 'underprivileged': 20614, 'twillstein': 20615, 'odenkirk': 20616, 'eldon': 20617, 'intimidation': 20618, 'groom': 20619, 'lou': 20620, 'patrcik': 20621, 'avenging': 20622, 'townsperson': 20623, 'codger': 20624, 'sonja': 20625, 'horny': 20626, 'snobby': 20627, 'operated': 20628, 'dinosaurs': 20629, 'prehistoric': 20630, 'indianapolis': 20631, 'buckling': 20632, '996': 20633, 'viking': 20634, 'trails': 20635, 'hasidim': 20636, 'communists': 20637, \"n'\": 20638, 'comings': 20639, 'nets': 20640, 'jennings': 20641, 'abby': 20642, 'asthmatic': 20643, \"jennings'\": 20644, '20laurie': 20645, 'treason': 20646, 'fernand': 20647, \"dantes'\": 20648, 'dagmara': 20649, 'dominczyk': 20650, 'conman': 20651, 'skipped': 20652, 'bail': 20653, 'voltage': 20654, 'humanitarian': 20655, 'reconnaissance': 20656, 'trudy': 20657, 'wot': 20658, 'sciltre': 20659, 'lovemaking': 20660, 'leg': 20661, 'brace': 20662, 'assessing': 20663, 'hospitals': 20664, 'resolves': 20665, 'towel': 20666, 'seedier': 20667, 'eligible': 20668, \"'full\": 20669, \"frontal'\": 20670, 'thingfs': 20671, 'contributors': 20672, 'mimi': 20673, 'leder': 20674, 'coates': 20675, 'katz': 20676, 'weill': 20677, 'annihilation': 20678, 'coville': 20679, 'kinneson': 20680, 'disconsolate': 20681, 'comprised': 20682, 'unfortunatly': 20683, \"maenads'\": 20684, 'eroticism': 20685, 'brainwash': 20686, 'heterosexuals': 20687, 'railroad': 20688, 'universities': 20689, 'stations': 20690, 'monuments': 20691, 'traverse': 20692, 'reprisals': 20693, 'clans': 20694, 'rounding': 20695, 'bartender': 20696, '12th': 20697, 'mack': 20698, 'unsteady': 20699, 'posse': 20700, 'piling': 20701, 'profits': 20702, 'plummeting': 20703, 'panda': 20704, 'civilized': 20705, 'bodyguard': 20706, 'independently': 20707, 'buckle': 20708, 'armature': 20709, 'signal': 20710, 'biding': 20711, \"producers'\": 20712, 'nephews': 20713, 'cripple': 20714, 'stored': 20715, 'papagianakopoulous': 20716, 'unimpressed': 20717, 'frills': 20718, 'adriano': 20719, 'giannini': 20720, 'hutchen': 20721, 'modelling': 20722, 'intricacies': 20723, 'shelters': 20724, 'vienna': 20725, 'bratislava': 20726, 'embarking': 20727, 'danube': 20728, 'sleuthing': 20729, 'cannibal': 20730, 'banco': 20731, 'ambrosiano': 20732, 'vatican': 20733, 'masonry': 20734, 'calvi': 20735, 'notoriously': 20736, 'blackfriars': 20737, 'math': 20738, 'mindlessly': 20739, 'administering': 20740, \"'drip'\": 20741, 'farms': 20742, 'diligently': 20743, 'gilbert': 20744, 'maladroit': 20745, \"'boys'\": 20746, 'ruhrpott': 20747, 'wrathful': 20748, 'tranny': 20749, 'sailors': 20750, 'captains': 20751, 'femmes': 20752, '16mm': 20753, 'manipulates': 20754, 'transaction': 20755, 'infertile': 20756, 'miseducation': 20757, 'podbielska': 20758, 'subliminal': 20759, 'reputed': 20760, 'vortexes': 20761, 'repose': 20762, 'seperated': 20763, 'wheeling': 20764, 'mcdormand': 20765, 'nivola': 20766, 'phileine': 20767, 'maxto': 20768, 'bizzare': 20769, 'midge': 20770, 'hirsch': 20771, 'bud': 20772, 'lung': 20773, 'troublesome': 20774, 'waged': 20775, 'legislative': 20776, 'prohibit': 20777, 'vibrators': 20778, 'dildos': 20779, 'criminalizing': 20780, \"'deviant'\": 20781, '2054': 20782, 'dc': 20783, 'intoxicated': 20784, 'locker': 20785, 'barcelona': 20786, 'dragonwheel': 20787, 'krista': 20788, 'macdonald': 20789, 'gavine': 20790, 'cling': 20791, 'roguishly': 20792, 'starkey': 20793, 'norwood': 20794, 'summons': 20795, 'outmaneuvered': 20796, 'cranham': 20797, 'trainee': 20798, 'knit': 20799, 'overzealous': 20800, 'kool': 20801, 'puteri': 20802, 'megawati': 20803, 'thankful': 20804, 'shahirah': 20805, 'paparazzi': 20806, 'nola': 20807, 'kansas': 20808, 'forging': 20809, 'hospitalized': 20810, 'glauber': 20811, 'correspondence': 20812, 'evolution': 20813, 'contribute': 20814, 'spoilt': 20815, 'brat': 20816, 'busty': 20817, 'wigglesworth': 20818, 'marcia': 20819, 'stood': 20820, 'punks': 20821, 'pad': 20822, 'cashier': 20823, 'costumers': 20824, 'holloway': 20825, 'chosing': 20826, 'buckley': 20827, 'neonatal': 20828, 'episodically': 20829, 'lilly': 20830, 'athens': 20831, 'bureau': 20832, 'chagrin': 20833, 'basket': 20834, 'twins': 20835, 'samhain': 20836, 'cottage': 20837, 'druids': 20838, 'celtic': 20839, 'prices': 20840, 'barad': 20841, 'orthanc': 20842, 'outsmarting': 20843, 'decamp': 20844, 'contents': 20845, 'tranquilino': 20846, 'tingwell': 20847, 'billings': 20848, 'grandma': 20849, 'intercedes': 20850, 'polaroid': 20851, 'reclaims': 20852, 'pawn': 20853, 'rutter': 20854, 'pollak': 20855, 'wiped': 20856, 'narcotic': 20857, 'iara': 20858, \"'gammasphere'\": 20859, \"'monsters'\": 20860, 'schwann': 20861, 'regarded': 20862, 'instructs': 20863, 'restoring': 20864, '57': 20865, '1969': 20866, 'genderbending': 20867, 'salenger': 20868, 'westwood': 20869, 'flipping': 20870, 'irrevocable': 20871, 'aravasu': 20872, 'desecrating': 20873, 'theron': 20874, 'backstabber': 20875, 'signals': 20876, 'jams': 20877, 'swamp': 20878, 'meatballs': 20879, 'breathing': 20880, 'slumber': 20881, 'decadence': 20882, 'delaney': 20883, 'wages': 20884, 'yaya': 20885, 'scot': 20886, 'patriot': 20887, 'soulmate': 20888, 'recklessly': 20889, 'reliving': 20890, 'restrictions': 20891, 'nazis': 20892, 'persistant': 20893, 'pots': 20894, 'superstition': 20895, 'montains': 20896, 'witt': 20897, 'kilpatrick': 20898, 'superintendent': 20899, 'bowler': 20900, 'contracted': 20901, 'defective': 20902, \"'return\": 20903, \"land'\": 20904, \"sands'\": 20905, '66': 20906, 'geo': 20907, 'kidnappers': 20908, 'cabo': 20909, 'planting': 20910, 'boardwalk': 20911, 'tipped': 20912, 'priestley': 20913, 'reagles': 20914, 'alexie': 20915, 'skyler': 20916, 'shaye': 20917, 'foreighn': 20918, 'ambassador': 20919, 'ditch': 20920, 'tribes': 20921, 'doubts': 20922, 'upped': 20923, 'unassisted': 20924, 'circumnavigation': 20925, 'sloop': 20926, 'becalmed': 20927, 'undergone': 20928, \"'casting\": 20929, \"couch'\": 20930, 'liaison': 20931, 'coincidentally': 20932, 'mismatch': 20933, 'troublemaking': 20934, 'ar': 20935, 'mausoleum': 20936, 'ajileo': 20937, 'zapotitlan': 20938, 'salinas': 20939, 'perilious': 20940, 'swordsman': 20941, 'merrily': 20942, 'pistols': 20943, 'albino': 20944, 'tyrone': 20945, 'ussr': 20946, 'malfunction': 20947, 'reactor': 20948, '1961': 20949, 'warring': 20950, 'socialism': 20951, 'bethlehem': 20952, 'millennia': 20953, 'greeted': 20954, 'alden': 20955, 'correspondent': 20956, 'enterprising': 20957, 'pornographers': 20958, \"o'toole\": 20959, 'vaus': 20960, 'modifies': 20961, 'spontaneously': 20962, 'fright': 20963, 'naomi': 20964, 'upstart': 20965, 'stern': 20966, 'famed': 20967, 'concerts': 20968, 'yat': 20969, 'mok': 20970, 'kassie': 20971, 'kerry': 20972, 'subjected': 20973, 'jerky': 20974, 'urging': 20975, 'comrades': 20976, 'outlining': 20977, 'expounding': 20978, 'peculiarities': 20979, 'nations': 20980, 'brightest': 20981, 'culled': 20982, 'lyric': 20983, 'tislam': 20984, 'yvette': 20985, 'freemen': 20986, 'overworked': 20987, 'er': 20988, 'fractures': 20989, 'parrot': 20990, 'lotte': 20991, 'judgement': 20992, 'trademarks': 20993, 'bosnia': 20994, 'jeckyll': 20995, 'po': 20996, 'patti': 20997, 'independant': 20998, 'junnie': 20999, 'vancouver': 21000, 'macivor': 21001, '3a': 21002, '3c': 21003, 'pyrenees': 21004, 'marrieds': 21005, 'celibate': 21006, 'validity': 21007, 'kickboxing': 21008, 'cribsheet': 21009, 'applebee': 21010, 'banded': 21011, 'afar': 21012, 'dispatcher': 21013, 'backwards': 21014, 'voted': 21015, 'bluffed': 21016, 'shahrul': 21017, 'operative': 21018, 'bruoght': 21019, 'sleepiness': 21020, 'superpowers': 21021, '1890s': 21022, 'pseudonym': 21023, 'accomplishing': 21024, 'breeding': 21025, 'chickens': 21026, 'alec': 21027, 'adolph': 21028, 'spirituality': 21029, 'spectre': 21030, 'serenity': 21031, 'ticketing': 21032, 'exonerated': 21033, 'reprimanded': 21034, 'nerdy': 21035, 'mutagenically': 21036, 'ceilings': 21037, 'warns': 21038, 'perversions': 21039, 'pills': 21040, 'electro': 21041, 'woodpussy': 21042, 'pyro': 21043, 'nebulous': 21044, 'futura': 21045, 'deluxe': 21046, 'roving': 21047, 'mathematics': 21048, 'neural': 21049, 'networks': 21050, 'ecological': 21051, 'fractals': 21052, 'mitzvah': 21053, 'hendler': 21054, 'kurt': 21055, 'conditioned': 21056, 'guevera': 21057, \"ramirez'\": 21058, 'cruiser': 21059, 'obessive': 21060, 'escapees': 21061, 'sruggling': 21062, 'depart': 21063, 'coexist': 21064, 'purchased': 21065, 'sierra': 21066, 'eared': 21067, 'internecine': 21068, 'elsa': 21069, 'offences': 21070, 'girly': 21071, 'panel': 21072, 'consist': 21073, 'everymen': 21074, 'documentarian': 21075, 'ferral': 21076, 'mitchener': 21077, 'fragility': 21078, 'deluge': 21079, 'unluckiest': 21080, 'contagious': 21081, \"rollers'\": 21082, 'interprets': 21083, 'enroute': 21084, 'moll': 21085, 'patrolling': 21086, 'daylight': 21087, 'overdosing': 21088, 'skating': 21089, \"'realness'\": 21090, 'mothlike': 21091, 'taller': 21092, 'reported': 21093, 'beautician': 21094, 'adjust': 21095, 'syndromes': 21096, 'bloodier': 21097, \"carlos'\": 21098, 'wrath': 21099, 'pridefilled': 21100, 'commentator': 21101, 'brands': 21102, 'sleepwalking': 21103, 'receptionist': 21104, 'heyl': 21105, 'mccall': 21106, 'maori': 21107, \"'pound\": 21108, \"flesh'\": 21109, 'forfeit': 21110, 'tragicomedy': 21111, 'underachieving': 21112, 'lanny': 21113, 'concludes': 21114, 'staging': 21115, 'customs': 21116, 'violations': 21117, 'enquirer': 21118, 'lieu': 21119, 'arrivals': 21120, 'dunn': 21121, 'braceface': 21122, 'brandi': 21123, 'dumbest': 21124, 'sat': 21125, 'february': 21126, 'freed': 21127, 'wannabes': 21128, 'gym': 21129, 'crips': 21130, 'bloods': 21131, 'expand': 21132, 'bereft': 21133, 'blau': 21134, 'trevor': 21135, \"times'\": 21136, 'romanticised': 21137, 'presumably': 21138, 'quoted': 21139, 'infuriates': 21140, 'peer': 21141, 'inhabited': 21142, 'stalag': 21143, 'pows': 21144, 'freefalls': 21145, 'newlyweds': 21146, 'savagily': 21147, 'teasing': 21148, 'jess': 21149, 'scheduled': 21150, 'contracts': 21151, 'tins': 21152, 'glenrowan': 21153, 'tore': 21154, 'crab': 21155, 'uranus': 21156, 'tinsel': 21157, 'tarts': 21158, 'charlene': 21159, 'gillian': 21160, 'chung': 21161, 'schoolmates': 21162, \"'studying'\": 21163, 'senate': 21164, 'saver': 21165, 'kolker': 21166, 'goat': 21167, 'spiders': 21168, 'venomous': 21169, 'gina': 21170, 'gershon': 21171, 'clamdandy': 21172, 'bauford': 21173, 'linus': 21174, 'roache': 21175, 'industrialist': 21176, 'impassioned': 21177, 'plea': 21178, 'ace': 21179, 'fuente': 21180, 'downside': 21181, 'tosses': 21182, 'identical': 21183, 'cookies': 21184, 'shuts': 21185, 'infection': 21186, 'eberl': 21187, 'colombe': 21188, 'jacobsen': 21189, 'mollen': 21190, 'chester': 21191, 'invaders': 21192, 'avail': 21193, 'spens': 21194, 'oceans': 21195, 'attended': 21196, 'vicous': 21197, 'vipers': 21198, 'liberalism': 21199, 'bags': 21200, 'undauntedly': 21201, 'marko': 21202, 'ashe': 21203, 'adamsom': 21204, 'deviants': 21205, 'outcasts': 21206, 'wrecked': 21207, 'townsville': 21208, 'atis': 21209, 'jamison': 21210, '365': 21211, 'vengence': 21212, 'renews': 21213, 'slaughtering': 21214, 'shies': 21215, 'disrespectful': 21216, 'lashes': 21217, 'reactivate': 21218, 'sonic': 21219, 'mainlining': 21220, 'lamont': 21221, 'vicky': 21222, 'counting': 21223, 'amerasian': 21224, 'babylift': 21225, 'crazier': 21226, 'nightscape': 21227, 'extending': 21228, 'fertilizing': 21229, 'isnt': 21230, 'birkin': 21231, 'reopened': 21232, 'daed': 21233, 'oblique': 21234, 'topography': 21235, 'esoterical': 21236, 'moreover': 21237, 'moulding': 21238, 'sith': 21239, 'browning': 21240, 'philipps': 21241, \"castle'\": 21242, 'dodie': 21243, '1948': 21244, 'dalmatians': 21245, 'fittest': 21246, 'bonhomme': 21247, 'schemer': 21248, 'indefatigable': 21249, 'optimist': 21250, 'plastik': 21251, \"journey'\": 21252, 'kaja': 21253, 'stroll': 21254, 'clowns': 21255, 'grandmas': 21256, 'preachers': 21257, 'undetected': 21258, 'forerunners': 21259, 'stabilized': 21260, 'sulty': 21261, 'flirting': 21262, 'porceline': 21263, 'cock': 21264, 'softwipe': 21265, 'manufacturer': 21266, 'distributor': 21267, 'plied': 21268, 'toliet': 21269, 'counts': 21270, \"euripides'\": 21271, 'bahk': 21272, \"ai'\": 21273, 'thebes': 21274, 'semele': 21275, 'scarred': 21276, 'offspring': 21277, 'schendel': 21278, 'curators': 21279, 'knife': 21280, 'tubbing': 21281, 'webster': 21282, 'accidents': 21283, 'boland': 21284, 'backers': 21285, 'repeating': 21286, 'mothmen': 21287, 'mets': 21288, 'cap': 21289, 'jacket': 21290, 'alleyway': 21291, 'dreamcatcher': 21292, 'mille': 21293, 'catastrophe': 21294, 'driveway': 21295, 'removalist': 21296, 'policies': 21297, 'maths': 21298, 'sciences': 21299, 'interrogated': 21300, 'mountaineer': 21301, 'newer': 21302, 'digi': 21303, 'draco': 21304, 'felton': 21305, 'weasly': 21306, 'hermione': 21307, 'gilderoy': 21308, 'lockhart': 21309, 'donde': 21310, 'cae': 21311, 'sol': 21312, 'ol': 21313, 'bales': 21314, 'responsable': 21315, 'warding': 21316, 'sculpted': 21317, 'tomin': 21318, 'bazaar': 21319, 'schmitt': 21320, 'gaffga': 21321, 'quotes': 21322}\n"
]
],
[
[
"<!--## Split Dataset-->",
"_____no_output_____"
],
[
"# Data Preprocessing\n<hr>",
"_____no_output_____"
],
[
"## Define `clean_doc` function",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # remove remaining tokens that are not alphabetic\n# tokens = [word for word in tokens if word.isalpha()]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens",
"_____no_output_____"
]
],
[
[
"## Develop Vocabulary\n\nA part of preparing text for text classification involves defining and tailoring the vocabulary of words supported by the model. **We can do this by loading all of the documents in the dataset and building a set of words.**\n\nThe larger the vocabulary, the more sparse the representation of each word or document. So, we may decide to support all of these words, or perhaps discard some. The final chosen vocabulary can then be saved to a file for later use, such as filtering words in new documents in the future.",
"_____no_output_____"
],
[
"We can use `Counter` class and create an instance called `vocab` as follows:",
"_____no_output_____"
]
],
[
[
"from collections import Counter\n\nvocab = Counter()\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab",
"_____no_output_____"
],
[
"# Example\nadd_doc_to_vocab(sentences, vocab)\nprint(len(vocab))\nvocab",
"14591\n"
],
[
"vocab.items()",
"_____no_output_____"
],
[
"# #########################\n# # Define the vocabulary #\n# #########################\n\n# from collections import Counter\n# from nltk.corpus import stopwords\n# stopwords = stopwords.words('english')\n# stemmer = PorterStemmer()\n \n# def clean_doc(doc):\n# # split into tokens by white space\n# tokens = doc.split()\n# # prepare regex for char filtering\n# re_punc = re.compile('[%s]' % re.escape(punctuation))\n# # remove punctuation from each word\n# tokens = [re_punc.sub('', w) for w in tokens]\n# # filter out stop words\n# tokens = [w for w in tokens if not w in stopwords]\n# # filter out short tokens\n# tokens = [word for word in tokens if len(word) >= 1]\n# # Stem the token\n# tokens = [stemmer.stem(token) for token in tokens]\n# return tokens\n\n# def add_doc_to_vocab(docs, vocab):\n# '''\n# input:\n# docs: a list of sentences (docs)\n# vocab: a vocabulary dictionary\n# output:\n# return an updated vocabulary\n# '''\n# for doc in docs:\n# tokens = clean_doc(doc)\n# vocab.update(tokens)\n# return vocab\n \n\n# # prepare cross validation with 10 splits and shuffle = True\n# kfold = KFold(10, True)\n\n# # Separate the sentences and the labels\n# sentences, labels = list(corpus.sentence), list(corpus.label)\n\n# acc_list = []\n\n# # kfold.split() will return set indices for each split\n# for train, test in kfold.split(sentences):\n# # Instantiate a vocab object\n# vocab = Counter()\n \n# train_x, test_x = [], []\n# train_y, test_y = [], []\n \n# for i in train:\n# train_x.append(sentences[i])\n# train_y.append(labels[i])\n \n# for i in test:\n# test_x.append(sentences[i])\n# test_y.append(labels[i])\n \n# vocab = add_doc_to_vocab(train_x, vocab)\n# print(len(train_x), len(test_x))\n# print(len(vocab))",
"_____no_output_____"
]
],
[
[
"<dir>",
"_____no_output_____"
],
[
"# Bag-of-Words Representation\n<hr>\n\nOnce we define our vocab obtained from the training data, we need to **convert each review into a representation that we can feed to a Multilayer Perceptron Model.**\n\nAs a reminder, here are the summary what we will do:\n- extract features from the text so the text input can be used with ML algorithms like neural networks\n- we do by converting the text into a vector representation. The larger the vocab, the longer the representation.\n- we will score the words in a document inside the vector. These scores are placed in the corresponding location in the vector representation.",
"_____no_output_____"
]
],
[
[
"def doc_to_line(doc):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join([token for token in tokens])\n return line",
"_____no_output_____"
],
[
"def clean_docs(docs):\n lines = []\n for doc in docs:\n line = doc_to_line(doc)\n lines.append(line)\n return lines",
"_____no_output_____"
],
[
"print(sentences[:5])\nclean_sentences = clean_docs(sentences[:5])\nprint()\nprint( clean_sentences)",
"['smart and alert , thirteen conversations about one thing is a small gem .', 'color , musical bounce and warm seas lapping on island shores . and just enough science to send you home thinking .', 'it is not a mass market entertainment but an uncompromising attempt by one artist to think about another .', 'a light hearted french film about the spiritual quest of a fashion model seeking peace of mind while in a love affair with a veterinarian who is a non practicing jew .', 'my wife is an actress has its moments in looking at the comic effects of jealousy . in the end , though , it is only mildly amusing when it could have been so much more .']\n\n['smart alert thirteen convers one thing small gem', 'color music bounc warm sea lap island shore enough scienc send home think', 'mass market entertain uncompromis attempt one artist think anoth', 'light heart french film spiritu quest fashion model seek peac mind love affair veterinarian non practic jew', 'wife actress moment look comic effect jealousi end though mildli amus could much']\n"
]
],
[
[
"## Bag-of-Words Vectors\n\nWe will use the **Keras API** to **convert sentences to encoded document vectors**. Although the `Tokenizer` class from TF Keras provides cleaning and vocab definition, it's better we do this ourselves so that we know exactly we are doing.",
"_____no_output_____"
]
],
[
[
"def create_tokenizer(sentence):\n tokenizer = Tokenizer()\n tokenizer.fit_on_texts(lines)\n return tokenizer",
"_____no_output_____"
]
],
[
[
"This process determines a consistent way to **convert the vocabulary to a fixed-length vector**, which is the total number of words in the vocabulary `vocab`. \n\nNext, documents can then be encoded using the Tokenizer by calling `texts_to_matrix()`. \n\nThe function takes both a list of documents to encode and an encoding mode, which is the method used to score words in the document. Here we specify **freq** to score words based on their frequency in the document. \n\nThis can be used to encode the loaded training and test data, for example:\n\n`Xtrain = tokenizer.texts_to_matrix(train_docs, mode='freq')`\n\n`Xtest = tokenizer.texts_to_matrix(test_docs, mode='freq')`",
"_____no_output_____"
]
],
[
[
"# #########################\n# # Define the vocabulary #\n# #########################\n\n# from collections import Counter\n# from nltk.corpus import stopwords\n# stopwords = stopwords.words('english')\n# stemmer = PorterStemmer()\n \n# def clean_doc(doc):\n# # split into tokens by white space\n# tokens = doc.split()\n# # prepare regex for char filtering\n# re_punc = re.compile('[%s]' % re.escape(punctuation))\n# # remove punctuation from each word\n# tokens = [re_punc.sub('', w) for w in tokens]\n# # filter out stop words\n# tokens = [w for w in tokens if not w in stopwords]\n# # filter out short tokens\n# tokens = [word for word in tokens if len(word) >= 1]\n# # Stem the token\n# tokens = [stemmer.stem(token) for token in tokens]\n# return tokens\n\n# def add_doc_to_vocab(docs, vocab):\n# '''\n# input:\n# docs: a list of sentences (docs)\n# vocab: a vocabulary dictionary\n# output:\n# return an updated vocabulary\n# '''\n# for doc in docs:\n# tokens = clean_doc(doc)\n# vocab.update(tokens)\n# return vocab\n \n# def doc_to_line(doc, vocab):\n# tokens = clean_doc(doc)\n# # filter by vocab\n# tokens = [token for token in tokens if token in vocab]\n# line = ' '.join(tokens)\n# return line\n\n# def clean_docs(docs, vocab):\n# lines = []\n# for doc in docs:\n# line = doc_to_line(doc, vocab)\n# lines.append(line)\n# return lines\n\n# def create_tokenizer(sentences):\n# tokenizer = Tokenizer()\n# tokenizer.fit_on_texts(sentences)\n# return tokenizer\n\n# # prepare cross validation with 10 splits and shuffle = True\n# kfold = KFold(10, True)\n\n# # Separate the sentences and the labels\n# sentences, labels = list(corpus.sentence), list(corpus.label)\n\n# acc_list = []\n\n# # kfold.split() will return set indices for each split\n# for train, test in kfold.split(sentences):\n# # Instantiate a vocab object\n# vocab = Counter()\n \n# train_x, test_x = [], []\n# train_y, test_y = [], []\n \n# for i in train:\n# train_x.append(sentences[i])\n# train_y.append(labels[i])\n \n# for i in test:\n# test_x.append(sentences[i])\n# test_y.append(labels[i])\n \n# # Turn the labels into a numpy array\n# train_y = np.array(train_y)\n# test_y = np.array(test_y)\n \n# # Define a vocabulary for each fold\n# vocab = add_doc_to_vocab(train_x, vocab)\n# print('The number of vocab: ', len(vocab))\n \n# # Clean the sentences\n# train_x = clean_docs(train_x, vocab)\n# test_x = clean_docs(test_x, vocab)\n \n# # Define the tokenizer\n# tokenizer = create_tokenizer(train_x)\n \n# # encode data using freq mode\n# Xtrain = tokenizer.texts_to_matrix(train_x, mode='freq')\n# Xtest = tokenizer.texts_to_matrix(test_x, mode='freq')\n \n\n# print(Xtrain.shape)\n# print(train_x[0])\n# print(Xtrain[0])\n# print(Xtest.shape)\n# print(test_x[0])\n# print(Xtest[0])",
"_____no_output_____"
]
],
[
[
"# Training and Testing the Model 3",
"_____no_output_____"
],
[
"## MLP Model 3\n\nNow, we will build Multilayer Perceptron (MLP) models to classify encoded documents as either positive or negative.\n\nAs you might have expected, the models are simply feedforward network with fully connected layers called `Dense` in the `Keras` library.\n\nNow, we will define our MLP neural network with very little trial and error so cannot be considered tuned for this problem. The configuration is as follows:\n- First hidden layer with 100 neurons and Relu activation function\n- Second hidden layer with 50 neurons and Relu activation function\n- Dropout Layer for each fully connected layer with p = 0.5\n- Output layer with Sigmoid activation function\n- Optimizer: Adam (The best learning algorithm so far)\n- Loss function: binary cross-entropy (suited for binary classification problem)",
"_____no_output_____"
]
],
[
[
"def train_mlp_3(train_x, train_y, batch_size = 50, epochs = 10, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=50, activation='relu'),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose)\n return model",
"_____no_output_____"
],
[
"callbacks = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', min_delta=0, \n patience=5, verbose=2, \n mode='auto', restore_best_weights=True)",
"_____no_output_____"
]
],
[
[
"## Train and Test the Model",
"_____no_output_____"
]
],
[
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\ndef create_tokenizer(sentences):\n tokenizer = Tokenizer()\n tokenizer.fit_on_texts(sentences)\n return tokenizer\n\ndef train_mlp_3(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=50, activation='relu'),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\nacc_list = []\n\n# kfold.split() will return set indices for each split\nfor train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n \n train_x, test_x = [], []\n train_y, test_y = [], []\n \n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n \n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n \n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n \n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n \n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n \n # Define the tokenizer\n tokenizer = create_tokenizer(train_x)\n \n # encode data using freq mode\n Xtrain = tokenizer.texts_to_matrix(train_x, mode='freq')\n Xtest = tokenizer.texts_to_matrix(test_x, mode='freq')\n \n # train the model\n model = train_mlp_3(Xtrain, train_y, Xtest, test_y)\n \n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n \n acc_list.append(acc)\n\nacc_list = np.array(acc_list)\nprint()\nprint('The test ccuracy for each training:\\n{}'.format(acc_list))\nprint('The mean of the test accuracy: ', acc_list.mean())",
"C:\\Users\\Diardano Raihan\\Anaconda3\\envs\\tf-gpu\\lib\\site-packages\\sklearn\\utils\\validation.py:72: FutureWarning: Pass shuffle=True as keyword args. From version 1.0 (renaming of 0.25) passing these as positional arguments will result in an error\n \"will result in an error\", FutureWarning)\n"
],
[
"model.summary()",
"Model: \"sequential_9\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_27 (Dense) (None, 100) 1394000 \n_________________________________________________________________\ndropout_18 (Dropout) (None, 100) 0 \n_________________________________________________________________\ndense_28 (Dense) (None, 50) 5050 \n_________________________________________________________________\ndropout_19 (Dropout) (None, 50) 0 \n_________________________________________________________________\ndense_29 (Dense) (None, 1) 51 \n=================================================================\nTotal params: 1,399,101\nTrainable params: 1,399,101\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Comparing the Word Scoring Methods",
"_____no_output_____"
],
[
"When we use `text_to_matrix()` function, we are given 4 different methods for scoring words:\n- `binary`: words are marked as 1 (present) or 0 (absent)\n- `count`: words are counted based on their occurrence (integer)\n- `tfidf`: words are scored based on their frequency of occurrence in their own document, but also are being penalized if they are common across all documents\n- `freq`: wrods are scored based on their frequency of occurrence in their own document",
"_____no_output_____"
]
],
[
[
"# prepare bag-of-words encoding of docs\ndef prepare_data(train_docs, test_docs, mode):\n # create the tokenizer\n tokenizer = Tokenizer()\n # fit the tokenizer on the documents\n tokenizer.fit_on_texts(train_docs)\n # encode training data set\n Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)\n # encode test data set\n Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)\n return Xtrain, Xtest",
"_____no_output_____"
],
