
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a42dc8c848d051f7a3b75d3825d8050a177663a
| 289,842 |
ipynb
|
Jupyter Notebook
|
MusicVAE_interpolate_2bar.ipynb
|
JonathanMairena/CIS519_Pop_Music_Style_Transfer
|
b288bb1808a298a9a61383b123922e3f5e00dfac
|
[
"MIT"
] | 1 |
2022-03-03T23:35:58.000Z
|
2022-03-03T23:35:58.000Z
|
MusicVAE_interpolate_2bar.ipynb
|
JonathanMairena/AI-Music-Generation-and-Interpolation-with-Google-Magenta
|
b288bb1808a298a9a61383b123922e3f5e00dfac
|
[
"MIT"
] | null | null | null |
MusicVAE_interpolate_2bar.ipynb
|
JonathanMairena/AI-Music-Generation-and-Interpolation-with-Google-Magenta
|
b288bb1808a298a9a61383b123922e3f5e00dfac
|
[
"MIT"
] | null | null | null | 289,842 | 289,842 | 0.810973 |
[
[
[
"#@title Environment Setup\n\nimport glob\n\nBASE_DIR = \"gs://download.magenta.tensorflow.org/models/music_vae/colab2\"\n\nprint('Installing dependencies...')\n!apt-get update -qq && apt-get install -qq libfluidsynth1 fluid-soundfont-gm build-essential libasound2-dev libjack-dev\n!pip install -q pyfluidsynth\n!pip install -qU magenta\n\n# Hack to allow python to pick up the newly-installed fluidsynth lib.\n# This is only needed for the hosted Colab environment.\nimport ctypes.util\norig_ctypes_util_find_library = ctypes.util.find_library\ndef proxy_find_library(lib):\n if lib == 'fluidsynth':\n return 'libfluidsynth.so.1'\n else:\n return orig_ctypes_util_find_library(lib)\nctypes.util.find_library = proxy_find_library\n\n\nprint('Importing libraries and defining some helper functions...')\nfrom google.colab import files\nimport magenta.music as mm\nfrom magenta.models.music_vae import configs\nfrom magenta.models.music_vae.trained_model import TrainedModel\nimport numpy as np\nimport os\nimport tensorflow.compat.v1 as tf\n\ntf.disable_v2_behavior()\n\n# Necessary until pyfluidsynth is updated (>1.2.5).\nimport warnings\nwarnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n\ndef play(note_sequence):\n mm.play_sequence(note_sequence, synth=mm.fluidsynth)\n\ndef interpolate(model, start_seq, end_seq, num_steps, max_length=32,\n assert_same_length=True, temperature=0.5,\n individual_duration=4.0):\n \"\"\"Interpolates between a start and end sequence.\"\"\"\n note_sequences = model.interpolate(\n start_seq, end_seq,num_steps=num_steps, length=max_length,\n temperature=temperature,\n assert_same_length=assert_same_length)\n\n print('Start Seq Reconstruction')\n play(note_sequences[0])\n print('End Seq Reconstruction')\n play(note_sequences[-1])\n print('Mean Sequence')\n play(note_sequences[num_steps // 2])\n print('Start -> End Interpolation')\n interp_seq = mm.sequences_lib.concatenate_sequences(\n note_sequences, [individual_duration] * len(note_sequences))\n play(interp_seq)\n mm.plot_sequence(interp_seq)\n return interp_seq if num_steps > 3 else note_sequences[num_steps // 2]\n\ndef download(note_sequence, filename):\n mm.sequence_proto_to_midi_file(note_sequence, filename)\n files.download(filename)\n\nprint('Done')",
"Installing dependencies...\nSelecting previously unselected package fluid-soundfont-gm.\n(Reading database ... 155222 files and directories currently installed.)\nPreparing to unpack .../fluid-soundfont-gm_3.1-5.1_all.deb ...\nUnpacking fluid-soundfont-gm (3.1-5.1) ...\nSelecting previously unselected package libfluidsynth1:amd64.\nPreparing to unpack .../libfluidsynth1_1.1.9-1_amd64.deb ...\nUnpacking libfluidsynth1:amd64 (1.1.9-1) ...\nSetting up fluid-soundfont-gm (3.1-5.1) ...\nSetting up libfluidsynth1:amd64 (1.1.9-1) ...\nProcessing triggers for libc-bin (2.27-3ubuntu1.3) ...\n/sbin/ldconfig.real: /usr/local/lib/python3.7/dist-packages/ideep4py/lib/libmkldnn.so.0 is not a symbolic link\n\n\u001b[K |████████████████████████████████| 1.4 MB 4.3 MB/s \n\u001b[K |████████████████████████████████| 2.3 MB 29.6 MB/s \n\u001b[K |████████████████████████████████| 352 kB 54.7 MB/s \n\u001b[K |████████████████████████████████| 204 kB 51.4 MB/s \n\u001b[K |████████████████████████████████| 1.4 MB 37.5 MB/s \n\u001b[K |████████████████████████████████| 87 kB 7.0 MB/s \n\u001b[K |████████████████████████████████| 254 kB 49.4 MB/s \n\u001b[K |████████████████████████████████| 1.6 MB 40.3 MB/s \n\u001b[K |████████████████████████████████| 3.6 MB 23.0 MB/s \n\u001b[K |████████████████████████████████| 5.6 MB 12.0 MB/s \n\u001b[K |████████████████████████████████| 210 kB 37.5 MB/s \n\u001b[K |████████████████████████████████| 69 kB 7.5 MB/s \n\u001b[K |████████████████████████████████| 20.2 MB 7.4 MB/s \n\u001b[K |████████████████████████████████| 48 kB 4.5 MB/s \n\u001b[K |████████████████████████████████| 1.1 MB 43.1 MB/s \n\u001b[K |████████████████████████████████| 981 kB 41.3 MB/s \n\u001b[K |████████████████████████████████| 367 kB 27.6 MB/s \n\u001b[K |████████████████████████████████| 79 kB 6.9 MB/s \n\u001b[K |████████████████████████████████| 366 kB 44.0 MB/s \n\u001b[K |████████████████████████████████| 5.8 MB 45.2 MB/s \n\u001b[K |████████████████████████████████| 191 kB 53.3 MB/s \n\u001b[K |████████████████████████████████| 251 kB 44.1 MB/s \n\u001b[K |████████████████████████████████| 191 kB 51.1 MB/s \n\u001b[K |████████████████████████████████| 178 kB 46.3 MB/s \n\u001b[?25h Building wheel for librosa (setup.py) ... \u001b[?25l\u001b[?25hdone\n Building wheel for mir-eval (setup.py) ... \u001b[?25l\u001b[?25hdone\n Building wheel for pretty-midi (setup.py) ... \u001b[?25l\u001b[?25hdone\n Building wheel for pygtrie (setup.py) ... \u001b[?25l\u001b[?25hdone\n Building wheel for python-rtmidi (setup.py) ... \u001b[?25l\u001b[?25hdone\n Building wheel for bz2file (setup.py) ... \u001b[?25l\u001b[?25hdone\nImporting libraries and defining some helper functions...\n"
],
[
"#@title Drive Setup\n#@markdown If your training sample is in google drive you need to connect it. \n#@markdown You can also upload the data to a temporary folder but it will be \n#@markdown lost when the session is closed.\nfrom google.colab import drive\ndrive.mount('/content/drive')",
"Mounted at /content/drive\n"
],
[
"!music_vae_generate \\\n--config=cat-mel_2bar_big \\\n--checkpoint_file=/content/drive/My\\ Drive/cat-mel_2bar_big.tar \\\n--mode=interpolate \\\n--num_outputs=5 \\\n--input_midi_1=/2bar902_1.mid \\\n--input_midi_2=/2bar907_1.mid \\\n--output_dir=/tmp/music_vae/generated2",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nI1204 00:31:49.411712 140656584951680 music_vae_generate.py:145] Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nINFO:tensorflow:Loading model...\nI1204 00:31:49.413679 140656584951680 music_vae_generate.py:149] Loading model...\nINFO:tensorflow:Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nI1204 00:31:49.417099 140656584951680 base_model.py:152] Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nINFO:tensorflow:\nEncoder Cells (bidirectional):\n units: [2048]\n\nI1204 00:31:49.422918 140656584951680 lstm_models.py:79] \nEncoder Cells (bidirectional):\n units: [2048]\n\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1204 00:31:49.435388 140656584951680 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1204 00:31:49.445984 140656584951680 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nINFO:tensorflow:\nDecoder Cells:\n units: [2048, 2048, 2048]\n\nI1204 00:31:49.446506 140656584951680 lstm_models.py:225] \nDecoder Cells:\n units: [2048, 2048, 2048]\n\nWARNING:tensorflow:Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nW1204 00:31:49.446693 140656584951680 lstm_utils.py:139] Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW1204 00:31:49.446911 140656584951680 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1204 00:31:49.474192 140656584951680 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:99: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n name=name),\n/usr/local/lib/python3.7/dist-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.\n return layer.apply(inputs)\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:751: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n self._names[\"W\"], [input_size + self._num_units, self._num_units * 4])\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:754: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n initializer=tf.constant_initializer(0.0))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nW1204 00:31:49.979497 140656584951680 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\nW1204 00:31:49.979975 140656584951680 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:199: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:205: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\nW1204 00:31:50.222687 140656584951680 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\n2021-12-04 00:31:50.828773: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\nINFO:tensorflow:Unbundling checkpoint.\nI1204 00:31:50.978690 140656584951680 trained_model.py:123] Unbundling checkpoint.\nINFO:tensorflow:Restoring parameters from /tmp/tmpwdh2095l/cat-mel_2bar_big.ckpt\nI1204 00:31:58.526226 140656584951680 saver.py:1399] Restoring parameters from /tmp/tmpwdh2095l/cat-mel_2bar_big.ckpt\nINFO:tensorflow:Interpolating...\nI1204 00:32:01.488698 140656584951680 music_vae_generate.py:160] Interpolating...\nINFO:tensorflow:Outputting 5 files as `/tmp/music_vae/generated2/cat-mel_2bar_big_interpolate_2021-12-04_003149-*-of-005.mid`...\nI1204 00:32:02.016971 140656584951680 music_vae_generate.py:179] Outputting 5 files as `/tmp/music_vae/generated2/cat-mel_2bar_big_interpolate_2021-12-04_003149-*-of-005.mid`...\nINFO:tensorflow:Done.\nI1204 00:32:02.023710 140656584951680 music_vae_generate.py:183] Done.\n"
],
[
"!convert_dir_to_note_sequences \\\n--input_dir=/content/drive/My\\ Drive/pop909_melody_train \\\n--output_file=/temp/notesequences.tfrecord \\\n--log=INFO",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Converting files in '/content/drive/My Drive/pop909_melody_train/'.\nI1203 02:45:23.992699 140258690758528 convert_dir_to_note_sequences.py:83] Converting files in '/content/drive/My Drive/pop909_melody_train/'.\nINFO:tensorflow:0 files converted.\nI1203 02:45:27.248002 140258690758528 convert_dir_to_note_sequences.py:89] 0 files converted.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/003.mid.\nI1203 02:45:27.550435 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/003.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/573.mid.\nI1203 02:45:27.824595 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/573.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/567.mid.\nI1203 02:45:28.124248 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/567.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/017.mid.\nI1203 02:45:28.486176 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/017.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/229.mid.\nI1203 02:45:28.779031 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/229.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/598.mid.\nI1203 02:45:29.064579 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/598.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/201.mid.\nI1203 02:45:29.353967 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/201.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/203.mid.\nI1203 02:45:29.705045 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/203.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/771.mid.\nI1203 02:45:29.986034 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/771.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/217.mid.\nI1203 02:45:30.272809 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/217.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/798.mid.\nI1203 02:45:30.554108 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/798.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/559.mid.\nI1203 02:45:30.847168 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/559.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/571.mid.\nI1203 02:45:31.110090 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/571.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/029.mid.\nI1203 02:45:31.433234 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/029.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/773.mid.\nI1203 02:45:33.866647 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/773.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/767.mid.\nI1203 02:45:34.159548 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/767.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/001.mid.\nI1203 02:45:34.437804 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/001.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/015.mid.\nI1203 02:45:34.782840 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/015.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/834.mid.\nI1203 02:45:35.118943 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/834.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/808.mid.\nI1203 02:45:35.410057 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/808.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/388.mid.\nI1203 02:45:35.711594 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/388.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/377.mid.\nI1203 02:45:35.990911 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/377.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/363.mid.\nI1203 02:45:36.277807 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/363.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/175.mid.\nI1203 02:45:36.554100 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/175.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/820.mid.\nI1203 02:45:36.840084 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/820.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/438.mid.\nI1203 02:45:37.154420 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/438.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/149.mid.\nI1203 02:45:37.461292 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/149.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/607.mid.\nI1203 02:45:37.817923 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/607.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/405.mid.\nI1203 02:45:38.194109 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/405.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/439.mid.\nI1203 02:45:38.491116 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/439.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/606.mid.\nI1203 02:45:38.773089 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/606.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/160.mid.\nI1203 02:45:39.065442 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/160.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/174.mid.\nI1203 02:45:39.431757 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/174.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/404.mid.\nI1203 02:45:39.714947 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/404.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/389.mid.\nI1203 02:45:39.974511 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/389.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/410.mid.\nI1203 02:45:40.246634 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/410.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/376.mid.\nI1203 02:45:40.502688 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/376.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/362.mid.\nI1203 02:45:40.805616 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/362.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/148.mid.\nI1203 02:45:41.080893 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/148.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/612.mid.\nI1203 02:45:41.372224 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/612.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/821.mid.\nI1203 02:45:41.657995 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/821.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/835.mid.\nI1203 02:45:41.972828 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/835.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/809.mid.\nI1203 02:45:42.321121 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/809.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/766.mid.\nI1203 02:45:42.664851 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/766.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/772.mid.\nI1203 02:45:42.964985 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/772.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/014.mid.\nI1203 02:45:43.225597 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/014.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/558.mid.\nI1203 02:45:43.611767 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/558.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/028.mid.\nI1203 02:45:43.899991 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/028.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/799.mid.\nI1203 02:45:44.289307 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/799.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/564.mid.\nI1203 02:45:44.689540 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/564.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/401.mid.\nI1203 02:45:44.972230 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/401.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/367.mid.\nI1203 02:45:45.332395 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/367.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/165.mid.\nI1203 02:45:45.710888 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/165.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/415.mid.\nI1203 02:45:45.986334 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/415.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/818.mid.\nI1203 02:45:46.314458 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/818.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/429.mid.\nI1203 02:45:46.606865 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/429.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/398.mid.\nI1203 02:45:46.969397 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/398.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/159.mid.\nI1203 02:45:47.234676 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/159.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/603.mid.\nI1203 02:45:47.507720 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/603.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/824.mid.\nI1203 02:45:47.833277 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/824.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/011.mid.\nI1203 02:45:48.122200 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/011.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/207.mid.\nI1203 02:45:48.431383 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/207.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/239.mid.\nI1203 02:45:48.739860 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/239.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/763.mid.\nI1203 02:45:49.043071 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/763.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/561.mid.\nI1203 02:45:49.440958 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/561.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/211.mid.\nI1203 02:45:49.721723 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/211.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/549.mid.\nI1203 02:45:50.129745 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/549.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/039.mid.\nI1203 02:45:50.425762 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/039.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/213.mid.\nI1203 02:45:50.777043 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/213.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/777.mid.\nI1203 02:45:51.053905 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/777.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/577.mid.\nI1203 02:45:51.388997 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/577.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/563.mid.\nI1203 02:45:51.658656 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/563.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/826.mid.\nI1203 02:45:51.944966 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/826.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/775.mid.\nI1203 02:45:52.245652 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/775.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/013.mid.\nI1203 02:45:52.535923 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/013.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/832.mid.\nI1203 02:45:52.824423 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/832.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/198.mid.\nI1203 02:45:53.119946 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/198.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/007.mid.\nI1203 02:45:53.399286 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/007.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/205.mid.\nI1203 02:45:53.673346 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/205.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/749.mid.\nI1203 02:45:53.996105 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/749.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/629.mid.\nI1203 02:45:54.263174 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/629.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/370.mid.\nI1203 02:45:54.560747 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/370.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/615.mid.\nI1203 02:45:54.922710 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/615.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/167.mid.\nI1203 02:45:55.218324 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/167.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/417.mid.\nI1203 02:45:55.573604 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/417.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/359.mid.\nI1203 02:45:55.960816 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/359.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/365.mid.\nI1203 02:45:56.269111 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/365.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/416.mid.\nI1203 02:45:56.596114 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/416.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/371.mid.\nI1203 02:45:56.865994 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/371.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/403.mid.\nI1203 02:45:57.171633 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/403.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/364.mid.\nI1203 02:45:57.447214 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/364.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/006.mid.\nI1203 02:45:57.752343 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/006.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/827.mid.\nI1203 02:45:58.040651 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/827.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/402.mid.\nI1203 02:45:58.396641 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/402.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/628.mid.\nI1203 02:45:58.757667 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/628.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/600.mid.\nI1203 02:45:59.029016 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/600.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/172.mid.\nI1203 02:45:59.874475 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/172.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/166.mid.\nI1203 02:46:00.160611 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/166.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/358.mid.\nI1203 02:46:00.430748 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/358.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/614.mid.\nI1203 02:46:00.745771 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/614.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/760.mid.\nI1203 02:46:01.114425 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/760.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/204.mid.\nI1203 02:46:01.394134 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/204.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/599.mid.\nI1203 02:46:01.704411 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/599.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/210.mid.\nI1203 02:46:02.064977 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/210.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/562.mid.\nI1203 02:46:02.466356 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/562.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/774.mid.\nI1203 02:46:02.795881 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/774.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/748.mid.\nI1203 02:46:03.054297 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/748.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/572.mid.\nI1203 02:46:03.412742 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/572.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/589.mid.\nI1203 02:46:03.693790 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/589.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/012.mid.\nI1203 02:46:04.068404 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/012.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/214.mid.\nI1203 02:46:04.379279 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/214.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/837.mid.\nI1203 02:46:04.666480 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/837.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/758.mid.\nI1203 02:46:04.956194 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/758.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/016.mid.\nI1203 02:46:05.237544 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/016.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/002.mid.\nI1203 02:46:05.582465 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/002.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/200.mid.\nI1203 02:46:05.949966 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/200.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/566.mid.\nI1203 02:46:06.212607 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/566.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/770.mid.\nI1203 02:46:06.533408 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/770.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/823.mid.\nI1203 02:46:06.853024 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/823.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/228.mid.\nI1203 02:46:07.126974 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/228.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/189.mid.\nI1203 02:46:07.511696 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/189.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/348.mid.\nI1203 02:46:07.861427 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/348.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/610.mid.\nI1203 02:46:08.200450 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/610.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/406.mid.\nI1203 02:46:08.532446 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/406.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/162.mid.\nI1203 02:46:08.817811 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/162.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/412.mid.\nI1203 02:46:09.156341 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/412.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/604.mid.\nI1203 02:46:09.513208 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/604.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/360.mid.\nI1203 02:46:09.850671 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/360.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/374.mid.\nI1203 02:46:10.202070 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/374.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/176.mid.\nI1203 02:46:10.582345 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/176.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/349.mid.\nI1203 02:46:10.855255 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/349.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/361.mid.\nI1203 02:46:11.302110 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/361.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/163.mid.\nI1203 02:46:11.647861 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/163.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/822.mid.\nI1203 02:46:12.007525 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/822.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/611.mid.\nI1203 02:46:12.419296 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/611.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/639.mid.\nI1203 02:46:12.785818 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/639.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/413.mid.\nI1203 02:46:13.157432 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/413.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/407.mid.\nI1203 02:46:13.474133 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/407.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/759.mid.\nI1203 02:46:13.764008 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/759.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/836.mid.\nI1203 02:46:14.125373 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/836.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/765.mid.\nI1203 02:46:14.391515 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/765.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/698.mid.\nI1203 02:46:14.696218 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/698.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/883.mid.\nI1203 02:46:15.066468 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/883.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/303.mid.\nI1203 02:46:15.459416 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/303.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/471.mid.\nI1203 02:46:15.835655 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/471.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/854.mid.\nI1203 02:46:16.131121 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/854.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/667.mid.\nI1203 02:46:16.416891 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/667.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/101.mid.\nI1203 02:46:16.765254 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/101.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/129.mid.\nI1203 02:46:17.181339 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/129.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/115.mid.\nI1203 02:46:17.451971 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/115.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/673.mid.\nI1203 02:46:17.746617 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/673.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/317.mid.\nI1203 02:46:18.033385 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/317.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/882.mid.\nI1203 02:46:18.327502 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/882.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/459.mid.\nI1203 02:46:18.616944 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/459.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/672.mid.\nI1203 02:46:18.984786 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/672.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/128.mid.\nI1203 02:46:19.361974 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/128.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/114.mid.\nI1203 02:46:19.672307 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/114.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/458.mid.\nI1203 02:46:19.945940 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/458.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/666.mid.\nI1203 02:46:20.318319 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/666.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/316.mid.\nI1203 02:46:20.661494 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/316.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/464.mid.\nI1203 02:46:21.044664 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/464.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/100.mid.\nI1203 02:46:21.410724 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/100.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/869.mid.\nI1203 02:46:21.735781 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/869.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/048.mid.\nI1203 02:46:22.078487 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/048.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/074.mid.\nI1203 02:46:22.673737 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/074.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/706.mid.\nI1203 02:46:23.085657 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/706.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/538.mid.\nI1203 02:46:23.361958 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/538.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/712.mid.\nI1203 02:46:23.638470 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/712.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/060.mid.\nI1203 02:46:23.944984 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/060.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/262.mid.\nI1203 02:46:24.228435 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/262.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/855.mid.\nI1203 02:46:24.625070 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/855.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/504.mid.\nI1203 02:46:24.920147 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/504.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/260.mid.\nI1203 02:46:25.278326 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/260.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/512.mid.\nI1203 02:46:25.658270 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/512.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/506.mid.\nI1203 02:46:26.024712 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/506.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/276.mid.\nI1203 02:46:26.301339 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/276.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/089.mid.\nI1203 02:46:26.568727 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/089.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/274.mid.\nI1203 02:46:26.935525 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/274.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/289.mid.\nI1203 02:46:27.249333 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/289.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/248.mid.\nI1203 02:46:27.541590 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/248.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/062.mid.\nI1203 02:46:27.851518 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/062.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/710.mid.\nI1203 02:46:28.152888 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/710.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/116.mid.\nI1203 02:46:28.446133 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/116.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/102.mid.\nI1203 02:46:28.742888 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/102.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/499.mid.\nI1203 02:46:29.092565 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/499.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/880.mid.\nI1203 02:46:29.423003 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/880.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/658.mid.\nI1203 02:46:29.699047 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/658.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/472.mid.\nI1203 02:46:30.028730 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/472.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/843.mid.\nI1203 02:46:30.289658 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/843.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/314.mid.\nI1203 02:46:30.630359 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/314.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/670.mid.\nI1203 02:46:30.909839 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/670.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/466.mid.\nI1203 02:46:31.241189 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/466.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/473.mid.\nI1203 02:46:31.529284 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/473.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/300.mid.\nI1203 02:46:31.857442 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/300.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/659.mid.\nI1203 02:46:32.143340 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/659.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/329.mid.\nI1203 02:46:32.439892 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/329.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/328.mid.\nI1203 02:46:32.734142 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/328.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/467.mid.\nI1203 02:46:33.069945 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/467.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/895.mid.\nI1203 02:46:33.417953 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/895.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/301.mid.\nI1203 02:46:33.719642 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/301.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/315.mid.\nI1203 02:46:34.012918 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/315.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/881.mid.\nI1203 02:46:34.296762 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/881.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/739.mid.\nI1203 02:46:34.644026 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/739.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/063.mid.\nI1203 02:46:34.986842 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/063.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/705.mid.\nI1203 02:46:35.299397 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/705.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/856.mid.\nI1203 02:46:35.659084 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/856.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/665.mid.\nI1203 02:46:35.934422 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/665.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/077.mid.\nI1203 02:46:36.262082 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/077.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/249.mid.\nI1203 02:46:36.540432 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/249.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/842.mid.\nI1203 02:46:36.872245 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/842.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/671.mid.\nI1203 02:46:37.222831 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/671.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/261.mid.\nI1203 02:46:37.582168 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/261.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/560.mid.\nI1203 02:46:37.974038 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/560.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/507.mid.\nI1203 02:46:38.274882 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/507.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/762.mid.\nI1203 02:46:38.554203 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/762.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/574.mid.\nI1203 02:46:38.892333 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/574.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/038.mid.\nI1203 02:46:39.215993 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/038.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/789.mid.\nI1203 02:46:39.490141 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/789.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/010.mid.\nI1203 02:46:39.867852 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/010.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/548.mid.\nI1203 02:46:40.157886 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/548.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/206.mid.\nI1203 02:46:40.524978 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/206.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/004.mid.\nI1203 02:46:40.863825 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/004.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/170.mid.\nI1203 02:46:41.225495 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/170.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/819.mid.\nI1203 02:46:41.591784 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/819.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/158.mid.\nI1203 02:46:41.866471 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/158.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/366.mid.\nI1203 02:46:42.158600 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/366.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/164.mid.\nI1203 02:46:42.467311 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/164.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/428.mid.\nI1203 02:46:42.803488 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/428.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/776.mid.\nI1203 02:46:43.133303 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/776.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/372.mid.\nI1203 02:46:43.481901 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/372.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/602.mid.\nI1203 02:46:43.858084 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/602.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/649.mid.\nI1203 02:46:44.197693 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/649.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/661.mid.\nI1203 02:46:44.569691 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/661.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/891.mid.\nI1203 02:46:44.965786 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/891.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/477.mid.\nI1203 02:46:45.318967 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/477.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/113.mid.\nI1203 02:46:45.592840 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/113.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/339.mid.\nI1203 02:46:45.855463 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/339.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/463.mid.\nI1203 02:46:46.149864 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/463.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/885.mid.\nI1203 02:46:46.448737 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/885.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/675.mid.\nI1203 02:46:46.817537 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/675.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/107.mid.\nI1203 02:46:47.081197 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/107.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/305.mid.\nI1203 02:46:47.364053 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/305.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/489.mid.\nI1203 02:46:47.646952 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/489.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/660.mid.\nI1203 02:46:48.003096 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/660.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/476.mid.\nI1203 02:46:48.356647 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/476.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/310.mid.\nI1203 02:46:48.710125 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/310.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/304.mid.\nI1203 02:46:49.068038 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/304.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/106.mid.\nI1203 02:46:49.430362 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/106.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/112.mid.\nI1203 02:46:49.788372 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/112.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/462.mid.\nI1203 02:46:50.151812 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/462.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/338.mid.\nI1203 02:46:50.439623 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/338.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/674.mid.\nI1203 02:46:50.712623 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/674.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/728.mid.\nI1203 02:46:50.995308 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/728.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/714.mid.\nI1203 02:46:51.255712 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/714.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/884.mid.\nI1203 02:46:51.529083 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/884.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/099.mid.\nI1203 02:46:51.810654 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/099.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/890.mid.\nI1203 02:46:52.124444 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/890.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/648.mid.\nI1203 02:46:52.424328 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/648.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/853.mid.\nI1203 02:46:52.778717 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/853.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/066.mid.\nI1203 02:46:53.058133 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/066.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/847.mid.\nI1203 02:46:53.422381 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/847.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/270.mid.\nI1203 02:46:53.697568 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/270.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/500.mid.\nI1203 02:46:54.012189 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/500.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/516.mid.\nI1203 02:46:54.290374 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/516.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/299.mid.\nI1203 02:46:54.558136 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/299.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/264.mid.\nI1203 02:46:54.909232 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/264.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/272.mid.\nI1203 02:46:55.181349 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/272.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/258.mid.\nI1203 02:46:55.515501 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/258.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/702.mid.\nI1203 02:46:55.871491 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/702.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/502.mid.\nI1203 02:46:56.242779 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/502.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/266.mid.\nI1203 02:46:56.593236 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/266.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/716.mid.\nI1203 02:46:56.939771 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/716.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/110.mid.\nI1203 02:46:57.253848 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/110.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/879.mid.\nI1203 02:46:57.589222 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/879.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/104.mid.\nI1203 02:46:57.966345 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/104.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/851.mid.\nI1203 02:46:58.268776 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/851.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/845.mid.\nI1203 02:46:58.537022 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/845.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/892.mid.\nI1203 02:46:58.810541 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/892.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/138.mid.\nI1203 02:46:59.179773 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/138.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/662.mid.\nI1203 02:46:59.455075 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/662.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/676.mid.\nI1203 02:46:59.719499 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/676.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/448.mid.\nI1203 02:47:00.020570 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/448.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/474.mid.\nI1203 02:47:00.399420 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/474.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/475.mid.\nI1203 02:47:00.690958 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/475.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/460.mid.\nI1203 02:47:01.004315 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/460.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/313.mid.\nI1203 02:47:01.333328 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/313.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/461.mid.\nI1203 02:47:01.619827 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/461.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/307.mid.\nI1203 02:47:01.912226 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/307.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/111.mid.\nI1203 02:47:02.302339 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/111.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/105.mid.\nI1203 02:47:02.656808 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/105.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/312.mid.\nI1203 02:47:02.966801 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/312.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/677.mid.\nI1203 02:47:03.261120 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/677.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/071.mid.\nI1203 02:47:03.542260 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/071.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/663.mid.\nI1203 02:47:03.905201 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/663.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/703.mid.\nI1203 02:47:04.183544 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/703.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/878.mid.\nI1203 02:47:04.475335 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/878.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/887.mid.\nI1203 02:47:04.817305 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/887.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/844.mid.\nI1203 02:47:05.138469 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/844.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/139.mid.\nI1203 02:47:05.408966 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/139.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/688.mid.\nI1203 02:47:05.757590 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/688.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/850.mid.\nI1203 02:47:06.126252 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/850.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/065.mid.\nI1203 02:47:06.452315 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/065.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/515.mid.\nI1203 02:47:06.815758 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/515.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/059.mid.\nI1203 02:47:07.101862 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/059.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/529.mid.\nI1203 02:47:07.446941 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/529.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/501.mid.\nI1203 02:47:07.793143 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/501.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/277.mid.\nI1203 02:47:08.109984 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/277.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/273.mid.\nI1203 02:47:08.462667 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/273.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/717.mid.\nI1203 02:47:08.828109 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/717.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/511.mid.\nI1203 02:47:09.085321 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/511.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/267.mid.\nI1203 02:47:09.471381 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/267.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/505.mid.\nI1203 02:47:09.852500 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/505.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/840.mid.\nI1203 02:47:10.235216 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/840.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/061.mid.\nI1203 02:47:10.516597 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/061.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/868.mid.\nI1203 02:47:10.846377 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/868.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/908.mid.\nI1203 02:47:11.126650 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/908.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/707.mid.\nI1203 02:47:11.422154 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/707.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/263.mid.\nI1203 02:47:11.693153 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/263.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/049.mid.\nI1203 02:47:12.040222 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/049.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/075.mid.\nI1203 02:47:12.323394 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/075.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/713.mid.\nI1203 02:47:12.696512 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/713.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/054.mid.\nI1203 02:47:12.980369 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/054.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/901.mid.\nI1203 02:47:13.252389 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/901.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/685.mid.\nI1203 02:47:13.538922 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/685.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/646.mid.\nI1203 02:47:13.797198 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/646.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/691.mid.\nI1203 02:47:14.069931 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/691.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/875.mid.\nI1203 02:47:14.342291 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/875.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/726.mid.\nI1203 02:47:14.682483 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/726.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/040.mid.\nI1203 02:47:14.963031 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/040.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/068.mid.\nI1203 02:47:15.244923 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/068.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/652.mid.\nI1203 02:47:15.515661 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/652.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/487.mid.\nI1203 02:47:15.855174 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/487.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/450.mid.\nI1203 02:47:16.140644 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/450.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/108.mid.\nI1203 02:47:16.490291 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/108.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/444.mid.\nI1203 02:47:16.793122 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/444.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/451.mid.\nI1203 02:47:17.055788 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/451.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/336.mid.\nI1203 02:47:17.340800 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/336.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/479.mid.\nI1203 02:47:17.614113 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/479.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/478.mid.\nI1203 02:47:17.969778 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/478.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/322.mid.\nI1203 02:47:18.280344 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/322.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/337.mid.\nI1203 02:47:18.583379 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/337.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/874.mid.\nI1203 02:47:18.863995 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/874.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/653.mid.\nI1203 02:47:19.154374 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/653.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/135.mid.\nI1203 02:47:19.460708 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/135.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/121.mid.\nI1203 02:47:19.759341 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/121.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/860.mid.\nI1203 02:47:20.116253 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/860.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/647.mid.\nI1203 02:47:20.390129 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/647.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/109.mid.\nI1203 02:47:20.766047 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/109.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/690.mid.\nI1203 02:47:21.053239 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/690.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/323.mid.\nI1203 02:47:21.347812 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/323.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/684.mid.\nI1203 02:47:21.661617 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/684.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/055.mid.\nI1203 02:47:22.011244 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/055.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/282.mid.\nI1203 02:47:22.306702 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/282.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/519.mid.\nI1203 02:47:22.646838 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/519.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/280.mid.\nI1203 02:47:23.008441 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/280.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/294.mid.\nI1203 02:47:23.359466 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/294.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/243.mid.\nI1203 02:47:23.769161 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/243.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/041.mid.\nI1203 02:47:24.107650 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/041.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/733.mid.\nI1203 02:47:24.449981 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/733.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/096.mid.\nI1203 02:47:24.754590 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/096.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/296.mid.\nI1203 02:47:25.013184 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/296.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/094.mid.\nI1203 02:47:25.347898 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/094.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/043.mid.\nI1203 02:47:25.742105 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/043.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/241.mid.\nI1203 02:47:26.017565 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/241.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/080.mid.\nI1203 02:47:26.366553 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/080.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/731.mid.\nI1203 02:47:26.646570 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/731.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/255.mid.\nI1203 02:47:26.910604 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/255.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/527.mid.\nI1203 02:47:27.234844 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/527.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/057.mid.\nI1203 02:47:27.605168 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/057.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/269.mid.\nI1203 02:47:27.969094 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/269.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/719.mid.\nI1203 02:47:28.287777 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/719.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/692.mid.\nI1203 02:47:28.564729 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/692.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/862.mid.\nI1203 02:47:28.850746 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/862.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/123.mid.\nI1203 02:47:29.204675 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/123.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/889.mid.\nI1203 02:47:29.469400 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/889.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/686.mid.\nI1203 02:47:29.811770 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/686.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/484.mid.\nI1203 02:47:30.162000 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/484.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/645.mid.\nI1203 02:47:30.490436 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/645.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/876.mid.\nI1203 02:47:30.817170 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/876.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/490.mid.\nI1203 02:47:31.113632 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/490.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/335.mid.\nI1203 02:47:31.398278 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/335.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/452.mid.\nI1203 02:47:31.755049 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/452.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/446.mid.\nI1203 02:47:32.062565 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/446.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/308.mid.\nI1203 02:47:32.453160 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/308.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/485.mid.\nI1203 02:47:32.740372 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/485.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/334.mid.\nI1203 02:47:33.067296 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/334.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/447.mid.\nI1203 02:47:33.413735 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/447.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/453.mid.\nI1203 02:47:33.693264 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/453.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/320.mid.\nI1203 02:47:33.995465 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/320.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/309.mid.\nI1203 02:47:34.336146 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/309.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/678.mid.\nI1203 02:47:34.705480 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/678.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/888.mid.\nI1203 02:47:34.990395 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/888.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/650.mid.\nI1203 02:47:35.294976 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/650.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/730.mid.\nI1203 02:47:35.572696 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/730.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/863.mid.\nI1203 02:47:35.871701 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/863.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/122.mid.\nI1203 02:47:36.147278 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/122.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/718.mid.\nI1203 02:47:36.469033 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/718.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/644.mid.\nI1203 02:47:36.847188 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/644.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/877.mid.\nI1203 02:47:37.123451 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/877.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/136.mid.\nI1203 02:47:37.400810 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/136.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/056.mid.\nI1203 02:47:37.756159 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/056.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/081.mid.\nI1203 02:47:38.134650 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/081.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/297.mid.\nI1203 02:47:38.428845 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/297.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/526.mid.\nI1203 02:47:38.706727 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/526.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/095.mid.\nI1203 02:47:39.069870 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/095.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/903.mid.\nI1203 02:47:39.359284 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/903.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/042.mid.\nI1203 02:47:39.725573 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/042.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/532.mid.\nI1203 02:47:40.022878 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/532.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/268.mid.\nI1203 02:47:40.294653 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/268.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/724.mid.\nI1203 02:47:40.679621 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/724.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/254.mid.\nI1203 02:47:40.958138 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/254.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/073.mid.\nI1203 02:47:41.336478 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/073.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/283.mid.\nI1203 02:47:41.712865 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/283.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/846.mid.\nI1203 02:47:42.032126 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/846.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/067.mid.\nI1203 02:47:42.311572 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/067.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/729.mid.\nI1203 02:47:42.657529 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/729.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/517.mid.\nI1203 02:47:42.930244 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/517.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/271.mid.\nI1203 02:47:43.302623 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/271.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/503.mid.\nI1203 02:47:43.691879 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/503.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/265.mid.\nI1203 02:47:44.044509 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/265.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/331.mid.\nI1203 02:47:44.378743 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/331.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/325.mid.\nI1203 02:47:44.655468 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/325.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/318.mid.\nI1203 02:47:44.956567 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/318.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/330.mid.\nI1203 02:47:45.243189 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/330.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/442.mid.\nI1203 02:47:45.578727 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/442.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/480.mid.\nI1203 02:47:45.928739 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/480.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/456.mid.\nI1203 02:47:46.278597 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/456.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/319.mid.\nI1203 02:47:46.556620 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/319.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/324.mid.\nI1203 02:47:46.874983 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/324.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/899.mid.\nI1203 02:47:47.157188 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/899.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/682.mid.\nI1203 02:47:47.496264 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/682.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/696.mid.\nI1203 02:47:47.786006 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/696.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/669.mid.\nI1203 02:47:48.164117 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/669.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/127.mid.\nI1203 02:47:48.461289 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/127.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/641.mid.\nI1203 02:47:48.751355 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/641.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/735.mid.\nI1203 02:47:49.038910 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/735.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/133.mid.\nI1203 02:47:49.303910 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/133.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/872.mid.\nI1203 02:47:49.656004 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/872.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/655.mid.\nI1203 02:47:50.066170 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/655.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/053.mid.\nI1203 02:47:50.451445 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/053.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/251.mid.\nI1203 02:47:50.835556 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/251.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/245.mid.\nI1203 02:47:51.189533 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/245.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/537.mid.\nI1203 02:47:51.548975 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/537.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/047.mid.\nI1203 02:47:51.897067 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/047.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/090.mid.\nI1203 02:47:52.292441 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/090.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/084.mid.\nI1203 02:47:52.652389 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/084.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/279.mid.\nI1203 02:47:52.915814 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/279.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/906.mid.\nI1203 02:47:53.287318 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/906.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/721.mid.\nI1203 02:47:53.616563 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/721.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/292.mid.\nI1203 02:47:53.896124 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/292.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/535.mid.\nI1203 02:47:54.247941 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/535.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/079.mid.\nI1203 02:47:54.594000 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/079.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/290.mid.\nI1203 02:47:54.847004 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/290.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/286.mid.\nI1203 02:47:55.118487 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/286.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/086.mid.\nI1203 02:47:55.475435 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/086.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/253.mid.\nI1203 02:47:55.769557 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/253.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/509.mid.\nI1203 02:47:56.063787 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/509.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/521.mid.\nI1203 02:47:56.390280 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/521.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/904.mid.\nI1203 02:47:56.663984 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/904.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/051.mid.\nI1203 02:47:56.987011 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/051.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/045.mid.\nI1203 02:47:57.254833 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/045.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/680.mid.\nI1203 02:47:57.612485 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/680.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/737.mid.\nI1203 02:47:57.917667 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/737.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/864.mid.\nI1203 02:47:58.206292 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/864.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/119.mid.\nI1203 02:47:58.570947 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/119.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/858.mid.\nI1203 02:47:58.912160 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/858.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/723.mid.\nI1203 02:47:59.248282 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/723.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/870.mid.\nI1203 02:47:59.525454 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/870.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/694.mid.\nI1203 02:47:59.802272 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/694.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/125.mid.\nI1203 02:48:00.079435 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/125.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/441.mid.\nI1203 02:48:00.346510 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/441.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/496.mid.\nI1203 02:48:00.694812 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/496.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/643.mid.\nI1203 02:48:00.989887 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/643.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/657.mid.\nI1203 02:48:01.346550 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/657.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/482.mid.\nI1203 02:48:01.631477 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/482.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/469.mid.\nI1203 02:48:01.895556 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/469.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/333.mid.\nI1203 02:48:02.213120 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/333.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/327.mid.\nI1203 02:48:02.498203 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/327.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/455.mid.\nI1203 02:48:02.781502 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/455.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/332.mid.\nI1203 02:48:03.038792 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/332.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/468.mid.\nI1203 02:48:03.381327 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/468.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/118.mid.\nI1203 02:48:03.658580 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/118.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/642.mid.\nI1203 02:48:03.944088 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/642.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/656.mid.\nI1203 02:48:04.334594 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/656.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/124.mid.\nI1203 02:48:04.612953 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/124.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/483.mid.\nI1203 02:48:04.901525 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/483.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/440.mid.\nI1203 02:48:05.181445 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/440.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/681.mid.\nI1203 02:48:05.454427 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/681.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/454.mid.\nI1203 02:48:05.720121 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/454.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/695.mid.\nI1203 02:48:06.045434 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/695.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/871.mid.\nI1203 02:48:06.466609 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/871.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/865.mid.\nI1203 02:48:06.802756 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/865.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/050.mid.\nI1203 02:48:07.119679 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/050.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/093.mid.\nI1203 02:48:07.405943 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/093.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/087.mid.\nI1203 02:48:07.766839 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/087.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/246.mid.\nI1203 02:48:08.130312 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/246.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/859.mid.\nI1203 02:48:08.476598 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/859.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/044.mid.\nI1203 02:48:08.764492 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/044.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/905.mid.\nI1203 02:48:09.019305 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/905.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/520.mid.\nI1203 02:48:09.318661 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/520.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/281.mid.\nI1203 02:48:09.614877 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/281.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/530.mid.\nI1203 02:48:09.893599 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/530.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/252.mid.\nI1203 02:48:10.182983 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/252.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/097.mid.\nI1203 02:48:10.460125 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/097.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/285.mid.\nI1203 02:48:10.731998 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/285.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/518.mid.\nI1203 02:48:11.040418 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/518.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/508.mid.\nI1203 02:48:11.318485 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/508.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/524.mid.\nI1203 02:48:11.615175 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/524.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/291.mid.\nI1203 02:48:11.905656 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/291.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/083.mid.\nI1203 02:48:12.292260 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/083.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/181.mid.\nI1203 02:48:12.588979 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/181.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/022.mid.\nI1203 02:48:12.854329 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/022.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/036.mid.\nI1203 02:48:13.193765 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/036.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/750.mid.\nI1203 02:48:13.467620 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/750.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/552.mid.\nI1203 02:48:13.777582 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/552.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/787.mid.\nI1203 02:48:14.075791 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/787.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/208.mid.\nI1203 02:48:14.424333 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/208.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/744.mid.\nI1203 02:48:14.705482 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/744.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/546.mid.\nI1203 02:48:14.984759 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/546.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/220.mid.\nI1203 02:48:15.266044 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/220.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/234.mid.\nI1203 02:48:15.605301 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/234.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/222.mid.\nI1203 02:48:15.902676 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/222.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/550.mid.\nI1203 02:48:16.158352 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/550.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/591.mid.\nI1203 02:48:16.481093 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/591.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/578.mid.\nI1203 02:48:16.768404 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/578.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/791.mid.\nI1203 02:48:17.054635 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/791.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/585.mid.\nI1203 02:48:17.334790 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/585.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/593.mid.\nI1203 02:48:17.636924 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/593.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/785.mid.\nI1203 02:48:17.914023 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/785.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/544.mid.\nI1203 02:48:18.316467 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/544.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/020.mid.\nI1203 02:48:18.629211 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/020.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/154.mid.\nI1203 02:48:18.966009 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/154.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/626.mid.\nI1203 02:48:19.236983 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/626.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/829.mid.\nI1203 02:48:19.511526 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/829.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/632.mid.\nI1203 02:48:19.867150 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/632.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/752.mid.\nI1203 02:48:20.165347 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/752.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/034.mid.\nI1203 02:48:20.438216 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/034.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/197.mid.\nI1203 02:48:20.728068 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/197.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/801.mid.\nI1203 02:48:21.009311 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/801.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/140.mid.\nI1203 02:48:21.288435 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/140.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/168.mid.\nI1203 02:48:21.552647 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/168.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/424.mid.\nI1203 02:48:21.826542 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/424.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/356.mid.\nI1203 02:48:22.173507 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/356.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/419.mid.\nI1203 02:48:22.521142 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/419.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/431.mid.\nI1203 02:48:22.816746 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/431.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/425.mid.\nI1203 02:48:23.166893 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/425.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/381.mid.\nI1203 02:48:23.517412 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/381.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/343.mid.\nI1203 02:48:23.866665 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/343.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/342.mid.\nI1203 02:48:24.235332 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/342.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/395.mid.\nI1203 02:48:24.515714 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/395.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/380.mid.\nI1203 02:48:24.836341 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/380.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/196.mid.\nI1203 02:48:25.134163 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/196.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/009.mid.\nI1203 02:48:25.412085 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/009.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/814.mid.\nI1203 02:48:25.772719 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/814.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/800.mid.\nI1203 02:48:26.056657 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/800.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/394.mid.\nI1203 02:48:26.389665 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/394.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/169.mid.\nI1203 02:48:26.701439 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/169.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/633.mid.\nI1203 02:48:26.974370 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/633.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/141.mid.\nI1203 02:48:27.298060 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/141.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/182.mid.\nI1203 02:48:27.644872 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/182.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/828.mid.\nI1203 02:48:28.003991 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/828.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/545.mid.\nI1203 02:48:28.291182 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/545.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/237.mid.\nI1203 02:48:28.622356 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/237.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/753.mid.\nI1203 02:48:28.967190 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/753.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/579.mid.\nI1203 02:48:29.281506 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/579.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/035.mid.\nI1203 02:48:29.568629 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/035.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/551.mid.\nI1203 02:48:29.917614 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/551.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/021.mid.\nI1203 02:48:30.195966 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/021.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/790.mid.\nI1203 02:48:30.465533 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/790.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/747.mid.\nI1203 02:48:30.763608 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/747.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/223.mid.\nI1203 02:48:31.045793 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/223.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/293.mid.\nI1203 02:48:31.387193 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/293.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/536.mid.\nI1203 02:48:31.677930 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/536.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/091.mid.\nI1203 02:48:31.943849 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/091.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/522.mid.\nI1203 02:48:32.224872 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/522.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/592.mid.\nI1203 02:48:32.521998 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/592.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/287.mid.\nI1203 02:48:32.799383 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/287.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/244.mid.\nI1203 02:48:33.088447 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/244.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/085.mid.\nI1203 02:48:33.386147 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/085.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/586.mid.\nI1203 02:48:33.731683 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/586.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/708.mid.\nI1203 02:48:33.994563 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/708.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/640.mid.\nI1203 02:48:34.281494 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/640.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/720.mid.\nI1203 02:48:34.586437 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/720.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/052.mid.\nI1203 02:48:34.881828 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/052.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/697.mid.\nI1203 02:48:35.173132 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/697.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/654.mid.\nI1203 02:48:35.475558 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/654.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/132.mid.\nI1203 02:48:35.809734 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/132.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/046.mid.\nI1203 02:48:36.184033 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/046.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/734.mid.\nI1203 02:48:36.529896 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/734.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/126.mid.\nI1203 02:48:36.891367 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/126.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/495.mid.\nI1203 02:48:37.167945 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/495.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/636.mid.\nI1203 02:48:37.464571 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/636.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/232.mid.\nI1203 02:48:37.754043 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/232.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/781.mid.\nI1203 02:48:38.030032 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/781.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/187.mid.\nI1203 02:48:38.370394 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/187.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/805.mid.\nI1203 02:48:38.652349 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/805.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/150.mid.\nI1203 02:48:38.951153 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/150.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/795.mid.\nI1203 02:48:39.221447 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/795.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/018.mid.\nI1203 02:48:39.431403 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/018.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/226.mid.\nI1203 02:48:39.797730 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/226.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/030.mid.\nI1203 02:48:40.195570 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/030.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/540.mid.\nI1203 02:48:40.472477 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/540.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/583.mid.\nI1203 02:48:40.775568 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/583.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/595.mid.\nI1203 02:48:41.122422 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/595.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/224.mid.\nI1203 02:48:41.437069 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/224.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/581.mid.\nI1203 02:48:41.737961 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/581.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/218.mid.\nI1203 02:48:42.092448 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/218.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/556.mid.\nI1203 02:48:42.421063 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/556.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/568.mid.\nI1203 02:48:42.765423 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/568.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/542.mid.\nI1203 02:48:43.104463 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/542.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/797.mid.\nI1203 02:48:43.383414 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/797.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/783.mid.\nI1203 02:48:43.641179 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/783.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/608.mid.\nI1203 02:48:43.982958 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/608.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/032.mid.\nI1203 02:48:44.299756 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/032.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/807.mid.\nI1203 02:48:44.652368 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/807.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/620.mid.\nI1203 02:48:45.008786 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/620.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/026.mid.\nI1203 02:48:45.305897 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/026.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/185.mid.\nI1203 02:48:45.614463 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/185.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/740.mid.\nI1203 02:48:45.949197 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/740.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/754.mid.\nI1203 02:48:46.221786 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/754.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/191.mid.\nI1203 02:48:46.620166 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/191.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/152.mid.\nI1203 02:48:46.913178 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/152.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/634.mid.\nI1203 02:48:47.190617 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/634.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/436.mid.\nI1203 02:48:47.464967 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/436.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/437.mid.\nI1203 02:48:47.736744 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/437.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/351.mid.\nI1203 02:48:48.110509 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/351.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/344.mid.\nI1203 02:48:48.500974 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/344.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/345.mid.\nI1203 02:48:48.799085 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/345.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/423.mid.\nI1203 02:48:49.082828 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/423.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/378.mid.\nI1203 02:48:49.439236 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/378.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/350.mid.\nI1203 02:48:49.737229 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/350.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/379.mid.\nI1203 02:48:50.044545 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/379.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/621.mid.\nI1203 02:48:50.403690 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/621.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/190.mid.\nI1203 02:48:50.784026 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/190.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/184.mid.\nI1203 02:48:51.111108 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/184.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/153.mid.\nI1203 02:48:51.429689 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/153.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/609.mid.\nI1203 02:48:51.698694 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/609.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/147.mid.\nI1203 02:48:51.961726 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/147.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/386.mid.\nI1203 02:48:52.253550 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/386.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/392.mid.\nI1203 02:48:52.527070 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/392.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/635.mid.\nI1203 02:48:52.800737 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/635.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/806.mid.\nI1203 02:48:53.142442 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/806.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/782.mid.\nI1203 02:48:53.412174 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/782.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/231.mid.\nI1203 02:48:53.703793 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/231.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/755.mid.\nI1203 02:48:53.972804 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/755.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/543.mid.\nI1203 02:48:54.376059 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/543.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/796.mid.\nI1203 02:48:54.761794 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/796.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/033.mid.\nI1203 02:48:55.012104 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/033.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/225.mid.\nI1203 02:48:55.314850 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/225.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/027.mid.\nI1203 02:48:55.562641 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/027.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/769.mid.\nI1203 02:48:55.828565 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/769.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/557.mid.\nI1203 02:48:56.188508 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/557.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/235.mid.\nI1203 02:48:56.466351 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/235.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/594.mid.\nI1203 02:48:56.790993 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/594.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/580.mid.\nI1203 02:48:57.165623 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/580.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/590.mid.\nI1203 02:48:57.454663 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/590.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/584.mid.\nI1203 02:48:57.741702 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/584.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/219.mid.\nI1203 02:48:58.071536 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/219.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/553.mid.\nI1203 02:48:58.372455 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/553.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/547.mid.\nI1203 02:48:58.727573 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/547.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/209.mid.\nI1203 02:48:59.068898 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/209.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/792.mid.\nI1203 02:48:59.378351 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/792.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/786.mid.\nI1203 02:48:59.661881 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/786.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/037.mid.\nI1203 02:49:00.029071 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/037.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/745.mid.\nI1203 02:49:00.367276 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/745.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/779.mid.\nI1203 02:49:00.643470 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/779.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/180.mid.\nI1203 02:49:00.969081 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/180.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/751.mid.\nI1203 02:49:01.341613 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/751.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/023.mid.\nI1203 02:49:01.618928 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/023.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/802.mid.\nI1203 02:49:01.938840 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/802.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/816.mid.\nI1203 02:49:02.232964 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/816.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/143.mid.\nI1203 02:49:02.531130 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/143.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/433.mid.\nI1203 02:49:02.818555 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/433.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/382.mid.\nI1203 02:49:03.211848 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/382.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/631.mid.\nI1203 02:49:03.562217 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/631.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/341.mid.\nI1203 02:49:03.854096 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/341.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/427.mid.\nI1203 02:49:04.517412 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/427.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/396.mid.\nI1203 02:49:04.838986 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/396.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/157.mid.\nI1203 02:49:05.184200 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/157.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/355.mid.\nI1203 02:49:05.523607 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/355.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/625.mid.\nI1203 02:49:05.857944 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/625.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/369.mid.\nI1203 02:49:06.152602 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/369.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/195.mid.\nI1203 02:49:06.526920 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/195.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/624.mid.\nI1203 02:49:06.871813 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/624.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/354.mid.\nI1203 02:49:07.221717 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/354.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/156.mid.\nI1203 02:49:07.489343 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/156.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/397.mid.\nI1203 02:49:07.783158 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/397.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/432.mid.\nI1203 02:49:08.097675 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/432.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/618.mid.\nI1203 02:49:08.458128 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/618.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/817.mid.\nI1203 02:49:08.848036 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/817.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/426.mid.\nI1203 02:49:09.200503 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/426.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/622.mid.\nI1203 02:49:09.492205 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/622.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/144.mid.\nI1203 02:49:09.777783 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/144.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/347.mid.\nI1203 02:49:10.079131 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/347.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/346.mid.\nI1203 02:49:10.443923 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/346.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/421.mid.\nI1203 02:49:10.716598 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/421.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/434.mid.\nI1203 02:49:11.002521 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/434.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/391.mid.\nI1203 02:49:11.328135 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/391.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/385.mid.\nI1203 02:49:11.622994 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/385.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/408.mid.\nI1203 02:49:11.976949 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/408.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/420.mid.\nI1203 02:49:12.245902 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/420.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/353.mid.\nI1203 02:49:12.591952 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/353.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/151.mid.\nI1203 02:49:12.877344 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/151.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/409.mid.\nI1203 02:49:13.144287 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/409.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/145.mid.\nI1203 02:49:13.444945 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/145.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/390.mid.\nI1203 02:49:13.848622 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/390.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/179.mid.\nI1203 02:49:14.127984 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/179.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/623.mid.\nI1203 02:49:14.438675 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/623.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/384.mid.\nI1203 02:49:14.791875 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/384.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/435.mid.\nI1203 02:49:15.131994 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/435.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/637.mid.\nI1203 02:49:15.486523 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/637.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/541.mid.\nI1203 02:49:15.885043 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/541.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/192.mid.\nI1203 02:49:16.172952 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/192.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/794.mid.\nI1203 02:49:16.464555 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/794.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/031.mid.\nI1203 02:49:16.757733 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/031.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/804.mid.\nI1203 02:49:17.263381 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/804.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/810.mid.\nI1203 02:49:17.567745 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/810.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/780.mid.\nI1203 02:49:17.870284 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/780.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/743.mid.\nI1203 02:49:18.154378 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/743.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/025.mid.\nI1203 02:49:18.440609 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/025.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/555.mid.\nI1203 02:49:18.747184 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/555.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/233.mid.\nI1203 02:49:19.028569 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/233.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/582.mid.\nI1203 02:49:19.341337 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/582.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/227.mid.\nI1203 02:49:19.642920 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/227.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/569.mid.\nI1203 02:49:19.911326 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/569.mid.\nINFO:tensorflow:Converted MIDI file /content/drive/My Drive/pop909_melody_train/596.mid.\nI1203 02:49:20.209470 140258690758528 convert_dir_to_note_sequences.py:153] Converted MIDI file /content/drive/My Drive/pop909_melody_train/596.mid.\n"
],
[
"!music_vae_train \\\n--config=cat-mel_2bar_big \\\n--run_dir=/temp/music_vae/ \\\n--mode=train \\\n--examples_path=/temp/notesequences.tfrecord \\\n--hparams=max_seq_len=32, z_size=512, free_bits=0, max_beta=0.5, beta_rate=0.99999, batch_size=512, grad_clip=1.0, clip_mode='global_norm', grad_norm_clip_to_zero=10000, learning_rate=0.01, decay_rate=0.9999, min_learning_rate=0.00001",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\n2021-12-03 02:50:47.153522: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\nINFO:tensorflow:Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 512, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nI1203 02:50:47.229152 139669353023360 base_model.py:152] Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 512, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nINFO:tensorflow:\nEncoder Cells (bidirectional):\n units: [2048]\n\nI1203 02:50:47.233515 139669353023360 lstm_models.py:79] \nEncoder Cells (bidirectional):\n units: [2048]\n\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 02:50:47.244729 139669353023360 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 02:50:47.253320 139669353023360 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nINFO:tensorflow:\nDecoder Cells:\n units: [2048, 2048, 2048]\n\nI1203 02:50:47.253702 139669353023360 lstm_models.py:225] \nDecoder Cells:\n units: [2048, 2048, 2048]\n\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW1203 02:50:47.253847 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 02:50:47.281068 139669353023360 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nINFO:tensorflow:Reading examples from file: /temp/notesequences.tfrecord\nI1203 02:50:47.281445 139669353023360 data.py:1812] Reading examples from file: /temp/notesequences.tfrecord\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nW1203 02:50:47.483284 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\nW1203 02:50:47.483592 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:751: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n self._names[\"W\"], [input_size + self._num_units, self._num_units * 4])\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:754: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n initializer=tf.constant_initializer(0.0))\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:199: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\n/usr/local/lib/python3.7/dist-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.\n return layer.apply(inputs)\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:205: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\nW1203 02:50:47.835018 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:99: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n name=name),\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/util/dispatch.py:1096: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\nW1203 02:50:48.206182 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/util/dispatch.py:1096: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\n/usr/local/lib/python3.7/dist-packages/tensorflow/python/framework/indexed_slices.py:450: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor(\"gradients/decoder/while/BasicDecoderStep/ScheduledOutputTrainingHelperNextInputs/cond/GatherNd_1/Switch_grad/cond_grad/Merge_1:0\", shape=(?,), dtype=int32), values=Tensor(\"gradients/decoder/while/BasicDecoderStep/ScheduledOutputTrainingHelperNextInputs/cond/GatherNd_1/Switch_grad/cond_grad/Merge:0\", shape=(?, 602), dtype=float32), dense_shape=Tensor(\"gradients/decoder/while/BasicDecoderStep/ScheduledOutputTrainingHelperNextInputs/cond/GatherNd_1/Switch_grad/cond_grad/Merge_2:0\", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.\n \"shape. This may consume a large amount of memory.\" % value)\nINFO:tensorflow:Create CheckpointSaverHook.\nI1203 02:50:54.376144 139669353023360 basic_session_run_hooks.py:562] Create CheckpointSaverHook.\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/training/training_util.py:401: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.\nW1203 02:50:55.436328 139669353023360 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/training/training_util.py:401: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.\nINFO:tensorflow:Graph was finalized.\nI1203 02:50:55.532791 139669353023360 monitored_session.py:247] Graph was finalized.\nINFO:tensorflow:Running local_init_op.\nI1203 02:50:56.820437 139669353023360 session_manager.py:531] Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nI1203 02:50:56.879397 139669353023360 session_manager.py:534] Done running local_init_op.\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 0...\nI1203 02:51:00.975925 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 0...\nINFO:tensorflow:Saving checkpoints for 0 into /temp/music_vae/train/model.ckpt.\nI1203 02:51:00.980081 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 0 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 0...\nI1203 02:51:05.038708 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 0...\nINFO:tensorflow:global_step = 0, loss = 144.08934\nI1203 02:51:20.571126 139669353023360 basic_session_run_hooks.py:270] global_step = 0, loss = 144.08934\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 23...\nI1203 02:52:05.915359 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 23...\nINFO:tensorflow:Saving checkpoints for 23 into /temp/music_vae/train/model.ckpt.\nI1203 02:52:05.915555 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 23 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 23...\nI1203 02:52:11.893583 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 23...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 52...\nI1203 02:53:06.087393 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 52...\nINFO:tensorflow:Saving checkpoints for 52 into /temp/music_vae/train/model.ckpt.\nI1203 02:53:06.087645 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 52 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 52...\nI1203 02:53:11.910954 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 52...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 81...\nI1203 02:54:06.173102 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 81...\nINFO:tensorflow:Saving checkpoints for 81 into /temp/music_vae/train/model.ckpt.\nI1203 02:54:06.173297 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 81 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 81...\nI1203 02:54:11.884466 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 81...\nINFO:tensorflow:global_step/sec: 0.478957\nI1203 02:54:49.357667 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.478957\nINFO:tensorflow:global_step = 100, loss = 70.26725 (208.788 sec)\nI1203 02:54:49.358705 139669353023360 basic_session_run_hooks.py:268] global_step = 100, loss = 70.26725 (208.788 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 110...\nI1203 02:55:06.207272 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 110...\nINFO:tensorflow:Saving checkpoints for 110 into /temp/music_vae/train/model.ckpt.\nI1203 02:55:06.207499 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 110 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 110...\nI1203 02:55:12.079192 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 110...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 139...\nI1203 02:56:06.321778 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 139...\nINFO:tensorflow:Saving checkpoints for 139 into /temp/music_vae/train/model.ckpt.\nI1203 02:56:06.322008 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 139 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 139...\nI1203 02:56:12.079684 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 139...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 168...\nI1203 02:57:06.370914 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 168...\nINFO:tensorflow:Saving checkpoints for 168 into /temp/music_vae/train/model.ckpt.\nI1203 02:57:06.371149 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 168 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 168...\nI1203 02:57:12.160774 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 168...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 197...\nI1203 02:58:06.464705 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 197...\nINFO:tensorflow:Saving checkpoints for 197 into /temp/music_vae/train/model.ckpt.\nI1203 02:58:06.464944 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 197 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 197...\nI1203 02:58:12.079776 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 197...\nINFO:tensorflow:global_step/sec: 0.475638\nI1203 02:58:19.601712 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.475638\nINFO:tensorflow:global_step = 200, loss = 63.516884 (210.244 sec)\nI1203 02:58:19.602700 139669353023360 basic_session_run_hooks.py:268] global_step = 200, loss = 63.516884 (210.244 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 227...\nI1203 02:59:08.250406 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 227...\nINFO:tensorflow:Saving checkpoints for 227 into /temp/music_vae/train/model.ckpt.\nI1203 02:59:08.250641 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 227 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 227...\nI1203 02:59:14.075977 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 227...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 256...\nI1203 03:00:08.357453 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 256...\nINFO:tensorflow:Saving checkpoints for 256 into /temp/music_vae/train/model.ckpt.\nI1203 03:00:08.357664 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 256 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 256...\nI1203 03:00:14.033430 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 256...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 286...\nI1203 03:01:10.217389 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 286...\nINFO:tensorflow:Saving checkpoints for 286 into /temp/music_vae/train/model.ckpt.\nI1203 03:01:10.217651 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 286 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 286...\nI1203 03:01:16.054366 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 286...\nINFO:tensorflow:global_step/sec: 0.488791\nI1203 03:01:44.188316 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.488791\nINFO:tensorflow:global_step = 300, loss = 58.26317 (204.587 sec)\nI1203 03:01:44.189318 139669353023360 basic_session_run_hooks.py:268] global_step = 300, loss = 58.26317 (204.587 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 315...\nI1203 03:02:10.432631 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 315...\nINFO:tensorflow:Saving checkpoints for 315 into /temp/music_vae/train/model.ckpt.\nI1203 03:02:10.432880 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 315 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 315...\nI1203 03:02:16.336551 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 315...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 344...\nI1203 03:03:10.731610 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 344...\nINFO:tensorflow:Saving checkpoints for 344 into /temp/music_vae/train/model.ckpt.\nI1203 03:03:10.731883 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 344 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 344...\nI1203 03:03:16.661882 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 344...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 373...\nI1203 03:04:11.016312 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 373...\nINFO:tensorflow:Saving checkpoints for 373 into /temp/music_vae/train/model.ckpt.\nI1203 03:04:11.016519 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 373 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 373...\nI1203 03:04:16.943375 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 373...\nINFO:tensorflow:global_step/sec: 0.487335\nI1203 03:05:09.386103 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.487335\nINFO:tensorflow:global_step = 400, loss = 56.1703 (205.198 sec)\nI1203 03:05:09.387091 139669353023360 basic_session_run_hooks.py:268] global_step = 400, loss = 56.1703 (205.198 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 402...\nI1203 03:05:11.261923 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 402...\nINFO:tensorflow:Saving checkpoints for 402 into /temp/music_vae/train/model.ckpt.\nI1203 03:05:11.262126 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 402 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 402...\nI1203 03:05:17.016310 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 402...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 431...\nI1203 03:06:11.398704 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 431...\nINFO:tensorflow:Saving checkpoints for 431 into /temp/music_vae/train/model.ckpt.\nI1203 03:06:11.398941 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 431 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 431...\nI1203 03:06:17.051226 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 431...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 460...\nI1203 03:07:11.437063 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 460...\nINFO:tensorflow:Saving checkpoints for 460 into /temp/music_vae/train/model.ckpt.\nI1203 03:07:11.437333 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 460 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 460...\nI1203 03:07:17.061975 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 460...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 490...\nI1203 03:08:13.312975 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 490...\nINFO:tensorflow:Saving checkpoints for 490 into /temp/music_vae/train/model.ckpt.\nI1203 03:08:13.313166 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 490 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 490...\nI1203 03:08:18.876229 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 490...\nINFO:tensorflow:global_step/sec: 0.475947\nI1203 03:08:39.493675 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.475947\nINFO:tensorflow:global_step = 500, loss = 53.10021 (210.108 sec)\nI1203 03:08:39.494651 139669353023360 basic_session_run_hooks.py:268] global_step = 500, loss = 53.10021 (210.108 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 520...\nI1203 03:09:15.103680 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 520...\nINFO:tensorflow:Saving checkpoints for 520 into /temp/music_vae/train/model.ckpt.\nI1203 03:09:15.103922 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 520 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 520...\nI1203 03:09:20.959284 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 520...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 549...\nI1203 03:10:15.314094 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 549...\nINFO:tensorflow:Saving checkpoints for 549 into /temp/music_vae/train/model.ckpt.\nI1203 03:10:15.314292 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 549 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 549...\nI1203 03:10:21.233292 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 549...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 578...\nI1203 03:11:15.656969 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 578...\nINFO:tensorflow:Saving checkpoints for 578 into /temp/music_vae/train/model.ckpt.\nI1203 03:11:15.657227 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 578 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 578...\nI1203 03:11:21.306256 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 578...\nINFO:tensorflow:global_step/sec: 0.485814\nI1203 03:12:05.333988 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.485814\nINFO:tensorflow:global_step = 600, loss = 48.059044 (205.840 sec)\nI1203 03:12:05.334943 139669353023360 basic_session_run_hooks.py:268] global_step = 600, loss = 48.059044 (205.840 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 607...\nI1203 03:12:16.587702 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 607...\nINFO:tensorflow:Saving checkpoints for 607 into /temp/music_vae/train/model.ckpt.\nI1203 03:12:16.587921 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 607 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 607...\nI1203 03:12:22.362596 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 607...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 636...\nI1203 03:13:16.778208 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 636...\nINFO:tensorflow:Saving checkpoints for 636 into /temp/music_vae/train/model.ckpt.\nI1203 03:13:16.778437 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 636 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 636...\nI1203 03:13:22.637731 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 636...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 665...\nI1203 03:14:17.107502 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 665...\nINFO:tensorflow:Saving checkpoints for 665 into /temp/music_vae/train/model.ckpt.\nI1203 03:14:17.107782 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 665 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 665...\nI1203 03:14:22.940076 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 665...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 694...\nI1203 03:15:17.367277 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 694...\nINFO:tensorflow:Saving checkpoints for 694 into /temp/music_vae/train/model.ckpt.\nI1203 03:15:17.367506 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 694 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 694...\nI1203 03:15:23.133656 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 694...\nINFO:tensorflow:global_step/sec: 0.473967\nI1203 03:15:36.319120 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.473967\nINFO:tensorflow:global_step = 700, loss = 41.90347 (210.985 sec)\nI1203 03:15:36.320022 139669353023360 basic_session_run_hooks.py:268] global_step = 700, loss = 41.90347 (210.985 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 723...\nI1203 03:16:17.565869 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 723...\nINFO:tensorflow:Saving checkpoints for 723 into /temp/music_vae/train/model.ckpt.\nI1203 03:16:17.566071 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 723 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 723...\nI1203 03:16:23.421252 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 723...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 752...\nI1203 03:17:17.836449 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 752...\nINFO:tensorflow:Saving checkpoints for 752 into /temp/music_vae/train/model.ckpt.\nI1203 03:17:17.836664 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 752 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 752...\nI1203 03:17:23.666645 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 752...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 781...\nI1203 03:18:18.086213 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 781...\nINFO:tensorflow:Saving checkpoints for 781 into /temp/music_vae/train/model.ckpt.\nI1203 03:18:18.086437 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 781 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 781...\nI1203 03:18:23.935505 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 781...\nINFO:tensorflow:global_step/sec: 0.487308\nI1203 03:19:01.528134 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.487308\nINFO:tensorflow:global_step = 800, loss = 39.731457 (205.209 sec)\nI1203 03:19:01.529203 139669353023360 basic_session_run_hooks.py:268] global_step = 800, loss = 39.731457 (205.209 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 810...\nI1203 03:19:18.431230 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 810...\nINFO:tensorflow:Saving checkpoints for 810 into /temp/music_vae/train/model.ckpt.\nI1203 03:19:18.431438 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 810 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 810...\nI1203 03:19:24.318277 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 810...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 839...\nI1203 03:20:19.156031 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 839...\nINFO:tensorflow:Saving checkpoints for 839 into /temp/music_vae/train/model.ckpt.\nI1203 03:20:19.156230 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 839 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 839...\nI1203 03:20:24.943698 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 839...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 868...\nI1203 03:21:19.384487 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 868...\nINFO:tensorflow:Saving checkpoints for 868 into /temp/music_vae/train/model.ckpt.\nI1203 03:21:19.384701 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 868 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 868...\nI1203 03:21:25.233755 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 868...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 897...\nI1203 03:22:19.707814 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 897...\nINFO:tensorflow:Saving checkpoints for 897 into /temp/music_vae/train/model.ckpt.\nI1203 03:22:19.708023 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 897 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 897...\nI1203 03:22:25.498751 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 897...\nINFO:tensorflow:global_step/sec: 0.472769\nI1203 03:22:33.047887 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.472769\nINFO:tensorflow:global_step = 900, loss = 29.619362 (211.520 sec)\nI1203 03:22:33.048821 139669353023360 basic_session_run_hooks.py:268] global_step = 900, loss = 29.619362 (211.520 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 926...\nI1203 03:23:19.985725 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 926...\nINFO:tensorflow:Saving checkpoints for 926 into /temp/music_vae/train/model.ckpt.\nI1203 03:23:19.985939 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 926 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 926...\nI1203 03:23:25.868302 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 926...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 955...\nI1203 03:24:20.360436 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 955...\nINFO:tensorflow:Saving checkpoints for 955 into /temp/music_vae/train/model.ckpt.\nI1203 03:24:20.360687 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 955 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 955...\nI1203 03:24:26.246134 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 955...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 984...\nI1203 03:25:20.749521 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 984...\nINFO:tensorflow:Saving checkpoints for 984 into /temp/music_vae/train/model.ckpt.\nI1203 03:25:20.749763 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 984 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 984...\nI1203 03:25:26.523728 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 984...\nINFO:tensorflow:global_step/sec: 0.486836\nI1203 03:25:58.455903 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.486836\nINFO:tensorflow:global_step = 1000, loss = 21.407303 (205.408 sec)\nI1203 03:25:58.456719 139669353023360 basic_session_run_hooks.py:268] global_step = 1000, loss = 21.407303 (205.408 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1013...\nI1203 03:26:20.997588 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1013...\nINFO:tensorflow:Saving checkpoints for 1013 into /temp/music_vae/train/model.ckpt.\nI1203 03:26:20.997783 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1013 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1013...\nI1203 03:26:26.664468 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1013...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1042...\nI1203 03:27:21.185008 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1042...\nINFO:tensorflow:Saving checkpoints for 1042 into /temp/music_vae/train/model.ckpt.\nI1203 03:27:21.185214 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1042 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1042...\nI1203 03:27:27.120826 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1042...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1071...\nI1203 03:28:21.922061 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1071...\nINFO:tensorflow:Saving checkpoints for 1071 into /temp/music_vae/train/model.ckpt.\nI1203 03:28:21.922277 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1071 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1071...\nI1203 03:28:27.782921 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1071...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1100...\nI1203 03:29:22.271414 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1100...\nINFO:tensorflow:Saving checkpoints for 1100 into /temp/music_vae/train/model.ckpt.\nI1203 03:29:22.271625 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1100 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1100...\nI1203 03:29:28.109643 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1100...\nINFO:tensorflow:global_step/sec: 0.472669\nI1203 03:29:30.020625 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.472669\nINFO:tensorflow:global_step = 1100, loss = 13.497618 (211.565 sec)\nI1203 03:29:30.021544 139669353023360 basic_session_run_hooks.py:268] global_step = 1100, loss = 13.497618 (211.565 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1129...\nI1203 03:30:22.653809 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1129...\nINFO:tensorflow:Saving checkpoints for 1129 into /temp/music_vae/train/model.ckpt.\nI1203 03:30:22.654052 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1129 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1129...\nI1203 03:30:28.536039 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1129...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1158...\nI1203 03:31:23.102532 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1158...\nINFO:tensorflow:Saving checkpoints for 1158 into /temp/music_vae/train/model.ckpt.\nI1203 03:31:23.102722 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1158 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1158...\nI1203 03:31:30.313453 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1158...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1186...\nI1203 03:32:23.155656 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1186...\nINFO:tensorflow:Saving checkpoints for 1186 into /temp/music_vae/train/model.ckpt.\nI1203 03:32:23.155874 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1186 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1186...\nI1203 03:32:29.036461 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1186...\nINFO:tensorflow:global_step/sec: 0.482532\nI1203 03:32:57.266597 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.482532\nINFO:tensorflow:global_step = 1200, loss = 9.050905 (207.246 sec)\nI1203 03:32:57.267586 139669353023360 basic_session_run_hooks.py:268] global_step = 1200, loss = 9.050905 (207.246 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1215...\nI1203 03:33:23.604844 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1215...\nINFO:tensorflow:Saving checkpoints for 1215 into /temp/music_vae/train/model.ckpt.\nI1203 03:33:23.605063 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1215 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1215...\nI1203 03:33:29.483255 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1215...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1244...\nI1203 03:34:24.012206 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1244...\nINFO:tensorflow:Saving checkpoints for 1244 into /temp/music_vae/train/model.ckpt.\nI1203 03:34:24.012421 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1244 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1244...\nI1203 03:34:29.988125 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1244...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1273...\nI1203 03:35:24.519829 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1273...\nINFO:tensorflow:Saving checkpoints for 1273 into /temp/music_vae/train/model.ckpt.\nI1203 03:35:24.520053 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1273 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1273...\nI1203 03:35:30.312442 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1273...\nINFO:tensorflow:global_step/sec: 0.486026\nI1203 03:36:23.011087 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.486026\nINFO:tensorflow:global_step = 1300, loss = 5.4161477 (205.745 sec)\nI1203 03:36:23.012105 139669353023360 basic_session_run_hooks.py:268] global_step = 1300, loss = 5.4161477 (205.745 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1302...\nI1203 03:36:24.895815 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1302...\nINFO:tensorflow:Saving checkpoints for 1302 into /temp/music_vae/train/model.ckpt.\nI1203 03:36:24.896018 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1302 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1302...\nI1203 03:36:30.763196 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1302...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1331...\nI1203 03:37:25.333763 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1331...\nINFO:tensorflow:Saving checkpoints for 1331 into /temp/music_vae/train/model.ckpt.\nI1203 03:37:25.333987 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1331 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1331...\nI1203 03:37:31.088488 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1331...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1360...\nI1203 03:38:25.648322 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1360...\nINFO:tensorflow:Saving checkpoints for 1360 into /temp/music_vae/train/model.ckpt.\nI1203 03:38:25.648520 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1360 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1360...\nI1203 03:38:31.323152 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1360...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1389...\nI1203 03:39:26.964506 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1389...\nINFO:tensorflow:Saving checkpoints for 1389 into /temp/music_vae/train/model.ckpt.\nI1203 03:39:26.964701 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1389 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1389...\nI1203 03:39:33.658267 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1389...\nINFO:tensorflow:global_step/sec: 0.468927\nI1203 03:39:56.263968 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.468927\nINFO:tensorflow:global_step = 1400, loss = 4.475214 (213.253 sec)\nI1203 03:39:56.264891 139669353023360 basic_session_run_hooks.py:268] global_step = 1400, loss = 4.475214 (213.253 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1418...\nI1203 03:40:28.263850 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1418...\nINFO:tensorflow:Saving checkpoints for 1418 into /temp/music_vae/train/model.ckpt.\nI1203 03:40:28.264085 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1418 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1418...\nI1203 03:40:34.006994 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1418...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1447...\nI1203 03:41:28.624663 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1447...\nINFO:tensorflow:Saving checkpoints for 1447 into /temp/music_vae/train/model.ckpt.\nI1203 03:41:28.624903 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1447 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1447...\nI1203 03:41:34.513139 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1447...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1476...\nI1203 03:42:29.087889 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1476...\nINFO:tensorflow:Saving checkpoints for 1476 into /temp/music_vae/train/model.ckpt.\nI1203 03:42:29.088105 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1476 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1476...\nI1203 03:42:35.978287 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1476...\nINFO:tensorflow:global_step/sec: 0.483636\nI1203 03:43:23.031185 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.483636\nINFO:tensorflow:global_step = 1500, loss = 3.4644697 (206.767 sec)\nI1203 03:43:23.032084 139669353023360 basic_session_run_hooks.py:268] global_step = 1500, loss = 3.4644697 (206.767 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1505...\nI1203 03:43:30.560002 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1505...\nINFO:tensorflow:Saving checkpoints for 1505 into /temp/music_vae/train/model.ckpt.\nI1203 03:43:30.560210 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1505 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1505...\nI1203 03:43:36.447489 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1505...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1534...\nI1203 03:44:31.031287 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1534...\nINFO:tensorflow:Saving checkpoints for 1534 into /temp/music_vae/train/model.ckpt.\nI1203 03:44:31.031509 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1534 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1534...\nI1203 03:44:36.858720 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1534...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1563...\nI1203 03:45:31.501899 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1563...\nINFO:tensorflow:Saving checkpoints for 1563 into /temp/music_vae/train/model.ckpt.\nI1203 03:45:31.502094 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1563 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1563...\nI1203 03:45:37.338397 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1563...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1592...\nI1203 03:46:31.974105 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1592...\nINFO:tensorflow:Saving checkpoints for 1592 into /temp/music_vae/train/model.ckpt.\nI1203 03:46:31.974344 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1592 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1592...\nI1203 03:46:37.783822 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1592...\nINFO:tensorflow:global_step/sec: 0.471031\nI1203 03:46:55.331589 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.471031\nINFO:tensorflow:global_step = 1600, loss = 3.0284853 (212.300 sec)\nI1203 03:46:55.332444 139669353023360 basic_session_run_hooks.py:268] global_step = 1600, loss = 3.0284853 (212.300 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1621...\nI1203 03:47:33.017445 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1621...\nINFO:tensorflow:Saving checkpoints for 1621 into /temp/music_vae/train/model.ckpt.\nI1203 03:47:33.017636 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1621 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1621...\nI1203 03:47:38.785698 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1621...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1650...\nI1203 03:48:33.404128 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1650...\nINFO:tensorflow:Saving checkpoints for 1650 into /temp/music_vae/train/model.ckpt.\nI1203 03:48:33.404346 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1650 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1650...\nI1203 03:48:39.232867 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1650...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1679...\nI1203 03:49:33.827976 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1679...\nINFO:tensorflow:Saving checkpoints for 1679 into /temp/music_vae/train/model.ckpt.\nI1203 03:49:33.828181 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1679 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1679...\nI1203 03:49:39.501726 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1679...\nINFO:tensorflow:global_step/sec: 0.486383\nI1203 03:50:20.930895 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.486383\nINFO:tensorflow:global_step = 1700, loss = 2.7201269 (205.599 sec)\nI1203 03:50:20.931779 139669353023360 basic_session_run_hooks.py:268] global_step = 1700, loss = 2.7201269 (205.599 sec)\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1708...\nI1203 03:50:34.097480 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1708...\nINFO:tensorflow:Saving checkpoints for 1708 into /temp/music_vae/train/model.ckpt.\nI1203 03:50:34.097674 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1708 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1708...\nI1203 03:50:39.960547 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1708...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1737...\nI1203 03:51:34.606448 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1737...\nINFO:tensorflow:Saving checkpoints for 1737 into /temp/music_vae/train/model.ckpt.\nI1203 03:51:34.606666 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1737 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1737...\nI1203 03:51:40.367456 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1737...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1766...\nI1203 03:52:34.947774 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1766...\nINFO:tensorflow:Saving checkpoints for 1766 into /temp/music_vae/train/model.ckpt.\nI1203 03:52:34.947984 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1766 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1766...\nI1203 03:52:40.841462 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1766...\nINFO:tensorflow:Calling checkpoint listeners before saving checkpoint 1795...\nI1203 03:53:35.459548 139669353023360 basic_session_run_hooks.py:630] Calling checkpoint listeners before saving checkpoint 1795...\nINFO:tensorflow:Saving checkpoints for 1795 into /temp/music_vae/train/model.ckpt.\nI1203 03:53:35.459748 139669353023360 basic_session_run_hooks.py:634] Saving checkpoints for 1795 into /temp/music_vae/train/model.ckpt.\nINFO:tensorflow:Calling checkpoint listeners after saving checkpoint 1795...\nI1203 03:53:41.197258 139669353023360 basic_session_run_hooks.py:642] Calling checkpoint listeners after saving checkpoint 1795...\nINFO:tensorflow:global_step/sec: 0.472595\nI1203 03:53:52.528522 139669353023360 basic_session_run_hooks.py:718] global_step/sec: 0.472595\nINFO:tensorflow:global_step = 1800, loss = 2.9041214 (211.598 sec)\nI1203 03:53:52.529410 139669353023360 basic_session_run_hooks.py:268] global_step = 1800, loss = 2.9041214 (211.598 sec)\nTraceback (most recent call last):\n File \"/usr/local/bin/music_vae_train\", line 8, in <module>\n sys.exit(console_entry_point())\n File \"/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/music_vae_train.py\", line 336, in console_entry_point\n tf.app.run(main)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/platform/app.py\", line 40, in run\n _run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)\n File \"/usr/local/lib/python3.7/dist-packages/absl/app.py\", line 303, in run\n _run_main(main, args)\n File \"/usr/local/lib/python3.7/dist-packages/absl/app.py\", line 251, in _run_main\n sys.exit(main(argv))\n File \"/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/music_vae_train.py\", line 331, in main\n run(configs.CONFIG_MAP)\n File \"/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/music_vae_train.py\", line 312, in run\n task=FLAGS.task)\n File \"/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/music_vae_train.py\", line 211, in train\n is_chief=is_chief)\n File \"/usr/local/lib/python3.7/dist-packages/tf_slim/training/training.py\", line 551, in train\n loss = session.run(train_op, run_metadata=run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/monitored_session.py\", line 790, in run\n run_metadata=run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/monitored_session.py\", line 1319, in run\n run_metadata=run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/monitored_session.py\", line 1405, in run\n return self._sess.run(*args, **kwargs)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/monitored_session.py\", line 1478, in run\n run_metadata=run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/training/monitored_session.py\", line 1236, in run\n return self._sess.run(*args, **kwargs)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 971, in run\n run_metadata_ptr)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 1194, in _run\n feed_dict_tensor, options, run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 1374, in _do_run\n run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 1380, in _do_call\n return fn(*args)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 1364, in _run_fn\n target_list, run_metadata)\n File \"/usr/local/lib/python3.7/dist-packages/tensorflow/python/client/session.py\", line 1458, in _call_tf_sessionrun\n run_metadata)\nKeyboardInterrupt\n^C\n"
],
[
"!music_vae_generate \\\n--config=cat-mel_2bar_big \\\n--input_midi_1=/064.mid \\\n--input_midi_2=/058.mid \\\n--checkpoint_file=/temp/music_vae/train/model.ckpt-1795 \\\n--mode=interpolate \\\n--num_outputs=3 \\\n--output_dir=/tmp/music_vae/generated8",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nI1203 05:05:17.448658 140238771197824 music_vae_generate.py:145] Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\n5 valid inputs extracted from `/064.mid`. Outputting these potential inputs as `/tmp/music_vae/generated8/cat-mel_2bar_big_input1-extractions_2021-12-03_050517-*-of-005.mid`. Call script again with one of these instead.\n"
],
[
"!music_vae_generate \\\n--config=cat-mel_2bar_big \\\n--input_midi_1=/2bar058_1.mid \\\n--input_midi_2=/2bar064_1.mid \\\n--checkpoint_file=/temp/music_vae/train/model.ckpt-1795 \\\n--mode=interpolate \\\n--num_outputs=5 \\\n--output_dir=/tmp/music_vae/generated9",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nI1203 05:08:16.192370 140189778814848 music_vae_generate.py:145] Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nINFO:tensorflow:Loading model...\nI1203 05:08:16.194088 140189778814848 music_vae_generate.py:149] Loading model...\nINFO:tensorflow:Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nI1203 05:08:16.195101 140189778814848 base_model.py:152] Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nINFO:tensorflow:\nEncoder Cells (bidirectional):\n units: [2048]\n\nI1203 05:08:16.199400 140189778814848 lstm_models.py:79] \nEncoder Cells (bidirectional):\n units: [2048]\n\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:08:16.210198 140189778814848 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:08:16.218949 140189778814848 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nINFO:tensorflow:\nDecoder Cells:\n units: [2048, 2048, 2048]\n\nI1203 05:08:16.219322 140189778814848 lstm_models.py:225] \nDecoder Cells:\n units: [2048, 2048, 2048]\n\nWARNING:tensorflow:Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nW1203 05:08:16.219442 140189778814848 lstm_utils.py:139] Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW1203 05:08:16.219583 140189778814848 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:08:16.243781 140189778814848 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:99: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n name=name),\n/usr/local/lib/python3.7/dist-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.\n return layer.apply(inputs)\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:751: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n self._names[\"W\"], [input_size + self._num_units, self._num_units * 4])\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:754: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n initializer=tf.constant_initializer(0.0))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nW1203 05:08:16.620641 140189778814848 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\nW1203 05:08:16.621015 140189778814848 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:199: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:205: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\nW1203 05:08:16.829783 140189778814848 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\n2021-12-03 05:08:17.528782: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\nINFO:tensorflow:Restoring parameters from /temp/music_vae/train/model.ckpt-1795\nI1203 05:08:17.544991 140189778814848 saver.py:1399] Restoring parameters from /temp/music_vae/train/model.ckpt-1795\nINFO:tensorflow:Interpolating...\nI1203 05:08:18.120698 140189778814848 music_vae_generate.py:160] Interpolating...\nINFO:tensorflow:Outputting 5 files as `/tmp/music_vae/generated9/cat-mel_2bar_big_interpolate_2021-12-03_050816-*-of-005.mid`...\nI1203 05:08:18.547316 140189778814848 music_vae_generate.py:179] Outputting 5 files as `/tmp/music_vae/generated9/cat-mel_2bar_big_interpolate_2021-12-03_050816-*-of-005.mid`...\nINFO:tensorflow:Done.\nI1203 05:08:18.551558 140189778814848 music_vae_generate.py:183] Done.\n"
],
[
"!music_vae_generate \\\n--config=cat-mel_2bar_big \\\n--input_midi_1=/756.mid \\\n--input_midi_2=/746.mid \\\n--checkpoint_file=/temp/music_vae/train/model.ckpt-1795 \\\n--mode=interpolate \\\n--num_outputs=3 \\\n--output_dir=/tmp/music_vae/generated10",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nI1203 05:12:13.377929 140329205884800 music_vae_generate.py:145] Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\n5 valid inputs extracted from `/756.mid`. Outputting these potential inputs as `/tmp/music_vae/generated10/cat-mel_2bar_big_input1-extractions_2021-12-03_051213-*-of-005.mid`. Call script again with one of these instead.\n"
],
[
"!music_vae_generate \\\n--config=cat-mel_2bar_big \\\n--input_midi_1=/2bar902_1.mid \\\n--input_midi_2=/2bar907_1.mid \\\n--checkpoint_file=/temp/music_vae/train/model.ckpt-1795 \\\n--mode=interpolate \\\n--num_outputs=5 \\\n--output_dir=/tmp/music_vae/generated13",
"/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\n/usr/local/lib/python3.7/dist-packages/librosa/util/decorators.py:9: NumbaDeprecationWarning: An import was requested from a module that has moved location.\nImport of 'jit' requested from: 'numba.decorators', please update to use 'numba.core.decorators' or pin to Numba version 0.48.0. This alias will not be present in Numba version 0.50.0.\n from numba.decorators import jit as optional_jit\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/compat/v2_compat.py:111: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.\nInstructions for updating:\nnon-resource variables are not supported in the long term\nINFO:tensorflow:Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nI1203 05:25:41.822828 140145199908736 music_vae_generate.py:145] Attempting to extract examples from input MIDIs using config `cat-mel_2bar_big`...\nINFO:tensorflow:Loading model...\nI1203 05:25:41.824357 140145199908736 music_vae_generate.py:149] Loading model...\nINFO:tensorflow:Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nI1203 05:25:41.825363 140145199908736 base_model.py:152] Building MusicVAE model with BidirectionalLstmEncoder, CategoricalLstmDecoder, and hparams:\n{'max_seq_len': 32, 'z_size': 512, 'free_bits': 0, 'max_beta': 0.5, 'beta_rate': 0.99999, 'batch_size': 5, 'grad_clip': 1.0, 'clip_mode': 'global_norm', 'grad_norm_clip_to_zero': 10000, 'learning_rate': 0.001, 'decay_rate': 0.9999, 'min_learning_rate': 1e-05, 'conditional': True, 'dec_rnn_size': [2048, 2048, 2048], 'enc_rnn_size': [2048], 'dropout_keep_prob': 1.0, 'sampling_schedule': 'inverse_sigmoid', 'sampling_rate': 1000, 'use_cudnn': False, 'residual_encoder': False, 'residual_decoder': False, 'control_preprocessing_rnn_size': [256]}\nINFO:tensorflow:\nEncoder Cells (bidirectional):\n units: [2048]\n\nI1203 05:25:41.829643 140145199908736 lstm_models.py:79] \nEncoder Cells (bidirectional):\n units: [2048]\n\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:25:41.840180 140145199908736 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:25:41.848670 140145199908736 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nINFO:tensorflow:\nDecoder Cells:\n units: [2048, 2048, 2048]\n\nI1203 05:25:41.849043 140145199908736 lstm_models.py:225] \nDecoder Cells:\n units: [2048, 2048, 2048]\n\nWARNING:tensorflow:Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nW1203 05:25:41.849161 140145199908736 lstm_utils.py:139] Setting non-training sampling schedule from inverse_sigmoid:1000.000000 to constant:1.0.\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW1203 05:25:41.849300 140145199908736 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:145: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:`tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\nW1203 05:25:41.872884 140145199908736 rnn_cell_impl.py:1259] `tf.nn.rnn_cell.MultiRNNCell` is deprecated. This class is equivalent as `tf.keras.layers.StackedRNNCells`, and will be replaced by that in Tensorflow 2.0.\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/lstm_utils.py:99: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n name=name),\n/usr/local/lib/python3.7/dist-packages/keras/legacy_tf_layers/core.py:255: UserWarning: `layer.apply` is deprecated and will be removed in a future version. Please use `layer.__call__` method instead.\n return layer.apply(inputs)\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:751: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n self._names[\"W\"], [input_size + self._num_units, self._num_units * 4])\n/usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:754: UserWarning: `layer.add_variable` is deprecated and will be removed in a future version. Please use `layer.add_weight` method instead.\n initializer=tf.constant_initializer(0.0))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nW1203 05:25:42.243994 140145199908736 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/magenta/contrib/rnn.py:474: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.Bidirectional(keras.layers.RNN(cell))`, which is equivalent to this API\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\nW1203 05:25:42.244329 140145199908736 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/rnn.py:450: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `keras.layers.RNN(cell)`, which is equivalent to this API\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:199: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\n/usr/local/lib/python3.7/dist-packages/magenta/models/music_vae/base_model.py:205: UserWarning: `tf.layers.dense` is deprecated and will be removed in a future version. Please use `tf.keras.layers.Dense` instead.\n kernel_initializer=tf.random_normal_initializer(stddev=0.001))\nWARNING:tensorflow:From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\nW1203 05:25:42.412222 140145199908736 deprecation.py:347] From /usr/local/lib/python3.7/dist-packages/tensorflow_probability/python/bijectors/affine_linear_operator.py:116: LinearOperator.graph_parents (from tensorflow.python.ops.linalg.linear_operator) is deprecated and will be removed in a future version.\nInstructions for updating:\nDo not call `graph_parents`.\n2021-12-03 05:25:43.117141: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\nINFO:tensorflow:Restoring parameters from /temp/music_vae/train/model.ckpt-1795\nI1203 05:25:43.132822 140145199908736 saver.py:1399] Restoring parameters from /temp/music_vae/train/model.ckpt-1795\nINFO:tensorflow:Interpolating...\nI1203 05:25:43.675645 140145199908736 music_vae_generate.py:160] Interpolating...\nINFO:tensorflow:Outputting 5 files as `/tmp/music_vae/generated13/cat-mel_2bar_big_interpolate_2021-12-03_052541-*-of-005.mid`...\nI1203 05:25:44.096948 140145199908736 music_vae_generate.py:179] Outputting 5 files as `/tmp/music_vae/generated13/cat-mel_2bar_big_interpolate_2021-12-03_052541-*-of-005.mid`...\nINFO:tensorflow:Done.\nI1203 05:25:44.101229 140145199908736 music_vae_generate.py:183] Done.\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a42def7c54f70b9845f10a7ded5a3cf8cbde95b
| 262,716 |
ipynb
|
Jupyter Notebook
|
slides/2022-03-28-gradient-descent.ipynb
|
cu-numcomp/spring22
|
f4c1f9287bff2c10645809e65c21829064493a66
|
[
"MIT"
] | null | null | null |
slides/2022-03-28-gradient-descent.ipynb
|
cu-numcomp/spring22
|
f4c1f9287bff2c10645809e65c21829064493a66
|
[
"MIT"
] | null | null | null |
slides/2022-03-28-gradient-descent.ipynb
|
cu-numcomp/spring22
|
f4c1f9287bff2c10645809e65c21829064493a66
|
[
"MIT"
] | 2 |
2022-02-09T21:05:12.000Z
|
2022-03-11T20:34:46.000Z
| 151.85896 | 15,399 | 0.650132 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a42e0d2eef18bce6012e6b238def1c25dcfb715
| 51,839 |
ipynb
|
Jupyter Notebook
|
dd_1/Part 3/Section 09 - Specialized Dictionaries/04 - Counter.ipynb
|
rebekka-halal/bg
|
616a40286fe1d34db2916762c477676ed8067cdb
|
[
"Apache-2.0"
] | null | null | null |
dd_1/Part 3/Section 09 - Specialized Dictionaries/04 - Counter.ipynb
|
rebekka-halal/bg
|
616a40286fe1d34db2916762c477676ed8067cdb
|
[
"Apache-2.0"
] | null | null | null |
dd_1/Part 3/Section 09 - Specialized Dictionaries/04 - Counter.ipynb
|
rebekka-halal/bg
|
616a40286fe1d34db2916762c477676ed8067cdb
|
[
"Apache-2.0"
] | null | null | null | 22.806423 | 572 | 0.402342 |
[
[
[
"### Counter",
"_____no_output_____"
],
[
"The `Counter` dictionary is one that specializes for helping with, you guessed it, counters!\n\nActually we used a `defaultdict` earlier to do something similar:",
"_____no_output_____"
]
],
[
[
"from collections import defaultdict, Counter",
"_____no_output_____"
]
],
[
[
"Let's say we want to count the frequency of each character in a string:",
"_____no_output_____"
]
],
[
[
"sentence = 'the quick brown fox jumps over the lazy dog'",
"_____no_output_____"
],
[
"counter = defaultdict(int)",
"_____no_output_____"
],
[
"for c in sentence:\n counter[c] += 1",
"_____no_output_____"
],
[
"counter",
"_____no_output_____"
]
],
[
[
"We can do the same thing using a `Counter` - unlike the `defaultdict` we don't specify a default factory - it's always zero (it's a counter after all):",
"_____no_output_____"
]
],
[
[
"counter = Counter()\nfor c in sentence:\n counter[c] += 1",
"_____no_output_____"
],
[
"counter",
"_____no_output_____"
]
],
[
[
"OK, so if that's all there was to `Counter` it would be pretty odd to have a data structure different than `OrderedDict`.\n\nBut `Counter` has a slew of additional methods which make sense in the context of counters:\n\n1. Iterate through all the elements of counters, but repeat the elements as many times as their frequency\n2. Find the `n` most common (by frequency) elements\n3. Decrement the counters based on another `Counter` (or iterable)\n4. Increment the counters based on another `Counter` (or iterable)\n5. Specialized constructor for additional flexibility\n\nIf you are familiar with multisets, then this is essentially a data structure that can be used for multisets.",
"_____no_output_____"
],
[
"#### Constructor",
"_____no_output_____"
],
[
"It is so common to create a frequency distribution of elements in an iterable, that this is supported automatically:",
"_____no_output_____"
]
],
[
[
"c1 = Counter('able was I ere I saw elba')\nc1",
"_____no_output_____"
]
],
[
[
"Of course this works for iterables in general, not just strings:",
"_____no_output_____"
]
],
[
[
"import random",
"_____no_output_____"
],
[
"random.seed(0)",
"_____no_output_____"
],
[
"my_list = [random.randint(0, 10) for _ in range(1_000)]",
"_____no_output_____"
],
[
"c2 = Counter(my_list)",
"_____no_output_____"
],
[
"c2",
"_____no_output_____"
]
],
[
[
"We can also initialize a `Counter` object by passing in keyword arguments, or even a dictionary:",
"_____no_output_____"
]
],
[
[
"c2 = Counter(a=1, b=10)\nc2",
"_____no_output_____"
],
[
"c3 = Counter({'a': 1, 'b': 10})\nc3",
"_____no_output_____"
]
],
[
[
"Technically we can store values other than integers in a `Counter` object - it's possible but of limited use since the default is still `0` irrespective of what other values are contained in the object.",
"_____no_output_____"
],
[
"#### Finding the n most Common Elements",
"_____no_output_____"
],
[
"Let's find the `n` most common words (by frequency) in a paragraph of text. Words are considered delimited by white space or punctuation marks such as `.`, `,`, `!`, etc - basically anything except a character or a digit.\nThis is actually quite difficult to do, so we'll use a close enough approximation that will cover most cases just fine, using a regular expression:",
"_____no_output_____"
]
],
[
[
"import re",
"_____no_output_____"
],
[
"sentence = '''\nhis module implements pseudo-random number generators for various distributions.\n\nFor integers, there is uniform selection from a range. For sequences, there is uniform selection of a random element, a function to generate a random permutation of a list in-place, and a function for random sampling without replacement.\n\nOn the real line, there are functions to compute uniform, normal (Gaussian), lognormal, negative exponential, gamma, and beta distributions. For generating distributions of angles, the von Mises distribution is available.\n\nAlmost all module functions depend on the basic function random(), which generates a random float uniformly in the semi-open range [0.0, 1.0). Python uses the Mersenne Twister as the core generator. It produces 53-bit precision floats and has a period of 2**19937-1. The underlying implementation in C is both fast and threadsafe. The Mersenne Twister is one of the most extensively tested random number generators in existence. However, being completely deterministic, it is not suitable for all purposes, and is completely unsuitable for cryptographic purposes.'''",
"_____no_output_____"
],
[
"words = re.split('\\W', sentence)",
"_____no_output_____"
],
[
"words",
"_____no_output_____"
]
],
[
[
"But what are the frequencies of each word, and what are the 5 most frequent words?",
"_____no_output_____"
]
],
[
[
"word_count = Counter(words)",
"_____no_output_____"
],
[
"word_count",
"_____no_output_____"
],
[
"word_count.most_common(5)",
"_____no_output_____"
]
],
[
[
"#### Using Repeated Iteration",
"_____no_output_____"
]
],
[
[
"c1 = Counter('abba')\nc1",
"_____no_output_____"
],
[
"for c in c1:\n print(c)",
"a\nb\n"
]
],
[
[
"However, we can have an iteration that repeats the counter keys as many times as the indicated frequency:",
"_____no_output_____"
]
],
[
[
"for c in c1.elements():\n print(c)",
"a\na\nb\nb\n"
]
],
[
[
"What's interesting about this functionality is that we can turn this around and use it as a way to create an iterable that has repeating elements.\n\nSuppose we want to to iterate through a list of (integer) numbers that are each repeated as many times as the number itself.\n\nFor example 1 should repeat once, 2 should repeat twice, and so on.\n\nThis is actually not that easy to do!\n\nHere's one possible way to do it:",
"_____no_output_____"
]
],
[
[
"l = []\nfor i in range(1, 11):\n for _ in range(i):\n l.append(i)\nprint(l)",
"[1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10]\n"
]
],
[
[
"But we could use a `Counter` object as well:",
"_____no_output_____"
]
],
[
[
"c1 = Counter()\nfor i in range(1, 11):\n c1[i] = i",
"_____no_output_____"
],
[
"c1",
"_____no_output_____"
],
[
"print(c1.elements())",
"<itertools.chain object at 0x1047aa518>\n"
]
],
[
[
"So you'll notice that we have a `chain` object here. That's one big advantage to using the `Counter` object - the repeated iterable does not actually exist as list like our previous implementation - this is a lazy iterable, so this is far more memory efficient.\n\nAnd we can iterate through that `chain` quite easily:",
"_____no_output_____"
]
],
[
[
"for i in c1.elements():\n print(i, end=', ')",
"1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 7, 7, 7, 7, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, "
]
],
[
[
"Just for fun, how could we reproduce this functionality using a plain dictionary?",
"_____no_output_____"
]
],
[
[
"class RepeatIterable:\n def __init__(self, **kwargs):\n self.d = kwargs\n \n def __setitem__(self, key, value):\n self.d[key] = value\n \n def __getitem__(self, key):\n self.d[key] = self.d.get(key, 0)\n return self.d[key]",
"_____no_output_____"
],
[
"r = RepeatIterable(x=10, y=20)",
"_____no_output_____"
],
[
"r.d",
"_____no_output_____"
],
[
"r['a'] = 100",
"_____no_output_____"
],
[
"r['a']",
"_____no_output_____"
],
[
"r['b']",
"_____no_output_____"
],
[
"r.d",
"_____no_output_____"
]
],
[
[
"Now we have to implement that `elements` iterator:",
"_____no_output_____"
]
],
[
[
"class RepeatIterable:\n def __init__(self, **kwargs):\n self.d = kwargs\n \n def __setitem__(self, key, value):\n self.d[key] = value\n \n def __getitem__(self, key):\n self.d[key] = self.d.get(key, 0)\n return self.d[key]\n \n def elements(self):\n for k, frequency in self.d.items():\n for i in range(frequency):\n yield k",
"_____no_output_____"
],
[
"r = RepeatIterable(a=2, b=3, c=1)",
"_____no_output_____"
],
[
"for e in r.elements():\n print(e, end=', ')",
"a, a, b, b, b, c, "
]
],
[
[
"#### Updating from another Iterable or Counter",
"_____no_output_____"
],
[
"Lastly let's see how we can update a `Counter` object using another `Counter` object. \n\nWhen both objects have the same key, we have a choice - do we add the count of one to the count of the other, or do we subtract them?\n\nWe can do either, by using the `update` (additive) or `subtract` methods.",
"_____no_output_____"
]
],
[
[
"c1 = Counter(a=1, b=2, c=3)\nc2 = Counter(b=1, c=2, d=3)\n\nc1.update(c2)\nprint(c1)",
"Counter({'c': 5, 'b': 3, 'd': 3, 'a': 1})\n"
]
],
[
[
"On the other hand we can subtract instead of add counters:",
"_____no_output_____"
]
],
[
[
"c1 = Counter(a=1, b=2, c=3)\nc2 = Counter(b=1, c=2, d=3)\n\nc1.subtract(c2)\nprint(c1)",
"Counter({'a': 1, 'b': 1, 'c': 1, 'd': -3})\n"
]
],
[
[
"Notice the key `d` - since `Counters` default missing keys to `0`, when `d: 3` in `c2` was subtracted from `c1`, the counter for `d` was defaulted to `0`.",
"_____no_output_____"
],
[
"Just as the constructor for a `Counter` can take different arguments, so too can the `update` and `subtract` methods.",
"_____no_output_____"
]
],
[
[
"c1 = Counter('aabbccddee')\nprint(c1)\nc1.update('abcdef')\nprint(c1)",
"Counter({'a': 2, 'b': 2, 'c': 2, 'd': 2, 'e': 2})\nCounter({'a': 3, 'b': 3, 'c': 3, 'd': 3, 'e': 3, 'f': 1})\n"
]
],
[
[
"#### Mathematical Operations",
"_____no_output_____"
],
[
"These `Counter` objects also support several other mathematical operations when both operands are `Counter` objects. In all these cases the result is a new `Counter` object.\n\n* `+`: same as `update`, but returns a new `Counter` object instead of an in-place update.\n* `-`: subtracts one counter from another, but discards zero and negative values\n* `&`: keeps the **minimum** of the key values\n* `|`: keeps the **maximum** of the key values",
"_____no_output_____"
]
],
[
[
"c1 = Counter('aabbcc')\nc2 = Counter('abc')\nc1 + c2",
"_____no_output_____"
],
[
"c1 - c2",
"_____no_output_____"
],
[
"c1 = Counter(a=5, b=1)\nc2 = Counter(a=1, b=10)\n\nc1 & c2",
"_____no_output_____"
],
[
"c1 | c2",
"_____no_output_____"
]
],
[
[
"The **unary** `+` can also be used to remove any non-positive count from the Counter:",
"_____no_output_____"
]
],
[
[
"c1 = Counter(a=10, b=-10)\n+c1",
"_____no_output_____"
]
],
[
[
"The **unary** `-` changes the sign of each counter, and removes any non-positive result:",
"_____no_output_____"
]
],
[
[
"-c1",
"_____no_output_____"
]
],
[
[
"##### Example",
"_____no_output_____"
],
[
"Let's assume you are working for a company that produces different kinds of widgets.\nYou are asked to identify the top 3 best selling widgets.\n\nYou have two separate data sources - one data source can give you a history of all widget orders (widget name, quantity), while another data source can give you a history of widget refunds (widget name, quantity refunded).\n\nFrom these two data sources, you need to determine the top selling widgets (taking refinds into account of course).",
"_____no_output_____"
],
[
"Let's simulate both of these lists:",
"_____no_output_____"
]
],
[
[
"import random\nrandom.seed(0)\n\nwidgets = ['battery', 'charger', 'cable', 'case', 'keyboard', 'mouse']\n\norders = [(random.choice(widgets), random.randint(1, 5)) for _ in range(100)]\nrefunds = [(random.choice(widgets), random.randint(1, 3)) for _ in range(20)]",
"_____no_output_____"
],
[
"orders",
"_____no_output_____"
],
[
"refunds",
"_____no_output_____"
]
],
[
[
"Let's first load these up into counter objects.\n\nTo do this we're going to iterate through the various lists and update our counters:",
"_____no_output_____"
]
],
[
[
"sold_counter = Counter()\nrefund_counter = Counter()\n\nfor order in orders:\n sold_counter[order[0]] += order[1]\n\nfor refund in refunds:\n refund_counter[refund[0]] += refund[1]",
"_____no_output_____"
],
[
"sold_counter",
"_____no_output_____"
],
[
"refund_counter",
"_____no_output_____"
],
[
"net_counter = sold_counter - refund_counter",
"_____no_output_____"
],
[
"net_counter",
"_____no_output_____"
],
[
"net_counter.most_common(3)",
"_____no_output_____"
]
],
[
[
"We could actually do this a little differently, not using loops to populate our initial counters.\n\nRecall the `repeat()` function in `itertools`:",
"_____no_output_____"
]
],
[
[
"from itertools import repeat",
"_____no_output_____"
],
[
"list(repeat('battery', 5))",
"_____no_output_____"
],
[
"orders[0]",
"_____no_output_____"
],
[
"list(repeat(*orders[0]))",
"_____no_output_____"
]
],
[
[
"So we could use the `repeat()` method to essentially repeat each widget for each item of `orders`. We need to chain this up for each element of `orders` - this will give us a single iterable that we can then use in the constructor for a `Counter` object. We can do this using a generator expression for example:",
"_____no_output_____"
]
],
[
[
"from itertools import chain",
"_____no_output_____"
],
[
"list(chain.from_iterable(repeat(*order) for order in orders))",
"_____no_output_____"
],
[
"order_counter = Counter(chain.from_iterable(repeat(*order) for order in orders))",
"_____no_output_____"
],
[
"order_counter",
"_____no_output_____"
]
],
[
[
"#### Alternate Solution not using Counter",
"_____no_output_____"
]
],
[
[
"What if we don't want to use a `Counter` object.\nWe can still do it (relatively easily) as follows:",
"_____no_output_____"
]
],
[
[
"net_sales = {}\nfor order in orders:\n key = order[0]\n cnt = order[1]\n net_sales[key] = net_sales.get(key, 0) + cnt\n \nfor refund in refunds:\n key = refund[0]\n cnt = refund[1]\n net_sales[key] = net_sales.get(key, 0) - cnt\n\n# eliminate non-positive values (to mimic what - does for Counters)\nnet_sales = {k: v for k, v in net_sales.items() if v > 0}\n\n# we now have to sort the dictionary\n# this means sorting the keys based on the values\nsorted_net_sales = sorted(net_sales.items(), key=lambda t: t[1], reverse=True)\n\n# Top three\nsorted_net_sales[:3]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"raw",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"raw"
],
[
"markdown"
],
[
"code"
]
] |
4a42f252df367aa1b69b08dd796fa05d0cc33e81
| 7,643 |
ipynb
|
Jupyter Notebook
|
notebooks/Notability - 01 - Download DBPedia and Gender Data.ipynb
|
clauwag/WikipediaGenderInequality
|
dc7a95520667282bb270f2c2a339884354476771
|
[
"MIT"
] | 12 |
2016-01-20T01:21:12.000Z
|
2021-02-07T15:18:50.000Z
|
notebooks/Notability - 01 - Download DBPedia and Gender Data.ipynb
|
clauwag/WikipediaGenderInequality
|
dc7a95520667282bb270f2c2a339884354476771
|
[
"MIT"
] | null | null | null |
notebooks/Notability - 01 - Download DBPedia and Gender Data.ipynb
|
clauwag/WikipediaGenderInequality
|
dc7a95520667282bb270f2c2a339884354476771
|
[
"MIT"
] | 3 |
2018-01-05T12:13:12.000Z
|
2021-08-10T20:02:27.000Z
| 31.582645 | 159 | 0.548607 |
[
[
[
"# Download Data\n\nThis notebook downloads the necessary data to replicate the results of our paper on Gender Inequalities on Wikipedia.\n\nNote that we use a file named `dbpedia_config.py` where we set which language editions we will we study, as well as where to save and load data files.\n\nBy [Eduardo Graells-Garrido](http://carnby.github.io).",
"_____no_output_____"
]
],
[
[
"!cat dbpedia_config.py",
"# The DBpedia editions we will consider\r\nMAIN_LANGUAGE = 'en'\r\nLANGUAGES = 'en|bg|ca|cs|de|es|eu|fr|hu|id|it|ja|ko|nl|pl|pt|ru|tr|ar|el'.split('|')\r\n\r\n# Where are we going to download the data files\r\n#DATA_FOLDER = '/home/egraells/resources/dbpedia'\r\nDATA_FOLDER = '/media/egraells/113A88F901102CA6/data/dbpedia_2015'\r\n\r\n# Folder to store analysis results\r\nTARGET_FOLDER = '/home/egraells/phd/notebooks/pajaritos/person_results'\r\n\r\n# This is used when crawling WikiData.\r\nQUERY_WIKIDATA_GENDER = False\r\nYOUR_EMAIL = '[email protected]'"
],
[
"import subprocess\nimport os\nimport dbpedia_config",
"_____no_output_____"
],
[
"target = dbpedia_config.DATA_FOLDER\nlanguages = dbpedia_config.LANGUAGES",
"_____no_output_____"
],
[
"# Ontology\n# note that previously (2014 version and earlier) this was in bzip format.\nif not os.path.exists('{0}/dbpedia.owl'.format(target)):\n subprocess.call(['/usr/bin/wget', \n 'http://downloads.dbpedia.org/2015-10/dbpedia_2015-10.owl',\n '-O', '{0}/dbpedia.owl'.format(target)], \n stdout=None, stderr=None)",
"_____no_output_____"
],
[
"# current version: http://wiki.dbpedia.org/Downloads2015-04\ndb_uri = 'http://downloads.dbpedia.org/2015-10/core-i18n'",
"_____no_output_____"
],
[
"for lang in languages:\n if not os.path.exists('{0}/instance_types_{1}.ttl.bz2'.format(target, lang)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/instance_types_{0}.ttl.bz2'.format(lang, db_uri),\n '-O', '{0}/instance_types_{1}.ttl.bz2'.format(target, lang)], \n stdout=None, stderr=None)\n \n if not os.path.exists('{0}/interlanguage_links_{1}.ttl.bz2'.format(target, lang)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/interlanguage_links_{0}.ttl.bz2'.format(lang, db_uri),\n '-O', '{0}/interlanguage_links_{1}.ttl.bz2'.format(target, lang)], \n stdout=None, stderr=None)\n \n if not os.path.exists('{0}/labels_{1}.ttl.bz2'.format(target, lang)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/labels_{0}.ttl.bz2'.format(lang, db_uri),\n '-O', '{0}/labels_{1}.ttl.bz2'.format(target, lang)], \n stdout=None, stderr=None)\n \n if not os.path.exists('{0}/mappingbased_literals_{1}.ttl.bz2'.format(target, lang)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/mappingbased_literals_{0}.ttl.bz2'.format(lang, db_uri),\n '-O', '{0}/mappingbased_literals_{1}.ttl.bz2'.format(target, lang)], \n stdout=None, stderr=None)\n \n if not os.path.exists('{0}/mappingbased_objects_{1}.ttl.bz2'.format(target, lang)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/mappingbased_objects_{0}.ttl.bz2'.format(lang, db_uri),\n '-O', '{0}/mappingbased_objects_{1}.ttl.bz2'.format(target, lang)], \n stdout=None, stderr=None)",
"_____no_output_____"
],
[
"# http://oldwiki.dbpedia.org/Datasets/NLP#h172-7\ndbpedia_gender = 'http://wifo5-04.informatik.uni-mannheim.de/downloads/datasets/genders_en.nt.bz2'\n\nif not os.path.exists('{0}/genders_en.nt.bz2'.format(target)):\n subprocess.call(['/usr/bin/wget', \n dbpedia_gender,\n '-O', '{0}/genders_en.nt.bz2'.format(target)], \n stdout=None, stderr=None)",
"_____no_output_____"
],
[
"# http://www.davidbamman.com/?p=12\n# note that, in previous versions, this was a text file. now it's a bzipped file with n-triplets.\nwikipedia_gender = 'http://www.ark.cs.cmu.edu/bio/data/wiki.genders.txt'\n\nif not os.path.exists('{0}/wiki.genders.txt'.format(target)):\n subprocess.call(['/usr/bin/wget', \n dbpedia_gender,\n '-O', '{0}/wiki.genders.txt'.format(target)], \n stdout=None, stderr=None)",
"_____no_output_____"
],
[
"if not os.path.exists('{0}/long_abstracts_{1}.nt.bz2'.format(target, dbpedia_config.MAIN_LANGUAGE)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/long_abstracts_{0}.ttl.bz2'.format(dbpedia_config.MAIN_LANGUAGE, db_uri),\n '-O', '{0}/long_abstracts_{1}.ttl.bz2'.format(target, dbpedia_config.MAIN_LANGUAGE)], \n stdout=None, stderr=None)",
"_____no_output_____"
],
[
"# network data for english only\nif not os.path.exists('{0}/page_links_{1}.ttl.bz2'.format(target, dbpedia_config.MAIN_LANGUAGE)):\n subprocess.call(['/usr/bin/wget', \n '{1}/{0}/page_links_{0}.nt.bz2'.format(dbpedia_config.MAIN_LANGUAGE, db_uri),\n '-O', '{0}/page_links_{1}.ttl.bz2'.format(target, dbpedia_config.MAIN_LANGUAGE)], \n stdout=None, stderr=None)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a42f51e5d62815e3a7b4ad3925d730735bb5c7e
| 48,407 |
ipynb
|
Jupyter Notebook
|
appendix/teach_me_qiskit_2018/quantum_cryptography_qkd/Quantum_Cryptography2.ipynb
|
kardashin/qiskit-tutorial
|
0deb92bbd89f29e8e9d94f4bf095cb0fbd83c41d
|
[
"Apache-2.0"
] | 2 |
2018-09-13T05:40:53.000Z
|
2019-05-12T15:00:58.000Z
|
appendix/teach_me_qiskit_2018/quantum_cryptography_qkd/Quantum_Cryptography2.ipynb
|
kardashin/qiskit-tutorial
|
0deb92bbd89f29e8e9d94f4bf095cb0fbd83c41d
|
[
"Apache-2.0"
] | null | null | null |
appendix/teach_me_qiskit_2018/quantum_cryptography_qkd/Quantum_Cryptography2.ipynb
|
kardashin/qiskit-tutorial
|
0deb92bbd89f29e8e9d94f4bf095cb0fbd83c41d
|
[
"Apache-2.0"
] | null | null | null | 56.156613 | 16,488 | 0.722829 |
[
[
[
"# Quantum Cryptography: Quantum Key Distribution\n***\n### Contributors:\nA.J. Rasmusson, Richard Barney",
"_____no_output_____"
],
[
"Have you ever wanted to send a super secret message to a friend? Then you need a key to encrypt your message, and your friend needs the same key to decrypt your message. But, how do you send a super secret key to your friend without your eavesdropping enemies finding out what it is? Businesses and governments face this problem every day. People are always innovating new ways to intercept personal data or other sensitive information. Ideally, we'd like to find a way to share information that cannot be intercepted. [Quantum key distribution](https://en.wikipedia.org/wiki/Quantum_key_distribution) (QKD) was created as a solution to this problem. In this tutorial, you'll learn about and implement a version of the [BB84 QKD protocol](https://en.wikipedia.org/wiki/BB84), developed by Bennet and Brassard, to generate a secure, [one-time pad](https://en.wikipedia.org/wiki/One-time_pad) encryption key.\n\nQuantum key distribution is all about making the right information publicly known at the right times (and keeping the secret information secret). This tutorial will take you through a quantum key distribution between you (Alice) and your friend Bob. After you get a feel for the ropes by sending your first encrypted message to Bob, we'll introduce Eve--your eavesdropping enemy. You'll learn how to detect Eve's presence and thus prevent her from intercepting your super secret key and decrypting your messages.",
"_____no_output_____"
]
],
[
[
"#import all the packages\n\n# Checking the version of PYTHON\nimport sys\nif sys.version_info < (3,5):\n raise Exception('Please use Python version 3.5 or greater.')\n\n#append to system path so qiskit and Qconfig can be found from home directory\nsys.path.append('../qiskit-sdk-py/')\n\n# Import the QuantumProgram and configuration\nfrom qiskit import QuantumProgram\n#import Qconfig\n\n#other useful packages\nimport math",
"_____no_output_____"
]
],
[
[
"## Part 1: Encrypting and Decrypting a Message",
"_____no_output_____"
],
[
"### Pick Your Super Secret Message\nThe super secret message you want to send must be the same or less than the length of the super secret key.\n\nIf the key is shorter than the message, you will be forced to use parts of the key more than once. This may allow your lurking enemies to pick up a pattern in your encrypted message and possibly decrypt it. (As you'll see later on, we need to start out with a key at least double the number of characters used in your message. For now, don't worry about those details, pick your message! For this tutorial, we picked the initial key to be 3x greater--just to be safe.) Enter your message on the line below which reads \"mes = \".",
"_____no_output_____"
]
],
[
[
"#Super secret message\nmes = 'hello world'\nprint('Your super secret message: ',mes)\n\n#initial size of key\nn = len(mes)*3\n\n#break up message into smaller parts if length > 10\nnlist = []\nfor i in range(int(n/10)):\n nlist.append(10)\nif n%10 != 0:\n nlist.append(n%10)\n\nprint('Initial key length: ',n)",
"Your super secret message: hello world\nInitial key length: 33\n"
]
],
[
[
"### The Big Picture\nNow that you (Alice) have the key, here's the big question: how are we going to get your key to Bob without eavesdroppers intercepting it? Quantum key distribution! Here are the steps and big picture (the effects of eavesdropping will be discussed later on):\n1. You (Alice) generate a random string--the key you wish to give to Bob.\n2. You (Alice) convert your string bits into corresponding qubits.\n3. You (Alice) send those qubits to Bob, BUT! you randomly rotate some into a superposition. This effectively turns your key into random noise. (This is good because your lurking enemies might measure your qubits.)\n4. Bob receives yours qubits AND randomly rotates some qubits in the opposite direction before measuring.\n5. Alice and Bob publicly share which qubits they rotated. When they both did the same thing (either both did nothing or both rotated), they know the original key bit value made it to Bob! (Overall, you can see that only some of the bits from Alice's original key should make it.)\n6. Alice and Bob create their keys. Alice modifies her original key by keeping only the bits that she knows made it to Bob. Bob does the same.\n\nAlice and Bob now have matching keys! They can now use this key to encrypt and decrypt their messages.\n\n<img src='QKDnoEve.png'>\nHere we see Alice sending the initial key to Bob. She sends her qubits and rotates them based on her rotation string. Bob rotates the incoming qubits based on his rotation string and measures the qubits.",