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\n# prepare bag-of-words encoding of docs\ndef prepare_data(train_docs, test_docs, mode):\n # create the tokenizer\n tokenizer = Tokenizer()\n # fit the tokenizer on the documents\n tokenizer.fit_on_texts(train_docs)\n # encode training data set\n Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)\n # encode test data set\n Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)\n return Xtrain, Xtest\n\ndef train_mlp_3(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=50, activation='relu'),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\n# Run Experiment of 4 different modes\nmodes = ['binary', 'count', 'tfidf', 'freq']\nresults = pd.DataFrame()\n\nfor mode in modes:\n print('mode: ', mode)\n acc_list = []\n \n # kfold.split() will return set indices for each split\n for train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n\n train_x, test_x = [], []\n train_y, test_y = [], []\n\n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n\n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n\n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n\n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n\n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n\n # encode data using freq mode\n Xtrain, Xtest = prepare_data(train_x, test_x, mode)\n\n # train the model\n model = train_mlp_3(Xtrain, train_y, Xtest, test_y, verbose=0)\n\n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n\n acc_list.append(acc)\n \n results[mode] = acc_list\n acc_list = np.array(acc_list)\n print('The test ccuracy for each training:\\n{}'.format(acc_list))\n print('The mean of the test accuracy: ', acc_list.mean())\n print()\n\nprint(results)",
"mode: binary\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 87.90000081062317\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.39999842643738\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.69999957084656\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.30000066757202\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.80000019073486\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.20000100135803\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.49999809265137\nRestoring model weights from the end of the best epoch.\nEpoch 00013: early stopping\nTest Accuracy: 89.70000147819519\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.6000018119812\nThe test ccuracy for each training:\n[0.87900001 0.90600002 0.90399998 0.917 0.89300001 0.898\n 0.90200001 0.89499998 0.89700001 0.90600002]\nThe mean of the test accuracy: 0.899700003862381\n\nmode: count\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.99999761581421\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.30000066757202\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.80000019073486\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 88.99999856948853\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.20000100135803\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.70000147819519\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 89.99999761581421\nThe test ccuracy for each training:\n[0.89999998 0.903 0.89300001 0.898 0.88999999 0.90600002\n 0.91000003 0.90200001 0.89700001 0.89999998]\nThe mean of the test accuracy: 0.8999000012874603\n\nmode: tfidf\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.99999856948853\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.20000100135803\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.10000133514404\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.70000147819519\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.49999809265137\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.89999794960022\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.70000147819519\nThe test ccuracy for each training:\n[0.903 0.88999999 0.90200001 0.89899999 0.91100001 0.89700001\n 0.903 0.89499998 0.90899998 0.89700001]\nThe mean of the test accuracy: 0.9005999982357025\n\nmode: freq\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 90.39999842643738\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.39999842643738\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.99999761581421\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.79999828338623\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.49999904632568\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 89.60000276565552\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.20000100135803\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 90.49999713897705\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 91.69999957084656\nThe test ccuracy for each training:\n[0.89899999 0.90399998 0.90399998 0.89999998 0.91799998 0.88499999\n 0.89600003 0.90200001 0.90499997 0.917 ]\nThe mean of the test accuracy: 0.9029999911785126\n\n binary count tfidf freq\n0 0.879 0.900 0.903 0.899\n1 0.906 0.903 0.890 0.904\n2 0.904 0.893 0.902 0.904\n3 0.917 0.898 0.899 0.900\n4 0.893 0.890 0.911 0.918\n5 0.898 0.906 0.897 0.885\n6 0.902 0.910 0.903 0.896\n7 0.895 0.902 0.895 0.902\n8 0.897 0.897 0.909 0.905\n9 0.906 0.900 0.897 0.917\n"
],
[
"import seaborn as sns\n\nresults.boxplot()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Summary",
"_____no_output_____"
]
],
[
[
"results",
"_____no_output_____"
],
[
"results.describe()",
"_____no_output_____"
],
[
"report = results\nreport = report.to_excel('BoW_MLP_SUBJ_3.xlsx', sheet_name='model_3')",
"_____no_output_____"
]
],
[
[
"# Training and Testing the Model 2",
"_____no_output_____"
],
[
"## MLP Model 2\n\nNow, we will build Multilayer Perceptron (MLP) models to classify encoded documents as either positive or negative.\n\nAs you might have expected, the models are simply feedforward network with fully connected layers called `Dense` in the `Keras` library.\n\nNow, we will define our MLP neural network with very little trial and error so cannot be considered tuned for this problem. The configuration is as follows:\n- First hidden layer with 100 neurons and Relu activation function\n- Dropout layer with p = 0.5\n- Output layer with Sigmoid activation function\n- Optimizer: Adam (The best learning algorithm so far)\n- Loss function: binary cross-entropy (suited for binary classification problem)",
"_____no_output_____"
]
],
[
[
"def train_mlp_2(train_x, train_y, batch_size = 50, epochs = 10, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose)\n return model",
"_____no_output_____"
]
],
[
[
"## Train and Test the Model",
"_____no_output_____"
]
],
[
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\ndef create_tokenizer(sentences):\n tokenizer = Tokenizer()\n tokenizer.fit_on_texts(sentences)\n return tokenizer\n\ndef train_mlp_2(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\nacc_list = []\n\n# kfold.split() will return set indices for each split\nfor train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n \n train_x, test_x = [], []\n train_y, test_y = [], []\n \n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n \n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n \n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n \n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n \n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n \n # Define the tokenizer\n tokenizer = create_tokenizer(train_x)\n \n # encode data using freq mode\n Xtrain = tokenizer.texts_to_matrix(train_x, mode='freq')\n Xtest = tokenizer.texts_to_matrix(test_x, mode='freq')\n \n # train the model\n model = train_mlp_2(Xtrain, train_y, Xtest, test_y)\n \n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n \n acc_list.append(acc)\n\nacc_list = np.array(acc_list)\nprint()\nprint('The test ccuracy for each training:\\n{}'.format(acc_list))\nprint('The mean of the test accuracy: ', acc_list.mean())",
"C:\\Users\\Diardano Raihan\\Anaconda3\\envs\\tf-gpu\\lib\\site-packages\\sklearn\\utils\\validation.py:72: FutureWarning: Pass shuffle=True as keyword args. From version 1.0 (renaming of 0.25) passing these as positional arguments will result in an error\n \"will result in an error\", FutureWarning)\n"
]
],
[
[
"## Comparing the Word Scoring Methods\n\nWhen we use `text_to_matrix()` function, we are given 4 different methods for scoring words:\n- `binary`: words are marked as 1 (present) or 0 (absent)\n- `count`: words are counted based on their occurrence (integer)\n- `tfidf`: words are scored based on their frequency of occurrence in their own document, but also are being penalized if they are common across all documents\n- `freq`: wrods are scored based on their frequency of occurrence in their own document",
"_____no_output_____"
]
],
[
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\n# prepare bag-of-words encoding of docs\ndef prepare_data(train_docs, test_docs, mode):\n # create the tokenizer\n tokenizer = Tokenizer()\n # fit the tokenizer on the documents\n tokenizer.fit_on_texts(train_docs)\n # encode training data set\n Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)\n # encode test data set\n Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)\n return Xtrain, Xtest\n\ndef train_mlp_2(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=100, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\n# Run Experiment of 4 different modes\nmodes = ['binary', 'count', 'tfidf', 'freq']\nresults = pd.DataFrame()\n\nfor mode in modes:\n print('mode: ', mode)\n acc_list = []\n \n # kfold.split() will return set indices for each split\n for train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n\n train_x, test_x = [], []\n train_y, test_y = [], []\n\n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n\n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n\n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n\n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n\n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n\n # encode data using freq mode\n Xtrain, Xtest = prepare_data(train_x, test_x, mode)\n\n # train the model\n model = train_mlp_2(Xtrain, train_y, Xtest, test_y, verbose=0)\n\n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n\n acc_list.append(acc)\n \n results[mode] = acc_list\n acc_list = np.array(acc_list)\n print('The test ccuracy for each training:\\n{}'.format(acc_list))\n print('The mean of the test accuracy: ', acc_list.mean())\n print()\n\nprint(results)",
"mode: binary\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 91.60000085830688\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.99999856948853\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 88.09999823570251\nRestoring model weights from the end of the best epoch.\nEpoch 00014: early stopping\nTest Accuracy: 89.80000019073486\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.99999856948853\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.89999794960022\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.99999761581421\nThe test ccuracy for each training:\n[0.91000003 0.91600001 0.88999999 0.88099998 0.898 0.90600002\n 0.88999999 0.90899998 0.91000003 0.89999998]\nThe mean of the test accuracy: 0.9009999990463257\n\nmode: count\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 90.70000052452087\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 91.29999876022339\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.80000019073486\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.10000133514404\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.20000100135803\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.49999713897705\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.89999985694885\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.60000276565552\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.99999856948853\nThe test ccuracy for each training:\n[0.90700001 0.91299999 0.898 0.91100001 0.90200001 0.90499997\n 0.889 0.89899999 0.89600003 0.88999999]\nThe mean of the test accuracy: 0.9009999990463257\n\nmode: tfidf\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.39999842643738\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 92.29999780654907\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 89.60000276565552\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.70000052452087\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.99999761581421\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 91.20000004768372\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 90.20000100135803\nThe test ccuracy for each training:\n[0.90399998 0.90600002 0.92299998 0.89600003 0.90700001 0.89899999\n 0.90600002 0.89999998 0.912 0.90200001]\nThe mean of the test accuracy: 0.9055000007152557\n\nmode: freq\nRestoring model weights from the end of the best epoch.\nEpoch 00011: early stopping\nTest Accuracy: 89.99999761581421\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 88.80000114440918\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 91.60000085830688\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.79999923706055\nRestoring model weights from the end of the best epoch.\nEpoch 00011: early stopping\nTest Accuracy: 90.70000052452087\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 88.99999856948853\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 91.39999747276306\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 92.10000038146973\nThe test ccuracy for each training:\n[0.89999998 0.903 0.88800001 0.89899999 0.91600001 0.90799999\n 0.90700001 0.88999999 0.91399997 0.921 ]\nThe mean of the test accuracy: 0.9045999944210052\n\n binary count tfidf freq\n0 0.910 0.907 0.904 0.900\n1 0.916 0.913 0.906 0.903\n2 0.890 0.898 0.923 0.888\n3 0.881 0.911 0.896 0.899\n4 0.898 0.902 0.907 0.916\n5 0.906 0.905 0.899 0.908\n6 0.890 0.889 0.906 0.907\n7 0.909 0.899 0.900 0.890\n8 0.910 0.896 0.912 0.914\n9 0.900 0.890 0.902 0.921\n"
],
[
"results.boxplot()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Summary",
"_____no_output_____"
]
],
[
[
"results",
"_____no_output_____"
],
[
"results.describe()",
"_____no_output_____"
],
[
"report = results\nreport = report.to_excel('BoW_MLP_SUBJ_2.xlsx', sheet_name='model_2')",
"_____no_output_____"
]
],
[
[
"# Training and Testing the Model 1",
"_____no_output_____"
],
[
"## MLP Model 1\n\nNow, we will build Multilayer Perceptron (MLP) models to classify encoded documents as either positive or negative.\n\nAs you might have expected, the models are simply feedforward network with fully connected layers called `Dense` in the `Keras` library.\n\nNow, we will define our MLP neural network with very little trial and error so cannot be considered tuned for this problem. The configuration is as follows:\n- First hidden layer with 50 neurons and Relu activation function\n- Dropout layer with p = 0.5\n- Output layer with Sigmoid activation function\n- Optimizer: Adam (The best learning algorithm so far)\n- Loss function: binary cross-entropy (suited for binary classification problem)",
"_____no_output_____"
]
],
[
[
"def train_mlp_1(train_x, train_y, batch_size = 50, epochs = 10, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=50, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose)\n return model",
"_____no_output_____"
]
],
[
[
"## Train and Test the Model",
"_____no_output_____"
]
],
[
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\ndef create_tokenizer(sentences):\n tokenizer = Tokenizer()\n tokenizer.fit_on_texts(sentences)\n return tokenizer\n\ndef train_mlp_1(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=50, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\nacc_list = []\n\n# kfold.split() will return set indices for each split\nfor train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n \n train_x, test_x = [], []\n train_y, test_y = [], []\n \n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n \n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n \n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n \n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n \n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n \n # Define the tokenizer\n tokenizer = create_tokenizer(train_x)\n \n # encode data using freq mode\n Xtrain = tokenizer.texts_to_matrix(train_x, mode='freq')\n Xtest = tokenizer.texts_to_matrix(test_x, mode='freq')\n \n # train the model\n model = train_mlp_1(Xtrain, train_y, Xtest, test_y)\n \n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n \n acc_list.append(acc)\n\nacc_list = np.array(acc_list)\nprint()\nprint('The test ccuracy for each training:\\n{}'.format(acc_list))\nprint('The mean of the test accuracy: ', acc_list.mean())",
"C:\\Users\\Diardano Raihan\\Anaconda3\\envs\\tf-gpu\\lib\\site-packages\\sklearn\\utils\\validation.py:72: FutureWarning: Pass shuffle=True as keyword args. From version 1.0 (renaming of 0.25) passing these as positional arguments will result in an error\n \"will result in an error\", FutureWarning)\n"
]
],
[
[
"## Comparing the Word Scoring Methods\n\nWhen we use `text_to_matrix()` function, we are given 4 different methods for scoring words:\n- `binary`: words are marked as 1 (present) or 0 (absent)\n- `count`: words are counted based on their occurrence (integer)\n- `tfidf`: words are scored based on their frequency of occurrence in their own document, but also are being penalized if they are common across all documents\n- `freq`: wrods are scored based on their frequency of occurrence in their own document",
"_____no_output_____"
]
],
[
[
"#########################\n# Define the vocabulary #\n#########################\n\nfrom collections import Counter\nfrom nltk.corpus import stopwords\nstopwords = stopwords.words('english')\nstemmer = PorterStemmer()\n \ndef clean_doc(doc):\n # split into tokens by white space\n tokens = doc.split()\n # prepare regex for char filtering\n re_punc = re.compile('[%s]' % re.escape(punctuation))\n # remove punctuation from each word\n tokens = [re_punc.sub('', w) for w in tokens]\n # filter out stop words\n tokens = [w for w in tokens if not w in stopwords]\n # filter out short tokens\n tokens = [word for word in tokens if len(word) >= 1]\n # Stem the token\n tokens = [stemmer.stem(token) for token in tokens]\n return tokens\n\ndef add_doc_to_vocab(docs, vocab):\n '''\n input:\n docs: a list of sentences (docs)\n vocab: a vocabulary dictionary\n output:\n return an updated vocabulary\n '''\n for doc in docs:\n tokens = clean_doc(doc)\n vocab.update(tokens)\n return vocab\n \ndef doc_to_line(doc, vocab):\n tokens = clean_doc(doc)\n # filter by vocab\n tokens = [token for token in tokens if token in vocab]\n line = ' '.join(tokens)\n return line\n\ndef clean_docs(docs, vocab):\n lines = []\n for doc in docs:\n line = doc_to_line(doc, vocab)\n lines.append(line)\n return lines\n\n# prepare bag-of-words encoding of docs\ndef prepare_data(train_docs, test_docs, mode):\n # create the tokenizer\n tokenizer = Tokenizer()\n # fit the tokenizer on the documents\n tokenizer.fit_on_texts(train_docs)\n # encode training data set\n Xtrain = tokenizer.texts_to_matrix(train_docs, mode=mode)\n # encode test data set\n Xtest = tokenizer.texts_to_matrix(test_docs, mode=mode)\n return Xtrain, Xtest\n\ndef train_mlp_1(train_x, train_y, test_x, test_y, batch_size = 50, epochs = 20, verbose =2):\n \n n_words = train_x.shape[1]\n \n model = tf.keras.models.Sequential([\n tf.keras.layers.Dense( units=50, activation='relu', input_shape=(n_words,)),\n tf.keras.layers.Dropout(0.5),\n tf.keras.layers.Dense( units=1, activation='sigmoid')\n ])\n \n model.compile( loss = 'binary_crossentropy', optimizer = 'adam', metrics = ['accuracy'])\n model.fit(train_x, train_y, batch_size, epochs, verbose, callbacks = [callbacks], validation_data=(test_x, test_y))\n return model\n\n# prepare cross validation with 10 splits and shuffle = True\nkfold = KFold(10, True)\n\n# Separate the sentences and the labels\nsentences, labels = list(corpus.sentence), list(corpus.label)\n\n# Run Experiment of 4 different modes\nmodes = ['binary', 'count', 'tfidf', 'freq']\nresults = pd.DataFrame()\n\nfor mode in modes:\n print('mode: ', mode)\n acc_list = []\n \n # kfold.split() will return set indices for each split\n for train, test in kfold.split(sentences):\n # Instantiate a vocab object\n vocab = Counter()\n\n train_x, test_x = [], []\n train_y, test_y = [], []\n\n for i in train:\n train_x.append(sentences[i])\n train_y.append(labels[i])\n\n for i in test:\n test_x.append(sentences[i])\n test_y.append(labels[i])\n\n # Turn the labels into a numpy array\n train_y = np.array(train_y)\n test_y = np.array(test_y)\n\n # Define a vocabulary for each fold\n vocab = add_doc_to_vocab(train_x, vocab)\n # print('The number of vocab: ', len(vocab))\n\n # Clean the sentences\n train_x = clean_docs(train_x, vocab)\n test_x = clean_docs(test_x, vocab)\n\n # encode data using freq mode\n Xtrain, Xtest = prepare_data(train_x, test_x, mode)\n\n # train the model\n model = train_mlp_1(Xtrain, train_y, Xtest, test_y, verbose=0)\n\n # evaluate the model\n loss, acc = model.evaluate(Xtest, test_y, verbose=0)\n print('Test Accuracy: {}'.format(acc*100))\n\n acc_list.append(acc)\n \n results[mode] = acc_list\n acc_list = np.array(acc_list)\n print('The test ccuracy for each training:\\n{}'.format(acc_list))\n print('The mean of the test accuracy: ', acc_list.mean())\n print()\n\nprint(results)",
"mode: binary\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.99999761581421\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.49999713897705\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.69999957084656\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 88.80000114440918\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 90.6000018119812\nRestoring model weights from the end of the best epoch.\nEpoch 00013: early stopping\nTest Accuracy: 89.20000195503235\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.20000195503235\nThe test ccuracy for each training:\n[0.89999998 0.903 0.903 0.90499997 0.917 0.88800001\n 0.91000003 0.90600002 0.89200002 0.89200002]\nThe mean of the test accuracy: 0.9016000032424927\n\nmode: count\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 91.20000004768372\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 88.7000024318695\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 89.49999809265137\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.10000228881836\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 88.40000033378601\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 91.10000133514404\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.70000052452087\nRestoring model weights from the end of the best epoch.\nEpoch 00011: early stopping\nTest Accuracy: 90.6000018119812\nThe test ccuracy for each training:\n[0.912 0.88700002 0.91000003 0.89499998 0.89899999 0.90100002\n 0.884 0.91100001 0.90700001 0.90600002]\nThe mean of the test accuracy: 0.9012000083923339\n\nmode: tfidf\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 91.10000133514404\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 90.70000052452087\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.70000147819519\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.89999794960022\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 91.00000262260437\nRestoring model weights from the end of the best epoch.\nEpoch 00007: early stopping\nTest Accuracy: 89.89999890327454\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 89.0999972820282\nRestoring model weights from the end of the best epoch.\nEpoch 00008: early stopping\nTest Accuracy: 90.89999794960022\nRestoring model weights from the end of the best epoch.\nEpoch 00006: early stopping\nTest Accuracy: 91.90000295639038\nRestoring model weights from the end of the best epoch.\nEpoch 00010: early stopping\nTest Accuracy: 90.6000018119812\nThe test ccuracy for each training:\n[0.91100001 0.90700001 0.89700001 0.90899998 0.91000003 0.89899999\n 0.89099997 0.90899998 0.91900003 0.90600002]\nThe mean of the test accuracy: 0.9058000028133393\n\nmode: freq\nRestoring model weights from the end of the best epoch.\nEpoch 00017: early stopping\nTest Accuracy: 90.2999997138977\nRestoring model weights from the end of the best epoch.\nEpoch 00009: early stopping\nTest Accuracy: 90.39999842643738\nRestoring model weights from the end of the best epoch.\nEpoch 00015: early stopping\nTest Accuracy: 89.80000019073486\nRestoring model weights from the end of the best epoch.\nEpoch 00013: early stopping\nTest Accuracy: 91.29999876022339\nRestoring model weights from the end of the best epoch.\nEpoch 00011: early stopping\nTest Accuracy: 91.29999876022339\nRestoring model weights from the end of the best epoch.\nEpoch 00019: early stopping\nTest Accuracy: 90.49999713897705\nRestoring model weights from the end of the best epoch.\nEpoch 00015: early stopping\nTest Accuracy: 90.49999713897705\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 90.79999923706055\nRestoring model weights from the end of the best epoch.\nEpoch 00014: early stopping\nTest Accuracy: 91.20000004768372\nRestoring model weights from the end of the best epoch.\nEpoch 00012: early stopping\nTest Accuracy: 91.60000085830688\nThe test ccuracy for each training:\n[0.903 0.90399998 0.898 0.91299999 0.91299999 0.90499997\n 0.90499997 0.90799999 0.912 0.91600001]\nThe mean of the test accuracy: 0.907699990272522\n\n binary count tfidf freq\n0 0.900 0.912 0.911 0.903\n1 0.903 0.887 0.907 0.904\n2 0.903 0.910 0.897 0.898\n3 0.905 0.895 0.909 0.913\n4 0.917 0.899 0.910 0.913\n5 0.888 0.901 0.899 0.905\n6 0.910 0.884 0.891 0.905\n7 0.906 0.911 0.909 0.908\n8 0.892 0.907 0.919 0.912\n9 0.892 0.906 0.906 0.916\n"
],
[
"results.boxplot()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Summary",
"_____no_output_____"
]
],
[
[
"results",
"_____no_output_____"
],
[
"results.describe()",
"_____no_output_____"
],
[
"report = results\nreport = report.to_excel('BoW_MLP_SUBJ_1.xlsx', sheet_name='model_1')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a2aecc2dc527aa440a32dccd4a98da8ae40eea6
| 6,877 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Run Dx-checkpoint.ipynb
|
careforecast/base-forecast
|
366194c706e6f5118d8c51ba236a0cc2a24080b6
|
[
"MIT",
"Unlicense"
] | null | null | null |
.ipynb_checkpoints/Run Dx-checkpoint.ipynb
|
careforecast/base-forecast
|
366194c706e6f5118d8c51ba236a0cc2a24080b6
|
[
"MIT",
"Unlicense"
] | null | null | null |
.ipynb_checkpoints/Run Dx-checkpoint.ipynb
|
careforecast/base-forecast
|
366194c706e6f5118d8c51ba236a0cc2a24080b6
|
[
"MIT",
"Unlicense"
] | null | null | null | 22.473856 | 99 | 0.515777 |
[
[
[
"## install prerequisite",
"_____no_output_____"
]
],
[
[
"from utility.preprocessing1 import processing,load_pickle,get_augmentaion,train_test_split\nfrom models.model1 import padding,train_model,load_model,infer,DiagnosisDataset",
"_____no_output_____"
],
[
"DATA_SIZE=10000\nBASE_PATH=f'data/{DATA_SIZE}'\nFILE = f\"{BASE_PATH}/AdmissionsDiagnosesCorePopulatedTable.txt\"",
"_____no_output_____"
]
],
[
[
"## Run if you want to train your model with new data",
"_____no_output_____"
]
],
[
[
"# processing(FILE,DATA_SIZE)",
"_____no_output_____"
]
],
[
[
"## Load data from pickle",
"_____no_output_____"
]
],
[
[
"data_int,int2token,token2int=load_pickle(DATA_SIZE)",
"_____no_output_____"
]
],
[
[
"## if you need augmentaion",
"_____no_output_____"
]
],
[
[
"data_aug=get_augmentaion(data_int)",
"_____no_output_____"
]
],
[
[
"## Train test split",
"_____no_output_____"
]
],
[
[
"train, val = train_test_split(data_aug,ratio=0.05,random_seed=10)\nprint(f\"train: {len(train)} ,val: {len(val)}\")",
"_____no_output_____"
]
],
[
[
"# Train model",
"_____no_output_____"
]
],
[
[