"_____no_output_____"
],
[
"### Step 1: Alice Generates a Random Key\nYou and your friend need a super secret key so you can encrypt your message and your friend can decrypt it. Let's make a key--a pure random key.\n\nTo make a purely random string, we'll use quantum superposition. A qubit in the xy-plane of the [Bloch sphere](https://quantumexperience.ng.bluemix.net/qx/tutorial?sectionId=beginners-guide&page=004-The_Weird_and_Wonderful_World_of_the_Qubit~2F001-The_Weird_and_Wonderful_World_of_the_Qubit) is in a 50-50 [superposition](https://quantumexperience.ng.bluemix.net/qx/tutorial?sectionId=beginners-guide&page=005-Single-Qubit_Gates~2F002-Creating_superposition); 50% of the time it'll be measured as 0, and 50% of the time it'll be measured as 1. We have Alice prepare several qubits like this and measure them to generate a purely random string of 1s and 0s.",
"_____no_output_____"
]
],
[
[
"# Make random strings of length string_length\n\ndef randomStringGen(string_length):\n #output variables used to access quantum computer results at the end of the function\n output_list = []\n output = ''\n \n #start up your quantum program\n qp = QuantumProgram()\n backend = 'local_qasm_simulator' \n circuits = ['rs']\n \n #run circuit in batches of 10 qubits for fastest results. The results\n #from each run will be appended and then clipped down to the right n size.\n n = string_length\n temp_n = 10\n temp_output = ''\n for i in range(math.ceil(n/temp_n)):\n #initialize quantum registers for circuit\n q = qp.create_quantum_register('q',temp_n)\n c = qp.create_classical_register('c',temp_n)\n rs = qp.create_circuit('rs',[q],[c])\n \n #create temp_n number of qubits all in superpositions\n for i in range(temp_n):\n rs.h(q[i]) #the .h gate is the Hadamard gate that makes superpositions\n rs.measure(q[i],c[i])\n\n #execute circuit and extract 0s and 1s from key\n result = qp.execute(circuits, backend, shots=1)\n counts = result.get_counts('rs')\n result_key = list(result.get_counts('rs').keys())\n temp_output = result_key[0]\n output += temp_output\n \n #return output clipped to size of desired string length\n return output[:n]",
"_____no_output_____"
],
[
"key = randomStringGen(n)\nprint('Initial key: ',key)",
"Initial key: 111111000111011000011100011001111\n"
]
],
[
[
"### Steps 2-4: Send Alice's Qubits to Bob\nAlice turns her key bits into corresponding qubit states. If a bit is a 0 she will prepare a qubit on the negative z axis. If the bit is a 1 she will prepare a qubit on the positive z axis. Next, if Alice has a 1 in her rotate string, she rotates her key qubit with a [Hadamard](https://quantumexperience.ng.bluemix.net/qx/tutorial?sectionId=beginners-guide&page=005-Single-Qubit_Gates~2F002-Creating_superposition) gate. She then sends the qubit to Bob. If Bob has a 1 in his rotate string, he rotates the incoming qubit in the opposite direction with a Hadamard gate. Bob then measures the state of the qubit and records the result. The quantum circuit below executes each of these steps.",
"_____no_output_____"
]
],
[
[
"#generate random rotation strings for Alice and Bob\nAlice_rotate = randomStringGen(n)\nBob_rotate = randomStringGen(n)\nprint(\"Alice's rotation string:\",Alice_rotate)\nprint(\"Bob's rotation string: \",Bob_rotate)\n\n#start up your quantum program\nbackend = 'local_qasm_simulator' \nshots = 1\ncircuits = ['send_over']\nBob_result = ''\n\nfor ind,l in enumerate(nlist):\n #define temp variables used in breaking up quantum program if message length > 10\n if l < 10:\n key_temp = key[10*ind:10*ind+l]\n Ar_temp = Alice_rotate[10*ind:10*ind+l]\n Br_temp = Bob_rotate[10*ind:10*ind+l]\n else:\n key_temp = key[l*ind:l*(ind+1)]\n Ar_temp = Alice_rotate[l*ind:l*(ind+1)]\n Br_temp = Bob_rotate[l*ind:l*(ind+1)]\n \n #start up the rest of your quantum program\n qp2 = QuantumProgram()\n q = qp2.create_quantum_register('q',l)\n c = qp2.create_classical_register('c',l)\n send_over = qp2.create_circuit('send_over',[q],[c])\n \n #prepare qubits based on key; add Hadamard gates based on Alice's and Bob's\n #rotation strings\n for i,j,k,n in zip(key_temp,Ar_temp,Br_temp,range(0,len(key_temp))):\n i = int(i)\n j = int(j)\n k = int(k)\n if i > 0:\n send_over.x(q[n])\n #Look at Alice's rotation string\n if j > 0:\n send_over.h(q[n])\n #Look at Bob's rotation string\n if k > 0:\n send_over.h(q[n])\n send_over.measure(q[n],c[n])\n\n #execute quantum circuit\n result_so = qp2.execute(circuits, backend, shots=shots)\n counts_so = result_so.get_counts('send_over')\n result_key_so = list(result_so.get_counts('send_over').keys())\n Bob_result += result_key_so[0][::-1]\n \nprint(\"Bob's results: \", Bob_result)",
"Alice's rotation string: 110110100010110010011100011000010\nBob's rotation string: 010101100000101010010101111010111\nBob's results: 011100000101011000010101011011010\n"
]
],
[
[
"### Steps 5-6: Compare Rotation Strings and Make Keys\nAlice and Bob can now generate a secret quantum encryption key. First, they publicly share their rotation strings. If a bit in Alice's rotation string is the same as the corresponding bit in Bob's they know that Bob's result is the same as what Alice sent. They keep these bits to form the new key. (Alice based on her original key and Bob based on his measured results).",
"_____no_output_____"
]
],
[
[
"def makeKey(rotation1,rotation2,results):\n key = ''\n count = 0\n for i,j in zip(rotation1,rotation2):\n if i == j:\n key += results[count]\n count += 1\n return key\n \nAkey = makeKey(Bob_rotate,Alice_rotate,key)\nBkey = makeKey(Bob_rotate,Alice_rotate,Bob_result)\n\nprint(\"Alice's key:\",Akey)\nprint(\"Bob's key: \",Bkey)",
"Alice's key: 111000110000011011011\nBob's key: 111000110000011011011\n"
]
],
[
[
"### Pause\nWe see that using only the public knowledge of Bob's and Alice's rotation strings, Alice and Bob can create the same identical key based on Alice's initial random key and Bob's results. Wow!! :D\n\n<strong>If Alice's and Bob's key length is less than the message</strong>, the encryption is compromised. If this is the case for you, rerun all the cells above and see if you get a longer key. (We set the initial key length to 3x the message length to avoid this, but it's still possible.)",
"_____no_output_____"
],
[
"### Encrypt (and decrypt) using quantum key\nWe can now use our super secret key to encrypt and decrypt messages!! (of length less than the key). Note: the below \"encryption\" method is not powerful and should not be used for anything you want secure; it's just for fun. In real life, the super secret key you made and shared with Bob would be used in a much more sophisticated encryption algorithm.",
"_____no_output_____"
]
],
[
[
"#make key same length has message\nshortened_Akey = Akey[:len(mes)]\nencoded_m=''\n\n#encrypt message mes using encryption key final_key\nfor m,k in zip(mes,shortened_Akey):\n encoded_c = chr(ord(m) + 2*ord(k) % 256)\n encoded_m += encoded_c\nprint('encoded message: ',encoded_m)\n\n#make key same length has message\nshortened_Bkey = Bkey[:len(mes)]\n\n#decrypt message mes using encryption key final_key\nresult = ''\nfor m,k in zip(encoded_m,shortened_Bkey):\n encoded_c = chr(ord(m) - 2*ord(k) % 256)\n result += encoded_c\nprint('recovered message:',result)",
"encoded message: ÊÇÎÌÏÙÑÒÌÄ\nrecovered message: hello world\n"
]
],
[
[
"# Part 2: Eve the Eavesdropper\nWhat if someone is eavesdropping on Alice and Bob's line of communication? This process of random string making and rotations using quantum mechanics is only useful if it's robust against eavesdroppers.\n\nEve is your lurking enemy. She eavesdrops by intercepting your transmission to Bob. To be sneaky, Eve must send on the intercepted transmission--otherwise Bob will never receive anything and know that something is wrong!\n\nLet's explain further why Eve can be detected. If Eve intercepts a qubit from Alice, she will not know if Alice rotated its state or not. Eve can only measure a 0 or 1. And she can't measure the qubit and then send the same qubit on, because her measurement will destroy the quantum state. Consequently, Eve doesn't know when or when not to rotate to recreate Alice's original qubit. She may as well send on qubits that have not been rotated, hoping to get the rotation right 50% of the time. After she sends these qubits to Bob, Alice and Bob can compare select parts of their keys to see if they have discrepancies in places they should not.\n\nThe scheme goes as follows:\n1. Alice sends her qubit transmission Bob--but Eve measures the results\n2. To avoid suspicion, Eve prepares qubits corresponding to the bits she measured and sends them to Bob.\n3. Bob and Alice make their keys like normal\n4. Alice and Bob randomly select the same parts of their keys to share publicly\n5. If the selected part of the keys don't match, they know Eve was eavesdropping\n6. If the selected part of the keys DO match, they can be confident Eve wasn't eavesdropping\n7. They throw away the part of the key they made public and encrypt and decrypt super secret messages with the portion of the key they have left.\n\n<img src=\"QKD.png\">\nHere we see Alice sending her qubits, rotationing them based on her rotation string, and Eve intercepting the transmittion. Eve then sending her results onto Bob who--like normal--rotates and measures the qubits.",
"_____no_output_____"
],
[
"### Step 1: Eve intercepts Alice's transmission\n\nThe code below has Alice sending her qubits and Eve intercepting them. It then displays the results of Eve's measurements.",
"_____no_output_____"
]
],
[
[
"#start up your quantum program\nbackend = 'local_qasm_simulator' \nshots = 1\ncircuits = ['Eve']\n\nEve_result = ''\nfor ind,l in enumerate(nlist):\n #define temp variables used in breaking up quantum program if message length > 10\n if l < 10:\n key_temp = key[10*ind:10*ind+l]\n Ar_temp = Alice_rotate[10*ind:10*ind+l]\n else:\n key_temp = key[l*ind:l*(ind+1)]\n Ar_temp = Alice_rotate[l*ind:l*(ind+1)]\n \n #start up the rest of your quantum program\n qp3 = QuantumProgram()\n q = qp3.create_quantum_register('q',l)\n c = qp3.create_classical_register('c',l)\n Eve = qp3.create_circuit('Eve',[q],[c])\n \n #prepare qubits based on key; add Hadamard gates based on Alice's and Bob's\n #rotation strings\n for i,j,n in zip(key_temp,Ar_temp,range(0,len(key_temp))):\n i = int(i)\n j = int(j)\n if i > 0:\n Eve.x(q[n])\n if j > 0:\n Eve.h(q[n])\n Eve.measure(q[n],c[n])\n \n #execute\n result_eve = qp3.execute(circuits, backend, shots=shots)\n counts_eve = result_eve.get_counts('Eve')\n result_key_eve = list(result_eve.get_counts('Eve').keys())\n Eve_result += result_key_eve[0][::-1]\n\nprint(\"Eve's results: \", Eve_result)",
"Eve's results: 001111000111011000000100010001101\n"
]
],
[
[
"### Step 2: Eve deceives Bob\nEve sends her measured qubits on to Bob to deceive him! Since she doesn't know which of the qubits she measured were in a superposition or not, she doesn't even know whether to send the exact values she measured or opposite values. In the end, sending on the exact values is just as good a deception as mixing them up again.",
"_____no_output_____"
]
],
[
[
"#start up your quantum program\nbackend = 'local_qasm_simulator' \nshots = 1\ncircuits = ['Eve2']\n\nBob_badresult = ''\nfor ind,l in enumerate(nlist):\n #define temp variables used in breaking up quantum program if message length > 10\n if l < 10:\n key_temp = key[10*ind:10*ind+l]\n Eve_temp = Eve_result[10*ind:10*ind+l]\n Br_temp = Bob_rotate[10*ind:10*ind+l]\n else:\n key_temp = key[l*ind:l*(ind+1)]\n Eve_temp = Eve_result[l*ind:l*(ind+1)]\n Br_temp = Bob_rotate[l*ind:l*(ind+1)]\n \n #start up the rest of your quantum program\n qp4 = QuantumProgram()\n q = qp4.create_quantum_register('q',l)\n c = qp4.create_classical_register('c',l)\n Eve2 = qp4.create_circuit('Eve2',[q],[c])\n \n #prepare qubits\n for i,j,n in zip(Eve_temp,Br_temp,range(0,len(key_temp))):\n i = int(i)\n j = int(j)\n if i > 0:\n Eve2.x(q[n])\n if j > 0:\n Eve2.h(q[n])\n Eve2.measure(q[n],c[n])\n \n #execute\n result_eve = qp4.execute(circuits, backend, shots=shots)\n counts_eve = result_eve.get_counts('Eve2')\n result_key_eve = list(result_eve.get_counts('Eve2').keys())\n Bob_badresult += result_key_eve[0][::-1]\n \nprint(\"Bob's previous results (w/o Eve):\",Bob_result)\nprint(\"Bob's results from Eve:\\t\\t \",Bob_badresult)",
"Bob's previous results (w/o Eve): 011100000101011000010101011011010\nBob's results from Eve:\t\t 001011000111010000010000110001000\n"
]
],
[
[
"### Step 4: Spot Check\nAlice and Bob know Eve is lurking out there. They decide to pick a few random values from their individual keys and compare with each other. This requires making these subsections of their keys public (so the other can see them). If any of the values in their keys are different, they know Eve's eavesdropping messed up the superposition Alice originally created! If they find all the values are identical, they can be reasonably confident that Eve wasn't eavesdropping. Of course, making some random key values known to the public will require them to remove those values from their keys because those parts are no longer super secret. Also, Alice and Bob need to make sure they are sharing corresponding values from their respective keys.\n\nLet's make a check key. If the randomly generated check key is a one, Alice and Bob will compare that part of their keys with each other (aka make publicly known).",
"_____no_output_____"
]
],
[
[
"#make keys for Alice and Bob\nAkey = makeKey(Bob_rotate,Alice_rotate,key)\nBkey = makeKey(Bob_rotate,Alice_rotate,Bob_badresult)\nprint(\"Alice's key: \",Akey)\nprint(\"Bob's key: \",Bkey)\n\ncheck_key = randomStringGen(len(Akey))\nprint('spots to check:',check_key)",
"Alice's key: 111000110000011011011\nBob's key: 010000110000010010010\nspots to check: 110011110011111101101\n"
]
],
[
[
"### Steps 5-7: Compare strings and detect Eve\nAlice and Bob compare the subsections of their keys. If they notice any discrepancy, they know that Eve was trying to intercept their message. They create new keys by throwing away the parts they shared publicly. It's possible that by throwing these parts away, they will not have a key long enough to encrypt the message and they will have to try again.",
"_____no_output_____"
]
],
[
[
"#find which values in rotation string were used to make the key\nAlice_keyrotate = makeKey(Bob_rotate,Alice_rotate,Alice_rotate)\nBob_keyrotate = makeKey(Bob_rotate,Alice_rotate,Bob_rotate)\n\n# Detect Eve's interference\n#extract a subset of Alice's key\nsub_Akey = ''\nsub_Arotate = ''\ncount = 0\nfor i,j in zip(Alice_rotate,Akey):\n if int(check_key[count]) == 1:\n sub_Akey += Akey[count]\n sub_Arotate += Alice_keyrotate[count]\n count += 1\n\n#extract a subset of Bob's key\nsub_Bkey = ''\nsub_Brotate = ''\ncount = 0\nfor i,j in zip(Bob_rotate,Bkey):\n if int(check_key[count]) == 1:\n sub_Bkey += Bkey[count]\n sub_Brotate += Bob_keyrotate[count]\n count += 1\nprint(\"subset of Alice's key:\",sub_Akey)\nprint(\"subset of Bob's key: \",sub_Bkey)\n\n#compare Alice and Bob's key subsets\nsecure = True\nfor i,j in zip(sub_Akey,sub_Bkey):\n if i == j:\n secure = True\n else:\n secure = False\n break;\nif not secure:\n print('Eve detected!')\nelse:\n print('Eve escaped detection!')\n\n#sub_Akey and sub_Bkey are public knowledge now, so we remove them from Akey and Bkey\nif secure:\n new_Akey = ''\n new_Bkey = ''\n for index,i in enumerate(check_key):\n if int(i) == 0:\n new_Akey += Akey[index]\n new_Bkey += Bkey[index]\n print('new A and B keys: ',new_Akey,new_Bkey)\n if(len(mes)>len(new_Akey)):\n print('Your new key is not long enough.')",
"subset of Alice's key: 110011000110101\nsubset of Bob's key: 010011000100000\nEve detected!\n"
]
],
[
[
"# Probability of Detecting Eve\nThe longer the key, the more likely you will detect Eve. In fact, the [probability](hhttps://en.wikipedia.org/wiki/Quantum_key_distribution#Intercept_and_resend) goes up as a function of $1 - (3/4)^n$ where n is the number of bits Alice and Bob compare in their spot check. So, the longer the key, the more bits you can use to compare and the more likely you will detect Eve.",
"_____no_output_____"
]
],
[
[
"#!!! you may need to execute this cell twice in order to see the output due to an problem with matplotlib\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nx = np.arange(0., 30.0)\ny = 1-(3/4)**x\nplt.plot(y)\nplt.title('Probablity of detecting Eve')\nplt.xlabel('# of key bits compared')\nplt.ylabel('Probablity of detecting Eve')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a42fe7fa3426319c041a9929caa99b96507c159
| 31,469 |
ipynb
|
Jupyter Notebook
|
tricks/correlacao.ipynb
|
everton3x/python-tricks
|
3fdbe741155ee8d0225890393af191dcd7a782a0
|
[
"MIT"
] | null | null | null |
tricks/correlacao.ipynb
|
everton3x/python-tricks
|
3fdbe741155ee8d0225890393af191dcd7a782a0
|
[
"MIT"
] | null | null | null |
tricks/correlacao.ipynb
|
everton3x/python-tricks
|
3fdbe741155ee8d0225890393af191dcd7a782a0
|
[
"MIT"
] | null | null | null | 71.683371 | 17,508 | 0.705837 |
[
[
[
"# Correlação",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport matplotlib as mat\nimport matplotlib.pyplot as plt \nimport numpy as np \n%matplotlib inline",
"_____no_output_____"
],
[
"# Importando o dataset\ndf = pd.read_csv(\"data_sets/pima-data.csv\")\ndf.shape\ndf.head()",
"_____no_output_____"
],
[
"# Identificando a correlação entre as variáveis\n# Correlação não implica causalidade\ndef plot_corr(df, size=10):\n corr = df.corr() \n fig, ax = plt.subplots(figsize = (size, size))\n ax.matshow(corr) \n plt.xticks(range(len(corr.columns)), corr.columns) \n plt.yticks(range(len(corr.columns)), corr.columns)\n \nplot_corr(df)",
"_____no_output_____"
],
[
"# Visualizando a correlação em tabela\n# Coeficiente de correlação: \n# +1 = forte correlação positiva\n# 0 = não há correlação\n# -1 = forte correlação negativa\ndf.corr()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a430ced29d10055cc373aab3d3c6f5cca4cde95
| 3,628 |
ipynb
|
Jupyter Notebook
|
scripts/Deepcell_Preprocessing.ipynb
|
mapazarr/segmentation
|
3f6ca88378935a7b82a8b7da18d6ce054b870c55
|
[
"Apache-2.0"
] | null | null | null |
scripts/Deepcell_Preprocessing.ipynb
|
mapazarr/segmentation
|
3f6ca88378935a7b82a8b7da18d6ce054b870c55
|
[
"Apache-2.0"
] | null | null | null |
scripts/Deepcell_Preprocessing.ipynb
|
mapazarr/segmentation
|
3f6ca88378935a7b82a8b7da18d6ce054b870c55
|
[
"Apache-2.0"
] | null | null | null | 31.008547 | 262 | 0.56312 |
[
[
[
"### This is a notebook to run the preprocessing pipeline prior to uploading your TIFs to deepcell",
"_____no_output_____"
]
],
[
[
"# import required packages\nimport os\nimport numpy as np\nimport skimage.io as io\nimport xarray as xr\n\n# add package to system path\nimport sys\nsys.path.append(\"../\")\n\nfrom segmentation.utils import data_utils",
"_____no_output_____"
]
],
[
[
"## This script is currently configured as a template to run with the provided example data. If running your own data, make a copy of this notebook first before modifying it. Go to file-> make a copy to create a copy of this notebook",
"_____no_output_____"
]
],
[
[
"# load TIFs from GUI-based directory structure\ndata_dir = \"../data/example_dataset/input_data/\"\n\n# either get all points in the folder\npoints = os.listdir(data_dir)\npoints = [point for point in points if os.path.isdir(data_dir + point) and point.startswith(\"Point\")]\n\n# optionally, select a specific set of points manually\n# points = [\"Point1\", \"Point2\"]",
"_____no_output_____"
],
[
"# optionally, specify a set of channels to be summed together for better contrast\n\nsum_channels_xr = data_utils.load_imgs_from_dir(data_dir, img_sub_folder=\"TIFs\", fovs=points,\n imgs=[\"CD3.tif\", \"CD8.tif\"])\n\nchannel_sum = np.sum(sum_channels_xr.values, axis=3, dtype=\"uint8\")\n\nnew_channel_name = \"summed_channel\"\n\nsummed_xr = xr.DataArray(np.expand_dims(channel_sum, axis=-1), \n coords=[sum_channels_xr.fovs, sum_channels_xr.rows,\n sum_channels_xr.cols, [new_channel_name]],\n dims=sum_channels_xr.dims)\n\ntif_saves = [new_channel_name]\nfor point in summed_xr.fovs.values:\n for tif in tif_saves:\n save_path = os.path.join(data_dir, point, \"TIFs\", tif + \".tif\")\n io.imsave(save_path, summed_xr.loc[point, :, :, tif].values.astype(\"uint8\"))",
"_____no_output_____"
],
[
"# load channels to be included in deepcell data\ntifs = [\"HH3.tif\", \"Membrane.tif\"]\ndata_xr = data_utils.load_imgs_from_dir(data_dir, img_sub_folder=\"TIFs\", fovs=points, imgs=tifs)\n\n# save xarray for running through deepcell\ndata_xr.to_netcdf(os.path.join(data_dir, \"deepcell_input.xr\"), format=\"NETCDF3_64BIT\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a431377e3e82a09c6f1c51390574c66559a93ff
| 30,809 |
ipynb
|
Jupyter Notebook
|
site/en/tutorials/keras/basic_classification.ipynb
|
TheMichaelHu/docs
|
acfa4fa5b8b102df24caa3a35194999086ad954b
|
[
"Apache-2.0"
] | null | null | null |
site/en/tutorials/keras/basic_classification.ipynb
|
TheMichaelHu/docs
|
acfa4fa5b8b102df24caa3a35194999086ad954b
|
[
"Apache-2.0"
] | null | null | null |
site/en/tutorials/keras/basic_classification.ipynb
|
TheMichaelHu/docs
|
acfa4fa5b8b102df24caa3a35194999086ad954b
|
[
"Apache-2.0"
] | null | null | null | 31.183198 | 468 | 0.510143 |
[
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# Train your first neural network: basic classification",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/keras/basic_classification\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/keras/basic_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/keras/basic_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"This guide trains a neural network model to classify images of clothing, like sneakers and shirts. It's okay if you don't understand all the details, this is a fast-paced overview of a complete TensorFlow program with the details explained as we go.\n\nThis guide uses [tf.keras](https://www.tensorflow.org/guide/keras), a high-level API to build and train models in TensorFlow.",
"_____no_output_____"
]
],
[
[
"# TensorFlow and tf.keras\nimport tensorflow as tf\nfrom tensorflow import keras\n\n# Helper libraries\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nprint(tf.__version__)",
"_____no_output_____"
]
],
[
[
"## Import the Fashion MNIST dataset",
"_____no_output_____"
],
[
"This guide uses the [Fashion MNIST](https://github.com/zalandoresearch/fashion-mnist) dataset which contains 70,000 grayscale images in 10 categories. The images show individual articles of clothing at low resolution (28 by 28 pixels), as seen here:\n\n<table>\n <tr><td>\n <img src=\"https://tensorflow.org/images/fashion-mnist-sprite.png\"\n alt=\"Fashion MNIST sprite\" width=\"600\">\n </td></tr>\n <tr><td align=\"center\">\n <b>Figure 1.</b> <a href=\"https://github.com/zalandoresearch/fashion-mnist\">Fashion-MNIST samples</a> (by Zalando, MIT License).<br/> \n </td></tr>\n</table>\n\nFashion MNIST is intended as a drop-in replacement for the classic [MNIST](http://yann.lecun.com/exdb/mnist/) dataset—often used as the \"Hello, World\" of machine learning programs for computer vision. The MNIST dataset contains images of handwritten digits (0, 1, 2, etc) in an identical format to the articles of clothing we'll use here.\n\nThis guide uses Fashion MNIST for variety, and because it's a slightly more challenging problem than regular MNIST. Both datasets are relatively small and are used to verify that an algorithm works as expected. They're good starting points to test and debug code. \n\nWe will use 60,000 images to train the network and 10,000 images to evaluate how accurately the network learned to classify images. You can access the Fashion MNIST directly from TensorFlow, just import and load the data:",
"_____no_output_____"
]
],
[
[
"fashion_mnist = keras.datasets.fashion_mnist\n\n(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()",
"_____no_output_____"
]
],
[
[
"Loading the dataset returns four NumPy arrays:\n\n* The `train_images` and `train_labels` arrays are the *training set*—the data the model uses to learn.\n* The model is tested against the *test set*, the `test_images`, and `test_labels` arrays.\n\nThe images are 28x28 NumPy arrays, with pixel values ranging between 0 and 255. The *labels* are an array of integers, ranging from 0 to 9. These correspond to the *class* of clothing the image represents:\n\n<table>\n <tr>\n <th>Label</th>\n <th>Class</th> \n </tr>\n <tr>\n <td>0</td>\n <td>T-shirt/top</td> \n </tr>\n <tr>\n <td>1</td>\n <td>Trouser</td> \n </tr>\n <tr>\n <td>2</td>\n <td>Pullover</td> \n </tr>\n <tr>\n <td>3</td>\n <td>Dress</td> \n </tr>\n <tr>\n <td>4</td>\n <td>Coat</td> \n </tr>\n <tr>\n <td>5</td>\n <td>Sandal</td> \n </tr>\n <tr>\n <td>6</td>\n <td>Shirt</td> \n </tr>\n <tr>\n <td>7</td>\n <td>Sneaker</td> \n </tr>\n <tr>\n <td>8</td>\n <td>Bag</td> \n </tr>\n <tr>\n <td>9</td>\n <td>Ankle boot</td> \n </tr>\n</table>\n\nEach image is mapped to a single label. Since the *class names* are not included with the dataset, store them here to use later when plotting the images:",
"_____no_output_____"
]
],
[
[
"class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', \n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']",
"_____no_output_____"
]
],
[
[
"## Explore the data\n\nLet's explore the format of the dataset before training the model. The following shows there are 60,000 images in the training set, with each image represented as 28 x 28 pixels:",
"_____no_output_____"
]
],
[
[
"train_images.shape",
"_____no_output_____"
]
],
[
[
"Likewise, there are 60,000 labels in the training set:",
"_____no_output_____"
]
],
[
[
"len(train_labels)",
"_____no_output_____"
]
],
[
[
"Each label is an integer between 0 and 9:",
"_____no_output_____"
]
],
[
[
"train_labels",
"_____no_output_____"
]
],
[
[
"There are 10,000 images in the test set. Again, each image is represented as 28 x 28 pixels:",
"_____no_output_____"
]
],
[
[
"test_images.shape",
"_____no_output_____"
]
],
[
[
"And the test set contains 10,000 images labels:",
"_____no_output_____"
]
],
[
[
"len(test_labels)",
"_____no_output_____"
]
],
[
[
"## Preprocess the data\n\nThe data must be preprocessed before training the network. If you inspect the first image in the training set, you will see that the pixel values fall in the range of 0 to 255:",
"_____no_output_____"
]
],
[
[
"plt.figure()\nplt.imshow(train_images[0])\nplt.colorbar()\nplt.grid(False)\nplt.show()",
"_____no_output_____"
]
],
[
[
"We scale these values to a range of 0 to 1 before feeding to the neural network model. For this, we divide the values by 255. It's important that the *training set* and the *testing set* are preprocessed in the same way:",
"_____no_output_____"
]
],
[
[
"train_images = train_images / 255.0\n\ntest_images = test_images / 255.0",
"_____no_output_____"
]
],
[
[
"Display the first 25 images from the *training set* and display the class name below each image. Verify that the data is in the correct format and we're ready to build and train the network.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid(False)\n plt.imshow(train_images[i], cmap=plt.cm.binary)\n plt.xlabel(class_names[train_labels[i]])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Build the model\n\nBuilding the neural network requires configuring the layers of the model, then compiling the model.",
"_____no_output_____"
],
[
"### Setup the layers\n\nThe basic building block of a neural network is the *layer*. Layers extract representations from the data fed into them. And, hopefully, these representations are more meaningful for the problem at hand.\n\nMost of deep learning consists of chaining together simple layers. Most layers, like `tf.keras.layers.Dense`, have parameters that are learned during training.",
"_____no_output_____"
]
],
[
[
"model = keras.Sequential([\n keras.layers.Flatten(input_shape=(28, 28)),\n keras.layers.Dense(128, activation=tf.nn.relu),\n keras.layers.Dense(10, activation=tf.nn.softmax)\n])",
"_____no_output_____"
]
],
[
[
"The first layer in this network, `tf.keras.layers.Flatten`, transforms the format of the images from a 2d-array (of 28 by 28 pixels), to a 1d-array of 28 * 28 = 784 pixels. Think of this layer as unstacking rows of pixels in the image and lining them up. This layer has no parameters to learn; it only reformats the data.\n\nAfter the pixels are flattened, the network consists of a sequence of two `tf.keras.layers.Dense` layers. These are densely-connected, or fully-connected, neural layers. The first `Dense` layer has 128 nodes (or neurons). The second (and last) layer is a 10-node *softmax* layer—this returns an array of 10 probability scores that sum to 1. Each node contains a score that indicates the probability that the current image belongs to one of the 10 classes.\n\n### Compile the model\n\nBefore the model is ready for training, it needs a few more settings. These are added during the model's *compile* step:\n\n* *Loss function* —This measures how accurate the model is during training. We want to minimize this function to \"steer\" the model in the right direction.\n* *Optimizer* —This is how the model is updated based on the data it sees and its loss function.\n* *Metrics* —Used to monitor the training and testing steps. The following example uses *accuracy*, the fraction of the images that are correctly classified.",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam', \n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"## Train the model\n\nTraining the neural network model requires the following steps:\n\n1. Feed the training data to the model—in this example, the `train_images` and `train_labels` arrays.\n2. The model learns to associate images and labels.\n3. We ask the model to make predictions about a test set—in this example, the `test_images` array. We verify that the predictions match the labels from the `test_labels` array. \n\nTo start training, call the `model.fit` method—the model is \"fit\" to the training data:",
"_____no_output_____"
]
],
[
[
"model.fit(train_images, train_labels, epochs=5)",
"_____no_output_____"
]
],
[
[
"As the model trains, the loss and accuracy metrics are displayed. This model reaches an accuracy of about 0.88 (or 88%) on the training data.",
"_____no_output_____"
],
[
"## Evaluate accuracy\n\nNext, compare how the model performs on the test dataset:",
"_____no_output_____"
]
],
[
[
"test_loss, test_acc = model.evaluate(test_images, test_labels)\n\nprint('Test accuracy:', test_acc)",
"_____no_output_____"
]
],
[
[
"It turns out, the accuracy on the test dataset is a little less than the accuracy on the training dataset. This gap between training accuracy and test accuracy is an example of *overfitting*. Overfitting is when a machine learning model performs worse on new data than on their training data. ",
"_____no_output_____"
],
[
"## Make predictions\n\nWith the model trained, we can use it to make predictions about some images.",
"_____no_output_____"
]
],
[
[
"predictions = model.predict(test_images)",
"_____no_output_____"
]
],
[
[
"Here, the model has predicted the label for each image in the testing set. Let's take a look at the first prediction:",
"_____no_output_____"
]
],
[
[
"predictions[0]",
"_____no_output_____"
]
],
[
[
"A prediction is an array of 10 numbers. These describe the \"confidence\" of the model that the image corresponds to each of the 10 different articles of clothing. We can see which label has the highest confidence value:",
"_____no_output_____"
]
],
[
[
"np.argmax(predictions[0])",
"_____no_output_____"
]
],
[
[
"So the model is most confident that this image is an ankle boot, or `class_names[9]`. And we can check the test label to see this is correct:",
"_____no_output_____"
]
],
[
[
"test_labels[0]",
"_____no_output_____"
]
],
[
[
"We can graph this to look at the full set of 10 channels",
"_____no_output_____"
]
],
[
[
"def plot_image(i, predictions_array, true_label, img):\n predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]\n plt.grid(False)\n plt.xticks([])\n plt.yticks([])\n \n plt.imshow(img, cmap=plt.cm.binary)\n\n predicted_label = np.argmax(predictions_array)\n if predicted_label == true_label:\n color = 'blue'\n else:\n color = 'red'\n \n plt.xlabel(\"{} {:2.0f}% ({})\".format(class_names[predicted_label],\n 100*np.max(predictions_array),\n class_names[true_label]),\n color=color)\n\ndef plot_value_array(i, predictions_array, true_label):\n predictions_array, true_label = predictions_array[i], true_label[i]\n plt.grid(False)\n plt.xticks([])\n plt.yticks([])\n thisplot = plt.bar(range(10), predictions_array, color=\"#777777\")\n plt.ylim([0, 1]) \n predicted_label = np.argmax(predictions_array)\n \n thisplot[predicted_label].set_color('red')\n thisplot[true_label].set_color('blue')",
"_____no_output_____"
]
],
[
[
"Let's look at the 0th image, predictions, and prediction array. ",
"_____no_output_____"
]
],
[
[
"i = 0\nplt.figure(figsize=(6,3))\nplt.subplot(1,2,1)\nplot_image(i, predictions, test_labels, test_images)\nplt.subplot(1,2,2)\nplot_value_array(i, predictions, test_labels)",
"_____no_output_____"
],
[
"i = 12\nplt.figure(figsize=(6,3))\nplt.subplot(1,2,1)\nplot_image(i, predictions, test_labels, test_images)\nplt.subplot(1,2,2)\nplot_value_array(i, predictions, test_labels)",
"_____no_output_____"
]
],
[
[
"Let's plot several images with their predictions. Correct prediction labels are blue and incorrect prediction labels are red. The number gives the percent (out of 100) for the predicted label. Note that it can be wrong even when very confident. ",
"_____no_output_____"
]
],
[
[
"# Plot the first X test images, their predicted label, and the true label\n# Color correct predictions in blue, incorrect predictions in red\nnum_rows = 5\nnum_cols = 3\nnum_images = num_rows*num_cols\nplt.figure(figsize=(2*2*num_cols, 2*num_rows))\nfor i in range(num_images):\n plt.subplot(num_rows, 2*num_cols, 2*i+1)\n plot_image(i, predictions, test_labels, test_images)\n plt.subplot(num_rows, 2*num_cols, 2*i+2)\n plot_value_array(i, predictions, test_labels)\n",
"_____no_output_____"
]
],
[
[
"Finally, use the trained model to make a prediction about a single image. ",
"_____no_output_____"
]
],
[
[
"# Grab an image from the test dataset\nimg = test_images[0]\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"`tf.keras` models are optimized to make predictions on a *batch*, or collection, of examples at once. So even though we're using a single image, we need to add it to a list:",
"_____no_output_____"
]
],
[
[
"# Add the image to a batch where it's the only member.\nimg = (np.expand_dims(img,0))\n\nprint(img.shape)",
"_____no_output_____"
]
],
[
[
"Now predict the image:",
"_____no_output_____"
]
],
[
[
"predictions_single = model.predict(img)\n\nprint(predictions_single)",
"_____no_output_____"
],
[
"plot_value_array(0, predictions_single, test_labels)\n_ = plt.xticks(range(10), class_names, rotation=45)",
"_____no_output_____"
]
],
[
[
"`model.predict` returns a list of lists, one for each image in the batch of data. Grab the predictions for our (only) image in the batch:",
"_____no_output_____"
]
],
[
[
"np.argmax(predictions_single[0])",
"_____no_output_____"
]
],
[
[
"And, as before, the model predicts a label of 9.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a431d87bc9845219c5315d3cb43bb75473624c8
| 74,156 |
ipynb
|
Jupyter Notebook
|
Lab1-HealthRecords/ELMED219-2021-Lab1-NLP-example_medical_tweets.ipynb
|
Anne-hay/ELMED219-2021
|
cf5d328d85e8875ef6ca77caeabbe5629671eeb0
|
[
"MIT"
] | 5 |
2021-01-02T21:28:09.000Z
|
2021-12-17T20:19:20.000Z
|
Lab1-HealthRecords/ELMED219-2021-Lab1-NLP-example_medical_tweets.ipynb
|
Anne-hay/ELMED219-2021
|
cf5d328d85e8875ef6ca77caeabbe5629671eeb0
|
[
"MIT"
] | 1 |
2021-01-11T10:19:27.000Z
|
2021-01-11T10:19:41.000Z
|
Lab1-HealthRecords/ELMED219-2021-Lab1-NLP-example_medical_tweets.ipynb
|
Anne-hay/ELMED219-2021
|
cf5d328d85e8875ef6ca77caeabbe5629671eeb0
|
[
"MIT"
] | 5 |
2021-01-05T12:20:08.000Z
|
2021-09-30T09:42:15.000Z
| 40.434024 | 384 | 0.520821 |
[
[
[
"_ELMED219-2021_. Alexander S. Lundervold, 10.01.2021.",
"_____no_output_____"
],
[
"# Natural language processing and machine learning: a small case-study",
"_____no_output_____"
],
[
"This is a quick example of some techniques and ideas from natural language processing (NLP) and some modern approaches to NLP based on _deep learning_.",
"_____no_output_____"
],
[
"> Note: we'll take a close look at what deep learning is in tomorrow's lecture and lab.\n\n> Note: If you want to run this notebook on your own computer, ask Alexander for assistance. The software requirements are different from the other ELMED219 notebooks (and also slightly more tricky to install, depending on your setup). ",
"_____no_output_____"
],
[
"# Setup",
"_____no_output_____"
],
[
"We'll use the [spacy library]() for NLP and the [fastai]() library for deep learning.",
"_____no_output_____"
]
],
[
[
"import spacy",
"_____no_output_____"
],
[
"from fastai.text.all import *\nfrom pprint import pprint as pp",
"_____no_output_____"
]
],
[
[
"# Load data",
"_____no_output_____"
],
[
"We use a data set collected in the work of Wakamiya et.al, _Tweet Classification Toward Twitter-Based Disease Surveillance: New Data, Methods, and Evaluations_, 2019: https://www.jmir.org/2019/2/e12783/",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"The data us supposed to represent tweets that discusses one or more of eight symptoms. ",
"_____no_output_____"
],
[
"From the original paper:\n<img src=\"assets/medweb_examples.png\">",
"_____no_output_____"
],
[
"We'll only look at the English language tweets:",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('data/medweb/medwebdata.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"pp(df['Tweet'][10])",
"(\"They say we will have less pollen next spring, but it doesn't really matter \"\n 'to me, since my allergy gets severe in the autumn.')\n"
]
],
[
[
"From this text the goal is to determine whether the person is talking about one or more of the eight symptoms or conditions listed above:",
"_____no_output_____"
]
],
[
[
"list(df.columns[2:-2])",
"_____no_output_____"
]
],
[
[
"> **BUT:** How can a computer read??",
"_____no_output_____"
],
[
"<img src=\"http://2.bp.blogspot.com/_--uVHetkUIQ/TDae5jGna8I/AAAAAAAAAK0/sBSpLudWmcw/s1600/reading.gif\">",
"_____no_output_____"
],
[
"# Prepare the data",
"_____no_output_____"
],
[
"For a computer, everything is numbers. We have to convert the text to a series of numbers, and then feed those to the computer. \n\nThis can be done in two widely used steps in natural language processing: **tokenization** and **numericalization**:",
"_____no_output_____"
],
[
"## Tokenization",
"_____no_output_____"
],
[
"In tokenization the text is split into single words, called tokens. A simple way to achieve this is to split according to spaces in the text. But then we, among other things, lose punctuation, and also the fact that some words are contractions of multiple words (for example _isn't_ and _don't_). ",
"_____no_output_____"
],
[
"<img src=\"https://spacy.io/tokenization-57e618bd79d933c4ccd308b5739062d6.svg\">",
"_____no_output_____"
],
[
"Here are some result after tokenization:",
"_____no_output_____"
]
],
[
[
"data_lm = TextDataLoaders.from_df(df, text_col='Tweet', is_lm=True, valid_pct=0.1)\n\ndata_lm.show_batch(max_n=2)",
"_____no_output_____"
]
],
[
[
"Tokens starting with \"xx\" are special. `xxbos` means the beginning of the text, `xxmaj` means that the following word is capitalized, `xxup` means that the following word is in all caps, and so on.",
"_____no_output_____"
],
[
"The tokens `xxunk` replaces words that are rare in the text corpus. We keep only words that appear at least twice (with a set maximum number of different words, 60.000 in our case). This is called our **vocabulary**.",
"_____no_output_____"
],
[
"## Numericalization",
"_____no_output_____"
],
[
"We convert tokens to numbers by making a list of all the tokens that have been used and assign them to numbers.",
"_____no_output_____"
],
[
"The above text is replaced by numbers, as in this example",
"_____no_output_____"
]
],
[
[
"data_lm.train_ds[0][0]",
"_____no_output_____"
]
],
[
[
"> **We are now in a position where the computer can compute on the text.**",
"_____no_output_____"
],
[
"# \"Classical\" versus deep learning-based NLP",
"_____no_output_____"
]
],
[
[
"#import sys\n#!{sys.executable} -m spacy download en",
"_____no_output_____"
],
[
"nlp = spacy.load('en')",
"_____no_output_____"
]
],
[
[
"### Sentence Boundary Detection: splitting into sentences",
"_____no_output_____"
],
[
"Example sentence:\n> _\"Patient presents for initial evaluation of cough. Cough is reported to have developed acutely and has been present for 4 days. Symptom severity is moderate. Will return next week.\"_",
"_____no_output_____"
]
],
[
[
"sentence = \"Patient presents for initial evaluation of cough. Cough is reported to have developed acutely and has been present for 4 days. Symptom severity is moderate. Will return next week.\"\ndoc = nlp(sentence)\n \nfor sent in doc.sents:\n print(sent)",
"Patient presents for initial evaluation of cough.\nCough is reported to have developed acutely and has been present for 4 days.\nSymptom severity is moderate.\nWill return next week.\n"
]
],
[
[
"### Named Entity Recognition",
"_____no_output_____"
]
],
[
[
"for ent in doc.ents:\n print(ent.text, ent.label_)",
"4 days DATE\nnext week DATE\n"
],
[
"from spacy import displacy\ndisplacy.render(doc, style='ent', jupyter=True)",
"_____no_output_____"
]
],
[
[
"### Dependency parsing",
"_____no_output_____"
]
],
[
[
"displacy.render(doc, style='dep', jupyter=True, options={'distance': 90})",
"_____no_output_____"
]
],
[
[
"> There's a lot more to natural language processing, of course! Have a look at [spaCy 101: Everything you need to know](https://spacy.io/usage/spacy-101) for some examples.",
"_____no_output_____"
],
[
"In general, data preparation and feature engineering is a huge and difficult undertaking when using machine learning to analyse text. \n\nHowever, in what's called _deep learning_ (discussed in detail tomorrow) most of this work is done by the computer! That's because deep learning does feature extraction _and_ prediction in the same model. \n\nThis results in much less work and, often, _in much better models_!",
"_____no_output_____"
],
[
"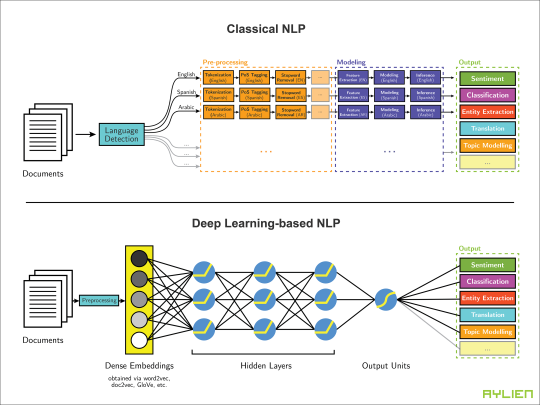",
"_____no_output_____"
],
[
"# Deep learning language model",
"_____no_output_____"
],
[
"We now come to a relatively new and very powerful idea for deep learning and NLP. An idea that created a small revolution in NLP a couple of years ago ([1](https://blog.openai.com/language-unsupervised/), [2](http://ruder.io/nlp-imagenet/))",
"_____no_output_____"
],
[
"We want to create a system that can classify text into one or more categories. This is a difficult problem as the computer must somehow implicitly learn to \"read\". \n\nIdea: why not _first_ teach the computer to \"read\" and _then_ let it loose on the classification task?\n\nWe can teach the computer to \"understand\" language by training it to predict the next word of a sentence, using as much training data we can get hold of. This is called ***language modelling*** in NLP. \n\nThis is a difficult task: to guess the next word of a sentence one has to know a lot about language, and also a lot about the world.\n\n> What word fits here? _\"The light turned green and Per crossed the ___\"_",
"_____no_output_____"
],
[
"Luckily, obtaining large amounts of training data for language models is simple: any text can be used. The labels are simply the next word of a subpart of the text. \n\nWe can for example use Wikipedia. After the model performs alright at predicting the next word of Wikipedia text, we can fine-tune it on text that's closer to the classification task we're after. \n\n> This is often called ***transfer learning***.",
"_____no_output_____"
],
[
"We can use the tweet text to fine-tune a model that's already been pretrained on Wikipedia:",
"_____no_output_____"
]
],
[
[
"data_lm = TextDataLoaders.from_df(df, text_col='Tweet', is_lm=True, valid_pct=0.1)\n\ndata_lm.show_batch(max_n=3)",
"_____no_output_____"
],
[
"learn = language_model_learner(data_lm, AWD_LSTM, pretrained=True, \n metrics=[accuracy, Perplexity()], wd=0.1).to_fp16()",
"_____no_output_____"
]
],
[
[
"Let's start training:",
"_____no_output_____"
]
],
[
[
"learn.fit_one_cycle(1, 1e-2)",
"_____no_output_____"
],
[
"learn.unfreeze()\nlearn.fit_one_cycle(10, 1e-3)",
"_____no_output_____"
]
],
[
[
"...and save the parts of the model that we can reuse for classification later:",
"_____no_output_____"
]
],
[
[
"learn.save_encoder('medweb_finetuned')",
"_____no_output_____"
]
],
[
[
"## Test the language model",
"_____no_output_____"
],
[
"We can test the language model by having it guess the next given number of words on a starting text:",
"_____no_output_____"
]
],
[
[
"def make_text(seed_text, nb_words):\n \"\"\"\n Use the trained language model to produce text. \n Input:\n seed_text: some text to get the model started\n nb_words: number of words to produce\n \"\"\"\n pred = learn.predict(seed_text, nb_words, temperature=0.75)\n pp(pred)",
"_____no_output_____"
],
[
"make_text(\"I'm not feeling too good as my\", 10)",
"_____no_output_____"
],
[
"make_text(\"No, that's a\", 40)",
"_____no_output_____"
]
],
[
[
"Now we have something that seems to produce text that resembles the text to be classified. ",
"_____no_output_____"
],
[
"> **Note:** It's interesting to see that the model can come up with text that makes some sense (mostly thanks to training on Wikipedia), and that the text resembles the medical tweets (thanks to the fine-tuning). \n\n> **Note** also that an accuracy of 30-40% when predicting the next word of a sentence is pretty impressive, as the number of possibilities is very large (equal to the size of the vocabulary).\n\n> **Also note** that this is not the task we care about: it's a pretext task before the tweet classification. ",
"_____no_output_____"
],
[
"# Classifier",
"_____no_output_____"
]
],
[
[
"medweb = DataBlock(blocks=(TextBlock.from_df(text_cols='Tweet', seq_len=12, vocab=data_lm.vocab), MultiCategoryBlock), \n get_x = ColReader(cols='text'), \n get_y = ColReader(cols='labels', label_delim=\";\"),\n splitter = ColSplitter(col='is_test'))\n\ndata = medweb.dataloaders(df, bs=8)",
"_____no_output_____"
]
],
[
[
"Now our task is to predict the possible classes the tweets can be assigned to:",
"_____no_output_____"
]
],
[
[
"data.show_batch()",
"_____no_output_____"
],
[
"learn_clf = text_classifier_learner(data, AWD_LSTM, seq_len=16, pretrained=True, \n drop_mult=0.5, metrics=accuracy_multi).to_fp16()",
"_____no_output_____"
],
[
"learn_clf = learn_clf.load_encoder('medweb_finetuned')",
"_____no_output_____"
],
[
"learn_clf.fine_tune(12, base_lr=1e-2)",
"_____no_output_____"
]
],
[
[
"## Is it a good classifier?",
"_____no_output_____"
],
[
"We can test it out on some example text:",
"_____no_output_____"
]
],
[
[
"learn_clf.predict(\"I'm feeling really bad. My head hurts. My nose is runny. I've felt like this for days.\")",
"_____no_output_____"
]
],
[
[
"It seems to produce reasonable results. _But remember that this is a very small data set._ One cannot expect very great things when asking the model to make predictions on text outside the small material it has been trained on. This illustrates the need for \"big data\" in deep learning.",
"_____no_output_____"
],
[
"### How does it compare to other approaches?",
"_____no_output_____"
],
[
"From the [original article](https://www.jmir.org/2019/2/e12783/) that presented the data set:",
"_____no_output_____"
],
[
"<img src=\"assets/medweb_results.png\">",
"_____no_output_____"
],
[
"# End notes\n\n* This of course only skratches the surface of NLP and deep learning applied to NLP. The goal was to \"lift the curtain\" and show some of the ideas behind modern text analysis software.\n* If you're interested in digging into deep learning for NLP you should check out `fastai` (used above) and also `Hugging Face`: https://huggingface.co. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a43289c396e49532bd8ede93af4e3b5b2b9e5f2
| 7,058 |
ipynb
|
Jupyter Notebook
|
lessons/07_Rekursion/05_RekursionBeispiele.ipynb
|
bomelino/xeus-cling
|
20c3996804438fc2eb14fa9d2170ea10a53aa9cb
|
[
"BSD-3-Clause"
] | null | null | null |
lessons/07_Rekursion/05_RekursionBeispiele.ipynb
|
bomelino/xeus-cling
|
20c3996804438fc2eb14fa9d2170ea10a53aa9cb
|
[
"BSD-3-Clause"
] | null | null | null |
lessons/07_Rekursion/05_RekursionBeispiele.ipynb
|
bomelino/xeus-cling
|
20c3996804438fc2eb14fa9d2170ea10a53aa9cb
|
[
"BSD-3-Clause"
] | null | null | null | 21.259036 | 183 | 0.475772 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a432c4ef9738c1b2c2ade7d9fdabc31b7bb0b7f
| 25,139 |
ipynb
|
Jupyter Notebook
|
affinitydesigner.ipynb
|
kalz2q/myjupyternotebooks
|
daab7169bd6e515c94207371471044bd5992e009
|
[
"MIT"
] | null | null | null |
affinitydesigner.ipynb
|
kalz2q/myjupyternotebooks
|
daab7169bd6e515c94207371471044bd5992e009
|
[
"MIT"
] | null | null | null |
affinitydesigner.ipynb
|
kalz2q/myjupyternotebooks
|
daab7169bd6e515c94207371471044bd5992e009
|
[
"MIT"
] | null | null | null | 248.90099 | 5,790 | 0.651816 |
[
[
[
"<a href=\"https://colab.research.google.com/github/kalz2q/mycolabnotebooks/blob/master/affinitydesigner.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# メモ\naffinity designer を学ぶ\n",
"_____no_output_____"
]
],
[
[
"%%html\n<svg width=\"300\" viewBox=\"0 0 348 316\" xmlns=\"http://www.w3.org/2000/svg\" xml:space=\"preserve\" style=\"fill-rule:evenodd;clip-rule:evenodd;stroke-linejoin:round;stroke-miterlimit:2\"><path d=\"M486.164 398.146c2.45.093 12.441.502 15.805 1.174 11.935 2.387 23.571 1.381 35.674 1.381 20.092 0 48.896-3.66 73.566-12.632 16.986-6.177 31.996-14.917 41.252-26.488 19.944-24.929 18.465-56.276 8.519-85.211-15.674-45.595-44.719-80.416-86.639-104.235-31.185-17.718-69.82-28.067-105.704-28.067-87.093 0-172.7 76.964-142.21 168.433 4.568 13.705 11.67 27.178 20.466 38.706 25.816 33.834 68.594 47.593 108.706 52.617a4.874 4.874 0 0 0 1.534-.051l29.031-5.627Zm-1.628-9.622-28.493 5.522h-.002c-37.391-4.784-77.35-17.249-101.392-48.757-8.152-10.684-14.733-23.172-18.966-35.873-28.308-84.922 52.095-155.592 132.954-155.592 34.248 0 71.121 9.883 100.885 26.794 39.786 22.606 67.356 55.65 82.232 98.924 8.857 25.766 10.848 53.745-6.911 75.945-8.263 10.328-21.807 17.9-36.968 23.414-23.551 8.564-51.052 12.044-70.232 12.044-11.452 0-22.467 1.067-33.761-1.191-3.798-.76-15.293-1.281-17.549-1.365-.297-.011-.472-.015-.503-.016a4.706 4.706 0 0 0-1.294.151Z\" style=\"fill:#0800ff\" transform=\"translate(-320.133 -88.683)\"/><path d=\"M433.374 178.23c-.615 3.031-2.362 10.974-2.126 16.825.157 3.876 1.319 7.011 3.08 8.773 1.228 1.228 2.505 1.552 3.595 1.588a5.1 5.1 0 0 0 2.939-.797c.695-.436 1.483-1.171 2.072-2.316.52-1.01.958-2.995 1.248-4.013.801-2.802.821-7.009.35-11.457-.3-2.837-.775-5.789-1.232-8.435 4.57-21.973 12.196-39.671 23.939-59.072 2.511-4.148 7.67-11.16 11.734-15.941.36 5.596-.345 12.302-.203 14.577 1.092 17.465 7.185 34.175 8.142 51.399.14 2.535-.764 8.912-.429 13.405.251 3.364 1.338 5.978 2.707 7.346 1.388 1.388 2.852 1.671 4.143 1.58 1.193-.084 2.465-.553 3.563-1.742.59-.638 1.286-1.819 1.741-3.304.409-1.333.808-3.523.885-3.961.956-3.406 3.184-10.014 4.162-12.873 4.347-12.706 8.651-25.402 13.927-37.762-.121 2.311-.324 4.621-.648 6.725-2.541 16.517-4.013 33.221 1.968 49.172.845 2.253 2.388 3.135 3.873 3.477 1.355.312 4.137.06 6.556-2.921 4.148-5.109 12.571-23.639 13.435-25.244 3.866-7.179 13.565-26.837 22.755-39.461.377-.517.749-1.023 1.119-1.515-.269 2.453-.564 5.075-.868 7.663-.81 6.883-.073 14.213.406 21.467.42 6.35.668 12.639-1.085 18.4-1.41 4.632-5.697 9.626-8.806 14.597-2.766 4.422-4.692 8.866-4.692 12.968a4.88 4.88 0 0 0 4.878 4.878 4.88 4.88 0 0 0 4.878-4.878c0-3.311 2.455-6.753 4.865-10.334 3.292-4.892 6.827-9.847 8.21-14.39 2.087-6.856 1.987-14.328 1.487-21.885-.44-6.651-1.194-13.371-.452-19.683 1.196-10.169 2.193-19.205 2.209-20.84.033-3.396-2.399-4.512-2.8-4.704-1.23-.589-2.537-.683-3.922-.128-3.852 1.54-8.633 6.213-13.314 12.642-9.457 12.989-19.48 33.191-23.458 40.578-.584 1.086-4.781 10.49-8.531 17.43-2.329-11.748-.91-23.836.932-35.806 1.598-10.388.926-22.874.529-25.203-.817-4.798-5.454-4.436-6.105-4.273-2.882.721-5.414 2.944-7.306 6.031-1.86 3.033-3.144 6.937-4.123 9.176-5.16 11.794-9.404 23.903-13.571 36.058-1.851-14.884-6.574-29.504-7.523-44.694-.171-2.738.807-11.733-.137-17.811-.671-4.324-2.541-7.456-4.825-8.802-.915-.54-2.048-.864-3.437-.656-.873.13-2.563.789-4.414 2.508-4.24 3.937-13.125 15.608-16.802 21.683-7.762 12.824-13.802 24.947-18.409 37.921-.26-10.551.623-20.994 2.923-31.809.028-.132 4.935-20.87 5.981-24.919l.09-.34a4.866 4.866 0 0 0-.563-4.278c-1.289-1.926-3.007-2.389-4.807-2.108-.694.108-2.368.384-3.518 2.458-.052.093-.359.71-.648 1.827-1.063 4.115-6.049 25.196-6.077 25.33-3.956 18.596-4.014 36.162-1.344 54.852.183 1.281.502 3.028.854 5.021Zm7.599-81.721c1.207 1.648 2.761 2.1 4.396 1.903a4.873 4.873 0 0 1-4.396-1.903Zm7.956-.257c-1.037 1.625-2.405 1.973-3.133 2.098a4.845 4.845 0 0 0 1.776-.734 4.84 4.84 0 0 0 1.357-1.364Z\" style=\"fill:#0b00ff\" transform=\"translate(-320.133 -88.683)\"/><path d=\"M463.917 344.892a29.243 29.243 0 0 1 2.547-.002c4.668.248 9.715.949 11.603.949 14.005 0 27.968-2.735 42.084-1.726 5.107.364 10.222.869 15.349.869.59 0 3.812.191 5.57-.024 1.306-.161 2.29-.574 2.862-.931 1.845-1.149 2.446-2.763 2.446-4.351a4.88 4.88 0 0 0-6.98-4.403 833.022 833.022 0 0 0-3.898-.047c-4.895 0-9.778-.496-14.654-.845-14.349-1.025-28.544 1.702-42.779 1.702-2.143 0-8.469-.952-13.513-1.02-2.85-.038-5.379.237-7.04.814-3.149 1.095-4.564 3.248-4.787 5.616-.147 1.564.27 3.888 2.779 6.535a4.881 4.881 0 0 0 6.896.184 4.86 4.86 0 0 0 1.515-3.32Zm72.711-5.458c-.004.08-.006.161-.006.242l.006-.242Zm.212-1.201Z\" style=\"fill:#e63025\" transform=\"translate(-324.225 -87.076)\"/><path d=\"M585.591 268.866a4.871 4.871 0 0 0 3.913 1.967 4.88 4.88 0 0 0 4.878-4.878c0-2.028-.665-3.495-1.567-4.593-.944-1.149-2.232-1.958-3.837-2.341-1.243-.297-2.767-.316-4.361-.054-2.559.422-5.382 1.575-6.586 2.131-3.938 1.817-7.22 4.618-11.144 6.429-3.926 1.812-7.332 2.265-10.495 3.121-4.208 1.138-8.09 2.791-12.091 7.117a4.88 4.88 0 0 0 .269 6.893 4.88 4.88 0 0 0 6.893-.269c3.058-3.306 6.085-4.016 9.407-4.808 3.09-.737 6.392-1.482 10.105-3.196 3.924-1.811 7.207-4.612 11.144-6.429.534-.247 2.273-.754 3.472-1.09ZM387.15 262.967a4.882 4.882 0 0 0 4.623 3.766 4.861 4.861 0 0 0 3.744-1.605c.403.186.803.375 1.19.564 4.549 2.22 11.175 6.153 12.462 6.922.586 1.135 2.551 4.904 4.138 7.608 1.812 3.088 3.902 5.856 5.626 7.12 1.653 1.212 3.312 1.58 4.745 1.452 1.359-.121 2.668-.651 3.834-1.817a4.88 4.88 0 0 0 0-6.898 4.863 4.863 0 0 0-3.412-1.427c-.862-1.19-2.442-3.431-3.352-5.082-1.877-3.405-3.496-6.593-4.054-7.275-.455-.556-1.669-1.601-3.513-2.76-2.899-1.82-7.802-4.467-12.195-6.611-3.035-1.481-5.839-2.722-7.628-3.339-1.426-.493-2.533-.651-3.156-.651-2.255 0-3.429 1.045-4.134 1.919-.786.974-1.25 2.191-1.102 3.712.058.596.243 1.368.699 2.211.261.482 1.146 1.722 1.485 2.191Zm33.595 16.987c-.045.04-.089.081-.132.125l.132-.125Z\" style=\"fill:#0b00ff\" transform=\"translate(-320.133 -88.683)\"/></svg>",
"_____no_output_____"
],
[
"%%html\n<svg width=\"300\" viewBox=\"0 0 348 316\" style=\"background-color:hotpink;\" ><path d=\"M486.164 398.146c2.45.093 12.441.502 15.805 1.174 11.935 2.387 23.571 1.381 35.674 1.381 20.092 0 48.896-3.66 73.566-12.632 16.986-6.177 31.996-14.917 41.252-26.488 19.944-24.929 18.465-56.276 8.519-85.211-15.674-45.595-44.719-80.416-86.639-104.235-31.185-17.718-69.82-28.067-105.704-28.067-87.093 0-172.7 76.964-142.21 168.433 4.568 13.705 11.67 27.178 20.466 38.706 25.816 33.834 68.594 47.593 108.706 52.617a4.874 4.874 0 0 0 1.534-.051l29.031-5.627Zm-1.628-9.622-28.493 5.522h-.002c-37.391-4.784-77.35-17.249-101.392-48.757-8.152-10.684-14.733-23.172-18.966-35.873-28.308-84.922 52.095-155.592 132.954-155.592 34.248 0 71.121 9.883 100.885 26.794 39.786 22.606 67.356 55.65 82.232 98.924 8.857 25.766 10.848 53.745-6.911 75.945-8.263 10.328-21.807 17.9-36.968 23.414-23.551 8.564-51.052 12.044-70.232 12.044-11.452 0-22.467 1.067-33.761-1.191-3.798-.76-15.293-1.281-17.549-1.365-.297-.011-.472-.015-.503-.016a4.706 4.706 0 0 0-1.294.151Z\" style=\"fill:#0800ff\" transform=\"translate(-320.133 -88.683)\"/><path d=\"M433.374 178.23c-.615 3.031-2.362 10.974-2.126 16.825.157 3.876 1.319 7.011 3.08 8.773 1.228 1.228 2.505 1.552 3.595 1.588a5.1 5.1 0 0 0 2.939-.797c.695-.436 1.483-1.171 2.072-2.316.52-1.01.958-2.995 1.248-4.013.801-2.802.821-7.009.35-11.457-.3-2.837-.775-5.789-1.232-8.435 4.57-21.973 12.196-39.671 23.939-59.072 2.511-4.148 7.67-11.16 11.734-15.941.36 5.596-.345 12.302-.203 14.577 1.092 17.465 7.185 34.175 8.142 51.399.14 2.535-.764 8.912-.429 13.405.251 3.364 1.338 5.978 2.707 7.346 1.388 1.388 2.852 1.671 4.143 1.58 1.193-.084 2.465-.553 3.563-1.742.59-.638 1.286-1.819 1.741-3.304.409-1.333.808-3.523.885-3.961.956-3.406 3.184-10.014 4.162-12.873 4.347-12.706 8.651-25.402 13.927-37.762-.121 2.311-.324 4.621-.648 6.725-2.541 16.517-4.013 33.221 1.968 49.172.845 2.253 2.388 3.135 3.873 3.477 1.355.312 4.137.06 6.556-2.921 4.148-5.109 12.571-23.639 13.435-25.244 3.866-7.179 13.565-26.837 22.755-39.461.377-.517.749-1.023 1.119-1.515-.269 2.453-.564 5.075-.868 7.663-.81 6.883-.073 14.213.406 21.467.42 6.35.668 12.639-1.085 18.4-1.41 4.632-5.697 9.626-8.806 14.597-2.766 4.422-4.692 8.866-4.692 12.968a4.88 4.88 0 0 0 4.878 4.878 4.88 4.88 0 0 0 4.878-4.878c0-3.311 2.455-6.753 4.865-10.334 3.292-4.892 6.827-9.847 8.21-14.39 2.087-6.856 1.987-14.328 1.487-21.885-.44-6.651-1.194-13.371-.452-19.683 1.196-10.169 2.193-19.205 2.209-20.84.033-3.396-2.399-4.512-2.8-4.704-1.23-.589-2.537-.683-3.922-.128-3.852 1.54-8.633 6.213-13.314 12.642-9.457 12.989-19.48 33.191-23.458 40.578-.584 1.086-4.781 10.49-8.531 17.43-2.329-11.748-.91-23.836.932-35.806 1.598-10.388.926-22.874.529-25.203-.817-4.798-5.454-4.436-6.105-4.273-2.882.721-5.414 2.944-7.306 6.031-1.86 3.033-3.144 6.937-4.123 9.176-5.16 11.794-9.404 23.903-13.571 36.058-1.851-14.884-6.574-29.504-7.523-44.694-.171-2.738.807-11.733-.137-17.811-.671-4.324-2.541-7.456-4.825-8.802-.915-.54-2.048-.864-3.437-.656-.873.13-2.563.789-4.414 2.508-4.24 3.937-13.125 15.608-16.802 21.683-7.762 12.824-13.802 24.947-18.409 37.921-.26-10.551.623-20.994 2.923-31.809.028-.132 4.935-20.87 5.981-24.919l.09-.34a4.866 4.866 0 0 0-.563-4.278c-1.289-1.926-3.007-2.389-4.807-2.108-.694.108-2.368.384-3.518 2.458-.052.093-.359.71-.648 1.827-1.063 4.115-6.049 25.196-6.077 25.33-3.956 18.596-4.014 36.162-1.344 54.852.183 1.281.502 3.028.854 5.021Zm7.599-81.721c1.207 1.648 2.761 2.1 4.396 1.903a4.873 4.873 0 0 1-4.396-1.903Zm7.956-.257c-1.037 1.625-2.405 1.973-3.133 2.098a4.845 4.845 0 0 0 1.776-.734 4.84 4.84 0 0 0 1.357-1.364Z\" style=\"fill:#0b00ff\" transform=\"translate(-320.133 -88.683)\"/><path d=\"M463.917 344.892a29.243 29.243 0 0 1 2.547-.002c4.668.248 9.715.949 11.603.949 14.005 0 27.968-2.735 42.084-1.726 5.107.364 10.222.869 15.349.869.59 0 3.812.191 5.57-.024 1.306-.161 2.29-.574 2.862-.931 1.845-1.149 2.446-2.763 2.446-4.351a4.88 4.88 0 0 0-6.98-4.403 833.022 833.022 0 0 0-3.898-.047c-4.895 0-9.778-.496-14.654-.845-14.349-1.025-28.544 1.702-42.779 1.702-2.143 0-8.469-.952-13.513-1.02-2.85-.038-5.379.237-7.04.814-3.149 1.095-4.564 3.248-4.787 5.616-.147 1.564.27 3.888 2.779 6.535a4.881 4.881 0 0 0 6.896.184 4.86 4.86 0 0 0 1.515-3.32Zm72.711-5.458c-.004.08-.006.161-.006.242l.006-.242Zm.212-1.201Z\" style=\"fill:#e63025\" transform=\"translate(-324.225 -87.076)\"/><path d=\"M585.591 268.866a4.871 4.871 0 0 0 3.913 1.967 4.88 4.88 0 0 0 4.878-4.878c0-2.028-.665-3.495-1.567-4.593-.944-1.149-2.232-1.958-3.837-2.341-1.243-.297-2.767-.316-4.361-.054-2.559.422-5.382 1.575-6.586 2.131-3.938 1.817-7.22 4.618-11.144 6.429-3.926 1.812-7.332 2.265-10.495 3.121-4.208 1.138-8.09 2.791-12.091 7.117a4.88 4.88 0 0 0 .269 6.893 4.88 4.88 0 0 0 6.893-.269c3.058-3.306 6.085-4.016 9.407-4.808 3.09-.737 6.392-1.482 10.105-3.196 3.924-1.811 7.207-4.612 11.144-6.429.534-.247 2.273-.754 3.472-1.09ZM387.15 262.967a4.882 4.882 0 0 0 4.623 3.766 4.861 4.861 0 0 0 3.744-1.605c.403.186.803.375 1.19.564 4.549 2.22 11.175 6.153 12.462 6.922.586 1.135 2.551 4.904 4.138 7.608 1.812 3.088 3.902 5.856 5.626 7.12 1.653 1.212 3.312 1.58 4.745 1.452 1.359-.121 2.668-.651 3.834-1.817a4.88 4.88 0 0 0 0-6.898 4.863 4.863 0 0 0-3.412-1.427c-.862-1.19-2.442-3.431-3.352-5.082-1.877-3.405-3.496-6.593-4.054-7.275-.455-.556-1.669-1.601-3.513-2.76-2.899-1.82-7.802-4.467-12.195-6.611-3.035-1.481-5.839-2.722-7.628-3.339-1.426-.493-2.533-.651-3.156-.651-2.255 0-3.429 1.045-4.134 1.919-.786.974-1.25 2.191-1.102 3.712.058.596.243 1.368.699 2.211.261.482 1.146 1.722 1.485 2.191Zm33.595 16.987c-.045.04-.089.081-.132.125l.132-.125Z\" style=\"fill:#0b00ff\" transform=\"translate(-320.133 -88.683)\"/></svg>\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4a435b130bb743dfe22995cc0fad65d9ed97be94
| 10,615 |
ipynb
|
Jupyter Notebook
|
examples/gwo_hourly_example.ipynb
|
jsasaki-utokyo/metdata
|
063bdcdeef92e98bcc76372bbd0b98c57cc43849
|
[
"MIT"
] | null | null | null |
examples/gwo_hourly_example.ipynb
|
jsasaki-utokyo/metdata
|
063bdcdeef92e98bcc76372bbd0b98c57cc43849
|
[
"MIT"
] | null | null | null |
examples/gwo_hourly_example.ipynb
|
jsasaki-utokyo/metdata
|
063bdcdeef92e98bcc76372bbd0b98c57cc43849
|
[
"MIT"
] | 1 |
2022-02-12T02:14:16.000Z
|
2022-02-12T02:14:16.000Z
| 29.817416 | 260 | 0.56618 |
[
[
[
"# Pocessing GWO hourly meteorological data\n**Author: Jun Sasaki Coded on February 13, 2022 Updated on February 14, 2022.**<br>\nExtract and plot GWO (Ground Weather Observation) hourly data.",
"_____no_output_____"
]
],
[
[
"from metdata import gwo\nfrom datetime import datetime\nimport matplotlib.pyplot as plt\nfrom matplotlib.ticker import MultipleLocator, FormatStrFormatter\nfrom matplotlib.dates import date2num, YearLocator, MonthLocator, DayLocator, DateFormatter\nimport pandas as pd\nimport numpy as np\nfrom pandas.plotting import register_matplotlib_converters\n\n# Set GWO/Hourly/ directory path containing GWO data\ndirpath = \"d:/dat/met/JMA_DataBase/GWO/Hourly/\"\n%matplotlib inline",
"_____no_output_____"
],
[
"datetime_ini = \"2020-12-1 00:00:00\"\ndatetime_end = \"2021-12-30 00:00:00\"\n#datetime_ini = \"2010-9-2 00:00:00\"\n#datetime_end = \"2010-9-3 00:00:00\"\nstn = \"Tokyo\"\nmet = gwo.Hourly(datetime_ini=datetime_ini, datetime_end=datetime_end,\n stn=stn, dirpath=dirpath)",
"_____no_output_____"
]
],
[
[
"## Gets pandas DataFrame\npandas DataFrame can be obtained by invoking `.df` method",
"_____no_output_____"
]
],
[
[
"print(met.df.columns)\nmet.df.head()",
"_____no_output_____"
]
],
[
[
"# Plot using [Matplotlib](https://matplotlib.org/stable/index.html)\nExtract a 1D scalar or vector variable from DataFrame.",
"_____no_output_____"
]
],
[
[
"data = gwo.Data1D(df=met.df, col_1='kion')",
"_____no_output_____"
]
],
[
[
"## Example of scalar 1-D time series plot\n- Rolling mean is applied to `Plot1D()` by setting its arguments of `window` in odd integer number and `center` (default is `True`).",
"_____no_output_____"
]
],
[
[
"### xlim = (parse(\"2014-01-15\"), parse(\"2014-02-16\")) ### ex. for datetime\nylabel='Temperature (degC)'\nxlim = None\n#xlim = (parse(\"1990-09-02\"), parse(\"1992-09-03\"))\ndx = 7\nylim = None\ndy = 2\n\n## Set window=1 when no plot.\nwindow=1\n#try:\nplot_config = gwo.Data1D_PlotConfig(xlim=xlim, ylim=ylim, \n x_minor_locator=DayLocator(interval=dx),\n y_minor_locator = MultipleLocator(dy),\n format_xdata = DateFormatter('%Y-%m-%d'),\n ylabel = ylabel)\ngwo.Plot1D(plot_config, data, window=window,\n center=True).save_plot('data.png', dpi=600)",
"_____no_output_____"
]
],
[
[
"## Example of time series wind vector plot with its speed",
"_____no_output_____"
]
],
[
[
"wind = gwo.Data1D(met.df, 'u', 'v')\nprint(wind.v[0:10])",
"_____no_output_____"
],
[
"#xlim = (parse(\"2013-12-25 00:00:00\"),parse(\"2014-01-10 00:00:00\"))\nvlabel = 'Wind speed (m/s)'\nylabel = 'Wind vector (m/s)'\npng_vector = \"gwo_hourly_wind.png\"\nxlim = None\n#xlim = (parse(\"1990-09-02\"), parse(\"1990-09-03\"))\ndx = 7 # x_minor_locator interval\n#ylim = None\nylim = (-15, 15)\ndy = 1 # y_minor_locator interval\nwindow=25 # Rolling mean window in odd integer; center: rolling mean at center\nmagnitude = True # True: Plot magnitudes, False: No magnitudes\n\nplot_config = gwo.Data1D_PlotConfig(xlim = xlim, ylim = ylim,\n x_minor_locator = DayLocator(interval=dx),\n y_minor_locator = MultipleLocator(dy),\n format_xdata = DateFormatter('%Y-%m-%d'),\n ylabel=ylabel, vlabel=vlabel, vlabel_loc = 'lower center')\ngwo.Plot1D(plot_config, wind, window=window, \n center=True).save_vector_plot(png_vector, \n magnitude = magnitude, dpi=600)",
"_____no_output_____"
]
],
[
[
"# Plot using [hvPlot](https://hvplot.holoviz.org/)\nThis is for interactive plotting but not suitable for saving graphics into files.",
"_____no_output_____"
]
],
[
[
"import hvplot.pandas",
"_____no_output_____"
],
[
"data.df[['kion', 'sped']].hvplot()",
"_____no_output_____"
],
[
"def hook(plot, element):\n plot.handles['xaxis'].axis_label_text_font_style = 'normal'\n plot.handles['yaxis'].axis_label_text_font_style = 'normal'",
"_____no_output_____"
]
],
[
[
"### How to specify options for hvPlot (オプション指定方法)\n- Many of the Holoviews options can be specified with the hvPlot argument.\n- `hooks` defines the function `hook(plot, element)`, which is specified in hvPlot as `.opts(hooks=[hook])`. Unconfirmed, but it seems that all options can be specified, including Bokeh options that are not defined as arguments in hvPlot or Holoviews.\n- 基本的にはhvplotの引数でHoloviewsのオプションの多くが指定できる\n- `hooks`は関数`hook(plot, element)`を定義し,hvPlotで`.opts(hooks=[hook])`として指定する.未確認だが,hvPlotやHoloviewsの引数としては定義されていないBokehのオプションを含め,すべてのオプションが指定できそう",
"_____no_output_____"
]
],
[
[
"data.df['kion'].hvplot(xlim=(datetime(2020,1,2), datetime(2020,3,4)), \n xticks=10, ylabel='Temperature (degC)',\n ylim=(-4,35), yticks=10, width=600, height=200,\n line_color='red', line_width=0.5,\n fontsize={'xticks':12,'yticks':12 ,'ylabel':14},\n title='').opts(hooks=[hook])",
"_____no_output_____"
]
],
[
[
"# Check missing rows in DataFrame.",
"_____no_output_____"
]
],
[
[
"datetime_ini = \"2010-9-2 00:00:00\"\ndatetime_end = \"2010-9-2 23:00:00\"\nstn = \"Chiba\"\ndirpath = \"d:/dat/met/JMA_DataBase/GWO/Hourly/\"\n\nmet_check = gwo.Check(datetime_ini=datetime_ini, datetime_end=datetime_end,\n stn=stn, dirpath=dirpath)\n## Create a complete pandas DatetieIndex\ndatetime_index = pd.date_range(datetime_ini, datetime_end, freq='H')",
"_____no_output_____"
],
[
"met_check.df.index",
"_____no_output_____"
],
[
"datetime_index.values[0] in met_check.df.index.values",
"_____no_output_____"
]
],
[
[
"### Create a mask for extracting missing rows\n- [`np.isis(https://numpy.org/doc/stable/reference/generated/numpy.isin.html)`]()\n- [`np.logical_not()`](https://numpy.org/doc/stable/reference/generated/numpy.logical_not.html).",
"_____no_output_____"
]
],
[
[
"mask = np.logical_not(np.isin(datetime_index, met_check.df.index))\ndatetime_index[mask]",
"_____no_output_____"
],
[
"mask",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a435c4b1b9ed7105e9133c4fae07fe4f4881d55
| 10,552 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/1_statistics-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/1_statistics-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/1_statistics-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null | 31.404762 | 1,207 | 0.544067 |
[
[
[
"#### Measures of central tendencies",
"_____no_output_____"
]
],
[
[
"from typing import List",
"_____no_output_____"
],
[
"daily_minutes = [1,68.77,51.25,52.08,38.36,44.54,57.13,51.4,41.42,31.22,34.76,54.01,38.79,47.59,49.1,27.66,41.03,36.73,48.65,28.12,46.62,35.57,32.98,35,26.07,23.77,39.73,40.57,31.65,31.21,36.32,20.45,21.93,26.02,27.34,23.49,46.94,30.5,33.8,24.23,21.4,27.94,32.24,40.57,25.07,19.42,22.39,18.42,46.96,23.72,26.41,26.97,36.76,40.32,35.02,29.47,30.2,31,38.11,38.18,36.31,21.03,30.86,36.07,28.66,29.08,37.28,15.28,24.17,22.31,30.17,25.53,19.85,35.37,44.6,17.23,13.47,26.33,35.02,32.09,24.81,19.33,28.77,24.26,31.98,25.73,24.86,16.28,34.51,15.23,39.72,40.8,26.06,35.76,34.76,16.13,44.04,18.03,19.65,32.62,35.59,39.43,14.18,35.24,40.13,41.82,35.45,36.07,43.67,24.61,20.9,21.9,18.79,27.61,27.21,26.61,29.77,20.59,27.53,13.82,33.2,25,33.1,36.65,18.63,14.87,22.2,36.81,25.53,24.62,26.25,18.21,28.08,19.42,29.79,32.8,35.99,28.32,27.79,35.88,29.06,36.28,14.1,36.63,37.49,26.9,18.58,38.48,24.48,18.95,33.55,14.24,29.04,32.51,25.63,22.22,19,32.73,15.16,13.9,27.2,32.01,29.27,33,13.74,20.42,27.32,18.23,35.35,28.48,9.08,24.62,20.12,35.26,19.92,31.02,16.49,12.16,30.7,31.22,34.65,13.13,27.51,33.2,31.57,14.1,33.42,17.44,10.12,24.42,9.82,23.39,30.93,15.03,21.67,31.09,33.29,22.61,26.89,23.48,8.38,27.81,32.35,23.84]\ndaily_hours = [x_i / 60 for x_i in daily_minutes]\nnum_friends = [100.0,49,41,40,25,21,21,19,19,18,18,16,15,15,15,15,14,14,13,13,13,13,12,12,11,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,9,8,8,8,8,8,8,8,8,8,8,8,8,8,7,7,7,7,7,7,7,7,7,7,7,7,7,7,7,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,6,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,5,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,4,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]",
"_____no_output_____"
],
[
"def mean(xs: List[float]) -> float:\n return sum(xs) / len(xs)\n\nassert mean([1,1,1]) == 1\nassert mean([5,3]) == 4",
"_____no_output_____"
],
[
"# underscore is used to denote a private function\ndef _median_odd(xs:List[float]) -> float:\n \"\"\"if len(xs) is odd, the median is the middle element\"\"\"\n return sorted(xs)[len(xs) // 2]",
"_____no_output_____"
],
[
"def _median_even(xs:List[float]) -> float:\n \"\"\"If len(xs) is even, it's the average of the middle two elements\"\"\"\n sorted_xs = sorted(xs)\n hi_midpoint = len(xs) // 2\n low_midpoint = hi_midpoint - 1\n return (sorted_xs[hi_midpoint] + sorted_xs[low_midpoint]) / 2",
"_____no_output_____"
],
[
"def median(v: List[float]) -> float:\n \"\"\"Finds the 'middle-most value of v\"\"\"\n return _median_even(v) if len(v) % 2 == 0 else _median_odd(v)\n \n\nassert median([1, 10, 2, 9, 5]) == 5\nassert median([1, 9, 2, 10]) == (2 + 9) / 2",
"_____no_output_____"
],
[
"def quantile(xs: List[float], p: float) -> float:\n \"\"\"Returns the pth percentile vakue in x\"\"\"\n p_index = int(p * len(xs))\n return sorted(xs)[p_index]",
"_____no_output_____"
],
[
"assert quantile(num_friends, 0.10) == 1\nassert quantile(num_friends, 0.25) == 3\nassert quantile(num_friends, 0.75) == 9\nassert quantile(num_friends, 0.90) == 13",
"_____no_output_____"
],
[
"from collections import Counter",
"_____no_output_____"
],
[
"def mode(x: List[float]) -> List[float]:\n \"\"\"Returns a list, since there might be more then one mode\"\"\"\n counts = Counter(x)\n max_count = max(counts.values())\n return [x_i for x_i, count in counts.items()\n if count == max_count]\n\nassert set(mode(num_friends)) == {1,6}",
"_____no_output_____"
]
],
[
[
"#### Dispersion",
"_____no_output_____"
]
],
[
[
"def data_range(xs: List[float]) -> float:\n return max(xs) - min(xs)\n\nassert data_range(num_friends) == 99",
"_____no_output_____"
],
[
"from linear_algebra import sum_of_squares",
"_____no_output_____"
],
[
"def de_mean(xs: List[float]) -> List[float]:\n \"\"\"Translate xs by subtrating its mean(so result as mean 0)\"\"\"\n x_bar = mean(xs)\n return [x - x_bar for x in xs]",
"_____no_output_____"
],
[
"# sample of the large population (n-1) therefore almost the average square deviation from its mean\n# how a single variable deviates from its mean\n\ndef variance(xs: List[float]) -> float:\n \"\"\"Almost the average square deviation from the mean\"\"\"\n \n assert len(xs) >= 2, \"variance requires at least two elements\"\n n = len(xs)\n deviations = de_mean(xs)\n return sum_of_squares(deviations) / (n -1)\n\nassert 81.54 < variance(num_friends) < 81.55",
"_____no_output_____"
],
[
"import math",
"_____no_output_____"
],
[
"# variance as a different unit to mean, range.. in this case it would be friends**2; std deviation reverts back to original unit \n# suffers from the same outlier problem as the mean\n\ndef standard_deviation(xs: List[float]) -> float:\n \"\"\" The standard deviation is the square root of the variance\"\"\"\n return math.sqrt(variance(xs))\n\nassert 0.02 < standard_deviation(num_friends) < 9.04",
"_____no_output_____"
],
[
"# plainly unaffected by small number of outliers\n\ndef interquartile_range(xs: List[float]) -> float:\n \"\"\"Returns de difference of the 75%-ile and the 25%-ile\"\"\"\n return quantile(xs, 0.75) - quantile(xs, 0.25)\n\nassert interquartile_range(num_friends) == 6",
"_____no_output_____"
]
],
[
[
"#### Correlation",
"_____no_output_____"
]
],
[
[
"from linear_algebra import dot",
"_____no_output_____"
],
[
"# covariance can be difficult to interpret; a \"large \" positive number means when x is up so does y \n# and \"large\" negative when x is large but y is small. closer to zero nocovariance\n\ndef covariance(xs: List[float], ys: List[float]) -> float:\n assert len(xs) == len(ys), \"xs and ys must have the same sumber of elements\"\n \n n = len(xs) \n return dot(de_mean(xs), de_mean(ys)) / (n - 1)\n\nassert 22.42 < covariance(num_friends, daily_minutes) < 22.43\nassert 22.42 / 60 < covariance(num_friends, daily_hours) < 22.43 / 60 ",
"_____no_output_____"
],
[
"# the correlation in unitless and always lies between -1 (perfect anticorrelation) and 1 (perfect correlation)\n# correlation measures relation between varables ALL ELSE BEING EQUAL (SEE PAG 72)\n\ndef correlation(xs: List[float], ys: List[float]) -> float:\n \"\"\"Measures how much xs and ys vary in tandem about their means\"\"\"\n \n stdev_x = standard_deviation(xs)\n stdev_y = standard_deviation(ys)\n if stdev_x > 0 and stdev_y > 0:\n return covariance(xs, ys) / stdev_x / stdev_y\n else:\n return 0 # if no variation, correlation is zero\n\nassert 0.24 < correlation(num_friends, daily_minutes) < 0.25\nassert 0.24 < correlation(num_friends, daily_hours) < 0.25",
"_____no_output_____"
],
[
"# remove one outlier, 100 seems incorrect data point\n\noutlier = num_friends.index(100)\n\nnum_friends_good = [friends\n for idx, friends in enumerate(num_friends)\n if idx != outlier]\n\ndaily_minutes_good = [minutes\n for idx, minutes in enumerate(daily_minutes)\n if idx != outlier]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a437da9b421f9b16812bee8d4970255134d2caa
| 33,632 |
ipynb
|
Jupyter Notebook
|
casestudies/margin_analysis.ipynb
|
wesleybeckner/ds_for_engineers
|
b66e97d6b021d222fdda98798fefd5469b2cc6b9
|
[
"MIT"
] | 1 |
2021-11-14T13:06:35.000Z
|
2021-11-14T13:06:35.000Z
|
casestudies/margin_analysis.ipynb
|
wesleybeckner/ds_for_engineers
|
b66e97d6b021d222fdda98798fefd5469b2cc6b9
|
[
"MIT"
] | null | null | null |
casestudies/margin_analysis.ipynb
|
wesleybeckner/ds_for_engineers
|
b66e97d6b021d222fdda98798fefd5469b2cc6b9
|
[
"MIT"
] | null | null | null | 33,632 | 33,632 | 0.620213 |
[
[
[
"pip install jupyter-dash",
"Collecting jupyter-dash\n Downloading https://files.pythonhosted.org/packages/46/21/d3893ad0b7a7061115938d6c38f5862522d45c4199fb7e8fde0765781e13/jupyter_dash-0.4.0-py3-none-any.whl\nRequirement already satisfied: ipython in /usr/local/lib/python3.7/dist-packages (from jupyter-dash) (5.5.0)\nCollecting dash\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/bc/b4/0bd5c94fdcb0eccb93c3c8068fe10f5607e542337d0b8f6e2d88078316a9/dash-1.19.0.tar.gz (75kB)\n\u001b[K |████████████████████████████████| 81kB 3.4MB/s \n\u001b[?25hRequirement already satisfied: ipykernel in /usr/local/lib/python3.7/dist-packages (from jupyter-dash) (4.10.1)\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from jupyter-dash) (2.23.0)\nRequirement already satisfied: retrying in /usr/local/lib/python3.7/dist-packages (from jupyter-dash) (1.3.3)\nRequirement already satisfied: flask in /usr/local/lib/python3.7/dist-packages (from jupyter-dash) (1.1.2)\nCollecting ansi2html\n Downloading https://files.pythonhosted.org/packages/c6/85/3a46be84afbb16b392a138cd396117f438c7b2e91d8dc327621d1ae1b5dc/ansi2html-1.6.0-py3-none-any.whl\nRequirement already satisfied: traitlets>=4.2 in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (5.0.5)\nRequirement already satisfied: pygments in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (2.6.1)\nRequirement already satisfied: pickleshare in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (0.7.5)\nRequirement already satisfied: setuptools>=18.5 in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (54.1.2)\nRequirement already satisfied: decorator in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (4.4.2)\nRequirement already satisfied: pexpect; sys_platform != \"win32\" in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (4.8.0)\nRequirement already satisfied: simplegeneric>0.8 in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (0.8.1)\nRequirement already satisfied: prompt-toolkit<2.0.0,>=1.0.4 in /usr/local/lib/python3.7/dist-packages (from ipython->jupyter-dash) (1.0.18)\nCollecting flask-compress\n Downloading https://files.pythonhosted.org/packages/c6/d5/69b13600230d24310b98a52da561113fc01a5c17acf77152761eef3e50f1/Flask_Compress-1.9.0-py3-none-any.whl\nRequirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (from dash->jupyter-dash) (4.4.1)\nCollecting dash_renderer==1.9.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/be/a6/dd1edfe7b1102274e93991736c35b2a5e1a63b524c8d9f41bbb30f17340b/dash_renderer-1.9.0.tar.gz (1.0MB)\n\u001b[K |████████████████████████████████| 1.0MB 6.5MB/s \n\u001b[?25hCollecting dash-core-components==1.15.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/22/78/ae0829e673f3df77403bcdb35073b1ed2f156080f5bcac6f21c1047d73fe/dash_core_components-1.15.0.tar.gz (3.5MB)\n\u001b[K |████████████████████████████████| 3.5MB 9.1MB/s \n\u001b[?25hCollecting dash-html-components==1.1.2\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/3f/25/56de2708128fe375eecc2e18e0ccdc3a853494966e36334ec8a30be99b94/dash_html_components-1.1.2.tar.gz (188kB)\n\u001b[K |████████████████████████████████| 194kB 27.7MB/s \n\u001b[?25hCollecting dash-table==4.11.2\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/3d/ae/96cb64b58d76391604b57f8c747f9a19ab2122e7ba214e2e0cf35484962b/dash_table-4.11.2.tar.gz (1.8MB)\n\u001b[K |████████████████████████████████| 1.8MB 14.3MB/s \n\u001b[?25hRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from dash->jupyter-dash) (0.16.0)\nRequirement already satisfied: jupyter-client in /usr/local/lib/python3.7/dist-packages (from ipykernel->jupyter-dash) (5.3.5)\nRequirement already satisfied: tornado>=4.0 in /usr/local/lib/python3.7/dist-packages (from ipykernel->jupyter-dash) (5.1.1)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->jupyter-dash) (2.10)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->jupyter-dash) (2020.12.5)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->jupyter-dash) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->jupyter-dash) (1.24.3)\nRequirement already satisfied: six>=1.7.0 in /usr/local/lib/python3.7/dist-packages (from retrying->jupyter-dash) (1.15.0)\nRequirement already satisfied: click>=5.1 in /usr/local/lib/python3.7/dist-packages (from flask->jupyter-dash) (7.1.2)\nRequirement already satisfied: Werkzeug>=0.15 in /usr/local/lib/python3.7/dist-packages (from flask->jupyter-dash) (1.0.1)\nRequirement already satisfied: itsdangerous>=0.24 in /usr/local/lib/python3.7/dist-packages (from flask->jupyter-dash) (1.1.0)\nRequirement already satisfied: Jinja2>=2.10.1 in /usr/local/lib/python3.7/dist-packages (from flask->jupyter-dash) (2.11.3)\nRequirement already satisfied: ipython-genutils in /usr/local/lib/python3.7/dist-packages (from traitlets>=4.2->ipython->jupyter-dash) (0.2.0)\nRequirement already satisfied: ptyprocess>=0.5 in /usr/local/lib/python3.7/dist-packages (from pexpect; sys_platform != \"win32\"->ipython->jupyter-dash) (0.7.0)\nRequirement already satisfied: wcwidth in /usr/local/lib/python3.7/dist-packages (from prompt-toolkit<2.0.0,>=1.0.4->ipython->jupyter-dash) (0.2.5)\nCollecting brotli\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/15/ea/5bd575511b37bbd1c794606a0a621e6feff8e96b7dd007a86a5d218b2d94/Brotli-1.0.9-cp37-cp37m-manylinux1_x86_64.whl (357kB)\n\u001b[K |████████████████████████████████| 358kB 46.2MB/s \n\u001b[?25hRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from jupyter-client->ipykernel->jupyter-dash) (2.8.1)\nRequirement already satisfied: pyzmq>=13 in /usr/local/lib/python3.7/dist-packages (from jupyter-client->ipykernel->jupyter-dash) (22.0.3)\nRequirement already satisfied: jupyter-core>=4.6.0 in /usr/local/lib/python3.7/dist-packages (from jupyter-client->ipykernel->jupyter-dash) (4.7.1)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.7/dist-packages (from Jinja2>=2.10.1->flask->jupyter-dash) (1.1.1)\nBuilding wheels for collected packages: dash, dash-renderer, dash-core-components, dash-html-components, dash-table\n Building wheel for dash (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash: filename=dash-1.19.0-cp37-none-any.whl size=84011 sha256=e13d18811fb1e6f0f08b5c7943a57dad9e99c7a04b0e6ee256b32981295e7a6e\n Stored in directory: /root/.cache/pip/wheels/f7/50/a7/a230ff7f503b10120bff18c2524a375bb85a61ce6b519c8a77\n Building wheel for dash-renderer (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash-renderer: filename=dash_renderer-1.9.0-cp37-none-any.whl size=1014870 sha256=1722245aabcb456216a37ec77b7579139d6dbec068690bcf3e8cd8cd699d8075\n Stored in directory: /root/.cache/pip/wheels/46/a0/ec/2be2e8fc750e623d76f9690c397cc5ab28b33d0a16a49e10c5\n Building wheel for dash-core-components (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash-core-components: filename=dash_core_components-1.15.0-cp37-none-any.whl size=3527014 sha256=dc1e4dab784f7f42053a2fbfdc3a52df4a13956741954aff7162e4fff0b1ee97\n Stored in directory: /root/.cache/pip/wheels/53/3d/be/d628d6f66eedf9597f0c89c8ff43a5020ad1c25152c77d8e9f\n Building wheel for dash-html-components (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash-html-components: filename=dash_html_components-1.1.2-cp37-none-any.whl size=427830 sha256=c0b283278617e4b4207c82e52bce6738603933cd34cc21b707891b02712db3c7\n Stored in directory: /root/.cache/pip/wheels/44/95/70/0dc41f9b4e31b8a7ea22193aad5647b2c85cfab37bf13c0242\n Building wheel for dash-table (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash-table: filename=dash_table-4.11.2-cp37-none-any.whl size=1839869 sha256=6ea20e7862a7b0b85140d803c433ffec0727780cef69c9aba84bf07a6b5d99d6\n Stored in directory: /root/.cache/pip/wheels/72/d9/f6/2ad62ac0037f1f0c0d3d10948a596b594a069057df0656ac3f\nSuccessfully built dash dash-renderer dash-core-components dash-html-components dash-table\nInstalling collected packages: brotli, flask-compress, dash-renderer, dash-core-components, dash-html-components, dash-table, dash, ansi2html, jupyter-dash\nSuccessfully installed ansi2html-1.6.0 brotli-1.0.9 dash-1.19.0 dash-core-components-1.15.0 dash-html-components-1.1.2 dash-renderer-1.9.0 dash-table-4.11.2 flask-compress-1.9.0 jupyter-dash-0.4.0\n"
],
[
"pip install dash_daq",
"Collecting dash_daq\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/16/c1/9c6adfc3646990965a5b2ca073f579cc9c09d15553fcfcd83aefd1255494/dash_daq-0.5.0.tar.gz (642kB)\n\u001b[K |████████████████████████████████| 645kB 4.3MB/s \n\u001b[?25hRequirement already satisfied: dash>=1.6.1 in /usr/local/lib/python3.7/dist-packages (from dash_daq) (1.19.0)\nRequirement already satisfied: dash-core-components==1.15.0 in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (1.15.0)\nRequirement already satisfied: Flask>=1.0.4 in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (1.1.2)\nRequirement already satisfied: dash-renderer==1.9.0 in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (1.9.0)\nRequirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (4.4.1)\nRequirement already satisfied: flask-compress in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (1.9.0)\nRequirement already satisfied: dash-html-components==1.1.2 in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (1.1.2)\nRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (0.16.0)\nRequirement already satisfied: dash-table==4.11.2 in /usr/local/lib/python3.7/dist-packages (from dash>=1.6.1->dash_daq) (4.11.2)\nRequirement already satisfied: itsdangerous>=0.24 in /usr/local/lib/python3.7/dist-packages (from Flask>=1.0.4->dash>=1.6.1->dash_daq) (1.1.0)\nRequirement already satisfied: click>=5.1 in /usr/local/lib/python3.7/dist-packages (from Flask>=1.0.4->dash>=1.6.1->dash_daq) (7.1.2)\nRequirement already satisfied: Werkzeug>=0.15 in /usr/local/lib/python3.7/dist-packages (from Flask>=1.0.4->dash>=1.6.1->dash_daq) (1.0.1)\nRequirement already satisfied: Jinja2>=2.10.1 in /usr/local/lib/python3.7/dist-packages (from Flask>=1.0.4->dash>=1.6.1->dash_daq) (2.11.3)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from plotly->dash>=1.6.1->dash_daq) (1.15.0)\nRequirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.7/dist-packages (from plotly->dash>=1.6.1->dash_daq) (1.3.3)\nRequirement already satisfied: brotli in /usr/local/lib/python3.7/dist-packages (from flask-compress->dash>=1.6.1->dash_daq) (1.0.9)\nRequirement already satisfied: MarkupSafe>=0.23 in /usr/local/lib/python3.7/dist-packages (from Jinja2>=2.10.1->Flask>=1.0.4->dash>=1.6.1->dash_daq) (1.1.1)\nBuilding wheels for collected packages: dash-daq\n Building wheel for dash-daq (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for dash-daq: filename=dash_daq-0.5.0-cp37-none-any.whl size=669704 sha256=ecb13f7d04814efe141b83827f0ab7e82c0c604b4caba2b07cda1a00ff679833\n Stored in directory: /root/.cache/pip/wheels/1c/9c/f7/84731716eaa9fc952cdbdd1f87df3ca9b8805c317c609efcd6\nSuccessfully built dash-daq\nInstalling collected packages: dash-daq\nSuccessfully installed dash-daq-0.5.0\n"
],
[
"pip install --ignore-installed --upgrade plotly==4.5.0",
"Collecting plotly==4.5.0\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/06/e1/88762ade699460dc3229c890f9845d16484a40955a590b65052f0958613c/plotly-4.5.0-py2.py3-none-any.whl (7.1MB)\n\u001b[K |████████████████████████████████| 7.1MB 4.4MB/s \n\u001b[?25hCollecting retrying>=1.3.3\n Downloading https://files.pythonhosted.org/packages/44/ef/beae4b4ef80902f22e3af073397f079c96969c69b2c7d52a57ea9ae61c9d/retrying-1.3.3.tar.gz\nCollecting six\n Downloading https://files.pythonhosted.org/packages/ee/ff/48bde5c0f013094d729fe4b0316ba2a24774b3ff1c52d924a8a4cb04078a/six-1.15.0-py2.py3-none-any.whl\nBuilding wheels for collected packages: retrying\n Building wheel for retrying (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for retrying: filename=retrying-1.3.3-cp37-none-any.whl size=11430 sha256=37b4849aabb66f79c101f16093ae3b6d67e5c102e6008e34b1a4fcab895494d4\n Stored in directory: /root/.cache/pip/wheels/d7/a9/33/acc7b709e2a35caa7d4cae442f6fe6fbf2c43f80823d46460c\nSuccessfully built retrying\n\u001b[31mERROR: datascience 0.10.6 has requirement folium==0.2.1, but you'll have folium 0.8.3 which is incompatible.\u001b[0m\n\u001b[31mERROR: albumentations 0.1.12 has requirement imgaug<0.2.7,>=0.2.5, but you'll have imgaug 0.2.9 which is incompatible.\u001b[0m\nInstalling collected packages: six, retrying, plotly\nSuccessfully installed plotly-4.5.0 retrying-1.3.3 six-1.15.0\n"
]
],
[
[
"At this point, restart the runtime environment for Colab",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport datetime\nimport matplotlib.pyplot as plt\nimport random\nimport scipy.stats",
"_____no_output_____"
],
[
"import plotly.express as px\nfrom jupyter_dash import JupyterDash\nimport dash_core_components as dcc\nimport dash_daq as daq\nimport dash_html_components as html\nfrom dash.dependencies import Input, Output\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom itertools import cycle",
"_____no_output_____"
],
[
"import plotly\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"print(plotly.__version__)",
"4.5.0\n"
],
[
"df = pd.read_csv('https://raw.githubusercontent.com/wesleybeckner/ds_for_engineers/main/data/truffle_margin/margin_data.csv')\ndf['Width'] = df['Width'].apply(str)\ndf['Height'] = df['Height'].apply(str)",
"_____no_output_____"
],
[
"descriptors = df.columns[:-3]",
"_____no_output_____"
],
[
"delimiters = df.columns[:-3]\nmoodsdf = pd.DataFrame()\npop = list(df['EBITDA'])\n# pop = np.random.choice(pop, size=int(1e5))\nfor delimiter in delimiters:\n grouped = df.groupby(delimiter)['EBITDA']\n group_with_values = grouped.apply(list)\n\n # bootstrap population of values based on groups\n# pop = np.random.choice((np.concatenate(group_with_values)), \n# size=int(1e4))\n \n for index, group in enumerate(group_with_values):\n stat, p, m, table = scipy.stats.median_test(group, pop)\n median = np.median(group)\n mean = np.mean(group)\n size = len(group)\n moodsdf = pd.concat([moodsdf, \n pd.DataFrame([delimiter, group_with_values.index[index],\n stat, p, m, mean, median, size, table]).T])\nmoodsdf.columns = ['descriptor', 'group', 'pearsons_chi_square', 'p_value', 'grand_median', 'group_mean',\n 'group_median', 'size', 'table']\n",
"_____no_output_____"
],
[
"moodsdf = moodsdf.loc[moodsdf['p_value'] < 1e-3]\nmoodsdf = moodsdf.sort_values('group_median').reset_index(drop=True)",
"_____no_output_____"
],
[
"def make_violin_plot(sort='Worst', select=[0,5], descriptors=None):\n\n if sort == 'Best':\n local_df = moodsdf.sort_values('group_median', ascending=False)\n local_df = local_df.reset_index(drop=True)\n else:\n local_df = moodsdf\n if descriptors != None:\n local_df = local_df.loc[local_df['descriptor'].isin(descriptors)]\n fig = go.Figure()\n for index in range(select[0],select[1]):\n x = df.loc[(df[local_df.iloc[index]['descriptor']] == \\\n local_df.iloc[index]['group'])]['EBITDA']\n y = local_df.iloc[index]['descriptor'] + ': ' + df.loc[(df[local_df\\\n .iloc[index]['descriptor']] == local_df.iloc[index]['group'])]\\\n [local_df.iloc[index]['descriptor']]\n name = '€ {:.0f}'.format(x.median())\n fig.add_trace(go.Violin(x=y,\n y=x,\n name=name,\n box_visible=True,\n meanline_visible=True))\n fig.update_layout({\n \"plot_bgcolor\": \"#FFFFFF\",\n \"paper_bgcolor\": \"#FFFFFF\",\n \"title\": 'EBITDA by Product Descriptor (Median in Legend)',\n \"yaxis.title\": \"EBITDA (€)\",\n \"height\": 325,\n \"font\": dict(\n size=10),\n \"margin\": dict(\n l=0,\n r=0,\n b=0,\n t=30,\n pad=4\n ),\n })\n\n return fig\n\ndef make_sunburst_plot(clickData=None, toAdd=None, col=None, val=None):\n if clickData != None:\n col = clickData[\"points\"][0]['x'].split(\": \")[0]\n val = clickData[\"points\"][0]['x'].split(\": \")[1]\n elif col == None:\n col = moodsdf.iloc[-1]['descriptor']\n val = moodsdf.iloc[-1]['group']\n\n desc = list(descriptors[:-2])\n if col in desc:\n desc.remove(col)\n if toAdd != None:\n for item in toAdd:\n desc.append(item)\n test = df.loc[df[col] == val]\n fig = px.sunburst(test, path=desc[:], color='EBITDA', title='{}: {}'.format(\n col, val),\n color_continuous_scale=px.colors.sequential.Viridis\n )\n fig.update_layout({\n \"plot_bgcolor\": \"#FFFFFF\",\n \"title\": '(Select in Violin) {}: {}'.format(col,val),\n \"paper_bgcolor\": \"#FFFFFF\",\n \"height\": 325,\n \"font\": dict(\n size=10),\n \"margin\": dict(\n l=0,\n r=0,\n b=0,\n t=30,\n pad=4\n ),\n })\n return fig\n\ndef make_ebit_plot(df, select=None, sort='Worst', descriptors=None):\n families = df[df.columns[0]].unique()\n colors = ['#636EFA', '#EF553B', '#00CC96', '#AB63FA', '#FFA15A', '#19D3F3',\\\n '#FF6692', '#B6E880', '#FF97FF', '#FECB52']\n colors_cycle = cycle(colors)\n \n color_dic = {'{}'.format(i): '{}'.format(j) for i, j in zip(families,\n colors)}\n \n fig = go.Figure()\n\n\n if select == None:\n for data in px.scatter(\n df,\n x='Product',\n y='EBITDA',\n color=df.columns[0],\n color_discrete_map=color_dic,\n opacity=1).data:\n fig.add_trace(\n data\n )\n\n elif select != None:\n color_dic = {'{}'.format(i): '{}'.format(j) for i, j in zip(select,\n colors)}\n for data in px.scatter(\n df,\n x='Product',\n y='EBITDA',\n color=df.columns[0],\n\n color_discrete_map=color_dic,\n opacity=0.09).data:\n fig.add_trace(\n data\n )\n\n if sort == 'Best':\n local_df = moodsdf.sort_values('group_median', ascending=False)\n elif sort == 'Worst':\n local_df = moodsdf\n \n\n\n new_df = pd.DataFrame()\n if descriptors != None:\n local_df = local_df.loc[local_df['descriptor'].isin(descriptors)]\n for index in select:\n x = df.loc[(df[local_df.iloc[index]\\\n ['descriptor']] == local_df.iloc[index]['group'])]\n x['color'] = next(colors_cycle) # for line shapes\n new_df = pd.concat([new_df, x])\n new_df = new_df.reset_index(drop=True)\n# for data in px.scatter(\n# new_df,\n# x='Product',\n# y='EBITDA',\n# color=df.columns[0],\n\n# color_discrete_map=color_dic,\n# opacity=1).data:\n# fig.add_trace(\n# data\n# )\n shapes=[]\n\n for index, i in enumerate(new_df['Product']):\n shapes.append({'type': 'line',\n 'xref': 'x',\n 'yref': 'y',\n 'x0': i,\n 'y0': -4e5,\n 'x1': i,\n 'y1': 4e5,\n 'line':dict(\n dash=\"dot\",\n color=new_df['color'][index],)})\n fig.update_layout(shapes=shapes)\n fig.update_layout({\n \"plot_bgcolor\": \"#FFFFFF\",\n \"paper_bgcolor\": \"#FFFFFF\",\n \"title\": 'Rank Order EBITDA by {}'.format(df.columns[0]),\n \"yaxis.title\": \"EBITDA (€)\",\n \"height\": 325,\n \"font\": dict(\n size=10),\n \"xaxis\": dict(\n showticklabels=False\n ),\n \"margin\": dict(\n l=0,\n r=0,\n b=0,\n t=30,\n pad=4\n),\n \"xaxis.tickfont.size\": 8,\n })\n return fig",
"_____no_output_____"
],
[
"# Build App\nexternal_stylesheets = ['../assets/styles.css', '../assets/s1.css', 'https://codepen.io/chriddyp/pen/bWLwgP.css']\n\napp = JupyterDash(__name__, external_stylesheets=external_stylesheets)\napp.layout = html.Div([\n html.Div([\n html.Div([\n html.P('Descriptors'),\n dcc.Dropdown(id='descriptor_dropdown',\n options=[{'label': i, 'value': i} for i in descriptors],\n value=descriptors,\n multi=True,\n className=\"dcc_control\"),\n html.P('Number of Descriptors:', id='descriptor-number'),\n dcc.RangeSlider(\n id='select',\n min=0,\n max=moodsdf.shape[0],\n step=1,\n value=[0,10]),\n html.P('Sort by:'),\n dcc.RadioItems(\n id='sort',\n options=[{'label': i, 'value': j} for i, j in \\\n [['Low EBITDA', 'Worst'],\n ['High EBITDA', 'Best']]],\n value='Best',\n labelStyle={'display': 'inline-block'},\n style={\"margin-bottom\": \"10px\"},),\n html.P('Toggle view Violin/Descriptor Data'),\n daq.BooleanSwitch(\n id='daq-violin',\n on=False,\n style={\"margin-bottom\": \"10px\", \"margin-left\": \"0px\",\n 'display': 'inline-block'}),\n \n ], \n className='mini_container',\n id='descriptorBlock',\n style={'width': '32%', 'display': 'inline-block'}\n ), \n html.Div([\n dcc.Graph(\n id='ebit_plot',\n figure=make_ebit_plot(df)),\n ], \n className='mini_container',\n style={'width': '65%', 'float': 'right', 'display': 'inline-block'},\n id='ebit-family-block'\n ),\n\n ], className='row container-display',\n \n ),\n\n html.Div([\n html.Div([\n dcc.Graph(\n id='violin_plot',\n figure=make_violin_plot()),\n ], \n className='mini_container',\n style={'width': '65%', 'display': 'inline-block'},\n id='violin',\n ),\n html.Div([\n dcc.Dropdown(id='length_width_dropdown',\n options=[{'label': 'Height', 'value': 'Height'},\n {'label': 'Width', 'value': 'Width'}],\n value=['Width'],\n multi=True,\n placeholder=\"Include in sunburst chart...\",\n className=\"dcc_control\"),\n dcc.Graph(\n id='sunburst_plot',\n figure=make_sunburst_plot()\n ),\n ], \n className='mini_container',\n style={'width': '32%', 'display': 'inline-block'},\n id='sunburst',\n ),\n ], className='row container-display',\n style={'margin-bottom': '50px'},\n ),\n], className='pretty container'\n)",
"_____no_output_____"
],
[
"@app.callback(\n Output('sunburst_plot', 'figure'),\n [Input('violin_plot', 'clickData'),\n Input('length_width_dropdown', 'value'),\n Input('sort', 'value'),\n Input('select', 'value'),\n Input('descriptor_dropdown', 'value')])\ndef display_sunburst_plot(clickData, toAdd, sort, select, descriptors):\n if sort == 'Best':\n local_df = moodsdf.sort_values('group_median', ascending=False)\n local_df = local_df.reset_index(drop=True)\n else:\n local_df = moodsdf\n if descriptors != None:\n local_df = local_df.loc[local_df['descriptor'].isin(descriptors)]\n local_df = local_df.reset_index(drop=True)\n col = local_df['descriptor'][select[0]]\n val = local_df['group'][select[0]]\n return make_sunburst_plot(clickData, toAdd, col, val)\n\[email protected](\n [Output('select', 'max'),\n Output('select', 'value')],\n [Input('descriptor_dropdown', 'value')]\n)\ndef update_descriptor_choices(descriptors):\n max_value = moodsdf.loc[moodsdf['descriptor'].isin(descriptors)].shape[0]\n value = min(5, max_value)\n return max_value, [0, value]\n\[email protected](\n Output('descriptor-number', 'children'),\n [Input('select', 'value')]\n)\ndef display_descriptor_number(select):\n return \"Number of Descriptors: {}\".format(select[1]-select[0])\n\[email protected](\n Output('violin_plot', 'figure'),\n [Input('sort', 'value'),\n Input('select', 'value'),\n Input('descriptor_dropdown', 'value')]\n)\ndef display_violin_plot(sort, select, descriptors):\n return make_violin_plot(sort, select, descriptors)\n\[email protected](\n Output('ebit_plot', 'figure'),\n [Input('sort', 'value'),\n Input('select', 'value'),\n Input('descriptor_dropdown', 'value'),\n Input('daq-violin', 'on')]\n)\ndef display_ebit_plot(sort, select, descriptors, switch):\n if switch == True:\n select = list(np.arange(select[0],select[1]))\n return make_ebit_plot(df, select, sort=sort, descriptors=descriptors)\n else:\n return make_ebit_plot(df)",
"_____no_output_____"
],
[
"app.run_server(mode='external', port='8881')",
"Dash app running on:\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a4385285de4f5cdb2c02719ec110b633349bb7e
| 4,192 |
ipynb
|
Jupyter Notebook
|
pyextension/robosoc2dplot/test/test.ipynb
|
rug/robosoc2d
|
7a018f8ef6974f96a44df018b8adb185e2c07c63
|
[
"MIT"
] | null | null | null |
pyextension/robosoc2dplot/test/test.ipynb
|
rug/robosoc2d
|
7a018f8ef6974f96a44df018b8adb185e2c07c63
|
[
"MIT"
] | null | null | null |
pyextension/robosoc2dplot/test/test.ipynb
|
rug/robosoc2d
|
7a018f8ef6974f96a44df018b8adb185e2c07c63
|
[
"MIT"
] | null | null | null | 29.111111 | 190 | 0.608302 |
[
[
[
"%matplotlib inline\nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nrobosoc2d.simulator_step_if_playing(sim_handle)\nfig, ax = r2plot.draw(sim_handle)",
"_____no_output_____"
],
[
"# \"%matplotlib notebook\" is unsupported on Google Colab\n%matplotlib notebook\n#uncomment the line below (write \"%matplotlib notebook\" twice) if you previously used \"%matplotlib inline\": for some reason it wouldn't work otherwise in many Jupyter versions !\n#%matplotlib notebook \nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nr2plot.play_whole_game_in_notebook(sim_handle, 0.05)",
"_____no_output_____"
],
[
"# equivalent to the previous cell but without using \"play_whole_game_in_notebook()\", in case you need to process something in the inner loop.\n# \"%matplotlib notebook\" is unsupported on Google Colab\n%matplotlib notebook \nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\nimport time\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nfig, ax = r2plot.draw(sim_handle)\nwhile(robosoc2d.simulator_step_if_playing(sim_handle)):\n ax.clear()\n r2plot.draw(sim_handle, axes=ax)\n fig.canvas.draw()\n time.sleep(0.001)\n",
"_____no_output_____"
],
[
"# step by step update clicking a button\n%matplotlib notebook\nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nr2plot.play_steps_in_notebook(sim_handle)",
"_____no_output_____"
],
[
"%matplotlib inline\nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\n_ = r2plot.play_whole_game_in_notebook_inline(sim_handle, 0.05)",
"_____no_output_____"
],
[
"# equivalent to the previous cell but without using \"play_whole_game_in_notebook_inline()\", in case you need to process something in the inner loop.\n%matplotlib inline\nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\nimport time\nfrom IPython.display import clear_output\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nwhile(robosoc2d.simulator_step_if_playing(sim_handle)):\n fig, ax = r2plot.draw(sim_handle)\n r2plot.show()\n time.sleep(0.05)\n clear_output(wait=True)",
"_____no_output_____"
],
[
"# step by step update clicking a button\n%matplotlib inline\nimport robosoc2d\nimport robosoc2dplot.plot as r2plot\n\nsim_handle = robosoc2d.build_simpleplayer_simulator([], 4, [], 4)\nr2plot.play_steps_in_notebook_inline(sim_handle)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a438bd53f5cc3397f4f0571d042aeaff3053f2f
| 36,469 |
ipynb
|
Jupyter Notebook
|
scripts/check_output.ipynb
|
in-rolls/parse_elex_rolls
|
f8f41ac4f848c6a29be1d98dcfb00d1549c16e43
|
[
"MIT"
] | 3 |
2018-02-20T17:15:09.000Z
|
2020-06-17T16:26:06.000Z
|
scripts/check_output.ipynb
|
in-rolls/parse_elex_rolls
|
f8f41ac4f848c6a29be1d98dcfb00d1549c16e43
|
[
"MIT"
] | 2 |
2018-07-09T16:01:26.000Z
|
2019-07-08T05:35:19.000Z
|
scripts/check_output.ipynb
|
in-rolls/parse_searchable_rolls
|
f8f41ac4f848c6a29be1d98dcfb00d1549c16e43
|
[
"MIT"
] | 3 |
2021-08-24T10:49:50.000Z
|
2022-01-22T01:11:36.000Z
| 35.614258 | 206 | 0.327566 |
[
[
[
"from glob import glob\n\nfor fn in glob('/opt/data/searchable_rolls/*.csv.gz'):\n print(fn)",
"/opt/data/searchable_rolls/chandigarh.csv.gz\n/opt/data/searchable_rolls/haryana.csv.gz\n/opt/data/searchable_rolls/himachal.csv.gz\n"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('/opt/data/searchable_rolls/chandigarh.csv.gz')\ndf",
"/opt/anaconda3/envs/jupyter/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3146: DtypeWarning: Columns (2) have mixed types.Specify dtype option on import or set low_memory=False.\n has_raised = await self.run_ast_nodes(code_ast.body, cell_name,\n"
],
[
"df.relationship.unique()",
"_____no_output_____"
],
[
"df.age.unique()",
"_____no_output_____"
],
[
"df.sex.unique()",
"_____no_output_____"
],
[
"df = pd.read_csv('/opt/data/searchable_rolls/haryana.csv.gz')\ndf",
"/opt/anaconda3/envs/jupyter/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3146: DtypeWarning: Columns (2) have mixed types.Specify dtype option on import or set low_memory=False.\n has_raised = await self.run_ast_nodes(code_ast.body, cell_name,\n"
],
[
"df.relationship.unique()",
"_____no_output_____"
],
[
"df.age.unique()",
"_____no_output_____"
],
[
"df.sex.unique()",
"_____no_output_____"
],
[
"df = pd.read_csv('/opt/data/searchable_rolls/himachal.csv.gz')\ndf",
"/opt/anaconda3/envs/jupyter/lib/python3.8/site-packages/IPython/core/interactiveshell.py:3146: DtypeWarning: Columns (0,2) have mixed types.Specify dtype option on import or set low_memory=False.\n has_raised = await self.run_ast_nodes(code_ast.body, cell_name,\n"
],
[
"df.relationship.unique()",
"_____no_output_____"
],
[
"df.age.unique()",
"_____no_output_____"
],
[
"df.sex.unique()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a439466f9a30d276eae4c4a7edb744958113b8d
| 273,085 |
ipynb
|
Jupyter Notebook
|
Assignment 1/Problem1.ipynb
|
AmineBellahsen/IFT6135_representation_learning
|
d93865a2e1d7b42d4808927ce928dc875a436730
|
[
"MIT"
] | null | null | null |
Assignment 1/Problem1.ipynb
|
AmineBellahsen/IFT6135_representation_learning
|
d93865a2e1d7b42d4808927ce928dc875a436730
|
[
"MIT"
] | null | null | null |
Assignment 1/Problem1.ipynb
|
AmineBellahsen/IFT6135_representation_learning
|
d93865a2e1d7b42d4808927ce928dc875a436730
|
[
"MIT"
] | null | null | null | 156.675273 | 44,244 | 0.832851 |
[
[
[
"## Problem 1\n___\n\nIn this problem, we will build a Multilayer Perceptron (MLP) and train it on the MNIST hand-written digit dataset.\n\n### Summary:\n___\n\n[Question 1](#1.1) \n[Question 2](#1.2) \n[Question 3](#1.3) \n[Question 4](#1.4) \n\n___\n\n### 1. Building the Model <a id='1.1'></a>\n__________\n**1.1) Build an MLP and choose the values of $h^1$ and $h^2$ such that the total number of parameters (including biases) falls within the range of [0.5M, 1.0M].**\n\nThe model is implemented within the NN class below.\n\nGiven that the input size is 784 and we have 10 classes, we estimaed the size of each hidden layer as follow:\n\n- first hidden layer: 500 units\n- second hidden layer: 400 units\n\nThe total number of parameters in our model with these settings is: $(784+1)*500 + (500+1)*400 + (400+1)*10 = 596910$\n\n\n**1.2) Implement the forward and backward propagation of the MLP in numpy without using any of the deep learning frameworks that provides automatic differentiation.**\n\nOur algorithm implements minibatch gradient descent, which allows us to save a lot of computation thanks to numpy's optimizations for matrix operations (we can use 1-example stochastic gradient descent by specifying batch_size = 1).\n\nWe implemented the forward and backward propagation using matrices to represent the minibatches and the neural network parameters. This way, we avoid using looped sums and replace them by numpy matrix operations.\n\nWe have also let to the user the possibility to use biases or not.\n\nIn our implementation, all matrices are transposed compared to the course notations. This has to be highlighted because it changes the order of all matrix operations.\n\n#### Forward:\nEach batch is represented by a $\\mbox{batch_size} \\times 784$ matrix. It can be treated as the output $H_0$ of an imaginary layer with index $0$.\n\nFor each hidden layer $i$ within $1\\leq i \\leq L$, we compute the preactivations matrix as $ A_{i} = H_{i-1}W_{i} + b_{i}$, with the following dimensions: \n\n- $A_i$ : the preactivations matrix of dimensions $\\mbox{batch_size} \\times h^{i}$\n- $H_{i-1}$ : the postactivations matrix of dimensions $\\mbox{batch_size} \\times h^{i-1}$\n- $W_{i}$ : the weights matrix of dimensions $h^{i-1} \\times h^{i}$ ($h^i$ being the number of units of the $i^{th}$ layer)\n- $b_{i}$: the biases matrix of dimensions $1 \\times h^{i}$\n\nAs we can see, $H_{i-1}W_{i}$ and $b_{i}$ don't have the same first dimension, but thanks to the broadcast property provided by numpy, this is not an issue.\n\nAfter using this linear transformation, we apply an activation function (for example ReLU) on $A_{i}$, which gives us $H_{i} = \\mbox{activation}(A_{i})$.\n\nThe only exception is the output layer, which has a different activation function (softmax) that defines the outputs $H_{L+1}$ as a $batch\\_size \\times 10$ matrix of $batch\\_size$ sets of total probabilities over the $10$ possible labels.\n\n#### Backward:\n\nWe have implemented the backpropagation algorithm as follows:\n\nThe preactivation gradients of the output layer $L+1$ are represented by the $batch\\_size \\times 10$ matrix $\\nabla A_{L+1}$, which is calculated according to:\n\n$$\n\\nabla A_{L+1} = -(\\mbox{true labels} - H_{L+1})\n$$\n\n(The 'true labels' matrix is a one-hot encoding of the real class of each example of the minibatch)\n\nThen for each layer $i$ starting from $L+1$ to $1$:\n\n- The weights gradients matrix is computed as:\n\n$$\n\\nabla W_{i} = \\frac{H_{i-1}^T \\nabla A_i}{\\mbox{batch_size}}\n$$\n\nThis operation saves us a lot of computation and memory thanks to optimized matrix operations, as it computes at once the element-wise mean over the minibatch of the $\\mbox{batch_size}$ matrices of dimensions $h^{i-1} \\times h^{i}$ that would have been computed if we had considered each example separately. Indeed the matrix-product\n\n$$\n\\underset{(h^{i-1} \\times \\mbox{batch_size})}{H_{i-1}^T} \\underset{(\\mbox{batch_size} \\times h^{i})}{\\nabla A_i}\n$$\n\nis the element-wise sum of the $\\mbox{batch_size}$ matrices obtained for each example of the minibatch by the vector-product\n\n$$\n\\underset{(h^{i-1} \\times 1)}{h_{i-1}^T} \\underset{(1 \\times h^{i})}{\\nabla a_i}\n$$\n\npresented in the course. Dividing by $\\mbox{batch_size}$ gives us directly the average that has to be used for the upcoming update.\n\n- Similarly, the biases gradients matrix is computed as:\n\n$$\n\\nabla db_i = \\mbox{mean over batch dimension}(\\nabla A_i)\n$$\n\nwhich gives us a $1 \\times h^{i}$ vector of the mean of the biases gradients over the minibatch, homogeneous to the $b_i$ vector as we have seen before.\n\n- If the layer $i$ is not the layer $1$, we also need to compute $\\nabla H_{i-1}$ and $\\nabla A_{i-1}$ as follows:\n\n$$\n\\nabla H_{i-1} = \\nabla A_i \\nabla W_i^T\n\\\\\n\\nabla A_{i-1} = \\nabla H_{i-1} \\odot \\mbox{activation}(A_{i-1})\n$$\n\nso we can retropropagate gradients to the previous ($i-1$) layer and compute $\\nabla W_{i-1}$ and $\\nabla b_{i-1}$.\n\n\n**1.3) Train the MLP using the probability loss ($\\textit{cross entropy}$) as training criterion. We minimize this criterion to optimize the model parameters using $\\textit{stochastic gradient descent}$.**\n\nOur algorithm minimizes the cross entropy, estimated by:\n\n$$\n-\\frac{1}{N}\\sum_{i=1}^{N} \\mbox{true labels} * \\mbox{log}(\\mbox{prediction})\n$$\n\nTo choose our best model, we pick the one with the highest validation accuracy and we keep this model in the bestWeights attribute, which can be saved on the hard drive to be loaded later in test mode. When the validation accuracy ceases to improve for a number of epochs defined by the patience attribute, the training stops as we consider being in overfitting regime (early stopping).",
"_____no_output_____"
]
],
[
[
"# This part of the code implements live plotting of the train and validation loss and accuracy:\nfrom IPython.display import clear_output\nfrom matplotlib import pyplot as plt\nimport collections\n%matplotlib inline\n\ndef live_plot(data_dict1, title1, data_dict2, title2, figsize=(7,5), bestEpoch=0):\n \"\"\"\n plots the train and test error and the accuracy \n after each epoch\n \"\"\"\n clear_output(wait=True)\n plt.figure(figsize=figsize)\n plt.subplot(1,2,1)\n for label,data in data_dict1.items():\n plt.plot(data, label=label)\n if label == 'validation accuracy':\n plt.plot(bestEpoch, data[bestEpoch], \"ro\")\n plt.title(title1)\n plt.grid(True)\n plt.xlabel('epoch')\n plt.legend(loc='center left')\n plt.subplot(1,2,2)\n for label,data in data_dict2.items():\n plt.plot(data, label=label)\n if label == 'validation loss':\n plt.plot(bestEpoch, data[bestEpoch], \"ro\")\n plt.title(title2)\n plt.grid(True)\n plt.xlabel('epoch')\n plt.legend(loc='center left')\n plt.show();\n\n# This part implements the NN:\nimport numpy as np\nimport pickle\nimport copy\nimport time\n\n\"\"\"MLP class :\n\nThe model implemented as follows :\nEach layers is represented by a b vector (biases) and a W matrix (weights)\nThese are referenced by the weights dictionary. The format is :\nself.weights[f\"X{n}\"] where X = b, W\nNB : In our implementation, all matrices are transposed compared to the class notations\n\"\"\"\nclass NN(object):\n \n def __init__(self,\n hidden_dims = (1024, 2048), # dimensions of each hidden layers\n n_hidden = 2, # number of hidden layers\n mode = 'train', # current mode : train/test\n datapath = None, # path where to find the .pkl file\n model_path = None, # path where to save/load the model \n epsilon = 1e-6, # for cross entropy calculus stability : log(x) = log(epsilon) if x < epsilon\n lr = 1e-1, # learning rate\n n_epochs = 1000, # max number of epochs\n batch_size = 1000, # batch size for training\n compute_biases = True, # whether biases are used or not\n seed = None, # seed for reproducibility\n activation = \"relu\", # activation function\n init_method = \"glorot\", # initialization method\n patience = 5): # number of useless iterations before early stopping\n \"\"\"\n - method: (string) - initializes the weight matrices\n -> \"zero\" for a Zero initialisation of the weights\n -> \"normal\" for a Normal initialisation of the weights\n -> \"glorot\" for a Uniform initialisation of the weights\n \"\"\"\n assert len(hidden_dims) == n_hidden, \"Hidden dims mismatch!\"\n \n self.hidden_dims = hidden_dims\n self.n_hidden = n_hidden\n self.mode = mode\n self.datapath = datapath\n self.model_path = model_path\n self.epsilon = epsilon\n self.lr = lr\n self.n_epochs = n_epochs\n self.batch_size = batch_size\n self.compute_biases = compute_biases\n self.init_method = init_method\n self.seed = seed\n self.activation_str = activation\n self.patience = patience\n \n self.dataplot1 = collections.defaultdict(list) # history of the train and validation accuracies\n self.dataplot2 = collections.defaultdict(list) # history of the train and validation losses\n \n self.earlyStopped = False # this is set to True when early stopping happens\n self.bestValAccuracy = 0 # max value of the validation accuracy\n self.bestEpoch = 0 # epoch where we reached the min value of the validation loss\n self.bestWeights = None # optimal weights dictionary (contains biases when compute_biases=True)\n \n # train, validation and test sets :\n if datapath.lower().endswith(\".npy\"):\n self.tr, self.va, self.te = np.load(open(datapath, \"rb\"))\n elif datapath.lower().endswith(\".pkl\"):\n u = pickle._Unpickler(open(datapath, 'rb'))\n u.encoding = 'latin1'\n self.tr, self.va, self.te = u.load()\n else:\n raise Exception(\"Unknown data source type!\")\n\n def initialize_weights(self, dims):\n \"\"\"\n Initializes the weights and biases according to the specified method :\n - dims: (list of two integers) - the size of input/output layers\n :return: None\n \"\"\"\n if self.seed is not None:\n np.random.seed(self.seed)\n if self.mode == \"train\":\n self.weights = {}\n all_dims = [dims[0]] + list(self.hidden_dims) + [dims[1]]\n #print(\"Layers dimensions are : \", all_dims)\n for layer_n in range(1, self.n_hidden + 2):\n if self.init_method == \"zero\":\n self.weights[f\"W{layer_n}\"] = np.zeros(shape=(all_dims[layer_n - 1],all_dims[layer_n])).astype('float64')\n elif self.init_method == \"normal\":\n #Be aware of the error you get \"true divide\", can be solved by dividing by dim_layer[n-1] \n self.weights[f\"W{layer_n}\"] = np.random.normal(loc=0.0, scale=1.0, size=(all_dims[layer_n - 1],\n all_dims[layer_n])).astype('float64')/all_dims[layer_n-1]\n elif self.init_method == \"glorot\":\n b = np.sqrt(6.0/(all_dims[layer_n]+all_dims[layer_n-1]))\n self.weights[f\"W{layer_n}\"] = np.random.uniform(low=-b, high=b, size=(all_dims[layer_n - 1],\n all_dims[layer_n])).astype('float64')\n else:\n raise Exception(\"The provided name for the initialization method is invalid.\")\n \n if self.compute_biases:\n self.weights[f\"b{layer_n}\"] = np.zeros((1, all_dims[layer_n]))\n \n elif self.mode == \"test\": # test mode is to load the weights of an existing model\n self.weights = np.load(self.model_path)\n else:\n raise Exception(\"Unknown Mode!\")\n \n def relu(self,x, prime=False):# Prime for Step function, else ReLu\n \"\"\"\n Definition of the Relu function and its derivative\n \"\"\"\n if prime:\n return x > 0\n return np.maximum(0, x)\n \n def sigmoid(self,x, prime=False):\n \"\"\"\n Defition of the Sigmoid function and its derivative\n \"\"\"\n if prime:\n return self.sigmoid(x)*(1 - self.sigmoid(x))\n return 1/(1 + np.exp(-x))\n \n def tanh(self,x, prime=False):\n \"\"\"\n Defition of the tanh function and its derivative\n \"\"\"\n if prime:\n return 1 - np.power(self.tanh(x),2)\n return np.tanh(x)\n \n def activation(self, input_, prime=False):\n \"\"\"\n Selecting and applying a given activation function\n on the preactivation values\n \"\"\"\n if self.activation_str == \"relu\":\n return self.relu(input_,prime)\n elif self.activation_str == \"sigmoid\":\n return self.sigmoid(input_,prime)\n elif self.activation_str == \"tanh\":\n return self.tanh(input_,prime)\n else:\n raise Exception(\"Unsupported activation!\")\n\n def softmax(self, input_): # Computes the softmax of the input\n \"\"\"\n Definition of the softmax function: activation function\n for the output layer\n \"\"\"\n Z = np.exp(input_ - np.max(input_)) # softmax(x-C) = softmax(x) (stability)\n return Z / np.sum(Z, axis=1, keepdims=True)\n \n def forward(self, input_): # Forward propagation : computes the outputs (cache) from the input\n \"\"\"\n Implementation of the forward propagation process to calculate\n the preactivation values and the values of the hidden units\n \"\"\"\n cache = {\"H0\": input_}\n for layer in range(1, self.n_hidden + 1):\n if self.compute_biases:\n cache[f\"A{layer}\"] = cache[f\"H{layer-1}\"] @ self.weights[f\"W{layer}\"] + self.weights[f\"b{layer}\"]\n else:\n cache[f\"A{layer}\"] = cache[f\"H{layer-1}\"] @ self.weights[f\"W{layer}\"]\n cache[f\"H{layer}\"] = self.activation(cache[f\"A{layer}\"])\n\n layer = self.n_hidden + 1\n if self.compute_biases:\n cache[f\"A{layer}\"] = cache[f\"H{layer-1}\"] @ self.weights[f\"W{layer}\"] + self.weights[f\"b{layer}\"]\n else:\n cache[f\"A{layer}\"] = cache[f\"H{layer-1}\"] @ self.weights[f\"W{layer}\"]\n cache[f\"H{layer}\"] = self.softmax(cache[f\"A{layer}\"]) # softmax on last layer\n return cache\n \n def backward(self, cache, labels): # Backward propagation : computes the gradients from the outputs (cache)\n \"\"\"\n Implementation of the backward propagation process\n \"\"\"\n output = cache[f\"H{self.n_hidden+1}\"]\n grads = {f\"dA{self.n_hidden+1}\": - (labels - output)}\n for layer in range(self.n_hidden + 1, 0, -1):\n # the following operation averages at once all the matrices\n # that we would have calculated for each example of the minibatch if we had not represented it in matrix form :\n grads[f\"dW{layer}\"] = cache[f\"H{layer-1}\"].T @ grads[f\"dA{layer}\"] / self.batch_size\n # we need to do the same for the biases gradients :\n if self.compute_biases:\n grads[f\"db{layer}\"] = np.mean(grads[f\"dA{layer}\"], axis=0, keepdims=True)\n if layer > 1:\n grads[f\"dH{layer-1}\"] = grads[f\"dA{layer}\"] @ self.weights[f\"W{layer}\"].T\n grads[f\"dA{layer-1}\"] = grads[f\"dH{layer-1}\"] * self.activation(cache[f\"A{layer-1}\"], prime=True)\n return grads\n \n def update(self, grads): # To update the weights and the biases\n \"\"\"\n Updating the weights and the biases with a given gradient input\n \"\"\"\n for layer in range(1, self.n_hidden + 1):\n self.weights[f\"W{layer}\"] = self.weights[f\"W{layer}\"] - self.lr * grads[f\"dW{layer}\"]\n if self.compute_biases:\n self.weights[f\"b{layer}\"] = self.weights[f\"b{layer}\"] - self.lr * grads[f\"db{layer}\"]\n \n def loss(self, prediction, labels): # Computes the cross entropy\n \"\"\"\n Calculating the cross entropy loss \n \"\"\"\n prediction[np.where(prediction < self.epsilon)] = self.epsilon\n prediction[np.where(prediction > 1 - self.epsilon)] = 1 - self.epsilon\n return -1 * np.sum(labels * np.log(prediction)) / prediction.shape[0]\n \n def compute_loss_and_accuracy(self, X, y): # Stores the accuracy/loss of the train/validation sets\n \"\"\"\n Computing the loss and accuracy metrics and the prediction on a given dataset\n \"\"\"\n on_y = self._one_hot(y)\n vCache = self.forward(X)\n vOut = np.argmax(vCache[f\"H{self.n_hidden + 1}\"], axis=1)\n vAccuracy = np.mean(y == vOut)\n vLoss = self.loss(vCache[f\"H{self.n_hidden+1}\"], on_y)\n return vLoss, vAccuracy, vOut\n \n def _one_hot(self,y):\n \"\"\"\n Implementation of the OneHot Encoding\n \"\"\"\n _, y_train = self.tr\n return np.eye(np.max(y_train) - np.min(y_train) + 1)[y]\n \n def train(self,show_graph = True, save_model = False):\n \"\"\"\n Implementation of the training process\n \"\"\"\n X_train, y_train = self.tr\n y_onehot = self._one_hot(y_train)\n dims = [X_train.shape[1], y_onehot.shape[1]]\n self.initialize_weights(dims)\n n_batches = int(np.ceil(X_train.shape[0] / self.batch_size))\n countES = 0\n for epoch in range(self.n_epochs):\n for batch in range(n_batches):\n minibatchX = X_train[self.batch_size * batch:self.batch_size * (batch + 1), :]\n minibatchY = y_onehot[self.batch_size * batch:self.batch_size * (batch + 1), :]\n cache = self.forward(minibatchX)\n grads = self.backward(cache, minibatchY)\n self.update(grads)\n \n X_tr, y_tr = self.tr\n trLoss, trAccuracy,_ = self.compute_loss_and_accuracy(X_tr, y_tr)\n X_val, y_val = self.va\n valLoss, valAccuracy,_ = self.compute_loss_and_accuracy(X_val, y_val)\n \n if valAccuracy > self.bestValAccuracy:\n self.bestValAccuracy = valAccuracy # we choose or best model according to Accuracy\n self.bestEpoch = epoch\n self.bestWeights = copy.deepcopy(self.weights)\n countES = 0\n \n self.dataplot1['train accuracy'].append(trAccuracy)\n self.dataplot1['validation accuracy'].append(valAccuracy)\n self.dataplot2['train loss'].append(trLoss)\n self.dataplot2['validation loss'].append(valLoss)\n if show_graph:\n live_plot(self.dataplot1, \"Accuracy\", self.dataplot2, \"Loss\", (14,5), self.bestEpoch)\n countES += 1\n if countES >= self.patience: # early stopping\n self.earlyStopped = True\n break\n \n if save_model:\n # Save the best model:\n if self.model_path is None:\n string_hdims = \"-\".join(map(str,self.hidden_dims))\n model_name = f\"best-model-init-{self.init_method}-lr-{self.lr}-hdims-{string_hdims}-batches-{self.batch_size}.npz\"\n np.savez(model_name,**self.bestWeights)\n else:\n np.savez(self.model_path,**self.bestWeights)\n self.weights = copy.deepcopy(self.bestWeights)\n return self.dataplot1, self.dataplot2\n \n def test(self):\n \"\"\"\n Implementation of the testing process\n \"\"\"\n X_te, y_te = self.te\n vLoss, vAccuracy,_ = self.compute_loss_and_accuracy(X_te, y_te)\n print(f\"Test Accuracy:{vAccuracy}, Test Loss:{vLoss}\")\n \n def finite_difference(self, eps, lay, nb_params = 10):\n \"\"\"\n eps: epsilon step used to estimate the finite differencef\n lay: layer where to estimate the finite difference\n \"\"\"\n X, y = self.va\n self.batch_size = 1\n first_label = self._one_hot(y[0]).reshape(1,-1)\n realCache = self.forward(X[0].reshape(1,-1))\n realGrad = self.backward(realCache, first_label)\n gradient_approx = np.zeros(nb_params)\n gradient_real = np.zeros(nb_params)\n increment = 0\n for iLine, line in enumerate(self.weights[f\"W{lay}\"]):\n for iCol, col in enumerate(line):\n self.weights[f\"W{lay}\"][iLine, iCol] += eps\n # w+ :\n plusCache = self.forward(X[0].reshape(1,-1))\n self.weights[f\"W{lay}\"][iLine, iCol] -= 2*eps\n # w- :\n moinsCache = self.forward(X[0].reshape(1,-1))\n plusLoss = self.loss(plusCache[f\"H{self.n_hidden+1}\"],first_label)\n moinsLoss = self.loss(moinsCache[f\"H{self.n_hidden+1}\"],first_label)\n gradient_approx[increment] = (plusLoss - moinsLoss)/(2*eps)\n gradient_real[increment] = realGrad[f\"dW{lay}\"][iLine,iCol]\n self.weights[f\"W{lay}\"][iLine, iCol] += eps\n increment += 1\n if increment==10:\n self.weights = copy.deepcopy(self.bestWeights)\n return gradient_approx, gradient_real, np.max(np.abs(gradient_approx - gradient_real)) # np.linalg.norm(gradient_approx - gradient_real)\n self.weights = copy.deepcopy(self.bestWeights)\n return gradient_approx, gradient_real, np.max(np.abs(gradient_approx - gradient_real))",
"_____no_output_____"
]
],
[
[
"For the following questions, the architecture we chose is a 2-layer neural network of size $(500, 400)$. The batch size is $100$, and the learning rate is $0.5$, which we found converges very quickly with this setting.\n\n### 2. Initialization <a id='1.2'></a>\n___\n\n**2.1) Train the model for 10 epochs using the initialization methods and record the average loss measured on the training data at the end of each epoch (10 values for each setup).**\n\n**- Initialization with zeros:** The training phase stops after 5 epochs because we use the early stopping option which stops it from reaching 10 epochs.",
"_____no_output_____"
]
],
[
[
"#Zero_Init\nneural_net = NN(hidden_dims=(500, 400),\n n_hidden=2, # number of hidden layers\n mode='train', # current mode : train/test\n datapath=\"mnist.pkl\", # path where to find the .pkl file\n model_path=None, # path where to save/load the model \n epsilon = 1e-8, # for cross entropy calculus stability : log(x) = log(epsilon) if x < epsilon\n lr = 5e-1, # learning rate\n n_epochs = 10, # max number of epochs\n batch_size = 100, # batch size for training\n compute_biases = True, # whether biases are used or not\n init_method = \"zero\") # initialization method\n_,_ = neural_net.train()",
"_____no_output_____"
]
],
[
[
"**- Initialization with a Standard Normal distribution:**",
"_____no_output_____"
]
],
[
[
"#Normal init\nneural_net = NN(hidden_dims=(500, 400),\n n_hidden=2, # number of hidden layers\n mode='train', # current mode : train/test\n datapath=\"mnist.pkl\", # path where to find the .pkl file\n model_path=None, # path where to save/load the model \n epsilon = 1e-8, # for cross entropy calculus stability : log(x) = log(epsilon) if x < epsilon\n lr = 5e-1, # learning rate\n n_epochs = 10, # max number of epochs\n batch_size = 100, # batch size for training\n compute_biases = True, # whether biases are used or not\n init_method = \"normal\") # initialization method\nnormal_hist_acc, normal_hist_loss = neural_net.train()",
"_____no_output_____"
]
],
[
[
"**- Initialization with Glorot method:**",
"_____no_output_____"
]
],
[
[
"#Glorot_Init\nneural_net = NN(hidden_dims=(500, 400),\n n_hidden=2, # number of hidden layers\n mode='train', # current mode : train/test\n datapath=\"mnist.pkl\", # path where to find the .pkl file\n model_path=None, # path where to save/load the model \n epsilon = 1e-8, # for cross entropy calculus stability : log(x) = log(epsilon) if x < epsilon\n lr = 5e-1, # learning rate\n n_epochs = 20, # max number of epochs\n batch_size = 100, # batch size for training\n compute_biases = True, # whether biases are used or not\n init_method = \"glorot\") # initialization method\nglorot_hist_acc, glorot_hist_loss = neural_net.train()",
"_____no_output_____"
]
],
[
[
"**2.2) Compare the three setups by plotting the losses against the training time (epoch) and comment on the result.**\n\n- Zero initialization for the weights leads to no change at all in accuracy. We can indeed show that doing so will lead to no possible update of the weights during the retropropagation, as\n\n$$\n\\nabla H_{i-1} = \\nabla A_i \\nabla W_i^T\n$$\n\nwill give zero gradients. Actually, only the biases of the last layer will be changed according to\n\n$$\n\\nabla A_{L+1} = -(\\mbox{true labels} - H_{L+1})\\\\\n\\mbox{and}\\\\\n\\nabla b_i = \\mbox{mean over batch dimension}(\\nabla A_i)\n$$\n\nin such a way that will not impact the predictions over each example from an epoch to another.\n\n- If we simply generate the weights following a normal distribution $N(0,1)$, this leads to quick numeric explosion and errors. Indeed, weights will add up and are likely to lead to exponential overflows (or zero divisions in our stabilized softmax). We chose to tackle this issue by dividing the normal weights by the dimension of the previous layer. This way, preactivation values will stay around \\[-1,1\\] at each layer. After 10 epochs, this initialization method leads to a 91% accuracy and no overfitting (the model needs to train more).\n\n- If we use the formula from Glorot, Bengio - 2010, we observe extremely fast convergence as the validation accuracy reaches 96% after the first epoch (versus 48% for normal initialization) and the model starts overfitting (regarding the validation accuracy) at more than 98% accuracy after 17 epochs.",
"_____no_output_____"
],
[
"### 3. Hyperparameter Search <a id='1.3'></a>\n___\n\n**3.1) Find out a combination of hyper-parameters (model architecture, learning rate, nonlinearity, etc.) such that the average accuracy rate on the validation set ($r^{(valid)}$) is at least 97\\%.**\n\nAlthough we have found a model that performs better than 98% relatively quickly by hand, in this part we perform a random search in hope to find a better model.",
"_____no_output_____"
]
],
[
[
"from IPython.display import clear_output\n\nclass RandomSearch:\n \n def __init__(self, model, params, n_itters, seed = None):\n self.params = params # parameters assignation grid (dictionary)\n self.n_itters = n_itters # number of searches\n self.model = model # NN class to use for random search\n self.seed = seed # seed for reproducibility\n \n def run(self):\n if self.seed is not None:\n np.random.seed(self.seed)\n results = []\n best_acc = None\n best_loss = None\n params = [p for p in self._generate_grid()]\n for it, selected_params in enumerate(params):\n print(f\"Random search: test n°{it+1} - KeyboardInterrupt to stop after this iteration\")\n try:\n #print(f\"{it}\",\"-\".join(map(lambda x: str(x),selected_params.items())))\n instance_model = self.model(seed = self.seed,**selected_params)\n acc, loss = instance_model.train(show_graph=False,save_model=False)\n id_best = np.argmax(acc[\"validation accuracy\"])\n results.append((selected_params,\n loss[\"validation loss\"][id_best],\n acc[\"validation accuracy\"][id_best],\n instance_model.earlyStopped))\n \n #if best_acc is None or best_loss> loss[\"validation loss\"][id_best]:\n #print(f\"Found a better model: Accuracy from {best_acc} to {acc['validation accuracy'][id_best]}\")\n #best_loss = loss[\"validation loss\"][id_best]\n #best_acc = acc[\"validation accuracy\"][id_best]\n #print(f'Model {it+1}, accuracy {acc[\"validation accuracy\"][id_best]:.5f}, loss {loss[\"validation loss\"][id_best]:.5f}, Best Model: acc {best_acc:.5f}, loss {best_loss:.5f}')\n except KeyboardInterrupt:\n break\n clear_output(wait=True)\n return results\n \n def _generate_grid(self):\n for it in range(self.n_itters):\n yield self._select_params()\n \n def _select_params(self):\n selected_params = {}\n for key,value in self.params.items():\n if key == \"hidden_dims\":\n continue\n elif key == \"n_hidden\":\n assert type(value) == int and value>0\n hidden_units = []\n for _ in range(value):\n hidden_units.append(np.random.choice(self.params[\"hidden_dims\"]))\n selected_params[\"hidden_dims\"] = hidden_units\n selected_params[key]=value\n elif type(value)==list or type(value)==tuple:\n selected_params[key] = np.random.choice(self.params[key])\n else:\n selected_params[key]=value\n return selected_params\n ",
"_____no_output_____"
],
[
"from collections import defaultdict\nimport pandas as pd\n\ngrid_params = {\n \"hidden_dims\":[400,500,600],\n \"n_hidden\":2,\n \"lr\":[.3,.5,.7],\n \"n_epochs\":[10,15,20],\n \"batch_size\":[75,100,125],\n \"activation\":[\"tanh\",\"sigmoid\",\"relu\"],\n \"datapath\":\"mnist.pkl\",\n \"patience\":[3,5,10]\n}\n\nrd_search = RandomSearch(\n model = NN,\n params = grid_params,\n n_itters = 10,\n seed = 42\n)\n\nexperiments = rd_search.run()\n\noutput = defaultdict(list)\nfor obs in experiments:\n for key,val in obs[0].items():\n output[key].append(val)\n output[\"loss\"].append(obs[1])\n output[\"accuracy\"].append(obs[2])\n output[\"train_complete\"].append(obs[3])\n\nsorted_output= pd.DataFrame(output)\nsorted_output.sort_values(by=\"accuracy\",ascending=False)",
"_____no_output_____"
]
],
[
[
"ReLU has not been randomly selected here, so we don't know about its efficience as an activation function. However it is clear that sigmoid is ineffective with these parameters. It is unclear how the other parameters affect the performance. No model has been fully trained, which implies that either de patience is too large, or the number of epochs is too small.\n\nWe now perform another random search considering only relu and tanh, smaller patience, and slightly wider ranges for the other parameters:",
"_____no_output_____"
]
],
[
[
"from collections import defaultdict\nimport pandas as pd\n\ngrid_params = {\n \"hidden_dims\":[400,500,600],\n \"n_hidden\":2,\n \"lr\":[.5,.75,.1],\n \"n_epochs\":[10,20,30],\n \"batch_size\":[50,100,150],\n \"activation\":[\"tanh\",\"relu\"],\n \"datapath\":\"mnist.pkl\",\n \"patience\":[1,2,3]\n}\n\nrd_search = RandomSearch(\n model = NN,\n params = grid_params,\n n_itters = 10,\n seed = 43\n)\n\nexperiments = rd_search.run()\n\noutput = defaultdict(list)\nfor obs in experiments:\n for key,val in obs[0].items():\n output[key].append(val)\n output[\"loss\"].append(obs[1])\n output[\"accuracy\"].append(obs[2])\n output[\"train_complete\"].append(obs[3])\n\nsorted_output= pd.DataFrame(output)\nsorted_output.sort_values(by=\"accuracy\",ascending=False)",
"_____no_output_____"
]
],
[
[
"Stopping using sigmoid as an activation function has sensibly improved our overall performance. It now becomes clear that the determining parameter is the learning rate. Reducing patience too much might also have stopped the training too early. As increasing the learning rate seems to increase the performance, let us try another iteration of Random Search using greater learning rates, greater number of epochs, and greater patience:",
"_____no_output_____"
]
],
[
[
"from collections import defaultdict\nimport pandas as pd\n\ngrid_params = {\n \"hidden_dims\":[400,500,600],\n \"n_hidden\":2,\n \"lr\":[.75,1.0,1.5,2.0,2.5],\n \"n_epochs\":[20,30,40],\n \"batch_size\":[50,100,150],\n \"activation\":[\"tanh\",\"relu\"],\n \"datapath\":\"mnist.pkl\",\n \"patience\":[5,10]\n}\n\nrd_search = RandomSearch(\n model = NN,\n params = grid_params,\n n_itters = 10,\n seed = 45\n)\n\nexperiments = rd_search.run()\n\noutput = defaultdict(list)\nfor obs in experiments:\n for key,val in obs[0].items():\n output[key].append(val)\n output[\"loss\"].append(obs[1])\n output[\"accuracy\"].append(obs[2])\n output[\"train_complete\"].append(obs[3])\n\nsorted_output= pd.DataFrame(output)\nsorted_output.sort_values(by=\"accuracy\",ascending=False)",
"_____no_output_____"
]
],
[
[
"tanh seems to be our best activation function, although it is apparently slow to train compared to ReLU regarding the number of epochs, as only one out of seven tanh have completed full training here. Since we now have a small dataset of hyperparamters, we could go further using regression techniques to find an even better combination. We could also have implemented an heuristic similar to what we have done here by hand in three itartions that would converge toward a locally optimal combination of the hyperparameters (e.g. simulated annealing). However for now let us just fully train our best model:",
"_____no_output_____"
]
],
[
[
"neural_net = NN(hidden_dims=(500, 500),\n n_hidden=2,\n mode='train',\n datapath=\"mnist.pkl\",\n lr = 1.5,\n n_epochs = 1000, # arbitrarily big number because we want to reach early stopping\n batch_size = 50,\n activation = 'tanh',\n patience = 10,\n seed = 45)\nhist_acc, hist_loss = neural_net.train()",
"_____no_output_____"
],
[
"print(\"Model validation accuracy: \", neural_net.bestValAccuracy)",
"Model validation accuracy: 0.9841\n"
]
],
[
[
"Nothing has changed: during Random Search we did not wait until the end of patience, although we had found the same optimum. We also notice that the optimum regarding validation accuracy is way into the overfitting regime regarding validation loss.",
"_____no_output_____"
],
[
"### 4. Validation of the gratients using Finite Difference <a id='1.4'></a>\n___\n\nIn this part we use finite difference to check whether our calculations of the gradients are correct or not.\n\nThe finite difference gradients $\\nabla^N$ are an estimation of the gradients with respect to each parameter of the second layer. Let $\\theta$ be the vector of all the paramaters of this layer, the finite difference of the $i^{\\mbox{th}}$ parameters is defined as:\n\n$$\\nabla^N_i = \\frac{L(\\theta_1, \\dots, \\theta_{i-1}, \\theta_i + \\epsilon, \\theta_{i+1}, \\dots, \\theta_p) - L(\\theta_1, \\dots, \\theta_{i-1}, \\theta_i - \\epsilon, \\theta_{i+1}, \\dots, \\theta_p)}{2 \\epsilon}$$\n\nwhere $\\epsilon = \\frac{1}{N}$\n\n#### The model we will use is:",
"_____no_output_____"
]
],
[
[
"neural_net = NN(hidden_dims=(500, 400),\n n_hidden=2, # number of hidden layers\n mode='train', # current mode : train/test\n datapath=\"mnist.pkl\", # path where to find the .pkl file\n model_path=None, # path where to save/load the model \n epsilon = 1e-8, # for cross entropy calculus stability : log(x) = log(epsilon) if x < epsilon\n lr = 5e-1, # learning rate\n n_epochs = 10, # max number of epochs\n batch_size = 100, # batch size for training\n compute_biases = True, # whether biases are used or not\n init_method = \"glorot\", # initialization method\n seed = 42) # seed to reproduce results\nhist_acc, hist_loss = neural_net.train()",
"_____no_output_____"
]
],
[
[
"#### 4.1) Evaluate the finite difference gradients $\\nabla^N \\in \\mathbb{R}^p$ using $\\epsilon = \\frac{1}{N}$ for different values of $N$\n\nNow, we compute the forward and the backward algorithms using only one example from the validation dataset (We will use the first example). Then we compute the gradients approximations and we calculate the difference using $\\max_{1 \\leq i \\leq p} |\\nabla^N_i - \\frac{\\partial L}{\\partial \\theta_i}| $. We will use the finite_difference method in the NN class.",
"_____no_output_____"
]
],
[
[
"N=[]\n# Choose 20 values for N\nfor i in range(0,5):\n for k in range(1,5):\n N.append(k*(10**i))\n \ndiff = np.zeros(len(N))\n# For each N, compute finite_difference.\nfor n in range(len(N)):\n app,re,diff[n] = neural_net.finite_difference(1/N[n],2)",
"_____no_output_____"
]
],
[
[
"#### 4.2) Plot the maximum difference between the true gradient and the finite difference gradient as a function of $N$\n\nLet us see the evolution of the finite_difference. We will use the logarithmic scale.",
"_____no_output_____"
]
],
[
[
"plt.plot(N,diff)\nplt.title('Max difference between computed gradients and finite differences')\nplt.xlabel('N')\nplt.ylabel('Max difference')\nplt.yscale('log')\nplt.xscale('log')",
"_____no_output_____"
],
[
"print(\"The steepest positive gradient is \", np.max(re), \", and the steepest negative gradient is \", np.min(re))",
"The steepest positive gradient is 1.0220947612060307e-06 , and the steepest negative gradient is -7.972305787772131e-07\n"
],
[
"print(\"The difference is minimal for epsilon = \", 1/N[np.argmin(diff)])",
"The difference is minimal for epsilon = 0.0033333333333333335\n"
]
],
[
[
"We notice that the difference between our real gradients and estimated gradients is small. Therefore, we can consider that our real gradients are well calculated (steepest real gradients are of the order of $10^{-7}$, which means that the difference is still very significant).\n\nWe also notice that the estimated gradients are closest to the real gradients for $\\epsilon = 0.003$, which is not the smallest tested value although theoretically we should get closer to the real gradients as $\\epsilon$ decreases. This might be explained by numerical unstability. We become numerically unstable for very small values of $\\epsilon$ (ref. the deep learning course given by Andrew NG ). ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a439c3bfa762ad9f5cdd28556626b34cd290a07
| 355,573 |
ipynb
|
Jupyter Notebook
|
doc/draw/dotplot.ipynb
|
rahulghangas/cogent3
|
f00cf822efce5f3141b3c7dafac81cb94a311e22
|
[
"BSD-3-Clause"
] | null | null | null |
doc/draw/dotplot.ipynb
|
rahulghangas/cogent3
|
f00cf822efce5f3141b3c7dafac81cb94a311e22
|
[
"BSD-3-Clause"
] | null | null | null |
doc/draw/dotplot.ipynb
|
rahulghangas/cogent3
|
f00cf822efce5f3141b3c7dafac81cb94a311e22
|
[
"BSD-3-Clause"
] | null | null | null | 24.349312 | 18,744 | 0.348615 |
[
[
[
"# Dotplot\n\nThis is a useful technique ([Gibbs and McIntyre](https://www.ncbi.nlm.nih.gov/pubmed/5456129)) for comparing sequences. All `cogent3` sequence collections classes (`SequenceCollection`, `Alignment` and `ArrayAlignment`) have a dotplot method.\n\nThe method returns a drawable, as demonstrated below between unaligned sequences.",
"_____no_output_____"
]
],
[
[
"from cogent3 import load_unaligned_seqs\n\nseqs = load_unaligned_seqs(\"../data/SCA1-cds.fasta\", moltype=\"dna\")\ndraw = seqs.dotplot()\ndraw.show()",
"_____no_output_____"
]
],
[
[
"If sequence names are not provided, two randomly chosen sequences are selected (see below). The plot title reflects the parameter values for defining a match. `window` is the size of the sequence segments being compared. `threshold` is the number of exact matches within `window` required for the two sequence segments to be considered a match. `gap` is the size of a gap between adjacent matches before merging.",
"_____no_output_____"
],
[
"## Modifying the matching parameters\n\nIf we set window and threshold to be equal, this is equivalent to an exact match approach.",
"_____no_output_____"
]
],
[
[
"draw = seqs.dotplot(name1=\"Human\", name2=\"Mouse\", window=8, threshold=8)\ndraw.show()",
"_____no_output_____"
]
],
[
[
"## Displaying dotplot for the reverse complement",
"_____no_output_____"
]
],
[
[
"draw = seqs.dotplot(name1=\"Human\", name2=\"Mouse\", rc=True)\ndraw.show()",
"_____no_output_____"
]
],
[
[
"**NOTE:** clicking on an entry in the legend turns it off",
"_____no_output_____"
],
[
"## Setting plot attributes\n\nI'll modify the title and figure width. ",
"_____no_output_____"
]
],
[
[
"draw = seqs.dotplot(name1=\"Human\", name2=\"Mouse\", rc=True, title=\"SCA1\", width=400)\ndraw.show()",
"_____no_output_____"
]
],
[
[
"## All options",
"_____no_output_____"
]
],
[
[
"help(seqs.dotplot)",
"Help on method dotplot in module cogent3.core.alignment:\n\ndotplot(name1=None, name2=None, window=20, threshold=None, min_gap=0, width=500, title=None, rc=False, show_progress=False) method of cogent3.core.alignment.SequenceCollection instance\n make a dotplot between specified sequences. Random sequences\n chosen if names not provided.\n \n Parameters\n ----------\n name1, name2 : str or None\n names of sequences. If one is not provided, a random choice is made\n window : int\n k-mer size for comparison between sequences\n threshold : int\n windows where the sequences are identical >= threshold are a match\n min_gap : int\n permitted gap for joining adjacent line segments, default is no gap\n joining\n width : int\n figure width. Figure height is computed based on the ratio of\n len(seq1) / len(seq2)\n title\n title for the plot\n rc : bool or None\n include dotplot of reverse compliment also. Only applies to Nucleic\n acids moltypes\n Returns\n -------\n a Drawable or AnnotatedDrawable\n\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a43a7a51368312d08d72ed186313fc7a4f98ea4
| 4,977 |
ipynb
|
Jupyter Notebook
|
examples/IsingSolver.ipynb
|
ncrubin/grove
|
5f8024445263fc8b5ead39520e9e5f019bfe3e31
|
[
"Apache-2.0"
] | 1 |
2020-07-15T15:41:23.000Z
|
2020-07-15T15:41:23.000Z
|
examples/IsingSolver.ipynb
|
amanmehara/grove
|
8c27a5d12923d6ace57956db6a249e8d01e33f35
|
[
"Apache-2.0"
] | null | null | null |
examples/IsingSolver.ipynb
|
amanmehara/grove
|
8c27a5d12923d6ace57956db6a249e8d01e33f35
|
[
"Apache-2.0"
] | 1 |
2021-11-27T16:20:00.000Z
|
2021-11-27T16:20:00.000Z
| 32.960265 | 359 | 0.614627 |
[
[
[
"This Notebook is a short example of how to use the Ising solver implemented using the QAOA algorithm. We start by declaring the import of the ising function.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
],
[
[
"from grove.ising.ising_qaoa import ising\nfrom mock import patch",
"_____no_output_____"
]
],
[
[
"This code finds the global minima of an Ising model with external fields of the form\n$$f(x)= \\Sigma_i h_i x_i + \\Sigma_{i,j} J_{i,j} x_i x_j.$$\nTwo adjacent sites $i,j$ have an interaction equal to $J_{i,j}$. There is also an external magnetic field $h_i$ that affects each individual spin. The discrete variables take the values $x_i \\in \\{+1,-1\\}$.\n\nIn order to assert the correctness of the code we will find the minima of the following Ising model\n$$f(x)=x_0+x_1-x_2+x_3-2 x_0 x_1 +3 x_2 x_3.$$\nWhich corresponds to $x_{min}=[-1, -1, 1, -1]$ in numerical order, with a minimum value of $f(x_{min})=-9$. \n\nThis Ising code runs on quantum hardware, which means that we need to specify a connection to a QVM or QPU. Due to the absence of a real connection in this notebook, we will mock out the response to correspond to the expected value. In order to run this notebook on a QVM or QPU, replace cxn with a valid PyQuil connection object.\n\n\n\n ",
"_____no_output_____"
]
],
[
[
"with patch(\"pyquil.api.SyncConnection\") as cxn:\n cxn.run_and_measure.return_value = [[1,1,0,1]]\n cxn.expectation.return_value = [-0.4893891813015294, 0.8876822987380573, -0.4893891813015292, -0.9333372094534063, -0.9859245403423198, 0.9333372094534065]",
"_____no_output_____"
]
],
[
[
"The input for the code in the default mode corresponds simply to the parameters $h_i$ and $J_{i,j}$, that we specify as a list in numerical order and a dictionary. The code returns the bitstring of the minima, the minimum value, and the QAOA quantum circuit used to obtain that result.",
"_____no_output_____"
]
],
[
[
"J = {(0, 1): -2, (2, 3): 3}\nh = [1, 1, -1, 1]\n\nsolution, min_energy, circuit = ising(h, J, connection=cxn)",
"_____no_output_____"
]
],
[
[
"It is also possible to specify the Trotterization order for the QAOA algorithm used to implement the Ising model. By default this value is equal to double the number of variables. It is also possible to change the verbosity of the function, which is True by default. There are more advanced parameters that can be specified and are not described here. ",
"_____no_output_____"
]
],
[
[
"solution_2, min_energy_2, circuit_2 = ising(h, J, num_steps=9, verbose=False, connection=cxn)",
"_____no_output_____"
]
],
[
[
"For large Ising problems, or those with many and close suboptimal minima, it is possible for the code to not return the global minima. Increasing the number of steps can solve this problem.\n\nFinally, we will check if the correct bitstring was found, corresponding to the global minima, in both runs.",
"_____no_output_____"
]
],
[
[
"assert solution == [-1, -1, 1, -1], \"Found bitstring for first run does not correspond to global minima\"\nprint(\"Energy for first run solution\", min_energy)\nassert solution_2 == [-1, -1, 1, -1], \"Found bitstring for second run does not correspond to global minima\"\nprint(\"Energy for second run solution\", min_energy_2)",
"_____no_output_____"
]
],
[
[
"If the assertions succeeded, and the energy was equal to $-9$, we have found the correct solution for both runs. ",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a43a9e164f0ba9fbe20408d960fdc05a1628213
| 7,380 |
ipynb
|
Jupyter Notebook
|
archive/2018/Clase 3 - Funcion de coste, gradiente y optimizacion.ipynb
|
Rondamon/IntroduccionAprendizajeAutomatico
|
fcce8b5229d1eb1bff1cac98683f0e5b9f160201
|
[
"MIT"
] | 15 |
2018-06-17T14:59:35.000Z
|
2021-08-12T19:32:35.000Z
|
archive/2018/Clase 3 - Funcion de coste, gradiente y optimizacion.ipynb
|
Rondamon/IntroduccionAprendizajeAutomatico
|
fcce8b5229d1eb1bff1cac98683f0e5b9f160201
|
[
"MIT"
] | null | null | null |
archive/2018/Clase 3 - Funcion de coste, gradiente y optimizacion.ipynb
|
Rondamon/IntroduccionAprendizajeAutomatico
|
fcce8b5229d1eb1bff1cac98683f0e5b9f160201
|
[
"MIT"
] | 68 |
2018-06-01T23:53:41.000Z
|
2022-02-09T02:29:03.000Z
| 28.384615 | 104 | 0.540379 |
[
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\n\nfrom matplotlib.colors import ListedColormap\nfrom ml.data import create_lineal_data\nfrom ml.visualization import decision_boundary\n\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"# Función de coste y gradiente\n\n## Generación de datos\n\n### Entrenamiento",
"_____no_output_____"
]
],
[
[
"np.random.seed(0) # Para hacer más determinística la generación de datos\n\nsamples_per_class = 5\n\nXa = np.c_[create_lineal_data(0.75, 0.9, spread=0.2, data_size=samples_per_class)]\nXb = np.c_[create_lineal_data(0.5, 0.75, spread=0.2, data_size=samples_per_class)]\nX_train = np.r_[Xa, Xb]\ny_train = np.r_[np.zeros(samples_per_class), np.ones(samples_per_class)]\n\ncmap_dots = ListedColormap(['tomato', 'dodgerblue'])\n\nplt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cmap_dots, edgecolors='k')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Validación",
"_____no_output_____"
]
],
[
[
"np.random.seed(0) # Para hacer más determinística la generación de datos\n\nsamples_per_class = 25\n\nXa = np.c_[create_lineal_data(0.75, 0.9, spread=0.2, data_size=samples_per_class)]\nXb = np.c_[create_lineal_data(0.5, 0.75, spread=0.2, data_size=samples_per_class)]\nX_val = np.r_[Xa, Xb]\ny_val = np.r_[np.zeros(samples_per_class), np.ones(samples_per_class)]\n\ncmap_dots = ListedColormap(['tomato', 'dodgerblue'])\n\nplt.scatter(X_val[:, 0], X_val[:, 1], c=y_val, cmap=cmap_dots, edgecolors='k')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Regresión Logística\n\n### Función de coste y gradiente",
"_____no_output_____"
]
],
[
[
"def sigmoid(x):\n return 1 / (1 + np.exp(-x))\n\ndef logloss(w, x, y):\n m = y.shape[0]\n y_hat = sigmoid(x.dot(w))\n cost1 = np.log(y_hat).dot(y)\n cost2 = np.log(1 - y_hat).dot(1 - y)\n J = -(cost1 + cost2)\n\n return J\n\ndef logloss_gradient(w, x, y):\n m = y.shape[0]\n y_hat = sigmoid(x.dot(w))\n gradient = np.dot(x.T, y_hat - y)\n \n return gradient",
"_____no_output_____"
]
],
[
[
"### Algoritmo de optimización (descenso por la gradiente)",
"_____no_output_____"
]
],
[
[
"def gradient_descent(w, x_train, y_train, x_val, y_va, cost_function,\n cost_function_gradient, alpha=0.01, max_iter=1000):\n train_costs = np.zeros(max_iter)\n val_costs = np.zeros(max_iter)\n\n for iteration in range(max_iter):\n train_costs[iteration] = cost_function(w, x_train, y_train)\n val_costs[iteration] = cost_function(w, x_val, y_val)\n gradient = cost_function_gradient(w, x_train, y_train)\n w = w - alpha * gradient\n \n return w, train_costs, val_costs",
"_____no_output_____"
],
[
"# Agregar el vector de bias a los ejemplos (bias trick)\nX_b_train = np.c_[np.ones(X_train.shape[0]), X_train]\nX_b_val = np.c_[np.ones(X_val.shape[0]), X_val]\n\nw0 = np.zeros(X_b_train.shape[1]) # Initial weights\n\nw, train_costs, val_costs = gradient_descent(w0, X_b_train, y_train, X_b_val, y_val,\n logloss, logloss_gradient, max_iter=20000)",
"_____no_output_____"
]
],
[
[
"### Exactitud (entrenamiento vs validación)",
"_____no_output_____"
]
],
[
[
"y_pred = (X_b_train.dot(w) >= 0.5).astype(np.int) # Obtenemos las predicciones (como 0 o 1)\naccuracy = (y_train == y_pred).astype(np.int).sum() / y_train.shape[0] # Calcular la exactitud\n\nprint(\"Exactitud del algoritmo para conjunto de entrenamiento: %.2f\" % accuracy)\n\ny_pred = (X_b_val.dot(w) >= 0.5).astype(np.int) # Obtenemos las predicciones (como 0 o 1)\naccuracy = (y_val == y_pred).astype(np.int).sum() / y_val.shape[0] # Calcular la exactitud\n\nprint(\"Exactitud del algoritmo para conjunto de validación: %.2f\" % accuracy)",
"_____no_output_____"
]
],
[
[
"### Curva de aprendizaje (entrenamiento vs validación)",
"_____no_output_____"
]
],
[
[
"plt.plot(train_costs, label=\"Datos de entrenamiento\")\nplt.plot(val_costs, label=\"Datos de validación\")\nplt.xlabel(\"Iteraciones\")\nplt.ylabel(\"Costo\")\nplt.title(\"Curva de aprendizaje\")\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Frontera de decisión",
"_____no_output_____"
]
],
[
[
"xx, yy, Z = decision_boundary(np.r_[X_train, X_val], w)\n\ncmap_back = ListedColormap(['lightcoral', 'skyblue'])\ncmap_dots = ['tomato', 'dodgerblue', 'red', 'darkslateblue']\n\nplt.figure(figsize=(6, 5), dpi= 80, facecolor='w', edgecolor='k')\nplt.pcolormesh(xx, yy, Z, cmap=cmap_back)\n\nfor i in (0, 1):\n plt.scatter(X_train[y_train==i, 0], X_train[y_train==i, 1], \n color=cmap_dots[i], label='Entrenamiento clase %d' % i,\n edgecolor='k', s=20)\n plt.scatter(X_val[y_val==i, 0], X_val[y_val==i, 1],\n color=cmap_dots[i+2], label='Validación clase %d' % i,\n edgecolor='k', s=20)\nplt.xlim(xx.min(), xx.max())\nplt.ylim(yy.min(), yy.max())\nplt.legend()\nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a43baf72e84074933cb412d6e903e23cfbc1efd
| 677,714 |
ipynb
|
Jupyter Notebook
|
math_linear_algebra.ipynb
|
otamilocintra/ml2gh
|
917bd7c7576dff094ea493f85e178e2ed5ef6e24
|
[
"Apache-2.0"
] | null | null | null |
math_linear_algebra.ipynb
|
otamilocintra/ml2gh
|
917bd7c7576dff094ea493f85e178e2ed5ef6e24
|
[
"Apache-2.0"
] | null | null | null |
math_linear_algebra.ipynb
|
otamilocintra/ml2gh
|
917bd7c7576dff094ea493f85e178e2ed5ef6e24
|
[
"Apache-2.0"
] | null | null | null | 148.29628 | 30,973 | 0.869021 |
[
[
[
"**Math - Linear Algebra**\n\n*Linear Algebra is the branch of mathematics that studies [vector spaces](https://en.wikipedia.org/wiki/Vector_space) and linear transformations between vector spaces, such as rotating a shape, scaling it up or down, translating it (ie. moving it), etc.*\n\n*Machine Learning relies heavily on Linear Algebra, so it is essential to understand what vectors and matrices are, what operations you can perform with them, and how they can be useful.*",
"_____no_output_____"
],
[
"# Vectors\n## Definition\nA vector is a quantity defined by a magnitude and a direction. For example, a rocket's velocity is a 3-dimensional vector: its magnitude is the speed of the rocket, and its direction is (hopefully) up. A vector can be represented by an array of numbers called *scalars*. Each scalar corresponds to the magnitude of the vector with regards to each dimension.\n\nFor example, say the rocket is going up at a slight angle: it has a vertical speed of 5,000 m/s, and also a slight speed towards the East at 10 m/s, and a slight speed towards the North at 50 m/s. The rocket's velocity may be represented by the following vector:\n\n**velocity** $= \\begin{pmatrix}\n10 \\\\\n50 \\\\\n5000 \\\\\n\\end{pmatrix}$\n\nNote: by convention vectors are generally presented in the form of columns. Also, vector names are generally lowercase to distinguish them from matrices (which we will discuss below) and in bold (when possible) to distinguish them from simple scalar values such as ${meters\\_per\\_second} = 5026$.\n\nA list of N numbers may also represent the coordinates of a point in an N-dimensional space, so it is quite frequent to represent vectors as simple points instead of arrows. A vector with 1 element may be represented as an arrow or a point on an axis, a vector with 2 elements is an arrow or a point on a plane, a vector with 3 elements is an arrow or point in space, and a vector with N elements is an arrow or a point in an N-dimensional space… which most people find hard to imagine.\n\n\n## Purpose\nVectors have many purposes in Machine Learning, most notably to represent observations and predictions. For example, say we built a Machine Learning system to classify videos into 3 categories (good, spam, clickbait) based on what we know about them. For each video, we would have a vector representing what we know about it, such as:\n\n**video** $= \\begin{pmatrix}\n10.5 \\\\\n5.2 \\\\\n3.25 \\\\\n7.0\n\\end{pmatrix}$\n\nThis vector could represent a video that lasts 10.5 minutes, but only 5.2% viewers watch for more than a minute, it gets 3.25 views per day on average, and it was flagged 7 times as spam. As you can see, each axis may have a different meaning.\n\nBased on this vector our Machine Learning system may predict that there is an 80% probability that it is a spam video, 18% that it is clickbait, and 2% that it is a good video. This could be represented as the following vector:\n\n**class_probabilities** $= \\begin{pmatrix}\n0.80 \\\\\n0.18 \\\\\n0.02\n\\end{pmatrix}$",
"_____no_output_____"
],
[
"## Vectors in python\nIn python, a vector can be represented in many ways, the simplest being a regular python list of numbers:",
"_____no_output_____"
]
],
[
[
"[10.5, 5.2, 3.25, 7.0]",
"_____no_output_____"
]
],
[
[
"Since we plan to do quite a lot of scientific calculations, it is much better to use NumPy's `ndarray`, which provides a lot of convenient and optimized implementations of essential mathematical operations on vectors (for more details about NumPy, check out the [NumPy tutorial](tools_numpy.ipynb)). For example:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nvideo = np.array([10.5, 5.2, 3.25, 7.0])\nvideo",
"_____no_output_____"
]
],
[
[
"The size of a vector can be obtained using the `size` attribute:",
"_____no_output_____"
]
],
[
[
"video.size",
"_____no_output_____"
]
],
[
[
"The $i^{th}$ element (also called *entry* or *item*) of a vector $\\textbf{v}$ is noted $\\textbf{v}_i$.\n\nNote that indices in mathematics generally start at 1, but in programming they usually start at 0. So to access $\\textbf{video}_3$ programmatically, we would write:",
"_____no_output_____"
]
],
[
[
"video[2] # 3rd element",
"_____no_output_____"
]
],
[
[
"## Plotting vectors\nTo plot vectors we will use matplotlib, so let's start by importing it (for details about matplotlib, check the [matplotlib tutorial](tools_matplotlib.ipynb)):",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### 2D vectors\nLet's create a couple very simple 2D vectors to plot:",
"_____no_output_____"
]
],
[
[
"u = np.array([2, 5])\nv = np.array([3, 1])",
"_____no_output_____"
]
],
[
[
"These vectors each have 2 elements, so they can easily be represented graphically on a 2D graph, for example as points:",
"_____no_output_____"
]
],
[
[
"x_coords, y_coords = zip(u, v)\nplt.scatter(x_coords, y_coords, color=[\"r\",\"b\"])\nplt.axis([0, 9, 0, 6])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Vectors can also be represented as arrows. Let's create a small convenience function to draw nice arrows:",
"_____no_output_____"
]
],
[
[
"def plot_vector2d(vector2d, origin=[0, 0], **options):\n return plt.arrow(origin[0], origin[1], vector2d[0], vector2d[1],\n head_width=0.2, head_length=0.3, length_includes_head=True,\n **options)",
"_____no_output_____"
]
],
[
[
"Now let's draw the vectors **u** and **v** as arrows:",
"_____no_output_____"
]
],
[
[
"plot_vector2d(u, color=\"r\")\nplot_vector2d(v, color=\"b\")\nplt.axis([0, 9, 0, 6])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3D vectors\nPlotting 3D vectors is also relatively straightforward. First let's create two 3D vectors:",
"_____no_output_____"
]
],
[
[
"a = np.array([1, 2, 8])\nb = np.array([5, 6, 3])",
"_____no_output_____"
]
],
[
[
"Now let's plot them using matplotlib's `Axes3D`:",
"_____no_output_____"
]
],
[
[
"from mpl_toolkits.mplot3d import Axes3D\n\nsubplot3d = plt.subplot(111, projection='3d')\nx_coords, y_coords, z_coords = zip(a,b)\nsubplot3d.scatter(x_coords, y_coords, z_coords)\nsubplot3d.set_zlim3d([0, 9])\nplt.show()",
"_____no_output_____"
]
],
[
[
"It is a bit hard to visualize exactly where in space these two points are, so let's add vertical lines. We'll create a small convenience function to plot a list of 3d vectors with vertical lines attached:",
"_____no_output_____"
]
],
[
[
"def plot_vectors3d(ax, vectors3d, z0, **options):\n for v in vectors3d:\n x, y, z = v\n ax.plot([x,x], [y,y], [z0, z], color=\"gray\", linestyle='dotted', marker=\".\")\n x_coords, y_coords, z_coords = zip(*vectors3d)\n ax.scatter(x_coords, y_coords, z_coords, **options)\n\nsubplot3d = plt.subplot(111, projection='3d')\nsubplot3d.set_zlim([0, 9])\nplot_vectors3d(subplot3d, [a,b], 0, color=(\"r\",\"b\"))\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Norm\nThe norm of a vector $\\textbf{u}$, noted $\\left \\Vert \\textbf{u} \\right \\|$, is a measure of the length (a.k.a. the magnitude) of $\\textbf{u}$. There are multiple possible norms, but the most common one (and the only one we will discuss here) is the Euclidian norm, which is defined as:\n\n$\\left \\Vert \\textbf{u} \\right \\| = \\sqrt{\\sum_{i}{\\textbf{u}_i}^2}$\n\nWe could implement this easily in pure python, recalling that $\\sqrt x = x^{\\frac{1}{2}}$",
"_____no_output_____"
]
],
[
[
"def vector_norm(vector):\n squares = [element**2 for element in vector]\n return sum(squares)**0.5\n\nprint(\"||\", u, \"|| =\")\nvector_norm(u)",
"|| [2 5] || =\n"
]
],
[
[
"However, it is much more efficient to use NumPy's `norm` function, available in the `linalg` (**Lin**ear **Alg**ebra) module:",
"_____no_output_____"
]
],
[
[
"import numpy.linalg as LA\nLA.norm(u)",
"_____no_output_____"
]
],
[
[
"Let's plot a little diagram to confirm that the length of vector $\\textbf{v}$ is indeed $\\approx5.4$:",
"_____no_output_____"
]
],
[
[
"radius = LA.norm(u)\nplt.gca().add_artist(plt.Circle((0,0), radius, color=\"#DDDDDD\"))\nplot_vector2d(u, color=\"red\")\nplt.axis([0, 8.7, 0, 6])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looks about right!",
"_____no_output_____"
],
[
"## Addition\nVectors of same size can be added together. Addition is performed *elementwise*:",
"_____no_output_____"
]
],
[
[
"print(\" \", u)\nprint(\"+\", v)\nprint(\"-\"*10)\nu + v",
" [2 5]\n+ [3 1]\n----------\n"
]
],
[
[
"Let's look at what vector addition looks like graphically:",
"_____no_output_____"
]
],
[
[
"plot_vector2d(u, color=\"r\")\nplot_vector2d(v, color=\"b\")\nplot_vector2d(v, origin=u, color=\"b\", linestyle=\"dotted\")\nplot_vector2d(u, origin=v, color=\"r\", linestyle=\"dotted\")\nplot_vector2d(u+v, color=\"g\")\nplt.axis([0, 9, 0, 7])\nplt.text(0.7, 3, \"u\", color=\"r\", fontsize=18)\nplt.text(4, 3, \"u\", color=\"r\", fontsize=18)\nplt.text(1.8, 0.2, \"v\", color=\"b\", fontsize=18)\nplt.text(3.1, 5.6, \"v\", color=\"b\", fontsize=18)\nplt.text(2.4, 2.5, \"u+v\", color=\"g\", fontsize=18)\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Vector addition is **commutative**, meaning that $\\textbf{u} + \\textbf{v} = \\textbf{v} + \\textbf{u}$. You can see it on the previous image: following $\\textbf{u}$ *then* $\\textbf{v}$ leads to the same point as following $\\textbf{v}$ *then* $\\textbf{u}$.\n\nVector addition is also **associative**, meaning that $\\textbf{u} + (\\textbf{v} + \\textbf{w}) = (\\textbf{u} + \\textbf{v}) + \\textbf{w}$.",
"_____no_output_____"
],
[
"If you have a shape defined by a number of points (vectors), and you add a vector $\\textbf{v}$ to all of these points, then the whole shape gets shifted by $\\textbf{v}$. This is called a [geometric translation](https://en.wikipedia.org/wiki/Translation_%28geometry%29):",
"_____no_output_____"
]
],
[
[
"t1 = np.array([2, 0.25])\nt2 = np.array([2.5, 3.5])\nt3 = np.array([1, 2])\n\nx_coords, y_coords = zip(t1, t2, t3, t1)\nplt.plot(x_coords, y_coords, \"c--\", x_coords, y_coords, \"co\")\n\nplot_vector2d(v, t1, color=\"r\", linestyle=\":\")\nplot_vector2d(v, t2, color=\"r\", linestyle=\":\")\nplot_vector2d(v, t3, color=\"r\", linestyle=\":\")\n\nt1b = t1 + v\nt2b = t2 + v\nt3b = t3 + v\n\nx_coords_b, y_coords_b = zip(t1b, t2b, t3b, t1b)\nplt.plot(x_coords_b, y_coords_b, \"b-\", x_coords_b, y_coords_b, \"bo\")\n\nplt.text(4, 4.2, \"v\", color=\"r\", fontsize=18)\nplt.text(3, 2.3, \"v\", color=\"r\", fontsize=18)\nplt.text(3.5, 0.4, \"v\", color=\"r\", fontsize=18)\n\nplt.axis([0, 6, 0, 5])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Finally, substracting a vector is like adding the opposite vector.",
"_____no_output_____"
],
[
"## Multiplication by a scalar\nVectors can be multiplied by scalars. All elements in the vector are multiplied by that number, for example:",
"_____no_output_____"
]
],
[
[
"print(\"1.5 *\", u, \"=\")\n\n1.5 * u",
"1.5 * [2 5] =\n"
]
],
[
[
"Graphically, scalar multiplication results in changing the scale of a figure, hence the name *scalar*. The distance from the origin (the point at coordinates equal to zero) is also multiplied by the scalar. For example, let's scale up by a factor of `k = 2.5`:",
"_____no_output_____"
]
],
[
[
"k = 2.5\nt1c = k * t1\nt2c = k * t2\nt3c = k * t3\n\nplt.plot(x_coords, y_coords, \"c--\", x_coords, y_coords, \"co\")\n\nplot_vector2d(t1, color=\"r\")\nplot_vector2d(t2, color=\"r\")\nplot_vector2d(t3, color=\"r\")\n\nx_coords_c, y_coords_c = zip(t1c, t2c, t3c, t1c)\nplt.plot(x_coords_c, y_coords_c, \"b-\", x_coords_c, y_coords_c, \"bo\")\n\nplot_vector2d(k * t1, color=\"b\", linestyle=\":\")\nplot_vector2d(k * t2, color=\"b\", linestyle=\":\")\nplot_vector2d(k * t3, color=\"b\", linestyle=\":\")\n\nplt.axis([0, 9, 0, 9])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"As you might guess, dividing a vector by a scalar is equivalent to multiplying by its multiplicative inverse (reciprocal):\n\n$\\dfrac{\\textbf{u}}{\\lambda} = \\dfrac{1}{\\lambda} \\times \\textbf{u}$",
"_____no_output_____"
],
[
"Scalar multiplication is **commutative**: $\\lambda \\times \\textbf{u} = \\textbf{u} \\times \\lambda$.\n\nIt is also **associative**: $\\lambda_1 \\times (\\lambda_2 \\times \\textbf{u}) = (\\lambda_1 \\times \\lambda_2) \\times \\textbf{u}$.\n\nFinally, it is **distributive** over addition of vectors: $\\lambda \\times (\\textbf{u} + \\textbf{v}) = \\lambda \\times \\textbf{u} + \\lambda \\times \\textbf{v}$.",
"_____no_output_____"
],
[
"## Zero, unit and normalized vectors\n* A **zero-vector ** is a vector full of 0s.\n* A **unit vector** is a vector with a norm equal to 1.\n* The **normalized vector** of a non-null vector $\\textbf{u}$, noted $\\hat{\\textbf{u}}$, is the unit vector that points in the same direction as $\\textbf{u}$. It is equal to: $\\hat{\\textbf{u}} = \\dfrac{\\textbf{u}}{\\left \\Vert \\textbf{u} \\right \\|}$\n\n",
"_____no_output_____"
]
],
[
[
"plt.gca().add_artist(plt.Circle((0,0),1,color='c'))\nplt.plot(0, 0, \"ko\")\nplot_vector2d(v / LA.norm(v), color=\"k\")\nplot_vector2d(v, color=\"b\", linestyle=\":\")\nplt.text(0.3, 0.3, \"$\\hat{u}$\", color=\"k\", fontsize=18)\nplt.text(1.5, 0.7, \"$u$\", color=\"b\", fontsize=18)\nplt.axis([-1.5, 5.5, -1.5, 3.5])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Dot product\n### Definition\nThe dot product (also called *scalar product* or *inner product* in the context of the Euclidian space) of two vectors $\\textbf{u}$ and $\\textbf{v}$ is a useful operation that comes up fairly often in linear algebra. It is noted $\\textbf{u} \\cdot \\textbf{v}$, or sometimes $⟨\\textbf{u}|\\textbf{v}⟩$ or $(\\textbf{u}|\\textbf{v})$, and it is defined as:\n\n$\\textbf{u} \\cdot \\textbf{v} = \\left \\Vert \\textbf{u} \\right \\| \\times \\left \\Vert \\textbf{v} \\right \\| \\times cos(\\theta)$\n\nwhere $\\theta$ is the angle between $\\textbf{u}$ and $\\textbf{v}$.\n\nAnother way to calculate the dot product is:\n\n$\\textbf{u} \\cdot \\textbf{v} = \\sum_i{\\textbf{u}_i \\times \\textbf{v}_i}$\n\n### In python\nThe dot product is pretty simple to implement:",
"_____no_output_____"
]
],
[
[
"def dot_product(v1, v2):\n return sum(v1i * v2i for v1i, v2i in zip(v1, v2))\n\ndot_product(u, v)",
"_____no_output_____"
]
],
[
[
"But a *much* more efficient implementation is provided by NumPy with the `dot` function:",
"_____no_output_____"
]
],
[
[
"np.dot(u,v)",
"_____no_output_____"
]
],
[
[
"Equivalently, you can use the `dot` method of `ndarray`s:",
"_____no_output_____"
]
],
[
[
"u.dot(v)",
"_____no_output_____"
]
],
[
[
"**Caution**: the `*` operator will perform an *elementwise* multiplication, *NOT* a dot product:",
"_____no_output_____"
]
],
[
[
"print(\" \",u)\nprint(\"* \",v, \"(NOT a dot product)\")\nprint(\"-\"*10)\n\nu * v",
" [2 5]\n* [3 1] (NOT a dot product)\n----------\n"
]
],
[
[
"### Main properties\n* The dot product is **commutative**: $\\textbf{u} \\cdot \\textbf{v} = \\textbf{v} \\cdot \\textbf{u}$.\n* The dot product is only defined between two vectors, not between a scalar and a vector. This means that we cannot chain dot products: for example, the expression $\\textbf{u} \\cdot \\textbf{v} \\cdot \\textbf{w}$ is not defined since $\\textbf{u} \\cdot \\textbf{v}$ is a scalar and $\\textbf{w}$ is a vector.\n* This also means that the dot product is **NOT associative**: $(\\textbf{u} \\cdot \\textbf{v}) \\cdot \\textbf{w} ≠ \\textbf{u} \\cdot (\\textbf{v} \\cdot \\textbf{w})$ since neither are defined.\n* However, the dot product is **associative with regards to scalar multiplication**: $\\lambda \\times (\\textbf{u} \\cdot \\textbf{v}) = (\\lambda \\times \\textbf{u}) \\cdot \\textbf{v} = \\textbf{u} \\cdot (\\lambda \\times \\textbf{v})$\n* Finally, the dot product is **distributive** over addition of vectors: $\\textbf{u} \\cdot (\\textbf{v} + \\textbf{w}) = \\textbf{u} \\cdot \\textbf{v} + \\textbf{u} \\cdot \\textbf{w}$.",
"_____no_output_____"
],
[
"### Calculating the angle between vectors\nOne of the many uses of the dot product is to calculate the angle between two non-zero vectors. Looking at the dot product definition, we can deduce the following formula:\n\n$\\theta = \\arccos{\\left ( \\dfrac{\\textbf{u} \\cdot \\textbf{v}}{\\left \\Vert \\textbf{u} \\right \\| \\times \\left \\Vert \\textbf{v} \\right \\|} \\right ) }$\n\nNote that if $\\textbf{u} \\cdot \\textbf{v} = 0$, it follows that $\\theta = \\dfrac{π}{2}$. In other words, if the dot product of two non-null vectors is zero, it means that they are orthogonal.\n\nLet's use this formula to calculate the angle between $\\textbf{u}$ and $\\textbf{v}$ (in radians):",
"_____no_output_____"
]
],
[
[
"def vector_angle(u, v):\n cos_theta = u.dot(v) / LA.norm(u) / LA.norm(v)\n return np.arccos(np.clip(cos_theta, -1, 1))\n\ntheta = vector_angle(u, v)\nprint(\"Angle =\", theta, \"radians\")\nprint(\" =\", theta * 180 / np.pi, \"degrees\")",
"Angle = 0.868539395286 radians\n = 49.7636416907 degrees\n"
]
],
[
[
"Note: due to small floating point errors, `cos_theta` may be very slightly outside of the $[-1, 1]$ interval, which would make `arccos` fail. This is why we clipped the value within the range, using NumPy's `clip` function.",
"_____no_output_____"
],
[
"### Projecting a point onto an axis\nThe dot product is also very useful to project points onto an axis. The projection of vector $\\textbf{v}$ onto $\\textbf{u}$'s axis is given by this formula:\n\n$\\textbf{proj}_{\\textbf{u}}{\\textbf{v}} = \\dfrac{\\textbf{u} \\cdot \\textbf{v}}{\\left \\Vert \\textbf{u} \\right \\| ^2} \\times \\textbf{u}$\n\nWhich is equivalent to:\n\n$\\textbf{proj}_{\\textbf{u}}{\\textbf{v}} = (\\textbf{v} \\cdot \\hat{\\textbf{u}}) \\times \\hat{\\textbf{u}}$\n",
"_____no_output_____"
]
],
[
[
"u_normalized = u / LA.norm(u)\nproj = v.dot(u_normalized) * u_normalized\n\nplot_vector2d(u, color=\"r\")\nplot_vector2d(v, color=\"b\")\n\nplot_vector2d(proj, color=\"k\", linestyle=\":\")\nplt.plot(proj[0], proj[1], \"ko\")\n\nplt.plot([proj[0], v[0]], [proj[1], v[1]], \"b:\")\n\nplt.text(1, 2, \"$proj_u v$\", color=\"k\", fontsize=18)\nplt.text(1.8, 0.2, \"$v$\", color=\"b\", fontsize=18)\nplt.text(0.8, 3, \"$u$\", color=\"r\", fontsize=18)\n\nplt.axis([0, 8, 0, 5.5])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Matrices\nA matrix is a rectangular array of scalars (ie. any number: integer, real or complex) arranged in rows and columns, for example:\n\n\\begin{bmatrix} 10 & 20 & 30 \\\\ 40 & 50 & 60 \\end{bmatrix}\n\nYou can also think of a matrix as a list of vectors: the previous matrix contains either 2 horizontal 3D vectors or 3 vertical 2D vectors.\n\nMatrices are convenient and very efficient to run operations on many vectors at a time. We will also see that they are great at representing and performing linear transformations such rotations, translations and scaling.",
"_____no_output_____"
],
[
"## Matrices in python\nIn python, a matrix can be represented in various ways. The simplest is just a list of python lists:",
"_____no_output_____"
]
],
[
[
"[\n [10, 20, 30],\n [40, 50, 60]\n]",
"_____no_output_____"
]
],
[
[
"A much more efficient way is to use the NumPy library which provides optimized implementations of many matrix operations:",
"_____no_output_____"
]
],
[
[
"A = np.array([\n [10,20,30],\n [40,50,60]\n])\nA",
"_____no_output_____"
]
],
[
[
"By convention matrices generally have uppercase names, such as $A$.\n\nIn the rest of this tutorial, we will assume that we are using NumPy arrays (type `ndarray`) to represent matrices.",
"_____no_output_____"
],
[
"## Size\nThe size of a matrix is defined by its number of rows and number of columns. It is noted $rows \\times columns$. For example, the matrix $A$ above is an example of a $2 \\times 3$ matrix: 2 rows, 3 columns. Caution: a $3 \\times 2$ matrix would have 3 rows and 2 columns.\n\nTo get a matrix's size in NumPy:",
"_____no_output_____"
]
],
[
[
"A.shape",
"_____no_output_____"
]
],
[
[
"**Caution**: the `size` attribute represents the number of elements in the `ndarray`, not the matrix's size:",
"_____no_output_____"
]
],
[
[
"A.size",
"_____no_output_____"
]
],
[
[
"## Element indexing\nThe number located in the $i^{th}$ row, and $j^{th}$ column of a matrix $X$ is sometimes noted $X_{i,j}$ or $X_{ij}$, but there is no standard notation, so people often prefer to explicitely name the elements, like this: \"*let $X = (x_{i,j})_{1 ≤ i ≤ m, 1 ≤ j ≤ n}$*\". This means that $X$ is equal to:\n\n$X = \\begin{bmatrix}\n x_{1,1} & x_{1,2} & x_{1,3} & \\cdots & x_{1,n}\\\\\n x_{2,1} & x_{2,2} & x_{2,3} & \\cdots & x_{2,n}\\\\\n x_{3,1} & x_{3,2} & x_{3,3} & \\cdots & x_{3,n}\\\\\n \\vdots & \\vdots & \\vdots & \\ddots & \\vdots \\\\\n x_{m,1} & x_{m,2} & x_{m,3} & \\cdots & x_{m,n}\\\\\n\\end{bmatrix}$\n\nHowever in this notebook we will use the $X_{i,j}$ notation, as it matches fairly well NumPy's notation. Note that in math indices generally start at 1, but in programming they usually start at 0. So to access $A_{2,3}$ programmatically, we need to write this:",
"_____no_output_____"
]
],
[
[
"A[1,2] # 2nd row, 3rd column",
"_____no_output_____"
]
],
[
[
"The $i^{th}$ row vector is sometimes noted $M_i$ or $M_{i,*}$, but again there is no standard notation so people often prefer to explicitely define their own names, for example: \"*let **x**$_{i}$ be the $i^{th}$ row vector of matrix $X$*\". We will use the $M_{i,*}$, for the same reason as above. For example, to access $A_{2,*}$ (ie. $A$'s 2nd row vector):",
"_____no_output_____"
]
],
[
[
"A[1, :] # 2nd row vector (as a 1D array)",
"_____no_output_____"
]
],
[
[
"Similarly, the $j^{th}$ column vector is sometimes noted $M^j$ or $M_{*,j}$, but there is no standard notation. We will use $M_{*,j}$. For example, to access $A_{*,3}$ (ie. $A$'s 3rd column vector):",
"_____no_output_____"
]
],
[
[
"A[:, 2] # 3rd column vector (as a 1D array)",
"_____no_output_____"
]
],
[
[
"Note that the result is actually a one-dimensional NumPy array: there is no such thing as a *vertical* or *horizontal* one-dimensional array. If you need to actually represent a row vector as a one-row matrix (ie. a 2D NumPy array), or a column vector as a one-column matrix, then you need to use a slice instead of an integer when accessing the row or column, for example:",
"_____no_output_____"
]
],
[
[
"A[1:2, :] # rows 2 to 3 (excluded): this returns row 2 as a one-row matrix",
"_____no_output_____"
],
[
"A[:, 2:3] # columns 3 to 4 (excluded): this returns column 3 as a one-column matrix",
"_____no_output_____"
]
],
[
[
"## Square, triangular, diagonal and identity matrices\nA **square matrix** is a matrix that has the same number of rows and columns, for example a $3 \\times 3$ matrix:\n\n\\begin{bmatrix}\n 4 & 9 & 2 \\\\\n 3 & 5 & 7 \\\\\n 8 & 1 & 6\n\\end{bmatrix}",
"_____no_output_____"
],
[
"An **upper triangular matrix** is a special kind of square matrix where all the elements *below* the main diagonal (top-left to bottom-right) are zero, for example:\n\n\\begin{bmatrix}\n 4 & 9 & 2 \\\\\n 0 & 5 & 7 \\\\\n 0 & 0 & 6\n\\end{bmatrix}",
"_____no_output_____"
],
[
"Similarly, a **lower triangular matrix** is a square matrix where all elements *above* the main diagonal are zero, for example:\n\n\\begin{bmatrix}\n 4 & 0 & 0 \\\\\n 3 & 5 & 0 \\\\\n 8 & 1 & 6\n\\end{bmatrix}",
"_____no_output_____"
],
[
"A **triangular matrix** is one that is either lower triangular or upper triangular.",
"_____no_output_____"
],
[
"A matrix that is both upper and lower triangular is called a **diagonal matrix**, for example:\n\n\\begin{bmatrix}\n 4 & 0 & 0 \\\\\n 0 & 5 & 0 \\\\\n 0 & 0 & 6\n\\end{bmatrix}\n\nYou can construct a diagonal matrix using NumPy's `diag` function:",
"_____no_output_____"
]
],
[
[
"np.diag([4, 5, 6])",
"_____no_output_____"
]
],
[
[
"If you pass a matrix to the `diag` function, it will happily extract the diagonal values:",
"_____no_output_____"
]
],
[
[
"D = np.array([\n [1, 2, 3],\n [4, 5, 6],\n [7, 8, 9],\n ])\nnp.diag(D)",
"_____no_output_____"
]
],
[
[
"Finally, the **identity matrix** of size $n$, noted $I_n$, is a diagonal matrix of size $n \\times n$ with $1$'s in the main diagonal, for example $I_3$:\n\n\\begin{bmatrix}\n 1 & 0 & 0 \\\\\n 0 & 1 & 0 \\\\\n 0 & 0 & 1\n\\end{bmatrix}\n\nNumpy's `eye` function returns the identity matrix of the desired size:",
"_____no_output_____"
]
],
[
[
"np.eye(3)",
"_____no_output_____"
]
],
[
[
"The identity matrix is often noted simply $I$ (instead of $I_n$) when its size is clear given the context. It is called the *identity* matrix because multiplying a matrix with it leaves the matrix unchanged as we will see below.",
"_____no_output_____"
],
[
"## Adding matrices\nIf two matrices $Q$ and $R$ have the same size $m \\times n$, they can be added together. Addition is performed *elementwise*: the result is also a $m \\times n$ matrix $S$ where each element is the sum of the elements at the corresponding position: $S_{i,j} = Q_{i,j} + R_{i,j}$\n\n$S =\n\\begin{bmatrix}\n Q_{11} + R_{11} & Q_{12} + R_{12} & Q_{13} + R_{13} & \\cdots & Q_{1n} + R_{1n} \\\\\n Q_{21} + R_{21} & Q_{22} + R_{22} & Q_{23} + R_{23} & \\cdots & Q_{2n} + R_{2n} \\\\\n Q_{31} + R_{31} & Q_{32} + R_{32} & Q_{33} + R_{33} & \\cdots & Q_{3n} + R_{3n} \\\\\n \\vdots & \\vdots & \\vdots & \\ddots & \\vdots \\\\\n Q_{m1} + R_{m1} & Q_{m2} + R_{m2} & Q_{m3} + R_{m3} & \\cdots & Q_{mn} + R_{mn} \\\\\n\\end{bmatrix}$\n\nFor example, let's create a $2 \\times 3$ matrix $B$ and compute $A + B$:",
"_____no_output_____"
]
],
[
[
"B = np.array([[1,2,3], [4, 5, 6]])\nB",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
],
[
"A + B",
"_____no_output_____"
]
],
[
[
"**Addition is *commutative***, meaning that $A + B = B + A$:",
"_____no_output_____"
]
],
[
[
"B + A",
"_____no_output_____"
]
],
[
[
"**It is also *associative***, meaning that $A + (B + C) = (A + B) + C$:",
"_____no_output_____"
]
],
[
[
"C = np.array([[100,200,300], [400, 500, 600]])\n\nA + (B + C)",
"_____no_output_____"
],
[
"(A + B) + C",
"_____no_output_____"
]
],
[
[
"## Scalar multiplication\nA matrix $M$ can be multiplied by a scalar $\\lambda$. The result is noted $\\lambda M$, and it is a matrix of the same size as $M$ with all elements multiplied by $\\lambda$:\n\n$\\lambda M =\n\\begin{bmatrix}\n \\lambda \\times M_{11} & \\lambda \\times M_{12} & \\lambda \\times M_{13} & \\cdots & \\lambda \\times M_{1n} \\\\\n \\lambda \\times M_{21} & \\lambda \\times M_{22} & \\lambda \\times M_{23} & \\cdots & \\lambda \\times M_{2n} \\\\\n \\lambda \\times M_{31} & \\lambda \\times M_{32} & \\lambda \\times M_{33} & \\cdots & \\lambda \\times M_{3n} \\\\\n \\vdots & \\vdots & \\vdots & \\ddots & \\vdots \\\\\n \\lambda \\times M_{m1} & \\lambda \\times M_{m2} & \\lambda \\times M_{m3} & \\cdots & \\lambda \\times M_{mn} \\\\\n\\end{bmatrix}$\n\nA more concise way of writing this is:\n\n$(\\lambda M)_{i,j} = \\lambda (M)_{i,j}$\n\nIn NumPy, simply use the `*` operator to multiply a matrix by a scalar. For example:",
"_____no_output_____"
]
],
[
[
"2 * A",
"_____no_output_____"
]
],
[
[
"Scalar multiplication is also defined on the right hand side, and gives the same result: $M \\lambda = \\lambda M$. For example:",
"_____no_output_____"
]
],
[
[
"A * 2",
"_____no_output_____"
]
],
[
[
"This makes scalar multiplication **commutative**.\n\nIt is also **associative**, meaning that $\\alpha (\\beta M) = (\\alpha \\times \\beta) M$, where $\\alpha$ and $\\beta$ are scalars. For example:",
"_____no_output_____"
]
],
[
[
"2 * (3 * A)",
"_____no_output_____"
],
[
"(2 * 3) * A",
"_____no_output_____"
]
],
[
[
"Finally, it is **distributive over addition** of matrices, meaning that $\\lambda (Q + R) = \\lambda Q + \\lambda R$:",
"_____no_output_____"
]
],
[
[
"2 * (A + B)",
"_____no_output_____"
],
[
"2 * A + 2 * B",
"_____no_output_____"
]
],
[
[
"## Matrix multiplication\nSo far, matrix operations have been rather intuitive. But multiplying matrices is a bit more involved.\n\nA matrix $Q$ of size $m \\times n$ can be multiplied by a matrix $R$ of size $n \\times q$. It is noted simply $QR$ without multiplication sign or dot. The result $P$ is an $m \\times q$ matrix where each element is computed as a sum of products:\n\n$P_{i,j} = \\sum_{k=1}^n{Q_{i,k} \\times R_{k,j}}$\n\nThe element at position $i,j$ in the resulting matrix is the sum of the products of elements in row $i$ of matrix $Q$ by the elements in column $j$ of matrix $R$.\n\n$P =\n\\begin{bmatrix}\nQ_{11} R_{11} + Q_{12} R_{21} + \\cdots + Q_{1n} R_{n1} &\n Q_{11} R_{12} + Q_{12} R_{22} + \\cdots + Q_{1n} R_{n2} &\n \\cdots &\n Q_{11} R_{1q} + Q_{12} R_{2q} + \\cdots + Q_{1n} R_{nq} \\\\\nQ_{21} R_{11} + Q_{22} R_{21} + \\cdots + Q_{2n} R_{n1} &\n Q_{21} R_{12} + Q_{22} R_{22} + \\cdots + Q_{2n} R_{n2} &\n \\cdots &\n Q_{21} R_{1q} + Q_{22} R_{2q} + \\cdots + Q_{2n} R_{nq} \\\\\n \\vdots & \\vdots & \\ddots & \\vdots \\\\\nQ_{m1} R_{11} + Q_{m2} R_{21} + \\cdots + Q_{mn} R_{n1} &\n Q_{m1} R_{12} + Q_{m2} R_{22} + \\cdots + Q_{mn} R_{n2} &\n \\cdots &\n Q_{m1} R_{1q} + Q_{m2} R_{2q} + \\cdots + Q_{mn} R_{nq}\n\\end{bmatrix}$\n\nYou may notice that each element $P_{i,j}$ is the dot product of the row vector $Q_{i,*}$ and the column vector $R_{*,j}$:\n\n$P_{i,j} = Q_{i,*} \\cdot R_{*,j}$\n\nSo we can rewrite $P$ more concisely as:\n\n$P =\n\\begin{bmatrix}\nQ_{1,*} \\cdot R_{*,1} & Q_{1,*} \\cdot R_{*,2} & \\cdots & Q_{1,*} \\cdot R_{*,q} \\\\\nQ_{2,*} \\cdot R_{*,1} & Q_{2,*} \\cdot R_{*,2} & \\cdots & Q_{2,*} \\cdot R_{*,q} \\\\\n\\vdots & \\vdots & \\ddots & \\vdots \\\\\nQ_{m,*} \\cdot R_{*,1} & Q_{m,*} \\cdot R_{*,2} & \\cdots & Q_{m,*} \\cdot R_{*,q}\n\\end{bmatrix}$\n",
"_____no_output_____"
],
[
"Let's multiply two matrices in NumPy, using `ndarray`'s `dot` method:\n\n$E = AD = \\begin{bmatrix}\n 10 & 20 & 30 \\\\\n 40 & 50 & 60\n\\end{bmatrix} \n\\begin{bmatrix}\n 2 & 3 & 5 & 7 \\\\\n 11 & 13 & 17 & 19 \\\\\n 23 & 29 & 31 & 37\n\\end{bmatrix} = \n\\begin{bmatrix}\n 930 & 1160 & 1320 & 1560 \\\\\n 2010 & 2510 & 2910 & 3450\n\\end{bmatrix}$",
"_____no_output_____"
]
],
[
[
"D = np.array([\n [ 2, 3, 5, 7],\n [11, 13, 17, 19],\n [23, 29, 31, 37]\n ])\nE = A.dot(D)\nE",
"_____no_output_____"
]
],
[
[
"Let's check this result by looking at one element, just to be sure: looking at $E_{2,3}$ for example, we need to multiply elements in $A$'s $2^{nd}$ row by elements in $D$'s $3^{rd}$ column, and sum up these products:",
"_____no_output_____"
]
],
[
[
"40*5 + 50*17 + 60*31",
"_____no_output_____"
],
[
"E[1,2] # row 2, column 3",
"_____no_output_____"
]
],
[
[
"Looks good! You can check the other elements until you get used to the algorithm.\n\nWe multiplied a $2 \\times 3$ matrix by a $3 \\times 4$ matrix, so the result is a $2 \\times 4$ matrix. The first matrix's number of columns has to be equal to the second matrix's number of rows. If we try to multiple $D$ by $A$, we get an error because D has 4 columns while A has 2 rows:",
"_____no_output_____"
]
],
[
[
"try:\n D.dot(A)\nexcept ValueError as e:\n print(\"ValueError:\", e)",
"ValueError: shapes (3,4) and (2,3) not aligned: 4 (dim 1) != 2 (dim 0)\n"
]
],
[
[
"This illustrates the fact that **matrix multiplication is *NOT* commutative**: in general $QR ≠ RQ$\n\nIn fact, $QR$ and $RQ$ are only *both* defined if $Q$ has size $m \\times n$ and $R$ has size $n \\times m$. Let's look at an example where both *are* defined and show that they are (in general) *NOT* equal:",
"_____no_output_____"
]
],
[
[
"F = np.array([\n [5,2],\n [4,1],\n [9,3]\n ])\nA.dot(F)",
"_____no_output_____"
],
[
"F.dot(A)",
"_____no_output_____"
]
],
[
[
"On the other hand, **matrix multiplication *is* associative**, meaning that $Q(RS) = (QR)S$. Let's create a $4 \\times 5$ matrix $G$ to illustrate this:",
"_____no_output_____"
]
],
[
[
"G = np.array([\n [8, 7, 4, 2, 5],\n [2, 5, 1, 0, 5],\n [9, 11, 17, 21, 0],\n [0, 1, 0, 1, 2]])\nA.dot(D).dot(G) # (AB)G",
"_____no_output_____"
],
[
"A.dot(D.dot(G)) # A(BG)",
"_____no_output_____"
]
],
[
[
"It is also ***distributive* over addition** of matrices, meaning that $(Q + R)S = QS + RS$. For example:",
"_____no_output_____"
]
],
[
[
"(A + B).dot(D)",
"_____no_output_____"
],
[
"A.dot(D) + B.dot(D)",
"_____no_output_____"
]
],
[
[
"The product of a matrix $M$ by the identity matrix (of matching size) results in the same matrix $M$. More formally, if $M$ is an $m \\times n$ matrix, then:\n\n$M I_n = I_m M = M$\n\nThis is generally written more concisely (since the size of the identity matrices is unambiguous given the context):\n\n$MI = IM = M$\n\nFor example:",
"_____no_output_____"
]
],
[
[
"A.dot(np.eye(3))",
"_____no_output_____"
],
[
"np.eye(2).dot(A)",
"_____no_output_____"
]
],
[
[
"**Caution**: NumPy's `*` operator performs elementwise multiplication, *NOT* a matrix multiplication:",
"_____no_output_____"
]
],
[
[
"A * B # NOT a matrix multiplication",
"_____no_output_____"
]
],
[
[
"**The @ infix operator**\n\nPython 3.5 [introduced](https://docs.python.org/3/whatsnew/3.5.html#pep-465-a-dedicated-infix-operator-for-matrix-multiplication) the `@` infix operator for matrix multiplication, and NumPy 1.10 added support for it. If you are using Python 3.5+ and NumPy 1.10+, you can simply write `A @ D` instead of `A.dot(D)`, making your code much more readable (but less portable). This operator also works for vector dot products.",
"_____no_output_____"
]
],
[
[
"import sys\nprint(\"Python version: {}.{}.{}\".format(*sys.version_info))\nprint(\"Numpy version:\", np.version.version)\n\n# Uncomment the following line if your Python version is ≥3.5\n# and your NumPy version is ≥1.10:\n\n#A @ D",
"Python version: 3.5.3\nNumpy version: 1.12.1\n"
]
],
[
[
"Note: `Q @ R` is actually equivalent to `Q.__matmul__(R)` which is implemented by NumPy as `np.matmul(Q, R)`, not as `Q.dot(R)`. The main difference is that `matmul` does not support scalar multiplication, while `dot` does, so you can write `Q.dot(3)`, which is equivalent to `Q * 3`, but you cannot write `Q @ 3` ([more details](http://stackoverflow.com/a/34142617/38626)).",
"_____no_output_____"
],
[
"## Matrix transpose\nThe transpose of a matrix $M$ is a matrix noted $M^T$ such that the $i^{th}$ row in $M^T$ is equal to the $i^{th}$ column in $M$:\n\n$ A^T =\n\\begin{bmatrix}\n 10 & 20 & 30 \\\\\n 40 & 50 & 60\n\\end{bmatrix}^T =\n\\begin{bmatrix}\n 10 & 40 \\\\\n 20 & 50 \\\\\n 30 & 60\n\\end{bmatrix}$\n\nIn other words, ($A^T)_{i,j}$ = $A_{j,i}$\n\nObviously, if $M$ is an $m \\times n$ matrix, then $M^T$ is an $n \\times m$ matrix.\n\nNote: there are a few other notations, such as $M^t$, $M′$, or ${^t}M$.\n\nIn NumPy, a matrix's transpose can be obtained simply using the `T` attribute:",
"_____no_output_____"
]
],
[
[
"A",
"_____no_output_____"
],
[
"A.T",
"_____no_output_____"
]
],
[
[
"As you might expect, transposing a matrix twice returns the original matrix:",
"_____no_output_____"
]
],
[
[
"A.T.T",
"_____no_output_____"
]
],
[
[
"Transposition is distributive over addition of matrices, meaning that $(Q + R)^T = Q^T + R^T$. For example:",
"_____no_output_____"
]
],
[
[
"(A + B).T",
"_____no_output_____"
],
[
"A.T + B.T",
"_____no_output_____"
]
],
[
[
"Moreover, $(Q \\cdot R)^T = R^T \\cdot Q^T$. Note that the order is reversed. For example:",
"_____no_output_____"
]
],
[
[
"(A.dot(D)).T",
"_____no_output_____"
],
[
"D.T.dot(A.T)",
"_____no_output_____"
]
],
[
[
"A **symmetric matrix** $M$ is defined as a matrix that is equal to its transpose: $M^T = M$. This definition implies that it must be a square matrix whose elements are symmetric relative to the main diagonal, for example:\n\n\\begin{bmatrix}\n 17 & 22 & 27 & 49 \\\\\n 22 & 29 & 36 & 0 \\\\\n 27 & 36 & 45 & 2 \\\\\n 49 & 0 & 2 & 99\n\\end{bmatrix}\n\nThe product of a matrix by its transpose is always a symmetric matrix, for example:",
"_____no_output_____"
]
],
[
[
"D.dot(D.T)",
"_____no_output_____"
]
],
[
[
"## Converting 1D arrays to 2D arrays in NumPy\nAs we mentionned earlier, in NumPy (as opposed to Matlab, for example), 1D really means 1D: there is no such thing as a vertical 1D-array or a horizontal 1D-array. So you should not be surprised to see that transposing a 1D array does not do anything:",
"_____no_output_____"
]
],
[
[
"u",
"_____no_output_____"
],
[
"u.T",
"_____no_output_____"
]
],
[
[
"We want to convert $\\textbf{u}$ into a row vector before transposing it. There are a few ways to do this:",
"_____no_output_____"
]
],
[
[
"u_row = np.array([u])\nu_row",
"_____no_output_____"
]
],
[
[
"Notice the extra square brackets: this is a 2D array with just one row (ie. a 1x2 matrix). In other words it really is a **row vector**.",
"_____no_output_____"
]
],
[
[
"u[np.newaxis, :]",
"_____no_output_____"
]
],
[
[
"This quite explicit: we are asking for a new vertical axis, keeping the existing data as the horizontal axis.",
"_____no_output_____"
]
],
[
[
"u[np.newaxis]",
"_____no_output_____"
]
],
[
[
"This is equivalent, but a little less explicit.",
"_____no_output_____"
]
],
[
[
"u[None]",
"_____no_output_____"
]
],
[
[
"This is the shortest version, but you probably want to avoid it because it is unclear. The reason it works is that `np.newaxis` is actually equal to `None`, so this is equivalent to the previous version.\n\nOk, now let's transpose our row vector:",
"_____no_output_____"
]
],
[
[
"u_row.T",
"_____no_output_____"
]
],
[
[
"Great! We now have a nice **column vector**.\n\nRather than creating a row vector then transposing it, it is also possible to convert a 1D array directly into a column vector:",
"_____no_output_____"
]
],
[
[
"u[:, np.newaxis]",
"_____no_output_____"
]
],
[
[
"## Plotting a matrix\nWe have already seen that vectors can been represented as points or arrows in N-dimensional space. Is there a good graphical representation of matrices? Well you can simply see a matrix as a list of vectors, so plotting a matrix results in many points or arrows. For example, let's create a $2 \\times 4$ matrix `P` and plot it as points:",
"_____no_output_____"
]
],
[
[
"P = np.array([\n [3.0, 4.0, 1.0, 4.6],\n [0.2, 3.5, 2.0, 0.5]\n ])\nx_coords_P, y_coords_P = P\nplt.scatter(x_coords_P, y_coords_P)\nplt.axis([0, 5, 0, 4])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Of course we could also have stored the same 4 vectors as row vectors instead of column vectors, resulting in a $4 \\times 2$ matrix (the transpose of $P$, in fact). It is really an arbitrary choice.\n\nSince the vectors are ordered, you can see the matrix as a path and represent it with connected dots:",
"_____no_output_____"
]
],
[
[
"plt.plot(x_coords_P, y_coords_P, \"bo\")\nplt.plot(x_coords_P, y_coords_P, \"b--\")\nplt.axis([0, 5, 0, 4])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Or you can represent it as a polygon: matplotlib's `Polygon` class expects an $n \\times 2$ NumPy array, not a $2 \\times n$ array, so we just need to give it $P^T$:",
"_____no_output_____"
]
],
[
[
"from matplotlib.patches import Polygon\nplt.gca().add_artist(Polygon(P.T))\nplt.axis([0, 5, 0, 4])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Geometric applications of matrix operations\nWe saw earlier that vector addition results in a geometric translation, vector multiplication by a scalar results in rescaling (zooming in or out, centered on the origin), and vector dot product results in projecting a vector onto another vector, rescaling and measuring the resulting coordinate.\n\nSimilarly, matrix operations have very useful geometric applications.",
"_____no_output_____"
],
[
"### Addition = multiple geometric translations\nFirst, adding two matrices together is equivalent to adding all their vectors together. For example, let's create a $2 \\times 4$ matrix $H$ and add it to $P$, and look at the result:",
"_____no_output_____"
]
],
[
[