"n_feature=16\nn_hidden=128 \nn_layer=1\ndrop_prob=0.10 \nbatch_size=32\ninput_size=11\nnum_epoch = 150\npad_value=2625 \n\nsave_path=f\"save_model/latest-b{batch_size}-e{num_epoch}_model.pth\"\n\ntrain_model(\n n_feature=n_feature,\n n_hidden=n_hidden,\n n_layer=n_layer,\n drop_prob=drop_prob,\n batch_size=batch_size,\n input_size=input_size,\n num_epoch=num_epoch,\n pad_value=pad_value,\n train=train,\n val=val,\n save_path=save_path\n)",
"_____no_output_____"
]
],
[
[
"## Load model ",
"_____no_output_____"
]
],
[
[
"DATA_SIZE=10000\ndata_int,int2token,token2int=load_pickle(DATA_SIZE)\ntrain, val = train_test_split(data_int,ratio=0.0,random_seed=10)\n\nn_feature=16\nn_hidden=128\nn_layer=1\ndrop_prob=0.10\npad_value=2625\ninput_size=11\n\nsave_path=\"save_model/latest_32_model.pth\"\nmodel=load_model(n_feature,n_hidden,n_layer,drop_prob,save_path)",
"_____no_output_____"
]
],
[
[
"## Evaluation",
"_____no_output_____"
]
],
[
[
"\nimport random\nimport torch\nimport torch.nn.functional as F\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\neval_data = DiagnosisDataset(train,11,pad_value=2625)\n\nrandom.seed(1)\nlist_rand = random.sample(range(8000),8000)\ncorrect = []\nwrong = []\nfor idx in list_rand:\n ip = torch.from_numpy(eval_data[idx][0]).view(1,-1)\n gt = eval_data[idx][1]\n with torch.no_grad():\n y_hat, _ = model(ip.to(device))\n y_hat = F.softmax(y_hat,1).cpu()\n _, indx = torch.max(y_hat,1)\n if indx.item() == gt:\n correct.append(gt)\n else:\n wrong.append({\"true\":gt, \"predicted\":indx.item(),\"index\":idx})\ntotal = len(correct) + len(wrong)\nprint(f\"accuracy: {len(correct)/total}\")\n",
"_____no_output_____"
]
],
[
[
"## Test model\n",
"_____no_output_____"
]
],
[
[
"\ndef predict():\n num=int(input(\"How many Diagnoses code do you have for next code prediction ?\\n\"))\n x_test=[]\n for x in range(num):\n x_code=input(f\"Enter Diagnoses code {x+1} = \").strip().upper()\n try:\n x_test.append(token2int[x_code])\n except:\n print(\"Embedding not present\")\n x=[int2token[x] for x in x_test]\n x_test=padding(x_test,input_size,pad_value)\n idy=infer(x_test,model)\n y=int2token[idy]\n print(\"\\n........Prediction........\\n\")\n print(f\"{x} --> {y}\")\n\npredict()",
"_____no_output_____"
],
[
"[int2token[x] for x in train[73]]",
"_____no_output_____"
],
[
"# p=['F32.4', 'Q27.1', 'H05.321', 'M31.30']",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a2afc33f5ef9a1a3e7bb421e41a237349d00a91
| 728,523 |
ipynb
|
Jupyter Notebook
|
drive-download-20210817T064431Z-001/Exoplanet_Wasp33b.ipynb
|
nadlnaru/TESSy
|
cad958794fe15f083ac262fcd4d3440ea43ef152
|
[
"MIT"
] | null | null | null |
drive-download-20210817T064431Z-001/Exoplanet_Wasp33b.ipynb
|
nadlnaru/TESSy
|
cad958794fe15f083ac262fcd4d3440ea43ef152
|
[
"MIT"
] | null | null | null |
drive-download-20210817T064431Z-001/Exoplanet_Wasp33b.ipynb
|
nadlnaru/TESSy
|
cad958794fe15f083ac262fcd4d3440ea43ef152
|
[
"MIT"
] | 5 |
2021-08-16T10:45:21.000Z
|
2021-09-22T12:29:38.000Z
| 328.311402 | 163,258 | 0.894848 |
[
[
[
"!pip install exoplanet",
"Collecting exoplanet\n Downloading exoplanet-0.5.1-py3-none-any.whl (41 kB)\n\u001b[?25l\r\u001b[K |████████ | 10 kB 21.6 MB/s eta 0:00:01\r\u001b[K |████████████████ | 20 kB 27.5 MB/s eta 0:00:01\r\u001b[K |████████████████████████ | 30 kB 14.2 MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 40 kB 10.1 MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 41 kB 83 kB/s \n\u001b[?25hCollecting aesara-theano-fallback>=0.0.2\n Downloading aesara_theano_fallback-0.0.4-py3-none-any.whl (5.4 kB)\nRequirement already satisfied: astropy>=3.1 in /usr/local/lib/python3.7/dist-packages (from exoplanet) (4.3.1)\nRequirement already satisfied: pymc3>=3.9 in /usr/local/lib/python3.7/dist-packages (from exoplanet) (3.11.2)\nCollecting exoplanet-core>=0.1\n Downloading exoplanet_core-0.1.2-cp37-cp37m-manylinux2014_x86_64.whl (211 kB)\n\u001b[?25l\r\u001b[K |█▌ | 10 kB 24.2 MB/s eta 0:00:01\r\u001b[K |███ | 20 kB 29.9 MB/s eta 0:00:01\r\u001b[K |████▋ | 30 kB 31.9 MB/s eta 0:00:01\r\u001b[K |██████▏ | 40 kB 35.5 MB/s eta 0:00:01\r\u001b[K |███████▊ | 51 kB 39.6 MB/s eta 0:00:01\r\u001b[K |█████████▎ | 61 kB 6.8 MB/s eta 0:00:01\r\u001b[K |██████████▉ | 71 kB 7.3 MB/s eta 0:00:01\r\u001b[K |████████████▍ | 81 kB 8.1 MB/s eta 0:00:01\r\u001b[K |██████████████ | 92 kB 8.5 MB/s eta 0:00:01\r\u001b[K |███████████████▌ | 102 kB 9.2 MB/s eta 0:00:01\r\u001b[K |█████████████████ | 112 kB 9.2 MB/s eta 0:00:01\r\u001b[K |██████████████████▋ | 122 kB 9.2 MB/s eta 0:00:01\r\u001b[K |████████████████████▏ | 133 kB 9.2 MB/s eta 0:00:01\r\u001b[K |█████████████████████▊ | 143 kB 9.2 MB/s eta 0:00:01\r\u001b[K |███████████████████████▎ | 153 kB 9.2 MB/s eta 0:00:01\r\u001b[K |████████████████████████▊ | 163 kB 9.2 MB/s eta 0:00:01\r\u001b[K |██████████████████████████▎ | 174 kB 9.2 MB/s eta 0:00:01\r\u001b[K |███████████████████████████▉ | 184 kB 9.2 MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▍ | 194 kB 9.2 MB/s eta 0:00:01\r\u001b[K |███████████████████████████████ | 204 kB 9.2 MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 211 kB 9.2 MB/s \n\u001b[?25hRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from astropy>=3.1->exoplanet) (4.6.3)\nRequirement already satisfied: pyerfa>=1.7.3 in /usr/local/lib/python3.7/dist-packages (from astropy>=3.1->exoplanet) (2.0.0)\nRequirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.7/dist-packages (from astropy>=3.1->exoplanet) (1.19.5)\nRequirement already satisfied: patsy>=0.5.1 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (0.5.1)\nRequirement already satisfied: cachetools>=4.2.1 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (4.2.2)\nRequirement already satisfied: scipy>=1.2.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (1.4.1)\nRequirement already satisfied: semver in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (2.13.0)\nRequirement already satisfied: arviz>=0.11.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (0.11.2)\nRequirement already satisfied: dill in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (0.3.4)\nRequirement already satisfied: pandas>=0.24.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (1.1.5)\nRequirement already satisfied: typing-extensions>=3.7.4 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (3.7.4.3)\nRequirement already satisfied: theano-pymc==1.1.2 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (1.1.2)\nRequirement already satisfied: fastprogress>=0.2.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->exoplanet) (1.0.0)\nRequirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from theano-pymc==1.1.2->pymc3>=3.9->exoplanet) (3.0.12)\nRequirement already satisfied: matplotlib>=3.0 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->exoplanet) (3.2.2)\nRequirement already satisfied: xarray>=0.16.1 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->exoplanet) (0.18.2)\nRequirement already satisfied: netcdf4 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->exoplanet) (1.5.7)\nRequirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->exoplanet) (21.0)\nRequirement already satisfied: setuptools>=38.4 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->exoplanet) (57.4.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->exoplanet) (2.8.2)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->exoplanet) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->exoplanet) (1.3.1)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->exoplanet) (0.10.0)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from cycler>=0.10->matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->exoplanet) (1.15.0)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.24.0->pymc3>=3.9->exoplanet) (2018.9)\nRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->astropy>=3.1->exoplanet) (3.5.0)\nRequirement already satisfied: cftime in /usr/local/lib/python3.7/dist-packages (from netcdf4->arviz>=0.11.0->pymc3>=3.9->exoplanet) (1.5.0)\nInstalling collected packages: exoplanet-core, aesara-theano-fallback, exoplanet\nSuccessfully installed aesara-theano-fallback-0.0.4 exoplanet-0.5.1 exoplanet-core-0.1.2\n"
],
[
"import exoplanet as xo\n\nexoplanet.utils.docs_setup()\nprint(f\"exoplanet.__version__ = '{exoplanet.__version__}'\")",
"exoplanet.__version__ = '0.5.1'\n"
],
[
"!pip install lightkurve",
"Collecting lightkurve\n Downloading lightkurve-2.0.10-py3-none-any.whl (245 kB)\n\u001b[?25l\r\u001b[K |█▍ | 10 kB 18.9 MB/s eta 0:00:01\r\u001b[K |██▊ | 20 kB 21.8 MB/s eta 0:00:01\r\u001b[K |████ | 30 kB 24.7 MB/s eta 0:00:01\r\u001b[K |█████▍ | 40 kB 21.5 MB/s eta 0:00:01\r\u001b[K |██████▊ | 51 kB 7.1 MB/s eta 0:00:01\r\u001b[K |████████ | 61 kB 5.9 MB/s eta 0:00:01\r\u001b[K |█████████▍ | 71 kB 5.8 MB/s eta 0:00:01\r\u001b[K |██████████▊ | 81 kB 6.5 MB/s eta 0:00:01\r\u001b[K |████████████ | 92 kB 6.6 MB/s eta 0:00:01\r\u001b[K |█████████████▍ | 102 kB 5.9 MB/s eta 0:00:01\r\u001b[K |██████████████▊ | 112 kB 5.9 MB/s eta 0:00:01\r\u001b[K |████████████████ | 122 kB 5.9 MB/s eta 0:00:01\r\u001b[K |█████████████████▍ | 133 kB 5.9 MB/s eta 0:00:01\r\u001b[K |██████████████████▊ | 143 kB 5.9 MB/s eta 0:00:01\r\u001b[K |████████████████████ | 153 kB 5.9 MB/s eta 0:00:01\r\u001b[K |█████████████████████▍ | 163 kB 5.9 MB/s eta 0:00:01\r\u001b[K |██████████████████████▊ | 174 kB 5.9 MB/s eta 0:00:01\r\u001b[K |████████████████████████ | 184 kB 5.9 MB/s eta 0:00:01\r\u001b[K |█████████████████████████▍ | 194 kB 5.9 MB/s eta 0:00:01\r\u001b[K |██████████████████████████▊ | 204 kB 5.9 MB/s eta 0:00:01\r\u001b[K |████████████████████████████ | 215 kB 5.9 MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▍ | 225 kB 5.9 MB/s eta 0:00:01\r\u001b[K |██████████████████████████████▊ | 235 kB 5.9 MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 245 kB 5.9 MB/s \n\u001b[?25hRequirement already satisfied: scipy>=0.19.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (1.4.1)\nRequirement already satisfied: patsy>=0.5.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (0.5.1)\nCollecting oktopus>=0.1.2\n Downloading oktopus-0.1.2.tar.gz (10 kB)\nCollecting fbpca>=1.0\n Downloading fbpca-1.0.tar.gz (11 kB)\nRequirement already satisfied: beautifulsoup4>=4.6.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (4.6.3)\nRequirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (1.19.5)\nRequirement already satisfied: requests>=2.22.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (2.23.0)\nRequirement already satisfied: tqdm>=4.25.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (4.62.0)\nCollecting uncertainties>=3.1.4\n Downloading uncertainties-3.1.6-py2.py3-none-any.whl (98 kB)\n\u001b[K |████████████████████████████████| 98 kB 6.8 MB/s \n\u001b[?25hRequirement already satisfied: pandas>=1.1.4 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (1.1.5)\nRequirement already satisfied: matplotlib>=1.5.3 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (3.2.2)\nRequirement already satisfied: astropy>=4.1 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (4.3.1)\nCollecting memoization>=0.3.1\n Downloading memoization-0.4.0.tar.gz (41 kB)\n\u001b[K |████████████████████████████████| 41 kB 167 kB/s \n\u001b[?25hCollecting astroquery>=0.3.10\n Downloading astroquery-0.4.3-py3-none-any.whl (4.4 MB)\n\u001b[K |████████████████████████████████| 4.4 MB 45.4 MB/s \n\u001b[?25hRequirement already satisfied: bokeh>=1.0 in /usr/local/lib/python3.7/dist-packages (from lightkurve) (2.3.3)\nCollecting scikit-learn>=0.24.0\n Downloading scikit_learn-0.24.2-cp37-cp37m-manylinux2010_x86_64.whl (22.3 MB)\n\u001b[K |████████████████████████████████| 22.3 MB 1.3 MB/s \n\u001b[?25hRequirement already satisfied: importlib-metadata in /usr/local/lib/python3.7/dist-packages (from astropy>=4.1->lightkurve) (4.6.3)\nRequirement already satisfied: pyerfa>=1.7.3 in /usr/local/lib/python3.7/dist-packages (from astropy>=4.1->lightkurve) (2.0.0)\nCollecting keyring>=4.0\n Downloading keyring-23.1.0-py3-none-any.whl (32 kB)\nCollecting pyvo>=1.1\n Downloading pyvo-1.1-py3-none-any.whl (802 kB)\n\u001b[K |████████████████████████████████| 802 kB 43.6 MB/s \n\u001b[?25hRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from astroquery>=0.3.10->lightkurve) (1.15.0)\nRequirement already satisfied: html5lib>=0.999 in /usr/local/lib/python3.7/dist-packages (from astroquery>=0.3.10->lightkurve) (1.0.1)\nRequirement already satisfied: packaging>=16.8 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (21.0)\nRequirement already satisfied: typing-extensions>=3.7.4 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (3.7.4.3)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (2.8.2)\nRequirement already satisfied: PyYAML>=3.10 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (3.13)\nRequirement already satisfied: tornado>=5.1 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (5.1.1)\nRequirement already satisfied: pillow>=7.1.0 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (7.1.2)\nRequirement already satisfied: Jinja2>=2.9 in /usr/local/lib/python3.7/dist-packages (from bokeh>=1.0->lightkurve) (2.11.3)\nRequirement already satisfied: webencodings in /usr/local/lib/python3.7/dist-packages (from html5lib>=0.999->astroquery>=0.3.10->lightkurve) (0.5.1)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.7/dist-packages (from Jinja2>=2.9->bokeh>=1.0->lightkurve) (2.0.1)\nCollecting SecretStorage>=3.2\n Downloading SecretStorage-3.3.1-py3-none-any.whl (15 kB)\nCollecting jeepney>=0.4.2\n Downloading jeepney-0.7.1-py3-none-any.whl (54 kB)\n\u001b[K |████████████████████████████████| 54 kB 2.3 MB/s \n\u001b[?25hRequirement already satisfied: zipp>=0.5 in /usr/local/lib/python3.7/dist-packages (from importlib-metadata->astropy>=4.1->lightkurve) (3.5.0)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5.3->lightkurve) (2.4.7)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5.3->lightkurve) (0.10.0)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5.3->lightkurve) (1.3.1)\nRequirement already satisfied: autograd in /usr/local/lib/python3.7/dist-packages (from oktopus>=0.1.2->lightkurve) (1.3)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas>=1.1.4->lightkurve) (2018.9)\nCollecting mimeparse\n Downloading mimeparse-0.1.3.tar.gz (4.4 kB)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests>=2.22.0->lightkurve) (2021.5.30)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests>=2.22.0->lightkurve) (3.0.4)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests>=2.22.0->lightkurve) (2.10)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests>=2.22.0->lightkurve) (1.24.3)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.7/dist-packages (from scikit-learn>=0.24.0->lightkurve) (1.0.1)\nCollecting threadpoolctl>=2.0.0\n Downloading threadpoolctl-2.2.0-py3-none-any.whl (12 kB)\nCollecting cryptography>=2.0\n Downloading cryptography-3.4.7-cp36-abi3-manylinux2014_x86_64.whl (3.2 MB)\n\u001b[K |████████████████████████████████| 3.2 MB 42.0 MB/s \n\u001b[?25hRequirement already satisfied: cffi>=1.12 in /usr/local/lib/python3.7/dist-packages (from cryptography>=2.0->SecretStorage>=3.2->keyring>=4.0->astroquery>=0.3.10->lightkurve) (1.14.6)\nRequirement already satisfied: pycparser in /usr/local/lib/python3.7/dist-packages (from cffi>=1.12->cryptography>=2.0->SecretStorage>=3.2->keyring>=4.0->astroquery>=0.3.10->lightkurve) (2.20)\nRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from uncertainties>=3.1.4->lightkurve) (0.16.0)\nBuilding wheels for collected packages: fbpca, memoization, oktopus, mimeparse\n Building wheel for fbpca (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for fbpca: filename=fbpca-1.0-py3-none-any.whl size=11376 sha256=bda0c951feef9bdb85cacfde65d4464b7b369cf99925b8731ffcd4d6e8fadbc1\n Stored in directory: /root/.cache/pip/wheels/93/08/0c/1b9866c35c8d3f136d100dfe88036a32e0795437daca089f70\n Building wheel for memoization (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for memoization: filename=memoization-0.4.0-py3-none-any.whl size=50466 sha256=ce4d6c6bc0e34a30c82406a1d529842ee6585a88f30eff00c1f60de4c9b97de0\n Stored in directory: /root/.cache/pip/wheels/38/f7/65/161985e7311dd484a23b3a5c9149995dbf11db6cede602e7ef\n Building wheel for oktopus (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for oktopus: filename=oktopus-0.1.2-py3-none-any.whl size=12778 sha256=fa7cb66ffcf13db7dbcbfcc047aa78f4d8b2c493ece2c673a4a44f9c6e208b0e\n Stored in directory: /root/.cache/pip/wheels/19/22/e3/6d224a32d6f94f28113d6d26c8bef81d7e05978d0efed29517\n Building wheel for mimeparse (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for mimeparse: filename=mimeparse-0.1.3-py3-none-any.whl size=3864 sha256=a63167d6aa4db36bcd263647f8b02a13fc670bf531b71ea66b52709457dbac46\n Stored in directory: /root/.cache/pip/wheels/49/b4/2d/0081759ae1833bd694024801f7aacddcda8a687e8d5fbaeebd\nSuccessfully built fbpca memoization oktopus mimeparse\nInstalling collected packages: jeepney, cryptography, SecretStorage, mimeparse, threadpoolctl, pyvo, keyring, uncertainties, scikit-learn, oktopus, memoization, fbpca, astroquery, lightkurve\n Attempting uninstall: scikit-learn\n Found existing installation: scikit-learn 0.22.2.post1\n Uninstalling scikit-learn-0.22.2.post1:\n Successfully uninstalled scikit-learn-0.22.2.post1\nSuccessfully installed SecretStorage-3.3.1 astroquery-0.4.3 cryptography-3.4.7 fbpca-1.0 jeepney-0.7.1 keyring-23.1.0 lightkurve-2.0.10 memoization-0.4.0 mimeparse-0.1.3 oktopus-0.1.2 pyvo-1.1 scikit-learn-0.24.2 threadpoolctl-2.2.0 uncertainties-3.1.6\n"
],
[
"import numpy as np\nimport lightkurve as lk\nimport matplotlib.pyplot as plt\nfrom astropy.io import fits\n\n#1 Download TPF\n\nlc_file = lk.search_lightcurve('WASP-33', mission='TESS').download(quality_bitmask=\"hardest\", flux_column=\"pdcsap_flux\")\nlc = lc_file.remove_nans().normalize().remove_outliers()\ntime = lc.time.value\nflux = lc.flux\n\n# For the purposes of this example, we'll discard some of the data\nm = (lc.quality == 0) & (\n np.random.default_rng(261136679).uniform(size=len(time)) < 0.3\n)\n\nwith fits.open(lc_file.filename) as hdu:\n hdr = hdu[1].header\n\ntexp = hdr[\"FRAMETIM\"] * hdr[\"NUM_FRM\"]\ntexp /= 60.0 * 60.0 * 24.0\n\nref_time = 0.5 * (np.min(time) + np.max(time))\nx = np.ascontiguousarray(time[m] - ref_time, dtype=np.float64)\ny = np.ascontiguousarray(1e3 * (flux[m] - 1.0), dtype=np.float64)\n\nplt.plot(x, y, \".k\")\nplt.xlabel(\"time [days]\")\nplt.ylabel(\"relative flux [ppt]\")\n_ = plt.xlim(x.min(), x.max())",
"/usr/local/lib/python3.7/dist-packages/lightkurve/search.py:352: LightkurveWarning: Warning: 3 files available to download. Only the first file has been downloaded. Please use `download_all()` or specify additional criteria (e.g. quarter, campaign, or sector) to limit your search.\n LightkurveWarning,\n"
]
],
[
[
"# Transit Search\n\nuse the box least squares periodogram from AstroPy, to estimate the period, phase, and depth of the transit.",
"_____no_output_____"
]
],
[
[
"from astropy.timeseries import BoxLeastSquares\n\nperiod_grid = np.exp(np.linspace(np.log(1), np.log(15), 50000))\n\nbls = BoxLeastSquares(x, y)\nbls_power = bls.power(period_grid, 0.1, oversample=20)\n\n# Save the highest peak as the planet candidate\nindex = np.argmax(bls_power.power)\nbls_period = bls_power.period[index]\nbls_t0 = bls_power.transit_time[index]\nbls_depth = bls_power.depth[index]\ntransit_mask = bls.transit_mask(x, bls_period, 0.2, bls_t0)\n\nfig, axes = plt.subplots(2, 1, figsize=(10, 10))\n\n# Plot the periodogram\nax = axes[0]\nax.axvline(np.log10(bls_period), color=\"C1\", lw=5, alpha=0.8)\nax.plot(np.log10(bls_power.period), bls_power.power, \"k\")\nax.annotate(\n \"period = {0:.4f} d\".format(bls_period),\n (0, 1),\n xycoords=\"axes fraction\",\n xytext=(5, -5),\n textcoords=\"offset points\",\n va=\"top\",\n ha=\"left\",\n fontsize=12,\n)\nax.set_ylabel(\"bls power\")\nax.set_yticks([])\nax.set_xlim(np.log10(period_grid.min()), np.log10(period_grid.max()))\nax.set_xlabel(\"log10(period)\")\n\n# Plot the folded transit\nax = axes[1]\nx_fold = (x - bls_t0 + 0.5 * bls_period) % bls_period - 0.5 * bls_period\nm = np.abs(x_fold) < 0.4\nax.plot(x_fold[m], y[m], \".k\")\n\n# Overplot the phase binned light curve\nbins = np.linspace(-0.41, 0.41, 32)\ndenom, _ = np.histogram(x_fold, bins)\nnum, _ = np.histogram(x_fold, bins, weights=y)\ndenom[num == 0] = 1.0\nax.plot(0.5 * (bins[1:] + bins[:-1]), num / denom, color=\"C1\")\n\nax.set_xlim(-0.3, 0.3)\nax.set_ylabel(\"de-trended flux [ppt]\")\n_ = ax.set_xlabel(\"time since transit\")",
"_____no_output_____"
]
],
[
[
"# The transit model in PyMC3\n\n",
"_____no_output_____"
]
],
[
[
"!pip install pymc3_ext",
"Collecting pymc3_ext\n Downloading pymc3_ext-0.1.0-py2.py3-none-any.whl (22 kB)\nRequirement already satisfied: aesara-theano-fallback>=0.0.2 in /usr/local/lib/python3.7/dist-packages (from pymc3_ext) (0.0.4)\nRequirement already satisfied: pymc3>=3.9 in /usr/local/lib/python3.7/dist-packages (from pymc3_ext) (3.11.2)\nRequirement already satisfied: patsy>=0.5.1 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (0.5.1)\nRequirement already satisfied: scipy>=1.2.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (1.4.1)\nRequirement already satisfied: dill in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (0.3.4)\nRequirement already satisfied: cachetools>=4.2.1 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (4.2.2)\nRequirement already satisfied: theano-pymc==1.1.2 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (1.1.2)\nRequirement already satisfied: semver in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (2.13.0)\nRequirement already satisfied: arviz>=0.11.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (0.11.2)\nRequirement already satisfied: typing-extensions>=3.7.4 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (3.7.4.3)\nRequirement already satisfied: numpy>=1.15.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (1.19.5)\nRequirement already satisfied: fastprogress>=0.2.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (1.0.0)\nRequirement already satisfied: pandas>=0.24.0 in /usr/local/lib/python3.7/dist-packages (from pymc3>=3.9->pymc3_ext) (1.1.5)\nRequirement already satisfied: filelock in /usr/local/lib/python3.7/dist-packages (from theano-pymc==1.1.2->pymc3>=3.9->pymc3_ext) (3.0.12)\nRequirement already satisfied: xarray>=0.16.1 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (0.18.2)\nRequirement already satisfied: packaging in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (21.0)\nRequirement already satisfied: setuptools>=38.4 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (57.4.0)\nRequirement already satisfied: netcdf4 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (1.5.7)\nRequirement already satisfied: matplotlib>=3.0 in /usr/local/lib/python3.7/dist-packages (from arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (3.2.2)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (2.8.2)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (1.3.1)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (0.10.0)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from cycler>=0.10->matplotlib>=3.0->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (1.15.0)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas>=0.24.0->pymc3>=3.9->pymc3_ext) (2018.9)\nRequirement already satisfied: cftime in /usr/local/lib/python3.7/dist-packages (from netcdf4->arviz>=0.11.0->pymc3>=3.9->pymc3_ext) (1.5.0)\nInstalling collected packages: pymc3-ext\nSuccessfully installed pymc3-ext-0.1.0\n"
],
[
"!pip install celerite2",
"Collecting celerite2\n Downloading celerite2-0.2.0-cp37-cp37m-manylinux2014_x86_64.whl (864 kB)\n\u001b[K |████████████████████████████████| 864 kB 5.2 MB/s \n\u001b[?25hRequirement already satisfied: numpy>=1.13.0 in /usr/local/lib/python3.7/dist-packages (from celerite2) (1.19.5)\nInstalling collected packages: celerite2\nSuccessfully installed celerite2-0.2.0\n"
],
[
"import pymc3 as pm\nimport aesara_theano_fallback.tensor as tt\n\nimport pymc3_ext as pmx\nfrom celerite2.theano import terms, GaussianProcess\n\nphase_lc = np.linspace(-0.3, 0.3, 100)\n\n\ndef build_model(mask=None, start=None):\n if mask is None:\n mask = np.ones(len(x), dtype=bool)\n with pm.Model() as model:\n\n # Parameters for the stellar properties\n mean = pm.Normal(\"mean\", mu=0.0, sd=10.0)\n u_star = xo.QuadLimbDark(\"u_star\")\n star = xo.LimbDarkLightCurve(u_star)\n\n # Stellar parameters from exo.mast\n M_star = 1.50, 0.03\n R_star = 1.44, 0.03\n BoundedNormal = pm.Bound(pm.Normal, lower=0, upper=3)\n m_star = BoundedNormal(\n \"m_star\", mu=M_star[0], sd=M_star[1]\n )\n r_star = BoundedNormal(\n \"r_star\", mu=R_star[0], sd=R_star[1]\n )\n\n # Orbital parameters for the planets\n t0 = pm.Normal(\"t0\", mu=bls_t0, sd=1)\n log_period = pm.Normal(\"log_period\", mu=np.log(bls_period), sd=1)\n period = pm.Deterministic(\"period\", tt.exp(log_period))\n\n # Fit in terms of transit depth (assuming b<1)\n b = pm.Uniform(\"b\", lower=0, upper=1)\n log_depth = pm.Normal(\"log_depth\", mu=np.log(bls_depth), sigma=2.0)\n ror = pm.Deterministic(\n \"ror\",\n star.get_ror_from_approx_transit_depth(\n 1e-3 * tt.exp(log_depth), b\n ),\n )\n r_pl = pm.Deterministic(\"r_pl\", ror * r_star)\n\n # log_r_pl = pm.Normal(\n # \"log_r_pl\",\n # sd=1.0,\n # mu=0.5 * np.log(1e-3 * np.array(bls_depth))\n # + np.log(R_star_huang[0]),\n # )\n # r_pl = pm.Deterministic(\"r_pl\", tt.exp(log_r_pl))\n # ror = pm.Deterministic(\"ror\", r_pl / r_star)\n # b = xo.distributions.ImpactParameter(\"b\", ror=ror)\n\n ecs = pmx.UnitDisk(\"ecs\", testval=np.array([0.01, 0.0]))\n ecc = pm.Deterministic(\"ecc\", tt.sum(ecs ** 2))\n omega = pm.Deterministic(\"omega\", tt.arctan2(ecs[1], ecs[0]))\n xo.eccentricity.kipping13(\"ecc_prior\", fixed=True, observed=ecc)\n\n # Transit jitter & GP parameters\n log_sigma_lc = pm.Normal(\n \"log_sigma_lc\", mu=np.log(np.std(y[mask])), sd=10\n )\n log_rho_gp = pm.Normal(\"log_rho_gp\", mu=0, sd=10)\n log_sigma_gp = pm.Normal(\n \"log_sigma_gp\", mu=np.log(np.std(y[mask])), sd=10\n )\n\n # Orbit model\n orbit = xo.orbits.KeplerianOrbit(\n r_star=r_star,\n m_star=m_star,\n period=period,\n t0=t0,\n b=b,\n ecc=ecc,\n omega=omega,\n )\n\n # Compute the model light curve\n light_curves = (\n star.get_light_curve(orbit=orbit, r=r_pl, t=x[mask], texp=texp)\n * 1e3\n )\n light_curve = tt.sum(light_curves, axis=-1) + mean\n resid = y[mask] - light_curve\n\n # GP model for the light curve\n kernel = terms.SHOTerm(\n sigma=tt.exp(log_sigma_gp),\n rho=tt.exp(log_rho_gp),\n Q=1 / np.sqrt(2),\n )\n gp = GaussianProcess(kernel, t=x[mask], yerr=tt.exp(log_sigma_lc))\n gp.marginal(\"gp\", observed=resid)\n # pm.Deterministic(\"gp_pred\", gp.predict(resid))\n\n # Compute and save the phased light curve models\n pm.Deterministic(\n \"lc_pred\",\n 1e3\n * star.get_light_curve(\n orbit=orbit, r=r_pl, t=t0 + phase_lc, texp=texp\n )[..., 0],\n )\n\n # Fit for the maximum a posteriori parameters, I've found that I can get\n # a better solution by trying different combinations of parameters in turn\n if start is None:\n start = model.test_point\n map_soln = pmx.optimize(\n start=start, vars=[log_sigma_lc, log_sigma_gp, log_rho_gp]\n )\n map_soln = pmx.optimize(start=map_soln, vars=[log_depth])\n map_soln = pmx.optimize(start=map_soln, vars=[b])\n map_soln = pmx.optimize(start=map_soln, vars=[log_period, t0])\n map_soln = pmx.optimize(start=map_soln, vars=[u_star])\n map_soln = pmx.optimize(start=map_soln, vars=[log_depth])\n map_soln = pmx.optimize(start=map_soln, vars=[b])\n map_soln = pmx.optimize(start=map_soln, vars=[ecs])\n map_soln = pmx.optimize(start=map_soln, vars=[mean])\n map_soln = pmx.optimize(\n start=map_soln, vars=[log_sigma_lc, log_sigma_gp, log_rho_gp]\n )\n map_soln = pmx.optimize(start=map_soln)\n\n extras = dict(\n zip(\n [\"light_curves\", \"gp_pred\"],\n pmx.eval_in_model([light_curves, gp.predict(resid)], map_soln),\n )\n )\n\n return model, map_soln, extras\n\n\nmodel0, map_soln0, extras0 = build_model()",