"H = np.array([\n [ 0.5, -0.2, 0.2, -0.1],\n [ 0.4, 0.4, 1.5, 0.6]\n ])\nP_moved = P + H\n\nplt.gca().add_artist(Polygon(P.T, alpha=0.2))\nplt.gca().add_artist(Polygon(P_moved.T, alpha=0.3, color=\"r\"))\nfor vector, origin in zip(H.T, P.T):\n plot_vector2d(vector, origin=origin)\n\nplt.text(2.2, 1.8, \"$P$\", color=\"b\", fontsize=18)\nplt.text(2.0, 3.2, \"$P+H$\", color=\"r\", fontsize=18)\nplt.text(2.5, 0.5, \"$H_{*,1}$\", color=\"k\", fontsize=18)\nplt.text(4.1, 3.5, \"$H_{*,2}$\", color=\"k\", fontsize=18)\nplt.text(0.4, 2.6, \"$H_{*,3}$\", color=\"k\", fontsize=18)\nplt.text(4.4, 0.2, \"$H_{*,4}$\", color=\"k\", fontsize=18)\n\nplt.axis([0, 5, 0, 4])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"If we add a matrix full of identical vectors, we get a simple geometric translation:",
"_____no_output_____"
]
],
[
[
"H2 = np.array([\n [-0.5, -0.5, -0.5, -0.5],\n [ 0.4, 0.4, 0.4, 0.4]\n ])\nP_translated = P + H2\n\nplt.gca().add_artist(Polygon(P.T, alpha=0.2))\nplt.gca().add_artist(Polygon(P_translated.T, alpha=0.3, color=\"r\"))\nfor vector, origin in zip(H2.T, P.T):\n plot_vector2d(vector, origin=origin)\n\nplt.axis([0, 5, 0, 4])\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Although matrices can only be added together if they have the same size, NumPy allows adding a row vector or a column vector to a matrix: this is called *broadcasting* and is explained in further details in the [NumPy tutorial](tools_numpy.ipynb). We could have obtained the same result as above with:",
"_____no_output_____"
]
],
[
[
"P + [[-0.5], [0.4]] # same as P + H2, thanks to NumPy broadcasting",
"_____no_output_____"
]
],
[
[
"### Scalar multiplication\nMultiplying a matrix by a scalar results in all its vectors being multiplied by that scalar, so unsurprisingly, the geometric result is a rescaling of the entire figure. For example, let's rescale our polygon by a factor of 60% (zooming out, centered on the origin):",
"_____no_output_____"
]
],
[
[
"def plot_transformation(P_before, P_after, text_before, text_after, axis = [0, 5, 0, 4], arrows=False):\n if arrows:\n for vector_before, vector_after in zip(P_before.T, P_after.T):\n plot_vector2d(vector_before, color=\"blue\", linestyle=\"--\")\n plot_vector2d(vector_after, color=\"red\", linestyle=\"-\")\n plt.gca().add_artist(Polygon(P_before.T, alpha=0.2))\n plt.gca().add_artist(Polygon(P_after.T, alpha=0.3, color=\"r\"))\n plt.text(P_before[0].mean(), P_before[1].mean(), text_before, fontsize=18, color=\"blue\")\n plt.text(P_after[0].mean(), P_after[1].mean(), text_after, fontsize=18, color=\"red\")\n plt.axis(axis)\n plt.grid()\n\nP_rescaled = 0.60 * P\nplot_transformation(P, P_rescaled, \"$P$\", \"$0.6 P$\", arrows=True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Matrix multiplication – Projection onto an axis\nMatrix multiplication is more complex to visualize, but it is also the most powerful tool in the box.\n\nLet's start simple, by defining a $1 \\times 2$ matrix $U = \\begin{bmatrix} 1 & 0 \\end{bmatrix}$. This row vector is just the horizontal unit vector.",
"_____no_output_____"
]
],
[
[
"U = np.array([[1, 0]])",
"_____no_output_____"
]
],
[
[
"Now let's look at the dot product $U \\cdot P$:",
"_____no_output_____"
]
],
[
[
"U.dot(P)",
"_____no_output_____"
]
],
[
[
"These are the horizontal coordinates of the vectors in $P$. In other words, we just projected $P$ onto the horizontal axis:",
"_____no_output_____"
]
],
[
[
"def plot_projection(U, P):\n U_P = U.dot(P)\n \n axis_end = 100 * U\n plot_vector2d(axis_end[0], color=\"black\")\n\n plt.gca().add_artist(Polygon(P.T, alpha=0.2))\n for vector, proj_coordinate in zip(P.T, U_P.T):\n proj_point = proj_coordinate * U\n plt.plot(proj_point[0][0], proj_point[0][1], \"ro\")\n plt.plot([vector[0], proj_point[0][0]], [vector[1], proj_point[0][1]], \"r--\")\n\n plt.axis([0, 5, 0, 4])\n plt.grid()\n plt.show()\n\nplot_projection(U, P)",
"_____no_output_____"
]
],
[
[
"We can actually project on any other axis by just replacing $U$ with any other unit vector. For example, let's project on the axis that is at a 30° angle above the horizontal axis:",
"_____no_output_____"
]
],
[
[
"angle30 = 30 * np.pi / 180 # angle in radians\nU_30 = np.array([[np.cos(angle30), np.sin(angle30)]])\n\nplot_projection(U_30, P)",
"_____no_output_____"
]
],
[
[
"Good! Remember that the dot product of a unit vector and a matrix basically performs a projection on an axis and gives us the coordinates of the resulting points on that axis.",
"_____no_output_____"
],
[
"### Matrix multiplication – Rotation\nNow let's create a $2 \\times 2$ matrix $V$ containing two unit vectors that make 30° and 120° angles with the horizontal axis:\n\n$V = \\begin{bmatrix} \\cos(30°) & \\sin(30°) \\\\ \\cos(120°) & \\sin(120°) \\end{bmatrix}$",
"_____no_output_____"
]
],
[
[
"angle120 = 120 * np.pi / 180\nV = np.array([\n [np.cos(angle30), np.sin(angle30)],\n [np.cos(angle120), np.sin(angle120)]\n ])\nV",
"_____no_output_____"
]
],
[
[
"Let's look at the product $VP$:",
"_____no_output_____"
]
],
[
[
"V.dot(P)",
"_____no_output_____"
]
],
[
[
"The first row is equal to $V_{1,*} P$, which is the coordinates of the projection of $P$ onto the 30° axis, as we have seen above. The second row is $V_{2,*} P$, which is the coordinates of the projection of $P$ onto the 120° axis. So basically we obtained the coordinates of $P$ after rotating the horizontal and vertical axes by 30° (or equivalently after rotating the polygon by -30° around the origin)! Let's plot $VP$ to see this:",
"_____no_output_____"
]
],
[
[
"P_rotated = V.dot(P)\nplot_transformation(P, P_rotated, \"$P$\", \"$VP$\", [-2, 6, -2, 4], arrows=True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Matrix $V$ is called a **rotation matrix**.",
"_____no_output_____"
],
[
"### Matrix multiplication – Other linear transformations\nMore generally, any linear transformation $f$ that maps n-dimensional vectors to m-dimensional vectors can be represented as an $m \\times n$ matrix. For example, say $\\textbf{u}$ is a 3-dimensional vector:\n\n$\\textbf{u} = \\begin{pmatrix} x \\\\ y \\\\ z \\end{pmatrix}$\n\nand $f$ is defined as:\n\n$f(\\textbf{u}) = \\begin{pmatrix}\nax + by + cz \\\\\ndx + ey + fz\n\\end{pmatrix}$\n\nThis transormation $f$ maps 3-dimensional vectors to 2-dimensional vectors in a linear way (ie. the resulting coordinates only involve sums of multiples of the original coordinates). We can represent this transformation as matrix $F$:\n\n$F = \\begin{bmatrix}\na & b & c \\\\\nd & e & f\n\\end{bmatrix}$\n\nNow, to compute $f(\\textbf{u})$ we can simply do a matrix multiplication:\n\n$f(\\textbf{u}) = F \\textbf{u}$\n\nIf we have a matric $G = \\begin{bmatrix}\\textbf{u}_1 & \\textbf{u}_2 & \\cdots & \\textbf{u}_q \\end{bmatrix}$, where each $\\textbf{u}_i$ is a 3-dimensional column vector, then $FG$ results in the linear transformation of all vectors $\\textbf{u}_i$ as defined by the matrix $F$:\n\n$FG = \\begin{bmatrix}f(\\textbf{u}_1) & f(\\textbf{u}_2) & \\cdots & f(\\textbf{u}_q) \\end{bmatrix}$\n\nTo summarize, the matrix on the left hand side of a dot product specifies what linear transormation to apply to the right hand side vectors. We have already shown that this can be used to perform projections and rotations, but any other linear transformation is possible. For example, here is a transformation known as a *shear mapping*:",
"_____no_output_____"
]
],
[
[
"F_shear = np.array([\n [1, 1.5],\n [0, 1]\n ])\nplot_transformation(P, F_shear.dot(P), \"$P$\", \"$F_{shear} P$\",\n axis=[0, 10, 0, 7])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's look at how this transformation affects the **unit square**: ",
"_____no_output_____"
]
],
[
[
"Square = np.array([\n [0, 0, 1, 1],\n [0, 1, 1, 0]\n ])\nplot_transformation(Square, F_shear.dot(Square), \"$Square$\", \"$F_{shear} Square$\",\n axis=[0, 2.6, 0, 1.8])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Now let's look at a **squeeze mapping**:",
"_____no_output_____"
]
],
[
[
"F_squeeze = np.array([\n [1.4, 0],\n [0, 1/1.4]\n ])\nplot_transformation(P, F_squeeze.dot(P), \"$P$\", \"$F_{squeeze} P$\",\n axis=[0, 7, 0, 5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"The effect on the unit square is:",
"_____no_output_____"
]
],
[
[
"plot_transformation(Square, F_squeeze.dot(Square), \"$Square$\", \"$F_{squeeze} Square$\",\n axis=[0, 1.8, 0, 1.2])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's show a last one: reflection through the horizontal axis:",
"_____no_output_____"
]
],
[
[
"F_reflect = np.array([\n [1, 0],\n [0, -1]\n ])\nplot_transformation(P, F_reflect.dot(P), \"$P$\", \"$F_{reflect} P$\",\n axis=[-2, 9, -4.5, 4.5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Matrix inverse\nNow that we understand that a matrix can represent any linear transformation, a natural question is: can we find a transformation matrix that reverses the effect of a given transformation matrix $F$? The answer is yes… sometimes! When it exists, such a matrix is called the **inverse** of $F$, and it is noted $F^{-1}$.\n\nFor example, the rotation, the shear mapping and the squeeze mapping above all have inverse transformations. Let's demonstrate this on the shear mapping:",
"_____no_output_____"
]
],
[
[
"F_inv_shear = np.array([\n [1, -1.5],\n [0, 1]\n])\nP_sheared = F_shear.dot(P)\nP_unsheared = F_inv_shear.dot(P_sheared)\nplot_transformation(P_sheared, P_unsheared, \"$P_{sheared}$\", \"$P_{unsheared}$\",\n axis=[0, 10, 0, 7])\nplt.plot(P[0], P[1], \"b--\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"We applied a shear mapping on $P$, just like we did before, but then we applied a second transformation to the result, and *lo and behold* this had the effect of coming back to the original $P$ (we plotted the original $P$'s outline to double check). The second transformation is the inverse of the first one.\n\nWe defined the inverse matrix $F_{shear}^{-1}$ manually this time, but NumPy provides an `inv` function to compute a matrix's inverse, so we could have written instead:",
"_____no_output_____"
]
],
[
[
"F_inv_shear = LA.inv(F_shear)\nF_inv_shear",
"_____no_output_____"
]
],
[
[
"Only square matrices can be inversed. This makes sense when you think about it: if you have a transformation that reduces the number of dimensions, then some information is lost and there is no way that you can get it back. For example say you use a $2 \\times 3$ matrix to project a 3D object onto a plane. The result may look like this:",
"_____no_output_____"
]
],
[
[
"plt.plot([0, 0, 1, 1, 0, 0.1, 0.1, 0, 0.1, 1.1, 1.0, 1.1, 1.1, 1.0, 1.1, 0.1],\n [0, 1, 1, 0, 0, 0.1, 1.1, 1.0, 1.1, 1.1, 1.0, 1.1, 0.1, 0, 0.1, 0.1],\n \"r-\")\nplt.axis([-0.5, 2.1, -0.5, 1.5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Looking at this image, it is impossible to tell whether this is the projection of a cube or the projection of a narrow rectangular object. Some information has been lost in the projection.\n\nEven square transformation matrices can lose information. For example, consider this transformation matrix:",
"_____no_output_____"
]
],
[
[
"F_project = np.array([\n [1, 0],\n [0, 0]\n ])\nplot_transformation(P, F_project.dot(P), \"$P$\", \"$F_{project} \\cdot P$\",\n axis=[0, 6, -1, 4])\nplt.show()",
"_____no_output_____"
]
],
[
[
"This transformation matrix performs a projection onto the horizontal axis. Our polygon gets entirely flattened out so some information is entirely lost and it is impossible to go back to the original polygon using a linear transformation. In other words, $F_{project}$ has no inverse. Such a square matrix that cannot be inversed is called a **singular matrix** (aka degenerate matrix). If we ask NumPy to calculate its inverse, it raises an exception:",
"_____no_output_____"
]
],
[
[
"try:\n LA.inv(F_project)\nexcept LA.LinAlgError as e:\n print(\"LinAlgError:\", e)",
"LinAlgError: Singular matrix\n"
]
],
[
[
"Here is another example of a singular matrix. This one performs a projection onto the axis at a 30° angle above the horizontal axis:",
"_____no_output_____"
]
],
[
[
"angle30 = 30 * np.pi / 180\nF_project_30 = np.array([\n [np.cos(angle30)**2, np.sin(2*angle30)/2],\n [np.sin(2*angle30)/2, np.sin(angle30)**2]\n ])\nplot_transformation(P, F_project_30.dot(P), \"$P$\", \"$F_{project\\_30} \\cdot P$\",\n axis=[0, 6, -1, 4])\nplt.show()",
"_____no_output_____"
]
],
[
[
"But this time, due to floating point rounding errors, NumPy manages to calculate an inverse (notice how large the elements are, though):",
"_____no_output_____"
]
],
[
[
"LA.inv(F_project_30)",
"_____no_output_____"
]
],
[
[
"As you might expect, the dot product of a matrix by its inverse results in the identity matrix:\n\n$M \\cdot M^{-1} = M^{-1} \\cdot M = I$\n\nThis makes sense since doing a linear transformation followed by the inverse transformation results in no change at all.",
"_____no_output_____"
]
],
[
[
"F_shear.dot(LA.inv(F_shear))",
"_____no_output_____"
]
],
[
[
"Another way to express this is that the inverse of the inverse of a matrix $M$ is $M$ itself:\n\n$((M)^{-1})^{-1} = M$",
"_____no_output_____"
]
],
[
[
"LA.inv(LA.inv(F_shear))",
"_____no_output_____"
]
],
[
[
"Also, the inverse of scaling by a factor of $\\lambda$ is of course scaling by a factor or $\\frac{1}{\\lambda}$:\n\n$ (\\lambda \\times M)^{-1} = \\frac{1}{\\lambda} \\times M^{-1}$\n\nOnce you understand the geometric interpretation of matrices as linear transformations, most of these properties seem fairly intuitive.\n\nA matrix that is its own inverse is called an **involution**. The simplest examples are reflection matrices, or a rotation by 180°, but there are also more complex involutions, for example imagine a transformation that squeezes horizontally, then reflects over the vertical axis and finally rotates by 90° clockwise. Pick up a napkin and try doing that twice: you will end up in the original position. Here is the corresponding involutory matrix:",
"_____no_output_____"
]
],
[
[
"F_involution = np.array([\n [0, -2],\n [-1/2, 0]\n ])\nplot_transformation(P, F_involution.dot(P), \"$P$\", \"$F_{involution} \\cdot P$\",\n axis=[-8, 5, -4, 4])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Finally, a square matrix $H$ whose inverse is its own transpose is an **orthogonal matrix**:\n\n$H^{-1} = H^T$\n\nTherefore:\n\n$H \\cdot H^T = H^T \\cdot H = I$\n\nIt corresponds to a transformation that preserves distances, such as rotations and reflections, and combinations of these, but not rescaling, shearing or squeezing. Let's check that $F_{reflect}$ is indeed orthogonal:",
"_____no_output_____"
]
],
[
[
"F_reflect.dot(F_reflect.T)",
"_____no_output_____"
]
],
[
[
"## Determinant\nThe determinant of a square matrix $M$, noted $\\det(M)$ or $\\det M$ or $|M|$ is a value that can be calculated from its elements $(M_{i,j})$ using various equivalent methods. One of the simplest methods is this recursive approach:\n\n$|M| = M_{1,1}\\times|M^{(1,1)}| - M_{2,1}\\times|M^{(2,1)}| + M_{3,1}\\times|M^{(3,1)}| - M_{4,1}\\times|M^{(4,1)}| + \\cdots ± M_{n,1}\\times|M^{(n,1)}|$\n\n* Where $M^{(i,j)}$ is the matrix $M$ without row $i$ and column $j$.\n\nFor example, let's calculate the determinant of the following $3 \\times 3$ matrix:\n\n$M = \\begin{bmatrix}\n 1 & 2 & 3 \\\\\n 4 & 5 & 6 \\\\\n 7 & 8 & 0\n\\end{bmatrix}$\n\nUsing the method above, we get:\n\n$|M| = 1 \\times \\left | \\begin{bmatrix} 5 & 6 \\\\ 8 & 0 \\end{bmatrix} \\right |\n - 2 \\times \\left | \\begin{bmatrix} 4 & 6 \\\\ 7 & 0 \\end{bmatrix} \\right |\n + 3 \\times \\left | \\begin{bmatrix} 4 & 5 \\\\ 7 & 8 \\end{bmatrix} \\right |$\n\nNow we need to compute the determinant of each of these $2 \\times 2$ matrices (these determinants are called **minors**):\n\n$\\left | \\begin{bmatrix} 5 & 6 \\\\ 8 & 0 \\end{bmatrix} \\right | = 5 \\times 0 - 6 \\times 8 = -48$\n\n$\\left | \\begin{bmatrix} 4 & 6 \\\\ 7 & 0 \\end{bmatrix} \\right | = 4 \\times 0 - 6 \\times 7 = -42$\n\n$\\left | \\begin{bmatrix} 4 & 5 \\\\ 7 & 8 \\end{bmatrix} \\right | = 4 \\times 8 - 5 \\times 7 = -3$\n\nNow we can calculate the final result:\n\n$|M| = 1 \\times (-48) - 2 \\times (-42) + 3 \\times (-3) = 27$",
"_____no_output_____"
],
[
"To get the determinant of a matrix, you can call NumPy's `det` function in the `numpy.linalg` module:",
"_____no_output_____"
]
],
[
[
"M = np.array([\n [1, 2, 3],\n [4, 5, 6],\n [7, 8, 0]\n ])\nLA.det(M)",
"_____no_output_____"
]
],
[
[
"One of the main uses of the determinant is to *determine* whether a square matrix can be inversed or not: if the determinant is equal to 0, then the matrix *cannot* be inversed (it is a singular matrix), and if the determinant is not 0, then it *can* be inversed.\n\nFor example, let's compute the determinant for the $F_{project}$, $F_{project\\_30}$ and $F_{shear}$ matrices that we defined earlier:",
"_____no_output_____"
]
],
[
[
"LA.det(F_project)",
"_____no_output_____"
]
],
[
[
"That's right, $F_{project}$ is singular, as we saw earlier.",
"_____no_output_____"
]
],
[
[
"LA.det(F_project_30)",
"_____no_output_____"
]
],
[
[
"This determinant is suspiciously close to 0: it really should be 0, but it's not due to tiny floating point errors. The matrix is actually singular.",
"_____no_output_____"
]
],
[
[
"LA.det(F_shear)",
"_____no_output_____"
]
],
[
[
"Perfect! This matrix *can* be inversed as we saw earlier. Wow, math really works!",
"_____no_output_____"
],
[
"The determinant can also be used to measure how much a linear transformation affects surface areas: for example, the projection matrices $F_{project}$ and $F_{project\\_30}$ completely flatten the polygon $P$, until its area is zero. This is why the determinant of these matrices is 0. The shear mapping modified the shape of the polygon, but it did not affect its surface area, which is why the determinant is 1. You can try computing the determinant of a rotation matrix, and you should also find 1. What about a scaling matrix? Let's see:",
"_____no_output_____"
]
],
[
[
"F_scale = np.array([\n [0.5, 0],\n [0, 0.5]\n ])\nplot_transformation(P, F_scale.dot(P), \"$P$\", \"$F_{scale} \\cdot P$\",\n axis=[0, 6, -1, 4])\nplt.show()",
"_____no_output_____"
]
],
[
[
"We rescaled the polygon by a factor of 1/2 on both vertical and horizontal axes so the surface area of the resulting polygon is 1/4$^{th}$ of the original polygon. Let's compute the determinant and check that:",
"_____no_output_____"
]
],
[
[
"LA.det(F_scale)",
"_____no_output_____"
]
],
[
[
"Correct!\n\nThe determinant can actually be negative, when the transformation results in a \"flipped over\" version of the original polygon (eg. a left hand glove becomes a right hand glove). For example, the determinant of the `F_reflect` matrix is -1 because the surface area is preserved but the polygon gets flipped over:",
"_____no_output_____"
]
],
[
[
"LA.det(F_reflect)",
"_____no_output_____"
]
],
[
[
"## Composing linear transformations\nSeveral linear transformations can be chained simply by performing multiple dot products in a row. For example, to perform a squeeze mapping followed by a shear mapping, just write:",
"_____no_output_____"
]
],
[
[
"P_squeezed_then_sheared = F_shear.dot(F_squeeze.dot(P))",
"_____no_output_____"
]
],
[
[
"Since the dot product is associative, the following code is equivalent:",
"_____no_output_____"
]
],
[
[
"P_squeezed_then_sheared = (F_shear.dot(F_squeeze)).dot(P)",
"_____no_output_____"
]
],
[
[
"Note that the order of the transformations is the reverse of the dot product order.\n\nIf we are going to perform this composition of linear transformations more than once, we might as well save the composition matrix like this:",
"_____no_output_____"
]
],
[
[
"F_squeeze_then_shear = F_shear.dot(F_squeeze)\nP_squeezed_then_sheared = F_squeeze_then_shear.dot(P)",
"_____no_output_____"
]
],
[
[
"From now on we can perform both transformations in just one dot product, which can lead to a very significant performance boost.",
"_____no_output_____"
],
[
"What if you want to perform the inverse of this double transformation? Well, if you squeezed and then you sheared, and you want to undo what you have done, it should be obvious that you should unshear first and then unsqueeze. In more mathematical terms, given two invertible (aka nonsingular) matrices $Q$ and $R$:\n\n$(Q \\cdot R)^{-1} = R^{-1} \\cdot Q^{-1}$\n\nAnd in NumPy:",
"_____no_output_____"
]
],
[
[
"LA.inv(F_shear.dot(F_squeeze)) == LA.inv(F_squeeze).dot(LA.inv(F_shear))",
"_____no_output_____"
]
],
[
[
"## Singular Value Decomposition\nIt turns out that any $m \\times n$ matrix $M$ can be decomposed into the dot product of three simple matrices:\n* a rotation matrix $U$ (an $m \\times m$ orthogonal matrix)\n* a scaling & projecting matrix $\\Sigma$ (an $m \\times n$ diagonal matrix)\n* and another rotation matrix $V^T$ (an $n \\times n$ orthogonal matrix)\n\n$M = U \\cdot \\Sigma \\cdot V^{T}$\n\nFor example, let's decompose the shear transformation:",
"_____no_output_____"
]
],
[
[
"U, S_diag, V_T = LA.svd(F_shear) # note: in python 3 you can rename S_diag to Σ_diag\nU",
"_____no_output_____"
],
[
"S_diag",
"_____no_output_____"
]
],
[
[
"Note that this is just a 1D array containing the diagonal values of Σ. To get the actual matrix Σ, we can use NumPy's `diag` function:",
"_____no_output_____"
]
],
[
[
"S = np.diag(S_diag)\nS",
"_____no_output_____"
]
],
[
[
"Now let's check that $U \\cdot \\Sigma \\cdot V^T$ is indeed equal to `F_shear`:",
"_____no_output_____"
]
],
[
[
"U.dot(np.diag(S_diag)).dot(V_T)",
"_____no_output_____"
],
[
"F_shear",
"_____no_output_____"
]
],
[
[
"It worked like a charm. Let's apply these transformations one by one (in reverse order) on the unit square to understand what's going on. First, let's apply the first rotation $V^T$:",
"_____no_output_____"
]
],
[
[
"plot_transformation(Square, V_T.dot(Square), \"$Square$\", \"$V^T \\cdot Square$\",\n axis=[-0.5, 3.5 , -1.5, 1.5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Now let's rescale along the vertical and horizontal axes using $\\Sigma$:",
"_____no_output_____"
]
],
[
[
"plot_transformation(V_T.dot(Square), S.dot(V_T).dot(Square), \"$V^T \\cdot Square$\", \"$\\Sigma \\cdot V^T \\cdot Square$\",\n axis=[-0.5, 3.5 , -1.5, 1.5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"Finally, we apply the second rotation $U$:",
"_____no_output_____"
]
],
[
[
"plot_transformation(S.dot(V_T).dot(Square), U.dot(S).dot(V_T).dot(Square),\"$\\Sigma \\cdot V^T \\cdot Square$\", \"$U \\cdot \\Sigma \\cdot V^T \\cdot Square$\",\n axis=[-0.5, 3.5 , -1.5, 1.5])\nplt.show()",
"_____no_output_____"
]
],
[
[
"And we can see that the result is indeed a shear mapping of the original unit square.",
"_____no_output_____"
],
[
"## Eigenvectors and eigenvalues\nAn **eigenvector** of a square matrix $M$ (also called a **characteristic vector**) is a non-zero vector that remains on the same line after transformation by the linear transformation associated with $M$. A more formal definition is any vector $v$ such that:\n\n$M \\cdot v = \\lambda \\times v$\n\nWhere $\\lambda$ is a scalar value called the **eigenvalue** associated to the vector $v$.\n\nFor example, any horizontal vector remains horizontal after applying the shear mapping (as you can see on the image above), so it is an eigenvector of $M$. A vertical vector ends up tilted to the right, so vertical vectors are *NOT* eigenvectors of $M$.\n\nIf we look at the squeeze mapping, we find that any horizontal or vertical vector keeps its direction (although its length changes), so all horizontal and vertical vectors are eigenvectors of $F_{squeeze}$.\n\nHowever, rotation matrices have no eigenvectors at all (except if the rotation angle is 0° or 180°, in which case all non-zero vectors are eigenvectors).\n\nNumPy's `eig` function returns the list of unit eigenvectors and their corresponding eigenvalues for any square matrix. Let's look at the eigenvectors and eigenvalues of the squeeze mapping matrix $F_{squeeze}$:",
"_____no_output_____"
]
],
[
[
"eigenvalues, eigenvectors = LA.eig(F_squeeze)\neigenvalues # [λ0, λ1, …]",
"_____no_output_____"
],
[
"eigenvectors # [v0, v1, …]",
"_____no_output_____"
]
],
[
[
"Indeed the horizontal vectors are stretched by a factor of 1.4, and the vertical vectors are shrunk by a factor of 1/1.4=0.714…, so far so good. Let's look at the shear mapping matrix $F_{shear}$:",
"_____no_output_____"
]
],
[
[
"eigenvalues2, eigenvectors2 = LA.eig(F_shear)\neigenvalues2 # [λ0, λ1, …]",
"_____no_output_____"
],
[
"eigenvectors2 # [v0, v1, …]",
"_____no_output_____"
]
],
[
[
"Wait, what!? We expected just one unit eigenvector, not two. The second vector is almost equal to $\\begin{pmatrix}-1 \\\\ 0 \\end{pmatrix}$, which is on the same line as the first vector $\\begin{pmatrix}1 \\\\ 0 \\end{pmatrix}$. This is due to floating point errors. We can safely ignore vectors that are (almost) colinear (ie. on the same line).",
"_____no_output_____"
],
[
"## Trace\nThe trace of a square matrix $M$, noted $tr(M)$ is the sum of the values on its main diagonal. For example:",
"_____no_output_____"
]
],
[
[
"D = np.array([\n [100, 200, 300],\n [ 10, 20, 30],\n [ 1, 2, 3],\n ])\nnp.trace(D)",
"_____no_output_____"
]
],
[
[
"The trace does not have a simple geometric interpretation (in general), but it has a number of properties that make it useful in many areas:\n* $tr(A + B) = tr(A) + tr(B)$\n* $tr(A \\cdot B) = tr(B \\cdot A)$\n* $tr(A \\cdot B \\cdot \\cdots \\cdot Y \\cdot Z) = tr(Z \\cdot A \\cdot B \\cdot \\cdots \\cdot Y)$\n* $tr(A^T \\cdot B) = tr(A \\cdot B^T) = tr(B^T \\cdot A) = tr(B \\cdot A^T) = \\sum_{i,j}X_{i,j} \\times Y_{i,j}$\n* …\n\nIt does, however, have a useful geometric interpretation in the case of projection matrices (such as $F_{project}$ that we discussed earlier): it corresponds to the number of dimensions after projection. For example:",
"_____no_output_____"
]
],
[
[
"np.trace(F_project)",
"_____no_output_____"
]
],
[
[
"# What next?\nThis concludes this introduction to Linear Algebra. Although these basics cover most of what you will need to know for Machine Learning, if you wish to go deeper into this topic there are many options available: Linear Algebra [books](http://linear.axler.net/), [Khan Academy](https://www.khanacademy.org/math/linear-algebra) lessons, or just [Wikipedia](https://en.wikipedia.org/wiki/Linear_algebra) pages. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a43bb37ac72cbea9d1923b17d9c07e91a1c1e36
| 50,928 |
ipynb
|
Jupyter Notebook
|
example/StochasticProcess/BSRM_matlab.ipynb
|
volpatto/UQpy
|
acbe1d6e655e98917f56b324f019881ea9ccca82
|
[
"MIT"
] | 1 |
2020-09-03T12:10:39.000Z
|
2020-09-03T12:10:39.000Z
|
example/StochasticProcess/BSRM_matlab.ipynb
|
AniketSanjayDesai/UQpy
|
7825789aad93476090350c169f26d463ab6f3d4f
|
[
"MIT"
] | null | null | null |
example/StochasticProcess/BSRM_matlab.ipynb
|
AniketSanjayDesai/UQpy
|
7825789aad93476090350c169f26d463ab6f3d4f
|
[
"MIT"
] | 1 |
2021-04-04T14:17:55.000Z
|
2021-04-04T14:17:55.000Z
| 223.368421 | 39,480 | 0.891415 |
[
[
[
"from UQpy.StochasticProcess import BSRM\nfrom UQpy.RunModel import RunModel\nimport numpy as np\nfrom scipy.stats import skew\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn')",
"_____no_output_____"
]
],
[
[
"The input parameters necessary for the generation of the stochastic processes are given below:",
"_____no_output_____"
]
],
[
[
"n_sim = 10 # Num of samples\n\nn = 1 # Num of dimensions\n\n# Input parameters\nT = 600 # Time(1 / T = dw)\nnt = 12000 # Num.of Discretized Time\nF = 1 / T * nt / 2 # Frequency.(Hz)\nnf = 6000 # Num of Discretized Freq.\n\n# # Generation of Input Data(Stationary)\ndt = T / nt\nt = np.linspace(0, T - dt, nt)\ndf = F / nf\nf = np.linspace(0, F - df, nf)",
"_____no_output_____"
]
],
[
[
"Defining the Power Spectral Density($S$)",
"_____no_output_____"
]
],
[
[
"S = 32 * 1 / np.sqrt(2 * np.pi) * np.exp(-1 / 2 * f ** 2)\n\n# Generating the 2 dimensional mesh grid\nfx = f\nfy = f\nFx, Fy = np.meshgrid(f, f)\n\nb = 95 * 2 * 1 / (2 * np.pi) * np.exp(2 * (-1 / 2 * (Fx ** 2 + Fy ** 2)))\nB_Real = b\nB_Imag = b\n\nB_Real[0, :] = 0\nB_Real[:, 0] = 0\nB_Imag[0, :] = 0\nB_Imag[:, 0] = 0",
"_____no_output_____"
]
],
[
[
"Defining the Bispectral Density($B$)",
"_____no_output_____"
]
],
[
[
"B_Complex = B_Real + 1j * B_Imag\nB_Ampl = np.absolute(B_Complex)",
"_____no_output_____"
]
],
[
[
"Make sure that the input parameters are in order to prevent aliasing",
"_____no_output_____"
]
],
[
[
"t_u = 2*np.pi/2/F\n\nif dt>t_u:\n print('Error')",
"_____no_output_____"
],
[
"BSRM_object = BSRM(n_sim, S, B_Complex, dt, df, nt, nf)\nsamples = BSRM_object.samples",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nplt.title('Realisation of the BiSpectral Representation Method')\nplt.plot(t, samples[0])\nax.yaxis.grid(True)\nax.xaxis.grid(True)\nplt.show()",
"_____no_output_____"
],
[
"print('The mean of the samples is ', np.mean(samples), 'whereas the expected mean is 0.000')\nprint('The variance of the samples is ', np.var(samples), 'whereas the expected variance is ', np.sum(S)*df*2)\nprint('The skewness of the samples is ', np.mean(skew(samples, axis=0)), 'whereas the expected skewness is ', np.sum(B_Real)*df**2*6/(np.sum(S)*df*2)**(3/2))",
"The mean of the samples is 0.00969425473754 whereas the expected mean is 0.000\nThe variance of the samples is 32.1408879391 whereas the expected variance is 32.0212769216\nThe skewness of the samples is 0.725660081057 whereas the expected skewness is 0.784945966965\n"
],
[
"import time\n\nt = time.time()\nz = RunModel(cpu=4, model_type=None, model_script='UQpy_Model.sh', input_script='UQpy_Input.sh', \n output_script='UQpy_Output.sh', samples=BSRM_object.samples, dimension=2)\nt_run = time.time()-t\nprint(t_run)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a43c533af2b664c2df6614b551bca1ca30608ec
| 30,646 |
ipynb
|
Jupyter Notebook
|
csv/movies_generate_csv.ipynb
|
shaggyday/evaluating-human-rationales
|
d2499ef29a915bd327b05af00ea635e3315946a0
|
[
"MIT"
] | null | null | null |
csv/movies_generate_csv.ipynb
|
shaggyday/evaluating-human-rationales
|
d2499ef29a915bd327b05af00ea635e3315946a0
|
[
"MIT"
] | null | null | null |
csv/movies_generate_csv.ipynb
|
shaggyday/evaluating-human-rationales
|
d2499ef29a915bd327b05af00ea635e3315946a0
|
[
"MIT"
] | null | null | null | 112.25641 | 14,316 | 0.846114 |
[
[
[
"import pandas as pd\nimport os\nfrom tqdm import tqdm\nfrom utils import avg, evidence_to_mask, text_len_scatter\n\ndef to_data_df(df, data_dir):\n data_df = []\n columns = ['text', 'classification', 'rationale' ,'query']\n for i in tqdm(range(len(df))):\n df_row = df.loc[i]\n \n doc_id = df_row['annotation_id']\n query = df_row['query']\n evidence_list = df_row['evidences']\n if evidence_list:\n evidence_list = evidence_list[0]\n classification = df_row['classification']\n \n text = ''\n file = f'{data_dir}/docs/{doc_id}'\n if os.path.isfile(file):\n f = open(file, 'r', encoding=\"utf-8\") \n for line in f.readlines():\n text += line.rstrip() + ' '\n else:\n print(\"???\")\n print(file)\n quit()\n \n tokens = text.split()\n rationale_mask = evidence_to_mask(tokens, evidence_list)\n \n # joining text and query with [SEP]\n# QA = f\"{text}\"\n# QA = f\"{text}[SEP] {query}\"\n# QA = f\"{query} [SEP] {text}\"\n \n QA = text\n rationale_mask = rationale_mask\n \n data_df.append([QA, classification, rationale_mask, query])\n data_df = pd.DataFrame(data_df, columns=columns)\n# return data_df\n \n data_df_shuffled=data_df.sample(frac=1).reset_index(drop=True)\n return data_df_shuffled",
"_____no_output_____"
],
[
"dataset = \"movies\"",
"_____no_output_____"
],
[
"data_dir = f'../data/{dataset}'\ntrain = pd.read_json(f'{data_dir}/train.jsonl', lines=True)\ntest = pd.read_json(f'{data_dir}/test.jsonl', lines=True)\nval = pd.read_json(f'{data_dir}/val.jsonl', lines=True)",
"_____no_output_____"
],
[
"train_data_df = to_data_df(train, data_dir)\n# train_data_df.to_csv(f\"{dataset}/train.csv\",index_label=\"id\")\ntest_data_df = to_data_df(test, data_dir)\n# test_data_df.to_csv(f\"{dataset}/test.csv\",index_label=\"id\")\nval_data_df = to_data_df(val, data_dir)\n# val_data_df.to_csv(f\"{dataset}/val.csv\",index_label=\"id\")",
"100%|████████████████████████████████████████████████████████████████████████████| 1600/1600 [00:01<00:00, 1249.03it/s]\n100%|██████████████████████████████████████████████████████████████████████████████| 199/199 [00:00<00:00, 1421.07it/s]\n100%|██████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 1625.49it/s]\n"
],
[
"d = text_len_scatter(train_data_df,test_data_df,val_data_df)\n",
"_____no_output_____"
],
[
"LABELSIZE = 23\nall_texts = list(train_data_df['text']) + list(test_data_df['text']) + list(val_data_df['text'])\nall_text_lens = [len(x.split()) for x in all_texts]\nimport matplotlib.pyplot as plt\nplt.hist(all_text_lens)\nplt.ylabel(ylabel=\"number of instances \", fontsize=LABELSIZE)\nplt.xlabel(xlabel=\"text length\", fontsize=LABELSIZE)\nplt.axvline(x=512, linestyle=\"dashed\", color=\"black\")\nplt.savefig(\"movies_distribution.png\", bbox_inches = 'tight', dpi=300)\nplt.show()",
"_____no_output_____"
],
[
"def generate_class_stats(train_df, test_df, val_df):\n text_lens_0 = []\n text_lens_1 = []\n rationale_lens_0 = []\n rationale_lens_1 = []\n rationale_percent_0 = []\n rationale_percent_1 = []\n class_distribution = [0,0]\n for df in [train_df, test_df, val_df]:\n for i in range(len(df)):\n df_row = df.loc[i]\n clas = df_row['classification']\n text = df_row['text']\n rationale = df_row['rationale']\n text_len = len(text.split())\n rationale_len = rationale.count(1)\n rationale_percent = rationale_len/text_len\n if clas == \"NEG\":\n text_lens_0.append(text_len)\n rationale_lens_0.append(rationale_len)\n rationale_percent_0.append(rationale_percent)\n class_distribution[0] += 1\n else:\n text_lens_1.append(text_len)\n rationale_lens_1.append(rationale_len)\n rationale_percent_1.append(rationale_percent)\n class_distribution[1] += 1\n return text_lens_0,text_lens_1,rationale_lens_0,rationale_lens_1,rationale_percent_0,rationale_percent_1,class_distribution",
"_____no_output_____"
],
[
"text_lens_0,text_lens_1,rationale_lens_0,rationale_lens_1,rationale_percent_0,rationale_percent_1,class_distribution = generate_class_stats(train_data_df,test_data_df,val_data_df)\ntext_lens_all = text_lens_0 + text_lens_1\nrationale_lens_all = rationale_lens_0 + rationale_lens_1\nrationale_percent_all = rationale_percent_0 + rationale_percent_1\nclass_distr = [class_distribution[0]/sum(class_distribution),class_distribution[1]/sum(class_distribution)]",
"_____no_output_____"
],
[
"for l in [rationale_lens_all,text_lens_all,rationale_percent_all,text_lens_0,text_lens_1,rationale_lens_0,rationale_lens_1,rationale_percent_0,rationale_percent_1]:\n print(avg(l))",
"30.925462731365684\n774.2696348174087\n0.04227329387265028\n731.786\n816.7957957957958\n36.84\n25.005005005005007\n0.052422732743648545\n0.03211369540318255\n"
],
[
"class_distr",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a43d14d89713bad3db9d85502197e7acb0144be
| 5,511 |
ipynb
|
Jupyter Notebook
|
2019-11-15-voila/notebooks/1.GradientDescent.ipynb
|
zgle-fork/quantstack-talks
|
0c70513c1665d2e5a0ec1ca61ecb907c815bb82d
|
[
"BSD-3-Clause"
] | 82 |
2017-04-14T20:18:55.000Z
|
2021-12-25T23:38:52.000Z
|
2019-11-15-voila/notebooks/1.GradientDescent.ipynb
|
martinRenou/quantstack-talks
|
13e2fc1bfc044fd92d1090ca51ae6b2cfc75d253
|
[
"BSD-3-Clause"
] | 3 |
2017-04-07T18:37:21.000Z
|
2020-07-11T09:37:53.000Z
|
2019-11-15-voila/notebooks/1.GradientDescent.ipynb
|
martinRenou/quantstack-talks
|
13e2fc1bfc044fd92d1090ca51ae6b2cfc75d253
|
[
"BSD-3-Clause"
] | 59 |
2017-04-07T11:16:56.000Z
|
2022-03-25T14:48:55.000Z
| 27.833333 | 170 | 0.510071 |
[
[
[
"# Notebook served by Voilà",
"_____no_output_____"
],
[
"#### Notebook copied from https://github.com/ChakriCherukuri/mlviz",
"_____no_output_____"
],
[
"<h2>Gradient Descent</h2>\n* Given a the multi-variable function $\\large {F(x)}$ differentiable in a neighborhood of a point $\\large a$\n* $\\large F(x)$ decreases fastest if one goes from $\\large a$ in the direction of the negative gradient of $\\large F$ at $\\large a$, $\\large -\\nabla{F(a)}$\n\n<h3>Gradient Descent Algorithm:</h3>\n* Choose a starting point, $\\large x_0$\n* Choose the sequence $\\large x_0, x_1, x_2, ...$ such that\n$ \\large x_{n+1} = x_n - \\eta \\nabla(F(x_n) $\n\nSo convergence of the gradient descent depends on the starting point $\\large x_0$ and the learning rate $\\large \\eta$",
"_____no_output_____"
]
],
[
[
"from time import sleep\n\nimport numpy as np\n\nfrom ipywidgets import *\nimport bqplot.pyplot as plt\nfrom bqplot import Toolbar",
"_____no_output_____"
],
[
"f = lambda x: np.exp(-x) * np.sin(5 * x)\ndf = lambda x: -np.exp(-x) * np.sin(5 * x) + 5 * np.cos(5 *x) * np.exp(-x)",
"_____no_output_____"
],
[
"x = np.linspace(0.5, 2.5, 500)\ny = f(x)",
"_____no_output_____"
],
[
"def update_sol_path(x, y):\n with sol_path.hold_sync():\n sol_path.x = x\n sol_path.y = y\n \n with sol_points.hold_sync():\n sol_points.x = x\n sol_points.y = y",
"_____no_output_____"
],
[
"def gradient_descent(x0, f, df, eta=.1, tol=1e-6, num_iters=10):\n x = [x0]\n i = 0\n \n while i < num_iters:\n x_prev = x[-1]\n grad = df(x_prev)\n x_curr = x_prev - eta * grad\n x.append(x_curr)\n sol_lbl.value = sol_lbl_tmpl.format(x_curr)\n sleep(.5)\n \n update_sol_path(x, [f(i) for i in x])\n \n if np.abs(x_curr - x_prev) < tol:\n break\n i += 1",
"_____no_output_____"
],
[
"txt_layout = Layout(width='150px')\nx0_box = FloatText(description='x0', layout=txt_layout, value=2.4)\neta_box = FloatText(description='Learning Rate', \n style={'description_width':'initial'}, \n layout=txt_layout, value=.1)\n\ngo_btn = Button(description='GO', button_style='success', layout=Layout(width='50px'))\nreset_btn = Button(description='Reset', button_style='success', layout=Layout(width='100px'))\n\nsol_lbl_tmpl = 'x = {:.4f}'\nsol_lbl = Label()\n# sol_lbl.layout.width = '300px'\n\n# plot of curve and solution\nfig_layout = Layout(width='720px', height='500px')\nfig = plt.figure(layout=fig_layout, title='Gradient Descent', display_toolbar=True)\nfig.pyplot = Toolbar(figure=fig)\n\ncurve = plt.plot(x, y, colors=['dodgerblue'], stroke_width=2)\nsol_path = plt.plot([], [], colors=['#ccc'], opacities=[.7])\nsol_points = plt.plot([], [], 'mo', default_size=20)\n\ndef optimize():\n f.marks = [curve]\n gradient_descent(x0_box.value, f, df, eta=eta_box.value)\n\ndef reset():\n curve.scales['x'].min = .4\n curve.scales['x'].max = 2.5\n \n curve.scales['y'].min = -.5\n curve.scales['y'].max = .4\n sol_path.x = sol_path.y = []\n sol_points.x = sol_points.y = []\n sol_lbl.value = ''\n \ngo_btn.on_click(lambda btn: optimize())\nreset_btn.on_click(lambda btn: reset())\n\nfinal_fig = VBox([fig, fig.pyplot], \n layout=Layout(overflow_x='hidden'))\nHBox([final_fig, VBox([x0_box, eta_box, go_btn, reset_btn, sol_lbl])])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a43d2636cc1244a7b7aad5b2a2e31bb4e00d16e
| 48,107 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/guide-checkpoint.ipynb
|
henrydambanemuya/bmotif-python
|
cba6296f19473672bb530f263b6a87ccab55d9f1
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/guide-checkpoint.ipynb
|
henrydambanemuya/bmotif-python
|
cba6296f19473672bb530f263b6a87ccab55d9f1
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/guide-checkpoint.ipynb
|
henrydambanemuya/bmotif-python
|
cba6296f19473672bb530f263b6a87ccab55d9f1
|
[
"MIT"
] | null | null | null | 30.778631 | 429 | 0.276197 |
[
[
[
"This notebook shows how to use the main functions of bmotif on a small example bipartite network.\n\nFirst, import modules:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"from BMotifs import Motifs",
"_____no_output_____"
]
],
[
[
"Create a small binary NumPy array to use as example data:",
"_____no_output_____"
]
],
[
[
"matrix=[[1,1,1,0,0,0,1],\n [0,0,1,0,0,0,0],\n [1,1,0,1,0,0,0],\n [0,0,1,1,0,1,0],\n [0,1,1,0,0,0,1]]\n\nmatrix=np.array(matrix)",
"_____no_output_____"
]
],
[
[
"Generate all the matrices for the motif counts:",
"_____no_output_____"
]
],
[
[
"p=Motifs(M=matrix)",
"Iniziating the matrices ...\nAlmonst Done ...\nDone\n"
]
],
[
[
"Count the frequency with which each node occurs in each of the 148 unique positions across all bipartite motifs up to six nodes.\n\nThe output is a pandas table with 148 rows, one for each unique position within motifs. There are also 13 columns: the first column (MotifID) gives the ID of the motif position, the next 5 columns (A1, A2, A3, A4, A5) give the frequency with which each row node occurs in each motif position, the final 7 columns (B1, B2, B3, B4, B5, B6, B7) give the frequency with which each column node occurs in each motif position.\n\nNaN is returned when a node cannot occur in a given position because that position can only be occupied by nodes in the other level. For example, position 1 (MotifID 1) can only be occupied by column nodes and therefore a count of NaN is returned for all row nodes.",
"_____no_output_____"
]
],
[
[
"p.count_pos_motifs(range(1,149))\np.position_motifs",
"_____no_output_____"
]
],
[
[
"Count the frequency with which each of the 44 bipartite motifs up to six nodes occurs in the network.\n\nThe output is a pandas table with one row for each motif. The first column (MotifID) gives the ID of the motif, the second column gives the frequency with which that motif occurs in the network.",
"_____no_output_____"
]
],
[
[
"p.count_motifs(range(1,45))\np.motifs",
"_____no_output_____"
],
[
"\n\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a43ef7e19f4f91ff39d6db0677d54c57ae39848
| 350,403 |
ipynb
|
Jupyter Notebook
|
wrangle_act.ipynb
|
YingluDeng/Twitter_WeRateDog_Project
|
9f028ea17598e336cb2a97642655e7a65c6f94ea
|
[
"Apache-2.0"
] | null | null | null |
wrangle_act.ipynb
|
YingluDeng/Twitter_WeRateDog_Project
|
9f028ea17598e336cb2a97642655e7a65c6f94ea
|
[
"Apache-2.0"
] | null | null | null |
wrangle_act.ipynb
|
YingluDeng/Twitter_WeRateDog_Project
|
9f028ea17598e336cb2a97642655e7a65c6f94ea
|
[
"Apache-2.0"
] | null | null | null | 70.759895 | 83,332 | 0.697805 |
[
[
[
"# Wrangle & Analyze Data \n### (WeRateDogs Twitter Archive)",
"_____no_output_____"
],
[
"<ul>\n<li><a href=\"#intro\">Introduction</a></li>\n<li><a href=\"#wrangle\">Data Wrangling</a></li> \n <ul>\n <li><a href=\"#gather\">Gathering Data</a></li>\n <li><a href=\"#assess\">Assessing Data</a></li>\n <li><a href=\"#clean\">Cleaning Data</a></li>\n </ul>\n<li><a href=\"#analyze\">Storing, Analyzing and Visualizing Data</a></li>\n</ul>",
"_____no_output_____"
],
[
"<a id='intro'></a>\n## Introduction\n\n> The dataset which will be wrangling (and analyzing and visualizing) is the tweet archive of Twitter user @dog_rates, also known as WeRateDogs. WeRateDogs is a Twitter account that rates people's dogs with a humorous comment about the dog. I will use Python (and its libraries) to analyze and vusualize the dataset through jupyter notebook. ",
"_____no_output_____"
]
],
[
[
"#import library\nimport pandas as pd\nimport numpy as np\nimport requests\nimport os\nimport time\n\nimport matplotlib.pyplot as plt\nfrom matplotlib import cm\n%matplotlib inline\n\nimport seaborn as sns\n",
"_____no_output_____"
]
],
[
[
"<a id='wrangle'></a>\n# Data Wrangling\n<a id='gather'></a>\n## Gathering Data\n> <b>In this part, we will gather three parts of data</b>\n<ol>\n <li>The WeRateDogs Twitter archive. Downloading the file named twitter-archive-enhanced.csv</li>\n <li>The tweet image predictions, i.e., what breed of dog (or other object, animal, etc.) is present in each tweet according to a neural network. This file (image_predictions.tsv) is hosted on Udacity's servers and should be downloaded programmatically using the Requests library and the following URL: https://d17h27t6h515a5.cloudfront.net/topher/2017/August/599fd2ad_image-predictions/image-predictions.tsv</li>\n <li>Each tweet's retweet count and favorite (\"like\") count at minimum. Using the tweet IDs in the WeRateDogs Twitter archive, query the Twitter API for each tweet's JSON data using Python's Tweepy library and store each tweet's entire set of JSON data in a file called tweet_json.txt file. Each tweet's JSON data should be written to its own line. Then read this .txt file line by line into a pandas DataFrame with (at minimum) tweet ID, retweet count, and favorite count. Note: do not include your Twitter API keys, secrets, and tokens in your project submission.</li>\n</ol>",
"_____no_output_____"
],
[
"<b>Step 1. Importing Twitter Archieve File</b>",
"_____no_output_____"
]
],
[
[
"#import csv file\ndf_archive = pd.read_csv('twitter-archive-enhanced.csv')\ndf_archive.head()",
"_____no_output_____"
]
],
[
[
"<b>Step 2. Programatically Download Tweet Image Predictions TSV</b>",
"_____no_output_____"
]
],
[
[
"#using requests library to download tweet image prediction tsv and store it as image_predictions.tsv\nurl = 'https://d17h27t6h515a5.cloudfront.net/topher/2017/August/599fd2ad_image-predictions/image-predictions.tsv'\nresponse = requests.get(url)\nwith open('image_predictions.tsv', mode='wb') as file:\n file.write(response.content)\n \n# Import the tweet image predictions TSV file into a DataFrame\ndf_img = pd.read_csv('image_predictions.tsv', sep='\\t')\ndf_img.head()",
"_____no_output_____"
]
],
[
[
"<b>Step 3. Downloading Tweet JSON Data</b>",
"_____no_output_____"
]
],
[
[
"import tweepy\nfrom tweepy import OAuthHandler\nimport json\nfrom timeit import default_timer as timer\n\n# Query Twitter API for each tweet in the Twitter archive and save JSON in a text file\n# These are hidden to comply with Twitter's API terms and conditions\nconsumer_key = 'HIDDEN'\nconsumer_secret = 'HIDDEN'\naccess_token = 'HIDDEN'\naccess_secret = 'HIDDEN'\n\nauth = OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_secret)\n\napi = tweepy.API(auth, wait_on_rate_limit=True)\n\n# NOTE TO STUDENT WITH MOBILE VERIFICATION ISSUES:\n# NOTE TO REVIEWER: this student had mobile verification issues so the following\n# Twitter API code was sent to this student from a Udacity instructor\n# Tweet IDs for which to gather additional data via Twitter's API\ntweet_ids = df_archive.tweet_id.values\nlen(tweet_ids)\n\n# Query Twitter's API for JSON data for each tweet ID in the Twitter archive\ncount = 0\nfails_dict = {}\nstart = timer()\n# Save each tweet's returned JSON as a new line in a .txt file\nwith open('tweet_json.txt', 'w') as outfile:\n # This loop will likely take 20-30 minutes to run because of Twitter's rate limit\n for tweet_id in tweet_ids:\n count += 1\n print(str(count) + \": \" + str(tweet_id))\n try:\n tweet = api.get_status(tweet_id, tweet_mode='extended')\n print(\"Success\")\n json.dump(tweet._json, outfile)\n outfile.write('\\n')\n except tweepy.TweepError as e:\n print(\"Fail\")\n fails_dict[tweet_id] = e\n pass\nend = timer()\nprint(end - start)\nprint(fails_dict)",
"1: 892420643555336193\nFail\n2: 892177421306343426\nFail\n3: 891815181378084864\nFail\n4: 891689557279858688\nFail\n5: 891327558926688256\nFail\n6: 891087950875897856\nFail\n7: 890971913173991426\nFail\n8: 890729181411237888\nFail\n9: 890609185150312448\nFail\n10: 890240255349198849\nFail\n11: 890006608113172480\nFail\n12: 889880896479866881\nFail\n13: 889665388333682689\nFail\n14: 889638837579907072\nFail\n15: 889531135344209921\nFail\n16: 889278841981685760\nFail\n17: 888917238123831296\nFail\n18: 888804989199671297\nFail\n19: 888554962724278272\nFail\n20: 888202515573088257\nFail\n21: 888078434458587136\nFail\n22: 887705289381826560\nFail\n23: 887517139158093824\nFail\n24: 887473957103951883\nFail\n25: 887343217045368832\nFail\n26: 887101392804085760\nFail\n27: 886983233522544640\nFail\n28: 886736880519319552\nFail\n29: 886680336477933568\nFail\n30: 886366144734445568\nFail\n31: 886267009285017600\nFail\n32: 886258384151887873\nFail\n33: 886054160059072513\nFail\n34: 885984800019947520\nFail\n35: 885528943205470208\nFail\n36: 885518971528720385\nFail\n37: 885311592912609280\nFail\n38: 885167619883638784\nFail\n39: 884925521741709313\nFail\n40: 884876753390489601\nFail\n41: 884562892145688576\nFail\n42: 884441805382717440\nFail\n43: 884247878851493888\nFail\n44: 884162670584377345\nFail\n45: 883838122936631299\nFail\n46: 883482846933004288\nFail\n47: 883360690899218434\nFail\n48: 883117836046086144\nFail\n49: 882992080364220416\nFail\n50: 882762694511734784\nFail\n51: 882627270321602560\nFail\n52: 882268110199369728\nFail\n53: 882045870035918850\nFail\n54: 881906580714921986\nFail\n55: 881666595344535552\nFail\n56: 881633300179243008\nFail\n57: 881536004380872706\nFail\n58: 881268444196462592\nFail\n59: 880935762899988482\nFail\n60: 880872448815771648\nFail\n61: 880465832366813184\nFail\n62: 880221127280381952\nFail\n63: 880095782870896641\nFail\n64: 879862464715927552\nFail\n65: 879674319642796034\nFail\n66: 879492040517615616\nFail\n67: 879415818425184262\nFail\n68: 879376492567855104\nFail\n69: 879130579576475649\nFail\n70: 879050749262655488\nFail\n71: 879008229531029506\nFail\n72: 878776093423087618\nFail\n73: 878604707211726852\nFail\n74: 878404777348136964\nFail\n75: 878316110768087041\nFail\n76: 878281511006478336\nFail\n77: 878057613040115712\nFail\n78: 877736472329191424\nFail\n79: 877611172832227328\nFail\n80: 877556246731214848\nFail\n81: 877316821321428993\nFail\n82: 877201837425926144\nFail\n83: 876838120628539392\nFail\n84: 876537666061221889\nFail\n85: 876484053909872640\nFail\n86: 876120275196170240\nFail\n87: 875747767867523072\nFail\n88: 875144289856114688\nFail\n89: 875097192612077568\nFail\n90: 875021211251597312\nFail\n91: 874680097055178752\nFail\n92: 874434818259525634\nFail\n93: 874296783580663808\n"
],
[
"# read json txt file and save as a df\ntw_json = []\n\nwith open('tweet-json.txt', 'r') as json_data:\n #make a loop to read file\n line = json_data.readline()\n while line:\n status = json.loads(line)\n\n # extract variable \n status_id = status['id']\n status_ret_count = status['retweet_count']\n status_fav_count = status['favorite_count']\n \n # make a dictionary\n json_file = {'tweet_id': status_id, \n 'retweet_count': status_ret_count, \n 'favorite_count': status_fav_count\n }\n tw_json.append(json_file)\n\n # read next line\n line = json_data.readline()\n\n#convert the dictionary list to a df\ndf_json = pd.DataFrame(tw_json, columns = ['tweet_id', 'retweet_count', 'favorite_count'])\ndf_json.head()",
"_____no_output_____"
]
],
[
[
"<a id='assess'></a>\n# Assessing Data\n> <b>After gathering each of the above pieces of data, assess them visually and programmatically for quality and tidiness issues.</b> \n\n>Using two types of assessment: \n>1. Visual assessment: scrolling through the data in your preferred software application (Google Sheets, Excel, a text editor, etc.).\n>2. Programmatic assessment: using code to view specific portions and summaries of the data (pandas' head, tail, and info methods, for example).\n\n\n<ul>\n<li><a href=\"#quality\"><b>Quality Issues</b></a> -- issues with content. Low quality data is also known as dirty data.</li>\n\n<li><a href=\"#tidy\"><b>Tidiness Issues</b></a> -- issues with structure that prevent easy analysis. Untidy data is also known as messy data. Tidy data requirements:</li>\n <ol>\n <li>Each variable forms a column.</li>\n <li>Each observation forms a row.</li>\n <li>Each type of observational unit forms a table.</li>\n </ol>\n</ul>",
"_____no_output_____"
],
[
"<b>Step 1. Assessing Twitter Archive File</b>",
"_____no_output_____"
]
],
[
[
"#print out the head()\ndf_archive.head()",
"_____no_output_____"
],
[
"df_archive.shape",
"_____no_output_____"
],
[
"df_archive.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2356 entries, 0 to 2355\nData columns (total 17 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 2356 non-null int64 \n 1 in_reply_to_status_id 78 non-null float64\n 2 in_reply_to_user_id 78 non-null float64\n 3 timestamp 2356 non-null object \n 4 source 2356 non-null object \n 5 text 2356 non-null object \n 6 retweeted_status_id 181 non-null float64\n 7 retweeted_status_user_id 181 non-null float64\n 8 retweeted_status_timestamp 181 non-null object \n 9 expanded_urls 2297 non-null object \n 10 rating_numerator 2356 non-null int64 \n 11 rating_denominator 2356 non-null int64 \n 12 name 2356 non-null object \n 13 doggo 2356 non-null object \n 14 floofer 2356 non-null object \n 15 pupper 2356 non-null object \n 16 puppo 2356 non-null object \ndtypes: float64(4), int64(3), object(10)\nmemory usage: 313.0+ KB\n"
]
],
[
[
"There are 2356 rows and 17 columns. \nFrom the info above, we found that six columns have missing values including 'in_reply_to_status_id', 'in_reply_to_user_id', 'retweeted_status_user_id', 'retweeted_status_timestamp'.",
"_____no_output_____"
]
],
[
[
"#check with in_reply_to_status_id column\ndf_archive.in_reply_to_status_id.value_counts()",
"_____no_output_____"
],
[
"type(df_archive['tweet_id'][0])",
"_____no_output_____"
],
[
"type(df_archive['in_reply_to_status_id'][1])",
"_____no_output_____"
],
[
"type(df_archive['in_reply_to_user_id'][1])",
"_____no_output_____"
],
[
"type(df_archive['retweeted_status_id'][1])",
"_____no_output_____"
],
[
"type(df_archive['retweeted_status_user_id'][1])",
"_____no_output_____"
]
],
[
[
"<b>Problem #1: The format of id is wrong and it should be changed to integer.</b>",
"_____no_output_____"
]
],
[
[
"#check column rating_numerator\ndf_archive.rating_numerator.describe()",
"_____no_output_____"
],
[
"df_archive.rating_numerator.value_counts().sort_index()",
"_____no_output_____"
],
[
"#check column rating_denominator\ndf_archive.rating_denominator.describe()",
"_____no_output_____"
],
[
"df_archive.rating_denominator.value_counts().sort_index()",
"_____no_output_____"
]
],
[
[
"<b>Problem #2: The rating denominator could only be 10 and other values are invalid.</b>",
"_____no_output_____"
]
],
[
[
"#check timestamp column\ndf_archive['timestamp'].value_counts()",
"_____no_output_____"
],
[
"type(df_archive['timestamp'][0]) ",
"_____no_output_____"
],
[
"df_archive['retweeted_status_timestamp'].value_counts()",
"_____no_output_____"
],
[
"type(df_archive['retweeted_status_timestamp'][0]) ",
"_____no_output_____"
]
],
[
[
"<b>Problem #3: When we explore the type of two timestamp columns, one is string, the other one is float. The format of timestamp should be changed to datetime.</b>",
"_____no_output_____"
]
],
[
[
"df_archive.name.value_counts().sort_index(ascending = True)",
"_____no_output_____"
],
[
"#collect all error names \nerror_name = df_archive.name.str.contains('^[a-z]', regex = True)\ndf_archive[error_name].name.value_counts().sort_index()",
"_____no_output_____"
],
[
"len(df_archive[error_name])",
"_____no_output_____"
]
],
[
[
"<b>Problem #4: There are 109 invalid names not starting with a capitalized alphabet.</b>",
"_____no_output_____"
]
],
[
[
"#check with four columns of dogs' stage\ndf_archive.doggo.value_counts()",
"_____no_output_____"
],
[
"df_archive.floofer.value_counts()",
"_____no_output_____"
],
[
"df_archive.pupper.value_counts()",
"_____no_output_____"
],
[
"df_archive.puppo.value_counts()",
"_____no_output_____"
]
],
[
[
"<b>Problem #5: The \"None\" value should be changed to \"NaN\" in these four columns.</b>",
"_____no_output_____"
]
],
[
[
"#show the number of retweet \ndf_archive.retweeted_status_id.isnull().value_counts()",
"_____no_output_____"
],
[
"df_archive.retweeted_status_user_id.isnull().value_counts()",
"_____no_output_____"
]
],
[
[
"<b>Problem #6: As we do not want the duplicated information, so we would clear away the rows of retweet.</b>",
"_____no_output_____"
]
],
[
[
"df_archive.source.value_counts()",
"_____no_output_____"
]
],
[
[
"<b>Problem #7: source name should be changed and moved the attached link. </b>",
"_____no_output_____"
],
[
"<b>Step 2. Tweet Image Predictions</b>",
"_____no_output_____"
]
],
[
[
"df_img.head()",
"_____no_output_____"
],
[
"df_img.shape",
"_____no_output_____"
],
[
"df_img.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2075 entries, 0 to 2074\nData columns (total 12 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 2075 non-null int64 \n 1 jpg_url 2075 non-null object \n 2 img_num 2075 non-null int64 \n 3 p1 2075 non-null object \n 4 p1_conf 2075 non-null float64\n 5 p1_dog 2075 non-null bool \n 6 p2 2075 non-null object \n 7 p2_conf 2075 non-null float64\n 8 p2_dog 2075 non-null bool \n 9 p3 2075 non-null object \n 10 p3_conf 2075 non-null float64\n 11 p3_dog 2075 non-null bool \ndtypes: bool(3), float64(3), int64(2), object(4)\nmemory usage: 152.1+ KB\n"
]
],
[
[
"<b>Problem #8: There are 2075 rows and 12 columns. Based on Twitter Archive file (2356 rows), we know some pictures are missing.</b>",
"_____no_output_____"
]
],
[
[
"#check if id duplicate\ndf_img.tweet_id.duplicated().value_counts()",
"_____no_output_____"
],
[
"##check if jpg duplicate\ndf_img.jpg_url.duplicated().value_counts()",
"_____no_output_____"
]
],
[
[
"<b>Problem #9: There are 66 jpg_url which are duplicated.</b>",
"_____no_output_____"
]
],
[
[
"#check the image number column\ndf_img.img_num.value_counts()",
"_____no_output_____"
]
],
[
[
"Some people have posted more than one picture.",
"_____no_output_____"
],
[
"<b>Step 3. Checking JSON File</b>",
"_____no_output_____"
]
],
[
[
"df_json.head()",
"_____no_output_____"
],
[
"df_json.shape",
"_____no_output_____"
],
[
"df_json.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2354 entries, 0 to 2353\nData columns (total 3 columns):\n # Column Non-Null Count Dtype\n--- ------ -------------- -----\n 0 tweet_id 2354 non-null int64\n 1 retweet_count 2354 non-null int64\n 2 favorite_count 2354 non-null int64\ndtypes: int64(3)\nmemory usage: 55.3 KB\n"
],
[
"df_json.describe()",
"_____no_output_____"
],
[
"df_json.tweet_id.duplicated().value_counts()",
"_____no_output_____"
],
[
"df_json['tweet_id'].nunique()",
"_____no_output_____"
]
],
[
[
"There are 2354 rows and 3 columns. No null variables. No duplicated tweet id.",
"_____no_output_____"
]
],
[
[
"type(df_json['tweet_id'][0])",
"_____no_output_____"
],
[
"type(df_json['retweet_count'][0])",
"_____no_output_____"
],
[
"type(df_json['favorite_count'][0])",
"_____no_output_____"
]
],
[
[
"The format of variable is correct.",
"_____no_output_____"
],
[
"<a id='quality'></a>\n# Summary\n## Quality Issue\n<b>Twitter Archive File</b>\n<ol>\n <li>The format of id is wrong and it should be changed to integer.</li>\n <li>The rating denominator could only be 10 and other values are invalid.</li>\n <li>When we explore the type of two timestamp columns, one is string, the other one is float. The format of timestamp should be changed to datetime.</li>\n <li>There are 109 invalid names not starting with a capitalized alphabet.</li>\n <li>In four columns of dog's stage, the \"None\" value should be changed to \"NaN\" in these four columns.</li>\n <li>As we do not want the duplicated information, so we would clear away the rows of retweet based on retweet id.</li>\n <li>Change the value for source column.</li>\n</ol>\n\n<b>Tweet Image Predictions TSV</b>\n<ul>\n <li>There are 2075 rows in prediction file, 2354 rows in JSON data. Based on Twitter Archive file (2356 rows), we know some rows are not matching.</li>\n <li>There are 66 jpg_url which are duplicated.</li>\n</ul>\n\n<b>JSON File</b>\n<ul>\n <li>No quality issue for the json file.</li>\n</ul>\n\n\n<a id='tidy'></a>\n## Tidiness Issue\n<ul>\n <li>df_archive could drop empty columns of retweet infomation like 'in_reply_to_status_id', 'in_reply_to_user_id', 'retweeted_status_user_id', 'retweeted_status_timestamp'.</li>\n <li>The four columns of dog's stage should be merged into one column.</li>\n <li>Merging JSON file, df_archive dataframe and img file into one.</li>\n</ul>\n",
"_____no_output_____"
],
[
"<a id='clean'></a>\n## Cleaning Data\n> <b>Store the clean DataFrame(s) in a CSV file with the main one named twitter_archive_master.csv. Analyze and visualize your wrangled data in your wrangle_act.ipynb Jupyter Notebook.</b>\n\n>The issues that satisfy the Project Motivation must be cleaned:\n>1. Cleaning includes merging individual pieces of data according to the rules of tidy data.\n>2. The fact that the rating numerators are greater than the denominators does not need to be cleaned. This unique rating system is a big part of the popularity of WeRateDogs.",
"_____no_output_____"
],
[
"### Dealing with tidiness issue\n#### 1. Drop the columns we do not use",
"_____no_output_____"
]
],
[
[
"#make a copy of three data files\ndf_archive_clean = df_archive.copy()\ndf_img_clean = df_img.copy()\ndf_json_clean = df_json.copy()",
"_____no_output_____"
],
[
"#drop useless columns\ndf_archive_clean = df_archive_clean.drop(['in_reply_to_status_id', 'in_reply_to_user_id', 'retweeted_status_user_id', 'retweeted_status_timestamp'], axis=1)",
"_____no_output_____"
],
[
"#fill the null url\ndf_archive_clean.expanded_urls.head()",
"_____no_output_____"
],
[
"#the website url should be 'https://twitter.com/dog_rates/status/' plus their id, so we could fill it\ndf_archive_clean.expanded_urls = 'https://twitter.com/dog_rates/status/' + df_archive_clean.tweet_id.astype(str)",
"_____no_output_____"
],
[
"#check with the df see if everything is fixed\ndf_archive_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2356 entries, 0 to 2355\nData columns (total 13 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 2356 non-null int64 \n 1 timestamp 2356 non-null object \n 2 source 2356 non-null object \n 3 text 2356 non-null object \n 4 retweeted_status_id 181 non-null float64\n 5 expanded_urls 2356 non-null object \n 6 rating_numerator 2356 non-null int64 \n 7 rating_denominator 2356 non-null int64 \n 8 name 2356 non-null object \n 9 doggo 2356 non-null object \n 10 floofer 2356 non-null object \n 11 pupper 2356 non-null object \n 12 puppo 2356 non-null object \ndtypes: float64(1), int64(3), object(9)\nmemory usage: 239.4+ KB\n"
]
],
[
[
"#### 2. Merge four columns of dog's stage into one",
"_____no_output_____"
]
],
[
[
"#replace 'None' to ''\ndf_archive_clean[['doggo', 'floofer', 'pupper', 'puppo']] = df_archive_clean[['doggo', 'floofer', 'pupper', 'puppo']].replace('None', '')",
"_____no_output_____"
],
[
"df_archive_clean.head()",
"_____no_output_____"
],
[
"#combine four columns to stage\ndf_archive_clean['dog_stage'] = df_archive_clean['doggo'] + df_archive_clean['floofer'] + df_archive_clean['pupper'] + df_archive_clean['puppo']",
"_____no_output_____"
],
[
"#drop other four stages columns\ndf_archive_clean = df_archive_clean.drop(['doggo', 'floofer', 'pupper', 'puppo'], axis=1)",
"_____no_output_____"
],
[
"df_archive_clean.dog_stage.value_counts()",
"_____no_output_____"
],
[
"#replace the null value and multiple stage\ndf_archive_clean['dog_stage'] = df_archive_clean['dog_stage'].replace('', np.nan)\ndf_archive_clean['dog_stage'] = df_archive_clean['dog_stage'].replace('doggopupper', 'multiple')\ndf_archive_clean['dog_stage'] = df_archive_clean['dog_stage'].replace('doggofloofer', 'multiple')\ndf_archive_clean['dog_stage'] = df_archive_clean['dog_stage'].replace('doggopuppo', 'multiple')",
"_____no_output_____"
],
[
"#double check with our df\ndf_archive_clean.dog_stage.value_counts()",
"_____no_output_____"
]
],
[
[
"#### 3. Merge three files into one",
"_____no_output_____"
]
],
[
[
"master_clean = pd.merge(df_archive_clean, df_img_clean, on = 'tweet_id', how = 'inner')\nmaster_clean = pd.merge(master_clean, df_json_clean, on = 'tweet_id', how = 'inner')",
"_____no_output_____"
],
[
"master_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 2073 entries, 0 to 2072\nData columns (total 23 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 2073 non-null int64 \n 1 timestamp 2073 non-null object \n 2 source 2073 non-null object \n 3 text 2073 non-null object \n 4 retweeted_status_id 79 non-null float64\n 5 expanded_urls 2073 non-null object \n 6 rating_numerator 2073 non-null int64 \n 7 rating_denominator 2073 non-null int64 \n 8 name 2073 non-null object \n 9 dog_stage 320 non-null object \n 10 jpg_url 2073 non-null object \n 11 img_num 2073 non-null int64 \n 12 p1 2073 non-null object \n 13 p1_conf 2073 non-null float64\n 14 p1_dog 2073 non-null bool \n 15 p2 2073 non-null object \n 16 p2_conf 2073 non-null float64\n 17 p2_dog 2073 non-null bool \n 18 p3 2073 non-null object \n 19 p3_conf 2073 non-null float64\n 20 p3_dog 2073 non-null bool \n 21 retweet_count 2073 non-null int64 \n 22 favorite_count 2073 non-null int64 \ndtypes: bool(3), float64(4), int64(6), object(10)\nmemory usage: 346.2+ KB\n"
]
],
[
[
"### Dealing with quality issue\n#### 1. change data format and drop the retweet rows",
"_____no_output_____"
]
],
[
[
"#change timestamp format from string to datetime\nmaster_clean.timestamp = pd.to_datetime(master_clean.timestamp)",
"_____no_output_____"
],
[
"#change id format from float to int\nid_clean = master_clean.retweeted_status_id\nid_clean = id_clean.dropna()\nid_clean = id_clean.astype('int64')",
"_____no_output_____"
],
[
"#drop the retweet rows\nmaster_clean = master_clean.drop(master_clean[master_clean.retweeted_status_id.apply(lambda x : x in id_clean.values)].index.values, axis = 0)\nmaster_clean = master_clean.drop('retweeted_status_id', axis=1)",
"_____no_output_____"
],
[
"master_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 1994 entries, 0 to 2072\nData columns (total 22 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 1994 non-null int64 \n 1 timestamp 1994 non-null datetime64[ns, UTC]\n 2 source 1994 non-null object \n 3 text 1994 non-null object \n 4 expanded_urls 1994 non-null object \n 5 rating_numerator 1994 non-null int64 \n 6 rating_denominator 1994 non-null int64 \n 7 name 1994 non-null object \n 8 dog_stage 306 non-null object \n 9 jpg_url 1994 non-null object \n 10 img_num 1994 non-null int64 \n 11 p1 1994 non-null object \n 12 p1_conf 1994 non-null float64 \n 13 p1_dog 1994 non-null bool \n 14 p2 1994 non-null object \n 15 p2_conf 1994 non-null float64 \n 16 p2_dog 1994 non-null bool \n 17 p3 1994 non-null object \n 18 p3_conf 1994 non-null float64 \n 19 p3_dog 1994 non-null bool \n 20 retweet_count 1994 non-null int64 \n 21 favorite_count 1994 non-null int64 \ndtypes: bool(3), datetime64[ns, UTC](1), float64(3), int64(6), object(9)\nmemory usage: 317.4+ KB\n"
]
],
[
[
"#### 2. fix the rating part",
"_____no_output_____"
]
],
[
[
"# rating_denominator should be 10.\nmaster_clean.rating_denominator.value_counts()",
"_____no_output_____"
],
[
"#check those rating_denominator is not equal to 10\npd.set_option('display.max_colwidth', 150)\nmaster_clean[['tweet_id', 'text', 'rating_numerator', 'rating_denominator']].query('rating_denominator != 10')",
"_____no_output_____"
],
[
"master_clean.query('rating_denominator != 10').shape[0]",
"_____no_output_____"
],
[
"#find the error rating and fix it\n#740373189193256964(14/10);722974582966214656(13/10);716439118184652801(11/10);666287406224695296(9/10);682962037429899265(10/10);\nmaster_clean.loc[master_clean.tweet_id == 740373189193256964, 'rating_numerator':'rating_denominator'] = [14, 10]\nmaster_clean.loc[master_clean.tweet_id == 722974582966214656, 'rating_numerator':'rating_denominator'] = [13, 10]\nmaster_clean.loc[master_clean.tweet_id == 716439118184652801, 'rating_numerator':'rating_denominator'] = [11, 10]\nmaster_clean.loc[master_clean.tweet_id == 666287406224695296, 'rating_numerator':'rating_denominator'] = [9, 10]\nmaster_clean.loc[master_clean.tweet_id == 682962037429899265, 'rating_numerator':'rating_denominator'] = [10, 10]",
"_____no_output_____"
],
[
"#number of rows that rating denominator is not equal to 10\nmaster_clean.query('rating_denominator != 10').shape[0]",
"_____no_output_____"
],
[
"master_clean[['text', 'rating_numerator', 'rating_denominator']].query('rating_denominator != 10')",
"_____no_output_____"
],
[
"#drop all the rows above\nmaster_clean = master_clean.drop([345, 415, 734, 924, 1022, 1047, 1065, 1131, 1207, 1379, 1380, 1512, 1571], axis = 0)",
"_____no_output_____"
],
[
"master_clean.query('rating_denominator != 10').shape[0] #the rows are droped",
"_____no_output_____"
],
[
"master_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 1981 entries, 0 to 2072\nData columns (total 22 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 1981 non-null int64 \n 1 timestamp 1981 non-null datetime64[ns, UTC]\n 2 source 1981 non-null object \n 3 text 1981 non-null object \n 4 expanded_urls 1981 non-null object \n 5 rating_numerator 1981 non-null int64 \n 6 rating_denominator 1981 non-null int64 \n 7 name 1981 non-null object \n 8 dog_stage 306 non-null object \n 9 jpg_url 1981 non-null object \n 10 img_num 1981 non-null int64 \n 11 p1 1981 non-null object \n 12 p1_conf 1981 non-null float64 \n 13 p1_dog 1981 non-null bool \n 14 p2 1981 non-null object \n 15 p2_conf 1981 non-null float64 \n 16 p2_dog 1981 non-null bool \n 17 p3 1981 non-null object \n 18 p3_conf 1981 non-null float64 \n 19 p3_dog 1981 non-null bool \n 20 retweet_count 1981 non-null int64 \n 21 favorite_count 1981 non-null int64 \ndtypes: bool(3), datetime64[ns, UTC](1), float64(3), int64(6), object(9)\nmemory usage: 315.3+ KB\n"
]
],
[
[
"#### 3. replace those invalid names to 'None'",
"_____no_output_____"
]
],
[
[
"master_clean.reset_index(drop=True, inplace=True)",
"_____no_output_____"
],
[
"error_name = master_clean.name.str.contains('^[a-z]', regex = True)\nmaster_clean[error_name].name.value_counts().sort_index()",
"_____no_output_____"
],
[
"#change name to 'None'\nsave = []\ncounter = 0\nfor i in master_clean.name:\n \n if error_name[counter] == False:\n save.append(i)\n else:\n save.append('None')\n counter += 1",
"_____no_output_____"
],
[
"master_clean.name = np.array(save)",
"_____no_output_____"
],
[
"master_clean.name.value_counts()",
"_____no_output_____"
]
],
[
[
"#### 4. creat a new column called 'breed' and if p1 confidence >= 95% and p1_dog is True or p2 confidence <= 1% and p2_dog is True, then put the predicted breed into breed column",
"_____no_output_____"
]
],
[
[
"#create breed column\nmaster_clean['breed'] = 'None'",
"_____no_output_____"
],
[
"master_clean.breed.value_counts()",
"_____no_output_____"
],
[
"#put all right category into breed\nsave = []\nfor i in range(master_clean.breed.shape[0]):\n if master_clean.p1_conf.iloc[i] >= 0.95 and master_clean.p1_dog.iloc[i]:\n save.append(master_clean.p1.iloc[i])\n elif master_clean.p2_conf.iloc[i] <= 0.01 and master_clean.p2_dog.iloc[i]:\n save.append(master_clean.p2.iloc[i]) \n else:\n save.append('Unsure')",
"_____no_output_____"
],
[
"master_clean['breed'] = np.array(save)",
"_____no_output_____"
],
[
"#format the breed names\nmaster_clean['breed'] = master_clean.breed.str.capitalize().str.replace('_',' ')",
"_____no_output_____"
],
[
"master_clean.breed.value_counts()",
"_____no_output_____"
]
],
[
[
"#### 5. drop p1/p2/p3 columns",
"_____no_output_____"
]
],
[
[
"#drop p2 p3 columns\nmaster_clean = master_clean.drop(['p1','p1_conf','p1_dog','p2','p2_conf','p2_dog','p3','p3_conf','p3_dog'], axis = 1)",
"_____no_output_____"
],
[
"master_clean.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 1981 entries, 0 to 1980\nData columns (total 14 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 tweet_id 1981 non-null int64 \n 1 timestamp 1981 non-null datetime64[ns, UTC]\n 2 source 1981 non-null object \n 3 text 1981 non-null object \n 4 expanded_urls 1981 non-null object \n 5 rating_numerator 1981 non-null int64 \n 6 rating_denominator 1981 non-null int64 \n 7 name 1981 non-null object \n 8 dog_stage 306 non-null object \n 9 jpg_url 1981 non-null object \n 10 img_num 1981 non-null int64 \n 11 retweet_count 1981 non-null int64 \n 12 favorite_count 1981 non-null int64 \n 13 breed 1981 non-null object \ndtypes: datetime64[ns, UTC](1), int64(6), object(7)\nmemory usage: 216.8+ KB\n"
]
],
[
[
"#### 6. rename source column",
"_____no_output_____"
]
],
[
[
"master_clean.source.value_counts()",
"_____no_output_____"
],
[
"master_clean3 = master_clean",
"_____no_output_____"
],
[
"master_clean3['source'] = master_clean3.source.replace({'<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>' : 'Twitter for Iphone',\n '<a href=\"http://twitter.com\" rel=\"nofollow\">Twitter Web Client</a>' : 'Twitter Web Client', \n '<a href=\"https://about.twitter.com/products/tweetdeck\" rel=\"nofollow\">TweetDeck</a>' : 'TweetDeck'\n }) \n \n \n \n ",
"_____no_output_____"
],
[
"master_clean3.source.value_counts()",
"_____no_output_____"
]
],
[
[
"<a id='analyze'></a>\n## Storing, Analyzing and Visualizing Data\n> <b>Clean each of the issues you documented while assessing. Perform this cleaning in wrangle_act.ipynb as well. The result should be a high quality and tidy master pandas DataFrame (or DataFrames, if appropriate).Then analyze and visualize the wrangled data. </b>\n<ul>\n<li><a href=\"#insight\">Insights</a> </li>\n<li><a href=\"#visual\">Visualization</a></li>\n</ul>",
"_____no_output_____"
],
[
"<b>Storing</b>",
"_____no_output_____"
]
],
[
[
"master_clean.to_csv('twitter_archive_master.csv')\ntwitter_archive_master = pd.read_csv('twitter_archive_master.csv')\ntwitter_archive_master.head()",
"_____no_output_____"
]
],
[
[
"<a id='insight'></a>\n## Insights\n### Q1: Which dog has highest retweet counts?\n",
"_____no_output_____"
]
],
[
[
"twitter_archive_master.sort_values(by = 'retweet_count', ascending = False).iloc[0]",
"_____no_output_____"
]
],
[
[
"The dog has highest retweet counts. Its stage is doggo. The pose retweeted 79515 times and received 131075 favorite counts. ",
"_____no_output_____"
],
[
"### Q2: Which dog receive most favorite counts?",
"_____no_output_____"
]
],
[
[
"twitter_archive_master.sort_values(by = 'favorite_count', ascending = False).iloc[0]",
"_____no_output_____"
]
],
[
[
"The dog has most favorite counts, its stage is puppo. The pose retweeted 48265 times and received 132810 favorite counts. ",
"_____no_output_____"
],
[
"### Q3: What way do users most use to log in WeRateDog?",
"_____no_output_____"
]
],
[
[
"twitter_archive_master.source.value_counts()",
"_____no_output_____"
],
[
"#calculate the proportion\ntwitter_archive_master.source.value_counts().iloc[0]/twitter_archive_master.shape[0]",
"_____no_output_____"
]
],
[
[
"98% of the WeRateDog users like to use Twitter through iPhone. ",
"_____no_output_____"
],
[
"### Q4: What is the relation between retweet counts and favorite counts?",
"_____no_output_____"
]
],
[
[
"twitter_archive_master.describe()",
"_____no_output_____"
],
[
"twitter_archive_master.retweet_count.mean()",
"_____no_output_____"
],
[
"twitter_archive_master.favorite_count.mean()",
"_____no_output_____"
],
[
"twitter_archive_master.favorite_count.mean()/twitter_archive_master.retweet_count.mean()",
"_____no_output_____"
]
],
[
[
"The mean of retweet counts is 27775.6, the mean of favorite counts is 8925.8. And the the favorite counts are as three times as many as the retweet counts. It means that people would always thump up for a pose, but they might not retweet it.",
"_____no_output_____"
],
[
"<a id='visual'></a>\n## Visualization\n### #1. What is the most popular dog breed?",
"_____no_output_____"
]
],
[
[
"#see the value of breed\ntwitter_archive_master.breed.value_counts()",
"_____no_output_____"
],
[
"#total dog breed (without unsure)\ntwitter_archive_master.breed.value_counts().shape[0] - 1",
"_____no_output_____"
],
[
"#create a bar chart to find popular dog breed\nplt.figure(figsize = (9, 9))\nbreed_filter=twitter_archive_master.groupby('breed').filter(lambda x: len(x) >= 3 and len(x) <= 100)\nbreed_filter['breed'].value_counts(ascending=True).plot(kind = 'barh', alpha = 0.8, color = 'pink')\n\nplt.title('The Most Popular Dog Breed', fontsize=20)\nplt.xlabel('Counts',fontsize=18)\nplt.ylabel('Dog Breed',fontsize=18);",
"_____no_output_____"
]
],
[
[
"Through this chart, the most popular dog breed is Pug with 21 counts. The second popular dog breeds are Pembroke and Samoyed with 19 counts. The third is Golden retriever with 18 counts. The dog breed has 50 categories in total. ",
"_____no_output_____"
],
[
"### #2. What is the proportion of dog stages? And what's the relation between favorite counts and its dog stage?",
"_____no_output_____"
]
],
[
[
"twitter_archive_master.dog_stage.value_counts()",
"_____no_output_____"
],
[
"#create a pie chart\nplt.figure(figsize=(12,9))\nsns.set(style='darkgrid')\nname = twitter_archive_master['dog_stage'].value_counts()\nexplode = (0, 0, 0, 0, 0.1)\nplt.pie(name, explode, labels = name.index, shadow=True, textprops={'fontsize': 20}, autopct='%1.1f%%', startangle = 230)\nplt.axis('equal') \n\nplt.title('The Proportion of Dog Stage', fontsize=35)\nplt.legend();",
"_____no_output_____"
],
[
"#calculate the average favorite counts based on dog stage\navg_fav = twitter_archive_master.groupby('dog_stage').favorite_count.mean()\navg_fav",
"_____no_output_____"
],
[
"#create a bar chart to represent the relation between fav_counts and dog_stage\nplt.figure(figsize = (9, 9))\nplt.bar(avg_fav.index.values, avg_fav, color = 'orange', alpha = 0.8)\nplt.title('The Relation between Favorite Counts and Dog Stage', fontsize=18)\nplt.xlabel('Dog Stage', fontsize=15)\nplt.ylabel('Favorite Counts', fontsize=15);",
"_____no_output_____"
]
],
[
[
"Based on the pie chart, the largest proportion of dog stage is pupper accounting for 66.3%, and the less of it is floofer with 2.3%. But from the bar chart, the pupper receives less favorite counts. The dog stage which gets most of favorite counts is puppo, puppo is only 7.2% of all dog stage. The floofer receives average 13206 favorite counts which is the second largest proportion of receiving favorite counts. So, the relation between favorite counts and dog stage number has not positive relationship.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a43f1b4cf427658e64be73bb6f403f3ec4e74ec
| 10,757 |
ipynb
|
Jupyter Notebook
|
symbolic/angvelxform_dot.ipynb
|
tahsinkose/spatialmath-python
|
ff9ec369864d601a72454014061db1a76e05c1b3
|
[
"MIT"
] | null | null | null |
symbolic/angvelxform_dot.ipynb
|
tahsinkose/spatialmath-python
|
ff9ec369864d601a72454014061db1a76e05c1b3
|
[
"MIT"
] | null | null | null |
symbolic/angvelxform_dot.ipynb
|
tahsinkose/spatialmath-python
|
ff9ec369864d601a72454014061db1a76e05c1b3
|
[
"MIT"
] | null | null | null | 29.552198 | 913 | 0.515943 |
[
[
[
"# Determine derivative of Jacobian from angular velocity to exponential rates\n\nPeter Corke 2021\n\nSymPy code to deterine the time derivative of the mapping from angular velocity to exponential coordinate rates.",
"_____no_output_____"
]
],
[
[
"from sympy import *",
"_____no_output_____"
]
],
[
[
"A rotation matrix can be expressed in terms of exponential coordinates (also called Euler vector)\n\n$\n\\mathbf{R} = e^{[\\varphi]_\\times} \n$\nwhere $\\mathbf{R} \\in SO(3)$ and $\\varphi \\in \\mathbb{R}^3$.\n\nThe mapping from angular velocity $\\omega$ to exponential coordinate rates $\\dot{\\varphi}$ is\n\n$\n\\dot{\\varphi} = \\mathbf{A} \\omega\n$\n\nwhere $\\mathbf{A}$ is given by (2.107) of [Robot Dynamics Lecture Notes, Robotic Systems Lab, ETH Zurich, 2018](https://ethz.ch/content/dam/ethz/special-interest/mavt/robotics-n-intelligent-systems/rsl-dam/documents/RobotDynamics2018/RD_HS2018script.pdf)\n\n\n$\n\\mathbf{A} = I_{3 \\times 3} - \\frac{1}{2} [v]_\\times + [v]^2_\\times \\frac{1}{\\theta^2} \\left( 1 - \\frac{\\theta}{2} \\frac{\\sin \\theta}{1 - \\cos \\theta} \\right)\n$\nwhere $\\theta = \\| \\varphi \\|$ and $v = \\hat{\\varphi}$\n\nWe simplify the equation as\n\n$\n\\mathbf{A} = I_{3 \\times 3} - \\frac{1}{2} [v]_\\times + [v]^2_\\times \\Theta\n$\n\nwhere\n$\n\\Theta = \\frac{1}{\\theta^2} \\left( 1 - \\frac{\\theta}{2} \\frac{\\sin \\theta}{1 - \\cos \\theta} \\right)\n$\n\nWe can find the derivative using the chain rule\n\n$\n\\dot{\\mathbf{A}} = - \\frac{1}{2} [\\dot{v}]_\\times + 2 [v]_\\times [\\dot{v}]_\\times \\Theta + [v]^2_\\times \\dot{\\Theta}\n$\n\nWe start by defining some symbols",
"_____no_output_____"
]
],
[
[
"Theta, theta, theta_dot, t = symbols('Theta theta theta_dot t', real=True)",
"_____no_output_____"
]
],
[
[
"We start by finding an expression for $\\Theta$ which depends on $\\theta(t)$",
"_____no_output_____"
]
],
[
[
"theta_t = Function(theta)(t)",
"_____no_output_____"
],
[
"Theta = 1 / theta_t ** 2 * (1 - theta_t / 2 * sin(theta_t) / (1 - cos(theta_t)))\nTheta",
"_____no_output_____"
]
],
[
[
"and now determine the derivative",
"_____no_output_____"
]
],
[
[
"T_dot = Theta.diff(t)\nT_dot",
"_____no_output_____"
]
],
[
[
"which is a somewhat complex expression that depends on $\\theta(t)$ and $\\dot{\\theta}(t)$.\n\nWe will remove the time dependency and generate code",
"_____no_output_____"
]
],
[
[
"T_dot = T_dot.subs([(theta_t.diff(t), theta_dot), (theta_t, theta)])",
"_____no_output_____"
],
[
"pycode(T_dot)",
"_____no_output_____"
]
],
[
[
"In order to evaluate the line above we need an expression for $\\theta$ and $\\dot{\\theta}$. $\\theta$ is the norm of $\\varphi$ whose elements are functions of time",
"_____no_output_____"
]
],
[
[
"phi_names = ('varphi_0', 'varphi_1', 'varphi_2')\nphi = [] # names of angles, eg. theta\nphi_t = [] # angles as function of time, eg. theta(t)\nphi_d = [] # derivative of above, eg. d theta(t) / dt\nphi_n = [] # symbol to represent above, eg. theta_dot\nfor i in phi_names:\n phi.append(symbols(i, real=True))\n phi_t.append(Function(phi[-1])(t))\n phi_d.append(phi_t[-1].diff(t))\n phi_n.append(i + '_dot')",
"_____no_output_____"
]
],
[
[
"Compute the norm",
"_____no_output_____"
]
],
[
[
"theta = Matrix(phi_t).norm()\ntheta",
"_____no_output_____"
]
],
[
[
"and find its derivative",
"_____no_output_____"
]
],
[
[
"theta_dot = theta.diff(t)\ntheta_dot",
"_____no_output_____"
]
],
[
[
"and now remove the time dependenices",
"_____no_output_____"
]
],
[
[
"theta_dot = theta_dot.subs(a for a in zip(phi_d, phi_n))\ntheta_dot = theta_dot.subs(a for a in zip(phi_t, phi))\ntheta_dot",
"_____no_output_____"
]
],
[
[
"which is simply the dot product over the norm.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a43f3e07840d2cedb8cd3bd7aa04d84996dc7fd
| 16,113 |
ipynb
|
Jupyter Notebook
|
GetStarted/02_adding_data_to_qgis.ipynb
|
pberezina/earthengine-py-notebooks
|
4cbe3c52bcc9ed3f1337bf097aa5799442991a5e
|
[
"MIT"
] | 1 |
2020-03-20T19:39:34.000Z
|
2020-03-20T19:39:34.000Z
|
GetStarted/02_adding_data_to_qgis.ipynb
|
pberezina/earthengine-py-notebooks
|
4cbe3c52bcc9ed3f1337bf097aa5799442991a5e
|
[
"MIT"
] | null | null | null |
GetStarted/02_adding_data_to_qgis.ipynb
|
pberezina/earthengine-py-notebooks
|
4cbe3c52bcc9ed3f1337bf097aa5799442991a5e
|
[
"MIT"
] | null | null | null | 86.629032 | 10,232 | 0.848073 |
[
[
[
"<table class=\"ee-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://github.com/giswqs/earthengine-py-notebooks/tree/master/GetStarted/02_adding_data_to_qgis.ipynb\"><img width=32px src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /> View source on GitHub</a></td>\n <td><a target=\"_blank\" href=\"https://nbviewer.jupyter.org/github/giswqs/earthengine-py-notebooks/blob/master/GetStarted/02_adding_data_to_qgis.ipynb\"><img width=26px src=\"https://upload.wikimedia.org/wikipedia/commons/thumb/3/38/Jupyter_logo.svg/883px-Jupyter_logo.svg.png\" />Notebook Viewer</a></td>\n <td><a target=\"_blank\" href=\"https://mybinder.org/v2/gh/giswqs/earthengine-py-notebooks/master?filepath=GetStarted/02_adding_data_to_qgis.ipynb\"><img width=58px src=\"https://mybinder.org/static/images/logo_social.png\" />Run in binder</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/giswqs/earthengine-py-notebooks/blob/master/GetStarted/02_adding_data_to_qgis.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /> Run in Google Colab</a></td>\n</table>",
"_____no_output_____"
],
[
"## Install Earth Engine API\nInstall the [Earth Engine Python API](https://developers.google.com/earth-engine/python_install) and [geehydro](https://github.com/giswqs/geehydro). The **geehydro** Python package builds on the [folium](https://github.com/python-visualization/folium) package and implements several methods for displaying Earth Engine data layers, such as `Map.addLayer()`, `Map.setCenter()`, `Map.centerObject()`, and `Map.setOptions()`.\nThe following script checks if the geehydro package has been installed. If not, it will install geehydro, which automatically install its dependencies, including earthengine-api and folium.",
"_____no_output_____"
]
],
[
[
"import subprocess\n\ntry:\n import geehydro\nexcept ImportError:\n print('geehydro package not installed. Installing ...')\n subprocess.check_call([\"python\", '-m', 'pip', 'install', 'geehydro'])",
"_____no_output_____"
]
],
[
[
"Import libraries",
"_____no_output_____"
]
],
[
[
"import ee\nimport folium\nimport geehydro",
"_____no_output_____"
]
],
[
[
"Authenticate and initialize Earth Engine API. You only need to authenticate the Earth Engine API once. ",
"_____no_output_____"
]
],
[
[
"try:\n ee.Initialize()\nexcept Exception as e:\n ee.Authenticate()\n ee.Initialize()",
"_____no_output_____"
]
],
[
[
"## Create an interactive map \nThis step creates an interactive map using [folium](https://github.com/python-visualization/folium). The default basemap is the OpenStreetMap. Additional basemaps can be added using the `Map.setOptions()` function. \nThe optional basemaps can be `ROADMAP`, `SATELLITE`, `HYBRID`, `TERRAIN`, or `ESRI`.",
"_____no_output_____"
]
],
[
[
"Map = folium.Map(location=[40, -100], zoom_start=4)\nMap.setOptions('HYBRID')",
"_____no_output_____"
]
],
[
[
"## Add Earth Engine Python script ",
"_____no_output_____"
]
],
[
[
"# Load an image.\nimage = ee.Image('LANDSAT/LC08/C01/T1/LC08_044034_20140318')\n\n# Center the map on the image.\nMap.centerObject(image, 9)\n\n# Display the image.\nMap.addLayer(image, {}, 'Landsat 8 original image')\n\n# Define visualization parameters in an object literal.\nvizParams = {'bands': ['B5', 'B4', 'B3'],\n 'min': 5000, 'max': 15000, 'gamma': 1.3}\n\n# Center the map on the image and display.\nMap.centerObject(image, 9)\nMap.addLayer(image, vizParams, 'Landsat 8 False color')\n\n# Use Map.addLayer() to add features and feature collections to the map. For example,\ncounties = ee.FeatureCollection('TIGER/2016/Counties')\nMap.addLayer(ee.Image().paint(counties, 0, 2), {}, 'counties')\n",
"_____no_output_____"
]
],
[
[
"## Display Earth Engine data layers ",
"_____no_output_____"
]
],
[
[
"Map.setControlVisibility(layerControl=True, fullscreenControl=True, latLngPopup=True)\nMap",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a43f6cf02b5680d41fbdac5f544044eb5da51af
| 1,832 |
ipynb
|
Jupyter Notebook
|
iWildCam2020_app.ipynb
|
rausial/kaggle_challenges_fastai-
|
d6f5605e0d76e77f7b987100eb3ce18b26512292
|
[
"Apache-2.0"
] | null | null | null |
iWildCam2020_app.ipynb
|
rausial/kaggle_challenges_fastai-
|
d6f5605e0d76e77f7b987100eb3ce18b26512292
|
[
"Apache-2.0"
] | 2 |
2021-09-28T05:37:05.000Z
|
2022-02-26T10:04:14.000Z
|
iWildCam2020_app.ipynb
|
rausial/kaggle_challenges_fastai-
|
d6f5605e0d76e77f7b987100eb3ce18b26512292
|
[
"Apache-2.0"
] | null | null | null | 20.58427 | 88 | 0.527293 |
[
[
[
"from fastai.vision.widgets import *\nfrom fastai.vision.all import *\n\nfrom pathlib import Path",
"_____no_output_____"
],
[
"path = Path()\npath.ls(file_exts='.pkl')",
"_____no_output_____"
],
[
"learn_inf = load_learner(path/'export.pkl')",
"_____no_output_____"
],
[
"btn_upload = widgets.FileUpload()\nout_pl = widgets.Output()\nlbl_pred = widgets.Label()",
"_____no_output_____"
],
[
"def on_click(change):\n img = PILImage.create(btn_upload.data[-1])\n out_pl.clear_output()\n with out_pl: display(img.to_thumb(512, 512))\n pred,pred_idx,probs = learn_inf.predict(img)\n lbl_pred.value = f'Prediction: {pred}; Probability: {probs[pred_idx]:.04f}'\n\nbtn_upload.observe(on_click, names=['data'])",
"_____no_output_____"
],
[
"display(VBox([widgets.Label('Sube tu fototrampa'), \n btn_upload, out_pl, lbl_pred]))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a43fd00964506a67d6d491d41d89edb5e30c86d
| 314,098 |
ipynb
|
Jupyter Notebook
|
Starbucks_Capstone_notebook.ipynb
|
youssefmecky96/Starbucks-Model-to-predict-user-response-
|
c47f428fbbde0fe331d8b97b1f62d187f52a051b
|
[
"MIT",
"Unlicense"
] | null | null | null |
Starbucks_Capstone_notebook.ipynb
|
youssefmecky96/Starbucks-Model-to-predict-user-response-
|
c47f428fbbde0fe331d8b97b1f62d187f52a051b
|
[
"MIT",
"Unlicense"
] | null | null | null |
Starbucks_Capstone_notebook.ipynb
|
youssefmecky96/Starbucks-Model-to-predict-user-response-
|
c47f428fbbde0fe331d8b97b1f62d187f52a051b
|
[
"MIT",
"Unlicense"
] | 1 |
2021-03-27T18:00:36.000Z
|
2021-03-27T18:00:36.000Z
| 96.054434 | 75,216 | 0.784987 |
[
[
[
"# Starbucks Capstone Challenge\n\n## Project Overview \nThis data set contains simulated data that mimics customer behavior on the Starbucks rewards mobile app. Once every few days, Starbucks sends out an offer to users of the mobile app. An offer can be merely an advertisement for a drink or an actual offer such as a discount or BOGO (buy one get one free). Some users might not receive any offer during certain weeks. \n\nNot all users receive the same offer, and that is the challenge to solve with this data set.\nHere we have 3 simulated datasets from starbucks about offers to users, users info and events like transcations and giving out offers. \n\n## Our Aim\n#### 1-try to predict using a machine learning given a user's info and offer's info if that user is likely to use the offer and that could help figuring out which users should starbucks target\n#### 2-find the most correlated features that affects offers getting completed from both the user side and the offer side\n#### 3-(Bonus)to predict the total amount a person could spend on starbucks products given that person demographics\n\n\n### Exploration\nFirst thing I will do here is simply check all 3 data sets see if we can find anything intersting and figure out there structure, possible outliers and try to do a few visulaizations to see the distbution of age for the users and income of the users, and percentage of males to females \n### Cleaning\nSecond thing I will clean the data so that it can be input to the ML learning model to predict if a user would respond to an offer or not and to predict the total amount a user would spend at starbucks\n### Implementation\nI will check the correlation from the cleaned dataframe and in order to predict if a user will respond to an offer or not I will build the a random forrest model and use gridsearch to optimize the hyperparameters.\nI will build a random forrest and a gradient booster model to predict the total amount users would spend at starbucks as well and use gridsearch to optimize the hyperparameters\n### Conclusion and future optimiztions\nThis section covers the results of the model and what I sugget to improve the results\n## Metrics \nI will use to evalute the preformance of the offer success model 3 metrics the F1-score, precision, and recall\n\nPrecision is the ratio of correctly predicted positive observations to the total predicted positive observations.\n\nPrecision = TP/TP+FP\n\nRecall (Sensitivity) - Recall is the ratio of correctly predicted positive observations to the all observations in actual class \n\nRecall = TP/TP+FN\n\nF1 score - F1 Score is the weighted average of Precision and Recall. Therefore, this score takes both false positives and false negatives into account. \n\nF1 Score = 2*(Recall * Precision) / (Recall + Precision)\n\nI will use to evalute the preformance of the total amount spent by users model using R-Sqaured or the coefficient of determination which is a statistical measure in a regression model that determines the proportion of variance in the dependent variable that can be explained by the independent variable. In other words, r-squared shows how well the data fit the regression model (the goodness of fit). \n\nR_squared=1−(sum squared regression (SSR)/total sum of squares (SST))\n\nSST, is the squared differences between the observed dependent variable and its mean\n\nSSR, is the sum of the differences between the predicted value and the mean of the dependent variable. Think of it as a measure that describes how well our line fits the data.\n\n",
"_____no_output_____"
],
[
"# Data Sets\n\nThe data is contained in three files:\n\n* portfolio.json - containing offer ids and meta data about each offer (duration, type, etc.)\n* profile.json - demographic data for each customer\n* transcript.json - records for transactions, offers received, offers viewed, and offers completed\n\nHere is the schema and explanation of each variable in the files:\n\n**portfolio.json**\n* id (string) - offer id\n* offer_type (string) - type of offer ie BOGO, discount, informational\n* difficulty (int) - minimum required spend to complete an offer\n* reward (int) - reward given for completing an offer\n* duration (int) - time for offer to be open, in days\n* channels (list of strings)\n\n**profile.json**\n* age (int) - age of the customer \n* became_member_on (int) - date when customer created an app account\n* gender (str) - gender of the customer (note some entries contain 'O' for other rather than M or F)\n* id (str) - customer id\n* income (float) - customer's income\n\n**transcript.json**\n* event (str) - record description (ie transaction, offer received, offer viewed, etc.)\n* person (str) - customer id\n* time (int) - time in hours since start of test. The data begins at time t=0\n* value - (dict of strings) - either an offer id or transaction amount depending on the record\n\n",
"_____no_output_____"
],
[
"## Exploring the 3 dataframes",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport math\nimport json\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import metrics\nfrom sklearn.metrics import r2_score\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.metrics import classification_report\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.svm import LinearSVC\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.svm import SVC\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.neighbors import KNeighborsRegressor\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.ensemble import GradientBoostingClassifier\n% matplotlib inline\n\n# read in the json files\nportfolio = pd.read_json('data/portfolio.json', orient='records', lines=True)\nprofile = pd.read_json('data/profile.json', orient='records', lines=True)\ntranscript = pd.read_json('data/transcript.json', orient='records', lines=True)",
"_____no_output_____"
],
[
"portfolio.head()",
"_____no_output_____"
],
[
"portfolio.shape",
"_____no_output_____"
],
[
"portfolio",
"_____no_output_____"
],
[
"profile.head()\n",
"_____no_output_____"
],
[
"profile.dtypes",
"_____no_output_____"
],
[
"mean=profile['age'].mean()\nstd=profile['age'].std()\nprint(\"The mean for the age of the customers is {} and the stddev is {}\".format(mean,std))",
"The mean for the age of the customers is 62.53141176470588 and the stddev is 26.738579945767242\n"
],
[
"mean_1=profile['income'].mean()\nstd_1=profile['income'].std()\nprint(\"The income for the age of the customers is {} and the stddev is {}\".format(mean_1,std_1))",
"The income for the age of the customers is 65404.9915682968 and the stddev is 21598.299410229498\n"
],
[
" profile.isnull().sum() * 100 / len(profile)",
"_____no_output_____"
]
],
[
[
"It seems that the exact percentage of users that didn't report gender didn't report income as well",
"_____no_output_____"
],
[
"### Data Visualization",
"_____no_output_____"
]
],
[
[
"#Age Distribution\nplt.hist(profile['age'])\nplt.xlabel('Age')\nplt.ylabel('Number of customers')",
"_____no_output_____"
]
],
[
[
"We can see an some outliers here probably with a fake age as there are too many near 120 years howver most of the users seem to be between 40 and 80 years old ",
"_____no_output_____"
]
],
[
[
"#Income distribution\nprofile_nonan=profile.dropna(axis=0)\nplt.hist(profile_nonan['income'])\nplt.xlabel('income')\nplt.ylabel('Number of customers')",
"_____no_output_____"
],
[
"#Percentage of male ,female and others\nlabels=['Male','Female','Other']\nsizes=[sum(profile_nonan['gender']=='M'),sum(profile_nonan['gender']=='F'),sum(profile_nonan['gender']=='O')]\nfig1, ax1 = plt.subplots()\nax1.pie(sizes, labels=labels, autopct='%1.1f%%',\n shadow=True, startangle=90)",
"_____no_output_____"
],
[
"transcript.head()",
"_____no_output_____"
]
],
[
[
"## Data Preprocessing",
"_____no_output_____"
]
],
[
[
"portfolio.head()",
"_____no_output_____"
],
[
"#changing channel and offer type into dummy variable\nportfolio['email']=portfolio['channels'].astype(str).str.contains('email').astype(int)\nportfolio['web']=portfolio['channels'].astype(str).str.contains('web').astype(int)\nportfolio['mobile']=portfolio['channels'].astype(str).str.contains('mobile').astype(int)\nportfolio['social']=portfolio['channels'].astype(str).str.contains('social').astype(int)\nportfolio.drop(['channels'],axis=1,inplace=True)\nportfolio = pd.concat([portfolio.drop('offer_type', axis=1), pd.get_dummies(portfolio['offer_type'])], axis=1)",
"_____no_output_____"
],
[
"\nportfolio.head()",
"_____no_output_____"
],
[
"profile.head()",
"_____no_output_____"
],
[
"#drop dummy gender variable \nprofile = pd.concat([profile.drop('gender', axis=1), pd.get_dummies(profile['gender'])], axis=1)\n",
"_____no_output_____"
],
[
"##profile['became_member_on'] = profile['became_member_on'].apply(lambda x: pd.to_datetime(str(x), format='%Y%m%d'))\n",
"_____no_output_____"
],
[
"profile.head()",
"_____no_output_____"
],
[
"transcript.head()",
"_____no_output_____"
],
[
"#Values for event \nnp.unique(transcript.event.values)",
"_____no_output_____"
],
[
"transcript_offer=transcript[transcript['value'].astype(str).str.contains('offer')]\ntranscript_offer.head()",
"_____no_output_____"
],
[
"#to get only the id and nothing else and removing the value column\ntranscript_offer['offer_id']=transcript_offer['value'].astype(str).str.slice(14,46)\ntranscript_offer.drop(['value'],inplace=True,axis=1)",
"/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n/opt/conda/lib/python3.6/site-packages/pandas/core/frame.py:3697: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n errors=errors)\n"
],
[
"#get dummy vars for event and drop event\ndummies=pd.get_dummies(transcript_offer['event'])\ntranscript_offer = pd.concat([transcript_offer,dummies], axis=1)\ntranscript_offer.drop(['event'],inplace=True,axis=1)\ntranscript_offer.head()",
"_____no_output_____"
],
[
"df = transcript_offer[(~transcript_offer.duplicated(['person','offer_id']))]",
"_____no_output_____"
],
[
"sum(transcript_offer.duplicated(['person','offer_id']))",
"_____no_output_____"
]
],
[
[
"To create a model to predict if a user responds to an offer we I want us to have each row represnts if a user recived offer,viewed it and completed it so we need to combine our dummy varaibles by person and offer_id",
"_____no_output_____"
]
],
[
[
"df['offer completed']=transcript_offer.groupby(['person','offer_id']).sum()['offer completed'].values\ndf['offer received']=transcript_offer.groupby(['person','offer_id']).sum()['offer received'].values\ndf['offer viewed']=transcript_offer.groupby(['person','offer_id']).sum()['offer viewed'].values\ndf.shape",
"/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \"\"\"Entry point for launching an IPython kernel.\n/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n"
],
[
"#creat Df for transactions\ntranscript_transcation=transcript[transcript['value'].astype(str).str.contains('amount')]",
"_____no_output_____"
],
[
"#to get only the amount and nothing else and removing the value column\ntranscript_transcation['amount']=transcript_transcation['value'].astype(str).str.slice(10,-1)\n\ntranscript_transcation.drop(['value'],inplace=True,axis=1)",
"/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n/opt/conda/lib/python3.6/site-packages/pandas/core/frame.py:3697: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n errors=errors)\n"
],
[
"#check if amount is int\ntranscript_transcation.dtypes",
"_____no_output_____"
],
[
"#transform amount into int\ntranscript_transcation['amount']=pd.to_numeric(transcript_transcation['amount'])",
"/opt/conda/lib/python3.6/site-packages/ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"transcript_transcation.head()",
"_____no_output_____"
],
[
"#get total spent by each user \ntotal=dict(transcript_transcation.groupby(['person']).sum()['amount'])\n",
"_____no_output_____"
],
[
"#append that total to the profile Df to each user will \nprofile['total'] = profile.id.map(total)\nprofile.head()",
"_____no_output_____"
],
[
"df=pd.merge(df,profile,left_on='person', right_on='id',how='left')\ndf.head()",
"_____no_output_____"
],
[
"df=pd.merge(df,portfolio,left_on='offer_id', right_on='id',how='left')\ndf.head()",
"_____no_output_____"
],
[
" df.isnull().sum() * 100 / len(df)",
"_____no_output_____"
],
[
"df.dropna(inplace=True,axis=0)",
"_____no_output_____"
],
[
"#We want to evaluate if a person will respond to an offer therfore I will drop users who didn't view the offer\ndf=df[df['offer viewed']>=1]",
"_____no_output_____"
]
],
[
[
"## Modelling and Implementation",
"_____no_output_____"
]
],
[
[
"Var_Corr_person_income = profile.drop(['id'],axis=1).corr()\n# plot the heatmap and annotation on it\nfig, ax = plt.subplots(figsize=(8,8))\nsns.heatmap(Var_Corr_person_income, xticklabels=Var_Corr_person_income.columns, yticklabels=Var_Corr_person_income.columns, annot=True,ax=ax)",
"_____no_output_____"
]
],
[
[
"total_amount_spent seems to have a positive correlation with income and females and a negative correlation with age \nso it seems that younger females with hgiher income will spend more money on starbucks",
"_____no_output_____"
]
],
[
[
"\nprofile.dropna(inplace=True)\nX_total=profile.drop(['total','id'],axis=1)\ny_total=profile['total']\n\nx_train_total,x_test_total,y_train_total,y_test_total=train_test_split(X_total,y_total,test_size=.20,random_state=42)",
"_____no_output_____"
],
[
"pipeline_total = Pipeline(\n [\n (\"clf\",RandomForestRegressor())\n ]\n )\nparameters = { \n 'clf__n_estimators':[100,200],\n 'clf__n_jobs':[-1],\n 'clf__max_depth':[5,10]\n \n }\ncv_total = GridSearchCV(pipeline_total, param_grid=parameters,n_jobs=-1)",
"_____no_output_____"
],
[
"cv_total.fit(x_train_total,y_train_total)\n\n",
"_____no_output_____"
],
[
"y_pred_total=cv_total.predict(x_test_total)\nr2_score=r2_score(y_test_total, y_pred_total)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"#checking which features of a person most affect the offer being completed \nVar_Corr_person_offer = df[['offer completed','age','became_member_on','income','F', 'M',\n 'O', 'total']].corr()\n# plot the heatmap and annotation on it\nfig, ax = plt.subplots(figsize=(8,8))\nsns.heatmap(Var_Corr_person_offer, xticklabels=Var_Corr_person_offer.columns, yticklabels=Var_Corr_person_offer.columns, annot=True,ax=ax)",
"_____no_output_____"
]
],
[
[
"From the above not many deductions could be made buy it does't look like a strong correlation with any of these users features ",
"_____no_output_____"
]
],
[
[
"#emails value is always one so will remove it from here and from the model\nVar_Corr_offer = df[['offer completed','difficulty', 'duration', 'reward',\n 'web', 'mobile', 'social', 'bogo', 'discount', 'informational']].corr()\n# plot the heatmap and annotation on it\nfig, ax = plt.subplots(figsize=(10,10))\nsns.heatmap(Var_Corr_offer, xticklabels=Var_Corr_offer.columns, yticklabels=Var_Corr_offer.columns, annot=True,ax=ax)",
"_____no_output_____"
]
],
[
[
"The correlation between the offer being completed and other offer features are also not particulary strong the strongest one seems to be if the offer channel is social media with correlation =0.014",
"_____no_output_____"
]
],
[
[
"X=df.drop(['person','time','offer_id','id_x','id_y','offer completed'],axis=1)\ny=df['offer completed']\n#changing the y classes to either success or failure only instead of the count\ny[y>1]=1\nx_train,x_test,y_train,y_test=train_test_split(X,y,test_size=.20)",
"_____no_output_____"
],
[
"X.columns",
"_____no_output_____"
],
[
"\npipeline_KNN = Pipeline(\n [\n \n \n (\"clf\", KNeighborsClassifier())\n ]\n )\nparameters = {\n \n \n \n \n 'clf__n_jobs':[-1],\n \n \n }\ncv_KNN = GridSearchCV(pipeline_KNN, param_grid=parameters,n_jobs=-1,cv=10)\ncv_KNN.fit(x_train, y_train)\ny_pred_KNN=cv_KNN.predict(x_test)\nprint(classification_report(y_test, y_pred_KNN))",
" precision recall f1-score support\n\n 0 0.49 0.49 0.49 4204\n 1 0.49 0.49 0.49 4180\n\navg / total 0.49 0.49 0.49 8384\n\n"
],
[
"#check for overfitting\ny_pred_KNN_train=cv_KNN.predict(x_train)\nprint(classification_report(y_train, y_pred_KNN_train))",
" precision recall f1-score support\n\n 0 0.69 0.69 0.69 16887\n 1 0.69 0.68 0.68 16645\n\navg / total 0.69 0.69 0.69 33532\n\n"
],
[
"\npipeline_RF = Pipeline(\n [\n \n \n (\"clf\", RandomForestClassifier())\n ]\n )\nparameters = {\n \n \n \n 'clf__n_estimators':[100,200],\n 'clf__n_jobs':[-1],\n 'clf__max_depth':[5,10]\n \n }\ncv_RF = GridSearchCV(pipeline_RF, param_grid=parameters,n_jobs=-1,cv=10)\ncv_RF.fit(x_train, y_train)\ny_pred_RF=cv_RF.predict(x_test)\nprint(classification_report(y_test, y_pred_RF))",
"_____no_output_____"
]
],
[
[
"The n_estimators here are the number of trees and max_depth is the depth of the tree so it is important to iterate to find a on them to see which one preforms the best and doesn't under or overfit ,and n_jobs=-1 means to use full processing power. I use a cross validation fold of 10 as well to avoid overfitting ",
"_____no_output_____"
]
],
[
[
"#check for overfitting by predicating on train data to see accuacry\ny_pred_RF_Train=cv_RF.predict(x_train)\nprint(classification_report(y_train, y_pred_RF_Train))",
"_____no_output_____"
],
[
"# to improve scores will try standaridization and Gradient boosting \nparameters = {\n \n \"learning_rate\": [ 0.1, 0.2],\n \"max_depth\":[5,10],\n \n \n \n }\nscaler = StandardScaler()\nx_train=scaler.fit_transform(x_train)\nx_test=scaler.fit_transform(x_test)\ncv_GB = GridSearchCV(GradientBoostingClassifier(), parameters, cv=10, n_jobs=-1)\ncv_GB.fit(x_train, y_train)\ny_pred_gb=cv_GB.predict(x_test)\nprint(classification_report(y_test, y_pred_gb))",
"_____no_output_____"
]
],
[
[
"learning_rate shrinks the contribution of each tree, max depth is the depth of the tree both of these are important to avoid under and over fitting.",
"_____no_output_____"
]
],
[
[
"#check for overfitting by predicating on train data to see accuacry\ny_pred_gb_Train=cv_GB.predict(x_train)\nprint(classification_report(y_train, y_pred_gb_Train))",
"_____no_output_____"
]
],
[
[
"### Model Evaluation and validation",
"_____no_output_____"
]
],
[
[
"## Evaluating the total amount spent model \nr2_score",
"_____no_output_____"
],
[
"## Evaluting Both ML models \nprint(classification_report(y_test, y_pred_KNN,target_names=['KNN_no','KNN_yes']))\nprint(classification_report(y_test, y_pred_RF,target_names=['rand_forrest_no','rand_forrest_yes']))\nprint(classification_report(y_test, y_pred_gb,target_names=['gradient_boosting_no','gradient_boosting_yes']))\n\n",
"_____no_output_____"
]
],
[
[
"### Justfication\n#### For the offer predication\nI tried at first KNN, then Random Forrest and gradient booster. In the begning Random forest was overfitting as it was doing so well on the training set with an accuarcy of 100% and on the test set 40% so I added the hyperparameter max_depth to limit the tree depth and tried to find a balance between that and number of trees.\nGradient booster didn't overfit as it is more robust to it the grid search main objective here was to optimize further.\nwhen the classification was reporting how many offers were completed and thus had 4 classes it had a much lower test accuarcy I fixed this by changing the values 0 if it was a 0 and to 1 if if it is more\nWe also have the results of both models on the training sets with the hyperparameter optimization. \nAlmost all models result in a 50% average F1 score with doing better with predicating users not accepting the offer. We tested on the training set to ensure no overfitting happened.\n#### For total amount\nWe achieved a R2 score of 0.216 which is not great but looks promising with more data\n",
"_____no_output_____"
],
[
"## Conclusion",
"_____no_output_____"
],
[
"### Reflection\nHere we were attempting to create a ML model to accuartely predict if a user would respond to an offer given his info and the offer info that would help us create personalized offers that we know that users would use and help us understand which users prefer which offers\nWhat was particulary challenging was to pre process the data to set it up to feed it to the models as we created a dataframe of every unique user offer combination,the details of the user and the offer.we could set this up as a function and use that as soon as we have more data, we also found some abnormalities in the age distbution that might be something to check for the future,The customer gender seems to be almost equally even between male and female with just a few classified as others.\nI used a random forrest model and a gradient booster and preformed a gridsearch to optimizte hyperparameters \n if anyone has any ideas about how to improve I would love to hear from you \n\n### Improvements\n Two things I would do to try to improve this either get more data see if that improves the model preformance since even on the training data with different models and different hyperaparameters the training accuracy is not sky high or capture more features get for example a customer statisfaction rating get customers to fill out a survey of how often do they go to starbucks, get other info about the users like where they live how near is starbucks to them ,etc... . Another thing we could do is a wider grid search with more parameters but that model would require quite some time to go through everything\n\n\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a440928ee46831a8ffd57d9e5fc51a5a87077b4
| 66,675 |
ipynb
|
Jupyter Notebook
|
bronze/B76_Multiple_Rotations.ipynb
|
dilyaraahmetshina/quantum_computings
|
a618bae55def65b17974f3ad402ce27817f91842
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
bronze/B76_Multiple_Rotations.ipynb
|
dilyaraahmetshina/quantum_computings
|
a618bae55def65b17974f3ad402ce27817f91842
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null |
bronze/B76_Multiple_Rotations.ipynb
|
dilyaraahmetshina/quantum_computings
|
a618bae55def65b17974f3ad402ce27817f91842
|
[
"Apache-2.0",
"CC-BY-4.0"
] | null | null | null | 49.134119 | 14,508 | 0.6024 |
[
[
[
"<table>\n <tr>\n <td style=\"background-color:#ffffff;\"><a href=\"https://qsoftware.lu.lv/index.php/qworld/\" target=\"_blank\"><img src=\"..\\images\\qworld.jpg\" width=\"70%\" align=\"left\"></a></td>\n <td style=\"background-color:#ffffff;\" width=\"*\"></td>\n <td style=\"background-color:#ffffff;vertical-align:text-top;\"><a href=\"https://qsoftware.lu.lv\" target=\"_blank\"><img src=\"..\\images\\logo.jpg\" width=\"25%\" align=\"right\"></a></td> \n </tr>\n <tr><td colspan=\"3\" align=\"right\" style=\"color:#777777;background-color:#ffffff;font-size:12px;\">\n prepared by <a href=\"http://abu.lu.lv\" target=\"_blank\">Abuzer Yakaryilmaz</a>\n </td></tr>\n <tr><td colspan=\"3\" align=\"right\" style=\"color:#bbbbbb;background-color:#ffffff;font-size:11px;font-style:italic;\">\n This cell contains some macros. If there is a problem with displaying mathematical formulas, please run this cell to load these macros.\n </td></tr>\n</table>\n$ \\newcommand{\\bra}[1]{\\langle #1|} $\n$ \\newcommand{\\ket}[1]{|#1\\rangle} $\n$ \\newcommand{\\braket}[2]{\\langle #1|#2\\rangle} $\n$ \\newcommand{\\dot}[2]{ #1 \\cdot #2} $\n$ \\newcommand{\\biginner}[2]{\\left\\langle #1,#2\\right\\rangle} $\n$ \\newcommand{\\mymatrix}[2]{\\left( \\begin{array}{#1} #2\\end{array} \\right)} $\n$ \\newcommand{\\myvector}[1]{\\mymatrix{c}{#1}} $\n$ \\newcommand{\\myrvector}[1]{\\mymatrix{r}{#1}} $\n$ \\newcommand{\\mypar}[1]{\\left( #1 \\right)} $\n$ \\newcommand{\\mybigpar}[1]{ \\Big( #1 \\Big)} $\n$ \\newcommand{\\sqrttwo}{\\frac{1}{\\sqrt{2}}} $\n$ \\newcommand{\\dsqrttwo}{\\dfrac{1}{\\sqrt{2}}} $\n$ \\newcommand{\\onehalf}{\\frac{1}{2}} $\n$ \\newcommand{\\donehalf}{\\dfrac{1}{2}} $\n$ \\newcommand{\\hadamard}{ \\mymatrix{rr}{ \\sqrttwo & \\sqrttwo \\\\ \\sqrttwo & -\\sqrttwo }} $\n$ \\newcommand{\\vzero}{\\myvector{1\\\\0}} $\n$ \\newcommand{\\vone}{\\myvector{0\\\\1}} $\n$ \\newcommand{\\vhadamardzero}{\\myvector{ \\sqrttwo \\\\ \\sqrttwo } } $\n$ \\newcommand{\\vhadamardone}{ \\myrvector{ \\sqrttwo \\\\ -\\sqrttwo } } $\n$ \\newcommand{\\myarray}[2]{ \\begin{array}{#1}#2\\end{array}} $\n$ \\newcommand{\\X}{ \\mymatrix{cc}{0 & 1 \\\\ 1 & 0} } $\n$ \\newcommand{\\Z}{ \\mymatrix{rr}{1 & 0 \\\\ 0 & -1} } $\n$ \\newcommand{\\Htwo}{ \\mymatrix{rrrr}{ \\frac{1}{2} & \\frac{1}{2} & \\frac{1}{2} & \\frac{1}{2} \\\\ \\frac{1}{2} & -\\frac{1}{2} & \\frac{1}{2} & -\\frac{1}{2} \\\\ \\frac{1}{2} & \\frac{1}{2} & -\\frac{1}{2} & -\\frac{1}{2} \\\\ \\frac{1}{2} & -\\frac{1}{2} & -\\frac{1}{2} & \\frac{1}{2} } } $\n$ \\newcommand{\\CNOT}{ \\mymatrix{cccc}{1 & 0 & 0 & 0 \\\\ 0 & 1 & 0 & 0 \\\\ 0 & 0 & 0 & 1 \\\\ 0 & 0 & 1 & 0} } $\n$ \\newcommand{\\norm}[1]{ \\left\\lVert #1 \\right\\rVert } $",
"_____no_output_____"
],
[
"<h2>Multiple Rotations</h2>",
"_____no_output_____"
],
[
"The trivial way of implementing more than one rotation in parallel is to use a separate qubit for each rotation.\n\nIf we have $ t $ different rotations with angles $ \\theta_1,\\ldots,\\theta_t $, then we can use $ t $ qubits.\n\nAlternatively, we can use $ \\log_2 (t) + 1 $ qubits (assuming that $t$ is a power of 2) that implement the following unitary matrix:",
"_____no_output_____"
],
[
"$$\n R(\\theta_1,\\ldots,\\theta_t) = \n \\mymatrix{rr|rr|cc|rr}{\n \\cos \\theta_1 & -\\sin \\theta_1 & 0 & 0 & \\cdots & \\cdots & 0 & 0 \\\\ \n \\sin \\theta_1 & \\cos \\theta_1 & 0 & 0 & \\cdots & \\cdots & 0 & 0 \\\\ \\hline\n 0 & 0 & \\cos \\theta_2 & -\\sin \\theta_2 & \\cdots & \\cdots & 0 & 0 \\\\ \n 0 & 0 & \\sin \\theta_2 & \\cos \\theta_2 & \\cdots & \\cdots & 0 & 0 \\\\ \\hline\n \\vdots & \\vdots & \\vdots & \\vdots & \\ddots & & \\vdots & \\vdots \\\\ \n \\vdots & \\vdots & \\vdots & \\vdots & & \\ddots & \\vdots & \\vdots \\\\ \\hline\n 0 & 0 & 0 & 0 & \\cdots & \\cdots & \\cos \\theta_t & -\\sin \\theta_t \\\\ \n 0 & 0 & 0 & 0 & \\cdots & \\cdots & \\sin \\theta_t & \\cos \\theta_t \\\\ \n } .\n$$",
"_____no_output_____"
],
[
"We can use this idea to solve the problem $\\sf MOD_p$ (see <a href=\"B72_Rotation_Automata.ipynb\" target=\"_blank\">Rotation Automata</a>). \n\nWe implement $ t $ rotation automata in this way.\n\nAt the beginning of the computation, we apply Hadamard operator in each qubit. Then, we apply the operator $ R(\\theta_1,\\ldots,\\theta_t) $ for each symbol from the stream. Once the stream is finished, we apply Hadamard operator in each qubit again. \n\nIf we observe only state 0 in each qubit, then we consider the stream having the length of a multiple of $\\sf p$. Otherwise, we consider the stream having the length of not a multiple of $\\sf p$.",
"_____no_output_____"
],
[
"<h3> Constructing $ R(\\theta_1,\\theta_2) $ </h3>",
"_____no_output_____"
],
[
"When $t=2$, $ \\log_2 (2) + 1 = 2 $. So, both implementations use the same number of qubits.\n\nBut, it is a good starting point to construct the following unitary operator:",
"_____no_output_____"
],
[
"$$\n R(\\theta_1,\\theta_2) =\n \\mymatrix{rrrr}{ \n \\cos \\theta_1 & -\\sin \\theta_1 & 0 & 0 \\\\\n \\sin \\theta_1 & \\cos \\theta_1 & 0 & 0 \\\\\n 0 & 0 & \\cos \\theta_2 & -\\sin \\theta_2 \\\\\n 0 & 0 & \\sin \\theta_2 & \\cos \\theta_2 \\\\\n } .\n$$",
"_____no_output_____"
],
[
"<div style=\"background-color:#f8f8f8;\">\n<b> Technical Remark:</b>\n\nWhen two qubits are combined (tensored) in qiskit, say $ qreg[0] $ and $ qreg[1] $, they are ordered as $ qreg[1] \\otimes qreg[0] $.\n\nIf there are $n$ qubits, say $ qreg[0],\\ldots,qreg[n-1] $ to be combined, they are ordered in qiskit as \n\n$$ qreg[n-1] \\otimes \\cdots \\otimes qreg[0] . $$\n</div>",
"_____no_output_____"
],
[
"We use a controlled rotation gate $ cu3 $ in qiskit. \n\n<b> Gate $u3$: </b>\n\nThe gate $ u3 $ is a generic one-qubit gate for rotation on Bloch sphere. It takes three parameters, and if we pass zeros as the second and third parameters, we implement our rotation gate $ ry $:\n\n u3(2*theta,0,0,qubit)\nis equivalent to\n\n ry(2*theta,qubit)\nBoth make a rotation with angle $\\theta$ in the real-valued qubit in counter-clockwise direction.",
"_____no_output_____"
],
[
"<b> Gate $cu3$: </b>\n\nThe two-qubit gate $ cu3 $ takes five parameters. We use it as follows:\n\n cu3(2*theta,0,0,control_qubit,target_qubit)\nIf the control qubit is in state $ \\ket{1} $, then the rotation\n \n ry(2*theta,target_qubit)\nis applied (to the target qubit). ",
"_____no_output_____"
],
[
"The base states of two qubits are ordered as $ \\myarray{c}{00 \\\\ 01 \\\\ 10 \\\\ 11 } $ \nor equivalently grouped as $ \\myarray{c}{ 0 \\otimes \\myvector{0 \\\\ 1} \\\\ \\hline 1 \\otimes \\myvector{0 \\\\ 1} } $. \n\nWe can apply a rotation to the first qubit controlled by the second qubit.\n\nTo construct $ R(\\theta_1,\\theta_2) $:\n<ol>\n <li> When the second qubit is in state $ \\ket{0} $, we can apply the rotation with angle $ \\theta_1 $. </li>\n <li> When the second qubit is in state $ \\ket{1} $, we can apply the rotation with angle $ \\theta_2 $. </li>\n</ol>\n\nNow, we implement this by also printing the constructed unitary matrix.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi\n\n# the angles of rotations\ntheta1 = pi/4\ntheta2 = pi/6\n\n# the circuit with two qubits\nqreg = QuantumRegister(2) \ncreg = ClassicalRegister(2) \nmycircuit = QuantumCircuit(qreg,creg)\n\n\n# when the second qubit is in |0>, the first qubit is rotated by theta1\nmycircuit.x(qreg[1])\nmycircuit.cu3(2*theta1,0,0,qreg[1],qreg[0])\nmycircuit.x(qreg[1])\n\n# when the second qubit is in |1>, the first qubit is rotated by theta2\nmycircuit.cu3(2*theta2,0,0,qreg[1],qreg[0])\n \n# we read the unitary matrix\njob = execute(mycircuit,Aer.get_backend('unitary_simulator'),optimization_level=0)\nu=job.result().get_unitary(mycircuit,decimals=3)\n# we print the unitary matrix in nice format\nfor i in range(len(u)):\n s=\"\"\n for j in range(len(u)):\n val = str(u[i][j].real)\n while(len(val)<8): val = \" \"+val\n s = s + val\n print(s)\n \n\n",
" 0.707 -0.707 0.0 0.0\n 0.707 0.707 0.0 0.0\n 0.0 0.0 0.866 -0.5\n 0.0 0.0 0.5 0.866\n"
]
],
[
[
"<h3>Task 1</h3>\n\nVerify that the printed matrix is $ R(\\pi/4,\\pi/6) $.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi\n\n# the angles of rotations\ntheta1 = pi/4\ntheta2 = pi/6\n\n\nprint(round(cos(theta1),3),-round(sin(theta1),3),0,0)\nprint(round(sin(theta1),3),-round(cos(theta1),3),0,0)\nprint(0,0,round(cos(theta2),3),-round(sin(theta2),3))\nprint(0,0,round(sin(theta2),3),-round(cos(theta2),3))",
"0.707 -0.707 0 0\n0.707 -0.707 0 0\n0 0 0.866 -0.5\n0 0 0.5 -0.866\n"
]
],
[
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task1\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3> Constructing $ R(\\theta_1,\\theta_2,\\theta_3,\\theta_4) $ </h3>",
"_____no_output_____"
],
[
"We can use $ \\log_2(4) + 1 = 3 $ qubits to construct $ R(\\theta_1,\\theta_2,\\theta_3,\\theta_4) $.",
"_____no_output_____"
],
[
"The base states of three qubits are ordered as $ \\myarray{c}{000 \\\\ 001 \\\\ 010 \\\\ 011 \\\\ 100 \\\\ 101 \\\\ 110 \\\\ 111 } $ \nor equivalently grouped as $ \n \\myarray{c}{ \n 00 \\otimes \\myvector{0 \\\\ 1} \\\\ \\hline \n 01 \\otimes \\myvector{0 \\\\ 1} \\\\ \\hline \n 10 \\otimes \\myvector{0 \\\\ 1} \\\\ \\hline \n 11 \\otimes \\myvector{0 \\\\ 1} \n } $. ",
"_____no_output_____"
],
[
"By using a rotation gate controlled by two qubits, we can easily implement our unitary operator.\n\nBut, if we have a rotation gate controlled by only one qubit, then we use additional tricks (and qubits) and controlled CNOT gate by two qubits (also called Toffoli gate):\n\n circuit.ccx(control-qubit1,control-qubit2,target-qubit)\n<div style=\"background-color:#f9f9f9;\">\nIn general, if $ t = 2^n $, then we can construct $ R(\\theta_1,\\ldots,\\theta_t) $ by using no more than $ 2\\log_2(t) $ qubits (instead of $t$ qubits). \n</div>",
"_____no_output_____"
],
[
"<h3> Pseudo construction </h3>\n \nWe start with a construction using three angles.",
"_____no_output_____"
],
[
"<h3> Task 2</h3>\n\nConsider a quantum circuit with 3 qubits.\n\nWhen the third qubit is in state $ \\ket{1} $, apply the gate \n\n cu3(2*theta1,0,0,qreg[2],qreg[0]) \n\nWhen the second qubit is in state $ \\ket{1} $, apply the gate\n \n cu3(2*theta2,0,0,qreg[1],qreg[0])\n \nWhen the third qubit is in state $ \\ket{0} $, apply the gate\n\n cu3(2*theta3,0,0,qreg[2],qreg[0])\n\nGuess the corresponding unitary matrix, which should be of the form:\n\n$$\n \\mymatrix{rr|rr|rr|rr}{\n \\cos a_1 & -\\sin a_1 & 0 & 0 & 0 & 0 & 0 & 0 \\\\\n \\sin a_1 & \\cos a_1 & 0 & 0 & 0 & 0 & 0 & 0 \\\\ \\hline\n 0 & 0 & \\cos a_2 & -\\sin a_2 & 0 & 0 & 0 & 0 \\\\\n 0 & 0 & \\sin a_2 & \\cos a_2 & 0 & 0 & 0 & 0 \\\\ \\hline\n 0 & 0 & 0 & 0 & \\cos a_3 & -\\sin a_3 & 0 & 0 \\\\\n 0 & 0 & 0 & 0 & \\sin a_3 & \\cos a_3 & 0 & 0 \\\\ \\hline\n 0 & 0 & 0 & 0 & 0 & 0 & \\cos a_4 & -\\sin a_4 \\\\\n 0 & 0 & 0 & 0 & 0 & 0 & \\sin a_4 & \\cos a_4 \\\\ \n }\n$$\n\nIn other words, find $a_1$, $ a_2 $, $a_3$, and $a_4$ in terms of $ \\theta_1 $, $\\theta_2$, and $ \\theta_3 $.",
"_____no_output_____"
],
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task2\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3>Task 3</h3>\n\nImplement Task 2 by picking three angles, and verify the constructed matrix.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi, sin, cos\n\n# the angle of rotation\ntheta1 = pi/23\ntheta2 = 2*pi/23\ntheta3 = 4*pi/23\n\n\nprecision = 3\n\nprint(\"a1 = theta3 => sin(a1) = \",round(sin(theta3),precision))\nprint(\"a2 = theta2+theta3 => sin(a2) = \",round(sin(theta2+theta3),precision))\nprint(\"a3 = theta1 => sin(a3) = \",round(sin(theta1),precision))\nprint(\"a4 = theta1+theta2 => sin(a4) = \",round(sin(theta1+theta2),precision))\nprint()\n\nq = QuantumRegister(3) \nc = ClassicalRegister(3) \nqc = QuantumCircuit(q,c)\n\n\nqc.cu3(2*theta1,0,0,q[2],q[0])\nqc.cu3(2*theta2,0,0,q[1],q[0])\n\n\nqc.x(q[2])\nqc.cu3(2*theta3,0,0,q[2],q[0])\nqc.x(q[2])\n\n\njob = execute(qc,Aer.get_backend('unitary_simulator'),optimization_level=0)\nunitary_matrix=job.result().get_unitary(qc,decimals=precision)\nfor i in range(len(unitary_matrix)):\n s=\"\"\n for j in range(len(unitary_matrix)):\n val = str(unitary_matrix[i][j].real)\n while(len(val)<precision+4): val = \" \"+val\n s = s + val\n print(s)",
"a1 = theta3 => sin(a1) = 0.52\na2 = theta2+theta3 => sin(a2) = 0.731\na3 = theta1 => sin(a3) = 0.136\na4 = theta1+theta2 => sin(a4) = 0.398\n\n 0.854 -0.52 0.0 0.0 0.0 0.0 0.0 0.0\n 0.52 0.854 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.683 -0.731 0.0 0.0 0.0 0.0\n 0.0 0.0 0.731 0.683 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.991 -0.136 0.0 0.0\n 0.0 0.0 0.0 0.0 0.136 0.991 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.917 -0.398\n 0.0 0.0 0.0 0.0 0.0 0.0 0.398 0.917\n"
]
],
[
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task3\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3>Task 4</h3>\n\nCreate a circuit for solving problem $ \\sf MOD_{31} $ by using the implementation in Task 3.\n\nPick $ \\theta_1 $, $ \\theta_2 $, and $ \\theta_3 $ randomly.\n\nAt the beginning of the stream and after reading the stream, apply Hadamard operators to each qubit.\n\nExecute your quantum program on the streams of lengths from 1 to 31.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi, sin, cos\nfrom random import randrange\n\n\na1 = randrange(1,31)\ntheta1 =a1*2*pi/31\na2 = randrange(1,31)\ntheta2 = a2*2*pi/31\na3 = randrange(1,31)\ntheta3 = a3*2*pi/31\n\nmax_percentange = 0\n \n# fExecute your quantum program on the streams of lengths from 1 to 31.\nfor i in range(1,32): \n # initialize the circuit\n q = QuantumRegister(3) \n c = ClassicalRegister(3) \n qc = QuantumCircuit(q,c)\n \n # apply Hadamard operators to each qubit\n for m in range(3):\n qc.h(q[m]) \n \n print(\"stream of length\",i,\"is being read\")\n for j in range(i): \n # controlled rotation when the third qubit is |1>\n qc.cu3(2*theta1,0,0,q[2],q[0])\n\n # controlled rotation when the second qubit is |1>\n qc.cu3(2*theta2,0,0,q[1],q[0])\n\n # controlled rotation when the third qubit is |0>\n qc.x(q[2])\n qc.cu3(2*theta3,0,0,q[2],q[0])\n qc.x(q[2])\n \n # apply Hadamard operators to each qubit\n for m in range(3):\n qc.h(q[m]) \n # measure \n qc.measure(q,c)\n # execute the circuit N times\n N = 1000\n job = execute(qc,Aer.get_backend('qasm_simulator'),shots=N)\n counts = job.result().get_counts(qc)\n print(counts)\n if '000' in counts.keys():\n c = counts['000']\n else:\n c = 0\n print('000 is observed',c,'times out of',N)\n percentange = round(c/N*100,1)\n if max_percentange < percentange and i != 31: max_percentange = percentange\n print(\"the ration of 000 is \",percentange,\"%\")\n print() \nprint(\"maximum percentage of observing unwanted '000' is\",max_percentange)",
"stream of length 1 is being read\n{'010': 74, '011': 736, '110': 149, '001': 4, '000': 21, '111': 10, '101': 6}\n000 is observed 21 times out of 1000\nthe ration of 000 is 2.1 %\n\nstream of length 2 is being read\n{'001': 139, '100': 174, '101': 319, '010': 18, '011': 35, '110': 37, '000': 266, '111': 12}\n000 is observed 266 times out of 1000\nthe ration of 000 is 26.6 %\n\nstream of length 3 is being read\n{'001': 10, '100': 116, '101': 77, '010': 60, '011': 29, '110': 303, '000': 5, '111': 400}\n000 is observed 5 times out of 1000\nthe ration of 000 is 0.5 %\n\nstream of length 4 is being read\n{'011': 2, '110': 40, '001': 2, '100': 589, '111': 289, '101': 78}\n000 is observed 0 times out of 1000\nthe ration of 000 is 0.0 %\n\nstream of length 5 is being read\n{'010': 107, '110': 1, '001': 81, '100': 385, '111': 426}\n000 is observed 0 times out of 1000\nthe ration of 000 is 0.0 %\n\nstream of length 6 is being read\n{'001': 184, '100': 166, '101': 11, '010': 332, '011': 32, '110': 15, '000': 14, '111': 246}\n000 is observed 14 times out of 1000\nthe ration of 000 is 1.4 %\n\nstream of length 7 is being read\n{'001': 516, '100': 54, '101': 22, '010': 151, '011': 61, '110': 7, '000': 179, '111': 10}\n000 is observed 179 times out of 1000\nthe ration of 000 is 17.9 %\n\nstream of length 8 is being read\n{'010': 353, '011': 535, '110': 3, '001': 43, '000': 63, '111': 3}\n000 is observed 63 times out of 1000\nthe ration of 000 is 6.3 %\n\nstream of length 9 is being read\n{'010': 2, '011': 36, '110': 7, '001': 104, '000': 626, '100': 38, '101': 187}\n000 is observed 626 times out of 1000\nthe ration of 000 is 62.6 %\n\nstream of length 10 is being read\n{'010': 5, '011': 390, '110': 598, '000': 1, '111': 5, '101': 1}\n000 is observed 1 times out of 1000\nthe ration of 000 is 0.1 %\n\nstream of length 11 is being read\n{'011': 1, '110': 10, '001': 3, '000': 54, '100': 30, '101': 902}\n000 is observed 54 times out of 1000\nthe ration of 000 is 5.4 %\n\nstream of length 12 is being read\n{'010': 13, '011': 7, '110': 686, '001': 1, '100': 14, '111': 226, '101': 53}\n000 is observed 0 times out of 1000\nthe ration of 000 is 0.0 %\n\nstream of length 13 is being read\n{'001': 108, '100': 343, '101': 280, '010': 20, '011': 24, '110': 45, '000': 115, '111': 65}\n000 is observed 115 times out of 1000\nthe ration of 000 is 11.5 %\n\nstream of length 14 is being read\n{'001': 156, '100': 80, '101': 14, '010': 377, '011': 91, '110': 41, '000': 38, '111': 203}\n000 is observed 38 times out of 1000\nthe ration of 000 is 3.8 %\n\nstream of length 15 is being read\n{'010': 383, '011': 10, '001': 563, '000': 9, '100': 22, '111': 13}\n000 is observed 9 times out of 1000\nthe ration of 000 is 0.9 %\n\nstream of length 16 is being read\n{'010': 398, '011': 10, '001': 539, '000': 8, '100': 31, '111': 13, '101': 1}\n000 is observed 8 times out of 1000\nthe ration of 000 is 0.8 %\n\nstream of length 17 is being read\n{'001': 143, '100': 88, '101': 17, '010': 369, '011': 99, '110': 43, '000': 42, '111': 199}\n000 is observed 42 times out of 1000\nthe ration of 000 is 4.2 %\n\nstream of length 18 is being read\n{'001': 114, '100': 320, '101': 277, '010': 32, '011': 23, '110': 56, '000': 122, '111': 56}\n000 is observed 122 times out of 1000\nthe ration of 000 is 12.2 %\n\nstream of length 19 is being read\n{'010': 2, '011': 18, '110': 714, '000': 3, '100': 10, '111': 209, '101': 44}\n000 is observed 3 times out of 1000\nthe ration of 000 is 0.3 %\n\nstream of length 20 is being read\n{'110': 9, '001': 5, '000': 66, '100': 33, '101': 887}\n000 is observed 66 times out of 1000\nthe ration of 000 is 6.6 %\n\nstream of length 21 is being read\n{'010': 5, '011': 377, '110': 612, '000': 1, '111': 3, '101': 2}\n000 is observed 1 times out of 1000\nthe ration of 000 is 0.1 %\n\nstream of length 22 is being read\n{'001': 117, '100': 31, '101': 185, '010': 2, '011': 24, '110': 6, '000': 634, '111': 1}\n000 is observed 634 times out of 1000\nthe ration of 000 is 63.4 %\n\nstream of length 23 is being read\n{'001': 52, '100': 1, '101': 2, '010': 356, '011': 510, '110': 3, '000': 74, '111': 2}\n000 is observed 74 times out of 1000\nthe ration of 000 is 7.4 %\n\nstream of length 24 is being read\n{'001': 507, '100': 50, '101': 20, '010': 143, '011': 59, '110': 7, '000': 196, '111': 18}\n000 is observed 196 times out of 1000\nthe ration of 000 is 19.6 %\n\nstream of length 25 is being read\n{'001': 208, '100': 143, '101': 8, '010': 364, '011': 19, '110': 20, '000': 9, '111': 229}\n000 is observed 9 times out of 1000\nthe ration of 000 is 0.9 %\n\nstream of length 26 is being read\n{'010': 105, '110': 5, '001': 91, '100': 381, '111': 418}\n000 is observed 0 times out of 1000\nthe ration of 000 is 0.0 %\n\nstream of length 27 is being read\n{'010': 1, '110': 48, '001': 1, '100': 630, '111': 238, '101': 82}\n000 is observed 0 times out of 1000\nthe ration of 000 is 0.0 %\n\nstream of length 28 is being read\n{'001': 17, '100': 102, '101': 58, '010': 69, '011': 34, '110': 264, '000': 8, '111': 448}\n000 is observed 8 times out of 1000\nthe ration of 000 is 0.8 %\n\nstream of length 29 is being read\n{'001': 138, '100': 173, '101': 330, '010': 20, '011': 24, '110': 29, '000': 270, '111': 16}\n000 is observed 270 times out of 1000\nthe ration of 000 is 27.0 %\n\nstream of length 30 is being read\n{'010': 70, '011': 743, '110': 145, '001': 1, '000': 12, '111': 26, '101': 3}\n000 is observed 12 times out of 1000\nthe ration of 000 is 1.2 %\n\nstream of length 31 is being read\n{'000': 1000}\n000 is observed 1000 times out of 1000\nthe ration of 000 is 100.0 %\n\nmaximum percentage of observing unwanted '000' is 63.4\n"
]
],
[
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task4\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3>Task 5 (optional)</h3>\n\nBased on Task 4, design your own solution for problem $ \\sf MOD_{91} $ by using four qubits.\n\nRemark that up to 8 different rotations can be implemented by using four qubits.",
"_____no_output_____"
]
],
[
[
"#\n# your solution is here\n#\n",
"_____no_output_____"
]
],
[
[
"<h3> Main construction </h3>",
"_____no_output_____"
],
[
"To implement an operator controlled by two qubits, we use an auxiliary qubit.\n\nDepending on the desired values of two qubits, the auxiliary qubit is flipped to $ \\ket{1} $ and then the operation is implemented controlled by the auxiliary qubit.\n\nHere we describe the case when the control qubits are in state $ \\ket{01} $. \n\nWe also draw the circuit. ",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi\n\n# initialize the circuit\nqreg = QuantumRegister(4) \ncircuit = QuantumCircuit(qreg)\n\n# we use the fourth qubit as the auxiliary\n\n# apply a rotation to the first qubit when the third and second qubits are in states |0> and |1>\n# change the state of the third qubit to |1>\ncircuit.x(qreg[2])\n# if both the third and second qubits are in states |1>, the state of auxiliary qubit is changed to |1> \ncircuit.ccx(qreg[2],qreg[1],qreg[3])\n# the rotation is applied to the first qubit if the state of auxiliary qubit is |1>\ncircuit.cu3(2*pi/6,0,0,qreg[3],qreg[0])\n# reverse the effects\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.x(qreg[2])\n\ncircuit.draw()",
"_____no_output_____"
]
],
[
[
"Based on this idea, different rotation operators are applied to the first qubit when the third and second qubits are in $ \\ket{00} $, $ \\ket{01} $, $ \\ket{10} $, and $ \\ket{11} $. \n\nWe present how to construct $ R(\\pi/10,2\\pi/10,3\\pi/10,4\\pi/10) $. ",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi,sin\n\n# the angles of rotations\ntheta1 = pi/10\ntheta2 = 2*pi/10\ntheta3 = 3*pi/10\ntheta4 = 4*pi/10\n\n# for verification, print sin(theta)'s\nprint(\"sin(theta1) = \",round(sin(theta1),3))\nprint(\"sin(theta2) = \",round(sin(theta2),3))\nprint(\"sin(theta3) = \",round(sin(theta3),3))\nprint(\"sin(theta4) = \",round(sin(theta4),3))\nprint()\n\nqreg = QuantumRegister(4) \ncircuit = QuantumCircuit(qreg)\n\n# the third qubit is in |0>\n# the second qubit is in |0>\ncircuit.x(qreg[2])\ncircuit.x(qreg[1])\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.cu3(2*theta1,0,0,qreg[3],qreg[0])\n# reverse the effects\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.x(qreg[1])\ncircuit.x(qreg[2])\n\n\n# the third qubit is in |0>\n# the second qubit is in |1>\ncircuit.x(qreg[2])\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.cu3(2*theta2,0,0,qreg[3],qreg[0])\n# reverse the effects\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.x(qreg[2])\n\n# the third qubit is in |1>\n# the second qubit is in |0>\ncircuit.x(qreg[1])\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.cu3(2*theta3,0,0,qreg[3],qreg[0])\n# reverse the effects\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.x(qreg[1])\n\n# the third qubit is in |1>\n# the second qubit is in |1>\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\ncircuit.cu3(2*theta4,0,0,qreg[3],qreg[0])\n# reverse the effects\ncircuit.ccx(qreg[2],qreg[1],qreg[3])\n\n# read the corresponding unitary matrix\njob = execute(circuit,Aer.get_backend('unitary_simulator'),optimization_level=0)\nunitary_matrix=job.result().get_unitary(circuit,decimals=3)\nfor i in range(len(unitary_matrix)):\n s=\"\"\n for j in range(len(unitary_matrix)):\n val = str(unitary_matrix[i][j].real)\n while(len(val)<7): val = \" \"+val\n s = s + val\n print(s)",
"sin(theta1) = 0.309\nsin(theta2) = 0.588\nsin(theta3) = 0.809\nsin(theta4) = 0.951\n\n 0.951 -0.309 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.309 0.951 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.809 -0.588 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.588 0.809 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.588 -0.809 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.809 0.588 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.309 -0.951 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.951 0.309 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 -0.951 -0.309 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.309 -0.951 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 -0.809 -0.588 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.588 -0.809 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 -0.588 -0.809 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.809 -0.588 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 -0.309 -0.951\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.951 -0.309\n"
]
],
[
[
"<b>Remarks:</b> \n\nThe constructed matrix is bigger than our main matrix because of the auxiliary qubit.\n\nOur main matrix appears at the top-left quarter of the constructed matrix.\n\nThe rest of the constructed matrix does not affect our computation unless the auxiliary qubit is set to state $ \\ket{1} $ (except the auxiliary operations).",
"_____no_output_____"
],
[
"<h3>Task 6 (optional)</h3>\n\nAssume that $\\theta_1=\\frac{\\pi}{11}$, $\\theta_2=2\\frac{\\pi}{11}$, $\\theta_3=4\\frac{\\pi}{11}$, and $\\theta_4=8\\frac{\\pi}{11}$ are the given angles in the above construction.\n\nCalculate (by hand or in your mind) the angles of the rotations in the bottom-left quarter of the constructed matrix by following the construction steps.",
"_____no_output_____"
],
[
"<h3>Task 7</h3>\n\nCreate a circuit for solving problem $ \\sf MOD_{61} $ by using the above implementation.\n\nPick $ \\theta_1 $, $ \\theta_2 $, $ \\theta_3 $, and $ \\theta_4 $ randomly.\n\nAt the beginning of the stream and after reading the stream, apply Hadamard operators to each qubit.\n\nExecute your quantum program on the streams of lengths 1, 11, 21, 31, 41, 51, and 61.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi,sin\nfrom random import randrange\n\n# the angle of rotation\nk1 = randrange(1,61)\ntheta1 = k1*2*pi/61\nk2 = randrange(1,61)\ntheta2 = k2*2*pi/61\nk3 = randrange(1,61)\ntheta3 = k3*2*pi/61\nk4 = randrange(1,61)\ntheta4 = k4*2*pi/61\n\nmax_percentange = 0\n\n# for each stream of length of 1, 11, 21, 31, 41, 51, and 61\nfor i in [1,11,21,31,41,51,61]: \n#for i in range(1,62): \n # initialize the circuit\n qreg = QuantumRegister(4) \n creg = ClassicalRegister(4)\n circuit = QuantumCircuit(qreg,creg)\n\n # Hadamard operators before reading the stream\n for m in range(3):\n circuit.h(qreg[m]) \n \n # read the stream of length i\n print(\"stream of length\",i,\"is being read\")\n for j in range(i): \n # the third qubit is in |0>\n # the second qubit is in |0>\n circuit.x(qreg[2])\n circuit.x(qreg[1])\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.cu3(2*theta1,0,0,qreg[3],qreg[0])\n # reverse the effects\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.x(qreg[1])\n circuit.x(qreg[2])\n\n\n # the third qubit is in |0>\n # the second qubit is in |1>\n circuit.x(qreg[2])\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.cu3(2*theta2,0,0,qreg[3],qreg[0])\n # reverse the effects\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.x(qreg[2])\n\n # the third qubit is in |1>\n # the second qubit is in |0>\n circuit.x(qreg[1])\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.cu3(2*theta3,0,0,qreg[3],qreg[0])\n # reverse the effects\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.x(qreg[1])\n\n # the third qubit is in |1>\n # the second qubit is in |1>\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n circuit.cu3(2*theta4,0,0,qreg[3],qreg[0])\n # reverse the effects\n circuit.ccx(qreg[2],qreg[1],qreg[3])\n \n # Hadamard operators after reading the stream\n for m in range(3):\n circuit.h(qreg[m]) \n # we measure after reading the whole stream\n circuit.measure(qreg,creg)\n # execute the circuit N times\n N = 1000\n job = execute(circuit,Aer.get_backend('qasm_simulator'),shots=N)\n counts = job.result().get_counts(circuit)\n print(counts)\n if '0000' in counts.keys():\n c = counts['0000']\n else:\n c = 0\n print('0000 is observed',c,'times out of',N)\n percentange = round(c/N*100,1)\n if max_percentange < percentange and i != 61: max_percentange = percentange\n print(\"the ration of 0000 is \",percentange,\"%\")\n print() \nprint(\"maximum percentage of observing unwanted '0000' is\",max_percentange)\n",
"stream of length 1 is being read\n{'0001': 232, '0100': 144, '0101': 250, '0010': 5, '0011': 79, '0110': 4, '0000': 223, '0111': 63}\n0000 is observed 223 times out of 1000\nthe ration of 0000 is 22.3 %\n\nstream of length 11 is being read\n{'0001': 48, '0100': 118, '0101': 88, '0010': 100, '0011': 150, '0110': 132, '0000': 245, '0111': 119}\n0000 is observed 245 times out of 1000\nthe ration of 0000 is 24.5 %\n\nstream of length 21 is being read\n{'0001': 95, '0100': 458, '0101': 137, '0010': 82, '0011': 34, '0110': 71, '0000': 108, '0111': 15}\n0000 is observed 108 times out of 1000\nthe ration of 0000 is 10.8 %\n\nstream of length 31 is being read\n{'0010': 9, '0011': 124, '0110': 728, '0001': 10, '0000': 1, '0111': 97, '0101': 31}\n0000 is observed 1 times out of 1000\nthe ration of 0000 is 0.1 %\n\nstream of length 41 is being read\n{'0001': 110, '0100': 11, '0101': 418, '0010': 148, '0011': 69, '0110': 187, '0000': 5, '0111': 52}\n0000 is observed 5 times out of 1000\nthe ration of 0000 is 0.5 %\n\nstream of length 51 is being read\n{'0001': 34, '0100': 135, '0101': 48, '0010': 232, '0011': 380, '0110': 48, '0000': 113, '0111': 10}\n0000 is observed 113 times out of 1000\nthe ration of 0000 is 11.3 %\n\nstream of length 61 is being read\n{'0000': 1000}\n0000 is observed 1000 times out of 1000\nthe ration of 0000 is 100.0 %\n\nmaximum percentage of observing unwanted '0000' is 24.5\n"
]
],
[
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task7\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3>Task 8</h3>\n\nHow many qubits we use to implement the main construction having 16 rotations in parallel?\n\nPlease specify the number of control qubits and auxiliary qubits.",
"_____no_output_____"
],
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task8\">click for our solution</a>",
"_____no_output_____"
],
[
"<h3>Bonus (saving some qubits)</h3>\n\nWe can use additional trick to save some qubits in our implementation. The idea relies on the following fact: if you apply a rotation between two NOT gates, the rotation will happen in the opposite direction.\n\nWe can use this idea to implement a rotation by $\\theta$ in the following way:\n<ul>\n <li>Rotate in the qubit by $\\frac{\\theta}{2}$;</li>\n <li>Apply NOT to the qubit;</li>\n <li>Rotate in the qubit by $-\\frac{\\theta}{2}$;</li>\n <li>Apply NOT to the qubit.</li>\n</ul>\n\nAs a result we will rotate in the qubit by $\\theta$. We can control NOT and rotation operations and perform a rotation only when all control qubits are in state 1, relying on the following simple facts:\n<ul>\n <li>Two NOT gates result into identity operation;</li>\n <li>Rotations by $\\frac{\\theta}{2}$ and $-\\frac{\\theta}{2}$ result into identity operation.</li>\n</ul>\n\nBelow you can see the code that shows how can we use the discussed ideas to control rotations on one qubit by three qubits. If the state of at least one of the control qubits is 0, then the identity will be applied to the controlled qubit.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi\n\nqreg11 = QuantumRegister(4)\ncreg11 = ClassicalRegister(4)\n\ntheta = pi/4\n\n# define our quantum circuit\nmycircuit11 = QuantumCircuit(qreg11,creg11)\n\ndef ccc_ry(angle,q1,q2,q3,q4):\n mycircuit11.cu3(angle/2,0,0,q3,q4)\n mycircuit11.ccx(q1,q2,q4)\n mycircuit11.cu3(-angle/2,0,0,q3,q4)\n mycircuit11.ccx(q1,q2,q4)\n \nccc_ry(2*theta,qreg11[3],qreg11[2],qreg11[1],qreg11[0])\n\nmycircuit11.draw(output='mpl')",
"_____no_output_____"
]
],
[
[
"The code below demonstrates the implementation of 8 rotations with total 4 qubits, one of which is controlled by others.",
"_____no_output_____"
]
],
[
[
"from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit, execute, Aer\nfrom math import pi\n\nqreg12 = QuantumRegister(4)\ncreg12 = ClassicalRegister(4)\n\ntheta1 = pi/16\ntheta2 = 2*pi/16\ntheta3 = 3*pi/16\ntheta4 = 4*pi/16\ntheta5 = 5*pi/16\ntheta6 = 6*pi/16\ntheta7 = 7*pi/16\ntheta8 = 8*pi/16\n\n# define our quantum circuit\nmycircuit12 = QuantumCircuit(qreg12,creg12)\n\ndef ccc_ry(angle,q1,q2,q3,q4):\n mycircuit12.cu3(angle/2,0,0,q3,q4)\n mycircuit12.ccx(q1,q2,q4)\n mycircuit12.cu3(-angle/2,0,0,q3,q4)\n mycircuit12.ccx(q1,q2,q4)\n \nmycircuit12.x(qreg12[3])\nmycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[1])\nccc_ry(2*theta1,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\nmycircuit12.x(qreg12[1])\nmycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[3])\n\nmycircuit12.x(qreg12[3])\nmycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[1])\nccc_ry(2*theta2,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\n#mycircuit12.x(qreg12[1])\nmycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[3])\n\nmycircuit12.x(qreg12[3])\n#mycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[1])\nccc_ry(2*theta3,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\nmycircuit12.x(qreg12[1])\n#mycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[3])\n\nmycircuit12.x(qreg12[3])\n#mycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[1])\nccc_ry(2*theta4,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\n#mycircuit12.x(qreg12[1])\n#mycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[3])\n\n#mycircuit12.x(qreg12[3])\nmycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[1])\nccc_ry(2*theta5,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\nmycircuit12.x(qreg12[1])\nmycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[3])\n\n#mycircuit12.x(qreg12[3])\nmycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[1])\nccc_ry(2*theta6,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\n#mycircuit12.x(qreg12[1])\nmycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[3])\n\n#mycircuit12.x(qreg12[3])\n#mycircuit12.x(qreg12[2])\nmycircuit12.x(qreg12[1])\nccc_ry(2*theta7,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\nmycircuit12.x(qreg12[1])\n#mycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[3])\n\n#mycircuit12.x(qreg12[3])\n#mycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[1])\nccc_ry(2*theta8,qreg12[3],qreg12[2],qreg12[1],qreg12[0])\n#mycircuit12.x(qreg12[1])\n#mycircuit12.x(qreg12[2])\n#mycircuit12.x(qreg12[3])\n\njob = execute(mycircuit12,Aer.get_backend('unitary_simulator'),optimization_level=0)\nu=job.result().get_unitary(mycircuit12,decimals=3)\nfor i in range(len(u)):\n s=\"\"\n for j in range(len(u)):\n val = str(u[i][j].real)\n while(len(val)<7): val = \" \"+val\n s = s + val\n print(s)",
" 0.981 -0.195 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.195 0.981 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.924 -0.383 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.383 0.924 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.831 -0.556 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.556 0.831 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.707 -0.707 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.707 0.707 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.556 -0.831 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.831 0.556 0.0 0.0 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.383 -0.924 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.924 0.383 0.0 0.0 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.195 -0.981 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.981 0.195 0.0 0.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 -1.0\n 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0 0.0\n"
]
],
[
[
"<h3>Task 9</h3>\n\nBy using the discussed ideas, how many qubits can we have to implement 16 rotations in parallel?\n\nPlease specify the number of control qubits and auxiliary qubits.",
"_____no_output_____"
],
[
"<a href=\"B76_Multiple_Rotations_Solutions.ipynb#task9\">click for our solution</a>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a440e44dfbb047a588ecdc4174cd675e2a310a8
| 8,078 |
ipynb
|
Jupyter Notebook
|
experiments/TimeGAN.ipynb
|
IlyaTrofimov/MTopDiv
|
d9a19524c74cd35a30369b3f83cd944a7cbc6383
|
[
"MIT"
] | 13 |
2021-11-18T09:05:12.000Z
|
2022-03-08T22:04:19.000Z
|
experiments/TimeGAN.ipynb
|
IlyaTrofimov/MTopDiv
|
d9a19524c74cd35a30369b3f83cd944a7cbc6383
|
[
"MIT"
] | 2 |
2021-11-17T11:11:16.000Z
|
2021-12-23T15:31:36.000Z
|
experiments/TimeGAN.ipynb
|
IlyaTrofimov/MTopDiv
|
d9a19524c74cd35a30369b3f83cd944a7cbc6383
|
[
"MIT"
] | null | null | null | 21.832432 | 109 | 0.481802 |
[
[
[
"import os\nimport sys\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nimport pickle\nfrom tqdm.notebook import tqdm\nfrom tqdm import trange\n%matplotlib inline",
"_____no_output_____"
],
[
"def read_list_of_arrays(filename):\n A = pickle.load(open(filename, 'rb'))\n \n if len(A) == 3:\n print(A[1][0], A[2][0])\n A = A[0]\n \n dim = A[0].flatten().shape[0]\n B = np.zeros((len(A), dim))\n\n for i in range(len(A)):\n B[i, :] = A[i].flatten()\n \n return B",
"_____no_output_____"
],
[
"epochs = np.arange(500, 5500, 500)",
"_____no_output_____"
],
[
"epochs",
"_____no_output_____"
],
[
"cloud_base = read_list_of_arrays('/gan-clouds/timegan_data.pickle')\n\nclouds = []\nfor ep in epochs:\n epo = ep \n clouds.append(read_list_of_arrays('/gan-clouds/timegan_various_epochs5k/model_%d.pickle' % epo))",
"_____no_output_____"
],
[
"cloud_base.shape",
"_____no_output_____"
],
[
"for cloud in clouds:\n print(cloud.shape)",
"_____no_output_____"
]
],
[
[
"### Compute cross-barcodes ",
"_____no_output_____"
]
],
[
[
"import mtd",
"_____no_output_____"
],
[
"res1 = []\ntrials = 50\n\nfor i in trange(len(clouds)):\n np.random.seed(7)\n barcs = [mtd.calc_cross_barcodes(cloud_base, clouds[i], batch_size1 = 100, batch_size2 = 1000,\\\n cuda = 1, pdist_device = 'gpu') for _ in range(trials)]\n res1.append(barcs)",
"_____no_output_____"
],
[
"res2 = []\ntrials = 50\n\nfor i in trange(len(clouds)):\n np.random.seed(7)\n barcs = [mtd.calc_cross_barcodes(clouds[i], cloud_base, batch_size1 = 100, batch_size2 = 1000,\\\n cuda = 1, pdist_device = 'gpu') for _ in range(trials)]\n res2.append(barcs)",
"_____no_output_____"
]
],
[
[
"### Absolute barcodes",
"_____no_output_____"
]
],
[
[
"barc = mtd.calc_cross_barcodes(clouds[-1], np.zeros((0,0)), batch_size1 = 100, batch_size2 = 0)",
"_____no_output_____"
],
[
"barc = mtd.calc_cross_barcodes(cloud_base, np.zeros((0,0)), batch_size1 = 100, batch_size2 = 0)",
"_____no_output_____"
],
[
"def get_scores(res, args_dict, trials = 10):\n\n scores = []\n\n for i in range(len(res)): \n barc_list = []\n \n for exp_id, elem in enumerate(res[i]):\n barc_list.append(mtd.get_score(elem, **args_dict))\n \n r = sum(barc_list) / len(barc_list)\n \n scores.append(r)\n\n return scores",
"_____no_output_____"
],
[
"scores = get_scores(res1, {'h_idx' : 1, 'kind' : 'sum_length'})",
"_____no_output_____"
],
[
"for ep, s in zip(epochs, scores):\n print(s)",
"_____no_output_____"
],
[
"scores = get_scores(res2, {'h_idx' : 1, 'kind' : 'sum_length'})",
"_____no_output_____"
],
[
"for ep, s in zip(epochs, scores):\n print(s)",
"_____no_output_____"
],
[
"#pickle.dump(res1, open('res1_timegan.pickle', 'wb'))\n#pickle.dump(res2, open('res2_timegan.pickle', 'wb'))",
"_____no_output_____"
]
],
[
[
"### PCA",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom sklearn.decomposition import PCA",
"_____no_output_____"
],
[
"%pylab inline",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# Create data\ndef plot2(data, groups = (\"base\", \"cloud\")):\n colors = (\"red\", \"green\")\n\n # Create plot\n fig = plt.figure()\n ax = fig.add_subplot(1, 1, 1)\n\n for data, color, group in zip(data, colors, groups):\n x, y = data\n ax.scatter(x, y, alpha=0.5, c=color, edgecolors='none', s=5, label=group)\n\n #plt.title('Matplot scatter plot')\n plt.legend(loc=2)\n plt.show()",
"_____no_output_____"
]
],
[
[
"#### PCA from base+last GAN",
"_____no_output_____"
]
],
[
[
"all_pca = []\n\nfor i in range(len(epochs)):\n pca = PCA(n_components=2)\n\n cb = np.concatenate((cloud_base, clouds[-1]))\n pca.fit(cb)\n\n cb = cloud_base\n cloud_base_pca = pca.transform(cb)\n data = [(cloud_base_pca[:,0], cloud_base_pca[:,1])]\n\n cg = clouds[i]\n\n cloud_pca = pca.transform(cg)\n data.append((cloud_pca[:,0], cloud_pca[:,1]))\n \n all_pca.append(data)\n\n plot2(data, groups = (\"real\", \"generated, epoch %d\" % epochs[i]))",
"_____no_output_____"
],
[
"#pickle.dump(all_pca, open('timegan_all_pca.pickle', 'wb'))",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4417beca270b9cbf27e0c8f8ff9b16f677af88
| 270,926 |
ipynb
|
Jupyter Notebook
|
Code/6_Visualisation.ipynb
|
carlomarxdk/GAN-Population-Synthesis
|
c602c279a2066eca1f563ad03d030fa782647e7a
|
[
"MIT"
] | null | null | null |
Code/6_Visualisation.ipynb
|
carlomarxdk/GAN-Population-Synthesis
|
c602c279a2066eca1f563ad03d030fa782647e7a
|
[
"MIT"
] | null | null | null |
Code/6_Visualisation.ipynb
|
carlomarxdk/GAN-Population-Synthesis
|
c602c279a2066eca1f563ad03d030fa782647e7a
|
[
"MIT"
] | null | null | null | 242.98296 | 96,724 | 0.880392 |
[
[
[
"import torch\nimport argparse\nimport csv \nimport datetime\n\nimport math\nimport torch.nn as nn \nfrom torch.nn.functional import leaky_relu, softmax\nfrom sklearn.model_selection import train_test_split\nfrom torch.utils.data import DataLoader\nfrom collections import Counter\n\nfrom GANutils import *\nfrom utils import *\nfrom validationUtils import *\nfrom plotUtils import *\nfrom TUutils import *\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom IPython.display import clear_output",
"_____no_output_____"
],
[
"df = pd.read_csv('Logs/wgangp-2019-11-28_114731.csv', header=None)\ndata = pd.read_pickle('Data/TU_onehot')\ndata = back_from_dummies(data)\ndata = data.drop(['HomeAdrMunCode'], axis=1)\ndata_oh = encode_onehot(data)",
"/opt/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py:3606: FutureWarning: SparseDataFrame is deprecated and will be removed in a future version.\nUse a regular DataFrame whose columns are SparseArrays instead.\n\nSee http://pandas.pydata.org/pandas-docs/stable/user_guide/sparse.html#migrating for more.\n\n result = self._constructor(new_data).__finalize__(self)\n"
],
[
"# Creates four polar axes, and accesses them through the returned array\ndf = pd.read_csv('Logs/wgangp-2019-11-30_130226.csv', header=None)\n\n## Logs/wgangp-2019-11-28_114731.csv - good \n## Logs/wgangp-2019-11-30_105956 + converged too fast\n\nfig, axes = plt.subplots(2, 2, figsize=(20,10))\n\naxes[0, 0].plot(df[1])\naxes[0, 0].set_title('Critic Loss')\naxes[0, 0].set_ylabel('Loss')\naxes[0, 0].set_xlabel('Epoch')\naxes[0, 1].plot(df[2])\naxes[0, 1].set_title('Generator Loss')\naxes[0, 1].set_ylabel('Loss')\naxes[0, 1].set_xlabel('Epoch')\n\naxes[1, 0].plot(df[3])\naxes[1, 0].plot(df[4])\naxes[1, 0].legend(['Real Data', 'Fake Data'])\naxes[1, 0].set_title('Average Scores')\naxes[1, 0].set_ylabel('Score')\naxes[1, 0].set_xlabel('Epoch')\n\naxes[1, 1].plot(df[3] - df[4])\naxes[1, 1].set_title('Margin')\naxes[1, 1].set_ylabel('Score')\naxes[1, 1].set_xlabel('Epoch')\n\n\nplt.show()\nfig.savefig('Figs/1.png')",
"_____no_output_____"
],
[
"def gen_noise(size:int, batch_size:int):\n '''\n Generates a 1-d vector of gaussian sampled random values\n '''\n n = Variable(torch.randn([batch_size,size]), requires_grad=False)\n return n\ndef sample_gumbel(shape, eps=1e-20):\n unif = torch.rand(*shape).to(device)\n g = -torch.log(-torch.log(unif + eps))\n return g\n\ndef sample_gumbel_softmax(logits, temperature):\n \"\"\"\n Input:\n logits: Tensor of log probs, shape = BS x k\n temperature = scalar\n \n Output: Tensor of values sampled from Gumbel softmax.\n These will tend towards a one-hot representation in the limit of temp -> 0\n shape = BS x k\n \"\"\"\n g = sample_gumbel(logits.shape)\n h = (g + logits)/temperature\n h_max = h.max(dim=-1, keepdim=True)[0]\n h = h - h_max\n cache = torch.exp(h)\n y = cache / cache.sum(dim=-1, keepdim=True)\n return y\n\nINPUT_SIZE = 100\ncuda = torch.cuda.is_available()\ndevice = torch.device(\"cuda:0\" if cuda else \"cpu\")",
"_____no_output_____"
],
[
"class Generator (nn.Module):\n def __init__(self, \n input_size: int, \n hidden_size: int, \n temperature: float,\n cat: Counter):\n super(Generator, self).__init__()\n self.cat = cat\n self.cat_n = list(cat.values())\n self.output_size = sum(self.cat.values())\n self.temperature = torch.Tensor([temperature]).to(device)\n self.l1 = nn.Sequential( \n nn.Linear(input_size, hidden_size),\n nn.LeakyReLU(negative_slope=0.2),\n nn.BatchNorm1d(hidden_size, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),\n nn.Dropout(0.3)\n )\n self.l2 = nn.Sequential( \n nn.Linear(hidden_size, hidden_size * 2),\n nn.LeakyReLU(negative_slope = 0.2),\n nn.BatchNorm1d(hidden_size * 2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),\n nn.Dropout(0.3)\n )\n self.l3 = nn.Sequential( \n nn.Linear(hidden_size * 2, hidden_size * 3),\n nn.LeakyReLU(negative_slope = 0.2),\n nn.BatchNorm1d(hidden_size * 3, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),\n nn.Dropout(0.3)\n )\n self.l4 = nn.Sequential( \n nn.Linear(hidden_size * 3, hidden_size * 2),\n nn.LeakyReLU(negative_slope = 0.2),\n nn.BatchNorm1d(hidden_size * 2, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),\n nn.Dropout(0.3)\n )\n self.out = nn.Sequential( \n nn.Linear(hidden_size * 2, self.output_size))\n \n def forward(self,x):\n x=self.l1(x)\n x=self.l2(x)\n x=self.l3(x)\n x=self.l4(x)\n x=self.out(x)\n ### Softmax per class\n x = (x.split(self.cat_n, dim=1))\n out = torch.cat([sample_gumbel_softmax(v, temperature = self.temperature) for v in x], dim=1)\n return out\n\nG = torch.load('Logs/wgangp-2019-11-30_130226')",
"_____no_output_____"
],
[
"G = G.to(device)\nz = gen_noise(INPUT_SIZE, 100000).to(device)",
"_____no_output_____"
],
[
"output = G.forward(z)\noutput = output.cpu().detach().numpy()\noutput = output.astype(int)",
"_____no_output_____"
],
[
"fake_oh = pd.DataFrame(output, columns=data_oh.columns)\nfake_oh.head()\nfake = back_from_dummies(fake_oh)\nfake.head()",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
],
[
"data = data.astype('category')\nfake = fake.astype('category')",
"_____no_output_____"
],
[
"evaluate(data, fake, ['RespSex', 'RespPrimOcc', 'RespEdulevel'], data.columns, data, data)",
"MAE:4.302910520592929e-05, MSE:8.015860813807761e-08, RMSE:0.00028312295586560554, SRSME:0.018831401498636668\ncorr = 0.993873\nMAE = 0.000109\nRMSE = 0.000450\nSRMSE = 0.788674\nr2 = 0.987783\n"
],
[
"evaluate(data, fake, ['HomeAdrNUTS', 'NuclFamType','RespSex', 'ResphasDrivlic'], data.columns, data, data)",
"MAE:0.00024333216841748267, MSE:3.5436880290657916e-07, RMSE:0.0005952888398975569, SRSME:0.01579479779060915\ncorr = 0.987135\nMAE = 0.000388\nRMSE = 0.000751\nSRMSE = 0.332067\nr2 = 0.971440\n"
],
[
"data = pd.read_pickle('Data/TU_onehot')\ndata = back_from_dummies(data)",
"/opt/anaconda3/lib/python3.7/site-packages/pandas/core/generic.py:3606: FutureWarning: SparseDataFrame is deprecated and will be removed in a future version.\nUse a regular DataFrame whose columns are SparseArrays instead.\n\nSee http://pandas.pydata.org/pandas-docs/stable/user_guide/sparse.html#migrating for more.\n\n result = self._constructor(new_data).__finalize__(self)\n"
],
[
"data.astype('category').describe()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a441dce7906b207b2bb152273b03e0c8dab6e49
| 4,742 |
ipynb
|
Jupyter Notebook
|
01_RampUp/week1/05_Primer_notebook_de_Jupyter_en_GoogleColab_12052021.ipynb
|
talitacardenas/The_Bridge_School_DataScience_PT
|
7c059d06a0eb53c0370d1db8868e0e7cb88c857b
|
[
"Apache-2.0"
] | null | null | null |
01_RampUp/week1/05_Primer_notebook_de_Jupyter_en_GoogleColab_12052021.ipynb
|
talitacardenas/The_Bridge_School_DataScience_PT
|
7c059d06a0eb53c0370d1db8868e0e7cb88c857b
|
[
"Apache-2.0"
] | null | null | null |
01_RampUp/week1/05_Primer_notebook_de_Jupyter_en_GoogleColab_12052021.ipynb
|
talitacardenas/The_Bridge_School_DataScience_PT
|
7c059d06a0eb53c0370d1db8868e0e7cb88c857b
|
[
"Apache-2.0"
] | null | null | null | 22.798077 | 377 | 0.531 |
[
[
[
"# Encabezado tipo 1\n## Encabezado tipo 2\n\nSe llama **Markdown**\n\n1. Elemento de lista\n2. Elemento de lista\n\n",
"_____no_output_____"
],
[
"En Jupyter para ejecutar una celda tecleamos:\n\n- CTRL + ENTER\n\nO si queremos añadir una nueva línea de código y a la vez ejecutar\n\n- ALT + ENTER",
"_____no_output_____"
]
],
[
[
"# Si quiero escribir un comentario en una celda utilizamos el fragmento #\n# Si son más líneas también\nsuma = 20 + 10 # también podemos redactar un comentario al lado del código",
"_____no_output_____"
],
[
"print(suma) # imprimimos el valor resultante de la variable anterior",
"30\n"
],
[
"suma",
"_____no_output_____"
],
[
"print(\"El resultado de esta operación es: \" + suma)",
"_____no_output_____"
]
],
[
[
"Veamos que nos devolverá un error porque estamos intentando imprimir una cadena de texto y un valor numérico.\nLa solución sería de transformar nuestro valor numérico en STRING",
"_____no_output_____"
]
],
[
[
"# Volvemos a repetir la operación anterior convertiendo la variable numérica en string\nprint(\"El resultado de esta operación es: \" + str(suma))",
"El resultado de esta operación es: 30\n"
],
[
"sum",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4442e6d098eee01831a92579262db902887565
| 133,690 |
ipynb
|
Jupyter Notebook
|
sandbox/generate_class_imbalance_sp.ipynb
|
ml4sts/ml-sim
|
fe4452276b503330809353902515504a058b4f79
|
[
"MIT"
] | 1 |
2021-01-28T18:34:08.000Z
|
2021-01-28T18:34:08.000Z
|
sandbox/generate_class_imbalance_sp.ipynb
|
ml4sts/ml-sim
|
fe4452276b503330809353902515504a058b4f79
|
[
"MIT"
] | 4 |
2021-06-03T22:36:45.000Z
|
2022-03-31T21:55:25.000Z
|
sandbox/generate_class_imbalance_sp.ipynb
|
brownsarahm/ml-sim
|
26c03e65c57a2ffc3784e6e79eaa76100f0bf391
|
[
"MIT"
] | 1 |
2022-03-21T14:45:36.000Z
|
2022-03-21T14:45:36.000Z
| 164.440344 | 41,132 | 0.86744 |
[
[
[
"# SP via class imbalance\n\nExample [test scores](https://www.brookings.edu/blog/social-mobility-memos/2015/07/29/when-average-isnt-good-enough-simpsons-paradox-in-education-and-earnings/)\n\nSImpson's paradox can also occur due to a class imbalance, where for example, over time the value of several differnt subgroups all increase, but the totla average decreases over tme. This is also am mportant tpe to catch because this can inicate a large class disparity beased on the subgrouping variable. ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pylab as plt\nfrom mlsim import sp_plot",
"_____no_output_____"
],
[
"t = np.linspace(0,50,11)\ncount_rate = np.asarray([1,1.5,1.4])\ncount_pow = np.asarray([1,1.4, 1.3])\ncount_0 = np.asarray([100,60,40])\ncount = np.asarray([count_0 + count_rate*(t_i**count_pow) for t_i in t])\nshare = count/np.asarray([np.sum(count, axis=1)]*3).T\nscore_rate = np.asarray([.2, .25, .3])\nscore_0 = [310,290,280]\nscores_group = np.asarray([score_0 + score_rate*t_i for t_i in t])\ntotal_score = np.sum(scores_group*share,axis=1)\n",
"_____no_output_____"
],
[
"total_score",
"_____no_output_____"
],
[
"plt.plot(t,scores_group)\nplt.plot(t,total_score,'k', label ='average')\nplt.title('score per group and averge');",
"_____no_output_____"
],
[
"plt.plot(t,count)\nplt.title('count per group over time');",
"_____no_output_____"
]
],
[
[
"We can change the numbers a bit to see tht it still works. ",
"_____no_output_____"
]
],
[
[
"t = np.linspace(0,50,11)\ncount_rate = np.asarray([.5,3,1.8])\ncount_pow = np.asarray([1,1,1.15]) #1.24, 1.13])\ngroup_names = ['W','B','H']\ncount_0 = np.asarray([200,60,40])\ncount = np.asarray([np.floor(count_0 + count_rate*(t_i**count_pow)) for t_i in t])\nshare = count/np.asarray([np.sum(count, axis=1)]*3).T\nscore_rate = np.asarray([.1, .112, .25])\nscore_0 = [310,270,265]\nscores_group = np.asarray([score_0 + score_rate*t_i for t_i in t])\ntotal_score = np.sum(scores_group*share,axis=1)\n\nplt.figure(figsize=(12,4))\nplt.subplot(1,3,1)\nplt.plot(t,scores_group)\nplt.plot(t,total_score,'k', label ='average')\nplt.title('score per group and averge');\n\nplt.subplot(1,3,2)\nplt.plot(t,count)\nplt.title('count per group');\n\nplt.subplot(1,3,3)\nplt.plot(t,share)\nplt.title('% per group');",
"_____no_output_____"
]
],
[
[
"The above is occuring in aggregate data, we should generate and aim to detect from the individual measurements. So we can expand the above generator. We'll use the group score and counts to draw the indivdual rows of our table. ",
"_____no_output_____"
]
],
[
[
"dat = [[t_t,np.random.normal(loc=sg,scale=5),g ]\n for sg_t, c_t,t_t in zip(scores_group,count,t) \n for sg,c,g in zip(sg_t,c_t,group_names) \n for i in range(int(c))]",
"_____no_output_____"
],
[
"len(dat)",
"_____no_output_____"
],
[
"df = pd.DataFrame(data=dat,columns = ['year','score','race'])",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.groupby(['race','year']).mean().unstack()",
"_____no_output_____"
],
[
"df.groupby(['year']).mean().T",
"_____no_output_____"
]
],
[
[
"The overall goes down while each of the groupwise means goes up, as expected. ",
"_____no_output_____"
]
],
[
[
"df.groupby('race').corr()",
"_____no_output_____"
],
[
"df.corr()",
"_____no_output_____"
]
],
[
[
"We can see this in the correlation matrices as well, so our existing detector will work, but it has an intuitively different generating mechanism.",
"_____no_output_____"
]
],
[
[
"sp_plot(df,'year','score','race',domain_range=[-1, 51, 225, 350])",
"_____no_output_____"
]
],
[
[
"Vizually, the scatter plots for this are also somewhat different, the groups are not as separable as they were in the regression-based examples we worked with initially. ",
"_____no_output_____"
],
[
"# Generalizing this ",
"_____no_output_____"
],
[
"instead of setting a growth rate and being completely computational, we can set the start and end and then add noise in the middle",
"_____no_output_____"
]
],
[
[
"# set this final value\nscore_t = (score_0*score_growth*N_t).T\ntotal_t = .85*total_0\ncount_t = total_t*np.linalg.pinv(score_t)\n\n\ncount = np.linspace(count_0,count_t,N_t)\nshare = count/np.asarray([np.sum(count, axis=1)]*3).T\nscores_group = np.asarray([score_0 + score_rate*t_i for t_i in t])\ntotal_score = np.sum(scores_group*share,axis=1)\n\nplt.figure(figsize=(12,5))\nplt.subplot(1,2,1)\nplt.plot(t,scores_group)\nplt.plot(t,total_score,'k', label ='average')\nplt.title('score per group and averge');\n\nplt.subplot(1,2,2)\nplt.plot(t,count)\nplt.title('count per group');",
"_____no_output_____"
],
[
"N_t = 11\nt = np.linspace(0,50,N_t)\ngroup_names = ['W','B','H']\n`\n\ncount_0 = np.asarray([200,60,40])\ncount_0\n\nshare_0 = count_0/np.asarray([np.sum(count_0)]*3).T\nscore_0 = np.asarray([310,270,265])\nscore_growth = [1.1,1.3,1.4]\ntotal_0 = np.sum(share_0*score_0)\ntotal_0",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4a444336ad0326e6870ec70182dabea38293c887
| 5,044 |
ipynb
|
Jupyter Notebook
|
chapter2/homework/computer/4-5/201611680340.4.5.ipynb
|
hpishacker/python_tutorial
|
9005f0db9dae10bdc1d1c3e9e5cf2268036cd5bd
|
[
"MIT"
] | 76 |
2017-09-26T01:07:26.000Z
|
2021-02-23T03:06:25.000Z
|
chapter2/homework/computer/4-5/201611680340.4.5.ipynb
|
hpishacker/python_tutorial
|
9005f0db9dae10bdc1d1c3e9e5cf2268036cd5bd
|
[
"MIT"
] | 5 |
2017-12-10T08:40:11.000Z
|
2020-01-10T03:39:21.000Z
|
chapter2/homework/computer/4-5/201611680340.4.5.ipynb
|
hacker-14/python_tutorial
|
4a110b12aaab1313ded253f5207ff263d85e1b56
|
[
"MIT"
] | 112 |
2017-09-26T01:07:30.000Z
|
2021-11-25T19:46:51.000Z
| 24.72549 | 100 | 0.427637 |
[
[
[
"#写函数,求n个随机整数均值的平方根,整数范围在m与k之间\nimport random,math\n\ndef pingfanggeng():\n m = int(input('请输入一个大于0的整数,作为随机整数的下界,回车结束。'))\n k = int(input('请输入一个大于0的整数,作为随机整数的上界,回车结束。'))\n n = int(input('请输入随机整数的个数,回车结束。'))\n i=0\n total=0\n while i<n:\n total=total+random.randint(m,k)\n i=i+1\n average=total/n\n number=math.sqrt(average)\n print(number)\ndef main():\n pingfanggeng()\nif __name__ == '__main__':\n main() ",
"_____no_output_____"
],
[
"#写函数,共n个随机整数,整数范围在m与k之间,求西格玛log(随机整数)及西格玛1/log(随机整数)\nimport random,math\n\ndef xigema():\n m = int(input('请输入一个大于0的整数,作为随机整数的下界,回车结束。'))\n k = int(input('请输入一个大于0的整数,作为随机整数的上界,回车结束。'))\n n = int(input('请输入随机整数的个数,回车结束。'))\n i=0\n total1=0\n total2=0\n while i<n:\n total1=total1+math.log(random.randint(m,k))\n total2=total2+1/(math.log(random.randint(m,k)))\n i=i+1\n print(total1)\n print(total2) \ndef main():\n xigema()\nif __name__ == '__main__':\n main() ",
"请输入一个大于0的整数,作为随机整数的下界,回车结束。2\n请输入一个大于0的整数,作为随机整数的上界,回车结束。999\n请输入随机整数的个数,回车结束。4\n25.173304010367737\n0.6847556258672631\n"
],
[
"#写函数,求s=a+aa+aaa+aaaa+aa...a的值,其中a是[1,9]之间的随机整数。例如2+22+222+2222+22222(此时共有5个数相加),几个数相加由键盘输入\nimport random\ndef sa():\n n = int(input('请输入整数的个数,回车结束。'))\n a=random.randint(1,9)\n i=0\n s=0\n f=0\n while i<n:\n f=math.pow(10,i)*a+f\n s=s+f\n i=i+1\n print(s)\ndef main():\n sa()\nif __name__ == '__main__':\n main() ",
"请输入整数的个数,回车结束。4\n9872.0\n"
],
[
"import random, math\n\n\ndef win():\n print('Win!')\ndef lose():\n print('Lose!')\n\ndef menu():\n print('''=====游戏菜单=====\n 1. 游戏说明\n 2. 开始游戏\n 3. 退出游戏\n 4. 制作团队\n =====游戏菜单=====''')\n \ndef guess_game():\n n = int(input('请输入一个大于0的整数,作为神秘整数的上界,回车结束。'))\n number = int(input('请输入神秘整数,回车结束。'))\n max_times = math.ceil(math.log(n, 2))\n guess_times = 0\n \n while guess_times <= max_times:\n guess = random.randint(1, n)\n guess_times += 1\n print('一共可以猜', max_times, '次')\n print('你已经猜了', guess_times, '次')\n \n if guess == number:\n win()\n print('神秘数字是:', guess)\n print('你比标准次数少', max_times-guess_times, '次')\n break\n elif guess > number:\n print('抱歉,你猜大了')\n else:\n print('抱歉,你猜小了')\n \n else:\n print('神秘数字是:', number)\n lose()\n\n# 主函数\ndef main():\n while True:\n menu()\n choice = int(input('请输入你的选择'))\n if choice == 1:\n show_instruction()\n elif choice == 2:\n guess_game()\n elif choice == 3:\n game_over()\n break\n else:\n show_team()\n\n\n#主程序\nif __name__ == '__main__':\n main()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a4448094c8b6900a2949b3377ab916baa0e0726
| 12,422 |
ipynb
|
Jupyter Notebook
|
Week 9/Pandas_Part2_Indexing-Selecting-Assigning_STUDENT.ipynb
|
troopercrzy/cu-leeds-baim3220-003-spring-2021
|
e0dcb7d250d4bf29f670975f477717b630276be1
|
[
"Apache-2.0"
] | 3 |
2021-01-21T18:19:00.000Z
|
2021-05-17T14:28:11.000Z
|
Week 9/Pandas_Part2_Indexing-Selecting-Assigning_STUDENT.ipynb
|
troopercrzy/cu-leeds-baim3220-003-spring-2021
|
e0dcb7d250d4bf29f670975f477717b630276be1
|
[
"Apache-2.0"
] | null | null | null |
Week 9/Pandas_Part2_Indexing-Selecting-Assigning_STUDENT.ipynb
|
troopercrzy/cu-leeds-baim3220-003-spring-2021
|
e0dcb7d250d4bf29f670975f477717b630276be1
|
[
"Apache-2.0"
] | 11 |
2021-01-19T18:34:37.000Z
|
2021-04-28T18:44:11.000Z
| 23.84261 | 118 | 0.55603 |
[
[
[
"# `pandas` Part 2: this notebook is a 2nd lesson on `pandas`\n## The main objective of this tutorial is to slice up some DataFrames using `pandas`\n>- Reading data into DataFrames is step 1\n>- But most of the time we will want to select specific pieces of data from our datasets \n\n# Learning Objectives\n## By the end of this tutorial you will be able to:\n1. Select specific data from a pandas DataFrame\n2. Insert data into a DataFrame\n\n## Files Needed for this lesson: `winemag-data-130k-v2.csv`\n>- Download this csv from Canvas prior to the lesson\n\n## The general steps to working with pandas:\n1. import pandas as pd\n>- Note the `as pd` is optional but is a common alias used for pandas and makes writing the code a bit easier\n2. Create or load data into a pandas DataFrame or Series\n>- In practice, you will likely be loading more datasets than creating but we will learn both\n3. Reading data with `pd.read_`\n>- Excel files: `pd.read_excel('fileName.xlsx')`\n>- Csv files: `pd.read_csv('fileName.csv')`\n4. After steps 1-3 you will want to check out your DataFrame\n>- Use `shape` to see how many records and columns are in your DataFrame\n>- Use `head()` to show the first 5-10 records in your DataFrame\n5. Then you will likely want to slice up your data into smaller subset datasets\n>- This step is the focus of this lesson",
"_____no_output_____"
],
[
"Narrated type-along videos are available:\n\n- Part 1: https://youtu.be/uA96V-u8wkE\n- Part 2: https://youtu.be/fsc0G77c5Kc",
"_____no_output_____"
],
[
"# First, check your working directory",
"_____no_output_____"
],
[
"# Step 1: Import pandas and give it an alias",
"_____no_output_____"
],
[
"# Step 2 Read Data Into a DataFrame\n>- Knowing how to create your own data can be useful\n>- However, most of the time we will read data into a DataFrame from a csv or Excel file\n\n## File Needed: `winemag-data-130k-v2.csv`\n>- Make sure you download this file from Canvas and place in your working directory",
"_____no_output_____"
],
[
"### Read the csv file with `pd.read_csv('fileName.csv`)\n>- Set the index to column 0",
"_____no_output_____"
],
[
"### Check how many rows/records and columns are in the the `wine_reviews` DataFrame\n>- Use `shape`",
"_____no_output_____"
],
[
"### Check a couple of rows of data",
"_____no_output_____"
],
[
"### Now we can access columns in the dataframe using syntax similar to how we access values in a dictionary",
"_____no_output_____"
],
[
"### To get a single value...",
"_____no_output_____"
],
[
"### Using the indexing operator and attribute selection like we did above should seem familiar\n>- We have accessed data like this using dictionaries\n>- However, pandas also has it's own selection/access operators, `loc` and `iloc`\n>- For basic operations, we can use the familiar dictionary syntax\n>- As we get more advanced, we should use `loc` and `iloc`\n>- It might help to think of `loc` as \"label based location\" and `iloc` as \"index based location\"\n\n### Both `loc` and `iloc` start with with the row then the column\n#### Use `iloc` for index based location similar to what we have done with lists and dictionaries\n#### Use `loc` for label based location. This uses the column names vs indexes to retrieve the data we want. ",
"_____no_output_____"
],
[
"# First, let's look at index based selection using `iloc`\n\n## As we work these examples, remember we specify row first then column",
"_____no_output_____"
],
[
"### Selecting the first row using `iloc`\n>- For the wine reviews dataset this is our header row",
"_____no_output_____"
],
[
"### To return all the rows of a particular column with `iloc`\n>- To get everything, just put a `:` for row and/or column",
"_____no_output_____"
],
[
"### To return the first three rows of the first column...",
"_____no_output_____"
],
[
"### To return the second and third rows...",
"_____no_output_____"
],
[
"### We can also pass a list for the rows to get specific values",
"_____no_output_____"
],
[
"### Can we pass lists for both rows and columns...?",
"_____no_output_____"
],
[
"### We can also go from the end of the rows just like we did with lists\n>- The following gets the last 5 records for country in the dataset",
"_____no_output_____"
],
[
"### To get the last 5 records for all columns...",
"_____no_output_____"
],
[
"# Label-Based Selection with `loc`\n## With `loc`, we use the names of the columns to retrieve data",
"_____no_output_____"
],
[
"### Get all the records for the following fields/columns using `loc`:\n>- taster_name\n>- taster_twitter_handle\n>- points",
"_____no_output_____"
],
[
"# Notice we have been using the default index so far\n## We can change the index with `set_index`",
"_____no_output_____"
],
[
"# Conditional Selection\n>- Suppose we only want to analyze data for one country, reviewer, etc... \n>- Or we want to pull the data only for points and/or prices above a certain criteria",
"_____no_output_____"
],
[
"## Which wines are from the US with 95 or greater points?",
"_____no_output_____"
],
[
"# Some notes on our previous example:\n>- We just quickly took at dataset that has almost 130K rows and reduced it to one that has 993 \n>- This tells us that less that 1% of the wines are from the US and have ratings of 95 or higher\n>- With some simple slicing using pandas we already have some decent start to an analytics project ",
"_____no_output_____"
],
[
"# Q: What are all the wines from Italy or that have a rating higher than 95?\n>- To return the results for an \"or\" question use the pipe `|` between your conditions ",
"_____no_output_____"
],
[
"# Q: What are all the wines from Italy or France? \n>- We can do this with an or statement or the `isin()` selector\n>- Note: if you know SQL, this is the same thing as the IN () statement \n>- Using `isin()` replaces multiple \"or\" statements and makes your code a little shorter",
"_____no_output_____"
],
[
"# Q: What are all the wines without prices?\n>- Here we can use the `isnull` method to show when values are not entered for a particular column",
"_____no_output_____"
],
[
"# What are all the wines with prices? \n>- Use `notnull()`",
"_____no_output_____"
],
[
"# We can also add columns/fields to our DataFrames",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a4449a4e6fde238a4bb13dc7f339cc7faba2178
| 545,999 |
ipynb
|
Jupyter Notebook
|
notebooks/exp101_analysis.ipynb
|
CoAxLab/infomercial
|
fa5d1c1e5c1351735dda2961a2a94f71cd17e270
|
[
"MIT"
] | 4 |
2019-11-14T03:13:25.000Z
|
2021-01-04T17:30:23.000Z
|
notebooks/exp101_analysis.ipynb
|
CoAxLab/infomercial
|
fa5d1c1e5c1351735dda2961a2a94f71cd17e270
|
[
"MIT"
] | null | null | null |
notebooks/exp101_analysis.ipynb
|
CoAxLab/infomercial
|
fa5d1c1e5c1351735dda2961a2a94f71cd17e270
|
[
"MIT"
] | null | null | null | 150.828453 | 214,464 | 0.843897 |
[
[
[
"# Exp 101 analysis\n\nSee `./informercial/Makefile` for experimental\ndetails.",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np\n\nfrom IPython.display import Image\nimport matplotlib\nimport matplotlib.pyplot as plt\n\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport seaborn as sns\nsns.set_style('ticks')\n\nmatplotlib.rcParams.update({'font.size': 16})\nmatplotlib.rc('axes', titlesize=16)\n\nfrom infomercial.exp import meta_bandit\nfrom infomercial.exp import epsilon_bandit\nfrom infomercial.exp import beta_bandit\nfrom infomercial.exp import softbeta_bandit\nfrom infomercial.local_gym import bandit\nfrom infomercial.exp.meta_bandit import load_checkpoint\n\nimport gym",
"_____no_output_____"
],
[
"def plot_meta(env_name, result):\n \"\"\"Plots!\"\"\"\n \n # episodes, actions, scores_E, scores_R, values_E, values_R, ties, policies\n episodes = result[\"episodes\"]\n actions =result[\"actions\"]\n bests =result[\"p_bests\"]\n scores_E = result[\"scores_E\"]\n scores_R = result[\"scores_R\"]\n values_R = result[\"values_R\"]\n values_E = result[\"values_E\"]\n ties = result[\"ties\"]\n policies = result[\"policies\"]\n \n # -\n env = gym.make(env_name)\n best = env.best\n print(f\"Best arm: {best}, last arm: {actions[-1]}\")\n\n # Plotz\n fig = plt.figure(figsize=(6, 14))\n grid = plt.GridSpec(6, 1, wspace=0.3, hspace=0.8)\n\n # Arm\n plt.subplot(grid[0, 0])\n plt.scatter(episodes, actions, color=\"black\", alpha=.5, s=2, label=\"Bandit\")\n plt.plot(episodes, np.repeat(best, np.max(episodes)+1), \n color=\"red\", alpha=0.8, ls='--', linewidth=2)\n plt.ylim(-.1, np.max(actions)+1.1)\n plt.ylabel(\"Arm choice\")\n plt.xlabel(\"Episode\")\n\n # Policy\n policies = np.asarray(policies)\n episodes = np.asarray(episodes)\n plt.subplot(grid[1, 0])\n m = policies == 0\n plt.scatter(episodes[m], policies[m], alpha=.4, s=2, label=\"$\\pi_E$\", color=\"purple\")\n m = policies == 1\n plt.scatter(episodes[m], policies[m], alpha=.4, s=2, label=\"$\\pi_R$\", color=\"grey\")\n plt.ylim(-.1, 1+.1)\n plt.ylabel(\"Controlling\\npolicy\")\n plt.xlabel(\"Episode\")\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n _ = sns.despine()\n \n # score\n plt.subplot(grid[2, 0])\n plt.scatter(episodes, scores_E, color=\"purple\", alpha=0.4, s=2, label=\"E\")\n plt.plot(episodes, scores_E, color=\"purple\", alpha=0.4)\n plt.scatter(episodes, scores_R, color=\"grey\", alpha=0.4, s=2, label=\"R\")\n plt.plot(episodes, scores_R, color=\"grey\", alpha=0.4)\n plt.plot(episodes, np.repeat(tie_threshold, np.max(episodes)+1), \n color=\"violet\", alpha=0.8, ls='--', linewidth=2)\n plt.ylabel(\"Score\")\n plt.xlabel(\"Episode\")\n# plt.semilogy()\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n _ = sns.despine()\n\n # Q\n plt.subplot(grid[3, 0])\n plt.scatter(episodes, values_E, color=\"purple\", alpha=0.4, s=2, label=\"$Q_E$\")\n plt.scatter(episodes, values_R, color=\"grey\", alpha=0.4, s=2, label=\"$Q_R$\")\n plt.plot(episodes, np.repeat(tie_threshold, np.max(episodes)+1), \n color=\"violet\", alpha=0.8, ls='--', linewidth=2)\n plt.ylabel(\"Value\")\n plt.xlabel(\"Episode\")\n# plt.semilogy()\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n _ = sns.despine()\n\n \n # Ties\n plt.subplot(grid[4, 0])\n plt.scatter(episodes, bests, color=\"red\", alpha=.5, s=2)\n plt.ylabel(\"p(best)\")\n plt.xlabel(\"Episode\")\n plt.ylim(0, 1)\n\n # Ties\n plt.subplot(grid[5, 0])\n plt.scatter(episodes, ties, color=\"black\", alpha=.5, s=2, label=\"$\\pi_{tie}$ : 1\\n $\\pi_\\pi$ : 0\")\n plt.ylim(-.1, 1+.1)\n plt.ylabel(\"Ties index\")\n plt.xlabel(\"Episode\")\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n \n \ndef plot_epsilon(env_name, result):\n \"\"\"Plots!\"\"\"\n \n # episodes, actions, scores_E, scores_R, values_E, values_R, ties, policies\n episodes = result[\"episodes\"]\n actions =result[\"actions\"]\n bests =result[\"p_bests\"]\n scores_R = result[\"scores_R\"]\n values_R = result[\"values_R\"]\n epsilons = result[\"epsilons\"]\n \n # -\n env = gym.make(env_name)\n best = env.best\n print(f\"Best arm: {best}, last arm: {actions[-1]}\")\n\n # Plotz\n fig = plt.figure(figsize=(6, 14))\n grid = plt.GridSpec(6, 1, wspace=0.3, hspace=0.8)\n\n # Arm\n plt.subplot(grid[0, 0])\n plt.scatter(episodes, actions, color=\"black\", alpha=.5, s=2, label=\"Bandit\")\n for b in best:\n plt.plot(episodes, np.repeat(b, np.max(episodes)+1), \n color=\"red\", alpha=0.8, ls='--', linewidth=2)\n plt.ylim(-.1, np.max(actions)+1.1)\n plt.ylabel(\"Arm choice\")\n plt.xlabel(\"Episode\")\n\n # score\n plt.subplot(grid[1, 0])\n plt.scatter(episodes, scores_R, color=\"grey\", alpha=0.4, s=2, label=\"R\")\n plt.ylabel(\"Score\")\n plt.xlabel(\"Episode\")\n# plt.semilogy()\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n _ = sns.despine()\n\n # Q\n plt.subplot(grid[2, 0])\n plt.scatter(episodes, values_R, color=\"grey\", alpha=0.4, s=2, label=\"$Q_R$\")\n plt.ylabel(\"Value\")\n plt.xlabel(\"Episode\")\n# plt.semilogy()\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n _ = sns.despine()\n\n # best\n plt.subplot(grid[3, 0])\n plt.scatter(episodes, bests, color=\"red\", alpha=.5, s=2)\n plt.ylabel(\"p(best)\")\n plt.xlabel(\"Episode\")\n plt.ylim(0, 1)\n\n # Decay\n plt.subplot(grid[4, 0])\n plt.scatter(episodes, epsilons, color=\"black\", alpha=.5, s=2)\n plt.ylabel(\"$\\epsilon_R$\")\n plt.xlabel(\"Episode\")\n plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n \ndef plot_critic(critic_name, env_name, result):\n # -\n env = gym.make(env_name)\n best = env.best\n \n # Data\n critic = result[critic_name]\n arms = list(critic.keys())\n values = list(critic.values())\n\n # Plotz\n fig = plt.figure(figsize=(8, 3))\n grid = plt.GridSpec(1, 1, wspace=0.3, hspace=0.8)\n\n # Arm\n plt.subplot(grid[0])\n plt.scatter(arms, values, color=\"black\", alpha=.5, s=30)\n plt.plot([best]*10, np.linspace(min(values), max(values), 10), color=\"red\", alpha=0.8, ls='--', linewidth=2)\n plt.ylabel(\"Value\")\n plt.xlabel(\"Arm\")",
"_____no_output_____"
]
],
[
[
"# Load and process data",
"_____no_output_____"
]
],
[
[
"data_path =\"/Users/qualia/Code/infomercial/data/\"\nexp_name = \"exp97\"\nsorted_params = load_checkpoint(os.path.join(data_path, f\"{exp_name}_sorted.pkl\"))",
"_____no_output_____"
],
[
"# print(sorted_params.keys())\nbest_params = sorted_params[0]\nsorted_params",
"_____no_output_____"
]
],
[
[
"# Performance\n\nof best parameters",
"_____no_output_____"
]
],
[
[
"env_name = 'BanditTwoHigh10-v0'\nnum_episodes = 1000\n\n# Run w/ best params\nresult = epsilon_bandit(\n env_name=env_name,\n num_episodes=num_episodes, \n lr_R=best_params[\"lr_R\"],\n epsilon=best_params[\"epsilon\"],\n seed_value=2,\n)\n\nprint(best_params)\nplot_epsilon(env_name, result=result)",
"No handles with labels found to put in legend.\n"
],
[
"plot_critic('critic_R', env_name, result)",
"_____no_output_____"
]
],
[
[
"# Sensitivity\n\nto parameter choices",
"_____no_output_____"
]
],
[
[
"total_Rs = [] \neps = []\nlrs_R = []\nlrs_E = []\ntrials = list(sorted_params.keys())\nfor t in trials:\n total_Rs.append(sorted_params[t]['total_R'])\n lrs_R.append(sorted_params[t]['lr_R'])\n eps.append(sorted_params[t]['epsilon'])\n \n# Init plot\nfig = plt.figure(figsize=(5, 18))\ngrid = plt.GridSpec(6, 1, wspace=0.3, hspace=0.8)\n\n# Do plots:\n# Arm\nplt.subplot(grid[0, 0])\nplt.scatter(trials, total_Rs, color=\"black\", alpha=.5, s=6, label=\"total R\")\nplt.xlabel(\"Sorted params\")\nplt.ylabel(\"total R\")\n_ = sns.despine()\n\n\nplt.subplot(grid[1, 0])\nplt.scatter(trials, lrs_R, color=\"black\", alpha=.5, s=6, label=\"total R\")\nplt.xlabel(\"Sorted params\")\nplt.ylabel(\"lr_R\")\n_ = sns.despine()\n\nplt.subplot(grid[2, 0])\nplt.scatter(lrs_R, total_Rs, color=\"black\", alpha=.5, s=6, label=\"total R\")\nplt.xlabel(\"lrs_R\")\nplt.ylabel(\"total_Rs\")\n_ = sns.despine()\n\nplt.subplot(grid[3, 0])\nplt.scatter(eps, total_Rs, color=\"black\", alpha=.5, s=6, label=\"total R\")\nplt.xlabel(\"epsilon\")\nplt.ylabel(\"total_Rs\")\n_ = sns.despine()",
"_____no_output_____"
]
],
[
[
"# Parameter correlations",
"_____no_output_____"
]
],
[
[
"from scipy.stats import spearmanr\nspearmanr(eps, lrs_R)",
"_____no_output_____"
],
[
"spearmanr(eps, total_Rs)",
"_____no_output_____"
],
[
"spearmanr(lrs_R, total_Rs)",
"_____no_output_____"
]
],
[
[
"# Distributions\n\nof parameters",
"_____no_output_____"
]
],
[
[
"# Init plot\nfig = plt.figure(figsize=(5, 6))\ngrid = plt.GridSpec(3, 1, wspace=0.3, hspace=0.8)\n\nplt.subplot(grid[0, 0])\nplt.hist(eps, color=\"black\")\nplt.xlabel(\"epsilon\")\nplt.ylabel(\"Count\")\n_ = sns.despine()\n\nplt.subplot(grid[1, 0])\nplt.hist(lrs_R, color=\"black\")\nplt.xlabel(\"lr_R\")\nplt.ylabel(\"Count\")\n_ = sns.despine()",
"_____no_output_____"
]
],
[
[
"of total reward",
"_____no_output_____"
]
],
[
[
"# Init plot\nfig = plt.figure(figsize=(5, 2))\ngrid = plt.GridSpec(1, 1, wspace=0.3, hspace=0.8)\n\nplt.subplot(grid[0, 0])\nplt.hist(total_Rs, color=\"black\", bins=50)\nplt.xlabel(\"Total reward\")\nplt.ylabel(\"Count\")\n# plt.xlim(0, 10)\n_ = sns.despine()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a445a50415c354bb84c0c013389f97296f634ce
| 258,838 |
ipynb
|
Jupyter Notebook
|
Analytics/Predictive Modelling .ipynb
|
r0han99/terrorism-analysis
|
617a33809fe94e75e871135715f3ddcca1740239
|
[
"MIT"
] | null | null | null |
Analytics/Predictive Modelling .ipynb
|
r0han99/terrorism-analysis
|
617a33809fe94e75e871135715f3ddcca1740239
|
[
"MIT"
] | null | null | null |
Analytics/Predictive Modelling .ipynb
|
r0han99/terrorism-analysis
|
617a33809fe94e75e871135715f3ddcca1740239
|
[
"MIT"
] | 1 |
2021-09-14T14:10:04.000Z
|
2021-09-14T14:10:04.000Z
| 162.280878 | 105,956 | 0.837879 |
[
[
[
"### Shallow Vs Deep Learning Methodology to Uncover patterns of Terrorism",
"_____no_output_____"
]
],
[
[
"# required modules ",
"_____no_output_____"
],
[
"# Data Libraries \nimport pandas as pd \nimport numpy as np\n\n# plotting libraries \nimport matplotlib.pyplot as plt \nimport plotly.graph_objects as go\nimport seaborn as sns\n\n#predictive modelling \nimport sklearn \nfrom tensorflow.keras.layers import Dense, Activation, BatchNormalization\n\n# ignore warnings \nimport warnings \nwarnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n",
"_____no_output_____"
],
[
"# data path \n# MacOS\nabspath = '../Data/Data.csv'\nmetadata = '../Data/terrorism_metadata.csv'\n# Windows \n# abspath = None\n# metadata = None",
"_____no_output_____"
],
[
"# Functional Meta-Data --> usage - meta_data['column-name']\nmeta = pd.read_csv(metadata)\nmeta = meta.drop(meta.columns[2:],axis=1)\nmeta_data = {}\nfor x,y in zip(list(meta['Column']),list(meta['Desc'])):\n meta_data[x] = y\n\n# meta_data",
"_____no_output_____"
],
[
"# Data \ndata = pd.read_csv(abspath,encoding='latin1',low_memory=False)",
"_____no_output_____"
],
[
"data = data.drop('Unnamed: 0',axis=1) # dropping the redundant column",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,7))\nsns.heatmap(data.corr(),annot=True, cmap='BuGn',fmt='.2f')",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
],
[
"data = data.drop('eventid',axis=1)",
"_____no_output_____"
],
[
"plt.figure(figsize=(10,7))\nsns.heatmap(data.corr(),annot=True, cmap='BuGn',fmt='.2f')",
"_____no_output_____"
],
[
"meta_data",
"_____no_output_____"
],
[
"data.head(4)",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
],
[
"delcols = ['longitude','latitude','country_txt',\n 'city','provstate','natlty1_txt'\n ,'propextent',\n 'attacktype1_txt','targsubtype1_txt','corp1']",
"_____no_output_____"
],
[
"df = data.drop(delcols, axis=1)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"regions = list(df['region_txt'].unique())\nprint('Total regions {}'.format(regions.__len__()))\nprint(regions)",
"Total regions 12\n['Central America & Caribbean', 'North America', 'Southeast Asia', 'Western Europe', 'East Asia', 'South America', 'Eastern Europe', 'Sub-Saharan Africa', 'Middle East & North Africa', 'Australasia & Oceania', 'South Asia', 'Central Asia']\n"
],
[
"# Segregating data according to regions\nregion_dfs = {}\nfor region in regions:\n region_dfs[region] = df[df['region_txt']==region]",
"_____no_output_____"
],
[
"datasheet = df.drop('gname',axis=1)",
"_____no_output_____"
],
[
"# finding out amount of data that exists for each region\nregion_qdata = {}\nfor region, df in zip(region_dfs.keys(),region_dfs.values()):\n print(f'{region.upper()}',end=' ')\n print(df.shape)\n region_qdata[df.shape[0]] = region\n ",
"CENTRAL AMERICA & CARIBBEAN (10344, 18)\nNORTH AMERICA (3456, 18)\nSOUTHEAST ASIA (12485, 18)\nWESTERN EUROPE (16639, 18)\nEAST ASIA (802, 18)\nSOUTH AMERICA (18978, 18)\nEASTERN EUROPE (5144, 18)\nSUB-SAHARAN AFRICA (17550, 18)\nMIDDLE EAST & NORTH AFRICA (50474, 18)\nAUSTRALASIA & OCEANIA (282, 18)\nSOUTH ASIA (44974, 18)\nCENTRAL ASIA (563, 18)\n"
],
[
"# considering only the regions with higher datapoints for more predictability \nfinal_dfs={}\nfor qty,region in zip(region_qdata.keys(),region_qdata.values()):\n if qty > 10**4:\n final_dfs[region] = region_dfs[region]\n ",
"_____no_output_____"
],
[
"# Need to generalise the numerous other classes and aggregate them into one category \n# Need to check for class imbalance",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a445d7ada2ae1d1a40e808c2b57372ac0fec05f
| 16,487 |
ipynb
|
Jupyter Notebook
|
docs/examples/example1.ipynb
|
RolandoAndrade/general-simulation-framework
|
2fe2a981d365a7f482f6a7d4797a5f711b2dd502
|
[
"MIT"
] | 1 |
2021-06-02T12:37:56.000Z
|
2021-06-02T12:37:56.000Z
|
docs/examples/example1.ipynb
|
RolandoAndrade/general-simulation-framework
|
2fe2a981d365a7f482f6a7d4797a5f711b2dd502
|
[
"MIT"
] | null | null | null |
docs/examples/example1.ipynb
|
RolandoAndrade/general-simulation-framework
|
2fe2a981d365a7f482f6a7d4797a5f711b2dd502
|
[
"MIT"
] | null | null | null | 51.845912 | 5,456 | 0.707224 |
[
[
[
"# Creating a Linear Cellular Automaton\n\nLet's start by creating a linear cellular automaton\n\n \n\n> A cellular automaton is a discrete model of computation studied in automata theory.\n\nIt consists of a regular grid of cells, each in one of a finite number of states, such as on and off (in contrast to a coupled map lattice). The grid can be in any finite number of dimensions. For each cell, a set of cells called its neighborhood is defined relative to the specified cell.An initial state (time t = 0) is selected by assigning a state for each cell. A new generation is created (advancing t by 1), according to some fixed rule (generally, a mathematical function) that determines the new state of each cell in terms of the current state of the cell and the states of the cells in its neighborhood. Typically, the rule for updating the state of cells is the same for each cell and does not change over time.\n\n\n\n",
"_____no_output_____"
],
[
"\n## Rules\n\nFor this example, the rule for updating the state of the cells is:\n\n> For each cell of the automaton, it will take the state of its left neighboring cell.\n\nWith this rule, the cells will move one step to the right side every generation.\n",
"_____no_output_____"
],
[
"## Implementing cells\n\nTo implement cells, you can extend the class `DiscreteTimeModel`, and define the abstract protected methods.",
"_____no_output_____"
]
],
[
[