"optimizing logp for variables: [log_rho_gp, log_sigma_gp, log_sigma_lc]\n"
]
],
[
[
"plot the initial light curve model",
"_____no_output_____"
]
],
[
[
"def plot_light_curve(soln, extras, mask=None):\n if mask is None:\n mask = np.ones(len(x), dtype=bool)\n\n fig, axes = plt.subplots(3, 1, figsize=(10, 7), sharex=True)\n\n ax = axes[0]\n ax.plot(x[mask], y[mask], \"k\", label=\"data\")\n gp_mod = extras[\"gp_pred\"] + soln[\"mean\"]\n ax.plot(x[mask], gp_mod, color=\"C2\", label=\"gp model\")\n ax.legend(fontsize=10)\n ax.set_ylabel(\"relative flux [ppt]\")\n\n ax = axes[1]\n ax.plot(x[mask], y[mask] - gp_mod, \"k\", label=\"de-trended data\")\n for i, l in enumerate(\"b\"):\n mod = extras[\"light_curves\"][:, i]\n ax.plot(x[mask], mod, label=\"planet {0}\".format(l))\n ax.legend(fontsize=10, loc=3)\n ax.set_ylabel(\"de-trended flux [ppt]\")\n\n ax = axes[2]\n mod = gp_mod + np.sum(extras[\"light_curves\"], axis=-1)\n ax.plot(x[mask], y[mask] - mod, \"k\")\n ax.axhline(0, color=\"#aaaaaa\", lw=1)\n ax.set_ylabel(\"residuals [ppt]\")\n ax.set_xlim(x[mask].min(), x[mask].max())\n ax.set_xlabel(\"time [days]\")\n\n return fig\n\n\n_ = plot_light_curve(map_soln0, extras0)",
"_____no_output_____"
]
],
[
[
"sigma clipping to remove significant outliers",
"_____no_output_____"
]
],
[
[
"mod = (\n extras0[\"gp_pred\"]\n + map_soln0[\"mean\"]\n + np.sum(extras0[\"light_curves\"], axis=-1)\n)\nresid = y - mod\nrms = np.sqrt(np.median(resid ** 2))\nmask = np.abs(resid) < 5 * rms\n\nplt.figure(figsize=(10, 5))\nplt.plot(x, resid, \"k\", label=\"data\")\nplt.plot(x[~mask], resid[~mask], \"xr\", label=\"outliers\")\nplt.axhline(0, color=\"#aaaaaa\", lw=1)\nplt.ylabel(\"residuals [ppt]\")\nplt.xlabel(\"time [days]\")\nplt.legend(fontsize=12, loc=3)\n_ = plt.xlim(x.min(), x.max())",
"_____no_output_____"
]
],
[
[
"re-build the model using the data without outlier",
"_____no_output_____"
]
],
[
[
"model, map_soln, extras = build_model(mask, map_soln0)\n_ = plot_light_curve(map_soln, extras, mask)",
"optimizing logp for variables: [log_rho_gp, log_sigma_gp, log_sigma_lc]\n"
],
[
"import platform\n\nwith model:\n trace = pm.sample(\n tune=1500,\n draws=1000,\n start=map_soln,\n # Parallel sampling runs poorly or crashes on macos\n cores=1 if platform.system() == \"Darwin\" else 2,\n chains=2,\n target_accept=0.95,\n return_inferencedata=True,\n random_seed=[261136679, 261136680],\n init=\"adapt_full\",\n )",
"Auto-assigning NUTS sampler...\nInitializing NUTS using adapt_full...\nMultiprocess sampling (2 chains in 2 jobs)\nNUTS: [log_sigma_gp, log_rho_gp, log_sigma_lc, ecs, log_depth, b, log_period, t0, r_star, m_star, u_star, mean]\n"
],
[
"import arviz as az\n\naz.summary(\n trace,\n var_names=[\n \"omega\",\n \"ecc\",\n \"r_pl\",\n \"b\",\n \"t0\",\n \"period\",\n \"r_star\",\n \"m_star\",\n \"u_star\",\n \"mean\",\n ],\n)",
"_____no_output_____"
],
[
"flat_samps = trace.posterior.stack(sample=(\"chain\", \"draw\"))\n\n# Compute the GP prediction\ngp_mod = extras[\"gp_pred\"] + map_soln[\"mean\"] # np.median(\n# flat_samps[\"gp_pred\"].values + flat_samps[\"mean\"].values[None, :], axis=-1\n# )\n\n# Get the posterior median orbital parameters\np = np.median(flat_samps[\"period\"])\nt0 = np.median(flat_samps[\"t0\"])\n\n# Plot the folded data\nx_fold = (x[mask] - t0 + 0.5 * p) % p - 0.5 * p\nplt.plot(x_fold, y[mask] - gp_mod, \".k\", label=\"data\", zorder=-1000)\n\n# Overplot the phase binned light curve\nbins = np.linspace(-0.41, 0.41, 50)\ndenom, _ = np.histogram(x_fold, bins)\nnum, _ = np.histogram(x_fold, bins, weights=y[mask])\ndenom[num == 0] = 1.0\nplt.plot(\n 0.5 * (bins[1:] + bins[:-1]), num / denom, \"o\", color=\"C2\", label=\"binned\"\n)\n\n# Plot the folded model\npred = np.percentile(flat_samps[\"lc_pred\"], [16, 50, 84], axis=-1)\nplt.plot(phase_lc, pred[1], color=\"C1\", label=\"model\")\nart = plt.fill_between(\n phase_lc, pred[0], pred[2], color=\"C1\", alpha=0.5, zorder=1000\n)\nart.set_edgecolor(\"none\")\n\n# Annotate the plot with the planet's period\ntxt = \"period = {0:.5f} +/- {1:.5f} d\".format(\n np.mean(flat_samps[\"period\"].values), np.std(flat_samps[\"period\"].values)\n)\nplt.annotate(\n txt,\n (0, 0),\n xycoords=\"axes fraction\",\n xytext=(5, 5),\n textcoords=\"offset points\",\n ha=\"left\",\n va=\"bottom\",\n fontsize=12,\n)\n\nplt.legend(fontsize=10, loc=4)\nplt.xlim(-0.5 * p, 0.5 * p)\nplt.xlabel(\"time since transit [days]\")\nplt.ylabel(\"de-trended flux\")\n_ = plt.xlim(-0.15, 0.15)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a2b06ac10a20f2ec3925bcc950a370ad146d098
| 44,009 |
ipynb
|
Jupyter Notebook
|
Bad passwords and the NIST guidelines/notebook.ipynb
|
veeralakrishna/DataCamp-Project-Solutions-Pyhton
|
1996c71f170be2e410e9344ed76a707e6fac39a9
|
[
"MIT"
] | 98 |
2019-02-10T06:32:25.000Z
|
2022-03-25T22:58:11.000Z
|
Bad passwords and the NIST guidelines/notebook.ipynb
|
bibekuchiha/DataCamp-Portfolio-Project-Solutions--Python
|
1996c71f170be2e410e9344ed76a707e6fac39a9
|
[
"MIT"
] | null | null | null |
Bad passwords and the NIST guidelines/notebook.ipynb
|
bibekuchiha/DataCamp-Portfolio-Project-Solutions--Python
|
1996c71f170be2e410e9344ed76a707e6fac39a9
|
[
"MIT"
] | 60 |
2020-05-27T21:36:09.000Z
|
2022-03-23T04:28:15.000Z
| 44,009 | 44,009 | 0.555705 |
[
[
[
"## 1. The NIST Special Publication 800-63B\n<p>If you – 50 years ago – needed to come up with a secret password you were probably part of a secret espionage organization or (more likely) you were pretending to be a spy when playing as a kid. Today, many of us are forced to come up with new passwords <em>all the time</em> when signing into sites and apps. As a password <em>inventeur</em> it is your responsibility to come up with good, hard-to-crack passwords. But it is also in the interest of sites and apps to make sure that you use good passwords. The problem is that it's really hard to define what makes a good password. However, <em>the National Institute of Standards and Technology</em> (NIST) knows what the second best thing is: To make sure you're at least not using a <em>bad</em> password. </p>\n<p>In this notebook, we will go through the rules in <a href=\"https://pages.nist.gov/800-63-3/sp800-63b.html\">NIST Special Publication 800-63B</a> which details what checks a <em>verifier</em> (what the NIST calls a second party responsible for storing and verifying passwords) should perform to make sure users don't pick bad passwords. We will go through the passwords of users from a fictional company and use python to flag the users with bad passwords. But us being able to do this already means the fictional company is breaking one of the rules of 800-63B:</p>\n<blockquote>\n <p>Verifiers SHALL store memorized secrets in a form that is resistant to offline attacks. Memorized secrets SHALL be salted and hashed using a suitable one-way key derivation function.</p>\n</blockquote>\n<p>That is, never save users' passwords in plaintext, always encrypt the passwords! Keeping this in mind for the next time we're building a password management system, let's load in the data.</p>\n<p><em>Warning: The list of passwords and the fictional user database both contain <strong>real</strong> passwords leaked from <strong>real</strong> websites. These passwords have not been filtered in any way and include words that are explicit, derogatory and offensive.</em></p>",
"_____no_output_____"
]
],
[
[
"# Importing the pandas module\nimport pandas as pd\n\n# Loading in datasets/users.csv \nusers = pd.read_csv('datasets/users.csv')\n\n# Printing out how many users we've got\nprint(users)\n\n# Taking a look at the 12 first users\nusers.head(12)",
" id user_name password\n0 1 vance.jennings joobheco\n1 2 consuelo.eaton 0869347314\n2 3 mitchel.perkins fabypotter\n3 4 odessa.vaughan aharney88\n4 5 araceli.wilder acecdn3000\n5 6 shawn.harrington 5278049\n6 7 evelyn.gay master\n7 8 noreen.hale murphy\n8 9 gladys.ward lwsves2\n9 10 brant.zimmerman 1190KAREN5572497\n10 11 leanna.abbott aivlys24\n11 12 milford.hubbard hubbard\n12 13 mamie.fox mitonguito\n13 14 jamie.cochran 310356\n14 15 nathaniel.robinson angelmajo\n15 16 lorrie.gay oZ4k0QE\n16 17 domingo.dyer chelsea\n17 18 martin.pacheco zvc1939\n18 19 shelby.massey nickgd\n19 20 rosella.barrett O2gv3LlcfG\n20 21 karina.morton dada4943\n21 22 leticia.sanford cocacola\n22 23 jenny.woodard woodard\n23 24 brandie.webster sentry31\n24 25 sabrina.suarez OTEL3Q0D8y\n25 26 dianna.munoz AJ9Da\n26 27 julia.savage ewokzs\n27 28 loretta.bass WvNV1aKyFEcPe\n28 29 joaquin.walters YyGjz8E\n29 30 rene.small toreze00\n.. ... ... ...\n952 953 christa.morrison mercedes\n953 954 clarence.britt 28may1997\n954 955 carmela.clayton N2XTArGRVhKl5\n955 956 royce.combs Ct3EayTGuHs4Ic2\n956 957 devon.holman raiders\n957 958 becky.hickman AQiCWRGL\n958 959 deena.holmes 9xQUdbKNhYsW\n959 960 mark.chandler ye6491982\n960 961 carmelo.byers asdfgh\n961 962 mohammed.carpenter ujXSn2dZWhF\n962 963 rico.valentine ap10172203\n963 964 angel.jefferson 51183208\n964 965 chrystal.burns DILWYN\n965 966 irma.vasquez spider\n966 967 taylor.kent summer\n967 968 deloris.dixon seeks\n968 969 julian.gross Passion!\n969 970 joey.poole lagrimason\n970 971 noel.montoya colours\n971 972 josef.hoffman pharmacy2012\n972 973 jorge.patrick 09196921342\n973 974 rogelio.payne ilamujoy\n974 975 lucille.stark buddaball\n975 976 freeman.rose rangers\n976 977 monica.flores broktaydrew16\n977 978 autumn.alford akgkhk82\n978 979 miriam.haynes jhavonne93\n979 980 genaro.russo v2PfqcQDleA\n980 981 lora.quinn antonau\n981 982 elmer.mccormick goldfish92\n\n[982 rows x 3 columns]\n"
]
],
[
[
"## 2. Passwords should not be too short\n<p>If we take a look at the first 12 users above we already see some bad passwords. But let's not get ahead of ourselves and start flagging passwords <em>manually</em>. What is the first thing we should check according to the NIST Special Publication 800-63B?</p>\n<blockquote>\n <p>Verifiers SHALL require subscriber-chosen memorized secrets to be at least 8 characters in length.</p>\n</blockquote>\n<p>Ok, so the passwords of our users shouldn't be too short. Let's start by checking that!</p>",
"_____no_output_____"
]
],
[
[
"# Calculating the lengths of users' passwords\nimport pandas as pd\nusers = pd.read_csv('datasets/users.csv')\nusers['length'] = users.password.str.len()\nusers['too_short'] = users['length'] < 8\nprint(users['too_short'].sum())\n\n# Taking a look at the 12 first rows\nusers.head(12)",
"376\n"
]
],
[
[
"## 3. Common passwords people use\n<p>Already this simple rule flagged a couple of offenders among the first 12 users. Next up in Special Publication 800-63B is the rule that</p>\n<blockquote>\n <p>verifiers SHALL compare the prospective secrets against a list that contains values known to be commonly-used, expected, or compromised.</p>\n <ul>\n <li>Passwords obtained from previous breach corpuses.</li>\n <li>Dictionary words.</li>\n <li>Repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).</li>\n <li>Context-specific words, such as the name of the service, the username, and derivatives thereof.</li>\n </ul>\n</blockquote>\n<p>We're going to check these in order and start with <em>Passwords obtained from previous breach corpuses</em>, that is, websites where hackers have leaked all the users' passwords. As many websites don't follow the NIST guidelines and encrypt passwords there now exist large lists of the most popular passwords. Let's start by loading in the 10,000 most common passwords which I've taken from <a href=\"https://github.com/danielmiessler/SecLists/tree/master/Passwords\">here</a>.</p>",
"_____no_output_____"
]
],
[
[
"# Reading in the top 10000 passwords\ncommon_passwords = pd.read_csv(\"datasets/10_million_password_list_top_10000.txt\",\n header=None,\n squeeze=True)\n\n# Taking a look at the top 20\ncommon_passwords.head(20)",
"_____no_output_____"
]
],
[
[
"## 4. Passwords should not be common passwords\n<p>The list of passwords was ordered, with the most common passwords first, and so we shouldn't be surprised to see passwords like <code>123456</code> and <code>qwerty</code> above. As hackers also have access to this list of common passwords, it's important that none of our users use these passwords!</p>\n<p>Let's flag all the passwords in our user database that are among the top 10,000 used passwords.</p>",
"_____no_output_____"
]
],
[
[
"# Flagging the users with passwords that are common passwords\nusers['common_password'] = users['password'].isin(common_passwords)\n\n# Counting and printing the number of users using common passwords\nprint(users['common_password'].sum())\n\n# Taking a look at the 12 first rows\nusers.head(12)",
"129\n"
]
],
[
[
"## 5. Passwords should not be common words\n<p>Ay ay ay! It turns out many of our users use common passwords, and of the first 12 users there are already two. However, as most common passwords also tend to be short, they were already flagged as being too short. What is the next thing we should check?</p>\n<blockquote>\n <p>Verifiers SHALL compare the prospective secrets against a list that contains [...] dictionary words.</p>\n</blockquote>\n<p>This follows the same logic as before: It is easy for hackers to check users' passwords against common English words and therefore common English words make bad passwords. Let's check our users' passwords against the top 10,000 English words from <a href=\"https://github.com/first20hours/google-10000-english\">Google's Trillion Word Corpus</a>.</p>",
"_____no_output_____"
]
],
[
[
"# Reading in a list of the 10000 most common words\nwords = pd.read_csv(\"datasets/google-10000-english.txt\", header=None,\n squeeze=True)\n\n# Flagging the users with passwords that are common words\nusers['common_word'] = users['password'].str.lower().isin(words)\n\n# Counting and printing the number of users using common words as passwords\nprint(users['common_word'].sum())\n\n# Taking a look at the 12 first rows\nusers.head(12)",
"137\n"
]
],
[
[
"## 6. Passwords should not be your name\n<p>It turns out many of our passwords were common English words too! Next up on the NIST list:</p>\n<blockquote>\n <p>Verifiers SHALL compare the prospective secrets against a list that contains [...] context-specific words, such as the name of the service, the username, and derivatives thereof.</p>\n</blockquote>\n<p>Ok, so there are many things we could check here. One thing to notice is that our users' usernames consist of their first names and last names separated by a dot. For now, let's just flag passwords that are the same as either a user's first or last name.</p>",
"_____no_output_____"
]
],
[
[
"# Extracting first and last names into their own columns\nusers['first_name'] = users['user_name'].str.extract(r'(^\\w+)', expand=False)\nusers['last_name'] = users['user_name'].str.extract(r'(\\w+$)', expand=False)\n\n# Flagging the users with passwords that matches their names\nusers['uses_name'] = (users['password'] == users['first_name']) | (users['password'] == users['last_name'])\n# Counting and printing the number of users using names as passwords\nprint(users['uses_name'].count())\n\n# Taking a look at the 12 first rows\nusers.head(12)",
"982\n"
]
],
[
[
"## 7. Passwords should not be repetitive\n<p>Milford Hubbard (user number 12 above), what where you thinking!? Ok, so the last thing we are going to check is a bit tricky:</p>\n<blockquote>\n <p>verifiers SHALL compare the prospective secrets [so that they don't contain] repetitive or sequential characters (e.g. ‘aaaaaa’, ‘1234abcd’).</p>\n</blockquote>\n<p>This is tricky to check because what is <em>repetitive</em> is hard to define. Is <code>11111</code> repetitive? Yes! Is <code>12345</code> repetitive? Well, kind of. Is <code>13579</code> repetitive? Maybe not..? To check for <em>repetitiveness</em> can be arbitrarily complex, but here we're only going to do something simple. We're going to flag all passwords that contain 4 or more repeated characters.</p>",
"_____no_output_____"
]
],
[
[
"### Flagging the users with passwords with >= 4 repeats\nusers['too_many_repeats'] = users['password'].str.contains(r'(.)\\1\\1\\1')\n\n# Taking a look at the users with too many repeats\nusers.head(12)",
"_____no_output_____"
]
],
[
[
"## 8. All together now!\n<p>Now we have implemented all the basic tests for bad passwords suggested by NIST Special Publication 800-63B! What's left is just to flag all bad passwords and maybe to send these users an e-mail that strongly suggests they change their password.</p>",
"_____no_output_____"
]
],
[
[
"# Flagging all passwords that are bad\nusers['bad_password'] = (users['too_short'])|(users['common_password'])|(users['common_word'])|(users['uses_name'])|(users['too_many_repeats'])\n\n# Counting and printing the number of bad passwords\nprint(sum(users['bad_password']))\n\n# Looking at the first 25 bad passwords\nusers[users['bad_password']==True]['password'].head(25)",
"424\n"
]
],
[
[
"## 9. Otherwise, the password should be up to the user\n<p>In this notebook, we've implemented the password checks recommended by the NIST Special Publication 800-63B. It's certainly possible to better implement these checks, for example, by using a longer list of common passwords. Also note that the NIST checks in no way guarantee that a chosen password is good, just that it's not obviously bad.</p>\n<p>Apart from the checks we've implemented above the NIST is also clear with what password rules should <em>not</em> be imposed:</p>\n<blockquote>\n <p>Verifiers SHOULD NOT impose other composition rules (e.g., requiring mixtures of different character types or prohibiting consecutively repeated characters) for memorized secrets. Verifiers SHOULD NOT require memorized secrets to be changed arbitrarily (e.g., periodically).</p>\n</blockquote>\n<p>So the next time a website or app tells you to \"include both a number, symbol and an upper and lower case character in your password\" you should send them a copy of <a href=\"https://pages.nist.gov/800-63-3/sp800-63b.html\">NIST Special Publication 800-63B</a>.</p>",
"_____no_output_____"
]
],
[
[
"# Enter a password that passes the NIST requirements\n# PLEASE DO NOT USE AN EXISTING PASSWORD HERE\nnew_password = \"test@2019\"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2b2e6c02b75e8ec849173c29681bc99e181d1d
| 22,111 |
ipynb
|
Jupyter Notebook
|
site/en/guide/keras/custom_callback.ipynb
|
sriyogesh94/docs
|
b2e7670f95d360c64493d1b3a9ff84c96d285ca4
|
[
"Apache-2.0"
] | 2 |
2019-09-11T03:14:24.000Z
|
2019-09-11T03:14:28.000Z
|
site/en/guide/keras/custom_callback.ipynb
|
sriyogesh94/docs
|
b2e7670f95d360c64493d1b3a9ff84c96d285ca4
|
[
"Apache-2.0"
] | null | null | null |
site/en/guide/keras/custom_callback.ipynb
|
sriyogesh94/docs
|
b2e7670f95d360c64493d1b3a9ff84c96d285ca4
|
[
"Apache-2.0"
] | 1 |
2019-09-15T17:30:32.000Z
|
2019-09-15T17:30:32.000Z
| 39.483929 | 695 | 0.552169 |
[
[
[
"##### Copyright 2019 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/guide/keras/custom_callback\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/guide/keras/custom_callback.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/guide/keras/custom_callback.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/guide/keras/custom_callback.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Writing custom Keras callbacks\nA custom callback is a powerful tool to customize the behavior of a Keras model during training, evaluation, or inference, including reading/changing the Keras model. Examples include `tf.keras.callbacks.TensorBoard` where the training progress and results can be exported and visualized with TensorBoard, or `tf.keras.callbacks.ModelCheckpoint` where the model is automatically saved during training, and more. In this guide, you will learn what Keras callback is, when it will be called, what it can do, and how you can build your own. Towards the end of this guide, there will be demos of creating a couple of simple callback applications to get you started on your custom callback.",
"_____no_output_____"
],
[
"## Setup",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\ntry:\n # %tensorflow_version only exists in Colab.\n %tensorflow_version 2.x\nexcept Exception:\n pass\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"## Introduction to Keras callbacks\nIn Keras, `Callback` is a python class meant to be subclassed to provide specific functionality, with a set of methods called at various stages of training (including batch/epoch start and ends), testing, and predicting. Callbacks are useful to get a view on internal states and statistics of the model during training. You can pass a list of callbacks (as the keyword argument `callbacks`) to any of `tf.keras.Model.fit()`, `tf.keras.Model.evaluate()`, and `tf.keras.Model.predict()` methods. The methods of the callbacks will then be called at different stages of training/evaluating/inference.\n\nTo get started, let's import tensorflow and define a simple Sequential Keras model:",
"_____no_output_____"
]
],
[
[
"# Define the Keras model to add callbacks to\ndef get_model():\n model = tf.keras.Sequential()\n model.add(tf.keras.layers.Dense(1, activation = 'linear', input_dim = 784))\n model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=0.1), loss='mean_squared_error', metrics=['mae'])\n return model",
"_____no_output_____"
]
],
[
[
"Then, load the MNIST data for training and testing from Keras datasets API:",
"_____no_output_____"
]
],
[
[
"# Load example MNIST data and pre-process it\n(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()\nx_train = x_train.reshape(60000, 784).astype('float32') / 255\nx_test = x_test.reshape(10000, 784).astype('float32') / 255",
"_____no_output_____"
]
],
[
[
"Now, define a simple custom callback to track the start and end of every batch of data. During those calls, it prints the index of the current batch.",
"_____no_output_____"
]
],
[
[
"import datetime\n\nclass MyCustomCallback(tf.keras.callbacks.Callback):\n\n def on_train_batch_begin(self, batch, logs=None):\n print('Training: batch {} begins at {}'.format(batch, datetime.datetime.now().time()))\n\n def on_train_batch_end(self, batch, logs=None):\n print('Training: batch {} ends at {}'.format(batch, datetime.datetime.now().time()))\n\n def on_test_batch_begin(self, batch, logs=None):\n print('Evaluating: batch {} begins at {}'.format(batch, datetime.datetime.now().time()))\n\n def on_test_batch_end(self, batch, logs=None):\n print('Evaluating: batch {} ends at {}'.format(batch, datetime.datetime.now().time()))",
"_____no_output_____"
]
],
[
[
"Providing a callback to model methods such as `tf.keras.Model.fit()` ensures the methods are called at those stages:",
"_____no_output_____"
]
],
[
[
"model = get_model()\n_ = model.fit(x_train, y_train,\n batch_size=64,\n epochs=1,\n steps_per_epoch=5,\n verbose=0,\n callbacks=[MyCustomCallback()])",
"_____no_output_____"
]
],
[
[
"## Model methods that take callbacks\nUsers can supply a list of callbacks to the following `tf.keras.Model` methods:\n#### [`fit()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#fit), [`fit_generator()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#fit_generator)\nTrains the model for a fixed number of epochs (iterations over a dataset, or data yielded batch-by-batch by a Python generator).\n#### [`evaluate()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#evaluate), [`evaluate_generator()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#evaluate_generator)\nEvaluates the model for given data or data generator. Outputs the loss and metric values from the evaluation.\n#### [`predict()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#predict), [`predict_generator()`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model#predict_generator)\nGenerates output predictions for the input data or data generator.\n",
"_____no_output_____"
]
],
[
[
"_ = model.evaluate(x_test, y_test, batch_size=128, verbose=0, steps=5,\n callbacks=[MyCustomCallback()])",
"_____no_output_____"
]
],
[
[
"## An overview of callback methods\n\n\n### Common methods for training/testing/predicting\nFor training, testing, and predicting, following methods are provided to be overridden.\n#### `on_(train|test|predict)_begin(self, logs=None)`\nCalled at the beginning of `fit`/`evaluate`/`predict`.\n#### `on_(train|test|predict)_end(self, logs=None)`\nCalled at the end of `fit`/`evaluate`/`predict`.\n#### `on_(train|test|predict)_batch_begin(self, batch, logs=None)`\nCalled right before processing a batch during training/testing/predicting. Within this method, `logs` is a dict with `batch` and `size` available keys, representing the current batch number and the size of the batch.\n#### `on_(train|test|predict)_batch_end(self, batch, logs=None)`\nCalled at the end of training/testing/predicting a batch. Within this method, `logs` is a dict containing the stateful metrics result.\n\n### Training specific methods\nIn addition, for training, following are provided.\n#### on_epoch_begin(self, epoch, logs=None)\nCalled at the beginning of an epoch during training.\n#### on_epoch_end(self, epoch, logs=None)\nCalled at the end of an epoch during training.\n",
"_____no_output_____"
],
[
"### Usage of `logs` dict\nThe `logs` dict contains the loss value, and all the metrics at the end of a batch or epoch. Example includes the loss and mean absolute error.",
"_____no_output_____"
]
],
[
[
"class LossAndErrorPrintingCallback(tf.keras.callbacks.Callback):\n\n def on_train_batch_end(self, batch, logs=None):\n print('For batch {}, loss is {:7.2f}.'.format(batch, logs['loss']))\n\n def on_test_batch_end(self, batch, logs=None):\n print('For batch {}, loss is {:7.2f}.'.format(batch, logs['loss']))\n\n def on_epoch_end(self, epoch, logs=None):\n print('The average loss for epoch {} is {:7.2f} and mean absolute error is {:7.2f}.'.format(epoch, logs['loss'], logs['mae']))\n\nmodel = get_model()\n_ = model.fit(x_train, y_train,\n batch_size=64,\n steps_per_epoch=5,\n epochs=3,\n verbose=0,\n callbacks=[LossAndErrorPrintingCallback()])",
"_____no_output_____"
]
],
[
[
"Similarly, one can provide callbacks in `evaluate()` calls.",
"_____no_output_____"
]
],
[
[
"_ = model.evaluate(x_test, y_test, batch_size=128, verbose=0, steps=20,\n callbacks=[LossAndErrorPrintingCallback()])",
"_____no_output_____"
]
],
[
[
"## Examples of Keras callback applications\nThe following section will guide you through creating simple Callback applications.",
"_____no_output_____"
],
[
"### Early stopping at minimum loss\nFirst example showcases the creation of a `Callback` that stops the Keras training when the minimum of loss has been reached by mutating the attribute `model.stop_training` (boolean). Optionally, the user can provide an argument `patience` to specfify how many epochs the training should wait before it eventually stops.\n\n`tf.keras.callbacks.EarlyStopping` provides a more complete and general implementation.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nclass EarlyStoppingAtMinLoss(tf.keras.callbacks.Callback):\n \"\"\"Stop training when the loss is at its min, i.e. the loss stops decreasing.\n\n Arguments:\n patience: Number of epochs to wait after min has been hit. After this\n number of no improvement, training stops.\n \"\"\"\n\n def __init__(self, patience=0):\n super(EarlyStoppingAtMinLoss, self).__init__()\n\n self.patience = patience\n\n # best_weights to store the weights at which the minimum loss occurs.\n self.best_weights = None\n\n def on_train_begin(self, logs=None):\n # The number of epoch it has waited when loss is no longer minimum.\n self.wait = 0\n # The epoch the training stops at.\n self.stopped_epoch = 0\n # Initialize the best as infinity.\n self.best = np.Inf\n\n def on_epoch_end(self, epoch, logs=None):\n current = logs.get('loss')\n if np.less(current, self.best):\n self.best = current\n self.wait = 0\n # Record the best weights if current results is better (less).\n self.best_weights = self.model.get_weights()\n else:\n self.wait += 1\n if self.wait >= self.patience:\n self.stopped_epoch = epoch\n self.model.stop_training = True\n print('Restoring model weights from the end of the best epoch.')\n self.model.set_weights(self.best_weights)\n\n def on_train_end(self, logs=None):\n if self.stopped_epoch > 0:\n print('Epoch %05d: early stopping' % (self.stopped_epoch + 1))",
"_____no_output_____"
],
[
"model = get_model()\n_ = model.fit(x_train, y_train,\n batch_size=64,\n steps_per_epoch=5,\n epochs=30,\n verbose=0,\n callbacks=[LossAndErrorPrintingCallback(), EarlyStoppingAtMinLoss()])",
"_____no_output_____"
]
],
[
[
"### Learning rate scheduling\n\nOne thing that is commonly done in model training is changing the learning rate as more epochs have passed. Keras backend exposes get_value api which can be used to set the variables. In this example, we're showing how a custom Callback can be used to dymanically change the learning rate.\n\nNote: this is just an example implementation see `callbacks.LearningRateScheduler` and `keras.optimizers.schedules` for more general implementations.",
"_____no_output_____"
]
],
[
[
"class LearningRateScheduler(tf.keras.callbacks.Callback):\n \"\"\"Learning rate scheduler which sets the learning rate according to schedule.\n\n Arguments:\n schedule: a function that takes an epoch index\n (integer, indexed from 0) and current learning rate\n as inputs and returns a new learning rate as output (float).\n \"\"\"\n\n def __init__(self, schedule):\n super(LearningRateScheduler, self).__init__()\n self.schedule = schedule\n\n def on_epoch_begin(self, epoch, logs=None):\n if not hasattr(self.model.optimizer, 'lr'):\n raise ValueError('Optimizer must have a \"lr\" attribute.')\n # Get the current learning rate from model's optimizer.\n lr = float(tf.keras.backend.get_value(self.model.optimizer.lr))\n # Call schedule function to get the scheduled learning rate.\n scheduled_lr = self.schedule(epoch, lr)\n # Set the value back to the optimizer before this epoch starts\n tf.keras.backend.set_value(self.model.optimizer.lr, scheduled_lr)\n print('\\nEpoch %05d: Learning rate is %6.4f.' % (epoch, scheduled_lr))",
"_____no_output_____"
],
[
"LR_SCHEDULE = [\n # (epoch to start, learning rate) tuples\n (3, 0.05), (6, 0.01), (9, 0.005), (12, 0.001)\n]\n\ndef lr_schedule(epoch, lr):\n \"\"\"Helper function to retrieve the scheduled learning rate based on epoch.\"\"\"\n if epoch < LR_SCHEDULE[0][0] or epoch > LR_SCHEDULE[-1][0]:\n return lr\n for i in range(len(LR_SCHEDULE)):\n if epoch == LR_SCHEDULE[i][0]:\n return LR_SCHEDULE[i][1]\n return lr\n\nmodel = get_model()\n_ = model.fit(x_train, y_train,\n batch_size=64,\n steps_per_epoch=5,\n epochs=15,\n verbose=0,\n callbacks=[LossAndErrorPrintingCallback(), LearningRateScheduler(lr_schedule)])",
"_____no_output_____"
]
],
[
[
"### Standard Keras callbacks\nBe sure to check out the existing Keras callbacks by [visiting the api doc](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/callbacks). Applications include logging to CSV, saving the model, visualizing on TensorBoard and a lot more.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a2b35718968be6e3bc536dcde3e927504ac01f2
| 410,482 |
ipynb
|
Jupyter Notebook
|
tutorials/Certification_Trainings/Healthcare/3_Clinical_Entity_Resolvers.ipynb
|
kbarlow-databricks/JohnSnowLabsTraining
|
f2c9463f0501739d2b5b35670b1d381edbc5267a
|
[
"Apache-2.0"
] | 3 |
2020-04-18T20:21:11.000Z
|
2022-02-08T23:57:46.000Z
|
tutorials/Certification_Trainings/Healthcare/3_Clinical_Entity_Resolvers.ipynb
|
mhibdr/spark-nlp-workshop
|
21fc6f5a75b77691c1207df190a703bf4ccafc8e
|
[
"Apache-2.0"
] | null | null | null |
tutorials/Certification_Trainings/Healthcare/3_Clinical_Entity_Resolvers.ipynb
|
mhibdr/spark-nlp-workshop
|
21fc6f5a75b77691c1207df190a703bf4ccafc8e
|
[
"Apache-2.0"
] | null | null | null | 314.304747 | 365,546 | 0.909409 |
[
[
[
"",
"_____no_output_____"
],
[
"[](https://colab.research.google.com/github/JohnSnowLabs/spark-nlp-workshop/blob/master/tutorials/Certification_Trainings/Healthcare/3.Clinical_Entity_Resolvers.ipynb)",
"_____no_output_____"
],
[
"# Clinical Entity Resolvers",
"_____no_output_____"
],
[
"## Colab Setup",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open('license_keys.json') as f_in:\n license_keys = json.load(f_in)\n\nlicense_keys.keys()",
"_____no_output_____"
],
[
"# template for license_key.json\n\n{'secret':\"xxx\",\n'SPARK_NLP_LICENSE': 'aaa',\n'JSL_OCR_LICENSE': 'bbb',\n'AWS_ACCESS_KEY_ID':\"ccc\",\n'AWS_SECRET_ACCESS_KEY':\"ddd\",\n'JSL_OCR_SECRET':\"eee\"}",
"_____no_output_____"
],
[
"import os\n\n# Install java\n! apt-get install -y openjdk-8-jdk-headless -qq > /dev/null\nos.environ[\"JAVA_HOME\"] = \"/usr/lib/jvm/java-8-openjdk-amd64\"\nos.environ[\"PATH\"] = os.environ[\"JAVA_HOME\"] + \"/bin:\" + os.environ[\"PATH\"]\n! java -version\n\n# Install pyspark\n! pip install --ignore-installed -q pyspark==2.4.4\n\nsecret = license_keys['secret']\nos.environ['SPARK_NLP_LICENSE'] = license_keys['SPARK_NLP_LICENSE']\nos.environ['JSL_OCR_LICENSE'] = license_keys['JSL_OCR_LICENSE']\nos.environ['AWS_ACCESS_KEY_ID']= license_keys['AWS_ACCESS_KEY_ID']\nos.environ['AWS_SECRET_ACCESS_KEY'] = license_keys['AWS_SECRET_ACCESS_KEY']\n\n! python -m pip install --upgrade spark-nlp-jsl==2.4.2 --extra-index-url https://pypi.johnsnowlabs.com/$secret\n\n# Install Spark NLP\n! pip install --ignore-installed -q spark-nlp==2.4.5\n\nimport sparknlp\n\nprint (sparknlp.version())\n\nimport json\nimport os\nfrom pyspark.ml import Pipeline\nfrom pyspark.sql import SparkSession\n\n\nfrom sparknlp.annotator import *\nfrom sparknlp_jsl.annotator import *\nfrom sparknlp.base import *\nimport sparknlp_jsl\n\n\ndef start(secret):\n builder = SparkSession.builder \\\n .appName(\"Spark NLP Licensed\") \\\n .master(\"local[*]\") \\\n .config(\"spark.driver.memory\", \"8G\") \\\n .config(\"spark.serializer\", \"org.apache.spark.serializer.KryoSerializer\") \\\n .config(\"spark.kryoserializer.buffer.max\", \"900M\") \\\n .config(\"spark.jars.packages\", \"com.johnsnowlabs.nlp:spark-nlp_2.11:2.4.5\") \\\n .config(\"spark.jars\", \"https://pypi.johnsnowlabs.com/\"+secret+\"/spark-nlp-jsl-2.4.2.jar\")\n \n return builder.getOrCreate()\n\n\nspark = start(secret) # if you want to start the session with custom params as in start function above\n# sparknlp_jsl.start(secret)",
"_____no_output_____"
],
[
"\n# if you want to load the licensed models from S3 with your license key\n\n! pip install awscli --upgrade",
"_____no_output_____"
],
[
"spark",
"_____no_output_____"
]
],
[
[
"# Clinical Resolvers",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"## Entity Resolvers for ICD-10",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom sparknlp.base import *\nfrom sparknlp.annotator import *\nfrom pyspark.ml import Pipeline, PipelineModel\nimport pyspark.sql.functions as F\nimport string\nimport numpy as np\nimport sparknlp\nfrom sparknlp.util import *\nfrom sparknlp.pretrained import ResourceDownloader\nfrom pyspark.sql import functions as F\nfrom sparknlp_jsl.annotator import *",
"_____no_output_____"
],
[
"from sparknlp_jsl.annotator import *\n\ndocumentAssembler = DocumentAssembler()\\\n .setInputCol(\"text\")\\\n .setOutputCol(\"document\")\n\n# Sentence Detector annotator, processes various sentences per line\n\nsentenceDetector = SentenceDetector()\\\n .setInputCols([\"document\"])\\\n .setOutputCol(\"sentence\")\n\n# Tokenizer splits words in a relevant format for NLP\n\ntokenizer = Tokenizer()\\\n .setInputCols([\"sentence\"])\\\n .setOutputCol(\"token\")\n\n# Clinical word embeddings trained on PubMED dataset\nword_embeddings = WordEmbeddingsModel.pretrained(\"embeddings_clinical\", \"en\", \"clinical/models\")\\\n .setInputCols([\"sentence\", \"token\"])\\\n .setOutputCol(\"embeddings\")\n\n# NER model trained on i2b2 (sampled from MIMIC) dataset\nclinical_ner = NerDLModel.pretrained(\"ner_clinical\", \"en\", \"clinical/models\") \\\n .setInputCols([\"sentence\", \"token\", \"embeddings\"]) \\\n .setOutputCol(\"ner\")\n",
"embeddings_clinical download started this may take some time.\nApproximate size to download 1.6 GB\n[OK!]\nner_clinical download started this may take some time.\nApproximate size to download 13.8 MB\n[OK!]\n"
],
[
"!aws s3 cp s3://auxdata.johnsnowlabs.com/clinical/models/chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip",
"download: s3://auxdata.johnsnowlabs.com/clinical/models/chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip to ./chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip\n"
],
[
"!unzip chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip -d chunkresolve_icd10cm",
"Archive: chunkresolve_icd10cm_clinical_en_2.4.2_2.4_1583085234727.zip\n inflating: chunkresolve_icd10cm/metadata/._SUCCESS.crc \n inflating: chunkresolve_icd10cm/metadata/_SUCCESS \n inflating: chunkresolve_icd10cm/metadata/part-00000 \n inflating: chunkresolve_icd10cm/metadata/.part-00000.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00006.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00018.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00016.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00021 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00010 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00008 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00011.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/._SUCCESS.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00014.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00004 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00023 \n inflating: chunkresolve_icd10cm/fields/searchTree/_SUCCESS \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00001.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00013 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00006 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00002 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00011 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00013.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00002.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00000 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00017 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00015.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00020 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00014 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00007 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00022 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00005 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00005.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00007.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00016 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00000.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00008.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00012 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00003.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00022.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00018 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00017.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00021.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00004.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00020.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00001 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00019.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00023.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00012.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00015 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00009 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00010.crc \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00003 \n inflating: chunkresolve_icd10cm/fields/searchTree/part-00019 \n inflating: chunkresolve_icd10cm/fields/searchTree/.part-00009.crc \n"
],
[
"icd_ner_converter = NerConverter()\\\n .setInputCols([\"sentence\", \"token\", \"ner\"])\\\n .setOutputCol(\"ner_chunk\")\\\n.setWhiteList(['PROBLEM'])\n\nchunk_embeddings = ChunkEmbeddings()\\\n .setInputCols(\"ner_chunk\", \"embeddings\")\\\n .setOutputCol(\"chunk_embeddings\")\\\n\nchunk_tokenizer = ChunkTokenizer()\\\n .setInputCols(\"ner_chunk\")\\\n .setOutputCol(\"ner_token\")\n\n\nentity_resolver_icd10 = ChunkEntityResolverModel.load(\"chunkresolve_icd10cm\")\\\n .setInputCols([\"ner_token\", \"chunk_embeddings\"])\\\n .setOutputCol(\"icd10cm_code\")\\\n .setDistanceFunction(\"COSINE\")\n\npipeline_icd10 = Pipeline(\n stages = [\n documentAssembler,\n sentenceDetector,\n tokenizer,\n word_embeddings,\n clinical_ner,\n icd_ner_converter,\n chunk_embeddings,\n chunk_tokenizer,\n entity_resolver_icd10\n ])\n\n\nempty_data = spark.createDataFrame([[\"\"]]).toDF(\"text\")\n\nmodel_icd10 = pipeline_icd10.fit(empty_data)\n",
"_____no_output_____"
],
[
"! wget \thttps://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/pubmed/pubmed_sample_text_small.csv\n",
"--2020-04-09 19:35:54-- https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/resources/en/pubmed/pubmed_sample_text_small.csv\nResolving s3.amazonaws.com (s3.amazonaws.com)... 52.217.14.110\nConnecting to s3.amazonaws.com (s3.amazonaws.com)|52.217.14.110|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 9363435 (8.9M) [text/csv]\nSaving to: ‘pubmed_sample_text_small.csv’\n\npubmed_sample_text_ 100%[===================>] 8.93M --.-KB/s in 0.1s \n\n2020-04-09 19:35:54 (69.1 MB/s) - ‘pubmed_sample_text_small.csv’ saved [9363435/9363435]\n\n"
],
[
"import pyspark.sql.functions as F\n\npubMedDF = spark.read\\\n .option(\"header\", \"true\")\\\n .csv(\"pubmed_sample_text_small.csv\")\\\n \npubMedDF.show(truncate=50)",
"+--------------------------------------------------+\n| text|\n+--------------------------------------------------+\n|The human KCNJ9 (Kir 3.3, GIRK3) is a member of...|\n|BACKGROUND: At present, it is one of the most i...|\n|OBJECTIVE: To investigate the relationship betw...|\n|Combined EEG/fMRI recording has been used to lo...|\n|Kohlschutter syndrome is a rare neurodegenerati...|\n|Statistical analysis of neuroimages is commonly...|\n|The synthetic DOX-LNA conjugate was characteriz...|\n|Our objective was to compare three different me...|\n|We conducted a phase II study to assess the eff...|\n|\"\"\"Monomeric sarcosine oxidase (MSOX) is a flav...|\n|We presented the tachinid fly Exorista japonica...|\n|The literature dealing with the water conductin...|\n|A novel approach to synthesize chitosan-O-isopr...|\n|An HPLC-ESI-MS-MS method has been developed for...|\n|The localizing and lateralizing values of eye a...|\n|OBJECTIVE: To evaluate the effectiveness and ac...|\n|For the construction of new combinatorial libra...|\n|We report the results of a screen for genetic a...|\n|Intraparenchymal pericatheter cyst is rarely re...|\n|It is known that patients with Klinefelter's sy...|\n+--------------------------------------------------+\nonly showing top 20 rows\n\n"
],
[
"result = model_icd10.transform(pubMedDF.limit(100))",
"_____no_output_____"
],
[
"result.show()",
"+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+\n| text| document| sentence| token| embeddings| ner| ner_chunk| chunk_embeddings| ner_token| icd10cm_code|\n+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+\n|The human KCNJ9 (...|[[document, 0, 95...|[[document, 0, 12...|[[token, 0, 2, Th...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 210, 254...|[[word_embeddings...|[[token, 210, 210...|[[entity, 210, 25...|\n|BACKGROUND: At pr...|[[document, 0, 14...|[[document, 0, 19...|[[token, 0, 9, BA...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 84, 96, ...|[[word_embeddings...|[[token, 84, 89, ...|[[entity, 84, 96,...|\n|OBJECTIVE: To inv...|[[document, 0, 15...|[[document, 0, 30...|[[token, 0, 8, OB...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 130, 152...|[[word_embeddings...|[[token, 130, 136...|[[entity, 130, 15...|\n|Combined EEG/fMRI...|[[document, 0, 16...|[[document, 0, 16...|[[token, 0, 7, Co...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 172, 194...|[[word_embeddings...|[[token, 172, 174...|[[entity, 172, 19...|\n|Kohlschutter synd...|[[document, 0, 25...|[[document, 0, 20...|[[token, 0, 11, K...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 0, 20, K...|[[word_embeddings...|[[token, 0, 11, K...|[[entity, 0, 20, ...|\n|Statistical analy...|[[document, 0, 10...|[[document, 0, 34...|[[token, 0, 10, S...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 937, 979...|[[word_embeddings...|[[token, 937, 937...|[[entity, 937, 97...|\n|The synthetic DOX...|[[document, 0, 57...|[[document, 0, 10...|[[token, 0, 2, Th...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 90, 106,...|[[word_embeddings...|[[token, 90, 93, ...|[[entity, 90, 106...|\n|Our objective was...|[[document, 0, 24...|[[document, 0, 19...|[[token, 0, 2, Ou...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 205, 239...|[[word_embeddings...|[[token, 205, 211...|[[entity, 205, 23...|\n|We conducted a ph...|[[document, 0, 14...|[[document, 0, 24...|[[token, 0, 1, We...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 138, 167...|[[word_embeddings...|[[token, 138, 152...|[[entity, 138, 16...|\n|\"\"\"Monomeric sarc...|[[document, 0, 14...|[[document, 0, 14...|[[token, 0, 2, \"\"...|[[word_embeddings...|[[named_entity, 0...| []| []| []| []|\n|We presented the ...|[[document, 0, 12...|[[document, 0, 26...|[[token, 0, 1, We...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 213, 221...|[[word_embeddings...|[[token, 213, 221...|[[entity, 213, 22...|\n|The literature de...|[[document, 0, 16...|[[document, 0, 13...|[[token, 0, 2, Th...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 63, 83, ...|[[word_embeddings...|[[token, 63, 69, ...|[[entity, 63, 83,...|\n|A novel approach ...|[[document, 0, 64...|[[document, 0, 97...|[[token, 0, 0, A,...|[[word_embeddings...|[[named_entity, 0...| []| []| []| []|\n|An HPLC-ESI-MS-MS...|[[document, 0, 90...|[[document, 0, 24...|[[token, 0, 1, An...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 246, 261...|[[word_embeddings...|[[token, 246, 248...|[[entity, 246, 26...|\n|The localizing an...|[[document, 0, 72...|[[document, 0, 12...|[[token, 0, 2, Th...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 42, 98, ...|[[word_embeddings...|[[token, 42, 44, ...|[[entity, 42, 98,...|\n|OBJECTIVE: To eva...|[[document, 0, 13...|[[document, 0, 43...|[[token, 0, 8, OB...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 400, 421...|[[word_embeddings...|[[token, 400, 400...|[[entity, 400, 42...|\n|For the construct...|[[document, 0, 32...|[[document, 0, 20...|[[token, 0, 2, Fo...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 24, 50, ...|[[word_embeddings...|[[token, 24, 26, ...|[[entity, 24, 50,...|\n|We report the res...|[[document, 0, 13...|[[document, 0, 38...|[[token, 0, 1, We...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 63, 94, ...|[[word_embeddings...|[[token, 63, 69, ...|[[entity, 63, 94,...|\n|Intraparenchymal ...|[[document, 0, 10...|[[document, 0, 53...|[[token, 0, 15, I...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 0, 33, I...|[[word_embeddings...|[[token, 0, 15, I...|[[entity, 0, 33, ...|\n|It is known that ...|[[document, 0, 34...|[[document, 0, 14...|[[token, 0, 1, It...|[[word_embeddings...|[[named_entity, 0...|[[chunk, 31, 52, ...|[[word_embeddings...|[[token, 31, 43, ...|[[entity, 31, 52,...|\n+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+\nonly showing top 20 rows\n\n"
],
[
"def get_icd10_codes(model, text):\n \n data = spark.createDataFrame([[text]]).toDF(\"text\")\n \n output = model.transform(data)\n \n result = output.select(F.explode(F.arrays_zip(\"ner_chunk.begin\",\n \"ner_chunk.end\",\n \"ner_chunk.result\", \"ner_chunk.metadata\", \"icd10cm_code.result\", \"icd10cm_code.metadata\")).alias(\"icd10cm_result\")) \\\n .select(F.expr(\"icd10cm_result['2']\").alias(\"ner\"),\n F.expr(\"icd10cm_result['3'].entity\").alias(\"entity\"),\n F.expr(\"icd10cm_result['0']\").alias(\"begin\"),\n F.expr(\"icd10cm_result['1']\").alias(\"end\"),\n F.expr(\"icd10cm_result['4']\").alias(\"code\"),\n F.expr(\"icd10cm_result['5'].resolved_text\").alias(\"resolved_text\"),\n F.expr(\"icd10cm_result['5'].alternative_codes\").alias(\"alternative_codes\"),\n F.expr(\"round(icd10cm_result['5'].confidence_ratio,2)\").alias(\"confidence_ratio\"))\\\n .distinct()\\\n .toPandas()\n \n return result",
"_____no_output_____"
],
[
"%%time\n\ntext = 'He has a brain damage and lung cancer'\n\ndf = get_icd10_codes(model_icd10, text)",
"CPU times: user 109 ms, sys: 18 ms, total: 127 ms\nWall time: 6.03 s\n"
],
[
"df",
"_____no_output_____"
]
],
[
[
"# RxNorm Resolver",
"_____no_output_____"
]
],
[
[
"rxnorm_resolution_l1 = DocumentLogRegClassifierModel.pretrained(\"resolve_rxnorm_clinical_l1\", \"en\", \"clinical/models\")\\\n .setInputCols(\"ner_token\").setOutputCol(\"partition\")\n\nrxnorm_resolution_l2 = ResourceDownloader.downloadPipeline(\"resolve_rxnorm_clinical_l2\", \"en\", \"clinical/models\")\n\nrxnorm_resolution = PipelineModel([rxnorm_resolution_l1, RecursivePipelineModel(rxnorm_resolution_l2)])\n\nposology_ner_model_large = NerDLModel.pretrained('ner_posology', \"en\", \"clinical/models\")\\\n .setInputCols([\"sentence\", \"token\", \"embeddings\"]) \\\n .setOutputCol(\"ner\")\n\ndrug_converter = NerConverter()\\\n .setInputCols([\"sentence\", \"token\", \"ner\"])\\\n .setOutputCol(\"ner_chunk\")\\\n.setWhiteList(['DRUG'])\n\npipeline_rx = Pipeline(\n stages = [\n documentAssembler,\n sentenceDetector,\n tokenizer,\n word_embeddings,\n posology_ner_model_large,\n drug_converter,\n chunk_embeddings,\n chunk_tokenizer,\n rxnorm_resolution\n ])\n\nmodel_rxnorm = pipeline_rx.fit(empty_data)\n \n",
"resolve_rxnorm_clinical_l1 download started this may take some time.\nApproximate size to download 7.5 MB\n[OK!]\nresolve_rxnorm_clinical_l2 download started this may take some time.\nApprox size to download 276.1 MB\n[OK!]\nner_posology download started this may take some time.\nApproximate size to download 13.7 MB\n[OK!]\n"
],
[
"def get_rxnorm_codes(text):\n \n data = spark.createDataFrame([[text]]).toDF(\"text\")\n \n output = model_rxnorm.transform(data)\n \n result = output.select(F.explode(F.arrays_zip(\"ner_chunk.begin\",\n \"ner_chunk.end\",\n \"ner_chunk.result\", \"ner_chunk.metadata\", \"rxnorm_code.result\", \"rxnorm_code.metadata\")).alias(\"rxnorm_result\")) \\\n .select(F.expr(\"rxnorm_result['2']\").alias(\"ner\"),\n F.expr(\"rxnorm_result['3'].entity\").alias(\"entity\"),\n F.expr(\"rxnorm_result['0']\").alias(\"begin\"),\n F.expr(\"rxnorm_result['1']\").alias(\"end\"),\n F.expr(\"rxnorm_result['4']\").alias(\"code\"),\n F.expr(\"rxnorm_result['5'].resolved_text\").alias(\"resolved_text\"),\n F.expr(\"rxnorm_result['5'].alternative_codes\").alias(\"alternative_codes\"),\n F.expr(\"round(rxnorm_result['5'].confidence_ratio,2)\").alias(\"confidence_ratio\")) \\\n .distinct()\\\n .toPandas()\n \n return result\n\n",
"_____no_output_____"
],
[
"\ntext = 'He has a brain damage and needs to take an Advil and Aspirin'\n\nget_rxnorm_codes(text)",
"_____no_output_____"
]
],
[
[
"## Snomed Resolver",
"_____no_output_____"
]
],
[
[
" #SNOMED Resolution\nner_snomed_resolver_l1 = DocumentLogRegClassifierModel.pretrained(\"resolve_snomed_clinical_l1\", \"en\", \"clinical/models\")\\\n .setInputCols(\"ner_token\").setOutputCol(\"partition\")\n\nner_snomed_resolver_l2 = ResourceDownloader.downloadPipeline(\"resolve_snomed_clinical_l2\", \"en\", \"clinical/models\")\n\n\nner_snomed_resolver_l2.stages[-1].setInputCols(\"partition\",\"ner_token\",\"chunk_embeddings\")\n",
"resolve_snomed_clinical_l1 download started this may take some time.\nApproximate size to download 15.3 MB\n[OK!]\nresolve_snomed_clinical_l2 download started this may take some time.\nApprox size to download 583.4 MB\n[OK!]\n"
],
[
"from pyspark.ml import PipelineModel\n\nsnomed_resolution = PipelineModel([ner_snomed_resolver_l1, RecursivePipelineModel(ner_snomed_resolver_l2)])\n",
"_____no_output_____"
],
[
"clinical_converter = NerConverter()\\\n .setInputCols([\"sentence\", \"token\", \"ner\"])\\\n .setOutputCol(\"ner_chunk\")\n\n\ndef get_snomed_model():\n pipeline_snomed = Pipeline(\n stages = [\n documentAssembler,\n sentenceDetector,\n tokenizer,\n word_embeddings,\n posology_ner_model_large,\n clinical_converter,\n chunk_embeddings,\n chunk_tokenizer,\n snomed_resolution\n ])\n\n model_snomed = pipeline_snomed.fit(empty_data)\n \n return model_snomed\n\n\nmodel_snomed = get_snomed_model()",
"_____no_output_____"
],
[
"def get_snomed_codes(text):\n \n data = spark.createDataFrame([[text]]).toDF(\"text\")\n \n output = model_snomed.transform(data)\n \n result = output.select(F.explode(F.arrays_zip(\"ner_chunk.begin\",\n \"ner_chunk.end\",\n \"ner_chunk.result\", \"ner_chunk.metadata\", \"snomed_code.result\", \"snomed_code.metadata\")).alias(\"snomed_result\")) \\\n .select(F.expr(\"snomed_result['2']\").alias(\"ner\"),\n F.expr(\"snomed_result['3'].entity\").alias(\"entity\"),\n F.expr(\"snomed_result['0']\").alias(\"begin\"),\n F.expr(\"snomed_result['1']\").alias(\"end\"),\n F.expr(\"snomed_result['4']\").alias(\"code\"),\n F.expr(\"snomed_result['5'].resolved_text\").alias(\"resolved_text\"),\n F.expr(\"snomed_result['5'].alternative_codes\").alias(\"alternative_codes\"),\n F.expr(\"round(snomed_result['5'].confidence_ratio,2)\").alias(\"confidence_ratio\")) \\\n .distinct()\\\n .toPandas()\n\n return result\n",
"_____no_output_____"
],
[
"%%time\n\ntext = 'He has a brain damage and needs to take Parol or Aspirin'\n\ndf = get_snomed_codes(text)",
"CPU times: user 469 ms, sys: 105 ms, total: 575 ms\nWall time: 22.5 s\n"
],
[
"df",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2b403546f04063bafaeed85a5eaed130ddbd36
| 126,597 |
ipynb
|
Jupyter Notebook
|
2020-1-Summer/text/jupyter/CE_2020_03_modeling_electrical_circuit.ipynb
|
stephans3/control-engineering-edu
|
d4f21669845cfd370a92dc29a911a54f348cb03c
|
[
"MIT"
] | null | null | null |
2020-1-Summer/text/jupyter/CE_2020_03_modeling_electrical_circuit.ipynb
|
stephans3/control-engineering-edu
|
d4f21669845cfd370a92dc29a911a54f348cb03c
|
[
"MIT"