"from typing import Dict\nfrom gsf.dynamic_system.dynamic_systems import DiscreteEventDynamicSystem\nfrom gsf.models.models import DiscreteTimeModel\n\n\nclass Cell(DiscreteTimeModel):\n \"\"\"Cell of the linear cellular automaton\n\n It has an state alive or dead. When receives an input, changes its state to that input.\n Its output is the state.\n\n Attributes:\n _symbol (str): Symbol that represents the cell when it is printed in console.\n \"\"\"\n _symbol: str\n\n def __init__(self, dynamic_system: DiscreteEventDynamicSystem, state: bool, symbol: str = None):\n \"\"\"\n Args:\n dynamic_system (DiscreteEventDynamicSystem): Automaton Grid where the cell belongs.\n state (bool); State that indicates whether the cell is alive (True) or dead (False).\n symbol (str): Symbol that represents the cell when it is printed in console.\n \"\"\"\n super().__init__(dynamic_system, state=state)\n self._symbol = symbol or \"\\u2665\"\n\n def _state_transition(self, state: bool, inputs: Dict[str, bool]) -> bool:\n \"\"\"\n Receives an input and changes the state of the cell.\n Args:\n state (bool); Current state of the cell.\n inputs: A dictionary where the key is the input source cell and the value the output of that cell.\n\n Returns:\n The new state of the cell.\n \"\"\"\n next_state: bool = list(inputs.values())[0]\n return next_state\n\n def _output_function(self, state: bool) -> bool:\n \"\"\"\n Returns the state of the cell.\n \"\"\"\n return state\n\n def __str__(self):\n \"\"\"Prints the cell with the defined symbol\"\"\"\n is_alive = self.get_state()\n if is_alive:\n return self._symbol\n else:\n return \"-\"",
"_____no_output_____"
]
],
[
[
"The `Cell` class, must receive the `DiscreteEventDynamicSystem` where the model belongs. We also include the state of the cell as a bool and a symbol that represents the cells when they will be printed.\n\nWhen a generation is running, the framework will obtain the outputs of every cell defined by `_output_function`, and will inject them on the next model by `_state_transition`. The state transition member, receives a dict with the source input model and its state, and returns the new state that will take the cell.\n\n`DiscreteTimeModels` will schedule their transitions indefinitely every so often with a constant period in between.\n\n",
"_____no_output_____"
],
[
"## Implementing the Automaton\n\nThe Automaton is a dynamic system, a discrete event dynamic system, so it extends `DiscreteEventDynamicSystem`.",
"_____no_output_____"
]
],
[
[
"from random import random, seed\nfrom typing import List\n\nfrom gsf.dynamic_system.dynamic_systems import DiscreteEventDynamicSystem\n\n\nclass LinearAutomaton(DiscreteEventDynamicSystem):\n \"\"\"Linear Automaton implementation\n\n It has a group of cells, connected between them. The output cell of each cell is its right neighbor.\n Attributes:\n _cells (List[Cell]): Group of cells of the linear automaton.\n \"\"\"\n _cells: List[Cell]\n\n def __init__(self, cells: int = 5, random_seed: int = 42):\n \"\"\"\n Args:\n cells (int): Number of cells of the automaton.\n random_seed (int): Random seed for determinate the state of the seeds.\n \"\"\"\n super().__init__()\n seed(random_seed)\n self._create_cells(cells)\n self._create_relations(cells)\n\n def _create_cells(self, cells: int):\n \"\"\"Appends the cells to the automaton.\n Args:\n cells (int): Number of cells of the automaton.\n \"\"\"\n self._cells = []\n for i in range(cells):\n is_alive = random() < 0.5\n self._cells.append(Cell(self, is_alive))\n\n def _create_relations(self, cells: int):\n \"\"\"Creates the connections between the left cell and the right cell.\n Args:\n cells (int): Number of cells of the automaton.\n \"\"\"\n for i in range(cells):\n self._cells[i-1].add(self._cells[i])\n\n def __str__(self):\n \"\"\"Changes the format to show the linear automaton when is printed\"\"\"\n s = \"\"\n for cell in self._cells:\n s += str(cell)\n return s",
"_____no_output_____"
]
],
[
[
"The `LinearAutomaton` receives the number of cells that it will have and a random seed to determine the initial random state of the cells.\n\nFirst it creates the cells, setting the state as alive or dead with a probability of 0.5, and giving as `DiscreteEventDynamicSystem` the current linear automaton.\n\nThen, it connects the models, setting as the output of the `cell[i-1]`, the `cell[i]`.\n\n`DiscreteEventDynamicSystem`s link models, route outputs and inputs between models and execute the transitions of the models.",
"_____no_output_____"
],
[
"## Running the simulation\n\nWe defined a dynamic system, so we can simulate it. Use the class `DiscreteEventExperiment` to run 5 geneations!",
"_____no_output_____"
]
],
[
[
"from gsf.experiments.experiment_builders import DiscreteEventExperiment\n\nlinear_automaton = LinearAutomaton(cells=10)\nexperiment = DiscreteEventExperiment(linear_automaton)\nprint(linear_automaton)\nexperiment.simulation_control.start(stop_time=5)\nexperiment.simulation_control.wait()\nprint(linear_automaton)",
"-♥♥♥---♥♥♥\n--♥♥♥-♥♥♥-\n"
]
],
[
[
"Create the experiment with the linear automaton as `DiscreteEventDynamicSystem`. Then, run it during 5 generations.\n\nAs the simulation runs in a different thread, we wait for it to finish with `experiment.simulation_control.wait()`.\n\nTry the example by your custom params and have fun.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a44627967d8b79cf54e0cd923f5bd4244b42d00
| 305,274 |
ipynb
|
Jupyter Notebook
|
past-team-code/Fall2018Team1/News Articles Data/1027_Cleaned_articles (Without Keywords).ipynb
|
shun-lin/project-paradigm-chatbot
|
8c8a7d68d18ab04c78b5b705180aca26c428181b
|
[
"MIT"
] | 1 |
2019-03-10T19:38:55.000Z
|
2019-03-10T19:38:55.000Z
|
past-team-code/Fall2018Team1/News Articles Data/1027_Cleaned_articles (Without Keywords).ipynb
|
shun-lin/project-paradigm-chatbot
|
8c8a7d68d18ab04c78b5b705180aca26c428181b
|
[
"MIT"
] | null | null | null |
past-team-code/Fall2018Team1/News Articles Data/1027_Cleaned_articles (Without Keywords).ipynb
|
shun-lin/project-paradigm-chatbot
|
8c8a7d68d18ab04c78b5b705180aca26c428181b
|
[
"MIT"
] | null | null | null | 52.34465 | 19,012 | 0.62229 |
[
[
[
"# Import Libaries and Packages\nimport numpy as np\nimport pandas as pd\nimport re",
"_____no_output_____"
]
],
[
[
"## Clean Articles Final\n\nThis noteboks performs the following procedures:\n \n 1. Reads in extracted and cleanded data from prior processes as a csv. \n 2. Performs addtional preprocessing.\n 3. Discards data that does not contain selected keywords.",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(\"text_edit.csv\").drop('Unnamed: 0', axis = 1)\ndf = df.sort_values('timeStamp', ascending = True)\ndf.head()",
"_____no_output_____"
],
[
"df.tail()",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"__Preprocess and Clean Data__",
"_____no_output_____"
]
],
[
[
"#Reset index\ndf= df.reset_index()\ndf = df.drop('index', axis = 1)\ndf.head()",
"_____no_output_____"
]
],
[
[
"#### Methodology: \nWe have a list of keywords (defined below) that we deem relevant to Bitcoin trading and price. If an article does not mention one of these keywords in the first 300 characters (heuristic/empirical analysis of where the lede of an article ends) we deem it irrelevant.",
"_____no_output_____"
]
],
[
[
"#Sample of first 300 characters of the first 30 articles. \n#As you can see, relevant articles will mention Bitcoin or a keyword in this selection.\nfor article in df['contents'][:30]:\n print(article)",
"A complete payments platform engineered for growth.\tBuild and scale your recurring business model.\tEverything platforms need to get sellers paid.\tYour business data at your fingertips.\tThe best way to start an internet business.\tFight fraud with machine learning.\tShare this post on Twitter\t\nTom Karlo\n on January 23, 2018\n\tAt Stripe, we’ve long been excited about the possibilities of cryptocurrencies and the experimentation and innovation that’s come with them. In 2014, we became the first major payments company to support Bitcoin payments.\tOur hope was that Bitcoin could become a universal, decentralized substrate for online transactions and help our customers enable buyers in places that had less credit card penetration or use cases where credit card fees were prohibitive.\tOver the past year or two, as block size limits have been reached, Bitcoin has evolved to become better-suited to being an asset than being a means of exchange. Given the overall success that the Bitcoin community has achieved, it’s hard to quibble with the decisions that have been made along the way. (And we’re certainly happy to see any novel, ambitious project do so well.)\tThis has led to Bitcoin becoming less useful for payments, however. Transaction confirmation times have risen substantially; this, in turn, has led to an increase in the failure rate of transactions denominated in fiat currencies. (By the time the transaction is confirmed, fluctuations in Bitcoin price mean that it’s for the “wrong” amount.) Furthermore, fees have risen a great deal. For a regular Bitcoin transaction, a fee of tens of U.S. dollars is common, making Bitcoin transactions about as expensive as bank wires.\tBecause of this, we’ve seen the desire from our customers to accept Bitcoin decrease. And of the businesses that are accepting Bitcoin on Stripe, we’ve seen their revenues from Bitcoin decline substantially. Empirically, there are fewer and fewer use cases for which accepting or paying with Bitcoin makes sense.\tTherefore, starting today, we are winding down support for Bitcoin payments. Over the next three months we will work with affected Stripe users to ensure a smooth transition before we stop processing Bitcoin transactions on April 23, 2018.\tDespite this, we remain very optimistic about cryptocurrencies overall. There are a lot of efforts that we view as promising and that we can certainly imagine enabling support for in the future. We’re interested in what’s happening with Lightning and other proposals to enable faster payments. OmiseGO is an ambitious and clever proposal; more broadly, Ethereum continues to spawn many high-potential projects. We may add support for Stellar (to which we provided seed funding) if substantive use continues to grow. It’s possible that Bitcoin Cash, Litecoin, or another Bitcoin variant, will find a way to achieve significant popularity while keeping settlement times and transaction fees very low. Bitcoin itself may become viable for payments again in the future. And, of course, there’ll be more ideas and technologies in the years ahead.\tSo, we will continue to pay close attention to the ecosystem and to look for opportunities to help our customers by adding support for cryptocurrencies and new distributed protocols in the future.\t\n January 23, 2018\n \nAs it scrambles to serve a massively expanding userbase, cryptocurrency marketplace and wallet provider Coinbase has hired former Twitter VP Tina Bhatnagar to oversee its customer service operations. \tCompetitive base, double OTELondon, UK or Paris, France or Frankfurt, Germany (other major cities in Europe considered)\t\n\n© Finextra Research 2018\n\nSo many cryptocurrencies. So much money to be made or lost. Marketplace Tech host Molly Wood spoke with Martin Weiss, who’s behind the ratings.\t Martin Weiss: As you’ve seen in the news, the market for cryptocurrencies is wild. It’s one of the few places we’ve seen so much fear, greed and panic.\t So we felt that this is exactly when individual investors and consumers need some rational guidance that’s based on fact and not fiction. Wood: So as you’ve done this analysis, do you believe that there are cryptocurrencies that are stable and aren’t going to have wild fluctuations, and that do represent …\t I mean, I find it hard to believe that there are some that represent a good investment. Weiss: It’s like any other investment, especially new investments — or like any other new technology, the marketplace as a whole is very volatile, no doubt.\t But with that extra risk also comes a very unusual reward potential. Weiss: No. Read more from marketplace.org…\tthumbnail courtesy of marketplace.org\tIs chief doer at You Brand, Inc. and also master curator at the WordPress content curation platform Curation Suite.\t\nUsername or Email Address\n\n\t\nPassword\n\n\t Remember Me\t\n\n\n\t\nBy\n\nPress Association\n\t\nPublished:\n 19:05 EDT, 22 January 2018\n\n | \nUpdated:\n 08:47 EDT, 23 January 2018\n\n\t\tBitFlyer, the world’s largest Bitcoin exchange, has been given the green light for a European launch.\tThe Tokyo-based firm has been awarded a payment institution (PI) licence for the European Union, building on its regulatory approval in the US and Japan.\tBitFlyer handles about a quarter of the globe’s Bitcoin exchange volumes, with more than 250 billion US dollars worth of Bitcoin being traded on its platform last year.\tA Bitcoin ATM, as the operator of the world´s largest Bitcoin exchange looks to launch into Europe (PA)\tDespite the hysteria surrounding the virtual currency, Bitcoin has endured a choppy ride since the end of 2017.\tIt has fallen from December highs of nearly 20,000 US dollars (£14,465) to 10,624.42 US dollars (£7,629) on January 22, according to Coindesk data.\tYuzo Kano, founder and chief executive of bitFlyer, said: “When I set up bitFlyer in 2014, I did so with global ambitions and the belief that approved regulatory status is fundamental to the long-term future of Bitcoin and the virtual currency industry.\t“I am proud that we are now the most compliant virtual currency exchange in the world; this coveted regulatory status gives our customers, our company and the virtual currency industry as a whole a very positive future outlook.”\tBitFlyer is the only exchange licensed in Europe that can give traders access to the globe’s biggest Bitcoin trading market in Japan.\tIt is estimated that around 10 billion euro (£8.7 billion) of Bitcoin is traded worldwide per month, making the euro the third largest Bitcoin market after the Japanese Yen and the US dollar.\tThe exchange received its European PI licence from Luxembourg regulator Commission de Surveillance du Secteur Financier.\tGermany’s Bundesbank has called for global regulation of Bitcoin, while France’s finance minister wants tougher rules for cryptocurrencies.\tMeanwhile, US billionaire Warren Buffett has also ruled out a foray into cryptocurrencies, warning that the Bitcoin boom will “come to a bad ending”.\tThe chairman and chief executive of Berkshire Hathaway has joined the chorus of voices criticising the digital currency, which endured a rollercoaster ride at the tail end of 2017.\tHowever, JP Morgan chief executive Jamie Dimon said he now regrets calling Bitcoin a “fraud”.\tSorry we are not currently accepting comments on this article.\tPublished by Associated Newspapers Ltd\tPart of the Daily Mail, The Mail on Sunday & Metro Media Group\nInitial coin offerings (ICOs) are a regulatory wild west. This isn’t inherently a bad thing, as a lack of regulation sometimes allows technology and ideas that are ahead of their time to flourish when they might otherwise be constrained. There are pockets of ICO investing, however, that may be on the darker side of murky and, for the long-term health of the ICO ecosystem, may require regulation. In particular, a closer look should be taken at pre-sale ICO investments from institutional investors (venture capital funds, cryptocurrency hedge funds, etc.) and the impact these investments can have. When properly implemented, regulation can make markets more efficient and fair on the whole and plays an important part in the financial world.\tAn initial coin offering (ICO) is a means of crowdfunding a cryptocurrency project. In an ICO, some quantity of the cryptocurrency is preallocated to investors in the form of “tokens,” in exchange for other cryptocurrencies (or occasionally fiat currency, like dollars), commonly Bitcoin or Ethereum. These tokens become functional units of cryptocurrency if the ICO’s funding goal is met and the project launches. ICOs help a cryptocurrency launch by gaining funds for development costs, attracting developer attention to the project, and increasing usage and adoption of the coin by increasing the number of people who hold the coin. Developer adoption is important because, once a cryptocurrency project is launched, the development process has just begun and having the help and support of a large community is critical to its long-term success. ICOs are a low cost fundraising option because they avoid regulatory compliance and other interactions with intermediary financial institutions. ICOs usually take place over a period of days to weeks and are split into a pre-sale period and a public sale period with a funding cap that must be reached for the project to launch.\tA pre-sale is a token sale round that take place before a public token sale happens. The ability to buy tokens during this period is restricted to select individuals or institutions that are placed on a “whitelist” and allowed to buy coins before a public sale. Pre-sales often give a percent bonus number of coins to participants and sometimes require a minimum contribution amount.\tA pre-sale is a way to reward early supporters by guaranteeing them an allocation of tokens and to build up attention for a project over a series of weeks and months. Even the best projects must be adept at marketing and telling their story to gain funding and developer adoption; having a good team and a promising white paper (a document which details the goals and plans for a cryptocurrency project) is not enough. Having well known investors in a pre-sale (either as individuals or institutions) can increase hype and lead others to invest.\tGiven the current behavior of individual investors and the common lack of holding obligations for institutions in most ICOs, the current system could be exploited. Consider the following:\tThe combination of the above facts make participating in a pre-sale ICO round almost risk-free for firms with a strong following and a willingness to sell shortly after the hype of the public sale once a cryptocurrency is listed on an exchange. There is no evidence to suggest that this activity has been taking place, but for now, individuals should closely evaluate any ICOs before participating and not take the presence of well-respected investor as conclusive evidence of a project’s quality or likelihood of success. This is always sound advice but should be kept in mind given the opportunity for funds to leverage their position.\tFollow on Medium for future articles and find more at: https://twitter.com/phil_glazer\tBy clapping more or less, you can signal to us which stories really stand out.\tInvesting @ MGV. Previously @KKR_Co & @UCBerkeley | [email protected]\thow hackers start their afternoons.\nHannah Murphy in London\tBitFlyer, the Tokyo-based operator of one of the world’s largest bitcoin exchanges, is expanding into Europe after receiving regulatory approval, as the infrastructure that supports cryptocurrency trading continues to grow off the back of the recent boom. \tThe exchange — which has an 80 per cent share of bitcoin trading in Japan and 20-30 per cent of the global market — is launching its European service on Tuesday after gaining a payment institution licence from Luxembourg’s financial regulator. \tThe platform, which allows users to store bitcoin and place complex trades, said it was responding to increased demand for cryptocurrency trading among professional and institutional investors. That audience is currently “underserved” in Europe, the company said. \tMore than 400 exchanges have sprung up across the globe in recent years to cater for crypto capital markets, many of which are unregulated. BitFlyer’s expansion comes as larger exchanges seek to legitimise a marketplace where investors, to date, have been afforded few protections despite the risk of extreme price volatility, hacks and service outages.\tBitFlyer was now the “most compliant virtual currency exchange in the world”, chief executive Yuzo Kano, a former Goldman Sachs trader said. “Approved regulatory status is fundamental to the long-term future of bitcoin and the virtual currency industry,” he added. \tThe price of a bitcoin tripled in value in the last two months of 2017, hitting an all-time high of nearly $20,000 and fuelling concerns among regulators of a bubble. Price rises were buoyed by the introduction of bitcoin futures trading in December on two traditional Chicago exchanges, the CME Group and Cboe Global Markets. The price has since fallen and is now trading closer to $10,000. \tBitFlyer, which also launched in the US in November, has become one of the largest cryptocurrency exchanges, raising $36m in venture capital funding, from blue-chip backers including Mitsubishi UFJ, Mizuho and Sumitomo Mitsui banks. In 2017, it facilitated more than $250bn of cryptocurrency trading on its platform — $150bn of which came in the final months of the year as prices surged. \tMr Kano last month told the Financial Times that soaring demand among Japanese investors for leveraged bitcoin trading, in particular, had driven prices higher. On its Tokyo platform, users are able to trade bitcoin proper as well as bitcoin derivatives with leverage of up to 15 times their cash deposits. \tIn Europe, the platform “won’t be offering leverage to start with but will be working with the regulator to discuss that in future”, said Andy Bryant, chief operating officer of the European division.\tMr Bryant added that the company would now be the only licensed European exchange offering cross-border trading with Japan, which he called “the deepest and largest market in the world”. \tThe company was granted a payment institution licence from Luxembourg’s Commission de Surveillance du Secteur Financier, meaning it will have to carry out anti-money laundering checks when signing up customers, as a bank would. It also secured a banking partnership with an unnamed European bank. \t“We’re delighted that one of the most successful Japanese start-ups chose Luxembourg as their EU platform,” Pierre Gramegna, the country’s finance minister said on Tuesday. \tBitFlyer will only offer trading of bitcoin/euro pairs but said it planned to support other virtual currencies — such as Litecoin and Ethereum — and more fiat currencies in the coming months.\tInternational Edition\nNot a Topix user yet?\tForgot Your Password?\tNews on P2P continually updated from thousands of sources around the net.\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n\t\n P2P news is powered by NewsRank ®\n\t25 Celebrity Kids Who Are Embarrassments To Their Famous Parents\t30 Celebrities Who Love Donald Trump's Truth Bombs\tHow Did These Pop And Rock Goddesses Look Like In Their Heyday Vs. Years Later?\t29 Celebrity Red Sox Superfans\t36 Stars Who Chopped Off Their Long Hair\tGrab A Tissue: 19 Stars Who Visited Sick Kids In Hospital\tWe Found Them: The 27 Worst Alternative-Music Bands Of All Time\tThen And Now: 1980s Superstars Who Used To Be Smoking Hot\t27 Reality Stars Who Died Too Young\t33 Binge-Worthy '90s Shows Netflix NEEDS To Bring Back\t21 Shockingly Ridiculous Alibis That These People Somehow Wanted Us To Believe\t58 min ago | CBS\tIran: \"Grave consequences\" if Trump bails on nuke deal\t1 hr ago | Fox News\tThe Latest: UN envoy warns of crisis in Syria's Idlib\t2 hrs ago | NY Times\tN.B.A. Stars Talk a Good Game in the Playoffs\t2 hrs ago | LA Times\tThe U.S. can send a message to North Korea by cutting its...\t3 hrs ago | LA Times\tHow 'Made in China 2025' became the real threat in a trad...\t5 hrs ago | NY Times\tNonfiction: The Walls That Hillary Clinton Created\t5 hrs ago | Fox News\t5 foods Barbara Bush loved\t5 hrs ago | NY Times\tFear and Hope in South Korea on Eve of Summit With Kim Jo...\t6 hrs ago | Fox News\tSupreme Court and the Trump travel ban case: What's reall...\t8 hrs ago | Fox News\tKanye West professes 'love' for Donald Trump, criticizes ...\tSacramento, CA\tExplore More Topix\tAbout Topix\tThe Topix Network\t\n \n \n \n \n Comments made yesterday:\n 20,156 \n • \n Total comments across all topics: 289,278,112\n\n var g_tpdnum = 289278112;\n var tpd_rate = 3600;\n setInterval(function() { chrome_updateTotalPosts(); }, tpd_rate);\n \n\tUpdated: Mon Apr 23, 2018 09:40 pm\tCopyright © 2018 Topix LLC\t• Flag inappropriate postPost has been flagged for review\t• Send feedback\t• Cancel\tInternational users, click here.\tNotify me when there are new discussions.\tEnter your email to get updates on this discussion.\tEnter your email to get updates when people reply.\tShare your thoughts with the world\n\n\n\n\n var postLoadFunctions = {};\n var foresee_enabled = 1\n var dynamic_yield_enabled = 1\n \n\n\n\n\tCNBC_Comscore = 'Markets';\n\n\n\n\t\tvar mpscall = {\n\t\t\t\t\t\t'site' : 'cnbc.com-relaunch' , \n\n\t\t\t\t\t'content_id' : '104960297' , \n\n\t\t\t\t\t'path' : '/id/104960297' , \n\n\t\t\t\t\t'is_content' : '1' , \n\n\t\t\t\t\t'is_sponsored' : '0' , \n\n\t\t\t\t\t'adunits' : 'Top Banner|Badge A|Badge B|Badge C|Badge D|Flex Ad First|Box Ad 1|Non Iframe Custom|Inline Custom|Movable Box Ad|Responsive Rectangle' , \n\n\t\t\t\t\t'keywords' : '~' , \n\n\t\t\t\t\t'cat' : 'Markets' , \n\n\t\t\t\t\t'cag[configuration_franchise]' : 'Markets' , \n\n\t\t\t\t\t'cag[attribution_author]' : 'Chloe Aiello' , \n\n\t\t\t\t\t'cag[attribution_source]' : 'CNBC US Source' , \n\n\t\t\t\t\t'cag[related_primary]' : 'Markets|Exchange-traded funds|Investment strategy|Philip Morris International Inc|Scott's Liquid Gold Inc|Marijuana|ETFMG Alternative Harvest ETF|Finance|US: News|Fast Money|ETFs|Investing' , \n\n\t\t\t\t\t'cag[type_franchise]' : 'Markets|Finance|US: News|Fast Money|ETFs|Investing|Markets|Marijuana' , \n\n\t\t\t\t\t'cag[type_creator]' : 'Chloe Aiello' , \n\n\t\t\t\t\t'cag[type_source]' : 'CNBC US Source' , \n\n\t\t\t\t\t'cag[type_tag]' : 'Markets|Exchange-traded funds|Investment strategy|Marijuana' , \n\n\t\t\t\t\t'cag[type_company]' : 'Philip Morris International Inc|Scott's Liquid Gold Inc' , \n\n\t\t\t\t\t'cag[type_security]' : 'ETFMG Alternative Harvest ETF' , \n\n\t\t\t\t\t'cag[brand]' : 'none' , \n\n\t\t\t\t\t'cag[template]' : 'story_simple' , \n\n\t\t\t\t\t'cag[device]' : 'web' , \n\n\t\t\t\t\t'hline' : 'Markets' , \n\n\t\t\t\t\t'type' : 'cnbcnewsstory' , \n\n\t\t\t\t\t'template' : 'story_simple' , \n\n\t\t\t\t\t'title' : 'Here&#039;s why one investor is way more comfortable with marijuana than bitcoin' , \n\n\t\t\t\t\t'pubdate' : '1516667164' , \n\n\t\t\t\t\t'stitle' : 'Growing marijuana ETFs show renrew' , \n\n\t\t\t\t\t'byline' : 'Chloe Aiello' , \n\n\t\t\t\t\t'subtype' : 'marketsection' , \n\n\t\t\t\t\t'id' : '104960297' , \n\n\t\t\t\t\t'nid' : '104960297' \n\n\t\t\n\t\t}, mpsopts = {\n\t\t \n\t\t\"host\" : 'mps.cnbc.com',\n\t\t\"updatecorrelator\" : true\n\n\t\t};\n\n\t\tvar mps = mps || {};\n\t\tmps._ext = mps._ext || {};\n\t\tmps._adsheld = [];\n\t\tmps._queue = mps._queue || {};\n\t\tmps._queue.mpsloaded = mps._queue.mpsloaded || [];\n\t\tmps._queue.mpsinit = mps._queue.mpsinit || [];\n\t\tmps._queue.gptloaded = mps._queue.gptloaded || [];\n\t\tmps._queue.adload = mps._queue.adload || [];\n\t\tmps._queue.adclone = mps._queue.adclone || [];\n\t\tmps._queue.adview = mps._queue.adview || [];\n\t\tmps._queue.refreshads = mps._queue.refreshads || [];\n\t\tmps.__timer = Date.now ? Date.now() : (function() { return +new Date })();\n\t\tmps.__intcode = \"v2\";\n\t\tif (typeof mps.getAd != \"function\") mps.getAd = function(adunit) {\n\t\t if (typeof adunit != \"string\") return false;\n\t\t var slotid = \"mps-getad-\" + adunit.replace(/\\W/g, \"\");\n\t\t if (!mps._ext || !mps._ext.loaded) {\n\t\t mps._queue.gptloaded.push(function() {\n\t\t typeof mps._gptfirst == \"function\" && mps._gptfirst(adunit, slotid);\n\t\t mps.insertAd(\"#\" + slotid, adunit)\n\t\t });\n\t\t mps._adsheld.push(adunit)\n\t\t }\n\t\t return '<div id=\"' + slotid + '\" class=\"mps-wrapper\" data-mps-fill-slot=\"' + adunit + '\"></div>'\n\t\t};\n\t\t(function() {\n\t\t head = document.head || document.getElementsByTagName(\"head\")[0], mpsload = document.createElement(\"script\");\n\t\t mpsload.src = \"//\" + mpsopts.host + \"/fetch/ext/load-\" + mpscall.site + \".js?nowrite=2\";\n\t\t mpsload.id = \"mps-load\";\n\t\t head.insertBefore(mpsload, head.firstChild)\n\t\t})();\n\n\t\n\n\n\n\n \n\n\n\nwindow.NREUM||(NREUM={}),__nr_require=function(t,e,n){function r(n){if(!e[n]){var o=e[n]={exports:{}};t[n][0].call(o.exports,function(e){var o=t[n][1][e];return r(o||e)},o,o.exports)}return e[n].exports}if(\"function\"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(t,e,n){function r(t){try{c.console&&console.log(t)}catch(e){}}var o,i=t(\"ee\"),a=t(19),c={};try{o=localStorage.getItem(\"__nr_flags\").split(\",\"),console&&\"function\"==typeof console.log&&(c.console=!0,o.indexOf(\"dev\")!==-1&&(c.dev=!0),o.indexOf(\"nr_dev\")!==-1&&(c.nrDev=!0))}catch(s){}c.nrDev&&i.on(\"internal-error\",function(t){r(t.stack)}),c.dev&&i.on(\"fn-err\",function(t,e,n){r(n.stack)}),c.dev&&(r(\"NR AGENT IN DEVELOPMENT MODE\"),r(\"flags: \"+a(c,function(t,e){return t}).join(\", \")))},{}],2:[function(t,e,n){function r(t,e,n,r,o){try{d?d-=1:i(\"err\",[o||new UncaughtException(t,e,n)])}catch(c){try{i(\"ierr\",[c,s.now(),!0])}catch(u){}}return\"function\"==typeof f&&f.apply(this,a(arguments))}function UncaughtException(t,e,n){this.message=t||\"Uncaught error with no additional information\",this.sourceURL=e,this.line=n}function o(t){i(\"err\",[t,s.now()])}var i=t(\"handle\"),a=t(20),c=t(\"ee\"),s=t(\"loader\"),f=window.onerror,u=!1,d=0;s.features.err=!0,t(1),window.onerror=r;try{throw new Error}catch(p){\"stack\"in p&&(t(12),t(11),\"addEventListener\"in window&&t(6),s.xhrWrappable&&t(13),u=!0)}c.on(\"fn-start\",function(t,e,n){u&&(d+=1)}),c.on(\"fn-err\",function(t,e,n){u&&(this.thrown=!0,o(n))}),c.on(\"fn-end\",function(){u&&!this.thrown&&d>0&&(d-=1)}),c.on(\"internal-error\",function(t){i(\"ierr\",[t,s.now(),!0])})},{}],3:[function(t,e,n){t(\"loader\").features.ins=!0},{}],4:[function(t,e,n){function r(){C++,M=y.hash,this[u]=b.now()}function o(){C--,y.hash!==M&&i(0,!0);var t=b.now();this[l]=~~this[l]+t-this[u],this[d]=t}function i(t,e){E.emit(\"newURL\",[\"\"+y,e])}function a(t,e){t.on(e,function(){this[e]=b.now()})}var c=\"-start\",s=\"-end\",f=\"-body\",u=\"fn\"+c,d=\"fn\"+s,p=\"cb\"+c,h=\"cb\"+s,l=\"jsTime\",m=\"fetch\",v=\"addEventListener\",w=window,y=w.location,b=t(\"loader\");if(w[v]&&b.xhrWrappable){var g=t(9),x=t(10),E=t(8),O=t(6),R=t(12),P=t(7),T=t(13),S=t(\"ee\"),N=S.get(\"tracer\");t(14),b.features.spa=!0;var M,j=w[v],C=0;S.on(u,r),S.on(p,r),S.on(d,o),S.on(h,o),S.buffer([u,d,\"xhr-done\",\"xhr-resolved\"]),O.buffer([u]),R.buffer([\"setTimeout\"+s,\"clearTimeout\"+c,u]),T.buffer([u,\"new-xhr\",\"send-xhr\"+c]),P.buffer([m+c,m+\"-done\",m+f+c,m+f+s]),E.buffer([\"newURL\"]),g.buffer([u]),x.buffer([\"propagate\",p,h,\"executor-err\",\"resolve\"+c]),N.buffer([u,\"no-\"+u]),a(T,\"send-xhr\"+c),a(S,\"xhr-resolved\"),a(S,\"xhr-done\"),a(P,m+c),a(P,m+\"-done\"),E.on(\"pushState-end\",i),E.on(\"replaceState-end\",i),j(\"hashchange\",i,!0),j(\"load\",i,!0),j(\"popstate\",function(){i(0,C>1)},!0)}},{}],5:[function(t,e,n){function r(t){}if(window.performance&&window.performance.timing&&window.performance.getEntriesByType){var o=t(\"ee\"),i=t(\"handle\"),a=t(12),c=t(11),s=\"learResourceTimings\",f=\"addEventListener\",u=\"resourcetimingbufferfull\",d=\"bstResource\",p=\"resource\",h=\"-start\",l=\"-end\",m=\"fn\"+h,v=\"fn\"+l,w=\"bstTimer\",y=\"pushState\",b=t(\"loader\");b.features.stn=!0,t(8);var g=NREUM.o.EV;o.on(m,function(t,e){var n=t[0];n instanceof g&&(this.bstStart=b.now())}),o.on(v,function(t,e){var n=t[0];n instanceof g&&i(\"bst\",[n,e,this.bstStart,b.now()])}),a.on(m,function(t,e,n){this.bstStart=b.now(),this.bstType=n}),a.on(v,function(t,e){i(w,[e,this.bstStart,b.now(),this.bstType])}),c.on(m,function(){this.bstStart=b.now()}),c.on(v,function(t,e){i(w,[e,this.bstStart,b.now(),\"requestAnimationFrame\"])}),o.on(y+h,function(t){this.time=b.now(),this.startPath=location.pathname+location.hash}),o.on(y+l,function(t){i(\"bstHist\",[location.pathname+location.hash,this.startPath,this.time])}),f in window.performance&&(window.performance[\"c\"+s]?window.performance[f](u,function(t){i(d,[window.performance.getEntriesByType(p)]),window.performance[\"c\"+s]()},!1):window.performance[f](\"webkit\"+u,function(t){i(d,[window.performance.getEntriesByType(p)]),window.performance[\"webkitC\"+s]()},!1)),document[f](\"scroll\",r,{passive:!0}),document[f](\"keypress\",r,!1),document[f](\"click\",r,!1)}},{}],6:[function(t,e,n){function r(t){for(var e=t;e&&!e.hasOwnProperty(u);)e=Object.getPrototypeOf(e);e&&o(e)}function o(t){c.inPlace(t,[u,d],\"-\",i)}function i(t,e){return t[1]}var a=t(\"ee\").get(\"events\"),c=t(22)(a,!0),s=t(\"gos\"),f=XMLHttpRequest,u=\"addEventListener\",d=\"removeEventListener\";e.exports=a,\"getPrototypeOf\"in Object?(r(document),r(window),r(f.prototype)):f.prototype.hasOwnProperty(u)&&(o(window),o(f.prototype)),a.on(u+\"-start\",function(t,e){var n=t[1],r=s(n,\"nr@wrapped\",function(){function t(){if(\"function\"==typeof n.handleEvent)return n.handleEvent.apply(n,arguments)}var e={object:t,\"function\":n}[typeof n];return e?c(e,\"fn-\",null,e.name||\"anonymous\"):n});this.wrapped=t[1]=r}),a.on(d+\"-start\",function(t){t[1]=this.wrapped||t[1]})},{}],7:[function(t,e,n){function r(t,e,n){var r=t[e];\"function\"==typeof r&&(t[e]=function(){var t=r.apply(this,arguments);return o.emit(n+\"start\",arguments,t),t.then(function(e){return o.emit(n+\"end\",[null,e],t),e},function(e){throw o.emit(n+\"end\",[e],t),e})})}var o=t(\"ee\").get(\"fetch\"),i=t(19);e.exports=o;var a=window,c=\"fetch-\",s=c+\"body-\",f=[\"arrayBuffer\",\"blob\",\"json\",\"text\",\"formData\"],u=a.Request,d=a.Response,p=a.fetch,h=\"prototype\";u&&d&&p&&(i(f,function(t,e){r(u[h],e,s),r(d[h],e,s)}),r(a,\"fetch\",c),o.on(c+\"end\",function(t,e){var n=this;e?e.clone().arrayBuffer().then(function(t){n.rxSize=t.byteLength,o.emit(c+\"done\",[null,e],n)}):o.emit(c+\"done\",[t],n)}))},{}],8:[function(t,e,n){var r=t(\"ee\").get(\"history\"),o=t(22)(r);e.exports=r,o.inPlace(window.history,[\"pushState\",\"replaceState\"],\"-\")},{}],9:[function(t,e,n){var r=t(\"ee\").get(\"mutation\"),o=t(22)(r),i=NREUM.o.MO;e.exports=r,i&&(window.MutationObserver=function(t){return this instanceof i?new i(o(t,\"fn-\")):i.apply(this,arguments)},MutationObserver.prototype=i.prototype)},{}],10:[function(t,e,n){function r(t){var e=a.context(),n=c(t,\"executor-\",e),r=new f(n);return a.context(r).getCtx=function(){return e},a.emit(\"new-promise\",[r,e],e),r}function o(t,e){return e}var i=t(22),a=t(\"ee\").get(\"promise\"),c=i(a),s=t(19),f=NREUM.o.PR;e.exports=a,f&&(window.Promise=r,[\"all\",\"race\"].forEach(function(t){var e=f[t];f[t]=function(n){function r(t){return function(){a.emit(\"propagate\",[null,!o],i),o=o||!t}}var o=!1;s(n,function(e,n){Promise.resolve(n).then(r(\"all\"===t),r(!1))});var i=e.apply(f,arguments),c=f.resolve(i);return c}}),[\"resolve\",\"reject\"].forEach(function(t){var e=f[t];f[t]=function(t){var n=e.apply(f,arguments);return t!==n&&a.emit(\"propagate\",[t,!0],n),n}}),f.prototype[\"catch\"]=function(t){return this.then(null,t)},f.prototype=Object.create(f.prototype,{constructor:{value:r}}),s(Object.getOwnPropertyNames(f),function(t,e){try{r[e]=f[e]}catch(n){}}),a.on(\"executor-start\",function(t){t[0]=c(t[0],\"resolve-\",this),t[1]=c(t[1],\"resolve-\",this)}),a.on(\"executor-err\",function(t,e,n){t[1](n)}),c.inPlace(f.prototype,[\"then\"],\"then-\",o),a.on(\"then-start\",function(t,e){this.promise=e,t[0]=c(t[0],\"cb-\",this),t[1]=c(t[1],\"cb-\",this)}),a.on(\"then-end\",function(t,e,n){this.nextPromise=n;var r=this.promise;a.emit(\"propagate\",[r,!0],n)}),a.on(\"cb-end\",function(t,e,n){a.emit(\"propagate\",[n,!0],this.nextPromise)}),a.on(\"propagate\",function(t,e,n){this.getCtx&&!e||(this.getCtx=function(){if(t instanceof Promise)var e=a.context(t);return e&&e.getCtx?e.getCtx():this})}),r.toString=function(){return\"\"+f})},{}],11:[function(t,e,n){var r=t(\"ee\").get(\"raf\"),o=t(22)(r),i=\"equestAnimationFrame\";e.exports=r,o.inPlace(window,[\"r\"+i,\"mozR\"+i,\"webkitR\"+i,\"msR\"+i],\"raf-\"),r.on(\"raf-start\",function(t){t[0]=o(t[0],\"fn-\")})},{}],12:[function(t,e,n){function r(t,e,n){t[0]=a(t[0],\"fn-\",null,n)}function o(t,e,n){this.method=n,this.timerDuration=isNaN(t[1])?0:+t[1],t[0]=a(t[0],\"fn-\",this,n)}var i=t(\"ee\").get(\"timer\"),a=t(22)(i),c=\"setTimeout\",s=\"setInterval\",f=\"clearTimeout\",u=\"-start\",d=\"-\";e.exports=i,a.inPlace(window,[c,\"setImmediate\"],c+d),a.inPlace(window,[s],s+d),a.inPlace(window,[f,\"clearImmediate\"],f+d),i.on(s+u,r),i.on(c+u,o)},{}],13:[function(t,e,n){function r(t,e){d.inPlace(e,[\"onreadystatechange\"],\"fn-\",c)}function o(){var t=this,e=u.context(t);t.readyState>3&&!e.resolved&&(e.resolved=!0,u.emit(\"xhr-resolved\",[],t)),d.inPlace(t,y,\"fn-\",c)}function i(t){b.push(t),l&&(x?x.then(a):v?v(a):(E=-E,O.data=E))}function a(){for(var t=0;t<b.length;t++)r([],b[t]);b.length&&(b=[])}function c(t,e){return e}function s(t,e){for(var n in t)e[n]=t[n];return e}t(6);var f=t(\"ee\"),u=f.get(\"xhr\"),d=t(22)(u),p=NREUM.o,h=p.XHR,l=p.MO,m=p.PR,v=p.SI,w=\"readystatechange\",y=[\"onload\",\"onerror\",\"onabort\",\"onloadstart\",\"onloadend\",\"onprogress\",\"ontimeout\"],b=[];e.exports=u;var g=window.XMLHttpRequest=function(t){var e=new h(t);try{u.emit(\"new-xhr\",[e],e),e.addEventListener(w,o,!1)}catch(n){try{u.emit(\"internal-error\",[n])}catch(r){}}return e};if(s(h,g),g.prototype=h.prototype,d.inPlace(g.prototype,[\"open\",\"send\"],\"-xhr-\",c),u.on(\"send-xhr-start\",function(t,e){r(t,e),i(e)}),u.on(\"open-xhr-start\",r),l){var x=m&&m.resolve();if(!v&&!m){var E=1,O=document.createTextNode(E);new l(a).observe(O,{characterData:!0})}}else f.on(\"fn-end\",function(t){t[0]&&t[0].type===w||a()})},{}],14:[function(t,e,n){function r(t){var e=this.params,n=this.metrics;if(!this.ended){this.ended=!0;for(var r=0;r<d;r++)t.removeEventListener(u[r],this.listener,!1);if(!e.aborted){if(n.duration=a.now()-this.startTime,4===t.readyState){e.status=t.status;var i=o(t,this.lastSize);if(i&&(n.rxSize=i),this.sameOrigin){var s=t.getResponseHeader(\"X-NewRelic-App-Data\");s&&(e.cat=s.split(\", \").pop())}}else e.status=0;n.cbTime=this.cbTime,f.emit(\"xhr-done\",[t],t),c(\"xhr\",[e,n,this.startTime])}}}function o(t,e){var n=t.responseType;if(\"json\"===n&&null!==e)return e;var r=\"arraybuffer\"===n||\"blob\"===n||\"json\"===n?t.response:t.responseText;return l(r)}function i(t,e){var n=s(e),r=t.params;r.host=n.hostname+\":\"+n.port,r.pathname=n.pathname,t.sameOrigin=n.sameOrigin}var a=t(\"loader\");if(a.xhrWrappable){var c=t(\"handle\"),s=t(15),f=t(\"ee\"),u=[\"load\",\"error\",\"abort\",\"timeout\"],d=u.length,p=t(\"id\"),h=t(18),l=t(17),m=window.XMLHttpRequest;a.features.xhr=!0,t(13),f.on(\"new-xhr\",function(t){var e=this;e.totalCbs=0,e.called=0,e.cbTime=0,e.end=r,e.ended=!1,e.xhrGuids={},e.lastSize=null,h&&(h>34||h<10)||window.opera||t.addEventListener(\"progress\",function(t){e.lastSize=t.loaded},!1)}),f.on(\"open-xhr-start\",function(t){this.params={method:t[0]},i(this,t[1]),this.metrics={}}),f.on(\"open-xhr-end\",function(t,e){\"loader_config\"in NREUM&&\"xpid\"in NREUM.loader_config&&this.sameOrigin&&e.setRequestHeader(\"X-NewRelic-ID\",NREUM.loader_config.xpid)}),f.on(\"send-xhr-start\",function(t,e){var n=this.metrics,r=t[0],o=this;if(n&&r){var i=l(r);i&&(n.txSize=i)}this.startTime=a.now(),this.listener=function(t){try{\"abort\"===t.type&&(o.params.aborted=!0),(\"load\"!==t.type||o.called===o.totalCbs&&(o.onloadCalled||\"function\"!=typeof e.onload))&&o.end(e)}catch(n){try{f.emit(\"internal-error\",[n])}catch(r){}}};for(var c=0;c<d;c++)e.addEventListener(u[c],this.listener,!1)}),f.on(\"xhr-cb-time\",function(t,e,n){this.cbTime+=t,e?this.onloadCalled=!0:this.called+=1,this.called!==this.totalCbs||!this.onloadCalled&&\"function\"==typeof n.onload||this.end(n)}),f.on(\"xhr-load-added\",function(t,e){var n=\"\"+p(t)+!!e;this.xhrGuids&&!this.xhrGuids[n]&&(this.xhrGuids[n]=!0,this.totalCbs+=1)}),f.on(\"xhr-load-removed\",function(t,e){var n=\"\"+p(t)+!!e;this.xhrGuids&&this.xhrGuids[n]&&(delete this.xhrGuids[n],this.totalCbs-=1)}),f.on(\"addEventListener-end\",function(t,e){e instanceof m&&\"load\"===t[0]&&f.emit(\"xhr-load-added\",[t[1],t[2]],e)}),f.on(\"removeEventListener-end\",function(t,e){e instanceof m&&\"load\"===t[0]&&f.emit(\"xhr-load-removed\",[t[1],t[2]],e)}),f.on(\"fn-start\",function(t,e,n){e instanceof m&&(\"onload\"===n&&(this.onload=!0),(\"load\"===(t[0]&&t[0].type)||this.onload)&&(this.xhrCbStart=a.now()))}),f.on(\"fn-end\",function(t,e){this.xhrCbStart&&f.emit(\"xhr-cb-time\",[a.now()-this.xhrCbStart,this.onload,e],e)})}},{}],15:[function(t,e,n){e.exports=function(t){var e=document.createElement(\"a\"),n=window.location,r={};e.href=t,r.port=e.port;var o=e.href.split(\"://\");!r.port&&o[1]&&(r.port=o[1].split(\"/\")[0].split(\"@\").pop().split(\":\")[1]),r.port&&\"0\"!==r.port||(r.port=\"https\"===o[0]?\"443\":\"80\"),r.hostname=e.hostname||n.hostname,r.pathname=e.pathname,r.protocol=o[0],\"/\"!==r.pathname.charAt(0)&&(r.pathname=\"/\"+r.pathname);var i=!e.protocol||\":\"===e.protocol||e.protocol===n.protocol,a=e.hostname===document.domain&&e.port===n.port;return r.sameOrigin=i&&(!e.hostname||a),r}},{}],16:[function(t,e,n){function r(){}function o(t,e,n){return function(){return i(t,[f.now()].concat(c(arguments)),e?null:this,n),e?void 0:this}}var i=t(\"handle\"),a=t(19),c=t(20),s=t(\"ee\").get(\"tracer\"),f=t(\"loader\"),u=NREUM;\"undefined\"==typeof window.newrelic&&(newrelic=u);var d=[\"setPageViewName\",\"setCustomAttribute\",\"setErrorHandler\",\"finished\",\"addToTrace\",\"inlineHit\",\"addRelease\"],p=\"api-\",h=p+\"ixn-\";a(d,function(t,e){u[e]=o(p+e,!0,\"api\")}),u.addPageAction=o(p+\"addPageAction\",!0),u.setCurrentRouteName=o(p+\"routeName\",!0),e.exports=newrelic,u.interaction=function(){return(new r).get()};var l=r.prototype={createTracer:function(t,e){var n={},r=this,o=\"function\"==typeof e;return i(h+\"tracer\",[f.now(),t,n],r),function(){if(s.emit((o?\"\":\"no-\")+\"fn-start\",[f.now(),r,o],n),o)try{return e.apply(this,arguments)}finally{s.emit(\"fn-end\",[f.now()],n)}}}};a(\"setName,setAttribute,save,ignore,onEnd,getContext,end,get\".split(\",\"),function(t,e){l[e]=o(h+e)}),newrelic.noticeError=function(t){\"string\"==typeof t&&(t=new Error(t)),i(\"err\",[t,f.now()])}},{}],17:[function(t,e,n){e.exports=function(t){if(\"string\"==typeof t&&t.length)return t.length;if(\"object\"==typeof t){if(\"undefined\"!=typeof ArrayBuffer&&t instanceof ArrayBuffer&&t.byteLength)return t.byteLength;if(\"undefined\"!=typeof Blob&&t instanceof Blob&&t.size)return t.size;if(!(\"undefined\"!=typeof FormData&&t instanceof FormData))try{return JSON.stringify(t).length}catch(e){return}}}},{}],18:[function(t,e,n){var r=0,o=navigator.userAgent.match(/Firefox[/s](d+.d+)/);o&&(r=+o[1]),e.exports=r},{}],19:[function(t,e,n){function r(t,e){var n=[],r=\"\",i=0;for(r in t)o.call(t,r)&&(n[i]=e(r,t[r]),i+=1);return n}var o=Object.prototype.hasOwnProperty;e.exports=r},{}],20:[function(t,e,n){function r(t,e,n){e||(e=0),\"undefined\"==typeof n&&(n=t?t.length:0);for(var r=-1,o=n-e||0,i=Array(o<0?0:o);++r<o;)i[r]=t[e+r];return i}e.exports=r},{}],21:[function(t,e,n){e.exports={exists:\"undefined\"!=typeof window.performance&&window.performance.timing&&\"undefined\"!=typeof window.performance.timing.navigationStart}},{}],22:[function(t,e,n){function r(t){return!(t&&t instanceof Function&&t.apply&&!t[a])}var o=t(\"ee\"),i=t(20),a=\"nr@original\",c=Object.prototype.hasOwnProperty,s=!1;e.exports=function(t,e){function n(t,e,n,o){function nrWrapper(){var r,a,c,s;try{a=this,r=i(arguments),c=\"function\"==typeof n?n(r,a):n||{}}catch(f){p([f,\"\",[r,a,o],c])}u(e+\"start\",[r,a,o],c);try{return s=t.apply(a,r)}catch(d){throw u(e+\"err\",[r,a,d],c),d}finally{u(e+\"end\",[r,a,s],c)}}return r(t)?t:(e||(e=\"\"),nrWrapper[a]=t,d(t,nrWrapper),nrWrapper)}function f(t,e,o,i){o||(o=\"\");var a,c,s,f=\"-\"===o.charAt(0);for(s=0;s<e.length;s++)c=e[s],a=t[c],r(a)||(t[c]=n(a,f?c+o:o,i,c))}function u(n,r,o){if(!s||e){var i=s;s=!0;try{t.emit(n,r,o,e)}catch(a){p([a,n,r,o])}s=i}}function d(t,e){if(Object.defineProperty&&Object.keys)try{var n=Object.keys(t);return n.forEach(function(n){Object.defineProperty(e,n,{get:function(){return t[n]},set:function(e){return t[n]=e,e}})}),e}catch(r){p([r])}for(var o in t)c.call(t,o)&&(e[o]=t[o]);return e}function p(e){try{t.emit(\"internal-error\",e)}catch(n){}}return t||(t=o),n.inPlace=f,n.flag=a,n}},{}],ee:[function(t,e,n){function r(){}function o(t){function e(t){return t&&t instanceof r?t:t?s(t,c,i):i()}function n(n,r,o,i){if(!p.aborted||i){t&&t(n,r,o);for(var a=e(o),c=l(n),s=c.length,f=0;f<s;f++)c[f].apply(a,r);var d=u[y[n]];return d&&d.push([b,n,r,a]),a}}function h(t,e){w[t]=l(t).concat(e)}function l(t){return w[t]||[]}function m(t){return d[t]=d[t]||o(n)}function v(t,e){f(t,function(t,n){e=e||\"feature\",y[n]=e,e in u||(u[e]=[])})}var w={},y={},b={on:h,emit:n,get:m,listeners:l,context:e,buffer:v,abort:a,aborted:!1};return b}function i(){return new r}function a(){(u.api||u.feature)&&(p.aborted=!0,u=p.backlog={})}var c=\"nr@context\",s=t(\"gos\"),f=t(19),u={},d={},p=e.exports=o();p.backlog=u},{}],gos:[function(t,e,n){function r(t,e,n){if(o.call(t,e))return t[e];var r=n();if(Object.defineProperty&&Object.keys)try{return Object.defineProperty(t,e,{value:r,writable:!0,enumerable:!1}),r}catch(i){}return t[e]=r,r}var o=Object.prototype.hasOwnProperty;e.exports=r},{}],handle:[function(t,e,n){function r(t,e,n,r){o.buffer([t],r),o.emit(t,e,n)}var o=t(\"ee\").get(\"handle\");e.exports=r,r.ee=o},{}],id:[function(t,e,n){function r(t){var e=typeof t;return!t||\"object\"!==e&&\"function\"!==e?-1:t===window?0:a(t,i,function(){return o++})}var o=1,i=\"nr@id\",a=t(\"gos\");e.exports=r},{}],loader:[function(t,e,n){function r(){if(!x++){var t=g.info=NREUM.info,e=p.getElementsByTagName(\"script\")[0];if(setTimeout(u.abort,3e4),!(t&&t.licenseKey&&t.applicationID&&e))return u.abort();f(y,function(e,n){t[e]||(t[e]=n)}),s(\"mark\",[\"onload\",a()+g.offset],null,\"api\");var n=p.createElement(\"script\");n.src=\"https://\"+t.agent,e.parentNode.insertBefore(n,e)}}function o(){\"complete\"===p.readyState&&i()}function i(){s(\"mark\",[\"domContent\",a()+g.offset],null,\"api\")}function a(){return E.exists&&performance.now?Math.round(performance.now()):(c=Math.max((new Date).getTime(),c))-g.offset}var c=(new Date).getTime(),s=t(\"handle\"),f=t(19),u=t(\"ee\"),d=window,p=d.document,h=\"addEventListener\",l=\"attachEvent\",m=d.XMLHttpRequest,v=m&&m.prototype;NREUM.o={ST:setTimeout,SI:d.setImmediate,CT:clearTimeout,XHR:m,REQ:d.Request,EV:d.Event,PR:d.Promise,MO:d.MutationObserver};var w=\"\"+location,y={beacon:\"bam.nr-data.net\",errorBeacon:\"bam.nr-data.net\",agent:\"js-agent.newrelic.com/nr-spa-1039.min.js\"},b=m&&v&&v[h]&&!/CriOS/.test(navigator.userAgent),g=e.exports={offset:c,now:a,origin:w,features:{},xhrWrappable:b};t(16),p[h]?(p[h](\"DOMContentLoaded\",i,!1),d[h](\"load\",r,!1)):(p[l](\"onreadystatechange\",o),d[l](\"onload\",r)),s(\"mark\",[\"firstbyte\",c],null,\"api\");var x=0,E=t(21)},{}]},{},[\"loader\",2,14,5,3,4]);\n;NREUM.info={beacon:\"bam.nr-data.net\",errorBeacon:\"bam.nr-data.net\",licenseKey:\"356631dc7f\",applicationID:\"22258555\",sa:1}\n\n\nvar admantx_url =\ndocument.addEventListener(\"DOMContentLoaded\", function(event) {\n mps._queue.mpsloaded.push(function(){\n mps._log('**** LOADED: cnbc-cms-header-insert');\n if (window.mps) {\n if (window.CNBC_Premium && CNBC_Premium.isPremium && document.cookie.indexOf('ispro=true') == -1 && (mps.pagevars.type!=\"franchise\")) {\n mps.nlformtypes = mps.nlformtypes || [];\n mps.nlformtypes.push('paywall');\n }\n\n //<!-- Omniture s_code path -->\n mps.scodePath=\"//fm.cnbc.com/applications/cnbc.com/staticcontent/scripts/omniture/s_code.js?v=1.6.4.1\";\n //<!-- end: Omniture s_code path -->\n\n //<!-- Google PII Fix BEGIN -->\n mps._queue.mpsinit.push(function() {\n (function(){\n mps._urlContainsEmail = function() {\n var _qs = window.location.href;\n if (!_qs) {\n return false;\n }\n var _regex = /([^=&/<>()[].,;:s@\"]+(.[^=&/<>()[].,;:s@\"]+)*)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}])|(([a-zA-Z-0-9]+.)+[a-zA-Z]{2,}))/;\n return _regex.test(_qs);\n };\n if (mps._urlContainsEmail()) {\n mps._debug('[MPS]: email address detected in url, bypass gpt.');\n if (mps.response && mps.response.dart && typeof(mps.response.dart.adunits) === 'object') {\n if (typeof(window._mpspixZ) != 'string') {\n window._mpspixZ = (function(a){var b=\"abcdefghiklmnopqrstuvwxyz\".split(\"\");a||(a=Math.floor(Math.random()*b.length));for(var c=\"\",d=0;d<a;d++)c+=b[Math.floor(Math.random()*b.length)];return c})(12)\n }\n for (var i in mps.response.dart.adunits) {\n var pixelurl = ((document.location.protocol === 'https') ? 'https' : 'http') + '://pix.nbcuni.com/a-pii.gif?X=piiblock&S=' + mps.pagevars.instance + '&P=' + mps.pagevars.mpsid + '&A=' + i + '&U=' + encodeURIComponent(window.location.href) + '&_=' + window._mpspixZ;\n mps.response.dart.adunits[i].data = '<img id=\"div-gpt-x-0\" class=\"mps-slot\" data-mps-slot=\"x\" data-mps-loadset=\"0\" style=\"width:0;height:0;margin:0;padding:0;border:0;display:none;\" src=\"' + pixelurl + '\"/>';\n }\n }\n mps.cloneAd = function() { return false; }\n return true;\n } else {\n return false;\n }\n })();\n });\n //<!-- Google PII Fix END -->\n }\n });\n});\n\n\n\n var setAdblockerCookie = function(adblocker) {\n var d = new Date();\n d.setTime(d.getTime() + 60 * 60 * 24 * 30 * 1000);\n document.cookie = \"__adblocker=\" + (adblocker ? \"true\" : \"false\") + \"; expires=\" + d.toUTCString() + \"; path=/\";\n }\n var script = document.createElement(\"script\");\n script.setAttribute(\"async\", true);\n script.setAttribute(\"src\", \"//www.npttech.com/advertising.js\");\n script.setAttribute(\"onerror\", \"setAdblockerCookie(true);\");\n script.setAttribute(\"onload\", \"setAdblockerCookie(false);\");\n document.getElementsByTagName(\"head\")[0].appendChild(script);\n\n\n\n\n var admantx_url = ('https:'==document.location.protocol?'https:':'http:')+'//usasync01.admantx.com/admantx/service?request=' + escape('{\"decorator\":\"template.nbc_template\",\"key\":\"62263fff3cc1d07f85c7f8261a0c8f7dc096b35f59c82a713f20a9db8d562ff2\",\"method\":\"descriptor\",\"filter\":\"default\",\"mode\":\"async\",\"type\":\"URL\",\"body\":\"' + escape(document.location.href) + '\"}');\n\n function admantx_callback(data) {\n if (top.__nbcudigitaladops_inject && top.__nbcudigitaladops_inject.dtprm) {\n if (data && data.admants) {\n if (data.status == \"OK\") {\n for (var x = 0; x < data.admants.length; x++) {\n var kv = 'adg=' + data.admants[x] + ';';\n top.__nbcudigitaladops_inject.dtprm(kv)\n }\n } else {\n top.__nbcudigitaladops_inject.dtprm(\"asg=othererror;\")\n }\n }\n }\n }\n (function() {\n var sct = document.createElement('script');\n sct.src = admantx_url;\n sct.type = 'text/javascript';\n sct.async = 'true';\n var domel = document.getElementsByTagName('script')[0];\n domel.parentNode.insertBefore(sct, domel);\n })();\n\n\n\n\n if(typeof window.MediaSource !== 'function') {\n if(typeof document.getElementsByTagName('meta')['tp:PreferredRuntimes'] === 'object') {\n document.getElementsByTagName('meta')['tp:PreferredRuntimes'].setAttribute(\"content\", \"flash,html5\");\n }\n}\n\n\n\n\n\n\n\tCryptocurrency ETFs proved too risky for ETF Managers Group Founder and CEO Sam Masucci, but he threw caution to the wind with his latest marijuana ETF — and it's paying off.\t\"The business is growing, the companies entering it are growing,\" Masucci said on CNBC's \"Fast Money.\"\t\"We see this as a tremendous investment opportunity.\"\tETF Managers Group in late December launched Alternative Harvest ETF, which tracks around 30 domestic and international stocks that may benefit from the growing marijuana industry. The ETF started with $5 million in assets under management and has grown to around $400 million in just under a month, Masucci said.\tSince Attorney General Jeff Sessions rescinded the Cole Memo, sending pot stocks tumbling, there is reason to be concerned when dealing big money in marijuana. But Masucci has accepted a degree of volatility, something he wasn't willing to do with cryptocurrency.\t\"We can't explain the volatility within bitcoin. Until we are comfortable with it and we know how to trade it, we don't see ourselves getting involved,\" he said.\tA majority of Alternative Harvest's companies are based in Canada or other countries, where legalization is impending or where regulations are more lax. As far as domestic companies go, Masucci said ETF Managers Group was careful to pick those best suited to benefit from the cannabis boom, like hydroponics company Scott's Miracle Gro or cigarette manufacturer Philip Morris.\t\"We will continue to participate in those companies that are largest, and right now, the largest piece is outside of the U.S.,\" Masucci said. \tDespite Sessions' actions, Masucci has high hopes that the U.S. cannabis industry will stick around. \t\"Twenty-eight states now have approved medical marijuana, 16 more have it on the docket for this year,\" Masucci said.\t\"There are so many medical advancements now happening with the cannabidiol oils and the uses of the plant, I don't see that going away,\" he added.\t\tPlaying\tShare this video...\tWatch Next...\nReal time prices\"vires in numeris.\"\tBitcoin\tETHEREUM\tNAGA\tReceive all Bitcoinist news in Telegram!\tMiami has apparently witnessed the “hottest” winter ever in its history, as thousands of Bitcoin enthusiasts had gathered at James L Knight Center for the North American Bitcoin Conference (NABC) on Jan 18 and 19. Known as BTCMiami, the conference was organized by the UAE-based Keynote, who has successfully led 12 blockchain and cryptocurrency events worldwide since 2012. \tEnjoying a rigorous reputation in the field of cryptocurrency and blockchain, NABC has been attracting company representatives, economists, researchers, and media operatives. Even a mobile app was particularly created for the sole purpose of networking among the conference attendees.\tAchain VP Kyle Liu Speaking at BTCMiami\tAchain, one of the world’s leading public blockchain platforms, had its spokesperson Kyle Lu share the basic principles as well as recent updates of its forking theory. The theory outlines Achain’s vision of a collaborative blockchain system — something that is rather divergent from the competitiveness and exclusiveness that most blockchain solutions tend to emphasize. That being said, under a mutual agreement from all participants (namely, the VEP), Achain fosters a full range of free communication, such as requesting, approving, executing, and returning feedbacks (mandatory for all constituent nodes).\tKyle Lu, vice president of Achain, has also founded ICO Star, a global crypto-assets investment platform. Meanwhile being a serial entrepreneur in big data and mobile internet, Kyle Lu is making waves in business transformation and disruptive technology adoption.\tAs of now, Achain serves as a foundation for multiple blockchain-based services and individual programs. It already runs more than 50 smart contracts and 30 digital assets.\tAchain’s booth at BTCMiami\tLater at the event, Achain opened up a Q&A booth to make its technology intelligible and accessible to its potential partners and the crowd. The project’s management executives regard the North American market as the team’s next strategic step. Over the recent months, it had already grown its presence in Southeast Asia, particularly with the launching of Indonesian-based DAPP project Pundi X at Blockshow Asia 2017 in Singapore.\tImages courtesy of Achain\tThe content of this article was provided by the company referenced. Bitcoinist does not endorse and is not responsible for or liable for any content, accuracy, quality, advertising, products or other materials on this page. Readers should do their own research before taking any actions related to the company.\tThe combined cryptocurrency market cap has passed $400 million again for the first time since March 8 as Bitcoin price soars to multi-week highs. Bitcoin Price Bulls Are Back Data from major exchanges and Coinmarketcap shows that as of press time April 24, the implied value of all tracked assets has reached $421 million. Building on its latest uptick which began Friday, Bitcoin reached further highs of $9280 Tuesday, managing to find support at the\tIn what one senior analyst calls a struggle “to remain relevant,” Bitcoin Cash (BCH) has been burning $12 worth of its own supply every day — hoping the increased scarcity will help in its fight against its dominant competitor, Bitcoin (BTC). ‘Purely a PR game’ Bitcoin Cash (BCH), a hard-forked cryptocurrency meant to solve Bitcoin’s (BTC) scalability issues, is up 100 percent against the USD in the last seven days. Trading against rival BTC, BCH\t \t© 2018 Bitcoinist.com. All Rights Reserved.\nThe bitcoin craze has officially jumped to real estate. \tDespite the risky, volatile nature of cryptocurrency, homes and property across the U.S., Australia, Canada, and beyond are for sale for the unpredictable coin. Even after one bitcoin dropped from $14,000 to $11,000 in value in a matter of days, homeowners are still putting up their homes for some of that flashy money.\tSEE ALSO: Cool, so people are selling their houses in exchange for Bitcoin now\tIt's not just a few listings here and there. According to Bitcoin Real Estate, a site that has been tracking the business for several years, the trend is growing more and more and not slowing down.\tAt the end of 2017 a Miami condo reportedly sold for 17.7 bitcoin and actual cryptocurrency was exchanged between the buyer and seller. Not just bitcoin converted into cash, which is the more popular way to use the coin.\tTrulia spokeswoman Andrea McDonald found 80 listings on the site that reference cryptocurrency in some way. Many just note \"bitcoin accepted,\" but others really get into it.\tA property near Joshua Tree National Park in Southern California makes that case for paying with cryptocurrency, insisting that the property \"can be a nice investment for future at a very reasonable $5,250 per acre for a total of $2.1 million or 124 bitcoins.\"\tAnother home in West Palm Beach, Florida, is open to buyers with bitcoin and ethereum and litecoin, but with the caveat that cryptocurrencies are constantly changing. \"Owner financing possible $149,900 USD, 13 bitcoin 375 ethereum, 950 litecoin (crypto price subject to change. Inquire crypto price at time of interest),\" the listing says.\tSo far Trulia hasn't officially seen a sale go down with the coin, McDonald said, but it's probably just a matter of time.\tSF real estate listings be like pic.twitter.com/yKPDmNc9uu\t— Jill Carlson (@_jillruth) January 12, 2018\tRedfin, another online real estate database, has also seen a crypto trend in its listings, especially in hubs like the Bay Area and Miami. The number of listings that accepted cryptocurrency jumped from 75 in December to 134 in mid-January. Some of those 134 listings have sold, but as a Redfin spokesman explained it's unclear if cryptocurrency was used for all or a portion of the sale price.\tSome of the listings are trying so hard to initiate a cryptosale. A Florida home used all caps and asterisks to lure in investors, screaming, \"**BITCOIN SALE PREFERRED! Unique opportunity to be one of the first transactions using Bitcoin.**\". Another listing for a property in Washington state, meanwhile, was generous with exclamation points: \"Seller willing to accept BITCOIN!!! The new rate of cryptocurrency that [sic] taking the world by storm!\" \tAaron Drucker, a Redfin agent in Miami, said in a phone call that including cryptocurrency in a listing gives a property more exposure. He's also noticed that bitcoin listings tend to be luxury condos. \"Earlier investors in bitcoin have made a lot of money,\" he said. \"They may want to convert some of that into a tangible asset.\"\t\"I wouldn’t recommend this for first-time home buyers.\"\tBut bitcoin sales aren't for everyone. \"I wouldn’t recommend this for first-time home buyers,\" he added. \"But if you want to buy a second home, this might be something to consider.\" No matter how you look it at, Drucker said, it's \"definitely risky.\"\tOthers are using bitcoin and other coins for their lucrative value. A Redfin agent in San Diego helped a buyer cash out two bitcoin valued then at nearly $7,500 each to cover closing costs for a home in Carlsbad, California. \tCarina Isentaeva, a Redfin agent in San Francisco, is in the center of the crypto-mania. In a call she said it's all about \"crypto homes\" now. She had a deal that fell through because the buyer's ICO flopped. But more surprising to Isentaeva was that the seller was willing to work with a cryptocurrency contingent sale. \"You couldn’t imagine this a few years ago,\" she said. \"Everyone would want to see a bank statement,\" not ICO filing paperwork.\tAnother big issue holding up more sales with actual cryptocurrency is regulation. Just finding an escrow service that will handle a crypto sale instead of traditional cash is difficult. As Isentaeva noted, the technology is moving much faster than government and laws. So the workaround is to convert bitcoin into cash and then buy property. But eventually the tech should catch up and the transaction will be more streamlined — at least that's what Isentaeva hopes.\tBut no matter the difficulties, the crypto listings keep coming. Welcome to the neighborhood, bitcoiners.\t\n-Bitcoin news, price, information & analysis\tIn a lengthy document to their highest profile clients, the Goldman Sachs Private Wealth Management division has warned about the danger of investing in cryptocurrency. For the banking giant, the rise in Bitcoin and other digital currencies during 2017 is a sure signal that the entire space is in an economic bubble.\tTypically for crypto naysayers, during the 108 page document the authors mention the Dutch “Tulipmania” of the seventh century, as well as the “dot-com” bubble of the turn of this century. However, they also go on to highlight the surge in the price of the stocks of firms loosely associating themselves with the cryptocurrency space:\t“The mania surrounding cryptocurrencies is probably even better illustrated by the price surges seen in companies that announce some type of affiliation with blockchain technology or cryptocurrencies.”\tFor Goldman Sachs, recent examples like Long Blockchain (LBCC) (formerly Long Island Ice Tea Group) and the Crypto Company (previously a sports bra company) seeing the value of their shares increase by a percentage of five figures is clear evidence of an economic bubble.\tDuring the document, Sharmin Mossavar-Rahmani and Brett Nelson (both senior officials at the Investment Strategy Group Goldman Sachs) do acknowledge some practical uses for the rapidly growing technology behind cryptocurrency. Again, they reiterated the enthusiasm for blockchain common amongst most central bankers of the world. However, for them Bitcoin does not provide enough of the advantages that other digital currencies could potentially deliver. They write:\t“We think the concept of a digital currency that leverages blockchain technology is viable given the benefits it could provide: ease of execution globally, lower transaction costs, reduction of corruption since all transactions could be traced, safety of ownership, and so on. But bitcoin does not provide any of these key advantages. Quite the contrary. Not only is there no ease of execution, but settlement often takes as many as 10 days. In late 2017, the price discrepancies among 17 US exchanges for one bitcoin amounted to $4,156, or about a 31% difference between the high and low prices. Transaction costs have skyrocketed, and frequent hacking has wiped out entire wallets and exchanges of their bitcoin holdings.”\tThe pair go on to highlight their scepticism that Bitcoin and other cryptos will maintain their current value in the long run. They’re also doubtful that cryptocurrency will replace the dollar as a global reserve currency.\tThe document, titled “(Un) Steady as She Goes” does not focus purely on Bitcoin, however. It serves as a round up of the various events happening in the previous 12 months that have affected the value of the dollar. It was sent exclusively to Goldman’s wealthiest clients. To be considered worthy of membership of the firm’s Private Wealth Management division, clients must have at least $10 million in assets that are available for investment purposes.\t \t \t \tshame on you talking about bitcoin (your worst enemy Nr 1 ) its natural goldman sachs talks like this regarding bitcoin rulles de world and put banks in danger …\tGoldman Sachs and its handling of mortgage-backed securities leading up to the 2007 financial crisis.\tYep, glad they have our back. So concerned about us when they don’t have their greasy paws in the till to profit from this time. Bummer…\tWhat a great response! It’s so true since when did they start caring about its investors or I mean the general public? Lol I know when they started losing money because everyone started investing in Crypto currencies instead of with them.\tBeen saying this for years. Bitcoin is like pokemon cards, everyone thinks the rare ones are valuable until they realize the only value they have is what someone else is potentially going to pay for it\tWhat price would you put on a censorship resistant means of exchanging value? I’m not being frivolous, I am genuinely curious.\tAnd just like that, your typical cryptocuck shows no understanding of basic economics\tanswer the question\tGet the latest news delivered to your inbox.\tFirst marketplace to sell & buy sensor data\tA next-generation blockchain commerce (bCommerce) infrastructure\tBlockchain platform for HR and educational services\tCrypto-based KYC checking platform\tCrypto economy zone\tReal estate platform of the future with blockchain technology\tCrypto-based loyalty platform\tHotel casino with crypto-economics\tcrypto mining company with extra low energy costs\tFinancial services platform\tCryptocurrency recycling mechanism\tUp to 100% cashback online and offline marketplace\tGlobal decentralized marketplace\tfixed income assets network\tCatalyzing the Future of Collaboration\tCrypto-Financial Services Network\tCryptocurrency based on natural resources \tPeer-to-peer (P2P) financing platform\tMovies streaming and film funding platform\tA blockchain based electricity trading & bidding platform\tAI for cryptocurrency price prediction\tСardboard building-sets for children and adults\tSocial platform for visual content monetization\tSmart reputation management on the blockchain\tFintech company that is building a base protocol to solve the payments challenges of today\tBlockchain platform for investment in neuro-medicine and neuro-technologies.\tBlockchain-enabled business platform\tplatform on blockchain for group investments\tPlatform created for soccer fans and team managements worldwide\tOnline shop with crypto payment\tNewsBTC is a news service that covers bitcoin news, technical analysis & forecasts for bitcoin and other altcoins. Here at NewsBTC, we are dedicated to enlightening people all around the world about bitcoin and other cryptocurrencies. We cover news related to bitcoin exchanges, bitcoin mining and price forecasts for various virtual currencies.\tFeaturing live charts, price analysis, breaking news, currency converter and more. The only bitcoin app you need!\t© 2018 NewsBTC. All Rights Reserved.\tCreated by Svecc Design.\t if (!window.AdButler){(function(){var s = document.createElement(\"script\"); s.async = true; s.type = \"text/javascript\";s.src = 'https://servedbyadbutler.com/app.js';var n = document.getElementsByTagName(\"script\")[0]; n.parentNode.insertBefore(s, n);}());} var AdButler = AdButler || {}; AdButler.ads = AdButler.ads || [];\nvar abkw = window.abkw || '';\nvar plc301228 = window.plc301228 || 0;\ndocument.write('<'+'div id=\"placement_301228_'+plc301228+'\"></'+'div>');\nAdButler.ads.push({handler: function(opt){ AdButler.register(172179, 301228, [250,250], 'placement_301228_'+opt.place, opt); }, opt: { place: plc301228++, keywords: abkw, domain: 'servedbyadbutler.com', click:'CLICK_MACRO_PLACEHOLDER' }});\nLitecoin has had a quite good public image in 2017, adding to the phenomenal rise from around $4 to a peak of $370. However, as the digital asset came into the spotlight, and the Litecoin Foundation tentatively started to promote Litecoin more, criticisms appeared.\t Popularity came with closer scrutiny, and a previously drama-free coin acquired its own negative points. Bullish on Litecoin Price: Top 5 Reasons for the Litecoin Boom With a lot of newcomers to the world of cryptocurrency, Litecoin would not be seen as a staple, but as just another coin deserving renewed scrutiny. And while older investors may be used to Litecoin, the renewed popularity brings the spotlight to the flaws.\t 1. Litecoin was artificially inflated: Litecoin was added to Coinbase last spring, and some see the move as artificial, mostly due to the influence of Charlie Lee as the technical director.\t From then onward, Litecoin quickly appreciated, and Charlie Lee became one of the most influential voices in the crypto community. In November and December, Litecoin saw another rapid appreciation, breaking above $100, coinciding with an appearance of Charlie Lee on CNBC TV.\t Without the accidental publicity, Litecoin had a rather negative image among traders, being called a “chicken” for its short-lived flights. Some believe the current values of Litecoin are not fair and the coin was pushed to the front without too much merit, being simply a copy of Bitcoin. 2. Read more from cryptovest.com…\tthumbnail courtesy of cryptovest.com\tIs chief doer at You Brand, Inc. and also master curator at the WordPress content curation platform Curation Suite.\t\nUsername or Email Address\n\n\t\nPassword\n\n\t Remember Me\t\n\n\n\t\n\n\t\t\tTrending:\t\t\tA Longmont man has been charged by the federal government with running a Bitcoin-based Ponzi scheme, defrauding hundreds of investors for $1.1 million\tDillon Dean and his company The Entrepreneurs Headquarters (THE) were formally charged by the U.S. Commodity Futures Trading Commission (CFTC) last week. The government agency alleges that Dean, through TEH, conducted a “fraudulent Ponzi-style” scheme, misappropriated funds and failed to register with the CFTC “in any capacity.”\tDean did not respond to requests for comment. Due to the government shutdown, officials for the CFTC could not be reached, according to a recorded message greeting callers to the agency.\tMore than 600 investors gave at least $1.1 million worth of Bitcoin to TEH,which promised that it would be pooled and invested in various options. The CFTC claims that, rather than investing, Dean used the funds to pay other investors, “in the manner of a Ponzi scheme.”\t“Defendants were not actually engaged in trading on behalf of their customers, and Defendants’ purported trading profits were fictitious,” the CFTC statement read. “As alleged in the Complaint, Defendants stopped making payments to their customers, having misappropriated over $1 million in customers’ funds.”\tAngry investors first alerted the Daily Camera to Dean’s alleged fraud in December, after he posted a message to a private Facebook group alleging that TEH was hit by hackers. Requests for refunds were intermittently honored, and communication with Dean became less and less frequent.\tNo money was ever returned to Louisiana-based investor Collin Bercier, who says he invested $50,000 worth of Bitcoin with TEH. Given the crypto-currency’s recent meteoric rise, that initial investment would be worth well over $1 million today, he said.\tTo read more of this story go to dailycamera.com\n...\tWell managed bug bounty service offerings are Uber to traditional consultancies taxis.\t* Indicates a required field.\tUnderstanding Mobile Device Wi-Fi Traffic AnalysisBy Erik Choron\tLearning CBC Bit-flipping Through GamificationBy Jeremy Druin\tUsing Virtualization in Internal Forensic Training and AssessmentBy Courtney Imbert\tLast 25 Papers »\tLooking for a way to advance your #cybersecurity career? Che [...]April 24, 2018 - 12:15 PM\tHelp us understand the true costs of endpoint management. Ta [...]April 24, 2018 - 11:01 AM\tIt is an exciting time to work in the #cybersecurity industr [...]April 24, 2018 - 9:45 AM\t301-654-SANS(7267)\n Mon-Fri 9am - 8pm EST/EDT\[email protected]\t\"It has really been an eye opener concerning the depth of security training and awareness that SANS has to offer.\"- Michael Hall, Drivesavers\t\"As a security professional, this info is foundational to do a competent job, let alone be successful.\"- Michael Foster, Providence Health and Security\t\"Because of the use of real-world examples it's easier to apply what you learn.\"- Danny Hill, Friedkin Companies, Inc.\nIn its latest note published earlier today, the analysts at Goldman Sachs warned on Bitcoin (BTC) and cryptocurrency overvaluation.\tKey Points:\tNo doubt BTC rise over the past year has pushed it into bubble territory.\tThe \"meteoric rise in a short time has dwarfed the rise seen during the dot-com bubble\".\tCryptocurrencies have moved beyond bubble levels in financial markets and even beyond the levels seen during the Dutch 'tulip mania' between 1634 and early 1637.\t\r\n Information on these pages contains forward-looking statements that involve risks and uncertainties. Markets and instruments profiled on this page are for informational purposes only and should not in any way come across as a recommendation to buy or sell in these securities. You should do your own thorough research before making any investment decisions. FXStreet does not in any way guarantee that this information is free from mistakes, errors, or material misstatements. It also does not guarantee that this information is of a timely nature. Investing in Forex involves a great deal of risk, including the loss of all or a portion of your investment, as well as emotional distress. All risks, losses and costs associated with investing, including total loss of principal, are your responsibility.\r\n \tNote: All information on this page is subject to change. The use of this website constitutes acceptance of our user agreement. Please read our privacy policy and legal disclaimer.\tTrading foreign exchange on margin carries a high level of risk and may not be suitable for all investors. The high degree of leverage can work against you as well as for you. Before deciding to trade foreign exchange you should carefully consider your investment objectives, level of experience and risk appetite. The possibility exists that you could sustain a loss of some or all of your initial investment and therefore you should not invest money that you cannot afford to lose. You should be aware of all the risks associated with foreign exchange trading and seek advice from an independent financial advisor if you have any doubts.\tOpinions expressed at FXStreet are those of the individual authors and do not necessarily represent the opinion of FXStreet or its management. FXStreet has not verified the accuracy or basis-in-fact of any claim or statement made by any independent author: errors and Omissions may occur.Any opinions, news, research, analyses, prices or other information contained on this website, by FXStreet, its employees, partners or contributors, is provided as general market commentary and does not constitute investment advice. FXStreet will not accept liability for any loss or damage, including without limitation to, any loss of profit, which may arise directly or indirectly from use of or reliance on such information.\nHyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.\twax_on: Hyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.My kids LOVE that movie. To the point where I've actually thought about *hack cough* buying it. On a recent plane trip there was a complete meltdown because of all the movies I had loaded onto the iPad, Boss Baby wasn't one of them.\tHyjamon: wax_on: Hyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.My kids LOVE that movie. To the point where I've actually thought about *hack cough* buying it. On a recent plane trip there was a complete meltdown because of all the movies I had loaded onto the iPad, Boss Baby wasn't one of them.*daddy fist bump* granted that isn''t the movie to cause meltdown for my brood, but I understand the mechanics.\"whaddaya mean the tablet doesn't work in the car/plane/train?!\"\tVaginosilicosis: I read the article, sorta, it was painful but I have no idea what he thought he was buying. WTF is \"bitcoin gear\"? Did this toolbag think he was buying actual Bitcoins or did he think he was buying a mining rig...either way I don't think $3k buys much of either.\tHyjamon: Hyjamon: wax_on: Hyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.My kids LOVE that movie. To the point where I've actually thought about *hack cough* buying it. On a recent plane trip there was a complete meltdown because of all the movies I had loaded onto the iPad, Boss Baby wasn't one of them.*daddy fist bump* granted that isn''t the movie to cause meltdown for my brood, but I understand the mechanics.\"whaddaya mean the tablet doesn't work in the car/plane/train?!\"currently mine are into Captain Underpants...I can appreciate it, but Kevin Hart's voice just won't allow me to get into it.paddington bear 2 was ....bearable/groan\tBedstead Polisher: I'm still waiting for that perfect moment to cash in on my Beanie Babies.\tdrunk_bouncnbaloruber: I am shocked...SHOCKED, that \"Bitcoin\" and \"scam\" are used in the same sentenced.[reactiongifs.us image 360x240]\twax_on: Hyjamon: Hyjamon: wax_on: Hyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.My kids LOVE that movie. To the point where I've actually thought about *hack cough* buying it. On a recent plane trip there was a complete meltdown because of all the movies I had loaded onto the iPad, Boss Baby wasn't one of them.*daddy fist bump* granted that isn''t the movie to cause meltdown for my brood, but I understand the mechanics.\"whaddaya mean the tablet doesn't work in the car/plane/train?!\"currently mine are into Captain Underpants...I can appreciate it, but Kevin Hart's voice just won't allow me to get into it.paddington bear 2 was ....bearable/groanOh yeah, Captain Underpants. I rented that one and we watched it 3 times in 48 hours, I think they're over it now. It didn't make me squirm though. We watched Paddington 1 on Netflix the other night and my bigger boy said it was boring. We decided not to see Paddington 2.I've tried to get my kids to watch Pixar films but other than 'Cars' they're not interested, even 'Monsters Inc.' didn't go over with my monster obsessed little boys. Happily the Disney crap hasn't gotten to them, I think that stuff is more appealing to girls. My current TV happy spot is 'Sarah & Duck' on Netflix. Ahh, calming.Not that my kids get saturated with media. But some evenings when I'm sick of dealing with little kids and trying to get dinner on the table and they're refusing to play in their room, parking them on the couch in front of the TV is just about the only option. Don't know what parents did before the advent of moving images.\twax_on: Hyjamon: Hyjamon: wax_on: Hyjamon: Movie was terrible. I have changed 1000's of diapers and yet to run across something that stunk more that than movie.My kids LOVE that movie. To the point where I've actually thought about *hack cough* buying it. On a recent plane trip there was a complete meltdown because of all the movies I had loaded onto the iPad, Boss Baby wasn't one of them.*daddy fist bump* granted that isn''t the movie to cause meltdown for my brood, but I understand the mechanics.\"whaddaya mean the tablet doesn't work in the car/plane/train?!\"currently mine are into Captain Underpants...I can appreciate it, but Kevin Hart's voice just won't allow me to get into it.paddington bear 2 was ....bearable/groanOh yeah, Captain Underpants. I rented that one and we watched it 3 times in 48 hours, I think they're over it now. It didn't make me squirm though. We watched Paddington 1 on Netflix the other night and my bigger boy said it was boring. We decided not to see Paddington 2.I've tried to get my kids to watch Pixar films but other than 'Cars' they're not interested, even 'Monsters Inc.' didn't go over with my monster obsessed little boys. Happily the Disney crap hasn't gotten to them, I think that stuff is more appealing to girls. My current TV happy spot is 'Sarah & Duck' on Netflix. Ahh, calming.Not that my kids get saturated with media. But some evenings when I'm sick of dealing with little kids and trying to get dinner on the table and they're refusing to play in their room, parking them on the couch in front of the TV is just about the only option. Don't know what parents did before the advent of moving images.\tIf you like these links, you'll love\tCome for the Total, stay for the Farking.\tSign up for the Fark NotNewsletter!\tLinks are submitted by members of the Fark community.\tWhen community members submit a link, they also write a custom headline for the story.\tOther Farkers comment on the links. This is the number of comments. Click here to read them.\tYou need to create an account to submit links or post comments.\tClick here to submit a link.\tAlso on Fark\tSubmit a Link »\t\n Copyright © 1999 - 2018 Fark, Inc | Last updated: Apr 24 2018 09:29:56\nContact Us | Report a bug/error msg | Advertise on Fark | Terms of service/legal/privacy policy\n Runtime: 0.143 sec (143 ms) \nzulius: [img.fark.net image 425x170]/in case you don't know, \"Shut Up and Dance\" black mirror episode...//the whole series is worth a binge...\tTanqueray: [img.fark.net image 780x226]\tWant more news before we break it? Try\tSee what's behind the green doorand help keep the tap flowing\tSign up for the Fark NotNewsletter!\tLinks are submitted by members of the Fark community.\tWhen community members submit a link, they also write a custom headline for the story.\tOther Farkers comment on the links. This is the number of comments. Click here to read them.\tYou need to create an account to submit links or post comments.\tClick here to submit a link.\tAlso on Fark\tSubmit a Link »\t\n Copyright © 1999 - 2018 Fark, Inc | Last updated: Apr 24 2018 09:29:54\nContact Us | Report a bug/error msg | Advertise on Fark | Terms of service/legal/privacy policy\n Runtime: 0.280 sec (279 ms) \nWhen the mystical Satoshi Nakamoto implemented the first blockchain a decade ago, they probably didn’t imagine it would explode into the disruptive force it is today. Initially used to support the first cryptocurrency, bitcoin, various iterations of the blockchain are increasingly finding their way into industries outside of fintech, bringing unprecedented change to these industries.\tThe blockchain, a decentralized ledger that permanently records transactions on its network, has provided the building blocks for many of the disruptive trends we’ve seen in recent years. It has seen the rise of dozens of cryptocurrencies in addition to bitcoin, some of which have had a wild rally in 2017, including bitcoin itself.\tWe’ve also seen Initial Coin Offerings (ICOs), the blockchain-based funding model, become more valuable than some traditional funding models. In 2017, ICO-backed startups raised over $3.2 billion in funding from token sales, surpassing amounts raised by early-stage VC funding.\tBut perhaps the most interesting applications of the blockchain have come from its use away from its parent industry, fintech. It’s been used in real estate, record management, asset tracking, and has shown a lot of promise in healthcare, identity management, and dozens of other traditional niches.\tHere are some of the most interesting implementations of the blockchain you’ll likely see this year.\tReal Estate\tTowards the end of last year, the first known blockchain-based real estate transaction was completed when TechCrunch co-founder, Michael Arrington, snapped up a Ukrainian apartment for about $60,000 via the Ethereum blockchain. The transaction was conducted entirely via smart contracts, a feature native to the Ethereum blockchain.\tThe sale represented one of the neatest implementations of the blockchain in the real world. Soon, blockchain-powered startups such as Ubitquity and Propy, the real estate company that brokered the Ukrainian transaction, will be helping everyday clients search for apartments, organize their storage lots, and close overseas property deals without ever visiting a bank or a lawyer.\tMedia\tThere’s also been increased interest in the blockchain from both old and new media companies, primarily because of the potential to transform content distribution.\tAt the 2018 edition of the CES tech exhibition, Kodak announced plans to launch its own token, the KodakCoin, to help manage licensing and image rights for photographers. KodakCoin would run on a blockchain designed to keep track of image rights and compensate creators for their work.\tComcast is also perfecting its blockchain-powered ad network, enabling companies to buy ads on over-the-top (OTT) and broadcast TV via the blockchain.\tIn addition to Kodak and Comcast, a good number of startups are helping bring blockchain technologies into traditional media.\tMedical and healthcare\tThe blockchain’s decentralized network also makes it a perfect fit for the healthcare industry, especially in the areas of supply chain management, record keeping, and asset tracking.\tAnd it’s not only early-stage startups that are using the blockchain to tackle healthcare issues. Last year, IBM Watson and the US FDA signed an agreement to develop a blockchain-based system to keep track of patient data from medical records, genome testing, clinical trials, and other traditional sources of patient data.\tIt’s definitely going to be a fun and interesting year for the blockchain.\t\n\n\n\n(adsbygoogle = window.adsbygoogle || []).push({});\n\t\n\n\n\t\n\n\tFree Daily Newsletter!\tSHOP!\tHiddenValueStocks\tTesla Model Y Release Date, Features, News And Rumors\tSamsung Galaxy X Release Date, Features, News And Rumors\tPlayStation 5 Release Date, Specs, News And Rumors\tGoPro Hero 6 Price, Specs: Everything You Need To Know\tSamsung Galaxy Note 9 Release Date, Features And Specs\tGoogle Pixel 3 release date, specs, news and rumors\tBitcoin Price Prediction Latest News And Update\tiOS 11 Jailbreak: What Is The Jailbreaking Status?\tiPad Pro 3: The Ultimate Wish List For The Apple Tablet\tApple Watch Series 4 Release Date, Price And Features [RUMORS]\t2017 Hedge Fund Letters\tFamous Investor Book List\t\n\n\n (adsbygoogle = window.adsbygoogle || []).push({});\n\t\n\n\n\n(adsbygoogle = window.adsbygoogle || []).push({});\n\nHey look, a visual representation of Bitcoin prices. Photo by Priscilla Du Preez on Unsplash Just like a hiker hoofing up and down across a jagged mountain range, anyone who follows the price of Bitcoin is probably getting pretty tired.\t From a high of over $19,000 in December of last year to around $10,000 today, the price has been changing so quickly that any news coverage of it is quickly out of date. As if the wild changes weren’t enough, the price can even vary slightly depending on where you look for it.\t Here’s what generates those crazy prices, and the small differences between them, that you might see the next time you shop for cryptocurrencies. The price at any moment is a natural result of the trading that happens on cryptocurrency exchanges in a process called price discovery.\t For example, consider Coinbase.com— a popular hub, or brokerage, for people who want to buy or sell Bitcoin. If you purchase there, the entity selling you the cryptocurrency is actually Coinbase itself.\t Coinbase.com has a sister site, called GDAX, which stands for Global Digital Asset Exchange—that’s a marketplace for professional traders and institutions, and that’s where the price discovery happens. The price of the last trade on GDAX is the value of Bitcoin there at the moment, and that’s also the basis for the price you see on Coinbase.com. Read more from popsci.com…\tthumbnail courtesy of popsci.com\tIs chief doer at You Brand, Inc. and also master curator at the WordPress content curation platform Curation Suite.\t\nUsername or Email Address\n\n\t\nPassword\n\n\t Remember Me\t\n\n\n\t\nGiven the volatility of cryptocurrencies like Bitcoin (BTC), Ethereum (ETH), and Ripple (XRP), it's good to keep track of your transaction history and get a better idea where you stand financially. Though tracking down past trades on Binance may seem convoluted at first, it gets surprisingly intuitive once you get the hang of it.\tStaying on top of all your transactions — whether they're trades, deposits, or withdrawals — not only helps in painting a clearer picture of how much you've spent, but also aids in understanding your portfolio's overall health. This in turn can help you decide on pulling the trigger on future transactions to ensure you get the most out of your trades.\tTo start, open the Binance app for Android or iPhone and tap on \"Funds.\" From there, tap on \"History\" in the upper-right corner of the screen. You'll now see a page containing logs for all your deposits and withdrawals. Tap on the Deposits History tab to view all your past deposits into Binance, or select the Withdrawals History tab on the right to see all your past withdrawals out of the exchange.\tTo view your trade history on Binance, tap on \"Markets,\" then select any base currency. Alternatively, if you have any trading pairs saved, select \"Favorites,\" then tap on any trading pair. Either way, select either \"Buy\" or \"Sell\" from within the summary page to get into that coin or pair's buy or sell page.\tInside the coin or trading pair's buy or sell page, tap on \"Trade History\" in the upper-right corner of the screen. You'll now be taken to a page detailing all your past transactions. From here, you can check out all your past trades, including the time of the transaction, amount of coins bought or sold (along with their rates), and fees paid if you have an iPhone.\tIf you're using an Android device, you'll need to tap on each transaction summary within the \"Order History\" page to view the history in detail.\tDon't Miss: Fees & Fine Print You Need to Know Before Trading Bitcoins & Other Cryptocurrencies on Binance\nperformance.mark('first image displayed');The economist Joseph Stiglitz speaking at the 2016 IMF World Bank Spring Meeting in Washington.\n Thomson Reuters\n \t It's not a secret that Joseph Stiglitz, the Nobel Prize-winning economist and Columbia professor, is not a special fan of bitcoin. \t He has called for the cryptocurrency to be outlawed, arguing that it is used primarily for illicit purposes such as money laundering and tax evasion. \t Pressed about it during a Bloomberg Television interview from Davos, Switzerland, where the World Economic Forum is happening this week, Stiglitz explained his rationale in simple terms. Essentially, he says, bitcoin is attempting to solve a problem that never existed. \t \"We have a good medium of exchange called the dollar,\" he told Tom Keene of \"Bloomberg Surveillance\" on Tuesday morning from the snow-capped Swiss peaks. \"We can trade in that. Why do people want bitcoin? For secrecy.\" \t The banking system can and is already moving toward greater use of digital payments, Stiglitz added, \"but you don't need bitcoin for that.\" \t \"My feeling is that when you regulate it so that you couldn't engage in money laundering and all these other things, there would be no demand for bitcoin,\" he said. \"So by regulating the abuses you are going to regulate it out of existence.\" \t The price of bitcoin crashed recently after a jaw-dropping run-up that drove it to a peak of nearly $20,000 a coin. The decline has been driven in part by fear of increased regulation in major Asian economies like South Korea and China. \t\n Market Insider\n \t Get the latest Bitcoin price here.>>\t\t\nThomson Reuters\t\tDave Lutz, head of ETFs at JonesTrading, has an overview of today's markets.\tHere's Lutz:\tGood Morning! US Futures were marked higher, led by QQQs as NFLX leaps 8%+ on numbers, but drawdowns in the commodity complex, coupled with profit-taking from all-time highs has weighed over the last hour. Earlier the DAX kissed a record high, led by a 2% squeeze in Healthcare - Airlines acting well behind EasyJet, while Retailers liking Carrefour headers. Right now the DAX is up 50bp in heavy trade, with volumes 40% above recent trend – Selling in the Banks seems to be a big trigger in the futures weakness in the last hour. The FTSE shrugging off stronger Sterling despite Banks lower and Miners getting hit, as Consumer names act well. It was a Strong overnight in Asia despite Trump Tariff Headers - Nikkei up 1.3% - Hang Seng up 1.7% as Consumer and Tech ripped higher - Shanghai up 1.3% - KOSPI adding 1.4% as Sammy jumped 2% - Aussie added 70bp - Sensex squeezed thru 36,000\tBOJ comments has a decent bid under both Yen and JGB’s – causing a rally across the Sovereign complex. A Strong ZEW has Bunds trading higher, pressing the German 10YY 2bp lower and weighing on Treasury Yields. Ahead of ECB Thursday, the Euro is drifting as it looses ground to the British Pound, as Sterling tests $1.40 overnight. Gold is bid despite the $ being slightly higher, while Bitcoin is rolling to test $10,000 on more South Korea Headers. Ore was hit for 4.5% in Singapore, driving Copper off 2% to fresh 2018 lows, while Platinum drops 50bp. WTI is up small despite the IEA seeing “Potential Further Upward Revision Of US Shale Output” – While Natty Gas continues to squeeze higher, up 3%, bringing YTD gains close to 13%. \tYour Personalized Market Center\nReal time prices\"vires in numeris.\"\tBitcoin\tETHEREUM\tNAGA\tReceive all Bitcoinist news in Telegram!\tEven though India is straddling the regulation fence when it comes to cryptocurrencies, the country’s major banks have taken the decision to temporarily close the accounts of a few of India’s top Bitcoin exchanges.\tAccording to the Economic Times, The State Bank of India, Axis Bank, HDFC Bank, ICICI Bank and Yes Bank are a few of the financial institutions that have provisionally shut down accounts of some top-performing exchanges. Anonymous sources have said that the closure is based on the fact that the exchange accounts were being used for a different reason than for what they were initially opened for.\tIt has previously been reported that even though India has not banned cryptocurrencies, the government has been attempting to regulate exchanges.\tSuspicious Transaction Reports need to be filed with the Financial Intelligence Unit by banks if anything out of the ordinary comes up on the accounts of the exchanges. A banker who prefers to remain anonymous said:\tWe have asked some of these companies to explain the businesses that they are involved in and why it was not specified when opening the accounts. We will also be flagging some of these suspicious transactions with the concerned agencies.\t\tIn addition to the closures, the banks are seeking more collateral on loans, and have also banned cash withdrawals from some exchanges.\tA source said:\tSince last month, banks have been asking for additional collateral with 1:1 ratio.\tSources have said that 10 exchanges have been targeted including Unocoin, Zebpay, CoinSecure, and BtcxIndia. The latter three, and most of the banks, have not responded to the suspension claims.\tAn emailed response from Sathvik Vishwanath, a promoter of Unocoin, to Economic Times stated:\tThe banks have not contacted the company or the promoters regarding the actions you have mentioned.\tIn addition, an anonymous banker involved has said:\tReserve Bank of India has not issued any directive to us, it’s a cautionary move on our part. We are wary about the purpose for which some of these current accounts are being used.\t\tAuthorities have also been looking into the tax implications of these exchanges, of which the top 10 could account for as much as $6 billion. A tax official who is part of a team looking into possibly applying a sales tax on Bitcoin exchanges had this to say:\tThese exchanges tend to show the total volumes both on buy and sell side as their revenue. In many instances, the exchanges themselves buy and sell cryptocurrencies on their own platform.\tA suspension of accounts will result in an inevitable cashflow issue for these exchanges, leading promoters to even offer their personal property as collateral. Even so, an investment banker has said that these platforms produce high revenue and strong margins. He did, however, add:\tWe would not like to invest till the taxation part is clarified.\tAs in most countries, tax processes on cryptocurrencies still remain unclear in India. Even so, two exchanges have already asked the Authority for Advance Rulings to determine if exchanges are required to pay goods and services tax (GST).\tWhat do you think of these alleged temporary suspensions? Do you think exchanges in India should be subjected to tax deductions? Let us know in the comments below!\tImages courtesy of AdobeStock, Shutterstock\tThe combined cryptocurrency market cap has passed $400 million again for the first time since March 8 as Bitcoin price soars to multi-week highs. Bitcoin Price Bulls Are Back Data from major exchanges and Coinmarketcap shows that as of press time April 24, the implied value of all tracked assets has reached $421 million. Building on its latest uptick which began Friday, Bitcoin reached further highs of $9280 Tuesday, managing to find support at the\tIn what one senior analyst calls a struggle “to remain relevant,” Bitcoin Cash (BCH) has been burning $12 worth of its own supply every day — hoping the increased scarcity will help in its fight against its dominant competitor, Bitcoin (BTC). ‘Purely a PR game’ Bitcoin Cash (BCH), a hard-forked cryptocurrency meant to solve Bitcoin’s (BTC) scalability issues, is up 100 percent against the USD in the last seven days. Trading against rival BTC, BCH\t \t© 2018 Bitcoinist.com. All Rights Reserved.\n\n\nElaine Ou | Bloomberg \t\t\t\t\t\t\t\t \t\t\t\t\t\t\t\t \t\t\t\t\t\t\t\t \t\t\t\t\t\t\t \n\n\t\t\t\t\t\t\t Last Updated at January 23, 2018 08:14 IST\n\thttp://mybs.in/2VjrETa\t\tCritics of Bitcoin often argue that it’s useless as a means of payment, one of the key elements of any successful currency. That’s not quite right, and likely to become less so.\t\r\nFirst, a reminder on how Bitcoin works. If I want to send someone some Bitcoin, I simply broadcast my intention to the network. I then wait for the transaction to be picked up by “miners,” who process transactions in return for fees and newly minted Bitcoin. If all goes well, my transaction will be included in a block, which becomes part of the global immutable ledger known as the Bitcoin blockchain. (Disclosure: I own some Bitcoin, because as a blockchain engineer I sometimes receive it as payment.)\n\r\nDespite complaints about the lack of usability, the network is being used to make a lot of payments. In the last three months of 2017, it processed almost $150 billion in transactions, nearly ten times what it did a year earlier and more than seven times what Western Union moves among consumers in a typical quarter. It’s important to note, though, that the actual number of transactions hasn’t changed -- it’s the average value of each transaction that keeps growing.document.write(\"<!--\");if(isUserBanner==\"free\"&&(displayConBanner==1))document.write(\"-->\");googletag.cmd.push(function(){googletag.defineOutOfPageSlot('/6516239/outofpage_1x1_desktop','div-gpt-ad-1490771277198-0').addService(googletag.pubads());googletag.pubads().enableSyncRendering();googletag.enableServices();});\n\t\r\nGranted, this is far from an ideal system if you want to pay for a cup of coffee. That’s because transactions must compete to get picked up by miners, who favor the ones that offer the biggest fees. Somebody who wants to move $1 million can easily afford to offer $20, but someone who wants to buy a pizza probably can’t. As a result, smaller transactions can languish -- a sort of inequality that has led some to accuse Bitcoin of becoming just another toy for the elite.\t\r\nWhat to do? One popular workaround involves exchanges and wallet providers such as Coinbase and Xapo, which hold Bitcoin on behalf of millions of individual customers. Coinbase last year estimated that they were storing about 10 percent of all bitcoin in circulation, and others have similarly large balances. People who use the same provider can make Bitcoin payments to one another instantly, through the provider’s own books, without the cost or delay of broadcasting to the blockchain. Xapo, for example, processes about 500,000 transactions a day off the blockchain, and only 30,000 on.\t\r\nSo transactions can be fast and cheap, as long as users are willing to rely on a trusted central counterparty -- but that’s exactly the kind of system that Bitcoin was designed to subvert. Not to mention the fact that wallet providers and exchanges have become prime targets for hackers.\t\r\nSo how can regular folks transact in Bitcoin while remaining true to its peer-to-peer ethos? A fledgling network called Lightning offers one solution: It allows people to create two-way channels through which they can make numerous small payments, with only the final balances settled on the blockchain. To deal with the issue of trust, it requires users to put down deposits that can be forfeited if they fail to make good on their obligations.\t\r\nLightning is still in its infancy, and might not be enough to make Bitcoin universally accessible. It does, however, have the potential to offer low-cost payment processing while retaining Bitcoin’s permissionless nature. Other solutions based on the same technology might even enable decentralized exchanges.\t\nBitcoin will never be the universal communal ledger that many early advocates imagined. It’s simply not realistic to replicate every petty cash transfer on computers all around the world. That said, if the Bitcoin blockchain acts as a sort of wholesale settlement backbone for numerous retail networks such as Lightning, it could yet fulfill the goal of creating a genuine peer-to-peer payment system. That would be an impressive achievement in itself.\t\r\nThis column does not necessarily reflect the opinion of the editorial board or Bloomberg LP and its owners.\r\n\tPREVIOUS STORY\tNEXT STORY\tCopyrights © 2018 Business Standard Private Ltd. All rights reserved.\t\tUpgrade To Premium Services\t Business Standard is happy to inform you of the launch of \"Business Standard Premium Services\"\tAs a premium subscriber you get an across device unfettered access to a range of services which include:\t\tPremium Services \tIn Partnership with \tDear Guest,\tWelcome to the premium services of Business Standard brought to you courtesy FIS.\r\n Kindly visit the Manage my subscription page to discover the benefits of this programme.\n\r\n Enjoy Reading!\r\n Team Business Standard\r\n \n-Bitcoin news, price, information & analysis\tTwo of Scandinavia’s largest banks have expressed their concern over Bitcoin and other digital currencies. According to a memo sent on Monday, Nordea will no longer allow its employees to trade cryptocurrency. \tThe ban was confirmed by a phone call received by news outlet Bloomberg which also set a date for the new regulation coming into effect – February 28. Afroditi Kellburg, a spokesperson at the bank cites the “unregulated nature” of the digital currency market as reasoning behind the decision. Additional concerns were the lack of protective measures in place to support investors in the space and the lack of transparency some cryptos have. Finally, Kellburg also highlighted issues with volatility and liquidity to the news source.\tThe policy from Nordea will include some “transitional provision for staff with existing holdings” and will allow “for certain exceptions”. This means that any of the 31,500 current employees at the financial institution will be able to keep their existing crypto holdings.\tMeanwhile, another Scandinavian bank has also expressed skepticism about the cryptocurrency market. Danske Bank A/S is the second largest Nordic bank. They too are discouraging employees from trading digital currencies. However, they are yet to make a decision on whether a similar blanket ban is required. Danske spokesperson Kenni Leth told the news source via email:\t“We’re sceptical toward cryptocurrencies and are advising our employees not to trade them, but we don’t impose an actual ban… We’re currently analysing the situation and time will tell whether there’ll be a formal ban.”\tNeither of the aforementioned Nordic banks currently offer any products for their clients to get involved with the cryptocurrency space. In the same email, Leth from Danske Bank stated:\t“Due to lack of maturity and transparency in the various cryptocurrencies, we have decided not to provide trading of such securities on our various investment platforms.”\tToday’s sentiment coming from the two banking institutions is in line with that expressed by Nordea’s Chief Executive Office Casper von Koskull. In an interview from last December, he called Bitcoin an “absurd” construction alleging that it completely defied logic. He went on to highlight an oft-repeated criticism of cryptocurrency, that it’s used to conduct financial crimes.\tMeanwhile the European Banking Federation have yet to impose any regulation surrounding Bitcoin. However, a spokesperson for them, Raymond Frenken, has also weighed on the topic of banks banning investment in cryptocurrency. Bloomberg report:\t“If banks like Nordea are going to have a very specific policy on this — and we’re hearing regulators are taking a look at this, including the ECB and central banks — probably it will be that it’s changing. With developments like this, it’s more likely that it will have to be discussed in the context of the European Banking Federation.”\tThe EBF spokesperson concluded by stating that this was the first they’d heard of a bank banning Bitcoin investments. “This could very well be a first”.\t \tAbsolute scum journalism, fud title for clickbait.\tSo, a bank(fiat) doesn’t want it’s employees to trade crypos(which is decentralised and they could anyways)…. And you call this ‘Nordic banks hostile’? Ulterior motives here, how much you get paid to create/post this anti-crypto fake news?\tThis is thankfully most will look at and see it for what it is before the weak hands strikes.\tShame on you, just shame on you.\tYour money is supposed to be your money, once an employee leaves work, they should be free to do what they want with their pay. I would hate to work for an organization who doesn’t even let me do as I want after work.\tGet the latest news delivered to your inbox.\tFirst marketplace to sell & buy sensor data\tA next-generation blockchain commerce (bCommerce) infrastructure\tBlockchain platform for HR and educational services\tCrypto-based KYC checking platform\tCrypto economy zone\tReal estate platform of the future with blockchain technology\tCrypto-based loyalty platform\tHotel casino with crypto-economics\tcrypto mining company with extra low energy costs\tFinancial services platform\tCryptocurrency recycling mechanism\tUp to 100% cashback online and offline marketplace\tGlobal decentralized marketplace\tfixed income assets network\tCatalyzing the Future of Collaboration\tCrypto-Financial Services Network\tCryptocurrency based on natural resources \tPeer-to-peer (P2P) financing platform\tMovies streaming and film funding platform\tA blockchain based electricity trading & bidding platform\tAI for cryptocurrency price prediction\tСardboard building-sets for children and adults\tSocial platform for visual content monetization\tSmart reputation management on the blockchain\tFintech company that is building a base protocol to solve the payments challenges of today\tBlockchain platform for investment in neuro-medicine and neuro-technologies.\tBlockchain-enabled business platform\tplatform on blockchain for group investments\tPlatform created for soccer fans and team managements worldwide\tOnline shop with crypto payment\tNewsBTC is a news service that covers bitcoin news, technical analysis & forecasts for bitcoin and other altcoins. Here at NewsBTC, we are dedicated to enlightening people all around the world about bitcoin and other cryptocurrencies. We cover news related to bitcoin exchanges, bitcoin mining and price forecasts for various virtual currencies.\tFeaturing live charts, price analysis, breaking news, currency converter and more. The only bitcoin app you need!\t© 2018 NewsBTC. All Rights Reserved.\tCreated by Svecc Design.\t if (!window.AdButler){(function(){var s = document.createElement(\"script\"); s.async = true; s.type = \"text/javascript\";s.src = 'https://servedbyadbutler.com/app.js';var n = document.getElementsByTagName(\"script\")[0]; n.parentNode.insertBefore(s, n);}());} var AdButler = AdButler || {}; AdButler.ads = AdButler.ads || [];\nvar abkw = window.abkw || '';\nvar plc301228 = window.plc301228 || 0;\ndocument.write('<'+'div id=\"placement_301228_'+plc301228+'\"></'+'div>');\nAdButler.ads.push({handler: function(opt){ AdButler.register(172179, 301228, [250,250], 'placement_301228_'+opt.place, opt); }, opt: { place: plc301228++, keywords: abkw, domain: 'servedbyadbutler.com', click:'CLICK_MACRO_PLACEHOLDER' }});\n-Bitcoin news, price, information & analysis\tBitcoin Price Key Highlights\tBitcoin price continued its slump and may be setting its sights on the lower Fib extension levels.\tTechnical Indicators Signals\tThe 100 SMA is below the longer-term 200 SMA so the path of least resistance is to the downside. In other words, the selloff is more likely to continue than to reverse.\tThese moving averages are close to the channel resistance, adding an extra upside barrier in the event of a test. If selling pressure persists, bitcoin price could break through the 38.2% level then move on to the 50% extension at $9148.52.\tThe next support is at the 61.8% extension at the bottom of the channel around $8200 then the 76.4% extension is located at $7066.67. Stronger selling momentum could lead to move all the way down to the full extension at $5205.62.\tStochastic is pulling up from the oversold region, though, indicating that buyers could take over price action and probably lead to a move up to the area of interest at $13,000-14,000. RSI, on the other hand, is still pointing down to signal that sellers are in control.\t\tMarket Factors\tThe dollar drew some support from the passage of the funding bill in Congress that effectively ends the government shutdown. Equities and bond yields also ticked higher, drawing investors back to the U.S. markets again.\tMeanwhile, bitcoin price tumbled once more as South Korean regulators took more steps to remove anonymity in transactions. The Vice Chairman of the Financial Services Commission real names on a virtual coin exchange wallet and bank account must be the same for a user to be able to make deposits starting January 30.\tlifes-a-bitch-coin.\tLove a sellers market to be frank #frankcoin\tGet the latest news delivered to your inbox.\tFirst marketplace to sell & buy sensor data\tA next-generation blockchain commerce (bCommerce) infrastructure\tBlockchain platform for HR and educational services\tCrypto-based KYC checking platform\tCrypto economy zone\tReal estate platform of the future with blockchain technology\tCrypto-based loyalty platform\tHotel casino with crypto-economics\tcrypto mining company with extra low energy costs\tFinancial services platform\tCryptocurrency recycling mechanism\tUp to 100% cashback online and offline marketplace\tGlobal decentralized marketplace\tfixed income assets network\tCatalyzing the Future of Collaboration\tCrypto-Financial Services Network\tCryptocurrency based on natural resources \tPeer-to-peer (P2P) financing platform\tMovies streaming and film funding platform\tA blockchain based electricity trading & bidding platform\tAI for cryptocurrency price prediction\tСardboard building-sets for children and adults\tSocial platform for visual content monetization\tSmart reputation management on the blockchain\tFintech company that is building a base protocol to solve the payments challenges of today\tBlockchain platform for investment in neuro-medicine and neuro-technologies.\tBlockchain-enabled business platform\tplatform on blockchain for group investments\tPlatform created for soccer fans and team managements worldwide\tOnline shop with crypto payment\tNewsBTC is a news service that covers bitcoin news, technical analysis & forecasts for bitcoin and other altcoins. Here at NewsBTC, we are dedicated to enlightening people all around the world about bitcoin and other cryptocurrencies. We cover news related to bitcoin exchanges, bitcoin mining and price forecasts for various virtual currencies.\tFeaturing live charts, price analysis, breaking news, currency converter and more. The only bitcoin app you need!\t© 2018 NewsBTC. All Rights Reserved.\tCreated by Svecc Design.\t if (!window.AdButler){(function(){var s = document.createElement(\"script\"); s.async = true; s.type = \"text/javascript\";s.src = 'https://servedbyadbutler.com/app.js';var n = document.getElementsByTagName(\"script\")[0]; n.parentNode.insertBefore(s, n);}());} var AdButler = AdButler || {}; AdButler.ads = AdButler.ads || [];\nvar abkw = window.abkw || '';\nvar plc301228 = window.plc301228 || 0;\ndocument.write('<'+'div id=\"placement_301228_'+plc301228+'\"></'+'div>');\nAdButler.ads.push({handler: function(opt){ AdButler.register(172179, 301228, [250,250], 'placement_301228_'+opt.place, opt); }, opt: { place: plc301228++, keywords: abkw, domain: 'servedbyadbutler.com', click:'CLICK_MACRO_PLACEHOLDER' }});\nPosted:\n22 Jan 2018, 19:52\n ,\n by Cosmin Vasile\n\tTags :\niOS-iOS+ Android-Android+ Apps-Apps+ \tMy go-to browser.\t\n\n Want to comment? Please login or register. \n\nPosted:\n22 Jan 2018, 19:52\n ,\n by Cosmin Vasile\n\tTags :\niOS-iOS+ Android-Android+ Apps-Apps+ \tMy go-to browser.\t\n\n Want to comment? Please login or register. \n\nBy\n\nReuters\n\t\nPublished:\n 21:52 EDT, 22 January 2018\n\n | \nUpdated:\n 00:12 EDT, 23 January 2018\n\n\t\tBy Cynthia Kim\tSEOUL, Jan 23 (Reuters) - South Korea will ban the use of anonymous bank accounts in cryptocurrency trading from Jan. 30, regulators said on Tuesday in a widely telegraphed move designed to stop virtual coins from being used for money laundering and other crimes.\tThe measure comes on top of stepped up efforts by Seoul to temper South Koreans' obsession with cryptocurrencies. Everyone from housewives to college students and office workers have rushed to trade the market despite warnings from global policymakers about investing in an asset that lacks broad regulatory oversight. The bitcoin price in South Korea extended loss following the latest regulatory announcement, down 3.34 percent at $12,699 as of 0409 GMT, according to Bithumb, the country's second-largest virtual currency exchange.\tBitcoin slumped nearly 20 percent last week to a four-week low on the Luxembourg-based Bitstamp exchange, pressured by worries over a possible ban on trading the virtual asset in South Korean exchanges. In Tuesday afternoon trade, it was up 5.4 percent at $10,925.\tPolicy makers around the world are calling for tougher, coordinated regulation of cryptocurrency trading. South Korea's chief financial regulator last week said the government may consider shutting down domestic virtual currency exchanges.\tSouth Korea's Presidential office has clarified that an outright ban on trading on the virtual currency exchanges is only one of the steps being considered, and not a measure that has been finalized.\t\"The government is still discussing whether an outright ban is needed or not, internally,\" a government official who declined to be named said after Tuesday's briefing.\tOver the past month, government statements have underscored differences between the Justice Ministry, which has pushed for a more hardline approach, and regulators who have shown a reluctance to enforce an outright ban.\tStarting Jan. 30, cryptocurrency traders in South Korea will not be allowed to make deposits into their virtual currency exchange wallets unless the names on their bank accounts matches the account name in cryptocurrency exchanges, Kim Yong-beom, vice chairman of the Financial Services Commission told a news conference in Seoul.\t\"Everyone knew this was coming, as the government already said they will enforce the real-name system before. Rather, I can see this as a chance to go in, not out. I don't see any reason to take my money out,\" said a local bitcoin investor who only agreed to be identified by his family name Ahn.\tThe regulator has previously said it will come up with detailed guidelines for local banks to properly identify its clients by their real names in cryptocurrency transactions.\tTo make deposits into virtual coin wallets, cryptocurrency traders will need to identify themselves with their real names at the exchange and have those matched with information at local banks by Jan. 30. (Reporting by Cynthia Kim; Additional reporting by Dahee Kim; Editing by Sam Holmes & Shri Navaratnam)\tSorry we are not currently accepting comments on this article.\tPublished by Associated Newspapers Ltd\tPart of the Daily Mail, The Mail on Sunday & Metro Media Group\n3 Min Read\tSEOUL (Reuters) - South Korea will ban the use of anonymous bank accounts in cryptocurrency trading from Jan. 30, regulators said on Tuesday in a widely telegraphed move designed to stop virtual coins from being used for money laundering and other crimes. \tThe measure comes on top of stepped up efforts by Seoul to temper South Koreans’ obsession with cryptocurrencies. Everyone from housewives to college students and office workers have rushed to trade the market despite warnings from global policymakers about investing in an asset that lacks broad regulatory oversight. \tThe bitcoin price in South Korea extended loss following the latest regulatory announcement, down 3.34 percent at $12,699 as of 0409 GMT, according to Bithumb, the country’s second-largest virtual currency exchange. \tBitcoin BTC=BTSP slumped nearly 20 percent last week to a four-week low on the Luxembourg-based Bitstamp exchange, pressured by worries over a possible ban on trading the virtual asset in South Korean exchanges. In Tuesday afternoon trade, it was up 5.4 percent at $10,925. \tPolicy makers around the world are calling for tougher, coordinated regulation of cryptocurrency trading. South Korea’s chief financial regulator last week said the government may consider shutting down domestic virtual currency exchanges. \tSouth Korea’s Presidential office has clarified that an outright ban on trading on the virtual currency exchanges is only one of the steps being considered, and not a measure that has been finalized. \t“The government is still discussing whether an outright ban is needed or not, internally,” a government official who declined to be named said after Tuesday’s briefing. \tOver the past month, government statements have underscored differences between the Justice Ministry, which has pushed for a more hardline approach, and regulators who have shown a reluctance to enforce an outright ban. \tStarting Jan. 30, cryptocurrency traders in South Korea will not be allowed to make deposits into their virtual currency exchange wallets unless the names on their bank accounts matches the account name in cryptocurrency exchanges, Kim Yong-beom, vice chairman of the Financial Services Commission told a news conference in Seoul. \t“Everyone knew this was coming, as the government already said they will enforce the real-name system before. Rather, I can see this as a chance to go in, not out. I don’t see any reason to take my money out,” said a local bitcoin investor who only agreed to be identified by his family name Ahn. \tThe regulator has previously said it will come up with detailed guidelines for local banks to properly identify its clients by their real names in cryptocurrency transactions. \tTo make deposits into virtual coin wallets, cryptocurrency traders will need to identify themselves with their real names at the exchange and have those matched with information at local banks by Jan. 30. \tReporting by Cynthia Kim; Additional reporting by Dahee Kim; Editing by Sam Holmes & Shri Navaratnam\tAll quotes delayed a minimum of 15 minutes. See here for a complete list of exchanges and delays.\t© 2018 Reuters. All Rights Reserved.\n"
]
],
[
[
"__Filtering Keyword List__",
"_____no_output_____"
]
],
[
[
"#Define list of keywords and new \nkeywords = pd.read_csv(\"corpora10_27.csv\")\nkeywords=keywords.iloc[:,0]\ndf_final = df\n\n",
"_____no_output_____"
],
[
"df_final.head()",
"_____no_output_____"
],
[
"#Traverse the articles array. \n#If you find an article that does not contain a keyword in the first 300 characters, remove it.\nn_removed = 0\nindices_to_drop = []\n\nfor i in df_final.index:\n first300 = df_final['contents'][i] #Grab first 300 characters of article text\n title = df_final['title'][i]\n n_keywords = 0\n try:\n assert type(first300) is str\n assert type(title) is str\n except:\n print(\"Found error in article\", i, \"- Passing\")\n indices_to_drop.append(i)\n continue\n \n for keyword in keywords:\n if keyword in first300 or keyword in title:\n n_keywords += 1\n break\n else:\n pass\n \n if n_keywords == 0:\n indices_to_drop.append(i)\n \n if len(indices_to_drop) % 100 == 0:\n print(\"Marked\", len(indices_to_drop), \"articles for removal\")\n \n if i % 10 == 0:\n print(\"Article\", i)\n \nprint(\"Total:\", len(indices_to_drop), \"articles marked for removal.\")",
"Marked 0 articles for removal\nArticle 0\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 10\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 20\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 30\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 40\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 50\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 60\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 70\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 80\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 90\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 100\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 110\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 120\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 130\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 140\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 150\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 160\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 170\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 180\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 190\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 200\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 210\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 220\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 230\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 240\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 250\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 260\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 270\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 280\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 290\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 300\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 310\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 320\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 330\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 340\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 350\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 360\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 370\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 380\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 390\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 400\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 410\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 420\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 430\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 440\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 450\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 460\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 470\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 480\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 490\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 500\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nMarked 0 articles for removal\nArticle 510\nMarked 0 articles for removal\n"
],
[
"df_final = df_final.drop(indices_to_drop)",
"_____no_output_____"
],
[
"df_final = df_final.reset_index()\ndf_final = df_final.drop('index', axis = 1)\ndf_final.head()",
"_____no_output_____"
],
[
"df_final.to_csv(\"final_articles_1027.csv\")",
"_____no_output_____"
]
],
[
[
"___",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a4464747e980693ce629dc204f17b8ec7cdffc7
| 13,707 |
ipynb
|
Jupyter Notebook
|
notebooks/python/raw/ex_7.ipynb
|
guesswhohaha/learntools
|
c1bd607ade5227f8c8977ff05bf9d04d0a8b7732
|
[
"Apache-2.0"
] | null | null | null |
notebooks/python/raw/ex_7.ipynb
|
guesswhohaha/learntools
|
c1bd607ade5227f8c8977ff05bf9d04d0a8b7732
|
[
"Apache-2.0"
] | null | null | null |
notebooks/python/raw/ex_7.ipynb
|
guesswhohaha/learntools
|
c1bd607ade5227f8c8977ff05bf9d04d0a8b7732
|
[
"Apache-2.0"
] | null | null | null | 37.045946 | 370 | 0.572189 |
[
[
[
"# Try It Yourself\n\nThere are only three problems in this last set of exercises, but they're all pretty tricky, so be on guard! \n\nRun the setup code below before working on the questions.",
"_____no_output_____"
]
],
[
[
"from learntools.core import binder; binder.bind(globals())\nfrom learntools.python.ex7 import *\nprint('Setup complete.')",
"_____no_output_____"
]
],
[
[
"# Exercises",
"_____no_output_____"
],
[
"## 1.\n\nAfter completing the exercises on lists and tuples, Jimmy noticed that, according to his `estimate_average_slot_payout` function, the slot machines at the Learn Python Casino are actually rigged *against* the house, and are profitable to play in the long run.\n\nStarting with $200 in his pocket, Jimmy has played the slots 500 times, recording his new balance in a list after each spin. He used Python's `matplotlib` library to make a graph of his balance over time:",
"_____no_output_____"
]
],
[
[
"# Import the jimmy_slots submodule\nfrom learntools.python import jimmy_slots\n# Call the get_graph() function to get Jimmy's graph\ngraph = jimmy_slots.get_graph()\ngraph",
"_____no_output_____"
]
],
[
[
"As you can see, he's hit a bit of bad luck recently. He wants to tweet this along with some choice emojis, but, as it looks right now, his followers will probably find it confusing. He's asked if you can help him make the following changes:\n\n1. Add the title \"Results of 500 slot machine pulls\"\n2. Make the y-axis start at 0. \n3. Add the label \"Balance\" to the y-axis\n\nAfter calling `type(graph)` you see that Jimmy's graph is of type `matplotlib.axes._subplots.AxesSubplot`. Hm, that's a new one. By calling `dir(graph)`, you find three methods that seem like they'll be useful: `.set_title()`, `.set_ylim()`, and `.set_ylabel()`. \n\nUse these methods to complete the function `prettify_graph` according to Jimmy's requests. We've already checked off the first request for you (setting a title).\n\n(Remember: if you don't know what these methods do, use the `help()` function!)",
"_____no_output_____"
]
],
[
[
"def prettify_graph(graph):\n \"\"\"Modify the given graph according to Jimmy's requests: add a title, make the y-axis\n start at 0, label the y-axis. (And, if you're feeling ambitious, format the tick marks\n as dollar amounts using the \"$\" symbol.)\n \"\"\"\n graph.set_title(\"Results of 500 slot machine pulls\")\n # Complete steps 2 and 3 here\n\ngraph = jimmy_slots.get_graph()\nprettify_graph(graph)\ngraph",
"_____no_output_____"
]
],
[
[
"**Bonus:** Can you format the numbers on the y-axis so they look like dollar amounts? e.g. $200 instead of just 200.\n\n(We're not going to tell you what method(s) to use here. You'll need to go digging yourself with `dir(graph)` and/or `help(graph)`.)",
"_____no_output_____"
]
],
[
[
"# Check your answer (Run this code cell to receive credit!)\nq1.solution()",
"_____no_output_____"
]
],
[
[
"## 2. <span title=\"Spicy\" style=\"color: coral\">🌶️🌶️</span>\n\nThis is a very hard problem. Feel free to skip it if you are short on time:\n\nLuigi is trying to perform an analysis to determine the best items for winning races on the Mario Kart circuit. He has some data in the form of lists of dictionaries that look like...\n\n [\n {'name': 'Peach', 'items': ['green shell', 'banana', 'green shell',], 'finish': 3},\n {'name': 'Bowser', 'items': ['green shell',], 'finish': 1},\n # Sometimes the racer's name wasn't recorded\n {'name': None, 'items': ['mushroom',], 'finish': 2},\n {'name': 'Toad', 'items': ['green shell', 'mushroom'], 'finish': 1},\n ]\n\n`'items'` is a list of all the power-up items the racer picked up in that race, and `'finish'` was their placement in the race (1 for first place, 3 for third, etc.).\n\nHe wrote the function below to take a list like this and return a dictionary mapping each item to how many times it was picked up by first-place finishers.",
"_____no_output_____"
]
],
[
[
"def best_items(racers):\n \"\"\"Given a list of racer dictionaries, return a dictionary mapping items to the number\n of times those items were picked up by racers who finished in first place.\n \"\"\"\n winner_item_counts = {}\n for i in range(len(racers)):\n # The i'th racer dictionary\n racer = racers[i]\n # We're only interested in racers who finished in first\n if racer['finish'] == 1:\n for i in racer['items']:\n # Add one to the count for this item (adding it to the dict if necessary)\n if i not in winner_item_counts:\n winner_item_counts[i] = 0\n winner_item_counts[i] += 1\n\n # Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.\n if racer['name'] is None:\n print(\"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})\".format(\n i+1, len(racers), racer['name'])\n )\n return winner_item_counts",
"_____no_output_____"
]
],
[
[
"He tried it on a small example list above and it seemed to work correctly:",
"_____no_output_____"
]
],
[
[
"sample = [\n {'name': 'Peach', 'items': ['green shell', 'banana', 'green shell',], 'finish': 3},\n {'name': 'Bowser', 'items': ['green shell',], 'finish': 1},\n {'name': None, 'items': ['mushroom',], 'finish': 2},\n {'name': 'Toad', 'items': ['green shell', 'mushroom'], 'finish': 1},\n]\nbest_items(sample)",
"_____no_output_____"
]
],
[
[
"However, when he tried running it on his full dataset, the program crashed with a `TypeError`.\n\nCan you guess why? Try running the code cell below to see the error message Luigi is getting. Once you've identified the bug, fix it in the cell below (so that it runs without any errors).\n\nHint: Luigi's bug is similar to one we encountered in the [tutorial](#$TUTORIAL_URL$) when we talked about star imports.",
"_____no_output_____"
]
],
[
[
"# Import luigi's full dataset of race data\nfrom learntools.python.luigi_analysis import full_dataset\n\n# Fix me!\ndef best_items(racers):\n winner_item_counts = {}\n for i in range(len(racers)):\n # The i'th racer dictionary\n racer = racers[i]\n # We're only interested in racers who finished in first\n if racer['finish'] == 1:\n for i in racer['items']:\n # Add one to the count for this item (adding it to the dict if necessary)\n if i not in winner_item_counts:\n winner_item_counts[i] = 0\n winner_item_counts[i] += 1\n\n # Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.\n if racer['name'] is None:\n print(\"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})\".format(\n i+1, len(racers), racer['name'])\n )\n return winner_item_counts\n\n# Try analyzing the imported full dataset\nbest_items(full_dataset)",
"_____no_output_____"
],
[
"#_COMMENT_IF(PROD)_\nq2.hint()",
"_____no_output_____"
],
[
"# Check your answer (Run this code cell to receive credit!)\nq2.solution()",
"_____no_output_____"
]
],
[
[
"## 3. <span title=\"A bit spicy\" style=\"color: darkgreen \">🌶️</span>\n\nSuppose we wanted to create a new type to represent hands in blackjack. One thing we might want to do with this type is overload the comparison operators like `>` and `<=` so that we could use them to check whether one hand beats another. e.g. it'd be cool if we could do this:\n\n```python\n>>> hand1 = BlackjackHand(['K', 'A'])\n>>> hand2 = BlackjackHand(['7', '10', 'A'])\n>>> hand1 > hand2\nTrue\n```\n\nWell, we're not going to do all that in this question (defining custom classes is a bit beyond the scope of these lessons), but the code we're asking you to write in the function below is very similar to what we'd have to write if we were defining our own `BlackjackHand` class. (We'd put it in the `__gt__` magic method to define our custom behaviour for `>`.)\n\nFill in the body of the `blackjack_hand_greater_than` function according to the docstring.",
"_____no_output_____"
]
],
[
[
"def blackjack_hand_greater_than(hand_1, hand_2):\n \"\"\"\n Return True if hand_1 beats hand_2, and False otherwise.\n \n In order for hand_1 to beat hand_2 the following must be true:\n - The total of hand_1 must not exceed 21\n - The total of hand_1 must exceed the total of hand_2 OR hand_2's total must exceed 21\n \n Hands are represented as a list of cards. Each card is represented by a string.\n \n When adding up a hand's total, cards with numbers count for that many points. Face\n cards ('J', 'Q', and 'K') are worth 10 points. 'A' can count for 1 or 11.\n \n When determining a hand's total, you should try to count aces in the way that \n maximizes the hand's total without going over 21. e.g. the total of ['A', 'A', '9'] is 21,\n the total of ['A', 'A', '9', '3'] is 14.\n \n Examples:\n >>> blackjack_hand_greater_than(['K'], ['3', '4'])\n True\n >>> blackjack_hand_greater_than(['K'], ['10'])\n False\n >>> blackjack_hand_greater_than(['K', 'K', '2'], ['3'])\n False\n \"\"\"\n pass\n\n# Check your answer\nq3.check()",
"_____no_output_____"
],
[
"#_COMMENT_IF(PROD)_\nq3.hint()\n#_COMMENT_IF(PROD)_\nq3.solution()",
"_____no_output_____"
]
],
[
[
"## The end\n\nYou've finished the Python course. Congrats!\n\nAs always, if you have any questions about these exercises, or anything else you encountered in the course, come to the [Learn Forum](https://kaggle.com/learn-forum).\n\nYou probably didn't put in all these hours of learning Python just to play silly games of chance, right? If you're interested in applying your newfound Python skills to some data science tasks, check out some of our other **[Kaggle Courses](https://www.kaggle.com/learn/overview)**. Some good next steps are:\n\n1. [Machine learning with scikit-learn](https://www.kaggle.com/learn/intro-to-machine-learning)\n2. [Pandas for data manipulation](https://www.kaggle.com/learn/pandas)\n3. [Deep learning with TensorFlow](https://www.kaggle.com/learn/deep-learning)\n\nHappy Pythoning!\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a446dc78ea387519c244bcf3efb90c2d70ba8e9
| 2,741 |
ipynb
|
Jupyter Notebook
|
notebooks/Byte_pair_encoding.ipynb
|
jyuan1986/MyDSExperiments
|
8c3b6f5c9a525e180d08bfb52a98f8651be1e6d8
|
[
"MIT"
] | null | null | null |
notebooks/Byte_pair_encoding.ipynb
|
jyuan1986/MyDSExperiments
|
8c3b6f5c9a525e180d08bfb52a98f8651be1e6d8
|
[
"MIT"
] | null | null | null |
notebooks/Byte_pair_encoding.ipynb
|
jyuan1986/MyDSExperiments
|
8c3b6f5c9a525e180d08bfb52a98f8651be1e6d8
|
[
"MIT"
] | null | null | null | 24.04386 | 101 | 0.461875 |
[
[
[
"# Byte Pair Encoding (BPE)\n## Deals with representing a given vocabulary in NLP tasks, in particular used in Bert model",
"_____no_output_____"
],
[
"## The process of BPE:\n## (1) use char vocabulary as base and express each word as a sequence of chars\n## (2) add a \"end-of-word\" char to each word (for back-translation purpose)\n## (3) ",
"_____no_output_____"
]
],
[
[
"import re, collections\ndef get_stats(vocab):\n \"\"\"\"\"\"\n pairs = collections.defaultdict(int)\n for word, freq in vocab.items():\n symbols = word.split()\n for i in range(len(symbols)-1):\n pairs[symbols[i],symbols[i+1]] += freq\n return pairs\n\ndef merge_vocab(pair, v_in):\n v_out = {}\n bigram = re.escape(' '.join(pair))\n p = re.compile(r'(?<!\\S)' + bigram + r'(?!\\S)')\n for word in v_in:\n w_out = p.sub(''.join(pair), word)\n v_out[w_out] = v_in[word]\n return v_out",
"_____no_output_____"
],
[
"vocab = {'l o w </w>' : 5, 'l o w e r </w>' : 2, 'n e w e s t </w>':6, 'w i d e s t </w>':3}\nnum_merges = 10\nfor i in range(num_merges):\n pairs = get_stats(vocab)\n best = max(pairs, key=pairs.get)\n vocab = merge_vocab(best, vocab)\n print(best)",
"('e', 's')\n('es', 't')\n('est', '</w>')\n('l', 'o')\n('lo', 'w')\n('n', 'e')\n('ne', 'w')\n('new', 'est</w>')\n('low', '</w>')\n('w', 'i')\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4a447ffdd24c3c35517a6d9f45d211e8c7b7eaf9
| 197,754 |
ipynb
|
Jupyter Notebook
|
Exercise_4_solution (1).ipynb
|
tuhinmallick/DataScience-Survival-Skils
|
bd65895c4091c386e38eb09531e0f7334f3ba9ca
|
[
"MIT"
] | null | null | null |
Exercise_4_solution (1).ipynb
|
tuhinmallick/DataScience-Survival-Skils
|
bd65895c4091c386e38eb09531e0f7334f3ba9ca
|
[
"MIT"
] | null | null | null |
Exercise_4_solution (1).ipynb
|
tuhinmallick/DataScience-Survival-Skils
|
bd65895c4091c386e38eb09531e0f7334f3ba9ca
|
[
"MIT"
] | null | null | null | 197,754 | 197,754 | 0.919223 |
[
[
[
"# Exercise 4\n\nHi everyone, today we are going to have an introduction to Machine Learning and Deep Learning, as well as we will work with the Linear/Logistic regression and Correlation. ",
"_____no_output_____"
],
[
"# Part 1: Curve Fitting:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Sometimes we are going to find some S-shaped curves while working with neural networks. Such curves are the so-called [Sigmoid function](https://en.wikipedia.org/wiki/Sigmoid_function). \nA simple sigmoid function is given by: \n$$\\sigma (x) = \\frac{1}{1+exp{(-x)}}$$",
"_____no_output_____"
]
],
[
[
"# We define then the sigmoid function \ndef sigmoid(x, a, b, c, d):\n return a * 1/(1+np.exp(-b*x+c))+d # we consider here amplitude, slope, shift and relative shift.",
"_____no_output_____"
]
],
[
[
"$$\\sigma_{a,b,c,d} (x) = a \\cdot \\frac{1}{1+exp{(-b \\cdot x + c)}} + d$$",
"_____no_output_____"
]
],
[
[
"true_x = np.arange(-10, 10, .1) # Array for x-axis\n\ntrue_y = sigmoid(true_x, 1, 2.1, 3.3, 0) # Creating a sigmoid using some given values and the x-array\n\n#########\n## Generate some fake measurements from experiment\n#########\nxdata = np.arange(-10,10,1)\n\ny = sigmoid(xdata, 1, 2.1, 3.3, 0) \ny_noise = 0.1 * np.random.randn(y.size) # generating some random values (noise)\nydata = y+y_noise # Adding this noise to the original sigmoid function\nprint(ydata)\n\n# Plot:\nplt.plot(true_x, true_y, '--', label = 'original sigmoid')\nplt.plot(xdata, ydata, 'ko', label = 'noisy measurements')\nplt.legend()",
"[-0.07304102 0.05222294 -0.14322197 0.05636411 0.09228258 -0.06598913\n 0.0306376 -0.11428606 -0.0013905 0.07315164 0.09008001 0.376238\n 0.81456665 0.89728541 0.84211688 1.07603004 0.94482012 0.92393488\n 0.96941752 1.0065511 ]\n"
]
],
[
[
"## Fitting using 'curve_fit'",
"_____no_output_____"
]
],
[
[
"from scipy.optimize import curve_fit",
"_____no_output_____"
],
[
"values = curve_fit(sigmoid, xdata, ydata)[0] \n#curve_fit() returns the values for the parameters (popt) and their covariance (pcov)\n# Why [0]? This way we save only popt on 'values'\n\n\ny_fit=sigmoid(xdata, *values) # Evaluating such values \n\n# Plot\nplt.plot(true_x, true_y, '--', label = 'original sigmoid')\nplt.plot(xdata, ydata, 'ko', label = 'sigmoid with noise')\nplt.plot(xdata, y_fit, label = 'curve obtained with curve_fit')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"Note: You can get also a so-called 'optimize warning'. This could be solved by using another optimzation method and/or bounds.\n\nOptimzation methods available are: \n* [Levenberg-Marquardt algorithm](https://en.wikipedia.org/wiki/Levenberg%E2%80%93Marquardt_algorithm) ('lm').\n\n* [Trust Region Reflective algorithm](https://optimization.mccormick.northwestern.edu/index.php/Trust-region_methods) (‘trf’).\n\n* [Dogleg algorithm](https://en.wikipedia.org/wiki/Powell%27s_dog_leg_method) (‘dogbox’)\n\nCheck [SciPy's documentation](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.curve_fit.html)",
"_____no_output_____"
],
[
"## Using minimize",
"_____no_output_____"
]
],
[
[
"from scipy.optimize import minimize",
"_____no_output_____"
]
],
[
[
"To use [minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) we need to define a function to be... guess what?\n\nCorrect! minimized",
"_____no_output_____"
]
],
[
[
"def helper(values, x_data, y_data):\n # We minimize the mean-squared error (MSE)\n # we need to return a single number! (--> .sum()!)\n return ((y_data-sigmoid(x_data, *values))**2).sum()",
"_____no_output_____"
],
[
"m = minimize(helper, [1, 1, 1, 1], args=(xdata, ydata)) # Where [1, 1, 1, 1] represents the initial guess!\nm",
"_____no_output_____"
],
[
"y_fit2= sigmoid(xdata, *m.x) # Evaluating with the x-array obtained with minimize(),\n # *m.x --> python hack to quickly unpack the values\nplt.plot(xdata, ydata, 'ko', label = 'sigmoid with noise')\nplt.plot(xdata, y_fit2, label = 'curve obtained with minimize')\nplt.legend()",
"_____no_output_____"
],
[
"plt.plot(xdata, y_fit2, '-', label = 'curve obtained with minimize')\nplt.plot(xdata, y_fit, '-', label = 'curve obtained with curve_fit')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"# Using scikit-learn (To Do):\n\nYou will have to run a similar calculation but now with [scikit-learn](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html).",
"_____no_output_____"
],
[
"First of all, you have to define a linear function, namely: $$y = mx+b$$",
"_____no_output_____"
],
[
"1. To Do: Define the linear function",
"_____no_output_____"
]
],
[
[
"def linearFunction(x, m, b):\n return m*x+b",
"_____no_output_____"
],
[
"x = np.arange(-4,4,0.5)\nm = 2\nb = 1",
"_____no_output_____"
],
[
"line = linearFunction(x,m,b) # Creating a line using your function and the values given\nrng = np.random.default_rng()\nl_noise = 0.5 * rng.normal(size=x.size)\nnoisy_line = line+l_noise\n\nplt.plot(x, line, '--', label = 'original linear')\nplt.plot(x, noisy_line, 'k', label = 'noisy linear')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"## 2.To Do: Use scikit-learn to perform linear regression \n\n--> Use the documentation\n\nThe plotting assumes that the LinearModel is called `reg`, and the predicted line is called `line_pred`.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression",
"_____no_output_____"
],
[
"X = x.reshape((-1, 1))\n\nreg = LinearRegression()\nreg.fit(X, noisy_line)\n\nline_pred = reg.predict(X) ",
"_____no_output_____"
],
[
"print('Intercept b:', reg.intercept_)\nprint('\\nSlope m:', reg.coef_)",
"Intercept b: 0.9584455141835295\n\nSlope m: [1.82669047]\n"
],
[
"plt.plot(x, noisy_line, 'k--', label = 'noisy linear')\nplt.plot(x, line_pred, label = 'prediction')\nplt.legend()",
"_____no_output_____"
],
[
"plt.plot(x, line, '--', label = 'original')\nplt.plot(x, line_pred, 'o', label = 'prediction')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"## Curve fitting/Minimize\n\n3. To Do: Now use `curve_fit` **or** `minimize` to fit the linear equation using the noisy data `x` and `noisy_line`.",
"_____no_output_____"
]
],
[
[
"## Curve fit\nvalues = curve_fit(linearFunction, x, noisy_line)[0] \npred_curve_fit = linearFunction(x, *values) \n\n## Minimize\ndef helper(values, x_data, y_data):\n return ((y_data-linearFunction(x_data, *values))**2).sum()\n\nm = minimize(helper, [1, 1], args=(x, noisy_line))\npred_minimize_fit = linearFunction(x, *m.x)\n\n## Plot everything\nplt.plot(x, line, '--', label = 'original')\nplt.plot(x, pred_curve_fit, 'x', label = 'pred_curve_fit', markersize=12)\nplt.plot(x, pred_minimize_fit, 'o', label = 'pred_minimize_fit')\nplt.legend()",
"_____no_output_____"
]
],
[
[
"___________________________________",
"_____no_output_____"
],
[
"# Part 2: MLP and CNN\n",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf # Library for machine learning and AI ",
"_____no_output_____"
]
],
[
[
"* Video: [Why Tensorflow?](https://www.youtube.com/watch?v=yjprpOoH5c8)\n* Keras is an API for defining a model by layers (More info: [tf.keras](https://www.tensorflow.org/api_docs/python/tf/keras), [Building models with tf.keras](https://www.deeplearningdemystified.com/article/pdl-1))\n* MNIST is a size-normalized database of handwritten digits used very often as example in deep and machine learning.",
"_____no_output_____"
]
],
[
[
"mnist = tf.keras.datasets.mnist #loading mnist\n(x_train, y_train), (x_test, y_test) = mnist.load_data() #assigning the test and train data\nx_train, x_test = x_train / 255.0, x_test / 255.0",
"_____no_output_____"
]
],
[
[
"4. To Do: What represents _x_ and what _y_ in this example? \n\nAnswer: x - Training data, e.g. images; y - Labels",
"_____no_output_____"
],
[
"5. To Do: Plot a sample of the dataset and print its respective label",
"_____no_output_____"
]
],
[
[
"random_sample = np.random.randint(0, len(x_train))\nplt.imshow(x_train[random_sample])\nprint('Label:', y_train[random_sample])",
"Label: 6\n"
]
],
[
[
"## Creating the MLP model",
"_____no_output_____"
]
],
[
[
"model = tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape=(28, 28)),\n tf.keras.layers.Dense(128, activation='relu'),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10, activation='softmax')\n]) # Multilayer perceptron",
"_____no_output_____"
]
],
[
[
"6. To Do: Name 5 examples of activation functions",
"_____no_output_____"
],
[
"Answer:\n\n* Sigmoid\n* Tanh\n* ReLU \n* Linear \n* Binary\n\n\n\n",
"_____no_output_____"
]
],
[
[
"model.compile(\"adam\", \"sparse_categorical_crossentropy\", metrics=['acc']) #Configurations of the model",
"_____no_output_____"
]
],
[
[
"7. To Do: What is `adam`? \n",
"_____no_output_____"
],
[
"Answer: An optimizer",
"_____no_output_____"
],
[
"8. To Do: What does `sparse_categorical_crossentropy` mean? ",
"_____no_output_____"
],
[
"Answer: Loss-Function --> Labels are integers",
"_____no_output_____"
],
[
"9. To Do: What are `epochs`? \n\n\n",
"_____no_output_____"
],
[
"Answer: Specifies iterations over the entire dataset during the training process",
"_____no_output_____"
]
],
[
[
"h = model.fit(x_train, y_train, epochs=10) # Training the model",
"Epoch 1/10\n1875/1875 [==============================] - 9s 3ms/step - loss: 0.2951 - acc: 0.9135\nEpoch 2/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.1469 - acc: 0.9562\nEpoch 3/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.1083 - acc: 0.9667\nEpoch 4/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0886 - acc: 0.9724\nEpoch 5/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0753 - acc: 0.9766\nEpoch 6/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0641 - acc: 0.9795\nEpoch 7/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0587 - acc: 0.9817\nEpoch 8/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0532 - acc: 0.9827\nEpoch 9/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0493 - acc: 0.9839\nEpoch 10/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.0442 - acc: 0.9856\n"
]
],
[
[
"# Plotting how the model learned:",
"_____no_output_____"
],
[
"The 'keys()' method returns the list of keys contained in a dictionary, e.g.:",
"_____no_output_____"
]
],
[
[
"print(h.history.keys())",
"dict_keys(['loss', 'acc'])\n"
]
],
[
[
"10. To Do: Plot the loss (edit just one line)",
"_____no_output_____"
]
],
[
[
"x_axis = np.arange(10)\ny_axis = h.history['loss']\nplt.plot(x_axis, y_axis, 'ko--')\nplt.ylabel(\"loss\")\nplt.xlabel(\"epoch\")\nplt.xticks(np.arange(10), np.arange(10)+1) # sets the ticks for the plot on the x axis",
"_____no_output_____"
]
],
[
[
"# Evaluating the model on previously unseen data: ",
"_____no_output_____"
]
],
[
[
"model.evaluate(x_test, y_test)",
"313/313 [==============================] - 1s 3ms/step - loss: 0.0668 - acc: 0.9806\n"
]
],
[
[
"## MAGIC, around 98% accuracy!",
"_____no_output_____"
],
[
"# Convolutional Neural Network",
"_____no_output_____"
],
[
"CNNs have usually a higher performance than other neural networks for image analysis. They contain a convolutional layer, a pooling layer and a Fully Connected (FC) layer:",
"_____no_output_____"
]
],
[
[
"cnn = tf.keras.models.Sequential([\n tf.keras.layers.Conv2D(8, (3,3), input_shape=(28,28,1), padding='same', activation='relu'),\n tf.keras.layers.MaxPool2D(),\n tf.keras.layers.Conv2D(16, (3,3), padding='same', activation='relu'),\n tf.keras.layers.MaxPool2D(),\n tf.keras.layers.Conv2D(32, (3,3), padding='same', activation='relu'),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(128, activation='relu'),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10, activation='softmax')\n])",
"_____no_output_____"
]
],
[
[
"11. To Do: What is \"(3,3)\" doing in Conv2D?",
"_____no_output_____"
],
[
"Answer: Kernel size",
"_____no_output_____"
],
[
"12. To Do: Next, **compile** the model similar to the MLP shown above:",
"_____no_output_____"
]
],
[
[
"cnn.compile(\"adam\", \"sparse_categorical_crossentropy\", metrics=['acc'])",
"_____no_output_____"
]
],
[
[
"13. To Do: Next, you will **fit** the model. There is an error. Can you fix it? ",
"_____no_output_____"
]
],
[
[
"h2 = cnn.fit(x_train[..., None], y_train, epochs=10)",
"Epoch 1/10\n1875/1875 [==============================] - 37s 5ms/step - loss: 0.1633 - acc: 0.9496\nEpoch 2/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0541 - acc: 0.9835\nEpoch 3/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0390 - acc: 0.9874\nEpoch 4/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0290 - acc: 0.9907\nEpoch 5/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0245 - acc: 0.9924\nEpoch 6/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0207 - acc: 0.9937\nEpoch 7/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0183 - acc: 0.9942\nEpoch 8/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0160 - acc: 0.9949\nEpoch 9/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0139 - acc: 0.9957\nEpoch 10/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0127 - acc: 0.9960\n"
]
],
[
[
"Plot and evaluate your fancy CNN⚛",
"_____no_output_____"
]
],
[
[
"plt.plot(np.arange(10), h2.history['loss'], 'ko--')\nplt.ylabel(\"loss\")\nplt.xlabel(\"epoch\")\nplt.xticks(np.arange(10), np.arange(10)+1)",
"_____no_output_____"
],
[
"cnn.evaluate(x_test, y_test)",
"313/313 [==============================] - 1s 4ms/step - loss: 0.0439 - acc: 0.9902\n"
]
],
[
[
"Report here the final test accuracy: 99%",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a44860ad0e1a8aac2e8cf7c6426f9cecabb7c87
| 268,281 |
ipynb
|
Jupyter Notebook
|
uhecr_model/checks/modify_exposure/figures/figures_PAO_SBG_epsx1.ipynb
|
uhecr-project/uhecr_model
|
8a2e8ab6f11cd2700f6455dff54c746cf3ffb143
|
[
"MIT"
] | null | null | null |
uhecr_model/checks/modify_exposure/figures/figures_PAO_SBG_epsx1.ipynb
|
uhecr-project/uhecr_model
|
8a2e8ab6f11cd2700f6455dff54c746cf3ffb143
|
[
"MIT"
] | 2 |
2021-07-12T08:01:11.000Z
|
2021-08-04T03:01:30.000Z
|
uhecr_model/checks/modify_exposure/figures/figures_PAO_SBG_epsx1.ipynb
|
uhecr-project/uhecr_model
|
8a2e8ab6f11cd2700f6455dff54c746cf3ffb143
|
[
"MIT"
] | null | null | null | 562.433962 | 167,457 | 0.943231 |
[
[
[
"# Figures for comparison of arrival direction and joint models\n\nHere use the output from the `arrival_vs_joint` notebook to plot the figures shown in the paper.\n<br>\n<br>\n*This code is used to produce Figures 6, 7 and 8 (left panel) in Capel & Mortlock (2019).* ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport h5py\nimport matplotlib as mpl\nfrom matplotlib import pyplot as plt\nimport seaborn as sns\nfrom pandas import DataFrame\n\nfrom fancy import Data, Results\nfrom fancy.plotting import AllSkyMap, Corner\nfrom fancy.plotting.colours import *\n\n# to match paper style\nplt.style.use('minimalist') ",
"_____no_output_____"
],
[
"# Define output files\nsource_type = \"SBG_23\"\ndetector_type = \"PAO\"\n\nexp_factor = 1.\n\nsim_output_file = '../output/joint_model_simulation_{0}_{2}_epsx{1:.0f}.h5'.format(source_type, exp_factor, detector_type)\narrival_output_file = '../output/arrival_direction_fit_{0}_{2}_epsx{1:.0f}.h5'.format(source_type, exp_factor, detector_type)\njoint_output_file = '../output/joint_fit_{0}_{2}_epsx{1:.0f}.h5'.format(source_type, exp_factor, detector_type)",
"_____no_output_____"
],
[
"'''set detector and detector properties'''\nif detector_type == \"TA\":\n from fancy.detector.TA2015 import detector_params, Eth\nelif detector_type == \"PAO\":\n from fancy.detector.auger2014 import detector_params, Eth\nelse:\n raise Exception(\"Undefined detector type!\")",
"_____no_output_____"
]
],
[
[
"## Figure 6\n\nThe simulated data set and the Auger exposure.",
"_____no_output_____"
]
],
[
[
"from astropy.coordinates import SkyCoord\nfrom astropy import units as u\n\nfrom fancy.detector.exposure import m_dec\nfrom fancy.interfaces.stan import Direction\n\n# modify exposure contained in detector_params\n# detector_params[3] == alpha_T\ndetector_params[3] *= exp_factor",
"_____no_output_____"
],
[
"# Read in simulation data\nwith h5py.File(sim_output_file, 'r') as f:\n uhecr = f['uhecr']\n arrival_direction = Direction(uhecr['unit_vector'][()])\n energy = uhecr['energy'][()]\n \n source = f['source']\n source_direction = Direction(source['unit_vector'][()]) ",
"_____no_output_____"
],
[
"# Calculate the exposure as a function of declination\nnum_points = 220\nrightascensions = np.linspace(-180, 180, num_points)\ndeclinations = np.linspace(-np.pi/2, np.pi/2, num_points)\n\nm = np.asarray([m_dec(d, detector_params) for d in declinations])\nexposure_factor = (m / np.max(m))",
"_____no_output_____"
],
[
"# reset exposure factor\ndetector_params[3] /= exp_factor",
"_____no_output_____"
],
[
"# Colourmaps and normalisation\n# Exposure\nexp_cmap = mpl.colors.LinearSegmentedColormap.from_list('custom', \n [lightgrey, grey], N = 6)\nnorm_proj = mpl.colors.Normalize(exposure_factor.min(), exposure_factor.max())\n\n# UHECR energy\n# max. of energy bin, set s.t. values in \n# max(np.digitize(energy, energy_bins) - 1) < len(uhecr_color)\nEmax = np.ceil(np.max(energy) / 10.) * 10. \n\n\nuhecr_color = [lightblue, midblue, darkblue]\nuhecr_cmap = mpl.colors.ListedColormap(uhecr_color)\nenergy_bins = np.logspace(np.log(Eth), np.log(Emax), 4, base = np.e)\nuhecr_norm = mpl.colors.BoundaryNorm(energy_bins, uhecr_cmap.N)\n\n# Legend\nlegend_elements = [mpl.lines.Line2D([0], [0], marker='o', color = 'w', \n label = 'sources', markersize = 10, \n markerfacecolor = 'k'), \n mpl.lines.Line2D([0], [0], marker='o', color='w', \n label='UHECRs', markersize = 15, \n markerfacecolor = midblue, alpha = 0.8)]",
"_____no_output_____"
],
[
"# Figure\nfig, ax = plt.subplots()\nfig.set_size_inches((12, 6))\nskymap = AllSkyMap(projection = 'hammer', lon_0 = 0, lat_0 = 0);\n\n# Sources\nfor lon, lat in np.nditer([source_direction.lons, source_direction.lats]):\n skymap.tissot(lon, lat, 2.0, 30, facecolor = 'k', alpha = 1.0, zorder = 5)\n \n# UHECRs\nfor lon, lat, E in np.nditer([arrival_direction.lons, arrival_direction.lats, energy]):\n i = np.digitize(E, energy_bins) - 1\n skymap.tissot(lon, lat, 3.0 + (i*2), 30, \n facecolor = uhecr_cmap.colors[i], alpha = 0.8, zorder = i+2)\n \n# Exposure\n# Uses scatter as bug with AllSkyMap.pcolormesh and contour that I still need to fix...\nfor dec, proj in np.nditer([declinations, exposure_factor]):\n decs = np.tile(dec, num_points)\n c = SkyCoord(ra = rightascensions * u.rad,\n dec = decs * u.rad, frame = 'icrs')\n lon = c.galactic.l.deg\n lat = c.galactic.b.deg\n if (proj == 0):\n skymap.scatter(lon, lat, latlon = True, linewidth = 3,\n color = white, alpha = 1, zorder = 1)\n else:\n skymap.scatter(lon, lat, latlon = True, linewidth = 3,\n color = exp_cmap(norm_proj(proj)), alpha = 1, zorder = 1)\n \n# Annotation\nskymap.draw_border()\nskymap.draw_standard_labels(minimal = True, fontsize = 20)\nax.legend(handles = legend_elements, bbox_to_anchor = (0.8, 0.85), fontsize = 20)\n\n# Colorbar\ncb_ax = plt.axes([0.25, 0, .5, .05], frameon = False)\nbar = mpl.colorbar.ColorbarBase(cb_ax, norm = uhecr_norm, cmap = uhecr_cmap,\n orientation = 'horizontal', drawedges = True, \n alpha = 1)\nbar.set_label('$\\hat{E}$ / EeV', color = 'k', fontsize = 20)\nbar.ax.tick_params(labelsize = 20) ",
"_____no_output_____"
]
],
[
[
"## Figure 7\n\nComparison of the joint and arrival direction fits.",
"_____no_output_____"
]
],
[
[
"# Get f samples for both models and true f value.\nf_a = Results(arrival_output_file).get_chain(['f'])['f']\nf_j = Results(joint_output_file).get_chain(['f'])['f']\nf_true = Results(sim_output_file).get_truths(['f'])['f']",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nfig.set_size_inches((6, 4))\n\nsns.distplot(f_a, hist = False, \n kde_kws = {'shade' : True, 'lw' : 2, 'zorder' : 0}, \n color = grey, label = 'arrival direction')\nsns.distplot(f_j, hist = False, \n kde_kws = {'shade' : True, 'lw' : 2, 'zorder' : 1}, \n color = purple, label = 'joint')\nax.axvline(f_true, 0, 10, color = 'k', zorder = 3, lw = 2., alpha = 0.7)\n\nax.set_xlim(0, 1)\n# ax.set_ylim(0, 10)\nax.set_xlabel('$f$')\nax.set_ylabel('$P(f | \\hat{E}, \\hat{\\omega})$')\nax.legend(bbox_to_anchor = (0.65, 1.0));",
"_____no_output_____"
]
],
[
[
"## Figure 8 (left panel)",
"_____no_output_____"
]
],
[
[
"# Get chains from joint fit and truths from simulation\nresults_sim = Results(sim_output_file)\nresults_fit = Results(joint_output_file)\n\nkeys = ['F0', 'L', 'alpha', 'B', 'f']\nchain = results_fit.get_chain(keys)\n\n# Convert form Stan units to plot units\nchain['F0'] = chain['F0'] / 1.0e3 # km^-2 yr^-1\nchain['L'] = chain['L'] * 10 # 10^-38 yr^-1\n\ntruth_keys = ['F0', 'L', 'alpha', 'B', 'f']\ntruth = results_sim.get_truths(truth_keys)\ninfo_keys = ['Eth', 'Eth_sim']\ninfo = results_sim.get_truths(info_keys)\n\n# Correct for different Eth in sim and fit\n# Also scale to plot units\nflux_scale = (info['Eth'] / info['Eth_sim'])**(1 - truth['alpha'])\ntruth['F0'] = truth['F0'] * flux_scale # km^-2 yr^-1\ntruth['L'] = truth['L'][0] * flux_scale / 1.0e39 * 10 # 10^-38 yr^-1",
"_____no_output_____"
],
[
"labels = {}\nlabels['L'] = r'$L$ / $10^{38}$ $\\mathrm{yr}^{-1}$'\nlabels['F0'] = r'$F_0$ / $\\mathrm{km}^{-2} \\ \\mathrm{yr}^{-1}$'\nlabels['B'] = r'$B$ / $\\mathrm{nG}$'\nlabels['alpha'] = r'$\\alpha$'\nlabels['f'] = r'$f$' ",
"_____no_output_____"
],
[
"params = np.column_stack([chain[key] for key in keys])\ntruths = [truth[key] for key in keys]\n\n# Make nicely labelled dict\nchain_for_df = {}\nfor key in keys:\n chain_for_df[labels[key]] = chain[key]\n\n# Make ordered dataframe\ndf = DataFrame(data = chain_for_df)\ndf = df[[labels['F0'], labels['L'], labels['alpha'], labels['B'], labels['f']]]",
"_____no_output_____"
],
[
"corner = Corner(df, truths, color=purple, contour_color=purple_contour) ",
"_____no_output_____"
]
],
[
[
"### Footnote\n\nIn the paper I made a small typo in the plot labelling, $F_0$ is indeed in units of $\\rm{km}^{-2} \\ yr^{-1}$. Also, there are some small differences in the fit posteriors due to the use of a random seed. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a448bdbad93868830919f85617d8bf5e5a20f50
| 11,200 |
ipynb
|
Jupyter Notebook
|
1. Setting up the Data Science Environment.ipynb
|
jsd784/Jasvir-Intro-Data-Science-Python-master
|
e88e3b7015604d86e7bc7416da329800b105742c
|
[
"BSD-3-Clause"
] | null | null | null |
1. Setting up the Data Science Environment.ipynb
|
jsd784/Jasvir-Intro-Data-Science-Python-master
|
e88e3b7015604d86e7bc7416da329800b105742c
|
[
"BSD-3-Clause"
] | null | null | null |
1. Setting up the Data Science Environment.ipynb
|
jsd784/Jasvir-Intro-Data-Science-Python-master
|
e88e3b7015604d86e7bc7416da329800b105742c
|
[
"BSD-3-Clause"
] | null | null | null | 53.080569 | 447 | 0.651875 |
[
[
[
"# Setting up the Data Science Environment\n\nOne of the largest hurdles beginners face is setting up an environment that they can quickly get up and running and analyzing data.\n\n### Objectives\n\n1. Understand the difference between interactive computing and executing a file\n1. Ensure that Anaconda is installed properly with Python 3\n1. Know what a path is and why its useful\n1. Understand the difference between a Python, iPython, Jupyter Notebook, and Jupyter Lab\n1. Know how to execute a Python file from the command line\n1. Be aware of Anaconda Navigator\n1. Most important Jupyter Notebook tips",
"_____no_output_____"
],
[
"# Interactive Computing vs Executing a File\n\n### Interactive Computing\nNearly all the work that we do today will be done **interactively**, meaning that we will be typing one, or at most a few lines of code into an **input** area and executing it. The result will be displayed in an **output** area.\n\n### Executing a Python File\nThe other way we can execute Python code is by writing it within a file and then executing the entire contents of that file.\n\n### Interactive Computing for Data Science\nInteractive computing is the most popular way to analyze data using Python. You can get instant feedback which will direct how the analysis progresses.\n\n### Writing Code in Files to Build Software\nAll software has code written in a text file. This code is executed in its entirety. You cannot add or change code once the file has been executed. Although most tutorials (including this one) will use an interactive environment to do data science, you will eventually need to take your exploratory work from an interactive session and put in inside of a file.\n\n# Ensuring that Anaconda is Installed Properly with Python 3\nYou should have already [downloaded Anaconda][1]. Jan 1, 2020 will mark the last day that Python will be officially supported. Let's ensure that you are running the latest version of Python 3.\n\n1. Open up a terminal (Mac/Linux) or the Command Prompt (and not the Anaconda Prompt on Windows) and enter in **`python`**\n1. Ensure that in the header you see Python version 3.X where X >= 6 \n![][2]\n3. If you don't see this header with the three arrow **`>>>`** prompts and instead see an error, then we need to troubleshoot here.\n\n## Troubleshooting\n\n### Windows\nThe error message that you will see is **`'python' is not recognized as an internal or external command...`**\n\nThis means that your computer cannot find where the program **`python`** is located on your machine. Let's find out where it is located.\n1. Open up the program **Anaconda Prompt**\n1. Type in **`python`** and you should now be able to get the interactive prompt\n1. Exit out of the prompt by typing in **`exit()`**\n1. The reason you cannot get **`python`** to run in the **Command Prompt** is that during installation you did not check the box to add\n\n1. It is perfectly well and good to use **Anaconda Prompt** from now on\n1. If you so desire, you can [manually configure][3] your **Command Prompt**\n\n### Mac/Linux\nThe error message you should have received is **`python: command not found`**. Let's try and find out where Python is installed on your machine.\n\n1. Run the command: **`$ which -a python`** \n![][4]\n1. This outputs a list of all the locations where there is an executable file with the name **`python`**\n1. This location must be contained in something called the **path**. The path is a list (separated by colons) containing directories to look through to find executable files\n1. Let's output the path with the command: **`$ echo $PATH`**\n![][5]\n1. My path contains the directory (**`/Users/Ted/Anaconda/bin`**) from above so running the command **`python`** works for me.\n1. If your path does not have the directory outputted from step 1 then we will need to edit a file called **`.bash_profile`** (or **`.profile`** on some linux machines)\n1. Make sure you are in your home directory and run the command:\n> **`nano .bash_profile`**\n1. This will open up the file **`.bash_profile`**, which may be empty\n1. Add the following line inside of it: **`export PATH=\"/Users/Ted/anaconda3/bin:$PATH\"`**\n1. Exit (**`ctrl + x`**) and make sure to save\n1. Close and reopen the terminal and execute: **`$ echo $PATH`**\n1. The path should be updated with the Anaconda directory prepended to the front\n1. Again, type in **`python`** and you should be good to go\n1. **`.bash_profile`** is itself a file of commands that get executed each time you open a new terminal. \n\n### More on the path (all operating systems)\nThe path is a list of directories that the computer will search in order, from left to right, to find an executable program with the name you entered on the command line. It is possible to have many executables with the same name but in different folders. The first one found will be the one executed.\n\n### Displaying the path\n* Windows: **`$ path`** or **`$ set %PATH%`**\n* Mac/Linux **`$ echo $PATH`**\n\n### Finding the location of a program\n* Windows: **` where program_name`**\n* Mac\\Linux: **`which program_name`**\n\n### Editing the path\n* Windows: Use the [set (or setx)][6] command or from a [GUI][7]\n* Mac\\Linux: By editing the **`.bash_profile`** as seen above\n\n# python vs ipython\n**`python`** and **`ipython`** are both executable programs that run Python interactively from the command line. The **`python`** command runs the default interpreter, which comes prepackaged with Python. There is almost no reason to ever run this program. It has been surpassed by **`ipython`** (interactive Python) which you also run from the command line. It adds lots of functionality such as syntax highlighting and special commands.\n\n# iPython vs Jupyter Notebook\nThe Jupyter Notebook is a browser based version of iPython. Instead of being stuck within the confines of the command line, you are given a powerful web application that allows you to intertwine both code, text, and images. [See this][8] for more details of the internals\n![][9]\n\n\n# Jupyter Lab\nJupyter Lab is yet another interactive browser-based program that allows you to have windows for notebooks, terminals, data previews, and text editors all on one screen.\n\n# Executing Python Files\nAn entire file of Python code can be executed either from the command line or from within this notebook. We execute the file by placing the location of the file after the **`python`** command. For instance, if you are in the home directory of this repository, the following run the following on the command line to play a number guessing game.\n\n**`python scripts/guess_number.py`**\n\n### Use a magic function to run a script inside the notebook\nInstead of going to the command line, you can run a script directly in the notebook. Run the next two cells.\n\n\n[1]: https://www.anaconda.com/download\n[2]: ../images/pythonterminal.png\n[3]: https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444\n[4]: ../images/which_python.png\n[5]: ../images/path_mac.png\n[6]: https://stackoverflow.com/questions/9546324/adding-directory-to-path-environment-variable-in-windows\n[7]: https://www.computerhope.com/issues/ch000549.htm\n[8]: http://jupyter.readthedocs.io/en/latest/architecture/how_jupyter_ipython_work.html\n[9]: ../images/jupyter_internal.png",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook",
"_____no_output_____"
]
],
[
[
"%run /Users/jasvirdhillon/Documents/GitHub/Intro-Data-Science-Python-master/scripts/rain.py",
"_____no_output_____"
],
[
"# Anaconda Navigator vs Command Line\nAnaconda comes with a simple GUI to launch Jupyter Notebooks and Labs and several other programs. This is just a point and click method for doing the same thing on the command line.",
"_____no_output_____"
],
[
"# Important Jupyter Notebook Tips\n\n### Code vs Markdown Cells\n* Each cell is either a **Code** cell or a **Markdown** cell.\n* Code cells always have **`In [ ]`** to the left of them and understand Python code\n* Markdown cells have nothing to the left and understand [markdown](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet), a simple language to quickly formatting text.\n\n### Edit vs Command Mode\n* Each cell is either in **edit** or **command** mode\n* When in edit mode, the border of the cell will be **green** and there will be a cursor in the cell so you can type\n* When in command mode, the border will be **blue** with no cursor present\n* When in edit mode, press **ESC** to switch to command mode\n* When in command mode, press **Enter** to switch to edit mode (or just click in the cell)\n\n### Keyboard Shortcuts\n* **Shift + Enter** executes the current code block and moves the cursor to the next cell\n* **Ctrl + Enter** executes the current code block and keeps the cursor in the same cell\n* Press **Tab** frequently when writing code to get a pop-up menu with the available commands\n* When calling a method, press **Shift + Tab + Tab** to have a pop-up menu with the documentation\n* **ESC** then **a** inserts a cell above\n* **ESC** then **b** inserts a cell below\n* **ESC** then **d + d** deletes a cell",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a44a1d34b6d7b658e77496e5f4bc0ef6f8f94b4
| 62,778 |
ipynb
|
Jupyter Notebook
|
temp_codes/.ipynb_checkpoints/main_cond_bs900_gate_sup-checkpoint.ipynb
|
minhtannguyen/ffjord
|
f3418249eaa4647f4339aea8d814cf2ce33be141
|
[
"MIT"
] | null | null | null |
temp_codes/.ipynb_checkpoints/main_cond_bs900_gate_sup-checkpoint.ipynb
|
minhtannguyen/ffjord
|
f3418249eaa4647f4339aea8d814cf2ce33be141
|
[
"MIT"
] | null | null | null |
temp_codes/.ipynb_checkpoints/main_cond_bs900_gate_sup-checkpoint.ipynb
|
minhtannguyen/ffjord
|
f3418249eaa4647f4339aea8d814cf2ce33be141
|
[
"MIT"
] | null | null | null | 57.122839 | 888 | 0.468301 |
[
[
[
"import os\nos.environ['CUDA_VISIBLE_DEVICES']='0,1,2,3,4,5'",
"_____no_output_____"
],
[
"%run -p train_cnf_conditional_gate.py --data mnist --dims 64,64,64 --strides 1,1,1,1 --num_blocks 2 --layer_type concat --multiscale True --rademacher True --batch_size 900 --test_batch_size 900 --save experiments/cnf_cond_bs900_gate --conditional True --log_freq 10 --weight_y 0.5",
"/tancode/repos/tan-ffjord/train_cnf_conditional_gate.py\nimport argparse\nimport os\nimport time\nimport numpy as np\n\nimport torch\nimport torch.optim as optim\nimport torchvision.datasets as dset\nimport torchvision.transforms as tforms\nfrom torchvision.utils import save_image\n\nimport lib.layers as layers\nimport lib.utils as utils\nimport lib.odenvp_conditional_gate as odenvp\nimport lib.multiscale_parallel as multiscale_parallel\nimport lib.modules as modules\nimport lib.thops as thops\n\nfrom train_misc import standard_normal_logprob\nfrom train_misc import set_cnf_options, count_nfe, count_parameters, count_total_time\nfrom train_misc import add_spectral_norm, spectral_norm_power_iteration\nfrom train_misc import create_regularization_fns, get_regularization, append_regularization_to_log\n\nfrom tensorboardX import SummaryWriter\n\n# go fast boi!!\ntorch.backends.cudnn.benchmark = True\nSOLVERS = [\"dopri5\", \"bdf\", \"rk4\", \"midpoint\", 'adams', 'explicit_adams']\nparser = argparse.ArgumentParser(\"Continuous Normalizing Flow\")\nparser.add_argument(\"--data\", choices=[\"mnist\", \"svhn\", \"cifar10\", 'lsun_church'], type=str, default=\"mnist\")\nparser.add_argument(\"--dims\", type=str, default=\"8,32,32,8\")\nparser.add_argument(\"--strides\", type=str, default=\"2,2,1,-2,-2\")\nparser.add_argument(\"--num_blocks\", type=int, default=1, help='Number of stacked CNFs.')\n\nparser.add_argument(\"--conv\", type=eval, default=True, choices=[True, False])\nparser.add_argument(\n \"--layer_type\", type=str, default=\"ignore\",\n choices=[\"ignore\", \"concat\", \"concat_v2\", \"squash\", \"concatsquash\", \"concatcoord\", \"hyper\", \"blend\"]\n)\nparser.add_argument(\"--divergence_fn\", type=str, default=\"approximate\", choices=[\"brute_force\", \"approximate\"])\nparser.add_argument(\n \"--nonlinearity\", type=str, default=\"softplus\", choices=[\"tanh\", \"relu\", \"softplus\", \"elu\", \"swish\"]\n)\nparser.add_argument('--solver', type=str, default='dopri5', choices=SOLVERS)\nparser.add_argument('--atol', type=float, default=1e-5)\nparser.add_argument('--rtol', type=float, default=1e-5)\nparser.add_argument(\"--step_size\", type=float, default=None, help=\"Optional fixed step size.\")\n\nparser.add_argument('--test_solver', type=str, default=None, choices=SOLVERS + [None])\nparser.add_argument('--test_atol', type=float, default=None)\nparser.add_argument('--test_rtol', type=float, default=None)\n\nparser.add_argument(\"--imagesize\", type=int, default=None)\nparser.add_argument(\"--alpha\", type=float, default=1e-6)\nparser.add_argument('--time_length', type=float, default=1.0)\nparser.add_argument('--train_T', type=eval, default=True)\n\nparser.add_argument(\"--num_epochs\", type=int, default=1000)\nparser.add_argument(\"--batch_size\", type=int, default=200)\nparser.add_argument(\n \"--batch_size_schedule\", type=str, default=\"\", help=\"Increases the batchsize at every given epoch, dash separated.\"\n)\nparser.add_argument(\"--test_batch_size\", type=int, default=200)\nparser.add_argument(\"--lr\", type=float, default=1e-3)\nparser.add_argument(\"--warmup_iters\", type=float, default=1000)\nparser.add_argument(\"--weight_decay\", type=float, default=0.0)\nparser.add_argument(\"--spectral_norm_niter\", type=int, default=10)\nparser.add_argument(\"--weight_y\", type=float, default=0.5)\n\nparser.add_argument(\"--add_noise\", type=eval, default=True, choices=[True, False])\nparser.add_argument(\"--batch_norm\", type=eval, default=False, choices=[True, False])\nparser.add_argument('--residual', type=eval, default=False, choices=[True, False])\nparser.add_argument('--autoencode', type=eval, default=False, choices=[True, False])\nparser.add_argument('--rademacher', type=eval, default=True, choices=[True, False])\nparser.add_argument('--spectral_norm', type=eval, default=False, choices=[True, False])\nparser.add_argument('--multiscale', type=eval, default=False, choices=[True, False])\nparser.add_argument('--parallel', type=eval, default=False, choices=[True, False])\nparser.add_argument('--conditional', type=eval, default=True, choices=[True, False])\n\n# Regularizations\nparser.add_argument('--l1int', type=float, default=None, help=\"int_t ||f||_1\")\nparser.add_argument('--l2int', type=float, default=None, help=\"int_t ||f||_2\")\nparser.add_argument('--dl2int', type=float, default=None, help=\"int_t ||f^T df/dt||_2\")\nparser.add_argument('--JFrobint', type=float, default=None, help=\"int_t ||df/dx||_F\")\nparser.add_argument('--JdiagFrobint', type=float, default=None, help=\"int_t ||df_i/dx_i||_F\")\nparser.add_argument('--JoffdiagFrobint', type=float, default=None, help=\"int_t ||df/dx - df_i/dx_i||_F\")\n\nparser.add_argument(\"--time_penalty\", type=float, default=0, help=\"Regularization on the end_time.\")\nparser.add_argument(\n \"--max_grad_norm\", type=float, default=1e10,\n help=\"Max norm of graidents (default is just stupidly high to avoid any clipping)\"\n)\n\nparser.add_argument(\"--begin_epoch\", type=int, default=1)\nparser.add_argument(\"--resume\", type=str, default=None)\nparser.add_argument(\"--save\", type=str, default=\"experiments/cnf\")\nparser.add_argument(\"--val_freq\", type=int, default=1)\nparser.add_argument(\"--log_freq\", type=int, default=1)\n\nargs = parser.parse_args()\n\n# logger\nutils.makedirs(args.save)\nlogger = utils.get_logger(logpath=os.path.join(args.save, 'logs'), filepath=os.path.abspath(__file__)) # write to log file\nwriter = SummaryWriter(os.path.join(args.save, 'tensorboard')) # write to tensorboard\n\nif args.layer_type == \"blend\":\n logger.info(\"!! Setting time_length from None to 1.0 due to use of Blend layers.\")\n args.time_length = 1.0\n\nlogger.info(args)\n\n\ndef add_noise(x):\n \"\"\"\n [0, 1] -> [0, 255] -> add noise -> [0, 1]\n \"\"\"\n if args.add_noise:\n noise = x.new().resize_as_(x).uniform_()\n x = x * 255 + noise\n x = x / 256\n return x\n\n\ndef update_lr(optimizer, itr):\n iter_frac = min(float(itr + 1) / max(args.warmup_iters, 1), 1.0)\n lr = args.lr * iter_frac\n for param_group in optimizer.param_groups:\n param_group[\"lr\"] = lr\n\n\ndef get_train_loader(train_set, epoch):\n if args.batch_size_schedule != \"\":\n epochs = [0] + list(map(int, args.batch_size_schedule.split(\"-\")))\n n_passed = sum(np.array(epochs) <= epoch)\n current_batch_size = int(args.batch_size * n_passed)\n else:\n current_batch_size = args.batch_size\n train_loader = torch.utils.data.DataLoader(\n dataset=train_set, batch_size=current_batch_size, shuffle=True, drop_last=True, pin_memory=True\n )\n logger.info(\"===> Using batch size {}. Total {} iterations/epoch.\".format(current_batch_size, len(train_loader)))\n return train_loader\n\n\ndef get_dataset(args):\n trans = lambda im_size: tforms.Compose([tforms.Resize(im_size), tforms.ToTensor(), add_noise])\n\n if args.data == \"mnist\":\n im_dim = 1\n im_size = 28 if args.imagesize is None else args.imagesize\n train_set = dset.MNIST(root=\"./data\", train=True, transform=trans(im_size), download=True)\n test_set = dset.MNIST(root=\"./data\", train=False, transform=trans(im_size), download=True)\n elif args.data == \"svhn\":\n im_dim = 3\n im_size = 32 if args.imagesize is None else args.imagesize\n train_set = dset.SVHN(root=\"./data\", split=\"train\", transform=trans(im_size), download=True)\n test_set = dset.SVHN(root=\"./data\", split=\"test\", transform=trans(im_size), download=True)\n elif args.data == \"cifar10\":\n im_dim = 3\n im_size = 32 if args.imagesize is None else args.imagesize\n train_set = dset.CIFAR10(\n root=\"./data\", train=True, transform=tforms.Compose([\n tforms.Resize(im_size),\n tforms.RandomHorizontalFlip(),\n tforms.ToTensor(),\n add_noise,\n ]), download=True\n )\n test_set = dset.CIFAR10(root=\"./data\", train=False, transform=trans(im_size), download=True)\n elif args.data == 'celeba':\n im_dim = 3\n im_size = 64 if args.imagesize is None else args.imagesize\n train_set = dset.CelebA(\n train=True, transform=tforms.Compose([\n tforms.ToPILImage(),\n tforms.Resize(im_size),\n tforms.RandomHorizontalFlip(),\n tforms.ToTensor(),\n add_noise,\n ])\n )\n test_set = dset.CelebA(\n train=False, transform=tforms.Compose([\n tforms.ToPILImage(),\n tforms.Resize(im_size),\n tforms.ToTensor(),\n add_noise,\n ])\n )\n elif args.data == 'lsun_church':\n im_dim = 3\n im_size = 64 if args.imagesize is None else args.imagesize\n train_set = dset.LSUN(\n './data', ['church_outdoor_train'], transform=tforms.Compose([\n tforms.Resize(96),\n tforms.RandomCrop(64),\n tforms.Resize(im_size),\n tforms.ToTensor(),\n add_noise,\n ])\n )\n test_set = dset.LSUN(\n './data', ['church_outdoor_val'], transform=tforms.Compose([\n tforms.Resize(96),\n tforms.RandomCrop(64),\n tforms.Resize(im_size),\n tforms.ToTensor(),\n add_noise,\n ])\n ) \n elif args.data == 'imagenet_64':\n im_dim = 3\n im_size = 64 if args.imagesize is None else args.imagesize\n train_set = dset.ImageFolder(\n train=True, transform=tforms.Compose([\n tforms.ToPILImage(),\n tforms.Resize(im_size),\n tforms.RandomHorizontalFlip(),\n tforms.ToTensor(),\n add_noise,\n ])\n )\n test_set = dset.ImageFolder(\n train=False, transform=tforms.Compose([\n tforms.ToPILImage(),\n tforms.Resize(im_size),\n tforms.ToTensor(),\n add_noise,\n ])\n )\n \n data_shape = (im_dim, im_size, im_size)\n if not args.conv:\n data_shape = (im_dim * im_size * im_size,)\n\n test_loader = torch.utils.data.DataLoader(\n dataset=test_set, batch_size=args.test_batch_size, shuffle=False, drop_last=True\n )\n return train_set, test_loader, data_shape\n\n\ndef compute_bits_per_dim(x, model):\n zero = torch.zeros(x.shape[0], 1).to(x)\n\n # Don't use data parallelize if batch size is small.\n # if x.shape[0] < 200:\n # model = model.module\n \n z, delta_logp = model(x, zero) # run model forward\n\n logpz = standard_normal_logprob(z).view(z.shape[0], -1).sum(1, keepdim=True) # logp(z)\n logpx = logpz - delta_logp\n\n logpx_per_dim = torch.sum(logpx) / x.nelement() # averaged over batches\n bits_per_dim = -(logpx_per_dim - np.log(256)) / np.log(2)\n\n return bits_per_dim\n\ndef compute_bits_per_dim_conditional(x, y, model):\n zero = torch.zeros(x.shape[0], 1).to(x)\n y_onehot = thops.onehot(y, num_classes=model.module.y_class).to(x)\n\n # Don't use data parallelize if batch size is small.\n # if x.shape[0] < 200:\n # model = model.module\n \n z, delta_logp = model(x, zero) # run model forward\n \n # prior\n mean, logs = model.module._prior(y_onehot)\n\n logpz = modules.GaussianDiag.logp(mean, logs, z).view(-1,1) # logp(z)\n logpx = logpz - delta_logp\n\n logpx_per_dim = torch.sum(logpx) / x.nelement() # averaged over batches\n bits_per_dim = -(logpx_per_dim - np.log(256)) / np.log(2)\n \n # compute xentropy loss\n y_logits = model.module.project_class(z)\n loss_xent = model.module.loss_class(y_logits, y.to(x.get_device()))\n y_predicted = np.argmax(y_logits.cpu().detach().numpy(), axis=1)\n\n return bits_per_dim, loss_xent, y_predicted\n\ndef create_model(args, data_shape, regularization_fns):\n hidden_dims = tuple(map(int, args.dims.split(\",\")))\n strides = tuple(map(int, args.strides.split(\",\")))\n\n if args.multiscale:\n model = odenvp.ODENVP(\n (args.batch_size, *data_shape),\n n_blocks=args.num_blocks,\n intermediate_dims=hidden_dims,\n nonlinearity=args.nonlinearity,\n alpha=args.alpha,\n cnf_kwargs={\"T\": args.time_length, \"train_T\": args.train_T, \"regularization_fns\": regularization_fns, \"solver\": args.solver, \"atol\": args.atol, \"rtol\": args.rtol},)\n elif args.parallel:\n model = multiscale_parallel.MultiscaleParallelCNF(\n (args.batch_size, *data_shape),\n n_blocks=args.num_blocks,\n intermediate_dims=hidden_dims,\n alpha=args.alpha,\n time_length=args.time_length,\n )\n else:\n if args.autoencode:\n\n def build_cnf():\n autoencoder_diffeq = layers.AutoencoderDiffEqNet(\n hidden_dims=hidden_dims,\n input_shape=data_shape,\n strides=strides,\n conv=args.conv,\n layer_type=args.layer_type,\n nonlinearity=args.nonlinearity,\n )\n odefunc = layers.AutoencoderODEfunc(\n autoencoder_diffeq=autoencoder_diffeq,\n divergence_fn=args.divergence_fn,\n residual=args.residual,\n rademacher=args.rademacher,\n )\n cnf = layers.CNF(\n odefunc=odefunc,\n T=args.time_length,\n regularization_fns=regularization_fns,\n solver=args.solver,\n )\n return cnf\n else:\n\n def build_cnf():\n diffeq = layers.ODEnet(\n hidden_dims=hidden_dims,\n input_shape=data_shape,\n strides=strides,\n conv=args.conv,\n layer_type=args.layer_type,\n nonlinearity=args.nonlinearity,\n )\n odefunc = layers.ODEfunc(\n diffeq=diffeq,\n divergence_fn=args.divergence_fn,\n residual=args.residual,\n rademacher=args.rademacher,\n )\n cnf = layers.CNF(\n odefunc=odefunc,\n T=args.time_length,\n train_T=args.train_T,\n regularization_fns=regularization_fns,\n solver=args.solver,\n )\n return cnf\n\n chain = [layers.LogitTransform(alpha=args.alpha)] if args.alpha > 0 else [layers.ZeroMeanTransform()]\n chain = chain + [build_cnf() for _ in range(args.num_blocks)]\n if args.batch_norm:\n chain.append(layers.MovingBatchNorm2d(data_shape[0]))\n model = layers.SequentialFlow(chain)\n return model\n\n\nif __name__ == \"__main__\":\n\n # get deivce\n device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n cvt = lambda x: x.type(torch.float32).to(device, non_blocking=True)\n\n # load dataset\n train_set, test_loader, data_shape = get_dataset(args)\n\n # build model\n regularization_fns, regularization_coeffs = create_regularization_fns(args)\n model = create_model(args, data_shape, regularization_fns)\n\n if args.spectral_norm: add_spectral_norm(model, logger)\n set_cnf_options(args, model)\n\n logger.info(model)\n logger.info(\"Number of trainable parameters: {}\".format(count_parameters(model)))\n \n writer.add_text('info', \"Number of trainable parameters: {}\".format(count_parameters(model)))\n\n # optimizer\n optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)\n\n # restore parameters\n if args.resume is not None:\n checkpt = torch.load(args.resume, map_location=lambda storage, loc: storage)\n model.load_state_dict(checkpt[\"state_dict\"])\n if \"optim_state_dict\" in checkpt.keys():\n optimizer.load_state_dict(checkpt[\"optim_state_dict\"])\n # Manually move optimizer state to device.\n for state in optimizer.state.values():\n for k, v in state.items():\n if torch.is_tensor(v):\n state[k] = cvt(v)\n\n if torch.cuda.is_available():\n model = torch.nn.DataParallel(model).cuda()\n\n # For visualization.\n if args.conditional:\n fixed_y = torch.from_numpy(np.arange(model.module.y_class)).repeat(model.module.y_class).type(torch.long).to(device, non_blocking=True)\n fixed_y_onehot = thops.onehot(fixed_y, num_classes=model.module.y_class)\n with torch.no_grad():\n mean, logs = model.module._prior(fixed_y_onehot)\n fixed_z = modules.GaussianDiag.sample(mean, logs)\n else:\n fixed_z = cvt(torch.randn(100, *data_shape))\n \n time_epoch_meter = utils.RunningAverageMeter(0.97)\n time_meter = utils.RunningAverageMeter(0.97)\n loss_meter = utils.RunningAverageMeter(0.97) # track total loss\n nll_meter = utils.RunningAverageMeter(0.97) # track negative log-likelihood\n xent_meter = utils.RunningAverageMeter(0.97) # track xentropy score\n error_meter = utils.RunningAverageMeter(0.97) # track error score\n steps_meter = utils.RunningAverageMeter(0.97)\n grad_meter = utils.RunningAverageMeter(0.97)\n tt_meter = utils.RunningAverageMeter(0.97)\n\n if args.spectral_norm and not args.resume: spectral_norm_power_iteration(model, 500)\n\n best_loss_nll = float(\"inf\")\n if args.conditional: best_error_score = float(\"inf\")\n \n itr = 0\n for epoch in range(args.begin_epoch, args.num_epochs + 1):\n start_epoch = time.time()\n model.train()\n train_loader = get_train_loader(train_set, epoch)\n for _, (x, y) in enumerate(train_loader):\n start = time.time()\n update_lr(optimizer, itr)\n optimizer.zero_grad()\n\n if not args.conv:\n x = x.view(x.shape[0], -1)\n\n # cast data and move to device\n x = cvt(x)\n \n # compute loss\n if args.conditional:\n loss_nll, loss_xent, y_predicted = compute_bits_per_dim_conditional(x, y, model)\n loss = loss_nll + args.weight_y * loss_xent\n error_score = 1. - np.mean(y_predicted.astype(int) == y.numpy()) \n \n else:\n loss = compute_bits_per_dim(x, model)\n loss_nll, loss_xent, error_score = loss, 0., 0.\n \n if regularization_coeffs:\n reg_states = get_regularization(model, regularization_coeffs)\n reg_loss = sum(\n reg_state * coeff for reg_state, coeff in zip(reg_states, regularization_coeffs) if coeff != 0\n )\n loss = loss + reg_loss\n total_time = count_total_time(model)\n loss = loss + total_time * args.time_penalty\n\n loss.backward()\n grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)\n\n optimizer.step()\n\n if args.spectral_norm: spectral_norm_power_iteration(model, args.spectral_norm_niter)\n \n time_meter.update(time.time() - start)\n loss_meter.update(loss.item())\n nll_meter.update(loss_nll.item())\n if args.conditional:\n xent_meter.update(loss_xent.item())\n else:\n xent_meter.update(loss_xent)\n error_meter.update(error_score)\n steps_meter.update(count_nfe(model))\n grad_meter.update(grad_norm)\n tt_meter.update(total_time)\n \n # write to tensorboard\n writer.add_scalars('time', {'train': time_meter.val}, itr)\n writer.add_scalars('loss', {'train': loss_meter.val}, itr)\n writer.add_scalars('bits/dim', {'train': nll_meter.val}, itr)\n writer.add_scalars('xent', {'train': xent_meter.val}, itr)\n writer.add_scalars('error', {'train': error_meter.val}, itr)\n writer.add_scalars('nfe', {'train': steps_meter.val}, itr)\n writer.add_scalars('grad', {'train': grad_meter.val}, itr)\n writer.add_scalars('total_time', {'train': tt_meter.val}, itr)\n\n if itr % args.log_freq == 0:\n atol_indx = 0; rtol_indx = 0\n for layer in model.module.transforms.named_children():\n for sublayer in layer[1].named_children():\n for subsublayer in sublayer[1].named_children():\n if hasattr(subsublayer[1], 'atol'):\n writer.add_scalars('atol_%i'%atol_indx, {'train': subsublayer[1].atol}, itr)\n atol_indx += 1\n if hasattr(subsublayer[1], 'rtol'):\n writer.add_scalars('rtol_%i'%rtol_indx, {'train': subsublayer[1].rtol}, itr)\n rtol_indx += 1\n \n log_message = (\n \"Iter {:04d} | Time {:.4f}({:.4f}) | Bit/dim {:.4f}({:.4f}) | Xent {:.4f}({:.4f}) | Loss {:.4f}({:.4f}) | Error {:.4f}({:.4f}) \"\n \"Steps {:.0f}({:.2f}) | Grad Norm {:.4f}({:.4f}) | Total Time {:.2f}({:.2f})\".format(\n itr, time_meter.val, time_meter.avg, nll_meter.val, nll_meter.avg, xent_meter.val, xent_meter.avg, loss_meter.val, loss_meter.avg, error_meter.val, error_meter.avg, steps_meter.val, steps_meter.avg, grad_meter.val, grad_meter.avg, tt_meter.val, tt_meter.avg\n )\n )\n if regularization_coeffs:\n log_message = append_regularization_to_log(log_message, regularization_fns, reg_states)\n logger.info(log_message)\n writer.add_text('info', log_message, itr)\n\n itr += 1\n \n # compute test loss\n model.eval()\n if epoch % args.val_freq == 0:\n with torch.no_grad():\n start = time.time()\n logger.info(\"validating...\")\n writer.add_text('info', \"validating...\", epoch)\n losses_nll = []; losses_xent = []; losses = []\n total_correct = 0\n for (x, y) in test_loader:\n if not args.conv:\n x = x.view(x.shape[0], -1)\n x = cvt(x)\n if args.conditional:\n loss_nll, loss_xent, y_predicted = compute_bits_per_dim_conditional(x, y, model)\n loss = loss_nll + args.weight_y * loss_xent\n total_correct += np.sum(y_predicted.astype(int) == y.numpy())\n else:\n loss = compute_bits_per_dim(x, model)\n loss_nll, loss_xent = loss, 0.\n \n losses_nll.append(loss_nll.cpu().numpy()); losses.append(loss.cpu().numpy())\n if args.conditional: \n losses_xent.append(loss_xent.cpu().numpy())\n else:\n losses_xent.append(loss_xent)\n \n atol_indx = 0; rtol_indx = 0\n for layer in model.module.transforms.named_children():\n for sublayer in layer[1].named_children():\n for subsublayer in sublayer[1].named_children():\n if hasattr(subsublayer[1], 'atol'):\n writer.add_scalars('atol_%i'%atol_indx, {'validation': subsublayer[1].atol}, itr)\n atol_indx += 1\n if hasattr(subsublayer[1], 'rtol'):\n writer.add_scalars('rtol_%i'%rtol_indx, {'validation': subsublayer[1].rtol}, itr)\n rtol_indx += 1\n \n loss_nll = np.mean(losses_nll); loss_xent = np.mean(losses_xent); loss = np.mean(losses)\n error_score = 1. - total_correct / len(test_loader.dataset)\n time_epoch_meter.update(time.time() - start_epoch)\n \n # write to tensorboard\n writer.add_scalars('time', {'validation': time.time() - start}, epoch)\n writer.add_scalars('epoch_time', {'validation': time_epoch_meter.val}, epoch)\n writer.add_scalars('bits/dim', {'validation': loss_nll}, epoch)\n writer.add_scalars('xent', {'validation': loss_xent}, epoch)\n writer.add_scalars('loss', {'validation': loss}, epoch)\n writer.add_scalars('error', {'validation': error_score}, epoch)\n \n log_message = \"Epoch {:04d} | Time {:.4f}, Epoch Time {:.4f}({:.4f}), Bit/dim {:.4f}, Xent {:.4f}, Loss {:.4f}, Error {:.4f}\".format(epoch, time.time() - start, time_epoch_meter.val, time_epoch_meter.avg, loss_nll, loss_xent, loss, error_score)\n logger.info(log_message)\n writer.add_text('info', log_message, epoch)\n \n for name, param in model.named_parameters():\n writer.add_histogram(name, param.clone().cpu().data.numpy(), epoch)\n \n utils.makedirs(args.save)\n torch.save({\n \"args\": args,\n \"state_dict\": model.module.state_dict() if torch.cuda.is_available() else model.state_dict(),\n \"optim_state_dict\": optimizer.state_dict(),\n }, os.path.join(args.save, \"current_checkpt.pth\"))\n \n if loss_nll < best_loss_nll:\n best_loss_nll = loss_nll\n utils.makedirs(args.save)\n torch.save({\n \"args\": args,\n \"state_dict\": model.module.state_dict() if torch.cuda.is_available() else model.state_dict(),\n \"optim_state_dict\": optimizer.state_dict(),\n }, os.path.join(args.save, \"best_nll_checkpt.pth\"))\n \n if args.conditional:\n if error_score < best_error_score:\n best_error_score = error_score\n utils.makedirs(args.save)\n torch.save({\n \"args\": args,\n \"state_dict\": model.module.state_dict() if torch.cuda.is_available() else model.state_dict(),\n \"optim_state_dict\": optimizer.state_dict(),\n }, os.path.join(args.save, \"best_error_checkpt.pth\"))\n \n\n # visualize samples and density\n with torch.no_grad():\n fig_filename = os.path.join(args.save, \"figs\", \"{:04d}.jpg\".format(epoch))\n utils.makedirs(os.path.dirname(fig_filename))\n generated_samples = model(fixed_z, reverse=True).view(-1, *data_shape)\n save_image(generated_samples, fig_filename, nrow=10)\n writer.add_images('generated_images', generated_samples.repeat(1,3,1,1), epoch)\n\nNamespace(JFrobint=None, JdiagFrobint=None, JoffdiagFrobint=None, add_noise=True, alpha=1e-06, atol=1e-05, autoencode=False, batch_norm=False, batch_size=900, batch_size_schedule='', begin_epoch=1, conditional=True, conv=True, data='mnist', dims='64,64,64', divergence_fn='approximate', dl2int=None, imagesize=None, l1int=None, l2int=None, layer_type='concat', log_freq=10, lr=0.001, max_grad_norm=10000000000.0, multiscale=True, nonlinearity='softplus', num_blocks=2, num_epochs=1000, parallel=False, rademacher=True, residual=False, resume=None, rtol=1e-05, save='experiments/cnf_cond_bs900_gate', solver='dopri5', spectral_norm=False, spectral_norm_niter=10, step_size=None, strides='1,1,1,1', test_atol=None, test_batch_size=900, test_rtol=None, test_solver=None, time_length=1.0, time_penalty=0, train_T=True, val_freq=1, warmup_iters=1000, weight_decay=0.0, weight_y=0.5)\nODENVP(\n (transforms): ModuleList(\n (0): StackedCNFLayers(\n (chain): ModuleList(\n (0): LogitTransform()\n (1): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(1, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(2, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (2): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(1, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(2, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 1, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (3): SqueezeLayer()\n (4): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(4, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (5): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(4, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n )\n )\n (1): StackedCNFLayers(\n (chain): ModuleList(\n (0): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(2, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (1): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(2, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (2): SqueezeLayer()\n (3): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(8, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(9, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (4): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(8, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(9, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n )\n )\n (2): StackedCNFLayers(\n (chain): ModuleList(\n (0): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(4, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n (1): CNF_Gate(\n (gate_net): FeedforwardGateI(\n (maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv1): Conv2d(4, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv2): Conv2d(10, 10, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(10, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (avg_layer): AdaptiveAvgPool2d(output_size=(1, 1))\n (linear_layer): Conv2d(10, 2, kernel_size=(1, 1), stride=(1, 1))\n (sigmoid): Sigmoid()\n )\n (odefunc): RegularizedODEfunc(\n (odefunc): ODEfunc(\n (diffeq): ODEnet(\n (layers): ModuleList(\n (0): ConcatConv2d(\n (_layer): Conv2d(5, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (1): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (2): ConcatConv2d(\n (_layer): Conv2d(65, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n (3): ConcatConv2d(\n (_layer): Conv2d(65, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))\n )\n )\n (activation_fns): ModuleList(\n (0): Softplus(beta=1, threshold=20)\n (1): Softplus(beta=1, threshold=20)\n (2): Softplus(beta=1, threshold=20)\n )\n )\n )\n )\n )\n )\n )\n )\n (project_ycond): LinearZeros(in_features=10, out_features=1568, bias=True)\n (project_class): LinearZeros(in_features=784, out_features=10, bias=True)\n)\nNumber of trainable parameters: 841930\n===> Using batch size 900. Total 66 iterations/epoch.\n/tancode/repos/tan-ffjord/lib/layers/odefunc.py:286: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).\n t = torch.tensor(t).type_as(y)\nIter 0000 | Time 35.7568(35.7568) | Bit/dim 25.7151(25.7151) | Xent 2.3026(2.3026) | Loss 26.8664(26.8664) | Error 0.9089(0.9089) Steps 0(0.00) | Grad Norm 214.1670(214.1670) | Total Time 0.00(0.00)\nIter 0010 | Time 9.1110(28.7820) | Bit/dim 23.1668(25.4179) | Xent 2.2724(2.2990) | Loss 24.3030(26.5674) | Error 0.9000(0.9015) Steps 0(0.00) | Grad Norm 187.6678(211.0325) | Total Time 0.00(0.00)\nIter 0020 | Time 9.3441(23.6407) | Bit/dim 17.9474(24.0566) | Xent 2.1863(2.2802) | Loss 19.0406(25.1967) | Error 0.6078(0.8741) Steps 0(0.00) | Grad Norm 134.0828(197.5293) | Total Time 0.00(0.00)\nIter 0030 | Time 9.2968(19.8540) | Bit/dim 13.5228(21.7241) | Xent 2.0710(2.2378) | Loss 14.5583(22.8430) | Error 0.3267(0.7425) Steps 0(0.00) | Grad Norm 68.0596(171.0199) | Total Time 0.00(0.00)\nIter 0040 | Time 9.3432(17.0782) | Bit/dim 11.2567(19.1876) | Xent 1.9301(2.1706) | Loss 12.2218(20.2729) | Error 0.2667(0.6218) Steps 0(0.00) | Grad Norm 27.3918(136.9274) | Total Time 0.00(0.00)\nIter 0050 | Time 9.3700(15.0225) | Bit/dim 9.5967(16.8394) | Xent 1.7755(2.0845) | Loss 10.4845(17.8816) | Error 0.2367(0.5245) Steps 0(0.00) | Grad Norm 16.9720(106.3831) | Total Time 0.00(0.00)\nIter 0060 | Time 9.1017(13.4979) | Bit/dim 8.2749(14.7036) | Xent 1.6648(1.9890) | Loss 9.1073(15.6981) | Error 0.2333(0.4502) Steps 0(0.00) | Grad Norm 14.9455(82.3605) | Total Time 0.00(0.00)\nvalidating...\nEpoch 0001 | Time 36.1224, Epoch Time 685.7047(685.7047), Bit/dim 7.5649, Xent 1.6036, Loss 8.3667, Error 0.2316\n===> Using batch size 900. Total 66 iterations/epoch.\nIter 0070 | Time 9.2239(12.3985) | Bit/dim 7.0157(12.8251) | Xent 1.5935(1.8930) | Loss 7.8125(13.7716) | Error 0.2278(0.3956) Steps 0(0.00) | Grad Norm 14.6998(64.7610) | Total Time 0.00(0.00)\nIter 0080 | Time 9.2792(11.5685) | Bit/dim 5.8926(11.1308) | Xent 1.5617(1.8068) | Loss 6.6735(12.0342) | Error 0.2300(0.3500) Steps 0(0.00) | Grad Norm 11.3315(51.1040) | Total Time 0.00(0.00)\nIter 0090 | Time 9.1897(10.9599) | Bit/dim 4.8628(9.5944) | Xent 1.5592(1.7382) | Loss 5.6423(10.4635) | Error 0.2344(0.3143) Steps 0(0.00) | Grad Norm 9.6873(40.3818) | Total Time 0.00(0.00)\nIter 0100 | Time 9.3245(10.4935) | Bit/dim 4.0225(8.2086) | Xent 1.5766(1.6950) | Loss 4.8108(9.0561) | Error 0.2222(0.2891) Steps 0(0.00) | Grad Norm 8.4580(32.1233) | Total Time 0.00(0.00)\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a44b8704662eb11b30aaecf36a03d9e69eea9bc
| 106,091 |
ipynb
|
Jupyter Notebook
|
notebooks/03. Plots.ipynb
|
schuetzgroup/fret-analysis
|
a74df8e3ffbfb709e2defa00fea79c94223ebd3c
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/03. Plots.ipynb
|
schuetzgroup/fret-analysis
|
a74df8e3ffbfb709e2defa00fea79c94223ebd3c
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/03. Plots.ipynb
|
schuetzgroup/fret-analysis
|
a74df8e3ffbfb709e2defa00fea79c94223ebd3c
|
[
"BSD-3-Clause"
] | null | null | null | 438.392562 | 86,416 | 0.941267 |
[
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\n \nfrom smfret_analysis import print_info, Plotter",
"_____no_output_____"
],
[
"print_info()",
"smFRET analysis software version 2.1\n(git revision 2.2-22-g8665d59)\nOutput version 13\nUsing sdt-python version 17.0\n"
]
],
[
[
"# FRET efficiencies",
"_____no_output_____"
]
],
[
[
"p = Plotter()",
"_____no_output_____"
],
[
"fig, ax = p.scatter(frame=None, ylim=(0, 1));\nfig.savefig(\"scatter.pdf\", bbox_inches=\"tight\")",
"_____no_output_____"
],
[
"fig, ax = p.hist(group_re=(r\"(.+) (cells|no-cells)\", 1, 2),\n hist_args={\"alpha\": 0.6, \"density\": False});\nfig.savefig(\"hist.pdf\", bbox_inches=\"tight\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a44b8adb13eb5630085b58cbe7c3bc0689dff69
| 116,227 |
ipynb
|
Jupyter Notebook
|
how-to-be-a-kaggler/competitive-data-science-predict-future-sales/Examples_from_other_students/CourseSubmission-master/Code/explore_tune_model.ipynb
|
alexlaw19/hse-coursera
|
21d23c3690f374f2ca9d3cdb8ae7e57ac3fbcba5
|
[
"Apache-2.0"
] | null | null | null |
how-to-be-a-kaggler/competitive-data-science-predict-future-sales/Examples_from_other_students/CourseSubmission-master/Code/explore_tune_model.ipynb
|
alexlaw19/hse-coursera
|
21d23c3690f374f2ca9d3cdb8ae7e57ac3fbcba5
|
[
"Apache-2.0"
] | null | null | null |
how-to-be-a-kaggler/competitive-data-science-predict-future-sales/Examples_from_other_students/CourseSubmission-master/Code/explore_tune_model.ipynb
|
alexlaw19/hse-coursera
|
21d23c3690f374f2ca9d3cdb8ae7e57ac3fbcba5
|
[
"Apache-2.0"
] | null | null | null | 74.266454 | 20,300 | 0.739045 |
[
[
[
"import os, sys, time\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline \nimport seaborn as sns\nimport scipy.sparse \n\nimport sklearn\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.model_selection import PredefinedSplit\nfrom sklearn.linear_model import LinearRegression, ElasticNet, ElasticNetCV\nimport xgboost as xgb\nimport lightgbm as lgbm\n\nsys.path.insert(1, './')\nimport Utility\nimport imp\n#imp.reload(Utility) \nfrom Utility import *",
"_____no_output_____"
],
[
"for p in [np, pd, sklearn, lgbm]:\n print (p.__name__, p.__version__)",
"numpy 1.18.1\npandas 1.0.1\nsklearn 0.22.1\nlightgbm 2.3.1\n"
]
],
[
[
"In this file, we load cleaned training data, train model, and save model.",
"_____no_output_____"
],
[
"# Load Cleaned Data",
"_____no_output_____"
]
],
[
[
"train_df = pd.read_hdf('../CleanData/trainDF.h5', 'df')\nvalid_df = pd.read_hdf('../CleanData/validDF.h5', 'df')",
"_____no_output_____"
],
[
"train_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 5068102 entries, 4488710 to 9556811\nData columns (total 49 columns):\n # Column Dtype \n--- ------ ----- \n 0 shop_id int8 \n 1 item_id int16 \n 2 date_block_num int8 \n 3 avg_item_price float32\n 4 target float32\n 5 target_shop float32\n 6 target_item float32\n 7 item_category_id int8 \n 8 target_item_category float32\n 9 avg_item_price_lag_1 float32\n 10 target_lag_1 float32\n 11 target_shop_lag_1 float32\n 12 target_item_lag_1 float32\n 13 target_item_category_lag_1 float32\n 14 avg_item_price_lag_2 float32\n 15 target_lag_2 float32\n 16 target_shop_lag_2 float32\n 17 target_item_lag_2 float32\n 18 target_item_category_lag_2 float32\n 19 avg_item_price_lag_3 float32\n 20 target_lag_3 float32\n 21 target_shop_lag_3 float32\n 22 target_item_lag_3 float32\n 23 target_item_category_lag_3 float32\n 24 avg_item_price_lag_4 float32\n 25 target_lag_4 float32\n 26 target_shop_lag_4 float32\n 27 target_item_lag_4 float32\n 28 target_item_category_lag_4 float32\n 29 avg_item_price_lag_5 float32\n 30 target_lag_5 float32\n 31 target_shop_lag_5 float32\n 32 target_item_lag_5 float32\n 33 target_item_category_lag_5 float32\n 34 avg_item_price_lag_6 float32\n 35 target_lag_6 float32\n 36 target_shop_lag_6 float32\n 37 target_item_lag_6 float32\n 38 target_item_category_lag_6 float32\n 39 avg_item_price_lag_12 float32\n 40 target_lag_12 float32\n 41 target_shop_lag_12 float32\n 42 target_item_lag_12 float32\n 43 target_item_category_lag_12 float32\n 44 month int8 \n 45 shop_mean float64\n 46 item_mean float64\n 47 shop_item_mean float64\n 48 item_category_mean float64\ndtypes: float32(40), float64(4), int16(1), int8(4)\nmemory usage: 995.7 MB\n"
],
[
"valid_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 1356992 entries, 9556812 to 10913803\nData columns (total 49 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 shop_id 1356992 non-null int8 \n 1 item_id 1356992 non-null int16 \n 2 date_block_num 1356992 non-null int8 \n 3 avg_item_price 1356992 non-null float32\n 4 target 1356992 non-null float32\n 5 target_shop 1356992 non-null float32\n 6 target_item 1356992 non-null float32\n 7 item_category_id 1356992 non-null int8 \n 8 target_item_category 1356992 non-null float32\n 9 avg_item_price_lag_1 1356992 non-null float32\n 10 target_lag_1 1356992 non-null float32\n 11 target_shop_lag_1 1356992 non-null float32\n 12 target_item_lag_1 1356992 non-null float32\n 13 target_item_category_lag_1 1356992 non-null float32\n 14 avg_item_price_lag_2 1356992 non-null float32\n 15 target_lag_2 1356992 non-null float32\n 16 target_shop_lag_2 1356992 non-null float32\n 17 target_item_lag_2 1356992 non-null float32\n 18 target_item_category_lag_2 1356992 non-null float32\n 19 avg_item_price_lag_3 1356992 non-null float32\n 20 target_lag_3 1356992 non-null float32\n 21 target_shop_lag_3 1356992 non-null float32\n 22 target_item_lag_3 1356992 non-null float32\n 23 target_item_category_lag_3 1356992 non-null float32\n 24 avg_item_price_lag_4 1356992 non-null float32\n 25 target_lag_4 1356992 non-null float32\n 26 target_shop_lag_4 1356992 non-null float32\n 27 target_item_lag_4 1356992 non-null float32\n 28 target_item_category_lag_4 1356992 non-null float32\n 29 avg_item_price_lag_5 1356992 non-null float32\n 30 target_lag_5 1356992 non-null float32\n 31 target_shop_lag_5 1356992 non-null float32\n 32 target_item_lag_5 1356992 non-null float32\n 33 target_item_category_lag_5 1356992 non-null float32\n 34 avg_item_price_lag_6 1356992 non-null float32\n 35 target_lag_6 1356992 non-null float32\n 36 target_shop_lag_6 1356992 non-null float32\n 37 target_item_lag_6 1356992 non-null float32\n 38 target_item_category_lag_6 1356992 non-null float32\n 39 avg_item_price_lag_12 1356992 non-null float32\n 40 target_lag_12 1356992 non-null float32\n 41 target_shop_lag_12 1356992 non-null float32\n 42 target_item_lag_12 1356992 non-null float32\n 43 target_item_category_lag_12 1356992 non-null float32\n 44 month 1356992 non-null int8 \n 45 shop_mean 1356992 non-null float64\n 46 item_mean 1356992 non-null float64\n 47 shop_item_mean 1356992 non-null float64\n 48 item_category_mean 1356992 non-null float64\ndtypes: float32(40), float64(4), int16(1), int8(4)\nmemory usage: 266.6 MB\n"
],
[
"Y_train = train_df['target']\nY_valid = valid_df['target']",
"_____no_output_____"
]
],
[
[
"# LightGBM",
"_____no_output_____"
]
],
[
[
"lgbm_features = ['avg_item_price_lag_1', 'target_lag_1', 'target_shop_lag_1', 'target_item_lag_1', \n 'target_item_category_lag_1', 'avg_item_price_lag_2', 'target_lag_2', 'target_shop_lag_2',\n 'target_item_lag_2', 'target_item_category_lag_2', 'avg_item_price_lag_3', 'target_lag_3', \n 'target_shop_lag_3', 'target_item_lag_3', 'target_item_category_lag_3', 'avg_item_price_lag_4', \n 'target_lag_4', 'target_shop_lag_4', 'target_item_lag_4', 'target_item_category_lag_4',\n 'avg_item_price_lag_5', 'target_lag_5', 'target_shop_lag_5', 'target_item_lag_5', \n 'target_item_category_lag_5', 'avg_item_price_lag_6', 'target_lag_6', 'target_shop_lag_6',\n 'target_item_lag_6', 'target_item_category_lag_6', 'avg_item_price_lag_12', 'target_lag_12', \n 'target_shop_lag_12', 'target_item_lag_12', 'target_item_category_lag_12', 'shop_mean',\n 'item_mean', 'shop_item_mean', 'item_category_mean', 'month']\nlgbm_train_data = lgbm.Dataset(train_df[lgbm_features], label=Y_train, feature_name=lgbm_features) #categorical_feature\nlgbm_valid_data = lgbm.Dataset(valid_df[lgbm_features], label=Y_valid, feature_name=lgbm_features)\n\nparams = {'objective':'regression', 'metric':['rmse'], 'boosting_type':'gbdt', 'num_rounds':100, 'eta':0.2, \n 'max_depth':8, 'min_data_in_leaf':150, 'min_gain_to_split':0.01, \n 'feature_fraction':0.7, 'bagging_freq':0, 'bagging_fraction':1.0, 'lambda_l1':0,\n 'lambda_l2':0.001, 'early_stopping_round':20, 'verbosity':1}\neval_metrics = {}\nstart = time.time()\nlgbm_model= lgbm.train(params, lgbm_train_data, valid_sets=[lgbm_train_data, lgbm_valid_data],\n valid_names=['train', 'valid'], evals_result=eval_metrics, verbose_eval=True)\nend = time.time()\nprint(end-start)",
"/opt/anaconda3/lib/python3.7/site-packages/lightgbm/engine.py:148: UserWarning: Found `num_rounds` in params. Will use it instead of argument\n warnings.warn(\"Found `{}` in params. Will use it instead of argument\".format(alias))\n/opt/anaconda3/lib/python3.7/site-packages/lightgbm/engine.py:153: UserWarning: Found `early_stopping_round` in params. Will use it instead of argument\n warnings.warn(\"Found `{}` in params. Will use it instead of argument\".format(alias))\n"
],
[
"# Plot training progress of light GBM across number of iterations.\nplot_lgbm_eval_metrics(eval_metrics)",
"_____no_output_____"
],
[
"# Show variable importance.\nshow_lgbm_var_imp(lgbm_model)",
"_____no_output_____"
],
[
"# Predict on training and validation set.\nZ_train_lgbm = lgbm_model.predict(train_df[lgbm_features])\nZ_valid_lgbm = lgbm_model.predict(valid_df[lgbm_features]).clip(0,20)",
"_____no_output_____"
],
[
"# Compute performance on training and validation set.\ncompute_reg_score(Y_train, Z_train_lgbm)\nprint('-'*100)\ncompute_reg_score(Y_valid, Z_valid_lgbm)",
"Count Y: 5068102\nSum Y: 1488707.0\nAvg Y: 0.29374054074287415\nAvg Z: 0.2937405355158621\nr: 0.792027359733317\nfr: 1.039283492454184\nR2: 0.626411074653827\nRMSE: 0.7410751181344507\nMAE: 0.28809301305536694\n----------------------------------------------------------------------------------------------------\nCount Y: 1356992\nSum Y: 359979.0\nAvg Y: 0.2652771770954132\nAvg Z: 0.2548725722475108\nr: 0.7104745468128915\nfr: 0.9911100796058334\nR2: 0.5046411858309808\nRMSE: 0.7623360977813964\nMAE: 0.28481842688531606\n"
]
],
[
[
"# Linear Model",
"_____no_output_____"
]
],
[
[
"# Start with linear model using all features. We will use elastic net with some parameters, and fine tune later.\nlr_features = ['avg_item_price_lag_1', 'target_lag_1', 'target_shop_lag_1', 'target_item_lag_1', \n 'target_item_category_lag_1', 'avg_item_price_lag_2', 'target_lag_2', 'target_shop_lag_2',\n 'target_item_lag_2', 'target_item_category_lag_2', 'avg_item_price_lag_3', 'target_lag_3', \n 'target_shop_lag_3', 'target_item_lag_3', 'target_item_category_lag_3', 'avg_item_price_lag_4', \n 'target_lag_4', 'target_shop_lag_4', 'target_item_lag_4', 'target_item_category_lag_4',\n 'avg_item_price_lag_5', 'target_lag_5', 'target_shop_lag_5', 'target_item_lag_5', \n 'target_item_category_lag_5', 'avg_item_price_lag_6', 'target_lag_6', 'target_shop_lag_6',\n 'target_item_lag_6', 'target_item_category_lag_6', 'avg_item_price_lag_12', 'target_lag_12', \n 'target_shop_lag_12', 'target_item_lag_12', 'target_item_category_lag_12', 'shop_mean',\n 'item_mean', 'shop_item_mean', 'item_category_mean', 'month']\n#lr_model = LinearRegression(normalize=True, n_jobs=-1)\nlr_model = ElasticNet(normalize=True, alpha=1e-8, l1_ratio=0.1)\nlr_model.fit(train_df[lr_features], Y_train)",
"_____no_output_____"
],
[
"# Predict on training and validation set.\nZ_train_lr = lr_model.predict(train_df[lr_features])\nZ_valid_lr = lr_model.predict(valid_df[lr_features]).clip(0,20)",
"_____no_output_____"
],
[
"# Compute performance on training and validation set.\ncompute_reg_score(Y_train, Z_train_lr)\nprint('-'*100)\ncompute_reg_score(Y_valid, Z_valid_lr)",
"Count Y: 5068102\nSum Y: 1488707.0\nAvg Y: 0.29374054074287415\nAvg Z: 0.2937405363980431\nr: 0.6416182672395958\nfr: 1.0225127162726126\nR2: 0.41147443120378624\nRMSE: 0.9301391041520919\nMAE: 0.3503528175829209\n----------------------------------------------------------------------------------------------------\nCount Y: 1356992\nSum Y: 359979.0\nAvg Y: 0.2652771770954132\nAvg Z: 0.31740612925307055\nr: 0.6031473507315439\nfr: 0.9720847150975326\nR2: 0.3611704642461234\nRMSE: 0.8657231497112244\nMAE: 0.34794879982227955\n"
],
[
"# Let's examine the coeeficients estimated by elastic net.\nbeta = lr_model.coef_\nbeta = pd.Series(beta, index=lr_features)\nbeta",
"_____no_output_____"
],
[
"# Beta coefficients are all non-zeros. We will need to tune elastic net to do feature selection for linear model.",
"_____no_output_____"
],
[
"# Do cross-validation to tune elastic net.\n# Prepare cross validation data.\ntest_fold = np.full(train_df.shape[0], -1, dtype=np.int8)\nsel = train_df['date_block_num']>=25 #use 25,26,27 as validation set when tuning elastic net\ntest_fold[sel] = 0 \nps = PredefinedSplit(test_fold=test_fold)\n# Base params\nmax_iter = 1000\nalphas = None\n#alphas = [.1, .2, .3, .4, .5, .6, .7, .8, .9, 1]\nn_alphas = 10\n#l1_ratio = [.1, .3, .5, .7, .9, .95, .99, 1]\nl1_ratio = [.1, .5, 1]\necv_params = {'cv': ps, 'random_state': 0, # Changing this could do ensembling options \n 'alphas': alphas, 'n_alphas': n_alphas, 'l1_ratio': l1_ratio,\n 'eps': 0.001, 'tol': 0.0001, 'max_iter': max_iter, 'fit_intercept': True, 'normalize': True, \n 'positive': False, 'selection': 'random', 'verbose': 2, 'n_jobs': -1\n }\n# Tune\necv = ElasticNetCV()\necv = ecv.set_params(**ecv_params)\necv = ecv.fit(train_df[lr_features], Y_train)",
"[Parallel(n_jobs=-1)]: Using backend ThreadingBackend with 4 concurrent workers.\n"
],
[
"# Get best parameter from ElasticNetCV.\nbest_params = (ecv.alpha_, ecv.l1_ratio_, ecv.n_iter_)\nbest_params",
"_____no_output_____"
],
[
"# Get the corresponding elastic net coefficients.\nbeta = pd.Series(ecv.coef_, index=lr_features)\nbeta",
"_____no_output_____"
],
[
"# Let's visualize the magnitude of coefficients estimated by the best elastic net model.\nfig = plt.figure(figsize=(12,6))\nsel = np.abs(beta)>0.01\nbeta[sel].plot.bar()\nplt.xticks(rotation=45)",
"_____no_output_____"
],
[
"# Generate predictions from the best elastic net model.\nZ_train_ecv = ecv.predict(train_df[lr_features])\nZ_valid_ecv = ecv.predict(valid_df[lr_features]).clip(0,20)",
"_____no_output_____"
],
[
"# Compute performance of the best elastic net model.\ncompute_reg_score(Y_train, Z_train_ecv)\nprint('-'*100)\ncompute_reg_score(Y_valid, Z_valid_ecv)",
"Count Y: 5068102\nSum Y: 1488707.0\nAvg Y: 0.29374054074287415\nAvg Z: 0.2937405363980436\nr: 0.640858115257683\nfr: 1.0182084458087866\nR2: 0.41056777373735354\nRMSE: 0.9308552948016093\nMAE: 0.3470643763449833\n----------------------------------------------------------------------------------------------------\nCount Y: 1356992\nSum Y: 359979.0\nAvg Y: 0.2652771770954132\nAvg Z: 0.3176384568119213\nr: 0.6037251728589164\nfr: 0.9709495312789024\nR2: 0.3618208500895894\nRMSE: 0.8652823455277013\nMAE: 0.3486087998770418\n"
],
[
"# Performance is comparable to the model without fine-tuning.",
"_____no_output_____"
],
[
"# We will retrain linear model on the training data using features selected by the best elastic net model only.\nlr_features = ['target_lag_1', 'target_lag_2', 'target_lag_3', 'target_lag_4', 'target_lag_5', 'target_lag_6', \n 'shop_mean', 'item_mean', 'shop_item_mean', 'item_category_mean']\nlr_model = LinearRegression(normalize=True, n_jobs=-1)\nlr_model.fit(train_df[lr_features], Y_train)",
"_____no_output_____"
],
[
"# Let's examine the estimated coefficients.\nbeta = lr_model.coef_\nbeta = pd.Series(beta, index=lr_features)\nbeta",
"_____no_output_____"
],
[
"# Predict on training and validation set.\nZ_train_lr = lr_model.predict(train_df[lr_features])\nZ_valid_lr = lr_model.predict(valid_df[lr_features]).clip(0,20)",
"_____no_output_____"
],
[
"# Compute performance on training and validation set.\ncompute_reg_score(Y_train, Z_train_lr)\nprint('-'*100)\ncompute_reg_score(Y_valid, Z_valid_lr)",
"Count Y: 5068102\nSum Y: 1488707.0\nAvg Y: 0.29374054074287415\nAvg Z: 0.2937405363980436\nr: 0.6304554729603922\nfr: 0.9999999915421738\nR2: 0.39747409286985846\nRMSE: 0.9411375419697358\nMAE: 0.3391042227989815\n----------------------------------------------------------------------------------------------------\nCount Y: 1356992\nSum Y: 359979.0\nAvg Y: 0.2652771770954132\nAvg Z: 0.283242317688553\nr: 0.597095783902275\nfr: 0.961311261703089\nR2: 0.3556707931790931\nRMSE: 0.8694416606068114\nMAE: 0.322825979722477\n"
]
],
[
[
"# Ensembling",
"_____no_output_____"
],
[
"We will combine predictions from light GBM and linear model. First, check that the two set of predictions are not overly correlated.",
"_____no_output_____"
]
],
[
[
"plt.scatter(Z_valid_lgbm, Z_valid_lr)",
"_____no_output_____"
],
[
"# They are somewhat correlated.",
"_____no_output_____"
]
],
[
[
"### Weighted Averaging",
"_____no_output_____"
],
[
"We will use a simple convex combination to combine the two set of predictions. We will find the optimal combination coefficient alpha using grid search on the range of alphas_to_try. The best alpha should have the lowest RMSE on the validation predictions.",
"_____no_output_____"
]
],
[
[
"alphas_to_try = np.linspace(0, 1, 1001)\n\nbest_alpha = 0 \nrmse_train_simple_mix = np.inf \nfor alpha in alphas_to_try:\n Z_mix = alpha*Z_valid_lgbm + (1 - alpha)*Z_valid_lr\n rmse = np.sqrt(mean_squared_error(Y_valid, Z_mix)) \n if rmse<rmse_train_simple_mix:\n best_alpha = alpha\n rmse_train_simple_mix = rmse",
"_____no_output_____"
],
[
"best_alpha",
"_____no_output_____"
],
[
"# Compute performance of the best combined validation prediction.\nZ_mix = best_alpha*Z_valid_lgbm + (1 - best_alpha)*Z_valid_lr\ncompute_reg_score(Y_valid, Z_mix)",
"Count Y: 1356992\nSum Y: 359979.0\nAvg Y: 0.2652771770954132\nAvg Z: 0.255610185628978\nr: 0.7105128447943058\nfr: 0.9982715998932865\nR2: 0.5047473242242364\nRMSE: 0.7622544221748303\nMAE: 0.285438631177365\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a44b8adf97f665d44d0858ba09223e687c2ab22
| 9,079 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/0_getting_data-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/0_getting_data-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/0_getting_data-checkpoint.ipynb
|
giordafrancis/DSfS
|
e854db2da376e1c3efe7740073b55f8692cb0863
|
[
"MIT"
] | null | null | null | 25.94 | 155 | 0.52638 |
[
[
[
"#### stdin and stdout ** skipped**\n\npiping data at the command line if you run Python scripts through it. ",
"_____no_output_____"
]
],
[
[
"import sys, re",
"_____no_output_____"
],
[
"sys.argv[0]",
"_____no_output_____"
],
[
"# sys.argv is the list of command-line arguments\n# sys.argv[0] is the name of the program itself\n# sys.argv[1] will be the regex specified at the command line\nregex = sys.argv[1]\n\nfor line in sys.stdin:\n if re.search(regex, line):\n sys.stdout.write(line)",
"_____no_output_____"
]
],
[
[
"#### Reading and writting files",
"_____no_output_____"
],
[
"For example, imagine you have a file full of email addresses, one per line, and that\nyou need to generate a histogram of the domains. The rules for correctly extracting\ndomains are somewhat subtle (e.g., the Public Suffix List), but a good first approximation\nis to just take the parts of the email addresses that come after the @. (Which\ngives the wrong answer for email addresses like [email protected].)",
"_____no_output_____"
]
],
[
[
"def get_domain(email_address: str) -> str:\n \"\"\"Split on '@' and return the las piece\"\"\"\n return email_address.lower().split(\"@\")[-1]\n\n# a couple of tests\nassert get_domain(\"[email protected]\") == \"gmail.com\"\nassert get_domain(\"[email protected]\") == \"hotmail.com\"\n",
"_____no_output_____"
],
[
"# Just stick some data there\nwith open('data/email_addresses.txt', 'w') as f:\n f.write(\"[email protected]\\n\")\n f.write(\"[email protected]\\n\")\n f.write(\"this is a fake line\\n\")\n f.write(\"[email protected]\\n\")\n f.write(\"[email protected]\\n\")",
"_____no_output_____"
],
[
"from collections import Counter\n\nwith open('data/email_addresses.txt', 'r') as f:\n domain_counts = Counter(get_domain(line.strip())\n for line in f\n if \"@\" in line)",
"_____no_output_____"
],
[
"domain_counts",
"_____no_output_____"
]
],
[
[
"Delimited files",
"_____no_output_____"
]
],
[
[
"import csv",
"_____no_output_____"
],
[
"with open('data/colon_delimited_stock_prices.txt', 'w') as f:\n f.write(\"\"\"date:symbol:closing_price\n6/20/2014:AAPL:90.91\n6/20/2014:MSFT:41.68\n6/20/2014:FB:64.5\n\"\"\")",
"_____no_output_____"
],
[
"def process_row(closing_price:float) -> float:\n return closing_price > 61",
"_____no_output_____"
],
[
"with open('data/colon_delimited_stock_prices.txt') as f:\n colon_reader = csv.DictReader(f, delimiter = \":\")\n for dict_row in colon_reader:\n #print(dict_row)\n date = dict_row[\"date\"]\n symbol = dict_row[\"symbol\"]\n closing_price = float(dict_row[\"closing_price\"])\n bigger_61 = process_row(closing_price)\n print(bigger_61)",
"True\nFalse\nTrue\n"
],
[
"today_prices = { 'AAPL' : 90.91, 'MSFT' : 41.68, 'FB' : 64.5 }",
"_____no_output_____"
],
[
"with open(\"data/comma_delimited_stock_prices.txt\", \"w\") as f:\n csv_writer = csv.DictWriter(f, delimiter = ',', fieldnames=[\"stock\", \"price\"])\n csv_writer.writeheader()\n for stock, price in today_prices.items():\n csv_writer.writerow({\"stock\": stock, \"price\": price})",
"_____no_output_____"
]
],
[
[
"\n#### Scrapping the web **fun but not completed now**",
"_____no_output_____"
],
[
"Using an Unauthenticated API **same as above**\n\n- goot twitter authentication example and use of Twython API\n",
"_____no_output_____"
]
],
[
[
"import requests, json",
"_____no_output_____"
],
[
"github_user = \"giordafrancis\"\nendpoint = f\"https://api.github.com/users/{github_user}\"",
"_____no_output_____"
],
[
"repos = json.loads(requests.get(endpoint).text)\nrepos",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a44badc6df34df813e85254b449695b0c2868a3
| 140,660 |
ipynb
|
Jupyter Notebook
|
spotify_analysis.ipynb
|
germarr/spotify-trends-analysis
|
cf5c87f0479e10bfc989cb47957a1471bfbd69e7
|
[
"MIT"
] | null | null | null |
spotify_analysis.ipynb
|
germarr/spotify-trends-analysis
|
cf5c87f0479e10bfc989cb47957a1471bfbd69e7
|
[
"MIT"
] | null | null | null |
spotify_analysis.ipynb
|
germarr/spotify-trends-analysis
|
cf5c87f0479e10bfc989cb47957a1471bfbd69e7
|
[
"MIT"
] | null | null | null | 52.406855 | 2,310 | 0.569643 |
[
[
[
"# **Spotify Data Analysis**\n---\nI want to accomplish 2 things with this project. First, I want to learn how to use the Spotify API. Learning how to use this API serves as a great gateway into the API Universe. \nThe documentation is amazing, the API calls you can make to Spotify, per day, is more than enough for almost any kind of project and, the information you can get from it is really interesting.\n\nI also wanto to do some research on the song profiles that different countries consume and predict if new releases could be successful in different regions. To accomplish this, I'm going to create a dataframe with all the songs from some of the most popular playlists per country. Once I have these songs I'm going to use the [**Spotify Audio Features**](https://developer.spotify.com/documentation/web-api/reference/#endpoint-get-several-audio-features) on each song and, as the last step, I'm going to use a Machine Learning model to use these features as my Dependent Variable in a prediction exercise. \n\nIn addition to that, I wanted to do some research on the characteristics of music that each country consumes and how this consumption has changed over the last decade. To do this I want to create a dataset with all the songs from the most important albums of the last 20 years, analyze their characteristics, and see if there's a particular change in the consumption of certain types of artists or genres.",
"_____no_output_____"
],
[
"## 1. Required Libraries\n---",
"_____no_output_____"
]
],
[
[
"import requests\nimport base64\nimport datetime\nimport pandas as pd\nfrom urllib.parse import urlencode",
"_____no_output_____"
],
[
"from IPython.display import Image\nfrom IPython.core.display import HTML ",
"_____no_output_____"
]
],
[
[
"## 2. Helper Functions\n---\nI created several functions inside the `helper_func.py` python file. I use them inside this notebook to gather all the data I need from Spotify, in the most efficient way possible.",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\nimport helper_func as hf",
"_____no_output_____"
]
],
[
[
"### 2.1 Description\n---",
"_____no_output_____"
],
[
"* `auth()`: This functions generates the `access_token` by requesting the Client_ID and the Client_Secret. This token is important because it's the key to use all the functionalities of the API.\n* `search_spotify()`: The purpose of this function is to do searches using the Spotify API and get a JSON file with the information that was requested. Using this function, we can search for information about albums, artists, playlists, tracks, shows, and episodes.\n* `get_list_of_albums()`: This query will return a dataframe with all the albums from a single artist. \n* `album_information()`: This function returns key information about a list of album ids.\n* `get_multiple_artists_from_albums()`: Some albums have more than 1 artist. This function creates a dataframe that creates new columns for each of the artists that collaborated on the album.\n* `songs_information()`:This function returns a dataframe with all the songs from an artist along with additional data from those songs and the function also returns a list with the unique ids from those songs.\n* `artists_from_songs()`: Some songs have more than 1 performer. This list creates a dataframe that adds new columns for each artist that was involved with the song.\n* `multiple_artists_songs()`: This function can return a dataframe with detailed information about an artist.\n* `song_features()`: This function returns a dataframe with the features that Spotify assigns to each song.\n* `playlist_data()`: This function returns a dataframe with key data about a particular playlist.",
"_____no_output_____"
],
[
"## 3. Set-Up\n---",
"_____no_output_____"
],
[
"### 3.1 Access Token\n---\nDepending on the level of access you want, there are several ways of interacting with the Spotify API.\nFor my personal workflow I created a function called `auth()`. This function handles all the steps that needed to be fullfilled to get the access token. When called, the function will ask for a `Client_ID` and a `Client_Secret`. You can learn how to get those access in this [**article**](https://developer.spotify.com/documentation/general/guides/app-settings/).\n\n\n<ins>**Notes:**</ins>\n* [**Here**](https://developer.spotify.com/documentation/general/guides/authorization-guide/#client-credentials-flow) you can find the article in which Spotify explains how the `access token` works. In addition, it also mentions different workflows that can be followed in order to get the token. ",
"_____no_output_____"
]
],
[
[
"access_token = hf.auth()",
"client_id: 6d9cda272a144d6988f08949e9f4cad9\nclient_secret: 28eb8fce5c3448acae7406415e84d1d9\n"
]
],
[
[
"## 4. Getting Data From Spotify\n---\nThe data from this project comes from the Spotify API. To learn more about the different calls you can make to the API check their documentation by clicking [**here**](https://developer.spotify.com/documentation/web-api/reference/).\n\nI'll be using the \"helper functions\" that I previously imported as `hf`",
"_____no_output_____"
],
[
"### 4.1 `Search` function.\n---\nThere´s a function inside the `helper_functions` library called `search_spotify`. The purpose of this function is to do searches using the Spotify API and get a JSON file in return with the inforamtion that was requested. \nUsing this function, we can search information about albums, artists, playlists, tracks, shows and episodes.\n\nThis function accepts 3 parameters:\n* `access_token`: The json response we get after running the `hf.auth()`´function.\n* `query`: The term we want to look for.\n* `search_type`: Add the string 'albums', 'artists', 'playlists', 'tracks', 'shows' or 'episodes' depending on what result you're looking to get.\n\n<ins>**Notes:**</ins>\n* Click [**here**](https://developer.spotify.com/documentation/web-api/reference/#category-search) to learn more about the \"Search\" module of the Spotify API.\n* If you want to test the \"Search\" API call in a Spotify Console click [**here**](https://developer.spotify.com/console/get-search-item/).",
"_____no_output_____"
]
],
[
[
"# Search_Type Options: album , artist, playlist, track, show and episode\nalbums = hf.search_spotify(access_token, query=\"Fine Line\", search_type='album')\nalbum_cover = albums[\"albums\"][\"items\"][0][\"images\"][1][\"url\"]\nalbum_id = albums[\"albums\"][\"items\"][0][\"id\"]\nImage(url= f\"{album_cover}\", width=200, height=200)",
"_____no_output_____"
]
],
[
[
"### 4.2 Albums Function\n---\nThere´s a function inside the `helper_functions` library called `get_list_of_albums()`. The purpose of this function is to return a list with all the albums from a single artist.\n\nThe parameters that this function accepts are: \n>* `at`: The Access_Token. REQUIRED\n>* `artist`: String with the name of a single artist. OPTIONAL\n>* `lookup_id`: ID of a single Artist. OPTIONAL.\n>* `market`: Choose the country you would like to get the information from. The default is \"US\". OPTIONAL\n\n<ins>**Notes:**</ins>\n* You must choose to use `artist` or `lookup_id` but not the two at the same time. \n* Click [**here**](https://developer.spotify.com/documentation/web-api/reference/#category-albums)) to learn more about the \"Albums\" module on the Spotify API.\n* If you want to test the \"Tracks\" API call in a Spotify Console click [**here**](https://developer.spotify.com/console/albums/).\n",
"_____no_output_____"
]
],
[
[
"albums_ids= hf.get_list_of_albums(at=access_token, artist=\"Ed Sheeran\", lookup_id=None)\nalbums_ids[0:5]",
"_____no_output_____"
]
],
[
[
"### 4.2.1 Information About the Albums\n---\nThere´s a function inside the helper_functions library called `album_information()`. The purpose of this function is to return a dataframe with key information about the albums that are passed to it.\n\nThis function simultaneously will return a json file that can be used by other functions inside the the `hf` library.\n\nThis function accepts the next parameters:\n>* `list_of_albums`. A python list with all the albums that we want to transform into a dataset. REQUIRED.\n>* `at`: Which is the Access_Token. REQUIRED\n>* `market`: Choose the country you would like to get the information from. The default is \"US\". OPTIONAL\n",
"_____no_output_____"
]
],
[
[
"album_info_list, albums_json = hf.album_information(list_of_albums = albums_ids, at=access_token) \nalbum_info_list.head()",
"_____no_output_____"
]
],
[
[
"### 4.2.2 Multiple Artists on a single Album\n---\nSome albums have more than 1 artist. This function creates a dataframe that creates new columns for each of the artists that collaborated on the album.\n\nThe only parameter this function accepts is:\n>* `albums_json`: A json file previously generated when the `album_information()` function is called. REQUIRED.",
"_____no_output_____"
]
],
[
[
"album_info_list, albums_json = album_information(list_of_albums = albums_ids, at=access_token) \nalbum_info_list.head()",
"_____no_output_____"
]
],
[
[
"### 4.3 Get all the `Tracks` from a single Artist.\n---\nThere´s a function inside the `helper_functions` library called `song_information()`. The purpose of this function is to get all the tracks from an artist.\n\nThe only parameter this function accepts is:\n>* `albums_json`: A json file previously generated when the `album_information()` function is called. REQUIRED.\n\n\n<ins>**Notes:**</ins>\n* Click [**here**](https://developer.spotify.com/documentation/web-api/reference/#category-tracks) to learn more about the \"Tracks\" module on the Spotify API.\n* If you want to test the \"Tracks\" API call in a Spotify Console click [**here**](https://developer.spotify.com/console/get-several-tracks/).",
"_____no_output_____"
]
],
[
[
"list_of_songs_, list_of_songs_tolist = hf.songs_information(albums_json= albums_json)\nlist_of_songs_.head()",
"_____no_output_____"
]
],
[
[
"### 4.4 Get all the artists that colaborate on the Tracks we're exploring\n---\nThere´s a method inside the `helper_functions` library called `artists_from_songs()`. This function helps to create a dataframe that adds new columns for each artist that was involved with the song.\n\nThis function accepts the next parameters:\n>* `list_of_songs_ids`: A python list with the unique ids of songs. A list of these characteristics is generated after calling the `songs_information()` function. However, it works with any python list as long as it has the unique id's that Spotify assigns to each song. REQUIRED.\n>* `at`: The Access_Token. REQUIRED\n\n\n<ins>**Notes:**</ins>\n* To get a list with all the albums from a single artist, I recommend to use the `album_ids()` method from the `hf` library.\n",
"_____no_output_____"
]
],
[
[
"artists_in_albums_, songs_json, artists_id_, songs_id_ = hf.artists_from_songs(list_of_songs_ids= list_of_songs_tolist,at=access_token)\nartists_in_albums_",
"_____no_output_____"
]
],
[
[
"The function also returns a list with all the artist’s id's. In my example I stored it in the variable called `artists_id_`. Here's an example of how that variable would look like if we printed it:",
"_____no_output_____"
]
],
[
[
"songs_id_[0:10]",
"_____no_output_____"
]
],
[
[
"### 4.5 Get data from the artists\n---\nThere´s a method inside the `helper_functions` library called `multiple_artists_songs()`. This function helps to create a dataframe with key information about the artists we're passing to it.\n\nThe parameters that this function accepts are:\n>* `at`: The Access Token\n>* `list_of_artists_ids`: A python list with the id's that Spotify assigns to each artist. The function `list_of_songs_tolist()` returns a list with this characteristics.",
"_____no_output_____"
]
],
[
[
"artist_list_df= hf.multiple_artists_songs(list_of_artists_ids=artists_id_,at=access_token)\nartist_list_df.head()",
"_____no_output_____"
]
],
[
[
"### 4.6 Get Features from each song\n---\nThis function returns a dataframe with the features that Spotify assigns to each song.\nThe parameters that this function accept are:\n>* `at`: The Access Token \n>* `list_of_songs_ids`: A python list with the unique id's that Spotify assigns to each track. The functions `list_of_songs_ids()` and `artists_from_songs()` return a list with this characteristisc.\n",
"_____no_output_____"
]
],
[
[
"song_features, songs_features_json= hf.song_features(list_of_songs_ids=list_of_songs_tolist, at=access_token)\nsong_features",
"_____no_output_____"
]
],
[
[
"### 4.7 Information from Playlists\n---\nThis function returns a dataframe with key data about a particular playlist.\nThe parameters that this function accepts are:\n>* `at`: The Access Token\n>* `playlist_id`: The unique id that Spotify assigns to each playlist.\n\n<ins>**Notes:**</ins>\n* Click [**here**](https://developer.spotify.com/documentation/web-api/reference/#category-playlists) to learn more about the information you can get from the \"Playlist\" API call.\n\n",
"_____no_output_____"
]
],
[
[
"play_list_json_V2, empty_list_one_V2= hf.playlist_data(at=access_token, playlist_id=\"37i9dQZF1DWWZJHBoz7SEG\")\nempty_list_one_V2.head()",
"_____no_output_____"
]
],
[
[
"## 5. Data Analysis\n---\nNow we have the neccesary functions to start analyzing our data. As mentioned at the beggining of this notebook, we want to get a sample of songs from different countries and analyze the charactersitics of those songs. Creating this dataframe is going to be a 3 step process:\n1. Get 10 playlists from each country. This will create a robust sample dataframe.\n2. Get all the songs from those playlists and create a dataframe with them.\n3. Once we have the dataframe with all of our songs, we add the features to them.",
"_____no_output_____"
],
[
"### 5.1. Getting the playlists\n---\nSpotify has an API call that gathers the top playlists per country. There's a function inside our `hf` library called `top_playlists()` which accepts a list of countries as parameters and returns a dataframe with the top playlists from those countries. ",
"_____no_output_____"
]
],
[
[
"top_playlists_per_country = hf.top_playlists(country= [\"CA\",\"GB\"], at=access_token)\ntop_playlists_per_country.iloc[[8,9,10,11],:]",
"_____no_output_____"
]
],
[
[
"### 5.2 Songs from the playlists\n---\nWe can use the `playlist_data()` function to get the songs from the playlists we got in the last step.",
"_____no_output_____"
]
],
[
[
"def get_songs_from_recommended_playlists(playlists):\n \n # Getting the playlists id's from the \"top_playlists()\" function\n playlists_ids= playlists.playlist_id.tolist()\n count_playlists_ids= range(len(playlists_ids))\n df_countries= playlists[[\"playlist_id\",\"country\"]] \n \n # Getting all the songs from the playlists ids\n empty_list_one=[]\n \n for ids_of_songs in count_playlists_ids:\n play_list_json_V2, songs_from_playlist= hf.playlist_data(at=access_token, playlist_id=f\"{playlists_ids[ids_of_songs]}\")\n empty_list_one.append(songs_from_playlist)\n \n df_songs_many_features = pd.concat(empty_list_one).merge(df_countries, on=\"playlist_id\", how=\"inner\").drop_duplicates(subset=\"song_id\")\n list_df_songs_many_features = df_songs_many_features.song_id.tolist()\n\n return list_df_songs_many_features, df_songs_many_features\n\nlist_df_songs_many_features, df_songs_many_features = get_songs_from_recommended_playlists(playlists=top_playlists_per_country)\n\ndf_songs_many_features.head()",
"_____no_output_____"
]
],
[
[
"### 5.3 Adding features to each song.\n---\nNow that we have all the songs from each playlist, we can use the `song_features()` function to add their features.",
"_____no_output_____"
]
],
[
[
"song_features = hf.song_features(list_of_songs_ids=list_df_songs_many_features, at=access_token)",
"2mjkEoiMDNarJvDQnOvStg,2vvSCgK0NMYiOImew2oYbJ,39vf62opOHTgnMh0bWSwju,3HG0bL6apxDTfjijRapnI2,3OrMbFUgXjchOYTU8TeLO7,3VXl2FieAjX3nqDsTwkX8g,3YlUuMG4Guve8SxlxYqJ2W,3rOThiv6lE8uYQJRF1APCM,3ujPhHwu1MYWjLZCmJWKRB,41EdsGaHftwAuwdJYsD9uw,48eQQlY608dm0wjJJ3VkFN,4LNWwDQY9IcdbzsEEvPXgD,4MjW0jp8b9hAe1dmzJIBCG,4Np4NOxEBsYvPNBZ8W0BDu,4T0ID31kp0iHMJyvAZ8oK7,4WyhOKXtCkNVcgfTBpYaxm,4YCTdBLEM0GSSvRenOseC1,4cnoGoLpEPe3Kp4zQMW4Fw,4ebMR5EAgtEwlYH5Yj4G8Q,4hDlAKBTP2Bcepfb28H60s,4iELCZDu8BTCgP0MWNLQ9u,4l8fwDaGkOWJqvNacpcBTo,4n0Hki3RG2Fa35s5PORLIq,4npxPQ7jYsO9RL6aN9EDjl,4tBdLWvYYr5IjJpvwiZr85,5ACjF83kNOF5awgCam7nDv,5IxCT70ElYRTxbkcx7nXRl,5PdtQ4Ms8T7anDn5UyBtN8,5R0dsmon2gTLCkXaCDDGKf,5V3Fl99ZzV7s9NBvjNM3W2,5VDnV2q6OrlrPsHsDZtIP1,5XU99uJiaZIlfy1ID23veH,5jFVQLyCudes6YFmS84jML,63GyZaNNNigHM47t7eaGzA,65kSgWVGY4JIWNLWnfEwbe,65ximzcC9MLQNOYHmiWpJ9,682HD7Z4WzSxqyjEJQgtBU,6NiUjNWHzjvPWLwvXQrFdU,6NzTCxQukuyhipmtcizNwq,6S7o5V57f8sa1Ri3UNqmmf,6UYbt0ZVXP5pnrhzk8z2d8,6ahaGOEIb9WO7zIExmMcWR,6bNA5yC5I0NPJBISlFZKcB,6cm0CsFVU8QTLTVegPgHDm,6g0Ky5fiJAjkCmRq927A9I,6oXB0d6u18Km0FtUE6Rl4p,75s1E7gtxXQaKkHMyOOtOp,77AxBZJthAYBdBkNWUtwCy,79FRd4gq3o7yXSexLVsAFh,7czIjs2dvjjmGEQ8k4FJGl,7lw2xTVW3Kudde3467EtjG,7tg8Bj8WQxHLPQUShlzFuv,055Mme9ReKK99jRFA5UJ55,074x9OaRq8m4Kn3J3Qgavf,0H9bGUSoZbBQwyKtz9KlsC,0UBjV0qdhBKQLnl8tNXb9e,0jthLAprNDx2G2jB6U1O24,10bmUjdCwAcLNMaFs6BLNO,13YIDpKrL2caqJ3YF52uzJ,17c5OegHmEprnHUHfGFkCs,1CRy08G60mS5jvhB27xMpS,1YtunxXssdmetIJ9vt8396,1g0XpS8Vum5MoMH3rm1WcN,1hsRoc4GvW9lAisQ6PfU2u,25eUamqv7WCarKRaZobtD4,2KP2670rcQA5XRZyQcVhDK,2LXe1Mv9mkho8AYAEoLOcn,2ZEq4HT450Ye9IFGPTl9qV,2ZXUcOTsYd2xvJkuAYbKfP,2r4mpuIYFgKsjeykJTQMqX,2xLx2E3oqQnoeW3rW8aX2J,3JsmrruMp8AWcbEZ4342JY,3gF8IZu75GhdYD4w7AFZi0,3qvf9mABpuuYtBcEtD1F0H,4E8A1xYxVFzI1Mb0ayWG0n,4FUFk1uJuPtUJrDQ8ZSylK,4L3oBxjWLPgQkf2FXIWgx8,4QUA94c3ycZm8dnpPih4sf,4aeV60MWU0Q6sWwNE3IfWz,4cG7HUWYHBV6R6tHn1gxrl,4pmrGhfdYdKeuV0eTCRTHG,4raMIjIjMc8JohHth7l9lG,50v2TSRV31bwpAPkjWejNL,560XM9FI9xl5H6RK8S1LqH,56SkLjnwBXnAkHSf6jBPk3,5KGn7C4GflN0EFMNqDmUY9,5YaskwnGDZFDRipaqzbwQx,5aYWnrsYvJk8NT7PmUcxVN,5lWUeSYO61UYgNlFlqcwYl,5qiQbOa6AFEO3P111y9Jry,6oQV4xYifCFSWvT7a8l6we,6pB9dIjPnPf2aWZhid4CNZ,6xbs6pv0C2voTU2Or3RaqD,6y1UtRcHQU07aUs3oxZ8Yn,76EE4eTWEwluQUs0a7rfTN,7FsIngLOQfepBExSA1PnZD,7sB52Tox2keO1abXK3dD3l,7soydniaZqM6zwvwYKE36F,7uBaKZZVK0OZ6cqFGpGRXI,7xxCKRR8IV1Qm7MeqqCrBv\n0Fh466H56VQzcAvAuVG2qG,0R0ffG48co3XBZi73dtyFP,0XQG2DC9cqB0wIyxEsDsWE,0gciviPVwkD0YbtJIKm1bI,0pb80sjfmKD994rnymQef2,11jALbqbvABzPKe44hM5KS,16aDvB2Pw7jc1dbnW2kE1j,1AFqQtfrQ0VMLeZxrSPrfM,1Bu2ICXvqpoCM1cmWTyvrJ,1JsJnmUKULIbbNy7ePgYD3,1LF4nyE8xZJRet2Q5PebJn,1LbyWN7ws0tQfnGMqAvD55,1VlTXiHOAbQf7eXe15gBU9,1egwcq1nnndit84sSLCuUf,1oKw8KL1SDtba01hVtgMAG,20BzuQ18mwBuvOiiJUz6ln,23rdvAmYhhkQbUVyaN0Bdw,2DSz4s2QI7Fd8QKZVGNb7T,2fhJe88ojZi6zqpC8zjicL,2g1IHsmZ15G2pmFu6rTMCh,2xsK1pXFX2Dlx7xH33Tc1N,2yotZbP75ZFz29DdhLZMyG,3Hiqb8tsHXkBr9dHt4IuuH,3IIf1SrFn0nlVbFDglVXxV,3JwaOKoVVv3uTfNBf1RHKK,3K85yXfvc8iGLDklDBUAXb,3Pevs0j3N02qNVFSqyyz0L,3XE248EzS2oKV2VfQD73VB,3gIDmjFv7xaRa4tUF4GGXk,41Fimqq5VMmOdHgdh2VGXR,46jyHtJNVXtSpiC28yPU7d,4RUphASXlXEs8SJQvES7N0,4acNIYmvJykLV0faSBH8YD,4p4MvXHTOdvfuP1tgmQqtK,4sGCBGyyNPVv3ZExd9RJ8a,4tPo56YuTnYEFOiuOyZWe5,4yIpo7va8wM0SR59BvwO6L,5RiBp4mj9gsVN0oigQ0Q0e,5fVHnXgkgwChihVXUpAcKs,5mG9fDwgBlZmFoyOP6dDSE,5rzJpM33yH0bHF6XOmmqnb,5tCVAAxy3tbGux1ivbtjfg,62xrslsJ8crkaQ8jdm3C35,657ok2Bk1W8xDJfPBFi73X,6Ajue5zNJ44SGKXnqXSrhg,6G8sFs8Nw2yQ6zHLmSSb7r,6GfiNirfUb6OQqeDQOelpd,6L6P4SI85euz5yGQl05Csv,6PbDGsz1YF8vKNVmn0Lu9c,6eXViRiXJKufjfzY3Ntxhx,6gH1BYRCZ38i5dauknRN60,6l33m7UxaR3pbNtNa8QARI,77EU6IESxSZ6oDJ9S1hMYl,77VtotY5X2jt4SKVbNBZ0d,7FxpFmKr8WR8wUJNyLJojE,7KoBPeQKmwaRNii358LEhl,7ixqe1qERxHzAezc4Uq243,7jk39nc0yNVVlcAgDaU5ib,7tEgXYCi32cOG6s9Fut8T2,7wCFdwCbImHKnPhUvEfd6W,05FzWxV5hv2Idl8dNXj8w9,0AeeF13izccNchF1S9vleU,0Mq7DQeSqhxaw8l4H42Wfw,0TXKuxXRgNApAxJ4yXs9vm,0WWSIH1IDXlRtbR2GHStVg,0aTTn1Xb7rRH0TXkUx5OCJ,0e7KI2BC2gCOTslq4B1dGW,0feWyfoxidgOIQoHWs14En,0pORLCI6Ep1eyqHJXbUPKG,0rwcfDbRd4s6aKEsoiDCDg,0tlztRFDgCSnAbUxllcZJJ,0xmB1LYDQFjkvERTFvM3SJ,1FUsdEihuTkXTV5TlaImXk,1I3FIa5RtcPg3iXpZWLUUy,1IApuzXhafsVkrijOUUhVt,1M2R7cAdnwWO08JinxumOU,1PpS40SKQ4u9KTTAv1KXSE,1Rk6DIreZBbisRdjn9qXlj,1YKNNhIys3VyjLGkLz8Ij5,1ZeDNZoKgEOTRmTTg1zQd4,1ZxkEYMc2koZHb62qmUBzW,1aCUQHjrufaZidtCCwN1jq,1egyWKeo2iMvB0y4GaUjnt,1i7m2zBOyHU6BlT5FJDH2J,1iKW2yrouUd2E3tK4tj8Tu,1paOXtSfaeFcZfzt9msquZ,1vix6YVpdY98myRMBH5uVr,1yfVygcEjrdjTp5LEi71at,207MPtrf1FZ2AeXUeJim2S,25LIQhNOvT4Kr0krjqM8UA,2FrBZoOPQRucM6OtLhVqGf,2Ftpp7gRbhtrLjpoTnc2Or,2H1yw9lzoyz6UEIpjyX5sb,2KusH57WCXaAyocRjxhItH,2LNzaAAzQMSp6TGpFi3oIB,2NklaeisqDcFGwEihTFxPp,2PJEppZXXaTmwLALhfcUUA,2c7dkbjkvXXmsc1YwjcX3U,2iApsJ1wlWTPixdKWJSK0r,2iT2jsukd43TG8qqTYg4Lo\n06ZDLodo1UDVavc3MXREZ3,0BTGqPIW9acmhhUmENkq5r,0F7rEdewJ6cSLylOZZpDu7,0HJYzGavqzjiKMmm4F0UZv,0JC3ynTNoZaWjZHXzeapYy,0KhXVmAN4sqeEgsqRd39f2,0Ri0LzOMJmqi9HGZE5cRYV,0RlcC3HghyVZdhOj2SiuKF,0Uyh92tLyb9JawG8lmWCzJ,0b5w1gamS9f239Sms9guAB,0pLmfgIANOX9FB9uZDU43x,0rFZaQ4crlGAzuCjWCQ2xu,13oGc1Mi9niBlo5eTmgGMa,174rZBKJAqD10VBnOjlQQ3,18JosZY3HzD3lMy6iOOSAY,1AM1o0mKbgAK5oMpY8B3Z7,1Dx8rIZaXzZPvUQRF2j9hB,1GmTWBGiDUfg1KoIet7eS5,1X1KDnhTnb28tpJlgOV3lD,1YZBMqN8kHaaRPXpQTC3kb,1jCsCYgzQQHk3bDJDuFbNi,1m2xMsxbtxv21Brome189p,1urmwhtXPiakhcqvqUi3rp,1vwUsp52io0AGQ5yv470IC,1xu91y5jf13yxAssdfsbPt,22NLm3IIR9NLG0cUYtmHMW,25cUhiAod71TIQSNicOaW3,2E90KUsor4U2abOJGFKtfx,2HWelwHQS4EdRqIycZOc3O,2PMjP3wgjcwBAIFntxNej7,2PN3gbuBn5WBEwrEJH3xiu,2VjXGuPVVxyhMgER3Uz2Fe,2aBxt229cbLDOvtL7Xbb9x,2fE4MbwX3QGMzNaMjGVhtw,2hQEm32MiAw2YVlR05tuL4,2sQuds8s3EVbhXJpgVWpO4,2uZwyxrg6VPvlVsvclIfel,3CbnA6S33amyRNmgmfi33H,3LmvfNUQtglbTrydsdIqFU,3OUApyz3jDB3syGUNGqB1d,3UGNdLrhhsK0SY9gNqe8TT,3XVBdLihbNbxUwZosxcGuJ,3bhkiDcl6VPhWbfZ8x3MNl,3fLBmhcgWkPI47LfVQ8paB,3l3xTXsUXeWlkPqzMs7mPD,3w8Mw9GHYepoTWOSdiyosj,41PWz0hAiU9FqsmjR9Wh62,4G1qRhOk1YY0kewtMaCrMC,4H0ZQZqKL19tJxi1cSjtey,4MTHIKGWNTBoubzDMkXFfa,4PF832BvZOBmAMxeYvOZIa,4SF1747p541umnykBp352Q,4V2F0DZrAXOWq9hkwMMG3x,4hrae8atte6cRlSC9a7VCO,4iuNZTcvT9diFySSzVsnVS,4l34rbUYqKWufYEWriVnB5,4o4wEDRqotccDTXiQ7TORu,4oPNN7syJYSjzDhRerF966,4zAxfkmJqsaHqFu1YPMS5a,51YwhosVVOwTuI8EJt1bA5,5FXOEdfNW7nYQrBWtW49Cl,5L0KDoZklMgs9GPoonneEl,5PMKzsUsTpZZGsCcJBuhP2,5WphWTUIfRe7x8NZss79cY,5ZCv9I8mgChcYkSrLuLSTc,5dxHF4lrDimKqnI3GaZUmC,5k3VjTwIsOjQ2woGz3Yx71,5kxddRG1RZaZROadk7iC4D,5mbODTX3uNkpNk0d76wG60,5ojJNnX5ND2gMGojPd3NiO,5qrzhg9Fmu8Amg2uMhHfe5,5xLDmkobOw674TLTBBmnuN,68vgtRHr7iZHpzGpon6Jlo,6AzzMupvtP4u4B8d5OWVUi,6CTWathupIiDs7U4InHnDA,6CUTYJQKcDwcQ63EulINUo,6N9uyMZf9pbNOuomveWscp,6SkGfPa77E4giShVbk9N6R,6TlRNJaezOdzdECnQeRuMM,6Xo9osN1HErsEJoqwj4eDg,6a5jHgwqYMk9wlYJYfs3c9,6brl7bwOHmGFkNw3MBqssT,6fRLVZ4jKzuqyDPlIdbq9q,6gpEUabUe4Qtc0jek4BC50,6j5Swqhcc12eHvPQc6uaQS,6kLZ1DzSxBkNVvdQm6CX0N,6pWzCKTrKrwbUPzY8RLCoP,6uSa5iCMwPr10Ftpz8w09b,6xSsJNkReuJzerqcIlBzBi,6zMUIb4uce1CzpbjR3vMdN,78CTv7ypHvXQlEjXYst2n9,7AjfklMN4WpQYz5FkT4E66,7DFnq8FYhHMCylykf6ZCxA,7J41dYQolQJEtj3UmKLu5r,7JZsiH6YoMEofHGCggumhG,7cvkXf3AwPGT041PyOi5VX,7lVNTXkI3cHFvcXiI8damb,7vVIj8Tm1wCawjvwVZdeLD,7x5ayrIxbFqXoufyPrAm3M,7ytES33eLYS9WaZLKqWfYM\n0bKc8BrUxV31G68GF54iwM,0fh2oLBQgkOgfeYQhfxlQR,0lS9dFaFRWNlYne6AGUCYt,0lZDZfqfPQ7U1lDfbuh3om,0vphVAymDM9mmDht7zrJOe,0zpxyiNMRtqZDc1tJ6VH0Q,1BF9m1HktaohWorz9jJZ7T,1J81WQ1q1PFTAvRiILs61d,1M71UXZgXm5w2SjYqZjBah,1RL9gghbn6lqDyCTPteNfB,1YsO1Anlu6kw9wxRxDQQPM,1hENA2vJhhTlyHsAkLoO6r,1ohFMqksKG9NJrCkbrh5u9,1yZpDUGKSgUBZ7iNRv91Lb,26g34RVVmlgNKtElHZ6Qib,27aYh53XI1y6KwNuXOaqC3,2Apr74VNX9Nmk0Oeee2mih,2V2CRsNTYky2SO2C5G6rkX,2h8OnhWZCRGNjptZ9IurZw,2nv9hJPc3Bg9CDg1cmmlWs,3DrtCfR7VLLIdYLFz2PpHo,3QUUdjrDFtbPNVGwJEuMRU,3Uj4iZtbF2tN2OrenMVhYk,3Zx9LUaK1Rye71mwNwsZlV,3rXqlaAA6aprvQ9SSTQLVN,3s5oaR6gBjQPFGpKz9AlaX,3tjMLbJjWE3y8SfdyPUgwg,3vT5wxE5bEr8eIFIfxdsdJ,4JM0niU3snun9zaR70w8xz,4T8sxVtjvlDsm69BINOirw,4XDPNzYcvHEeZRfUw1Er4D,4Ymu5NdgJvsPNAsBSOqzeS,5DT5Dhf5VqvXk866uuH8CI,5O2YyBz2E0xVgSng44UTnV,5Rcz4OsTYPX4A4PHOxr7Zc,5WMXCbXEjqfVrvZ6YtInor,5kdo4INdzQh1NaeKX5an5u,6TU4YF3DTv3Gm9I0xyMBtO,6TzQjClzByON9eYIccj6O1,6fqcYvVt2gP0tosjQjUEJK,6i2vNKeIYi8t3OcxLEOJKv,6vhVeoN1qJNJfdiIJAK4A9,6ytVMBHu1ZXvaBvufHCBOX,6zK9ee7MZJPIq2e4NBbtLa,72iPHDnxdNcN9DyLrUy31M,76uVXixtaRku87tqrVHuci,7ilulch8bT3gQy6RH0X1VN,7nSBHckG4tTFkp0xqNZDs5,07w1RR0V3wRZ3KMzuR3akq,08mXEVmBXN3wIv4hkBhFDz,09s7wcZDLIMebqdIlaCLym,0Dva4BUUvU1eSe3EV5F3Wa,0f3cDvW4301VLlot6a1Jqd,0ftR6PhIBwtcDc7Kp7dqT1,0gdCMJ1y8MvBwLd0x0W1BJ,0qI1sBGz9cVtTzuH27p7kS,0qmQbxSIt10XDEw90Bqvhx,0x793wJ65lAhUZ6HQ0DD8Z,1HGG6EhM7r9B9Ol9EgkUee,1bG8lyFcshiNlf8q35aKa7,1gmlkortUXcobzlQ6qX6Bz,1oXdYtT3GQ3eSHt4PX4sHT,1tm7cZeRQFQsc2Nrpv8PYj,1wQkqjVCvWS9hHDhOu1tus,2Mb2RkFgaHvncY1NS0IP0W,2j4qGx9w68huk7vkmVCd8v,2k0VyWeDuwYDG21UXy2153,37mG6IjvmVd0bKf83D7ZGt,3B9RslXowdYE5QUO1eLAIR,3KWdd2kA6bQzcof7fyyXPi,3QMSLzrZD7czeeCoT9aT8g,3cy2jsGqXCDVGyWzVQ9tu0,3ggpI6hqvqvlSim7E7TFaX,3pyZgKNXWnJnP8Rk66X16v,492NouSl6yRRXCMdnNwC70,4ArCSNcokdqkileKI6YtGK,4KXAxtfKpp4UPlVRHDNWgN,4Q2BYoTPLRGcKeahgDmj7C,4Z9IYOhTxpte9BRNqidSe5,584Ubv2TTCneWaXiB1mN4V,5DtfJeOrEzT5qtZ4i93AF1,5LA5c2VrjC4y8VvulyysTO,5PdgXXqYHBSBYe3EajDygp,5Px2dGdODSnXKDsC5LGDxB,5qsQETO2bXy91QNhrroLam,5wp6dhW0dCOO0TG4MGCIPT,5zXHvE9EVrLmModPOIBf2d,68xHBNPekcpaxuEkSyeLny,6B43OuVBkeGFxhpY2HBdo2,6Bhdiee45ytzB8b2tgHdzR,6fYzsHuMF3Jh3UaB8AfQwC,6hNphdzRIjNroU4fyFQGDS,6r3u99JfzeSrmnyHX5IB4A,6rFCbfnOPMjICtT8523Ayg,74pi6g6BZD0eUFH48g5zm3,7565A20v9StvND4PA5JYbC,7AK3ox5iJh2dBjrEHrKzPG,7arxkv44KAWNXW05mLmErS,7daqCWAQmmvCbUFdyUDxsB,7uPP69rJXlMpXVEPXX4T9D\n2IZ94xc5h7ZG6ewnlOnoF4,2VJ3kR1trvTSqgjzQzOBSN,2XmmXjIilP5LGRzfS81iAE,2ZNYPrxXovn8UXPAMcRzXW,2ixO74rwcwtYBywwU0lFCH,2uw5hohGYWpoL8YjW1SVkM,3EAAQxNBGI0Qj8L8M6dlr8,3LTa8NTyjX4wAl0aeph7DL,3j31o1q3Us3vT3jn1ESYsH,3uDd3junBHvLXEo5brFz1e,3urWN7J12GHbhcMogrcCRG,4GoJ9G3pAWFOqSnMR2r4Sw,4HUdOergB6uBFP87FXKEb4,4Hjy15hBmjDawzRnjYgHqz,4WDvLRwxbZUkzp5vaaMnkh,4eGE2I4OAH6aOvnirdg5jH,4fOYETeXvq7Ub4E9FMY3JB,56Mb7S3hgCT3oie2GbM9dm,57RBxwnJ93nONk3jcSmvKK,5AzQHRrqWZvXq56YyErQme,5LQYiQZ6Ew3hra8tX7ufbg,5P2pi2d7s49Qfdamzoa1px,5PXSLEDCRKHy0iSWJwuzDH,5ah8n1zTdzGsJyZWjhrjJ8,5oIbdNNLyExLpISVf60L8M,63R9bDr2t80g3VlZiih1n8,6B38dDfInY0y3A59QQX0tj,6EJdMfuTTtkT3ODpuT0MyP,6U0yPo1UvnR7YyKeFLqBYk,6acvmEGrn3MBOaLKkJuwwX,6aeMEGcyoqE8BHsykSkYkL,6fZ9jS0g7vJp0gWbaLaU6T,6rRiESNqdflMKMnuRediwt,6yl9XtN0rGunHD4wdU2qJW,6zcdePwBdxixzDGOgUGhfS,76wKJDUcp8C0KJUYsaCPP0,77A7wOnLIeI4oapd58yuj8,7AILf7MVG0SEl6skEXhAar,7nwMW7wEflF5EteE5F9Rrq,01hyJrAHoH26GHSWzKLeXB,070DusgGH4WJKyRIXrZz6u,09rEul97KHgoBd2AG1pzF6,0AW12rdgg7BEKo4POOUUbQ,0Hdzza1KQrGEzwVPtipMOq,0HvtGDMR4hVmNK3HBUIUOS,0J6AcQFq8RnR4jWYYZNPbm,0JIsc98iJvP4ySokSFFRY8,0YWm63Fld60fXms4TQ8M37,0g9lBzTwOmnx3zLUTR9x62,13kXJkIMVc1BKrgud0gZB8,1RvPfvzAg6jbzWsODpDILb,1Sitb65qvjW8eGNeUAgVqN,2SWeZfgjcKdR6E6Jj2ZtMU,2nOtqboltnadNSXWSFOdKT,2tRnuEZU70qgyrmAEtzPx0,377mv3pv1Nday6pjadqEwr,3IGKKAcwW7rGGRy1PvxGou,3J8t0fiePfXwQhgOGU3wtA,3MTwJVEBKql21xN1hdSLlp,3NLm801woJocONz1NmPJZR,3PhFcC1MNjYnjrWKgtk4HX,3cZ15fnmPlpNbpa47bRQ7T,3jWZXDktZVgDelnDJx9DtO,3oPrZEuRod8pkBTVkZ2csE,3sdLbza2Dux2AIp3BXjSZL,40m7Ext5J4Nxaky0rlXkNm,47PdEZPuwJ1wOBCVexAm5O,4HayGBr8v4oLrS4bd22iWW,4NRWOq8GohOo62jFxIzMF8,4QQFYNshQlEkgQESyO3OCr,4UBvcf6BZhHTNyizI9R1jf,4tA2fAzDdltaUtL0gtmvou,4vrmslCxVAuPRxvi8T1pHs,4xoQ8jM9JvjWNNC6bk3VZC,5C4sp6JprCFTO9ZQcg4qXs,5EiQP0rUHERC8QP1OT3TrH,5UIwJW6dlOJgQKbpMDWPvm,5WHabC4LXrFeA0kobfktOF,5gL8tr0Fr2oao8bE8epUXO,5nix8zPVtS3DDLz2OSoveE,65fKF9bTdqSuFMOY8Cd5DT,662b8itZU1kjUkGPOufG5n,6GjXUXS1DMRypQlH86KwNm,6RkRuJgT2iNBsqEJX93zwo,6X8rafA2jNs00EYtlao12t,6uksFpENKduAMBgTetGBF5,75jNxKPVjq08hKLkskLzXS,7dRIjh8tx6qY0mnLNAxeOk,7hwZbuE6lr35OLMqATaAUw,0415NTHmXsbZjXYD05KGsG,05l1cO30H6M0XyEO3gV9xQ,0G81wbukZMMcnl166M0dls,0GNDtlr5gUvO8SfjIkj3bP,0HIOQguOwVGiWw9TMCXQj1,0KMxGLlQIDrUA9eiMryYXw,0LNjQJFTmm1c2tGKET5DGQ,0LjpThe4YPL9VG0MFozbwE,0RzjYWRNLheCV2sDXElyvF,0TWXvcLKY9qiJaSnbAwEU0,0bHco4SUI1EJmxtcRohKIn\n1HyF8oeszW3S6jH06da7kc,1IUe9CBv83sg56rTorIVLp,1MaL94GiYXnWEExO4tPo3w,1Mbf1MT7A0FSYUVs9Az24Z,1QHQ8xwQpH5MHHZ4jSXX36,1YVvhuvxNEXPNFFxWpoeIK,1aTm8TO1G472gJR3c4g9Iv,1aU0CFHRycE2Va7CVmDZEX,1eENdH1bdiDgMIWy4FKle1,1i08QuMuJk5RPROZkCkt8k,1qexZcBQUxrTM3RGeLU7Nr,1waE1SpgsOgxVcsJio3jOo,24Q4s34r5lTO9bCkdZnNaO,2PUoynqedBx15JbPYxzA5v,2Vd91FjcKOHXn8kiFv0gnV,2XwakW5X0FkLa7xGfgDwot,2YXXVcHEfVAeOhcDrHvzzG,2gMo97mAY1eW2iJ8fF6sDw,2h9zGXhmqHZR2uKZyPp6gi,2mXs5X2hDss3gdOAwaWgl7,2mnHERT3I2AP2g4S1V8rXH,2vQ4scL1dp9w3jKBv99GVm,35Yml7NjICscuKAGuX3iZx,381txcpzL73JjcdV2690sm,3BXxpljx5qawevsOU6UzHY,3TBlhRMVYhU1rF907RC9JG,3TCIHrNMw2vupAQfg3krlO,3VlcsvQirSTpAJfet47IcJ,3W6rVL0dVOtawapQTECE14,3ZDiGCemtha740KIO5Ocpy,3r1ZQqUe14xxssPt2Rkd6j,3rKCZIXrsC7T6XPJhXKAQJ,3uGD7qaTWdiIDQZxnKOXr2,3vAghG2o6zdjgWQikWlYKn,42Rzf70H0cM88EDU5YV0cq,4FHNG73v2Ws7QQqR2kvIUp,4Ka14ZacUwKRU67DcFP5qi,4LRV7mkO2L1yBVhmbDvdqV,4MzZYs0cRFhnmqhJsxvLZz,4OFTmdZIFPwlQTtXbdXvBJ,4VdLOyYe6ZEyLx0LbYdyvy,4rmmrBFMAgKPodbKPBIMKp,4vF5CLuFgNo6o3Rt2FrNoA,4wwtlq6dqi0ztt989n4yiQ,50dqV0dmuAMzLtEbt09SCp,52uw4LhiFFnIHduoLVILMm,56y8h73SZXnIzR0fGSQlca,5HkG3ZdLOVZQI4rpUdGZCa,5IRmwahDW9Du2lJMpCHeFj,5XpGnwCqMlGFi1x4YdlKFE,5ZVmS3L1zuMHJ6SsAsZe2X,5ewuV9PoExpWPIedXbEIJv,5i3gMF4xQnyFWXtmkI1JfD,5qGiDfE4iUmc9ZChUCunTO,69zMzxv7BgdLXTauZvOCm3,6AEMRuYsKv69womNo3qpmS,6AYzbLak1YhYu5litfcTdV,6BHSLFa3gVZQPYHcHsIWAY,6JMuZsTQprhBrbywStSwer,6LJueYS7PEtp9VEnClV0da,6LTIZenP15l2VvkvPF2lFM,6RuFOroO9VO0aMGEzirLHk,6TMCj9pbXE0PmopzQdhiZw,6WI53B4DbKjscn9mvPCMDO,6YHg42gULO5UiwXS2QJAmt,6ZUPb0L9JcZM1e7c1nGCIx,6cCJLQydZi0hOugxKQPZUZ,6cn3ydXeMViI9FKbvU5yC6,6ho42Ki13hVke3brhpCpS5,6m9JbPIC8saBo8pVm08x0j,6sgixfeGX4201VuiX2kWSz,6vxsTyUImTPvkmzXTX7ivf,70w16KjhO0HQz6eqllKYJo,77FxLSbbPmRet4It3IWRB9,7aYv33i1kUIlBcTMJPUzFm,7j0rOyP9heljOUoUuFTr1Z,7kgNuTgyO9T26DGV6aXptE,7map9ciIR1obUQ4dOKo9IY,7n9VYCn2kax80iFDnP3owN,7qxkgMuJLZ2jaDvk0RnjNf,7sXnyp8hFOpGPS1Yep4OhK,7vDowfH8q4mCTn7BajjTdx,7vGRko4f6X3H4EfhwPsIJY,00dV6gjuXDt6WcSSuC3kmY,0HMX3S2zvBGjps6AGuotTj,0IVo4wNFrtN5clVpeZts6g,0L5oYrkC94ArMJDmjtvJWC,0RY9bINkVMkkI9tGabZa88,0Y91dPJdliSt0f2TFUuSrQ,0uxohsqS7JLISPsCnWI1gj,1AxbUpPCy8bWLI3lxDf85X,1MZvOLu9qjQDQMmoPeluHR,1OAdujv6QdbdHH3fQiOXdi,1SkO0tOC6zsf7YgudT5Obi,1kTuXtS7Itr6X3JG70700y,1tINcimiPOKgJjzEGa1kiS,1vOU3stFGmTptKkRHL4Agc,20bTVYNJ8KNoWmtD6CyIXs,2Bhmk25Iq2BU5ij4BadRrJ,2HmeG2z05ySfw470XPHFV8\n1VhGpGEKywAKiCd3OmRev3,1co2ylVRZ7R4VrFyIzoPZG,1glbxURPMi2PpcD4AmufxL,1rIlWy93o6je85WpMpxg6Y,1vViUoB7DpXUX10isPj7YL,1xvQ1dL7KqGKWxqR0dkSeY,2JpahlAlHmqVCMTtUN0aZI,2MdnNxK70QIHwW999cttyQ,2Utg4Imeeq5cI6DQ8AupwV,2VKWrVYPGgJzBmRGc8LWkh,2Wq70oxNy3i4KOW175fUs2,2iVPty0FBstGSURghngIgo,2lxGdnAk0OiFAZTy5lKyKn,2mmkokfVO72zAHkz9OTRZO,2myAatrsAXWSYBCJzphYle,2sXivDlzfbHQAPrGYKhWbP,2yh46DDBBxoDN45rCH8nBt,3AMGT6wBi8UYxmYK4dS1mP,3ARfOz1BOZdiaUkcjb5Ul7,3AliQT2GgiDBN16poZPdG2,3B9bfvdtGxZp4IKU2esmQ3,3HRRUkWDZ7bCnYMFkkRCsA,3I3WY0C7AQMe6Z6hMUQqd5,3I7JFFCxYmFnhU5qrsIpZo,3JXtJtFkP8gVIl3BM2ajr5,3U5RTSxDKkhA6rtHEXpI6H,3WiissyVFRpCVrqbyPKZxZ,3c0jigaQuhR3R4c6RGX6Ao,3dS8RW1e5gd5rbSmNjDAPe,3eMTcFDfBkdUxzRDAb8Krs,3f3o11I6fICW22aTW3ZK2k,3hZJql1Z6TQXZaiT09NCPL,3iNliE9VdKaPmpUangZfTB,3igpedNqhZcfhXMLtqn4Cr,3pJnfyKoVePwVmljB6Wun1,3pPVu5GqeYai4ZFNP0j9Wr,3q257jNovvy9u7dW3BOo4u,3qOEq8x1ayOUmvcEvzkPux,3qXCSie16apmOW2VHeeY1K,3xE0JN7dBupo1lrr6WvZSl,3yhqUuC2ahWeC8PP4mj5Gl,46yWOqnL99hM5O7OD0Y8Tf,4FFFy9Nm4wUyhc5eMHuQ0z,4Uke8Qv2jsLGq2pKSXjSXO,4WsMQ3rw3Y5JPHIgJcG8Qc,4YxLJVcYXgN1Kxb67BvxEZ,4gp5cj5GLbJddPV8Ftphb1,4h5GTzoptGcmml3VwBkP6t,4pLt09DV3FFjNTLqbxhJcO,4t6nAyyW8FEEXbN5MLAjtL,4vDA036RKeQjigYZmANk3Y,59qHsSncWfBdugXAp2E5AH,5GuS3tJuRwbdNObPdCEVfI,5H6H2pYhX8tYGQ2DG4QeB0,5LS7VV5Gp3evv8pjcpTDDu,5OO8eMfRfnz1YbfQBww27q,5PhZsptr69P2co6x4oldeg,5kR4Gu963Yj5PSLbkhdlhB,5uPgn899inp8HOHHzwUQhG,5vl7yLTgL1cpEmUqtMhk9n,6DGMmL7Y0CG0OFEvRepJpq,6ICtpZePn3FKPcJJr8p9Cy,6KZtv7JVe8fKXaIHPj3Gb2,6M97uxgvb8dEPDIetC7OgD,6MV97AqFAH2PLEzfuX5qzS,6Ox51SkYx2CyHuWIHMfTUq,6afEJtnbZmuMvOfPoGjwkC,6bt1Qb3CCzQkXkXu3FzEeX,6hNwn4kKfeuDJUDqNFI4s9,6kwqwIUxDK84yXyfL7jvGf,6lnhnrHB83cj7EO38t4vgP,6mib8jl6fASfaAahkDoCr8,6o71Foef4Jf2LMFnHuvQo4,6qeY26kCmlIzpLZVibJU4M,6vkmvL8i9sfIHoAlzJcfAO,71i3ssLhtbdlUIK2fOoqNr,732WjGszph77XuuwYTpjpJ,789zWw6YwOpoDXoyRXaG1R,7l92bhAAWWCnRrbmekFSor,7m6PhceApKOx7Z2hFM4fIX,7oEbJXeTbSSWBNVr0RHRgM,7oj0ajSBpsNjSZAL51fIAM,7pwDWr9QNRAv6N63MY2mRn,019BTPndXWHWyntcFBe2ch,01DELyfvCU3ZJUCDGWNfTz,0BFGPgLej2COqSzwxKmpkU,0BWqXtl5RSRWEDfoL2HdV9,0CwVkwUUCZPYZdj7SafQYL,0DKa36fiJjoRInV60vHWry,0Q1y8Inh5CnoSENHEeNuLC,0RVsJTnSwdLQ6F8ruukszk,0f5IlhiVWUUq4SGHyrRxIt,0gRNSWEe6X27ggYGdqDT2r,0ivVJooq6VM3NibR2PpWtr,0kKOC50fPTnqmrYvtJInsT,0wOCx6BAKo9ZSpejgL8C2Y,0wfA2oMurJfrGYjLCfGxvV,0yMF30FFvzQLlBDhHuwsPd,111z9TkkoGcVODDNHYRLd2,1DOG1X3H2A6g6WN5ZQTLaR\n7Gft2Bcqci72mLpl7gNOr3,7LOrMKPfsaAhekoVOAFcEq,7dOvcHRRbuWLU1bqso4Bet,7ffDwJqt9QSia8H5rEDGpE,7gUpHwmxXyJ4JVra6UHpKA,7gX11niZqP8hyy9wfAtSfS,7upm07Y3Fx4AJs5G5OqG1A,7yWcDUgTm9RLNxjPPHXVxp,015ROS1oTBabLaOLMzDF47,02SS3PqtrKPZpWnTtyTFaN,04F42oEuKrRComYJfJuyVR,09a1pEvY2wSOspwZv36WVV,0BD07BDyj2yzdo2TeITJNH,0Bo3X0RlboVKipzxpzwXfo,0ZdynJJkrQ6pFxt50x9y3K,0o4z9a1hPLutLeNY68wdgg,0omwXDRLUssZ7fgl9vkL4m,0sHFw13WH3LtSB3yP8UMYJ,0yTfXjMmoCQVmn2kYjBodD,14ahZtLV5yKtqQATTfQta0,1EdTbKWP1qUfrVWpEgUBCv,1IIw5oVR1xE4bzdl4JgGsc,1K0Shi82LENoyXxAjJj8XG,1Kwa1zBDS4CaTGHPZ3pKau,1MV2ab1Q81XpS8yCZYYFGN,1PZDyestTVydtHpaIcfUJg,1hblRUhOt2Yi618eAJGGiK,1sTtlEZeVeeEnxEztJNkYN,1sgbUhDNA9IcOPNfeIWJ7F,1tXKuzYRdQsKa32ZUPiq0A,1y1RZ1WceXGSr0X7Q6mG0M,218q4fCmVERKhXEZDr6g4P,26xSz7VJP1AERCJfgaXeMZ,2G8eh8xA9e3idRI1gD5Khs,2LXDBnBlnUHUtjnZWwWTEu,2LqczHHyVkIN9WlaQyFG1R,2O8GAg2e0odKtTlPklQZ07,2e5lOBWjUUB08Aa8xpG2PS,2m6ikQazVLpm5XYxAy3OFz,2qmhfzORJFrOQgFKYlnm6Z,2smYox7uyoZCKgMHoqfg4X,2yRlcQn3yUqseUYHw2XzNZ,2ygvZOXrIeVL4xZmAWJT2C,35arSG83D9FCN2Ts0qOuoc,3AvUUJ8HopzSeDTi9aFiCN,3MMLO6TUL07tze9IXud0Vc,3SONA2HtyUilUPckrSOiln,3d93pRHHPjkrDE5Jn4G7Yl,3hDNIAnUnraurZCuiuPegu,3k7Ih6fxF30qtvsgWPopvn,3mLFCocZgUvih60frphM6l,3yyNv0TmK4I412gcWhBltL,43tQOLiTfoVwURdx5Ei7yr,4BAkJk9QFtYWycVXRvhmhk,4FF0tP9mkoiFKLiXFeXm0q,4HtwantcVnMCOzGmiyeGmT,4NHMvLCOEyDvj0vxFiwNAZ,4Qx7ThsDRXzhxxAaSPLlI6,4ReJJcpW8HtVnqzhf6DwNV,4VHd2JFgcpgYOvJWP2D1aX,4eGwQiJNa2zboopOEOvXjf,4j8Dz7TdDXoJ2z5zhqEwYX,4y3BUo2hp0MxylfbUaqRyJ,5HOqxHVvi2JZfFGviilqmJ,5blpjo0tFAlmc7CmnCWa4T,5dtgtmWdO4pOASLQdOfWSr,5iZuZah6zg3CRQzQGi51Vf,5ocop7SJaAtCK7cGc5p2JD,5qYP2Jpli9QkYdgqAy5DEV,5tVMIkfYa1gRl58ByUsNkx,69psSAnAf9PdNniP0MKIqL,6HFyjxSYCJqIOfFPhUn9zo,6Jkwjsiv88sZT3LY3Wfv8z,6dH6NIftdswHruAjD80ZHB,6xyOZrXp6UGOFa30jewqIV,6ynqLEZvcA4Wqv8B23IyYN,6zRqVnBUDNSur3jQQQJVOl,7BL33HmuFQien4olebugdj,7DbLT5HzDpQFo6ReMTkPzj,7FjIYiD53wxlQmzTT6Wdpf,7HKrIgAJKM57tIg19iLnUC,7HjVMDiXcG6bHC9FHGE428,7kpe2K0hdSssLj4G4YjxdU,03wyufh9uNomZdlKIcQ0E4,05Hfo7g7n8wcnxCPOLbTuj,0AZDlFjlawdbKtsF8kWi0z,0CoSBNNeO8JgayAfLttECk,0DCuRxadki9VQU5pskJrUG,0LWWi4CHmFfPDV005TLzPP,0N2rkPnpGdWSP9xotxYl2F,0RgAkhVOWf3CZnWtFA1891,0UmaYgHfAEEMwxYGHSDMmu,0dHaNi8L1XuvDKxx1V7DFB,0dLptfXupd4zsgppQgrvVO,0wHtZIo4VfYdXVKj3xrxWG,119a8rsOkvUFXPwpVCQUPW,13MOQ6oQqkrZEDkZOHukCw,1LcIr9UrZgmkMGJ6U5aIIm,1RfSykRvuEDqTUimaVE64E,1TMwDvcIQpZKiio3glvpq7\n7FJuyR7uB1j6Jo2bRYqqEk,7GcaGWYmbvanxJJJmSFSiU,7KqV9IuvQDZQmQTcUGMjZn,7Lo4ttaSjayGC5xI0RoStc,7cOqhBY3TbiTynwVmXdz4P,7gSDwT0DGfJaIHP42q80B4,7gbmYMWMvFiX7T4dHquhoT,7hL3vqL81Owl1VEK1vC0JE,7wFQdlPyTuFPDoV8NmqRCN,7yw3MDzi4ULVetx831m5xx,7zqltjN7tbDRX80tP3SOCP,01B4EffzLZbFRVRMyRgta1,0GRhNXSDCobL5I8aTNFHEa,0Mweaj3stYJ09jRC8dvkJO,0OdwUAhjMCgsLXNJKRupmS,0PycpHBpbbh1x1QPsErwfD,0XDMbuw3mMWjRkvL9Pb2uV,0hREmEVmD1culIVeShGzwo,0nR0ejXiTIg57q07kTL5ZL,0ut7f4KB9sZQ8uhA4HyOMt,0zbc8UgOfYyG96pAWjx3hH,16gW9O8A4rIMx5OOVlzsSn,18I4ulh1koJ5ZrgbSxmlOV,1Csuelaz28su9FOIubAA7b,1DMB324qRaRdBhykzbE8Ts,1PqNl4dRtEANgIGSkXhvqU,1ZMr9dH3uCv8y4QHD6QjcD,1jRhmp69z3clRhNjev6P6f,1kq9lzEHoY3p8naHWpqNlh,1lp9iHcHlHn23q62d71FPz,1nbcFrG36KT9BPGk3phSrv,1oqGOxkwnI7FbvRXJUVKER,1pZDDj7xhGT6EpzxB33T41,1ulB5740qjdSila4Vjnb7Z,25raxlYX65MJqdjoSKIPI0,2CtJDDZiXVryDNAlsGyK5W,2CyeJDKRCAJprR45hdkLvG,2DvC1wX7KffnxLQ3OcQhA4,2Gp72ppIBWnO0fzRrOwWDs,2KDIA4Lp7mfoczkG44LcsX,2MuIQnJTw4dEGntnK6MSNn,2OjZhG8BnvrsVWqGnZk4PO,2WHNbtmjL3a2pKc4LfSlxR,2WphjSfmTbX4wZ48SzYwaH,2Z51LzRdQNIfIAES5HeVPj,2dzeI4sQBhKRyWSGVZwpFa,2iJ5Z2kGwxCNbUltnqoamc,2r28OVJXaUWY5gkMdAzpeu,2v705YlYolKiu6P2FbqOat,34v1NtHTE8i9OFftsGBMGo,3MlA3b8KVJuratU2qdW4Yb,3Ns2ZM0iVP42GKYVcnWKU0,3f03fwCowqjrdjJ9fDEuvu,3gaH1EhTC53WZeFRj3hGtp,3lJB4seMO9GYSOSuGLp2CA,3mNbESTcSwgN0qSr0I4Vzi,3onPL6KjCPM0K8wZkDeU7y,3pYB28IRzhtR5cHXLINchp,3q9HEjBxDYlQJ4kBMDowVy,3uHWdehoLyQZJECjiTI4a6,3xnFWXU2SfZ7q7Nes4Ncr8,41SFzxB4828Q0ZF23vSfmL,4CQgSmxceVrNEpMT75aAkY,4JXAmuFEv9Wo5SiShmwOJd,4NGlYlqJu6lbT70D5HlCdI,4PLBytUtyx1j2tESposvlP,4RgMyZb1frf45zF2BSjMD4,4ZJXI6GhniCI0kSuin51lF,4eVher74890dyHmM7pxtsA,4kNARr2y3rK8avzRFSRocv,4vsz52WPo1lXXwCOqjh4Ls,4zfdaZxEFXgZDrGP8UWq10,52Wf6E7Vc2eBSCybpsJyJY,55wcEIrK4xMyhJytaOYF3d,5BVjDW5lJJhxRB0yDqlgyb,5EU4O1aPqqLFcrJ1UW8C5L,5JdkPxWojjdgoJyKXmKH7U,5MIxT8fcc0KT6V9suVDh8O,5N0G5cRxTO7zP2c0pREZbw,5naGbqecQUheZgOhtXPDj7,5rlFNMWX8yeJo3WbdtP2BT,5z9VyMWkBCHB8iSVaLq3jk,65cQkOFngSgj37Gnzp4ry4,65hfmtV2gkBmqXf9t03Zxk,69j2pu1X0fjchT6JACO8OJ,6AZaYGEOY2ySnSx2rhi60n,6Azo4zZfM5g7Mh6jbs8Lt7,6Bi6dsPsxx5XAFVEukl9BW,6FloUWDjW3r51mRYyw0vv5,6G270KT3xyySp9mmp5vTyg,6S9FPtDyQGFyvcdKJUFuKG,6YOZH75ovjTxm9RWs3XDKl,6drMkkht8gSXMUkyNIuUcN,6jF6VwQeIiy18FUH0wuIQN,6oIXKVgSbMmUQKe663B2yg,6qRIH2KDx2NW81J2PR5Lke,6u6xrnKXzVVlInlfiHFZsP,6uQs8IhevnDdW5RWiYtXhU,6zetwLIMcYw2FNb7nxsPMB,72An6g3tlKeyxkGxO8Hnez\n5ZwP9znDfvsOxs2lTARAS2,5uEYRdEIh9Bo4fpjDd4Na9,5uNhltpaL5Qb4n0hBGoFdl,5wibR7lM8TpbBYJDExo0xt,68r3MgpETkFLxzqhH7MvSm,6KlcGuI9v6rRB97ZMbH8m5,6NfB3bE7rYP1nwJxCtLBJv,6YMSywt3HpzVLoxDN6tzqo,6ZvXQhiIbP4XpbrHN6brAI,6jszq1eOfkoGeiNOFfA8ma,6kLrO8KR0sx5nwyWL40d2u,6mLJ7zIYSd0UU4clzjKjMC,6tYsmYQYk29YO6occEwf3P,6xPfr99nsLrhed1BHJJoGw,6zm3myLdhev6UuL8xOewow,79qOs49qSotfX46OGByR0M,7A6CcLFrekQwaE7YgNFhMf,7Csd6ozp0Ci3ZDfvRgzrWz,7E4y9kiorG4jMSvND0sfYz,7FiYF0ocZO3hwxrPkJ5wQs,7k2Ol1Tzgvt7mywZQvu6zB,7lTXqBURoqMMzzYA6fFF6s,7s9GCH2s1koH3AwgQHRwYh,00IZUJ6m7HLqbhYOYz0Pwd,06paPnT9vsd9qonDCsOzTX,06rWrBD4tarbSCS30Mgqm6,0HszX8sne5nRies936E878,0JzPnwc3eDdyBeReXFLgXr,0V31InZ8QrZ4bFHeZRXvXG,0WyvsmJXKcfJbacofb8I4M,0cBRrW5BtRCWZSv9VYUFOD,0iBIo7Eti8pHuCivtVfn93,0xbjfAQ7AGDt2Lg1GiuceX,0ziEXANIOhPg4FSUqlnCW6,11ajMb44YwKShSy6H1SMWx,19FGwof6PoJ1YDF7X08bRw,19hkRoctnBAVQ7VnLYM6je,1HIkv4ULSAxJZPt2PYdYoV,1Nagyi5mquIU038cAvfYLH,1UIgJwMums20e9wSpt72fF,1e1a7eAlICks9mch3UVsEH,1igYHbrE9ppeHAyeBbE2jN,1jGG6qWJJqDREGjyW1wMR2,1n1hxhDUWWEpo96PSsKA7t,1nSaFifwF894eGEYetgEb6,1pyQNeYwRZ7AMKMrGx4tzU,1ull53OZ1oxddXqqHbuOdb,1wenAEpaBQWPkytWh7faaR,27uZP20oinX6Wkf5LrjIY9,29JgeJq2KlSrv8IjxmzPvb,2AijGC8IQAbnlt1w7JtRGy,2Md1BsOoHfDo2Ies0qhK7P,2OxhWFN3yz0PbfhMZJHWBz,2QytWkKdacqQXz6huD2ngO,2XWwIwTPWJnmrb2XDhdM8w,2jmB8OOjWrZCazZET9Urs7,303gLkrAiKSp2dbcQTMtbP,3CDtSNMuw0ZCPrEONSgMwQ,3DK1vWJQDH0KIKcXIAGFPg,3JYPW2mu0eiDW6UOk9iG2i,3d18BL1R5jhfiEmTVQZ8jX,3m4aK18DyxHSQC1ULdXeKQ,3qctD2hzLDR1BiL3gA6xTs,3rcGdVnKnW80fTHeKvpFj3,3xEYBeaHu9zHOeuyAOhSQh,3zUgroKnf6j3hGaBiuMThZ,49zHMYNLmYGLSpTM429MfA,4Cuu1Ip7u09ujBI05FCDbU,4GJE2R4A0VGUQjndarcFuq,4P0NV264FS8R3IalT3qKNv,4Qr7jxogVZA4rglb4IPyGD,4jhAuG9rGfvl3cKX5WBFdE,4lAfXpZKFDEudiEzLB9uHm,4lHLa0Z48pb3T7iuZ6T9xR,4tLlPj0h30JMGrU8bzJJqh,5BfvUt5ztFuAyhWjgWzjr1,5LKYpQK8GYRShD6b9zHU8T,5PnxopXlAJgOJbGgr0fgEu,5bbP8vP3X5BNXQXi3Eeunp,5duEBHOOAvBi3SAjJTUf1Z,5fFQBL8Pnvnc9uszdadT7i,5jL5AvNlmB3iJ0dizXhKuT,5mGX47d06oWOwFTXAuJOA9,5nWMTc5ahMykir61VYsl0x,67YvDTNbfIM8FGYz58hn1r,6Ch0D6Quq9cNWymH5e4Nnz,6N55O0p3Yd10UkyA25l49x,6OGrgMBmMS3v8r3NLceb8I,6VAbBcVW6E5TdL3Ufj6R51,6VbVuMbEi9LhL5GTHqpkBx,6WhWYLxIDeUDTtKmp8F7mX,6a0L4tcMx3V4peuQJfQBBT,6a4MQYjKSAdN34HEP9s8uM,6af9FJSSiyRV36QDcoSgwy,6peVCJCHKSJBMggL6ndtbB,6tHS4wXcmeGVRv7DEUrV3g,6yrHBA800t9cesLW51CqXV,712s3bbR2XKQvW25gemXz8,781SNFn2D2ifFxUtkwYLdw,7DTMOIzJ0z6zYZDAvm3UIE\n3Pj6u2KTgepyyidp5xfbHp,3YmgsYX80v0EtBZekgcB6w,3aHYf6AXlWujDG9CzzT95i,3asNbWPgAEprRUbBTWtp3u,3btb2PBGvkz3HdKnB3gTwq,3n1HsYVwX6qMvihf5uZDKs,3u496zSa1XZ9JHJrYBD46G,431jBnFABGAR3D2NbfsT1W,4Agtk2MrapdZAVN7v6PuFO,4E6ip8v7Fl9iGXFBKWMrgM,4EsmXLlN8LWGdyKitjflX9,4IazlP0NMBXhS1hF6H7et6,4KLcQpDco4VnbW0MpDchyB,4T0Z5SG6t3r7XFUp4yfMi9,4VfVTVATBhOD2lRu2C9ADD,4pBhTGnL5N5KqsyqU58jee,51V7IK66jWw2AB3UZ18zxh,58Mh6zmqSo9IvysPAXnG0h,5DrWXIfH9NG8Ynthh7QgJe,5RzEyrxL09e1D80CXHmFAx,5XFEsmU9fTFfOad3PQzPCm,5eIJ16jgF0ggzAKuCBCPwT,5l0nX3AhmmF717aKSs8qSH,5srKMwXoeyrRnyTnNbpgIW,5w5bqUkym4ALTA6zbH0Gi6,61hQlUjEFhaNU5wv0gUdNH,64GTOCthlImNdqmAJnIvlB,64K0ROJyvFSq0Kbl9rIyMA,6ATqL4f1nFWwASrWi8nF6e,6FMNyCW0vrpct9XfMGJLJv,6FeeeMmlluJnjspdMNIkQH,6Pgmqg15yVexuOgtzuxwoX,6TtDPG6eFqDGooeyKYXaea,6drtmkgMWpehwKX2si4DEl,6g9UET0Nva0RexOkglSh2e,6uA3l7SKpGUvc7zUsTuOmn,7DED69q572q2RPvXtxeafl,7KGMmSI2vaHim1DlfES5U2,7L6G0wpIUiPXuvoo7qhb06,7lPN2DXiMsVn7XUKtOW1CS,7neh3zxtgTMy8sokYe5rt2,7oAPdBSCOudFMNF9I5VOFy,7wP2MseLG1bIceX1H7oeVM,7wvKge5Y2xY4stReNo86sC,06kxa3al7bUqRRo5nAFduZ,06nCnkVALuvvNcBwVRNTUS,06pN6y0eFrCBJzm8Ybgt1z,08pnZCD7bB3voKAA3ShGTw,0BwEzkVtELJI3suZINw6Yb,0O39si7MdD998p8y5R45ty,0RzusHyWJSvNh4NRjtOdOb,0TWBgAGgGICZ5TQJs2vVND,0Ynou2LoIOmqRiyu4elKYX,0buwgzsh8fD57lvbXxyROq,0iQd47VJs14l8EA00PlI71,0uH5ORp6Ai5PP0SUofxoc7,0vvR7ogspsWehDhpZPNhZF,0xAjCLCwfRUZQe6t2G2Ywe,113lSt9DqvRoHCDhlkT2yU,13qSIkriq6c8jWFLv6Lt7z,1EpF7SUZOEdYXAJF6QC43Z,1Ge8px4DSNseb1atf9XumE,1LDAyB24s26kvMt6hXFBks,1R62WYOr9YiRCsjHAiiMun,1RXh1aAInzM41tTIMwLMxX,1dK5t2UGFfEAY7vBDb75Gz,1hnDaOYkZwW6ZSDeDXmNFo,1t9WkESChRAN8T9p3az6Pg,287t0mzafBAnQcMHERySLi,28vLnMn03ikIZuIFVu97r5,2QO12LQMSu7iCJEl1uWPnO,2bBMU4VHB1pjUe1AETSGs3,2jEulJUhzjEzfdHfHXwVxL,2kzTOJVs4NVgUijKCXj7tk,2m9ryxnEcVoQNr22KRxe09,2xhaxIUaEj6RCYLhrQCn1i,37KlI45scNKbu1ZXnRwXPj,38baA0WZfWLpm3lyyr3IIs,3YrHn8rV4DSyMjryTLIxo0,3bNIlJBpwgwFNnFuSjH6Uh,3hWfKBt3n7j1xqIy6LA5ve,3iLwZIDtKxGC277rHmX4is,3syIqcdNRjbFcWkEMRRT1d,42k4Jpfrcd7FO1x9Gf4HkP,44xO8889yUQHn70P73NILS,46lyJh9GYmWsHez3EsvmAx,4AHev1XQrEMMX8xN9mBXUv,4AqN8IdKCfItCSbuaFch81,4Gq2ikHCdv7v2Wfvb7Z8Ns,4RWfDoLIuYNW0q1CVcDb2k,4oPRbl21srYBygZSzHpD0A,4p0GHOWH3hp9ZUVGd46Bhl,4rQWeoQSHpBFP4Qk6mlw0T,4xcnF8r49cAgMjl7heL4Qk,4zdaqhDpl2pXrwTsqbqRG8,51BuQF7Zmh9Cni56n4uto9,5BMXfwG0l57VbehGPq2Uv2,5QUbOFOkbDlt4ZY7bdL4Am,5YtJCl83jA1ZlXtjWcCLys,5YvYKEQEYJp4orh4z3Dnpk\n1xTrwHzhHuNb5URVfuBp0f,26yBLIT9pT9sVmGV1G5ok6,28gOU6aiAGqn3INdkrbabZ,2Kdsm65RzsJyhZomFvrjvI,2KgeYkljkGLetuA97xfU2Z,2NDMLu8ZNrAsAsPAoW5VOx,2PqhgyoxhBy20P06e9uL3L,2XxZMORO6ThgSuC8OnVBgm,2ZfVt2skRwfEq1Wb3D7GmP,2iwLygOHE2YStc23isxS3b,2ixabSVbccs9np9r5CpbWW,2kNtI2GZUKQxG8axWnP8ck,2m3RjRXib3un5AEh08k8Fe,2onRIu5qA3PJZfnXZC1jVa,2pIZ6QqkFK6Ayg8pZGjomA,2x0Ou7VYnH19v1rBfMnjHf,2yhdug7HfG1Yt2KM3KQDBw,3RPHlHhb6g0rqcMVwwfxcF,3Xsmpypmc2DcxQBbmnnrB5,3YJJjQPAbDT7mGpX3WtQ9A,3Yz87ZZz3UbjBTE9d7QHD1,3ZAqnUmljWv0X1rDx5CP77,3gyIcFToYNdOJycgMShtb2,3hNywmR93yvj68y2zl8mRt,3j1c2sTsEvadyuHzOmzbkB,3pGM3BwG6I2Di6rklM9qPx,3qGedrgOaSZu0SMAihkalw,3rpjITXrhxmKpmOM8syGVs,42hsIbao6zbdBEwnmNuxb8,48jV8AW50589btXi0Hs5f4,4DkSghl14yN70T0RX5pe9x,4YMc3A256xFBS0xcT77Qce,4jbzmPDdZMp4JFcif3OPnH,59lpmLRHEkHxufzKdOFRRA,5A3aEJL7HkijkxLFXMv7FN,5BFe78RJ9sUnv2Zwklb6SH,5NYwjzQXE8ug35TRHoDeuW,5SFssNXGjeOxdAnECfgttm,5d1TzfQh1uuIwh3HQXMyGa,5dl8x4xLEzZC0f927WBTUG,5ed0x7s2O191nQ9gfmAhHM,5fUzMvyRsUklP0Pdmsh9Mz,5vvn5HATa05iKVql6oYULV,631vHs3ww9xol6wcFuD3wI,65lZrz3d2nPrryy7VawRai,6B0sgxZ0OijMr6F154GOOg,6CldyxMa4XuHWAhAlaPWmt,6HOLZtVDh5EgvPnW4z23n2,6RQ0i7rApnnWSI8uEiGVVF,6TV5YIX27b0ewliqXo5gWx,6TxXpZ17qTxOVDleRQ3aM9,6UHn3RCz0gFk8elCDzhLDZ,6ZVVax9sMTB6HPKu36eYZs,6baEctngXfwznwWO8X1RTf,6cMKaS2ZRD8GDgdTdufanl,6smHuWvMAMQfVO855qtTDw,6u3CPnFMKANYgfdiifFOiJ,70um118ETgSKTghQNF9iEC,75rGONmoi48LLYBFaGiYsv,781pCS1OuWtdIYyNVPV86K,7MiE0I58L6n6L7lmPKwe73,7h4WvFZjJQvH87W9fTIjyl,7rNjupJkjsc3ANGeW0RCYj,7tc04xLTn7fG4IUujpuC9r,7yLskBcT5sTLZDniZTjqxv,02Jf3pdSKAUgseNZSiJbwp,03B2SfXuvDh1m9F4tqrX07,08iZ1xoqxBCzoZJjXdZKKa,08ridJsmOI6aii2YBuLbVc,0ANkt7hXhZb7rdCr9UavOb,0HJQertovXVPTYykT0573t,0S56IEuDXtCKIgRrIKu3PS,0bbpa5ixzoMAoA7otQ3AcA,0dJAianQRB8TllmviWfbNG,0hACTWp6cK3XwFQtlvzlC9,0iBBOvVQ8QCK7F95boCn3C,0ooz46SAYMJsdOPnwW4nKK,0sAwbGaFnlxrxFgQfNzGJS,0vybLr0ztXWBM4c4FyTnKx,165HspTvquvzycHyGj6fBX,16NGKSGdga9PpKni7czkLl,1EJLqTbCBWrXIZsWoJ9XPy,1NEI9OCVnnUEHT8om6IOO7,1S85LGnDPKKOkfuFaK6vFu,1UVIYIX9lGfkOUeXPdbURa,1WPh1UpH8ryponOGyI1Yt9,1koSROGPbhkEzxOE8JYHXW,1urRGHiUreDGfEGi6KuudL,1w3ElgYBA0YGN9ddJn7NFN,2BiRV6nrFB8gAZ3xUZBWHs,2MgI3hW0GwHNUoSs4o2Ozm,2U0MM0z9qND9Q9M1bkUm5I,2VtBZy6AL9JrnO5ipoYCNd,2WnNcasDsu7LkkktEoaz2h,2dMBKKnoP50eJJHGbn2eUW,2tigH2DP65aAzAlyAFNoRZ,2xInE7D1xaV9K6JZ6oyJ7E,32rOqszN6ubqWBGO8MBkZz,3CjQ4ldVj8piCOykETyC6C,3EetDRais2bTue3poVvXYj\n1pnL2LoyZmKtxsWjsfRlHN,20MdbhyLiZjyVoc2vbf7SB,20lTQxwyKRLUzycbzIl8kA,22zJbNjvH4ZFplXfypE9Yo,239bGYtMgOU7OqFlt5LJPb,27sfdhX5ndVTQoscsB50LY,28G4d150k0L97C2rEBlafm,28RDzdBt25o1sU2MFOTlRK,2BQHeP5BLPpkEOlEv5CTVD,2FCGlkyYXNxnoPhio8eNfL,2N1lLLY43Gm7cQyQtnp3TY,2NKZj5P2qpPZAH98ERdWc8,2NSe87osMF90QPPQIErhdC,2X7X0jEaVxzxQPanxDYsxT,2ZGHA6poKjdYF53JdhJfMl,2ZtoEn6SXuuZingX5FNPJQ,2iGFdHJ9PNdXuPWCpjw61T,2j46EsGcn2W7AJrqKTJ9yF,2kUWRvNpKmcpesv1fCdOAO,2lo2Sv1jLOp7aNhGvgt6qQ,2lteOvX9fOLjSQ9oQbCJEN,33gIRI0EOFISryPJtSVCqJ,399nIYTpN4745fwu3mTUzP,3KNWGc3CrZFWML2P9jNE9r,3MnFHWYVWEZjkfU58VgZrz,3THc1qpseFOdr5z6JqAk7y,3UDwredvomtpZsvMO2WTJl,3UET3oVThA6MgDpjEgjyLq,3a2qhSVtcRBha7vJ6KHhyT,3xaMOSIFw8RE33XQ9xmVOz,4HsjdCwpCmwsBJY6JNiA9r,4J9BGcZInwo34jQz7OoZ6R,4PTfPO12EmNNR4eXPweff2,4R2RjRNPvXNLonRYuybrzq,4SKr92Xfu1wUKoU9pC9FcP,4SsyIzSN2SLe65Kf14lXkV,4df7sF3EBW2MU5FFanAIQB,4dm7JxtQF3zX7QTTgmVKWx,4kQtxAuiMW992AmzaEparm,4lLctkMLQJAlg8sTzfBFGY,4qhO29pgBSBxOwZSpO5RQC,4qhwhVDsbTfBsYDd0pmnzy,4rpWFuyEOVCjKp655XI1Fw,4vJGPuwAEtR9xmRZHdWOqm,514VtijAeGzvPlYsFXHXfp,5E6zp4z4SmkssW22mqEcNM,5LIEYSV0w4kg0VYQFJCuCf,5esJWlCmHOhkznATDXXJpI,5gKETtS1wc1OGaucMkGQLg,5iDhyg8xIAkK1EJtZdL4Vr,5qNV1GAcGCPfUJfDkUNF5E,5x1VyIiwZSY1yTj82IrFQf,5yAibZYjXyGkFPZvQLAdiM,5zYZD2nQRCDEMleFB5pkzq,64hbPzpaWfHw2V5j11odlp,6CCnuRpzllSnEodJwJMCoN,6CzyUPXfxPfbb5fy078dhD,6HQY0FUesf8elD9rUXtZb8,6Lg74NbMBkG8mezUTNomyq,6NB5YYtXAzfZOu2vTflAHA,6UzLLH6dYuOvpjnavhDQS0,6ZaMggVJMXNUJ2mkKjeWon,6dstnzUD4KT1IJeHQI6PK7,6fLf9lcj39RoTbszvQ7mYr,6hMZvq2jUNbxQNicH92fNu,6rBu6ddDehUlPtpeuqvyBx,6t5R6YTK8d6n7wxjZI3JLp,6wKUnfSAJRQagiCuvNgMbB,70IzGRRdLL511jD0GaK2hr,74GGj9rWMmSzJEzn4k0rjs,79zj5tWtSS5XVAU9nuW24l,7cEjFMHqhnJEbpbnHUQP7E,7cHDCbp1I6oZVwox0fEFcG,7iGASYouVLuiMggmfEB8MM,7kSVT8tsNSc3QjAy9UAief,7lfazyv2rEYZpwVC5gGxyO,7mV63vY1vlPhDh41veyTHl,7qY8npe1fAwNhuY6Sx663F,060OLe1AoWYRWX2n44fRft,0BWBqb5XxraObLopqskk6D,0GWjgWGW8mAqvcYqG3oXOe,0GZKyGkM5CgqiL6C5UlCUj,0GbOcV7JYQH9fb8UpZ9eVr,0GqhoSy21Qhp6036saeWLx,0LrwwSU0ycsvTxoqGcvjAe,0Ms6ayU5y7ABR44fguYPr6,0QNC3y9arOsMX5STsC1EJ9,0dgrO1wzOO5DchWAFG7Njf,0gmStTUTuiU807EB4KafOX,0oHEteATZnAZuA9dl1dXF3,0q9v0aM8nBBF045S4lUMJE,0z776mgVazsVcW25OW385L,1JeMiZSw82XdNMuDjFKHrR,1Qu24vc8msUVLcMZWa4k1x,1fAE0TQ3xblvOgnmM7yL1s,1jNKhbKmDgYSHHSCEeMXey,1nxudYVyc5RLm8LrSMzeTa,1qxZswAdBvM0JMUoV83J1b,1wTCMgEUPWbrQAYGOMqGT5,1xNQ7UujtJn6OqaXwnWkIa\n1MtNCqVb1vZrVBNhj9s0nj,1PRK8nwjcVenWC89YE70JN,1WRUvodAury62J0Q4dEiXv,1eghB226Hjl5hzGCnf6clD,1fnuVg9eapwVKDEDJDtrmz,1lm4Rt80cpRYDICBHAQSgi,1o9TscZvL0rxSVWu7KnuFm,1t8YnDkg2vKr98xG1x6F0T,1vcQPEfIjTROyT3Naij7VY,28f3pmNktnO0VoG1QBQj9T,2AeWXl2c0yCkQEojtzJLOD,2CGIIXw8elzjB7EO8pvQsy,2ENxOXbxhfJ3lfItO0MFDv,2OPIBIFwuhZUDv6r7mOzxC,2Upn2NeU2VAvIrfANP4CS6,2WWIH4AGsgDS5uAqrG2MUr,2bGd94PnM9kaQOCxOrIDh8,2cq73gnBJQAhRLN1bC0Hse,2iR0hlqkAWmWDZiNE1fsS8,2oI1Avedp7KK4Wytv2Dx0O,2t4vqHPcbOrWMHww5Yhge1,2x93RFNdEs1JtWoHsDQqTj,2yrhCmYZKJHpOFk8OW2rjU,30YcHE9G59JzX1xdNaVjH5,31ukS4CiKvL4fORCLpxu9I,32dHm4zKKUkZhjM1CvoQEh,3NHAk5w34NzcACwN0qZyRp,3Q4gttWQ6hxqWOa3tHoTNi,3S9dLUmwHtG5biX8wb484C,3ZS56YqCo0hQZAG7IV4hVd,3aRQdut8LdDFOZotCq9JfO,3bw97Xuo2CyfkG4UnIY5vQ,3fvYkmihQtdNvXJYde9YfF,3mJciW64jC99FbpilAoqp8,41RrVUJeCOVsBmjUM2sdQs,487ohJvLfiPk3NM85VnMwJ,48Zho9HnU486cLIOYegCBI,4IXbOaE1P02n6451QBZ10X,4S7kM8qWXTQhe7dhHlW3H2,4SwW8YMx6n6CTZLhdmx9MR,4TfYHSdHY5ucMN0ulunbSR,4dJSZF4YyHHD4b2s2bVFHa,4l2zHzgXnNXWAAGPd6pIAI,4l4nhR86tP7jFjAjZkJK9B,4vim94cgAFeVv2X9muMsJz,4zlyyFvmFDQ7NVheNN5C4o,50JKXElzwzA68grxhQNZQe,50e4rmzgFjLEmdk1xGi3tR,51C5DGEFEGVxvwdI4HHcHf,53vDaizT9oMm0Zf2qSlojC,58VNpcJpI5dEKxYByCkbXc,5AHSYSrni7xVCzlanStMRf,5F4zfKfeVqBjJnR6mMJqTj,5GQM18ieTPWcu0Q9w3Pfxg,5PFjBc1ilRlWmjYjmFSFjB,5UENaYjBUcVkqppoDTaCdX,5VNNvLU6mg3EIIjGpmZKt0,5aFoXADqE288FAlbXYmcy6,5eiD8KqhdRr2mI9oVq6yex,5nlDJ3StDhSrueqDCkbhd2,5oFFhphev7gVsU1IV9eQVO,62LwRhWSZvQMM0DRMTCEIj,65DNVdD9RHfZLmZjba0HlR,68f1qQCx2oHxPJ12CB4QqD,6EJx2i6wJEmCzULdcWi4Ed,6I9gDbfmE9hmHHWQVmvkGZ,6NXVs4Rfy8Fj2DOHTZqoon,6PMO0mi7cZMXh7n8nuz6OC,6R96ZO5xu3Qa4NNlNDduo4,6UnpzHhMPBWCAjcmRDa5As,6ZUpwQDvyrKnEOf4NMT02s,6j0YZhCegUh1jJCqoA5d8J,6pdHy1pCt7KElVEmk4oK0W,6xwbA7nGMYeAWPy9dXDx3R,74D7JUfU6HYeMx4bZhsHnG,7D4UOYrP7GfwUnhs6gWc2I,7JUzw0pLY9zL2UcL4Ene80,7JVlElUz583S3EJIjeEYmR,024CnsOMQ92GJoCcMKiwgy,06kiLCDL8nl4cbrBbz6ktz,07FsSUab3PIzOriknAqQli,0JmudqX8823E6sxCTbCWGn,0JvG23hQr8r5jK8sRDV56D,0N48WjkYqRjnjGpTGAA0Ok,0OmanxdBHQLM8eYzfexeCN,0Qs8tnF0BucrwNwjmYqLel,0lQ6omsWPn0jUDkT4frBuu,0qQiPk5BT3jBwucog23UXX,0vqrPAcQlHWXfWeMDCZihP,0zEcIEPHJj4MsE021bP11Y,124cRsjCieRBFKiwr0yPqV,1BBYJdtHPOhITu6oDZyhHc,1CuzE9zBtKzfsDvxR4moPf,1GydoUDvF2vWHibzqhe3D4,1PktdmpT9r2gAOQtASLK4z,1SaSWoU2n74qoGG4TXDWiz,1ShsVA7nrhUVGFWXWU3M8T,1eapCpP1Qb0pNrTaxTiFW6,1k1WXy8A5NjSMaTB5ibcO3,1mGRwSfyiVBnvMbfOKAP2x\n7agHHBRK0Tp1rH3G28QdFk,7hQRArXZgttCMAwYrpXGUH,7kMEd6Qm7QJiI7rK6Nd63I,7krYEnB1OI1RbnJBamJT13,7nQ5vYfpRleN1UPTD1vgj1,7vET1MIDGL49eL3dXicoWn,7zVVkNOKWMd46nwMUgHPmL,7zWL0T5Ud2q5dGFKCGFUfD,01va2FpLNEdeWuAR1t4isp,0CbpyAMleqUa79hu7cHCTC,0Ffc5uaUh9KjfDh4V5zap8,0jP3qBFFQWc8zwRLRRCiiv,0nqOHGjG9XzXXPnE4x6525,1AQmokCoF8vBV2rbsZocJe,1BmeLBbdFj6bzcRVeTAb8c,1CPrEZMMxSaAJaPSI2lE18,1HoiDgVRtvRrYL5IR1f8MM,1KBPIUAzEJmNto1Jo4kKzw,1WoCmFELBHedFJsk1DdL8l,1XQcnIA8QsYmNuNVUzWVMQ,1Y2YJi6gW86yeIPAFeXmJn,1hHUuZlOB8mmkjDRWhD0GV,1kxTvKWHmsT8YQcStMMA02,2QMvcDXdOjZEw6dNQ8QF71,2cOV2F941Zhh2ukRdIunLg,2eas9BFx6VBTAJlRCDLwGo,2eo8y66iRTXfnCReLa2YEr,2f0rTgPd0wV4097wFERC4H,2pYJvgN5jyrMSf0g6xHSFn,2tOy7B83BxDM3dZbFRVDK2,2vXTIj85dC98Mld2ZZNl10,2zzuoMntCJuPVGDmHZWHzU,3BYkskiy3beCXgmj2JpoYm,3Io2O3o9JKwLEuVoHXNdQp,3Is9sv9NtsU5mQeCdfFYge,3L9DGIYkhe5hiTJWz5txeZ,3P7T9WJJNQjogqncxzgBd9,3h4mSJoFomCd2NxNnCgqso,3maqVYkwbQv9bYcOzLN4u7,3tT43aXdwwxfuP5HTB4DPG,4BOfXUfhIup8ygRyusecKZ,4Eij6HFandN2T7ZDSNDEw1,4LGPdRI30RGuXYIWtQpnpo,4QZPq8EZc4lYrLx84mTj4i,4VfTEbZjBjd91uvj8QK3Sd,4bHnrP4GhZhXjb3dMsBfio,4bZq5DOgmeT8j61qk0tnsz,4iUEvBL3saTJ1WVM3PqTxe,4irZfzudAZkwXQE8bbLLqD,4myKAtFRhPg0sUtozGtong,4yfpZ9zSEJYXQDh98P9apD,58a6wy42qZ8tFRLtxIy01X,5AH3RP5ydYukgVOjsNhYKX,5MEj1s4PwpJZlguWawL2uP,5ONmGbuqdZ8qAeBrHY2XHx,5OiJ1PW7dCrwaaho8vkVx1,5WOiPS4H7FzJIiGg9ddw5z,5aRvXtDm4fEATfsALhFXfm,5hMRMZPHw9LbkSiofv0RdT,5ipliYl84z26IyTnGMbZVT,5p7dU3mxI2JGny4aa5rMcx,5yydysXtYKznv2CleWb7iN,6164pJUwTYW9GY8m6WRmuq,66GFbCV8kNgA1mnHwodmut,6HCV4EC9w0XqT5yyHt5ay2,6XI1FYkhBQSbrmYozNAtlt,6agkNUDLq6en8MRRL52EkS,6iMwA4xGkYF02EoXuuFNFR,6kqSgZKtoHf6qQNbV9H1Bp,6nP6N4XHdSbAYax7h96fiK,6q0BV2laTS5lk2oSC21jXh,6rs7ASfQNEBkozaCner4eA,70BV5G9EEyJG4Gl9U5ovv6,70j3ObnSEoaUpoFVXR1DPO,75SrDeHv5d27PFXMRuNAtZ,76GawWqBDrAdNzJDwqwiNF,7hmNm4msXbykTrRw7YOJgu,7ryLBzMIZ7pbI9yENXiqqw,7sugsyshUfQYfgYiPDHXy4,7uBtyQOhLKOmAMS27giKVH,7wPnBMpOg37u95HwUkr5Gn,02UJ1sCanP94fS2MdsWafh,09m6It4feoA7uVhZxWUcbt,0ATuh4eIdNTroYMisRimuz,0BKjosTqxAhWzOUfpwI1X0,0E1ECahwlKkFkoi5uFHfRB,0EXjHqEgvA6pfC2dFgjftW,0IWrKtouUcmhMWugWn9Fw2,0W6XPogEpsX8BLZxU6AQDv,0XkQ23l4GT8sFHgeNRGAO4,0fEKZALs896q8nwORwAcOE,0hRm3YT8lIWEmqltByyCTI,0ly3IpcCvbPDoLDydGvnYx,182kd2xfm6OJp37N5VyXGB,1DMMm8W09RGTKMYI5krnTD,1DUJl5raWzu0WNbArdlNHQ,1GWfE9hhvDZ8femz44SDzp,1H89H0hdMKjj7Q2I5vYM0V,1KjTyAb1Gs61RMiVkS8YtQ,1LyDCI7Adz9s0z57TXezgQ\n01TfjDpIKnUXpJBjzv4j1i,04upOOfD7Ma3nCUbXAbcWR,0SK6p0iQBwpWNwKVI4iLwq,0d2CMyvh7aI8nvBdygh8NY,0fMVy8dyJaTe2q8HQRPSwk,0uxx8eoacMQpkArNKF2OsW,0zcoHn2jVo6JqI3oTy8Cs6,17PdmeprVb2IgAhpvYeI1n,17y6jGPmCWZxE8pPESM5YZ,1HGf4BXTUc5nsNdYUV7jGJ,1K22ZdS0yD0XUdOhFlxOTQ,1PGW8J6iBDcXRApFJKGoEu,1SedJ3dLWoCqnPIGeEMUJH,1Siiu4SvM6VW4J85iSEmP3,1dhZpGydDfXmRRadEDZkKd,1mv7TVpHvGmDiY5XDACGzd,1xQP4UrPOu6kXnkT7DidoF,27STTw6VummiIOwGXLcx7w,27TpVlgt0CFrWTc9s53wKt,2BLckhLAFhDIM0mLe7Ewu2,2JhgWdWYaK81My49mZLTTE,2kQkKSsZlfdLBPHS3xkymN,2makzTITmsymJXodmnvgce,2nH368TennTHS4C0lhjHiE,2y7rO69GYPU9b8G48YIEoK,34XhfQkqHG9I6wkbjUGhyq,3FJf0fBUt0cAZiJwmSk40N,3UDvm8ln2Xo11NZY34lT9G,3a16cyvnuGsTWobb2Fv2hz,3awnZSyvKdi7rBLttHk36K,3h7WS9ec4fGBCICDNqJiuM,3lqwzVDXldGc6vhXWJwgcV,45FEnKJczSLOLGbykJgQfS,461qq5XnmwjXTt1sBgI4lX,4HAD8HMT4iPQvU4l86GUpW,4Zsk0wRmvyY50mr1RmBIS8,4asnG2FAYBaWsl4LO61RON,4cyZ7aTi6QPHHc6z3SaeB1,4eKJMJXp1kH5YYBufCVCdz,4rMm9Mdhv6sQQPhNYN7mTu,4ss2xkQpXlobsXWaT7Rsa6,4x3mum2YGHtIBrgUKiNt4F,533eJdmn6uZGlSgazlPq4z,5C4Hc6Vx5SJCBEWANoRLhP,5DKHMeIl16A1Wso6Gbre96,5G3KLx6yl6mbzxuZqc29KK,5HteVOVEL4pzmXtEUE94C6,5MthcZ6FiOGA1iUmNrfNDV,5O0aOOM4de60hINma1AB0k,5OsJvm24pLAk5jCkPfWe7r,5QfxkK7QrmnKUPhBuOujXX,5RO3d49CngMOg1ZPg0tJVt,5RmUd1skWw9kMFlxPgfcYW,5SCnpFq10mpi2MbTrgoy17,5StePCCyMSeT40ZFLnoHbo,5TKiYi86CmkBSqS3lm2q5h,5Ts8lPA57FWWPhLi9qmDra,5j6vXkbMcoSsbfQ7HxqkZc,5toJOk9lwGQE323SnQ8Tii,5zNAonQgwFH7SigniiFNR4,62AD9i6STX9ahXbyer7t6n,635tFez7SSP4EXTjKUXCNo,67OaKaJvf529K1PUuc3dxf,6MZzm2xeKugnSxUIzyfqjk,6SdW1PtDQZ06dumP6KUjJT,6azzowCgbr9ket0QwHbYEw,6eDi8YYhSsBZLSu2E0xjW3,6q5hX5qXc1EbGlzVc4XEGX,6qNPcUFKv6BkPPxnpyPSXT,77GOTBYCjJHCEJsZUdVcV1\n"
],
[
"song_features.head()",
"_____no_output_____"
]
],
[
[
"### 5.3.1 Merging the features with the playlist information\n---",
"_____no_output_____"
]
],
[
[
"df_p = song_features.merge(df_songs_many_features, on=\"song_id\", how=\"inner\")\ndf_p.head()",
"_____no_output_____"
]
],
[
[
"### 5.4 Getting the preliminary data analysis\n---",
"_____no_output_____"
]
],
[
[
"comparing_countries = df_p.iloc[:,[0,20,24,1,2,3,4,5,6,7,8,9,10,11,-1]].groupby(\"country\").mean().transpose()\ncomparing_countries",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a44ce83623a58bdea88b5893b3abd449f5799cd
| 2,164 |
ipynb
|
Jupyter Notebook
|
Chapter13_ParallelCode/threads.ipynb
|
stefan-ewald/UdemyPythonPro
|
21b4bc0988b9fe3df6e8d6870d2f90929cde293d
|
[
"MIT"
] | 4 |
2020-12-28T23:43:35.000Z
|
2022-01-01T18:34:18.000Z
|
Chapter13_ParallelCode/threads.ipynb
|
stefan-ewald/UdemyPythonPro
|
21b4bc0988b9fe3df6e8d6870d2f90929cde293d
|
[
"MIT"
] | null | null | null |
Chapter13_ParallelCode/threads.ipynb
|
stefan-ewald/UdemyPythonPro
|
21b4bc0988b9fe3df6e8d6870d2f90929cde293d
|
[
"MIT"
] | 9 |
2020-09-26T19:29:28.000Z
|
2022-02-07T06:41:00.000Z
| 19.150442 | 77 | 0.485675 |
[
[
[
"from threading import Thread\r\nimport time",
"_____no_output_____"
]
],
[
[
"# Threads",
"_____no_output_____"
]
],
[
[
"def worker(sleep_time: float) -> None:\r\n print(\"Start worker\")\r\n time.sleep(sleep_time)\r\n print(\"End worker\")",
"_____no_output_____"
],
[
"t1 = Thread(target=worker, name=\"t1\", args=(2.0,))",
"_____no_output_____"
],
[
"print(f\"Ident: {t1.ident}\")\r\nprint(f\"Alive: {t1.is_alive()}\")\r\nprint(f\"Name: {t1.name}\")",
"Ident: None\nAlive: False\nName: t1\n"
],
[
"t1.start()\r\n\r\nprint(f\"Ident: {t1.ident}\")\r\nprint(f\"Alive: {t1.is_alive()}\")\r\nprint(f\"Name: {t1.name}\")\r\n\r\nt1.join()",
"Start worker\nIdent: 10476\nAlive: True\nName: t1\n"
]
]
] |
[
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a44e8e68654b87f467cf19a27ed0036b770679a
| 5,318 |
ipynb
|
Jupyter Notebook
|
Random Forest/drafts/Untitled.ipynb
|
georgetown-analytics/Data-Oriented-Proposal-Engine
|
8548c311c949f790ccd6699a16970cfe7c50d52a
|
[
"MIT"
] | 1 |
2021-02-20T22:00:04.000Z
|
2021-02-20T22:00:04.000Z
|
Random Forest/drafts/Untitled.ipynb
|
jharmon96/Data-Oriented-Proposal-Engine
|
f013ac0b48d0bbe06c70c737cf5cd7a8cc9075ac
|
[
"MIT"
] | 3 |
2019-11-02T18:20:55.000Z
|
2019-11-16T18:18:13.000Z
|
Random Forest/drafts/Untitled.ipynb
|
jharmon96/Data-Oriented-Proposal-Engine
|
f013ac0b48d0bbe06c70c737cf5cd7a8cc9075ac
|
[
"MIT"
] | 5 |
2019-11-02T17:57:41.000Z
|
2020-03-04T01:37:38.000Z
| 69.064935 | 1,486 | 0.671681 |
[
[
[
"# Import libraries\n\nimport psycopg2\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"conn = psycopg2.connect(server='PostgresSQL 11', database='usaspending', user='postgres', password='gtown2019', host='127.0.0.1', port='5432')\ndf = pd.read_sql_query('SELECT * FROM consolidated_data', con=conn)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code"
]
] |
4a44f3d55960b2f875e485c053c77213cfbf50c2
| 33,752 |
ipynb
|
Jupyter Notebook
|
paper/03_OutoftheBox_benchmark_comparison_AttentiveFP/07_BBBP_classification_attentiveFP_split.ipynb
|
riversdark/bidd-molmap
|
7e3325433e2f29c189161859c63398574af6572b
|
[
"MIT"
] | 75 |
2020-07-07T01:18:30.000Z
|
2022-03-25T13:40:19.000Z
|
paper/03_OutoftheBox_benchmark_comparison_AttentiveFP/07_BBBP_classification_attentiveFP_split.ipynb
|
riversdark/bidd-molmap
|
7e3325433e2f29c189161859c63398574af6572b
|
[
"MIT"
] | 12 |
2020-09-28T14:11:17.000Z
|
2022-02-10T04:33:25.000Z
|
paper/03_OutoftheBox_benchmark_comparison_AttentiveFP/07_BBBP_classification_attentiveFP_split.ipynb
|
riversdark/bidd-molmap
|
7e3325433e2f29c189161859c63398574af6572b
|
[
"MIT"
] | 24 |
2020-07-22T08:52:59.000Z
|
2022-03-14T09:59:44.000Z
| 56.536013 | 186 | 0.378674 |
[
[
[
"from molmap import model as molmodel\nimport molmap\n\nimport matplotlib.pyplot as plt\n\nimport pandas as pd\nfrom tqdm import tqdm\nfrom joblib import load, dump\ntqdm.pandas(ascii=True)\nimport numpy as np\n\nimport tensorflow as tf\nimport os\nos.environ[\"CUDA_VISIBLE_DEVICES\"]=\"1\"\nnp.random.seed(123)\ntf.compat.v1.set_random_seed(123)\n\n\ntmp_feature_dir = './tmpignore'\nif not os.path.exists(tmp_feature_dir):\n os.makedirs(tmp_feature_dir)",
"RDKit WARNING: [20:34:18] Enabling RDKit 2019.09.2 jupyter extensions\n"
],
[
"\ndef get_attentiveFP_idx(df):\n \"\"\" attentiveFP dataset\"\"\"\n train, valid,test = load('./split_and_data/07_BBBP_attentiveFP.data')\n print('training set: %s, valid set: %s, test set %s' % (len(train), len(valid), len(test)))\n train_idx = df[df.smiles.isin(train.smiles)].index\n valid_idx = df[df.smiles.isin(valid.smiles)].index\n test_idx = df[df.smiles.isin(test.smiles)].index\n print('training set: %s, valid set: %s, test set %s' % (len(train_idx), len(valid_idx), len(test_idx)))\n return train_idx, valid_idx, test_idx \n",
"_____no_output_____"
],
[
"task_name = 'BBBP'\n\nfrom chembench import load_data\ndf, _ = load_data(task_name)\n\ntrain_idx, valid_idx, test_idx = get_attentiveFP_idx(df) \nlen(train_idx), len(valid_idx), len(test_idx)\n\nmp1 = molmap.loadmap('../descriptor.mp')\nmp2 = molmap.loadmap('../fingerprint.mp')",
"loading dataset: BBBP number of split times: 3\ntraining set: 1628, valid set: 204, test set 204\ntraining set: 1628, valid set: 204, test set 204\n"
],
[
"tmp_feature_dir = '../02_OutofTheBox_benchmark_comparison_DMPNN/tmpignore'\nif not os.path.exists(tmp_feature_dir):\n os.makedirs(tmp_feature_dir)\n\n \nsmiles_col = df.columns[0]\nvalues_col = df.columns[1:]\nY = df[values_col].astype('float').values\nY = Y.reshape(-1, 1)\n\n\nX1_name = os.path.join(tmp_feature_dir, 'X1_%s.data' % task_name)\nX2_name = os.path.join(tmp_feature_dir, 'X2_%s.data' % task_name)\nif not os.path.exists(X1_name):\n X1 = mp1.batch_transform(df.smiles, n_jobs = 8)\n dump(X1, X1_name)\nelse:\n X1 = load(X1_name)\n\nif not os.path.exists(X2_name): \n X2 = mp2.batch_transform(df.smiles, n_jobs = 8)\n dump(X2, X2_name)\nelse:\n X2 = load(X2_name)\n\nmolmap1_size = X1.shape[1:]\nmolmap2_size = X2.shape[1:]",
"_____no_output_____"
],
[
"def get_pos_weights(trainY):\n \"\"\"pos_weights: neg_n / pos_n \"\"\"\n dfY = pd.DataFrame(trainY)\n pos = dfY == 1\n pos_n = pos.sum(axis=0)\n neg = dfY == 0\n neg_n = neg.sum(axis=0)\n pos_weights = (neg_n / pos_n).values\n neg_weights = (pos_n / neg_n).values\n return pos_weights, neg_weights\n\n\nprcs_metrics = ['MUV', 'PCBA']",
"_____no_output_____"
],
[
"print(len(train_idx), len(valid_idx), len(test_idx))\n\ntrainX = (X1[train_idx], X2[train_idx])\ntrainY = Y[train_idx]\n\nvalidX = (X1[valid_idx], X2[valid_idx])\nvalidY = Y[valid_idx]\n\ntestX = (X1[test_idx], X2[test_idx])\ntestY = Y[test_idx] ",
"1628 204 204\n"
],
[
"epochs = 800\npatience = 50 #early stopping\n\ndense_layers = [256, 128, 32]\n\nbatch_size = 128\nlr = 1e-4\nweight_decay = 0\n\nmonitor = 'val_loss'\ndense_avf = 'relu'\nlast_avf = None #sigmoid in loss\n\nif task_name in prcs_metrics:\n metric = 'PRC'\nelse:\n metric = 'ROC'",
"_____no_output_____"
],
[
"results = []\nfor i, seed in enumerate([7, 77, 77]):\n\n np.random.seed(seed)\n tf.compat.v1.set_random_seed(seed)\n\n pos_weights, neg_weights = get_pos_weights(trainY)\n loss = lambda y_true, y_pred: molmodel.loss.weighted_cross_entropy(y_true,y_pred, pos_weights, MASK = -1)\n\n model = molmodel.net.DoublePathNet(molmap1_size, molmap2_size, \n n_outputs=Y.shape[-1], \n dense_layers=dense_layers, \n dense_avf = dense_avf, \n last_avf=last_avf)\n\n opt = tf.keras.optimizers.Adam(lr=lr, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0) #\n #import tensorflow_addons as tfa\n #opt = tfa.optimizers.AdamW(weight_decay = 0.1,learning_rate=0.001,beta1=0.9,beta2=0.999, epsilon=1e-08)\n model.compile(optimizer = opt, loss = loss)\n \n if i == 0:\n performance = molmodel.cbks.CLA_EarlyStoppingAndPerformance((trainX, trainY), \n (validX, validY), \n patience = patience, \n criteria = monitor,\n metric = metric,\n )\n model.fit(trainX, trainY, batch_size=batch_size, \n epochs=epochs, verbose= 0, shuffle = True, \n validation_data = (validX, validY), \n callbacks=[performance]) \n\n\n else:\n model.fit(trainX, trainY, batch_size=batch_size, \n epochs = performance.best_epoch + 1, verbose = 1, shuffle = True, \n validation_data = (validX, validY)) \n \n performance.model.set_weights(model.get_weights())\n \n best_epoch = performance.best_epoch\n trainable_params = model.count_params()\n \n train_aucs = performance.evaluate(trainX, trainY) \n valid_aucs = performance.evaluate(validX, validY) \n test_aucs = performance.evaluate(testX, testY)\n\n\n final_res = {\n 'task_name':task_name, \n 'train_auc':np.nanmean(train_aucs), \n 'valid_auc':np.nanmean(valid_aucs), \n 'test_auc':np.nanmean(test_aucs), \n 'metric':metric,\n '# trainable params': trainable_params,\n 'best_epoch': best_epoch,\n 'batch_size':batch_size,\n 'lr': lr,\n 'weight_decay':weight_decay\n }\n \n results.append(final_res)",
"epoch: 0001, loss: 0.3060 - val_loss: 0.3057; auc: 0.8488 - val_auc: 0.8665 \nepoch: 0002, loss: 0.2888 - val_loss: 0.2801; auc: 0.8528 - val_auc: 0.8652 \nepoch: 0003, loss: 0.2643 - val_loss: 0.2489; auc: 0.8491 - val_auc: 0.8584 \nepoch: 0004, loss: 0.2397 - val_loss: 0.2218; auc: 0.8555 - val_auc: 0.8608 \nepoch: 0005, loss: 0.2233 - val_loss: 0.2204; auc: 0.8677 - val_auc: 0.8688 \nepoch: 0006, loss: 0.2073 - val_loss: 0.1994; auc: 0.8805 - val_auc: 0.8822 \nepoch: 0007, loss: 0.2163 - val_loss: 0.2129; auc: 0.8907 - val_auc: 0.8891 \nepoch: 0008, loss: 0.1993 - val_loss: 0.1883; auc: 0.8986 - val_auc: 0.8956 \nepoch: 0009, loss: 0.1902 - val_loss: 0.1839; auc: 0.9046 - val_auc: 0.9009 \nepoch: 0010, loss: 0.1845 - val_loss: 0.1748; auc: 0.9104 - val_auc: 0.9066 \nepoch: 0011, loss: 0.1798 - val_loss: 0.1710; auc: 0.9177 - val_auc: 0.9104 \nepoch: 0012, loss: 0.1748 - val_loss: 0.1705; auc: 0.9243 - val_auc: 0.9177 \nepoch: 0013, loss: 0.1709 - val_loss: 0.1810; auc: 0.9260 - val_auc: 0.9226 \nepoch: 0014, loss: 0.1685 - val_loss: 0.1624; auc: 0.9330 - val_auc: 0.9252 \nepoch: 0015, loss: 0.1566 - val_loss: 0.1620; auc: 0.9391 - val_auc: 0.9305 \nepoch: 0016, loss: 0.1517 - val_loss: 0.1563; auc: 0.9431 - val_auc: 0.9335 \nepoch: 0017, loss: 0.1505 - val_loss: 0.1825; auc: 0.9462 - val_auc: 0.9326 \nepoch: 0018, loss: 0.1514 - val_loss: 0.1545; auc: 0.9493 - val_auc: 0.9348 \nepoch: 0019, loss: 0.1387 - val_loss: 0.1499; auc: 0.9535 - val_auc: 0.9386 \nepoch: 0020, loss: 0.1342 - val_loss: 0.1584; auc: 0.9576 - val_auc: 0.9394 \nepoch: 0021, loss: 0.1308 - val_loss: 0.1500; auc: 0.9603 - val_auc: 0.9403 \nepoch: 0022, loss: 0.1231 - val_loss: 0.1525; auc: 0.9640 - val_auc: 0.9441 \nepoch: 0023, loss: 0.1284 - val_loss: 0.1497; auc: 0.9660 - val_auc: 0.9430 \nepoch: 0024, loss: 0.1360 - val_loss: 0.1791; auc: 0.9668 - val_auc: 0.9412 \nepoch: 0025, loss: 0.1170 - val_loss: 0.1445; auc: 0.9698 - val_auc: 0.9436 \nepoch: 0026, loss: 0.1128 - val_loss: 0.1429; auc: 0.9719 - val_auc: 0.9440 \nepoch: 0027, loss: 0.1060 - val_loss: 0.1580; auc: 0.9741 - val_auc: 0.9454 \nepoch: 0028, loss: 0.1005 - val_loss: 0.1493; auc: 0.9772 - val_auc: 0.9448 \nepoch: 0029, loss: 0.0977 - val_loss: 0.1580; auc: 0.9793 - val_auc: 0.9448 \nepoch: 0030, loss: 0.0968 - val_loss: 0.1423; auc: 0.9795 - val_auc: 0.9437 \nepoch: 0031, loss: 0.0970 - val_loss: 0.1880; auc: 0.9825 - val_auc: 0.9425 \nepoch: 0032, loss: 0.0838 - val_loss: 0.1453; auc: 0.9831 - val_auc: 0.9443 \nepoch: 0033, loss: 0.0805 - val_loss: 0.1812; auc: 0.9855 - val_auc: 0.9445 \nepoch: 0034, loss: 0.0805 - val_loss: 0.1559; auc: 0.9861 - val_auc: 0.9439 \nepoch: 0035, loss: 0.0746 - val_loss: 0.1482; auc: 0.9876 - val_auc: 0.9428 \nepoch: 0036, loss: 0.0697 - val_loss: 0.1735; auc: 0.9885 - val_auc: 0.9443 \nepoch: 0037, loss: 0.0679 - val_loss: 0.1903; auc: 0.9891 - val_auc: 0.9432 \nepoch: 0038, loss: 0.0631 - val_loss: 0.1532; auc: 0.9900 - val_auc: 0.9427 \nepoch: 0039, loss: 0.0612 - val_loss: 0.2298; auc: 0.9904 - val_auc: 0.9376 \nepoch: 0040, loss: 0.0566 - val_loss: 0.1578; auc: 0.9908 - val_auc: 0.9436 \nepoch: 0041, loss: 0.0532 - val_loss: 0.1905; auc: 0.9918 - val_auc: 0.9396 \nepoch: 0042, loss: 0.0494 - val_loss: 0.2155; auc: 0.9923 - val_auc: 0.9410 \nepoch: 0043, loss: 0.0468 - val_loss: 0.2466; auc: 0.9930 - val_auc: 0.9377 \nepoch: 0044, loss: 0.0462 - val_loss: 0.2177; auc: 0.9935 - val_auc: 0.9376 \nepoch: 0045, loss: 0.0427 - val_loss: 0.1878; auc: 0.9942 - val_auc: 0.9390 \nepoch: 0046, loss: 0.0468 - val_loss: 0.2289; auc: 0.9944 - val_auc: 0.9349 \nepoch: 0047, loss: 0.0391 - val_loss: 0.2586; auc: 0.9951 - val_auc: 0.9341 \nepoch: 0048, loss: 0.0384 - val_loss: 0.1863; auc: 0.9957 - val_auc: 0.9381 \nepoch: 0049, loss: 0.0405 - val_loss: 0.2035; auc: 0.9960 - val_auc: 0.9400 \nepoch: 0050, loss: 0.0347 - val_loss: 0.2995; auc: 0.9966 - val_auc: 0.9334 \nepoch: 0051, loss: 0.0342 - val_loss: 0.1820; auc: 0.9969 - val_auc: 0.9387 \nepoch: 0052, loss: 0.0284 - val_loss: 0.2451; auc: 0.9977 - val_auc: 0.9355 \nepoch: 0053, loss: 0.0261 - val_loss: 0.2427; auc: 0.9982 - val_auc: 0.9343 \nepoch: 0054, loss: 0.0260 - val_loss: 0.2676; auc: 0.9983 - val_auc: 0.9334 \nepoch: 0055, loss: 0.0243 - val_loss: 0.2602; auc: 0.9987 - val_auc: 0.9330 \nepoch: 0056, loss: 0.0229 - val_loss: 0.2737; auc: 0.9987 - val_auc: 0.9334 \nepoch: 0057, loss: 0.0211 - val_loss: 0.3067; auc: 0.9989 - val_auc: 0.9307 \nepoch: 0058, loss: 0.0220 - val_loss: 0.3349; auc: 0.9990 - val_auc: 0.9302 \nepoch: 0059, loss: 0.0208 - val_loss: 0.2369; auc: 0.9991 - val_auc: 0.9335 \nepoch: 0060, loss: 0.0190 - val_loss: 0.2921; auc: 0.9991 - val_auc: 0.9296 \nepoch: 0061, loss: 0.0206 - val_loss: 0.2541; auc: 0.9991 - val_auc: 0.9334 \nepoch: 0062, loss: 0.0174 - val_loss: 0.3034; auc: 0.9991 - val_auc: 0.9300 \nepoch: 0063, loss: 0.0214 - val_loss: 0.1918; auc: 0.9991 - val_auc: 0.9344 \nepoch: 0064, loss: 0.0218 - val_loss: 0.2016; auc: 0.9992 - val_auc: 0.9368 \nepoch: 0065, loss: 0.0218 - val_loss: 0.3486; auc: 0.9992 - val_auc: 0.9295 \nepoch: 0066, loss: 0.0169 - val_loss: 0.3765; auc: 0.9992 - val_auc: 0.9245 \nepoch: 0067, loss: 0.0177 - val_loss: 0.4002; auc: 0.9992 - val_auc: 0.9267 \nepoch: 0068, loss: 0.0177 - val_loss: 0.2772; auc: 0.9992 - val_auc: 0.9302 \nepoch: 0069, loss: 0.0143 - val_loss: 0.3354; auc: 0.9993 - val_auc: 0.9280 \nepoch: 0070, loss: 0.0135 - val_loss: 0.2867; auc: 0.9993 - val_auc: 0.9305 \nepoch: 0071, loss: 0.0131 - val_loss: 0.2847; auc: 0.9993 - val_auc: 0.9303 \nepoch: 0072, loss: 0.0144 - val_loss: 0.2904; auc: 0.9993 - val_auc: 0.9285 \nepoch: 0073, loss: 0.0167 - val_loss: 0.2467; auc: 0.9994 - val_auc: 0.9296 \nepoch: 0074, loss: 0.0170 - val_loss: 0.3256; auc: 0.9993 - val_auc: 0.9295 \nepoch: 0075, loss: 0.0181 - val_loss: 0.4798; auc: 0.9992 - val_auc: 0.9234 \nepoch: 0076, loss: 0.0183 - val_loss: 0.2225; auc: 0.9994 - val_auc: 0.9312 \nepoch: 0077, loss: 0.0198 - val_loss: 0.3755; auc: 0.9992 - val_auc: 0.9296 \nepoch: 0078, loss: 0.0133 - val_loss: 0.3319; auc: 0.9994 - val_auc: 0.9282 \nepoch: 0079, loss: 0.0161 - val_loss: 0.3206; auc: 0.9993 - val_auc: 0.9286 \nepoch: 0080, loss: 0.0156 - val_loss: 0.4503; auc: 0.9994 - val_auc: 0.9252 \n\nRestoring model weights from the end of the best epoch.\n\nEpoch 00080: early stopping\nTrain on 1628 samples, validate on 204 samples\nEpoch 1/30\n1628/1628 [==============================] - 2s 1ms/sample - loss: 0.3064 - val_loss: 0.3049\nEpoch 2/30\n1628/1628 [==============================] - 1s 621us/sample - loss: 0.2854 - val_loss: 0.2743\nEpoch 3/30\n1628/1628 [==============================] - 1s 571us/sample - loss: 0.2576 - val_loss: 0.2385\nEpoch 4/30\n1628/1628 [==============================] - 1s 619us/sample - loss: 0.2317 - val_loss: 0.2135\nEpoch 5/30\n1628/1628 [==============================] - 1s 610us/sample - loss: 0.2166 - val_loss: 0.2046\nEpoch 6/30\n1628/1628 [==============================] - 1s 632us/sample - loss: 0.2039 - val_loss: 0.1901\nEpoch 7/30\n1628/1628 [==============================] - 1s 628us/sample - loss: 0.1950 - val_loss: 0.1955\nEpoch 8/30\n1628/1628 [==============================] - 1s 627us/sample - loss: 0.1838 - val_loss: 0.1769\nEpoch 9/30\n1628/1628 [==============================] - 1s 624us/sample - loss: 0.1813 - val_loss: 0.1712\nEpoch 10/30\n1628/1628 [==============================] - 1s 633us/sample - loss: 0.1691 - val_loss: 0.1675\nEpoch 11/30\n1628/1628 [==============================] - 1s 632us/sample - loss: 0.1637 - val_loss: 0.1632\nEpoch 12/30\n1628/1628 [==============================] - 1s 638us/sample - loss: 0.1610 - val_loss: 0.1607\nEpoch 13/30\n1628/1628 [==============================] - 1s 593us/sample - loss: 0.1565 - val_loss: 0.1648\nEpoch 14/30\n1628/1628 [==============================] - 1s 604us/sample - loss: 0.1462 - val_loss: 0.1561\nEpoch 15/30\n1628/1628 [==============================] - 1s 639us/sample - loss: 0.1402 - val_loss: 0.1522\nEpoch 16/30\n1628/1628 [==============================] - 1s 627us/sample - loss: 0.1335 - val_loss: 0.1495\nEpoch 17/30\n1628/1628 [==============================] - 1s 601us/sample - loss: 0.1299 - val_loss: 0.1591\nEpoch 18/30\n1628/1628 [==============================] - 1s 629us/sample - loss: 0.1251 - val_loss: 0.1483\nEpoch 19/30\n1628/1628 [==============================] - 1s 613us/sample - loss: 0.1172 - val_loss: 0.1449\nEpoch 20/30\n1628/1628 [==============================] - 1s 597us/sample - loss: 0.1147 - val_loss: 0.1464\nEpoch 21/30\n1628/1628 [==============================] - 1s 603us/sample - loss: 0.1132 - val_loss: 0.1460\nEpoch 22/30\n1628/1628 [==============================] - 1s 604us/sample - loss: 0.1035 - val_loss: 0.1645\nEpoch 23/30\n1628/1628 [==============================] - 1s 614us/sample - loss: 0.1000 - val_loss: 0.1444\nEpoch 24/30\n1628/1628 [==============================] - 1s 601us/sample - loss: 0.0943 - val_loss: 0.1454\nEpoch 25/30\n1628/1628 [==============================] - 1s 610us/sample - loss: 0.0927 - val_loss: 0.1466\nEpoch 26/30\n1628/1628 [==============================] - 1s 594us/sample - loss: 0.0950 - val_loss: 0.1460\nEpoch 27/30\n1628/1628 [==============================] - 1s 611us/sample - loss: 0.0888 - val_loss: 0.1430\nEpoch 28/30\n1628/1628 [==============================] - 1s 620us/sample - loss: 0.0767 - val_loss: 0.1594\nEpoch 29/30\n1628/1628 [==============================] - 1s 630us/sample - loss: 0.0701 - val_loss: 0.1660\nEpoch 30/30\n1628/1628 [==============================] - 1s 603us/sample - loss: 0.0681 - val_loss: 0.1982\nTrain on 1628 samples, validate on 204 samples\nEpoch 1/30\n1628/1628 [==============================] - 3s 2ms/sample - loss: 0.3064 - val_loss: 0.3041\nEpoch 2/30\n1628/1628 [==============================] - 1s 599us/sample - loss: 0.2851 - val_loss: 0.2735\nEpoch 3/30\n1628/1628 [==============================] - 1s 620us/sample - loss: 0.2573 - val_loss: 0.2381\nEpoch 4/30\n1628/1628 [==============================] - 1s 620us/sample - loss: 0.2313 - val_loss: 0.2132\nEpoch 5/30\n1628/1628 [==============================] - 1s 618us/sample - loss: 0.2165 - val_loss: 0.2054\nEpoch 6/30\n1628/1628 [==============================] - 1s 653us/sample - loss: 0.2041 - val_loss: 0.1910\nEpoch 7/30\n1628/1628 [==============================] - 1s 630us/sample - loss: 0.1947 - val_loss: 0.1955\nEpoch 8/30\n1628/1628 [==============================] - 1s 647us/sample - loss: 0.1834 - val_loss: 0.1772\nEpoch 9/30\n1628/1628 [==============================] - 1s 671us/sample - loss: 0.1809 - val_loss: 0.1716\nEpoch 10/30\n1628/1628 [==============================] - 1s 635us/sample - loss: 0.1684 - val_loss: 0.1674\nEpoch 11/30\n1628/1628 [==============================] - 1s 657us/sample - loss: 0.1629 - val_loss: 0.1633\nEpoch 12/30\n1628/1628 [==============================] - 1s 667us/sample - loss: 0.1601 - val_loss: 0.1608\nEpoch 13/30\n1628/1628 [==============================] - 1s 658us/sample - loss: 0.1561 - val_loss: 0.1650\nEpoch 14/30\n1628/1628 [==============================] - 1s 654us/sample - loss: 0.1453 - val_loss: 0.1554\nEpoch 15/30\n1628/1628 [==============================] - 1s 656us/sample - loss: 0.1394 - val_loss: 0.1515\nEpoch 16/30\n1628/1628 [==============================] - 1s 662us/sample - loss: 0.1327 - val_loss: 0.1486\nEpoch 17/30\n1628/1628 [==============================] - 1s 669us/sample - loss: 0.1293 - val_loss: 0.1585\nEpoch 18/30\n1628/1628 [==============================] - 1s 620us/sample - loss: 0.1245 - val_loss: 0.1476\nEpoch 19/30\n1628/1628 [==============================] - 1s 667us/sample - loss: 0.1166 - val_loss: 0.1437\nEpoch 20/30\n1628/1628 [==============================] - 1s 702us/sample - loss: 0.1143 - val_loss: 0.1451\nEpoch 21/30\n1628/1628 [==============================] - 1s 660us/sample - loss: 0.1127 - val_loss: 0.1447\nEpoch 22/30\n1628/1628 [==============================] - 1s 658us/sample - loss: 0.1029 - val_loss: 0.1622\nEpoch 23/30\n1628/1628 [==============================] - 1s 629us/sample - loss: 0.0994 - val_loss: 0.1425\nEpoch 24/30\n1628/1628 [==============================] - 1s 645us/sample - loss: 0.0943 - val_loss: 0.1432\nEpoch 25/30\n1628/1628 [==============================] - 1s 646us/sample - loss: 0.0923 - val_loss: 0.1454\nEpoch 26/30\n1628/1628 [==============================] - 1s 636us/sample - loss: 0.0936 - val_loss: 0.1440\nEpoch 27/30\n1628/1628 [==============================] - 1s 643us/sample - loss: 0.0878 - val_loss: 0.1415\nEpoch 28/30\n1628/1628 [==============================] - 1s 624us/sample - loss: 0.0760 - val_loss: 0.1563\nEpoch 29/30\n1628/1628 [==============================] - 1s 647us/sample - loss: 0.0695 - val_loss: 0.1659\nEpoch 30/30\n1628/1628 [==============================] - 1s 666us/sample - loss: 0.0678 - val_loss: 0.2006\n"
],
[
"pd.DataFrame(results).test_auc.mean()",
"_____no_output_____"
],
[
"pd.DataFrame(results).test_auc.std()",
"_____no_output_____"
],
[
"pd.DataFrame(results).to_csv('./results/%s.csv' % task_name)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a44fff7c3afdb3af1bd4428cd9e3238e1d14a19
| 15,477 |
ipynb
|
Jupyter Notebook
|
vessel_data_preparation.ipynb
|
esilaban/vessel_activity_classification
|
6270e32c4fa9284cbf9093abaff94ca1649df5d3
|
[
"MIT"
] | null | null | null |
vessel_data_preparation.ipynb
|
esilaban/vessel_activity_classification
|
6270e32c4fa9284cbf9093abaff94ca1649df5d3
|
[
"MIT"
] | null | null | null |
vessel_data_preparation.ipynb
|
esilaban/vessel_activity_classification
|
6270e32c4fa9284cbf9093abaff94ca1649df5d3
|
[
"MIT"
] | null | null | null | 38.12069 | 285 | 0.568779 |
[
[
[
"import numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport geopy.distance as gd\n\nfrom mpl_toolkits.basemap import Basemap\nfrom datetime import datetime, timedelta\n\npd.options.mode.chained_assignment = None\n\n# from pandarallel import pandarallel",
"_____no_output_____"
],
[
"vessel_information = pd.read_csv(\"./data/Vessel_information.csv\")\nlist_vessel_id = vessel_information.loc[(vessel_information['type'] == 'CSV'), 'vessel_id'].to_list()",
"_____no_output_____"
],
[
"df_vessel_daily_data = pd.read_pickle(\"./data/df_vessel_daily_2019_complete.pkl\")\ndf_vessel_daily_data.loc[df_vessel_daily_data['time_offset'] == 'Z', 'time_offset'] = '00:00'\ndf_vessel_daily_data = df_vessel_daily_data.loc[df_vessel_daily_data.time_offset.isna() == False]",
"_____no_output_____"
],
[
"df_positions_jan2019 = pd.read_csv(\"./data/positions_jan2019.csv\")\ndf_positions_feb2019 = pd.read_csv(\"./data/positions_feb2019.csv\")\ndf_positions_mar2019 = pd.read_csv(\"./data/positions_mar2019.csv\")\ndf_positions_apr2019 = pd.read_csv(\"./data/positions_apr2019.csv\")\ndf_positions_may2019 = pd.read_csv(\"./data/positions_may2019.csv\")\ndf_positions_jun2019 = pd.read_csv(\"./data/positions_june2019.csv\")\ndf_positions_jul2019 = pd.read_csv(\"./data/positions_july2019.csv\")\ndf_positions_aug2019 = pd.read_csv(\"./data/positions_aug2019.csv\")\ndf_positions_sep2019 = pd.read_csv(\"./data/positions_sept2019.csv\")\ndf_positions_oct2019 = pd.read_csv(\"./data/positions_oct2019.csv\")\ndf_positions_nov2019 = pd.read_csv(\"./data/positions_nov2019.csv\")\ndf_positions_dec2019 = pd.read_csv(\"./data/positions_dec2019.csv\")\n\n\nlist_df_position = [df_positions_jan2019, df_positions_feb2019, \n df_positions_mar2019, df_positions_apr2019, \n df_positions_may2019, df_positions_jun2019, \n df_positions_jul2019, df_positions_aug2019, \n df_positions_sep2019, df_positions_oct2019, \n df_positions_nov2019, df_positions_dec2019,\n ]\n\ndf_positions_2019 = pd.concat(list_df_position, axis=0, ignore_index=True)\n\n\ndf_positions_2019 = df_positions_2019[(df_positions_2019['vessel_id'].isin(list_vessel_id))]\ndf_positions_2019[\"new_position_received_time\"] = pd.to_datetime(df_positions_2019['position_received_time'])\ndf_positions_2019['new_position_received_time'] = df_positions_2019['new_position_received_time'].dt.tz_localize(None)",
"_____no_output_____"
],
[
"df_positions_2019.drop_duplicates(subset=['vessel_id', 'course', 'destination', 'draught', 'heading',\n 'latitude', 'longitude', 'nav_status', 'speed', 'eta_time',\n 'position_received_time', 'location', 'api_source'], inplace=True)",
"_____no_output_____"
],
[
"df_positions_2019.sort_values(by=['vessel_id', 'new_position_received_time'], inplace=True)",
"_____no_output_____"
],
[
"for vessel_id in list_vessel_id:\n df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'prev_lon'] = df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'longitude'].shift(1)\n df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'prev_lat'] = df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'latitude'].shift(1)\n \n df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'prev_receive_time'] = df_positions_2019.loc[df_positions_2019['vessel_id']==vessel_id, 'new_position_received_time'].shift(1)",
"_____no_output_____"
],
[
"df_positions_2019['prev_coord'] = df_positions_2019.apply(lambda x: (x.prev_lat, x.prev_lon), axis=1)\ndf_positions_2019['curr_coord'] = df_positions_2019.apply(lambda x: (x.latitude, x.longitude), axis=1)",
"_____no_output_____"
],
[
"# Here is the calculation of mile since the last record (current_coordinate - previous_coordinate)\n# This process takes sometime to complete\ndf_positions_2019['mile_since'] = df_positions_2019.loc[df_positions_2019['prev_lon'].notnull()].apply(\n lambda x: gd.distance(x.prev_coord, x.curr_coord).nm, axis=1) \n\ndf_positions_2019[['prev_coord', 'curr_coord', 'mile_since']].head(2)",
"_____no_output_____"
],
[
"# Here is the calculation of hour since the last record (current_time - previous_time)\n# Then convert to hourly format\ndf_positions_2019['hour_since'] = (df_positions_2019.new_position_received_time - df_positions_2019.prev_receive_time)/np.timedelta64(1, 'h')\ndf_positions_2019[['hour_since']].head(2)\n",
"_____no_output_____"
],
[
"# Here is the calculation of speed (mile_since - hour_since) --> nautical_mile/hour\ndf_positions_2019.at[(df_positions_2019['hour_since'] == 0) & (df_positions_2019['mile_since'] > 0), 'hour_since']=0.001\n\ndf_positions_2019['speed_nm'] = (df_positions_2019.mile_since / df_positions_2019.hour_since)\n",
"_____no_output_____"
],
[
"df_positions_2019.loc[(df_positions_2019['hour_since'] == 0) & (df_positions_2019['mile_since'] == 0), 'speed_nm'] = 0",
"_____no_output_____"
],
[
"df_positions_2019.columns",
"_____no_output_____"
],
[
"def apply_label_combine_transit(label, new_label):\n for idx, row in df_vessel_daily_data[(df_vessel_daily_data['activity'] == label)\n &\n (df_vessel_daily_data['vessel_id'].isin(list_vessel_id))].iterrows():\n consumption_at_period = row.fuel/row.report_hours\n df_positions_2019.loc[((df_positions_2019['new_position_received_time']+timedelta(hours=(int(row.time_offset.split(\":\")[0])), \n minutes=(int(row.time_offset.split(\":\")[1]))))\n >= row.new_report_time-timedelta(hours=row.report_hours )) \n & \n ((df_positions_2019['new_position_received_time']+timedelta(hours=(int(row.time_offset.split(\":\")[0])), \n minutes=(int(row.time_offset.split(\":\")[1]))))\n < row.new_report_time)\n &\n (df_positions_2019['vessel_id']== row.vessel_id)\n , ['activity_label', 'activity_label2', 'time_period', 'ref_date','transit_type', 'daily_vessel_id', 'fuel_consumption_average']] = [new_label, row.activity_mode, row.time_period, row.new_report_time, label, row.id, consumption_at_period] ",
"_____no_output_____"
],
[
"def convert_activity_mode(row):\n data = {'activity_mode':['002 - Anchor Handling - Medium Main-eng.',\n '011 - Towing - Manual',\n '010 - Towing - DP Auto Pos',\n 'AH - Towing',\n '003 - Anchor Handling - Heavy Tention'],\n 'activity':['AH', 'Towing', 'Towing', 'Towing', 'AH']} \n df_lookup = pd.DataFrame(data)\n df_temp = df_lookup.loc[df_lookup['activity_mode'] == row.activity_label2]\n if df_temp.values.size > 0:\n return df_temp.activity.values[0]\n else:\n return None",
"_____no_output_____"
],
[
"# def calculate_fuel_consumption(related_dataframe):\n# for idx, row in df_vessel_daily_data.loc[(df_vessel_daily_data['vessel_id'].isin(list_vessel_id))\n# ].iterrows():\n# # print(row.time_offset)\n# consumption_at_period = row.fuel/row.report_hours\n# df_positions_2019.loc[\n# ((df_positions_2019['new_position_received_time'] \n# + timedelta(hours=(int(row.time_offset.split(\":\")[0])),\n# minutes=(int(row.time_offset.split(\":\")[1])))) >= row.new_report_time-timedelta(hours=row.report_hours)) \n# & \n# ((df_positions_2019['new_position_received_time'] \n# + timedelta(hours=(int(row.time_offset.split(\":\")[0])),\n# minutes=(int(row.time_offset.split(\":\")[1])))) < row.new_report_time)\n# , 'fuel_consumption_average'] = consumption_at_period\n",
"_____no_output_____"
],
[
"df_positions_2019.to_pickle(\"data/[CSV]df_positions_2019_ver1.pkl\")",
"_____no_output_____"
]
],
[
[
"#### resize the df_positions (take out some not used columns, resize columns type) ",
"_____no_output_____"
]
],
[
[
"df_positions_2019.columns",
"_____no_output_____"
],
[
"df_positions_2019[['id', 'vessel_id']].apply(pd.to_numeric, errors='ignore', downcast='integer').info()\ndf_positions_2019[['course', 'draught', 'longitude', 'latitude',\n 'speed', 'prev_lon', 'prev_lat', \n 'mile_since', 'hour_since', 'speed_nm']].apply(pd.to_numeric, errors='ignore', downcast='float').info()",
"_____no_output_____"
],
[
"# pd.to_numeric(df_positions_90_2019[['id', 'vessel_id']], )\ndf_positions_2019['vessel_id'] = df_positions_2019['vessel_id'].astype('int16')\ndf_positions_2019['id'] = df_positions_2019['id'].astype('int32')\n\ndf_positions_2019[['course', 'draught', 'longitude', 'latitude',\n 'speed', 'prev_lon', 'prev_lat', \n 'mile_since', 'hour_since', 'speed_nm']] = df_positions_2019[['course', 'draught', 'longitude', 'latitude',\n 'speed', 'prev_lon', 'prev_lat', \n 'mile_since', 'hour_since', 'speed_nm']].astype('float32')",
"_____no_output_____"
],
[
"df_positions_2019 = df_positions_2019[['id', 'vessel_id','speed', \n 'new_position_received_time', \n 'prev_receive_time', 'prev_coord', 'curr_coord', 'mile_since',\n 'hour_since', 'speed_nm']]",
"_____no_output_____"
],
[
"df_positions_2019.to_pickle(\"data/[resized]df_CSV_positions_2019.pkl\")",
"_____no_output_____"
],
[
"df_positions_2019 = pd.read_pickle(\"./data/[resized]df_CSV_positions_2019.pkl\")",
"_____no_output_____"
]
],
[
[
"#### End of resizing block",
"_____no_output_____"
],
[
"#### Do the model still need this?",
"_____no_output_____"
]
],
[
[
"df_positions_2019.loc[(df_positions_2019.fuel_consumption_average.isna()==False) \n &\n (df_positions_2019.speed_nm.isna()==False), 'speed_consumption_average'] = df_positions_2019.loc[(df_positions_2019.fuel_consumption_average>0)\n &\n (df_positions_2019.speed_nm > 0)].apply(lambda x: x.speed_nm/x.fuel_consumption_average, axis=1)",
"_____no_output_____"
],
[
"# For CSV type\napply_label_combine_transit('DP', 'DP')\napply_label_combine_transit('Standby','Standby')\napply_label_combine_transit('Transit Eco', 'TransitCombine')\napply_label_combine_transit('Transit', 'TransitCombine')\napply_label_combine_transit('Transit Max', 'TransitCombine')\napply_label_combine_transit('Port', 'Port')\napply_label_combine_transit('AH/Towing', 'AH/Towing')",
"_____no_output_____"
],
[
"df_positions_2019.loc[(df_positions_2019['activity_label'] == 'AH/Towing'), 'activity_label'] = df_positions_2019.loc[(df_positions_2019['activity_label'] == 'AH/Towing')].apply(lambda x: convert_activity_mode(x), axis=1)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a4507177608de5f249363b4afd4d737dcc5d69b
| 66,908 |
ipynb
|
Jupyter Notebook
|
discrete_time_fourier_transform/theorems.ipynb
|
swchao/signalsAndSystemsLecture
|
7f135d091499e1d3d635bac6ddf22adee15454f8
|
[
"MIT"
] | 3 |
2019-01-27T12:39:27.000Z
|
2022-03-15T10:26:12.000Z
|
discrete_time_fourier_transform/theorems.ipynb
|
swchao/signalsAndSystemsLecture
|
7f135d091499e1d3d635bac6ddf22adee15454f8
|
[
"MIT"
] | null | null | null |
discrete_time_fourier_transform/theorems.ipynb
|
swchao/signalsAndSystemsLecture
|
7f135d091499e1d3d635bac6ddf22adee15454f8
|
[
"MIT"
] | 2 |
2020-09-18T06:26:48.000Z
|
2021-12-10T06:11:45.000Z
| 149.348214 | 18,270 | 0.830992 |
[
[
[
"# The Discrete-Time Fourier Transform\n\n*This Jupyter notebook is part of a [collection of notebooks](../index.ipynb) in the bachelors module Signals and Systems, Comunications Engineering, Universität Rostock. Please direct questions and suggestions to [[email protected]](mailto:[email protected]).*",
"_____no_output_____"
],
[
"## Theorems\n\nThe theorems of the discrete-time Fourier transform (DTFT) relate basic operations applied to discrete signals to their equivalents in the DTFT domain. They are of use to transform signals composed from modified [standard signals](../discrete_signals/standard_signals.ipynb), for the computation of the response of a linear time-invariant (LTI) system and to predict the consequences of modifying a signal or system by certain operations.",
"_____no_output_____"
],
[
"### Convolution Theorem\n\nThe [convolution theorem](https://en.wikipedia.org/wiki/Convolution_theorem) states that the DTFT of the linear convolution of two discrete signals $x[k]$ and $y[k]$ is equal to the scalar multiplication of their DTFTs $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$ and $Y(e^{j \\Omega}) = \\mathcal{F}_* \\{ y[k] \\}$\n\n\\begin{equation}\n\\mathcal{F}_* \\{ x[k] * y[k] \\} = X(e^{j \\Omega}) \\cdot Y(e^{j \\Omega})\n\\end{equation}\n\nThe theorem can be proven by introducing the [definition of the linear convolution](../discrete_systems/linear_convolution.ipynb) into the [definition of the DTFT](definition.ipynb) and changing the order of summation\n\n\\begin{align}\n\\mathcal{F} \\{ x[k] * y[k] \\} &= \\sum_{k = -\\infty}^{\\infty} \\left( \\sum_{\\kappa = -\\infty}^{\\infty} x[\\kappa] \\cdot y[k - \\kappa] \\right) e^{-j \\Omega k} \\\\\n&= \\sum_{\\kappa = -\\infty}^{\\infty} \\left( \\sum_{k = -\\infty}^{\\infty} y[k - \\kappa] \\, e^{-j \\Omega k} \\right) x[\\kappa] \\\\\n&= Y(e^{j \\Omega}) \\cdot \\sum_{\\kappa = -\\infty}^{\\infty} x[\\kappa] \\, e^{-j \\Omega \\kappa} \\\\\n&= Y(e^{j \\Omega}) \\cdot X(e^{j \\Omega})\n\\end{align}\n\nThe convolution theorem is very useful in the context of LTI systems. The output signal $y[k]$ of an LTI system is given as the convolution of the input signal $x[k]$ with its impulse response $h[k]$. Hence, the signals and the system can be represented equivalently in the time and frequency domain\n\n\n\nCalculation of the system response by transforming the problem into the DTFT domain can be beneficial since this replaces the computation of the linear convolution by a scalar multiplication. The (inverse) DTFT is known for many signals or can be derived by applying the properties and theorems to standard signals and their transforms. In many cases this procedure simplifies the calculation of the system response significantly.\n\nThe convolution theorem can also be useful to derive the DTFT of a signal. The key is here to express the signal as convolution of two other signals for which the transforms are known. This is illustrated in the following example.",
"_____no_output_____"
],
[
"#### Transformation of the triangular signal\n\nThe linear convolution of two [rectangular signals](../discrete_signals/standard_signals.ipynb#Rectangular-Signal) of lengths $N$ and $M$ defines a [signal of trapezoidal shape](../discrete_systems/linear_convolution.ipynb#Finite-Length-Signals)\n\n\\begin{equation}\nx[k] = \\text{rect}_N[k] * \\text{rect}_M[k]\n\\end{equation}\n\nApplication of the convolution theorem together with the [DTFT of the rectangular signal](definition.ipynb#Transformation-of-the-Rectangular-Signal) yields its DTFT as\n\n\\begin{equation}\nX(e^{j \\Omega}) = \\mathcal{F}_* \\{ \\text{rect}_N[k] \\} \\cdot \\mathcal{F}_* \\{ \\text{rect}_M[k] \\} =\ne^{-j \\Omega \\frac{N+M-2}{2}} \\cdot \\frac{\\sin(\\frac{N \\Omega}{2}) \\sin(\\frac{M \\Omega}{2})}{\\sin^2 ( \\frac{\\Omega}{2} )}\n\\end{equation}\n\nThe transform of the triangular signal can be derived from this result. The convolution of two rectangular signals of equal length $N=M$ yields the triangular signal $\\Lambda[k]$ of length $2N - 1$\n\n\\begin{equation}\n\\Lambda_{2N - 1}[k] = \\begin{cases} k + 1 & \\text{for } 0 \\leq k < N \\\\\n2N - 1 - k & \\text{for } N \\leq k < 2N - 1 \\\\\n0 & \\text{otherwise}\n\\end{cases}\n\\end{equation}\n\nFrom above result the DTFT of the triangular signal is derived by substitution of $N$ by $M$\n\n\\begin{equation}\n\\mathcal{F}_* \\{ \\Lambda_{2N - 1}[k] \\} =\ne^{-j \\Omega (N-1)} \\cdot \\frac{\\sin^2(\\frac{N \\Omega}{2}) }{\\sin^2 ( \\frac{\\Omega}{2} )}\n\\end{equation}\n\nBoth the signal and the magnitude of its DTFT are plotted for illustration",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport sympy as sym\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nN = 7\n\nx = np.convolve(np.ones(N), np.ones(N), mode='full')\nplt.stem(x)\nplt.xlabel('$k$')\nplt.ylabel('$x[k]$')\n\nW = sym.symbols('Omega')\nX = sym.exp(-sym.I*W *(N-1)) * sym.sin(N*W/2)**2 / sym.sin(W/2)**2\nsym.plot(sym.Abs(X), (W, -5, 5), xlabel='$\\Omega$', ylabel='$|X(e^{j \\Omega})|$');",
"_____no_output_____"
]
],
[
[
"**Exercise**\n\n* Change the length of the triangular signal in above example. How does its DTFT change?\n* The triangular signal introduced above is of odd length $2N - 1$\n * Define a triangular signal of even length by convolving two rectangular signals\n * Derive its DTFT\n * Compare the DTFTs of a triangular signal of odd/even length",
"_____no_output_____"
],
[
"### Shift Theorem\n\nThe [shift of a signal](../discrete_signals/operations.ipynb#Shift) $x[k]$ can be expressed by a convolution with a shifted Dirac impulse\n\n\\begin{equation}\nx[k - \\kappa] = x[k] * \\delta[k - \\kappa]\n\\end{equation}\n\nfor $\\kappa \\in \\mathbb{Z}$. This follows from the sifting property of the Dirac impulse. Applying the DTFT to the left- and right-hand side and exploiting the convolution theorem yields\n\n\\begin{equation}\n\\mathcal{F}_* \\{ x[k - \\kappa] \\} = X(e^{j \\Omega}) \\cdot e^{- j \\Omega \\kappa}\n\\end{equation}\n\nwhere $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$. Note that $\\mathcal{F}_* \\{ \\delta(k - \\kappa) \\} = e^{- j \\Omega \\kappa}$ can be derived from the definition of the DTFT together with the sifting property of the Dirac impulse. Above relation is known as shift theorem of the DTFT.\n\nExpressing the DTFT $X(e^{j \\Omega}) = |X(e^{j \\Omega})| \\cdot e^{j \\varphi(e^{j \\Omega})}$ by its absolute value $|X(e^{j \\Omega})|$ and phase $\\varphi(e^{j \\Omega})$ results in\n\n\\begin{equation}\n\\mathcal{F}_* \\{ x[k - \\kappa] \\} = | X(e^{j \\Omega}) | \\cdot e^{j (\\varphi(e^{j \\Omega}) - \\Omega \\kappa)}\n\\end{equation}\n\nShifting of a signal does not change the absolute value of its spectrum but it subtracts the linear contribution $\\Omega \\kappa$ from its phase.",
"_____no_output_____"
],
[
"### Multiplication Theorem\n\nThe transform of a multiplication of two signals $x[k] \\cdot y[k]$ is derived by introducing the signals into the definition of the DTFT, expressing the signal $x[k]$ by its spectrum $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$ and rearranging terms\n\n\\begin{align}\n\\mathcal{F}_* \\{ x[k] \\cdot y[k] \\} &= \\sum_{k=-\\infty}^{\\infty} x[k] \\cdot y[k] \\, e^{-j \\Omega k} \\\\\n&= \\sum_{k=-\\infty}^{\\infty} \\left( \\frac{1}{2 \\pi} \\int_{-\\pi}^{\\pi} X(e^{j \\nu}) \\, e^{j \\nu k} \\; d \\nu \\right) y[k] \\, e^{-j \\Omega k} \\\\\n&= \\frac{1}{2 \\pi} \\int_{-\\pi}^{\\pi} X(e^{j \\nu}) \\sum_{k=-\\infty}^{\\infty} y[k] \\, e^{-j (\\Omega - \\nu) k} \\; d\\nu \\\\\n&= \\frac{1}{2 \\pi} \\int_{-\\pi}^{\\pi} X(e^{j \\nu}) \\cdot Y(e^{j (\\Omega - \\nu)}) d\\nu\n\\end{align}\n\nwhere $Y(e^{j \\Omega}) = \\mathcal{F}_* \\{ y[k] \\}$.\n\nThe [periodic (cyclic/circular) convolution](https://en.wikipedia.org/wiki/Circular_convolution) of two aperiodic signals $h(t)$ and $g(t)$ is defined as\n\n\\begin{equation}\nh(t) \\circledast_{T} g(t) = \\int_{-\\infty}^{\\infty} h(\\tau) \\cdot g_\\text{p}(t - \\tau) \\; d\\tau \n\\end{equation}\n\nwhere $T$ denotes the period of the convolution, $g_\\text{p}(t) = \\sum_{n=-\\infty}^{\\infty} g(t + n T)$ the periodic summation of $g(t)$ and $\\tau \\in \\mathbb{R}$ an arbitrary constant. The periodic convolution is commonly abbreviated by $\\circledast_{T}$. With $h_\\text{p}(t)$ denoting the periodic summation of $h(t)$ the periodic convolution can be rewritten as\n\n\\begin{equation}\nh(t) \\circledast_{T} g(t) = \\int_{\\tau_0}^{\\tau_0 + T} h_\\text{p}(\\tau) \\cdot g_\\text{p}(t - \\tau) \\; d\\tau \n\\end{equation}\n\nwhere $\\tau_0 \\in \\mathbb{R}$ denotes an arbitrary constant. The latter definition holds also for two [periodic signals](../periodic_signals/spectrum.ipynb) $h(t)$ and $g(t)$ with period $T$.\n\nComparison of the DTFT of two multiplied signals with the definition of the periodic convolution reveals that the preliminary result above can be expressed as\n\n\\begin{equation}\n\\mathcal{F}_* \\{ x[k] \\cdot y[k] \\} = \\frac{1}{2\\pi} \\, X(e^{j \\Omega}) \\circledast_{2 \\pi} Y(e^{j \\Omega}) \n\\end{equation}\n\nThe DTFT of a multiplication of two signals $x[k] \\cdot y[k]$ is given by the periodic convolution of their transforms $X(e^{j \\Omega})$ and $Y(e^{j \\Omega})$ weighted with $\\frac{1}{2 \\pi}$. The periodic convolution has a period of $T = 2 \\pi$. Note, the convolution is performed with respect to the normalized angular frequency $\\Omega$.\n\nApplications of the multiplication theorem include the modulation and windowing of signals. The former leads to the modulation theorem introduced later, the latter is illustrated by the following example.",
"_____no_output_____"
],
[
"**Example**\n\nWindowing of signals is used to derive signals of finite duration from signals of infinite duration or to truncate signals to a shorter length. The signal $x[k]$ is multiplied by a weighting function $w[k]$ in order to derive the finite length signal\n\n\\begin{equation}\ny[k] = w[k] \\cdot x[k]\n\\end{equation}\n\nApplication of the multiplication theorem yields the spectrum $Y(e^{j \\Omega}) = \\mathcal{F}_* \\{ y[k] \\}$ of the windowed signal as\n\n\\begin{equation}\nY(e^{j \\Omega}) = \\frac{1}{2 \\pi} W(e^{j \\Omega}) \\circledast X(e^{j \\Omega})\n\\end{equation}\n\nwhere $W(e^{j \\Omega}) = \\mathcal{F}_* \\{ w[k] \\}$ and $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$. In order to illustrate the consequence of windowing, a cosine signal $x[k] = \\cos(\\Omega_0 k)$ is truncated to a finite length using a rectangular signal\n\n\\begin{equation}\ny[k] = \\text{rect}_N[k] \\cdot \\cos(\\Omega_0 k)\n\\end{equation}\n\nwhere $N$ denotes the length of the truncated signal and $\\Omega_0$ its normalized angular frequency. Using the DTFT of the [rectangular signal](definition.ipynb#Transformation-of-the-Rectangular-Signal) and the [cosine signal](properties.ipynb#Transformation-of-the-cosine-and-sine-signal) yields\n\n\\begin{align}\nY(e^{j \\Omega}) &= \\frac{1}{2 \\pi} e^{-j \\Omega \\frac{N-1}{2}} \\cdot \\frac{\\sin \\left(\\frac{N \\Omega}{2} \\right)}{\\sin \\left( \\frac{\\Omega}{2} \\right)} \\circledast \\frac{1}{2} \\left[ {\\bot \\!\\! \\bot \\!\\! \\bot} \\left( \\frac{\\Omega + \\Omega_0}{2 \\pi} \\right) + {\\bot \\!\\! \\bot \\!\\! \\bot} \\left( \\frac{\\Omega - \\Omega_0}{2 \\pi} \\right) \\right] \\\\\n&= \\frac{1}{2} \\left[ e^{-j (\\Omega+\\Omega_0) \\frac{N-1}{2}} \\cdot \\frac{\\sin \\left(\\frac{N (\\Omega+\\Omega_0)}{2} \\right)}{\\sin \\left( \\frac{\\Omega+\\Omega_0}{2} \\right)} + e^{-j (\\Omega-\\Omega_0) \\frac{N-1}{2}} \\cdot \\frac{\\sin \\left(\\frac{N (\\Omega-\\Omega_0)}{2} \\right)}{\\sin \\left( \\frac{\\Omega-\\Omega_0}{2} \\right)} \\right]\n\\end{align}\n\nThe latter identity results from the sifting property of the Dirac impulse and the periodicity of both spectra. The signal $y[k]$ and its magnitude spectrum $|Y(e^{j \\Omega})|$ are plotted for specific values of $N$ and $\\Omega_0$.",
"_____no_output_____"
]
],
[
[
"N = 20\nW0 = 2*np.pi/10\n\nk = np.arange(N)\nx = np.cos(W0 * k)\n\nplt.stem(k, x)\nplt.xlabel('$k$')\nplt.ylabel('$y[k]$');",
"_____no_output_____"
],
[
"W = sym.symbols('Omega')\n\nY = 1/2 * ((sym.exp(-sym.I*(W+W0)*(N-1)/2) * sym.sin(N*(W+W0)/2) / sym.sin((W+W0)/2)) + \n (sym.exp(-sym.I*(W-W0)*(N-1)/2) * sym.sin(N*(W-W0)/2) / sym.sin((W-W0)/2)))\n\nsym.plot(sym.Abs(Y), (W, -sym.pi, sym.pi), xlabel='$\\Omega$', ylabel='$|Y(e^{j \\Omega})|$');",
"_____no_output_____"
]
],
[
[
"**Exercise**\n\n* Change the length $N$ of the signal by modifying the example. How does the spectrum change if you decrease or increase the length?\n\n* What happens if you change the normalized angular frequency $\\Omega_0$ of the signal?\n\n* Assume a signal that is composed from a superposition of two finite length cosine signals with different frequencies. What qualitative condition has to hold that you can derive these frequencies from inspection of the spectrum?",
"_____no_output_____"
],
[
"### Modulation Theorem\n\nThe complex modulation of a signal $x[k]$ is defined as $e^{j \\Omega_0 k} \\cdot x[k]$ with $\\Omega_0 \\in \\mathbb{R}$. The DTFT of the modulated signal is derived by applying the multiplication theorem\n\n\\begin{equation}\n\\mathcal{F}_* \\left\\{ e^{j \\Omega_0 k} \\cdot x[k] \\right\\} = \\frac{1}{2 \\pi} \\cdot {\\bot \\!\\! \\bot \\!\\! \\bot}\\left( \\frac{\\Omega - \\Omega_0}{2 \\pi} \\right) \\circledast X(e^{j \\Omega}) \n= X \\big( e^{j \\, (\\Omega - \\Omega_0)} \\big)\n\\end{equation}\n\nwhere $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$. Above result states that the complex modulation of a signal leads to a shift of its spectrum. This result is known as modulation theorem.",
"_____no_output_____"
],
[
"**Example**\n\nAn example for the application of the modulation theorem is the [downsampling/decimation](https://en.wikipedia.org/wiki/Decimation_(signal_processing) of a discrete signal $x[k]$. Downsampling refers to lowering the sampling rate of a signal. The example focuses on the special case of removing every second sample, hence halving the sampling rate. The downsampling is modeled by defining a signal $x_\\frac{1}{2}[k]$ where every second sample is set to zero\n\n\\begin{equation}\nx_\\frac{1}{2}[k] = \\begin{cases} \nx[k] & \\text{for even } k \\\\\n0 & \\text{for odd } k\n\\end{cases}\n\\end{equation}\n\nIn order to derive the spectrum $X_\\frac{1}{2}(e^{j \\Omega}) = \\mathcal{F}_* \\{ x_\\frac{1}{2}[k] \\}$, the signal $u[k]$ is introduced where every second sample is zero\n\n\\begin{equation}\nu[k] = \\frac{1}{2} ( 1 + e^{j \\pi k} ) = \\begin{cases} 1 & \\text{for even } k \\\\\n0 & \\text{for odd } k \\end{cases}\n\\end{equation}\n\nUsing $u[k]$, the process of setting every second sample of $x[k]$ to zero can be expressed as\n\n\\begin{equation}\nx_\\frac{1}{2}[k] = u[k] \\cdot x[k]\n\\end{equation}\n\nNow the spectrum $X_\\frac{1}{2}(e^{j \\Omega})$ is derived by applying the multiplication theorem and introducing the [DTFT of the exponential signal](definition.ipynb#Transformation-of-the-Exponential-Signal). This results in\n\n\\begin{equation}\nX_\\frac{1}{2}(e^{j \\Omega}) = \\frac{1}{4 \\pi} \\left( {\\bot \\!\\! \\bot \\!\\! \\bot}\\left( \\frac{\\Omega}{2 \\pi} \\right) + \n{\\bot \\!\\! \\bot \\!\\! \\bot}\\left( \\frac{\\Omega - \\pi}{2 \\pi} \\right) \\right) \\circledast X(e^{j \\Omega}) =\n\\frac{1}{2} X(e^{j \\Omega}) + \\frac{1}{2} X(e^{j (\\Omega- \\pi)})\n\\end{equation}\n\nwhere $X(e^{j \\Omega}) = \\mathcal{F}_* \\{ x[k] \\}$. The spectrum $X_\\frac{1}{2}(e^{j \\Omega})$ consists of the spectrum of the original signal $X(e^{j \\Omega})$ superimposed by the shifted spectrum $X(e^{j (\\Omega- \\pi)})$ of the original signal. This may lead to overlaps that constitute aliasing. In order to avoid aliasing, the spectrum of the signal $x[k]$ has to be band-limited to $-\\frac{\\pi}{2} < \\Omega < \\frac{\\pi}{2}$ before downsampling.",
"_____no_output_____"
],
[
"### Parseval's Theorem\n\n[Parseval's theorem](https://en.wikipedia.org/wiki/Parseval's_theorem) relates the energy of a discrete signal to its spectrum. The squared absolute value of a signal $x[k]$ represents its instantaneous power. It can be expressed as\n\n\\begin{equation}\n| x[k] |^2 = x[k] \\cdot x^*[k]\n\\end{equation}\n\nwhere $x^*[k]$ denotes the complex conjugate of $x[k]$. Transformation of the right-hand side and application of the multiplication theorem results in\n\n\\begin{equation}\n\\mathcal{F}_* \\{ x[k] \\cdot x^*[k] \\} = \\frac{1}{2 \\pi} \\cdot X(e^{j \\Omega}) \\circledast_{2 \\pi} X^*(e^{-j \\Omega})\n\\end{equation}\n\nIntroducing the definition of the DTFT and the periodic convolution\n\n\\begin{equation}\n\\sum_{k = -\\infty}^{\\infty} x[k] \\cdot x^*[k] \\, e^{-j \\Omega k} =\n\\frac{1}{2 \\pi} \\int_{-\\pi}^{\\pi} X(e^{j \\nu}) \\cdot X^*(e^{j (\\Omega - \\nu)}) \\; d\\nu\n\\end{equation}\n\nSetting $\\Omega = 0$ followed by the substitution $\\nu = \\Omega$ yields Parseval's theorem\n\n\\begin{equation}\n\\sum_{k = -\\infty}^{\\infty} | x[k] |^2 = \\frac{1}{2 \\pi} \\int_{-\\pi}^{\\pi} | X(e^{j \\Omega}) |^2 \\; d\\Omega\n\\end{equation}\n\nThe sum over the samples of the squared absolute signal is equal to the integral over its squared absolute spectrum divided by $2 \\pi$. Since the left-hand side represents the energy $E$ of the signal $x[k]$, Parseval's theorem states that the energy can be computed alternatively in the spectral domain by integrating over the squared absolute value of the spectrum.",
"_____no_output_____"
],
[
"**Copyright**\n\nThe notebooks are provided as [Open Educational Resource](https://de.wikipedia.org/wiki/Open_Educational_Resources). Feel free to use the notebooks for your own educational purposes. The text is licensed under [Creative Commons Attribution 4.0](https://creativecommons.org/licenses/by/4.0/), the code of the IPython examples under the [MIT license](https://opensource.org/licenses/MIT). Please attribute the work as follows: *Lecture Notes on Signals and Systems* by Sascha Spors.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a45142c6a501ceb9546c87e1b41cd4d7ea0bc7f
| 2,118 |
ipynb
|
Jupyter Notebook
|
note/tutorial/quickstart.ipynb
|
eliavw/nba-anomaly-generator
|
a1e162095b76a3406411925093381e9ace9258c7
|
[
"MIT"
] | null | null | null |
note/tutorial/quickstart.ipynb
|
eliavw/nba-anomaly-generator
|
a1e162095b76a3406411925093381e9ace9258c7
|
[
"MIT"
] | null | null | null |
note/tutorial/quickstart.ipynb
|
eliavw/nba-anomaly-generator
|
a1e162095b76a3406411925093381e9ace9258c7
|
[
"MIT"
] | null | null | null | 16.045455 | 45 | 0.480642 |
[
[
[
"# Quickstart\n\nnba-anomaly-generator quickstart guide.",
"_____no_output_____"
],
[
"# Preliminaries",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import nba-anomaly-generator\nimport numpy as np\nimport pandas as pd\n\nimport sklearn\nfrom sklearn.datasets import load_iris",
"_____no_output_____"
]
],
[
[
"# Setup",
"_____no_output_____"
]
],
[
[
"iris = load_iris()\n\nX = iris.get('data')\ny = iris.get('target')\n\nmatrix = np.c_[X, y]",
"_____no_output_____"
]
],
[
[
"# Fit",
"_____no_output_____"
],
[
"# Predict",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a451861445e4a179ffe1190cb051a4e07146ef9
| 5,329 |
ipynb
|
Jupyter Notebook
|
Problem3-LevelMedium.ipynb
|
tyburam/daily-coding-problems
|
a2b871f9fce3d0fa422cb7adccd740ed594990bb
|
[
"MIT"
] | null | null | null |
Problem3-LevelMedium.ipynb
|
tyburam/daily-coding-problems
|
a2b871f9fce3d0fa422cb7adccd740ed594990bb
|
[
"MIT"
] | null | null | null |
Problem3-LevelMedium.ipynb
|
tyburam/daily-coding-problems
|
a2b871f9fce3d0fa422cb7adccd740ed594990bb
|
[
"MIT"
] | null | null | null | 25.018779 | 179 | 0.513417 |
[
[
[
"# Problem statement\n\nGood morning! Here's your coding interview problem for today.\n\nThis problem was asked by Google.\n\nGiven the root to a binary tree, implement serialize(root), which serializes the tree into a string, and deserialize(s), which deserializes the string back into the tree.\n\nFor example, given the following Node class\n\n```\nclass Node:\n def __init__(self, val, left=None, right=None):\n self.val = val\n self.left = left\n self.right = right\n```\nThe following test should pass:\n\n```\nnode = Node('root', Node('left', Node('left.left')), Node('right'))\nassert deserialize(serialize(node)).left.left.val == 'left.left'\n```",
"_____no_output_____"
],
[
"## Class",
"_____no_output_____"
]
],
[
[
"class Node:\n def __init__(self, val, left=None, right=None):\n self.val = val\n self.left = left\n self.right = right\n \n def __str__(self):\n lval = \"None\" if self.left is None else str(self.left)\n rval = \"None\" if self.right is None else str(self.right)\n return \"(value={}, left={}, right={})\".format(self.val, lval, rval)",
"_____no_output_____"
]
],
[
[
"## Methods",
"_____no_output_____"
]
],
[
[
"def serialize(node):\n if node is None:\n return \"None\"\n return \"{},{},{}\".format(node.val, serialize(node.left), serialize(node.right))",
"_____no_output_____"
],
[
"def deserialize(serial):\n def _deserialize(serial):\n if serial is None or len(serial) == 0: # nothing means an empty node\n return None\n node = None\n value = serial.pop(0) # getting the first value of list\n if value == 'None': # if it's special value it means empty node\n return node\n node = Node(value) # otherwise create a new node\n node.left = _deserialize(serial) # left children is right after the node value so we start by deserializing left\n node.right = _deserialize(serial) # right is last\n return node # return whole tree\n\n if serial is None or serial == \"\": # nothing in the input\n return None\n separated = serial.split(',')\n if separated is None or len(separated) == 0: # something is bad about this string\n return None\n return _deserialize(separated)",
"_____no_output_____"
]
],
[
[
"## Testing it out",
"_____no_output_____"
]
],
[
[
"node = Node('root', Node('left', Node('left.left')), Node('right'))",
"_____no_output_____"
],
[
"print(node)",
"(value=root, left=(value=left, left=(value=left.left, left=None, right=None), right=None), right=(value=right, left=None, right=None))\n"
],
[
"result = serialize(node)\nresult",
"_____no_output_____"
],
[
"print(deserialize(result))",
"(value=root, left=(value=left, left=(value=left.left, left=None, right=None), right=None), right=(value=right, left=None, right=None))\n"
],
[
"assert deserialize(serialize(node)).left.left.val == 'left.left'",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a452e5f0178a2a7fbd9ed73db96f452c9a307a3
| 7,728 |
ipynb
|
Jupyter Notebook
|
examples/jupyter-examples/6. KakaoBrunch12M.ipynb
|
gony0/buffalo
|
f93dc4f95a526ec711cd605cc39c6ff347d976ed
|
[
"Apache-2.0"
] | 577 |
2019-08-28T19:56:43.000Z
|
2022-03-22T19:44:58.000Z
|
examples/jupyter-examples/6. KakaoBrunch12M.ipynb
|
gony0/buffalo
|
f93dc4f95a526ec711cd605cc39c6ff347d976ed
|
[
"Apache-2.0"
] | 35 |
2019-08-28T23:48:58.000Z
|
2022-02-10T02:13:47.000Z
|
examples/jupyter-examples/6. KakaoBrunch12M.ipynb
|
gony0/buffalo
|
f93dc4f95a526ec711cd605cc39c6ff347d976ed
|
[
"Apache-2.0"
] | 128 |
2019-08-28T21:41:10.000Z
|
2022-02-21T17:46:17.000Z
| 29.162264 | 136 | 0.530409 |
[
[
[
"# KakaoBrunch12M\nKakaoBrunch12M은 [카카오 아레나에서 공개한 데이터](https://arena.kakao.com/datasets?id=2)로 [브런치 서비스](https://brunch.co.kr) 사용자를 통해 수집한 데이터입니다.\n\n이 예제에서는 브런치 데이터에서 ALS를 활용해 특정 글과 유사한 글을 추천하는 예제와 개인화 추천 예제 두 가지를 살펴보겠습니다.",
"_____no_output_____"
]
],
[
[
"import buffalo.data\nfrom buffalo.algo.als import ALS\nfrom buffalo.algo.options import ALSOption\nfrom buffalo.misc import aux\nfrom buffalo.misc import log \nfrom buffalo.data.mm import MatrixMarketOptions\n\nlog.set_log_level(1) # set log level 3 or higher to check more information",
"_____no_output_____"
]
],
[
[
"## 데이터 불러오기",
"_____no_output_____"
]
],
[
[
"# 브런치 데이터를 ./data/kakao-brunch-12m/ 아래에 위치했다고 가정하겠습니다.\ndata_opt = MatrixMarketOptions().get_default_option()\ndata_opt.input = aux.Option(\n {\n 'main': 'data/kakao-brunch-12m/main',\n 'iid': 'data/kakao-brunch-12m/iid', \n 'uid': 'data/kakao-brunch-12m/uid'\n }\n)\ndata_opt\n",
"_____no_output_____"
],
[
"import os\nimport shutil\n# KakaoBrunch12M 데이터에는 '#' 으로 시작하는 아이템과 사용자 아이디가 있는데,\n# numpy에서 이런 라인은 주석으로 인식하기 때문에 다른 문자로 치환할 필요가 있습니다.\nfor filename in ['main', 'uid', 'iid']:\n src = f'./data/kakao-brunch-12m/{filename}'\n dest = f'./data/kakao-brunch-12m/{filename}.tmp'\n with open(src, 'r') as fin:\n with open(dest, 'w') as fout:\n while True:\n read = fin.read(4098)\n if len(read) == 0:\n break\n read = read.replace('#', '$')\n fout.write(read)\n shutil.move(dest, src)\ndata = buffalo.data.load(data_opt)\ndata.create()",
"_____no_output_____"
]
],
[
[
"## 유사아이템 추천",
"_____no_output_____"
]
],
[
[
"# ALS 알고리즘의 기본 옵션으로 파라미터를 학습을 하겠습니다.\n# 앞선 예제에 비해서는 데이터가 크기 때문에 워커 개수를 늘렸습니다.\nals_opt = ALSOption().get_default_option()\nals_opt.num_workers = 4\nmodel = ALS(als_opt, data=data)\nmodel.initialize()\nmodel.train()\nmodel.save('brunch.als.model')",
"_____no_output_____"
],
[
"# https://brunch.co.kr/@brunch/148 - 작가 인터뷰 - 브랜드 마케터, 정혜윤 by 브런치팀\nmodel.load('brunch.als.model')\nsimilar_items = model.most_similar('@brunch_148', 5)\nfor rank, (item, score) in enumerate(similar_items):\n bid, aid = item.split('_')\n print(f'{rank + 1:02d}. {score:.3f} https://brunch.co.kr/{bid}/{aid}')",
"01. 0.994 https://brunch.co.kr/@brunch/149\n02. 0.968 https://brunch.co.kr/@brunch/147\n03. 0.950 https://brunch.co.kr/@brunch/144\n04. 0.944 https://brunch.co.kr/@brunch/145\n05. 0.934 https://brunch.co.kr/@brunch/143\n"
]
],
[
[
"브런치팀이 쓴 글중에서 아래와 같은 글들이 유사한 결과로 나왔습니다.\n- https://brunch.co.kr/@brunch/149 : 글의 완성도를 높이는 팁, 맞춤법 검사\n- https://brunch.co.kr/@brunch/147 : 크리에이터스 데이'글력' 후기\n- https://brunch.co.kr/@brunch/144 : 글을 읽고 쓰는 것, 이 두 가지에만 집중하세요.\n- https://brunch.co.kr/@brunch/145 : 10인의 에디터와 함께 하는, 브런치북 프로젝트 #6\n- https://brunch.co.kr/@brunch/143 : 크리에이터스 스튜디오 '글쓰기 클래스' 후기",
"_____no_output_____"
],
[
"## 개인화 추천 예제",
"_____no_output_____"
]
],
[
[
"# 사용자에 대한 개인화 추천 결과는 topk_recommendation으로 얻을 수 있습니다.\n# ALS 모델을 사용하는 가장 기본적인 방식입니다. \nfor rank, item in enumerate(model.topk_recommendation('$424ec49fa8423d82629c73e6d5ae9408')):\n bid, aid = item.split('_')\n print(f'{rank + 1:02d}. https://brunch.co.kr/{bid}/{aid}')",
"01. https://brunch.co.kr/@sweetannie/145\n02. https://brunch.co.kr/@intlovesong/28\n03. https://brunch.co.kr/@tenbody/1164\n04. https://brunch.co.kr/@dailylife/207\n05. https://brunch.co.kr/@steven/179\n06. https://brunch.co.kr/@conbus/43\n07. https://brunch.co.kr/@bzup/281\n08. https://brunch.co.kr/@deckey1985/51\n09. https://brunch.co.kr/@brunch/151\n10. https://brunch.co.kr/@tenbody/1305\n"
],
[
"# get_weighted_feature를 응용하면 임의의 관심사를 가진 사용자에게 \n# 전달할 추천 결과를 만들 수 있습니다.\npersonal_feat = model.get_weighted_feature({\n '@lonelyplanet_3': 1, # https://brunch.co.kr/@lonelyplanet/3\n '@tube007_66': 1 # https://brunch.co.kr/@tube007/66\n})\nsimilar_items = model.most_similar(personal_feat, 10)\nfor rank, (item, score) in enumerate(similar_items):\n bid, aid = item.split('_')\n print(f'{rank + 1:02d}. {score:.3f} https://brunch.co.kr/{bid}/{aid}')",
"01. 0.991 https://brunch.co.kr/@lonelyplanet/3\n02. 0.939 https://brunch.co.kr/@tube007/66\n03. 0.924 https://brunch.co.kr/@leeseonyoung/38\n04. 0.909 https://brunch.co.kr/@looktothesky/8\n05. 0.898 https://brunch.co.kr/@juliakimcued/95\n06. 0.894 https://brunch.co.kr/@koncreate/38\n07. 0.894 https://brunch.co.kr/@sound4u2005/56\n08. 0.894 https://brunch.co.kr/@enormous-hat/332\n09. 0.894 https://brunch.co.kr/@nakyungseol/20\n10. 0.883 https://brunch.co.kr/@yehyun86/80\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
4a453ca23693219c5a55968aa64b6613904a65a9
| 334,607 |
ipynb
|
Jupyter Notebook
|
_notebooks/2020-03-15-us-growth-by-state-map.ipynb
|
RebelTat/covid19-dashboard
|
c1c154a6d2c2671338c5c9ed5147e2ae642e9506
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-03-15-us-growth-by-state-map.ipynb
|
RebelTat/covid19-dashboard
|
c1c154a6d2c2671338c5c9ed5147e2ae642e9506
|
[
"Apache-2.0"
] | 2 |
2021-03-30T12:32:40.000Z
|
2022-02-26T09:48:38.000Z
|
_notebooks/2020-03-15-us-growth-by-state-map.ipynb
|
RebelTat/covid19-dashboard
|
c1c154a6d2c2671338c5c9ed5147e2ae642e9506
|
[
"Apache-2.0"
] | null | null | null | 798.584726 | 320,900 | 0.543085 |
[
[
[
"# Interactive Map - Confirmed Cases in the US by State\n> Interactive Visualizations of The Count and Growth of COVID-19 in the US.\n\n- comments: true\n- author: Asif Imran\n- categories: [growth, usa, altair, interactive]\n- image: images/us-growth-state-map.png\n- permalink: /growth-map-us-states/",
"_____no_output_____"
]
],
[
[
"#hide\nimport requests\nimport numpy as np\nimport pandas as pd\nimport altair as alt\n\nalt.data_transformers.disable_max_rows()\n\n#https://github.com/altair-viz/altair/issues/1005#issuecomment-403237407\ndef to_altair_datetime(dt):\n return alt.DateTime(year=dt.year, month=dt.month, date=dt.day,\n hours=dt.hour, minutes=dt.minute, seconds=dt.second,\n milliseconds=0.001 * dt.microsecond)",
"_____no_output_____"
],
[
"#hide\nabbr2state = {\n 'AK': 'Alaska',\n 'AL': 'Alabama',\n 'AR': 'Arkansas',\n 'AS': 'American Samoa',\n 'AZ': 'Arizona',\n 'CA': 'California',\n 'CO': 'Colorado',\n 'CT': 'Connecticut',\n 'DC': 'District of Columbia',\n 'DE': 'Delaware',\n 'FL': 'Florida',\n 'GA': 'Georgia',\n 'GU': 'Guam',\n 'HI': 'Hawaii',\n 'IA': 'Iowa',\n 'ID': 'Idaho',\n 'IL': 'Illinois',\n 'IN': 'Indiana',\n 'KS': 'Kansas',\n 'KY': 'Kentucky',\n 'LA': 'Louisiana',\n 'MA': 'Massachusetts',\n 'MD': 'Maryland',\n 'ME': 'Maine',\n 'MI': 'Michigan',\n 'MN': 'Minnesota',\n 'MO': 'Missouri',\n 'MP': 'Northern Mariana Islands',\n 'MS': 'Mississippi',\n 'MT': 'Montana',\n 'NA': 'National',\n 'NC': 'North Carolina',\n 'ND': 'North Dakota',\n 'NE': 'Nebraska',\n 'NH': 'New Hampshire',\n 'NJ': 'New Jersey',\n 'NM': 'New Mexico',\n 'NV': 'Nevada',\n 'NY': 'New York',\n 'OH': 'Ohio',\n 'OK': 'Oklahoma',\n 'OR': 'Oregon',\n 'PA': 'Pennsylvania',\n 'PR': 'Puerto Rico',\n 'RI': 'Rhode Island',\n 'SC': 'South Carolina',\n 'SD': 'South Dakota',\n 'TN': 'Tennessee',\n 'TX': 'Texas',\n 'UT': 'Utah',\n 'VA': 'Virginia',\n 'VI': 'Virgin Islands',\n 'VT': 'Vermont',\n 'WA': 'Washington',\n 'WI': 'Wisconsin',\n 'WV': 'West Virginia',\n 'WY': 'Wyoming'\n}\n\nstate2abbr = {s:a for a,s in abbr2state.items()}",
"_____no_output_____"
],
[
"#hide\nstates_daily_url = 'https://covidtracking.com/api/states/daily'\nstates_daily_raw = pd.DataFrame(requests.get(states_daily_url).json())\n\nus_daily_df = states_daily_raw.copy()\n\ncols_keep = ['date','state','positive','dateChecked','positiveIncrease','death']\nus_daily_df = us_daily_df[cols_keep]\nus_daily_df['date'] = pd.to_datetime(us_daily_df['date'], format='%Y%m%d')\nus_daily_df['dateChecked'] = pd.to_datetime(us_daily_df['dateChecked'])\n\nus_state_capitals_url = 'https://vega.github.io/vega-datasets/data/us-state-capitals.json'\nstate_cap_df = pd.DataFrame(requests.get(us_state_capitals_url).json())\n\nstate_cap_df['state'] = state_cap_df['state'].apply(lambda s: state2abbr.get(s))\n\nus_daily_df = us_daily_df.merge(state_cap_df, on='state', how='left')\n\nus_daily_df.rename(columns={'positive':'confirmed_count', \n 'positiveIncrease':'new_cases'}, inplace=True)\n\nstate_df = us_daily_df.sort_values('date').groupby(['state']).tail(1)",
"_____no_output_____"
],
[
"#hide\nstates_data = 'https://vega.github.io/vega-datasets/data/us-10m.json'\nstates = alt.topo_feature(states_data, feature='states')\nselector = alt.selection_single(empty='none', fields=['state'], nearest=True, init={'state':'CA'})\n\ncurr_date = state_df.date.max().date().strftime('%Y-%m-%d')\ndmax = (us_daily_df.date.max() + pd.DateOffset(days=3))\ndmin = us_daily_df.date.min()\n\n# US states background\nbackground = alt.Chart(states).mark_geoshape(\n fill='lightgray',\n stroke='white'\n).properties(\n width=500,\n height=400\n).project('albersUsa')\n\n\npoints = alt.Chart(state_df).mark_circle().encode(\n longitude='lon:Q',\n latitude='lat:Q',\n size=alt.Size('confirmed_count:Q', title= 'Number of Confirmed Cases'),\n color=alt.value('steelblue'),\n tooltip=['state:N','confirmed_count:Q']\n).properties(\n title=f'Total Confirmed Cases by State as of {curr_date}'\n).add_selection(selector)\n\n\ntimeseries = alt.Chart(us_daily_df).mark_bar().properties(\n width=500,\n height=350,\n title=\"New Cases by Day\",\n).encode(\n x=alt.X('date:T', title='Date', timeUnit='yearmonthdate',\n axis=alt.Axis(format='%y/%m/%d', labelAngle=-30), \n scale=alt.Scale(domain=[to_altair_datetime(dmin), to_altair_datetime(dmax)])),\n y=alt.Y('new_cases:Q',\n axis=alt.Axis(title='# of New Cases',titleColor='steelblue'),\n ),\n color=alt.Color('state:O'),\n tooltip=['state:N','date:T','confirmed_count:Q', 'new_cases:Q']\n).transform_filter(\n selector\n).add_selection(alt.selection_single()\n)\n\ntimeseries_cs = alt.Chart(us_daily_df).mark_line(color='red').properties(\n width=500,\n height=350,\n).encode(\n x=alt.X('date:T', title='Date', timeUnit='yearmonthdate', \n axis=alt.Axis(format='%y/%m/%d', labelAngle=-30),\n scale=alt.Scale(domain=[to_altair_datetime(dmin), to_altair_datetime(dmax)])),\n y=alt.Y('confirmed_count:Q',\n #scale=alt.Scale(type='log'),\n axis=alt.Axis(title='# of Confirmed Cases', titleColor='red'),\n ),\n).transform_filter(\n selector\n).add_selection(alt.selection_single(nearest=True)\n)\n\n\n\nfinal_chart = alt.vconcat(\n background + points, \n alt.layer(timeseries, timeseries_cs).resolve_scale(y='independent'),\n).resolve_scale(\n color='independent',\n shape='independent',\n).configure(\n padding={'left':10, 'bottom':40}\n).configure_axis(\n labelFontSize=10,\n labelPadding=10,\n titleFontSize=12,\n).configure_view(\n stroke=None\n)\n",
"_____no_output_____"
]
],
[
[
"### Click On State To Filter Chart Below",
"_____no_output_____"
]
],
[
[
"#hide_input\nfinal_chart",
"_____no_output_____"
]
],
[
[
"Prepared by [Asif Imran](https://twitter.com/5sigma)[^1]\n\n[^1]: Source: [\"https://covidtracking.com/api/\"](https://covidtracking.com/api/). ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a455456ca1f4ea7d87c6d2186479558e50aa778
| 779 |
ipynb
|
Jupyter Notebook
|
pset_loops/loop_challenges/nb/p2.ipynb
|
mottaquikarim/pydev-psets
|
9749e0d216ee0a5c586d0d3013ef481cc21dee27
|
[
"MIT"
] | 5 |
2019-04-08T20:05:37.000Z
|
2019-12-04T20:48:45.000Z
|
pset_loops/loop_challenges/nb/p2.ipynb
|
mottaquikarim/pydev-psets
|
9749e0d216ee0a5c586d0d3013ef481cc21dee27
|
[
"MIT"
] | 8 |
2019-04-15T15:16:05.000Z
|
2022-02-12T10:33:32.000Z
|
pset_loops/loop_challenges/nb/p2.ipynb
|
mottaquikarim/pydev-psets
|
9749e0d216ee0a5c586d0d3013ef481cc21dee27
|
[
"MIT"
] | 2 |
2019-04-10T00:14:42.000Z
|
2020-02-26T20:35:21.000Z
| 25.966667 | 279 | 0.545571 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a455bdc0ee6a07a4f4998b2b90725ae57ed08f9
| 22,063 |
ipynb
|
Jupyter Notebook
|
7.25.ipynb
|
Kim0903/jincaifeng
|
8a6727b5060f0f1dd45b62a2fc10cb875a26634a
|
[
"Apache-2.0"
] | null | null | null |
7.25.ipynb
|
Kim0903/jincaifeng
|
8a6727b5060f0f1dd45b62a2fc10cb875a26634a
|
[
"Apache-2.0"
] | null | null | null |
7.25.ipynb
|
Kim0903/jincaifeng
|
8a6727b5060f0f1dd45b62a2fc10cb875a26634a
|
[
"Apache-2.0"
] | null | null | null | 16.538981 | 59 | 0.387663 |
[
[
[
"# 列表List\n- 一个列表可以储存任意大小的数据集合,你可以理解为他是一个容器",
"_____no_output_____"
]
],
[
[
"a = [1,2,3,'a',1.0,True,[1,2]]\na",
"_____no_output_____"
]
],
[
[
"## 先来一个例子爽一爽\n",
"_____no_output_____"
],
[
"## 创建一个列表\n- a = [1,2,3,4,5]",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"a = [[1,2],[3,4]]\nnp.array(a)",
"_____no_output_____"
]
],
[
[
"## 列表的一般操作\n",
"_____no_output_____"
]
],
[
[
"a = 'Kim'\nb = 'im'\nb in a",
"_____no_output_____"
],
[
"a = [1,2,'Kim',1.0]\nb = 'im'\nb in a",
"_____no_output_____"
],
[
"a = [1]#列表只能相加和相乘\nb = [2]\na + b",
"_____no_output_____"
],
[
"a = [1]\nb = 5\na * b",
"_____no_output_____"
],
[
"a = [1,2,3,4,5]\na[-1]",
"_____no_output_____"
],
[
"a = [1,2,4,5]\na[1:3]#前闭后开",
"_____no_output_____"
],
[
"a = [1,2,4,5]\na[3:0:-1]#开始:结尾:步长(前闭后开)一旦超过索引值的范围,默认最后一位索引",
"_____no_output_____"
],
[
"a = [1,2,4,5]\na[::-1][:3]",
"_____no_output_____"
],
[
"a = [1,2,4,5]\na[::2]",
"_____no_output_____"
],
[
"a = [1,2,4,5,[100,200,300]]\na[4][2]",
"_____no_output_____"
],
[
"a = [[0,1,2],[3,4,5],[6,7,8]]\nb = np.array(a)\nb",
"_____no_output_____"
],
[
"a = [[0,1,2],[3,4,5],[6,7,8]]\nb = a[0][0:2]\nprint(b)\nc = a[1][0:2]\nprint(c)\nd = a[0]",
"[0, 1]\n[3, 4]\n"
],
[
"a = [[0,1,2],[3,4,5],[6,7,8]]\nfor i in range(2):\n for j in range(2):\n print(a[i][j:j+2])\n print(a[i+1][j:j+2])\n print('--------')",
"[0, 1]\n[3, 4]\n--------\n[1, 2]\n[4, 5]\n--------\n[3, 4]\n[6, 7]\n--------\n[4, 5]\n[7, 8]\n--------\n"
],
[
"a = [1,2,3,[1,2,3]]\nlen(a)",
"_____no_output_____"
],
[
"a = [1,2,3,[1,2,3]]\nN = len(a)\nb = a[3][::]\nprint(b)\nc = len(b)\nprint(c)\nprint(N -1 + c)",
"[1, 2, 3]\n3\n6\n"
],
[
"def K():\n a = [1,2,3,[1,2,3]]\n \n N = len(a)\n b = a[3][::]\n print(b)\n c = len(b)\n print(c)\n print(N -1 + c)",
"_____no_output_____"
],
[
"K()",
"[1, 2, 3]\n3\n6\n"
]
],
[
[
"# 列表索引操作\n- Mylist[index]\n- 正序索引,逆序索引\n- 列表一定注意越界\n- ",
"_____no_output_____"
]
],
[
[
"b = [1,2,3]\nmax(b)",
"_____no_output_____"
],
[
"b = [1,2,3]\nsum(b)",
"_____no_output_____"
],
[
"b = [1,2,3,True]\nmin(b)",
"_____no_output_____"
],
[
"a = [1,2,3,[1,2,3,4]]\nfor i in a:\n print(i)",
"1\n2\n3\n[1, 2, 3, 4]\n"
],
[
"a = [1,2,3]\nb = [1,2,3]\nb == a",
"_____no_output_____"
]
],
[
[
"## 列表切片操作\n- Mylist[start:end]\n- 正序切片,逆序切片",
"_____no_output_____"
],
[
"## 列表 +、*、in 、not in",
"_____no_output_____"
],
[
"## 使用for循环遍历元素\n- for 循环可以遍历一切可迭代元素",
"_____no_output_____"
],
[
"## EP:\n- 使用while 循环遍历列表",
"_____no_output_____"
]
],
[
[
"Kim = [1,2,3,4,5]\nfor i in Kim:\n print(i)",
"1\n2\n3\n4\n5\n"
],
[
"i = 0\nwhile i < len(Kim):\n print(Kim[i])\n i +=1",
"1\n2\n3\n4\n5\n"
]
],
[
[
"## 列表的比较\n- \\>,<,>=,<=,==,!=",
"_____no_output_____"
],
[
"## 列表生成式\n[x for x in range(10)]",
"_____no_output_____"
]
],
[
[
"U = [x for x in range(10)]\nU",
"_____no_output_____"
],
[
"U = [x for x in range(10) if x%2==0]\nU",
"_____no_output_____"
],
[
"U = [x + 10 for x in range(10)]\nU",
"_____no_output_____"
],
[
"import random\nK = [random.randint(0,10) for i in range(10)]\nK",
"_____no_output_____"
]
],
[
[
"## 列表的方法\n",
"_____no_output_____"
]
],
[
[
"a = 10\nb = [100]\nb.append(a)\nb",
"_____no_output_____"
],
[
"a = [1,2,3,4]\nb = [100,200,300]\nfor i in b:\n a.append(i)\na",
"_____no_output_____"
],
[
"a = [1,2,3,3,4,5,5]\na.count(3)",
"_____no_output_____"
],
[
"a = [1,2,2,[2,2]]\nfor i in a:\n if type(i) is list:\n print(i.count(2))\n ",
"2\n"
],
[
"a = [1,2,3,4]\nb = [300,400]\nb.extend(a)\na +b",
"_____no_output_____"
],
[
"a = [1,2,3,4]#查询1\na.index(1)",
"_____no_output_____"
],
[
"a = [1,2,3,4]\na.insert(1,12)\na",
"_____no_output_____"
],
[
"b = [1,2,3,4,6]#所有偶数前加100\nc = []",
"_____no_output_____"
],
[
"for i in b:\n if i %2 == 0 and i != 100 and i not in c:\n c.append(i)\n index_ = b.index(i)\n b.insert(index_,100)\nb",
"_____no_output_____"
],
[
"a = [1,1,1,2,3]\na.remove(1)\na",
"_____no_output_____"
],
[
"a = [1,2,1,5,1,7,1,9,1]\nfor i in a:\n if i//1 == 1:\n a.remove(1)\na",
"1\n1\n1\n1\n1\n"
]
],
[
[
"## 将字符串分割成列表\n- split 按照自定义的内容拆分",
"_____no_output_____"
],
[
"## EP:\n\n",
"_____no_output_____"
],
[
"## 列表的复制\n- copy 浅复制\n- deepcopy import copy 深复制\n- http://www.pythontutor.com/visualize.html#mode=edit",
"_____no_output_____"
],
[
"## 列表排序\n- sort\n- sorted\n- 列表的多级排序\n - 匿名函数",
"_____no_output_____"
],
[
"## EP:\n- 手动排序该列表[5,3,8,0,17],以升序或者降序",
"_____no_output_____"
],
[
"- 1\n",
"_____no_output_____"
]
],
[
[
"score = eval(input('Enter scores:'))\nb = max(score)\nfor i in score:\n if i >= b - 10:\n print(i,'grade is A')\n elif i >= b - 20:\n print(i,'grade is B')\n elif i >= b - 30:\n print(i,'grade is C') \n elif i >= b - 40:\n print(i,'grade is D')\n else:\n print(i,'grade is F')",
"Enter scores:45,66,82,95\n45 grade is F\n66 grade is C\n82 grade is B\n95 grade is A\n"
]
],
[
[
"- 2\n",
"_____no_output_____"
]
],
[
[
"a = [1,5,3,4,7]\na[::-1]",
"_____no_output_____"
]
],
[
[
"- 3\n",
"_____no_output_____"
]
],
[
[
"T=[-1,11,1,11,12,-1]\nfor i in T:\n count_=T.count(i) \n print(i,\"出现\",count_,'次') ",
"-1 出现 2 次\n11 出现 2 次\n1 出现 1 次\n11 出现 2 次\n12 出现 1 次\n-1 出现 2 次\n"
]
],
[
[
"- 4\n",
"_____no_output_____"
]
],
[
[
"score = [65,58,94,77,86,91,80]\nsum_ = sum(score)\ngeshu = len(score)\naverange = sum_/geshu\nN1 = 0\nN2 = 0\nfor i in score:\n if i > averange:\n N1 += 1\n if i < averange:\n N2 += 1 \nprint('大于平均数的分数有:',N1,'个')\nprint('小于平均数的分数有:',N2,'个')",
"大于平均数的分数有: 4 个\n小于平均数的分数有: 3 个\n"
]
],
[
[
"- 5\n",
"_____no_output_____"
]
],
[
[
"import random\nK1 = [random.randint(0,10) for i in range(10)]\nK2 = [random.randint(0,10) for i in range(10)]\nprint(K1,'\\n',K1,'\\n')",
"[4, 10, 9, 5, 1, 3, 3, 1, 3, 3] \n [4, 10, 9, 5, 1, 3, 3, 1, 3, 3] \n\n"
]
],
[
[
"- 6\n",
"_____no_output_____"
],
[
"- 7\n\n",
"_____no_output_____"
],
[
"- 8\n",
"_____no_output_____"
],
[
"- 9\n",
"_____no_output_____"
],
[
"- 10\n",
"_____no_output_____"
],
[
"- 11\n",
"_____no_output_____"
],
[
"- 12\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a4568752f42cc359e992beef6d98d1c80532ff1
| 94,428 |
ipynb
|
Jupyter Notebook
|
Credit Risk Evaluator.ipynb
|
JacobTrevithick/Supervised-Machine-Learning-Predicting-Credit-Risk
|
a316487ad458e5187de82206d7f8008581b647fb
|
[
"ADSL"
] | null | null | null |
Credit Risk Evaluator.ipynb
|
JacobTrevithick/Supervised-Machine-Learning-Predicting-Credit-Risk
|
a316487ad458e5187de82206d7f8008581b647fb
|
[
"ADSL"
] | null | null | null |
Credit Risk Evaluator.ipynb
|
JacobTrevithick/Supervised-Machine-Learning-Predicting-Credit-Risk
|
a316487ad458e5187de82206d7f8008581b647fb
|
[
"ADSL"
] | null | null | null | 43.858802 | 13,014 | 0.423836 |
[
[
[
"%matplotlib inline\nfrom matplotlib import pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom sklearn.feature_selection import SelectFromModel\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.preprocessing import StandardScaler, LabelEncoder",
"_____no_output_____"
],
[
"train_df = pd.read_csv(Path('Resources/2019loans.csv'))\ntest_df = pd.read_csv(Path('Resources/2020Q1loans.csv'))\ntrain_df.head()",
"_____no_output_____"
],
[
"test_df.head()",
"_____no_output_____"
],
[
"# Convert categorical data to numeric and separate target feature for training data\nX_train = train_df.drop('loan_status', axis=1)\nX_train_dummies = pd.get_dummies(X_train)\n\ny_train_label = LabelEncoder().fit_transform(train_df['loan_status'])\n\nprint(y_train_label)\nprint(X_train_dummies.columns)\nX_train_dummies",
"[1 1 1 ... 0 0 0]\nIndex(['Unnamed: 0', 'index', 'loan_amnt', 'int_rate', 'installment',\n 'annual_inc', 'dti', 'delinq_2yrs', 'inq_last_6mths', 'open_acc',\n 'pub_rec', 'revol_bal', 'total_acc', 'out_prncp', 'out_prncp_inv',\n 'total_pymnt', 'total_pymnt_inv', 'total_rec_prncp', 'total_rec_int',\n 'total_rec_late_fee', 'recoveries', 'collection_recovery_fee',\n 'last_pymnt_amnt', 'collections_12_mths_ex_med', 'policy_code',\n 'acc_now_delinq', 'tot_coll_amt', 'tot_cur_bal', 'open_acc_6m',\n 'open_act_il', 'open_il_12m', 'open_il_24m', 'mths_since_rcnt_il',\n 'total_bal_il', 'il_util', 'open_rv_12m', 'open_rv_24m', 'max_bal_bc',\n 'all_util', 'total_rev_hi_lim', 'inq_fi', 'total_cu_tl', 'inq_last_12m',\n 'acc_open_past_24mths', 'avg_cur_bal', 'bc_open_to_buy', 'bc_util',\n 'chargeoff_within_12_mths', 'delinq_amnt', 'mo_sin_old_il_acct',\n 'mo_sin_old_rev_tl_op', 'mo_sin_rcnt_rev_tl_op', 'mo_sin_rcnt_tl',\n 'mort_acc', 'mths_since_recent_bc', 'mths_since_recent_inq',\n 'num_accts_ever_120_pd', 'num_actv_bc_tl', 'num_actv_rev_tl',\n 'num_bc_sats', 'num_bc_tl', 'num_il_tl', 'num_op_rev_tl',\n 'num_rev_accts', 'num_rev_tl_bal_gt_0', 'num_sats', 'num_tl_120dpd_2m',\n 'num_tl_30dpd', 'num_tl_90g_dpd_24m', 'num_tl_op_past_12m',\n 'pct_tl_nvr_dlq', 'percent_bc_gt_75', 'pub_rec_bankruptcies',\n 'tax_liens', 'tot_hi_cred_lim', 'total_bal_ex_mort', 'total_bc_limit',\n 'total_il_high_credit_limit', 'home_ownership_ANY',\n 'home_ownership_MORTGAGE', 'home_ownership_OWN', 'home_ownership_RENT',\n 'verification_status_Not Verified',\n 'verification_status_Source Verified', 'verification_status_Verified',\n 'pymnt_plan_n', 'initial_list_status_f', 'initial_list_status_w',\n 'application_type_Individual', 'application_type_Joint App',\n 'hardship_flag_N', 'hardship_flag_Y', 'debt_settlement_flag_N',\n 'debt_settlement_flag_Y'],\n dtype='object')\n"
],
[
"# Convert categorical data to numeric and separate target feature for testing data\nX_test = test_df.drop('loan_status', axis=1)\nX_test_dummies = pd.get_dummies(X_test)\n\ny_test_label = LabelEncoder().fit_transform(test_df['loan_status'])\n\nprint(y_test_label)\nprint(X_test_dummies.columns)\nX_test_dummies",
"[1 1 1 ... 0 0 0]\nIndex(['Unnamed: 0', 'index', 'loan_amnt', 'int_rate', 'installment',\n 'annual_inc', 'dti', 'delinq_2yrs', 'inq_last_6mths', 'open_acc',\n 'pub_rec', 'revol_bal', 'total_acc', 'out_prncp', 'out_prncp_inv',\n 'total_pymnt', 'total_pymnt_inv', 'total_rec_prncp', 'total_rec_int',\n 'total_rec_late_fee', 'recoveries', 'collection_recovery_fee',\n 'last_pymnt_amnt', 'collections_12_mths_ex_med', 'policy_code',\n 'acc_now_delinq', 'tot_coll_amt', 'tot_cur_bal', 'open_acc_6m',\n 'open_act_il', 'open_il_12m', 'open_il_24m', 'mths_since_rcnt_il',\n 'total_bal_il', 'il_util', 'open_rv_12m', 'open_rv_24m', 'max_bal_bc',\n 'all_util', 'total_rev_hi_lim', 'inq_fi', 'total_cu_tl', 'inq_last_12m',\n 'acc_open_past_24mths', 'avg_cur_bal', 'bc_open_to_buy', 'bc_util',\n 'chargeoff_within_12_mths', 'delinq_amnt', 'mo_sin_old_il_acct',\n 'mo_sin_old_rev_tl_op', 'mo_sin_rcnt_rev_tl_op', 'mo_sin_rcnt_tl',\n 'mort_acc', 'mths_since_recent_bc', 'mths_since_recent_inq',\n 'num_accts_ever_120_pd', 'num_actv_bc_tl', 'num_actv_rev_tl',\n 'num_bc_sats', 'num_bc_tl', 'num_il_tl', 'num_op_rev_tl',\n 'num_rev_accts', 'num_rev_tl_bal_gt_0', 'num_sats', 'num_tl_120dpd_2m',\n 'num_tl_30dpd', 'num_tl_90g_dpd_24m', 'num_tl_op_past_12m',\n 'pct_tl_nvr_dlq', 'percent_bc_gt_75', 'pub_rec_bankruptcies',\n 'tax_liens', 'tot_hi_cred_lim', 'total_bal_ex_mort', 'total_bc_limit',\n 'total_il_high_credit_limit', 'home_ownership_ANY',\n 'home_ownership_MORTGAGE', 'home_ownership_OWN', 'home_ownership_RENT',\n 'verification_status_Not Verified',\n 'verification_status_Source Verified', 'verification_status_Verified',\n 'pymnt_plan_n', 'initial_list_status_f', 'initial_list_status_w',\n 'application_type_Individual', 'application_type_Joint App',\n 'hardship_flag_N', 'hardship_flag_Y', 'debt_settlement_flag_N'],\n dtype='object')\n"
],
[
"# add missing dummy variables to testing set\n# check which column is missing from the test set\nfor col in X_train_dummies.columns:\n if col not in X_test_dummies.columns:\n print(col)\n\ndef labeler(binary):\n \"\"\"flips bits\n\n Args:\n binary (int/float): 0 or 1\n\n Returns:\n [int]: [1 or 0]\n \"\"\"\n if int(binary) == 0:\n return 1\n else:\n return 0\n\nX_test_dummies['debt_settlement_flag_Y'] = X_test_dummies['debt_settlement_flag_N'].apply(lambda x: labeler(x))\n\nX_test_dummies\n",
"debt_settlement_flag_Y\n"
]
],
[
[
"# Logistic vs. Random Forest Model Unscaled data\n\n## Predictions\n\nI predict the logistic regression model will perform worse on the unscaled dataset compared to the random forest model. Logistic regression models classify the lable based on an arithmatic equation 'weighted' by the feature's numerical value. Therefore, since the dataset is unscaled and highly skewed, the LR is likely to underperform. The random forest classifier is not affected by the scaling of the dataset, so I predict greater accuracy.",
"_____no_output_____"
]
],
[
[
"# Train the Logistic Regression model on the unscaled data and print the model score\nclassifier = LogisticRegression(max_iter=1000)\n\nclassifier.fit(X_train_dummies, y_train_label)\n\nprint(f\"Training test score: {classifier.score(X_train_dummies, y_train_label)}\")\nprint(f\"Testing test score: {classifier.score(X_test_dummies, y_test_label)}\")",
"Training test score: 0.7011494252873564\nTesting test score: 0.5808166737558486\n"
],
[
"# Train a Random Forest Classifier model and print the model score\nclassifier_rf = RandomForestClassifier(n_estimators=200)\n\nclassifier_rf.fit(X_train_dummies, y_train_label)\n\nprint(f\"Training test score: {classifier_rf.score(X_train_dummies, y_train_label)}\")\nprint(f\"Testing test score: {classifier_rf.score(X_test_dummies, y_test_label)}\")",
"Training test score: 1.0\nTesting test score: 0.6112292641429179\n"
]
],
[
[
"## Performance\n\nAs expected, the random forest model outperformed the logisitic regression. The random forest is also overfitted to the training data set indicated by a training test r^2 score of 1.0. I anticipate the logistic regression to perform much better with the scaled dataset.",
"_____no_output_____"
]
],
[
[
"# Scale the data\nscaler = StandardScaler().fit(X_train_dummies)\nX_train_scaled = scaler.transform(X_train_dummies)\nX_test_scaled = scaler.transform(X_test_dummies)",
"_____no_output_____"
],
[
"# Train the Logistic Regression model on the scaled data and print the model score\nclassifier_LR = LogisticRegression(max_iter=1000)\n\nclassifier_LR.fit(X_train_scaled, y_train_label)\n\nprint(f\"Training test score: {classifier_LR.score(X_train_scaled, y_train_label)}\")\nprint(f\"Testing test score: {classifier_LR.score(X_test_scaled, y_test_label)}\")",
"Training test score: 0.7128899835796387\nTesting test score: 0.7201190982560612\n"
],
[
"# Train a Random Forest Classifier model on the scaled data and print the model score\nclassifier_rf = RandomForestClassifier(n_estimators=200)\n\nclassifier_rf.fit(X_train_scaled, y_train_label)\n\nprint(f\"Training test score: {classifier_rf.score(X_train_scaled, y_train_label)}\")\nprint(f\"Testing test score: {classifier_rf.score(X_test_scaled, y_test_label)}\")",
"Training test score: 1.0\nTesting test score: 0.5878349638451723\n"
]
],
[
[
"## Performance on scaled data\n\nThe logistic regression model outperformed the random forest model when the data is scaled using the StandardScaler() function. The logistic regression model dramatically increased the testing data set r^2 score from 0.58 -> 0.72, while the random forest decreased the testing data set r^2 score from 0.62 -> 0.58",
"_____no_output_____"
],
[
"## Trying feature selection on dataset\n\n# Prediction\n\nSince there are so many features in this training model, I anticipate there are many that are not impactful in the models' decisions\n\nHere I will find the non-essential features and remove them from the model and retest",
"_____no_output_____"
]
],
[
[
"# Determining what features are important in the random forest model\nfeatures = classifier_rf.feature_importances_\n\nplt.bar(x = range(len(features)), height=features)\nplt.xlabel('Feature number')\nplt.ylabel('Feature importance')\nplt.title('Feature importance vs. feature index')\nplt.show()",
"_____no_output_____"
],
[
"sel = SelectFromModel(classifier_LR)\nsel.fit(X_train_scaled, y_train_label)\nsel.get_support()",
"_____no_output_____"
],
[
"# feature selection\n# transforming unscaled datasets to remove unimportant features\nX_selected_train = sel.transform(X_train_dummies)\nX_selected_test = sel.transform(X_test_dummies)\n\n# scale filtered datasets\nscaler = StandardScaler().fit(X_selected_train)\nX_selected_train_scaled = scaler.transform(X_selected_train)\nX_selected_test_scaled = scaler.transform(X_selected_test)",
"_____no_output_____"
],
[
"classifier_LR_selected = LogisticRegression(max_iter=1000).fit(X_selected_train_scaled, y_train_label)\n\nprint(f'Training Score: {classifier_LR_selected.score(X_selected_train_scaled, y_train_label)}')\nprint(f'Testing Score: {classifier_LR_selected.score(X_selected_test_scaled, y_test_label)}')",
"Training Score: 0.7063218390804598\nTesting Score: 0.7033177371331348\n"
],
[
"sel = SelectFromModel(classifier_rf)\nsel.fit(X_train_scaled, y_train_label)\nsel.get_support()\n\n# feature selection\nX_selected_train = sel.transform(X_train_dummies)\nX_selected_test = sel.transform(X_test_dummies)\nscaler = StandardScaler().fit(X_selected_train)\nX_selected_train_scaled = scaler.transform(X_selected_train)\nX_selected_test_scaled = scaler.transform(X_selected_test)\n\n\nclassifier_rf = RandomForestClassifier(n_estimators=200)\nclassifier_rf.fit(X_selected_train_scaled, y_train_label)\n\nprint(f'Training Score: {classifier_rf.score(X_selected_train_scaled, y_train_label)}')\nprint(f'Testing Score: {classifier_rf.score(X_selected_test_scaled, y_test_label)}')",
"Training Score: 1.0\nTesting Score: 0.6142067205444491\n"
]
],
[
[
"## Results\n\nFeature selection had little effect on the Random forest testing score, and the logisitic regession performed slightly worse witht he reduce datasets.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a456fac68a78e3c52479c84fa82908962be5ce5
| 8,368 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/investigate-a-dataset-template-checkpoint.ipynb
|
anjalinagel12/movieRecommender
|
985a6915a26ec87e26d9f4c46de063d3ef66dccb
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/investigate-a-dataset-template-checkpoint.ipynb
|
anjalinagel12/movieRecommender
|
985a6915a26ec87e26d9f4c46de063d3ef66dccb
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/investigate-a-dataset-template-checkpoint.ipynb
|
anjalinagel12/movieRecommender
|
985a6915a26ec87e26d9f4c46de063d3ef66dccb
|
[
"MIT"
] | null | null | null | 38.562212 | 511 | 0.64412 |
[
[
[
"> **Tip**: Welcome to the Investigate a Dataset project! You will find tips in quoted sections like this to help organize your approach to your investigation. Before submitting your project, it will be a good idea to go back through your report and remove these sections to make the presentation of your work as tidy as possible. First things first, you might want to double-click this Markdown cell and change the title so that it reflects your dataset and investigation.\n\n# Project: Investigate a Dataset (Replace this with something more specific!)\n\n## Table of Contents\n<ul>\n<li><a href=\"#intro\">Introduction</a></li>\n<li><a href=\"#wrangling\">Data Wrangling</a></li>\n<li><a href=\"#eda\">Exploratory Data Analysis</a></li>\n<li><a href=\"#conclusions\">Conclusions</a></li>\n</ul>",
"_____no_output_____"
],
[
"<a id='intro'></a>\n## Introduction\n\n> **Tip**: In this section of the report, provide a brief introduction to the dataset you've selected for analysis. At the end of this section, describe the questions that you plan on exploring over the course of the report. Try to build your report around the analysis of at least one dependent variable and three independent variables.\n>\n> If you haven't yet selected and downloaded your data, make sure you do that first before coming back here. If you're not sure what questions to ask right now, then make sure you familiarize yourself with the variables and the dataset context for ideas of what to explore.",
"_____no_output_____"
]
],
[
[
"#The dataset which is selected is tmdb-movies.csv i.e. movies dataset which contains data on movies and ratings.\n#Revenue,Runtime and Popularity is tend to be explored.Over a period span reveneue v/s runtime, runtime v/s popularity and popularity v/s revenue is to be explored.\n#Questions which will be answered are: \n# 1.Over the decades, what are the popular runtimes?\n# 2.Spanning the time periods, is revenue proportional to popularity?\n# 3.Does runtime affect popularity?\n#only visualization and basic correlations are attempted in this project.And any investigation and exploratory are tentative at its best.",
"_____no_output_____"
],
[
"# Use this cell to set up import statements for all of the packages that you\n# plan to use.\n\n# Remember to include a 'magic word' so that your visualizations are plotted\n# inline with the notebook. See this page for more:\n# http://ipython.readthedocs.io/en/stable/interactive/magics.html\n\nimport pandas as pd\nimport numpy as np\nimport csv\nimport datetime as datetime\nimport matplotlib.pyplot as plt\n% matplotlib inline",
"_____no_output_____"
]
],
[
[
"<a id='wrangling'></a>\n## Data Wrangling\n\n> **Tip**: In this section of the report, you will load in the data, check for cleanliness, and then trim and clean your dataset for analysis. Make sure that you document your steps carefully and justify your cleaning decisions.\n\n### General Properties",
"_____no_output_____"
]
],
[
[
"# Load your data and print out a few lines. Perform operations to inspect data\n# types and look for instances of missing or possibly errant data.\n\ndf=pd.read_csv('tmdb-movies.csv')\n",
"_____no_output_____"
]
],
[
[
"> **Tip**: You should _not_ perform too many operations in each cell. Create cells freely to explore your data. One option that you can take with this project is to do a lot of explorations in an initial notebook. These don't have to be organized, but make sure you use enough comments to understand the purpose of each code cell. Then, after you're done with your analysis, create a duplicate notebook where you will trim the excess and organize your steps so that you have a flowing, cohesive report.\n\n> **Tip**: Make sure that you keep your reader informed on the steps that you are taking in your investigation. Follow every code cell, or every set of related code cells, with a markdown cell to describe to the reader what was found in the preceding cell(s). Try to make it so that the reader can then understand what they will be seeing in the following cell(s).\n\n### Data Cleaning (Replace this with more specific notes!)",
"_____no_output_____"
]
],
[
[
"# After discussing the structure of the data and any problems that need to be\n# cleaned, perform those cleaning steps in the second part of this section.\n",
"_____no_output_____"
]
],
[
[
"<a id='eda'></a>\n## Exploratory Data Analysis\n\n> **Tip**: Now that you've trimmed and cleaned your data, you're ready to move on to exploration. Compute statistics and create visualizations with the goal of addressing the research questions that you posed in the Introduction section. It is recommended that you be systematic with your approach. Look at one variable at a time, and then follow it up by looking at relationships between variables.\n\n### Research Question 1 (Replace this header name!)",
"_____no_output_____"
]
],
[
[
"# Use this, and more code cells, to explore your data. Don't forget to add\n# Markdown cells to document your observations and findings.\n",
"_____no_output_____"
]
],
[
[
"### Research Question 2 (Replace this header name!)",
"_____no_output_____"
]
],
[
[
"# Continue to explore the data to address your additional research\n# questions. Add more headers as needed if you have more questions to\n# investigate.\n",
"_____no_output_____"
]
],
[
[
"<a id='conclusions'></a>\n## Conclusions\n\n> **Tip**: Finally, summarize your findings and the results that have been performed. Make sure that you are clear with regards to the limitations of your exploration. If you haven't done any statistical tests, do not imply any statistical conclusions. And make sure you avoid implying causation from correlation!\n\n> **Tip**: Once you are satisfied with your work, you should save a copy of the report in HTML or PDF form via the **File** > **Download as** submenu. Before exporting your report, check over it to make sure that the flow of the report is complete. You should probably remove all of the \"Tip\" quotes like this one so that the presentation is as tidy as possible. Congratulations!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a45719c660a178a7885d5efc2e01efdd236b55d
| 144,642 |
ipynb
|
Jupyter Notebook
|
notebook/Bogota_Mov_notebook.ipynb
|
IvanJaimesN/Bogota_Mov
|
0f9bbe8f8973834db838a66b2598331d81e02e41
|
[
"MIT"
] | 1 |
2022-03-04T20:22:47.000Z
|
2022-03-04T20:22:47.000Z
|
notebook/Bogota_Mov_notebook.ipynb
|
IvanJaimesN/Bogota_Mov
|
0f9bbe8f8973834db838a66b2598331d81e02e41
|
[
"MIT"
] | null | null | null |
notebook/Bogota_Mov_notebook.ipynb
|
IvanJaimesN/Bogota_Mov
|
0f9bbe8f8973834db838a66b2598331d81e02e41
|
[
"MIT"
] | null | null | null | 88.088916 | 80,284 | 0.758991 |
[
[
[
"# Análisis de la Movilidad en Bogotá",
"_____no_output_____"
],
[
"¿Cuáles son las rutas más críticas de movilidad y sus características en la ciudad de Bogotá?\n\nSe toman los datos de la plataforma:\nhttps://datos.movilidadbogota.gov.co",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport os",
"_____no_output_____"
],
[
"os.chdir('../data_raw')",
"_____no_output_____"
],
[
"data_file_list = !ls",
"_____no_output_____"
],
[
"data_file_list",
"_____no_output_____"
],
[
"data_file_list[len(data_file_list)-1]",
"_____no_output_____"
]
],
[
[
"La adquisición de datos será de 4 meses del año 2019 con el propósito de optimizar espacio de almacenamiento y cargas de procesamiento.",
"_____no_output_____"
]
],
[
[
"''' Función df_builder\nRecibe como parámetro de entrada una lista de archivos CSV,\nhace la lectura y concatena los dataframes, siendo esta concatenación el retorno.\nLos datos en los archivos CSV deben tener la misma estructura.\n'''\ndef df_builder(data_list):\n n_files = len(data_list) - 1\n df_full = pd.read_csv(data_list[n_files])\n \n for i in range(n_files):\n df_i = pd.read_csv(data_list[i])\n df_full = pd.concat([df_full, df_i])\n \n return df_full",
"_____no_output_____"
],
[
"df_mov = df_builder(data_file_list)",
"_____no_output_____"
],
[
"df_mov.shape",
"_____no_output_____"
],
[
"df_mov.describe",
"_____no_output_____"
],
[
"df_mov.dtypes",
"_____no_output_____"
],
[
"## Limpieza de datos\n# Verificación que todos los registros correspondan con el año de estudio: 2019\ndf_mov['AÑO'].value_counts()",
"_____no_output_____"
]
],
[
[
"Dentro de los datasets obtenidos se encuentran datos de otros años.\nVamos a eliminar los registros del año 2020.",
"_____no_output_____"
]
],
[
[
"df_mov.shape # Tamaño original",
"_____no_output_____"
],
[
"## Borrar los renglones cuando el AÑO es igual que 2020\ndf_mov = df_mov.loc[df_mov['AÑO'] == 2019]",
"_____no_output_____"
],
[
"df_mov['AÑO'].value_counts() # Verificación ",
"_____no_output_____"
],
[
"df_mov.shape # Tamaño final del dataframe",
"_____no_output_____"
]
],
[
[
"### Columnas sin datos",
"_____no_output_____"
],
[
"Vamos a verificar las columnas que no tienen datos (Nan), posterior las eliminamos para tener un dataset más limpio.",
"_____no_output_____"
]
],
[
[
"df_mov['CODIGO'].value_counts()",
"_____no_output_____"
],
[
"df_mov['COEF_BRT'].value_counts()",
"_____no_output_____"
],
[
"df_mov['COEF_MIXTO'].value_counts()",
"_____no_output_____"
],
[
"df_mov['VEL_MEDIA_BRT'].value_counts()",
"_____no_output_____"
],
[
"df_mov['VEL_MEDIA_MIXTO'].value_counts()",
"_____no_output_____"
],
[
"df_mov['VEL_MEDIA_PONDERADA'].value_counts()",
"_____no_output_____"
],
[
"df_mov['VEL_PONDERADA'].value_counts()",
"_____no_output_____"
],
[
"## Borrar las columnas\ndf_mov = df_mov.drop(labels=['CODIGO', 'COEF_BRT', 'COEF_MIXTO', 'VEL_MEDIA_BRT',\n 'VEL_MEDIA_MIXTO', 'VEL_MEDIA_PONDERADA', 'VEL_PONDERADA'], axis=1)",
"_____no_output_____"
],
[
"df_mov.describe",
"_____no_output_____"
],
[
"df_mov.columns",
"_____no_output_____"
],
[
"df_mov.to_csv('../notebook/data/data_Mov_Bogota_2019.csv', index=None)",
"_____no_output_____"
]
],
[
[
"## Análisis Unidimensional de las Variables",
"_____no_output_____"
]
],
[
[
"## Conteo de la ocurrencia de una variable y un valor\n\n# Conteo de la movilidad en cada mes\ndf_mov_sorted = df_mov.sort_values('MES')\ndf_mov_sorted['MES'].hist(bins=15, xrot=45, grid=True)\n##plt.xticks(rotation=45)",
"_____no_output_____"
],
[
"df_mov['DIA_SEMANA'].value_counts(normalize=True)",
"_____no_output_____"
],
[
"df_mov['NAME_FROM'].value_counts()",
"_____no_output_____"
],
[
"df_mov['NAME_TO'].value_counts()",
"_____no_output_____"
],
[
"df_mov",
"_____no_output_____"
]
],
[
[
"## Análisis Multidimensional de las Variables",
"_____no_output_____"
],
[
"Velocidad promedio versus la trayectoria realizada.\n\nLa trayectoria se va a definir como la concatenación entre NAME_FROM y NAME_TO.",
"_____no_output_____"
]
],
[
[
"df_mov['TRAYEC'] = df_mov['NAME_FROM'] + ' - ' +df_mov['NAME_TO']",
"_____no_output_____"
],
[
"df_mov['TRAYEC'].value_counts()",
"_____no_output_____"
]
],
[
[
"Mediana de la velocidad promedio en cada trayecto. VEL_PROMEDIO que es más común en cada trayecto:",
"_____no_output_____"
]
],
[
[
"medianVel_Tray = df_mov.groupby('TRAYEC').median()['VEL_PROMEDIO']\nmedianVel_Tray",
"_____no_output_____"
]
],
[
[
"## Análisis de Texto",
"_____no_output_____"
]
],
[
[
"import nltk\nfrom nltk.corpus import stopwords\nprint(stopwords.words('spanish'))",
"['de', 'la', 'que', 'el', 'en', 'y', 'a', 'los', 'del', 'se', 'las', 'por', 'un', 'para', 'con', 'no', 'una', 'su', 'al', 'lo', 'como', 'más', 'pero', 'sus', 'le', 'ya', 'o', 'este', 'sí', 'porque', 'esta', 'entre', 'cuando', 'muy', 'sin', 'sobre', 'también', 'me', 'hasta', 'hay', 'donde', 'quien', 'desde', 'todo', 'nos', 'durante', 'todos', 'uno', 'les', 'ni', 'contra', 'otros', 'ese', 'eso', 'ante', 'ellos', 'e', 'esto', 'mí', 'antes', 'algunos', 'qué', 'unos', 'yo', 'otro', 'otras', 'otra', 'él', 'tanto', 'esa', 'estos', 'mucho', 'quienes', 'nada', 'muchos', 'cual', 'poco', 'ella', 'estar', 'estas', 'algunas', 'algo', 'nosotros', 'mi', 'mis', 'tú', 'te', 'ti', 'tu', 'tus', 'ellas', 'nosotras', 'vosotros', 'vosotras', 'os', 'mío', 'mía', 'míos', 'mías', 'tuyo', 'tuya', 'tuyos', 'tuyas', 'suyo', 'suya', 'suyos', 'suyas', 'nuestro', 'nuestra', 'nuestros', 'nuestras', 'vuestro', 'vuestra', 'vuestros', 'vuestras', 'esos', 'esas', 'estoy', 'estás', 'está', 'estamos', 'estáis', 'están', 'esté', 'estés', 'estemos', 'estéis', 'estén', 'estaré', 'estarás', 'estará', 'estaremos', 'estaréis', 'estarán', 'estaría', 'estarías', 'estaríamos', 'estaríais', 'estarían', 'estaba', 'estabas', 'estábamos', 'estabais', 'estaban', 'estuve', 'estuviste', 'estuvo', 'estuvimos', 'estuvisteis', 'estuvieron', 'estuviera', 'estuvieras', 'estuviéramos', 'estuvierais', 'estuvieran', 'estuviese', 'estuvieses', 'estuviésemos', 'estuvieseis', 'estuviesen', 'estando', 'estado', 'estada', 'estados', 'estadas', 'estad', 'he', 'has', 'ha', 'hemos', 'habéis', 'han', 'haya', 'hayas', 'hayamos', 'hayáis', 'hayan', 'habré', 'habrás', 'habrá', 'habremos', 'habréis', 'habrán', 'habría', 'habrías', 'habríamos', 'habríais', 'habrían', 'había', 'habías', 'habíamos', 'habíais', 'habían', 'hube', 'hubiste', 'hubo', 'hubimos', 'hubisteis', 'hubieron', 'hubiera', 'hubieras', 'hubiéramos', 'hubierais', 'hubieran', 'hubiese', 'hubieses', 'hubiésemos', 'hubieseis', 'hubiesen', 'habiendo', 'habido', 'habida', 'habidos', 'habidas', 'soy', 'eres', 'es', 'somos', 'sois', 'son', 'sea', 'seas', 'seamos', 'seáis', 'sean', 'seré', 'serás', 'será', 'seremos', 'seréis', 'serán', 'sería', 'serías', 'seríamos', 'seríais', 'serían', 'era', 'eras', 'éramos', 'erais', 'eran', 'fui', 'fuiste', 'fue', 'fuimos', 'fuisteis', 'fueron', 'fuera', 'fueras', 'fuéramos', 'fuerais', 'fueran', 'fuese', 'fueses', 'fuésemos', 'fueseis', 'fuesen', 'sintiendo', 'sentido', 'sentida', 'sentidos', 'sentidas', 'siente', 'sentid', 'tengo', 'tienes', 'tiene', 'tenemos', 'tenéis', 'tienen', 'tenga', 'tengas', 'tengamos', 'tengáis', 'tengan', 'tendré', 'tendrás', 'tendrá', 'tendremos', 'tendréis', 'tendrán', 'tendría', 'tendrías', 'tendríamos', 'tendríais', 'tendrían', 'tenía', 'tenías', 'teníamos', 'teníais', 'tenían', 'tuve', 'tuviste', 'tuvo', 'tuvimos', 'tuvisteis', 'tuvieron', 'tuviera', 'tuvieras', 'tuviéramos', 'tuvierais', 'tuvieran', 'tuviese', 'tuvieses', 'tuviésemos', 'tuvieseis', 'tuviesen', 'teniendo', 'tenido', 'tenida', 'tenidos', 'tenidas', 'tened']\n"
],
[
"list_lite_NAME_TO = df_mov['NAME_TO'].value_counts().sort_values(ascending=False).index[0:10]\nlist_lite_NAME_TO",
"_____no_output_____"
],
[
"df_mov_filter_lite_NAME_TO = df_mov[df_mov['NAME_TO'].isin(list_lite_NAME_TO)]\ndf_mov_filter_lite_NAME_TO",
"_____no_output_____"
],
[
"textos_destino = ''\nfor row in df_mov_filter_lite_NAME_TO['NAME_TO']:\n textos_destino = textos_destino + ' ' + row",
"_____no_output_____"
],
[
"## to check the ModuleNotFoundError: No module named 'wordcloud'\n## install:\n## /anaconda3/bin/python -m pip install wordcloud\nimport sys\nprint(sys.executable)",
"/home/ivan/anaconda3/bin/python\n"
],
[
"from wordcloud import WordCloud\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"wc = WordCloud(background_color= 'white')\nwc.generate(textos_destino)\n\nplt.axis(\"off\")\nplt.imshow(wc, interpolation='bilinear')\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a457ae1d16a75639748c70ef92f90784a7affc3
| 154,920 |
ipynb
|
Jupyter Notebook
|
home-work5.ipynb
|
vladdez/RD_forscasting
|
2b0445bc1ff65bda71257cadaf1aa093fc149995
|
[
"MIT"
] | null | null | null |
home-work5.ipynb
|
vladdez/RD_forscasting
|
2b0445bc1ff65bda71257cadaf1aa093fc149995
|
[
"MIT"
] | null | null | null |
home-work5.ipynb
|
vladdez/RD_forscasting
|
2b0445bc1ff65bda71257cadaf1aa093fc149995
|
[
"MIT"
] | null | null | null | 523.378378 | 114,268 | 0.906481 |
[
[
[
"Домашнее задание \n===\n\nДанные\n----\nДанные содержат информацию о продажах автомобилей в месяц. \n\nЗадание\n--\n* Построить модель предсказаний, используя библиотеку Propeht. \n* Сделать предсказание на год вперед (12 месяцев)\n* При постоении модели использовать кросс-валидацию",
"_____no_output_____"
]
],
[
[
"from fbprophet import Prophet\nfrom fbprophet.diagnostics import cross_validation\nfrom fbprophet.diagnostics import performance_metrics\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"df = pd.read_csv('../datatest/monthly-car-sales.csv')\ndf['Month'] = pd.to_datetime(df['Month'])\ndf.rename(columns = {'Month': 'ds',\n 'Sales': 'y'},\n inplace=True)\ndf.head()",
"_____no_output_____"
]
],
[
[
"1. prophet model",
"_____no_output_____"
]
],
[
[
"m = Prophet()\nm.fit(df)\nfuture = m.make_future_dataframe(periods=12, freq='M')\nforecast = m.predict(future)",
"INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.\nINFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.\n"
],
[
"forecast",
"_____no_output_____"
],
[
"fig = m.plot(forecast)\nax = fig.add_subplot(111)\nax.axvline(x=forecast['ds'].max() - pd.Timedelta('365 days'), c='red', lw=2, alpha=0.5, ls='--')\nfig.show()",
"<ipython-input-18-d929e4e8c99a>:2: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.\n ax = fig.add_subplot(111)\n<ipython-input-18-d929e4e8c99a>:4: UserWarning: Matplotlib is currently using module://ipykernel.pylab.backend_inline, which is a non-GUI backend, so cannot show the figure.\n fig.show()\n"
],
[
"df_cv = cross_validation(m, horizon='365 days')\ncutoffs = df_cv.groupby('cutoff').mean().reset_index()['cutoff']\ndf_cv1 = df_cv[df_cv['cutoff']==df_cv['cutoff'].unique()[0]]",
"INFO:fbprophet:Making 10 forecasts with cutoffs between 1963-06-03 12:00:00 and 1967-12-02 00:00:00\n"
],
[
"fig, ax = plt.subplots()\n\nax.plot(m.history['ds'], m.history['y'], 'k.', label = 'Historical')\nax.plot(df_cv1['ds'], df_cv1['yhat'], ls = '-', label = 'Horizon', color='blue')\nax.fill_between(df_cv1['ds'],\n df_cv1['yhat_lower'],\n df_cv1['yhat_upper'],\n color = 'blue',\n alpha = 0.2)\nfor i in range(len(cutoffs)):\n plt_dict = {'x': cutoffs[i],\n 'c': 'red',\n 'ls':'--'\n }\n if i == 0:\n plt_dict['label'] = 'Cuttofs'\n ax.axvline(**plt_dict)\nax.legend()\nplt.show()",
"_____no_output_____"
],
[
"\ndf_p = performance_metrics(df_cv)\ndf_p.head()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a457d64eecca65538975cd671c7b2737d67a775
| 350,431 |
ipynb
|
Jupyter Notebook
|
11_training_deep_neural_networks.ipynb
|
BStudent/handson-ml2
|
1dc4f2fc684e4d14d71f9bdc67d7b03f76b715d6
|
[
"Apache-2.0"
] | 4 |
2020-11-13T01:58:47.000Z
|
2020-12-24T22:06:42.000Z
|
11_training_deep_neural_networks.ipynb
|
BStudent/handson-ml2
|
1dc4f2fc684e4d14d71f9bdc67d7b03f76b715d6
|
[
"Apache-2.0"
] | 9 |
2020-02-01T09:41:53.000Z
|
2022-03-12T00:12:00.000Z
|
11_training_deep_neural_networks.ipynb
|
BStudent/handson-ml2
|
1dc4f2fc684e4d14d71f9bdc67d7b03f76b715d6
|
[
"Apache-2.0"
] | 5 |
2020-01-21T14:08:33.000Z
|
2021-06-24T12:53:51.000Z
| 82.202909 | 32,804 | 0.760603 |
[
[
[
"**Chapter 11 – Training Deep Neural Networks**",
"_____no_output_____"
],
[
"_This notebook contains all the sample code and solutions to the exercises in chapter 11._",
"_____no_output_____"
],
[
"<table align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/ageron/handson-ml2/blob/master/11_training_deep_neural_networks.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Setup",
"_____no_output_____"
],
[
"First, let's import a few common modules, ensure MatplotLib plots figures inline and prepare a function to save the figures. We also check that Python 3.5 or later is installed (although Python 2.x may work, it is deprecated so we strongly recommend you use Python 3 instead), as well as Scikit-Learn ≥0.20 and TensorFlow ≥2.0.",
"_____no_output_____"
]
],
[
[
"# Python ≥3.5 is required\nimport sys\nassert sys.version_info >= (3, 5)\n\n# Scikit-Learn ≥0.20 is required\nimport sklearn\nassert sklearn.__version__ >= \"0.20\"\n\ntry:\n # %tensorflow_version only exists in Colab.\n %tensorflow_version 2.x\nexcept Exception:\n pass\n\n# TensorFlow ≥2.0 is required\nimport tensorflow as tf\nfrom tensorflow import keras\nassert tf.__version__ >= \"2.0\"\n\n# Common imports\nimport numpy as np\nimport os\n\n# to make this notebook's output stable across runs\nnp.random.seed(42)\n\n# To plot pretty figures\n%matplotlib inline\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nmpl.rc('axes', labelsize=14)\nmpl.rc('xtick', labelsize=12)\nmpl.rc('ytick', labelsize=12)\n\n# Where to save the figures\nPROJECT_ROOT_DIR = \".\"\nCHAPTER_ID = \"deep\"\nIMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, \"images\", CHAPTER_ID)\nos.makedirs(IMAGES_PATH, exist_ok=True)\n\ndef save_fig(fig_id, tight_layout=True, fig_extension=\"png\", resolution=300):\n path = os.path.join(IMAGES_PATH, fig_id + \".\" + fig_extension)\n print(\"Saving figure\", fig_id)\n if tight_layout:\n plt.tight_layout()\n plt.savefig(path, format=fig_extension, dpi=resolution)",
"_____no_output_____"
]
],
[
[
"# Vanishing/Exploding Gradients Problem",
"_____no_output_____"
]
],
[
[
"def logit(z):\n return 1 / (1 + np.exp(-z))",
"_____no_output_____"
],
[
"z = np.linspace(-5, 5, 200)\n\nplt.plot([-5, 5], [0, 0], 'k-')\nplt.plot([-5, 5], [1, 1], 'k--')\nplt.plot([0, 0], [-0.2, 1.2], 'k-')\nplt.plot([-5, 5], [-3/4, 7/4], 'g--')\nplt.plot(z, logit(z), \"b-\", linewidth=2)\nprops = dict(facecolor='black', shrink=0.1)\nplt.annotate('Saturating', xytext=(3.5, 0.7), xy=(5, 1), arrowprops=props, fontsize=14, ha=\"center\")\nplt.annotate('Saturating', xytext=(-3.5, 0.3), xy=(-5, 0), arrowprops=props, fontsize=14, ha=\"center\")\nplt.annotate('Linear', xytext=(2, 0.2), xy=(0, 0.5), arrowprops=props, fontsize=14, ha=\"center\")\nplt.grid(True)\nplt.title(\"Sigmoid activation function\", fontsize=14)\nplt.axis([-5, 5, -0.2, 1.2])\n\nsave_fig(\"sigmoid_saturation_plot\")\nplt.show()",
"Saving figure sigmoid_saturation_plot\n"
]
],
[
[
"## Xavier and He Initialization",
"_____no_output_____"
]
],
[
[
"[name for name in dir(keras.initializers) if not name.startswith(\"_\")]",
"_____no_output_____"
],
[
"keras.layers.Dense(10, activation=\"relu\", kernel_initializer=\"he_normal\")",
"_____no_output_____"
],
[
"init = keras.initializers.VarianceScaling(scale=2., mode='fan_avg',\n distribution='uniform')\nkeras.layers.Dense(10, activation=\"relu\", kernel_initializer=init)",
"_____no_output_____"
]
],
[
[
"## Nonsaturating Activation Functions",
"_____no_output_____"
],
[
"### Leaky ReLU",
"_____no_output_____"
]
],
[
[
"def leaky_relu(z, alpha=0.01):\n return np.maximum(alpha*z, z)",
"_____no_output_____"
],
[
"plt.plot(z, leaky_relu(z, 0.05), \"b-\", linewidth=2)\nplt.plot([-5, 5], [0, 0], 'k-')\nplt.plot([0, 0], [-0.5, 4.2], 'k-')\nplt.grid(True)\nprops = dict(facecolor='black', shrink=0.1)\nplt.annotate('Leak', xytext=(-3.5, 0.5), xy=(-5, -0.2), arrowprops=props, fontsize=14, ha=\"center\")\nplt.title(\"Leaky ReLU activation function\", fontsize=14)\nplt.axis([-5, 5, -0.5, 4.2])\n\nsave_fig(\"leaky_relu_plot\")\nplt.show()",
"Saving figure leaky_relu_plot\n"
],
[
"[m for m in dir(keras.activations) if not m.startswith(\"_\")]",
"_____no_output_____"
],
[
"[m for m in dir(keras.layers) if \"relu\" in m.lower()]",
"_____no_output_____"
]
],
[
[
"Let's train a neural network on Fashion MNIST using the Leaky ReLU:",
"_____no_output_____"
]
],
[
[
"(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()\nX_train_full = X_train_full / 255.0\nX_test = X_test / 255.0\nX_valid, X_train = X_train_full[:5000], X_train_full[5000:]\ny_valid, y_train = y_train_full[:5000], y_train_full[5000:]",
"_____no_output_____"
],
[