] | null | null | null |
2020-1-Summer/text/jupyter/CE_2020_03_modeling_electrical_circuit.ipynb
|
stephans3/control-engineering-edu
|
d4f21669845cfd370a92dc29a911a54f348cb03c
|
[
"MIT"
] | null | null | null | 95.834217 | 282 | 0.576886 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a2b4357a52865e9d5711597af8907d8bec8b172
| 328,037 |
ipynb
|
Jupyter Notebook
|
notebooks/iModulon/gene_annotation_motif.ipynb
|
talbulus/Synechococcus_elongatus
|
7255bef8a653c704c7173d2ab5e85cb72b0a1816
|
[
"MIT"
] | null | null | null |
notebooks/iModulon/gene_annotation_motif.ipynb
|
talbulus/Synechococcus_elongatus
|
7255bef8a653c704c7173d2ab5e85cb72b0a1816
|
[
"MIT"
] | null | null | null |
notebooks/iModulon/gene_annotation_motif.ipynb
|
talbulus/Synechococcus_elongatus
|
7255bef8a653c704c7173d2ab5e85cb72b0a1816
|
[
"MIT"
] | null | null | null | 59.664787 | 84,468 | 0.606304 |
[
[
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Get-information-from-GFF-file\" data-toc-modified-id=\"Get-information-from-GFF-file-1\"><span class=\"toc-item-num\">1 </span>Get information from GFF file</a></span><ul class=\"toc-item\"><li><span><a href=\"#Convert-GFF-to-Pandas-DataFrame\" data-toc-modified-id=\"Convert-GFF-to-Pandas-DataFrame-1.1\"><span class=\"toc-item-num\">1.1 </span>Convert GFF to Pandas DataFrame</a></span></li></ul></li><li><span><a href=\"#KEGG-and-COGs\" data-toc-modified-id=\"KEGG-and-COGs-2\"><span class=\"toc-item-num\">2 </span>KEGG and COGs</a></span><ul class=\"toc-item\"><li><span><a href=\"#Generate-nucleotide-fasta-files-for-CDS\" data-toc-modified-id=\"Generate-nucleotide-fasta-files-for-CDS-2.1\"><span class=\"toc-item-num\">2.1 </span>Generate nucleotide fasta files for CDS</a></span></li><li><span><a href=\"#Run-EggNOG-Mapper\" data-toc-modified-id=\"Run-EggNOG-Mapper-2.2\"><span class=\"toc-item-num\">2.2 </span>Run EggNOG Mapper</a></span></li><li><span><a href=\"#Get-KEGG-attributes\" data-toc-modified-id=\"Get-KEGG-attributes-2.3\"><span class=\"toc-item-num\">2.3 </span>Get KEGG attributes</a></span></li><li><span><a href=\"#Save-KEGG-information\" data-toc-modified-id=\"Save-KEGG-information-2.4\"><span class=\"toc-item-num\">2.4 </span>Save KEGG information</a></span></li><li><span><a href=\"#Save-COGs-to-annotation-dataframe\" data-toc-modified-id=\"Save-COGs-to-annotation-dataframe-2.5\"><span class=\"toc-item-num\">2.5 </span>Save COGs to annotation dataframe</a></span></li></ul></li><li><span><a href=\"#Uniprot-ID-mapping\" data-toc-modified-id=\"Uniprot-ID-mapping-3\"><span class=\"toc-item-num\">3 </span>Uniprot ID mapping</a></span></li><li><span><a href=\"#Add-Biocyc-Operon-information\" data-toc-modified-id=\"Add-Biocyc-Operon-information-4\"><span class=\"toc-item-num\">4 </span>Add Biocyc Operon information</a></span><ul class=\"toc-item\"><li><span><a href=\"#Assign-unique-IDs-to-operons\" data-toc-modified-id=\"Assign-unique-IDs-to-operons-4.1\"><span class=\"toc-item-num\">4.1 </span>Assign unique IDs to operons</a></span></li></ul></li><li><span><a href=\"#Clean-up-and-save-annotation\" data-toc-modified-id=\"Clean-up-and-save-annotation-5\"><span class=\"toc-item-num\">5 </span>Clean up and save annotation</a></span><ul class=\"toc-item\"><li><span><a href=\"#Final-statistics\" data-toc-modified-id=\"Final-statistics-5.1\"><span class=\"toc-item-num\">5.1 </span>Final statistics</a></span></li><li><span><a href=\"#Fill-missing-values\" data-toc-modified-id=\"Fill-missing-values-5.2\"><span class=\"toc-item-num\">5.2 </span>Fill missing values</a></span></li></ul></li><li><span><a href=\"#GO-Annotations\" data-toc-modified-id=\"GO-Annotations-6\"><span class=\"toc-item-num\">6 </span>GO Annotations</a></span></li></ul></div>",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('..')",
"_____no_output_____"
],
[
"import pymodulon\nfrom pymodulon.gene_util import *\nimport os\nfrom Bio import SeqIO",
"_____no_output_____"
],
[
"pymodulon.__path__",
"_____no_output_____"
],
[
"org_dir = '/home/tahani/Documents/elongatus/data/'\nkegg_organism_code = 'syf'\nseq_dir = '/home/tahani/Documents/elongatus/sequence_files/'",
"_____no_output_____"
]
],
[
[
"# Get information from GFF file",
"_____no_output_____"
],
[
"## Convert GFF to Pandas DataFrame",
"_____no_output_____"
]
],
[
[
"annot_list = []\nfor filename in os.listdir(seq_dir):\n if filename.endswith('.gff3'):\n gff = os.path.join(seq_dir,filename)\n annot_list.append(gff2pandas(gff))\nkeep_cols = ['accession','start','end','strand','gene_name','locus_tag','old_locus_tag','gene_product','ncbi_protein']\nDF_annot = pd.concat(annot_list)[keep_cols]\nDF_annot = DF_annot.drop_duplicates('locus_tag')\nDF_annot.set_index('locus_tag',drop=True,inplace=True)",
"_____no_output_____"
],
[
"tpm_file = os.path.join(org_dir,'0_log_tpm.csv')\nDF_log_tpm = pd.read_csv(tpm_file,index_col=0)",
"_____no_output_____"
]
],
[
[
"Check that the genes are the same in the expression dataset as in the annotation dataframe.",
"_____no_output_____"
]
],
[
[
"# Mismatched genes are listed below\ntest = DF_annot.sort_index().index == DF_log_tpm.sort_index().index\nDF_annot[~test]",
"_____no_output_____"
]
],
[
[
"# KEGG and COGs",
"_____no_output_____"
],
[
"## Generate nucleotide fasta files for CDS",
"_____no_output_____"
]
],
[
[
"cds_list = []\nfor filename in os.listdir(seq_dir):\n if filename.endswith('.fasta'):\n fasta = os.path.join(seq_dir,filename)\n seq = SeqIO.read(fasta,'fasta')\n \n # Get gene information for genes in this fasta file\n df_genes = DF_annot[DF_annot.accession == seq.id]\n for i,row in df_genes.iterrows():\n cds = seq[row.start-1:row.end]\n if row.strand == '-':\n cds = seq[row.start-1:row.end].reverse_complement()\n cds.id = row.name\n cds.description = row.gene_name if pd.notnull(row.gene_name) else row.name\n cds_list.append(cds)",
"_____no_output_____"
],
[
"SeqIO.write(cds_list,os.path.join(seq_dir,'CDS.fna'),'fasta')",
"_____no_output_____"
]
],
[
[
"## Run EggNOG Mapper\n1. Go to http://eggnog-mapper.embl.de/.\n1. Upload the CDS.fna file from your organism directory (within the sequence_files folder)\n1. Make sure to limit the taxonomy to the correct level\n1. After the job is submitted, you must follow the link in your email to run the job.\n1. Once the job completes (after ~4 hrs), download the annotations file.\n1. Save the annotation file to `<org_dir>/data/eggNOG.annotations`",
"_____no_output_____"
],
[
"## Get KEGG attributes",
"_____no_output_____"
]
],
[
[
"DF_eggnog = pd.read_csv(os.path.join(org_dir,'Synechococcus_elongatus.annotations'),sep='\\t',skiprows=4,header=None)\neggnog_cols = ['query_name','seed eggNOG ortholog','seed ortholog evalue','seed ortholog score',\n 'Predicted taxonomic group','Predicted protein name','Gene Ontology terms',\n 'EC number','KEGG_orth','KEGG_pathway','KEGG_module','KEGG_reaction',\n 'KEGG_rclass','BRITE','KEGG_TC','CAZy','BiGG Reaction','tax_scope',\n 'eggNOG OGs','bestOG_deprecated','COG','eggNOG free text description']\n\nDF_eggnog.columns = eggnog_cols\n\n# Strip last three rows as they are comments\nDF_eggnog = DF_eggnog.iloc[:-3]\n\n# Set locus tag as index\nDF_eggnog = DF_eggnog.set_index('query_name')\nDF_eggnog.index.name = 'locus_tag'",
"_____no_output_____"
],
[
"DF_kegg = DF_eggnog[['KEGG_orth','KEGG_pathway','KEGG_module','KEGG_reaction']]\n\n# Melt dataframe\nDF_kegg = DF_kegg.reset_index().melt(id_vars='locus_tag') \n\n# Remove null values\nDF_kegg = DF_kegg[DF_kegg.value.notnull()]\n\n# Split comma-separated values into their own rows\nlist2struct = []\nfor name,row in DF_kegg.iterrows():\n for val in row.value.split(','):\n list2struct.append([row.locus_tag,row.variable,val])\n\nDF_kegg = pd.DataFrame(list2struct,columns=['gene_id','database','kegg_id'])\n\n# Remove ko entries, as only map entries are searchable in KEGG pathway\nDF_kegg = DF_kegg[~DF_kegg.kegg_id.str.startswith('ko')]\n\nDF_kegg.head()",
"_____no_output_____"
]
],
[
[
"## Save KEGG information",
"_____no_output_____"
]
],
[
[
"DF_kegg.to_csv(os.path.join(org_dir,'2_kegg_mapping.csv'))",
"_____no_output_____"
]
],
[
[
"## Save COGs to annotation dataframe",
"_____no_output_____"
]
],
[
[
"DF_annot['COG'] = DF_eggnog.COG\n\n# Make sure COG only has one entry per gene\nDF_annot['COG'] = [item[0] if isinstance(item,str) else item for item in DF_annot['COG']]",
"_____no_output_____"
],
[
"DF_annot",
"_____no_output_____"
]
],
[
[
"# Uniprot ID mapping",
"_____no_output_____"
]
],
[
[
"# Try the uniprot ID mapping tool - Use EMBL for Genbank file and P_REFSEQ_AC for Refseq file\nmapping_uniprot = uniprot_id_mapping(DF_annot.ncbi_protein.fillna(''),input_id='P_REFSEQ_AC',output_id='ACC',\n input_name='ncbi_protein',output_name='uniprot')\n\n# Merge with current annotation\nDF_annot = pd.merge(DF_annot.reset_index(),mapping_uniprot,how='left',on='ncbi_protein')\nDF_annot.set_index('locus_tag',inplace=True)\nassert(len(DF_annot) == len(DF_annot))",
"_____no_output_____"
],
[
"DF_annot.head()",
"_____no_output_____"
]
],
[
[
"# Add Biocyc Operon information",
"_____no_output_____"
],
[
"To obtain operon information, follow the steps below\n1. Go to Biocyc.org (you may need to create an account and/or login)\n2. Change the organism database to your organism/strain\n3. Select SmartTables -> Special SmartTables\n4. Select \"All genes of <organism>\"\n5. Select the \"Gene Name\" column\n6. Under \"ADD TRANSFORM COLUMN\" select \"Genes in same transcription unit\"\n7. Select the \"Genes in same transcription unit\" column\n8. Under \"ADD PROPERTY COLUMN\" select \"Accession-1\"\n9. Under OPERATIONS, select \"Export\" -> \"to Spreadsheet File...\"\n10. Select \"common names\" and click \"Export smarttable\"\n11. Move file to \"<org_dir>/data/\" and name it as \"biocyc_operon_annotations.txt\"\n12. Run the code cell below this",
"_____no_output_____"
]
],
[
[
"DF_annot.head()",
"_____no_output_____"
],
[
"DF_biocyc = pd.read_csv(os.path.join(org_dir,'biocyc_operons_annotations.txt'),sep='\\t')\nDF_biocyc = DF_biocyc.set_index('Accession-2').sort_values('Left-End-Position')\nDF_biocyc",
"_____no_output_____"
],
[
"DF_biocyc = DF_biocyc.loc[~DF_biocyc.index.duplicated(keep=\"first\")]\nDF_biocyc",
"_____no_output_____"
],
[
"# Only keep genes in the final annotation file\nDF_biocyc = DF_biocyc.reindex(list(DF_annot.index))\nDF_biocyc",
"_____no_output_____"
]
],
[
[
"## Assign unique IDs to operons",
"_____no_output_____"
]
],
[
[
"counter = 0\noperon_name_mapper = {}\noperon_list = []\nfor i,row in DF_biocyc.iterrows():\n operon = row[\"Genes in same transcription unit\"]\n if operon not in operon_name_mapper.keys() or pd.isnull(operon):\n counter += 1\n operon_name_mapper[operon] = \"Op\"+str(counter)\n operon_list.append(operon_name_mapper[operon])",
"_____no_output_____"
],
[
"# Add operons to annotation file\n\nDF_biocyc['operon'] = operon_list\nDF_annot['operon'] = DF_biocyc['operon']\nDF_biocyc",
"_____no_output_____"
]
],
[
[
"# Clean up and save annotation",
"_____no_output_____"
]
],
[
[
"# Temporarily remove warning\npd.set_option('mode.chained_assignment', None)",
"_____no_output_____"
],
[
"# Reorder annotation file\nif 'old_locus_tag' in DF_annot.columns:\n order = ['gene_name','accession','old_locus_tag','start','end','strand','gene_product','COG','uniprot','operon']\nelse:\n order = ['gene_name','accession','start','end','strand','gene_product','COG','uniprot','operon']\n \nDF_annot = DF_annot[order]",
"_____no_output_____"
],
[
"DF_annot.head()",
"_____no_output_____"
]
],
[
[
"## Final statistics",
"_____no_output_____"
]
],
[
[
"import seaborn as sns\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"sns.set_style('ticks')",
"_____no_output_____"
],
[
"fig,ax = plt.subplots()\nDF_annot.count().plot(kind='bar',ax=ax)\nax.set_ylabel('# of Values',fontsize=18)\nax.tick_params(labelsize=16)",
"_____no_output_____"
]
],
[
[
"## Fill missing values",
"_____no_output_____"
]
],
[
[
"# Fill in missing gene names with locus tag names\nDF_annot['tmp_name'] = DF_annot.copy().index.tolist()\nDF_annot.gene_name.fillna(DF_annot.tmp_name,inplace=True)\nDF_annot.drop('tmp_name',axis=1,inplace=True)\n\n# Fill missing COGs with X\nDF_annot['COG'].fillna('X',inplace=True)\n\n# Change single letter COG annotation to full description\nDF_annot['COG'] = DF_annot.COG.apply(cog2str)",
"_____no_output_____"
],
[
"counts = DF_annot.COG.value_counts()\nplt.pie(counts.values,labels=counts.index);",
"_____no_output_____"
]
],
[
[
"## Adding gene names from BioCyc ",
"_____no_output_____"
]
],
[
[
"DF_annot\nNone",
"_____no_output_____"
],
[
"from os import path\nDF_biocyc = pd.read_csv(os.path.join(org_dir,'1_biocyc_gene_annotation.csv'), sep='\\t', error_bad_lines= False)",
"_____no_output_____"
],
[
"DF_annot['cycbio_gene_name'] = DF_annot.index\nDF_annot['cycbio_gene_product'] = DF_annot.index",
"_____no_output_____"
],
[
"#dict(zip(df.A,df.B))\nname_dict = dict(zip(DF_biocyc.locus_tag, DF_biocyc.gene_name))\nproduct_dict = dict(zip(DF_biocyc.locus_tag, DF_biocyc.Product))",
"_____no_output_____"
],
[
"DF_annot = DF_annot.replace({'cycbio_gene_name':name_dict})\nDF_annot = DF_annot.replace({'cycbio_gene_product':product_dict})",
"_____no_output_____"
]
],
[
[
"## Adding Maries Annotation",
"_____no_output_____"
]
],
[
[
"from os import path\nDF_marie = pd.read_csv(os.path.join(org_dir,'marie.csv'), error_bad_lines=True)\nDF_marie",
"_____no_output_____"
],
[
"DF_marie = DF_marie.fillna('no')\nDF_marie",
"_____no_output_____"
],
[
"DF_annot['marie_gene'] = DF_annot.index\nDF_annot['marie_product'] = DF_annot.index\nDF_annot['marie_annot'] = DF_annot.index",
"_____no_output_____"
],
[
"#dict(zip(df.A,df.B))\nname_dict = dict(zip(DF_marie['PCC7942_NCBI-alias'], DF_marie['gene_name']))\nproduct_dict = dict(zip(DF_marie['PCC7942_NCBI-alias'], DF_marie['Annotation_description']))\nnew_anot = dict(zip(DF_marie['PCC7942_NCBI-alias'],DF_marie['PCC7942_PG_locus']))",
"_____no_output_____"
],
[
"name_dict",
"_____no_output_____"
],
[
"for key, value in name_dict.items():\n if value == 'no':\n name_dict[key] = new_anot[key]",
"_____no_output_____"
],
[
"name_dict",
"_____no_output_____"
],
[
"DF_annot = DF_annot.replace({'marie_gene':name_dict})\nDF_annot = DF_annot.replace({'marie_product':product_dict})\nDF_annot = DF_annot.replace({'marie_annot':new_anot})\n# DF_annot.head()",
"_____no_output_____"
],
[
"order = ['old_locus_tag','marie_annot', 'marie_gene', 'marie_product', 'cycbio_gene_name','cycbio_gene_product', \n 'gene_name', 'gene_product','COG','uniprot','operon','accession','start','end','strand']\nDF_annot = DF_annot[order]\nDF_annot[30:38]",
"_____no_output_____"
],
[
"DF_annot",
"_____no_output_____"
],
[
"DF_annot.to_csv(os.path.join(org_dir,'gene_info_operon.csv'))",
"_____no_output_____"
]
],
[
[
"# GO Annotations",
"_____no_output_____"
],
[
"To start, download the GO Annotations for your organism from AmiGO 2\n1. Go to http://amigo.geneontology.org/amigo/search/annotation\n1. Filter for your organism\n1. Click `CustomDL`\n1. Drag `GO class (direct)` to the end of your Selected Fields\n1. Save as `GO_annotations.txt` in the `data` folder of your organism directory",
"_____no_output_____"
]
],
[
[
"DF_GO = pd.read_csv(os.path.join(org_dir,'3_go_annotation.txt'),sep='\\t',header=None)",
"_____no_output_____"
],
[
"DF_GO = pd.read_csv(os.path.join(org_dir,'3_go_annotation.txt'),sep='\\t',header=None,usecols=[3,9,18])\nDF_GO.columns = ['gene_name','gene_product','gene_ontology']\nDF_GO.gene_name.fillna(DF_GO.gene_name,inplace=True)\nDF_GO.head()",
"_____no_output_____"
]
],
[
[
"Take a look at the `gene_id` column:\n1. Make sure there are no null entries\n2. Check if it uses the new or old locus tag (if applicable)\n\nIf it looks like it uses the old locus tag, set old_locus_tag to `True`",
"_____no_output_____"
]
],
[
[
"old_locus_tag = False",
"_____no_output_____"
],
[
"DF_GO[DF_GO.gene_name.isnull()]",
"_____no_output_____"
],
[
"# if not old_locus_tag:\n# convert_tags = {value:key for key,value in DF_annot.old_locus_tag.items()}\n# DF_GO.gene_name = DF_GO.gene_name.apply(lambda x: convert_tags[x])",
"_____no_output_____"
],
[
"DF_GO.head()",
"_____no_output_____"
],
[
"# DF_GO[['gene_id','gene_ontology']].to_csv(os.path.join(org_dir,'data','GO_annotations.csv'))",
"_____no_output_____"
],
[
"DF_GO.to_csv(os.path.join(org_dir,'2_GO_annotations.csv'))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2b586d27e91907d0b4ad158985b717292db282
| 217,094 |
ipynb
|
Jupyter Notebook
|
Different_Devices/SAKURA_AES/SAKURA_CDPA_Demo.ipynb
|
CDPA-SCA/Cross-Device-Profiled-Attack
|
a0139e4eaa8e197b11269bdbbe70a7ecf090b312
|
[
"MIT"
] | 2 |
2021-09-22T07:20:06.000Z
|
2021-10-15T05:55:52.000Z
|
Different_Devices/SAKURA_AES/SAKURA_CDPA_Demo.ipynb
|
CDPA-SCA/Cross-Device-Profiled-Attack
|
a0139e4eaa8e197b11269bdbbe70a7ecf090b312
|
[
"MIT"
] | null | null | null |
Different_Devices/SAKURA_AES/SAKURA_CDPA_Demo.ipynb
|
CDPA-SCA/Cross-Device-Profiled-Attack
|
a0139e4eaa8e197b11269bdbbe70a7ecf090b312
|
[
"MIT"
] | 3 |
2021-04-23T12:52:39.000Z
|
2022-02-28T07:49:23.000Z
| 185.709153 | 31,268 | 0.864335 |
[
[
[
"from torchvision import transforms\nfrom torch.utils.data import Dataset, DataLoader\nimport torch\nfrom torch import optim\nfrom torch.autograd import Variable\nimport numpy as np\nimport os\nimport math\nfrom torch import nn\nfrom sklearn.metrics import confusion_matrix\nimport matplotlib.pyplot as plt \nimport itertools\nimport random\nfrom sklearn import preprocessing\nfrom scipy import io\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"",
"_____no_output_____"
]
],
[
[
"## DataLoader",
"_____no_output_____"
]
],
[
[
"### handle the dataset\nclass TorchDataset(Dataset):\n def __init__(self, trs_file, label_file, trace_num, trace_offset, trace_length):\n self.trs_file = trs_file\n self.label_file = label_file\n self.trace_num = trace_num\n self.trace_offset = trace_offset\n self.trace_length = trace_length\n self.ToTensor = transforms.ToTensor()\n def __getitem__(self, i):\n index = i % self.trace_num\n trace = self.trs_file[index,:]\n label = self.label_file[index]\n trace = trace[self.trace_offset:self.trace_offset+self.trace_length]\n trace = np.reshape(trace,(1,-1))\n trace = self.ToTensor(trace)\n trace = np.reshape(trace, (1,-1))\n label = torch.tensor(label, dtype=torch.long) \n return trace.float(), label\n def __len__(self):\n return self.trace_num\n \n### data loader for training\ndef load_training(batch_size, kwargs):\n data = TorchDataset(**kwargs)\n train_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=1, pin_memory=True)\n return train_loader\n\n### data loader for testing\ndef load_testing(batch_size, kwargs):\n data = TorchDataset(**kwargs)\n test_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=False, drop_last=True, num_workers=1, pin_memory=True)\n return test_loader",
"_____no_output_____"
]
],
[
[
"## Arrays and Functions",
"_____no_output_____"
]
],
[
[
"Sbox = [99, 124, 119, 123, 242, 107, 111, 197, 48, 1, 103, 43, 254, 215, 171, 118, 202, 130, 201, 125, 250, 89, 71,\n 240, 173, 212, 162, 175, 156, 164, 114, 192, 183, 253, 147, 38, 54, 63, 247, 204, 52, 165, 229, 241, 113, 216,\n 49, 21, 4, 199, 35, 195, 24, 150, 5, 154, 7, 18, 128, 226, 235, 39, 178, 117, 9, 131, 44, 26, 27, 110, 90, 160,\n 82, 59, 214, 179, 41, 227, 47, 132, 83, 209, 0, 237, 32, 252, 177, 91, 106, 203, 190, 57, 74, 76, 88, 207, 208,\n 239, 170, 251, 67, 77, 51, 133, 69, 249, 2, 127, 80, 60, 159, 168, 81, 163, 64, 143, 146, 157, 56, 245, 188,\n 182, 218, 33, 16, 255, 243, 210, 205, 12, 19, 236, 95, 151, 68, 23, 196, 167, 126, 61, 100, 93, 25, 115, 96,\n 129, 79, 220, 34, 42, 144, 136, 70, 238, 184, 20, 222, 94, 11, 219, 224, 50, 58, 10, 73, 6, 36, 92, 194, 211,\n 172, 98, 145, 149, 228, 121, 231, 200, 55, 109, 141, 213, 78, 169, 108, 86, 244, 234, 101, 122, 174, 8, 186,\n 120, 37, 46, 28, 166, 180, 198, 232, 221, 116, 31, 75, 189, 139, 138, 112, 62, 181, 102, 72, 3, 246, 14, 97,\n 53, 87, 185, 134, 193, 29, 158, 225, 248, 152, 17, 105, 217, 142, 148, 155, 30, 135, 233, 206, 85, 40, 223, 140,\n 161, 137, 13, 191, 230, 66, 104, 65, 153, 45, 15, 176, 84, 187, 22]\n\nInvSbox = [82, 9, 106, 213, 48, 54, 165, 56, 191, 64, 163, 158, 129, 243, 215, 251, 124, 227, 57, 130, 155, 47, 255, 135,\n 52, 142, 67, 68, 196, 222, 233, 203, 84, 123, 148, 50, 166, 194, 35, 61,238, 76, 149, 11, 66, 250, 195, 78, 8,\n 46, 161, 102, 40, 217, 36, 178, 118, 91, 162, 73, 109, 139, 209, 37, 114, 248, 246, 100, 134, 104, 152, 22, 212,\n 164, 92, 204, 93, 101, 182, 146, 108, 112, 72, 80, 253, 237, 185, 218, 94, 21, 70, 87, 167, 141, 157, 132, 144,\n 216, 171, 0, 140, 188, 211, 10, 247, 228, 88, 5, 184, 179, 69, 6, 208, 44, 30, 143, 202, 63, 15, 2, 193, 175, 189,\n 3, 1, 19, 138, 107, 58, 145, 17, 65, 79, 103, 220, 234, 151, 242, 207, 206, 240, 180, 230, 115, 150, 172, 116, 34,\n 231, 173, 53, 133, 226, 249, 55, 232, 28, 117, 223, 110, 71, 241, 26, 113, 29, 41, 197, 137, 111, 183, 98, 14, 170,\n 24,190, 27, 252, 86, 62, 75, 198, 210, 121, 32, 154, 219, 192, 254, 120, 205, 90, 244, 31, 221, 168, 51, 136, 7,\n 199, 49, 177, 18, 16, 89, 39, 128, 236, 95, 96, 81, 127, 169, 25, 181,74, 13, 45, 229, 122, 159, 147, 201, 156,\n 239, 160, 224, 59, 77, 174, 42, 245, 176, 200, 235, 187, 60, 131, 83, 153, 97, 23, 43, 4, 126, 186, 119, 214, 38,\n 225, 105, 20, 99, 85, 33,12, 125]\n\nHW_byte = [0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 1, 2, 2,\n 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 1, 2, 2, 3, 2, 3,\n 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3,\n 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4,\n 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5,\n 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4,\n 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 4, 5, 5, 6, 5,\n 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8]\n\n### To train a network \ndef train(epoch, model, freeze_BN = False):\n \"\"\"\n - epoch : the current epoch\n - model : the current model \n - freeze_BN : whether to freeze batch normalization layers\n \"\"\"\n if freeze_BN:\n model.eval() # enter eval mode to freeze batch normalization layers\n else:\n model.train() # enter training mode \n # Instantiate the Iterator\n iter_source = iter(source_train_loader)\n # get the number of batches\n num_iter = len(source_train_loader)\n clf_criterion = nn.CrossEntropyLoss()\n # train on each batch of data\n for i in range(1, num_iter+1):\n source_data, source_label = iter_source.next()\n if cuda:\n source_data, source_label = source_data.cuda(), source_label.cuda()\n source_data, source_label = Variable(source_data), Variable(source_label)\n optimizer.zero_grad()\n source_preds = model(source_data)\n preds = source_preds.data.max(1, keepdim=True)[1]\n correct_batch = preds.eq(source_label.data.view_as(preds)).sum()\n loss = clf_criterion(source_preds, source_label)\n # optimzie the cross-entropy loss\n loss.backward()\n optimizer.step()\n if i % log_interval == 0:\n print('Train Epoch {}: [{}/{} ({:.0f}%)]\\tLoss: {:.6f}\\tAcc: {:.6f}%'.format(\n epoch, i * len(source_data), len(source_train_loader) * batch_size,\n 100. * i / len(source_train_loader), loss.data, float(correct_batch) * 100. /batch_size))\n \n### validation \ndef validation(model):\n # enter evaluation mode\n model.eval()\n valid_loss = 0\n # the number of correct prediction\n correct_valid = 0\n clf_criterion = nn.CrossEntropyLoss()\n for data, label in source_valid_loader:\n if cuda:\n data, label = data.cuda(), label.cuda()\n data, label = Variable(data), Variable(label)\n valid_preds = model(data)\n # sum up batch loss\n valid_loss += clf_criterion(valid_preds, label) \n # get the index of the max probability\n pred = valid_preds.data.max(1)[1] \n # get the number of correct prediction\n correct_valid += pred.eq(label.data.view_as(pred)).cpu().sum()\n valid_loss /= len(source_valid_loader)\n valid_acc = 100. * correct_valid / len(source_valid_loader.dataset)\n print('Validation: loss: {:.4f}, accuracy: {}/{} ({:.6f}%)'.format(\n valid_loss.data, correct_valid, len(source_valid_loader.dataset),\n valid_acc))\n return valid_loss, valid_acc\n\n### test/attack\ndef test(model, device_id, disp_GE=True, model_flag='pretrained'):\n \"\"\"\n - model : the current model \n - device_id : id of the tested device\n - disp_GE : whether to attack/calculate guessing entropy (GE)\n - model_flag : a string for naming GE result\n \"\"\"\n # enter evaluation mode\n model.eval()\n test_loss = 0\n # the number of correct prediction\n correct = 0\n epoch = 0\n clf_criterion = nn.CrossEntropyLoss()\n if device_id == source_device_id: # attack on the source domain\n test_num = source_test_num\n test_loader = source_test_loader\n real_key = real_key_01\n else: # attack on the target domain\n test_num = target_test_num\n test_loader = target_test_loader\n real_key = real_key_02\n # Initialize the prediction and label lists(tensors)\n predlist=torch.zeros(0,dtype=torch.long, device='cpu')\n lbllist=torch.zeros(0,dtype=torch.long, device='cpu')\n test_preds_all = torch.zeros((test_num, class_num), dtype=torch.float, device='cpu')\n for data, label in test_loader:\n if cuda:\n data, label = data.cuda(), label.cuda()\n data, label = Variable(data), Variable(label)\n test_preds = model(data)\n # sum up batch loss\n test_loss += clf_criterion(test_preds, label) \n # get the index of the max probability\n pred = test_preds.data.max(1)[1]\n # get the softmax results for attack/showing guessing entropy\n softmax = nn.Softmax(dim=1)\n test_preds_all[epoch*batch_size:(epoch+1)*batch_size, :] =softmax(test_preds)\n # get the predictions (predlist) and real labels (lbllist) for showing confusion matrix\n predlist=torch.cat([predlist,pred.view(-1).cpu()])\n lbllist=torch.cat([lbllist,label.view(-1).cpu()])\n # get the number of correct prediction\n correct += pred.eq(label.data.view_as(pred)).cpu().sum()\n epoch += 1\n test_loss /= len(test_loader)\n print('Target test loss: {:.4f}, Target test accuracy: {}/{} ({:.2f}%)\\n'.format(\n test_loss.data, correct, len(test_loader.dataset),\n 100. * correct / len(test_loader.dataset)))\n # get the confusion matrix\n confusion_mat = confusion_matrix(lbllist.numpy(), predlist.numpy())\n # show the confusion matrix\n plot_sonfusion_matrix(confusion_mat, classes = range(class_num))\n # show the guessing entropy and success rate\n if disp_GE:\n plot_guessing_entropy(test_preds_all.numpy(), real_key, device_id, model_flag)\n\n### fine-tune a pre-trained model\ndef CDP_train(epoch, model):\n \"\"\"\n - epoch : the current epoch\n - model : the current model \n \"\"\"\n # enter evaluation mode to freeze the BN and dropout (if have) layer when fine-tuning\n model.eval()\n # Instantiate the Iterator for source tprofiling traces\n iter_source = iter(source_train_loader)\n # Instantiate the Iterator for target traces\n iter_target = iter(target_finetune_loader)\n num_iter_target = len(target_finetune_loader)\n finetune_trace_all = torch.zeros((num_iter_target, batch_size, 1, trace_length))\n for i in range(num_iter_target):\n finetune_trace_all[i,:,:,:], _ = iter_target.next()\n # get the number of batches\n num_iter = len(source_train_loader)\n clf_criterion = nn.CrossEntropyLoss()\n # train on each batch of data\n for i in range(1, num_iter+1):\n # get traces and labels for source domain\n source_data, source_label = iter_source.next()\n # get traces for target domain\n target_data = finetune_trace_all[(i-1)%num_iter_target,:,:,:]\n if cuda:\n source_data, source_label = source_data.cuda(), source_label.cuda()\n target_data = target_data.cuda()\n source_data, source_label = Variable(source_data), Variable(source_label)\n target_data = Variable(target_data)\n optimizer.zero_grad()\n # get predictions and MMD loss\n source_preds, mmd_loss = model(source_data, target_data)\n preds = source_preds.data.max(1, keepdim=True)[1]\n # get classification loss on source doamin\n clf_loss = clf_criterion(source_preds, source_label)\n # the total loss function\n loss = clf_loss + lambda_*mmd_loss\n # optimzie the total loss\n loss.backward()\n optimizer.step()\n if i % log_interval == 0:\n print('Train Epoch {}: [{}/{} ({:.0f}%)]\\ttotal_loss: {:.6f}\\tclf_loss: {:.6f}\\tmmd_loss: {:.6f}'.format(\n epoch, i * len(source_data), len(source_train_loader) * batch_size,\n 100. * i / len(source_train_loader), loss.data, clf_loss.data, mmd_loss.data))\n\n### Validation for fine-tuning phase \ndef CDP_validation(model):\n # enter evaluation mode\n clf_criterion = nn.CrossEntropyLoss()\n model.eval()\n # Instantiate the Iterator for source validation traces\n iter_source = iter(source_valid_loader)\n # Instantiate the Iterator for target traces\n iter_target = iter(target_finetune_loader)\n num_iter_target = len(target_finetune_loader)\n finetune_trace_all = torch.zeros((num_iter_target, batch_size, 1, trace_length))\n for i in range(num_iter_target):\n finetune_trace_all[i,:,:,:], _ = iter_target.next()\n # get the number of batches\n num_iter = len(source_valid_loader)\n # the classification loss\n total_clf_loss = 0\n # the MMD loss\n total_mmd_loss = 0\n # the total loss\n total_loss = 0\n # the number of correct prediction\n correct = 0\n for i in range(1, num_iter+1):\n # get traces and labels for source domain\n source_data, source_label = iter_source.next()\n # get traces for target domain\n target_data = finetune_trace_all[(i-1)%num_iter_target,:,:,:]\n if cuda:\n source_data, source_label = source_data.cuda(), source_label.cuda()\n target_data = target_data.cuda()\n source_data, source_label = Variable(source_data), Variable(source_label)\n target_data = Variable(target_data)\n valid_preds, mmd_loss = model(source_data, target_data)\n clf_loss = clf_criterion(valid_preds, source_label) \n # sum up batch loss\n loss = clf_loss + lambda_*mmd_loss\n total_clf_loss += clf_loss\n total_mmd_loss += mmd_loss\n total_loss += loss\n # get the index of the max probability\n pred = valid_preds.data.max(1)[1] \n correct += pred.eq(source_label.data.view_as(pred)).cpu().sum()\n total_loss /= len(source_valid_loader)\n total_clf_loss /= len(source_valid_loader)\n total_mmd_loss /= len(source_valid_loader)\n print('Validation: total_loss: {:.4f}, clf_loss: {:.4f}, mmd_loss: {:.4f}, accuracy: {}/{} ({:.2f}%)'.format(\n total_loss.data, total_clf_loss, total_mmd_loss, correct, len(source_valid_loader.dataset),\n 100. * correct / len(source_valid_loader.dataset)))\n return total_loss\n\n### kernel function\ndef guassian_kernel(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):\n \"\"\"\n - source : source data\n - target : target data\n - kernel_mul : multiplicative step of bandwidth (sigma)\n - kernel_num : the number of guassian kernels\n - fix_sigma : use a fix value of bandwidth\n \"\"\"\n n_samples = int(source.size()[0])+int(target.size()[0])\n total = torch.cat([source, target], dim=0)\n total0 = total.unsqueeze(0).expand(int(total.size(0)), \\\n int(total.size(0)), \\\n int(total.size(1)))\n total1 = total.unsqueeze(1).expand(int(total.size(0)), \\\n int(total.size(0)), \\\n int(total.size(1)))\n # |x-y|\n L2_distance = ((total0-total1)**2).sum(2) \n \n # bandwidth\n if fix_sigma:\n bandwidth = fix_sigma\n else:\n bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)\n # take the current bandwidth as the median value, and get a list of bandwidths (for example, when bandwidth is 1, we get [0.25,0.5,1,2,4]).