"tf.random.set_seed(42)\nnp.random.seed(42)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, kernel_initializer=\"he_normal\"),\n keras.layers.LeakyReLU(),\n keras.layers.Dense(100, kernel_initializer=\"he_normal\"),\n keras.layers.LeakyReLU(),\n keras.layers.Dense(10, activation=\"softmax\")\n])",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model.fit(X_train, y_train, epochs=10,\n validation_data=(X_valid, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/10\n55000/55000 [==============================] - 3s 50us/sample - loss: 1.2806 - accuracy: 0.6250 - val_loss: 0.8883 - val_accuracy: 0.7152\nEpoch 2/10\n55000/55000 [==============================] - 2s 40us/sample - loss: 0.7954 - accuracy: 0.7373 - val_loss: 0.7135 - val_accuracy: 0.7648\nEpoch 3/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.6816 - accuracy: 0.7727 - val_loss: 0.6356 - val_accuracy: 0.7882\nEpoch 4/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.6215 - accuracy: 0.7935 - val_loss: 0.5922 - val_accuracy: 0.8012\nEpoch 5/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.5830 - accuracy: 0.8081 - val_loss: 0.5596 - val_accuracy: 0.8172\nEpoch 6/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.5553 - accuracy: 0.8155 - val_loss: 0.5338 - val_accuracy: 0.8240\nEpoch 7/10\n55000/55000 [==============================] - 2s 40us/sample - loss: 0.5340 - accuracy: 0.8221 - val_loss: 0.5157 - val_accuracy: 0.8310\nEpoch 8/10\n55000/55000 [==============================] - 2s 41us/sample - loss: 0.5172 - accuracy: 0.8265 - val_loss: 0.5035 - val_accuracy: 0.8336\nEpoch 9/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.5036 - accuracy: 0.8299 - val_loss: 0.4950 - val_accuracy: 0.8354\nEpoch 10/10\n55000/55000 [==============================] - 2s 42us/sample - loss: 0.4922 - accuracy: 0.8324 - val_loss: 0.4797 - val_accuracy: 0.8430\n"
]
],
[
[
"Now let's try PReLU:",
"_____no_output_____"
]
],
[
[
"tf.random.set_seed(42)\nnp.random.seed(42)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, kernel_initializer=\"he_normal\"),\n keras.layers.PReLU(),\n keras.layers.Dense(100, kernel_initializer=\"he_normal\"),\n keras.layers.PReLU(),\n keras.layers.Dense(10, activation=\"softmax\")\n])",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model.fit(X_train, y_train, epochs=10,\n validation_data=(X_valid, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/10\n55000/55000 [==============================] - 3s 61us/sample - loss: 1.3460 - accuracy: 0.6233 - val_loss: 0.9251 - val_accuracy: 0.7208\nEpoch 2/10\n55000/55000 [==============================] - 3s 56us/sample - loss: 0.8208 - accuracy: 0.7359 - val_loss: 0.7318 - val_accuracy: 0.7626\nEpoch 3/10\n55000/55000 [==============================] - 3s 55us/sample - loss: 0.6974 - accuracy: 0.7695 - val_loss: 0.6500 - val_accuracy: 0.7886\nEpoch 4/10\n55000/55000 [==============================] - 3s 55us/sample - loss: 0.6338 - accuracy: 0.7904 - val_loss: 0.6000 - val_accuracy: 0.8070\nEpoch 5/10\n55000/55000 [==============================] - 3s 57us/sample - loss: 0.5920 - accuracy: 0.8045 - val_loss: 0.5662 - val_accuracy: 0.8172\nEpoch 6/10\n55000/55000 [==============================] - 3s 55us/sample - loss: 0.5620 - accuracy: 0.8138 - val_loss: 0.5416 - val_accuracy: 0.8230\nEpoch 7/10\n55000/55000 [==============================] - 3s 55us/sample - loss: 0.5393 - accuracy: 0.8203 - val_loss: 0.5218 - val_accuracy: 0.8302\nEpoch 8/10\n55000/55000 [==============================] - 3s 57us/sample - loss: 0.5216 - accuracy: 0.8248 - val_loss: 0.5051 - val_accuracy: 0.8340\nEpoch 9/10\n55000/55000 [==============================] - 3s 59us/sample - loss: 0.5069 - accuracy: 0.8289 - val_loss: 0.4923 - val_accuracy: 0.8384\nEpoch 10/10\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.4948 - accuracy: 0.8322 - val_loss: 0.4847 - val_accuracy: 0.8372\n"
]
],
[
[
"### ELU",
"_____no_output_____"
]
],
[
[
"def elu(z, alpha=1):\n return np.where(z < 0, alpha * (np.exp(z) - 1), z)",
"_____no_output_____"
],
[
"plt.plot(z, elu(z), \"b-\", linewidth=2)\nplt.plot([-5, 5], [0, 0], 'k-')\nplt.plot([-5, 5], [-1, -1], 'k--')\nplt.plot([0, 0], [-2.2, 3.2], 'k-')\nplt.grid(True)\nplt.title(r\"ELU activation function ($\\alpha=1$)\", fontsize=14)\nplt.axis([-5, 5, -2.2, 3.2])\n\nsave_fig(\"elu_plot\")\nplt.show()",
"Saving figure elu_plot\n"
]
],
[
[
"Implementing ELU in TensorFlow is trivial, just specify the activation function when building each layer:",
"_____no_output_____"
]
],
[
[
"keras.layers.Dense(10, activation=\"elu\")",
"_____no_output_____"
]
],
[
[
"### SELU",
"_____no_output_____"
],
[
"This activation function was proposed in this [great paper](https://arxiv.org/pdf/1706.02515.pdf) by Günter Klambauer, Thomas Unterthiner and Andreas Mayr, published in June 2017. During training, a neural network composed exclusively of a stack of dense layers using the SELU activation function and LeCun initialization will self-normalize: the output of each layer will tend to preserve the same mean and variance during training, which solves the vanishing/exploding gradients problem. As a result, this activation function outperforms the other activation functions very significantly for such neural nets, so you should really try it out. Unfortunately, the self-normalizing property of the SELU activation function is easily broken: you cannot use ℓ<sub>1</sub> or ℓ<sub>2</sub> regularization, regular dropout, max-norm, skip connections or other non-sequential topologies (so recurrent neural networks won't self-normalize). However, in practice it works quite well with sequential CNNs. If you break self-normalization, SELU will not necessarily outperform other activation functions.",
"_____no_output_____"
]
],
[
[
"from scipy.special import erfc\n\n# alpha and scale to self normalize with mean 0 and standard deviation 1\n# (see equation 14 in the paper):\nalpha_0_1 = -np.sqrt(2 / np.pi) / (erfc(1/np.sqrt(2)) * np.exp(1/2) - 1)\nscale_0_1 = (1 - erfc(1 / np.sqrt(2)) * np.sqrt(np.e)) * np.sqrt(2 * np.pi) * (2 * erfc(np.sqrt(2))*np.e**2 + np.pi*erfc(1/np.sqrt(2))**2*np.e - 2*(2+np.pi)*erfc(1/np.sqrt(2))*np.sqrt(np.e)+np.pi+2)**(-1/2)",
"_____no_output_____"
],
[
"def selu(z, scale=scale_0_1, alpha=alpha_0_1):\n return scale * elu(z, alpha)",
"_____no_output_____"
],
[
"plt.plot(z, selu(z), \"b-\", linewidth=2)\nplt.plot([-5, 5], [0, 0], 'k-')\nplt.plot([-5, 5], [-1.758, -1.758], 'k--')\nplt.plot([0, 0], [-2.2, 3.2], 'k-')\nplt.grid(True)\nplt.title(\"SELU activation function\", fontsize=14)\nplt.axis([-5, 5, -2.2, 3.2])\n\nsave_fig(\"selu_plot\")\nplt.show()",
"Saving figure selu_plot\n"
]
],
[
[
"By default, the SELU hyperparameters (`scale` and `alpha`) are tuned in such a way that the mean output of each neuron remains close to 0, and the standard deviation remains close to 1 (assuming the inputs are standardized with mean 0 and standard deviation 1 too). Using this activation function, even a 1,000 layer deep neural network preserves roughly mean 0 and standard deviation 1 across all layers, avoiding the exploding/vanishing gradients problem:",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\nZ = np.random.normal(size=(500, 100)) # standardized inputs\nfor layer in range(1000):\n W = np.random.normal(size=(100, 100), scale=np.sqrt(1 / 100)) # LeCun initialization\n Z = selu(np.dot(Z, W))\n means = np.mean(Z, axis=0).mean()\n stds = np.std(Z, axis=0).mean()\n if layer % 100 == 0:\n print(\"Layer {}: mean {:.2f}, std deviation {:.2f}\".format(layer, means, stds))",
"Layer 0: mean -0.00, std deviation 1.00\nLayer 100: mean 0.02, std deviation 0.96\nLayer 200: mean 0.01, std deviation 0.90\nLayer 300: mean -0.02, std deviation 0.92\nLayer 400: mean 0.05, std deviation 0.89\nLayer 500: mean 0.01, std deviation 0.93\nLayer 600: mean 0.02, std deviation 0.92\nLayer 700: mean -0.02, std deviation 0.90\nLayer 800: mean 0.05, std deviation 0.83\nLayer 900: mean 0.02, std deviation 1.00\n"
]
],
[
[
"Using SELU is easy:",
"_____no_output_____"
]
],
[
[
"keras.layers.Dense(10, activation=\"selu\",\n kernel_initializer=\"lecun_normal\")",
"_____no_output_____"
]
],
[
[
"Let's create a neural net for Fashion MNIST with 100 hidden layers, using the SELU activation function:",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\ntf.random.set_seed(42)",
"_____no_output_____"
],
[
"model = keras.models.Sequential()\nmodel.add(keras.layers.Flatten(input_shape=[28, 28]))\nmodel.add(keras.layers.Dense(300, activation=\"selu\",\n kernel_initializer=\"lecun_normal\"))\nfor layer in range(99):\n model.add(keras.layers.Dense(100, activation=\"selu\",\n kernel_initializer=\"lecun_normal\"))\nmodel.add(keras.layers.Dense(10, activation=\"softmax\"))",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
]
],
[
[
"Now let's train it. Do not forget to scale the inputs to mean 0 and standard deviation 1:",
"_____no_output_____"
]
],
[
[
"pixel_means = X_train.mean(axis=0, keepdims=True)\npixel_stds = X_train.std(axis=0, keepdims=True)\nX_train_scaled = (X_train - pixel_means) / pixel_stds\nX_valid_scaled = (X_valid - pixel_means) / pixel_stds\nX_test_scaled = (X_test - pixel_means) / pixel_stds",
"_____no_output_____"
],
[
"history = model.fit(X_train_scaled, y_train, epochs=5,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/5\n55000/55000 [==============================] - 35s 644us/sample - loss: 1.0197 - accuracy: 0.6154 - val_loss: 0.7386 - val_accuracy: 0.7348\nEpoch 2/5\n55000/55000 [==============================] - 33s 607us/sample - loss: 0.7149 - accuracy: 0.7401 - val_loss: 0.6187 - val_accuracy: 0.7774\nEpoch 3/5\n55000/55000 [==============================] - 32s 583us/sample - loss: 0.6193 - accuracy: 0.7803 - val_loss: 0.5926 - val_accuracy: 0.8036\nEpoch 4/5\n55000/55000 [==============================] - 32s 586us/sample - loss: 0.5555 - accuracy: 0.8043 - val_loss: 0.5208 - val_accuracy: 0.8262\nEpoch 5/5\n55000/55000 [==============================] - 32s 573us/sample - loss: 0.5159 - accuracy: 0.8238 - val_loss: 0.4790 - val_accuracy: 0.8358\n"
]
],
[
[
"Now look at what happens if we try to use the ReLU activation function instead:",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\ntf.random.set_seed(42)",
"_____no_output_____"
],
[
"model = keras.models.Sequential()\nmodel.add(keras.layers.Flatten(input_shape=[28, 28]))\nmodel.add(keras.layers.Dense(300, activation=\"relu\", kernel_initializer=\"he_normal\"))\nfor layer in range(99):\n model.add(keras.layers.Dense(100, activation=\"relu\", kernel_initializer=\"he_normal\"))\nmodel.add(keras.layers.Dense(10, activation=\"softmax\"))",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model.fit(X_train_scaled, y_train, epochs=5,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/5\n55000/55000 [==============================] - 18s 319us/sample - loss: 1.9174 - accuracy: 0.2242 - val_loss: 1.3856 - val_accuracy: 0.3846\nEpoch 2/5\n55000/55000 [==============================] - 15s 279us/sample - loss: 1.2147 - accuracy: 0.4750 - val_loss: 1.0691 - val_accuracy: 0.5510\nEpoch 3/5\n55000/55000 [==============================] - 15s 281us/sample - loss: 0.9576 - accuracy: 0.6025 - val_loss: 0.7688 - val_accuracy: 0.7036\nEpoch 4/5\n55000/55000 [==============================] - 15s 281us/sample - loss: 0.8116 - accuracy: 0.6762 - val_loss: 0.7276 - val_accuracy: 0.7288\nEpoch 5/5\n55000/55000 [==============================] - 15s 278us/sample - loss: 0.8167 - accuracy: 0.6862 - val_loss: 0.7697 - val_accuracy: 0.7032\n"
]
],
[
[
"Not great at all, we suffered from the vanishing/exploding gradients problem.",
"_____no_output_____"
],
[
"# Batch Normalization",
"_____no_output_____"
]
],
[
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(300, activation=\"relu\"),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(100, activation=\"relu\"),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(10, activation=\"softmax\")\n])",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"sequential_3\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nflatten_3 (Flatten) (None, 784) 0 \n_________________________________________________________________\nbatch_normalization_v2 (Batc (None, 784) 3136 \n_________________________________________________________________\ndense_210 (Dense) (None, 300) 235500 \n_________________________________________________________________\nbatch_normalization_v2_1 (Ba (None, 300) 1200 \n_________________________________________________________________\ndense_211 (Dense) (None, 100) 30100 \n_________________________________________________________________\nbatch_normalization_v2_2 (Ba (None, 100) 400 \n_________________________________________________________________\ndense_212 (Dense) (None, 10) 1010 \n=================================================================\nTotal params: 271,346\nTrainable params: 268,978\nNon-trainable params: 2,368\n_________________________________________________________________\n"
],
[
"bn1 = model.layers[1]\n[(var.name, var.trainable) for var in bn1.variables]",
"_____no_output_____"
],
[
"bn1.updates",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model.fit(X_train, y_train, epochs=10,\n validation_data=(X_valid, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/10\n55000/55000 [==============================] - 5s 85us/sample - loss: 0.8756 - accuracy: 0.7140 - val_loss: 0.5514 - val_accuracy: 0.8212\nEpoch 2/10\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.5765 - accuracy: 0.8033 - val_loss: 0.4742 - val_accuracy: 0.8436\nEpoch 3/10\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.5146 - accuracy: 0.8216 - val_loss: 0.4382 - val_accuracy: 0.8530\nEpoch 4/10\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.4821 - accuracy: 0.8322 - val_loss: 0.4170 - val_accuracy: 0.8604\nEpoch 5/10\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.4589 - accuracy: 0.8402 - val_loss: 0.4003 - val_accuracy: 0.8658\nEpoch 6/10\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.4428 - accuracy: 0.8459 - val_loss: 0.3883 - val_accuracy: 0.8698\nEpoch 7/10\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.4220 - accuracy: 0.8521 - val_loss: 0.3792 - val_accuracy: 0.8720\nEpoch 8/10\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.4150 - accuracy: 0.8546 - val_loss: 0.3696 - val_accuracy: 0.8754\nEpoch 9/10\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.4013 - accuracy: 0.8589 - val_loss: 0.3629 - val_accuracy: 0.8746\nEpoch 10/10\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.3931 - accuracy: 0.8615 - val_loss: 0.3581 - val_accuracy: 0.8766\n"
]
],
[
[
"Sometimes applying BN before the activation function works better (there's a debate on this topic). Moreover, the layer before a `BatchNormalization` layer does not need to have bias terms, since the `BatchNormalization` layer some as well, it would be a waste of parameters, so you can set `use_bias=False` when creating those layers:",
"_____no_output_____"
]
],
[
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(300, use_bias=False),\n keras.layers.BatchNormalization(),\n keras.layers.Activation(\"relu\"),\n keras.layers.Dense(100, use_bias=False),\n keras.layers.Activation(\"relu\"),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(10, activation=\"softmax\")\n])",
"_____no_output_____"
],
[
"model.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model.fit(X_train, y_train, epochs=10,\n validation_data=(X_valid, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/10\n55000/55000 [==============================] - 5s 89us/sample - loss: 0.8617 - accuracy: 0.7095 - val_loss: 0.5649 - val_accuracy: 0.8102\nEpoch 2/10\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.5803 - accuracy: 0.8015 - val_loss: 0.4833 - val_accuracy: 0.8344\nEpoch 3/10\n55000/55000 [==============================] - 4s 79us/sample - loss: 0.5153 - accuracy: 0.8208 - val_loss: 0.4463 - val_accuracy: 0.8462\nEpoch 4/10\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.4846 - accuracy: 0.8307 - val_loss: 0.4256 - val_accuracy: 0.8530\nEpoch 5/10\n55000/55000 [==============================] - 4s 79us/sample - loss: 0.4576 - accuracy: 0.8402 - val_loss: 0.4106 - val_accuracy: 0.8590\nEpoch 6/10\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.4401 - accuracy: 0.8467 - val_loss: 0.3973 - val_accuracy: 0.8610\nEpoch 7/10\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.4296 - accuracy: 0.8482 - val_loss: 0.3899 - val_accuracy: 0.8650\nEpoch 8/10\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.4127 - accuracy: 0.8559 - val_loss: 0.3818 - val_accuracy: 0.8658\nEpoch 9/10\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.4007 - accuracy: 0.8588 - val_loss: 0.3741 - val_accuracy: 0.8682\nEpoch 10/10\n55000/55000 [==============================] - 4s 79us/sample - loss: 0.3929 - accuracy: 0.8621 - val_loss: 0.3694 - val_accuracy: 0.8734\n"
]
],
[
[
"## Gradient Clipping",
"_____no_output_____"
],
[
"All Keras optimizers accept `clipnorm` or `clipvalue` arguments:",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.SGD(clipvalue=1.0)",
"_____no_output_____"
],
[
"optimizer = keras.optimizers.SGD(clipnorm=1.0)",
"_____no_output_____"
]
],
[
[
"## Reusing Pretrained Layers",
"_____no_output_____"
],
[
"### Reusing a Keras model",
"_____no_output_____"
],
[
"Let's split the fashion MNIST training set in two:\n* `X_train_A`: all images of all items except for sandals and shirts (classes 5 and 6).\n* `X_train_B`: a much smaller training set of just the first 200 images of sandals or shirts.\n\nThe validation set and the test set are also split this way, but without restricting the number of images.\n\nWe will train a model on set A (classification task with 8 classes), and try to reuse it to tackle set B (binary classification). We hope to transfer a little bit of knowledge from task A to task B, since classes in set A (sneakers, ankle boots, coats, t-shirts, etc.) are somewhat similar to classes in set B (sandals and shirts). However, since we are using `Dense` layers, only patterns that occur at the same location can be reused (in contrast, convolutional layers will transfer much better, since learned patterns can be detected anywhere on the image, as we will see in the CNN chapter).",
"_____no_output_____"
]
],
[
[
"def split_dataset(X, y):\n y_5_or_6 = (y == 5) | (y == 6) # sandals or shirts\n y_A = y[~y_5_or_6]\n y_A[y_A > 6] -= 2 # class indices 7, 8, 9 should be moved to 5, 6, 7\n y_B = (y[y_5_or_6] == 6).astype(np.float32) # binary classification task: is it a shirt (class 6)?\n return ((X[~y_5_or_6], y_A),\n (X[y_5_or_6], y_B))\n\n(X_train_A, y_train_A), (X_train_B, y_train_B) = split_dataset(X_train, y_train)\n(X_valid_A, y_valid_A), (X_valid_B, y_valid_B) = split_dataset(X_valid, y_valid)\n(X_test_A, y_test_A), (X_test_B, y_test_B) = split_dataset(X_test, y_test)\nX_train_B = X_train_B[:200]\ny_train_B = y_train_B[:200]",
"_____no_output_____"
],
[
"X_train_A.shape",
"_____no_output_____"
],
[
"X_train_B.shape",
"_____no_output_____"
],
[
"y_train_A[:30]",
"_____no_output_____"
],
[
"y_train_B[:30]",
"_____no_output_____"
],
[
"tf.random.set_seed(42)\nnp.random.seed(42)",
"_____no_output_____"
],
[
"model_A = keras.models.Sequential()\nmodel_A.add(keras.layers.Flatten(input_shape=[28, 28]))\nfor n_hidden in (300, 100, 50, 50, 50):\n model_A.add(keras.layers.Dense(n_hidden, activation=\"selu\"))\nmodel_A.add(keras.layers.Dense(8, activation=\"softmax\"))",
"_____no_output_____"
],
[
"model_A.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model_A.fit(X_train_A, y_train_A, epochs=20,\n validation_data=(X_valid_A, y_valid_A))",
"Train on 43986 samples, validate on 4014 samples\nEpoch 1/20\n43986/43986 [==============================] - 3s 78us/sample - loss: 0.5887 - accuracy: 0.8123 - val_loss: 0.3749 - val_accuracy: 0.8734\nEpoch 2/20\n43986/43986 [==============================] - 3s 69us/sample - loss: 0.3516 - accuracy: 0.8793 - val_loss: 0.3223 - val_accuracy: 0.8874\nEpoch 3/20\n43986/43986 [==============================] - 3s 68us/sample - loss: 0.3160 - accuracy: 0.8894 - val_loss: 0.3009 - val_accuracy: 0.8956\nEpoch 4/20\n43986/43986 [==============================] - 3s 70us/sample - loss: 0.2963 - accuracy: 0.8979 - val_loss: 0.2850 - val_accuracy: 0.9036\nEpoch 5/20\n43986/43986 [==============================] - 3s 68us/sample - loss: 0.2825 - accuracy: 0.9035 - val_loss: 0.2767 - val_accuracy: 0.9076\nEpoch 6/20\n43986/43986 [==============================] - 3s 69us/sample - loss: 0.2720 - accuracy: 0.9068 - val_loss: 0.2672 - val_accuracy: 0.9093\nEpoch 7/20\n43986/43986 [==============================] - 3s 72us/sample - loss: 0.2638 - accuracy: 0.9093 - val_loss: 0.2658 - val_accuracy: 0.9103\nEpoch 8/20\n43986/43986 [==============================] - 3s 70us/sample - loss: 0.2570 - accuracy: 0.9120 - val_loss: 0.2592 - val_accuracy: 0.9106\nEpoch 9/20\n43986/43986 [==============================] - 3s 71us/sample - loss: 0.2514 - accuracy: 0.9139 - val_loss: 0.2570 - val_accuracy: 0.9128\nEpoch 10/20\n43986/43986 [==============================] - 3s 72us/sample - loss: 0.2465 - accuracy: 0.9166 - val_loss: 0.2557 - val_accuracy: 0.9108\nEpoch 11/20\n43986/43986 [==============================] - 3s 69us/sample - loss: 0.2418 - accuracy: 0.9178 - val_loss: 0.2484 - val_accuracy: 0.9178\nEpoch 12/20\n43986/43986 [==============================] - 3s 70us/sample - loss: 0.2379 - accuracy: 0.9192 - val_loss: 0.2461 - val_accuracy: 0.9178\nEpoch 13/20\n43986/43986 [==============================] - 3s 71us/sample - loss: 0.2342 - accuracy: 0.9199 - val_loss: 0.2425 - val_accuracy: 0.9188\nEpoch 14/20\n43986/43986 [==============================] - 3s 68us/sample - loss: 0.2313 - accuracy: 0.9215 - val_loss: 0.2412 - val_accuracy: 0.9185\nEpoch 15/20\n43986/43986 [==============================] - 3s 68us/sample - loss: 0.2280 - accuracy: 0.9222 - val_loss: 0.2382 - val_accuracy: 0.9173\nEpoch 16/20\n43986/43986 [==============================] - 3s 71us/sample - loss: 0.2252 - accuracy: 0.9224 - val_loss: 0.2360 - val_accuracy: 0.9205\nEpoch 17/20\n43986/43986 [==============================] - 3s 71us/sample - loss: 0.2229 - accuracy: 0.9232 - val_loss: 0.2419 - val_accuracy: 0.9158\nEpoch 18/20\n43986/43986 [==============================] - 3s 71us/sample - loss: 0.2195 - accuracy: 0.9249 - val_loss: 0.2357 - val_accuracy: 0.9170\nEpoch 19/20\n43986/43986 [==============================] - 3s 68us/sample - loss: 0.2177 - accuracy: 0.9254 - val_loss: 0.2331 - val_accuracy: 0.9200\nEpoch 20/20\n43986/43986 [==============================] - 3s 70us/sample - loss: 0.2154 - accuracy: 0.9260 - val_loss: 0.2372 - val_accuracy: 0.9158\n"
],
[
"model_A.save(\"my_model_A.h5\")",
"_____no_output_____"
],
[
"model_B = keras.models.Sequential()\nmodel_B.add(keras.layers.Flatten(input_shape=[28, 28]))\nfor n_hidden in (300, 100, 50, 50, 50):\n model_B.add(keras.layers.Dense(n_hidden, activation=\"selu\"))\nmodel_B.add(keras.layers.Dense(1, activation=\"sigmoid\"))",
"_____no_output_____"
],
[
"model_B.compile(loss=\"binary_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model_B.fit(X_train_B, y_train_B, epochs=20,\n validation_data=(X_valid_B, y_valid_B))",
"Train on 200 samples, validate on 986 samples\nEpoch 1/20\n200/200 [==============================] - 0s 2ms/sample - loss: 0.9537 - accuracy: 0.4800 - val_loss: 0.6472 - val_accuracy: 0.5710\nEpoch 2/20\n200/200 [==============================] - 0s 318us/sample - loss: 0.5805 - accuracy: 0.6850 - val_loss: 0.4863 - val_accuracy: 0.8428\nEpoch 3/20\n200/200 [==============================] - 0s 318us/sample - loss: 0.4561 - accuracy: 0.8750 - val_loss: 0.4116 - val_accuracy: 0.8905\nEpoch 4/20\n200/200 [==============================] - 0s 308us/sample - loss: 0.3885 - accuracy: 0.9100 - val_loss: 0.3650 - val_accuracy: 0.9148\nEpoch 5/20\n200/200 [==============================] - 0s 311us/sample - loss: 0.3426 - accuracy: 0.9250 - val_loss: 0.3308 - val_accuracy: 0.9270\nEpoch 6/20\n200/200 [==============================] - 0s 317us/sample - loss: 0.3084 - accuracy: 0.9300 - val_loss: 0.3044 - val_accuracy: 0.9371\nEpoch 7/20\n200/200 [==============================] - 0s 309us/sample - loss: 0.2810 - accuracy: 0.9400 - val_loss: 0.2806 - val_accuracy: 0.9432\nEpoch 8/20\n200/200 [==============================] - 0s 313us/sample - loss: 0.2572 - accuracy: 0.9500 - val_loss: 0.2607 - val_accuracy: 0.9462\nEpoch 9/20\n200/200 [==============================] - 0s 312us/sample - loss: 0.2372 - accuracy: 0.9600 - val_loss: 0.2439 - val_accuracy: 0.9513\nEpoch 10/20\n200/200 [==============================] - 0s 319us/sample - loss: 0.2202 - accuracy: 0.9600 - val_loss: 0.2290 - val_accuracy: 0.9523\nEpoch 11/20\n200/200 [==============================] - 0s 315us/sample - loss: 0.2047 - accuracy: 0.9650 - val_loss: 0.2161 - val_accuracy: 0.9564\nEpoch 12/20\n200/200 [==============================] - 0s 325us/sample - loss: 0.1917 - accuracy: 0.9700 - val_loss: 0.2046 - val_accuracy: 0.9584\nEpoch 13/20\n200/200 [==============================] - 0s 335us/sample - loss: 0.1798 - accuracy: 0.9750 - val_loss: 0.1944 - val_accuracy: 0.9604\nEpoch 14/20\n200/200 [==============================] - 0s 319us/sample - loss: 0.1690 - accuracy: 0.9750 - val_loss: 0.1860 - val_accuracy: 0.9604\nEpoch 15/20\n200/200 [==============================] - 0s 319us/sample - loss: 0.1594 - accuracy: 0.9850 - val_loss: 0.1774 - val_accuracy: 0.9635\nEpoch 16/20\n200/200 [==============================] - 0s 343us/sample - loss: 0.1508 - accuracy: 0.9850 - val_loss: 0.1691 - val_accuracy: 0.9675\nEpoch 17/20\n200/200 [==============================] - 0s 328us/sample - loss: 0.1426 - accuracy: 0.9900 - val_loss: 0.1621 - val_accuracy: 0.9686\nEpoch 18/20\n200/200 [==============================] - 0s 340us/sample - loss: 0.1355 - accuracy: 0.9900 - val_loss: 0.1558 - val_accuracy: 0.9706\nEpoch 19/20\n200/200 [==============================] - 0s 306us/sample - loss: 0.1288 - accuracy: 0.9900 - val_loss: 0.1505 - val_accuracy: 0.9706\nEpoch 20/20\n200/200 [==============================] - 0s 312us/sample - loss: 0.1230 - accuracy: 0.9900 - val_loss: 0.1454 - val_accuracy: 0.9716\n"
],
[
"model.summary()",
"Model: \"sequential_4\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nflatten_4 (Flatten) (None, 784) 0 \n_________________________________________________________________\nbatch_normalization_v2_3 (Ba (None, 784) 3136 \n_________________________________________________________________\ndense_213 (Dense) (None, 300) 235500 \n_________________________________________________________________\nbatch_normalization_v2_4 (Ba (None, 300) 1200 \n_________________________________________________________________\nactivation (Activation) (None, 300) 0 \n_________________________________________________________________\ndense_214 (Dense) (None, 100) 30100 \n_________________________________________________________________\nactivation_1 (Activation) (None, 100) 0 \n_________________________________________________________________\nbatch_normalization_v2_5 (Ba (None, 100) 400 \n_________________________________________________________________\ndense_215 (Dense) (None, 10) 1010 \n=================================================================\nTotal params: 271,346\nTrainable params: 268,978\nNon-trainable params: 2,368\n_________________________________________________________________\n"
],
[
"model_A = keras.models.load_model(\"my_model_A.h5\")\nmodel_B_on_A = keras.models.Sequential(model_A.layers[:-1])\nmodel_B_on_A.add(keras.layers.Dense(1, activation=\"sigmoid\"))",
"_____no_output_____"
],
[
"model_A_clone = keras.models.clone_model(model_A)\nmodel_A_clone.set_weights(model_A.get_weights())",
"_____no_output_____"
],
[
"for layer in model_B_on_A.layers[:-1]:\n layer.trainable = False\n\nmodel_B_on_A.compile(loss=\"binary_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"history = model_B_on_A.fit(X_train_B, y_train_B, epochs=4,\n validation_data=(X_valid_B, y_valid_B))\n\nfor layer in model_B_on_A.layers[:-1]:\n layer.trainable = True\n\nmodel_B_on_A.compile(loss=\"binary_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])\nhistory = model_B_on_A.fit(X_train_B, y_train_B, epochs=16,\n validation_data=(X_valid_B, y_valid_B))",
"Train on 200 samples, validate on 986 samples\nEpoch 1/4\n200/200 [==============================] - 0s 2ms/sample - loss: 0.5851 - accuracy: 0.6600 - val_loss: 0.5855 - val_accuracy: 0.6318\nEpoch 2/4\n200/200 [==============================] - 0s 303us/sample - loss: 0.5484 - accuracy: 0.6850 - val_loss: 0.5484 - val_accuracy: 0.6775\nEpoch 3/4\n200/200 [==============================] - 0s 294us/sample - loss: 0.5116 - accuracy: 0.7250 - val_loss: 0.5141 - val_accuracy: 0.7160\nEpoch 4/4\n200/200 [==============================] - 0s 316us/sample - loss: 0.4779 - accuracy: 0.7450 - val_loss: 0.4859 - val_accuracy: 0.7363\nTrain on 200 samples, validate on 986 samples\nEpoch 1/16\n200/200 [==============================] - 0s 2ms/sample - loss: 0.3989 - accuracy: 0.8050 - val_loss: 0.3419 - val_accuracy: 0.8702\nEpoch 2/16\n200/200 [==============================] - 0s 328us/sample - loss: 0.2795 - accuracy: 0.9300 - val_loss: 0.2624 - val_accuracy: 0.9280\nEpoch 3/16\n200/200 [==============================] - 0s 319us/sample - loss: 0.2128 - accuracy: 0.9650 - val_loss: 0.2150 - val_accuracy: 0.9544\nEpoch 4/16\n200/200 [==============================] - 0s 318us/sample - loss: 0.1720 - accuracy: 0.9800 - val_loss: 0.1826 - val_accuracy: 0.9635\nEpoch 5/16\n200/200 [==============================] - 0s 317us/sample - loss: 0.1436 - accuracy: 0.9800 - val_loss: 0.1586 - val_accuracy: 0.9736\nEpoch 6/16\n200/200 [==============================] - 0s 317us/sample - loss: 0.1231 - accuracy: 0.9850 - val_loss: 0.1407 - val_accuracy: 0.9807\nEpoch 7/16\n200/200 [==============================] - 0s 325us/sample - loss: 0.1074 - accuracy: 0.9900 - val_loss: 0.1270 - val_accuracy: 0.9828\nEpoch 8/16\n200/200 [==============================] - 0s 326us/sample - loss: 0.0953 - accuracy: 0.9950 - val_loss: 0.1158 - val_accuracy: 0.9848\nEpoch 9/16\n200/200 [==============================] - 0s 319us/sample - loss: 0.0854 - accuracy: 1.0000 - val_loss: 0.1076 - val_accuracy: 0.9878\nEpoch 10/16\n200/200 [==============================] - 0s 322us/sample - loss: 0.0781 - accuracy: 1.0000 - val_loss: 0.1007 - val_accuracy: 0.9888\nEpoch 11/16\n200/200 [==============================] - 0s 316us/sample - loss: 0.0718 - accuracy: 1.0000 - val_loss: 0.0944 - val_accuracy: 0.9888\nEpoch 12/16\n200/200 [==============================] - 0s 319us/sample - loss: 0.0662 - accuracy: 1.0000 - val_loss: 0.0891 - val_accuracy: 0.9899\nEpoch 13/16\n200/200 [==============================] - 0s 318us/sample - loss: 0.0613 - accuracy: 1.0000 - val_loss: 0.0846 - val_accuracy: 0.9899\nEpoch 14/16\n200/200 [==============================] - 0s 332us/sample - loss: 0.0574 - accuracy: 1.0000 - val_loss: 0.0806 - val_accuracy: 0.9899\nEpoch 15/16\n200/200 [==============================] - 0s 320us/sample - loss: 0.0538 - accuracy: 1.0000 - val_loss: 0.0770 - val_accuracy: 0.9899\nEpoch 16/16\n200/200 [==============================] - 0s 320us/sample - loss: 0.0505 - accuracy: 1.0000 - val_loss: 0.0740 - val_accuracy: 0.9899\n"
]
],
[
[
"So, what's the final verdict?",
"_____no_output_____"
]
],
[
[
"model_B.evaluate(X_test_B, y_test_B)",
"2000/2000 [==============================] - 0s 41us/sample - loss: 0.1431 - accuracy: 0.9705\n"
],
[
"model_B_on_A.evaluate(X_test_B, y_test_B)",
"2000/2000 [==============================] - 0s 38us/sample - loss: 0.0689 - accuracy: 0.9925\n"
]
],
[
[
"Great! We got quite a bit of transfer: the error rate dropped by a factor of almost 4!",
"_____no_output_____"
]
],
[
[
"(100 - 97.05) / (100 - 99.25)",
"_____no_output_____"
]
],
[
[
"# Faster Optimizers",
"_____no_output_____"
],
[
"## Momentum optimization",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9)",
"_____no_output_____"
]
],
[
[
"## Nesterov Accelerated Gradient",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.SGD(lr=0.001, momentum=0.9, nesterov=True)",
"_____no_output_____"
]
],
[
[
"## AdaGrad",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.Adagrad(lr=0.001)",
"_____no_output_____"
]
],
[
[
"## RMSProp",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.RMSprop(lr=0.001, rho=0.9)",
"_____no_output_____"
]
],
[
[
"## Adam Optimization",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999)",
"_____no_output_____"
]
],
[
[
"## Adamax Optimization",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.Adamax(lr=0.001, beta_1=0.9, beta_2=0.999)",
"_____no_output_____"
]
],
[
[
"## Nadam Optimization",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.Nadam(lr=0.001, beta_1=0.9, beta_2=0.999)",
"_____no_output_____"
]
],
[
[
"## Learning Rate Scheduling",
"_____no_output_____"
],
[
"### Power Scheduling",
"_____no_output_____"
],
[
"```lr = lr0 / (1 + steps / s)**c```\n* Keras uses `c=1` and `s = 1 / decay`",
"_____no_output_____"
]
],
[
[
"optimizer = keras.optimizers.SGD(lr=0.01, decay=1e-4)",
"_____no_output_____"
],
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"n_epochs = 25\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 4s 66us/sample - loss: 0.4840 - accuracy: 0.8296 - val_loss: 0.4038 - val_accuracy: 0.8630\nEpoch 2/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.3787 - accuracy: 0.8653 - val_loss: 0.3846 - val_accuracy: 0.8706\nEpoch 3/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.3461 - accuracy: 0.8770 - val_loss: 0.3606 - val_accuracy: 0.8776\nEpoch 4/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.3248 - accuracy: 0.8844 - val_loss: 0.3661 - val_accuracy: 0.8738\nEpoch 5/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.3092 - accuracy: 0.8902 - val_loss: 0.3516 - val_accuracy: 0.8792\nEpoch 6/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.2967 - accuracy: 0.8938 - val_loss: 0.3467 - val_accuracy: 0.8810\nEpoch 7/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.2862 - accuracy: 0.8967 - val_loss: 0.3398 - val_accuracy: 0.8844\nEpoch 8/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2771 - accuracy: 0.8997 - val_loss: 0.3384 - val_accuracy: 0.8832\nEpoch 9/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2696 - accuracy: 0.9035 - val_loss: 0.3345 - val_accuracy: 0.8860\nEpoch 10/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2628 - accuracy: 0.9057 - val_loss: 0.3343 - val_accuracy: 0.8830\nEpoch 11/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2568 - accuracy: 0.9083 - val_loss: 0.3290 - val_accuracy: 0.8882\nEpoch 12/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2510 - accuracy: 0.9099 - val_loss: 0.3243 - val_accuracy: 0.8904\nEpoch 13/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2459 - accuracy: 0.9118 - val_loss: 0.3271 - val_accuracy: 0.8874\nEpoch 14/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2415 - accuracy: 0.9130 - val_loss: 0.3259 - val_accuracy: 0.8886\nEpoch 15/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2370 - accuracy: 0.9157 - val_loss: 0.3249 - val_accuracy: 0.8896\nEpoch 16/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2332 - accuracy: 0.9177 - val_loss: 0.3267 - val_accuracy: 0.8892\nEpoch 17/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.2296 - accuracy: 0.9177 - val_loss: 0.3251 - val_accuracy: 0.8880\nEpoch 18/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2257 - accuracy: 0.9194 - val_loss: 0.3221 - val_accuracy: 0.8900\nEpoch 19/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2228 - accuracy: 0.9212 - val_loss: 0.3237 - val_accuracy: 0.8910\nEpoch 20/25\n55000/55000 [==============================] - 3s 60us/sample - loss: 0.2198 - accuracy: 0.9223 - val_loss: 0.3217 - val_accuracy: 0.8904\nEpoch 21/25\n55000/55000 [==============================] - 3s 63us/sample - loss: 0.2166 - accuracy: 0.9238 - val_loss: 0.3185 - val_accuracy: 0.8938\nEpoch 22/25\n55000/55000 [==============================] - 3s 61us/sample - loss: 0.2140 - accuracy: 0.9252 - val_loss: 0.3212 - val_accuracy: 0.8902\nEpoch 23/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2113 - accuracy: 0.9256 - val_loss: 0.3235 - val_accuracy: 0.8898\nEpoch 24/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2088 - accuracy: 0.9262 - val_loss: 0.3216 - val_accuracy: 0.8930\nEpoch 25/25\n55000/55000 [==============================] - 3s 62us/sample - loss: 0.2061 - accuracy: 0.9273 - val_loss: 0.3199 - val_accuracy: 0.8922\n"
],
[
"learning_rate = 0.01\ndecay = 1e-4\nbatch_size = 32\nn_steps_per_epoch = len(X_train) // batch_size\nepochs = np.arange(n_epochs)\nlrs = learning_rate / (1 + decay * epochs * n_steps_per_epoch)\n\nplt.plot(epochs, lrs, \"o-\")\nplt.axis([0, n_epochs - 1, 0, 0.01])\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Learning Rate\")\nplt.title(\"Power Scheduling\", fontsize=14)\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Exponential Scheduling",
"_____no_output_____"
],
[
"```lr = lr0 * 0.1**(epoch / s)```",
"_____no_output_____"
]
],
[
[
"def exponential_decay_fn(epoch):\n return 0.01 * 0.1**(epoch / 20)",
"_____no_output_____"
],
[
"def exponential_decay(lr0, s):\n def exponential_decay_fn(epoch):\n return lr0 * 0.1**(epoch / s)\n return exponential_decay_fn\n\nexponential_decay_fn = exponential_decay(lr0=0.01, s=20)",
"_____no_output_____"
],
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 25",
"_____no_output_____"
],
[
"lr_scheduler = keras.callbacks.LearningRateScheduler(exponential_decay_fn)\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid),\n callbacks=[lr_scheduler])",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 6s 107us/sample - loss: 0.8245 - accuracy: 0.7595 - val_loss: 1.0870 - val_accuracy: 0.7106\nEpoch 2/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.6391 - accuracy: 0.8064 - val_loss: 0.6125 - val_accuracy: 0.8160\nEpoch 3/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.5962 - accuracy: 0.8174 - val_loss: 0.6526 - val_accuracy: 0.8086\nEpoch 4/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.5420 - accuracy: 0.8306 - val_loss: 0.7521 - val_accuracy: 0.7766\nEpoch 5/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.4853 - accuracy: 0.8460 - val_loss: 0.5616 - val_accuracy: 0.8314\nEpoch 6/25\n55000/55000 [==============================] - 5s 98us/sample - loss: 0.4443 - accuracy: 0.8571 - val_loss: 0.5430 - val_accuracy: 0.8664\nEpoch 7/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.4128 - accuracy: 0.8687 - val_loss: 0.4954 - val_accuracy: 0.8610\nEpoch 8/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.3763 - accuracy: 0.8773 - val_loss: 0.5770 - val_accuracy: 0.8578\nEpoch 9/25\n55000/55000 [==============================] - 6s 102us/sample - loss: 0.3459 - accuracy: 0.8847 - val_loss: 0.5267 - val_accuracy: 0.8688\nEpoch 10/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.3250 - accuracy: 0.8931 - val_loss: 0.4606 - val_accuracy: 0.8644\nEpoch 11/25\n55000/55000 [==============================] - 5s 97us/sample - loss: 0.2984 - accuracy: 0.9010 - val_loss: 0.5083 - val_accuracy: 0.8610\nEpoch 12/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.2736 - accuracy: 0.9080 - val_loss: 0.4497 - val_accuracy: 0.8826\nEpoch 13/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.2603 - accuracy: 0.9128 - val_loss: 0.4366 - val_accuracy: 0.8808\nEpoch 14/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.2382 - accuracy: 0.9197 - val_loss: 0.4692 - val_accuracy: 0.8828\nEpoch 15/25\n55000/55000 [==============================] - 6s 102us/sample - loss: 0.2240 - accuracy: 0.9252 - val_loss: 0.4609 - val_accuracy: 0.8774\nEpoch 16/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.2020 - accuracy: 0.9306 - val_loss: 0.4950 - val_accuracy: 0.8808\nEpoch 17/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.1950 - accuracy: 0.9340 - val_loss: 0.4985 - val_accuracy: 0.8856\nEpoch 18/25\n55000/55000 [==============================] - 6s 102us/sample - loss: 0.1785 - accuracy: 0.9388 - val_loss: 0.5071 - val_accuracy: 0.8854\nEpoch 19/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.1649 - accuracy: 0.9447 - val_loss: 0.4798 - val_accuracy: 0.8890\nEpoch 20/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.1561 - accuracy: 0.9471 - val_loss: 0.5023 - val_accuracy: 0.8896\nEpoch 21/25\n55000/55000 [==============================] - 5s 98us/sample - loss: 0.1442 - accuracy: 0.9520 - val_loss: 0.5253 - val_accuracy: 0.8952\nEpoch 22/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.1369 - accuracy: 0.9540 - val_loss: 0.5558 - val_accuracy: 0.8922\nEpoch 23/25\n55000/55000 [==============================] - 5s 98us/sample - loss: 0.1277 - accuracy: 0.9576 - val_loss: 0.5786 - val_accuracy: 0.8908\nEpoch 24/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.1204 - accuracy: 0.9611 - val_loss: 0.5991 - val_accuracy: 0.8902\nEpoch 25/25\n55000/55000 [==============================] - 6s 102us/sample - loss: 0.1130 - accuracy: 0.9638 - val_loss: 0.5984 - val_accuracy: 0.8894\n"
],
[
"plt.plot(history.epoch, history.history[\"lr\"], \"o-\")\nplt.axis([0, n_epochs - 1, 0, 0.011])\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Learning Rate\")\nplt.title(\"Exponential Scheduling\", fontsize=14)\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"The schedule function can take the current learning rate as a second argument:",
"_____no_output_____"
]
],
[
[
"def exponential_decay_fn(epoch, lr):\n return lr * 0.1**(1 / 20)",
"_____no_output_____"
]
],
[
[
"If you want to update the learning rate at each iteration rather than at each epoch, you must write your own callback class:",
"_____no_output_____"
]
],
[
[
"K = keras.backend\n\nclass ExponentialDecay(keras.callbacks.Callback):\n def __init__(self, s=40000):\n super().__init__()\n self.s = s\n\n def on_batch_begin(self, batch, logs=None):\n # Note: the `batch` argument is reset at each epoch\n lr = K.get_value(self.model.optimizer.lr)\n K.set_value(self.model.optimizer.lr, lr * 0.1**(1 / s))\n\n def on_epoch_end(self, epoch, logs=None):\n logs = logs or {}\n logs['lr'] = K.get_value(self.model.optimizer.lr)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nlr0 = 0.01\noptimizer = keras.optimizers.Nadam(lr=lr0)\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])\nn_epochs = 25\n\ns = 20 * len(X_train) // 32 # number of steps in 20 epochs (batch size = 32)\nexp_decay = ExponentialDecay(s)\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid),\n callbacks=[exp_decay])",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 7s 132us/sample - loss: 0.8067 - accuracy: 0.7678 - val_loss: 0.7942 - val_accuracy: 0.7780\nEpoch 2/25\n55000/55000 [==============================] - 7s 122us/sample - loss: 0.6784 - accuracy: 0.7937 - val_loss: 0.8375 - val_accuracy: 0.8120\nEpoch 3/25\n55000/55000 [==============================] - 6s 114us/sample - loss: 0.6060 - accuracy: 0.8148 - val_loss: 0.6303 - val_accuracy: 0.8304\nEpoch 4/25\n55000/55000 [==============================] - 6s 114us/sample - loss: 0.5279 - accuracy: 0.8341 - val_loss: 0.5724 - val_accuracy: 0.8196\nEpoch 5/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.4803 - accuracy: 0.8486 - val_loss: 0.5488 - val_accuracy: 0.8486\nEpoch 6/25\n55000/55000 [==============================] - 6s 113us/sample - loss: 0.4305 - accuracy: 0.8611 - val_loss: 0.4778 - val_accuracy: 0.8470\nEpoch 7/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.3969 - accuracy: 0.8699 - val_loss: 0.4922 - val_accuracy: 0.8584\nEpoch 8/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.3799 - accuracy: 0.8777 - val_loss: 0.5417 - val_accuracy: 0.8614\nEpoch 9/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.3475 - accuracy: 0.8851 - val_loss: 0.5032 - val_accuracy: 0.8734\nEpoch 10/25\n55000/55000 [==============================] - 6s 110us/sample - loss: 0.3256 - accuracy: 0.8937 - val_loss: 0.4433 - val_accuracy: 0.8802\nEpoch 11/25\n55000/55000 [==============================] - 6s 110us/sample - loss: 0.2944 - accuracy: 0.9017 - val_loss: 0.4888 - val_accuracy: 0.8742\nEpoch 12/25\n55000/55000 [==============================] - 6s 110us/sample - loss: 0.2767 - accuracy: 0.9077 - val_loss: 0.4626 - val_accuracy: 0.8706\nEpoch 13/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.2572 - accuracy: 0.9134 - val_loss: 0.4750 - val_accuracy: 0.8770\nEpoch 14/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.2391 - accuracy: 0.9185 - val_loss: 0.4633 - val_accuracy: 0.8900\nEpoch 15/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.2180 - accuracy: 0.9251 - val_loss: 0.4573 - val_accuracy: 0.8768\nEpoch 16/25\n55000/55000 [==============================] - 6s 110us/sample - loss: 0.2029 - accuracy: 0.9311 - val_loss: 0.4748 - val_accuracy: 0.8840\nEpoch 17/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.1884 - accuracy: 0.9357 - val_loss: 0.5171 - val_accuracy: 0.8840\nEpoch 18/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.1813 - accuracy: 0.9382 - val_loss: 0.5293 - val_accuracy: 0.8822\nEpoch 19/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.1618 - accuracy: 0.9445 - val_loss: 0.5328 - val_accuracy: 0.8872\nEpoch 20/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.1570 - accuracy: 0.9483 - val_loss: 0.5453 - val_accuracy: 0.8870\nEpoch 21/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.1422 - accuracy: 0.9523 - val_loss: 0.5596 - val_accuracy: 0.8892\nEpoch 22/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.1329 - accuracy: 0.9563 - val_loss: 0.5717 - val_accuracy: 0.8894\nEpoch 23/25\n55000/55000 [==============================] - 6s 110us/sample - loss: 0.1248 - accuracy: 0.9592 - val_loss: 0.5959 - val_accuracy: 0.8930\nEpoch 24/25\n55000/55000 [==============================] - 6s 112us/sample - loss: 0.1178 - accuracy: 0.9606 - val_loss: 0.5875 - val_accuracy: 0.8896\nEpoch 25/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.1103 - accuracy: 0.9646 - val_loss: 0.6103 - val_accuracy: 0.8904\n"
],
[
"n_steps = n_epochs * len(X_train) // 32\nsteps = np.arange(n_steps)\nlrs = lr0 * 0.1**(steps / s)",
"_____no_output_____"
],
[
"plt.plot(steps, lrs, \"-\", linewidth=2)\nplt.axis([0, n_steps - 1, 0, lr0 * 1.1])\nplt.xlabel(\"Batch\")\nplt.ylabel(\"Learning Rate\")\nplt.title(\"Exponential Scheduling (per batch)\", fontsize=14)\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Piecewise Constant Scheduling",
"_____no_output_____"
]
],
[
[
"def piecewise_constant_fn(epoch):\n if epoch < 5:\n return 0.01\n elif epoch < 15:\n return 0.005\n else:\n return 0.001",
"_____no_output_____"
],
[
"def piecewise_constant(boundaries, values):\n boundaries = np.array([0] + boundaries)\n values = np.array(values)\n def piecewise_constant_fn(epoch):\n return values[np.argmax(boundaries > epoch) - 1]\n return piecewise_constant_fn\n\npiecewise_constant_fn = piecewise_constant([5, 15], [0.01, 0.005, 0.001])",
"_____no_output_____"
],
[
"lr_scheduler = keras.callbacks.LearningRateScheduler(piecewise_constant_fn)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 25\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid),\n callbacks=[lr_scheduler])",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.8151 - accuracy: 0.7655 - val_loss: 0.6868 - val_accuracy: 0.7780\nEpoch 2/25\n55000/55000 [==============================] - 6s 102us/sample - loss: 0.8153 - accuracy: 0.7659 - val_loss: 1.0604 - val_accuracy: 0.7148\nEpoch 3/25\n55000/55000 [==============================] - 6s 104us/sample - loss: 0.9138 - accuracy: 0.7218 - val_loss: 1.3223 - val_accuracy: 0.6660\nEpoch 4/25\n55000/55000 [==============================] - 6s 103us/sample - loss: 0.8506 - accuracy: 0.7627 - val_loss: 0.6807 - val_accuracy: 0.8174\nEpoch 5/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.7213 - accuracy: 0.8068 - val_loss: 1.0441 - val_accuracy: 0.8030\nEpoch 6/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.4882 - accuracy: 0.8548 - val_loss: 0.5411 - val_accuracy: 0.8494\nEpoch 7/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.4721 - accuracy: 0.8568 - val_loss: 0.5808 - val_accuracy: 0.8448\nEpoch 8/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.4412 - accuracy: 0.8659 - val_loss: 0.5466 - val_accuracy: 0.8526\nEpoch 9/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.4234 - accuracy: 0.8718 - val_loss: 0.5611 - val_accuracy: 0.8528\nEpoch 10/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.4300 - accuracy: 0.8721 - val_loss: 0.5049 - val_accuracy: 0.8650\nEpoch 11/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.4162 - accuracy: 0.8768 - val_loss: 0.5957 - val_accuracy: 0.8534\nEpoch 12/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.4122 - accuracy: 0.8780 - val_loss: 0.5707 - val_accuracy: 0.8640\nEpoch 13/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.3951 - accuracy: 0.8833 - val_loss: 0.5523 - val_accuracy: 0.8690\nEpoch 14/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.3961 - accuracy: 0.8834 - val_loss: 0.7371 - val_accuracy: 0.8452\nEpoch 15/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.4201 - accuracy: 0.8839 - val_loss: 0.6546 - val_accuracy: 0.8558\nEpoch 16/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2645 - accuracy: 0.9162 - val_loss: 0.4655 - val_accuracy: 0.8844\nEpoch 17/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2440 - accuracy: 0.9222 - val_loss: 0.4758 - val_accuracy: 0.8830\nEpoch 18/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2320 - accuracy: 0.9256 - val_loss: 0.4917 - val_accuracy: 0.8880\nEpoch 19/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2248 - accuracy: 0.9279 - val_loss: 0.4644 - val_accuracy: 0.8878\nEpoch 20/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2172 - accuracy: 0.9302 - val_loss: 0.5036 - val_accuracy: 0.8848\nEpoch 21/25\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.2139 - accuracy: 0.9327 - val_loss: 0.4921 - val_accuracy: 0.8914\nEpoch 22/25\n55000/55000 [==============================] - 6s 101us/sample - loss: 0.2030 - accuracy: 0.9360 - val_loss: 0.5197 - val_accuracy: 0.8860\nEpoch 23/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.2014 - accuracy: 0.9360 - val_loss: 0.5231 - val_accuracy: 0.8892\nEpoch 24/25\n55000/55000 [==============================] - 5s 100us/sample - loss: 0.1912 - accuracy: 0.9391 - val_loss: 0.5223 - val_accuracy: 0.8876\nEpoch 25/25\n55000/55000 [==============================] - 5s 99us/sample - loss: 0.1872 - accuracy: 0.9418 - val_loss: 0.5068 - val_accuracy: 0.8886\n"
],
[
"plt.plot(history.epoch, [piecewise_constant_fn(epoch) for epoch in history.epoch], \"o-\")\nplt.axis([0, n_epochs - 1, 0, 0.011])\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Learning Rate\")\nplt.title(\"Piecewise Constant Scheduling\", fontsize=14)\nplt.grid(True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Performance Scheduling",
"_____no_output_____"
]
],
[
[
"tf.random.set_seed(42)\nnp.random.seed(42)",
"_____no_output_____"
],
[
"lr_scheduler = keras.callbacks.ReduceLROnPlateau(factor=0.5, patience=5)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\noptimizer = keras.optimizers.SGD(lr=0.02, momentum=0.9)\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])\nn_epochs = 25\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid),\n callbacks=[lr_scheduler])",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 4s 79us/sample - loss: 0.5954 - accuracy: 0.8055 - val_loss: 0.5432 - val_accuracy: 0.8154\nEpoch 2/25\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.5194 - accuracy: 0.8345 - val_loss: 0.5184 - val_accuracy: 0.8468\nEpoch 3/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.5080 - accuracy: 0.8453 - val_loss: 0.5780 - val_accuracy: 0.8384\nEpoch 4/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.5360 - accuracy: 0.8452 - val_loss: 0.7195 - val_accuracy: 0.8350\nEpoch 5/25\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.5239 - accuracy: 0.8504 - val_loss: 0.5219 - val_accuracy: 0.8562\nEpoch 6/25\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.5163 - accuracy: 0.8528 - val_loss: 0.5669 - val_accuracy: 0.8382\nEpoch 7/25\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.5088 - accuracy: 0.8561 - val_loss: 0.6591 - val_accuracy: 0.8268\nEpoch 8/25\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.3022 - accuracy: 0.8938 - val_loss: 0.3955 - val_accuracy: 0.8834\nEpoch 9/25\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.2501 - accuracy: 0.9087 - val_loss: 0.4060 - val_accuracy: 0.8792\nEpoch 10/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.2304 - accuracy: 0.9158 - val_loss: 0.3998 - val_accuracy: 0.8846\nEpoch 11/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.2155 - accuracy: 0.9206 - val_loss: 0.3880 - val_accuracy: 0.8898\nEpoch 12/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.2034 - accuracy: 0.9253 - val_loss: 0.4049 - val_accuracy: 0.8838\nEpoch 13/25\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.1878 - accuracy: 0.9285 - val_loss: 0.4440 - val_accuracy: 0.8838\nEpoch 14/25\n55000/55000 [==============================] - 4s 80us/sample - loss: 0.1839 - accuracy: 0.9325 - val_loss: 0.4478 - val_accuracy: 0.8838\nEpoch 15/25\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.1747 - accuracy: 0.9348 - val_loss: 0.5072 - val_accuracy: 0.8806\nEpoch 16/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.1689 - accuracy: 0.9367 - val_loss: 0.4897 - val_accuracy: 0.8790\nEpoch 17/25\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.1090 - accuracy: 0.9576 - val_loss: 0.4571 - val_accuracy: 0.8900\nEpoch 18/25\n55000/55000 [==============================] - 4s 74us/sample - loss: 0.0926 - accuracy: 0.9639 - val_loss: 0.4563 - val_accuracy: 0.8934\nEpoch 19/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.0861 - accuracy: 0.9671 - val_loss: 0.5103 - val_accuracy: 0.8898\nEpoch 20/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.0794 - accuracy: 0.9692 - val_loss: 0.5065 - val_accuracy: 0.8936\nEpoch 21/25\n55000/55000 [==============================] - 4s 75us/sample - loss: 0.0737 - accuracy: 0.9721 - val_loss: 0.5516 - val_accuracy: 0.8928\nEpoch 22/25\n55000/55000 [==============================] - 4s 76us/sample - loss: 0.0547 - accuracy: 0.9803 - val_loss: 0.5315 - val_accuracy: 0.8944\nEpoch 23/25\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.0487 - accuracy: 0.9827 - val_loss: 0.5429 - val_accuracy: 0.8928\nEpoch 24/25\n55000/55000 [==============================] - 4s 80us/sample - loss: 0.0455 - accuracy: 0.9844 - val_loss: 0.5554 - val_accuracy: 0.8918\nEpoch 25/25\n55000/55000 [==============================] - 4s 79us/sample - loss: 0.0427 - accuracy: 0.9850 - val_loss: 0.5730 - val_accuracy: 0.8920\n"
],
[
"plt.plot(history.epoch, history.history[\"lr\"], \"bo-\")\nplt.xlabel(\"Epoch\")\nplt.ylabel(\"Learning Rate\", color='b')\nplt.tick_params('y', colors='b')\nplt.gca().set_xlim(0, n_epochs - 1)\nplt.grid(True)\n\nax2 = plt.gca().twinx()\nax2.plot(history.epoch, history.history[\"val_loss\"], \"r^-\")\nax2.set_ylabel('Validation Loss', color='r')\nax2.tick_params('y', colors='r')\n\nplt.title(\"Reduce LR on Plateau\", fontsize=14)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### tf.keras schedulers",
"_____no_output_____"
]
],
[
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\ns = 20 * len(X_train) // 32 # number of steps in 20 epochs (batch size = 32)\nlearning_rate = keras.optimizers.schedules.ExponentialDecay(0.01, s, 0.1)\noptimizer = keras.optimizers.SGD(learning_rate)\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])\nn_epochs = 25\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.4887 - accuracy: 0.8282 - val_loss: 0.4245 - val_accuracy: 0.8526\nEpoch 2/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.3830 - accuracy: 0.8641 - val_loss: 0.3798 - val_accuracy: 0.8688\nEpoch 3/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.3491 - accuracy: 0.8758 - val_loss: 0.3650 - val_accuracy: 0.8730\nEpoch 4/25\n55000/55000 [==============================] - 4s 78us/sample - loss: 0.3267 - accuracy: 0.8839 - val_loss: 0.3564 - val_accuracy: 0.8746\nEpoch 5/25\n55000/55000 [==============================] - 4s 72us/sample - loss: 0.3102 - accuracy: 0.8893 - val_loss: 0.3493 - val_accuracy: 0.8770\nEpoch 6/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.2969 - accuracy: 0.8939 - val_loss: 0.3400 - val_accuracy: 0.8818\nEpoch 7/25\n55000/55000 [==============================] - 4s 77us/sample - loss: 0.2855 - accuracy: 0.8983 - val_loss: 0.3385 - val_accuracy: 0.8830\nEpoch 8/25\n55000/55000 [==============================] - 4s 68us/sample - loss: 0.2764 - accuracy: 0.9025 - val_loss: 0.3372 - val_accuracy: 0.8824\nEpoch 9/25\n55000/55000 [==============================] - 4s 67us/sample - loss: 0.2684 - accuracy: 0.9039 - val_loss: 0.3337 - val_accuracy: 0.8848\nEpoch 10/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.2613 - accuracy: 0.9072 - val_loss: 0.3277 - val_accuracy: 0.8862\nEpoch 11/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.2555 - accuracy: 0.9086 - val_loss: 0.3273 - val_accuracy: 0.8860\nEpoch 12/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.2500 - accuracy: 0.9111 - val_loss: 0.3244 - val_accuracy: 0.8840\nEpoch 13/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.2454 - accuracy: 0.9124 - val_loss: 0.3194 - val_accuracy: 0.8904\nEpoch 14/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.2414 - accuracy: 0.9141 - val_loss: 0.3226 - val_accuracy: 0.8884\nEpoch 15/25\n55000/55000 [==============================] - 4s 73us/sample - loss: 0.2378 - accuracy: 0.9160 - val_loss: 0.3233 - val_accuracy: 0.8860\nEpoch 16/25\n55000/55000 [==============================] - 4s 69us/sample - loss: 0.2347 - accuracy: 0.9174 - val_loss: 0.3207 - val_accuracy: 0.8904\nEpoch 17/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.2318 - accuracy: 0.9179 - val_loss: 0.3195 - val_accuracy: 0.8892\nEpoch 18/25\n55000/55000 [==============================] - 4s 69us/sample - loss: 0.2293 - accuracy: 0.9193 - val_loss: 0.3184 - val_accuracy: 0.8916\nEpoch 19/25\n55000/55000 [==============================] - 4s 67us/sample - loss: 0.2272 - accuracy: 0.9201 - val_loss: 0.3196 - val_accuracy: 0.8886\nEpoch 20/25\n55000/55000 [==============================] - 4s 68us/sample - loss: 0.2253 - accuracy: 0.9206 - val_loss: 0.3190 - val_accuracy: 0.8918\nEpoch 21/25\n55000/55000 [==============================] - 4s 68us/sample - loss: 0.2235 - accuracy: 0.9214 - val_loss: 0.3176 - val_accuracy: 0.8912\nEpoch 22/25\n55000/55000 [==============================] - 4s 69us/sample - loss: 0.2220 - accuracy: 0.9220 - val_loss: 0.3181 - val_accuracy: 0.8900\nEpoch 23/25\n55000/55000 [==============================] - 4s 71us/sample - loss: 0.2206 - accuracy: 0.9226 - val_loss: 0.3187 - val_accuracy: 0.8894\nEpoch 24/25\n55000/55000 [==============================] - 4s 68us/sample - loss: 0.2193 - accuracy: 0.9231 - val_loss: 0.3168 - val_accuracy: 0.8908\nEpoch 25/25\n55000/55000 [==============================] - 4s 68us/sample - loss: 0.2181 - accuracy: 0.9234 - val_loss: 0.3171 - val_accuracy: 0.8898\n"
]
],
[
[
"For piecewise constant scheduling, try this:",
"_____no_output_____"
]
],
[
[
"learning_rate = keras.optimizers.schedules.PiecewiseConstantDecay(\n boundaries=[5. * n_steps_per_epoch, 15. * n_steps_per_epoch],\n values=[0.01, 0.005, 0.001])",
"_____no_output_____"
]
],
[
[
"### 1Cycle scheduling",
"_____no_output_____"
]
],
[
[
"K = keras.backend\n\nclass ExponentialLearningRate(keras.callbacks.Callback):\n def __init__(self, factor):\n self.factor = factor\n self.rates = []\n self.losses = []\n def on_batch_end(self, batch, logs):\n self.rates.append(K.get_value(self.model.optimizer.lr))\n self.losses.append(logs[\"loss\"])\n K.set_value(self.model.optimizer.lr, self.model.optimizer.lr * self.factor)\n\ndef find_learning_rate(model, X, y, epochs=1, batch_size=32, min_rate=10**-5, max_rate=10):\n init_weights = model.get_weights()\n iterations = len(X) // batch_size * epochs\n factor = np.exp(np.log(max_rate / min_rate) / iterations)\n init_lr = K.get_value(model.optimizer.lr)\n K.set_value(model.optimizer.lr, min_rate)\n exp_lr = ExponentialLearningRate(factor)\n history = model.fit(X, y, epochs=epochs, batch_size=batch_size,\n callbacks=[exp_lr])\n K.set_value(model.optimizer.lr, init_lr)\n model.set_weights(init_weights)\n return exp_lr.rates, exp_lr.losses\n\ndef plot_lr_vs_loss(rates, losses):\n plt.plot(rates, losses)\n plt.gca().set_xscale('log')\n plt.hlines(min(losses), min(rates), max(rates))\n plt.axis([min(rates), max(rates), min(losses), (losses[0] + min(losses)) / 2])\n plt.xlabel(\"Learning rate\")\n plt.ylabel(\"Loss\")",
"_____no_output_____"
],
[
"tf.random.set_seed(42)\nnp.random.seed(42)\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\",\n optimizer=keras.optimizers.SGD(lr=1e-3),\n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"batch_size = 128\nrates, losses = find_learning_rate(model, X_train_scaled, y_train, epochs=1, batch_size=batch_size)\nplot_lr_vs_loss(rates, losses)",
"Train on 55000 samples\n55000/55000 [==============================] - 2s 28us/sample - loss: nan - accuracy: 0.3888\n"
],
[
"class OneCycleScheduler(keras.callbacks.Callback):\n def __init__(self, iterations, max_rate, start_rate=None,\n last_iterations=None, last_rate=None):\n self.iterations = iterations\n self.max_rate = max_rate\n self.start_rate = start_rate or max_rate / 10\n self.last_iterations = last_iterations or iterations // 10 + 1\n self.half_iteration = (iterations - self.last_iterations) // 2\n self.last_rate = last_rate or self.start_rate / 1000\n self.iteration = 0\n def _interpolate(self, iter1, iter2, rate1, rate2):\n return ((rate2 - rate1) * (self.iteration - iter1)\n / (iter2 - iter1) + rate1)\n def on_batch_begin(self, batch, logs):\n if self.iteration < self.half_iteration:\n rate = self._interpolate(0, self.half_iteration, self.start_rate, self.max_rate)\n elif self.iteration < 2 * self.half_iteration:\n rate = self._interpolate(self.half_iteration, 2 * self.half_iteration,\n self.max_rate, self.start_rate)\n else:\n rate = self._interpolate(2 * self.half_iteration, self.iterations,\n self.start_rate, self.last_rate)\n rate = max(rate, self.last_rate)\n self.iteration += 1\n K.set_value(self.model.optimizer.lr, rate)",
"_____no_output_____"
],
[
"n_epochs = 25\nonecycle = OneCycleScheduler(len(X_train) // batch_size * n_epochs, max_rate=0.05)\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs, batch_size=batch_size,\n validation_data=(X_valid_scaled, y_valid),\n callbacks=[onecycle])",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.6569 - accuracy: 0.7750 - val_loss: 0.4875 - val_accuracy: 0.8300\nEpoch 2/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.4584 - accuracy: 0.8391 - val_loss: 0.4390 - val_accuracy: 0.8476\nEpoch 3/25\n55000/55000 [==============================] - 1s 21us/sample - loss: 0.4124 - accuracy: 0.8541 - val_loss: 0.4102 - val_accuracy: 0.8570\nEpoch 4/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.3842 - accuracy: 0.8643 - val_loss: 0.3893 - val_accuracy: 0.8652\nEpoch 5/25\n55000/55000 [==============================] - 1s 21us/sample - loss: 0.3641 - accuracy: 0.8707 - val_loss: 0.3736 - val_accuracy: 0.8678\nEpoch 6/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.3456 - accuracy: 0.8781 - val_loss: 0.3652 - val_accuracy: 0.8726\nEpoch 7/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.3318 - accuracy: 0.8818 - val_loss: 0.3596 - val_accuracy: 0.8768\nEpoch 8/25\n55000/55000 [==============================] - 1s 24us/sample - loss: 0.3180 - accuracy: 0.8862 - val_loss: 0.3845 - val_accuracy: 0.8602\nEpoch 9/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.3062 - accuracy: 0.8893 - val_loss: 0.3824 - val_accuracy: 0.8660\nEpoch 10/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.2938 - accuracy: 0.8934 - val_loss: 0.3516 - val_accuracy: 0.8742\nEpoch 11/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.2838 - accuracy: 0.8975 - val_loss: 0.3609 - val_accuracy: 0.8740\nEpoch 12/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.2716 - accuracy: 0.9025 - val_loss: 0.3843 - val_accuracy: 0.8666\nEpoch 13/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.2541 - accuracy: 0.9091 - val_loss: 0.3282 - val_accuracy: 0.8844\nEpoch 14/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.2390 - accuracy: 0.9139 - val_loss: 0.3336 - val_accuracy: 0.8838\nEpoch 15/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.2273 - accuracy: 0.9177 - val_loss: 0.3283 - val_accuracy: 0.8884\nEpoch 16/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.2156 - accuracy: 0.9234 - val_loss: 0.3288 - val_accuracy: 0.8862\nEpoch 17/25\n55000/55000 [==============================] - 1s 26us/sample - loss: 0.2062 - accuracy: 0.9265 - val_loss: 0.3215 - val_accuracy: 0.8896\nEpoch 18/25\n55000/55000 [==============================] - 1s 24us/sample - loss: 0.1973 - accuracy: 0.9299 - val_loss: 0.3284 - val_accuracy: 0.8912\nEpoch 19/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.1892 - accuracy: 0.9344 - val_loss: 0.3229 - val_accuracy: 0.8904\nEpoch 20/25\n55000/55000 [==============================] - 1s 22us/sample - loss: 0.1822 - accuracy: 0.9366 - val_loss: 0.3196 - val_accuracy: 0.8902\nEpoch 21/25\n55000/55000 [==============================] - 1s 24us/sample - loss: 0.1758 - accuracy: 0.9388 - val_loss: 0.3184 - val_accuracy: 0.8940\nEpoch 22/25\n55000/55000 [==============================] - 1s 27us/sample - loss: 0.1699 - accuracy: 0.9422 - val_loss: 0.3221 - val_accuracy: 0.8912\nEpoch 23/25\n55000/55000 [==============================] - 1s 26us/sample - loss: 0.1657 - accuracy: 0.9444 - val_loss: 0.3173 - val_accuracy: 0.8944\nEpoch 24/25\n55000/55000 [==============================] - 1s 23us/sample - loss: 0.1630 - accuracy: 0.9457 - val_loss: 0.3162 - val_accuracy: 0.8946\nEpoch 25/25\n55000/55000 [==============================] - 1s 26us/sample - loss: 0.1610 - accuracy: 0.9464 - val_loss: 0.3169 - val_accuracy: 0.8942\n"
]
],
[
[
"# Avoiding Overfitting Through Regularization",
"_____no_output_____"
],
[
"## $\\ell_1$ and $\\ell_2$ regularization",
"_____no_output_____"
]
],
[
[
"layer = keras.layers.Dense(100, activation=\"elu\",\n kernel_initializer=\"he_normal\",\n kernel_regularizer=keras.regularizers.l2(0.01))\n# or l1(0.1) for ℓ1 regularization with a factor or 0.1\n# or l1_l2(0.1, 0.01) for both ℓ1 and ℓ2 regularization, with factors 0.1 and 0.01 respectively",
"_____no_output_____"
],
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dense(300, activation=\"elu\",\n kernel_initializer=\"he_normal\",\n kernel_regularizer=keras.regularizers.l2(0.01)),\n keras.layers.Dense(100, activation=\"elu\",\n kernel_initializer=\"he_normal\",\n kernel_regularizer=keras.regularizers.l2(0.01)),\n keras.layers.Dense(10, activation=\"softmax\",\n kernel_regularizer=keras.regularizers.l2(0.01))\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 2\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/2\n55000/55000 [==============================] - 7s 128us/sample - loss: 1.6073 - accuracy: 0.8112 - val_loss: 0.7314 - val_accuracy: 0.8242\nEpoch 2/2\n55000/55000 [==============================] - 6s 117us/sample - loss: 0.7193 - accuracy: 0.8256 - val_loss: 0.7029 - val_accuracy: 0.8304\n"
],
[
"from functools import partial\n\nRegularizedDense = partial(keras.layers.Dense,\n activation=\"elu\",\n kernel_initializer=\"he_normal\",\n kernel_regularizer=keras.regularizers.l2(0.01))\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n RegularizedDense(300),\n RegularizedDense(100),\n RegularizedDense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 2\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/2\n55000/55000 [==============================] - 7s 129us/sample - loss: 1.6597 - accuracy: 0.8128 - val_loss: 0.7630 - val_accuracy: 0.8080\nEpoch 2/2\n55000/55000 [==============================] - 7s 124us/sample - loss: 0.7176 - accuracy: 0.8271 - val_loss: 0.6848 - val_accuracy: 0.8360\n"
]
],
[
[
"## Dropout",
"_____no_output_____"
]
],
[
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.Dropout(rate=0.2),\n keras.layers.Dense(300, activation=\"elu\", kernel_initializer=\"he_normal\"),\n keras.layers.Dropout(rate=0.2),\n keras.layers.Dense(100, activation=\"elu\", kernel_initializer=\"he_normal\"),\n keras.layers.Dropout(rate=0.2),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 2\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/2\n55000/55000 [==============================] - 8s 145us/sample - loss: 0.5741 - accuracy: 0.8030 - val_loss: 0.3841 - val_accuracy: 0.8572\nEpoch 2/2\n55000/55000 [==============================] - 7s 134us/sample - loss: 0.4218 - accuracy: 0.8469 - val_loss: 0.3534 - val_accuracy: 0.8728\n"
]
],
[
[
"## Alpha Dropout",
"_____no_output_____"
]
],
[
[
"tf.random.set_seed(42)\nnp.random.seed(42)",
"_____no_output_____"
],
[
"model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n keras.layers.AlphaDropout(rate=0.2),\n keras.layers.Dense(300, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.AlphaDropout(rate=0.2),\n keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\"),\n keras.layers.AlphaDropout(rate=0.2),\n keras.layers.Dense(10, activation=\"softmax\")\n])\noptimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True)\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])\nn_epochs = 20\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/20\n55000/55000 [==============================] - 6s 111us/sample - loss: 0.6639 - accuracy: 0.7582 - val_loss: 0.5840 - val_accuracy: 0.8410\nEpoch 2/20\n55000/55000 [==============================] - 5s 97us/sample - loss: 0.5517 - accuracy: 0.7968 - val_loss: 0.5747 - val_accuracy: 0.8430\nEpoch 3/20\n55000/55000 [==============================] - 5s 94us/sample - loss: 0.5260 - accuracy: 0.8062 - val_loss: 0.5233 - val_accuracy: 0.8486\nEpoch 4/20\n55000/55000 [==============================] - 5s 94us/sample - loss: 0.5055 - accuracy: 0.8136 - val_loss: 0.4687 - val_accuracy: 0.8606\nEpoch 5/20\n55000/55000 [==============================] - 5s 96us/sample - loss: 0.4897 - accuracy: 0.8187 - val_loss: 0.5188 - val_accuracy: 0.8588\nEpoch 6/20\n55000/55000 [==============================] - 5s 93us/sample - loss: 0.4812 - accuracy: 0.8217 - val_loss: 0.4929 - val_accuracy: 0.8508\nEpoch 7/20\n55000/55000 [==============================] - 5s 90us/sample - loss: 0.4687 - accuracy: 0.8251 - val_loss: 0.4840 - val_accuracy: 0.8572\nEpoch 8/20\n55000/55000 [==============================] - 5s 90us/sample - loss: 0.4709 - accuracy: 0.8249 - val_loss: 0.4227 - val_accuracy: 0.8660\nEpoch 9/20\n55000/55000 [==============================] - 5s 92us/sample - loss: 0.4515 - accuracy: 0.8313 - val_loss: 0.4796 - val_accuracy: 0.8670\nEpoch 10/20\n55000/55000 [==============================] - 5s 93us/sample - loss: 0.4508 - accuracy: 0.8329 - val_loss: 0.4901 - val_accuracy: 0.8588\nEpoch 11/20\n55000/55000 [==============================] - 5s 93us/sample - loss: 0.4484 - accuracy: 0.8338 - val_loss: 0.4678 - val_accuracy: 0.8640\nEpoch 12/20\n55000/55000 [==============================] - 5s 95us/sample - loss: 0.4417 - accuracy: 0.8366 - val_loss: 0.4684 - val_accuracy: 0.8610\nEpoch 13/20\n55000/55000 [==============================] - 5s 93us/sample - loss: 0.4421 - accuracy: 0.8370 - val_loss: 0.4347 - val_accuracy: 0.8640\nEpoch 14/20\n55000/55000 [==============================] - 5s 98us/sample - loss: 0.4377 - accuracy: 0.8369 - val_loss: 0.4204 - val_accuracy: 0.8734\nEpoch 15/20\n55000/55000 [==============================] - 5s 95us/sample - loss: 0.4329 - accuracy: 0.8384 - val_loss: 0.4820 - val_accuracy: 0.8718\nEpoch 16/20\n55000/55000 [==============================] - 6s 100us/sample - loss: 0.4328 - accuracy: 0.8388 - val_loss: 0.4447 - val_accuracy: 0.8754\nEpoch 17/20\n55000/55000 [==============================] - 5s 96us/sample - loss: 0.4243 - accuracy: 0.8413 - val_loss: 0.4502 - val_accuracy: 0.8776\nEpoch 18/20\n55000/55000 [==============================] - 5s 95us/sample - loss: 0.4242 - accuracy: 0.8432 - val_loss: 0.4070 - val_accuracy: 0.8720\nEpoch 19/20\n55000/55000 [==============================] - 5s 94us/sample - loss: 0.4195 - accuracy: 0.8437 - val_loss: 0.4738 - val_accuracy: 0.8670\nEpoch 20/20\n55000/55000 [==============================] - 5s 96us/sample - loss: 0.4191 - accuracy: 0.8439 - val_loss: 0.4163 - val_accuracy: 0.8790\n"
],
[
"model.evaluate(X_test_scaled, y_test)",
"10000/10000 [==============================] - 0s 39us/sample - loss: 0.4535 - accuracy: 0.8680\n"
],
[
"model.evaluate(X_train_scaled, y_train)",
"55000/55000 [==============================] - 2s 41us/sample - loss: 0.3357 - accuracy: 0.8887\n"
],
[
"history = model.fit(X_train_scaled, y_train)",
"_____no_output_____"
]
],
[
[
"## MC Dropout",
"_____no_output_____"
]
],
[
[
"tf.random.set_seed(42)\nnp.random.seed(42)",
"_____no_output_____"
],
[
"y_probas = np.stack([model(X_test_scaled, training=True)\n for sample in range(100)])\ny_proba = y_probas.mean(axis=0)\ny_std = y_probas.std(axis=0)",
"_____no_output_____"
],
[
"np.round(model.predict(X_test_scaled[:1]), 2)",
"_____no_output_____"
],
[
"np.round(y_probas[:, :1], 2)",
"_____no_output_____"
],
[
"np.round(y_proba[:1], 2)",
"_____no_output_____"
],
[
"y_std = y_probas.std(axis=0)\nnp.round(y_std[:1], 2)",
"_____no_output_____"
],
[
"y_pred = np.argmax(y_proba, axis=1)",
"_____no_output_____"
],
[
"accuracy = np.sum(y_pred == y_test) / len(y_test)\naccuracy",
"_____no_output_____"
],
[
"class MCDropout(keras.layers.Dropout):\n def call(self, inputs):\n return super().call(inputs, training=True)\n\nclass MCAlphaDropout(keras.layers.AlphaDropout):\n def call(self, inputs):\n return super().call(inputs, training=True)",
"_____no_output_____"
],
[
"tf.random.set_seed(42)\nnp.random.seed(42)",
"_____no_output_____"
],
[
"mc_model = keras.models.Sequential([\n MCAlphaDropout(layer.rate) if isinstance(layer, keras.layers.AlphaDropout) else layer\n for layer in model.layers\n])",
"_____no_output_____"
],
[
"mc_model.summary()",
"Model: \"sequential_36\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nflatten_33 (Flatten) (None, 784) 0 \n_________________________________________________________________\nmc_alpha_dropout_3 (MCAlphaD (None, 784) 0 \n_________________________________________________________________\ndense_311 (Dense) (None, 300) 235500 \n_________________________________________________________________\nmc_alpha_dropout_4 (MCAlphaD (None, 300) 0 \n_________________________________________________________________\ndense_312 (Dense) (None, 100) 30100 \n_________________________________________________________________\nmc_alpha_dropout_5 (MCAlphaD (None, 100) 0 \n_________________________________________________________________\ndense_313 (Dense) (None, 10) 1010 \n=================================================================\nTotal params: 266,610\nTrainable params: 266,610\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"optimizer = keras.optimizers.SGD(lr=0.01, momentum=0.9, nesterov=True)\nmc_model.compile(loss=\"sparse_categorical_crossentropy\", optimizer=optimizer, metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"mc_model.set_weights(model.get_weights())",
"_____no_output_____"
]
],
[
[
"Now we can use the model with MC Dropout:",
"_____no_output_____"
]
],
[
[
"np.round(np.mean([mc_model.predict(X_test_scaled[:1]) for sample in range(100)], axis=0), 2)",
"_____no_output_____"
]
],
[
[
"## Max norm",
"_____no_output_____"
]
],
[
[
"layer = keras.layers.Dense(100, activation=\"selu\", kernel_initializer=\"lecun_normal\",\n kernel_constraint=keras.constraints.max_norm(1.))",
"_____no_output_____"
],
[
"MaxNormDense = partial(keras.layers.Dense,\n activation=\"selu\", kernel_initializer=\"lecun_normal\",\n kernel_constraint=keras.constraints.max_norm(1.))\n\nmodel = keras.models.Sequential([\n keras.layers.Flatten(input_shape=[28, 28]),\n MaxNormDense(300),\n MaxNormDense(100),\n keras.layers.Dense(10, activation=\"softmax\")\n])\nmodel.compile(loss=\"sparse_categorical_crossentropy\", optimizer=\"nadam\", metrics=[\"accuracy\"])\nn_epochs = 2\nhistory = model.fit(X_train_scaled, y_train, epochs=n_epochs,\n validation_data=(X_valid_scaled, y_valid))",
"Train on 55000 samples, validate on 5000 samples\nEpoch 1/2\n55000/55000 [==============================] - 8s 147us/sample - loss: 0.4745 - accuracy: 0.8329 - val_loss: 0.3988 - val_accuracy: 0.8584\nEpoch 2/2\n55000/55000 [==============================] - 7s 135us/sample - loss: 0.3554 - accuracy: 0.8688 - val_loss: 0.3681 - val_accuracy: 0.8726\n"
]
],
[
[
"# Exercises",
"_____no_output_____"
],
[
"## 1. to 7.",
"_____no_output_____"
],
[
"See appendix A.",
"_____no_output_____"
],
[
"## 8. Deep Learning",
"_____no_output_____"
],
[
"### 8.1.",
"_____no_output_____"
],
[
"_Exercise: Build a DNN with five hidden layers of 100 neurons each, He initialization, and the ELU activation function._",
"_____no_output_____"
],
[
"### 8.2.",
"_____no_output_____"
],
[
"_Exercise: Using Adam optimization and early stopping, try training it on MNIST but only on digits 0 to 4, as we will use transfer learning for digits 5 to 9 in the next exercise. You will need a softmax output layer with five neurons, and as always make sure to save checkpoints at regular intervals and save the final model so you can reuse it later._",
"_____no_output_____"
],
[
"### 8.3.",
"_____no_output_____"
],
[
"_Exercise: Tune the hyperparameters using cross-validation and see what precision you can achieve._",
"_____no_output_____"
],
[
"### 8.4.",
"_____no_output_____"
],
[
"_Exercise: Now try adding Batch Normalization and compare the learning curves: is it converging faster than before? Does it produce a better model?_",
"_____no_output_____"
],
[
"### 8.5.",
"_____no_output_____"
],
[
"_Exercise: is the model overfitting the training set? Try adding dropout to every layer and try again. Does it help?_",
"_____no_output_____"
],
[
"## 9. Transfer learning",
"_____no_output_____"
],
[
"### 9.1.",
"_____no_output_____"
],
[
"_Exercise: create a new DNN that reuses all the pretrained hidden layers of the previous model, freezes them, and replaces the softmax output layer with a new one._",
"_____no_output_____"
],
[
"### 9.2.",
"_____no_output_____"
],
[
"_Exercise: train this new DNN on digits 5 to 9, using only 100 images per digit, and time how long it takes. Despite this small number of examples, can you achieve high precision?_",
"_____no_output_____"
],
[
"### 9.3.",
"_____no_output_____"
],
[
"_Exercise: try caching the frozen layers, and train the model again: how much faster is it now?_",
"_____no_output_____"
],
[
"### 9.4.",
"_____no_output_____"
],
[
"_Exercise: try again reusing just four hidden layers instead of five. Can you achieve a higher precision?_",
"_____no_output_____"
],
[
"### 9.5.",
"_____no_output_____"
],
[
"_Exercise: now unfreeze the top two hidden layers and continue training: can you get the model to perform even better?_",
"_____no_output_____"
],
[
"## 10. Pretraining on an auxiliary task",
"_____no_output_____"
],
[
"In this exercise you will build a DNN that compares two MNIST digit images and predicts whether they represent the same digit or not. Then you will reuse the lower layers of this network to train an MNIST classifier using very little training data.",
"_____no_output_____"
],
[
"### 10.1.\nExercise: _Start by building two DNNs (let's call them DNN A and B), both similar to the one you built earlier but without the output layer: each DNN should have five hidden layers of 100 neurons each, He initialization, and ELU activation. Next, add one more hidden layer with 10 units on top of both DNNs. You should use the `keras.layers.concatenate()` function to concatenate the outputs of both DNNs, then feed the result to the hidden layer. Finally, add an output layer with a single neuron using the logistic activation function._",
"_____no_output_____"
],
[
"### 10.2.\n_Exercise: split the MNIST training set in two sets: split #1 should containing 55,000 images, and split #2 should contain contain 5,000 images. Create a function that generates a training batch where each instance is a pair of MNIST images picked from split #1. Half of the training instances should be pairs of images that belong to the same class, while the other half should be images from different classes. For each pair, the training label should be 0 if the images are from the same class, or 1 if they are from different classes._",
"_____no_output_____"
],
[
"### 10.3.\n_Exercise: train the DNN on this training set. For each image pair, you can simultaneously feed the first image to DNN A and the second image to DNN B. The whole network will gradually learn to tell whether two images belong to the same class or not._",
"_____no_output_____"
],
[
"### 10.4.\n_Exercise: now create a new DNN by reusing and freezing the hidden layers of DNN A and adding a softmax output layer on top with 10 neurons. Train this network on split #2 and see if you can achieve high performance despite having only 500 images per class._",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a457dc5c0b687f54e3319332b4ec803986fe673
| 74,987 |
ipynb
|
Jupyter Notebook
|
Amexpert-2019-baseline.ipynb
|
bhavul/AmExpert2019Hackathon
|
a7eea69b0d6fe5c46918d89161679b3d4bc7cbab
|
[
"Apache-2.0"
] | null | null | null |
Amexpert-2019-baseline.ipynb
|
bhavul/AmExpert2019Hackathon
|
a7eea69b0d6fe5c46918d89161679b3d4bc7cbab
|
[
"Apache-2.0"
] | null | null | null |
Amexpert-2019-baseline.ipynb
|
bhavul/AmExpert2019Hackathon
|
a7eea69b0d6fe5c46918d89161679b3d4bc7cbab
|
[
"Apache-2.0"
] | null | null | null | 31.922946 | 230 | 0.475629 |
[
[
[
"## Imports",
"_____no_output_____"
]
],
[
[
"from bayes_opt import BayesianOptimization",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nfrom datetime import timedelta\nfrom tqdm import tqdm_notebook as tqdm\nfrom sklearn import metrics\nfrom sklearn.model_selection import StratifiedKFold\nimport lightgbm as lgb\nfrom matplotlib import pyplot as plt\n#import seaborn as sns\nfrom collections import defaultdict, Counter\nfrom sklearn.preprocessing import StandardScaler, MinMaxScaler, PolynomialFeatures, RobustScaler\nfrom sklearn.model_selection import KFold\nfrom sklearn.metrics import roc_auc_score as auc\nfrom sklearn.linear_model import LogisticRegression\nfrom scipy.special import logit",
"_____no_output_____"
],
[
"import lightgbm\nfrom xgboost import XGBClassifier\nfrom bayes_opt import BayesianOptimization\nfrom sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"import xgboost as xgb",
"_____no_output_____"
],
[
"file = {\n\t'test' : './Data/test_QyjYwdj.csv',\n\t'train':'./Data/train.csv',\n\t'submission':'./Data/sample_submission_Byiv0dS.csv',\n\t'coupon_item_mapping' :'./Data/coupon_item_mapping.csv',\n\t'campaign_data' : './Data/campaign_data.csv',\n\t'item_data' : './Data/item_data.csv',\n\t'customer_transaction_data':'./Data/customer_transaction_data.csv',\n\t'customer_demographics':'./Data/customer_demographics.csv',\n}\n",
"_____no_output_____"
],
[
"train = pd.read_csv(file.get(\"train\"))#\ntest = pd.read_csv(file.get(\"test\"))#\n\ncoupon_item_mapping = pd.read_csv(file.get(\"coupon_item_mapping\"))#No\nitem_data = pd.read_csv(file.get(\"item_data\"))# may be yes\ncustomer_transaction_data = pd.read_csv(file.get(\"customer_transaction_data\"))#may be yes \n\ncampaign_data = pd.read_csv(file.get(\"campaign_data\"))#\ncustomer_demographics = pd.read_csv(file.get(\"customer_demographics\"))#\nsubmission = pd.read_csv(file.get(\"submission\"))\n",
"_____no_output_____"
],
[
"train.shape",
"_____no_output_____"
],
[
"data = pd.concat([train, test], sort=False).reset_index(drop = True)\n",
"_____no_output_____"
],
[
"ltr = len(train)",
"_____no_output_____"
],
[
"data = data.merge(campaign_data, on='campaign_id')# campaign_data\ndata['start_date'] = pd.to_datetime(data['start_date'], dayfirst=True)\ndata['end_date'] = pd.to_datetime(data['end_date'], dayfirst=True)\n",
"_____no_output_____"
],
[
"data['campaign_type'].factorize()",
"_____no_output_____"
],
[
"data['campaign_type'] = pd.Series(data['campaign_type'].factorize()[0]).replace(-1, np.nan)",
"_____no_output_____"
],
[
"customer_demographics['no_of_children'] = customer_demographics['no_of_children'].replace('3+', 3).astype(float)\ncustomer_demographics['family_size'] = customer_demographics['family_size'].replace('5+', 5).astype(float)\ncustomer_demographics['marital_status'] = pd.Series(customer_demographics['marital_status'].factorize()[0]).replace(-1, np.nan)\ncustomer_demographics['age_range'] = pd.Series(customer_demographics['age_range'].factorize()[0]).replace(-1, np.nan)",
"_____no_output_____"
],
[
"# use train data itself\nredeemed_before_count = train.groupby(\"customer_id\")['redemption_status'].sum().to_dict()\ndata['no_of_times_redeemed_before'] = data['customer_id'].map(redeemed_before_count)",
"_____no_output_____"
],
[
"# rented\nrented_mean = customer_demographics.groupby(\"customer_id\")['rented'].mean().to_dict()\ndata['rented_mean'] = data['customer_id'].map(rented_mean)",
"_____no_output_____"
],
[
"# income_bracket\nincome_bracket_sum = customer_demographics.groupby(\"customer_id\")['income_bracket'].sum().to_dict()\ndata['income_bracket_sum'] = data['customer_id'].map(income_bracket_sum)",
"_____no_output_____"
],
[
"# age_range\nage_range_mean = customer_demographics.groupby(\"customer_id\")['age_range'].mean().to_dict()\ndata['age_range_mean'] = data['customer_id'].map(age_range_mean)\n",
"_____no_output_____"
],
[
"# family_size\nfamily_size_mean = customer_demographics.groupby(\"customer_id\")['family_size'].mean().to_dict()\ndata['family_size_mean'] = data['customer_id'].map(family_size_mean)",
"_____no_output_____"
],
[
"# no_of_children - actual number\nno_of_children_mean = customer_demographics.groupby(\"customer_id\")['no_of_children'].mean().to_dict()\ndata['no_of_children_mean'] = data['customer_id'].map(no_of_children_mean)\n# actually represents if they have children or not\nno_of_children_count = customer_demographics.groupby(\"customer_id\")['no_of_children'].count().to_dict()\ndata['no_of_children_count'] = data['customer_id'].map(no_of_children_count)\n",
"_____no_output_____"
],
[
"# marital_status\nmarital_status_count = customer_demographics.groupby(\"customer_id\")['marital_status'].count().to_dict()\ndata['marital_status_count'] = data['customer_id'].map(marital_status_count)\n",
"_____no_output_____"
],
[
"# customer_transaction_data\ncustomer_transaction_data['date'] = pd.to_datetime(customer_transaction_data['date'])\n# quantity\t\nquantity_mean = customer_transaction_data.groupby(\"customer_id\")['quantity'].mean().to_dict()\ndata['quantity_mean'] = data['customer_id'].map(quantity_mean)\n#coupon_discount\ncoupon_discount_mean = customer_transaction_data.groupby(\"customer_id\")['coupon_discount'].mean().to_dict()\ndata['coupon_discount_mean'] = data['customer_id'].map(coupon_discount_mean)\n# other_discount\nother_discount_mean = customer_transaction_data.groupby(\"customer_id\")['other_discount'].mean().to_dict()\ndata['other_discount_mean'] = data['customer_id'].map(other_discount_mean)\n# day\ncustomer_transaction_data['day'] = customer_transaction_data.date.dt.day\ndate_day_mean = customer_transaction_data.groupby(\"customer_id\")['day'].mean().to_dict()\ndata['date_day_mean'] = data['customer_id'].map(date_day_mean)\n\n# selling_price\nselling_price_mean = customer_transaction_data.groupby(\"customer_id\")['selling_price'].mean().to_dict()\ndata['selling_price_mean'] = data['customer_id'].map(selling_price_mean)\nselling_price_mean = customer_transaction_data.groupby(\"customer_id\")['selling_price'].sum().to_dict()\ndata['selling_price_sum'] = data['customer_id'].map(selling_price_mean)\nselling_price_mean = customer_transaction_data.groupby(\"customer_id\")['selling_price'].min().to_dict()\ndata['selling_price_min'] = data['customer_id'].map(selling_price_mean)\nselling_price_mean = customer_transaction_data.groupby(\"customer_id\")['selling_price'].max().to_dict()\ndata['selling_price_max'] = data['customer_id'].map(selling_price_mean)\nselling_price_mean = customer_transaction_data.groupby(\"customer_id\")['selling_price'].nunique().to_dict()\ndata['selling_price_nunique'] = data['customer_id'].map(selling_price_mean)",
"_____no_output_____"
],
[
"coupon_item_mapping = coupon_item_mapping.merge(item_data, how = 'left', on = 'item_id')\ncoupon_item_mapping['brand_type'] = pd.Series(coupon_item_mapping['brand_type'].factorize()[0]).replace(-1, np.nan)\ncoupon_item_mapping['category'] = pd.Series(coupon_item_mapping['category'].factorize()[0]).replace(-1, np.nan)\n\ncategory = coupon_item_mapping.groupby(\"coupon_id\")['category'].mean().to_dict()\ndata['category_mean'] = data['coupon_id'].map(category)\ncategory = coupon_item_mapping.groupby(\"coupon_id\")['category'].count().to_dict()\ndata['category_count'] = data['coupon_id'].map(category)\ncategory = coupon_item_mapping.groupby(\"coupon_id\")['category'].nunique().to_dict()\ndata['category_nunique'] = data['coupon_id'].map(category)\ncategory = coupon_item_mapping.groupby(\"coupon_id\")['category'].max().to_dict()\ndata['category_max'] = data['coupon_id'].map(category)\ncategory = coupon_item_mapping.groupby(\"coupon_id\")['category'].min().to_dict()\ndata['category_min'] = data['coupon_id'].map(category)\n\nbrand_mean = coupon_item_mapping.groupby(\"coupon_id\")['brand'].mean().to_dict()\ndata['brand_mean'] = data['coupon_id'].map(brand_mean)\nbrand_mean = coupon_item_mapping.groupby(\"coupon_id\")['brand'].count().to_dict()\ndata['brand_count'] = data['coupon_id'].map(brand_mean)\nbrand_mean = coupon_item_mapping.groupby(\"coupon_id\")['brand'].min().to_dict()\ndata['brand_min'] = data['coupon_id'].map(brand_mean)\nbrand_mean = coupon_item_mapping.groupby(\"coupon_id\")['brand'].max().to_dict()\ndata['brand_max'] = data['coupon_id'].map(brand_mean)\nbrand_mean = coupon_item_mapping.groupby(\"coupon_id\")['brand'].nunique().to_dict()\ndata['brand_nunique'] = data['coupon_id'].map(brand_mean)\n",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"train_cols = ['campaign_id','coupon_id','campaign_type','rented_mean','income_bracket_sum','age_range_mean','family_size_mean',\n 'no_of_children_mean',\n 'no_of_children_count',\n 'marital_status_count',\n 'quantity_mean',\n 'coupon_discount_mean',\n 'other_discount_mean',\n 'date_day_mean',\n 'category_mean',\n 'category_nunique',\n 'category_max',\n 'category_min',\n 'brand_mean',\n 'brand_max',\n 'brand_nunique',\n 'selling_price_mean',\n 'selling_price_min',\n 'selling_price_nunique']",
"_____no_output_____"
],
[
"len(train_cols)",
"_____no_output_____"
],
[
"train = data[data['redemption_status'].notnull()]\ntest = data[data['redemption_status'].isnull()]\n",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"train.isna().sum()",
"_____no_output_____"
],
[
"test.isna().sum()",
"_____no_output_____"
],
[
"pd.get_dummies(data[train_cols].fillna(0), columns=train_cols, drop_first=True, sparse=True).columns",
"_____no_output_____"
],
[
"train.columns",
"_____no_output_____"
],
[
"train.shape",
"_____no_output_____"
],
[
"test.shape",
"_____no_output_____"
],
[
"target.shape",
"_____no_output_____"
],
[
"train_np = train[train_cols].fillna(0).values\ntest_np = test[train_cols].fillna(0).values",
"_____no_output_____"
],
[
"def run_cv_model(train, test, target, model_fn, params={}, eval_fn=None, label='model'):\n kf = StratifiedKFold(n_splits=5, shuffle = True, random_state = 228)\n fold_splits = kf.split(train, target)\n cv_scores = []\n pred_full_test = 0\n pred_train = np.zeros((train.shape[0]))\n i = 1\n for dev_index, val_index in fold_splits:\n print('Started ' + label + ' fold ' + str(i) + '/5')\n dev_X, val_X = train[dev_index], train[val_index]\n dev_y, val_y = target[dev_index], target[val_index]\n params2 = params.copy()\n pred_val_y, pred_test_y = model_fn(dev_X, dev_y, val_X, val_y, test, params2)\n pred_full_test = pred_full_test + pred_test_y\n pred_train[val_index] = pred_val_y\n if eval_fn is not None:\n cv_score = eval_fn(val_y, pred_val_y)\n cv_scores.append(cv_score)\n print(label + ' cv score {}: {}'.format(i, cv_score))\n i += 1\n print('{} cv scores : {}'.format(label, cv_scores))\n print('{} cv mean score : {}'.format(label, np.mean(cv_scores)))\n print('{} cv std score : {}'.format(label, np.std(cv_scores)))\n pred_full_test = pred_full_test / 10.0\n results = {'label': label,\n 'train': pred_train, 'test': pred_full_test,\n 'cv': cv_scores}\n return results\n\n\ndef runLR(train_X, train_y, test_X, test_y, test_X2, params):\n print('Train LR')\n model = LogisticRegression(**params)\n model.fit(train_X, train_y)\n print('Predict 1/2')\n pred_test_y = logit(model.predict_proba(test_X)[:, 1])\n print('Predict 2/2')\n pred_test_y2 = logit(model.predict_proba(test_X2)[:, 1])\n return pred_test_y, pred_test_y2",
"_____no_output_____"
],
[
"target = train['redemption_status'].values\nlr_params = {'solver': 'lbfgs','C': 1.8,'max_iter' : 2000}\nresults = run_cv_model(train_np, test_np, target, runLR, lr_params, auc, 'lr')",
"Started lr fold 1/5\nTrain LR\n"
],
[
"tmp = dict(zip(test.id.values, results['test']))\nanswer1 = pd.DataFrame()\nanswer1['id'] = test.id.values\nanswer1['redemption_status'] = answer1['id'].map(tmp)\nanswer1.to_csv('submit_new.csv', index = None)",
"_____no_output_____"
]
],
[
[
"**xgboost**",
"_____no_output_____"
]
],
[
[
"def runXgb(train_X, train_y, test_X, test_y, test_X2, params):\n print('Train LR')\n model = XGBClassifier(random_state=42)\n model.fit(train_X, train_y)\n print('Predict 1/2')\n pred_test_y = logit(model.predict_proba(test_X)[:, 1])\n print('Predict 2/2')\n pred_test_y2 = logit(model.predict_proba(test_X2)[:, 1])\n return pred_test_y, pred_test_y2",
"_____no_output_____"
],
[
"target = train['redemption_status'].values\nlr_params = {'solver': 'lbfgs','C': 1.8,'max_iter' : 2000}\nresults = run_cv_model(train_np, test_np, target, runXgb, lr_params, auc, 'xgb')",
"Started lr fold 1/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 1: 0.9196237640532701\nStarted lr fold 2/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 2: 0.9069978756889896\nStarted lr fold 3/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 3: 0.9192505981241135\nStarted lr fold 4/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 4: 0.9319179493694114\nStarted lr fold 5/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 5: 0.8962757510956787\nStarted lr fold 6/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 6: 0.9253500525784619\nStarted lr fold 7/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 7: 0.9145855829151758\nStarted lr fold 8/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 8: 0.9036667301842716\nStarted lr fold 9/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 9: 0.9028039493835263\nStarted lr fold 10/5\nTrain LR\nPredict 1/2\nPredict 2/2\nlr cv score 10: 0.9265609794493103\nlr cv scores : [0.9196237640532701, 0.9069978756889896, 0.9192505981241135, 0.9319179493694114, 0.8962757510956787, 0.9253500525784619, 0.9145855829151758, 0.9036667301842716, 0.9028039493835263, 0.9265609794493103]\nlr cv mean score : 0.9147033232842208\nlr cv std score : 0.011214068575508933\n"
],
[
"tmp = dict(zip(test.id.values, results['test']))\nanswer1 = pd.DataFrame()\nanswer1['id'] = test.id.values\nanswer1['redemption_status'] = answer1['id'].map(tmp)\nanswer1.to_csv('submit_new_xgb.csv', index = None)",
"_____no_output_____"
],
[
"target = train['redemption_status'].values\nlr_params = {'solver': 'lbfgs','C': 1.8,'max_iter' : 2000}\nresults = run_cv_model(train_np, test_np, target, runXgb, lr_params, auc, 'xgb')",
"Started xgb fold 1/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 1: 0.9604805812566606\nStarted xgb fold 2/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 2: 0.9641646023445054\nStarted xgb fold 3/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 3: 0.9680991650963703\nStarted xgb fold 4/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 4: 0.9692248382065451\nStarted xgb fold 5/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 5: 0.9586562144918944\nStarted xgb fold 6/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 6: 0.9692371888519546\nStarted xgb fold 7/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 7: 0.9671155244084041\nStarted xgb fold 8/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 8: 0.9604417649425167\nStarted xgb fold 9/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 9: 0.9643022238219248\nStarted xgb fold 10/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb cv score 10: 0.969627447192169\nxgb cv scores : [0.9604805812566606, 0.9641646023445054, 0.9680991650963703, 0.9692248382065451, 0.9586562144918944, 0.9692371888519546, 0.9671155244084041, 0.9604417649425167, 0.9643022238219248, 0.969627447192169]\nxgb cv mean score : 0.9651349550612945\nxgb cv std score : 0.003921039172382897\n"
],
[
"tmp = dict(zip(test.id.values, results['test']))\nanswer1 = pd.DataFrame()\nanswer1['id'] = test.id.values\nanswer1['redemption_status'] = answer1['id'].map(tmp)\nanswer1.to_csv('submit_new_xgb_with_my_inception_feature.csv', index = None)",
"_____no_output_____"
]
],
[
[
"### Bayesian Optimisation",
"_____no_output_____"
]
],
[
[
"dtrain = xgb.DMatrix(train_np, label=target)",
"_____no_output_____"
],
[
"train_np.shape",
"_____no_output_____"
],
[
"def bo_tune_xgb(max_depth, gamma, n_estimators ,learning_rate, subsample):\n params = {'max_depth': int(max_depth),\n 'gamma': gamma,\n 'n_estimators': int(n_estimators),\n 'learning_rate':learning_rate,\n 'subsample': float(subsample),\n 'eta': 0.1,\n 'objective':'binary:logistic',\n 'eval_metric': 'auc'}\n #Cross validating with the specified parameters in 5 folds and 70 iterations\n cv_result = xgb.cv(params, dtrain, num_boost_round=70, nfold=5)\n #Return the negative RMSE\n return cv_result['test-auc-mean'].iloc[-1]",
"_____no_output_____"
],
[
"xgb_bo = BayesianOptimization(bo_tune_xgb, {'max_depth': (3, 10), \n 'gamma': (0, 1),\n 'learning_rate':(0,1),\n 'n_estimators':(100,120),\n 'subsample':(0.1,0.3)\n })",
"_____no_output_____"
],
[
"xgb_bo.maximize(n_iter=5, init_points=8, acq='ei')",
"| iter | target | gamma | learni... | max_depth | n_esti... | subsample |\n-------------------------------------------------------------------------------------\n| \u001b[0m 1 \u001b[0m | \u001b[0m 0.8971 \u001b[0m | \u001b[0m 0.4825 \u001b[0m | \u001b[0m 0.4488 \u001b[0m | \u001b[0m 4.53 \u001b[0m | \u001b[0m 117.1 \u001b[0m | \u001b[0m 0.2903 \u001b[0m |\n| \u001b[0m 2 \u001b[0m | \u001b[0m 0.833 \u001b[0m | \u001b[0m 0.04989 \u001b[0m | \u001b[0m 0.9978 \u001b[0m | \u001b[0m 3.954 \u001b[0m | \u001b[0m 113.9 \u001b[0m | \u001b[0m 0.1999 \u001b[0m |\n| \u001b[0m 3 \u001b[0m | \u001b[0m 0.8611 \u001b[0m | \u001b[0m 0.2141 \u001b[0m | \u001b[0m 0.4501 \u001b[0m | \u001b[0m 7.414 \u001b[0m | \u001b[0m 108.3 \u001b[0m | \u001b[0m 0.1594 \u001b[0m |\n| \u001b[0m 4 \u001b[0m | \u001b[0m 0.8727 \u001b[0m | \u001b[0m 0.2158 \u001b[0m | \u001b[0m 0.6634 \u001b[0m | \u001b[0m 3.655 \u001b[0m | \u001b[0m 119.4 \u001b[0m | \u001b[0m 0.1952 \u001b[0m |\n| \u001b[95m 5 \u001b[0m | \u001b[95m 0.8993 \u001b[0m | \u001b[95m 0.2872 \u001b[0m | \u001b[95m 0.4883 \u001b[0m | \u001b[95m 3.239 \u001b[0m | \u001b[95m 113.1 \u001b[0m | \u001b[95m 0.2781 \u001b[0m |\n| \u001b[0m 6 \u001b[0m | \u001b[0m 0.8809 \u001b[0m | \u001b[0m 0.3213 \u001b[0m | \u001b[0m 0.4004 \u001b[0m | \u001b[0m 8.183 \u001b[0m | \u001b[0m 117.6 \u001b[0m | \u001b[0m 0.2675 \u001b[0m |\n| \u001b[95m 7 \u001b[0m | \u001b[95m 0.9074 \u001b[0m | \u001b[95m 0.923 \u001b[0m | \u001b[95m 0.1733 \u001b[0m | \u001b[95m 3.168 \u001b[0m | \u001b[95m 106.2 \u001b[0m | \u001b[95m 0.1987 \u001b[0m |\n| \u001b[0m 8 \u001b[0m | \u001b[0m 0.8323 \u001b[0m | \u001b[0m 0.7869 \u001b[0m | \u001b[0m 0.8965 \u001b[0m | \u001b[0m 7.656 \u001b[0m | \u001b[0m 119.3 \u001b[0m | \u001b[0m 0.2554 \u001b[0m |\n| \u001b[0m 9 \u001b[0m | \u001b[0m 0.5 \u001b[0m | \u001b[0m 1.0 \u001b[0m | \u001b[0m 0.0 \u001b[0m | \u001b[0m 3.0 \u001b[0m | \u001b[0m 115.3 \u001b[0m | \u001b[0m 0.3 \u001b[0m |\n| \u001b[0m 10 \u001b[0m | \u001b[0m 0.5 \u001b[0m | \u001b[0m 0.0 \u001b[0m | \u001b[0m 0.0 \u001b[0m | \u001b[0m 3.0 \u001b[0m | \u001b[0m 110.0 \u001b[0m | \u001b[0m 0.3 \u001b[0m |\n| \u001b[0m 11 \u001b[0m | \u001b[0m 0.7679 \u001b[0m | \u001b[0m 1.0 \u001b[0m | \u001b[0m 1.0 \u001b[0m | \u001b[0m 5.304 \u001b[0m | \u001b[0m 100.6 \u001b[0m | \u001b[0m 0.1 \u001b[0m |\n| \u001b[0m 12 \u001b[0m | \u001b[0m 0.5 \u001b[0m | \u001b[0m 1.0 \u001b[0m | \u001b[0m 0.0 \u001b[0m | \u001b[0m 10.0 \u001b[0m | \u001b[0m 104.1 \u001b[0m | \u001b[0m 0.3 \u001b[0m |\n| \u001b[0m 13 \u001b[0m | \u001b[0m 0.5 \u001b[0m | \u001b[0m 1.0 \u001b[0m | \u001b[0m 0.0 \u001b[0m | \u001b[0m 10.0 \u001b[0m | \u001b[0m 112.1 \u001b[0m | \u001b[0m 0.3 \u001b[0m |\n=====================================================================================\n"
],
[
"def runXgbHighest(train_X, train_y, test_X, test_y, test_X2, params):\n print('Train LR')\n model = XGBClassifier(random_state=42, learning_rate=0.03455, gamma=0.1887, max_depth=8, n_estimators=116, subsample=0.2643)\n model.fit(train_X, train_y)\n print('Predict 1/2')\n pred_test_y = logit(model.predict_proba(test_X)[:, 1])\n print('Predict 2/2')\n pred_test_y2 = logit(model.predict_proba(test_X2)[:, 1])\n return pred_test_y, pred_test_y2",
"_____no_output_____"
],
[
"target = train['redemption_status'].values\nlr_params = {'solver': 'lbfgs','C': 1.8,'max_iter' : 2000}\nresults = run_cv_model(train_np, test_np, target, runXgbHighest, lr_params, auc, 'xgb-bpo')",
"Started xgb-bpo fold 1/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 1: 0.9554970958339507\nStarted xgb-bpo fold 2/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 2: 0.9634103307855716\nStarted xgb-bpo fold 3/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 3: 0.9661248262087753\nStarted xgb-bpo fold 4/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 4: 0.9712794562893016\nStarted xgb-bpo fold 5/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 5: 0.9562954768407755\nStarted xgb-bpo fold 6/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 6: 0.9679112588483553\nStarted xgb-bpo fold 7/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 7: 0.9626587057935113\nStarted xgb-bpo fold 8/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 8: 0.959531345938049\nStarted xgb-bpo fold 9/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 9: 0.9605696823413999\nStarted xgb-bpo fold 10/5\nTrain LR\nPredict 1/2\nPredict 2/2\nxgb-bpo cv score 10: 0.9698125965996909\nxgb-bpo cv scores : [0.9554970958339507, 0.9634103307855716, 0.9661248262087753, 0.9712794562893016, 0.9562954768407755, 0.9679112588483553, 0.9626587057935113, 0.959531345938049, 0.9605696823413999, 0.9698125965996909]\nxgb-bpo cv mean score : 0.9633090775479383\nxgb-bpo cv std score : 0.005170663802747549\n"
],
[
"tmp = dict(zip(test.id.values, results['test']))\nanswer1 = pd.DataFrame()\nanswer1['id'] = test.id.values\nanswer1['redemption_status'] = answer1['id'].map(tmp)\nanswer1.to_csv('submit_new_xgb_with_my_inception_feature_BPO.csv', index = None)",
"_____no_output_____"
],
[
"def runXgbHighest2(train_X, train_y, test_X, test_y, test_X2, params):\n print('Train LR')\n model = XGBClassifier(random_state=42, learning_rate=0.1733, gamma=0.923, max_depth=3, n_estimators=106, subsample=0.1987)\n model.fit(train_X, train_y)\n print('Predict 1/2')\n pred_test_y = logit(model.predict_proba(test_X)[:, 1])\n print('Predict 2/2')\n pred_test_y2 = logit(model.predict_proba(test_X2)[:, 1])\n print('feature importance : {}'.format(model.feature_importances_))\n return pred_test_y, pred_test_y2",
"_____no_output_____"
],
[
"target = train['redemption_status'].values\nlr_params = {'solver': 'lbfgs','C': 1.8,'max_iter' : 2000}\nresults = run_cv_model(train_np, test_np, target, runXgbHighest2, lr_params, auc, 'xgb-bpo2')",
"Started xgb-bpo2 fold 1/5\nTrain LR\nPredict 1/2\nPredict 2/2\nfeature importance : [0.05037954 0.04591098 0.05606027 0.03044404 0.04609721 0.0337368\n 0.05608289 0.03338706 0. 0.0485968 0.04821579 0.05407567\n 0.03965615 0.03938425 0.06306253 0.02905087 0.03927152 0.03638927\n 0.05644433 0.04014567 0.03124542 0.04412053 0.03865521 0.03958711]\nxgb-bpo2 cv score 1: 0.9153043463685573\nStarted xgb-bpo2 fold 2/5\nTrain LR\nPredict 1/2\nPredict 2/2\nfeature importance : [0.05307731 0.04672448 0.05680313 0.0479537 0.03344129 0.04509368\n 0.02907523 0. 0. 0.03389921 0.04171652 0.05706872\n 0.03926303 0.04610841 0.047458 0.04981609 0.05788095 0.04451828\n 0.05359478 0.04155997 0.04086689 0.04405981 0.0406845 0.0493359 ]\nxgb-bpo2 cv score 2: 0.9277235819694692\nStarted xgb-bpo2 fold 3/5\nTrain LR\nPredict 1/2\nPredict 2/2\nfeature importance : [0.05655163 0.04777016 0.06292161 0.0517264 0.04835346 0.03664533\n 0.03281117 0. 0. 0.05184841 0.04450717 0.05238169\n 0.0376266 0.04430813 0.0495269 0.04030379 0.03992847 0.0461232\n 0.05115718 0.04447303 0.02687925 0.04876933 0.04060897 0.04477812]\nxgb-bpo2 cv score 3: 0.9001875974818798\nStarted xgb-bpo2 fold 4/5\nTrain LR\nPredict 1/2\nPredict 2/2\nfeature importance : [0.04816479 0.04339594 0.06282289 0. 0.05181263 0.02832247\n 0.02851094 0.04499105 0. 0.04509948 0.03927634 0.05259936\n 0.03851651 0.04232266 0.05089379 0.05259987 0.05147269 0.06226695\n 0.0569682 0.0433233 0.0283847 0.04341668 0.03487258 0.04996615]\nxgb-bpo2 cv score 4: 0.9102317598611082\nStarted xgb-bpo2 fold 5/5\nTrain LR\nPredict 1/2\nPredict 2/2\nfeature importance : [0.05382433 0.04921471 0.06266589 0.03617982 0.04662308 0.04141796\n 0.01766203 0.03672034 0. 0.02891087 0.04258856 0.05705872\n 0.03792675 0.04301045 0.03520577 0.04179351 0.04757439 0.07518928\n 0.05066955 0.05031457 0.02105836 0.04312341 0.03551601 0.04575156]\nxgb-bpo2 cv score 5: 0.9097265895645685\nxgb-bpo2 cv scores : [0.9153043463685573, 0.9277235819694692, 0.9001875974818798, 0.9102317598611082, 0.9097265895645685]\nxgb-bpo2 cv mean score : 0.9126347750491167\nxgb-bpo2 cv std score : 0.008988469942163907\n"
],
[
"tmp = dict(zip(test.id.values, results['test']))\nanswer1 = pd.DataFrame()\nanswer1['id'] = test.id.values\nanswer1['redemption_status'] = answer1['id'].map(tmp)\nanswer1.to_csv('submit_new_xgb_BPO_2.csv', index = None)",
"_____no_output_____"
],
[
"def runXgbHighest3(train_X, train_y, test_X, test_y, test_X2, params):\n print('Train LR')\n model = XGBClassifier(random_state=42, learning_rate=0.4501, gamma=0.2141, max_depth=7, n_estimators=108, subsample=0.1594)\n model.fit(train_X, train_y)\n print('Predict 1/2')\n pred_test_y = logit(model.predict_proba(test_X)[:, 1])\n print('Predict 2/2')\n pred_test_y2 = logit(model.predict_proba(test_X2)[:, 1])\n return pred_test_y, pred_test_y2",
"_____no_output_____"
]
],
[
[
"**Tetsing sanity of data**",
"_____no_output_____"
]
],
[
[
"item_data.head()",
"_____no_output_____"
],
[
"coupon_item_mapping.head()",
"_____no_output_____"
],
[
"coupon_item_mapping.shape",
"_____no_output_____"
],
[
"coupon_item_mapping.merge(item_data, how = 'left', on = 'item_id').shape",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"ltr",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"train.shape",
"_____no_output_____"
],
[
"test.shape",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"data.isna().sum()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a45a263775235cb3667d1682e6df73d998e5884
| 74,495 |
ipynb
|
Jupyter Notebook
|
01-NLP.ipynb
|
sphurthy/ML
|
076a81ce1d4d45354ccb5d5ce4c74b943499064c
|
[
"Unlicense"
] | null | null | null |
01-NLP.ipynb
|
sphurthy/ML
|
076a81ce1d4d45354ccb5d5ce4c74b943499064c
|
[
"Unlicense"
] | 9 |
2020-09-25T21:49:09.000Z
|
2022-02-10T01:24:14.000Z
|
01-NLP.ipynb
|
sphurthy/ML
|
076a81ce1d4d45354ccb5d5ce4c74b943499064c
|
[
"Unlicense"
] | 1 |
2020-04-07T12:52:55.000Z
|
2020-04-07T12:52:55.000Z
| 44.741742 | 12,200 | 0.653547 |
[
[
[
"___\n\n<a href='http://www.pieriandata.com'> <img src='../Pierian_Data_Logo.png' /></a>\n___\n# NLP (Natural Language Processing) with Python\n\nThis is the notebook that goes along with the NLP video lecture!\n\nIn this lecture we will discuss a higher level overview of the basics of Natural Language Processing, which basically consists of combining machine learning techniques with text, and using math and statistics to get that text in a format that the machine learning algorithms can understand!\n\nOnce you've completed this lecture you'll have a project using some Yelp Text Data!\n \n**Requirements: You will need to have NLTK installed, along with downloading the corpus for stopwords. To download everything with a conda installation, run the cell below. Or reference the full video lecture**",
"_____no_output_____"
]
],
[
[
"# ONLY RUN THIS CELL IF YOU NEED \n# TO DOWNLOAD NLTK AND HAVE CONDA\n# WATCH THE VIDEO FOR FULL INSTRUCTIONS ON THIS STEP\n\n# Uncomment the code below and run:\n\n\n# !conda install nltk #This installs nltk\n# import nltk # Imports the library\n# nltk.download() #Download the necessary datasets",
"_____no_output_____"
]
],
[
[
"## Get the Data",
"_____no_output_____"
],
[
"We'll be using a dataset from the [UCI datasets](https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection)! This dataset is already located in the folder for this section.",
"_____no_output_____"
],
[
"The file we are using contains a collection of more than 5 thousand SMS phone messages. You can check out the **readme** file for more info.\n\nLet's go ahead and use rstrip() plus a list comprehension to get a list of all the lines of text messages:",
"_____no_output_____"
]
],
[
[
"messages = [line.rstrip() for line in open('smsspamcollection/SMSSpamCollection')]\nprint(len(messages))",
"5574\n"
]
],
[
[
"A collection of texts is also sometimes called \"corpus\". Let's print the first ten messages and number them using **enumerate**:",
"_____no_output_____"
]
],
[
[
"for message_no, message in enumerate(messages[:10]):\n print(message_no, message)\n print('\\n')",
"0 ham\tGo until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...\n\n\n1 ham\tOk lar... Joking wif u oni...\n\n\n2 spam\tFree entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's\n\n\n3 ham\tU dun say so early hor... U c already then say...\n\n\n4 ham\tNah I don't think he goes to usf, he lives around here though\n\n\n5 spam\tFreeMsg Hey there darling it's been 3 week's now and no word back! I'd like some fun you up for it still? Tb ok! XxX std chgs to send, £1.50 to rcv\n\n\n6 ham\tEven my brother is not like to speak with me. They treat me like aids patent.\n\n\n7 ham\tAs per your request 'Melle Melle (Oru Minnaminunginte Nurungu Vettam)' has been set as your callertune for all Callers. Press *9 to copy your friends Callertune\n\n\n8 spam\tWINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.\n\n\n9 spam\tHad your mobile 11 months or more? U R entitled to Update to the latest colour mobiles with camera for Free! Call The Mobile Update Co FREE on 08002986030\n\n\n"
]
],
[
[
"Due to the spacing we can tell that this is a [TSV](http://en.wikipedia.org/wiki/Tab-separated_values) (\"tab separated values\") file, where the first column is a label saying whether the given message is a normal message (commonly known as \"ham\") or \"spam\". The second column is the message itself. (Note our numbers aren't part of the file, they are just from the **enumerate** call).\n\nUsing these labeled ham and spam examples, we'll **train a machine learning model to learn to discriminate between ham/spam automatically**. Then, with a trained model, we'll be able to **classify arbitrary unlabeled messages** as ham or spam.\n\nFrom the official SciKit Learn documentation, we can visualize our process:",
"_____no_output_____"
],
[
"<img src='http://www.astroml.org/sklearn_tutorial/_images/plot_ML_flow_chart_3.png' width=600/>",
"_____no_output_____"
],
[
"Instead of parsing TSV manually using Python, we can just take advantage of pandas! Let's go ahead and import it!",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"We'll use **read_csv** and make note of the **sep** argument, we can also specify the desired column names by passing in a list of *names*.",
"_____no_output_____"
]
],
[
[
"messages = pd.read_csv('smsspamcollection/SMSSpamCollection', sep='\\t',\n names=[\"label\", \"message\"])\nmessages.head()",
"_____no_output_____"
]
],
[
[
"## Exploratory Data Analysis\n\nLet's check out some of the stats with some plots and the built-in methods in pandas!",
"_____no_output_____"
]
],
[
[
"messages.describe()",
"_____no_output_____"
]
],
[
[
"Let's use **groupby** to use describe by label, this way we can begin to think about the features that separate ham and spam!",
"_____no_output_____"
]
],
[
[
"messages.groupby('label').describe()",
"_____no_output_____"
]
],
[
[
"As we continue our analysis we want to start thinking about the features we are going to be using. This goes along with the general idea of [feature engineering](https://en.wikipedia.org/wiki/Feature_engineering). The better your domain knowledge on the data, the better your ability to engineer more features from it. Feature engineering is a very large part of spam detection in general. I encourage you to read up on the topic!\n\nLet's make a new column to detect how long the text messages are:",
"_____no_output_____"
]
],
[
[
"messages['length'] = messages['message'].apply(len)\nmessages.head()",
"_____no_output_____"
]
],
[
[
"### Data Visualization\nLet's visualize this! Let's do the imports:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\n\n%matplotlib inline",
"_____no_output_____"
],
[
"messages['length'].plot(bins=50, kind='hist') ",
"_____no_output_____"
]
],
[
[
"Play around with the bin size! Looks like text length may be a good feature to think about! Let's try to explain why the x-axis goes all the way to 1000ish, this must mean that there is some really long message!",
"_____no_output_____"
]
],
[
[
"messages.length.describe()",
"_____no_output_____"
]
],
[
[
"Woah! 910 characters, let's use masking to find this message:",
"_____no_output_____"
]
],
[
[
"messages[messages['length'] == 910]['message'].iloc[0]",
"_____no_output_____"
]
],
[
[
"Looks like we have some sort of Romeo sending texts! But let's focus back on the idea of trying to see if message length is a distinguishing feature between ham and spam:",
"_____no_output_____"
]
],
[
[
"messages.hist(column='length', by='label', bins=50,figsize=(12,4))",
"_____no_output_____"
]
],
[
[
"Very interesting! Through just basic EDA we've been able to discover a trend that spam messages tend to have more characters. (Sorry Romeo!)\n\nNow let's begin to process the data so we can eventually use it with SciKit Learn!",
"_____no_output_____"
],
[
"## Text Pre-processing",
"_____no_output_____"
],
[
"Our main issue with our data is that it is all in text format (strings). The classification algorithms that we've learned about so far will need some sort of numerical feature vector in order to perform the classification task. There are actually many methods to convert a corpus to a vector format. The simplest is the the [bag-of-words](http://en.wikipedia.org/wiki/Bag-of-words_model) approach, where each unique word in a text will be represented by one number.\n\n\nIn this section we'll convert the raw messages (sequence of characters) into vectors (sequences of numbers).\n\nAs a first step, let's write a function that will split a message into its individual words and return a list. We'll also remove very common words, ('the', 'a', etc..). To do this we will take advantage of the NLTK library. It's pretty much the standard library in Python for processing text and has a lot of useful features. We'll only use some of the basic ones here.\n\nLet's create a function that will process the string in the message column, then we can just use **apply()** in pandas do process all the text in the DataFrame.\n\nFirst removing punctuation. We can just take advantage of Python's built-in **string** library to get a quick list of all the possible punctuation:",
"_____no_output_____"
]
],
[
[
"import string\n\nmess = 'Sample message! Notice: it has punctuation.'\n\n# Check characters to see if they are in punctuation\nnopunc = [char for char in mess if char not in string.punctuation]\n\n# Join the characters again to form the string.\nnopunc = ''.join(nopunc)",
"_____no_output_____"
]
],
[
[
"Now let's see how to remove stopwords. We can impot a list of english stopwords from NLTK (check the documentation for more languages and info).",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import stopwords\nstopwords.words('english')[0:10] # Show some stop words",
"_____no_output_____"
],
[
"nopunc.split()",
"_____no_output_____"
],
[
"# Now just remove any stopwords\nclean_mess = [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]",
"_____no_output_____"
],
[
"clean_mess",
"_____no_output_____"
]
],
[
[
"Now let's put both of these together in a function to apply it to our DataFrame later on:",
"_____no_output_____"
]
],
[
[
"def text_process(mess):\n \"\"\"\n Takes in a string of text, then performs the following:\n 1. Remove all punctuation\n 2. Remove all stopwords\n 3. Returns a list of the cleaned text\n \"\"\"\n # Check characters to see if they are in punctuation\n nopunc = [char for char in mess if char not in string.punctuation]\n\n # Join the characters again to form the string.\n nopunc = ''.join(nopunc)\n \n # Now just remove any stopwords\n return [word for word in nopunc.split() if word.lower() not in stopwords.words('english')]",
"_____no_output_____"
]
],
[
[
"Here is the original DataFrame again:",
"_____no_output_____"
]
],
[
[
"messages.head()",
"_____no_output_____"
]
],
[
[
"Now let's \"tokenize\" these messages. Tokenization is just the term used to describe the process of converting the normal text strings in to a list of tokens (words that we actually want).\n\nLet's see an example output on on column:\n\n**Note:**\nWe may get some warnings or errors for symbols we didn't account for or that weren't in Unicode (like a British pound symbol)",
"_____no_output_____"
]
],
[
[
"# Check to make sure its working\nmessages['message'].head(5).apply(text_process)",
"_____no_output_____"
],
[
"# Show original dataframe\nmessages.head()",
"_____no_output_____"
]
],
[
[
"### Continuing Normalization\n\nThere are a lot of ways to continue normalizing this text. Such as [Stemming](https://en.wikipedia.org/wiki/Stemming) or distinguishing by [part of speech](http://www.nltk.org/book/ch05.html).\n\nNLTK has lots of built-in tools and great documentation on a lot of these methods. Sometimes they don't work well for text-messages due to the way a lot of people tend to use abbreviations or shorthand, For example:\n \n 'Nah dawg, IDK! Wut time u headin to da club?'\n \nversus\n\n 'No dog, I don't know! What time are you heading to the club?'\n \nSome text normalization methods will have trouble with this type of shorthand and so I'll leave you to explore those more advanced methods through the [NLTK book online](http://www.nltk.org/book/).\n\nFor now we will just focus on using what we have to convert our list of words to an actual vector that SciKit-Learn can use.",
"_____no_output_____"
],
[
"## Vectorization",
"_____no_output_____"
],
[
"Currently, we have the messages as lists of tokens (also known as [lemmas](http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html)) and now we need to convert each of those messages into a vector the SciKit Learn's algorithm models can work with.\n\nNow we'll convert each message, represented as a list of tokens (lemmas) above, into a vector that machine learning models can understand.\n\nWe'll do that in three steps using the bag-of-words model:\n\n1. Count how many times does a word occur in each message (Known as term frequency)\n\n2. Weigh the counts, so that frequent tokens get lower weight (inverse document frequency)\n\n3. Normalize the vectors to unit length, to abstract from the original text length (L2 norm)\n\nLet's begin the first step:",
"_____no_output_____"
],
[
"Each vector will have as many dimensions as there are unique words in the SMS corpus. We will first use SciKit Learn's **CountVectorizer**. This model will convert a collection of text documents to a matrix of token counts.\n\nWe can imagine this as a 2-Dimensional matrix. Where the 1-dimension is the entire vocabulary (1 row per word) and the other dimension are the actual documents, in this case a column per text message. \n\nFor example:\n\n<table border = “1“>\n<tr>\n<th></th> <th>Message 1</th> <th>Message 2</th> <th>...</th> <th>Message N</th> \n</tr>\n<tr>\n<td><b>Word 1 Count</b></td><td>0</td><td>1</td><td>...</td><td>0</td>\n</tr>\n<tr>\n<td><b>Word 2 Count</b></td><td>0</td><td>0</td><td>...</td><td>0</td>\n</tr>\n<tr>\n<td><b>...</b></td> <td>1</td><td>2</td><td>...</td><td>0</td>\n</tr>\n<tr>\n<td><b>Word N Count</b></td> <td>0</td><td>1</td><td>...</td><td>1</td>\n</tr>\n</table>\n\n\nSince there are so many messages, we can expect a lot of zero counts for the presence of that word in that document. Because of this, SciKit Learn will output a [Sparse Matrix](https://en.wikipedia.org/wiki/Sparse_matrix).",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer",
"_____no_output_____"
]
],
[
[
"There are a lot of arguments and parameters that can be passed to the CountVectorizer. In this case we will just specify the **analyzer** to be our own previously defined function:",
"_____no_output_____"
]
],
[
[
"# Might take awhile...\nbow_transformer = CountVectorizer(analyzer=text_process).fit(messages['message'])\n\n# Print total number of vocab words\nprint(len(bow_transformer.vocabulary_))",
"11444\n"
]
],
[
[
"Let's take one text message and get its bag-of-words counts as a vector, putting to use our new `bow_transformer`:",
"_____no_output_____"
]
],
[
[
"message4 = messages['message'][3]\nprint(message4)",
"U dun say so early hor... U c already then say...\n"
]
],
[
[
"Now let's see its vector representation:",
"_____no_output_____"
]
],
[
[
"bow4 = bow_transformer.transform([message4])\nprint(bow4)\nprint(bow4.shape)",
" (0, 4073)\t2\n (0, 4638)\t1\n (0, 5270)\t1\n (0, 6214)\t1\n (0, 6232)\t1\n (0, 7197)\t1\n (0, 9570)\t2\n(1, 11444)\n"
]
],
[
[
"This means that there are seven unique words in message number 4 (after removing common stop words). Two of them appear twice, the rest only once. Let's go ahead and check and confirm which ones appear twice:",
"_____no_output_____"
]
],
[
[
"print(bow_transformer.get_feature_names()[4073])\nprint(bow_transformer.get_feature_names()[9570])",
"U\nsay\n"
]
],
[
[
"Now we can use **.transform** on our Bag-of-Words (bow) transformed object and transform the entire DataFrame of messages. Let's go ahead and check out how the bag-of-words counts for the entire SMS corpus is a large, sparse matrix:",
"_____no_output_____"
]
],
[
[
"messages_bow = bow_transformer.transform(messages['message'])",
"_____no_output_____"
],
[
"print('Shape of Sparse Matrix: ', messages_bow.shape)\nprint('Amount of Non-Zero occurences: ', messages_bow.nnz)",
"Shape of Sparse Matrix: (5572, 11444)\nAmount of Non-Zero occurences: 50795\n"
],
[
"sparsity = (100.0 * messages_bow.nnz / (messages_bow.shape[0] * messages_bow.shape[1]))\nprint('sparsity: {}'.format(round(sparsity)))",
"sparsity: 0\n"
]
],
[
[
"After the counting, the term weighting and normalization can be done with [TF-IDF](http://en.wikipedia.org/wiki/Tf%E2%80%93idf), using scikit-learn's `TfidfTransformer`.\n\n____\n### So what is TF-IDF?\nTF-IDF stands for *term frequency-inverse document frequency*, and the tf-idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus. Variations of the tf-idf weighting scheme are often used by search engines as a central tool in scoring and ranking a document's relevance given a user query.\n\nOne of the simplest ranking functions is computed by summing the tf-idf for each query term; many more sophisticated ranking functions are variants of this simple model.\n\nTypically, the tf-idf weight is composed by two terms: the first computes the normalized Term Frequency (TF), aka. the number of times a word appears in a document, divided by the total number of words in that document; the second term is the Inverse Document Frequency (IDF), computed as the logarithm of the number of the documents in the corpus divided by the number of documents where the specific term appears.\n\n**TF: Term Frequency**, which measures how frequently a term occurs in a document. Since every document is different in length, it is possible that a term would appear much more times in long documents than shorter ones. Thus, the term frequency is often divided by the document length (aka. the total number of terms in the document) as a way of normalization: \n\n*TF(t) = (Number of times term t appears in a document) / (Total number of terms in the document).*\n\n**IDF: Inverse Document Frequency**, which measures how important a term is. While computing TF, all terms are considered equally important. However it is known that certain terms, such as \"is\", \"of\", and \"that\", may appear a lot of times but have little importance. Thus we need to weigh down the frequent terms while scale up the rare ones, by computing the following: \n\n*IDF(t) = log_e(Total number of documents / Number of documents with term t in it).*\n\nSee below for a simple example.\n\n**Example:**\n\nConsider a document containing 100 words wherein the word cat appears 3 times. \n\nThe term frequency (i.e., tf) for cat is then (3 / 100) = 0.03. Now, assume we have 10 million documents and the word cat appears in one thousand of these. Then, the inverse document frequency (i.e., idf) is calculated as log(10,000,000 / 1,000) = 4. Thus, the Tf-idf weight is the product of these quantities: 0.03 * 4 = 0.12.\n____\n\nLet's go ahead and see how we can do this in SciKit Learn:",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfTransformer\n\ntfidf_transformer = TfidfTransformer().fit(messages_bow)\ntfidf4 = tfidf_transformer.transform(bow4)\nprint(tfidf4)",
" (0, 9570)\t0.538562626293\n (0, 7197)\t0.438936565338\n (0, 6232)\t0.318721689295\n (0, 6214)\t0.299537997237\n (0, 5270)\t0.297299574059\n (0, 4638)\t0.266198019061\n (0, 4073)\t0.408325899334\n"
]
],
[
[
"We'll go ahead and check what is the IDF (inverse document frequency) of the word `\"u\"` and of word `\"university\"`?",
"_____no_output_____"
]
],
[
[
"print(tfidf_transformer.idf_[bow_transformer.vocabulary_['u']])\nprint(tfidf_transformer.idf_[bow_transformer.vocabulary_['university']])",
"3.28005242674\n8.5270764989\n"
]
],
[
[
"To transform the entire bag-of-words corpus into TF-IDF corpus at once:",
"_____no_output_____"
]
],
[
[
"messages_tfidf = tfidf_transformer.transform(messages_bow)\nprint(messages_tfidf.shape)",
"(5572, 11444)\n"
]
],
[
[
"There are many ways the data can be preprocessed and vectorized. These steps involve feature engineering and building a \"pipeline\". I encourage you to check out SciKit Learn's documentation on dealing with text data as well as the expansive collection of available papers and books on the general topic of NLP.",
"_____no_output_____"
],
[
"## Training a model",
"_____no_output_____"
],
[
"With messages represented as vectors, we can finally train our spam/ham classifier. Now we can actually use almost any sort of classification algorithms. For a [variety of reasons](http://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn-note07-2up.pdf), the Naive Bayes classifier algorithm is a good choice.",
"_____no_output_____"
],
[
"We'll be using scikit-learn here, choosing the [Naive Bayes](http://en.wikipedia.org/wiki/Naive_Bayes_classifier) classifier to start with:",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import MultinomialNB\nspam_detect_model = MultinomialNB().fit(messages_tfidf, messages['label'])",
"_____no_output_____"
]
],
[
[
"Let's try classifying our single random message and checking how we do:",
"_____no_output_____"
]
],
[
[
"print('predicted:', spam_detect_model.predict(tfidf4)[0])\nprint('expected:', messages.label[3])",
"predicted: ham\nexpected: ham\n"
]
],
[
[
"Fantastic! We've developed a model that can attempt to predict spam vs ham classification!\n\n## Part 6: Model Evaluation\nNow we want to determine how well our model will do overall on the entire dataset. Let's begin by getting all the predictions:",
"_____no_output_____"
]
],
[
[
"all_predictions = spam_detect_model.predict(messages_tfidf)\nprint(all_predictions)",
"['ham' 'ham' 'spam' ..., 'ham' 'ham' 'ham']\n"
]
],
[
[
"We can use SciKit Learn's built-in classification report, which returns [precision, recall,](https://en.wikipedia.org/wiki/Precision_and_recall) [f1-score](https://en.wikipedia.org/wiki/F1_score), and a column for support (meaning how many cases supported that classification). Check out the links for more detailed info on each of these metrics and the figure below:",
"_____no_output_____"
],
[
"<img src='https://upload.wikimedia.org/wikipedia/commons/thumb/2/26/Precisionrecall.svg/700px-Precisionrecall.svg.png' width=400 />",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import classification_report\nprint (classification_report(messages['label'], all_predictions))",
" precision recall f1-score support\n\n ham 0.98 1.00 0.99 4825\n spam 1.00 0.85 0.92 747\n\navg / total 0.98 0.98 0.98 5572\n\n"
]
],
[
[
"There are quite a few possible metrics for evaluating model performance. Which one is the most important depends on the task and the business effects of decisions based off of the model. For example, the cost of mis-predicting \"spam\" as \"ham\" is probably much lower than mis-predicting \"ham\" as \"spam\".",
"_____no_output_____"
],
[
"In the above \"evaluation\",we evaluated accuracy on the same data we used for training. **You should never actually evaluate on the same dataset you train on!**\n\nSuch evaluation tells us nothing about the true predictive power of our model. If we simply remembered each example during training, the accuracy on training data would trivially be 100%, even though we wouldn't be able to classify any new messages.\n\nA proper way is to split the data into a training/test set, where the model only ever sees the **training data** during its model fitting and parameter tuning. The **test data** is never used in any way. This is then our final evaluation on test data is representative of true predictive performance.\n\n## Train Test Split",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\nmsg_train, msg_test, label_train, label_test = \\\ntrain_test_split(messages['message'], messages['label'], test_size=0.2)\n\nprint(len(msg_train), len(msg_test), len(msg_train) + len(msg_test))",
"4457 1115 5572\n"
]
],
[
[
"The test size is 20% of the entire dataset (1115 messages out of total 5572), and the training is the rest (4457 out of 5572). Note the default split would have been 30/70.\n\n## Creating a Data Pipeline\n\nLet's run our model again and then predict off the test set. We will use SciKit Learn's [pipeline](http://scikit-learn.org/stable/modules/pipeline.html) capabilities to store a pipeline of workflow. This will allow us to set up all the transformations that we will do to the data for future use. Let's see an example of how it works:",
"_____no_output_____"
]
],
[
[
"from sklearn.pipeline import Pipeline\n\npipeline = Pipeline([\n ('bow', CountVectorizer(analyzer=text_process)), # strings to token integer counts\n ('tfidf', TfidfTransformer()), # integer counts to weighted TF-IDF scores\n ('classifier', MultinomialNB()), # train on TF-IDF vectors w/ Naive Bayes classifier\n])",
"_____no_output_____"
]
],
[
[
"Now we can directly pass message text data and the pipeline will do our pre-processing for us! We can treat it as a model/estimator API:",
"_____no_output_____"
]
],
[
[
"pipeline.fit(msg_train,label_train)",
"_____no_output_____"
],
[
"predictions = pipeline.predict(msg_test)",
"_____no_output_____"
],
[
"print(classification_report(predictions,label_test))",
" precision recall f1-score support\n\n ham 1.00 0.96 0.98 1001\n spam 0.75 1.00 0.85 114\n\navg / total 0.97 0.97 0.97 1115\n\n"
]
],
[
[
"Now we have a classification report for our model on a true testing set! There is a lot more to Natural Language Processing than what we've covered here, and its vast expanse of topic could fill up several college courses! I encourage you to check out the resources below for more information on NLP!",
"_____no_output_____"
],
[
"## More Resources\n\nCheck out the links below for more info on Natural Language Processing:\n\n[NLTK Book Online](http://www.nltk.org/book/)\n\n[Kaggle Walkthrough](https://www.kaggle.com/c/word2vec-nlp-tutorial/details/part-1-for-beginners-bag-of-words)\n\n[SciKit Learn's Tutorial](http://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html)",
"_____no_output_____"
],
[
"# Good Job!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a45a2845e35f46f75f8a241d20b2461cb9a729b
| 972,384 |
ipynb
|
Jupyter Notebook
|
_notebooks/2022-03-13-Final_Notebook.ipynb
|
karinnm/Final_FastPage
|
9c1bb88a32807ca0dca80d004221093882397725
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2022-03-13-Final_Notebook.ipynb
|
karinnm/Final_FastPage
|
9c1bb88a32807ca0dca80d004221093882397725
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2022-03-13-Final_Notebook.ipynb
|
karinnm/Final_FastPage
|
9c1bb88a32807ca0dca80d004221093882397725
|
[
"Apache-2.0"
] | null | null | null | 137.614492 | 108,740 | 0.857737 |
[
[
[
"# \"The Evolution of Music Industry Sales\"\n> \"Deep dive analysis into music industry sales over the past 40 years.\"\n\n- toc:true\n- branch: master\n- badges: true\n- comments: true\n- author: Karinn Murdock\n- categories: [fastpages, jupyter]",
"_____no_output_____"
],
[
"Karinn Murdock",
"_____no_output_____"
],
[
"03/14/2022",
"_____no_output_____"
],
[
"# The Evolution of Music Industry Sales",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"For my final project, I am exploring the music industry and how it has changed over the years. More specifically, I want to look at how music industry sales have changed in the past 40 years in terms of types of sales (CDs, streaming, etc). In answering this overarching research question, I also want to explore (1) how the rise of new sale formats has led to the demise of others, and (2) which sales formats will be most popular moving forward.",
"_____no_output_____"
],
[
"The music industry has seen drastic change in recent years as a result of the Internet and music streaming platforms such as Spotify and Apple Music. Since the industry is changing so quickly, it is difficult for artists, record labels, and other companies to keep up. The topic I am researching is important to both artists and business executives in the music industry as they must understand the current sales landscape in order to maximize sales and cater to customer's preferences. By understanding which sale formats are most popular now, which ones are on the decline, and which ones will be popular in the future, artists and companies can know where to focus their marketing and distribution resources going forward. ",
"_____no_output_____"
],
[
"## Methods",
"_____no_output_____"
],
[
"The data source I will use to explore my research question is a dataset I found on data.world. This dataset is on music industry sales over the past 40 years and was created by the Recording Industry Association of America (RIAA). According to RIAA, this is the most comprehensive data on U.S. recorded music revenues. This dataset goes all the way back to 1973 and lists format of sale, metric of sale, year of sale, and value of sale. A link to the dataset can be found here: https://data.world/makeovermonday/2020w21-visualizing-40-years-of-music-industry-sales",
"_____no_output_____"
],
[
"This dataset contains data on 23 different sales formats, from cassette sales to album sales to on-demand streaming sales. For each format (except a few), the sales value is listed for each year in three different metrics: units sold, revenue at time of sale, and revenue adjusted to present value. The \"Value (Actual)\" column is displayed in millions for both unit values and revenue values. ",
"_____no_output_____"
],
[
"As stated in my introduction, I intend to analyze how music industry sales have changed since 1973 in terms of type of sales, as well as and how new sales formats have affected older sales formats. For my analysis, I decided to only work with the revenue adjusted to present value data, as I found it to be the most insightful. I split my analysis roughly into 5 main steps. First, I am creating bar charts of every sales formats in order to understand how sales of each format have changed since 1973. Second, I am going to create pie charts at different points in time to see how the composition of music sales has changed. Third, I am going to look at the correlation of different sales formats in the 2000's to understand which formats are correlated and which are anti-correlated. To take this analysis one step further, I am going to conduct linear regression analysis. Lastly, I am going to look at the growth rates of particular sales formats in 2019 to reveal which formats are increasing in popularity. ",
"_____no_output_____"
],
[
"## Results",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nimport matplotlib.pyplot as plt\nfrom matplotlib.pyplot import figure\nimport ipywidgets\nimport numpy as np\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.metrics import mean_squared_error, r2_score",
"_____no_output_____"
]
],
[
[
"### Data Exploration",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('MusicData2.csv')",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
],
[
[
"The dataset has 5 columns and 3008 rows of data.",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
],
[
"#hide\ndf.head()",
"_____no_output_____"
],
[
"#hide\ndf.tail()",
"_____no_output_____"
],
[
"#hide\ndf.dtypes",
"_____no_output_____"
]
],
[
[
"Finding summary statistics:",
"_____no_output_____"
]
],
[
[
"#hide\ndf.describe()",
"_____no_output_____"
],
[
"#hide\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 3008 entries, 0 to 3007\nData columns (total 5 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Format 3008 non-null object \n 1 Metric 3008 non-null object \n 2 Year 3008 non-null int64 \n 3 Number of Records 3008 non-null int64 \n 4 Value (Actual) 1351 non-null float64\ndtypes: float64(1), int64(2), object(2)\nmemory usage: 117.6+ KB\n"
],
[
"df",
"_____no_output_____"
]
],
[
[
"Looking at the data, the column \"Value (Actual)\" has missing information for many of the data entries. Additionally, it seems some of the data in the \"Value (Actual)\" column is measuring sales based on units sold while other entries are measuring sales by revenue.",
"_____no_output_____"
],
[
"### Cleaning the Data",
"_____no_output_____"
],
[
"First, I am replacing all NaN values with a zero.",
"_____no_output_____"
]
],
[
[
"new_df = df.fillna(0)\nnew_df",
"_____no_output_____"
]
],
[
[
"In some of the earlier years, certain formats such as Ringtones hadn't been created yet. I don't want to include these sales formats in my dataset for the years when the value is 0.0, so I am creating a new dataframe with these values removed.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nnew_df_no_values_0 = new_df[new_df[\"Value (Actual)\"] != 0.0].reset_index(drop=True)\nnew_df_no_values_0",
"_____no_output_____"
]
],
[
[
"There are only 1274 rows now (in comparison to 3008 rows before) since some of the rows were irrelevant. ",
"_____no_output_____"
],
[
"Creating a dataframe that has the units sold data for each year and format:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nunits = new_df_no_values_0[new_df_no_values_0['Metric'] == 'Units']\nunits",
"_____no_output_____"
],
[
"len(list(set(units[\"Format\"])))",
"_____no_output_____"
]
],
[
[
"The units sold data contains data on 17 different sales formats.",
"_____no_output_____"
],
[
"Creating a dataframe that has the present value of revenue sales data for each year and format:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nadjusted = new_df_no_values_0[new_df_no_values_0['Metric'] == 'Value (Adjusted)'].reset_index(drop=True)\nadjusted",
"_____no_output_____"
],
[
"len(list(set(adjusted[\"Format\"])))",
"_____no_output_____"
]
],
[
[
"The value (adjusted) data contains data for 23 different sales format. This dataset is missing units sold data for some of the more recent sales format types, such as On-Demand Streaming and Limited Tier Paid Subscriptions. As a result, I am going to use the value (adjusted) data for my analysis. ",
"_____no_output_____"
]
],
[
[
"#hide\nvalue = new_df_no_values_0[new_df_no_values_0['Metric'] == 'Value'].reset_index(drop=True)\nvalue",
"_____no_output_____"
]
],
[
[
"### Exploratory Data Visualizations",
"_____no_output_____"
],
[
"Creating dataframes with the adjusted revenue sales data for each sales format:",
"_____no_output_____"
]
],
[
[
"# step 1: get all unique Format types\nformat_types = list(set(adjusted[\"Format\"]))\nformat_types\n# step 2: create an empty list to input new data_frames\nformat_dfs = []\n# step 3: create all the new data frames and add to list\nfor i in np.arange(len(format_types)):\n first_format_type = format_types[i]\n format_df = adjusted[adjusted[\"Format\"] == first_format_type]\n format_dfs.append(format_df)",
"_____no_output_____"
],
[
"#hide\nformat_dfs[0] = adjusted[adjusted[\"Format\"] == 'Download Music Video']\nformat_dfs[1] = adjusted[adjusted[\"Format\"] == 'Download Album']\nformat_dfs[2] = adjusted[adjusted[\"Format\"] == 'Other Ad-Supported Streaming']\nformat_dfs[3] = adjusted[adjusted[\"Format\"] == 'Paid Subscription']\nformat_dfs[4] = adjusted[adjusted[\"Format\"] == 'Synchronization']\nformat_dfs[5] = adjusted[adjusted[\"Format\"] == 'Cassette']\nformat_dfs[6] = adjusted[adjusted[\"Format\"] == 'On-Demand Streaming (Ad-Supported)']\nformat_dfs[7] = adjusted[adjusted[\"Format\"] == 'Limited Tier Paid Subscription']\nformat_dfs[8] = adjusted[adjusted[\"Format\"] == 'Ringtones & Ringbacks']\nformat_dfs[9] = adjusted[adjusted[\"Format\"] == '8 - Track']\nformat_dfs[10] = adjusted[adjusted[\"Format\"] == 'CD']\nformat_dfs[11] = adjusted[adjusted[\"Format\"] == 'Vinyl Single']\nformat_dfs[12] = adjusted[adjusted[\"Format\"] == 'CD Single']\nformat_dfs[13] = adjusted[adjusted[\"Format\"] == 'Kiosk']\nformat_dfs[14] = adjusted[adjusted[\"Format\"] == 'DVD Audio']\nformat_dfs[15] = adjusted[adjusted[\"Format\"] == 'SACD']\nformat_dfs[16] = adjusted[adjusted[\"Format\"] == 'Other Digital']\nformat_dfs[17] = adjusted[adjusted[\"Format\"] == 'Other Tapes']\nformat_dfs[18] = adjusted[adjusted[\"Format\"] == 'SoundExchange Distributions']\nformat_dfs[19] = adjusted[adjusted[\"Format\"] == 'LP/EP']\nformat_dfs[20] = adjusted[adjusted[\"Format\"] == 'Download Single']\nformat_dfs[21] = adjusted[adjusted[\"Format\"] == 'Cassette Single']\nformat_dfs[22] = adjusted[adjusted[\"Format\"] == 'Music Video (Physical)']",
"_____no_output_____"
]
],
[
[
"Creating dataframes containing graph titles for each sales format:",
"_____no_output_____"
]
],
[
[
"name_dfs = list(set(adjusted[\"Format\"]))\nname_dfs[0] = 'Download Music Video Sales'\nname_dfs[1] = 'Download Album Sales'\nname_dfs[2] = 'Other Ad-Supported Streaming Sales'\nname_dfs[3] = 'Paid Subscription Sales'\nname_dfs[4] = 'Synchronization Sales'\nname_dfs[5] = 'Cassette Sales'\nname_dfs[6] = 'On-Demand Streaming (Ad-Supported) Sales'\nname_dfs[7] = 'Limited Tier Paid Subscription Sales'\nname_dfs[8] = 'Ringtones & Ringbacks Sales'\nname_dfs[9] = '8 - Track Sales'\nname_dfs[10] = 'CD Sales'\nname_dfs[11] = 'Vinyl Single Sales'\nname_dfs[12] = 'CD Single Sales'\nname_dfs[13] = 'Kiosk Sales'\nname_dfs[14] = 'DVD Audio Sales'\nname_dfs[15] = 'SACD Sales'\nname_dfs[16] = 'Other Digital Sales'\nname_dfs[17] = 'Other Tapes Sales'\nname_dfs[18] = 'SoundExchange Distributions Sales'\nname_dfs[19] = 'LP/EP Sales'\nname_dfs[20] = 'Download Single Sales'\nname_dfs[21] = 'Cassette Single Sales'\nname_dfs[22] = 'Music Video (Physical) Sales'",
"_____no_output_____"
],
[
"def widgetplot(x):\n p = format_dfs[x].plot(kind='bar', x='Year', y='Value (Actual)', figsize=(10,6))\n\n p.set_title(name_dfs[x], fontsize=14)\n p.set_xlabel('Year', fontsize=13)\n p.set_ylabel('Revenue ($ in millions)', fontsize=13)\n p.legend(['Revenue (in millions, adjusted to PV)'])\n plt.show()\nipywidgets.interactive(widgetplot, x=(0,22))",
"_____no_output_____"
]
],
[
[
"Starting with **Download Music Video sales** (x=0), Download Music Video sales began in 2005 and peaked in 2008/2009, before significantly declining. In 2019, Download Music Video sales were just under $2 million. \n\n**Download Album sales** (x=1) began in 2004, peaked in 2013, and have been declining since. However, it still remains a popular format as sales in 2019 were over $394 million. \n\n**Other Ad-Supported Streaming sales** (x=2) weren't introduced until 2016. Sales were highest in 2017 and have declined slightly since but still remain a popular format, accounting for over $251 million in sales in 2019.\n\n**Paid Subscription sales** (x=3), which became available in 2005, have significantly increased in recent years. Paid Subscription sales were highest in 2019, making up over $5.9 billion in sales.\n\n**Synchronization sales** (x=4) started in 2009 and have been relatively constant since with a slight increase in the last few years. In 2019, Synchronization sales were around $276 million.\n\n**Cassette sales** (x=5) peaked in 1988 and have decreased significantly since. Data on Cassette sales is not reported after 2008, as cassettes lost popularity. \n\n**On-Demand Streaming (Ad-Supported) sales** (x=6) began in 2011 and have been increasing every year since. In 2019, On-Demand Streaming sales exceeded $908 million.\n\n**Limited Tier Paid Subscription sales** (x=7) began in 2016 and have also been increasing every year since. Limited Tier Paid Subscription sales were over $829 mil in 2019.\n\n**Ringtones and Ringbacks** (x=8) were introduced in 2005. Sales peaked shortly after in 2007 and have decreased significantly since. In 2019, Ringtones and Ringbacks sales were around $21 million. \n\n**8-Track sales** (x=9) peaked in 1978 before decreasing. Data for 8-Tracks sales stopped after 1982, as this format lost popularity. \n\n**CD sales** (x=10) began in 1983 and peaked in 1999/2000. CD sales have decreased significantly since yet remain a popular sales format, with over $614 million in sales in 2019. \n\n**Vinyl Single sales** (x=11) peaked in 1979 and have decreased significantly since, but still remain a used sales format. Vinyl Single sales is one of the sales formats that has been around the longest in the industry. In 2019, sales of Vinyl Singles were around $6.8 million.\n\n**CD Single sales** (x=12) data begins in 1988 and peaked in 1997. CD Single sales declined significantly after 1997. In 2018 and 2019, CD Single sales have been under $1 million. \n\n**Kiosk sales** (x=13) began in 2005 and peaked in 2009/2010 before declining. There was a resurgence of Kiosk sales in 2013 followed by another decline. In 2019, Kiosk sales were around $1.5 million.\n\n**DVD Audio sales** (x=14) started in 2001 and peaked in 2005. Sales dropped significantly between 2011-2013 and have increased slightly since. In 2019, DVD Audio sales totaled just over $1 million.\n\n**SACD sales** (x=15) became available in 2003 and also peaked in 2003. Since 2003, SACD sales have dropped sharply, accounting for less than half a million in sales in 2019.\n\n**Other Digital sales** (x=16) were introduced in 2016 and have been increasing slightly since. In 2019, sales were around $21.5 million.\n\n**Other Tapes sales** (x=17) began in 1973 and only lasted until 1976. Other Tapes sales peaked in 1973.\n\n**SoundExchange Distributions sales** (x=18) began in 2004 and have been increasing for the most part since. In 2019, SoundExchange Distributions sales were over $908 million.\n\n**LP/EP sales** (x=19) peaked in 1978 before declining sharply. Around 2008 LP/EP sales began to slowly climb again, yet sales still remain much lower than seen in the 1970s. In 2019, LP/EP sales were over $497 million. \n\n**Download Single sales** (x=20) were introduced in 2004 and peaked in 2012. Since 2012, Download Single sales have been declining but still remain a popular format, accounting for over $414 million in sales in 2019.\n\n**Cassette Single sales** (x=21) began in 1987 and peaked in 1992. Data on Cassette Single sales ends in 2002, as sales sharply declined to below $1 million.\n\n**Music Video (Physical) sales** (x=22) became available in 1989 and saw peak sales in 1998 and 2004. Sales have steadily declined since, with 2019 sales around $27 million.",
"_____no_output_____"
],
[
"By analyzing these bar charts, we can see which sales formats have seen increased sales in recent years and which ones have seen declining sales. Formats that have seen increased sales recently include Synchronization, Paid Subscriptions, On-Demand Streaming (Ad-Supported), Limited Tier Paid Subscriptions, Other Digital, SoundExchange Distributions, and LP/EP. \n\nFormats that have seen a decline in sales recently include Download Music Video, Download Album, Other Ad-Supported Streaming, Ringtones and Ringbacks, CDs, Vinyl Singles, CD Singles, Kiosks, DVD Audios, SACDs, Download Single, and Music Video (Physical).",
"_____no_output_____"
],
[
"Next, I want to look at how the composition of music industry sales changed from 1973 to 2019. To do this, I am going to look at four different points in time, each 15 years apart.",
"_____no_output_____"
],
[
"Looking at the most popular sales formats in 1973:",
"_____no_output_____"
]
],
[
[
"df_1973 = adjusted[adjusted['Year'] == 1973]",
"_____no_output_____"
],
[
"#collapse-output\ndf_1973_index = df_1973.set_index(\"Format\")\ndf_1973_index",
"_____no_output_____"
]
],
[
[
"Looking at the most popular sales formats in 1988:",
"_____no_output_____"
]
],
[
[
"#collapse-output\ndf_1988 = adjusted[adjusted['Year'] == 1988]\ndf_1988_index = df_1988.set_index(\"Format\")\ndf_1988_index",
"_____no_output_____"
]
],
[
[
"Looking at the most popular sales formats in 2003:",
"_____no_output_____"
]
],
[
[
"#collapse-output\ndf_2003 = adjusted[adjusted['Year'] == 2003]\ndf_2003_index = df_2003.set_index(\"Format\")\ndf_2003_index",
"_____no_output_____"
]
],
[
[
"Looking at the most popular sales formats in 2018:",
"_____no_output_____"
]
],
[
[
"#collapse-output\ndf_2018 = adjusted[adjusted['Year'] == 2018]\ndf_2018_index = df_2018.set_index(\"Format\")\ndf_2018_index",
"_____no_output_____"
]
],
[
[
"Plotting the sales data from 1973, 1988, 2003, and 2018:",
"_____no_output_____"
]
],
[
[
"a = df_1973_index.plot(kind='pie', y='Value (Actual)',figsize=(17,8))\nplt.legend(bbox_to_anchor=(1.0, 1.0))\na.set_title('Music Industry Sales in 1973', fontsize=14)\n\nb = df_1988_index.plot(kind='pie', y='Value (Actual)',figsize=(17,8))\nplt.legend(bbox_to_anchor=(1.0, 1.0))\nb.set_title('Music Industry Sales in 1988', fontsize=14)\n\nc = df_2003_index.plot(kind='pie', y='Value (Actual)',figsize=(17,8))\nplt.legend(bbox_to_anchor=(1.0, 1.0))\nc.set_title('Music Industry Sales in 2003', fontsize=14)\n\nd = df_2018_index.plot(kind='pie', y='Value (Actual)',figsize=(19,9))\nplt.legend(bbox_to_anchor=(1.6, 1.0))\nd.set_title('Music Industry Sales in 2018', fontsize=14)",
"_____no_output_____"
]
],
[
[
"Looking at the above pie charts provides insight into the most commonly used sales formats during these four points in time as well as how music industry sales have changed between 1973 and 2018. **In 1973**, the most common music sales format was an LP or EP album, accounting for almost 2/3rds of sales. Other popular sales formats in 1973 included 8-tracks, vinyl singles, cassettes, and other tapes. **In 1988**, the most common music sales format was cassettes, followed by CDs. Cassettes accounted for over half of music sales in 1988. Other common sales formats included LP/EP albums, vinyl singles, cassette singles, and CD singles. 15 years later **in 2003**, the most popular music sales format was by far the CD, making up over 80% of music sales. Other sales formats included physical music videos, cassettes, CD singles, LP/EP albums, super audio CDs, vinyl singles, and dvd audios. \n\nMost recently, **in 2018**, the most common music sales format was a paid subscription, accounting for a little under half of music sales. Other popular music formats include soundexchange distributions, CDs, on-demand streaming (ad-supported), limited tier paid subscriptions, single downloads, album downloads, LP/EP albums, synchronization, and other ad-supported streaming. Less popular but still used sales formats in 2018 included CD singles, DVD audios, downloading music videos, kiosks, physical music videos, other digital, ringtones and ringbacks, and vinyl singles.\n\nAs shown by the charts above, the number of sales formats available to purchase music increased dramatically between 2003 and 2018. In those 15 years, sales of CDs and other physical formats dropped significantly while sales shifted more towards technology-based formats. ",
"_____no_output_____"
],
[
"### Correlation Analysis",
"_____no_output_____"
],
[
"To begin my analysis, I am going to look at the correlation between different sales formats throughout the 2000's.",
"_____no_output_____"
],
[
"Looking at the correlation between **Paid Subscription sales and CD sales** since 2005:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[3]",
"_____no_output_____"
],
[
"# finding CD sales from 2005 and onwards, since paid subscription sales don't arise until 2005\ncds_2005_on = format_dfs[10][format_dfs[10]['Year']>= 2005]",
"_____no_output_____"
],
[
"print(format_dfs[3]['Value (Actual)'].reset_index(drop=True).corr(cds_2005_on['Value (Actual)'].reset_index(drop=True)))",
"-0.5719970540170898\n"
]
],
[
[
"Since 2005, **Paid Subscription sales and CD sales have been negatively correlated**, with a correlation of **-0.57**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[3].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\ncds_2005_on.plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Paid Subscription vs CD Sales')\nax.legend(['Paid Subscription Sales', 'CD Sales'])",
"_____no_output_____"
]
],
[
[
"Since Paid Subscriptions became available in 2005, Paid Subscription sales have been increasing, while CD sales have been decreasing. This makes sense as the two formats are negatively correlated. Prior to 2015, CD sales were higher than Paid Subscription sales. However, since 2015 it appears that Paid Subscription sales have surpassed CD sales.",
"_____no_output_____"
],
[
"Looking at the correlation between **On-Demand Streaming sales and CD sales** since 2011:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[6]",
"_____no_output_____"
],
[
"# finding CD sales from 2011 and onwards, since on-demand streaming sales didn't arise until 2011\ncds_2011_on = format_dfs[10][format_dfs[10]['Year']>= 2011]",
"_____no_output_____"
],
[
"print(cds_2011_on['Value (Actual)'].reset_index(drop=True).corr(format_dfs[6]['Value (Actual)'].reset_index(drop=True)))",
"-0.9323705630229808\n"
]
],
[
[
"Since 2011, **On-Demand Streaming (Ad-Supported) sales and CD sales have been very negatively correlated**, with a correlation of **-0.93**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[6].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\ncds_2011_on.plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('On-Demand Streaming vs CD Sales')\nax.legend(['On-Demand Streaming Sales', 'CD Sales'])",
"_____no_output_____"
]
],
[
[
"Since On-Demand Streaming arose in 2011, On-Demand Streaming sales have been increasing, while CD sales have been decreasing. This is consistent with the results of the correlation analysis. Prior to 2018, CD sales were higher than On-Demand Streaming sales. However, since roughly 2018, On-Demand Streaming sales have surpassed CD sales.",
"_____no_output_____"
],
[
"Looking at the correlation between **Paid Subscription sales and Cassette sales** between 2005 and 2008:",
"_____no_output_____"
]
],
[
[
"# finding paid subscription sales from 2008 and before since the Cassette sales data ends in 2008\nps_before_2008 = format_dfs[3][format_dfs[3]['Year']<=2008]",
"_____no_output_____"
],
[
"# finding cassette sales from 2005 and on, since paid subscriptions aren't available until 2005\ncassette_2005_on = format_dfs[5][format_dfs[5]['Year']>=2005]",
"_____no_output_____"
],
[
"print(ps_before_2008['Value (Actual)'].reset_index(drop=True).corr(cassette_2005_on['Value (Actual)'].reset_index(drop=True)))",
"-0.9141174644189466\n"
]
],
[
[
"Between 2005 and 2008, **Paid Subscription sales and Cassette sales were very negatively correlated**, with a correlation of **-0.91**",
"_____no_output_____"
]
],
[
[
"ax = ps_before_2008.plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\ncassette_2005_on.plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Paid Subscription vs Cassette Sales')\nax.legend(['Paid Subscription Sales', 'Cassette Sales'])",
"_____no_output_____"
]
],
[
[
"Between 2005 and 2008 (when Paid Subscription and Cassette sales overlapped as sales formats) Paid Subscription sales were significantly higher than Cassette sales. Additionally, Paid Subscription sales increased between 2005 and 2008 while Cassette sales decreased.",
"_____no_output_____"
],
[
"Looking at correlation between **Paid Subscription Sales and On-Demand Streaming sales** after 2011: ",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[6]",
"_____no_output_____"
],
[
"# finding paid subscription sales from 2011 and on, as on-demand streaming begins in 2011\nps_2011_on = format_dfs[3][format_dfs[3]['Year']>=2011]",
"_____no_output_____"
],
[
"print(ps_2011_on['Value (Actual)'].reset_index(drop=True).corr(format_dfs[6]['Value (Actual)'].reset_index(drop=True)))",
"0.9851826999334489\n"
]
],
[
[
"Since 2011, **Paid Subscription sales and On-Demand Streaming sales** have been very highly correlated, with a correlation of **0.98**",
"_____no_output_____"
]
],
[
[
"ax = ps_2011_on.plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[6].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Paid Subscription vs On-Demand Streaming Sales')\nax.legend(['Paid Subscription Sales', 'On-Demand Streaming Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2011, both Paid Subscription sales as well as On-Demand Streaming sales have increased, which makes sense since they are highly correlated. However, Paid Subscription sales increased at a higher rate than On-Demand Streaming sales.",
"_____no_output_____"
],
[
"Looking at the correlation between **On-Demand Streaming (Ad-Supported) sales and Other Ad-Supported Streaming sales** after 2016:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[2]",
"_____no_output_____"
],
[
"# finding on-demand streaming sales since 2016\nods_2016_on = format_dfs[6][format_dfs[6]['Year']>=2016]",
"_____no_output_____"
],
[
"print(ods_2016_on['Value (Actual)'].reset_index(drop=True).corr(format_dfs[2]['Value (Actual)'].reset_index(drop=True)))",
"0.767500469481728\n"
]
],
[
[
"Since 2016, when Other Ad-Supported Streaming became an option, **Other Ad-Supported Streaming sales and On-Demand Streaming (Ad-Supported) have been highly correlated**, with a correlation of **0.77**",
"_____no_output_____"
]
],
[
[
"ax = ods_2016_on.plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[2].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('On-Demand Streaming vs Other Ad-Supported Streaming Sales')\nax.legend(['On-Demand Streaming Sales', 'Other Ad-Supported Streaming Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2016, both On-Demand Streaming (Ad-Supported) sales and Other Ad-Supported Streaming sales have increased, which is consistent with the correlation results. Despite both sales formats increasing, On-Demand Streaming (Ad-Supported) sales were higher than Other Ad-Supported Streaming sales between 2016 and 2019. ",
"_____no_output_____"
],
[
"Looking at the correlation between **On-Demand Streaming (Ad-Supported) Sales and Download Album sales** since 2011:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[6]",
"_____no_output_____"
],
[
"# finding download album sales since 2011 (when On-Demand Streaming became an option)\ndownload_album_2011_on = format_dfs[1][format_dfs[1]['Year']>=2011]",
"_____no_output_____"
],
[
"print(download_album_2011_on['Value (Actual)'].reset_index(drop=True).corr(format_dfs[6]['Value (Actual)'].reset_index(drop=True)))",
"-0.9715897248193843\n"
]
],
[
[
"Since 2011, **Download Album sales and On-Demand Streaming (Ad-Supported) sales have been very negatively correlated**, with a correlation of **-0.97**",
"_____no_output_____"
]
],
[
[
"ax = download_album_2011_on.plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[6].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Download Album vs On-Demand Streaming Sales')\nax.legend(['Download Album Sales', 'On-Demand Streaming Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2011, On-Demand Streaming sales have been increasing, while Download Album sales have been decreasing. This makes sense since the two formats are negatively correlated. Prior to 2017, Download Album sales were higher than On-Demand Streaming sales. However, after 2017 On-Demand Streaming sales surpassed Download Album sales.",
"_____no_output_____"
]
],
[
[
"#hide\nprint(format_dfs[0]['Value (Actual)'].reset_index(drop=True).corr(format_dfs[1]['Value (Actual)'].reset_index(drop=True)))",
"-0.07942243204594712\n"
],
[
"#hide\nax = format_dfs[0].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[1].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Download Music Video vs Download Album Sales')\nplt.legend(['Download Music Video Sales', 'Download Album Sales'], bbox_to_anchor=(0.38, 1.0),)",
"_____no_output_____"
]
],
[
[
"Looking at the correlation between **CD Single sales and Download Single sales** after 2004:",
"_____no_output_____"
]
],
[
[
"# finding CD single sales since 2004 (when download singles became available)\ncd_single_2004_on = format_dfs[12][format_dfs[12]['Year']>=2004]",
"_____no_output_____"
],
[
"print(cd_single_2004_on['Value (Actual)'].reset_index(drop=True).corr(format_dfs[20]['Value (Actual)'].reset_index(drop=True)))",
"-0.4073087892744402\n"
]
],
[
[
"Since 2004, **CD Single sales and Download Single sales have been negatively correlated**, with a correlation of **-0.4**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[20].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\ncd_single_2004_on.plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Download Single vs CD Single Sales')\nax.legend(['Download Single Sales', 'CD Single Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2004, Download Single sales have been higher than CD Single sales. Between 2004 and now, CD Single Sales slightly decreased, while Download Single sales increased until roughly 2012, and have been decreasing ever since.",
"_____no_output_____"
],
[
"Looking at the correlation between **Other Ad-Supported Streaming sales and Limited Tier Paid Subscription sales**:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[2]",
"_____no_output_____"
],
[
"print(format_dfs[2]['Value (Actual)'].reset_index(drop=True).corr(format_dfs[7]['Value (Actual)'].reset_index(drop=True)))",
"0.8876592647894722\n"
]
],
[
[
"Since 2016, **Other Ad-Supported Streaming sales and Limited Tier Paid Subscription sales have been highly correlated**, with a correlation of **0.89**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[2].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[7].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Other Ad-Supported Streaming vs Limited Tier Paid Subscription Sales')\nax.legend(['Other Ad-Supported Streaming Sales', 'Limited Tier Paid Subscription Sales'])",
"_____no_output_____"
]
],
[
[
"Since both Other Ad-Supported Streaming and Limited Tier Paid Subscriptions became available in 2016, both of these sale formats have increased. However, Limited Tier Paid Subscriptions sales have been higher than Other Ad-Supported Streaming sales and also seem to be increasing at a higher rate.",
"_____no_output_____"
],
[
"Looking at the correlation between **Paid Subscription sales and SoundExchange Distributions sales**:",
"_____no_output_____"
]
],
[
[
"print(format_dfs[3]['Value (Actual)'].reset_index(drop=True).corr(format_dfs[18]['Value (Actual)'].reset_index(drop=True)))",
"0.7744466362621104\n"
]
],
[
[
"Since 2005, **Paid Subscription sales and SoundExchange Distrubtions sales have been highly correlated**, with a correlation of **0.77**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[3].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[18].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Paid Subscription vs SoundExchange Distributions Sales')\nax.legend(['Paid Subscription Sales', 'SoundExchange Distributions Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2005, both Paid Subscription sales and SoundExchange Distribution sales have increased. However, Paid Subscription sales have increased at a higher rate.",
"_____no_output_____"
],
[
"Looking at the correlation between **Download Album sales and Download Single sales**:",
"_____no_output_____"
]
],
[
[
"print(format_dfs[1]['Value (Actual)'].reset_index(drop=True).corr(format_dfs[20]['Value (Actual)'].reset_index(drop=True)))",
"0.934879112862656\n"
]
],
[
[
"Since 2004, **Download Album sales and Download Single sales have been highly correlated**, with a correlation of **0.93**",
"_____no_output_____"
]
],
[
[
"ax = format_dfs[1].plot(kind='line', x='Year', y='Value (Actual)', figsize=(9,6))\nformat_dfs[20].plot(kind='line', x='Year', y='Value (Actual)', ax=ax)\nax.set_title('Download Album vs Download Single Sales')\nax.legend(['Download Album Sales', 'Download Single Sales'])",
"_____no_output_____"
]
],
[
[
"Since 2004, Download Album sales and Download Single sales have been very similar. Both sales formats increased until roughly 2012, when they both reached their peak sales and began decreasing. Prior to roughly 2016, Download Single sales were higher than Download Album sales, but since 2016 they have been almost the same. ",
"_____no_output_____"
],
[
"Based on the above correlation analysis, sales formats that have been highly correlated in the 2000's include:\n\n(1) Other Ad-Supported Streaming and Limited Tier Paid Subscription sales (r = 0.89)\n\n(2) Paid Subscription and On-Demand Streaming (Ad-Supported) sales (r = 0.98)\n\n(3) On-Demand Streaming (Ad-Supported) and Other Ad-Supported Streaming sales (r = 0.77)\n\n(4) Paid Subscription and SoundExchange Distributions sales (r = 0.77)\n \n(5) Download Album and Download Single sales (r = 0.93)\n\nSince these formats have been highly correlated throughout the 2000's, when one of the sales formats has increased, so has the other correlated format. Similarly, if one of the sales formats decreased, the correlated sales format also decreased. ",
"_____no_output_____"
],
[
"Sales formats that have been negatively correlated in the 2000's include: \n\n(1) Paid Subscription and CD sales (r = -0.57)\n\n(2) On-Demand Streaming (Ad-Supported) and CD sales (r = -0.93)\n\n(3) Paid Subscription and Cassette sales (r = -0.91)\n\n(4) On-Demand Streaming (Ad-Supported) and Download Album sales (r = -0.97)\n\n(5) CD Single and Download Single sales (r = -0.4)\n\nSince these formats have been negatively correlated or anti-correlated throughout the 2000's, when one of the sales formats increases, the other sales format decreases. For example, while Paid Subscription sales increased in the 2000's, CD sales decreased in the 2000's. Based on the above correlations, it appears that the newer streaming formats are negatively correlated with some of the older sales formats. As these streaming options increase in sales, their counterparts see decreased sales.",
"_____no_output_____"
],
[
"### Linear Regression Analysis",
"_____no_output_____"
],
[
"To see how well sales of one format can predict sales of another, correlated format, I am plotting the linear regression of **highly correlated** sales formats. ",
"_____no_output_____"
],
[
"Since Other Ad-Supported Streaming and Limited Tier Paid Subscription sales are highly correlated (r=0.89), we might be able to use linear regression to predict Limited Tier Paid Subscription sales from Other Ad-Supported Streaming sales.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nX = adjusted[adjusted[\"Format\"] == 'Other Ad-Supported Streaming'][['Value (Actual)']]\nY = adjusted[adjusted[\"Format\"] == 'Limited Tier Paid Subscription'][['Value (Actual)']]\nprint (X)\nprint (Y)",
" Value (Actual)\n303 86.559597\n304 273.040319\n305 255.967444\n306 251.064710\n Value (Actual)\n259 280.536691\n260 617.032318\n261 760.591366\n262 829.498740\n"
],
[
"reg = LinearRegression().fit(X, Y)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * X",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(X,Y,'ro',X,ytrain,'b-')\n\nplt.title(\"Other Ad-Supported Streaming vs Limited Tier Paid Subscription\")\nplt.xlabel(\"Other Ad-Supported Streaming Sales\")\nplt.ylabel(\"Limited Tier Paid Subscription Sales\")",
"_____no_output_____"
]
],
[
[
"To test how well the model fits the data, I am calculating the mean squared error and R-squared value.",
"_____no_output_____"
]
],
[
[
"mean_squared_error(Y, ytrain)",
"_____no_output_____"
],
[
"r2_score(Y, ytrain)",
"_____no_output_____"
]
],
[
[
"Based on the R-squared value of 0.79, the model fits the data decently well. As a result, it seems **Other Ad-Supported Streaming sales can be used to predict Limited Tier Paid Subscription sales**. However, since data is only available for 2016-2019 for these sales formats, there might not be enough data to make this assumption ",
"_____no_output_____"
],
[
"Since Paid Subscription and On-Demand Streaming (Ad-Supported) sales have been highly correlated (r=0.985) since 2011, we may be able to use linear regression to predict On-Demand Streaming sales using Paid Subscription sales. ",
"_____no_output_____"
]
],
[
[
"# creating a new dataframe with the adjusted data from 2011 and after \nadjusted_2011_on = adjusted[adjusted['Year']>=2011]",
"_____no_output_____"
],
[
"#collapse-output\nPS = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'Paid Subscription'][['Value (Actual)']]\nOD = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'On-Demand Streaming (Ad-Supported)'][['Value (Actual)']]\nprint (PS)\nprint (OD)",
" Value (Actual)\n321 281.639932\n322 445.276306\n323 706.011657\n324 831.834028\n325 1247.676869\n326 2390.487545\n327 3651.028327\n328 4740.333581\n329 5934.397625\n Value (Actual)\n294 129.340695\n295 190.339616\n296 242.396098\n297 306.475448\n298 401.245264\n299 521.288175\n300 686.918081\n301 773.294917\n302 908.149331\n"
],
[
"reg = LinearRegression().fit(PS, OD)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * PS",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(PS, OD,'ro',PS,ytrain,'b-')\n\nplt.title(\"Paid Subscription vs On-Demand Streaming\")\nplt.xlabel(\"Paid Subscription Sales\")\nplt.ylabel(\"On-Demand Streaming (Ad-Supported) Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(OD, ytrain)",
"_____no_output_____"
],
[
"r2_score(OD, ytrain)",
"_____no_output_____"
]
],
[
[
"The high R-squared value of 0.97 indicates that the regression line is a good fit for the data. As a result, **Paid Subscription sales can be used to predict On-Demand Streaming sales**. ",
"_____no_output_____"
],
[
"On-Demand Streaming (Ad-Supported) and Other-Ad Supported Streaming sales also have a high correlation (r=0.77). Thus, we might be able to predict Other Ad-Supported Streaming sales using On-Demand Streaming sales by finding the linear regression. ",
"_____no_output_____"
]
],
[
[
"# creating a dataframe with the adjusted data from 2016-2019\nadjusted_2016_on = adjusted[adjusted['Year']>=2016]",
"_____no_output_____"
],
[
"#collapse-output\nDS = adjusted_2016_on[adjusted_2016_on[\"Format\"] == 'On-Demand Streaming (Ad-Supported)'][['Value (Actual)']]\nAS = adjusted_2016_on[adjusted_2016_on[\"Format\"] == 'Other Ad-Supported Streaming'][['Value (Actual)']]\nprint (DS)\nprint (AS)",
" Value (Actual)\n299 521.288175\n300 686.918081\n301 773.294917\n302 908.149331\n Value (Actual)\n303 86.559597\n304 273.040319\n305 255.967444\n306 251.064710\n"
],
[
"reg = LinearRegression().fit(DS, AS)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * DS",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(DS, AS,'ro',DS,ytrain,'b-')\n\nplt.title(\"On-Demand Streaming vs Other Ad-Supported Streaming\")\nplt.xlabel(\"On-Demand Streaming (Ad-Supported) Sales\")\nplt.ylabel(\"Other Ad-Supported Streaming Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(AS, ytrain)",
"_____no_output_____"
],
[
"r2_score(AS, ytrain)",
"_____no_output_____"
]
],
[
[
"The R-squared value of 0.59 indicates that the regression line is not a good fit for the data. As a result, **we cannot use On-Demand Streaming sales to predict Other Ad-Supported Streaming sales**. ",
"_____no_output_____"
],
[
"Paid Subscription and SoundExchange Distributions sales have a strong correlation (r=0.77). By finding the linear regression, we can can predict future SoundExchange Distributions sales using Paid Subscription sales.",
"_____no_output_____"
]
],
[
[
"# creating a dataframe with the adjusted data for sales since 2005\nadjusted_2005_on = adjusted[adjusted['Year']>=2005]",
"_____no_output_____"
],
[
"#collapse-output\nPS2 = adjusted_2005_on[adjusted_2005_on[\"Format\"] == 'Paid Subscription'][['Value (Actual)']]\nSD = adjusted_2005_on[adjusted_2005_on[\"Format\"] == 'SoundExchange Distributions'][['Value (Actual)']]\nprint (PS2)\nprint (SD)",
" Value (Actual)\n315 195.309905\n316 261.490444\n317 288.585326\n318 262.896754\n319 245.722059\n320 249.025694\n321 281.639932\n322 445.276306\n323 706.011657\n324 831.834028\n325 1247.676869\n326 2390.487545\n327 3651.028327\n328 4740.333581\n329 5934.397625\n Value (Actual)\n363 26.704571\n364 41.594988\n365 44.644397\n366 118.742888\n367 185.304463\n368 292.171389\n369 331.875949\n370 514.445212\n371 647.930274\n372 835.213587\n373 865.719793\n374 941.535965\n375 680.027595\n376 970.064513\n377 908.200000\n"
],
[
"reg = LinearRegression().fit(PS2, SD)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * PS2",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(PS2, SD,'ro',PS2,ytrain,'b-')\n\nplt.title(\"Paid Subscription vs SoundExchange Distributions\")\nplt.xlabel(\"Paid Subscription Sales\")\nplt.ylabel(\"SoundExchange Distributions Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(SD, ytrain)",
"_____no_output_____"
],
[
"r2_score(SD, ytrain)",
"_____no_output_____"
]
],
[
[
"As with the previous regression, the regression line does not fit the data, as indicated by the R-squared value of 0.5. Consequently, **Paid Subscription sales cannot be used to predict SoundExchange Distribution sales**.",
"_____no_output_____"
],
[
"The last formats I found to be highly correlated are Download Album and Download Single sales (r=0.93). We can predict future Download Album sales using Download Single sales by finding the linear regression.",
"_____no_output_____"
]
],
[
[
"# creating a dataframe with the adjusted data since 2004\nadjusted_2004_on = adjusted[adjusted['Year']>=2004]",
"_____no_output_____"
],
[
"#collapse-output\nDS = adjusted_2004_on[adjusted_2004_on[\"Format\"] == 'Download Single'][['Value (Actual)']]\nDA = adjusted_2004_on[adjusted_2004_on[\"Format\"] == 'Download Album'][['Value (Actual)']]\nprint (DS)\nprint (DA)",
" Value (Actual)\n181 186.769010\n182 475.577000\n183 736.282015\n184 1000.182475\n185 1225.664089\n186 1396.635564\n187 1566.845282\n188 1730.301179\n189 1831.258646\n190 1726.739156\n191 1463.655387\n192 1278.449595\n193 958.879103\n194 707.692711\n195 499.316974\n196 414.804251\n Value (Actual)\n150 61.579637\n151 177.637762\n152 349.879793\n153 613.428807\n154 754.373567\n155 886.958917\n156 1022.834349\n157 1217.030020\n158 1341.590983\n159 1352.202953\n160 1207.247578\n161 1148.145081\n162 925.232201\n163 697.237618\n164 508.704388\n165 394.533006\n"
],
[
"reg = LinearRegression().fit(DS, DA)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * DS",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(DS, DA,'ro',DS,ytrain,'b-')\n\nplt.title(\"Download Single vs Download Album\")\nplt.xlabel(\"Download Single\")\nplt.ylabel(\"Download Album\")",
"_____no_output_____"
],
[
"mean_squared_error(DA, ytrain)",
"_____no_output_____"
],
[
"r2_score(DA, ytrain)",
"_____no_output_____"
]
],
[
[
"An R-squared of 0.87 indicates that the regression line sufficiently fits the data. Resultantly, **Download Single sales can be used to predict Download Album sales**.",
"_____no_output_____"
],
[
"Next, I am going to perform linear regression on the sales formats that are **negatively correlated** in order to see which sales formats can be used to accurately predict other sales formats.",
"_____no_output_____"
],
[
"Since Paid Subscription sales and CD sales are negatively correlated, (r=-0.57), we might be able to predict CD sales based on Paid Subscription sales using linear regression.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nPS2 = adjusted_2005_on[adjusted_2005_on[\"Format\"] == 'Paid Subscription'][['Value (Actual)']]\nCD = adjusted_2005_on[adjusted_2005_on[\"Format\"] == 'CD'][['Value (Actual)']]\nprint (PS2)\nprint (CD)",
" Value (Actual)\n315 195.309905\n316 261.490444\n317 288.585326\n318 262.896754\n319 245.722059\n320 249.025694\n321 281.639932\n322 445.276306\n323 706.011657\n324 831.834028\n325 1247.676869\n326 2390.487545\n327 3651.028327\n328 4740.333581\n329 5934.397625\n Value (Actual)\n32 13771.442760\n33 11885.767850\n34 9190.702658\n35 6496.779627\n36 5146.578220\n37 3973.859173\n38 3524.136143\n39 2767.776149\n40 2349.534897\n41 1918.215115\n42 1558.633452\n43 1204.497778\n44 1102.774352\n45 711.041239\n46 614.509780\n"
],
[
"reg = LinearRegression().fit(PS2, CD)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * PS2",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(PS2,CD,'ro',PS2,ytrain,'b-')\n\nplt.title(\"Paid Subscription vs CD\")\nplt.xlabel(\"Paid Subscription Sales\")\nplt.ylabel(\"CD Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(CD, ytrain)",
"_____no_output_____"
],
[
"r2_score(CD, ytrain)",
"_____no_output_____"
]
],
[
[
"Based on the extremely high mean squared error and low R-squared value, this regression line does not fit the data well. As a result, **CD sales cannot be predicted based on Paid Subscription sales**, as the correlation isn't high enough.",
"_____no_output_____"
],
[
"Since On-Demand Streaming (Ad-Supported) sales and CD sales are negatively correlated, (r=-0.93), we might be able to predict CD sales based on On-Demand Streaming sales using linear regression.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nOD = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'On-Demand Streaming (Ad-Supported)'][['Value (Actual)']]\nCD2 = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'CD'][['Value (Actual)']]\nprint (OD)\nprint (CD2)",
" Value (Actual)\n294 129.340695\n295 190.339616\n296 242.396098\n297 306.475448\n298 401.245264\n299 521.288175\n300 686.918081\n301 773.294917\n302 908.149331\n Value (Actual)\n38 3524.136143\n39 2767.776149\n40 2349.534897\n41 1918.215115\n42 1558.633452\n43 1204.497778\n44 1102.774352\n45 711.041239\n46 614.509780\n"
],
[
"reg = LinearRegression().fit(OD, CD2)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * OD",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(OD,CD2,'ro',OD,ytrain,'b-')\n\nplt.title(\"On-Demand Streaming vs CD\")\nplt.xlabel(\"On-Demand Streaming (Ad-Supported) Sales\")\nplt.ylabel(\"CD Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(CD2, ytrain)",
"_____no_output_____"
],
[
"r2_score(CD2, ytrain)",
"_____no_output_____"
]
],
[
[
"While the mean squared error value is quite high, the R-squared of 0.87 implies that the regression line sufficiently fits the data. Therefore, **we can use On-Demand Streaming Sales to predict CD Sales** using this regression line.",
"_____no_output_____"
],
[
"On-Demand Streaming (Ad-Supported) sales and Download Album sales are very negatively correlated, (r=-0.97). As a result, we might be able to use linear regression to predict On-Demand Streaming sales using Download Album sales.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nDA2 = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'Download Album'][['Value (Actual)']]\nOD = adjusted_2011_on[adjusted_2011_on[\"Format\"] == 'On-Demand Streaming (Ad-Supported)'][['Value (Actual)']]\nprint (DA2)\nprint (OD)",
" Value (Actual)\n157 1217.030020\n158 1341.590983\n159 1352.202953\n160 1207.247578\n161 1148.145081\n162 925.232201\n163 697.237618\n164 508.704388\n165 394.533006\n Value (Actual)\n294 129.340695\n295 190.339616\n296 242.396098\n297 306.475448\n298 401.245264\n299 521.288175\n300 686.918081\n301 773.294917\n302 908.149331\n"
],
[
"reg = LinearRegression().fit(DA2, OD)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * DA2",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(DA2,OD,'ro',DA2,ytrain,'b-')\n\nplt.title(\"Download Album vs On-Demand Streaming\")\nplt.xlabel(\"Download Album Sales\")\nplt.ylabel(\"On-Demand Streaming (Ad-Supported) Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(OD, ytrain)",
"_____no_output_____"
],
[
"r2_score(OD, ytrain)",
"_____no_output_____"
]
],
[
[
"The high R-squared value of 0.94 demonstrates that the regression line fits the data very well. As a result, **we should be able to predict On-Demand Streaming sales by looking at Download Album sales**.",
"_____no_output_____"
],
[
"Lastly, CD Single sales and Download Single sales are also negatively correlated (r=-0.4). This correlation is on the lower end, but I am still going to perform linear regression to see if we can predict Download Single sales based on CD Single sales.",
"_____no_output_____"
]
],
[
[
"#collapse-output\nCDS = adjusted_2004_on[adjusted_2004_on[\"Format\"] == 'CD Single'][['Value (Actual)']]\nDS = adjusted_2004_on[adjusted_2004_on[\"Format\"] == 'Download Single'][['Value (Actual)']]\nprint (CDS)\nprint (DS)",
" Value (Actual)\n63 20.300979\n64 14.268619\n65 9.764677\n66 15.045902\n67 4.156001\n68 3.694173\n69 3.400068\n70 3.977965\n71 3.591198\n72 2.684057\n73 3.905024\n74 1.291079\n75 0.280361\n76 1.542259\n77 0.157981\n78 0.181679\n Value (Actual)\n181 186.769010\n182 475.577000\n183 736.282015\n184 1000.182475\n185 1225.664089\n186 1396.635564\n187 1566.845282\n188 1730.301179\n189 1831.258646\n190 1726.739156\n191 1463.655387\n192 1278.449595\n193 958.879103\n194 707.692711\n195 499.316974\n196 414.804251\n"
],
[
"reg = LinearRegression().fit(CDS, DS)",
"_____no_output_____"
],
[
"reg.coef_",
"_____no_output_____"
],
[
"reg.intercept_",
"_____no_output_____"
],
[
"ytrain = reg.intercept_ + reg.coef_ * CDS",
"_____no_output_____"
],
[
"figure(figsize=(9, 5))\nplt.plot(CDS,DS,'ro',CDS,ytrain,'b-')\n\nplt.title(\"CD Single vs Download Single\")\nplt.xlabel(\"CD Single Sales\")\nplt.ylabel(\"Download Single Sales\")",
"_____no_output_____"
],
[
"mean_squared_error(DS, ytrain)",
"_____no_output_____"
],
[
"r2_score(DS, ytrain)",
"_____no_output_____"
]
],
[
[
"As I predicted, the correlation between CD Single sales and Download Single sales isn't strong enough to create an accurate regression line. As indicated by the high mean squared error and low R-squared value, **Download Single sales cannot be predicted based on CD Single sales**.",
"_____no_output_____"
],
[
"In summary, the linear regression analysis revealed that a few of the sales formats have a strong enough correlation that sales of one can predict sales of the other. The results revealed that: Limited Tier Paid Subscription sales can be predicted based on Other Ad-Supported Streaming sales, On-Demand Streaming sales can be predicted based on Paid Subscription sales, and Download Album sales can be predicted by looking at Download Single sales. As a result, we can expect that if one of the sales formats sees an increase in sales and popularity, the correlated sales format will also see an increase in sales and popularity. Similarly, if one sales format sees a decrease in sales, then the correlated sales format will most likely also see a decrease in sales. \n\nFor the negatively correlated formats, the linear regression analysis revealed that: CD sales can be predicted using On-Demand Streaming sales, and On-Demand Streaming sales can be predicted by looking at Download Album sales. More specifically, a decrease in CD sales can be predicted by an increase in On-Demand Streaming sales and an increase in On-Demand Streaming sales can be predicted by a decrease in Download Album sales.",
"_____no_output_____"
],
[
"### Growth Rate Analysis",
"_____no_output_____"
],
[
"As a last step in my analysis, I am going to look at the growth rates of popular sales formats in 2019. This information will help to predict which formats might have high growth in the near future.",
"_____no_output_____"
],
[
"Popular sales formats in recent years include: Other Ad-Supported Streaming, Paid Subscription, Synchronization, On-Demand Streaming (Ad-Supported), Limited Tier Paid Subscription, Other Digital Sales, SoundExchange Distributions, CDs, LP/EP, Download Single, and Download Album.",
"_____no_output_____"
],
[
"Other Ad-Supported Streaming:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[2]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Other Ad-Supported Streaming sales decreased by 1.9%.**",
"_____no_output_____"
],
[
"Paid Subscription:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[3]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Paid Subscription sales increased by 25%.**",
"_____no_output_____"
],
[
"Synchronization:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[4]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Synchronization sales decreased by 4.96%.**",
"_____no_output_____"
],
[
"On-Demand Streaming (Ad-Supported):",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[6]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **On-Demand Streaming (Ad-Supported) sales increased by 17.4%.**",
"_____no_output_____"
],
[
"Limited Tier Paid Subscription:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[7]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Limited Tier Paid Subscription sales increased by 9.1%.**",
"_____no_output_____"
],
[
"Other Digital:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[16]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Other Digital sales increased by 6.5%.**",
"_____no_output_____"
],
[
"SoundExchange Distributions:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[18]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **SoundExchange Distributions sales decreased by 6.4%.**",
"_____no_output_____"
],
[
"CDs:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[10]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **CD sales decreased by 13.6%.**",
"_____no_output_____"
],
[
"LP/EP:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[19]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **LP/EP sales increased by 16.6%.**",
"_____no_output_____"
],
[
"Download Single:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[20]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Download Single sales decreased by 16.9%.**",
"_____no_output_____"
],
[
"Download Album:",
"_____no_output_____"
]
],
[
[
"#collapse-output\nformat_dfs[1]['Value (Actual)'].pct_change(periods=1)",
"_____no_output_____"
]
],
[
[
"In 2019, **Download Album sales decreased by 22.4%.**",
"_____no_output_____"
],
[
"By looking at the sales growth rates for each sales format in 2019, we are able to see which formats have increasing sales and which have decreasing sales. If we assume these trends will continue into the near future, we can predict which sales formats will be most popular going forward as well as which formats are being used less. \n\nSales formats that saw positive growth in 2019 include Paid Subscription sales, On-Demand Streaming (Ad-Supported) sales, LP/EP sales, Limited Tier Paid Subscription sales, and Other Digital sales. As a result, I expect that these sales formats will continue to increase in the near future and they will eventually make up the majority of all music industry sales. Paid Subscription services not only had the highest sales of all the formats in 2018, but also saw the largest increase in sales in 2019, increasing 25%. Looking at the sales formats that are increasing in popularity, we can see that streaming services, both paid and free, are taking over the music industry as the most popular way to consume music. In addition to streaming services, it seems that LP albums and EP albums are also making a comeback in terms of popularity. \n\nSales formats that saw negative growth in 2019 include Download Album sales, Download Single sales, CD sales, SoundExchange Distributions sales, Synchronization sales, and Other Ad-Supported Streaming sales. It is reasonable to assume that the majority of these formats are decreasing in popularity and thus sales in these formats will continue to decrease into the future. Download Album, Download Single, and CD sales saw the largest decrease by far, demonstrating that consumers are steering away from downloading music or buying \"hard copies\". Instead, consumers are getting their music from streaming services like Spotify, Apple Music, and Pandora or opting to buy LP/EP albums instead. ",
"_____no_output_____"
],
[
"## Discussion ",
"_____no_output_____"
],
[
"Through my analysis, I revealed how music industry sales have changed since 1973 and especially throughout the 2000's. Music industry sales have been greatly affected by technology, as consumers now have access to a plethora of music formats that didn't even exist 15 years ago. My analysis revealed which music sale formats have been strongly correlated in the 2000s and which formats have been strongly anti-correlated. Since correlation doesn't imply causation, I cannot say that certain formats led to the demise of other formats. But, it is interesting to see how the rise of new formats is correlated to the decline of more traditional music formats. In my correlation analysis, I found that streaming formats were highly correlated with other streaming formats, meaning that sales of both increased similarly during the 2000s. More specifically, I found: \n\n(1) Other Ad-Supported Streaming and Limited Tier Paid Subscription sales to be highly correlated,\n\n(2) Paid Subscription and On-Demand Streaming (Ad-Supported) sales to be highly correlated,\n\n(3) On-Demand Streaming (Ad-Supported) and Other Ad-Supported Streaming sales to be highly correlated,\n\n(4) Paid Subscription and SoundExchange Distributions sales to be highly correlated, and\n\n(5) Download Album and Download Single sales to be highly correlated.\n\nIn contrast, I found that streaming formats were very anti-correlated with older sales formats. While these streaming formats saw increased sales throughout the 2000's, the older sales formats had large decreases in sales. To be specific, I found: \n\n(1) Paid Subscription and CD sales to be moderately anti-correlated,\n\n(2) On-Demand Streaming (Ad-Supported) and CD sales to be very anti-correlated,\n\n(3) Paid Subscription and Cassette sales to be very anti-correlated,\n\n(4) On-Demand Streaming (Ad-Supported) and Download Album sales to be very anti-correlated, and\n\n(5) CD Single and Download Single sales to be moderately anti-correlated.\n\nMy analysis also reveals where music industry sales may be focused in the future. Plotting the different sales formats revealed that a number of them have been steadily increasing in recent years. The formats that have seen increasing sales over the past few years are \n\n(1) Synchronizations, \n\n(2) Paid Subscriptions, \n\n(3) On-Demand Streaming (Ad-Supported),\n\n(4) Limited Tier Paid Subscriptions,\n\n(5) Other Digital,\n\n(6) SoundExchange Distributions, and\n\n(7) LP/EP. \n\nFormats that have seen decreasing sales over the past few years include:\n\n(1) Download Music Video,\n\n(2) Download Album,\n\n(3) Other Ad-Supported Streaming,\n\n(4) Ringtones and Ringbacks,\n\n(5) CDs,\n\n(6) Vinyl Singles,\n\n(7) CD Singles,\n\n(8) Kiosks,\n\n(9) DVD Audios,\n\n(10) SACDs,\n\n(11) Download Single, and\n\n(12) Music Video (Physical).\n\nIt is clear that sales are shifting away from traditional sales formats like owning an album to technology-based formats like streaming an album. Additionally, it appears that consumers like the flexibility streaming platforms provide to jump from one artist to another, without having to commit to a whole album. As a result, I would advise artists and managers to shift away from these formats. Instead of focusing on promoting an album in order to increase album sales, artists should focus their strategy and marketing efforts on streaming platforms. By putting their music on platforms like Spotify and Apple Music, artists will not only expose their music to a wider audience but also put themselves in a better place to make sales. \n\nMy analysis also demonstrated how quickly popularity of music sales formats shifts. These new sales formats that are seeing high growth now will probably continue to grow into the near future, but as even newer formats are made available, they too will begin to see decreased sales. Therefore, it is imperative that people in the music industry monitor new technologies and changes in the landscapes so they can stay on top of new trends. My correlation and linear regression analysis revealed which formats's sales are closely correlated. In the future, if we begin to see a decrease in a particular sales format, we should be cautious of a decrease in the correlated sales format as well. In conclusion, my analysis provided insight into the past and future of music industry sales. This analysis is of interest to me as I feel I now have a much stronger understanding of the music industry sales landscape and where the industry is heading in the future. With this knowledge, artists, managers, and others working in the industry can hopefully better focus their marketing and predict potential sales avenues. ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a45c5f68000b880e31756b39da0f1f04b1040c2