\n bandwidth /= kernel_mul ** (kernel_num // 2)\n bandwidth_list = [bandwidth * (kernel_mul**i) for i in range(kernel_num)]\n\n #exp(-|x-y|/bandwidth)\n kernel_val = [torch.exp(-L2_distance / bandwidth_temp) for \\\n bandwidth_temp in bandwidth_list]\n\n # return the final kernel matrix\n return sum(kernel_val)\n\n### MMD loss function based on guassian kernels\ndef mmd_rbf(source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):\n \"\"\"\n - source : source data\n - target : target data\n - kernel_mul : multiplicative step of bandwidth (sigma)\n - kernel_num : the number of guassian kernels\n - fix_sigma : use a fix value of bandwidth\n \"\"\"\n loss = 0.0\n batch_size = int(source.size()[0])\n kernels = guassian_kernel(source, target,kernel_mul=kernel_mul,kernel_num=kernel_num, fix_sigma=fix_sigma)\n XX = kernels[:batch_size, :batch_size] # Source<->Source\n YY = kernels[batch_size:, batch_size:] # Target<->Target\n XY = kernels[:batch_size, batch_size:] # Source<->Target\n YX = kernels[batch_size:, :batch_size] # Target<->Source\n loss = torch.mean(XX + YY - XY -YX)\n return loss\n\n### show the guessing entropy and success rate\ndef plot_guessing_entropy(preds, real_key, device_id, model_flag):\n \"\"\"\n - preds : the probability for each class (n*256 for a byte, n*9 for Hamming weight)\n - real_key : the key of the target device\n - device_id : id of the target device\n - model_flag : a string for naming GE result\n \"\"\"\n # GE/SR is averaged over 100 attacks \n num_averaged = 100\n # max trace num for attack\n trace_num_max = 5000\n # the step trace num increases\n step = 1\n if trace_num_max > 400 and trace_num_max < 1000:\n step = 2\n if trace_num_max >= 1000 and trace_num_max < 5000:\n step = 4\n if trace_num_max >= 5000 and trace_num_max < 10000:\n step = 5\n guessing_entropy = np.zeros((num_averaged, int(trace_num_max/step)))\n success_flag = np.zeros((num_averaged, int(trace_num_max/step)))\n if device_id == target_device_id: # attack on the target domain\n ciphertext = ciphertexts_target\n elif device_id == source_device_id: # attack on the source domain\n ciphertext = ciphertexts_source\n # try to attack multiples times for average\n for time in range(num_averaged):\n # select the attack traces randomly\n random_index = list(range(ciphertext.shape[0]))\n random.shuffle(random_index)\n random_index = random_index[0:trace_num_max]\n # initialize score matrix\n score_mat = np.zeros((trace_num_max, 256))\n for key_guess in range(0, 256):\n for i in range(0, trace_num_max):\n temp = int(ciphertext[random_index[i], 1]) ^ key_guess\n initialState = InvSbox[temp]\n media_value = initialState ^ int(ciphertext[random_index[i], 5])\n if labeling_method == 'identity':\n label = media_value\n elif labeling_method == 'hw':\n label = HW_byte[media_value]\n score_mat[i, key_guess] = preds[random_index[i], label]\n score_mat = np.log(score_mat+1e-40)\n for i in range(0, trace_num_max, step):\n log_likelihood = np.sum(score_mat[0:i+1,:], axis=0)\n ranked = np.argsort(log_likelihood)[::-1]\n guessing_entropy[time,int(i/step)] = list(ranked).index(real_key)\n if list(ranked).index(real_key) == 0:\n success_flag[time, int(i/step)] = 1\n guessing_entropy = np.mean(guessing_entropy,axis=0)\n plt.figure(figsize=(12,4))\n plt.subplot(1, 2, 1)\n x = range(0, trace_num_max, step)\n p1, = plt.plot(x, guessing_entropy[0:int(trace_num_max/step)],color='red')\n plt.xlabel('Number of trace')\n plt.ylabel('Guessing entropy')\n #np.save('./results/entropy_'+ labeling_method + '_{}_to_{}_'.format(source_device_id, device_id) + model_flag, guessing_entropy)\n plt.subplot(1, 2, 2) \n success_flag = np.sum(success_flag, axis=0)\n success_rate = success_flag/num_averaged \n p2, = plt.plot(x, success_rate[0:int(trace_num_max/step)], color='red')\n plt.xlabel('Number of trace')\n plt.ylabel('Success rate')\n plt.show()\n #np.save('./results/success_rate_' + labeling_method + '_{}_to_{}_'.format(source_device_id, device_id) + model_flag, success_rate)\n \n### show the confusion matrix \ndef plot_sonfusion_matrix(cm, classes, normalize=False, title='Confusion matrix',cmap=plt.cm.Blues):\n plt.imshow(cm, interpolation='nearest', cmap=cmap)\n plt.title(title)\n plt.colorbar()\n plt.ylim((len(classes)-0.5, -0.5))\n plt.tight_layout()\n plt.ylabel('True label')\n plt.xlabel('Predict label')\n plt.show()",
"_____no_output_____"
]
],
[
[
"# Setups",
"_____no_output_____"
]
],
[
[
"source_device_id = 1\ntarget_device_id = 2\n# roundkeys of the three devices are : 0x21, 0xCD, 0x8F\nreal_key_01 = 0x21 # key of the source domain \nreal_key_02 = 0xCD # key of the target domain\nlambda_ = 0.05 # Penalty coefficient\nlabeling_method = 'identity' # labeling of trace\npreprocess = 'horizontal_standardization' # preprocess method\nbatch_size = 200\ntotal_epoch = 200\nfinetune_epoch = 15 # epoch number for fine-tuning\nlr = 0.001 # learning rate\nlog_interval = 50 # epoch interval to log training information\ntrain_num = 85000\nvalid_num = 5000\nsource_test_num = 9900\ntarget_finetune_num = 200\ntarget_test_num = 9400\ntrace_offset = 0\ntrace_length = 1000\nsource_file_path = './Data/device1/'\ntarget_file_path = './Data/device2/'\nno_cuda =False\ncuda = not no_cuda and torch.cuda.is_available()\nseed = 8\ntorch.manual_seed(seed)\nif cuda:\n torch.cuda.manual_seed(seed)\nif labeling_method == 'identity':\n class_num = 256\nelif labeling_method == 'hw':\n class_num = 9\n\n# to load traces and labels\nX_train_source = np.load(source_file_path + 'X_train.npy')\nY_train_source = np.load(source_file_path + 'Y_train.npy')\nX_attack_source = np.load(source_file_path + 'X_attack.npy')\nY_attack_source = np.load(source_file_path + 'Y_attack.npy')\nX_attack_target = np.load(target_file_path + 'X_attack.npy')\nY_attack_target = np.load(target_file_path + 'Y_attack.npy')\n\n# to load ciphertexts\nciphertexts_source = np.load(source_file_path + 'ciphertexts_attack.npy')\nciphertexts_target = np.load(target_file_path + 'ciphertexts_attack.npy')\nciphertexts_target = ciphertexts_target[target_finetune_num:target_finetune_num+target_test_num]\n\n# preprocess of traces\nif preprocess == 'horizontal_standardization':\n mn = np.repeat(np.mean(X_train_source, axis=1, keepdims=True), X_train_source.shape[1], axis=1)\n std = np.repeat(np.std(X_train_source, axis=1, keepdims=True), X_train_source.shape[1], axis=1)\n X_train_source = (X_train_source - mn)/std\n\n mn = np.repeat(np.mean(X_attack_source, axis=1, keepdims=True), X_attack_source.shape[1], axis=1)\n std = np.repeat(np.std(X_attack_source, axis=1, keepdims=True), X_attack_source.shape[1], axis=1)\n X_attack_source = (X_attack_source - mn)/std\n \n mn = np.repeat(np.mean(X_attack_target, axis=1, keepdims=True), X_attack_target.shape[1], axis=1)\n std = np.repeat(np.std(X_attack_target, axis=1, keepdims=True), X_attack_target.shape[1], axis=1)\n X_attack_target = (X_attack_target - mn)/std\n \nelif preprocess == 'horizontal_scaling':\n scaler = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(X_train_source.T)\n X_train_source = scaler.transform(X_train_source.T).T\n\n scaler = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(X_attack_source.T)\n X_attack_source = scaler.transform(X_attack_source.T).T\n \n scaler = preprocessing.MinMaxScaler(feature_range=(-1, 1)).fit(X_attack_target.T)\n X_attack_target = scaler.transform(X_attack_target.T).T\n \n# parameters of data loader\nkwargs_source_train = {\n 'trs_file': X_train_source[0:train_num,:],\n 'label_file': Y_train_source[0:train_num],\n 'trace_num':train_num,\n 'trace_offset':trace_offset,\n 'trace_length':trace_length,\n}\nkwargs_source_valid = {\n 'trs_file': X_train_source[train_num:train_num+valid_num,:],\n 'label_file': Y_train_source[train_num:train_num+valid_num],\n 'trace_num':valid_num,\n 'trace_offset':trace_offset,\n 'trace_length':trace_length,\n}\nkwargs_source_test = {\n 'trs_file': X_attack_source,\n 'label_file': Y_attack_source,\n 'trace_num':source_test_num,\n 'trace_offset':trace_offset,\n 'trace_length':trace_length,\n}\nkwargs_target_finetune = {\n 'trs_file': X_attack_target[0:target_finetune_num,:],\n 'label_file': Y_attack_target[0:target_finetune_num],\n 'trace_num':target_finetune_num,\n 'trace_offset':trace_offset,\n 'trace_length':trace_length,\n}\nkwargs_target = {\n 'trs_file': X_attack_target[target_finetune_num:target_finetune_num+target_test_num, :],\n 'label_file': Y_attack_target[target_finetune_num:target_finetune_num+target_test_num],\n 'trace_num':target_test_num,\n 'trace_offset':trace_offset,\n 'trace_length':trace_length,\n}\nsource_train_loader = load_training(batch_size, kwargs_source_train)\nsource_valid_loader = load_training(batch_size, kwargs_source_valid)\nsource_test_loader = load_testing(batch_size, kwargs_source_test)\ntarget_finetune_loader = load_training(batch_size, kwargs_target_finetune)\ntarget_test_loader = load_testing(batch_size, kwargs_target)\nprint('Load data complete!')",
"Load data complete!\n"
]
],
[
[
"# Model",
"_____no_output_____"
]
],
[
[
"### the pre-trained model\nclass Net(nn.Module):\n def __init__(self, num_classes=class_num):\n super(Net, self).__init__()\n # the encoder part\n self.features = nn.Sequential(\n nn.Conv1d(1, 8, kernel_size=1),\n nn.SELU(),\n nn.BatchNorm1d(8),\n nn.AvgPool1d(kernel_size=2, stride=2),\n nn.Conv1d(8, 16, kernel_size=11),\n nn.SELU(),\n nn.BatchNorm1d(16),\n nn.AvgPool1d(kernel_size=11, stride=11),\n nn.Conv1d(16, 32, kernel_size=2),\n nn.SELU(),\n nn.BatchNorm1d(32),\n nn.AvgPool1d(kernel_size=3, stride=3),\n nn.Flatten()\n )\n # the fully-connected layer 1\n self.classifier_1 = nn.Sequential(\n nn.Linear(448, 2),\n nn.SELU(),\n )\n # the output layer\n self.final_classifier = nn.Sequential(\n nn.Linear(2, num_classes)\n )\n \n # how the network runs\n def forward(self, input):\n x = self.features(input)\n x = x.view(x.size(0), -1)\n x = self.classifier_1(x)\n output = self.final_classifier(x)\n return output\n\n### the fine-tuning model\nclass CDP_Net(nn.Module):\n def __init__(self, num_classes=class_num):\n super(CDP_Net, self).__init__()\n # the encoder part\n self.features = nn.Sequential(\n nn.Conv1d(1, 8, kernel_size=1),\n nn.SELU(),\n nn.BatchNorm1d(8),\n nn.AvgPool1d(kernel_size=2, stride=2),\n nn.Conv1d(8, 16, kernel_size=11),\n nn.SELU(),\n nn.BatchNorm1d(16),\n nn.AvgPool1d(kernel_size=11, stride=11),\n nn.Conv1d(16, 32, kernel_size=2),\n nn.SELU(),\n nn.BatchNorm1d(32),\n nn.AvgPool1d(kernel_size=3, stride=3),\n nn.Flatten()\n )\n # the fully-connected layer 1\n self.classifier_1 = nn.Sequential(\n nn.Linear(448, 2),\n nn.SELU(),\n )\n # the output layer\n self.final_classifier = nn.Sequential(\n nn.Linear(2, num_classes)\n )\n\n # how the network runs\n def forward(self, source, target):\n mmd_loss = 0\n #source data flow\n source = self.features(source)\n source_0 = source.view(source.size(0), -1)\n source_1 = self.classifier_1(source_0)\n\n #target data flow\n target = self.features(target)\n target = target.view(target.size(0), -1)\n mmd_loss += mmd_rbf(source_0, target)\n target = self.classifier_1(target)\n mmd_loss += mmd_rbf(source_1, target)\n \n result = self.final_classifier(source_1)\n return result, mmd_loss",
"_____no_output_____"
]
],
[
[
"## Performance of the pre-trained model",
"_____no_output_____"
]
],
[
[
"# create a network\nmodel = Net(num_classes=class_num)\nprint('Construct model complete')\nif cuda:\n model.cuda()\n# load the pre-trained network\ncheckpoint = torch.load('./models/pre-trained_device{}.pth'.format(source_device_id))\npretrained_dict = checkpoint['model_state_dict']\nmodel_dict = pretrained_dict\nmodel.load_state_dict(model_dict)\n# evaluate the pre-trained model on source and target domain\nwith torch.no_grad():\n \n print('Result on source device:')\n test(model, source_device_id, model_flag='pretrained_source')\n \n print('Result on target device:')\n test(model, target_device_id, model_flag='pretrained_target')",
"Construct model complete\nResult on source device:\nTarget test loss: 5.5299, Target test accuracy: 59/9900 (0.60%)\n\n"
]
],
[
[
"## Cross-Device Profiling: fine-tune 15 epochs",
"_____no_output_____"
]
],
[
[
"# create a network\nCDP_model = CDP_Net(num_classes=class_num)\nprint('Construct model complete')\nif cuda:\n CDP_model.cuda()\n# initialize a big enough loss number\nmin_loss = 1000\n# load the pre-trained model\ncheckpoint = torch.load('./models/pre-trained_device{}.pth'.format(source_device_id))\npretrained_dict = checkpoint['model_state_dict']\nCDP_model.load_state_dict(pretrained_dict)\noptimizer = optim.Adam([\n {'params': CDP_model.features.parameters()},\n {'params': CDP_model.classifier_1.parameters()},\n {'params': CDP_model.final_classifier.parameters()}\n ], lr=lr)\n# restore the optimizer state\noptimizer.load_state_dict(checkpoint['optimizer_state_dict'])\nfor epoch in range(1, finetune_epoch + 1):\n print(f'Train Epoch {epoch}:')\n CDP_train(epoch, CDP_model)\n with torch.no_grad():\n valid_loss = CDP_validation(CDP_model)\n # save the model that achieves the lowest validation loss\n if valid_loss < min_loss:\n min_loss = valid_loss\n torch.save({\n 'epoch': epoch,\n 'model_state_dict': CDP_model.state_dict(),\n 'optimizer_state_dict': optimizer.state_dict()\n }, './models/best_valid_loss_finetuned_device{}_to_{}.pth'.format(source_device_id, target_device_id))\n\ntorch.save({\n 'epoch': epoch,\n 'model_state_dict': CDP_model.state_dict(),\n 'optimizer_state_dict': optimizer.state_dict()\n }, './models/last_valid_loss_finetuned_device{}_to_{}.pth'.format(source_device_id, target_device_id))",
"Construct model complete\nTrain Epoch 1:\nTrain Epoch 1: [10000/85000 (12%)]\ttotal_loss: 5.611550\tclf_loss: 5.526998\tmmd_loss: 1.691060\nTrain Epoch 1: [20000/85000 (24%)]\ttotal_loss: 5.607505\tclf_loss: 5.536800\tmmd_loss: 1.414101\nTrain Epoch 1: [30000/85000 (35%)]\ttotal_loss: 5.582577\tclf_loss: 5.516282\tmmd_loss: 1.325902\nTrain Epoch 1: [40000/85000 (47%)]\ttotal_loss: 5.583940\tclf_loss: 5.522779\tmmd_loss: 1.223209\nTrain Epoch 1: [50000/85000 (59%)]\ttotal_loss: 5.587979\tclf_loss: 5.529202\tmmd_loss: 1.175551\nTrain Epoch 1: [60000/85000 (71%)]\ttotal_loss: 5.561944\tclf_loss: 5.513365\tmmd_loss: 0.971581\nTrain Epoch 1: [70000/85000 (82%)]\ttotal_loss: 5.582853\tclf_loss: 5.538470\tmmd_loss: 0.887664\nTrain Epoch 1: [80000/85000 (94%)]\ttotal_loss: 5.569809\tclf_loss: 5.525914\tmmd_loss: 0.877902\nValidation: total_loss: 5.5907, clf_loss: 5.5450, mmd_loss: 0.9146, accuracy: 27/5000 (0.54%)\nTrain Epoch 2:\nTrain Epoch 2: [10000/85000 (12%)]\ttotal_loss: 5.570718\tclf_loss: 5.525162\tmmd_loss: 0.911123\nTrain Epoch 2: [20000/85000 (24%)]\ttotal_loss: 5.590009\tclf_loss: 5.546586\tmmd_loss: 0.868470\nTrain Epoch 2: [30000/85000 (35%)]\ttotal_loss: 5.582355\tclf_loss: 5.546153\tmmd_loss: 0.724033\nTrain Epoch 2: [40000/85000 (47%)]\ttotal_loss: 5.573089\tclf_loss: 5.536055\tmmd_loss: 0.740675\nTrain Epoch 2: [50000/85000 (59%)]\ttotal_loss: 5.568609\tclf_loss: 5.537515\tmmd_loss: 0.621878\nTrain Epoch 2: [60000/85000 (71%)]\ttotal_loss: 5.568110\tclf_loss: 5.536889\tmmd_loss: 0.624407\nTrain Epoch 2: [70000/85000 (82%)]\ttotal_loss: 5.559078\tclf_loss: 5.527311\tmmd_loss: 0.635342\nTrain Epoch 2: [80000/85000 (94%)]\ttotal_loss: 5.564308\tclf_loss: 5.536345\tmmd_loss: 0.559276\nValidation: total_loss: 5.5695, clf_loss: 5.5413, mmd_loss: 0.5633, accuracy: 21/5000 (0.42%)\nTrain Epoch 3:\nTrain Epoch 3: [10000/85000 (12%)]\ttotal_loss: 5.562810\tclf_loss: 5.534667\tmmd_loss: 0.562847\nTrain Epoch 3: [20000/85000 (24%)]\ttotal_loss: 5.552950\tclf_loss: 5.528317\tmmd_loss: 0.492648\nTrain Epoch 3: [30000/85000 (35%)]\ttotal_loss: 5.550319\tclf_loss: 5.522788\tmmd_loss: 0.550624\nTrain Epoch 3: [40000/85000 (47%)]\ttotal_loss: 5.555224\tclf_loss: 5.531003\tmmd_loss: 0.484411\nTrain Epoch 3: [50000/85000 (59%)]\ttotal_loss: 5.544055\tclf_loss: 5.519972\tmmd_loss: 0.481665\nTrain Epoch 3: [60000/85000 (71%)]\ttotal_loss: 5.539459\tclf_loss: 5.519021\tmmd_loss: 0.408768\nTrain Epoch 3: [70000/85000 (82%)]\ttotal_loss: 5.544116\tclf_loss: 5.525546\tmmd_loss: 0.371412\nTrain Epoch 3: [80000/85000 (94%)]\ttotal_loss: 5.530533\tclf_loss: 5.510821\tmmd_loss: 0.394243\nValidation: total_loss: 5.5635, clf_loss: 5.5414, mmd_loss: 0.4422, accuracy: 35/5000 (0.70%)\nTrain Epoch 4:\nTrain Epoch 4: [10000/85000 (12%)]\ttotal_loss: 5.554886\tclf_loss: 5.531442\tmmd_loss: 0.468895\nTrain Epoch 4: [20000/85000 (24%)]\ttotal_loss: 5.558092\tclf_loss: 5.539462\tmmd_loss: 0.372609\nTrain Epoch 4: [30000/85000 (35%)]\ttotal_loss: 5.564084\tclf_loss: 5.544658\tmmd_loss: 0.388520\nTrain Epoch 4: [40000/85000 (47%)]\ttotal_loss: 5.532979\tclf_loss: 5.512877\tmmd_loss: 0.402048\nTrain Epoch 4: [50000/85000 (59%)]\ttotal_loss: 5.558336\tclf_loss: 5.541459\tmmd_loss: 0.337546\nTrain Epoch 4: [60000/85000 (71%)]\ttotal_loss: 5.550915\tclf_loss: 5.532774\tmmd_loss: 0.362828\nTrain Epoch 4: [70000/85000 (82%)]\ttotal_loss: 5.549815\tclf_loss: 5.531983\tmmd_loss: 0.356640\nTrain Epoch 4: [80000/85000 (94%)]\ttotal_loss: 5.535037\tclf_loss: 5.516386\tmmd_loss: 0.373016\nValidation: total_loss: 5.5584, clf_loss: 5.5383, mmd_loss: 0.4024, accuracy: 19/5000 (0.38%)\nTrain Epoch 5:\nTrain Epoch 5: [10000/85000 (12%)]\ttotal_loss: 5.556221\tclf_loss: 5.538424\tmmd_loss: 0.355947\nTrain Epoch 5: [20000/85000 (24%)]\ttotal_loss: 5.585702\tclf_loss: 5.566539\tmmd_loss: 0.383263\nTrain Epoch 5: [30000/85000 (35%)]\ttotal_loss: 5.545860\tclf_loss: 5.527275\tmmd_loss: 0.371701\nTrain Epoch 5: [40000/85000 (47%)]\ttotal_loss: 5.536720\tclf_loss: 5.520508\tmmd_loss: 0.324237\nTrain Epoch 5: [50000/85000 (59%)]\ttotal_loss: 5.537317\tclf_loss: 5.521014\tmmd_loss: 0.326059\nTrain Epoch 5: [60000/85000 (71%)]\ttotal_loss: 5.557662\tclf_loss: 5.543156\tmmd_loss: 0.290107\nTrain Epoch 5: [70000/85000 (82%)]\ttotal_loss: 5.543343\tclf_loss: 5.527592\tmmd_loss: 0.315020\nTrain Epoch 5: [80000/85000 (94%)]\ttotal_loss: 5.557942\tclf_loss: 5.536702\tmmd_loss: 0.424804\nValidation: total_loss: 5.5543, clf_loss: 5.5375, mmd_loss: 0.3368, accuracy: 22/5000 (0.44%)\nTrain Epoch 6:\nTrain Epoch 6: [10000/85000 (12%)]\ttotal_loss: 5.536806\tclf_loss: 5.522661\tmmd_loss: 0.282908\nTrain Epoch 6: [20000/85000 (24%)]\ttotal_loss: 5.547135\tclf_loss: 5.532386\tmmd_loss: 0.294983\nTrain Epoch 6: [30000/85000 (35%)]\ttotal_loss: 5.547656\tclf_loss: 5.533467\tmmd_loss: 0.283782\nTrain Epoch 6: [40000/85000 (47%)]\ttotal_loss: 5.553191\tclf_loss: 5.537421\tmmd_loss: 0.315405\nTrain Epoch 6: [50000/85000 (59%)]\ttotal_loss: 5.553687\tclf_loss: 5.541275\tmmd_loss: 0.248243\nTrain Epoch 6: [60000/85000 (71%)]\ttotal_loss: 5.547265\tclf_loss: 5.532590\tmmd_loss: 0.293495\nTrain Epoch 6: [70000/85000 (82%)]\ttotal_loss: 5.530961\tclf_loss: 5.518097\tmmd_loss: 0.257280\nTrain Epoch 6: [80000/85000 (94%)]\ttotal_loss: 5.546267\tclf_loss: 5.535819\tmmd_loss: 0.208958\nValidation: total_loss: 5.5548, clf_loss: 5.5397, mmd_loss: 0.3023, accuracy: 23/5000 (0.46%)\nTrain Epoch 7:\nTrain Epoch 7: [10000/85000 (12%)]\ttotal_loss: 5.542663\tclf_loss: 5.531461\tmmd_loss: 0.224039\nTrain Epoch 7: [20000/85000 (24%)]\ttotal_loss: 5.564538\tclf_loss: 5.551375\tmmd_loss: 0.263256\nTrain Epoch 7: [30000/85000 (35%)]\ttotal_loss: 5.562449\tclf_loss: 5.548662\tmmd_loss: 0.275745\nTrain Epoch 7: [40000/85000 (47%)]\ttotal_loss: 5.531148\tclf_loss: 5.518132\tmmd_loss: 0.260320\nTrain Epoch 7: [50000/85000 (59%)]\ttotal_loss: 5.553807\tclf_loss: 5.539937\tmmd_loss: 0.277404\nTrain Epoch 7: [60000/85000 (71%)]\ttotal_loss: 5.560606\tclf_loss: 5.546211\tmmd_loss: 0.287909\nTrain Epoch 7: [70000/85000 (82%)]\ttotal_loss: 5.532974\tclf_loss: 5.521007\tmmd_loss: 0.239335\nTrain Epoch 7: [80000/85000 (94%)]\ttotal_loss: 5.539823\tclf_loss: 5.527849\tmmd_loss: 0.239476\nValidation: total_loss: 5.5515, clf_loss: 5.5371, mmd_loss: 0.2886, accuracy: 23/5000 (0.46%)\nTrain Epoch 8:\nTrain Epoch 8: [10000/85000 (12%)]\ttotal_loss: 5.526750\tclf_loss: 5.513521\tmmd_loss: 0.264568\nTrain Epoch 8: [20000/85000 (24%)]\ttotal_loss: 5.540723\tclf_loss: 5.529256\tmmd_loss: 0.229341\nTrain Epoch 8: [30000/85000 (35%)]\ttotal_loss: 5.555903\tclf_loss: 5.545890\tmmd_loss: 0.200250\nTrain Epoch 8: [40000/85000 (47%)]\ttotal_loss: 5.555923\tclf_loss: 5.545367\tmmd_loss: 0.211115\nTrain Epoch 8: [50000/85000 (59%)]\ttotal_loss: 5.542874\tclf_loss: 5.532015\tmmd_loss: 0.217166\nTrain Epoch 8: [60000/85000 (71%)]\ttotal_loss: 5.533825\tclf_loss: 5.522051\tmmd_loss: 0.235472\nTrain Epoch 8: [70000/85000 (82%)]\ttotal_loss: 5.526968\tclf_loss: 5.516859\tmmd_loss: 0.202180\nTrain Epoch 8: [80000/85000 (94%)]\ttotal_loss: 5.549257\tclf_loss: 5.539373\tmmd_loss: 0.197666\nValidation: total_loss: 5.5477, clf_loss: 5.5367, mmd_loss: 0.2215, accuracy: 28/5000 (0.56%)\nTrain Epoch 9:\nTrain Epoch 9: [10000/85000 (12%)]\ttotal_loss: 5.535160\tclf_loss: 5.526380\tmmd_loss: 0.175597\nTrain Epoch 9: [20000/85000 (24%)]\ttotal_loss: 5.531317\tclf_loss: 5.521431\tmmd_loss: 0.197707\nTrain Epoch 9: [30000/85000 (35%)]\ttotal_loss: 5.545790\tclf_loss: 5.535900\tmmd_loss: 0.197804\nTrain Epoch 9: [40000/85000 (47%)]\ttotal_loss: 5.520488\tclf_loss: 5.512385\tmmd_loss: 0.162044\nTrain Epoch 9: [50000/85000 (59%)]\ttotal_loss: 5.538799\tclf_loss: 5.523127\tmmd_loss: 0.313450\nTrain Epoch 9: [60000/85000 (71%)]\ttotal_loss: 5.537116\tclf_loss: 5.527378\tmmd_loss: 0.194755\nTrain Epoch 9: [70000/85000 (82%)]\ttotal_loss: 5.550889\tclf_loss: 5.540767\tmmd_loss: 0.202431\nTrain Epoch 9: [80000/85000 (94%)]\ttotal_loss: 5.533551\tclf_loss: 5.525331\tmmd_loss: 0.164396\nValidation: total_loss: 5.5467, clf_loss: 5.5369, mmd_loss: 0.1972, accuracy: 27/5000 (0.54%)\nTrain Epoch 10:\nTrain Epoch 10: [10000/85000 (12%)]\ttotal_loss: 5.532702\tclf_loss: 5.522844\tmmd_loss: 0.197166\nTrain Epoch 10: [20000/85000 (24%)]\ttotal_loss: 5.525824\tclf_loss: 5.517118\tmmd_loss: 0.174132\nTrain Epoch 10: [30000/85000 (35%)]\ttotal_loss: 5.540892\tclf_loss: 5.530239\tmmd_loss: 0.213073\nTrain Epoch 10: [40000/85000 (47%)]\ttotal_loss: 5.534965\tclf_loss: 5.526424\tmmd_loss: 0.170810\nTrain Epoch 10: [50000/85000 (59%)]\ttotal_loss: 5.523986\tclf_loss: 5.517505\tmmd_loss: 0.129634\n"
]
],
[
[
"## Performance of the fine-tuned model",
"_____no_output_____"
]
],
[
[
"# create a network\nmodel = Net(num_classes=class_num)\nprint('Construct model complete')\nif cuda:\n model.cuda()\n# load the fine-tuned model\ncheckpoint = torch.load('./models/best_valid_loss_finetuned_device{}_to_{}.pth'.format(source_device_id, target_device_id))\nfinetuned_dict = checkpoint['model_state_dict']\nmodel.load_state_dict(finetuned_dict)\nprint('Results after fine-tuning:')\n# evaluate the fine-tuned model on source and target domain\nwith torch.no_grad():\n print('Result on source device:')\n test(model, source_device_id, model_flag='finetuned_source')\n print('Result on target device:')\n test(model, target_device_id, model_flag='finetuned_target')",
"Construct model complete\nResults after fine-tuning:\nResult on source device:\nTarget test loss: 5.5339, Target test accuracy: 53/9900 (0.54%)\n\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a2b6209132d2704083d035fd8f8ca2c8da1ef89
| 438,795 |
ipynb
|
Jupyter Notebook
|
CV_P1_Facial_Keypoints/1. Load and Visualize Data.ipynb
|
huanghyw/youda-dl
|
fe6f20f1da40f853f9a5b4af59362881890066f5
|
[
"Apache-2.0"
] | 1 |
2021-01-06T02:23:57.000Z
|
2021-01-06T02:23:57.000Z
|
CV_P1_Facial_Keypoints/1. Load and Visualize Data.ipynb
|
huanghyw/youda-dl
|
fe6f20f1da40f853f9a5b4af59362881890066f5
|
[
"Apache-2.0"
] | null | null | null |
CV_P1_Facial_Keypoints/1. Load and Visualize Data.ipynb
|
huanghyw/youda-dl
|
fe6f20f1da40f853f9a5b4af59362881890066f5
|
[
"Apache-2.0"
] | null | null | null | 645.286765 | 127,632 | 0.945081 |
[
[
[
"# Facial Keypoint Detection\n \nThis project will be all about defining and training a convolutional neural network to perform facial keypoint detection, and using computer vision techniques to transform images of faces. The first step in any challenge like this will be to load and visualize the data you'll be working with. \n\nLet's take a look at some examples of images and corresponding facial keypoints.\n\n<img src='images/key_pts_example.png' width=50% height=50%/>\n\nFacial keypoints (also called facial landmarks) are the small magenta dots shown on each of the faces in the image above. In each training and test image, there is a single face and **68 keypoints, with coordinates (x, y), for that face**. These keypoints mark important areas of the face: the eyes, corners of the mouth, the nose, etc. These keypoints are relevant for a variety of tasks, such as face filters, emotion recognition, pose recognition, and so on. Here they are, numbered, and you can see that specific ranges of points match different portions of the face.\n\n<img src='images/landmarks_numbered.jpg' width=30% height=30%/>\n\n---",
"_____no_output_____"
],
[
"## Load and Visualize Data\n\nThe first step in working with any dataset is to become familiar with your data; you'll need to load in the images of faces and their keypoints and visualize them! This set of image data has been extracted from the [YouTube Faces Dataset](https://www.cs.tau.ac.il/~wolf/ytfaces/), which includes videos of people in YouTube videos. These videos have been fed through some processing steps and turned into sets of image frames containing one face and the associated keypoints.\n\n#### Training and Testing Data\n\nThis facial keypoints dataset consists of 5770 color images. All of these images are separated into either a training or a test set of data.\n\n* 3462 of these images are training images, for you to use as you create a model to predict keypoints.\n* 2308 are test images, which will be used to test the accuracy of your model.\n\nThe information about the images and keypoints in this dataset are summarized in CSV files, which we can read in using `pandas`. Let's read the training CSV and get the annotations in an (N, 2) array where N is the number of keypoints and 2 is the dimension of the keypoint coordinates (x, y).\n\n---",
"_____no_output_____"
]
],
[
[
"# import the required libraries\nimport glob\nimport os\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\n\nimport cv2",
"_____no_output_____"
],
[
"key_pts_frame = pd.read_csv('data/training_frames_keypoints.csv')\n\nn = 0\nimage_name = key_pts_frame.iloc[n, 0]\nkey_pts = key_pts_frame.iloc[n, 1:].as_matrix()\nkey_pts = key_pts.astype('float').reshape(-1, 2)\n\nprint('Image name: ', image_name)\nprint('Landmarks shape: ', key_pts.shape)\nprint('First 4 key pts: {}'.format(key_pts[:4]))",
"Image name: Luis_Fonsi_21.jpg\nLandmarks shape: (68, 2)\nFirst 4 key pts: [[ 45. 98.]\n [ 47. 106.]\n [ 49. 110.]\n [ 53. 119.]]\n"
],
[
"# print out some stats about the data\nprint('Number of images: ', key_pts_frame.shape[0])",
"Number of images: 3462\n"
]
],
[
[
"## Look at some images\n\nBelow, is a function `show_keypoints` that takes in an image and keypoints and displays them. As you look at this data, **note that these images are not all of the same size**, and neither are the faces! To eventually train a neural network on these images, we'll need to standardize their shape.",
"_____no_output_____"
]
],
[
[
"def show_keypoints(image, key_pts):\n \"\"\"Show image with keypoints\"\"\"\n plt.imshow(image)\n plt.scatter(key_pts[:, 0], key_pts[:, 1], s=20, marker='.', c='m')\n",
"_____no_output_____"
],
[
"# Display a few different types of images by changing the index n\n\n# select an image by index in our data frame\nn = 0\nimage_name = key_pts_frame.iloc[n, 0]\nkey_pts = key_pts_frame.iloc[n, 1:].as_matrix()\nkey_pts = key_pts.astype('float').reshape(-1, 2)\n\nplt.figure(figsize=(5, 5))\nimage_show = mpimg.imread(os.path.join('data/training/', image_name));\nshow_keypoints(image_show, key_pts)\nplt.show()",
"_____no_output_____"
],
[
"print(\"image shape: \", image_show.shape)",
"image shape: (192, 176, 4)\n"
]
],
[
[
"## Dataset class and Transformations\n\nTo prepare our data for training, we'll be using PyTorch's Dataset class. Much of this this code is a modified version of what can be found in the [PyTorch data loading tutorial](http://pytorch.org/tutorials/beginner/data_loading_tutorial.html).\n\n#### Dataset class\n\n``torch.utils.data.Dataset`` is an abstract class representing a\ndataset. This class will allow us to load batches of image/keypoint data, and uniformly apply transformations to our data, such as rescaling and normalizing images for training a neural network.\n\n\nYour custom dataset should inherit ``Dataset`` and override the following\nmethods:\n\n- ``__len__`` so that ``len(dataset)`` returns the size of the dataset.\n- ``__getitem__`` to support the indexing such that ``dataset[i]`` can\n be used to get the i-th sample of image/keypoint data.\n\nLet's create a dataset class for our face keypoints dataset. We will\nread the CSV file in ``__init__`` but leave the reading of images to\n``__getitem__``. This is memory efficient because all the images are not\nstored in the memory at once but read as required.\n\nA sample of our dataset will be a dictionary\n``{'image': image, 'keypoints': key_pts}``. Our dataset will take an\noptional argument ``transform`` so that any required processing can be\napplied on the sample. We will see the usefulness of ``transform`` in the\nnext section.\n",
"_____no_output_____"
]
],
[
[
"from torch.utils.data import Dataset, DataLoader\n\nclass FacialKeypointsDataset(Dataset):\n \"\"\"Face Landmarks dataset.\"\"\"\n\n def __init__(self, csv_file, root_dir, transform=None):\n \"\"\"\n Args:\n csv_file (string): Path to the csv file with annotations.\n root_dir (string): Directory with all the images.\n transform (callable, optional): Optional transform to be applied\n on a sample.\n \"\"\"\n self.key_pts_frame = pd.read_csv(csv_file)\n self.root_dir = root_dir\n self.transform = transform\n\n def __len__(self):\n return len(self.key_pts_frame)\n\n def __getitem__(self, idx):\n image_name = os.path.join(self.root_dir,\n self.key_pts_frame.iloc[idx, 0])\n \n image = mpimg.imread(image_name)\n \n # if image has an alpha color channel, get rid of it\n if(image.shape[2] == 4):\n image = image[:,:,0:3]\n \n key_pts = self.key_pts_frame.iloc[idx, 1:].as_matrix()\n key_pts = key_pts.astype('float').reshape(-1, 2)\n sample = {'image': image, 'keypoints': key_pts}\n\n if self.transform:\n sample = self.transform(sample)\n\n return sample",
"_____no_output_____"
]
],
[
[
"Now that we've defined this class, let's instantiate the dataset and display some images.",
"_____no_output_____"
]
],
[
[
"# Construct the dataset\nface_dataset = FacialKeypointsDataset(csv_file='data/training_frames_keypoints.csv',\n root_dir='data/training/')\n\n# print some stats about the dataset\nprint('Length of dataset: ', len(face_dataset))",
"Length of dataset: 3462\n"
],
[
"# Display a few of the images from the dataset\nnum_to_display = 3\n\nfor i in range(num_to_display):\n \n # define the size of images\n fig = plt.figure(figsize=(20,10))\n \n # randomly select a sample\n rand_i = np.random.randint(0, len(face_dataset))\n sample = face_dataset[rand_i]\n\n # print the shape of the image and keypoints\n print(i, sample['image'].shape, sample['keypoints'].shape)\n\n ax = plt.subplot(1, num_to_display, i + 1)\n ax.set_title('Sample #{}'.format(i))\n \n # Using the same display function, defined earlier\n show_keypoints(sample['image'], sample['keypoints'])\n",
"0 (283, 276, 3) (68, 2)\n1 (198, 176, 3) (68, 2)\n2 (128, 100, 3) (68, 2)\n"
]
],
[
[
"## Transforms\n\nNow, the images above are not of the same size, and neural networks often expect images that are standardized; a fixed size, with a normalized range for color ranges and coordinates, and (for PyTorch) converted from numpy lists and arrays to Tensors.\n\nTherefore, we will need to write some pre-processing code.\nLet's create four transforms:\n\n- ``Normalize``: to convert a color image to grayscale values with a range of [0,1] and normalize the keypoints to be in a range of about [-1, 1]\n- ``Rescale``: to rescale an image to a desired size.\n- ``RandomCrop``: to crop an image randomly.\n- ``ToTensor``: to convert numpy images to torch images.\n\n\nWe will write them as callable classes instead of simple functions so\nthat parameters of the transform need not be passed everytime it's\ncalled. For this, we just need to implement ``__call__`` method and \n(if we require parameters to be passed in), the ``__init__`` method. \nWe can then use a transform like this:\n\n tx = Transform(params)\n transformed_sample = tx(sample)\n\nObserve below how these transforms are generally applied to both the image and its keypoints.\n\n",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torchvision import transforms, utils\n# tranforms\n\nclass Normalize(object):\n \"\"\"Convert a color image to grayscale and normalize the color range to [0,1].\"\"\" \n\n def __call__(self, sample):\n image, key_pts = sample['image'], sample['keypoints']\n \n image_copy = np.copy(image)\n key_pts_copy = np.copy(key_pts)\n\n # convert image to grayscale\n image_copy = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)\n \n # scale color range from [0, 255] to [0, 1]\n image_copy= image_copy/255.0\n \n # scale keypoints to be centered around 0 with a range of [-1, 1]\n # mean = 100, sqrt = 50, so, pts should be (pts - 100)/50\n key_pts_copy = (key_pts_copy - 100)/50.0\n\n\n return {'image': image_copy, 'keypoints': key_pts_copy}\n\n\nclass Rescale(object):\n \"\"\"Rescale the image in a sample to a given size.\n\n Args:\n output_size (tuple or int): Desired output size. If tuple, output is\n matched to output_size. If int, smaller of image edges is matched\n to output_size keeping aspect ratio the same.\n \"\"\"\n\n def __init__(self, output_size):\n assert isinstance(output_size, (int, tuple))\n self.output_size = output_size\n\n def __call__(self, sample):\n image, key_pts = sample['image'], sample['keypoints']\n\n h, w = image.shape[:2]\n if isinstance(self.output_size, int):\n if h > w:\n new_h, new_w = self.output_size * h / w, self.output_size\n else:\n new_h, new_w = self.output_size, self.output_size * w / h\n else:\n new_h, new_w = self.output_size\n\n new_h, new_w = int(new_h), int(new_w)\n\n img = cv2.resize(image, (new_w, new_h))\n \n # scale the pts, too\n key_pts = key_pts * [new_w / w, new_h / h]\n\n return {'image': img, 'keypoints': key_pts}\n\n\nclass RandomCrop(object):\n \"\"\"Crop randomly the image in a sample.\n\n Args:\n output_size (tuple or int): Desired output size. If int, square crop\n is made.\n \"\"\"\n\n def __init__(self, output_size):\n assert isinstance(output_size, (int, tuple))\n if isinstance(output_size, int):\n self.output_size = (output_size, output_size)\n else:\n assert len(output_size) == 2\n self.output_size = output_size\n\n def __call__(self, sample):\n image, key_pts = sample['image'], sample['keypoints']\n\n h, w = image.shape[:2]\n new_h, new_w = self.output_size\n\n top = np.random.randint(0, h - new_h)\n left = np.random.randint(0, w - new_w)\n\n image = image[top: top + new_h,\n left: left + new_w]\n\n key_pts = key_pts - [left, top]\n\n return {'image': image, 'keypoints': key_pts}\n\n\nclass ToTensor(object):\n \"\"\"Convert ndarrays in sample to Tensors.\"\"\"\n\n def __call__(self, sample):\n image, key_pts = sample['image'], sample['keypoints']\n \n # if image has no grayscale color channel, add one\n if(len(image.shape) == 2):\n # add that third color dim\n image = image.reshape(image.shape[0], image.shape[1], 1)\n \n # swap color axis because\n # numpy image: H x W x C\n # torch image: C X H X W\n image = image.transpose((2, 0, 1))\n \n return {'image': torch.from_numpy(image),\n 'keypoints': torch.from_numpy(key_pts)}",
"_____no_output_____"
]
],
[
[
"## Test out the transforms\n\nLet's test these transforms out to make sure they behave as expected. As you look at each transform, note that, in this case, **order does matter**. For example, you cannot crop a image using a value smaller than the original image (and the orginal images vary in size!), but, if you first rescale the original image, you can then crop it to any size smaller than the rescaled size.",
"_____no_output_____"
]
],
[
[
"# test out some of these transforms\nrescale = Rescale(100)\ncrop = RandomCrop(50)\ncomposed = transforms.Compose([Rescale(250),\n RandomCrop(224)])\n\n# apply the transforms to a sample image\ntest_num = 500\nsample = face_dataset[test_num]\n\nfig = plt.figure()\nfor i, tx in enumerate([rescale, crop, composed]):\n transformed_sample = tx(sample)\n\n ax = plt.subplot(1, 3, i + 1)\n plt.tight_layout()\n ax.set_title(type(tx).__name__)\n show_keypoints(transformed_sample['image'], transformed_sample['keypoints'])\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Create the transformed dataset\n\nApply the transforms in order to get grayscale images of the same shape. Verify that your transform works by printing out the shape of the resulting data (printing out a few examples should show you a consistent tensor size).",
"_____no_output_____"
]
],
[
[
"# define the data tranform\n# order matters! i.e. rescaling should come before a smaller crop\ndata_transform = transforms.Compose([Rescale(250),\n RandomCrop(224),\n Normalize(),\n ToTensor()])\n\n# create the transformed dataset\ntransformed_dataset = FacialKeypointsDataset(csv_file='data/training_frames_keypoints.csv',\n root_dir='data/training/',\n transform=data_transform)\n",
"_____no_output_____"
],
[
"# print some stats about the transformed data\nprint('Number of images: ', len(transformed_dataset))\n\n# make sure the sample tensors are the expected size\nfor i in range(5):\n sample = transformed_dataset[i]\n print(i, sample['image'].size(), sample['keypoints'].size())\n",
"Number of images: 3462\n0 torch.Size([1, 224, 224]) torch.Size([68, 2])\n1 torch.Size([1, 224, 224]) torch.Size([68, 2])\n2 torch.Size([1, 224, 224]) torch.Size([68, 2])\n3 torch.Size([1, 224, 224]) torch.Size([68, 2])\n4 torch.Size([1, 224, 224]) torch.Size([68, 2])\n"
]
],
[
[
"## Data Iteration and Batching\n\nRight now, we are iterating over this data using a ``for`` loop, but we are missing out on a lot of PyTorch's dataset capabilities, specifically the abilities to:\n\n- Batch the data\n- Shuffle the data\n- Load the data in parallel using ``multiprocessing`` workers.\n\n``torch.utils.data.DataLoader`` is an iterator which provides all these\nfeatures, and we'll see this in use in the *next* notebook, Notebook 2, when we load data in batches to train a neural network!\n\n---\n\n",
"_____no_output_____"
],
[
"## Ready to Train!\n\nNow that you've seen how to load and transform our data, you're ready to build a neural network to train on this data.\n\nIn the next notebook, you'll be tasked with creating a CNN for facial keypoint detection.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a2b8d25f4c9146130756f5eaa3a6e4eeec673f0
| 625,678 |
ipynb
|
Jupyter Notebook
|
notebooks/hough_normalization.ipynb
|
davmre/sigvisa
|
91a1f163b8f3a258dfb78d88a07f2a11da41bd04
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/hough_normalization.ipynb
|
davmre/sigvisa
|
91a1f163b8f3a258dfb78d88a07f2a11da41bd04
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/hough_normalization.ipynb
|
davmre/sigvisa
|
91a1f163b8f3a258dfb78d88a07f2a11da41bd04
|
[
"BSD-3-Clause"
] | null | null | null | 3,345.871658 | 208,530 | 0.950377 |
[
[
[
"import numpy as np\nimport sys\nimport os\nimport traceback\nimport itertools\nimport pickle\nimport time\n\nimport scipy.weave as weave\nfrom scipy.weave import converters\n\nfrom sigvisa.infer.propose_hough import visualize_hough_array, normalize_global",
"_____no_output_____"
],
[
"global_array = np.load(\"/home/dmoore/python/sigvisa/global_array.npy\")\none_ev = np.load(\"/home/dmoore/python/sigvisa/one_ev.npy\")\nev_prob = np.load(\"/home/dmoore/python/sigvisa/ev_prob.npy\")\n\n#nll=-627.371666715 # dprk\n#nll = -953.590075323\n#nll = -649.552376493\nnll= -593.447450136",
"_____no_output_____"
],
[
"ev_prior=1.0/global_array.size\nprint ev_prior\n\nev_prior = ev_prior**2\nprint ev_prior\n",
"4.17535139757e-07\n1.74335592932e-13\n"
],
[
"f = plt.figure(figsize=(15, 15))\nax = f.add_subplot(111)\nvisualize_hough_array(one_ev, [], fname=None, ax=ax, timeslice=None)\n\n",
"_____no_output_____"
],
[
"f = plt.figure(figsize=(15, 15))\nax = f.add_subplot(111)\nvisualize_hough_array(ev_prob, [], fname=None, ax=ax, timeslice=None)\n",
"_____no_output_____"
],
[
"\n\n\nev_prob2 = normalize_global(global_array.copy(), nll, one_event_semantics=False, ev_prior=ev_prior)\n\n\nf = plt.figure(figsize=(15, 15))\nax = f.add_subplot(111)\nvisualize_hough_array(ev_prob2, [], fname=None, ax=ax, timeslice=None)\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a2b90bef2d3ffed810162a7a66e0760be30384b
| 12,724 |
ipynb
|
Jupyter Notebook
|
docs/notyet/misc/simple-use-cases.ipynb
|
chrismurf/simulus
|
b49ccd0659bb5f4114c6d354c74287796de7f15d
|
[
"MIT"
] | 2 |
2020-05-23T08:45:11.000Z
|
2021-08-14T03:36:54.000Z
|
docs/notyet/misc/simple-use-cases.ipynb
|
chrismurf/simulus
|
b49ccd0659bb5f4114c6d354c74287796de7f15d
|
[
"MIT"
] | 6 |
2020-03-24T17:25:00.000Z
|
2021-12-13T20:05:22.000Z
|
docs/notyet/misc/simple-use-cases.ipynb
|
chrismurf/simulus
|
b49ccd0659bb5f4114c6d354c74287796de7f15d
|
[
"MIT"
] | 2 |
2020-01-30T16:48:27.000Z
|
2021-08-14T03:36:59.000Z
| 37.756677 | 338 | 0.586294 |
[
[
[
"# Simple Use Cases\n\nSimulus is a discrete-event simulator in Python. This document is to demonstrate how to run simulus via a few examples. This is not a tutorial. For that, use [Simulus Tutorial](simulus-tutorial.ipynb). All the examples shown in this guide can be found under the `examples/demos` directory in the simulus source-code distribution.\n\nIt's really simple to install simulus. Assuming you have installed pip, you can simply do the following to install simulus:\n\n```\npip install simulus\n```\n\nIf you don't have administrative privilege to install packages on your machine, you can install it in the per-user managed location using:\n\n```\npip install --user simulus\n```",
"_____no_output_____"
],
[
"If all are fine at this point, you can simply import the module 'simulus' to start using the simulator. ",
"_____no_output_____"
]
],
[
[
"import simulus",
"_____no_output_____"
]
],
[
[
"### Use Case #1: Direct Event Scheduling\n\nOne can schedule functions to be executed at designated simulation time. The functions in this case are called event handlers (using the discrete-event simulation terminology).",
"_____no_output_____"
]
],
[
[
"# %load \"../examples/demos/case-1.py\"\nimport simulus\n\n# An event handler is a user-defined function; in this case, we take\n# one positional argument 'sim', and place all keyworded arguments in\n# the dictionary 'params'\ndef myfunc(sim, **params):\n print(str(sim.now) + \": myfunc() runs with params=\" + str(params))\n\n # schedule the next event 10 seconds from now\n sim.sched(myfunc, sim, **params, offset=10)\n\n# create an anonymous simulator\nsim1 = simulus.simulator() \n\n# schedule the first event at 10 seconds\nsim1.sched(myfunc, sim1, until=10, msg=\"hello world\", value=100)\n\n# advance simulation until 100 seconds\nsim1.run(until=100)\nprint(\"simulator.run() ends at \" + str(sim1.now))\n\n# we can advance simulation for another 50 seconds\nsim1.run(offset=50)\nprint(\"simulator.run() ends at \" + str(sim1.now))\n",
"_____no_output_____"
]
],
[
[
"### Use Case #2: Simulation Process\n\nA simulation process is an independent thread of execution. A process can be blocked and therefore advances its simulation time either by sleeping for some duration of time or by being blocked from synchronization primitives (such as semaphores).",
"_____no_output_____"
]
],
[
[
"# %load \"../examples/demos/case-2.py\"\nimport simulus\n\n# A process for simulus is a python function with two parameters: \n# the first parameter is the simulator, and the second parameter is\n# the dictionary containing user-defined parameters for the process\ndef myproc(sim, intv, id):\n print(str(sim.now) + \": myproc(%d) runs with intv=%r\" % (id, intv))\n while True:\n # suspend the process for some time\n sim.sleep(intv)\n print(str(sim.now) + \": myproc(%d) resumes execution\" % id)\n\n# create an anonymous simulator\nsim2 = simulus.simulator()\n\n# start a process 100 seconds from now\nsim2.process(myproc, sim2, 10, 0, offset=100)\n# start another process 5 seconds from now\nsim2.process(myproc, sim2, 20, 1, offset=5)\n\n# advance simulation until 200 seconds\nsim2.run(until=200)\nprint(\"simulator.run() ends at \" + str(sim2.now))\n\nsim2.run(offset=50)\nprint(\"simulator.run() ends at \" + str(sim2.now))\n",
"_____no_output_____"
]
],
[
[
"### Use Case #3: Process Synchronization with Semaphores\n\nWe illustrate the use of semaphore in the context of a classic producer-consumer problem. We are simulating a single-server queue (M/M/1) here.",
"_____no_output_____"
]
],
[
[
"# %load \"../examples/demos/case-3.py\"\nimport simulus\n\nfrom random import seed, expovariate\nfrom statistics import mean, median, stdev\n\n# make it repeatable\nseed(12345) \n\n# configuration of the single server queue: the mean inter-arrival\n# time, and the mean service time\ncfg = {\"mean_iat\":1, \"mean_svc\":0.8}\n\n# keep the time of job arrivals, starting services, and departures\narrivals = []\nstarts = []\nfinishes = []\n\n# the producer process waits for some random time from an \n# exponential distribution, and increments the semaphore \n# to represent a new item being produced, and then repeats \ndef producer(sim, mean_iat, sem):\n while True:\n iat = expovariate(1.0/mean_iat)\n sim.sleep(iat)\n #print(\"%g: job arrives (iat=%g)\" % (sim.now, iat))\n arrivals.append(sim.now)\n sem.signal()\n \n# the consumer process waits for the semaphore (it decrements\n# the value and blocks if the value is non-positive), waits for\n# some random time from another exponential distribution, and\n# then repeats\ndef consumer(sim, mean_svc, sem):\n while True:\n sem.wait()\n #print(\"%g: job starts service\" % sim.now)\n starts.append(sim.now)\n svc = expovariate(1.0/mean_svc)\n sim.sleep(svc)\n #print(\"%g: job departs (svc=%g)\" % (sim.now, svc))\n finishes.append(sim.now)\n\n# create an anonymous simulator\nsim3 = simulus.simulator()\n\n# create a semaphore with initial value of zero\nsem = sim3.semaphore(0)\n\n# start the producer and consumer processes\nsim3.process(producer, sim3, cfg['mean_iat'], sem)\nsim3.process(consumer, sim3, cfg['mean_svc'], sem)\n\n# advance simulation until 100 seconds\nsim3.run(until=1000)\nprint(\"simulator.run() ends at \" + str(sim3.now))\n\n# calculate and output statistics\nprint(f'Results: jobs=arrivals:{len(arrivals)}, starts:{len(starts)}, finishes:{len(finishes)}')\nwaits = [start - arrival for arrival, start in zip(arrivals, starts)]\ntotals = [finish - arrival for arrival, finish in zip(arrivals, finishes)]\nprint(f'Wait Time: mean={mean(waits):.1f}, stdev={stdev(waits):.1f}, median={median(waits):.1f}. max={max(waits):.1f}')\nprint(f'Total Time: mean={mean(totals):.1f}, stdev={stdev(totals):.1f}, median={median(totals):.1f}. max={max(totals):.1f}')\nmy_lambda = 1.0/cfg['mean_iat'] # mean arrival rate\nmy_mu = 1.0/cfg['mean_svc'] # mean service rate\nmy_rho = my_lambda/my_mu # server utilization\nmy_lq = my_rho*my_rho/(1-my_rho) # number in queue\nmy_wq = my_lq/my_lambda # wait in queue\nmy_w = my_wq+1/my_mu # wait in system\nprint(f'Theoretical Results: mean wait time = {my_wq:.1f}, mean total time = {my_w:.1f}')\n",
"_____no_output_____"
]
],
[
[
"### Use Case #4: Dynamic Processes\n\nWe continue with the previous example. At the time, rathar than using semaphores, we can achieve exactly the same results by dynamically creating processes.",
"_____no_output_____"
]
],
[
[
"# %load \"../examples/demos/case-4.py\"\nimport simulus\n\nfrom random import seed, expovariate\nfrom statistics import mean, median, stdev\n\n# make it repeatable\nseed(12345) \n\n# configuration of the single server queue: the mean inter-arrival\n# time, and the mean service time\ncfg = {\"mean_iat\":1, \"mean_svc\":0.8}\n\n# keep the time of job arrivals, starting services, and departures\narrivals = []\nstarts = []\nfinishes = []\n\n# we keep the account of the number of jobs in the system (those who\n# have arrived but not yet departed); this is used to indicate whether\n# there's a consumer process currently running; the value is more than\n# 1, we don't need to create a new consumer process\njobs_in_system = 0\n\n# the producer process waits for some random time from an exponential\n# distribution to represent a new item being produced, creates a\n# consumer process when necessary to represent the item being\n# consumed, and then repeats\ndef producer(sim, mean_iat, mean_svc):\n global jobs_in_system\n while True:\n iat = expovariate(1.0/mean_iat)\n sim.sleep(iat)\n #print(\"%g: job arrives (iat=%g)\" % (sim.now, iat))\n arrivals.append(sim.now)\n jobs_in_system += 1\n if jobs_in_system <= 1:\n sim.process(consumer, sim, mean_svc)\n \n# the consumer process waits for the semaphore (it decrements\n# the value and blocks if the value is non-positive), waits for\n# some random time from another exponential distribution, and\n# then repeats\ndef consumer(sim, mean_svc):\n global jobs_in_system\n while jobs_in_system > 0:\n #print(\"%g: job starts service\" % sim.now)\n starts.append(sim.now)\n svc = expovariate(1.0/mean_svc)\n sim.sleep(svc)\n #print(\"%g: job departs (svc=%g)\" % (sim.now, svc))\n finishes.append(sim.now)\n jobs_in_system -= 1\n\n# create an anonymous simulator\nsim3 = simulus.simulator()\n\n# start the producer process only\nsim3.process(producer, sim3, cfg['mean_iat'], cfg['mean_svc'])\n\n# advance simulation until 100 seconds\nsim3.run(until=1000)\nprint(\"simulator.run() ends at \" + str(sim3.now))\n\n# calculate and output statistics\nprint(f'Results: jobs=arrival:{len(arrivals)}, starts:{len(starts)}, finishes:{len(finishes)}')\nwaits = [start - arrival for arrival, start in zip(arrivals, starts)]\ntotals = [finish - arrival for arrival, finish in zip(arrivals, finishes)]\nprint(f'Wait Time: mean={mean(waits):.1f}, stdev={stdev(waits):.1f}, median={median(waits):.1f}. max={max(waits):.1f}')\nprint(f'Total Time: mean={mean(totals):.1f}, stdev={stdev(totals):.1f}, median={median(totals):.1f}. max={max(totals):.1f}')\nmy_lambda = 1.0/cfg['mean_iat'] # mean arrival rate\nmy_mu = 1.0/cfg['mean_svc'] # mean service rate\nmy_rho = my_lambda/my_mu # server utilization\nmy_lq = my_rho*my_rho/(1-my_rho) # number in queue\nmy_wq = my_lq/my_lambda # wait in queue\nmy_w = my_wq+1/my_mu # wait in system\nprint(f'Theoretical Results: mean wait time = {my_wq:.1f}, mean total time = {my_w:.1f}')\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.