| 622,348 |
ipynb
|
Jupyter Notebook
|
Image Classifier Project.ipynb
|
jinshengye-git/aipnd-project
|
aaab0e6ff382e5a02b7b7fb12ae32726c77a7d7a
|
[
"MIT"
] | null | null | null |
Image Classifier Project.ipynb
|
jinshengye-git/aipnd-project
|
aaab0e6ff382e5a02b7b7fb12ae32726c77a7d7a
|
[
"MIT"
] | null | null | null |
Image Classifier Project.ipynb
|
jinshengye-git/aipnd-project
|
aaab0e6ff382e5a02b7b7fb12ae32726c77a7d7a
|
[
"MIT"
] | null | null | null | 532.832192 | 557,676 | 0.924076 |
[
[
[
"# Developing an AI application\n\nGoing forward, AI algorithms will be incorporated into more and more everyday applications. For example, you might want to include an image classifier in a smart phone app. To do this, you'd use a deep learning model trained on hundreds of thousands of images as part of the overall application architecture. A large part of software development in the future will be using these types of models as common parts of applications. \n\nIn this project, you'll train an image classifier to recognize different species of flowers. You can imagine using something like this in a phone app that tells you the name of the flower your camera is looking at. In practice you'd train this classifier, then export it for use in your application. We'll be using [this dataset](http://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html) of 102 flower categories, you can see a few examples below. \n\n<img src='assets/Flowers.png' width=500px>\n\nThe project is broken down into multiple steps:\n\n* Load and preprocess the image dataset\n* Train the image classifier on your dataset\n* Use the trained classifier to predict image content\n\nWe'll lead you through each part which you'll implement in Python.\n\nWhen you've completed this project, you'll have an application that can be trained on any set of labeled images. Here your network will be learning about flowers and end up as a command line application. But, what you do with your new skills depends on your imagination and effort in building a dataset. For example, imagine an app where you take a picture of a car, it tells you what the make and model is, then looks up information about it. Go build your own dataset and make something new.\n\nFirst up is importing the packages you'll need. It's good practice to keep all the imports at the beginning of your code. As you work through this notebook and find you need to import a package, make sure to add the import up here.",
"_____no_output_____"
]
],
[
[
"# Imports here\n%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\nimport torch\nimport numpy as np\nfrom torch import nn\nfrom torch import optim\n\nfrom torchvision import datasets, transforms, models\nfrom collections import OrderedDict\nfrom PIL import Image\nfrom torch.autograd import Variable",
"_____no_output_____"
]
],
[
[
"## Load the data\n\nHere you'll use `torchvision` to load the data ([documentation](http://pytorch.org/docs/0.3.0/torchvision/index.html)). The data should be included alongside this notebook, otherwise you can [download it here](https://s3.amazonaws.com/content.udacity-data.com/nd089/flower_data.tar.gz). The dataset is split into three parts, training, validation, and testing. For the training, you'll want to apply transformations such as random scaling, cropping, and flipping. This will help the network generalize leading to better performance. You'll also need to make sure the input data is resized to 224x224 pixels as required by the pre-trained networks.\n\nThe validation and testing sets are used to measure the model's performance on data it hasn't seen yet. For this you don't want any scaling or rotation transformations, but you'll need to resize then crop the images to the appropriate size.\n\nThe pre-trained networks you'll use were trained on the ImageNet dataset where each color channel was normalized separately. For all three sets you'll need to normalize the means and standard deviations of the images to what the network expects. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`, calculated from the ImageNet images. These values will shift each color channel to be centered at 0 and range from -1 to 1.\n ",
"_____no_output_____"
]
],
[
[
"data_dir = 'flower_data'\ntrain_dir = data_dir + '/train'\nvalid_dir = data_dir + '/valid'\ntest_dir = data_dir + '/test'",
"_____no_output_____"
],
[
"# TODO: Define your transforms for the training, validation, and testing sets\ndata_transforms = {\n 'training' : transforms.Compose([transforms.RandomRotation(30),\n transforms.RandomResizedCrop(224),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], \n [0.229, 0.224, 0.225])]),\n \n 'validating' : transforms.Compose([transforms.Resize(256),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], \n [0.229, 0.224, 0.225])]),\n\n 'testing' : transforms.Compose([transforms.Resize(256),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], \n [0.229, 0.224, 0.225])])\n}\n\n# TODO: Load the datasets with ImageFolder\nimage_datasets = {\n 'training' : datasets.ImageFolder(train_dir, transform=data_transforms['training']),\n 'validating' : datasets.ImageFolder(valid_dir, transform=data_transforms['validating']),\n 'testing' : datasets.ImageFolder(test_dir, transform=data_transforms['testing'])\n}\n\n# TODO: Using the image datasets and the trainforms, define the dataloaders\ndataloaders = {\n 'training' : torch.utils.data.DataLoader(image_datasets['training'], batch_size=64, shuffle=True),\n 'validating' : torch.utils.data.DataLoader(image_datasets['validating'], batch_size=64, shuffle=True),\n 'testing' : torch.utils.data.DataLoader(image_datasets['testing'], batch_size=30, shuffle=False)\n} ",
"_____no_output_____"
]
],
[
[
"### Label mapping\n\nYou'll also need to load in a mapping from category label to category name. You can find this in the file `cat_to_name.json`. It's a JSON object which you can read in with the [`json` module](https://docs.python.org/2/library/json.html). This will give you a dictionary mapping the integer encoded categories to the actual names of the flowers.",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open('cat_to_name.json', 'r') as f:\n cat_to_name = json.load(f)",
"_____no_output_____"
]
],
[
[
"# Building and training the classifier\n\nNow that the data is ready, it's time to build and train the classifier. As usual, you should use one of the pretrained models from `torchvision.models` to get the image features. Build and train a new feed-forward classifier using those features.\n\nWe're going to leave this part up to you. Refer to [the rubric](https://review.udacity.com/#!/rubrics/1663/view) for guidance on successfully completing this section. Things you'll need to do:\n\n* Load a [pre-trained network](http://pytorch.org/docs/master/torchvision/models.html) (If you need a starting point, the VGG networks work great and are straightforward to use)\n* Define a new, untrained feed-forward network as a classifier, using ReLU activations and dropout\n* Train the classifier layers using backpropagation using the pre-trained network to get the features\n* Track the loss and accuracy on the validation set to determine the best hyperparameters\n\nWe've left a cell open for you below, but use as many as you need. Our advice is to break the problem up into smaller parts you can run separately. Check that each part is doing what you expect, then move on to the next. You'll likely find that as you work through each part, you'll need to go back and modify your previous code. This is totally normal!\n\nWhen training make sure you're updating only the weights of the feed-forward network. You should be able to get the validation accuracy above 70% if you build everything right. Make sure to try different hyperparameters (learning rate, units in the classifier, epochs, etc) to find the best model. Save those hyperparameters to use as default values in the next part of the project.\n\nOne last important tip if you're using the workspace to run your code: To avoid having your workspace disconnect during the long-running tasks in this notebook, please read in the earlier page in this lesson called Intro to\nGPU Workspaces about Keeping Your Session Active. You'll want to include code from the workspace_utils.py module.\n\n**Note for Workspace users:** If your network is over 1 GB when saved as a checkpoint, there might be issues with saving backups in your workspace. Typically this happens with wide dense layers after the convolutional layers. If your saved checkpoint is larger than 1 GB (you can open a terminal and check with `ls -lh`), you should reduce the size of your hidden layers and train again.",
"_____no_output_____"
]
],
[
[
"# TODO: Build and train your network\n\ndef model_config(hidden_units):\n \n model = models.densenet121(pretrained=True)\n\n # Freeze parameters so we don't backprop through them\n for param in model.parameters():\n param.requires_grad = False\n\n classifier_input_size = model.classifier.in_features\n classifier_output_size = len(cat_to_name.keys())\n \n classifier = nn.Sequential(OrderedDict([\n ('fc1', nn.Linear(classifier_input_size, hidden_units)),\n ('relu', nn.ReLU()),\n ('fc2', nn.Linear(hidden_units, classifier_output_size)),\n ('output', nn.LogSoftmax(dim=1))\n ]))\n\n model.classifier = classifier\n\n return model\n\ndef model_create(learning_rate, hidden_units, class_to_idx):\n \n # Load model\n model = model_config(hidden_units) \n criterion = nn.NLLLoss()\n optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)\n\n # Save class to index mapping\n model.class_to_idx = class_to_idx\n\n return model, optimizer, criterion\n\n\n\n\ndef do_deep_learning(model, trainloader, epochs, print_every, criterion, optimizer, device='gpu'):\n epochs = epochs\n print_every = print_every\n steps = 0\n \n model.to('cuda') # use cuda\n\n for e in range(epochs):\n running_loss = 0\n for ii, (inputs, labels) in enumerate(trainloader):\n steps += 1\n\n inputs, labels = inputs.to('cuda'), labels.to('cuda')\n\n optimizer.zero_grad()\n\n # Forward and backward passes\n outputs = model.forward(inputs)\n loss = criterion(outputs, labels)\n loss.backward()\n optimizer.step()\n\n running_loss += loss.item()\n\n if steps % print_every == 0:\n print(\"Epoch: {}/{}... \".format(e+1, epochs),\n \"Loss: {:.4f}\".format(running_loss/print_every))\n\n running_loss = 0\n\n \nclass_to_idx = image_datasets['training'].class_to_idx\n\nhidden_units = 500\nlearning_rate = 0.005\nepochs = 10\nprint_every = 50\n\nmodel, optimizer, criterion = model_create(learning_rate, hidden_units, class_to_idx)\n\ndo_deep_learning(model, dataloaders['training'], epochs, print_every, criterion, optimizer, 'gpu')",
"Epoch: 1/10... Loss: 3.7718\nEpoch: 1/10... Loss: 2.1328\nEpoch: 2/10... Loss: 1.2037\nEpoch: 2/10... Loss: 0.9970\nEpoch: 3/10... Loss: 0.7009\nEpoch: 3/10... Loss: 0.6824\nEpoch: 4/10... Loss: 0.5373\nEpoch: 4/10... Loss: 0.5754\nEpoch: 5/10... Loss: 0.4189\nEpoch: 5/10... Loss: 0.5143\nEpoch: 6/10... Loss: 0.3290\nEpoch: 6/10... Loss: 0.4842\nEpoch: 7/10... Loss: 0.2911\nEpoch: 7/10... Loss: 0.4681\nEpoch: 8/10... Loss: 0.2243\nEpoch: 8/10... Loss: 0.4359\nEpoch: 9/10... Loss: 0.1883\nEpoch: 9/10... Loss: 0.4015\nEpoch: 10/10... Loss: 0.1639\nEpoch: 10/10... Loss: 0.3697\n"
]
],
[
[
"## Testing your network\n\nIt's good practice to test your trained network on test data, images the network has never seen either in training or validation. This will give you a good estimate for the model's performance on completely new images. Run the test images through the network and measure the accuracy, the same way you did validation. You should be able to reach around 70% accuracy on the test set if the model has been trained well.",
"_____no_output_____"
]
],
[
[
"# TODO: Do validation on the test set\ndef validation(model, dataloaders, criterion):\n correct = 0\n total = 0\n model.eval() #turn off dropout\n with torch.no_grad():\n for data in dataloaders:\n images, labels = data\n gpu = torch.cuda.is_available()\n if gpu:\n images = Variable(images.float().cuda())\n labels = Variable(labels.long().cuda()) \n else:\n images = Variable(images, volatile=True)\n labels = Variable(labels, volatile=True)\n outputs = model.forward(images)\n _, predicted = torch.max(outputs.data, 1)\n total += labels.size(0)\n correct += (predicted == labels).sum().item()\n\n print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))\n \nvalidation(model, dataloaders['testing'], criterion)",
"Accuracy of the network on the 10000 test images: 93 %\n"
]
],
[
[
"## Save the checkpoint\n\nNow that your network is trained, save the model so you can load it later for making predictions. You probably want to save other things such as the mapping of classes to indices which you get from one of the image datasets: `image_datasets['train'].class_to_idx`. You can attach this to the model as an attribute which makes inference easier later on.\n\n```model.class_to_idx = image_datasets['train'].class_to_idx```\n\nRemember that you'll want to completely rebuild the model later so you can use it for inference. Make sure to include any information you need in the checkpoint. If you want to load the model and keep training, you'll want to save the number of epochs as well as the optimizer state, `optimizer.state_dict`. You'll likely want to use this trained model in the next part of the project, so best to save it now.",
"_____no_output_____"
]
],
[
[
"# TODO: Save the checkpoint\ncheckpoint = {'input_size': 1024,\n 'struc': 'densenet121',\n 'learing_rate': learning_rate,\n 'optimizer' : optimizer.state_dict(),\n 'class_to_idx' : model.class_to_idx,\n 'output_size': 102,\n 'epochs': epochs,\n 'arch': 'densenet121',\n 'state_dict': model.state_dict()\n \n }\n\ntorch.save(checkpoint, 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"## Loading the checkpoint\n\nAt this point it's good to write a function that can load a checkpoint and rebuild the model. That way you can come back to this project and keep working on it without having to retrain the network.",
"_____no_output_____"
]
],
[
[
"# TODO: Write a function that loads a checkpoint and rebuilds the model\n\ndef load_checkpoint(filepath):\n checkpoint = torch.load(filepath)\n class_to_idx = checkpoint['class_to_idx']\n learning_rate = checkpoint['learing_rate']\n model, optimizer, criterion = model_create(learning_rate, hidden_units, class_to_idx)\n model.load_state_dict(checkpoint['state_dict'])\n model.optimizer = checkpoint['optimizer']\n model.epochs = checkpoint['epochs']\n \n if torch.cuda.is_available():\n model.cuda()\n criterion.cuda()\n \n return model\n\n\nmodel = load_checkpoint('checkpoint.pth')\nprint(model)",
"DenseNet(\n (features): Sequential(\n (conv0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)\n (norm0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu0): ReLU(inplace)\n (pool0): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)\n (denseblock1): _DenseBlock(\n (denselayer1): _DenseLayer(\n (norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer2): _DenseLayer(\n (norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer3): _DenseLayer(\n (norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer4): _DenseLayer(\n (norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer5): _DenseLayer(\n (norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer6): _DenseLayer(\n (norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n )\n (transition1): _Transition(\n (norm): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace)\n (conv): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (pool): AvgPool2d(kernel_size=2, stride=2, padding=0)\n )\n (denseblock2): _DenseBlock(\n (denselayer1): _DenseLayer(\n (norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer2): _DenseLayer(\n (norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer3): _DenseLayer(\n (norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer4): _DenseLayer(\n (norm1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer5): _DenseLayer(\n (norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer6): _DenseLayer(\n (norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer7): _DenseLayer(\n (norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer8): _DenseLayer(\n (norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer9): _DenseLayer(\n (norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer10): _DenseLayer(\n (norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer11): _DenseLayer(\n (norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer12): _DenseLayer(\n (norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n )\n (transition2): _Transition(\n (norm): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace)\n (conv): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (pool): AvgPool2d(kernel_size=2, stride=2, padding=0)\n )\n (denseblock3): _DenseBlock(\n (denselayer1): _DenseLayer(\n (norm1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer2): _DenseLayer(\n (norm1): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer3): _DenseLayer(\n (norm1): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer4): _DenseLayer(\n (norm1): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer5): _DenseLayer(\n (norm1): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer6): _DenseLayer(\n (norm1): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer7): _DenseLayer(\n (norm1): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer8): _DenseLayer(\n (norm1): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer9): _DenseLayer(\n (norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer10): _DenseLayer(\n (norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer11): _DenseLayer(\n (norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer12): _DenseLayer(\n (norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer13): _DenseLayer(\n (norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer14): _DenseLayer(\n (norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer15): _DenseLayer(\n (norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer16): _DenseLayer(\n (norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer17): _DenseLayer(\n (norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer18): _DenseLayer(\n (norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer19): _DenseLayer(\n (norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer20): _DenseLayer(\n (norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer21): _DenseLayer(\n (norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer22): _DenseLayer(\n (norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer23): _DenseLayer(\n (norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer24): _DenseLayer(\n (norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n )\n (transition3): _Transition(\n (norm): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace)\n (conv): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (pool): AvgPool2d(kernel_size=2, stride=2, padding=0)\n )\n (denseblock4): _DenseBlock(\n (denselayer1): _DenseLayer(\n (norm1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer2): _DenseLayer(\n (norm1): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer3): _DenseLayer(\n (norm1): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer4): _DenseLayer(\n (norm1): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer5): _DenseLayer(\n (norm1): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer6): _DenseLayer(\n (norm1): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer7): _DenseLayer(\n (norm1): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer8): _DenseLayer(\n (norm1): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer9): _DenseLayer(\n (norm1): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer10): _DenseLayer(\n (norm1): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer11): _DenseLayer(\n (norm1): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer12): _DenseLayer(\n (norm1): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer13): _DenseLayer(\n (norm1): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer14): _DenseLayer(\n (norm1): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer15): _DenseLayer(\n (norm1): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n (denselayer16): _DenseLayer(\n (norm1): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu1): ReLU(inplace)\n (conv1): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)\n (norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu2): ReLU(inplace)\n (conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n )\n )\n (norm5): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n )\n (classifier): Sequential(\n (fc1): Linear(in_features=1024, out_features=500, bias=True)\n (relu): ReLU()\n (fc2): Linear(in_features=500, out_features=102, bias=True)\n (output): LogSoftmax()\n )\n)\n"
]
],
[
[
"# Inference for classification\n\nNow you'll write a function to use a trained network for inference. That is, you'll pass an image into the network and predict the class of the flower in the image. Write a function called `predict` that takes an image and a model, then returns the top $K$ most likely classes along with the probabilities. It should look like \n\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```\n\nFirst you'll need to handle processing the input image such that it can be used in your network. \n\n## Image Preprocessing\n\nYou'll want to use `PIL` to load the image ([documentation](https://pillow.readthedocs.io/en/latest/reference/Image.html)). It's best to write a function that preprocesses the image so it can be used as input for the model. This function should process the images in the same manner used for training. \n\nFirst, resize the images where the shortest side is 256 pixels, keeping the aspect ratio. This can be done with the [`thumbnail`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) or [`resize`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) methods. Then you'll need to crop out the center 224x224 portion of the image.\n\nColor channels of images are typically encoded as integers 0-255, but the model expected floats 0-1. You'll need to convert the values. It's easiest with a Numpy array, which you can get from a PIL image like so `np_image = np.array(pil_image)`.\n\nAs before, the network expects the images to be normalized in a specific way. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`. You'll want to subtract the means from each color channel, then divide by the standard deviation. \n\nAnd finally, PyTorch expects the color channel to be the first dimension but it's the third dimension in the PIL image and Numpy array. You can reorder dimensions using [`ndarray.transpose`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.ndarray.transpose.html). The color channel needs to be first and retain the order of the other two dimensions.",
"_____no_output_____"
]
],
[
[
"def process_image(image):\n ''' Scales, crops, and normalizes a PIL image for a PyTorch model,\n returns an Numpy array\n '''\n \n # TODO: Process a PIL image for use in a PyTorch model\n width, height = image.size\n \n short = width if width < height else height\n long = height if height > width else width\n \n new_short, new_long = 256, int(256/short*long)\n \n im = image.resize((new_short,new_long))\n \n left, top = (new_short - 224) / 2, (new_long - 224) / 2\n area = (left, top, 224+left, 224+top)\n img_new = im.crop(area)\n np_img = np.array(img_new)\n \n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n \n np_img = (np_img / 255 - mean) / std\n image = np.transpose(np_img, (2, 0, 1))\n \n return image.astype(np.float32)",
"_____no_output_____"
]
],
[
[
"To check your work, the function below converts a PyTorch tensor and displays it in the notebook. If your `process_image` function works, running the output through this function should return the original image (except for the cropped out portions).",
"_____no_output_____"
]
],
[
[
"def imshow(image, ax=None, title=None):\n \"\"\"Imshow for Tensor.\"\"\"\n if ax is None:\n fig, ax = plt.subplots()\n \n # PyTorch tensors assume the color channel is the first dimension\n # but matplotlib assumes is the third dimension\n image = image.numpy().transpose((1, 2, 0))\n \n # Undo preprocessing\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n image = std * image + mean\n \n # Image needs to be clipped between 0 and 1 or it looks like noise when displayed\n image = np.clip(image, 0, 1)\n \n ax.imshow(image)\n \n return ax",
"_____no_output_____"
]
],
[
[
"## Class Prediction\n\nOnce you can get images in the correct format, it's time to write a function for making predictions with your model. A common practice is to predict the top 5 or so (usually called top-$K$) most probable classes. You'll want to calculate the class probabilities then find the $K$ largest values.\n\nTo get the top $K$ largest values in a tensor use [`x.topk(k)`](http://pytorch.org/docs/master/torch.html#torch.topk). This method returns both the highest `k` probabilities and the indices of those probabilities corresponding to the classes. You need to convert from these indices to the actual class labels using `class_to_idx` which hopefully you added to the model or from an `ImageFolder` you used to load the data ([see here](#Save-the-checkpoint)). Make sure to invert the dictionary so you get a mapping from index to class as well.\n\nAgain, this method should take a path to an image and a model checkpoint, then return the probabilities and classes.\n\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```",
"_____no_output_____"
]
],
[
[
"def predict(image_path, model, topk=5):\n ''' Predict the class (or classes) of an image using a trained deep learning model.\n '''\n \n # TODO: Implement the code to predict the class from an image file\n model.eval()\n \n gpu = torch.cuda.is_available()\n image = Image.open(image_path)\n np_image = process_image(image)\n \n tensor_image = torch.from_numpy(np_image)\n\n if gpu:\n tensor_image = Variable(tensor_image.float().cuda())\n else: \n tensor_image = Variable(tensor_image)\n\n tensor_image = tensor_image.unsqueeze(0)\n output = model.forward(tensor_image) \n ps = torch.exp(output).data.topk(topk)\n \n probs = ps[0].cpu() if gpu else ps[0]\n classes = ps[1].cpu() if gpu else ps[1]\n \n inverted_class_to_idx = {model.class_to_idx[c]: c for c in model.class_to_idx}\n \n mapped_classes = list(inverted_class_to_idx[label] for label in classes.numpy()[0] )\n \n\n return probs.numpy()[0], mapped_classes",
"_____no_output_____"
]
],
[
[
"## Sanity Checking\n\nNow that you can use a trained model for predictions, check to make sure it makes sense. Even if the testing accuracy is high, it's always good to check that there aren't obvious bugs. Use `matplotlib` to plot the probabilities for the top 5 classes as a bar graph, along with the input image. It should look like this:\n\n<img src='assets/inference_example.png' width=300px>\n\nYou can convert from the class integer encoding to actual flower names with the `cat_to_name.json` file (should have been loaded earlier in the notebook). To show a PyTorch tensor as an image, use the `imshow` function defined above.",
"_____no_output_____"
]
],
[
[
"# TODO: Display an image along with the top 5 classes\ndef sanity_check(image, model): \n\n fig = plt.figure(figsize=[15,15])\n ax1 = plt.subplot(2,1,1)\n ax2 = plt.subplot(2,1,2)\n \n probs, classes = predict(image, model)\n max_index = np.argmax(probs)\n max_label = classes[max_index]\n\n image = Image.open(image)\n ax1.axis('off')\n ax1.set_title(cat_to_name[max_label])\n ax1.imshow(image)\n\n labels = (cat_to_name[c] for c in classes)\n tick_y = np.arange(5)\n ax2.set_yticklabels(labels)\n ax2.set_yticks(tick_y)\n ax2.invert_yaxis() \n ax2.set_xlabel('Probs')\n ax2.barh(tick_y, probs, color='b')\n\n plt.show()\n \nsanity_check(test_dir + '/84/image_02563.jpg', model)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a45c704a5ae4f5cdf21774e51fd09817b9e8583
| 96,771 |
ipynb
|
Jupyter Notebook
|
experiments/exp.ipynb
|
vladislavv17/Expresso-zindi-competiton
|
a2b27da4d1afba68abd38216fd13c591ff4e1e16
|
[
"MIT"
] | null | null | null |
experiments/exp.ipynb
|
vladislavv17/Expresso-zindi-competiton
|
a2b27da4d1afba68abd38216fd13c591ff4e1e16
|
[
"MIT"
] | null | null | null |
experiments/exp.ipynb
|
vladislavv17/Expresso-zindi-competiton
|
a2b27da4d1afba68abd38216fd13c591ff4e1e16
|
[
"MIT"
] | 1 |
2021-10-01T11:05:11.000Z
|
2021-10-01T11:05:11.000Z
| 45.646698 | 189 | 0.590673 |
[
[
[
"import pandas as pd\nimport seaborn as sns",
"_____no_output_____"
],
[
"desc = pd.read_csv('data/VariableDefinitions.csv')\ntrain = pd.read_csv('data/Train.csv')\ntest = pd.read_csv('data/Test.csv')\nsub = pd.read_csv('data/Samplesubmission.csv')",
"_____no_output_____"
],
[
"df.loc[1].values",
"_____no_output_____"
],
[
"desc.drop(['Unnamed: 1'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"desc.iloc[2:, ].values",
"_____no_output_____"
],
[
"train.head(2)",
"_____no_output_____"
],
[
"train.dtypes",
"_____no_output_____"
],
[
"train.isna().sum()",
"_____no_output_____"
],
[
"test.isna().sum()",
"_____no_output_____"
],
[
"train['is_train'] = True\ntest['is_train'] = False\n\nfull = pd.concat([train.drop('CHURN', axis=1), test], ignore_index=True)",
"_____no_output_____"
],
[
"for col in full.columns:\n\n if full[col].isna().sum() == 0:\n continue\n\n full[col + '_isna'] = full[col].isna().astype('int')\n filler = train[col].mode()[0]\n\n if train[col].dtype != 'object':\n filler = train[col].median()\n \n full[col].fillna(filler, inplace=True)\n\nfull = full.drop('MRG', axis=1)\n\nfreq_map = train['TOP_PACK'].value_counts().to_dict()\nfull['TOP_PACK'] = full['TOP_PACK'].map(freq_map)\nfull.fillna(0, inplace=True)",
"_____no_output_____"
],
[
"full.isna().sum()",
"_____no_output_____"
],
[
"full = pd.get_dummies(full.drop('user_id', axis=1))",
"_____no_output_____"
],
[
"train, target = full[full['is_train']], train['CHURN']",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import roc_auc_score\nfrom xgboost import XGBClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom catboost import CatBoostClassifier\nfrom lightgbm import LGBMClassifier",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(train, target)",
"_____no_output_____"
],
[
"lgbm = LGBMClassifier(learning_rate=0.075)\n\nlgbm.fit(X_train, y_train)",
"_____no_output_____"
],
[
"roc_auc_score(y_test, lgbm.predict_proba(X_test)[:, 1])",
"_____no_output_____"
],
[
"cbc = CatBoostClassifier()\n\ncbc.fit(X_train, y_train)",
"Learning rate set to 0.241482\n0:\tlearn: 0.4062262\ttotal: 470ms\tremaining: 7m 49s\n1:\tlearn: 0.3155420\ttotal: 808ms\tremaining: 6m 43s\n2:\tlearn: 0.2832153\ttotal: 1.09s\tremaining: 6m 1s\n3:\tlearn: 0.2685991\ttotal: 1.36s\tremaining: 5m 39s\n4:\tlearn: 0.2620563\ttotal: 1.63s\tremaining: 5m 24s\n5:\tlearn: 0.2581516\ttotal: 1.92s\tremaining: 5m 18s\n6:\tlearn: 0.2560946\ttotal: 2.18s\tremaining: 5m 9s\n7:\tlearn: 0.2550714\ttotal: 2.43s\tremaining: 5m 1s\n8:\tlearn: 0.2544022\ttotal: 2.74s\tremaining: 5m 1s\n9:\tlearn: 0.2539632\ttotal: 3.01s\tremaining: 4m 57s\n10:\tlearn: 0.2534264\ttotal: 3.31s\tremaining: 4m 57s\n11:\tlearn: 0.2530723\ttotal: 3.59s\tremaining: 4m 55s\n12:\tlearn: 0.2529483\ttotal: 3.95s\tremaining: 4m 59s\n13:\tlearn: 0.2528528\ttotal: 4.25s\tremaining: 4m 59s\n14:\tlearn: 0.2527004\ttotal: 4.54s\tremaining: 4m 58s\n15:\tlearn: 0.2526301\ttotal: 4.86s\tremaining: 4m 58s\n16:\tlearn: 0.2525172\ttotal: 5.16s\tremaining: 4m 58s\n17:\tlearn: 0.2524322\ttotal: 5.46s\tremaining: 4m 57s\n18:\tlearn: 0.2523626\ttotal: 5.74s\tremaining: 4m 56s\n19:\tlearn: 0.2523020\ttotal: 6.02s\tremaining: 4m 55s\n20:\tlearn: 0.2522225\ttotal: 6.32s\tremaining: 4m 54s\n21:\tlearn: 0.2521789\ttotal: 6.62s\tremaining: 4m 54s\n22:\tlearn: 0.2521268\ttotal: 6.88s\tremaining: 4m 52s\n23:\tlearn: 0.2521047\ttotal: 7.23s\tremaining: 4m 54s\n24:\tlearn: 0.2520528\ttotal: 7.56s\tremaining: 4m 54s\n25:\tlearn: 0.2520030\ttotal: 7.83s\tremaining: 4m 53s\n26:\tlearn: 0.2519619\ttotal: 8.2s\tremaining: 4m 55s\n27:\tlearn: 0.2519291\ttotal: 8.45s\tremaining: 4m 53s\n28:\tlearn: 0.2518874\ttotal: 8.81s\tremaining: 4m 54s\n29:\tlearn: 0.2518461\ttotal: 9.19s\tremaining: 4m 57s\n30:\tlearn: 0.2518004\ttotal: 9.49s\tremaining: 4m 56s\n31:\tlearn: 0.2517571\ttotal: 9.8s\tremaining: 4m 56s\n32:\tlearn: 0.2517267\ttotal: 10.1s\tremaining: 4m 56s\n33:\tlearn: 0.2516967\ttotal: 10.4s\tremaining: 4m 56s\n34:\tlearn: 0.2516725\ttotal: 10.8s\tremaining: 4m 57s\n35:\tlearn: 0.2516528\ttotal: 11.1s\tremaining: 4m 56s\n36:\tlearn: 0.2516403\ttotal: 11.4s\tremaining: 4m 55s\n37:\tlearn: 0.2516232\ttotal: 11.6s\tremaining: 4m 54s\n38:\tlearn: 0.2516003\ttotal: 12s\tremaining: 4m 56s\n39:\tlearn: 0.2515761\ttotal: 12.5s\tremaining: 4m 59s\n40:\tlearn: 0.2515413\ttotal: 12.8s\tremaining: 5m\n41:\tlearn: 0.2515166\ttotal: 13.1s\tremaining: 4m 58s\n42:\tlearn: 0.2514958\ttotal: 13.4s\tremaining: 4m 58s\n43:\tlearn: 0.2514496\ttotal: 13.8s\tremaining: 4m 59s\n44:\tlearn: 0.2514249\ttotal: 14.2s\tremaining: 5m\n45:\tlearn: 0.2514163\ttotal: 14.5s\tremaining: 5m 1s\n46:\tlearn: 0.2513967\ttotal: 14.8s\tremaining: 5m\n47:\tlearn: 0.2513873\ttotal: 15.2s\tremaining: 5m 1s\n48:\tlearn: 0.2513726\ttotal: 15.6s\tremaining: 5m 1s\n49:\tlearn: 0.2513565\ttotal: 15.9s\tremaining: 5m 1s\n50:\tlearn: 0.2513356\ttotal: 16.2s\tremaining: 5m 1s\n51:\tlearn: 0.2513192\ttotal: 16.6s\tremaining: 5m 1s\n52:\tlearn: 0.2513023\ttotal: 16.9s\tremaining: 5m 2s\n53:\tlearn: 0.2512802\ttotal: 17.4s\tremaining: 5m 4s\n54:\tlearn: 0.2512569\ttotal: 17.7s\tremaining: 5m 4s\n55:\tlearn: 0.2512489\ttotal: 18s\tremaining: 5m 3s\n56:\tlearn: 0.2512343\ttotal: 18.3s\tremaining: 5m 2s\n57:\tlearn: 0.2512032\ttotal: 18.6s\tremaining: 5m 1s\n58:\tlearn: 0.2511874\ttotal: 18.9s\tremaining: 5m 1s\n59:\tlearn: 0.2511754\ttotal: 19.2s\tremaining: 5m\n60:\tlearn: 0.2511641\ttotal: 19.5s\tremaining: 4m 59s\n61:\tlearn: 0.2511485\ttotal: 19.8s\tremaining: 4m 58s\n62:\tlearn: 0.2511276\ttotal: 20.1s\tremaining: 4m 58s\n63:\tlearn: 0.2511111\ttotal: 20.3s\tremaining: 4m 57s\n64:\tlearn: 0.2510997\ttotal: 20.6s\tremaining: 4m 56s\n65:\tlearn: 0.2510836\ttotal: 20.9s\tremaining: 4m 56s\n66:\tlearn: 0.2510669\ttotal: 21.2s\tremaining: 4m 55s\n67:\tlearn: 0.2510535\ttotal: 21.6s\tremaining: 4m 56s\n68:\tlearn: 0.2510443\ttotal: 22s\tremaining: 4m 56s\n69:\tlearn: 0.2510285\ttotal: 22.3s\tremaining: 4m 55s\n70:\tlearn: 0.2510100\ttotal: 22.6s\tremaining: 4m 55s\n71:\tlearn: 0.2509976\ttotal: 22.9s\tremaining: 4m 54s\n72:\tlearn: 0.2509870\ttotal: 23.1s\tremaining: 4m 53s\n73:\tlearn: 0.2509655\ttotal: 23.4s\tremaining: 4m 53s\n74:\tlearn: 0.2509478\ttotal: 23.7s\tremaining: 4m 52s\n75:\tlearn: 0.2509382\ttotal: 24s\tremaining: 4m 51s\n76:\tlearn: 0.2509180\ttotal: 24.3s\tremaining: 4m 51s\n77:\tlearn: 0.2509119\ttotal: 24.6s\tremaining: 4m 50s\n78:\tlearn: 0.2509042\ttotal: 25s\tremaining: 4m 51s\n79:\tlearn: 0.2508959\ttotal: 25.3s\tremaining: 4m 50s\n80:\tlearn: 0.2508804\ttotal: 25.6s\tremaining: 4m 50s\n81:\tlearn: 0.2508687\ttotal: 25.9s\tremaining: 4m 49s\n82:\tlearn: 0.2508503\ttotal: 26.3s\tremaining: 4m 50s\n83:\tlearn: 0.2508316\ttotal: 26.6s\tremaining: 4m 50s\n84:\tlearn: 0.2508164\ttotal: 27s\tremaining: 4m 50s\n85:\tlearn: 0.2507896\ttotal: 27.4s\tremaining: 4m 51s\n86:\tlearn: 0.2507796\ttotal: 27.7s\tremaining: 4m 50s\n87:\tlearn: 0.2507710\ttotal: 28s\tremaining: 4m 50s\n88:\tlearn: 0.2507593\ttotal: 28.3s\tremaining: 4m 49s\n89:\tlearn: 0.2507454\ttotal: 28.6s\tremaining: 4m 48s\n90:\tlearn: 0.2507382\ttotal: 28.8s\tremaining: 4m 48s\n91:\tlearn: 0.2507163\ttotal: 29.1s\tremaining: 4m 47s\n92:\tlearn: 0.2507070\ttotal: 29.5s\tremaining: 4m 47s\n93:\tlearn: 0.2506959\ttotal: 29.9s\tremaining: 4m 47s\n94:\tlearn: 0.2506810\ttotal: 30.2s\tremaining: 4m 47s\n95:\tlearn: 0.2506605\ttotal: 30.5s\tremaining: 4m 47s\n96:\tlearn: 0.2506461\ttotal: 30.9s\tremaining: 4m 48s\n97:\tlearn: 0.2506329\ttotal: 31.3s\tremaining: 4m 47s\n98:\tlearn: 0.2506181\ttotal: 31.6s\tremaining: 4m 47s\n99:\tlearn: 0.2506020\ttotal: 31.9s\tremaining: 4m 46s\n100:\tlearn: 0.2505846\ttotal: 32.2s\tremaining: 4m 46s\n101:\tlearn: 0.2505642\ttotal: 32.5s\tremaining: 4m 46s\n102:\tlearn: 0.2505579\ttotal: 32.8s\tremaining: 4m 45s\n103:\tlearn: 0.2505413\ttotal: 33.1s\tremaining: 4m 44s\n104:\tlearn: 0.2505321\ttotal: 33.4s\tremaining: 4m 44s\n105:\tlearn: 0.2505205\ttotal: 33.6s\tremaining: 4m 43s\n106:\tlearn: 0.2505114\ttotal: 34s\tremaining: 4m 43s\n107:\tlearn: 0.2505049\ttotal: 34.3s\tremaining: 4m 43s\n108:\tlearn: 0.2504875\ttotal: 34.6s\tremaining: 4m 43s\n109:\tlearn: 0.2504762\ttotal: 35s\tremaining: 4m 42s\n110:\tlearn: 0.2504669\ttotal: 35.3s\tremaining: 4m 42s\n111:\tlearn: 0.2504552\ttotal: 35.6s\tremaining: 4m 42s\n112:\tlearn: 0.2504491\ttotal: 36s\tremaining: 4m 42s\n113:\tlearn: 0.2504317\ttotal: 36.4s\tremaining: 4m 42s\n114:\tlearn: 0.2504194\ttotal: 36.7s\tremaining: 4m 42s\n115:\tlearn: 0.2504118\ttotal: 37.2s\tremaining: 4m 43s\n116:\tlearn: 0.2504107\ttotal: 37.4s\tremaining: 4m 42s\n117:\tlearn: 0.2503999\ttotal: 37.8s\tremaining: 4m 42s\n118:\tlearn: 0.2503896\ttotal: 38s\tremaining: 4m 41s\n119:\tlearn: 0.2503794\ttotal: 38.4s\tremaining: 4m 41s\n120:\tlearn: 0.2503710\ttotal: 38.8s\tremaining: 4m 41s\n121:\tlearn: 0.2503613\ttotal: 39.1s\tremaining: 4m 41s\n122:\tlearn: 0.2503496\ttotal: 39.5s\tremaining: 4m 41s\n123:\tlearn: 0.2503391\ttotal: 39.9s\tremaining: 4m 41s\n124:\tlearn: 0.2503285\ttotal: 40.2s\tremaining: 4m 41s\n125:\tlearn: 0.2503197\ttotal: 40.6s\tremaining: 4m 41s\n126:\tlearn: 0.2503122\ttotal: 40.9s\tremaining: 4m 41s\n127:\tlearn: 0.2503058\ttotal: 41.2s\tremaining: 4m 40s\n128:\tlearn: 0.2502940\ttotal: 41.5s\tremaining: 4m 40s\n129:\tlearn: 0.2502791\ttotal: 41.8s\tremaining: 4m 39s\n130:\tlearn: 0.2502691\ttotal: 42.1s\tremaining: 4m 39s\n131:\tlearn: 0.2502563\ttotal: 42.4s\tremaining: 4m 38s\n132:\tlearn: 0.2502460\ttotal: 42.7s\tremaining: 4m 38s\n133:\tlearn: 0.2502343\ttotal: 43s\tremaining: 4m 38s\n134:\tlearn: 0.2502240\ttotal: 43.3s\tremaining: 4m 37s\n135:\tlearn: 0.2502093\ttotal: 43.6s\tremaining: 4m 37s\n136:\tlearn: 0.2501995\ttotal: 44s\tremaining: 4m 36s\n137:\tlearn: 0.2501914\ttotal: 44.3s\tremaining: 4m 36s\n138:\tlearn: 0.2501823\ttotal: 44.6s\tremaining: 4m 36s\n139:\tlearn: 0.2501740\ttotal: 44.9s\tremaining: 4m 35s\n140:\tlearn: 0.2501690\ttotal: 45.2s\tremaining: 4m 35s\n141:\tlearn: 0.2501607\ttotal: 45.5s\tremaining: 4m 34s\n142:\tlearn: 0.2501528\ttotal: 45.8s\tremaining: 4m 34s\n143:\tlearn: 0.2501457\ttotal: 46.1s\tremaining: 4m 33s\n144:\tlearn: 0.2501346\ttotal: 46.4s\tremaining: 4m 33s\n145:\tlearn: 0.2501289\ttotal: 46.7s\tremaining: 4m 33s\n146:\tlearn: 0.2501221\ttotal: 47s\tremaining: 4m 32s\n147:\tlearn: 0.2501101\ttotal: 47.3s\tremaining: 4m 32s\n148:\tlearn: 0.2501029\ttotal: 47.7s\tremaining: 4m 32s\n149:\tlearn: 0.2500875\ttotal: 48s\tremaining: 4m 32s\n150:\tlearn: 0.2500803\ttotal: 48.3s\tremaining: 4m 31s\n151:\tlearn: 0.2500695\ttotal: 48.7s\tremaining: 4m 31s\n152:\tlearn: 0.2500636\ttotal: 49s\tremaining: 4m 31s\n153:\tlearn: 0.2500561\ttotal: 49.2s\tremaining: 4m 30s\n154:\tlearn: 0.2500449\ttotal: 49.5s\tremaining: 4m 30s\n155:\tlearn: 0.2500324\ttotal: 49.9s\tremaining: 4m 29s\n156:\tlearn: 0.2500152\ttotal: 50.3s\tremaining: 4m 30s\n157:\tlearn: 0.2500089\ttotal: 50.6s\tremaining: 4m 29s\n"
],
[
"roc_auc_score(y_test, cbc.predict_proba(X_test)[:, 1])",
"_____no_output_____"
],
[
"positive = target.sum()\nnegative = target.shape[0] - positive\nweight = positive / negative\n\nxgb = XGBClassifier(scale_pos_weight=weight)\n\nxgb.fit(X_train, y_train)",
"_____no_output_____"
],
[
"roc_auc_score(y_test, xgb.predict_proba(X_test)[:, 1])",
"_____no_output_____"
],
[
"# roc_auc_score(y_test, xgb.predict_proba(X_test)[:, 1]) -- for unweighted",
"_____no_output_____"
],
[
"xgb.fit(train, target)",
"_____no_output_____"
],
[
"def make_submission(prediction, filename):\n sub['CHURN'] = prediction\n sub.to_csv('data/submissions/{}.csv'.format(filename), index=False)",
"_____no_output_____"
],
[
"prediction = xgb.predict_proba(full[~full['is_train']])\n\nmake_submission(prediction[:, 1], 'xgboost_baseline')",
"_____no_output_____"
],
[
"lr = LogisticRegression()\n\nlr.fit(X_train, y_train)",
"c:\\users\\ivan\\appdata\\local\\programs\\python\\python38\\lib\\site-packages\\sklearn\\linear_model\\_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):\nSTOP: TOTAL NO. of ITERATIONS REACHED LIMIT.\n\nIncrease the number of iterations (max_iter) or scale the data as shown in:\n https://scikit-learn.org/stable/modules/preprocessing.html\nPlease also refer to the documentation for alternative solver options:\n https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression\n n_iter_i = _check_optimize_result(\n"
],
[
"roc_auc_score(y_test, lr.predict_proba(X_test)[:, 1])",
"_____no_output_____"
],
[
"from hyperopt import hp, fmin, tpe, Trials, STATUS_OK\nimport numpy as np",
"_____no_output_____"
],
[
"X, X_test, y, y_test = train_test_split(train, target)\n\nspace = {\n 'learning_rate': hp.uniform('learning_rate', 0.05, 0.3),\n 'max_depth': hp.choice('max_depth', np.arange(5, 25, 1, dtype=int)),\n 'min_child_weight': hp.choice('min_child_weight', np.arange(1, 10, 1, dtype=int)),\n 'colsample_bytree': hp.uniform('colsample_bytree', 0.2, 0.9),\n 'subsample': hp.uniform('subsample', 0.6, 1),\n 'n_estimators': hp.choice('n_estimators', np.arange(20, 100, 2, dtype=int)),\n}\n\nlgb_fit_params = {\n 'eval_metric': 'auc',\n 'early_stopping_rounds': 50,\n 'verbose': False,\n# 'num_iterations': 1000\n}\n\ndef objective(params):\n model = LGBMClassifier(\n **params\n )\n \n X_train, X_val, y_train, y_val = train_test_split(X, y)\n \n model.fit(X_train, y_train,\n **lgb_fit_params, \n eval_set=[(X_val, y_val)])\n \n prediction = model.predict_proba(X_test)\n score = roc_auc_score(y_test, prediction[:, 1])\n \n return -score",
"_____no_output_____"
],
[
"best = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=50)",
"100%|███████████████████████████████████████████████| 50/50 [11:51<00:00, 14.24s/trial, best loss: -0.9310295155359264]\n"
],
[
"best",
"_____no_output_____"
],
[
"lgb = LGBMClassifier(**best)\n\nlgb.fit(train.values, target.values)",
"_____no_output_____"
],
[
"prediction = xgb.predict_proba(full[~full['is_train']])\n\nmake_submission(prediction[:, 1], 'lgbm_tuned')",
"_____no_output_____"
],
[
"target[target==1].index",
"_____no_output_____"
],
[
"positive = target.sum()\nnegative = target.shape[0] - positive\nneed = negative - positive\n\nnew_idx = np.hstack([np.random.choice(target[target==1].index, need), target[target==1].index])\n\nX_oversampled = pd.concat([train[target==0], train.loc[new_idx]])\ny_oversampled = pd.concat([target[target==0], target.loc[new_idx]])",
"_____no_output_____"
],
[
"idx = np.random.choice(target[target==1].index, int(positive * 0.3), replace=False)",
"_____no_output_____"
],
[
"test_idx1 = np.random.choice(target[target==1].index, int(positive * 0.3), replace=False)\ntest_idx0 = np.random.choice(target[target==0].index, int(negative * 0.3), replace=False)\nfull_test_idx = np.hstack([test_idx0, test_idx1])\nfull_train_idx = np.setdiff1d(target.index, full_test_idx)\n\nX_train, X_test, y_train, y_test = X_oversampled.loc[full_train_idx], X_oversampled.loc[full_test_idx],\\\n y_oversampled.loc[full_train_idx], y_oversampled.loc[full_test_idx]",
"_____no_output_____"
],
[
"lr = LogisticRegression()\n\nlr.fit(X_train, y_train)\n\nroc_auc_score(y_test, lr.predict_proba(X_test)[:, 1])",
"c:\\users\\ivan\\appdata\\local\\programs\\python\\python38\\lib\\site-packages\\sklearn\\linear_model\\_logistic.py:762: ConvergenceWarning: lbfgs failed to converge (status=1):\nSTOP: TOTAL NO. of ITERATIONS REACHED LIMIT.\n\nIncrease the number of iterations (max_iter) or scale the data as shown in:\n https://scikit-learn.org/stable/modules/preprocessing.html\nPlease also refer to the documentation for alternative solver options:\n https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression\n n_iter_i = _check_optimize_result(\n"
],
[
"lgbm = LGBMClassifier(**best)\n\nlgbm.fit(X_train, y_train)\n\nroc_auc_score(y_test, lgbm.predict_proba(X_test)[:, 1])",
"_____no_output_____"
],
[
"lgbm = LGBMClassifier(**best)\n\nlgbm.fit(X_oversampled, y_oversampled)",
"_____no_output_____"
],
[
"prediction = lgbm.predict_proba(full[~full['is_train']])\n\nmake_submission(prediction[:, 1], 'lgbm_tuned_oversample')",
"_____no_output_____"
],
[
"xgb = XGBClassifier()\n\nxgb.fit(X_oversampled, y_oversampled)",
"_____no_output_____"
],
[
"prediction = xgb.predict_proba(full[~full['is_train']])\n\nmake_submission(prediction[:, 1], 'xgb_oversample')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a45e1f479a9dfc52221b1e3ad3145055d279a8f
| 125,750 |
ipynb
|
Jupyter Notebook
|
Project 5 - Movie Recommender System/Movie-Recommendation-with -EDA - Radhika Omkar Datar.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | 1 |
2020-09-11T18:11:54.000Z
|
2020-09-11T18:11:54.000Z
|
Project 5 - Movie Recommender System/Movie-Recommendation-with -EDA - Radhika Omkar Datar.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | null | null | null |
Project 5 - Movie Recommender System/Movie-Recommendation-with -EDA - Radhika Omkar Datar.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | 1 |
2020-07-22T19:47:15.000Z
|
2020-07-22T19:47:15.000Z
| 64.190914 | 24,465 | 0.614155 |
[
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\ndf = pd.read_csv('movies_metadata.csv', low_memory=False)\ndf.head()",
"_____no_output_____"
]
],
[
[
"# Understanding Data",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
],
[
"df.tail()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 45466 entries, 0 to 45465\nData columns (total 24 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 adult 45466 non-null object \n 1 belongs_to_collection 4494 non-null object \n 2 budget 45466 non-null object \n 3 genres 45466 non-null object \n 4 homepage 7782 non-null object \n 5 id 45466 non-null object \n 6 imdb_id 45449 non-null object \n 7 original_language 45455 non-null object \n 8 original_title 45466 non-null object \n 9 overview 44512 non-null object \n 10 popularity 45461 non-null object \n 11 poster_path 45080 non-null object \n 12 production_companies 45463 non-null object \n 13 production_countries 45463 non-null object \n 14 release_date 45379 non-null object \n 15 revenue 45460 non-null float64\n 16 runtime 45203 non-null float64\n 17 spoken_languages 45460 non-null object \n 18 status 45379 non-null object \n 19 tagline 20412 non-null object \n 20 title 45460 non-null object \n 21 video 45460 non-null object \n 22 vote_average 45460 non-null float64\n 23 vote_count 45460 non-null float64\ndtypes: float64(4), object(20)\nmemory usage: 8.3+ MB\n"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
]
],
[
[
"# Univariate Analysis",
"_____no_output_____"
]
],
[
[
"df[\"vote_average\"].hist(bins=20)",
"_____no_output_____"
],
[
"df[\"vote_count\"].hist(bins=20)",
"_____no_output_____"
],
[
"sns.boxplot(df[\"vote_average\"])",
"_____no_output_____"
],
[
"sns.boxplot(df[\"vote_count\"])",
"_____no_output_____"
]
],
[
[
"# Building Recommender System",
"_____no_output_____"
]
],
[
[
"c=df['vote_average'].mean()\nc",
"_____no_output_____"
],
[
"m=df['vote_count'].quantile(0.9)\nm",
"_____no_output_____"
],
[
"qm=df[(df['runtime']>150)&(df['revenue']>300000000)&(df['homepage'].notna())]",
"_____no_output_____"
],
[
"qm.head()",
"_____no_output_____"
],
[
"qm.shape",
"_____no_output_____"
],
[
"qm['vote_count']>=m",
"_____no_output_____"
],
[
"qm=qm[qm['vote_count']>=m]",
"_____no_output_____"
],
[
"qm.shape",
"_____no_output_____"
],
[
"def wr(x,m=m,c=c):\n v=x['vote_count']\n r=x['vote_average']\n return (v/(v+m)*r)+(m/(m+v)*c)",
"_____no_output_____"
],
[
"qm['score']=qm.apply(wr,axis=1)",
"_____no_output_____"
],
[
"qm.head()",
"_____no_output_____"
],
[
"qm=qm.sort_values('score',ascending=False)",
"_____no_output_____"
],
[
"qm[['title','vote_count','vote_average','score']].head(10)",
"_____no_output_____"
],
[
"d=df.sort_values('vote_count',ascending=False)\nplt.figure(figsize=(18,6))\n\nplt.barh(d['title'].head(15),d['vote_count'].head(15),align='center',color='cornflowerblue')\nplt.gca().invert_yaxis()\nplt.xlabel(\"Votes\")\nplt.title(\"MOst voted Movies\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a45ee7bc73bb452aeb197cbed96258a8c806a3c
| 840,279 |
ipynb
|
Jupyter Notebook
|
notebooks/Paper05_SelectionResults.ipynb
|
nikita-loik/mrna_display
|
e43eda55cab355a846f006f002aa7cb1c406a317
|
[
"MIT"
] | null | null | null |
notebooks/Paper05_SelectionResults.ipynb
|
nikita-loik/mrna_display
|
e43eda55cab355a846f006f002aa7cb1c406a317
|
[
"MIT"
] | null | null | null |
notebooks/Paper05_SelectionResults.ipynb
|
nikita-loik/mrna_display
|
e43eda55cab355a846f006f002aa7cb1c406a317
|
[
"MIT"
] | null | null | null | 1,261.68018 | 423,260 | 0.951589 |
[
[
[
"# -*- coding: utf-8 -*-\nimport matplotlib.pyplot as plt\nimport matplotlib\nfrom matplotlib import rcParams\nrcParams['font.family'] = 'monospace'\n#rcParams['font.sans-serif'] = ['Tahoma']\nimport numpy as np\n\nimport math\nimport datetime\nimport networkx as nx\nimport os",
"_____no_output_____"
],
[
"def TodaysDate():\n \n Today = datetime.date.today()\n TodaysDate = Today.strftime('%d%b%Y')\n \n return TodaysDate",
"_____no_output_____"
],
[
"def DNAcoding_sequence(DNASequence, QualityScoreSequence, start_sequence, stop_sequence):\n#utilises ONLY ONE stop_sequence, returns ONLY ONE coding_sequence\n \n QualityScoreString = \"\"\"!\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\"\"\"\n ThresholdQualityScore = 29 # ThresholdQualityScore must be between 0 and 93\n ThresholdQualityString = QualityScoreString[ThresholdQualityScore:]\n \n MinLength = 24\n MaxLength = 240\n \n StartIndex = DNASequence.find(start_sequence) + len(start_sequence)\n StopIndex = DNASequence.rfind(stop_sequence)\n coding_sequence = DNASequence[StartIndex:StopIndex]\n if MinLength <= len(coding_sequence) and len(coding_sequence) <= MaxLength and len(coding_sequence)%3 == 0:\n for Character in QualityScoreSequence[StartIndex:StopIndex]:\n if Character not in ThresholdQualityString:\n return None\n return str(coding_sequence)",
"_____no_output_____"
],
[
"def Translation(coding_sequence):\n#translates DNA sequence\n\n TranslationCode = {\n 'AAA':'K','AAC':'N','AAG':'K','AAU':'N',\n 'ACA':'T','ACC':'T','ACG':'T','ACU':'T',\n 'AGA':'R','AGC':'S','AGG':'R','AGU':'S',\n 'AUA':'I','AUC':'I','AUG':'M','AUU':'I',\n \n 'CAA':'Q','CAC':'H','CAG':'Q','CAU':'H',\n 'CCA':'P','CCC':'P','CCG':'P','CCU':'P',\n 'CGA':'R','CGC':'R','CGG':'R','CGU':'R',\n 'CUA':'L','CUC':'L','CUG':'L','CUU':'L',\n \n 'GAA':'E','GAC':'D','GAG':'E','GAU':'D',\n 'GCA':'A','GCC':'A','GCG':'A','GCU':'A',\n 'GGA':'G','GGC':'G','GGG':'G','GGU':'G',\n 'GUA':'V','GUC':'V','GUG':'V','GUU':'V',\n \n 'UAA':'#','UAC':'Y','UAG':'*','UAU':'Y',\n 'UCA':'S','UCC':'S','UCG':'S','UCU':'S',\n 'UGA':'&','UGC':'C','UGG':'W','UGU':'C',\n 'UUA':'L','UUC':'F','UUG':'L','UUU':'F'\n }\n # UAA (ochre) — #\n # UAG (amber) — *\n # UGA (opal) — &\n \n TranscriptionCode = {'A':'A','C':'C','G':'G','T':'U','U':'T'}\n \n RNASequence = ''\n for Nucleotide in coding_sequence:\n RNASequence += TranscriptionCode.get(Nucleotide,'X')\n #converts DNA to RNA\n #print RNASequence\n \n peptide = ''\n while len(RNASequence) != 0:\n peptide += TranslationCode.get(RNASequence[0:3],'Do not fuck with me!')\n RNASequence = RNASequence[3:]\n return peptide",
"_____no_output_____"
],
[
"def SingleSelectionRoundSummary(fastq_file_path):\n#returns a list of lists with peptide-sequences and their frequencies, sorted by frequency in descending order\n \n RawDataFile = open(fastq_file_path, 'r')\n lines = RawDataFile.readlines()\n RawDataFile.close\n \n #start_sequence = 'ATG' # Met codon\n #stop_sequence = 'TGCGGCAGC'# Akane seams to have trimmed siquences\n #stop_sequence = 'TAG' # amber stop codon\n \n start_sequence = 'TAATACGACTCACTATAGGGTTAACTTTAAGAAGGAGATATACATATG' # NNK - T7g10M.F48 \n stop_sequence = 'TGCGGCAGCGGCAGCGGCAGCTAGGACGGGGGGCGGAAA' #NNK - CGS3an13.R39 \n #start_sequence = 'TAATACGACTCACTATAGGGTTGAACTTTAAGTAGGAGATATATCCATG' #NNU - T7-CH-F49\n #stop_sequence = 'TGTGGGTCTGGGTCTGGGTCTTAGGACGGGGGGCGGAAA' #NNU - CGS3-CH-R39\n \n SingleSelectionRoundSummary = {}\n #creates empty SingleSelectionRoundSummary dictionary to store the results from a single round of selection\n #SingleSelectionRoundSummary = {peptideY: {coding_sequence_YZ: Occurrence_YZ}}\n \n #populates SingleSelectionRoundSummary dictionary with the results from a single round of selection\n for i,line in enumerate(lines):\n if start_sequence in line and stop_sequence in line:\n coding_sequence = DNAcoding_sequence(line, lines[i + 2], start_sequence, stop_sequence)\n if coding_sequence != None:\n peptide = Translation(coding_sequence)\n if peptide not in SingleSelectionRoundSummary:\n SingleSelectionRoundSummary[str(peptide)] = {str(coding_sequence) : 1}\n else:\n if coding_sequence not in SingleSelectionRoundSummary[str(peptide)]:\n SingleSelectionRoundSummary[str(peptide)][str(coding_sequence)] = 1\n else:\n SingleSelectionRoundSummary[str(peptide)][str(coding_sequence)] += 1\n\n return SingleSelectionRoundSummary",
"_____no_output_____"
],
[
"def HammingDistance(Sequence1, Sequence2):\n \n if len(Sequence1) < len(Sequence2):\n Sequence1 = Sequence1 + (len(Sequence2) - len(Sequence1)) * '%'\n elif len(Sequence1) > len(Sequence2):\n Sequence2 = Sequence2 + (len(Sequence1) - len(Sequence2)) * '%'\n \n HammingDistance = 0\n for i in range(len(Sequence1)):\n if Sequence1[i] == Sequence2[i]:\n HammingDistance = HammingDistance\n else:\n HammingDistance = HammingDistance + 1\n \n return HammingDistance",
"_____no_output_____"
],
[
"def HammingDistanceBasedFormating(Sequence1, Sequence2):\n \n if len(Sequence1) < len(Sequence2):\n Sequence1 = Sequence1 + (len(Sequence2) - len(Sequence1)) * '.'\n elif len(Sequence1) > len(Sequence2):\n Sequence2 = Sequence2 + (len(Sequence1) - len(Sequence2)) * '.'\n \n HammingDistance = 0\n FormatedSequence2 = ''\n for i in range(len(Sequence1)):\n if Sequence1[i] == Sequence2[i]:\n FormatedSequence2 += Sequence2[i].lower()\n HammingDistance = HammingDistance\n else:\n FormatedSequence2 += Sequence2[i]\n HammingDistance = HammingDistance + 1 \n return FormatedSequence2",
"_____no_output_____"
],
[
"def Completedisplay_summary(data_directory_path):\n# returns a display_summary dictionary with the following structure\n# display_summary = {SelectionRound_X: {peptideXY: {CodingDNA_XYZ: Occurrence_XYZ}}}\n\n Completedisplay_summary = {}\n # creates empty display_summary dictionary to store the results from all the rounds of selection\n\n for file in os.listdir(data_directory_path):\n \n file_path = os.path.join(data_directory_path, file)\n \n if file.endswith('.fastq'): # this conditional is necessary; without it some shit appears in the beginning of the file list\n cycle_numberFirstDigit = file[file.find('.')-2]\n cycle_numberSecondDigit = file[file.find('.')-1]\n if cycle_numberFirstDigit == '0':\n cycle_number = int(cycle_numberSecondDigit)\n #print cycle_number\n elif cycle_numberFirstDigit != '0':\n cycle_number = int(file[file.find('.')-2 : file.find('.')])\n #print cycle_number\n #(1.A) extracts the round number from the file name (file name should have two digit number before full stop — '00.') \n \n SelectionRoundSummary = SingleSelectionRoundSummary(file_path)\n #(1.B) extracts single round results \n \n Completedisplay_summary[cycle_number] = SelectionRoundSummary\n #(1.C) populate ConcatenatedResultsList\n #print ConcatenatedResultsList\n \n return Completedisplay_summary",
"_____no_output_____"
],
[
"def peptidesOccurrences_BY_Round(data_directory_path):\n display_summary = Completedisplay_summary(data_directory_path)\n \n peptidesOccurrences_BY_Round = {}\n for Round in display_summary:\n peptidesOccurrences_IN_Round = {}\n for peptide in display_summary[Round]:\n peptidesOccurrences_IN_Round[peptide] = sum(display_summary[Round][peptide].values())\n peptidesOccurrences_BY_Round[Round] = peptidesOccurrences_IN_Round\n \n return peptidesOccurrences_BY_Round",
"_____no_output_____"
],
[
"def DNAsOccurrences_BY_Round(data_directory_path):\n display_summary = Completedisplay_summary(data_directory_path)\n \n DNAsOccurrences_BY_Round = {}\n for Round in display_summary:\n DNAsOccurrences_IN_Round = {}\n for peptide in display_summary[Round]:\n for DNA in display_summary[Round][peptide]:\n DNAsOccurrences_IN_Round[DNA] = display_summary[Round][peptide][DNA]\n DNAsOccurrences_BY_Round[Round] = DNAsOccurrences_IN_Round\n\n return DNAsOccurrences_BY_Round",
"_____no_output_____"
],
[
"def TotalReads_BY_Round(data_directory_path):\n display_summary = Completedisplay_summary(data_directory_path)\n peptides_BY_Round = peptidesOccurrences_BY_Round(data_directory_path)\n \n TotalReads_BY_Round = {}\n for Round in display_summary:\n TotalReads_BY_Round[Round] = sum(peptides_BY_Round[Round].values())\n \n return TotalReads_BY_Round",
"_____no_output_____"
],
[
"def BaseRoundSortedpeptidesList(data_directory_path, base_cycle):\n peptides_BY_Round = peptidesOccurrences_BY_Round(data_directory_path) \n \n peptidesOccurrencesInBaseRound = peptides_BY_Round[base_cycle]\n BaseRoundSortedpeptidesList = sorted(peptidesOccurrencesInBaseRound, key = peptidesOccurrencesInBaseRound.get, reverse = True)\n \n return BaseRoundSortedpeptidesList",
"_____no_output_____"
],
[
"def peptidesRank_IN_BaseRound(data_directory_path, base_cycle):\n peptides_BY_Round = peptidesOccurrences_BY_Round(data_directory_path)\n BaseRoundSortedpeptides = BaseRoundSortedpeptidesList(data_directory_path, base_cycle)\n \n BasepeptideCount = 0\n peptideRank = 1\n \n peptidesRank_IN_BaseRound = {}\n \n for peptide in BaseRoundSortedpeptides:\n peptideCount = peptides_BY_Round[base_cycle][peptide]\n if peptideCount < BasepeptideCount:\n peptideRank += 1\n \n peptidesRank_IN_BaseRound[peptide] = peptideRank\n BasepeptideCount = peptideCount\n \n return peptidesRank_IN_BaseRound",
"_____no_output_____"
],
[
"def BaseRoundSortedDNAsList(data_directory_path, base_cycle):\n DNAs_BY_Round = DNAsOccurrences_BY_Round(data_directory_path) \n \n DNAsOccurrences_IN_BaseRound = DNAs_BY_Round[base_cycle]\n BaseRoundSortedDNAsList = sorted(DNAsOccurrences_IN_BaseRound, key = DNAsOccurrences_IN_BaseRound.get, reverse = True)\n \n return BaseRoundSortedDNAsList",
"_____no_output_____"
],
[
"def DNAClonesOccurrences_BY_Round_BY_peptide(data_directory_path):\n display_summary = Completedisplay_summary(data_directory_path)\n \n DNAClonesOccurrences_BY_Round_BY_peptide = {}\n for Round in display_summary:\n DNAClonesOccurrences_BY_peptide = {}\n for peptide in display_summary[Round]:\n DNAClonesOccurrences_BY_peptide[peptide] = len(display_summary[Round][peptide])\n DNAClonesOccurrences_BY_Round_BY_peptide[Round] = DNAClonesOccurrences_BY_peptide\n \n return DNAClonesOccurrences_BY_Round_BY_peptide",
"_____no_output_____"
],
[
"def peptidesAppearances_BY_Round(BaseRoundSortedpeptidesList, peptidesOccurrences_BY_Round):\n \n peptidesAppearances_BY_Round = {}\n \n for peptide in BaseRoundSortedpeptidesList:\n peptidesAppearances_BY_Round[peptide] = []\n for Round in peptidesOccurrences_BY_Round:\n if peptide in peptidesOccurrences_BY_Round[Round]:\n peptidesAppearances_BY_Round[peptide] += [Round]\n return peptidesAppearances_BY_Round",
"_____no_output_____"
],
[
"def DNAsAppearances_BY_Round(BaseRoundSortedDNAsList, DNAsOccurrences_BY_Round):\n \n DNAsAppearances_BY_Round = {}\n \n for DNA in BaseRoundSortedDNAsList:\n DNAsAppearances_BY_Round[DNA] = []\n for Round in DNAsOccurrences_BY_Round:\n if DNA in DNAsOccurrences_BY_Round[Round]:\n DNAsAppearances_BY_Round[DNA] += [Round]\n return DNAsAppearances_BY_Round",
"_____no_output_____"
],
[
"def display_summaryReport(data_directory_path, base_cycle, n_top_peptides, file_name):\n \n today = TodaysDate() \n \n display_summaryFileNameCSV = str(today) + 'display_summary' + file_name + '.csv'\n display_summaryReportFile = open(display_summaryFileNameCSV, 'w')\n \n display_summary = Completedisplay_summary(data_directory_path)\n SortedRoundsList = sorted(display_summary.keys())\n \n peptides_BY_Round = peptidesOccurrences_BY_Round(data_directory_path)\n Totalpeptides_BY_Round = TotalReads_BY_Round(data_directory_path)\n \n BaseRoundSortedpeptides = BaseRoundSortedpeptidesList(data_directory_path, base_cycle)\n #for i in range(len(BaseRoundSortedpeptides)):\n # print ('>seq' + str(i + 1) + '\\n' + BaseRoundSortedpeptides[i])\n #BaseRoundTopSortedpeptides = BaseRoundSortedpeptides[0 : (n_top_peptides)]\n BaseRoundTopSortedpeptides = ['VWDPRTFYLSRI', 'WDANTIFIKRV', 'WNPRTIFIKRA', 'VWDPRTFYLSRT',\n 'IWDTGTFYLSRT', 'WWNTRSFYLSRI', 'FWDPRTFYLSRI', 'VWDPSTFYLSRI',\n 'KWDTRTFYLSRY', 'KWDTRTFYLSRI', 'IWDPRTFYLSRI', 'IWDTGTFYLSRI',\n 'VWDPRTFYLSRM', 'AWDPRTFYLSRI', 'VWDSRTFYLSRI', 'VWDPGTFYLSRI',\n 'VWDPRTFYMSRI', 'VWDPRTFYLSRS', 'VWDPRTFYLSRV', 'WNPRTIFIKRV',\n 'VRDPRTFYLSRI', 'VWDPKTFYLSRI', 'VWDPRTFYLSRN', 'FRFPFYIQRR'\n ]\n BaseRoundpeptidesRank = peptidesRank_IN_BaseRound(data_directory_path, base_cycle)\n #print (BaseRoundSortedpeptides)\n \n Top24peptidesKDs = {'VWDPRTFYLSRI' : '3', 'WDANTIFIKRV' : '4', 'WNPRTIFIKRA' : '>1000', 'VWDPRTFYLSRT' : '3',\n 'IWDTGTFYLSRT' : '7', 'WWNTRSFYLSRI' : '12', 'FWDPRTFYLSRI' : '4', 'VWDPSTFYLSRI' : '3',\n 'KWDTRTFYLSRY' : '5', 'KWDTRTFYLSRI' : '6', 'IWDPRTFYLSRI' : '1', 'VWDPRTFYLSRM' : '4',\n 'IWDTGTFYLSRI' : '>1000', 'VWDPGTFYLSRI' : '<1', 'VWDSRTFYLSRI' : '3', 'AWDPRTFYLSRI': '6',\n 'VWDPRTFYLSRS' : '6', 'VWDPRTFYMSRI' : '1', 'VWDPRTFYLSRV' : '3', 'WNPRTIFIKRV' : '>1000',\n 'VRDPRTFYLSRI' : '>1000', 'VWDPRTFYLSRN' : '>1000', 'VWDPKTFYLSRI' : '14', 'FRFPFYIQRR' : '>1000'\n }\n \n display_summaryReportFile.write('peptide sequence' + ',' +\n 'rank (#)' + ',' +\n 'cDNA mutants' + ',')\n for Round in SortedRoundsList:\n display_summaryReportFile.write('C' +\n str(Round) +\n ' count (#) [frequency(%)]' + ',')\n display_summaryReportFile.write('\\n')\n \n for peptide in BaseRoundTopSortedpeptides:\n #for peptide in Top24peptidesKDs:\n BaseRoundpeptideFraction = float((peptides_BY_Round[Round].get(peptide, 0)))/float(Totalpeptides_BY_Round[base_cycle])\n peptideRank = BaseRoundpeptidesRank[peptide]\n Formatedpeptide = HammingDistanceBasedFormating(BaseRoundTopSortedpeptides[0], peptide)\n peptidecDNAMutants = len(display_summary[base_cycle][peptide])\n display_summaryReportFile.write(Formatedpeptide + ',' +\n str(peptideRank) + ',' +\n str(peptidecDNAMutants) + ',')\n\n \n for Round in SortedRoundsList:\n peptideFraction = float((peptides_BY_Round[Round].get(peptide, 0)))/float(Totalpeptides_BY_Round[Round])\n\n BaseFraction = peptideFraction\n \n display_summaryReportFile.write(str(peptides_BY_Round[Round].get(peptide, 0)) +\n ' [' + '{:.1%}'.format(peptideFraction) + ']' + ',')\n \n display_summaryReportFile.write('\\n')\n \n display_summaryReportFile.write('total count (#)' + ',' + ',')\n for Round in SortedRoundsList:\n display_summaryReportFile.write(str(Totalpeptides_BY_Round[Round]) + ',')\n display_summaryReportFile.write('\\n\\n\\n')\n \n display_summaryReportFile.close()\n \n#-------------------------------------------------------------------------------\n \n # Create a figure of size 8x6 inches, 500 dots per inch\n plt.figure(\n figsize = (8, 6),\n dpi = 250)\n # Create 'ggplot' style\n plt.style.use('fivethirtyeight')\n # Create a new subplot from a grid of 1x1\n Graph = plt.subplot(1, 1, 1)\n \n Xs = []\n Ys = []\n \n Rank = 1\n peptideFractionInFinalRound = 0\n \n # Map colours onto lines\n \n cNorm = matplotlib.colors.Normalize(vmin = 1,\n vmax = 20)\n scalarMap = matplotlib.cm.ScalarMappable(norm = cNorm,\n cmap = 'tab20')\n \n peptideLabels = []\n \n for peptide in BaseRoundTopSortedpeptides:\n #for peptide in Top24peptidesKDs:\n peptidesFractions_BY_Round = []\n for Round in SortedRoundsList:\n peptidesFractions_BY_Round += [\n float((peptides_BY_Round[Round].get(peptide, 0)))/float(Totalpeptides_BY_Round[Round])]\n \n x = SortedRoundsList\n y = peptidesFractions_BY_Round\n Xs += x\n Ys += y\n \n# peptideColour = scalarMap.to_rgba(BaseRoundTopSortedpeptides.index(peptide))\n peptideRank = BaseRoundpeptidesRank[peptide]\n# print(peptideRank)\n peptideColour = scalarMap.to_rgba(peptideRank)\n peptideKD = Top24peptidesKDs[peptide]\n Formatedpeptide = HammingDistanceBasedFormating(BaseRoundTopSortedpeptides[0], peptide)\n \n peptideLabel = f\"{Formatedpeptide} ({peptidesFractions_BY_Round[-1]:.2%}, {peptideKD} nM)\"\n \n #Set peptideLabel\n peptideLabels += [peptideLabel]\n \n plt.plot(x, y,\n 'o-',\n c = peptideColour,\n lw = 2.0,\n ms = 4.0,\n mew = 0.1,\n mec = '#191919')\n\n \n XMin = min(Xs) - 0.05*(max(Xs) - min(Xs))\n XMax = max(Xs) + 0.05*(max(Xs) - min(Xs))\n YMin = min(Ys) - 0.05*(max(Ys) - min(Ys))\n YMax = max(Ys) + 0.05*(max(Ys) - min(Ys))\n \n plt.axis([XMin, XMax, YMin, YMax])\n \n plt.xticks(fontsize = 10)\n plt.yticks(fontsize = 10)\n \n plt.xlabel('mRNA Display Cycle (#)',\n fontsize = 10)\n plt.ylabel('Ligand Fraction (%)',\n fontsize = 10)\n \n legend = plt.legend(peptideLabels,\n title = 'cyclic-peptide random region (ligand fraction after last cycle, k$_D$)',\n loc = 'upper center',\n bbox_to_anchor = (0.5, -0.10),\n fancybox = True,\n shadow = False,\n fontsize = 10,\n ncol = 3)\n \n Graph.get_legend().get_title().set_size('small')\n \n display_summaryFileNamePNG = str(today) + 'display_summary' + file_name + '.png'\n \n plt.savefig(display_summaryFileNamePNG,\n bbox_extra_artists = [legend],\n bbox_inches = 'tight',\n dpi = 180)\n plt.show()\n plt.close()",
"_____no_output_____"
],
[
"data_directory_path = '../sample_input/'\nbase_cycle = 6\nTopNpeptidesNumber = 24\nSummaryFileName = 'Paper05_PHD2SelectionResults'\n\ndisplay_summaryReport(data_directory_path, base_cycle, TopNpeptidesNumber, SummaryFileName)",
"_____no_output_____"
],
[
"data_directory_path = 'sample_input/'\nbase_cycle = 6\nTopNpeptidesNumber = 24\nSummaryFileName = 'Paper05_PHD2SelectionResults'\n\ndisplay_summaryReport(data_directory_path, base_cycle, TopNpeptidesNumber, SummaryFileName)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a45f7ae7783fb04a57d7f739ceb56a8c1eb4832
| 311,586 |
ipynb
|
Jupyter Notebook
|
Image Classifier Project.ipynb
|
PZebarth/Python-Deep-Learning-ML
|
9ec064dc0c084e606540606094393a8ae1199a4e
|
[
"Unlicense"
] | null | null | null |
Image Classifier Project.ipynb
|
PZebarth/Python-Deep-Learning-ML
|
9ec064dc0c084e606540606094393a8ae1199a4e
|
[
"Unlicense"
] | null | null | null |
Image Classifier Project.ipynb
|
PZebarth/Python-Deep-Learning-ML
|
9ec064dc0c084e606540606094393a8ae1199a4e
|
[
"Unlicense"
] | null | null | null | 401.528351 | 150,052 | 0.924721 |
[
[
[
"# Developing an AI application\n\nGoing forward, AI algorithms will be incorporated into more and more everyday applications. For example, you might want to include an image classifier in a smart phone app. To do this, you'd use a deep learning model trained on hundreds of thousands of images as part of the overall application architecture. A large part of software development in the future will be using these types of models as common parts of applications. \n\nIn this project, I'll train an image classifier to recognize different species of flowers. You can imagine using something like this in a phone app that tells you the name of the flower your camera is looking at. In practice you'd train this classifier, then export it for use in your application. We'll be using [this dataset](http://www.robots.ox.ac.uk/~vgg/data/flowers/102/index.html) of 102 flower categories, you can see a few examples below. \n\n<img src='assets/Flowers.png' width=500px>\n\nThe project is broken down into multiple steps:\n\n* Load and preprocess the image dataset\n* Train the image classifier on our dataset\n* Use the trained classifier to predict image content\n\nI'll lead you through each part which we'll implement in Python.\n\nWhen I've completed this project, you'll have an application that can be trained on any set of labeled images. Here our network will be learning about flowers and end up as a command line application. But, what you do with your new skills depends on your imagination and effort in building a dataset. For example, imagine an app where you take a picture of a car, it tells you what the make and model is, then looks up information about it. Go build your own dataset and make something new.\n\nFirst up is importing the packages I'll need. It's good practice to keep all the imports at the beginning of your code.",
"_____no_output_____"
]
],
[
[
"import torch\nfrom torch import nn, optim\nfrom torchvision import datasets, transforms, models\nimport matplotlib.pyplot as plt\n% matplotlib inline\nfrom PIL import Image\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## Load the data\n\nHere I'll use `torchvision` to load the data ([documentation](http://pytorch.org/docs/0.3.0/torchvision/index.html)). The data should be included alongside this notebook, otherwise you can [download it here](https://s3.amazonaws.com/content.udacity-data.com/nd089/flower_data.tar.gz). The dataset is split into three parts, training, validation, and testing. For the training, you'll want to apply transformations such as random scaling, cropping, and flipping. This will help the network generalize leading to better performance. I'll also need to make sure the input data is resized to 224x224 pixels as required by the pre-trained networks.\n\nThe validation and testing sets are used to measure the model's performance on data it hasn't seen yet. For this I don't want any scaling or rotation transformations, but I'll need to resize then crop the images to the appropriate size.\n\nThe pre-trained networks I'll use were trained on the ImageNet dataset where each color channel was normalized separately. For all three sets I'll need to normalize the means and standard deviations of the images to what the network expects. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`, calculated from the ImageNet images. These values will shift each color channel to be centered at 0 and range from -1 to 1.\n ",
"_____no_output_____"
]
],
[
[
"data_dir = 'flowers'\ntrain_dir = data_dir + '/train'\nvalid_dir = data_dir + '/valid'\ntest_dir = data_dir + '/test'",
"_____no_output_____"
],
[
"# Define our transforms for the training, validation, and testing sets\n\ntrain_transforms = transforms.Compose([transforms.RandomResizedCrop(224),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], \n [0.229, 0.224, 0.225])])\n\nvalid_transforms = transforms.Compose([transforms.Resize(255),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406],\n [0.229, 0.224, 0.225])])\n\ntest_transforms = transforms.Compose([transforms.Resize(255),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406],\n [0.229, 0.224, 0.225])])\n\n# Load the datasets with ImageFolder\n\ntrain_data = datasets.ImageFolder(train_dir, transform = train_transforms)\nvalid_data = datasets.ImageFolder(valid_dir, transform = valid_transforms)\ntest_data = datasets.ImageFolder(test_dir, transform = test_transforms)\n\n# Using the image datasets and the trainforms, define the dataloaders\n\ntrain_loader = torch.utils.data.DataLoader(train_data, batch_size=17, shuffle=True)\nvalid_loader = torch.utils.data.DataLoader(valid_data, batch_size=17)\ntest_loader = torch.utils.data.DataLoader(test_data, batch_size=17)",
"_____no_output_____"
]
],
[
[
"### Label mapping\n\nI'll also need to load in a mapping from category label to category name. You can find this in the file `cat_to_name.json`. It's a JSON object which you can read in with the [`json` module](https://docs.python.org/2/library/json.html). This will give us a dictionary mapping the integer encoded categories to the actual names of the flowers.",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open('cat_to_name.json', 'r') as f:\n cat_to_name = json.load(f)",
"_____no_output_____"
]
],
[
[
"# Building and training the classifier\n\nNow that the data is ready, it's time to build and train the classifier. As usual, you should use one of the pretrained models from `torchvision.models` to get the image features. Build and train a new feed-forward classifier using those features.\n\nThings I'll need to do:\n\n* Load a [pre-trained network](http://pytorch.org/docs/master/torchvision/models.html)\n* Define a new, untrained feed-forward network as a classifier, using ReLU activations and dropout\n* Train the classifier layers using backpropagation using the pre-trained network to get the features\n* Track the loss and accuracy on the validation set to determine the best hyperparameters\n\nWhen training we need to make sure we're updating only the weights of the feed-forward network. We should be able to get the validation accuracy above 70% if we build everything right. We can try different hyperparameters (learning rate, units in the classifier, epochs, etc) to find the best model. Save those hyperparameters to use as default values in the next part of the project.\n\n**Note for Workspace users:** If your network is over 1 GB when saved as a checkpoint, there might be issues with saving backups in your workspace. Typically this happens with wide dense layers after the convolutional layers. If your saved checkpoint is larger than 1 GB (you can open a terminal and check with `ls -lh`), you should reduce the size of your hidden layers and train again.",
"_____no_output_____"
]
],
[
[
"model = models.vgg16(pretrained = True)\nmodel",
"Downloading: \"https://download.pytorch.org/models/vgg16-397923af.pth\" to /root/.torch/models/vgg16-397923af.pth\n100%|██████████| 553433881/553433881 [00:08<00:00, 63486648.32it/s]\n"
],
[
"for param in model.parameters():\n param.requires_grad = False\n \nclassifier = nn.Sequential(\n nn.Linear(25088, 4096),\n nn.ReLU(),\n nn.Dropout(0.2),\n nn.Linear(4096, 512),\n nn.ReLU(),\n nn.Dropout(0.2),\n nn.Linear(512, 102),\n nn.LogSoftmax(dim=1)\n )",
"_____no_output_____"
],
[
"device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nmodel.to(device);\nmodel.classifier = classifier\ncriterion = nn.NLLLoss()\noptimizer = optim.Adam(model.classifier.parameters(), lr=0.001)\n\nepochs = 5\nsteps = 0\ntrain_losses, valid_losses = [], []\n\nfor i in range(epochs):\n running_loss = 0\n \n for images,labels in train_loader:\n steps += 1\n images, labels = images.to(device), labels.to(device)\n optimizer.zero_grad()\n log_ps = model(images).to(device)\n loss = criterion(log_ps, labels)\n loss.backward()\n optimizer.step()\n running_loss += loss.item()\n \n else:\n valid_loss = 0\n accuracy = 0\n model.eval()\n \n with torch.no_grad():\n \n for images, labels in valid_loader:\n images, labels = images.to(device), labels.to(device)\n log_ps = model(images)\n valid_loss += criterion(log_ps, labels)\n ps = torch.exp(log_ps)\n top_p, top_class = ps.topk(1, dim=1)\n equals = top_class == labels.view(*top_class.shape)\n accuracy += torch.mean(equals.type(torch.FloatTensor))\n \n model.train()\n train_losses.append(running_loss/len(train_loader))\n valid_losses.append(valid_loss/len(valid_loader))\n \n print(\"Epoch: {}/{}.. \".format(i+1, epochs),\n \"Training Loss: {:.3f}.. \".format(running_loss/len(train_loader)),\n \"Validation Loss: {:.3f}.. \".format(valid_loss/len(valid_loader)),\n \"Validation Accuracy: {:.3f}\".format(accuracy/len(valid_loader)))\n ",
"Epoch: 1/5.. Training Loss: 2.794.. Validation Loss: 1.257.. Validation Accuracy: 0.655\nEpoch: 2/5.. Training Loss: 1.620.. Validation Loss: 0.868.. Validation Accuracy: 0.762\nEpoch: 3/5.. Training Loss: 1.280.. Validation Loss: 0.730.. Validation Accuracy: 0.803\nEpoch: 4/5.. Training Loss: 1.233.. Validation Loss: 0.637.. Validation Accuracy: 0.848\nEpoch: 5/5.. Training Loss: 1.113.. Validation Loss: 0.644.. Validation Accuracy: 0.850\n"
]
],
[
[
"## Testing your network\n\nIt's good practice to test your trained network on test data, images the network has never seen either in training or validation. This will give us a good estimate for the model's performance on completely new images. I need to run the test images through the network and measure the accuracy, the same way I did validation. We should be able to reach around 70% accuracy on the test set if the model has been trained well.",
"_____no_output_____"
]
],
[
[
"# Validation on the test set\n\ntest_loss = 0\naccuracy = 0\nmodel.eval()\n\nwith torch.no_grad():\n\n for images, labels in test_loader:\n images, labels = images.to(device), labels.to(device)\n log_ps = model(images)\n test_loss += criterion(log_ps, labels)\n ps = torch.exp(log_ps)\n top_p, top_class = ps.topk(1, dim=1)\n equals = top_class == labels.view(*top_class.shape)\n accuracy += torch.mean(equals.type(torch.FloatTensor))\n\nprint(\"Testing Accuracy: {:.3f}\".format(accuracy/len(test_loader)))",
"Testing Accuracy: 0.800\n"
]
],
[
[
"## Save the checkpoint\n\nNow that our network is trained, I will save the model so we can load it later for making predictions. I probably want to save other things such as the mapping of classes to indices which you get from one of the image datasets: `image_datasets['train'].class_to_idx`. I can attach this to the model as an attribute which makes inference easier later on.\n\n```model.class_to_idx = image_datasets['train'].class_to_idx```\n\nRemember that we'll want to completely rebuild the model later so you can use it for inference. Make sure to include any information you need in the checkpoint. If we want to load the model and keep training, we'll want to save the number of epochs as well as the optimizer state, `optimizer.state_dict`. We'll likely want to use this trained model in the next part of the project, so best to save it now.",
"_____no_output_____"
]
],
[
[
"model.class_to_idx = train_data.class_to_idx\nmodel.cpu()\n\ncheckpoint = {'class_to_idx': model.class_to_idx,\n 'state_dict': model.state_dict()}\n\ntorch.save(checkpoint, 'checkpoint.pth')",
"_____no_output_____"
]
],
[
[
"## Loading the checkpoint\n\nAt this point it's good to write a function that can load a checkpoint and rebuild the model. That way I can come back to this project and keep working on it without having to retrain the network.",
"_____no_output_____"
]
],
[
[
"def load_checkpoint(filepath):\n\n checkpoint = torch.load(filepath)\n \n model = models.vgg16(pretrained = True)\n criterion = nn.NLLLoss()\n optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)\n\n for param in model.parameters():\n param.requires_grad = False\n \n model.class_to_idx = checkpoint['class_to_idx']\n\n classifier = nn.Sequential(\n nn.Linear(25088, 4096),\n nn.ReLU(),\n nn.Dropout(0.2),\n nn.Linear(4096, 512),\n nn.ReLU(),\n nn.Dropout(0.2),\n nn.Linear(512, 102),\n nn.LogSoftmax(dim=1)\n )\n \n model.classifier = classifier\n \n model.load_state_dict(checkpoint['state_dict'])\n \n return model",
"_____no_output_____"
],
[
"model = load_checkpoint('checkpoint.pth')\nmodel",
"_____no_output_____"
]
],
[
[
"# Inference for classification\n\nNow I'll write a function to use a trained network for inference. That is, I'll pass an image into the network and predict the class of the flower in the image. Writing a function called `predict` that takes an image and a model, then returns the top $K$ most likely classes along with the probabilities. It should look like \n\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```\n\nFirst I'll need to handle processing the input image such that it can be used in your network. \n\n## Image Preprocessing\n\nI'll want to use `PIL` to load the image ([documentation](https://pillow.readthedocs.io/en/latest/reference/Image.html)). It's best to write a function that preprocesses the image so it can be used as input for the model. This function should process the images in the same manner used for training. \n\nFirst, resize the images where the shortest side is 256 pixels, keeping the aspect ratio. This can be done with the [`thumbnail`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) or [`resize`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) methods. Then I'll need to crop out the center 224x224 portion of the image.\n\nColor channels of images are typically encoded as integers 0-255, but the model expected floats 0-1. I'll need to convert the values. It's easiest with a Numpy array, which you can get from a PIL image like so `np_image = np.array(pil_image)`.\n\nAs before, the network expects the images to be normalized in a specific way. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`. I'll want to subtract the means from each color channel, then divide by the standard deviation. \n\nAnd finally, PyTorch expects the color channel to be the first dimension but it's the third dimension in the PIL image and Numpy array. I can reorder dimensions using [`ndarray.transpose`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.ndarray.transpose.html). The color channel needs to be first and retain the order of the other two dimensions.",
"_____no_output_____"
]
],
[
[
"def process_image(image):\n ''' Scales, crops, and normalizes a PIL image for a PyTorch model,\n returns an Numpy array\n '''\n im = Image.open(image)\n \n size = 256, 256\n im.thumbnail(size)\n \n crop_size = 224\n left = (size[0] - crop_size)/2\n upper = (size[1] - crop_size)/2\n right = left + crop_size\n lower = upper + crop_size\n im_crop = im.crop(box = (left, upper, right, lower))\n \n np_image = (np.array(im_crop))/255\n mean = [0.485, 0.456, 0.406]\n std = [0.229, 0.224, 0.225]\n np_image = (np_image - mean) / std\n \n processed_image = np_image.transpose(2,0,1)\n \n return processed_image",
"_____no_output_____"
]
],
[
[
"To check our work, the function below converts a PyTorch tensor and displays it in the notebook. If your `process_image` function works, running the output through this function should return the original image (except for the cropped out portions).",
"_____no_output_____"
]
],
[
[
"def imshow(image, ax=None, title=None):\n \"\"\"Imshow for Tensor.\"\"\"\n if ax is None:\n fig, ax = plt.subplots()\n \n # PyTorch tensors assume the color channel is the first dimension\n # but matplotlib assumes is the third dimension\n image = image.transpose((1, 2, 0))\n \n # Undo preprocessing\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n image = std * image + mean\n \n # Image needs to be clipped between 0 and 1 or it looks like noise when displayed\n image = np.clip(image, 0, 1)\n \n ax.imshow(image)\n \n return ax",
"_____no_output_____"
],
[
"image_path = 'flowers/train/1/image_06742.jpg'\nimshow(process_image(image_path))",
"_____no_output_____"
]
],
[
[
"## Class Prediction\n\nOnce we can get images in the correct format, it's time to write a function for making predictions with our model. A common practice is to predict the top 5 or so (usually called top-$K$) most probable classes. I'll want to calculate the class probabilities then find the $K$ largest values.\n\nTo get the top $K$ largest values in a tensor use [`x.topk(k)`](http://pytorch.org/docs/master/torch.html#torch.topk). This method returns both the highest `k` probabilities and the indices of those probabilities corresponding to the classes. I need to convert from these indices to the actual class labels using `class_to_idx` which hopefully we added to the model or from an `ImageFolder` you used to load the data ([see here](#Save-the-checkpoint)). I need to make sure to invert the dictionary so you get a mapping from index to class as well.\n\nAgain, this method should take a path to an image and a model checkpoint, then return the probabilities and classes.\n\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```",
"_____no_output_____"
]
],
[
[
"def predict(image_path, model, top_k=5):\n ''' Predict the class (or classes) of an image using a trained deep learning model.\n '''\n model.to(\"cpu\")\n model.eval()\n \n image = process_image(image_path)\n tensor = torch.tensor(image).float().unsqueeze_(0)\n \n with torch.no_grad():\n log_ps = model.forward(tensor)\n \n ps = torch.exp(log_ps)\n probs, classes = ps.topk(top_k, dim=1)\n \n return probs , classes",
"_____no_output_____"
],
[
"predict('flowers/train/1/image_06734.jpg', model, top_k=5)",
"_____no_output_____"
]
],
[
[
"## Sanity Checking\n\nNow that we can use a trained model for predictions, we can check to make sure it makes sense. Even if the testing accuracy is high, it's always good to check that there aren't obvious bugs. Using `matplotlib` to plot the probabilities for the top 5 classes as a bar graph, along with the input image. \n\nYou can convert from the class integer encoding to actual flower names with the `cat_to_name.json` file. To show a PyTorch tensor as an image, use the `imshow` function defined above.",
"_____no_output_____"
]
],
[
[
"def image_prediction(image_path):\n \n plt.figure(figsize=(5,10))\n ax = plt.subplot(2,1,1)\n \n image = process_image(image_path)\n imshow(image, ax).axis('off')\n\n probs, classes = predict(image_path, model, top_k=5)\n probs = probs.data.numpy().squeeze()\n classes = classes.data.numpy().squeeze()\n\n idx = {val: i for i, val in model.class_to_idx.items()}\n labels = [idx[labels] for labels in classes]\n flowers = [cat_to_name[labels] for labels in labels]\n\n plt.subplot(2,1,2)\n plt.barh(flowers, probs)",
"_____no_output_____"
],
[
"image_path = 'flowers/train/1/image_06742.jpg'\nimage_prediction(image_path)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a4600211f1830f8cb0e0fa37e3291978782b03c
| 25,766 |
ipynb
|
Jupyter Notebook
|
LinViscoFit.ipynb
|
NREL/pyvisco
|
99350fd0b24cd7583b5a06fe940c4023128ba39f
|
[
"BSD-3-Clause"
] | null | null | null |
LinViscoFit.ipynb
|
NREL/pyvisco
|
99350fd0b24cd7583b5a06fe940c4023128ba39f
|
[
"BSD-3-Clause"
] | null | null | null |
LinViscoFit.ipynb
|
NREL/pyvisco
|
99350fd0b24cd7583b5a06fe940c4023128ba39f
|
[
"BSD-3-Clause"
] | null | null | null | 39.579109 | 772 | 0.608243 |
[
[
[
"%%html\n<style>\n .jp-Cell {max-width: 1024px !important; margin: auto}\n .jp-Cell-inputWrapper {max-width: 1024px !important; margin: auto}\n .jp-MarkdownOutput p {text-align: justify;}\n .jupyter-matplotlib-figure {margin: auto;}\n</style>",
"_____no_output_____"
],
[
"%matplotlib widget\nfrom pyvisco import inter\nGUI = inter.Control()",
"_____no_output_____"
]
],
[
[
"# PYVISCO - Prony series identification for linear viscoelastic material models\nAuthor: Martin Springer | [email protected]\n***\n\n## Overview\nThe mechanical response of linear viscoelastic materials is often described with Generalized Maxwell models. The necessary material model parameters are typically identified by fitting a Prony series to the experimental measurement data in either the frequency-domain (via Dynamic Mechanical Thermal Analysis) or time-domain (via relaxation measurements). Pyvisco performs the necessary data processing of the experimental measurements, mathematical operations, and curve-fitting routines to identify the Prony series parameters. The experimental data can be provided as raw measurement sets at different temperatures or as pre-processed master curves.\n* If raw measurement data are provided, the time-temperature superposition principle is applied to create a master curve and obtain the shift functions prior to the Prony series parameters identification. \n* If master curves are provided, the shift procedure can be skipped, and the Prony series parameters identified directly. \nAn optional minimization routine is provided to reduce the number of Prony elements. This routine is helpful for Finite Element simulations where reducing the computational complexity of the linear viscoelastic material models can shorten the simulation time.",
"_____no_output_____"
]
],
[
[
"display(GUI.b_theory)\ndisplay(GUI.out_theory)",
"_____no_output_____"
]
],
[
[
"***\n## Parameter identification\n\n### Specify measurement type and upload input data\n\nIn this section the measurement type of the input data is specified and the experimental data are uploaded. A set of example input files can be downloaded here: [Example input files](https://github.com/NREL/pyvisco/raw/main/examples/examples.zip)\n\n#### Conventions \nEach input file needs to consist of two header rows. The first row indicates the column variables and the second row the corresponding units. The conventions used in this notebook are summarized below. Tensile moduli are denoted as $E$ and shear moduli are denoted as $G$. Only the tensile moduli are summarized in the table below. For shear modulus data, replace `E` with `G`, e.g. `E_relax` -> `G_relax`.\n\n| Physical quantity | Symbol | Variable | Unit |\n| :--------------------- | :-------------: | :--------- | :----: |\n| Relaxation modulus: | $E(t)$ | `E_relax` | `[Pa, kPa, MPa, GPa]` |\n| Storage modulus: | $E'(\\omega)$ | `E_stor` | `[Pa, kPa, MPa, GPa]` |\n| Loss modulus: | $E''(\\omega)$ | `E_loss` | `[Pa, kPa, MPa, GPa]` |\n| Complex modulus: | $\\lvert E^{*}\\rvert$ | `E_comp` | `[Pa, kPa, MPa, GPa]` |\n| Loss factor: | $\\tan(\\delta)$ | `tan_del` | `-` |\n| Instantaneous modulus: | $E_0$ | `E_0` | `[Pa, kPa, MPa, GPa]` |\n| Equilibrium modulus: | $E_{inf}$ | `E_inf` | `[Pa, kPa, MPa, GPa]` |\n| Angular frequency: | $\\omega$ | `omega` | `rad/s` |\n| Frequency: | $f$ | `f` | `Hz` |\n| Time: | $t$ | `t` | `s` |\n| Temperature: | $\\theta$ | `T` | `°C` |\n| Relaxation times: | $\\tau_i$ | `tau_i` | `s` |\n| Relaxation moduli: | $E_i$ | `E_i` | `[Pa, kPa, MPa, GPa]` |\n| Norm. relaxation moduli: | $\\alpha_i$ | `alpha_i` | `-` |\n| Shift factor: | $$\\log (a_{T}) $$ | `log_aT` | `-` |\n\n***\n#### Domain\nThe Prony series parameters can be either fitted from measurement data of Dynamic Mechanical Thermal Analysis (DMTA) in the frequency domain (freq) or from relaxation experiments in the time domain (time). \n\n#### Loading\nMeasurement data can be provided from either tensile or shear experiments. Tensile moduli are denoted as $E$ and shear moduli are denoted as $G$.\n\n#### Instrument\n* **Eplexor:** DMTA measurements conducted with a Netzsch Gabo DMA EPLEXOR can be directly uploaded as Excel files. Use the `Excel Export!` feature of the Eplexor software with the default template to create the input files. \n* **user:** Comma-separated values (csv) files are used for measurements conducted with other instruments. Prepare the input files in accordance to the performed measurement. The table below shows example headers, where the first row indicates the column quanitity and the second row the corresponding unit.\n\n| Domain | Tensile | shear | \n| :----------- | :------------- | :--------- |\n|**Frequency domain:** | `f, E_stor, E_loss` | `f, G_stor, G_loss` |\n| | `Hz, MPa, MPa` | `Hz, GPa, GPa` |\n|**Time domain:** | `t, E_relax` | `t, G_relax` |\n| | `s, MPa` | `s, GPa` |\n\n\n#### Type\n\nEither **raw** data containing measurements at different temperatures or ready to fit **master** curves can be uploaded. \n\nInput files of **raw** measurement data need to specify the individual temperature sets of the performed experimental characterization:\n* **Eplexor:** The notebook identifies the corresponding temperature sets automatically (only available in the frequency domain).\n* **user:** Two additional columns need to be included in the input file. One column describing the temperature `T` of the measurement point and a second column `Set` to identify the corresponding measurement set of the data point (e.g. `f, E_stor, E_loss, T, Set`). All measurement points at the same temperature level are marked with the same number, e.g. 0 for the first measurement set. The first measurement set (0) represents the coldest temperature followed by the second set (1) at the next higher temperature level and so forth (see the provided [example input file](https://github.com/NREL/pyvisco/blob/main/examples/time_user_raw.csv) for further details).",
"_____no_output_____"
]
],
[
[
"display(GUI.w_inp_gen)",
"_____no_output_____"
]
],
[
[
"***\n#### Optional shift factor upload\n\nAlready existing shift factors can be uploaded as a csv file with the header=`T, log_aT` and units=`C, -`, where `T` is the temperature level of the measurement set in Celsius and `log_aT` is the base 10 logarithm of the shift factor, $\\log(a_T)$.\n\n* **master:** Uploading the shift factors allows for the calculation of polynomial (D1 to D4) shift functions and the Williams–Landel–Ferry (WLF) shift function, but is not required for the Prony series estimation. \n> _**Note**_: If a master curve from the Eplexor software is provided, the default behavior of the notebook is to use the WLF shift function from the Eplexor software. However, in the time-temperature superpostion section, a checkbox is provided to overwrite the WLF fit of the Eplexor software and conduct another WLF fit with the algorithm in this notebook.\n\n* **raw:** The shift factors can either be directly determined for the desired reference temperature in the time-temperature superposition section (no upload necessary) or user-specified shift factors can be uploaded to be used in the creation of the master curve. ",
"_____no_output_____"
]
],
[
[
"display(GUI.w_inp_shift)",
"_____no_output_____"
]
],
[
[
"***\n#### Reference temperature \n\nTemperature chosen to contruct the master curve through application of the time-temperature superposition principle $[\\log(a_T) = 0]$.",
"_____no_output_____"
]
],
[
[
"display(GUI.w_RefT)",
"_____no_output_____"
]
],
[
[
"***\n#### Check uploaded data",
"_____no_output_____"
]
],
[
[
"display(GUI.w_check_inp)",
"_____no_output_____"
]
],
[
[
"***\n### Time-temperature superposition (shift functions)\n\nThis section allows the calculation of shift factors from raw input data to create a master curve. The shift factors are then used to fit polynomial and WLF shift functions.\n\n#### Shift factors $\\log(a_{T})$ - Create master curve from raw input\n\nThe time-temperature superposition principle is applied to create a master curve from the individual measurement sets at different temperature levels. \n\n> _**Note**_:This subsection only applies to raw measurement data. If a master curve was uploaded, procede to the next step. \n\n * **user shift factors uploaded:** The provided shift factors will be used to create the master curve from the raw measurement sets (_**Note**_: the `fit and overwrite provided shift factors` checkbox allows you to overwrite the uploaded user shift factors and fit new ones). \n * **No user shift factors uploaded:** The measurement sets from the raw input file are used to estimate the shift factors and create a master curve. Measurement sets below the desired reference temperatures are shifted to lower frequencies (longer time periods), whereas measurement sets at temperatures higher than the reference temperature are shifted to higher frequencies (shorter time periods). The `manually adjust shift factors` checkbox allows you to modify the obtained shift factors manually. (_**Note**_: In the frequency domain, only the storage modulus input data are considered to create the master curve from the raw input data. The shift factors obtained from the storage modulus master curve are then used to create the loss modulus master curve.)",
"_____no_output_____"
]
],
[
[
"display(GUI.w_aT)",
"_____no_output_____"
]
],
[
[
"***\n#### Shift functions (WLF & Polynomial degree 1 to 4)\n\nIf shift factors are available, the WLF shift function and polynomial functions of degree 1 to 4 can be fitted and plotted below. (_**Note**_: If the WLF shift functions was already provided by the Eplexor software, the checkbox below let's you overwrite the WLF fit of the Eplexor software with a WLF fit of this notebook.) \n\n> _**Note**_:This subsection only provides shift functions and is not required to perform the parameter identification of the Prony series.",
"_____no_output_____"
]
],
[
[
"display(GUI.w_shift)",
"_____no_output_____"
]
],
[
[
"***\n### Estimate Prony series parameters\n\n#### Pre-process (smooth) master curve\n\nA moving median filter to remove outliers in the measurement data can be applied before the Prony series parameters are identified. The window size can be adjusted through the slider above the figure. A window size of 1 means that no filtering procedure is performed and the input data are fitted directly.",
"_____no_output_____"
]
],
[
[
"display(GUI.w_smooth)",
"_____no_output_____"
]
],
[
[
"***\n#### Define the number and discretization of the Prony series\n\nThe number of Prony terms, $N$, needs to be defined before the parameter $\\tau_i$ and $\\alpha_i$ can be identified. The `default` behavior is to equally space one Prony term per decade along the logarithmic time axis, e.g., $\\tau_i$ = [1E-1, 1E0, 1E1,...] (s). This discretization typically delivers accurate results for engineering applications. \n> _**Note:**_ The fine discretization can be computationally heavy for using the viscoelastic material models in Finite Element simulations. Hence, the default discretization can be modified by either using the optimization routine provided below or by manually defining the number of Prony terms (`manual`). Here, the user can decide whether to round the lowest and highest relaxation times, $\\tau_i$, to the nearest base 10 number within the measurement window `round` or to use the exact minimum and maximum values of the experimental data for the relaxation times `exact`. ",
"_____no_output_____"
]
],
[
[
"display(GUI.w_dis)",
"_____no_output_____"
]
],
[
[
"***\n#### Curve fitting\n\nTwo different curve fitting routines for the Prony series parameters are employed and are dependent on the domain of the input data:\n\n* **Frequency domain**: A generalized collocation method using stiffness matrices is used as described in [Kraus, M. A., and M. Niederwald. Eur J Eng Mech 37.1 (2017): 82-106](https://journals.ub.ovgu.de/index.php/techmech/article/view/600). This methods utilizes both the storage and loss modulus master curves to estimate the Prony series parameters.\n \n \n* **Time domain**: A least-squares minimization is performed using the L-BFGS-B method from the scipy package. The implementation is similar to the optimization problem described by [Barrientos, E., Pelayo, F., Noriega, Á. et al. Mech Time-Depend Mater 23, 193–206 (2019)](https://doi.org/10.1007/s11043-018-9394-z) for a homogenous distribution of discrete times. ",
"_____no_output_____"
]
],
[
[
"display(GUI.w_out_fit_prony)",
"_____no_output_____"
]
],
[
[
"***\n#### Generalized Maxwell model\n\nThe fitted Prony series parameters in combination with the Generalized Maxwell model can be used to calculate the linear viscoelastic material parameters in both the time and frequency domain. ",
"_____no_output_____"
]
],
[
[
"display(GUI.w_out_GMaxw)",
"_____no_output_____"
]
],
[
[
"***\n### Optional: Minimize number of Prony elements (for Finite Element simulations)\n\nThe Generalized Maxwell model with a high number of Prony terms can be computationally expensive. Especially, when used in combination with numerical frameworks as the Finite Element Method. Reducing the number of Prony elements will decrease the accuracy of the linear viscoelastic material model, but can help to speed up subsequent numerical simulations.\n\nWe provide a simple routine to create an additional Generalized Maxwell model with a reduced number of Prony elements. The routine starts with the number of Prony terms specified above and subsequently reduces the number of terms. A least squares minimization is performed to fit the reduced term Prony parameters. The least squares residual is used to suggest an optimal number of Prony terms for subsequent FEM simulations ($R_{opt}^2 \\approx$ $1.5 R_0^2$). However, the user can change this default setting by selecting a different number of Prony terms below.\n\n> **_Note:_** This routine is computationally more demanding and can take a few minutes to complete. The runtime depends on the initial number of Prony elements and the number of data points in the measurement sets.",
"_____no_output_____"
]
],
[
[
"display(GUI.w_out_fit_min)",
"_____no_output_____"
]
],
[
[
"***\n## Download results\n\nA zip archive including the identified Prony series parameters, (shift factors and shift functions), results of the Generalized Maxwell model, and figures can be dowloaded below.",
"_____no_output_____"
]
],
[
[
"#display(GUI.db_zip)\ndisplay(GUI.w_out_down)",
"_____no_output_____"
]
],
[
[
"***\n## Start over!\nClear all input data and reload an empty notebook.",
"_____no_output_____"
]
],
[
[
"display(GUI.w_reload)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a460411c509e80a02c963ae5da8d787760525bc
| 33,781 |
ipynb
|
Jupyter Notebook
|
_notebooks/2020-01-01-NumPy.ipynb
|
unverciftci/derin_ogrenme
|
1c7f57da411313c57057c447ef1a0dfc9fd2fda5
|
[
"Apache-2.0"
] | null | null | null |
_notebooks/2020-01-01-NumPy.ipynb
|
unverciftci/derin_ogrenme
|
1c7f57da411313c57057c447ef1a0dfc9fd2fda5
|
[
"Apache-2.0"
] | 1 |
2021-09-28T02:59:29.000Z
|
2021-09-28T02:59:29.000Z
|
_notebooks/2020-01-01-NumPy.ipynb
|
tayfununal/derin_ogrenme
|
b94d05c328788dbb11edd50c39e1acacd02e0622
|
[
"Apache-2.0"
] | 2 |
2020-06-10T07:36:18.000Z
|
2020-06-13T21:31:14.000Z
| 28.034025 | 413 | 0.413368 |
[
[
[
"# Numpy (✗)\n> Makine Öğrenmesi ve Derin Öğrenme için gerekli Numpy konuları.\n\n- toc: true \n- badges: true\n- comments: true\n- categories: [jupyter]\n- image: images/chart-preview.png",
"_____no_output_____"
],
[
"# Set up",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"# Set seed for reproducibility\nnp.random.seed(seed=1234)",
"_____no_output_____"
]
],
[
[
"# Basics",
"_____no_output_____"
],
[
"Let's take a took at how to create tensors with NumPy.\n* **Tensor**: collection of values \n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/tensors.png\" width=\"650\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Scalar\nx = np.array(6) # scalar\nprint (\"x: \", x)\n# Number of dimensions\nprint (\"x ndim: \", x.ndim)\n# Dimensions\nprint (\"x shape:\", x.shape)\n# Size of elements\nprint (\"x size: \", x.size)\n# Data type\nprint (\"x dtype: \", x.dtype)",
"x: 6\nx ndim: 0\nx shape: ()\nx size: 1\nx dtype: int64\n"
],
[
"# Vector\nx = np.array([1.3 , 2.2 , 1.7])\nprint (\"x: \", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype) # notice the float datatype",
"x: [1.3 2.2 1.7]\nx ndim: 1\nx shape: (3,)\nx size: 3\nx dtype: float64\n"
],
[
"# Matrix\nx = np.array([[1,2], [3,4]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)",
"x:\n [[1 2]\n [3 4]]\nx ndim: 2\nx shape: (2, 2)\nx size: 4\nx dtype: int64\n"
],
[
"# 3-D Tensor\nx = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])\nprint (\"x:\\n\", x)\nprint (\"x ndim: \", x.ndim)\nprint (\"x shape:\", x.shape)\nprint (\"x size: \", x.size)\nprint (\"x dtype: \", x.dtype)",
"x:\n [[[1 2]\n [3 4]]\n\n [[5 6]\n [7 8]]]\nx ndim: 3\nx shape: (2, 2, 2)\nx size: 8\nx dtype: int64\n"
]
],
[
[
"NumPy also comes with several functions that allow us to create tensors quickly.",
"_____no_output_____"
]
],
[
[
"# Functions\nprint (\"np.zeros((2,2)):\\n\", np.zeros((2,2)))\nprint (\"np.ones((2,2)):\\n\", np.ones((2,2)))\nprint (\"np.eye((2)):\\n\", np.eye((2))) # identity matrix \nprint (\"np.random.random((2,2)):\\n\", np.random.random((2,2)))",
"np.zeros((2,2)):\n [[0. 0.]\n [0. 0.]]\nnp.ones((2,2)):\n [[1. 1.]\n [1. 1.]]\nnp.eye((2)):\n [[1. 0.]\n [0. 1.]]\nnp.random.random((2,2)):\n [[0.19151945 0.62210877]\n [0.43772774 0.78535858]]\n"
]
],
[
[
"# Indexing",
"_____no_output_____"
],
[
"Keep in mind that when indexing the row and column, indices start at 0. And like indexing with lists, we can use negative indices as well (where -1 is the last item).",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/indexing.png\" width=\"300\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Indexing\nx = np.array([1, 2, 3])\nprint (\"x: \", x)\nprint (\"x[0]: \", x[0])\nx[0] = 0\nprint (\"x: \", x)",
"x: [1 2 3]\nx[0]: 1\nx: [0 2 3]\n"
],
[
"# Slicing\nx = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])\nprint (x)\nprint (\"x column 1: \", x[:, 1]) \nprint (\"x row 0: \", x[0, :]) \nprint (\"x rows 0,1 & cols 1,2: \\n\", x[0:2, 1:3]) ",
"[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nx column 1: [ 2 6 10]\nx row 0: [1 2 3 4]\nx rows 0,1 & cols 1,2: \n [[2 3]\n [6 7]]\n"
],
[
"# Integer array indexing\nprint (x)\nrows_to_get = np.array([0, 1, 2])\nprint (\"rows_to_get: \", rows_to_get)\ncols_to_get = np.array([0, 2, 1])\nprint (\"cols_to_get: \", cols_to_get)\n# Combine sequences above to get values to get\nprint (\"indexed values: \", x[rows_to_get, cols_to_get]) # (0, 0), (1, 2), (2, 1)",
"[[ 1 2 3 4]\n [ 5 6 7 8]\n [ 9 10 11 12]]\nrows_to_get: [0 1 2]\ncols_to_get: [0 2 1]\nindexed values: [ 1 7 10]\n"
],
[
"# Boolean array indexing\nx = np.array([[1, 2], [3, 4], [5, 6]])\nprint (\"x:\\n\", x)\nprint (\"x > 2:\\n\", x > 2)\nprint (\"x[x > 2]:\\n\", x[x > 2])",
"x:\n [[1 2]\n [3 4]\n [5 6]]\nx > 2:\n [[False False]\n [ True True]\n [ True True]]\nx[x > 2]:\n [3 4 5 6]\n"
]
],
[
[
"# Arithmetic\n",
"_____no_output_____"
]
],
[
[
"# Basic math\nx = np.array([[1,2], [3,4]], dtype=np.float64)\ny = np.array([[1,2], [3,4]], dtype=np.float64)\nprint (\"x + y:\\n\", np.add(x, y)) # or x + y\nprint (\"x - y:\\n\", np.subtract(x, y)) # or x - y\nprint (\"x * y:\\n\", np.multiply(x, y)) # or x * y",
"x + y:\n [[2. 4.]\n [6. 8.]]\nx - y:\n [[0. 0.]\n [0. 0.]]\nx * y:\n [[ 1. 4.]\n [ 9. 16.]]\n"
]
],
[
[
"### Dot product",
"_____no_output_____"
],
[
"One of the most common NumPy operations we’ll use in machine learning is matrix multiplication using the dot product. We take the rows of our first matrix (2) and the columns of our second matrix (2) to determine the dot product, giving us an output of `[2 X 2]`. The only requirement is that the inside dimensions match, in this case the first matrix has 3 columns and the second matrix has 3 rows. \n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/dot.gif\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Dot product\na = np.array([[1,2,3], [4,5,6]], dtype=np.float64) # we can specify dtype\nb = np.array([[7,8], [9,10], [11, 12]], dtype=np.float64)\nc = a.dot(b)\nprint (f\"{a.shape} · {b.shape} = {c.shape}\")\nprint (c)",
"(2, 3) · (3, 2) = (2, 2)\n[[ 58. 64.]\n [139. 154.]]\n"
]
],
[
[
"### Axis operations",
"_____no_output_____"
],
[
"We can also do operations across a specific axis.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/axis.gif\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Sum across a dimension\nx = np.array([[1,2],[3,4]])\nprint (x)\nprint (\"sum all: \", np.sum(x)) # adds all elements\nprint (\"sum axis=0: \", np.sum(x, axis=0)) # sum across rows\nprint (\"sum axis=1: \", np.sum(x, axis=1)) # sum across columns",
"[[1 2]\n [3 4]]\nsum all: 10\nsum axis=0: [4 6]\nsum axis=1: [3 7]\n"
],
[
"# Min/max\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"min: \", x.min())\nprint (\"max: \", x.max())\nprint (\"min axis=0: \", x.min(axis=0))\nprint (\"min axis=1: \", x.min(axis=1))",
"min: 1\nmax: 6\nmin axis=0: [1 2 3]\nmin axis=1: [1 4]\n"
]
],
[
[
"### Broadcasting",
"_____no_output_____"
],
[
"Here, we’re adding a vector with a scalar. Their dimensions aren’t compatible as is but how does NumPy still gives us the right result? This is where broadcasting comes in. The scalar is *broadcast* across the vector so that they have compatible shapes.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/broadcasting.png\" width=\"300\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Broadcasting\nx = np.array([1,2]) # vector\ny = np.array(3) # scalar\nz = x + y\nprint (\"z:\\n\", z)",
"z:\n [4 5]\n"
]
],
[
[
"# Advanced",
"_____no_output_____"
],
[
"### Transposing",
"_____no_output_____"
],
[
"We often need to change the dimensions of our tensors for operations like the dot product. If we need to switch two dimensions, we can transpose \nthe tensor.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/transpose.png\" width=\"400\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Transposing\nx = np.array([[1,2,3], [4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.transpose(x, (1,0)) # flip dimensions at index 0 and 1\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)",
"x:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny:\n [[1 4]\n [2 5]\n [3 6]]\ny.shape: (3, 2)\n"
]
],
[
[
"### Reshaping",
"_____no_output_____"
],
[
"Sometimes, we'll need to alter the dimensions of the matrix. Reshaping allows us to transform a tensor into different permissible shapes -- our reshaped tensor has the same amount of values in the tensor. (1X6 = 2X3). We can also use `-1` on a dimension and NumPy will infer the dimension based on our input tensor.\n\nThe way reshape works is by looking at each dimension of the new tensor and separating our original tensor into that many units. So here the dimension at index 0 of the new tensor is 2 so we divide our original tensor into 2 units, and each of those has 3 values.\n\n<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/reshape.png\" width=\"450\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Reshaping\nx = np.array([[1,2,3,4,5,6]])\nprint (x)\nprint (\"x.shape: \", x.shape)\ny = np.reshape(x, (2, 3))\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape)\nz = np.reshape(x, (2, -1))\nprint (\"z: \\n\", z)\nprint (\"z.shape: \", z.shape)",
"[[1 2 3 4 5 6]]\nx.shape: (1, 6)\ny: \n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\nz: \n [[1 2 3]\n [4 5 6]]\nz.shape: (2, 3)\n"
]
],
[
[
"### Unintended reshaping",
"_____no_output_____"
],
[
"Though reshaping is very convenient to manipulate tensors, we must be careful of their pitfalls as well. Let's look at the example below. Suppose we have `x`, which has the shape `[2 X 3 X 4]`. \n```\n[[[ 1 1 1 1]\n [ 2 2 2 2]\n [ 3 3 3 3]]\n [[10 10 10 10]\n [20 20 20 20]\n [30 30 30 30]]]\n```\nWe want to reshape x so that it has shape `[3 X 8]` which we'll get by moving the dimension at index 0 to become the dimension at index 1 and then combining the last two dimensions. But when we do this, we want our output \n\nto look like:\n✅\n```\n[[ 1 1 1 1 10 10 10 10]\n [ 2 2 2 2 20 20 20 20]\n [ 3 3 3 3 30 30 30 30]]\n```\nand not like:\n❌\n```\n[[ 1 1 1 1 2 2 2 2]\n [ 3 3 3 3 10 10 10 10]\n [20 20 20 20 30 30 30 30]]\n ```\neven though they both have the same shape `[3X8]`.",
"_____no_output_____"
]
],
[
[
"x = np.array([[[1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]],\n [[10, 10, 10, 10], [20, 20, 20, 20], [30, 30, 30, 30]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)",
"x:\n [[[ 1 1 1 1]\n [ 2 2 2 2]\n [ 3 3 3 3]]\n\n [[10 10 10 10]\n [20 20 20 20]\n [30 30 30 30]]]\nx.shape: (2, 3, 4)\n"
]
],
[
[
"When we naively do a reshape, we get the right shape but the values are not what we're looking for.",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/reshape_wrong.png\" width=\"600\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Unintended reshaping\nz_incorrect = np.reshape(x, (x.shape[1], -1))\nprint (\"z_incorrect:\\n\", z_incorrect)\nprint (\"z_incorrect.shape: \", z_incorrect.shape)",
"z_incorrect:\n [[ 1 1 1 1 2 2 2 2]\n [ 3 3 3 3 10 10 10 10]\n [20 20 20 20 30 30 30 30]]\nz_incorrect.shape: (3, 8)\n"
]
],
[
[
"Instead, if we transpose the tensor and then do a reshape, we get our desired tensor. Transpose allows us to put our two vectors that we want to combine together and then we use reshape to join them together.\nAlways create a dummy example like this when you’re unsure about reshaping. Blindly going by the tensor shape can lead to lots of issues downstream.",
"_____no_output_____"
],
[
"<div align=\"left\">\n<img src=\"https://raw.githubusercontent.com/madewithml/images/master/basics/03_NumPy/reshape_right.png\" width=\"600\">\n</div>",
"_____no_output_____"
]
],
[
[
"# Intended reshaping\ny = np.transpose(x, (1,0,2))\nprint (\"y:\\n\", y)\nprint (\"y.shape: \", y.shape)\nz_correct = np.reshape(y, (y.shape[0], -1))\nprint (\"z_correct:\\n\", z_correct)\nprint (\"z_correct.shape: \", z_correct.shape)",
"y:\n [[[ 1 1 1 1]\n [10 10 10 10]]\n\n [[ 2 2 2 2]\n [20 20 20 20]]\n\n [[ 3 3 3 3]\n [30 30 30 30]]]\ny.shape: (3, 2, 4)\nz_correct:\n [[ 1 1 1 1 10 10 10 10]\n [ 2 2 2 2 20 20 20 20]\n [ 3 3 3 3 30 30 30 30]]\nz_correct.shape: (3, 8)\n"
]
],
[
[
"### Adding/removing dimensions",
"_____no_output_____"
],
[
"We can also easily add and remove dimensions to our tensors and we'll want to do this to make tensors compatible for certain operations.",
"_____no_output_____"
]
],
[
[
"# Adding dimensions\nx = np.array([[1,2,3],[4,5,6]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.expand_dims(x, 1) # expand dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are added",
"x:\n [[1 2 3]\n [4 5 6]]\nx.shape: (2, 3)\ny: \n [[[1 2 3]]\n\n [[4 5 6]]]\ny.shape: (2, 1, 3)\n"
],
[
"# Removing dimensions\nx = np.array([[[1,2,3]],[[4,5,6]]])\nprint (\"x:\\n\", x)\nprint (\"x.shape: \", x.shape)\ny = np.squeeze(x, 1) # squeeze dim 1\nprint (\"y: \\n\", y)\nprint (\"y.shape: \", y.shape) # notice extra set of brackets are gone",
"x:\n [[[1 2 3]]\n\n [[4 5 6]]]\nx.shape: (2, 1, 3)\ny: \n [[1 2 3]\n [4 5 6]]\ny.shape: (2, 3)\n"
]
],
[
[
"# Additional resources",
"_____no_output_____"
],
[
"* **NumPy reference manual**: We don't have to memorize anything here and we will be taking a closer look at NumPy in the later lessons. If you want to learn more checkout the [NumPy reference manual](https://docs.scipy.org/doc/numpy-1.15.1/reference/).",
"_____no_output_____"
],
[
"---\nShare and discover ML projects at <a href=\"https://madewithml.com/\">Made With ML</a>.\n\n<div align=\"left\">\n<a class=\"ai-header-badge\" target=\"_blank\" href=\"https://github.com/madewithml/basics\"><img src=\"https://img.shields.io/github/stars/madewithml/basics.svg?style=social&label=Star\"></a> \n<a class=\"ai-header-badge\" target=\"_blank\" href=\"https://www.linkedin.com/company/madewithml\"><img src=\"https://img.shields.io/badge/style--5eba00.svg?label=LinkedIn&logo=linkedin&style=social\"></a> \n<a class=\"ai-header-badge\" target=\"_blank\" href=\"https://twitter.com/madewithml\"><img src=\"https://img.shields.io/twitter/follow/madewithml.svg?label=Follow&style=social\"></a>\n</div>\n ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4a460f667c987c6f9effc7cff0b190939adf3f6b
| 62,191 |
ipynb
|
Jupyter Notebook
|
homeworksMAT281/C1_data_analysis/03_pandas/03_pandas.ipynb
|
MariodotR/Aplica
|
8ecb8d84cf313df6543a01720488550f96a4575f
|
[
"MIT"
] | null | null | null |
homeworksMAT281/C1_data_analysis/03_pandas/03_pandas.ipynb
|
MariodotR/Aplica
|
8ecb8d84cf313df6543a01720488550f96a4575f
|
[
"MIT"
] | null | null | null |
homeworksMAT281/C1_data_analysis/03_pandas/03_pandas.ipynb
|
MariodotR/Aplica
|
8ecb8d84cf313df6543a01720488550f96a4575f
|
[
"MIT"
] | null | null | null | 27.951011 | 360 | 0.404769 |
[
[
[
"<img src=\"images/usm.jpg\" width=\"480\" height=\"240\" align=\"left\"/>",
"_____no_output_____"
],
[
"# MAT281 - Introducción a Pandas",
"_____no_output_____"
],
[
"## Objetivos de la clase\n\n* Aprender conceptos básicos de la librería pandas.\n",
"_____no_output_____"
],
[
"## Contenidos\n\n* [Pandas](#c1)",
"_____no_output_____"
],
[
"<a id='c1'></a>\n\n## Pandas\n\n<img src=\"images/pandas.jpeg\" width=\"360\" height=\"240\" align=\"center\"/>\n\n\n[Pandas](https://pandas.pydata.org/) es un paquete de Python que proporciona estructuras de datos rápidas, flexibles y expresivas diseñadas para que trabajar con datos \"relacionales\" o \"etiquetados\" sea fácil e intuitivo. \n\nSu objetivo es ser el bloque de construcción fundamental de alto nivel para hacer análisis de datos prácticos del mundo real en Python. Además, tiene el objetivo más amplio de convertirse en la herramienta de análisis/manipulación de datos de código abierto más potente y flexible disponible en cualquier idioma. Ya está en camino hacia este objetivo.\n\n",
"_____no_output_____"
],
[
"### Series y DataFrames\n\n* Las **series** son arreglos unidimensionales con etiquetas. Se puede pensar como una generalización de los diccionarios de Python. \n\n* Los **dataframe** son arreglos bidimensionales y una extensión natural de las series. Se puede pensar como la generalización de un numpy.array.\n",
"_____no_output_____"
],
[
"## 1.- Pandas Series\n\n### Operaciones Básicas con series",
"_____no_output_____"
]
],
[
[
"# importar libreria: pandas, os\nimport pandas as pd\nimport numpy as np\nimport os",
"_____no_output_____"
],
[
"# crear serie\nmy_serie = pd.Series(range(3, 33, 3), index=list('abcdefghij'))\n\n# imprimir serie\nprint(\"serie:\")\nprint( my_serie )",
"serie:\na 3\nb 6\nc 9\nd 12\ne 15\nf 18\ng 21\nh 24\ni 27\nj 30\ndtype: int64\n"
],
[
"# tipo \nprint(\"type:\")\nprint( type(my_serie) )",
"type:\n<class 'pandas.core.series.Series'>\n"
],
[
"# valores \nprint(\"values:\")\nprint(my_serie.values)",
"values:\n[ 3 6 9 12 15 18 21 24 27 30]\n"
],
[
"# indice\nprint(\"index:\")\nprint(my_serie.index)",
"index:\nIndex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'], dtype='object')\n"
],
[
"# acceder al valor de la serie: directo\nprint(\"direct:\")\nprint(my_serie['b'])",
"direct:\n6\n"
],
[
"# acceder al valor de la serie: loc\nprint(\"loc:\")\nprint(my_serie.loc['b'])",
"loc:\n6\n"
],
[
"# acceder al valor de la serie: iloc con indice\nprint(\"iloc:\")\nprint(my_serie.iloc[1])",
"iloc:\n6\n"
],
[
"# editar valores\nprint(\"edit:\")\nprint(\"\\nold 'd':\",my_serie.loc['d'] )\nmy_serie.loc['d'] = 1000\nprint(\"new 'd':\",my_serie.loc['d'] )",
"edit:\n\nold 'd': 12\nnew 'd': 1000\n"
]
],
[
[
"### Manejo de Fechas\n\nPandas también trae módulos para trabajar el formato de fechas.",
"_____no_output_____"
]
],
[
[
"# crear serie de fechas\ndate_rng = pd.date_range(start='1/1/2019', end='1/03/2019', freq='4H')\n\n# imprimir serie\nprint(\"serie:\")\nprint( date_rng )",
"serie:\nDatetimeIndex(['2019-01-01 00:00:00', '2019-01-01 04:00:00',\n '2019-01-01 08:00:00', '2019-01-01 12:00:00',\n '2019-01-01 16:00:00', '2019-01-01 20:00:00',\n '2019-01-02 00:00:00', '2019-01-02 04:00:00',\n '2019-01-02 08:00:00', '2019-01-02 12:00:00',\n '2019-01-02 16:00:00', '2019-01-02 20:00:00',\n '2019-01-03 00:00:00'],\n dtype='datetime64[ns]', freq='4H')\n"
],
[
"# tipo \nprint(\"type:\\n\")\nprint( type(date_rng) )",
"type:\n\n<class 'pandas.core.indexes.datetimes.DatetimeIndex'>\n"
],
[
"# elementos de datetime a string \nstring_date_rng = [str(x) for x in date_rng]\n\nprint(\"datetime to string: \\n\")\nprint( np.array(string_date_rng) )",
"datetime to string: \n\n['2019-01-01 00:00:00' '2019-01-01 04:00:00' '2019-01-01 08:00:00'\n '2019-01-01 12:00:00' '2019-01-01 16:00:00' '2019-01-01 20:00:00'\n '2019-01-02 00:00:00' '2019-01-02 04:00:00' '2019-01-02 08:00:00'\n '2019-01-02 12:00:00' '2019-01-02 16:00:00' '2019-01-02 20:00:00'\n '2019-01-03 00:00:00']\n"
],
[
"# elementos de string a datetime \ntimestamp_date_rng = pd.to_datetime(string_date_rng, infer_datetime_format=True)\n\nprint(\"string to datetime:\\n\")\nprint( timestamp_date_rng )",
"string to datetime:\n\nDatetimeIndex(['2019-01-01 00:00:00', '2019-01-01 04:00:00',\n '2019-01-01 08:00:00', '2019-01-01 12:00:00',\n '2019-01-01 16:00:00', '2019-01-01 20:00:00',\n '2019-01-02 00:00:00', '2019-01-02 04:00:00',\n '2019-01-02 08:00:00', '2019-01-02 12:00:00',\n '2019-01-02 16:00:00', '2019-01-02 20:00:00',\n '2019-01-03 00:00:00'],\n dtype='datetime64[ns]', freq=None)\n"
],
[
"# obtener fechas\nprint(\"date:\\n\")\nprint(timestamp_date_rng.date)",
"date:\n\n[datetime.date(2019, 1, 1) datetime.date(2019, 1, 1)\n datetime.date(2019, 1, 1) datetime.date(2019, 1, 1)\n datetime.date(2019, 1, 1) datetime.date(2019, 1, 1)\n datetime.date(2019, 1, 2) datetime.date(2019, 1, 2)\n datetime.date(2019, 1, 2) datetime.date(2019, 1, 2)\n datetime.date(2019, 1, 2) datetime.date(2019, 1, 2)\n datetime.date(2019, 1, 3)]\n"
],
[
"# obtener horas\nprint(\"hour:\\n\")\nprint(timestamp_date_rng.hour)",
"hour:\n\nInt64Index([0, 4, 8, 12, 16, 20, 0, 4, 8, 12, 16, 20, 0], dtype='int64')\n"
]
],
[
[
"### Operaciones matemáticas\n\nAl igual que numpy, las series de pandas pueden realizar operaciones matemáticas similares (mientrás los arreglos a operar sean del tipo numérico). Por otro lado existen otras funciones de utilidad.",
"_____no_output_____"
]
],
[
[
"# crear serie\ns1 = pd.Series([1,1,1,2,2,2,3,3,3,4,5,5,5,5])\n\n\nprint(f\"max: {s1.max()}\") # maximo\nprint(f\"min: {s1.min()}\") # minimo\nprint(f\"mean: {s1.mean()}\") # promedio\nprint(f\"median: {s1.median()}\") # mediana",
"max: 5\nmin: 1\nmean: 3.0\nmedian: 3.0\n"
]
],
[
[
"### Masking\n\nExisten módulos para acceder a valores que queremos que cumplan una determinada regla. Por ejemplo, acceder al valor máximo de una serie. En este caso a esta regla la denominaremos *mask*.\n",
"_____no_output_____"
]
],
[
[
"# 1. definir valor maximo \nn_max = s1.max()\n\n# 2.- definir \"mask\" que busca el valor\nmask = (s1 == n_max)\n\n# 3.- aplicar mask sobre la serie\ns1[mask]",
"_____no_output_____"
]
],
[
[
"### Valores Nulos o datos perdidos\n\nEn algunas ocaciones, los arreglos no tienen información en una determinada posición, lo cual puede ser perjudicial si no se tiene control sobre estos valores.\n\n### a) Encontrar valores nulos",
"_____no_output_____"
]
],
[
[
"# crear serie\ns_null = pd.Series([1,2,np.nan,4,5,6,7,np.nan,9])\ns_null",
"_____no_output_____"
],
[
"# mask valores nulos\nprint(\"is null?:\\n\")\nprint(s_null.isnull() )",
"is null?:\n\n0 False\n1 False\n2 True\n3 False\n4 False\n5 False\n6 False\n7 True\n8 False\ndtype: bool\n"
],
[
"# filtrar valores nulos\nprint(\"null serie: \\n\")\nprint(s_null[s_null.isnull()] )",
"null serie: \n\n2 NaN\n7 NaN\ndtype: float64\n"
]
],
[
[
"### b) Encontrar valores no nulos",
"_____no_output_____"
]
],
[
[
"# imprimir serie\nprint(\"serie:\")\nprint( s_null )",
"serie:\n0 1.0\n1 2.0\n2 NaN\n3 4.0\n4 5.0\n5 6.0\n6 7.0\n7 NaN\n8 9.0\ndtype: float64\n"
],
[
"# mask valores no nulos\nprint(\"\\nis not null?:\")\nprint(s_null.notnull() )",
"\nis not null?:\n0 True\n1 True\n2 False\n3 True\n4 True\n5 True\n6 True\n7 False\n8 True\ndtype: bool\n"
],
[
"# filtrar valores no nulos\nprint(\"\\nserie with not null values\")\nprint(s_null[s_null.notnull()] )",
"\nserie with not null values\n0 1.0\n1 2.0\n3 4.0\n4 5.0\n5 6.0\n6 7.0\n8 9.0\ndtype: float64\n"
]
],
[
[
"La pregunta que nos queda hacer es: ¿ Qué se debe hacer con los valores nulos ?, la respuesta es **depende**.\n\n * Si tenemos muchos datos, lo más probable es que se puedan eliminar estos datos sin culpa.\n * Si se tienen poco datos, lo más probable es que se necesite inputar un valor por defecto a los valores nulos (**ejemplo**: el promedio).",
"_____no_output_____"
],
[
"## 2.- Pandas Dataframes\n\n### Trabajando con DataFrames\n\n\n<img src=\"images/dataframe.png\" width=\"360\" height=\"240\" align=\"center\"/>\n\n\nComo se mencina anteriormente, los dataframes son arreglos de series, los cuales pueden ser de distintos tipos (numéricos, string, etc.). En esta parte mostraremos un ejemplo aplicado de las distintas funcionalidades de los dataframes.",
"_____no_output_____"
],
[
"### Creación de dataframes\n\nLa creación se puede hacer de variadas formas con listas, dictionarios , numpy array , entre otros.\n",
"_____no_output_____"
]
],
[
[
"# empty dataframe\ndf_empty = pd.DataFrame()\ndf_empty",
"_____no_output_____"
],
[
"# dataframe with list\ndf_list = pd.DataFrame(\n [\n [\"nombre_01\", \"apellido_01\", 60],\n [\"nombre_02\", \"apellido_02\", 14]\n ], columns = [\"nombre\", \"apellido\", \"edad\"]\n)\ndf_list",
"_____no_output_____"
],
[
"# dataframe with dct\ndf_dct = pd.DataFrame(\n {\n \"nombre\": [\"nombre_01\", \"nombre_02\"],\n \"apellido\": [\"apellido_01\", \"apellido_02\"],\n \"edad\": np.array([60,14]),\n }\n)\ndf_dct",
"_____no_output_____"
]
],
[
[
"### Lectura de datos con dataframes\n\nEn general, cuando se trabajan con datos, estos se almacenan en algún lugar y en algún tipo de formato, por ejemplo:\n * .txt\n * .csv\n * .xlsx\n * .db\n * etc.\n \n \n\nPara cada formato, existe un módulo para realizar la lectura de datos. En este caso, se analiza el conjunto de datos 'player_data.csv', el cual muestra informacion básica de algunos jugadores de la NBA.\n\n<img src=\"images/nba_logo.jpg\" width=\"360\" height=\"240\" align=\"center\"/>\n",
"_____no_output_____"
]
],
[
[
"# load data ## crea la ruta\nplayer_data = pd.read_csv(os.path.join('data', 'player_data.csv'), index_col='name')",
"_____no_output_____"
]
],
[
[
"### Módulos básicos\n\nExisten módulos para comprender rápidamente la naturaleza del dataframe.",
"_____no_output_____"
]
],
[
[
"# first 5 rows\nprint(\"first 5 rows:\")\nplayer_data.head(5)",
"first 5 rows:\n"
],
[
"# last 5 rows\nprint(\"\\nlast 5 rows:\")\nplayer_data.tail(5)",
"\nlast 5 rows:\n"
],
[
"# tipo\nprint(\"\\ntype of dataframe:\")\ntype(player_data)",
"\ntype of dataframe:\n"
],
[
"# tipo por columns\nprint(\"\\ntype of columns:\")\nplayer_data.dtypes",
"\ntype of columns:\n"
],
[
"# dimension\nprint(\"\\nshape:\")\nplayer_data.shape",
"\nshape:\n"
],
[
"# columna posicion\nprint(\"\\ncolumn 'position': \")\nplayer_data['position'].head()",
"\ncolumn 'position': \n"
],
[
"player_data.columns",
"_____no_output_____"
]
],
[
[
"### Exploración de datos\n\nExisten módulos de pandas que realizan resumen de la información que dispone el dataframe.",
"_____no_output_____"
]
],
[
[
"# descripcion \nplayer_data.describe(include='all')",
"_____no_output_____"
]
],
[
[
"### Operando sobre Dataframes\n\nCuando se trabaja con un conjunto de datos, se crea una dinámica de preguntas y respuestas, en donde a medida que necesito información, se va accediendo al dataframe. En algunas ocaciones es directo, basta un simple módulo, aunque en otras será necesaria realizar operaciones un poco más complejas. \n\nPor ejemplo, del conjunto de datos en estudio, se esta interesado en responder las siguientes preguntas:\n",
"_____no_output_____"
],
[
"### a) Determine si el dataframe tiene valores nulos ",
"_____no_output_____"
]
],
[
[
"player_data.notnull().all(axis=1).head(10)",
"_____no_output_____"
]
],
[
[
"### b) Elimine los valores nulos del dataframe",
"_____no_output_____"
]
],
[
[
"player_data = player_data[lambda df: df.notnull().all(axis=1)]\nplayer_data.head()",
"_____no_output_____"
]
],
[
[
"### c) Determinar el tiempo de cada jugador en su posición.",
"_____no_output_____"
]
],
[
[
"# Determinar el tiempo de cada jugador en su posición.\nplayer_data['duration'] = player_data['year_end'] - player_data['year_start']\nplayer_data.head()",
"_____no_output_____"
]
],
[
[
"### d) Castear la fecha de str a objeto datetime",
"_____no_output_____"
]
],
[
[
"# Castear la fecha de str a objeto datetime\nplayer_data['birth_date_dt'] = pd.to_datetime(player_data['birth_date'], format=\"%B %d, %Y\")\nplayer_data.head()",
"_____no_output_____"
]
],
[
[
"### e) Determinar todas las posiciones.",
"_____no_output_____"
]
],
[
[
"# Determinar todas las posiciones.\npositions = player_data['position'].unique()\npositions",
"_____no_output_____"
]
],
[
[
"### f) Iterar sobre cada posición y encontrar el mayor valor.",
"_____no_output_____"
]
],
[
[
"# Iterar sobre cada posición y encontrar el mayor valor\n##serie vacia\nnba_position_duration = pd.Series()\n#iterar\nfor position in positions:\n #filtramos por posicion\n df_aux = player_data.loc[lambda x: x['position'] == position]\n #encontrar max\n max_duration = df_aux['duration'].max()\n nba_position_duration.loc[position] = max_duration\nnba_position_duration",
"C:\\Users\\Mario\\miniconda3\\envs\\mat281\\lib\\site-packages\\ipykernel_launcher.py:3: DeprecationWarning: The default dtype for empty Series will be 'object' instead of 'float64' in a future version. Specify a dtype explicitly to silence this warning.\n This is separate from the ipykernel package so we can avoid doing imports until\n"
]
],
[
[
"### g) Dermine los jugadores más altos de la NBA",
"_____no_output_____"
]
],
[
[
"# iteracion jugador mas alto\nheight_split = player_data['height'].str.split('-')\nfor player, height_list in height_split.items():\n if height_list == height_list:\n # Para manejar el caso en que la altura sea nan.\n height = int(height_list[0]) * 30.48 + int(height_list[1]) * 2.54\n player_data.loc[player, \"height_cm\"] = height\n else:\n player_data.loc[player, \"height_cm\"] = np.nan\n\nmax_height = player_data['height_cm'].max()\ntallest_player = player_data.loc[lambda x: x['height_cm'] == max_height].index.tolist()\nprint(tallest_player)",
"['Manute Bol']\n"
]
],
[
[
"## Referencia\n\n1. [Python Pandas Tutorial: A Complete Introduction for Beginners](https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/)\n2. [General functions](https://pandas.pydata.org/pandas-docs/stable/reference/general_functions.html)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a461206c91810a78a520342e906bac92a45b7ee
| 402,317 |
ipynb
|
Jupyter Notebook
|
11 Regression Algorithms/1. Simple Linear Regression - Py &R/Simple Linear Regression - Fuel Consumption Project Solutions.ipynb
|
IshmaelAsabere/Machine_Learning-Various-Topics
|
2c663ab73e2631522dac0fa1ec49042aa2088da4
|
[
"MIT"
] | null | null | null |
11 Regression Algorithms/1. Simple Linear Regression - Py &R/Simple Linear Regression - Fuel Consumption Project Solutions.ipynb
|
IshmaelAsabere/Machine_Learning-Various-Topics
|
2c663ab73e2631522dac0fa1ec49042aa2088da4
|
[
"MIT"
] | null | null | null |
11 Regression Algorithms/1. Simple Linear Regression - Py &R/Simple Linear Regression - Fuel Consumption Project Solutions.ipynb
|
IshmaelAsabere/Machine_Learning-Various-Topics
|
2c663ab73e2631522dac0fa1ec49042aa2088da4
|
[
"MIT"
] | null | null | null | 215.8353 | 214,884 | 0.895615 |
[
[
[
"\n# CODE TO PERFORM SIMPLE LINEAR REGRESSION ON FUEL CONSUMPTION DATASET\n# Dr. Ryan @STEMplicity\n\n\n",
"_____no_output_____"
],
[
"# PROBLEM STATEMENT",
"_____no_output_____"
],
[
"- You have been hired as a consultant to a major Automotive Manufacturer and you have been tasked to develop a model to predict the impact of increasing the vehicle horsepower (HP) on fuel economy (Mileage Per Gallon (MPG)). You gathered the data:\n- Data set:\n - Independant variable X: Vehicle Horse Power \n - Dependant variable Y: Mileage Per Gallon (MPG) ",
"_____no_output_____"
],
[
"# STEP #1: LIBRARIES IMPORT\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"# STEP #2: IMPORT DATASET",
"_____no_output_____"
]
],
[
[
"# Import data\nfueleconomy_df = pd.read_csv('FuelEconomy.csv')",
"_____no_output_____"
],
[
"# Preview data\nfueleconomy_df.head(100)",
"_____no_output_____"
],
[
"# Preview Data\nfueleconomy_df.head(5)",
"_____no_output_____"
],
[
"# Preview Data\nfueleconomy_df.tail(5)",
"_____no_output_____"
],
[
"# Get statistical sumaries\nfueleconomy_df.describe()",
"_____no_output_____"
],
[
"# summarise data\nfueleconomy_df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 100 entries, 0 to 99\nData columns (total 2 columns):\nHorse Power 100 non-null float64\nFuel Economy (MPG) 100 non-null float64\ndtypes: float64(2)\nmemory usage: 1.6 KB\n"
]
],
[
[
"# STEP#3: VISUALIZE DATASET",
"_____no_output_____"
]
],
[
[
"fueleconomy_df.head(4)",
"_____no_output_____"
],
[
"# Visualise the data\n# Observe the negative relationship\nsns.jointplot(x = 'Horse Power', y = 'Fuel Economy (MPG)', data = fueleconomy_df)",
"_____no_output_____"
],
[
"sns.jointplot(x = 'Fuel Economy (MPG)', y = 'Horse Power', data = fueleconomy_df)",
"_____no_output_____"
],
[
"sns.pairplot(fueleconomy_df)",
"_____no_output_____"
],
[
"# Visualise with lmplot x = 'Horse Power', vs y = 'Fuel Economy (MPG)'\nsns.lmplot(x = 'Horse Power', y = 'Fuel Economy (MPG)', data = fueleconomy_df)",
"_____no_output_____"
],
[
"# Visualise with lmplot x = 'Fuel Economy (MPG)', vs y = 'Horse Power'\nsns.lmplot(x = 'Fuel Economy (MPG)', y = 'Horse Power', data = fueleconomy_df)",
"_____no_output_____"
]
],
[
[
"# STEP#4: CREATE TESTING AND TRAINING DATASET",
"_____no_output_____"
]
],
[
[
"X = fueleconomy_df[['Horse Power']]",
"_____no_output_____"
],
[
"y = fueleconomy_df['Fuel Economy (MPG)']",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"# Shape of X\nX.shape",
"_____no_output_____"
],
[
"# Implement train, test, split\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3)",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"X_test.shape",
"_____no_output_____"
]
],
[
[
"# STEP#5: TRAIN THE MODEL",
"_____no_output_____"
]
],
[
[
"X_train.shape",
"_____no_output_____"
],
[
"X_test.shape",
"_____no_output_____"
],
[
"# Import relevant modules\nfrom sklearn.linear_model import LinearRegression\n\n# Instantiate a regressor\nregressor = LinearRegression(fit_intercept = True)\n\n# fit the model\nregressor.fit(X_train, y_train)",
"_____no_output_____"
],
[
"# obtain the parameters\nprint('Linear Model Coeff (m):', regressor.coef_)\nprint('Linear Model Coeff (b):', regressor.intercept_)",
"Linear Model Coeff (m): [-0.07045156]\nLinear Model Coeff (b): 38.041238126646476\n"
]
],
[
[
"# STEP#6: TEST THE MODEL ",
"_____no_output_____"
]
],
[
[
"# Passing along our testing data to the regressor\ny_predict = regressor.predict(X_test)\ny_predict",
"_____no_output_____"
],
[
"# Comparing to y-test, which is the true value\ny_test",
"_____no_output_____"
],
[
"# Visualise the data\nplt.scatter(X_train, y_train, color = 'gray')\nplt.plot(X_train, regressor.predict(X_train), color = 'blue')\nplt.xlabel('Horse Power (HP)')\nplt.ylabel('MPG')\nplt.title('HP vs. MPG (Training Set)')",
"_____no_output_____"
],
[
"plt.scatter(X_test, y_test, color = 'gray')\nplt.plot(X_test, regressor.predict(X_test), color = 'blue')\nplt.xlabel('Horse Power (HP)')\nplt.ylabel('MPG')\nplt.title('HP vs. MPG (Testing Set)')",
"_____no_output_____"
],
[
"# Predicting MPG based on a given Horse Power\nHP = 500\nMPG = regressor.predict(HP)\nMPG",
"_____no_output_____"
],
[
"HP = int(input(\"What Horse Power Do you want to Predict?\" ))\nMPG = regressor.predict(HP)\ntwoSigFigs = round(HP, 2)\nnumToString = str(twoSigFigs)\nprint (\"The Fuel Consumption (MPG) \" + numToString + \"units.\")",
"_____no_output_____"
]
],
[
[
"# EXCELLENT JOB! NOW YOU BECAME EXPERT IN SIMPLE LINEAR REGRESSION",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a46245de351cc783115973ef69fee3356191457
| 535,439 |
ipynb
|
Jupyter Notebook
|
decommissioned/02_Algorithms_0.2.ipynb
|
mdalvi/club-mahindra-data-olympics
|
92dc9f431c4b9c4c4e4d5f8510a703301b0d3137
|
[
"MIT"
] | 2 |
2020-05-18T20:02:15.000Z
|
2021-01-19T14:08:10.000Z
|
decommissioned/02_Algorithms_0.2.ipynb
|
mdalvi/club-mahindra-data-olympics
|
92dc9f431c4b9c4c4e4d5f8510a703301b0d3137
|
[
"MIT"
] | null | null | null |
decommissioned/02_Algorithms_0.2.ipynb
|
mdalvi/club-mahindra-data-olympics
|
92dc9f431c4b9c4c4e4d5f8510a703301b0d3137
|
[
"MIT"
] | 1 |
2019-06-01T04:50:38.000Z
|
2019-06-01T04:50:38.000Z
| 466.410279 | 242,532 | 0.933595 |
[
[
[
"import os\n\nimport numpy as np\nimport pandas as pd\n\nimport matplotlib.pyplot as plt\n%matplotlib inline\nimport seaborn as sns\nsns.set_style(\"whitegrid\", {'axes.grid' : False})\n\nimport joblib\n\nimport catboost\nimport xgboost as xgb\nimport lightgbm as lgb\n\nfrom category_encoders import BinaryEncoder\n\nfrom sklearn.metrics import mean_squared_error\nfrom sklearn.ensemble import ExtraTreesRegressor\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.model_selection import train_test_split\n\nfrom sklearn.preprocessing import FunctionTransformer",
"_____no_output_____"
],
[
"def run_lgbm(X_train, X_test, y_train, y_test, feature_names, categorical_features='auto', model_params=None, fit_params=None, seed=21):\n\n X_train_GBM = lgb.Dataset(X_train, label=y_train, feature_name=feature_names, categorical_feature=categorical_features, free_raw_data=False)\n X_test_GBM = lgb.Dataset(X_test, label=y_test, reference=X_train_GBM, feature_name=feature_names, free_raw_data=False)\n \n if model_params is None:\n model_params = {'seed': seed, 'num_threads': 16, 'objective':'root_mean_squared_error', \n 'metric': ['root_mean_squared_error'] }\n \n if fit_params is None:\n fit_params = {'verbose_eval': True, 'num_boost_round': 300, 'valid_sets': [X_test_GBM], \n 'early_stopping_rounds': 30,'categorical_feature': categorical_features, 'feature_name': feature_names}\n \n model = lgb.train(model_params, X_train_GBM, **fit_params)\n y_pred = model.predict(X_test, model.best_iteration)\n return model, y_pred, mean_squared_error(y_test, y_pred)\n\n\ndef run_lr(X_train, X_test, y_train, y_test, model_params=None):\n \n if model_params is None:\n model_params = {'n_jobs': 16}\n \n model = LinearRegression(**model_params)\n model.fit(X_train, y_train)\n y_pred = model.predict(X_test)\n return model, y_pred, mean_squared_error(y_test, y_pred)\n\ndef run_etr(X_train, X_test, y_train, y_test, model_params=None, seed=21):\n \n if model_params is None:\n model_params = {'verbose': 1, 'n_estimators': 300, 'criterion': 'mse', 'n_jobs': 16, 'random_state': seed}\n \n model = ExtraTreesRegressor(**model_params)\n model.fit(X_train, y_train)\n y_pred = model.predict(X_test)\n return model, y_pred, mean_squared_error(y_test, y_pred)\n\ndef run_xgb(X_train, X_test, y_train, y_test, feature_names, model_params=None, fit_params=None, seed=21):\n \n dtrain = xgb.DMatrix(X_train, y_train, feature_names=feature_names)\n dtest = xgb.DMatrix(X_test, y_test, feature_names=feature_names)\n \n if model_params is None:\n model_params = {'booster': 'gbtree', 'nthread': 16, 'objective': 'reg:linear', 'eval_metric': 'rmse', 'seed': seed, \n 'verbosity': 1}\n \n if fit_params is None:\n fit_params = {'num_boost_round': 300, 'evals': [(dtest, 'eval')], 'early_stopping_rounds': 30}\n \n model = xgb.train(model_params, dtrain, **fit_params)\n y_pred = model.predict(dtest)\n return model, y_pred, mean_squared_error(y_test, y_pred)\n\ndef run_catb(X_train, X_test, y_train, y_test, feature_names, cat_features=None, model_params=None, fit_params=None, predict_params=None, seed=21):\n \n train_pool = catboost.Pool(X_train, y_train, cat_features=cat_features)\n test_pool = catboost.Pool(X_test, y_test, cat_features=cat_features)\n\n if model_params is None:\n model_params = {'n_estimators': 300, 'thread_count': 16, 'loss_function': 'RMSE', 'eval_metric': 'RMSE', \n 'random_state': seed, 'verbose': True}\n \n if fit_params is None:\n fit_params = {'use_best_model': True, 'eval_set': test_pool}\n \n if predict_params is None:\n predict_params = {'thread_count': 16}\n \n model = catboost.CatBoostRegressor(**model_params)\n model.fit(train_pool, **fit_params)\n y_pred = model.predict(test_pool, **predict_params)\n return model, y_pred, mean_squared_error(y_test, y_pred)",
"_____no_output_____"
],
[
"df_train_dataset = pd.read_pickle('data/df/df_train_dataset.pkl')\ndf_validation_dataset = pd.read_pickle('data/df/df_validation_dataset.pkl')",
"_____no_output_____"
],
[
"continuous_features = joblib.load('data/iterables/continuous_features.joblib')\ncategorical_features = joblib.load('data/iterables/categorical_features.joblib')\ncategorical_features_encoded = joblib.load('data/iterables/categorical_features_encoded.joblib')\ntarget_features = joblib.load('data/iterables/target_features.joblib')\ntarget_transformer = joblib.load('models/preprocessing/target_transformer.joblib')",
"_____no_output_____"
],
[
"df_train_dataset.shape, df_validation_dataset.shape",
"_____no_output_____"
],
[
"X = df_train_dataset[categorical_features_encoded + continuous_features]\ny = df_train_dataset[target_features].values.flatten()\nprint(X.shape, y.shape)",
"(338192, 244) (338192,)\n"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, shuffle=True, random_state=10)\n\n# https://github.com/scikit-learn/scikit-learn/issues/8723\nX_train = X_train.copy()\nX_test = X_test.copy()\n\nprint(X_train.shape, X_test.shape, y_train.shape, y_test.shape)",
"(270553, 244) (67639, 244) (270553,) (67639,)\n"
],
[
"X_train.reset_index(inplace=True, drop=True)\nX_test.reset_index(inplace=True, drop=True)",
"_____no_output_____"
]
],
[
[
"## Linear reg",
"_____no_output_____"
]
],
[
[
"reg_linear, y_pred, score = run_lr(X_train, X_test, y_train, y_test)\nprint('mse', score, 'rmse', score ** .5)",
"mse 0.015624353968690895 rmse 0.12499741584805221\n"
],
[
"y_pred_val = reg_linear.predict(df_validation_dataset[categorical_features_encoded + continuous_features].values)\ny_pred_val = target_transformer.inverse_transform(np.expand_dims(y_pred_val, axis=1))",
"_____no_output_____"
]
],
[
[
"## Xgb",
"_____no_output_____"
]
],
[
[
"reg_xgb, y_pred, score = run_xgb(X_train, X_test, y_train, y_test, feature_names=categorical_features_encoded + continuous_features)\nprint('mse', score, 'rmse', score ** .5)",
"[0]\teval-rmse:1.16798\nWill train until eval-rmse hasn't improved in 30 rounds.\n[1]\teval-rmse:0.822731\n[2]\teval-rmse:0.583056\n[3]\teval-rmse:0.418018\n[4]\teval-rmse:0.306134\n[5]\teval-rmse:0.232302\n[6]\teval-rmse:0.185548\n[7]\teval-rmse:0.157575\n[8]\teval-rmse:0.141769\n[9]\teval-rmse:0.133266\n[10]\teval-rmse:0.128829\n[11]\teval-rmse:0.12656\n[12]\teval-rmse:0.125394\n[13]\teval-rmse:0.124782\n[14]\teval-rmse:0.12442\n[15]\teval-rmse:0.124222\n[16]\teval-rmse:0.124115\n[17]\teval-rmse:0.124053\n[18]\teval-rmse:0.12399\n[19]\teval-rmse:0.12397\n[20]\teval-rmse:0.123947\n[21]\teval-rmse:0.123903\n[22]\teval-rmse:0.12387\n[23]\teval-rmse:0.123855\n[24]\teval-rmse:0.123854\n[25]\teval-rmse:0.123834\n[26]\teval-rmse:0.123821\n[27]\teval-rmse:0.123816\n[28]\teval-rmse:0.123792\n[29]\teval-rmse:0.123766\n[30]\teval-rmse:0.123752\n[31]\teval-rmse:0.123755\n[32]\teval-rmse:0.123754\n[33]\teval-rmse:0.12376\n[34]\teval-rmse:0.123769\n[35]\teval-rmse:0.12378\n[36]\teval-rmse:0.123785\n[37]\teval-rmse:0.123786\n[38]\teval-rmse:0.123778\n[39]\teval-rmse:0.123763\n[40]\teval-rmse:0.123768\n[41]\teval-rmse:0.123783\n[42]\teval-rmse:0.123766\n[43]\teval-rmse:0.123771\n[44]\teval-rmse:0.123756\n[45]\teval-rmse:0.123756\n[46]\teval-rmse:0.123757\n[47]\teval-rmse:0.123746\n[48]\teval-rmse:0.123777\n[49]\teval-rmse:0.123787\n[50]\teval-rmse:0.123783\n[51]\teval-rmse:0.123796\n[52]\teval-rmse:0.123789\n[53]\teval-rmse:0.123787\n[54]\teval-rmse:0.123797\n[55]\teval-rmse:0.123795\n[56]\teval-rmse:0.123798\n[57]\teval-rmse:0.12379\n[58]\teval-rmse:0.123787\n[59]\teval-rmse:0.123782\n[60]\teval-rmse:0.123808\n[61]\teval-rmse:0.123813\n[62]\teval-rmse:0.123812\n[63]\teval-rmse:0.123817\n[64]\teval-rmse:0.123818\n[65]\teval-rmse:0.12382\n[66]\teval-rmse:0.123816\n[67]\teval-rmse:0.123814\n[68]\teval-rmse:0.123819\n[69]\teval-rmse:0.123824\n[70]\teval-rmse:0.123835\n[71]\teval-rmse:0.12383\n[72]\teval-rmse:0.123821\n[73]\teval-rmse:0.123834\n[74]\teval-rmse:0.123841\n[75]\teval-rmse:0.123842\n[76]\teval-rmse:0.123847\n[77]\teval-rmse:0.123844\nStopping. Best iteration:\n[47]\teval-rmse:0.123746\n\nmse 0.015337382945193302 rmse 0.12384418817689145\n"
],
[
"d_val = xgb.DMatrix(df_validation_dataset[categorical_features_encoded + continuous_features].values, feature_names=categorical_features_encoded + continuous_features)\ny_pred_val = reg_xgb.predict(d_val)\ny_pred_val = target_transformer.inverse_transform(np.expand_dims(y_pred_val, axis=1))",
"_____no_output_____"
],
[
"df_validation_dataset[target_features] = y_pred_val\ndf_validation_dataset[['reservation_id', 'amount_spent_per_room_night_scaled']].to_csv('submission.csv', index=False)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(nrows=1, ncols=1)\nfig.set_size_inches(24, 24)\nxgb.plot_importance(reg_xgb, ax=ax, max_num_features=100, height=0.5);",
"_____no_output_____"
]
],
[
[
"## Lgbm",
"_____no_output_____"
]
],
[
[
"df_train_dataset = pd.read_pickle('data/df/df_train_dataset.pkl')\ndf_validation_dataset = pd.read_pickle('data/df/df_validation_dataset.pkl')",
"_____no_output_____"
],
[
"continuous_features = joblib.load('data/iterables/continuous_features.joblib')\ncategorical_features = joblib.load('data/iterables/categorical_features.joblib')\ntarget_features = joblib.load('data/iterables/target_features.joblib')\ntarget_transformer = joblib.load('models/preprocessing/target_transformer.joblib')",
"_____no_output_____"
],
[
"df_train_dataset.shape, df_validation_dataset.shape",
"_____no_output_____"
],
[
"X = df_train_dataset[categorical_features + continuous_features]\ny = df_train_dataset[target_features].values.flatten()\nprint(X.shape, y.shape)",
"(338192, 107) (338192,)\n"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, test_size=0.2, shuffle=True, random_state=10)\n\n# https://github.com/scikit-learn/scikit-learn/issues/8723\nX_train = X_train.copy()\nX_test = X_test.copy()\n\nprint(X_train.shape, X_test.shape, y_train.shape, y_test.shape)",
"(270553, 107) (67639, 107) (270553,) (67639,)\n"
],
[
"X_train.reset_index(inplace=True, drop=True)\nX_test.reset_index(inplace=True, drop=True)",
"_____no_output_____"
],
[
"feature_names = categorical_features + continuous_features\nreg_lgbm, y_pred, score = run_lgbm(X_train, X_test, y_train, y_test, feature_names, categorical_features)\nprint('mse', score, 'rmse', score ** .5)",
"/home/ec2-user/anaconda3/lib/python3.6/site-packages/lightgbm/basic.py:1209: UserWarning: categorical_feature in Dataset is overridden.\nNew categorical_feature is ['booking_type_code', 'cat_are_all_travelling', 'cat_booking_date_day', 'cat_booking_date_is_weekend', 'cat_booking_date_month', 'cat_booking_date_week', 'cat_booking_date_weekday', 'cat_booking_date_year', 'cat_cf_is_cluster_changed', 'cat_cf_is_resort_changed', 'cat_cf_is_resort_region_changed', 'cat_cf_is_resort_type_changed', 'cat_cf_is_room_type_booked_changed', 'cat_cf_is_season_holidayed_changed', 'cat_cf_is_state_resort_changed', 'cat_checkin_date_day', 'cat_checkin_date_is_weekend', 'cat_checkin_date_month', 'cat_checkin_date_week', 'cat_checkin_date_weekday', 'cat_checkin_date_year', 'cat_checkout_date_day', 'cat_checkout_date_is_weekend', 'cat_checkout_date_month', 'cat_checkout_date_week', 'cat_checkout_date_weekday', 'cat_checkout_date_year', 'cat_has_children', 'cat_stay_nights_diff', 'channel_code', 'cluster_code', 'main_product_code', 'member_age_buckets', 'memberid', 'persontravellingid', 'reservationstatusid_code', 'resort_id', 'resort_region_code', 'resort_type_code', 'room_type_booked_code', 'season_holidayed_code', 'state_code_residence', 'state_code_resort']\n 'New categorical_feature is {}'.format(sorted(list(categorical_feature))))\n/home/ec2-user/anaconda3/lib/python3.6/site-packages/lightgbm/basic.py:762: UserWarning: categorical_feature in param dict is overridden.\n warnings.warn('categorical_feature in param dict is overridden.')\n"
],
[
"y_pred_val = reg_lgbm.predict(df_validation_dataset[categorical_features + continuous_features].values, reg_lgbm.best_iteration)\ny_pred_val = target_transformer.inverse_transform(np.expand_dims(y_pred_val, axis=1))",
"_____no_output_____"
],
[
"df_validation_dataset[target_features] = y_pred_val\ndf_validation_dataset[['reservation_id', 'amount_spent_per_room_night_scaled']].to_csv('submission.csv', index=False)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(nrows=1, ncols=1)\nfig.set_size_inches(24, 24)\nlgb.plot_importance(reg_lgbm, ax=ax, height=0.5, max_num_features=100);",
"_____no_output_____"
]
],
[
[
"## Catboost",
"_____no_output_____"
]
],
[
[
"feature_names = categorical_features + continuous_features\ncat_features = [i for i, c in enumerate(feature_names) if c in categorical_features]\nreg_catb, y_pred, score = run_catb(X_train, X_test, y_train, y_test, feature_names, cat_features)\nprint('mse', score, 'rmse', score ** .5)",
"0:\tlearn: 2.0969338\ttest: 2.0957568\tbest: 2.0957568 (0)\ttotal: 144ms\tremaining: 43.2s\n1:\tlearn: 2.0343070\ttest: 2.0331304\tbest: 2.0331304 (1)\ttotal: 343ms\tremaining: 51.2s\n2:\tlearn: 1.9735700\ttest: 1.9723949\tbest: 1.9723949 (2)\ttotal: 564ms\tremaining: 55.9s\n3:\tlearn: 1.9146573\ttest: 1.9134850\tbest: 1.9134850 (3)\ttotal: 699ms\tremaining: 51.7s\n4:\tlearn: 1.8575216\ttest: 1.8563512\tbest: 1.8563512 (4)\ttotal: 863ms\tremaining: 50.9s\n5:\tlearn: 1.8021070\ttest: 1.8009389\tbest: 1.8009389 (5)\ttotal: 882ms\tremaining: 43.2s\n6:\tlearn: 1.7483649\ttest: 1.7471992\tbest: 1.7471992 (6)\ttotal: 931ms\tremaining: 39s\n7:\tlearn: 1.6962399\ttest: 1.6950785\tbest: 1.6950785 (7)\ttotal: 1.14s\tremaining: 41.7s\n8:\tlearn: 1.6456931\ttest: 1.6445336\tbest: 1.6445336 (8)\ttotal: 1.21s\tremaining: 39s\n9:\tlearn: 1.5966731\ttest: 1.5954937\tbest: 1.5954937 (9)\ttotal: 1.37s\tremaining: 39.7s\n10:\tlearn: 1.5491282\ttest: 1.5479491\tbest: 1.5479491 (10)\ttotal: 1.56s\tremaining: 40.9s\n11:\tlearn: 1.5030256\ttest: 1.5018493\tbest: 1.5018493 (11)\ttotal: 1.57s\tremaining: 37.8s\n12:\tlearn: 1.4583178\ttest: 1.4571444\tbest: 1.4571444 (12)\ttotal: 1.62s\tremaining: 35.9s\n13:\tlearn: 1.4149656\ttest: 1.4137945\tbest: 1.4137945 (13)\ttotal: 1.78s\tremaining: 36.4s\n14:\tlearn: 1.3729224\ttest: 1.3717542\tbest: 1.3717542 (14)\ttotal: 1.95s\tremaining: 37.1s\n15:\tlearn: 1.3321554\ttest: 1.3309902\tbest: 1.3309902 (15)\ttotal: 2.19s\tremaining: 38.8s\n16:\tlearn: 1.2926247\ttest: 1.2914518\tbest: 1.2914518 (16)\ttotal: 2.37s\tremaining: 39.4s\n17:\tlearn: 1.2542887\ttest: 1.2531204\tbest: 1.2531204 (17)\ttotal: 2.48s\tremaining: 38.8s\n18:\tlearn: 1.2171209\ttest: 1.2159547\tbest: 1.2159547 (18)\ttotal: 2.69s\tremaining: 39.8s\n19:\tlearn: 1.1810755\ttest: 1.1799106\tbest: 1.1799106 (19)\ttotal: 2.92s\tremaining: 40.9s\n20:\tlearn: 1.1461285\ttest: 1.1449675\tbest: 1.1449675 (20)\ttotal: 2.94s\tremaining: 39.1s\n21:\tlearn: 1.1122410\ttest: 1.1110776\tbest: 1.1110776 (21)\ttotal: 3.16s\tremaining: 39.9s\n22:\tlearn: 1.0793874\ttest: 1.0782333\tbest: 1.0782333 (22)\ttotal: 3.38s\tremaining: 40.8s\n23:\tlearn: 1.0475360\ttest: 1.0463860\tbest: 1.0463860 (23)\ttotal: 3.44s\tremaining: 39.6s\n24:\tlearn: 1.0166573\ttest: 1.0155113\tbest: 1.0155113 (24)\ttotal: 3.67s\tremaining: 40.4s\n25:\tlearn: 0.9867209\ttest: 0.9855794\tbest: 0.9855794 (25)\ttotal: 3.79s\tremaining: 40s\n26:\tlearn: 0.9576989\ttest: 0.9565619\tbest: 0.9565619 (26)\ttotal: 3.85s\tremaining: 38.9s\n27:\tlearn: 0.9295702\ttest: 0.9284357\tbest: 0.9284357 (27)\ttotal: 4.05s\tremaining: 39.4s\n28:\tlearn: 0.9022981\ttest: 0.9011686\tbest: 0.9011686 (28)\ttotal: 4.08s\tremaining: 38.1s\n29:\tlearn: 0.8758684\ttest: 0.8747365\tbest: 0.8747365 (29)\ttotal: 4.3s\tremaining: 38.7s\n30:\tlearn: 0.8502453\ttest: 0.8491188\tbest: 0.8491188 (30)\ttotal: 4.35s\tremaining: 37.7s\n31:\tlearn: 0.8254004\ttest: 0.8242775\tbest: 0.8242775 (31)\ttotal: 4.56s\tremaining: 38.2s\n32:\tlearn: 0.8013298\ttest: 0.8002133\tbest: 0.8002133 (32)\ttotal: 4.71s\tremaining: 38.1s\n33:\tlearn: 0.7780023\ttest: 0.7768908\tbest: 0.7768908 (33)\ttotal: 4.93s\tremaining: 38.6s\n34:\tlearn: 0.7553958\ttest: 0.7542904\tbest: 0.7542904 (34)\ttotal: 4.98s\tremaining: 37.7s\n35:\tlearn: 0.7334884\ttest: 0.7323846\tbest: 0.7323846 (35)\ttotal: 5.21s\tremaining: 38.2s\n36:\tlearn: 0.7122573\ttest: 0.7111580\tbest: 0.7111580 (36)\ttotal: 5.44s\tremaining: 38.7s\n37:\tlearn: 0.6916816\ttest: 0.6905950\tbest: 0.6905950 (37)\ttotal: 5.66s\tremaining: 39s\n38:\tlearn: 0.6717536\ttest: 0.6706737\tbest: 0.6706737 (38)\ttotal: 5.71s\tremaining: 38.2s\n39:\tlearn: 0.6524195\ttest: 0.6513491\tbest: 0.6513491 (39)\ttotal: 5.85s\tremaining: 38s\n40:\tlearn: 0.6337177\ttest: 0.6326547\tbest: 0.6326547 (40)\ttotal: 5.93s\tremaining: 37.5s\n41:\tlearn: 0.6155691\ttest: 0.6145170\tbest: 0.6145170 (41)\ttotal: 6.18s\tremaining: 37.9s\n42:\tlearn: 0.5980130\ttest: 0.5969703\tbest: 0.5969703 (42)\ttotal: 6.35s\tremaining: 37.9s\n43:\tlearn: 0.5810150\ttest: 0.5799823\tbest: 0.5799823 (43)\ttotal: 6.55s\tremaining: 38.1s\n44:\tlearn: 0.5645583\ttest: 0.5635342\tbest: 0.5635342 (44)\ttotal: 6.57s\tremaining: 37.2s\n45:\tlearn: 0.5486237\ttest: 0.5476087\tbest: 0.5476087 (45)\ttotal: 6.71s\tremaining: 37s\n46:\tlearn: 0.5331921\ttest: 0.5321873\tbest: 0.5321873 (46)\ttotal: 6.76s\tremaining: 36.4s\n47:\tlearn: 0.5182575\ttest: 0.5172611\tbest: 0.5172611 (47)\ttotal: 6.98s\tremaining: 36.6s\n48:\tlearn: 0.5038006\ttest: 0.5028141\tbest: 0.5028141 (48)\ttotal: 7s\tremaining: 35.8s\n49:\tlearn: 0.4897816\ttest: 0.4888071\tbest: 0.4888071 (49)\ttotal: 7.18s\tremaining: 35.9s\n50:\tlearn: 0.4762405\ttest: 0.4752766\tbest: 0.4752766 (50)\ttotal: 7.2s\tremaining: 35.2s\n51:\tlearn: 0.4631386\ttest: 0.4621855\tbest: 0.4621855 (51)\ttotal: 7.26s\tremaining: 34.6s\n52:\tlearn: 0.4504407\ttest: 0.4494991\tbest: 0.4494991 (52)\ttotal: 7.51s\tremaining: 35s\n53:\tlearn: 0.4381704\ttest: 0.4372429\tbest: 0.4372429 (53)\ttotal: 7.74s\tremaining: 35.2s\n54:\tlearn: 0.4263111\ttest: 0.4253954\tbest: 0.4253954 (54)\ttotal: 7.86s\tremaining: 35s\n55:\tlearn: 0.4148135\ttest: 0.4139108\tbest: 0.4139108 (55)\ttotal: 8.07s\tremaining: 35.2s\n56:\tlearn: 0.4036824\ttest: 0.4028011\tbest: 0.4028011 (56)\ttotal: 8.26s\tremaining: 35.2s\n57:\tlearn: 0.3929582\ttest: 0.3920898\tbest: 0.3920898 (57)\ttotal: 8.4s\tremaining: 35s\n58:\tlearn: 0.3825667\ttest: 0.3817134\tbest: 0.3817134 (58)\ttotal: 8.45s\tremaining: 34.5s\n59:\tlearn: 0.3725080\ttest: 0.3716717\tbest: 0.3716717 (59)\ttotal: 8.67s\tremaining: 34.7s\n60:\tlearn: 0.3627830\ttest: 0.3619658\tbest: 0.3619658 (60)\ttotal: 8.91s\tremaining: 34.9s\n61:\tlearn: 0.3534287\ttest: 0.3526265\tbest: 0.3526265 (61)\ttotal: 8.96s\tremaining: 34.4s\n62:\tlearn: 0.3443442\ttest: 0.3435530\tbest: 0.3435530 (62)\ttotal: 9.17s\tremaining: 34.5s\n63:\tlearn: 0.3355556\ttest: 0.3347849\tbest: 0.3347849 (63)\ttotal: 9.34s\tremaining: 34.5s\n64:\tlearn: 0.3270923\ttest: 0.3263409\tbest: 0.3263409 (64)\ttotal: 9.48s\tremaining: 34.3s\n65:\tlearn: 0.3189090\ttest: 0.3181765\tbest: 0.3181765 (65)\ttotal: 9.7s\tremaining: 34.4s\n66:\tlearn: 0.3110289\ttest: 0.3103005\tbest: 0.3103005 (66)\ttotal: 9.91s\tremaining: 34.5s\n67:\tlearn: 0.3034400\ttest: 0.3027292\tbest: 0.3027292 (67)\ttotal: 10.1s\tremaining: 34.3s\n68:\tlearn: 0.2961227\ttest: 0.2954303\tbest: 0.2954303 (68)\ttotal: 10.3s\tremaining: 34.4s\n69:\tlearn: 0.2890371\ttest: 0.2883486\tbest: 0.2883486 (69)\ttotal: 10.5s\tremaining: 34.6s\n70:\tlearn: 0.2821929\ttest: 0.2815339\tbest: 0.2815339 (70)\ttotal: 10.6s\tremaining: 34.3s\n71:\tlearn: 0.2755766\ttest: 0.2749321\tbest: 0.2749321 (71)\ttotal: 10.9s\tremaining: 34.4s\n72:\tlearn: 0.2692179\ttest: 0.2686040\tbest: 0.2686040 (72)\ttotal: 11.1s\tremaining: 34.5s\n73:\tlearn: 0.2630757\ttest: 0.2625090\tbest: 0.2625090 (73)\ttotal: 11.3s\tremaining: 34.6s\n74:\tlearn: 0.2572476\ttest: 0.2567003\tbest: 0.2567003 (74)\ttotal: 11.3s\tremaining: 34s\n75:\tlearn: 0.2515583\ttest: 0.2510396\tbest: 0.2510396 (75)\ttotal: 11.6s\tremaining: 34.1s\n76:\tlearn: 0.2461179\ttest: 0.2456206\tbest: 0.2456206 (76)\ttotal: 11.6s\tremaining: 33.7s\n77:\tlearn: 0.2408297\ttest: 0.2403745\tbest: 0.2403745 (77)\ttotal: 11.8s\tremaining: 33.7s\n78:\tlearn: 0.2358435\ttest: 0.2354086\tbest: 0.2354086 (78)\ttotal: 11.9s\tremaining: 33.2s\n79:\tlearn: 0.2310023\ttest: 0.2305840\tbest: 0.2305840 (79)\ttotal: 12.1s\tremaining: 33.2s\n80:\tlearn: 0.2263217\ttest: 0.2259300\tbest: 0.2259300 (80)\ttotal: 12.3s\tremaining: 33.3s\n81:\tlearn: 0.2218009\ttest: 0.2214254\tbest: 0.2214254 (81)\ttotal: 12.5s\tremaining: 33.3s\n82:\tlearn: 0.2174737\ttest: 0.2171319\tbest: 0.2171319 (82)\ttotal: 12.7s\tremaining: 33.3s\n83:\tlearn: 0.2133008\ttest: 0.2129859\tbest: 0.2129859 (83)\ttotal: 13s\tremaining: 33.3s\n84:\tlearn: 0.2093541\ttest: 0.2090594\tbest: 0.2090594 (84)\ttotal: 13.2s\tremaining: 33.3s\n85:\tlearn: 0.2055330\ttest: 0.2052648\tbest: 0.2052648 (85)\ttotal: 13.4s\tremaining: 33.4s\n86:\tlearn: 0.2018782\ttest: 0.2016342\tbest: 0.2016342 (86)\ttotal: 13.7s\tremaining: 33.5s\n87:\tlearn: 0.1983932\ttest: 0.1981821\tbest: 0.1981821 (87)\ttotal: 13.9s\tremaining: 33.5s\n88:\tlearn: 0.1950389\ttest: 0.1948512\tbest: 0.1948512 (88)\ttotal: 14s\tremaining: 33.3s\n89:\tlearn: 0.1918002\ttest: 0.1916282\tbest: 0.1916282 (89)\ttotal: 14.3s\tremaining: 33.3s\n90:\tlearn: 0.1887052\ttest: 0.1885573\tbest: 0.1885573 (90)\ttotal: 14.5s\tremaining: 33.3s\n91:\tlearn: 0.1857734\ttest: 0.1856426\tbest: 0.1856426 (91)\ttotal: 14.7s\tremaining: 33.2s\n92:\tlearn: 0.1829621\ttest: 0.1828567\tbest: 0.1828567 (92)\ttotal: 14.9s\tremaining: 33.2s\n93:\tlearn: 0.1802510\ttest: 0.1801653\tbest: 0.1801653 (93)\ttotal: 15.2s\tremaining: 33.2s\n94:\tlearn: 0.1777452\ttest: 0.1776816\tbest: 0.1776816 (94)\ttotal: 15.2s\tremaining: 32.8s\n"
],
[
"feature_names = categorical_features + continuous_features\ncat_features = [i for i, c in enumerate(feature_names) if c in categorical_features]\nval_pool = catboost.Pool(df_validation_dataset[categorical_features + continuous_features].values, feature_names=feature_names, cat_features=cat_features)\ny_pred_val = reg_catb.predict(val_pool)\ny_pred_val = target_transformer.inverse_transform(np.expand_dims(y_pred_val, axis=1))",
"_____no_output_____"
],
[
"df_validation_dataset[target_features] = y_pred_val\ndf_validation_dataset[['reservation_id', 'amount_spent_per_room_night_scaled']].to_csv('submission.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a46356fecdc50792fd2e494687dd2275978981c
| 19,190 |
ipynb
|
Jupyter Notebook
|
demo.ipynb
|
mahabubul-alam/QAOA_Compiler
|
7480ff7740611d3d3ebb5da170b91e98254173a4
|
[
"Apache-2.0"
] | null | null | null |
demo.ipynb
|
mahabubul-alam/QAOA_Compiler
|
7480ff7740611d3d3ebb5da170b91e98254173a4
|
[
"Apache-2.0"
] | null | null | null |
demo.ipynb
|
mahabubul-alam/QAOA_Compiler
|
7480ff7740611d3d3ebb5da170b91e98254173a4
|
[
"Apache-2.0"
] | 1 |
2021-07-09T03:13:28.000Z
|
2021-07-09T03:13:28.000Z
| 41.092077 | 3,096 | 0.567483 |
[
[
[
"## Tutorial on QAOA Compiler\n\nThis tutorial shows how to use the QAOA compiler for QAOA circuit compilation and optimization. (https://github.com/mahabubul-alam/QAOA-Compiler).",
"_____no_output_____"
],
[
"### Inputs to the QAOA Compiler\nThe compiler takes three json files as the inputs. The files hold the following information:\n* ZZ-interactions and their corresponding coefficients in the problem Hamiltonian (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/examples/QAOA_circ.json)\n* Target hardware supported gates and corresponding reliabilities (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/examples/QC.json)\n* Configurations for compilation (e.g., target p-value, routing method, random seed, etc.) (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/examples/Config.json)",
"_____no_output_____"
],
[
"\n\nThe input ZZ-interactions json file content for the above graph MaxCut problem is shown below:\n\n```\n{\n \"(0, 2)\": \"-0.5\", // ZZ-interaction between the qubit pair (0, 2) with a coefficient of -0.5 \n \"(1, 2)\": \"-0.5\"\n}\n```\n\nA script is provided under utils (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/utils/construct_qaoa_circ_json.py) to generate this input json file for arbitrary unweighted graph.",
"_____no_output_____"
],
[
"The hardware json file must have the following information:\n* Supported single-qubit gates\n* Supported two-qubit gates\n* Reliabilities of the supported single-qubit operations\n* Reliabilities of the supported two-qubit operations <br>\n\nA json file's content for a hypothetical 3-qubit hardware is shown below:\n\n```\n{\n \"1Q\": [ //native single-qubit gates of the target hardware\n \"u3\"\n ],\n \"2Q\": [ //native two-qubit gate of the target hardware\n \"cx\"\n ],\n \"u3\": {\n \"0\": 0.991, //\"qubit\" : success probability of u3\n \"1\": 0.995,\n \"2\": 0.998\n }\n \"cx\": {\n \"(0,1)\": 0.96, //\"(qubit1,qubit2)\" : success probability of cx between qubit1, qubit2 (both directions)\n \"(1,2)\": 0.97,\n \"(2,0)\": 0.98,\n }\n}\n \n```\n\nA script is provided under utils (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/utils/construct_qc.py) to generate json files for the quantum processors from IBM.",
"_____no_output_____"
],
[
"The configuration json file should hold the following information:\n* Target backend compiler (currently supports qiskit)\n* Target p-value\n* Packing Limit (see https://www.microarch.org/micro53/papers/738300a215.pdf)\n* Target routing method (any routing method that are supported by the qiskit compiler, e.g., sabre, stochastic_swap, basic_swap, etc.)\n* Random seed for the qiskit transpiler\n* Chosen optimization level for the qiskit compiler (0~3)\n\nThe content of a sample configuration json file is shown below:\n\n```\n{\n \"Backend\" : \"qiskit\",\n \"Target_p\" : \"1\",\n \"Packing_Limit\" : \"10e10\",\n \"Route_Method\" : \"sabre\",\n \"Trans_Seed\" : \"0\",\n \"Opt_Level\" : \"3\"\n}\n```",
"_____no_output_____"
],
[
"### How to Run\n```\npython run.py -arg arg_val\n```\n* -device_json string (mandatory): Target device configuration file location. This file holds the information on basis gates, reliability, and allowed two-qubit operations. It has to be written in json format. An example can be found [here](https://github.com/mahabubul-alam/QAOA_Compiler/blob/main/examples/QC.json).\n\n* -circuit_json string (mandatory): Problem QAOA-circuit file location. This file holds the required ZZ interactions between various qubit-pairs to encode the cost hamiltonian. It has to be written in json format. An example can be found [here](https://github.com/mahabubul-alam/QAOA_Compiler/blob/main/examples/QAOA_circ.json).\n\n* -config_json string (mandatory): Compiler configuration file location. This file holds target p-level, and chosen packing limit, qiskit transpiler seed, optimization level, and routing method. It has to be written in json format. An example can be found [here](https://github.com/mahabubul-alam/QAOA_Compiler/blob/main/examples/Config.json).\n\n* -policy_compilation string: Chosen compilation policy. The current version supports the following policies: Instruction Parallelization-only ('IP'), Iterative Compilation ('IterC'), Incremental Compilation ('IC'), Variation-aware Incremental Compilation ('VIC'). The default value is 'IC'.\n\n* -target_IterC string: Minimization objective of Iterative Compilation. The current version supports the following minimization objectives: Circuit Depth ('D'), Native two-qubit gate-count ('GC_2Q'), Estimated Success Probability ('ESP'). The default value is 'GC_2Q'.\n\n* -initial_layout_method string: The chosen initial layout method. Currently supported methods: 'vqp', 'qaim', 'random'. The default method is 'qaim'.\n\n* -output_qasm_file_name string: File name to write the compiled parametric QAOA circuit. The output is written in qasm format. The default value is 'QAOA.qasm'. The output qasm files are written following this naming style: {Method(IP/IC/VIC/IterC)}_{output_qasm_file_name}.\n",
"_____no_output_____"
]
],
[
[
"!python run.py -device_json examples/QC.json -circuit_json examples/QAOA_circ.json -config_json examples/Config.json -policy_compilation VIC -initial_layout_method vqp",
"############################################################################\nVariation-aware Incremental Compilation (VIC) completed (initial layout: vqp)!\nQASM File Written: VIC_QAOA.qasm\n##################### Notes on the Output File #############################\n(naive) Depth: 130, gate-count(2Q): 227, ESP: 0.0019301743858659978\n(VIC) Depth: 69, gate-count(2Q): 151, ESP: 0.015510689327353987\nThe circuit is written with beta/gamma parameters at different p-lavels (https://arxiv.org/pdf/1411.4028.pdf)\nbX --> beta parameter at p=X\ngX --> gamma parameter at p=X (https://arxiv.org/pdf/1411.4028.pdf)\n############################################################################\n"
]
],
[
[
"### Output QAOA Circuits\n\nThe tool generates 3 QASM files:\n* The uncompiled circuit (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/uncompiled_QAOA.qasm)\n* Compiled QAOA circuit with conventinal approach (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/naive_compiled_QAOA.qasm)\n* Optimized QAOA circuit with chosen set of optimization policies (https://github.com/mahabubul-alam/QAOA-Compiler/blob/main/VIC_QAOA.qasm)\n\nA sample QASM file is shown below:",
"_____no_output_____"
]
],
[
[
"!cat VIC_QAOA.qasm",
"OPENQASM 2.0;\ninclude \"qelib1.inc\";\nqreg q[20];\ncreg c[12];\nh q[4];\nh q[2];\nh q[3];\nh q[14];\nh q[11];\nh q[7];\nh q[9];\nh q[16];\nh q[19];\nh q[10];\nh q[5];\nh q[17];\ncx q[4],q[7];\nu3(0,0,-1.0*g1) q[7];\ncx q[4],q[7];\ncx q[9],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[9],q[5];\ncx q[11],q[2];\nu3(0,0,-1.0*g1) q[2];\ncx q[11],q[2];\ncx q[3],q[14];\nu3(0,0,-1.0*g1) q[14];\ncx q[3],q[14];\ncx q[10],q[17];\nu3(0,0,-1.0*g1) q[17];\ncx q[10],q[17];\ncx q[16],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[16],q[19];\ncx q[3],q[7];\nu3(0,0,-1.0*g1) q[7];\ncx q[3],q[7];\ncx q[11],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[11],q[5];\ncx q[14],q[10];\nu3(0,0,-1.0*g1) q[10];\ncx q[14],q[10];\ncx q[9],q[16];\nu3(0,0,-1.0*g1) q[16];\ncx q[9],q[16];\ncx q[2],q[16];\ncx q[16],q[2];\ncx q[2],q[16];\ncx q[4],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[4],q[19];\ncx q[17],q[19];\ncx q[19],q[17];\ncx q[17],q[19];\ncx q[16],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[16],q[19];\ncx q[4],q[3];\nu3(0,0,-1.0*g1) q[3];\ncx q[4],q[3];\ncx q[11],q[2];\nu3(0,0,-1.0*g1) q[2];\ncx q[11],q[2];\ncx q[14],q[16];\nu3(0,0,-1.0*g1) q[16];\ncx q[14],q[16];\ncx q[9],q[16];\ncx q[16],q[9];\ncx q[9],q[16];\ncx q[17],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[17],q[5];\ncx q[10],q[19];\ncx q[19],q[10];\ncx q[10],q[19];\ncx q[16],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[16],q[19];\ncx q[4],q[2];\nu3(0,0,-1.0*g1) q[2];\ncx q[4],q[2];\ncx q[7],q[9];\nu3(0,0,-1.0*g1) q[9];\ncx q[7],q[9];\ncx q[14],q[16];\nu3(0,0,-1.0*g1) q[16];\ncx q[14],q[16];\ncx q[5],q[17];\ncx q[17],q[5];\ncx q[5],q[17];\ncx q[11],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[11],q[5];\ncx q[19],q[17];\nu3(0,0,-1.0*g1) q[17];\ncx q[19],q[17];\ncx q[14],q[10];\nu3(0,0,-1.0*g1) q[10];\ncx q[14],q[10];\ncx q[16],q[9];\nu3(0,0,-1.0*g1) q[9];\ncx q[16],q[9];\ncx q[7],q[9];\ncx q[9],q[7];\ncx q[7],q[9];\ncx q[9],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[9],q[5];\ncx q[4],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[4],q[19];\ncx q[3],q[4];\ncx q[4],q[3];\ncx q[3],q[4];\ncx q[4],q[2];\nu3(0,0,-1.0*g1) q[2];\ncx q[4],q[2];\ncx q[4],q[7];\nu3(0,0,-1.0*g1) q[7];\ncx q[4],q[7];\ncx q[9],q[2];\nu3(0,0,-1.0*g1) q[2];\ncx q[9],q[2];\ncx q[3],q[14];\nu3(0,0,-1.0*g1) q[14];\ncx q[3],q[14];\ncx q[9],q[16];\ncx q[16],q[9];\ncx q[9],q[16];\ncx q[9],q[5];\nu3(0,0,-1.0*g1) q[5];\ncx q[9],q[5];\ncx q[17],q[10];\nu3(0,0,-1.0*g1) q[10];\ncx q[17],q[10];\ncx q[5],q[11];\ncx q[11],q[5];\ncx q[5],q[11];\ncx q[5],q[9];\nu3(0,0,-1.0*g1) q[9];\ncx q[5],q[9];\ncx q[10],q[14];\ncx q[14],q[10];\ncx q[10],q[14];\ncx q[10],q[17];\nu3(0,0,-1.0*g1) q[17];\ncx q[10],q[17];\ncx q[16],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[16],q[19];\ncx q[2],q[16];\ncx q[16],q[2];\ncx q[2],q[16];\ncx q[16],q[14];\nu3(0,0,-1.0*g1) q[14];\ncx q[16],q[14];\ncx q[4],q[2];\ncx q[2],q[4];\ncx q[4],q[2];\ncx q[2],q[11];\nu3(0,0,-1.0*g1) q[11];\ncx q[2],q[11];\ncx q[2],q[9];\nu3(0,0,-1.0*g1) q[9];\ncx q[2],q[9];\ncx q[10],q[17];\ncx q[17],q[10];\ncx q[10],q[17];\ncx q[14],q[10];\ncx q[10],q[14];\ncx q[14],q[10];\ncx q[17],q[5];\ncx q[3],q[14];\nu3(0,0,-1.0*g1) q[14];\ncx q[3],q[14];\nu3(0,0,-1.0*g1) q[5];\ncx q[17],q[5];\ncx q[16],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[16],q[19];\ncx q[7],q[9];\ncx q[9],q[7];\ncx q[7],q[9];\ncx q[3],q[7];\nu3(0,0,-1.0*g1) q[7];\ncx q[3],q[7];\ncx q[16],q[14];\nu3(0,0,-1.0*g1) q[14];\ncx q[16],q[14];\ncx q[5],q[17];\ncx q[17],q[5];\ncx q[5],q[17];\ncx q[17],q[10];\nu3(0,0,-1.0*g1) q[10];\ncx q[17],q[10];\ncx q[5],q[11];\nu3(0,0,-1.0*g1) q[11];\ncx q[5],q[11];\ncx q[16],q[19];\ncx q[19],q[16];\ncx q[16],q[19];\ncx q[2],q[16];\nu3(0,0,-1.0*g1) q[16];\ncx q[2],q[16];\ncx q[3],q[4];\ncx q[4],q[3];\ncx q[3],q[4];\ncx q[17],q[19];\ncx q[19],q[17];\ncx q[17],q[19];\ncx q[4],q[19];\nu3(0,0,-1.0*g1) q[19];\ncx q[4],q[19];\nrx(b1) q[4];\nrx(b1) q[9];\nrx(b1) q[2];\nrx(b1) q[5];\nrx(b1) q[19];\nrx(b1) q[3];\nrx(b1) q[7];\nrx(b1) q[17];\nrx(b1) q[11];\nrx(b1) q[16];\nrx(b1) q[14];\nrx(b1) q[10];\nbarrier q[0],q[1],q[2],q[3],q[4],q[5],q[6],q[7],q[8],q[9],q[10],q[11],q[12],q[13],q[14],q[15],q[16],q[17],q[18],q[19];\nmeasure q[4] -> c[0];\nmeasure q[9] -> c[1];\nmeasure q[2] -> c[2];\nmeasure q[5] -> c[3];\nmeasure q[19] -> c[4];\nmeasure q[3] -> c[5];\nmeasure q[7] -> c[6];\nmeasure q[17] -> c[7];\nmeasure q[11] -> c[8];\nmeasure q[16] -> c[9];\nmeasure q[14] -> c[10];\nmeasure q[10] -> c[11];\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4635fd7dc7dbe4f4d54ae60a36cede856a1501
| 15,233 |
ipynb
|
Jupyter Notebook
|
notes/practice_1.ipynb
|
bdanver/machine_learning
|
f2dbc6344db29fcbe238cbb7f5efbd7caa957fce
|
[
"Apache-2.0"
] | null | null | null |
notes/practice_1.ipynb
|
bdanver/machine_learning
|
f2dbc6344db29fcbe238cbb7f5efbd7caa957fce
|
[
"Apache-2.0"
] | null | null | null |
notes/practice_1.ipynb
|
bdanver/machine_learning
|
f2dbc6344db29fcbe238cbb7f5efbd7caa957fce
|
[
"Apache-2.0"
] | null | null | null | 25.013136 | 93 | 0.378389 |
[
[
[
"miles = 1820\ngallons = 97\nmpg = miles / gallons\nprint(mpg)",
"18.762886597938145\n"
],
[
"print(mpg)",
"18.762886597938145\n"
]
],
[
[
"# Intro to Numpy \n## importing a library",
"_____no_output_____"
],
[
"as np = Is an alias. So that is what we are going to refer to numpy as",
"_____no_output_____"
]
],
[
[
"import numpy as np\ngert = np.array([1, 2, 3, 4])",
"_____no_output_____"
],
[
"gert",
"_____no_output_____"
],
[
"gert_2D = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])",
"_____no_output_____"
],
[
"gert_2D",
"_____no_output_____"
]
],
[
[
"## Other ways to create arrays",
"_____no_output_____"
]
],
[
[
"gumbo = [x for x in range(10)]",
"_____no_output_____"
],
[
"gumbo",
"_____no_output_____"
],
[
"gumbo_2D = [[x + y * 10 for x in range(10)] for y in range(10)]\ngumbo_2D",
"_____no_output_____"
]
],
[
[
"## In Numpy",
"_____no_output_____"
]
],
[
[
"## numpy is already imported, so don't need to repeat\nwonton = np.arange(100)\nwonton",
"_____no_output_____"
],
[
"wonton.reshape([10,10])",
"_____no_output_____"
],
[
"wonton[3]",
"_____no_output_____"
],
[
"gumbo_2D[7][2]",
"_____no_output_____"
]
],
[
[
"## Comparing Numpy and Python\n### Speed",
"_____no_output_____"
]
],
[
[
"%time pyT1 = [[x + y * 1000 for x in range(1000)] for y in range (1000)]",
"CPU times: user 97.5 ms, sys: 20.9 ms, total: 118 ms\nWall time: 120 ms\n"
],
[
"%time npT1 = np.arange(1000000).reshape((1000, 1000))",
"CPU times: user 2.81 ms, sys: 0 ns, total: 2.81 ms\nWall time: 2.36 ms\n"
]
],
[
[
"## Add 1 to each element\n## Python",
"_____no_output_____"
]
],
[
[
"## this is a 2D array \ndef add1():\n for i in range(5):\n for j in range(5):\n pyT1[i][j] = pyT1[i][j] + 1\n # print(pyT1[i][j])\n%time add1()\n",
"CPU times: user 46 µs, sys: 0 ns, total: 46 µs\nWall time: 51 µs\n"
],
[
"%time npT1 + 1",
"CPU times: user 3.22 ms, sys: 3.08 ms, total: 6.3 ms\nWall time: 8.27 ms\n"
]
],
[
[
"## Numpy Functions",
"_____no_output_____"
]
],
[
[
"npT1.sum()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a46390679ebbf43d7ffecdb3db227bd98aeca20
| 47,840 |
ipynb
|
Jupyter Notebook
|
notebooks/0107-Errata_01.ipynb
|
Ahmed22188/csharp_with_csharpfritz
|
0db04e0ebc332c05d25c2cd3c285488751cb4811
|
[
"MIT"
] | 1 |
2021-10-04T22:14:54.000Z
|
2021-10-04T22:14:54.000Z
|
notebooks/0107-Errata_01.ipynb
|
Ahmed22188/csharp_with_csharpfritz
|
0db04e0ebc332c05d25c2cd3c285488751cb4811
|
[
"MIT"
] | null | null | null |
notebooks/0107-Errata_01.ipynb
|
Ahmed22188/csharp_with_csharpfritz
|
0db04e0ebc332c05d25c2cd3c285488751cb4811
|
[
"MIT"
] | null | null | null | 30.106986 | 948 | 0.522262 |
[
[
[
"# Session 7: The Errata Review No. 1\n\nThis session is a review of the prior six sessions and covering those pieces that were left off. Not necessarily errors, but missing pieces to complete the picture from the series. These topics answer some questions and will help complete the picture of the C# language features discussed to this point.\n\n## Increment and Assignment operators\n\nIn session 1, we reviewed operators and interacting with numbers. We skipped the [increment](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/arithmetic-operators?WT.mc_id=visualstudio-twitch-jefritz#increment-operator-) `++` and [decrement](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/arithmetic-operators?WT.mc_id=visualstudio-twitch-jefritz#decrement-operator---) `--` operators. These operators allow you to increment and decrement values quickly. You can place these operators before and after the variable you would like to act on, and they will be incremented or decremented before or after being returned.\n\nLet's take a look:",
"_____no_output_____"
]
],
[
[
"var counter = 1;\ndisplay(counter--); // Running ++ AFTER counter will display 1\ndisplay(counter); // and then display 2 in the next row",
"_____no_output_____"
],
[
"var counter = 1;\ndisplay(--counter); // Running ++ BEFORE counter will display 2 as it is incrementing the variable before \n // displaying it",
"_____no_output_____"
]
],
[
[
"## Logical negation operator\n\nSometimes you want to invert the value of a boolean, converting from `true` to `false` and from `false` to `true`. Quite simply, just prefix your test or boolean value with the [negation operator](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/boolean-logical-operators?WT.mc_id=visualstudio-twitch-jefritz#logical-negation-operator-) `!` to invert values",
"_____no_output_____"
]
],
[
[
"var isTrue = true;\ndisplay(!isTrue);\n\ndisplay(!(1 > 2))\n",
"_____no_output_____"
]
],
[
[
"## TypeOf, GetType and NameOf methods\n\nSometimes you need to work with the type of a variable or the name of a value. The methods `typeof`, `GetType()` and `nameof` allow you to interact with the types and pass them along for further interaction.\n\n[typeof](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/type-testing-and-cast?WT.mc_id=visualstudio-twitch-jefritz#typeof-operator) allows you to get a reference to a type for use in methods where you need to inspect the underlying type system",
"_____no_output_____"
]
],
[
[
"display(typeof(int));",
"_____no_output_____"
]
],
[
[
"Conversely, the `GetType()` method allows you to get the type information for a variable already in use. Every object in C# has the `GetType()` method available.",
"_____no_output_____"
]
],
[
[
"var myInt = 5;\ndisplay(myInt.GetType());",
"_____no_output_____"
]
],
[
[
"The [`nameof` expression](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/nameof?WT.mc_id=visualstudio-twitch-jefritz) gives the name of a type or member as a string. This is particularly useful when you are generating error messages.",
"_____no_output_____"
]
],
[
[
"class People {\n public string Name { get; set; }\n public TimeSpan CalculateAge() => DateTime.Now.Subtract(new DateTime(2000,1,1));\n}\n\nvar fritz = new People { Name=\"Fritz\" };\n\ndisplay(nameof(People));\ndisplay(typeof(People));\ndisplay(nameof(fritz.Name));",
"_____no_output_____"
]
],
[
[
"## String Formatting\n\nFormatting and working with strings or text is a fundamental building block of working with user-input. We failed to cover the various ways to interact with those strings. Let's take a look at a handful of the ways to work with text data.\n\n## Concatenation\n\nYou may have seen notes and output that concatenates strings by using the [`+` operator](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/addition-operator?WT.mc_id=visualstudio-twitch-jefritz#string-concatenation). This is the simplest form of concatenation and only works when both sides of the `+` operator are strings. ",
"_____no_output_____"
]
],
[
[
"var greeting = \"Hello\";\ndisplay(greeting + \" World!\");\n\n// += also works\ngreeting += \" C# developers\";\ndisplay(greeting);",
"_____no_output_____"
]
],
[
[
"If you have multiple strings to combine, the `+` operator gets a little unwieldy and is not as performance aware as several other techniques. We can [combine multiple strings](https://docs.microsoft.com/en-us/dotnet/csharp/how-to/concatenate-multiple-strings?WT.mc_id=visualstudio-twitch-jefritz) using the `Concat`, `Join`, `Format` and interpolation features of C#.",
"_____no_output_____"
]
],
[
[
"var greeting = \"Good\";\nvar time = DateTime.Now.Hour < 12 && DateTime.Now.Hour > 3 ? \"Morning\" : DateTime.Now.Hour < 17 ? \"Afternoon\" : \"Evening\";\nvar name = \"Visual Studio Channel\";\n\n// Use string.concat with a comma separated list of arguments \ndisplay(string.Concat(greeting, \" \", time, \" \", name + \"!\"));",
"_____no_output_____"
],
[
"var terms = new [] {greeting, time, name};\n\n// Use string.Join to assembly values in an array with a separator\ndisplay(string.Join(\" \", terms));",
"_____no_output_____"
],
[
"// Use string.Format to configure a template string and load values into it based on position\nvar format = \"Good {1} {0}\";\ndisplay(string.Format(format, time, name));",
"_____no_output_____"
],
[
"// With C# 7 and later you can now use string interpolation to format a string. \n// Simply prefix a string with a $ to allow you to insert C# expressions in { } inside\n// a string\n\nvar names = new string[] {\"Fritz\", \"Scott\", \"Maria\", \"Jayme\"};\n\ndisplay($\"Good {time} {name} {string.Join(\",\",names)}\");\n",
"_____no_output_____"
],
[
"// Another technique that can be used when you don't know the exact number of strings\n// to concatenate is to use the StringBuilder class.\n\nvar sb = new StringBuilder();\nsb.AppendFormat(\"Good {0}\", time);\nsb.Append(\" \");\nsb.Append(name);\n\ndisplay(sb.ToString());",
"_____no_output_____"
]
],
[
[
"### Parsing strings with Split\n\nYou can turn a string into an array of strings using the `Split` method on a string variable. Pass the character that identifies the boundary between elements of your array to turn it into an array:",
"_____no_output_____"
]
],
[
[
"var phrase = \"Good Morning Cleveland\";\ndisplay(phrase.Split(' '));\ndisplay(phrase.Split(' ')[2]);",
"_____no_output_____"
],
[
"var fibonacci = \"1,1,2,3,5,8,13,21\";\ndisplay(fibonacci.Split(','));",
"_____no_output_____"
]
],
[
[
"## A Deeper Dive on Enums\n\nWe briefly discussed enumeration types in session 3 and touched on using the `enum` keyword to represent related values. Let's go a little further into conversions and working with the enum types.\n\n### Conversions\n\n[Enum types](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/enum?WT.mc_id=visualstudio-twitch-jefritz) are extensions on top of numeric types. By default, they wrap the `int` integer data type. While this base numeric type can be overridden, we can also convert data into and out of the enum using standard explicit conversion operators ",
"_____no_output_____"
]
],
[
[
"enum DotNetLanguages : byte {\n csharp = 100,\n visual_basic = 2,\n fsharp = 3\n}\n\nvar myLanguage = DotNetLanguages.csharp;\ndisplay(myLanguage);\ndisplay((byte)myLanguage);\ndisplay((int)myLanguage);\n\n// Push a numeric type INTO DotNetLanguages\nmyLanguage = (DotNetLanguages)2;\ndisplay(myLanguage);",
"_____no_output_____"
]
],
[
[
"### Working with strings using Parse and TryParse\n\nWhat about the string value of the enumeration itself? We can work with that using the [`Parse`](https://docs.microsoft.com/en-us/dotnet/api/system.enum.parse?view=netcore-3.1&WT.mc_id=visualstudio-twitch-jefritz) and [`TryParse`](https://docs.microsoft.com/en-us/dotnet/api/system.enum.tryparse?view=netcore-3.1&WT.mc_id=visualstudio-twitch-jefritz) methods of the Enum object to convert a string into the Enum type",
"_____no_output_____"
]
],
[
[
"var thisLanguage = \"csharp\";\nmyLanguage = Enum.Parse<DotNetLanguages>(thisLanguage);\ndisplay(myLanguage);\n\n// Use the optional boolean flag parameter to indicate if the Parse operation is case-insensitive \nthisLanguage = \"CSharp\";\nmyLanguage = Enum.Parse<DotNetLanguages>(thisLanguage, true);\ndisplay(myLanguage);",
"_____no_output_____"
],
[
"// TryParse has a similar signature, but returns a boolean to indicate success \nvar success = Enum.TryParse<DotNetLanguages>(\"Visual_Basic\", true, out var foo);\ndisplay(success);\ndisplay(foo);",
"_____no_output_____"
]
],
[
[
"### GetValues and the Enumeration's available values\n\nThe constant values of the enum type can be exposed using the [Enum.GetValues](https://docs.microsoft.com/en-us/dotnet/api/system.enum.getvalues?view=netcore-3.1&WT.mc_id=visualstudio-twitch-jefritz) method. This returns an array of the numeric values of the enum. Let's inspect our `DotNetLanguages` type: ",
"_____no_output_____"
]
],
[
[
"var languages = Enum.GetValues(typeof(DotNetLanguages));\ndisplay(languages);",
"_____no_output_____"
],
[
"// We can convert back to the named values of the enum with a little conversion\nforeach (var l in languages) {\n display((DotNetLanguages)l);\n}",
"_____no_output_____"
]
],
[
[
"## Classes vs. Structs\n\nIn the second session we introduced the `class` keyword to create reference types. There is another keyword, `struct`, that allows you to create [Structure](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/struct?WT.mc_id=visualstudio-twitch-jefritz) **value types** which will be allocated in memory and reclaimed more quickly than a class. While a `struct` looks like a class in syntax, there are some constraints:\n\n- A constructor must be defined that configures all properties / fields\n- The parameterless constructor is not allowed\n- Instance Fields / Properties cannot be assigned in their declaration\n- Finalizers are not allowed\n- A struct cannot inherit from another type, but can implement interfaces \n\nStructs are typically used to store related numeric types. Let's tinker with an example:",
"_____no_output_____"
]
],
[
[
"struct Rectangle {\n \n public Rectangle(int length, int width) {\n this.Length = length;\n this.Width = width;\n }\n \n public static readonly int Depth = DateTime.Now.Minute;\n \n public int Length {get;set;}\n public int Width {get;set;}\n \n public int Area { get { return Length * Width;}}\n public int Perimeter { get { return Length*2 + Width*2;}}\n \n}\n\nvar myRectangle = new Rectangle(2, 5);\ndisplay(myRectangle);\ndisplay(Rectangle.Depth);",
"_____no_output_____"
],
[
"enum CountryCode {\n USA = 1\n}\n\nstruct PhoneNumber {\n \n public PhoneNumber(CountryCode countryCode, string exchange, string number) {\n this.CountryCode = countryCode;\n this.Exchange = exchange;\n this.Number = number;\n }\n \n public CountryCode CountryCode { get; set;}\n public string Exchange { get; set;}\n public string Number {get; set;}\n \n}\n\nvar jennysNumber = new PhoneNumber(CountryCode.USA, \"867\", \"5309\");\ndisplay(jennysNumber);\n",
"_____no_output_____"
]
],
[
[
"### When should I use a struct instead of a class?\n\nThis is a common question among C# developers. How do you decide? Since a `struct` is a simple value type, there are [several guidelines to help you decide](https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/choosing-between-class-and-struct?WT.mc_id=visualstudio-twitch-jefritz):\n\n**Choose a struct INSTEAD of a class if all of these are true about the type:**\n- It will be small and short-lived in memory\n- It represents a single value\n- It can be represented in 16 bytes or less\n- It will not be changed, and is immutable\n- You will not be converting it to a class (called `boxing` and `unboxing`)",
"_____no_output_____"
],
[
"## Stopping and Skipping Loops \n\nIn session four we learned about loops using `for`, `while`, and `do`. We can speed up our loop by moving to the next iteration in the loop and we can stop a loop process completely using the `continue` and `break` keywords. Let's take a look at some examples:",
"_____no_output_____"
]
],
[
[
"for (var i=1; i<10_000_000; i++) {\n display(i);\n if (i%10 == 0) break; // Stop if the value is a multiple of 10\n}",
"_____no_output_____"
],
[
"// We can skip an iteration in the loop using the continue keyword\nfor (var i = 1; i<10_000_000; i++) {\n if (i%3 == 0) continue; // Skip this iteration\n display(i);\n if (i%10 == 0) break;\n}",
"_____no_output_____"
]
],
[
[
"## Initializing Collections\n\nIn the fifth session we explored Arrays, Lists, and Dictionary types. We saw that you could initialize an array with syntax like the following:",
"_____no_output_____"
]
],
[
[
"var fibonacci = new int[] {1,1,2,3,5,8,13};\ndisplay(fibonacci);\n\n//var coordinates = new int[,] {{1,2}, {2,3}};\n//display(coordinates);",
"_____no_output_____"
]
],
[
[
"We can also initialize List and Dictionary types using the curly braces notation:",
"_____no_output_____"
]
],
[
[
"var myList = new List<string> {\n \"C#\",\n \"Visual Basic\",\n \"F#\"\n};\ndisplay(myList);\n\nvar myShapes = new List<Rectangle> {\n new Rectangle(2, 5),\n new Rectangle(3, 4),\n new Rectangle(4, 3)\n};\ndisplay(myShapes);\n",
"_____no_output_____"
],
[
"var myDictionary = new Dictionary<int, string> {\n {100, \"C#\"},\n {200, \"Visual Basic\"},\n {300, \"F#\"}\n};\ndisplay(myDictionary);",
"_____no_output_____"
]
],
[
[
"## Dictionary Types\n\nThis question was raised on an earlier stream, and [David Fowler](https://twitter.com/davidfowl) (.NET Engineering Team Architect) wrote a series of [Tweets](https://twitter.com/davidfowl/status/1444467842418548737) about it based on discussions with [Stephen Toub](https://twitter.com/stephentoub/) (Architect for the .NET Libraries) \n\nThere are 4 built-in Dictionary types with .NET:\n\n- [Hashtable](https://docs.microsoft.com/dotnet/api/system.collections.hashtable)\n - This is the most efficient dictionary type with keys organized by the hash of their values.\n\t- David says: \"Good read speed (no lock required), sameish weight as dictionary but more expensive to mutate and no generics!\"",
"_____no_output_____"
]
],
[
[
"var hashTbl = new Hashtable();\nhashTbl.Add(\"key1\", \"value1\");\nhashTbl.Add(\"key2\", \"value2\");\n\ndisplay(hashTbl);",
"_____no_output_____"
]
],
[
[
"\n- [Dictionary](https://docs.microsoft.com/dotnet/api/system.collections.generic.dictionary-2)\n - A generic dictionary object that you can search easily by keys.\n - David says: \"Lightweight to create and 'medium' update speed. Poor read speed when used with a lock. As an immutable object it has the best read speed and heavy to update.\"",
"_____no_output_____"
]
],
[
[
"private readonly Dictionary<string,string> readonlyDictionary = new() { \n\t{\"txt\", \"Text Files\"},\n\t{\"wav\", \"Sound Files\"},\n\t{\"mp3\", \"Compressed Music Files\"},\n};\n\ndisplay(readonlyDictionary);\n\nreadonlyDictionary.Add(\"mp4\", \"Video Files\"); \ndisplay(newDictionary);",
"_____no_output_____"
]
],
[
[
"- [ConcurrentDictionary](https://docs.microsoft.com/dotnet/api/system.collections.concurrent.concurrentdictionary-2)\n - A thread-safe version of Dictionary that is optimized for use by multiple threads. It is not recommended for use by a single thread due to the extra overhead allocate for multi-threaded support.\n - David says: \"Poorish read speed, no locking required but more allocations require to update than a dictionary.\"\n\nInstead of Adding, Updating and Getting values from the ConcurrentDictionary, we TryAdd, TryUpdate, and TryGetValue. TryAdd will return false if the key already exists, and TryUpdate will return false if the key does not exist. TryGetValue will return false if the key does not exist. We can also AddOrUpdate to add a value if the key does not exist and GetOrAdd to add a value if the key does not exist.",
"_____no_output_____"
]
],
[
[
"using System.Collections.Concurrent;\n\nvar cd = new ConcurrentDictionary<string, string>();\ncd.AddOrUpdate(\"key1\", \"value1\", (key, oldValue) => \"value2\");\ncd.AddOrUpdate(\"key1\", \"value1\", (key, oldValue) => \"value2\");\n\ndisplay(cd.TryAdd(\"key2\", \"value1\"));\ndisplay(cd);",
"_____no_output_____"
]
],
[
[
"- [ImmutableDictionary](https://docs.microsoft.com/dotnet/api/system.collections.immutable.immutabledictionary-2)\n - A new type in .NET Core and .NET 5/6 that is a read-only version of Dictionary. Changes to it's contents involve creation of a new Dictionary object and copying of the contents.\n\t- David says: \"Poorish read speed, no locking required but more allocations required to update than a dictionary.\"",
"_____no_output_____"
]
],
[
[
"using System.Collections.Immutable;\n\nvar d = ImmutableDictionary.CreateBuilder<string,string>();\nd.Add(\"key1\", \"value1\");\nd.Add(\"key2\", \"value2\");\n\nvar theDict = d.ToImmutable();\n//theDict = theDict.Add(\"key3\", \"value3\");\ndisplay(theDict);",
"_____no_output_____"
]
],
[
[
"## Const and Static keywords\n\n\n",
"_____no_output_____"
]
],
[
[
"const int Five = 5;\n\n// Five = 6;\ndisplay(Five);",
"\n(3,1): error CS0131: The left-hand side of an assignment must be a variable, property or indexer\n\n"
],
[
"class Student {\n \n public const decimal MaxGPA = 5.0m;\n \n}\n\ndisplay(Student.MaxGPA);",
"_____no_output_____"
],
[
"class Student {\n \n public static bool InClass = false;\n public string Name { get; set; }\n\n public override string ToString() {\n return Name + \": \" + Student.InClass;\n }\n\n public static void GoToClass() {\n Student.InClass = true;\n }\n \n public static void DitchClass() {\n Student.InClass = false;\n }\n \n}\n\nvar students = new Student[] { new Student { Name=\"Hugo\" }, new Student {Name=\"Fritz\"}, new Student {Name=\"Lily\"}};\nforeach (var s in students) {\n display(s.ToString());\n}",
"_____no_output_____"
],
[
"Student.GoToClass();\nforeach (var s in students) {\n display(s.ToString());\n}",
"_____no_output_____"
],
[
"static class DateMethods {\n \n public static int CalculateAge(DateTime date1, DateTime date2) {\n return 10;\n }\n \n}\n\ndisplay(DateMethods.CalculateAge(DateTime.Now, DateTime.Now))",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a4668ab9294442a43126613b81a049412e7df98
| 470,102 |
ipynb
|
Jupyter Notebook
|
Simulations/visualization/v_bend_in_times_10/Factory2.0.ipynb
|
openhearted99/AGN_variability_project
|
24befc9946cf4b5e929cb665d0af5af7d5ea1bcc
|
[
"MIT"
] | null | null | null |
Simulations/visualization/v_bend_in_times_10/Factory2.0.ipynb
|
openhearted99/AGN_variability_project
|
24befc9946cf4b5e929cb665d0af5af7d5ea1bcc
|
[
"MIT"
] | null | null | null |
Simulations/visualization/v_bend_in_times_10/Factory2.0.ipynb
|
openhearted99/AGN_variability_project
|
24befc9946cf4b5e929cb665d0af5af7d5ea1bcc
|
[
"MIT"
] | null | null | null | 459.982387 | 128,868 | 0.926167 |
[
[
[
"\"\"\"\nMade on July 10th, 2019\n@author: Theodore Pena\n@contact: [email protected]\n\"\"\"\n\nline_color = 'purple' # Color for the 10-panel plots\nx_Delta = np.log10(54) # In our time units, the time between SDSS and HSC\ndefault_Delta_value = -0.0843431604042636\ndata_path = '/home/tpena01/AGN_variability_project/Simulations/light_curves/v_bend_in_times_10/results_v_bend_in_times_10_{}.bin'",
"_____no_output_____"
]
],
[
[
"# Setup and imports",
"_____no_output_____"
]
],
[
[
"import sys\nprint(\"sys version: {}\".format(sys.version))\n# This project is entirely in python 3.7\n\nimport matplotlib\nimport matplotlib.pyplot as plt\n%matplotlib qt \n# If you don't have an X server, line 7 might crash your kernel. Try '%matplotlib inline' instead.\n\nimport numpy as np\nprint(\"numpy version: {}\".format(np.__version__))\n\nfrom tqdm import tqdm\n# This gives for loops progress bars.\n\nimport random\n# This helps choosing random numbers from our arrays\nrandom.seed() # Randomize seed\n\nfrom IPython.core.display import display, HTML\n# An alternate, cleaner take on the jupyter workspace\ndisplay(HTML(\"<style>.container { width:100% !important; }</style>\"))",
"sys version: 3.7.3 (default, Mar 27 2019, 22:11:17) \n[GCC 7.3.0]\nnumpy version: 1.16.2\n"
]
],
[
[
"# Data extraction function",
"_____no_output_____"
]
],
[
[
"def extract_data(brightest_percent_lower=1, brightest_percent_upper=0, num_random_points=1000, t_max=10000, length_curve=2**24, num_curves=20):\n \"\"\"\n Input: Parameters documented in the cell above\n Output: Graph of delta Eddington ratio as a function of delta time. \n \"\"\"\n \n if brightest_percent_lower <= brightest_percent_upper:\n sys.exit('Can\\'t have an interval where the lower bound is greater than or equal to the upper bound. Remember, things are reversed. 100% is a reasonable lower bound, and brightest_percent_upper defaults to zero.')\n \n \n # Load the data\n default_curves = []\n for i in tqdm(range(num_curves + 1)):\n\n if i == 0:\n continue # for some reason the results files start at 1 and not 0\n\n _er_curve = np.zeros(length_curve, dtype=float)\n _er_curve = np.fromfile(data_path.format(str(i)))\n default_curves.append(_er_curve)\n\n default_curves = np.array(default_curves)\n\n default_curves = np.log10(default_curves) # Move everything into the log domain\n \n \n # Cut out the last t_max points\n cut_curves = np.zeros((np.array(list(default_curves.shape)) - np.array([0, t_max])))\n for i in tqdm(range(num_curves)):\n cut_curves[i, :] = default_curves[i, :-t_max]\n \n ##\n # Select all points brighter than brightest_percent_lower%\n num_brightest_lower = int(np.floor((cut_curves[0].shape[0] * (brightest_percent_lower/100))))\n \n if brightest_percent_lower == 100:\n num_brightest_lower = cut_curves[0].shape[0]\n \n if brightest_percent_lower == 0:\n sys.exit('Cannot use 0 as a lower bound.')\n \n else:\n indices_lower = []\n for i in tqdm(range(num_curves)):\n indices_lower.append(np.argpartition(cut_curves[i, :], -num_brightest_lower)[-num_brightest_lower:])\n\n indices_lower = np.array(indices_lower)\n \n \n # Select all points brighter than brightest_percent_upper%\n num_brightest_upper = int(np.floor((cut_curves[0].shape[0] * (brightest_percent_upper/100))))\n \n \n if brightest_percent_upper == 100:\n num_brightest_upper = cut_curves[0].shape[0]\n \n if brightest_percent_upper == 0:\n indices_upper = []\n for i in range(num_curves):\n indices_upper.append(np.array([]))\n \n else:\n indices_upper = []\n for i in tqdm(range(num_curves)):\n indices_upper.append(np.argpartition(cut_curves[i, :], -num_brightest_upper)[-num_brightest_upper:])\n\n indices_upper = np.array(indices_upper)\n \n \n indices = []\n for i in range(num_curves):\n indices.append(np.setdiff1d(indices_lower[i], indices_upper[i], assume_unique=True))\n \n ##\n \n # Randomly sample from the chosen indices\n chosen_indices = []\n for brightest_points_in_curve in tqdm(indices):\n chosen_indices.append(random.sample(list(brightest_points_in_curve), num_random_points))\n\n chosen_indices = np.array(chosen_indices, dtype=int)\n \n \n # Find the smallest number that we've chosen (We print this out later)\n small_points = []\n for i in tqdm(range(num_curves)):\n small_points.append(np.min(cut_curves[i][chosen_indices[i]]))\n\n smallest_point = \"Min log(Edd): \" + str(np.min(small_points))[:6]\n \n \n # Select all our points\n t_examine = np.logspace(0, np.log10(t_max), np.log(t_max)*10 + 1).astype(int)\n t_log = np.log10(t_examine) # Used later\n\n t_array = np.tile(t_examine, (num_random_points, 1))\n\n master_array = np.zeros(t_examine.shape, dtype=int)\n\n for i in tqdm(range(num_curves)):\n indices_array = np.tile(chosen_indices[i, :], (t_array.shape[1], 1)).T\n\n indices_array = indices_array + t_array \n master_array = np.vstack((default_curves[i][indices_array], master_array))\n\n master_array = np.delete(master_array, -1, 0)\n\n starting_vals = np.copy(master_array[:, 0])\n for i in tqdm(range(master_array.shape[1])):\n master_array[:, i] = master_array[:, i] - starting_vals\n \n\n # Find our trends\n means = []\n stands = []\n\n for i in tqdm(range(master_array.shape[1])):\n means.append(np.mean(master_array[:, i]))\n stands.append(np.std(master_array[:, i]))\n\n means = np.array(means)\n stands = np.array(stands)\n \n \n # Get a line of best fit\n best_fit = np.poly1d(np.poly1d(np.polyfit(t_log.astype(float)[1:], means.astype(float)[1:], 1)))\n \n return (t_log, means, stands, best_fit, smallest_point)",
"_____no_output_____"
]
],
[
[
"# Main",
"_____no_output_____"
]
],
[
[
"t_log100, means100, stands100, best_fit100, smallest_point100 = extract_data(brightest_percent_lower=100, brightest_percent_upper=50)\n\nt_log50, means50, stands50, best_fit50, smallest_point50 = extract_data(brightest_percent_lower=50, brightest_percent_upper=10)\n\nt_log10, means10, stands10, best_fit10, smallest_point10 = extract_data(brightest_percent_lower=10, brightest_percent_upper=5)\n\nt_log5, means5, stands5, best_fit5, smallest_point5 = extract_data(brightest_percent_lower=5, brightest_percent_upper=1)\n\nt_log1, means1, stands1, best_fit1, smallest_point1 = extract_data(brightest_percent_lower=1, brightest_percent_upper=0.5)\n\nt_log05, means05, stands05, best_fit05, smallest_point05 = extract_data(brightest_percent_lower=0.5, brightest_percent_upper=0.1)\n\nt_log01, means01, stands01, best_fit01, smallest_point01 = extract_data(brightest_percent_lower=0.1, brightest_percent_upper=0.05)\n\nt_log005, means005, stands005, best_fit005, smallest_point005 = extract_data(brightest_percent_lower=0.05, brightest_percent_upper=0.02)\n\nt_log002, means002, stands002, best_fit002, smallest_point002 = extract_data(brightest_percent_lower=0.02, brightest_percent_upper=0.006)\n\nt_loginf, meansinf, standsinf, best_fitinf, smallest_pointinf = extract_data(brightest_percent_lower=0.006)",
"100%|██████████| 21/21 [00:09<00:00, 2.13it/s]\n100%|██████████| 20/20 [00:02<00:00, 8.52it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.52it/s]\n100%|██████████| 20/20 [00:06<00:00, 3.32it/s]\n100%|██████████| 20/20 [00:08<00:00, 2.38it/s]\n100%|██████████| 20/20 [00:00<00:00, 2510.06it/s]\n100%|██████████| 20/20 [00:01<00:00, 17.76it/s]\n100%|██████████| 93/93 [00:00<00:00, 3703.56it/s]\n100%|██████████| 93/93 [00:00<00:00, 2771.37it/s]\n100%|██████████| 21/21 [00:09<00:00, 2.12it/s]\n100%|██████████| 20/20 [00:02<00:00, 6.92it/s]\n100%|██████████| 20/20 [00:06<00:00, 2.95it/s]\n100%|██████████| 20/20 [00:06<00:00, 3.13it/s]\n100%|██████████| 20/20 [00:06<00:00, 3.03it/s]\n100%|██████████| 20/20 [00:00<00:00, 10201.40it/s]\n100%|██████████| 20/20 [00:00<00:00, 163.08it/s]\n100%|██████████| 93/93 [00:00<00:00, 3287.13it/s]\n100%|██████████| 93/93 [00:00<00:00, 1701.17it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.56it/s]\n100%|██████████| 20/20 [00:03<00:00, 5.53it/s]\n100%|██████████| 20/20 [00:05<00:00, 3.64it/s]\n100%|██████████| 20/20 [00:05<00:00, 3.29it/s]\n100%|██████████| 20/20 [00:00<00:00, 21.22it/s]\n100%|██████████| 20/20 [00:00<00:00, 2658.16it/s]\n100%|██████████| 20/20 [00:00<00:00, 186.11it/s]\n100%|██████████| 93/93 [00:00<00:00, 2336.37it/s]\n100%|██████████| 93/93 [00:00<00:00, 1764.14it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.06it/s]\n100%|██████████| 20/20 [00:02<00:00, 6.78it/s]\n100%|██████████| 20/20 [00:05<00:00, 3.41it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.03it/s]\n100%|██████████| 20/20 [00:00<00:00, 32.92it/s]\n100%|██████████| 20/20 [00:00<00:00, 3679.54it/s]\n100%|██████████| 20/20 [00:00<00:00, 211.82it/s]\n100%|██████████| 93/93 [00:00<00:00, 2885.67it/s]\n100%|██████████| 93/93 [00:00<00:00, 1758.92it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.67it/s]\n100%|██████████| 20/20 [00:02<00:00, 7.47it/s]\n100%|██████████| 20/20 [00:05<00:00, 4.03it/s]\n100%|██████████| 20/20 [00:05<00:00, 3.59it/s]\n100%|██████████| 20/20 [00:00<00:00, 190.12it/s]\n100%|██████████| 20/20 [00:00<00:00, 4872.85it/s]\n100%|██████████| 20/20 [00:00<00:00, 278.90it/s]\n100%|██████████| 93/93 [00:00<00:00, 2750.34it/s]\n100%|██████████| 93/93 [00:00<00:00, 1389.11it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.51it/s]\n100%|██████████| 20/20 [00:03<00:00, 5.50it/s]\n100%|██████████| 20/20 [00:05<00:00, 3.85it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.13it/s]\n100%|██████████| 20/20 [00:00<00:00, 196.71it/s]\n100%|██████████| 20/20 [00:00<00:00, 13214.57it/s]\n100%|██████████| 20/20 [00:00<00:00, 289.44it/s]\n100%|██████████| 93/93 [00:00<00:00, 2448.79it/s]\n100%|██████████| 93/93 [00:00<00:00, 1556.02it/s]\n100%|██████████| 21/21 [00:03<00:00, 7.50it/s]\n100%|██████████| 20/20 [00:02<00:00, 7.62it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.17it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.27it/s]\n100%|██████████| 20/20 [00:00<00:00, 514.90it/s]\n100%|██████████| 20/20 [00:00<00:00, 8029.68it/s]\n100%|██████████| 20/20 [00:00<00:00, 384.35it/s]\n100%|██████████| 93/93 [00:00<00:00, 1876.18it/s]\n100%|██████████| 93/93 [00:00<00:00, 1543.54it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.70it/s]\n100%|██████████| 20/20 [00:02<00:00, 7.14it/s]\n100%|██████████| 20/20 [00:04<00:00, 3.98it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.24it/s]\n100%|██████████| 20/20 [00:00<00:00, 620.80it/s]\n100%|██████████| 20/20 [00:00<00:00, 11663.80it/s]\n100%|██████████| 20/20 [00:00<00:00, 423.97it/s]\n100%|██████████| 93/93 [00:00<00:00, 2366.16it/s]\n100%|██████████| 93/93 [00:00<00:00, 1693.29it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.59it/s]\n100%|██████████| 20/20 [00:02<00:00, 7.64it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.11it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.35it/s]\n100%|██████████| 20/20 [00:00<00:00, 686.44it/s]\n100%|██████████| 20/20 [00:00<00:00, 17761.19it/s]\n100%|██████████| 20/20 [00:00<00:00, 439.49it/s]\n100%|██████████| 93/93 [00:00<00:00, 2485.00it/s]\n100%|██████████| 93/93 [00:00<00:00, 1631.57it/s]\n100%|██████████| 21/21 [00:02<00:00, 7.63it/s]\n100%|██████████| 20/20 [00:02<00:00, 7.41it/s]\n100%|██████████| 20/20 [00:04<00:00, 4.45it/s]\n100%|██████████| 20/20 [00:00<00:00, 686.61it/s]\n100%|██████████| 20/20 [00:00<00:00, 20286.84it/s]\n100%|██████████| 20/20 [00:00<00:00, 401.40it/s]\n100%|██████████| 93/93 [00:00<00:00, 2497.73it/s]\n100%|██████████| 93/93 [00:00<00:00, 1825.34it/s]\n"
],
[
"log_t_1 = [means100[np.where(t_log100==1)[0][0]], means50[np.where(t_log50==1)[0][0]], means10[np.where(t_log10==1)[0][0]], means5[np.where(t_log5==1)[0][0]], means1[np.where(t_log1==1)[0][0]], means05[np.where(t_log05==1)[0][0]], means01[np.where(t_log01==1)[0][0]], means005[np.where(t_log005==1)[0][0]], means002[np.where(t_log002==1)[0][0]], meansinf[np.where(t_loginf==1)[0][0]]]\nlog_t_2 = [means100[np.where(t_log100==2)[0][0]], means50[np.where(t_log50==2)[0][0]], means10[np.where(t_log10==2)[0][0]], means5[np.where(t_log5==2)[0][0]], means1[np.where(t_log1==2)[0][0]], means05[np.where(t_log05==2)[0][0]], means01[np.where(t_log01==2)[0][0]], means005[np.where(t_log005==2)[0][0]], means002[np.where(t_log002==2)[0][0]], meansinf[np.where(t_loginf==2)[0][0]]]\nlog_t_3 = [means100[np.where(t_log100==3)[0][0]], means50[np.where(t_log50==3)[0][0]], means10[np.where(t_log10==3)[0][0]], means5[np.where(t_log5==3)[0][0]], means1[np.where(t_log1==3)[0][0]], means05[np.where(t_log05==3)[0][0]], means01[np.where(t_log01==3)[0][0]], means005[np.where(t_log005==3)[0][0]], means002[np.where(t_log002==3)[0][0]], meansinf[np.where(t_loginf==3)[0][0]]]\nlog_t_4 = [means100[np.where(t_log100==4)[0][0]], means50[np.where(t_log50==4)[0][0]], means10[np.where(t_log10==4)[0][0]], means5[np.where(t_log5==4)[0][0]], means1[np.where(t_log1==4)[0][0]], means05[np.where(t_log05==4)[0][0]], means01[np.where(t_log01==4)[0][0]], means005[np.where(t_log005==4)[0][0]], means002[np.where(t_log002==4)[0][0]], meansinf[np.where(t_loginf==4)[0][0]]]\n\nlog_t_1_stands = np.log10(np.array([stands100[np.where(t_log100==1)[0][0]], stands50[np.where(t_log50==1)[0][0]], stands10[np.where(t_log10==1)[0][0]], stands5[np.where(t_log5==1)[0][0]], stands1[np.where(t_log1==1)[0][0]], stands05[np.where(t_log05==1)[0][0]], stands01[np.where(t_log01==1)[0][0]], stands005[np.where(t_log005==1)[0][0]], stands002[np.where(t_log002==1)[0][0]], standsinf[np.where(t_loginf==1)[0][0]]]))\nlog_t_2_stands = np.log10(np.array([stands100[np.where(t_log100==2)[0][0]], stands50[np.where(t_log50==2)[0][0]], stands10[np.where(t_log10==2)[0][0]], stands5[np.where(t_log5==2)[0][0]], stands1[np.where(t_log1==2)[0][0]], stands05[np.where(t_log05==2)[0][0]], stands01[np.where(t_log01==2)[0][0]], stands005[np.where(t_log005==2)[0][0]], stands002[np.where(t_log002==2)[0][0]], standsinf[np.where(t_loginf==2)[0][0]]]))\nlog_t_3_stands = np.log10(np.array([stands100[np.where(t_log100==3)[0][0]], stands50[np.where(t_log50==3)[0][0]], stands10[np.where(t_log10==3)[0][0]], stands5[np.where(t_log5==3)[0][0]], stands1[np.where(t_log1==3)[0][0]], stands05[np.where(t_log05==3)[0][0]], stands01[np.where(t_log01==3)[0][0]], stands005[np.where(t_log005==3)[0][0]], stands002[np.where(t_log002==3)[0][0]], standsinf[np.where(t_loginf==3)[0][0]]]))\nlog_t_4_stands = np.log10(np.array([stands100[np.where(t_log100==4)[0][0]], stands50[np.where(t_log50==4)[0][0]], stands10[np.where(t_log10==4)[0][0]], stands5[np.where(t_log5==4)[0][0]], stands1[np.where(t_log1==4)[0][0]], stands05[np.where(t_log05==4)[0][0]], stands01[np.where(t_log01==4)[0][0]], stands005[np.where(t_log005==4)[0][0]], stands002[np.where(t_log002==4)[0][0]], standsinf[np.where(t_loginf==4)[0][0]]]))\n\nx = np.log10(np.array([100, 50, 10, 5, 1, 0.5, 0.1, 0.05, 0.02, 0.006]))",
"_____no_output_____"
]
],
[
[
"# Delta value",
"_____no_output_____"
]
],
[
[
"Delta_value = means05[np.where(t_log05==x_Delta)][0]\nprint('For this set of parameters, Delta is ' + str(Delta_value - default_Delta_value) + '.')\nprint('Remember, a negative delta (approximately) means that the curve was steeper than the default plot of log Edd. Ratio as a function of time.')",
"For this set of parameters, Delta is -0.006778220973546592.\nRemember, a negative delta (approximately) means that the curve was steeper than the default plot of log Edd. Ratio as a function of time.\n"
]
],
[
[
"# Graphs",
"_____no_output_____"
],
[
"## 10-panel plots",
"_____no_output_____"
]
],
[
[
"# Delta Eddington ratio plots\nwith plt.style.context('seaborn-paper'):\n fig, ax = plt.subplots(5, 2, figsize=(20, 10), sharex=True, sharey=True, gridspec_kw={'width_ratios': [1, 1], 'wspace':0, 'left':0.04, 'right':0.96, 'bottom':0.05, 'top':0.92})\n fig.suptitle('Data from: ' + data_path)\n ax[0,0].set_title('100%', fontsize=13)\n ax[0,0].tick_params(direction='in', length=6, width=1.5)\n ax[0,0].spines['top'].set_linewidth(1.5)\n ax[0,0].spines['right'].set_linewidth(1.5)\n ax[0,0].spines['bottom'].set_linewidth(1.5)\n ax[0,0].spines['left'].set_linewidth(1.5)\n \n ax[0,0].hlines(0, 0, t_log100[-1] + 0.2, linewidth=1, linestyle='--')\n ax[0,0].errorbar(t_log100, means100, yerr=stands100, fmt='s', alpha=0.5, color=line_color)\n ax[0,0].plot(t_log100[1:], best_fit100(t_log100[1:].astype(float)), ls='--', color='orange')\n \n ax[0,0].text(0, -1, smallest_point100)\n \n \n \n ax[0,1].set_title('50%', fontsize=13)\n ax[0,1].tick_params(direction='in', length=6, width=1.5)\n ax[0,1].spines['top'].set_linewidth(1.5)\n ax[0,1].spines['right'].set_linewidth(1.5)\n ax[0,1].spines['bottom'].set_linewidth(1.5)\n ax[0,1].spines['left'].set_linewidth(1.5)\n \n ax[0,1].hlines(0, 0, t_log50[-1] +0.2, linewidth=1, linestyle='--')\n ax[0,1].errorbar(t_log50, means50, yerr=stands50, fmt='s', alpha=0.5, color=line_color)\n ax[0,1].plot(t_log50[1:], best_fit50(t_log50[1:].astype(float)), ls='--', color='orange')\n \n ax[0,1].text(0, -1, smallest_point50)\n \n \n \n ax[1,0].set_title('10%', fontsize=13)\n ax[1,0].tick_params(direction='in', length=6, width=1.5)\n ax[1,0].spines['top'].set_linewidth(1.5)\n ax[1,0].spines['right'].set_linewidth(1.5)\n ax[1,0].spines['bottom'].set_linewidth(1.5)\n ax[1,0].spines['left'].set_linewidth(1.5)\n \n ax[1,0].hlines(0, 0, t_log10[-1] +0.2, linewidth=1, linestyle='--')\n ax[1,0].errorbar(t_log10, means10, yerr=stands10, fmt='s', alpha=0.5, color=line_color)\n ax[1,0].plot(t_log10[1:], best_fit10(t_log10[1:].astype(float)), ls='--', color='orange')\n \n ax[1,0].text(0, -1, smallest_point10)\n \n \n \n ax[1,1].set_title('5%', fontsize=13)\n ax[1,1].tick_params(direction='in', length=6, width=1.5)\n ax[1,1].spines['top'].set_linewidth(1.5)\n ax[1,1].spines['right'].set_linewidth(1.5)\n ax[1,1].spines['bottom'].set_linewidth(1.5)\n ax[1,1].spines['left'].set_linewidth(1.5)\n \n ax[1,1].hlines(0, 0, t_log5[-1] +0.2, linewidth=1, linestyle='--')\n ax[1,1].errorbar(t_log5, means5, yerr=stands5, fmt='s', alpha=0.5, color=line_color)\n ax[1,1].plot(t_log5[1:], best_fit5(t_log5[1:].astype(float)), ls='--', color='orange')\n \n ax[1,1].text(0, -1, smallest_point5)\n \n \n \n ax[2,0].set_title('1%', fontsize=13)\n ax[2,0].tick_params(direction='in', length=6, width=1.5)\n ax[2,0].spines['top'].set_linewidth(1.5)\n ax[2,0].spines['right'].set_linewidth(1.5)\n ax[2,0].spines['bottom'].set_linewidth(1.5)\n ax[2,0].spines['left'].set_linewidth(1.5)\n \n ax[2,0].hlines(0, 0, t_log1[-1] +0.2, linewidth=1, linestyle='--')\n ax[2,0].errorbar(t_log1, means1, yerr=stands1, fmt='s', alpha=0.5, color=line_color)\n ax[2,0].plot(t_log1[1:], best_fit1(t_log1[1:].astype(float)), ls='--', color='orange')\n \n ax[2,0].text(0, -1, smallest_point1)\n \n\n \n \n ax[2,1].set_title('0.5%', fontsize=13)\n ax[2,1].tick_params(direction='in', length=6, width=1.5)\n ax[2,1].spines['top'].set_linewidth(1.5)\n ax[2,1].spines['right'].set_linewidth(1.5)\n ax[2,1].spines['bottom'].set_linewidth(1.5)\n ax[2,1].spines['left'].set_linewidth(1.5)\n \n ax[2,1].hlines(0, 0, t_log05[-1] +0.2, linewidth=1, linestyle='--')\n ax[2,1].errorbar(t_log05, means05, yerr=stands05, fmt='s', alpha=0.5, color=line_color)\n ax[2,1].plot(t_log05[1:], best_fit05(t_log05[1:].astype(float)), ls='--', color='orange')\n \n ax[2,1].text(0, -1, smallest_point05)\n \n \n ax[3,0].set_title('0.1%', fontsize=13)\n ax[3,0].tick_params(direction='in', length=6, width=1.5)\n ax[3,0].spines['top'].set_linewidth(1.5)\n ax[3,0].spines['right'].set_linewidth(1.5)\n ax[3,0].spines['bottom'].set_linewidth(1.5)\n ax[3,0].spines['left'].set_linewidth(1.5)\n \n ax[3,0].hlines(0, 0, t_log01[-1] +0.2, linewidth=1, linestyle='--')\n ax[3,0].errorbar(t_log01, means01, yerr=stands01, fmt='s', alpha=0.5, color=line_color)\n ax[3,0].plot(t_log01[1:], best_fit01(t_log01[1:].astype(float)), ls='--', color='orange')\n \n ax[3,0].text(0, -1, smallest_point01)\n \n\n \n \n ax[3,1].set_title('0.05%', fontsize=13)\n ax[3,1].tick_params(direction='in', length=6, width=1.5)\n ax[3,1].spines['top'].set_linewidth(1.5)\n ax[3,1].spines['right'].set_linewidth(1.5)\n ax[3,1].spines['bottom'].set_linewidth(1.5)\n ax[3,1].spines['left'].set_linewidth(1.5)\n \n ax[3,1].hlines(0, 0, t_log005[-1] +0.2, linewidth=1, linestyle='--')\n ax[3,1].errorbar(t_log005, means005, yerr=stands005, fmt='s', alpha=0.5, color=line_color)\n ax[3,1].plot(t_log005[1:], best_fit005(t_log005[1:].astype(float)), ls='--', color='orange')\n \n ax[3,1].text(0, -1, smallest_point005)\n \n \n \n ax[4,0].set_title('0.02%', fontsize=13)\n ax[4,0].tick_params(direction='in', length=6, width=1.5)\n ax[4,0].spines['top'].set_linewidth(1.5)\n ax[4,0].spines['right'].set_linewidth(1.5)\n ax[4,0].spines['bottom'].set_linewidth(1.5)\n ax[4,0].spines['left'].set_linewidth(1.5)\n ax[4,0].set_xlabel('log(t/time units)', fontsize=13)\n ax[4,0].set_ylabel('Mean $\\Delta$log(Edd. Ratio)', fontsize=13)\n \n ax[4,0].hlines(0, 0, t_log002[-1] +0.2, linewidth=1, linestyle='--')\n ax[4,0].errorbar(t_log002, means002, yerr=stands002, fmt='s', alpha=0.5, color=line_color)\n ax[4,0].plot(t_log002[1:], best_fit002(t_log002[1:].astype(float)), ls='--', color='orange')\n \n ax[4,0].text(0, -1, smallest_point002)\n \n \n \n ax[4,1].set_title('As small as possible (0.006%)', fontsize=13)\n ax[4,1].tick_params(direction='in', length=6, width=1.5)\n ax[4,1].spines['top'].set_linewidth(1.5)\n ax[4,1].spines['right'].set_linewidth(1.5)\n ax[4,1].spines['bottom'].set_linewidth(1.5)\n ax[4,1].spines['left'].set_linewidth(1.5)\n ax[4,1].set_xlabel('log(t/time units)', fontsize=13)\n \n ax[4,1].hlines(0, 0, t_loginf[-1] +0.2, linewidth=1, linestyle='--')\n ax[4,1].errorbar(t_loginf, meansinf, yerr=standsinf, fmt='s', alpha=0.5, color=line_color)\n ax[4,1].plot(t_loginf[1:], best_fitinf(t_loginf[1:].astype(float)), ls='--', color='orange')\n \n ax[4,1].text(0, -1, smallest_pointinf)\n \nplt.savefig('10-panel_eddington_plot.pdf', bbox_inches='tight') \nplt.show()",
"_____no_output_____"
],
[
"# Structure function plots\nwith plt.style.context('seaborn-paper'):\n fig, ax = plt.subplots(5, 2, figsize=(20, 10), sharex=True, sharey=True, gridspec_kw={'width_ratios': [1, 1], 'wspace':0, 'left':0.04, 'right':0.96, 'bottom':0.05, 'top':0.92})\n fig.suptitle('Data from: ' + data_path)\n \n ax[0,0].set_title('100%', fontsize=13)\n ax[0,0].tick_params(direction='in', length=6, width=1.5)\n ax[0,0].spines['top'].set_linewidth(1.5)\n ax[0,0].spines['right'].set_linewidth(1.5)\n ax[0,0].spines['bottom'].set_linewidth(1.5)\n ax[0,0].spines['left'].set_linewidth(1.5)\n \n \n ax[0,0].plot(t_log100[1:], np.log10(stands100[1:]), color=line_color)\n \n ax[0,0].text(0.5, -1, smallest_point100)\n \n \n \n ax[0,1].set_title('50%', fontsize=13)\n ax[0,1].tick_params(direction='in', length=6, width=1.5)\n ax[0,1].spines['top'].set_linewidth(1.5)\n ax[0,1].spines['right'].set_linewidth(1.5)\n ax[0,1].spines['bottom'].set_linewidth(1.5)\n ax[0,1].spines['left'].set_linewidth(1.5)\n \n \n ax[0,1].plot(t_log50[1:], np.log10(stands50[1:]), color=line_color)\n \n ax[0,1].text(0.5, -1, smallest_point50)\n \n \n \n ax[1,0].set_title('10%', fontsize=13)\n ax[1,0].tick_params(direction='in', length=6, width=1.5)\n ax[1,0].spines['top'].set_linewidth(1.5)\n ax[1,0].spines['right'].set_linewidth(1.5)\n ax[1,0].spines['bottom'].set_linewidth(1.5)\n ax[1,0].spines['left'].set_linewidth(1.5)\n \n \n ax[1,0].plot(t_log10[1:], np.log10(stands10[1:]), color=line_color)\n \n ax[1,0].text(0.5, -1, smallest_point10)\n \n \n \n ax[1,1].set_title('5%', fontsize=13)\n ax[1,1].tick_params(direction='in', length=6, width=1.5)\n ax[1,1].spines['top'].set_linewidth(1.5)\n ax[1,1].spines['right'].set_linewidth(1.5)\n ax[1,1].spines['bottom'].set_linewidth(1.5)\n ax[1,1].spines['left'].set_linewidth(1.5)\n \n \n ax[1,1].plot(t_log5[1:], np.log10(stands5[1:]), color=line_color)\n \n ax[1,1].text(0.5, -1, smallest_point5)\n \n \n \n ax[2,0].set_title('1%', fontsize=13)\n ax[2,0].tick_params(direction='in', length=6, width=1.5)\n ax[2,0].spines['top'].set_linewidth(1.5)\n ax[2,0].spines['right'].set_linewidth(1.5)\n ax[2,0].spines['bottom'].set_linewidth(1.5)\n ax[2,0].spines['left'].set_linewidth(1.5)\n \n \n ax[2,0].plot(t_log1[1:], np.log10(stands1[1:]), color=line_color)\n \n ax[2,0].text(0.5, -1, smallest_point1)\n \n\n \n \n ax[2,1].set_title('0.5%', fontsize=13)\n ax[2,1].tick_params(direction='in', length=6, width=1.5)\n ax[2,1].spines['top'].set_linewidth(1.5)\n ax[2,1].spines['right'].set_linewidth(1.5)\n ax[2,1].spines['bottom'].set_linewidth(1.5)\n ax[2,1].spines['left'].set_linewidth(1.5)\n \n \n ax[2,1].plot(t_log05[1:], np.log10(stands05[1:]), color=line_color)\n \n ax[2,1].text(0.5, -1, smallest_point05)\n \n \n ax[3,0].set_title('0.1%', fontsize=13)\n ax[3,0].tick_params(direction='in', length=6, width=1.5)\n ax[3,0].spines['top'].set_linewidth(1.5)\n ax[3,0].spines['right'].set_linewidth(1.5)\n ax[3,0].spines['bottom'].set_linewidth(1.5)\n ax[3,0].spines['left'].set_linewidth(1.5)\n \n \n ax[3,0].plot(t_log01[1:], np.log10(stands01[1:]), color=line_color)\n \n ax[3,0].text(0.5, -1, smallest_point01)\n \n\n \n \n ax[3,1].set_title('0.05%', fontsize=13)\n ax[3,1].tick_params(direction='in', length=6, width=1.5)\n ax[3,1].spines['top'].set_linewidth(1.5)\n ax[3,1].spines['right'].set_linewidth(1.5)\n ax[3,1].spines['bottom'].set_linewidth(1.5)\n ax[3,1].spines['left'].set_linewidth(1.5)\n \n \n ax[3,1].plot(t_log005[1:], np.log10(stands005[1:]), color=line_color)\n \n ax[3,1].text(0.5, -1, smallest_point005)\n \n \n \n ax[4,0].set_title('0.02%', fontsize=13)\n ax[4,0].tick_params(direction='in', length=6, width=1.5)\n ax[4,0].spines['top'].set_linewidth(1.5)\n ax[4,0].spines['right'].set_linewidth(1.5)\n ax[4,0].spines['bottom'].set_linewidth(1.5)\n ax[4,0].spines['left'].set_linewidth(1.5)\n ax[4,0].set_xlabel('log(t/time units)', fontsize=13)\n ax[4,0].set_ylabel('log(SF)', fontsize=13)\n \n \n ax[4,0].plot(t_log002[1:], np.log10(stands002[1:]), color=line_color)\n \n ax[4,0].text(0.5, -1, smallest_point002)\n \n \n \n ax[4,1].set_title('As small as possible (0.006%)', fontsize=13)\n ax[4,1].tick_params(direction='in', length=6, width=1.5)\n ax[4,1].spines['top'].set_linewidth(1.5)\n ax[4,1].spines['right'].set_linewidth(1.5)\n ax[4,1].spines['bottom'].set_linewidth(1.5)\n ax[4,1].spines['left'].set_linewidth(1.5)\n ax[4,1].set_xlabel('log(t/time units)', fontsize=13)\n \n \n ax[4,1].plot(t_loginf[1:], np.log10(standsinf[1:]), color=line_color)\n \n ax[4,1].text(0.5, -1, smallest_pointinf)\n \nplt.savefig('10-panel_SF_plot.pdf', bbox_inches='tight') \nplt.show()",
"/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:14: RuntimeWarning: divide by zero encountered in log10\n \n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:28: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:42: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:56: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:70: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:85: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:98: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:113: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:129: RuntimeWarning: divide by zero encountered in log10\n/home/tpena01/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:144: RuntimeWarning: divide by zero encountered in log10\n"
]
],
[
[
"## 4-Line plots",
"_____no_output_____"
]
],
[
[
"# PSD regime determination plot\nwith plt.style.context('seaborn-paper'):\n fig, ax = plt.subplots(1, figsize=(20, 10))\n \n ax.set_title('Mean change in log(Edd. Ratio) as a function of chosen percent. Data from: '+ data_path, fontsize=13)\n ax.tick_params(direction='in', length=6, width=1.5)\n ax.spines['top'].set_linewidth(1.5)\n ax.spines['right'].set_linewidth(1.5)\n ax.spines['bottom'].set_linewidth(1.5)\n ax.spines['left'].set_linewidth(1.5)\n ax.set_xlabel('log(% total data)', fontsize=18)\n ax.set_xlim(x[0], x[-1])\n ax.set_ylabel('Mean $\\Delta$log(Edd. Ratio)', fontsize=18)\n \n ax.plot(x, log_t_1, label='log(t/time units) = 1', marker='o', markersize=10)\n ax.plot(x, log_t_2, label='log(t/time units) = 2', marker='o', markersize=10)\n ax.plot(x, log_t_3, label='log(t/time units) = 3', marker='o', markersize=10)\n ax.plot(x, log_t_4, label='log(t/time units) = 4', marker='o', markersize=10)\n \n ax.legend(prop={'size':18})\n \nplt.savefig('4-line_eddington_plot.pdf', bbox_inches='tight') \nplt.show()",
"_____no_output_____"
],
[
"# Structure functions in a strange space\nwith plt.style.context('seaborn-paper'):\n fig, ax = plt.subplots(1, figsize=(20, 10))\n \n ax.set_title('log(SF) as a function of log(chosen percent). Data from: ' + data_path, fontsize=13)\n ax.tick_params(direction='in', length=6, width=1.5)\n ax.spines['top'].set_linewidth(1.5)\n ax.spines['right'].set_linewidth(1.5)\n ax.spines['bottom'].set_linewidth(1.5)\n ax.spines['left'].set_linewidth(1.5)\n ax.set_xlabel('log(% total data)', fontsize=18)\n ax.set_xlim(x[0], x[-1])\n ax.set_ylabel('log(SF)', fontsize=18)\n \n ax.plot(x, log_t_1_stands, label='log(t/time units) = 1', marker='o', markersize=10)\n ax.plot(x, log_t_2_stands, label='log(t/time units) = 2', marker='o', markersize=10)\n ax.plot(x, log_t_3_stands, label='log(t/time units) = 3', marker='o', markersize=10)\n ax.plot(x, log_t_4_stands, label='log(t/time units) = 4', marker='o', markersize=10)\n \n ax.legend(prop={'size':18})\n \nplt.savefig('4-line_SF_plot.pdf', bbox_inches='tight') \nplt.show()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a466b6b0345402e841b98dc054cfd1460164729
| 890,173 |
ipynb
|
Jupyter Notebook
|
notebooks/2-linear-algebra-ii.ipynb
|
jmcca11um/ML-foundations
|
2997fa373f04952b66a3d89a480fc08a38ffedc9
|
[
"MIT"
] | 1 |
2020-07-07T10:31:17.000Z
|
2020-07-07T10:31:17.000Z
|
notebooks/2-linear-algebra-ii.ipynb
|
jmcca11um/ML-foundations
|
2997fa373f04952b66a3d89a480fc08a38ffedc9
|
[
"MIT"
] | null | null | null |
notebooks/2-linear-algebra-ii.ipynb
|
jmcca11um/ML-foundations
|
2997fa373f04952b66a3d89a480fc08a38ffedc9
|
[
"MIT"
] | null | null | null | 132.821993 | 109,928 | 0.891515 |
[
[
[
"<a href=\"https://colab.research.google.com/github/jonkrohn/ML-foundations/blob/master/notebooks/2-linear-algebra-ii.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Linear Algebra II: Matrix Operations",
"_____no_output_____"
],
[
"This topic, *Linear Algebra II: Matrix Operations*, builds on the basics of linear algebra. It is essential because these intermediate-level manipulations of tensors lie at the heart of most machine learning approaches and are especially predominant in deep learning. \n\nThrough the measured exposition of theory paired with interactive examples, you’ll develop an understanding of how linear algebra is used to solve for unknown values in high-dimensional spaces as well as to reduce the dimensionality of complex spaces. The content covered in this topic is itself foundational for several other topics in the *Machine Learning Foundations* series, especially *Probability & Information Theory* and *Optimization*. ",
"_____no_output_____"
],
[
"Over the course of studying this topic, you'll: \n\n* Develop a geometric intuition of what’s going on beneath the hood of machine learning algorithms, including those used for deep learning. \n* Be able to more intimately grasp the details of machine learning papers as well as all of the other subjects that underlie ML, including calculus, statistics, and optimization algorithms. \n* Reduce the dimensionalty of complex spaces down to their most informative elements with techniques such as eigendecomposition, singular value decomposition, and principal components analysis.",
"_____no_output_____"
],
[
"**Note that this Jupyter notebook is not intended to stand alone. It is the companion code to a lecture or to videos from Jon Krohn's [Machine Learning Foundations](https://github.com/jonkrohn/ML-foundations) series, which offer detail on the following:**\n\n*Review of Matrix Properties*\n\n* Modern Linear Algebra Applications\n* Tensors, Vectors, and Norms\n* Matrix Multiplication\n* Matrix Inversion\n* Identity, Diagonal and Orthogonal Matrices\n\n*Segment 2: Eigendecomposition*\n\n* Eigenvectors\n* Eigenvalues\n* Matrix Determinants\n* Matrix Decomposition \n* Applications of Eigendecomposition\n\n*Segment 3: Matrix Operations for Machine Learning*\n\n* Singular Value Decomposition (SVD)\n* The Moore-Penrose Pseudoinverse\n* The Trace Operator\n* Principal Component Analysis (PCA): A Simple Machine Learning Algorithm\n* Resources for Further Study of Linear Algebra",
"_____no_output_____"
],
[
"## Segment 1: Review of Tensor Properties",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch",
"_____no_output_____"
]
],
[
[
"### Vector Transposition",
"_____no_output_____"
]
],
[
[
"x = np.array([25, 2, 5])\nx",
"_____no_output_____"
],
[
"x.shape",
"_____no_output_____"
],
[
"x = np.array([[25, 2, 5]])\nx",
"_____no_output_____"
],
[
"x.shape",
"_____no_output_____"
],
[
"x.T",
"_____no_output_____"
],
[
"x.T.shape",
"_____no_output_____"
],
[
"x_p = torch.tensor([25, 2, 5])\nx_p",
"_____no_output_____"
],
[
"x_p.T",
"_____no_output_____"
],
[
"x_p.view(3, 1) # \"view\" because we're changing output but not the way x is stored in memory",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"## $L^2$ Norm",
"_____no_output_____"
]
],
[
[
"x",
"_____no_output_____"
],
[
"(25**2 + 2**2 + 5**2)**(1/2)",
"_____no_output_____"
],
[
"np.linalg.norm(x)",
"_____no_output_____"
]
],
[
[
"So, if units in this 3-dimensional vector space are meters, then the vector $x$ has a length of 25.6m",
"_____no_output_____"
]
],
[
[
"# the following line of code will fail because torch.norm() requires input to be float not integer\n# torch.norm(p)",
"_____no_output_____"
],
[
"torch.norm(torch.tensor([25, 2, 5.]))",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Matrices",
"_____no_output_____"
]
],
[
[
"X = np.array([[25, 2], [5, 26], [3, 7]])\nX",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"X_p = torch.tensor([[25, 2], [5, 26], [3, 7]])\nX_p",
"_____no_output_____"
],
[
"X_p.shape",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Matrix Transposition",
"_____no_output_____"
]
],
[
[
"X",
"_____no_output_____"
],
[
"X.T",
"_____no_output_____"
],
[
"X_p.T",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Matrix Multiplication",
"_____no_output_____"
],
[
"Scalars are applied to each element of matrix:",
"_____no_output_____"
]
],
[
[
"X*3",
"_____no_output_____"
],
[
"X*3+3",
"_____no_output_____"
],
[
"X_p*3",
"_____no_output_____"
],
[
"X_p*3+3",
"_____no_output_____"
]
],
[
[
"Using the multiplication operator on two tensors of the same size in PyTorch (or Numpy or TensorFlow) applies element-wise operations. This is the **Hadamard product** (denoted by the $\\odot$ operator, e.g., $A \\odot B$) *not* **matrix multiplication**: ",
"_____no_output_____"
]
],
[
[
"A = np.array([[3, 4], [5, 6], [7, 8]])\nA",
"_____no_output_____"
],
[
"X",
"_____no_output_____"
],
[
"X * A",
"_____no_output_____"
],
[
"A_p = torch.tensor([[3, 4], [5, 6], [7, 8]])\nA_p",
"_____no_output_____"
],
[
"X_p * A_p",
"_____no_output_____"
]
],
[
[
"Matrix multiplication with a vector: ",
"_____no_output_____"
]
],
[
[
"b = np.array([1, 2])\nb",
"_____no_output_____"
],
[
"np.dot(A, b) # even though technically dot products is between 2 vectors",
"_____no_output_____"
],
[
"b_p = torch.tensor([1, 2])\nb_p",
"_____no_output_____"
],
[
"torch.matmul(A_p, b_p)",
"_____no_output_____"
]
],
[
[
"Matrix multiplication with two matrices:",
"_____no_output_____"
]
],
[
[
"B = np.array([[1, 9], [2, 0]])\nB",
"_____no_output_____"
],
[
"np.dot(A, B) # note first column is same as Xb",
"_____no_output_____"
],
[
"B_p = torch.tensor([[1, 9], [2, 0]])\nB_p",
"_____no_output_____"
],
[
"torch.matmul(A_p, B_p) ",
"_____no_output_____"
]
],
[
[
"### Matrix Inversion",
"_____no_output_____"
]
],
[
[
"X = np.array([[4, 2], [-5, -3]])\nX",
"_____no_output_____"
],
[
"Xinv = np.linalg.inv(X)\nXinv",
"_____no_output_____"
],
[
"y = np.array([4, -7])\ny",
"_____no_output_____"
],
[
"w = np.dot(Xinv, y)\nw",
"_____no_output_____"
]
],
[
[
"Show that $y = Xw$: ",
"_____no_output_____"
]
],
[
[
"np.dot(X, w)",
"_____no_output_____"
],
[
"X_p = torch.tensor([[4, 2], [-5, -3.]]) # note that torch.inverse() requires floats\nX_p",
"_____no_output_____"
],
[
"Xinv_p = torch.inverse(X_p)\nXinv_p",
"_____no_output_____"
],
[
"y_p = torch.tensor([4, -7.])\ny_p",
"_____no_output_____"
],
[
"w_p = torch.matmul(Xinv_p, y_p)\nw_p",
"_____no_output_____"
],
[
"torch.matmul(X_p, w_p)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"## Segment 2: Eigendecomposition",
"_____no_output_____"
],
[
"### Eigenvectors and Eigenvalues",
"_____no_output_____"
],
[
"Let's say we have a vector $v$:",
"_____no_output_____"
]
],
[
[
"v = np.array([3, 1])\nv",
"_____no_output_____"
]
],
[
[
"Let's plot $v$ using Hadrien Jean's handy `plotVectors` function (from [this notebook](https://github.com/hadrienj/deepLearningBook-Notes/blob/master/2.7%20Eigendecomposition/2.7%20Eigendecomposition.ipynb) under [MIT license](https://github.com/hadrienj/deepLearningBook-Notes/blob/master/LICENSE)).",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"def plotVectors(vecs, cols, alpha=1):\n \"\"\"\n Plot set of vectors.\n\n Parameters\n ----------\n vecs : array-like\n Coordinates of the vectors to plot. Each vectors is in an array. For\n instance: [[1, 3], [2, 2]] can be used to plot 2 vectors.\n cols : array-like\n Colors of the vectors. For instance: ['red', 'blue'] will display the\n first vector in red and the second in blue.\n alpha : float\n Opacity of vectors\n\n Returns:\n\n fig : instance of matplotlib.figure.Figure\n The figure of the vectors\n \"\"\"\n plt.figure()\n plt.axvline(x=0, color='#A9A9A9', zorder=0)\n plt.axhline(y=0, color='#A9A9A9', zorder=0)\n\n for i in range(len(vecs)):\n x = np.concatenate([[0,0],vecs[i]])\n plt.quiver([x[0]],\n [x[1]],\n [x[2]],\n [x[3]],\n angles='xy', scale_units='xy', scale=1, color=cols[i],\n alpha=alpha)",
"_____no_output_____"
],
[
"plotVectors([v], cols=['lightblue'])\n_ = plt.xlim(-1, 5)\n_ = plt.ylim(-1, 5)",
"_____no_output_____"
]
],
[
[
"\"Applying\" a matrix to a vector (i.e., performing matrix-vector multiplication) can linearly transform the vector, e.g, rotate it or rescale it.",
"_____no_output_____"
],
[
"The identity matrix, introduced earlier, is the exception that proves the rule: Applying an identity matrix does not transform the vector: ",
"_____no_output_____"
]
],
[
[
"I = np.array([[1, 0], [0, 1]])\nI",
"_____no_output_____"
],
[
"Iv = np.dot(I, v)\nIv",
"_____no_output_____"
],
[
"v == Iv",
"_____no_output_____"
],
[
"plotVectors([Iv], cols=['blue'])\n_ = plt.xlim(-1, 5)\n_ = plt.ylim(-1, 5)",
"_____no_output_____"
]
],
[
[
"In contrast, let's see what happens when we apply (some non-identity matrix) $A$ to the vector $v$: ",
"_____no_output_____"
]
],
[
[
"A = np.array([[-1, 4], [2, -2]])\nA",
"_____no_output_____"
],
[
"Av = np.dot(A, v)\nAv",
"_____no_output_____"
],
[
"plotVectors([v, Av], ['lightblue', 'blue'])\n_ = plt.xlim(-1, 5)\n_ = plt.ylim(-1, 5)",
"_____no_output_____"
],
[
"# a second example:\nv2 = np.array([2, 1])\nplotVectors([v2, np.dot(A, v2)], ['lightgreen', 'green'])\n_ = plt.xlim(-1, 5)\n_ = plt.ylim(-1, 5)",
"_____no_output_____"
]
],
[
[
"We can concatenate several vectors together into a matrix (say, $V$), where each column is a separate vector. Then, whatever linear transformations we apply to $V$ will be independently applied to each column (vector): ",
"_____no_output_____"
]
],
[
[
"v",
"_____no_output_____"
],
[
"# recall that we need to convert array to 2D to transpose into column, e.g.:\nnp.matrix(v).T ",
"_____no_output_____"
],
[
"v3 = np.array([-3, -1]) # mirror image of x over both axes\nv4 = np.array([-1, 1])",
"_____no_output_____"
],
[
"V = np.concatenate((np.matrix(v).T, \n np.matrix(v2).T,\n np.matrix(v3).T,\n np.matrix(v4).T), \n axis=1)\nV",
"_____no_output_____"
],
[
"IV = np.dot(I, V)\nIV",
"_____no_output_____"
],
[
"AV = np.dot(A, V)\nAV",
"_____no_output_____"
],
[
"# function to convert column of matrix to 1D vector: \ndef vectorfy(mtrx, clmn):\n return np.array(mtrx[:,clmn]).reshape(-1)",
"_____no_output_____"
],
[
"vectorfy(V, 0)",
"_____no_output_____"
],
[
"vectorfy(V, 0) == v",
"_____no_output_____"
],
[
"plotVectors([vectorfy(V, 0), vectorfy(V, 1), vectorfy(V, 2), vectorfy(V, 3),\n vectorfy(AV, 0), vectorfy(AV, 1), vectorfy(AV, 2), vectorfy(AV, 3)], \n ['lightblue', 'lightgreen', 'lightgray', 'orange',\n 'blue', 'green', 'gray', 'red'])\n_ = plt.xlim(-4, 6)\n_ = plt.ylim(-5, 5)",
"_____no_output_____"
]
],
[
[
"Now that we can appreciate linear transformation of vectors by matrices, let's move on to working with eigenvectors and eigenvalues. \n\nAn **eigenvector** (*eigen* is German for \"typical\"; we could translate *eigenvector* to \"characteristic vector\") is a special vector $v$ such that when it is transformed by some matrix (let's say $A$), the product $Av$ has the exact same direction as $v$.\n\nAn **eigenvalue** is a scalar (traditionally represented as $\\lambda$) that simply scales the eigenvector $v$ such that the following equation is satisfied: \n\n$Av = \\lambda v$",
"_____no_output_____"
],
[
"Easiest way to understand this is to work through an example: ",
"_____no_output_____"
]
],
[
[
"A",
"_____no_output_____"
]
],
[
[
"Eigenvectors and eigenvalues can be derived algebraically (e.g., with the [QR algorithm](https://en.wikipedia.org/wiki/QR_algorithm), which was independent developed in the 1950s by both [Vera Kublanovskaya](https://en.wikipedia.org/wiki/Vera_Kublanovskaya) and John Francis), however this is outside scope of today's class. We'll cheat with NumPy `eig()` method, which returns a tuple of: \n\n* a vector of eigenvalues\n* a matrix of eigenvectors",
"_____no_output_____"
]
],
[
[
"lambdas, V = np.linalg.eig(A) ",
"_____no_output_____"
]
],
[
[
"The matrix contains as many eigenvectors as there are columns of A: ",
"_____no_output_____"
]
],
[
[
"V # each column is a separate eigenvector v",
"_____no_output_____"
]
],
[
[
"With a corresponding eigenvalue for each eigenvector:",
"_____no_output_____"
]
],
[
[
"lambdas",
"_____no_output_____"
]
],
[
[
"Let's confirm that $Av = \\lambda v$ for the first eigenvector: ",
"_____no_output_____"
]
],
[
[
"v = V[:,0] \nv",
"_____no_output_____"
],
[
"lambduh = lambdas[0] # note that \"lambda\" is reserved term in Python\nlambduh",
"_____no_output_____"
],
[
"Av = np.dot(A, v)\nAv",
"_____no_output_____"
],
[
"lambduh * v",
"_____no_output_____"
],
[
"plotVectors([Av, v], ['blue', 'lightblue'])\n_ = plt.xlim(-1, 2)\n_ = plt.ylim(-1, 2)",
"_____no_output_____"
]
],
[
[
"And again for the second eigenvector of A: ",
"_____no_output_____"
]
],
[
[
"v2 = V[:,1]\nv2",
"_____no_output_____"
],
[
"lambda2 = lambdas[1]\nlambda2",
"_____no_output_____"
],
[
"Av2 = np.dot(A, v2)\nAv2",
"_____no_output_____"
],
[
"lambda2 * v2",
"_____no_output_____"
],
[
"plotVectors([Av, v, Av2, v2], \n ['blue', 'lightblue', 'green', 'lightgreen'])\n_ = plt.xlim(-1, 4)\n_ = plt.ylim(-3, 2)",
"_____no_output_____"
]
],
[
[
"Using the PyTorch `eig()` method, we can do exactly the same: ",
"_____no_output_____"
]
],
[
[
"A",
"_____no_output_____"
],
[
"A_p = torch.tensor([[-1, 4], [2, -2.]]) # must be float for PyTorch eig()\nA_p",
"_____no_output_____"
],
[
"eigens = torch.eig(A_p, eigenvectors=True) \neigens",
"_____no_output_____"
],
[
"v_p = eigens.eigenvectors[:,0]\nv_p",
"_____no_output_____"
],
[
"lambda_p = eigens.eigenvalues[0][0]\nlambda_p",
"_____no_output_____"
],
[
"Av_p = torch.matmul(A_p, v_p)\nAv_p",
"_____no_output_____"
],
[
"lambda_p * v_p",
"_____no_output_____"
],
[
"v2_p = eigens.eigenvectors[:,1]\nv2_p",
"_____no_output_____"
],
[
"lambda2_p = eigens.eigenvalues[1][0]\nlambda2_p",
"_____no_output_____"
],
[
"Av2_p = torch.matmul(A_p, v2_p)\nAv2_p",
"_____no_output_____"
],
[
"lambda2_p * v2_p",
"_____no_output_____"
],
[
"plotVectors([Av_p.numpy(), v_p.numpy(), Av2_p.numpy(), v2_p.numpy()], \n ['blue', 'lightblue', 'green', 'lightgreen'])\n_ = plt.xlim(-1, 4)\n_ = plt.ylim(-3, 2)",
"_____no_output_____"
]
],
[
[
"### Eigenvectors in >2 Dimensions",
"_____no_output_____"
],
[
"While plotting gets trickier in higher-dimensional spaces, we can nevertheless find and use eigenvectors with more than two dimensions. Here's a 3D example (there are three dimensions handled over three rows): ",
"_____no_output_____"
]
],
[
[
"X",
"_____no_output_____"
],
[
"lambdas_X, V_X = np.linalg.eig(X) ",
"_____no_output_____"
],
[
"V_X # one eigenvector per column of X",
"_____no_output_____"
],
[
"lambdas_X # a corresponding eigenvalue for each eigenvector",
"_____no_output_____"
]
],
[
[
"Confirm $Xv = \\lambda v$ for an example vector: ",
"_____no_output_____"
]
],
[
[
"v_X = V_X[:,0] \nv_X",
"_____no_output_____"
],
[
"lambda_X = lambdas_X[0] \nlambda_X",
"_____no_output_____"
],
[
"np.dot(X, v_X) # matrix multiplication",
"_____no_output_____"
],
[
"lambda_X * v_X",
"_____no_output_____"
]
],
[
[
"**Exercises**:\n\n1. Use PyTorch to confirm $Xv = \\lambda v$ for the first eigenvector of $X$.\n2. Confirm $Xv = \\lambda v$ for the remaining eigenvectors of $X$ (you can use NumPy or PyTorch, whichever you prefer).",
"_____no_output_____"
],
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### 2x2 Matrix Determinants",
"_____no_output_____"
]
],
[
[
"X",
"_____no_output_____"
],
[
"np.linalg.det(X)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
]
],
[
[
"N = np.array([[-4, 1], [-8, 2]])\nN",
"_____no_output_____"
],
[
"np.linalg.det(N)",
"_____no_output_____"
],
[
"# Uncommenting the following line results in a \"singular matrix\" error\n# Ninv = np.linalg.inv(N)",
"_____no_output_____"
],
[
"N = torch.tensor([[-4, 1], [-8, 2.]]) # must use float not int",
"_____no_output_____"
],
[
"torch.det(N) ",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Generalizing Determinants",
"_____no_output_____"
]
],
[
[
"X = np.array([[1, 2, 4], [2, -1, 3], [0, 5, 1]])\nX",
"_____no_output_____"
],
[
"np.linalg.det(X)",
"_____no_output_____"
]
],
[
[
"### Determinants & Eigenvalues",
"_____no_output_____"
]
],
[
[
"lambdas, V = np.linalg.eig(X)\nlambdas",
"_____no_output_____"
],
[
"np.product(lambdas)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
]
],
[
[
"np.abs(np.product(lambdas))",
"_____no_output_____"
],
[
"B = np.array([[1, 0], [0, 1]])\nB",
"_____no_output_____"
],
[
"plotVectors([vectorfy(B, 0), vectorfy(B, 1)],\n ['lightblue', 'lightgreen'])\n_ = plt.xlim(-1, 3)\n_ = plt.ylim(-1, 3)",
"_____no_output_____"
],
[
"N",
"_____no_output_____"
],
[
"np.linalg.det(N)",
"_____no_output_____"
],
[
"NB = np.dot(N, B)\nNB",
"_____no_output_____"
],
[
"plotVectors([vectorfy(B, 0), vectorfy(B, 1), vectorfy(NB, 0), vectorfy(NB, 1)],\n ['lightblue', 'lightgreen', 'blue', 'green'])\n_ = plt.xlim(-6, 6)\n_ = plt.ylim(-9, 3)",
"_____no_output_____"
],
[
"I",
"_____no_output_____"
],
[
"np.linalg.det(I)",
"_____no_output_____"
],
[
"IB = np.dot(I, B)\nIB",
"_____no_output_____"
],
[
"plotVectors([vectorfy(B, 0), vectorfy(B, 1), vectorfy(IB, 0), vectorfy(IB, 1)],\n ['lightblue', 'lightgreen', 'blue', 'green'])\n_ = plt.xlim(-1, 3)\n_ = plt.ylim(-1, 3)",
"_____no_output_____"
],
[
"J = np.array([[-0.5, 0], [0, 2]])\nJ",
"_____no_output_____"
],
[
"np.linalg.det(J)",
"_____no_output_____"
],
[
"np.abs(np.linalg.det(J))",
"_____no_output_____"
],
[
"JB = np.dot(J, B)\nJB",
"_____no_output_____"
],
[
"plotVectors([vectorfy(B, 0), vectorfy(B, 1), vectorfy(JB, 0), vectorfy(JB, 1)],\n ['lightblue', 'lightgreen', 'blue', 'green'])\n_ = plt.xlim(-1, 3)\n_ = plt.ylim(-1, 3)",
"_____no_output_____"
],
[
"doubleI = I*2",
"_____no_output_____"
],
[
"np.linalg.det(doubleI)",
"_____no_output_____"
],
[
"doubleIB = np.dot(doubleI, B)\ndoubleIB",
"_____no_output_____"
],
[
"plotVectors([vectorfy(B, 0), vectorfy(B, 1), vectorfy(doubleIB, 0), vectorfy(doubleIB, 1)],\n ['lightblue', 'lightgreen', 'blue', 'green'])\n_ = plt.xlim(-1, 3)\n_ = plt.ylim(-1, 3)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Eigendecomposition",
"_____no_output_____"
],
[
"The **eigendecomposition** of some matrix $A$ is \n\n$A = V \\Lambda V^{-1}$\n\nWhere: \n\n* As in examples above, $V$ is the concatenation of all the eigenvectors of $A$\n* $\\Lambda$ (upper-case $\\lambda$) is the diagonal matrix diag($\\lambda$). Note that the convention is to arrange the lambda values in descending order; as a result, the first eigenvector (and its associated eigenvector) may be a primary characteristic of the matrix $A$.",
"_____no_output_____"
]
],
[
[
"# This was used earlier as a matrix X; it has nice clean integer eigenvalues...\nA = np.array([[4, 2], [-5, -3]]) \nA",
"_____no_output_____"
],
[
"lambdas, V = np.linalg.eig(A)",
"_____no_output_____"
],
[
"V",
"_____no_output_____"
],
[
"Vinv = np.linalg.inv(V)\nVinv",
"_____no_output_____"
],
[
"Lambda = np.diag(lambdas)\nLambda",
"_____no_output_____"
]
],
[
[
"Confirm that $A = V \\Lambda V^{-1}$: ",
"_____no_output_____"
]
],
[
[
"np.dot(V, np.dot(Lambda, Vinv))",
"_____no_output_____"
]
],
[
[
"Eigendecomposition is not possible with all matrices. And in some cases where it is possible, the eigendecomposition involves complex numbers instead of straightforward real numbers. \n\nIn machine learning, however, we are typically working with real symmetric matrices, which can be conveniently and efficiently decomposed into real-only eigenvectors and real-only eigenvalues. If $A$ is a real symmetric matrix then...\n\n$A = Q \\Lambda Q^T$\n\n...where $Q$ is analogous to $V$ from the previous equation except that it's special because it's an orthogonal matrix. ",
"_____no_output_____"
]
],
[
[
"A = np.array([[2, 1], [1, 2]])\nA",
"_____no_output_____"
],
[
"lambdas, Q = np.linalg.eig(A)",
"_____no_output_____"
],
[
"lambdas",
"_____no_output_____"
],
[
"Lambda = np.diag(lambdas)\nLambda",
"_____no_output_____"
],
[
"Q",
"_____no_output_____"
]
],
[
[
"Recalling that $Q^TQ = QQ^T = I$, can demonstrate that $Q$ is an orthogonal matrix: ",
"_____no_output_____"
]
],
[
[
"np.dot(Q.T, Q)",
"_____no_output_____"
],
[
"np.dot(Q, Q.T)",
"_____no_output_____"
]
],
[
[
"Let's confirm $A = Q \\Lambda Q^T$: ",
"_____no_output_____"
]
],
[
[
"np.dot(Q, np.dot(Lambda, Q.T))",
"_____no_output_____"
]
],
[
[
"**Exercises**:\n\n1. Use PyTorch to decompose the matrix $P$ (below) into its components $V$, $\\Lambda$, and $V^{-1}$. Confirm that $P = V \\Lambda V^{-1}$.\n2. Use PyTorch to decompose the symmetric matrix $S$ (below) into its components $Q$, $\\Lambda$, and $Q^T$. Confirm that $S = Q \\Lambda Q^T$.",
"_____no_output_____"
]
],
[
[
"P = torch.tensor([[25, 2, -5], [3, -2, 1], [5, 7, 4.]])\nP",
"_____no_output_____"
],
[
"S = torch.tensor([[25, 2, -5], [2, -2, 1], [-5, 1, 4.]])\nS",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"## Segment 3: Matrix Operations for ML",
"_____no_output_____"
],
[
"### Singular Value Decomposition (SVD)",
"_____no_output_____"
],
[
"As on slides, SVD of matrix $A$ is: \n\n$A = UDV^T$\n\nWhere: \n\n* $U$ is an orthogonal $m \\times m$ matrix; its columns are the **left-singular vectors** of $A$.\n* $V$ is an orthogonal $n \\times n$ matrix; its columns are the **right-singular vectors** of $A$.\n* $D$ is a diagonal $m \\times n$ matrix; elements along its diagonal are the **singular values** of $A$.",
"_____no_output_____"
]
],
[
[
"A = np.array([[-1, 2], [3, -2], [5, 7]])\nA",
"_____no_output_____"
],
[
"U, d, VT = np.linalg.svd(A) # V is already transposed",
"_____no_output_____"
],
[
"U",
"_____no_output_____"
],
[
"VT",
"_____no_output_____"
],
[
"d",
"_____no_output_____"
],
[
"np.diag(d)",
"_____no_output_____"
],
[
"D = np.concatenate((np.diag(d), [[0, 0]]), axis=0)\nD",
"_____no_output_____"
],
[
"np.dot(U, np.dot(D, VT))",
"_____no_output_____"
]
],
[
[
"SVD and eigendecomposition are closely related to each other: \n\n* Left-singular vectors of $A$ = eigenvectors of $AA^T$.\n* Right-singular vectors of $A$ = eigenvectors of $A^TA$.\n* Non-zero singular values of $A$ = square roots of eigenvectors of $AA^T$ = square roots of eigenvectors of $A^TA$\n\n**Exercise**: Using the matrix `P` from the preceding PyTorch exercises, demonstrate that these three SVD-eigendecomposition equations are true. ",
"_____no_output_____"
],
[
"### Image Compression via SVD",
"_____no_output_____"
],
[
"The section features code adapted from [Frank Cleary's](https://gist.github.com/frankcleary/4d2bd178708503b556b0).",
"_____no_output_____"
]
],
[
[
"import time\nfrom PIL import Image",
"_____no_output_____"
]
],
[
[
"Fetch photo of Oboe, a terrier, with the book *Deep Learning Illustrated*: ",
"_____no_output_____"
]
],
[
[
"! wget https://raw.githubusercontent.com/jonkrohn/DLTFpT/master/notebooks/oboe-with-book.jpg",
"--2020-06-09 01:18:55-- https://raw.githubusercontent.com/jonkrohn/DLTFpT/master/notebooks/oboe-with-book.jpg\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.208.133\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.208.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 419564 (410K) [image/jpeg]\nSaving to: ‘oboe-with-book.jpg’\n\noboe-with-book.jpg 100%[===================>] 409.73K --.-KB/s in 0.08s \n\n2020-06-09 01:18:56 (5.10 MB/s) - ‘oboe-with-book.jpg’ saved [419564/419564]\n\n"
],
[
"img = Image.open('oboe-with-book.jpg')\nplt.imshow(img)",
"_____no_output_____"
]
],
[
[
"Convert image to grayscale so that we don't have to deal with the complexity of multiple color channels: ",
"_____no_output_____"
]
],
[
[
"imggray = img.convert('LA')\nplt.imshow(imggray)",
"_____no_output_____"
]
],
[
[
"Convert data into numpy matrix, which doesn't impact image data: ",
"_____no_output_____"
]
],
[
[
"imgmat = np.array(list(imggray.getdata(band=0)), float)\nimgmat.shape = (imggray.size[1], imggray.size[0])\nimgmat = np.matrix(imgmat)\nplt.imshow(imgmat, cmap='gray')",
"_____no_output_____"
]
],
[
[
"Calculate SVD of the image: ",
"_____no_output_____"
]
],
[
[
"U, sigma, V = np.linalg.svd(imgmat)",
"_____no_output_____"
]
],
[
[
"As eigenvalues are arranged in descending order in diag($\\lambda$) so to are singular values, by convention, arranged in descending order in $D$ (or, in this code, diag($\\sigma$)). Thus, the first left-singular vector of $U$ and first right-singular vector of $V$ may represent the most prominent feature of the image: ",
"_____no_output_____"
]
],
[
[
"reconstimg = np.matrix(U[:, :1]) * np.diag(sigma[:1]) * np.matrix(V[:1, :])\nplt.imshow(reconstimg, cmap='gray')",
"_____no_output_____"
]
],
[
[
"Additional singular vectors improve the image quality: ",
"_____no_output_____"
]
],
[
[
"for i in [2, 4, 8, 16, 32, 64]:\n reconstimg = np.matrix(U[:, :i]) * np.diag(sigma[:i]) * np.matrix(V[:i, :])\n plt.imshow(reconstimg, cmap='gray')\n title = \"n = %s\" % i\n plt.title(title)\n plt.show()",
"_____no_output_____"
]
],
[
[
"With 64 singular vectors, the image is reconstructed quite well, however the data footprint is much smaller than the original image:",
"_____no_output_____"
]
],
[
[
"imgmat.shape",
"_____no_output_____"
],
[
"full_representation = 4032*3024\nfull_representation",
"_____no_output_____"
],
[
"svd64_rep = 64*4032 + 64 + 64*3024\nsvd64_rep",
"_____no_output_____"
],
[
"svd64_rep/full_representation",
"_____no_output_____"
]
],
[
[
"Specifically, the image represented as 64 singular vectors is 3.7% of the size of the original!",
"_____no_output_____"
],
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### The Moore-Penrose Pseudoinverse",
"_____no_output_____"
],
[
"Let's calculate the pseudoinverse $A^+$ of some matrix $A$ using the formula from the slides: \n\n$A^+ = VD^+U^T$",
"_____no_output_____"
]
],
[
[
"A",
"_____no_output_____"
]
],
[
[
"As shown earlier, the NumPy SVD method returns $U$, $d$, and $V^T$:",
"_____no_output_____"
]
],
[
[
"U, d, VT = np.linalg.svd(A)",
"_____no_output_____"
],
[
"U",
"_____no_output_____"
],
[
"VT",
"_____no_output_____"
],
[
"d",
"_____no_output_____"
]
],
[
[
"To create $D^+$, we first invert the non-zero values of $d$: ",
"_____no_output_____"
]
],
[
[
"D = np.diag(d)\nD",
"_____no_output_____"
],
[
"1/8.669",
"_____no_output_____"
],
[
"1/4.104",
"_____no_output_____"
]
],
[
[
"...and then we would take the tranpose of the resulting matrix.\n\nBecause $D$ is a diagonal matrix, this can, however, be done in a single step by inverting $D$: ",
"_____no_output_____"
]
],
[
[
"Dinv = np.linalg.inv(D)\nDinv",
"_____no_output_____"
]
],
[
[
"The final $D^+$ matrix needs to have a shape that can undergo matrix multiplication in the $A^+ = VD^+U^T$ equation. These dimensions can be obtained from $A$: ",
"_____no_output_____"
]
],
[
[
"A.shape[0]",
"_____no_output_____"
],
[
"A.shape[1]",
"_____no_output_____"
],
[
"Dplus = np.zeros((3, 2)).T\nDplus",
"_____no_output_____"
],
[
"Dplus[:2, :2] = Dinv\nDplus",
"_____no_output_____"
]
],
[
[
"Now we have everything we need to calculate $A^+$ with $VD^+U^T$: ",
"_____no_output_____"
]
],
[
[
"np.dot(VT.T, np.dot(Dplus, U.T))",
"_____no_output_____"
]
],
[
[
"Working out this derivation is helpful for understanding how Moore-Penrose pseudoinverses work, but unsurprisingly NumPy is loaded with an existing method `pinv()`: ",
"_____no_output_____"
]
],
[
[
"np.linalg.pinv(A)",
"_____no_output_____"
]
],
[
[
"**Exercise** \n\nUse the `torch.svd()` method to calculate the pseudoinverse of `A_p`, confirming that your result matches the output of `torch.pinverse(A_p)`: ",
"_____no_output_____"
]
],
[
[
"A_p = torch.tensor([[-1, 2], [3, -2], [5, 7.]])\nA_p",
"_____no_output_____"
],
[
"torch.pinverse(A_p)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"For regression problems, we typically have many more cases ($n$, or rows of $X$) than features to predict ($m$, or columns of $X$). Let's solve a miniature example of such an overdetermined situation. \n\nWe have eight data points ($n$ = 8): ",
"_____no_output_____"
]
],
[
[
"x1 = [0, 1, 2, 3, 4, 5, 6, 7.]\ny = [1.86, 1.31, .62, .33, .09, -.67, -1.23, -1.37]",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\n_ = ax.scatter(x1, y)",
"_____no_output_____"
]
],
[
[
"Although it appears there is only one predictor ($x_1$), we need a second one (let's call it $x_0$) in order to allow for a $y$-intercept (therefore, $m$ = 2). Without this second variable, the line we fit to the plot would need to pass through the origin (0, 0). The $y$-intercept is constant across all the points so we can set it equal to `1` across the board:",
"_____no_output_____"
]
],
[
[
"x0 = np.ones(8)\nx0",
"_____no_output_____"
]
],
[
[
"Concatenate $x_0$ and $x_1$ into a matrix $X$: ",
"_____no_output_____"
]
],
[
[
"X = np.concatenate((np.matrix(x0).T, np.matrix(x1).T), axis=1)\nX",
"_____no_output_____"
]
],
[
[
"From the slides, we know that we can compute the weights $w$ using the pseudoinverse of $w = X^+y$: ",
"_____no_output_____"
]
],
[
[
"w = np.dot(np.linalg.pinv(X), y)\nw",
"_____no_output_____"
]
],
[
[
"The first weight corresponds to the $y$-intercept of the line, which is typically denoted as $b$: ",
"_____no_output_____"
]
],
[
[
"b = np.asarray(w).reshape(-1)[0]\nb",
"_____no_output_____"
]
],
[
[
"While the second weight corresponds to the slope of the line, which is typically denoted as $m$: ",
"_____no_output_____"
]
],
[
[
"m = np.asarray(w).reshape(-1)[1]\nm",
"_____no_output_____"
]
],
[
[
"With the weights we can plot the line to confirm it fits the points: ",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.scatter(x1, y)\n\nx_min, x_max = ax.get_xlim()\ny_min, y_max = b, b + m*(x_max-x_min)\n\nax.plot([x_min, x_max], [y_min, y_max])\n_ = ax.set_xlim([x_min, x_max])",
"_____no_output_____"
]
],
[
[
"### The Trace Operator",
"_____no_output_____"
],
[
"Denoted as Tr($A$). Simply the sum of the diagonal elements of a matrix: $$\\sum_i A_{i,i}$$",
"_____no_output_____"
]
],
[
[
"A = np.array([[25, 2], [5, 4]])\nA",
"_____no_output_____"
],
[
"25 + 4",
"_____no_output_____"
],
[
"np.trace(A)",
"_____no_output_____"
]
],
[
[
"The trace operator has a number of useful properties that come in handy while rearranging linear algebra equations, e.g.:\n\n* Tr($A$) = Tr($A^T$)\n* Assuming the matrix shapes line up: Tr(ABC) = Tr(CAB) = Tr(BCA)",
"_____no_output_____"
],
[
"In particular, the trace operator can provide a convenient way to calculate a matrix's Frobenius norm: $$||A||_F = \\sqrt{\\mathrm{Tr}(AA^\\mathrm{T})}$$",
"_____no_output_____"
],
[
"**Exercise**\n\nUsing the matrix `A_p`: \n\n1. Identify the PyTorch trace method and the trace of the matrix.\n2. Further, use the PyTorch Frobenius norm method (for the left-hand side of the equation) and the trace method (for the right-hand side of the equation) to demonstrate that $||A||_F = \\sqrt{\\mathrm{Tr}(AA^\\mathrm{T})}$",
"_____no_output_____"
]
],
[
[
"A_p",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
],
[
"### Principal Component Analysis",
"_____no_output_____"
],
[
"This PCA example code is adapted from [here](https://jupyter.brynmawr.edu/services/public/dblank/CS371%20Cognitive%20Science/2016-Fall/PCA.ipynb).",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets\niris = datasets.load_iris()",
"_____no_output_____"
],
[
"iris.data.shape",
"_____no_output_____"
],
[
"iris.get(\"feature_names\")",
"_____no_output_____"
],
[
"iris.data[0:6,:]",
"_____no_output_____"
],
[
"from sklearn.decomposition import PCA",
"_____no_output_____"
],
[
"pca = PCA(n_components=2)",
"_____no_output_____"
],
[
"X = pca.fit_transform(iris.data)",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"X[0:6,:]",
"_____no_output_____"
],
[
"plt.scatter(X[:, 0], X[:, 1])",
"_____no_output_____"
],
[
"iris.target.shape",
"_____no_output_____"
],
[
"iris.target[0:6]",
"_____no_output_____"
],
[
"unique_elements, counts_elements = np.unique(iris.target, return_counts=True)\nnp.asarray((unique_elements, counts_elements))",
"_____no_output_____"
],
[
"list(iris.target_names)",
"_____no_output_____"
],
[
"plt.scatter(X[:, 0], X[:, 1], c=iris.target)",
"_____no_output_____"
]
],
[
[
"**Return to slides here.**",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a467a95d470d90f6e147b21b9b5399f8c9c1308
| 415,706 |
ipynb
|
Jupyter Notebook
|
x-archive-temp/ca07-SKL_Classification/Classification.ipynb
|
UCBerkeley-SCET/DataX-Berkeley
|
f912d22c838b511d3ada4ecfa3548afd80437b74
|
[
"Apache-2.0"
] | 117 |
2019-09-02T06:08:46.000Z
|
2022-03-09T18:15:26.000Z
|
x-archive-temp/ca07-SKL_Classification/Classification.ipynb
|
UCBerkeley-SCET/DataX-Berkeley
|
f912d22c838b511d3ada4ecfa3548afd80437b74
|
[
"Apache-2.0"
] | 4 |
2020-06-24T22:20:31.000Z
|
2022-02-28T01:37:36.000Z
|
x-archive-temp/ca07-SKL_Classification/Classification.ipynb
|
UCBerkeley-SCET/DataX-Berkeley
|
f912d22c838b511d3ada4ecfa3548afd80437b74
|
[
"Apache-2.0"
] | 78 |
2020-06-19T09:41:01.000Z
|
2022-02-05T00:13:29.000Z
| 605.985423 | 214,432 | 0.932565 |
[
[
[
"\n\n## Classification\n\nClassification - predicting the discrete class ($y$) of an object from a vector of input features ($\\vec x$). \nModels used in this notebook include: Logistic Regression, Support Vector Machines, KNN\n\n**Author List**: Kevin Li\n\n**Original Sources**: http://scikit-learn.org, http://archive.ics.uci.edu/ml/datasets/Iris\n\n**License**: Feel free to do whatever you want to with this code\n",
"_____no_output_____"
],
[
"## Iris Dataset",
"_____no_output_____"
]
],
[
[
"from sklearn import datasets\n\n# import some data to play with\niris = datasets.load_iris()\nX = iris.data\nY = iris.target\n# type(iris)",
"_____no_output_____"
],
[
"print(\"feature vector shape=\", X.shape)\nprint(\"class shape=\", Y.shape)",
"('feature vector shape=', (150, 4))\n('class shape=', (150,))\n"
],
[
"print(iris.target_names, type(iris.target_names))\nprint(iris.feature_names, type(iris.feature_names))",
"(array(['setosa', 'versicolor', 'virginica'], \n dtype='|S10'), <type 'numpy.ndarray'>)\n(['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'], <type 'list'>)\n"
],
[
"print type (X)\nprint X[0:5]\nprint type (Y)\nprint Y[0:5]\nprint \"---\"\nprint(iris.DESCR)",
"<type 'numpy.ndarray'>\n[[ 3.5 1.4]\n [ 3. 1.4]\n [ 3.2 1.3]\n [ 3.1 1.5]\n [ 3.6 1.4]]\n<type 'numpy.ndarray'>\n[0 0 0 0 0]\n---\nIris Plants Database\n====================\n\nNotes\n-----\nData Set Characteristics:\n :Number of Instances: 150 (50 in each of three classes)\n :Number of Attributes: 4 numeric, predictive attributes and the class\n :Attribute Information:\n - sepal length in cm\n - sepal width in cm\n - petal length in cm\n - petal width in cm\n - class:\n - Iris-Setosa\n - Iris-Versicolour\n - Iris-Virginica\n :Summary Statistics:\n\n ============== ==== ==== ======= ===== ====================\n Min Max Mean SD Class Correlation\n ============== ==== ==== ======= ===== ====================\n sepal length: 4.3 7.9 5.84 0.83 0.7826\n sepal width: 2.0 4.4 3.05 0.43 -0.4194\n petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)\n petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)\n ============== ==== ==== ======= ===== ====================\n\n :Missing Attribute Values: None\n :Class Distribution: 33.3% for each of 3 classes.\n :Creator: R.A. Fisher\n :Donor: Michael Marshall (MARSHALL%[email protected])\n :Date: July, 1988\n\nThis is a copy of UCI ML iris datasets.\nhttp://archive.ics.uci.edu/ml/datasets/Iris\n\nThe famous Iris database, first used by Sir R.A Fisher\n\nThis is perhaps the best known database to be found in the\npattern recognition literature. Fisher's paper is a classic in the field and\nis referenced frequently to this day. (See Duda & Hart, for example.) The\ndata set contains 3 classes of 50 instances each, where each class refers to a\ntype of iris plant. One class is linearly separable from the other 2; the\nlatter are NOT linearly separable from each other.\n\nReferences\n----------\n - Fisher,R.A. \"The use of multiple measurements in taxonomic problems\"\n Annual Eugenics, 7, Part II, 179-188 (1936); also in \"Contributions to\n Mathematical Statistics\" (John Wiley, NY, 1950).\n - Duda,R.O., & Hart,P.E. (1973) Pattern Classification and Scene Analysis.\n (Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.\n - Dasarathy, B.V. (1980) \"Nosing Around the Neighborhood: A New System\n Structure and Classification Rule for Recognition in Partially Exposed\n Environments\". IEEE Transactions on Pattern Analysis and Machine\n Intelligence, Vol. PAMI-2, No. 1, 67-71.\n - Gates, G.W. (1972) \"The Reduced Nearest Neighbor Rule\". IEEE Transactions\n on Information Theory, May 1972, 431-433.\n - See also: 1988 MLC Proceedings, 54-64. Cheeseman et al\"s AUTOCLASS II\n conceptual clustering system finds 3 classes in the data.\n - Many, many more ...\n\n"
],
[
"# specifies that figures should be shown inline, directly in the notebook.\n%pylab inline",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"# Learn more about thhis visualization package at http://seaborn.pydata.org/\n# http://seaborn.pydata.org/tutorial/axis_grids.html\n# http://seaborn.pydata.org/tutorial/aesthetics.html#aesthetics-tutorial\n\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nsns.set(style=\"white\")\n\ndf = sns.load_dataset(\"iris\")\nprint \"df is a \", type(df)\n\ng = sns.PairGrid(df, diag_sharey=False,hue=\"species\")\ng.map_lower(sns.kdeplot, cmap=\"Blues_d\")\ng.map_upper(plt.scatter)\ng.map_diag(sns.kdeplot, lw=3)",
"df is a <class 'pandas.core.frame.DataFrame'>\n"
],
[
"# sns.load_dataset?\nsns.load_dataset",
"_____no_output_____"
]
],
[
[
" - Logistic Regression: `linear_model.LogisticRegression`\n - KNN Classification: `neighbors.KNeighborsClassifier`\n - LDA / QDA: `lda.LDA` / `lda.QDA`\n - Naive Bayes: `naive_bayes.GaussianNB`\n - Support Vector Machines: `svm.SVC`\n - Classification Trees: `tree.DecisionTreeClassifier`\n - Random Forest: `ensemble.RandomForestClassifier`\n - Multi-class & multi-label Classification is supported: `multiclass.OneVsRest` `multiclass.OneVsOne` \n - Boosting & Ensemble Learning: xgboost, cart",
"_____no_output_____"
],
[
"## Logistic Regression\n\nA standard logistic sigmoid function\n<img src=\"https://upload.wikimedia.org/wikipedia/commons/thumb/8/88/Logistic-curve.svg/320px-Logistic-curve.svg.png\" width=\"50%\">",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn import linear_model, datasets\n\n# set_context\nsns.set_context(\"talk\")\n\n\n# import some data to play with\niris = datasets.load_iris()\nX = iris.data[:, 1:3] # we only take the first two features.\nY = iris.target\n\nh = .02 # step size in the mesh\n\n# https://en.wikipedia.org/wiki/Logistic_regression\nlogreg = linear_model.LogisticRegression(C=1e5)\n\n# we create an instance of Neighbours Classifier and fit the data.\nlogreg.fit(X, Y)\n\n# Plot the decision boundary. For that, we will assign a color to each\n# point in the mesh [x_min, x_max]x[y_min, y_max].\nx_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5\ny_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5\nxx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))\nZ = logreg.predict(np.c_[xx.ravel(), yy.ravel()])\n# numpy.ravel: Return a contiguous flattened array.\n\n# Put the result into a color plot\nZ = Z.reshape(xx.shape)\nplt.figure(1, figsize=(4, 3))\nplt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)\n\n# Plot also the training points\nplt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=get_cmap(\"Spectral\"))\nplt.xlabel('Sepal length')\nplt.ylabel('Sepal width')\n\n#plt.xlim(xx.min(), xx.max())\n#plt.ylim(yy.min(), yy.max())\n#plt.xticks(())\n#plt.yticks(())\n\nplt.show()\n\n",
"_____no_output_____"
]
],
[
[
"## Support Vector Machines (Bell Labs, 1992)\n\n<img src=\"http://docs.opencv.org/2.4/_images/optimal-hyperplane.png\" width=\"50%\">",
"_____no_output_____"
]
],
[
[
"# adapted from http://scikit-learn.org/0.13/auto_examples/svm/plot_iris.html#example-svm-plot-iris-py\n%matplotlib inline\nimport numpy as np\nfrom sklearn import svm, datasets\n\nsns.set_context(\"talk\")\n\n# import some data to play with\niris = datasets.load_iris()\nX = iris.data[:, 1:3] # we only take the first two features. We could\n # avoid this ugly slicing by using a two-dim dataset\nY = iris.target\n\nh = 0.02 # step size in the mesh\n\n# we create an instance of SVM and fit out data. We do not scale our\n# data since we want to plot the support vectors\nC = 1.0 # SVM regularization parameter\nsvc = svm.SVC(kernel='linear', C=C).fit(X, Y)\nrbf_svc = svm.SVC(kernel='rbf', gamma=0.7, C=C).fit(X, Y)\npoly_svc = svm.SVC(kernel='poly', degree=3, C=C).fit(X, Y)\nlin_svc = svm.LinearSVC(C=C).fit(X, Y)\n\n# create a mesh to plot in\nx_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1\ny_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1\nxx, yy = np.meshgrid(np.arange(x_min, x_max, h),\n np.arange(y_min, y_max, h))\n\n# title for the plots\ntitles = ['SVC with linear kernel',\n 'SVC with RBF kernel',\n 'SVC with polynomial (degree 3) kernel',\n 'LinearSVC (linear kernel)']\n\nclfs = [svc, rbf_svc, poly_svc, lin_svc]\n\nf,axs = plt.subplots(2,2)\n\nfor i, clf in enumerate(clfs):\n # Plot the decision boundary. For that, we will assign a color to each\n # point in the mesh [x_min, m_max]x[y_min, y_max].\n ax = axs[i//2][i % 2]\n \n Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])\n\n # Put the result into a color plot\n Z = Z.reshape(xx.shape)\n ax.contourf(xx, yy, Z,cmap=get_cmap(\"Spectral\"))\n ax.axis('off')\n\n # Plot also the training points\n ax.scatter(X[:, 0], X[:, 1], c=Y,cmap=get_cmap(\"Spectral\"))\n\n ax.set_title(titles[i])",
"_____no_output_____"
]
],
[
[
"## Beyond Linear SVM",
"_____no_output_____"
]
],
[
[
"# SVM with polynomial kernel visualization\nfrom IPython.display import YouTubeVideo\nYouTubeVideo(\"3liCbRZPrZA\")",
"_____no_output_____"
]
],
[
[
"## kNearestNeighbors (kNN)",
"_____no_output_____"
]
],
[
[
"# %load http://scikit-learn.org/stable/_downloads/plot_classification.py\n\"\"\"\n================================\nNearest Neighbors Classification\n================================\n\nSample usage of Nearest Neighbors classification.\nIt will plot the decision boundaries for each class.\n\"\"\"\nprint(__doc__)\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import ListedColormap\nfrom sklearn import neighbors, datasets\n\nn_neighbors = 15\n\n# import some data to play with\niris = datasets.load_iris()\nX = iris.data[:, :2] # we only take the first two features. We could\n # avoid this ugly slicing by using a two-dim dataset\ny = iris.target\n\nh = .02 # step size in the mesh\n\n# Create color maps\ncmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])\ncmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])\n\nfor weights in ['uniform', 'distance']:\n # we create an instance of Neighbours Classifier and fit the data.\n clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)\n clf.fit(X, y)\n\n # Plot the decision boundary. For that, we will assign a color to each\n # point in the mesh [x_min, x_max]x[y_min, y_max].\n x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1\n y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1\n xx, yy = np.meshgrid(np.arange(x_min, x_max, h),\n np.arange(y_min, y_max, h))\n Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])\n\n # Put the result into a color plot\n Z = Z.reshape(xx.shape)\n plt.figure()\n plt.pcolormesh(xx, yy, Z, cmap=cmap_light)\n\n # Plot also the training points\n plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold)\n plt.xlim(xx.min(), xx.max())\n plt.ylim(yy.min(), yy.max())\n plt.title(\"3-Class classification (k = %i, weights = '%s')\"\n % (n_neighbors, weights))\n\nplt.show()\n",
"\n================================\nNearest Neighbors Classification\n================================\n\nSample usage of Nearest Neighbors classification.\nIt will plot the decision boundaries for each class.\n\n"
]
],
[
[
"##### Back to the Iris Data Set",
"_____no_output_____"
]
],
[
[
"iris = datasets.load_iris()\niris_X = iris.data\niris_y = iris.target\n\nindices = np.random.permutation(len(iris_X))\niris_X_train = iris_X[indices[:-10]]\niris_y_train = iris_y[indices[:-10]]\niris_X_test = iris_X[indices[-10:]]\niris_y_test = iris_y[indices[-10:]]\n# Create and fit a nearest-neighbor classifier\n\nfrom sklearn.neighbors import KNeighborsClassifier\nknn = KNeighborsClassifier()\nknn.fit(iris_X_train, iris_y_train) \nKNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',\n metric_params=None, n_jobs=1, n_neighbors=15, p=2,\n weights='uniform')\nprint(\"predicted:\", knn.predict(iris_X_test))\nprint(\"actual :\", iris_y_test)",
"('predicted:', array([1, 0, 2, 0, 0, 2, 1, 0, 0, 0]))\n('actual :', array([1, 0, 2, 0, 0, 2, 1, 0, 0, 0]))\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a4681fff21955e3d19771e848f4ba01335fd997
| 7,923 |
ipynb
|
Jupyter Notebook
|
07_instancias.ipynb
|
Cloudevel/cd601
|
56b07fa3c63c139f13dd7ec9bdfc7064b6f96ab1
|
[
"MIT"
] | 6 |
2021-10-13T23:21:44.000Z
|
2022-03-31T06:03:17.000Z
|
07_instancias.ipynb
|
Cloudevel/cd601
|
56b07fa3c63c139f13dd7ec9bdfc7064b6f96ab1
|
[
"MIT"
] | null | null | null |
07_instancias.ipynb
|
Cloudevel/cd601
|
56b07fa3c63c139f13dd7ec9bdfc7064b6f96ab1
|
[
"MIT"
] | 2 |
2021-11-23T20:43:33.000Z
|
2022-01-08T07:32:55.000Z
| 19.230583 | 405 | 0.513189 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a469ebddb944d9ead949077ca7b75b2be477cf7
| 22,877 |
ipynb
|
Jupyter Notebook
|
2_analysis/DataPrepLV.ipynb
|
lukas-pkl/presidential_attention
|
015ff5bcf05577f5b43c976007e02162be2b11d6
|
[
"MIT"
] | null | null | null |
2_analysis/DataPrepLV.ipynb
|
lukas-pkl/presidential_attention
|
015ff5bcf05577f5b43c976007e02162be2b11d6
|
[
"MIT"
] | null | null | null |
2_analysis/DataPrepLV.ipynb
|
lukas-pkl/presidential_attention
|
015ff5bcf05577f5b43c976007e02162be2b11d6
|
[
"MIT"
] | null | null | null | 33.155072 | 114 | 0.400927 |
[
[
[
"from datetime import datetime\n\nfrom pymongo import MongoClient\nimport pandas as pd\n\nimport constants\nfrom tqdm import tqdm\n",
"_____no_output_____"
],
[
"mongo = MongoClient(constants.mongo_conn_string)\nmongo_lt_col = mongo[constants.mongo_db][constants.mongo_lv_annotated_col]",
"_____no_output_____"
],
[
"query = {}\n\ncursor = mongo_lt_col.find(query, {\"_id\":0, \"text\":0})\n\ndata = [i for i in cursor]\nprint(len(data))\n\ndf = pd.DataFrame(data)\nprint(df.shape)\ndf.head()",
"28864\n(28864, 10)\n"
],
[
"df.to_parquet(\"DataLV.parquet\")",
"_____no_output_____"
]
],
[
[
"# Basic Data",
"_____no_output_____"
]
],
[
[
"df.year.value_counts()",
"_____no_output_____"
],
[
"df.cabinet_no.value_counts()",
"_____no_output_____"
],
[
"df.president.value_counts()",
"_____no_output_____"
]
],
[
[
"# Adding dummies for media & presidential attention for each policy sphere",
"_____no_output_____"
]
],
[
[
"ministries = set()\nfor i in list(df.cabinet_ents):\n for a in i:\n ministries.add(a)\n \nfor item in tqdm(list(ministries)):\n df[item]= df.apply(lambda x : int(item in x[\"cabinet_ents\"]), axis = 1)\n\n\ndef prez_attention( list_min , minister):\n if \"Prezidents\" in list_min and minister in list_min:\n return 1\n else:\n return 0\n \nfor item in tqdm(list(ministries)):\n if item != \"Prezidenta\":\n df[\"president_\"+item]= df.apply(lambda x : prez_attention(x[\"cabinet_ents\"], item), axis = 1)\n \ndf.head() ",
"100%|██████████| 19/19 [00:07<00:00, 2.57it/s]\n100%|██████████| 19/19 [00:07<00:00, 2.46it/s]\n"
],
[
"df.columns",
"_____no_output_____"
],
[
"df.to_parquet(\"DataEnhanced_LV.parquet\")",
"_____no_output_____"
],
[
"df.to_csv(\"DataEnhanced_LV.csv\")",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a469fbb36c20fa035d7c25565d58d0bca0e2f83
| 412,541 |
ipynb
|
Jupyter Notebook
|
StrokePrediction.ipynb
|
davidedomini/stroke_predictions
|
2f61276a95f4aa3d3105306abcc2d31c5d4cd1d9
|
[
"MIT"
] | null | null | null |
StrokePrediction.ipynb
|
davidedomini/stroke_predictions
|
2f61276a95f4aa3d3105306abcc2d31c5d4cd1d9
|
[
"MIT"
] | null | null | null |
StrokePrediction.ipynb
|
davidedomini/stroke_predictions
|
2f61276a95f4aa3d3105306abcc2d31c5d4cd1d9
|
[
"MIT"
] | null | null | null | 80.511514 | 47,718 | 0.693424 |
[
[
[
"<a href=\"https://colab.research.google.com/github/davidedomini/stroke_predictions/blob/main/StrokePrediction.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Stroke Prediction\n\n**Davide Domini** <br> \[email protected]<br> <br>\nProgrammazione di applicazioni data intensive <br>\nLaurea in Ingegneria e Scienze Informatiche \nDISI - Università di Bologna, Cesena\n\n\n",
"_____no_output_____"
],
[
"Citazioni: \n* Stroke Preditction Dataset https://www.kaggle.com/fedesoriano/stroke-prediction-dataset\n\n\n\n\n",
"_____no_output_____"
],
[
"##Descrizione del problema e comprensione dei dati",
"_____no_output_____"
],
[
"*In questo progetto si vuole realizzare un modello in grado di predire la presenza o meno di un ictus in base ad alcune caratteristiche fisiche e di stile di vita di alcuni pazienti*",
"_____no_output_____"
],
[
"Vengono importate le librerie necessarie\n- **NumPy** per lavorare agilmente con l'algebra lineare\n- **Pandas** per gestire meglio i dati in formato tabellare\n- **Seaborn** per disegnare i grafici (basata su **matplotlib**)\n- **Urllib** per recuperare il dataset dalla repo github\n- **Sklearn** per avere i modelli di classificazione\n- **Imblearn** per applicare l'oversampling alla classe meno numerosa",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd \nimport matplotlib.pyplot as plt\nimport seaborn as sb\nimport os.path\nimport math\nfrom urllib.request import urlretrieve\nfrom imblearn.over_sampling import SMOTE\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.metrics import precision_score, recall_score, f1_score\nfrom sklearn.model_selection import KFold, StratifiedKFold\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.metrics import mean_squared_error\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import SVC\nfrom sklearn.tree import DecisionTreeClassifier\nimport graphviz\nfrom sklearn import tree\nfrom sklearn.dummy import DummyClassifier\nfrom xgboost import XGBClassifier\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"###Caricamento dei dati e preprocessing\n\nViene recuperato il file del dataset dalla repo GitHub",
"_____no_output_____"
]
],
[
[
"dataset_url = \"https://raw.githubusercontent.com/davidedomini/stroke_predictions/main/healthcare-dataset-stroke-data.csv\"\n\nif not os.path.exists(\"healthcare-dataset-stroke-data.csv\"):\n urlretrieve(dataset_url, \"healthcare-dataset-stroke-data.csv\")",
"_____no_output_____"
],
[
"stroke_dataset = pd.read_csv(\"healthcare-dataset-stroke-data.csv\", sep=\",\")\nstroke_dataset.head(10)",
"_____no_output_____"
]
],
[
[
"Osservando il dataframe notiamo che il campo `id` è solo un identificatore univoco del paziente, non avendo nessuna importanza ai fini del modello lo impostiamo come index",
"_____no_output_____"
]
],
[
[
"stroke_dataset.set_index(\"id\", inplace=True)\nstroke_dataset.head(10)",
"_____no_output_____"
]
],
[
[
"###Comprensione delle feature",
"_____no_output_____"
],
[
"Descrizione:\n\n1. **id**: identificatore univoco del paziente\n2. **gender**: [Nominale] genere del paziente, può essere \"Male\", \"Female\" o \"Other\"\n3. **age**: [Intervallo] età del paziente\n4. **hypertension**: [Nominale] rappresenta la presenza di ipertensione nel paziente, assume valore 0 se non presente e valore 1 se presente\n5. **heart_disease**: [Nominale] rappresenta la presenza di cardiopatia nel paziente, assume valore 0 se non presente e valore 1 se presente\n6. **ever_married**: [Nominale] indica se il paziente è mai stato sposato, assume valore \"Yes\" o \"No\"\n7. **work_type**: [Nominale] indica il tipo di lavoro del paziente, assume valori \"children\", \"Govt_jov\", \"Never_Worked\", \"Private\" o \"Self-employed\"\n8. **Residence_type**: [Nominale] indica la zona di residenza del paziente, assume valori \"Rural\" o \"Urban\"\n9. **avg_glucose_level**: [Intervallo] indica il livello di glucosio medio nel sangue\n10. **bmi**: [Intervallo] indica l'indice di massa corporea, si calcola come: $$ \\frac{massa}{altezza^2} $$ \n11. **smoking_status**: [Nominale] indica le abitudini del paziente con il fumo, assume valori \"formerly smoked\", \"never smoked\", \"smokes\" o \"Unknown\"\n12. **stroke**: [Nominale] indica se il paziente ha avuto un ictus, assume valore 0 oppure 1\n\n$\\Rightarrow$ Siccome la variabile `stroke` da predire è discreta si tratta di un problema di classificazione (con due classi)\n",
"_____no_output_____"
],
[
"###Esplorazione delle singole feature",
"_____no_output_____"
]
],
[
[
"stroke_dataset.describe()",
"_____no_output_____"
]
],
[
[
"Con il metodo describe possiamo ottenere varie informazioni sulle feature presenti nel dataset:\n\n\n* L'età media dei pazienti è circa 43 anni, il più giovane ha meno di un anno mentre il più anziano ne ha 82, inoltre possiamo notare che comunque il 50% ha più di 45 anni\n* Il livello di glucosio medio nel sangue è circa 106, di solito questo valore dovrebbe stare nell'intervallo [70;100], dal 75-esimo percentile possiamo notare che circa il 25% dei pazienti ha livelli preoccupanti che denotano una probabile presenza di diabete\n* La media dei valori del BMI assume valore 28, leggermente troppo alto in quanto una persona con peso regolare dovrebbe stare nell'intervallo [18;25], inoltre abbiamo 10 come valore minimo e 97 come valore massimo il che indica che abbiamo alcuni casi di grave magrezza e grave obesità\n\n",
"_____no_output_____"
],
[
"Inoltre dal riassunto precedente del dataframe possiamo notare che ci sono alcuni valori NaN quindi controlliamo meglio",
"_____no_output_____"
]
],
[
[
"stroke_dataset.isna().sum()",
"_____no_output_____"
]
],
[
[
"Vista la presenza di 201 valori mancanti nella colonna bmi procediamo alla rimozione",
"_____no_output_____"
]
],
[
[
"stroke_dataset.dropna(inplace=True)\nstroke_dataset.isna().sum()",
"_____no_output_____"
],
[
"stroke_dataset[\"stroke\"].value_counts().plot.pie(autopct=\"%.1f%%\");",
"_____no_output_____"
]
],
[
[
"Dal grafico a torta della feature `stroke` notiamo che le due classi sono estremamente sbilanciate, questo protrebbe creare problemi in seguito quindi nelle prossime sezioni verranno applicate tecniche come dare un peso diverso alle due classi oppure under/over -sampling di una delle due classi",
"_____no_output_____"
]
],
[
[
"sb.displot(stroke_dataset[\"avg_glucose_level\"]);",
"_____no_output_____"
],
[
"sb.displot(stroke_dataset[\"bmi\"]);",
"_____no_output_____"
]
],
[
[
"Dai precedenti grafici per le distribuzioni delle feature `avg_glucose_level` e `bmi` osserviamo che:\n* Il livello medio di glucosio è molto concentrato nell'intervallo che va circa da 60 a 100\n* Il bmi è molto concentrato nell'intevallo [20;40]",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(15,10))\n\nplt.subplot(1,2,1)\nsb.histplot(x=\"gender\", data=stroke_dataset);\n\nplt.subplot(1,2,2)\nsb.histplot(x=\"age\", data=stroke_dataset);",
"_____no_output_____"
]
],
[
[
"Da questi istogrammi possiamo notare che:\n\n\n* I pazienti sono più donne che uomini\n* Il numero di pazienti ha due picchi intorno ai 40 anni e agli 80 anni\n\n",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(20,10))\n\nplt.subplot(3,2,1)\nsb.countplot(x=\"hypertension\", data=stroke_dataset);\n\nplt.subplot(3,2,2)\nsb.countplot(x=\"ever_married\", data=stroke_dataset);\n\nplt.subplot(3,2,3)\nsb.countplot(x=\"smoking_status\", data=stroke_dataset);\n\nplt.subplot(3,2,4)\nsb.countplot(x=\"heart_disease\", data=stroke_dataset);\n\nplt.subplot(3,2,5)\nsb.countplot(x=\"Residence_type\", data=stroke_dataset);\n\nplt.subplot(3,2,6)\nsb.countplot(x=\"work_type\", data=stroke_dataset);\n",
"_____no_output_____"
]
],
[
[
"Da questi altri grafici invece notiamo che:\n\n\n* Sono molti di più i pazienti senza ipertensione che quelli che ne soffrono\n* Abbiamo meno pazienti che non sono mai stati sposati\n* Molti dei pazienti non hanno mai fumato, però ce ne sono anche molti in cui abbiamo stato sconosciuto, quindi questo potrebbe andare a pareggiare i conti nella realtà\n* Pochi pazienti sono cardiopatici\n* La differenza fra chi abita in zone urbane e chi in zone rurali è pressochè nulla \n\n",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(20,10))\n\nplt.subplot(2,2,1)\nsb.boxplot(x=\"age\", data=stroke_dataset);\n\nplt.subplot(2,2,2)\nsb.boxplot(x=\"bmi\", data=stroke_dataset);\n\nplt.subplot(2,2,3)\nsb.boxplot(x=\"avg_glucose_level\", data=stroke_dataset);",
"_____no_output_____"
]
],
[
[
"Da questi ultimi grafici possiamo notare che la feature `avg_glucose_level` sembra avere molti valori outlier, a primo impatto potremmo pensare di rimuoverne almeno una parte per non avere valori anomali quindi facciamo un'analisi più approfondita per decidere se è il caso di farlo o no",
"_____no_output_____"
]
],
[
[
"sb.displot(x='avg_glucose_level', hue='stroke', data = stroke_dataset, palette=\"pastel\", multiple=\"stack\");",
"_____no_output_____"
],
[
"stroke_avg165 = stroke_dataset[stroke_dataset.avg_glucose_level >= 160].loc[:,\"stroke\"].sum()\nstroke_tot = stroke_dataset.loc[:,\"stroke\"].sum()\nstroke_perc = stroke_avg165 / stroke_tot\nprint(f\"Abbiamo {stroke_tot} ictus totali, di cui {stroke_avg165} sono avvenuti in pazienti con un valore di glucosio medio nel sangue non nella norma, in percentuale sono quindi il {stroke_perc:.1%}\")",
"Abbiamo 209 ictus totali, di cui 76 sono avvenuti in pazienti con un valore di glucosio medio nel sangue non nella norma, in percentuale sono quindi il 36.4%\n"
]
],
[
[
"Da questa ulteriore analisi possiamo quindi osservare due cose:\n\n\n1. Una buona fetta degli ictus totali è presente in persone con il livello medio di glucosio nel sangue non nella norma\n2. Se consideriamo due frazioni distinte del dataset, nella prima sezione contenente i pazienti con un livello di glucosio medio inferiore a 160 abbiamo che i casi di ictus sono una piccola frazione dei casi totali mentre nella seconda sezione i casi con ictus sono una frazione molto più grande dei casi totali \n\nIn virtù di questi risultati decidiamo di tenere anche i dati outlier per la feature `avg_glucose_level`\n\n\n",
"_____no_output_____"
],
[
"###Esplorazione dei legami fra le feature",
"_____no_output_____"
]
],
[
[
"sb.displot(x='age', hue='stroke', data = stroke_dataset, palette=\"pastel\", multiple=\"stack\");",
"_____no_output_____"
]
],
[
[
"Un primo legame interessante è quello fra età e presenza di ictus, possiamo notare come praticamente la totalità degli ictus si sia verificata in pazienti con più di 35-40 anni.\nIn particolare abbiamo un picco nei pazienti più anziani intorno agli 80 anni",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(25,20))\n\nplt.subplot(4,2,1)\nsb.countplot(x='hypertension', hue='stroke', data = stroke_dataset, palette=\"pastel\");\n\nplt.subplot(4,2,2)\nsb.countplot(x='heart_disease', hue='stroke', data = stroke_dataset, palette=\"pastel\");\n\nplt.subplot(4,2,3)\nsb.countplot(x='ever_married', hue='stroke', data = stroke_dataset, palette=\"pastel\");\n\nplt.subplot(4,2,4)\nsb.countplot(x='work_type', hue='stroke', data = stroke_dataset, palette=\"pastel\");\n\nplt.subplot(4,2,5)\nsb.countplot(x='Residence_type', hue='stroke', data = stroke_dataset, palette=\"pastel\");\n\nplt.subplot(4,2,6)\nsb.countplot(x='smoking_status', hue='stroke', data = stroke_dataset, palette=\"pastel\");",
"_____no_output_____"
]
],
[
[
"Notiamo quindi che:\n\n\n* Ipertensione e cardiopatia sembrano influire abbastanza sugli ictus\n* Molti dei pazienti che hanno presentato ictus erano sposati\n* La distribuzione rispetto alla zona di residenza è uniforme, circa metà e metà\n* Abitudini scorrette con il fumo possono incidere sulla presenza di ictus\n* La maggior parte dei pazienti con ictus lavorava nel settore privato o era un lavoratore autonomo\n\n\n",
"_____no_output_____"
]
],
[
[
"corr_matrix = stroke_dataset.corr()\nmask = np.triu(np.ones_like(corr_matrix, dtype=bool))\nf, ax = plt.subplots(figsize=(11,9))\ncmap = sb.diverging_palette(230,20,as_cmap=True)\nsb.heatmap(corr_matrix, mask=mask, cmap=cmap, vmax=.3, center=0, square=True, linewidths=.5, cbar_kws={\"shrink\": .5});\n\n#credits: https://seaborn.pydata.org/examples/many_pairwise_correlations.html?highlight=correlation%20matrix",
"_____no_output_____"
]
],
[
[
"Da questa matrice di correlazione possiamo osservare che:\n\n\n* L'età sembra influire in modo abbastanza uguale su tute le altre feature presenti \n* Gli ictus sono correlati in modo più forte con l'età, in minor modo con ipertensione, cardiopatia e glucosio mentre molto meno con il bmi\n* È probabile che chi ha un livello medio di glucosio nel sangue più alto abbia anche problemi di ipertensione e/o cardiopatia\n\n*Comunque i valori di correlazione non sono molto alti quindi probabilmente sarà necessario usare modelli con feature non lineari*\n\n",
"_____no_output_____"
],
[
"##Feature Engineering",
"_____no_output_____"
],
[
"Andiamo ora a trasformare le varie feature categoriche, queste verranno splittate creando tante feature quanti sono i possibili valori che potevano assumere\n\n\n* Ad esempio la feature `Residence_type` poteva assumere valori *Urban* o *Rural* quindi verranno create due nuove feature `Residence_type_Urban` e `Residence_type_Rural`, se una determinata istanza aveva valore Urban ora avrà valore 1 nella rispettiva feature e valore 0 nell'altra\n\nIn egual modo vengono trasformate tutte le altre feature categoriche\n\n\n",
"_____no_output_____"
]
],
[
[
"categorical_features = [\"gender\", \"work_type\", \"Residence_type\", \"smoking_status\"]\nstroke_dataset = pd.get_dummies(stroke_dataset, columns=categorical_features, prefix=categorical_features)",
"_____no_output_____"
],
[
"stroke_dataset.head(10)",
"_____no_output_____"
]
],
[
[
"Un altro aspetto da considerare è che la feature `ever_married` assume valori *Yes* e *No*, quindi andremo a modificarla applicando la seguente trasformazione:\n* Yes = 1\n* No = 0",
"_____no_output_____"
]
],
[
[
"stroke_dataset[\"ever_married\"] = np.where(stroke_dataset[\"ever_married\"] == \"Yes\", 1, 0)",
"_____no_output_____"
],
[
"stroke_dataset.head(10)",
"_____no_output_____"
]
],
[
[
"In questo modo abbiamo ottenuto tutte feature numeriche su cui possiamo lavorare agilmente",
"_____no_output_____"
],
[
"Applichiamo una tecnica di oversampling al dataset per ottenere un bilanciamento delle classi",
"_____no_output_____"
]
],
[
[
"sm = SMOTE(random_state=42)\ny = stroke_dataset[\"stroke\"]\nX = stroke_dataset.drop(\"stroke\", axis=1)\nX_res, y_res = sm.fit_resample(X, y)",
"/usr/local/lib/python3.7/dist-packages/sklearn/utils/deprecation.py:87: FutureWarning: Function safe_indexing is deprecated; safe_indexing is deprecated in version 0.22 and will be removed in version 0.24.\n warnings.warn(msg, category=FutureWarning)\n"
]
],
[
[
"Dal seguente grafico notiamo che ora le classi sono bilanciate",
"_____no_output_____"
]
],
[
[
"pd.value_counts(y_res).plot.pie(autopct=\"%.1f%%\", title=\"Stroke\");",
"_____no_output_____"
]
],
[
[
"Andiamo ora a suddividere i dati in training set e validations set",
"_____no_output_____"
]
],
[
[
"X_train, X_val, y_train, y_val = train_test_split(\n X_res,y_res,\n test_size = 1/3,\n random_state = 42\n)",
"_____no_output_____"
]
],
[
[
"Applichiamo una standardiddazione dei dati",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\nX_train_S = scaler.fit_transform(X_train)\nX_val_S = scaler.transform(X_val)",
"_____no_output_____"
]
],
[
[
"In tutti i modelli in cui verrà applicata la `Grid Search` useremo una divisione con la classe `StratifiedKFold` in modo da avere in ogni sub-fold la stessa distribuzione per i dati",
"_____no_output_____"
],
[
"La seguente funzione calcola l'intervallo di accuratezza per un modello di classificazione con confidenza al 95% dato l'f-1 score secondo la seguente formula: \n$$ p = \\frac{f + \\frac{z^2}{2N} \\pm z \\sqrt{\\frac{f}{N} - \\frac{f^2}{N} + \\frac{z^2}{4N^2} } }{1+\\frac{z^2}{N}} $$\n",
"_____no_output_____"
]
],
[
[
"def accuracy_interval(f):\n N = len(y_val)\n n_min = f + ( 1.96**2/(2*N) - 1.96 * np.sqrt( (f/N) - (f**2/N) + (1.96**2/(4*N**2) ) ) ) \n n_max = f + ( 1.96**2/(2*N) + 1.96 * np.sqrt( (f/N) - (f**2/N) + (1.96**2/(4*N**2) ) ) ) \n d = 1 + (1.96**2 / N)\n e_min = n_min / d\n e_max = n_max / d\n return np.round(e_min,4), np.round(e_max,4)",
"_____no_output_____"
]
],
[
[
"Creo un dizionario vuoto in cui man mano inserirò i valori f1-score di ogni modello in modo da poter fare un confronto finale",
"_____no_output_____"
]
],
[
[
"accuracy = {}",
"_____no_output_____"
]
],
[
[
"##Perceptron",
"_____no_output_____"
]
],
[
[
"model = Perceptron(random_state=42)\nmodel.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"y_pred = model.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=model.classes_, columns=model.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.7504810776138551, recall: 0.7372400756143668, f1-score: 0.7428169058825398\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Perceptron\"] = i\nprint(i)",
"(0.7272, 0.7578)\n"
]
],
[
[
"Aggiungiamo GridSearch e CrossValidation",
"_____no_output_____"
]
],
[
[
"model = Perceptron(random_state=42)\nparameters = {\n \"penalty\": [None, \"l1\", \"l2\", \"elasticnet\"],\n \"alpha\": np.logspace(-4, 0, 5),\n \"tol\": np.logspace(-9, 6, 6)\n}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"pd.DataFrame(gs.cv_results_).sort_values(\"rank_test_score\").head(5)",
"_____no_output_____"
],
[
"gs.best_params_",
"_____no_output_____"
],
[
"print(f'Best score: {round(gs.best_score_ * 100, 4):.4f}%')",
"Best score: 76.0291%\n"
],
[
"pc_imp = pd.Series(gs.best_estimator_.coef_[0], index=X.columns)\npc_imp.nlargest(4).plot(kind='barh');",
"_____no_output_____"
]
],
[
[
"A seguito della penalizzazione l1, che la GridSearch identifica come parametro migliore, notiamo che le feature più rilevanti sono:\n\n\n* Età\n* Tipo di lavoro: privato\n* Livello medio di glucosio nel sangue\n\n",
"_____no_output_____"
]
],
[
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.6675126903553299, recall: 0.8286074354127284, f1-score: 0.6987234402641411\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Perceptron with gs\"] = i\nprint(i)",
"(0.6824, 0.7145)\n"
],
[
"perceptron_mse = mean_squared_error(y_val, y_pred)\nprint('MSE: {}'.format(perceptron_mse))",
"MSE: 0.295788130185067\n"
]
],
[
[
"##Logistic regression",
"_____no_output_____"
]
],
[
[
"model = LogisticRegression(random_state=42, solver=\"saga\")",
"_____no_output_____"
],
[
"model.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"y_pred = model.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=model.classes_, columns=model.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.8039867109634552, recall: 0.7624448645242596, f1-score: 0.785539020011014\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Logistic Regression\"] = i\nprint(i)",
"(0.7708, 0.7996)\n"
],
[
"model = LogisticRegression(random_state=42, solver=\"saga\")\nparameters = {\n \"penalty\": [\"l1\"],\n \"C\": [0.3, 0.8, 1],#np.logspace(-4, 0, 5),\n \"tol\": np.logspace(-9, 6, 6)\n}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n/usr/local/lib/python3.7/dist-packages/sklearn/linear_model/_sag.py:330: ConvergenceWarning: The max_iter was reached which means the coef_ did not converge\n \"the coef_ did not converge\", ConvergenceWarning)\n"
],
[
"pd.DataFrame(gs.cv_results_).sort_values(\"rank_test_score\").head(5)",
"_____no_output_____"
],
[
"gs.best_params_",
"_____no_output_____"
],
[
"print(f'Best score: {round(gs.best_score_ * 100, 4):.4f}%')",
"Best score: 78.2953%\n"
],
[
"pc_imp = pd.Series(gs.best_estimator_.coef_[0], index=X.columns)\npc_imp.nlargest(4).plot(kind='barh');",
"_____no_output_____"
],
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.8043912175648703, recall: 0.7618147448015122, f1-score: 0.7855352636756341\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Logistic regression with gs\"] = i\nprint(i)",
"(0.7708, 0.7996)\n"
],
[
"logisticregression_mse = mean_squared_error(y_val, y_pred)\nprint('MSE: {}'.format(logisticregression_mse))",
"MSE: 0.21442246330567966\n"
]
],
[
[
"##SVM",
"_____no_output_____"
]
],
[
[
"model = SVC()\nparameters = {\n \"kernel\": [\"rbf\"],\n \"C\": np.logspace(-2, 0, 3)\n}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"pd.DataFrame(gs.cv_results_).sort_values(\"rank_test_score\").head(5)",
"_____no_output_____"
],
[
"gs.best_params_",
"_____no_output_____"
],
[
"print(f'Best score: {round(gs.best_score_ * 100, 4):.4f}%')",
"Best score: 92.7385%\n"
],
[
"svm_imp = pd.Series(gs.best_estimator_.support_vectors_[0], index=X.columns)\nsvm_imp.nlargest(4).plot(kind='barh');",
"_____no_output_____"
],
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.9045936395759717, recall: 0.9678638941398866, f1-score: 0.9318775955681893\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Support Vector Machines\"] = i\nprint(i)",
"(0.9225, 0.9402)\n"
],
[
"svm_mse = mean_squared_error(y_val, y_pred)\nprint('MSE: {}'.format(svm_mse))",
"MSE: 0.06796426292278239\n"
]
],
[
[
"##Decision tree",
"_____no_output_____"
],
[
"I parametri che andiamo a testare nella grid search sono:\n- `min_samples_split` che è il numero minimo di campioni che deve avere una foglia per poter essere splittata\n- `min_samples_leaf` numero minimo di campioni per ogni foglia (i.e. se splittiamo un nodo questo split è valido solo se lascia in ogni foglia che crea almeno min_samples_leaf campioni)\n- `max_depth` profondità massima che può raggiungere l'albero (con `None` cresce senza limiti su questo parametro)\n- `max_features` il numero massimo di feature da considerare per ogni split",
"_____no_output_____"
]
],
[
[
"model = DecisionTreeClassifier(random_state=42)\n\nnum_features = X_train_S.shape[1]\n\nparameters = {\n 'min_samples_split': range(2, 4, 1),\n 'min_samples_leaf': range(1, 4, 1), \n 'max_depth': [None] + [i for i in range(2, 7)],\n 'max_features': range(2, num_features, 1)}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"gs.best_score_",
"_____no_output_____"
],
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.9330085261875761, recall: 0.9653434152488973, f1-score: 0.9473032063508854\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"Decision tree\"] = i\nprint(i)",
"(0.9389, 0.9546)\n"
],
[
"decisiontree_mse = mean_squared_error(y_val, y_pred)\nprint('MSE: {}'.format(decisiontree_mse))",
"MSE: 0.05264837268666241\n"
]
],
[
[
"###Visualizzazione dell'albero decisionale\n",
"_____no_output_____"
],
[
"Nei nodi troviamo:\n\n- Il criterio con cui viene effettuato il taglio \n\n\n- Il parametro `gini` che indica la qualità della suddivisione, rappresenta la frequenza con cui un elemento scelto casualmente dall'insieme verrebbe etichettato in modo errato se fosse etichettato casualmente in base alla distribuzione delle etichette nel sottoinsieme, è calcolato come:\n$$Gini = 1 - \\sum_{i=1}^C p_i^2 $$\n\n $\\Rightarrow$ Assume valore 0 quando tutte le istanze nel nodo hanno una stessa label\n\n- Il parametro `samples` che indica la percentuale di campioni presenti in quel nodo\n- Il parametro `value` che indica la percentuale di istanze per ogni classe",
"_____no_output_____"
]
],
[
[
"dot_data = tree.export_graphviz(gs.best_estimator_, out_file=None, \n feature_names=X.columns, \n filled=True,\n proportion=True,\n max_depth=3)\n\n# Draw graph\ngraph = graphviz.Source(dot_data, format=\"png\") \ngraph",
"_____no_output_____"
]
],
[
[
"##XGBoost",
"_____no_output_____"
]
],
[
[
"model = XGBClassifier(nthread=8, objective='binary:logistic')\n\n\nparameters = {\n 'eta': [0.002, 0.1, 0.5],\n 'max_depth': [6],\n 'n_estimators': [150, 300],\n 'alpha': [0.0001, 0.001]\n}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"gs.best_score_",
"_____no_output_____"
],
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\n\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.9529269764634882, recall: 0.9949590422180214, f1-score: 0.9725251828365269\n"
],
[
"i = accuracy_interval(f1)\naccuracy[\"XGBoost\"] = i\nprint(i)",
"(0.9662, 0.9777)\n"
],
[
"xgboost_mse = mean_squared_error(y_val, y_pred)\nprint('MSE: {}'.format(decisiontree_mse))",
"MSE: 0.05264837268666241\n"
]
],
[
[
"##Model comparison",
"_____no_output_____"
],
[
"Prendiamo una confidenza del 95%, di conseguenza dalla tabella della distribuzione z otteniamo 1.96 come valore per `z` ",
"_____no_output_____"
],
[
"La seguente funzione implementa il confronto fra due modelli dati i rispettivi errori `e1` ed `e2` e la cardinalità del test set `n` secondo le formule :\n\n$$ d = |e_1 - e_2| $$\n\n$$ \\sigma_t^2 = \\sigma_1^2 + \\sigma_2^2 = \\frac{e_1(1-e_1)}{n} + \\frac{e_2(1-e_2)}{n}$$\n\n$$d_t = d \\pm z_{1-\\alpha} \\cdot \\sigma_t$$",
"_____no_output_____"
]
],
[
[
"def intervallo(mse1, mse2):\n d = np.abs(mse1 - mse2)\n variance = (mse1 * (1 - mse1)) / len(X_val) + (mse2 * (1 - mse2)) / len(X_val)\n d_min = d - 1.96 * np.sqrt(variance)\n d_max = d + 1.96 * np.sqrt(variance)\n return d_min, d_max",
"_____no_output_____"
]
],
[
[
"Andiamo a calcolare l'intervallo fra tutte le coppie di modelli",
"_____no_output_____"
]
],
[
[
"from itertools import combinations\nmse = [(\"perceptron_mse\", \"Perceptron\"), (\"logisticregression_mse\",\"Logistic Regression\"),\n (\"svm_mse\", \"SVM\"), (\"decisiontree_mse\", \"Decision Tree\"), (\"xgboost_mse\", \"XGBoost\")]\n\nprint (f\"{'Models':<40} {'Interval':<15}\")\nfor m1, m2 in list(combinations(mse, 2)):\n mse1, mse2 = eval(m1[0]), eval(m2[0])\n name1, name2 = m1[1], m2[1]\n comparison = name1 + \" vs \" + name2\n print (f\"{comparison:<40} {np.round(intervallo(mse1 , mse2), 4)} \")",
"Models Interval \nPerceptron vs Logistic Regression [0.0599 0.1029] \nPerceptron vs SVM [0.2096 0.2461] \nPerceptron vs Decision Tree [0.2254 0.2609] \nPerceptron vs XGBoost [0.2514 0.2853] \nLogistic Regression vs SVM [0.1296 0.1633] \nLogistic Regression vs Decision Tree [0.1454 0.1781] \nLogistic Regression vs XGBoost [0.1715 0.2024] \nSVM vs Decision Tree [0.0035 0.0271] \nSVM vs XGBoost [0.03 0.051] \nDecision Tree vs XGBoost [0.0155 0.0349] \n"
]
],
[
[
"###Confronto con un modello casuale",
"_____no_output_____"
],
[
"La seguente funzione calcola, come la precedente, l'intervallo per il confronto fra due modelli ma utilizza una confidenza al 99% invece del 95%",
"_____no_output_____"
]
],
[
[
"def intervallo99(mse1, mse2):\n d = np.abs(mse1 - mse2)\n variance = (mse1 * (1 - mse1)) / len(X_val) + (mse2 * (1 - mse2)) / len(X_val)\n d_min = d - 2.58 * np.sqrt(variance)\n d_max = d + 2.58 * np.sqrt(variance)\n return d_min, d_max",
"_____no_output_____"
],
[
"random = DummyClassifier(strategy=\"uniform\", random_state=42)\nrandom.fit(X_train_S, y_train)\ny_pred = random.predict(X_val_S)\nprint(random.score(X_val_S, y_val))",
"0.5028717294192725\n"
],
[
"mse_random = mean_squared_error(y_val, y_pred)\nprint(mse_random)",
"0.4971282705807275\n"
],
[
"print (f\"{'Models':<40} Interval\")\nfor m in mse:\n mse_i = eval(m[0])\n name_i = m[1]\n comparison = name_i + \" vs Random\"\n print (f\"{comparison:<40} {np.round(intervallo99(mse_i , mse_random), 4)} \")",
"Models Interval\nPerceptron vs Random [0.1701 0.2325] \nLogistic Regression vs Random [0.2529 0.3125] \nSVM vs Random [0.4034 0.455 ] \nDecision Tree vs Random [0.4192 0.4697] \nXGBoost vs Random [0.4454 0.4939] \n"
]
],
[
[
"Possiamo vedere come la differenza fra tutti i modelli e uno random sia sempre statisticamente significativa quindi i modelli implementati sono tutti accettabili ",
"_____no_output_____"
],
[
"##Conclusioni",
"_____no_output_____"
],
[
"Dalla precedente sezione *Model Comparison* possiamo vedere che fra tutti i modelli la differenza è stasticamente significativa.",
"_____no_output_____"
],
[
"Riassunto dei vari f1-score:",
"_____no_output_____"
]
],
[
[
"print (f\"{'Model':<40} f-1 score\")\nfor k in accuracy.keys():\n print(f\"{k:<40} {accuracy[k]}\")",
"Model f-1 score\nPerceptron (0.7272, 0.7578)\nPerceptron with gs (0.6824, 0.7145)\nLogistic Regression (0.7708, 0.7996)\nLogistic regression with gs (0.7708, 0.7996)\nSupport Vector Machines (0.9225, 0.9402)\nDecision tree (0.9389, 0.9546)\nXGBoost (0.9662, 0.9777)\n"
]
],
[
[
"Visti i risultati ottenuti per l'indice *f1-score* per i vari modelli si può dire che i migliori sono:\n- SVM con kernel RBF non lineare\n- Decision tree\n- XGBoost\n\nQuesto probabilmente è dovuto al fatto che inizialmente la correlazione fra le 11 feature di input è abbastanza bassa quindi usando modelli non lineari andiamo a separare meglio i dati.\n\nQuesto lo si può notare anche dal fatto che se implementiamo un modello SVM con kernel lineare otteniamo un f-1 score molto più basso (come si vede nell'esempio di seguito) ",
"_____no_output_____"
]
],
[
[
"model = SVC()\nparameters = {\n \"kernel\": [\"linear\"],\n \"C\": np.logspace(-2, 0, 3)\n}\n\nskf = StratifiedKFold(3, shuffle=True, random_state=42)\ngs = GridSearchCV(model, parameters, cv=skf)\n\ngs.fit(X_train_S, y_train)",
"_____no_output_____"
],
[
"y_pred = gs.predict(X_val_S)\ncm = confusion_matrix(y_val, y_pred)\npd.DataFrame(cm, index=gs.best_estimator_.classes_, columns=gs.best_estimator_.classes_)",
"_____no_output_____"
],
[
"X_val.shape",
"_____no_output_____"
],
[
"precision = precision_score(y_val, y_pred, pos_label=0)\nrecall = recall_score(y_val, y_pred, pos_label=0)\nf1 = f1_score(y_val, y_pred, average=\"macro\")\nprint(f\"precision: {precision}, recall: {recall}, f1-score: {f1}\")",
"precision: 0.8130584192439863, recall: 0.7454316320100819, f1-score: 0.7841151753117035\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a46a6e9dea1c774d20c35d9d05d272e5c305e41
| 1,840 |
ipynb
|
Jupyter Notebook
|
analysis/Ryan/milestone 2/Markdown_Intro.ipynb
|
data301-2020-winter2/course-project-group_1000
|
4b54282b754717e26f72ed67497a24b990b2a00c
|
[
"MIT"
] | null | null | null |
analysis/Ryan/milestone 2/Markdown_Intro.ipynb
|
data301-2020-winter2/course-project-group_1000
|
4b54282b754717e26f72ed67497a24b990b2a00c
|
[
"MIT"
] | 1 |
2021-03-23T23:37:23.000Z
|
2021-04-10T16:10:33.000Z
|
analysis/Ryan/milestone 2/Markdown_Intro.ipynb
|
data301-2020-winter2/course-project-group_1000
|
4b54282b754717e26f72ed67497a24b990b2a00c
|
[
"MIT"
] | 1 |
2021-02-14T06:29:32.000Z
|
2021-02-14T06:29:32.000Z
| 25.915493 | 163 | 0.569022 |
[
[
[
"### Task 1: Introduction to Markdown\n---",
"_____no_output_____"
],
[
"Jupyter Notebooks are an **extremely** powerful tool that can be used to create executable documents that contains *code*, *text*, *images* and *paragraphs*.",
"_____no_output_____"
],
[
"##### Things to do in Task 1:\n1. use *at least* three of the listed elements in README files inside the project folder.\n2. I should have a notebook demonstrating the use of *at least* three elements. (Which is this one)",
"_____no_output_____"
],
[
"---\n#### Tasks to do in Milestone 2\n\n+ Task 1: Introduction to Markdown **(done)**\n+ Task 2: Introduction to Git **(done)**\n+ Task 3: Method Chaining and Python Programs\n - Step 1: Build and test your method chains\n - Step 2: Wrap your method chains in a function\n - Step 3: Move your function into a new .py file\n+ Task 4: Conduct an EDA on the dataset\n+ Conduct your analysis to help answer your research questions",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a46bbadaa46a038a998f845b6aba39d0912a9b1
| 89,517 |
ipynb
|
Jupyter Notebook
|
chaotic_pendulum/chaotic_pendulum.ipynb
|
deadbeatfour/notebooks
|
72cdd56cc0ca238acf6d858166774ea55ea6b12b
|
[
"MIT"
] | null | null | null |
chaotic_pendulum/chaotic_pendulum.ipynb
|
deadbeatfour/notebooks
|
72cdd56cc0ca238acf6d858166774ea55ea6b12b
|
[
"MIT"
] | null | null | null |
chaotic_pendulum/chaotic_pendulum.ipynb
|
deadbeatfour/notebooks
|
72cdd56cc0ca238acf6d858166774ea55ea6b12b
|
[
"MIT"
] | null | null | null | 260.223837 | 67,888 | 0.9152 |
[
[
[
"%pylab inline\nfrom numpy import *\nfrom scipy import integrate\nfrom ipywidgets import interact",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"## Callable function for the differential equation",
"_____no_output_____"
]
],
[
[
"def driven_pendulum(t,theta,A,w,Q):\n return [\n theta[1],\n A*sin(w*t) - theta[1]/Q - sin(theta[0])\n ]",
"_____no_output_____"
]
],
[
[
"## Chaotic Pendulum Behavior",
"_____no_output_____"
]
],
[
[
"def chaotic(init_angle=0,init_vel=0,driv_ampl=1.5,driv_freq=2./3,qual=0.5):\n initial_conditions,t0 = [init_angle, init_vel],0\n time_list = []\n sol = []\n time_step = 0.01\n end_time = 20\n system = integrate.ode(driven_pendulum)\n system.set_f_params(driv_ampl,driv_freq,qual)\n system.set_initial_value(initial_conditions,t0)\n while system.successful and system.t < end_time:\n time_list.append(system.t)\n sol.append(system.integrate(system.t+time_step))\n sol =asarray(sol)\n fig = figure(figsize=(20,5))\n ax1 = fig.add_subplot(1,2,1)\n ax1.set_ylim(-2,2)\n ax1.set_xlabel(\"time\").set_color('white')\n ax1.plot(time_list,sol)\n ax2 = fig.add_subplot(1,2,2)\n# ax2.set_xlim(-2,2)\n# ax2.set_ylim(-2,2)\n ax2.set_xlabel(\"position\").set_color('white')\n ax2.set_ylabel(\"velocity\").set_color('white')\n ax2.set_title(\"Phase space plot\").set_color('white')\n ax2.plot(sol.T[0],sol.T[1])\n \ninteract(\n chaotic,\n init_angle=(-1.0,1.0,0.1),\n init_vel=(-2.0,2.0,0.1),\n driv_ampl=(0.0,10.0,0.5),\n driv_freq=(0.0,2.0,0.1),\n qual=(0.1,10.0,0.01)\n )",
"Widget Javascript not detected. It may not be installed or enabled properly.\n"
]
],
[
[
"## Looking at Resonance",
"_____no_output_____"
]
],
[
[
"def resonance(qual=0.5):\n initial_conditions,t0 = [0,0],0\n\n time_step = 0.01\n end_time = 20\n freq_list = linspace(0,5,10**2)\n p2p = []\n for driv_freq in freq_list:\n sol = []\n system = integrate.ode(driven_pendulum)\n system.set_f_params(1,driv_freq,qual)\n system.set_initial_value(initial_conditions,t0)\n while system.successful and system.t < end_time:\n# time_list.append(system.t)\n sol.append(system.integrate(system.t+time_step))\n sol=asarray(sol)\n # Peak to Peak current\n p2p.append(sol.T[1].max() - sol.T[1].min())\n fig = figure(figsize=(20,5))\n ax1 = fig.add_subplot(1,1,1)\n ax1.set_ylim(0,10)\n ax1.set_xlabel(\"frequency\").set_color('white')\n ax1.set_ylabel(\"response current\").set_color('white')\n ax1.plot(freq_list,p2p) \ninteract(\n resonance,\n qual=(0.1,10.0,0.01)\n )",
"Widget Javascript not detected. It may not be installed or enabled properly.\n"
]
],
[
[
"So this resembles nothing like the beautiful resonance curves we see. Chaos has no resonance.",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a46e7f2ccc6e1f3f8508a9425b22b6619f3afbe
| 118,935 |
ipynb
|
Jupyter Notebook
|
notebooks/ME_eval_NLVR2.ipynb
|
bouzaien/vilbert-multi-task-1
|
0d82c5d372c24aa2e8f5e92cac32ee7ecf81456e
|
[
"MIT"
] | 2 |
2021-01-14T14:07:40.000Z
|
2021-03-09T10:57:36.000Z
|
notebooks/ME_eval_NLVR2.ipynb
|
bouzaien/vilbert-multi-task-1
|
0d82c5d372c24aa2e8f5e92cac32ee7ecf81456e
|
[
"MIT"
] | 1 |
2021-02-08T15:27:40.000Z
|
2021-02-08T15:27:40.000Z
|
notebooks/ME_eval_NLVR2.ipynb
|
bouzaien/vilbert-multi-task-1
|
0d82c5d372c24aa2e8f5e92cac32ee7ecf81456e
|
[
"MIT"
] | 1 |
2021-01-12T16:52:28.000Z
|
2021-01-12T16:52:28.000Z
| 94.243265 | 41,400 | 0.826115 |
[
[
[
"# Inference",
"_____no_output_____"
],
[
"## Imports & Args",
"_____no_output_____"
]
],
[
[
"import argparse\nimport json\nimport logging\nimport os\nimport random\nfrom io import open\nimport numpy as np\nimport math\nimport _pickle as cPickle\nfrom scipy.stats import spearmanr\n\nfrom tensorboardX import SummaryWriter\nfrom tqdm import tqdm\nfrom bisect import bisect\nimport yaml\nfrom easydict import EasyDict as edict\nimport sys\nimport pdb\n\nimport torch\nimport torch.nn.functional as F\nimport torch.nn as nn\n\nfrom vilbert.task_utils import (\n LoadDatasetEval,\n LoadLosses,\n ForwardModelsTrain,\n ForwardModelsVal,\n EvaluatingModel,\n)\n\nimport vilbert.utils as utils\nimport torch.distributed as dist",
"WARNING:tensorflow:From /home/aloui/miniconda3/envs/vilbert-mt/lib/python3.6/site-packages/tensorpack/callbacks/hooks.py:17: The name tf.train.SessionRunHook is deprecated. Please use tf.estimator.SessionRunHook instead.\n\nWARNING:tensorflow:From /home/aloui/miniconda3/envs/vilbert-mt/lib/python3.6/site-packages/tensorpack/tfutils/optimizer.py:18: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.\n\nWARNING:tensorflow:From /home/aloui/miniconda3/envs/vilbert-mt/lib/python3.6/site-packages/tensorpack/tfutils/sesscreate.py:20: The name tf.train.SessionCreator is deprecated. Please use tf.compat.v1.train.SessionCreator instead.\n\n"
],
[
"def evaluate(\n args,\n task_dataloader_val,\n task_stop_controller,\n task_cfg,\n device,\n task_id,\n model,\n task_losses,\n epochId,\n default_gpu,\n tbLogger,\n):\n\n model.eval()\n for i, batch in enumerate(task_dataloader_val[task_id]):\n loss, score, batch_size = ForwardModelsVal(\n args, task_cfg, device, task_id, batch, model, task_losses\n )\n tbLogger.step_val(\n epochId, float(loss), float(score), task_id, batch_size, \"val\"\n )\n if default_gpu:\n sys.stdout.write(\"%d/%d\\r\" % (i, len(task_dataloader_val[task_id])))\n sys.stdout.flush()\n\n # update the multi-task scheduler.\n task_stop_controller[task_id].step(tbLogger.getValScore(task_id))\n score = tbLogger.showLossVal(task_id, task_stop_controller)",
"_____no_output_____"
],
[
"logging.basicConfig(\n format=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\n datefmt=\"%m/%d/%Y %H:%M:%S\",\n level=logging.INFO,\n)\nlogger = logging.getLogger(__name__)",
"_____no_output_____"
],
[
"parser = argparse.ArgumentParser()\n\nparser.add_argument(\n \"--bert_model\",\n default=\"bert-base-uncased\",\n type=str,\n help=\"Bert pre-trained model selected in the list: bert-base-uncased, \"\n \"bert-large-uncased, bert-base-cased, bert-base-multilingual, bert-base-chinese.\",\n)\nparser.add_argument(\n \"--from_pretrained\",\n default=\"bert-base-uncased\",\n type=str,\n help=\"Bert pre-trained model selected in the list: bert-base-uncased, \"\n \"bert-large-uncased, bert-base-cased, bert-base-multilingual, bert-base-chinese.\",\n)\nparser.add_argument(\n \"--output_dir\",\n default=\"results\",\n type=str,\n help=\"The output directory where the model checkpoints will be written.\",\n)\nparser.add_argument(\n \"--config_file\",\n default=\"config/bert_config.json\",\n type=str,\n help=\"The config file which specified the model details.\",\n)\nparser.add_argument(\n \"--no_cuda\", action=\"store_true\", help=\"Whether not to use CUDA when available\"\n)\nparser.add_argument(\n \"--do_lower_case\",\n default=True,\n type=bool,\n help=\"Whether to lower case the input text. True for uncased models, False for cased models.\",\n)\nparser.add_argument(\n \"--local_rank\",\n type=int,\n default=-1,\n help=\"local_rank for distributed training on gpus\",\n)\nparser.add_argument(\n \"--seed\", type=int, default=42, help=\"random seed for initialization\"\n)\nparser.add_argument(\n \"--fp16\",\n action=\"store_true\",\n help=\"Whether to use 16-bit float precision instead of 32-bit\",\n)\nparser.add_argument(\n \"--loss_scale\",\n type=float,\n default=0,\n help=\"Loss scaling to improve fp16 numeric stability. Only used when fp16 set to True.\\n\"\n \"0 (default value): dynamic loss scaling.\\n\"\n \"Positive power of 2: static loss scaling value.\\n\",\n)\nparser.add_argument(\n \"--num_workers\",\n type=int,\n default=16,\n help=\"Number of workers in the dataloader.\",\n)\nparser.add_argument(\n \"--save_name\", default=\"\", type=str, help=\"save name for training.\"\n)\nparser.add_argument(\n \"--use_chunk\",\n default=0,\n type=float,\n help=\"whether use chunck for parallel training.\",\n)\nparser.add_argument(\n \"--batch_size\", default=30, type=int, help=\"what is the batch size?\"\n)\nparser.add_argument(\n \"--tasks\", default=\"\", type=str, help=\"1-2-3... training task separate by -\"\n)\nparser.add_argument(\n \"--in_memory\",\n default=False,\n type=bool,\n help=\"whether use chunck for parallel training.\",\n)\nparser.add_argument(\n \"--baseline\", action=\"store_true\", help=\"whether use single stream baseline.\"\n)\nparser.add_argument(\"--split\", default=\"\", type=str, help=\"which split to use.\")\nparser.add_argument(\n \"--dynamic_attention\",\n action=\"store_true\",\n help=\"whether use dynamic attention.\",\n)\nparser.add_argument(\n \"--clean_train_sets\",\n default=True,\n type=bool,\n help=\"whether clean train sets for multitask data.\",\n)\nparser.add_argument(\n \"--visual_target\",\n default=0,\n type=int,\n help=\"which target to use for visual branch. \\\n 0: soft label, \\\n 1: regress the feature, \\\n 2: NCE loss.\",\n)\nparser.add_argument(\n \"--task_specific_tokens\",\n action=\"store_true\",\n help=\"whether to use task specific tokens for the multi-task learning.\",\n)",
"_____no_output_____"
]
],
[
[
"## load the textual input",
"_____no_output_____"
]
],
[
[
"args = parser.parse_args(['--bert_model', 'bert-base-uncased',\n '--from_pretrained', 'save/NLVR2_bert_base_6layer_6conect-finetune_from_multi_task_model-task_12/pytorch_model_19.bin',\n '--config_file', 'config/bert_base_6layer_6conect.json',\n '--tasks', '19',\n '--split', 'trainval_dc', # this is the deep captions training split\n '--save_name', 'task-19',\n '--task_specific_tokens',\n '--batch_size', '128'])",
"_____no_output_____"
],
[
"with open(\"vilbert_tasks.yml\", \"r\") as f:\n task_cfg = edict(yaml.safe_load(f))\n\nrandom.seed(args.seed)\nnp.random.seed(args.seed)\ntorch.manual_seed(args.seed)\n\nif args.baseline:\n from pytorch_transformers.modeling_bert import BertConfig\n from vilbert.basebert import BaseBertForVLTasks\nelse:\n from vilbert.vilbert import BertConfig\n from vilbert.vilbert import VILBertForVLTasks\n\ntask_names = []\nfor i, task_id in enumerate(args.tasks.split(\"-\")):\n task = \"TASK\" + task_id\n name = task_cfg[task][\"name\"]\n task_names.append(name)\n\n# timeStamp = '-'.join(task_names) + '_' + args.config_file.split('/')[1].split('.')[0]\ntimeStamp = args.from_pretrained.split(\"/\")[-1] + \"-\" + args.save_name\nsavePath = os.path.join(args.output_dir, timeStamp)\nconfig = BertConfig.from_json_file(args.config_file)\n\nif args.task_specific_tokens:\n config.task_specific_tokens = True\n\nif args.local_rank == -1 or args.no_cuda:\n device = torch.device(\n \"cuda\" if torch.cuda.is_available() and not args.no_cuda else \"cpu\"\n )\n n_gpu = torch.cuda.device_count()\nelse:\n torch.cuda.set_device(args.local_rank)\n device = torch.device(\"cuda\", args.local_rank)\n n_gpu = 1\n # Initializes the distributed backend which will take care of sychronizing nodes/GPUs\n torch.distributed.init_process_group(backend=\"nccl\")\n\nlogger.info(\n \"device: {} n_gpu: {}, distributed training: {}, 16-bits training: {}\".format(\n device, n_gpu, bool(args.local_rank != -1), args.fp16\n )\n)\n\ndefault_gpu = False\nif dist.is_available() and args.local_rank != -1:\n rank = dist.get_rank()\n if rank == 0:\n default_gpu = True\nelse:\n default_gpu = True\n\nif default_gpu and not os.path.exists(savePath):\n os.makedirs(savePath)\n\ntask_batch_size, task_num_iters, task_ids, task_datasets_val, task_dataloader_val = LoadDatasetEval(\n args, task_cfg, args.tasks.split(\"-\")\n)\n\ntbLogger = utils.tbLogger(\n timeStamp,\n savePath,\n task_names,\n task_ids,\n task_num_iters,\n 1,\n save_logger=False,\n txt_name=\"eval.txt\",\n)\n# num_labels = max([dataset.num_labels for dataset in task_datasets_val.values()])\n\nif args.dynamic_attention:\n config.dynamic_attention = True\nif \"roberta\" in args.bert_model:\n config.model = \"roberta\"\n\nif args.visual_target == 0:\n config.v_target_size = 1601\n config.visual_target = args.visual_target\nelse:\n config.v_target_size = 2048\n config.visual_target = args.visual_target\n\nif args.task_specific_tokens:\n config.task_specific_tokens = True",
"08/24/2020 08:48:16 - INFO - __main__ - device: cuda n_gpu: 1, distributed training: False, 16-bits training: False\n08/24/2020 08:48:17 - INFO - pytorch_transformers.tokenization_utils - loading file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt from cache at /home/aloui/.cache/torch/pytorch_transformers/26bc1ad6c0ac742e9b52263248f6d0f00068293b33709fae12320c0e35ccfbbb.542ce4285a40d23a559526243235df47c5f75c197f04f37d1a0c124c32c9a084\n08/24/2020 08:48:17 - INFO - vilbert.task_utils - Loading ME Dataset with batch size 128\n08/24/2020 08:48:17 - INFO - vilbert.datasets.me_dataset - Loading from datasets/ME/cache/ME_trainval_dc_23_cleaned.pkl\n08/24/2020 08:48:19 - INFO - vilbert.utils - logging file at: pytorch_model_19.bin-task-19\n"
],
[
"task_batch_size, task_num_iters, task_ids, task_datasets_val, task_dataloader_val",
"_____no_output_____"
],
[
"len(task_datasets_val['TASK19']), len(task_dataloader_val['TASK19'])",
"_____no_output_____"
]
],
[
[
"## load the pretrained model",
"_____no_output_____"
]
],
[
[
"num_labels = 0\n\nif args.baseline:\n model = BaseBertForVLTasks.from_pretrained(\n args.from_pretrained,\n config=config,\n num_labels=num_labels,\n default_gpu=default_gpu,\n )\nelse:\n model = VILBertForVLTasks.from_pretrained(\n args.from_pretrained,\n config=config,\n num_labels=num_labels,\n default_gpu=default_gpu,\n )\n\ntask_losses = LoadLosses(args, task_cfg, args.tasks.split(\"-\"))\nmodel.to(device)\nif args.local_rank != -1:\n try:\n from apex.parallel import DistributedDataParallel as DDP\n except ImportError:\n raise ImportError(\n \"Please install apex from https://www.github.com/nvidia/apex to use distributed and fp16 training.\"\n )\n model = DDP(model, delay_allreduce=True)\n\nelif n_gpu > 1:\n model = nn.DataParallel(model)",
"08/24/2020 08:48:19 - INFO - vilbert.utils - loading weights file save/NLVR2_bert_base_6layer_6conect-finetune_from_multi_task_model-task_12/pytorch_model_19.bin\n"
]
],
[
[
"## Propagate Training Split",
"_____no_output_____"
]
],
[
[
"print(\"***** Running evaluation *****\")\nprint(\" Num Iters: \", task_num_iters)\nprint(\" Batch size: \", task_batch_size)\n\npooled_output_mul_list, pooled_output_sum_list, pooled_output_t_list, pooled_output_v_list = list(), list(), list(), list()\ntargets_list = list()\n\nmodel.eval()\n# when run evaluate, we run each task sequentially.\nfor task_id in task_ids:\n results = []\n others = []\n for i, batch in enumerate(task_dataloader_val[task_id]):\n loss, score, batch_size, results, others, target = EvaluatingModel(\n args,\n task_cfg,\n device,\n task_id,\n batch,\n model,\n task_dataloader_val,\n task_losses,\n results,\n others,\n )\n \n pooled_output_mul_list.append(model.pooled_output_mul)\n pooled_output_sum_list.append(model.pooled_output_sum)\n pooled_output_t_list.append(model.pooled_output_t)\n pooled_output_v_list.append(model.pooled_output_v)\n targets_list.append(target)\n\n tbLogger.step_val(0, float(loss), float(score), task_id, batch_size, \"val\")\n sys.stdout.write(\"%d/%d\\r\" % (i, len(task_dataloader_val[task_id])))\n sys.stdout.flush()\n # save the result or evaluate the result.\n ave_score = tbLogger.showLossVal(task_id)\n\n if args.split:\n json_path = os.path.join(savePath, args.split)\n else:\n json_path = os.path.join(savePath, task_cfg[task_id][\"val_split\"])\n\n json.dump(results, open(json_path + \"_result.json\", \"w\"))\n json.dump(others, open(json_path + \"_others.json\", \"w\"))",
"***** Running evaluation *****\n Num Iters: {'TASK19': 63}\n Batch size: {'TASK19': 128}\n62/63\r"
]
],
[
[
"## save ViLBERT output",
"_____no_output_____"
]
],
[
[
"pooled_output_mul = torch.cat(pooled_output_mul_list, 0)\npooled_output_sum = torch.cat(pooled_output_sum_list, 0)\npooled_output_t = torch.cat(pooled_output_t_list, 0)\npooled_output_v = torch.cat(pooled_output_v_list, 0)\nconcat_pooled_output = torch.cat([pooled_output_t, pooled_output_v], 1)\ntargets = torch.cat(targets_list, 0)",
"_____no_output_____"
],
[
"targets",
"_____no_output_____"
],
[
"train_save_path = \"datasets/ME/out_features/train_dc_features_nlvr2.pkl\"",
"_____no_output_____"
],
[
"pooled_dict = {\n \"pooled_output_mul\": pooled_output_mul,\n \"pooled_output_sum\": pooled_output_sum,\n \"pooled_output_t\": pooled_output_t,\n \"pooled_output_v\": pooled_output_v,\n \"concat_pooled_output\": concat_pooled_output,\n \"targets\": targets,\n}",
"_____no_output_____"
],
[
"pooled_dict.keys()",
"_____no_output_____"
],
[
"cPickle.dump(pooled_dict, open(train_save_path, 'wb'))\n#cPickle.dump(val_pooled_dict, open(val_save_path, 'wb'))",
"_____no_output_____"
]
],
[
[
"# Training a Regressor",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torch.utils.data as Data\nfrom torch.autograd import Variable\nfrom statistics import mean\nimport matplotlib.pyplot as plt\nimport _pickle as cPickle\nfrom tqdm import tqdm\nfrom scipy.stats import spearmanr",
"_____no_output_____"
],
[
"train_save_path = \"datasets/ME/out_features/train_dc_features_nlvr2.pkl\"\n# val_save_path = \"datasets/ME/out_features/val_features.pkl\"",
"_____no_output_____"
],
[
"pooled_dict = cPickle.load(open(train_save_path, 'rb'))\n#val_pooled_dict = cPickle.load(open(val_save_path, 'rb'))",
"_____no_output_____"
],
[
"pooled_output_mul = pooled_dict[\"pooled_output_mul\"]\npooled_output_sum = pooled_dict[\"pooled_output_sum\"]\npooled_output_t = pooled_dict[\"pooled_output_t\"]\npooled_output_v = pooled_dict[\"pooled_output_v\"]\nconcat_pooled_output = pooled_dict[\"concat_pooled_output\"]\ntargets = pooled_dict[\"targets\"]",
"_____no_output_____"
],
[
"indices = {\n \"0\": {},\n \"1\": {},\n \"2\": {},\n \"3\": {},\n}",
"_____no_output_____"
],
[
"import numpy as np\nfrom sklearn.model_selection import KFold\n\nkf = KFold(n_splits=4)\n\nfor i, (train_index, test_index) in enumerate(kf.split(pooled_output_mul)):\n indices[str(i)][\"train\"] = train_index\n indices[str(i)][\"test\"] = test_index",
"_____no_output_____"
],
[
"class Net(nn.Module):\n def __init__(self, input_size, hidden_size_1, hidden_size_2, num_scores):\n super(Net, self).__init__()\n self.out = nn.Sequential(\n nn.Linear(input_size, hidden_size_1), \n GeLU(), \n nn.Linear(hidden_size_1, hidden_size_2), \n GeLU(), \n nn.Linear(hidden_size_2, num_scores)\n )\n\n def forward(self, x):\n return self.out(x)",
"_____no_output_____"
],
[
"class LinNet(nn.Module):\n def __init__(self, input_size, hidden_size_1, num_scores):\n super(LinNet, self).__init__()\n self.out = nn.Sequential(\n nn.Linear(input_size, hidden_size_1),\n nn.Linear(hidden_size_1, num_scores),\n )\n\n def forward(self, x):\n return self.out(x)",
"_____no_output_____"
],
[
"class SimpleLinNet(nn.Module):\n def __init__(self, input_size, num_scores):\n super(SimpleLinNet, self).__init__()\n self.out = nn.Sequential(\n nn.Linear(input_size, num_scores),\n )\n\n def forward(self, x):\n return self.out(x)",
"_____no_output_____"
],
[
"class SigLinNet(nn.Module):\n def __init__(self, input_size, \n hidden_size_1,\n hidden_size_2, \n hidden_size_3, \n num_scores):\n super(SigLinNet, self).__init__()\n self.out = nn.Sequential(\n nn.Linear(input_size, hidden_size_1),\n nn.Sigmoid(),\n nn.Linear(hidden_size_1, hidden_size_2),\n nn.Sigmoid(),\n nn.Linear(hidden_size_2, hidden_size_3),\n nn.Sigmoid(),\n nn.Linear(hidden_size_3, num_scores),\n )\n\n def forward(self, x):\n return self.out(x)",
"_____no_output_____"
],
[
"class ReLuLinNet(nn.Module):\n def __init__(self, input_size, hidden_size_1, hidden_size_2, num_scores):\n super(ReLuLinNet, self).__init__()\n self.out = nn.Sequential(\n nn.Linear(input_size, hidden_size_1),\n nn.ReLU(),\n nn.Dropout(0.1),\n nn.Linear(hidden_size_1, hidden_size_2),\n nn.ReLU(),\n nn.Dropout(0.1),\n nn.Linear(hidden_size_2, num_scores),\n )\n\n def forward(self, x):\n return self.out(x)",
"_____no_output_____"
],
[
"def train_reg(inputs, targets, input_size, output_size, split, model, batch_size, epoch, lr, score, *argv):\n torch.manual_seed(42)\n nets = []\n los = []\n\n for i in range(len(split)):\n ind = list(split[str(i)][\"train\"])\n if score == \"both\":\n torch_dataset = Data.TensorDataset(inputs[ind], targets[ind])\n elif score == \"stm\":\n torch_dataset = Data.TensorDataset(inputs[ind], targets[ind,0].reshape(-1,1))\n elif score == \"ltm\":\n torch_dataset = Data.TensorDataset(inputs[ind], targets[ind,1].reshape(-1,1))\n\n loader = Data.DataLoader(\n dataset=torch_dataset, \n batch_size=batch_size, \n shuffle=True\n )\n\n net = model(input_size, *argv, output_size)\n net.cuda()\n\n optimizer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=1e-4)\n loss_func = torch.nn.MSELoss()\n\n losses = []\n net.train()\n for _ in tqdm(range(epoch), desc=\"Split %d\" % i):\n errors = []\n for step, (batch_in, batch_out) in enumerate(loader):\n optimizer.zero_grad()\n\n b_in = Variable(batch_in)\n b_out = Variable(batch_out)\n\n prediction = net(b_in)\n\n loss = loss_func(prediction, b_out)\n errors.append(loss.item())\n\n loss.backward()\n optimizer.step()\n losses.append(mean(errors))\n #if not (epoch+1) % 10:\n # print('Epoch {}: train loss: {}'.format(epoch+1, mean(errors))\n nets.append(net)\n los.append(losses)\n return nets, los",
"_____no_output_____"
],
[
"def test_reg(nets, inputs, targets, split, score):\n losses = list()\n rhos = {\"stm\": [], \"ltm\": []}\n \n loss_func = torch.nn.MSELoss()\n\n for i, net in enumerate(nets):\n ind = list(split[str(i)][\"test\"])\n if score == \"both\":\n torch_dataset_val = Data.TensorDataset(inputs[ind], targets[ind])\n elif score == \"stm\":\n torch_dataset_val = Data.TensorDataset(inputs[ind], targets[ind,0].reshape(-1,1))\n elif score == \"ltm\":\n torch_dataset_val = Data.TensorDataset(inputs[ind], targets[ind,1].reshape(-1,1))\n\n loader_val = Data.DataLoader(\n dataset=torch_dataset_val, \n batch_size=VAL_BATCH_SIZE, \n shuffle=False\n )\n\n dataiter_val = iter(loader_val)\n in_, out_ = dataiter_val.next()\n\n curr_net = net\n\n curr_net.eval()\n pred_scores = curr_net(in_)\n\n loss = loss_func(pred_scores, out_)\n losses.append(loss.item())\n\n r, _ = spearmanr(\n pred_scores.cpu().detach().numpy()[:,0], \n out_.cpu().detach().numpy()[:,0], \n axis=0\n )\n rhos[\"stm\"].append(r)\n\n r, _ = spearmanr(\n pred_scores.cpu().detach().numpy()[:,1], \n out_.cpu().detach().numpy()[:,1], \n axis=0\n )\n rhos[\"ltm\"].append(r)\n \n return rhos, losses",
"_____no_output_____"
],
[
"BATCH_SIZE = 128\nVAL_BATCH_SIZE = 2000\nEPOCH = 200\nlr = 4e-4",
"_____no_output_____"
]
],
[
[
"## 1024-input train",
"_____no_output_____"
]
],
[
[
"nets, los = train_reg(\n pooled_output_v, \n targets, \n 1024, # input size\n 2, # output size\n indices, # train and validation indices for each split\n SigLinNet, # model class to be used\n BATCH_SIZE, \n EPOCH, \n lr,\n \"both\", # predict both scores\n 512, 64, 32 # sizes of hidden network layers\n)",
"Split 0: 100%|██████████| 200/200 [00:23<00:00, 8.60it/s]\nSplit 1: 100%|██████████| 200/200 [00:22<00:00, 8.83it/s]\nSplit 2: 100%|██████████| 200/200 [00:23<00:00, 8.71it/s]\nSplit 3: 100%|██████████| 200/200 [00:22<00:00, 8.73it/s]\n"
],
[
"for l in los:\n plt.plot(l[3:])\nplt.yscale('log')",
"_____no_output_____"
]
],
[
[
"## 1024-input test",
"_____no_output_____"
]
],
[
[
"rhos, losses = test_reg(nets, pooled_output_v, targets, indices, \"both\")",
"_____no_output_____"
],
[
"rhos",
"_____no_output_____"
],
[
"mean(rhos[\"stm\"]), mean(rhos[\"ltm\"])",
"_____no_output_____"
]
],
[
[
"## 2048-input train",
"_____no_output_____"
]
],
[
[
"nets_2, los_2 = train_reg(\n concat_pooled_output, \n targets, \n 2048, \n 2, \n indices, \n SigLinNet, \n BATCH_SIZE, \n EPOCH, \n lr,\n \"both\",\n 512, 64, 32\n)",
"Split 0: 100%|██████████| 200/200 [00:22<00:00, 8.84it/s]\nSplit 1: 100%|██████████| 200/200 [00:22<00:00, 8.90it/s]\nSplit 2: 100%|██████████| 200/200 [00:22<00:00, 8.63it/s]\nSplit 3: 100%|██████████| 200/200 [00:22<00:00, 8.79it/s]\n"
],
[
"for l in los_2:\n plt.plot(l[3:])\nplt.yscale('log')",
"_____no_output_____"
]
],
[
[
"## 2048-input test",
"_____no_output_____"
]
],
[
[
"rhos_2, losses_2 = test_reg(nets_2, concat_pooled_output, targets, indices, \"both\")",
"_____no_output_____"
],
[
"rhos_2",
"_____no_output_____"
],
[
"mean(rhos_2[\"stm\"]), mean(rhos_2[\"ltm\"])",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a46ed193fd9e11a7d6980dd87b47adec75b180a
| 25,152 |
ipynb
|
Jupyter Notebook
|
NetOwl to ArcGIS GeoEvent Cosmos DB.ipynb
|
GeoJamesJones/enrich-cosmosdb
|
1e085c4013caba24d3929993662e0e361d425525
|
[
"MIT"
] | null | null | null |
NetOwl to ArcGIS GeoEvent Cosmos DB.ipynb
|
GeoJamesJones/enrich-cosmosdb
|
1e085c4013caba24d3929993662e0e361d425525
|
[
"MIT"
] | null | null | null |
NetOwl to ArcGIS GeoEvent Cosmos DB.ipynb
|
GeoJamesJones/enrich-cosmosdb
|
1e085c4013caba24d3929993662e0e361d425525
|
[
"MIT"
] | null | null | null | 51.435583 | 157 | 0.384582 |
[
[
[
"import datetime\nimport time\nimport json\nimport os\nimport string\nimport requests\nimport sys\nimport traceback\n\nimport azure.cosmos.cosmos_client as cosmos_client\n\nfrom helpers import keys\nfrom helpers import nlp_helper\nfrom gremlin_python.driver import client, serializer",
"_____no_output_____"
],
[
"config = {\n 'ENDPOINT': keys.cosmos_uri,\n 'PRIMARYKEY': keys.cosmos_primary_key,\n 'DATABASE': 'NetOwl',\n 'CONTAINER': 'Entities',\n 'LINK-CONTAINER': 'Links',\n 'EVENT-CONTAINER': 'Events'\n}",
"_____no_output_____"
],
[
"docs_path = r'C:\\Users\\jame9353\\Box Sync\\Data\\Early Bird'\njson_out_dir = r'C:\\Data\\json'\ngeoevent_url = r'https://ge-1.eastus.cloudapp.azure.com:6143/geoevent/rest/receiver/netowl-geoentities-in'\n\nout_ext = \".json\"",
"_____no_output_____"
],
[
"print(\"Connecting to Cosmos DB Graph Client...\")\ngraph_client = client.Client('wss://pilot-graph.gremlin.cosmosdb.azure.com:443/','g', \n username=\"/dbs/NetOwl/colls/Links\", \n password=\"whE1lJjFxzVSCQ7ppNDc5hMCwNl7x8C0BeMTF6dGq4pTN3c8qDVyUBLutYwQZJW1haxJP6W8wckzqBepDcGlAQ==\",\n message_serializer=serializer.GraphSONMessageSerializer()\n )\nprint(\"Successfully connected to Cosmos DB Graph Client\")",
"_____no_output_____"
],
[
"# Initialize the Cosmos client\n\nprint(\"Connecting to Cosmos DB SQL API...\")\nclient = cosmos_client.CosmosClient(url_connection=config['ENDPOINT'], auth={\n 'masterKey': config['PRIMARYKEY']})\n\nprint(\"Creating Database...\")\n# Create a database\ndb = client.CreateDatabase({'id': config['DATABASE']})\n\n# Create container options\noptions = {\n 'offerThroughput': 400\n}\n\ncontainer_definition = {\n 'id': config['CONTAINER']\n}\n\nlink_container_definition = {\n 'id': config['LINK-CONTAINER']\n}\n\nevent_container_definition = {\n 'id': config['EVENT-CONTAINER']\n}\n\n# Create a container for Entities\nprint(\"Creating \" + str(config['CONTAINER']) + \" container...\")\ncontainer = client.CreateContainer(db['_self'], container_definition, options)\n\n# Create a container for Links\nprint(\"Creating \" + str(config['LINK-CONTAINER']) + \" container...\")\nlink_container = client.CreateContainer(db['_self'], link_container_definition, options)\n\n# Create a container for Events\nprint(\"Creating \" + str(config['EVENT-CONTAINER']) + \" container...\")\nevent_container = client.CreateContainer(db['_self'], event_container_definition, options)",
"_____no_output_____"
],
[
"numchars = 100 # number of characters to retrieve for head/tail\n\n# Function to watch a folder and detect new images on a 1 second refresh interval\n#before = dict ([(f, None) for f in os.listdir (docs_path)])\nbefore = {}\ncount = 0\nerrors = 0\n\nprint(\"Beginning monitor of \" + str(docs_path) + \" at \" + str(datetime.datetime.now()))\n\nwhile True: \n \n # Compares the folder contents after the sleep to what existed beforehand, and makes a list of adds and removes\n after = dict ([(f, None) for f in os.listdir (docs_path)])\n added = [f for f in after if not f in before]\n removed = [f for f in before if not f in after]\n\n if added: print(\"Added: \", \", \".join (added))\n if removed: print(\"Removed: \", \", \".join (removed))\n before = after\n \n for filename in added:\n if filename.endswith(\".htm\"):\n print(\"Processing \" + filename + \" at \" + str(datetime.datetime.now()))\n start = time.time()\n \n # create empty lists for objects\n rdfobjs = []\n rdfobjsGeo = []\n linkobjs = []\n eventobjs = []\n orgdocs = []\n\n haslinks = False\n bigstring = \"\" # keeps track of what was sent\n\n newhead = \"\" # empty string to catch empty head/tail\n newtail = \"\"\n \n filepath = os.path.join(docs_path, filename)\n nlp_helper.netowl_curl(filepath, json_out_dir, out_ext, keys.netowl_key)\n outfile = os.path.join(json_out_dir, filename + out_ext)\n \n with open(outfile, 'r', encoding=\"utf-8\") as file:\n rdfstring = json.load(file)\n uniquets = str(time.time()) # unique time stamp for each doc\n doc = rdfstring['document'][0] # gets main part\n \n if 'text' in doc:\n v = doc['text'][0]\n if 'content' in v:\n bigstring = v['content']\n \n if 'entity' not in doc:\n print(\"ERROR: Nothing returned from NetOwl, or other unspecified error.\") # NOQA E501\n break\n \n ents = (doc['entity']) # gets all entities in doc\n \n for e in ents:\n\n # gather data from each entity\n # rdfvalue = nof.cleanup_text(e['value']) # value (ie name)\n rdfvalue = nlp_helper.cleanup_text(e['value']) # value (ie name)\n rdfid = e['id']\n rdfid = filename.split(\".\")[0] + \"-\" + rdfid # unique to each entity\n\n # test for geo (decide which type of obj to make - geo or non-geo)\n \n if 'geodetic' in e:\n\n if 'link-ref' in e:\n refrels = []\n linkdescs = []\n haslinks = True\n for k in e['link-ref']: # every link-ref per entity\n refrels.append(k['idref']) # keep these - all references # noqa: E501\n if 'role-type' in k: # test the role type is source # noqa: E501\n if k['role-type'] == \"source\":\n linkdesc = rdfvalue + \" is a \" + k['role'] + \" in \" + k['entity-arg'][0]['value'] # noqa: E501\n linkdescs.append(linkdesc)\n else:\n linkdescs.append(\"This item has parent links but no children\") # noqa: E501\n else:\n haslinks = False\n \n if 'entity-ref' in e:\n isGeo = False # already plotted, relegate to rdfobj list # noqa: E501\n else:\n lat = float(e['geodetic']['latitude'])\n longg = float(e['geodetic']['longitude'])\n isGeo = True\n \n else:\n isGeo = False\n \n # check for addresses\n if e['ontology'] == \"entity:address:mail\":\n address = e['value']\n # location = nof.geocode_address(address) # returns x,y\n location = geocode_address(address) # returns x,y\n isGeo = True\n # set lat long\n lat = location['y']\n longg = location['x']\n # check for links\n if 'link-ref' in e:\n refrels = []\n linkdescs = []\n haslinks = True\n for k in e['link-ref']: # every link-ref per entity\n refrels.append(k['idref']) # keep these - all references # noqa: E501\n if 'role-type' in k: # test the role type is source # noqa: E501\n if k['role-type'] == \"source\":\n linkdesc = rdfvalue + \" is a \" + k['role'] + \" in \" + k['entity-arg'][0]['value'] # noqa: E501\n linkdescs.append(linkdesc)\n else:\n linkdescs.append(\"This item has parent links but no children\") # noqa: E501\n else:\n haslinks = False\n \n # set up head and tail\n if 'entity-mention' in e:\n em = e['entity-mention'][0]\n if 'head' in em:\n newhead = nlp_helper.get_head(bigstring, int(em['head']), numchars)\n if 'tail' in em:\n newtail = nlp_helper.get_tail(bigstring, int(em['tail']), numchars)\n \n else:\n em = None\n \n if isGeo:\n\n if haslinks:\n # add refrels to new obj\n rdfobj = nlp_helper.RDFitemGeo(rdfid, rdfvalue, longg, lat, uniquets, filename, # noqa: E501\n refrels)\n ld = str(linkdescs)\n if len(ld) > 255:\n ld = ld[:254] # shorten long ones\n rdfobj.set_link_details(ld)\n else:\n rdfobj = nlp_helper.RDFitemGeo(rdfid, rdfvalue, longg, lat, uniquets, filename) # noqa: E501\n rdfobj.set_link_details(\"No links for this point\")\n \n # set type for symbology\n rdfobj.set_type(\"placename\") # default\n rdfobj.set_subtype(\"unknown\") # default\n if e['ontology'] == \"entity:place:city\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"city\")\n if e['ontology'] == \"entity:place:country\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"country\")\n if e['ontology'] == \"entity:place:province\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"province\")\n if e['ontology'] == \"entity:place:continent\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"continent\")\n if e['ontology'] == \"entity:numeric:coordinate:mgrs\":\n rdfobj.set_type(\"coordinate\")\n rdfobj.set_subtype(\"MGRS\")\n if e['ontology'] == \"entity:numeric:coordinate:latlong\": # noqa: E501\n rdfobj.set_type(\"coordinate\")\n rdfobj.set_subtype(\"latlong\")\n if e['ontology'] == \"entity:address:mail\":\n rdfobj.set_type(\"address\")\n rdfobj.set_subtype(\"mail\")\n if e['ontology'] == \"entity:place:other\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"descriptor\")\n if e['ontology'] == \"entity:place:landform\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"landform\")\n if e['ontology'] == \"entity:organization:facility\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"facility\")\n if e['ontology'] == \"entity:place:water\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"water\")\n if e['ontology'] == \"entity:place:county\":\n rdfobj.set_type(\"placename\")\n rdfobj.set_subtype(\"county\")\n\n rdfobj.set_head(newhead)\n rdfobj.set_tail(newtail)\n item = rdfobj.toJSON()\n cosmos_item = client.CreateItem(container['_self'],{\n \"head\": rdfobj.head,\n \"id\": rdfobj.id,\n \"lat\": rdfobj.lat,\n \"linkdetails\": rdfobj.linkdetails,\n \"links\": rdfobj.links,\n \"long\": rdfobj.long,\n \"orgdoc\": rdfobj.orgdoc,\n \"subtype\": rdfobj.subtype,\n \"tail\": rdfobj.tail,\n \"timest\": rdfobj.timest,\n \"type\": rdfobj.type,\n \"value\": rdfobj.value\n })\n \n rdfobjsGeo.append(rdfobj)\n \n nlp_helper.post_to_geoevent(item, geoevent_url)\n \n else: # not geo\n ontology = e['ontology']\n if haslinks:\n rdfobj = nlp_helper.RDFitem(rdfid, rdfvalue, uniquets, filename, ontology, refrels) # noqa: E501\n else: # has neither links nor address\n rdfobj = nlp_helper.RDFitem(rdfid, rdfvalue, uniquets, filename, ontology)\n\n rdfobj.set_head(newhead)\n rdfobj.set_tail(newtail)\n \n cosmos_item = client.CreateItem(container['_self'],{\n \"value\": rdfobj.value,\n \"links\": rdfobj.links,\n \"orgdoc\": rdfobj.orgdoc, \n \"id\": rdfobj.id, \n \"type\": rdfobj.type,\n \"head\": rdfobj.head,\n \"tail\": rdfobj.tail\n })\n\n rdfobjs.append(rdfobj)\n \n if 'link' in doc:\n linksys = (doc['link'])\n for l in linksys:\n linkid = filename.split(\".\")[0] + \"-\" + l['id']\n if 'entity-arg' in l:\n fromid = filename.split(\".\")[0] + \"-\" + l['entity-arg'][0]['idref']\n toid = filename.split(\".\")[0] + \"-\" + l['entity-arg'][1]['idref']\n fromvalue = l['entity-arg'][0]['value']\n tovalue = l['entity-arg'][1]['value']\n fromrole = l['entity-arg'][0]['role']\n torole = l['entity-arg'][1]['role']\n fromroletype = l['entity-arg'][0]['role-type']\n toroletype = l['entity-arg'][1]['role-type']\n # build link objects\n linkobj = nlp_helper.RDFlinkItem(linkid, fromid, toid, fromvalue, tovalue,\n fromrole, torole, fromroletype,\n toroletype, uniquets)\n \n cosmos_link_item = client.CreateItem(link_container['_self'],{\n \"linkid\": linkobj.linkid,\n \"fromid\": linkobj.fromid,\n \"toid\": linkobj.toid,\n \"fromvalue\":linkobj.fromvalue,\n \"tovalue\":linkobj.tovalue,\n \"fromrole\":linkobj.fromrole,\n \"torole\": linkobj.torole,\n \"fromroletype\": linkobj.fromroletype,\n \"toroletype\": linkobj.toroletype\n })\n \n linkobjs.append(linkobj)\n \n _gremlin_insert_vertices = [\"g.addV('{0}').property('type', '{1}').property('id', '{0}')\".format(fromvalue, fromroletype),\n \"g.addV('{0}').property('type', '{1}').property('id', '{0}')\".format(tovalue, toroletype)]\n \n _gremlin_insert_edges = [\"g.V('{0}').addE('linked').to(g.V('{1}'))\".format(fromvalue, tovalue)]\n \n #try:\n #nlp_helper.insert_vertices(_gremlin_insert_vertices, graph_client)\n #except:\n #print('Error on node insertion')\n \n #nlp_helper.insert_edges(_gremlin_insert_edges, graph_client)\n \n \n if 'event' in doc:\n events = doc['event']\n for e in events:\n evid = e['id']\n evvalue = e['value']\n if 'entity-arg' in e:\n fromid = filename.split(\".\")[0] + \"-\" + e['entity-arg'][0]['idref']\n fromvalue = e['entity-arg'][0]['value']\n fromrole = e['entity-arg'][0]['role']\n if len(e['entity-arg']) > 1:\n toid = filename.split(\".\")[0] + \"-\" + e['entity-arg'][1]['idref']\n tovalue = e['entity-arg'][1]['value']\n torole = e['entity-arg'][1]['role']\n else:\n toid = None\n tovalue = None\n torole = None\n \n \n eventobj = nlp_helper.RDFeventItem(evvalue, evid, fromid, toid,\n fromvalue, tovalue, fromrole,\n torole, filename, uniquets)\n \n cosmos_event_item = client.CreateItem(event_container['_self'],{\n \"eventvalue\": eventobj.eventvalue,\n \"eventid\": eventobj.eventid,\n \"fromid\": eventobj.fromid,\n \"toid\": eventobj.toid,\n \"fromvalue\": eventobj.fromvalue,\n \"tovalue\": eventobj.tovalue,\n \"fromrole\": eventobj.fromrole,\n \"torole\": eventobj.torole,\n \"orgdoc\": eventobj.orgdoc\n })\n \n eventobjs.append(eventobj)\n \n _gremlin_insert_vertices = [\"g.addV('{0}').property('type', '{1}').property('id', '{0}')\".format(fromvalue, fromroletype),\n \"g.addV('{0}').property('type', '{1}').property('id', '{0}')\".format(tovalue, toroletype)]\n \n _gremlin_insert_edges = [\"g.V('{0}').addE('{1}').to(g.V('{2}'))\".format(fromvalue, fromrole, tovalue)]\n \n #try:\n #nlp_helper.insert_vertices(_gremlin_insert_vertices, graph_client)\n #except:\n #print('Error on node insertion')\n \n #nlp_helper.insert_edges(_gremlin_insert_edges, graph_client)\n \n end = time.time()\n process_time = end - start\n print(\"Non-Geospatial Entities Found: \" + str(len(rdfobjs)))\n print(\"Geospatial Entities Found: \" + str(len(rdfobjsGeo)))\n print(\"Links Found: \" + str(len(linkobjs)))\n print(\"Events Found: \" + str(len(eventobjs)))\n print(\"Process took {0} seconds\".format(str(process_time)))\n count +=1\n \n if count > 4:\n print(\"Exiting\")\n break",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a46f9250f9114755bec4c9900eed974f2d9937d
| 5,577 |
ipynb
|
Jupyter Notebook
|
2020/Day 09.ipynb
|
AwesomeGitHubRepos/adventofcode
|
84ba7963a5d7905973f14bb1c2e3a59165f8b398
|
[
"MIT"
] | 96 |
2018-04-21T07:53:34.000Z
|
2022-03-15T11:00:02.000Z
|
2020/Day 09.ipynb
|
AwesomeGitHubRepos/adventofcode
|
84ba7963a5d7905973f14bb1c2e3a59165f8b398
|
[
"MIT"
] | 17 |
2019-02-07T05:14:47.000Z
|
2021-12-27T12:11:04.000Z
|
2020/Day 09.ipynb
|
AwesomeGitHubRepos/adventofcode
|
84ba7963a5d7905973f14bb1c2e3a59165f8b398
|
[
"MIT"
] | 14 |
2019-02-05T06:34:15.000Z
|
2022-01-24T17:35:00.000Z
| 29.352632 | 379 | 0.525372 |
[
[
[
"# Day 9 - Finding the sum, again, with a running series\n\n* https://adventofcode.com/2020/day/9\n\nThis looks to be a variant of the [day 1, part 1 puzzle](./Day%2001.ipynb); finding the sum of two numbers in a set. Only now, we have to make sure we know what number to remove as we progres! This calls for a _sliding window_ iterator really, where we view the whole series through a slit X entries wide as it moves along the inputs.\n\nAs this puzzle is easier with a set of numbers, I create a sliding window of size `preamble + 2`, so we have access to the value to be removed and the value to be checked, at the same time; to achieve this, I created a window function that takes an *offset*, where you can take `offset` fewer items at the start, then have the window grow until it reaches the desired size:",
"_____no_output_____"
]
],
[
[
"from collections import deque\nfrom itertools import islice\nfrom typing import Iterable, Iterator, TypeVar\n\nT = TypeVar(\"T\")\n\ndef window(iterable: Iterable[T], n: int = 2, offset: int = 0) -> Iterator[deque[T]]:\n it = iter(iterable)\n queue = deque(islice(it, n - offset), maxlen=n)\n yield queue\n append = queue.append\n for elem in it:\n append(elem)\n yield queue\n\ndef next_invalid(numbers: Iterable[int], preamble: int = 25) -> int:\n it = window(numbers, preamble + 2, 2)\n pool = set(next(it))\n for win in it:\n to_check = win[-1]\n if len(win) == preamble + 2:\n # remove the value now outside of our preamble window\n pool.remove(win[0])\n\n # validate the value can be created from a sum\n for a in pool:\n b = to_check - a\n if b == a:\n continue\n if b in pool:\n # number validated\n break\n else:\n # no valid sum found\n return to_check\n\n pool.add(to_check)\n\ntest = [int(v) for v in \"\"\"\\\n35\n20\n15\n25\n47\n40\n62\n55\n65\n95\n102\n117\n150\n182\n127\n219\n299\n277\n309\n576\n\"\"\".split()]\nassert next_invalid(test, 5) == 127",
"_____no_output_____"
],
[
"import aocd\nnumber_stream = [int(v) for v in aocd.get_data(day=9, year=2020).split()]",
"_____no_output_____"
],
[
"print(\"Part 1:\", next_invalid(number_stream))",
"Part 1: 18272118\n"
]
],
[
[
"## Part 2\n\nTo solve the second part, you need a _dynamic_ window size over the input stream, and a running total. When the running total equals the value from part 1, we can then take the min and max values from the window.\n\n- While the running total is too low, grow the window one stap and add the extra value to the total\n- If the running total is too high, remove a value at the back of the window from the running total, and shrink that side of the window by one step.\n\nWith the Python `deque` (double-ended queue) already used in part one, this is a trivial task to achieve:",
"_____no_output_____"
]
],
[
[
"def find_weakness(numbers: Iterable[int], preamble: int = 25) -> int:\n invalid = next_invalid(numbers, preamble)\n it = iter(numbers)\n total = next(it)\n window = deque([total])\n while total != invalid and window:\n if total < invalid:\n window.append(next(it))\n total += window[-1]\n else:\n total -= window.popleft()\n if not window:\n raise ValueError(\"Could not find a weakness\")\n return min(window) + max(window)\n\nassert find_weakness(test, 5) == 62\n",
"_____no_output_____"
],
[
"print(\"Part 2:\", find_weakness(number_stream))",
"Part 2: 2186361\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a46fa1a23fb5f6bc7c8cf037719ac5150c39849
| 28,412 |
ipynb
|
Jupyter Notebook
|
Notebooks/Class-5-Matplotlib.ipynb
|
vacquaviva/PHYS3600ID_ML
|
747038261f8a0ee2424325bc1821e91418a111d4
|
[
"MIT"
] | null | null | null |
Notebooks/Class-5-Matplotlib.ipynb
|
vacquaviva/PHYS3600ID_ML
|
747038261f8a0ee2424325bc1821e91418a111d4
|
[
"MIT"
] | null | null | null |
Notebooks/Class-5-Matplotlib.ipynb
|
vacquaviva/PHYS3600ID_ML
|
747038261f8a0ee2424325bc1821e91418a111d4
|
[
"MIT"
] | 2 |
2019-07-01T01:34:20.000Z
|
2019-07-04T17:33:50.000Z
| 30.161359 | 487 | 0.584471 |
[
[
[
"# Intro to matplotlib - plotting in Python",
"_____no_output_____"
],
[
"Most of this material is reproduced or adapted from\n\nhttps://github.com/jakevdp/PythonDataScienceHandbook\n\nThe text is released under the [CC-BY-NC-ND license](https://creativecommons.org/licenses/by-nc-nd/3.0/us/legalcode), and code is released under the [MIT license](https://opensource.org/licenses/MIT). \n\nFor this lecture, we also grab references from \n\n[http://jrjohansson.github.io](http://jrjohansson.github.io)\n\nThis work is licensed under a [CC-BY license](https://creativecommons.org/licenses/by/3.0/).",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"Matplotlib is a 2D and 3D graphics library for generating scientific figures. \n\nMore information at the Matplotlib web page: http://matplotlib.org/",
"_____no_output_____"
],
[
"### Importing Matplotlib\n\nJust as we use the ``np`` shorthand for NumPy, we will use some standard shorthands for Matplotlib imports:",
"_____no_output_____"
]
],
[
[
"#Do imports\n\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"The ``plt`` interface is what we will use most often.",
"_____no_output_____"
],
[
"#### Plotting from a Jupyter notebook\n\nPlotting interactively within notebook can be done with the ``%matplotlib`` command.\n\n- ``%matplotlib notebook`` will lead to *interactive* plots embedded within the notebook\n- ``%matplotlib inline`` will lead to *static* images of your plot embedded in the notebook\n\nWe will generally opt for ``%matplotlib inline``:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"After running this command (it needs to be done only once per kernel/session), any cell within the notebook that creates a plot will embed a PNG image of the resulting graphic:",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0, 10, 100)\n\nfig = plt.figure()\n\nplt.plot(x, np.sin(x), '-')\nplt.plot(x, np.cos(x), '--');",
"_____no_output_____"
]
],
[
[
"### Saving Figures to File\n\nOne nice feature of Matplotlib is the ability to save figures in a wide variety of formats.\nSaving a figure can be done using the ``savefig()`` command.\nFor example, to save the previous figure as a PNG file, you can run this:",
"_____no_output_____"
]
],
[
[
"fig.savefig('my_figure.png')",
"_____no_output_____"
]
],
[
[
"We now have a file called ``my_figure.png`` in the current working directory:",
"_____no_output_____"
]
],
[
[
"!ls -lh my_figure.png #This won't work in Windows (you could use !dir my_figure.png )",
"_____no_output_____"
]
],
[
[
"In ``savefig()``, the file format is inferred from the extension of the given filename.\nDepending on what backends you have installed, many different file formats are available.\nThe list of supported file types can be found for your system by using the following method of the figure canvas object:",
"_____no_output_____"
]
],
[
[
"fig.canvas.get_supported_filetypes()",
"_____no_output_____"
]
],
[
[
"# Simple Line Plots",
"_____no_output_____"
],
[
"Perhaps the simplest of all plots is the visualization of a single function $y = f(x)$.",
"_____no_output_____"
],
[
"For all Matplotlib plots, we start by creating a figure and an axes.\nIn their simplest form, a figure and axes can be created as follows:",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = plt.axes()\n\n#This is called the object-oriented interface because we define two objects, one of the\n#class figure and one of the class axes.",
"_____no_output_____"
]
],
[
[
"In Matplotlib, the *figure* (an instance of the class ``plt.Figure``) can be thought of as a single container that contains all the objects representing axes, graphics, text, and labels.\nThe *axes* (an instance of the class ``plt.Axes``) is what we see above: a bounding box with ticks and labels, which will eventually contain the plot elements that make up our visualization.\n\nOnce we have created an axes, we can use the ``ax.plot`` function to plot some data. Let's start with a simple sinusoid:",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = plt.axes()\n\nx = np.linspace(0, 10, 1000) #what is this line doing?\nax.plot(x, np.sin(x));",
"_____no_output_____"
]
],
[
[
"Alternatively, we can use the pylab interface and let the figure and axes be created for us in the background:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x));\n# This is simpler but less flexible.",
"_____no_output_____"
]
],
[
[
"If we want to create a single figure with multiple lines, we can simply call the ``plot`` function multiple times:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x))\nplt.plot(x, np.cos(x))\nplt.plot(x, np.cos(x)+1);",
"_____no_output_____"
]
],
[
[
"That's all there is to plotting simple functions in Matplotlib!\nWe'll now dive into some more details about how to control the appearance of the axes and lines.",
"_____no_output_____"
],
[
"## Adjusting the Plot: Line Colors and Styles",
"_____no_output_____"
],
[
"The first adjustment you might wish to make to a plot is to control the line colors and styles.\nThe ``plt.plot()`` function takes additional arguments that can be used to specify these.\nTo adjust the color, you can use the ``color`` keyword, which accepts a string argument representing virtually any imaginable color.\nThe color can be specified in a variety of ways:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x - 0), color='blue') # specify color by name\nplt.plot(x, np.sin(x - 1), color='g') # short color code (rgbcmyk)\nplt.plot(x, np.sin(x - 2), color='0.75') # Grayscale between 0 and 1\nplt.plot(x, np.sin(x - 3), color='#FFDD44') # Hex code (RRGGBB from 00 to FF)\nplt.plot(x, np.sin(x - 4), color=(1.0,0.2,0.3)) # RGB tuple, values 0 to 1\nplt.plot(x, np.sin(x - 5), color='chartreuse'); # all HTML color names supported",
"_____no_output_____"
]
],
[
[
"If no color is specified, Matplotlib will automatically cycle through a set of default colors for multiple lines.\n\nSimilarly, the line style can be adjusted using the ``linestyle`` keyword:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, x + 0, linestyle='solid')\nplt.plot(x, x + 1, linestyle='dashed')\nplt.plot(x, x + 2, linestyle='dashdot')\nplt.plot(x, x + 3, linestyle='dotted');\n\n# For short, you can use the following codes:\nplt.plot(x, x + 4, linestyle='-') # solid\nplt.plot(x, x + 5, linestyle='--') # dashed\nplt.plot(x, x + 6, linestyle='-.') # dashdot\nplt.plot(x, x + 7, linestyle=':'); # dotted",
"_____no_output_____"
]
],
[
[
"If you would like to be extremely terse, these ``linestyle`` and ``color`` codes can be combined into a single non-keyword argument to the ``plt.plot()`` function:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, x + 0, '-g') # solid green\nplt.plot(x, x + 1, '--c') # dashed cyan\nplt.plot(x, x + 2, '-.k') # dashdot black\nplt.plot(x, x + 3, ':r'); # dotted red",
"_____no_output_____"
]
],
[
[
"These single-character color codes reflect the standard abbreviations in the RGB (Red/Green/Blue) and CMYK (Cyan/Magenta/Yellow/blacK) color systems, commonly used for digital color graphics.\n\nThere are many other keyword arguments that can be used to fine-tune the appearance of the plot; for more details, I'd suggest viewing the docstring of the ``plt.plot()`` function.",
"_____no_output_____"
],
[
"## Adjusting the Plot: Axes Limits\n\nMatplotlib does a decent job of choosing default axes limits for your plot, but sometimes it's nice to have finer control.\nThe most basic way to adjust axis limits is to use the ``plt.xlim()`` and ``plt.ylim()`` methods:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x))\n\nplt.xlim(-1, 11)\nplt.ylim(-5, 5);",
"_____no_output_____"
]
],
[
[
"If for some reason you'd like either axis to be displayed in reverse, you can simply reverse the order of the arguments:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x))\n\nplt.xlim(10, 0)\nplt.ylim(1.2, -1.2);",
"_____no_output_____"
]
],
[
[
"A useful related method is ``plt.axis()`` (note here the potential confusion between *axes* with an *e*, and *axis* with an *i*).\nThe ``plt.axis()`` method allows you to set the ``x`` and ``y`` limits with a single call, by passing a list which specifies ``[xmin, xmax, ymin, ymax]``:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x))\nplt.axis([-1, 11, -1.5, 1.5]);",
"_____no_output_____"
]
],
[
[
"It allows even higher-level specifications, such as ensuring an equal aspect ratio so that on your screen, one unit in ``x`` is equal to one unit in ``y``:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, np.sin(x))\nplt.axis('equal');",
"_____no_output_____"
]
],
[
[
"For more information on axis limits and the other capabilities of the ``plt.axis`` method, refer to the ``plt.axis`` docstring.",
"_____no_output_____"
],
[
"## Labeling Plots\n\nEvery plot should include a title, axis labels, and a simple legend.",
"_____no_output_____"
]
],
[
[
"# Let's do this one together\n\nx = np.linspace(0,10,100)\n\nplt.plot(x, np.tan(x), label = 'Tan(x)');\nplt.plot(x, np.arctan(x), label = 'Arctan(x)');\nplt.title('Tangent of x');\nplt.xlabel('x');\nplt.ylabel('Tan(x)');\nplt.legend(loc = 'upper right');\n",
"_____no_output_____"
]
],
[
[
"The position, size, and style of these labels can be adjusted using optional arguments to the function.\nFor more information, see the Matplotlib documentation and the docstrings of each of these functions.",
"_____no_output_____"
],
[
"When multiple lines are being shown within a single axes, it can be useful to create a plot legend that labels each line type.\nAgain, Matplotlib has a built-in way of quickly creating such a legend.\nIt is done via the (you guessed it) ``plt.legend()`` method.\nYou can specify the label of each line using the ``label`` keyword of the plot function:",
"_____no_output_____"
]
],
[
[
"#plt.legend(loc=0) # let matplotlib decide the optimal location; default choice\n#plt.legend(loc=1) # upper right corner\n#plt.legend(loc=2) # upper left corner\n#plt.legend(loc=3) # lower left corner\n#plt.legend(loc=4) # lower right corner",
"_____no_output_____"
]
],
[
[
"As you can see, the ``plt.legend()`` function keeps track of the line style and color, and matches these with the correct label.\nMore information on specifying and formatting plot legends can be found in the ``plt.legend`` docstring.",
"_____no_output_____"
],
[
"## Aside: Matplotlib Gotchas\n\nWhile most ``plt`` functions translate directly to ``ax`` methods (such as ``plt.plot()`` → ``ax.plot()``, ``plt.legend()`` → ``ax.legend()``, etc.), this is not the case for all commands.\nIn particular, functions to set limits, labels, and titles are slightly modified.\nFor transitioning between MATLAB-style functions and object-oriented methods, make the following changes:\n\n- ``plt.xlabel()`` → ``ax.set_xlabel()``\n- ``plt.ylabel()`` → ``ax.set_ylabel()``\n- ``plt.xlim()`` → ``ax.set_xlim()``\n- ``plt.ylim()`` → ``ax.set_ylim()``\n- ``plt.title()`` → ``ax.set_title()``\n\nIn the object-oriented interface to plotting, rather than calling these functions individually, it is often more convenient to use the ``ax.set()`` method to set all these properties at once:",
"_____no_output_____"
]
],
[
[
"ax = plt.axes()\nax.plot(x, np.sin(x))\nax.set(xlim=(0, 10), ylim=(-2, 2),\n xlabel='x', ylabel='sin(x)',\n title='Your old friend, the sine curve');",
"_____no_output_____"
]
],
[
[
"For simple plots, the choice of which style to use is largely a matter of preference, but the object-oriented approach can become a necessity as plots become more complicated.",
"_____no_output_____"
],
[
"## Scatter Plots with ``plt.plot``\n\nIn the previous section we looked at ``plt.plot``/``ax.plot`` to produce line plots.\nIt turns out that this same function can produce scatter plots as well:",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0, 10, 30)\ny = np.sin(x)\n\n#plt.plot(x, y, '*', color='black');\nplt.plot(x, y, '*k'); #same thing",
"_____no_output_____"
]
],
[
[
"As you saw above, you can give \"plot\" a marker (without a line), and it will produce a scatter plot.\n\nThe third argument in the function call is a character that represents the type of symbol used for the plotting. Just as you can specify options such as ``'-'``, ``'--'`` to control the line style, the marker style has its own set of short string codes. The full list of available symbols can be seen in the documentation of ``plt.plot``, or in Matplotlib's online documentation. Most of the possibilities are fairly intuitive, and we'll show a number of the more common ones here:",
"_____no_output_____"
]
],
[
[
"#What is this code doing?\n\nfor marker in ['o', '.', ',', 'x', '+', 'v', '^', '<', '>', 's', 'd']:\n plt.plot(np.random.uniform(size=5), np.random.uniform(size=5), marker,\n label=\"marker='{0}'\".format(marker))\nplt.legend(numpoints=1)\nplt.xlim(0, 1.8);\n",
"_____no_output_____"
]
],
[
[
"For even more possibilities, these character codes can be used together with line and color codes to plot points along with a line connecting them:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, y, '-ok');",
"_____no_output_____"
]
],
[
[
"Additional keyword arguments to ``plt.plot`` specify a wide range of properties of the lines and markers:",
"_____no_output_____"
]
],
[
[
"plt.plot(x, y, '-p', color='gray',\n markersize=15, linewidth=4,\n markerfacecolor='white',\n markeredgecolor='gray',\n markeredgewidth=2)\nplt.ylim(-1.2, 1.2);",
"_____no_output_____"
],
[
"#Of course, most scatter plots are not meant to represent a sine curve but some relationship between x and y, for example\n\nx = np.linspace(-3,3,100)\ny = x**2 + np.random.rand(100) #what is this doing?",
"_____no_output_____"
],
[
"plt.plot(x,y,'o'); #(note: the semicolon here suppresses text output)",
"_____no_output_____"
]
],
[
[
"This type of flexibility in the ``plt.plot`` function allows for a wide variety of possible visualization options.\nFor a full description of the options available, refer to the ``plt.plot`` documentation.",
"_____no_output_____"
],
[
"## Scatter Plots with ``plt.scatter``\n\nA second, more powerful method of creating scatter plots is the ``plt.scatter`` function, which can be used very similarly to the ``plt.plot`` function:",
"_____no_output_____"
]
],
[
[
"plt.scatter(x, y, marker='o');",
"_____no_output_____"
]
],
[
[
"The primary difference of ``plt.scatter`` from ``plt.plot`` is that it can be used to create scatter plots where the properties of each individual point (size, face color, edge color, etc.) can be individually controlled or mapped to data.\n\nLet's show this by creating a random scatter plot with points of many colors and sizes.\nIn order to better see the overlapping results, we'll also use the ``alpha`` keyword to adjust the transparency level:",
"_____no_output_____"
]
],
[
[
"#What is this code doing?\n\nx = np.random.uniform(size=100) #create a new array with 100 random values\ny = np.random.uniform(size=100) #same\ncolors = np.random.uniform(size=100) #same\nsizes = 1000 * np.random.uniform(size=100) \n\nplt.scatter(x, y, c=colors, s=sizes, alpha=0.3,\n cmap='viridis')\nplt.colorbar(); # show color scale",
"_____no_output_____"
]
],
[
[
"Notice that the color argument is automatically mapped to a color scale (shown here by the ``colorbar()`` command), and that the size argument is given in pixels.\n#### In this way, the color and size of points can be used to convey information in the visualization, in order to visualize multidimensional data.",
"_____no_output_____"
],
[
"## ``plot`` Versus ``scatter``: A Note on Efficiency\n\nAside from the different features available in ``plt.plot`` and ``plt.scatter``, why might you choose to use one over the other? While it doesn't matter as much for small amounts of data, as datasets get larger than a few thousand points, ``plt.plot`` can be noticeably more efficient than ``plt.scatter``.\nThe reason is that ``plt.scatter`` has the capability to render a different size and/or color for each point, so the renderer must do the extra work of constructing each point individually.\nIn ``plt.plot``, on the other hand, the points are always essentially clones of each other, so the work of determining the appearance of the points is done only once for the entire set of data.\nFor large datasets, the difference between these two can lead to vastly different performance, and for this reason, ``plt.plot`` should be preferred over ``plt.scatter`` for large datasets.",
"_____no_output_____"
],
[
"# Visualizing Errors",
"_____no_output_____"
],
[
"For any scientific measurement, accurate accounting for errors is nearly as important, if not more important, than accurate reporting of the number itself.\n\nIn visualization of data and results, showing these errors effectively can make a plot convey much more complete information.",
"_____no_output_____"
],
[
"## Basic Errorbars\n\nA basic errorbar can be created with a single Matplotlib function call:",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0, 10, 50)\ndy = 0.8\ndx = 0.3\ny = np.sin(x) + dy * np.random.randn(50)\n\nplt.errorbar(x, y, xerr = dx, yerr=dy, fmt='*k');",
"_____no_output_____"
]
],
[
[
"Here the ``fmt`` is a format code controlling the appearance of lines and points, and has the same syntax as the shorthand used in ``plt.plot`` that we saw above.\n\nIn addition to these basic options, the ``errorbar`` function has many options to fine-tune the outputs.\n\nIn crowded plots it might be useful to make the errorbars lighter than the points themselves:",
"_____no_output_____"
]
],
[
[
"plt.errorbar(x, y, xerr=dx, yerr=dy, fmt='o', color='black',\n ecolor='lightgray', elinewidth=3, capsize=0);",
"_____no_output_____"
]
],
[
[
"# Histograms, Binnings, and Density",
"_____no_output_____"
],
[
"A simple histogram can be a great first step in understanding a dataset.\nIn class 2 we saw a preview of Matplotlib's histogram function, which creates a basic histogram in one line:",
"_____no_output_____"
]
],
[
[
"data = np.random.randn(1000)",
"_____no_output_____"
],
[
"plt.hist(data); #How will the data look like?",
"_____no_output_____"
],
[
"plt.hist(data,density=True,bins=20); #How will the data look like?",
"_____no_output_____"
]
],
[
[
"The ``hist()`` function has many options to tune both the calculation and the display; \nhere's an example of a more customized histogram:",
"_____no_output_____"
]
],
[
[
"# what do these things mean?\ndata = np.random.randn(1000)\nplt.hist(data, bins=30, density=True, alpha=0.7,\n histtype='stepfilled', color='steelblue',\n edgecolor='none');",
"_____no_output_____"
]
],
[
[
"The ``plt.hist`` docstring has more information on other customization options available.\nPlotting histograms along with some transparency ``alpha`` can be very useful when comparing histograms of several distributions:",
"_____no_output_____"
]
],
[
[
"x1 = np.random.normal(0, 0.8, 1000) #what is this doing?\nx2 = np.random.normal(-2, 1, 1000)\nx3 = np.random.normal(3, 2, 1000)\n\nkwargs = dict(histtype='stepfilled', alpha=0.5, density=True, bins=40)\n\nplt.hist(x1, **kwargs)\nplt.hist(x2, **kwargs)\nplt.hist(x3, **kwargs);",
"_____no_output_____"
]
],
[
[
"If you would like to simply compute the histogram (that is, count the number of points in a given bin) and not display it, the ``np.histogram()`` function is available:",
"_____no_output_____"
]
],
[
[
"counts, bin_edges = np.histogram(data, bins=5)\nprint(counts)\nprint(bin_edges)",
"_____no_output_____"
]
],
[
[
"## Further reading",
"_____no_output_____"
],
[
"* http://www.matplotlib.org - The project web page for matplotlib, see in particular https://matplotlib.org/tutorials/index.html\n* https://github.com/matplotlib/matplotlib - The source code for matplotlib.\n* http://matplotlib.org/gallery.html - A large gallery showcaseing various types of plots matplotlib can create. Highly recommended! \n* http://www.loria.fr/~rougier/teaching/matplotlib - A good matplotlib tutorial.\n* http://scipy-lectures.github.io/matplotlib/matplotlib.html - Another good matplotlib reference.\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a46ff7e4703332354b9e82a447a3b8f1bc64dc6
| 56,163 |
ipynb
|
Jupyter Notebook
|
notebooks/02.02-Campus-SEIR-modeling.ipynb
|
jckantor/CBE40455-2020
|
318bd71b7259c6f2f810cc55f268e2477c6b8cfd
|
[
"MIT"
] | 6 |
2020-08-18T13:22:49.000Z
|
2020-12-31T23:30:56.000Z
|
notebooks/02.02-Campus-SEIR-modeling.ipynb
|
jckantor/CBE40455-2020
|
318bd71b7259c6f2f810cc55f268e2477c6b8cfd
|
[
"MIT"
] | null | null | null |
notebooks/02.02-Campus-SEIR-modeling.ipynb
|
jckantor/CBE40455-2020
|
318bd71b7259c6f2f810cc55f268e2477c6b8cfd
|
[
"MIT"
] | 2 |
2020-11-07T21:36:12.000Z
|
2021-12-11T20:38:20.000Z
| 128.226027 | 19,752 | 0.861065 |
[
[
[
"# Campus SEIR Modeling\n\n",
"_____no_output_____"
],
[
"## Campus infection data\n\nThe following data consists of new infections reported since August 3, 2020, from diagnostic testing administered by the Wellness Center and University Health Services at the University of Notre Dame. The data is publically available on the [Notre Dame Covid-19 Dashboard](https://here.nd.edu/our-approach/dashboard/).",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as mdates\nfrom scipy.integrate import solve_ivp\nfrom scipy.optimize import minimize\nfrom datetime import timedelta\n\ndata = [\n [\"2020-08-03\", 0],\n [\"2020-08-04\", 0],\n [\"2020-08-05\", 0],\n [\"2020-08-06\", 1],\n [\"2020-08-07\", 0],\n [\"2020-08-08\", 1],\n [\"2020-08-09\", 2],\n [\"2020-08-10\", 4],\n [\"2020-08-11\", 4],\n [\"2020-08-12\", 7],\n [\"2020-08-13\", 10],\n [\"2020-08-14\", 14],\n [\"2020-08-15\", 3],\n [\"2020-08-16\", 15],\n [\"2020-08-17\", 80],\n]\n\ndf = pd.DataFrame(data, columns=[\"date\", \"new cases\"])\ndf[\"date\"] = pd.to_datetime(df[\"date\"])\n\nfig, ax = plt.subplots(figsize=(8,4))\nax.bar(df[\"date\"], df[\"new cases\"], width=0.6)\nax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MO))\nax.xaxis.set_major_formatter(mdates.DateFormatter(\"%b %d\"))\nplt.title(\"Reported New Infections\")\nplt.grid()",
"/Users/jeff/opt/anaconda3/lib/python3.7/site-packages/pandas/plotting/_matplotlib/converter.py:103: FutureWarning: Using an implicitly registered datetime converter for a matplotlib plotting method. The converter was registered by pandas on import. Future versions of pandas will require you to explicitly register matplotlib converters.\n\nTo register the converters:\n\t>>> from pandas.plotting import register_matplotlib_converters\n\t>>> register_matplotlib_converters()\n warnings.warn(msg, FutureWarning)\n"
]
],
[
[
"## Fitting an SEIR model to campus data\n\nBecause of the limited amount of data available at the time this notebook was prepared, the model fitting has been limited to an SEIR model for infectious disease in a homogeneous population. In an SEIR model, the progression of an epidemic can be modeled by the rate processes shown in the following diagram.\n\n$$\\text{Susceptible}\n\\xrightarrow {\\frac{\\beta S I}{N}} \n\\text{Exposed} \n\\xrightarrow{\\alpha E} \n\\text{Infectious} \n\\xrightarrow{\\gamma I} \n\\text{Recovered} $$\n\nwhich yeild the following model for the population of the four compartments\n\n$$\\begin{align*}\n\\frac{dS}{dt} &= -\\beta S \\frac{I}{N} \\\\\n\\frac{dE}{dt} &= \\beta S \\frac{I}{N} - \\alpha E \\\\\n\\frac{dI}{dt} &= \\alpha E - \\gamma I \\\\\n\\frac{dR}{dt} &= \\gamma I \\\\\n\\end{align*}$$\n\nThe recovery rate is given by $\\gamma = 1/t_{recovery}$ where the average recovery time $t_{recovery}$ is estimated as 8 days. \n\n\n| Parameter | Description | Estimated Value | Source |\n| :-- | :-- | :-- | :-- |\n| $N$ | campus population | 15,000 | estimate |\n| $\\alpha$ | 1/average latency period | 1/(3.0 d) |\n| $\\gamma$ | 1/average recovery period | 1/(8.0 d) | literature |\n| $\\beta$ | infection rate constant | tbd | fitted to data | \n| $I_0$ | initial infectives on Aug 3, 2020 | tbd | fitted to data \n| $R_0$ | reproduction number | ${\\beta}/{\\gamma}$ |",
"_____no_output_____"
]
],
[
[
"N = 15000 # estimated campus population\ngamma = 1/8.0 # recovery rate = 1 / average recovery time in days\nalpha = 1/3.0\n\ndef model(t, y, beta):\n S, E, I, R = y\n dSdt = -beta*S*I/N\n dEdt = beta*S*I/N - alpha*E\n dIdt = alpha*E - gamma*I\n dRdt = gamma*I\n return np.array([dSdt, dEdt, dIdt, dRdt])\n\ndef solve_model(t, params):\n beta, I_initial = params\n IC = [N - I_initial, I_initial, 0.0, 0.0]\n soln = solve_ivp(lambda t, y: model(t, y, beta), np.array([t[0], t[-1]]), \n IC, t_eval=t, atol=1e-6, rtol=1e-9)\n S, E, I, R = soln.y\n U = beta*S*I/N\n return S, E, I, R, U\n\ndef residuals(df, params):\n S, E, I, R, U = solve_model(df.index, params)\n return np.linalg.norm(df[\"new cases\"] - U)\n\ndef fit_model(df, params_est=[0.5, 0.5]):\n return minimize(lambda params: residuals(df, params), params_est, method=\"Nelder-Mead\").x\n\ndef plot_data(df):\n plt.plot(df.index, np.array(df[\"new cases\"]), \"r.\", ms=20, label=\"data\")\n plt.xlabel(\"days\")\n plt.title(\"new cases\")\n plt.legend()\n\ndef plot_model(t, params):\n print(\"R0 =\", round(beta/gamma, 1))\n S, E, I, R, U = solve_model(t, params)\n plt.plot(t, U, lw=3, label=\"model\")\n plt.xlabel(\"days\")\n plt.title(\"new cases\")\n plt.legend()\n\nplot_data(df)\nbeta, I_initial = fit_model(df)\nplot_model(df.index, [beta, I_initial])",
"R0 = 42.3\n"
]
],
[
[
"## Fitted parameter values",
"_____no_output_____"
]
],
[
[
"from tabulate import tabulate\nparameter_table = [\n [\"N\", 15000],\n [\"I0\", I_initial],\n [\"beta\", beta],\n [\"gamma\", gamma],\n [\"R0\", beta/gamma]\n]\nprint(tabulate(parameter_table, headers=[\"Parameter\", \"Value\"]))",
"Parameter Value\n----------- ---------------\nN 15000\nI0 2.30269e-05\nbeta 5.28165\ngamma 0.125\nR0 42.2532\n"
]
],
[
[
"## Short term predictions of newly confirmed cases\n\nUsing the fitted parameters, the following code presents a short term projection of newly diagnosed infections. Roughly speaking, the model projects a 50% increase per day in newly diagnosed cases as a result of testing sympotomatic individuals. \n\nThe number of infected but asympotomatic individuals is unknown at this time, but can be expected to be a 2x multiple of this projection.",
"_____no_output_____"
]
],
[
[
"# prediction horizon (days ahead)\nH = 1\n\n# retrospective lag\nK = 6\n\nfig, ax = plt.subplots(1, 1, figsize=(12, 4))\nfor k in range(0, K+1):\n # use data up to k days ago\n if k > 0:\n beta, I_initial = fit_model(df[:-k])\n P = max(df[:-k].index) + H\n c = 'b'\n a = 0.25\n else:\n beta, I_initial = fit_model(df)\n P = max(df.index) + H\n c = 'r'\n a = 1.0\n\n # simulation\n t = np.linspace(0, P, P+1)\n S, E, I, R, U = solve_model(t, [beta, I_initial])\n\n # plotting\n dates = [df[\"date\"][0] + timedelta(days=t) for t in t]\n ax.plot(dates, U, c, lw=3, alpha=a)\n\nax.plot(df[\"date\"], df[\"new cases\"], \"r.\", ms=25, label=\"new infections (data)\")\nax.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.MO))\nax.xaxis.set_major_formatter(mdates.DateFormatter(\"%b %d\"))\nax.grid(True)\nax.set_title(f\"{H} day-ahead predictions of confirmed new cases\");",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a47036731826beb231cccde82a1be1c5e9e06ac
| 107,471 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/ETL-Project-NY-Dogs-checkpoint.ipynb
|
emtodd11/ETL-Project
|
c894127a7f08ffbd4ef2bfba09fabd3508038801
|
[
"MIT"
] | 1 |
2019-05-20T00:53:41.000Z
|
2019-05-20T00:53:41.000Z
|
.ipynb_checkpoints/ETL-Project-NY-Dogs-checkpoint.ipynb
|
emtodd11/NYC-Top-Dog-Names-DB-Analysis
|
c894127a7f08ffbd4ef2bfba09fabd3508038801
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/ETL-Project-NY-Dogs-checkpoint.ipynb
|
emtodd11/NYC-Top-Dog-Names-DB-Analysis
|
c894127a7f08ffbd4ef2bfba09fabd3508038801
|
[
"MIT"
] | null | null | null | 48.366787 | 588 | 0.455472 |
[
[
[
"# dependencies\n\nimport pandas as pd\nfrom sqlalchemy import create_engine, inspect",
"_____no_output_____"
],
[
"# read raw data csv\n\ncsv_file = \"NYC_Dog_Licensing_Dataset.csv\"\nall_dog_data = pd.read_csv(csv_file)\nall_dog_data.head(10)",
"_____no_output_____"
],
[
"# trim data frame to necessary columns\n\ndog_data_df = all_dog_data[['AnimalName','AnimalGender','BreedName','Borough','ZipCode']]\ndog_data_df.head(10)",
"_____no_output_____"
],
[
"# remove incomplete rows\n\ndog_data_df.count()",
"_____no_output_____"
],
[
"cleaned_dog_data_df = dog_data_df.dropna(how='any')",
"_____no_output_____"
],
[
"cleaned_dog_data_df.count()",
"_____no_output_____"
],
[
"# reformat zip code as integer\n\ncleaned_dog_data_df['ZipCode'] = cleaned_dog_data_df['ZipCode'].astype(int)\ncleaned_dog_data_df.head(10)",
"C:\\Users\\emily\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n"
],
[
"# connect to postgres to create dog database\n\nengine = create_engine('postgres://postgres:postgres@localhost:5432')\nconn = engine.connect()\nconn.execute(\"commit\")\nconn.execute(\"drop database if exists dog_db\")\nconn.execute(\"commit\")\nconn.execute(\"create database dog_db\")",
"_____no_output_____"
],
[
"# import dataframe into database table\n\nengine = create_engine('postgres://postgres:postgres@localhost:5432/dog_db')\nconn = engine.connect()\ncleaned_dog_data_df.to_sql('dog_names', con=conn, if_exists='replace', index=False)",
"_____no_output_____"
],
[
"# check for data\n\nengine.execute('SELECT * FROM dog_names').fetchall()",
"_____no_output_____"
],
[
"# inspect table names and column names\n\ninspector = inspect(engine)\ninspector.get_table_names()",
"_____no_output_____"
],
[
"inspector = inspect(engine)\ncolumns = inspector.get_columns('dog_names')\nprint(columns)",
"[{'name': 'AnimalName', 'type': TEXT(), 'nullable': True, 'default': None, 'autoincrement': False, 'comment': None}, {'name': 'AnimalGender', 'type': TEXT(), 'nullable': True, 'default': None, 'autoincrement': False, 'comment': None}, {'name': 'BreedName', 'type': TEXT(), 'nullable': True, 'default': None, 'autoincrement': False, 'comment': None}, {'name': 'Borough', 'type': TEXT(), 'nullable': True, 'default': None, 'autoincrement': False, 'comment': None}, {'name': 'ZipCode', 'type': INTEGER(), 'nullable': True, 'default': None, 'autoincrement': False, 'comment': None}]\n"
],
[
"# query the table and save as dataframe for analysis\n\ndog_table = pd.read_sql_query('select * from dog_names', con=engine)\ndog_table.head(20)",
"_____no_output_____"
],
[
"dog_data = dog_table.loc[(dog_table[\"AnimalName\"] != \"UNKNOWN\") & (dog_table[\"AnimalName\"] != \"NAME NOT PROVIDED\"), :]\ndog_data.head(20)",
"_____no_output_____"
],
[
"name_counts = pd.DataFrame(dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nname_counts_df = name_counts.rename(columns={\"AnimalName\":\"Count\"})\nname_counts_df.head()",
"_____no_output_____"
],
[
"top_names = name_counts_df.sort_values([\"Count\"], ascending=False)\ntop_names.head(12)",
"_____no_output_____"
],
[
"f_dog_data = dog_data.loc[dog_data[\"AnimalGender\"] == \"F\", :]\nf_dog_data.head()",
"_____no_output_____"
],
[
"f_name_counts = pd.DataFrame(f_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nf_name_counts_df = f_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nf_top_names = f_name_counts_df.sort_values([\"Count\"], ascending=False)\nf_top_names.head(12)",
"_____no_output_____"
],
[
"m_dog_data = dog_data.loc[dog_data[\"AnimalGender\"] == \"M\", :]\nm_name_counts = pd.DataFrame(m_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nm_name_counts_df = m_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nm_top_names = m_name_counts_df.sort_values([\"Count\"], ascending=False)\nm_top_names.head(12)",
"_____no_output_____"
],
[
"borough_counts = pd.DataFrame(dog_data.groupby(\"Borough\")[\"AnimalName\"].count())\nborough_counts_df = borough_counts.rename(columns={\"AnimalName\":\"Count\"})\nborough_dogs = borough_counts_df.sort_values([\"Count\"], ascending=False)\nborough_dogs.head()",
"_____no_output_____"
],
[
"top_boroughs = dog_data.loc[(dog_data[\"Borough\"] == \"Manhattan\") | (dog_data[\"Borough\"] == \"Brooklyn\") | (dog_data[\"Borough\"] == \"Queens\") | (dog_data[\"Borough\"] == \"Bronx\") | (dog_data[\"Borough\"] == \"Staten Island\"), :]\nf_m_top_boroughs = top_boroughs.loc[(top_boroughs[\"AnimalGender\"] == \"F\") | (top_boroughs[\"AnimalGender\"] == \"M\"), :]\nf_m_top_boroughs.head()",
"_____no_output_____"
],
[
"borough_data = f_m_top_boroughs.groupby(['Borough','AnimalGender'])[\"AnimalName\"].count()\nborough_dogs = pd.DataFrame(borough_data)\nborough_dogs",
"_____no_output_____"
],
[
"mt_dog_data = dog_data.loc[dog_data[\"Borough\"].str.contains(\"Manhattan\", case=False), :]\nmt_name_counts = pd.DataFrame(mt_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nmt_name_counts_df = mt_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nmt_top_names = mt_name_counts_df.sort_values([\"Count\"], ascending=False)\nmt_top_names.head(12)",
"_____no_output_____"
],
[
"bk_dog_data = dog_data.loc[dog_data[\"Borough\"].str.contains(\"Brooklyn\", case=False), :]\nbk_name_counts = pd.DataFrame(bk_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nbk_name_counts_df = bk_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nbk_top_names = bk_name_counts_df.sort_values([\"Count\"], ascending=False)\nbk_top_names.head(12)",
"_____no_output_____"
],
[
"qn_dog_data = dog_data.loc[dog_data[\"Borough\"].str.contains(\"Queens\", case=False), :]\nqn_name_counts = pd.DataFrame(qn_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nqn_name_counts_df = qn_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nqn_top_names = qn_name_counts_df.sort_values([\"Count\"], ascending=False)\nqn_top_names.head(12)",
"_____no_output_____"
],
[
"bx_dog_data = dog_data.loc[dog_data[\"Borough\"].str.contains(\"Bronx\", case=False), :]\nbx_name_counts = pd.DataFrame(bx_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nbx_name_counts_df = bx_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nbx_top_names = bx_name_counts_df.sort_values([\"Count\"], ascending=False)\nbx_top_names.head(12)",
"_____no_output_____"
],
[
"si_dog_data = dog_data.loc[dog_data[\"Borough\"].str.contains(\"Staten Island\", case=False), :]\nsi_name_counts = pd.DataFrame(si_dog_data.groupby(\"AnimalName\")[\"AnimalName\"].count())\nsi_name_counts_df = si_name_counts.rename(columns={\"AnimalName\":\"Count\"})\nsi_top_names = si_name_counts_df.sort_values([\"Count\"], ascending=False)\nsi_top_names.head(12)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a470ffd912c35f215408c35f615e6226314ae10
| 130 |
ipynb
|
Jupyter Notebook
|
data_statistical_packages.ipynb
|
carloseduardosg73/quantecon-notebooks-jl
|
4e2b5aaf5bf14d9db743b9fdfe1619e34daeb268
|
[
"BSD-3-Clause"
] | null | null | null |
data_statistical_packages.ipynb
|
carloseduardosg73/quantecon-notebooks-jl
|
4e2b5aaf5bf14d9db743b9fdfe1619e34daeb268
|
[
"BSD-3-Clause"
] | null | null | null |
data_statistical_packages.ipynb
|
carloseduardosg73/quantecon-notebooks-jl
|
4e2b5aaf5bf14d9db743b9fdfe1619e34daeb268
|
[
"BSD-3-Clause"
] | null | null | null | 32.5 | 75 | 0.884615 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a47150d66e3bfd9baa0bcf0942647ab76952baa
| 2,340 |
ipynb
|
Jupyter Notebook
|
notes/week08/lab/Task2.ipynb
|
ubco-cmps/data301_course
|
f65b3e4cdf4e7f506395980abb588fce93f94726
|
[
"MIT"
] | 4 |
2020-10-02T06:03:56.000Z
|
2022-01-19T02:01:13.000Z
|
notes/week08/lab/Task2.ipynb
|
ubco-cmps/data301_course
|
f65b3e4cdf4e7f506395980abb588fce93f94726
|
[
"MIT"
] | 10 |
2020-09-01T04:50:46.000Z
|
2022-01-07T06:29:37.000Z
|
notes/week08/lab/Task2.ipynb
|
ubco-cmps/data301_course
|
f65b3e4cdf4e7f506395980abb588fce93f94726
|
[
"MIT"
] | 5 |
2020-10-05T20:19:40.000Z
|
2021-11-08T12:10:50.000Z
| 27.529412 | 124 | 0.565812 |
[
[
[
"## Task 2 - Creating and Calling Functions\n\n### 2.1 - Calculating Taxes\n\nWrite a Python function called `calc_tax()` that calculates and prints the tax on a purchased item.\nThe input of this function should be the name of the item (a string), and the pre-tax price of the item (a number).\n\nRequirements:\n\n- Add a docstring to this function so users know how to use it.\n- Calculate the provincial tax (5%) federal tax (7%), and store them as separate variables.\n- Choose one: \n - A) Add at least two assert statements as tests for your code OR \n - B) Use try/except statements to test for inputs to the function.\n- Print the item amount, the provincial tax, the federal tax, and the total with all taxes included.\n- Round tax amounts, and the final price to the nearest cent and display with exactly two decimal points.\n\n#### Sample Output\n\n> \\>\\> calc_tax('candy', 10) # Run the `calc_tax()` function on candy to get the following output\n> \n> candy\n>\n> pre-tax price of: \\$10.00\n> \n> provincial tax: \\$0.50\n> \n> federal tax: \\$0.70\n> \n> total price of: $11.00\n",
"_____no_output_____"
]
],
[
[
"#add your import statements here\n\n\n",
"_____no_output_____"
],
[
"# Your solution here",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
]
] |
4a472c4628439e9b2cf5867ba513f7c67dd9f01e
| 4,064 |
ipynb
|
Jupyter Notebook
|
deep-image-prior.ipynb
|
wkiino/deep-image-prior
|
0dedc2023e2fdaafe7dafc081081014b7fbcee08
|
[
"MIT"
] | null | null | null |
deep-image-prior.ipynb
|
wkiino/deep-image-prior
|
0dedc2023e2fdaafe7dafc081081014b7fbcee08
|
[
"MIT"
] | 2 |
2021-03-19T13:02:29.000Z
|
2021-06-08T21:34:03.000Z
|
deep-image-prior.ipynb
|
hideo130/deep-image-prior
|
0dedc2023e2fdaafe7dafc081081014b7fbcee08
|
[
"MIT"
] | null | null | null | 4,064 | 4,064 | 0.5406 |
[
[
[
"Google Driveでdeep image prior(DIP)を試すコードです.\nノートブック上の編集 ノートブックの設定でGPUを選択するとGPUを利用してDIPを試すことができます.",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\nfrom pathlib import Path\ndrive.mount(\"/content/drive\")\n# Google drive上にpythonというディレクトリで作業する場合です.\n\n%cd \"/content/drive/My Drive/python/\"\nif not Path(\"./deep-image-prior/\").exists():\n !git clone https://github.com/wkiino/deep-image-prior.git\n %cd deep-image-prior\nelse:\n %cd deep-image-prior\n !git pull\n!pip3 install -r requirements.txt\nif not Path(\"./datasets/hsimg/data.tiff\").exists():\n !curl -O http://colorimaginglab.ugr.es/pages/data/hyperspectral/scene9_sp/! ./datasets/hsimg/data.tiff\n\n%cd src/",
"_____no_output_____"
],
[
"#gpuが使えるか確認\n!nvidia-smi",
"Mon May 25 07:13:09 2020 \n+-----------------------------------------------------------------------------+\n| NVIDIA-SMI 440.82 Driver Version: 418.67 CUDA Version: 10.1 |\n|-------------------------------+----------------------+----------------------+\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\n|===============================+======================+======================|\n| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |\n| N/A 52C P8 30W / 149W | 0MiB / 11441MiB | 0% Default |\n+-------------------------------+----------------------+----------------------+\n \n+-----------------------------------------------------------------------------+\n| Processes: GPU Memory |\n| GPU PID Type Process name Usage |\n|=============================================================================|\n| No running processes found |\n+-----------------------------------------------------------------------------+\n"
]
],
[
[
"通常画像にDIP試す場合\nimage.typeにdenoise,inpaint1,inpaint2,inpaint3を指定することで実行できます",
"_____no_output_____"
]
],
[
[
"# 実行例 通常画像のデノイズを行う\n!python train_normal.py image.type=denoise image=img base_options.epochs=2000",
"_____no_output_____"
],
[
"# 実行例 通常画像のインペインティングを行う\n!python train_normal.py image.type=inpaint3 image=img base_options.epochs=2000",
"_____no_output_____"
]
],
[
[
"ハイパースペクトル画像にDIPを試す場合,image.typeにdenoise,inpaint1,inpaint2を指定することで実行できます.",
"_____no_output_____"
]
],
[
[
"# 実行例 ハイパースペクトル画像でインペインティングを行う.\n!python train.py image.type=inpaint1 base_options.epochs=2000",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.